
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_52175
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-167
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error reading integer
From VS (might not be a ptvsd bug, not sure at this point):
Create new python application
Add new item, python unit test
Set the unit test as startup file
F5
Result:
```
---------------------------
Microsoft Visual Studio
---------------------------
Error reading integer. Unexpected token: Boolean. Path 'exitCode'.
---------------------------
OK
---------------------------
```
</issue>
<code>
[start of ptvsd/debugger.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License. See LICENSE in the project root
3 # for license information.
4
5 import sys
6
7
8 __author__ = "Microsoft Corporation <[email protected]>"
9 __version__ = "4.0.0a1"
10
11 DONT_DEBUG = []
12
13
14 def debug(filename, port_num, debug_id, debug_options, run_as):
15 # TODO: docstring
16
17 # import the wrapper first, so that it gets a chance
18 # to detour pydevd socket functionality.
19 import ptvsd.wrapper
20 import pydevd
21
22 args = [
23 '--port', str(port_num),
24 '--client', '127.0.0.1',
25 ]
26 if run_as == 'module':
27 args.append('--module')
28 args.extend(('--file', filename + ":"))
29 else:
30 args.extend(('--file', filename))
31 sys.argv[1:0] = args
32 try:
33 pydevd.main()
34 except SystemExit as ex:
35 ptvsd.wrapper.ptvsd_sys_exit_code = ex.code
36 raise
37
[end of ptvsd/debugger.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ptvsd/debugger.py b/ptvsd/debugger.py
--- a/ptvsd/debugger.py
+++ b/ptvsd/debugger.py
@@ -32,5 +32,5 @@
try:
pydevd.main()
except SystemExit as ex:
- ptvsd.wrapper.ptvsd_sys_exit_code = ex.code
+ ptvsd.wrapper.ptvsd_sys_exit_code = int(ex.code)
raise
|
{"golden_diff": "diff --git a/ptvsd/debugger.py b/ptvsd/debugger.py\n--- a/ptvsd/debugger.py\n+++ b/ptvsd/debugger.py\n@@ -32,5 +32,5 @@\n try:\n pydevd.main()\n except SystemExit as ex:\n- ptvsd.wrapper.ptvsd_sys_exit_code = ex.code\n+ ptvsd.wrapper.ptvsd_sys_exit_code = int(ex.code)\n raise\n", "issue": "Error reading integer\nFrom VS (might not be a ptvsd bug, not sure at this point):\r\nCreate new python application\r\nAdd new item, python unit test\r\nSet the unit test as startup file\r\nF5\r\n\r\nResult:\r\n```\r\n---------------------------\r\nMicrosoft Visual Studio\r\n---------------------------\r\nError reading integer. Unexpected token: Boolean. Path 'exitCode'.\r\n---------------------------\r\nOK \r\n---------------------------\r\n```\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport sys\n\n\n__author__ = \"Microsoft Corporation <[email protected]>\"\n__version__ = \"4.0.0a1\"\n\nDONT_DEBUG = []\n\n\ndef debug(filename, port_num, debug_id, debug_options, run_as):\n # TODO: docstring\n\n # import the wrapper first, so that it gets a chance\n # to detour pydevd socket functionality.\n import ptvsd.wrapper\n import pydevd\n\n args = [\n '--port', str(port_num),\n '--client', '127.0.0.1',\n ]\n if run_as == 'module':\n args.append('--module')\n args.extend(('--file', filename + \":\"))\n else:\n args.extend(('--file', filename))\n sys.argv[1:0] = args\n try:\n pydevd.main()\n except SystemExit as ex:\n ptvsd.wrapper.ptvsd_sys_exit_code = ex.code\n raise\n", "path": "ptvsd/debugger.py"}]}
| 931 | 104 |
gh_patches_debug_57163
|
rasdani/github-patches
|
git_diff
|
Bitmessage__PyBitmessage-2004
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Adding Protocol specification to docs (WIP)
I am slowly formatting Protocol Specification doc. I see some typos and mistakes in the wiki, which I also hope to fix.
[A quick preview](https://pybitmessage-test.readthedocs.io/en/doc/protocol.html)
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 """
3 Configuration file for the Sphinx documentation builder.
4
5 For a full list of options see the documentation:
6 http://www.sphinx-doc.org/en/master/config
7 """
8
9 import os
10 import sys
11
12 sys.path.insert(0, os.path.abspath('../src'))
13
14 from importlib import import_module
15
16 import version # noqa:E402
17
18
19 # -- Project information -----------------------------------------------------
20
21 project = u'PyBitmessage'
22 copyright = u'2019, The Bitmessage Team' # pylint: disable=redefined-builtin
23 author = u'The Bitmessage Team'
24
25 # The short X.Y version
26 version = unicode(version.softwareVersion)
27
28 # The full version, including alpha/beta/rc tags
29 release = version
30
31 # -- General configuration ---------------------------------------------------
32
33 # If your documentation needs a minimal Sphinx version, state it here.
34 #
35 # needs_sphinx = '1.0'
36
37 # Add any Sphinx extension module names here, as strings. They can be
38 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
39 # ones.
40 extensions = [
41 'sphinx.ext.autodoc',
42 'sphinx.ext.coverage', # FIXME: unused
43 'sphinx.ext.imgmath', # legacy unused
44 'sphinx.ext.intersphinx',
45 'sphinx.ext.linkcode',
46 'sphinx.ext.napoleon',
47 'sphinx.ext.todo',
48 'sphinxcontrib.apidoc',
49 'm2r',
50 ]
51
52 default_role = 'obj'
53
54 # Add any paths that contain templates here, relative to this directory.
55 templates_path = ['_templates']
56
57 # The suffix(es) of source filenames.
58 # You can specify multiple suffix as a list of string:
59 #
60 source_suffix = ['.rst', '.md']
61
62 # The master toctree document.
63 master_doc = 'index'
64
65 # The language for content autogenerated by Sphinx. Refer to documentation
66 # for a list of supported languages.
67 #
68 # This is also used if you do content translation via gettext catalogs.
69 # Usually you set "language" from the command line for these cases.
70 # language = None
71
72 # List of patterns, relative to source directory, that match files and
73 # directories to ignore when looking for source files.
74 # This pattern also affects html_static_path and html_extra_path .
75 exclude_patterns = ['_build']
76
77 # The name of the Pygments (syntax highlighting) style to use.
78 pygments_style = 'sphinx'
79
80 # Don't prepend every class or function name with full module path
81 add_module_names = False
82
83 # A list of ignored prefixes for module index sorting.
84 modindex_common_prefix = ['pybitmessage.']
85
86
87 # -- Options for HTML output -------------------------------------------------
88
89 # The theme to use for HTML and HTML Help pages. See the documentation for
90 # a list of builtin themes.
91 #
92 html_theme = 'sphinx_rtd_theme'
93
94 # Theme options are theme-specific and customize the look and feel of a theme
95 # further. For a list of options available for each theme, see the
96 # documentation.
97 #
98 # html_theme_options = {}
99
100 # Add any paths that contain custom static files (such as style sheets) here,
101 # relative to this directory. They are copied after the builtin static files,
102 # so a file named "default.css" will overwrite the builtin "default.css".
103 html_static_path = ['_static']
104
105 html_css_files = [
106 'custom.css',
107 ]
108
109 # Custom sidebar templates, must be a dictionary that maps document names
110 # to template names.
111 #
112 # The default sidebars (for documents that don't match any pattern) are
113 # defined by theme itself. Builtin themes are using these templates by
114 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
115 # 'searchbox.html']``.
116 #
117 # html_sidebars = {}
118
119 html_show_sourcelink = False
120
121 # -- Options for HTMLHelp output ---------------------------------------------
122
123 # Output file base name for HTML help builder.
124 htmlhelp_basename = 'PyBitmessagedoc'
125
126
127 # -- Options for LaTeX output ------------------------------------------------
128
129 latex_elements = {
130 # The paper size ('letterpaper' or 'a4paper').
131 #
132 # 'papersize': 'letterpaper',
133
134 # The font size ('10pt', '11pt' or '12pt').
135 #
136 # 'pointsize': '10pt',
137
138 # Additional stuff for the LaTeX preamble.
139 #
140 # 'preamble': '',
141
142 # Latex figure (float) alignment
143 #
144 # 'figure_align': 'htbp',
145 }
146
147 # Grouping the document tree into LaTeX files. List of tuples
148 # (source start file, target name, title,
149 # author, documentclass [howto, manual, or own class]).
150 latex_documents = [
151 (master_doc, 'PyBitmessage.tex', u'PyBitmessage Documentation',
152 u'The Bitmessage Team', 'manual'),
153 ]
154
155
156 # -- Options for manual page output ------------------------------------------
157
158 # One entry per manual page. List of tuples
159 # (source start file, name, description, authors, manual section).
160 man_pages = [
161 (master_doc, 'pybitmessage', u'PyBitmessage Documentation',
162 [author], 1)
163 ]
164
165
166 # -- Options for Texinfo output ----------------------------------------------
167
168 # Grouping the document tree into Texinfo files. List of tuples
169 # (source start file, target name, title, author,
170 # dir menu entry, description, category)
171 texinfo_documents = [
172 (master_doc, 'PyBitmessage', u'PyBitmessage Documentation',
173 author, 'PyBitmessage', 'One line description of project.',
174 'Miscellaneous'),
175 ]
176
177
178 # -- Options for Epub output -------------------------------------------------
179
180 # Bibliographic Dublin Core info.
181 epub_title = project
182 epub_author = author
183 epub_publisher = author
184 epub_copyright = copyright
185
186 # The unique identifier of the text. This can be a ISBN number
187 # or the project homepage.
188 #
189 # epub_identifier = ''
190
191 # A unique identification for the text.
192 #
193 # epub_uid = ''
194
195 # A list of files that should not be packed into the epub file.
196 epub_exclude_files = ['search.html']
197
198
199 # -- Extension configuration -------------------------------------------------
200
201 autodoc_mock_imports = [
202 'debug',
203 'pybitmessage.bitmessagekivy',
204 'pybitmessage.bitmessageqt.foldertree',
205 'pybitmessage.helper_startup',
206 'pybitmessage.mock',
207 'pybitmessage.network.httpd',
208 'pybitmessage.network.https',
209 'ctypes',
210 'dialog',
211 'gi',
212 'kivy',
213 'logging',
214 'msgpack',
215 'numpy',
216 'pkg_resources',
217 'pycanberra',
218 'pyopencl',
219 'PyQt4',
220 'PyQt5',
221 'qrcode',
222 'stem',
223 'xdg',
224 ]
225 autodoc_member_order = 'bysource'
226
227 # Apidoc settings
228 apidoc_module_dir = '../pybitmessage'
229 apidoc_output_dir = 'autodoc'
230 apidoc_excluded_paths = [
231 'bitmessagekivy', 'build_osx.py',
232 'bitmessageqt/addressvalidator.py', 'bitmessageqt/foldertree.py',
233 'bitmessageqt/migrationwizard.py', 'bitmessageqt/newaddresswizard.py',
234 'helper_startup.py',
235 'kivymd', 'mock', 'main.py', 'navigationdrawer', 'network/http*',
236 'src', 'tests', 'version.py'
237 ]
238 apidoc_module_first = True
239 apidoc_separate_modules = True
240 apidoc_toc_file = False
241 apidoc_extra_args = ['-a']
242
243 # Napoleon settings
244 napoleon_google_docstring = True
245
246
247 # linkcode function
248 def linkcode_resolve(domain, info):
249 """This generates source URL's for sphinx.ext.linkcode"""
250 if domain != 'py' or not info['module']:
251 return
252 try:
253 home = os.path.abspath(import_module('pybitmessage').__path__[0])
254 mod = import_module(info['module']).__file__
255 except ImportError:
256 return
257 repo = 'https://github.com/Bitmessage/PyBitmessage/blob/v0.6/src%s'
258 path = mod.replace(home, '')
259 if path != mod:
260 # put the link only for top level definitions
261 if len(info['fullname'].split('.')) > 1:
262 return
263 if path.endswith('.pyc'):
264 path = path[:-1]
265 return repo % path
266
267
268 # -- Options for intersphinx extension ---------------------------------------
269
270 # Example configuration for intersphinx: refer to the Python standard library.
271 intersphinx_mapping = {'https://docs.python.org/2.7/': None}
272
273 # -- Options for todo extension ----------------------------------------------
274
275 # If true, `todo` and `todoList` produce output, else they produce nothing.
276 todo_include_todos = True
277
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -19,7 +19,7 @@
# -- Project information -----------------------------------------------------
project = u'PyBitmessage'
-copyright = u'2019, The Bitmessage Team' # pylint: disable=redefined-builtin
+copyright = u'2019-2022, The Bitmessage Team' # pylint: disable=redefined-builtin
author = u'The Bitmessage Team'
# The short X.Y version
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -19,7 +19,7 @@\n # -- Project information -----------------------------------------------------\n \n project = u'PyBitmessage'\n-copyright = u'2019, The Bitmessage Team' # pylint: disable=redefined-builtin\n+copyright = u'2019-2022, The Bitmessage Team' # pylint: disable=redefined-builtin\n author = u'The Bitmessage Team'\n \n # The short X.Y version\n", "issue": "Adding Protocol specification to docs (WIP)\nI am slowly formatting Protocol Specification doc. I see some typos and mistakes in the wiki, which I also hope to fix.\r\n\r\n[A quick preview](https://pybitmessage-test.readthedocs.io/en/doc/protocol.html)\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nConfiguration file for the Sphinx documentation builder.\n\nFor a full list of options see the documentation:\nhttp://www.sphinx-doc.org/en/master/config\n\"\"\"\n\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath('../src'))\n\nfrom importlib import import_module\n\nimport version # noqa:E402\n\n\n# -- Project information -----------------------------------------------------\n\nproject = u'PyBitmessage'\ncopyright = u'2019, The Bitmessage Team' # pylint: disable=redefined-builtin\nauthor = u'The Bitmessage Team'\n\n# The short X.Y version\nversion = unicode(version.softwareVersion)\n\n# The full version, including alpha/beta/rc tags\nrelease = version\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n 'sphinx.ext.autodoc',\n 'sphinx.ext.coverage', # FIXME: unused\n 'sphinx.ext.imgmath', # legacy unused\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.linkcode',\n 'sphinx.ext.napoleon',\n 'sphinx.ext.todo',\n 'sphinxcontrib.apidoc',\n 'm2r',\n]\n\ndefault_role = 'obj'\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\nsource_suffix = ['.rst', '.md']\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\n# language = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = ['_build']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# Don't prepend every class or function name with full module path\nadd_module_names = False\n\n# A list of ignored prefixes for module index sorting.\nmodindex_common_prefix = ['pybitmessage.']\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\nhtml_css_files = [\n 'custom.css',\n]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\n# html_sidebars = {}\n\nhtml_show_sourcelink = False\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'PyBitmessagedoc'\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'PyBitmessage.tex', u'PyBitmessage Documentation',\n u'The Bitmessage Team', 'manual'),\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'pybitmessage', u'PyBitmessage Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'PyBitmessage', u'PyBitmessage Documentation',\n author, 'PyBitmessage', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n# -- Options for Epub output -------------------------------------------------\n\n# Bibliographic Dublin Core info.\nepub_title = project\nepub_author = author\nepub_publisher = author\nepub_copyright = copyright\n\n# The unique identifier of the text. This can be a ISBN number\n# or the project homepage.\n#\n# epub_identifier = ''\n\n# A unique identification for the text.\n#\n# epub_uid = ''\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = ['search.html']\n\n\n# -- Extension configuration -------------------------------------------------\n\nautodoc_mock_imports = [\n 'debug',\n 'pybitmessage.bitmessagekivy',\n 'pybitmessage.bitmessageqt.foldertree',\n 'pybitmessage.helper_startup',\n 'pybitmessage.mock',\n 'pybitmessage.network.httpd',\n 'pybitmessage.network.https',\n 'ctypes',\n 'dialog',\n 'gi',\n 'kivy',\n 'logging',\n 'msgpack',\n 'numpy',\n 'pkg_resources',\n 'pycanberra',\n 'pyopencl',\n 'PyQt4',\n 'PyQt5',\n 'qrcode',\n 'stem',\n 'xdg',\n]\nautodoc_member_order = 'bysource'\n\n# Apidoc settings\napidoc_module_dir = '../pybitmessage'\napidoc_output_dir = 'autodoc'\napidoc_excluded_paths = [\n 'bitmessagekivy', 'build_osx.py',\n 'bitmessageqt/addressvalidator.py', 'bitmessageqt/foldertree.py',\n 'bitmessageqt/migrationwizard.py', 'bitmessageqt/newaddresswizard.py',\n 'helper_startup.py',\n 'kivymd', 'mock', 'main.py', 'navigationdrawer', 'network/http*',\n 'src', 'tests', 'version.py'\n]\napidoc_module_first = True\napidoc_separate_modules = True\napidoc_toc_file = False\napidoc_extra_args = ['-a']\n\n# Napoleon settings\nnapoleon_google_docstring = True\n\n\n# linkcode function\ndef linkcode_resolve(domain, info):\n \"\"\"This generates source URL's for sphinx.ext.linkcode\"\"\"\n if domain != 'py' or not info['module']:\n return\n try:\n home = os.path.abspath(import_module('pybitmessage').__path__[0])\n mod = import_module(info['module']).__file__\n except ImportError:\n return\n repo = 'https://github.com/Bitmessage/PyBitmessage/blob/v0.6/src%s'\n path = mod.replace(home, '')\n if path != mod:\n # put the link only for top level definitions\n if len(info['fullname'].split('.')) > 1:\n return\n if path.endswith('.pyc'):\n path = path[:-1]\n return repo % path\n\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {'https://docs.python.org/2.7/': None}\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n", "path": "docs/conf.py"}]}
| 3,222 | 123 |
gh_patches_debug_3811
|
rasdani/github-patches
|
git_diff
|
openmc-dev__openmc-926
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Unable to run examples/python/pincell
Hi,
After generating the xml files and trying to `openmc` I get the following error:
```
Reading tallies XML file...
ERROR: Two or more meshes use the same unique ID: 1
```
</issue>
<code>
[start of examples/python/pincell/build-xml.py]
1 import openmc
2
3 ###############################################################################
4 # Simulation Input File Parameters
5 ###############################################################################
6
7 # OpenMC simulation parameters
8 batches = 100
9 inactive = 10
10 particles = 1000
11
12
13 ###############################################################################
14 # Exporting to OpenMC materials.xml file
15 ###############################################################################
16
17
18 # Instantiate some Materials and register the appropriate Nuclides
19 uo2 = openmc.Material(material_id=1, name='UO2 fuel at 2.4% wt enrichment')
20 uo2.set_density('g/cm3', 10.29769)
21 uo2.add_element('U', 1., enrichment=2.4)
22 uo2.add_element('O', 2.)
23
24 helium = openmc.Material(material_id=2, name='Helium for gap')
25 helium.set_density('g/cm3', 0.001598)
26 helium.add_element('He', 2.4044e-4)
27
28 zircaloy = openmc.Material(material_id=3, name='Zircaloy 4')
29 zircaloy.set_density('g/cm3', 6.55)
30 zircaloy.add_element('Sn', 0.014 , 'wo')
31 zircaloy.add_element('Fe', 0.00165, 'wo')
32 zircaloy.add_element('Cr', 0.001 , 'wo')
33 zircaloy.add_element('Zr', 0.98335, 'wo')
34
35 borated_water = openmc.Material(material_id=4, name='Borated water')
36 borated_water.set_density('g/cm3', 0.740582)
37 borated_water.add_element('B', 4.0e-5)
38 borated_water.add_element('H', 5.0e-2)
39 borated_water.add_element('O', 2.4e-2)
40 borated_water.add_s_alpha_beta('c_H_in_H2O')
41
42 # Instantiate a Materials collection and export to XML
43 materials_file = openmc.Materials([uo2, helium, zircaloy, borated_water])
44 materials_file.export_to_xml()
45
46
47 ###############################################################################
48 # Exporting to OpenMC geometry.xml file
49 ###############################################################################
50
51 # Instantiate ZCylinder surfaces
52 fuel_or = openmc.ZCylinder(surface_id=1, x0=0, y0=0, R=0.39218, name='Fuel OR')
53 clad_ir = openmc.ZCylinder(surface_id=2, x0=0, y0=0, R=0.40005, name='Clad IR')
54 clad_or = openmc.ZCylinder(surface_id=3, x0=0, y0=0, R=0.45720, name='Clad OR')
55 left = openmc.XPlane(surface_id=4, x0=-0.62992, name='left')
56 right = openmc.XPlane(surface_id=5, x0=0.62992, name='right')
57 bottom = openmc.YPlane(surface_id=6, y0=-0.62992, name='bottom')
58 top = openmc.YPlane(surface_id=7, y0=0.62992, name='top')
59
60 left.boundary_type = 'reflective'
61 right.boundary_type = 'reflective'
62 top.boundary_type = 'reflective'
63 bottom.boundary_type = 'reflective'
64
65 # Instantiate Cells
66 fuel = openmc.Cell(cell_id=1, name='cell 1')
67 gap = openmc.Cell(cell_id=2, name='cell 2')
68 clad = openmc.Cell(cell_id=3, name='cell 3')
69 water = openmc.Cell(cell_id=4, name='cell 4')
70
71 # Use surface half-spaces to define regions
72 fuel.region = -fuel_or
73 gap.region = +fuel_or & -clad_ir
74 clad.region = +clad_ir & -clad_or
75 water.region = +clad_or & +left & -right & +bottom & -top
76
77 # Register Materials with Cells
78 fuel.fill = uo2
79 gap.fill = helium
80 clad.fill = zircaloy
81 water.fill = borated_water
82
83 # Instantiate Universe
84 root = openmc.Universe(universe_id=0, name='root universe')
85
86 # Register Cells with Universe
87 root.add_cells([fuel, gap, clad, water])
88
89 # Instantiate a Geometry, register the root Universe, and export to XML
90 geometry = openmc.Geometry(root)
91 geometry.export_to_xml()
92
93
94 ###############################################################################
95 # Exporting to OpenMC settings.xml file
96 ###############################################################################
97
98 # Instantiate a Settings object, set all runtime parameters, and export to XML
99 settings_file = openmc.Settings()
100 settings_file.batches = batches
101 settings_file.inactive = inactive
102 settings_file.particles = particles
103
104 # Create an initial uniform spatial source distribution over fissionable zones
105 bounds = [-0.62992, -0.62992, -1, 0.62992, 0.62992, 1]
106 uniform_dist = openmc.stats.Box(bounds[:3], bounds[3:], only_fissionable=True)
107 settings_file.source = openmc.source.Source(space=uniform_dist)
108
109 entropy_mesh = openmc.Mesh()
110 entropy_mesh.lower_left = [-0.39218, -0.39218, -1.e50]
111 entropy_mesh.upper_right = [0.39218, 0.39218, 1.e50]
112 entropy_mesh.dimension = [10, 10, 1]
113 settings_file.entropy_mesh = entropy_mesh
114 settings_file.export_to_xml()
115
116
117 ###############################################################################
118 # Exporting to OpenMC tallies.xml file
119 ###############################################################################
120
121 # Instantiate a tally mesh
122 mesh = openmc.Mesh(mesh_id=1)
123 mesh.type = 'regular'
124 mesh.dimension = [100, 100, 1]
125 mesh.lower_left = [-0.62992, -0.62992, -1.e50]
126 mesh.upper_right = [0.62992, 0.62992, 1.e50]
127
128 # Instantiate some tally Filters
129 energy_filter = openmc.EnergyFilter([0., 4., 20.e6])
130 mesh_filter = openmc.MeshFilter(mesh)
131
132 # Instantiate the Tally
133 tally = openmc.Tally(tally_id=1, name='tally 1')
134 tally.filters = [energy_filter, mesh_filter]
135 tally.scores = ['flux', 'fission', 'nu-fission']
136
137 # Instantiate a Tallies collection and export to XML
138 tallies_file = openmc.Tallies([tally])
139 tallies_file.export_to_xml()
140
[end of examples/python/pincell/build-xml.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/python/pincell/build-xml.py b/examples/python/pincell/build-xml.py
--- a/examples/python/pincell/build-xml.py
+++ b/examples/python/pincell/build-xml.py
@@ -119,7 +119,7 @@
###############################################################################
# Instantiate a tally mesh
-mesh = openmc.Mesh(mesh_id=1)
+mesh = openmc.Mesh()
mesh.type = 'regular'
mesh.dimension = [100, 100, 1]
mesh.lower_left = [-0.62992, -0.62992, -1.e50]
|
{"golden_diff": "diff --git a/examples/python/pincell/build-xml.py b/examples/python/pincell/build-xml.py\n--- a/examples/python/pincell/build-xml.py\n+++ b/examples/python/pincell/build-xml.py\n@@ -119,7 +119,7 @@\n ###############################################################################\n \n # Instantiate a tally mesh\n-mesh = openmc.Mesh(mesh_id=1)\n+mesh = openmc.Mesh()\n mesh.type = 'regular'\n mesh.dimension = [100, 100, 1]\n mesh.lower_left = [-0.62992, -0.62992, -1.e50]\n", "issue": "Unable to run examples/python/pincell\nHi,\r\n\r\nAfter generating the xml files and trying to `openmc` I get the following error:\r\n```\r\nReading tallies XML file...\r\nERROR: Two or more meshes use the same unique ID: 1\r\n```\n", "before_files": [{"content": "import openmc\n\n###############################################################################\n# Simulation Input File Parameters\n###############################################################################\n\n# OpenMC simulation parameters\nbatches = 100\ninactive = 10\nparticles = 1000\n\n\n###############################################################################\n# Exporting to OpenMC materials.xml file\n###############################################################################\n\n\n# Instantiate some Materials and register the appropriate Nuclides\nuo2 = openmc.Material(material_id=1, name='UO2 fuel at 2.4% wt enrichment')\nuo2.set_density('g/cm3', 10.29769)\nuo2.add_element('U', 1., enrichment=2.4)\nuo2.add_element('O', 2.)\n\nhelium = openmc.Material(material_id=2, name='Helium for gap')\nhelium.set_density('g/cm3', 0.001598)\nhelium.add_element('He', 2.4044e-4)\n\nzircaloy = openmc.Material(material_id=3, name='Zircaloy 4')\nzircaloy.set_density('g/cm3', 6.55)\nzircaloy.add_element('Sn', 0.014 , 'wo')\nzircaloy.add_element('Fe', 0.00165, 'wo')\nzircaloy.add_element('Cr', 0.001 , 'wo')\nzircaloy.add_element('Zr', 0.98335, 'wo')\n\nborated_water = openmc.Material(material_id=4, name='Borated water')\nborated_water.set_density('g/cm3', 0.740582)\nborated_water.add_element('B', 4.0e-5)\nborated_water.add_element('H', 5.0e-2)\nborated_water.add_element('O', 2.4e-2)\nborated_water.add_s_alpha_beta('c_H_in_H2O')\n\n# Instantiate a Materials collection and export to XML\nmaterials_file = openmc.Materials([uo2, helium, zircaloy, borated_water])\nmaterials_file.export_to_xml()\n\n\n###############################################################################\n# Exporting to OpenMC geometry.xml file\n###############################################################################\n\n# Instantiate ZCylinder surfaces\nfuel_or = openmc.ZCylinder(surface_id=1, x0=0, y0=0, R=0.39218, name='Fuel OR')\nclad_ir = openmc.ZCylinder(surface_id=2, x0=0, y0=0, R=0.40005, name='Clad IR')\nclad_or = openmc.ZCylinder(surface_id=3, x0=0, y0=0, R=0.45720, name='Clad OR')\nleft = openmc.XPlane(surface_id=4, x0=-0.62992, name='left')\nright = openmc.XPlane(surface_id=5, x0=0.62992, name='right')\nbottom = openmc.YPlane(surface_id=6, y0=-0.62992, name='bottom')\ntop = openmc.YPlane(surface_id=7, y0=0.62992, name='top')\n\nleft.boundary_type = 'reflective'\nright.boundary_type = 'reflective'\ntop.boundary_type = 'reflective'\nbottom.boundary_type = 'reflective'\n\n# Instantiate Cells\nfuel = openmc.Cell(cell_id=1, name='cell 1')\ngap = openmc.Cell(cell_id=2, name='cell 2')\nclad = openmc.Cell(cell_id=3, name='cell 3')\nwater = openmc.Cell(cell_id=4, name='cell 4')\n\n# Use surface half-spaces to define regions\nfuel.region = -fuel_or\ngap.region = +fuel_or & -clad_ir\nclad.region = +clad_ir & -clad_or\nwater.region = +clad_or & +left & -right & +bottom & -top\n\n# Register Materials with Cells\nfuel.fill = uo2\ngap.fill = helium\nclad.fill = zircaloy\nwater.fill = borated_water\n\n# Instantiate Universe\nroot = openmc.Universe(universe_id=0, name='root universe')\n\n# Register Cells with Universe\nroot.add_cells([fuel, gap, clad, water])\n\n# Instantiate a Geometry, register the root Universe, and export to XML\ngeometry = openmc.Geometry(root)\ngeometry.export_to_xml()\n\n\n###############################################################################\n# Exporting to OpenMC settings.xml file\n###############################################################################\n\n# Instantiate a Settings object, set all runtime parameters, and export to XML\nsettings_file = openmc.Settings()\nsettings_file.batches = batches\nsettings_file.inactive = inactive\nsettings_file.particles = particles\n\n# Create an initial uniform spatial source distribution over fissionable zones\nbounds = [-0.62992, -0.62992, -1, 0.62992, 0.62992, 1]\nuniform_dist = openmc.stats.Box(bounds[:3], bounds[3:], only_fissionable=True)\nsettings_file.source = openmc.source.Source(space=uniform_dist)\n\nentropy_mesh = openmc.Mesh()\nentropy_mesh.lower_left = [-0.39218, -0.39218, -1.e50]\nentropy_mesh.upper_right = [0.39218, 0.39218, 1.e50]\nentropy_mesh.dimension = [10, 10, 1]\nsettings_file.entropy_mesh = entropy_mesh\nsettings_file.export_to_xml()\n\n\n###############################################################################\n# Exporting to OpenMC tallies.xml file\n###############################################################################\n\n# Instantiate a tally mesh\nmesh = openmc.Mesh(mesh_id=1)\nmesh.type = 'regular'\nmesh.dimension = [100, 100, 1]\nmesh.lower_left = [-0.62992, -0.62992, -1.e50]\nmesh.upper_right = [0.62992, 0.62992, 1.e50]\n\n# Instantiate some tally Filters\nenergy_filter = openmc.EnergyFilter([0., 4., 20.e6])\nmesh_filter = openmc.MeshFilter(mesh)\n\n# Instantiate the Tally\ntally = openmc.Tally(tally_id=1, name='tally 1')\ntally.filters = [energy_filter, mesh_filter]\ntally.scores = ['flux', 'fission', 'nu-fission']\n\n# Instantiate a Tallies collection and export to XML\ntallies_file = openmc.Tallies([tally])\ntallies_file.export_to_xml()\n", "path": "examples/python/pincell/build-xml.py"}]}
| 2,378 | 139 |
gh_patches_debug_7240
|
rasdani/github-patches
|
git_diff
|
ansible__awx-14489
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tower Settings of type on/off idempotency not working
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
- [X] I am **NOT** reporting a (potential) security vulnerability. (These should be emailed to `[email protected]` instead.)
### Bug Summary
When trying to set the setting named AWX_MOUNT_ISOLATED_PATHS_ON_K8S to true, no matter what I put in the playbook it is always marked as "changed: true", even if the setting is already true..
Sample Task:
```
- name: SET AWX EXPOSE HOST PATHS
awx.awx.settings:
name: "AWX_MOUNT_ISOLATED_PATHS_ON_K8S"
value: true
```
When I change the playbook value and register the results of the task to review the results I get this:
| Value In Playbook | Resulting Debug|
| ------- | ------- |
| true | ok: [awxlab] => {<br> "this_setting": {<br> "changed": true,<br> "failed": false,<br> "new_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": "True"<br> },<br> "old_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": true<br> },<br> "value": true<br> }<br>}|
| True | ok: [awxlab] => {<br> "this_setting": {<br> "changed": true,<br> "failed": false,<br> "new_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": "True"<br> },<br> "old_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": true<br> },<br> "value": true<br> }<br>}|
| "true" | ok: [awxlab] => {<br> "this_setting": {<br> "changed": true,<br> "failed": false,<br> "new_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": "true"<br> },<br> "old_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": true<br> },<br> "value": true<br> }<br>}|
| "True" | ok: [awxlab] => {<br> "this_setting": {<br> "changed": true,<br> "failed": false,<br> "new_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": "True"<br> },<br> "old_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": true<br> },<br> "value": true<br> }<br>}
| yes | ok: [awxlab] => {<br> "this_setting": {<br> "changed": true,<br> "failed": false,<br> "new_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": "True"<br> },<br> "old_values": {<br> "AWX_MOUNT_ISOLATED_PATHS_ON_K8S": true<br> },<br> "value": true<br> }<br>}
The documentation says this:
```> AWX.AWX.SETTINGS ([...]collections/ansible_collections/awx/awx/plugins/modules/settings.py)
Modify Automation Platform Controller settings. See https://www.ansible.com/tower for an overview.
OPTIONS (= is mandatory):
- value
Value to be modified for given setting.
**If given a non-string type, will make best effort to cast it to type API expects.**
For better control over types, use the `settings' param instead.
default: null
type: str
```
This leads me to believe that the logic used to sanitize the input might be doing a little extra or the conversion of 'settings' parameters to/from name/value parameters.
The documentation does show an example of how to use both the settings parameter and the name/value parameter. So, this may be lower priority but I wanted to get this somewhere that could be search by others who may be running into this issue.
### AWX version
23.1.0
### Select the relevant components
- [ ] UI
- [ ] UI (tech preview)
- [ ] API
- [ ] Docs
- [X] Collection
- [ ] CLI
- [ ] Other
### Installation method
kubernetes
### Modifications
no
### Ansible version
2.15.4
### Operating system
CentOS Stream release 9
### Web browser
Firefox
### Steps to reproduce
Use a playbook that modifies a boolean setting.
Use the awx.awx.setting module.
Use the name/value parameters instead of the settings paremeter.
Sample:
```
- name: SET AWX EXPOSE HOST PATHS
awx.awx.settings:
name: "AWX_MOUNT_ISOLATED_PATHS_ON_K8S"
value: true
register: this_setting
- name: Debug this setting
debug: var=this_setting
```
### Expected results
When the setting is already true, idempotency keeps the playbook from trying to update the setting again.
### Actual results
Regardless if the setting is true or not, the playbook always updates the setting.
### Additional information
_No response_
</issue>
<code>
[start of awx_collection/plugins/modules/settings.py]
1 #!/usr/bin/python
2 # coding: utf-8 -*-
3
4 # (c) 2018, Nikhil Jain <[email protected]>
5 # GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)
6
7 from __future__ import absolute_import, division, print_function
8
9 __metaclass__ = type
10
11
12 ANSIBLE_METADATA = {'metadata_version': '1.1', 'status': ['preview'], 'supported_by': 'community'}
13
14
15 DOCUMENTATION = '''
16 ---
17 module: settings
18 author: "Nikhil Jain (@jainnikhil30)"
19 short_description: Modify Automation Platform Controller settings.
20 description:
21 - Modify Automation Platform Controller settings. See
22 U(https://www.ansible.com/tower) for an overview.
23 options:
24 name:
25 description:
26 - Name of setting to modify
27 type: str
28 value:
29 description:
30 - Value to be modified for given setting.
31 - If given a non-string type, will make best effort to cast it to type API expects.
32 - For better control over types, use the C(settings) param instead.
33 type: str
34 settings:
35 description:
36 - A data structure to be sent into the settings endpoint
37 type: dict
38 requirements:
39 - pyyaml
40 extends_documentation_fragment: awx.awx.auth
41 '''
42
43 EXAMPLES = '''
44 - name: Set the value of AWX_ISOLATION_BASE_PATH
45 settings:
46 name: AWX_ISOLATION_BASE_PATH
47 value: "/tmp"
48 register: testing_settings
49
50 - name: Set the value of AWX_ISOLATION_SHOW_PATHS
51 settings:
52 name: "AWX_ISOLATION_SHOW_PATHS"
53 value: "'/var/lib/awx/projects/', '/tmp'"
54 register: testing_settings
55
56 - name: Set the LDAP Auth Bind Password
57 settings:
58 name: "AUTH_LDAP_BIND_PASSWORD"
59 value: "Password"
60 no_log: true
61
62 - name: Set all the LDAP Auth Bind Params
63 settings:
64 settings:
65 AUTH_LDAP_BIND_PASSWORD: "password"
66 AUTH_LDAP_USER_ATTR_MAP:
67 email: "mail"
68 first_name: "givenName"
69 last_name: "surname"
70 '''
71
72 from ..module_utils.controller_api import ControllerAPIModule
73
74 try:
75 import yaml
76
77 HAS_YAML = True
78 except ImportError:
79 HAS_YAML = False
80
81
82 def coerce_type(module, value):
83 # If our value is already None we can just return directly
84 if value is None:
85 return value
86
87 yaml_ish = bool((value.startswith('{') and value.endswith('}')) or (value.startswith('[') and value.endswith(']')))
88 if yaml_ish:
89 if not HAS_YAML:
90 module.fail_json(msg="yaml is not installed, try 'pip install pyyaml'")
91 return yaml.safe_load(value)
92 elif value.lower in ('true', 'false', 't', 'f'):
93 return {'t': True, 'f': False}[value[0].lower()]
94 try:
95 return int(value)
96 except ValueError:
97 pass
98 return value
99
100
101 def main():
102 # Any additional arguments that are not fields of the item can be added here
103 argument_spec = dict(
104 name=dict(),
105 value=dict(),
106 settings=dict(type='dict'),
107 )
108
109 # Create a module for ourselves
110 module = ControllerAPIModule(
111 argument_spec=argument_spec,
112 required_one_of=[['name', 'settings']],
113 mutually_exclusive=[['name', 'settings']],
114 required_if=[['name', 'present', ['value']]],
115 )
116
117 # Extract our parameters
118 name = module.params.get('name')
119 value = module.params.get('value')
120 new_settings = module.params.get('settings')
121
122 # If we were given a name/value pair we will just make settings out of that and proceed normally
123 if new_settings is None:
124 new_value = coerce_type(module, value)
125
126 new_settings = {name: new_value}
127
128 # Load the existing settings
129 existing_settings = module.get_endpoint('settings/all')['json']
130
131 # Begin a json response
132 json_output = {'changed': False, 'old_values': {}, 'new_values': {}}
133
134 # Check any of the settings to see if anything needs to be updated
135 needs_update = False
136 for a_setting in new_settings:
137 if a_setting not in existing_settings or existing_settings[a_setting] != new_settings[a_setting]:
138 # At least one thing is different so we need to patch
139 needs_update = True
140 json_output['old_values'][a_setting] = existing_settings[a_setting]
141 json_output['new_values'][a_setting] = new_settings[a_setting]
142
143 if module._diff:
144 json_output['diff'] = {'before': json_output['old_values'], 'after': json_output['new_values']}
145
146 # If nothing needs an update we can simply exit with the response (as not changed)
147 if not needs_update:
148 module.exit_json(**json_output)
149
150 if module.check_mode and module._diff:
151 json_output['changed'] = True
152 module.exit_json(**json_output)
153
154 # Make the call to update the settings
155 response = module.patch_endpoint('settings/all', **{'data': new_settings})
156
157 if response['status_code'] == 200:
158 # Set the changed response to True
159 json_output['changed'] = True
160
161 # To deal with the old style values we need to return 'value' in the response
162 new_values = {}
163 for a_setting in new_settings:
164 new_values[a_setting] = response['json'][a_setting]
165
166 # If we were using a name we will just add a value of a string, otherwise we will return an array in values
167 if name is not None:
168 json_output['value'] = new_values[name]
169 else:
170 json_output['values'] = new_values
171
172 module.exit_json(**json_output)
173 elif 'json' in response and '__all__' in response['json']:
174 module.fail_json(msg=response['json']['__all__'])
175 else:
176 module.fail_json(**{'msg': "Unable to update settings, see response", 'response': response})
177
178
179 if __name__ == '__main__':
180 main()
181
[end of awx_collection/plugins/modules/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/awx_collection/plugins/modules/settings.py b/awx_collection/plugins/modules/settings.py
--- a/awx_collection/plugins/modules/settings.py
+++ b/awx_collection/plugins/modules/settings.py
@@ -89,7 +89,7 @@
if not HAS_YAML:
module.fail_json(msg="yaml is not installed, try 'pip install pyyaml'")
return yaml.safe_load(value)
- elif value.lower in ('true', 'false', 't', 'f'):
+ elif value.lower() in ('true', 'false', 't', 'f'):
return {'t': True, 'f': False}[value[0].lower()]
try:
return int(value)
|
{"golden_diff": "diff --git a/awx_collection/plugins/modules/settings.py b/awx_collection/plugins/modules/settings.py\n--- a/awx_collection/plugins/modules/settings.py\n+++ b/awx_collection/plugins/modules/settings.py\n@@ -89,7 +89,7 @@\n if not HAS_YAML:\n module.fail_json(msg=\"yaml is not installed, try 'pip install pyyaml'\")\n return yaml.safe_load(value)\n- elif value.lower in ('true', 'false', 't', 'f'):\n+ elif value.lower() in ('true', 'false', 't', 'f'):\n return {'t': True, 'f': False}[value[0].lower()]\n try:\n return int(value)\n", "issue": "Tower Settings of type on/off idempotency not working\n### Please confirm the following\n\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\n- [X] I am **NOT** reporting a (potential) security vulnerability. (These should be emailed to `[email protected]` instead.)\n\n### Bug Summary\n\nWhen trying to set the setting named AWX_MOUNT_ISOLATED_PATHS_ON_K8S to true, no matter what I put in the playbook it is always marked as \"changed: true\", even if the setting is already true..\r\n\r\nSample Task:\r\n```\r\n - name: SET AWX EXPOSE HOST PATHS\r\n awx.awx.settings:\r\n name: \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\"\r\n value: true\r\n\r\n```\r\n\r\nWhen I change the playbook value and register the results of the task to review the results I get this:\r\n\r\n| Value In Playbook | Resulting Debug|\r\n| ------- | ------- |\r\n| true | ok: [awxlab] => {<br> \"this_setting\": {<br> \"changed\": true,<br> \"failed\": false,<br> \"new_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": \"True\"<br> },<br> \"old_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": true<br> },<br> \"value\": true<br> }<br>}|\r\n| True | ok: [awxlab] => {<br> \"this_setting\": {<br> \"changed\": true,<br> \"failed\": false,<br> \"new_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": \"True\"<br> },<br> \"old_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": true<br> },<br> \"value\": true<br> }<br>}|\r\n| \"true\" | ok: [awxlab] => {<br> \"this_setting\": {<br> \"changed\": true,<br> \"failed\": false,<br> \"new_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": \"true\"<br> },<br> \"old_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": true<br> },<br> \"value\": true<br> }<br>}|\r\n| \"True\" | ok: [awxlab] => {<br> \"this_setting\": {<br> \"changed\": true,<br> \"failed\": false,<br> \"new_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": \"True\"<br> },<br> \"old_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": true<br> },<br> \"value\": true<br> }<br>}\r\n| yes | ok: [awxlab] => {<br> \"this_setting\": {<br> \"changed\": true,<br> \"failed\": false,<br> \"new_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": \"True\"<br> },<br> \"old_values\": {<br> \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\": true<br> },<br> \"value\": true<br> }<br>}\r\n\r\n\r\nThe documentation says this:\r\n```> AWX.AWX.SETTINGS ([...]collections/ansible_collections/awx/awx/plugins/modules/settings.py)\r\n\r\n Modify Automation Platform Controller settings. See https://www.ansible.com/tower for an overview.\r\n\r\nOPTIONS (= is mandatory):\r\n- value\r\n Value to be modified for given setting.\r\n **If given a non-string type, will make best effort to cast it to type API expects.**\r\n For better control over types, use the `settings' param instead.\r\n default: null\r\n type: str\r\n```\r\n\r\nThis leads me to believe that the logic used to sanitize the input might be doing a little extra or the conversion of 'settings' parameters to/from name/value parameters.\r\n\r\nThe documentation does show an example of how to use both the settings parameter and the name/value parameter. So, this may be lower priority but I wanted to get this somewhere that could be search by others who may be running into this issue.\n\n### AWX version\n\n23.1.0\n\n### Select the relevant components\n\n- [ ] UI\n- [ ] UI (tech preview)\n- [ ] API\n- [ ] Docs\n- [X] Collection\n- [ ] CLI\n- [ ] Other\n\n### Installation method\n\nkubernetes\n\n### Modifications\n\nno\n\n### Ansible version\n\n2.15.4\n\n### Operating system\n\nCentOS Stream release 9\n\n### Web browser\n\nFirefox\n\n### Steps to reproduce\n\nUse a playbook that modifies a boolean setting.\r\nUse the awx.awx.setting module.\r\nUse the name/value parameters instead of the settings paremeter.\r\nSample:\r\n```\r\n - name: SET AWX EXPOSE HOST PATHS\r\n awx.awx.settings:\r\n name: \"AWX_MOUNT_ISOLATED_PATHS_ON_K8S\"\r\n value: true\r\n register: this_setting\r\n \r\n - name: Debug this setting\r\n debug: var=this_setting\r\n```\n\n### Expected results\n\nWhen the setting is already true, idempotency keeps the playbook from trying to update the setting again.\n\n### Actual results\n\nRegardless if the setting is true or not, the playbook always updates the setting.\n\n### Additional information\n\n_No response_\n", "before_files": [{"content": "#!/usr/bin/python\n# coding: utf-8 -*-\n\n# (c) 2018, Nikhil Jain <[email protected]>\n# GNU General Public License v3.0+ (see COPYING or https://www.gnu.org/licenses/gpl-3.0.txt)\n\nfrom __future__ import absolute_import, division, print_function\n\n__metaclass__ = type\n\n\nANSIBLE_METADATA = {'metadata_version': '1.1', 'status': ['preview'], 'supported_by': 'community'}\n\n\nDOCUMENTATION = '''\n---\nmodule: settings\nauthor: \"Nikhil Jain (@jainnikhil30)\"\nshort_description: Modify Automation Platform Controller settings.\ndescription:\n - Modify Automation Platform Controller settings. See\n U(https://www.ansible.com/tower) for an overview.\noptions:\n name:\n description:\n - Name of setting to modify\n type: str\n value:\n description:\n - Value to be modified for given setting.\n - If given a non-string type, will make best effort to cast it to type API expects.\n - For better control over types, use the C(settings) param instead.\n type: str\n settings:\n description:\n - A data structure to be sent into the settings endpoint\n type: dict\nrequirements:\n - pyyaml\nextends_documentation_fragment: awx.awx.auth\n'''\n\nEXAMPLES = '''\n- name: Set the value of AWX_ISOLATION_BASE_PATH\n settings:\n name: AWX_ISOLATION_BASE_PATH\n value: \"/tmp\"\n register: testing_settings\n\n- name: Set the value of AWX_ISOLATION_SHOW_PATHS\n settings:\n name: \"AWX_ISOLATION_SHOW_PATHS\"\n value: \"'/var/lib/awx/projects/', '/tmp'\"\n register: testing_settings\n\n- name: Set the LDAP Auth Bind Password\n settings:\n name: \"AUTH_LDAP_BIND_PASSWORD\"\n value: \"Password\"\n no_log: true\n\n- name: Set all the LDAP Auth Bind Params\n settings:\n settings:\n AUTH_LDAP_BIND_PASSWORD: \"password\"\n AUTH_LDAP_USER_ATTR_MAP:\n email: \"mail\"\n first_name: \"givenName\"\n last_name: \"surname\"\n'''\n\nfrom ..module_utils.controller_api import ControllerAPIModule\n\ntry:\n import yaml\n\n HAS_YAML = True\nexcept ImportError:\n HAS_YAML = False\n\n\ndef coerce_type(module, value):\n # If our value is already None we can just return directly\n if value is None:\n return value\n\n yaml_ish = bool((value.startswith('{') and value.endswith('}')) or (value.startswith('[') and value.endswith(']')))\n if yaml_ish:\n if not HAS_YAML:\n module.fail_json(msg=\"yaml is not installed, try 'pip install pyyaml'\")\n return yaml.safe_load(value)\n elif value.lower in ('true', 'false', 't', 'f'):\n return {'t': True, 'f': False}[value[0].lower()]\n try:\n return int(value)\n except ValueError:\n pass\n return value\n\n\ndef main():\n # Any additional arguments that are not fields of the item can be added here\n argument_spec = dict(\n name=dict(),\n value=dict(),\n settings=dict(type='dict'),\n )\n\n # Create a module for ourselves\n module = ControllerAPIModule(\n argument_spec=argument_spec,\n required_one_of=[['name', 'settings']],\n mutually_exclusive=[['name', 'settings']],\n required_if=[['name', 'present', ['value']]],\n )\n\n # Extract our parameters\n name = module.params.get('name')\n value = module.params.get('value')\n new_settings = module.params.get('settings')\n\n # If we were given a name/value pair we will just make settings out of that and proceed normally\n if new_settings is None:\n new_value = coerce_type(module, value)\n\n new_settings = {name: new_value}\n\n # Load the existing settings\n existing_settings = module.get_endpoint('settings/all')['json']\n\n # Begin a json response\n json_output = {'changed': False, 'old_values': {}, 'new_values': {}}\n\n # Check any of the settings to see if anything needs to be updated\n needs_update = False\n for a_setting in new_settings:\n if a_setting not in existing_settings or existing_settings[a_setting] != new_settings[a_setting]:\n # At least one thing is different so we need to patch\n needs_update = True\n json_output['old_values'][a_setting] = existing_settings[a_setting]\n json_output['new_values'][a_setting] = new_settings[a_setting]\n\n if module._diff:\n json_output['diff'] = {'before': json_output['old_values'], 'after': json_output['new_values']}\n\n # If nothing needs an update we can simply exit with the response (as not changed)\n if not needs_update:\n module.exit_json(**json_output)\n\n if module.check_mode and module._diff:\n json_output['changed'] = True\n module.exit_json(**json_output)\n\n # Make the call to update the settings\n response = module.patch_endpoint('settings/all', **{'data': new_settings})\n\n if response['status_code'] == 200:\n # Set the changed response to True\n json_output['changed'] = True\n\n # To deal with the old style values we need to return 'value' in the response\n new_values = {}\n for a_setting in new_settings:\n new_values[a_setting] = response['json'][a_setting]\n\n # If we were using a name we will just add a value of a string, otherwise we will return an array in values\n if name is not None:\n json_output['value'] = new_values[name]\n else:\n json_output['values'] = new_values\n\n module.exit_json(**json_output)\n elif 'json' in response and '__all__' in response['json']:\n module.fail_json(msg=response['json']['__all__'])\n else:\n module.fail_json(**{'msg': \"Unable to update settings, see response\", 'response': response})\n\n\nif __name__ == '__main__':\n main()\n", "path": "awx_collection/plugins/modules/settings.py"}]}
| 3,673 | 151 |
gh_patches_debug_29809
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-3691
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add type hints to humanize.py
Add type hints to `src/toil/lib/humanize.py` so it can be checked under mypy during linting.
Refers to #3568.
┆Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-946)
┆Issue Number: TOIL-946
</issue>
<code>
[start of src/toil/lib/humanize.py]
1 # Used by cactus; now a wrapper and not used in Toil.
2 # TODO: Remove from cactus and then remove from Toil.
3 # See https://github.com/DataBiosphere/toil/pull/3529#discussion_r611735988
4
5 # http://code.activestate.com/recipes/578019-bytes-to-human-human-to-bytes-converter/
6 import logging
7 from typing import Optional, SupportsInt
8 from toil.lib.conversions import bytes2human as b2h, human2bytes as h2b
9
10 """
11 Bytes-to-human / human-to-bytes converter.
12 Based on: http://goo.gl/kTQMs
13 Working with Python 2.x and 3.x.
14
15 Author: Giampaolo Rodola' <g.rodola [AT] gmail [DOT] com>
16 License: MIT
17 """
18
19 logger = logging.getLogger(__name__)
20
21
22 def bytes2human(n: SupportsInt, fmt: Optional[str] = None, symbols: Optional[str] = None) -> str:
23 """
24 Convert n bytes into a human readable string based on format.
25 symbols can be either "customary", "customary_ext", "iec" or "iec_ext",
26 see: http://goo.gl/kTQMs
27 """
28 logger.warning('Deprecated toil method. Please use "toil.lib.conversions.bytes2human()" instead."')
29 return b2h(n)
30
31
32 def human2bytes(s):
33 """
34 Attempts to guess the string format based on default symbols
35 set and return the corresponding bytes as an integer.
36
37 When unable to recognize the format ValueError is raised.
38 """
39 logger.warning('Deprecated toil method. Please use "toil.lib.conversions.human2bytes()" instead."')
40 return h2b(s)
41
[end of src/toil/lib/humanize.py]
[start of contrib/admin/mypy-with-ignore.py]
1 #!/usr/bin/env python3
2 """
3 Runs mypy and ignores files that do not yet have passing type hints.
4
5 Does not type check test files (any path including "src/toil/test").
6 """
7 import os
8 import subprocess
9 import sys
10
11 os.environ['MYPYPATH'] = 'contrib/typeshed'
12 pkg_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')) # noqa
13 sys.path.insert(0, pkg_root) # noqa
14
15 from src.toil.lib.resources import glob # type: ignore
16
17
18 def main():
19 all_files_to_check = []
20 for d in ['dashboard', 'docker', 'docs', 'src']:
21 all_files_to_check += glob(glob_pattern='*.py', directoryname=os.path.join(pkg_root, d))
22
23 # TODO: Remove these paths as typing is added and mypy conflicts are addressed
24 ignore_paths = [os.path.abspath(f) for f in [
25 'docker/Dockerfile.py',
26 'docs/conf.py',
27 'docs/vendor/sphinxcontrib/fulltoc.py',
28 'docs/vendor/sphinxcontrib/__init__.py',
29 'src/toil/job.py',
30 'src/toil/leader.py',
31 'src/toil/common.py',
32 'src/toil/worker.py',
33 'src/toil/toilState.py',
34 'src/toil/__init__.py',
35 'src/toil/resource.py',
36 'src/toil/deferred.py',
37 'src/toil/version.py',
38 'src/toil/wdl/utils.py',
39 'src/toil/wdl/wdl_types.py',
40 'src/toil/wdl/wdl_synthesis.py',
41 'src/toil/wdl/wdl_analysis.py',
42 'src/toil/wdl/wdl_functions.py',
43 'src/toil/wdl/toilwdl.py',
44 'src/toil/wdl/versions/draft2.py',
45 'src/toil/wdl/versions/v1.py',
46 'src/toil/wdl/versions/dev.py',
47 'src/toil/provisioners/clusterScaler.py',
48 'src/toil/provisioners/abstractProvisioner.py',
49 'src/toil/provisioners/gceProvisioner.py',
50 'src/toil/provisioners/__init__.py',
51 'src/toil/provisioners/node.py',
52 'src/toil/provisioners/aws/boto2Context.py',
53 'src/toil/provisioners/aws/awsProvisioner.py',
54 'src/toil/provisioners/aws/__init__.py',
55 'src/toil/batchSystems/slurm.py',
56 'src/toil/batchSystems/gridengine.py',
57 'src/toil/batchSystems/singleMachine.py',
58 'src/toil/batchSystems/abstractBatchSystem.py',
59 'src/toil/batchSystems/parasol.py',
60 'src/toil/batchSystems/kubernetes.py',
61 'src/toil/batchSystems/torque.py',
62 'src/toil/batchSystems/options.py',
63 'src/toil/batchSystems/registry.py',
64 'src/toil/batchSystems/lsf.py',
65 'src/toil/batchSystems/__init__.py',
66 'src/toil/batchSystems/abstractGridEngineBatchSystem.py',
67 'src/toil/batchSystems/lsfHelper.py',
68 'src/toil/batchSystems/htcondor.py',
69 'src/toil/batchSystems/mesos/batchSystem.py',
70 'src/toil/batchSystems/mesos/executor.py',
71 'src/toil/batchSystems/mesos/conftest.py',
72 'src/toil/batchSystems/mesos/__init__.py',
73 'src/toil/batchSystems/mesos/test/__init__.py',
74 'src/toil/cwl/conftest.py',
75 'src/toil/cwl/__init__.py',
76 'src/toil/cwl/cwltoil.py',
77 'src/toil/fileStores/cachingFileStore.py',
78 'src/toil/fileStores/abstractFileStore.py',
79 'src/toil/fileStores/nonCachingFileStore.py',
80 'src/toil/fileStores/__init__.py',
81 'src/toil/jobStores/utils.py',
82 'src/toil/jobStores/conftest.py',
83 'src/toil/jobStores/fileJobStore.py',
84 'src/toil/jobStores/__init__.py',
85 'src/toil/jobStores/googleJobStore.py',
86 'src/toil/jobStores/aws/utils.py',
87 'src/toil/jobStores/aws/jobStore.py',
88 'src/toil/jobStores/aws/__init__.py',
89 'src/toil/utils/__init__.py',
90 'src/toil/lib/memoize.py',
91 'src/toil/lib/throttle.py',
92 'src/toil/lib/humanize.py',
93 'src/toil/lib/iterables.py',
94 'src/toil/lib/bioio.py',
95 'src/toil/lib/ec2.py',
96 'src/toil/lib/expando.py',
97 'src/toil/lib/exceptions.py',
98 'src/toil/lib/__init__.py',
99 'src/toil/lib/generatedEC2Lists.py',
100 'src/toil/lib/retry.py',
101 'src/toil/lib/objects.py',
102 'src/toil/lib/io.py',
103 'src/toil/lib/docker.py',
104 'src/toil/lib/encryption/_dummy.py',
105 'src/toil/lib/encryption/conftest.py',
106 'src/toil/lib/encryption/__init__.py',
107 'src/toil/lib/aws/utils.py',
108 'src/toil/lib/aws/__init__.py'
109 ]]
110
111 filtered_files_to_check = []
112 for file_path in all_files_to_check:
113 if file_path not in ignore_paths and 'src/toil/test' not in file_path:
114 filtered_files_to_check.append(file_path)
115 # follow-imports type checks pypi projects we don't control, so we skip it; why is this their default?
116 args = ['mypy', '--follow-imports=skip'] + filtered_files_to_check
117 p = subprocess.run(args=args, stdout=subprocess.PIPE)
118 result = p.stdout.decode()
119 print(result)
120 if 'Success: no issues found' not in result:
121 exit(1)
122
123
124 if __name__ == '__main__':
125 main()
126
[end of contrib/admin/mypy-with-ignore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/contrib/admin/mypy-with-ignore.py b/contrib/admin/mypy-with-ignore.py
--- a/contrib/admin/mypy-with-ignore.py
+++ b/contrib/admin/mypy-with-ignore.py
@@ -89,7 +89,6 @@
'src/toil/utils/__init__.py',
'src/toil/lib/memoize.py',
'src/toil/lib/throttle.py',
- 'src/toil/lib/humanize.py',
'src/toil/lib/iterables.py',
'src/toil/lib/bioio.py',
'src/toil/lib/ec2.py',
diff --git a/src/toil/lib/humanize.py b/src/toil/lib/humanize.py
--- a/src/toil/lib/humanize.py
+++ b/src/toil/lib/humanize.py
@@ -4,7 +4,7 @@
# http://code.activestate.com/recipes/578019-bytes-to-human-human-to-bytes-converter/
import logging
-from typing import Optional, SupportsInt
+from typing import SupportsInt
from toil.lib.conversions import bytes2human as b2h, human2bytes as h2b
"""
@@ -19,17 +19,15 @@
logger = logging.getLogger(__name__)
-def bytes2human(n: SupportsInt, fmt: Optional[str] = None, symbols: Optional[str] = None) -> str:
+def bytes2human(n: SupportsInt) -> str:
"""
- Convert n bytes into a human readable string based on format.
- symbols can be either "customary", "customary_ext", "iec" or "iec_ext",
- see: http://goo.gl/kTQMs
+ Convert n bytes into a human readable string.
"""
logger.warning('Deprecated toil method. Please use "toil.lib.conversions.bytes2human()" instead."')
return b2h(n)
-def human2bytes(s):
+def human2bytes(s: str) -> int:
"""
Attempts to guess the string format based on default symbols
set and return the corresponding bytes as an integer.
|
{"golden_diff": "diff --git a/contrib/admin/mypy-with-ignore.py b/contrib/admin/mypy-with-ignore.py\n--- a/contrib/admin/mypy-with-ignore.py\n+++ b/contrib/admin/mypy-with-ignore.py\n@@ -89,7 +89,6 @@\n 'src/toil/utils/__init__.py',\n 'src/toil/lib/memoize.py',\n 'src/toil/lib/throttle.py',\n- 'src/toil/lib/humanize.py',\n 'src/toil/lib/iterables.py',\n 'src/toil/lib/bioio.py',\n 'src/toil/lib/ec2.py',\ndiff --git a/src/toil/lib/humanize.py b/src/toil/lib/humanize.py\n--- a/src/toil/lib/humanize.py\n+++ b/src/toil/lib/humanize.py\n@@ -4,7 +4,7 @@\n \n # http://code.activestate.com/recipes/578019-bytes-to-human-human-to-bytes-converter/\n import logging\n-from typing import Optional, SupportsInt\n+from typing import SupportsInt\n from toil.lib.conversions import bytes2human as b2h, human2bytes as h2b\n \n \"\"\"\n@@ -19,17 +19,15 @@\n logger = logging.getLogger(__name__)\n \n \n-def bytes2human(n: SupportsInt, fmt: Optional[str] = None, symbols: Optional[str] = None) -> str:\n+def bytes2human(n: SupportsInt) -> str:\n \"\"\"\n- Convert n bytes into a human readable string based on format.\n- symbols can be either \"customary\", \"customary_ext\", \"iec\" or \"iec_ext\",\n- see: http://goo.gl/kTQMs\n+ Convert n bytes into a human readable string.\n \"\"\"\n logger.warning('Deprecated toil method. Please use \"toil.lib.conversions.bytes2human()\" instead.\"')\n return b2h(n)\n \n \n-def human2bytes(s):\n+def human2bytes(s: str) -> int:\n \"\"\"\n Attempts to guess the string format based on default symbols\n set and return the corresponding bytes as an integer.\n", "issue": "Add type hints to humanize.py\nAdd type hints to `src/toil/lib/humanize.py` so it can be checked under mypy during linting.\n\nRefers to #3568.\n\n\u2506Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-946)\n\u2506Issue Number: TOIL-946\n\n", "before_files": [{"content": "# Used by cactus; now a wrapper and not used in Toil.\n# TODO: Remove from cactus and then remove from Toil.\n# See https://github.com/DataBiosphere/toil/pull/3529#discussion_r611735988\n\n# http://code.activestate.com/recipes/578019-bytes-to-human-human-to-bytes-converter/\nimport logging\nfrom typing import Optional, SupportsInt\nfrom toil.lib.conversions import bytes2human as b2h, human2bytes as h2b\n\n\"\"\"\nBytes-to-human / human-to-bytes converter.\nBased on: http://goo.gl/kTQMs\nWorking with Python 2.x and 3.x.\n\nAuthor: Giampaolo Rodola' <g.rodola [AT] gmail [DOT] com>\nLicense: MIT\n\"\"\"\n\nlogger = logging.getLogger(__name__)\n\n\ndef bytes2human(n: SupportsInt, fmt: Optional[str] = None, symbols: Optional[str] = None) -> str:\n \"\"\"\n Convert n bytes into a human readable string based on format.\n symbols can be either \"customary\", \"customary_ext\", \"iec\" or \"iec_ext\",\n see: http://goo.gl/kTQMs\n \"\"\"\n logger.warning('Deprecated toil method. Please use \"toil.lib.conversions.bytes2human()\" instead.\"')\n return b2h(n)\n\n\ndef human2bytes(s):\n \"\"\"\n Attempts to guess the string format based on default symbols\n set and return the corresponding bytes as an integer.\n\n When unable to recognize the format ValueError is raised.\n \"\"\"\n logger.warning('Deprecated toil method. Please use \"toil.lib.conversions.human2bytes()\" instead.\"')\n return h2b(s)\n", "path": "src/toil/lib/humanize.py"}, {"content": "#!/usr/bin/env python3\n\"\"\"\nRuns mypy and ignores files that do not yet have passing type hints.\n\nDoes not type check test files (any path including \"src/toil/test\").\n\"\"\"\nimport os\nimport subprocess\nimport sys\n\nos.environ['MYPYPATH'] = 'contrib/typeshed'\npkg_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')) # noqa\nsys.path.insert(0, pkg_root) # noqa\n\nfrom src.toil.lib.resources import glob # type: ignore\n\n\ndef main():\n all_files_to_check = []\n for d in ['dashboard', 'docker', 'docs', 'src']:\n all_files_to_check += glob(glob_pattern='*.py', directoryname=os.path.join(pkg_root, d))\n\n # TODO: Remove these paths as typing is added and mypy conflicts are addressed\n ignore_paths = [os.path.abspath(f) for f in [\n 'docker/Dockerfile.py',\n 'docs/conf.py',\n 'docs/vendor/sphinxcontrib/fulltoc.py',\n 'docs/vendor/sphinxcontrib/__init__.py',\n 'src/toil/job.py',\n 'src/toil/leader.py',\n 'src/toil/common.py',\n 'src/toil/worker.py',\n 'src/toil/toilState.py',\n 'src/toil/__init__.py',\n 'src/toil/resource.py',\n 'src/toil/deferred.py',\n 'src/toil/version.py',\n 'src/toil/wdl/utils.py',\n 'src/toil/wdl/wdl_types.py',\n 'src/toil/wdl/wdl_synthesis.py',\n 'src/toil/wdl/wdl_analysis.py',\n 'src/toil/wdl/wdl_functions.py',\n 'src/toil/wdl/toilwdl.py',\n 'src/toil/wdl/versions/draft2.py',\n 'src/toil/wdl/versions/v1.py',\n 'src/toil/wdl/versions/dev.py',\n 'src/toil/provisioners/clusterScaler.py',\n 'src/toil/provisioners/abstractProvisioner.py',\n 'src/toil/provisioners/gceProvisioner.py',\n 'src/toil/provisioners/__init__.py',\n 'src/toil/provisioners/node.py',\n 'src/toil/provisioners/aws/boto2Context.py',\n 'src/toil/provisioners/aws/awsProvisioner.py',\n 'src/toil/provisioners/aws/__init__.py',\n 'src/toil/batchSystems/slurm.py',\n 'src/toil/batchSystems/gridengine.py',\n 'src/toil/batchSystems/singleMachine.py',\n 'src/toil/batchSystems/abstractBatchSystem.py',\n 'src/toil/batchSystems/parasol.py',\n 'src/toil/batchSystems/kubernetes.py',\n 'src/toil/batchSystems/torque.py',\n 'src/toil/batchSystems/options.py',\n 'src/toil/batchSystems/registry.py',\n 'src/toil/batchSystems/lsf.py',\n 'src/toil/batchSystems/__init__.py',\n 'src/toil/batchSystems/abstractGridEngineBatchSystem.py',\n 'src/toil/batchSystems/lsfHelper.py',\n 'src/toil/batchSystems/htcondor.py',\n 'src/toil/batchSystems/mesos/batchSystem.py',\n 'src/toil/batchSystems/mesos/executor.py',\n 'src/toil/batchSystems/mesos/conftest.py',\n 'src/toil/batchSystems/mesos/__init__.py',\n 'src/toil/batchSystems/mesos/test/__init__.py',\n 'src/toil/cwl/conftest.py',\n 'src/toil/cwl/__init__.py',\n 'src/toil/cwl/cwltoil.py',\n 'src/toil/fileStores/cachingFileStore.py',\n 'src/toil/fileStores/abstractFileStore.py',\n 'src/toil/fileStores/nonCachingFileStore.py',\n 'src/toil/fileStores/__init__.py',\n 'src/toil/jobStores/utils.py',\n 'src/toil/jobStores/conftest.py',\n 'src/toil/jobStores/fileJobStore.py',\n 'src/toil/jobStores/__init__.py',\n 'src/toil/jobStores/googleJobStore.py',\n 'src/toil/jobStores/aws/utils.py',\n 'src/toil/jobStores/aws/jobStore.py',\n 'src/toil/jobStores/aws/__init__.py',\n 'src/toil/utils/__init__.py',\n 'src/toil/lib/memoize.py',\n 'src/toil/lib/throttle.py',\n 'src/toil/lib/humanize.py',\n 'src/toil/lib/iterables.py',\n 'src/toil/lib/bioio.py',\n 'src/toil/lib/ec2.py',\n 'src/toil/lib/expando.py',\n 'src/toil/lib/exceptions.py',\n 'src/toil/lib/__init__.py',\n 'src/toil/lib/generatedEC2Lists.py',\n 'src/toil/lib/retry.py',\n 'src/toil/lib/objects.py',\n 'src/toil/lib/io.py',\n 'src/toil/lib/docker.py',\n 'src/toil/lib/encryption/_dummy.py',\n 'src/toil/lib/encryption/conftest.py',\n 'src/toil/lib/encryption/__init__.py',\n 'src/toil/lib/aws/utils.py',\n 'src/toil/lib/aws/__init__.py'\n ]]\n\n filtered_files_to_check = []\n for file_path in all_files_to_check:\n if file_path not in ignore_paths and 'src/toil/test' not in file_path:\n filtered_files_to_check.append(file_path)\n # follow-imports type checks pypi projects we don't control, so we skip it; why is this their default?\n args = ['mypy', '--follow-imports=skip'] + filtered_files_to_check\n p = subprocess.run(args=args, stdout=subprocess.PIPE)\n result = p.stdout.decode()\n print(result)\n if 'Success: no issues found' not in result:\n exit(1)\n\n\nif __name__ == '__main__':\n main()\n", "path": "contrib/admin/mypy-with-ignore.py"}]}
| 2,727 | 460 |
gh_patches_debug_17990
|
rasdani/github-patches
|
git_diff
|
rotki__rotki-3143
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrading DB from v26->v27 can fail if user balancer LP events stored in their DB
## Problem Definition
A user who upgraded from v1.16.2 to v1.18.1 notified us that they saw a DB upgrade failure from v26->v27. Which means the app versions v1.17.2 to v1.18.0.
Turns out that for specific user DBs who have had some Balancer LP events detected and had both the balancer events and the balancer pools DB table populated the DB upgrade would fail, since the upgrade deletes the balancer pools table first, hence possibly hitting a constraint.
## Workaround
Workaround is rather easy. Download v1.17.0-v1.17.2, since that can open v26 DB, purge all uniswap and balancer data, and then open with v1.18.XX.
## Task
Fix the upgrade so that this does not occur even for this special case of users.
</issue>
<code>
[start of rotkehlchen/db/upgrades/v26_v27.py]
1 from typing import TYPE_CHECKING
2
3 if TYPE_CHECKING:
4 from rotkehlchen.db.dbhandler import DBHandler
5
6
7 def upgrade_v26_to_v27(db: 'DBHandler') -> None:
8 """Upgrades the DB from v26 to v27
9
10 - Deletes and recreates the tables that were changed after removing UnknownEthereumToken
11 """
12 cursor = db.conn.cursor()
13 cursor.execute('DROP TABLE IF EXISTS balancer_pools;')
14
15 cursor.execute('DROP TABLE IF EXISTS balancer_events;')
16 cursor.execute("""
17 CREATE TABLE IF NOT EXISTS balancer_events (
18 tx_hash VARCHAR[42] NOT NULL,
19 log_index INTEGER NOT NULL,
20 address VARCHAR[42] NOT NULL,
21 timestamp INTEGER NOT NULL,
22 type TEXT NOT NULL,
23 pool_address_token TEXT NOT NULL,
24 lp_amount TEXT NOT NULL,
25 usd_value TEXT NOT NULL,
26 amount0 TEXT NOT NULL,
27 amount1 TEXT NOT NULL,
28 amount2 TEXT,
29 amount3 TEXT,
30 amount4 TEXT,
31 amount5 TEXT,
32 amount6 TEXT,
33 amount7 TEXT,
34 FOREIGN KEY (pool_address_token) REFERENCES assets(identifier) ON UPDATE CASCADE,
35 PRIMARY KEY (tx_hash, log_index)
36 );
37 """)
38 cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE "balancer_events%";')
39
40 cursor.execute('DROP TABLE IF EXISTS amm_swaps;')
41 cursor.execute("""
42 CREATE TABLE IF NOT EXISTS amm_swaps (
43 tx_hash VARCHAR[42] NOT NULL,
44 log_index INTEGER NOT NULL,
45 address VARCHAR[42] NOT NULL,
46 from_address VARCHAR[42] NOT NULL,
47 to_address VARCHAR[42] NOT NULL,
48 timestamp INTEGER NOT NULL,
49 location CHAR(1) NOT NULL DEFAULT('A') REFERENCES location(location),
50 token0_identifier TEXT NOT NULL,
51 token1_identifier TEXT NOT NULL,
52 amount0_in TEXT,
53 amount1_in TEXT,
54 amount0_out TEXT,
55 amount1_out TEXT,
56 FOREIGN KEY(token0_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,
57 FOREIGN KEY(token1_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,
58 PRIMARY KEY (tx_hash, log_index)
59 );""")
60 cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE "balancer_trades%";')
61 cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE "uniswap_trades%";')
62
63 cursor.execute('DROP TABLE IF EXISTS uniswap_events;')
64 cursor.execute("""
65 CREATE TABLE IF NOT EXISTS uniswap_events (
66 tx_hash VARCHAR[42] NOT NULL,
67 log_index INTEGER NOT NULL,
68 address VARCHAR[42] NOT NULL,
69 timestamp INTEGER NOT NULL,
70 type TEXT NOT NULL,
71 pool_address VARCHAR[42] NOT NULL,
72 token0_identifier TEXT NOT NULL,
73 token1_identifier TEXT NOT NULL,
74 amount0 TEXT,
75 amount1 TEXT,
76 usd_price TEXT,
77 lp_amount TEXT,
78 FOREIGN KEY(token0_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,
79 FOREIGN KEY(token1_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,
80 PRIMARY KEY (tx_hash, log_index)
81 );""")
82 cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE "uniswap_events%";')
83
84 db.conn.commit()
85
[end of rotkehlchen/db/upgrades/v26_v27.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rotkehlchen/db/upgrades/v26_v27.py b/rotkehlchen/db/upgrades/v26_v27.py
--- a/rotkehlchen/db/upgrades/v26_v27.py
+++ b/rotkehlchen/db/upgrades/v26_v27.py
@@ -10,8 +10,6 @@
- Deletes and recreates the tables that were changed after removing UnknownEthereumToken
"""
cursor = db.conn.cursor()
- cursor.execute('DROP TABLE IF EXISTS balancer_pools;')
-
cursor.execute('DROP TABLE IF EXISTS balancer_events;')
cursor.execute("""
CREATE TABLE IF NOT EXISTS balancer_events (
@@ -35,6 +33,7 @@
PRIMARY KEY (tx_hash, log_index)
);
""")
+ cursor.execute('DROP TABLE IF EXISTS balancer_pools;')
cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE "balancer_events%";')
cursor.execute('DROP TABLE IF EXISTS amm_swaps;')
|
{"golden_diff": "diff --git a/rotkehlchen/db/upgrades/v26_v27.py b/rotkehlchen/db/upgrades/v26_v27.py\n--- a/rotkehlchen/db/upgrades/v26_v27.py\n+++ b/rotkehlchen/db/upgrades/v26_v27.py\n@@ -10,8 +10,6 @@\n - Deletes and recreates the tables that were changed after removing UnknownEthereumToken\n \"\"\"\n cursor = db.conn.cursor()\n- cursor.execute('DROP TABLE IF EXISTS balancer_pools;')\n-\n cursor.execute('DROP TABLE IF EXISTS balancer_events;')\n cursor.execute(\"\"\"\n CREATE TABLE IF NOT EXISTS balancer_events (\n@@ -35,6 +33,7 @@\n PRIMARY KEY (tx_hash, log_index)\n );\n \"\"\")\n+ cursor.execute('DROP TABLE IF EXISTS balancer_pools;')\n cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE \"balancer_events%\";')\n \n cursor.execute('DROP TABLE IF EXISTS amm_swaps;')\n", "issue": "Upgrading DB from v26->v27 can fail if user balancer LP events stored in their DB\n## Problem Definition\r\n\r\nA user who upgraded from v1.16.2 to v1.18.1 notified us that they saw a DB upgrade failure from v26->v27. Which means the app versions v1.17.2 to v1.18.0.\r\n\r\nTurns out that for specific user DBs who have had some Balancer LP events detected and had both the balancer events and the balancer pools DB table populated the DB upgrade would fail, since the upgrade deletes the balancer pools table first, hence possibly hitting a constraint.\r\n\r\n## Workaround\r\n\r\nWorkaround is rather easy. Download v1.17.0-v1.17.2, since that can open v26 DB, purge all uniswap and balancer data, and then open with v1.18.XX.\r\n\r\n## Task\r\n\r\nFix the upgrade so that this does not occur even for this special case of users.\n", "before_files": [{"content": "from typing import TYPE_CHECKING\n\nif TYPE_CHECKING:\n from rotkehlchen.db.dbhandler import DBHandler\n\n\ndef upgrade_v26_to_v27(db: 'DBHandler') -> None:\n \"\"\"Upgrades the DB from v26 to v27\n\n - Deletes and recreates the tables that were changed after removing UnknownEthereumToken\n \"\"\"\n cursor = db.conn.cursor()\n cursor.execute('DROP TABLE IF EXISTS balancer_pools;')\n\n cursor.execute('DROP TABLE IF EXISTS balancer_events;')\n cursor.execute(\"\"\"\nCREATE TABLE IF NOT EXISTS balancer_events (\n tx_hash VARCHAR[42] NOT NULL,\n log_index INTEGER NOT NULL,\n address VARCHAR[42] NOT NULL,\n timestamp INTEGER NOT NULL,\n type TEXT NOT NULL,\n pool_address_token TEXT NOT NULL,\n lp_amount TEXT NOT NULL,\n usd_value TEXT NOT NULL,\n amount0 TEXT NOT NULL,\n amount1 TEXT NOT NULL,\n amount2 TEXT,\n amount3 TEXT,\n amount4 TEXT,\n amount5 TEXT,\n amount6 TEXT,\n amount7 TEXT,\n FOREIGN KEY (pool_address_token) REFERENCES assets(identifier) ON UPDATE CASCADE,\n PRIMARY KEY (tx_hash, log_index)\n);\n\"\"\")\n cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE \"balancer_events%\";')\n\n cursor.execute('DROP TABLE IF EXISTS amm_swaps;')\n cursor.execute(\"\"\"\nCREATE TABLE IF NOT EXISTS amm_swaps (\n tx_hash VARCHAR[42] NOT NULL,\n log_index INTEGER NOT NULL,\n address VARCHAR[42] NOT NULL,\n from_address VARCHAR[42] NOT NULL,\n to_address VARCHAR[42] NOT NULL,\n timestamp INTEGER NOT NULL,\n location CHAR(1) NOT NULL DEFAULT('A') REFERENCES location(location),\n token0_identifier TEXT NOT NULL,\n token1_identifier TEXT NOT NULL,\n amount0_in TEXT,\n amount1_in TEXT,\n amount0_out TEXT,\n amount1_out TEXT,\n FOREIGN KEY(token0_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,\n FOREIGN KEY(token1_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,\n PRIMARY KEY (tx_hash, log_index)\n);\"\"\")\n cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE \"balancer_trades%\";')\n cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE \"uniswap_trades%\";')\n\n cursor.execute('DROP TABLE IF EXISTS uniswap_events;')\n cursor.execute(\"\"\"\nCREATE TABLE IF NOT EXISTS uniswap_events (\n tx_hash VARCHAR[42] NOT NULL,\n log_index INTEGER NOT NULL,\n address VARCHAR[42] NOT NULL,\n timestamp INTEGER NOT NULL,\n type TEXT NOT NULL,\n pool_address VARCHAR[42] NOT NULL,\n token0_identifier TEXT NOT NULL,\n token1_identifier TEXT NOT NULL,\n amount0 TEXT,\n amount1 TEXT,\n usd_price TEXT,\n lp_amount TEXT,\n FOREIGN KEY(token0_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,\n FOREIGN KEY(token1_identifier) REFERENCES assets(identifier) ON UPDATE CASCADE,\n PRIMARY KEY (tx_hash, log_index)\n);\"\"\")\n cursor.execute('DELETE FROM used_query_ranges WHERE name LIKE \"uniswap_events%\";')\n\n db.conn.commit()\n", "path": "rotkehlchen/db/upgrades/v26_v27.py"}]}
| 1,629 | 228 |
gh_patches_debug_27803
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-614
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Option to access hydra configs from interpolation
The hydra config node is removed from the tree before the program stats, which makes it impossible to rely on it at runtime.
The reason it's removed is that otherwise the user config would be very large even for a simple program.
That config however is still available at runtime through the HydraConfig singleston.
The idea here is to simply register a resolver function by the name of hydra, which would provide access to hydra config.
User usage would look like:
```yaml
gpu_id: ${hydra:job.num}
```
This can be useful for accessing everything inside the hydra config, including parameters only available at runtime.
In addition, provide an option to call to_absolute_dir from interpolations.
</issue>
<code>
[start of hydra/core/utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import copy
3 import logging
4 import os
5 import re
6 import sys
7 import warnings
8 from contextlib import contextmanager
9 from dataclasses import dataclass
10 from os.path import basename, dirname, splitext
11 from pathlib import Path
12 from time import localtime, strftime
13 from typing import Any, Dict, Optional, Sequence, Tuple, Union
14
15 from omegaconf import DictConfig, OmegaConf, open_dict
16
17 from hydra.core.hydra_config import HydraConfig
18 from hydra.core.singleton import Singleton
19 from hydra.types import TaskFunction
20
21 log = logging.getLogger(__name__)
22
23
24 def configure_log(
25 log_config: DictConfig, verbose_config: Union[bool, str, Sequence[str]]
26 ) -> None:
27 assert isinstance(verbose_config, (bool, str)) or OmegaConf.is_list(verbose_config)
28 if log_config is not None:
29 conf: Dict[str, Any] = OmegaConf.to_container( # type: ignore
30 log_config, resolve=True
31 )
32 logging.config.dictConfig(conf)
33 else:
34 # default logging to stdout
35 root = logging.getLogger()
36 root.setLevel(logging.INFO)
37 handler = logging.StreamHandler(sys.stdout)
38 formatter = logging.Formatter(
39 "[%(asctime)s][%(name)s][%(levelname)s] - %(message)s"
40 )
41 handler.setFormatter(formatter)
42 root.addHandler(handler)
43 if isinstance(verbose_config, bool):
44 if verbose_config:
45 logging.getLogger().setLevel(logging.DEBUG)
46 else:
47 if isinstance(verbose_config, str):
48 verbose_list = OmegaConf.create([verbose_config])
49 elif OmegaConf.is_list(verbose_config):
50 verbose_list = verbose_config # type: ignore
51 else:
52 assert False
53
54 for logger in verbose_list:
55 logging.getLogger(logger).setLevel(logging.DEBUG)
56
57
58 def _save_config(cfg: DictConfig, filename: str, output_dir: Path) -> None:
59 output_dir.mkdir(parents=True, exist_ok=True)
60 with open(str(output_dir / filename), "w") as file:
61 file.write(cfg.pretty())
62
63
64 def filter_overrides(overrides: Sequence[str]) -> Sequence[str]:
65 """
66 :param overrides: overrides list
67 :return: returning a new overrides list with all the keys starting with hydra. filtered.
68 """
69 return [x for x in overrides if not x.startswith("hydra.")]
70
71
72 def run_job(
73 config: DictConfig,
74 task_function: TaskFunction,
75 job_dir_key: str,
76 job_subdir_key: Optional[str],
77 ) -> "JobReturn":
78 old_cwd = os.getcwd()
79 working_dir = str(OmegaConf.select(config, job_dir_key))
80 if job_subdir_key is not None:
81 # evaluate job_subdir_key lazily.
82 # this is running on the client side in sweep and contains things such as job:id which
83 # are only available there.
84 subdir = str(OmegaConf.select(config, job_subdir_key))
85 working_dir = os.path.join(working_dir, subdir)
86 try:
87 ret = JobReturn()
88 ret.working_dir = working_dir
89 task_cfg = copy.deepcopy(config)
90 with open_dict(task_cfg):
91 del task_cfg["hydra"]
92 ret.cfg = task_cfg
93 ret.hydra_cfg = OmegaConf.create({"hydra": HydraConfig.get()})
94 overrides = OmegaConf.to_container(config.hydra.overrides.task)
95 assert isinstance(overrides, list)
96 ret.overrides = overrides
97 # handle output directories here
98 Path(str(working_dir)).mkdir(parents=True, exist_ok=True)
99 os.chdir(working_dir)
100 hydra_output = Path(config.hydra.output_subdir)
101
102 configure_log(config.hydra.job_logging, config.hydra.verbose)
103
104 hydra_cfg = OmegaConf.masked_copy(config, "hydra")
105 assert isinstance(hydra_cfg, DictConfig)
106
107 _save_config(task_cfg, "config.yaml", hydra_output)
108 _save_config(hydra_cfg, "hydra.yaml", hydra_output)
109 _save_config(config.hydra.overrides.task, "overrides.yaml", hydra_output)
110 with env_override(hydra_cfg.hydra.job.env_set):
111 ret.return_value = task_function(task_cfg)
112 ret.task_name = JobRuntime.instance().get("name")
113
114 # shut down logging to ensure job log files are closed.
115 # If logging is still required after run_job caller is responsible to re-initialize it.
116 logging.shutdown()
117
118 return ret
119 finally:
120 os.chdir(old_cwd)
121
122
123 def get_valid_filename(s: str) -> str:
124 s = str(s).strip().replace(" ", "_")
125 return re.sub(r"(?u)[^-\w.]", "", s)
126
127
128 def setup_globals() -> None:
129 try:
130 OmegaConf.register_resolver(
131 "now", lambda pattern: strftime(pattern, localtime())
132 )
133 except AssertionError:
134 # calling it again in no_workers mode will throw. safe to ignore.
135 pass
136
137
138 @dataclass
139 class JobReturn:
140 overrides: Optional[Sequence[str]] = None
141 return_value: Any = None
142 cfg: Optional[DictConfig] = None
143 hydra_cfg: Optional[DictConfig] = None
144 working_dir: Optional[str] = None
145 task_name: Optional[str] = None
146
147
148 class JobRuntime(metaclass=Singleton):
149 def __init__(self) -> None:
150 self.conf: DictConfig = OmegaConf.create()
151 self.set("name", "UNKNOWN_NAME")
152
153 def get(self, key: str) -> Any:
154 ret = OmegaConf.select(self.conf, key)
155 if ret is None:
156 raise KeyError(f"Key not found in {type(self).__name__}: {key}")
157 return ret
158
159 def set(self, key: str, value: Any) -> None:
160 log.debug(f"Setting {type(self).__name__}:{key}={value}")
161 self.conf[key] = value
162
163
164 def split_config_path(
165 config_path: Optional[str], config_name: Optional[str]
166 ) -> Tuple[Optional[str], Optional[str]]:
167 if config_path is None or config_path == "":
168 return None, config_name
169 split_file = splitext(config_path)
170 if split_file[1] in (".yaml", ".yml"):
171 # assuming dir/config.yaml form
172 config_file: Optional[str] = basename(config_path)
173 config_dir: Optional[str] = dirname(config_path)
174 msg = (
175 "\nUsing config_path to specify the config name is deprecated, specify the config name via config_name"
176 "\nSee https://hydra.cc/next/upgrades/0.11_to_1.0/config_path_changes"
177 )
178 warnings.warn(
179 category=UserWarning, message=msg,
180 )
181 else:
182 # assuming dir form without a config file.
183 config_file = None
184 config_dir = config_path
185
186 if config_dir == "":
187 config_dir = None
188
189 if config_file == "":
190 config_file = None
191
192 if config_file is not None:
193 if config_name is not None:
194 raise ValueError(
195 "Config name should be specified in either normalized_config_path or config_name, but not both"
196 )
197 config_name = config_file
198
199 return config_dir, config_name
200
201
202 @contextmanager
203 def env_override(env: Dict[str, str]) -> Any:
204 """Temporarily set environment variables inside the context manager and
205 fully restore previous environment afterwards
206 """
207 original_env = {key: os.getenv(key) for key in env}
208 os.environ.update(env)
209 try:
210 yield
211 finally:
212 for key, value in original_env.items():
213 if value is None:
214 del os.environ[key]
215 else:
216 os.environ[key] = value
217
[end of hydra/core/utils.py]
[start of hydra/core/hydra_config.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 from typing import Any, Optional
3
4 from omegaconf import DictConfig, OmegaConf
5
6 from hydra.conf import HydraConf
7 from hydra.core.singleton import Singleton
8
9
10 class HydraConfig(metaclass=Singleton):
11 def __init__(self) -> None:
12 self.cfg: Optional[HydraConf] = None
13
14 def set_config(self, cfg: DictConfig) -> None:
15 assert cfg is not None
16 OmegaConf.set_readonly(cfg.hydra, True)
17 assert OmegaConf.get_type(cfg, "hydra") == HydraConf
18 self.cfg = cfg # type: ignore
19
20 @staticmethod
21 def get() -> HydraConf:
22 instance = HydraConfig.instance()
23 if instance.cfg is None:
24 raise ValueError("HydraConfig was not set")
25 return instance.cfg.hydra # type: ignore
26
27 @staticmethod
28 def initialized() -> bool:
29 instance = HydraConfig.instance()
30 return instance.cfg is not None
31
32 @staticmethod
33 def instance(*args: Any, **kwargs: Any) -> "HydraConfig":
34 return Singleton.instance(HydraConfig, *args, **kwargs) # type: ignore
35
[end of hydra/core/hydra_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/core/hydra_config.py b/hydra/core/hydra_config.py
--- a/hydra/core/hydra_config.py
+++ b/hydra/core/hydra_config.py
@@ -15,7 +15,7 @@
assert cfg is not None
OmegaConf.set_readonly(cfg.hydra, True)
assert OmegaConf.get_type(cfg, "hydra") == HydraConf
- self.cfg = cfg # type: ignore
+ self.cfg = OmegaConf.masked_copy(cfg, "hydra") # type: ignore
@staticmethod
def get() -> HydraConf:
diff --git a/hydra/core/utils.py b/hydra/core/utils.py
--- a/hydra/core/utils.py
+++ b/hydra/core/utils.py
@@ -10,7 +10,7 @@
from os.path import basename, dirname, splitext
from pathlib import Path
from time import localtime, strftime
-from typing import Any, Dict, Optional, Sequence, Tuple, Union
+from typing import Any, Dict, Optional, Sequence, Tuple, Union, cast
from omegaconf import DictConfig, OmegaConf, open_dict
@@ -126,13 +126,18 @@
def setup_globals() -> None:
- try:
- OmegaConf.register_resolver(
- "now", lambda pattern: strftime(pattern, localtime())
- )
- except AssertionError:
- # calling it again in no_workers mode will throw. safe to ignore.
- pass
+ def register(name: str, f: Any) -> None:
+ try:
+ OmegaConf.register_resolver(name, f)
+ except AssertionError:
+ # calling it again in no_workers mode will throw. safe to ignore.
+ pass
+
+ register("now", lambda pattern: strftime(pattern, localtime()))
+ register(
+ "hydra",
+ lambda path: OmegaConf.select(cast(DictConfig, HydraConfig.get()), path),
+ )
@dataclass
|
{"golden_diff": "diff --git a/hydra/core/hydra_config.py b/hydra/core/hydra_config.py\n--- a/hydra/core/hydra_config.py\n+++ b/hydra/core/hydra_config.py\n@@ -15,7 +15,7 @@\n assert cfg is not None\n OmegaConf.set_readonly(cfg.hydra, True)\n assert OmegaConf.get_type(cfg, \"hydra\") == HydraConf\n- self.cfg = cfg # type: ignore\n+ self.cfg = OmegaConf.masked_copy(cfg, \"hydra\") # type: ignore\n \n @staticmethod\n def get() -> HydraConf:\ndiff --git a/hydra/core/utils.py b/hydra/core/utils.py\n--- a/hydra/core/utils.py\n+++ b/hydra/core/utils.py\n@@ -10,7 +10,7 @@\n from os.path import basename, dirname, splitext\n from pathlib import Path\n from time import localtime, strftime\n-from typing import Any, Dict, Optional, Sequence, Tuple, Union\n+from typing import Any, Dict, Optional, Sequence, Tuple, Union, cast\n \n from omegaconf import DictConfig, OmegaConf, open_dict\n \n@@ -126,13 +126,18 @@\n \n \n def setup_globals() -> None:\n- try:\n- OmegaConf.register_resolver(\n- \"now\", lambda pattern: strftime(pattern, localtime())\n- )\n- except AssertionError:\n- # calling it again in no_workers mode will throw. safe to ignore.\n- pass\n+ def register(name: str, f: Any) -> None:\n+ try:\n+ OmegaConf.register_resolver(name, f)\n+ except AssertionError:\n+ # calling it again in no_workers mode will throw. safe to ignore.\n+ pass\n+\n+ register(\"now\", lambda pattern: strftime(pattern, localtime()))\n+ register(\n+ \"hydra\",\n+ lambda path: OmegaConf.select(cast(DictConfig, HydraConfig.get()), path),\n+ )\n \n \n @dataclass\n", "issue": "Option to access hydra configs from interpolation\nThe hydra config node is removed from the tree before the program stats, which makes it impossible to rely on it at runtime.\r\nThe reason it's removed is that otherwise the user config would be very large even for a simple program.\r\nThat config however is still available at runtime through the HydraConfig singleston.\r\n\r\nThe idea here is to simply register a resolver function by the name of hydra, which would provide access to hydra config.\r\n\r\nUser usage would look like:\r\n```yaml\r\ngpu_id: ${hydra:job.num}\r\n```\r\n\r\nThis can be useful for accessing everything inside the hydra config, including parameters only available at runtime.\r\n\r\nIn addition, provide an option to call to_absolute_dir from interpolations.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport copy\nimport logging\nimport os\nimport re\nimport sys\nimport warnings\nfrom contextlib import contextmanager\nfrom dataclasses import dataclass\nfrom os.path import basename, dirname, splitext\nfrom pathlib import Path\nfrom time import localtime, strftime\nfrom typing import Any, Dict, Optional, Sequence, Tuple, Union\n\nfrom omegaconf import DictConfig, OmegaConf, open_dict\n\nfrom hydra.core.hydra_config import HydraConfig\nfrom hydra.core.singleton import Singleton\nfrom hydra.types import TaskFunction\n\nlog = logging.getLogger(__name__)\n\n\ndef configure_log(\n log_config: DictConfig, verbose_config: Union[bool, str, Sequence[str]]\n) -> None:\n assert isinstance(verbose_config, (bool, str)) or OmegaConf.is_list(verbose_config)\n if log_config is not None:\n conf: Dict[str, Any] = OmegaConf.to_container( # type: ignore\n log_config, resolve=True\n )\n logging.config.dictConfig(conf)\n else:\n # default logging to stdout\n root = logging.getLogger()\n root.setLevel(logging.INFO)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\n \"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s\"\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n if isinstance(verbose_config, bool):\n if verbose_config:\n logging.getLogger().setLevel(logging.DEBUG)\n else:\n if isinstance(verbose_config, str):\n verbose_list = OmegaConf.create([verbose_config])\n elif OmegaConf.is_list(verbose_config):\n verbose_list = verbose_config # type: ignore\n else:\n assert False\n\n for logger in verbose_list:\n logging.getLogger(logger).setLevel(logging.DEBUG)\n\n\ndef _save_config(cfg: DictConfig, filename: str, output_dir: Path) -> None:\n output_dir.mkdir(parents=True, exist_ok=True)\n with open(str(output_dir / filename), \"w\") as file:\n file.write(cfg.pretty())\n\n\ndef filter_overrides(overrides: Sequence[str]) -> Sequence[str]:\n \"\"\"\n :param overrides: overrides list\n :return: returning a new overrides list with all the keys starting with hydra. filtered.\n \"\"\"\n return [x for x in overrides if not x.startswith(\"hydra.\")]\n\n\ndef run_job(\n config: DictConfig,\n task_function: TaskFunction,\n job_dir_key: str,\n job_subdir_key: Optional[str],\n) -> \"JobReturn\":\n old_cwd = os.getcwd()\n working_dir = str(OmegaConf.select(config, job_dir_key))\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n # are only available there.\n subdir = str(OmegaConf.select(config, job_subdir_key))\n working_dir = os.path.join(working_dir, subdir)\n try:\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n with open_dict(task_cfg):\n del task_cfg[\"hydra\"]\n ret.cfg = task_cfg\n ret.hydra_cfg = OmegaConf.create({\"hydra\": HydraConfig.get()})\n overrides = OmegaConf.to_container(config.hydra.overrides.task)\n assert isinstance(overrides, list)\n ret.overrides = overrides\n # handle output directories here\n Path(str(working_dir)).mkdir(parents=True, exist_ok=True)\n os.chdir(working_dir)\n hydra_output = Path(config.hydra.output_subdir)\n\n configure_log(config.hydra.job_logging, config.hydra.verbose)\n\n hydra_cfg = OmegaConf.masked_copy(config, \"hydra\")\n assert isinstance(hydra_cfg, DictConfig)\n\n _save_config(task_cfg, \"config.yaml\", hydra_output)\n _save_config(hydra_cfg, \"hydra.yaml\", hydra_output)\n _save_config(config.hydra.overrides.task, \"overrides.yaml\", hydra_output)\n with env_override(hydra_cfg.hydra.job.env_set):\n ret.return_value = task_function(task_cfg)\n ret.task_name = JobRuntime.instance().get(\"name\")\n\n # shut down logging to ensure job log files are closed.\n # If logging is still required after run_job caller is responsible to re-initialize it.\n logging.shutdown()\n\n return ret\n finally:\n os.chdir(old_cwd)\n\n\ndef get_valid_filename(s: str) -> str:\n s = str(s).strip().replace(\" \", \"_\")\n return re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n\ndef setup_globals() -> None:\n try:\n OmegaConf.register_resolver(\n \"now\", lambda pattern: strftime(pattern, localtime())\n )\n except AssertionError:\n # calling it again in no_workers mode will throw. safe to ignore.\n pass\n\n\n@dataclass\nclass JobReturn:\n overrides: Optional[Sequence[str]] = None\n return_value: Any = None\n cfg: Optional[DictConfig] = None\n hydra_cfg: Optional[DictConfig] = None\n working_dir: Optional[str] = None\n task_name: Optional[str] = None\n\n\nclass JobRuntime(metaclass=Singleton):\n def __init__(self) -> None:\n self.conf: DictConfig = OmegaConf.create()\n self.set(\"name\", \"UNKNOWN_NAME\")\n\n def get(self, key: str) -> Any:\n ret = OmegaConf.select(self.conf, key)\n if ret is None:\n raise KeyError(f\"Key not found in {type(self).__name__}: {key}\")\n return ret\n\n def set(self, key: str, value: Any) -> None:\n log.debug(f\"Setting {type(self).__name__}:{key}={value}\")\n self.conf[key] = value\n\n\ndef split_config_path(\n config_path: Optional[str], config_name: Optional[str]\n) -> Tuple[Optional[str], Optional[str]]:\n if config_path is None or config_path == \"\":\n return None, config_name\n split_file = splitext(config_path)\n if split_file[1] in (\".yaml\", \".yml\"):\n # assuming dir/config.yaml form\n config_file: Optional[str] = basename(config_path)\n config_dir: Optional[str] = dirname(config_path)\n msg = (\n \"\\nUsing config_path to specify the config name is deprecated, specify the config name via config_name\"\n \"\\nSee https://hydra.cc/next/upgrades/0.11_to_1.0/config_path_changes\"\n )\n warnings.warn(\n category=UserWarning, message=msg,\n )\n else:\n # assuming dir form without a config file.\n config_file = None\n config_dir = config_path\n\n if config_dir == \"\":\n config_dir = None\n\n if config_file == \"\":\n config_file = None\n\n if config_file is not None:\n if config_name is not None:\n raise ValueError(\n \"Config name should be specified in either normalized_config_path or config_name, but not both\"\n )\n config_name = config_file\n\n return config_dir, config_name\n\n\n@contextmanager\ndef env_override(env: Dict[str, str]) -> Any:\n \"\"\"Temporarily set environment variables inside the context manager and\n fully restore previous environment afterwards\n \"\"\"\n original_env = {key: os.getenv(key) for key in env}\n os.environ.update(env)\n try:\n yield\n finally:\n for key, value in original_env.items():\n if value is None:\n del os.environ[key]\n else:\n os.environ[key] = value\n", "path": "hydra/core/utils.py"}, {"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom typing import Any, Optional\n\nfrom omegaconf import DictConfig, OmegaConf\n\nfrom hydra.conf import HydraConf\nfrom hydra.core.singleton import Singleton\n\n\nclass HydraConfig(metaclass=Singleton):\n def __init__(self) -> None:\n self.cfg: Optional[HydraConf] = None\n\n def set_config(self, cfg: DictConfig) -> None:\n assert cfg is not None\n OmegaConf.set_readonly(cfg.hydra, True)\n assert OmegaConf.get_type(cfg, \"hydra\") == HydraConf\n self.cfg = cfg # type: ignore\n\n @staticmethod\n def get() -> HydraConf:\n instance = HydraConfig.instance()\n if instance.cfg is None:\n raise ValueError(\"HydraConfig was not set\")\n return instance.cfg.hydra # type: ignore\n\n @staticmethod\n def initialized() -> bool:\n instance = HydraConfig.instance()\n return instance.cfg is not None\n\n @staticmethod\n def instance(*args: Any, **kwargs: Any) -> \"HydraConfig\":\n return Singleton.instance(HydraConfig, *args, **kwargs) # type: ignore\n", "path": "hydra/core/hydra_config.py"}]}
| 3,252 | 443 |
gh_patches_debug_11800
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-2017
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Backwards incompatible change to MSE for pixelwise regression
## 🐛 Bug
#1937 introduces an unintended consequence: pixelwise regression is no longer supported.
### To Reproduce
Run the following script:
```python
import torch
import torchmetrics
B = 4
H = W = 3
x = torch.rand(B, H, W)
y = torch.rand(B, H, W)
torchmetrics.functional.mean_squared_error(x, y)
```
This results in the following error msg:
```
Traceback (most recent call last):
File "test.py", line 10, in <module>
torchmetrics.functional.mean_squared_error(x, y, num_outputs=H * W)
File "lib/python3.10/site-packages/torchmetrics/functional/regression/mse.py", line 84, in mean_squared_error
sum_squared_error, n_obs = _mean_squared_error_update(preds, target, num_outputs=num_outputs)
File "lib/python3.10/site-packages/torchmetrics/functional/regression/mse.py", line 35, in _mean_squared_error_update
_check_data_shape_to_num_outputs(preds, target, num_outputs, allow_1d_reshape=True)
File "lib/python3.10/site-packages/torchmetrics/functional/regression/utils.py", line 31, in _check_data_shape_to_num_outputs
raise ValueError(
ValueError: Expected both predictions and target to be either 1- or 2-dimensional tensors, but got 3 and 3.
```
### Expected behavior
I would expect the MSE metrics to support pixelwise regression (predicting a single regression value for each pixel in an image). The above script works fine with torchmetrics 1.0.3.
### Environment
- TorchMetrics version: 1.1.0, spack
- Python & PyTorch Version: 3.10.10, 2.1.0
- Any other relevant information such as OS: macOS
### Additional context
@SkafteNicki @Borda @justusschock
</issue>
<code>
[start of src/torchmetrics/functional/regression/mse.py]
1 # Copyright The Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Tuple, Union
15
16 import torch
17 from torch import Tensor
18
19 from torchmetrics.functional.regression.utils import _check_data_shape_to_num_outputs
20 from torchmetrics.utilities.checks import _check_same_shape
21
22
23 def _mean_squared_error_update(preds: Tensor, target: Tensor, num_outputs: int) -> Tuple[Tensor, int]:
24 """Update and returns variables required to compute Mean Squared Error.
25
26 Check for same shape of input tensors.
27
28 Args:
29 preds: Predicted tensor
30 target: Ground truth tensor
31 num_outputs: Number of outputs in multioutput setting
32
33 """
34 _check_same_shape(preds, target)
35 _check_data_shape_to_num_outputs(preds, target, num_outputs, allow_1d_reshape=True)
36 if num_outputs == 1:
37 preds = preds.view(-1)
38 target = target.view(-1)
39 diff = preds - target
40 sum_squared_error = torch.sum(diff * diff, dim=0)
41 n_obs = target.shape[0]
42 return sum_squared_error, n_obs
43
44
45 def _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: Union[int, Tensor], squared: bool = True) -> Tensor:
46 """Compute Mean Squared Error.
47
48 Args:
49 sum_squared_error: Sum of square of errors over all observations
50 n_obs: Number of predictions or observations
51 squared: Returns RMSE value if set to False.
52
53 Example:
54 >>> preds = torch.tensor([0., 1, 2, 3])
55 >>> target = torch.tensor([0., 1, 2, 2])
56 >>> sum_squared_error, n_obs = _mean_squared_error_update(preds, target, num_outputs=1)
57 >>> _mean_squared_error_compute(sum_squared_error, n_obs)
58 tensor(0.2500)
59
60 """
61 return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)
62
63
64 def mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True, num_outputs: int = 1) -> Tensor:
65 """Compute mean squared error.
66
67 Args:
68 preds: estimated labels
69 target: ground truth labels
70 squared: returns RMSE value if set to False
71 num_outputs: Number of outputs in multioutput setting
72
73 Return:
74 Tensor with MSE
75
76 Example:
77 >>> from torchmetrics.functional.regression import mean_squared_error
78 >>> x = torch.tensor([0., 1, 2, 3])
79 >>> y = torch.tensor([0., 1, 2, 2])
80 >>> mean_squared_error(x, y)
81 tensor(0.2500)
82
83 """
84 sum_squared_error, n_obs = _mean_squared_error_update(preds, target, num_outputs=num_outputs)
85 return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)
86
[end of src/torchmetrics/functional/regression/mse.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/torchmetrics/functional/regression/mse.py b/src/torchmetrics/functional/regression/mse.py
--- a/src/torchmetrics/functional/regression/mse.py
+++ b/src/torchmetrics/functional/regression/mse.py
@@ -16,7 +16,6 @@
import torch
from torch import Tensor
-from torchmetrics.functional.regression.utils import _check_data_shape_to_num_outputs
from torchmetrics.utilities.checks import _check_same_shape
@@ -32,7 +31,6 @@
"""
_check_same_shape(preds, target)
- _check_data_shape_to_num_outputs(preds, target, num_outputs, allow_1d_reshape=True)
if num_outputs == 1:
preds = preds.view(-1)
target = target.view(-1)
|
{"golden_diff": "diff --git a/src/torchmetrics/functional/regression/mse.py b/src/torchmetrics/functional/regression/mse.py\n--- a/src/torchmetrics/functional/regression/mse.py\n+++ b/src/torchmetrics/functional/regression/mse.py\n@@ -16,7 +16,6 @@\n import torch\n from torch import Tensor\n \n-from torchmetrics.functional.regression.utils import _check_data_shape_to_num_outputs\n from torchmetrics.utilities.checks import _check_same_shape\n \n \n@@ -32,7 +31,6 @@\n \n \"\"\"\n _check_same_shape(preds, target)\n- _check_data_shape_to_num_outputs(preds, target, num_outputs, allow_1d_reshape=True)\n if num_outputs == 1:\n preds = preds.view(-1)\n target = target.view(-1)\n", "issue": "Backwards incompatible change to MSE for pixelwise regression\n## \ud83d\udc1b Bug\r\n\r\n#1937 introduces an unintended consequence: pixelwise regression is no longer supported.\r\n\r\n### To Reproduce\r\n\r\nRun the following script:\r\n```python\r\nimport torch\r\nimport torchmetrics\r\n\r\nB = 4\r\nH = W = 3\r\n\r\nx = torch.rand(B, H, W)\r\ny = torch.rand(B, H, W)\r\n\r\ntorchmetrics.functional.mean_squared_error(x, y)\r\n```\r\nThis results in the following error msg:\r\n```\r\nTraceback (most recent call last):\r\n File \"test.py\", line 10, in <module>\r\n torchmetrics.functional.mean_squared_error(x, y, num_outputs=H * W)\r\n File \"lib/python3.10/site-packages/torchmetrics/functional/regression/mse.py\", line 84, in mean_squared_error\r\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target, num_outputs=num_outputs)\r\n File \"lib/python3.10/site-packages/torchmetrics/functional/regression/mse.py\", line 35, in _mean_squared_error_update\r\n _check_data_shape_to_num_outputs(preds, target, num_outputs, allow_1d_reshape=True)\r\n File \"lib/python3.10/site-packages/torchmetrics/functional/regression/utils.py\", line 31, in _check_data_shape_to_num_outputs\r\n raise ValueError(\r\nValueError: Expected both predictions and target to be either 1- or 2-dimensional tensors, but got 3 and 3.\r\n```\r\n\r\n### Expected behavior\r\n\r\nI would expect the MSE metrics to support pixelwise regression (predicting a single regression value for each pixel in an image). The above script works fine with torchmetrics 1.0.3.\r\n\r\n### Environment\r\n\r\n- TorchMetrics version: 1.1.0, spack\r\n- Python & PyTorch Version: 3.10.10, 2.1.0\r\n- Any other relevant information such as OS: macOS\r\n\r\n### Additional context\r\n\r\n@SkafteNicki @Borda @justusschock \n", "before_files": [{"content": "# Copyright The Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Tuple, Union\n\nimport torch\nfrom torch import Tensor\n\nfrom torchmetrics.functional.regression.utils import _check_data_shape_to_num_outputs\nfrom torchmetrics.utilities.checks import _check_same_shape\n\n\ndef _mean_squared_error_update(preds: Tensor, target: Tensor, num_outputs: int) -> Tuple[Tensor, int]:\n \"\"\"Update and returns variables required to compute Mean Squared Error.\n\n Check for same shape of input tensors.\n\n Args:\n preds: Predicted tensor\n target: Ground truth tensor\n num_outputs: Number of outputs in multioutput setting\n\n \"\"\"\n _check_same_shape(preds, target)\n _check_data_shape_to_num_outputs(preds, target, num_outputs, allow_1d_reshape=True)\n if num_outputs == 1:\n preds = preds.view(-1)\n target = target.view(-1)\n diff = preds - target\n sum_squared_error = torch.sum(diff * diff, dim=0)\n n_obs = target.shape[0]\n return sum_squared_error, n_obs\n\n\ndef _mean_squared_error_compute(sum_squared_error: Tensor, n_obs: Union[int, Tensor], squared: bool = True) -> Tensor:\n \"\"\"Compute Mean Squared Error.\n\n Args:\n sum_squared_error: Sum of square of errors over all observations\n n_obs: Number of predictions or observations\n squared: Returns RMSE value if set to False.\n\n Example:\n >>> preds = torch.tensor([0., 1, 2, 3])\n >>> target = torch.tensor([0., 1, 2, 2])\n >>> sum_squared_error, n_obs = _mean_squared_error_update(preds, target, num_outputs=1)\n >>> _mean_squared_error_compute(sum_squared_error, n_obs)\n tensor(0.2500)\n\n \"\"\"\n return sum_squared_error / n_obs if squared else torch.sqrt(sum_squared_error / n_obs)\n\n\ndef mean_squared_error(preds: Tensor, target: Tensor, squared: bool = True, num_outputs: int = 1) -> Tensor:\n \"\"\"Compute mean squared error.\n\n Args:\n preds: estimated labels\n target: ground truth labels\n squared: returns RMSE value if set to False\n num_outputs: Number of outputs in multioutput setting\n\n Return:\n Tensor with MSE\n\n Example:\n >>> from torchmetrics.functional.regression import mean_squared_error\n >>> x = torch.tensor([0., 1, 2, 3])\n >>> y = torch.tensor([0., 1, 2, 2])\n >>> mean_squared_error(x, y)\n tensor(0.2500)\n\n \"\"\"\n sum_squared_error, n_obs = _mean_squared_error_update(preds, target, num_outputs=num_outputs)\n return _mean_squared_error_compute(sum_squared_error, n_obs, squared=squared)\n", "path": "src/torchmetrics/functional/regression/mse.py"}]}
| 1,908 | 179 |
gh_patches_debug_41543
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-3366
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
float32 parameters leads to significant performance loss of parameter resolver
**Description of the issue**
Calling `cirq.resolve_parameters` to resolve the parameters of a symbolic circuit with `np.float32` parameters leads to a significant performance loss. I ran into this bug while working on loading circuit parameters from a `.npy` file on [this TensorQuantum Dataset PR](https://github.com/tensorflow/quantum/pull/304). Verifying that the circuits produced the expected wave functions took ~30 minutes on the CI, since we have to check hundreds of circuits. On further investigation, I discovered that the parameters were 32-bit, and casting them to 64-bit decreased the parameter resolve time by a large margin.
**How to reproduce the issue**
```python
import cirq
import sympy
import time
import numpy as np
from collections import namedtuple
import matplotlib.pyplot as plt
def unique_name():
"""Generator to generate an infinite number of unique names.
Yields:
Python `str` of the form "theta_<integer>".
"""
num = 0
while True:
yield "theta_" + str(num)
num += 1
def time_resolve_param(dtype, nspins, max_depth):
depth_grid = list(range(2, max_depth, 2))
times = []
for depth in depth_grid:
qubits = cirq.GridQubit.rect(nspins, 1)
# Symbolic parameters
name_generator = unique_name()
symbol_names = [next(name_generator) for _ in range(depth)]
symbols = [sympy.Symbol(name) for name in symbol_names]
# Random values with dtype
params = np.random.randn(2 * depth).astype(dtype)
params = dict(zip(symbol_names, params.flatten()))
# Define the circuit.
circuit = cirq.Circuit(cirq.H.on_each(qubits))
zipped_qubits = list(zip(qubits, qubits[1:]))
for d in range(depth):
for q1, q2 in zipped_qubits:
circuit.append(cirq.ZZ(q1, q2)**(symbols[d]))
# Resolve parameters and time
resolve_start = time.time()
param_resolver = cirq.resolve_parameters(circuit, params)
t_param = time.time() - resolve_start
times.append(t_param)
return depth_grid, times
if __name__ == "__main__":
NSPINS = 10
MAXDEPTH = 50
grid, times_32 = time_resolve_param(np.float32, NSPINS, MAXDEPTH)
_, times_64 = time_resolve_param(np.float64, NSPINS, MAXDEPTH)
plt.plot(grid, times_32, label='np.float32')
plt.plot(grid, times_64, label='np.float64')
plt.xlabel('circuit depth')
plt.ylabel('time (s)')
plt.legend()
plt.grid()
plt.show()
```
This produces the following figure
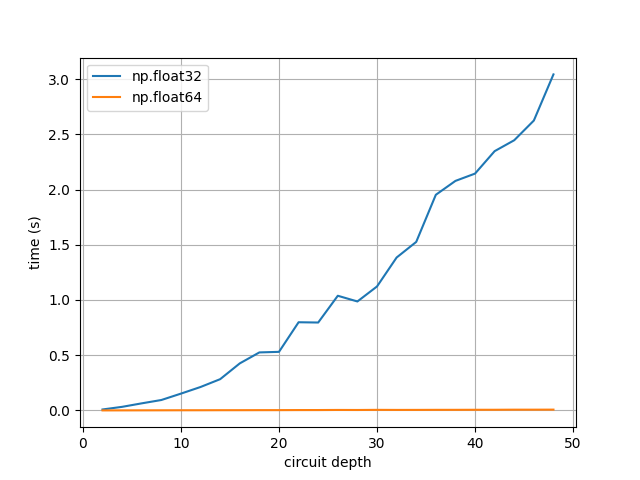
As we can see, with increasing circuit depth the time it takes to resolve the 32-bit parameters creates a massive slowdown.
**Cirq version**
Cirq 0.8.2
</issue>
<code>
[start of cirq/study/resolver.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Resolves ParameterValues to assigned values."""
16
17 from typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast
18 import numpy as np
19 import sympy
20 from cirq._compat import proper_repr
21 from cirq._doc import document
22
23 if TYPE_CHECKING:
24 import cirq
25
26
27 ParamDictType = Dict['cirq.TParamKey', 'cirq.TParamVal']
28 document(
29 ParamDictType, # type: ignore
30 """Dictionary from symbols to values.""")
31
32 ParamResolverOrSimilarType = Union['cirq.ParamResolver', ParamDictType, None]
33 document(
34 ParamResolverOrSimilarType, # type: ignore
35 """Something that can be used to turn parameters into values.""")
36
37
38 class ParamResolver:
39 """Resolves parameters to actual values.
40
41 A parameter is a variable whose value has not been determined.
42 A ParamResolver is an object that can be used to assign values for these
43 variables.
44
45 ParamResolvers are hashable.
46
47 Attributes:
48 param_dict: A dictionary from the ParameterValue key (str) to its
49 assigned value.
50 """
51
52 def __new__(cls, param_dict: 'cirq.ParamResolverOrSimilarType' = None):
53 if isinstance(param_dict, ParamResolver):
54 return param_dict
55 return super().__new__(cls)
56
57 def __init__(self,
58 param_dict: 'cirq.ParamResolverOrSimilarType' = None) -> None:
59 if hasattr(self, 'param_dict'):
60 return # Already initialized. Got wrapped as part of the __new__.
61
62 self._param_hash: Optional[int] = None
63 self.param_dict = cast(ParamDictType,
64 {} if param_dict is None else param_dict)
65
66 def value_of(self,
67 value: Union['cirq.TParamKey', float]) -> 'cirq.TParamVal':
68 """Attempt to resolve a parameter to its assigned value.
69
70 Floats are returned without modification. Strings are resolved via
71 the parameter dictionary with exact match only. Otherwise, strings
72 are considered to be sympy.Symbols with the name as the input string.
73
74 A sympy.Symbol is first checked for exact match in the parameter
75 dictionary. Otherwise, it is treated as a sympy.Basic.
76
77 A sympy.Basic is resolved using sympy substitution.
78
79 Note that passing a formula to this resolver can be slow due to the
80 underlying sympy library. For circuits relying on quick performance,
81 it is recommended that all formulas are flattened before-hand using
82 cirq.flatten or other means so that formula resolution is avoided.
83 If unable to resolve a sympy.Symbol, returns it unchanged.
84 If unable to resolve a name, returns a sympy.Symbol with that name.
85
86 Args:
87 value: The parameter to try to resolve.
88
89 Returns:
90 The value of the parameter as resolved by this resolver.
91 """
92 # Input is a float, no resolution needed: return early
93 if isinstance(value, float):
94 return value
95
96 # Handles 2 cases:
97 # Input is a string and maps to a number in the dictionary
98 # Input is a symbol and maps to a number in the dictionary
99 # In both cases, return it directly.
100 if value in self.param_dict:
101 param_value = self.param_dict[value]
102 if isinstance(param_value, (float, int)):
103 return param_value
104
105 # Input is a string and is not in the dictionary.
106 # Treat it as a symbol instead.
107 if isinstance(value, str):
108 # If the string is in the param_dict as a value, return it.
109 # Otherwise, try using the symbol instead.
110 return self.value_of(sympy.Symbol(value))
111
112 # Input is a symbol (sympy.Symbol('a')) and its string maps to a number
113 # in the dictionary ({'a': 1.0}). Return it.
114 if (isinstance(value, sympy.Symbol) and value.name in self.param_dict):
115 param_value = self.param_dict[value.name]
116 if isinstance(param_value, (float, int)):
117 return param_value
118
119 # The following resolves common sympy expressions
120 # If sympy did its job and wasn't slower than molasses,
121 # we wouldn't need the following block.
122 if isinstance(value, sympy.Add):
123 summation = self.value_of(value.args[0])
124 for addend in value.args[1:]:
125 summation += self.value_of(addend)
126 return summation
127 if isinstance(value, sympy.Mul):
128 product = self.value_of(value.args[0])
129 for factor in value.args[1:]:
130 product *= self.value_of(factor)
131 return product
132 if isinstance(value, sympy.Pow) and len(value.args) == 2:
133 return np.power(self.value_of(value.args[0]),
134 self.value_of(value.args[1]))
135 if value == sympy.pi:
136 return np.pi
137 if value == sympy.S.NegativeOne:
138 return -1
139
140 # Input is either a sympy formula or the dictionary maps to a
141 # formula. Use sympy to resolve the value.
142 # Note that sympy.subs() is slow, so we want to avoid this and
143 # only use it for cases that require complicated resolution.
144 if isinstance(value, sympy.Basic):
145 v = value.subs(self.param_dict)
146 if v.free_symbols:
147 return v
148 elif sympy.im(v):
149 return complex(v)
150 else:
151 return float(v)
152
153 # No known way to resolve this variable, return unchanged.
154 return value
155
156 def __iter__(self) -> Iterator[Union[str, sympy.Symbol]]:
157 return iter(self.param_dict)
158
159 def __bool__(self) -> bool:
160 return bool(self.param_dict)
161
162 def __getitem__(self,
163 key: Union[sympy.Basic, float, str]) -> 'cirq.TParamVal':
164 return self.value_of(key)
165
166 def __hash__(self) -> int:
167 if self._param_hash is None:
168 self._param_hash = hash(frozenset(self.param_dict.items()))
169 return self._param_hash
170
171 def __eq__(self, other):
172 if not isinstance(other, ParamResolver):
173 return NotImplemented
174 return self.param_dict == other.param_dict
175
176 def __ne__(self, other):
177 return not self == other
178
179 def __repr__(self) -> str:
180 param_dict_repr = ('{' + ', '.join([
181 f'{proper_repr(k)}: {proper_repr(v)}'
182 for k, v in self.param_dict.items()
183 ]) + '}')
184 return f'cirq.ParamResolver({param_dict_repr})'
185
186 def _json_dict_(self) -> Dict[str, Any]:
187 return {
188 'cirq_type': self.__class__.__name__,
189 # JSON requires mappings to have keys of basic types.
190 'param_dict': list(self.param_dict.items())
191 }
192
193 @classmethod
194 def _from_json_dict_(cls, param_dict, **kwargs):
195 return cls(dict(param_dict))
196
[end of cirq/study/resolver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq/study/resolver.py b/cirq/study/resolver.py
--- a/cirq/study/resolver.py
+++ b/cirq/study/resolver.py
@@ -13,7 +13,7 @@
# limitations under the License.
"""Resolves ParameterValues to assigned values."""
-
+import numbers
from typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast
import numpy as np
import sympy
@@ -89,9 +89,11 @@
Returns:
The value of the parameter as resolved by this resolver.
"""
- # Input is a float, no resolution needed: return early
- if isinstance(value, float):
- return value
+
+ # Input is a pass through type, no resolution needed: return early
+ v = _sympy_pass_through(value)
+ if v is not None:
+ return v
# Handles 2 cases:
# Input is a string and maps to a number in the dictionary
@@ -99,8 +101,9 @@
# In both cases, return it directly.
if value in self.param_dict:
param_value = self.param_dict[value]
- if isinstance(param_value, (float, int)):
- return param_value
+ v = _sympy_pass_through(param_value)
+ if v is not None:
+ return v
# Input is a string and is not in the dictionary.
# Treat it as a symbol instead.
@@ -111,10 +114,11 @@
# Input is a symbol (sympy.Symbol('a')) and its string maps to a number
# in the dictionary ({'a': 1.0}). Return it.
- if (isinstance(value, sympy.Symbol) and value.name in self.param_dict):
+ if isinstance(value, sympy.Symbol) and value.name in self.param_dict:
param_value = self.param_dict[value.name]
- if isinstance(param_value, (float, int)):
- return param_value
+ v = _sympy_pass_through(param_value)
+ if v is not None:
+ return v
# The following resolves common sympy expressions
# If sympy did its job and wasn't slower than molasses,
@@ -132,10 +136,6 @@
if isinstance(value, sympy.Pow) and len(value.args) == 2:
return np.power(self.value_of(value.args[0]),
self.value_of(value.args[1]))
- if value == sympy.pi:
- return np.pi
- if value == sympy.S.NegativeOne:
- return -1
# Input is either a sympy formula or the dictionary maps to a
# formula. Use sympy to resolve the value.
@@ -193,3 +193,15 @@
@classmethod
def _from_json_dict_(cls, param_dict, **kwargs):
return cls(dict(param_dict))
+
+
+def _sympy_pass_through(val: Any) -> Optional[Any]:
+ if isinstance(val, numbers.Number) and not isinstance(val, sympy.Basic):
+ return val
+ if isinstance(val, sympy.core.numbers.IntegerConstant):
+ return val.p
+ if isinstance(val, sympy.core.numbers.RationalConstant):
+ return val.p / val.q
+ if val == sympy.pi:
+ return np.pi
+ return None
|
{"golden_diff": "diff --git a/cirq/study/resolver.py b/cirq/study/resolver.py\n--- a/cirq/study/resolver.py\n+++ b/cirq/study/resolver.py\n@@ -13,7 +13,7 @@\n # limitations under the License.\n \n \"\"\"Resolves ParameterValues to assigned values.\"\"\"\n-\n+import numbers\n from typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast\n import numpy as np\n import sympy\n@@ -89,9 +89,11 @@\n Returns:\n The value of the parameter as resolved by this resolver.\n \"\"\"\n- # Input is a float, no resolution needed: return early\n- if isinstance(value, float):\n- return value\n+\n+ # Input is a pass through type, no resolution needed: return early\n+ v = _sympy_pass_through(value)\n+ if v is not None:\n+ return v\n \n # Handles 2 cases:\n # Input is a string and maps to a number in the dictionary\n@@ -99,8 +101,9 @@\n # In both cases, return it directly.\n if value in self.param_dict:\n param_value = self.param_dict[value]\n- if isinstance(param_value, (float, int)):\n- return param_value\n+ v = _sympy_pass_through(param_value)\n+ if v is not None:\n+ return v\n \n # Input is a string and is not in the dictionary.\n # Treat it as a symbol instead.\n@@ -111,10 +114,11 @@\n \n # Input is a symbol (sympy.Symbol('a')) and its string maps to a number\n # in the dictionary ({'a': 1.0}). Return it.\n- if (isinstance(value, sympy.Symbol) and value.name in self.param_dict):\n+ if isinstance(value, sympy.Symbol) and value.name in self.param_dict:\n param_value = self.param_dict[value.name]\n- if isinstance(param_value, (float, int)):\n- return param_value\n+ v = _sympy_pass_through(param_value)\n+ if v is not None:\n+ return v\n \n # The following resolves common sympy expressions\n # If sympy did its job and wasn't slower than molasses,\n@@ -132,10 +136,6 @@\n if isinstance(value, sympy.Pow) and len(value.args) == 2:\n return np.power(self.value_of(value.args[0]),\n self.value_of(value.args[1]))\n- if value == sympy.pi:\n- return np.pi\n- if value == sympy.S.NegativeOne:\n- return -1\n \n # Input is either a sympy formula or the dictionary maps to a\n # formula. Use sympy to resolve the value.\n@@ -193,3 +193,15 @@\n @classmethod\n def _from_json_dict_(cls, param_dict, **kwargs):\n return cls(dict(param_dict))\n+\n+\n+def _sympy_pass_through(val: Any) -> Optional[Any]:\n+ if isinstance(val, numbers.Number) and not isinstance(val, sympy.Basic):\n+ return val\n+ if isinstance(val, sympy.core.numbers.IntegerConstant):\n+ return val.p\n+ if isinstance(val, sympy.core.numbers.RationalConstant):\n+ return val.p / val.q\n+ if val == sympy.pi:\n+ return np.pi\n+ return None\n", "issue": "float32 parameters leads to significant performance loss of parameter resolver\n**Description of the issue**\r\nCalling `cirq.resolve_parameters` to resolve the parameters of a symbolic circuit with `np.float32` parameters leads to a significant performance loss. I ran into this bug while working on loading circuit parameters from a `.npy` file on [this TensorQuantum Dataset PR](https://github.com/tensorflow/quantum/pull/304). Verifying that the circuits produced the expected wave functions took ~30 minutes on the CI, since we have to check hundreds of circuits. On further investigation, I discovered that the parameters were 32-bit, and casting them to 64-bit decreased the parameter resolve time by a large margin.\r\n\r\n**How to reproduce the issue**\r\n\r\n```python\r\n\r\nimport cirq\r\nimport sympy\r\nimport time\r\nimport numpy as np\r\nfrom collections import namedtuple\r\nimport matplotlib.pyplot as plt\r\n\r\n\r\ndef unique_name():\r\n \"\"\"Generator to generate an infinite number of unique names.\r\n\r\n Yields:\r\n Python `str` of the form \"theta_<integer>\".\r\n\r\n \"\"\"\r\n num = 0\r\n while True:\r\n yield \"theta_\" + str(num)\r\n num += 1\r\n\r\n\r\ndef time_resolve_param(dtype, nspins, max_depth):\r\n depth_grid = list(range(2, max_depth, 2))\r\n times = []\r\n for depth in depth_grid:\r\n qubits = cirq.GridQubit.rect(nspins, 1)\r\n\r\n # Symbolic parameters\r\n name_generator = unique_name()\r\n symbol_names = [next(name_generator) for _ in range(depth)]\r\n symbols = [sympy.Symbol(name) for name in symbol_names]\r\n\r\n # Random values with dtype\r\n params = np.random.randn(2 * depth).astype(dtype)\r\n params = dict(zip(symbol_names, params.flatten()))\r\n\r\n # Define the circuit.\r\n circuit = cirq.Circuit(cirq.H.on_each(qubits))\r\n zipped_qubits = list(zip(qubits, qubits[1:]))\r\n for d in range(depth):\r\n for q1, q2 in zipped_qubits:\r\n circuit.append(cirq.ZZ(q1, q2)**(symbols[d]))\r\n\r\n # Resolve parameters and time\r\n resolve_start = time.time()\r\n param_resolver = cirq.resolve_parameters(circuit, params)\r\n t_param = time.time() - resolve_start\r\n times.append(t_param)\r\n\r\n return depth_grid, times\r\n\r\n\r\nif __name__ == \"__main__\":\r\n NSPINS = 10\r\n MAXDEPTH = 50\r\n grid, times_32 = time_resolve_param(np.float32, NSPINS, MAXDEPTH)\r\n _, times_64 = time_resolve_param(np.float64, NSPINS, MAXDEPTH)\r\n\r\n plt.plot(grid, times_32, label='np.float32')\r\n plt.plot(grid, times_64, label='np.float64')\r\n plt.xlabel('circuit depth')\r\n plt.ylabel('time (s)')\r\n plt.legend()\r\n plt.grid()\r\n plt.show()\r\n\r\n\r\n```\r\nThis produces the following figure\r\n\r\n\r\n\r\nAs we can see, with increasing circuit depth the time it takes to resolve the 32-bit parameters creates a massive slowdown.\r\n\r\n**Cirq version**\r\nCirq 0.8.2\r\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Resolves ParameterValues to assigned values.\"\"\"\n\nfrom typing import Any, Dict, Iterator, Optional, TYPE_CHECKING, Union, cast\nimport numpy as np\nimport sympy\nfrom cirq._compat import proper_repr\nfrom cirq._doc import document\n\nif TYPE_CHECKING:\n import cirq\n\n\nParamDictType = Dict['cirq.TParamKey', 'cirq.TParamVal']\ndocument(\n ParamDictType, # type: ignore\n \"\"\"Dictionary from symbols to values.\"\"\")\n\nParamResolverOrSimilarType = Union['cirq.ParamResolver', ParamDictType, None]\ndocument(\n ParamResolverOrSimilarType, # type: ignore\n \"\"\"Something that can be used to turn parameters into values.\"\"\")\n\n\nclass ParamResolver:\n \"\"\"Resolves parameters to actual values.\n\n A parameter is a variable whose value has not been determined.\n A ParamResolver is an object that can be used to assign values for these\n variables.\n\n ParamResolvers are hashable.\n\n Attributes:\n param_dict: A dictionary from the ParameterValue key (str) to its\n assigned value.\n \"\"\"\n\n def __new__(cls, param_dict: 'cirq.ParamResolverOrSimilarType' = None):\n if isinstance(param_dict, ParamResolver):\n return param_dict\n return super().__new__(cls)\n\n def __init__(self,\n param_dict: 'cirq.ParamResolverOrSimilarType' = None) -> None:\n if hasattr(self, 'param_dict'):\n return # Already initialized. Got wrapped as part of the __new__.\n\n self._param_hash: Optional[int] = None\n self.param_dict = cast(ParamDictType,\n {} if param_dict is None else param_dict)\n\n def value_of(self,\n value: Union['cirq.TParamKey', float]) -> 'cirq.TParamVal':\n \"\"\"Attempt to resolve a parameter to its assigned value.\n\n Floats are returned without modification. Strings are resolved via\n the parameter dictionary with exact match only. Otherwise, strings\n are considered to be sympy.Symbols with the name as the input string.\n\n A sympy.Symbol is first checked for exact match in the parameter\n dictionary. Otherwise, it is treated as a sympy.Basic.\n\n A sympy.Basic is resolved using sympy substitution.\n\n Note that passing a formula to this resolver can be slow due to the\n underlying sympy library. For circuits relying on quick performance,\n it is recommended that all formulas are flattened before-hand using\n cirq.flatten or other means so that formula resolution is avoided.\n If unable to resolve a sympy.Symbol, returns it unchanged.\n If unable to resolve a name, returns a sympy.Symbol with that name.\n\n Args:\n value: The parameter to try to resolve.\n\n Returns:\n The value of the parameter as resolved by this resolver.\n \"\"\"\n # Input is a float, no resolution needed: return early\n if isinstance(value, float):\n return value\n\n # Handles 2 cases:\n # Input is a string and maps to a number in the dictionary\n # Input is a symbol and maps to a number in the dictionary\n # In both cases, return it directly.\n if value in self.param_dict:\n param_value = self.param_dict[value]\n if isinstance(param_value, (float, int)):\n return param_value\n\n # Input is a string and is not in the dictionary.\n # Treat it as a symbol instead.\n if isinstance(value, str):\n # If the string is in the param_dict as a value, return it.\n # Otherwise, try using the symbol instead.\n return self.value_of(sympy.Symbol(value))\n\n # Input is a symbol (sympy.Symbol('a')) and its string maps to a number\n # in the dictionary ({'a': 1.0}). Return it.\n if (isinstance(value, sympy.Symbol) and value.name in self.param_dict):\n param_value = self.param_dict[value.name]\n if isinstance(param_value, (float, int)):\n return param_value\n\n # The following resolves common sympy expressions\n # If sympy did its job and wasn't slower than molasses,\n # we wouldn't need the following block.\n if isinstance(value, sympy.Add):\n summation = self.value_of(value.args[0])\n for addend in value.args[1:]:\n summation += self.value_of(addend)\n return summation\n if isinstance(value, sympy.Mul):\n product = self.value_of(value.args[0])\n for factor in value.args[1:]:\n product *= self.value_of(factor)\n return product\n if isinstance(value, sympy.Pow) and len(value.args) == 2:\n return np.power(self.value_of(value.args[0]),\n self.value_of(value.args[1]))\n if value == sympy.pi:\n return np.pi\n if value == sympy.S.NegativeOne:\n return -1\n\n # Input is either a sympy formula or the dictionary maps to a\n # formula. Use sympy to resolve the value.\n # Note that sympy.subs() is slow, so we want to avoid this and\n # only use it for cases that require complicated resolution.\n if isinstance(value, sympy.Basic):\n v = value.subs(self.param_dict)\n if v.free_symbols:\n return v\n elif sympy.im(v):\n return complex(v)\n else:\n return float(v)\n\n # No known way to resolve this variable, return unchanged.\n return value\n\n def __iter__(self) -> Iterator[Union[str, sympy.Symbol]]:\n return iter(self.param_dict)\n\n def __bool__(self) -> bool:\n return bool(self.param_dict)\n\n def __getitem__(self,\n key: Union[sympy.Basic, float, str]) -> 'cirq.TParamVal':\n return self.value_of(key)\n\n def __hash__(self) -> int:\n if self._param_hash is None:\n self._param_hash = hash(frozenset(self.param_dict.items()))\n return self._param_hash\n\n def __eq__(self, other):\n if not isinstance(other, ParamResolver):\n return NotImplemented\n return self.param_dict == other.param_dict\n\n def __ne__(self, other):\n return not self == other\n\n def __repr__(self) -> str:\n param_dict_repr = ('{' + ', '.join([\n f'{proper_repr(k)}: {proper_repr(v)}'\n for k, v in self.param_dict.items()\n ]) + '}')\n return f'cirq.ParamResolver({param_dict_repr})'\n\n def _json_dict_(self) -> Dict[str, Any]:\n return {\n 'cirq_type': self.__class__.__name__,\n # JSON requires mappings to have keys of basic types.\n 'param_dict': list(self.param_dict.items())\n }\n\n @classmethod\n def _from_json_dict_(cls, param_dict, **kwargs):\n return cls(dict(param_dict))\n", "path": "cirq/study/resolver.py"}]}
| 3,446 | 767 |
gh_patches_debug_31092
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1888
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Refactor EventWrapper
It seems we can maybe remove EventWrapper class now since we depend on GDB >= 9.2?
https://github.com/pwndbg/pwndbg/issues/1854#issuecomment-1664527390
</issue>
<code>
[start of pwndbg/gdblib/events.py]
1 """
2 Enables callbacks into functions to be automatically invoked
3 when various events occur to the debuggee (e.g. STOP on SIGINT)
4 by using a decorator.
5 """
6
7 from __future__ import annotations
8
9 import sys
10 from functools import partial
11 from functools import wraps
12 from typing import Any
13 from typing import Callable
14
15 import gdb
16
17 from pwndbg.gdblib.config import config
18
19 debug = config.add_param("debug-events", False, "display internal event debugging info")
20
21
22 # There is no GDB way to get a notification when the binary itself
23 # is loaded from disk, by the operating system, before absolutely
24 # anything happens
25 #
26 # However, we get an Objfile event when the binary is loaded, before
27 # its entry point is invoked.
28 #
29 # We also get an Objfile event when we load up GDB, so we need
30 # to detect when the binary is running or not.
31 #
32 # Additionally, when attaching to a process running under QEMU, the
33 # very first event which is fired is a 'stop' event. We need to
34 # capture this so that we can fire off all of the 'start' events first.
35 class StartEvent:
36 def __init__(self) -> None:
37 self.registered: list[Callable] = []
38 self.running = False
39
40 def connect(self, function) -> None:
41 if function not in self.registered:
42 self.registered.append(function)
43
44 def disconnect(self, function) -> None:
45 if function in self.registered:
46 self.registered.remove(function)
47
48 def on_new_objfile(self) -> None:
49 if self.running or not gdb.selected_thread():
50 return
51
52 self.running = True
53
54 for function in self.registered:
55 if debug:
56 sys.stdout.write(
57 "{!r} {}.{}\n".format("start", function.__module__, function.__name__)
58 )
59 function()
60
61 def on_exited(self) -> None:
62 self.running = False
63
64 def on_stop(self) -> None:
65 self.on_new_objfile()
66
67
68 gdb.events.start = StartEvent()
69
70
71 class EventWrapper:
72 """
73 Wrapper for GDB events which may not exist on older GDB versions but we still can
74 fire them manually (to invoke them you have to call `invoke_callbacks`).
75 """
76
77 def __init__(self, name: str) -> None:
78 self.name = name
79
80 self._event = getattr(gdb.events, self.name, None)
81 self._is_real_event = self._event is not None
82
83 def connect(self, func) -> None:
84 if self._event is not None:
85 self._event.connect(func)
86
87 def disconnect(self, func) -> None:
88 if self._event is not None:
89 self._event.disconnect(func)
90
91 @property
92 def is_real_event(self) -> bool:
93 return self._is_real_event
94
95 def invoke_callbacks(self) -> None:
96 """
97 As an optimization please don't call this if your GDB has this event (check `.is_real_event`).
98 """
99 for f in registered[self]:
100 f()
101
102
103 # Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook
104 before_prompt_event = EventWrapper("before_prompt")
105 gdb.events.before_prompt = before_prompt_event
106
107
108 # In order to support reloading, we must be able to re-fire
109 # all 'objfile' and 'stop' events.
110 registered: dict[Any, list[Callable]] = {
111 gdb.events.exited: [],
112 gdb.events.cont: [],
113 gdb.events.new_objfile: [],
114 gdb.events.stop: [],
115 gdb.events.start: [],
116 gdb.events.new_thread: [],
117 gdb.events.before_prompt: [], # The real event might not exist, but we wrap it
118 gdb.events.memory_changed: [],
119 gdb.events.register_changed: [],
120 }
121
122
123 # When performing remote debugging, gdbserver is very noisy about which
124 # objects are loaded. This greatly slows down the debugging session.
125 # In order to combat this, we keep track of which objfiles have been loaded
126 # this session, and only emit objfile events for each *new* file.
127 objfile_cache: dict[str, set[str]] = {}
128
129
130 def connect(func, event_handler, name=""):
131 if debug:
132 print("Connecting", func.__name__, event_handler)
133
134 @wraps(func)
135 def caller(*a):
136 if debug:
137 sys.stdout.write(f"{name!r} {func.__module__}.{func.__name__} {a!r}\n")
138
139 if a and isinstance(a[0], gdb.NewObjFileEvent):
140 objfile = a[0].new_objfile
141 handler = f"{func.__module__}.{func.__name__}"
142 path = objfile.filename
143 dispatched = objfile_cache.get(path, set())
144
145 if handler in dispatched:
146 return
147
148 dispatched.add(handler)
149 objfile_cache[path] = dispatched
150
151 try:
152 func()
153 except Exception as e:
154 import pwndbg.exception
155
156 pwndbg.exception.handle()
157 raise e
158
159 registered[event_handler].append(caller)
160 event_handler.connect(caller)
161 return func
162
163
164 def exit(func):
165 return connect(func, gdb.events.exited, "exit")
166
167
168 def cont(func):
169 return connect(func, gdb.events.cont, "cont")
170
171
172 def new_objfile(func):
173 return connect(func, gdb.events.new_objfile, "obj")
174
175
176 def stop(func):
177 return connect(func, gdb.events.stop, "stop")
178
179
180 def start(func):
181 return connect(func, gdb.events.start, "start")
182
183
184 def thread(func):
185 return connect(func, gdb.events.new_thread, "thread")
186
187
188 before_prompt = partial(connect, event_handler=gdb.events.before_prompt, name="before_prompt")
189
190
191 def reg_changed(func):
192 try:
193 return connect(func, gdb.events.register_changed, "reg_changed")
194 except AttributeError:
195 return func
196
197
198 def mem_changed(func):
199 try:
200 return connect(func, gdb.events.memory_changed, "mem_changed")
201 except AttributeError:
202 return func
203
204
205 def log_objfiles(ofile=None) -> None:
206 if not (debug and ofile):
207 return
208
209 name = ofile.new_objfile.filename
210
211 print("objfile: %r" % name)
212 gdb.execute("info sharedlibrary")
213
214
215 gdb.events.new_objfile.connect(log_objfiles)
216
217
218 def after_reload(start=True) -> None:
219 if gdb.selected_inferior().pid:
220 for f in registered[gdb.events.stop]:
221 f()
222 for f in registered[gdb.events.start]:
223 if start:
224 f()
225 for f in registered[gdb.events.new_objfile]:
226 f()
227 for f in registered[gdb.events.before_prompt]:
228 f()
229
230
231 def on_reload() -> None:
232 for event, functions in registered.items():
233 for function in functions:
234 event.disconnect(function)
235 registered[event] = []
236
237
238 @new_objfile
239 def _start_newobjfile() -> None:
240 gdb.events.start.on_new_objfile()
241
242
243 @exit
244 def _start_exit() -> None:
245 gdb.events.start.on_exited()
246
247
248 @stop
249 def _start_stop() -> None:
250 gdb.events.start.on_stop()
251
252
253 @exit
254 def _reset_objfiles() -> None:
255 global objfile_cache
256 objfile_cache = {}
257
[end of pwndbg/gdblib/events.py]
[start of pwndbg/gdblib/prompt.py]
1 from __future__ import annotations
2
3 from os import environ
4
5 import gdb
6
7 import pwndbg.decorators
8 import pwndbg.gdblib.events
9 import pwndbg.gdblib.functions
10 import pwndbg.lib.cache
11 import pwndbg.profiling
12 from pwndbg.color import disable_colors
13 from pwndbg.color import message
14 from pwndbg.lib.tips import color_tip
15 from pwndbg.lib.tips import get_tip_of_the_day
16
17 funcs_list_str = ", ".join(message.notice("$" + f.name) for f in pwndbg.gdblib.functions.functions)
18
19 num_pwndbg_cmds = sum(
20 1 for _ in filter(lambda c: not (c.shell or c.is_alias), pwndbg.commands.commands)
21 )
22 num_shell_cmds = sum(1 for _ in filter(lambda c: c.shell, pwndbg.commands.commands))
23 hint_lines = (
24 "loaded %i pwndbg commands and %i shell commands. Type %s for a list."
25 % (num_pwndbg_cmds, num_shell_cmds, message.notice("pwndbg [--shell | --all] [filter]")),
26 f"created {funcs_list_str} GDB functions (can be used with print/break)",
27 )
28
29 for line in hint_lines:
30 print(message.prompt("pwndbg: ") + message.system(line))
31
32 # noinspection PyPackageRequirements
33 show_tip = pwndbg.gdblib.config.add_param(
34 "show-tips", True, "whether to display the tip of the day on startup"
35 )
36
37 cur = None
38
39
40 def initial_hook(*a) -> None:
41 if show_tip and not pwndbg.decorators.first_prompt:
42 colored_tip = color_tip(get_tip_of_the_day())
43 print(
44 message.prompt("------- tip of the day")
45 + message.system(" (disable with %s)" % message.notice("set show-tips off"))
46 + message.prompt(" -------")
47 )
48 print(colored_tip)
49 pwndbg.decorators.first_prompt = True
50
51 prompt_hook(*a)
52
53 if environ.get("PWNDBG_PROFILE") == "1":
54 pwndbg.profiling.profiler.stop("pwndbg-first-prompt.pstats")
55
56 gdb.prompt_hook = prompt_hook
57
58
59 context_shown = False
60
61
62 def prompt_hook(*a) -> None:
63 global cur, context_shown
64
65 new = (gdb.selected_inferior(), gdb.selected_thread())
66
67 if cur != new:
68 pwndbg.gdblib.events.after_reload(start=cur is None)
69 cur = new
70
71 if pwndbg.gdblib.proc.alive and pwndbg.gdblib.proc.thread_is_stopped and not context_shown:
72 pwndbg.commands.context.context()
73 context_shown = True
74
75
76 @pwndbg.gdblib.events.cont
77 def reset_context_shown(*a) -> None:
78 global context_shown
79 context_shown = False
80
81
82 @pwndbg.gdblib.config.trigger(message.config_prompt_color, disable_colors)
83 def set_prompt() -> None:
84 prompt = "pwndbg> "
85
86 if not disable_colors:
87 prompt = "\x02" + prompt + "\x01" # STX + prompt + SOH
88 prompt = message.prompt(prompt)
89 prompt = "\x01" + prompt + "\x02" # SOH + prompt + STX
90
91 gdb.execute(f"set prompt {prompt}")
92
93
94 if pwndbg.gdblib.events.before_prompt_event.is_real_event:
95 gdb.prompt_hook = initial_hook
96
97 else:
98 # Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook
99 def extended_prompt_hook(*a):
100 pwndbg.gdblib.events.before_prompt_event.invoke_callbacks()
101 return prompt_hook(*a)
102
103 gdb.prompt_hook = extended_prompt_hook
104
[end of pwndbg/gdblib/prompt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwndbg/gdblib/events.py b/pwndbg/gdblib/events.py
--- a/pwndbg/gdblib/events.py
+++ b/pwndbg/gdblib/events.py
@@ -67,44 +67,6 @@
gdb.events.start = StartEvent()
-
-class EventWrapper:
- """
- Wrapper for GDB events which may not exist on older GDB versions but we still can
- fire them manually (to invoke them you have to call `invoke_callbacks`).
- """
-
- def __init__(self, name: str) -> None:
- self.name = name
-
- self._event = getattr(gdb.events, self.name, None)
- self._is_real_event = self._event is not None
-
- def connect(self, func) -> None:
- if self._event is not None:
- self._event.connect(func)
-
- def disconnect(self, func) -> None:
- if self._event is not None:
- self._event.disconnect(func)
-
- @property
- def is_real_event(self) -> bool:
- return self._is_real_event
-
- def invoke_callbacks(self) -> None:
- """
- As an optimization please don't call this if your GDB has this event (check `.is_real_event`).
- """
- for f in registered[self]:
- f()
-
-
-# Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook
-before_prompt_event = EventWrapper("before_prompt")
-gdb.events.before_prompt = before_prompt_event
-
-
# In order to support reloading, we must be able to re-fire
# all 'objfile' and 'stop' events.
registered: dict[Any, list[Callable]] = {
diff --git a/pwndbg/gdblib/prompt.py b/pwndbg/gdblib/prompt.py
--- a/pwndbg/gdblib/prompt.py
+++ b/pwndbg/gdblib/prompt.py
@@ -89,15 +89,4 @@
prompt = "\x01" + prompt + "\x02" # SOH + prompt + STX
gdb.execute(f"set prompt {prompt}")
-
-
-if pwndbg.gdblib.events.before_prompt_event.is_real_event:
- gdb.prompt_hook = initial_hook
-
-else:
- # Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook
- def extended_prompt_hook(*a):
- pwndbg.gdblib.events.before_prompt_event.invoke_callbacks()
- return prompt_hook(*a)
-
- gdb.prompt_hook = extended_prompt_hook
+gdb.prompt_hook = initial_hook
|
{"golden_diff": "diff --git a/pwndbg/gdblib/events.py b/pwndbg/gdblib/events.py\n--- a/pwndbg/gdblib/events.py\n+++ b/pwndbg/gdblib/events.py\n@@ -67,44 +67,6 @@\n \n gdb.events.start = StartEvent()\n \n-\n-class EventWrapper:\n- \"\"\"\n- Wrapper for GDB events which may not exist on older GDB versions but we still can\n- fire them manually (to invoke them you have to call `invoke_callbacks`).\n- \"\"\"\n-\n- def __init__(self, name: str) -> None:\n- self.name = name\n-\n- self._event = getattr(gdb.events, self.name, None)\n- self._is_real_event = self._event is not None\n-\n- def connect(self, func) -> None:\n- if self._event is not None:\n- self._event.connect(func)\n-\n- def disconnect(self, func) -> None:\n- if self._event is not None:\n- self._event.disconnect(func)\n-\n- @property\n- def is_real_event(self) -> bool:\n- return self._is_real_event\n-\n- def invoke_callbacks(self) -> None:\n- \"\"\"\n- As an optimization please don't call this if your GDB has this event (check `.is_real_event`).\n- \"\"\"\n- for f in registered[self]:\n- f()\n-\n-\n-# Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook\n-before_prompt_event = EventWrapper(\"before_prompt\")\n-gdb.events.before_prompt = before_prompt_event\n-\n-\n # In order to support reloading, we must be able to re-fire\n # all 'objfile' and 'stop' events.\n registered: dict[Any, list[Callable]] = {\ndiff --git a/pwndbg/gdblib/prompt.py b/pwndbg/gdblib/prompt.py\n--- a/pwndbg/gdblib/prompt.py\n+++ b/pwndbg/gdblib/prompt.py\n@@ -89,15 +89,4 @@\n prompt = \"\\x01\" + prompt + \"\\x02\" # SOH + prompt + STX\n \n gdb.execute(f\"set prompt {prompt}\")\n-\n-\n-if pwndbg.gdblib.events.before_prompt_event.is_real_event:\n- gdb.prompt_hook = initial_hook\n-\n-else:\n- # Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook\n- def extended_prompt_hook(*a):\n- pwndbg.gdblib.events.before_prompt_event.invoke_callbacks()\n- return prompt_hook(*a)\n-\n- gdb.prompt_hook = extended_prompt_hook\n+gdb.prompt_hook = initial_hook\n", "issue": "Refactor EventWrapper\nIt seems we can maybe remove EventWrapper class now since we depend on GDB >= 9.2?\r\n\r\nhttps://github.com/pwndbg/pwndbg/issues/1854#issuecomment-1664527390\n", "before_files": [{"content": "\"\"\"\nEnables callbacks into functions to be automatically invoked\nwhen various events occur to the debuggee (e.g. STOP on SIGINT)\nby using a decorator.\n\"\"\"\n\nfrom __future__ import annotations\n\nimport sys\nfrom functools import partial\nfrom functools import wraps\nfrom typing import Any\nfrom typing import Callable\n\nimport gdb\n\nfrom pwndbg.gdblib.config import config\n\ndebug = config.add_param(\"debug-events\", False, \"display internal event debugging info\")\n\n\n# There is no GDB way to get a notification when the binary itself\n# is loaded from disk, by the operating system, before absolutely\n# anything happens\n#\n# However, we get an Objfile event when the binary is loaded, before\n# its entry point is invoked.\n#\n# We also get an Objfile event when we load up GDB, so we need\n# to detect when the binary is running or not.\n#\n# Additionally, when attaching to a process running under QEMU, the\n# very first event which is fired is a 'stop' event. We need to\n# capture this so that we can fire off all of the 'start' events first.\nclass StartEvent:\n def __init__(self) -> None:\n self.registered: list[Callable] = []\n self.running = False\n\n def connect(self, function) -> None:\n if function not in self.registered:\n self.registered.append(function)\n\n def disconnect(self, function) -> None:\n if function in self.registered:\n self.registered.remove(function)\n\n def on_new_objfile(self) -> None:\n if self.running or not gdb.selected_thread():\n return\n\n self.running = True\n\n for function in self.registered:\n if debug:\n sys.stdout.write(\n \"{!r} {}.{}\\n\".format(\"start\", function.__module__, function.__name__)\n )\n function()\n\n def on_exited(self) -> None:\n self.running = False\n\n def on_stop(self) -> None:\n self.on_new_objfile()\n\n\ngdb.events.start = StartEvent()\n\n\nclass EventWrapper:\n \"\"\"\n Wrapper for GDB events which may not exist on older GDB versions but we still can\n fire them manually (to invoke them you have to call `invoke_callbacks`).\n \"\"\"\n\n def __init__(self, name: str) -> None:\n self.name = name\n\n self._event = getattr(gdb.events, self.name, None)\n self._is_real_event = self._event is not None\n\n def connect(self, func) -> None:\n if self._event is not None:\n self._event.connect(func)\n\n def disconnect(self, func) -> None:\n if self._event is not None:\n self._event.disconnect(func)\n\n @property\n def is_real_event(self) -> bool:\n return self._is_real_event\n\n def invoke_callbacks(self) -> None:\n \"\"\"\n As an optimization please don't call this if your GDB has this event (check `.is_real_event`).\n \"\"\"\n for f in registered[self]:\n f()\n\n\n# Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook\nbefore_prompt_event = EventWrapper(\"before_prompt\")\ngdb.events.before_prompt = before_prompt_event\n\n\n# In order to support reloading, we must be able to re-fire\n# all 'objfile' and 'stop' events.\nregistered: dict[Any, list[Callable]] = {\n gdb.events.exited: [],\n gdb.events.cont: [],\n gdb.events.new_objfile: [],\n gdb.events.stop: [],\n gdb.events.start: [],\n gdb.events.new_thread: [],\n gdb.events.before_prompt: [], # The real event might not exist, but we wrap it\n gdb.events.memory_changed: [],\n gdb.events.register_changed: [],\n}\n\n\n# When performing remote debugging, gdbserver is very noisy about which\n# objects are loaded. This greatly slows down the debugging session.\n# In order to combat this, we keep track of which objfiles have been loaded\n# this session, and only emit objfile events for each *new* file.\nobjfile_cache: dict[str, set[str]] = {}\n\n\ndef connect(func, event_handler, name=\"\"):\n if debug:\n print(\"Connecting\", func.__name__, event_handler)\n\n @wraps(func)\n def caller(*a):\n if debug:\n sys.stdout.write(f\"{name!r} {func.__module__}.{func.__name__} {a!r}\\n\")\n\n if a and isinstance(a[0], gdb.NewObjFileEvent):\n objfile = a[0].new_objfile\n handler = f\"{func.__module__}.{func.__name__}\"\n path = objfile.filename\n dispatched = objfile_cache.get(path, set())\n\n if handler in dispatched:\n return\n\n dispatched.add(handler)\n objfile_cache[path] = dispatched\n\n try:\n func()\n except Exception as e:\n import pwndbg.exception\n\n pwndbg.exception.handle()\n raise e\n\n registered[event_handler].append(caller)\n event_handler.connect(caller)\n return func\n\n\ndef exit(func):\n return connect(func, gdb.events.exited, \"exit\")\n\n\ndef cont(func):\n return connect(func, gdb.events.cont, \"cont\")\n\n\ndef new_objfile(func):\n return connect(func, gdb.events.new_objfile, \"obj\")\n\n\ndef stop(func):\n return connect(func, gdb.events.stop, \"stop\")\n\n\ndef start(func):\n return connect(func, gdb.events.start, \"start\")\n\n\ndef thread(func):\n return connect(func, gdb.events.new_thread, \"thread\")\n\n\nbefore_prompt = partial(connect, event_handler=gdb.events.before_prompt, name=\"before_prompt\")\n\n\ndef reg_changed(func):\n try:\n return connect(func, gdb.events.register_changed, \"reg_changed\")\n except AttributeError:\n return func\n\n\ndef mem_changed(func):\n try:\n return connect(func, gdb.events.memory_changed, \"mem_changed\")\n except AttributeError:\n return func\n\n\ndef log_objfiles(ofile=None) -> None:\n if not (debug and ofile):\n return\n\n name = ofile.new_objfile.filename\n\n print(\"objfile: %r\" % name)\n gdb.execute(\"info sharedlibrary\")\n\n\ngdb.events.new_objfile.connect(log_objfiles)\n\n\ndef after_reload(start=True) -> None:\n if gdb.selected_inferior().pid:\n for f in registered[gdb.events.stop]:\n f()\n for f in registered[gdb.events.start]:\n if start:\n f()\n for f in registered[gdb.events.new_objfile]:\n f()\n for f in registered[gdb.events.before_prompt]:\n f()\n\n\ndef on_reload() -> None:\n for event, functions in registered.items():\n for function in functions:\n event.disconnect(function)\n registered[event] = []\n\n\n@new_objfile\ndef _start_newobjfile() -> None:\n gdb.events.start.on_new_objfile()\n\n\n@exit\ndef _start_exit() -> None:\n gdb.events.start.on_exited()\n\n\n@stop\ndef _start_stop() -> None:\n gdb.events.start.on_stop()\n\n\n@exit\ndef _reset_objfiles() -> None:\n global objfile_cache\n objfile_cache = {}\n", "path": "pwndbg/gdblib/events.py"}, {"content": "from __future__ import annotations\n\nfrom os import environ\n\nimport gdb\n\nimport pwndbg.decorators\nimport pwndbg.gdblib.events\nimport pwndbg.gdblib.functions\nimport pwndbg.lib.cache\nimport pwndbg.profiling\nfrom pwndbg.color import disable_colors\nfrom pwndbg.color import message\nfrom pwndbg.lib.tips import color_tip\nfrom pwndbg.lib.tips import get_tip_of_the_day\n\nfuncs_list_str = \", \".join(message.notice(\"$\" + f.name) for f in pwndbg.gdblib.functions.functions)\n\nnum_pwndbg_cmds = sum(\n 1 for _ in filter(lambda c: not (c.shell or c.is_alias), pwndbg.commands.commands)\n)\nnum_shell_cmds = sum(1 for _ in filter(lambda c: c.shell, pwndbg.commands.commands))\nhint_lines = (\n \"loaded %i pwndbg commands and %i shell commands. Type %s for a list.\"\n % (num_pwndbg_cmds, num_shell_cmds, message.notice(\"pwndbg [--shell | --all] [filter]\")),\n f\"created {funcs_list_str} GDB functions (can be used with print/break)\",\n)\n\nfor line in hint_lines:\n print(message.prompt(\"pwndbg: \") + message.system(line))\n\n# noinspection PyPackageRequirements\nshow_tip = pwndbg.gdblib.config.add_param(\n \"show-tips\", True, \"whether to display the tip of the day on startup\"\n)\n\ncur = None\n\n\ndef initial_hook(*a) -> None:\n if show_tip and not pwndbg.decorators.first_prompt:\n colored_tip = color_tip(get_tip_of_the_day())\n print(\n message.prompt(\"------- tip of the day\")\n + message.system(\" (disable with %s)\" % message.notice(\"set show-tips off\"))\n + message.prompt(\" -------\")\n )\n print(colored_tip)\n pwndbg.decorators.first_prompt = True\n\n prompt_hook(*a)\n\n if environ.get(\"PWNDBG_PROFILE\") == \"1\":\n pwndbg.profiling.profiler.stop(\"pwndbg-first-prompt.pstats\")\n\n gdb.prompt_hook = prompt_hook\n\n\ncontext_shown = False\n\n\ndef prompt_hook(*a) -> None:\n global cur, context_shown\n\n new = (gdb.selected_inferior(), gdb.selected_thread())\n\n if cur != new:\n pwndbg.gdblib.events.after_reload(start=cur is None)\n cur = new\n\n if pwndbg.gdblib.proc.alive and pwndbg.gdblib.proc.thread_is_stopped and not context_shown:\n pwndbg.commands.context.context()\n context_shown = True\n\n\[email protected]\ndef reset_context_shown(*a) -> None:\n global context_shown\n context_shown = False\n\n\[email protected](message.config_prompt_color, disable_colors)\ndef set_prompt() -> None:\n prompt = \"pwndbg> \"\n\n if not disable_colors:\n prompt = \"\\x02\" + prompt + \"\\x01\" # STX + prompt + SOH\n prompt = message.prompt(prompt)\n prompt = \"\\x01\" + prompt + \"\\x02\" # SOH + prompt + STX\n\n gdb.execute(f\"set prompt {prompt}\")\n\n\nif pwndbg.gdblib.events.before_prompt_event.is_real_event:\n gdb.prompt_hook = initial_hook\n\nelse:\n # Old GDBs doesn't have gdb.events.before_prompt, so we will emulate it using gdb.prompt_hook\n def extended_prompt_hook(*a):\n pwndbg.gdblib.events.before_prompt_event.invoke_callbacks()\n return prompt_hook(*a)\n\n gdb.prompt_hook = extended_prompt_hook\n", "path": "pwndbg/gdblib/prompt.py"}]}
| 3,918 | 601 |
gh_patches_debug_25572
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-5039
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tails NetworkManager hook still running under Python2
## Description
Despite the shebang line in the `securedrop_init.py` pointing to Python3, the script is still run via Python2 due to the calling script hardcoding `/usr/bin/python` in the NetworkManager hook:
https://github.com/freedomofpress/securedrop/blob/1d8484e3d42f63b9cec68be14e587175fa01adfc/install_files/ansible-base/roles/tails-config/files/65-configure-tor-for-securedrop.sh#L17
## Steps to Reproduce
Review diffs and relevant files above.
## Expected Behavior
All Tails 4 admin tooling is Python 3.
## Actual Behavior
We're still calling the nm hook via Python 2.
## Comments
The PR to resolve is simple, but we'll have to factor in the QA time to verify we haven't introduced side-effects.
</issue>
<code>
[start of install_files/ansible-base/roles/tails-config/files/securedrop_init.py]
1 #!/usr/bin/python3
2
3 import grp
4 import os
5 import io
6 import pwd
7 import sys
8 import subprocess
9
10 from shutil import copyfile
11
12
13 # check for root
14 if os.geteuid() != 0:
15 sys.exit('You need to run this as root')
16
17 # paths
18 path_torrc_additions = '/home/amnesia/Persistent/.securedrop/torrc_additions'
19 path_torrc_backup = '/etc/tor/torrc.bak'
20 path_torrc = '/etc/tor/torrc'
21 path_desktop = '/home/amnesia/Desktop/'
22 path_persistent_desktop = '/lib/live/mount/persistence/TailsData_unlocked/dotfiles/Desktop/' # noqa: E501
23 path_securedrop_root = '/home/amnesia/Persistent/securedrop'
24 path_securedrop_admin_venv = os.path.join(path_securedrop_root,
25 'admin/.venv3/bin/python')
26 path_securedrop_admin_init = os.path.join(path_securedrop_root,
27 'admin/securedrop_admin/__init__.py')
28 path_gui_updater = os.path.join(path_securedrop_root,
29 'journalist_gui/SecureDropUpdater')
30
31 paths_v3_authfiles = {
32 "app-journalist": os.path.join(path_securedrop_root,
33 'install_files/ansible-base/app-journalist.auth_private'),
34 "app-ssh": os.path.join(path_securedrop_root,
35 'install_files/ansible-base/app-ssh.auth_private'),
36 "mon-ssh": os.path.join(path_securedrop_root,
37 'install_files/ansible-base/mon-ssh.auth_private')
38 }
39 path_onion_auth_dir = '/var/lib/tor/onion_auth'
40
41 # load torrc_additions
42 if os.path.isfile(path_torrc_additions):
43 with io.open(path_torrc_additions) as f:
44 torrc_additions = f.read()
45 else:
46 sys.exit('Error opening {0} for reading'.format(path_torrc_additions))
47
48 # load torrc
49 if os.path.isfile(path_torrc_backup):
50 with io.open(path_torrc_backup) as f:
51 torrc = f.read()
52 else:
53 if os.path.isfile(path_torrc):
54 with io.open(path_torrc) as f:
55 torrc = f.read()
56 else:
57 sys.exit('Error opening {0} for reading'.format(path_torrc))
58
59 # save a backup
60 with io.open(path_torrc_backup, 'w') as f:
61 f.write(torrc)
62
63 # append the additions
64 with io.open(path_torrc, 'w') as f:
65 f.write(torrc + torrc_additions)
66
67 # check for v3 aths files
68 v3_authfiles_present = False
69 for f in paths_v3_authfiles.values():
70 if os.path.isfile(f):
71 v3_authfiles_present = True
72
73 # if there are v3 authfiles, make dir and copy them into place
74 debian_tor_uid = pwd.getpwnam("debian-tor").pw_uid
75 debian_tor_gid = grp.getgrnam("debian-tor").gr_gid
76
77 if not os.path.isdir(path_onion_auth_dir):
78 os.mkdir(path_onion_auth_dir)
79
80 os.chmod(path_onion_auth_dir, 0o700)
81 os.chown(path_onion_auth_dir, debian_tor_uid, debian_tor_gid)
82
83 for key, f in paths_v3_authfiles.items():
84 if os.path.isfile(f):
85 filename = os.path.basename(f)
86 new_f = os.path.join(path_onion_auth_dir, filename)
87 copyfile(f, new_f)
88 os.chmod(new_f, 0o400)
89 os.chown(new_f, debian_tor_uid, debian_tor_gid)
90
91 # restart tor
92 try:
93 subprocess.check_call(['systemctl', 'restart', '[email protected]'])
94 except subprocess.CalledProcessError:
95 sys.exit('Error restarting Tor')
96
97 # Turn off "automatic-decompression" in Nautilus to ensure the original
98 # submission filename is restored (see
99 # https://github.com/freedomofpress/securedrop/issues/1862#issuecomment-311519750).
100 subprocess.call(['/usr/bin/dconf', 'write',
101 '/org/gnome/nautilus/preferences/automatic-decompression',
102 'false'])
103
104 # Set journalist.desktop and source.desktop links as trusted with Nautilus (see
105 # https://github.com/freedomofpress/securedrop/issues/2586)
106 # set euid and env variables to amnesia user
107 amnesia_gid = grp.getgrnam('amnesia').gr_gid
108 amnesia_uid = pwd.getpwnam('amnesia').pw_uid
109 os.setresgid(amnesia_gid, amnesia_gid, -1)
110 os.setresuid(amnesia_uid, amnesia_uid, -1)
111 env = os.environ.copy()
112 env['XDG_CURRENT_DESKTOP'] = 'GNOME'
113 env['DESKTOP_SESSION'] = 'default'
114 env['DISPLAY'] = ':1'
115 env['XDG_RUNTIME_DIR'] = '/run/user/{}'.format(amnesia_uid)
116 env['XDG_DATA_DIR'] = '/usr/share/gnome:/usr/local/share/:/usr/share/'
117 env['HOME'] = '/home/amnesia'
118 env['LOGNAME'] = 'amnesia'
119 env['DBUS_SESSION_BUS_ADDRESS'] = 'unix:path=/run/user/{}/bus'.format(
120 amnesia_uid)
121
122 # remove existing shortcut, recreate symlink and change metadata attribute
123 # to trust .desktop
124 for shortcut in ['source.desktop', 'journalist.desktop']:
125 subprocess.call(['rm', path_desktop + shortcut], env=env)
126 subprocess.call(['ln', '-s', path_persistent_desktop + shortcut,
127 path_desktop + shortcut], env=env)
128 subprocess.call(['gio', 'set', path_desktop + shortcut,
129 'metadata::trusted', 'true'], env=env)
130
131 # in Tails 4, reload gnome-shell desktop icons extension to update with changes above
132 cmd = ["lsb_release", "--id", "--short"]
133 p = subprocess.check_output(cmd)
134 distro_id = p.rstrip()
135 if distro_id == 'Debian' and os.uname()[1] == 'amnesia':
136 subprocess.call(['gnome-shell-extension-tool', '-r', 'desktop-icons@csoriano'], env=env)
137
138 # reacquire uid0 and notify the user
139 os.setresuid(0, 0, -1)
140 os.setresgid(0, 0, -1)
141 subprocess.call(['tails-notify-user',
142 'SecureDrop successfully auto-configured!',
143 'You can now access the Journalist Interface.\n',
144 'If you are an admin, you can now SSH to the servers.'])
145
146 # As the amnesia user, check for SecureDrop workstation updates.
147 os.setresgid(amnesia_gid, amnesia_gid, -1)
148 os.setresuid(amnesia_uid, amnesia_uid, -1)
149 output = subprocess.check_output([path_securedrop_admin_venv,
150 path_securedrop_admin_init,
151 '--root', path_securedrop_root,
152 'check_for_updates'], env=env)
153
154 flag_location = "/home/amnesia/Persistent/.securedrop/securedrop_update.flag"
155 if 'Update needed' in output or os.path.exists(flag_location):
156 # Start the SecureDrop updater GUI.
157 subprocess.Popen(['python3', path_gui_updater], env=env)
158
[end of install_files/ansible-base/roles/tails-config/files/securedrop_init.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/install_files/ansible-base/roles/tails-config/files/securedrop_init.py b/install_files/ansible-base/roles/tails-config/files/securedrop_init.py
--- a/install_files/ansible-base/roles/tails-config/files/securedrop_init.py
+++ b/install_files/ansible-base/roles/tails-config/files/securedrop_init.py
@@ -138,10 +138,10 @@
# reacquire uid0 and notify the user
os.setresuid(0, 0, -1)
os.setresgid(0, 0, -1)
+success_message = 'You can now access the Journalist Interface.\nIf you are an admin, you can now SSH to the servers.' # noqa: E501
subprocess.call(['tails-notify-user',
'SecureDrop successfully auto-configured!',
- 'You can now access the Journalist Interface.\n',
- 'If you are an admin, you can now SSH to the servers.'])
+ success_message])
# As the amnesia user, check for SecureDrop workstation updates.
os.setresgid(amnesia_gid, amnesia_gid, -1)
@@ -152,6 +152,6 @@
'check_for_updates'], env=env)
flag_location = "/home/amnesia/Persistent/.securedrop/securedrop_update.flag"
-if 'Update needed' in output or os.path.exists(flag_location):
+if b'Update needed' in output or os.path.exists(flag_location):
# Start the SecureDrop updater GUI.
subprocess.Popen(['python3', path_gui_updater], env=env)
|
{"golden_diff": "diff --git a/install_files/ansible-base/roles/tails-config/files/securedrop_init.py b/install_files/ansible-base/roles/tails-config/files/securedrop_init.py\n--- a/install_files/ansible-base/roles/tails-config/files/securedrop_init.py\n+++ b/install_files/ansible-base/roles/tails-config/files/securedrop_init.py\n@@ -138,10 +138,10 @@\n # reacquire uid0 and notify the user\n os.setresuid(0, 0, -1)\n os.setresgid(0, 0, -1)\n+success_message = 'You can now access the Journalist Interface.\\nIf you are an admin, you can now SSH to the servers.' # noqa: E501\n subprocess.call(['tails-notify-user',\n 'SecureDrop successfully auto-configured!',\n- 'You can now access the Journalist Interface.\\n',\n- 'If you are an admin, you can now SSH to the servers.'])\n+ success_message])\n \n # As the amnesia user, check for SecureDrop workstation updates.\n os.setresgid(amnesia_gid, amnesia_gid, -1)\n@@ -152,6 +152,6 @@\n 'check_for_updates'], env=env)\n \n flag_location = \"/home/amnesia/Persistent/.securedrop/securedrop_update.flag\"\n-if 'Update needed' in output or os.path.exists(flag_location):\n+if b'Update needed' in output or os.path.exists(flag_location):\n # Start the SecureDrop updater GUI.\n subprocess.Popen(['python3', path_gui_updater], env=env)\n", "issue": "Tails NetworkManager hook still running under Python2\n## Description\r\nDespite the shebang line in the `securedrop_init.py` pointing to Python3, the script is still run via Python2 due to the calling script hardcoding `/usr/bin/python` in the NetworkManager hook:\r\n\r\nhttps://github.com/freedomofpress/securedrop/blob/1d8484e3d42f63b9cec68be14e587175fa01adfc/install_files/ansible-base/roles/tails-config/files/65-configure-tor-for-securedrop.sh#L17\r\n\r\n## Steps to Reproduce\r\n\r\nReview diffs and relevant files above.\r\n\r\n## Expected Behavior\r\n\r\nAll Tails 4 admin tooling is Python 3. \r\n\r\n## Actual Behavior\r\nWe're still calling the nm hook via Python 2. \r\n\r\n## Comments\r\nThe PR to resolve is simple, but we'll have to factor in the QA time to verify we haven't introduced side-effects.\r\n\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport grp\nimport os\nimport io\nimport pwd\nimport sys\nimport subprocess\n\nfrom shutil import copyfile\n\n\n# check for root\nif os.geteuid() != 0:\n sys.exit('You need to run this as root')\n\n# paths\npath_torrc_additions = '/home/amnesia/Persistent/.securedrop/torrc_additions'\npath_torrc_backup = '/etc/tor/torrc.bak'\npath_torrc = '/etc/tor/torrc'\npath_desktop = '/home/amnesia/Desktop/'\npath_persistent_desktop = '/lib/live/mount/persistence/TailsData_unlocked/dotfiles/Desktop/' # noqa: E501\npath_securedrop_root = '/home/amnesia/Persistent/securedrop'\npath_securedrop_admin_venv = os.path.join(path_securedrop_root,\n 'admin/.venv3/bin/python')\npath_securedrop_admin_init = os.path.join(path_securedrop_root,\n 'admin/securedrop_admin/__init__.py')\npath_gui_updater = os.path.join(path_securedrop_root,\n 'journalist_gui/SecureDropUpdater')\n\npaths_v3_authfiles = {\n \"app-journalist\": os.path.join(path_securedrop_root,\n 'install_files/ansible-base/app-journalist.auth_private'),\n \"app-ssh\": os.path.join(path_securedrop_root,\n 'install_files/ansible-base/app-ssh.auth_private'),\n \"mon-ssh\": os.path.join(path_securedrop_root,\n 'install_files/ansible-base/mon-ssh.auth_private')\n}\npath_onion_auth_dir = '/var/lib/tor/onion_auth'\n\n# load torrc_additions\nif os.path.isfile(path_torrc_additions):\n with io.open(path_torrc_additions) as f:\n torrc_additions = f.read()\nelse:\n sys.exit('Error opening {0} for reading'.format(path_torrc_additions))\n\n# load torrc\nif os.path.isfile(path_torrc_backup):\n with io.open(path_torrc_backup) as f:\n torrc = f.read()\nelse:\n if os.path.isfile(path_torrc):\n with io.open(path_torrc) as f:\n torrc = f.read()\n else:\n sys.exit('Error opening {0} for reading'.format(path_torrc))\n\n # save a backup\n with io.open(path_torrc_backup, 'w') as f:\n f.write(torrc)\n\n# append the additions\nwith io.open(path_torrc, 'w') as f:\n f.write(torrc + torrc_additions)\n\n# check for v3 aths files\nv3_authfiles_present = False\nfor f in paths_v3_authfiles.values():\n if os.path.isfile(f):\n v3_authfiles_present = True\n\n# if there are v3 authfiles, make dir and copy them into place\ndebian_tor_uid = pwd.getpwnam(\"debian-tor\").pw_uid\ndebian_tor_gid = grp.getgrnam(\"debian-tor\").gr_gid\n\nif not os.path.isdir(path_onion_auth_dir):\n os.mkdir(path_onion_auth_dir)\n\nos.chmod(path_onion_auth_dir, 0o700)\nos.chown(path_onion_auth_dir, debian_tor_uid, debian_tor_gid)\n\nfor key, f in paths_v3_authfiles.items():\n if os.path.isfile(f):\n filename = os.path.basename(f)\n new_f = os.path.join(path_onion_auth_dir, filename)\n copyfile(f, new_f)\n os.chmod(new_f, 0o400)\n os.chown(new_f, debian_tor_uid, debian_tor_gid)\n\n# restart tor\ntry:\n subprocess.check_call(['systemctl', 'restart', '[email protected]'])\nexcept subprocess.CalledProcessError:\n sys.exit('Error restarting Tor')\n\n# Turn off \"automatic-decompression\" in Nautilus to ensure the original\n# submission filename is restored (see\n# https://github.com/freedomofpress/securedrop/issues/1862#issuecomment-311519750).\nsubprocess.call(['/usr/bin/dconf', 'write',\n '/org/gnome/nautilus/preferences/automatic-decompression',\n 'false'])\n\n# Set journalist.desktop and source.desktop links as trusted with Nautilus (see\n# https://github.com/freedomofpress/securedrop/issues/2586)\n# set euid and env variables to amnesia user\namnesia_gid = grp.getgrnam('amnesia').gr_gid\namnesia_uid = pwd.getpwnam('amnesia').pw_uid\nos.setresgid(amnesia_gid, amnesia_gid, -1)\nos.setresuid(amnesia_uid, amnesia_uid, -1)\nenv = os.environ.copy()\nenv['XDG_CURRENT_DESKTOP'] = 'GNOME'\nenv['DESKTOP_SESSION'] = 'default'\nenv['DISPLAY'] = ':1'\nenv['XDG_RUNTIME_DIR'] = '/run/user/{}'.format(amnesia_uid)\nenv['XDG_DATA_DIR'] = '/usr/share/gnome:/usr/local/share/:/usr/share/'\nenv['HOME'] = '/home/amnesia'\nenv['LOGNAME'] = 'amnesia'\nenv['DBUS_SESSION_BUS_ADDRESS'] = 'unix:path=/run/user/{}/bus'.format(\n amnesia_uid)\n\n# remove existing shortcut, recreate symlink and change metadata attribute\n# to trust .desktop\nfor shortcut in ['source.desktop', 'journalist.desktop']:\n subprocess.call(['rm', path_desktop + shortcut], env=env)\n subprocess.call(['ln', '-s', path_persistent_desktop + shortcut,\n path_desktop + shortcut], env=env)\n subprocess.call(['gio', 'set', path_desktop + shortcut,\n 'metadata::trusted', 'true'], env=env)\n\n# in Tails 4, reload gnome-shell desktop icons extension to update with changes above\ncmd = [\"lsb_release\", \"--id\", \"--short\"]\np = subprocess.check_output(cmd)\ndistro_id = p.rstrip()\nif distro_id == 'Debian' and os.uname()[1] == 'amnesia':\n subprocess.call(['gnome-shell-extension-tool', '-r', 'desktop-icons@csoriano'], env=env)\n\n# reacquire uid0 and notify the user\nos.setresuid(0, 0, -1)\nos.setresgid(0, 0, -1)\nsubprocess.call(['tails-notify-user',\n 'SecureDrop successfully auto-configured!',\n 'You can now access the Journalist Interface.\\n',\n 'If you are an admin, you can now SSH to the servers.'])\n\n# As the amnesia user, check for SecureDrop workstation updates.\nos.setresgid(amnesia_gid, amnesia_gid, -1)\nos.setresuid(amnesia_uid, amnesia_uid, -1)\noutput = subprocess.check_output([path_securedrop_admin_venv,\n path_securedrop_admin_init,\n '--root', path_securedrop_root,\n 'check_for_updates'], env=env)\n\nflag_location = \"/home/amnesia/Persistent/.securedrop/securedrop_update.flag\"\nif 'Update needed' in output or os.path.exists(flag_location):\n # Start the SecureDrop updater GUI.\n subprocess.Popen(['python3', path_gui_updater], env=env)\n", "path": "install_files/ansible-base/roles/tails-config/files/securedrop_init.py"}]}
| 2,737 | 349 |
gh_patches_debug_1586
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-12376
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
import_array hides true cause of import errors
When compiling for Python 3, it would be useful to utilize exception chaining to explain why "numpy.core.multiarray failed to import". I think you can use [PyException_SetCause](https://docs.python.org/3/c-api/exceptions.html#c.PyException_SetCause) to do this?
</issue>
<code>
[start of numpy/core/code_generators/generate_numpy_api.py]
1 from __future__ import division, print_function
2
3 import os
4 import genapi
5
6 from genapi import \
7 TypeApi, GlobalVarApi, FunctionApi, BoolValuesApi
8
9 import numpy_api
10
11 # use annotated api when running under cpychecker
12 h_template = r"""
13 #if defined(_MULTIARRAYMODULE) || defined(WITH_CPYCHECKER_STEALS_REFERENCE_TO_ARG_ATTRIBUTE)
14
15 typedef struct {
16 PyObject_HEAD
17 npy_bool obval;
18 } PyBoolScalarObject;
19
20 extern NPY_NO_EXPORT PyTypeObject PyArrayMapIter_Type;
21 extern NPY_NO_EXPORT PyTypeObject PyArrayNeighborhoodIter_Type;
22 extern NPY_NO_EXPORT PyBoolScalarObject _PyArrayScalar_BoolValues[2];
23
24 %s
25
26 #else
27
28 #if defined(PY_ARRAY_UNIQUE_SYMBOL)
29 #define PyArray_API PY_ARRAY_UNIQUE_SYMBOL
30 #endif
31
32 #if defined(NO_IMPORT) || defined(NO_IMPORT_ARRAY)
33 extern void **PyArray_API;
34 #else
35 #if defined(PY_ARRAY_UNIQUE_SYMBOL)
36 void **PyArray_API;
37 #else
38 static void **PyArray_API=NULL;
39 #endif
40 #endif
41
42 %s
43
44 #if !defined(NO_IMPORT_ARRAY) && !defined(NO_IMPORT)
45 static int
46 _import_array(void)
47 {
48 int st;
49 PyObject *numpy = PyImport_ImportModule("numpy.core._multiarray_umath");
50 PyObject *c_api = NULL;
51
52 if (numpy == NULL) {
53 PyErr_SetString(PyExc_ImportError, "numpy.core._multiarray_umath failed to import");
54 return -1;
55 }
56 c_api = PyObject_GetAttrString(numpy, "_ARRAY_API");
57 Py_DECREF(numpy);
58 if (c_api == NULL) {
59 PyErr_SetString(PyExc_AttributeError, "_ARRAY_API not found");
60 return -1;
61 }
62
63 #if PY_VERSION_HEX >= 0x03000000
64 if (!PyCapsule_CheckExact(c_api)) {
65 PyErr_SetString(PyExc_RuntimeError, "_ARRAY_API is not PyCapsule object");
66 Py_DECREF(c_api);
67 return -1;
68 }
69 PyArray_API = (void **)PyCapsule_GetPointer(c_api, NULL);
70 #else
71 if (!PyCObject_Check(c_api)) {
72 PyErr_SetString(PyExc_RuntimeError, "_ARRAY_API is not PyCObject object");
73 Py_DECREF(c_api);
74 return -1;
75 }
76 PyArray_API = (void **)PyCObject_AsVoidPtr(c_api);
77 #endif
78 Py_DECREF(c_api);
79 if (PyArray_API == NULL) {
80 PyErr_SetString(PyExc_RuntimeError, "_ARRAY_API is NULL pointer");
81 return -1;
82 }
83
84 /* Perform runtime check of C API version */
85 if (NPY_VERSION != PyArray_GetNDArrayCVersion()) {
86 PyErr_Format(PyExc_RuntimeError, "module compiled against "\
87 "ABI version 0x%%x but this version of numpy is 0x%%x", \
88 (int) NPY_VERSION, (int) PyArray_GetNDArrayCVersion());
89 return -1;
90 }
91 if (NPY_FEATURE_VERSION > PyArray_GetNDArrayCFeatureVersion()) {
92 PyErr_Format(PyExc_RuntimeError, "module compiled against "\
93 "API version 0x%%x but this version of numpy is 0x%%x", \
94 (int) NPY_FEATURE_VERSION, (int) PyArray_GetNDArrayCFeatureVersion());
95 return -1;
96 }
97
98 /*
99 * Perform runtime check of endianness and check it matches the one set by
100 * the headers (npy_endian.h) as a safeguard
101 */
102 st = PyArray_GetEndianness();
103 if (st == NPY_CPU_UNKNOWN_ENDIAN) {
104 PyErr_Format(PyExc_RuntimeError, "FATAL: module compiled as unknown endian");
105 return -1;
106 }
107 #if NPY_BYTE_ORDER == NPY_BIG_ENDIAN
108 if (st != NPY_CPU_BIG) {
109 PyErr_Format(PyExc_RuntimeError, "FATAL: module compiled as "\
110 "big endian, but detected different endianness at runtime");
111 return -1;
112 }
113 #elif NPY_BYTE_ORDER == NPY_LITTLE_ENDIAN
114 if (st != NPY_CPU_LITTLE) {
115 PyErr_Format(PyExc_RuntimeError, "FATAL: module compiled as "\
116 "little endian, but detected different endianness at runtime");
117 return -1;
118 }
119 #endif
120
121 return 0;
122 }
123
124 #if PY_VERSION_HEX >= 0x03000000
125 #define NUMPY_IMPORT_ARRAY_RETVAL NULL
126 #else
127 #define NUMPY_IMPORT_ARRAY_RETVAL
128 #endif
129
130 #define import_array() {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, "numpy.core.multiarray failed to import"); return NUMPY_IMPORT_ARRAY_RETVAL; } }
131
132 #define import_array1(ret) {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, "numpy.core.multiarray failed to import"); return ret; } }
133
134 #define import_array2(msg, ret) {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, msg); return ret; } }
135
136 #endif
137
138 #endif
139 """
140
141
142 c_template = r"""
143 /* These pointers will be stored in the C-object for use in other
144 extension modules
145 */
146
147 void *PyArray_API[] = {
148 %s
149 };
150 """
151
152 c_api_header = """
153 ===========
154 NumPy C-API
155 ===========
156 """
157
158 def generate_api(output_dir, force=False):
159 basename = 'multiarray_api'
160
161 h_file = os.path.join(output_dir, '__%s.h' % basename)
162 c_file = os.path.join(output_dir, '__%s.c' % basename)
163 d_file = os.path.join(output_dir, '%s.txt' % basename)
164 targets = (h_file, c_file, d_file)
165
166 sources = numpy_api.multiarray_api
167
168 if (not force and not genapi.should_rebuild(targets, [numpy_api.__file__, __file__])):
169 return targets
170 else:
171 do_generate_api(targets, sources)
172
173 return targets
174
175 def do_generate_api(targets, sources):
176 header_file = targets[0]
177 c_file = targets[1]
178 doc_file = targets[2]
179
180 global_vars = sources[0]
181 scalar_bool_values = sources[1]
182 types_api = sources[2]
183 multiarray_funcs = sources[3]
184
185 multiarray_api = sources[:]
186
187 module_list = []
188 extension_list = []
189 init_list = []
190
191 # Check multiarray api indexes
192 multiarray_api_index = genapi.merge_api_dicts(multiarray_api)
193 genapi.check_api_dict(multiarray_api_index)
194
195 numpyapi_list = genapi.get_api_functions('NUMPY_API',
196 multiarray_funcs)
197 ordered_funcs_api = genapi.order_dict(multiarray_funcs)
198
199 # Create dict name -> *Api instance
200 api_name = 'PyArray_API'
201 multiarray_api_dict = {}
202 for f in numpyapi_list:
203 name = f.name
204 index = multiarray_funcs[name][0]
205 annotations = multiarray_funcs[name][1:]
206 multiarray_api_dict[f.name] = FunctionApi(f.name, index, annotations,
207 f.return_type,
208 f.args, api_name)
209
210 for name, val in global_vars.items():
211 index, type = val
212 multiarray_api_dict[name] = GlobalVarApi(name, index, type, api_name)
213
214 for name, val in scalar_bool_values.items():
215 index = val[0]
216 multiarray_api_dict[name] = BoolValuesApi(name, index, api_name)
217
218 for name, val in types_api.items():
219 index = val[0]
220 multiarray_api_dict[name] = TypeApi(name, index, 'PyTypeObject', api_name)
221
222 if len(multiarray_api_dict) != len(multiarray_api_index):
223 keys_dict = set(multiarray_api_dict.keys())
224 keys_index = set(multiarray_api_index.keys())
225 raise AssertionError(
226 "Multiarray API size mismatch - "
227 "index has extra keys {}, dict has extra keys {}"
228 .format(keys_index - keys_dict, keys_dict - keys_index)
229 )
230
231 extension_list = []
232 for name, index in genapi.order_dict(multiarray_api_index):
233 api_item = multiarray_api_dict[name]
234 extension_list.append(api_item.define_from_array_api_string())
235 init_list.append(api_item.array_api_define())
236 module_list.append(api_item.internal_define())
237
238 # Write to header
239 s = h_template % ('\n'.join(module_list), '\n'.join(extension_list))
240 genapi.write_file(header_file, s)
241
242 # Write to c-code
243 s = c_template % ',\n'.join(init_list)
244 genapi.write_file(c_file, s)
245
246 # write to documentation
247 s = c_api_header
248 for func in numpyapi_list:
249 s += func.to_ReST()
250 s += '\n\n'
251 genapi.write_file(doc_file, s)
252
253 return targets
254
[end of numpy/core/code_generators/generate_numpy_api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numpy/core/code_generators/generate_numpy_api.py b/numpy/core/code_generators/generate_numpy_api.py
--- a/numpy/core/code_generators/generate_numpy_api.py
+++ b/numpy/core/code_generators/generate_numpy_api.py
@@ -50,7 +50,6 @@
PyObject *c_api = NULL;
if (numpy == NULL) {
- PyErr_SetString(PyExc_ImportError, "numpy.core._multiarray_umath failed to import");
return -1;
}
c_api = PyObject_GetAttrString(numpy, "_ARRAY_API");
|
{"golden_diff": "diff --git a/numpy/core/code_generators/generate_numpy_api.py b/numpy/core/code_generators/generate_numpy_api.py\n--- a/numpy/core/code_generators/generate_numpy_api.py\n+++ b/numpy/core/code_generators/generate_numpy_api.py\n@@ -50,7 +50,6 @@\n PyObject *c_api = NULL;\n \n if (numpy == NULL) {\n- PyErr_SetString(PyExc_ImportError, \"numpy.core._multiarray_umath failed to import\");\n return -1;\n }\n c_api = PyObject_GetAttrString(numpy, \"_ARRAY_API\");\n", "issue": "import_array hides true cause of import errors\nWhen compiling for Python 3, it would be useful to utilize exception chaining to explain why \"numpy.core.multiarray failed to import\". I think you can use [PyException_SetCause](https://docs.python.org/3/c-api/exceptions.html#c.PyException_SetCause) to do this?\n\n", "before_files": [{"content": "from __future__ import division, print_function\n\nimport os\nimport genapi\n\nfrom genapi import \\\n TypeApi, GlobalVarApi, FunctionApi, BoolValuesApi\n\nimport numpy_api\n\n# use annotated api when running under cpychecker\nh_template = r\"\"\"\n#if defined(_MULTIARRAYMODULE) || defined(WITH_CPYCHECKER_STEALS_REFERENCE_TO_ARG_ATTRIBUTE)\n\ntypedef struct {\n PyObject_HEAD\n npy_bool obval;\n} PyBoolScalarObject;\n\nextern NPY_NO_EXPORT PyTypeObject PyArrayMapIter_Type;\nextern NPY_NO_EXPORT PyTypeObject PyArrayNeighborhoodIter_Type;\nextern NPY_NO_EXPORT PyBoolScalarObject _PyArrayScalar_BoolValues[2];\n\n%s\n\n#else\n\n#if defined(PY_ARRAY_UNIQUE_SYMBOL)\n#define PyArray_API PY_ARRAY_UNIQUE_SYMBOL\n#endif\n\n#if defined(NO_IMPORT) || defined(NO_IMPORT_ARRAY)\nextern void **PyArray_API;\n#else\n#if defined(PY_ARRAY_UNIQUE_SYMBOL)\nvoid **PyArray_API;\n#else\nstatic void **PyArray_API=NULL;\n#endif\n#endif\n\n%s\n\n#if !defined(NO_IMPORT_ARRAY) && !defined(NO_IMPORT)\nstatic int\n_import_array(void)\n{\n int st;\n PyObject *numpy = PyImport_ImportModule(\"numpy.core._multiarray_umath\");\n PyObject *c_api = NULL;\n\n if (numpy == NULL) {\n PyErr_SetString(PyExc_ImportError, \"numpy.core._multiarray_umath failed to import\");\n return -1;\n }\n c_api = PyObject_GetAttrString(numpy, \"_ARRAY_API\");\n Py_DECREF(numpy);\n if (c_api == NULL) {\n PyErr_SetString(PyExc_AttributeError, \"_ARRAY_API not found\");\n return -1;\n }\n\n#if PY_VERSION_HEX >= 0x03000000\n if (!PyCapsule_CheckExact(c_api)) {\n PyErr_SetString(PyExc_RuntimeError, \"_ARRAY_API is not PyCapsule object\");\n Py_DECREF(c_api);\n return -1;\n }\n PyArray_API = (void **)PyCapsule_GetPointer(c_api, NULL);\n#else\n if (!PyCObject_Check(c_api)) {\n PyErr_SetString(PyExc_RuntimeError, \"_ARRAY_API is not PyCObject object\");\n Py_DECREF(c_api);\n return -1;\n }\n PyArray_API = (void **)PyCObject_AsVoidPtr(c_api);\n#endif\n Py_DECREF(c_api);\n if (PyArray_API == NULL) {\n PyErr_SetString(PyExc_RuntimeError, \"_ARRAY_API is NULL pointer\");\n return -1;\n }\n\n /* Perform runtime check of C API version */\n if (NPY_VERSION != PyArray_GetNDArrayCVersion()) {\n PyErr_Format(PyExc_RuntimeError, \"module compiled against \"\\\n \"ABI version 0x%%x but this version of numpy is 0x%%x\", \\\n (int) NPY_VERSION, (int) PyArray_GetNDArrayCVersion());\n return -1;\n }\n if (NPY_FEATURE_VERSION > PyArray_GetNDArrayCFeatureVersion()) {\n PyErr_Format(PyExc_RuntimeError, \"module compiled against \"\\\n \"API version 0x%%x but this version of numpy is 0x%%x\", \\\n (int) NPY_FEATURE_VERSION, (int) PyArray_GetNDArrayCFeatureVersion());\n return -1;\n }\n\n /*\n * Perform runtime check of endianness and check it matches the one set by\n * the headers (npy_endian.h) as a safeguard\n */\n st = PyArray_GetEndianness();\n if (st == NPY_CPU_UNKNOWN_ENDIAN) {\n PyErr_Format(PyExc_RuntimeError, \"FATAL: module compiled as unknown endian\");\n return -1;\n }\n#if NPY_BYTE_ORDER == NPY_BIG_ENDIAN\n if (st != NPY_CPU_BIG) {\n PyErr_Format(PyExc_RuntimeError, \"FATAL: module compiled as \"\\\n \"big endian, but detected different endianness at runtime\");\n return -1;\n }\n#elif NPY_BYTE_ORDER == NPY_LITTLE_ENDIAN\n if (st != NPY_CPU_LITTLE) {\n PyErr_Format(PyExc_RuntimeError, \"FATAL: module compiled as \"\\\n \"little endian, but detected different endianness at runtime\");\n return -1;\n }\n#endif\n\n return 0;\n}\n\n#if PY_VERSION_HEX >= 0x03000000\n#define NUMPY_IMPORT_ARRAY_RETVAL NULL\n#else\n#define NUMPY_IMPORT_ARRAY_RETVAL\n#endif\n\n#define import_array() {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, \"numpy.core.multiarray failed to import\"); return NUMPY_IMPORT_ARRAY_RETVAL; } }\n\n#define import_array1(ret) {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, \"numpy.core.multiarray failed to import\"); return ret; } }\n\n#define import_array2(msg, ret) {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, msg); return ret; } }\n\n#endif\n\n#endif\n\"\"\"\n\n\nc_template = r\"\"\"\n/* These pointers will be stored in the C-object for use in other\n extension modules\n*/\n\nvoid *PyArray_API[] = {\n%s\n};\n\"\"\"\n\nc_api_header = \"\"\"\n===========\nNumPy C-API\n===========\n\"\"\"\n\ndef generate_api(output_dir, force=False):\n basename = 'multiarray_api'\n\n h_file = os.path.join(output_dir, '__%s.h' % basename)\n c_file = os.path.join(output_dir, '__%s.c' % basename)\n d_file = os.path.join(output_dir, '%s.txt' % basename)\n targets = (h_file, c_file, d_file)\n\n sources = numpy_api.multiarray_api\n\n if (not force and not genapi.should_rebuild(targets, [numpy_api.__file__, __file__])):\n return targets\n else:\n do_generate_api(targets, sources)\n\n return targets\n\ndef do_generate_api(targets, sources):\n header_file = targets[0]\n c_file = targets[1]\n doc_file = targets[2]\n\n global_vars = sources[0]\n scalar_bool_values = sources[1]\n types_api = sources[2]\n multiarray_funcs = sources[3]\n\n multiarray_api = sources[:]\n\n module_list = []\n extension_list = []\n init_list = []\n\n # Check multiarray api indexes\n multiarray_api_index = genapi.merge_api_dicts(multiarray_api)\n genapi.check_api_dict(multiarray_api_index)\n\n numpyapi_list = genapi.get_api_functions('NUMPY_API',\n multiarray_funcs)\n ordered_funcs_api = genapi.order_dict(multiarray_funcs)\n\n # Create dict name -> *Api instance\n api_name = 'PyArray_API'\n multiarray_api_dict = {}\n for f in numpyapi_list:\n name = f.name\n index = multiarray_funcs[name][0]\n annotations = multiarray_funcs[name][1:]\n multiarray_api_dict[f.name] = FunctionApi(f.name, index, annotations,\n f.return_type,\n f.args, api_name)\n\n for name, val in global_vars.items():\n index, type = val\n multiarray_api_dict[name] = GlobalVarApi(name, index, type, api_name)\n\n for name, val in scalar_bool_values.items():\n index = val[0]\n multiarray_api_dict[name] = BoolValuesApi(name, index, api_name)\n\n for name, val in types_api.items():\n index = val[0]\n multiarray_api_dict[name] = TypeApi(name, index, 'PyTypeObject', api_name)\n\n if len(multiarray_api_dict) != len(multiarray_api_index):\n keys_dict = set(multiarray_api_dict.keys())\n keys_index = set(multiarray_api_index.keys())\n raise AssertionError(\n \"Multiarray API size mismatch - \"\n \"index has extra keys {}, dict has extra keys {}\"\n .format(keys_index - keys_dict, keys_dict - keys_index)\n )\n\n extension_list = []\n for name, index in genapi.order_dict(multiarray_api_index):\n api_item = multiarray_api_dict[name]\n extension_list.append(api_item.define_from_array_api_string())\n init_list.append(api_item.array_api_define())\n module_list.append(api_item.internal_define())\n\n # Write to header\n s = h_template % ('\\n'.join(module_list), '\\n'.join(extension_list))\n genapi.write_file(header_file, s)\n\n # Write to c-code\n s = c_template % ',\\n'.join(init_list)\n genapi.write_file(c_file, s)\n\n # write to documentation\n s = c_api_header\n for func in numpyapi_list:\n s += func.to_ReST()\n s += '\\n\\n'\n genapi.write_file(doc_file, s)\n\n return targets\n", "path": "numpy/core/code_generators/generate_numpy_api.py"}]}
| 3,254 | 129 |
gh_patches_debug_2978
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-20434
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Enable Scheduler from desk
Feature to enable scheduler from desk.
</issue>
<code>
[start of frappe/utils/scheduler.py]
1 # Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors
2 # License: MIT. See LICENSE
3 """
4 Events:
5 always
6 daily
7 monthly
8 weekly
9 """
10
11 # imports - standard imports
12 import os
13 import time
14 from typing import NoReturn
15
16 # imports - module imports
17 import frappe
18 from frappe.installer import update_site_config
19 from frappe.utils import cint, get_datetime, get_sites, now_datetime
20 from frappe.utils.background_jobs import get_jobs
21
22 DATETIME_FORMAT = "%Y-%m-%d %H:%M:%S"
23
24
25 def cprint(*args, **kwargs):
26 """Prints only if called from STDOUT"""
27 try:
28 os.get_terminal_size()
29 print(*args, **kwargs)
30 except Exception:
31 pass
32
33
34 def start_scheduler() -> NoReturn:
35 """Run enqueue_events_for_all_sites based on scheduler tick.
36 Specify scheduler_interval in seconds in common_site_config.json"""
37
38 tick = cint(frappe.get_conf().scheduler_tick_interval) or 60
39
40 while True:
41 time.sleep(tick)
42 enqueue_events_for_all_sites()
43
44
45 def enqueue_events_for_all_sites() -> None:
46 """Loop through sites and enqueue events that are not already queued"""
47
48 if os.path.exists(os.path.join(".", ".restarting")):
49 # Don't add task to queue if webserver is in restart mode
50 return
51
52 with frappe.init_site():
53 sites = get_sites()
54
55 for site in sites:
56 try:
57 enqueue_events_for_site(site=site)
58 except Exception:
59 frappe.logger("scheduler").debug(f"Failed to enqueue events for site: {site}", exc_info=True)
60
61
62 def enqueue_events_for_site(site: str) -> None:
63 def log_exc():
64 frappe.logger("scheduler").error(f"Exception in Enqueue Events for Site {site}", exc_info=True)
65
66 try:
67 frappe.init(site=site)
68 frappe.connect()
69 if is_scheduler_inactive():
70 return
71
72 enqueue_events(site=site)
73
74 frappe.logger("scheduler").debug(f"Queued events for site {site}")
75 except Exception as e:
76 if frappe.db.is_access_denied(e):
77 frappe.logger("scheduler").debug(f"Access denied for site {site}")
78 log_exc()
79
80 finally:
81 frappe.destroy()
82
83
84 def enqueue_events(site: str) -> list[str] | None:
85 if schedule_jobs_based_on_activity():
86 enqueued_jobs = []
87 for job_type in frappe.get_all("Scheduled Job Type", ("name", "method"), {"stopped": 0}):
88 job_type = frappe.get_cached_doc("Scheduled Job Type", job_type.name)
89 if _enqueued := job_type.enqueue():
90 enqueued_jobs.append(job_type.method)
91
92 return enqueued_jobs
93
94
95 def is_scheduler_inactive(verbose=True) -> bool:
96 if frappe.local.conf.maintenance_mode:
97 if verbose:
98 cprint(f"{frappe.local.site}: Maintenance mode is ON")
99 return True
100
101 if frappe.local.conf.pause_scheduler:
102 if verbose:
103 cprint(f"{frappe.local.site}: frappe.conf.pause_scheduler is SET")
104 return True
105
106 if is_scheduler_disabled(verbose=verbose):
107 return True
108
109 return False
110
111
112 def is_scheduler_disabled(verbose=True) -> bool:
113 if frappe.conf.disable_scheduler:
114 if verbose:
115 cprint(f"{frappe.local.site}: frappe.conf.disable_scheduler is SET")
116 return True
117
118 scheduler_disabled = not frappe.utils.cint(
119 frappe.db.get_single_value("System Settings", "enable_scheduler")
120 )
121 if scheduler_disabled:
122 if verbose:
123 cprint(f"{frappe.local.site}: SystemSettings.enable_scheduler is UNSET")
124 return scheduler_disabled
125
126
127 def toggle_scheduler(enable):
128 frappe.db.set_single_value("System Settings", "enable_scheduler", int(enable))
129
130
131 def enable_scheduler():
132 toggle_scheduler(True)
133
134
135 def disable_scheduler():
136 toggle_scheduler(False)
137
138
139 def schedule_jobs_based_on_activity(check_time=None):
140 """Returns True for active sites defined by Activity Log
141 Returns True for inactive sites once in 24 hours"""
142 if is_dormant(check_time=check_time):
143 # ensure last job is one day old
144 last_job_timestamp = _get_last_modified_timestamp("Scheduled Job Log")
145 if not last_job_timestamp:
146 return True
147 else:
148 if ((check_time or now_datetime()) - last_job_timestamp).total_seconds() >= 86400:
149 # one day is passed since jobs are run, so lets do this
150 return True
151 else:
152 # schedulers run in the last 24 hours, do nothing
153 return False
154 else:
155 # site active, lets run the jobs
156 return True
157
158
159 def is_dormant(check_time=None):
160 last_activity_log_timestamp = _get_last_modified_timestamp("Activity Log")
161 since = (frappe.get_system_settings("dormant_days") or 4) * 86400
162 if not last_activity_log_timestamp:
163 return True
164 if ((check_time or now_datetime()) - last_activity_log_timestamp).total_seconds() >= since:
165 return True
166 return False
167
168
169 def _get_last_modified_timestamp(doctype):
170 timestamp = frappe.db.get_value(
171 doctype, filters={}, fieldname="modified", order_by="modified desc"
172 )
173 if timestamp:
174 return get_datetime(timestamp)
175
176
177 @frappe.whitelist()
178 def activate_scheduler():
179 if is_scheduler_disabled():
180 enable_scheduler()
181 if frappe.conf.pause_scheduler:
182 update_site_config("pause_scheduler", 0)
183
184
185 @frappe.whitelist()
186 def get_scheduler_status():
187 if is_scheduler_inactive():
188 return {"status": "inactive"}
189 return {"status": "active"}
190
[end of frappe/utils/scheduler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/frappe/utils/scheduler.py b/frappe/utils/scheduler.py
--- a/frappe/utils/scheduler.py
+++ b/frappe/utils/scheduler.py
@@ -176,6 +176,11 @@
@frappe.whitelist()
def activate_scheduler():
+ frappe.only_for("Administrator")
+
+ if frappe.local.conf.maintenance_mode:
+ frappe.throw(frappe._("Scheduler can not be re-enabled when maintenance mode is active."))
+
if is_scheduler_disabled():
enable_scheduler()
if frappe.conf.pause_scheduler:
|
{"golden_diff": "diff --git a/frappe/utils/scheduler.py b/frappe/utils/scheduler.py\n--- a/frappe/utils/scheduler.py\n+++ b/frappe/utils/scheduler.py\n@@ -176,6 +176,11 @@\n \n @frappe.whitelist()\n def activate_scheduler():\n+\tfrappe.only_for(\"Administrator\")\n+\n+\tif frappe.local.conf.maintenance_mode:\n+\t\tfrappe.throw(frappe._(\"Scheduler can not be re-enabled when maintenance mode is active.\"))\n+\n \tif is_scheduler_disabled():\n \t\tenable_scheduler()\n \tif frappe.conf.pause_scheduler:\n", "issue": "Enable Scheduler from desk\nFeature to enable scheduler from desk.\n", "before_files": [{"content": "# Copyright (c) 2015, Frappe Technologies Pvt. Ltd. and Contributors\n# License: MIT. See LICENSE\n\"\"\"\nEvents:\n\talways\n\tdaily\n\tmonthly\n\tweekly\n\"\"\"\n\n# imports - standard imports\nimport os\nimport time\nfrom typing import NoReturn\n\n# imports - module imports\nimport frappe\nfrom frappe.installer import update_site_config\nfrom frappe.utils import cint, get_datetime, get_sites, now_datetime\nfrom frappe.utils.background_jobs import get_jobs\n\nDATETIME_FORMAT = \"%Y-%m-%d %H:%M:%S\"\n\n\ndef cprint(*args, **kwargs):\n\t\"\"\"Prints only if called from STDOUT\"\"\"\n\ttry:\n\t\tos.get_terminal_size()\n\t\tprint(*args, **kwargs)\n\texcept Exception:\n\t\tpass\n\n\ndef start_scheduler() -> NoReturn:\n\t\"\"\"Run enqueue_events_for_all_sites based on scheduler tick.\n\tSpecify scheduler_interval in seconds in common_site_config.json\"\"\"\n\n\ttick = cint(frappe.get_conf().scheduler_tick_interval) or 60\n\n\twhile True:\n\t\ttime.sleep(tick)\n\t\tenqueue_events_for_all_sites()\n\n\ndef enqueue_events_for_all_sites() -> None:\n\t\"\"\"Loop through sites and enqueue events that are not already queued\"\"\"\n\n\tif os.path.exists(os.path.join(\".\", \".restarting\")):\n\t\t# Don't add task to queue if webserver is in restart mode\n\t\treturn\n\n\twith frappe.init_site():\n\t\tsites = get_sites()\n\n\tfor site in sites:\n\t\ttry:\n\t\t\tenqueue_events_for_site(site=site)\n\t\texcept Exception:\n\t\t\tfrappe.logger(\"scheduler\").debug(f\"Failed to enqueue events for site: {site}\", exc_info=True)\n\n\ndef enqueue_events_for_site(site: str) -> None:\n\tdef log_exc():\n\t\tfrappe.logger(\"scheduler\").error(f\"Exception in Enqueue Events for Site {site}\", exc_info=True)\n\n\ttry:\n\t\tfrappe.init(site=site)\n\t\tfrappe.connect()\n\t\tif is_scheduler_inactive():\n\t\t\treturn\n\n\t\tenqueue_events(site=site)\n\n\t\tfrappe.logger(\"scheduler\").debug(f\"Queued events for site {site}\")\n\texcept Exception as e:\n\t\tif frappe.db.is_access_denied(e):\n\t\t\tfrappe.logger(\"scheduler\").debug(f\"Access denied for site {site}\")\n\t\tlog_exc()\n\n\tfinally:\n\t\tfrappe.destroy()\n\n\ndef enqueue_events(site: str) -> list[str] | None:\n\tif schedule_jobs_based_on_activity():\n\t\tenqueued_jobs = []\n\t\tfor job_type in frappe.get_all(\"Scheduled Job Type\", (\"name\", \"method\"), {\"stopped\": 0}):\n\t\t\tjob_type = frappe.get_cached_doc(\"Scheduled Job Type\", job_type.name)\n\t\t\tif _enqueued := job_type.enqueue():\n\t\t\t\tenqueued_jobs.append(job_type.method)\n\n\t\treturn enqueued_jobs\n\n\ndef is_scheduler_inactive(verbose=True) -> bool:\n\tif frappe.local.conf.maintenance_mode:\n\t\tif verbose:\n\t\t\tcprint(f\"{frappe.local.site}: Maintenance mode is ON\")\n\t\treturn True\n\n\tif frappe.local.conf.pause_scheduler:\n\t\tif verbose:\n\t\t\tcprint(f\"{frappe.local.site}: frappe.conf.pause_scheduler is SET\")\n\t\treturn True\n\n\tif is_scheduler_disabled(verbose=verbose):\n\t\treturn True\n\n\treturn False\n\n\ndef is_scheduler_disabled(verbose=True) -> bool:\n\tif frappe.conf.disable_scheduler:\n\t\tif verbose:\n\t\t\tcprint(f\"{frappe.local.site}: frappe.conf.disable_scheduler is SET\")\n\t\treturn True\n\n\tscheduler_disabled = not frappe.utils.cint(\n\t\tfrappe.db.get_single_value(\"System Settings\", \"enable_scheduler\")\n\t)\n\tif scheduler_disabled:\n\t\tif verbose:\n\t\t\tcprint(f\"{frappe.local.site}: SystemSettings.enable_scheduler is UNSET\")\n\treturn scheduler_disabled\n\n\ndef toggle_scheduler(enable):\n\tfrappe.db.set_single_value(\"System Settings\", \"enable_scheduler\", int(enable))\n\n\ndef enable_scheduler():\n\ttoggle_scheduler(True)\n\n\ndef disable_scheduler():\n\ttoggle_scheduler(False)\n\n\ndef schedule_jobs_based_on_activity(check_time=None):\n\t\"\"\"Returns True for active sites defined by Activity Log\n\tReturns True for inactive sites once in 24 hours\"\"\"\n\tif is_dormant(check_time=check_time):\n\t\t# ensure last job is one day old\n\t\tlast_job_timestamp = _get_last_modified_timestamp(\"Scheduled Job Log\")\n\t\tif not last_job_timestamp:\n\t\t\treturn True\n\t\telse:\n\t\t\tif ((check_time or now_datetime()) - last_job_timestamp).total_seconds() >= 86400:\n\t\t\t\t# one day is passed since jobs are run, so lets do this\n\t\t\t\treturn True\n\t\t\telse:\n\t\t\t\t# schedulers run in the last 24 hours, do nothing\n\t\t\t\treturn False\n\telse:\n\t\t# site active, lets run the jobs\n\t\treturn True\n\n\ndef is_dormant(check_time=None):\n\tlast_activity_log_timestamp = _get_last_modified_timestamp(\"Activity Log\")\n\tsince = (frappe.get_system_settings(\"dormant_days\") or 4) * 86400\n\tif not last_activity_log_timestamp:\n\t\treturn True\n\tif ((check_time or now_datetime()) - last_activity_log_timestamp).total_seconds() >= since:\n\t\treturn True\n\treturn False\n\n\ndef _get_last_modified_timestamp(doctype):\n\ttimestamp = frappe.db.get_value(\n\t\tdoctype, filters={}, fieldname=\"modified\", order_by=\"modified desc\"\n\t)\n\tif timestamp:\n\t\treturn get_datetime(timestamp)\n\n\[email protected]()\ndef activate_scheduler():\n\tif is_scheduler_disabled():\n\t\tenable_scheduler()\n\tif frappe.conf.pause_scheduler:\n\t\tupdate_site_config(\"pause_scheduler\", 0)\n\n\[email protected]()\ndef get_scheduler_status():\n\tif is_scheduler_inactive():\n\t\treturn {\"status\": \"inactive\"}\n\treturn {\"status\": \"active\"}\n", "path": "frappe/utils/scheduler.py"}]}
| 2,308 | 126 |
gh_patches_debug_24938
|
rasdani/github-patches
|
git_diff
|
edgedb__edgedb-3127
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Drop support for type union operator for scalars.
At the moment it's possible to apply type union operator to scalars, like `int64 | bigint`. This functions less intuitively than the same operation for object types.
```
edgedb> select 5 is int64;
{true}
edgedb> select 5 is (int64 | bigint);
{false}
edgedb> select (introspect (int64 | float32).name);
{'std::float64'}
```
The issue is that what the operation seems to do is answer the question of "what type would be the result set if you try to UNION values of these two disparate types?"
For object types, all objects are fundamentally related and therefore compatible enough to combine into a single set. The union type may not have all the links and properties directly accessible, but the underlying objects are of their specific types and remain unchanged. In practice it can meaningfully be used to denote a link which can validly take otherwise mostly unrelated object types (say `link attachment -> File | Link | Receipt`).
For scalar types we _cast_ the values, changing them, in order to produce a homogeneous set. So all values in the resulting set are strictly of a specific scalar type without any connection to their "former" type. This makes finding practical usage for scalar type unions much harder.
In addition to the above, we might want to introduce discriminated unions of scalars and the way the current `|` works with scalars could be counter-productive to that.
For all of the above reasons we can restrict `|` and `&` to only work for object types and potentially relax this in the future as the need arises.
</issue>
<code>
[start of edb/edgeql/compiler/typegen.py]
1 #
2 # This source file is part of the EdgeDB open source project.
3 #
4 # Copyright 2008-present MagicStack Inc. and the EdgeDB authors.
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17 #
18
19
20 """EdgeQL compiler type-related helpers."""
21
22
23 from __future__ import annotations
24
25 from typing import *
26
27 from edb import errors
28
29 from edb.ir import ast as irast
30 from edb.ir import typeutils as irtyputils
31 from edb.ir import utils as irutils
32
33 from edb.schema import abc as s_abc
34 from edb.schema import pointers as s_pointers
35 from edb.schema import types as s_types
36 from edb.schema import utils as s_utils
37
38 from edb.edgeql import ast as qlast
39
40 from . import context
41 from . import dispatch
42 from . import schemactx
43 from . import setgen
44
45
46 def type_to_ql_typeref(
47 t: s_types.Type,
48 *,
49 _name: Optional[str] = None,
50 ctx: context.ContextLevel,
51 ) -> qlast.TypeExpr:
52 return s_utils.typeref_to_ast(
53 ctx.env.schema,
54 t,
55 disambiguate_std='std' in ctx.modaliases,
56 )
57
58
59 def ql_typeexpr_to_ir_typeref(
60 ql_t: qlast.TypeExpr, *,
61 ctx: context.ContextLevel) -> irast.TypeRef:
62
63 stype = ql_typeexpr_to_type(ql_t, ctx=ctx)
64 return irtyputils.type_to_typeref(
65 ctx.env.schema, stype, cache=ctx.env.type_ref_cache
66 )
67
68
69 def ql_typeexpr_to_type(
70 ql_t: qlast.TypeExpr, *,
71 ctx: context.ContextLevel) -> s_types.Type:
72
73 types = _ql_typeexpr_to_type(ql_t, ctx=ctx)
74 if len(types) > 1:
75 return schemactx.get_union_type(types, ctx=ctx)
76 else:
77 return types[0]
78
79
80 def _ql_typeexpr_to_type(
81 ql_t: qlast.TypeExpr, *,
82 ctx: context.ContextLevel) -> List[s_types.Type]:
83
84 if isinstance(ql_t, qlast.TypeOf):
85 with ctx.new() as subctx:
86 # Use an empty scope tree, to avoid polluting things pointlessly
87 subctx.path_scope = irast.ScopeTreeNode()
88 ir_set = dispatch.compile(ql_t.expr, ctx=subctx)
89 stype = setgen.get_set_type(ir_set, ctx=subctx)
90
91 return [stype]
92
93 elif isinstance(ql_t, qlast.TypeOp):
94 if ql_t.op == '|':
95 return (_ql_typeexpr_to_type(ql_t.left, ctx=ctx) +
96 _ql_typeexpr_to_type(ql_t.right, ctx=ctx))
97
98 raise errors.UnsupportedFeatureError(
99 f'type operator {ql_t.op!r} is not implemented',
100 context=ql_t.context)
101
102 elif isinstance(ql_t, qlast.TypeName):
103 return [_ql_typename_to_type(ql_t, ctx=ctx)]
104
105 else:
106 raise errors.EdgeQLSyntaxError("Unexpected type expression",
107 context=ql_t.context)
108
109
110 def _ql_typename_to_type(
111 ql_t: qlast.TypeName, *,
112 ctx: context.ContextLevel) -> s_types.Type:
113 if ql_t.subtypes:
114 assert isinstance(ql_t.maintype, qlast.ObjectRef)
115 coll = s_types.Collection.get_class(ql_t.maintype.name)
116 ct: s_types.Type
117
118 if issubclass(coll, s_abc.Tuple):
119 t_subtypes = {}
120 named = False
121 for si, st in enumerate(ql_t.subtypes):
122 if st.name:
123 named = True
124 type_name = st.name
125 else:
126 type_name = str(si)
127
128 t_subtypes[type_name] = ql_typeexpr_to_type(st, ctx=ctx)
129
130 ctx.env.schema, ct = coll.from_subtypes(
131 ctx.env.schema, t_subtypes, {'named': named})
132 return ct
133 else:
134 a_subtypes = []
135 for st in ql_t.subtypes:
136 a_subtypes.append(ql_typeexpr_to_type(st, ctx=ctx))
137
138 ctx.env.schema, ct = coll.from_subtypes(ctx.env.schema, a_subtypes)
139 return ct
140 else:
141 return schemactx.get_schema_type(ql_t.maintype, ctx=ctx)
142
143
144 @overload
145 def ptrcls_from_ptrref( # NoQA: F811
146 ptrref: irast.PointerRef, *,
147 ctx: context.ContextLevel,
148 ) -> s_pointers.Pointer:
149 ...
150
151
152 @overload
153 def ptrcls_from_ptrref( # NoQA: F811
154 ptrref: irast.TupleIndirectionPointerRef, *,
155 ctx: context.ContextLevel,
156 ) -> irast.TupleIndirectionLink:
157 ...
158
159
160 @overload
161 def ptrcls_from_ptrref( # NoQA: F811
162 ptrref: irast.TypeIntersectionPointerRef, *,
163 ctx: context.ContextLevel,
164 ) -> irast.TypeIntersectionLink:
165 ...
166
167
168 @overload
169 def ptrcls_from_ptrref( # NoQA: F811
170 ptrref: irast.BasePointerRef, *,
171 ctx: context.ContextLevel,
172 ) -> s_pointers.PointerLike:
173 ...
174
175
176 def ptrcls_from_ptrref( # NoQA: F811
177 ptrref: irast.BasePointerRef, *,
178 ctx: context.ContextLevel,
179 ) -> s_pointers.PointerLike:
180
181 cached = ctx.env.ptr_ref_cache.get_ptrcls_for_ref(ptrref)
182 if cached is not None:
183 return cached
184
185 ctx.env.schema, ptr = irtyputils.ptrcls_from_ptrref(
186 ptrref, schema=ctx.env.schema)
187
188 return ptr
189
190
191 def collapse_type_intersection_rptr(
192 ir_set: irast.Set, *,
193 ctx: context.ContextLevel,
194 ) -> Tuple[irast.Set, List[s_pointers.Pointer]]:
195
196 ind_prefix, ind_ptrs = irutils.collapse_type_intersection(ir_set)
197 if not ind_ptrs:
198 return ir_set, []
199
200 rptr_specialization: Set[irast.PointerRef] = set()
201 for ind_ptr in ind_ptrs:
202 for ind_ptr in ind_ptrs:
203 if ind_ptr.ptrref.rptr_specialization:
204 rptr_specialization.update(
205 ind_ptr.ptrref.rptr_specialization)
206 elif (
207 not ind_ptr.ptrref.is_empty
208 and ind_ptr.source.rptr is not None
209 ):
210 assert isinstance(ind_ptr.source.rptr.ptrref, irast.PointerRef)
211 rptr_specialization.add(ind_ptr.source.rptr.ptrref)
212
213 ptrs = [ptrcls_from_ptrref(ptrref, ctx=ctx)
214 for ptrref in rptr_specialization]
215
216 return ind_prefix, ptrs
217
218
219 def type_to_typeref(
220 t: s_types.Type,
221 env: context.Environment,
222 ) -> irast.TypeRef:
223 schema = env.schema
224 cache = env.type_ref_cache
225 expr_type = t.get_expr_type(env.schema)
226 include_descendants = (
227 expr_type is s_types.ExprType.Update
228 or expr_type is s_types.ExprType.Delete
229 )
230 include_ancestors = (
231 expr_type is s_types.ExprType.Insert
232 or expr_type is s_types.ExprType.Update
233 or expr_type is s_types.ExprType.Delete
234 )
235 return irtyputils.type_to_typeref(
236 schema,
237 t,
238 include_descendants=include_descendants,
239 include_ancestors=include_ancestors,
240 cache=cache,
241 )
242
[end of edb/edgeql/compiler/typegen.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/edb/edgeql/compiler/typegen.py b/edb/edgeql/compiler/typegen.py
--- a/edb/edgeql/compiler/typegen.py
+++ b/edb/edgeql/compiler/typegen.py
@@ -92,8 +92,27 @@
elif isinstance(ql_t, qlast.TypeOp):
if ql_t.op == '|':
- return (_ql_typeexpr_to_type(ql_t.left, ctx=ctx) +
- _ql_typeexpr_to_type(ql_t.right, ctx=ctx))
+ # We need to validate that type ops are applied only to
+ # object types. So we check the base case here, when the
+ # left or right operand is a single type, because if it's
+ # a longer list, then we know that it was already composed
+ # of "|" or "&", or it is the result of inference by
+ # "typeof" and is a list of object types anyway.
+ left = _ql_typeexpr_to_type(ql_t.left, ctx=ctx)
+ right = _ql_typeexpr_to_type(ql_t.right, ctx=ctx)
+
+ if len(left) == 1 and not left[0].is_object_type():
+ raise errors.UnsupportedFeatureError(
+ f'cannot use type operator {ql_t.op!r} with non-object '
+ f'type {left[0].get_displayname(ctx.env.schema)}',
+ context=ql_t.left.context)
+ if len(right) == 1 and not right[0].is_object_type():
+ raise errors.UnsupportedFeatureError(
+ f'cannot use type operator {ql_t.op!r} with non-object '
+ f'type {right[0].get_displayname(ctx.env.schema)}',
+ context=ql_t.right.context)
+
+ return left + right
raise errors.UnsupportedFeatureError(
f'type operator {ql_t.op!r} is not implemented',
|
{"golden_diff": "diff --git a/edb/edgeql/compiler/typegen.py b/edb/edgeql/compiler/typegen.py\n--- a/edb/edgeql/compiler/typegen.py\n+++ b/edb/edgeql/compiler/typegen.py\n@@ -92,8 +92,27 @@\n \n elif isinstance(ql_t, qlast.TypeOp):\n if ql_t.op == '|':\n- return (_ql_typeexpr_to_type(ql_t.left, ctx=ctx) +\n- _ql_typeexpr_to_type(ql_t.right, ctx=ctx))\n+ # We need to validate that type ops are applied only to\n+ # object types. So we check the base case here, when the\n+ # left or right operand is a single type, because if it's\n+ # a longer list, then we know that it was already composed\n+ # of \"|\" or \"&\", or it is the result of inference by\n+ # \"typeof\" and is a list of object types anyway.\n+ left = _ql_typeexpr_to_type(ql_t.left, ctx=ctx)\n+ right = _ql_typeexpr_to_type(ql_t.right, ctx=ctx)\n+\n+ if len(left) == 1 and not left[0].is_object_type():\n+ raise errors.UnsupportedFeatureError(\n+ f'cannot use type operator {ql_t.op!r} with non-object '\n+ f'type {left[0].get_displayname(ctx.env.schema)}',\n+ context=ql_t.left.context)\n+ if len(right) == 1 and not right[0].is_object_type():\n+ raise errors.UnsupportedFeatureError(\n+ f'cannot use type operator {ql_t.op!r} with non-object '\n+ f'type {right[0].get_displayname(ctx.env.schema)}',\n+ context=ql_t.right.context)\n+\n+ return left + right\n \n raise errors.UnsupportedFeatureError(\n f'type operator {ql_t.op!r} is not implemented',\n", "issue": "Drop support for type union operator for scalars.\nAt the moment it's possible to apply type union operator to scalars, like `int64 | bigint`. This functions less intuitively than the same operation for object types.\r\n```\r\nedgedb> select 5 is int64;\r\n{true}\r\nedgedb> select 5 is (int64 | bigint);\r\n{false}\r\nedgedb> select (introspect (int64 | float32).name);\r\n{'std::float64'}\r\n```\r\nThe issue is that what the operation seems to do is answer the question of \"what type would be the result set if you try to UNION values of these two disparate types?\"\r\n\r\nFor object types, all objects are fundamentally related and therefore compatible enough to combine into a single set. The union type may not have all the links and properties directly accessible, but the underlying objects are of their specific types and remain unchanged. In practice it can meaningfully be used to denote a link which can validly take otherwise mostly unrelated object types (say `link attachment -> File | Link | Receipt`).\r\n\r\nFor scalar types we _cast_ the values, changing them, in order to produce a homogeneous set. So all values in the resulting set are strictly of a specific scalar type without any connection to their \"former\" type. This makes finding practical usage for scalar type unions much harder.\r\n\r\nIn addition to the above, we might want to introduce discriminated unions of scalars and the way the current `|` works with scalars could be counter-productive to that.\r\n\r\nFor all of the above reasons we can restrict `|` and `&` to only work for object types and potentially relax this in the future as the need arises.\n", "before_files": [{"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2008-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\n\"\"\"EdgeQL compiler type-related helpers.\"\"\"\n\n\nfrom __future__ import annotations\n\nfrom typing import *\n\nfrom edb import errors\n\nfrom edb.ir import ast as irast\nfrom edb.ir import typeutils as irtyputils\nfrom edb.ir import utils as irutils\n\nfrom edb.schema import abc as s_abc\nfrom edb.schema import pointers as s_pointers\nfrom edb.schema import types as s_types\nfrom edb.schema import utils as s_utils\n\nfrom edb.edgeql import ast as qlast\n\nfrom . import context\nfrom . import dispatch\nfrom . import schemactx\nfrom . import setgen\n\n\ndef type_to_ql_typeref(\n t: s_types.Type,\n *,\n _name: Optional[str] = None,\n ctx: context.ContextLevel,\n) -> qlast.TypeExpr:\n return s_utils.typeref_to_ast(\n ctx.env.schema,\n t,\n disambiguate_std='std' in ctx.modaliases,\n )\n\n\ndef ql_typeexpr_to_ir_typeref(\n ql_t: qlast.TypeExpr, *,\n ctx: context.ContextLevel) -> irast.TypeRef:\n\n stype = ql_typeexpr_to_type(ql_t, ctx=ctx)\n return irtyputils.type_to_typeref(\n ctx.env.schema, stype, cache=ctx.env.type_ref_cache\n )\n\n\ndef ql_typeexpr_to_type(\n ql_t: qlast.TypeExpr, *,\n ctx: context.ContextLevel) -> s_types.Type:\n\n types = _ql_typeexpr_to_type(ql_t, ctx=ctx)\n if len(types) > 1:\n return schemactx.get_union_type(types, ctx=ctx)\n else:\n return types[0]\n\n\ndef _ql_typeexpr_to_type(\n ql_t: qlast.TypeExpr, *,\n ctx: context.ContextLevel) -> List[s_types.Type]:\n\n if isinstance(ql_t, qlast.TypeOf):\n with ctx.new() as subctx:\n # Use an empty scope tree, to avoid polluting things pointlessly\n subctx.path_scope = irast.ScopeTreeNode()\n ir_set = dispatch.compile(ql_t.expr, ctx=subctx)\n stype = setgen.get_set_type(ir_set, ctx=subctx)\n\n return [stype]\n\n elif isinstance(ql_t, qlast.TypeOp):\n if ql_t.op == '|':\n return (_ql_typeexpr_to_type(ql_t.left, ctx=ctx) +\n _ql_typeexpr_to_type(ql_t.right, ctx=ctx))\n\n raise errors.UnsupportedFeatureError(\n f'type operator {ql_t.op!r} is not implemented',\n context=ql_t.context)\n\n elif isinstance(ql_t, qlast.TypeName):\n return [_ql_typename_to_type(ql_t, ctx=ctx)]\n\n else:\n raise errors.EdgeQLSyntaxError(\"Unexpected type expression\",\n context=ql_t.context)\n\n\ndef _ql_typename_to_type(\n ql_t: qlast.TypeName, *,\n ctx: context.ContextLevel) -> s_types.Type:\n if ql_t.subtypes:\n assert isinstance(ql_t.maintype, qlast.ObjectRef)\n coll = s_types.Collection.get_class(ql_t.maintype.name)\n ct: s_types.Type\n\n if issubclass(coll, s_abc.Tuple):\n t_subtypes = {}\n named = False\n for si, st in enumerate(ql_t.subtypes):\n if st.name:\n named = True\n type_name = st.name\n else:\n type_name = str(si)\n\n t_subtypes[type_name] = ql_typeexpr_to_type(st, ctx=ctx)\n\n ctx.env.schema, ct = coll.from_subtypes(\n ctx.env.schema, t_subtypes, {'named': named})\n return ct\n else:\n a_subtypes = []\n for st in ql_t.subtypes:\n a_subtypes.append(ql_typeexpr_to_type(st, ctx=ctx))\n\n ctx.env.schema, ct = coll.from_subtypes(ctx.env.schema, a_subtypes)\n return ct\n else:\n return schemactx.get_schema_type(ql_t.maintype, ctx=ctx)\n\n\n@overload\ndef ptrcls_from_ptrref( # NoQA: F811\n ptrref: irast.PointerRef, *,\n ctx: context.ContextLevel,\n) -> s_pointers.Pointer:\n ...\n\n\n@overload\ndef ptrcls_from_ptrref( # NoQA: F811\n ptrref: irast.TupleIndirectionPointerRef, *,\n ctx: context.ContextLevel,\n) -> irast.TupleIndirectionLink:\n ...\n\n\n@overload\ndef ptrcls_from_ptrref( # NoQA: F811\n ptrref: irast.TypeIntersectionPointerRef, *,\n ctx: context.ContextLevel,\n) -> irast.TypeIntersectionLink:\n ...\n\n\n@overload\ndef ptrcls_from_ptrref( # NoQA: F811\n ptrref: irast.BasePointerRef, *,\n ctx: context.ContextLevel,\n) -> s_pointers.PointerLike:\n ...\n\n\ndef ptrcls_from_ptrref( # NoQA: F811\n ptrref: irast.BasePointerRef, *,\n ctx: context.ContextLevel,\n) -> s_pointers.PointerLike:\n\n cached = ctx.env.ptr_ref_cache.get_ptrcls_for_ref(ptrref)\n if cached is not None:\n return cached\n\n ctx.env.schema, ptr = irtyputils.ptrcls_from_ptrref(\n ptrref, schema=ctx.env.schema)\n\n return ptr\n\n\ndef collapse_type_intersection_rptr(\n ir_set: irast.Set, *,\n ctx: context.ContextLevel,\n) -> Tuple[irast.Set, List[s_pointers.Pointer]]:\n\n ind_prefix, ind_ptrs = irutils.collapse_type_intersection(ir_set)\n if not ind_ptrs:\n return ir_set, []\n\n rptr_specialization: Set[irast.PointerRef] = set()\n for ind_ptr in ind_ptrs:\n for ind_ptr in ind_ptrs:\n if ind_ptr.ptrref.rptr_specialization:\n rptr_specialization.update(\n ind_ptr.ptrref.rptr_specialization)\n elif (\n not ind_ptr.ptrref.is_empty\n and ind_ptr.source.rptr is not None\n ):\n assert isinstance(ind_ptr.source.rptr.ptrref, irast.PointerRef)\n rptr_specialization.add(ind_ptr.source.rptr.ptrref)\n\n ptrs = [ptrcls_from_ptrref(ptrref, ctx=ctx)\n for ptrref in rptr_specialization]\n\n return ind_prefix, ptrs\n\n\ndef type_to_typeref(\n t: s_types.Type,\n env: context.Environment,\n) -> irast.TypeRef:\n schema = env.schema\n cache = env.type_ref_cache\n expr_type = t.get_expr_type(env.schema)\n include_descendants = (\n expr_type is s_types.ExprType.Update\n or expr_type is s_types.ExprType.Delete\n )\n include_ancestors = (\n expr_type is s_types.ExprType.Insert\n or expr_type is s_types.ExprType.Update\n or expr_type is s_types.ExprType.Delete\n )\n return irtyputils.type_to_typeref(\n schema,\n t,\n include_descendants=include_descendants,\n include_ancestors=include_ancestors,\n cache=cache,\n )\n", "path": "edb/edgeql/compiler/typegen.py"}]}
| 3,289 | 431 |
gh_patches_debug_31889
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-575
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
git unadd changes lost if hook fails on windows
```
D:\CubeadProjects\devops [test +0 ~2 -0 | +0 ~1 -0 !]> git cm "asd"
[WARNING] Unstaged files detected.
[INFO] Stashing unstaged files to C:\Users\56929\.pre-commit\patch1501482991.
run pylint...............................................................Failed
hookid: python-pylint
************* Module install
C: 10, 0: Exactly one space required around assignment
a=1
^ (bad-whitespace)
C: 46, 0: Line too long (108/100) (line-too-long)
W: 39, 4: Unused variable 'stylelint_root' (unused-variable)
W: 37, 4: Unused variable 'node_root' (unused-variable)
W: 24, 8: Unused variable 'checks' (unused-variable)
[WARNING] Stashed changes conflicted with hook auto-fixes... Rolling back fixes...
An unexpected error has occurred: CalledProcessError: Command: ('C:\\Program Files\\Git\\mingw64\\libexec\\git-core\\git.exe', 'apply', 'C:\\Users\\56929\\.pre-commit\\patch1501483011')
Return code: 1
Expected return code: 0
Output: (none)
Errors:
error: patch failed: svnchecker_stylelint_support/checks/Stylelint.py:20
error: svnchecker_stylelint_support/checks/Stylelint.py: patch does not apply
Check the log at ~/.pre-commit/pre-commit.log
```
### ~/.pre-commit/pre-commit.log
```
An unexpected error has occurred: CalledProcessError: Command: ('C:\\Program Files\\Git\\mingw64\\libexec\\git-core\\git.exe', 'apply', 'C:\\Users\\56929\\.pre-commit\\patch1501483011')
Return code: 1
Expected return code: 0
Output: (none)
Errors:
error: patch failed: svnchecker_stylelint_support/checks/Stylelint.py:20
error: svnchecker_stylelint_support/checks/Stylelint.py: patch does not apply
Traceback (most recent call last):
File "c:\python27\lib\site-packages\pre_commit\error_handler.py", line 48, in error_handler
yield
File "c:\python27\lib\site-packages\pre_commit\main.py", line 231, in main
return run(runner, args)
File "c:\python27\lib\site-packages\pre_commit\commands\run.py", line 273, in run
return _run_hooks(repo_hooks, args, environ)
File "c:\python27\lib\contextlib.py", line 24, in __exit__
self.gen.next()
File "c:\python27\lib\site-packages\pre_commit\staged_files_only.py", line 58, in staged_files_only
cmd_runner.run(('git', 'apply', patch_filename), encoding=None)
File "c:\python27\lib\site-packages\pre_commit\prefixed_command_runner.py", line 38, in run
return cmd_output(*replaced_cmd, __popen=self.__popen, **kwargs)
File "c:\python27\lib\site-packages\pre_commit\util.py", line 189, in cmd_output
returncode, cmd, retcode, output=(stdout, stderr),
CalledProcessError: Command: ('C:\\Program Files\\Git\\mingw64\\libexec\\git-core\\git.exe', 'apply', 'C:\\Users\\56929\\.pre-commit\\patch1501483011')
Return code: 1
Expected return code: 0
Output: (none)
Errors:
error: patch failed: svnchecker_stylelint_support/checks/Stylelint.py:20
error: svnchecker_stylelint_support/checks/Stylelint.py: patch does not apply
```
Then, I open the patch file. (C:\\Users\\56929\\.pre-commit\\patch1501483011),it looks like
```diff
diff --git a/svnchecker_stylelint_support/checks/Stylelint.py b/svnchecker_stylelint_support/checks/Stylelint.py
index 4422b4d..f85ecb1 100644
--- a/svnchecker_stylelint_support/checks/Stylelint.py
+++ b/svnchecker_stylelint_support/checks/Stylelint.py
@@ -20,3 +20,5 @@ def run(transaction, config):
return ('{}\n{}'.format(stdoutdata, stderrdata), 1)^M
^M
return ("", 0)^M
^M
^M
^M
```
</issue>
<code>
[start of pre_commit/staged_files_only.py]
1 from __future__ import unicode_literals
2
3 import contextlib
4 import io
5 import logging
6 import time
7
8 from pre_commit.util import CalledProcessError
9
10
11 logger = logging.getLogger('pre_commit')
12
13
14 @contextlib.contextmanager
15 def staged_files_only(cmd_runner):
16 """Clear any unstaged changes from the git working directory inside this
17 context.
18
19 Args:
20 cmd_runner - PrefixedCommandRunner
21 """
22 # Determine if there are unstaged files
23 tree = cmd_runner.run(('git', 'write-tree'))[1].strip()
24 retcode, diff_stdout_binary, _ = cmd_runner.run(
25 (
26 'git', 'diff-index', '--ignore-submodules', '--binary',
27 '--exit-code', '--no-color', '--no-ext-diff', tree, '--',
28 ),
29 retcode=None,
30 encoding=None,
31 )
32 if retcode and diff_stdout_binary.strip():
33 patch_filename = cmd_runner.path('patch{}'.format(int(time.time())))
34 logger.warning('Unstaged files detected.')
35 logger.info(
36 'Stashing unstaged files to {}.'.format(patch_filename),
37 )
38 # Save the current unstaged changes as a patch
39 with io.open(patch_filename, 'wb') as patch_file:
40 patch_file.write(diff_stdout_binary)
41
42 # Clear the working directory of unstaged changes
43 cmd_runner.run(('git', 'checkout', '--', '.'))
44 try:
45 yield
46 finally:
47 # Try to apply the patch we saved
48 try:
49 cmd_runner.run(
50 ('git', 'apply', '--whitespace=nowarn', patch_filename),
51 encoding=None,
52 )
53 except CalledProcessError:
54 logger.warning(
55 'Stashed changes conflicted with hook auto-fixes... '
56 'Rolling back fixes...',
57 )
58 # We failed to apply the patch, presumably due to fixes made
59 # by hooks.
60 # Roll back the changes made by hooks.
61 cmd_runner.run(('git', 'checkout', '--', '.'))
62 cmd_runner.run(
63 ('git', 'apply', patch_filename, '--whitespace=nowarn'),
64 encoding=None,
65 )
66 logger.info('Restored changes from {}.'.format(patch_filename))
67 else:
68 # There weren't any staged files so we don't need to do anything
69 # special
70 yield
71
[end of pre_commit/staged_files_only.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/staged_files_only.py b/pre_commit/staged_files_only.py
--- a/pre_commit/staged_files_only.py
+++ b/pre_commit/staged_files_only.py
@@ -11,6 +11,16 @@
logger = logging.getLogger('pre_commit')
+def _git_apply(cmd_runner, patch):
+ args = ('apply', '--whitespace=nowarn', patch)
+ try:
+ cmd_runner.run(('git',) + args, encoding=None)
+ except CalledProcessError:
+ # Retry with autocrlf=false -- see #570
+ cmd = ('git', '-c', 'core.autocrlf=false') + args
+ cmd_runner.run(cmd, encoding=None)
+
+
@contextlib.contextmanager
def staged_files_only(cmd_runner):
"""Clear any unstaged changes from the git working directory inside this
@@ -46,10 +56,7 @@
finally:
# Try to apply the patch we saved
try:
- cmd_runner.run(
- ('git', 'apply', '--whitespace=nowarn', patch_filename),
- encoding=None,
- )
+ _git_apply(cmd_runner, patch_filename)
except CalledProcessError:
logger.warning(
'Stashed changes conflicted with hook auto-fixes... '
@@ -59,10 +66,7 @@
# by hooks.
# Roll back the changes made by hooks.
cmd_runner.run(('git', 'checkout', '--', '.'))
- cmd_runner.run(
- ('git', 'apply', patch_filename, '--whitespace=nowarn'),
- encoding=None,
- )
+ _git_apply(cmd_runner, patch_filename)
logger.info('Restored changes from {}.'.format(patch_filename))
else:
# There weren't any staged files so we don't need to do anything
|
{"golden_diff": "diff --git a/pre_commit/staged_files_only.py b/pre_commit/staged_files_only.py\n--- a/pre_commit/staged_files_only.py\n+++ b/pre_commit/staged_files_only.py\n@@ -11,6 +11,16 @@\n logger = logging.getLogger('pre_commit')\n \n \n+def _git_apply(cmd_runner, patch):\n+ args = ('apply', '--whitespace=nowarn', patch)\n+ try:\n+ cmd_runner.run(('git',) + args, encoding=None)\n+ except CalledProcessError:\n+ # Retry with autocrlf=false -- see #570\n+ cmd = ('git', '-c', 'core.autocrlf=false') + args\n+ cmd_runner.run(cmd, encoding=None)\n+\n+\n @contextlib.contextmanager\n def staged_files_only(cmd_runner):\n \"\"\"Clear any unstaged changes from the git working directory inside this\n@@ -46,10 +56,7 @@\n finally:\n # Try to apply the patch we saved\n try:\n- cmd_runner.run(\n- ('git', 'apply', '--whitespace=nowarn', patch_filename),\n- encoding=None,\n- )\n+ _git_apply(cmd_runner, patch_filename)\n except CalledProcessError:\n logger.warning(\n 'Stashed changes conflicted with hook auto-fixes... '\n@@ -59,10 +66,7 @@\n # by hooks.\n # Roll back the changes made by hooks.\n cmd_runner.run(('git', 'checkout', '--', '.'))\n- cmd_runner.run(\n- ('git', 'apply', patch_filename, '--whitespace=nowarn'),\n- encoding=None,\n- )\n+ _git_apply(cmd_runner, patch_filename)\n logger.info('Restored changes from {}.'.format(patch_filename))\n else:\n # There weren't any staged files so we don't need to do anything\n", "issue": "git unadd changes lost if hook fails on windows\n```\r\nD:\\CubeadProjects\\devops [test +0 ~2 -0 | +0 ~1 -0 !]> git cm \"asd\"\r\n[WARNING] Unstaged files detected.\r\n[INFO] Stashing unstaged files to C:\\Users\\56929\\.pre-commit\\patch1501482991.\r\nrun pylint...............................................................Failed\r\nhookid: python-pylint\r\n\r\n************* Module install\r\nC: 10, 0: Exactly one space required around assignment\r\na=1\r\n ^ (bad-whitespace)\r\nC: 46, 0: Line too long (108/100) (line-too-long)\r\nW: 39, 4: Unused variable 'stylelint_root' (unused-variable)\r\nW: 37, 4: Unused variable 'node_root' (unused-variable)\r\nW: 24, 8: Unused variable 'checks' (unused-variable)\r\n\r\n[WARNING] Stashed changes conflicted with hook auto-fixes... Rolling back fixes...\r\nAn unexpected error has occurred: CalledProcessError: Command: ('C:\\\\Program Files\\\\Git\\\\mingw64\\\\libexec\\\\git-core\\\\git.exe', 'apply', 'C:\\\\Users\\\\56929\\\\.pre-commit\\\\patch1501483011')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors:\r\n error: patch failed: svnchecker_stylelint_support/checks/Stylelint.py:20\r\n error: svnchecker_stylelint_support/checks/Stylelint.py: patch does not apply\r\n\r\n\r\nCheck the log at ~/.pre-commit/pre-commit.log\r\n```\r\n\r\n### ~/.pre-commit/pre-commit.log\r\n```\r\nAn unexpected error has occurred: CalledProcessError: Command: ('C:\\\\Program Files\\\\Git\\\\mingw64\\\\libexec\\\\git-core\\\\git.exe', 'apply', 'C:\\\\Users\\\\56929\\\\.pre-commit\\\\patch1501483011')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors: \r\n error: patch failed: svnchecker_stylelint_support/checks/Stylelint.py:20\r\n error: svnchecker_stylelint_support/checks/Stylelint.py: patch does not apply\r\n \r\n\r\nTraceback (most recent call last):\r\n File \"c:\\python27\\lib\\site-packages\\pre_commit\\error_handler.py\", line 48, in error_handler\r\n yield\r\n File \"c:\\python27\\lib\\site-packages\\pre_commit\\main.py\", line 231, in main\r\n return run(runner, args)\r\n File \"c:\\python27\\lib\\site-packages\\pre_commit\\commands\\run.py\", line 273, in run\r\n return _run_hooks(repo_hooks, args, environ)\r\n File \"c:\\python27\\lib\\contextlib.py\", line 24, in __exit__\r\n self.gen.next()\r\n File \"c:\\python27\\lib\\site-packages\\pre_commit\\staged_files_only.py\", line 58, in staged_files_only\r\n cmd_runner.run(('git', 'apply', patch_filename), encoding=None)\r\n File \"c:\\python27\\lib\\site-packages\\pre_commit\\prefixed_command_runner.py\", line 38, in run\r\n return cmd_output(*replaced_cmd, __popen=self.__popen, **kwargs)\r\n File \"c:\\python27\\lib\\site-packages\\pre_commit\\util.py\", line 189, in cmd_output\r\n returncode, cmd, retcode, output=(stdout, stderr),\r\nCalledProcessError: Command: ('C:\\\\Program Files\\\\Git\\\\mingw64\\\\libexec\\\\git-core\\\\git.exe', 'apply', 'C:\\\\Users\\\\56929\\\\.pre-commit\\\\patch1501483011')\r\nReturn code: 1\r\nExpected return code: 0\r\nOutput: (none)\r\nErrors: \r\n error: patch failed: svnchecker_stylelint_support/checks/Stylelint.py:20\r\n error: svnchecker_stylelint_support/checks/Stylelint.py: patch does not apply\r\n```\r\nThen, I open the patch file. (C:\\\\Users\\\\56929\\\\.pre-commit\\\\patch1501483011),it looks like \r\n\r\n```diff\r\ndiff --git a/svnchecker_stylelint_support/checks/Stylelint.py b/svnchecker_stylelint_support/checks/Stylelint.py\r\nindex 4422b4d..f85ecb1 100644\r\n--- a/svnchecker_stylelint_support/checks/Stylelint.py\r\n+++ b/svnchecker_stylelint_support/checks/Stylelint.py\r\n@@ -20,3 +20,5 @@ def run(transaction, config):\r\n return ('{}\\n{}'.format(stdoutdata, stderrdata), 1)^M\r\n^M\r\n return (\"\", 0)^M\r\n^M\r\n^M\r\n^M\r\n```\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport io\nimport logging\nimport time\n\nfrom pre_commit.util import CalledProcessError\n\n\nlogger = logging.getLogger('pre_commit')\n\n\[email protected]\ndef staged_files_only(cmd_runner):\n \"\"\"Clear any unstaged changes from the git working directory inside this\n context.\n\n Args:\n cmd_runner - PrefixedCommandRunner\n \"\"\"\n # Determine if there are unstaged files\n tree = cmd_runner.run(('git', 'write-tree'))[1].strip()\n retcode, diff_stdout_binary, _ = cmd_runner.run(\n (\n 'git', 'diff-index', '--ignore-submodules', '--binary',\n '--exit-code', '--no-color', '--no-ext-diff', tree, '--',\n ),\n retcode=None,\n encoding=None,\n )\n if retcode and diff_stdout_binary.strip():\n patch_filename = cmd_runner.path('patch{}'.format(int(time.time())))\n logger.warning('Unstaged files detected.')\n logger.info(\n 'Stashing unstaged files to {}.'.format(patch_filename),\n )\n # Save the current unstaged changes as a patch\n with io.open(patch_filename, 'wb') as patch_file:\n patch_file.write(diff_stdout_binary)\n\n # Clear the working directory of unstaged changes\n cmd_runner.run(('git', 'checkout', '--', '.'))\n try:\n yield\n finally:\n # Try to apply the patch we saved\n try:\n cmd_runner.run(\n ('git', 'apply', '--whitespace=nowarn', patch_filename),\n encoding=None,\n )\n except CalledProcessError:\n logger.warning(\n 'Stashed changes conflicted with hook auto-fixes... '\n 'Rolling back fixes...',\n )\n # We failed to apply the patch, presumably due to fixes made\n # by hooks.\n # Roll back the changes made by hooks.\n cmd_runner.run(('git', 'checkout', '--', '.'))\n cmd_runner.run(\n ('git', 'apply', patch_filename, '--whitespace=nowarn'),\n encoding=None,\n )\n logger.info('Restored changes from {}.'.format(patch_filename))\n else:\n # There weren't any staged files so we don't need to do anything\n # special\n yield\n", "path": "pre_commit/staged_files_only.py"}]}
| 2,272 | 406 |
gh_patches_debug_7053
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-21237
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs: make links equally browsable on both GitHub and ReadTheDocs
Once upstream bug https://github.com/readthedocs/recommonmark/issues/179 is fixed, we can replace the `.html` part in links of the form `file_name.html#anchor` with `.md`.
This is a followup to https://github.com/zulip/zulip/pull/13232.
</issue>
<code>
[start of version.py]
1 import os
2
3 ZULIP_VERSION = "5.0-dev+git"
4
5 # Add information on number of commits and commit hash to version, if available
6 zulip_git_version_file = os.path.join(
7 os.path.dirname(os.path.abspath(__file__)), "zulip-git-version"
8 )
9 lines = [ZULIP_VERSION, ""]
10 if os.path.exists(zulip_git_version_file):
11 with open(zulip_git_version_file) as f:
12 lines = f.readlines() + ["", ""]
13 ZULIP_VERSION = lines.pop(0).strip()
14 ZULIP_MERGE_BASE = lines.pop(0).strip()
15
16 LATEST_MAJOR_VERSION = "4.0"
17 LATEST_RELEASE_VERSION = "4.10"
18 LATEST_RELEASE_ANNOUNCEMENT = "https://blog.zulip.com/2021/05/13/zulip-4-0-released/"
19
20 # Versions of the desktop app below DESKTOP_MINIMUM_VERSION will be
21 # prevented from connecting to the Zulip server. Versions above
22 # DESKTOP_MINIMUM_VERSION but below DESKTOP_WARNING_VERSION will have
23 # a banner at the top of the page asking the user to upgrade.
24 DESKTOP_MINIMUM_VERSION = "5.2.0"
25 DESKTOP_WARNING_VERSION = "5.4.3"
26
27 # Bump the API_FEATURE_LEVEL whenever an API change is made
28 # that clients might want to condition on. If we forget at
29 # the time we make the change, then bump it later as soon
30 # as we notice; clients using API_FEATURE_LEVEL will just not
31 # use the new feature/API until the bump.
32 #
33 # Changes should be accompanied by documentation explaining what the
34 # new level means in templates/zerver/api/changelog.md, as well as
35 # "**Changes**" entries in the endpoint's documentation in `zulip.yaml`.
36 API_FEATURE_LEVEL = 117
37
38 # Bump the minor PROVISION_VERSION to indicate that folks should provision
39 # only when going from an old version of the code to a newer version. Bump
40 # the major version to indicate that folks should provision in both
41 # directions.
42
43 # Typically,
44 # * adding a dependency only requires a minor version bump;
45 # * removing a dependency requires a major version bump;
46 # * upgrading a dependency requires a major version bump, unless the
47 # upgraded dependency is backwards compatible with all of our
48 # historical commits sharing the same major version, in which case a
49 # minor version bump suffices.
50
51 PROVISION_VERSION = "179.0"
52
[end of version.py]
[start of docs/conf.py]
1 # For documentation on Sphinx configuration options, see:
2 # https://www.sphinx-doc.org/en/master/usage/configuration.html
3 # https://myst-parser.readthedocs.io/en/latest/sphinx/reference.html
4 # https://sphinx-rtd-theme.readthedocs.io/en/stable/configuring.html
5
6 import os
7 import sys
8 from typing import Any
9
10 sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), "..")))
11 from version import LATEST_RELEASE_VERSION, ZULIP_VERSION
12
13 on_rtd = os.environ.get("READTHEDOCS") == "True"
14
15 # General configuration
16
17 extensions = [
18 "myst_parser",
19 "sphinx_rtd_theme",
20 ]
21 templates_path = ["_templates"]
22 project = "Zulip"
23 copyright = "2012–2015 Dropbox, Inc., 2015–2021 Kandra Labs, Inc., and contributors"
24 author = "The Zulip Team"
25 version = ZULIP_VERSION
26 release = ZULIP_VERSION
27 exclude_patterns = ["_build", "README.md"]
28 suppress_warnings = [
29 "myst.header",
30 ]
31 pygments_style = "sphinx"
32
33 # Options for Markdown parser
34
35 myst_enable_extensions = [
36 "colon_fence",
37 "substitution",
38 ]
39 myst_substitutions = {
40 "LATEST_RELEASE_VERSION": LATEST_RELEASE_VERSION,
41 }
42
43 # Options for HTML output
44
45 html_theme = "sphinx_rtd_theme"
46 html_theme_options = {
47 "collapse_navigation": not on_rtd, # makes local builds much faster
48 "logo_only": True,
49 }
50 html_logo = "images/zulip-logo.svg"
51 html_static_path = ["_static"]
52
53
54 def setup(app: Any) -> None:
55 # overrides for wide tables in RTD theme
56 app.add_css_file("theme_overrides.css") # path relative to _static
57
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -36,6 +36,7 @@
"colon_fence",
"substitution",
]
+myst_heading_anchors = 6
myst_substitutions = {
"LATEST_RELEASE_VERSION": LATEST_RELEASE_VERSION,
}
diff --git a/version.py b/version.py
--- a/version.py
+++ b/version.py
@@ -48,4 +48,4 @@
# historical commits sharing the same major version, in which case a
# minor version bump suffices.
-PROVISION_VERSION = "179.0"
+PROVISION_VERSION = "180.0"
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -36,6 +36,7 @@\n \"colon_fence\",\n \"substitution\",\n ]\n+myst_heading_anchors = 6\n myst_substitutions = {\n \"LATEST_RELEASE_VERSION\": LATEST_RELEASE_VERSION,\n }\ndiff --git a/version.py b/version.py\n--- a/version.py\n+++ b/version.py\n@@ -48,4 +48,4 @@\n # historical commits sharing the same major version, in which case a\n # minor version bump suffices.\n \n-PROVISION_VERSION = \"179.0\"\n+PROVISION_VERSION = \"180.0\"\n", "issue": "docs: make links equally browsable on both GitHub and ReadTheDocs\nOnce upstream bug https://github.com/readthedocs/recommonmark/issues/179 is fixed, we can replace the `.html` part in links of the form `file_name.html#anchor` with `.md`.\r\n\r\nThis is a followup to https://github.com/zulip/zulip/pull/13232.\n", "before_files": [{"content": "import os\n\nZULIP_VERSION = \"5.0-dev+git\"\n\n# Add information on number of commits and commit hash to version, if available\nzulip_git_version_file = os.path.join(\n os.path.dirname(os.path.abspath(__file__)), \"zulip-git-version\"\n)\nlines = [ZULIP_VERSION, \"\"]\nif os.path.exists(zulip_git_version_file):\n with open(zulip_git_version_file) as f:\n lines = f.readlines() + [\"\", \"\"]\nZULIP_VERSION = lines.pop(0).strip()\nZULIP_MERGE_BASE = lines.pop(0).strip()\n\nLATEST_MAJOR_VERSION = \"4.0\"\nLATEST_RELEASE_VERSION = \"4.10\"\nLATEST_RELEASE_ANNOUNCEMENT = \"https://blog.zulip.com/2021/05/13/zulip-4-0-released/\"\n\n# Versions of the desktop app below DESKTOP_MINIMUM_VERSION will be\n# prevented from connecting to the Zulip server. Versions above\n# DESKTOP_MINIMUM_VERSION but below DESKTOP_WARNING_VERSION will have\n# a banner at the top of the page asking the user to upgrade.\nDESKTOP_MINIMUM_VERSION = \"5.2.0\"\nDESKTOP_WARNING_VERSION = \"5.4.3\"\n\n# Bump the API_FEATURE_LEVEL whenever an API change is made\n# that clients might want to condition on. If we forget at\n# the time we make the change, then bump it later as soon\n# as we notice; clients using API_FEATURE_LEVEL will just not\n# use the new feature/API until the bump.\n#\n# Changes should be accompanied by documentation explaining what the\n# new level means in templates/zerver/api/changelog.md, as well as\n# \"**Changes**\" entries in the endpoint's documentation in `zulip.yaml`.\nAPI_FEATURE_LEVEL = 117\n\n# Bump the minor PROVISION_VERSION to indicate that folks should provision\n# only when going from an old version of the code to a newer version. Bump\n# the major version to indicate that folks should provision in both\n# directions.\n\n# Typically,\n# * adding a dependency only requires a minor version bump;\n# * removing a dependency requires a major version bump;\n# * upgrading a dependency requires a major version bump, unless the\n# upgraded dependency is backwards compatible with all of our\n# historical commits sharing the same major version, in which case a\n# minor version bump suffices.\n\nPROVISION_VERSION = \"179.0\"\n", "path": "version.py"}, {"content": "# For documentation on Sphinx configuration options, see:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\n# https://myst-parser.readthedocs.io/en/latest/sphinx/reference.html\n# https://sphinx-rtd-theme.readthedocs.io/en/stable/configuring.html\n\nimport os\nimport sys\nfrom typing import Any\n\nsys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), \"..\")))\nfrom version import LATEST_RELEASE_VERSION, ZULIP_VERSION\n\non_rtd = os.environ.get(\"READTHEDOCS\") == \"True\"\n\n# General configuration\n\nextensions = [\n \"myst_parser\",\n \"sphinx_rtd_theme\",\n]\ntemplates_path = [\"_templates\"]\nproject = \"Zulip\"\ncopyright = \"2012\u20132015 Dropbox, Inc., 2015\u20132021 Kandra Labs, Inc., and contributors\"\nauthor = \"The Zulip Team\"\nversion = ZULIP_VERSION\nrelease = ZULIP_VERSION\nexclude_patterns = [\"_build\", \"README.md\"]\nsuppress_warnings = [\n \"myst.header\",\n]\npygments_style = \"sphinx\"\n\n# Options for Markdown parser\n\nmyst_enable_extensions = [\n \"colon_fence\",\n \"substitution\",\n]\nmyst_substitutions = {\n \"LATEST_RELEASE_VERSION\": LATEST_RELEASE_VERSION,\n}\n\n# Options for HTML output\n\nhtml_theme = \"sphinx_rtd_theme\"\nhtml_theme_options = {\n \"collapse_navigation\": not on_rtd, # makes local builds much faster\n \"logo_only\": True,\n}\nhtml_logo = \"images/zulip-logo.svg\"\nhtml_static_path = [\"_static\"]\n\n\ndef setup(app: Any) -> None:\n # overrides for wide tables in RTD theme\n app.add_css_file(\"theme_overrides.css\") # path relative to _static\n", "path": "docs/conf.py"}]}
| 1,780 | 154 |
gh_patches_debug_22323
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-937
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Document simplemodels API
# Description
In discussion today with @coolalexzb, I realized that the [`pyhf.simplemodels`](https://github.com/scikit-hep/pyhf/blob/79984be837ef6e53bdd12a82163c34d47d507dba/src/pyhf/simplemodels.py) API is not documented in our docs. Even thought this isn't something we want people to really use, we still show it in our examples and so it needs documentation.
</issue>
<code>
[start of src/pyhf/simplemodels.py]
1 from . import Model
2
3
4 def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):
5 spec = {
6 'channels': [
7 {
8 'name': 'singlechannel',
9 'samples': [
10 {
11 'name': 'signal',
12 'data': signal_data,
13 'modifiers': [
14 {'name': 'mu', 'type': 'normfactor', 'data': None}
15 ],
16 },
17 {
18 'name': 'background',
19 'data': bkg_data,
20 'modifiers': [
21 {
22 'name': 'uncorr_bkguncrt',
23 'type': 'shapesys',
24 'data': bkg_uncerts,
25 }
26 ],
27 },
28 ],
29 }
30 ]
31 }
32 return Model(spec, batch_size=batch_size)
33
[end of src/pyhf/simplemodels.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyhf/simplemodels.py b/src/pyhf/simplemodels.py
--- a/src/pyhf/simplemodels.py
+++ b/src/pyhf/simplemodels.py
@@ -2,6 +2,38 @@
def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):
+ """
+ Construct a simple single channel :class:`~pyhf.pdf.Model` with a
+ :class:`~pyhf.modifiers.shapesys` modifier representing an uncorrelated
+ background uncertainty.
+
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.hepdata_like(
+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
+ ... )
+ >>> model.schema
+ 'model.json'
+ >>> model.config.channels
+ ['singlechannel']
+ >>> model.config.samples
+ ['background', 'signal']
+ >>> model.config.parameters
+ ['mu', 'uncorr_bkguncrt']
+ >>> model.expected_data(model.config.suggested_init())
+ array([ 62. , 63. , 277.77777778, 55.18367347])
+
+ Args:
+ signal_data (`list`): The data in the signal sample
+ bkg_data (`list`): The data in the background sample
+ bkg_uncerts (`list`): The statistical uncertainty on the background sample counts
+ batch_size (`None` or `int`): Number of simultaneous (batched) Models to compute
+
+ Returns:
+ ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema
+
+ """
spec = {
'channels': [
{
|
{"golden_diff": "diff --git a/src/pyhf/simplemodels.py b/src/pyhf/simplemodels.py\n--- a/src/pyhf/simplemodels.py\n+++ b/src/pyhf/simplemodels.py\n@@ -2,6 +2,38 @@\n \n \n def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):\n+ \"\"\"\n+ Construct a simple single channel :class:`~pyhf.pdf.Model` with a\n+ :class:`~pyhf.modifiers.shapesys` modifier representing an uncorrelated\n+ background uncertainty.\n+\n+ Example:\n+ >>> import pyhf\n+ >>> pyhf.set_backend(\"numpy\")\n+ >>> model = pyhf.simplemodels.hepdata_like(\n+ ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]\n+ ... )\n+ >>> model.schema\n+ 'model.json'\n+ >>> model.config.channels\n+ ['singlechannel']\n+ >>> model.config.samples\n+ ['background', 'signal']\n+ >>> model.config.parameters\n+ ['mu', 'uncorr_bkguncrt']\n+ >>> model.expected_data(model.config.suggested_init())\n+ array([ 62. , 63. , 277.77777778, 55.18367347])\n+\n+ Args:\n+ signal_data (`list`): The data in the signal sample\n+ bkg_data (`list`): The data in the background sample\n+ bkg_uncerts (`list`): The statistical uncertainty on the background sample counts\n+ batch_size (`None` or `int`): Number of simultaneous (batched) Models to compute\n+\n+ Returns:\n+ ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema\n+\n+ \"\"\"\n spec = {\n 'channels': [\n {\n", "issue": "Document simplemodels API\n# Description\r\n\r\nIn discussion today with @coolalexzb, I realized that the [`pyhf.simplemodels`](https://github.com/scikit-hep/pyhf/blob/79984be837ef6e53bdd12a82163c34d47d507dba/src/pyhf/simplemodels.py) API is not documented in our docs. Even thought this isn't something we want people to really use, we still show it in our examples and so it needs documentation.\n", "before_files": [{"content": "from . import Model\n\n\ndef hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):\n spec = {\n 'channels': [\n {\n 'name': 'singlechannel',\n 'samples': [\n {\n 'name': 'signal',\n 'data': signal_data,\n 'modifiers': [\n {'name': 'mu', 'type': 'normfactor', 'data': None}\n ],\n },\n {\n 'name': 'background',\n 'data': bkg_data,\n 'modifiers': [\n {\n 'name': 'uncorr_bkguncrt',\n 'type': 'shapesys',\n 'data': bkg_uncerts,\n }\n ],\n },\n ],\n }\n ]\n }\n return Model(spec, batch_size=batch_size)\n", "path": "src/pyhf/simplemodels.py"}]}
| 880 | 437 |
gh_patches_debug_22770
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-334
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error log still occurs when tracer is disabled (Django)
The tracer is logging the following error when disabled:
> 2017-07-05 12:54:36,552:[none]:[ddtrace.writer:134]:ERROR cannot send services: [Errno 111] Connection refused
This is occurring when integrated with Django with the following configuration:
```python
DATADOG_TRACE = {
'ENABLED': False
}
```
From reading the [documentation](http://pypi.datadoghq.com/trace/docs/#module-ddtrace.contrib.django) which states:
> ENABLED (default: not django_settings.DEBUG): defines if the tracer is enabled or not. If set to false, the code is still instrumented but no spans are sent to the trace agent. This setting cannot be changed at runtime and a restart is required. By default the tracer is disabled when in DEBUG mode, enabled otherwise.
It seems this log should not occur. If no spans are sent to the trace agent then presumably a connection should not be established?
Package Info
------------------
> datadog==0.15.0
> ddtrace==0.8.5
</issue>
<code>
[start of ddtrace/contrib/django/apps.py]
1 import logging
2
3 # 3rd party
4 from django.apps import AppConfig
5
6 # project
7 from .db import patch_db
8 from .conf import settings
9 from .cache import patch_cache
10 from .templates import patch_template
11 from .middleware import insert_exception_middleware
12
13 from ...ext import AppTypes
14
15
16 log = logging.getLogger(__name__)
17
18
19 class TracerConfig(AppConfig):
20 name = 'ddtrace.contrib.django'
21 label = 'datadog_django'
22
23 def ready(self):
24 """
25 Ready is called as soon as the registry is fully populated.
26 Tracing capabilities must be enabled in this function so that
27 all Django internals are properly configured.
28 """
29 tracer = settings.TRACER
30
31 if settings.TAGS:
32 tracer.set_tags(settings.TAGS)
33
34 # define the service details
35 tracer.set_service_info(
36 app='django',
37 app_type=AppTypes.web,
38 service=settings.DEFAULT_SERVICE,
39 )
40
41 # configure the tracer instance
42 # TODO[manu]: we may use configure() but because it creates a new
43 # AgentWriter, it breaks all tests. The configure() behavior must
44 # be changed to use it in this integration
45 tracer.enabled = settings.ENABLED
46 tracer.writer.api.hostname = settings.AGENT_HOSTNAME
47 tracer.writer.api.port = settings.AGENT_PORT
48
49 if settings.AUTO_INSTRUMENT:
50 # trace Django internals
51 insert_exception_middleware()
52 try:
53 patch_db(tracer)
54 except Exception:
55 log.exception('error patching Django database connections')
56
57 try:
58 patch_template(tracer)
59 except Exception:
60 log.exception('error patching Django template rendering')
61
62 try:
63 patch_cache(tracer)
64 except Exception:
65 log.exception('error patching Django cache')
66
[end of ddtrace/contrib/django/apps.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/django/apps.py b/ddtrace/contrib/django/apps.py
--- a/ddtrace/contrib/django/apps.py
+++ b/ddtrace/contrib/django/apps.py
@@ -31,13 +31,6 @@
if settings.TAGS:
tracer.set_tags(settings.TAGS)
- # define the service details
- tracer.set_service_info(
- app='django',
- app_type=AppTypes.web,
- service=settings.DEFAULT_SERVICE,
- )
-
# configure the tracer instance
# TODO[manu]: we may use configure() but because it creates a new
# AgentWriter, it breaks all tests. The configure() behavior must
@@ -46,6 +39,13 @@
tracer.writer.api.hostname = settings.AGENT_HOSTNAME
tracer.writer.api.port = settings.AGENT_PORT
+ # define the service details
+ tracer.set_service_info(
+ app='django',
+ app_type=AppTypes.web,
+ service=settings.DEFAULT_SERVICE,
+ )
+
if settings.AUTO_INSTRUMENT:
# trace Django internals
insert_exception_middleware()
|
{"golden_diff": "diff --git a/ddtrace/contrib/django/apps.py b/ddtrace/contrib/django/apps.py\n--- a/ddtrace/contrib/django/apps.py\n+++ b/ddtrace/contrib/django/apps.py\n@@ -31,13 +31,6 @@\n if settings.TAGS:\n tracer.set_tags(settings.TAGS)\n \n- # define the service details\n- tracer.set_service_info(\n- app='django',\n- app_type=AppTypes.web,\n- service=settings.DEFAULT_SERVICE,\n- )\n-\n # configure the tracer instance\n # TODO[manu]: we may use configure() but because it creates a new\n # AgentWriter, it breaks all tests. The configure() behavior must\n@@ -46,6 +39,13 @@\n tracer.writer.api.hostname = settings.AGENT_HOSTNAME\n tracer.writer.api.port = settings.AGENT_PORT\n \n+ # define the service details\n+ tracer.set_service_info(\n+ app='django',\n+ app_type=AppTypes.web,\n+ service=settings.DEFAULT_SERVICE,\n+ )\n+\n if settings.AUTO_INSTRUMENT:\n # trace Django internals\n insert_exception_middleware()\n", "issue": "Error log still occurs when tracer is disabled (Django)\nThe tracer is logging the following error when disabled:\r\n\r\n> 2017-07-05 12:54:36,552:[none]:[ddtrace.writer:134]:ERROR cannot send services: [Errno 111] Connection refused\r\n\r\nThis is occurring when integrated with Django with the following configuration:\r\n\r\n```python\r\nDATADOG_TRACE = {\r\n 'ENABLED': False\r\n}\r\n```\r\nFrom reading the [documentation](http://pypi.datadoghq.com/trace/docs/#module-ddtrace.contrib.django) which states:\r\n> ENABLED (default: not django_settings.DEBUG): defines if the tracer is enabled or not. If set to false, the code is still instrumented but no spans are sent to the trace agent. This setting cannot be changed at runtime and a restart is required. By default the tracer is disabled when in DEBUG mode, enabled otherwise.\r\n\r\nIt seems this log should not occur. If no spans are sent to the trace agent then presumably a connection should not be established?\r\n\r\nPackage Info\r\n------------------\r\n\r\n> datadog==0.15.0\r\n> ddtrace==0.8.5 \r\n\n", "before_files": [{"content": "import logging\n\n# 3rd party\nfrom django.apps import AppConfig\n\n# project\nfrom .db import patch_db\nfrom .conf import settings\nfrom .cache import patch_cache\nfrom .templates import patch_template\nfrom .middleware import insert_exception_middleware\n\nfrom ...ext import AppTypes\n\n\nlog = logging.getLogger(__name__)\n\n\nclass TracerConfig(AppConfig):\n name = 'ddtrace.contrib.django'\n label = 'datadog_django'\n\n def ready(self):\n \"\"\"\n Ready is called as soon as the registry is fully populated.\n Tracing capabilities must be enabled in this function so that\n all Django internals are properly configured.\n \"\"\"\n tracer = settings.TRACER\n\n if settings.TAGS:\n tracer.set_tags(settings.TAGS)\n\n # define the service details\n tracer.set_service_info(\n app='django',\n app_type=AppTypes.web,\n service=settings.DEFAULT_SERVICE,\n )\n\n # configure the tracer instance\n # TODO[manu]: we may use configure() but because it creates a new\n # AgentWriter, it breaks all tests. The configure() behavior must\n # be changed to use it in this integration\n tracer.enabled = settings.ENABLED\n tracer.writer.api.hostname = settings.AGENT_HOSTNAME\n tracer.writer.api.port = settings.AGENT_PORT\n\n if settings.AUTO_INSTRUMENT:\n # trace Django internals\n insert_exception_middleware()\n try:\n patch_db(tracer)\n except Exception:\n log.exception('error patching Django database connections')\n\n try:\n patch_template(tracer)\n except Exception:\n log.exception('error patching Django template rendering')\n\n try:\n patch_cache(tracer)\n except Exception:\n log.exception('error patching Django cache')\n", "path": "ddtrace/contrib/django/apps.py"}]}
| 1,310 | 254 |
gh_patches_debug_16404
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-796
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
show_results with yolov5 + lightning training throws error
## 🐛 Bug
**Describe the bug**
`show_results` with yolo don't work if the model was training with pytorch lightning
**To Reproduce**
Train a yolo model with pytorch-lightning and try to call `show_results`
**Full stacktrace**
```python
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-19-2cf4276b061d> in <module>()
----> 1 model_type.show_results(model, valid_ds, detection_threshold=.5)
9 frames
/usr/local/lib/python3.7/dist-packages/icevision/models/ultralytics/yolov5/show_results.py in show_results(model, dataset, detection_threshold, num_samples, ncols, denormalize_fn, show, device)
41 show=show,
42 detection_threshold=detection_threshold,
---> 43 device=device,
44 )
45
/usr/local/lib/python3.7/dist-packages/icevision/models/base_show_results.py in base_show_results(predict_fn, model, dataset, num_samples, ncols, denormalize_fn, show, **predict_kwargs)
19 ) -> None:
20 records = random.choices(dataset, k=num_samples)
---> 21 preds = predict_fn(model, records, **predict_kwargs)
22
23 show_preds(
/usr/local/lib/python3.7/dist-packages/icevision/models/ultralytics/yolov5/prediction.py in predict(model, dataset, detection_threshold, keep_images, device)
48 detection_threshold=detection_threshold,
49 keep_images=keep_images,
---> 50 device=device,
51 )
52
/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs)
24 def decorate_context(*args, **kwargs):
25 with self.__class__():
---> 26 return func(*args, **kwargs)
27 return cast(F, decorate_context)
28
/usr/local/lib/python3.7/dist-packages/icevision/models/ultralytics/yolov5/prediction.py in _predict_batch(model, batch, records, detection_threshold, keep_images, device)
24 model = model.eval().to(device)
25
---> 26 raw_preds = model(batch)[0]
27 return convert_raw_predictions(
28 batch=batch,
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/yolov5/models/yolo.py in forward(self, x, augment, profile)
121 return torch.cat(y, 1), None # augmented inference, train
122 else:
--> 123 return self.forward_once(x, profile) # single-scale inference, train
124
125 def forward_once(self, x, profile=False):
/usr/local/lib/python3.7/dist-packages/yolov5/models/yolo.py in forward_once(self, x, profile)
137 print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
138
--> 139 x = m(x) # run
140 y.append(x if m.i in self.save else None) # save output
141
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/yolov5/models/yolo.py in forward(self, x)
52
53 y = x[i].sigmoid()
---> 54 y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
55 y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
56 z.append(y.view(bs, -1, self.no))
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!
```
</issue>
<code>
[start of icevision/models/ultralytics/yolov5/prediction.py]
1 __all__ = ["predict", "predict_dl", "convert_raw_predictions"]
2
3 from icevision.imports import *
4 from icevision.utils import *
5 from icevision.core import *
6 from icevision.data import *
7 from icevision.models.utils import _predict_dl
8 from icevision.models.ultralytics.yolov5.dataloaders import *
9 from yolov5.utils.general import non_max_suppression
10
11
12 @torch.no_grad()
13 def _predict_batch(
14 model: nn.Module,
15 batch: Sequence[torch.Tensor],
16 records: Sequence[BaseRecord],
17 detection_threshold: float = 0.25,
18 nms_iou_threshold: float = 0.45,
19 keep_images: bool = False,
20 device: Optional[torch.device] = None,
21 ) -> List[Prediction]:
22 device = device or model_device(model)
23
24 batch = batch[0].to(device)
25 model = model.eval().to(device)
26
27 raw_preds = model(batch)[0]
28 return convert_raw_predictions(
29 batch=batch,
30 raw_preds=raw_preds,
31 records=records,
32 detection_threshold=detection_threshold,
33 nms_iou_threshold=nms_iou_threshold,
34 keep_images=keep_images,
35 )
36
37
38 def predict(
39 model: nn.Module,
40 dataset: Dataset,
41 detection_threshold: float = 0.25,
42 nms_iou_threshold: float = 0.45,
43 keep_images: bool = False,
44 device: Optional[torch.device] = None,
45 ) -> List[Prediction]:
46 batch, records = build_infer_batch(dataset)
47 return _predict_batch(
48 model=model,
49 batch=batch,
50 records=records,
51 detection_threshold=detection_threshold,
52 nms_iou_threshold=nms_iou_threshold,
53 keep_images=keep_images,
54 device=device,
55 )
56
57
58 def predict_dl(
59 model: nn.Module,
60 infer_dl: DataLoader,
61 show_pbar: bool = True,
62 keep_images: bool = False,
63 **predict_kwargs,
64 ):
65 return _predict_dl(
66 predict_fn=_predict_batch,
67 model=model,
68 infer_dl=infer_dl,
69 show_pbar=show_pbar,
70 keep_images=keep_images,
71 **predict_kwargs,
72 )
73
74
75 def convert_raw_predictions(
76 batch,
77 raw_preds: torch.Tensor,
78 records: Sequence[BaseRecord],
79 detection_threshold: float,
80 nms_iou_threshold: float,
81 keep_images: bool = False,
82 ) -> List[Prediction]:
83 dets = non_max_suppression(
84 raw_preds, conf_thres=detection_threshold, iou_thres=nms_iou_threshold
85 )
86 dets = [d.detach().cpu().numpy() for d in dets]
87 preds = []
88 for det, record, tensor_image in zip(dets, records, batch):
89
90 pred = BaseRecord(
91 (
92 ScoresRecordComponent(),
93 ImageRecordComponent(),
94 InstancesLabelsRecordComponent(),
95 BBoxesRecordComponent(),
96 )
97 )
98
99 pred.detection.set_class_map(record.detection.class_map)
100 pred.detection.set_labels_by_id(det[:, 5].astype(int))
101 pred.detection.set_bboxes([BBox.from_xyxy(*xyxy) for xyxy in det[:, :4]])
102 pred.detection.set_scores(det[:, 4])
103
104 if keep_images:
105 record.set_img(tensor_to_image(tensor_image))
106
107 preds.append(Prediction(pred=pred, ground_truth=record))
108
109 return preds
110
[end of icevision/models/ultralytics/yolov5/prediction.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/ultralytics/yolov5/prediction.py b/icevision/models/ultralytics/yolov5/prediction.py
--- a/icevision/models/ultralytics/yolov5/prediction.py
+++ b/icevision/models/ultralytics/yolov5/prediction.py
@@ -19,7 +19,17 @@
keep_images: bool = False,
device: Optional[torch.device] = None,
) -> List[Prediction]:
- device = device or model_device(model)
+ # device issue addressed on discord: https://discord.com/channels/735877944085446747/770279401791160400/832361687855923250
+ if device is not None:
+ raise ValueError(
+ "For YOLOv5 device can only be specified during model creation, "
+ "for more info take a look at the discussion here: "
+ "https://discord.com/channels/735877944085446747/770279401791160400/832361687855923250"
+ )
+ grid = model.model[-1].grid[-1]
+ # if `grid.numel() == 1` it means the grid isn't initialized yet and we can't
+ # trust it's device (will always be CPU)
+ device = grid.device if grid.numel() > 1 else model_device(model)
batch = batch[0].to(device)
model = model.eval().to(device)
|
{"golden_diff": "diff --git a/icevision/models/ultralytics/yolov5/prediction.py b/icevision/models/ultralytics/yolov5/prediction.py\n--- a/icevision/models/ultralytics/yolov5/prediction.py\n+++ b/icevision/models/ultralytics/yolov5/prediction.py\n@@ -19,7 +19,17 @@\n keep_images: bool = False,\n device: Optional[torch.device] = None,\n ) -> List[Prediction]:\n- device = device or model_device(model)\n+ # device issue addressed on discord: https://discord.com/channels/735877944085446747/770279401791160400/832361687855923250\n+ if device is not None:\n+ raise ValueError(\n+ \"For YOLOv5 device can only be specified during model creation, \"\n+ \"for more info take a look at the discussion here: \"\n+ \"https://discord.com/channels/735877944085446747/770279401791160400/832361687855923250\"\n+ )\n+ grid = model.model[-1].grid[-1]\n+ # if `grid.numel() == 1` it means the grid isn't initialized yet and we can't\n+ # trust it's device (will always be CPU)\n+ device = grid.device if grid.numel() > 1 else model_device(model)\n \n batch = batch[0].to(device)\n model = model.eval().to(device)\n", "issue": "show_results with yolov5 + lightning training throws error\n## \ud83d\udc1b Bug\r\n**Describe the bug**\r\n`show_results` with yolo don't work if the model was training with pytorch lightning\r\n\r\n**To Reproduce**\r\nTrain a yolo model with pytorch-lightning and try to call `show_results`\r\n\r\n**Full stacktrace**\r\n```python\r\n---------------------------------------------------------------------------\r\n\r\nRuntimeError Traceback (most recent call last)\r\n\r\n<ipython-input-19-2cf4276b061d> in <module>()\r\n----> 1 model_type.show_results(model, valid_ds, detection_threshold=.5)\r\n\r\n9 frames\r\n\r\n/usr/local/lib/python3.7/dist-packages/icevision/models/ultralytics/yolov5/show_results.py in show_results(model, dataset, detection_threshold, num_samples, ncols, denormalize_fn, show, device)\r\n 41 show=show,\r\n 42 detection_threshold=detection_threshold,\r\n---> 43 device=device,\r\n 44 )\r\n 45 \r\n\r\n/usr/local/lib/python3.7/dist-packages/icevision/models/base_show_results.py in base_show_results(predict_fn, model, dataset, num_samples, ncols, denormalize_fn, show, **predict_kwargs)\r\n 19 ) -> None:\r\n 20 records = random.choices(dataset, k=num_samples)\r\n---> 21 preds = predict_fn(model, records, **predict_kwargs)\r\n 22 \r\n 23 show_preds(\r\n\r\n/usr/local/lib/python3.7/dist-packages/icevision/models/ultralytics/yolov5/prediction.py in predict(model, dataset, detection_threshold, keep_images, device)\r\n 48 detection_threshold=detection_threshold,\r\n 49 keep_images=keep_images,\r\n---> 50 device=device,\r\n 51 )\r\n 52 \r\n\r\n/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py in decorate_context(*args, **kwargs)\r\n 24 def decorate_context(*args, **kwargs):\r\n 25 with self.__class__():\r\n---> 26 return func(*args, **kwargs)\r\n 27 return cast(F, decorate_context)\r\n 28 \r\n\r\n/usr/local/lib/python3.7/dist-packages/icevision/models/ultralytics/yolov5/prediction.py in _predict_batch(model, batch, records, detection_threshold, keep_images, device)\r\n 24 model = model.eval().to(device)\r\n 25 \r\n---> 26 raw_preds = model(batch)[0]\r\n 27 return convert_raw_predictions(\r\n 28 batch=batch,\r\n\r\n/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)\r\n 725 result = self._slow_forward(*input, **kwargs)\r\n 726 else:\r\n--> 727 result = self.forward(*input, **kwargs)\r\n 728 for hook in itertools.chain(\r\n 729 _global_forward_hooks.values(),\r\n\r\n/usr/local/lib/python3.7/dist-packages/yolov5/models/yolo.py in forward(self, x, augment, profile)\r\n 121 return torch.cat(y, 1), None # augmented inference, train\r\n 122 else:\r\n--> 123 return self.forward_once(x, profile) # single-scale inference, train\r\n 124 \r\n 125 def forward_once(self, x, profile=False):\r\n\r\n/usr/local/lib/python3.7/dist-packages/yolov5/models/yolo.py in forward_once(self, x, profile)\r\n 137 print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))\r\n 138 \r\n--> 139 x = m(x) # run\r\n 140 y.append(x if m.i in self.save else None) # save output\r\n 141 \r\n\r\n/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)\r\n 725 result = self._slow_forward(*input, **kwargs)\r\n 726 else:\r\n--> 727 result = self.forward(*input, **kwargs)\r\n 728 for hook in itertools.chain(\r\n 729 _global_forward_hooks.values(),\r\n\r\n/usr/local/lib/python3.7/dist-packages/yolov5/models/yolo.py in forward(self, x)\r\n 52 \r\n 53 y = x[i].sigmoid()\r\n---> 54 y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy\r\n 55 y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh\r\n 56 z.append(y.view(bs, -1, self.no))\r\n\r\nRuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu!\r\n```\r\n\n", "before_files": [{"content": "__all__ = [\"predict\", \"predict_dl\", \"convert_raw_predictions\"]\n\nfrom icevision.imports import *\nfrom icevision.utils import *\nfrom icevision.core import *\nfrom icevision.data import *\nfrom icevision.models.utils import _predict_dl\nfrom icevision.models.ultralytics.yolov5.dataloaders import *\nfrom yolov5.utils.general import non_max_suppression\n\n\[email protected]_grad()\ndef _predict_batch(\n model: nn.Module,\n batch: Sequence[torch.Tensor],\n records: Sequence[BaseRecord],\n detection_threshold: float = 0.25,\n nms_iou_threshold: float = 0.45,\n keep_images: bool = False,\n device: Optional[torch.device] = None,\n) -> List[Prediction]:\n device = device or model_device(model)\n\n batch = batch[0].to(device)\n model = model.eval().to(device)\n\n raw_preds = model(batch)[0]\n return convert_raw_predictions(\n batch=batch,\n raw_preds=raw_preds,\n records=records,\n detection_threshold=detection_threshold,\n nms_iou_threshold=nms_iou_threshold,\n keep_images=keep_images,\n )\n\n\ndef predict(\n model: nn.Module,\n dataset: Dataset,\n detection_threshold: float = 0.25,\n nms_iou_threshold: float = 0.45,\n keep_images: bool = False,\n device: Optional[torch.device] = None,\n) -> List[Prediction]:\n batch, records = build_infer_batch(dataset)\n return _predict_batch(\n model=model,\n batch=batch,\n records=records,\n detection_threshold=detection_threshold,\n nms_iou_threshold=nms_iou_threshold,\n keep_images=keep_images,\n device=device,\n )\n\n\ndef predict_dl(\n model: nn.Module,\n infer_dl: DataLoader,\n show_pbar: bool = True,\n keep_images: bool = False,\n **predict_kwargs,\n):\n return _predict_dl(\n predict_fn=_predict_batch,\n model=model,\n infer_dl=infer_dl,\n show_pbar=show_pbar,\n keep_images=keep_images,\n **predict_kwargs,\n )\n\n\ndef convert_raw_predictions(\n batch,\n raw_preds: torch.Tensor,\n records: Sequence[BaseRecord],\n detection_threshold: float,\n nms_iou_threshold: float,\n keep_images: bool = False,\n) -> List[Prediction]:\n dets = non_max_suppression(\n raw_preds, conf_thres=detection_threshold, iou_thres=nms_iou_threshold\n )\n dets = [d.detach().cpu().numpy() for d in dets]\n preds = []\n for det, record, tensor_image in zip(dets, records, batch):\n\n pred = BaseRecord(\n (\n ScoresRecordComponent(),\n ImageRecordComponent(),\n InstancesLabelsRecordComponent(),\n BBoxesRecordComponent(),\n )\n )\n\n pred.detection.set_class_map(record.detection.class_map)\n pred.detection.set_labels_by_id(det[:, 5].astype(int))\n pred.detection.set_bboxes([BBox.from_xyxy(*xyxy) for xyxy in det[:, :4]])\n pred.detection.set_scores(det[:, 4])\n\n if keep_images:\n record.set_img(tensor_to_image(tensor_image))\n\n preds.append(Prediction(pred=pred, ground_truth=record))\n\n return preds\n", "path": "icevision/models/ultralytics/yolov5/prediction.py"}]}
| 2,679 | 406 |
gh_patches_debug_6739
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-5734
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rewrite *other* fibonacci.py
I opened issue #5665 to have `fibonacci.py` rewritten, but apparently there are multiple files with that name. The PR that @citharus made (#5677) revamps the file `dynamic_programming/fibonacci.py` (thanks for your contributions btw!) whereas this issue seeks to revamp the file `maths/fibonacci.py`.
I'm opening this as a new issue since it's technically a different algorithm file and the two `fibonacci.py` files each use different algorithms to calculate the Fibonacci sequence.
</issue>
<code>
[start of maths/fibonacci.py]
1 # fibonacci.py
2 """
3 Calculates the Fibonacci sequence using iteration, recursion, and a simplified
4 form of Binet's formula
5
6 NOTE 1: the iterative and recursive functions are more accurate than the Binet's
7 formula function because the iterative function doesn't use floats
8
9 NOTE 2: the Binet's formula function is much more limited in the size of inputs
10 that it can handle due to the size limitations of Python floats
11 """
12
13 from math import sqrt
14 from time import time
15
16
17 def time_func(func, *args, **kwargs):
18 """
19 Times the execution of a function with parameters
20 """
21 start = time()
22 output = func(*args, **kwargs)
23 end = time()
24 if int(end - start) > 0:
25 print(f"{func.__name__} runtime: {(end - start):0.4f} s")
26 else:
27 print(f"{func.__name__} runtime: {(end - start) * 1000:0.4f} ms")
28 return output
29
30
31 def fib_iterative(n: int) -> list[int]:
32 """
33 Calculates the first n (0-indexed) Fibonacci numbers using iteration
34 >>> fib_iterative(0)
35 [0]
36 >>> fib_iterative(1)
37 [0, 1]
38 >>> fib_iterative(5)
39 [0, 1, 1, 2, 3, 5]
40 >>> fib_iterative(10)
41 [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
42 >>> fib_iterative(-1)
43 Traceback (most recent call last):
44 ...
45 Exception: n is negative
46 """
47 if n < 0:
48 raise Exception("n is negative")
49 if n == 0:
50 return [0]
51 fib = [0, 1]
52 for _ in range(n - 1):
53 fib.append(fib[-1] + fib[-2])
54 return fib
55
56
57 def fib_recursive(n: int) -> list[int]:
58 """
59 Calculates the first n (0-indexed) Fibonacci numbers using recursion
60 >>> fib_iterative(0)
61 [0]
62 >>> fib_iterative(1)
63 [0, 1]
64 >>> fib_iterative(5)
65 [0, 1, 1, 2, 3, 5]
66 >>> fib_iterative(10)
67 [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
68 >>> fib_iterative(-1)
69 Traceback (most recent call last):
70 ...
71 Exception: n is negative
72 """
73
74 def fib_recursive_term(i: int) -> int:
75 """
76 Calculates the i-th (0-indexed) Fibonacci number using recursion
77 """
78 if i < 0:
79 raise Exception("n is negative")
80 if i < 2:
81 return i
82 return fib_recursive_term(i - 1) + fib_recursive_term(i - 2)
83
84 if n < 0:
85 raise Exception("n is negative")
86 return [fib_recursive_term(i) for i in range(n + 1)]
87
88
89 def fib_binet(n: int) -> list[int]:
90 """
91 Calculates the first n (0-indexed) Fibonacci numbers using a simplified form
92 of Binet's formula:
93 https://en.m.wikipedia.org/wiki/Fibonacci_number#Computation_by_rounding
94
95 NOTE 1: this function diverges from fib_iterative at around n = 71, likely
96 due to compounding floating-point arithmetic errors
97
98 NOTE 2: this function overflows on n >= 1475 because of the size limitations
99 of Python floats
100 >>> fib_binet(0)
101 [0]
102 >>> fib_binet(1)
103 [0, 1]
104 >>> fib_binet(5)
105 [0, 1, 1, 2, 3, 5]
106 >>> fib_binet(10)
107 [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]
108 >>> fib_binet(-1)
109 Traceback (most recent call last):
110 ...
111 Exception: n is negative
112 >>> fib_binet(1475)
113 Traceback (most recent call last):
114 ...
115 Exception: n is too large
116 """
117 if n < 0:
118 raise Exception("n is negative")
119 if n >= 1475:
120 raise Exception("n is too large")
121 sqrt_5 = sqrt(5)
122 phi = (1 + sqrt_5) / 2
123 return [round(phi ** i / sqrt_5) for i in range(n + 1)]
124
125
126 if __name__ == "__main__":
127 num = 20
128 time_func(fib_iterative, num)
129 time_func(fib_recursive, num)
130 time_func(fib_binet, num)
131
[end of maths/fibonacci.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/maths/fibonacci.py b/maths/fibonacci.py
--- a/maths/fibonacci.py
+++ b/maths/fibonacci.py
@@ -95,8 +95,8 @@
NOTE 1: this function diverges from fib_iterative at around n = 71, likely
due to compounding floating-point arithmetic errors
- NOTE 2: this function overflows on n >= 1475 because of the size limitations
- of Python floats
+ NOTE 2: this function doesn't accept n >= 1475 because it overflows
+ thereafter due to the size limitations of Python floats
>>> fib_binet(0)
[0]
>>> fib_binet(1)
|
{"golden_diff": "diff --git a/maths/fibonacci.py b/maths/fibonacci.py\n--- a/maths/fibonacci.py\n+++ b/maths/fibonacci.py\n@@ -95,8 +95,8 @@\n NOTE 1: this function diverges from fib_iterative at around n = 71, likely\n due to compounding floating-point arithmetic errors\n \n- NOTE 2: this function overflows on n >= 1475 because of the size limitations\n- of Python floats\n+ NOTE 2: this function doesn't accept n >= 1475 because it overflows\n+ thereafter due to the size limitations of Python floats\n >>> fib_binet(0)\n [0]\n >>> fib_binet(1)\n", "issue": "Rewrite *other* fibonacci.py\nI opened issue #5665 to have `fibonacci.py` rewritten, but apparently there are multiple files with that name. The PR that @citharus made (#5677) revamps the file `dynamic_programming/fibonacci.py` (thanks for your contributions btw!) whereas this issue seeks to revamp the file `maths/fibonacci.py`.\r\n\r\nI'm opening this as a new issue since it's technically a different algorithm file and the two `fibonacci.py` files each use different algorithms to calculate the Fibonacci sequence.\n", "before_files": [{"content": "# fibonacci.py\n\"\"\"\nCalculates the Fibonacci sequence using iteration, recursion, and a simplified\nform of Binet's formula\n\nNOTE 1: the iterative and recursive functions are more accurate than the Binet's\nformula function because the iterative function doesn't use floats\n\nNOTE 2: the Binet's formula function is much more limited in the size of inputs\nthat it can handle due to the size limitations of Python floats\n\"\"\"\n\nfrom math import sqrt\nfrom time import time\n\n\ndef time_func(func, *args, **kwargs):\n \"\"\"\n Times the execution of a function with parameters\n \"\"\"\n start = time()\n output = func(*args, **kwargs)\n end = time()\n if int(end - start) > 0:\n print(f\"{func.__name__} runtime: {(end - start):0.4f} s\")\n else:\n print(f\"{func.__name__} runtime: {(end - start) * 1000:0.4f} ms\")\n return output\n\n\ndef fib_iterative(n: int) -> list[int]:\n \"\"\"\n Calculates the first n (0-indexed) Fibonacci numbers using iteration\n >>> fib_iterative(0)\n [0]\n >>> fib_iterative(1)\n [0, 1]\n >>> fib_iterative(5)\n [0, 1, 1, 2, 3, 5]\n >>> fib_iterative(10)\n [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]\n >>> fib_iterative(-1)\n Traceback (most recent call last):\n ...\n Exception: n is negative\n \"\"\"\n if n < 0:\n raise Exception(\"n is negative\")\n if n == 0:\n return [0]\n fib = [0, 1]\n for _ in range(n - 1):\n fib.append(fib[-1] + fib[-2])\n return fib\n\n\ndef fib_recursive(n: int) -> list[int]:\n \"\"\"\n Calculates the first n (0-indexed) Fibonacci numbers using recursion\n >>> fib_iterative(0)\n [0]\n >>> fib_iterative(1)\n [0, 1]\n >>> fib_iterative(5)\n [0, 1, 1, 2, 3, 5]\n >>> fib_iterative(10)\n [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]\n >>> fib_iterative(-1)\n Traceback (most recent call last):\n ...\n Exception: n is negative\n \"\"\"\n\n def fib_recursive_term(i: int) -> int:\n \"\"\"\n Calculates the i-th (0-indexed) Fibonacci number using recursion\n \"\"\"\n if i < 0:\n raise Exception(\"n is negative\")\n if i < 2:\n return i\n return fib_recursive_term(i - 1) + fib_recursive_term(i - 2)\n\n if n < 0:\n raise Exception(\"n is negative\")\n return [fib_recursive_term(i) for i in range(n + 1)]\n\n\ndef fib_binet(n: int) -> list[int]:\n \"\"\"\n Calculates the first n (0-indexed) Fibonacci numbers using a simplified form\n of Binet's formula:\n https://en.m.wikipedia.org/wiki/Fibonacci_number#Computation_by_rounding\n\n NOTE 1: this function diverges from fib_iterative at around n = 71, likely\n due to compounding floating-point arithmetic errors\n\n NOTE 2: this function overflows on n >= 1475 because of the size limitations\n of Python floats\n >>> fib_binet(0)\n [0]\n >>> fib_binet(1)\n [0, 1]\n >>> fib_binet(5)\n [0, 1, 1, 2, 3, 5]\n >>> fib_binet(10)\n [0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55]\n >>> fib_binet(-1)\n Traceback (most recent call last):\n ...\n Exception: n is negative\n >>> fib_binet(1475)\n Traceback (most recent call last):\n ...\n Exception: n is too large\n \"\"\"\n if n < 0:\n raise Exception(\"n is negative\")\n if n >= 1475:\n raise Exception(\"n is too large\")\n sqrt_5 = sqrt(5)\n phi = (1 + sqrt_5) / 2\n return [round(phi ** i / sqrt_5) for i in range(n + 1)]\n\n\nif __name__ == \"__main__\":\n num = 20\n time_func(fib_iterative, num)\n time_func(fib_recursive, num)\n time_func(fib_binet, num)\n", "path": "maths/fibonacci.py"}]}
| 2,058 | 166 |
gh_patches_debug_32824
|
rasdani/github-patches
|
git_diff
|
mozilla__pontoon-3056
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Project+locale AJAX endpoint logic is not uniform
At the moment, `/:code/:slug/ajax/` and `/:code/:slug/ajax/tags/` check if the locale & project exist and are visible to the user, while `/:code/:slug/ajax/contributors/` and `/:code/:slug/ajax/insights/` check that the ProjectLocale exists. [All of these](https://github.com/mozilla/pontoon/blob/master/pontoon/localizations/views.py) should check both conditions.
</issue>
<code>
[start of pontoon/localizations/views.py]
1 import math
2 from operator import attrgetter
3 from django.conf import settings
4 from django.core.exceptions import ImproperlyConfigured
5 from django.db.models import Q
6 from django.http import Http404, HttpResponseRedirect
7 from django.shortcuts import get_object_or_404, render
8 from django.views.generic.detail import DetailView
9
10 from pontoon.base.models import (
11 Locale,
12 Project,
13 ProjectLocale,
14 TranslatedResource,
15 )
16 from pontoon.base.utils import (
17 require_AJAX,
18 get_project_or_redirect,
19 get_locale_or_redirect,
20 )
21 from pontoon.contributors.views import ContributorsMixin
22 from pontoon.insights.utils import get_insights
23 from pontoon.tags.utils import TagsTool
24
25
26 def localization(request, code, slug):
27 """Locale-project overview."""
28 locale = get_locale_or_redirect(
29 code, "pontoon.localizations.localization", "code", slug=slug
30 )
31 if isinstance(locale, HttpResponseRedirect):
32 return locale
33
34 project = get_project_or_redirect(
35 slug, "pontoon.localizations.localization", "slug", request.user, code=code
36 )
37 if isinstance(project, HttpResponseRedirect):
38 return project
39
40 project_locale = get_object_or_404(
41 ProjectLocale,
42 locale=locale,
43 project=project,
44 )
45
46 resource_count = len(locale.parts_stats(project)) - 1
47
48 return render(
49 request,
50 "localizations/localization.html",
51 {
52 "locale": locale,
53 "project": project,
54 "project_locale": project_locale,
55 "resource_count": resource_count,
56 "tags_count": (
57 project.tag_set.filter(resources__isnull=False).distinct().count()
58 if project.tags_enabled
59 else None
60 ),
61 },
62 )
63
64
65 @require_AJAX
66 def ajax_resources(request, code, slug):
67 """Resources tab."""
68 locale = get_object_or_404(Locale, code=code)
69 project = get_object_or_404(
70 Project.objects.visible_for(request.user).available(),
71 slug=slug,
72 )
73
74 # Amend the parts dict with latest activity info.
75 translatedresources_qs = TranslatedResource.objects.filter(
76 resource__project=project, locale=locale
77 ).prefetch_related("resource", "latest_translation__user")
78
79 if not len(translatedresources_qs):
80 raise Http404
81
82 translatedresources = {s.resource.path: s for s in translatedresources_qs}
83 translatedresources = dict(list(translatedresources.items()))
84 parts = locale.parts_stats(project)
85
86 resource_priority_map = project.resource_priority_map()
87
88 for part in parts:
89 part["resource__priority"] = resource_priority_map.get(part["title"], None)
90
91 translatedresource = translatedresources.get(part["title"], None)
92 if translatedresource and translatedresource.latest_translation:
93 part[
94 "latest_activity"
95 ] = translatedresource.latest_translation.latest_activity
96 else:
97 part["latest_activity"] = None
98
99 part["chart"] = {
100 "unreviewed_strings": part["unreviewed_strings"],
101 "pretranslated_strings": part["pretranslated_strings"],
102 "strings_with_errors": part["strings_with_errors"],
103 "strings_with_warnings": part["strings_with_warnings"],
104 "total_strings": part["resource__total_strings"],
105 "approved_strings": part["approved_strings"],
106 "approved_share": round(
107 part["approved_strings"] / part["resource__total_strings"] * 100
108 ),
109 "unreviewed_share": round(
110 part["unreviewed_strings"] / part["resource__total_strings"] * 100
111 ),
112 "pretranslated_share": round(
113 part["pretranslated_strings"] / part["resource__total_strings"] * 100
114 ),
115 "errors_share": round(
116 part["strings_with_errors"] / part["resource__total_strings"] * 100
117 ),
118 "warnings_share": round(
119 part["strings_with_warnings"] / part["resource__total_strings"] * 100
120 ),
121 "completion_percent": int(
122 math.floor(
123 (
124 part["approved_strings"]
125 + part["pretranslated_strings"]
126 + part["strings_with_warnings"]
127 )
128 / part["resource__total_strings"]
129 * 100
130 )
131 ),
132 }
133
134 return render(
135 request,
136 "localizations/includes/resources.html",
137 {
138 "locale": locale,
139 "project": project,
140 "resources": parts,
141 "deadline": any(part["resource__deadline"] for part in parts),
142 "priority": any(part["resource__priority"] for part in parts),
143 },
144 )
145
146
147 @require_AJAX
148 def ajax_tags(request, code, slug):
149 """Tags tab."""
150 locale = get_object_or_404(Locale, code=code)
151 project = get_object_or_404(Project.objects.visible_for(request.user), slug=slug)
152
153 if not project.tags_enabled:
154 raise Http404
155
156 tags_tool = TagsTool(
157 locales=[locale],
158 projects=[project],
159 priority=True,
160 )
161
162 tags = sorted(tags_tool, key=attrgetter("priority"), reverse=True)
163
164 return render(
165 request,
166 "localizations/includes/tags.html",
167 {"locale": locale, "project": project, "tags": tags},
168 )
169
170
171 @require_AJAX
172 def ajax_insights(request, code, slug):
173 """Insights tab."""
174 if not settings.ENABLE_INSIGHTS:
175 raise ImproperlyConfigured("ENABLE_INSIGHTS variable not set in settings.")
176
177 pl = get_object_or_404(ProjectLocale, locale__code=code, project__slug=slug)
178 insights = get_insights(locale=pl.locale, project=pl.project)
179
180 return render(request, "localizations/includes/insights.html", insights)
181
182
183 class LocalizationContributorsView(ContributorsMixin, DetailView):
184 """
185 Renders view of contributors for the localization.
186 """
187
188 template_name = "localizations/includes/contributors.html"
189
190 def get_object(self):
191 return get_object_or_404(
192 ProjectLocale,
193 locale__code=self.kwargs["code"],
194 project__slug=self.kwargs["slug"],
195 )
196
197 def get_context_object_name(self, obj):
198 return "projectlocale"
199
200 def contributors_filter(self, **kwargs):
201 return Q(
202 entity__resource__project=self.object.project, locale=self.object.locale
203 )
204
[end of pontoon/localizations/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pontoon/localizations/views.py b/pontoon/localizations/views.py
--- a/pontoon/localizations/views.py
+++ b/pontoon/localizations/views.py
@@ -71,6 +71,9 @@
slug=slug,
)
+ # Check if ProjectLocale exists
+ get_object_or_404(ProjectLocale, locale=locale, project=project)
+
# Amend the parts dict with latest activity info.
translatedresources_qs = TranslatedResource.objects.filter(
resource__project=project, locale=locale
@@ -150,6 +153,9 @@
locale = get_object_or_404(Locale, code=code)
project = get_object_or_404(Project.objects.visible_for(request.user), slug=slug)
+ # Check if ProjectLocale exists
+ get_object_or_404(ProjectLocale, locale=locale, project=project)
+
if not project.tags_enabled:
raise Http404
@@ -174,6 +180,8 @@
if not settings.ENABLE_INSIGHTS:
raise ImproperlyConfigured("ENABLE_INSIGHTS variable not set in settings.")
+ get_object_or_404(Locale, code=code)
+ get_object_or_404(Project.objects.visible_for(request.user), slug=slug)
pl = get_object_or_404(ProjectLocale, locale__code=code, project__slug=slug)
insights = get_insights(locale=pl.locale, project=pl.project)
@@ -188,6 +196,10 @@
template_name = "localizations/includes/contributors.html"
def get_object(self):
+ get_object_or_404(Locale, code=self.kwargs["code"])
+ get_object_or_404(
+ Project.objects.visible_for(self.request.user), slug=self.kwargs["slug"]
+ )
return get_object_or_404(
ProjectLocale,
locale__code=self.kwargs["code"],
|
{"golden_diff": "diff --git a/pontoon/localizations/views.py b/pontoon/localizations/views.py\n--- a/pontoon/localizations/views.py\n+++ b/pontoon/localizations/views.py\n@@ -71,6 +71,9 @@\n slug=slug,\n )\n \n+ # Check if ProjectLocale exists\n+ get_object_or_404(ProjectLocale, locale=locale, project=project)\n+\n # Amend the parts dict with latest activity info.\n translatedresources_qs = TranslatedResource.objects.filter(\n resource__project=project, locale=locale\n@@ -150,6 +153,9 @@\n locale = get_object_or_404(Locale, code=code)\n project = get_object_or_404(Project.objects.visible_for(request.user), slug=slug)\n \n+ # Check if ProjectLocale exists\n+ get_object_or_404(ProjectLocale, locale=locale, project=project)\n+\n if not project.tags_enabled:\n raise Http404\n \n@@ -174,6 +180,8 @@\n if not settings.ENABLE_INSIGHTS:\n raise ImproperlyConfigured(\"ENABLE_INSIGHTS variable not set in settings.\")\n \n+ get_object_or_404(Locale, code=code)\n+ get_object_or_404(Project.objects.visible_for(request.user), slug=slug)\n pl = get_object_or_404(ProjectLocale, locale__code=code, project__slug=slug)\n insights = get_insights(locale=pl.locale, project=pl.project)\n \n@@ -188,6 +196,10 @@\n template_name = \"localizations/includes/contributors.html\"\n \n def get_object(self):\n+ get_object_or_404(Locale, code=self.kwargs[\"code\"])\n+ get_object_or_404(\n+ Project.objects.visible_for(self.request.user), slug=self.kwargs[\"slug\"]\n+ )\n return get_object_or_404(\n ProjectLocale,\n locale__code=self.kwargs[\"code\"],\n", "issue": "Project+locale AJAX endpoint logic is not uniform\nAt the moment, `/:code/:slug/ajax/` and `/:code/:slug/ajax/tags/` check if the locale & project exist and are visible to the user, while `/:code/:slug/ajax/contributors/` and `/:code/:slug/ajax/insights/` check that the ProjectLocale exists. [All of these](https://github.com/mozilla/pontoon/blob/master/pontoon/localizations/views.py) should check both conditions.\n", "before_files": [{"content": "import math\nfrom operator import attrgetter\nfrom django.conf import settings\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.db.models import Q\nfrom django.http import Http404, HttpResponseRedirect\nfrom django.shortcuts import get_object_or_404, render\nfrom django.views.generic.detail import DetailView\n\nfrom pontoon.base.models import (\n Locale,\n Project,\n ProjectLocale,\n TranslatedResource,\n)\nfrom pontoon.base.utils import (\n require_AJAX,\n get_project_or_redirect,\n get_locale_or_redirect,\n)\nfrom pontoon.contributors.views import ContributorsMixin\nfrom pontoon.insights.utils import get_insights\nfrom pontoon.tags.utils import TagsTool\n\n\ndef localization(request, code, slug):\n \"\"\"Locale-project overview.\"\"\"\n locale = get_locale_or_redirect(\n code, \"pontoon.localizations.localization\", \"code\", slug=slug\n )\n if isinstance(locale, HttpResponseRedirect):\n return locale\n\n project = get_project_or_redirect(\n slug, \"pontoon.localizations.localization\", \"slug\", request.user, code=code\n )\n if isinstance(project, HttpResponseRedirect):\n return project\n\n project_locale = get_object_or_404(\n ProjectLocale,\n locale=locale,\n project=project,\n )\n\n resource_count = len(locale.parts_stats(project)) - 1\n\n return render(\n request,\n \"localizations/localization.html\",\n {\n \"locale\": locale,\n \"project\": project,\n \"project_locale\": project_locale,\n \"resource_count\": resource_count,\n \"tags_count\": (\n project.tag_set.filter(resources__isnull=False).distinct().count()\n if project.tags_enabled\n else None\n ),\n },\n )\n\n\n@require_AJAX\ndef ajax_resources(request, code, slug):\n \"\"\"Resources tab.\"\"\"\n locale = get_object_or_404(Locale, code=code)\n project = get_object_or_404(\n Project.objects.visible_for(request.user).available(),\n slug=slug,\n )\n\n # Amend the parts dict with latest activity info.\n translatedresources_qs = TranslatedResource.objects.filter(\n resource__project=project, locale=locale\n ).prefetch_related(\"resource\", \"latest_translation__user\")\n\n if not len(translatedresources_qs):\n raise Http404\n\n translatedresources = {s.resource.path: s for s in translatedresources_qs}\n translatedresources = dict(list(translatedresources.items()))\n parts = locale.parts_stats(project)\n\n resource_priority_map = project.resource_priority_map()\n\n for part in parts:\n part[\"resource__priority\"] = resource_priority_map.get(part[\"title\"], None)\n\n translatedresource = translatedresources.get(part[\"title\"], None)\n if translatedresource and translatedresource.latest_translation:\n part[\n \"latest_activity\"\n ] = translatedresource.latest_translation.latest_activity\n else:\n part[\"latest_activity\"] = None\n\n part[\"chart\"] = {\n \"unreviewed_strings\": part[\"unreviewed_strings\"],\n \"pretranslated_strings\": part[\"pretranslated_strings\"],\n \"strings_with_errors\": part[\"strings_with_errors\"],\n \"strings_with_warnings\": part[\"strings_with_warnings\"],\n \"total_strings\": part[\"resource__total_strings\"],\n \"approved_strings\": part[\"approved_strings\"],\n \"approved_share\": round(\n part[\"approved_strings\"] / part[\"resource__total_strings\"] * 100\n ),\n \"unreviewed_share\": round(\n part[\"unreviewed_strings\"] / part[\"resource__total_strings\"] * 100\n ),\n \"pretranslated_share\": round(\n part[\"pretranslated_strings\"] / part[\"resource__total_strings\"] * 100\n ),\n \"errors_share\": round(\n part[\"strings_with_errors\"] / part[\"resource__total_strings\"] * 100\n ),\n \"warnings_share\": round(\n part[\"strings_with_warnings\"] / part[\"resource__total_strings\"] * 100\n ),\n \"completion_percent\": int(\n math.floor(\n (\n part[\"approved_strings\"]\n + part[\"pretranslated_strings\"]\n + part[\"strings_with_warnings\"]\n )\n / part[\"resource__total_strings\"]\n * 100\n )\n ),\n }\n\n return render(\n request,\n \"localizations/includes/resources.html\",\n {\n \"locale\": locale,\n \"project\": project,\n \"resources\": parts,\n \"deadline\": any(part[\"resource__deadline\"] for part in parts),\n \"priority\": any(part[\"resource__priority\"] for part in parts),\n },\n )\n\n\n@require_AJAX\ndef ajax_tags(request, code, slug):\n \"\"\"Tags tab.\"\"\"\n locale = get_object_or_404(Locale, code=code)\n project = get_object_or_404(Project.objects.visible_for(request.user), slug=slug)\n\n if not project.tags_enabled:\n raise Http404\n\n tags_tool = TagsTool(\n locales=[locale],\n projects=[project],\n priority=True,\n )\n\n tags = sorted(tags_tool, key=attrgetter(\"priority\"), reverse=True)\n\n return render(\n request,\n \"localizations/includes/tags.html\",\n {\"locale\": locale, \"project\": project, \"tags\": tags},\n )\n\n\n@require_AJAX\ndef ajax_insights(request, code, slug):\n \"\"\"Insights tab.\"\"\"\n if not settings.ENABLE_INSIGHTS:\n raise ImproperlyConfigured(\"ENABLE_INSIGHTS variable not set in settings.\")\n\n pl = get_object_or_404(ProjectLocale, locale__code=code, project__slug=slug)\n insights = get_insights(locale=pl.locale, project=pl.project)\n\n return render(request, \"localizations/includes/insights.html\", insights)\n\n\nclass LocalizationContributorsView(ContributorsMixin, DetailView):\n \"\"\"\n Renders view of contributors for the localization.\n \"\"\"\n\n template_name = \"localizations/includes/contributors.html\"\n\n def get_object(self):\n return get_object_or_404(\n ProjectLocale,\n locale__code=self.kwargs[\"code\"],\n project__slug=self.kwargs[\"slug\"],\n )\n\n def get_context_object_name(self, obj):\n return \"projectlocale\"\n\n def contributors_filter(self, **kwargs):\n return Q(\n entity__resource__project=self.object.project, locale=self.object.locale\n )\n", "path": "pontoon/localizations/views.py"}]}
| 2,533 | 443 |
gh_patches_debug_6077
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-3759
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remove translations for user kinds on backend
### Observed behavior
In role kinds we use the string "Classroom Assignable Coach": https://github.com/learningequality/kolibri/blob/develop/kolibri/auth/constants/role_kinds.py#L15
This string is not something that should be user-facing
### Expected behavior
implementation details hidden from user
### User-facing consequences
confusing, inconsistent terminology
### Context
https://crowdin.com/translate/kolibri/498/en-es#37506
</issue>
<code>
[start of kolibri/auth/constants/role_kinds.py]
1 """
2 This module contains constants representing the kinds of "roles" that a user can have with respect to a Collection.
3 """
4 from __future__ import unicode_literals
5
6 from django.utils.translation import ugettext_lazy as _
7
8 ADMIN = "admin"
9 COACH = "coach"
10 ASSIGNABLE_COACH = "classroom assignable coach"
11
12 choices = (
13 (ADMIN, _("Admin")),
14 (COACH, _("Coach")),
15 (ASSIGNABLE_COACH, _("Classroom Assignable Coach")),
16 )
17
[end of kolibri/auth/constants/role_kinds.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/auth/constants/role_kinds.py b/kolibri/auth/constants/role_kinds.py
--- a/kolibri/auth/constants/role_kinds.py
+++ b/kolibri/auth/constants/role_kinds.py
@@ -3,14 +3,12 @@
"""
from __future__ import unicode_literals
-from django.utils.translation import ugettext_lazy as _
-
ADMIN = "admin"
COACH = "coach"
ASSIGNABLE_COACH = "classroom assignable coach"
choices = (
- (ADMIN, _("Admin")),
- (COACH, _("Coach")),
- (ASSIGNABLE_COACH, _("Classroom Assignable Coach")),
+ (ADMIN, "Admin"),
+ (COACH, "Coach"),
+ (ASSIGNABLE_COACH, "Classroom Assignable Coach"),
)
|
{"golden_diff": "diff --git a/kolibri/auth/constants/role_kinds.py b/kolibri/auth/constants/role_kinds.py\n--- a/kolibri/auth/constants/role_kinds.py\n+++ b/kolibri/auth/constants/role_kinds.py\n@@ -3,14 +3,12 @@\n \"\"\"\n from __future__ import unicode_literals\n \n-from django.utils.translation import ugettext_lazy as _\n-\n ADMIN = \"admin\"\n COACH = \"coach\"\n ASSIGNABLE_COACH = \"classroom assignable coach\"\n \n choices = (\n- (ADMIN, _(\"Admin\")),\n- (COACH, _(\"Coach\")),\n- (ASSIGNABLE_COACH, _(\"Classroom Assignable Coach\")),\n+ (ADMIN, \"Admin\"),\n+ (COACH, \"Coach\"),\n+ (ASSIGNABLE_COACH, \"Classroom Assignable Coach\"),\n )\n", "issue": "remove translations for user kinds on backend\n### Observed behavior\r\n\r\nIn role kinds we use the string \"Classroom Assignable Coach\": https://github.com/learningequality/kolibri/blob/develop/kolibri/auth/constants/role_kinds.py#L15\r\n\r\nThis string is not something that should be user-facing\r\n\r\n### Expected behavior\r\n\r\nimplementation details hidden from user\r\n\r\n### User-facing consequences\r\n\r\nconfusing, inconsistent terminology\r\n\r\n\r\n### Context\r\n\r\nhttps://crowdin.com/translate/kolibri/498/en-es#37506\r\n\r\n\n", "before_files": [{"content": "\"\"\"\nThis module contains constants representing the kinds of \"roles\" that a user can have with respect to a Collection.\n\"\"\"\nfrom __future__ import unicode_literals\n\nfrom django.utils.translation import ugettext_lazy as _\n\nADMIN = \"admin\"\nCOACH = \"coach\"\nASSIGNABLE_COACH = \"classroom assignable coach\"\n\nchoices = (\n (ADMIN, _(\"Admin\")),\n (COACH, _(\"Coach\")),\n (ASSIGNABLE_COACH, _(\"Classroom Assignable Coach\")),\n)\n", "path": "kolibri/auth/constants/role_kinds.py"}]}
| 784 | 177 |
gh_patches_debug_31669
|
rasdani/github-patches
|
git_diff
|
oobabooga__text-generation-webui-628
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
silero_tts will not load if I am not connected to the internet
### Describe the bug
I used to be able to use this extension offline, but now I can't load the extension if I am not online. If I am online the extension loads just fine. The actual language models is saved on my machine via the .cache file: C:\Users\myself\.cache\torch\hub\snakers4_silero-models_master\src\silero\model
The model name is called v3_en.pt, it's being cached on my machine and when I load the extension with an internet connection the miniconda console says that it's using the cached model, so I don't know why I NEED to be connected to the internet for it to work.
### Is there an existing issue for this?
- [x] I have searched the existing issues
### Reproduction
Run this (change your install location as necessary) with and without an internet connection.
cd F:\OoBaboogaMarch17\text-generation-webui
conda activate textgen
python .\server.py --auto-devices --gptq-bits 4 --cai-chat --gptq-model-type LLaMa --extension silero_tts
### Screenshot
I'm including two screenshots, one when I am connected to the internet, and one when I am not connected to the internet.


### Logs
```shell
See screenshots
```
### System Info
```shell
Window 10, 4090, i9 13900, windows mode not wsl
```
</issue>
<code>
[start of extensions/silero_tts/script.py]
1 import time
2 from pathlib import Path
3
4 import gradio as gr
5 import torch
6 from extensions.silero_tts import tts_preprocessor
7 from modules import chat, shared
8 from modules.html_generator import chat_html_wrapper
9
10 torch._C._jit_set_profiling_mode(False)
11
12
13 params = {
14 'activate': True,
15 'speaker': 'en_56',
16 'language': 'en',
17 'model_id': 'v3_en',
18 'sample_rate': 48000,
19 'device': 'cpu',
20 'show_text': False,
21 'autoplay': True,
22 'voice_pitch': 'medium',
23 'voice_speed': 'medium',
24 }
25
26 current_params = params.copy()
27 voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
28 voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
29 voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
30 streaming_state = shared.args.no_stream # remember if chat streaming was enabled
31
32 # Used for making text xml compatible, needed for voice pitch and speed control
33 table = str.maketrans({
34 "<": "<",
35 ">": ">",
36 "&": "&",
37 "'": "'",
38 '"': """,
39 })
40
41
42 def xmlesc(txt):
43 return txt.translate(table)
44
45
46 def load_model():
47 model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
48 model.to(params['device'])
49 return model
50
51
52 model = load_model()
53
54
55 def remove_tts_from_history(name1, name2, mode):
56 for i, entry in enumerate(shared.history['internal']):
57 shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]
58 return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
59
60
61 def toggle_text_in_history(name1, name2, mode):
62 for i, entry in enumerate(shared.history['visible']):
63 visible_reply = entry[1]
64 if visible_reply.startswith('<audio'):
65 if params['show_text']:
66 reply = shared.history['internal'][i][1]
67 shared.history['visible'][i] = [shared.history['visible'][i][0], f"{visible_reply.split('</audio>')[0]}</audio>\n\n{reply}"]
68 else:
69 shared.history['visible'][i] = [shared.history['visible'][i][0], f"{visible_reply.split('</audio>')[0]}</audio>"]
70 return chat_html_wrapper(shared.history['visible'], name1, name2, mode)
71
72
73 def input_modifier(string):
74 """
75 This function is applied to your text inputs before
76 they are fed into the model.
77 """
78
79 # Remove autoplay from the last reply
80 if shared.is_chat() and len(shared.history['internal']) > 0:
81 shared.history['visible'][-1] = [shared.history['visible'][-1][0], shared.history['visible'][-1][1].replace('controls autoplay>', 'controls>')]
82
83 shared.processing_message = "*Is recording a voice message...*"
84 shared.args.no_stream = True # Disable streaming cause otherwise the audio output will stutter and begin anew every time the message is being updated
85 return string
86
87
88 def output_modifier(string):
89 """
90 This function is applied to the model outputs.
91 """
92
93 global model, current_params, streaming_state
94
95 for i in params:
96 if params[i] != current_params[i]:
97 model = load_model()
98 current_params = params.copy()
99 break
100
101 if not params['activate']:
102 return string
103
104 original_string = string
105 string = tts_preprocessor.preprocess(string)
106
107 if string == '':
108 string = '*Empty reply, try regenerating*'
109 else:
110 output_file = Path(f'extensions/silero_tts/outputs/{shared.character}_{int(time.time())}.wav')
111 prosody = '<prosody rate="{}" pitch="{}">'.format(params['voice_speed'], params['voice_pitch'])
112 silero_input = f'<speak>{prosody}{xmlesc(string)}</prosody></speak>'
113 model.save_wav(ssml_text=silero_input, speaker=params['speaker'], sample_rate=int(params['sample_rate']), audio_path=str(output_file))
114
115 autoplay = 'autoplay' if params['autoplay'] else ''
116 string = f'<audio src="file/{output_file.as_posix()}" controls {autoplay}></audio>'
117 if params['show_text']:
118 string += f'\n\n{original_string}'
119
120 shared.processing_message = "*Is typing...*"
121 shared.args.no_stream = streaming_state # restore the streaming option to the previous value
122 return string
123
124
125 def bot_prefix_modifier(string):
126 """
127 This function is only applied in chat mode. It modifies
128 the prefix text for the Bot and can be used to bias its
129 behavior.
130 """
131
132 return string
133
134
135 def ui():
136 # Gradio elements
137 with gr.Accordion("Silero TTS"):
138 with gr.Row():
139 activate = gr.Checkbox(value=params['activate'], label='Activate TTS')
140 autoplay = gr.Checkbox(value=params['autoplay'], label='Play TTS automatically')
141
142 show_text = gr.Checkbox(value=params['show_text'], label='Show message text under audio player')
143 voice = gr.Dropdown(value=params['speaker'], choices=voices_by_gender, label='TTS voice')
144 with gr.Row():
145 v_pitch = gr.Dropdown(value=params['voice_pitch'], choices=voice_pitches, label='Voice pitch')
146 v_speed = gr.Dropdown(value=params['voice_speed'], choices=voice_speeds, label='Voice speed')
147
148 with gr.Row():
149 convert = gr.Button('Permanently replace audios with the message texts')
150 convert_cancel = gr.Button('Cancel', visible=False)
151 convert_confirm = gr.Button('Confirm (cannot be undone)', variant="stop", visible=False)
152
153 # Convert history with confirmation
154 convert_arr = [convert_confirm, convert, convert_cancel]
155 convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)
156 convert_confirm.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
157 convert_confirm.click(remove_tts_from_history, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], shared.gradio['display'])
158 convert_confirm.click(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
159 convert_cancel.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)
160
161 # Toggle message text in history
162 show_text.change(lambda x: params.update({"show_text": x}), show_text, None)
163 show_text.change(toggle_text_in_history, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], shared.gradio['display'])
164 show_text.change(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)
165
166 # Event functions to update the parameters in the backend
167 activate.change(lambda x: params.update({"activate": x}), activate, None)
168 autoplay.change(lambda x: params.update({"autoplay": x}), autoplay, None)
169 voice.change(lambda x: params.update({"speaker": x}), voice, None)
170 v_pitch.change(lambda x: params.update({"voice_pitch": x}), v_pitch, None)
171 v_speed.change(lambda x: params.update({"voice_speed": x}), v_speed, None)
172
[end of extensions/silero_tts/script.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py
--- a/extensions/silero_tts/script.py
+++ b/extensions/silero_tts/script.py
@@ -21,6 +21,7 @@
'autoplay': True,
'voice_pitch': 'medium',
'voice_speed': 'medium',
+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json
}
current_params = params.copy()
@@ -44,14 +45,18 @@
def load_model():
- model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
+ model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
+ if Path(model_path).is_file():
+ print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
+ else:
+ print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
model.to(params['device'])
return model
-model = load_model()
-
-
def remove_tts_from_history(name1, name2, mode):
for i, entry in enumerate(shared.history['internal']):
shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]
@@ -132,6 +137,11 @@
return string
+def setup():
+ global model
+ model = load_model()
+
+
def ui():
# Gradio elements
with gr.Accordion("Silero TTS"):
|
{"golden_diff": "diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py\n--- a/extensions/silero_tts/script.py\n+++ b/extensions/silero_tts/script.py\n@@ -21,6 +21,7 @@\n 'autoplay': True,\n 'voice_pitch': 'medium',\n 'voice_speed': 'medium',\n+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json\n }\n \n current_params = params.copy()\n@@ -44,14 +45,18 @@\n \n \n def load_model():\n- model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])\n+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']\n+ model_path = torch_cache_path + \"/snakers4_silero-models_master/src/silero/model/\" + params['model_id'] + \".pt\"\n+ if Path(model_path).is_file():\n+ print(f'\\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')\n+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)\n+ else:\n+ print(f'\\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')\n+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])\n model.to(params['device'])\n return model\n \n \n-model = load_model()\n-\n-\n def remove_tts_from_history(name1, name2, mode):\n for i, entry in enumerate(shared.history['internal']):\n shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]\n@@ -132,6 +137,11 @@\n return string\n \n \n+def setup():\n+ global model\n+ model = load_model()\n+\n+\n def ui():\n # Gradio elements\n with gr.Accordion(\"Silero TTS\"):\n", "issue": "silero_tts will not load if I am not connected to the internet\n### Describe the bug\n\nI used to be able to use this extension offline, but now I can't load the extension if I am not online. If I am online the extension loads just fine. The actual language models is saved on my machine via the .cache file: C:\\Users\\myself\\.cache\\torch\\hub\\snakers4_silero-models_master\\src\\silero\\model\r\n\r\nThe model name is called v3_en.pt, it's being cached on my machine and when I load the extension with an internet connection the miniconda console says that it's using the cached model, so I don't know why I NEED to be connected to the internet for it to work.\n\n### Is there an existing issue for this?\n\n- [x] I have searched the existing issues\n\n### Reproduction\n\nRun this (change your install location as necessary) with and without an internet connection.\r\n\r\ncd F:\\OoBaboogaMarch17\\text-generation-webui\r\nconda activate textgen\r\npython .\\server.py --auto-devices --gptq-bits 4 --cai-chat --gptq-model-type LLaMa --extension silero_tts \n\n### Screenshot\n\nI'm including two screenshots, one when I am connected to the internet, and one when I am not connected to the internet.\r\n\r\n\r\n\r\n\n\n### Logs\n\n```shell\nSee screenshots\n```\n\n\n### System Info\n\n```shell\nWindow 10, 4090, i9 13900, windows mode not wsl\n```\n\n", "before_files": [{"content": "import time\nfrom pathlib import Path\n\nimport gradio as gr\nimport torch\nfrom extensions.silero_tts import tts_preprocessor\nfrom modules import chat, shared\nfrom modules.html_generator import chat_html_wrapper\n\ntorch._C._jit_set_profiling_mode(False)\n\n\nparams = {\n 'activate': True,\n 'speaker': 'en_56',\n 'language': 'en',\n 'model_id': 'v3_en',\n 'sample_rate': 48000,\n 'device': 'cpu',\n 'show_text': False,\n 'autoplay': True,\n 'voice_pitch': 'medium',\n 'voice_speed': 'medium',\n}\n\ncurrent_params = params.copy()\nvoices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']\nvoice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']\nvoice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']\nstreaming_state = shared.args.no_stream # remember if chat streaming was enabled\n\n# Used for making text xml compatible, needed for voice pitch and speed control\ntable = str.maketrans({\n \"<\": \"<\",\n \">\": \">\",\n \"&\": \"&\",\n \"'\": \"'\",\n '\"': \""\",\n})\n\n\ndef xmlesc(txt):\n return txt.translate(table)\n\n\ndef load_model():\n model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])\n model.to(params['device'])\n return model\n\n\nmodel = load_model()\n\n\ndef remove_tts_from_history(name1, name2, mode):\n for i, entry in enumerate(shared.history['internal']):\n shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]\n return chat_html_wrapper(shared.history['visible'], name1, name2, mode)\n\n\ndef toggle_text_in_history(name1, name2, mode):\n for i, entry in enumerate(shared.history['visible']):\n visible_reply = entry[1]\n if visible_reply.startswith('<audio'):\n if params['show_text']:\n reply = shared.history['internal'][i][1]\n shared.history['visible'][i] = [shared.history['visible'][i][0], f\"{visible_reply.split('</audio>')[0]}</audio>\\n\\n{reply}\"]\n else:\n shared.history['visible'][i] = [shared.history['visible'][i][0], f\"{visible_reply.split('</audio>')[0]}</audio>\"]\n return chat_html_wrapper(shared.history['visible'], name1, name2, mode)\n\n\ndef input_modifier(string):\n \"\"\"\n This function is applied to your text inputs before\n they are fed into the model.\n \"\"\"\n\n # Remove autoplay from the last reply\n if shared.is_chat() and len(shared.history['internal']) > 0:\n shared.history['visible'][-1] = [shared.history['visible'][-1][0], shared.history['visible'][-1][1].replace('controls autoplay>', 'controls>')]\n\n shared.processing_message = \"*Is recording a voice message...*\"\n shared.args.no_stream = True # Disable streaming cause otherwise the audio output will stutter and begin anew every time the message is being updated\n return string\n\n\ndef output_modifier(string):\n \"\"\"\n This function is applied to the model outputs.\n \"\"\"\n\n global model, current_params, streaming_state\n\n for i in params:\n if params[i] != current_params[i]:\n model = load_model()\n current_params = params.copy()\n break\n\n if not params['activate']:\n return string\n\n original_string = string\n string = tts_preprocessor.preprocess(string)\n\n if string == '':\n string = '*Empty reply, try regenerating*'\n else:\n output_file = Path(f'extensions/silero_tts/outputs/{shared.character}_{int(time.time())}.wav')\n prosody = '<prosody rate=\"{}\" pitch=\"{}\">'.format(params['voice_speed'], params['voice_pitch'])\n silero_input = f'<speak>{prosody}{xmlesc(string)}</prosody></speak>'\n model.save_wav(ssml_text=silero_input, speaker=params['speaker'], sample_rate=int(params['sample_rate']), audio_path=str(output_file))\n\n autoplay = 'autoplay' if params['autoplay'] else ''\n string = f'<audio src=\"file/{output_file.as_posix()}\" controls {autoplay}></audio>'\n if params['show_text']:\n string += f'\\n\\n{original_string}'\n\n shared.processing_message = \"*Is typing...*\"\n shared.args.no_stream = streaming_state # restore the streaming option to the previous value\n return string\n\n\ndef bot_prefix_modifier(string):\n \"\"\"\n This function is only applied in chat mode. It modifies\n the prefix text for the Bot and can be used to bias its\n behavior.\n \"\"\"\n\n return string\n\n\ndef ui():\n # Gradio elements\n with gr.Accordion(\"Silero TTS\"):\n with gr.Row():\n activate = gr.Checkbox(value=params['activate'], label='Activate TTS')\n autoplay = gr.Checkbox(value=params['autoplay'], label='Play TTS automatically')\n\n show_text = gr.Checkbox(value=params['show_text'], label='Show message text under audio player')\n voice = gr.Dropdown(value=params['speaker'], choices=voices_by_gender, label='TTS voice')\n with gr.Row():\n v_pitch = gr.Dropdown(value=params['voice_pitch'], choices=voice_pitches, label='Voice pitch')\n v_speed = gr.Dropdown(value=params['voice_speed'], choices=voice_speeds, label='Voice speed')\n\n with gr.Row():\n convert = gr.Button('Permanently replace audios with the message texts')\n convert_cancel = gr.Button('Cancel', visible=False)\n convert_confirm = gr.Button('Confirm (cannot be undone)', variant=\"stop\", visible=False)\n\n # Convert history with confirmation\n convert_arr = [convert_confirm, convert, convert_cancel]\n convert.click(lambda: [gr.update(visible=True), gr.update(visible=False), gr.update(visible=True)], None, convert_arr)\n convert_confirm.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)\n convert_confirm.click(remove_tts_from_history, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], shared.gradio['display'])\n convert_confirm.click(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)\n convert_cancel.click(lambda: [gr.update(visible=False), gr.update(visible=True), gr.update(visible=False)], None, convert_arr)\n\n # Toggle message text in history\n show_text.change(lambda x: params.update({\"show_text\": x}), show_text, None)\n show_text.change(toggle_text_in_history, [shared.gradio[k] for k in ['name1', 'name2', 'Chat mode']], shared.gradio['display'])\n show_text.change(lambda: chat.save_history(timestamp=False), [], [], show_progress=False)\n\n # Event functions to update the parameters in the backend\n activate.change(lambda x: params.update({\"activate\": x}), activate, None)\n autoplay.change(lambda x: params.update({\"autoplay\": x}), autoplay, None)\n voice.change(lambda x: params.update({\"speaker\": x}), voice, None)\n v_pitch.change(lambda x: params.update({\"voice_pitch\": x}), v_pitch, None)\n v_speed.change(lambda x: params.update({\"voice_speed\": x}), v_speed, None)\n", "path": "extensions/silero_tts/script.py"}]}
| 3,774 | 519 |
gh_patches_debug_11605
|
rasdani/github-patches
|
git_diff
|
fidals__shopelectro-342
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docker-compose.yml:93: Resurrect coala eslint.
The puzzle `322-dbccf9a1` from #322 has to be resolved:
https://github.com/fidals/shopelectro/blob/c827fa74e382579bf43fa368be3549cd108f6050/docker/docker-compose.yml#L93-L93
The puzzle was created by Artemiy on 08-Jun-18.
Estimate: 0 minutes,
If you have any technical questions, don't ask me, submit new tickets instead. The task will be "done" when the problem is fixed and the text of the puzzle is _removed_ from the source code. Here is more about [PDD](http://www.yegor256.com/2009/03/04/pdd.html) and [about me](http://www.yegor256.com/2017/04/05/pdd-in-action.html).
</issue>
<code>
[start of shopelectro/views/catalog.py]
1 from functools import partial
2
3 from django.conf import settings
4 from django.core.paginator import Paginator
5 from django.http import Http404, HttpResponse, HttpResponseBadRequest, HttpResponseForbidden
6 from django.shortcuts import render, get_object_or_404
7 from django.views.decorators.http import require_POST
8 from django_user_agents.utils import get_user_agent
9
10 from catalog.views import catalog
11 from images.models import Image
12 from pages import views as pages_views
13
14 from shopelectro import config
15 from shopelectro import models
16 from shopelectro.views.helpers import set_csrf_cookie
17
18 PRODUCTS_ON_PAGE_PC = 48
19 PRODUCTS_ON_PAGE_MOB = 12
20
21
22 def get_products_count(request):
23 """Calculate max products list size from request. List size depends on device type."""
24 mobile_view = get_user_agent(request).is_mobile
25 return PRODUCTS_ON_PAGE_MOB if mobile_view else PRODUCTS_ON_PAGE_PC
26
27
28 # CATALOG VIEWS
29 class CategoryTree(catalog.CategoryTree):
30 category_model = models.Category
31
32
33 @set_csrf_cookie
34 class ProductPage(catalog.ProductPage):
35 pk_url_kwarg = None
36 slug_url_kwarg = 'product_vendor_code'
37 slug_field = 'vendor_code'
38
39 queryset = (
40 models.Product.objects
41 .filter(category__isnull=False)
42 .prefetch_related('product_feedbacks', 'page__images')
43 .select_related('page')
44 )
45
46 def get_context_data(self, **kwargs):
47 context = super(ProductPage, self).get_context_data(**kwargs)
48
49 group_tags_pairs = (
50 models.Tag.objects
51 .filter(products=self.object)
52 .get_group_tags_pairs()
53 )
54
55 return {
56 **context,
57 'price_bounds': config.PRICE_BOUNDS,
58 'group_tags_pairs': group_tags_pairs
59 }
60
61
62 # SHOPELECTRO-SPECIFIC VIEWS
63 @set_csrf_cookie
64 class IndexPage(pages_views.CustomPageView):
65
66 def get_context_data(self, **kwargs):
67 """Extended method. Add product's images to context."""
68 context = super(IndexPage, self).get_context_data(**kwargs)
69 mobile_view = get_user_agent(self.request).is_mobile
70
71 top_products = (
72 models.Product.objects
73 .filter(id__in=settings.TOP_PRODUCTS)
74 .prefetch_related('category')
75 .select_related('page')
76 )
77
78 images = Image.objects.get_main_images_by_pages(
79 models.ProductPage.objects.filter(
80 shopelectro_product__in=top_products
81 )
82 )
83
84 categories = models.Category.objects.get_root_categories_by_products(
85 top_products)
86
87 prepared_top_products = []
88 if not mobile_view:
89 prepared_top_products = [
90 (product, images.get(product.page), categories.get(product))
91 for product in top_products
92 ]
93
94 return {
95 **context,
96 'category_tile': config.MAIN_PAGE_TILE,
97 'prepared_top_products': prepared_top_products,
98 }
99
100
101 def merge_products_and_images(products):
102 images = Image.objects.get_main_images_by_pages(
103 models.ProductPage.objects.filter(shopelectro_product__in=products)
104 )
105
106 return [
107 (product, images.get(product.page))
108 for product in products
109 ]
110
111
112 @set_csrf_cookie
113 class CategoryPage(catalog.CategoryPage):
114
115 def get_context_data(self, **kwargs):
116 """Add sorting options and view_types in context."""
117 context = super().get_context_data(**kwargs)
118 products_on_page = int(self.request.GET.get(
119 'step', get_products_count(self.request),
120 ))
121 page_number = int(self.request.GET.get('page', 1))
122 view_type = self.request.session.get('view_type', 'tile')
123 sorting = int(self.kwargs.get('sorting', 0))
124 sorting_option = config.category_sorting(sorting)
125 category = context['category']
126 if (
127 page_number < 1 or
128 products_on_page not in settings.CATEGORY_STEP_MULTIPLIERS
129 ):
130 raise Http404('Page does not exist.')
131
132 all_products = (
133 models.Product.objects
134 .prefetch_related('page__images')
135 .select_related('page')
136 .get_by_category(category, ordering=(sorting_option, ))
137 )
138
139 group_tags_pairs = (
140 models.Tag.objects
141 .filter(products__in=all_products)
142 .get_group_tags_pairs()
143 )
144
145 tags = self.kwargs.get('tags')
146
147 tag_titles = ''
148 if tags:
149 slugs = models.Tag.parse_url_tags(tags)
150 tags = models.Tag.objects.filter(slug__in=slugs)
151
152 all_products = (
153 all_products
154 .filter(tags__in=tags)
155 # Use distinct because filtering by QuerySet tags,
156 # that related with products by many-to-many relation.
157 .distinct(sorting_option.lstrip('-'))
158 )
159
160 tag_titles = models.serialize_tags_to_title(tags)
161
162 def template_context(page, tag_titles, tags):
163 return {
164 'page': page,
165 'tag_titles': tag_titles,
166 'tags': tags,
167 }
168
169 page = context['page']
170 page.get_template_render_context = partial(
171 template_context, page, tag_titles, tags)
172
173 paginated_page = Paginator(all_products, products_on_page).page(page_number)
174 total_products = all_products.count()
175 products = paginated_page.object_list
176 if not products:
177 raise Http404('Page without products does not exist.')
178
179 return {
180 **context,
181 'product_image_pairs': merge_products_and_images(products),
182 'group_tags_pairs': group_tags_pairs,
183 'total_products': total_products,
184 'products_count': (page_number - 1) * products_on_page + products.count(),
185 'paginated_page': paginated_page,
186 'sorting_options': config.category_sorting(),
187 'limits': settings.CATEGORY_STEP_MULTIPLIERS,
188 'sort': sorting,
189 'tags': tags,
190 'view_type': view_type,
191 'skip_canonical': bool(tags),
192 }
193
194
195 def load_more(request, category_slug, offset=0, limit=0, sorting=0, tags=None):
196 """
197 Load more products of a given category.
198
199 :param sorting: preferred sorting index from CATEGORY_SORTING tuple
200 :param request: HttpRequest object
201 :param category_slug: Slug for a given category
202 :param offset: used for slicing QuerySet.
203 :return: products list in html format
204 """
205 products_on_page = limit or get_products_count(request)
206 offset = int(offset)
207 if offset < 0:
208 return HttpResponseBadRequest('The offset is wrong. An offset should be greater than or equal to 0.')
209 if products_on_page not in settings.CATEGORY_STEP_MULTIPLIERS:
210 return HttpResponseBadRequest(
211 'The limit number is wrong. List of available numbers:'
212 f' {", ".join(map(str, settings.CATEGORY_STEP_MULTIPLIERS))}'
213 )
214 # increment page number because:
215 # 11 // 12 = 0, 0 // 12 = 0 but it should be the first page
216 # 12 // 12 = 1, 23 // 12 = 1, but it should be the second page
217 page_number = (offset // products_on_page) + 1
218 category = get_object_or_404(models.CategoryPage, slug=category_slug).model
219 sorting_option = config.category_sorting(int(sorting))
220
221 all_products = (
222 models.Product.objects
223 .prefetch_related('page__images')
224 .select_related('page')
225 .get_by_category(category, ordering=(sorting_option,))
226 )
227
228 if tags:
229 tag_entities = models.Tag.objects.filter(
230 slug__in=models.Tag.parse_url_tags(tags)
231 )
232
233 all_products = (
234 all_products
235 .filter(tags__in=tag_entities)
236 # Use distinct because filtering by QuerySet tags,
237 # that related with products by many-to-many relation.
238 .distinct(sorting_option.lstrip('-'))
239 )
240
241 paginated_page = Paginator(all_products, products_on_page).page(page_number)
242 products = paginated_page.object_list
243 view = request.session.get('view_type', 'tile')
244
245 return render(request, 'catalog/category_products.html', {
246 'product_image_pairs': merge_products_and_images(products),
247 'paginated_page': paginated_page,
248 'view_type': view,
249 'prods': products_on_page,
250 })
251
252
253 @require_POST
254 def save_feedback(request):
255 def get_keys_from_post(*args):
256 return {arg: request.POST.get(arg, '') for arg in args}
257
258 product_id = request.POST.get('id')
259 product = models.Product.objects.filter(id=product_id).first()
260 if not (product_id and product):
261 return HttpResponse(status=422)
262
263 fields = ['rating', 'name', 'dignities', 'limitations', 'general']
264 feedback_data = get_keys_from_post(*fields)
265
266 models.ProductFeedback.objects.create(product=product, **feedback_data)
267 return HttpResponse('ok')
268
269
270 @require_POST
271 def delete_feedback(request):
272 if not request.user.is_authenticated:
273 return HttpResponseForbidden('Not today, sly guy...')
274
275 feedback_id = request.POST.get('id')
276 feedback = models.ProductFeedback.objects.filter(id=feedback_id).first()
277 if not (feedback_id and feedback):
278 return HttpResponse(status=422)
279
280 feedback.delete()
281 return HttpResponse('Feedback with id={} was deleted.'.format(feedback_id))
282
283
284 class ProductsWithoutImages(catalog.ProductsWithoutImages):
285 model = models.Product
286
287
288 class ProductsWithoutText(catalog.ProductsWithoutText):
289 model = models.Product
290
[end of shopelectro/views/catalog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/shopelectro/views/catalog.py b/shopelectro/views/catalog.py
--- a/shopelectro/views/catalog.py
+++ b/shopelectro/views/catalog.py
@@ -205,7 +205,9 @@
products_on_page = limit or get_products_count(request)
offset = int(offset)
if offset < 0:
- return HttpResponseBadRequest('The offset is wrong. An offset should be greater than or equal to 0.')
+ return HttpResponseBadRequest(
+ 'The offset is wrong. An offset should be greater than or equal to 0.'
+ )
if products_on_page not in settings.CATEGORY_STEP_MULTIPLIERS:
return HttpResponseBadRequest(
'The limit number is wrong. List of available numbers:'
|
{"golden_diff": "diff --git a/shopelectro/views/catalog.py b/shopelectro/views/catalog.py\n--- a/shopelectro/views/catalog.py\n+++ b/shopelectro/views/catalog.py\n@@ -205,7 +205,9 @@\n products_on_page = limit or get_products_count(request)\n offset = int(offset)\n if offset < 0:\n- return HttpResponseBadRequest('The offset is wrong. An offset should be greater than or equal to 0.')\n+ return HttpResponseBadRequest(\n+ 'The offset is wrong. An offset should be greater than or equal to 0.'\n+ )\n if products_on_page not in settings.CATEGORY_STEP_MULTIPLIERS:\n return HttpResponseBadRequest(\n 'The limit number is wrong. List of available numbers:'\n", "issue": "docker-compose.yml:93: Resurrect coala eslint.\nThe puzzle `322-dbccf9a1` from #322 has to be resolved:\n\nhttps://github.com/fidals/shopelectro/blob/c827fa74e382579bf43fa368be3549cd108f6050/docker/docker-compose.yml#L93-L93\n\nThe puzzle was created by Artemiy on 08-Jun-18. \n\nEstimate: 0 minutes, \n\nIf you have any technical questions, don't ask me, submit new tickets instead. The task will be \"done\" when the problem is fixed and the text of the puzzle is _removed_ from the source code. Here is more about [PDD](http://www.yegor256.com/2009/03/04/pdd.html) and [about me](http://www.yegor256.com/2017/04/05/pdd-in-action.html).\n", "before_files": [{"content": "from functools import partial\n\nfrom django.conf import settings\nfrom django.core.paginator import Paginator\nfrom django.http import Http404, HttpResponse, HttpResponseBadRequest, HttpResponseForbidden\nfrom django.shortcuts import render, get_object_or_404\nfrom django.views.decorators.http import require_POST\nfrom django_user_agents.utils import get_user_agent\n\nfrom catalog.views import catalog\nfrom images.models import Image\nfrom pages import views as pages_views\n\nfrom shopelectro import config\nfrom shopelectro import models\nfrom shopelectro.views.helpers import set_csrf_cookie\n\nPRODUCTS_ON_PAGE_PC = 48\nPRODUCTS_ON_PAGE_MOB = 12\n\n\ndef get_products_count(request):\n \"\"\"Calculate max products list size from request. List size depends on device type.\"\"\"\n mobile_view = get_user_agent(request).is_mobile\n return PRODUCTS_ON_PAGE_MOB if mobile_view else PRODUCTS_ON_PAGE_PC\n\n\n# CATALOG VIEWS\nclass CategoryTree(catalog.CategoryTree):\n category_model = models.Category\n\n\n@set_csrf_cookie\nclass ProductPage(catalog.ProductPage):\n pk_url_kwarg = None\n slug_url_kwarg = 'product_vendor_code'\n slug_field = 'vendor_code'\n\n queryset = (\n models.Product.objects\n .filter(category__isnull=False)\n .prefetch_related('product_feedbacks', 'page__images')\n .select_related('page')\n )\n\n def get_context_data(self, **kwargs):\n context = super(ProductPage, self).get_context_data(**kwargs)\n\n group_tags_pairs = (\n models.Tag.objects\n .filter(products=self.object)\n .get_group_tags_pairs()\n )\n\n return {\n **context,\n 'price_bounds': config.PRICE_BOUNDS,\n 'group_tags_pairs': group_tags_pairs\n }\n\n\n# SHOPELECTRO-SPECIFIC VIEWS\n@set_csrf_cookie\nclass IndexPage(pages_views.CustomPageView):\n\n def get_context_data(self, **kwargs):\n \"\"\"Extended method. Add product's images to context.\"\"\"\n context = super(IndexPage, self).get_context_data(**kwargs)\n mobile_view = get_user_agent(self.request).is_mobile\n\n top_products = (\n models.Product.objects\n .filter(id__in=settings.TOP_PRODUCTS)\n .prefetch_related('category')\n .select_related('page')\n )\n\n images = Image.objects.get_main_images_by_pages(\n models.ProductPage.objects.filter(\n shopelectro_product__in=top_products\n )\n )\n\n categories = models.Category.objects.get_root_categories_by_products(\n top_products)\n\n prepared_top_products = []\n if not mobile_view:\n prepared_top_products = [\n (product, images.get(product.page), categories.get(product))\n for product in top_products\n ]\n\n return {\n **context,\n 'category_tile': config.MAIN_PAGE_TILE,\n 'prepared_top_products': prepared_top_products,\n }\n\n\ndef merge_products_and_images(products):\n images = Image.objects.get_main_images_by_pages(\n models.ProductPage.objects.filter(shopelectro_product__in=products)\n )\n\n return [\n (product, images.get(product.page))\n for product in products\n ]\n\n\n@set_csrf_cookie\nclass CategoryPage(catalog.CategoryPage):\n\n def get_context_data(self, **kwargs):\n \"\"\"Add sorting options and view_types in context.\"\"\"\n context = super().get_context_data(**kwargs)\n products_on_page = int(self.request.GET.get(\n 'step', get_products_count(self.request),\n ))\n page_number = int(self.request.GET.get('page', 1))\n view_type = self.request.session.get('view_type', 'tile')\n sorting = int(self.kwargs.get('sorting', 0))\n sorting_option = config.category_sorting(sorting)\n category = context['category']\n if (\n page_number < 1 or\n products_on_page not in settings.CATEGORY_STEP_MULTIPLIERS\n ):\n raise Http404('Page does not exist.')\n\n all_products = (\n models.Product.objects\n .prefetch_related('page__images')\n .select_related('page')\n .get_by_category(category, ordering=(sorting_option, ))\n )\n\n group_tags_pairs = (\n models.Tag.objects\n .filter(products__in=all_products)\n .get_group_tags_pairs()\n )\n\n tags = self.kwargs.get('tags')\n\n tag_titles = ''\n if tags:\n slugs = models.Tag.parse_url_tags(tags)\n tags = models.Tag.objects.filter(slug__in=slugs)\n\n all_products = (\n all_products\n .filter(tags__in=tags)\n # Use distinct because filtering by QuerySet tags,\n # that related with products by many-to-many relation.\n .distinct(sorting_option.lstrip('-'))\n )\n\n tag_titles = models.serialize_tags_to_title(tags)\n\n def template_context(page, tag_titles, tags):\n return {\n 'page': page,\n 'tag_titles': tag_titles,\n 'tags': tags,\n }\n\n page = context['page']\n page.get_template_render_context = partial(\n template_context, page, tag_titles, tags)\n\n paginated_page = Paginator(all_products, products_on_page).page(page_number)\n total_products = all_products.count()\n products = paginated_page.object_list\n if not products:\n raise Http404('Page without products does not exist.')\n\n return {\n **context,\n 'product_image_pairs': merge_products_and_images(products),\n 'group_tags_pairs': group_tags_pairs,\n 'total_products': total_products,\n 'products_count': (page_number - 1) * products_on_page + products.count(),\n 'paginated_page': paginated_page,\n 'sorting_options': config.category_sorting(),\n 'limits': settings.CATEGORY_STEP_MULTIPLIERS,\n 'sort': sorting,\n 'tags': tags,\n 'view_type': view_type,\n 'skip_canonical': bool(tags),\n }\n\n\ndef load_more(request, category_slug, offset=0, limit=0, sorting=0, tags=None):\n \"\"\"\n Load more products of a given category.\n\n :param sorting: preferred sorting index from CATEGORY_SORTING tuple\n :param request: HttpRequest object\n :param category_slug: Slug for a given category\n :param offset: used for slicing QuerySet.\n :return: products list in html format\n \"\"\"\n products_on_page = limit or get_products_count(request)\n offset = int(offset)\n if offset < 0:\n return HttpResponseBadRequest('The offset is wrong. An offset should be greater than or equal to 0.')\n if products_on_page not in settings.CATEGORY_STEP_MULTIPLIERS:\n return HttpResponseBadRequest(\n 'The limit number is wrong. List of available numbers:'\n f' {\", \".join(map(str, settings.CATEGORY_STEP_MULTIPLIERS))}'\n )\n # increment page number because:\n # 11 // 12 = 0, 0 // 12 = 0 but it should be the first page\n # 12 // 12 = 1, 23 // 12 = 1, but it should be the second page\n page_number = (offset // products_on_page) + 1\n category = get_object_or_404(models.CategoryPage, slug=category_slug).model\n sorting_option = config.category_sorting(int(sorting))\n\n all_products = (\n models.Product.objects\n .prefetch_related('page__images')\n .select_related('page')\n .get_by_category(category, ordering=(sorting_option,))\n )\n\n if tags:\n tag_entities = models.Tag.objects.filter(\n slug__in=models.Tag.parse_url_tags(tags)\n )\n\n all_products = (\n all_products\n .filter(tags__in=tag_entities)\n # Use distinct because filtering by QuerySet tags,\n # that related with products by many-to-many relation.\n .distinct(sorting_option.lstrip('-'))\n )\n\n paginated_page = Paginator(all_products, products_on_page).page(page_number)\n products = paginated_page.object_list\n view = request.session.get('view_type', 'tile')\n\n return render(request, 'catalog/category_products.html', {\n 'product_image_pairs': merge_products_and_images(products),\n 'paginated_page': paginated_page,\n 'view_type': view,\n 'prods': products_on_page,\n })\n\n\n@require_POST\ndef save_feedback(request):\n def get_keys_from_post(*args):\n return {arg: request.POST.get(arg, '') for arg in args}\n\n product_id = request.POST.get('id')\n product = models.Product.objects.filter(id=product_id).first()\n if not (product_id and product):\n return HttpResponse(status=422)\n\n fields = ['rating', 'name', 'dignities', 'limitations', 'general']\n feedback_data = get_keys_from_post(*fields)\n\n models.ProductFeedback.objects.create(product=product, **feedback_data)\n return HttpResponse('ok')\n\n\n@require_POST\ndef delete_feedback(request):\n if not request.user.is_authenticated:\n return HttpResponseForbidden('Not today, sly guy...')\n\n feedback_id = request.POST.get('id')\n feedback = models.ProductFeedback.objects.filter(id=feedback_id).first()\n if not (feedback_id and feedback):\n return HttpResponse(status=422)\n\n feedback.delete()\n return HttpResponse('Feedback with id={} was deleted.'.format(feedback_id))\n\n\nclass ProductsWithoutImages(catalog.ProductsWithoutImages):\n model = models.Product\n\n\nclass ProductsWithoutText(catalog.ProductsWithoutText):\n model = models.Product\n", "path": "shopelectro/views/catalog.py"}]}
| 3,610 | 165 |
gh_patches_debug_316
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-806
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
listen(0) in create_server() does not allow client to connect to linux server
## Environment data
- PTVSD version: 4.1.1
- OS and version: linux kernel 4.14.46
- Python version (& distribution if applicable, e.g. Anaconda): 2.7.13, 3.5.3
- Using VS Code or Visual Studio: N/A
## Actual behavior
server on linux never accepts connection, i.e. `client, _ = sock.accept()` in `connect()` in socket.py never returns. This is due to the `listen(0)` call in `create_server()`. This was changed from `listen(1)` in 322f6946. Although `listen(0)` does work correctly on mac, it does not on linux.
## Expected behavior
the incoming connection to be accepted
## Steps to reproduce:
run:
```python
ptvsd.enable_attach(address=('0.0.0.0', 9876), redirect_output=True)
ptvsd.wait_for_attach()
```
then from the command line, see that `telnet localhost 9876` hangs instead of connecting. some background history is at https://bugs.python.org/issue8498
</issue>
<code>
[start of ptvsd/socket.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License. See LICENSE in the project root
3 # for license information.
4
5 from __future__ import absolute_import
6
7 from collections import namedtuple
8 import contextlib
9 import errno
10 import socket
11 try:
12 from urllib.parse import urlparse
13 except ImportError:
14 from urlparse import urlparse
15
16
17 try:
18 ConnectionError # noqa
19 BrokenPipeError # noqa
20 ConnectionResetError # noqa
21 except NameError:
22 class BrokenPipeError(Exception):
23 # EPIPE and ESHUTDOWN
24 pass
25
26 class ConnectionResetError(Exception):
27 # ECONNRESET
28 pass
29
30
31 NOT_CONNECTED = (
32 errno.ENOTCONN,
33 errno.EBADF,
34 )
35
36 CLOSED = (
37 errno.EPIPE,
38 errno.ESHUTDOWN,
39 errno.ECONNRESET,
40 # Windows
41 10038, # "An operation was attempted on something that is not a socket"
42 10058,
43 )
44
45 EOF = NOT_CONNECTED + CLOSED
46
47
48 @contextlib.contextmanager
49 def convert_eof():
50 """A context manager to convert some socket errors into EOFError."""
51 try:
52 yield
53 except ConnectionResetError:
54 raise EOFError
55 except BrokenPipeError:
56 raise EOFError
57 except OSError as exc:
58 if exc.errno in EOF:
59 raise EOFError
60 raise
61
62
63 class TimeoutError(socket.timeout):
64 """A socket timeout happened."""
65
66
67 def is_socket(sock):
68 """Return True if the object can be used as a socket."""
69 return isinstance(sock, socket.socket)
70
71
72 def create_server(host, port):
73 """Return a local server socket listening on the given port."""
74 if host is None:
75 host = 'localhost'
76 server = _new_sock()
77 server.bind((host, port))
78 server.listen(0)
79 return server
80
81
82 def create_client():
83 """Return a client socket that may be connected to a remote address."""
84 return _new_sock()
85
86
87 def _new_sock():
88 sock = socket.socket(socket.AF_INET,
89 socket.SOCK_STREAM,
90 socket.IPPROTO_TCP)
91 sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
92 return sock
93
94
95 @contextlib.contextmanager
96 def ignored_errno(*ignored):
97 """A context manager that ignores the given errnos."""
98 try:
99 yield
100 except OSError as exc:
101 if exc.errno not in ignored:
102 raise
103
104
105 class KeepAlive(namedtuple('KeepAlive', 'interval idle maxfails')):
106 """TCP keep-alive settings."""
107
108 INTERVAL = 3 # seconds
109 IDLE = 1 # seconds after idle
110 MAX_FAILS = 5
111
112 @classmethod
113 def from_raw(cls, raw):
114 """Return the corresponding KeepAlive."""
115 if raw is None:
116 return None
117 elif isinstance(raw, cls):
118 return raw
119 elif isinstance(raw, (str, int, float)):
120 return cls(raw)
121 else:
122 try:
123 raw = dict(raw)
124 except TypeError:
125 return cls(*raw)
126 else:
127 return cls(**raw)
128
129 def __new__(cls, interval=None, idle=None, maxfails=None):
130 self = super(KeepAlive, cls).__new__(
131 cls,
132 float(interval) if interval or interval == 0 else cls.INTERVAL,
133 float(idle) if idle or idle == 0 else cls.IDLE,
134 float(maxfails) if maxfails or maxfails == 0 else cls.MAX_FAILS,
135 )
136 return self
137
138 def apply(self, sock):
139 """Set the keepalive values on the socket."""
140 sock.setsockopt(socket.SOL_SOCKET,
141 socket.SO_KEEPALIVE,
142 1)
143 interval = self.interval
144 idle = self.idle
145 maxfails = self.maxfails
146 try:
147 if interval > 0:
148 sock.setsockopt(socket.IPPROTO_TCP,
149 socket.TCP_KEEPINTVL,
150 interval)
151 if idle > 0:
152 sock.setsockopt(socket.IPPROTO_TCP,
153 socket.TCP_KEEPIDLE,
154 idle)
155 if maxfails >= 0:
156 sock.setsockopt(socket.IPPROTO_TCP,
157 socket.TCP_KEEPCNT,
158 maxfails)
159 except AttributeError:
160 # mostly linux-only
161 pass
162
163
164 def connect(sock, addr, keepalive=None):
165 """Return the client socket for the next connection."""
166 if addr is None:
167 if keepalive is None or keepalive is True:
168 keepalive = KeepAlive()
169 elif keepalive:
170 keepalive = KeepAlive.from_raw(keepalive)
171 client, _ = sock.accept()
172 if keepalive:
173 keepalive.apply(client)
174 return client
175 else:
176 if keepalive:
177 raise NotImplementedError
178 sock.connect(addr)
179 return sock
180
181
182 def shut_down(sock, how=socket.SHUT_RDWR, ignored=NOT_CONNECTED):
183 """Shut down the given socket."""
184 with ignored_errno(*ignored or ()):
185 sock.shutdown(how)
186
187
188 def close_socket(sock):
189 """Shutdown and close the socket."""
190 try:
191 shut_down(sock)
192 except Exception:
193 # TODO: Log errors?
194 pass
195 sock.close()
196
197
198 class Address(namedtuple('Address', 'host port')):
199 """An IP address to use for sockets."""
200
201 @classmethod
202 def from_raw(cls, raw, defaultport=None):
203 """Return an address corresponding to the given data."""
204 if isinstance(raw, cls):
205 return raw
206 elif isinstance(raw, int):
207 return cls(None, raw)
208 elif isinstance(raw, str):
209 if raw == '':
210 return cls('', defaultport)
211 parsed = urlparse(raw)
212 if not parsed.netloc:
213 if parsed.scheme:
214 raise ValueError('invalid address {!r}'.format(raw))
215 return cls.from_raw('x://' + raw, defaultport=defaultport)
216 return cls(
217 parsed.hostname or '',
218 parsed.port if parsed.port else defaultport,
219 )
220 elif not raw:
221 return cls(None, defaultport)
222 else:
223 try:
224 kwargs = dict(**raw)
225 except TypeError:
226 return cls(*raw)
227 else:
228 kwargs.setdefault('host', None)
229 kwargs.setdefault('port', defaultport)
230 return cls(**kwargs)
231
232 @classmethod
233 def as_server(cls, host, port):
234 """Return an address to use as a server address."""
235 return cls(host, port, isserver=True)
236
237 @classmethod
238 def as_client(cls, host, port):
239 """Return an address to use as a server address."""
240 return cls(host, port, isserver=False)
241
242 def __new__(cls, host, port, **kwargs):
243 if host == '*':
244 host = ''
245 isserver = kwargs.pop('isserver', None)
246 if isserver is None:
247 isserver = (host is None or host == '')
248 else:
249 isserver = bool(isserver)
250 if host is None:
251 host = 'localhost'
252 self = super(Address, cls).__new__(
253 cls,
254 str(host),
255 int(port) if port is not None else None,
256 **kwargs
257 )
258 self._isserver = isserver
259 return self
260
261 def __init__(self, *args, **kwargs):
262 if self.port is None:
263 raise TypeError('missing port')
264 if self.port <= 0 or self.port > 65535:
265 raise ValueError('port must be positive int < 65535')
266
267 def __repr__(self):
268 orig = super(Address, self).__repr__()
269 return '{}, isserver={})'.format(orig[:-1], self._isserver)
270
271 def __eq__(self, other):
272 if not super(Address, self).__eq__(other):
273 return False
274 try:
275 other = self.from_raw(other)
276 except Exception:
277 return False
278 return self._isserver == other._isserver
279
280 @property
281 def isserver(self):
282 return self._isserver
283
[end of ptvsd/socket.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ptvsd/socket.py b/ptvsd/socket.py
--- a/ptvsd/socket.py
+++ b/ptvsd/socket.py
@@ -75,7 +75,7 @@
host = 'localhost'
server = _new_sock()
server.bind((host, port))
- server.listen(0)
+ server.listen(1)
return server
|
{"golden_diff": "diff --git a/ptvsd/socket.py b/ptvsd/socket.py\n--- a/ptvsd/socket.py\n+++ b/ptvsd/socket.py\n@@ -75,7 +75,7 @@\n host = 'localhost'\n server = _new_sock()\n server.bind((host, port))\n- server.listen(0)\n+ server.listen(1)\n return server\n", "issue": "listen(0) in create_server() does not allow client to connect to linux server\n## Environment data\r\n\r\n- PTVSD version: 4.1.1\r\n- OS and version: linux kernel 4.14.46\r\n- Python version (& distribution if applicable, e.g. Anaconda): 2.7.13, 3.5.3\r\n- Using VS Code or Visual Studio: N/A\r\n\r\n## Actual behavior\r\nserver on linux never accepts connection, i.e. `client, _ = sock.accept()` in `connect()` in socket.py never returns. This is due to the `listen(0)` call in `create_server()`. This was changed from `listen(1)` in 322f6946. Although `listen(0)` does work correctly on mac, it does not on linux.\r\n\r\n## Expected behavior\r\nthe incoming connection to be accepted\r\n\r\n## Steps to reproduce:\r\nrun:\r\n```python\r\nptvsd.enable_attach(address=('0.0.0.0', 9876), redirect_output=True)\r\nptvsd.wait_for_attach()\r\n```\r\nthen from the command line, see that `telnet localhost 9876` hangs instead of connecting. some background history is at https://bugs.python.org/issue8498\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nfrom __future__ import absolute_import\n\nfrom collections import namedtuple\nimport contextlib\nimport errno\nimport socket\ntry:\n from urllib.parse import urlparse\nexcept ImportError:\n from urlparse import urlparse\n\n\ntry:\n ConnectionError # noqa\n BrokenPipeError # noqa\n ConnectionResetError # noqa\nexcept NameError:\n class BrokenPipeError(Exception):\n # EPIPE and ESHUTDOWN\n pass\n\n class ConnectionResetError(Exception):\n # ECONNRESET\n pass\n\n\nNOT_CONNECTED = (\n errno.ENOTCONN,\n errno.EBADF,\n)\n\nCLOSED = (\n errno.EPIPE,\n errno.ESHUTDOWN,\n errno.ECONNRESET,\n # Windows\n 10038, # \"An operation was attempted on something that is not a socket\"\n 10058,\n)\n\nEOF = NOT_CONNECTED + CLOSED\n\n\[email protected]\ndef convert_eof():\n \"\"\"A context manager to convert some socket errors into EOFError.\"\"\"\n try:\n yield\n except ConnectionResetError:\n raise EOFError\n except BrokenPipeError:\n raise EOFError\n except OSError as exc:\n if exc.errno in EOF:\n raise EOFError\n raise\n\n\nclass TimeoutError(socket.timeout):\n \"\"\"A socket timeout happened.\"\"\"\n\n\ndef is_socket(sock):\n \"\"\"Return True if the object can be used as a socket.\"\"\"\n return isinstance(sock, socket.socket)\n\n\ndef create_server(host, port):\n \"\"\"Return a local server socket listening on the given port.\"\"\"\n if host is None:\n host = 'localhost'\n server = _new_sock()\n server.bind((host, port))\n server.listen(0)\n return server\n\n\ndef create_client():\n \"\"\"Return a client socket that may be connected to a remote address.\"\"\"\n return _new_sock()\n\n\ndef _new_sock():\n sock = socket.socket(socket.AF_INET,\n socket.SOCK_STREAM,\n socket.IPPROTO_TCP)\n sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)\n return sock\n\n\[email protected]\ndef ignored_errno(*ignored):\n \"\"\"A context manager that ignores the given errnos.\"\"\"\n try:\n yield\n except OSError as exc:\n if exc.errno not in ignored:\n raise\n\n\nclass KeepAlive(namedtuple('KeepAlive', 'interval idle maxfails')):\n \"\"\"TCP keep-alive settings.\"\"\"\n\n INTERVAL = 3 # seconds\n IDLE = 1 # seconds after idle\n MAX_FAILS = 5\n\n @classmethod\n def from_raw(cls, raw):\n \"\"\"Return the corresponding KeepAlive.\"\"\"\n if raw is None:\n return None\n elif isinstance(raw, cls):\n return raw\n elif isinstance(raw, (str, int, float)):\n return cls(raw)\n else:\n try:\n raw = dict(raw)\n except TypeError:\n return cls(*raw)\n else:\n return cls(**raw)\n\n def __new__(cls, interval=None, idle=None, maxfails=None):\n self = super(KeepAlive, cls).__new__(\n cls,\n float(interval) if interval or interval == 0 else cls.INTERVAL,\n float(idle) if idle or idle == 0 else cls.IDLE,\n float(maxfails) if maxfails or maxfails == 0 else cls.MAX_FAILS,\n )\n return self\n\n def apply(self, sock):\n \"\"\"Set the keepalive values on the socket.\"\"\"\n sock.setsockopt(socket.SOL_SOCKET,\n socket.SO_KEEPALIVE,\n 1)\n interval = self.interval\n idle = self.idle\n maxfails = self.maxfails\n try:\n if interval > 0:\n sock.setsockopt(socket.IPPROTO_TCP,\n socket.TCP_KEEPINTVL,\n interval)\n if idle > 0:\n sock.setsockopt(socket.IPPROTO_TCP,\n socket.TCP_KEEPIDLE,\n idle)\n if maxfails >= 0:\n sock.setsockopt(socket.IPPROTO_TCP,\n socket.TCP_KEEPCNT,\n maxfails)\n except AttributeError:\n # mostly linux-only\n pass\n\n\ndef connect(sock, addr, keepalive=None):\n \"\"\"Return the client socket for the next connection.\"\"\"\n if addr is None:\n if keepalive is None or keepalive is True:\n keepalive = KeepAlive()\n elif keepalive:\n keepalive = KeepAlive.from_raw(keepalive)\n client, _ = sock.accept()\n if keepalive:\n keepalive.apply(client)\n return client\n else:\n if keepalive:\n raise NotImplementedError\n sock.connect(addr)\n return sock\n\n\ndef shut_down(sock, how=socket.SHUT_RDWR, ignored=NOT_CONNECTED):\n \"\"\"Shut down the given socket.\"\"\"\n with ignored_errno(*ignored or ()):\n sock.shutdown(how)\n\n\ndef close_socket(sock):\n \"\"\"Shutdown and close the socket.\"\"\"\n try:\n shut_down(sock)\n except Exception:\n # TODO: Log errors?\n pass\n sock.close()\n\n\nclass Address(namedtuple('Address', 'host port')):\n \"\"\"An IP address to use for sockets.\"\"\"\n\n @classmethod\n def from_raw(cls, raw, defaultport=None):\n \"\"\"Return an address corresponding to the given data.\"\"\"\n if isinstance(raw, cls):\n return raw\n elif isinstance(raw, int):\n return cls(None, raw)\n elif isinstance(raw, str):\n if raw == '':\n return cls('', defaultport)\n parsed = urlparse(raw)\n if not parsed.netloc:\n if parsed.scheme:\n raise ValueError('invalid address {!r}'.format(raw))\n return cls.from_raw('x://' + raw, defaultport=defaultport)\n return cls(\n parsed.hostname or '',\n parsed.port if parsed.port else defaultport,\n )\n elif not raw:\n return cls(None, defaultport)\n else:\n try:\n kwargs = dict(**raw)\n except TypeError:\n return cls(*raw)\n else:\n kwargs.setdefault('host', None)\n kwargs.setdefault('port', defaultport)\n return cls(**kwargs)\n\n @classmethod\n def as_server(cls, host, port):\n \"\"\"Return an address to use as a server address.\"\"\"\n return cls(host, port, isserver=True)\n\n @classmethod\n def as_client(cls, host, port):\n \"\"\"Return an address to use as a server address.\"\"\"\n return cls(host, port, isserver=False)\n\n def __new__(cls, host, port, **kwargs):\n if host == '*':\n host = ''\n isserver = kwargs.pop('isserver', None)\n if isserver is None:\n isserver = (host is None or host == '')\n else:\n isserver = bool(isserver)\n if host is None:\n host = 'localhost'\n self = super(Address, cls).__new__(\n cls,\n str(host),\n int(port) if port is not None else None,\n **kwargs\n )\n self._isserver = isserver\n return self\n\n def __init__(self, *args, **kwargs):\n if self.port is None:\n raise TypeError('missing port')\n if self.port <= 0 or self.port > 65535:\n raise ValueError('port must be positive int < 65535')\n\n def __repr__(self):\n orig = super(Address, self).__repr__()\n return '{}, isserver={})'.format(orig[:-1], self._isserver)\n\n def __eq__(self, other):\n if not super(Address, self).__eq__(other):\n return False\n try:\n other = self.from_raw(other)\n except Exception:\n return False\n return self._isserver == other._isserver\n\n @property\n def isserver(self):\n return self._isserver\n", "path": "ptvsd/socket.py"}]}
| 3,282 | 87 |
gh_patches_debug_12296
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-2359
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cannot run database migrations on the 3.7 branch
I built a beta out of the ```HEAD``` of the ```3.7``` branch, and the migrations fail to run:
```
[root@bodhi-backend01 bowlofeggs][STG]# /usr/bin/alembic -c /etc/bodhi/alembic.ini upgrade head
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] Will assume transactional DDL.
INFO [alembic.env] Emitting SQL to allow for global DDL locking with BDR
/usr/lib/python2.7/site-packages/alembic/util/messaging.py:69: UserWarning: Revision be25565a1211 referenced from be25565a1211 -> 59c0f5fbc1b2 (head), Add a greenwave_unsatisfied_requirements column to the updates table. is not present
warnings.warn(msg)
Traceback (most recent call last):
File "/usr/bin/alembic", line 12, in <module>
sys.exit(load_entry_point('alembic', 'console_scripts', 'alembic')())
File "/usr/lib/python2.7/site-packages/alembic/config.py", line 479, in main
CommandLine(prog=prog).main(argv=argv)
File "/usr/lib/python2.7/site-packages/alembic/config.py", line 473, in main
self.run_cmd(cfg, options)
File "/usr/lib/python2.7/site-packages/alembic/config.py", line 456, in run_cmd
**dict((k, getattr(options, k, None)) for k in kwarg)
File "/usr/lib/python2.7/site-packages/alembic/command.py", line 254, in upgrade
script.run_env()
File "/usr/lib/python2.7/site-packages/alembic/script/base.py", line 425, in run_env
util.load_python_file(self.dir, 'env.py')
File "/usr/lib/python2.7/site-packages/alembic/util/pyfiles.py", line 81, in load_python_file
module = load_module_py(module_id, path)
File "/usr/lib/python2.7/site-packages/alembic/util/compat.py", line 141, in load_module_py
mod = imp.load_source(module_id, path, fp)
File "/usr/lib/python2.7/site-packages/bodhi/server/migrations/env.py", line 112, in <module>
run_migrations_online()
File "/usr/lib/python2.7/site-packages/bodhi/server/migrations/env.py", line 104, in run_migrations_online
context.run_migrations()
File "<string>", line 8, in run_migrations
File "/usr/lib/python2.7/site-packages/alembic/runtime/environment.py", line 836, in run_migrations
self.get_context().run_migrations(**kw)
File "/usr/lib/python2.7/site-packages/alembic/runtime/migration.py", line 321, in run_migrations
for step in self._migrations_fn(heads, self):
File "/usr/lib/python2.7/site-packages/alembic/command.py", line 243, in upgrade
return script._upgrade_revs(revision, rev)
File "/usr/lib/python2.7/site-packages/alembic/script/base.py", line 334, in _upgrade_revs
revs = list(revs)
File "/usr/lib/python2.7/site-packages/alembic/script/revision.py", line 645, in _iterate_revisions
requested_lowers = self.get_revisions(lower)
File "/usr/lib/python2.7/site-packages/alembic/script/revision.py", line 299, in get_revisions
return sum([self.get_revisions(id_elem) for id_elem in id_], ())
File "/usr/lib/python2.7/site-packages/alembic/script/revision.py", line 301, in get_revisions
resolved_id, branch_label = self._resolve_revision_number(id_)
File "/usr/lib/python2.7/site-packages/alembic/script/revision.py", line 437, in _resolve_revision_number
self._revision_map
File "/usr/lib/python2.7/site-packages/alembic/util/langhelpers.py", line 239, in __get__
obj.__dict__[self.__name__] = result = self.fget(obj)
File "/usr/lib/python2.7/site-packages/alembic/script/revision.py", line 152, in _revision_map
down_revision = map_[downrev]
KeyError: 'be25565a1211'
```
It sounds like there's a migration on ```develop``` that is not on the ```3.7``` branch, and when I cherry-picked the migration back to ```3.7``` it now references a migration that does not exist. To fix this, I'll need to shuffle the order of the migrations.
</issue>
<code>
[start of bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py]
1 # Copyright (c) 2018 Red Hat, Inc.
2 #
3 # This file is part of Bodhi.
4 #
5 # This program is free software; you can redistribute it and/or
6 # modify it under the terms of the GNU General Public License
7 # as published by the Free Software Foundation; either version 2
8 # of the License, or (at your option) any later version.
9 #
10 # This program is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with this program; if not, write to the Free Software
17 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
18 """
19 Add a greenwave_unsatisfied_requirements column to the updates table.
20
21 Revision ID: 59c0f5fbc1b2
22 Revises: be25565a1211
23 Create Date: 2018-05-01 15:37:07.346034
24 """
25 from alembic import op
26 import sqlalchemy as sa
27
28
29 # revision identifiers, used by Alembic.
30 revision = '59c0f5fbc1b2'
31 down_revision = 'be25565a1211'
32
33
34 def upgrade():
35 """Add a greenwave_unsatisfied_requirements to the updates table."""
36 op.add_column('updates',
37 sa.Column('greenwave_unsatisfied_requirements', sa.UnicodeText(), nullable=True))
38
39
40 def downgrade():
41 """Drop the greenwave_unsatisfied_requirements from the updates table."""
42 op.drop_column('updates', 'greenwave_unsatisfied_requirements')
43
[end of bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py b/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py
--- a/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py
+++ b/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py
@@ -19,7 +19,7 @@
Add a greenwave_unsatisfied_requirements column to the updates table.
Revision ID: 59c0f5fbc1b2
-Revises: be25565a1211
+Revises: c21dd18b161a
Create Date: 2018-05-01 15:37:07.346034
"""
from alembic import op
@@ -28,7 +28,7 @@
# revision identifiers, used by Alembic.
revision = '59c0f5fbc1b2'
-down_revision = 'be25565a1211'
+down_revision = 'c21dd18b161a'
def upgrade():
|
{"golden_diff": "diff --git a/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py b/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py\n--- a/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py\n+++ b/bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py\n@@ -19,7 +19,7 @@\n Add a greenwave_unsatisfied_requirements column to the updates table.\n \n Revision ID: 59c0f5fbc1b2\n-Revises: be25565a1211\n+Revises: c21dd18b161a\n Create Date: 2018-05-01 15:37:07.346034\n \"\"\"\n from alembic import op\n@@ -28,7 +28,7 @@\n \n # revision identifiers, used by Alembic.\n revision = '59c0f5fbc1b2'\n-down_revision = 'be25565a1211'\n+down_revision = 'c21dd18b161a'\n \n \n def upgrade():\n", "issue": "Cannot run database migrations on the 3.7 branch\nI built a beta out of the ```HEAD``` of the ```3.7``` branch, and the migrations fail to run:\r\n\r\n```\r\n[root@bodhi-backend01 bowlofeggs][STG]# /usr/bin/alembic -c /etc/bodhi/alembic.ini upgrade head\r\nINFO [alembic.runtime.migration] Context impl PostgresqlImpl.\r\nINFO [alembic.runtime.migration] Will assume transactional DDL.\r\nINFO [alembic.env] Emitting SQL to allow for global DDL locking with BDR\r\n/usr/lib/python2.7/site-packages/alembic/util/messaging.py:69: UserWarning: Revision be25565a1211 referenced from be25565a1211 -> 59c0f5fbc1b2 (head), Add a greenwave_unsatisfied_requirements column to the updates table. is not present\r\n warnings.warn(msg)\r\nTraceback (most recent call last):\r\n File \"/usr/bin/alembic\", line 12, in <module>\r\n sys.exit(load_entry_point('alembic', 'console_scripts', 'alembic')())\r\n File \"/usr/lib/python2.7/site-packages/alembic/config.py\", line 479, in main\r\n CommandLine(prog=prog).main(argv=argv)\r\n File \"/usr/lib/python2.7/site-packages/alembic/config.py\", line 473, in main\r\n self.run_cmd(cfg, options)\r\n File \"/usr/lib/python2.7/site-packages/alembic/config.py\", line 456, in run_cmd\r\n **dict((k, getattr(options, k, None)) for k in kwarg)\r\n File \"/usr/lib/python2.7/site-packages/alembic/command.py\", line 254, in upgrade\r\n script.run_env()\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/base.py\", line 425, in run_env\r\n util.load_python_file(self.dir, 'env.py')\r\n File \"/usr/lib/python2.7/site-packages/alembic/util/pyfiles.py\", line 81, in load_python_file\r\n module = load_module_py(module_id, path)\r\n File \"/usr/lib/python2.7/site-packages/alembic/util/compat.py\", line 141, in load_module_py\r\n mod = imp.load_source(module_id, path, fp)\r\n File \"/usr/lib/python2.7/site-packages/bodhi/server/migrations/env.py\", line 112, in <module>\r\n run_migrations_online()\r\n File \"/usr/lib/python2.7/site-packages/bodhi/server/migrations/env.py\", line 104, in run_migrations_online\r\n context.run_migrations()\r\n File \"<string>\", line 8, in run_migrations\r\n File \"/usr/lib/python2.7/site-packages/alembic/runtime/environment.py\", line 836, in run_migrations\r\n self.get_context().run_migrations(**kw)\r\n File \"/usr/lib/python2.7/site-packages/alembic/runtime/migration.py\", line 321, in run_migrations\r\n for step in self._migrations_fn(heads, self):\r\n File \"/usr/lib/python2.7/site-packages/alembic/command.py\", line 243, in upgrade\r\n return script._upgrade_revs(revision, rev)\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/base.py\", line 334, in _upgrade_revs\r\n revs = list(revs)\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/revision.py\", line 645, in _iterate_revisions\r\n requested_lowers = self.get_revisions(lower)\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/revision.py\", line 299, in get_revisions\r\n return sum([self.get_revisions(id_elem) for id_elem in id_], ())\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/revision.py\", line 301, in get_revisions\r\n resolved_id, branch_label = self._resolve_revision_number(id_)\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/revision.py\", line 437, in _resolve_revision_number\r\n self._revision_map\r\n File \"/usr/lib/python2.7/site-packages/alembic/util/langhelpers.py\", line 239, in __get__\r\n obj.__dict__[self.__name__] = result = self.fget(obj)\r\n File \"/usr/lib/python2.7/site-packages/alembic/script/revision.py\", line 152, in _revision_map\r\n down_revision = map_[downrev]\r\nKeyError: 'be25565a1211'\r\n```\r\n\r\nIt sounds like there's a migration on ```develop``` that is not on the ```3.7``` branch, and when I cherry-picked the migration back to ```3.7``` it now references a migration that does not exist. To fix this, I'll need to shuffle the order of the migrations.\n", "before_files": [{"content": "# Copyright (c) 2018 Red Hat, Inc.\n#\n# This file is part of Bodhi.\n#\n# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\"\"\"\nAdd a greenwave_unsatisfied_requirements column to the updates table.\n\nRevision ID: 59c0f5fbc1b2\nRevises: be25565a1211\nCreate Date: 2018-05-01 15:37:07.346034\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = '59c0f5fbc1b2'\ndown_revision = 'be25565a1211'\n\n\ndef upgrade():\n \"\"\"Add a greenwave_unsatisfied_requirements to the updates table.\"\"\"\n op.add_column('updates',\n sa.Column('greenwave_unsatisfied_requirements', sa.UnicodeText(), nullable=True))\n\n\ndef downgrade():\n \"\"\"Drop the greenwave_unsatisfied_requirements from the updates table.\"\"\"\n op.drop_column('updates', 'greenwave_unsatisfied_requirements')\n", "path": "bodhi/server/migrations/versions/59c0f5fbc1b2_add_a_greenwave_unsatisfied_.py"}]}
| 2,213 | 318 |
gh_patches_debug_39319
|
rasdani/github-patches
|
git_diff
|
PaddlePaddle__PaddleSeg-266
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
LabelMe标注好图片之后,使用labelme2seg无法生成真值图片
我使用LabelMe标注好图片之后,使用labelme2seg生成真值图片,运行labelme2seg的时候报错,报错信息如下:
class_names: ('_background_', 'steel')
Saved class_names: D:\2\class_names.txt
Generating dataset from: D:\2\2020_5_15_13_19_46_995.json
Traceback (most recent call last):
File "D:\PaddleSeg\pdseg\tools\labelme2seg.py", line 90, in <module>
main(args)
File "D:\PaddleSeg\pdseg\tools\labelme2seg.py", line 78, in main
if lbl.min() >= 0 and lbl.max() <= 255:
AttributeError: 'tuple' object has no attribute 'min'
</issue>
<code>
[start of pdseg/tools/labelme2seg.py]
1 # coding: utf8
2 # Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 from __future__ import print_function
17
18 import argparse
19 import glob
20 import json
21 import os
22 import os.path as osp
23
24 import numpy as np
25 import PIL.Image
26 import labelme
27
28 from gray2pseudo_color import get_color_map_list
29
30
31 def parse_args():
32 parser = argparse.ArgumentParser(
33 formatter_class=argparse.ArgumentDefaultsHelpFormatter)
34 parser.add_argument('input_dir', help='input annotated directory')
35 return parser.parse_args()
36
37
38 def main(args):
39 output_dir = osp.join(args.input_dir, 'annotations')
40 if not osp.exists(output_dir):
41 os.makedirs(output_dir)
42 print('Creating annotations directory:', output_dir)
43
44 # get the all class names for the given dataset
45 class_names = ['_background_']
46 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
47 with open(label_file) as f:
48 data = json.load(f)
49 for shape in data['shapes']:
50 label = shape['label']
51 cls_name = label
52 if not cls_name in class_names:
53 class_names.append(cls_name)
54
55 class_name_to_id = {}
56 for i, class_name in enumerate(class_names):
57 class_id = i # starts with 0
58 class_name_to_id[class_name] = class_id
59 if class_id == 0:
60 assert class_name == '_background_'
61 class_names = tuple(class_names)
62 print('class_names:', class_names)
63
64 out_class_names_file = osp.join(args.input_dir, 'class_names.txt')
65 with open(out_class_names_file, 'w') as f:
66 f.writelines('\n'.join(class_names))
67 print('Saved class_names:', out_class_names_file)
68
69 color_map = get_color_map_list(256)
70
71 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
72 print('Generating dataset from:', label_file)
73 with open(label_file) as f:
74 base = osp.splitext(osp.basename(label_file))[0]
75 out_png_file = osp.join(output_dir, base + '.png')
76
77 data = json.load(f)
78
79 img_file = osp.join(osp.dirname(label_file), data['imagePath'])
80 img = np.asarray(PIL.Image.open(img_file))
81
82 lbl = labelme.utils.shapes_to_label(
83 img_shape=img.shape,
84 shapes=data['shapes'],
85 label_name_to_value=class_name_to_id,
86 )
87
88 if osp.splitext(out_png_file)[1] != '.png':
89 out_png_file += '.png'
90 # Assume label ranges [0, 255] for uint8,
91 if lbl.min() >= 0 and lbl.max() <= 255:
92 lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
93 lbl_pil.putpalette(color_map)
94 lbl_pil.save(out_png_file)
95 else:
96 raise ValueError(
97 '[%s] Cannot save the pixel-wise class label as PNG. '
98 'Please consider using the .npy format.' % out_png_file)
99
100
101 if __name__ == '__main__':
102 args = parse_args()
103 main(args)
104
[end of pdseg/tools/labelme2seg.py]
[start of pdseg/tools/jingling2seg.py]
1 # coding: utf8
2 # Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 from __future__ import print_function
17
18 import argparse
19 import glob
20 import json
21 import os
22 import os.path as osp
23
24 import numpy as np
25 import PIL.Image
26 import labelme
27
28 from gray2pseudo_color import get_color_map_list
29
30
31 def parse_args():
32 parser = argparse.ArgumentParser(
33 formatter_class=argparse.ArgumentDefaultsHelpFormatter)
34 parser.add_argument('input_dir', help='input annotated directory')
35 return parser.parse_args()
36
37
38 def main(args):
39 output_dir = osp.join(args.input_dir, 'annotations')
40 if not osp.exists(output_dir):
41 os.makedirs(output_dir)
42 print('Creating annotations directory:', output_dir)
43
44 # get the all class names for the given dataset
45 class_names = ['_background_']
46 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
47 with open(label_file) as f:
48 data = json.load(f)
49 if data['outputs']:
50 for output in data['outputs']['object']:
51 name = output['name']
52 cls_name = name
53 if not cls_name in class_names:
54 class_names.append(cls_name)
55
56 class_name_to_id = {}
57 for i, class_name in enumerate(class_names):
58 class_id = i # starts with 0
59 class_name_to_id[class_name] = class_id
60 if class_id == 0:
61 assert class_name == '_background_'
62 class_names = tuple(class_names)
63 print('class_names:', class_names)
64
65 out_class_names_file = osp.join(args.input_dir, 'class_names.txt')
66 with open(out_class_names_file, 'w') as f:
67 f.writelines('\n'.join(class_names))
68 print('Saved class_names:', out_class_names_file)
69
70 color_map = get_color_map_list(256)
71
72 for label_file in glob.glob(osp.join(args.input_dir, '*.json')):
73 print('Generating dataset from:', label_file)
74 with open(label_file) as f:
75 base = osp.splitext(osp.basename(label_file))[0]
76 out_png_file = osp.join(output_dir, base + '.png')
77
78 data = json.load(f)
79
80 data_shapes = []
81 if data['outputs']:
82 for output in data['outputs']['object']:
83 if 'polygon' in output.keys():
84 polygon = output['polygon']
85 name = output['name']
86
87 # convert jingling format to labelme format
88 points = []
89 for i in range(1, int(len(polygon) / 2) + 1):
90 points.append(
91 [polygon['x' + str(i)], polygon['y' + str(i)]])
92 shape = {
93 'label': name,
94 'points': points,
95 'shape_type': 'polygon'
96 }
97 data_shapes.append(shape)
98
99 if 'size' not in data:
100 continue
101 data_size = data['size']
102 img_shape = (data_size['height'], data_size['width'],
103 data_size['depth'])
104
105 lbl = labelme.utils.shapes_to_label(
106 img_shape=img_shape,
107 shapes=data_shapes,
108 label_name_to_value=class_name_to_id,
109 )
110
111 if osp.splitext(out_png_file)[1] != '.png':
112 out_png_file += '.png'
113 # Assume label ranges [0, 255] for uint8,
114 if lbl.min() >= 0 and lbl.max() <= 255:
115 lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')
116 lbl_pil.putpalette(color_map)
117 lbl_pil.save(out_png_file)
118 else:
119 raise ValueError(
120 '[%s] Cannot save the pixel-wise class label as PNG. '
121 'Please consider using the .npy format.' % out_png_file)
122
123
124 if __name__ == '__main__':
125 args = parse_args()
126 main(args)
127
[end of pdseg/tools/jingling2seg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pdseg/tools/jingling2seg.py b/pdseg/tools/jingling2seg.py
--- a/pdseg/tools/jingling2seg.py
+++ b/pdseg/tools/jingling2seg.py
@@ -20,12 +20,11 @@
import json
import os
import os.path as osp
-
import numpy as np
import PIL.Image
-import labelme
from gray2pseudo_color import get_color_map_list
+from labelme2seg import shape2label
def parse_args():
@@ -102,10 +101,10 @@
img_shape = (data_size['height'], data_size['width'],
data_size['depth'])
- lbl = labelme.utils.shapes_to_label(
- img_shape=img_shape,
+ lbl = shape2label(
+ img_size=img_shape,
shapes=data_shapes,
- label_name_to_value=class_name_to_id,
+ class_name_mapping=class_name_to_id,
)
if osp.splitext(out_png_file)[1] != '.png':
diff --git a/pdseg/tools/labelme2seg.py b/pdseg/tools/labelme2seg.py
--- a/pdseg/tools/labelme2seg.py
+++ b/pdseg/tools/labelme2seg.py
@@ -17,13 +17,14 @@
import argparse
import glob
+import math
import json
import os
import os.path as osp
-
import numpy as np
import PIL.Image
-import labelme
+import PIL.ImageDraw
+import cv2
from gray2pseudo_color import get_color_map_list
@@ -77,12 +78,12 @@
data = json.load(f)
img_file = osp.join(osp.dirname(label_file), data['imagePath'])
- img = np.asarray(PIL.Image.open(img_file))
+ img = np.asarray(cv2.imread(img_file))
- lbl = labelme.utils.shapes_to_label(
- img_shape=img.shape,
+ lbl = shape2label(
+ img_size=img.shape,
shapes=data['shapes'],
- label_name_to_value=class_name_to_id,
+ class_name_mapping=class_name_to_id,
)
if osp.splitext(out_png_file)[1] != '.png':
@@ -98,6 +99,27 @@
'Please consider using the .npy format.' % out_png_file)
+def shape2mask(img_size, points):
+ label_mask = PIL.Image.fromarray(np.zeros(img_size[:2], dtype=np.uint8))
+ image_draw = PIL.ImageDraw.Draw(label_mask)
+ points_list = [tuple(point) for point in points]
+ assert len(points_list) > 2, 'Polygon must have points more than 2'
+ image_draw.polygon(xy=points_list, outline=1, fill=1)
+ return np.array(label_mask, dtype=bool)
+
+
+def shape2label(img_size, shapes, class_name_mapping):
+ label = np.zeros(img_size[:2], dtype=np.int32)
+ for shape in shapes:
+ points = shape['points']
+ class_name = shape['label']
+ shape_type = shape.get('shape_type', None)
+ class_id = class_name_mapping[class_name]
+ label_mask = shape2mask(img_size[:2], points)
+ label[label_mask] = class_id
+ return label
+
+
if __name__ == '__main__':
args = parse_args()
main(args)
|
{"golden_diff": "diff --git a/pdseg/tools/jingling2seg.py b/pdseg/tools/jingling2seg.py\n--- a/pdseg/tools/jingling2seg.py\n+++ b/pdseg/tools/jingling2seg.py\n@@ -20,12 +20,11 @@\n import json\n import os\n import os.path as osp\n-\n import numpy as np\n import PIL.Image\n-import labelme\n \n from gray2pseudo_color import get_color_map_list\n+from labelme2seg import shape2label\n \n \n def parse_args():\n@@ -102,10 +101,10 @@\n img_shape = (data_size['height'], data_size['width'],\n data_size['depth'])\n \n- lbl = labelme.utils.shapes_to_label(\n- img_shape=img_shape,\n+ lbl = shape2label(\n+ img_size=img_shape,\n shapes=data_shapes,\n- label_name_to_value=class_name_to_id,\n+ class_name_mapping=class_name_to_id,\n )\n \n if osp.splitext(out_png_file)[1] != '.png':\ndiff --git a/pdseg/tools/labelme2seg.py b/pdseg/tools/labelme2seg.py\n--- a/pdseg/tools/labelme2seg.py\n+++ b/pdseg/tools/labelme2seg.py\n@@ -17,13 +17,14 @@\n \n import argparse\n import glob\n+import math\n import json\n import os\n import os.path as osp\n-\n import numpy as np\n import PIL.Image\n-import labelme\n+import PIL.ImageDraw\n+import cv2\n \n from gray2pseudo_color import get_color_map_list\n \n@@ -77,12 +78,12 @@\n data = json.load(f)\n \n img_file = osp.join(osp.dirname(label_file), data['imagePath'])\n- img = np.asarray(PIL.Image.open(img_file))\n+ img = np.asarray(cv2.imread(img_file))\n \n- lbl = labelme.utils.shapes_to_label(\n- img_shape=img.shape,\n+ lbl = shape2label(\n+ img_size=img.shape,\n shapes=data['shapes'],\n- label_name_to_value=class_name_to_id,\n+ class_name_mapping=class_name_to_id,\n )\n \n if osp.splitext(out_png_file)[1] != '.png':\n@@ -98,6 +99,27 @@\n 'Please consider using the .npy format.' % out_png_file)\n \n \n+def shape2mask(img_size, points):\n+ label_mask = PIL.Image.fromarray(np.zeros(img_size[:2], dtype=np.uint8))\n+ image_draw = PIL.ImageDraw.Draw(label_mask)\n+ points_list = [tuple(point) for point in points]\n+ assert len(points_list) > 2, 'Polygon must have points more than 2'\n+ image_draw.polygon(xy=points_list, outline=1, fill=1)\n+ return np.array(label_mask, dtype=bool)\n+\n+\n+def shape2label(img_size, shapes, class_name_mapping):\n+ label = np.zeros(img_size[:2], dtype=np.int32)\n+ for shape in shapes:\n+ points = shape['points']\n+ class_name = shape['label']\n+ shape_type = shape.get('shape_type', None)\n+ class_id = class_name_mapping[class_name]\n+ label_mask = shape2mask(img_size[:2], points)\n+ label[label_mask] = class_id\n+ return label\n+\n+\n if __name__ == '__main__':\n args = parse_args()\n main(args)\n", "issue": "LabelMe\u6807\u6ce8\u597d\u56fe\u7247\u4e4b\u540e\uff0c\u4f7f\u7528labelme2seg\u65e0\u6cd5\u751f\u6210\u771f\u503c\u56fe\u7247\n\u6211\u4f7f\u7528LabelMe\u6807\u6ce8\u597d\u56fe\u7247\u4e4b\u540e\uff0c\u4f7f\u7528labelme2seg\u751f\u6210\u771f\u503c\u56fe\u7247\uff0c\u8fd0\u884clabelme2seg\u7684\u65f6\u5019\u62a5\u9519\uff0c\u62a5\u9519\u4fe1\u606f\u5982\u4e0b\uff1a\r\nclass_names: ('_background_', 'steel')\r\nSaved class_names: D:\\2\\class_names.txt\r\nGenerating dataset from: D:\\2\\2020_5_15_13_19_46_995.json\r\nTraceback (most recent call last):\r\n File \"D:\\PaddleSeg\\pdseg\\tools\\labelme2seg.py\", line 90, in <module>\r\n main(args)\r\n File \"D:\\PaddleSeg\\pdseg\\tools\\labelme2seg.py\", line 78, in main\r\n if lbl.min() >= 0 and lbl.max() <= 255:\r\nAttributeError: 'tuple' object has no attribute 'min'\n", "before_files": [{"content": "# coding: utf8\n# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import print_function\n\nimport argparse\nimport glob\nimport json\nimport os\nimport os.path as osp\n\nimport numpy as np\nimport PIL.Image\nimport labelme\n\nfrom gray2pseudo_color import get_color_map_list\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument('input_dir', help='input annotated directory')\n return parser.parse_args()\n\n\ndef main(args):\n output_dir = osp.join(args.input_dir, 'annotations')\n if not osp.exists(output_dir):\n os.makedirs(output_dir)\n print('Creating annotations directory:', output_dir)\n\n # get the all class names for the given dataset\n class_names = ['_background_']\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n with open(label_file) as f:\n data = json.load(f)\n for shape in data['shapes']:\n label = shape['label']\n cls_name = label\n if not cls_name in class_names:\n class_names.append(cls_name)\n\n class_name_to_id = {}\n for i, class_name in enumerate(class_names):\n class_id = i # starts with 0\n class_name_to_id[class_name] = class_id\n if class_id == 0:\n assert class_name == '_background_'\n class_names = tuple(class_names)\n print('class_names:', class_names)\n\n out_class_names_file = osp.join(args.input_dir, 'class_names.txt')\n with open(out_class_names_file, 'w') as f:\n f.writelines('\\n'.join(class_names))\n print('Saved class_names:', out_class_names_file)\n\n color_map = get_color_map_list(256)\n\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n print('Generating dataset from:', label_file)\n with open(label_file) as f:\n base = osp.splitext(osp.basename(label_file))[0]\n out_png_file = osp.join(output_dir, base + '.png')\n\n data = json.load(f)\n\n img_file = osp.join(osp.dirname(label_file), data['imagePath'])\n img = np.asarray(PIL.Image.open(img_file))\n\n lbl = labelme.utils.shapes_to_label(\n img_shape=img.shape,\n shapes=data['shapes'],\n label_name_to_value=class_name_to_id,\n )\n\n if osp.splitext(out_png_file)[1] != '.png':\n out_png_file += '.png'\n # Assume label ranges [0, 255] for uint8,\n if lbl.min() >= 0 and lbl.max() <= 255:\n lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')\n lbl_pil.putpalette(color_map)\n lbl_pil.save(out_png_file)\n else:\n raise ValueError(\n '[%s] Cannot save the pixel-wise class label as PNG. '\n 'Please consider using the .npy format.' % out_png_file)\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "pdseg/tools/labelme2seg.py"}, {"content": "# coding: utf8\n# Copyright (c) 2019 PaddlePaddle Authors. All Rights Reserve.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import print_function\n\nimport argparse\nimport glob\nimport json\nimport os\nimport os.path as osp\n\nimport numpy as np\nimport PIL.Image\nimport labelme\n\nfrom gray2pseudo_color import get_color_map_list\n\n\ndef parse_args():\n parser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter)\n parser.add_argument('input_dir', help='input annotated directory')\n return parser.parse_args()\n\n\ndef main(args):\n output_dir = osp.join(args.input_dir, 'annotations')\n if not osp.exists(output_dir):\n os.makedirs(output_dir)\n print('Creating annotations directory:', output_dir)\n\n # get the all class names for the given dataset\n class_names = ['_background_']\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n with open(label_file) as f:\n data = json.load(f)\n if data['outputs']:\n for output in data['outputs']['object']:\n name = output['name']\n cls_name = name\n if not cls_name in class_names:\n class_names.append(cls_name)\n\n class_name_to_id = {}\n for i, class_name in enumerate(class_names):\n class_id = i # starts with 0\n class_name_to_id[class_name] = class_id\n if class_id == 0:\n assert class_name == '_background_'\n class_names = tuple(class_names)\n print('class_names:', class_names)\n\n out_class_names_file = osp.join(args.input_dir, 'class_names.txt')\n with open(out_class_names_file, 'w') as f:\n f.writelines('\\n'.join(class_names))\n print('Saved class_names:', out_class_names_file)\n\n color_map = get_color_map_list(256)\n\n for label_file in glob.glob(osp.join(args.input_dir, '*.json')):\n print('Generating dataset from:', label_file)\n with open(label_file) as f:\n base = osp.splitext(osp.basename(label_file))[0]\n out_png_file = osp.join(output_dir, base + '.png')\n\n data = json.load(f)\n\n data_shapes = []\n if data['outputs']:\n for output in data['outputs']['object']:\n if 'polygon' in output.keys():\n polygon = output['polygon']\n name = output['name']\n\n # convert jingling format to labelme format\n points = []\n for i in range(1, int(len(polygon) / 2) + 1):\n points.append(\n [polygon['x' + str(i)], polygon['y' + str(i)]])\n shape = {\n 'label': name,\n 'points': points,\n 'shape_type': 'polygon'\n }\n data_shapes.append(shape)\n\n if 'size' not in data:\n continue\n data_size = data['size']\n img_shape = (data_size['height'], data_size['width'],\n data_size['depth'])\n\n lbl = labelme.utils.shapes_to_label(\n img_shape=img_shape,\n shapes=data_shapes,\n label_name_to_value=class_name_to_id,\n )\n\n if osp.splitext(out_png_file)[1] != '.png':\n out_png_file += '.png'\n # Assume label ranges [0, 255] for uint8,\n if lbl.min() >= 0 and lbl.max() <= 255:\n lbl_pil = PIL.Image.fromarray(lbl.astype(np.uint8), mode='P')\n lbl_pil.putpalette(color_map)\n lbl_pil.save(out_png_file)\n else:\n raise ValueError(\n '[%s] Cannot save the pixel-wise class label as PNG. '\n 'Please consider using the .npy format.' % out_png_file)\n\n\nif __name__ == '__main__':\n args = parse_args()\n main(args)\n", "path": "pdseg/tools/jingling2seg.py"}]}
| 3,042 | 773 |
gh_patches_debug_33088
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-317
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
User should be able to configure multiple databases in settings
**Problem**
<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->
Currently, the user can only configure one Mathesar database in the settings. They should be able to configure as many databases to connect to Mathesar as they want.
**Proposed solution**
<!-- A clear and concise description of your proposed solution or feature. -->
The user should be able to configure multiple databases in the `.env` file.
**Additional context**
<!-- Add any other context or screenshots about the feature request here.-->
We might want to use `python-decouple`'s [built in CSV helper](https://github.com/henriquebastos/python-decouple/#built-in-csv-helper) for this.
Ideally, the user would be able to associate the database key with the connection information directly using a tuple or something like that.
</issue>
<code>
[start of config/settings.py]
1 """
2 Django settings for config project.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19 # Build paths inside the project like this: BASE_DIR / 'subdir'.
20 BASE_DIR = Path(__file__).resolve().parent.parent
21
22 # Application definition
23
24 INSTALLED_APPS = [
25 "django.contrib.admin",
26 "django.contrib.auth",
27 "django.contrib.contenttypes",
28 "django.contrib.sessions",
29 "django.contrib.messages",
30 "django.contrib.staticfiles",
31 "rest_framework",
32 "django_filters",
33 "django_property_filter",
34 "mathesar",
35 ]
36
37 MIDDLEWARE = [
38 "django.middleware.security.SecurityMiddleware",
39 "django.contrib.sessions.middleware.SessionMiddleware",
40 "django.middleware.common.CommonMiddleware",
41 "django.middleware.csrf.CsrfViewMiddleware",
42 "django.contrib.auth.middleware.AuthenticationMiddleware",
43 "django.contrib.messages.middleware.MessageMiddleware",
44 "django.middleware.clickjacking.XFrameOptionsMiddleware",
45 ]
46
47 ROOT_URLCONF = "config.urls"
48
49 TEMPLATES = [
50 {
51 "BACKEND": "django.template.backends.django.DjangoTemplates",
52 "DIRS": [],
53 "APP_DIRS": True,
54 "OPTIONS": {
55 "context_processors": [
56 "config.context_processors.get_settings",
57 "django.template.context_processors.debug",
58 "django.template.context_processors.request",
59 "django.contrib.auth.context_processors.auth",
60 "django.contrib.messages.context_processors.messages",
61 ],
62 },
63 },
64 ]
65
66 WSGI_APPLICATION = "config.wsgi.application"
67
68 # Database
69 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
70
71 # TODO: Add to documentation that database keys should not be than 128 characters.
72 DATABASES = {
73 decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),
74 decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
75 }
76
77 # pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
78 # and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
79 if decouple_config('TEST', default=False, cast=bool):
80 DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {
81 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']
82 }
83
84
85 # Quick-start development settings - unsuitable for production
86 # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
87
88 # SECURITY WARNING: keep the secret key used in production secret!
89 SECRET_KEY = decouple_config('SECRET_KEY')
90
91 # SECURITY WARNING: don't run with debug turned on in production!
92 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
93
94 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())
95
96 # Password validation
97 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
98
99 AUTH_PASSWORD_VALIDATORS = [
100 {
101 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
102 },
103 {
104 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
105 },
106 {
107 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
108 },
109 {
110 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
111 },
112 ]
113
114
115 # Internationalization
116 # https://docs.djangoproject.com/en/3.1/topics/i18n/
117
118 LANGUAGE_CODE = "en-us"
119
120 TIME_ZONE = "UTC"
121
122 USE_I18N = True
123
124 USE_L10N = True
125
126 USE_TZ = True
127
128
129 # Static files (CSS, JavaScript, Images)
130 # https://docs.djangoproject.com/en/3.1/howto/static-files/
131
132 STATIC_URL = "/static/"
133
134 CLIENT_DEV_URL = "http://localhost:3000"
135
136
137 # Media files (uploaded by the user)
138
139 MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
140
141 MEDIA_URL = "/media/"
142
[end of config/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/config/settings.py b/config/settings.py
--- a/config/settings.py
+++ b/config/settings.py
@@ -16,6 +16,16 @@
from decouple import Csv, config as decouple_config
from dj_database_url import parse as db_url
+
+# We use a 'tuple' with pipes as delimiters as decople naively splits the global
+# variables on commas when casting to Csv()
+def pipe_delim(pipe_string):
+ # Remove opening and closing brackets
+ pipe_string = pipe_string[1:-1]
+ # Split on pipe delim
+ return pipe_string.split("|")
+
+
# Build paths inside the project like this: BASE_DIR / 'subdir'.
BASE_DIR = Path(__file__).resolve().parent.parent
@@ -69,17 +79,20 @@
# https://docs.djangoproject.com/en/3.1/ref/settings/#databases
# TODO: Add to documentation that database keys should not be than 128 characters.
+
+# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'
+# See pipe_delim above for why we use pipes as delimiters
DATABASES = {
- decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),
- decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)
+ db_key: db_url(url_string)
+ for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))
}
+DATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)
# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
if decouple_config('TEST', default=False, cast=bool):
- DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {
- 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']
- }
+ for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):
+ DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}
# Quick-start development settings - unsuitable for production
|
{"golden_diff": "diff --git a/config/settings.py b/config/settings.py\n--- a/config/settings.py\n+++ b/config/settings.py\n@@ -16,6 +16,16 @@\n from decouple import Csv, config as decouple_config\n from dj_database_url import parse as db_url\n \n+\n+# We use a 'tuple' with pipes as delimiters as decople naively splits the global\n+# variables on commas when casting to Csv()\n+def pipe_delim(pipe_string):\n+ # Remove opening and closing brackets\n+ pipe_string = pipe_string[1:-1]\n+ # Split on pipe delim\n+ return pipe_string.split(\"|\")\n+\n+\n # Build paths inside the project like this: BASE_DIR / 'subdir'.\n BASE_DIR = Path(__file__).resolve().parent.parent\n \n@@ -69,17 +79,20 @@\n # https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n \n # TODO: Add to documentation that database keys should not be than 128 characters.\n+\n+# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'\n+# See pipe_delim above for why we use pipes as delimiters\n DATABASES = {\n- decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n- decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n+ db_key: db_url(url_string)\n+ for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))\n }\n+DATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)\n \n # pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n # and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\n if decouple_config('TEST', default=False, cast=bool):\n- DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n- 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n- }\n+ for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n+ DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n \n \n # Quick-start development settings - unsuitable for production\n", "issue": "User should be able to configure multiple databases in settings\n**Problem**\r\n<!-- Please provide a clear and concise description of the problem that this feature request is designed to solve.-->\r\nCurrently, the user can only configure one Mathesar database in the settings. They should be able to configure as many databases to connect to Mathesar as they want.\r\n\r\n**Proposed solution**\r\n<!-- A clear and concise description of your proposed solution or feature. -->\r\nThe user should be able to configure multiple databases in the `.env` file.\r\n\r\n**Additional context**\r\n<!-- Add any other context or screenshots about the feature request here.-->\r\nWe might want to use `python-decouple`'s [built in CSV helper](https://github.com/henriquebastos/python-decouple/#built-in-csv-helper) for this.\r\n\r\nIdeally, the user would be able to associate the database key with the connection information directly using a tuple or something like that.\n", "before_files": [{"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.get_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\nDATABASES = {\n decouple_config('DJANGO_DATABASE_KEY'): decouple_config('DJANGO_DATABASE_URL', cast=db_url),\n decouple_config('MATHESAR_DATABASE_KEY'): decouple_config('MATHESAR_DATABASE_URL', cast=db_url)\n}\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nif decouple_config('TEST', default=False, cast=bool):\n DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['TEST'] = {\n 'NAME': DATABASES[decouple_config('MATHESAR_DATABASE_KEY')]['NAME']\n }\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\nCLIENT_DEV_URL = \"http://localhost:3000\"\n\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n", "path": "config/settings.py"}]}
| 1,986 | 545 |
gh_patches_debug_17060
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-7654
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Build failed on OpenBSD 7.2
OpenBSD 7.2 upgraded LibreSSL to 3.6.0 (LIBRESSL_VERSION_NUMBER 0x3060000fL) that has OPENSSL_cleanup function.
Please update version check in src/_cffi_src/openssl/crypto.py to:
```
#if CRYPTOGRAPHY_IS_LIBRESSL && LIBRESSL_VERSION_NUMBER < 0x3060000fL
static const long Cryptography_HAS_OPENSSL_CLEANUP = 0;
void (*OPENSSL_cleanup)(void) = NULL;
#else
static const long Cryptography_HAS_OPENSSL_CLEANUP = 1;
#endif
```
</issue>
<code>
[start of src/_cffi_src/openssl/crypto.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 INCLUDES = """
7 #include <openssl/crypto.h>
8 """
9
10 TYPES = """
11 static const long Cryptography_HAS_MEM_FUNCTIONS;
12 static const long Cryptography_HAS_OPENSSL_CLEANUP;
13
14 static const int SSLEAY_VERSION;
15 static const int SSLEAY_CFLAGS;
16 static const int SSLEAY_PLATFORM;
17 static const int SSLEAY_DIR;
18 static const int SSLEAY_BUILT_ON;
19 static const int OPENSSL_VERSION;
20 static const int OPENSSL_CFLAGS;
21 static const int OPENSSL_BUILT_ON;
22 static const int OPENSSL_PLATFORM;
23 static const int OPENSSL_DIR;
24 """
25
26 FUNCTIONS = """
27 void OPENSSL_cleanup(void);
28
29 /* SSLeay was removed in 1.1.0 */
30 unsigned long SSLeay(void);
31 const char *SSLeay_version(int);
32 /* these functions were added to replace the SSLeay functions in 1.1.0 */
33 unsigned long OpenSSL_version_num(void);
34 const char *OpenSSL_version(int);
35
36 void *OPENSSL_malloc(size_t);
37 void OPENSSL_free(void *);
38
39
40 /* Signature is significantly different in LibreSSL, so expose via different
41 symbol name */
42 int Cryptography_CRYPTO_set_mem_functions(
43 void *(*)(size_t, const char *, int),
44 void *(*)(void *, size_t, const char *, int),
45 void (*)(void *, const char *, int));
46
47 void *Cryptography_malloc_wrapper(size_t, const char *, int);
48 void *Cryptography_realloc_wrapper(void *, size_t, const char *, int);
49 void Cryptography_free_wrapper(void *, const char *, int);
50 """
51
52 CUSTOMIZATIONS = """
53 /* In 1.1.0 SSLeay has finally been retired. We bidirectionally define the
54 values so you can use either one. This is so we can use the new function
55 names no matter what OpenSSL we're running on, but users on older pyOpenSSL
56 releases won't see issues if they're running OpenSSL 1.1.0 */
57 #if !defined(SSLEAY_VERSION)
58 # define SSLeay OpenSSL_version_num
59 # define SSLeay_version OpenSSL_version
60 # define SSLEAY_VERSION_NUMBER OPENSSL_VERSION_NUMBER
61 # define SSLEAY_VERSION OPENSSL_VERSION
62 # define SSLEAY_CFLAGS OPENSSL_CFLAGS
63 # define SSLEAY_BUILT_ON OPENSSL_BUILT_ON
64 # define SSLEAY_PLATFORM OPENSSL_PLATFORM
65 # define SSLEAY_DIR OPENSSL_DIR
66 #endif
67 #if !defined(OPENSSL_VERSION)
68 # define OpenSSL_version_num SSLeay
69 # define OpenSSL_version SSLeay_version
70 # define OPENSSL_VERSION SSLEAY_VERSION
71 # define OPENSSL_CFLAGS SSLEAY_CFLAGS
72 # define OPENSSL_BUILT_ON SSLEAY_BUILT_ON
73 # define OPENSSL_PLATFORM SSLEAY_PLATFORM
74 # define OPENSSL_DIR SSLEAY_DIR
75 #endif
76
77 #if CRYPTOGRAPHY_IS_LIBRESSL
78 static const long Cryptography_HAS_OPENSSL_CLEANUP = 0;
79 void (*OPENSSL_cleanup)(void) = NULL;
80 #else
81 static const long Cryptography_HAS_OPENSSL_CLEANUP = 1;
82 #endif
83
84 #if CRYPTOGRAPHY_IS_LIBRESSL || CRYPTOGRAPHY_IS_BORINGSSL
85 static const long Cryptography_HAS_MEM_FUNCTIONS = 0;
86 int (*Cryptography_CRYPTO_set_mem_functions)(
87 void *(*)(size_t, const char *, int),
88 void *(*)(void *, size_t, const char *, int),
89 void (*)(void *, const char *, int)) = NULL;
90
91 #else
92 static const long Cryptography_HAS_MEM_FUNCTIONS = 1;
93
94 int Cryptography_CRYPTO_set_mem_functions(
95 void *(*m)(size_t, const char *, int),
96 void *(*r)(void *, size_t, const char *, int),
97 void (*f)(void *, const char *, int)
98 ) {
99 return CRYPTO_set_mem_functions(m, r, f);
100 }
101 #endif
102
103 void *Cryptography_malloc_wrapper(size_t size, const char *path, int line) {
104 return malloc(size);
105 }
106
107 void *Cryptography_realloc_wrapper(void *ptr, size_t size, const char *path,
108 int line) {
109 return realloc(ptr, size);
110 }
111
112 void Cryptography_free_wrapper(void *ptr, const char *path, int line) {
113 free(ptr);
114 }
115 """
116
[end of src/_cffi_src/openssl/crypto.py]
[start of src/_cffi_src/openssl/cryptography.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 INCLUDES = """
7 /* define our OpenSSL API compatibility level to 1.0.1. Any symbols older than
8 that will raise an error during compilation. We can raise this number again
9 after we drop 1.0.2 support in the distant future. */
10 #define OPENSSL_API_COMPAT 0x10001000L
11
12 #if defined(_WIN32)
13 #define WIN32_LEAN_AND_MEAN
14 #include <windows.h>
15 #include <Wincrypt.h>
16 #include <Winsock2.h>
17 /*
18 undef some macros that are defined by wincrypt.h but are also types in
19 boringssl. openssl has worked around this but boring has not yet. see:
20 https://chromium.googlesource.com/chromium/src/+/refs/heads/main/base
21 /win/wincrypt_shim.h
22 */
23 #undef X509_NAME
24 #undef X509_EXTENSIONS
25 #undef PKCS7_SIGNER_INFO
26 #endif
27
28 #include <openssl/opensslv.h>
29
30
31 #if defined(LIBRESSL_VERSION_NUMBER)
32 #define CRYPTOGRAPHY_IS_LIBRESSL 1
33 #else
34 #define CRYPTOGRAPHY_IS_LIBRESSL 0
35 #endif
36
37 #if defined(OPENSSL_IS_BORINGSSL)
38 #define CRYPTOGRAPHY_IS_BORINGSSL 1
39 #else
40 #define CRYPTOGRAPHY_IS_BORINGSSL 0
41 #endif
42
43 #if CRYPTOGRAPHY_IS_LIBRESSL
44 #define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 \
45 (LIBRESSL_VERSION_NUMBER < 0x3050000f)
46
47 #else
48 #define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 (0)
49 #endif
50
51 #if OPENSSL_VERSION_NUMBER < 0x10101000
52 #error "pyca/cryptography MUST be linked with Openssl 1.1.1 or later"
53 #endif
54
55 #define CRYPTOGRAPHY_OPENSSL_111D_OR_GREATER \
56 (OPENSSL_VERSION_NUMBER >= 0x10101040 && !CRYPTOGRAPHY_IS_LIBRESSL)
57 #define CRYPTOGRAPHY_OPENSSL_300_OR_GREATER \
58 (OPENSSL_VERSION_NUMBER >= 0x30000000 && !CRYPTOGRAPHY_IS_LIBRESSL)
59
60 #define CRYPTOGRAPHY_OPENSSL_LESS_THAN_111B \
61 (OPENSSL_VERSION_NUMBER < 0x10101020 || CRYPTOGRAPHY_IS_LIBRESSL)
62 #define CRYPTOGRAPHY_OPENSSL_LESS_THAN_111D \
63 (OPENSSL_VERSION_NUMBER < 0x10101040 || CRYPTOGRAPHY_IS_LIBRESSL)
64 #define CRYPTOGRAPHY_OPENSSL_LESS_THAN_111E \
65 (OPENSSL_VERSION_NUMBER < 0x10101050 || CRYPTOGRAPHY_IS_LIBRESSL)
66 #if (CRYPTOGRAPHY_OPENSSL_LESS_THAN_111D && !CRYPTOGRAPHY_IS_LIBRESSL && \
67 !defined(OPENSSL_NO_ENGINE)) || defined(USE_OSRANDOM_RNG_FOR_TESTING)
68 #define CRYPTOGRAPHY_NEEDS_OSRANDOM_ENGINE 1
69 #else
70 #define CRYPTOGRAPHY_NEEDS_OSRANDOM_ENGINE 0
71 #endif
72 """
73
74 TYPES = """
75 static const int CRYPTOGRAPHY_OPENSSL_111D_OR_GREATER;
76 static const int CRYPTOGRAPHY_OPENSSL_300_OR_GREATER;
77
78 static const int CRYPTOGRAPHY_OPENSSL_LESS_THAN_111B;
79 static const int CRYPTOGRAPHY_OPENSSL_LESS_THAN_111E;
80 static const int CRYPTOGRAPHY_NEEDS_OSRANDOM_ENGINE;
81
82 static const int CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350;
83
84 static const int CRYPTOGRAPHY_IS_LIBRESSL;
85 static const int CRYPTOGRAPHY_IS_BORINGSSL;
86 """
87
88 FUNCTIONS = """
89 """
90
91 CUSTOMIZATIONS = """
92 """
93
[end of src/_cffi_src/openssl/cryptography.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/_cffi_src/openssl/crypto.py b/src/_cffi_src/openssl/crypto.py
--- a/src/_cffi_src/openssl/crypto.py
+++ b/src/_cffi_src/openssl/crypto.py
@@ -74,7 +74,7 @@
# define OPENSSL_DIR SSLEAY_DIR
#endif
-#if CRYPTOGRAPHY_IS_LIBRESSL
+#if CRYPTOGRAPHY_LIBRESSL_LESS_THAN_360
static const long Cryptography_HAS_OPENSSL_CLEANUP = 0;
void (*OPENSSL_cleanup)(void) = NULL;
#else
diff --git a/src/_cffi_src/openssl/cryptography.py b/src/_cffi_src/openssl/cryptography.py
--- a/src/_cffi_src/openssl/cryptography.py
+++ b/src/_cffi_src/openssl/cryptography.py
@@ -43,9 +43,12 @@
#if CRYPTOGRAPHY_IS_LIBRESSL
#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 \
(LIBRESSL_VERSION_NUMBER < 0x3050000f)
+#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_360 \
+ (LIBRESSL_VERSION_NUMBER < 0x3060000f)
#else
#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 (0)
+#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_360 (0)
#endif
#if OPENSSL_VERSION_NUMBER < 0x10101000
|
{"golden_diff": "diff --git a/src/_cffi_src/openssl/crypto.py b/src/_cffi_src/openssl/crypto.py\n--- a/src/_cffi_src/openssl/crypto.py\n+++ b/src/_cffi_src/openssl/crypto.py\n@@ -74,7 +74,7 @@\n # define OPENSSL_DIR SSLEAY_DIR\n #endif\n \n-#if CRYPTOGRAPHY_IS_LIBRESSL\n+#if CRYPTOGRAPHY_LIBRESSL_LESS_THAN_360\n static const long Cryptography_HAS_OPENSSL_CLEANUP = 0;\n void (*OPENSSL_cleanup)(void) = NULL;\n #else\ndiff --git a/src/_cffi_src/openssl/cryptography.py b/src/_cffi_src/openssl/cryptography.py\n--- a/src/_cffi_src/openssl/cryptography.py\n+++ b/src/_cffi_src/openssl/cryptography.py\n@@ -43,9 +43,12 @@\n #if CRYPTOGRAPHY_IS_LIBRESSL\n #define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 \\\n (LIBRESSL_VERSION_NUMBER < 0x3050000f)\n+#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_360 \\\n+ (LIBRESSL_VERSION_NUMBER < 0x3060000f)\n \n #else\n #define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 (0)\n+#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_360 (0)\n #endif\n \n #if OPENSSL_VERSION_NUMBER < 0x10101000\n", "issue": "Build failed on OpenBSD 7.2\nOpenBSD 7.2 upgraded LibreSSL to 3.6.0 (LIBRESSL_VERSION_NUMBER 0x3060000fL) that has OPENSSL_cleanup function.\r\n\r\nPlease update version check in src/_cffi_src/openssl/crypto.py to:\r\n```\r\n#if CRYPTOGRAPHY_IS_LIBRESSL && LIBRESSL_VERSION_NUMBER < 0x3060000fL\r\nstatic const long Cryptography_HAS_OPENSSL_CLEANUP = 0;\r\nvoid (*OPENSSL_cleanup)(void) = NULL;\r\n#else\r\nstatic const long Cryptography_HAS_OPENSSL_CLEANUP = 1;\r\n#endif\r\n```\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nINCLUDES = \"\"\"\n#include <openssl/crypto.h>\n\"\"\"\n\nTYPES = \"\"\"\nstatic const long Cryptography_HAS_MEM_FUNCTIONS;\nstatic const long Cryptography_HAS_OPENSSL_CLEANUP;\n\nstatic const int SSLEAY_VERSION;\nstatic const int SSLEAY_CFLAGS;\nstatic const int SSLEAY_PLATFORM;\nstatic const int SSLEAY_DIR;\nstatic const int SSLEAY_BUILT_ON;\nstatic const int OPENSSL_VERSION;\nstatic const int OPENSSL_CFLAGS;\nstatic const int OPENSSL_BUILT_ON;\nstatic const int OPENSSL_PLATFORM;\nstatic const int OPENSSL_DIR;\n\"\"\"\n\nFUNCTIONS = \"\"\"\nvoid OPENSSL_cleanup(void);\n\n/* SSLeay was removed in 1.1.0 */\nunsigned long SSLeay(void);\nconst char *SSLeay_version(int);\n/* these functions were added to replace the SSLeay functions in 1.1.0 */\nunsigned long OpenSSL_version_num(void);\nconst char *OpenSSL_version(int);\n\nvoid *OPENSSL_malloc(size_t);\nvoid OPENSSL_free(void *);\n\n\n/* Signature is significantly different in LibreSSL, so expose via different\n symbol name */\nint Cryptography_CRYPTO_set_mem_functions(\n void *(*)(size_t, const char *, int),\n void *(*)(void *, size_t, const char *, int),\n void (*)(void *, const char *, int));\n\nvoid *Cryptography_malloc_wrapper(size_t, const char *, int);\nvoid *Cryptography_realloc_wrapper(void *, size_t, const char *, int);\nvoid Cryptography_free_wrapper(void *, const char *, int);\n\"\"\"\n\nCUSTOMIZATIONS = \"\"\"\n/* In 1.1.0 SSLeay has finally been retired. We bidirectionally define the\n values so you can use either one. This is so we can use the new function\n names no matter what OpenSSL we're running on, but users on older pyOpenSSL\n releases won't see issues if they're running OpenSSL 1.1.0 */\n#if !defined(SSLEAY_VERSION)\n# define SSLeay OpenSSL_version_num\n# define SSLeay_version OpenSSL_version\n# define SSLEAY_VERSION_NUMBER OPENSSL_VERSION_NUMBER\n# define SSLEAY_VERSION OPENSSL_VERSION\n# define SSLEAY_CFLAGS OPENSSL_CFLAGS\n# define SSLEAY_BUILT_ON OPENSSL_BUILT_ON\n# define SSLEAY_PLATFORM OPENSSL_PLATFORM\n# define SSLEAY_DIR OPENSSL_DIR\n#endif\n#if !defined(OPENSSL_VERSION)\n# define OpenSSL_version_num SSLeay\n# define OpenSSL_version SSLeay_version\n# define OPENSSL_VERSION SSLEAY_VERSION\n# define OPENSSL_CFLAGS SSLEAY_CFLAGS\n# define OPENSSL_BUILT_ON SSLEAY_BUILT_ON\n# define OPENSSL_PLATFORM SSLEAY_PLATFORM\n# define OPENSSL_DIR SSLEAY_DIR\n#endif\n\n#if CRYPTOGRAPHY_IS_LIBRESSL\nstatic const long Cryptography_HAS_OPENSSL_CLEANUP = 0;\nvoid (*OPENSSL_cleanup)(void) = NULL;\n#else\nstatic const long Cryptography_HAS_OPENSSL_CLEANUP = 1;\n#endif\n\n#if CRYPTOGRAPHY_IS_LIBRESSL || CRYPTOGRAPHY_IS_BORINGSSL\nstatic const long Cryptography_HAS_MEM_FUNCTIONS = 0;\nint (*Cryptography_CRYPTO_set_mem_functions)(\n void *(*)(size_t, const char *, int),\n void *(*)(void *, size_t, const char *, int),\n void (*)(void *, const char *, int)) = NULL;\n\n#else\nstatic const long Cryptography_HAS_MEM_FUNCTIONS = 1;\n\nint Cryptography_CRYPTO_set_mem_functions(\n void *(*m)(size_t, const char *, int),\n void *(*r)(void *, size_t, const char *, int),\n void (*f)(void *, const char *, int)\n) {\n return CRYPTO_set_mem_functions(m, r, f);\n}\n#endif\n\nvoid *Cryptography_malloc_wrapper(size_t size, const char *path, int line) {\n return malloc(size);\n}\n\nvoid *Cryptography_realloc_wrapper(void *ptr, size_t size, const char *path,\n int line) {\n return realloc(ptr, size);\n}\n\nvoid Cryptography_free_wrapper(void *ptr, const char *path, int line) {\n free(ptr);\n}\n\"\"\"\n", "path": "src/_cffi_src/openssl/crypto.py"}, {"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\nINCLUDES = \"\"\"\n/* define our OpenSSL API compatibility level to 1.0.1. Any symbols older than\n that will raise an error during compilation. We can raise this number again\n after we drop 1.0.2 support in the distant future. */\n#define OPENSSL_API_COMPAT 0x10001000L\n\n#if defined(_WIN32)\n#define WIN32_LEAN_AND_MEAN\n#include <windows.h>\n#include <Wincrypt.h>\n#include <Winsock2.h>\n/*\n undef some macros that are defined by wincrypt.h but are also types in\n boringssl. openssl has worked around this but boring has not yet. see:\n https://chromium.googlesource.com/chromium/src/+/refs/heads/main/base\n /win/wincrypt_shim.h\n*/\n#undef X509_NAME\n#undef X509_EXTENSIONS\n#undef PKCS7_SIGNER_INFO\n#endif\n\n#include <openssl/opensslv.h>\n\n\n#if defined(LIBRESSL_VERSION_NUMBER)\n#define CRYPTOGRAPHY_IS_LIBRESSL 1\n#else\n#define CRYPTOGRAPHY_IS_LIBRESSL 0\n#endif\n\n#if defined(OPENSSL_IS_BORINGSSL)\n#define CRYPTOGRAPHY_IS_BORINGSSL 1\n#else\n#define CRYPTOGRAPHY_IS_BORINGSSL 0\n#endif\n\n#if CRYPTOGRAPHY_IS_LIBRESSL\n#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 \\\n (LIBRESSL_VERSION_NUMBER < 0x3050000f)\n\n#else\n#define CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350 (0)\n#endif\n\n#if OPENSSL_VERSION_NUMBER < 0x10101000\n #error \"pyca/cryptography MUST be linked with Openssl 1.1.1 or later\"\n#endif\n\n#define CRYPTOGRAPHY_OPENSSL_111D_OR_GREATER \\\n (OPENSSL_VERSION_NUMBER >= 0x10101040 && !CRYPTOGRAPHY_IS_LIBRESSL)\n#define CRYPTOGRAPHY_OPENSSL_300_OR_GREATER \\\n (OPENSSL_VERSION_NUMBER >= 0x30000000 && !CRYPTOGRAPHY_IS_LIBRESSL)\n\n#define CRYPTOGRAPHY_OPENSSL_LESS_THAN_111B \\\n (OPENSSL_VERSION_NUMBER < 0x10101020 || CRYPTOGRAPHY_IS_LIBRESSL)\n#define CRYPTOGRAPHY_OPENSSL_LESS_THAN_111D \\\n (OPENSSL_VERSION_NUMBER < 0x10101040 || CRYPTOGRAPHY_IS_LIBRESSL)\n#define CRYPTOGRAPHY_OPENSSL_LESS_THAN_111E \\\n (OPENSSL_VERSION_NUMBER < 0x10101050 || CRYPTOGRAPHY_IS_LIBRESSL)\n#if (CRYPTOGRAPHY_OPENSSL_LESS_THAN_111D && !CRYPTOGRAPHY_IS_LIBRESSL && \\\n !defined(OPENSSL_NO_ENGINE)) || defined(USE_OSRANDOM_RNG_FOR_TESTING)\n#define CRYPTOGRAPHY_NEEDS_OSRANDOM_ENGINE 1\n#else\n#define CRYPTOGRAPHY_NEEDS_OSRANDOM_ENGINE 0\n#endif\n\"\"\"\n\nTYPES = \"\"\"\nstatic const int CRYPTOGRAPHY_OPENSSL_111D_OR_GREATER;\nstatic const int CRYPTOGRAPHY_OPENSSL_300_OR_GREATER;\n\nstatic const int CRYPTOGRAPHY_OPENSSL_LESS_THAN_111B;\nstatic const int CRYPTOGRAPHY_OPENSSL_LESS_THAN_111E;\nstatic const int CRYPTOGRAPHY_NEEDS_OSRANDOM_ENGINE;\n\nstatic const int CRYPTOGRAPHY_LIBRESSL_LESS_THAN_350;\n\nstatic const int CRYPTOGRAPHY_IS_LIBRESSL;\nstatic const int CRYPTOGRAPHY_IS_BORINGSSL;\n\"\"\"\n\nFUNCTIONS = \"\"\"\n\"\"\"\n\nCUSTOMIZATIONS = \"\"\"\n\"\"\"\n", "path": "src/_cffi_src/openssl/cryptography.py"}]}
| 3,020 | 341 |
gh_patches_debug_33502
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-3397
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Better handling of posix replica URLs
Motivation
----------
With `rucio.rse.protocols.posix.Default` implementation, the replicas with "file" schema always have port `0` in them, eg
`TEST1: file://:0/tmp/testfile`
Modification
------------
Override `lfns2pfns()` in the posix protocol.
I will submit a pull request for this shortly.
</issue>
<code>
[start of lib/rucio/rse/protocols/posix.py]
1 # Copyright European Organization for Nuclear Research (CERN)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # You may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 # http://www.apache.org/licenses/LICENSE-2.0
7 #
8 # Authors:
9 # - Ralph Vigne, <[email protected]>, 2012-2014
10 # - Nicolo Magini, <[email protected]>, 2018
11 #
12 # PY3K COMPATIBLE
13
14 import os
15 import os.path
16 import shutil
17 from subprocess import call
18
19 from rucio.common import exception
20 from rucio.common.utils import adler32
21 from rucio.rse.protocols import protocol
22
23
24 class Default(protocol.RSEProtocol):
25 """ Implementing access to RSEs using the local filesystem."""
26
27 def exists(self, pfn):
28 """
29 Checks if the requested file is known by the referred RSE.
30
31 :param pfn: Physical file name
32
33 :returns: True if the file exists, False if it doesn't
34
35 :raises SourceNotFound: if the source file was not found on the referred storage.
36 """
37 status = ''
38 try:
39 status = os.path.exists(self.pfn2path(pfn))
40 except Exception as e:
41 raise exception.ServiceUnavailable(e)
42 return status
43
44 def connect(self):
45 """
46 Establishes the actual connection to the referred RSE.
47
48 :param: credentials needed to establish a connection with the stroage.
49
50 :raises RSEAccessDenied: if no connection could be established.
51 """
52 pass
53
54 def close(self):
55 """ Closes the connection to RSE."""
56 pass
57
58 def get(self, pfn, dest, transfer_timeout=None):
59 """ Provides access to files stored inside connected the RSE.
60
61 :param pfn: Physical file name of requested file
62 :param dest: Name and path of the files when stored at the client
63 :param transfer_timeout Transfer timeout (in seconds) - dummy
64
65 :raises DestinationNotAccessible: if the destination storage was not accessible.
66 :raises ServiceUnavailable: if some generic error occured in the library.
67 :raises SourceNotFound: if the source file was not found on the referred storage.
68 """
69 try:
70 shutil.copy(self.pfn2path(pfn), dest)
71 except IOError as e:
72 try: # To check if the error happend local or remote
73 with open(dest, 'wb'):
74 pass
75 call(['rm', '-rf', dest])
76 except IOError as e:
77 if e.errno == 2:
78 raise exception.DestinationNotAccessible(e)
79 else:
80 raise exception.ServiceUnavailable(e)
81 if e.errno == 2:
82 raise exception.SourceNotFound(e)
83 else:
84 raise exception.ServiceUnavailable(e)
85
86 def put(self, source, target, source_dir=None, transfer_timeout=None):
87 """
88 Allows to store files inside the referred RSE.
89
90 :param source: path to the source file on the client file system
91 :param target: path to the destination file on the storage
92 :param source_dir: Path where the to be transferred files are stored in the local file system
93 :param transfer_timeout Transfer timeout (in seconds) - dummy
94
95 :raises DestinationNotAccessible: if the destination storage was not accessible.
96 :raises ServiceUnavailable: if some generic error occured in the library.
97 :raises SourceNotFound: if the source file was not found on the referred storage.
98 """
99 target = self.pfn2path(target)
100
101 if source_dir:
102 sf = source_dir + '/' + source
103 else:
104 sf = source
105 try:
106 dirs = os.path.dirname(target)
107 if not os.path.exists(dirs):
108 os.makedirs(dirs)
109 shutil.copy(sf, target)
110 except IOError as e:
111 if e.errno == 2:
112 raise exception.SourceNotFound(e)
113 elif not self.exists(self.rse['prefix']):
114 path = ''
115 for p in self.rse['prefix'].split('/'):
116 path += p + '/'
117 os.mkdir(path)
118 shutil.copy(sf, self.pfn2path(target))
119 else:
120 raise exception.DestinationNotAccessible(e)
121
122 def delete(self, pfn):
123 """ Deletes a file from the connected RSE.
124
125 :param pfn: pfn to the to be deleted file
126
127 :raises ServiceUnavailable: if some generic error occured in the library.
128 :raises SourceNotFound: if the source file was not found on the referred storage.
129 """
130 try:
131 os.remove(self.pfn2path(pfn))
132 except OSError as e:
133 if e.errno == 2:
134 raise exception.SourceNotFound(e)
135
136 def rename(self, pfn, new_pfn):
137 """ Allows to rename a file stored inside the connected RSE.
138
139 :param path: path to the current file on the storage
140 :param new_path: path to the new file on the storage
141
142 :raises DestinationNotAccessible: if the destination storage was not accessible.
143 :raises ServiceUnavailable: if some generic error occured in the library.
144 :raises SourceNotFound: if the source file was not found on the referred storage.
145 """
146 path = self.pfn2path(pfn)
147 new_path = self.pfn2path(new_pfn)
148 try:
149 if not os.path.exists(os.path.dirname(new_path)):
150 os.makedirs(os.path.dirname(new_path))
151 os.rename(path, new_path)
152 except IOError as e:
153 if e.errno == 2:
154 if self.exists(self.pfn2path(path)):
155 raise exception.SourceNotFound(e)
156 else:
157 raise exception.DestinationNotAccessible(e)
158 else:
159 raise exception.ServiceUnavailable(e)
160
161 def pfn2path(self, pfn):
162 tmp = list(self.parse_pfns(pfn).values())[0]
163 return '/'.join([tmp['prefix'], tmp['path'], tmp['name']])
164
165 def stat(self, pfn):
166 """ Determines the file size in bytes and checksum (adler32) of the provided file.
167
168 :param pfn: The PFN the file.
169
170 :returns: a dict containing the keys filesize and adler32.
171 """
172 path = self.pfn2path(pfn)
173 return {'filesize': os.stat(path)[os.path.stat.ST_SIZE], 'adler32': adler32(path)}
174
[end of lib/rucio/rse/protocols/posix.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/rucio/rse/protocols/posix.py b/lib/rucio/rse/protocols/posix.py
--- a/lib/rucio/rse/protocols/posix.py
+++ b/lib/rucio/rse/protocols/posix.py
@@ -8,6 +8,7 @@
# Authors:
# - Ralph Vigne, <[email protected]>, 2012-2014
# - Nicolo Magini, <[email protected]>, 2018
+# - David Cameron, <[email protected]>, 2020
#
# PY3K COMPATIBLE
@@ -158,6 +159,43 @@
else:
raise exception.ServiceUnavailable(e)
+ def lfns2pfns(self, lfns):
+ """ Returns fully qualified PFNs for the file referred by each lfn in
+ the lfns list.
+
+ :param lfns: List of lfns. If lfn['path'] is present it is used as
+ the path to the file, otherwise the path is constructed
+ deterministically.
+
+ :returns: Fully qualified PFNs.
+ """
+ pfns = {}
+ prefix = self.attributes['prefix']
+
+ if not prefix.startswith('/'):
+ prefix = ''.join(['/', prefix])
+ if not prefix.endswith('/'):
+ prefix = ''.join([prefix, '/'])
+
+ lfns = [lfns] if isinstance(lfns, dict) else lfns
+ for lfn in lfns:
+ scope, name = str(lfn['scope']), lfn['name']
+ if lfn.get('path'):
+ pfns['%s:%s' % (scope, name)] = ''.join([self.attributes['scheme'],
+ '://',
+ self.attributes['hostname'],
+ prefix,
+ lfn['path'] if not lfn['path'].startswith('/') else lfn['path'][1:]
+ ])
+ else:
+ pfns['%s:%s' % (scope, name)] = ''.join([self.attributes['scheme'],
+ '://',
+ self.attributes['hostname'],
+ prefix,
+ self._get_path(scope=scope, name=name)
+ ])
+ return pfns
+
def pfn2path(self, pfn):
tmp = list(self.parse_pfns(pfn).values())[0]
return '/'.join([tmp['prefix'], tmp['path'], tmp['name']])
|
{"golden_diff": "diff --git a/lib/rucio/rse/protocols/posix.py b/lib/rucio/rse/protocols/posix.py\n--- a/lib/rucio/rse/protocols/posix.py\n+++ b/lib/rucio/rse/protocols/posix.py\n@@ -8,6 +8,7 @@\n # Authors:\n # - Ralph Vigne, <[email protected]>, 2012-2014\n # - Nicolo Magini, <[email protected]>, 2018\n+# - David Cameron, <[email protected]>, 2020\n #\n # PY3K COMPATIBLE\n \n@@ -158,6 +159,43 @@\n else:\n raise exception.ServiceUnavailable(e)\n \n+ def lfns2pfns(self, lfns):\n+ \"\"\" Returns fully qualified PFNs for the file referred by each lfn in\n+ the lfns list.\n+\n+ :param lfns: List of lfns. If lfn['path'] is present it is used as\n+ the path to the file, otherwise the path is constructed\n+ deterministically.\n+\n+ :returns: Fully qualified PFNs.\n+ \"\"\"\n+ pfns = {}\n+ prefix = self.attributes['prefix']\n+\n+ if not prefix.startswith('/'):\n+ prefix = ''.join(['/', prefix])\n+ if not prefix.endswith('/'):\n+ prefix = ''.join([prefix, '/'])\n+\n+ lfns = [lfns] if isinstance(lfns, dict) else lfns\n+ for lfn in lfns:\n+ scope, name = str(lfn['scope']), lfn['name']\n+ if lfn.get('path'):\n+ pfns['%s:%s' % (scope, name)] = ''.join([self.attributes['scheme'],\n+ '://',\n+ self.attributes['hostname'],\n+ prefix,\n+ lfn['path'] if not lfn['path'].startswith('/') else lfn['path'][1:]\n+ ])\n+ else:\n+ pfns['%s:%s' % (scope, name)] = ''.join([self.attributes['scheme'],\n+ '://',\n+ self.attributes['hostname'],\n+ prefix,\n+ self._get_path(scope=scope, name=name)\n+ ])\n+ return pfns\n+\n def pfn2path(self, pfn):\n tmp = list(self.parse_pfns(pfn).values())[0]\n return '/'.join([tmp['prefix'], tmp['path'], tmp['name']])\n", "issue": "Better handling of posix replica URLs\nMotivation\r\n----------\r\n\r\nWith `rucio.rse.protocols.posix.Default` implementation, the replicas with \"file\" schema always have port `0` in them, eg\r\n\r\n`TEST1: file://:0/tmp/testfile`\r\n\r\nModification\r\n------------\r\n\r\nOverride `lfns2pfns()` in the posix protocol.\r\n\r\nI will submit a pull request for this shortly.\r\n\n", "before_files": [{"content": "# Copyright European Organization for Nuclear Research (CERN)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# You may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Authors:\n# - Ralph Vigne, <[email protected]>, 2012-2014\n# - Nicolo Magini, <[email protected]>, 2018\n#\n# PY3K COMPATIBLE\n\nimport os\nimport os.path\nimport shutil\nfrom subprocess import call\n\nfrom rucio.common import exception\nfrom rucio.common.utils import adler32\nfrom rucio.rse.protocols import protocol\n\n\nclass Default(protocol.RSEProtocol):\n \"\"\" Implementing access to RSEs using the local filesystem.\"\"\"\n\n def exists(self, pfn):\n \"\"\"\n Checks if the requested file is known by the referred RSE.\n\n :param pfn: Physical file name\n\n :returns: True if the file exists, False if it doesn't\n\n :raises SourceNotFound: if the source file was not found on the referred storage.\n \"\"\"\n status = ''\n try:\n status = os.path.exists(self.pfn2path(pfn))\n except Exception as e:\n raise exception.ServiceUnavailable(e)\n return status\n\n def connect(self):\n \"\"\"\n Establishes the actual connection to the referred RSE.\n\n :param: credentials needed to establish a connection with the stroage.\n\n :raises RSEAccessDenied: if no connection could be established.\n \"\"\"\n pass\n\n def close(self):\n \"\"\" Closes the connection to RSE.\"\"\"\n pass\n\n def get(self, pfn, dest, transfer_timeout=None):\n \"\"\" Provides access to files stored inside connected the RSE.\n\n :param pfn: Physical file name of requested file\n :param dest: Name and path of the files when stored at the client\n :param transfer_timeout Transfer timeout (in seconds) - dummy\n\n :raises DestinationNotAccessible: if the destination storage was not accessible.\n :raises ServiceUnavailable: if some generic error occured in the library.\n :raises SourceNotFound: if the source file was not found on the referred storage.\n \"\"\"\n try:\n shutil.copy(self.pfn2path(pfn), dest)\n except IOError as e:\n try: # To check if the error happend local or remote\n with open(dest, 'wb'):\n pass\n call(['rm', '-rf', dest])\n except IOError as e:\n if e.errno == 2:\n raise exception.DestinationNotAccessible(e)\n else:\n raise exception.ServiceUnavailable(e)\n if e.errno == 2:\n raise exception.SourceNotFound(e)\n else:\n raise exception.ServiceUnavailable(e)\n\n def put(self, source, target, source_dir=None, transfer_timeout=None):\n \"\"\"\n Allows to store files inside the referred RSE.\n\n :param source: path to the source file on the client file system\n :param target: path to the destination file on the storage\n :param source_dir: Path where the to be transferred files are stored in the local file system\n :param transfer_timeout Transfer timeout (in seconds) - dummy\n\n :raises DestinationNotAccessible: if the destination storage was not accessible.\n :raises ServiceUnavailable: if some generic error occured in the library.\n :raises SourceNotFound: if the source file was not found on the referred storage.\n \"\"\"\n target = self.pfn2path(target)\n\n if source_dir:\n sf = source_dir + '/' + source\n else:\n sf = source\n try:\n dirs = os.path.dirname(target)\n if not os.path.exists(dirs):\n os.makedirs(dirs)\n shutil.copy(sf, target)\n except IOError as e:\n if e.errno == 2:\n raise exception.SourceNotFound(e)\n elif not self.exists(self.rse['prefix']):\n path = ''\n for p in self.rse['prefix'].split('/'):\n path += p + '/'\n os.mkdir(path)\n shutil.copy(sf, self.pfn2path(target))\n else:\n raise exception.DestinationNotAccessible(e)\n\n def delete(self, pfn):\n \"\"\" Deletes a file from the connected RSE.\n\n :param pfn: pfn to the to be deleted file\n\n :raises ServiceUnavailable: if some generic error occured in the library.\n :raises SourceNotFound: if the source file was not found on the referred storage.\n \"\"\"\n try:\n os.remove(self.pfn2path(pfn))\n except OSError as e:\n if e.errno == 2:\n raise exception.SourceNotFound(e)\n\n def rename(self, pfn, new_pfn):\n \"\"\" Allows to rename a file stored inside the connected RSE.\n\n :param path: path to the current file on the storage\n :param new_path: path to the new file on the storage\n\n :raises DestinationNotAccessible: if the destination storage was not accessible.\n :raises ServiceUnavailable: if some generic error occured in the library.\n :raises SourceNotFound: if the source file was not found on the referred storage.\n \"\"\"\n path = self.pfn2path(pfn)\n new_path = self.pfn2path(new_pfn)\n try:\n if not os.path.exists(os.path.dirname(new_path)):\n os.makedirs(os.path.dirname(new_path))\n os.rename(path, new_path)\n except IOError as e:\n if e.errno == 2:\n if self.exists(self.pfn2path(path)):\n raise exception.SourceNotFound(e)\n else:\n raise exception.DestinationNotAccessible(e)\n else:\n raise exception.ServiceUnavailable(e)\n\n def pfn2path(self, pfn):\n tmp = list(self.parse_pfns(pfn).values())[0]\n return '/'.join([tmp['prefix'], tmp['path'], tmp['name']])\n\n def stat(self, pfn):\n \"\"\" Determines the file size in bytes and checksum (adler32) of the provided file.\n\n :param pfn: The PFN the file.\n\n :returns: a dict containing the keys filesize and adler32.\n \"\"\"\n path = self.pfn2path(pfn)\n return {'filesize': os.stat(path)[os.path.stat.ST_SIZE], 'adler32': adler32(path)}\n", "path": "lib/rucio/rse/protocols/posix.py"}]}
| 2,449 | 559 |
gh_patches_debug_6430
|
rasdani/github-patches
|
git_diff
|
horovod__horovod-1342
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
terminate called after throwing an instance of 'gloo::EnforceNotMet' ifa != nullptr. Unable to find address for: eth0
hvd.init() throws following error
```
>>> hvd.init()
terminate called after throwing an instance of 'gloo::EnforceNotMet'
what(): [enforce fail at /tmp/pip-install-3dvzdqhs/horovod/third_party/gloo/gloo/transport/tcp/device.cc:88] ifa != nullptr. Unable to find address for: eth0
Aborted
```
What I understand is that gloo is hardcoded to check for eth0 and in my case (Centos 7.6) I have em1 and em2. I came acrros solution to export the below env variables but i am still seeing the issue
```
export GLOO_SOCKET_IFNAME=em2
export NCCL_SOCKET_IFNAME=em2
```
How can I get pass this?
**Environment:**
Framework: Keras
Tensorflow Version 1.13.1
Keras Version 2.2.4-tf
Horovod version: horovod==0.17.0.post1
Python version: 3.6
</issue>
<code>
[start of horovod/run/gloo_run.py]
1 # Copyright 2019 Uber Technologies, Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15
16 import os
17 import collections
18 import threading
19 import signal
20
21 from horovod.run.rendezvous.http_server import RendezvousServer
22 from horovod.run.common.util import env as env_util, safe_shell_exec
23 from horovod.run.util import threads
24 from psutil import net_if_addrs
25 from socket import AF_INET
26
27 try:
28 from shlex import quote
29 except ImportError:
30 from pipes import quote
31
32
33 class HostInfo:
34 def __init__(self, host_item):
35 hostname, slots = host_item.strip().split(':')
36 self.hostname = hostname
37 self.slots = int(slots)
38
39
40 class SlotInfo:
41 def __init__(self, hostname, rank, local_rank, cross_rank, size):
42 self.hostname = hostname
43 self.rank = rank
44 self.size = size
45 self.local_rank = local_rank
46 self.local_size = None
47 self.cross_rank = cross_rank
48 self.cross_size = None
49
50
51 def _allocate(hosts, np):
52 """
53 Find the allocation of processes on hosts, this function will try to
54 allocate as many as possible processes on the same host to leverage
55 local network.
56 :param hosts: list of addresses and number of processes on each host.
57 For example,
58 'worker-0:2,worker-1:2'
59 '10.11.11.11:4,10.11.11.12,4'
60 :type hosts: string
61 :param np: total number of processes to be allocated
62 :type np: int
63 :return: a list of the allocation of process on hosts in a AllocInfo object.
64 Members in the object include: hostname, rank, local_rank, cross_rank,
65 total_size, local_size, cross_size
66 :rtype: list[dict()]
67 """
68
69 host_list = []
70 # split the host string to host list
71 for host_item in hosts.split(','):
72 host_list.append(HostInfo(host_item))
73
74 rank = 0
75 alloc_list = []
76
77 # key: local_rank; value: cross_size for this local_rank
78 local_sizes = collections.defaultdict(int)
79 # key: cross_rank; value: local_size for this cross_rank
80 cross_sizes = collections.defaultdict(int)
81
82 # allocate processes into slots
83 for host_idx, host_info in enumerate(host_list):
84 for local_rank in range(host_info.slots):
85 if rank == np:
86 break
87 cross_rank = host_idx
88 alloc_list.append(
89 SlotInfo(
90 host_info.hostname,
91 rank,
92 local_rank,
93 cross_rank,
94 np))
95 cross_sizes[local_rank] += 1
96 local_sizes[cross_rank] += 1
97 rank += 1
98
99 if rank < np:
100 raise ValueError("Process number should not be larger than "
101 "total available slots.")
102
103 # Fill in the local_size and cross_size because we can only know these number after
104 # allocation is done.
105 for alloc_item in alloc_list:
106 alloc_item.local_size = local_sizes[alloc_item.cross_rank]
107 alloc_item.cross_size = cross_sizes[alloc_item.local_rank]
108
109 return alloc_list
110
111
112 def _launch_jobs(settings, host_alloc_plan, remote_host_names, _run_command):
113 """
114 executes the jobs defined by run command on hosts.
115 :param hosts_alloc: list of dict indicating the allocating info.
116 For example,
117 [{'Hostname':'worker-0', 'Rank': 0, 'Local_rank': 0, 'Cross_rank':0,
118 'Size':2, 'Local_size':1, 'Cross_size':2},
119 {'Hostname':'worker-1', 'Rank': 1, 'Local_rank': 0, 'Cross_rank':1,
120 'Size':2, 'Local_size':1, 'Cross_size':2}
121 ]
122 :type hosts_alloc: list(dict)
123 :param remote_host_names: names that are resolved to one of the addresses
124 of remote hosts interfaces.
125 :type remote_host_names: set
126 :param _run_command: command to execute
127 :type _run_command: string
128 :return:
129 :rtype:
130 """
131
132 def _exec_command(_command, _index, event_):
133 if settings.verbose:
134 print(_command)
135 try:
136 exit_code = safe_shell_exec.execute(_command, index=_index, event=event_)
137 if exit_code != 0:
138 print('Process {idx} exit with status code {ec}.'.format(idx=_index, ec=exit_code))
139 except Exception as e:
140 print('Exception happened during safe_shell_exec, exception '
141 'message: {message}'.format(message=e))
142 return 0
143
144 ssh_port_arg = '-p {ssh_port}'.format(ssh_port=settings.ssh_port) if settings.ssh_port else ''
145
146 # Create a event for communication between threads
147 event = threading.Event()
148
149 def set_event_on_sigterm(signum, frame):
150 event.set()
151
152 signal.signal(signal.SIGINT, set_event_on_sigterm)
153 signal.signal(signal.SIGTERM, set_event_on_sigterm)
154
155 args_list = []
156 for alloc_info in host_alloc_plan:
157 # generate env for rendezvous
158 horovod_rendez_env = 'HOROVOD_RANK={rank} HOROVOD_SIZE={size} ' \
159 'HOROVOD_LOCAL_RANK={local_rank} HOROVOD_LOCAL_SIZE={local_size} ' \
160 'HOROVOD_CROSS_RANK={cross_rank} HOROVOD_CROSS_SIZE={cross_size} ' \
161 .format(rank=alloc_info.rank, size=alloc_info.size,
162 local_rank=alloc_info.local_rank, local_size=alloc_info.local_size,
163 cross_rank=alloc_info.cross_rank, cross_size=alloc_info.cross_size)
164
165 host_name = alloc_info.hostname
166
167 env = os.environ.copy()
168 # TODO: Workaround for over-buffered outputs. Investigate how mpirun avoids this problem.
169 env['PYTHONUNBUFFERED'] = '1'
170 local_command = '{horovod_env} {env} {run_command}' .format(
171 horovod_env=horovod_rendez_env,
172 env=' '.join(['%s=%s' % (key, quote(value)) for key, value in env.items()
173 if env_util.is_exportable(key)]),
174 run_command=_run_command)
175
176 if host_name not in remote_host_names:
177 command = local_command
178 else:
179 command = 'ssh -o StrictHostKeyChecking=no {host} {ssh_port_arg} ' \
180 '{local_command}'.format(
181 host=host_name,
182 ssh_port_arg=ssh_port_arg,
183 local_command=quote('cd {pwd} >& /dev/null ; {local_command}'
184 .format(pwd=os.getcwd(), local_command=local_command))
185 )
186 args_list.append([command, alloc_info.rank, event])
187
188 # Each thread will use ssh command to launch the job on each remote host. If an
189 # error occurs in one thread, entire process will be terminated. Otherwise,
190 # threads will keep running and ssh session. In case, the main thread receives
191 # a SIGINT, the event will be set and the spawned threads will kill their
192 # corresponding middleman processes and thus the jobs will be killed as
193 # well.
194 threads.execute_function_multithreaded(_exec_command,
195 args_list,
196 block_until_all_done=True)
197
198
199 def gloo_run(settings, remote_host_names, common_intfs):
200 # allocate processes into slots
201 host_alloc_plan = _allocate(settings.hosts, settings.num_proc)
202
203 # create global rendezvous server
204 global_rendezv = RendezvousServer(settings.verbose)
205 # Start rendezvous server and get port that it is listening
206 global_rendezv_port = global_rendezv.start_server(host_alloc_plan)
207
208 # get the server IPv4 address
209 iface = list(common_intfs)[0]
210 server_ip = None
211 for addr in net_if_addrs()[iface]:
212 if addr.family == AF_INET:
213 server_ip = addr.address
214
215 if not server_ip:
216 raise RuntimeError(
217 'Cannot find an IPv4 address of the common interface.')
218
219 run_command = (
220 'HOROVOD_GLOO_RENDEZVOUS_ADDR={addr} '
221 'HOROVOD_GLOO_RENDEZVOUS_PORT={port} '
222 'HOROVOD_CONTROLLER=gloo '
223 'HOROVOD_CPU_OPERATIONS=gloo '
224 'HOROVOD_IFACE={iface} '
225 'NCCL_SOCKET_IFNAME={common_intfs} '
226 '{command}' # expect a lot of environment variables
227 .format(addr=server_ip,
228 port=global_rendezv_port,
229 iface=iface, # TODO: add multiple ifaces in future
230 common_intfs=','.join(common_intfs),
231 command=' '.join(quote(par) for par in settings.command)))
232
233 _launch_jobs(settings, host_alloc_plan, remote_host_names, run_command)
234 return
235
[end of horovod/run/gloo_run.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/horovod/run/gloo_run.py b/horovod/run/gloo_run.py
--- a/horovod/run/gloo_run.py
+++ b/horovod/run/gloo_run.py
@@ -221,7 +221,7 @@
'HOROVOD_GLOO_RENDEZVOUS_PORT={port} '
'HOROVOD_CONTROLLER=gloo '
'HOROVOD_CPU_OPERATIONS=gloo '
- 'HOROVOD_IFACE={iface} '
+ 'HOROVOD_GLOO_IFACE={iface} '
'NCCL_SOCKET_IFNAME={common_intfs} '
'{command}' # expect a lot of environment variables
.format(addr=server_ip,
|
{"golden_diff": "diff --git a/horovod/run/gloo_run.py b/horovod/run/gloo_run.py\n--- a/horovod/run/gloo_run.py\n+++ b/horovod/run/gloo_run.py\n@@ -221,7 +221,7 @@\n 'HOROVOD_GLOO_RENDEZVOUS_PORT={port} '\n 'HOROVOD_CONTROLLER=gloo '\n 'HOROVOD_CPU_OPERATIONS=gloo '\n- 'HOROVOD_IFACE={iface} '\n+ 'HOROVOD_GLOO_IFACE={iface} '\n 'NCCL_SOCKET_IFNAME={common_intfs} '\n '{command}' # expect a lot of environment variables\n .format(addr=server_ip,\n", "issue": "terminate called after throwing an instance of 'gloo::EnforceNotMet' ifa != nullptr. Unable to find address for: eth0\nhvd.init() throws following error\r\n```\r\n>>> hvd.init()\r\nterminate called after throwing an instance of 'gloo::EnforceNotMet'\r\n what(): [enforce fail at /tmp/pip-install-3dvzdqhs/horovod/third_party/gloo/gloo/transport/tcp/device.cc:88] ifa != nullptr. Unable to find address for: eth0\r\nAborted\r\n```\r\nWhat I understand is that gloo is hardcoded to check for eth0 and in my case (Centos 7.6) I have em1 and em2. I came acrros solution to export the below env variables but i am still seeing the issue\r\n```\r\nexport GLOO_SOCKET_IFNAME=em2\r\nexport NCCL_SOCKET_IFNAME=em2\r\n```\r\nHow can I get pass this?\r\n\r\n**Environment:**\r\nFramework: Keras\r\nTensorflow Version 1.13.1\r\nKeras Version 2.2.4-tf\r\nHorovod version: horovod==0.17.0.post1\r\nPython version: 3.6\r\n\n", "before_files": [{"content": "# Copyright 2019 Uber Technologies, Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\nimport os\nimport collections\nimport threading\nimport signal\n\nfrom horovod.run.rendezvous.http_server import RendezvousServer\nfrom horovod.run.common.util import env as env_util, safe_shell_exec\nfrom horovod.run.util import threads\nfrom psutil import net_if_addrs\nfrom socket import AF_INET\n\ntry:\n from shlex import quote\nexcept ImportError:\n from pipes import quote\n\n\nclass HostInfo:\n def __init__(self, host_item):\n hostname, slots = host_item.strip().split(':')\n self.hostname = hostname\n self.slots = int(slots)\n\n\nclass SlotInfo:\n def __init__(self, hostname, rank, local_rank, cross_rank, size):\n self.hostname = hostname\n self.rank = rank\n self.size = size\n self.local_rank = local_rank\n self.local_size = None\n self.cross_rank = cross_rank\n self.cross_size = None\n\n\ndef _allocate(hosts, np):\n \"\"\"\n Find the allocation of processes on hosts, this function will try to\n allocate as many as possible processes on the same host to leverage\n local network.\n :param hosts: list of addresses and number of processes on each host.\n For example,\n 'worker-0:2,worker-1:2'\n '10.11.11.11:4,10.11.11.12,4'\n :type hosts: string\n :param np: total number of processes to be allocated\n :type np: int\n :return: a list of the allocation of process on hosts in a AllocInfo object.\n Members in the object include: hostname, rank, local_rank, cross_rank,\n total_size, local_size, cross_size\n :rtype: list[dict()]\n \"\"\"\n\n host_list = []\n # split the host string to host list\n for host_item in hosts.split(','):\n host_list.append(HostInfo(host_item))\n\n rank = 0\n alloc_list = []\n\n # key: local_rank; value: cross_size for this local_rank\n local_sizes = collections.defaultdict(int)\n # key: cross_rank; value: local_size for this cross_rank\n cross_sizes = collections.defaultdict(int)\n\n # allocate processes into slots\n for host_idx, host_info in enumerate(host_list):\n for local_rank in range(host_info.slots):\n if rank == np:\n break\n cross_rank = host_idx\n alloc_list.append(\n SlotInfo(\n host_info.hostname,\n rank,\n local_rank,\n cross_rank,\n np))\n cross_sizes[local_rank] += 1\n local_sizes[cross_rank] += 1\n rank += 1\n\n if rank < np:\n raise ValueError(\"Process number should not be larger than \"\n \"total available slots.\")\n\n # Fill in the local_size and cross_size because we can only know these number after\n # allocation is done.\n for alloc_item in alloc_list:\n alloc_item.local_size = local_sizes[alloc_item.cross_rank]\n alloc_item.cross_size = cross_sizes[alloc_item.local_rank]\n\n return alloc_list\n\n\ndef _launch_jobs(settings, host_alloc_plan, remote_host_names, _run_command):\n \"\"\"\n executes the jobs defined by run command on hosts.\n :param hosts_alloc: list of dict indicating the allocating info.\n For example,\n [{'Hostname':'worker-0', 'Rank': 0, 'Local_rank': 0, 'Cross_rank':0,\n 'Size':2, 'Local_size':1, 'Cross_size':2},\n {'Hostname':'worker-1', 'Rank': 1, 'Local_rank': 0, 'Cross_rank':1,\n 'Size':2, 'Local_size':1, 'Cross_size':2}\n ]\n :type hosts_alloc: list(dict)\n :param remote_host_names: names that are resolved to one of the addresses\n of remote hosts interfaces.\n :type remote_host_names: set\n :param _run_command: command to execute\n :type _run_command: string\n :return:\n :rtype:\n \"\"\"\n\n def _exec_command(_command, _index, event_):\n if settings.verbose:\n print(_command)\n try:\n exit_code = safe_shell_exec.execute(_command, index=_index, event=event_)\n if exit_code != 0:\n print('Process {idx} exit with status code {ec}.'.format(idx=_index, ec=exit_code))\n except Exception as e:\n print('Exception happened during safe_shell_exec, exception '\n 'message: {message}'.format(message=e))\n return 0\n\n ssh_port_arg = '-p {ssh_port}'.format(ssh_port=settings.ssh_port) if settings.ssh_port else ''\n\n # Create a event for communication between threads\n event = threading.Event()\n\n def set_event_on_sigterm(signum, frame):\n event.set()\n\n signal.signal(signal.SIGINT, set_event_on_sigterm)\n signal.signal(signal.SIGTERM, set_event_on_sigterm)\n\n args_list = []\n for alloc_info in host_alloc_plan:\n # generate env for rendezvous\n horovod_rendez_env = 'HOROVOD_RANK={rank} HOROVOD_SIZE={size} ' \\\n 'HOROVOD_LOCAL_RANK={local_rank} HOROVOD_LOCAL_SIZE={local_size} ' \\\n 'HOROVOD_CROSS_RANK={cross_rank} HOROVOD_CROSS_SIZE={cross_size} ' \\\n .format(rank=alloc_info.rank, size=alloc_info.size,\n local_rank=alloc_info.local_rank, local_size=alloc_info.local_size,\n cross_rank=alloc_info.cross_rank, cross_size=alloc_info.cross_size)\n\n host_name = alloc_info.hostname\n\n env = os.environ.copy()\n # TODO: Workaround for over-buffered outputs. Investigate how mpirun avoids this problem.\n env['PYTHONUNBUFFERED'] = '1'\n local_command = '{horovod_env} {env} {run_command}' .format(\n horovod_env=horovod_rendez_env,\n env=' '.join(['%s=%s' % (key, quote(value)) for key, value in env.items()\n if env_util.is_exportable(key)]),\n run_command=_run_command)\n\n if host_name not in remote_host_names:\n command = local_command\n else:\n command = 'ssh -o StrictHostKeyChecking=no {host} {ssh_port_arg} ' \\\n '{local_command}'.format(\n host=host_name,\n ssh_port_arg=ssh_port_arg,\n local_command=quote('cd {pwd} >& /dev/null ; {local_command}'\n .format(pwd=os.getcwd(), local_command=local_command))\n )\n args_list.append([command, alloc_info.rank, event])\n\n # Each thread will use ssh command to launch the job on each remote host. If an\n # error occurs in one thread, entire process will be terminated. Otherwise,\n # threads will keep running and ssh session. In case, the main thread receives\n # a SIGINT, the event will be set and the spawned threads will kill their\n # corresponding middleman processes and thus the jobs will be killed as\n # well.\n threads.execute_function_multithreaded(_exec_command,\n args_list,\n block_until_all_done=True)\n\n\ndef gloo_run(settings, remote_host_names, common_intfs):\n # allocate processes into slots\n host_alloc_plan = _allocate(settings.hosts, settings.num_proc)\n\n # create global rendezvous server\n global_rendezv = RendezvousServer(settings.verbose)\n # Start rendezvous server and get port that it is listening\n global_rendezv_port = global_rendezv.start_server(host_alloc_plan)\n\n # get the server IPv4 address\n iface = list(common_intfs)[0]\n server_ip = None\n for addr in net_if_addrs()[iface]:\n if addr.family == AF_INET:\n server_ip = addr.address\n\n if not server_ip:\n raise RuntimeError(\n 'Cannot find an IPv4 address of the common interface.')\n\n run_command = (\n 'HOROVOD_GLOO_RENDEZVOUS_ADDR={addr} '\n 'HOROVOD_GLOO_RENDEZVOUS_PORT={port} '\n 'HOROVOD_CONTROLLER=gloo '\n 'HOROVOD_CPU_OPERATIONS=gloo '\n 'HOROVOD_IFACE={iface} '\n 'NCCL_SOCKET_IFNAME={common_intfs} '\n '{command}' # expect a lot of environment variables\n .format(addr=server_ip,\n port=global_rendezv_port,\n iface=iface, # TODO: add multiple ifaces in future\n common_intfs=','.join(common_intfs),\n command=' '.join(quote(par) for par in settings.command)))\n\n _launch_jobs(settings, host_alloc_plan, remote_host_names, run_command)\n return\n", "path": "horovod/run/gloo_run.py"}]}
| 3,513 | 167 |
gh_patches_debug_29111
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-365
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Broken `entry` command
### Description
The `entry` command pass arguments differently then the `run` command.
### Steps to reproduce
```
[dc@dc:pwndbg|dev *$%]$ gdb python
Loaded 113 commands. Type pwndbg [filter] for a list.
Reading symbols from python...(no debugging symbols found)...done.
pwndbg> set exception-verbose on
Set whether to print a full stacktracefor exceptions raised in Pwndbg commands to True
pwndbg> run -c "print(1); print(2)"
Starting program: /usr/bin/python -c "print(1); print(2)"
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/usr/lib/libthread_db.so.1".
1
2
[Inferior 1 (process 20590) exited normally]
pwndbg> entry -c "print(1); print(2)"
('-c', 'print(1); print(2)')
Running '%s' run -c print(1); print(2)
/bin/bash: -c: line 0: syntax error near unexpected token `('
/bin/bash: -c: line 0: `exec /usr/bin/python -c print(1); print(2)'
Traceback (most recent call last):
File "/home/dc/installed/pwndbg/pwndbg/commands/__init__.py", line 100, in __call__
return self.function(*args, **kwargs)
File "/home/dc/installed/pwndbg/pwndbg/commands/__init__.py", line 181, in _OnlyWithFile
return function(*a, **kw)
File "/home/dc/installed/pwndbg/pwndbg/commands/start.py", line 72, in entry
gdb.execute(run, from_tty=False)
gdb.error: During startup program exited with code 1.
If that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues
(Please don't forget to search if it hasn't been reported before)
PS: Pull requests are welcome
```
### My version
```
pwndbg> version
Gdb: GNU gdb (GDB) 8.0.1
Python: 3.6.3 (default, Oct 24 2017, 14:48:20) [GCC 7.2.0]
Pwndbg: 1.0.0 build: 5811010
```
</issue>
<code>
[start of pwndbg/commands/start.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 Launches the target process after setting a breakpoint at a convenient
5 entry point.
6 """
7 from __future__ import absolute_import
8 from __future__ import division
9 from __future__ import print_function
10 from __future__ import unicode_literals
11
12 import gdb
13
14 import pwndbg.commands
15 import pwndbg.elf
16 import pwndbg.events
17 import pwndbg.symbol
18
19 break_on_first_instruction = False
20
21
22 @pwndbg.events.start
23 def on_start():
24 global break_on_first_instruction
25 if break_on_first_instruction:
26 spec = "*%#x" % (int(pwndbg.elf.entry()))
27 gdb.Breakpoint(spec, temporary=True)
28 break_on_first_instruction = False
29
30
31 @pwndbg.commands.Command
32 def start(*a):
33 """
34 Set a breakpoint at a convenient location in the binary,
35 generally 'main', 'init', or the entry point.
36 """
37 run = 'run ' + ' '.join(a)
38
39 symbols = ["main",
40 "_main",
41 "start",
42 "_start",
43 "init",
44 "_init"]
45
46 for symbol in symbols:
47 address = pwndbg.symbol.address(symbol)
48
49 if not address:
50 continue
51
52 b = gdb.Breakpoint(symbol, temporary=True)
53 gdb.execute(run, from_tty=False, to_string=True)
54 return
55
56 # Try a breakpoint at the binary entry
57 entry(*a)
58
59
60 @pwndbg.commands.Command
61 @pwndbg.commands.OnlyWithFile
62 def entry(*a):
63 """
64 Set a breakpoint at the first instruction executed in
65 the target binary.
66 """
67 global break_on_first_instruction
68 break_on_first_instruction = True
69 run = 'run ' + ' '.join(a)
70 gdb.execute(run, from_tty=False)
71
[end of pwndbg/commands/start.py]
[start of pwndbg/prompt.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from __future__ import absolute_import
4 from __future__ import division
5 from __future__ import print_function
6 from __future__ import unicode_literals
7
8 import gdb
9
10 import pwndbg.events
11 import pwndbg.memoize
12
13 hint_msg = 'Loaded %i commands. Type pwndbg [filter] for a list.' % len(pwndbg.commands.Command.commands)
14
15 print(pwndbg.color.red(hint_msg))
16 cur = (gdb.selected_inferior(), gdb.selected_thread())
17
18
19 def prompt_hook(*a):
20 global cur
21 new = (gdb.selected_inferior(), gdb.selected_thread())
22
23 if cur != new:
24 pwndbg.events.after_reload(start=False)
25 cur = new
26
27 if pwndbg.proc.alive and pwndbg.proc.thread_is_stopped:
28 prompt_hook_on_stop(*a)
29
30
31 @pwndbg.memoize.reset_on_stop
32 def prompt_hook_on_stop(*a):
33 pwndbg.commands.context.context()
34
35
36 gdb.prompt_hook = prompt_hook
37
[end of pwndbg/prompt.py]
[start of pwndbg/dt.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """
4 Prints structures in a manner similar to Windbg's "dt" command.
5 """
6 from __future__ import absolute_import
7 from __future__ import division
8 from __future__ import print_function
9 from __future__ import unicode_literals
10
11 import glob
12 import os
13 import re
14 import subprocess
15 import tempfile
16
17 import gdb
18
19 import pwndbg.memory
20 import pwndbg.typeinfo
21
22
23 def get_type(v):
24 t = v.type
25 while not t.name:
26 if t.code == gdb.TYPE_CODE_PTR:
27 t = t.target()
28 return t.name
29
30 def get_typename(t):
31 return(str(t))
32
33 def get_arrsize(f):
34 t = f.type
35 if t.code != gdb.TYPE_CODE_ARRAY:
36 return 0
37 t2 = t.target()
38 s = t2.sizeof
39 return int(t.sizeof / t2.sizeof)
40
41 def get_field_by_name(obj, field):
42 # Dereference once
43 if obj.type.code == gdb.TYPE_CODE_PTR:
44 obj = obj.dereference()
45 for f in re.split('(->|\.|\[\d+\])', field):
46 if not f: continue
47 if f == '->':
48 obj = obj.dereference()
49 elif f == '.':
50 pass
51 elif f.startswith('['):
52 n = int(f.strip('[]'))
53 obj = obj.cast(obj.dereference().type.pointer())
54 obj += n
55 obj = obj.dereference()
56 else:
57 obj = obj[f]
58 return obj
59
60 def happy(typename):
61 prefix = ''
62 if 'unsigned' in typename:
63 prefix = 'u'
64 typename = typename.replace('unsigned ', '')
65 return prefix + {
66 'char': 'char',
67 'short int': 'short',
68 'long int': 'long',
69 'int': 'int',
70 'long long': 'longlong',
71 'float': 'float',
72 'double': 'double'
73 }[typename]
74
75 def dt(name='', addr=None, obj = None):
76 """
77 Dump out a structure type Windbg style.
78 """
79 # Return value is a list of strings.of
80 # We concatenate at the end.
81 rv = []
82
83 if obj and not name:
84 t = obj.type
85 while t.code == (gdb.TYPE_CODE_PTR):
86 t = t.target()
87 obj = obj.dereference()
88 name = str(t)
89
90 # Lookup the type name specified by the user
91 else:
92 t = pwndbg.typeinfo.load(name)
93
94 # If it's not a struct (e.g. int or char*), bail
95 if t.code not in (gdb.TYPE_CODE_STRUCT, gdb.TYPE_CODE_TYPEDEF, gdb.TYPE_CODE_UNION):
96 raise Exception("Not a structure: %s" % t)
97
98 # If an address was specified, create a Value of the
99 # specified type at that address.
100 if addr is not None:
101 obj = pwndbg.memory.poi(t, addr)
102
103 # Header, optionally include the name
104 header = name
105 if obj: header = "%s @ %s" % (header, hex(int(obj.address)))
106 rv.append(header)
107
108 if t.strip_typedefs().code == gdb.TYPE_CODE_ARRAY:
109 return "Arrays not supported yet"
110 if t.strip_typedefs().code not in (gdb.TYPE_CODE_STRUCT, gdb.TYPE_CODE_UNION):
111 t = {name: obj or gdb.Value(0).cast(t)}
112
113 for name, field in t.items():
114 # Offset into the parent structure
115 o = getattr(field, 'bitpos', 0)/8
116 extra = str(field.type)
117 ftype = field.type.strip_typedefs()
118
119 if obj and obj.type.strip_typedefs().code in (gdb.TYPE_CODE_STRUCT, gdb.TYPE_CODE_UNION):
120 v = obj[name]
121
122 if ftype.code == gdb.TYPE_CODE_INT:
123 v = hex(int(v))
124 if ftype.code in (gdb.TYPE_CODE_PTR, gdb.TYPE_CODE_ARRAY) \
125 and ftype.target() == pwndbg.typeinfo.uchar:
126 data = pwndbg.memory.read(v.address, ftype.sizeof)
127 v = ' '.join('%02x' % b for b in data)
128
129 extra = v
130
131 # Adjust trailing lines in 'extra' to line up
132 # This is necessary when there are nested structures.
133 # Ideally we'd expand recursively if the type is complex.
134 extra_lines = []
135 for i, line in enumerate(str(extra).splitlines()):
136 if i == 0: extra_lines.append(line)
137 else: extra_lines.append(35*' ' + line)
138 extra = '\n'.join(extra_lines)
139
140 line = " +0x%04x %-20s : %s" % (o, name, extra)
141 rv.append(line)
142
143 return ('\n'.join(rv))
144
[end of pwndbg/dt.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwndbg/commands/start.py b/pwndbg/commands/start.py
--- a/pwndbg/commands/start.py
+++ b/pwndbg/commands/start.py
@@ -9,6 +9,8 @@
from __future__ import print_function
from __future__ import unicode_literals
+import shlex
+
import gdb
import pwndbg.commands
@@ -66,5 +68,5 @@
"""
global break_on_first_instruction
break_on_first_instruction = True
- run = 'run ' + ' '.join(a)
+ run = 'run ' + ' '.join(map(shlex.quote, a))
gdb.execute(run, from_tty=False)
diff --git a/pwndbg/dt.py b/pwndbg/dt.py
--- a/pwndbg/dt.py
+++ b/pwndbg/dt.py
@@ -112,7 +112,8 @@
for name, field in t.items():
# Offset into the parent structure
- o = getattr(field, 'bitpos', 0)/8
+ o = getattr(field, 'bitpos', 0) // 8
+ b = getattr(field, 'bitpos', 0) % 8
extra = str(field.type)
ftype = field.type.strip_typedefs()
@@ -137,7 +138,9 @@
else: extra_lines.append(35*' ' + line)
extra = '\n'.join(extra_lines)
- line = " +0x%04x %-20s : %s" % (o, name, extra)
+ bitpos = '' if not b else ('.%i' % b)
+
+ line = " +0x%04x%s %-20s : %s" % (o, bitpos, name, extra)
rv.append(line)
return ('\n'.join(rv))
diff --git a/pwndbg/prompt.py b/pwndbg/prompt.py
--- a/pwndbg/prompt.py
+++ b/pwndbg/prompt.py
@@ -33,4 +33,5 @@
pwndbg.commands.context.context()
+
gdb.prompt_hook = prompt_hook
|
{"golden_diff": "diff --git a/pwndbg/commands/start.py b/pwndbg/commands/start.py\n--- a/pwndbg/commands/start.py\n+++ b/pwndbg/commands/start.py\n@@ -9,6 +9,8 @@\n from __future__ import print_function\n from __future__ import unicode_literals\n \n+import shlex\n+\n import gdb\n \n import pwndbg.commands\n@@ -66,5 +68,5 @@\n \"\"\"\n global break_on_first_instruction\n break_on_first_instruction = True\n- run = 'run ' + ' '.join(a)\n+ run = 'run ' + ' '.join(map(shlex.quote, a))\n gdb.execute(run, from_tty=False)\ndiff --git a/pwndbg/dt.py b/pwndbg/dt.py\n--- a/pwndbg/dt.py\n+++ b/pwndbg/dt.py\n@@ -112,7 +112,8 @@\n \n for name, field in t.items():\n # Offset into the parent structure\n- o = getattr(field, 'bitpos', 0)/8\n+ o = getattr(field, 'bitpos', 0) // 8\n+ b = getattr(field, 'bitpos', 0) % 8\n extra = str(field.type)\n ftype = field.type.strip_typedefs()\n \n@@ -137,7 +138,9 @@\n else: extra_lines.append(35*' ' + line)\n extra = '\\n'.join(extra_lines)\n \n- line = \" +0x%04x %-20s : %s\" % (o, name, extra)\n+ bitpos = '' if not b else ('.%i' % b)\n+\n+ line = \" +0x%04x%s %-20s : %s\" % (o, bitpos, name, extra)\n rv.append(line)\n \n return ('\\n'.join(rv))\ndiff --git a/pwndbg/prompt.py b/pwndbg/prompt.py\n--- a/pwndbg/prompt.py\n+++ b/pwndbg/prompt.py\n@@ -33,4 +33,5 @@\n pwndbg.commands.context.context()\n \n \n+\n gdb.prompt_hook = prompt_hook\n", "issue": "Broken `entry` command\n### Description\r\n\r\nThe `entry` command pass arguments differently then the `run` command.\r\n\r\n### Steps to reproduce\r\n\r\n```\r\n[dc@dc:pwndbg|dev *$%]$ gdb python\r\nLoaded 113 commands. Type pwndbg [filter] for a list.\r\nReading symbols from python...(no debugging symbols found)...done.\r\npwndbg> set exception-verbose on\r\nSet whether to print a full stacktracefor exceptions raised in Pwndbg commands to True\r\npwndbg> run -c \"print(1); print(2)\"\r\nStarting program: /usr/bin/python -c \"print(1); print(2)\"\r\n[Thread debugging using libthread_db enabled]\r\nUsing host libthread_db library \"/usr/lib/libthread_db.so.1\".\r\n1\r\n2\r\n[Inferior 1 (process 20590) exited normally]\r\npwndbg> entry -c \"print(1); print(2)\"\r\n('-c', 'print(1); print(2)')\r\nRunning '%s' run -c print(1); print(2)\r\n/bin/bash: -c: line 0: syntax error near unexpected token `('\r\n/bin/bash: -c: line 0: `exec /usr/bin/python -c print(1); print(2)'\r\nTraceback (most recent call last):\r\n File \"/home/dc/installed/pwndbg/pwndbg/commands/__init__.py\", line 100, in __call__\r\n return self.function(*args, **kwargs)\r\n File \"/home/dc/installed/pwndbg/pwndbg/commands/__init__.py\", line 181, in _OnlyWithFile\r\n return function(*a, **kw)\r\n File \"/home/dc/installed/pwndbg/pwndbg/commands/start.py\", line 72, in entry\r\n gdb.execute(run, from_tty=False)\r\ngdb.error: During startup program exited with code 1.\r\n\r\nIf that is an issue, you can report it on https://github.com/pwndbg/pwndbg/issues\r\n(Please don't forget to search if it hasn't been reported before)\r\nPS: Pull requests are welcome\r\n```\r\n\r\n### My version\r\n\r\n```\r\npwndbg> version\r\nGdb: GNU gdb (GDB) 8.0.1\r\nPython: 3.6.3 (default, Oct 24 2017, 14:48:20) [GCC 7.2.0]\r\nPwndbg: 1.0.0 build: 5811010\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nLaunches the target process after setting a breakpoint at a convenient\nentry point.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport gdb\n\nimport pwndbg.commands\nimport pwndbg.elf\nimport pwndbg.events\nimport pwndbg.symbol\n\nbreak_on_first_instruction = False\n\n\[email protected]\ndef on_start():\n global break_on_first_instruction\n if break_on_first_instruction:\n spec = \"*%#x\" % (int(pwndbg.elf.entry()))\n gdb.Breakpoint(spec, temporary=True)\n break_on_first_instruction = False\n\n\[email protected]\ndef start(*a):\n \"\"\"\n Set a breakpoint at a convenient location in the binary,\n generally 'main', 'init', or the entry point.\n \"\"\"\n run = 'run ' + ' '.join(a)\n\n symbols = [\"main\",\n \"_main\",\n \"start\",\n \"_start\",\n \"init\",\n \"_init\"]\n\n for symbol in symbols:\n address = pwndbg.symbol.address(symbol)\n\n if not address:\n continue\n\n b = gdb.Breakpoint(symbol, temporary=True)\n gdb.execute(run, from_tty=False, to_string=True)\n return\n\n # Try a breakpoint at the binary entry\n entry(*a)\n\n\[email protected]\[email protected]\ndef entry(*a):\n \"\"\"\n Set a breakpoint at the first instruction executed in\n the target binary.\n \"\"\"\n global break_on_first_instruction\n break_on_first_instruction = True\n run = 'run ' + ' '.join(a)\n gdb.execute(run, from_tty=False)\n", "path": "pwndbg/commands/start.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport gdb\n\nimport pwndbg.events\nimport pwndbg.memoize\n\nhint_msg = 'Loaded %i commands. Type pwndbg [filter] for a list.' % len(pwndbg.commands.Command.commands)\n\nprint(pwndbg.color.red(hint_msg))\ncur = (gdb.selected_inferior(), gdb.selected_thread())\n\n\ndef prompt_hook(*a):\n global cur\n new = (gdb.selected_inferior(), gdb.selected_thread())\n\n if cur != new:\n pwndbg.events.after_reload(start=False)\n cur = new\n\n if pwndbg.proc.alive and pwndbg.proc.thread_is_stopped:\n prompt_hook_on_stop(*a)\n\n\[email protected]_on_stop\ndef prompt_hook_on_stop(*a):\n pwndbg.commands.context.context()\n\n\ngdb.prompt_hook = prompt_hook\n", "path": "pwndbg/prompt.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nPrints structures in a manner similar to Windbg's \"dt\" command.\n\"\"\"\nfrom __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport glob\nimport os\nimport re\nimport subprocess\nimport tempfile\n\nimport gdb\n\nimport pwndbg.memory\nimport pwndbg.typeinfo\n\n\ndef get_type(v):\n t = v.type\n while not t.name:\n if t.code == gdb.TYPE_CODE_PTR:\n t = t.target()\n return t.name\n\ndef get_typename(t):\n return(str(t))\n\ndef get_arrsize(f):\n t = f.type\n if t.code != gdb.TYPE_CODE_ARRAY:\n return 0\n t2 = t.target()\n s = t2.sizeof\n return int(t.sizeof / t2.sizeof)\n\ndef get_field_by_name(obj, field):\n # Dereference once\n if obj.type.code == gdb.TYPE_CODE_PTR:\n obj = obj.dereference()\n for f in re.split('(->|\\.|\\[\\d+\\])', field):\n if not f: continue\n if f == '->':\n obj = obj.dereference()\n elif f == '.':\n pass\n elif f.startswith('['):\n n = int(f.strip('[]'))\n obj = obj.cast(obj.dereference().type.pointer())\n obj += n\n obj = obj.dereference()\n else:\n obj = obj[f]\n return obj\n\ndef happy(typename):\n prefix = ''\n if 'unsigned' in typename:\n prefix = 'u'\n typename = typename.replace('unsigned ', '')\n return prefix + {\n 'char': 'char',\n 'short int': 'short',\n 'long int': 'long',\n 'int': 'int',\n 'long long': 'longlong',\n 'float': 'float',\n 'double': 'double'\n }[typename]\n\ndef dt(name='', addr=None, obj = None):\n \"\"\"\n Dump out a structure type Windbg style.\n \"\"\"\n # Return value is a list of strings.of\n # We concatenate at the end.\n rv = []\n\n if obj and not name:\n t = obj.type\n while t.code == (gdb.TYPE_CODE_PTR):\n t = t.target()\n obj = obj.dereference()\n name = str(t)\n\n # Lookup the type name specified by the user\n else:\n t = pwndbg.typeinfo.load(name)\n\n # If it's not a struct (e.g. int or char*), bail\n if t.code not in (gdb.TYPE_CODE_STRUCT, gdb.TYPE_CODE_TYPEDEF, gdb.TYPE_CODE_UNION):\n raise Exception(\"Not a structure: %s\" % t)\n\n # If an address was specified, create a Value of the\n # specified type at that address.\n if addr is not None:\n obj = pwndbg.memory.poi(t, addr)\n\n # Header, optionally include the name\n header = name\n if obj: header = \"%s @ %s\" % (header, hex(int(obj.address)))\n rv.append(header)\n\n if t.strip_typedefs().code == gdb.TYPE_CODE_ARRAY:\n return \"Arrays not supported yet\"\n if t.strip_typedefs().code not in (gdb.TYPE_CODE_STRUCT, gdb.TYPE_CODE_UNION):\n t = {name: obj or gdb.Value(0).cast(t)}\n\n for name, field in t.items():\n # Offset into the parent structure\n o = getattr(field, 'bitpos', 0)/8\n extra = str(field.type)\n ftype = field.type.strip_typedefs()\n\n if obj and obj.type.strip_typedefs().code in (gdb.TYPE_CODE_STRUCT, gdb.TYPE_CODE_UNION):\n v = obj[name]\n\n if ftype.code == gdb.TYPE_CODE_INT:\n v = hex(int(v))\n if ftype.code in (gdb.TYPE_CODE_PTR, gdb.TYPE_CODE_ARRAY) \\\n and ftype.target() == pwndbg.typeinfo.uchar:\n data = pwndbg.memory.read(v.address, ftype.sizeof)\n v = ' '.join('%02x' % b for b in data)\n\n extra = v\n\n # Adjust trailing lines in 'extra' to line up\n # This is necessary when there are nested structures.\n # Ideally we'd expand recursively if the type is complex.\n extra_lines = []\n for i, line in enumerate(str(extra).splitlines()):\n if i == 0: extra_lines.append(line)\n else: extra_lines.append(35*' ' + line)\n extra = '\\n'.join(extra_lines)\n\n line = \" +0x%04x %-20s : %s\" % (o, name, extra)\n rv.append(line)\n\n return ('\\n'.join(rv))\n", "path": "pwndbg/dt.py"}]}
| 3,374 | 494 |
gh_patches_debug_3923
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-6173
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Create a script for 2.0 API Reference docs
</issue>
<code>
[start of docs/pydoc/renderers.py]
1 import os
2 import sys
3 import io
4 import dataclasses
5 import typing as t
6 import base64
7 import warnings
8 from pathlib import Path
9
10 import requests
11 import docspec
12 from pydoc_markdown.interfaces import Context, Renderer
13 from pydoc_markdown.contrib.renderers.markdown import MarkdownRenderer
14
15
16 README_FRONTMATTER = """---
17 title: {title}
18 excerpt: {excerpt}
19 category: {category}
20 slug: {slug}
21 parentDoc: {parent_doc}
22 order: {order}
23 hidden: false
24 ---
25
26 """
27
28
29 def create_headers(version: str):
30 # Utility function to create Readme.io headers.
31 # We assume the README_API_KEY env var is set since we check outside
32 # to show clearer error messages.
33 README_API_KEY = os.getenv("README_API_KEY")
34 token = base64.b64encode(f"{README_API_KEY}:".encode()).decode()
35 return {"authorization": f"Basic {token}", "x-readme-version": version}
36
37
38 @dataclasses.dataclass
39 class ReadmeRenderer(Renderer):
40 """
41 This custom Renderer is heavily based on the `MarkdownRenderer`,
42 it just prepends a front matter so that the output can be published
43 directly to readme.io.
44 """
45
46 # These settings will be used in the front matter output
47 title: str
48 category_slug: str
49 excerpt: str
50 slug: str
51 order: int
52 parent_doc_slug: str = ""
53 # Docs categories fetched from Readme.io
54 categories: t.Dict[str, str] = dataclasses.field(init=False)
55 # This exposes a special `markdown` settings value that can be used to pass
56 # parameters to the underlying `MarkdownRenderer`
57 markdown: MarkdownRenderer = dataclasses.field(default_factory=MarkdownRenderer)
58
59 def init(self, context: Context) -> None:
60 self.markdown.init(context)
61 self.version = self._doc_version()
62 self.categories = self._readme_categories(self.version)
63
64 def _doc_version(self) -> str:
65 """
66 Returns the docs version.
67 """
68 root = Path(__file__).absolute().parent.parent.parent
69 full_version = (root / "VERSION.txt").read_text()
70 major, minor = full_version.split(".")[:2]
71 if "rc0" in full_version:
72 return f"v{major}.{minor}-unstable"
73 return f"v{major}.{minor}"
74
75 def _readme_categories(self, version: str) -> t.Dict[str, str]:
76 """
77 Fetch the categories of the given version from Readme.io.
78 README_API_KEY env var must be set to correctly get the categories.
79 Returns dictionary containing all the categories slugs and their ids.
80 """
81 README_API_KEY = os.getenv("README_API_KEY")
82 if not README_API_KEY:
83 warnings.warn("README_API_KEY env var is not set, using a placeholder category ID")
84 return {"haystack-classes": "ID"}
85
86 headers = create_headers(version)
87
88 res = requests.get("https://dash.readme.com/api/v1/categories", headers=headers, timeout=60)
89
90 if not res.ok:
91 sys.exit(f"Error requesting {version} categories")
92
93 return {c["slug"]: c["id"] for c in res.json()}
94
95 def _doc_id(self, doc_slug: str, version: str) -> str:
96 """
97 Fetch the doc id of the given doc slug and version from Readme.io.
98 README_API_KEY env var must be set to correctly get the id.
99 If doc_slug is an empty string return an empty string.
100 """
101 if not doc_slug:
102 # Not all docs have a parent doc, in case we get no slug
103 # we just return an empty string.
104 return ""
105
106 README_API_KEY = os.getenv("README_API_KEY")
107 if not README_API_KEY:
108 warnings.warn("README_API_KEY env var is not set, using a placeholder doc ID")
109 return "fake-doc-id"
110
111 headers = create_headers(version)
112 res = requests.get(f"https://dash.readme.com/api/v1/docs/{doc_slug}", headers=headers, timeout=60)
113 if not res.ok:
114 sys.exit(f"Error requesting {doc_slug} doc for version {version}")
115
116 return res.json()["id"]
117
118 def render(self, modules: t.List[docspec.Module]) -> None:
119 if self.markdown.filename is None:
120 sys.stdout.write(self._frontmatter())
121 self.markdown.render_single_page(sys.stdout, modules)
122 else:
123 with io.open(self.markdown.filename, "w", encoding=self.markdown.encoding) as fp:
124 fp.write(self._frontmatter())
125 self.markdown.render_single_page(t.cast(t.TextIO, fp), modules)
126
127 def _frontmatter(self) -> str:
128 return README_FRONTMATTER.format(
129 title=self.title,
130 category=self.categories[self.category_slug],
131 parent_doc=self._doc_id(self.parent_doc_slug, self.version),
132 excerpt=self.excerpt,
133 slug=self.slug,
134 order=self.order,
135 )
136
[end of docs/pydoc/renderers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/pydoc/renderers.py b/docs/pydoc/renderers.py
--- a/docs/pydoc/renderers.py
+++ b/docs/pydoc/renderers.py
@@ -133,3 +133,16 @@
slug=self.slug,
order=self.order,
)
+
+
[email protected]
+class ReadmePreviewRenderer(ReadmeRenderer):
+ """
+ This custom Renderer behaves just like the ReadmeRenderer but renders docs with the hardcoded version 2.0 to generate correct category ids.
+ """
+
+ def _doc_version(self) -> str:
+ """
+ Returns the hardcoded docs version 2.0.
+ """
+ return "v2.0"
|
{"golden_diff": "diff --git a/docs/pydoc/renderers.py b/docs/pydoc/renderers.py\n--- a/docs/pydoc/renderers.py\n+++ b/docs/pydoc/renderers.py\n@@ -133,3 +133,16 @@\n slug=self.slug,\n order=self.order,\n )\n+\n+\[email protected]\n+class ReadmePreviewRenderer(ReadmeRenderer):\n+ \"\"\"\n+ This custom Renderer behaves just like the ReadmeRenderer but renders docs with the hardcoded version 2.0 to generate correct category ids.\n+ \"\"\"\n+\n+ def _doc_version(self) -> str:\n+ \"\"\"\n+ Returns the hardcoded docs version 2.0.\n+ \"\"\"\n+ return \"v2.0\"\n", "issue": "Create a script for 2.0 API Reference docs\n\n", "before_files": [{"content": "import os\nimport sys\nimport io\nimport dataclasses\nimport typing as t\nimport base64\nimport warnings\nfrom pathlib import Path\n\nimport requests\nimport docspec\nfrom pydoc_markdown.interfaces import Context, Renderer\nfrom pydoc_markdown.contrib.renderers.markdown import MarkdownRenderer\n\n\nREADME_FRONTMATTER = \"\"\"---\ntitle: {title}\nexcerpt: {excerpt}\ncategory: {category}\nslug: {slug}\nparentDoc: {parent_doc}\norder: {order}\nhidden: false\n---\n\n\"\"\"\n\n\ndef create_headers(version: str):\n # Utility function to create Readme.io headers.\n # We assume the README_API_KEY env var is set since we check outside\n # to show clearer error messages.\n README_API_KEY = os.getenv(\"README_API_KEY\")\n token = base64.b64encode(f\"{README_API_KEY}:\".encode()).decode()\n return {\"authorization\": f\"Basic {token}\", \"x-readme-version\": version}\n\n\[email protected]\nclass ReadmeRenderer(Renderer):\n \"\"\"\n This custom Renderer is heavily based on the `MarkdownRenderer`,\n it just prepends a front matter so that the output can be published\n directly to readme.io.\n \"\"\"\n\n # These settings will be used in the front matter output\n title: str\n category_slug: str\n excerpt: str\n slug: str\n order: int\n parent_doc_slug: str = \"\"\n # Docs categories fetched from Readme.io\n categories: t.Dict[str, str] = dataclasses.field(init=False)\n # This exposes a special `markdown` settings value that can be used to pass\n # parameters to the underlying `MarkdownRenderer`\n markdown: MarkdownRenderer = dataclasses.field(default_factory=MarkdownRenderer)\n\n def init(self, context: Context) -> None:\n self.markdown.init(context)\n self.version = self._doc_version()\n self.categories = self._readme_categories(self.version)\n\n def _doc_version(self) -> str:\n \"\"\"\n Returns the docs version.\n \"\"\"\n root = Path(__file__).absolute().parent.parent.parent\n full_version = (root / \"VERSION.txt\").read_text()\n major, minor = full_version.split(\".\")[:2]\n if \"rc0\" in full_version:\n return f\"v{major}.{minor}-unstable\"\n return f\"v{major}.{minor}\"\n\n def _readme_categories(self, version: str) -> t.Dict[str, str]:\n \"\"\"\n Fetch the categories of the given version from Readme.io.\n README_API_KEY env var must be set to correctly get the categories.\n Returns dictionary containing all the categories slugs and their ids.\n \"\"\"\n README_API_KEY = os.getenv(\"README_API_KEY\")\n if not README_API_KEY:\n warnings.warn(\"README_API_KEY env var is not set, using a placeholder category ID\")\n return {\"haystack-classes\": \"ID\"}\n\n headers = create_headers(version)\n\n res = requests.get(\"https://dash.readme.com/api/v1/categories\", headers=headers, timeout=60)\n\n if not res.ok:\n sys.exit(f\"Error requesting {version} categories\")\n\n return {c[\"slug\"]: c[\"id\"] for c in res.json()}\n\n def _doc_id(self, doc_slug: str, version: str) -> str:\n \"\"\"\n Fetch the doc id of the given doc slug and version from Readme.io.\n README_API_KEY env var must be set to correctly get the id.\n If doc_slug is an empty string return an empty string.\n \"\"\"\n if not doc_slug:\n # Not all docs have a parent doc, in case we get no slug\n # we just return an empty string.\n return \"\"\n\n README_API_KEY = os.getenv(\"README_API_KEY\")\n if not README_API_KEY:\n warnings.warn(\"README_API_KEY env var is not set, using a placeholder doc ID\")\n return \"fake-doc-id\"\n\n headers = create_headers(version)\n res = requests.get(f\"https://dash.readme.com/api/v1/docs/{doc_slug}\", headers=headers, timeout=60)\n if not res.ok:\n sys.exit(f\"Error requesting {doc_slug} doc for version {version}\")\n\n return res.json()[\"id\"]\n\n def render(self, modules: t.List[docspec.Module]) -> None:\n if self.markdown.filename is None:\n sys.stdout.write(self._frontmatter())\n self.markdown.render_single_page(sys.stdout, modules)\n else:\n with io.open(self.markdown.filename, \"w\", encoding=self.markdown.encoding) as fp:\n fp.write(self._frontmatter())\n self.markdown.render_single_page(t.cast(t.TextIO, fp), modules)\n\n def _frontmatter(self) -> str:\n return README_FRONTMATTER.format(\n title=self.title,\n category=self.categories[self.category_slug],\n parent_doc=self._doc_id(self.parent_doc_slug, self.version),\n excerpt=self.excerpt,\n slug=self.slug,\n order=self.order,\n )\n", "path": "docs/pydoc/renderers.py"}]}
| 1,927 | 157 |
gh_patches_debug_31872
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-2316
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HTML_SANITIZATION controllable from config panel
We should maybe make HTML_SANITIZATION controlable from the admin panel so that Admins can decide how they want to deal with HTML.
Of course this maybe could be done another way, it's just the general idea about the configuration value.
</issue>
<code>
[start of CTFd/admin/__init__.py]
1 import csv # noqa: I001
2 import datetime
3 import os
4 from io import StringIO
5
6 from flask import Blueprint, abort
7 from flask import current_app as app
8 from flask import (
9 jsonify,
10 redirect,
11 render_template,
12 render_template_string,
13 request,
14 send_file,
15 url_for,
16 )
17
18 admin = Blueprint("admin", __name__)
19
20 # isort:imports-firstparty
21 from CTFd.admin import challenges # noqa: F401,I001
22 from CTFd.admin import notifications # noqa: F401,I001
23 from CTFd.admin import pages # noqa: F401,I001
24 from CTFd.admin import scoreboard # noqa: F401,I001
25 from CTFd.admin import statistics # noqa: F401,I001
26 from CTFd.admin import submissions # noqa: F401,I001
27 from CTFd.admin import teams # noqa: F401,I001
28 from CTFd.admin import users # noqa: F401,I001
29 from CTFd.cache import (
30 cache,
31 clear_challenges,
32 clear_config,
33 clear_pages,
34 clear_standings,
35 )
36 from CTFd.models import (
37 Awards,
38 Challenges,
39 Configs,
40 Notifications,
41 Pages,
42 Solves,
43 Submissions,
44 Teams,
45 Tracking,
46 Unlocks,
47 Users,
48 db,
49 )
50 from CTFd.utils import config as ctf_config
51 from CTFd.utils import get_config, set_config
52 from CTFd.utils.csv import dump_csv, load_challenges_csv, load_teams_csv, load_users_csv
53 from CTFd.utils.decorators import admins_only
54 from CTFd.utils.exports import background_import_ctf
55 from CTFd.utils.exports import export_ctf as export_ctf_util
56 from CTFd.utils.security.auth import logout_user
57 from CTFd.utils.uploads import delete_file
58 from CTFd.utils.user import is_admin
59
60
61 @admin.route("/admin", methods=["GET"])
62 def view():
63 if is_admin():
64 return redirect(url_for("admin.statistics"))
65 return redirect(url_for("auth.login"))
66
67
68 @admin.route("/admin/plugins/<plugin>", methods=["GET", "POST"])
69 @admins_only
70 def plugin(plugin):
71 if request.method == "GET":
72 plugins_path = os.path.join(app.root_path, "plugins")
73
74 config_html_plugins = [
75 name
76 for name in os.listdir(plugins_path)
77 if os.path.isfile(os.path.join(plugins_path, name, "config.html"))
78 ]
79
80 if plugin in config_html_plugins:
81 config_html = open(
82 os.path.join(app.root_path, "plugins", plugin, "config.html")
83 ).read()
84 return render_template_string(config_html)
85 abort(404)
86 elif request.method == "POST":
87 for k, v in request.form.items():
88 if k == "nonce":
89 continue
90 set_config(k, v)
91 with app.app_context():
92 clear_config()
93 return "1"
94
95
96 @admin.route("/admin/import", methods=["GET", "POST"])
97 @admins_only
98 def import_ctf():
99 if request.method == "GET":
100 start_time = cache.get("import_start_time")
101 end_time = cache.get("import_end_time")
102 import_status = cache.get("import_status")
103 import_error = cache.get("import_error")
104 return render_template(
105 "admin/import.html",
106 start_time=start_time,
107 end_time=end_time,
108 import_status=import_status,
109 import_error=import_error,
110 )
111 elif request.method == "POST":
112 backup = request.files["backup"]
113 background_import_ctf(backup)
114 return redirect(url_for("admin.import_ctf"))
115
116
117 @admin.route("/admin/export", methods=["GET", "POST"])
118 @admins_only
119 def export_ctf():
120 backup = export_ctf_util()
121 ctf_name = ctf_config.ctf_name()
122 day = datetime.datetime.now().strftime("%Y-%m-%d_%T")
123 full_name = u"{}.{}.zip".format(ctf_name, day)
124 return send_file(
125 backup, cache_timeout=-1, as_attachment=True, attachment_filename=full_name
126 )
127
128
129 @admin.route("/admin/import/csv", methods=["POST"])
130 @admins_only
131 def import_csv():
132 csv_type = request.form["csv_type"]
133 # Try really hard to load data in properly no matter what nonsense Excel gave you
134 raw = request.files["csv_file"].stream.read()
135 try:
136 csvdata = raw.decode("utf-8-sig")
137 except UnicodeDecodeError:
138 try:
139 csvdata = raw.decode("cp1252")
140 except UnicodeDecodeError:
141 csvdata = raw.decode("latin-1")
142 csvfile = StringIO(csvdata)
143
144 loaders = {
145 "challenges": load_challenges_csv,
146 "users": load_users_csv,
147 "teams": load_teams_csv,
148 }
149
150 loader = loaders[csv_type]
151 reader = csv.DictReader(csvfile)
152 success = loader(reader)
153 if success is True:
154 return redirect(url_for("admin.config"))
155 else:
156 return jsonify(success), 500
157
158
159 @admin.route("/admin/export/csv")
160 @admins_only
161 def export_csv():
162 table = request.args.get("table")
163
164 output = dump_csv(name=table)
165
166 return send_file(
167 output,
168 as_attachment=True,
169 cache_timeout=-1,
170 attachment_filename="{name}-{table}.csv".format(
171 name=ctf_config.ctf_name(), table=table
172 ),
173 )
174
175
176 @admin.route("/admin/config", methods=["GET", "POST"])
177 @admins_only
178 def config():
179 # Clear the config cache so that we don't get stale values
180 clear_config()
181
182 configs = Configs.query.all()
183 configs = {c.key: get_config(c.key) for c in configs}
184
185 themes = ctf_config.get_themes()
186
187 # Remove current theme but ignore failure
188 try:
189 themes.remove(get_config("ctf_theme"))
190 except ValueError:
191 pass
192
193 return render_template("admin/config.html", themes=themes, **configs)
194
195
196 @admin.route("/admin/reset", methods=["GET", "POST"])
197 @admins_only
198 def reset():
199 if request.method == "POST":
200 require_setup = False
201 logout = False
202 next_url = url_for("admin.statistics")
203
204 data = request.form
205
206 if data.get("pages"):
207 _pages = Pages.query.all()
208 for p in _pages:
209 for f in p.files:
210 delete_file(file_id=f.id)
211
212 Pages.query.delete()
213
214 if data.get("notifications"):
215 Notifications.query.delete()
216
217 if data.get("challenges"):
218 _challenges = Challenges.query.all()
219 for c in _challenges:
220 for f in c.files:
221 delete_file(file_id=f.id)
222 Challenges.query.delete()
223
224 if data.get("accounts"):
225 Users.query.delete()
226 Teams.query.delete()
227 require_setup = True
228 logout = True
229
230 if data.get("submissions"):
231 Solves.query.delete()
232 Submissions.query.delete()
233 Awards.query.delete()
234 Unlocks.query.delete()
235 Tracking.query.delete()
236
237 if require_setup:
238 set_config("setup", False)
239 cache.clear()
240 logout_user()
241 next_url = url_for("views.setup")
242
243 db.session.commit()
244
245 clear_pages()
246 clear_standings()
247 clear_challenges()
248 clear_config()
249
250 if logout is True:
251 cache.clear()
252 logout_user()
253
254 db.session.close()
255 return redirect(next_url)
256
257 return render_template("admin/reset.html")
258
[end of CTFd/admin/__init__.py]
[start of CTFd/utils/config/pages.py]
1 from flask import current_app
2
3 from CTFd.cache import cache
4 from CTFd.models import Pages, db
5 from CTFd.utils import get_config, markdown
6 from CTFd.utils.dates import isoformat, unix_time_to_utc
7 from CTFd.utils.formatters import safe_format
8 from CTFd.utils.security.sanitize import sanitize_html
9
10
11 def format_variables(content):
12 ctf_name = get_config("ctf_name")
13 ctf_description = get_config("ctf_description")
14 ctf_start = get_config("start")
15 if ctf_start:
16 ctf_start = isoformat(unix_time_to_utc(int(ctf_start)))
17
18 ctf_end = get_config("end")
19 if ctf_end:
20 ctf_end = isoformat(unix_time_to_utc(int(ctf_end)))
21
22 ctf_freeze = get_config("freeze")
23 if ctf_freeze:
24 ctf_freeze = isoformat(unix_time_to_utc(int(ctf_freeze)))
25
26 content = safe_format(
27 content,
28 ctf_name=ctf_name,
29 ctf_description=ctf_description,
30 ctf_start=ctf_start,
31 ctf_end=ctf_end,
32 ctf_freeze=ctf_freeze,
33 )
34 return content
35
36
37 def build_html(html, sanitize=False):
38 html = format_variables(html)
39 if current_app.config["HTML_SANITIZATION"] is True or sanitize is True:
40 html = sanitize_html(html)
41 return html
42
43
44 def build_markdown(md, sanitize=False):
45 html = markdown(md)
46 html = format_variables(html)
47 if current_app.config["HTML_SANITIZATION"] is True or sanitize is True:
48 html = sanitize_html(html)
49 return html
50
51
52 @cache.memoize()
53 def get_pages():
54 db_pages = Pages.query.filter(
55 Pages.route != "index", Pages.draft.isnot(True), Pages.hidden.isnot(True)
56 ).all()
57 return db_pages
58
59
60 @cache.memoize()
61 def get_page(route):
62 page = db.session.execute(
63 Pages.__table__.select()
64 .where(Pages.route == route)
65 .where(Pages.draft.isnot(True))
66 ).fetchone()
67 if page:
68 # Convert the row into a transient ORM object so this change isn't commited accidentally
69 p = Pages(**page)
70 return p
71 return None
72
[end of CTFd/utils/config/pages.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/admin/__init__.py b/CTFd/admin/__init__.py
--- a/CTFd/admin/__init__.py
+++ b/CTFd/admin/__init__.py
@@ -48,7 +48,7 @@
db,
)
from CTFd.utils import config as ctf_config
-from CTFd.utils import get_config, set_config
+from CTFd.utils import get_app_config, get_config, set_config
from CTFd.utils.csv import dump_csv, load_challenges_csv, load_teams_csv, load_users_csv
from CTFd.utils.decorators import admins_only
from CTFd.utils.exports import background_import_ctf
@@ -190,7 +190,14 @@
except ValueError:
pass
- return render_template("admin/config.html", themes=themes, **configs)
+ force_html_sanitization = get_app_config("HTML_SANITIZATION")
+
+ return render_template(
+ "admin/config.html",
+ themes=themes,
+ **configs,
+ force_html_sanitization=force_html_sanitization
+ )
@admin.route("/admin/reset", methods=["GET", "POST"])
diff --git a/CTFd/utils/config/pages.py b/CTFd/utils/config/pages.py
--- a/CTFd/utils/config/pages.py
+++ b/CTFd/utils/config/pages.py
@@ -36,7 +36,11 @@
def build_html(html, sanitize=False):
html = format_variables(html)
- if current_app.config["HTML_SANITIZATION"] is True or sanitize is True:
+ if (
+ current_app.config["HTML_SANITIZATION"] is True
+ or bool(get_config("html_sanitization")) is True
+ or sanitize is True
+ ):
html = sanitize_html(html)
return html
@@ -44,7 +48,11 @@
def build_markdown(md, sanitize=False):
html = markdown(md)
html = format_variables(html)
- if current_app.config["HTML_SANITIZATION"] is True or sanitize is True:
+ if (
+ current_app.config["HTML_SANITIZATION"] is True
+ or bool(get_config("html_sanitization")) is True
+ or sanitize is True
+ ):
html = sanitize_html(html)
return html
|
{"golden_diff": "diff --git a/CTFd/admin/__init__.py b/CTFd/admin/__init__.py\n--- a/CTFd/admin/__init__.py\n+++ b/CTFd/admin/__init__.py\n@@ -48,7 +48,7 @@\n db,\n )\n from CTFd.utils import config as ctf_config\n-from CTFd.utils import get_config, set_config\n+from CTFd.utils import get_app_config, get_config, set_config\n from CTFd.utils.csv import dump_csv, load_challenges_csv, load_teams_csv, load_users_csv\n from CTFd.utils.decorators import admins_only\n from CTFd.utils.exports import background_import_ctf\n@@ -190,7 +190,14 @@\n except ValueError:\n pass\n \n- return render_template(\"admin/config.html\", themes=themes, **configs)\n+ force_html_sanitization = get_app_config(\"HTML_SANITIZATION\")\n+\n+ return render_template(\n+ \"admin/config.html\",\n+ themes=themes,\n+ **configs,\n+ force_html_sanitization=force_html_sanitization\n+ )\n \n \n @admin.route(\"/admin/reset\", methods=[\"GET\", \"POST\"])\ndiff --git a/CTFd/utils/config/pages.py b/CTFd/utils/config/pages.py\n--- a/CTFd/utils/config/pages.py\n+++ b/CTFd/utils/config/pages.py\n@@ -36,7 +36,11 @@\n \n def build_html(html, sanitize=False):\n html = format_variables(html)\n- if current_app.config[\"HTML_SANITIZATION\"] is True or sanitize is True:\n+ if (\n+ current_app.config[\"HTML_SANITIZATION\"] is True\n+ or bool(get_config(\"html_sanitization\")) is True\n+ or sanitize is True\n+ ):\n html = sanitize_html(html)\n return html\n \n@@ -44,7 +48,11 @@\n def build_markdown(md, sanitize=False):\n html = markdown(md)\n html = format_variables(html)\n- if current_app.config[\"HTML_SANITIZATION\"] is True or sanitize is True:\n+ if (\n+ current_app.config[\"HTML_SANITIZATION\"] is True\n+ or bool(get_config(\"html_sanitization\")) is True\n+ or sanitize is True\n+ ):\n html = sanitize_html(html)\n return html\n", "issue": "HTML_SANITIZATION controllable from config panel\nWe should maybe make HTML_SANITIZATION controlable from the admin panel so that Admins can decide how they want to deal with HTML. \r\n\r\nOf course this maybe could be done another way, it's just the general idea about the configuration value. \n", "before_files": [{"content": "import csv # noqa: I001\nimport datetime\nimport os\nfrom io import StringIO\n\nfrom flask import Blueprint, abort\nfrom flask import current_app as app\nfrom flask import (\n jsonify,\n redirect,\n render_template,\n render_template_string,\n request,\n send_file,\n url_for,\n)\n\nadmin = Blueprint(\"admin\", __name__)\n\n# isort:imports-firstparty\nfrom CTFd.admin import challenges # noqa: F401,I001\nfrom CTFd.admin import notifications # noqa: F401,I001\nfrom CTFd.admin import pages # noqa: F401,I001\nfrom CTFd.admin import scoreboard # noqa: F401,I001\nfrom CTFd.admin import statistics # noqa: F401,I001\nfrom CTFd.admin import submissions # noqa: F401,I001\nfrom CTFd.admin import teams # noqa: F401,I001\nfrom CTFd.admin import users # noqa: F401,I001\nfrom CTFd.cache import (\n cache,\n clear_challenges,\n clear_config,\n clear_pages,\n clear_standings,\n)\nfrom CTFd.models import (\n Awards,\n Challenges,\n Configs,\n Notifications,\n Pages,\n Solves,\n Submissions,\n Teams,\n Tracking,\n Unlocks,\n Users,\n db,\n)\nfrom CTFd.utils import config as ctf_config\nfrom CTFd.utils import get_config, set_config\nfrom CTFd.utils.csv import dump_csv, load_challenges_csv, load_teams_csv, load_users_csv\nfrom CTFd.utils.decorators import admins_only\nfrom CTFd.utils.exports import background_import_ctf\nfrom CTFd.utils.exports import export_ctf as export_ctf_util\nfrom CTFd.utils.security.auth import logout_user\nfrom CTFd.utils.uploads import delete_file\nfrom CTFd.utils.user import is_admin\n\n\[email protected](\"/admin\", methods=[\"GET\"])\ndef view():\n if is_admin():\n return redirect(url_for(\"admin.statistics\"))\n return redirect(url_for(\"auth.login\"))\n\n\[email protected](\"/admin/plugins/<plugin>\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef plugin(plugin):\n if request.method == \"GET\":\n plugins_path = os.path.join(app.root_path, \"plugins\")\n\n config_html_plugins = [\n name\n for name in os.listdir(plugins_path)\n if os.path.isfile(os.path.join(plugins_path, name, \"config.html\"))\n ]\n\n if plugin in config_html_plugins:\n config_html = open(\n os.path.join(app.root_path, \"plugins\", plugin, \"config.html\")\n ).read()\n return render_template_string(config_html)\n abort(404)\n elif request.method == \"POST\":\n for k, v in request.form.items():\n if k == \"nonce\":\n continue\n set_config(k, v)\n with app.app_context():\n clear_config()\n return \"1\"\n\n\[email protected](\"/admin/import\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef import_ctf():\n if request.method == \"GET\":\n start_time = cache.get(\"import_start_time\")\n end_time = cache.get(\"import_end_time\")\n import_status = cache.get(\"import_status\")\n import_error = cache.get(\"import_error\")\n return render_template(\n \"admin/import.html\",\n start_time=start_time,\n end_time=end_time,\n import_status=import_status,\n import_error=import_error,\n )\n elif request.method == \"POST\":\n backup = request.files[\"backup\"]\n background_import_ctf(backup)\n return redirect(url_for(\"admin.import_ctf\"))\n\n\[email protected](\"/admin/export\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef export_ctf():\n backup = export_ctf_util()\n ctf_name = ctf_config.ctf_name()\n day = datetime.datetime.now().strftime(\"%Y-%m-%d_%T\")\n full_name = u\"{}.{}.zip\".format(ctf_name, day)\n return send_file(\n backup, cache_timeout=-1, as_attachment=True, attachment_filename=full_name\n )\n\n\[email protected](\"/admin/import/csv\", methods=[\"POST\"])\n@admins_only\ndef import_csv():\n csv_type = request.form[\"csv_type\"]\n # Try really hard to load data in properly no matter what nonsense Excel gave you\n raw = request.files[\"csv_file\"].stream.read()\n try:\n csvdata = raw.decode(\"utf-8-sig\")\n except UnicodeDecodeError:\n try:\n csvdata = raw.decode(\"cp1252\")\n except UnicodeDecodeError:\n csvdata = raw.decode(\"latin-1\")\n csvfile = StringIO(csvdata)\n\n loaders = {\n \"challenges\": load_challenges_csv,\n \"users\": load_users_csv,\n \"teams\": load_teams_csv,\n }\n\n loader = loaders[csv_type]\n reader = csv.DictReader(csvfile)\n success = loader(reader)\n if success is True:\n return redirect(url_for(\"admin.config\"))\n else:\n return jsonify(success), 500\n\n\[email protected](\"/admin/export/csv\")\n@admins_only\ndef export_csv():\n table = request.args.get(\"table\")\n\n output = dump_csv(name=table)\n\n return send_file(\n output,\n as_attachment=True,\n cache_timeout=-1,\n attachment_filename=\"{name}-{table}.csv\".format(\n name=ctf_config.ctf_name(), table=table\n ),\n )\n\n\[email protected](\"/admin/config\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef config():\n # Clear the config cache so that we don't get stale values\n clear_config()\n\n configs = Configs.query.all()\n configs = {c.key: get_config(c.key) for c in configs}\n\n themes = ctf_config.get_themes()\n\n # Remove current theme but ignore failure\n try:\n themes.remove(get_config(\"ctf_theme\"))\n except ValueError:\n pass\n\n return render_template(\"admin/config.html\", themes=themes, **configs)\n\n\[email protected](\"/admin/reset\", methods=[\"GET\", \"POST\"])\n@admins_only\ndef reset():\n if request.method == \"POST\":\n require_setup = False\n logout = False\n next_url = url_for(\"admin.statistics\")\n\n data = request.form\n\n if data.get(\"pages\"):\n _pages = Pages.query.all()\n for p in _pages:\n for f in p.files:\n delete_file(file_id=f.id)\n\n Pages.query.delete()\n\n if data.get(\"notifications\"):\n Notifications.query.delete()\n\n if data.get(\"challenges\"):\n _challenges = Challenges.query.all()\n for c in _challenges:\n for f in c.files:\n delete_file(file_id=f.id)\n Challenges.query.delete()\n\n if data.get(\"accounts\"):\n Users.query.delete()\n Teams.query.delete()\n require_setup = True\n logout = True\n\n if data.get(\"submissions\"):\n Solves.query.delete()\n Submissions.query.delete()\n Awards.query.delete()\n Unlocks.query.delete()\n Tracking.query.delete()\n\n if require_setup:\n set_config(\"setup\", False)\n cache.clear()\n logout_user()\n next_url = url_for(\"views.setup\")\n\n db.session.commit()\n\n clear_pages()\n clear_standings()\n clear_challenges()\n clear_config()\n\n if logout is True:\n cache.clear()\n logout_user()\n\n db.session.close()\n return redirect(next_url)\n\n return render_template(\"admin/reset.html\")\n", "path": "CTFd/admin/__init__.py"}, {"content": "from flask import current_app\n\nfrom CTFd.cache import cache\nfrom CTFd.models import Pages, db\nfrom CTFd.utils import get_config, markdown\nfrom CTFd.utils.dates import isoformat, unix_time_to_utc\nfrom CTFd.utils.formatters import safe_format\nfrom CTFd.utils.security.sanitize import sanitize_html\n\n\ndef format_variables(content):\n ctf_name = get_config(\"ctf_name\")\n ctf_description = get_config(\"ctf_description\")\n ctf_start = get_config(\"start\")\n if ctf_start:\n ctf_start = isoformat(unix_time_to_utc(int(ctf_start)))\n\n ctf_end = get_config(\"end\")\n if ctf_end:\n ctf_end = isoformat(unix_time_to_utc(int(ctf_end)))\n\n ctf_freeze = get_config(\"freeze\")\n if ctf_freeze:\n ctf_freeze = isoformat(unix_time_to_utc(int(ctf_freeze)))\n\n content = safe_format(\n content,\n ctf_name=ctf_name,\n ctf_description=ctf_description,\n ctf_start=ctf_start,\n ctf_end=ctf_end,\n ctf_freeze=ctf_freeze,\n )\n return content\n\n\ndef build_html(html, sanitize=False):\n html = format_variables(html)\n if current_app.config[\"HTML_SANITIZATION\"] is True or sanitize is True:\n html = sanitize_html(html)\n return html\n\n\ndef build_markdown(md, sanitize=False):\n html = markdown(md)\n html = format_variables(html)\n if current_app.config[\"HTML_SANITIZATION\"] is True or sanitize is True:\n html = sanitize_html(html)\n return html\n\n\[email protected]()\ndef get_pages():\n db_pages = Pages.query.filter(\n Pages.route != \"index\", Pages.draft.isnot(True), Pages.hidden.isnot(True)\n ).all()\n return db_pages\n\n\[email protected]()\ndef get_page(route):\n page = db.session.execute(\n Pages.__table__.select()\n .where(Pages.route == route)\n .where(Pages.draft.isnot(True))\n ).fetchone()\n if page:\n # Convert the row into a transient ORM object so this change isn't commited accidentally\n p = Pages(**page)\n return p\n return None\n", "path": "CTFd/utils/config/pages.py"}]}
| 3,600 | 509 |
gh_patches_debug_33737
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1720
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Alibi explainer example times out
/kind bug
**What steps did you take and what happened:**
I am rolling out the Alibi Explainer example (as explained here https://github.com/kubeflow/kfserving/tree/v0.6.0/docs/samples/explanation/alibi/imagenet), although I have had to slightly adapt the InferenceService spec (see https://github.com/kubeflow/kfserving/issues/1707) as follows:
```
apiVersion: "serving.kubeflow.org/v1beta1"
kind: "InferenceService"
metadata:
name: imagenet
namespace: karl-schriek
spec:
predictor:
tensorflow:
storageUri: "gs://seldon-models/tfserving/imagenet/model"
resources:
requests:
cpu: 0.1
memory: 5Gi
limits:
memory: 10Gi
explainer:
alibi:
type: AnchorImages
storageUri: "gs://seldon-models/tfserving/imagenet/explainer"
config:
batch_size: "1" # reduced from 25 in attempt to prevent timeout
stop_on_first: "True"
min_samples_start: "1" # added in attempt to prevent timeout
resources:
requests:
cpu: 0.5
memory: 5Gi
limits:
memory: 10Gi
```
Predictor and explainer both roll out successfully. Requesting predictions work fine. Requesting an explaination on a single image results in an eventual timeout. The explainer Pod reports the following:
```
[I 210709 11:10:54 anchor_images:47] Calling explain on image of shape ((1, 299, 299, 3),)
[I 210709 11:10:54 anchor_images:48] anchor image call with {'batch_size': 1, 'stop_on_first': True}
```
After about 20 minutes it eventually also says the following:
```
skimage.measure.label's indexing starts from 0. In future version it will start from 1. To disable this warning, explicitely set the `start_label` parameter to 1.
[E 210709 11:30:11 web:1793] Uncaught exception POST /v1/models/imagenet:explain (127.0.0.1)
HTTPServerRequest(protocol='http', host='imagenet-explainer-default.karl-schriek.svc.cluster.local', method='POST', uri='/v1/models/imagenet:explain', version='HTTP/1.1', remote_ip='127.0.0.1')
Traceback (most recent call last):
File "/usr/local/lib/python3.7/site-packages/tornado/web.py", line 1704, in _execute
result = await result
File "/kfserving/kfserving/handlers/http.py", line 105, in post
response = await model(body, model_type=ModelType.EXPLAINER)
File "/kfserving/kfserving/kfmodel.py", line 58, in __call__
else self.explain(request)
File "/alibiexplainer/alibiexplainer/explainer.py", line 84, in explain
explanation = self.wrapper.explain(request["instances"])
File "/alibiexplainer/alibiexplainer/anchor_images.py", line 49, in explain
anchor_exp = self.anchors_image.explain(arr[0], **self.kwargs)
File "/usr/local/lib/python3.7/site-packages/alibi/explainers/anchor_image.py", line 409, in explain
return self.build_explanation(image, result, self.instance_label, params)
File "/usr/local/lib/python3.7/site-packages/alibi/explainers/anchor_image.py", line 447, in build_explanation
explanation = Explanation(meta=copy.deepcopy(self.meta), data=data)
AttributeError: 'AnchorImage' object has no attribute 'meta'
[E 210709 11:30:11 web:2243] 500 POST /v1/models/imagenet:explain (127.0.0.1) 1157265.30ms
```
The documentation states that the explanation may take a while, but surely it shouldn't time out with just a single image? This looks like a timeout, but I am not really sure if the `AttributeError: 'AnchorImage' object has no attribute 'meta'` suggests otherwise.
**What did you expect to happen:**
I would expect the request to succeed within a reasonable space of time.
- Istio Version: 1.10.2
- Knative Version: 0.24
- KFServing Version: 0.6.0
- Kubeflow version: 1.3+
- Kubernetes version: 1.20
</issue>
<code>
[start of python/alibiexplainer/setup.py]
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from setuptools import setup, find_packages
16
17 tests_require = [
18 'pytest',
19 'pytest-tornasync',
20 'mypy'
21 ]
22
23 setup(
24 name='alibiexplainer',
25 version='0.6.0',
26 author_email='[email protected]',
27 license='../../LICENSE.txt',
28 url='https://github.com/kubeflow/kfserving/python/kfserving/alibiexplainer',
29 description='Model Explaination Server. \
30 Not intended for use outside KFServing Frameworks Images',
31 long_description=open('README.md').read(),
32 python_requires='>=3.6',
33 packages=find_packages("alibiexplainer"),
34 install_requires=[
35 "tensorflow==2.3.2",
36 "kfserving>=0.6.0",
37 "pandas>=0.24.2",
38 "nest_asyncio>=1.4.0",
39 "alibi==0.5.5",
40 "scikit-learn == 0.20.3",
41 "argparse>=1.4.0",
42 "requests>=2.22.0",
43 "joblib>=0.13.2",
44 "dill>=0.3.0",
45 "grpcio>=1.22.0",
46 "xgboost==1.0.2",
47 "shap==0.36.0",
48 "numpy<1.19.0"
49 ],
50 tests_require=tests_require,
51 extras_require={'test': tests_require}
52 )
53
[end of python/alibiexplainer/setup.py]
[start of docs/samples/explanation/alibi/imagenet/train_explainer.py]
1 from tensorflow.keras.applications.inception_v3 import InceptionV3
2 from alibi.explainers import AnchorImage
3 import dill
4
5 model = InceptionV3(weights='imagenet')
6
7 segmentation_fn = 'slic'
8 kwargs = {'n_segments': 15, 'compactness': 20, 'sigma': .5}
9 image_shape = (299, 299, 3)
10 explainer = AnchorImage(lambda x: model.predict(x), image_shape, segmentation_fn=segmentation_fn,
11 segmentation_kwargs=kwargs,
12 images_background=None)
13
14
15 explainer.predict_fn = None # Clear explainer predict_fn as its a lambda and will be reset when loaded
16 with open("explainer.dill", 'wb') as f:
17 dill.dump(explainer, f)
18
[end of docs/samples/explanation/alibi/imagenet/train_explainer.py]
[start of python/alibiexplainer/alibiexplainer/anchor_text.py]
1 # Copyright 2019 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import kfserving
15 import logging
16 import numpy as np
17 import spacy
18 import alibi
19 from alibi.api.interfaces import Explanation
20 from alibi.utils.download import spacy_model
21 from alibi.utils.wrappers import ArgmaxTransformer
22 from alibiexplainer.explainer_wrapper import ExplainerWrapper
23 from typing import Callable, List, Optional
24
25 logging.basicConfig(level=kfserving.constants.KFSERVING_LOGLEVEL)
26
27
28 class AnchorText(ExplainerWrapper):
29 def __init__(
30 self,
31 predict_fn: Callable,
32 explainer: Optional[alibi.explainers.AnchorText],
33 spacy_language_model: str = "en_core_web_md",
34 **kwargs
35 ):
36 self.predict_fn = predict_fn
37 self.kwargs = kwargs
38 logging.info("Anchor Text args %s", self.kwargs)
39 if explainer is None:
40 logging.info("Loading Spacy Language model for %s", spacy_language_model)
41 spacy_model(model=spacy_language_model)
42 self.nlp = spacy.load(spacy_language_model)
43 logging.info("Language model loaded")
44 self.anchors_text = explainer
45
46 def explain(self, inputs: List) -> Explanation:
47 if self.anchors_text is None:
48 self.anchors_text = alibi.explainers.AnchorText(self.nlp, self.predict_fn)
49
50 # We assume the input has batch dimension but Alibi explainers presently assume no batch
51 input_words = inputs[0]
52
53 # check if predictor returns predicted class or prediction probabilities for each class
54 # if needed adjust predictor so it returns the predicted class
55 if np.argmax(self.predict_fn([input_words]).shape) == 0:
56 self.anchors_text.predictor = self.predict_fn
57 else:
58 self.anchors_text.predictor = ArgmaxTransformer(self.predict_fn)
59
60 anchor_exp = self.anchors_text.explain(input_words, **self.kwargs)
61 return anchor_exp
62
[end of python/alibiexplainer/alibiexplainer/anchor_text.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/samples/explanation/alibi/imagenet/train_explainer.py b/docs/samples/explanation/alibi/imagenet/train_explainer.py
deleted file mode 100644
--- a/docs/samples/explanation/alibi/imagenet/train_explainer.py
+++ /dev/null
@@ -1,17 +0,0 @@
-from tensorflow.keras.applications.inception_v3 import InceptionV3
-from alibi.explainers import AnchorImage
-import dill
-
-model = InceptionV3(weights='imagenet')
-
-segmentation_fn = 'slic'
-kwargs = {'n_segments': 15, 'compactness': 20, 'sigma': .5}
-image_shape = (299, 299, 3)
-explainer = AnchorImage(lambda x: model.predict(x), image_shape, segmentation_fn=segmentation_fn,
- segmentation_kwargs=kwargs,
- images_background=None)
-
-
-explainer.predict_fn = None # Clear explainer predict_fn as its a lambda and will be reset when loaded
-with open("explainer.dill", 'wb') as f:
- dill.dump(explainer, f)
diff --git a/python/alibiexplainer/alibiexplainer/anchor_text.py b/python/alibiexplainer/alibiexplainer/anchor_text.py
--- a/python/alibiexplainer/alibiexplainer/anchor_text.py
+++ b/python/alibiexplainer/alibiexplainer/anchor_text.py
@@ -45,7 +45,9 @@
def explain(self, inputs: List) -> Explanation:
if self.anchors_text is None:
- self.anchors_text = alibi.explainers.AnchorText(self.nlp, self.predict_fn)
+ self.anchors_text = alibi.explainers.AnchorText(predictor=self.predict_fn,
+ sampling_strategy='unknown',
+ nlp=self.nlp)
# We assume the input has batch dimension but Alibi explainers presently assume no batch
input_words = inputs[0]
diff --git a/python/alibiexplainer/setup.py b/python/alibiexplainer/setup.py
--- a/python/alibiexplainer/setup.py
+++ b/python/alibiexplainer/setup.py
@@ -36,7 +36,7 @@
"kfserving>=0.6.0",
"pandas>=0.24.2",
"nest_asyncio>=1.4.0",
- "alibi==0.5.5",
+ "alibi==0.6.0",
"scikit-learn == 0.20.3",
"argparse>=1.4.0",
"requests>=2.22.0",
@@ -44,8 +44,9 @@
"dill>=0.3.0",
"grpcio>=1.22.0",
"xgboost==1.0.2",
- "shap==0.36.0",
- "numpy<1.19.0"
+ "shap==0.39.0",
+ "numpy<1.19.0",
+ 'spacy[lookups]>=2.0.0, <4.0.0'
],
tests_require=tests_require,
extras_require={'test': tests_require}
|
{"golden_diff": "diff --git a/docs/samples/explanation/alibi/imagenet/train_explainer.py b/docs/samples/explanation/alibi/imagenet/train_explainer.py\ndeleted file mode 100644\n--- a/docs/samples/explanation/alibi/imagenet/train_explainer.py\n+++ /dev/null\n@@ -1,17 +0,0 @@\n-from tensorflow.keras.applications.inception_v3 import InceptionV3\n-from alibi.explainers import AnchorImage\n-import dill\n-\n-model = InceptionV3(weights='imagenet')\n-\n-segmentation_fn = 'slic'\n-kwargs = {'n_segments': 15, 'compactness': 20, 'sigma': .5}\n-image_shape = (299, 299, 3)\n-explainer = AnchorImage(lambda x: model.predict(x), image_shape, segmentation_fn=segmentation_fn,\n- segmentation_kwargs=kwargs,\n- images_background=None)\n-\n-\n-explainer.predict_fn = None # Clear explainer predict_fn as its a lambda and will be reset when loaded\n-with open(\"explainer.dill\", 'wb') as f:\n- dill.dump(explainer, f)\ndiff --git a/python/alibiexplainer/alibiexplainer/anchor_text.py b/python/alibiexplainer/alibiexplainer/anchor_text.py\n--- a/python/alibiexplainer/alibiexplainer/anchor_text.py\n+++ b/python/alibiexplainer/alibiexplainer/anchor_text.py\n@@ -45,7 +45,9 @@\n \n def explain(self, inputs: List) -> Explanation:\n if self.anchors_text is None:\n- self.anchors_text = alibi.explainers.AnchorText(self.nlp, self.predict_fn)\n+ self.anchors_text = alibi.explainers.AnchorText(predictor=self.predict_fn,\n+ sampling_strategy='unknown',\n+ nlp=self.nlp)\n \n # We assume the input has batch dimension but Alibi explainers presently assume no batch\n input_words = inputs[0]\ndiff --git a/python/alibiexplainer/setup.py b/python/alibiexplainer/setup.py\n--- a/python/alibiexplainer/setup.py\n+++ b/python/alibiexplainer/setup.py\n@@ -36,7 +36,7 @@\n \"kfserving>=0.6.0\",\n \"pandas>=0.24.2\",\n \"nest_asyncio>=1.4.0\",\n- \"alibi==0.5.5\",\n+ \"alibi==0.6.0\",\n \"scikit-learn == 0.20.3\",\n \"argparse>=1.4.0\",\n \"requests>=2.22.0\",\n@@ -44,8 +44,9 @@\n \"dill>=0.3.0\",\n \"grpcio>=1.22.0\",\n \"xgboost==1.0.2\",\n- \"shap==0.36.0\",\n- \"numpy<1.19.0\"\n+ \"shap==0.39.0\",\n+ \"numpy<1.19.0\",\n+ 'spacy[lookups]>=2.0.0, <4.0.0'\n ],\n tests_require=tests_require,\n extras_require={'test': tests_require}\n", "issue": "Alibi explainer example times out\n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\n\r\nI am rolling out the Alibi Explainer example (as explained here https://github.com/kubeflow/kfserving/tree/v0.6.0/docs/samples/explanation/alibi/imagenet), although I have had to slightly adapt the InferenceService spec (see https://github.com/kubeflow/kfserving/issues/1707) as follows:\r\n\r\n```\r\napiVersion: \"serving.kubeflow.org/v1beta1\"\r\nkind: \"InferenceService\"\r\nmetadata:\r\n name: imagenet\r\n namespace: karl-schriek\r\nspec:\r\n predictor:\r\n tensorflow:\r\n storageUri: \"gs://seldon-models/tfserving/imagenet/model\"\r\n resources:\r\n requests:\r\n cpu: 0.1\r\n memory: 5Gi \r\n limits:\r\n memory: 10Gi\r\n explainer:\r\n alibi:\r\n type: AnchorImages\r\n storageUri: \"gs://seldon-models/tfserving/imagenet/explainer\"\r\n config:\r\n batch_size: \"1\" # reduced from 25 in attempt to prevent timeout\r\n stop_on_first: \"True\"\r\n min_samples_start: \"1\" # added in attempt to prevent timeout\r\n resources:\r\n requests:\r\n cpu: 0.5\r\n memory: 5Gi \r\n limits:\r\n memory: 10Gi \r\n```\r\n\r\nPredictor and explainer both roll out successfully. Requesting predictions work fine. Requesting an explaination on a single image results in an eventual timeout. The explainer Pod reports the following:\r\n\r\n```\r\n[I 210709 11:10:54 anchor_images:47] Calling explain on image of shape ((1, 299, 299, 3),)\r\n[I 210709 11:10:54 anchor_images:48] anchor image call with {'batch_size': 1, 'stop_on_first': True}\r\n```\r\n\r\nAfter about 20 minutes it eventually also says the following:\r\n\r\n```\r\nskimage.measure.label's indexing starts from 0. In future version it will start from 1. To disable this warning, explicitely set the `start_label` parameter to 1.\r\n[E 210709 11:30:11 web:1793] Uncaught exception POST /v1/models/imagenet:explain (127.0.0.1)\r\n HTTPServerRequest(protocol='http', host='imagenet-explainer-default.karl-schriek.svc.cluster.local', method='POST', uri='/v1/models/imagenet:explain', version='HTTP/1.1', remote_ip='127.0.0.1')\r\n Traceback (most recent call last):\r\n File \"/usr/local/lib/python3.7/site-packages/tornado/web.py\", line 1704, in _execute\r\n result = await result\r\n File \"/kfserving/kfserving/handlers/http.py\", line 105, in post\r\n response = await model(body, model_type=ModelType.EXPLAINER)\r\n File \"/kfserving/kfserving/kfmodel.py\", line 58, in __call__\r\n else self.explain(request)\r\n File \"/alibiexplainer/alibiexplainer/explainer.py\", line 84, in explain\r\n explanation = self.wrapper.explain(request[\"instances\"])\r\n File \"/alibiexplainer/alibiexplainer/anchor_images.py\", line 49, in explain\r\n anchor_exp = self.anchors_image.explain(arr[0], **self.kwargs)\r\n File \"/usr/local/lib/python3.7/site-packages/alibi/explainers/anchor_image.py\", line 409, in explain\r\n return self.build_explanation(image, result, self.instance_label, params)\r\n File \"/usr/local/lib/python3.7/site-packages/alibi/explainers/anchor_image.py\", line 447, in build_explanation\r\n explanation = Explanation(meta=copy.deepcopy(self.meta), data=data)\r\n AttributeError: 'AnchorImage' object has no attribute 'meta'\r\n[E 210709 11:30:11 web:2243] 500 POST /v1/models/imagenet:explain (127.0.0.1) 1157265.30ms\r\n```\r\n\r\nThe documentation states that the explanation may take a while, but surely it shouldn't time out with just a single image? This looks like a timeout, but I am not really sure if the `AttributeError: 'AnchorImage' object has no attribute 'meta'` suggests otherwise.\r\n\r\n**What did you expect to happen:**\r\n\r\nI would expect the request to succeed within a reasonable space of time.\r\n\r\n\r\n- Istio Version: 1.10.2\r\n- Knative Version: 0.24\r\n- KFServing Version: 0.6.0\r\n- Kubeflow version: 1.3+\r\n- Kubernetes version: 1.20\r\n\n", "before_files": [{"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom setuptools import setup, find_packages\n\ntests_require = [\n 'pytest',\n 'pytest-tornasync',\n 'mypy'\n]\n\nsetup(\n name='alibiexplainer',\n version='0.6.0',\n author_email='[email protected]',\n license='../../LICENSE.txt',\n url='https://github.com/kubeflow/kfserving/python/kfserving/alibiexplainer',\n description='Model Explaination Server. \\\n Not intended for use outside KFServing Frameworks Images',\n long_description=open('README.md').read(),\n python_requires='>=3.6',\n packages=find_packages(\"alibiexplainer\"),\n install_requires=[\n \"tensorflow==2.3.2\",\n \"kfserving>=0.6.0\",\n \"pandas>=0.24.2\",\n \"nest_asyncio>=1.4.0\",\n \"alibi==0.5.5\",\n \"scikit-learn == 0.20.3\",\n \"argparse>=1.4.0\",\n \"requests>=2.22.0\",\n \"joblib>=0.13.2\",\n \"dill>=0.3.0\",\n \"grpcio>=1.22.0\",\n \"xgboost==1.0.2\",\n \"shap==0.36.0\",\n \"numpy<1.19.0\"\n ],\n tests_require=tests_require,\n extras_require={'test': tests_require}\n)\n", "path": "python/alibiexplainer/setup.py"}, {"content": "from tensorflow.keras.applications.inception_v3 import InceptionV3\nfrom alibi.explainers import AnchorImage\nimport dill\n\nmodel = InceptionV3(weights='imagenet')\n\nsegmentation_fn = 'slic'\nkwargs = {'n_segments': 15, 'compactness': 20, 'sigma': .5}\nimage_shape = (299, 299, 3)\nexplainer = AnchorImage(lambda x: model.predict(x), image_shape, segmentation_fn=segmentation_fn,\n segmentation_kwargs=kwargs,\n images_background=None)\n\n\nexplainer.predict_fn = None # Clear explainer predict_fn as its a lambda and will be reset when loaded\nwith open(\"explainer.dill\", 'wb') as f:\n dill.dump(explainer, f)\n", "path": "docs/samples/explanation/alibi/imagenet/train_explainer.py"}, {"content": "# Copyright 2019 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport kfserving\nimport logging\nimport numpy as np\nimport spacy\nimport alibi\nfrom alibi.api.interfaces import Explanation\nfrom alibi.utils.download import spacy_model\nfrom alibi.utils.wrappers import ArgmaxTransformer\nfrom alibiexplainer.explainer_wrapper import ExplainerWrapper\nfrom typing import Callable, List, Optional\n\nlogging.basicConfig(level=kfserving.constants.KFSERVING_LOGLEVEL)\n\n\nclass AnchorText(ExplainerWrapper):\n def __init__(\n self,\n predict_fn: Callable,\n explainer: Optional[alibi.explainers.AnchorText],\n spacy_language_model: str = \"en_core_web_md\",\n **kwargs\n ):\n self.predict_fn = predict_fn\n self.kwargs = kwargs\n logging.info(\"Anchor Text args %s\", self.kwargs)\n if explainer is None:\n logging.info(\"Loading Spacy Language model for %s\", spacy_language_model)\n spacy_model(model=spacy_language_model)\n self.nlp = spacy.load(spacy_language_model)\n logging.info(\"Language model loaded\")\n self.anchors_text = explainer\n\n def explain(self, inputs: List) -> Explanation:\n if self.anchors_text is None:\n self.anchors_text = alibi.explainers.AnchorText(self.nlp, self.predict_fn)\n\n # We assume the input has batch dimension but Alibi explainers presently assume no batch\n input_words = inputs[0]\n\n # check if predictor returns predicted class or prediction probabilities for each class\n # if needed adjust predictor so it returns the predicted class\n if np.argmax(self.predict_fn([input_words]).shape) == 0:\n self.anchors_text.predictor = self.predict_fn\n else:\n self.anchors_text.predictor = ArgmaxTransformer(self.predict_fn)\n\n anchor_exp = self.anchors_text.explain(input_words, **self.kwargs)\n return anchor_exp\n", "path": "python/alibiexplainer/alibiexplainer/anchor_text.py"}]}
| 3,141 | 730 |
gh_patches_debug_22565
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-874
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Concurrent execution results in uneven work per thread
I'm running `pre-commit` from current `master` to test the concurrency feature introduced with #851. While it in general seems to work, work is distributed pretty uneven. One hook we run is [`prospector`](https://github.com/guykisel/prospector-mirror) which is nice for testing, because it takes a relatively long time and it prints the time taken in its output.
Running `pre-commit run -a --verbose prospector | grep "Time Taken"` on a medium sized project (~100 Python files) results in the following distribution of work to the available 4 logical CPU cores:
```
Time Taken: 17.10 seconds
Time Taken: 8.70 seconds
Time Taken: 18.68 seconds
Time Taken: 108.02 seconds
```
Especially compared to running it with concurrency disabled (using `PRE_COMMIT_NO_CONCURRENCY`), it's pretty obvious that concurrency doesn't provide any real benefit here:
```
Time Taken: 116.95 seconds
```
I'd be happy to help debugging this further. Just tell me what other information you need. :slightly_smiling_face:
</issue>
<code>
[start of pre_commit/languages/helpers.py]
1 from __future__ import unicode_literals
2
3 import multiprocessing
4 import os
5 import shlex
6
7 from pre_commit.util import cmd_output
8 from pre_commit.xargs import xargs
9
10
11 def run_setup_cmd(prefix, cmd):
12 cmd_output(*cmd, cwd=prefix.prefix_dir, encoding=None)
13
14
15 def environment_dir(ENVIRONMENT_DIR, language_version):
16 if ENVIRONMENT_DIR is None:
17 return None
18 else:
19 return '{}-{}'.format(ENVIRONMENT_DIR, language_version)
20
21
22 def to_cmd(hook):
23 return tuple(shlex.split(hook['entry'])) + tuple(hook['args'])
24
25
26 def assert_version_default(binary, version):
27 if version != 'default':
28 raise AssertionError(
29 'For now, pre-commit requires system-installed {}'.format(binary),
30 )
31
32
33 def assert_no_additional_deps(lang, additional_deps):
34 if additional_deps:
35 raise AssertionError(
36 'For now, pre-commit does not support '
37 'additional_dependencies for {}'.format(lang),
38 )
39
40
41 def basic_get_default_version():
42 return 'default'
43
44
45 def basic_healthy(prefix, language_version):
46 return True
47
48
49 def no_install(prefix, version, additional_dependencies):
50 raise AssertionError('This type is not installable')
51
52
53 def target_concurrency(hook):
54 if hook['require_serial'] or 'PRE_COMMIT_NO_CONCURRENCY' in os.environ:
55 return 1
56 else:
57 # Travis appears to have a bunch of CPUs, but we can't use them all.
58 if 'TRAVIS' in os.environ:
59 return 2
60 else:
61 try:
62 return multiprocessing.cpu_count()
63 except NotImplementedError:
64 return 1
65
66
67 def run_xargs(hook, cmd, file_args):
68 return xargs(cmd, file_args, target_concurrency=target_concurrency(hook))
69
[end of pre_commit/languages/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/helpers.py b/pre_commit/languages/helpers.py
--- a/pre_commit/languages/helpers.py
+++ b/pre_commit/languages/helpers.py
@@ -2,12 +2,18 @@
import multiprocessing
import os
+import random
import shlex
+import six
+
from pre_commit.util import cmd_output
from pre_commit.xargs import xargs
+FIXED_RANDOM_SEED = 1542676186
+
+
def run_setup_cmd(prefix, cmd):
cmd_output(*cmd, cwd=prefix.prefix_dir, encoding=None)
@@ -64,5 +70,21 @@
return 1
+def _shuffled(seq):
+ """Deterministically shuffle identically under both py2 + py3."""
+ fixed_random = random.Random()
+ if six.PY2: # pragma: no cover (py2)
+ fixed_random.seed(FIXED_RANDOM_SEED)
+ else:
+ fixed_random.seed(FIXED_RANDOM_SEED, version=1)
+
+ seq = list(seq)
+ random.shuffle(seq, random=fixed_random.random)
+ return seq
+
+
def run_xargs(hook, cmd, file_args):
+ # Shuffle the files so that they more evenly fill out the xargs partitions,
+ # but do it deterministically in case a hook cares about ordering.
+ file_args = _shuffled(file_args)
return xargs(cmd, file_args, target_concurrency=target_concurrency(hook))
|
{"golden_diff": "diff --git a/pre_commit/languages/helpers.py b/pre_commit/languages/helpers.py\n--- a/pre_commit/languages/helpers.py\n+++ b/pre_commit/languages/helpers.py\n@@ -2,12 +2,18 @@\n \n import multiprocessing\n import os\n+import random\n import shlex\n \n+import six\n+\n from pre_commit.util import cmd_output\n from pre_commit.xargs import xargs\n \n \n+FIXED_RANDOM_SEED = 1542676186\n+\n+\n def run_setup_cmd(prefix, cmd):\n cmd_output(*cmd, cwd=prefix.prefix_dir, encoding=None)\n \n@@ -64,5 +70,21 @@\n return 1\n \n \n+def _shuffled(seq):\n+ \"\"\"Deterministically shuffle identically under both py2 + py3.\"\"\"\n+ fixed_random = random.Random()\n+ if six.PY2: # pragma: no cover (py2)\n+ fixed_random.seed(FIXED_RANDOM_SEED)\n+ else:\n+ fixed_random.seed(FIXED_RANDOM_SEED, version=1)\n+\n+ seq = list(seq)\n+ random.shuffle(seq, random=fixed_random.random)\n+ return seq\n+\n+\n def run_xargs(hook, cmd, file_args):\n+ # Shuffle the files so that they more evenly fill out the xargs partitions,\n+ # but do it deterministically in case a hook cares about ordering.\n+ file_args = _shuffled(file_args)\n return xargs(cmd, file_args, target_concurrency=target_concurrency(hook))\n", "issue": "Concurrent execution results in uneven work per thread\nI'm running `pre-commit` from current `master` to test the concurrency feature introduced with #851. While it in general seems to work, work is distributed pretty uneven. One hook we run is [`prospector`](https://github.com/guykisel/prospector-mirror) which is nice for testing, because it takes a relatively long time and it prints the time taken in its output.\r\n\r\nRunning `pre-commit run -a --verbose prospector | grep \"Time Taken\"` on a medium sized project (~100 Python files) results in the following distribution of work to the available 4 logical CPU cores:\r\n```\r\nTime Taken: 17.10 seconds\r\nTime Taken: 8.70 seconds\r\nTime Taken: 18.68 seconds\r\nTime Taken: 108.02 seconds\r\n```\r\n\r\nEspecially compared to running it with concurrency disabled (using `PRE_COMMIT_NO_CONCURRENCY`), it's pretty obvious that concurrency doesn't provide any real benefit here:\r\n```\r\nTime Taken: 116.95 seconds\r\n```\r\n\r\nI'd be happy to help debugging this further. Just tell me what other information you need. :slightly_smiling_face: \n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport multiprocessing\nimport os\nimport shlex\n\nfrom pre_commit.util import cmd_output\nfrom pre_commit.xargs import xargs\n\n\ndef run_setup_cmd(prefix, cmd):\n cmd_output(*cmd, cwd=prefix.prefix_dir, encoding=None)\n\n\ndef environment_dir(ENVIRONMENT_DIR, language_version):\n if ENVIRONMENT_DIR is None:\n return None\n else:\n return '{}-{}'.format(ENVIRONMENT_DIR, language_version)\n\n\ndef to_cmd(hook):\n return tuple(shlex.split(hook['entry'])) + tuple(hook['args'])\n\n\ndef assert_version_default(binary, version):\n if version != 'default':\n raise AssertionError(\n 'For now, pre-commit requires system-installed {}'.format(binary),\n )\n\n\ndef assert_no_additional_deps(lang, additional_deps):\n if additional_deps:\n raise AssertionError(\n 'For now, pre-commit does not support '\n 'additional_dependencies for {}'.format(lang),\n )\n\n\ndef basic_get_default_version():\n return 'default'\n\n\ndef basic_healthy(prefix, language_version):\n return True\n\n\ndef no_install(prefix, version, additional_dependencies):\n raise AssertionError('This type is not installable')\n\n\ndef target_concurrency(hook):\n if hook['require_serial'] or 'PRE_COMMIT_NO_CONCURRENCY' in os.environ:\n return 1\n else:\n # Travis appears to have a bunch of CPUs, but we can't use them all.\n if 'TRAVIS' in os.environ:\n return 2\n else:\n try:\n return multiprocessing.cpu_count()\n except NotImplementedError:\n return 1\n\n\ndef run_xargs(hook, cmd, file_args):\n return xargs(cmd, file_args, target_concurrency=target_concurrency(hook))\n", "path": "pre_commit/languages/helpers.py"}]}
| 1,317 | 333 |
gh_patches_debug_4351
|
rasdani/github-patches
|
git_diff
|
localstack__localstack-1589
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
describe-stream for dynamodb streams crashes
Steps to recreate:
1. create table
```
aws dynamodb create-table --table-name MusicCollection --attribute-definitions AttributeName=Artist,AttributeType=S AttributeName=SongTitle,AttributeType=S --key-schema AttributeName=Artist,KeyType=HASH AttributeName=SongTitle,KeyType=RANGE --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 --endpoint http://localhost:4569
```
2. add stream
```
aws dynamodb update-table --table-name MusicCollection --stream-specification StreamEnabled=true,StreamViewType=NEW_IMAGE --endpoint http://localhost:4569
```
3. describe stream using the stream arn from step 2.
```
aws dynamodbstreams describe-stream --stream-arn "arn:aws:dynamodb:eu-central-1:000000000000:table/MusicCollection/stream/2019-09-21T14:06:37.345" --endpoint http://localhost:4570
```
localstack logs:
```
Traceback (most recent call last):
File "/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/balrog/localstack/localstack/services/dynamodbstreams/dynamodbstreams_api.py", line 88, in post_request
shard['ShardId'] = shard_id(stream_name, shard['ShardId'])
File "/home/balrog/localstack/localstack/services/dynamodbstreams/dynamodbstreams_api.py", line 146, in shard_id
return '-'.join([kinesis_shard_id, random_id(stream_arn, kinesis_shard_id)])
File "/home/balrog/localstack/localstack/services/dynamodbstreams/dynamodbstreams_api.py", line 142, in random_id
return uuid.uuid5(namespace, kinesis_shard_id).hex
File "/usr/lib/python2.7/uuid.py", line 609, in uuid5
hash = sha1(namespace.bytes + name).digest()
UnicodeDecodeError: 'ascii' codec can't decode byte 0xe1 in position 4: ordinal not in range(128)
```
</issue>
<code>
[start of localstack/services/dynamodbstreams/dynamodbstreams_api.py]
1 import json
2 import uuid
3 import hashlib
4 from flask import Flask, jsonify, request, make_response
5 from localstack.services import generic_proxy
6 from localstack.utils.aws import aws_stack
7 from localstack.utils.common import to_str, to_bytes
8 from localstack.utils.analytics import event_publisher
9
10 APP_NAME = 'ddb_streams_api'
11
12 app = Flask(APP_NAME)
13
14 DDB_STREAMS = {}
15
16 DDB_KINESIS_STREAM_NAME_PREFIX = '__ddb_stream_'
17
18 ACTION_HEADER_PREFIX = 'DynamoDBStreams_20120810'
19
20 SEQUENCE_NUMBER_COUNTER = 1
21
22
23 def add_dynamodb_stream(table_name, latest_stream_label, view_type='NEW_AND_OLD_IMAGES', enabled=True):
24 if enabled:
25 # create kinesis stream as a backend
26 stream_name = get_kinesis_stream_name(table_name)
27 aws_stack.create_kinesis_stream(stream_name)
28 stream = {
29 'StreamArn': aws_stack.dynamodb_stream_arn(table_name=table_name,
30 latest_stream_label=latest_stream_label),
31 'TableName': table_name,
32 'StreamLabel': latest_stream_label,
33 'StreamStatus': 'ENABLED',
34 'KeySchema': [],
35 'Shards': []
36 }
37 table_arn = aws_stack.dynamodb_table_arn(table_name)
38 DDB_STREAMS[table_arn] = stream
39 # record event
40 event_publisher.fire_event(event_publisher.EVENT_DYNAMODB_CREATE_STREAM,
41 payload={'n': event_publisher.get_hash(table_name)})
42
43
44 def forward_events(records):
45 global SEQUENCE_NUMBER_COUNTER
46 kinesis = aws_stack.connect_to_service('kinesis')
47 for record in records:
48 if 'SequenceNumber' not in record['dynamodb']:
49 record['dynamodb']['SequenceNumber'] = str(SEQUENCE_NUMBER_COUNTER)
50 SEQUENCE_NUMBER_COUNTER += 1
51 table_arn = record['eventSourceARN']
52 stream = DDB_STREAMS.get(table_arn)
53 if stream:
54 table_name = table_name_from_stream_arn(stream['StreamArn'])
55 stream_name = get_kinesis_stream_name(table_name)
56 kinesis.put_record(StreamName=stream_name, Data=json.dumps(record), PartitionKey='TODO')
57
58
59 @app.route('/', methods=['POST'])
60 def post_request():
61 action = request.headers.get('x-amz-target')
62 data = json.loads(to_str(request.data))
63 result = {}
64 kinesis = aws_stack.connect_to_service('kinesis')
65 if action == '%s.ListStreams' % ACTION_HEADER_PREFIX:
66 result = {
67 'Streams': list(DDB_STREAMS.values()),
68 'LastEvaluatedStreamArn': 'TODO'
69 }
70 elif action == '%s.DescribeStream' % ACTION_HEADER_PREFIX:
71 for stream in DDB_STREAMS.values():
72 if stream['StreamArn'] == data['StreamArn']:
73 result = {
74 'StreamDescription': stream
75 }
76 # get stream details
77 dynamodb = aws_stack.connect_to_service('dynamodb')
78 table_name = table_name_from_stream_arn(stream['StreamArn'])
79 stream_name = get_kinesis_stream_name(table_name)
80 stream_details = kinesis.describe_stream(StreamName=stream_name)
81 table_details = dynamodb.describe_table(TableName=table_name)
82 stream['KeySchema'] = table_details['Table']['KeySchema']
83
84 # Replace Kinesis ShardIDs with ones that mimic actual
85 # DynamoDBStream ShardIDs.
86 stream_shards = stream_details['StreamDescription']['Shards']
87 for shard in stream_shards:
88 shard['ShardId'] = shard_id(stream_name, shard['ShardId'])
89 stream['Shards'] = stream_shards
90 break
91 if not result:
92 return error_response('Requested resource not found', error_type='ResourceNotFoundException')
93 elif action == '%s.GetShardIterator' % ACTION_HEADER_PREFIX:
94 # forward request to Kinesis API
95 stream_name = stream_name_from_stream_arn(data['StreamArn'])
96 stream_shard_id = kinesis_shard_id(data['ShardId'])
97 result = kinesis.get_shard_iterator(StreamName=stream_name,
98 ShardId=stream_shard_id, ShardIteratorType=data['ShardIteratorType'])
99 elif action == '%s.GetRecords' % ACTION_HEADER_PREFIX:
100 kinesis_records = kinesis.get_records(**data)
101 result = {'Records': [], 'NextShardIterator': kinesis_records.get('NextShardIterator')}
102 for record in kinesis_records['Records']:
103 result['Records'].append(json.loads(to_str(record['Data'])))
104 else:
105 print('WARNING: Unknown operation "%s"' % action)
106 return jsonify(result)
107
108
109 # -----------------
110 # HELPER FUNCTIONS
111 # -----------------
112
113 def error_response(message=None, error_type=None, code=400):
114 if not message:
115 message = 'Unknown error'
116 if not error_type:
117 error_type = 'UnknownError'
118 if 'com.amazonaws.dynamodb' not in error_type:
119 error_type = 'com.amazonaws.dynamodb.v20120810#%s' % error_type
120 content = {
121 'message': message,
122 '__type': error_type
123 }
124 return make_response(jsonify(content), code)
125
126
127 def get_kinesis_stream_name(table_name):
128 return DDB_KINESIS_STREAM_NAME_PREFIX + table_name
129
130
131 def table_name_from_stream_arn(stream_arn):
132 return stream_arn.split(':table/')[1].split('/')[0]
133
134
135 def stream_name_from_stream_arn(stream_arn):
136 table_name = table_name_from_stream_arn(stream_arn)
137 return get_kinesis_stream_name(table_name)
138
139
140 def random_id(stream_arn, kinesis_shard_id):
141 namespace = uuid.UUID(bytes=hashlib.sha1(to_bytes(stream_arn)).digest()[:16])
142 return uuid.uuid5(namespace, kinesis_shard_id).hex
143
144
145 def shard_id(stream_arn, kinesis_shard_id):
146 return '-'.join([kinesis_shard_id, random_id(stream_arn, kinesis_shard_id)])
147
148
149 def kinesis_shard_id(dynamodbstream_shard_id):
150 return dynamodbstream_shard_id.rsplit('-', 1)[0]
151
152
153 def serve(port, quiet=True):
154 generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)
155
[end of localstack/services/dynamodbstreams/dynamodbstreams_api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/localstack/services/dynamodbstreams/dynamodbstreams_api.py b/localstack/services/dynamodbstreams/dynamodbstreams_api.py
--- a/localstack/services/dynamodbstreams/dynamodbstreams_api.py
+++ b/localstack/services/dynamodbstreams/dynamodbstreams_api.py
@@ -139,7 +139,7 @@
def random_id(stream_arn, kinesis_shard_id):
namespace = uuid.UUID(bytes=hashlib.sha1(to_bytes(stream_arn)).digest()[:16])
- return uuid.uuid5(namespace, kinesis_shard_id).hex
+ return uuid.uuid5(namespace, to_bytes(kinesis_shard_id)).hex
def shard_id(stream_arn, kinesis_shard_id):
|
{"golden_diff": "diff --git a/localstack/services/dynamodbstreams/dynamodbstreams_api.py b/localstack/services/dynamodbstreams/dynamodbstreams_api.py\n--- a/localstack/services/dynamodbstreams/dynamodbstreams_api.py\n+++ b/localstack/services/dynamodbstreams/dynamodbstreams_api.py\n@@ -139,7 +139,7 @@\n \n def random_id(stream_arn, kinesis_shard_id):\n namespace = uuid.UUID(bytes=hashlib.sha1(to_bytes(stream_arn)).digest()[:16])\n- return uuid.uuid5(namespace, kinesis_shard_id).hex\n+ return uuid.uuid5(namespace, to_bytes(kinesis_shard_id)).hex\n \n \n def shard_id(stream_arn, kinesis_shard_id):\n", "issue": "describe-stream for dynamodb streams crashes\nSteps to recreate:\r\n1. create table\r\n```\r\naws dynamodb create-table --table-name MusicCollection --attribute-definitions AttributeName=Artist,AttributeType=S AttributeName=SongTitle,AttributeType=S --key-schema AttributeName=Artist,KeyType=HASH AttributeName=SongTitle,KeyType=RANGE --provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 --endpoint http://localhost:4569\r\n```\r\n2. add stream\r\n```\r\naws dynamodb update-table --table-name MusicCollection --stream-specification StreamEnabled=true,StreamViewType=NEW_IMAGE --endpoint http://localhost:4569 \r\n```\r\n3. describe stream using the stream arn from step 2.\r\n```\r\naws dynamodbstreams describe-stream --stream-arn \"arn:aws:dynamodb:eu-central-1:000000000000:table/MusicCollection/stream/2019-09-21T14:06:37.345\" --endpoint http://localhost:4570\r\n```\r\nlocalstack logs:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 2292, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1815, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1718, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1813, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/balrog/localstack/.venv/lib/python2.7/site-packages/flask/app.py\", line 1799, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/home/balrog/localstack/localstack/services/dynamodbstreams/dynamodbstreams_api.py\", line 88, in post_request\r\n shard['ShardId'] = shard_id(stream_name, shard['ShardId'])\r\n File \"/home/balrog/localstack/localstack/services/dynamodbstreams/dynamodbstreams_api.py\", line 146, in shard_id\r\n return '-'.join([kinesis_shard_id, random_id(stream_arn, kinesis_shard_id)])\r\n File \"/home/balrog/localstack/localstack/services/dynamodbstreams/dynamodbstreams_api.py\", line 142, in random_id\r\n return uuid.uuid5(namespace, kinesis_shard_id).hex\r\n File \"/usr/lib/python2.7/uuid.py\", line 609, in uuid5\r\n hash = sha1(namespace.bytes + name).digest()\r\nUnicodeDecodeError: 'ascii' codec can't decode byte 0xe1 in position 4: ordinal not in range(128)\r\n```\n", "before_files": [{"content": "import json\nimport uuid\nimport hashlib\nfrom flask import Flask, jsonify, request, make_response\nfrom localstack.services import generic_proxy\nfrom localstack.utils.aws import aws_stack\nfrom localstack.utils.common import to_str, to_bytes\nfrom localstack.utils.analytics import event_publisher\n\nAPP_NAME = 'ddb_streams_api'\n\napp = Flask(APP_NAME)\n\nDDB_STREAMS = {}\n\nDDB_KINESIS_STREAM_NAME_PREFIX = '__ddb_stream_'\n\nACTION_HEADER_PREFIX = 'DynamoDBStreams_20120810'\n\nSEQUENCE_NUMBER_COUNTER = 1\n\n\ndef add_dynamodb_stream(table_name, latest_stream_label, view_type='NEW_AND_OLD_IMAGES', enabled=True):\n if enabled:\n # create kinesis stream as a backend\n stream_name = get_kinesis_stream_name(table_name)\n aws_stack.create_kinesis_stream(stream_name)\n stream = {\n 'StreamArn': aws_stack.dynamodb_stream_arn(table_name=table_name,\n latest_stream_label=latest_stream_label),\n 'TableName': table_name,\n 'StreamLabel': latest_stream_label,\n 'StreamStatus': 'ENABLED',\n 'KeySchema': [],\n 'Shards': []\n }\n table_arn = aws_stack.dynamodb_table_arn(table_name)\n DDB_STREAMS[table_arn] = stream\n # record event\n event_publisher.fire_event(event_publisher.EVENT_DYNAMODB_CREATE_STREAM,\n payload={'n': event_publisher.get_hash(table_name)})\n\n\ndef forward_events(records):\n global SEQUENCE_NUMBER_COUNTER\n kinesis = aws_stack.connect_to_service('kinesis')\n for record in records:\n if 'SequenceNumber' not in record['dynamodb']:\n record['dynamodb']['SequenceNumber'] = str(SEQUENCE_NUMBER_COUNTER)\n SEQUENCE_NUMBER_COUNTER += 1\n table_arn = record['eventSourceARN']\n stream = DDB_STREAMS.get(table_arn)\n if stream:\n table_name = table_name_from_stream_arn(stream['StreamArn'])\n stream_name = get_kinesis_stream_name(table_name)\n kinesis.put_record(StreamName=stream_name, Data=json.dumps(record), PartitionKey='TODO')\n\n\[email protected]('/', methods=['POST'])\ndef post_request():\n action = request.headers.get('x-amz-target')\n data = json.loads(to_str(request.data))\n result = {}\n kinesis = aws_stack.connect_to_service('kinesis')\n if action == '%s.ListStreams' % ACTION_HEADER_PREFIX:\n result = {\n 'Streams': list(DDB_STREAMS.values()),\n 'LastEvaluatedStreamArn': 'TODO'\n }\n elif action == '%s.DescribeStream' % ACTION_HEADER_PREFIX:\n for stream in DDB_STREAMS.values():\n if stream['StreamArn'] == data['StreamArn']:\n result = {\n 'StreamDescription': stream\n }\n # get stream details\n dynamodb = aws_stack.connect_to_service('dynamodb')\n table_name = table_name_from_stream_arn(stream['StreamArn'])\n stream_name = get_kinesis_stream_name(table_name)\n stream_details = kinesis.describe_stream(StreamName=stream_name)\n table_details = dynamodb.describe_table(TableName=table_name)\n stream['KeySchema'] = table_details['Table']['KeySchema']\n\n # Replace Kinesis ShardIDs with ones that mimic actual\n # DynamoDBStream ShardIDs.\n stream_shards = stream_details['StreamDescription']['Shards']\n for shard in stream_shards:\n shard['ShardId'] = shard_id(stream_name, shard['ShardId'])\n stream['Shards'] = stream_shards\n break\n if not result:\n return error_response('Requested resource not found', error_type='ResourceNotFoundException')\n elif action == '%s.GetShardIterator' % ACTION_HEADER_PREFIX:\n # forward request to Kinesis API\n stream_name = stream_name_from_stream_arn(data['StreamArn'])\n stream_shard_id = kinesis_shard_id(data['ShardId'])\n result = kinesis.get_shard_iterator(StreamName=stream_name,\n ShardId=stream_shard_id, ShardIteratorType=data['ShardIteratorType'])\n elif action == '%s.GetRecords' % ACTION_HEADER_PREFIX:\n kinesis_records = kinesis.get_records(**data)\n result = {'Records': [], 'NextShardIterator': kinesis_records.get('NextShardIterator')}\n for record in kinesis_records['Records']:\n result['Records'].append(json.loads(to_str(record['Data'])))\n else:\n print('WARNING: Unknown operation \"%s\"' % action)\n return jsonify(result)\n\n\n# -----------------\n# HELPER FUNCTIONS\n# -----------------\n\ndef error_response(message=None, error_type=None, code=400):\n if not message:\n message = 'Unknown error'\n if not error_type:\n error_type = 'UnknownError'\n if 'com.amazonaws.dynamodb' not in error_type:\n error_type = 'com.amazonaws.dynamodb.v20120810#%s' % error_type\n content = {\n 'message': message,\n '__type': error_type\n }\n return make_response(jsonify(content), code)\n\n\ndef get_kinesis_stream_name(table_name):\n return DDB_KINESIS_STREAM_NAME_PREFIX + table_name\n\n\ndef table_name_from_stream_arn(stream_arn):\n return stream_arn.split(':table/')[1].split('/')[0]\n\n\ndef stream_name_from_stream_arn(stream_arn):\n table_name = table_name_from_stream_arn(stream_arn)\n return get_kinesis_stream_name(table_name)\n\n\ndef random_id(stream_arn, kinesis_shard_id):\n namespace = uuid.UUID(bytes=hashlib.sha1(to_bytes(stream_arn)).digest()[:16])\n return uuid.uuid5(namespace, kinesis_shard_id).hex\n\n\ndef shard_id(stream_arn, kinesis_shard_id):\n return '-'.join([kinesis_shard_id, random_id(stream_arn, kinesis_shard_id)])\n\n\ndef kinesis_shard_id(dynamodbstream_shard_id):\n return dynamodbstream_shard_id.rsplit('-', 1)[0]\n\n\ndef serve(port, quiet=True):\n generic_proxy.serve_flask_app(app=app, port=port, quiet=quiet)\n", "path": "localstack/services/dynamodbstreams/dynamodbstreams_api.py"}]}
| 3,003 | 155 |
gh_patches_debug_9732
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-9452
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[CT-3190] Pinning detective work
### Housekeeping
- [X] I am a maintainer of dbt-core
### Short description
We recently pinned `types-requests<2.31.0` because it had a dependency conflict with `urllib3` which we have pinned to `~=1.0` because of another conflict with `requests` requiring `openssl`.
This ticket is to look into if those pins are still required and clean them up if not.
### Acceptance criteria
We have confirmed that the pins are
- required to continue to work
_or_
- not required and we have re-pinned appropriately
### Impact to Other Teams
adapters - based on the notes it seems like `urllib3` is pinned for the snowflake adapter as well so we will want to ensure changing the dependencies does not adversely affect them
### Will backports be required?
no
### Context
_No response_
</issue>
<code>
[start of core/setup.py]
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 8):
6 print("Error: dbt does not support this version of Python.")
7 print("Please upgrade to Python 3.8 or higher.")
8 sys.exit(1)
9
10
11 from setuptools import setup
12
13 try:
14 from setuptools import find_namespace_packages
15 except ImportError:
16 # the user has a downlevel version of setuptools.
17 print("Error: dbt requires setuptools v40.1.0 or higher.")
18 print('Please upgrade setuptools with "pip install --upgrade setuptools" ' "and try again")
19 sys.exit(1)
20
21
22 this_directory = os.path.abspath(os.path.dirname(__file__))
23 with open(os.path.join(this_directory, "README.md")) as f:
24 long_description = f.read()
25
26
27 package_name = "dbt-core"
28 package_version = "1.8.0a1"
29 description = """With dbt, data analysts and engineers can build analytics \
30 the way engineers build applications."""
31
32
33 setup(
34 name=package_name,
35 version=package_version,
36 description=description,
37 long_description=long_description,
38 long_description_content_type="text/markdown",
39 author="dbt Labs",
40 author_email="[email protected]",
41 url="https://github.com/dbt-labs/dbt-core",
42 packages=find_namespace_packages(include=["dbt", "dbt.*"]),
43 include_package_data=True,
44 test_suite="test",
45 entry_points={
46 "console_scripts": ["dbt = dbt.cli.main:cli"],
47 },
48 install_requires=[
49 # ----
50 # dbt-core uses these packages deeply, throughout the codebase, and there have been breaking changes in past patch releases (even though these are major-version-one).
51 # Pin to the patch or minor version, and bump in each new minor version of dbt-core.
52 "agate~=1.7.0",
53 "Jinja2~=3.1.2",
54 "mashumaro[msgpack]~=3.9",
55 # ----
56 # Legacy: This package has not been updated since 2019, and it is unused in dbt's logging system (since v1.0)
57 # The dependency here will be removed along with the removal of 'legacy logging', in a future release of dbt-core
58 "logbook>=1.5,<1.6",
59 # ----
60 # dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility
61 # with major versions in each new minor version of dbt-core.
62 "click>=8.0.2,<9",
63 "networkx>=2.3,<4",
64 # ----
65 # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)
66 # and check compatibility / bump in each new minor version of dbt-core.
67 "pathspec>=0.9,<0.12",
68 "sqlparse>=0.2.3,<0.5",
69 # ----
70 # These are major-version-0 packages also maintained by dbt-labs. Accept patches.
71 "dbt-extractor~=0.5.0",
72 "minimal-snowplow-tracker~=0.0.2",
73 "dbt-semantic-interfaces~=0.5.0a2",
74 "dbt-common~=0.1.0",
75 "dbt-adapters~=0.1.0a2",
76 # ----
77 # Expect compatibility with all new versions of these packages, so lower bounds only.
78 "packaging>20.9",
79 "protobuf>=4.0.0",
80 "pytz>=2015.7",
81 "pyyaml>=6.0",
82 "daff>=1.3.46",
83 "typing-extensions>=4.4",
84 # ----
85 ],
86 zip_safe=False,
87 classifiers=[
88 "Development Status :: 5 - Production/Stable",
89 "License :: OSI Approved :: Apache Software License",
90 "Operating System :: Microsoft :: Windows",
91 "Operating System :: MacOS :: MacOS X",
92 "Operating System :: POSIX :: Linux",
93 "Programming Language :: Python :: 3.8",
94 "Programming Language :: Python :: 3.9",
95 "Programming Language :: Python :: 3.10",
96 "Programming Language :: Python :: 3.11",
97 ],
98 python_requires=">=3.8",
99 )
100
[end of core/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/setup.py b/core/setup.py
--- a/core/setup.py
+++ b/core/setup.py
@@ -61,6 +61,7 @@
# with major versions in each new minor version of dbt-core.
"click>=8.0.2,<9",
"networkx>=2.3,<4",
+ "requests<3.0.0", # should match dbt-common
# ----
# These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)
# and check compatibility / bump in each new minor version of dbt-core.
|
{"golden_diff": "diff --git a/core/setup.py b/core/setup.py\n--- a/core/setup.py\n+++ b/core/setup.py\n@@ -61,6 +61,7 @@\n # with major versions in each new minor version of dbt-core.\n \"click>=8.0.2,<9\",\n \"networkx>=2.3,<4\",\n+ \"requests<3.0.0\", # should match dbt-common\n # ----\n # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)\n # and check compatibility / bump in each new minor version of dbt-core.\n", "issue": "[CT-3190] Pinning detective work\n### Housekeeping\n\n- [X] I am a maintainer of dbt-core\n\n### Short description\n\nWe recently pinned `types-requests<2.31.0` because it had a dependency conflict with `urllib3` which we have pinned to `~=1.0` because of another conflict with `requests` requiring `openssl`.\r\n\r\nThis ticket is to look into if those pins are still required and clean them up if not. \n\n### Acceptance criteria\n\nWe have confirmed that the pins are\r\n- required to continue to work\r\n_or_\r\n- not required and we have re-pinned appropriately\n\n### Impact to Other Teams\n\nadapters - based on the notes it seems like `urllib3` is pinned for the snowflake adapter as well so we will want to ensure changing the dependencies does not adversely affect them\n\n### Will backports be required?\n\nno\n\n### Context\n\n_No response_\n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 8):\n print(\"Error: dbt does not support this version of Python.\")\n print(\"Please upgrade to Python 3.8 or higher.\")\n sys.exit(1)\n\n\nfrom setuptools import setup\n\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print(\"Error: dbt requires setuptools v40.1.0 or higher.\")\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" ' \"and try again\")\n sys.exit(1)\n\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, \"README.md\")) as f:\n long_description = f.read()\n\n\npackage_name = \"dbt-core\"\npackage_version = \"1.8.0a1\"\ndescription = \"\"\"With dbt, data analysts and engineers can build analytics \\\nthe way engineers build applications.\"\"\"\n\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt-core\",\n packages=find_namespace_packages(include=[\"dbt\", \"dbt.*\"]),\n include_package_data=True,\n test_suite=\"test\",\n entry_points={\n \"console_scripts\": [\"dbt = dbt.cli.main:cli\"],\n },\n install_requires=[\n # ----\n # dbt-core uses these packages deeply, throughout the codebase, and there have been breaking changes in past patch releases (even though these are major-version-one).\n # Pin to the patch or minor version, and bump in each new minor version of dbt-core.\n \"agate~=1.7.0\",\n \"Jinja2~=3.1.2\",\n \"mashumaro[msgpack]~=3.9\",\n # ----\n # Legacy: This package has not been updated since 2019, and it is unused in dbt's logging system (since v1.0)\n # The dependency here will be removed along with the removal of 'legacy logging', in a future release of dbt-core\n \"logbook>=1.5,<1.6\",\n # ----\n # dbt-core uses these packages in standard ways. Pin to the major version, and check compatibility\n # with major versions in each new minor version of dbt-core.\n \"click>=8.0.2,<9\",\n \"networkx>=2.3,<4\",\n # ----\n # These packages are major-version-0. Keep upper bounds on upcoming minor versions (which could have breaking changes)\n # and check compatibility / bump in each new minor version of dbt-core.\n \"pathspec>=0.9,<0.12\",\n \"sqlparse>=0.2.3,<0.5\",\n # ----\n # These are major-version-0 packages also maintained by dbt-labs. Accept patches.\n \"dbt-extractor~=0.5.0\",\n \"minimal-snowplow-tracker~=0.0.2\",\n \"dbt-semantic-interfaces~=0.5.0a2\",\n \"dbt-common~=0.1.0\",\n \"dbt-adapters~=0.1.0a2\",\n # ----\n # Expect compatibility with all new versions of these packages, so lower bounds only.\n \"packaging>20.9\",\n \"protobuf>=4.0.0\",\n \"pytz>=2015.7\",\n \"pyyaml>=6.0\",\n \"daff>=1.3.46\",\n \"typing-extensions>=4.4\",\n # ----\n ],\n zip_safe=False,\n classifiers=[\n \"Development Status :: 5 - Production/Stable\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n ],\n python_requires=\">=3.8\",\n)\n", "path": "core/setup.py"}]}
| 1,882 | 138 |
gh_patches_debug_40781
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-6812
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Inline, Minified Resources do not work in classic notebooks
This is due to an interaction with the classic notebooks use of JQuery, when output is published as `text/html`. New notebook code published a div and a script together as `text/html`. Propose to solve by publishing a single script as `application/javascript` (which should work) that creates the necessary div itself
</issue>
<code>
[start of bokeh/util/notebook.py]
1 ''' Functions useful for loading Bokeh code and data in Jupyter/Zeppelin notebooks.
2
3 '''
4 from __future__ import absolute_import
5
6 from IPython.display import publish_display_data
7
8 from ..embed import _wrap_in_script_tag
9
10 LOAD_MIME_TYPE = 'application/vnd.bokehjs_load.v0+json'
11 EXEC_MIME_TYPE = 'application/vnd.bokehjs_exec.v0+json'
12
13 _notebook_loaded = None
14
15 # TODO (bev) notebook_type and zeppelin bits should be removed after external zeppelin hook available
16 def load_notebook(resources=None, verbose=False, hide_banner=False, load_timeout=5000, notebook_type='jupyter'):
17 ''' Prepare the IPython notebook for displaying Bokeh plots.
18
19 Args:
20 resources (Resource, optional) :
21 how and where to load BokehJS from (default: CDN)
22
23 verbose (bool, optional) :
24 whether to report detailed settings (default: False)
25
26 hide_banner (bool, optional):
27 whether to hide the Bokeh banner (default: False)
28
29 load_timeout (int, optional) :
30 Timeout in milliseconds when plots assume load timed out (default: 5000)
31
32 notebook_type (string):
33 notebook_type (default: jupyter)
34
35 .. warning::
36 Clearing the output cell containing the published BokehJS
37 resources HTML code may cause Bokeh CSS styling to be removed.
38
39 Returns:
40 None
41
42 '''
43 nb_html, nb_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout)
44 lab_html, lab_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout, register_mimetype=False)
45 if notebook_type=='jupyter':
46 publish_display_data({'text/html': nb_html + _wrap_in_script_tag(nb_js),
47 LOAD_MIME_TYPE: {"script": lab_js, "div": lab_html}})
48 else:
49 _publish_zeppelin_data(lab_html, lab_js)
50
51
52 FINALIZE_JS = """
53 document.getElementById("%s").textContent = "BokehJS is loading...";
54 """
55
56 # TODO (bev) This will eventually go away
57 def _publish_zeppelin_data(html, js):
58 print('%html ' + html)
59 print('%html ' + '<script type="text/javascript">' + js + "</script>")
60
61 def _load_notebook_html(resources=None, verbose=False, hide_banner=False,
62 load_timeout=5000, register_mimetype=True):
63 global _notebook_loaded
64
65 from .. import __version__
66 from ..core.templates import AUTOLOAD_NB_JS, NOTEBOOK_LOAD
67 from ..util.serialization import make_id
68 from ..util.compiler import bundle_all_models
69 from ..resources import CDN
70
71 if resources is None:
72 resources = CDN
73
74 if resources.mode == 'inline':
75 js_info = 'inline'
76 css_info = 'inline'
77 else:
78 js_info = resources.js_files[0] if len(resources.js_files) == 1 else resources.js_files
79 css_info = resources.css_files[0] if len(resources.css_files) == 1 else resources.css_files
80
81 warnings = ["Warning: " + msg['text'] for msg in resources.messages if msg['type'] == 'warn']
82
83 if _notebook_loaded and verbose:
84 warnings.append('Warning: BokehJS previously loaded')
85
86 _notebook_loaded = resources
87
88 element_id = make_id()
89
90 html = NOTEBOOK_LOAD.render(
91 element_id = element_id,
92 verbose = verbose,
93 js_info = js_info,
94 css_info = css_info,
95 bokeh_version = __version__,
96 warnings = warnings,
97 hide_banner = hide_banner,
98 )
99
100 custom_models_js = bundle_all_models()
101
102 js = AUTOLOAD_NB_JS.render(
103 elementid = '' if hide_banner else element_id,
104 js_urls = resources.js_files,
105 css_urls = resources.css_files,
106 js_raw = resources.js_raw + [custom_models_js] + ([] if hide_banner else [FINALIZE_JS % element_id]),
107 css_raw = resources.css_raw_str,
108 force = True,
109 timeout = load_timeout,
110 register_mimetype = register_mimetype
111 )
112
113 return html, js
114
115 def get_comms(target_name):
116 ''' Create a Jupyter comms object for a specific target, that can
117 be used to update Bokeh documents in the Jupyter notebook.
118
119 Args:
120 target_name (str) : the target name the Comms object should connect to
121
122 Returns
123 Jupyter Comms
124
125 '''
126 from ipykernel.comm import Comm
127 return Comm(target_name=target_name, data={})
128
[end of bokeh/util/notebook.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bokeh/util/notebook.py b/bokeh/util/notebook.py
--- a/bokeh/util/notebook.py
+++ b/bokeh/util/notebook.py
@@ -5,8 +5,7 @@
from IPython.display import publish_display_data
-from ..embed import _wrap_in_script_tag
-
+JS_MIME_TYPE = 'application/javascript'
LOAD_MIME_TYPE = 'application/vnd.bokehjs_load.v0+json'
EXEC_MIME_TYPE = 'application/vnd.bokehjs_exec.v0+json'
@@ -40,33 +39,14 @@
None
'''
- nb_html, nb_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout)
- lab_html, lab_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout, register_mimetype=False)
- if notebook_type=='jupyter':
- publish_display_data({'text/html': nb_html + _wrap_in_script_tag(nb_js),
- LOAD_MIME_TYPE: {"script": lab_js, "div": lab_html}})
- else:
- _publish_zeppelin_data(lab_html, lab_js)
-
-FINALIZE_JS = """
-document.getElementById("%s").textContent = "BokehJS is loading...";
-"""
-
-# TODO (bev) This will eventually go away
-def _publish_zeppelin_data(html, js):
- print('%html ' + html)
- print('%html ' + '<script type="text/javascript">' + js + "</script>")
-
-def _load_notebook_html(resources=None, verbose=False, hide_banner=False,
- load_timeout=5000, register_mimetype=True):
global _notebook_loaded
from .. import __version__
- from ..core.templates import AUTOLOAD_NB_JS, NOTEBOOK_LOAD
+ from ..core.templates import NOTEBOOK_LOAD
from ..util.serialization import make_id
- from ..util.compiler import bundle_all_models
from ..resources import CDN
+ from ..util.compiler import bundle_all_models
if resources is None:
resources = CDN
@@ -99,18 +79,48 @@
custom_models_js = bundle_all_models()
+ nb_js = _loading_js(resources, element_id, custom_models_js, load_timeout, register_mime=True)
+ jl_js = _loading_js(resources, element_id, custom_models_js, load_timeout, register_mime=False)
+
+ if notebook_type=='jupyter':
+
+ if not hide_banner:
+ publish_display_data({'text/html': html})
+
+ publish_display_data({
+ JS_MIME_TYPE : nb_js,
+ LOAD_MIME_TYPE : {"script": jl_js}
+ })
+
+ else:
+ _publish_zeppelin_data(html, jl_js)
+
+
+FINALIZE_JS = """
+document.getElementById("%s").textContent = "BokehJS is loading...";
+"""
+
+# TODO (bev) This will eventually go away
+def _publish_zeppelin_data(html, js):
+ print('%html ' + html)
+ print('%html ' + '<script type="text/javascript">' + js + "</script>")
+
+def _loading_js(resources, element_id, custom_models_js, load_timeout=5000, register_mime=True):
+
+ from ..core.templates import AUTOLOAD_NB_JS
+
js = AUTOLOAD_NB_JS.render(
- elementid = '' if hide_banner else element_id,
- js_urls = resources.js_files,
- css_urls = resources.css_files,
- js_raw = resources.js_raw + [custom_models_js] + ([] if hide_banner else [FINALIZE_JS % element_id]),
- css_raw = resources.css_raw_str,
- force = True,
- timeout = load_timeout,
- register_mimetype = register_mimetype
+ elementid = element_id,
+ js_urls = resources.js_files,
+ css_urls = resources.css_files,
+ js_raw = resources.js_raw + [custom_models_js] + [FINALIZE_JS % element_id],
+ css_raw = resources.css_raw_str,
+ force = True,
+ timeout = load_timeout,
+ register_mime = register_mime
)
- return html, js
+ return js
def get_comms(target_name):
''' Create a Jupyter comms object for a specific target, that can
|
{"golden_diff": "diff --git a/bokeh/util/notebook.py b/bokeh/util/notebook.py\n--- a/bokeh/util/notebook.py\n+++ b/bokeh/util/notebook.py\n@@ -5,8 +5,7 @@\n \n from IPython.display import publish_display_data\n \n-from ..embed import _wrap_in_script_tag\n-\n+JS_MIME_TYPE = 'application/javascript'\n LOAD_MIME_TYPE = 'application/vnd.bokehjs_load.v0+json'\n EXEC_MIME_TYPE = 'application/vnd.bokehjs_exec.v0+json'\n \n@@ -40,33 +39,14 @@\n None\n \n '''\n- nb_html, nb_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout)\n- lab_html, lab_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout, register_mimetype=False)\n- if notebook_type=='jupyter':\n- publish_display_data({'text/html': nb_html + _wrap_in_script_tag(nb_js),\n- LOAD_MIME_TYPE: {\"script\": lab_js, \"div\": lab_html}})\n- else:\n- _publish_zeppelin_data(lab_html, lab_js)\n \n-\n-FINALIZE_JS = \"\"\"\n-document.getElementById(\"%s\").textContent = \"BokehJS is loading...\";\n-\"\"\"\n-\n-# TODO (bev) This will eventually go away\n-def _publish_zeppelin_data(html, js):\n- print('%html ' + html)\n- print('%html ' + '<script type=\"text/javascript\">' + js + \"</script>\")\n-\n-def _load_notebook_html(resources=None, verbose=False, hide_banner=False,\n- load_timeout=5000, register_mimetype=True):\n global _notebook_loaded\n \n from .. import __version__\n- from ..core.templates import AUTOLOAD_NB_JS, NOTEBOOK_LOAD\n+ from ..core.templates import NOTEBOOK_LOAD\n from ..util.serialization import make_id\n- from ..util.compiler import bundle_all_models\n from ..resources import CDN\n+ from ..util.compiler import bundle_all_models\n \n if resources is None:\n resources = CDN\n@@ -99,18 +79,48 @@\n \n custom_models_js = bundle_all_models()\n \n+ nb_js = _loading_js(resources, element_id, custom_models_js, load_timeout, register_mime=True)\n+ jl_js = _loading_js(resources, element_id, custom_models_js, load_timeout, register_mime=False)\n+\n+ if notebook_type=='jupyter':\n+\n+ if not hide_banner:\n+ publish_display_data({'text/html': html})\n+\n+ publish_display_data({\n+ JS_MIME_TYPE : nb_js,\n+ LOAD_MIME_TYPE : {\"script\": jl_js}\n+ })\n+\n+ else:\n+ _publish_zeppelin_data(html, jl_js)\n+\n+\n+FINALIZE_JS = \"\"\"\n+document.getElementById(\"%s\").textContent = \"BokehJS is loading...\";\n+\"\"\"\n+\n+# TODO (bev) This will eventually go away\n+def _publish_zeppelin_data(html, js):\n+ print('%html ' + html)\n+ print('%html ' + '<script type=\"text/javascript\">' + js + \"</script>\")\n+\n+def _loading_js(resources, element_id, custom_models_js, load_timeout=5000, register_mime=True):\n+\n+ from ..core.templates import AUTOLOAD_NB_JS\n+\n js = AUTOLOAD_NB_JS.render(\n- elementid = '' if hide_banner else element_id,\n- js_urls = resources.js_files,\n- css_urls = resources.css_files,\n- js_raw = resources.js_raw + [custom_models_js] + ([] if hide_banner else [FINALIZE_JS % element_id]),\n- css_raw = resources.css_raw_str,\n- force = True,\n- timeout = load_timeout,\n- register_mimetype = register_mimetype\n+ elementid = element_id,\n+ js_urls = resources.js_files,\n+ css_urls = resources.css_files,\n+ js_raw = resources.js_raw + [custom_models_js] + [FINALIZE_JS % element_id],\n+ css_raw = resources.css_raw_str,\n+ force = True,\n+ timeout = load_timeout,\n+ register_mime = register_mime\n )\n \n- return html, js\n+ return js\n \n def get_comms(target_name):\n ''' Create a Jupyter comms object for a specific target, that can\n", "issue": "Inline, Minified Resources do not work in classic notebooks\nThis is due to an interaction with the classic notebooks use of JQuery, when output is published as `text/html`. New notebook code published a div and a script together as `text/html`. Propose to solve by publishing a single script as `application/javascript` (which should work) that creates the necessary div itself \n", "before_files": [{"content": "''' Functions useful for loading Bokeh code and data in Jupyter/Zeppelin notebooks.\n\n'''\nfrom __future__ import absolute_import\n\nfrom IPython.display import publish_display_data\n\nfrom ..embed import _wrap_in_script_tag\n\nLOAD_MIME_TYPE = 'application/vnd.bokehjs_load.v0+json'\nEXEC_MIME_TYPE = 'application/vnd.bokehjs_exec.v0+json'\n\n_notebook_loaded = None\n\n# TODO (bev) notebook_type and zeppelin bits should be removed after external zeppelin hook available\ndef load_notebook(resources=None, verbose=False, hide_banner=False, load_timeout=5000, notebook_type='jupyter'):\n ''' Prepare the IPython notebook for displaying Bokeh plots.\n\n Args:\n resources (Resource, optional) :\n how and where to load BokehJS from (default: CDN)\n\n verbose (bool, optional) :\n whether to report detailed settings (default: False)\n\n hide_banner (bool, optional):\n whether to hide the Bokeh banner (default: False)\n\n load_timeout (int, optional) :\n Timeout in milliseconds when plots assume load timed out (default: 5000)\n\n notebook_type (string):\n notebook_type (default: jupyter)\n\n .. warning::\n Clearing the output cell containing the published BokehJS\n resources HTML code may cause Bokeh CSS styling to be removed.\n\n Returns:\n None\n\n '''\n nb_html, nb_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout)\n lab_html, lab_js = _load_notebook_html(resources, verbose, hide_banner, load_timeout, register_mimetype=False)\n if notebook_type=='jupyter':\n publish_display_data({'text/html': nb_html + _wrap_in_script_tag(nb_js),\n LOAD_MIME_TYPE: {\"script\": lab_js, \"div\": lab_html}})\n else:\n _publish_zeppelin_data(lab_html, lab_js)\n\n\nFINALIZE_JS = \"\"\"\ndocument.getElementById(\"%s\").textContent = \"BokehJS is loading...\";\n\"\"\"\n\n# TODO (bev) This will eventually go away\ndef _publish_zeppelin_data(html, js):\n print('%html ' + html)\n print('%html ' + '<script type=\"text/javascript\">' + js + \"</script>\")\n\ndef _load_notebook_html(resources=None, verbose=False, hide_banner=False,\n load_timeout=5000, register_mimetype=True):\n global _notebook_loaded\n\n from .. import __version__\n from ..core.templates import AUTOLOAD_NB_JS, NOTEBOOK_LOAD\n from ..util.serialization import make_id\n from ..util.compiler import bundle_all_models\n from ..resources import CDN\n\n if resources is None:\n resources = CDN\n\n if resources.mode == 'inline':\n js_info = 'inline'\n css_info = 'inline'\n else:\n js_info = resources.js_files[0] if len(resources.js_files) == 1 else resources.js_files\n css_info = resources.css_files[0] if len(resources.css_files) == 1 else resources.css_files\n\n warnings = [\"Warning: \" + msg['text'] for msg in resources.messages if msg['type'] == 'warn']\n\n if _notebook_loaded and verbose:\n warnings.append('Warning: BokehJS previously loaded')\n\n _notebook_loaded = resources\n\n element_id = make_id()\n\n html = NOTEBOOK_LOAD.render(\n element_id = element_id,\n verbose = verbose,\n js_info = js_info,\n css_info = css_info,\n bokeh_version = __version__,\n warnings = warnings,\n hide_banner = hide_banner,\n )\n\n custom_models_js = bundle_all_models()\n\n js = AUTOLOAD_NB_JS.render(\n elementid = '' if hide_banner else element_id,\n js_urls = resources.js_files,\n css_urls = resources.css_files,\n js_raw = resources.js_raw + [custom_models_js] + ([] if hide_banner else [FINALIZE_JS % element_id]),\n css_raw = resources.css_raw_str,\n force = True,\n timeout = load_timeout,\n register_mimetype = register_mimetype\n )\n\n return html, js\n\ndef get_comms(target_name):\n ''' Create a Jupyter comms object for a specific target, that can\n be used to update Bokeh documents in the Jupyter notebook.\n\n Args:\n target_name (str) : the target name the Comms object should connect to\n\n Returns\n Jupyter Comms\n\n '''\n from ipykernel.comm import Comm\n return Comm(target_name=target_name, data={})\n", "path": "bokeh/util/notebook.py"}]}
| 1,901 | 963 |
gh_patches_debug_59717
|
rasdani/github-patches
|
git_diff
|
pytorch__audio-1339
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Making `AudioMetaData` print friendly
`AudioMetaData` class reports meta-data of audio source. It is however not print friendly.
```python
print(torchaudio.info(src))
>>> <torchaudio.backend.common.AudioMetaData object at 0x7f1bc5cd2890>
```
It is nice if we can simply print the attributes like `dataclass` objects do.
```python
print(torchaudio.info(src))
>>> AudioMetaData(sample_rate=900, encoding="PCM", ...)
```
## Steps
There are two approaches I can think of
1. Add `__str__` method.
2. Use `dataclasses.dataclass`
For 2, the `info` function has to be TorchScript-compatible. This means that its return type `AudioMetaData` has to be TorchScript-able. For this reason, `dataclass` might not be applicable. This can be checked with the following test;
```bash
(cd test && pytest torchaudio_unittest/backend/sox_io/torchscript_test.py)
```
## Build and test
Please refer to the [contribution guide](https://github.com/pytorch/audio/blob/master/CONTRIBUTING.md) for how to setup development environment.
To test,
```bash
(cd test && pytest torchaudio_unittest/backend/sox_io/torchscript_test.py torchaudio_unittest/backend/sox_io/info_test.py torchaudio_unittest/backend/soundfile_io/info_test.py)
```
</issue>
<code>
[start of torchaudio/backend/common.py]
1 class AudioMetaData:
2 """Return type of ``torchaudio.info`` function.
3
4 This class is used by :ref:`"sox_io" backend<sox_io_backend>` and
5 :ref:`"soundfile" backend with the new interface<soundfile_backend>`.
6
7 :ivar int sample_rate: Sample rate
8 :ivar int num_frames: The number of frames
9 :ivar int num_channels: The number of channels
10 :ivar int bits_per_sample: The number of bits per sample. This is 0 for lossy formats,
11 or when it cannot be accurately inferred.
12 :ivar str encoding: Audio encoding
13 The values encoding can take are one of the following:
14
15 * ``PCM_S``: Signed integer linear PCM
16 * ``PCM_U``: Unsigned integer linear PCM
17 * ``PCM_F``: Floating point linear PCM
18 * ``FLAC``: Flac, Free Lossless Audio Codec
19 * ``ULAW``: Mu-law
20 * ``ALAW``: A-law
21 * ``MP3`` : MP3, MPEG-1 Audio Layer III
22 * ``VORBIS``: OGG Vorbis
23 * ``AMR_WB``: Adaptive Multi-Rate
24 * ``AMR_NB``: Adaptive Multi-Rate Wideband
25 * ``OPUS``: Opus
26 * ``UNKNOWN`` : None of above
27 """
28 def __init__(
29 self,
30 sample_rate: int,
31 num_frames: int,
32 num_channels: int,
33 bits_per_sample: int,
34 encoding: str,
35 ):
36 self.sample_rate = sample_rate
37 self.num_frames = num_frames
38 self.num_channels = num_channels
39 self.bits_per_sample = bits_per_sample
40 self.encoding = encoding
41
[end of torchaudio/backend/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torchaudio/backend/common.py b/torchaudio/backend/common.py
--- a/torchaudio/backend/common.py
+++ b/torchaudio/backend/common.py
@@ -38,3 +38,14 @@
self.num_channels = num_channels
self.bits_per_sample = bits_per_sample
self.encoding = encoding
+
+ def __str__(self):
+ return (
+ f"AudioMetaData("
+ f"sample_rate={self.sample_rate}, "
+ f"num_frames={self.num_frames}, "
+ f"num_channels={self.num_channels}, "
+ f"bits_per_sample={self.bits_per_sample}, "
+ f"encoding={self.encoding}"
+ f")"
+ )
|
{"golden_diff": "diff --git a/torchaudio/backend/common.py b/torchaudio/backend/common.py\n--- a/torchaudio/backend/common.py\n+++ b/torchaudio/backend/common.py\n@@ -38,3 +38,14 @@\n self.num_channels = num_channels\n self.bits_per_sample = bits_per_sample\n self.encoding = encoding\n+\n+ def __str__(self):\n+ return (\n+ f\"AudioMetaData(\"\n+ f\"sample_rate={self.sample_rate}, \"\n+ f\"num_frames={self.num_frames}, \"\n+ f\"num_channels={self.num_channels}, \"\n+ f\"bits_per_sample={self.bits_per_sample}, \"\n+ f\"encoding={self.encoding}\"\n+ f\")\"\n+ )\n", "issue": "Making `AudioMetaData` print friendly\n`AudioMetaData` class reports meta-data of audio source. It is however not print friendly.\r\n\r\n```python\r\nprint(torchaudio.info(src))\r\n>>> <torchaudio.backend.common.AudioMetaData object at 0x7f1bc5cd2890>\r\n```\r\n\r\nIt is nice if we can simply print the attributes like `dataclass` objects do.\r\n\r\n```python\r\nprint(torchaudio.info(src))\r\n>>> AudioMetaData(sample_rate=900, encoding=\"PCM\", ...)\r\n```\r\n\r\n## Steps\r\n\r\nThere are two approaches I can think of\r\n1. Add `__str__` method.\r\n2. Use `dataclasses.dataclass`\r\n\r\nFor 2, the `info` function has to be TorchScript-compatible. This means that its return type `AudioMetaData` has to be TorchScript-able. For this reason, `dataclass` might not be applicable. This can be checked with the following test;\r\n\r\n```bash\r\n(cd test && pytest torchaudio_unittest/backend/sox_io/torchscript_test.py)\r\n```\r\n\r\n## Build and test\r\n\r\nPlease refer to the [contribution guide](https://github.com/pytorch/audio/blob/master/CONTRIBUTING.md) for how to setup development environment.\r\n\r\nTo test, \r\n\r\n```bash\r\n(cd test && pytest torchaudio_unittest/backend/sox_io/torchscript_test.py torchaudio_unittest/backend/sox_io/info_test.py torchaudio_unittest/backend/soundfile_io/info_test.py)\r\n```\n", "before_files": [{"content": "class AudioMetaData:\n \"\"\"Return type of ``torchaudio.info`` function.\n\n This class is used by :ref:`\"sox_io\" backend<sox_io_backend>` and\n :ref:`\"soundfile\" backend with the new interface<soundfile_backend>`.\n\n :ivar int sample_rate: Sample rate\n :ivar int num_frames: The number of frames\n :ivar int num_channels: The number of channels\n :ivar int bits_per_sample: The number of bits per sample. This is 0 for lossy formats,\n or when it cannot be accurately inferred.\n :ivar str encoding: Audio encoding\n The values encoding can take are one of the following:\n\n * ``PCM_S``: Signed integer linear PCM\n * ``PCM_U``: Unsigned integer linear PCM\n * ``PCM_F``: Floating point linear PCM\n * ``FLAC``: Flac, Free Lossless Audio Codec\n * ``ULAW``: Mu-law\n * ``ALAW``: A-law\n * ``MP3`` : MP3, MPEG-1 Audio Layer III\n * ``VORBIS``: OGG Vorbis\n * ``AMR_WB``: Adaptive Multi-Rate\n * ``AMR_NB``: Adaptive Multi-Rate Wideband\n * ``OPUS``: Opus\n * ``UNKNOWN`` : None of above\n \"\"\"\n def __init__(\n self,\n sample_rate: int,\n num_frames: int,\n num_channels: int,\n bits_per_sample: int,\n encoding: str,\n ):\n self.sample_rate = sample_rate\n self.num_frames = num_frames\n self.num_channels = num_channels\n self.bits_per_sample = bits_per_sample\n self.encoding = encoding\n", "path": "torchaudio/backend/common.py"}]}
| 1,311 | 163 |
gh_patches_debug_444
|
rasdani/github-patches
|
git_diff
|
sktime__sktime-170
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation needs to be fixed
Single comment line on `sktime.utils.validation.forecasting` needs to be fixed. Check the image below.
Instead of `<<<<<<< HEAD:sktime/utils/validation/forecasting.py` we should see `Returns`.

</issue>
<code>
[start of sktime/utils/validation/forecasting.py]
1 import numpy as np
2 import pandas as pd
3 from sklearn.utils.validation import check_is_fitted
4
5 __author__ = "Markus Löning"
6 __all__ = ["validate_y", "validate_X", "validate_y_X", "validate_fh"]
7
8
9 def validate_y_X(y, X):
10 """Validate input data.
11
12 Parameters
13 ----------
14 y : pandas Series or numpy ndarray
15 X : pandas DataFrame
16
17 <<<<<<< HEAD:sktime/utils/validation/forecasting.py
18 Returns
19 -------
20 None
21
22 Raises
23 ------
24 ValueError
25 If y is an invalid input
26 """
27 validate_y(y)
28 validate_X(X)
29
30
31 def validate_y(y):
32 """Validate input data.
33
34 Parameters
35 ----------
36 y : pandas Series or numpy ndarray
37
38 Returns
39 -------
40 None
41
42 Raises
43 ------
44 ValueError
45 If y is an invalid input
46 """
47 # Check if pandas series
48 if not isinstance(y, pd.Series):
49 raise ValueError(f'y must be a pandas Series, but found: {type(y)}')
50
51 # Check if single row
52 if not y.shape[0] == 1:
53 raise ValueError(f'y must consist of a pandas Series with a single row, '
54 f'but found: {y.shape[0]} rows')
55
56 # Check if contained time series is either pandas series or numpy array
57 s = y.iloc[0]
58 if not isinstance(s, (np.ndarray, pd.Series)):
59 raise ValueError(f'y must contain a pandas Series or numpy array, '
60 f'but found: {type(s)}.')
61
62
63 def validate_X(X):
64 """Validate input data.
65
66 Parameters
67 ----------
68 X : pandas DataFrame
69
70 Returns
71 -------
72 None
73
74 Raises
75 ------
76 ValueError
77 If y is an invalid input
78 """
79 if X is not None:
80 if not isinstance(X, pd.DataFrame):
81 raise ValueError(f"`X` must a pandas DataFrame, but found: {type(X)}")
82 if X.shape[0] > 1:
83 raise ValueError(f"`X` must consist of a single row, but found: {X.shape[0]} rows")
84
85 # Check if index is the same for all columns.
86
87 # Get index from first row, can be either pd.Series or np.array.
88 first_index = X.iloc[0, 0].index if hasattr(X.iloc[0, 0], 'index') else pd.RangeIndex(X.iloc[0, 0].shape[0])
89
90 # Series must contain at least 2 observations, otherwise should be primitive.
91 if len(first_index) < 1:
92 raise ValueError(f'Time series must contain at least 2 observations, but found: '
93 f'{len(first_index)} observations in column: {X.columns[0]}')
94
95 # Compare with remaining columns
96 for c, col in enumerate(X.columns):
97 index = X.iloc[0, c].index if hasattr(X.iloc[0, c], 'index') else pd.RangeIndex(X.iloc[0, 0].shape[0])
98 if not np.array_equal(first_index, index):
99 raise ValueError(f'Found time series with unequal index in column {col}. '
100 f'Input time-series must have the same index.')
101
102
103 def validate_sp(sp):
104 """Validate seasonal periodicity.
105
106 Parameters
107 ----------
108 sp : int
109 Seasonal periodicity
110
111 Returns
112 -------
113 sp : int
114 Validated seasonal periodicity
115 """
116
117 if sp is None:
118 return sp
119
120 else:
121 if not isinstance(sp, int) and (sp >= 0):
122 raise ValueError(f"Seasonal periodicity (sp) has to be a positive integer, but found: "
123 f"{sp} of type: {type(sp)}")
124 return sp
125
126
127 def validate_fh(fh):
128 """Validate forecasting horizon.
129
130 Parameters
131 ----------
132 fh : int or list of int
133 Forecasting horizon with steps ahead to predict.
134
135 Returns
136 -------
137 fh : numpy array of int
138 Sorted and validated forecasting horizon.
139 """
140
141 # Check single integer
142 if np.issubdtype(type(fh), np.integer):
143 return np.array([fh], dtype=np.int)
144
145 # Check array-like input
146 elif isinstance(fh, list):
147 if len(fh) < 1:
148 raise ValueError(f"`fh` must specify at least one step, but found: "
149 f"{type(fh)} of length {len(fh)}")
150 if not np.all([np.issubdtype(type(h), np.integer) for h in fh]):
151 raise ValueError('If `fh` is passed as a list, '
152 'it has to be a list of integers')
153
154 elif isinstance(fh, np.ndarray):
155 if fh.ndim > 1:
156 raise ValueError(f"`fh` must be a 1d array, but found: "
157 f"{fh.ndim} dimensions")
158 if len(fh) < 1:
159 raise ValueError(f"`fh` must specify at least one step, but found: "
160 f"{type(fh)} of length {len(fh)}")
161 if not np.issubdtype(fh.dtype, np.integer):
162 raise ValueError(
163 f'If `fh` is passed as an array, it has to be an array of '
164 f'integers, but found an array of dtype: {fh.dtype}')
165
166 else:
167 raise ValueError(f"`fh` has to be either a list or array of integers, or a single "
168 f"integer, but found: {type(fh)}")
169
170 return np.asarray(np.sort(fh), dtype=np.int)
171
172
173 def check_is_fitted_in_transform(estimator, attributes, msg=None, all_or_any=all):
174 """Checks if the estimator is fitted during transform by verifying the presence of
175 "all_or_any" of the passed attributes and raises a NotFittedError with the
176 given message.
177
178 Parameters
179 ----------
180 estimator : estimator instance.
181 estimator instance for which the check is performed.
182 attributes : attribute name(s) given as string or a list/tuple of strings
183 Eg.:
184 ``["coef_", "estimator_", ...], "coef_"``
185 msg : string
186 The default error message is, "This %(name)s instance is not fitted
187 yet. Call 'fit' with appropriate arguments before using this method."
188 For custom messages if "%(name)s" is present in the message string,
189 it is substituted for the estimator name.
190 Eg. : "Estimator, %(name)s, must be fitted before sparsifying".
191 all_or_any : callable, {all, any}, default all
192 Specify whether all or any of the given attributes must exist.
193 Returns
194 -------
195 None
196
197 Raises
198 ------
199 NotFittedError
200 If the attributes are not found.
201 """
202 if msg is None:
203 msg = ("This %(name)s instance has not been fitted yet. Call 'transform' with "
204 "appropriate arguments before using this method.")
205
206 check_is_fitted(estimator, attributes=attributes, msg=msg, all_or_any=all_or_any)
207
208
209 def validate_time_index(time_index):
210 """Validate time index
211
212 Parameters
213 ----------
214 time_index : array-like
215
216 Returns
217 -------
218 time_index : ndarray
219 """
220 # period or datetime index are not support yet
221 # TODO add support for period/datetime indexing
222 if isinstance(time_index, (pd.PeriodIndex, pd.DatetimeIndex)):
223 raise NotImplementedError(f"{type(time_index)} is not fully supported yet, "
224 f"use pandas RangeIndex instead")
225
226 return np.asarray(time_index)
227
228
229 def check_consistent_time_indices(x, y):
230 """Check that x and y have consistent indices.
231
232 Parameters
233 ----------
234 x : pandas Series
235 y : pandas Series
236
237 Raises:
238 -------
239 ValueError
240 If time indicies are not equal
241 """
242
243 if not x.index.equals(y.index):
244 raise ValueError(f"Found input variables with inconsistent indices")
245
[end of sktime/utils/validation/forecasting.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sktime/utils/validation/forecasting.py b/sktime/utils/validation/forecasting.py
--- a/sktime/utils/validation/forecasting.py
+++ b/sktime/utils/validation/forecasting.py
@@ -14,7 +14,6 @@
y : pandas Series or numpy ndarray
X : pandas DataFrame
-<<<<<<< HEAD:sktime/utils/validation/forecasting.py
Returns
-------
None
|
{"golden_diff": "diff --git a/sktime/utils/validation/forecasting.py b/sktime/utils/validation/forecasting.py\n--- a/sktime/utils/validation/forecasting.py\n+++ b/sktime/utils/validation/forecasting.py\n@@ -14,7 +14,6 @@\n y : pandas Series or numpy ndarray\n X : pandas DataFrame\n \n-<<<<<<< HEAD:sktime/utils/validation/forecasting.py\n Returns\n -------\n None\n", "issue": "Documentation needs to be fixed \nSingle comment line on `sktime.utils.validation.forecasting` needs to be fixed. Check the image below.\r\n\r\nInstead of `<<<<<<< HEAD:sktime/utils/validation/forecasting.py` we should see `Returns`.\r\n \r\n\n", "before_files": [{"content": "import numpy as np\nimport pandas as pd\nfrom sklearn.utils.validation import check_is_fitted\n\n__author__ = \"Markus L\u00f6ning\"\n__all__ = [\"validate_y\", \"validate_X\", \"validate_y_X\", \"validate_fh\"]\n\n\ndef validate_y_X(y, X):\n \"\"\"Validate input data.\n\n Parameters\n ----------\n y : pandas Series or numpy ndarray\n X : pandas DataFrame\n\n<<<<<<< HEAD:sktime/utils/validation/forecasting.py\n Returns\n -------\n None\n\n Raises\n ------\n ValueError\n If y is an invalid input\n \"\"\"\n validate_y(y)\n validate_X(X)\n\n\ndef validate_y(y):\n \"\"\"Validate input data.\n\n Parameters\n ----------\n y : pandas Series or numpy ndarray\n\n Returns\n -------\n None\n\n Raises\n ------\n ValueError\n If y is an invalid input\n \"\"\"\n # Check if pandas series\n if not isinstance(y, pd.Series):\n raise ValueError(f'y must be a pandas Series, but found: {type(y)}')\n\n # Check if single row\n if not y.shape[0] == 1:\n raise ValueError(f'y must consist of a pandas Series with a single row, '\n f'but found: {y.shape[0]} rows')\n\n # Check if contained time series is either pandas series or numpy array\n s = y.iloc[0]\n if not isinstance(s, (np.ndarray, pd.Series)):\n raise ValueError(f'y must contain a pandas Series or numpy array, '\n f'but found: {type(s)}.')\n\n\ndef validate_X(X):\n \"\"\"Validate input data.\n\n Parameters\n ----------\n X : pandas DataFrame\n\n Returns\n -------\n None\n\n Raises\n ------\n ValueError\n If y is an invalid input\n \"\"\"\n if X is not None:\n if not isinstance(X, pd.DataFrame):\n raise ValueError(f\"`X` must a pandas DataFrame, but found: {type(X)}\")\n if X.shape[0] > 1:\n raise ValueError(f\"`X` must consist of a single row, but found: {X.shape[0]} rows\")\n\n # Check if index is the same for all columns.\n\n # Get index from first row, can be either pd.Series or np.array.\n first_index = X.iloc[0, 0].index if hasattr(X.iloc[0, 0], 'index') else pd.RangeIndex(X.iloc[0, 0].shape[0])\n\n # Series must contain at least 2 observations, otherwise should be primitive.\n if len(first_index) < 1:\n raise ValueError(f'Time series must contain at least 2 observations, but found: '\n f'{len(first_index)} observations in column: {X.columns[0]}')\n\n # Compare with remaining columns\n for c, col in enumerate(X.columns):\n index = X.iloc[0, c].index if hasattr(X.iloc[0, c], 'index') else pd.RangeIndex(X.iloc[0, 0].shape[0])\n if not np.array_equal(first_index, index):\n raise ValueError(f'Found time series with unequal index in column {col}. '\n f'Input time-series must have the same index.')\n\n\ndef validate_sp(sp):\n \"\"\"Validate seasonal periodicity.\n\n Parameters\n ----------\n sp : int\n Seasonal periodicity\n\n Returns\n -------\n sp : int\n Validated seasonal periodicity\n \"\"\"\n\n if sp is None:\n return sp\n\n else:\n if not isinstance(sp, int) and (sp >= 0):\n raise ValueError(f\"Seasonal periodicity (sp) has to be a positive integer, but found: \"\n f\"{sp} of type: {type(sp)}\")\n return sp\n\n\ndef validate_fh(fh):\n \"\"\"Validate forecasting horizon.\n\n Parameters\n ----------\n fh : int or list of int\n Forecasting horizon with steps ahead to predict.\n\n Returns\n -------\n fh : numpy array of int\n Sorted and validated forecasting horizon.\n \"\"\"\n\n # Check single integer\n if np.issubdtype(type(fh), np.integer):\n return np.array([fh], dtype=np.int)\n\n # Check array-like input\n elif isinstance(fh, list):\n if len(fh) < 1:\n raise ValueError(f\"`fh` must specify at least one step, but found: \"\n f\"{type(fh)} of length {len(fh)}\")\n if not np.all([np.issubdtype(type(h), np.integer) for h in fh]):\n raise ValueError('If `fh` is passed as a list, '\n 'it has to be a list of integers')\n\n elif isinstance(fh, np.ndarray):\n if fh.ndim > 1:\n raise ValueError(f\"`fh` must be a 1d array, but found: \"\n f\"{fh.ndim} dimensions\")\n if len(fh) < 1:\n raise ValueError(f\"`fh` must specify at least one step, but found: \"\n f\"{type(fh)} of length {len(fh)}\")\n if not np.issubdtype(fh.dtype, np.integer):\n raise ValueError(\n f'If `fh` is passed as an array, it has to be an array of '\n f'integers, but found an array of dtype: {fh.dtype}')\n\n else:\n raise ValueError(f\"`fh` has to be either a list or array of integers, or a single \"\n f\"integer, but found: {type(fh)}\")\n\n return np.asarray(np.sort(fh), dtype=np.int)\n\n\ndef check_is_fitted_in_transform(estimator, attributes, msg=None, all_or_any=all):\n \"\"\"Checks if the estimator is fitted during transform by verifying the presence of\n \"all_or_any\" of the passed attributes and raises a NotFittedError with the\n given message.\n \n Parameters\n ----------\n estimator : estimator instance.\n estimator instance for which the check is performed.\n attributes : attribute name(s) given as string or a list/tuple of strings\n Eg.:\n ``[\"coef_\", \"estimator_\", ...], \"coef_\"``\n msg : string\n The default error message is, \"This %(name)s instance is not fitted\n yet. Call 'fit' with appropriate arguments before using this method.\"\n For custom messages if \"%(name)s\" is present in the message string,\n it is substituted for the estimator name.\n Eg. : \"Estimator, %(name)s, must be fitted before sparsifying\".\n all_or_any : callable, {all, any}, default all\n Specify whether all or any of the given attributes must exist.\n Returns\n -------\n None\n \n Raises\n ------\n NotFittedError\n If the attributes are not found. \n \"\"\"\n if msg is None:\n msg = (\"This %(name)s instance has not been fitted yet. Call 'transform' with \"\n \"appropriate arguments before using this method.\")\n\n check_is_fitted(estimator, attributes=attributes, msg=msg, all_or_any=all_or_any)\n\n\ndef validate_time_index(time_index):\n \"\"\"Validate time index\n\n Parameters\n ----------\n time_index : array-like\n\n Returns\n -------\n time_index : ndarray\n \"\"\"\n # period or datetime index are not support yet\n # TODO add support for period/datetime indexing\n if isinstance(time_index, (pd.PeriodIndex, pd.DatetimeIndex)):\n raise NotImplementedError(f\"{type(time_index)} is not fully supported yet, \"\n f\"use pandas RangeIndex instead\")\n\n return np.asarray(time_index)\n\n\ndef check_consistent_time_indices(x, y):\n \"\"\"Check that x and y have consistent indices.\n\n Parameters\n ----------\n x : pandas Series\n y : pandas Series\n\n Raises:\n -------\n ValueError\n If time indicies are not equal\n \"\"\"\n\n if not x.index.equals(y.index):\n raise ValueError(f\"Found input variables with inconsistent indices\")\n", "path": "sktime/utils/validation/forecasting.py"}]}
| 3,016 | 96 |
gh_patches_debug_24917
|
rasdani/github-patches
|
git_diff
|
pytorch__examples-699
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
dcgan fails on "fake" dataset
I have been using the dcgan example as a stress test for a machine. To save time, I have made use of the `fake` dataset.
`python main.py --dataset 'fake'` fails because `dataroot` is a required parameter. However, the `fake` dataset, does not need such information.
</issue>
<code>
[start of dcgan/main.py]
1 from __future__ import print_function
2 import argparse
3 import os
4 import random
5 import torch
6 import torch.nn as nn
7 import torch.nn.parallel
8 import torch.backends.cudnn as cudnn
9 import torch.optim as optim
10 import torch.utils.data
11 import torchvision.datasets as dset
12 import torchvision.transforms as transforms
13 import torchvision.utils as vutils
14
15
16 parser = argparse.ArgumentParser()
17 parser.add_argument('--dataset', required=True, help='cifar10 | lsun | mnist |imagenet | folder | lfw | fake')
18 parser.add_argument('--dataroot', required=True, help='path to dataset')
19 parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
20 parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
21 parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')
22 parser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')
23 parser.add_argument('--ngf', type=int, default=64)
24 parser.add_argument('--ndf', type=int, default=64)
25 parser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')
26 parser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')
27 parser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')
28 parser.add_argument('--cuda', action='store_true', help='enables cuda')
29 parser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')
30 parser.add_argument('--netG', default='', help="path to netG (to continue training)")
31 parser.add_argument('--netD', default='', help="path to netD (to continue training)")
32 parser.add_argument('--outf', default='.', help='folder to output images and model checkpoints')
33 parser.add_argument('--manualSeed', type=int, help='manual seed')
34 parser.add_argument('--classes', default='bedroom', help='comma separated list of classes for the lsun data set')
35
36 opt = parser.parse_args()
37 print(opt)
38
39 try:
40 os.makedirs(opt.outf)
41 except OSError:
42 pass
43
44 if opt.manualSeed is None:
45 opt.manualSeed = random.randint(1, 10000)
46 print("Random Seed: ", opt.manualSeed)
47 random.seed(opt.manualSeed)
48 torch.manual_seed(opt.manualSeed)
49
50 cudnn.benchmark = True
51
52 if torch.cuda.is_available() and not opt.cuda:
53 print("WARNING: You have a CUDA device, so you should probably run with --cuda")
54
55 if opt.dataset in ['imagenet', 'folder', 'lfw']:
56 # folder dataset
57 dataset = dset.ImageFolder(root=opt.dataroot,
58 transform=transforms.Compose([
59 transforms.Resize(opt.imageSize),
60 transforms.CenterCrop(opt.imageSize),
61 transforms.ToTensor(),
62 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
63 ]))
64 nc=3
65 elif opt.dataset == 'lsun':
66 classes = [ c + '_train' for c in opt.classes.split(',')]
67 dataset = dset.LSUN(root=opt.dataroot, classes=classes,
68 transform=transforms.Compose([
69 transforms.Resize(opt.imageSize),
70 transforms.CenterCrop(opt.imageSize),
71 transforms.ToTensor(),
72 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
73 ]))
74 nc=3
75 elif opt.dataset == 'cifar10':
76 dataset = dset.CIFAR10(root=opt.dataroot, download=True,
77 transform=transforms.Compose([
78 transforms.Resize(opt.imageSize),
79 transforms.ToTensor(),
80 transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
81 ]))
82 nc=3
83
84 elif opt.dataset == 'mnist':
85 dataset = dset.MNIST(root=opt.dataroot, download=True,
86 transform=transforms.Compose([
87 transforms.Resize(opt.imageSize),
88 transforms.ToTensor(),
89 transforms.Normalize((0.5,), (0.5,)),
90 ]))
91 nc=1
92
93 elif opt.dataset == 'fake':
94 dataset = dset.FakeData(image_size=(3, opt.imageSize, opt.imageSize),
95 transform=transforms.ToTensor())
96 nc=3
97
98 assert dataset
99 dataloader = torch.utils.data.DataLoader(dataset, batch_size=opt.batchSize,
100 shuffle=True, num_workers=int(opt.workers))
101
102 device = torch.device("cuda:0" if opt.cuda else "cpu")
103 ngpu = int(opt.ngpu)
104 nz = int(opt.nz)
105 ngf = int(opt.ngf)
106 ndf = int(opt.ndf)
107
108
109 # custom weights initialization called on netG and netD
110 def weights_init(m):
111 classname = m.__class__.__name__
112 if classname.find('Conv') != -1:
113 m.weight.data.normal_(0.0, 0.02)
114 elif classname.find('BatchNorm') != -1:
115 m.weight.data.normal_(1.0, 0.02)
116 m.bias.data.fill_(0)
117
118
119 class Generator(nn.Module):
120 def __init__(self, ngpu):
121 super(Generator, self).__init__()
122 self.ngpu = ngpu
123 self.main = nn.Sequential(
124 # input is Z, going into a convolution
125 nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),
126 nn.BatchNorm2d(ngf * 8),
127 nn.ReLU(True),
128 # state size. (ngf*8) x 4 x 4
129 nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
130 nn.BatchNorm2d(ngf * 4),
131 nn.ReLU(True),
132 # state size. (ngf*4) x 8 x 8
133 nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
134 nn.BatchNorm2d(ngf * 2),
135 nn.ReLU(True),
136 # state size. (ngf*2) x 16 x 16
137 nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
138 nn.BatchNorm2d(ngf),
139 nn.ReLU(True),
140 # state size. (ngf) x 32 x 32
141 nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
142 nn.Tanh()
143 # state size. (nc) x 64 x 64
144 )
145
146 def forward(self, input):
147 if input.is_cuda and self.ngpu > 1:
148 output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
149 else:
150 output = self.main(input)
151 return output
152
153
154 netG = Generator(ngpu).to(device)
155 netG.apply(weights_init)
156 if opt.netG != '':
157 netG.load_state_dict(torch.load(opt.netG))
158 print(netG)
159
160
161 class Discriminator(nn.Module):
162 def __init__(self, ngpu):
163 super(Discriminator, self).__init__()
164 self.ngpu = ngpu
165 self.main = nn.Sequential(
166 # input is (nc) x 64 x 64
167 nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),
168 nn.LeakyReLU(0.2, inplace=True),
169 # state size. (ndf) x 32 x 32
170 nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
171 nn.BatchNorm2d(ndf * 2),
172 nn.LeakyReLU(0.2, inplace=True),
173 # state size. (ndf*2) x 16 x 16
174 nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
175 nn.BatchNorm2d(ndf * 4),
176 nn.LeakyReLU(0.2, inplace=True),
177 # state size. (ndf*4) x 8 x 8
178 nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
179 nn.BatchNorm2d(ndf * 8),
180 nn.LeakyReLU(0.2, inplace=True),
181 # state size. (ndf*8) x 4 x 4
182 nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
183 nn.Sigmoid()
184 )
185
186 def forward(self, input):
187 if input.is_cuda and self.ngpu > 1:
188 output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))
189 else:
190 output = self.main(input)
191
192 return output.view(-1, 1).squeeze(1)
193
194
195 netD = Discriminator(ngpu).to(device)
196 netD.apply(weights_init)
197 if opt.netD != '':
198 netD.load_state_dict(torch.load(opt.netD))
199 print(netD)
200
201 criterion = nn.BCELoss()
202
203 fixed_noise = torch.randn(opt.batchSize, nz, 1, 1, device=device)
204 real_label = 1
205 fake_label = 0
206
207 # setup optimizer
208 optimizerD = optim.Adam(netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
209 optimizerG = optim.Adam(netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
210
211 for epoch in range(opt.niter):
212 for i, data in enumerate(dataloader, 0):
213 ############################
214 # (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
215 ###########################
216 # train with real
217 netD.zero_grad()
218 real_cpu = data[0].to(device)
219 batch_size = real_cpu.size(0)
220 label = torch.full((batch_size,), real_label, device=device)
221
222 output = netD(real_cpu)
223 errD_real = criterion(output, label)
224 errD_real.backward()
225 D_x = output.mean().item()
226
227 # train with fake
228 noise = torch.randn(batch_size, nz, 1, 1, device=device)
229 fake = netG(noise)
230 label.fill_(fake_label)
231 output = netD(fake.detach())
232 errD_fake = criterion(output, label)
233 errD_fake.backward()
234 D_G_z1 = output.mean().item()
235 errD = errD_real + errD_fake
236 optimizerD.step()
237
238 ############################
239 # (2) Update G network: maximize log(D(G(z)))
240 ###########################
241 netG.zero_grad()
242 label.fill_(real_label) # fake labels are real for generator cost
243 output = netD(fake)
244 errG = criterion(output, label)
245 errG.backward()
246 D_G_z2 = output.mean().item()
247 optimizerG.step()
248
249 print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f'
250 % (epoch, opt.niter, i, len(dataloader),
251 errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
252 if i % 100 == 0:
253 vutils.save_image(real_cpu,
254 '%s/real_samples.png' % opt.outf,
255 normalize=True)
256 fake = netG(fixed_noise)
257 vutils.save_image(fake.detach(),
258 '%s/fake_samples_epoch_%03d.png' % (opt.outf, epoch),
259 normalize=True)
260
261 # do checkpointing
262 torch.save(netG.state_dict(), '%s/netG_epoch_%d.pth' % (opt.outf, epoch))
263 torch.save(netD.state_dict(), '%s/netD_epoch_%d.pth' % (opt.outf, epoch))
264
[end of dcgan/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dcgan/main.py b/dcgan/main.py
--- a/dcgan/main.py
+++ b/dcgan/main.py
@@ -15,7 +15,7 @@
parser = argparse.ArgumentParser()
parser.add_argument('--dataset', required=True, help='cifar10 | lsun | mnist |imagenet | folder | lfw | fake')
-parser.add_argument('--dataroot', required=True, help='path to dataset')
+parser.add_argument('--dataroot', required=False, help='path to dataset')
parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)
parser.add_argument('--batchSize', type=int, default=64, help='input batch size')
parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')
@@ -51,6 +51,9 @@
if torch.cuda.is_available() and not opt.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
+
+if opt.dataroot is None and str(opt.dataset).lower() != 'fake':
+ raise ValueError("`dataroot` parameter is required for dataset \"%s\"" % opt.dataset)
if opt.dataset in ['imagenet', 'folder', 'lfw']:
# folder dataset
|
{"golden_diff": "diff --git a/dcgan/main.py b/dcgan/main.py\n--- a/dcgan/main.py\n+++ b/dcgan/main.py\n@@ -15,7 +15,7 @@\n \n parser = argparse.ArgumentParser()\n parser.add_argument('--dataset', required=True, help='cifar10 | lsun | mnist |imagenet | folder | lfw | fake')\n-parser.add_argument('--dataroot', required=True, help='path to dataset')\n+parser.add_argument('--dataroot', required=False, help='path to dataset')\n parser.add_argument('--workers', type=int, help='number of data loading workers', default=2)\n parser.add_argument('--batchSize', type=int, default=64, help='input batch size')\n parser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')\n@@ -51,6 +51,9 @@\n \n if torch.cuda.is_available() and not opt.cuda:\n print(\"WARNING: You have a CUDA device, so you should probably run with --cuda\")\n+ \n+if opt.dataroot is None and str(opt.dataset).lower() != 'fake':\n+ raise ValueError(\"`dataroot` parameter is required for dataset \\\"%s\\\"\" % opt.dataset)\n \n if opt.dataset in ['imagenet', 'folder', 'lfw']:\n # folder dataset\n", "issue": "dcgan fails on \"fake\" dataset\nI have been using the dcgan example as a stress test for a machine. To save time, I have made use of the `fake` dataset.\r\n\r\n`python main.py --dataset 'fake'` fails because `dataroot` is a required parameter. However, the `fake` dataset, does not need such information.\n", "before_files": [{"content": "from __future__ import print_function\nimport argparse\nimport os\nimport random\nimport torch\nimport torch.nn as nn\nimport torch.nn.parallel\nimport torch.backends.cudnn as cudnn\nimport torch.optim as optim\nimport torch.utils.data\nimport torchvision.datasets as dset\nimport torchvision.transforms as transforms\nimport torchvision.utils as vutils\n\n\nparser = argparse.ArgumentParser()\nparser.add_argument('--dataset', required=True, help='cifar10 | lsun | mnist |imagenet | folder | lfw | fake')\nparser.add_argument('--dataroot', required=True, help='path to dataset')\nparser.add_argument('--workers', type=int, help='number of data loading workers', default=2)\nparser.add_argument('--batchSize', type=int, default=64, help='input batch size')\nparser.add_argument('--imageSize', type=int, default=64, help='the height / width of the input image to network')\nparser.add_argument('--nz', type=int, default=100, help='size of the latent z vector')\nparser.add_argument('--ngf', type=int, default=64)\nparser.add_argument('--ndf', type=int, default=64)\nparser.add_argument('--niter', type=int, default=25, help='number of epochs to train for')\nparser.add_argument('--lr', type=float, default=0.0002, help='learning rate, default=0.0002')\nparser.add_argument('--beta1', type=float, default=0.5, help='beta1 for adam. default=0.5')\nparser.add_argument('--cuda', action='store_true', help='enables cuda')\nparser.add_argument('--ngpu', type=int, default=1, help='number of GPUs to use')\nparser.add_argument('--netG', default='', help=\"path to netG (to continue training)\")\nparser.add_argument('--netD', default='', help=\"path to netD (to continue training)\")\nparser.add_argument('--outf', default='.', help='folder to output images and model checkpoints')\nparser.add_argument('--manualSeed', type=int, help='manual seed')\nparser.add_argument('--classes', default='bedroom', help='comma separated list of classes for the lsun data set')\n\nopt = parser.parse_args()\nprint(opt)\n\ntry:\n os.makedirs(opt.outf)\nexcept OSError:\n pass\n\nif opt.manualSeed is None:\n opt.manualSeed = random.randint(1, 10000)\nprint(\"Random Seed: \", opt.manualSeed)\nrandom.seed(opt.manualSeed)\ntorch.manual_seed(opt.manualSeed)\n\ncudnn.benchmark = True\n\nif torch.cuda.is_available() and not opt.cuda:\n print(\"WARNING: You have a CUDA device, so you should probably run with --cuda\")\n\nif opt.dataset in ['imagenet', 'folder', 'lfw']:\n # folder dataset\n dataset = dset.ImageFolder(root=opt.dataroot,\n transform=transforms.Compose([\n transforms.Resize(opt.imageSize),\n transforms.CenterCrop(opt.imageSize),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n ]))\n nc=3\nelif opt.dataset == 'lsun':\n classes = [ c + '_train' for c in opt.classes.split(',')]\n dataset = dset.LSUN(root=opt.dataroot, classes=classes,\n transform=transforms.Compose([\n transforms.Resize(opt.imageSize),\n transforms.CenterCrop(opt.imageSize),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n ]))\n nc=3\nelif opt.dataset == 'cifar10':\n dataset = dset.CIFAR10(root=opt.dataroot, download=True,\n transform=transforms.Compose([\n transforms.Resize(opt.imageSize),\n transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n ]))\n nc=3\n\nelif opt.dataset == 'mnist':\n dataset = dset.MNIST(root=opt.dataroot, download=True,\n transform=transforms.Compose([\n transforms.Resize(opt.imageSize),\n transforms.ToTensor(),\n transforms.Normalize((0.5,), (0.5,)),\n ]))\n nc=1\n\nelif opt.dataset == 'fake':\n dataset = dset.FakeData(image_size=(3, opt.imageSize, opt.imageSize),\n transform=transforms.ToTensor())\n nc=3\n\nassert dataset\ndataloader = torch.utils.data.DataLoader(dataset, batch_size=opt.batchSize,\n shuffle=True, num_workers=int(opt.workers))\n\ndevice = torch.device(\"cuda:0\" if opt.cuda else \"cpu\")\nngpu = int(opt.ngpu)\nnz = int(opt.nz)\nngf = int(opt.ngf)\nndf = int(opt.ndf)\n\n\n# custom weights initialization called on netG and netD\ndef weights_init(m):\n classname = m.__class__.__name__\n if classname.find('Conv') != -1:\n m.weight.data.normal_(0.0, 0.02)\n elif classname.find('BatchNorm') != -1:\n m.weight.data.normal_(1.0, 0.02)\n m.bias.data.fill_(0)\n\n\nclass Generator(nn.Module):\n def __init__(self, ngpu):\n super(Generator, self).__init__()\n self.ngpu = ngpu\n self.main = nn.Sequential(\n # input is Z, going into a convolution\n nn.ConvTranspose2d( nz, ngf * 8, 4, 1, 0, bias=False),\n nn.BatchNorm2d(ngf * 8),\n nn.ReLU(True),\n # state size. (ngf*8) x 4 x 4\n nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),\n nn.BatchNorm2d(ngf * 4),\n nn.ReLU(True),\n # state size. (ngf*4) x 8 x 8\n nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),\n nn.BatchNorm2d(ngf * 2),\n nn.ReLU(True),\n # state size. (ngf*2) x 16 x 16\n nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),\n nn.BatchNorm2d(ngf),\n nn.ReLU(True),\n # state size. (ngf) x 32 x 32\n nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),\n nn.Tanh()\n # state size. (nc) x 64 x 64\n )\n\n def forward(self, input):\n if input.is_cuda and self.ngpu > 1:\n output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))\n else:\n output = self.main(input)\n return output\n\n\nnetG = Generator(ngpu).to(device)\nnetG.apply(weights_init)\nif opt.netG != '':\n netG.load_state_dict(torch.load(opt.netG))\nprint(netG)\n\n\nclass Discriminator(nn.Module):\n def __init__(self, ngpu):\n super(Discriminator, self).__init__()\n self.ngpu = ngpu\n self.main = nn.Sequential(\n # input is (nc) x 64 x 64\n nn.Conv2d(nc, ndf, 4, 2, 1, bias=False),\n nn.LeakyReLU(0.2, inplace=True),\n # state size. (ndf) x 32 x 32\n nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),\n nn.BatchNorm2d(ndf * 2),\n nn.LeakyReLU(0.2, inplace=True),\n # state size. (ndf*2) x 16 x 16\n nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),\n nn.BatchNorm2d(ndf * 4),\n nn.LeakyReLU(0.2, inplace=True),\n # state size. (ndf*4) x 8 x 8\n nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),\n nn.BatchNorm2d(ndf * 8),\n nn.LeakyReLU(0.2, inplace=True),\n # state size. (ndf*8) x 4 x 4\n nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),\n nn.Sigmoid()\n )\n\n def forward(self, input):\n if input.is_cuda and self.ngpu > 1:\n output = nn.parallel.data_parallel(self.main, input, range(self.ngpu))\n else:\n output = self.main(input)\n\n return output.view(-1, 1).squeeze(1)\n\n\nnetD = Discriminator(ngpu).to(device)\nnetD.apply(weights_init)\nif opt.netD != '':\n netD.load_state_dict(torch.load(opt.netD))\nprint(netD)\n\ncriterion = nn.BCELoss()\n\nfixed_noise = torch.randn(opt.batchSize, nz, 1, 1, device=device)\nreal_label = 1\nfake_label = 0\n\n# setup optimizer\noptimizerD = optim.Adam(netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))\noptimizerG = optim.Adam(netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))\n\nfor epoch in range(opt.niter):\n for i, data in enumerate(dataloader, 0):\n ############################\n # (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))\n ###########################\n # train with real\n netD.zero_grad()\n real_cpu = data[0].to(device)\n batch_size = real_cpu.size(0)\n label = torch.full((batch_size,), real_label, device=device)\n\n output = netD(real_cpu)\n errD_real = criterion(output, label)\n errD_real.backward()\n D_x = output.mean().item()\n\n # train with fake\n noise = torch.randn(batch_size, nz, 1, 1, device=device)\n fake = netG(noise)\n label.fill_(fake_label)\n output = netD(fake.detach())\n errD_fake = criterion(output, label)\n errD_fake.backward()\n D_G_z1 = output.mean().item()\n errD = errD_real + errD_fake\n optimizerD.step()\n\n ############################\n # (2) Update G network: maximize log(D(G(z)))\n ###########################\n netG.zero_grad()\n label.fill_(real_label) # fake labels are real for generator cost\n output = netD(fake)\n errG = criterion(output, label)\n errG.backward()\n D_G_z2 = output.mean().item()\n optimizerG.step()\n\n print('[%d/%d][%d/%d] Loss_D: %.4f Loss_G: %.4f D(x): %.4f D(G(z)): %.4f / %.4f'\n % (epoch, opt.niter, i, len(dataloader),\n errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))\n if i % 100 == 0:\n vutils.save_image(real_cpu,\n '%s/real_samples.png' % opt.outf,\n normalize=True)\n fake = netG(fixed_noise)\n vutils.save_image(fake.detach(),\n '%s/fake_samples_epoch_%03d.png' % (opt.outf, epoch),\n normalize=True)\n\n # do checkpointing\n torch.save(netG.state_dict(), '%s/netG_epoch_%d.pth' % (opt.outf, epoch))\n torch.save(netD.state_dict(), '%s/netD_epoch_%d.pth' % (opt.outf, epoch))\n", "path": "dcgan/main.py"}]}
| 4,006 | 292 |
gh_patches_debug_4769
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-1447
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Scheduler only hosts on unix socket when run in the background
Support for hosting the central scheduler on a unix socket was added, which is nice, but the scheduler ignores the `--unix-socket` argument from the command line when `--background` is not also supplied.
This will work properly, and the scheduler will listen on the provided unix socket:
```
luigid --unix-socket /path/to/socket --background
```
With this command, the scheduler will still listen on the default port (8082):
```
luigid --unix-socket /path/to/socket
```
Fixing this would be a simple matter of passing the `unix_socket` argument onto the call to `server.run` in the case where the server is not daemonized, but was there a reason this functionality was left out in the first place? If so, it probably ought to be in the documentation; as is, reading it gives me the impression that I should be able to tell the scheduler to listen on a unix socket regardless of whether it's running in the background.
</issue>
<code>
[start of luigi/cmdline.py]
1 import os
2 import argparse
3 import logging
4 import sys
5
6 from luigi.retcodes import run_with_retcodes
7
8
9 def luigi_run(argv=sys.argv[1:]):
10 run_with_retcodes(argv)
11
12
13 def luigid(argv=sys.argv[1:]):
14 import luigi.server
15 import luigi.process
16 import luigi.configuration
17 parser = argparse.ArgumentParser(description=u'Central luigi server')
18 parser.add_argument(u'--background', help=u'Run in background mode', action='store_true')
19 parser.add_argument(u'--pidfile', help=u'Write pidfile')
20 parser.add_argument(u'--logdir', help=u'log directory')
21 parser.add_argument(u'--state-path', help=u'Pickled state file')
22 parser.add_argument(u'--address', help=u'Listening interface')
23 parser.add_argument(u'--unix-socket', help=u'Unix socket path')
24 parser.add_argument(u'--port', default=8082, help=u'Listening port')
25
26 opts = parser.parse_args(argv)
27
28 if opts.state_path:
29 config = luigi.configuration.get_config()
30 config.set('scheduler', 'state_path', opts.state_path)
31
32 if opts.background:
33 # daemonize sets up logging to spooled log files
34 logging.getLogger().setLevel(logging.INFO)
35 luigi.process.daemonize(luigi.server.run, api_port=opts.port,
36 address=opts.address, pidfile=opts.pidfile,
37 logdir=opts.logdir, unix_socket=opts.unix_socket)
38 else:
39 if opts.logdir:
40 logging.basicConfig(level=logging.INFO, format=luigi.process.get_log_format(),
41 filename=os.path.join(opts.logdir, "luigi-server.log"))
42 else:
43 logging.basicConfig(level=logging.INFO, format=luigi.process.get_log_format())
44 luigi.server.run(api_port=opts.port, address=opts.address)
45
[end of luigi/cmdline.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/luigi/cmdline.py b/luigi/cmdline.py
--- a/luigi/cmdline.py
+++ b/luigi/cmdline.py
@@ -41,4 +41,4 @@
filename=os.path.join(opts.logdir, "luigi-server.log"))
else:
logging.basicConfig(level=logging.INFO, format=luigi.process.get_log_format())
- luigi.server.run(api_port=opts.port, address=opts.address)
+ luigi.server.run(api_port=opts.port, address=opts.address, unix_socket=opts.unix_socket)
|
{"golden_diff": "diff --git a/luigi/cmdline.py b/luigi/cmdline.py\n--- a/luigi/cmdline.py\n+++ b/luigi/cmdline.py\n@@ -41,4 +41,4 @@\n filename=os.path.join(opts.logdir, \"luigi-server.log\"))\n else:\n logging.basicConfig(level=logging.INFO, format=luigi.process.get_log_format())\n- luigi.server.run(api_port=opts.port, address=opts.address)\n+ luigi.server.run(api_port=opts.port, address=opts.address, unix_socket=opts.unix_socket)\n", "issue": "Scheduler only hosts on unix socket when run in the background\nSupport for hosting the central scheduler on a unix socket was added, which is nice, but the scheduler ignores the `--unix-socket` argument from the command line when `--background` is not also supplied. \n\nThis will work properly, and the scheduler will listen on the provided unix socket:\n\n```\nluigid --unix-socket /path/to/socket --background\n```\n\nWith this command, the scheduler will still listen on the default port (8082):\n\n```\nluigid --unix-socket /path/to/socket\n```\n\nFixing this would be a simple matter of passing the `unix_socket` argument onto the call to `server.run` in the case where the server is not daemonized, but was there a reason this functionality was left out in the first place? If so, it probably ought to be in the documentation; as is, reading it gives me the impression that I should be able to tell the scheduler to listen on a unix socket regardless of whether it's running in the background.\n\n", "before_files": [{"content": "import os\nimport argparse\nimport logging\nimport sys\n\nfrom luigi.retcodes import run_with_retcodes\n\n\ndef luigi_run(argv=sys.argv[1:]):\n run_with_retcodes(argv)\n\n\ndef luigid(argv=sys.argv[1:]):\n import luigi.server\n import luigi.process\n import luigi.configuration\n parser = argparse.ArgumentParser(description=u'Central luigi server')\n parser.add_argument(u'--background', help=u'Run in background mode', action='store_true')\n parser.add_argument(u'--pidfile', help=u'Write pidfile')\n parser.add_argument(u'--logdir', help=u'log directory')\n parser.add_argument(u'--state-path', help=u'Pickled state file')\n parser.add_argument(u'--address', help=u'Listening interface')\n parser.add_argument(u'--unix-socket', help=u'Unix socket path')\n parser.add_argument(u'--port', default=8082, help=u'Listening port')\n\n opts = parser.parse_args(argv)\n\n if opts.state_path:\n config = luigi.configuration.get_config()\n config.set('scheduler', 'state_path', opts.state_path)\n\n if opts.background:\n # daemonize sets up logging to spooled log files\n logging.getLogger().setLevel(logging.INFO)\n luigi.process.daemonize(luigi.server.run, api_port=opts.port,\n address=opts.address, pidfile=opts.pidfile,\n logdir=opts.logdir, unix_socket=opts.unix_socket)\n else:\n if opts.logdir:\n logging.basicConfig(level=logging.INFO, format=luigi.process.get_log_format(),\n filename=os.path.join(opts.logdir, \"luigi-server.log\"))\n else:\n logging.basicConfig(level=logging.INFO, format=luigi.process.get_log_format())\n luigi.server.run(api_port=opts.port, address=opts.address)\n", "path": "luigi/cmdline.py"}]}
| 1,244 | 124 |
gh_patches_debug_20043
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-66
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Issue installing package groups (kde-applications for instance)
As mentioned in #61, support for package groups doesn't work.
The idea here is that it should be supported, we simply never verified that the [archinstall.find_package()](https://github.com/Torxed/archinstall/blob/master/archinstall/lib/packages.py#L7-L17) function can verify those, and apparently it can't. So we have to use another API endpoint or multiple to support this.
*The backplane supports it already, as the packages are sent as a unfiltered string to `pacman -S` more or less.*
</issue>
<code>
[start of archinstall/lib/packages.py]
1 import urllib.request, urllib.parse
2 import ssl, json
3 from .exceptions import *
4
5 BASE_URL = 'https://www.archlinux.org/packages/search/json/?name={package}'
6
7 def find_package(name):
8 """
9 Finds a specific package via the package database.
10 It makes a simple web-request, which might be a bit slow.
11 """
12 ssl_context = ssl.create_default_context()
13 ssl_context.check_hostname = False
14 ssl_context.verify_mode = ssl.CERT_NONE
15 response = urllib.request.urlopen(BASE_URL.format(package=name), context=ssl_context)
16 data = response.read().decode('UTF-8')
17 return json.loads(data)
18
19 def find_packages(*names):
20 """
21 This function returns the search results for many packages.
22 The function itself is rather slow, so consider not sending to
23 many packages to the search query.
24 """
25 result = {}
26 for package in names:
27 result[package] = find_package(package)
28 return result
29
30 def validate_package_list(packages :list):
31 """
32 Validates a list of given packages.
33 Raises `RequirementError` if one or more packages are not found.
34 """
35 invalid_packages = []
36 for package in packages:
37 if not find_package(package)['results']:
38 invalid_packages.append(package)
39
40 if invalid_packages:
41 raise RequirementError(f"Invalid package names: {invalid_packages}")
42
43 return True
[end of archinstall/lib/packages.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/archinstall/lib/packages.py b/archinstall/lib/packages.py
--- a/archinstall/lib/packages.py
+++ b/archinstall/lib/packages.py
@@ -3,6 +3,23 @@
from .exceptions import *
BASE_URL = 'https://www.archlinux.org/packages/search/json/?name={package}'
+BASE_GROUP_URL = 'https://www.archlinux.org/groups/x86_64/{group}/'
+
+def find_group(name):
+ ssl_context = ssl.create_default_context()
+ ssl_context.check_hostname = False
+ ssl_context.verify_mode = ssl.CERT_NONE
+ try:
+ response = urllib.request.urlopen(BASE_GROUP_URL.format(group=name), context=ssl_context)
+ except urllib.error.HTTPError as err:
+ if err.code == 404:
+ return False
+ else:
+ raise err
+
+ # Just to be sure some code didn't slip through the exception
+ if response.code == 200:
+ return True
def find_package(name):
"""
@@ -34,7 +51,7 @@
"""
invalid_packages = []
for package in packages:
- if not find_package(package)['results']:
+ if not find_package(package)['results'] and not find_group(package):
invalid_packages.append(package)
if invalid_packages:
|
{"golden_diff": "diff --git a/archinstall/lib/packages.py b/archinstall/lib/packages.py\n--- a/archinstall/lib/packages.py\n+++ b/archinstall/lib/packages.py\n@@ -3,6 +3,23 @@\n from .exceptions import *\n \n BASE_URL = 'https://www.archlinux.org/packages/search/json/?name={package}'\n+BASE_GROUP_URL = 'https://www.archlinux.org/groups/x86_64/{group}/'\n+\n+def find_group(name):\n+\tssl_context = ssl.create_default_context()\n+\tssl_context.check_hostname = False\n+\tssl_context.verify_mode = ssl.CERT_NONE\n+\ttry:\n+\t\tresponse = urllib.request.urlopen(BASE_GROUP_URL.format(group=name), context=ssl_context)\n+\texcept urllib.error.HTTPError as err:\n+\t\tif err.code == 404:\n+\t\t\treturn False\n+\t\telse:\n+\t\t\traise err\n+\t\n+\t# Just to be sure some code didn't slip through the exception\n+\tif response.code == 200:\n+\t\treturn True\n \n def find_package(name):\n \t\"\"\"\n@@ -34,7 +51,7 @@\n \t\"\"\"\n \tinvalid_packages = []\n \tfor package in packages:\n-\t\tif not find_package(package)['results']:\n+\t\tif not find_package(package)['results'] and not find_group(package):\n \t\t\tinvalid_packages.append(package)\n \t\n \tif invalid_packages:\n", "issue": "Issue installing package groups (kde-applications for instance)\nAs mentioned in #61, support for package groups doesn't work.\r\nThe idea here is that it should be supported, we simply never verified that the [archinstall.find_package()](https://github.com/Torxed/archinstall/blob/master/archinstall/lib/packages.py#L7-L17) function can verify those, and apparently it can't. So we have to use another API endpoint or multiple to support this.\r\n\r\n*The backplane supports it already, as the packages are sent as a unfiltered string to `pacman -S` more or less.*\n", "before_files": [{"content": "import urllib.request, urllib.parse\nimport ssl, json\nfrom .exceptions import *\n\nBASE_URL = 'https://www.archlinux.org/packages/search/json/?name={package}'\n\ndef find_package(name):\n\t\"\"\"\n\tFinds a specific package via the package database.\n\tIt makes a simple web-request, which might be a bit slow.\n\t\"\"\"\n\tssl_context = ssl.create_default_context()\n\tssl_context.check_hostname = False\n\tssl_context.verify_mode = ssl.CERT_NONE\n\tresponse = urllib.request.urlopen(BASE_URL.format(package=name), context=ssl_context)\n\tdata = response.read().decode('UTF-8')\n\treturn json.loads(data)\n\ndef find_packages(*names):\n\t\"\"\"\n\tThis function returns the search results for many packages.\n\tThe function itself is rather slow, so consider not sending to\n\tmany packages to the search query.\n\t\"\"\"\n\tresult = {}\n\tfor package in names:\n\t\tresult[package] = find_package(package)\n\treturn result\n\ndef validate_package_list(packages :list):\n\t\"\"\"\n\tValidates a list of given packages.\n\tRaises `RequirementError` if one or more packages are not found.\n\t\"\"\"\n\tinvalid_packages = []\n\tfor package in packages:\n\t\tif not find_package(package)['results']:\n\t\t\tinvalid_packages.append(package)\n\t\n\tif invalid_packages:\n\t\traise RequirementError(f\"Invalid package names: {invalid_packages}\")\n\n\treturn True", "path": "archinstall/lib/packages.py"}]}
| 1,044 | 291 |
gh_patches_debug_20952
|
rasdani/github-patches
|
git_diff
|
Lightning-AI__torchmetrics-2081
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Running Wrapper documentation code example does not render
Pointing out a documentation issue in the Running wrapper:
The code example does not render properly:

https://github.com/Lightning-AI/torchmetrics/blob/99d6d9d6ac4eb1b3398241df558604e70521e6b0/src/torchmetrics/wrappers/running.py#L46-L83
I assume this is because the first line after each `Example:` does not start with `>>>`?
</issue>
<code>
[start of src/torchmetrics/wrappers/running.py]
1 # Copyright The Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Any, Optional, Sequence, Union
15
16 from torch import Tensor
17
18 from torchmetrics.metric import Metric
19 from torchmetrics.utilities.imports import _MATPLOTLIB_AVAILABLE
20 from torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE
21 from torchmetrics.wrappers.abstract import WrapperMetric
22
23 if not _MATPLOTLIB_AVAILABLE:
24 __doctest_skip__ = ["Running.plot"]
25
26
27 class Running(WrapperMetric):
28 """Running wrapper for metrics.
29
30 Using this wrapper allows for calculating metrics over a running window of values, instead of the whole history of
31 values. This is beneficial when you want to get a better estimate of the metric during training and don't want to
32 wait for the whole training to finish to get epoch level estimates.
33
34 The running window is defined by the `window` argument. The window is a fixed size and this wrapper will store a
35 duplicate of the underlying metric state for each value in the window. Thus memory usage will increase linearly
36 with window size. Use accordingly. Also note that the running only works with metrics that have the
37 `full_state_update` set to `False`.
38
39 Importantly, the wrapper does not alter the value of the `forward` method of the underlying metric. Thus, forward
40 will still return the value on the current batch. To get the running value call `compute` instead.
41
42 Args:
43 base_metric: The metric to wrap.
44 window: The size of the running window.
45
46 Example:
47 # Single metric
48 >>> from torch import tensor
49 >>> from torchmetrics.wrappers import Running
50 >>> from torchmetrics.aggregation import SumMetric
51 >>> metric = Running(SumMetric(), window=3)
52 >>> for i in range(6):
53 ... current_val = metric(tensor([i]))
54 ... running_val = metric.compute()
55 ... total_val = tensor(sum(list(range(i+1)))) # value we would get from `compute` without running
56 ... print(f"{current_val=}, {running_val=}, {total_val=}")
57 current_val=tensor(0.), running_val=tensor(0.), total_val=tensor(0)
58 current_val=tensor(1.), running_val=tensor(1.), total_val=tensor(1)
59 current_val=tensor(2.), running_val=tensor(3.), total_val=tensor(3)
60 current_val=tensor(3.), running_val=tensor(6.), total_val=tensor(6)
61 current_val=tensor(4.), running_val=tensor(9.), total_val=tensor(10)
62 current_val=tensor(5.), running_val=tensor(12.), total_val=tensor(15)
63
64 Example:
65 # Metric collection
66 >>> from torch import tensor
67 >>> from torchmetrics.wrappers import Running
68 >>> from torchmetrics import MetricCollection
69 >>> from torchmetrics.aggregation import SumMetric, MeanMetric
70 >>> # note that running is input to collection, not the other way
71 >>> metric = MetricCollection({"sum": Running(SumMetric(), 3), "mean": Running(MeanMetric(), 3)})
72 >>> for i in range(6):
73 ... current_val = metric(tensor([i]))
74 ... running_val = metric.compute()
75 ... print(f"{current_val=}, {running_val=}")
76 current_val={'mean': tensor(0.), 'sum': tensor(0.)}, running_val={'mean': tensor(0.), 'sum': tensor(0.)}
77 current_val={'mean': tensor(1.), 'sum': tensor(1.)}, running_val={'mean': tensor(0.5000), 'sum': tensor(1.)}
78 current_val={'mean': tensor(2.), 'sum': tensor(2.)}, running_val={'mean': tensor(1.), 'sum': tensor(3.)}
79 current_val={'mean': tensor(3.), 'sum': tensor(3.)}, running_val={'mean': tensor(2.), 'sum': tensor(6.)}
80 current_val={'mean': tensor(4.), 'sum': tensor(4.)}, running_val={'mean': tensor(3.), 'sum': tensor(9.)}
81 current_val={'mean': tensor(5.), 'sum': tensor(5.)}, running_val={'mean': tensor(4.), 'sum': tensor(12.)}
82
83 """
84
85 def __init__(self, base_metric: Metric, window: int = 5) -> None:
86 super().__init__()
87 if not isinstance(base_metric, Metric):
88 raise ValueError(
89 f"Expected argument `metric` to be an instance of `torchmetrics.Metric` but got {base_metric}"
90 )
91 if not (isinstance(window, int) and window > 0):
92 raise ValueError(f"Expected argument `window` to be a positive integer but got {window}")
93 self.base_metric = base_metric
94 self.window = window
95
96 if base_metric.full_state_update is not False:
97 raise ValueError(
98 f"Expected attribute `full_state_update` set to `False` but got {base_metric.full_state_update}"
99 )
100 self._num_vals_seen = 0
101
102 for key in base_metric._defaults:
103 for i in range(window):
104 self.add_state(
105 name=key + f"_{i}", default=base_metric._defaults[key], dist_reduce_fx=base_metric._reductions[key]
106 )
107
108 def update(self, *args: Any, **kwargs: Any) -> None:
109 """Update the underlying metric and save state afterwards."""
110 val = self._num_vals_seen % self.window
111 self.base_metric.update(*args, **kwargs)
112 for key in self.base_metric._defaults:
113 setattr(self, key + f"_{val}", getattr(self.base_metric, key))
114 self.base_metric.reset()
115 self._num_vals_seen += 1
116
117 def forward(self, *args: Any, **kwargs: Any) -> Any:
118 """Forward input to the underlying metric and save state afterwards."""
119 val = self._num_vals_seen % self.window
120 res = self.base_metric.forward(*args, **kwargs)
121 for key in self.base_metric._defaults:
122 setattr(self, key + f"_{val}", getattr(self.base_metric, key))
123 self.base_metric.reset()
124 self._num_vals_seen += 1
125 self._computed = None
126 return res
127
128 def compute(self) -> Any:
129 """Compute the metric over the running window."""
130 for i in range(self.window):
131 self.base_metric._reduce_states({key: getattr(self, key + f"_{i}") for key in self.base_metric._defaults})
132 val = self.base_metric.compute()
133 self.base_metric.reset()
134 return val
135
136 def reset(self) -> None:
137 """Reset metric."""
138 super().reset()
139 self._num_vals_seen = 0
140
141 def plot(
142 self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None
143 ) -> _PLOT_OUT_TYPE:
144 """Plot a single or multiple values from the metric.
145
146 Args:
147 val: Either a single result from calling `metric.forward` or `metric.compute` or a list of these results.
148 If no value is provided, will automatically call `metric.compute` and plot that result.
149 ax: An matplotlib axis object. If provided will add plot to that axis
150
151 Returns:
152 Figure and Axes object
153
154 Raises:
155 ModuleNotFoundError:
156 If `matplotlib` is not installed
157
158 .. plot::
159 :scale: 75
160
161 >>> # Example plotting a single value
162 >>> import torch
163 >>> from torchmetrics.wrappers import Running
164 >>> from torchmetrics.aggregation import SumMetric
165 >>> metric = Running(SumMetric(), 2)
166 >>> metric.update(torch.randn(20, 2))
167 >>> fig_, ax_ = metric.plot()
168
169 .. plot::
170 :scale: 75
171
172 >>> # Example plotting multiple values
173 >>> import torch
174 >>> from torchmetrics.wrappers import Running
175 >>> from torchmetrics.aggregation import SumMetric
176 >>> metric = Running(SumMetric(), 2)
177 >>> values = [ ]
178 >>> for _ in range(3):
179 ... values.append(metric(torch.randn(20, 2)))
180 >>> fig_, ax_ = metric.plot(values)
181
182 """
183 return self._plot(val, ax)
184
[end of src/torchmetrics/wrappers/running.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/torchmetrics/wrappers/running.py b/src/torchmetrics/wrappers/running.py
--- a/src/torchmetrics/wrappers/running.py
+++ b/src/torchmetrics/wrappers/running.py
@@ -43,8 +43,7 @@
base_metric: The metric to wrap.
window: The size of the running window.
- Example:
- # Single metric
+ Example (single metric):
>>> from torch import tensor
>>> from torchmetrics.wrappers import Running
>>> from torchmetrics.aggregation import SumMetric
@@ -61,8 +60,7 @@
current_val=tensor(4.), running_val=tensor(9.), total_val=tensor(10)
current_val=tensor(5.), running_val=tensor(12.), total_val=tensor(15)
- Example:
- # Metric collection
+ Example (metric collection):
>>> from torch import tensor
>>> from torchmetrics.wrappers import Running
>>> from torchmetrics import MetricCollection
|
{"golden_diff": "diff --git a/src/torchmetrics/wrappers/running.py b/src/torchmetrics/wrappers/running.py\n--- a/src/torchmetrics/wrappers/running.py\n+++ b/src/torchmetrics/wrappers/running.py\n@@ -43,8 +43,7 @@\n base_metric: The metric to wrap.\n window: The size of the running window.\n \n- Example:\n- # Single metric\n+ Example (single metric):\n >>> from torch import tensor\n >>> from torchmetrics.wrappers import Running\n >>> from torchmetrics.aggregation import SumMetric\n@@ -61,8 +60,7 @@\n current_val=tensor(4.), running_val=tensor(9.), total_val=tensor(10)\n current_val=tensor(5.), running_val=tensor(12.), total_val=tensor(15)\n \n- Example:\n- # Metric collection\n+ Example (metric collection):\n >>> from torch import tensor\n >>> from torchmetrics.wrappers import Running\n >>> from torchmetrics import MetricCollection\n", "issue": "Running Wrapper documentation code example does not render\nPointing out a documentation issue in the Running wrapper:\r\n\r\nThe code example does not render properly: \r\n\r\n\r\nhttps://github.com/Lightning-AI/torchmetrics/blob/99d6d9d6ac4eb1b3398241df558604e70521e6b0/src/torchmetrics/wrappers/running.py#L46-L83\r\n\r\nI assume this is because the first line after each `Example:` does not start with `>>>`?\n", "before_files": [{"content": "# Copyright The Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Any, Optional, Sequence, Union\n\nfrom torch import Tensor\n\nfrom torchmetrics.metric import Metric\nfrom torchmetrics.utilities.imports import _MATPLOTLIB_AVAILABLE\nfrom torchmetrics.utilities.plot import _AX_TYPE, _PLOT_OUT_TYPE\nfrom torchmetrics.wrappers.abstract import WrapperMetric\n\nif not _MATPLOTLIB_AVAILABLE:\n __doctest_skip__ = [\"Running.plot\"]\n\n\nclass Running(WrapperMetric):\n \"\"\"Running wrapper for metrics.\n\n Using this wrapper allows for calculating metrics over a running window of values, instead of the whole history of\n values. This is beneficial when you want to get a better estimate of the metric during training and don't want to\n wait for the whole training to finish to get epoch level estimates.\n\n The running window is defined by the `window` argument. The window is a fixed size and this wrapper will store a\n duplicate of the underlying metric state for each value in the window. Thus memory usage will increase linearly\n with window size. Use accordingly. Also note that the running only works with metrics that have the\n `full_state_update` set to `False`.\n\n Importantly, the wrapper does not alter the value of the `forward` method of the underlying metric. Thus, forward\n will still return the value on the current batch. To get the running value call `compute` instead.\n\n Args:\n base_metric: The metric to wrap.\n window: The size of the running window.\n\n Example:\n # Single metric\n >>> from torch import tensor\n >>> from torchmetrics.wrappers import Running\n >>> from torchmetrics.aggregation import SumMetric\n >>> metric = Running(SumMetric(), window=3)\n >>> for i in range(6):\n ... current_val = metric(tensor([i]))\n ... running_val = metric.compute()\n ... total_val = tensor(sum(list(range(i+1)))) # value we would get from `compute` without running\n ... print(f\"{current_val=}, {running_val=}, {total_val=}\")\n current_val=tensor(0.), running_val=tensor(0.), total_val=tensor(0)\n current_val=tensor(1.), running_val=tensor(1.), total_val=tensor(1)\n current_val=tensor(2.), running_val=tensor(3.), total_val=tensor(3)\n current_val=tensor(3.), running_val=tensor(6.), total_val=tensor(6)\n current_val=tensor(4.), running_val=tensor(9.), total_val=tensor(10)\n current_val=tensor(5.), running_val=tensor(12.), total_val=tensor(15)\n\n Example:\n # Metric collection\n >>> from torch import tensor\n >>> from torchmetrics.wrappers import Running\n >>> from torchmetrics import MetricCollection\n >>> from torchmetrics.aggregation import SumMetric, MeanMetric\n >>> # note that running is input to collection, not the other way\n >>> metric = MetricCollection({\"sum\": Running(SumMetric(), 3), \"mean\": Running(MeanMetric(), 3)})\n >>> for i in range(6):\n ... current_val = metric(tensor([i]))\n ... running_val = metric.compute()\n ... print(f\"{current_val=}, {running_val=}\")\n current_val={'mean': tensor(0.), 'sum': tensor(0.)}, running_val={'mean': tensor(0.), 'sum': tensor(0.)}\n current_val={'mean': tensor(1.), 'sum': tensor(1.)}, running_val={'mean': tensor(0.5000), 'sum': tensor(1.)}\n current_val={'mean': tensor(2.), 'sum': tensor(2.)}, running_val={'mean': tensor(1.), 'sum': tensor(3.)}\n current_val={'mean': tensor(3.), 'sum': tensor(3.)}, running_val={'mean': tensor(2.), 'sum': tensor(6.)}\n current_val={'mean': tensor(4.), 'sum': tensor(4.)}, running_val={'mean': tensor(3.), 'sum': tensor(9.)}\n current_val={'mean': tensor(5.), 'sum': tensor(5.)}, running_val={'mean': tensor(4.), 'sum': tensor(12.)}\n\n \"\"\"\n\n def __init__(self, base_metric: Metric, window: int = 5) -> None:\n super().__init__()\n if not isinstance(base_metric, Metric):\n raise ValueError(\n f\"Expected argument `metric` to be an instance of `torchmetrics.Metric` but got {base_metric}\"\n )\n if not (isinstance(window, int) and window > 0):\n raise ValueError(f\"Expected argument `window` to be a positive integer but got {window}\")\n self.base_metric = base_metric\n self.window = window\n\n if base_metric.full_state_update is not False:\n raise ValueError(\n f\"Expected attribute `full_state_update` set to `False` but got {base_metric.full_state_update}\"\n )\n self._num_vals_seen = 0\n\n for key in base_metric._defaults:\n for i in range(window):\n self.add_state(\n name=key + f\"_{i}\", default=base_metric._defaults[key], dist_reduce_fx=base_metric._reductions[key]\n )\n\n def update(self, *args: Any, **kwargs: Any) -> None:\n \"\"\"Update the underlying metric and save state afterwards.\"\"\"\n val = self._num_vals_seen % self.window\n self.base_metric.update(*args, **kwargs)\n for key in self.base_metric._defaults:\n setattr(self, key + f\"_{val}\", getattr(self.base_metric, key))\n self.base_metric.reset()\n self._num_vals_seen += 1\n\n def forward(self, *args: Any, **kwargs: Any) -> Any:\n \"\"\"Forward input to the underlying metric and save state afterwards.\"\"\"\n val = self._num_vals_seen % self.window\n res = self.base_metric.forward(*args, **kwargs)\n for key in self.base_metric._defaults:\n setattr(self, key + f\"_{val}\", getattr(self.base_metric, key))\n self.base_metric.reset()\n self._num_vals_seen += 1\n self._computed = None\n return res\n\n def compute(self) -> Any:\n \"\"\"Compute the metric over the running window.\"\"\"\n for i in range(self.window):\n self.base_metric._reduce_states({key: getattr(self, key + f\"_{i}\") for key in self.base_metric._defaults})\n val = self.base_metric.compute()\n self.base_metric.reset()\n return val\n\n def reset(self) -> None:\n \"\"\"Reset metric.\"\"\"\n super().reset()\n self._num_vals_seen = 0\n\n def plot(\n self, val: Optional[Union[Tensor, Sequence[Tensor]]] = None, ax: Optional[_AX_TYPE] = None\n ) -> _PLOT_OUT_TYPE:\n \"\"\"Plot a single or multiple values from the metric.\n\n Args:\n val: Either a single result from calling `metric.forward` or `metric.compute` or a list of these results.\n If no value is provided, will automatically call `metric.compute` and plot that result.\n ax: An matplotlib axis object. If provided will add plot to that axis\n\n Returns:\n Figure and Axes object\n\n Raises:\n ModuleNotFoundError:\n If `matplotlib` is not installed\n\n .. plot::\n :scale: 75\n\n >>> # Example plotting a single value\n >>> import torch\n >>> from torchmetrics.wrappers import Running\n >>> from torchmetrics.aggregation import SumMetric\n >>> metric = Running(SumMetric(), 2)\n >>> metric.update(torch.randn(20, 2))\n >>> fig_, ax_ = metric.plot()\n\n .. plot::\n :scale: 75\n\n >>> # Example plotting multiple values\n >>> import torch\n >>> from torchmetrics.wrappers import Running\n >>> from torchmetrics.aggregation import SumMetric\n >>> metric = Running(SumMetric(), 2)\n >>> values = [ ]\n >>> for _ in range(3):\n ... values.append(metric(torch.randn(20, 2)))\n >>> fig_, ax_ = metric.plot(values)\n\n \"\"\"\n return self._plot(val, ax)\n", "path": "src/torchmetrics/wrappers/running.py"}]}
| 3,105 | 232 |
gh_patches_debug_63087
|
rasdani/github-patches
|
git_diff
|
translate__pootle-5160
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ensure tests can be run with `--reuse-db`
When iterating over a test that require DB access (or a few of them), currently a site-wide setup is made which in such scenario ends up being relatively time-consuming and tedious.
Ideally one could use [pytest-django's `--reuse-db` flag](http://pytest-django.readthedocs.org/en/latest/database.html#reuse-db-reuse-the-testing-database-between-test-runs) to considerably reduce setup time on test iterations, however at the current state of things such feature cannot be used due to the way the Pootle test DB environment is setup.
Let's try to fix that so we can benefit from `--reuse-db`.
</issue>
<code>
[start of pytest_pootle/plugin.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import os
10 import shutil
11 from pkgutil import iter_modules
12
13 import pytest
14
15 from . import fixtures
16 from .env import PootleTestEnv
17 from .fixtures import models as fixtures_models
18 from .fixtures.core import management as fixtures_core_management
19 from .fixtures.core import utils as fixtures_core_utils
20 from .fixtures import formats as fixtures_formats
21 from .fixtures import pootle_fs as fixtures_fs
22
23
24 def _load_fixtures(*modules):
25 for mod in modules:
26 path = mod.__path__
27 prefix = '%s.' % mod.__name__
28
29 for loader_, name, is_pkg in iter_modules(path, prefix):
30 if not is_pkg:
31 yield name
32
33
34 @pytest.fixture
35 def po_test_dir(request, tmpdir):
36 po_dir = str(tmpdir.mkdir("po"))
37
38 def rm_po_dir():
39 if os.path.exists(po_dir):
40 shutil.rmtree(po_dir)
41
42 request.addfinalizer(rm_po_dir)
43 return po_dir
44
45
46 @pytest.fixture
47 def po_directory(request, po_test_dir, settings):
48 """Sets up a tmp directory for PO files."""
49 from pootle_store.models import fs
50
51 translation_directory = settings.POOTLE_TRANSLATION_DIRECTORY
52
53 # Adjust locations
54 settings.POOTLE_TRANSLATION_DIRECTORY = po_test_dir
55 fs.location = po_test_dir
56
57 def _cleanup():
58 settings.POOTLE_TRANSLATION_DIRECTORY = translation_directory
59
60 request.addfinalizer(_cleanup)
61
62
63 @pytest.fixture(scope='session')
64 def tests_use_db(request):
65 return bool(
66 [item for item in request.node.items
67 if item.get_marker('django_db')])
68
69
70 @pytest.fixture(scope='session')
71 def tests_use_vfolders(request):
72 return bool(
73 [item for item in request.node.items
74 if item.get_marker('pootle_vfolders')])
75
76
77 @pytest.fixture(scope='session')
78 def tests_use_migration(request, tests_use_db):
79 return bool(
80 tests_use_db
81 and [item for item in request.node.items
82 if item.get_marker('django_migration')])
83
84
85 @pytest.fixture(autouse=True, scope='session')
86 def setup_db_if_needed(request, tests_use_db):
87 """Sets up the site DB only if tests requested to use the DB (autouse)."""
88 if tests_use_db:
89 return request.getfuncargvalue('post_db_setup')
90
91
92 @pytest.fixture(scope='session')
93 def post_db_setup(translations_directory, django_db_setup, django_db_blocker,
94 tests_use_db, tests_use_vfolders, request):
95 """Sets up the site DB for the test session."""
96 if tests_use_db:
97 with django_db_blocker.unblock():
98 PootleTestEnv().setup(
99 vfolders=tests_use_vfolders)
100
101
102 @pytest.fixture(scope='session')
103 def django_db_use_migrations(tests_use_migration):
104 return tests_use_migration
105
106
107 pytest_plugins = tuple(
108 _load_fixtures(
109 fixtures,
110 fixtures_core_management,
111 fixtures_core_utils,
112 fixtures_formats,
113 fixtures_models,
114 fixtures_fs))
115
[end of pytest_pootle/plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pytest_pootle/plugin.py b/pytest_pootle/plugin.py
--- a/pytest_pootle/plugin.py
+++ b/pytest_pootle/plugin.py
@@ -85,7 +85,7 @@
@pytest.fixture(autouse=True, scope='session')
def setup_db_if_needed(request, tests_use_db):
"""Sets up the site DB only if tests requested to use the DB (autouse)."""
- if tests_use_db:
+ if tests_use_db and not request.config.getvalue('reuse_db'):
return request.getfuncargvalue('post_db_setup')
|
{"golden_diff": "diff --git a/pytest_pootle/plugin.py b/pytest_pootle/plugin.py\n--- a/pytest_pootle/plugin.py\n+++ b/pytest_pootle/plugin.py\n@@ -85,7 +85,7 @@\n @pytest.fixture(autouse=True, scope='session')\n def setup_db_if_needed(request, tests_use_db):\n \"\"\"Sets up the site DB only if tests requested to use the DB (autouse).\"\"\"\n- if tests_use_db:\n+ if tests_use_db and not request.config.getvalue('reuse_db'):\n return request.getfuncargvalue('post_db_setup')\n", "issue": "Ensure tests can be run with `--reuse-db`\nWhen iterating over a test that require DB access (or a few of them), currently a site-wide setup is made which in such scenario ends up being relatively time-consuming and tedious.\n\nIdeally one could use [pytest-django's `--reuse-db` flag](http://pytest-django.readthedocs.org/en/latest/database.html#reuse-db-reuse-the-testing-database-between-test-runs) to considerably reduce setup time on test iterations, however at the current state of things such feature cannot be used due to the way the Pootle test DB environment is setup.\n\nLet's try to fix that so we can benefit from `--reuse-db`.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport os\nimport shutil\nfrom pkgutil import iter_modules\n\nimport pytest\n\nfrom . import fixtures\nfrom .env import PootleTestEnv\nfrom .fixtures import models as fixtures_models\nfrom .fixtures.core import management as fixtures_core_management\nfrom .fixtures.core import utils as fixtures_core_utils\nfrom .fixtures import formats as fixtures_formats\nfrom .fixtures import pootle_fs as fixtures_fs\n\n\ndef _load_fixtures(*modules):\n for mod in modules:\n path = mod.__path__\n prefix = '%s.' % mod.__name__\n\n for loader_, name, is_pkg in iter_modules(path, prefix):\n if not is_pkg:\n yield name\n\n\[email protected]\ndef po_test_dir(request, tmpdir):\n po_dir = str(tmpdir.mkdir(\"po\"))\n\n def rm_po_dir():\n if os.path.exists(po_dir):\n shutil.rmtree(po_dir)\n\n request.addfinalizer(rm_po_dir)\n return po_dir\n\n\[email protected]\ndef po_directory(request, po_test_dir, settings):\n \"\"\"Sets up a tmp directory for PO files.\"\"\"\n from pootle_store.models import fs\n\n translation_directory = settings.POOTLE_TRANSLATION_DIRECTORY\n\n # Adjust locations\n settings.POOTLE_TRANSLATION_DIRECTORY = po_test_dir\n fs.location = po_test_dir\n\n def _cleanup():\n settings.POOTLE_TRANSLATION_DIRECTORY = translation_directory\n\n request.addfinalizer(_cleanup)\n\n\[email protected](scope='session')\ndef tests_use_db(request):\n return bool(\n [item for item in request.node.items\n if item.get_marker('django_db')])\n\n\[email protected](scope='session')\ndef tests_use_vfolders(request):\n return bool(\n [item for item in request.node.items\n if item.get_marker('pootle_vfolders')])\n\n\[email protected](scope='session')\ndef tests_use_migration(request, tests_use_db):\n return bool(\n tests_use_db\n and [item for item in request.node.items\n if item.get_marker('django_migration')])\n\n\[email protected](autouse=True, scope='session')\ndef setup_db_if_needed(request, tests_use_db):\n \"\"\"Sets up the site DB only if tests requested to use the DB (autouse).\"\"\"\n if tests_use_db:\n return request.getfuncargvalue('post_db_setup')\n\n\[email protected](scope='session')\ndef post_db_setup(translations_directory, django_db_setup, django_db_blocker,\n tests_use_db, tests_use_vfolders, request):\n \"\"\"Sets up the site DB for the test session.\"\"\"\n if tests_use_db:\n with django_db_blocker.unblock():\n PootleTestEnv().setup(\n vfolders=tests_use_vfolders)\n\n\[email protected](scope='session')\ndef django_db_use_migrations(tests_use_migration):\n return tests_use_migration\n\n\npytest_plugins = tuple(\n _load_fixtures(\n fixtures,\n fixtures_core_management,\n fixtures_core_utils,\n fixtures_formats,\n fixtures_models,\n fixtures_fs))\n", "path": "pytest_pootle/plugin.py"}]}
| 1,638 | 129 |
gh_patches_debug_15855
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-10668
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Django: adapt admin code for 3.x
It seems that we missed an upgrade to make it fully compatible with Django 3.x
We are using `admin.ACTION_CHECKBOX_NAME` when it was deprecated and it was removed already:
> The compatibility import of django.contrib.admin.helpers.ACTION_CHECKBOX_NAME in django.contrib.admin is removed.
(from https://docs.djangoproject.com/en/4.0/releases/3.1/#id1)
The code lives at https://github.com/readthedocs/readthedocs.org/blob/e94c26074e9abdf7056b4e6502c52f8a6b128055/readthedocs/notifications/views.py#L48
</issue>
<code>
[start of readthedocs/notifications/views.py]
1 """Django views for the notifications app."""
2 from django.contrib import admin, messages
3 from django.http import HttpResponseRedirect
4 from django.views.generic import FormView
5
6 from .forms import SendNotificationForm
7
8
9 class SendNotificationView(FormView):
10
11 """
12 Form view for sending notifications to users from admin pages.
13
14 Accepts the following additional parameters:
15
16 :param queryset: Queryset to use to determine the users to send emails to
17 :param action_name: Name of the action to pass to the form template,
18 determines the action to pass back to the admin view
19 :param notification_classes: List of :py:class:`Notification` classes to
20 display in the form
21 """
22
23 form_class = SendNotificationForm
24 template_name = "notifications/send_notification_form.html"
25 action_name = "send_email"
26 notification_classes = []
27
28 def get_form_kwargs(self):
29 """
30 Override form kwargs based on input fields.
31
32 The admin posts to this view initially, so detect the send button on
33 form post variables. Drop additional fields if we see the send button.
34 """
35 kwargs = super().get_form_kwargs()
36 kwargs["notification_classes"] = self.notification_classes
37 if "send" not in self.request.POST:
38 kwargs.pop("data", None)
39 kwargs.pop("files", None)
40 return kwargs
41
42 def get_initial(self):
43 """Add selected ids to initial form data."""
44 initial = super().get_initial()
45 initial["_selected_action"] = self.request.POST.getlist(
46 admin.ACTION_CHECKBOX_NAME,
47 )
48 return initial
49
50 def form_valid(self, form):
51 """If form is valid, send notification to recipients."""
52 count = 0
53 notification_cls = form.cleaned_data["source"]
54 for obj in self.get_queryset().all():
55 for recipient in self.get_object_recipients(obj):
56 notification = notification_cls(
57 context_object=obj,
58 request=self.request,
59 user=recipient,
60 )
61 notification.send()
62 count += 1
63 if count == 0:
64 self.message_user("No recipients to send to", level=messages.ERROR)
65 else:
66 self.message_user("Queued {} messages".format(count))
67 return HttpResponseRedirect(self.request.get_full_path())
68
69 def get_object_recipients(self, obj):
70 """
71 Iterate over queryset objects and return User objects.
72
73 This allows for non-User querysets to pass back a list of Users to send
74 to. By default, assume we're working with :py:class:`User` objects and
75 just yield the single object.
76
77 For example, this could be made to return project owners with::
78
79 for owner in AdminPermission.members(project):
80 yield owner
81
82 :param obj: object from queryset, type is dependent on model class
83 :rtype: django.contrib.auth.models.User
84 """
85 yield obj
86
87 def get_queryset(self):
88 return self.kwargs.get("queryset")
89
90 def get_context_data(self, **kwargs):
91 """Return queryset in context."""
92 context = super().get_context_data(**kwargs)
93 recipients = []
94 for obj in self.get_queryset().all():
95 recipients.extend(self.get_object_recipients(obj))
96 context["recipients"] = recipients
97 context["action_name"] = self.action_name
98 return context
99
100 def message_user(
101 self,
102 message,
103 level=messages.INFO,
104 extra_tags="",
105 fail_silently=False,
106 ):
107 """
108 Implementation of.
109
110 :py:meth:`django.contrib.admin.options.ModelAdmin.message_user`
111
112 Send message through messages framework
113 """
114 # TODO generalize this or check if implementation in ModelAdmin is
115 # usable here
116 messages.add_message(
117 self.request,
118 level,
119 message,
120 extra_tags=extra_tags,
121 fail_silently=fail_silently,
122 )
123
[end of readthedocs/notifications/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/notifications/views.py b/readthedocs/notifications/views.py
--- a/readthedocs/notifications/views.py
+++ b/readthedocs/notifications/views.py
@@ -1,5 +1,5 @@
"""Django views for the notifications app."""
-from django.contrib import admin, messages
+from django.contrib import messages
from django.http import HttpResponseRedirect
from django.views.generic import FormView
@@ -42,9 +42,7 @@
def get_initial(self):
"""Add selected ids to initial form data."""
initial = super().get_initial()
- initial["_selected_action"] = self.request.POST.getlist(
- admin.ACTION_CHECKBOX_NAME,
- )
+ initial["_selected_action"] = self.request.POST.getlist("_selected_action")
return initial
def form_valid(self, form):
|
{"golden_diff": "diff --git a/readthedocs/notifications/views.py b/readthedocs/notifications/views.py\n--- a/readthedocs/notifications/views.py\n+++ b/readthedocs/notifications/views.py\n@@ -1,5 +1,5 @@\n \"\"\"Django views for the notifications app.\"\"\"\n-from django.contrib import admin, messages\n+from django.contrib import messages\n from django.http import HttpResponseRedirect\n from django.views.generic import FormView\n \n@@ -42,9 +42,7 @@\n def get_initial(self):\n \"\"\"Add selected ids to initial form data.\"\"\"\n initial = super().get_initial()\n- initial[\"_selected_action\"] = self.request.POST.getlist(\n- admin.ACTION_CHECKBOX_NAME,\n- )\n+ initial[\"_selected_action\"] = self.request.POST.getlist(\"_selected_action\")\n return initial\n \n def form_valid(self, form):\n", "issue": "Django: adapt admin code for 3.x\nIt seems that we missed an upgrade to make it fully compatible with Django 3.x\r\n\r\nWe are using `admin.ACTION_CHECKBOX_NAME` when it was deprecated and it was removed already:\r\n\r\n> The compatibility import of django.contrib.admin.helpers.ACTION_CHECKBOX_NAME in django.contrib.admin is removed.\r\n\r\n(from https://docs.djangoproject.com/en/4.0/releases/3.1/#id1)\r\n\r\nThe code lives at https://github.com/readthedocs/readthedocs.org/blob/e94c26074e9abdf7056b4e6502c52f8a6b128055/readthedocs/notifications/views.py#L48\n", "before_files": [{"content": "\"\"\"Django views for the notifications app.\"\"\"\nfrom django.contrib import admin, messages\nfrom django.http import HttpResponseRedirect\nfrom django.views.generic import FormView\n\nfrom .forms import SendNotificationForm\n\n\nclass SendNotificationView(FormView):\n\n \"\"\"\n Form view for sending notifications to users from admin pages.\n\n Accepts the following additional parameters:\n\n :param queryset: Queryset to use to determine the users to send emails to\n :param action_name: Name of the action to pass to the form template,\n determines the action to pass back to the admin view\n :param notification_classes: List of :py:class:`Notification` classes to\n display in the form\n \"\"\"\n\n form_class = SendNotificationForm\n template_name = \"notifications/send_notification_form.html\"\n action_name = \"send_email\"\n notification_classes = []\n\n def get_form_kwargs(self):\n \"\"\"\n Override form kwargs based on input fields.\n\n The admin posts to this view initially, so detect the send button on\n form post variables. Drop additional fields if we see the send button.\n \"\"\"\n kwargs = super().get_form_kwargs()\n kwargs[\"notification_classes\"] = self.notification_classes\n if \"send\" not in self.request.POST:\n kwargs.pop(\"data\", None)\n kwargs.pop(\"files\", None)\n return kwargs\n\n def get_initial(self):\n \"\"\"Add selected ids to initial form data.\"\"\"\n initial = super().get_initial()\n initial[\"_selected_action\"] = self.request.POST.getlist(\n admin.ACTION_CHECKBOX_NAME,\n )\n return initial\n\n def form_valid(self, form):\n \"\"\"If form is valid, send notification to recipients.\"\"\"\n count = 0\n notification_cls = form.cleaned_data[\"source\"]\n for obj in self.get_queryset().all():\n for recipient in self.get_object_recipients(obj):\n notification = notification_cls(\n context_object=obj,\n request=self.request,\n user=recipient,\n )\n notification.send()\n count += 1\n if count == 0:\n self.message_user(\"No recipients to send to\", level=messages.ERROR)\n else:\n self.message_user(\"Queued {} messages\".format(count))\n return HttpResponseRedirect(self.request.get_full_path())\n\n def get_object_recipients(self, obj):\n \"\"\"\n Iterate over queryset objects and return User objects.\n\n This allows for non-User querysets to pass back a list of Users to send\n to. By default, assume we're working with :py:class:`User` objects and\n just yield the single object.\n\n For example, this could be made to return project owners with::\n\n for owner in AdminPermission.members(project):\n yield owner\n\n :param obj: object from queryset, type is dependent on model class\n :rtype: django.contrib.auth.models.User\n \"\"\"\n yield obj\n\n def get_queryset(self):\n return self.kwargs.get(\"queryset\")\n\n def get_context_data(self, **kwargs):\n \"\"\"Return queryset in context.\"\"\"\n context = super().get_context_data(**kwargs)\n recipients = []\n for obj in self.get_queryset().all():\n recipients.extend(self.get_object_recipients(obj))\n context[\"recipients\"] = recipients\n context[\"action_name\"] = self.action_name\n return context\n\n def message_user(\n self,\n message,\n level=messages.INFO,\n extra_tags=\"\",\n fail_silently=False,\n ):\n \"\"\"\n Implementation of.\n\n :py:meth:`django.contrib.admin.options.ModelAdmin.message_user`\n\n Send message through messages framework\n \"\"\"\n # TODO generalize this or check if implementation in ModelAdmin is\n # usable here\n messages.add_message(\n self.request,\n level,\n message,\n extra_tags=extra_tags,\n fail_silently=fail_silently,\n )\n", "path": "readthedocs/notifications/views.py"}]}
| 1,770 | 178 |
gh_patches_debug_27494
|
rasdani/github-patches
|
git_diff
|
shuup__shuup-1977
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Admin UI: Fix media browser file upload
An exception is raised when you manually select the file while uploading it. To reproduce:
- Go to Products
- Select/Create a product
- Go to Files section
- Click over the dropzone area
- In the media browser window, click Upload
- Select a file and check the console (error)

</issue>
<code>
[start of shuup/admin/browser_config.py]
1 # -*- coding: utf-8 -*-
2 # This file is part of Shuup.
3 #
4 # Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.
5 #
6 # This source code is licensed under the OSL-3.0 license found in the
7 # LICENSE file in the root directory of this source tree.
8 from django.conf import settings
9
10 from shuup.utils.i18n import get_current_babel_locale
11
12
13 class BaseBrowserConfigProvider(object):
14 @classmethod
15 def get_browser_urls(cls, request, **kwargs):
16 return {}
17
18 @classmethod
19 def get_gettings(cls, request, **kwargs):
20 return {}
21
22
23 class DefaultBrowserConfigProvider(BaseBrowserConfigProvider):
24 @classmethod
25 def get_browser_urls(cls, request, **kwargs):
26 return {
27 "edit": "shuup_admin:edit",
28 "select": "shuup_admin:select",
29 "media": "shuup_admin:media.browse",
30 "product": "shuup_admin:shop_product.list",
31 "contact": "shuup_admin:contact.list",
32 "setLanguage": "shuup_admin:set-language",
33 "tour": "shuup_admin:tour",
34 "menu_toggle": "shuup_admin:menu_toggle"
35 }
36
37 @classmethod
38 def get_gettings(cls, request, **kwargs):
39 return {
40 "minSearchInputLength": settings.SHUUP_ADMIN_MINIMUM_INPUT_LENGTH_SEARCH or 1,
41 "dateInputFormat": settings.SHUUP_ADMIN_DATE_INPUT_FORMAT,
42 "datetimeInputFormat": settings.SHUUP_ADMIN_DATETIME_INPUT_FORMAT,
43 "timeInputFormat": settings.SHUUP_ADMIN_TIME_INPUT_FORMAT,
44 "datetimeInputStep": settings.SHUUP_ADMIN_DATETIME_INPUT_STEP,
45 "dateInputLocale": get_current_babel_locale().language
46 }
47
[end of shuup/admin/browser_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/shuup/admin/browser_config.py b/shuup/admin/browser_config.py
--- a/shuup/admin/browser_config.py
+++ b/shuup/admin/browser_config.py
@@ -7,6 +7,7 @@
# LICENSE file in the root directory of this source tree.
from django.conf import settings
+from shuup.admin.utils.permissions import has_permission
from shuup.utils.i18n import get_current_babel_locale
@@ -26,7 +27,7 @@
return {
"edit": "shuup_admin:edit",
"select": "shuup_admin:select",
- "media": "shuup_admin:media.browse",
+ "media": ("shuup_admin:media.browse" if has_permission(request.user, "shuup_admin:media.browse") else None),
"product": "shuup_admin:shop_product.list",
"contact": "shuup_admin:contact.list",
"setLanguage": "shuup_admin:set-language",
@@ -42,5 +43,6 @@
"datetimeInputFormat": settings.SHUUP_ADMIN_DATETIME_INPUT_FORMAT,
"timeInputFormat": settings.SHUUP_ADMIN_TIME_INPUT_FORMAT,
"datetimeInputStep": settings.SHUUP_ADMIN_DATETIME_INPUT_STEP,
- "dateInputLocale": get_current_babel_locale().language
+ "dateInputLocale": get_current_babel_locale().language,
+ "staticPrefix": settings.STATIC_URL,
}
|
{"golden_diff": "diff --git a/shuup/admin/browser_config.py b/shuup/admin/browser_config.py\n--- a/shuup/admin/browser_config.py\n+++ b/shuup/admin/browser_config.py\n@@ -7,6 +7,7 @@\n # LICENSE file in the root directory of this source tree.\n from django.conf import settings\n \n+from shuup.admin.utils.permissions import has_permission\n from shuup.utils.i18n import get_current_babel_locale\n \n \n@@ -26,7 +27,7 @@\n return {\n \"edit\": \"shuup_admin:edit\",\n \"select\": \"shuup_admin:select\",\n- \"media\": \"shuup_admin:media.browse\",\n+ \"media\": (\"shuup_admin:media.browse\" if has_permission(request.user, \"shuup_admin:media.browse\") else None),\n \"product\": \"shuup_admin:shop_product.list\",\n \"contact\": \"shuup_admin:contact.list\",\n \"setLanguage\": \"shuup_admin:set-language\",\n@@ -42,5 +43,6 @@\n \"datetimeInputFormat\": settings.SHUUP_ADMIN_DATETIME_INPUT_FORMAT,\n \"timeInputFormat\": settings.SHUUP_ADMIN_TIME_INPUT_FORMAT,\n \"datetimeInputStep\": settings.SHUUP_ADMIN_DATETIME_INPUT_STEP,\n- \"dateInputLocale\": get_current_babel_locale().language\n+ \"dateInputLocale\": get_current_babel_locale().language,\n+ \"staticPrefix\": settings.STATIC_URL,\n }\n", "issue": " Admin UI: Fix media browser file upload\nAn exception is raised when you manually select the file while uploading it. To reproduce:\r\n- Go to Products\r\n- Select/Create a product\r\n- Go to Files section\r\n- Click over the dropzone area\r\n- In the media browser window, click Upload\r\n- Select a file and check the console (error)\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# This file is part of Shuup.\n#\n# Copyright (c) 2012-2019, Shoop Commerce Ltd. All rights reserved.\n#\n# This source code is licensed under the OSL-3.0 license found in the\n# LICENSE file in the root directory of this source tree.\nfrom django.conf import settings\n\nfrom shuup.utils.i18n import get_current_babel_locale\n\n\nclass BaseBrowserConfigProvider(object):\n @classmethod\n def get_browser_urls(cls, request, **kwargs):\n return {}\n\n @classmethod\n def get_gettings(cls, request, **kwargs):\n return {}\n\n\nclass DefaultBrowserConfigProvider(BaseBrowserConfigProvider):\n @classmethod\n def get_browser_urls(cls, request, **kwargs):\n return {\n \"edit\": \"shuup_admin:edit\",\n \"select\": \"shuup_admin:select\",\n \"media\": \"shuup_admin:media.browse\",\n \"product\": \"shuup_admin:shop_product.list\",\n \"contact\": \"shuup_admin:contact.list\",\n \"setLanguage\": \"shuup_admin:set-language\",\n \"tour\": \"shuup_admin:tour\",\n \"menu_toggle\": \"shuup_admin:menu_toggle\"\n }\n\n @classmethod\n def get_gettings(cls, request, **kwargs):\n return {\n \"minSearchInputLength\": settings.SHUUP_ADMIN_MINIMUM_INPUT_LENGTH_SEARCH or 1,\n \"dateInputFormat\": settings.SHUUP_ADMIN_DATE_INPUT_FORMAT,\n \"datetimeInputFormat\": settings.SHUUP_ADMIN_DATETIME_INPUT_FORMAT,\n \"timeInputFormat\": settings.SHUUP_ADMIN_TIME_INPUT_FORMAT,\n \"datetimeInputStep\": settings.SHUUP_ADMIN_DATETIME_INPUT_STEP,\n \"dateInputLocale\": get_current_babel_locale().language\n }\n", "path": "shuup/admin/browser_config.py"}]}
| 1,165 | 327 |
gh_patches_debug_3697
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-903
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
A model doesn't know its input_shape after build
Reproduce the error as
``` python
model = Sequential()
model.add(Dense(1), input_shape=(784,))
model.build()
model.input_shape
```
Shouldn't the model know its `input_shape` after `build`? It knows `output_shape` for instance. Am I missing anything @matsuyamax ?
</issue>
<code>
[start of keras/layers/containers.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import
3 from __future__ import print_function
4
5 from collections import OrderedDict
6 import theano.tensor as T
7 from ..layers.core import Layer, Merge
8 from ..utils.theano_utils import ndim_tensor
9 from six.moves import range
10
11
12 class Sequential(Layer):
13 '''
14 Simple linear stack of layers.
15
16 inherited from Layer:
17 - get_params
18 - get_output_mask
19 - supports_masked_input
20 '''
21
22 def __init__(self, layers=[]):
23 self.layers = []
24 for layer in layers:
25 self.add(layer)
26
27 def set_previous(self, layer):
28 self.layers[0].previous = layer
29
30 def add(self, layer):
31 self.layers.append(layer)
32 if len(self.layers) > 1:
33 self.layers[-1].set_previous(self.layers[-2])
34 if not hasattr(self.layers[0], 'input'):
35 self.set_input()
36
37 @property
38 def params(self):
39 params = []
40 for l in self.layers:
41 if l.trainable:
42 params += l.get_params()[0]
43 return params
44
45 @property
46 def regularizers(self):
47 regularizers = []
48 for l in self.layers:
49 if l.trainable:
50 regularizers += l.get_params()[1]
51 return regularizers
52
53 @property
54 def constraints(self):
55 constraints = []
56 for l in self.layers:
57 if l.trainable:
58 constraints += l.get_params()[2]
59 return constraints
60
61 @property
62 def updates(self):
63 updates = []
64 for l in self.layers:
65 if l.trainable:
66 updates += l.get_params()[3]
67 return updates
68
69 @property
70 def output_shape(self):
71 return self.layers[-1].output_shape
72
73 def get_output(self, train=False):
74 return self.layers[-1].get_output(train)
75
76 def set_input(self):
77 for l in self.layers:
78 if hasattr(l, 'input'):
79 ndim = l.input.ndim
80 self.layers[0].input = ndim_tensor(ndim)
81 break
82
83 def get_input(self, train=False):
84 if not hasattr(self.layers[0], 'input'):
85 self.set_input()
86 return self.layers[0].get_input(train)
87
88 @property
89 def input(self):
90 return self.get_input()
91
92 def get_weights(self):
93 weights = []
94 for layer in self.layers:
95 weights += layer.get_weights()
96 return weights
97
98 def set_weights(self, weights):
99 for i in range(len(self.layers)):
100 nb_param = len(self.layers[i].params)
101 self.layers[i].set_weights(weights[:nb_param])
102 weights = weights[nb_param:]
103
104 def get_config(self):
105 return {"name": self.__class__.__name__,
106 "layers": [layer.get_config() for layer in self.layers]}
107
108 def count_params(self):
109 return sum([layer.count_params() for layer in self.layers])
110
111
112 class Graph(Layer):
113 '''
114 Implement a NN graph with arbitrary layer connections,
115 arbitrary number of inputs and arbitrary number of outputs.
116
117 Note: Graph can only be used as a layer
118 (connect, input, get_input, get_output)
119 when it has exactly one input and one output.
120
121 inherited from Layer:
122 - get_output_mask
123 - supports_masked_input
124 - get_weights
125 - set_weights
126 '''
127 def __init__(self):
128 self.namespace = set() # strings
129 self.nodes = OrderedDict() # layer-like
130 self.inputs = {} # layer-like
131 self.input_order = [] # strings
132 self.outputs = {} # layer-like
133 self.output_order = [] # strings
134 self.input_config = [] # dicts
135 self.output_config = [] # dicts
136 self.node_config = [] # dicts
137
138 @property
139 def nb_input(self):
140 return len(self.inputs)
141
142 @property
143 def nb_output(self):
144 return len(self.outputs)
145
146 @property
147 def params(self):
148 params = []
149 for l in self.nodes.values():
150 if l.trainable:
151 params += l.get_params()[0]
152 return params
153
154 @property
155 def regularizers(self):
156 regularizers = []
157 for l in self.nodes.values():
158 if l.trainable:
159 regularizers += l.get_params()[1]
160 return regularizers
161
162 @property
163 def constraints(self):
164 constraints = []
165 for l in self.nodes.values():
166 if l.trainable:
167 constraints += l.get_params()[2]
168 return constraints
169
170 @property
171 def updates(self):
172 updates = []
173 for l in self.nodes.values():
174 if l.trainable:
175 updates += l.get_params()[3]
176 return updates
177
178 def set_previous(self, layer, connection_map={}):
179 if self.nb_input != layer.nb_output:
180 raise Exception('Cannot connect layers: input count does not match output count.')
181 if self.nb_input == 1:
182 self.inputs[self.input_order[0]].set_previous(layer)
183 else:
184 if not connection_map:
185 raise Exception('Cannot attach multi-input layer: no connection_map provided.')
186 for k, v in connection_map.items():
187 if k in self.inputs and v in layer.outputs:
188 self.inputs[k].set_previous(layer.outputs[v])
189 else:
190 raise Exception('Invalid connection map.')
191
192 def get_input(self, train=False):
193 if len(self.inputs) == len(self.outputs) == 1:
194 return self.inputs[self.input_order[0]].get_input(train)
195 else:
196 return dict([(k, v.get_input(train)) for k, v in self.inputs.items()])
197
198 @property
199 def input(self):
200 return self.get_input()
201
202 @property
203 def output_shape(self):
204 if self.nb_output == 1:
205 # return tuple
206 return self.outputs[self.output_order[0]].output_shape
207 else:
208 # return dictionary mapping output names to shape tuples
209 return dict([(k, v.output_shape) for k, v in self.outputs.items()])
210
211 def get_output(self, train=False):
212 if len(self.inputs) == len(self.outputs) == 1:
213 return self.outputs[self.output_order[0]].get_output(train)
214 else:
215 return dict([(k, v.get_output(train)) for k, v in self.outputs.items()])
216
217 def add_input(self, name, input_shape, dtype='float'):
218 if name in self.namespace:
219 raise Exception('Duplicate node identifier: ' + name)
220 self.namespace.add(name)
221 self.input_order.append(name)
222 layer = Layer() # empty layer
223 layer.set_input_shape(input_shape)
224 ndim = len(input_shape) + 1
225 if dtype == 'float':
226 layer.input = ndim_tensor(ndim)
227 else:
228 if ndim == 2:
229 layer.input = T.imatrix()
230 else:
231 raise Exception('Type "int" can only be used with ndim==2 (Embedding).')
232 layer.input.name = name
233 self.inputs[name] = layer
234 self.input_config.append({'name': name,
235 'input_shape': input_shape,
236 'dtype': dtype})
237
238 def add_node(self, layer, name, input=None, inputs=[],
239 merge_mode='concat', concat_axis=-1, create_output=False):
240 if hasattr(layer, 'set_name'):
241 layer.set_name(name)
242 if name in self.namespace:
243 raise Exception('Duplicate node identifier: ' + name)
244 if input:
245 if input not in self.namespace:
246 raise Exception('Unknown node/input identifier: ' + input)
247 if input in self.nodes:
248 layer.set_previous(self.nodes[input])
249 elif input in self.inputs:
250 layer.set_previous(self.inputs[input])
251 if inputs:
252 to_merge = []
253 for n in inputs:
254 if n in self.nodes:
255 to_merge.append(self.nodes[n])
256 elif n in self.inputs:
257 to_merge.append(self.inputs[n])
258 else:
259 raise Exception('Unknown identifier: ' + n)
260 merge = Merge(to_merge, mode=merge_mode, concat_axis=concat_axis)
261 layer.set_previous(merge)
262
263 self.namespace.add(name)
264 self.nodes[name] = layer
265 self.node_config.append({'name': name,
266 'input': input,
267 'inputs': inputs,
268 'merge_mode': merge_mode,
269 'concat_axis': concat_axis,
270 'create_output': create_output})
271
272 if create_output:
273 self.add_output(name, input=name)
274
275 def add_output(self, name, input=None, inputs=[],
276 merge_mode='concat', concat_axis=-1):
277 if name in self.output_order:
278 raise Exception('Duplicate output identifier: ' + name)
279 if input:
280 if input not in self.namespace:
281 raise Exception('Unknown node/input identifier: ' + input)
282 if input in self.nodes:
283 self.outputs[name] = self.nodes[input]
284 elif input in self.inputs:
285 self.outputs[name] = self.inputs[input]
286 if inputs:
287 to_merge = []
288 for n in inputs:
289 if n not in self.nodes:
290 raise Exception('Unknown identifier: ' + n)
291 to_merge.append(self.nodes[n])
292 merge = Merge(to_merge, mode=merge_mode, concat_axis=concat_axis)
293 self.outputs[name] = merge
294
295 self.output_order.append(name)
296 self.output_config.append({'name': name,
297 'input': input,
298 'inputs': inputs,
299 'merge_mode': merge_mode,
300 'concat_axis': concat_axis})
301
302 def get_config(self):
303 return {"name": self.__class__.__name__,
304 "input_config": self.input_config,
305 "node_config": self.node_config,
306 "output_config": self.output_config,
307 "input_order": self.input_order,
308 "output_order": self.output_order,
309 "nodes": dict([(c["name"], self.nodes[c["name"]].get_config()) for c in self.node_config])}
310
311 def count_params(self):
312 return sum([layer.count_params() for layer in self.nodes.values()])
313
[end of keras/layers/containers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras/layers/containers.py b/keras/layers/containers.py
--- a/keras/layers/containers.py
+++ b/keras/layers/containers.py
@@ -84,7 +84,11 @@
if not hasattr(self.layers[0], 'input'):
self.set_input()
return self.layers[0].get_input(train)
-
+
+ @property
+ def input_shape(self):
+ return self.layers[0].input_shape
+
@property
def input(self):
return self.get_input()
|
{"golden_diff": "diff --git a/keras/layers/containers.py b/keras/layers/containers.py\n--- a/keras/layers/containers.py\n+++ b/keras/layers/containers.py\n@@ -84,7 +84,11 @@\n if not hasattr(self.layers[0], 'input'):\n self.set_input()\n return self.layers[0].get_input(train)\n-\n+ \n+ @property\n+ def input_shape(self):\n+ return self.layers[0].input_shape\n+ \n @property\n def input(self):\n return self.get_input()\n", "issue": "A model doesn't know its input_shape after build\nReproduce the error as\n\n``` python\nmodel = Sequential()\nmodel.add(Dense(1), input_shape=(784,))\nmodel.build()\n\nmodel.input_shape\n```\n\nShouldn't the model know its `input_shape` after `build`? It knows `output_shape` for instance. Am I missing anything @matsuyamax ?\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import\nfrom __future__ import print_function\n\nfrom collections import OrderedDict\nimport theano.tensor as T\nfrom ..layers.core import Layer, Merge\nfrom ..utils.theano_utils import ndim_tensor\nfrom six.moves import range\n\n\nclass Sequential(Layer):\n '''\n Simple linear stack of layers.\n\n inherited from Layer:\n - get_params\n - get_output_mask\n - supports_masked_input\n '''\n\n def __init__(self, layers=[]):\n self.layers = []\n for layer in layers:\n self.add(layer)\n\n def set_previous(self, layer):\n self.layers[0].previous = layer\n\n def add(self, layer):\n self.layers.append(layer)\n if len(self.layers) > 1:\n self.layers[-1].set_previous(self.layers[-2])\n if not hasattr(self.layers[0], 'input'):\n self.set_input()\n\n @property\n def params(self):\n params = []\n for l in self.layers:\n if l.trainable:\n params += l.get_params()[0]\n return params\n\n @property\n def regularizers(self):\n regularizers = []\n for l in self.layers:\n if l.trainable:\n regularizers += l.get_params()[1]\n return regularizers\n\n @property\n def constraints(self):\n constraints = []\n for l in self.layers:\n if l.trainable:\n constraints += l.get_params()[2]\n return constraints\n\n @property\n def updates(self):\n updates = []\n for l in self.layers:\n if l.trainable:\n updates += l.get_params()[3]\n return updates\n\n @property\n def output_shape(self):\n return self.layers[-1].output_shape\n\n def get_output(self, train=False):\n return self.layers[-1].get_output(train)\n\n def set_input(self):\n for l in self.layers:\n if hasattr(l, 'input'):\n ndim = l.input.ndim\n self.layers[0].input = ndim_tensor(ndim)\n break\n\n def get_input(self, train=False):\n if not hasattr(self.layers[0], 'input'):\n self.set_input()\n return self.layers[0].get_input(train)\n\n @property\n def input(self):\n return self.get_input()\n\n def get_weights(self):\n weights = []\n for layer in self.layers:\n weights += layer.get_weights()\n return weights\n\n def set_weights(self, weights):\n for i in range(len(self.layers)):\n nb_param = len(self.layers[i].params)\n self.layers[i].set_weights(weights[:nb_param])\n weights = weights[nb_param:]\n\n def get_config(self):\n return {\"name\": self.__class__.__name__,\n \"layers\": [layer.get_config() for layer in self.layers]}\n\n def count_params(self):\n return sum([layer.count_params() for layer in self.layers])\n\n\nclass Graph(Layer):\n '''\n Implement a NN graph with arbitrary layer connections,\n arbitrary number of inputs and arbitrary number of outputs.\n\n Note: Graph can only be used as a layer\n (connect, input, get_input, get_output)\n when it has exactly one input and one output.\n\n inherited from Layer:\n - get_output_mask\n - supports_masked_input\n - get_weights\n - set_weights\n '''\n def __init__(self):\n self.namespace = set() # strings\n self.nodes = OrderedDict() # layer-like\n self.inputs = {} # layer-like\n self.input_order = [] # strings\n self.outputs = {} # layer-like\n self.output_order = [] # strings\n self.input_config = [] # dicts\n self.output_config = [] # dicts\n self.node_config = [] # dicts\n\n @property\n def nb_input(self):\n return len(self.inputs)\n\n @property\n def nb_output(self):\n return len(self.outputs)\n\n @property\n def params(self):\n params = []\n for l in self.nodes.values():\n if l.trainable:\n params += l.get_params()[0]\n return params\n\n @property\n def regularizers(self):\n regularizers = []\n for l in self.nodes.values():\n if l.trainable:\n regularizers += l.get_params()[1]\n return regularizers\n\n @property\n def constraints(self):\n constraints = []\n for l in self.nodes.values():\n if l.trainable:\n constraints += l.get_params()[2]\n return constraints\n\n @property\n def updates(self):\n updates = []\n for l in self.nodes.values():\n if l.trainable:\n updates += l.get_params()[3]\n return updates\n\n def set_previous(self, layer, connection_map={}):\n if self.nb_input != layer.nb_output:\n raise Exception('Cannot connect layers: input count does not match output count.')\n if self.nb_input == 1:\n self.inputs[self.input_order[0]].set_previous(layer)\n else:\n if not connection_map:\n raise Exception('Cannot attach multi-input layer: no connection_map provided.')\n for k, v in connection_map.items():\n if k in self.inputs and v in layer.outputs:\n self.inputs[k].set_previous(layer.outputs[v])\n else:\n raise Exception('Invalid connection map.')\n\n def get_input(self, train=False):\n if len(self.inputs) == len(self.outputs) == 1:\n return self.inputs[self.input_order[0]].get_input(train)\n else:\n return dict([(k, v.get_input(train)) for k, v in self.inputs.items()])\n\n @property\n def input(self):\n return self.get_input()\n\n @property\n def output_shape(self):\n if self.nb_output == 1:\n # return tuple\n return self.outputs[self.output_order[0]].output_shape\n else:\n # return dictionary mapping output names to shape tuples\n return dict([(k, v.output_shape) for k, v in self.outputs.items()])\n\n def get_output(self, train=False):\n if len(self.inputs) == len(self.outputs) == 1:\n return self.outputs[self.output_order[0]].get_output(train)\n else:\n return dict([(k, v.get_output(train)) for k, v in self.outputs.items()])\n\n def add_input(self, name, input_shape, dtype='float'):\n if name in self.namespace:\n raise Exception('Duplicate node identifier: ' + name)\n self.namespace.add(name)\n self.input_order.append(name)\n layer = Layer() # empty layer\n layer.set_input_shape(input_shape)\n ndim = len(input_shape) + 1\n if dtype == 'float':\n layer.input = ndim_tensor(ndim)\n else:\n if ndim == 2:\n layer.input = T.imatrix()\n else:\n raise Exception('Type \"int\" can only be used with ndim==2 (Embedding).')\n layer.input.name = name\n self.inputs[name] = layer\n self.input_config.append({'name': name,\n 'input_shape': input_shape,\n 'dtype': dtype})\n\n def add_node(self, layer, name, input=None, inputs=[],\n merge_mode='concat', concat_axis=-1, create_output=False):\n if hasattr(layer, 'set_name'):\n layer.set_name(name)\n if name in self.namespace:\n raise Exception('Duplicate node identifier: ' + name)\n if input:\n if input not in self.namespace:\n raise Exception('Unknown node/input identifier: ' + input)\n if input in self.nodes:\n layer.set_previous(self.nodes[input])\n elif input in self.inputs:\n layer.set_previous(self.inputs[input])\n if inputs:\n to_merge = []\n for n in inputs:\n if n in self.nodes:\n to_merge.append(self.nodes[n])\n elif n in self.inputs:\n to_merge.append(self.inputs[n])\n else:\n raise Exception('Unknown identifier: ' + n)\n merge = Merge(to_merge, mode=merge_mode, concat_axis=concat_axis)\n layer.set_previous(merge)\n\n self.namespace.add(name)\n self.nodes[name] = layer\n self.node_config.append({'name': name,\n 'input': input,\n 'inputs': inputs,\n 'merge_mode': merge_mode,\n 'concat_axis': concat_axis,\n 'create_output': create_output})\n\n if create_output:\n self.add_output(name, input=name)\n\n def add_output(self, name, input=None, inputs=[],\n merge_mode='concat', concat_axis=-1):\n if name in self.output_order:\n raise Exception('Duplicate output identifier: ' + name)\n if input:\n if input not in self.namespace:\n raise Exception('Unknown node/input identifier: ' + input)\n if input in self.nodes:\n self.outputs[name] = self.nodes[input]\n elif input in self.inputs:\n self.outputs[name] = self.inputs[input]\n if inputs:\n to_merge = []\n for n in inputs:\n if n not in self.nodes:\n raise Exception('Unknown identifier: ' + n)\n to_merge.append(self.nodes[n])\n merge = Merge(to_merge, mode=merge_mode, concat_axis=concat_axis)\n self.outputs[name] = merge\n\n self.output_order.append(name)\n self.output_config.append({'name': name,\n 'input': input,\n 'inputs': inputs,\n 'merge_mode': merge_mode,\n 'concat_axis': concat_axis})\n\n def get_config(self):\n return {\"name\": self.__class__.__name__,\n \"input_config\": self.input_config,\n \"node_config\": self.node_config,\n \"output_config\": self.output_config,\n \"input_order\": self.input_order,\n \"output_order\": self.output_order,\n \"nodes\": dict([(c[\"name\"], self.nodes[c[\"name\"]].get_config()) for c in self.node_config])}\n\n def count_params(self):\n return sum([layer.count_params() for layer in self.nodes.values()])\n", "path": "keras/layers/containers.py"}]}
| 3,621 | 128 |
gh_patches_debug_12240
|
rasdani/github-patches
|
git_diff
|
GPflow__GPflow-1355
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
setup.py depends on external dataclasses package for python >= 3.8
Setup.py has a check
```python
is_py37 = sys.version_info.major == 3 and sys.version_info.minor == 7
```
and adds the PyPI `dataclasses` package to the requirements when `not is_py37`. (`dataclasses` has been incorporated in the stdlib in python 3.7.) With python 3.8 released, this check is inaccurate, as setup.py currently adds the dependency on dataclasses when the python version is 3.8 or later, not just when it's less than 3.7.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3
4 # pylint: skip-file
5
6 import os
7 import sys
8 from pathlib import Path
9
10 from pkg_resources import parse_version
11 from setuptools import find_packages, setup
12
13 is_py37 = sys.version_info.major == 3 and sys.version_info.minor == 7
14 on_rtd = os.environ.get("READTHEDOCS", None) == "True" # copied from the docs
15
16 # Dependencies of GPflow
17 requirements = ["numpy>=1.10.0", "scipy>=0.18.0", "multipledispatch>=0.4.9", "tabulate"]
18
19 if not is_py37:
20 requirements.append("dataclasses")
21
22 if not on_rtd:
23 requirements.append("tensorflow-probability>=0.9")
24
25 min_tf_version = "2.1.0"
26 tf_cpu = "tensorflow"
27 tf_gpu = "tensorflow-gpu"
28
29
30 # for latest_version() [see https://github.com/GPflow/GPflow/issues/1348]:
31 def latest_version(package_name):
32 import json
33 from urllib import request
34 import re
35
36 url = f"https://pypi.python.org/pypi/{package_name}/json"
37 data = json.load(request.urlopen(url))
38 # filter out rc and beta releases and, more generally, any releases that
39 # do not contain exclusively numbers and dots.
40 versions = [parse_version(v) for v in data["releases"].keys() if re.match("^[0-9.]+$", v)]
41 versions.sort()
42 return versions[-1] # return latest version
43
44
45 # Only detect TF if not installed or outdated. If not, do not do not list as
46 # requirement to avoid installing over e.g. tensorflow-gpu
47 # To avoid this, rely on importing rather than the package name (like pip).
48
49 try:
50 # If tf not installed, import raises ImportError
51 import tensorflow as tf
52
53 if parse_version(tf.__version__) < parse_version(min_tf_version):
54 # TF pre-installed, but below the minimum required version
55 raise DeprecationWarning("TensorFlow version below minimum requirement")
56 except (ImportError, DeprecationWarning):
57 # Add TensorFlow to dependencies to trigger installation/update
58 if not on_rtd:
59 # Do not add TF if we are installing GPflow on readthedocs
60 requirements.append(tf_cpu)
61 gast_requirement = (
62 "gast>=0.2.2,<0.3"
63 if latest_version("tensorflow") < parse_version("2.2")
64 else "gast>=0.3.3"
65 )
66 requirements.append(gast_requirement)
67
68
69 with open(str(Path(".", "VERSION").absolute())) as version_file:
70 version = version_file.read().strip()
71
72 packages = find_packages(".", exclude=["tests"])
73
74 setup(
75 name="gpflow",
76 version=version,
77 author="James Hensman, Alex Matthews",
78 author_email="[email protected]",
79 description="Gaussian process methods in TensorFlow",
80 license="Apache License 2.0",
81 keywords="machine-learning gaussian-processes kernels tensorflow",
82 url="http://github.com/GPflow/GPflow",
83 packages=packages,
84 include_package_data=True,
85 install_requires=requirements,
86 extras_require={"Tensorflow with GPU": [tf_gpu]},
87 python_requires=">=3.6",
88 classifiers=[
89 "License :: OSI Approved :: Apache Software License",
90 "Natural Language :: English",
91 "Operating System :: MacOS :: MacOS X",
92 "Operating System :: Microsoft :: Windows",
93 "Operating System :: POSIX :: Linux",
94 "Programming Language :: Python :: 3.6",
95 "Topic :: Scientific/Engineering :: Artificial Intelligence",
96 ],
97 )
98
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -10,13 +10,13 @@
from pkg_resources import parse_version
from setuptools import find_packages, setup
-is_py37 = sys.version_info.major == 3 and sys.version_info.minor == 7
on_rtd = os.environ.get("READTHEDOCS", None) == "True" # copied from the docs
# Dependencies of GPflow
requirements = ["numpy>=1.10.0", "scipy>=0.18.0", "multipledispatch>=0.4.9", "tabulate"]
-if not is_py37:
+if sys.version_info < (3, 7):
+ # became part of stdlib in python 3.7
requirements.append("dataclasses")
if not on_rtd:
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -10,13 +10,13 @@\n from pkg_resources import parse_version\n from setuptools import find_packages, setup\n \n-is_py37 = sys.version_info.major == 3 and sys.version_info.minor == 7\n on_rtd = os.environ.get(\"READTHEDOCS\", None) == \"True\" # copied from the docs\n \n # Dependencies of GPflow\n requirements = [\"numpy>=1.10.0\", \"scipy>=0.18.0\", \"multipledispatch>=0.4.9\", \"tabulate\"]\n \n-if not is_py37:\n+if sys.version_info < (3, 7):\n+ # became part of stdlib in python 3.7\n requirements.append(\"dataclasses\")\n \n if not on_rtd:\n", "issue": "setup.py depends on external dataclasses package for python >= 3.8\nSetup.py has a check\r\n```python\r\nis_py37 = sys.version_info.major == 3 and sys.version_info.minor == 7\r\n```\r\nand adds the PyPI `dataclasses` package to the requirements when `not is_py37`. (`dataclasses` has been incorporated in the stdlib in python 3.7.) With python 3.8 released, this check is inaccurate, as setup.py currently adds the dependency on dataclasses when the python version is 3.8 or later, not just when it's less than 3.7.\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n# pylint: skip-file\n\nimport os\nimport sys\nfrom pathlib import Path\n\nfrom pkg_resources import parse_version\nfrom setuptools import find_packages, setup\n\nis_py37 = sys.version_info.major == 3 and sys.version_info.minor == 7\non_rtd = os.environ.get(\"READTHEDOCS\", None) == \"True\" # copied from the docs\n\n# Dependencies of GPflow\nrequirements = [\"numpy>=1.10.0\", \"scipy>=0.18.0\", \"multipledispatch>=0.4.9\", \"tabulate\"]\n\nif not is_py37:\n requirements.append(\"dataclasses\")\n\nif not on_rtd:\n requirements.append(\"tensorflow-probability>=0.9\")\n\nmin_tf_version = \"2.1.0\"\ntf_cpu = \"tensorflow\"\ntf_gpu = \"tensorflow-gpu\"\n\n\n# for latest_version() [see https://github.com/GPflow/GPflow/issues/1348]:\ndef latest_version(package_name):\n import json\n from urllib import request\n import re\n\n url = f\"https://pypi.python.org/pypi/{package_name}/json\"\n data = json.load(request.urlopen(url))\n # filter out rc and beta releases and, more generally, any releases that\n # do not contain exclusively numbers and dots.\n versions = [parse_version(v) for v in data[\"releases\"].keys() if re.match(\"^[0-9.]+$\", v)]\n versions.sort()\n return versions[-1] # return latest version\n\n\n# Only detect TF if not installed or outdated. If not, do not do not list as\n# requirement to avoid installing over e.g. tensorflow-gpu\n# To avoid this, rely on importing rather than the package name (like pip).\n\ntry:\n # If tf not installed, import raises ImportError\n import tensorflow as tf\n\n if parse_version(tf.__version__) < parse_version(min_tf_version):\n # TF pre-installed, but below the minimum required version\n raise DeprecationWarning(\"TensorFlow version below minimum requirement\")\nexcept (ImportError, DeprecationWarning):\n # Add TensorFlow to dependencies to trigger installation/update\n if not on_rtd:\n # Do not add TF if we are installing GPflow on readthedocs\n requirements.append(tf_cpu)\n gast_requirement = (\n \"gast>=0.2.2,<0.3\"\n if latest_version(\"tensorflow\") < parse_version(\"2.2\")\n else \"gast>=0.3.3\"\n )\n requirements.append(gast_requirement)\n\n\nwith open(str(Path(\".\", \"VERSION\").absolute())) as version_file:\n version = version_file.read().strip()\n\npackages = find_packages(\".\", exclude=[\"tests\"])\n\nsetup(\n name=\"gpflow\",\n version=version,\n author=\"James Hensman, Alex Matthews\",\n author_email=\"[email protected]\",\n description=\"Gaussian process methods in TensorFlow\",\n license=\"Apache License 2.0\",\n keywords=\"machine-learning gaussian-processes kernels tensorflow\",\n url=\"http://github.com/GPflow/GPflow\",\n packages=packages,\n include_package_data=True,\n install_requires=requirements,\n extras_require={\"Tensorflow with GPU\": [tf_gpu]},\n python_requires=\">=3.6\",\n classifiers=[\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: MacOS :: MacOS X\",\n \"Operating System :: Microsoft :: Windows\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python :: 3.6\",\n \"Topic :: Scientific/Engineering :: Artificial Intelligence\",\n ],\n)\n", "path": "setup.py"}]}
| 1,662 | 192 |
gh_patches_debug_7214
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-540
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
assert_fingerprint SHA256 support is missing
assert_fingerprint only seems to support MD5 and SHA1. Would it be possible to add SHA256 support to it?
</issue>
<code>
[start of urllib3/util/ssl_.py]
1 from binascii import hexlify, unhexlify
2 from hashlib import md5, sha1
3
4 from ..exceptions import SSLError
5
6
7 SSLContext = None
8 HAS_SNI = False
9 create_default_context = None
10
11 import errno
12 import ssl
13
14 try: # Test for SSL features
15 from ssl import wrap_socket, CERT_NONE, PROTOCOL_SSLv23
16 from ssl import HAS_SNI # Has SNI?
17 except ImportError:
18 pass
19
20
21 try:
22 from ssl import OP_NO_SSLv2, OP_NO_SSLv3, OP_NO_COMPRESSION
23 except ImportError:
24 OP_NO_SSLv2, OP_NO_SSLv3 = 0x1000000, 0x2000000
25 OP_NO_COMPRESSION = 0x20000
26
27 try:
28 from ssl import _DEFAULT_CIPHERS
29 except ImportError:
30 _DEFAULT_CIPHERS = (
31 'ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+HIGH:'
32 'DH+HIGH:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+HIGH:RSA+3DES:ECDH+RC4:'
33 'DH+RC4:RSA+RC4:!aNULL:!eNULL:!MD5'
34 )
35
36 try:
37 from ssl import SSLContext # Modern SSL?
38 except ImportError:
39 import sys
40
41 class SSLContext(object): # Platform-specific: Python 2 & 3.1
42 supports_set_ciphers = sys.version_info >= (2, 7)
43
44 def __init__(self, protocol_version):
45 self.protocol = protocol_version
46 # Use default values from a real SSLContext
47 self.check_hostname = False
48 self.verify_mode = ssl.CERT_NONE
49 self.ca_certs = None
50 self.options = 0
51 self.certfile = None
52 self.keyfile = None
53 self.ciphers = None
54
55 def load_cert_chain(self, certfile, keyfile):
56 self.certfile = certfile
57 self.keyfile = keyfile
58
59 def load_verify_locations(self, location):
60 self.ca_certs = location
61
62 def set_ciphers(self, cipher_suite):
63 if not self.supports_set_ciphers:
64 raise TypeError(
65 'Your version of Python does not support setting '
66 'a custom cipher suite. Please upgrade to Python '
67 '2.7, 3.2, or later if you need this functionality.'
68 )
69 self.ciphers = cipher_suite
70
71 def wrap_socket(self, socket, server_hostname=None):
72 kwargs = {
73 'keyfile': self.keyfile,
74 'certfile': self.certfile,
75 'ca_certs': self.ca_certs,
76 'cert_reqs': self.verify_mode,
77 'ssl_version': self.protocol,
78 }
79 if self.supports_set_ciphers: # Platform-specific: Python 2.7+
80 return wrap_socket(socket, ciphers=self.ciphers, **kwargs)
81 else: # Platform-specific: Python 2.6
82 return wrap_socket(socket, **kwargs)
83
84
85 def assert_fingerprint(cert, fingerprint):
86 """
87 Checks if given fingerprint matches the supplied certificate.
88
89 :param cert:
90 Certificate as bytes object.
91 :param fingerprint:
92 Fingerprint as string of hexdigits, can be interspersed by colons.
93 """
94
95 # Maps the length of a digest to a possible hash function producing
96 # this digest.
97 hashfunc_map = {
98 16: md5,
99 20: sha1
100 }
101
102 fingerprint = fingerprint.replace(':', '').lower()
103 digest_length, odd = divmod(len(fingerprint), 2)
104
105 if odd or digest_length not in hashfunc_map:
106 raise SSLError('Fingerprint is of invalid length.')
107
108 # We need encode() here for py32; works on py2 and p33.
109 fingerprint_bytes = unhexlify(fingerprint.encode())
110
111 hashfunc = hashfunc_map[digest_length]
112
113 cert_digest = hashfunc(cert).digest()
114
115 if not cert_digest == fingerprint_bytes:
116 raise SSLError('Fingerprints did not match. Expected "{0}", got "{1}".'
117 .format(hexlify(fingerprint_bytes),
118 hexlify(cert_digest)))
119
120
121 def resolve_cert_reqs(candidate):
122 """
123 Resolves the argument to a numeric constant, which can be passed to
124 the wrap_socket function/method from the ssl module.
125 Defaults to :data:`ssl.CERT_NONE`.
126 If given a string it is assumed to be the name of the constant in the
127 :mod:`ssl` module or its abbrevation.
128 (So you can specify `REQUIRED` instead of `CERT_REQUIRED`.
129 If it's neither `None` nor a string we assume it is already the numeric
130 constant which can directly be passed to wrap_socket.
131 """
132 if candidate is None:
133 return CERT_NONE
134
135 if isinstance(candidate, str):
136 res = getattr(ssl, candidate, None)
137 if res is None:
138 res = getattr(ssl, 'CERT_' + candidate)
139 return res
140
141 return candidate
142
143
144 def resolve_ssl_version(candidate):
145 """
146 like resolve_cert_reqs
147 """
148 if candidate is None:
149 return PROTOCOL_SSLv23
150
151 if isinstance(candidate, str):
152 res = getattr(ssl, candidate, None)
153 if res is None:
154 res = getattr(ssl, 'PROTOCOL_' + candidate)
155 return res
156
157 return candidate
158
159
160 def create_urllib3_context(ssl_version=None, cert_reqs=ssl.CERT_REQUIRED,
161 options=None, ciphers=None):
162 """All arguments have the same meaning as ``ssl_wrap_socket``.
163
164 By default, this function does a lot of the same work that
165 ``ssl.create_default_context`` does on Python 3.4+. It:
166
167 - Disables SSLv2, SSLv3, and compression
168 - Sets a restricted set of server ciphers
169
170 If you wish to enable SSLv3, you can do::
171
172 from urllib3.util import ssl_
173 context = ssl_.create_urllib3_context()
174 context.options &= ~ssl_.OP_NO_SSLv3
175
176 You can do the same to enable compression (substituting ``COMPRESSION``
177 for ``SSLv3`` in the last line above).
178
179 :param ssl_version:
180 The desired protocol version to use. This will default to
181 PROTOCOL_SSLv23 which will negotiate the highest protocol that both
182 the server and your installation of OpenSSL support.
183 :param cert_reqs:
184 Whether to require the certificate verification. This defaults to
185 ``ssl.CERT_REQUIRED``.
186 :param options:
187 Specific OpenSSL options. These default to ``ssl.OP_NO_SSLv2``,
188 ``ssl.OP_NO_SSLv3``, ``ssl.OP_NO_COMPRESSION``.
189 :param ciphers:
190 Which cipher suites to allow the server to select.
191 :returns:
192 Constructed SSLContext object with specified options
193 :rtype: SSLContext
194 """
195 context = SSLContext(ssl_version or ssl.PROTOCOL_SSLv23)
196
197 if options is None:
198 options = 0
199 # SSLv2 is easily broken and is considered harmful and dangerous
200 options |= OP_NO_SSLv2
201 # SSLv3 has several problems and is now dangerous
202 options |= OP_NO_SSLv3
203 # Disable compression to prevent CRIME attacks for OpenSSL 1.0+
204 # (issue #309)
205 options |= OP_NO_COMPRESSION
206
207 context.options |= options
208
209 if getattr(context, 'supports_set_ciphers', True): # Platform-specific: Python 2.6
210 context.set_ciphers(ciphers or _DEFAULT_CIPHERS)
211
212 context.verify_mode = cert_reqs
213 if getattr(context, 'check_hostname', None) is not None: # Platform-specific: Python 3.2
214 context.check_hostname = (context.verify_mode == ssl.CERT_REQUIRED)
215 return context
216
217
218 def ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,
219 ca_certs=None, server_hostname=None,
220 ssl_version=None, ciphers=None, ssl_context=None):
221 """
222 All arguments except for server_hostname and ssl_context have the same
223 meaning as they do when using :func:`ssl.wrap_socket`.
224
225 :param server_hostname:
226 When SNI is supported, the expected hostname of the certificate
227 :param ssl_context:
228 A pre-made :class:`SSLContext` object. If none is provided, one will
229 be created using :func:`create_urllib3_context`.
230 :param ciphers:
231 A string of ciphers we wish the client to support. This is not
232 supported on Python 2.6 as the ssl module does not support it.
233 """
234 context = ssl_context
235 if context is None:
236 context = create_urllib3_context(ssl_version, cert_reqs,
237 ciphers=ciphers)
238
239 if ca_certs:
240 try:
241 context.load_verify_locations(ca_certs)
242 except IOError as e: # Platform-specific: Python 2.6, 2.7, 3.2
243 raise SSLError(e)
244 # Py33 raises FileNotFoundError which subclasses OSError
245 # These are not equivalent unless we check the errno attribute
246 except OSError as e: # Platform-specific: Python 3.3 and beyond
247 if e.errno == errno.ENOENT:
248 raise SSLError(e)
249 raise
250 if certfile:
251 context.load_cert_chain(certfile, keyfile)
252 if HAS_SNI: # Platform-specific: OpenSSL with enabled SNI
253 return context.wrap_socket(sock, server_hostname=server_hostname)
254 return context.wrap_socket(sock)
255
[end of urllib3/util/ssl_.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/urllib3/util/ssl_.py b/urllib3/util/ssl_.py
--- a/urllib3/util/ssl_.py
+++ b/urllib3/util/ssl_.py
@@ -1,5 +1,5 @@
from binascii import hexlify, unhexlify
-from hashlib import md5, sha1
+from hashlib import md5, sha1, sha256
from ..exceptions import SSLError
@@ -96,7 +96,8 @@
# this digest.
hashfunc_map = {
16: md5,
- 20: sha1
+ 20: sha1,
+ 32: sha256,
}
fingerprint = fingerprint.replace(':', '').lower()
|
{"golden_diff": "diff --git a/urllib3/util/ssl_.py b/urllib3/util/ssl_.py\n--- a/urllib3/util/ssl_.py\n+++ b/urllib3/util/ssl_.py\n@@ -1,5 +1,5 @@\n from binascii import hexlify, unhexlify\n-from hashlib import md5, sha1\n+from hashlib import md5, sha1, sha256\n \n from ..exceptions import SSLError\n \n@@ -96,7 +96,8 @@\n # this digest.\n hashfunc_map = {\n 16: md5,\n- 20: sha1\n+ 20: sha1,\n+ 32: sha256,\n }\n \n fingerprint = fingerprint.replace(':', '').lower()\n", "issue": "assert_fingerprint SHA256 support is missing\nassert_fingerprint only seems to support MD5 and SHA1. Would it be possible to add SHA256 support to it?\n\n", "before_files": [{"content": "from binascii import hexlify, unhexlify\nfrom hashlib import md5, sha1\n\nfrom ..exceptions import SSLError\n\n\nSSLContext = None\nHAS_SNI = False\ncreate_default_context = None\n\nimport errno\nimport ssl\n\ntry: # Test for SSL features\n from ssl import wrap_socket, CERT_NONE, PROTOCOL_SSLv23\n from ssl import HAS_SNI # Has SNI?\nexcept ImportError:\n pass\n\n\ntry:\n from ssl import OP_NO_SSLv2, OP_NO_SSLv3, OP_NO_COMPRESSION\nexcept ImportError:\n OP_NO_SSLv2, OP_NO_SSLv3 = 0x1000000, 0x2000000\n OP_NO_COMPRESSION = 0x20000\n\ntry:\n from ssl import _DEFAULT_CIPHERS\nexcept ImportError:\n _DEFAULT_CIPHERS = (\n 'ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:ECDH+HIGH:'\n 'DH+HIGH:ECDH+3DES:DH+3DES:RSA+AESGCM:RSA+AES:RSA+HIGH:RSA+3DES:ECDH+RC4:'\n 'DH+RC4:RSA+RC4:!aNULL:!eNULL:!MD5'\n )\n\ntry:\n from ssl import SSLContext # Modern SSL?\nexcept ImportError:\n import sys\n\n class SSLContext(object): # Platform-specific: Python 2 & 3.1\n supports_set_ciphers = sys.version_info >= (2, 7)\n\n def __init__(self, protocol_version):\n self.protocol = protocol_version\n # Use default values from a real SSLContext\n self.check_hostname = False\n self.verify_mode = ssl.CERT_NONE\n self.ca_certs = None\n self.options = 0\n self.certfile = None\n self.keyfile = None\n self.ciphers = None\n\n def load_cert_chain(self, certfile, keyfile):\n self.certfile = certfile\n self.keyfile = keyfile\n\n def load_verify_locations(self, location):\n self.ca_certs = location\n\n def set_ciphers(self, cipher_suite):\n if not self.supports_set_ciphers:\n raise TypeError(\n 'Your version of Python does not support setting '\n 'a custom cipher suite. Please upgrade to Python '\n '2.7, 3.2, or later if you need this functionality.'\n )\n self.ciphers = cipher_suite\n\n def wrap_socket(self, socket, server_hostname=None):\n kwargs = {\n 'keyfile': self.keyfile,\n 'certfile': self.certfile,\n 'ca_certs': self.ca_certs,\n 'cert_reqs': self.verify_mode,\n 'ssl_version': self.protocol,\n }\n if self.supports_set_ciphers: # Platform-specific: Python 2.7+\n return wrap_socket(socket, ciphers=self.ciphers, **kwargs)\n else: # Platform-specific: Python 2.6\n return wrap_socket(socket, **kwargs)\n\n\ndef assert_fingerprint(cert, fingerprint):\n \"\"\"\n Checks if given fingerprint matches the supplied certificate.\n\n :param cert:\n Certificate as bytes object.\n :param fingerprint:\n Fingerprint as string of hexdigits, can be interspersed by colons.\n \"\"\"\n\n # Maps the length of a digest to a possible hash function producing\n # this digest.\n hashfunc_map = {\n 16: md5,\n 20: sha1\n }\n\n fingerprint = fingerprint.replace(':', '').lower()\n digest_length, odd = divmod(len(fingerprint), 2)\n\n if odd or digest_length not in hashfunc_map:\n raise SSLError('Fingerprint is of invalid length.')\n\n # We need encode() here for py32; works on py2 and p33.\n fingerprint_bytes = unhexlify(fingerprint.encode())\n\n hashfunc = hashfunc_map[digest_length]\n\n cert_digest = hashfunc(cert).digest()\n\n if not cert_digest == fingerprint_bytes:\n raise SSLError('Fingerprints did not match. Expected \"{0}\", got \"{1}\".'\n .format(hexlify(fingerprint_bytes),\n hexlify(cert_digest)))\n\n\ndef resolve_cert_reqs(candidate):\n \"\"\"\n Resolves the argument to a numeric constant, which can be passed to\n the wrap_socket function/method from the ssl module.\n Defaults to :data:`ssl.CERT_NONE`.\n If given a string it is assumed to be the name of the constant in the\n :mod:`ssl` module or its abbrevation.\n (So you can specify `REQUIRED` instead of `CERT_REQUIRED`.\n If it's neither `None` nor a string we assume it is already the numeric\n constant which can directly be passed to wrap_socket.\n \"\"\"\n if candidate is None:\n return CERT_NONE\n\n if isinstance(candidate, str):\n res = getattr(ssl, candidate, None)\n if res is None:\n res = getattr(ssl, 'CERT_' + candidate)\n return res\n\n return candidate\n\n\ndef resolve_ssl_version(candidate):\n \"\"\"\n like resolve_cert_reqs\n \"\"\"\n if candidate is None:\n return PROTOCOL_SSLv23\n\n if isinstance(candidate, str):\n res = getattr(ssl, candidate, None)\n if res is None:\n res = getattr(ssl, 'PROTOCOL_' + candidate)\n return res\n\n return candidate\n\n\ndef create_urllib3_context(ssl_version=None, cert_reqs=ssl.CERT_REQUIRED,\n options=None, ciphers=None):\n \"\"\"All arguments have the same meaning as ``ssl_wrap_socket``.\n\n By default, this function does a lot of the same work that\n ``ssl.create_default_context`` does on Python 3.4+. It:\n\n - Disables SSLv2, SSLv3, and compression\n - Sets a restricted set of server ciphers\n\n If you wish to enable SSLv3, you can do::\n\n from urllib3.util import ssl_\n context = ssl_.create_urllib3_context()\n context.options &= ~ssl_.OP_NO_SSLv3\n\n You can do the same to enable compression (substituting ``COMPRESSION``\n for ``SSLv3`` in the last line above).\n\n :param ssl_version:\n The desired protocol version to use. This will default to\n PROTOCOL_SSLv23 which will negotiate the highest protocol that both\n the server and your installation of OpenSSL support.\n :param cert_reqs:\n Whether to require the certificate verification. This defaults to\n ``ssl.CERT_REQUIRED``.\n :param options:\n Specific OpenSSL options. These default to ``ssl.OP_NO_SSLv2``,\n ``ssl.OP_NO_SSLv3``, ``ssl.OP_NO_COMPRESSION``.\n :param ciphers:\n Which cipher suites to allow the server to select.\n :returns:\n Constructed SSLContext object with specified options\n :rtype: SSLContext\n \"\"\"\n context = SSLContext(ssl_version or ssl.PROTOCOL_SSLv23)\n\n if options is None:\n options = 0\n # SSLv2 is easily broken and is considered harmful and dangerous\n options |= OP_NO_SSLv2\n # SSLv3 has several problems and is now dangerous\n options |= OP_NO_SSLv3\n # Disable compression to prevent CRIME attacks for OpenSSL 1.0+\n # (issue #309)\n options |= OP_NO_COMPRESSION\n\n context.options |= options\n\n if getattr(context, 'supports_set_ciphers', True): # Platform-specific: Python 2.6\n context.set_ciphers(ciphers or _DEFAULT_CIPHERS)\n\n context.verify_mode = cert_reqs\n if getattr(context, 'check_hostname', None) is not None: # Platform-specific: Python 3.2\n context.check_hostname = (context.verify_mode == ssl.CERT_REQUIRED)\n return context\n\n\ndef ssl_wrap_socket(sock, keyfile=None, certfile=None, cert_reqs=None,\n ca_certs=None, server_hostname=None,\n ssl_version=None, ciphers=None, ssl_context=None):\n \"\"\"\n All arguments except for server_hostname and ssl_context have the same\n meaning as they do when using :func:`ssl.wrap_socket`.\n\n :param server_hostname:\n When SNI is supported, the expected hostname of the certificate\n :param ssl_context:\n A pre-made :class:`SSLContext` object. If none is provided, one will\n be created using :func:`create_urllib3_context`.\n :param ciphers:\n A string of ciphers we wish the client to support. This is not\n supported on Python 2.6 as the ssl module does not support it.\n \"\"\"\n context = ssl_context\n if context is None:\n context = create_urllib3_context(ssl_version, cert_reqs,\n ciphers=ciphers)\n\n if ca_certs:\n try:\n context.load_verify_locations(ca_certs)\n except IOError as e: # Platform-specific: Python 2.6, 2.7, 3.2\n raise SSLError(e)\n # Py33 raises FileNotFoundError which subclasses OSError\n # These are not equivalent unless we check the errno attribute\n except OSError as e: # Platform-specific: Python 3.3 and beyond\n if e.errno == errno.ENOENT:\n raise SSLError(e)\n raise\n if certfile:\n context.load_cert_chain(certfile, keyfile)\n if HAS_SNI: # Platform-specific: OpenSSL with enabled SNI\n return context.wrap_socket(sock, server_hostname=server_hostname)\n return context.wrap_socket(sock)\n", "path": "urllib3/util/ssl_.py"}]}
| 3,382 | 172 |
gh_patches_debug_37507
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-4036
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
st.metric doesn't like numpy.int64
### Summary
I summed a column in a dataframe and passed it to `st.metric` and it threw an error because it wanted a regular int.
Should it just do the right thing?
Also: The error about being an invalid type is showing the value of the variable instead of the type that it doesn't like.
### Steps to reproduce
Code snippet:
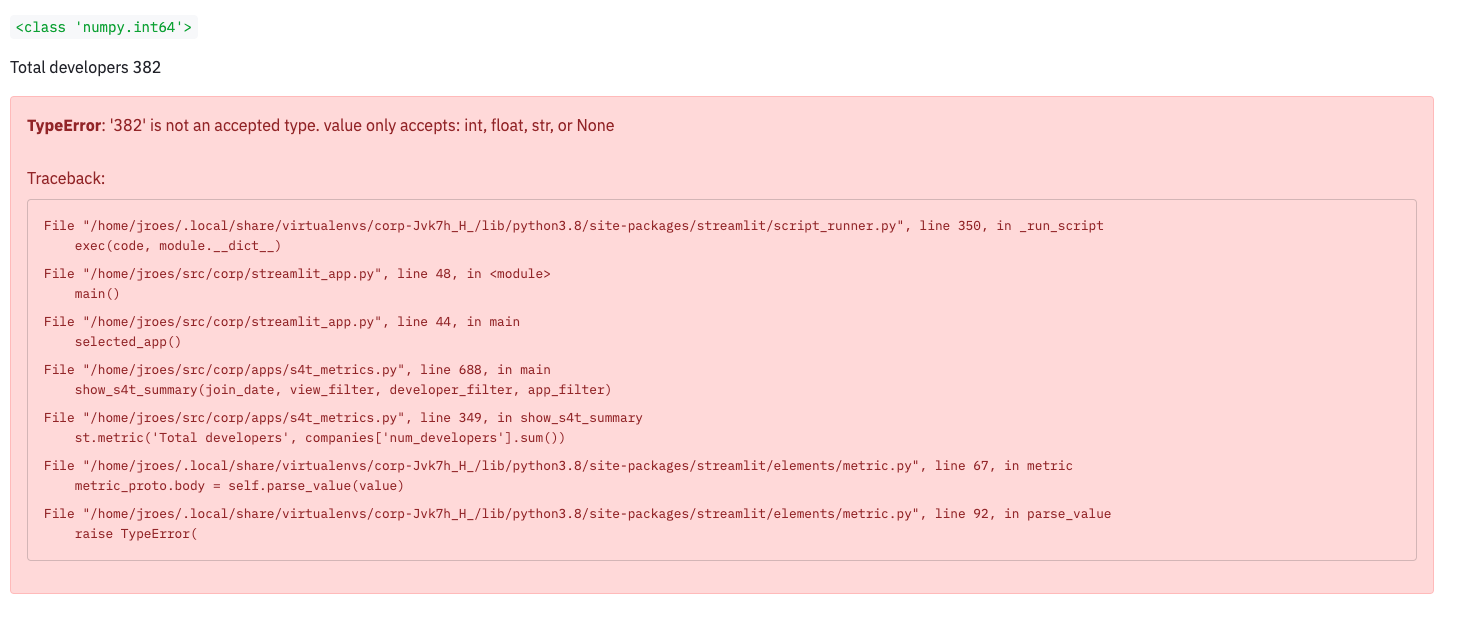
```
st.write(type(companies['num_developers'].sum()))
st.markdown(f'Total developers %d' % companies['num_developers'].sum())
st.metric('Total developers', companies['num_developers'].sum())
```
**Expected behavior:**
Expected it to just work!
**Actual behavior:**
Showed the error in the screenshot above.
### Is this a regression?
That is, did this use to work the way you expected in the past?
no
### Debug info
- Streamlit version: streamlit-nightly from today
</issue>
<code>
[start of lib/streamlit/elements/metric.py]
1 # Copyright 2018-2021 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from textwrap import dedent
16 from typing import cast, Optional
17
18 import attr
19
20 import streamlit
21 from streamlit.errors import StreamlitAPIException
22 from streamlit.proto.Metric_pb2 import Metric as MetricProto
23 from .utils import clean_text
24
25
26 @attr.s(auto_attribs=True, slots=True)
27 class MetricColorAndDirection:
28 color: Optional[int]
29 direction: Optional[int]
30
31
32 class MetricMixin:
33 def metric(self, label, value, delta=None, delta_color="normal"):
34 """Display a metric in big bold font, with an optional indicator of how the metric changed.
35
36 Tip: If you want to display a large number, it may be a good idea to
37 shorten it using packages like `millify <https://github.com/azaitsev/millify>`_
38 or `numerize <https://github.com/davidsa03/numerize>`_. E.g. ``1234`` can be
39 displayed as ``1.2k`` using ``st.metric("Short number", millify(1234))``.
40
41 Parameters
42 ----------
43 label : str
44 The header or Title for the metric
45 value : int, float, str, or None
46 Value of the metric. None is rendered as a long dash.
47 delta : int, float, str, or None
48 Indicator of how the metric changed, rendered with an arrow below
49 the metric. If delta is negative (int/float) or starts with a minus
50 sign (str), the arrow points down and the text is red; else the
51 arrow points up and the text is green. If None (default), no delta
52 indicator is shown.
53 delta_color : str
54 If "normal" (default), the delta indicator is shown as described
55 above. If "inverse", it is red when positive and green when
56 negative. This is useful when a negative change is considered
57 good, e.g. if cost decreased. If "off", delta is shown in gray
58 regardless of its value.
59
60 Example
61 -------
62 >>> st.metric(label="Temperature", value="70 °F", delta="1.2 °F")
63
64 .. output::
65 https://static.streamlit.io/0.86.0-mT2t/index.html?id=1TxwRhgBgFg62p2AXqJdM
66 height: 175px
67
68 ``st.metric`` looks especially nice in combination with ``st.columns``:
69
70 >>> col1, col2, col3 = st.columns(3)
71 >>> col1.metric("Temperature", "70 °F", "1.2 °F")
72 >>> col2.metric("Wind", "9 mph", "-8%")
73 >>> col3.metric("Humidity", "86%", "4%")
74
75 .. output::
76 https://static.streamlit.io/0.86.0-mT2t/index.html?id=4K9bKXhiPAxBNhktd8cxbg
77 height: 175px
78
79 The delta indicator color can also be inverted or turned off:
80
81 >>> st.metric(label="Gas price", value=4, delta=-0.5,
82 ... delta_color="inverse")
83 >>>
84 >>> st.metric(label="Active developers", value=123, delta=123,
85 ... delta_color="off")
86
87 .. output::
88 https://static.streamlit.io/0.86.0-mT2t/index.html?id=UTtQvbBQFaPtCmPcQ23wpP
89 height: 275px
90
91 """
92 metric_proto = MetricProto()
93 metric_proto.body = self.parse_value(value)
94 metric_proto.label = self.parse_label(label)
95 metric_proto.delta = self.parse_delta(delta)
96
97 color_and_direction = self.determine_delta_color_and_direction(
98 clean_text(delta_color), delta
99 )
100 metric_proto.color = color_and_direction.color
101 metric_proto.direction = color_and_direction.direction
102
103 return str(self.dg._enqueue("metric", metric_proto))
104
105 def parse_label(self, label):
106 if not isinstance(label, str):
107 raise TypeError(
108 f"'{str(label)}' is not an accepted type. label only accepts: str"
109 )
110 return label
111
112 def parse_value(self, value):
113 if value is None:
114 return "—"
115 if isinstance(value, float) or isinstance(value, int) or isinstance(value, str):
116 return str(value)
117 else:
118 raise TypeError(
119 f"'{str(value)}' is not an accepted type. value only accepts: "
120 "int, float, str, or None"
121 )
122
123 def parse_delta(self, delta):
124 if delta is None or delta == "":
125 return ""
126 if isinstance(delta, str):
127 return dedent(delta)
128 elif isinstance(delta, int) or isinstance(delta, float):
129 return str(delta)
130 else:
131 raise TypeError(
132 f"'{str(delta)}' is not an accepted type. delta only accepts:"
133 " int, float, str, or None"
134 )
135
136 def determine_delta_color_and_direction(self, delta_color, delta):
137 cd = MetricColorAndDirection(color=None, direction=None)
138
139 if delta is None or delta == "":
140 cd.color = MetricProto.MetricColor.GRAY
141 cd.direction = MetricProto.MetricDirection.NONE
142 return cd
143
144 if self.is_negative(delta):
145 if delta_color == "normal":
146 cd.color = MetricProto.MetricColor.RED
147 elif delta_color == "inverse":
148 cd.color = MetricProto.MetricColor.GREEN
149 elif delta_color == "off":
150 cd.color = MetricProto.MetricColor.GRAY
151 cd.direction = MetricProto.MetricDirection.DOWN
152 else:
153 if delta_color == "normal":
154 cd.color = MetricProto.MetricColor.GREEN
155 elif delta_color == "inverse":
156 cd.color = MetricProto.MetricColor.RED
157 elif delta_color == "off":
158 cd.color = MetricProto.MetricColor.GRAY
159 cd.direction = MetricProto.MetricDirection.UP
160
161 if cd.color is None or cd.direction is None:
162 raise StreamlitAPIException(
163 f"'{str(delta_color)}' is not an accepted value. delta_color only accepts: "
164 "'normal', 'inverse', or 'off'"
165 )
166 return cd
167
168 def is_negative(self, delta):
169 return dedent(str(delta)).startswith("-")
170
171 @property
172 def dg(self) -> "streamlit.delta_generator.DeltaGenerator":
173 return cast("streamlit.delta_generator.DeltaGenerator", self)
174
[end of lib/streamlit/elements/metric.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/elements/metric.py b/lib/streamlit/elements/metric.py
--- a/lib/streamlit/elements/metric.py
+++ b/lib/streamlit/elements/metric.py
@@ -13,13 +13,13 @@
# limitations under the License.
from textwrap import dedent
-from typing import cast, Optional
+from typing import Optional, cast
import attr
-
import streamlit
from streamlit.errors import StreamlitAPIException
from streamlit.proto.Metric_pb2 import Metric as MetricProto
+
from .utils import clean_text
@@ -105,7 +105,8 @@
def parse_label(self, label):
if not isinstance(label, str):
raise TypeError(
- f"'{str(label)}' is not an accepted type. label only accepts: str"
+ f"'{str(label)}' is of type {str(type(label))}, which is not an accepted type."
+ " label only accepts: str. Please convert the label to an accepted type."
)
return label
@@ -114,11 +115,20 @@
return "—"
if isinstance(value, float) or isinstance(value, int) or isinstance(value, str):
return str(value)
- else:
- raise TypeError(
- f"'{str(value)}' is not an accepted type. value only accepts: "
- "int, float, str, or None"
- )
+ elif hasattr(value, "item"):
+ # Add support for numpy values (e.g. int16, float64, etc.)
+ try:
+ # Item could also be just a variable, so we use try, except
+ if isinstance(value.item(), float) or isinstance(value.item(), int):
+ return str(value.item())
+ except Exception:
+ pass
+
+ raise TypeError(
+ f"'{str(value)}' is of type {str(type(value))}, which is not an accepted type."
+ " value only accepts: int, float, str, or None."
+ " Please convert the value to an accepted type."
+ )
def parse_delta(self, delta):
if delta is None or delta == "":
@@ -129,8 +139,9 @@
return str(delta)
else:
raise TypeError(
- f"'{str(delta)}' is not an accepted type. delta only accepts:"
- " int, float, str, or None"
+ f"'{str(delta)}' is of type {str(type(delta))}, which is not an accepted type."
+ " delta only accepts: int, float, str, or None."
+ " Please convert the value to an accepted type."
)
def determine_delta_color_and_direction(self, delta_color, delta):
|
{"golden_diff": "diff --git a/lib/streamlit/elements/metric.py b/lib/streamlit/elements/metric.py\n--- a/lib/streamlit/elements/metric.py\n+++ b/lib/streamlit/elements/metric.py\n@@ -13,13 +13,13 @@\n # limitations under the License.\n \n from textwrap import dedent\n-from typing import cast, Optional\n+from typing import Optional, cast\n \n import attr\n-\n import streamlit\n from streamlit.errors import StreamlitAPIException\n from streamlit.proto.Metric_pb2 import Metric as MetricProto\n+\n from .utils import clean_text\n \n \n@@ -105,7 +105,8 @@\n def parse_label(self, label):\n if not isinstance(label, str):\n raise TypeError(\n- f\"'{str(label)}' is not an accepted type. label only accepts: str\"\n+ f\"'{str(label)}' is of type {str(type(label))}, which is not an accepted type.\"\n+ \" label only accepts: str. Please convert the label to an accepted type.\"\n )\n return label\n \n@@ -114,11 +115,20 @@\n return \"\u2014\"\n if isinstance(value, float) or isinstance(value, int) or isinstance(value, str):\n return str(value)\n- else:\n- raise TypeError(\n- f\"'{str(value)}' is not an accepted type. value only accepts: \"\n- \"int, float, str, or None\"\n- )\n+ elif hasattr(value, \"item\"):\n+ # Add support for numpy values (e.g. int16, float64, etc.)\n+ try:\n+ # Item could also be just a variable, so we use try, except\n+ if isinstance(value.item(), float) or isinstance(value.item(), int):\n+ return str(value.item())\n+ except Exception:\n+ pass\n+\n+ raise TypeError(\n+ f\"'{str(value)}' is of type {str(type(value))}, which is not an accepted type.\"\n+ \" value only accepts: int, float, str, or None.\"\n+ \" Please convert the value to an accepted type.\"\n+ )\n \n def parse_delta(self, delta):\n if delta is None or delta == \"\":\n@@ -129,8 +139,9 @@\n return str(delta)\n else:\n raise TypeError(\n- f\"'{str(delta)}' is not an accepted type. delta only accepts:\"\n- \" int, float, str, or None\"\n+ f\"'{str(delta)}' is of type {str(type(delta))}, which is not an accepted type.\"\n+ \" delta only accepts: int, float, str, or None.\"\n+ \" Please convert the value to an accepted type.\"\n )\n \n def determine_delta_color_and_direction(self, delta_color, delta):\n", "issue": "st.metric doesn't like numpy.int64\n### Summary\r\n\r\nI summed a column in a dataframe and passed it to `st.metric` and it threw an error because it wanted a regular int.\r\n\r\nShould it just do the right thing?\r\n\r\nAlso: The error about being an invalid type is showing the value of the variable instead of the type that it doesn't like.\r\n\r\n### Steps to reproduce\r\n\r\nCode snippet:\r\n\r\n\r\n\r\n```\r\n st.write(type(companies['num_developers'].sum()))\r\n st.markdown(f'Total developers %d' % companies['num_developers'].sum())\r\n st.metric('Total developers', companies['num_developers'].sum())\r\n```\r\n\r\n**Expected behavior:**\r\n\r\nExpected it to just work!\r\n\r\n**Actual behavior:**\r\n\r\nShowed the error in the screenshot above.\r\n\r\n### Is this a regression?\r\n\r\nThat is, did this use to work the way you expected in the past?\r\nno\r\n\r\n### Debug info\r\n\r\n- Streamlit version: streamlit-nightly from today\r\n\n", "before_files": [{"content": "# Copyright 2018-2021 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom textwrap import dedent\nfrom typing import cast, Optional\n\nimport attr\n\nimport streamlit\nfrom streamlit.errors import StreamlitAPIException\nfrom streamlit.proto.Metric_pb2 import Metric as MetricProto\nfrom .utils import clean_text\n\n\[email protected](auto_attribs=True, slots=True)\nclass MetricColorAndDirection:\n color: Optional[int]\n direction: Optional[int]\n\n\nclass MetricMixin:\n def metric(self, label, value, delta=None, delta_color=\"normal\"):\n \"\"\"Display a metric in big bold font, with an optional indicator of how the metric changed.\n\n Tip: If you want to display a large number, it may be a good idea to\n shorten it using packages like `millify <https://github.com/azaitsev/millify>`_\n or `numerize <https://github.com/davidsa03/numerize>`_. E.g. ``1234`` can be\n displayed as ``1.2k`` using ``st.metric(\"Short number\", millify(1234))``.\n\n Parameters\n ----------\n label : str\n The header or Title for the metric\n value : int, float, str, or None\n Value of the metric. None is rendered as a long dash.\n delta : int, float, str, or None\n Indicator of how the metric changed, rendered with an arrow below\n the metric. If delta is negative (int/float) or starts with a minus\n sign (str), the arrow points down and the text is red; else the\n arrow points up and the text is green. If None (default), no delta\n indicator is shown.\n delta_color : str\n If \"normal\" (default), the delta indicator is shown as described\n above. If \"inverse\", it is red when positive and green when\n negative. This is useful when a negative change is considered\n good, e.g. if cost decreased. If \"off\", delta is shown in gray\n regardless of its value.\n\n Example\n -------\n >>> st.metric(label=\"Temperature\", value=\"70 \u00b0F\", delta=\"1.2 \u00b0F\")\n\n .. output::\n https://static.streamlit.io/0.86.0-mT2t/index.html?id=1TxwRhgBgFg62p2AXqJdM\n height: 175px\n\n ``st.metric`` looks especially nice in combination with ``st.columns``:\n\n >>> col1, col2, col3 = st.columns(3)\n >>> col1.metric(\"Temperature\", \"70 \u00b0F\", \"1.2 \u00b0F\")\n >>> col2.metric(\"Wind\", \"9 mph\", \"-8%\")\n >>> col3.metric(\"Humidity\", \"86%\", \"4%\")\n\n .. output::\n https://static.streamlit.io/0.86.0-mT2t/index.html?id=4K9bKXhiPAxBNhktd8cxbg\n height: 175px\n\n The delta indicator color can also be inverted or turned off:\n\n >>> st.metric(label=\"Gas price\", value=4, delta=-0.5,\n ... delta_color=\"inverse\")\n >>>\n >>> st.metric(label=\"Active developers\", value=123, delta=123,\n ... delta_color=\"off\")\n\n .. output::\n https://static.streamlit.io/0.86.0-mT2t/index.html?id=UTtQvbBQFaPtCmPcQ23wpP\n height: 275px\n\n \"\"\"\n metric_proto = MetricProto()\n metric_proto.body = self.parse_value(value)\n metric_proto.label = self.parse_label(label)\n metric_proto.delta = self.parse_delta(delta)\n\n color_and_direction = self.determine_delta_color_and_direction(\n clean_text(delta_color), delta\n )\n metric_proto.color = color_and_direction.color\n metric_proto.direction = color_and_direction.direction\n\n return str(self.dg._enqueue(\"metric\", metric_proto))\n\n def parse_label(self, label):\n if not isinstance(label, str):\n raise TypeError(\n f\"'{str(label)}' is not an accepted type. label only accepts: str\"\n )\n return label\n\n def parse_value(self, value):\n if value is None:\n return \"\u2014\"\n if isinstance(value, float) or isinstance(value, int) or isinstance(value, str):\n return str(value)\n else:\n raise TypeError(\n f\"'{str(value)}' is not an accepted type. value only accepts: \"\n \"int, float, str, or None\"\n )\n\n def parse_delta(self, delta):\n if delta is None or delta == \"\":\n return \"\"\n if isinstance(delta, str):\n return dedent(delta)\n elif isinstance(delta, int) or isinstance(delta, float):\n return str(delta)\n else:\n raise TypeError(\n f\"'{str(delta)}' is not an accepted type. delta only accepts:\"\n \" int, float, str, or None\"\n )\n\n def determine_delta_color_and_direction(self, delta_color, delta):\n cd = MetricColorAndDirection(color=None, direction=None)\n\n if delta is None or delta == \"\":\n cd.color = MetricProto.MetricColor.GRAY\n cd.direction = MetricProto.MetricDirection.NONE\n return cd\n\n if self.is_negative(delta):\n if delta_color == \"normal\":\n cd.color = MetricProto.MetricColor.RED\n elif delta_color == \"inverse\":\n cd.color = MetricProto.MetricColor.GREEN\n elif delta_color == \"off\":\n cd.color = MetricProto.MetricColor.GRAY\n cd.direction = MetricProto.MetricDirection.DOWN\n else:\n if delta_color == \"normal\":\n cd.color = MetricProto.MetricColor.GREEN\n elif delta_color == \"inverse\":\n cd.color = MetricProto.MetricColor.RED\n elif delta_color == \"off\":\n cd.color = MetricProto.MetricColor.GRAY\n cd.direction = MetricProto.MetricDirection.UP\n\n if cd.color is None or cd.direction is None:\n raise StreamlitAPIException(\n f\"'{str(delta_color)}' is not an accepted value. delta_color only accepts: \"\n \"'normal', 'inverse', or 'off'\"\n )\n return cd\n\n def is_negative(self, delta):\n return dedent(str(delta)).startswith(\"-\")\n\n @property\n def dg(self) -> \"streamlit.delta_generator.DeltaGenerator\":\n return cast(\"streamlit.delta_generator.DeltaGenerator\", self)\n", "path": "lib/streamlit/elements/metric.py"}]}
| 2,819 | 613 |
gh_patches_debug_9864
|
rasdani/github-patches
|
git_diff
|
getpelican__pelican-2720
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fixing some warnings and errors in the sample content.
The current sample content is not up-to-date with the current Pelican mechanism.
This will help new comers to understand better how Pelican works.
* More valid articles.
* More translations.
* Images are now correctly displayed.
</issue>
<code>
[start of samples/pelican.conf.py]
1 # -*- coding: utf-8 -*-
2
3 AUTHOR = 'Alexis Métaireau'
4 SITENAME = "Alexis' log"
5 SITESUBTITLE = 'A personal blog.'
6 SITEURL = 'http://blog.notmyidea.org'
7 TIMEZONE = "Europe/Paris"
8
9 # can be useful in development, but set to False when you're ready to publish
10 RELATIVE_URLS = True
11
12 GITHUB_URL = 'http://github.com/ametaireau/'
13 DISQUS_SITENAME = "blog-notmyidea"
14 REVERSE_CATEGORY_ORDER = True
15 LOCALE = "C"
16 DEFAULT_PAGINATION = 4
17 DEFAULT_DATE = (2012, 3, 2, 14, 1, 1)
18
19 FEED_ALL_RSS = 'feeds/all.rss.xml'
20 CATEGORY_FEED_RSS = 'feeds/{slug}.rss.xml'
21
22 LINKS = (('Biologeek', 'http://biologeek.org'),
23 ('Filyb', "http://filyb.info/"),
24 ('Libert-fr', "http://www.libert-fr.com"),
25 ('N1k0', "http://prendreuncafe.com/blog/"),
26 ('Tarek Ziadé', "http://ziade.org/blog"),
27 ('Zubin Mithra', "http://zubin71.wordpress.com/"),)
28
29 SOCIAL = (('twitter', 'http://twitter.com/ametaireau'),
30 ('lastfm', 'http://lastfm.com/user/akounet'),
31 ('github', 'http://github.com/ametaireau'),)
32
33 # global metadata to all the contents
34 DEFAULT_METADATA = {'yeah': 'it is'}
35
36 # path-specific metadata
37 EXTRA_PATH_METADATA = {
38 'extra/robots.txt': {'path': 'robots.txt'},
39 }
40
41 # static paths will be copied without parsing their contents
42 STATIC_PATHS = [
43 'pictures',
44 'extra/robots.txt',
45 ]
46
47 # custom page generated with a jinja2 template
48 TEMPLATE_PAGES = {'pages/jinja2_template.html': 'jinja2_template.html'}
49
50 # code blocks with line numbers
51 PYGMENTS_RST_OPTIONS = {'linenos': 'table'}
52
53 # foobar will not be used, because it's not in caps. All configuration keys
54 # have to be in caps
55 foobar = "barbaz"
56
[end of samples/pelican.conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/samples/pelican.conf.py b/samples/pelican.conf.py
--- a/samples/pelican.conf.py
+++ b/samples/pelican.conf.py
@@ -40,13 +40,16 @@
# static paths will be copied without parsing their contents
STATIC_PATHS = [
- 'pictures',
+ 'images',
'extra/robots.txt',
]
# custom page generated with a jinja2 template
TEMPLATE_PAGES = {'pages/jinja2_template.html': 'jinja2_template.html'}
+# there is no other HTML content
+READERS = {'html': None}
+
# code blocks with line numbers
PYGMENTS_RST_OPTIONS = {'linenos': 'table'}
|
{"golden_diff": "diff --git a/samples/pelican.conf.py b/samples/pelican.conf.py\n--- a/samples/pelican.conf.py\n+++ b/samples/pelican.conf.py\n@@ -40,13 +40,16 @@\n \n # static paths will be copied without parsing their contents\n STATIC_PATHS = [\n- 'pictures',\n+ 'images',\n 'extra/robots.txt',\n ]\n \n # custom page generated with a jinja2 template\n TEMPLATE_PAGES = {'pages/jinja2_template.html': 'jinja2_template.html'}\n \n+# there is no other HTML content\n+READERS = {'html': None}\n+\n # code blocks with line numbers\n PYGMENTS_RST_OPTIONS = {'linenos': 'table'}\n", "issue": "Fixing some warnings and errors in the sample content.\nThe current sample content is not up-to-date with the current Pelican mechanism.\r\n\r\nThis will help new comers to understand better how Pelican works.\r\n\r\n* More valid articles.\r\n* More translations.\r\n* Images are now correctly displayed.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nAUTHOR = 'Alexis M\u00e9taireau'\nSITENAME = \"Alexis' log\"\nSITESUBTITLE = 'A personal blog.'\nSITEURL = 'http://blog.notmyidea.org'\nTIMEZONE = \"Europe/Paris\"\n\n# can be useful in development, but set to False when you're ready to publish\nRELATIVE_URLS = True\n\nGITHUB_URL = 'http://github.com/ametaireau/'\nDISQUS_SITENAME = \"blog-notmyidea\"\nREVERSE_CATEGORY_ORDER = True\nLOCALE = \"C\"\nDEFAULT_PAGINATION = 4\nDEFAULT_DATE = (2012, 3, 2, 14, 1, 1)\n\nFEED_ALL_RSS = 'feeds/all.rss.xml'\nCATEGORY_FEED_RSS = 'feeds/{slug}.rss.xml'\n\nLINKS = (('Biologeek', 'http://biologeek.org'),\n ('Filyb', \"http://filyb.info/\"),\n ('Libert-fr', \"http://www.libert-fr.com\"),\n ('N1k0', \"http://prendreuncafe.com/blog/\"),\n ('Tarek Ziad\u00e9', \"http://ziade.org/blog\"),\n ('Zubin Mithra', \"http://zubin71.wordpress.com/\"),)\n\nSOCIAL = (('twitter', 'http://twitter.com/ametaireau'),\n ('lastfm', 'http://lastfm.com/user/akounet'),\n ('github', 'http://github.com/ametaireau'),)\n\n# global metadata to all the contents\nDEFAULT_METADATA = {'yeah': 'it is'}\n\n# path-specific metadata\nEXTRA_PATH_METADATA = {\n 'extra/robots.txt': {'path': 'robots.txt'},\n }\n\n# static paths will be copied without parsing their contents\nSTATIC_PATHS = [\n 'pictures',\n 'extra/robots.txt',\n ]\n\n# custom page generated with a jinja2 template\nTEMPLATE_PAGES = {'pages/jinja2_template.html': 'jinja2_template.html'}\n\n# code blocks with line numbers\nPYGMENTS_RST_OPTIONS = {'linenos': 'table'}\n\n# foobar will not be used, because it's not in caps. All configuration keys\n# have to be in caps\nfoobar = \"barbaz\"\n", "path": "samples/pelican.conf.py"}]}
| 1,198 | 159 |
gh_patches_debug_6938
|
rasdani/github-patches
|
git_diff
|
uclapi__uclapi-556
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move to WebPack
Building the frontend is annoying, and updating dependencies in a way that lets us test the updates is nothing short of tedious.
WebPack with proper bounds on the minor version of each component and dependency should help us stay in line and keep up to date with the frontend code.
</issue>
<code>
[start of backend/uclapi/uclapi/settings.py]
1 """
2 Django settings for uclapi project.
3
4 Generated by 'django-admin startproject' using Django 1.10.4.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/1.10/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/1.10/ref/settings/
11 """
12
13 import os
14 import requests
15 from distutils.util import strtobool
16
17 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
18 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
19
20
21 # Quick-start development settings - unsuitable for production
22 # See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/
23
24 # SECURITY WARNING: keep the secret key used in production secret!
25 SECRET_KEY = os.environ.get("SECRET_KEY")
26
27 # SECURITY WARNING: don't run with debug turned on in production!
28 # This value should be set by the UCLAPI_PRODUCTION environment
29 # variable anyway. If in production, debug should be false.
30 DEBUG = not strtobool(os.environ.get("UCLAPI_PRODUCTION"))
31
32 ALLOWED_HOSTS = ["localhost"]
33
34 # If a domain is specified then make this an allowed host
35 if os.environ.get("UCLAPI_DOMAIN"):
36 ALLOWED_HOSTS.append(os.environ.get("UCLAPI_DOMAIN"))
37
38 # If we are running under the AWS Elastic Load Balancer then enable internal
39 # requests so that the ELB and Health Checks work
40 if strtobool(os.environ.get("UCLAPI_RUNNING_ON_AWS_ELB")):
41 EC2_PRIVATE_IP = None
42 try:
43 EC2_PRIVATE_IP = requests.get(
44 "http://169.254.169.254/latest/meta-data/local-ipv4",
45 timeout=0.01
46 ).text
47 except requests.exceptions.RequestException:
48 pass
49
50 if EC2_PRIVATE_IP:
51 ALLOWED_HOSTS.append(EC2_PRIVATE_IP)
52
53 # Application definition
54
55 INSTALLED_APPS = [
56 'django.contrib.admin',
57 'django.contrib.auth',
58 'django.contrib.contenttypes',
59 'django.contrib.sessions',
60 'django.contrib.messages',
61 'django.contrib.staticfiles',
62 'rest_framework',
63 'dashboard',
64 'marketplace',
65 'roombookings',
66 'oauth',
67 'timetable',
68 'common',
69 'opbeat.contrib.django',
70 'raven.contrib.django.raven_compat',
71 'corsheaders',
72 'workspaces'
73 ]
74
75 MIDDLEWARE = [
76 'opbeat.contrib.django.middleware.OpbeatAPMMiddleware',
77 'django.middleware.security.SecurityMiddleware',
78 'django.contrib.sessions.middleware.SessionMiddleware',
79 'corsheaders.middleware.CorsMiddleware',
80 'django.middleware.common.CommonMiddleware',
81 'django.middleware.csrf.CsrfViewMiddleware',
82 'django.contrib.auth.middleware.AuthenticationMiddleware',
83 'django.contrib.messages.middleware.MessageMiddleware',
84 'django.middleware.clickjacking.XFrameOptionsMiddleware',
85 ]
86
87 if DEBUG:
88 MIDDLEWARE.append(
89 'dashboard.middleware.fake_shibboleth_middleware'
90 '.FakeShibbolethMiddleWare'
91 )
92
93 ROOT_URLCONF = 'uclapi.urls'
94
95 TEMPLATES = [
96 {
97 'BACKEND': 'django.template.backends.django.DjangoTemplates',
98 'DIRS': [],
99 'APP_DIRS': True,
100 'OPTIONS': {
101 'context_processors': [
102 'django.template.context_processors.debug',
103 'django.template.context_processors.request',
104 'django.contrib.auth.context_processors.auth',
105 'django.contrib.messages.context_processors.messages',
106 ],
107 },
108 },
109 ]
110
111 WSGI_APPLICATION = 'uclapi.wsgi.application'
112
113
114 # Database
115 # https://docs.djangoproject.com/en/1.10/ref/settings/#databases
116
117 DATABASES = {
118 'default': {
119 'ENGINE': 'django.db.backends.postgresql',
120 'NAME': os.environ.get("DB_UCLAPI_NAME"),
121 'USER': os.environ.get("DB_UCLAPI_USERNAME"),
122 'PASSWORD': os.environ.get("DB_UCLAPI_PASSWORD"),
123 'HOST': os.environ.get("DB_UCLAPI_HOST"),
124 'PORT': os.environ.get("DB_UCLAPI_PORT")
125 },
126 'roombookings': {
127 'ENGINE': 'django.db.backends.oracle',
128 'NAME': os.environ.get("DB_ROOMS_NAME"),
129 'USER': os.environ.get("DB_ROOMS_USERNAME"),
130 'PASSWORD': os.environ.get("DB_ROOMS_PASSWORD"),
131 'HOST': '',
132 'PORT': ''
133 },
134 'gencache': {
135 'ENGINE': 'django.db.backends.postgresql',
136 'NAME': os.environ.get("DB_CACHE_NAME"),
137 'USER': os.environ.get("DB_CACHE_USERNAME"),
138 'PASSWORD': os.environ.get("DB_CACHE_PASSWORD"),
139 'HOST': os.environ.get("DB_CACHE_HOST"),
140 'PORT': os.environ.get("DB_CACHE_PORT")
141 }
142 }
143
144 DATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']
145
146 # analytics
147 OPBEAT = {
148 'ORGANIZATION_ID': os.environ.get("OPBEAT_ORG_ID"),
149 'APP_ID': os.environ.get("OPBEAT_APP_ID"),
150 'SECRET_TOKEN': os.environ.get("OPBEAT_SECRET_TOKEN")
151 }
152
153 RAVEN_CONFIG = {
154 'dsn': os.environ.get("SENTRY_DSN"),
155 }
156
157
158 # Password validation
159 # https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators
160
161 AUTH_PASSWORD_VALIDATORS = [
162 {
163 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa
164 },
165 {
166 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa
167 },
168 {
169 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa
170 },
171 {
172 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa
173 },
174 ]
175
176
177 # Internationalization
178 # https://docs.djangoproject.com/en/1.10/topics/i18n/
179
180 LANGUAGE_CODE = 'en-us'
181
182 TIME_ZONE = 'UTC'
183
184 USE_I18N = True
185
186 USE_L10N = True
187
188 USE_TZ = False
189
190
191 # Static files (CSS, JavaScript, Images)
192 # https://docs.djangoproject.com/en/1.10/howto/static-files/
193
194 STATIC_URL = '/static/'
195 STATIC_ROOT = os.path.join(BASE_DIR, 'static')
196 STATICFILES_DIRS = [
197 os.path.join(BASE_DIR, "images"),
198 ]
199
200 # Cross Origin settings
201 CORS_ORIGIN_ALLOW_ALL = True
202 CORS_URLS_REGEX = r'^/roombookings/.*$'
203
204 # Fair use policy
205 fair_use_policy_path = os.path.join(
206 BASE_DIR,
207 'uclapi/UCLAPIAcceptableUsePolicy.txt'
208 )
209 with open(fair_use_policy_path, 'r', encoding='utf-8') as fp:
210 FAIR_USE_POLICY = list(fp)
211
212 REDIS_UCLAPI_HOST = os.environ["REDIS_UCLAPI_HOST"]
213
214 # Celery Settings
215 CELERY_BROKER_URL = 'redis://' + REDIS_UCLAPI_HOST
216 CELERY_ACCEPT_CONTENT = ['json']
217 CELERY_TASK_SERIALIZER = 'json'
218 CELERY_RESULT_SERIALIZER = 'json'
219
220
221 ROOMBOOKINGS_SETID = 'LIVE-17-18'
222
223 # S3 file storage settings
224 # There are three scenarios to consider:
225 # 1) Local development
226 # In local dev, AWS_S3_STATICS = False
227 # AWS_S3_STATICS_CREDENTIALS_ENABLED = False
228 # These allow you to use local statics using /static/ in the
229 # same way as you would normally.
230 # 2) Production
231 # In prod, AWS_S3_STATICS = True
232 # AWS_S3_STATICS_CREDENTIALS_ENABLED = False
233 # This means that S3 statics will be used, but no creds are
234 # needed on the boxes because web servers should never do
235 # uploads to the remote S3 bucket.
236 # 3) Deployment
237 # In deployment, AWS_S3_STATICS = True
238 # AWS_S3_STATICS_CREDENTIALS_ENABLED = True
239 # This will be done either from CI/CD or from the computer
240 # of a person who has permission to upload new statics to
241 # S3.
242
243 if strtobool(os.environ.get("AWS_S3_STATICS", "False")):
244 DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
245 STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'
246 AWS_STORAGE_BUCKET_NAME = os.environ["AWS_S3_BUCKET_NAME"]
247 AWS_LOCATION = os.environ["AWS_S3_BUCKET_PATH"]
248 AWS_S3_REGION_NAME = os.environ["AWS_S3_REGION"]
249
250 # This is a hack to not require AWS Access Credentials
251 # when the system is running in the Cloud. This avoids us from
252 # needing to store AWS credentials.
253 # https://github.com/jschneier/django-storages/issues/254#issuecomment-329813295 # noqa
254 AWS_S3_CUSTOM_DOMAIN = "{}.s3.amazonaws.com".format(
255 AWS_STORAGE_BUCKET_NAME
256 )
257
258 # If credentials are enabled, collectstatic can do uploads
259 if strtobool(os.environ["AWS_S3_STATICS_CREDENTIALS_ENABLED"]):
260 AWS_ACCESS_KEY_ID = os.environ["AWS_ACCESS_KEY_ID"]
261 AWS_SECRET_ACCESS_KEY = os.environ["AWS_ACCESS_SECRET"]
262 AWS_S3_OBJECT_PARAMETERS = {
263 'CacheControl': 'max-age=86400',
264 }
265 AWS_S3_ENCRYPTION = False
266 else:
267 AWS_QUERYSTRING_AUTH = False
268
[end of backend/uclapi/uclapi/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/uclapi/uclapi/settings.py b/backend/uclapi/uclapi/settings.py
--- a/backend/uclapi/uclapi/settings.py
+++ b/backend/uclapi/uclapi/settings.py
@@ -187,15 +187,11 @@
USE_TZ = False
-
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/1.10/howto/static-files/
STATIC_URL = '/static/'
STATIC_ROOT = os.path.join(BASE_DIR, 'static')
-STATICFILES_DIRS = [
- os.path.join(BASE_DIR, "images"),
-]
# Cross Origin settings
CORS_ORIGIN_ALLOW_ALL = True
|
{"golden_diff": "diff --git a/backend/uclapi/uclapi/settings.py b/backend/uclapi/uclapi/settings.py\n--- a/backend/uclapi/uclapi/settings.py\n+++ b/backend/uclapi/uclapi/settings.py\n@@ -187,15 +187,11 @@\n \n USE_TZ = False\n \n-\n # Static files (CSS, JavaScript, Images)\n # https://docs.djangoproject.com/en/1.10/howto/static-files/\n \n STATIC_URL = '/static/'\n STATIC_ROOT = os.path.join(BASE_DIR, 'static')\n-STATICFILES_DIRS = [\n- os.path.join(BASE_DIR, \"images\"),\n-]\n \n # Cross Origin settings\n CORS_ORIGIN_ALLOW_ALL = True\n", "issue": "Move to WebPack\nBuilding the frontend is annoying, and updating dependencies in a way that lets us test the updates is nothing short of tedious.\r\n\r\nWebPack with proper bounds on the minor version of each component and dependency should help us stay in line and keep up to date with the frontend code.\n", "before_files": [{"content": "\"\"\"\nDjango settings for uclapi project.\n\nGenerated by 'django-admin startproject' using Django 1.10.4.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/1.10/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.10/ref/settings/\n\"\"\"\n\nimport os\nimport requests\nfrom distutils.util import strtobool\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.10/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ.get(\"SECRET_KEY\")\n\n# SECURITY WARNING: don't run with debug turned on in production!\n# This value should be set by the UCLAPI_PRODUCTION environment\n# variable anyway. If in production, debug should be false.\nDEBUG = not strtobool(os.environ.get(\"UCLAPI_PRODUCTION\"))\n\nALLOWED_HOSTS = [\"localhost\"]\n\n# If a domain is specified then make this an allowed host\nif os.environ.get(\"UCLAPI_DOMAIN\"):\n ALLOWED_HOSTS.append(os.environ.get(\"UCLAPI_DOMAIN\"))\n\n# If we are running under the AWS Elastic Load Balancer then enable internal\n# requests so that the ELB and Health Checks work\nif strtobool(os.environ.get(\"UCLAPI_RUNNING_ON_AWS_ELB\")):\n EC2_PRIVATE_IP = None\n try:\n EC2_PRIVATE_IP = requests.get(\n \"http://169.254.169.254/latest/meta-data/local-ipv4\",\n timeout=0.01\n ).text\n except requests.exceptions.RequestException:\n pass\n\n if EC2_PRIVATE_IP:\n ALLOWED_HOSTS.append(EC2_PRIVATE_IP)\n\n# Application definition\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'dashboard',\n 'marketplace',\n 'roombookings',\n 'oauth',\n 'timetable',\n 'common',\n 'opbeat.contrib.django',\n 'raven.contrib.django.raven_compat',\n 'corsheaders',\n 'workspaces'\n]\n\nMIDDLEWARE = [\n 'opbeat.contrib.django.middleware.OpbeatAPMMiddleware',\n 'django.middleware.security.SecurityMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nif DEBUG:\n MIDDLEWARE.append(\n 'dashboard.middleware.fake_shibboleth_middleware'\n '.FakeShibbolethMiddleWare'\n )\n\nROOT_URLCONF = 'uclapi.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'uclapi.wsgi.application'\n\n\n# Database\n# https://docs.djangoproject.com/en/1.10/ref/settings/#databases\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql',\n 'NAME': os.environ.get(\"DB_UCLAPI_NAME\"),\n 'USER': os.environ.get(\"DB_UCLAPI_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_UCLAPI_PASSWORD\"),\n 'HOST': os.environ.get(\"DB_UCLAPI_HOST\"),\n 'PORT': os.environ.get(\"DB_UCLAPI_PORT\")\n },\n 'roombookings': {\n 'ENGINE': 'django.db.backends.oracle',\n 'NAME': os.environ.get(\"DB_ROOMS_NAME\"),\n 'USER': os.environ.get(\"DB_ROOMS_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_ROOMS_PASSWORD\"),\n 'HOST': '',\n 'PORT': ''\n },\n 'gencache': {\n 'ENGINE': 'django.db.backends.postgresql',\n 'NAME': os.environ.get(\"DB_CACHE_NAME\"),\n 'USER': os.environ.get(\"DB_CACHE_USERNAME\"),\n 'PASSWORD': os.environ.get(\"DB_CACHE_PASSWORD\"),\n 'HOST': os.environ.get(\"DB_CACHE_HOST\"),\n 'PORT': os.environ.get(\"DB_CACHE_PORT\")\n }\n}\n\nDATABASE_ROUTERS = ['uclapi.dbrouters.ModelRouter']\n\n# analytics\nOPBEAT = {\n 'ORGANIZATION_ID': os.environ.get(\"OPBEAT_ORG_ID\"),\n 'APP_ID': os.environ.get(\"OPBEAT_APP_ID\"),\n 'SECRET_TOKEN': os.environ.get(\"OPBEAT_SECRET_TOKEN\")\n}\n\nRAVEN_CONFIG = {\n 'dsn': os.environ.get(\"SENTRY_DSN\"),\n}\n\n\n# Password validation\n# https://docs.djangoproject.com/en/1.10/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', # noqa\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', # noqa\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.10/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = False\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.10/howto/static-files/\n\nSTATIC_URL = '/static/'\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static')\nSTATICFILES_DIRS = [\n os.path.join(BASE_DIR, \"images\"),\n]\n\n# Cross Origin settings\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/roombookings/.*$'\n\n# Fair use policy\nfair_use_policy_path = os.path.join(\n BASE_DIR,\n 'uclapi/UCLAPIAcceptableUsePolicy.txt'\n)\nwith open(fair_use_policy_path, 'r', encoding='utf-8') as fp:\n FAIR_USE_POLICY = list(fp)\n\nREDIS_UCLAPI_HOST = os.environ[\"REDIS_UCLAPI_HOST\"]\n\n# Celery Settings\nCELERY_BROKER_URL = 'redis://' + REDIS_UCLAPI_HOST\nCELERY_ACCEPT_CONTENT = ['json']\nCELERY_TASK_SERIALIZER = 'json'\nCELERY_RESULT_SERIALIZER = 'json'\n\n\nROOMBOOKINGS_SETID = 'LIVE-17-18'\n\n# S3 file storage settings\n# There are three scenarios to consider:\n# 1) Local development\n# In local dev, AWS_S3_STATICS = False\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = False\n# These allow you to use local statics using /static/ in the\n# same way as you would normally.\n# 2) Production\n# In prod, AWS_S3_STATICS = True\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = False\n# This means that S3 statics will be used, but no creds are\n# needed on the boxes because web servers should never do\n# uploads to the remote S3 bucket.\n# 3) Deployment\n# In deployment, AWS_S3_STATICS = True\n# AWS_S3_STATICS_CREDENTIALS_ENABLED = True\n# This will be done either from CI/CD or from the computer\n# of a person who has permission to upload new statics to\n# S3.\n\nif strtobool(os.environ.get(\"AWS_S3_STATICS\", \"False\")):\n DEFAULT_FILE_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'\n AWS_STORAGE_BUCKET_NAME = os.environ[\"AWS_S3_BUCKET_NAME\"]\n AWS_LOCATION = os.environ[\"AWS_S3_BUCKET_PATH\"]\n AWS_S3_REGION_NAME = os.environ[\"AWS_S3_REGION\"]\n\n # This is a hack to not require AWS Access Credentials\n # when the system is running in the Cloud. This avoids us from\n # needing to store AWS credentials.\n # https://github.com/jschneier/django-storages/issues/254#issuecomment-329813295 # noqa\n AWS_S3_CUSTOM_DOMAIN = \"{}.s3.amazonaws.com\".format(\n AWS_STORAGE_BUCKET_NAME\n )\n\n # If credentials are enabled, collectstatic can do uploads\n if strtobool(os.environ[\"AWS_S3_STATICS_CREDENTIALS_ENABLED\"]):\n AWS_ACCESS_KEY_ID = os.environ[\"AWS_ACCESS_KEY_ID\"]\n AWS_SECRET_ACCESS_KEY = os.environ[\"AWS_ACCESS_SECRET\"]\n AWS_S3_OBJECT_PARAMETERS = {\n 'CacheControl': 'max-age=86400',\n }\n AWS_S3_ENCRYPTION = False\n else:\n AWS_QUERYSTRING_AUTH = False\n", "path": "backend/uclapi/uclapi/settings.py"}]}
| 3,403 | 150 |
gh_patches_debug_36512
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-1704
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Log important events into a file
solaar does log warnings in case of failure, e.g.
```
12:25:57,373 WARNING [MainThread] logitech_receiver.diversion: cannot create uinput device: "/dev/uinput" cannot be opened for writing
```
but these warnings appear to be only visible on the console, on stdout. To see these warnings, (an auto-started) solaar needs to be stopped (pkill solaar) and the launched from the console. This enables users to see future log entries.
It would be nicer to have solaar (also) log important events into the journald log, enabling users to inspect the logs for any solaar events that failed ... looking _back_.
</issue>
<code>
[start of lib/solaar/gtk.py]
1 #!/usr/bin/env python3
2 # -*- python-mode -*-
3 # -*- coding: UTF-8 -*-
4
5 ## Copyright (C) 2012-2013 Daniel Pavel
6 ##
7 ## This program is free software; you can redistribute it and/or modify
8 ## it under the terms of the GNU General Public License as published by
9 ## the Free Software Foundation; either version 2 of the License, or
10 ## (at your option) any later version.
11 ##
12 ## This program is distributed in the hope that it will be useful,
13 ## but WITHOUT ANY WARRANTY; without even the implied warranty of
14 ## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 ## GNU General Public License for more details.
16 ##
17 ## You should have received a copy of the GNU General Public License along
18 ## with this program; if not, write to the Free Software Foundation, Inc.,
19 ## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
20
21 import importlib
22 import os.path
23
24 from logging import INFO as _INFO
25 from logging import WARNING as _WARNING
26 from logging import getLogger
27
28 import solaar.cli as _cli
29 import solaar.i18n as _i18n
30
31 from solaar import NAME, __version__
32
33 _log = getLogger(__name__)
34 del getLogger
35
36 #
37 #
38 #
39
40
41 def _require(module, os_package, gi=None, gi_package=None, gi_version=None):
42 try:
43 if gi is not None:
44 gi.require_version(gi_package, gi_version)
45 return importlib.import_module(module)
46 except (ImportError, ValueError):
47 import sys
48 sys.exit('%s: missing required system package %s' % (NAME, os_package))
49
50
51 battery_icons_style = 'regular'
52
53
54 def _parse_arguments():
55 import argparse
56 arg_parser = argparse.ArgumentParser(
57 prog=NAME.lower(), epilog='For more information see https://pwr-solaar.github.io/Solaar'
58 )
59 arg_parser.add_argument(
60 '-d',
61 '--debug',
62 action='count',
63 default=0,
64 help='print logging messages, for debugging purposes (may be repeated for extra verbosity)'
65 )
66 arg_parser.add_argument(
67 '-D',
68 '--hidraw',
69 action='store',
70 dest='hidraw_path',
71 metavar='PATH',
72 help='unifying receiver to use; the first detected receiver if unspecified. Example: /dev/hidraw2'
73 )
74 arg_parser.add_argument('--restart-on-wake-up', action='store_true', help='restart Solaar on sleep wake-up (experimental)')
75 arg_parser.add_argument(
76 '-w', '--window', choices=('show', 'hide', 'only'), help='start with window showing / hidden / only (no tray icon)'
77 )
78 arg_parser.add_argument(
79 '-b',
80 '--battery-icons',
81 choices=('regular', 'symbolic', 'solaar'),
82 help='prefer regular battery / symbolic battery / solaar icons'
83 )
84 arg_parser.add_argument('--tray-icon-size', type=int, help='explicit size for tray icons')
85 arg_parser.add_argument('-V', '--version', action='version', version='%(prog)s ' + __version__)
86 arg_parser.add_argument('--help-actions', action='store_true', help='print help for the optional actions')
87 arg_parser.add_argument('action', nargs=argparse.REMAINDER, choices=_cli.actions, help='optional actions to perform')
88
89 args = arg_parser.parse_args()
90
91 if args.help_actions:
92 _cli.print_help()
93 return
94
95 if args.window is None:
96 args.window = 'show' # default behaviour is to show main window
97
98 global battery_icons_style
99 battery_icons_style = args.battery_icons if args.battery_icons is not None else 'regular'
100 global tray_icon_size
101 tray_icon_size = args.tray_icon_size
102
103 import logging
104 if args.debug > 0:
105 log_level = logging.ERROR - 10 * args.debug
106 log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'
107 logging.basicConfig(level=max(log_level, logging.DEBUG), format=log_format, datefmt='%H:%M:%S')
108 else:
109 logging.root.addHandler(logging.NullHandler())
110 logging.root.setLevel(logging.ERROR)
111
112 if not args.action:
113 if logging.root.isEnabledFor(logging.INFO):
114 logging.info('language %s (%s), translations path %s', _i18n.language, _i18n.encoding, _i18n.path)
115
116 return args
117
118
119 # On first SIGINT, dump threads to stderr; on second, exit
120 def _handlesigint(signal, stack):
121 import signal
122 import sys
123 import faulthandler
124 signal.signal(signal.SIGINT, signal.SIG_DFL)
125
126 if _log.isEnabledFor(_INFO):
127 faulthandler.dump_traceback()
128
129 sys.exit('%s: exit due to keyboard interrupt' % (NAME.lower()))
130
131
132 def main():
133 _require('pyudev', 'python3-pyudev')
134
135 # handle ^C in console
136 import signal
137 signal.signal(signal.SIGINT, signal.SIG_DFL)
138 signal.signal(signal.SIGINT, _handlesigint)
139
140 args = _parse_arguments()
141 if not args:
142 return
143 if args.action:
144 # if any argument, run comandline and exit
145 return _cli.run(args.action, args.hidraw_path)
146
147 gi = _require('gi', 'python3-gi (in Ubuntu) or python3-gobject (in Fedora)')
148 _require('gi.repository.Gtk', 'gir1.2-gtk-3.0', gi, 'Gtk', '3.0')
149
150 udev_file = '42-logitech-unify-permissions.rules'
151 if _log.isEnabledFor(_WARNING) \
152 and not os.path.isfile('/etc/udev/rules.d/' + udev_file) \
153 and not os.path.isfile('/usr/lib/udev/rules.d/' + udev_file) \
154 and not os.path.isfile('/usr/local/lib/udev/rules.d/' + udev_file):
155 _log.warning('Solaar udev file not found in expected location')
156 _log.warning('See https://pwr-solaar.github.io/Solaar/installation for more information')
157 try:
158 import solaar.ui as ui
159 import solaar.listener as listener
160 listener.setup_scanner(ui.status_changed, ui.error_dialog)
161
162 import solaar.upower as _upower
163 if args.restart_on_wake_up:
164 _upower.watch(listener.start_all, listener.stop_all)
165 else:
166 _upower.watch(lambda: listener.ping_all(True))
167
168 # main UI event loop
169 ui.run_loop(listener.start_all, listener.stop_all, args.window != 'only', args.window != 'hide')
170 except Exception:
171 import sys
172 from traceback import format_exc
173 sys.exit('%s: error: %s' % (NAME.lower(), format_exc()))
174
175
176 if __name__ == '__main__':
177 main()
178
[end of lib/solaar/gtk.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/solaar/gtk.py b/lib/solaar/gtk.py
--- a/lib/solaar/gtk.py
+++ b/lib/solaar/gtk.py
@@ -19,19 +19,19 @@
## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
import importlib
+import logging
import os.path
+import tempfile
from logging import INFO as _INFO
from logging import WARNING as _WARNING
-from logging import getLogger
import solaar.cli as _cli
import solaar.i18n as _i18n
from solaar import NAME, __version__
-_log = getLogger(__name__)
-del getLogger
+_log = logging.getLogger(__name__)
#
#
@@ -49,6 +49,7 @@
battery_icons_style = 'regular'
+temp = tempfile.NamedTemporaryFile(prefix='Solaar_', mode='w', delete=True)
def _parse_arguments():
@@ -100,17 +101,21 @@
global tray_icon_size
tray_icon_size = args.tray_icon_size
- import logging
+ log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'
+ log_level = logging.ERROR - 10 * args.debug
+ logging.getLogger('').setLevel(min(log_level, logging.WARNING))
+ file_handler = logging.StreamHandler(temp)
+ file_handler.setLevel(max(min(log_level, logging.WARNING), logging.INFO))
+ file_handler.setFormatter(logging.Formatter(log_format))
+ logging.getLogger('').addHandler(file_handler)
if args.debug > 0:
- log_level = logging.ERROR - 10 * args.debug
- log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'
- logging.basicConfig(level=max(log_level, logging.DEBUG), format=log_format, datefmt='%H:%M:%S')
- else:
- logging.root.addHandler(logging.NullHandler())
- logging.root.setLevel(logging.ERROR)
+ stream_handler = logging.StreamHandler()
+ stream_handler.setFormatter(logging.Formatter(log_format))
+ stream_handler.setLevel(log_level)
+ logging.getLogger('').addHandler(stream_handler)
if not args.action:
- if logging.root.isEnabledFor(logging.INFO):
+ if _log.isEnabledFor(logging.INFO):
logging.info('language %s (%s), translations path %s', _i18n.language, _i18n.encoding, _i18n.path)
return args
@@ -172,6 +177,8 @@
from traceback import format_exc
sys.exit('%s: error: %s' % (NAME.lower(), format_exc()))
+ temp.close()
+
if __name__ == '__main__':
main()
|
{"golden_diff": "diff --git a/lib/solaar/gtk.py b/lib/solaar/gtk.py\n--- a/lib/solaar/gtk.py\n+++ b/lib/solaar/gtk.py\n@@ -19,19 +19,19 @@\n ## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n \n import importlib\n+import logging\n import os.path\n+import tempfile\n \n from logging import INFO as _INFO\n from logging import WARNING as _WARNING\n-from logging import getLogger\n \n import solaar.cli as _cli\n import solaar.i18n as _i18n\n \n from solaar import NAME, __version__\n \n-_log = getLogger(__name__)\n-del getLogger\n+_log = logging.getLogger(__name__)\n \n #\n #\n@@ -49,6 +49,7 @@\n \n \n battery_icons_style = 'regular'\n+temp = tempfile.NamedTemporaryFile(prefix='Solaar_', mode='w', delete=True)\n \n \n def _parse_arguments():\n@@ -100,17 +101,21 @@\n global tray_icon_size\n tray_icon_size = args.tray_icon_size\n \n- import logging\n+ log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'\n+ log_level = logging.ERROR - 10 * args.debug\n+ logging.getLogger('').setLevel(min(log_level, logging.WARNING))\n+ file_handler = logging.StreamHandler(temp)\n+ file_handler.setLevel(max(min(log_level, logging.WARNING), logging.INFO))\n+ file_handler.setFormatter(logging.Formatter(log_format))\n+ logging.getLogger('').addHandler(file_handler)\n if args.debug > 0:\n- log_level = logging.ERROR - 10 * args.debug\n- log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'\n- logging.basicConfig(level=max(log_level, logging.DEBUG), format=log_format, datefmt='%H:%M:%S')\n- else:\n- logging.root.addHandler(logging.NullHandler())\n- logging.root.setLevel(logging.ERROR)\n+ stream_handler = logging.StreamHandler()\n+ stream_handler.setFormatter(logging.Formatter(log_format))\n+ stream_handler.setLevel(log_level)\n+ logging.getLogger('').addHandler(stream_handler)\n \n if not args.action:\n- if logging.root.isEnabledFor(logging.INFO):\n+ if _log.isEnabledFor(logging.INFO):\n logging.info('language %s (%s), translations path %s', _i18n.language, _i18n.encoding, _i18n.path)\n \n return args\n@@ -172,6 +177,8 @@\n from traceback import format_exc\n sys.exit('%s: error: %s' % (NAME.lower(), format_exc()))\n \n+ temp.close()\n+\n \n if __name__ == '__main__':\n main()\n", "issue": "Log important events into a file\nsolaar does log warnings in case of failure, e.g.\r\n```\r\n12:25:57,373 WARNING [MainThread] logitech_receiver.diversion: cannot create uinput device: \"/dev/uinput\" cannot be opened for writing\r\n```\r\nbut these warnings appear to be only visible on the console, on stdout. To see these warnings, (an auto-started) solaar needs to be stopped (pkill solaar) and the launched from the console. This enables users to see future log entries.\r\n\r\nIt would be nicer to have solaar (also) log important events into the journald log, enabling users to inspect the logs for any solaar events that failed ... looking _back_.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- python-mode -*-\n# -*- coding: UTF-8 -*-\n\n## Copyright (C) 2012-2013 Daniel Pavel\n##\n## This program is free software; you can redistribute it and/or modify\n## it under the terms of the GNU General Public License as published by\n## the Free Software Foundation; either version 2 of the License, or\n## (at your option) any later version.\n##\n## This program is distributed in the hope that it will be useful,\n## but WITHOUT ANY WARRANTY; without even the implied warranty of\n## MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n## GNU General Public License for more details.\n##\n## You should have received a copy of the GNU General Public License along\n## with this program; if not, write to the Free Software Foundation, Inc.,\n## 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n\nimport importlib\nimport os.path\n\nfrom logging import INFO as _INFO\nfrom logging import WARNING as _WARNING\nfrom logging import getLogger\n\nimport solaar.cli as _cli\nimport solaar.i18n as _i18n\n\nfrom solaar import NAME, __version__\n\n_log = getLogger(__name__)\ndel getLogger\n\n#\n#\n#\n\n\ndef _require(module, os_package, gi=None, gi_package=None, gi_version=None):\n try:\n if gi is not None:\n gi.require_version(gi_package, gi_version)\n return importlib.import_module(module)\n except (ImportError, ValueError):\n import sys\n sys.exit('%s: missing required system package %s' % (NAME, os_package))\n\n\nbattery_icons_style = 'regular'\n\n\ndef _parse_arguments():\n import argparse\n arg_parser = argparse.ArgumentParser(\n prog=NAME.lower(), epilog='For more information see https://pwr-solaar.github.io/Solaar'\n )\n arg_parser.add_argument(\n '-d',\n '--debug',\n action='count',\n default=0,\n help='print logging messages, for debugging purposes (may be repeated for extra verbosity)'\n )\n arg_parser.add_argument(\n '-D',\n '--hidraw',\n action='store',\n dest='hidraw_path',\n metavar='PATH',\n help='unifying receiver to use; the first detected receiver if unspecified. Example: /dev/hidraw2'\n )\n arg_parser.add_argument('--restart-on-wake-up', action='store_true', help='restart Solaar on sleep wake-up (experimental)')\n arg_parser.add_argument(\n '-w', '--window', choices=('show', 'hide', 'only'), help='start with window showing / hidden / only (no tray icon)'\n )\n arg_parser.add_argument(\n '-b',\n '--battery-icons',\n choices=('regular', 'symbolic', 'solaar'),\n help='prefer regular battery / symbolic battery / solaar icons'\n )\n arg_parser.add_argument('--tray-icon-size', type=int, help='explicit size for tray icons')\n arg_parser.add_argument('-V', '--version', action='version', version='%(prog)s ' + __version__)\n arg_parser.add_argument('--help-actions', action='store_true', help='print help for the optional actions')\n arg_parser.add_argument('action', nargs=argparse.REMAINDER, choices=_cli.actions, help='optional actions to perform')\n\n args = arg_parser.parse_args()\n\n if args.help_actions:\n _cli.print_help()\n return\n\n if args.window is None:\n args.window = 'show' # default behaviour is to show main window\n\n global battery_icons_style\n battery_icons_style = args.battery_icons if args.battery_icons is not None else 'regular'\n global tray_icon_size\n tray_icon_size = args.tray_icon_size\n\n import logging\n if args.debug > 0:\n log_level = logging.ERROR - 10 * args.debug\n log_format = '%(asctime)s,%(msecs)03d %(levelname)8s [%(threadName)s] %(name)s: %(message)s'\n logging.basicConfig(level=max(log_level, logging.DEBUG), format=log_format, datefmt='%H:%M:%S')\n else:\n logging.root.addHandler(logging.NullHandler())\n logging.root.setLevel(logging.ERROR)\n\n if not args.action:\n if logging.root.isEnabledFor(logging.INFO):\n logging.info('language %s (%s), translations path %s', _i18n.language, _i18n.encoding, _i18n.path)\n\n return args\n\n\n# On first SIGINT, dump threads to stderr; on second, exit\ndef _handlesigint(signal, stack):\n import signal\n import sys\n import faulthandler\n signal.signal(signal.SIGINT, signal.SIG_DFL)\n\n if _log.isEnabledFor(_INFO):\n faulthandler.dump_traceback()\n\n sys.exit('%s: exit due to keyboard interrupt' % (NAME.lower()))\n\n\ndef main():\n _require('pyudev', 'python3-pyudev')\n\n # handle ^C in console\n import signal\n signal.signal(signal.SIGINT, signal.SIG_DFL)\n signal.signal(signal.SIGINT, _handlesigint)\n\n args = _parse_arguments()\n if not args:\n return\n if args.action:\n # if any argument, run comandline and exit\n return _cli.run(args.action, args.hidraw_path)\n\n gi = _require('gi', 'python3-gi (in Ubuntu) or python3-gobject (in Fedora)')\n _require('gi.repository.Gtk', 'gir1.2-gtk-3.0', gi, 'Gtk', '3.0')\n\n udev_file = '42-logitech-unify-permissions.rules'\n if _log.isEnabledFor(_WARNING) \\\n and not os.path.isfile('/etc/udev/rules.d/' + udev_file) \\\n and not os.path.isfile('/usr/lib/udev/rules.d/' + udev_file) \\\n and not os.path.isfile('/usr/local/lib/udev/rules.d/' + udev_file):\n _log.warning('Solaar udev file not found in expected location')\n _log.warning('See https://pwr-solaar.github.io/Solaar/installation for more information')\n try:\n import solaar.ui as ui\n import solaar.listener as listener\n listener.setup_scanner(ui.status_changed, ui.error_dialog)\n\n import solaar.upower as _upower\n if args.restart_on_wake_up:\n _upower.watch(listener.start_all, listener.stop_all)\n else:\n _upower.watch(lambda: listener.ping_all(True))\n\n # main UI event loop\n ui.run_loop(listener.start_all, listener.stop_all, args.window != 'only', args.window != 'hide')\n except Exception:\n import sys\n from traceback import format_exc\n sys.exit('%s: error: %s' % (NAME.lower(), format_exc()))\n\n\nif __name__ == '__main__':\n main()\n", "path": "lib/solaar/gtk.py"}]}
| 2,660 | 637 |
gh_patches_debug_42653
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-1892
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add docs references to plot_parallel docstring
Add links to the related functions and classes to all the places where they are mentioned in the [plot_parallel](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_parallel.html) docstring.
## Sample PR:
You can see https://github.com/arviz-devs/arviz/pull/1816 for the function, `plot_autocorr`.
## Source File
Source file: https://github.com/arviz-devs/arviz/blob/main/arviz/plots/parallelplot.py
## How to add links
Add the links in the docstring of doc. You can also check the docstring by going to the `[source]`.
* Add links to the ArviZ functions and classes using [Cross-referencing with Sphinx](https://docs.readthedocs.io/en/stable/guides/cross-referencing-with-sphinx.html).
* Add links to the xarray functions and classes using [Intersphinx](https://docs.readthedocs.io/en/stable/guides/intersphinx.html).
* Add the rest of the external links using this [syntax](https://sublime-and-sphinx-guide.readthedocs.io/en/latest/references.html#links-to-external-web-pages).
## `backend_kwargs` and `kwargs`
For adding `backend_kwargs` as they have been added in #1816, see [Adding backend_kwargs guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-backend_kwargs).
## See also section
Add the following functions in the "See also" section:
1. [plot_pair](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_pair.html)
2. [plot_trace](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_trace.html)
See [Adding "see also" section](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-see-also-section) for more details.
## Checking the preview of docs
For checking the preview of docs, you don't need t set up the project on your local machine. Just follow the [checking the preview guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#how-to-check-the-preview-of-docs).
</issue>
<code>
[start of arviz/plots/parallelplot.py]
1 """Parallel coordinates plot showing posterior points with and without divergences marked."""
2 import numpy as np
3 from scipy.stats import rankdata
4
5 from ..data import convert_to_dataset
6 from ..labels import BaseLabeller
7 from ..sel_utils import xarray_to_ndarray
8 from ..rcparams import rcParams
9 from ..stats.stats_utils import stats_variance_2d as svar
10 from ..utils import _numba_var, _var_names, get_coords
11 from .plot_utils import get_plotting_function
12
13
14 def plot_parallel(
15 data,
16 var_names=None,
17 filter_vars=None,
18 coords=None,
19 figsize=None,
20 textsize=None,
21 legend=True,
22 colornd="k",
23 colord="C1",
24 shadend=0.025,
25 labeller=None,
26 ax=None,
27 norm_method=None,
28 backend=None,
29 backend_config=None,
30 backend_kwargs=None,
31 show=None,
32 ):
33 """
34 Plot parallel coordinates plot showing posterior points with and without divergences.
35
36 Described by https://arxiv.org/abs/1709.01449
37
38 Parameters
39 ----------
40 data: obj
41 Any object that can be converted to an az.InferenceData object
42 Refer to documentation of az.convert_to_dataset for details
43 var_names: list of variable names
44 Variables to be plotted, if `None` all variable are plotted. Can be used to change the order
45 of the plotted variables. Prefix the variables by `~` when you want to exclude
46 them from the plot.
47 filter_vars: {None, "like", "regex"}, optional, default=None
48 If `None` (default), interpret var_names as the real variables names. If "like",
49 interpret var_names as substrings of the real variables names. If "regex",
50 interpret var_names as regular expressions on the real variables names. A la
51 `pandas.filter`.
52 coords: mapping, optional
53 Coordinates of var_names to be plotted. Passed to `Dataset.sel`
54 figsize: tuple
55 Figure size. If None it will be defined automatically.
56 textsize: float
57 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
58 on figsize.
59 legend: bool
60 Flag for plotting legend (defaults to True)
61 colornd: valid matplotlib color
62 color for non-divergent points. Defaults to 'k'
63 colord: valid matplotlib color
64 color for divergent points. Defaults to 'C1'
65 shadend: float
66 Alpha blending value for non-divergent points, between 0 (invisible) and 1 (opaque).
67 Defaults to .025
68 labeller : labeller instance, optional
69 Class providing the method `make_label_vert` to generate the labels in the plot.
70 Read the :ref:`label_guide` for more details and usage examples.
71 ax: axes, optional
72 Matplotlib axes or bokeh figures.
73 norm_method: str
74 Method for normalizing the data. Methods include normal, minmax and rank.
75 Defaults to none.
76 backend: str, optional
77 Select plotting backend {"matplotlib","bokeh"}. Default "matplotlib".
78 backend_config: dict, optional
79 Currently specifies the bounds to use for bokeh axes. Defaults to value set in rcParams.
80 backend_kwargs: bool, optional
81 These are kwargs specific to the backend being used. For additional documentation
82 check the plotting method of the backend.
83 show: bool, optional
84 Call backend show function.
85
86 Returns
87 -------
88 axes: matplotlib axes or bokeh figures
89
90 Examples
91 --------
92 Plot default parallel plot
93
94 .. plot::
95 :context: close-figs
96
97 >>> import arviz as az
98 >>> data = az.load_arviz_data('centered_eight')
99 >>> az.plot_parallel(data, var_names=["mu", "tau"])
100
101
102 Plot parallel plot with normalization
103
104 .. plot::
105 :context: close-figs
106
107 >>> az.plot_parallel(data, var_names=["mu", "tau"], norm_method='normal')
108
109 """
110 if coords is None:
111 coords = {}
112
113 if labeller is None:
114 labeller = BaseLabeller()
115
116 # Get diverging draws and combine chains
117 divergent_data = convert_to_dataset(data, group="sample_stats")
118 _, diverging_mask = xarray_to_ndarray(divergent_data, var_names=("diverging",), combined=True)
119 diverging_mask = np.squeeze(diverging_mask)
120
121 # Get posterior draws and combine chains
122 posterior_data = convert_to_dataset(data, group="posterior")
123 var_names = _var_names(var_names, posterior_data, filter_vars)
124 var_names, _posterior = xarray_to_ndarray(
125 get_coords(posterior_data, coords),
126 var_names=var_names,
127 combined=True,
128 label_fun=labeller.make_label_vert,
129 )
130 if len(var_names) < 2:
131 raise ValueError("Number of variables to be plotted must be 2 or greater.")
132 if norm_method is not None:
133 if norm_method == "normal":
134 mean = np.mean(_posterior, axis=1)
135 if _posterior.ndim <= 2:
136 standard_deviation = np.sqrt(_numba_var(svar, np.var, _posterior, axis=1))
137 else:
138 standard_deviation = np.std(_posterior, axis=1)
139 for i in range(0, np.shape(mean)[0]):
140 _posterior[i, :] = (_posterior[i, :] - mean[i]) / standard_deviation[i]
141 elif norm_method == "minmax":
142 min_elem = np.min(_posterior, axis=1)
143 max_elem = np.max(_posterior, axis=1)
144 for i in range(0, np.shape(min_elem)[0]):
145 _posterior[i, :] = ((_posterior[i, :]) - min_elem[i]) / (max_elem[i] - min_elem[i])
146 elif norm_method == "rank":
147 _posterior = rankdata(_posterior, axis=1, method="average")
148 else:
149 raise ValueError(f"{norm_method} is not supported. Use normal, minmax or rank.")
150
151 parallel_kwargs = dict(
152 ax=ax,
153 colornd=colornd,
154 colord=colord,
155 shadend=shadend,
156 diverging_mask=diverging_mask,
157 posterior=_posterior,
158 textsize=textsize,
159 var_names=var_names,
160 legend=legend,
161 figsize=figsize,
162 backend_kwargs=backend_kwargs,
163 backend_config=backend_config,
164 show=show,
165 )
166
167 if backend is None:
168 backend = rcParams["plot.backend"]
169 backend = backend.lower()
170
171 # TODO: Add backend kwargs
172 plot = get_plotting_function("plot_parallel", "parallelplot", backend)
173 ax = plot(**parallel_kwargs)
174
175 return ax
176
[end of arviz/plots/parallelplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/plots/parallelplot.py b/arviz/plots/parallelplot.py
--- a/arviz/plots/parallelplot.py
+++ b/arviz/plots/parallelplot.py
@@ -38,24 +38,25 @@
Parameters
----------
data: obj
- Any object that can be converted to an az.InferenceData object
- Refer to documentation of az.convert_to_dataset for details
+ Any object that can be converted to an :class:`arviz.InferenceData` object
+ refer to documentation of :func:`arviz.convert_to_dataset` for details
var_names: list of variable names
- Variables to be plotted, if `None` all variable are plotted. Can be used to change the order
- of the plotted variables. Prefix the variables by `~` when you want to exclude
+ Variables to be plotted, if `None` all variables are plotted. Can be used to change the
+ order of the plotted variables. Prefix the variables by ``~`` when you want to exclude
them from the plot.
filter_vars: {None, "like", "regex"}, optional, default=None
If `None` (default), interpret var_names as the real variables names. If "like",
interpret var_names as substrings of the real variables names. If "regex",
interpret var_names as regular expressions on the real variables names. A la
- `pandas.filter`.
+ ``pandas.filter``.
coords: mapping, optional
- Coordinates of var_names to be plotted. Passed to `Dataset.sel`
+ Coordinates of ``var_names`` to be plotted.
+ Passed to :meth:`xarray.Dataset.sel`.
figsize: tuple
Figure size. If None it will be defined automatically.
textsize: float
Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
- on figsize.
+ on ``figsize``.
legend: bool
Flag for plotting legend (defaults to True)
colornd: valid matplotlib color
@@ -66,7 +67,7 @@
Alpha blending value for non-divergent points, between 0 (invisible) and 1 (opaque).
Defaults to .025
labeller : labeller instance, optional
- Class providing the method `make_label_vert` to generate the labels in the plot.
+ Class providing the method ``make_label_vert`` to generate the labels in the plot.
Read the :ref:`label_guide` for more details and usage examples.
ax: axes, optional
Matplotlib axes or bokeh figures.
@@ -76,10 +77,12 @@
backend: str, optional
Select plotting backend {"matplotlib","bokeh"}. Default "matplotlib".
backend_config: dict, optional
- Currently specifies the bounds to use for bokeh axes. Defaults to value set in rcParams.
+ Currently specifies the bounds to use for bokeh axes.
+ Defaults to value set in ``rcParams``.
backend_kwargs: bool, optional
- These are kwargs specific to the backend being used. For additional documentation
- check the plotting method of the backend.
+ These are kwargs specific to the backend being used, passed to
+ :func:`matplotlib.pyplot.subplots` or
+ :func:`bokeh.plotting.figure`.
show: bool, optional
Call backend show function.
@@ -87,6 +90,12 @@
-------
axes: matplotlib axes or bokeh figures
+ See Also
+ --------
+ plot_pair : Plot a scatter, kde and/or hexbin matrix with (optional) marginals on the diagonal.
+ plot_trace : Plot distribution (histogram or kernel density estimates) and sampled values
+ or rank plot
+
Examples
--------
Plot default parallel plot
|
{"golden_diff": "diff --git a/arviz/plots/parallelplot.py b/arviz/plots/parallelplot.py\n--- a/arviz/plots/parallelplot.py\n+++ b/arviz/plots/parallelplot.py\n@@ -38,24 +38,25 @@\n Parameters\n ----------\n data: obj\n- Any object that can be converted to an az.InferenceData object\n- Refer to documentation of az.convert_to_dataset for details\n+ Any object that can be converted to an :class:`arviz.InferenceData` object\n+ refer to documentation of :func:`arviz.convert_to_dataset` for details\n var_names: list of variable names\n- Variables to be plotted, if `None` all variable are plotted. Can be used to change the order\n- of the plotted variables. Prefix the variables by `~` when you want to exclude\n+ Variables to be plotted, if `None` all variables are plotted. Can be used to change the\n+ order of the plotted variables. Prefix the variables by ``~`` when you want to exclude\n them from the plot.\n filter_vars: {None, \"like\", \"regex\"}, optional, default=None\n If `None` (default), interpret var_names as the real variables names. If \"like\",\n interpret var_names as substrings of the real variables names. If \"regex\",\n interpret var_names as regular expressions on the real variables names. A la\n- `pandas.filter`.\n+ ``pandas.filter``.\n coords: mapping, optional\n- Coordinates of var_names to be plotted. Passed to `Dataset.sel`\n+ Coordinates of ``var_names`` to be plotted.\n+ Passed to :meth:`xarray.Dataset.sel`.\n figsize: tuple\n Figure size. If None it will be defined automatically.\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n- on figsize.\n+ on ``figsize``.\n legend: bool\n Flag for plotting legend (defaults to True)\n colornd: valid matplotlib color\n@@ -66,7 +67,7 @@\n Alpha blending value for non-divergent points, between 0 (invisible) and 1 (opaque).\n Defaults to .025\n labeller : labeller instance, optional\n- Class providing the method `make_label_vert` to generate the labels in the plot.\n+ Class providing the method ``make_label_vert`` to generate the labels in the plot.\n Read the :ref:`label_guide` for more details and usage examples.\n ax: axes, optional\n Matplotlib axes or bokeh figures.\n@@ -76,10 +77,12 @@\n backend: str, optional\n Select plotting backend {\"matplotlib\",\"bokeh\"}. Default \"matplotlib\".\n backend_config: dict, optional\n- Currently specifies the bounds to use for bokeh axes. Defaults to value set in rcParams.\n+ Currently specifies the bounds to use for bokeh axes.\n+ Defaults to value set in ``rcParams``.\n backend_kwargs: bool, optional\n- These are kwargs specific to the backend being used. For additional documentation\n- check the plotting method of the backend.\n+ These are kwargs specific to the backend being used, passed to\n+ :func:`matplotlib.pyplot.subplots` or\n+ :func:`bokeh.plotting.figure`.\n show: bool, optional\n Call backend show function.\n \n@@ -87,6 +90,12 @@\n -------\n axes: matplotlib axes or bokeh figures\n \n+ See Also\n+ --------\n+ plot_pair : Plot a scatter, kde and/or hexbin matrix with (optional) marginals on the diagonal.\n+ plot_trace : Plot distribution (histogram or kernel density estimates) and sampled values\n+ or rank plot\n+\n Examples\n --------\n Plot default parallel plot\n", "issue": "Add docs references to plot_parallel docstring\nAdd links to the related functions and classes to all the places where they are mentioned in the [plot_parallel](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_parallel.html) docstring.\r\n\r\n## Sample PR:\r\nYou can see https://github.com/arviz-devs/arviz/pull/1816 for the function, `plot_autocorr`. \r\n\r\n## Source File\r\nSource file: https://github.com/arviz-devs/arviz/blob/main/arviz/plots/parallelplot.py\r\n\r\n## How to add links\r\nAdd the links in the docstring of doc. You can also check the docstring by going to the `[source]`. \r\n\r\n* Add links to the ArviZ functions and classes using [Cross-referencing with Sphinx](https://docs.readthedocs.io/en/stable/guides/cross-referencing-with-sphinx.html).\r\n* Add links to the xarray functions and classes using [Intersphinx](https://docs.readthedocs.io/en/stable/guides/intersphinx.html).\r\n* Add the rest of the external links using this [syntax](https://sublime-and-sphinx-guide.readthedocs.io/en/latest/references.html#links-to-external-web-pages).\r\n\r\n## `backend_kwargs` and `kwargs`\r\nFor adding `backend_kwargs` as they have been added in #1816, see [Adding backend_kwargs guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-backend_kwargs). \r\n\r\n\r\n## See also section\r\nAdd the following functions in the \"See also\" section:\r\n1. [plot_pair](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_pair.html)\r\n2. [plot_trace](https://arviz-devs.github.io/arviz/api/generated/arviz.plot_trace.html)\r\n\r\n\r\nSee [Adding \"see also\" section](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#adding-see-also-section) for more details. \r\n\r\n## Checking the preview of docs\r\nFor checking the preview of docs, you don't need t set up the project on your local machine. Just follow the [checking the preview guide](https://github.com/arviz-devs/arviz/wiki/ArviZ-Hacktoberfest-2021#how-to-check-the-preview-of-docs). \n", "before_files": [{"content": "\"\"\"Parallel coordinates plot showing posterior points with and without divergences marked.\"\"\"\nimport numpy as np\nfrom scipy.stats import rankdata\n\nfrom ..data import convert_to_dataset\nfrom ..labels import BaseLabeller\nfrom ..sel_utils import xarray_to_ndarray\nfrom ..rcparams import rcParams\nfrom ..stats.stats_utils import stats_variance_2d as svar\nfrom ..utils import _numba_var, _var_names, get_coords\nfrom .plot_utils import get_plotting_function\n\n\ndef plot_parallel(\n data,\n var_names=None,\n filter_vars=None,\n coords=None,\n figsize=None,\n textsize=None,\n legend=True,\n colornd=\"k\",\n colord=\"C1\",\n shadend=0.025,\n labeller=None,\n ax=None,\n norm_method=None,\n backend=None,\n backend_config=None,\n backend_kwargs=None,\n show=None,\n):\n \"\"\"\n Plot parallel coordinates plot showing posterior points with and without divergences.\n\n Described by https://arxiv.org/abs/1709.01449\n\n Parameters\n ----------\n data: obj\n Any object that can be converted to an az.InferenceData object\n Refer to documentation of az.convert_to_dataset for details\n var_names: list of variable names\n Variables to be plotted, if `None` all variable are plotted. Can be used to change the order\n of the plotted variables. Prefix the variables by `~` when you want to exclude\n them from the plot.\n filter_vars: {None, \"like\", \"regex\"}, optional, default=None\n If `None` (default), interpret var_names as the real variables names. If \"like\",\n interpret var_names as substrings of the real variables names. If \"regex\",\n interpret var_names as regular expressions on the real variables names. A la\n `pandas.filter`.\n coords: mapping, optional\n Coordinates of var_names to be plotted. Passed to `Dataset.sel`\n figsize: tuple\n Figure size. If None it will be defined automatically.\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n legend: bool\n Flag for plotting legend (defaults to True)\n colornd: valid matplotlib color\n color for non-divergent points. Defaults to 'k'\n colord: valid matplotlib color\n color for divergent points. Defaults to 'C1'\n shadend: float\n Alpha blending value for non-divergent points, between 0 (invisible) and 1 (opaque).\n Defaults to .025\n labeller : labeller instance, optional\n Class providing the method `make_label_vert` to generate the labels in the plot.\n Read the :ref:`label_guide` for more details and usage examples.\n ax: axes, optional\n Matplotlib axes or bokeh figures.\n norm_method: str\n Method for normalizing the data. Methods include normal, minmax and rank.\n Defaults to none.\n backend: str, optional\n Select plotting backend {\"matplotlib\",\"bokeh\"}. Default \"matplotlib\".\n backend_config: dict, optional\n Currently specifies the bounds to use for bokeh axes. Defaults to value set in rcParams.\n backend_kwargs: bool, optional\n These are kwargs specific to the backend being used. For additional documentation\n check the plotting method of the backend.\n show: bool, optional\n Call backend show function.\n\n Returns\n -------\n axes: matplotlib axes or bokeh figures\n\n Examples\n --------\n Plot default parallel plot\n\n .. plot::\n :context: close-figs\n\n >>> import arviz as az\n >>> data = az.load_arviz_data('centered_eight')\n >>> az.plot_parallel(data, var_names=[\"mu\", \"tau\"])\n\n\n Plot parallel plot with normalization\n\n .. plot::\n :context: close-figs\n\n >>> az.plot_parallel(data, var_names=[\"mu\", \"tau\"], norm_method='normal')\n\n \"\"\"\n if coords is None:\n coords = {}\n\n if labeller is None:\n labeller = BaseLabeller()\n\n # Get diverging draws and combine chains\n divergent_data = convert_to_dataset(data, group=\"sample_stats\")\n _, diverging_mask = xarray_to_ndarray(divergent_data, var_names=(\"diverging\",), combined=True)\n diverging_mask = np.squeeze(diverging_mask)\n\n # Get posterior draws and combine chains\n posterior_data = convert_to_dataset(data, group=\"posterior\")\n var_names = _var_names(var_names, posterior_data, filter_vars)\n var_names, _posterior = xarray_to_ndarray(\n get_coords(posterior_data, coords),\n var_names=var_names,\n combined=True,\n label_fun=labeller.make_label_vert,\n )\n if len(var_names) < 2:\n raise ValueError(\"Number of variables to be plotted must be 2 or greater.\")\n if norm_method is not None:\n if norm_method == \"normal\":\n mean = np.mean(_posterior, axis=1)\n if _posterior.ndim <= 2:\n standard_deviation = np.sqrt(_numba_var(svar, np.var, _posterior, axis=1))\n else:\n standard_deviation = np.std(_posterior, axis=1)\n for i in range(0, np.shape(mean)[0]):\n _posterior[i, :] = (_posterior[i, :] - mean[i]) / standard_deviation[i]\n elif norm_method == \"minmax\":\n min_elem = np.min(_posterior, axis=1)\n max_elem = np.max(_posterior, axis=1)\n for i in range(0, np.shape(min_elem)[0]):\n _posterior[i, :] = ((_posterior[i, :]) - min_elem[i]) / (max_elem[i] - min_elem[i])\n elif norm_method == \"rank\":\n _posterior = rankdata(_posterior, axis=1, method=\"average\")\n else:\n raise ValueError(f\"{norm_method} is not supported. Use normal, minmax or rank.\")\n\n parallel_kwargs = dict(\n ax=ax,\n colornd=colornd,\n colord=colord,\n shadend=shadend,\n diverging_mask=diverging_mask,\n posterior=_posterior,\n textsize=textsize,\n var_names=var_names,\n legend=legend,\n figsize=figsize,\n backend_kwargs=backend_kwargs,\n backend_config=backend_config,\n show=show,\n )\n\n if backend is None:\n backend = rcParams[\"plot.backend\"]\n backend = backend.lower()\n\n # TODO: Add backend kwargs\n plot = get_plotting_function(\"plot_parallel\", \"parallelplot\", backend)\n ax = plot(**parallel_kwargs)\n\n return ax\n", "path": "arviz/plots/parallelplot.py"}]}
| 2,970 | 847 |
gh_patches_debug_12299
|
rasdani/github-patches
|
git_diff
|
medtagger__MedTagger-145
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Race condition between API & Worker containers that updates fixtures on start
## Expected Behavior
Containers should start without any issues.
## Actual Behavior
Any of these two containers may fail to start due to unexpected exceptions while applying fixtures.
## Steps to Reproduce the Problem
1. Run `docker-compose up`.
2. Be lucky.
## Additional comment
Both of these containers start script for applying fixtures. Maybe only one should do it (preferrably API)? Maybe this script should be better protected for errors?
</issue>
<code>
[start of backend/medtagger/database/fixtures.py]
1 """Insert all database fixtures."""
2 import logging.config
3
4 from sqlalchemy import exists
5
6 from medtagger.database import db_session
7 from medtagger.database.models import ScanCategory, Role
8
9 logging.config.fileConfig('logging.conf')
10 logger = logging.getLogger(__name__)
11
12 CATEGORIES = [{
13 'key': 'KIDNEYS',
14 'name': 'Kidneys',
15 'image_path': '../../../assets/icon/kidneys_category_icon.svg',
16 }, {
17 'key': 'LIVER',
18 'name': 'Liver',
19 'image_path': '../../../assets/icon/liver_category_icon.svg',
20 }, {
21 'key': 'HEART',
22 'name': 'Hearth',
23 'image_path': '../../../assets/icon/heart_category_icon.svg',
24 }, {
25 'key': 'LUNGS',
26 'name': 'Lungs',
27 'image_path': '../../../assets/icon/lungs_category_icon.svg',
28 }]
29
30 ROLES = [
31 {
32 'name': 'admin',
33 },
34 {
35 'name': 'doctor',
36 },
37 {
38 'name': 'volunteer',
39 },
40 ]
41
42
43 def insert_scan_categories() -> None:
44 """Insert all default Scan Categories if don't exist."""
45 with db_session() as session:
46 for row in CATEGORIES:
47 category_key = row.get('key', '')
48 category_exists = session.query(exists().where(ScanCategory.key == category_key)).scalar()
49 if category_exists:
50 logger.info('Scan Category exists with key "%s"', category_key)
51 continue
52
53 category = ScanCategory(**row)
54 session.add(category)
55 logger.info('Scan Category added for key "%s"', category_key)
56
57
58 def insert_user_roles() -> None:
59 """Insert default user Roles."""
60 with db_session() as session:
61 for row in ROLES:
62 role_name = row.get('name', '')
63 role_exists = session.query(exists().where(Role.name == role_name)).scalar()
64 if role_exists:
65 logger.info('Role exists with name "%s"', role_name)
66 continue
67
68 role = Role(**row)
69 session.add(role)
70 logger.info('Role added for name "%s"', role_name)
71
72
73 def apply_all_fixtures() -> None:
74 """Apply all available fixtures."""
75 logger.info('Applying fixtures for Scan Categories...')
76 insert_scan_categories()
77 logger.info('Applying fixtures for user Roles...')
78 insert_user_roles()
79
80
81 if __name__ == '__main__':
82 apply_all_fixtures()
83
[end of backend/medtagger/database/fixtures.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/medtagger/database/fixtures.py b/backend/medtagger/database/fixtures.py
--- a/backend/medtagger/database/fixtures.py
+++ b/backend/medtagger/database/fixtures.py
@@ -2,6 +2,7 @@
import logging.config
from sqlalchemy import exists
+from sqlalchemy.exc import IntegrityError
from medtagger.database import db_session
from medtagger.database.models import ScanCategory, Role
@@ -79,4 +80,8 @@
if __name__ == '__main__':
- apply_all_fixtures()
+ try:
+ apply_all_fixtures()
+ except IntegrityError:
+ logger.error('An error occurred while applying fixtures! It is highly possible that there was'
+ 'a race condition between multiple processes applying fixtures at the same time.')
|
{"golden_diff": "diff --git a/backend/medtagger/database/fixtures.py b/backend/medtagger/database/fixtures.py\n--- a/backend/medtagger/database/fixtures.py\n+++ b/backend/medtagger/database/fixtures.py\n@@ -2,6 +2,7 @@\n import logging.config\n \n from sqlalchemy import exists\n+from sqlalchemy.exc import IntegrityError\n \n from medtagger.database import db_session\n from medtagger.database.models import ScanCategory, Role\n@@ -79,4 +80,8 @@\n \n \n if __name__ == '__main__':\n- apply_all_fixtures()\n+ try:\n+ apply_all_fixtures()\n+ except IntegrityError:\n+ logger.error('An error occurred while applying fixtures! It is highly possible that there was'\n+ 'a race condition between multiple processes applying fixtures at the same time.')\n", "issue": "Race condition between API & Worker containers that updates fixtures on start\n## Expected Behavior\r\n\r\nContainers should start without any issues.\r\n\r\n## Actual Behavior\r\n\r\nAny of these two containers may fail to start due to unexpected exceptions while applying fixtures.\r\n\r\n## Steps to Reproduce the Problem\r\n\r\n 1. Run `docker-compose up`.\r\n 2. Be lucky.\r\n\r\n## Additional comment\r\n\r\nBoth of these containers start script for applying fixtures. Maybe only one should do it (preferrably API)? Maybe this script should be better protected for errors?\r\n\n", "before_files": [{"content": "\"\"\"Insert all database fixtures.\"\"\"\nimport logging.config\n\nfrom sqlalchemy import exists\n\nfrom medtagger.database import db_session\nfrom medtagger.database.models import ScanCategory, Role\n\nlogging.config.fileConfig('logging.conf')\nlogger = logging.getLogger(__name__)\n\nCATEGORIES = [{\n 'key': 'KIDNEYS',\n 'name': 'Kidneys',\n 'image_path': '../../../assets/icon/kidneys_category_icon.svg',\n}, {\n 'key': 'LIVER',\n 'name': 'Liver',\n 'image_path': '../../../assets/icon/liver_category_icon.svg',\n}, {\n 'key': 'HEART',\n 'name': 'Hearth',\n 'image_path': '../../../assets/icon/heart_category_icon.svg',\n}, {\n 'key': 'LUNGS',\n 'name': 'Lungs',\n 'image_path': '../../../assets/icon/lungs_category_icon.svg',\n}]\n\nROLES = [\n {\n 'name': 'admin',\n },\n {\n 'name': 'doctor',\n },\n {\n 'name': 'volunteer',\n },\n]\n\n\ndef insert_scan_categories() -> None:\n \"\"\"Insert all default Scan Categories if don't exist.\"\"\"\n with db_session() as session:\n for row in CATEGORIES:\n category_key = row.get('key', '')\n category_exists = session.query(exists().where(ScanCategory.key == category_key)).scalar()\n if category_exists:\n logger.info('Scan Category exists with key \"%s\"', category_key)\n continue\n\n category = ScanCategory(**row)\n session.add(category)\n logger.info('Scan Category added for key \"%s\"', category_key)\n\n\ndef insert_user_roles() -> None:\n \"\"\"Insert default user Roles.\"\"\"\n with db_session() as session:\n for row in ROLES:\n role_name = row.get('name', '')\n role_exists = session.query(exists().where(Role.name == role_name)).scalar()\n if role_exists:\n logger.info('Role exists with name \"%s\"', role_name)\n continue\n\n role = Role(**row)\n session.add(role)\n logger.info('Role added for name \"%s\"', role_name)\n\n\ndef apply_all_fixtures() -> None:\n \"\"\"Apply all available fixtures.\"\"\"\n logger.info('Applying fixtures for Scan Categories...')\n insert_scan_categories()\n logger.info('Applying fixtures for user Roles...')\n insert_user_roles()\n\n\nif __name__ == '__main__':\n apply_all_fixtures()\n", "path": "backend/medtagger/database/fixtures.py"}]}
| 1,330 | 173 |
gh_patches_debug_20920
|
rasdani/github-patches
|
git_diff
|
spyder-ide__spyder-20450
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`spyder-line-profiler` fails silently with latest 5.x due to missing import in `py3compat`
<!--- **PLEASE READ:** When submitting here, please ensure you've completed the following checklist and checked the boxes to confirm. Issue reports without it may be closed. Thanks! --->
## Problem Description
Running Spyder 5.x from `bootstrap.py` in an env with `spyder-line-profiler` 0.3.1 shows a traceback in the cmd/terminal from where Spyder was launched and the plugin doesn't load.
Maybe related with https://github.com/spyder-ide/spyder/pull/20366 and probably also affects other external plugins which rely on the `py3compat` module
### What steps reproduce the problem?
1. Install `spyder-line-profiler` 0.3.1
2. Run Spyder from `bootstrap.py`
### What is the expected output? What do you see instead?
The plugin to be able to load
### Paste Traceback/Error Below (if applicable)
<!--- Copy from error dialog or View > Panes > Internal Console --->
```python-traceback
spyder_line_profiler: cannot import name 'pickle' from 'spyder.py3compat' (e:\acer\documentos\spyder\spyder\spyder\py3compat.py)
Traceback (most recent call last):
File "e:\acer\documentos\spyder\spyder\spyder\app\find_plugins.py", line 67, in find_external_plugins
mod = importlib.import_module(entry_point.module_name)
File "C:\Users\dalth\anaconda3\envs\spyder-env-manager\lib\importlib\__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1030, in _gcd_import
File "<frozen importlib._bootstrap>", line 1007, in _find_and_load
File "<frozen importlib._bootstrap>", line 986, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 680, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 850, in exec_module
File "<frozen importlib._bootstrap>", line 228, in _call_with_frames_removed
File "C:\Users\dalth\anaconda3\envs\spyder-env-manager\lib\site-packages\spyder_line_profiler\spyder\plugin.py", line 29, in <module>
from spyder_line_profiler.spyder.confpage import SpyderLineProfilerConfigPage
File "C:\Users\dalth\anaconda3\envs\spyder-env-manager\lib\site-packages\spyder_line_profiler\spyder\confpage.py", line 19, in <module>
from .widgets import SpyderLineProfilerWidget
File "C:\Users\dalth\anaconda3\envs\spyder-env-manager\lib\site-packages\spyder_line_profiler\spyder\widgets.py", line 38, in <module>
from spyder.py3compat import to_text_string, pickle
ImportError: cannot import name 'pickle' from 'spyder.py3compat' (e:\acer\documentos\spyder\spyder\spyder\py3compat.py)
```
## Versions
<!--- You can get this information from Help > About Spyder...
or (if Spyder won't launch) the "conda list" command
from the Anaconda Prompt/Terminal/command line. --->
* Spyder version: 5.5.0.dev0 4a5d86ecd (conda)
* Python version: 3.9.15 64-bit
* Qt version: 5.15.2
* PyQt5 version: 5.15.7
* Operating System: Windows 10
</issue>
<code>
[start of spyder/py3compat.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright © Spyder Project Contributors
4 # Licensed under the terms of the MIT License
5 # (see spyder/__init__.py for details)
6
7 """
8 spyder.py3compat
9 ----------------
10
11 Transitional module providing compatibility functions intended to help
12 migrating from Python 2 to Python 3.
13
14 This module should be fully compatible with:
15 * Python >=v2.6
16 * Python 3
17 """
18
19 import operator
20
21
22 #==============================================================================
23 # Data types
24 #==============================================================================
25 # Python 3
26 TEXT_TYPES = (str,)
27 INT_TYPES = (int,)
28
29
30 #==============================================================================
31 # Strings
32 #==============================================================================
33 def is_type_text_string(obj):
34 """Return True if `obj` is type text string, False if it is anything else,
35 like an instance of a class that extends the basestring class."""
36 return type(obj) in [str, bytes]
37
38 def is_text_string(obj):
39 """Return True if `obj` is a text string, False if it is anything else,
40 like binary data (Python 3) or QString (PyQt API #1)"""
41 return isinstance(obj, str)
42
43 def is_binary_string(obj):
44 """Return True if `obj` is a binary string, False if it is anything else"""
45 return isinstance(obj, bytes)
46
47 def is_string(obj):
48 """Return True if `obj` is a text or binary Python string object,
49 False if it is anything else, like a QString (PyQt API #1)"""
50 return is_text_string(obj) or is_binary_string(obj)
51
52 def to_text_string(obj, encoding=None):
53 """Convert `obj` to (unicode) text string"""
54 if encoding is None:
55 return str(obj)
56 elif isinstance(obj, str):
57 # In case this function is not used properly, this could happen
58 return obj
59 else:
60 return str(obj, encoding)
61
62 def to_binary_string(obj, encoding='utf-8'):
63 """Convert `obj` to binary string (bytes)"""
64 return bytes(obj, encoding)
65
66 #==============================================================================
67 # Misc.
68 #==============================================================================
69 # Python 3
70
71 def qbytearray_to_str(qba):
72 """Convert QByteArray object to str in a way compatible with Python 3"""
73 return str(bytes(qba.toHex().data()).decode())
74
75 # =============================================================================
76 # Dict funcs
77 # =============================================================================
78 def iterkeys(d, **kw):
79 return iter(d.keys(**kw))
80
81 def itervalues(d, **kw):
82 return iter(d.values(**kw))
83
84 def iteritems(d, **kw):
85 return iter(d.items(**kw))
86
87 def iterlists(d, **kw):
88 return iter(d.lists(**kw))
89
90 viewkeys = operator.methodcaller("keys")
91
92 viewvalues = operator.methodcaller("values")
93
94 viewitems = operator.methodcaller("items")
95
96
97 if __name__ == '__main__':
98 pass
99
[end of spyder/py3compat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/spyder/py3compat.py b/spyder/py3compat.py
--- a/spyder/py3compat.py
+++ b/spyder/py3compat.py
@@ -10,13 +10,10 @@
Transitional module providing compatibility functions intended to help
migrating from Python 2 to Python 3.
-
-This module should be fully compatible with:
- * Python >=v2.6
- * Python 3
"""
import operator
+import pickle # noqa. For compatibility with spyder-line-profiler
#==============================================================================
@@ -66,8 +63,6 @@
#==============================================================================
# Misc.
#==============================================================================
-# Python 3
-
def qbytearray_to_str(qba):
"""Convert QByteArray object to str in a way compatible with Python 3"""
return str(bytes(qba.toHex().data()).decode())
|
{"golden_diff": "diff --git a/spyder/py3compat.py b/spyder/py3compat.py\n--- a/spyder/py3compat.py\n+++ b/spyder/py3compat.py\n@@ -10,13 +10,10 @@\n \n Transitional module providing compatibility functions intended to help\n migrating from Python 2 to Python 3.\n-\n-This module should be fully compatible with:\n- * Python >=v2.6\n- * Python 3\n \"\"\"\n \n import operator\n+import pickle # noqa. For compatibility with spyder-line-profiler\n \n \n #==============================================================================\n@@ -66,8 +63,6 @@\n #==============================================================================\n # Misc.\n #==============================================================================\n-# Python 3\n-\n def qbytearray_to_str(qba):\n \"\"\"Convert QByteArray object to str in a way compatible with Python 3\"\"\"\n return str(bytes(qba.toHex().data()).decode())\n", "issue": "`spyder-line-profiler` fails silently with latest 5.x due to missing import in `py3compat`\n<!--- **PLEASE READ:** When submitting here, please ensure you've completed the following checklist and checked the boxes to confirm. Issue reports without it may be closed. Thanks! --->\r\n\r\n## Problem Description\r\n\r\nRunning Spyder 5.x from `bootstrap.py` in an env with `spyder-line-profiler` 0.3.1 shows a traceback in the cmd/terminal from where Spyder was launched and the plugin doesn't load.\r\n\r\nMaybe related with https://github.com/spyder-ide/spyder/pull/20366 and probably also affects other external plugins which rely on the `py3compat` module\r\n\r\n### What steps reproduce the problem?\r\n\r\n1. Install `spyder-line-profiler` 0.3.1 \r\n2. Run Spyder from `bootstrap.py`\r\n\r\n### What is the expected output? What do you see instead?\r\n\r\nThe plugin to be able to load\r\n\r\n### Paste Traceback/Error Below (if applicable)\r\n<!--- Copy from error dialog or View > Panes > Internal Console --->\r\n\r\n```python-traceback\r\nspyder_line_profiler: cannot import name 'pickle' from 'spyder.py3compat' (e:\\acer\\documentos\\spyder\\spyder\\spyder\\py3compat.py)\r\nTraceback (most recent call last):\r\n File \"e:\\acer\\documentos\\spyder\\spyder\\spyder\\app\\find_plugins.py\", line 67, in find_external_plugins\r\n mod = importlib.import_module(entry_point.module_name)\r\n File \"C:\\Users\\dalth\\anaconda3\\envs\\spyder-env-manager\\lib\\importlib\\__init__.py\", line 127, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"<frozen importlib._bootstrap>\", line 1030, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1007, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 986, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 680, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 850, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 228, in _call_with_frames_removed\r\n File \"C:\\Users\\dalth\\anaconda3\\envs\\spyder-env-manager\\lib\\site-packages\\spyder_line_profiler\\spyder\\plugin.py\", line 29, in <module>\r\n from spyder_line_profiler.spyder.confpage import SpyderLineProfilerConfigPage\r\n File \"C:\\Users\\dalth\\anaconda3\\envs\\spyder-env-manager\\lib\\site-packages\\spyder_line_profiler\\spyder\\confpage.py\", line 19, in <module>\r\n from .widgets import SpyderLineProfilerWidget\r\n File \"C:\\Users\\dalth\\anaconda3\\envs\\spyder-env-manager\\lib\\site-packages\\spyder_line_profiler\\spyder\\widgets.py\", line 38, in <module>\r\n from spyder.py3compat import to_text_string, pickle\r\nImportError: cannot import name 'pickle' from 'spyder.py3compat' (e:\\acer\\documentos\\spyder\\spyder\\spyder\\py3compat.py)\r\n```\r\n\r\n## Versions\r\n<!--- You can get this information from Help > About Spyder...\r\nor (if Spyder won't launch) the \"conda list\" command\r\nfrom the Anaconda Prompt/Terminal/command line. --->\r\n\r\n* Spyder version: 5.5.0.dev0 4a5d86ecd (conda)\r\n* Python version: 3.9.15 64-bit\r\n* Qt version: 5.15.2\r\n* PyQt5 version: 5.15.7\r\n* Operating System: Windows 10\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright \u00a9 Spyder Project Contributors\n# Licensed under the terms of the MIT License\n# (see spyder/__init__.py for details)\n\n\"\"\"\nspyder.py3compat\n----------------\n\nTransitional module providing compatibility functions intended to help\nmigrating from Python 2 to Python 3.\n\nThis module should be fully compatible with:\n * Python >=v2.6\n * Python 3\n\"\"\"\n\nimport operator\n\n\n#==============================================================================\n# Data types\n#==============================================================================\n# Python 3\nTEXT_TYPES = (str,)\nINT_TYPES = (int,)\n\n\n#==============================================================================\n# Strings\n#==============================================================================\ndef is_type_text_string(obj):\n \"\"\"Return True if `obj` is type text string, False if it is anything else,\n like an instance of a class that extends the basestring class.\"\"\"\n return type(obj) in [str, bytes]\n\ndef is_text_string(obj):\n \"\"\"Return True if `obj` is a text string, False if it is anything else,\n like binary data (Python 3) or QString (PyQt API #1)\"\"\"\n return isinstance(obj, str)\n\ndef is_binary_string(obj):\n \"\"\"Return True if `obj` is a binary string, False if it is anything else\"\"\"\n return isinstance(obj, bytes)\n\ndef is_string(obj):\n \"\"\"Return True if `obj` is a text or binary Python string object,\n False if it is anything else, like a QString (PyQt API #1)\"\"\"\n return is_text_string(obj) or is_binary_string(obj)\n\ndef to_text_string(obj, encoding=None):\n \"\"\"Convert `obj` to (unicode) text string\"\"\"\n if encoding is None:\n return str(obj)\n elif isinstance(obj, str):\n # In case this function is not used properly, this could happen\n return obj\n else:\n return str(obj, encoding)\n\ndef to_binary_string(obj, encoding='utf-8'):\n \"\"\"Convert `obj` to binary string (bytes)\"\"\"\n return bytes(obj, encoding)\n\n#==============================================================================\n# Misc.\n#==============================================================================\n# Python 3\n\ndef qbytearray_to_str(qba):\n \"\"\"Convert QByteArray object to str in a way compatible with Python 3\"\"\"\n return str(bytes(qba.toHex().data()).decode())\n\n# =============================================================================\n# Dict funcs\n# =============================================================================\ndef iterkeys(d, **kw):\n return iter(d.keys(**kw))\n\ndef itervalues(d, **kw):\n return iter(d.values(**kw))\n\ndef iteritems(d, **kw):\n return iter(d.items(**kw))\n\ndef iterlists(d, **kw):\n return iter(d.lists(**kw))\n\nviewkeys = operator.methodcaller(\"keys\")\n\nviewvalues = operator.methodcaller(\"values\")\n\nviewitems = operator.methodcaller(\"items\")\n\n\nif __name__ == '__main__':\n pass\n", "path": "spyder/py3compat.py"}]}
| 2,216 | 192 |
gh_patches_debug_22413
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-6626
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deleted content shows as 'Already on Device'
<!--
Instructions:
* Fill out the sections below, replace …'s with information about your issue
* Use the 'preview' function above this text box to verify formatting before submitting
-->
### Observed behavior
<!--
Description of the behavior that was observed, including screenshots or other references when applicable
-->
Deleted content still showing as 'Already on Device'

See [this video with subtitles](https://drive.google.com/file/d/1Q4TMfZ0asvxmsfWZJzbCbCbZQRM6lEpM/view?usp=sharing) till 2:40 for quicker understanding.
…
### Expected behavior
<!--
Description of what behavior was expected but did not occur
-->
Deleted content should not show as 'Already on Device'.
### User-facing consequences
<!--
Implications and real-world consequences for learners, coaches, admins, and other users of the application
-->
Confusion.
### Errors and logs
<!--
Relevant logs from:
* the command line
* ~/.kolibri/logs/kolibri.txt
* the browser console
Please wrap errors in triple backticks for clean formatting like this:
```
01:10 info: something happened
01:12 error: something bad happened
```
-->
Shall share if any needed.
### Steps to reproduce
<!--
Precise steps that someone else can follow in order to see this behavior
-->
1. Delete existing content from a channel. Here I am using token `zapok-dofil`.
2. Try to re-import the content.
### Context
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
Kolibri version: 0.13.1rc1, 0.13.0
OS: Linux / Windows
Content channel: multiple tried.
</issue>
<code>
[start of kolibri/core/content/management/commands/deletecontent.py]
1 import logging
2 import os
3
4 from django.core.management.base import CommandError
5 from django.db.models import Sum
6
7 from kolibri.core.content.models import ChannelMetadata
8 from kolibri.core.content.models import LocalFile
9 from kolibri.core.content.utils.annotation import propagate_forced_localfile_removal
10 from kolibri.core.content.utils.annotation import set_content_invisible
11 from kolibri.core.content.utils.import_export_content import get_files_to_transfer
12 from kolibri.core.content.utils.paths import get_content_database_file_path
13 from kolibri.core.tasks.management.commands.base import AsyncCommand
14 from kolibri.core.tasks.utils import db_task_write_lock
15 from kolibri.core.tasks.utils import get_current_job
16
17 logger = logging.getLogger(__name__)
18
19
20 def delete_metadata(channel, node_ids, exclude_node_ids, force_delete):
21 # Only delete all metadata if we are not doing selective deletion
22 delete_all_metadata = not (node_ids or exclude_node_ids)
23
24 if node_ids or exclude_node_ids:
25 # If we have been passed node ids do not do a full deletion pass
26 with db_task_write_lock:
27 set_content_invisible(channel.id, node_ids, exclude_node_ids)
28 # If everything has been made invisible, delete all the metadata
29 delete_all_metadata = not channel.root.available
30
31 if force_delete:
32 # Do this before we delete all the metadata, as otherwise we lose
33 # track of which local files were associated with the channel we
34 # just deleted.
35 unused_files, _ = get_files_to_transfer(
36 channel.id, node_ids, exclude_node_ids, True, renderable_only=False
37 )
38 with db_task_write_lock:
39 propagate_forced_localfile_removal(unused_files)
40
41 if delete_all_metadata:
42 logger.info("Deleting all channel metadata")
43 with db_task_write_lock:
44 channel.delete_content_tree_and_files()
45
46 return delete_all_metadata
47
48
49 class Command(AsyncCommand):
50 def add_arguments(self, parser):
51 parser.add_argument("channel_id", type=str)
52 # However, some optional arguments apply to both groups. Add them here!
53 node_ids_help_text = """
54 Specify one or more node IDs to delete. Only these ContentNodes and descendants will be deleted.
55
56 e.g.
57
58 kolibri manage deletecontent --node_ids <id1>,<id2>,[<ids>,...] <channel id>
59 """
60 parser.add_argument(
61 "--node_ids",
62 "-n",
63 # Split the comma separated string we get, into a list of strings
64 type=lambda x: x.split(","),
65 default=[],
66 required=False,
67 dest="node_ids",
68 help=node_ids_help_text,
69 )
70
71 exclude_node_ids_help_text = """
72 Specify one or more node IDs to exclude. Descendants of these node IDs will be not be deleted.
73
74 e.g.
75
76 kolibri manage deletecontent --exclude_node_ids <id1>,<id2>,[<ids>,...] <channel id>
77 """
78 parser.add_argument(
79 "--exclude_node_ids",
80 # Split the comma separated string we get, into a list of string
81 type=lambda x: x.split(","),
82 default=[],
83 required=False,
84 dest="exclude_node_ids",
85 help=exclude_node_ids_help_text,
86 )
87 parser.add_argument(
88 "-f",
89 "--force_delete",
90 action="store_true",
91 dest="force_delete",
92 default=False,
93 help="Ensure removal of files",
94 )
95
96 def handle_async(self, *args, **options):
97 channel_id = options["channel_id"]
98 node_ids = options["node_ids"]
99 exclude_node_ids = options["exclude_node_ids"]
100 force_delete = options["force_delete"]
101
102 try:
103 channel = ChannelMetadata.objects.get(pk=channel_id)
104 except ChannelMetadata.DoesNotExist:
105 raise CommandError(
106 "Channel matching id {id} does not exist".format(id=channel_id)
107 )
108
109 delete_all_metadata = delete_metadata(
110 channel, node_ids, exclude_node_ids, force_delete
111 )
112
113 unused_files = LocalFile.objects.get_unused_files()
114
115 # Get orphan files that are being deleted
116 total_file_deletion_operations = unused_files.count()
117 job = get_current_job()
118 if job:
119 total_file_deletion_size = unused_files.aggregate(Sum("file_size")).get(
120 "file_size__sum", 0
121 )
122 job.extra_metadata["file_size"] = total_file_deletion_size
123 job.extra_metadata["total_resources"] = total_file_deletion_operations
124 job.save_meta()
125
126 progress_extra_data = {"channel_id": channel_id}
127
128 additional_progress = sum((1, bool(delete_all_metadata)))
129
130 with self.start_progress(
131 total=total_file_deletion_operations + additional_progress
132 ) as progress_update:
133
134 for file in LocalFile.objects.delete_unused_files():
135 progress_update(1, progress_extra_data)
136
137 with db_task_write_lock:
138 LocalFile.objects.delete_orphan_file_objects()
139
140 progress_update(1, progress_extra_data)
141
142 if delete_all_metadata:
143 try:
144 os.remove(get_content_database_file_path(channel_id))
145 except OSError:
146 pass
147
148 progress_update(1, progress_extra_data)
149
[end of kolibri/core/content/management/commands/deletecontent.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/content/management/commands/deletecontent.py b/kolibri/core/content/management/commands/deletecontent.py
--- a/kolibri/core/content/management/commands/deletecontent.py
+++ b/kolibri/core/content/management/commands/deletecontent.py
@@ -8,6 +8,7 @@
from kolibri.core.content.models import LocalFile
from kolibri.core.content.utils.annotation import propagate_forced_localfile_removal
from kolibri.core.content.utils.annotation import set_content_invisible
+from kolibri.core.content.utils.importability_annotation import clear_channel_stats
from kolibri.core.content.utils.import_export_content import get_files_to_transfer
from kolibri.core.content.utils.paths import get_content_database_file_path
from kolibri.core.tasks.management.commands.base import AsyncCommand
@@ -43,6 +44,9 @@
with db_task_write_lock:
channel.delete_content_tree_and_files()
+ # Clear any previously set channel availability stats for this channel
+ clear_channel_stats(channel.id)
+
return delete_all_metadata
|
{"golden_diff": "diff --git a/kolibri/core/content/management/commands/deletecontent.py b/kolibri/core/content/management/commands/deletecontent.py\n--- a/kolibri/core/content/management/commands/deletecontent.py\n+++ b/kolibri/core/content/management/commands/deletecontent.py\n@@ -8,6 +8,7 @@\n from kolibri.core.content.models import LocalFile\n from kolibri.core.content.utils.annotation import propagate_forced_localfile_removal\n from kolibri.core.content.utils.annotation import set_content_invisible\n+from kolibri.core.content.utils.importability_annotation import clear_channel_stats\n from kolibri.core.content.utils.import_export_content import get_files_to_transfer\n from kolibri.core.content.utils.paths import get_content_database_file_path\n from kolibri.core.tasks.management.commands.base import AsyncCommand\n@@ -43,6 +44,9 @@\n with db_task_write_lock:\n channel.delete_content_tree_and_files()\n \n+ # Clear any previously set channel availability stats for this channel\n+ clear_channel_stats(channel.id)\n+\n return delete_all_metadata\n", "issue": "Deleted content shows as 'Already on Device'\n<!--\r\nInstructions:\r\n * Fill out the sections below, replace \u2026's with information about your issue\r\n * Use the 'preview' function above this text box to verify formatting before submitting\r\n-->\r\n\r\n### Observed behavior\r\n<!--\r\nDescription of the behavior that was observed, including screenshots or other references when applicable\r\n-->\r\n\r\nDeleted content still showing as 'Already on Device'\r\n\r\n\r\n\r\nSee [this video with subtitles](https://drive.google.com/file/d/1Q4TMfZ0asvxmsfWZJzbCbCbZQRM6lEpM/view?usp=sharing) till 2:40 for quicker understanding.\r\n\r\n\u2026\r\n\r\n### Expected behavior\r\n<!--\r\nDescription of what behavior was expected but did not occur\r\n-->\r\n\r\nDeleted content should not show as 'Already on Device'.\r\n\r\n### User-facing consequences\r\n<!--\r\nImplications and real-world consequences for learners, coaches, admins, and other users of the application\r\n-->\r\n\r\nConfusion.\r\n\r\n### Errors and logs\r\n<!--\r\nRelevant logs from:\r\n * the command line\r\n * ~/.kolibri/logs/kolibri.txt\r\n * the browser console\r\n\r\nPlease wrap errors in triple backticks for clean formatting like this:\r\n```\r\n01:10 info: something happened\r\n01:12 error: something bad happened\r\n```\r\n-->\r\n\r\nShall share if any needed.\r\n\r\n### Steps to reproduce\r\n<!--\r\nPrecise steps that someone else can follow in order to see this behavior\r\n-->\r\n\r\n1. Delete existing content from a channel. Here I am using token `zapok-dofil`.\r\n2. Try to re-import the content.\r\n\r\n### Context\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\n\r\nKolibri version: 0.13.1rc1, 0.13.0\r\nOS: Linux / Windows\r\nContent channel: multiple tried.\n", "before_files": [{"content": "import logging\nimport os\n\nfrom django.core.management.base import CommandError\nfrom django.db.models import Sum\n\nfrom kolibri.core.content.models import ChannelMetadata\nfrom kolibri.core.content.models import LocalFile\nfrom kolibri.core.content.utils.annotation import propagate_forced_localfile_removal\nfrom kolibri.core.content.utils.annotation import set_content_invisible\nfrom kolibri.core.content.utils.import_export_content import get_files_to_transfer\nfrom kolibri.core.content.utils.paths import get_content_database_file_path\nfrom kolibri.core.tasks.management.commands.base import AsyncCommand\nfrom kolibri.core.tasks.utils import db_task_write_lock\nfrom kolibri.core.tasks.utils import get_current_job\n\nlogger = logging.getLogger(__name__)\n\n\ndef delete_metadata(channel, node_ids, exclude_node_ids, force_delete):\n # Only delete all metadata if we are not doing selective deletion\n delete_all_metadata = not (node_ids or exclude_node_ids)\n\n if node_ids or exclude_node_ids:\n # If we have been passed node ids do not do a full deletion pass\n with db_task_write_lock:\n set_content_invisible(channel.id, node_ids, exclude_node_ids)\n # If everything has been made invisible, delete all the metadata\n delete_all_metadata = not channel.root.available\n\n if force_delete:\n # Do this before we delete all the metadata, as otherwise we lose\n # track of which local files were associated with the channel we\n # just deleted.\n unused_files, _ = get_files_to_transfer(\n channel.id, node_ids, exclude_node_ids, True, renderable_only=False\n )\n with db_task_write_lock:\n propagate_forced_localfile_removal(unused_files)\n\n if delete_all_metadata:\n logger.info(\"Deleting all channel metadata\")\n with db_task_write_lock:\n channel.delete_content_tree_and_files()\n\n return delete_all_metadata\n\n\nclass Command(AsyncCommand):\n def add_arguments(self, parser):\n parser.add_argument(\"channel_id\", type=str)\n # However, some optional arguments apply to both groups. Add them here!\n node_ids_help_text = \"\"\"\n Specify one or more node IDs to delete. Only these ContentNodes and descendants will be deleted.\n\n e.g.\n\n kolibri manage deletecontent --node_ids <id1>,<id2>,[<ids>,...] <channel id>\n \"\"\"\n parser.add_argument(\n \"--node_ids\",\n \"-n\",\n # Split the comma separated string we get, into a list of strings\n type=lambda x: x.split(\",\"),\n default=[],\n required=False,\n dest=\"node_ids\",\n help=node_ids_help_text,\n )\n\n exclude_node_ids_help_text = \"\"\"\n Specify one or more node IDs to exclude. Descendants of these node IDs will be not be deleted.\n\n e.g.\n\n kolibri manage deletecontent --exclude_node_ids <id1>,<id2>,[<ids>,...] <channel id>\n \"\"\"\n parser.add_argument(\n \"--exclude_node_ids\",\n # Split the comma separated string we get, into a list of string\n type=lambda x: x.split(\",\"),\n default=[],\n required=False,\n dest=\"exclude_node_ids\",\n help=exclude_node_ids_help_text,\n )\n parser.add_argument(\n \"-f\",\n \"--force_delete\",\n action=\"store_true\",\n dest=\"force_delete\",\n default=False,\n help=\"Ensure removal of files\",\n )\n\n def handle_async(self, *args, **options):\n channel_id = options[\"channel_id\"]\n node_ids = options[\"node_ids\"]\n exclude_node_ids = options[\"exclude_node_ids\"]\n force_delete = options[\"force_delete\"]\n\n try:\n channel = ChannelMetadata.objects.get(pk=channel_id)\n except ChannelMetadata.DoesNotExist:\n raise CommandError(\n \"Channel matching id {id} does not exist\".format(id=channel_id)\n )\n\n delete_all_metadata = delete_metadata(\n channel, node_ids, exclude_node_ids, force_delete\n )\n\n unused_files = LocalFile.objects.get_unused_files()\n\n # Get orphan files that are being deleted\n total_file_deletion_operations = unused_files.count()\n job = get_current_job()\n if job:\n total_file_deletion_size = unused_files.aggregate(Sum(\"file_size\")).get(\n \"file_size__sum\", 0\n )\n job.extra_metadata[\"file_size\"] = total_file_deletion_size\n job.extra_metadata[\"total_resources\"] = total_file_deletion_operations\n job.save_meta()\n\n progress_extra_data = {\"channel_id\": channel_id}\n\n additional_progress = sum((1, bool(delete_all_metadata)))\n\n with self.start_progress(\n total=total_file_deletion_operations + additional_progress\n ) as progress_update:\n\n for file in LocalFile.objects.delete_unused_files():\n progress_update(1, progress_extra_data)\n\n with db_task_write_lock:\n LocalFile.objects.delete_orphan_file_objects()\n\n progress_update(1, progress_extra_data)\n\n if delete_all_metadata:\n try:\n os.remove(get_content_database_file_path(channel_id))\n except OSError:\n pass\n\n progress_update(1, progress_extra_data)\n", "path": "kolibri/core/content/management/commands/deletecontent.py"}]}
| 2,452 | 223 |
gh_patches_debug_33821
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-993
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SSD model doesn't work
## 🐛 Bug
SSD model doesn't work anymore. It seems related to MMDetection updates made here:
https://github.com/open-mmlab/mmdetection/pull/5789/files
Refer to discussion on our Discord forum:
https://discord.com/channels/735877944085446747/780951885485965352/920249646964670464
</issue>
<code>
[start of icevision/models/mmdet/utils.py]
1 __all__ = [
2 "MMDetBackboneConfig",
3 "mmdet_configs_path",
4 "param_groups",
5 "MMDetBackboneConfig",
6 "create_model_config",
7 ]
8
9 from icevision.imports import *
10 from icevision.utils import *
11 from icevision.backbones import BackboneConfig
12 from icevision.models.mmdet.download_configs import download_mmdet_configs
13 from mmdet.models.detectors import *
14 from mmcv import Config
15 from mmdet.models.backbones.ssd_vgg import SSDVGG
16 from mmdet.models.backbones.csp_darknet import CSPDarknet
17
18
19 mmdet_configs_path = download_mmdet_configs()
20
21
22 class MMDetBackboneConfig(BackboneConfig):
23 def __init__(self, model_name, config_path, weights_url):
24 self.model_name = model_name
25 self.config_path = config_path
26 self.weights_url = weights_url
27 self.pretrained: bool
28
29 def __call__(self, pretrained: bool = True) -> "MMDetBackboneConfig":
30 self.pretrained = pretrained
31 return self
32
33
34 def param_groups(model):
35 body = model.backbone
36
37 layers = []
38 if isinstance(body, SSDVGG):
39 layers += [body.features]
40 layers += [body.extra, body.l2_norm]
41 elif isinstance(body, CSPDarknet):
42 layers += [body.stem.conv.conv, body.stem.conv.bn]
43 layers += [body.stage1, body.stage2, body.stage3, body.stage4]
44 layers += [model.neck]
45 else:
46 layers += [nn.Sequential(body.conv1, body.bn1)]
47 layers += [getattr(body, l) for l in body.res_layers]
48 layers += [model.neck]
49
50 if isinstance(model, SingleStageDetector):
51 layers += [model.bbox_head]
52 elif isinstance(model, TwoStageDetector):
53 layers += [nn.Sequential(model.rpn_head, model.roi_head)]
54 else:
55 raise RuntimeError(
56 "{model} must inherit either from SingleStageDetector or TwoStageDetector class"
57 )
58
59 _param_groups = [list(layer.parameters()) for layer in layers]
60 check_all_model_params_in_groups2(model, _param_groups)
61 return _param_groups
62
63
64 def create_model_config(
65 backbone: MMDetBackboneConfig,
66 pretrained: bool = True,
67 checkpoints_path: Optional[Union[str, Path]] = "checkpoints",
68 force_download=False,
69 cfg_options=None,
70 ):
71
72 model_name = backbone.model_name
73 config_path = backbone.config_path
74 weights_url = backbone.weights_url
75
76 # download weights
77 weights_path = None
78 if pretrained and weights_url:
79 save_dir = Path(checkpoints_path) / model_name
80 save_dir.mkdir(exist_ok=True, parents=True)
81
82 fname = Path(weights_url).name
83 weights_path = save_dir / fname
84
85 if not weights_path.exists() or force_download:
86 download_url(url=weights_url, save_path=str(weights_path))
87
88 cfg = Config.fromfile(config_path)
89
90 if cfg_options is not None:
91 cfg.merge_from_dict(cfg_options)
92
93 return cfg, weights_path
94
[end of icevision/models/mmdet/utils.py]
[start of icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py]
1 __all__ = [
2 "ssd300",
3 "ssd512",
4 ]
5
6 from icevision.imports import *
7 from icevision.models.mmdet.utils import *
8
9
10 class MMDetSSDBackboneConfig(MMDetBackboneConfig):
11 def __init__(self, **kwargs):
12 super().__init__(model_name="ssd", **kwargs)
13
14
15 base_config_path = mmdet_configs_path / "ssd"
16 base_weights_url = "http://download.openmmlab.com/mmdetection/v2.0/ssd"
17
18 ssd300 = MMDetSSDBackboneConfig(
19 config_path=base_config_path / "ssd300_coco.py",
20 weights_url=f"{base_weights_url}/ssd300_coco/ssd300_coco_20200307-a92d2092.pth",
21 )
22
23 ssd512 = MMDetSSDBackboneConfig(
24 config_path=base_config_path / "ssd512_coco.py",
25 weights_url=f"{base_weights_url}/ssd512_coco/ssd512_coco_20200308-038c5591.pth",
26 )
27
[end of icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py b/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py
--- a/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py
+++ b/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py
@@ -1,6 +1,7 @@
__all__ = [
"ssd300",
"ssd512",
+ "ssdlite_mobilenetv2",
]
from icevision.imports import *
@@ -17,10 +18,15 @@
ssd300 = MMDetSSDBackboneConfig(
config_path=base_config_path / "ssd300_coco.py",
- weights_url=f"{base_weights_url}/ssd300_coco/ssd300_coco_20200307-a92d2092.pth",
+ weights_url=f"{base_weights_url}/ssd300_coco/ssd300_coco_20210803_015428-d231a06e.pth",
)
ssd512 = MMDetSSDBackboneConfig(
config_path=base_config_path / "ssd512_coco.py",
- weights_url=f"{base_weights_url}/ssd512_coco/ssd512_coco_20200308-038c5591.pth",
+ weights_url=f"{base_weights_url}/ssd512_coco/ssd512_coco_20210803_022849-0a47a1ca.pth",
+)
+
+ssdlite_mobilenetv2 = MMDetSSDBackboneConfig(
+ config_path=base_config_path / "ssdlite_mobilenetv2_scratch_600e_coco.py",
+ weights_url=f"{base_weights_url}/ssd512_coco/ssdlite_mobilenetv2_scratch_600e_coco_20210629_110627-974d9307.pth",
)
diff --git a/icevision/models/mmdet/utils.py b/icevision/models/mmdet/utils.py
--- a/icevision/models/mmdet/utils.py
+++ b/icevision/models/mmdet/utils.py
@@ -35,18 +35,21 @@
body = model.backbone
layers = []
+
+ # add the backbone
if isinstance(body, SSDVGG):
layers += [body.features]
- layers += [body.extra, body.l2_norm]
elif isinstance(body, CSPDarknet):
layers += [body.stem.conv.conv, body.stem.conv.bn]
layers += [body.stage1, body.stage2, body.stage3, body.stage4]
- layers += [model.neck]
else:
layers += [nn.Sequential(body.conv1, body.bn1)]
layers += [getattr(body, l) for l in body.res_layers]
- layers += [model.neck]
+ # add the neck
+ layers += [model.neck]
+
+ # add the head
if isinstance(model, SingleStageDetector):
layers += [model.bbox_head]
elif isinstance(model, TwoStageDetector):
|
{"golden_diff": "diff --git a/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py b/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py\n--- a/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py\n+++ b/icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py\n@@ -1,6 +1,7 @@\n __all__ = [\n \"ssd300\",\n \"ssd512\",\n+ \"ssdlite_mobilenetv2\",\n ]\n \n from icevision.imports import *\n@@ -17,10 +18,15 @@\n \n ssd300 = MMDetSSDBackboneConfig(\n config_path=base_config_path / \"ssd300_coco.py\",\n- weights_url=f\"{base_weights_url}/ssd300_coco/ssd300_coco_20200307-a92d2092.pth\",\n+ weights_url=f\"{base_weights_url}/ssd300_coco/ssd300_coco_20210803_015428-d231a06e.pth\",\n )\n \n ssd512 = MMDetSSDBackboneConfig(\n config_path=base_config_path / \"ssd512_coco.py\",\n- weights_url=f\"{base_weights_url}/ssd512_coco/ssd512_coco_20200308-038c5591.pth\",\n+ weights_url=f\"{base_weights_url}/ssd512_coco/ssd512_coco_20210803_022849-0a47a1ca.pth\",\n+)\n+\n+ssdlite_mobilenetv2 = MMDetSSDBackboneConfig(\n+ config_path=base_config_path / \"ssdlite_mobilenetv2_scratch_600e_coco.py\",\n+ weights_url=f\"{base_weights_url}/ssd512_coco/ssdlite_mobilenetv2_scratch_600e_coco_20210629_110627-974d9307.pth\",\n )\ndiff --git a/icevision/models/mmdet/utils.py b/icevision/models/mmdet/utils.py\n--- a/icevision/models/mmdet/utils.py\n+++ b/icevision/models/mmdet/utils.py\n@@ -35,18 +35,21 @@\n body = model.backbone\n \n layers = []\n+\n+ # add the backbone\n if isinstance(body, SSDVGG):\n layers += [body.features]\n- layers += [body.extra, body.l2_norm]\n elif isinstance(body, CSPDarknet):\n layers += [body.stem.conv.conv, body.stem.conv.bn]\n layers += [body.stage1, body.stage2, body.stage3, body.stage4]\n- layers += [model.neck]\n else:\n layers += [nn.Sequential(body.conv1, body.bn1)]\n layers += [getattr(body, l) for l in body.res_layers]\n- layers += [model.neck]\n \n+ # add the neck\n+ layers += [model.neck]\n+\n+ # add the head\n if isinstance(model, SingleStageDetector):\n layers += [model.bbox_head]\n elif isinstance(model, TwoStageDetector):\n", "issue": "SSD model doesn't work\n## \ud83d\udc1b Bug\r\n\r\nSSD model doesn't work anymore. It seems related to MMDetection updates made here:\r\nhttps://github.com/open-mmlab/mmdetection/pull/5789/files\r\n\r\nRefer to discussion on our Discord forum:\r\nhttps://discord.com/channels/735877944085446747/780951885485965352/920249646964670464\n", "before_files": [{"content": "__all__ = [\n \"MMDetBackboneConfig\",\n \"mmdet_configs_path\",\n \"param_groups\",\n \"MMDetBackboneConfig\",\n \"create_model_config\",\n]\n\nfrom icevision.imports import *\nfrom icevision.utils import *\nfrom icevision.backbones import BackboneConfig\nfrom icevision.models.mmdet.download_configs import download_mmdet_configs\nfrom mmdet.models.detectors import *\nfrom mmcv import Config\nfrom mmdet.models.backbones.ssd_vgg import SSDVGG\nfrom mmdet.models.backbones.csp_darknet import CSPDarknet\n\n\nmmdet_configs_path = download_mmdet_configs()\n\n\nclass MMDetBackboneConfig(BackboneConfig):\n def __init__(self, model_name, config_path, weights_url):\n self.model_name = model_name\n self.config_path = config_path\n self.weights_url = weights_url\n self.pretrained: bool\n\n def __call__(self, pretrained: bool = True) -> \"MMDetBackboneConfig\":\n self.pretrained = pretrained\n return self\n\n\ndef param_groups(model):\n body = model.backbone\n\n layers = []\n if isinstance(body, SSDVGG):\n layers += [body.features]\n layers += [body.extra, body.l2_norm]\n elif isinstance(body, CSPDarknet):\n layers += [body.stem.conv.conv, body.stem.conv.bn]\n layers += [body.stage1, body.stage2, body.stage3, body.stage4]\n layers += [model.neck]\n else:\n layers += [nn.Sequential(body.conv1, body.bn1)]\n layers += [getattr(body, l) for l in body.res_layers]\n layers += [model.neck]\n\n if isinstance(model, SingleStageDetector):\n layers += [model.bbox_head]\n elif isinstance(model, TwoStageDetector):\n layers += [nn.Sequential(model.rpn_head, model.roi_head)]\n else:\n raise RuntimeError(\n \"{model} must inherit either from SingleStageDetector or TwoStageDetector class\"\n )\n\n _param_groups = [list(layer.parameters()) for layer in layers]\n check_all_model_params_in_groups2(model, _param_groups)\n return _param_groups\n\n\ndef create_model_config(\n backbone: MMDetBackboneConfig,\n pretrained: bool = True,\n checkpoints_path: Optional[Union[str, Path]] = \"checkpoints\",\n force_download=False,\n cfg_options=None,\n):\n\n model_name = backbone.model_name\n config_path = backbone.config_path\n weights_url = backbone.weights_url\n\n # download weights\n weights_path = None\n if pretrained and weights_url:\n save_dir = Path(checkpoints_path) / model_name\n save_dir.mkdir(exist_ok=True, parents=True)\n\n fname = Path(weights_url).name\n weights_path = save_dir / fname\n\n if not weights_path.exists() or force_download:\n download_url(url=weights_url, save_path=str(weights_path))\n\n cfg = Config.fromfile(config_path)\n\n if cfg_options is not None:\n cfg.merge_from_dict(cfg_options)\n\n return cfg, weights_path\n", "path": "icevision/models/mmdet/utils.py"}, {"content": "__all__ = [\n \"ssd300\",\n \"ssd512\",\n]\n\nfrom icevision.imports import *\nfrom icevision.models.mmdet.utils import *\n\n\nclass MMDetSSDBackboneConfig(MMDetBackboneConfig):\n def __init__(self, **kwargs):\n super().__init__(model_name=\"ssd\", **kwargs)\n\n\nbase_config_path = mmdet_configs_path / \"ssd\"\nbase_weights_url = \"http://download.openmmlab.com/mmdetection/v2.0/ssd\"\n\nssd300 = MMDetSSDBackboneConfig(\n config_path=base_config_path / \"ssd300_coco.py\",\n weights_url=f\"{base_weights_url}/ssd300_coco/ssd300_coco_20200307-a92d2092.pth\",\n)\n\nssd512 = MMDetSSDBackboneConfig(\n config_path=base_config_path / \"ssd512_coco.py\",\n weights_url=f\"{base_weights_url}/ssd512_coco/ssd512_coco_20200308-038c5591.pth\",\n)\n", "path": "icevision/models/mmdet/models/ssd/backbones/resnet_fpn.py"}]}
| 1,887 | 771 |
gh_patches_debug_21719
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-14628
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
endpoint in error-page-embed.js does not respect system.url-prefix
## Important Details
How are you running Sentry?
* [x ] On-Premise docker [9.1.1]
## Description
using raven-js with angular works as expected to capture exceptions.
when reporting errors we get the wrong endpoint from the sentry instance
javascript snippet:
```js
Raven
.config(`https://${environment.sentryKey}@MY_INSTANCE/PROJECT_NUMBER`,
{
environment: environment.production ? 'prod' : 'dev',
release: versions.version
}
)
.install();
export class RavenErrorHandler implements ErrorHandler {
handleError(error: any): void {
const err = error.originalError || error;
console.error(err);
Raven.captureException(err);
if (true) {
// fetches error-page-embed.js from sentry instance with wrong endpoint (docker endpoint)
Raven.showReportDialog();
}
}
}
```
this end point is set here: https://github.com/getsentry/sentry/blob/master/src/sentry/web/frontend/error_page_embed.py
```python
# using request.build_absolute_uri() instead of the value of system.url-prefix 'endpoint':
mark_safe('*/' + json.dumps(request.build_absolute_uri()) + ';/*'),
```
## Steps to Reproduce
web:9000 is the hostname of the docker container
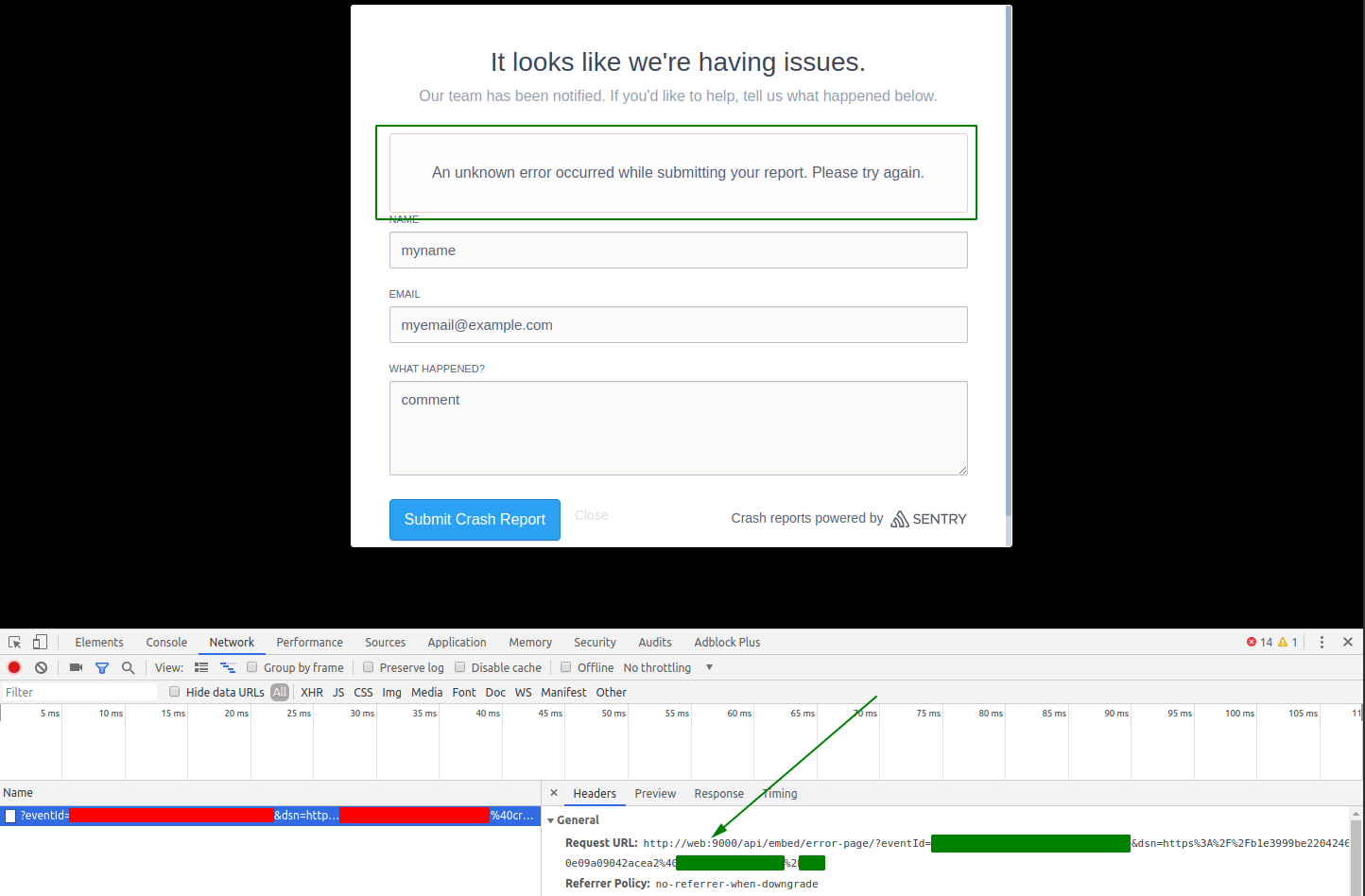
### What you expected to happen
system.url-prefix in config.yaml: error-page-embed.js should be respected
cc/ @max-wittig
</issue>
<code>
[start of src/sentry/web/frontend/error_page_embed.py]
1 from __future__ import absolute_import
2
3 import six
4
5 from django import forms
6 from django.db import IntegrityError, transaction
7 from django.http import HttpResponse
8 from django.views.generic import View
9 from django.template.loader import render_to_string
10 from django.utils import timezone
11 from django.utils.safestring import mark_safe
12 from django.utils.translation import ugettext_lazy as _
13 from django.views.decorators.csrf import csrf_exempt
14
15 from sentry import eventstore
16 from sentry.models import Event, ProjectKey, ProjectOption, UserReport
17 from sentry.web.helpers import render_to_response
18 from sentry.signals import user_feedback_received
19 from sentry.utils import json
20 from sentry.utils.http import is_valid_origin, origin_from_request
21 from sentry.utils.validators import normalize_event_id
22
23 GENERIC_ERROR = _("An unknown error occurred while submitting your report. Please try again.")
24 FORM_ERROR = _("Some fields were invalid. Please correct the errors and try again.")
25 SENT_MESSAGE = _("Your feedback has been sent. Thank you!")
26
27 DEFAULT_TITLE = _("It looks like we're having issues.")
28 DEFAULT_SUBTITLE = _("Our team has been notified.")
29 DEFAULT_SUBTITLE2 = _("If you'd like to help, tell us what happened below.")
30
31 DEFAULT_NAME_LABEL = _("Name")
32 DEFAULT_EMAIL_LABEL = _("Email")
33 DEFAULT_COMMENTS_LABEL = _("What happened?")
34
35 DEFAULT_CLOSE_LABEL = _("Close")
36 DEFAULT_SUBMIT_LABEL = _("Submit Crash Report")
37
38 DEFAULT_OPTIONS = {
39 "title": DEFAULT_TITLE,
40 "subtitle": DEFAULT_SUBTITLE,
41 "subtitle2": DEFAULT_SUBTITLE2,
42 "labelName": DEFAULT_NAME_LABEL,
43 "labelEmail": DEFAULT_EMAIL_LABEL,
44 "labelComments": DEFAULT_COMMENTS_LABEL,
45 "labelClose": DEFAULT_CLOSE_LABEL,
46 "labelSubmit": DEFAULT_SUBMIT_LABEL,
47 "errorGeneric": GENERIC_ERROR,
48 "errorFormEntry": FORM_ERROR,
49 "successMessage": SENT_MESSAGE,
50 }
51
52
53 class UserReportForm(forms.ModelForm):
54 name = forms.CharField(
55 max_length=128, widget=forms.TextInput(attrs={"placeholder": _("Jane Doe")})
56 )
57 email = forms.EmailField(
58 max_length=75,
59 widget=forms.TextInput(attrs={"placeholder": _("[email protected]"), "type": "email"}),
60 )
61 comments = forms.CharField(
62 widget=forms.Textarea(attrs={"placeholder": _("I clicked on 'X' and then hit 'Confirm'")})
63 )
64
65 class Meta:
66 model = UserReport
67 fields = ("name", "email", "comments")
68
69
70 class ErrorPageEmbedView(View):
71 def _get_project_key(self, request):
72 try:
73 dsn = request.GET["dsn"]
74 except KeyError:
75 return
76
77 try:
78 key = ProjectKey.from_dsn(dsn)
79 except ProjectKey.DoesNotExist:
80 return
81
82 return key
83
84 def _get_origin(self, request):
85 return origin_from_request(request)
86
87 def _smart_response(self, request, context=None, status=200):
88 json_context = json.dumps(context or {})
89 accept = request.META.get("HTTP_ACCEPT") or ""
90 if "text/javascript" in accept:
91 content_type = "text/javascript"
92 content = ""
93 else:
94 content_type = "application/json"
95 content = json_context
96 response = HttpResponse(content, status=status, content_type=content_type)
97 response["Access-Control-Allow-Origin"] = request.META.get("HTTP_ORIGIN", "")
98 response["Access-Control-Allow-Methods"] = "GET, POST, OPTIONS"
99 response["Access-Control-Max-Age"] = "1000"
100 response["Access-Control-Allow-Headers"] = "Content-Type, Authorization, X-Requested-With"
101 response["Vary"] = "Accept"
102 if content == "" and context:
103 response["X-Sentry-Context"] = json_context
104 return response
105
106 @csrf_exempt
107 def dispatch(self, request):
108 try:
109 event_id = request.GET["eventId"]
110 except KeyError:
111 return self._smart_response(
112 request, {"eventId": "Missing or invalid parameter."}, status=400
113 )
114
115 normalized_event_id = normalize_event_id(event_id)
116 if normalized_event_id:
117 event_id = normalized_event_id
118 elif event_id:
119 return self._smart_response(
120 request, {"eventId": "Missing or invalid parameter."}, status=400
121 )
122
123 key = self._get_project_key(request)
124 if not key:
125 return self._smart_response(
126 request, {"dsn": "Missing or invalid parameter."}, status=404
127 )
128
129 origin = self._get_origin(request)
130 if not is_valid_origin(origin, key.project):
131 return self._smart_response(request, status=403)
132
133 if request.method == "OPTIONS":
134 return self._smart_response(request)
135
136 # customization options
137 options = DEFAULT_OPTIONS.copy()
138 for name in six.iterkeys(options):
139 if name in request.GET:
140 options[name] = six.text_type(request.GET[name])
141
142 # TODO(dcramer): since we cant use a csrf cookie we should at the very
143 # least sign the request / add some kind of nonce
144 initial = {"name": request.GET.get("name"), "email": request.GET.get("email")}
145
146 form = UserReportForm(request.POST if request.method == "POST" else None, initial=initial)
147 if form.is_valid():
148 # TODO(dcramer): move this to post to the internal API
149 report = form.save(commit=False)
150 report.project = key.project
151 report.event_id = event_id
152
153 event = eventstore.get_event_by_id(report.project.id, report.event_id)
154
155 if event is not None:
156 Event.objects.bind_nodes([event])
157 report.environment = event.get_environment()
158 report.group = event.group
159
160 try:
161 with transaction.atomic():
162 report.save()
163 except IntegrityError:
164 # There was a duplicate, so just overwrite the existing
165 # row with the new one. The only way this ever happens is
166 # if someone is messing around with the API, or doing
167 # something wrong with the SDK, but this behavior is
168 # more reasonable than just hard erroring and is more
169 # expected.
170 UserReport.objects.filter(project=report.project, event_id=report.event_id).update(
171 name=report.name,
172 email=report.email,
173 comments=report.comments,
174 date_added=timezone.now(),
175 )
176
177 else:
178 if report.group:
179 report.notify()
180
181 user_feedback_received.send(project=report.project, group=report.group, sender=self)
182
183 return self._smart_response(request)
184 elif request.method == "POST":
185 return self._smart_response(request, {"errors": dict(form.errors)}, status=400)
186
187 show_branding = (
188 ProjectOption.objects.get_value(
189 project=key.project, key="feedback:branding", default="1"
190 )
191 == "1"
192 )
193
194 template = render_to_string(
195 "sentry/error-page-embed.html",
196 {
197 "form": form,
198 "show_branding": show_branding,
199 "title": options["title"],
200 "subtitle": options["subtitle"],
201 "subtitle2": options["subtitle2"],
202 "name_label": options["labelName"],
203 "email_label": options["labelEmail"],
204 "comments_label": options["labelComments"],
205 "submit_label": options["labelSubmit"],
206 "close_label": options["labelClose"],
207 },
208 )
209
210 context = {
211 "endpoint": mark_safe("*/" + json.dumps(request.build_absolute_uri()) + ";/*"),
212 "template": mark_safe("*/" + json.dumps(template) + ";/*"),
213 "strings": json.dumps_htmlsafe(
214 {
215 "generic_error": six.text_type(options["errorGeneric"]),
216 "form_error": six.text_type(options["errorFormEntry"]),
217 "sent_message": six.text_type(options["successMessage"]),
218 }
219 ),
220 }
221
222 return render_to_response(
223 "sentry/error-page-embed.js", context, request, content_type="text/javascript"
224 )
225
[end of src/sentry/web/frontend/error_page_embed.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/web/frontend/error_page_embed.py b/src/sentry/web/frontend/error_page_embed.py
--- a/src/sentry/web/frontend/error_page_embed.py
+++ b/src/sentry/web/frontend/error_page_embed.py
@@ -17,7 +17,7 @@
from sentry.web.helpers import render_to_response
from sentry.signals import user_feedback_received
from sentry.utils import json
-from sentry.utils.http import is_valid_origin, origin_from_request
+from sentry.utils.http import absolute_uri, is_valid_origin, origin_from_request
from sentry.utils.validators import normalize_event_id
GENERIC_ERROR = _("An unknown error occurred while submitting your report. Please try again.")
@@ -208,7 +208,9 @@
)
context = {
- "endpoint": mark_safe("*/" + json.dumps(request.build_absolute_uri()) + ";/*"),
+ "endpoint": mark_safe(
+ "*/" + json.dumps(absolute_uri(request.get_full_path())) + ";/*"
+ ),
"template": mark_safe("*/" + json.dumps(template) + ";/*"),
"strings": json.dumps_htmlsafe(
{
|
{"golden_diff": "diff --git a/src/sentry/web/frontend/error_page_embed.py b/src/sentry/web/frontend/error_page_embed.py\n--- a/src/sentry/web/frontend/error_page_embed.py\n+++ b/src/sentry/web/frontend/error_page_embed.py\n@@ -17,7 +17,7 @@\n from sentry.web.helpers import render_to_response\n from sentry.signals import user_feedback_received\n from sentry.utils import json\n-from sentry.utils.http import is_valid_origin, origin_from_request\n+from sentry.utils.http import absolute_uri, is_valid_origin, origin_from_request\n from sentry.utils.validators import normalize_event_id\n \n GENERIC_ERROR = _(\"An unknown error occurred while submitting your report. Please try again.\")\n@@ -208,7 +208,9 @@\n )\n \n context = {\n- \"endpoint\": mark_safe(\"*/\" + json.dumps(request.build_absolute_uri()) + \";/*\"),\n+ \"endpoint\": mark_safe(\n+ \"*/\" + json.dumps(absolute_uri(request.get_full_path())) + \";/*\"\n+ ),\n \"template\": mark_safe(\"*/\" + json.dumps(template) + \";/*\"),\n \"strings\": json.dumps_htmlsafe(\n {\n", "issue": "endpoint in error-page-embed.js does not respect system.url-prefix\n## Important Details\r\n\r\nHow are you running Sentry?\r\n\r\n* [x ] On-Premise docker [9.1.1]\r\n## Description\r\n\r\nusing raven-js with angular works as expected to capture exceptions.\r\nwhen reporting errors we get the wrong endpoint from the sentry instance\r\n\r\njavascript snippet:\r\n```js\r\nRaven\r\n .config(`https://${environment.sentryKey}@MY_INSTANCE/PROJECT_NUMBER`,\r\n {\r\n environment: environment.production ? 'prod' : 'dev',\r\n release: versions.version\r\n }\r\n )\r\n .install();\r\n\r\nexport class RavenErrorHandler implements ErrorHandler {\r\n handleError(error: any): void {\r\n const err = error.originalError || error;\r\n console.error(err);\r\n Raven.captureException(err);\r\n if (true) {\r\n // fetches error-page-embed.js from sentry instance with wrong endpoint (docker endpoint)\r\n Raven.showReportDialog();\r\n }\r\n }\r\n}\r\n```\r\n\r\nthis end point is set here: https://github.com/getsentry/sentry/blob/master/src/sentry/web/frontend/error_page_embed.py\r\n```python\r\n# using request.build_absolute_uri() instead of the value of system.url-prefix 'endpoint': \r\n \r\nmark_safe('*/' + json.dumps(request.build_absolute_uri()) + ';/*'),\r\n```\r\n\r\n## Steps to Reproduce\r\n\r\nweb:9000 is the hostname of the docker container\r\n\r\n\r\n### What you expected to happen\r\n\r\nsystem.url-prefix in config.yaml: error-page-embed.js should be respected\r\n\r\n\r\ncc/ @max-wittig\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\n\nimport six\n\nfrom django import forms\nfrom django.db import IntegrityError, transaction\nfrom django.http import HttpResponse\nfrom django.views.generic import View\nfrom django.template.loader import render_to_string\nfrom django.utils import timezone\nfrom django.utils.safestring import mark_safe\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.decorators.csrf import csrf_exempt\n\nfrom sentry import eventstore\nfrom sentry.models import Event, ProjectKey, ProjectOption, UserReport\nfrom sentry.web.helpers import render_to_response\nfrom sentry.signals import user_feedback_received\nfrom sentry.utils import json\nfrom sentry.utils.http import is_valid_origin, origin_from_request\nfrom sentry.utils.validators import normalize_event_id\n\nGENERIC_ERROR = _(\"An unknown error occurred while submitting your report. Please try again.\")\nFORM_ERROR = _(\"Some fields were invalid. Please correct the errors and try again.\")\nSENT_MESSAGE = _(\"Your feedback has been sent. Thank you!\")\n\nDEFAULT_TITLE = _(\"It looks like we're having issues.\")\nDEFAULT_SUBTITLE = _(\"Our team has been notified.\")\nDEFAULT_SUBTITLE2 = _(\"If you'd like to help, tell us what happened below.\")\n\nDEFAULT_NAME_LABEL = _(\"Name\")\nDEFAULT_EMAIL_LABEL = _(\"Email\")\nDEFAULT_COMMENTS_LABEL = _(\"What happened?\")\n\nDEFAULT_CLOSE_LABEL = _(\"Close\")\nDEFAULT_SUBMIT_LABEL = _(\"Submit Crash Report\")\n\nDEFAULT_OPTIONS = {\n \"title\": DEFAULT_TITLE,\n \"subtitle\": DEFAULT_SUBTITLE,\n \"subtitle2\": DEFAULT_SUBTITLE2,\n \"labelName\": DEFAULT_NAME_LABEL,\n \"labelEmail\": DEFAULT_EMAIL_LABEL,\n \"labelComments\": DEFAULT_COMMENTS_LABEL,\n \"labelClose\": DEFAULT_CLOSE_LABEL,\n \"labelSubmit\": DEFAULT_SUBMIT_LABEL,\n \"errorGeneric\": GENERIC_ERROR,\n \"errorFormEntry\": FORM_ERROR,\n \"successMessage\": SENT_MESSAGE,\n}\n\n\nclass UserReportForm(forms.ModelForm):\n name = forms.CharField(\n max_length=128, widget=forms.TextInput(attrs={\"placeholder\": _(\"Jane Doe\")})\n )\n email = forms.EmailField(\n max_length=75,\n widget=forms.TextInput(attrs={\"placeholder\": _(\"[email protected]\"), \"type\": \"email\"}),\n )\n comments = forms.CharField(\n widget=forms.Textarea(attrs={\"placeholder\": _(\"I clicked on 'X' and then hit 'Confirm'\")})\n )\n\n class Meta:\n model = UserReport\n fields = (\"name\", \"email\", \"comments\")\n\n\nclass ErrorPageEmbedView(View):\n def _get_project_key(self, request):\n try:\n dsn = request.GET[\"dsn\"]\n except KeyError:\n return\n\n try:\n key = ProjectKey.from_dsn(dsn)\n except ProjectKey.DoesNotExist:\n return\n\n return key\n\n def _get_origin(self, request):\n return origin_from_request(request)\n\n def _smart_response(self, request, context=None, status=200):\n json_context = json.dumps(context or {})\n accept = request.META.get(\"HTTP_ACCEPT\") or \"\"\n if \"text/javascript\" in accept:\n content_type = \"text/javascript\"\n content = \"\"\n else:\n content_type = \"application/json\"\n content = json_context\n response = HttpResponse(content, status=status, content_type=content_type)\n response[\"Access-Control-Allow-Origin\"] = request.META.get(\"HTTP_ORIGIN\", \"\")\n response[\"Access-Control-Allow-Methods\"] = \"GET, POST, OPTIONS\"\n response[\"Access-Control-Max-Age\"] = \"1000\"\n response[\"Access-Control-Allow-Headers\"] = \"Content-Type, Authorization, X-Requested-With\"\n response[\"Vary\"] = \"Accept\"\n if content == \"\" and context:\n response[\"X-Sentry-Context\"] = json_context\n return response\n\n @csrf_exempt\n def dispatch(self, request):\n try:\n event_id = request.GET[\"eventId\"]\n except KeyError:\n return self._smart_response(\n request, {\"eventId\": \"Missing or invalid parameter.\"}, status=400\n )\n\n normalized_event_id = normalize_event_id(event_id)\n if normalized_event_id:\n event_id = normalized_event_id\n elif event_id:\n return self._smart_response(\n request, {\"eventId\": \"Missing or invalid parameter.\"}, status=400\n )\n\n key = self._get_project_key(request)\n if not key:\n return self._smart_response(\n request, {\"dsn\": \"Missing or invalid parameter.\"}, status=404\n )\n\n origin = self._get_origin(request)\n if not is_valid_origin(origin, key.project):\n return self._smart_response(request, status=403)\n\n if request.method == \"OPTIONS\":\n return self._smart_response(request)\n\n # customization options\n options = DEFAULT_OPTIONS.copy()\n for name in six.iterkeys(options):\n if name in request.GET:\n options[name] = six.text_type(request.GET[name])\n\n # TODO(dcramer): since we cant use a csrf cookie we should at the very\n # least sign the request / add some kind of nonce\n initial = {\"name\": request.GET.get(\"name\"), \"email\": request.GET.get(\"email\")}\n\n form = UserReportForm(request.POST if request.method == \"POST\" else None, initial=initial)\n if form.is_valid():\n # TODO(dcramer): move this to post to the internal API\n report = form.save(commit=False)\n report.project = key.project\n report.event_id = event_id\n\n event = eventstore.get_event_by_id(report.project.id, report.event_id)\n\n if event is not None:\n Event.objects.bind_nodes([event])\n report.environment = event.get_environment()\n report.group = event.group\n\n try:\n with transaction.atomic():\n report.save()\n except IntegrityError:\n # There was a duplicate, so just overwrite the existing\n # row with the new one. The only way this ever happens is\n # if someone is messing around with the API, or doing\n # something wrong with the SDK, but this behavior is\n # more reasonable than just hard erroring and is more\n # expected.\n UserReport.objects.filter(project=report.project, event_id=report.event_id).update(\n name=report.name,\n email=report.email,\n comments=report.comments,\n date_added=timezone.now(),\n )\n\n else:\n if report.group:\n report.notify()\n\n user_feedback_received.send(project=report.project, group=report.group, sender=self)\n\n return self._smart_response(request)\n elif request.method == \"POST\":\n return self._smart_response(request, {\"errors\": dict(form.errors)}, status=400)\n\n show_branding = (\n ProjectOption.objects.get_value(\n project=key.project, key=\"feedback:branding\", default=\"1\"\n )\n == \"1\"\n )\n\n template = render_to_string(\n \"sentry/error-page-embed.html\",\n {\n \"form\": form,\n \"show_branding\": show_branding,\n \"title\": options[\"title\"],\n \"subtitle\": options[\"subtitle\"],\n \"subtitle2\": options[\"subtitle2\"],\n \"name_label\": options[\"labelName\"],\n \"email_label\": options[\"labelEmail\"],\n \"comments_label\": options[\"labelComments\"],\n \"submit_label\": options[\"labelSubmit\"],\n \"close_label\": options[\"labelClose\"],\n },\n )\n\n context = {\n \"endpoint\": mark_safe(\"*/\" + json.dumps(request.build_absolute_uri()) + \";/*\"),\n \"template\": mark_safe(\"*/\" + json.dumps(template) + \";/*\"),\n \"strings\": json.dumps_htmlsafe(\n {\n \"generic_error\": six.text_type(options[\"errorGeneric\"]),\n \"form_error\": six.text_type(options[\"errorFormEntry\"]),\n \"sent_message\": six.text_type(options[\"successMessage\"]),\n }\n ),\n }\n\n return render_to_response(\n \"sentry/error-page-embed.js\", context, request, content_type=\"text/javascript\"\n )\n", "path": "src/sentry/web/frontend/error_page_embed.py"}]}
| 3,218 | 248 |
gh_patches_debug_41100
|
rasdani/github-patches
|
git_diff
|
buildbot__buildbot-422
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Expose builder.tags to web templates.
This tiny PR exposes the builders' "tags" attribute to the templates, allowing me to customize the templates using that feature.
</issue>
<code>
[start of master/buildbot/steps/master.py]
1 # This file is part of Buildbot. Buildbot is free software: you can
2 # redistribute it and/or modify it under the terms of the GNU General Public
3 # License as published by the Free Software Foundation, version 2.
4 #
5 # This program is distributed in the hope that it will be useful, but WITHOUT
6 # ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
7 # FOR A PARTICULAR PURPOSE. See the GNU General Public License for more
8 # details.
9 #
10 # You should have received a copy of the GNU General Public License along with
11 # this program; if not, write to the Free Software Foundation, Inc., 51
12 # Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
13 #
14 # Copyright Buildbot Team Members
15
16 import os, types, re
17 from twisted.python import runtime
18 from twisted.internet import reactor
19 from buildbot.process.buildstep import BuildStep
20 from buildbot.process.buildstep import SUCCESS, FAILURE
21 from twisted.internet.protocol import ProcessProtocol
22
23 class MasterShellCommand(BuildStep):
24 """
25 Run a shell command locally - on the buildmaster. The shell command
26 COMMAND is specified just as for a RemoteShellCommand. Note that extra
27 logfiles are not supported.
28 """
29 name='MasterShellCommand'
30 description='Running'
31 descriptionDone='Ran'
32 descriptionSuffix = None
33 renderables = [ 'command', 'env', 'description', 'descriptionDone', 'descriptionSuffix' ]
34 haltOnFailure = True
35 flunkOnFailure = True
36
37 def __init__(self, command,
38 description=None, descriptionDone=None, descriptionSuffix=None,
39 env=None, path=None, usePTY=0,
40 **kwargs):
41 BuildStep.__init__(self, **kwargs)
42
43 self.command=command
44 if description:
45 self.description = description
46 if isinstance(self.description, str):
47 self.description = [self.description]
48 if descriptionDone:
49 self.descriptionDone = descriptionDone
50 if isinstance(self.descriptionDone, str):
51 self.descriptionDone = [self.descriptionDone]
52 if descriptionSuffix:
53 self.descriptionSuffix = descriptionSuffix
54 if isinstance(self.descriptionSuffix, str):
55 self.descriptionSuffix = [self.descriptionSuffix]
56 self.env=env
57 self.path=path
58 self.usePTY=usePTY
59
60 class LocalPP(ProcessProtocol):
61 def __init__(self, step):
62 self.step = step
63
64 def outReceived(self, data):
65 self.step.stdio_log.addStdout(data)
66
67 def errReceived(self, data):
68 self.step.stdio_log.addStderr(data)
69
70 def processEnded(self, status_object):
71 self.step.stdio_log.addHeader("exit status %d\n" % status_object.value.exitCode)
72 self.step.processEnded(status_object)
73
74 def start(self):
75 # render properties
76 command = self.command
77 # set up argv
78 if type(command) in types.StringTypes:
79 if runtime.platformType == 'win32':
80 argv = os.environ['COMSPEC'].split() # allow %COMSPEC% to have args
81 if '/c' not in argv: argv += ['/c']
82 argv += [command]
83 else:
84 # for posix, use /bin/sh. for other non-posix, well, doesn't
85 # hurt to try
86 argv = ['/bin/sh', '-c', command]
87 else:
88 if runtime.platformType == 'win32':
89 argv = os.environ['COMSPEC'].split() # allow %COMSPEC% to have args
90 if '/c' not in argv: argv += ['/c']
91 argv += list(command)
92 else:
93 argv = command
94
95 self.stdio_log = stdio_log = self.addLog("stdio")
96
97 if type(command) in types.StringTypes:
98 stdio_log.addHeader(command.strip() + "\n\n")
99 else:
100 stdio_log.addHeader(" ".join(command) + "\n\n")
101 stdio_log.addHeader("** RUNNING ON BUILDMASTER **\n")
102 stdio_log.addHeader(" in dir %s\n" % os.getcwd())
103 stdio_log.addHeader(" argv: %s\n" % (argv,))
104 self.step_status.setText(self.describe())
105
106 if self.env is None:
107 env = os.environ
108 else:
109 assert isinstance(self.env, dict)
110 env = self.env
111
112 # do substitution on variable values matching pattern: ${name}
113 p = re.compile('\${([0-9a-zA-Z_]*)}')
114 def subst(match):
115 return os.environ.get(match.group(1), "")
116 newenv = {}
117 for key in env.keys():
118 if env[key] is not None:
119 newenv[key] = p.sub(subst, env[key])
120 env = newenv
121 stdio_log.addHeader(" env: %r\n" % (env,))
122
123 # TODO add a timeout?
124 reactor.spawnProcess(self.LocalPP(self), argv[0], argv,
125 path=self.path, usePTY=self.usePTY, env=env )
126 # (the LocalPP object will call processEnded for us)
127
128 def processEnded(self, status_object):
129 if status_object.value.exitCode != 0:
130 self.descriptionDone = ["failed (%d)" % status_object.value.exitCode]
131 self.step_status.setText(self.describe(done=True))
132 self.finished(FAILURE)
133 else:
134 self.step_status.setText(self.describe(done=True))
135 self.finished(SUCCESS)
136
137 def describe(self, done=False):
138 desc = self.descriptionDone if done else self.description
139 if self.descriptionSuffix:
140 desc = desc[:]
141 desc.extend(self.descriptionSuffix)
142 return desc
143
[end of master/buildbot/steps/master.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/master/buildbot/steps/master.py b/master/buildbot/steps/master.py
--- a/master/buildbot/steps/master.py
+++ b/master/buildbot/steps/master.py
@@ -18,6 +18,7 @@
from twisted.internet import reactor
from buildbot.process.buildstep import BuildStep
from buildbot.process.buildstep import SUCCESS, FAILURE
+from twisted.internet import error
from twisted.internet.protocol import ProcessProtocol
class MasterShellCommand(BuildStep):
@@ -36,7 +37,7 @@
def __init__(self, command,
description=None, descriptionDone=None, descriptionSuffix=None,
- env=None, path=None, usePTY=0,
+ env=None, path=None, usePTY=0, interruptSignal="KILL",
**kwargs):
BuildStep.__init__(self, **kwargs)
@@ -56,6 +57,7 @@
self.env=env
self.path=path
self.usePTY=usePTY
+ self.interruptSignal = interruptSignal
class LocalPP(ProcessProtocol):
def __init__(self, step):
@@ -68,7 +70,10 @@
self.step.stdio_log.addStderr(data)
def processEnded(self, status_object):
- self.step.stdio_log.addHeader("exit status %d\n" % status_object.value.exitCode)
+ if status_object.value.exitCode is not None:
+ self.step.stdio_log.addHeader("exit status %d\n" % status_object.value.exitCode)
+ if status_object.value.signal is not None:
+ self.step.stdio_log.addHeader("signal %s\n" % status_object.value.signal)
self.step.processEnded(status_object)
def start(self):
@@ -121,12 +126,16 @@
stdio_log.addHeader(" env: %r\n" % (env,))
# TODO add a timeout?
- reactor.spawnProcess(self.LocalPP(self), argv[0], argv,
+ self.process = reactor.spawnProcess(self.LocalPP(self), argv[0], argv,
path=self.path, usePTY=self.usePTY, env=env )
# (the LocalPP object will call processEnded for us)
def processEnded(self, status_object):
- if status_object.value.exitCode != 0:
+ if status_object.value.signal is not None:
+ self.descriptionDone = ["killed (%s)" % status_object.value.signal]
+ self.step_status.setText(self.describe(done=True))
+ self.finished(FAILURE)
+ elif status_object.value.exitCode != 0:
self.descriptionDone = ["failed (%d)" % status_object.value.exitCode]
self.step_status.setText(self.describe(done=True))
self.finished(FAILURE)
@@ -140,3 +149,12 @@
desc = desc[:]
desc.extend(self.descriptionSuffix)
return desc
+
+ def interrupt(self, reason):
+ try:
+ self.process.signalProcess(self.interruptSignal)
+ except KeyError: # Process not started yet
+ pass
+ except error.ProcessExitedAlready:
+ pass
+ BuildStep.interrupt(self, reason)
|
{"golden_diff": "diff --git a/master/buildbot/steps/master.py b/master/buildbot/steps/master.py\n--- a/master/buildbot/steps/master.py\n+++ b/master/buildbot/steps/master.py\n@@ -18,6 +18,7 @@\n from twisted.internet import reactor\n from buildbot.process.buildstep import BuildStep\n from buildbot.process.buildstep import SUCCESS, FAILURE\n+from twisted.internet import error\n from twisted.internet.protocol import ProcessProtocol\n \n class MasterShellCommand(BuildStep):\n@@ -36,7 +37,7 @@\n \n def __init__(self, command,\n description=None, descriptionDone=None, descriptionSuffix=None,\n- env=None, path=None, usePTY=0,\n+ env=None, path=None, usePTY=0, interruptSignal=\"KILL\",\n **kwargs):\n BuildStep.__init__(self, **kwargs)\n \n@@ -56,6 +57,7 @@\n self.env=env\n self.path=path\n self.usePTY=usePTY\n+ self.interruptSignal = interruptSignal\n \n class LocalPP(ProcessProtocol):\n def __init__(self, step):\n@@ -68,7 +70,10 @@\n self.step.stdio_log.addStderr(data)\n \n def processEnded(self, status_object):\n- self.step.stdio_log.addHeader(\"exit status %d\\n\" % status_object.value.exitCode)\n+ if status_object.value.exitCode is not None:\n+ self.step.stdio_log.addHeader(\"exit status %d\\n\" % status_object.value.exitCode)\n+ if status_object.value.signal is not None:\n+ self.step.stdio_log.addHeader(\"signal %s\\n\" % status_object.value.signal)\n self.step.processEnded(status_object)\n \n def start(self):\n@@ -121,12 +126,16 @@\n stdio_log.addHeader(\" env: %r\\n\" % (env,))\n \n # TODO add a timeout?\n- reactor.spawnProcess(self.LocalPP(self), argv[0], argv,\n+ self.process = reactor.spawnProcess(self.LocalPP(self), argv[0], argv,\n path=self.path, usePTY=self.usePTY, env=env )\n # (the LocalPP object will call processEnded for us)\n \n def processEnded(self, status_object):\n- if status_object.value.exitCode != 0:\n+ if status_object.value.signal is not None:\n+ self.descriptionDone = [\"killed (%s)\" % status_object.value.signal]\n+ self.step_status.setText(self.describe(done=True))\n+ self.finished(FAILURE)\n+ elif status_object.value.exitCode != 0:\n self.descriptionDone = [\"failed (%d)\" % status_object.value.exitCode]\n self.step_status.setText(self.describe(done=True))\n self.finished(FAILURE)\n@@ -140,3 +149,12 @@\n desc = desc[:]\n desc.extend(self.descriptionSuffix)\n return desc\n+\n+ def interrupt(self, reason):\n+ try:\n+ self.process.signalProcess(self.interruptSignal)\n+ except KeyError: # Process not started yet\n+ pass\n+ except error.ProcessExitedAlready:\n+ pass\n+ BuildStep.interrupt(self, reason)\n", "issue": "Expose builder.tags to web templates.\nThis tiny PR exposes the builders' \"tags\" attribute to the templates, allowing me to customize the templates using that feature.\n\n", "before_files": [{"content": "# This file is part of Buildbot. Buildbot is free software: you can\n# redistribute it and/or modify it under the terms of the GNU General Public\n# License as published by the Free Software Foundation, version 2.\n#\n# This program is distributed in the hope that it will be useful, but WITHOUT\n# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS\n# FOR A PARTICULAR PURPOSE. See the GNU General Public License for more\n# details.\n#\n# You should have received a copy of the GNU General Public License along with\n# this program; if not, write to the Free Software Foundation, Inc., 51\n# Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n#\n# Copyright Buildbot Team Members\n\nimport os, types, re\nfrom twisted.python import runtime\nfrom twisted.internet import reactor\nfrom buildbot.process.buildstep import BuildStep\nfrom buildbot.process.buildstep import SUCCESS, FAILURE\nfrom twisted.internet.protocol import ProcessProtocol\n\nclass MasterShellCommand(BuildStep):\n \"\"\"\n Run a shell command locally - on the buildmaster. The shell command\n COMMAND is specified just as for a RemoteShellCommand. Note that extra\n logfiles are not supported.\n \"\"\"\n name='MasterShellCommand'\n description='Running'\n descriptionDone='Ran'\n descriptionSuffix = None\n renderables = [ 'command', 'env', 'description', 'descriptionDone', 'descriptionSuffix' ]\n haltOnFailure = True\n flunkOnFailure = True\n\n def __init__(self, command,\n description=None, descriptionDone=None, descriptionSuffix=None,\n env=None, path=None, usePTY=0,\n **kwargs):\n BuildStep.__init__(self, **kwargs)\n\n self.command=command\n if description:\n self.description = description\n if isinstance(self.description, str):\n self.description = [self.description]\n if descriptionDone:\n self.descriptionDone = descriptionDone\n if isinstance(self.descriptionDone, str):\n self.descriptionDone = [self.descriptionDone]\n if descriptionSuffix:\n self.descriptionSuffix = descriptionSuffix\n if isinstance(self.descriptionSuffix, str):\n self.descriptionSuffix = [self.descriptionSuffix]\n self.env=env\n self.path=path\n self.usePTY=usePTY\n\n class LocalPP(ProcessProtocol):\n def __init__(self, step):\n self.step = step\n\n def outReceived(self, data):\n self.step.stdio_log.addStdout(data)\n\n def errReceived(self, data):\n self.step.stdio_log.addStderr(data)\n\n def processEnded(self, status_object):\n self.step.stdio_log.addHeader(\"exit status %d\\n\" % status_object.value.exitCode)\n self.step.processEnded(status_object)\n\n def start(self):\n # render properties\n command = self.command\n # set up argv\n if type(command) in types.StringTypes:\n if runtime.platformType == 'win32':\n argv = os.environ['COMSPEC'].split() # allow %COMSPEC% to have args\n if '/c' not in argv: argv += ['/c']\n argv += [command]\n else:\n # for posix, use /bin/sh. for other non-posix, well, doesn't\n # hurt to try\n argv = ['/bin/sh', '-c', command]\n else:\n if runtime.platformType == 'win32':\n argv = os.environ['COMSPEC'].split() # allow %COMSPEC% to have args\n if '/c' not in argv: argv += ['/c']\n argv += list(command)\n else:\n argv = command\n\n self.stdio_log = stdio_log = self.addLog(\"stdio\")\n\n if type(command) in types.StringTypes:\n stdio_log.addHeader(command.strip() + \"\\n\\n\")\n else:\n stdio_log.addHeader(\" \".join(command) + \"\\n\\n\")\n stdio_log.addHeader(\"** RUNNING ON BUILDMASTER **\\n\")\n stdio_log.addHeader(\" in dir %s\\n\" % os.getcwd())\n stdio_log.addHeader(\" argv: %s\\n\" % (argv,))\n self.step_status.setText(self.describe())\n\n if self.env is None:\n env = os.environ\n else:\n assert isinstance(self.env, dict)\n env = self.env\n\n # do substitution on variable values matching pattern: ${name}\n p = re.compile('\\${([0-9a-zA-Z_]*)}')\n def subst(match):\n return os.environ.get(match.group(1), \"\")\n newenv = {}\n for key in env.keys():\n if env[key] is not None:\n newenv[key] = p.sub(subst, env[key])\n env = newenv\n stdio_log.addHeader(\" env: %r\\n\" % (env,))\n\n # TODO add a timeout?\n reactor.spawnProcess(self.LocalPP(self), argv[0], argv,\n path=self.path, usePTY=self.usePTY, env=env )\n # (the LocalPP object will call processEnded for us)\n\n def processEnded(self, status_object):\n if status_object.value.exitCode != 0:\n self.descriptionDone = [\"failed (%d)\" % status_object.value.exitCode]\n self.step_status.setText(self.describe(done=True))\n self.finished(FAILURE)\n else:\n self.step_status.setText(self.describe(done=True))\n self.finished(SUCCESS)\n\n def describe(self, done=False):\n desc = self.descriptionDone if done else self.description\n if self.descriptionSuffix:\n desc = desc[:]\n desc.extend(self.descriptionSuffix)\n return desc\n", "path": "master/buildbot/steps/master.py"}]}
| 2,107 | 689 |
gh_patches_debug_2569
|
rasdani/github-patches
|
git_diff
|
ephios-dev__ephios-1244
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API: `/api/users/by_email` returns 404 error for email addresses with dots before the @
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to `[ephios-url]/api/users/by_email/[email protected]/`
**Expected behaviour**
Assuming the user exists, the information about the user should be returned.
**Screenshots**
Instead the page 404s.
<img width="1511" alt="Screenshot 2024-03-27 at 18 54 08" src="https://github.com/ephios-dev/ephios/assets/2546622/1383feee-28b0-4825-a31e-c39e2cc3f2ab">
**Environment**
State which device, operating system, browser and browser version you are using.
MacOS 14.2.1 (23C71), Version 17.2.1 (19617.1.17.11.12)
**Additional context**
* The problem does not appear for the test emails `usaaa@localhost/`, `admin@localhost/` or `[email protected]`.
</issue>
<code>
[start of ephios/api/views/users.py]
1 from django.db.models import Q
2 from django.utils import timezone
3 from django_filters.rest_framework import DjangoFilterBackend
4 from oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope
5 from rest_framework import viewsets
6 from rest_framework.exceptions import PermissionDenied
7 from rest_framework.fields import SerializerMethodField
8 from rest_framework.filters import SearchFilter
9 from rest_framework.generics import RetrieveAPIView
10 from rest_framework.mixins import RetrieveModelMixin
11 from rest_framework.permissions import DjangoObjectPermissions
12 from rest_framework.relations import SlugRelatedField
13 from rest_framework.schemas.openapi import AutoSchema
14 from rest_framework.serializers import ModelSerializer
15 from rest_framework.viewsets import GenericViewSet
16 from rest_framework_guardian.filters import ObjectPermissionsFilter
17
18 from ephios.api.views.events import ParticipationSerializer
19 from ephios.core.models import LocalParticipation, Qualification, UserProfile
20 from ephios.core.services.qualification import collect_all_included_qualifications
21
22
23 class QualificationSerializer(ModelSerializer):
24 category = SlugRelatedField(slug_field="uuid", read_only=True)
25 includes = SerializerMethodField()
26
27 class Meta:
28 model = Qualification
29 fields = [
30 "uuid",
31 "title",
32 "abbreviation",
33 "category",
34 "includes",
35 ]
36
37 def get_includes(self, obj):
38 return [q.uuid for q in collect_all_included_qualifications(obj.includes.all())]
39
40
41 class UserProfileSerializer(ModelSerializer):
42 qualifications = SerializerMethodField()
43
44 class Meta:
45 model = UserProfile
46 fields = [
47 "id",
48 "display_name",
49 "date_of_birth",
50 "email",
51 "qualifications",
52 ]
53
54 def get_qualifications(self, obj):
55 return QualificationSerializer(
56 Qualification.objects.filter(
57 Q(grants__user=obj)
58 & (Q(grants__expires__gte=timezone.now()) | Q(grants__expires__isnull=True))
59 ),
60 many=True,
61 ).data
62
63
64 class UserProfileMeView(RetrieveAPIView):
65 serializer_class = UserProfileSerializer
66 queryset = UserProfile.objects.all()
67 permission_classes = [IsAuthenticatedOrTokenHasScope]
68 required_scopes = ["ME_READ"]
69 schema = AutoSchema(operation_id_base="OwnUserProfile")
70
71 def get_object(self):
72 if self.request.user is None:
73 raise PermissionDenied()
74 return self.request.user
75
76
77 class UserViewSet(viewsets.ReadOnlyModelViewSet):
78 serializer_class = UserProfileSerializer
79 queryset = UserProfile.objects.all()
80 permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoObjectPermissions]
81 required_scopes = ["CONFIDENTIAL_READ"]
82 search_fields = ["display_name", "email"]
83
84 filter_backends = [
85 DjangoFilterBackend,
86 SearchFilter,
87 ObjectPermissionsFilter,
88 ]
89
90
91 class UserByMailView(RetrieveModelMixin, GenericViewSet):
92 serializer_class = UserProfileSerializer
93 queryset = UserProfile.objects.all()
94 permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoObjectPermissions]
95 required_scopes = ["CONFIDENTIAL_READ"]
96 filter_backends = [ObjectPermissionsFilter]
97 lookup_url_kwarg = "email"
98 lookup_field = "email"
99 schema = AutoSchema(operation_id_base="UserProfileByMail")
100
101
102 class UserParticipationView(viewsets.ReadOnlyModelViewSet):
103 serializer_class = ParticipationSerializer
104 permission_classes = [IsAuthenticatedOrTokenHasScope]
105 filter_backends = [ObjectPermissionsFilter, DjangoFilterBackend]
106 filterset_fields = ["state"]
107 required_scopes = ["CONFIDENTIAL_READ"]
108
109 def get_queryset(self):
110 return LocalParticipation.objects.filter(user=self.kwargs.get("user"))
111
[end of ephios/api/views/users.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ephios/api/views/users.py b/ephios/api/views/users.py
--- a/ephios/api/views/users.py
+++ b/ephios/api/views/users.py
@@ -96,6 +96,7 @@
filter_backends = [ObjectPermissionsFilter]
lookup_url_kwarg = "email"
lookup_field = "email"
+ lookup_value_regex = "[^/]+" # customize to allow dots (".") in the lookup value
schema = AutoSchema(operation_id_base="UserProfileByMail")
|
{"golden_diff": "diff --git a/ephios/api/views/users.py b/ephios/api/views/users.py\n--- a/ephios/api/views/users.py\n+++ b/ephios/api/views/users.py\n@@ -96,6 +96,7 @@\n filter_backends = [ObjectPermissionsFilter]\n lookup_url_kwarg = \"email\"\n lookup_field = \"email\"\n+ lookup_value_regex = \"[^/]+\" # customize to allow dots (\".\") in the lookup value\n schema = AutoSchema(operation_id_base=\"UserProfileByMail\")\n", "issue": "API: `/api/users/by_email` returns 404 error for email addresses with dots before the @\n**Describe the bug**\r\nA clear and concise description of what the bug is.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to `[ephios-url]/api/users/by_email/[email protected]/`\r\n\r\n**Expected behaviour**\r\nAssuming the user exists, the information about the user should be returned.\r\n\r\n**Screenshots**\r\nInstead the page 404s.\r\n\r\n<img width=\"1511\" alt=\"Screenshot 2024-03-27 at 18 54 08\" src=\"https://github.com/ephios-dev/ephios/assets/2546622/1383feee-28b0-4825-a31e-c39e2cc3f2ab\">\r\n\r\n**Environment**\r\nState which device, operating system, browser and browser version you are using.\r\nMacOS 14.2.1 (23C71), Version 17.2.1 (19617.1.17.11.12)\r\n\r\n**Additional context**\r\n* The problem does not appear for the test emails `usaaa@localhost/`, `admin@localhost/` or `[email protected]`.\n", "before_files": [{"content": "from django.db.models import Q\nfrom django.utils import timezone\nfrom django_filters.rest_framework import DjangoFilterBackend\nfrom oauth2_provider.contrib.rest_framework import IsAuthenticatedOrTokenHasScope\nfrom rest_framework import viewsets\nfrom rest_framework.exceptions import PermissionDenied\nfrom rest_framework.fields import SerializerMethodField\nfrom rest_framework.filters import SearchFilter\nfrom rest_framework.generics import RetrieveAPIView\nfrom rest_framework.mixins import RetrieveModelMixin\nfrom rest_framework.permissions import DjangoObjectPermissions\nfrom rest_framework.relations import SlugRelatedField\nfrom rest_framework.schemas.openapi import AutoSchema\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import GenericViewSet\nfrom rest_framework_guardian.filters import ObjectPermissionsFilter\n\nfrom ephios.api.views.events import ParticipationSerializer\nfrom ephios.core.models import LocalParticipation, Qualification, UserProfile\nfrom ephios.core.services.qualification import collect_all_included_qualifications\n\n\nclass QualificationSerializer(ModelSerializer):\n category = SlugRelatedField(slug_field=\"uuid\", read_only=True)\n includes = SerializerMethodField()\n\n class Meta:\n model = Qualification\n fields = [\n \"uuid\",\n \"title\",\n \"abbreviation\",\n \"category\",\n \"includes\",\n ]\n\n def get_includes(self, obj):\n return [q.uuid for q in collect_all_included_qualifications(obj.includes.all())]\n\n\nclass UserProfileSerializer(ModelSerializer):\n qualifications = SerializerMethodField()\n\n class Meta:\n model = UserProfile\n fields = [\n \"id\",\n \"display_name\",\n \"date_of_birth\",\n \"email\",\n \"qualifications\",\n ]\n\n def get_qualifications(self, obj):\n return QualificationSerializer(\n Qualification.objects.filter(\n Q(grants__user=obj)\n & (Q(grants__expires__gte=timezone.now()) | Q(grants__expires__isnull=True))\n ),\n many=True,\n ).data\n\n\nclass UserProfileMeView(RetrieveAPIView):\n serializer_class = UserProfileSerializer\n queryset = UserProfile.objects.all()\n permission_classes = [IsAuthenticatedOrTokenHasScope]\n required_scopes = [\"ME_READ\"]\n schema = AutoSchema(operation_id_base=\"OwnUserProfile\")\n\n def get_object(self):\n if self.request.user is None:\n raise PermissionDenied()\n return self.request.user\n\n\nclass UserViewSet(viewsets.ReadOnlyModelViewSet):\n serializer_class = UserProfileSerializer\n queryset = UserProfile.objects.all()\n permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoObjectPermissions]\n required_scopes = [\"CONFIDENTIAL_READ\"]\n search_fields = [\"display_name\", \"email\"]\n\n filter_backends = [\n DjangoFilterBackend,\n SearchFilter,\n ObjectPermissionsFilter,\n ]\n\n\nclass UserByMailView(RetrieveModelMixin, GenericViewSet):\n serializer_class = UserProfileSerializer\n queryset = UserProfile.objects.all()\n permission_classes = [IsAuthenticatedOrTokenHasScope, DjangoObjectPermissions]\n required_scopes = [\"CONFIDENTIAL_READ\"]\n filter_backends = [ObjectPermissionsFilter]\n lookup_url_kwarg = \"email\"\n lookup_field = \"email\"\n schema = AutoSchema(operation_id_base=\"UserProfileByMail\")\n\n\nclass UserParticipationView(viewsets.ReadOnlyModelViewSet):\n serializer_class = ParticipationSerializer\n permission_classes = [IsAuthenticatedOrTokenHasScope]\n filter_backends = [ObjectPermissionsFilter, DjangoFilterBackend]\n filterset_fields = [\"state\"]\n required_scopes = [\"CONFIDENTIAL_READ\"]\n\n def get_queryset(self):\n return LocalParticipation.objects.filter(user=self.kwargs.get(\"user\"))\n", "path": "ephios/api/views/users.py"}]}
| 1,812 | 115 |
gh_patches_debug_8988
|
rasdani/github-patches
|
git_diff
|
beeware__toga-1454
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Your first Toga app" (helloworld) does not work as shown in the docs
I copy-pasted the code [found here](https://toga.readthedocs.io/en/latest/tutorial/tutorial-0.html). When I ran it, I got this error message:
```
$ python -m helloworld
Traceback (most recent call last):
File "C:\Users\brendan\AppData\Local\Programs\Python\Python39\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\brendan\AppData\Local\Programs\Python\Python39\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\bjk\tmp\beeware-toga\helloworld.py", line 2, in <module>
from tutorial import __version__
ModuleNotFoundError: No module named 'tutorial'
```
If I comment out the line `from tutorial import __version__` and delete the kwarg `version=__version__` in the call to `toga.App`, the module does run; i.e., the GUI window pops up and seems to work. However, during the run, I get a warning:
```
$ python -m helloworld
C:\Users\brendan\AppData\Local\Programs\Python\Python39\lib\site-packages\clr_loader\wrappers.py:20: DeprecationWarning:
builtin type GC Offset Base has no __module__ attribute
return self._callable(ffi.cast("void*", buf_arr), len(buf_arr))
```
Maybe it's just out-of-date documentation?
P.S. FWIW, a straight copy-paste of the second tutorial, "[A slightly less toy example](https://toga.readthedocs.io/en/latest/tutorial/tutorial-1.html)" works as is, although it does produce the same DeprecationWarning.
P.P.S. Ditto the fourth tutorial, "[Let’s build a browser!](https://toga.readthedocs.io/en/latest/tutorial/tutorial-3.html)"
</issue>
<code>
[start of examples/tutorial0/tutorial/app.py]
1 import toga
2 from tutorial import __version__
3
4
5 def button_handler(widget):
6 print("hello")
7
8
9 def build(app):
10 box = toga.Box()
11
12 button = toga.Button('Hello world', on_press=button_handler)
13 button.style.padding = 50
14 button.style.flex = 1
15 box.add(button)
16
17 return box
18
19
20 def main():
21 return toga.App(
22 'First App',
23 'org.beeware.helloworld',
24 author='Tiberius Yak',
25 description="A testing app",
26 version=__version__,
27 home_page="https://beeware.org",
28 startup=build
29 )
30
31
32 if __name__ == '__main__':
33 main().main_loop()
34
[end of examples/tutorial0/tutorial/app.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/tutorial0/tutorial/app.py b/examples/tutorial0/tutorial/app.py
--- a/examples/tutorial0/tutorial/app.py
+++ b/examples/tutorial0/tutorial/app.py
@@ -1,5 +1,4 @@
import toga
-from tutorial import __version__
def button_handler(widget):
@@ -18,15 +17,7 @@
def main():
- return toga.App(
- 'First App',
- 'org.beeware.helloworld',
- author='Tiberius Yak',
- description="A testing app",
- version=__version__,
- home_page="https://beeware.org",
- startup=build
- )
+ return toga.App('First App', 'org.beeware.helloworld', startup=build)
if __name__ == '__main__':
|
{"golden_diff": "diff --git a/examples/tutorial0/tutorial/app.py b/examples/tutorial0/tutorial/app.py\n--- a/examples/tutorial0/tutorial/app.py\n+++ b/examples/tutorial0/tutorial/app.py\n@@ -1,5 +1,4 @@\n import toga\n-from tutorial import __version__\n \n \n def button_handler(widget):\n@@ -18,15 +17,7 @@\n \n \n def main():\n- return toga.App(\n- 'First App',\n- 'org.beeware.helloworld',\n- author='Tiberius Yak',\n- description=\"A testing app\",\n- version=__version__,\n- home_page=\"https://beeware.org\",\n- startup=build\n- )\n+ return toga.App('First App', 'org.beeware.helloworld', startup=build)\n \n \n if __name__ == '__main__':\n", "issue": "\"Your first Toga app\" (helloworld) does not work as shown in the docs\nI copy-pasted the code [found here](https://toga.readthedocs.io/en/latest/tutorial/tutorial-0.html). When I ran it, I got this error message:\r\n\r\n```\r\n$ python -m helloworld\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\brendan\\AppData\\Local\\Programs\\Python\\Python39\\lib\\runpy.py\", line 197, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"C:\\Users\\brendan\\AppData\\Local\\Programs\\Python\\Python39\\lib\\runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"C:\\bjk\\tmp\\beeware-toga\\helloworld.py\", line 2, in <module>\r\n from tutorial import __version__\r\nModuleNotFoundError: No module named 'tutorial'\r\n```\r\n\r\nIf I comment out the line `from tutorial import __version__` and delete the kwarg `version=__version__` in the call to `toga.App`, the module does run; i.e., the GUI window pops up and seems to work. However, during the run, I get a warning:\r\n\r\n```\r\n$ python -m helloworld\r\nC:\\Users\\brendan\\AppData\\Local\\Programs\\Python\\Python39\\lib\\site-packages\\clr_loader\\wrappers.py:20: DeprecationWarning:\r\n builtin type GC Offset Base has no __module__ attribute\r\n return self._callable(ffi.cast(\"void*\", buf_arr), len(buf_arr))\r\n```\r\n\r\nMaybe it's just out-of-date documentation?\r\n\r\nP.S. FWIW, a straight copy-paste of the second tutorial, \"[A slightly less toy example](https://toga.readthedocs.io/en/latest/tutorial/tutorial-1.html)\" works as is, although it does produce the same DeprecationWarning.\r\n\r\nP.P.S. Ditto the fourth tutorial, \"[Let\u2019s build a browser!](https://toga.readthedocs.io/en/latest/tutorial/tutorial-3.html)\"\n", "before_files": [{"content": "import toga\nfrom tutorial import __version__\n\n\ndef button_handler(widget):\n print(\"hello\")\n\n\ndef build(app):\n box = toga.Box()\n\n button = toga.Button('Hello world', on_press=button_handler)\n button.style.padding = 50\n button.style.flex = 1\n box.add(button)\n\n return box\n\n\ndef main():\n return toga.App(\n 'First App',\n 'org.beeware.helloworld',\n author='Tiberius Yak',\n description=\"A testing app\",\n version=__version__,\n home_page=\"https://beeware.org\",\n startup=build\n )\n\n\nif __name__ == '__main__':\n main().main_loop()\n", "path": "examples/tutorial0/tutorial/app.py"}]}
| 1,213 | 174 |
gh_patches_debug_17822
|
rasdani/github-patches
|
git_diff
|
biolab__orange3-4432
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Select Rows" loses class labels with "Remove unused classes"
**Describe the bug**
Selecting a subset of discretized class values make them all unknown, if I use "Remove unused classes".
In contrast, it works well with a "raw" variable such as the class for iris.tab.
**To Reproduce**
- File (housing)
- Discretize (discretize to three intervals)
- Select Rows (MEDV, select 2/3 values, choose "Remove unused classes")
- Data Table (observe unknown class values)
**Orange version:**
master
</issue>
<code>
[start of Orange/preprocess/remove.py]
1 from collections import namedtuple
2
3 import numpy as np
4
5 from Orange.data import Domain, DiscreteVariable, Table
6 from Orange.preprocess.transformation import Lookup
7 from Orange.statistics.util import nanunique
8 from .preprocess import Preprocess
9
10 __all__ = ["Remove"]
11
12
13 class Remove(Preprocess):
14 """
15 Construct a preprocessor for removing constant features/classes
16 and unused values.
17 Given a data table, preprocessor returns a new table and a list of
18 results. In the new table, the constant features/classes and unused
19 values are removed. The list of results consists of two dictionaries.
20 The first one contains numbers of 'removed', 'reduced' and 'sorted'
21 features. The second one contains numbers of 'removed', 'reduced'
22 and 'sorted' features.
23
24 Parameters
25 ----------
26 attr_flags : int (default: 0)
27 If SortValues, values of discrete attributes are sorted.
28 If RemoveConstant, unused attributes are removed.
29 If RemoveUnusedValues, unused values are removed from discrete
30 attributes.
31 It is possible to merge operations in one by summing several types.
32
33 class_flags: int (default: 0)
34 If SortValues, values of discrete class attributes are sorted.
35 If RemoveConstant, unused class attributes are removed.
36 If RemoveUnusedValues, unused values are removed from discrete
37 class attributes.
38 It is possible to merge operations in one by summing several types.
39
40 Examples
41 --------
42 >>> from Orange.data import Table
43 >>> from Orange.preprocess import Remove
44 >>> data = Table("zoo")[:10]
45 >>> flags = sum([Remove.SortValues, Remove.RemoveConstant, Remove.RemoveUnusedValues])
46 >>> remover = Remove(attr_flags=flags, class_flags=flags)
47 >>> new_data = remover(data)
48 >>> attr_results, class_results = remover.attr_results, remover.class_results
49 """
50
51 SortValues, RemoveConstant, RemoveUnusedValues = 1, 2, 4
52
53 def __init__(self, attr_flags=0, class_flags=0, meta_flags=0):
54 self.attr_flags = attr_flags
55 self.class_flags = class_flags
56 self.meta_flags = meta_flags
57 self.attr_results = None
58 self.class_results = None
59 self.meta_results = None
60
61 def __call__(self, data):
62 """
63 Removes unused features or classes from the given data. Returns a new
64 data table.
65
66 Parameters
67 ----------
68 data : Orange.data.Table
69 A data table to remove features or classes from.
70
71 Returns
72 -------
73 data : Orange.data.Table
74 New data table.
75 """
76 if data is None:
77 return None
78
79 domain = data.domain
80 attrs_state = [purge_var_M(var, data, self.attr_flags)
81 for var in domain.attributes]
82 class_state = [purge_var_M(var, data, self.class_flags)
83 for var in domain.class_vars]
84 metas_state = [purge_var_M(var, data, self.meta_flags)
85 for var in domain.metas]
86
87 att_vars, self.attr_results = self.get_vars_and_results(attrs_state)
88 cls_vars, self.class_results = self.get_vars_and_results(class_state)
89 meta_vars, self.meta_results = self.get_vars_and_results(metas_state)
90
91 domain = Domain(att_vars, cls_vars, meta_vars)
92 return data.transform(domain)
93
94 def get_vars_and_results(self, state):
95 removed, reduced, sorted = 0, 0, 0
96 vars = []
97 for st in state:
98 removed += is_removed(st)
99 reduced += not is_removed(st) and is_reduced(st)
100 sorted += not is_removed(st) and is_sorted(st)
101 if not is_removed(st):
102 vars.append(merge_transforms(st).var)
103 res = {'removed': removed, 'reduced': reduced, 'sorted': sorted}
104 return vars, res
105
106
107 # Define a simple Purge expression 'language'.
108 #: A input variable (leaf expression).
109 Var = namedtuple("Var", ["var"])
110 #: Removed variable (can only ever be present as a root node).
111 Removed = namedtuple("Removed", ["sub", "var"])
112 #: A reduced variable
113 Reduced = namedtuple("Reduced", ["sub", "var"])
114 #: A sorted variable
115 Sorted = namedtuple("Sorted", ["sub", "var"])
116 #: A general (lookup) transformed variable.
117 #: (this node is returned as a result of `merge` which joins consecutive
118 #: Removed/Reduced nodes into a single Transformed node)
119 Transformed = namedtuple("Transformed", ["sub", "var"])
120
121
122 def is_var(exp):
123 """Is `exp` a `Var` node."""
124 return isinstance(exp, Var)
125
126
127 def is_removed(exp):
128 """Is `exp` a `Removed` node."""
129 return isinstance(exp, Removed)
130
131
132 def _contains(exp, cls):
133 """Does `node` contain a sub node of type `cls`"""
134 if isinstance(exp, cls):
135 return True
136 elif isinstance(exp, Var):
137 return False
138 else:
139 return _contains(exp.sub, cls)
140
141
142 def is_reduced(exp):
143 """Does `exp` contain a `Reduced` node."""
144 return _contains(exp, Reduced)
145
146
147 def is_sorted(exp):
148 """Does `exp` contain a `Reduced` node."""
149 return _contains(exp, Sorted)
150
151
152 def merge_transforms(exp):
153 """
154 Merge consecutive Removed, Reduced or Transformed nodes.
155
156 .. note:: Removed nodes are returned unchanged.
157
158 """
159 if isinstance(exp, (Var, Removed)):
160 return exp
161 elif isinstance(exp, (Reduced, Sorted, Transformed)):
162 prev = merge_transforms(exp.sub)
163 if isinstance(prev, (Reduced, Sorted, Transformed)):
164 B = exp.var.compute_value
165 assert isinstance(B, Lookup)
166 A = B.variable.compute_value
167 assert isinstance(A, Lookup)
168
169 new_var = DiscreteVariable(
170 exp.var.name,
171 values=exp.var.values,
172 ordered=exp.var.ordered,
173 compute_value=merge_lookup(A, B),
174 sparse=exp.var.sparse,
175 )
176 assert isinstance(prev.sub, Var)
177 return Transformed(prev.sub, new_var)
178 else:
179 assert prev is exp.sub
180 return exp
181 else:
182 raise TypeError
183
184
185 def purge_var_M(var, data, flags):
186 state = Var(var)
187 if flags & Remove.RemoveConstant:
188 var = remove_constant(state.var, data)
189 if var is None:
190 return Removed(state, state.var)
191
192 if state.var.is_discrete:
193 if flags & Remove.RemoveUnusedValues:
194 newattr = remove_unused_values(state.var, data)
195
196 if newattr is not state.var:
197 state = Reduced(state, newattr)
198
199 if flags & Remove.RemoveConstant and len(state.var.values) < 2:
200 return Removed(state, state.var)
201
202 if flags & Remove.SortValues:
203 newattr = sort_var_values(state.var)
204 if newattr is not state.var:
205 state = Sorted(state, newattr)
206
207 return state
208
209
210 def has_at_least_two_values(data, var):
211 ((dist, unknowns),) = data._compute_distributions([var])
212 # TODO this check is suboptimal for sparse since get_column_view
213 # densifies the data. Should be irrelevant after Pandas.
214 _, sparse = data.get_column_view(var)
215 if var.is_continuous:
216 dist = dist[1, :]
217 min_size = 0 if sparse and unknowns else 1
218 return np.sum(dist > 0.0) > min_size
219
220
221 def remove_constant(var, data):
222 if var.is_continuous:
223 if not has_at_least_two_values(data, var):
224 return None
225 else:
226 return var
227 elif var.is_discrete:
228 if len(var.values) < 2:
229 return None
230 else:
231 return var
232 else:
233 return var
234
235
236 def remove_unused_values(var, data):
237 unique = nanunique(data.get_column_view(var)[0].astype(float)).astype(int)
238 if len(unique) == len(var.values):
239 return var
240 used_values = [var.values[i] for i in unique]
241 return DiscreteVariable(var.name, values=used_values, sparse=var.sparse)
242
243
244 def sort_var_values(var):
245 newvalues = list(sorted(var.values))
246
247 if newvalues == list(var.values):
248 return var
249
250 translation_table = np.array(
251 [float(newvalues.index(value)) for value in var.values]
252 )
253
254 return DiscreteVariable(var.name, values=newvalues,
255 compute_value=Lookup(var, translation_table),
256 sparse=var.sparse)
257
258
259 def merge_lookup(A, B):
260 """
261 Merge two consecutive Lookup transforms into one.
262 """
263 lookup_table = np.array(A.lookup_table)
264 mask = np.isfinite(lookup_table)
265 indices = np.array(lookup_table[mask], dtype=int)
266 lookup_table[mask] = B.lookup_table[indices]
267 return Lookup(A.variable, lookup_table)
268
[end of Orange/preprocess/remove.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Orange/preprocess/remove.py b/Orange/preprocess/remove.py
--- a/Orange/preprocess/remove.py
+++ b/Orange/preprocess/remove.py
@@ -2,7 +2,7 @@
import numpy as np
-from Orange.data import Domain, DiscreteVariable, Table
+from Orange.data import Domain, DiscreteVariable
from Orange.preprocess.transformation import Lookup
from Orange.statistics.util import nanunique
from .preprocess import Preprocess
@@ -238,7 +238,10 @@
if len(unique) == len(var.values):
return var
used_values = [var.values[i] for i in unique]
- return DiscreteVariable(var.name, values=used_values, sparse=var.sparse)
+ translation_table = np.array([np.NaN] * len(var.values))
+ translation_table[unique] = range(len(used_values))
+ return DiscreteVariable(var.name, values=used_values, sparse=var.sparse,
+ compute_value=Lookup(var, translation_table))
def sort_var_values(var):
|
{"golden_diff": "diff --git a/Orange/preprocess/remove.py b/Orange/preprocess/remove.py\n--- a/Orange/preprocess/remove.py\n+++ b/Orange/preprocess/remove.py\n@@ -2,7 +2,7 @@\n \n import numpy as np\n \n-from Orange.data import Domain, DiscreteVariable, Table\n+from Orange.data import Domain, DiscreteVariable\n from Orange.preprocess.transformation import Lookup\n from Orange.statistics.util import nanunique\n from .preprocess import Preprocess\n@@ -238,7 +238,10 @@\n if len(unique) == len(var.values):\n return var\n used_values = [var.values[i] for i in unique]\n- return DiscreteVariable(var.name, values=used_values, sparse=var.sparse)\n+ translation_table = np.array([np.NaN] * len(var.values))\n+ translation_table[unique] = range(len(used_values))\n+ return DiscreteVariable(var.name, values=used_values, sparse=var.sparse,\n+ compute_value=Lookup(var, translation_table))\n \n \n def sort_var_values(var):\n", "issue": "\"Select Rows\" loses class labels with \"Remove unused classes\"\n**Describe the bug**\r\nSelecting a subset of discretized class values make them all unknown, if I use \"Remove unused classes\".\r\n\r\nIn contrast, it works well with a \"raw\" variable such as the class for iris.tab.\r\n\r\n**To Reproduce**\r\n- File (housing)\r\n- Discretize (discretize to three intervals)\r\n- Select Rows (MEDV, select 2/3 values, choose \"Remove unused classes\")\r\n- Data Table (observe unknown class values)\r\n\r\n**Orange version:**\r\nmaster\r\n\n", "before_files": [{"content": "from collections import namedtuple\n\nimport numpy as np\n\nfrom Orange.data import Domain, DiscreteVariable, Table\nfrom Orange.preprocess.transformation import Lookup\nfrom Orange.statistics.util import nanunique\nfrom .preprocess import Preprocess\n\n__all__ = [\"Remove\"]\n\n\nclass Remove(Preprocess):\n \"\"\"\n Construct a preprocessor for removing constant features/classes\n and unused values.\n Given a data table, preprocessor returns a new table and a list of\n results. In the new table, the constant features/classes and unused\n values are removed. The list of results consists of two dictionaries.\n The first one contains numbers of 'removed', 'reduced' and 'sorted'\n features. The second one contains numbers of 'removed', 'reduced'\n and 'sorted' features.\n\n Parameters\n ----------\n attr_flags : int (default: 0)\n If SortValues, values of discrete attributes are sorted.\n If RemoveConstant, unused attributes are removed.\n If RemoveUnusedValues, unused values are removed from discrete\n attributes.\n It is possible to merge operations in one by summing several types.\n\n class_flags: int (default: 0)\n If SortValues, values of discrete class attributes are sorted.\n If RemoveConstant, unused class attributes are removed.\n If RemoveUnusedValues, unused values are removed from discrete\n class attributes.\n It is possible to merge operations in one by summing several types.\n\n Examples\n --------\n >>> from Orange.data import Table\n >>> from Orange.preprocess import Remove\n >>> data = Table(\"zoo\")[:10]\n >>> flags = sum([Remove.SortValues, Remove.RemoveConstant, Remove.RemoveUnusedValues])\n >>> remover = Remove(attr_flags=flags, class_flags=flags)\n >>> new_data = remover(data)\n >>> attr_results, class_results = remover.attr_results, remover.class_results\n \"\"\"\n\n SortValues, RemoveConstant, RemoveUnusedValues = 1, 2, 4\n\n def __init__(self, attr_flags=0, class_flags=0, meta_flags=0):\n self.attr_flags = attr_flags\n self.class_flags = class_flags\n self.meta_flags = meta_flags\n self.attr_results = None\n self.class_results = None\n self.meta_results = None\n\n def __call__(self, data):\n \"\"\"\n Removes unused features or classes from the given data. Returns a new\n data table.\n\n Parameters\n ----------\n data : Orange.data.Table\n A data table to remove features or classes from.\n\n Returns\n -------\n data : Orange.data.Table\n New data table.\n \"\"\"\n if data is None:\n return None\n\n domain = data.domain\n attrs_state = [purge_var_M(var, data, self.attr_flags)\n for var in domain.attributes]\n class_state = [purge_var_M(var, data, self.class_flags)\n for var in domain.class_vars]\n metas_state = [purge_var_M(var, data, self.meta_flags)\n for var in domain.metas]\n\n att_vars, self.attr_results = self.get_vars_and_results(attrs_state)\n cls_vars, self.class_results = self.get_vars_and_results(class_state)\n meta_vars, self.meta_results = self.get_vars_and_results(metas_state)\n\n domain = Domain(att_vars, cls_vars, meta_vars)\n return data.transform(domain)\n\n def get_vars_and_results(self, state):\n removed, reduced, sorted = 0, 0, 0\n vars = []\n for st in state:\n removed += is_removed(st)\n reduced += not is_removed(st) and is_reduced(st)\n sorted += not is_removed(st) and is_sorted(st)\n if not is_removed(st):\n vars.append(merge_transforms(st).var)\n res = {'removed': removed, 'reduced': reduced, 'sorted': sorted}\n return vars, res\n\n\n# Define a simple Purge expression 'language'.\n#: A input variable (leaf expression).\nVar = namedtuple(\"Var\", [\"var\"])\n#: Removed variable (can only ever be present as a root node).\nRemoved = namedtuple(\"Removed\", [\"sub\", \"var\"])\n#: A reduced variable\nReduced = namedtuple(\"Reduced\", [\"sub\", \"var\"])\n#: A sorted variable\nSorted = namedtuple(\"Sorted\", [\"sub\", \"var\"])\n#: A general (lookup) transformed variable.\n#: (this node is returned as a result of `merge` which joins consecutive\n#: Removed/Reduced nodes into a single Transformed node)\nTransformed = namedtuple(\"Transformed\", [\"sub\", \"var\"])\n\n\ndef is_var(exp):\n \"\"\"Is `exp` a `Var` node.\"\"\"\n return isinstance(exp, Var)\n\n\ndef is_removed(exp):\n \"\"\"Is `exp` a `Removed` node.\"\"\"\n return isinstance(exp, Removed)\n\n\ndef _contains(exp, cls):\n \"\"\"Does `node` contain a sub node of type `cls`\"\"\"\n if isinstance(exp, cls):\n return True\n elif isinstance(exp, Var):\n return False\n else:\n return _contains(exp.sub, cls)\n\n\ndef is_reduced(exp):\n \"\"\"Does `exp` contain a `Reduced` node.\"\"\"\n return _contains(exp, Reduced)\n\n\ndef is_sorted(exp):\n \"\"\"Does `exp` contain a `Reduced` node.\"\"\"\n return _contains(exp, Sorted)\n\n\ndef merge_transforms(exp):\n \"\"\"\n Merge consecutive Removed, Reduced or Transformed nodes.\n\n .. note:: Removed nodes are returned unchanged.\n\n \"\"\"\n if isinstance(exp, (Var, Removed)):\n return exp\n elif isinstance(exp, (Reduced, Sorted, Transformed)):\n prev = merge_transforms(exp.sub)\n if isinstance(prev, (Reduced, Sorted, Transformed)):\n B = exp.var.compute_value\n assert isinstance(B, Lookup)\n A = B.variable.compute_value\n assert isinstance(A, Lookup)\n\n new_var = DiscreteVariable(\n exp.var.name,\n values=exp.var.values,\n ordered=exp.var.ordered,\n compute_value=merge_lookup(A, B),\n sparse=exp.var.sparse,\n )\n assert isinstance(prev.sub, Var)\n return Transformed(prev.sub, new_var)\n else:\n assert prev is exp.sub\n return exp\n else:\n raise TypeError\n\n\ndef purge_var_M(var, data, flags):\n state = Var(var)\n if flags & Remove.RemoveConstant:\n var = remove_constant(state.var, data)\n if var is None:\n return Removed(state, state.var)\n\n if state.var.is_discrete:\n if flags & Remove.RemoveUnusedValues:\n newattr = remove_unused_values(state.var, data)\n\n if newattr is not state.var:\n state = Reduced(state, newattr)\n\n if flags & Remove.RemoveConstant and len(state.var.values) < 2:\n return Removed(state, state.var)\n\n if flags & Remove.SortValues:\n newattr = sort_var_values(state.var)\n if newattr is not state.var:\n state = Sorted(state, newattr)\n\n return state\n\n\ndef has_at_least_two_values(data, var):\n ((dist, unknowns),) = data._compute_distributions([var])\n # TODO this check is suboptimal for sparse since get_column_view\n # densifies the data. Should be irrelevant after Pandas.\n _, sparse = data.get_column_view(var)\n if var.is_continuous:\n dist = dist[1, :]\n min_size = 0 if sparse and unknowns else 1\n return np.sum(dist > 0.0) > min_size\n\n\ndef remove_constant(var, data):\n if var.is_continuous:\n if not has_at_least_two_values(data, var):\n return None\n else:\n return var\n elif var.is_discrete:\n if len(var.values) < 2:\n return None\n else:\n return var\n else:\n return var\n\n\ndef remove_unused_values(var, data):\n unique = nanunique(data.get_column_view(var)[0].astype(float)).astype(int)\n if len(unique) == len(var.values):\n return var\n used_values = [var.values[i] for i in unique]\n return DiscreteVariable(var.name, values=used_values, sparse=var.sparse)\n\n\ndef sort_var_values(var):\n newvalues = list(sorted(var.values))\n\n if newvalues == list(var.values):\n return var\n\n translation_table = np.array(\n [float(newvalues.index(value)) for value in var.values]\n )\n\n return DiscreteVariable(var.name, values=newvalues,\n compute_value=Lookup(var, translation_table),\n sparse=var.sparse)\n\n\ndef merge_lookup(A, B):\n \"\"\"\n Merge two consecutive Lookup transforms into one.\n \"\"\"\n lookup_table = np.array(A.lookup_table)\n mask = np.isfinite(lookup_table)\n indices = np.array(lookup_table[mask], dtype=int)\n lookup_table[mask] = B.lookup_table[indices]\n return Lookup(A.variable, lookup_table)\n", "path": "Orange/preprocess/remove.py"}]}
| 3,299 | 229 |
gh_patches_debug_42590
|
rasdani/github-patches
|
git_diff
|
kserve__kserve-1687
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make default asyncio workers proportional to cpu-limit
/kind feature
Currently a custom transformer spawns threads promotional to the number of cores on the machine/node. This might be due to python (and tornatdo, asyncio) not being container aware. On nodes with high core count, more threads cause throttling when cpu-limit is comparatively low
Making the number of threads spawned proportional to cpu-limit would help with throttling.
</issue>
<code>
[start of python/kfserving/kfserving/utils/utils.py]
1 # Copyright 2020 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16
17
18 def is_running_in_k8s():
19 return os.path.isdir('/var/run/secrets/kubernetes.io/')
20
21
22 def get_current_k8s_namespace():
23 with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:
24 return f.readline()
25
26
27 def get_default_target_namespace():
28 if not is_running_in_k8s():
29 return 'default'
30 return get_current_k8s_namespace()
31
32
33 def set_isvc_namespace(inferenceservice):
34 isvc_namespace = inferenceservice.metadata.namespace
35 namespace = isvc_namespace or get_default_target_namespace()
36 return namespace
37
[end of python/kfserving/kfserving/utils/utils.py]
[start of python/kfserving/kfserving/kfserver.py]
1 # Copyright 2020 kubeflow.org.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import argparse
16 import logging
17 import json
18 import inspect
19 import sys
20 from typing import List, Optional
21 import tornado.ioloop
22 import tornado.web
23 import tornado.httpserver
24 import tornado.log
25
26 from kfserving.handlers.http import PredictHandler, ExplainHandler
27 from kfserving import KFModel
28 from kfserving.kfmodel_repository import KFModelRepository
29
30 DEFAULT_HTTP_PORT = 8080
31 DEFAULT_GRPC_PORT = 8081
32 DEFAULT_MAX_BUFFER_SIZE = 104857600
33
34 parser = argparse.ArgumentParser(add_help=False)
35 parser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,
36 help='The HTTP Port listened to by the model server.')
37 parser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,
38 help='The GRPC Port listened to by the model server.')
39 parser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,
40 help='The max buffer size for tornado.')
41 parser.add_argument('--workers', default=1, type=int,
42 help='The number of works to fork')
43 args, _ = parser.parse_known_args()
44
45 tornado.log.enable_pretty_logging()
46
47
48 class KFServer:
49 def __init__(self, http_port: int = args.http_port,
50 grpc_port: int = args.grpc_port,
51 max_buffer_size: int = args.max_buffer_size,
52 workers: int = args.workers,
53 registered_models: KFModelRepository = KFModelRepository()):
54 self.registered_models = registered_models
55 self.http_port = http_port
56 self.grpc_port = grpc_port
57 self.max_buffer_size = max_buffer_size
58 self.workers = workers
59 self._http_server: Optional[tornado.httpserver.HTTPServer] = None
60
61 def create_application(self):
62 return tornado.web.Application([
63 # Server Liveness API returns 200 if server is alive.
64 (r"/", LivenessHandler),
65 (r"/v2/health/live", LivenessHandler),
66 (r"/v1/models",
67 ListHandler, dict(models=self.registered_models)),
68 (r"/v2/models",
69 ListHandler, dict(models=self.registered_models)),
70 # Model Health API returns 200 if model is ready to serve.
71 (r"/v1/models/([a-zA-Z0-9_-]+)",
72 HealthHandler, dict(models=self.registered_models)),
73 (r"/v2/models/([a-zA-Z0-9_-]+)/status",
74 HealthHandler, dict(models=self.registered_models)),
75 (r"/v1/models/([a-zA-Z0-9_-]+):predict",
76 PredictHandler, dict(models=self.registered_models)),
77 (r"/v2/models/([a-zA-Z0-9_-]+)/infer",
78 PredictHandler, dict(models=self.registered_models)),
79 (r"/v1/models/([a-zA-Z0-9_-]+):explain",
80 ExplainHandler, dict(models=self.registered_models)),
81 (r"/v2/models/([a-zA-Z0-9_-]+)/explain",
82 ExplainHandler, dict(models=self.registered_models)),
83 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/load",
84 LoadHandler, dict(models=self.registered_models)),
85 (r"/v2/repository/models/([a-zA-Z0-9_-]+)/unload",
86 UnloadHandler, dict(models=self.registered_models)),
87 ])
88
89 def start(self, models: List[KFModel], nest_asyncio: bool = False):
90 for model in models:
91 self.register_model(model)
92
93 self._http_server = tornado.httpserver.HTTPServer(
94 self.create_application(), max_buffer_size=self.max_buffer_size)
95
96 logging.info("Listening on port %s", self.http_port)
97 self._http_server.bind(self.http_port)
98 logging.info("Will fork %d workers", self.workers)
99 self._http_server.start(self.workers)
100
101 # Need to start the IOLoop after workers have been started
102 # https://github.com/tornadoweb/tornado/issues/2426
103 # The nest_asyncio package needs to be installed by the downstream module
104 if nest_asyncio:
105 import nest_asyncio
106 nest_asyncio.apply()
107
108 tornado.ioloop.IOLoop.current().start()
109
110 def register_model(self, model: KFModel):
111 if not model.name:
112 raise Exception(
113 "Failed to register model, model.name must be provided.")
114 self.registered_models.update(model)
115 logging.info("Registering model: %s", model.name)
116
117
118 class LivenessHandler(tornado.web.RequestHandler): # pylint:disable=too-few-public-methods
119 def get(self):
120 self.write("Alive")
121
122
123 class HealthHandler(tornado.web.RequestHandler):
124 def initialize(self, models: KFModelRepository):
125 self.models = models # pylint:disable=attribute-defined-outside-init
126
127 def get(self, name: str):
128 model = self.models.get_model(name)
129 if model is None:
130 raise tornado.web.HTTPError(
131 status_code=404,
132 reason="Model with name %s does not exist." % name
133 )
134
135 if not model.ready:
136 raise tornado.web.HTTPError(
137 status_code=503,
138 reason="Model with name %s is not ready." % name
139 )
140
141 self.write(json.dumps({
142 "name": model.name,
143 "ready": model.ready
144 }))
145
146
147 class ListHandler(tornado.web.RequestHandler):
148 def initialize(self, models: KFModelRepository):
149 self.models = models # pylint:disable=attribute-defined-outside-init
150
151 def get(self):
152 self.write(json.dumps([ob.name for ob in self.models.get_models()]))
153
154
155 class LoadHandler(tornado.web.RequestHandler):
156 def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init
157 self.models = models
158
159 async def post(self, name: str):
160 try:
161 (await self.models.load(name)) if inspect.iscoroutinefunction(self.models.load) else self.models.load(name)
162 except Exception:
163 ex_type, ex_value, ex_traceback = sys.exc_info()
164 raise tornado.web.HTTPError(
165 status_code=500,
166 reason=f"Model with name {name} is not ready. "
167 f"Error type: {ex_type} error msg: {ex_value}"
168 )
169
170 if not self.models.is_model_ready(name):
171 raise tornado.web.HTTPError(
172 status_code=503,
173 reason=f"Model with name {name} is not ready."
174 )
175 self.write(json.dumps({
176 "name": name,
177 "load": True
178 }))
179
180
181 class UnloadHandler(tornado.web.RequestHandler):
182 def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init
183 self.models = models
184
185 def post(self, name: str):
186 try:
187 self.models.unload(name)
188 except KeyError:
189 raise tornado.web.HTTPError(
190 status_code=404,
191 reason="Model with name %s does not exist." % name
192 )
193 self.write(json.dumps({
194 "name": name,
195 "unload": True
196 }))
197
[end of python/kfserving/kfserving/kfserver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/kfserving/kfserving/kfserver.py b/python/kfserving/kfserving/kfserver.py
--- a/python/kfserving/kfserving/kfserver.py
+++ b/python/kfserving/kfserving/kfserver.py
@@ -22,6 +22,9 @@
import tornado.web
import tornado.httpserver
import tornado.log
+import asyncio
+from tornado import concurrent
+from .utils import utils
from kfserving.handlers.http import PredictHandler, ExplainHandler
from kfserving import KFModel
@@ -40,6 +43,8 @@
help='The max buffer size for tornado.')
parser.add_argument('--workers', default=1, type=int,
help='The number of works to fork')
+parser.add_argument('--max_asyncio_workers', default=None, type=int,
+ help='Max number of asyncio workers to spawn')
args, _ = parser.parse_known_args()
tornado.log.enable_pretty_logging()
@@ -50,12 +55,14 @@
grpc_port: int = args.grpc_port,
max_buffer_size: int = args.max_buffer_size,
workers: int = args.workers,
+ max_asyncio_workers: int = args.max_asyncio_workers,
registered_models: KFModelRepository = KFModelRepository()):
self.registered_models = registered_models
self.http_port = http_port
self.grpc_port = grpc_port
self.max_buffer_size = max_buffer_size
self.workers = workers
+ self.max_asyncio_workers = max_asyncio_workers
self._http_server: Optional[tornado.httpserver.HTTPServer] = None
def create_application(self):
@@ -87,6 +94,14 @@
])
def start(self, models: List[KFModel], nest_asyncio: bool = False):
+ if self.max_asyncio_workers is None:
+ # formula as suggest in https://bugs.python.org/issue35279
+ self.max_asyncio_workers = min(32, utils.cpu_count()+4)
+
+ logging.info(f"Setting asyncio max_workers as {self.max_asyncio_workers}")
+ asyncio.get_event_loop().set_default_executor(
+ concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))
+
for model in models:
self.register_model(model)
diff --git a/python/kfserving/kfserving/utils/utils.py b/python/kfserving/kfserving/utils/utils.py
--- a/python/kfserving/kfserving/utils/utils.py
+++ b/python/kfserving/kfserving/utils/utils.py
@@ -13,6 +13,8 @@
# limitations under the License.
import os
+import sys
+import psutil
def is_running_in_k8s():
@@ -34,3 +36,36 @@
isvc_namespace = inferenceservice.metadata.namespace
namespace = isvc_namespace or get_default_target_namespace()
return namespace
+
+
+def cpu_count():
+ """Get the available CPU count for this system.
+ Takes the minimum value from the following locations:
+ - Total system cpus available on the host.
+ - CPU Affinity (if set)
+ - Cgroups limit (if set)
+ """
+ count = os.cpu_count()
+
+ # Check CPU affinity if available
+ try:
+ affinity_count = len(psutil.Process().cpu_affinity())
+ if affinity_count > 0:
+ count = min(count, affinity_count)
+ except Exception:
+ pass
+
+ # Check cgroups if available
+ if sys.platform == "linux":
+ try:
+ with open("/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us") as f:
+ quota = int(f.read())
+ with open("/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us") as f:
+ period = int(f.read())
+ cgroups_count = int(quota / period)
+ if cgroups_count > 0:
+ count = min(count, cgroups_count)
+ except Exception:
+ pass
+
+ return count
|
{"golden_diff": "diff --git a/python/kfserving/kfserving/kfserver.py b/python/kfserving/kfserving/kfserver.py\n--- a/python/kfserving/kfserving/kfserver.py\n+++ b/python/kfserving/kfserving/kfserver.py\n@@ -22,6 +22,9 @@\n import tornado.web\n import tornado.httpserver\n import tornado.log\n+import asyncio\n+from tornado import concurrent\n+from .utils import utils\n \n from kfserving.handlers.http import PredictHandler, ExplainHandler\n from kfserving import KFModel\n@@ -40,6 +43,8 @@\n help='The max buffer size for tornado.')\n parser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\n+parser.add_argument('--max_asyncio_workers', default=None, type=int,\n+ help='Max number of asyncio workers to spawn')\n args, _ = parser.parse_known_args()\n \n tornado.log.enable_pretty_logging()\n@@ -50,12 +55,14 @@\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n+ max_asyncio_workers: int = args.max_asyncio_workers,\n registered_models: KFModelRepository = KFModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n+ self.max_asyncio_workers = max_asyncio_workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n \n def create_application(self):\n@@ -87,6 +94,14 @@\n ])\n \n def start(self, models: List[KFModel], nest_asyncio: bool = False):\n+ if self.max_asyncio_workers is None:\n+ # formula as suggest in https://bugs.python.org/issue35279\n+ self.max_asyncio_workers = min(32, utils.cpu_count()+4)\n+\n+ logging.info(f\"Setting asyncio max_workers as {self.max_asyncio_workers}\")\n+ asyncio.get_event_loop().set_default_executor(\n+ concurrent.futures.ThreadPoolExecutor(max_workers=self.max_asyncio_workers))\n+\n for model in models:\n self.register_model(model)\n \ndiff --git a/python/kfserving/kfserving/utils/utils.py b/python/kfserving/kfserving/utils/utils.py\n--- a/python/kfserving/kfserving/utils/utils.py\n+++ b/python/kfserving/kfserving/utils/utils.py\n@@ -13,6 +13,8 @@\n # limitations under the License.\n \n import os\n+import sys\n+import psutil\n \n \n def is_running_in_k8s():\n@@ -34,3 +36,36 @@\n isvc_namespace = inferenceservice.metadata.namespace\n namespace = isvc_namespace or get_default_target_namespace()\n return namespace\n+\n+\n+def cpu_count():\n+ \"\"\"Get the available CPU count for this system.\n+ Takes the minimum value from the following locations:\n+ - Total system cpus available on the host.\n+ - CPU Affinity (if set)\n+ - Cgroups limit (if set)\n+ \"\"\"\n+ count = os.cpu_count()\n+\n+ # Check CPU affinity if available\n+ try:\n+ affinity_count = len(psutil.Process().cpu_affinity())\n+ if affinity_count > 0:\n+ count = min(count, affinity_count)\n+ except Exception:\n+ pass\n+\n+ # Check cgroups if available\n+ if sys.platform == \"linux\":\n+ try:\n+ with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_quota_us\") as f:\n+ quota = int(f.read())\n+ with open(\"/sys/fs/cgroup/cpu,cpuacct/cpu.cfs_period_us\") as f:\n+ period = int(f.read())\n+ cgroups_count = int(quota / period)\n+ if cgroups_count > 0:\n+ count = min(count, cgroups_count)\n+ except Exception:\n+ pass\n+\n+ return count\n", "issue": "Make default asyncio workers proportional to cpu-limit\n/kind feature\r\n\r\nCurrently a custom transformer spawns threads promotional to the number of cores on the machine/node. This might be due to python (and tornatdo, asyncio) not being container aware. On nodes with high core count, more threads cause throttling when cpu-limit is comparatively low\r\n\r\nMaking the number of threads spawned proportional to cpu-limit would help with throttling.\r\n\n", "before_files": [{"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\n\n\ndef is_running_in_k8s():\n return os.path.isdir('/var/run/secrets/kubernetes.io/')\n\n\ndef get_current_k8s_namespace():\n with open('/var/run/secrets/kubernetes.io/serviceaccount/namespace', 'r') as f:\n return f.readline()\n\n\ndef get_default_target_namespace():\n if not is_running_in_k8s():\n return 'default'\n return get_current_k8s_namespace()\n\n\ndef set_isvc_namespace(inferenceservice):\n isvc_namespace = inferenceservice.metadata.namespace\n namespace = isvc_namespace or get_default_target_namespace()\n return namespace\n", "path": "python/kfserving/kfserving/utils/utils.py"}, {"content": "# Copyright 2020 kubeflow.org.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport argparse\nimport logging\nimport json\nimport inspect\nimport sys\nfrom typing import List, Optional\nimport tornado.ioloop\nimport tornado.web\nimport tornado.httpserver\nimport tornado.log\n\nfrom kfserving.handlers.http import PredictHandler, ExplainHandler\nfrom kfserving import KFModel\nfrom kfserving.kfmodel_repository import KFModelRepository\n\nDEFAULT_HTTP_PORT = 8080\nDEFAULT_GRPC_PORT = 8081\nDEFAULT_MAX_BUFFER_SIZE = 104857600\n\nparser = argparse.ArgumentParser(add_help=False)\nparser.add_argument('--http_port', default=DEFAULT_HTTP_PORT, type=int,\n help='The HTTP Port listened to by the model server.')\nparser.add_argument('--grpc_port', default=DEFAULT_GRPC_PORT, type=int,\n help='The GRPC Port listened to by the model server.')\nparser.add_argument('--max_buffer_size', default=DEFAULT_MAX_BUFFER_SIZE, type=int,\n help='The max buffer size for tornado.')\nparser.add_argument('--workers', default=1, type=int,\n help='The number of works to fork')\nargs, _ = parser.parse_known_args()\n\ntornado.log.enable_pretty_logging()\n\n\nclass KFServer:\n def __init__(self, http_port: int = args.http_port,\n grpc_port: int = args.grpc_port,\n max_buffer_size: int = args.max_buffer_size,\n workers: int = args.workers,\n registered_models: KFModelRepository = KFModelRepository()):\n self.registered_models = registered_models\n self.http_port = http_port\n self.grpc_port = grpc_port\n self.max_buffer_size = max_buffer_size\n self.workers = workers\n self._http_server: Optional[tornado.httpserver.HTTPServer] = None\n\n def create_application(self):\n return tornado.web.Application([\n # Server Liveness API returns 200 if server is alive.\n (r\"/\", LivenessHandler),\n (r\"/v2/health/live\", LivenessHandler),\n (r\"/v1/models\",\n ListHandler, dict(models=self.registered_models)),\n (r\"/v2/models\",\n ListHandler, dict(models=self.registered_models)),\n # Model Health API returns 200 if model is ready to serve.\n (r\"/v1/models/([a-zA-Z0-9_-]+)\",\n HealthHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/status\",\n HealthHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):predict\",\n PredictHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/infer\",\n PredictHandler, dict(models=self.registered_models)),\n (r\"/v1/models/([a-zA-Z0-9_-]+):explain\",\n ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/models/([a-zA-Z0-9_-]+)/explain\",\n ExplainHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/load\",\n LoadHandler, dict(models=self.registered_models)),\n (r\"/v2/repository/models/([a-zA-Z0-9_-]+)/unload\",\n UnloadHandler, dict(models=self.registered_models)),\n ])\n\n def start(self, models: List[KFModel], nest_asyncio: bool = False):\n for model in models:\n self.register_model(model)\n\n self._http_server = tornado.httpserver.HTTPServer(\n self.create_application(), max_buffer_size=self.max_buffer_size)\n\n logging.info(\"Listening on port %s\", self.http_port)\n self._http_server.bind(self.http_port)\n logging.info(\"Will fork %d workers\", self.workers)\n self._http_server.start(self.workers)\n\n # Need to start the IOLoop after workers have been started\n # https://github.com/tornadoweb/tornado/issues/2426\n # The nest_asyncio package needs to be installed by the downstream module\n if nest_asyncio:\n import nest_asyncio\n nest_asyncio.apply()\n\n tornado.ioloop.IOLoop.current().start()\n\n def register_model(self, model: KFModel):\n if not model.name:\n raise Exception(\n \"Failed to register model, model.name must be provided.\")\n self.registered_models.update(model)\n logging.info(\"Registering model: %s\", model.name)\n\n\nclass LivenessHandler(tornado.web.RequestHandler): # pylint:disable=too-few-public-methods\n def get(self):\n self.write(\"Alive\")\n\n\nclass HealthHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository):\n self.models = models # pylint:disable=attribute-defined-outside-init\n\n def get(self, name: str):\n model = self.models.get_model(name)\n if model is None:\n raise tornado.web.HTTPError(\n status_code=404,\n reason=\"Model with name %s does not exist.\" % name\n )\n\n if not model.ready:\n raise tornado.web.HTTPError(\n status_code=503,\n reason=\"Model with name %s is not ready.\" % name\n )\n\n self.write(json.dumps({\n \"name\": model.name,\n \"ready\": model.ready\n }))\n\n\nclass ListHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository):\n self.models = models # pylint:disable=attribute-defined-outside-init\n\n def get(self):\n self.write(json.dumps([ob.name for ob in self.models.get_models()]))\n\n\nclass LoadHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init\n self.models = models\n\n async def post(self, name: str):\n try:\n (await self.models.load(name)) if inspect.iscoroutinefunction(self.models.load) else self.models.load(name)\n except Exception:\n ex_type, ex_value, ex_traceback = sys.exc_info()\n raise tornado.web.HTTPError(\n status_code=500,\n reason=f\"Model with name {name} is not ready. \"\n f\"Error type: {ex_type} error msg: {ex_value}\"\n )\n\n if not self.models.is_model_ready(name):\n raise tornado.web.HTTPError(\n status_code=503,\n reason=f\"Model with name {name} is not ready.\"\n )\n self.write(json.dumps({\n \"name\": name,\n \"load\": True\n }))\n\n\nclass UnloadHandler(tornado.web.RequestHandler):\n def initialize(self, models: KFModelRepository): # pylint:disable=attribute-defined-outside-init\n self.models = models\n\n def post(self, name: str):\n try:\n self.models.unload(name)\n except KeyError:\n raise tornado.web.HTTPError(\n status_code=404,\n reason=\"Model with name %s does not exist.\" % name\n )\n self.write(json.dumps({\n \"name\": name,\n \"unload\": True\n }))\n", "path": "python/kfserving/kfserving/kfserver.py"}]}
| 3,169 | 900 |
gh_patches_debug_27206
|
rasdani/github-patches
|
git_diff
|
mars-project__mars-560
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Running Mars under docker can use psutil.virtual_memory() directly
**Is your feature request related to a problem? Please describe.**
When running in Docker containers with ``MARS_USE_PROCESS_STAT`` on, both cpu and memory usage are calculated by summing results of all processes. This can be effective for cpu. However, this method may produce larger memory usages than actual.
**Describe the solution you'd like**
We can specify different methods to measure cpu and memory usage to obtain more accurate memory usage for most of the cases.
</issue>
<code>
[start of mars/resource.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 1999-2018 Alibaba Group Holding Ltd.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import os
17 import subprocess # nosec
18 import sys
19 import time
20 from collections import namedtuple
21
22 import psutil
23
24 from .lib import nvutils
25
26 _proc = psutil.Process()
27 _timer = getattr(time, 'monotonic', time.time)
28
29 if 'MARS_USE_PROCESS_STAT' in os.environ:
30 _use_process_stat = bool(int(os.environ['MARS_USE_PROCESS_STAT'].strip('"')))
31 else:
32 _use_process_stat = False
33
34 if 'MARS_CPU_TOTAL' in os.environ:
35 _cpu_total = int(os.environ['MARS_CPU_TOTAL'].strip('"'))
36 else:
37 _cpu_total = psutil.cpu_count(logical=True)
38
39 if 'MARS_MEMORY_TOTAL' in os.environ:
40 _mem_total = int(os.environ['MARS_MEMORY_TOTAL'].strip('"'))
41 else:
42 _mem_total = None
43
44 _virt_memory_stat = namedtuple('virtual_memory', 'total available percent used free')
45
46 _shm_path = [pt.mountpoint for pt in psutil.disk_partitions(all=True)
47 if pt.mountpoint in ('/tmp', '/dev/shm') and pt.fstype == 'tmpfs']
48 if not _shm_path:
49 _shm_path = None
50 else:
51 _shm_path = _shm_path[0]
52
53
54 def virtual_memory():
55 sys_mem = psutil.virtual_memory()
56 if not _use_process_stat:
57 total = sys_mem.total
58 used = sys_mem.used + getattr(sys_mem, 'shared', 0)
59 available = sys_mem.available
60 free = sys_mem.free
61 percent = 100.0 * (total - available) / total
62 return _virt_memory_stat(total, available, percent, used, free)
63 else:
64 used = 0
65 for p in psutil.process_iter():
66 try:
67 used += p.memory_info().rss
68 except (psutil.NoSuchProcess, psutil.AccessDenied):
69 pass
70
71 if _shm_path:
72 shm_stats = psutil.disk_usage(_shm_path)
73 used += shm_stats.used
74
75 total = min(_mem_total or sys_mem.total, sys_mem.total)
76 # TODO sys_mem.available does not work in container
77 # available = min(sys_mem.available, total - used)
78 available = total - used
79 free = min(sys_mem.free, total - used)
80 percent = 100.0 * (total - available) / total
81 return _virt_memory_stat(total, available, percent, used, free)
82
83
84 def cpu_count():
85 return _cpu_total
86
87
88 _last_cpu_measure = None
89
90
91 def _take_process_cpu_snapshot():
92 num_cpus = cpu_count() or 1
93
94 def timer():
95 return _timer() * num_cpus
96
97 processes = [p for p in psutil.process_iter() if p.pid != _proc.pid]
98
99 pts = dict()
100 sts = dict()
101 for p in processes:
102 try:
103 pts[p.pid] = p.cpu_times()
104 sts[p.pid] = timer()
105 except (psutil.NoSuchProcess, psutil.AccessDenied):
106 pass
107
108 pts[_proc.pid] = _proc.cpu_times()
109 sts[_proc.pid] = timer()
110 return pts, sts
111
112
113 def cpu_percent():
114 global _last_cpu_measure
115 if not _use_process_stat:
116 return sum(psutil.cpu_percent(percpu=True))
117
118 num_cpus = cpu_count() or 1
119 pts, sts = _take_process_cpu_snapshot()
120
121 if _last_cpu_measure is None:
122 _last_cpu_measure = (pts, sts)
123 return None
124
125 old_pts, old_sts = _last_cpu_measure
126
127 percents = []
128 for pid in pts:
129 if pid not in old_pts:
130 continue
131 pt1 = old_pts[pid]
132 pt2 = pts[pid]
133 delta_proc = (pt2.user - pt1.user) + (pt2.system - pt1.system)
134 delta_time = sts[pid] - old_sts[pid]
135
136 try:
137 overall_cpus_percent = (delta_proc / delta_time) * 100
138 except ZeroDivisionError:
139 percents.append(0.0)
140 else:
141 single_cpu_percent = overall_cpus_percent * num_cpus
142 percents.append(single_cpu_percent)
143 _last_cpu_measure = (pts, sts)
144 return round(sum(percents), 1)
145
146
147 def disk_usage(d):
148 return psutil.disk_usage(d)
149
150
151 def iowait():
152 cpu_percent = psutil.cpu_times_percent()
153 try:
154 return cpu_percent.iowait
155 except AttributeError:
156 return None
157
158
159 _last_disk_io_meta = None
160 _win_diskperf_called = False
161
162
163 def disk_io_usage():
164 global _last_disk_io_meta, _win_diskperf_called
165
166 # Needed by psutil.disk_io_counters() under newer version of Windows.
167 # diskperf -y need to be called or no disk information can be found.
168 if sys.platform == 'win32' and not _win_diskperf_called: # pragma: no cover
169 CREATE_NO_WINDOW = 0x08000000
170 try:
171 proc = subprocess.Popen(['diskperf', '-y'], shell=False,
172 creationflags=CREATE_NO_WINDOW) # nosec
173 proc.wait()
174 except (subprocess.CalledProcessError, OSError):
175 pass
176 _win_diskperf_called = True
177
178 disk_counters = psutil.disk_io_counters()
179 tst = time.time()
180
181 read_bytes = disk_counters.read_bytes
182 write_bytes = disk_counters.write_bytes
183 if _last_disk_io_meta is None:
184 _last_disk_io_meta = (read_bytes, write_bytes, tst)
185 return None
186
187 last_read_bytes, last_write_bytes, last_time = _last_disk_io_meta
188 delta_time = tst - last_time
189 read_speed = (read_bytes - last_read_bytes) / delta_time
190 write_speed = (write_bytes - last_write_bytes) / delta_time
191
192 _last_disk_io_meta = (read_bytes, write_bytes, tst)
193 return read_speed, write_speed
194
195
196 _last_net_io_meta = None
197
198
199 def net_io_usage():
200 global _last_net_io_meta
201
202 net_counters = psutil.net_io_counters()
203 tst = time.time()
204
205 send_bytes = net_counters.bytes_sent
206 recv_bytes = net_counters.bytes_recv
207 if _last_net_io_meta is None:
208 _last_net_io_meta = (send_bytes, recv_bytes, tst)
209 return None
210
211 last_send_bytes, last_recv_bytes, last_time = _last_net_io_meta
212 delta_time = tst - last_time
213 recv_speed = (recv_bytes - last_recv_bytes) / delta_time
214 send_speed = (send_bytes - last_send_bytes) / delta_time
215
216 _last_net_io_meta = (send_bytes, recv_bytes, tst)
217 return recv_speed, send_speed
218
219
220 _cuda_info = namedtuple('cuda_info', 'driver_version cuda_version products gpu_count')
221 _cuda_card_stat = namedtuple('cuda_card_stat', 'product_name gpu_usage temperature fb_mem_info')
222
223
224 def cuda_info(): # pragma: no cover
225 driver_info = nvutils.get_driver_info()
226 if not driver_info:
227 return
228 gpu_count = nvutils.get_device_count()
229 return _cuda_info(
230 driver_version=driver_info.driver_version,
231 cuda_version=driver_info.cuda_version,
232 products=[nvutils.get_device_info(idx).name for idx in range(gpu_count)],
233 gpu_count=gpu_count,
234 )
235
236
237 def cuda_card_stats(): # pragma: no cover
238 infos = []
239 device_count = nvutils.get_device_count()
240 if not device_count:
241 return
242 for device_idx in range(device_count):
243 device_info = nvutils.get_device_info(device_idx)
244 device_status = nvutils.get_device_status(device_idx)
245
246 infos.append(_cuda_card_stat(
247 product_name=device_info.name,
248 gpu_usage=device_status.gpu_util,
249 temperature=device_status.temperature,
250 fb_mem_info=_virt_memory_stat(
251 total=device_status.fb_total_mem, used=device_status.fb_used_mem,
252 free=device_status.fb_free_mem, available=device_status.fb_free_mem,
253 percent=device_status.mem_util,
254 )
255 ))
256 return infos
257
[end of mars/resource.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mars/resource.py b/mars/resource.py
--- a/mars/resource.py
+++ b/mars/resource.py
@@ -26,10 +26,12 @@
_proc = psutil.Process()
_timer = getattr(time, 'monotonic', time.time)
+_cpu_use_process_stat = bool(int(os.environ.get('MARS_CPU_USE_PROCESS_STAT', '0').strip('"')))
+_mem_use_process_stat = bool(int(os.environ.get('MARS_MEM_USE_PROCESS_STAT', '0').strip('"')))
+
if 'MARS_USE_PROCESS_STAT' in os.environ:
- _use_process_stat = bool(int(os.environ['MARS_USE_PROCESS_STAT'].strip('"')))
-else:
- _use_process_stat = False
+ _cpu_use_process_stat = _mem_use_process_stat = \
+ bool(int(os.environ['MARS_USE_PROCESS_STAT'].strip('"')))
if 'MARS_CPU_TOTAL' in os.environ:
_cpu_total = int(os.environ['MARS_CPU_TOTAL'].strip('"'))
@@ -53,7 +55,7 @@
def virtual_memory():
sys_mem = psutil.virtual_memory()
- if not _use_process_stat:
+ if not _mem_use_process_stat:
total = sys_mem.total
used = sys_mem.used + getattr(sys_mem, 'shared', 0)
available = sys_mem.available
@@ -112,7 +114,7 @@
def cpu_percent():
global _last_cpu_measure
- if not _use_process_stat:
+ if not _cpu_use_process_stat:
return sum(psutil.cpu_percent(percpu=True))
num_cpus = cpu_count() or 1
|
{"golden_diff": "diff --git a/mars/resource.py b/mars/resource.py\n--- a/mars/resource.py\n+++ b/mars/resource.py\n@@ -26,10 +26,12 @@\n _proc = psutil.Process()\n _timer = getattr(time, 'monotonic', time.time)\n \n+_cpu_use_process_stat = bool(int(os.environ.get('MARS_CPU_USE_PROCESS_STAT', '0').strip('\"')))\n+_mem_use_process_stat = bool(int(os.environ.get('MARS_MEM_USE_PROCESS_STAT', '0').strip('\"')))\n+\n if 'MARS_USE_PROCESS_STAT' in os.environ:\n- _use_process_stat = bool(int(os.environ['MARS_USE_PROCESS_STAT'].strip('\"')))\n-else:\n- _use_process_stat = False\n+ _cpu_use_process_stat = _mem_use_process_stat = \\\n+ bool(int(os.environ['MARS_USE_PROCESS_STAT'].strip('\"')))\n \n if 'MARS_CPU_TOTAL' in os.environ:\n _cpu_total = int(os.environ['MARS_CPU_TOTAL'].strip('\"'))\n@@ -53,7 +55,7 @@\n \n def virtual_memory():\n sys_mem = psutil.virtual_memory()\n- if not _use_process_stat:\n+ if not _mem_use_process_stat:\n total = sys_mem.total\n used = sys_mem.used + getattr(sys_mem, 'shared', 0)\n available = sys_mem.available\n@@ -112,7 +114,7 @@\n \n def cpu_percent():\n global _last_cpu_measure\n- if not _use_process_stat:\n+ if not _cpu_use_process_stat:\n return sum(psutil.cpu_percent(percpu=True))\n \n num_cpus = cpu_count() or 1\n", "issue": "Running Mars under docker can use psutil.virtual_memory() directly\n**Is your feature request related to a problem? Please describe.**\r\nWhen running in Docker containers with ``MARS_USE_PROCESS_STAT`` on, both cpu and memory usage are calculated by summing results of all processes. This can be effective for cpu. However, this method may produce larger memory usages than actual.\r\n\r\n**Describe the solution you'd like**\r\nWe can specify different methods to measure cpu and memory usage to obtain more accurate memory usage for most of the cases.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 1999-2018 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport subprocess # nosec\nimport sys\nimport time\nfrom collections import namedtuple\n\nimport psutil\n\nfrom .lib import nvutils\n\n_proc = psutil.Process()\n_timer = getattr(time, 'monotonic', time.time)\n\nif 'MARS_USE_PROCESS_STAT' in os.environ:\n _use_process_stat = bool(int(os.environ['MARS_USE_PROCESS_STAT'].strip('\"')))\nelse:\n _use_process_stat = False\n\nif 'MARS_CPU_TOTAL' in os.environ:\n _cpu_total = int(os.environ['MARS_CPU_TOTAL'].strip('\"'))\nelse:\n _cpu_total = psutil.cpu_count(logical=True)\n\nif 'MARS_MEMORY_TOTAL' in os.environ:\n _mem_total = int(os.environ['MARS_MEMORY_TOTAL'].strip('\"'))\nelse:\n _mem_total = None\n\n_virt_memory_stat = namedtuple('virtual_memory', 'total available percent used free')\n\n_shm_path = [pt.mountpoint for pt in psutil.disk_partitions(all=True)\n if pt.mountpoint in ('/tmp', '/dev/shm') and pt.fstype == 'tmpfs']\nif not _shm_path:\n _shm_path = None\nelse:\n _shm_path = _shm_path[0]\n\n\ndef virtual_memory():\n sys_mem = psutil.virtual_memory()\n if not _use_process_stat:\n total = sys_mem.total\n used = sys_mem.used + getattr(sys_mem, 'shared', 0)\n available = sys_mem.available\n free = sys_mem.free\n percent = 100.0 * (total - available) / total\n return _virt_memory_stat(total, available, percent, used, free)\n else:\n used = 0\n for p in psutil.process_iter():\n try:\n used += p.memory_info().rss\n except (psutil.NoSuchProcess, psutil.AccessDenied):\n pass\n\n if _shm_path:\n shm_stats = psutil.disk_usage(_shm_path)\n used += shm_stats.used\n\n total = min(_mem_total or sys_mem.total, sys_mem.total)\n # TODO sys_mem.available does not work in container\n # available = min(sys_mem.available, total - used)\n available = total - used\n free = min(sys_mem.free, total - used)\n percent = 100.0 * (total - available) / total\n return _virt_memory_stat(total, available, percent, used, free)\n\n\ndef cpu_count():\n return _cpu_total\n\n\n_last_cpu_measure = None\n\n\ndef _take_process_cpu_snapshot():\n num_cpus = cpu_count() or 1\n\n def timer():\n return _timer() * num_cpus\n\n processes = [p for p in psutil.process_iter() if p.pid != _proc.pid]\n\n pts = dict()\n sts = dict()\n for p in processes:\n try:\n pts[p.pid] = p.cpu_times()\n sts[p.pid] = timer()\n except (psutil.NoSuchProcess, psutil.AccessDenied):\n pass\n\n pts[_proc.pid] = _proc.cpu_times()\n sts[_proc.pid] = timer()\n return pts, sts\n\n\ndef cpu_percent():\n global _last_cpu_measure\n if not _use_process_stat:\n return sum(psutil.cpu_percent(percpu=True))\n\n num_cpus = cpu_count() or 1\n pts, sts = _take_process_cpu_snapshot()\n\n if _last_cpu_measure is None:\n _last_cpu_measure = (pts, sts)\n return None\n\n old_pts, old_sts = _last_cpu_measure\n\n percents = []\n for pid in pts:\n if pid not in old_pts:\n continue\n pt1 = old_pts[pid]\n pt2 = pts[pid]\n delta_proc = (pt2.user - pt1.user) + (pt2.system - pt1.system)\n delta_time = sts[pid] - old_sts[pid]\n\n try:\n overall_cpus_percent = (delta_proc / delta_time) * 100\n except ZeroDivisionError:\n percents.append(0.0)\n else:\n single_cpu_percent = overall_cpus_percent * num_cpus\n percents.append(single_cpu_percent)\n _last_cpu_measure = (pts, sts)\n return round(sum(percents), 1)\n\n\ndef disk_usage(d):\n return psutil.disk_usage(d)\n\n\ndef iowait():\n cpu_percent = psutil.cpu_times_percent()\n try:\n return cpu_percent.iowait\n except AttributeError:\n return None\n\n\n_last_disk_io_meta = None\n_win_diskperf_called = False\n\n\ndef disk_io_usage():\n global _last_disk_io_meta, _win_diskperf_called\n\n # Needed by psutil.disk_io_counters() under newer version of Windows.\n # diskperf -y need to be called or no disk information can be found.\n if sys.platform == 'win32' and not _win_diskperf_called: # pragma: no cover\n CREATE_NO_WINDOW = 0x08000000\n try:\n proc = subprocess.Popen(['diskperf', '-y'], shell=False,\n creationflags=CREATE_NO_WINDOW) # nosec\n proc.wait()\n except (subprocess.CalledProcessError, OSError):\n pass\n _win_diskperf_called = True\n\n disk_counters = psutil.disk_io_counters()\n tst = time.time()\n\n read_bytes = disk_counters.read_bytes\n write_bytes = disk_counters.write_bytes\n if _last_disk_io_meta is None:\n _last_disk_io_meta = (read_bytes, write_bytes, tst)\n return None\n\n last_read_bytes, last_write_bytes, last_time = _last_disk_io_meta\n delta_time = tst - last_time\n read_speed = (read_bytes - last_read_bytes) / delta_time\n write_speed = (write_bytes - last_write_bytes) / delta_time\n\n _last_disk_io_meta = (read_bytes, write_bytes, tst)\n return read_speed, write_speed\n\n\n_last_net_io_meta = None\n\n\ndef net_io_usage():\n global _last_net_io_meta\n\n net_counters = psutil.net_io_counters()\n tst = time.time()\n\n send_bytes = net_counters.bytes_sent\n recv_bytes = net_counters.bytes_recv\n if _last_net_io_meta is None:\n _last_net_io_meta = (send_bytes, recv_bytes, tst)\n return None\n\n last_send_bytes, last_recv_bytes, last_time = _last_net_io_meta\n delta_time = tst - last_time\n recv_speed = (recv_bytes - last_recv_bytes) / delta_time\n send_speed = (send_bytes - last_send_bytes) / delta_time\n\n _last_net_io_meta = (send_bytes, recv_bytes, tst)\n return recv_speed, send_speed\n\n\n_cuda_info = namedtuple('cuda_info', 'driver_version cuda_version products gpu_count')\n_cuda_card_stat = namedtuple('cuda_card_stat', 'product_name gpu_usage temperature fb_mem_info')\n\n\ndef cuda_info(): # pragma: no cover\n driver_info = nvutils.get_driver_info()\n if not driver_info:\n return\n gpu_count = nvutils.get_device_count()\n return _cuda_info(\n driver_version=driver_info.driver_version,\n cuda_version=driver_info.cuda_version,\n products=[nvutils.get_device_info(idx).name for idx in range(gpu_count)],\n gpu_count=gpu_count,\n )\n\n\ndef cuda_card_stats(): # pragma: no cover\n infos = []\n device_count = nvutils.get_device_count()\n if not device_count:\n return\n for device_idx in range(device_count):\n device_info = nvutils.get_device_info(device_idx)\n device_status = nvutils.get_device_status(device_idx)\n\n infos.append(_cuda_card_stat(\n product_name=device_info.name,\n gpu_usage=device_status.gpu_util,\n temperature=device_status.temperature,\n fb_mem_info=_virt_memory_stat(\n total=device_status.fb_total_mem, used=device_status.fb_used_mem,\n free=device_status.fb_free_mem, available=device_status.fb_free_mem,\n percent=device_status.mem_util,\n )\n ))\n return infos\n", "path": "mars/resource.py"}]}
| 3,232 | 364 |
gh_patches_debug_3755
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-486
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API should not show marks publicly
The API shows all marks for all users publicly. Should be unregistered from API if it is not utterly necessary by some client-side ajax call.
</issue>
<code>
[start of apps/api/v0/urls.py]
1 # -*- coding: utf-8 -*-
2
3 from django.conf.urls import patterns, url, include
4
5 from tastypie.api import Api
6
7 from apps.api.v0.article import ArticleResource, ArticleLatestResource
8 from apps.api.v0.authentication import UserResource
9 from apps.api.v0.events import EventResource, AttendanceEventResource, AttendeeResource, CompanyResource, CompanyEventResource
10 from apps.api.v0.marks import MarkResource, EntryResource, MyMarksResource, MyActiveMarksResource
11 from apps.api.v0.offline import IssueResource
12
13 v0_api = Api(api_name='v0')
14
15 # users
16 v0_api.register(UserResource())
17
18 # event
19 v0_api.register(EventResource())
20 v0_api.register(AttendanceEventResource())
21 v0_api.register(CompanyResource())
22 v0_api.register(CompanyEventResource())
23
24 # article
25 v0_api.register(ArticleResource())
26 v0_api.register(ArticleLatestResource())
27
28 # marks
29 v0_api.register(MarkResource())
30 v0_api.register(EntryResource())
31 v0_api.register(MyMarksResource())
32 v0_api.register(MyActiveMarksResource())
33
34 # offline
35 v0_api.register(IssueResource())
36
37 # Set the urls to be included.
38 urlpatterns = patterns('',
39 url(r'^', include(v0_api.urls)),
40 )
41
[end of apps/api/v0/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/api/v0/urls.py b/apps/api/v0/urls.py
--- a/apps/api/v0/urls.py
+++ b/apps/api/v0/urls.py
@@ -26,10 +26,10 @@
v0_api.register(ArticleLatestResource())
# marks
-v0_api.register(MarkResource())
-v0_api.register(EntryResource())
-v0_api.register(MyMarksResource())
-v0_api.register(MyActiveMarksResource())
+#v0_api.register(MarkResource())
+#v0_api.register(EntryResource())
+#v0_api.register(MyMarksResource())
+#v0_api.register(MyActiveMarksResource())
# offline
v0_api.register(IssueResource())
|
{"golden_diff": "diff --git a/apps/api/v0/urls.py b/apps/api/v0/urls.py\n--- a/apps/api/v0/urls.py\n+++ b/apps/api/v0/urls.py\n@@ -26,10 +26,10 @@\n v0_api.register(ArticleLatestResource())\n \n # marks\n-v0_api.register(MarkResource())\n-v0_api.register(EntryResource())\n-v0_api.register(MyMarksResource())\n-v0_api.register(MyActiveMarksResource())\n+#v0_api.register(MarkResource())\n+#v0_api.register(EntryResource())\n+#v0_api.register(MyMarksResource())\n+#v0_api.register(MyActiveMarksResource())\n \n # offline\n v0_api.register(IssueResource())\n", "issue": "API should not show marks publicly\nThe API shows all marks for all users publicly. Should be unregistered from API if it is not utterly necessary by some client-side ajax call.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\nfrom django.conf.urls import patterns, url, include\n\nfrom tastypie.api import Api\n\nfrom apps.api.v0.article import ArticleResource, ArticleLatestResource\nfrom apps.api.v0.authentication import UserResource\nfrom apps.api.v0.events import EventResource, AttendanceEventResource, AttendeeResource, CompanyResource, CompanyEventResource\nfrom apps.api.v0.marks import MarkResource, EntryResource, MyMarksResource, MyActiveMarksResource\nfrom apps.api.v0.offline import IssueResource\n\nv0_api = Api(api_name='v0')\n\n# users\nv0_api.register(UserResource())\n\n# event\nv0_api.register(EventResource())\nv0_api.register(AttendanceEventResource())\nv0_api.register(CompanyResource())\nv0_api.register(CompanyEventResource())\n\n# article\nv0_api.register(ArticleResource())\nv0_api.register(ArticleLatestResource())\n\n# marks\nv0_api.register(MarkResource())\nv0_api.register(EntryResource())\nv0_api.register(MyMarksResource())\nv0_api.register(MyActiveMarksResource())\n\n# offline\nv0_api.register(IssueResource())\n\n# Set the urls to be included.\nurlpatterns = patterns('',\n url(r'^', include(v0_api.urls)),\n)\n", "path": "apps/api/v0/urls.py"}]}
| 918 | 149 |
gh_patches_debug_10096
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-265
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
On rerun, faded elements are becoming opaque one by one. Instead they become opaque all at once.
Steps to repro:
1. Run `examples/reference.py`
2. When done, rerun it.
**Expected:** on rerun, all elements fade out and then become opaque one by one even before the run is done.
**Actual:** on rerun, all elements fade out and only become opaque when the entire run is done.
I believe this bug was introduced with the Sidebar code.
</issue>
<code>
[start of lib/streamlit/watcher/LocalSourcesWatcher.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2018-2019 Streamlit Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 import fnmatch
17 import os
18 import sys
19 import collections
20
21 try:
22 # Python 2
23 import imp as importlib
24 except ImportError:
25 # Python 3
26 import importlib
27
28 from streamlit import config
29 from streamlit import util
30
31 from streamlit.logger import get_logger
32
33 LOGGER = get_logger(__name__)
34
35 try:
36 # If the watchdog module is installed.
37 from streamlit.watcher.EventBasedFileWatcher import (
38 EventBasedFileWatcher as FileWatcher,
39 )
40 except ImportError:
41 # Fallback that doesn't use watchdog.
42 from streamlit.watcher.PollingFileWatcher import PollingFileWatcher as FileWatcher
43
44 if not config.get_option("global.disableWatchdogWarning"):
45 msg = "\n $ xcode-select --install" if util.is_darwin() else ""
46
47 LOGGER.warning(
48 """
49 For better performance, install the Watchdog module:
50 %s
51 $ pip install watchdog
52
53 """
54 % msg
55 )
56
57
58 # Streamlit never watches files in the folders below.
59 DEFAULT_FOLDER_BLACKLIST = [
60 "**/.*",
61 "**/anaconda2",
62 "**/anaconda3",
63 "**/miniconda2",
64 "**/miniconda3",
65 ]
66
67
68 WatchedModule = collections.namedtuple("WatchedModule", ["watcher", "module_name"])
69
70
71 class LocalSourcesWatcher(object):
72 def __init__(self, report, on_file_changed):
73 self._report = report
74 self._on_file_changed = on_file_changed
75 self._is_closed = False
76
77 self._folder_blacklist = config.get_option("server.folderWatchBlacklist")
78
79 # Blacklist some additional folders, using glob syntax.
80 self._folder_blacklist.extend(DEFAULT_FOLDER_BLACKLIST)
81
82 # A dict of filepath -> WatchedModule.
83 self._watched_modules = {}
84
85 self._register_watcher(
86 self._report.script_path,
87 module_name=None, # Only the root script has None here.
88 )
89
90 def on_file_changed(self, filepath):
91 if filepath not in self._watched_modules:
92 LOGGER.error("Received event for non-watched file", filepath)
93 return
94
95 wm = self._watched_modules[filepath]
96
97 if wm.module_name is not None and wm.module_name in sys.modules:
98 del sys.modules[wm.module_name]
99
100 self._on_file_changed()
101
102 def close(self):
103 for wm in self._watched_modules.values():
104 wm.watcher.close()
105 self._watched_modules = {}
106 self._is_closed = True
107
108 def _register_watcher(self, filepath, module_name):
109 wm = WatchedModule(
110 watcher=FileWatcher(filepath, self.on_file_changed), module_name=module_name
111 )
112 self._watched_modules[filepath] = wm
113
114 def _deregister_watcher(self, filepath):
115 if filepath not in self._watched_modules:
116 return
117
118 if filepath == self._report.script_path:
119 return
120
121 wm = self._watched_modules[filepath]
122 wm.watcher.close()
123 del self._watched_modules[filepath]
124
125 def update_watched_modules(self):
126 if self._is_closed:
127 return
128
129 local_filepaths = []
130
131 # Clone modules dict here because we may alter the original dict inside
132 # the loop.
133 modules = dict(sys.modules)
134
135 for name, module in modules.items():
136 try:
137 spec = getattr(module, "__spec__", None)
138
139 if spec is None:
140 filepath = getattr(module, "__file__", None)
141 if filepath is None:
142 # Some modules have neither a spec nor a file. But we
143 # can ignore those since they're not the user-created
144 # modules we want to watch anyway.
145 continue
146 else:
147 filepath = spec.origin
148
149 if filepath is None:
150 # Built-in modules (and other stuff) don't have origins.
151 continue
152
153 filepath = os.path.abspath(filepath)
154
155 if not os.path.isfile(filepath):
156 # There are some modules that have a .origin, but don't
157 # point to real files. For example, there's a module where
158 # .origin is 'built-in'.
159 continue
160
161 is_in_blacklisted_folder = any(
162 _file_is_in_folder(filepath, blacklisted_folder)
163 for blacklisted_folder in self._folder_blacklist
164 )
165
166 if is_in_blacklisted_folder:
167 continue
168
169 file_is_new = filepath not in self._watched_modules
170 file_is_local = _file_is_in_folder(filepath, self._report.script_folder)
171
172 local_filepaths.append(filepath)
173
174 if file_is_local and file_is_new:
175 self._register_watcher(filepath, name)
176
177 except Exception:
178 # In case there's a problem introspecting some specific module,
179 # let's not stop the entire loop from running. For example,
180 # the __spec__ field in some modules (like IPython) is actually
181 # a dynamic property, which can crash if the underlying
182 # module's code has a bug (as discovered by one of our users).
183 continue
184
185 # Clone dict here because we may alter the original dict inside the
186 # loop.
187 watched_modules = dict(self._watched_modules)
188
189 # Remove no-longer-depended-on files from self._watched_modules
190 # Will this ever happen?
191 for filepath in watched_modules:
192 if filepath not in local_filepaths:
193 self._deregister_watcher(filepath)
194
195
196 def _file_is_in_folder(filepath, folderpath_glob):
197 # Strip trailing slash if it exists
198 if folderpath_glob.endswith("/"):
199 folderpath_glob = folderpath_glob[:-1]
200
201 file_dir = os.path.dirname(filepath)
202 return fnmatch.fnmatch(file_dir, folderpath_glob)
203
[end of lib/streamlit/watcher/LocalSourcesWatcher.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/watcher/LocalSourcesWatcher.py b/lib/streamlit/watcher/LocalSourcesWatcher.py
--- a/lib/streamlit/watcher/LocalSourcesWatcher.py
+++ b/lib/streamlit/watcher/LocalSourcesWatcher.py
@@ -194,9 +194,13 @@
def _file_is_in_folder(filepath, folderpath_glob):
- # Strip trailing slash if it exists
- if folderpath_glob.endswith("/"):
- folderpath_glob = folderpath_glob[:-1]
-
- file_dir = os.path.dirname(filepath)
+ # Make the glob always end with "/*" so we match files inside subfolders of
+ # folderpath_glob.
+ if not folderpath_glob.endswith("*"):
+ if folderpath_glob.endswith("/"):
+ folderpath_glob += "*"
+ else:
+ folderpath_glob += "/*"
+
+ file_dir = os.path.dirname(filepath) + "/"
return fnmatch.fnmatch(file_dir, folderpath_glob)
|
{"golden_diff": "diff --git a/lib/streamlit/watcher/LocalSourcesWatcher.py b/lib/streamlit/watcher/LocalSourcesWatcher.py\n--- a/lib/streamlit/watcher/LocalSourcesWatcher.py\n+++ b/lib/streamlit/watcher/LocalSourcesWatcher.py\n@@ -194,9 +194,13 @@\n \n \n def _file_is_in_folder(filepath, folderpath_glob):\n- # Strip trailing slash if it exists\n- if folderpath_glob.endswith(\"/\"):\n- folderpath_glob = folderpath_glob[:-1]\n-\n- file_dir = os.path.dirname(filepath)\n+ # Make the glob always end with \"/*\" so we match files inside subfolders of\n+ # folderpath_glob.\n+ if not folderpath_glob.endswith(\"*\"):\n+ if folderpath_glob.endswith(\"/\"):\n+ folderpath_glob += \"*\"\n+ else:\n+ folderpath_glob += \"/*\"\n+\n+ file_dir = os.path.dirname(filepath) + \"/\"\n return fnmatch.fnmatch(file_dir, folderpath_glob)\n", "issue": "On rerun, faded elements are becoming opaque one by one. Instead they become opaque all at once.\nSteps to repro:\r\n1. Run `examples/reference.py`\r\n2. When done, rerun it.\r\n\r\n**Expected:** on rerun, all elements fade out and then become opaque one by one even before the run is done.\r\n**Actual:** on rerun, all elements fade out and only become opaque when the entire run is done.\r\n\r\nI believe this bug was introduced with the Sidebar code.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2018-2019 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport fnmatch\nimport os\nimport sys\nimport collections\n\ntry:\n # Python 2\n import imp as importlib\nexcept ImportError:\n # Python 3\n import importlib\n\nfrom streamlit import config\nfrom streamlit import util\n\nfrom streamlit.logger import get_logger\n\nLOGGER = get_logger(__name__)\n\ntry:\n # If the watchdog module is installed.\n from streamlit.watcher.EventBasedFileWatcher import (\n EventBasedFileWatcher as FileWatcher,\n )\nexcept ImportError:\n # Fallback that doesn't use watchdog.\n from streamlit.watcher.PollingFileWatcher import PollingFileWatcher as FileWatcher\n\n if not config.get_option(\"global.disableWatchdogWarning\"):\n msg = \"\\n $ xcode-select --install\" if util.is_darwin() else \"\"\n\n LOGGER.warning(\n \"\"\"\n For better performance, install the Watchdog module:\n %s\n $ pip install watchdog\n\n \"\"\"\n % msg\n )\n\n\n# Streamlit never watches files in the folders below.\nDEFAULT_FOLDER_BLACKLIST = [\n \"**/.*\",\n \"**/anaconda2\",\n \"**/anaconda3\",\n \"**/miniconda2\",\n \"**/miniconda3\",\n]\n\n\nWatchedModule = collections.namedtuple(\"WatchedModule\", [\"watcher\", \"module_name\"])\n\n\nclass LocalSourcesWatcher(object):\n def __init__(self, report, on_file_changed):\n self._report = report\n self._on_file_changed = on_file_changed\n self._is_closed = False\n\n self._folder_blacklist = config.get_option(\"server.folderWatchBlacklist\")\n\n # Blacklist some additional folders, using glob syntax.\n self._folder_blacklist.extend(DEFAULT_FOLDER_BLACKLIST)\n\n # A dict of filepath -> WatchedModule.\n self._watched_modules = {}\n\n self._register_watcher(\n self._report.script_path,\n module_name=None, # Only the root script has None here.\n )\n\n def on_file_changed(self, filepath):\n if filepath not in self._watched_modules:\n LOGGER.error(\"Received event for non-watched file\", filepath)\n return\n\n wm = self._watched_modules[filepath]\n\n if wm.module_name is not None and wm.module_name in sys.modules:\n del sys.modules[wm.module_name]\n\n self._on_file_changed()\n\n def close(self):\n for wm in self._watched_modules.values():\n wm.watcher.close()\n self._watched_modules = {}\n self._is_closed = True\n\n def _register_watcher(self, filepath, module_name):\n wm = WatchedModule(\n watcher=FileWatcher(filepath, self.on_file_changed), module_name=module_name\n )\n self._watched_modules[filepath] = wm\n\n def _deregister_watcher(self, filepath):\n if filepath not in self._watched_modules:\n return\n\n if filepath == self._report.script_path:\n return\n\n wm = self._watched_modules[filepath]\n wm.watcher.close()\n del self._watched_modules[filepath]\n\n def update_watched_modules(self):\n if self._is_closed:\n return\n\n local_filepaths = []\n\n # Clone modules dict here because we may alter the original dict inside\n # the loop.\n modules = dict(sys.modules)\n\n for name, module in modules.items():\n try:\n spec = getattr(module, \"__spec__\", None)\n\n if spec is None:\n filepath = getattr(module, \"__file__\", None)\n if filepath is None:\n # Some modules have neither a spec nor a file. But we\n # can ignore those since they're not the user-created\n # modules we want to watch anyway.\n continue\n else:\n filepath = spec.origin\n\n if filepath is None:\n # Built-in modules (and other stuff) don't have origins.\n continue\n\n filepath = os.path.abspath(filepath)\n\n if not os.path.isfile(filepath):\n # There are some modules that have a .origin, but don't\n # point to real files. For example, there's a module where\n # .origin is 'built-in'.\n continue\n\n is_in_blacklisted_folder = any(\n _file_is_in_folder(filepath, blacklisted_folder)\n for blacklisted_folder in self._folder_blacklist\n )\n\n if is_in_blacklisted_folder:\n continue\n\n file_is_new = filepath not in self._watched_modules\n file_is_local = _file_is_in_folder(filepath, self._report.script_folder)\n\n local_filepaths.append(filepath)\n\n if file_is_local and file_is_new:\n self._register_watcher(filepath, name)\n\n except Exception:\n # In case there's a problem introspecting some specific module,\n # let's not stop the entire loop from running. For example,\n # the __spec__ field in some modules (like IPython) is actually\n # a dynamic property, which can crash if the underlying\n # module's code has a bug (as discovered by one of our users).\n continue\n\n # Clone dict here because we may alter the original dict inside the\n # loop.\n watched_modules = dict(self._watched_modules)\n\n # Remove no-longer-depended-on files from self._watched_modules\n # Will this ever happen?\n for filepath in watched_modules:\n if filepath not in local_filepaths:\n self._deregister_watcher(filepath)\n\n\ndef _file_is_in_folder(filepath, folderpath_glob):\n # Strip trailing slash if it exists\n if folderpath_glob.endswith(\"/\"):\n folderpath_glob = folderpath_glob[:-1]\n\n file_dir = os.path.dirname(filepath)\n return fnmatch.fnmatch(file_dir, folderpath_glob)\n", "path": "lib/streamlit/watcher/LocalSourcesWatcher.py"}]}
| 2,553 | 216 |
gh_patches_debug_5292
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-6881
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release SecureDrop 2.6.0
This is a tracking issue for the release of SecureDrop 2.6.0
Tentatively scheduled as follows:
**Pre-release announcement:** 06-15-2023
**Release date:** 06-22-2023
**Release manager:** @legoktm
**Deputy release manager:** @zenmonkeykstop
**Localization manager:** @cfm
**Communications manager:** @nathandyer
_SecureDrop maintainers and testers:_ As you QA 2.6.0, please report back your testing results as comments on this ticket. File GitHub issues for any problems found, tag them "QA: Release".
Test debian packages will be posted on https://apt-test.freedom.press signed with [the test key](https://gist.githubusercontent.com/conorsch/ec4008b111bc3142fca522693f3cce7e/raw/2968621e8ad92db4505a31fcc5776422d7d26729/apt-test%2520apt%2520pubkey).
# [QA Matrix for 2.6.0](https://docs.google.com/spreadsheets/d/1j-F9e45O9TWkbWZVzKUdbyYIP69yfALzlDx9bR49UHI/edit#gid=361662860)
# [Test Plan for 2.6.0](https://github.com/freedomofpress/securedrop/wiki/2.6.0-Test-Plan)
# Prepare release candidate (2.6.0~rc1)
- [ ] Link to latest version of Tails, including release candidates, to test against during QA
- [x] Prepare 2.6.0~rc1 release changelog
- [x] Branch off release/2.6.0 from develop
- [x] Prepare 2.6.0
- [x] Build debs, preserving build log, and put up `2.6.0~rc1` on test apt server
- [x] Commit build log.
After each test, please update the QA matrix and post details for Basic Server Testing, Application Acceptance Testing and release-specific testing below in comments to this ticket.
# Final release
- [x] Ensure builder in release branch is updated and/or update builder image
- [x] Push signed tag
- [x] Pre-Flight: Test updater logic in Tails (apt-qa tracks the `release` branch in the LFS repo)
- [x] Build final Debian packages(and preserve build log)
- [x] Commit package build log to https://github.com/freedomofpress/build-logs
- [x] Pre-Flight: Test that install and upgrade from 2.5.2 to 2.6.0 works w/ prod repo debs (apt-qa.freedom.press polls the `release` branch in the LFS repo for the debs)
- [x] Flip apt QA server to prod status (merge to `main` in the LFS repo)
- [x] Merge Docs branch changes to ``main`` and verify new docs build in securedrop-docs repo
- [x] Prepare release messaging
# Post release
- [x] Create GitHub release object
- [x] Once release object is created, update versions in `securedrop-docs` and Wagtail
- [x] Verify new docs show up on https://docs.securedrop.org
- [x] Publish announcements
- [ ] Merge changelog back to `develop`
- [ ] Update roadmap wiki page: https://github.com/freedomofpress/securedrop/wiki/Development-Roadmap
</issue>
<code>
[start of securedrop/version.py]
1 __version__ = "2.6.0~rc1"
2
[end of securedrop/version.py]
[start of securedrop/setup.py]
1 import setuptools
2
3 long_description = "The SecureDrop whistleblower platform."
4
5 setuptools.setup(
6 name="securedrop-app-code",
7 version="2.6.0~rc1",
8 author="Freedom of the Press Foundation",
9 author_email="[email protected]",
10 description="SecureDrop Server",
11 long_description=long_description,
12 long_description_content_type="text/markdown",
13 license="AGPLv3+",
14 python_requires=">=3.8",
15 url="https://github.com/freedomofpress/securedrop",
16 classifiers=[
17 "Development Status :: 5 - Stable",
18 "Programming Language :: Python :: 3",
19 "Topic :: Software Development :: Libraries :: Python Modules",
20 "License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)",
21 "Intended Audience :: Developers",
22 "Operating System :: OS Independent",
23 ],
24 )
25
[end of securedrop/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/setup.py b/securedrop/setup.py
--- a/securedrop/setup.py
+++ b/securedrop/setup.py
@@ -4,7 +4,7 @@
setuptools.setup(
name="securedrop-app-code",
- version="2.6.0~rc1",
+ version="2.7.0~rc1",
author="Freedom of the Press Foundation",
author_email="[email protected]",
description="SecureDrop Server",
diff --git a/securedrop/version.py b/securedrop/version.py
--- a/securedrop/version.py
+++ b/securedrop/version.py
@@ -1 +1 @@
-__version__ = "2.6.0~rc1"
+__version__ = "2.7.0~rc1"
|
{"golden_diff": "diff --git a/securedrop/setup.py b/securedrop/setup.py\n--- a/securedrop/setup.py\n+++ b/securedrop/setup.py\n@@ -4,7 +4,7 @@\n \n setuptools.setup(\n name=\"securedrop-app-code\",\n- version=\"2.6.0~rc1\",\n+ version=\"2.7.0~rc1\",\n author=\"Freedom of the Press Foundation\",\n author_email=\"[email protected]\",\n description=\"SecureDrop Server\",\ndiff --git a/securedrop/version.py b/securedrop/version.py\n--- a/securedrop/version.py\n+++ b/securedrop/version.py\n@@ -1 +1 @@\n-__version__ = \"2.6.0~rc1\"\n+__version__ = \"2.7.0~rc1\"\n", "issue": "Release SecureDrop 2.6.0\nThis is a tracking issue for the release of SecureDrop 2.6.0\r\n\r\nTentatively scheduled as follows:\r\n\r\n**Pre-release announcement:** 06-15-2023\r\n**Release date:** 06-22-2023\r\n\r\n**Release manager:** @legoktm \r\n**Deputy release manager:** @zenmonkeykstop \r\n**Localization manager:** @cfm\r\n**Communications manager:** @nathandyer \r\n\r\n_SecureDrop maintainers and testers:_ As you QA 2.6.0, please report back your testing results as comments on this ticket. File GitHub issues for any problems found, tag them \"QA: Release\".\r\n\r\nTest debian packages will be posted on https://apt-test.freedom.press signed with [the test key](https://gist.githubusercontent.com/conorsch/ec4008b111bc3142fca522693f3cce7e/raw/2968621e8ad92db4505a31fcc5776422d7d26729/apt-test%2520apt%2520pubkey).\r\n\r\n# [QA Matrix for 2.6.0](https://docs.google.com/spreadsheets/d/1j-F9e45O9TWkbWZVzKUdbyYIP69yfALzlDx9bR49UHI/edit#gid=361662860)\r\n# [Test Plan for 2.6.0](https://github.com/freedomofpress/securedrop/wiki/2.6.0-Test-Plan)\r\n\r\n# Prepare release candidate (2.6.0~rc1)\r\n- [ ] Link to latest version of Tails, including release candidates, to test against during QA\r\n- [x] Prepare 2.6.0~rc1 release changelog\r\n- [x] Branch off release/2.6.0 from develop\r\n- [x] Prepare 2.6.0\r\n- [x] Build debs, preserving build log, and put up `2.6.0~rc1` on test apt server\r\n- [x] Commit build log.\r\n\r\nAfter each test, please update the QA matrix and post details for Basic Server Testing, Application Acceptance Testing and release-specific testing below in comments to this ticket.\r\n\r\n# Final release\r\n- [x] Ensure builder in release branch is updated and/or update builder image\n- [x] Push signed tag \n- [x] Pre-Flight: Test updater logic in Tails (apt-qa tracks the `release` branch in the LFS repo)\n- [x] Build final Debian packages(and preserve build log)\n- [x] Commit package build log to https://github.com/freedomofpress/build-logs\n- [x] Pre-Flight: Test that install and upgrade from 2.5.2 to 2.6.0 works w/ prod repo debs (apt-qa.freedom.press polls the `release` branch in the LFS repo for the debs)\n- [x] Flip apt QA server to prod status (merge to `main` in the LFS repo)\n- [x] Merge Docs branch changes to ``main`` and verify new docs build in securedrop-docs repo\n- [x] Prepare release messaging\n\r\n# Post release\r\n- [x] Create GitHub release object \n- [x] Once release object is created, update versions in `securedrop-docs` and Wagtail\r\n- [x] Verify new docs show up on https://docs.securedrop.org\r\n- [x] Publish announcements\r\n- [ ] Merge changelog back to `develop`\r\n- [ ] Update roadmap wiki page: https://github.com/freedomofpress/securedrop/wiki/Development-Roadmap\n", "before_files": [{"content": "__version__ = \"2.6.0~rc1\"\n", "path": "securedrop/version.py"}, {"content": "import setuptools\n\nlong_description = \"The SecureDrop whistleblower platform.\"\n\nsetuptools.setup(\n name=\"securedrop-app-code\",\n version=\"2.6.0~rc1\",\n author=\"Freedom of the Press Foundation\",\n author_email=\"[email protected]\",\n description=\"SecureDrop Server\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n license=\"AGPLv3+\",\n python_requires=\">=3.8\",\n url=\"https://github.com/freedomofpress/securedrop\",\n classifiers=[\n \"Development Status :: 5 - Stable\",\n \"Programming Language :: Python :: 3\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n \"License :: OSI Approved :: GNU Affero General Public License v3 or later (AGPLv3+)\",\n \"Intended Audience :: Developers\",\n \"Operating System :: OS Independent\",\n ],\n)\n", "path": "securedrop/setup.py"}]}
| 1,627 | 175 |
gh_patches_debug_2507
|
rasdani/github-patches
|
git_diff
|
spotify__luigi-1494
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Python 3.5 support
Luigi may already work with Python 3.5, but since the README doesn't mention it I thought I'd ask.
Does Luigi support Python 3.5?
</issue>
<code>
[start of setup.py]
1 # Copyright (c) 2012 Spotify AB
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License"); you may not
4 # use this file except in compliance with the License. You may obtain a copy of
5 # the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
11 # WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
12 # License for the specific language governing permissions and limitations under
13 # the License.
14
15 import os
16
17 from setuptools import setup
18
19
20 def get_static_files(path):
21 return [os.path.join(dirpath.replace("luigi/", ""), ext)
22 for (dirpath, dirnames, filenames) in os.walk(path)
23 for ext in ["*.html", "*.js", "*.css", "*.png",
24 "*.eot", "*.svg", "*.ttf", "*.woff", "*.woff2"]]
25
26
27 luigi_package_data = sum(map(get_static_files, ["luigi/static", "luigi/templates"]), [])
28
29 readme_note = """\
30 .. note::
31
32 For the latest source, discussion, etc, please visit the
33 `GitHub repository <https://github.com/spotify/luigi>`_\n\n
34 """
35
36 with open('README.rst') as fobj:
37 long_description = readme_note + fobj.read()
38
39 install_requires = [
40 'tornado>=4.0,<5',
41 'python-daemon<3.0',
42 ]
43
44 if os.environ.get('READTHEDOCS', None) == 'True':
45 # So that we can build documentation for luigi.db_task_history and luigi.contrib.sqla
46 install_requires.append('sqlalchemy')
47 # readthedocs don't like python-daemon, see #1342
48 install_requires.remove('python-daemon<3.0')
49
50 setup(
51 name='luigi',
52 version='2.0.1',
53 description='Workflow mgmgt + task scheduling + dependency resolution',
54 long_description=long_description,
55 author='Erik Bernhardsson',
56 url='https://github.com/spotify/luigi',
57 license='Apache License 2.0',
58 packages=[
59 'luigi',
60 'luigi.contrib',
61 'luigi.contrib.hdfs',
62 'luigi.tools'
63 ],
64 package_data={
65 'luigi': luigi_package_data
66 },
67 entry_points={
68 'console_scripts': [
69 'luigi = luigi.cmdline:luigi_run',
70 'luigid = luigi.cmdline:luigid',
71 'luigi-grep = luigi.tools.luigi_grep:main',
72 'luigi-deps = luigi.tools.deps:main',
73 'luigi-migrate = luigi.tools.migrate:main'
74 ]
75 },
76 install_requires=install_requires,
77 classifiers=[
78 'Development Status :: 5 - Production/Stable',
79 'Environment :: Console',
80 'Environment :: Web Environment',
81 'Intended Audience :: Developers',
82 'Intended Audience :: System Administrators',
83 'License :: OSI Approved :: Apache Software License',
84 'Programming Language :: Python :: 2.7',
85 'Programming Language :: Python :: 3.3',
86 'Programming Language :: Python :: 3.4',
87 'Topic :: System :: Monitoring',
88 ],
89 )
90
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -84,6 +84,7 @@
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
+ 'Programming Language :: Python :: 3.5',
'Topic :: System :: Monitoring',
],
)
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -84,6 +84,7 @@\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n+ 'Programming Language :: Python :: 3.5',\n 'Topic :: System :: Monitoring',\n ],\n )\n", "issue": "Python 3.5 support\nLuigi may already work with Python 3.5, but since the README doesn't mention it I thought I'd ask.\n\nDoes Luigi support Python 3.5?\n\n", "before_files": [{"content": "# Copyright (c) 2012 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\"); you may not\n# use this file except in compliance with the License. You may obtain a copy of\n# the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT\n# WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the\n# License for the specific language governing permissions and limitations under\n# the License.\n\nimport os\n\nfrom setuptools import setup\n\n\ndef get_static_files(path):\n return [os.path.join(dirpath.replace(\"luigi/\", \"\"), ext)\n for (dirpath, dirnames, filenames) in os.walk(path)\n for ext in [\"*.html\", \"*.js\", \"*.css\", \"*.png\",\n \"*.eot\", \"*.svg\", \"*.ttf\", \"*.woff\", \"*.woff2\"]]\n\n\nluigi_package_data = sum(map(get_static_files, [\"luigi/static\", \"luigi/templates\"]), [])\n\nreadme_note = \"\"\"\\\n.. note::\n\n For the latest source, discussion, etc, please visit the\n `GitHub repository <https://github.com/spotify/luigi>`_\\n\\n\n\"\"\"\n\nwith open('README.rst') as fobj:\n long_description = readme_note + fobj.read()\n\ninstall_requires = [\n 'tornado>=4.0,<5',\n 'python-daemon<3.0',\n]\n\nif os.environ.get('READTHEDOCS', None) == 'True':\n # So that we can build documentation for luigi.db_task_history and luigi.contrib.sqla\n install_requires.append('sqlalchemy')\n # readthedocs don't like python-daemon, see #1342\n install_requires.remove('python-daemon<3.0')\n\nsetup(\n name='luigi',\n version='2.0.1',\n description='Workflow mgmgt + task scheduling + dependency resolution',\n long_description=long_description,\n author='Erik Bernhardsson',\n url='https://github.com/spotify/luigi',\n license='Apache License 2.0',\n packages=[\n 'luigi',\n 'luigi.contrib',\n 'luigi.contrib.hdfs',\n 'luigi.tools'\n ],\n package_data={\n 'luigi': luigi_package_data\n },\n entry_points={\n 'console_scripts': [\n 'luigi = luigi.cmdline:luigi_run',\n 'luigid = luigi.cmdline:luigid',\n 'luigi-grep = luigi.tools.luigi_grep:main',\n 'luigi-deps = luigi.tools.deps:main',\n 'luigi-migrate = luigi.tools.migrate:main'\n ]\n },\n install_requires=install_requires,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'Intended Audience :: System Administrators',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Topic :: System :: Monitoring',\n ],\n)\n", "path": "setup.py"}]}
| 1,477 | 92 |
gh_patches_debug_12339
|
rasdani/github-patches
|
git_diff
|
nextcloud__appstore-73
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Nightly support
- nightlies don't have a separate version number but a flag:
```
curl -X POST -u "user:password" http://localhost:8000/api/v1/apps/releases -H "Content-Type: application/json" -d '{"download":"https://example.com/release.tar.gz", "nightly":true }'
```
- this is also listed in the "get all apps" API with a `nightly: true` attribute https://nextcloudappstore.readthedocs.io/en/latest/restapi.html#get-all-apps-and-releases
- upload of a new nightly will delete the previous one for that app
- this allows to upgrade to a nightly (needs to be invoked by the admin and can be undone -> next regular release of the app will be installed)
</issue>
<code>
[start of nextcloudappstore/core/api/v1/urls.py]
1 from django.conf.urls import url
2 from django.views.decorators.http import etag
3 from nextcloudappstore.core.api.v1.views import Apps, AppReleases, \
4 app_api_etag, Categories, category_api_etag
5
6 urlpatterns = [
7 url(r'^platform/(?P<version>\d+\.\d+\.\d+)/apps\.json$',
8 etag(app_api_etag)(Apps.as_view()), name='apps'),
9 url(r'^apps/releases/?$', AppReleases.as_view(),
10 name='app-release-create'),
11 url(r'^apps/(?P<pk>[a-z_]+)/?$', Apps.as_view(), name='app-delete'),
12 url(r'^apps/(?P<app>[a-z_]+)/releases/(?P<version>\d+\.\d+\.\d+)/?$',
13 AppReleases.as_view(), name='app-release-delete'),
14 url(r'^categories.json$',
15 etag(category_api_etag)(Categories.as_view()), name='categories'),
16 ]
17
[end of nextcloudappstore/core/api/v1/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nextcloudappstore/core/api/v1/urls.py b/nextcloudappstore/core/api/v1/urls.py
--- a/nextcloudappstore/core/api/v1/urls.py
+++ b/nextcloudappstore/core/api/v1/urls.py
@@ -9,7 +9,8 @@
url(r'^apps/releases/?$', AppReleases.as_view(),
name='app-release-create'),
url(r'^apps/(?P<pk>[a-z_]+)/?$', Apps.as_view(), name='app-delete'),
- url(r'^apps/(?P<app>[a-z_]+)/releases/(?P<version>\d+\.\d+\.\d+)/?$',
+ url(r'^apps/(?P<app>[a-z_]+)/releases/(?P<version>\d+\.\d+\.\d+'
+ r'(?:-nightly)?)/?$',
AppReleases.as_view(), name='app-release-delete'),
url(r'^categories.json$',
etag(category_api_etag)(Categories.as_view()), name='categories'),
|
{"golden_diff": "diff --git a/nextcloudappstore/core/api/v1/urls.py b/nextcloudappstore/core/api/v1/urls.py\n--- a/nextcloudappstore/core/api/v1/urls.py\n+++ b/nextcloudappstore/core/api/v1/urls.py\n@@ -9,7 +9,8 @@\n url(r'^apps/releases/?$', AppReleases.as_view(),\n name='app-release-create'),\n url(r'^apps/(?P<pk>[a-z_]+)/?$', Apps.as_view(), name='app-delete'),\n- url(r'^apps/(?P<app>[a-z_]+)/releases/(?P<version>\\d+\\.\\d+\\.\\d+)/?$',\n+ url(r'^apps/(?P<app>[a-z_]+)/releases/(?P<version>\\d+\\.\\d+\\.\\d+'\n+ r'(?:-nightly)?)/?$',\n AppReleases.as_view(), name='app-release-delete'),\n url(r'^categories.json$',\n etag(category_api_etag)(Categories.as_view()), name='categories'),\n", "issue": "Nightly support\n- nightlies don't have a separate version number but a flag:\n\n```\ncurl -X POST -u \"user:password\" http://localhost:8000/api/v1/apps/releases -H \"Content-Type: application/json\" -d '{\"download\":\"https://example.com/release.tar.gz\", \"nightly\":true }'\n```\n- this is also listed in the \"get all apps\" API with a `nightly: true` attribute https://nextcloudappstore.readthedocs.io/en/latest/restapi.html#get-all-apps-and-releases\n- upload of a new nightly will delete the previous one for that app\n- this allows to upgrade to a nightly (needs to be invoked by the admin and can be undone -> next regular release of the app will be installed)\n\n", "before_files": [{"content": "from django.conf.urls import url\nfrom django.views.decorators.http import etag\nfrom nextcloudappstore.core.api.v1.views import Apps, AppReleases, \\\n app_api_etag, Categories, category_api_etag\n\nurlpatterns = [\n url(r'^platform/(?P<version>\\d+\\.\\d+\\.\\d+)/apps\\.json$',\n etag(app_api_etag)(Apps.as_view()), name='apps'),\n url(r'^apps/releases/?$', AppReleases.as_view(),\n name='app-release-create'),\n url(r'^apps/(?P<pk>[a-z_]+)/?$', Apps.as_view(), name='app-delete'),\n url(r'^apps/(?P<app>[a-z_]+)/releases/(?P<version>\\d+\\.\\d+\\.\\d+)/?$',\n AppReleases.as_view(), name='app-release-delete'),\n url(r'^categories.json$',\n etag(category_api_etag)(Categories.as_view()), name='categories'),\n]\n", "path": "nextcloudappstore/core/api/v1/urls.py"}]}
| 943 | 228 |
gh_patches_debug_37262
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-2206
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When user directly accesses '/auth/login' when already logged in, it should redirect the user to the home page
If a user session is active, the url `/auth/login/` should redirect to the home page i.e. database page. Currently, it displays the login page.
</issue>
<code>
[start of mathesar/urls.py]
1 from django.urls import include, path, re_path
2 from rest_framework_nested import routers
3
4 from mathesar import views
5 from mathesar.api.db import viewsets as db_viewsets
6 from mathesar.api.ui import viewsets as ui_viewsets
7 from mathesar.users.password_reset import MathesarPasswordResetConfirmView
8
9 db_router = routers.DefaultRouter()
10 db_router.register(r'tables', db_viewsets.TableViewSet, basename='table')
11 db_router.register(r'queries', db_viewsets.QueryViewSet, basename='query')
12 db_router.register(r'links', db_viewsets.LinkViewSet, basename='links')
13 db_router.register(r'schemas', db_viewsets.SchemaViewSet, basename='schema')
14 db_router.register(r'databases', db_viewsets.DatabaseViewSet, basename='database')
15 db_router.register(r'data_files', db_viewsets.DataFileViewSet, basename='data-file')
16
17 db_table_router = routers.NestedSimpleRouter(db_router, r'tables', lookup='table')
18 db_table_router.register(r'records', db_viewsets.RecordViewSet, basename='table-record')
19 db_table_router.register(r'settings', db_viewsets.TableSettingsViewSet, basename='table-setting')
20 db_table_router.register(r'columns', db_viewsets.ColumnViewSet, basename='table-column')
21 db_table_router.register(r'constraints', db_viewsets.ConstraintViewSet, basename='table-constraint')
22
23 ui_router = routers.DefaultRouter()
24 ui_router.register(r'version', ui_viewsets.VersionViewSet, basename='version')
25 ui_router.register(r'databases', ui_viewsets.DatabaseViewSet, basename='database')
26 ui_router.register(r'users', ui_viewsets.UserViewSet, basename='user')
27 ui_router.register(r'database_roles', ui_viewsets.DatabaseRoleViewSet, basename='database_role')
28 ui_router.register(r'schema_roles', ui_viewsets.SchemaRoleViewSet, basename='schema_role')
29
30 urlpatterns = [
31 path('api/db/v0/', include(db_router.urls)),
32 path('api/db/v0/', include(db_table_router.urls)),
33 path('api/ui/v0/', include(ui_router.urls)),
34 path('api/ui/v0/reflect/', views.reflect_all, name='reflect_all'),
35 path('auth/password_reset_confirm', MathesarPasswordResetConfirmView.as_view(), name='password_reset_confirm'),
36 path('auth/', include('django.contrib.auth.urls')),
37 path('', views.home, name='home'),
38 path('<db_name>/', views.schemas, name='schemas'),
39 re_path(
40 r'^(?P<db_name>\w+)/(?P<schema_id>\w+)/',
41 views.schema_home,
42 name='schema_home'
43 ),
44 ]
45
[end of mathesar/urls.py]
[start of config/settings.py]
1 """
2 Django settings for config project.
3
4 Generated by 'django-admin startproject' using Django 3.1.7.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.1/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.1/ref/settings/
11 """
12
13 import os
14 from pathlib import Path
15
16 from decouple import Csv, config as decouple_config
17 from dj_database_url import parse as db_url
18
19
20 # We use a 'tuple' with pipes as delimiters as decople naively splits the global
21 # variables on commas when casting to Csv()
22 def pipe_delim(pipe_string):
23 # Remove opening and closing brackets
24 pipe_string = pipe_string[1:-1]
25 # Split on pipe delim
26 return pipe_string.split("|")
27
28
29 # Build paths inside the project like this: BASE_DIR / 'subdir'.
30 BASE_DIR = Path(__file__).resolve().parent.parent
31
32 # Application definition
33
34 INSTALLED_APPS = [
35 "django.contrib.admin",
36 "django.contrib.auth",
37 "django.contrib.contenttypes",
38 "django.contrib.sessions",
39 "django.contrib.messages",
40 "django.contrib.staticfiles",
41 "rest_framework",
42 "django_filters",
43 "django_property_filter",
44 "mathesar",
45 ]
46
47 MIDDLEWARE = [
48 "django.middleware.security.SecurityMiddleware",
49 "django.contrib.sessions.middleware.SessionMiddleware",
50 "django.middleware.common.CommonMiddleware",
51 "django.middleware.csrf.CsrfViewMiddleware",
52 "django.contrib.auth.middleware.AuthenticationMiddleware",
53 "django.contrib.messages.middleware.MessageMiddleware",
54 "django.middleware.clickjacking.XFrameOptionsMiddleware",
55 "mathesar.middleware.CursorClosedHandlerMiddleware",
56 "mathesar.middleware.PasswordChangeNeededMiddleware",
57 'django_userforeignkey.middleware.UserForeignKeyMiddleware',
58 'django_request_cache.middleware.RequestCacheMiddleware',
59 ]
60
61 ROOT_URLCONF = "config.urls"
62
63 TEMPLATES = [
64 {
65 "BACKEND": "django.template.backends.django.DjangoTemplates",
66 "DIRS": [],
67 "APP_DIRS": True,
68 "OPTIONS": {
69 "context_processors": [
70 "config.context_processors.frontend_settings",
71 "django.template.context_processors.debug",
72 "django.template.context_processors.request",
73 "django.contrib.auth.context_processors.auth",
74 "django.contrib.messages.context_processors.messages",
75 ],
76 },
77 },
78 ]
79
80 WSGI_APPLICATION = "config.wsgi.application"
81
82 # Database
83 # https://docs.djangoproject.com/en/3.1/ref/settings/#databases
84
85 # TODO: Add to documentation that database keys should not be than 128 characters.
86
87 # MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'
88 # See pipe_delim above for why we use pipes as delimiters
89 DATABASES = {
90 db_key: db_url(url_string)
91 for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))
92 }
93 DATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)
94
95 for db_key, db_dict in DATABASES.items():
96 # Engine can be '.postgresql' or '.postgresql_psycopg2'
97 if not db_dict['ENGINE'].startswith('django.db.backends.postgresql'):
98 raise ValueError(
99 f"{db_key} is not a PostgreSQL database. "
100 f"{db_dict['ENGINE']} found for {db_key}'s engine."
101 )
102
103
104 # pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
105 # and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
106 TEST = decouple_config('TEST', default=False, cast=bool)
107 if TEST:
108 for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):
109 DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}
110
111
112 # Quick-start development settings - unsuitable for production
113 # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
114
115 # SECURITY WARNING: keep the secret key used in production secret!
116 SECRET_KEY = decouple_config('SECRET_KEY')
117
118 # SECURITY WARNING: don't run with debug turned on in production!
119 DEBUG = decouple_config('DEBUG', default=False, cast=bool)
120
121 ALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())
122
123 # Password validation
124 # https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators
125
126 AUTH_PASSWORD_VALIDATORS = [
127 {
128 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
129 },
130 {
131 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
132 },
133 {
134 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
135 },
136 {
137 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
138 },
139 ]
140
141
142 # Internationalization
143 # https://docs.djangoproject.com/en/3.1/topics/i18n/
144
145 LANGUAGE_CODE = "en-us"
146
147 TIME_ZONE = "UTC"
148
149 USE_I18N = True
150
151 USE_L10N = True
152
153 USE_TZ = True
154
155
156 # Static files (CSS, JavaScript, Images)
157 # https://docs.djangoproject.com/en/3.1/howto/static-files/
158 # https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/
159
160 STATIC_URL = "/static/"
161
162 # When running with DEBUG=False, the webserver needs to serve files from this location
163 # python manage.py collectstatic has to be run to collect all static files into this location
164 # The files need to served in brotli or gzip compressed format
165 STATIC_ROOT = os.path.join(BASE_DIR, 'static/')
166
167 # Media files (uploaded by the user)
168
169 MEDIA_ROOT = os.path.join(BASE_DIR, '.media/')
170
171 MEDIA_URL = "/media/"
172
173 # Update Authentication classes, removed BasicAuthentication
174 # Defaults: https://www.django-rest-framework.org/api-guide/settings/
175 REST_FRAMEWORK = {
176 'DEFAULT_AUTHENTICATION_CLASSES': [
177 'rest_framework.authentication.SessionAuthentication'
178 ],
179 'DEFAULT_PERMISSION_CLASSES': [
180 'rest_framework.permissions.IsAuthenticated',
181 ],
182 'DEFAULT_FILTER_BACKENDS': (
183 'django_filters.rest_framework.DjangoFilterBackend',
184 'rest_framework.filters.OrderingFilter',
185 ),
186 'TEST_REQUEST_DEFAULT_FORMAT': 'json',
187 'EXCEPTION_HANDLER':
188 'mathesar.exception_handlers.mathesar_exception_handler'
189 }
190 FRIENDLY_ERRORS = {
191 'FIELD_ERRORS': {
192 # By default drf-friendly-errors does contain error codes for ListSerializer type
193 'ListSerializer': {
194 'required': 2007,
195 'null': 2027,
196 'invalid_choice': 2083,
197 'not_a_list': 2123,
198 'empty': 2093
199 },
200 'PermittedPkRelatedField': {
201 'required': 2007,
202 'null': 2027,
203 'does_not_exist': 2151,
204 'incorrect_type': 2161
205 },
206 'PermittedSlugRelatedField': {
207 'required': 2007, 'invalid': 2002, 'null': 2027,
208 'does_not_exist': 2151, 'incorrect_type': 2161
209 },
210 },
211 'EXCEPTION_DICT': {
212 'Http404': 4005
213 }
214 }
215 # Mathesar settings
216 MATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')
217 MATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')
218 MATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')
219 MATHESAR_CLIENT_DEV_URL = 'http://localhost:3000'
220 MATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')
221 MATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)
222 MATHESAR_STATIC_NON_CODE_FILES_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/non-code/')
223
224 # UI source files have to be served by Django in order for static assets to be included during dev mode
225 # https://vitejs.dev/guide/assets.html
226 # https://vitejs.dev/guide/backend-integration.html
227 STATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION]
228
229 # Accounts
230 AUTH_USER_MODEL = 'mathesar.User'
231 LOGIN_URL = '/auth/login/'
232 LOGIN_REDIRECT_URL = '/'
233 LOGOUT_REDIRECT_URL = LOGIN_URL
234 DRF_ACCESS_POLICY = {
235 'reusable_conditions': ['mathesar.api.permission_conditions']
236 }
237
[end of config/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/config/settings.py b/config/settings.py
--- a/config/settings.py
+++ b/config/settings.py
@@ -100,7 +100,6 @@
f"{db_dict['ENGINE']} found for {db_key}'s engine."
)
-
# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'
# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']
TEST = decouple_config('TEST', default=False, cast=bool)
@@ -108,7 +107,6 @@
for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):
DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}
-
# Quick-start development settings - unsuitable for production
# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/
@@ -138,7 +136,6 @@
},
]
-
# Internationalization
# https://docs.djangoproject.com/en/3.1/topics/i18n/
@@ -152,7 +149,6 @@
USE_TZ = True
-
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/3.1/howto/static-files/
# https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/
diff --git a/mathesar/urls.py b/mathesar/urls.py
--- a/mathesar/urls.py
+++ b/mathesar/urls.py
@@ -1,3 +1,4 @@
+from django.contrib.auth.views import LoginView
from django.urls import include, path, re_path
from rest_framework_nested import routers
@@ -33,6 +34,7 @@
path('api/ui/v0/', include(ui_router.urls)),
path('api/ui/v0/reflect/', views.reflect_all, name='reflect_all'),
path('auth/password_reset_confirm', MathesarPasswordResetConfirmView.as_view(), name='password_reset_confirm'),
+ path('auth/login/', LoginView.as_view(redirect_authenticated_user=True), name='login'),
path('auth/', include('django.contrib.auth.urls')),
path('', views.home, name='home'),
path('<db_name>/', views.schemas, name='schemas'),
|
{"golden_diff": "diff --git a/config/settings.py b/config/settings.py\n--- a/config/settings.py\n+++ b/config/settings.py\n@@ -100,7 +100,6 @@\n f\"{db_dict['ENGINE']} found for {db_key}'s engine.\"\n )\n \n-\n # pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n # and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\n TEST = decouple_config('TEST', default=False, cast=bool)\n@@ -108,7 +107,6 @@\n for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n \n-\n # Quick-start development settings - unsuitable for production\n # See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n \n@@ -138,7 +136,6 @@\n },\n ]\n \n-\n # Internationalization\n # https://docs.djangoproject.com/en/3.1/topics/i18n/\n \n@@ -152,7 +149,6 @@\n \n USE_TZ = True\n \n-\n # Static files (CSS, JavaScript, Images)\n # https://docs.djangoproject.com/en/3.1/howto/static-files/\n # https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/\ndiff --git a/mathesar/urls.py b/mathesar/urls.py\n--- a/mathesar/urls.py\n+++ b/mathesar/urls.py\n@@ -1,3 +1,4 @@\n+from django.contrib.auth.views import LoginView\n from django.urls import include, path, re_path\n from rest_framework_nested import routers\n \n@@ -33,6 +34,7 @@\n path('api/ui/v0/', include(ui_router.urls)),\n path('api/ui/v0/reflect/', views.reflect_all, name='reflect_all'),\n path('auth/password_reset_confirm', MathesarPasswordResetConfirmView.as_view(), name='password_reset_confirm'),\n+ path('auth/login/', LoginView.as_view(redirect_authenticated_user=True), name='login'),\n path('auth/', include('django.contrib.auth.urls')),\n path('', views.home, name='home'),\n path('<db_name>/', views.schemas, name='schemas'),\n", "issue": "When user directly accesses '/auth/login' when already logged in, it should redirect the user to the home page\nIf a user session is active, the url `/auth/login/` should redirect to the home page i.e. database page. Currently, it displays the login page.\n", "before_files": [{"content": "from django.urls import include, path, re_path\nfrom rest_framework_nested import routers\n\nfrom mathesar import views\nfrom mathesar.api.db import viewsets as db_viewsets\nfrom mathesar.api.ui import viewsets as ui_viewsets\nfrom mathesar.users.password_reset import MathesarPasswordResetConfirmView\n\ndb_router = routers.DefaultRouter()\ndb_router.register(r'tables', db_viewsets.TableViewSet, basename='table')\ndb_router.register(r'queries', db_viewsets.QueryViewSet, basename='query')\ndb_router.register(r'links', db_viewsets.LinkViewSet, basename='links')\ndb_router.register(r'schemas', db_viewsets.SchemaViewSet, basename='schema')\ndb_router.register(r'databases', db_viewsets.DatabaseViewSet, basename='database')\ndb_router.register(r'data_files', db_viewsets.DataFileViewSet, basename='data-file')\n\ndb_table_router = routers.NestedSimpleRouter(db_router, r'tables', lookup='table')\ndb_table_router.register(r'records', db_viewsets.RecordViewSet, basename='table-record')\ndb_table_router.register(r'settings', db_viewsets.TableSettingsViewSet, basename='table-setting')\ndb_table_router.register(r'columns', db_viewsets.ColumnViewSet, basename='table-column')\ndb_table_router.register(r'constraints', db_viewsets.ConstraintViewSet, basename='table-constraint')\n\nui_router = routers.DefaultRouter()\nui_router.register(r'version', ui_viewsets.VersionViewSet, basename='version')\nui_router.register(r'databases', ui_viewsets.DatabaseViewSet, basename='database')\nui_router.register(r'users', ui_viewsets.UserViewSet, basename='user')\nui_router.register(r'database_roles', ui_viewsets.DatabaseRoleViewSet, basename='database_role')\nui_router.register(r'schema_roles', ui_viewsets.SchemaRoleViewSet, basename='schema_role')\n\nurlpatterns = [\n path('api/db/v0/', include(db_router.urls)),\n path('api/db/v0/', include(db_table_router.urls)),\n path('api/ui/v0/', include(ui_router.urls)),\n path('api/ui/v0/reflect/', views.reflect_all, name='reflect_all'),\n path('auth/password_reset_confirm', MathesarPasswordResetConfirmView.as_view(), name='password_reset_confirm'),\n path('auth/', include('django.contrib.auth.urls')),\n path('', views.home, name='home'),\n path('<db_name>/', views.schemas, name='schemas'),\n re_path(\n r'^(?P<db_name>\\w+)/(?P<schema_id>\\w+)/',\n views.schema_home,\n name='schema_home'\n ),\n]\n", "path": "mathesar/urls.py"}, {"content": "\"\"\"\nDjango settings for config project.\n\nGenerated by 'django-admin startproject' using Django 3.1.7.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.1/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.1/ref/settings/\n\"\"\"\n\nimport os\nfrom pathlib import Path\n\nfrom decouple import Csv, config as decouple_config\nfrom dj_database_url import parse as db_url\n\n\n# We use a 'tuple' with pipes as delimiters as decople naively splits the global\n# variables on commas when casting to Csv()\ndef pipe_delim(pipe_string):\n # Remove opening and closing brackets\n pipe_string = pipe_string[1:-1]\n # Split on pipe delim\n return pipe_string.split(\"|\")\n\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n \"django_filters\",\n \"django_property_filter\",\n \"mathesar\",\n]\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"mathesar.middleware.CursorClosedHandlerMiddleware\",\n \"mathesar.middleware.PasswordChangeNeededMiddleware\",\n 'django_userforeignkey.middleware.UserForeignKeyMiddleware',\n 'django_request_cache.middleware.RequestCacheMiddleware',\n]\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"config.context_processors.frontend_settings\",\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.1/ref/settings/#databases\n\n# TODO: Add to documentation that database keys should not be than 128 characters.\n\n# MATHESAR_DATABASES should be of the form '({db_name}|{db_url}), ({db_name}|{db_url})'\n# See pipe_delim above for why we use pipes as delimiters\nDATABASES = {\n db_key: db_url(url_string)\n for db_key, url_string in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim))\n}\nDATABASES[decouple_config('DJANGO_DATABASE_KEY')] = decouple_config('DJANGO_DATABASE_URL', cast=db_url)\n\nfor db_key, db_dict in DATABASES.items():\n # Engine can be '.postgresql' or '.postgresql_psycopg2'\n if not db_dict['ENGINE'].startswith('django.db.backends.postgresql'):\n raise ValueError(\n f\"{db_key} is not a PostgreSQL database. \"\n f\"{db_dict['ENGINE']} found for {db_key}'s engine.\"\n )\n\n\n# pytest-django will create a new database named 'test_{DATABASES[table_db]['NAME']}'\n# and use it for our API tests if we don't specify DATABASES[table_db]['TEST']['NAME']\nTEST = decouple_config('TEST', default=False, cast=bool)\nif TEST:\n for db_key, _ in decouple_config('MATHESAR_DATABASES', cast=Csv(pipe_delim)):\n DATABASES[db_key]['TEST'] = {'NAME': DATABASES[db_key]['NAME']}\n\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.1/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = decouple_config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = decouple_config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = decouple_config('ALLOWED_HOSTS', cast=Csv())\n\n# Password validation\n# https://docs.djangoproject.com/en/3.1/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.1/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.1/howto/static-files/\n# https://docs.djangoproject.com/en/3.1/ref/contrib/staticfiles/\n\nSTATIC_URL = \"/static/\"\n\n# When running with DEBUG=False, the webserver needs to serve files from this location\n# python manage.py collectstatic has to be run to collect all static files into this location\n# The files need to served in brotli or gzip compressed format\nSTATIC_ROOT = os.path.join(BASE_DIR, 'static/')\n\n# Media files (uploaded by the user)\n\nMEDIA_ROOT = os.path.join(BASE_DIR, '.media/')\n\nMEDIA_URL = \"/media/\"\n\n# Update Authentication classes, removed BasicAuthentication\n# Defaults: https://www.django-rest-framework.org/api-guide/settings/\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.SessionAuthentication'\n ],\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticated',\n ],\n 'DEFAULT_FILTER_BACKENDS': (\n 'django_filters.rest_framework.DjangoFilterBackend',\n 'rest_framework.filters.OrderingFilter',\n ),\n 'TEST_REQUEST_DEFAULT_FORMAT': 'json',\n 'EXCEPTION_HANDLER':\n 'mathesar.exception_handlers.mathesar_exception_handler'\n}\nFRIENDLY_ERRORS = {\n 'FIELD_ERRORS': {\n # By default drf-friendly-errors does contain error codes for ListSerializer type\n 'ListSerializer': {\n 'required': 2007,\n 'null': 2027,\n 'invalid_choice': 2083,\n 'not_a_list': 2123,\n 'empty': 2093\n },\n 'PermittedPkRelatedField': {\n 'required': 2007,\n 'null': 2027,\n 'does_not_exist': 2151,\n 'incorrect_type': 2161\n },\n 'PermittedSlugRelatedField': {\n 'required': 2007, 'invalid': 2002, 'null': 2027,\n 'does_not_exist': 2151, 'incorrect_type': 2161\n },\n },\n 'EXCEPTION_DICT': {\n 'Http404': 4005\n }\n}\n# Mathesar settings\nMATHESAR_MODE = decouple_config('MODE', default='PRODUCTION')\nMATHESAR_UI_BUILD_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/mathesar/')\nMATHESAR_MANIFEST_LOCATION = os.path.join(MATHESAR_UI_BUILD_LOCATION, 'manifest.json')\nMATHESAR_CLIENT_DEV_URL = 'http://localhost:3000'\nMATHESAR_UI_SOURCE_LOCATION = os.path.join(BASE_DIR, 'mathesar_ui/')\nMATHESAR_CAPTURE_UNHANDLED_EXCEPTION = decouple_config('CAPTURE_UNHANDLED_EXCEPTION', default=False)\nMATHESAR_STATIC_NON_CODE_FILES_LOCATION = os.path.join(BASE_DIR, 'mathesar/static/non-code/')\n\n# UI source files have to be served by Django in order for static assets to be included during dev mode\n# https://vitejs.dev/guide/assets.html\n# https://vitejs.dev/guide/backend-integration.html\nSTATICFILES_DIRS = [MATHESAR_UI_SOURCE_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION] if MATHESAR_MODE == 'DEVELOPMENT' else [MATHESAR_UI_BUILD_LOCATION, MATHESAR_STATIC_NON_CODE_FILES_LOCATION]\n\n# Accounts\nAUTH_USER_MODEL = 'mathesar.User'\nLOGIN_URL = '/auth/login/'\nLOGIN_REDIRECT_URL = '/'\nLOGOUT_REDIRECT_URL = LOGIN_URL\nDRF_ACCESS_POLICY = {\n 'reusable_conditions': ['mathesar.api.permission_conditions']\n}\n", "path": "config/settings.py"}]}
| 3,762 | 509 |
gh_patches_debug_13226
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-11092
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cleanup extra logic that handle python <=3.3
https://github.com/ipython/ipython/pull/10833 dis most of that but there seem to be some logic still handling python 3.3
https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/core/extensions.py#L17-L21
https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/utils/openpy.py#L117-L121
https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/utils/text.py#L512-L519
(3.4.2+)
https://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/core/magics/execution.py#L145-L149
There are possibly other places, this should be relatively easy to fix for a new contributor.
Each of these removal can be a separate PR.
</issue>
<code>
[start of IPython/core/extensions.py]
1 # encoding: utf-8
2 """A class for managing IPython extensions."""
3
4 # Copyright (c) IPython Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 import os
8 import os.path
9 import sys
10 from importlib import import_module
11
12 from traitlets.config.configurable import Configurable
13 from IPython.utils.path import ensure_dir_exists, compress_user
14 from IPython.utils.decorators import undoc
15 from traitlets import Instance
16
17 try:
18 from importlib import reload
19 except ImportError :
20 ## deprecated since 3.4
21 from imp import reload
22
23 #-----------------------------------------------------------------------------
24 # Main class
25 #-----------------------------------------------------------------------------
26
27 class ExtensionManager(Configurable):
28 """A class to manage IPython extensions.
29
30 An IPython extension is an importable Python module that has
31 a function with the signature::
32
33 def load_ipython_extension(ipython):
34 # Do things with ipython
35
36 This function is called after your extension is imported and the
37 currently active :class:`InteractiveShell` instance is passed as
38 the only argument. You can do anything you want with IPython at
39 that point, including defining new magic and aliases, adding new
40 components, etc.
41
42 You can also optionally define an :func:`unload_ipython_extension(ipython)`
43 function, which will be called if the user unloads or reloads the extension.
44 The extension manager will only call :func:`load_ipython_extension` again
45 if the extension is reloaded.
46
47 You can put your extension modules anywhere you want, as long as
48 they can be imported by Python's standard import mechanism. However,
49 to make it easy to write extensions, you can also put your extensions
50 in ``os.path.join(self.ipython_dir, 'extensions')``. This directory
51 is added to ``sys.path`` automatically.
52 """
53
54 shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)
55
56 def __init__(self, shell=None, **kwargs):
57 super(ExtensionManager, self).__init__(shell=shell, **kwargs)
58 self.shell.observe(
59 self._on_ipython_dir_changed, names=('ipython_dir',)
60 )
61 self.loaded = set()
62
63 @property
64 def ipython_extension_dir(self):
65 return os.path.join(self.shell.ipython_dir, u'extensions')
66
67 def _on_ipython_dir_changed(self, change):
68 ensure_dir_exists(self.ipython_extension_dir)
69
70 def load_extension(self, module_str):
71 """Load an IPython extension by its module name.
72
73 Returns the string "already loaded" if the extension is already loaded,
74 "no load function" if the module doesn't have a load_ipython_extension
75 function, or None if it succeeded.
76 """
77 if module_str in self.loaded:
78 return "already loaded"
79
80 from IPython.utils.syspathcontext import prepended_to_syspath
81
82 with self.shell.builtin_trap:
83 if module_str not in sys.modules:
84 with prepended_to_syspath(self.ipython_extension_dir):
85 mod = import_module(module_str)
86 if mod.__file__.startswith(self.ipython_extension_dir):
87 print(("Loading extensions from {dir} is deprecated. "
88 "We recommend managing extensions like any "
89 "other Python packages, in site-packages.").format(
90 dir=compress_user(self.ipython_extension_dir)))
91 mod = sys.modules[module_str]
92 if self._call_load_ipython_extension(mod):
93 self.loaded.add(module_str)
94 else:
95 return "no load function"
96
97 def unload_extension(self, module_str):
98 """Unload an IPython extension by its module name.
99
100 This function looks up the extension's name in ``sys.modules`` and
101 simply calls ``mod.unload_ipython_extension(self)``.
102
103 Returns the string "no unload function" if the extension doesn't define
104 a function to unload itself, "not loaded" if the extension isn't loaded,
105 otherwise None.
106 """
107 if module_str not in self.loaded:
108 return "not loaded"
109
110 if module_str in sys.modules:
111 mod = sys.modules[module_str]
112 if self._call_unload_ipython_extension(mod):
113 self.loaded.discard(module_str)
114 else:
115 return "no unload function"
116
117 def reload_extension(self, module_str):
118 """Reload an IPython extension by calling reload.
119
120 If the module has not been loaded before,
121 :meth:`InteractiveShell.load_extension` is called. Otherwise
122 :func:`reload` is called and then the :func:`load_ipython_extension`
123 function of the module, if it exists is called.
124 """
125 from IPython.utils.syspathcontext import prepended_to_syspath
126
127 if (module_str in self.loaded) and (module_str in sys.modules):
128 self.unload_extension(module_str)
129 mod = sys.modules[module_str]
130 with prepended_to_syspath(self.ipython_extension_dir):
131 reload(mod)
132 if self._call_load_ipython_extension(mod):
133 self.loaded.add(module_str)
134 else:
135 self.load_extension(module_str)
136
137 def _call_load_ipython_extension(self, mod):
138 if hasattr(mod, 'load_ipython_extension'):
139 mod.load_ipython_extension(self.shell)
140 return True
141
142 def _call_unload_ipython_extension(self, mod):
143 if hasattr(mod, 'unload_ipython_extension'):
144 mod.unload_ipython_extension(self.shell)
145 return True
146
147 @undoc
148 def install_extension(self, url, filename=None):
149 """
150 Deprecated.
151 """
152 # Ensure the extension directory exists
153 raise DeprecationWarning(
154 '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'
155 'Use pip or other package managers to manage ipython extensions.')
156
[end of IPython/core/extensions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/core/extensions.py b/IPython/core/extensions.py
--- a/IPython/core/extensions.py
+++ b/IPython/core/extensions.py
@@ -7,18 +7,13 @@
import os
import os.path
import sys
-from importlib import import_module
+from importlib import import_module, reload
from traitlets.config.configurable import Configurable
from IPython.utils.path import ensure_dir_exists, compress_user
from IPython.utils.decorators import undoc
from traitlets import Instance
-try:
- from importlib import reload
-except ImportError :
- ## deprecated since 3.4
- from imp import reload
#-----------------------------------------------------------------------------
# Main class
|
{"golden_diff": "diff --git a/IPython/core/extensions.py b/IPython/core/extensions.py\n--- a/IPython/core/extensions.py\n+++ b/IPython/core/extensions.py\n@@ -7,18 +7,13 @@\n import os\n import os.path\n import sys\n-from importlib import import_module\n+from importlib import import_module, reload\n \n from traitlets.config.configurable import Configurable\n from IPython.utils.path import ensure_dir_exists, compress_user\n from IPython.utils.decorators import undoc\n from traitlets import Instance\n \n-try:\n- from importlib import reload\n-except ImportError :\n- ## deprecated since 3.4\n- from imp import reload\n \n #-----------------------------------------------------------------------------\n # Main class\n", "issue": "Cleanup extra logic that handle python <=3.3\nhttps://github.com/ipython/ipython/pull/10833 dis most of that but there seem to be some logic still handling python 3.3\r\n\r\nhttps://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/core/extensions.py#L17-L21\r\n\r\nhttps://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/utils/openpy.py#L117-L121\r\n\r\nhttps://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/utils/text.py#L512-L519\r\n\r\n(3.4.2+)\r\n\r\nhttps://github.com/ipython/ipython/blob/dda523895e5a9c4185de763a25f038dc6fff76b8/IPython/core/magics/execution.py#L145-L149\r\n\r\nThere are possibly other places, this should be relatively easy to fix for a new contributor.\r\n\r\nEach of these removal can be a separate PR.\n", "before_files": [{"content": "# encoding: utf-8\n\"\"\"A class for managing IPython extensions.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\nimport os.path\nimport sys\nfrom importlib import import_module\n\nfrom traitlets.config.configurable import Configurable\nfrom IPython.utils.path import ensure_dir_exists, compress_user\nfrom IPython.utils.decorators import undoc\nfrom traitlets import Instance\n\ntry:\n from importlib import reload\nexcept ImportError :\n ## deprecated since 3.4\n from imp import reload\n\n#-----------------------------------------------------------------------------\n# Main class\n#-----------------------------------------------------------------------------\n\nclass ExtensionManager(Configurable):\n \"\"\"A class to manage IPython extensions.\n\n An IPython extension is an importable Python module that has\n a function with the signature::\n\n def load_ipython_extension(ipython):\n # Do things with ipython\n\n This function is called after your extension is imported and the\n currently active :class:`InteractiveShell` instance is passed as\n the only argument. You can do anything you want with IPython at\n that point, including defining new magic and aliases, adding new\n components, etc.\n \n You can also optionally define an :func:`unload_ipython_extension(ipython)`\n function, which will be called if the user unloads or reloads the extension.\n The extension manager will only call :func:`load_ipython_extension` again\n if the extension is reloaded.\n\n You can put your extension modules anywhere you want, as long as\n they can be imported by Python's standard import mechanism. However,\n to make it easy to write extensions, you can also put your extensions\n in ``os.path.join(self.ipython_dir, 'extensions')``. This directory\n is added to ``sys.path`` automatically.\n \"\"\"\n\n shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)\n\n def __init__(self, shell=None, **kwargs):\n super(ExtensionManager, self).__init__(shell=shell, **kwargs)\n self.shell.observe(\n self._on_ipython_dir_changed, names=('ipython_dir',)\n )\n self.loaded = set()\n\n @property\n def ipython_extension_dir(self):\n return os.path.join(self.shell.ipython_dir, u'extensions')\n\n def _on_ipython_dir_changed(self, change):\n ensure_dir_exists(self.ipython_extension_dir)\n\n def load_extension(self, module_str):\n \"\"\"Load an IPython extension by its module name.\n\n Returns the string \"already loaded\" if the extension is already loaded,\n \"no load function\" if the module doesn't have a load_ipython_extension\n function, or None if it succeeded.\n \"\"\"\n if module_str in self.loaded:\n return \"already loaded\"\n\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n with self.shell.builtin_trap:\n if module_str not in sys.modules:\n with prepended_to_syspath(self.ipython_extension_dir):\n mod = import_module(module_str)\n if mod.__file__.startswith(self.ipython_extension_dir):\n print((\"Loading extensions from {dir} is deprecated. \"\n \"We recommend managing extensions like any \"\n \"other Python packages, in site-packages.\").format(\n dir=compress_user(self.ipython_extension_dir)))\n mod = sys.modules[module_str]\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n return \"no load function\"\n\n def unload_extension(self, module_str):\n \"\"\"Unload an IPython extension by its module name.\n\n This function looks up the extension's name in ``sys.modules`` and\n simply calls ``mod.unload_ipython_extension(self)``.\n \n Returns the string \"no unload function\" if the extension doesn't define\n a function to unload itself, \"not loaded\" if the extension isn't loaded,\n otherwise None.\n \"\"\"\n if module_str not in self.loaded:\n return \"not loaded\"\n \n if module_str in sys.modules:\n mod = sys.modules[module_str]\n if self._call_unload_ipython_extension(mod):\n self.loaded.discard(module_str)\n else:\n return \"no unload function\"\n\n def reload_extension(self, module_str):\n \"\"\"Reload an IPython extension by calling reload.\n\n If the module has not been loaded before,\n :meth:`InteractiveShell.load_extension` is called. Otherwise\n :func:`reload` is called and then the :func:`load_ipython_extension`\n function of the module, if it exists is called.\n \"\"\"\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n if (module_str in self.loaded) and (module_str in sys.modules):\n self.unload_extension(module_str)\n mod = sys.modules[module_str]\n with prepended_to_syspath(self.ipython_extension_dir):\n reload(mod)\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n self.load_extension(module_str)\n\n def _call_load_ipython_extension(self, mod):\n if hasattr(mod, 'load_ipython_extension'):\n mod.load_ipython_extension(self.shell)\n return True\n\n def _call_unload_ipython_extension(self, mod):\n if hasattr(mod, 'unload_ipython_extension'):\n mod.unload_ipython_extension(self.shell)\n return True\n\n @undoc\n def install_extension(self, url, filename=None):\n \"\"\"\n Deprecated.\n \"\"\"\n # Ensure the extension directory exists\n raise DeprecationWarning(\n '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'\n 'Use pip or other package managers to manage ipython extensions.')\n", "path": "IPython/core/extensions.py"}]}
| 2,478 | 150 |
gh_patches_debug_20143
|
rasdani/github-patches
|
git_diff
|
angr__angr-3216
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Semantics of preconstrainer interface is confusing or wrong
<!--
*Disclaimer:
The angr suite is maintained by a small team of volunteers.
While we cannot guarantee any timeliness for fixes and enhancements, we will do our best.
For more real-time help with angr, from us and the community, join our [Slack.](https://angr.io/invite/)*
-->
**Describe the bug.**
Consider:
```
preconstrainer.preconstrain(value, exp1)
preconstrainer.remove_preconstraints()
preconstrainer.preconstrain(value, exp2)
```
After this sequence of calls, I expect `exp2 == value`, but **not** `exp1 == value`. Right now, angr constrains both. If this is intentional, how do I obtain my desired behavior? If not, that is the bug.
**Describe the solution you would like.**
<!--
A clear and concise description of what you want to happen.
-->
My personal preference would be to adjust the preconstrainer to match my expected behavior. Also I would like 10 BTC and a unicorn.
**Please include a sample of what *should* work if this feature is implemented.**
<!--
If this is related to a Python user interface/experience feature, please include an example of what this may look like.
If this is related to a certain kind of binary program, please attach one if possible.
-->
See above.
**Describe alternatives you have considered.**
<!--
A clear and concise description of any alternative solutions or features you've considered.
-->
I am going to manually clear `preconstrainer.preconstraints` and `preconstrainer.variable_map` but I shouldn't have to do that as the user.
</issue>
<code>
[start of angr/state_plugins/preconstrainer.py]
1 import logging
2 import claripy
3
4 from .plugin import SimStatePlugin
5 from .. import sim_options as o
6 from ..errors import AngrError
7
8
9 l = logging.getLogger(name=__name__)
10
11
12 class SimStatePreconstrainer(SimStatePlugin):
13 """
14 This state plugin manages the concept of preconstraining - adding constraints which you would like to remove later.
15
16 :param constrained_addrs : SimActions for memory operations whose addresses should be constrained during crash analysis
17 """
18
19 def __init__(self, constrained_addrs=None):
20 SimStatePlugin.__init__(self)
21
22 # map of variable string names to preconstraints, for re-applying constraints.
23 self.variable_map = {}
24 self.preconstraints = []
25 self._constrained_addrs = [] if constrained_addrs is None else constrained_addrs
26 self.address_concretization = []
27
28 def merge(self, others, merge_conditions, common_ancestor=None): # pylint: disable=unused-argument
29 l.warning("Merging is not implemented for preconstrainer!")
30 return False
31
32 def widen(self, others): # pylint: disable=unused-argument
33 l.warning("Widening is not implemented for preconstrainer!")
34 return False
35
36 @SimStatePlugin.memo
37 def copy(self, memo): # pylint: disable=unused-argument
38 c = SimStatePreconstrainer(constrained_addrs=self._constrained_addrs)
39
40 c.variable_map = dict(self.variable_map)
41 c.preconstraints = list(self.preconstraints)
42 c.address_concretization = list(self.address_concretization)
43
44 return c
45
46 def preconstrain(self, value, variable):
47 """
48 Add a preconstraint that ``variable == value`` to the state.
49
50 :param value: The concrete value. Can be a bitvector or a bytestring or an integer.
51 :param variable: The BVS to preconstrain.
52 """
53 if not isinstance(value, claripy.ast.Base):
54 value = self.state.solver.BVV(value, len(variable))
55 elif value.op != 'BVV':
56 raise ValueError("Passed a value to preconstrain that was not a BVV or a string")
57
58 if variable.op not in claripy.operations.leaf_operations:
59 l.warning("The variable %s to preconstrain is not a leaf AST. This may cause replacement failures in the "
60 "claripy replacement backend.", variable)
61 l.warning("Please use a leaf AST as the preconstraining variable instead.")
62
63 constraint = variable == value
64 l.debug("Preconstraint: %s", constraint)
65
66 # add the constraint for reconstraining later
67 self.variable_map[next(iter(variable.variables))] = constraint
68 self.preconstraints.append(constraint)
69 if o.REPLACEMENT_SOLVER in self.state.options:
70 self.state.solver._solver.add_replacement(variable, value, invalidate_cache=False)
71 else:
72 self.state.add_constraints(*self.preconstraints)
73 if not self.state.satisfiable():
74 l.warning("State went unsat while adding preconstraints")
75
76 def preconstrain_file(self, content, simfile, set_length=False):
77 """
78 Preconstrain the contents of a file.
79
80 :param content: The content to preconstrain the file to. Can be a bytestring or a list thereof.
81 :param simfile: The actual simfile to preconstrain
82 """
83 repair_entry_state_opts = False
84 if o.TRACK_ACTION_HISTORY in self.state.options:
85 repair_entry_state_opts = True
86 self.state.options -= {o.TRACK_ACTION_HISTORY}
87
88 if set_length: # disable read bounds
89 simfile.has_end = False
90
91 pos = 0
92 for write in content:
93 if type(write) is int:
94 write = bytes([write])
95 data, length, pos = simfile.read(pos, len(write), disable_actions=True, inspect=False, short_reads=False)
96 if not claripy.is_true(length == len(write)):
97 raise AngrError("Bug in either SimFile or in usage of preconstrainer: couldn't get requested data from file")
98 self.preconstrain(write, data)
99
100 # if the file is a stream, reset its position
101 if simfile.pos is not None:
102 simfile.pos = 0
103
104 if set_length: # enable read bounds; size is now maximum size
105 simfile.has_end = True
106
107 if repair_entry_state_opts:
108 self.state.options |= {o.TRACK_ACTION_HISTORY}
109
110 def preconstrain_flag_page(self, magic_content):
111 """
112 Preconstrain the data in the flag page.
113
114 :param magic_content: The content of the magic page as a bytestring.
115 """
116 for m, v in zip(magic_content, self.state.cgc.flag_bytes):
117 self.preconstrain(m, v)
118
119 def remove_preconstraints(self, to_composite_solver=True, simplify=True):
120 """
121 Remove the preconstraints from the state.
122
123 If you are using the zen plugin, this will also use that to filter the constraints.
124
125 :param to_composite_solver: Whether to convert the replacement solver to a composite solver. You probably
126 want this if you're switching from tracing to symbolic analysis.
127 :param simplify: Whether to simplify the resulting set of constraints.
128 """
129 if not self.preconstraints:
130 return
131
132 # cache key set creation
133 precon_cache_keys = set()
134
135 for con in self.preconstraints:
136 precon_cache_keys.add(con.cache_key)
137
138 # if we used the replacement solver we didn't add constraints we need to remove so keep all constraints
139 if o.REPLACEMENT_SOLVER in self.state.options:
140 new_constraints = self.state.solver.constraints
141 else:
142 new_constraints = list(filter(lambda x: x.cache_key not in precon_cache_keys, self.state.solver.constraints))
143
144
145 if self.state.has_plugin("zen_plugin"):
146 new_constraints = self.state.get_plugin("zen_plugin").filter_constraints(new_constraints)
147
148 if to_composite_solver:
149 self.state.options.discard(o.REPLACEMENT_SOLVER)
150 self.state.options.add(o.COMPOSITE_SOLVER)
151
152 # clear the solver's internal memory and replace it with the new solver options and constraints
153 self.state.solver.reload_solver(new_constraints)
154
155 if simplify:
156 l.debug("simplifying solver...")
157 self.state.solver.simplify()
158 l.debug("...simplification done")
159
160 def reconstrain(self):
161 """
162 Split the solver. If any of the subsolvers time out after a short timeout (10 seconds), re-add the
163 preconstraints associated with each of its variables. Hopefully these constraints still allow us to do
164 meaningful things to the state.
165 """
166
167 # test all solver splits
168 subsolvers = self.state.solver._solver.split()
169
170 for solver in subsolvers:
171 solver.timeout = 1000 * 10 # 10 seconds
172 if not solver.satisfiable():
173 for var in solver.variables:
174 if var in self.variable_map:
175 self.state.add_constraints(self.variable_map[var])
176 else:
177 l.warning("var %s not found in self.variable_map", var)
178
179
180 from angr.sim_state import SimState
181 SimState.register_default('preconstrainer', SimStatePreconstrainer)
182
[end of angr/state_plugins/preconstrainer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/angr/state_plugins/preconstrainer.py b/angr/state_plugins/preconstrainer.py
--- a/angr/state_plugins/preconstrainer.py
+++ b/angr/state_plugins/preconstrainer.py
@@ -64,12 +64,14 @@
l.debug("Preconstraint: %s", constraint)
# add the constraint for reconstraining later
+ if next(iter(variable.variables)) in self.variable_map:
+ l.warning("%s is already preconstrained. Are you misusing preconstrainer?", next(iter(variable.variables)))
self.variable_map[next(iter(variable.variables))] = constraint
self.preconstraints.append(constraint)
if o.REPLACEMENT_SOLVER in self.state.options:
self.state.solver._solver.add_replacement(variable, value, invalidate_cache=False)
else:
- self.state.add_constraints(*self.preconstraints)
+ self.state.add_constraints(constraint)
if not self.state.satisfiable():
l.warning("State went unsat while adding preconstraints")
|
{"golden_diff": "diff --git a/angr/state_plugins/preconstrainer.py b/angr/state_plugins/preconstrainer.py\n--- a/angr/state_plugins/preconstrainer.py\n+++ b/angr/state_plugins/preconstrainer.py\n@@ -64,12 +64,14 @@\n l.debug(\"Preconstraint: %s\", constraint)\n \n # add the constraint for reconstraining later\n+ if next(iter(variable.variables)) in self.variable_map:\n+ l.warning(\"%s is already preconstrained. Are you misusing preconstrainer?\", next(iter(variable.variables)))\n self.variable_map[next(iter(variable.variables))] = constraint\n self.preconstraints.append(constraint)\n if o.REPLACEMENT_SOLVER in self.state.options:\n self.state.solver._solver.add_replacement(variable, value, invalidate_cache=False)\n else:\n- self.state.add_constraints(*self.preconstraints)\n+ self.state.add_constraints(constraint)\n if not self.state.satisfiable():\n l.warning(\"State went unsat while adding preconstraints\")\n", "issue": "Semantics of preconstrainer interface is confusing or wrong\n<!--\r\n*Disclaimer:\r\nThe angr suite is maintained by a small team of volunteers.\r\nWhile we cannot guarantee any timeliness for fixes and enhancements, we will do our best.\r\nFor more real-time help with angr, from us and the community, join our [Slack.](https://angr.io/invite/)*\r\n-->\r\n\r\n**Describe the bug.**\r\nConsider:\r\n```\r\npreconstrainer.preconstrain(value, exp1)\r\npreconstrainer.remove_preconstraints()\r\npreconstrainer.preconstrain(value, exp2)\r\n```\r\n\r\nAfter this sequence of calls, I expect `exp2 == value`, but **not** `exp1 == value`. Right now, angr constrains both. If this is intentional, how do I obtain my desired behavior? If not, that is the bug.\r\n\r\n**Describe the solution you would like.**\r\n<!--\r\nA clear and concise description of what you want to happen.\r\n-->\r\nMy personal preference would be to adjust the preconstrainer to match my expected behavior. Also I would like 10 BTC and a unicorn.\r\n\r\n**Please include a sample of what *should* work if this feature is implemented.**\r\n<!--\r\nIf this is related to a Python user interface/experience feature, please include an example of what this may look like.\r\nIf this is related to a certain kind of binary program, please attach one if possible.\r\n-->\r\nSee above.\r\n\r\n**Describe alternatives you have considered.**\r\n<!--\r\nA clear and concise description of any alternative solutions or features you've considered.\r\n-->\r\nI am going to manually clear `preconstrainer.preconstraints` and `preconstrainer.variable_map` but I shouldn't have to do that as the user.\r\n\n", "before_files": [{"content": "import logging\nimport claripy\n\nfrom .plugin import SimStatePlugin\nfrom .. import sim_options as o\nfrom ..errors import AngrError\n\n\nl = logging.getLogger(name=__name__)\n\n\nclass SimStatePreconstrainer(SimStatePlugin):\n \"\"\"\n This state plugin manages the concept of preconstraining - adding constraints which you would like to remove later.\n\n :param constrained_addrs : SimActions for memory operations whose addresses should be constrained during crash analysis\n \"\"\"\n\n def __init__(self, constrained_addrs=None):\n SimStatePlugin.__init__(self)\n\n # map of variable string names to preconstraints, for re-applying constraints.\n self.variable_map = {}\n self.preconstraints = []\n self._constrained_addrs = [] if constrained_addrs is None else constrained_addrs\n self.address_concretization = []\n\n def merge(self, others, merge_conditions, common_ancestor=None): # pylint: disable=unused-argument\n l.warning(\"Merging is not implemented for preconstrainer!\")\n return False\n\n def widen(self, others): # pylint: disable=unused-argument\n l.warning(\"Widening is not implemented for preconstrainer!\")\n return False\n\n @SimStatePlugin.memo\n def copy(self, memo): # pylint: disable=unused-argument\n c = SimStatePreconstrainer(constrained_addrs=self._constrained_addrs)\n\n c.variable_map = dict(self.variable_map)\n c.preconstraints = list(self.preconstraints)\n c.address_concretization = list(self.address_concretization)\n\n return c\n\n def preconstrain(self, value, variable):\n \"\"\"\n Add a preconstraint that ``variable == value`` to the state.\n\n :param value: The concrete value. Can be a bitvector or a bytestring or an integer.\n :param variable: The BVS to preconstrain.\n \"\"\"\n if not isinstance(value, claripy.ast.Base):\n value = self.state.solver.BVV(value, len(variable))\n elif value.op != 'BVV':\n raise ValueError(\"Passed a value to preconstrain that was not a BVV or a string\")\n\n if variable.op not in claripy.operations.leaf_operations:\n l.warning(\"The variable %s to preconstrain is not a leaf AST. This may cause replacement failures in the \"\n \"claripy replacement backend.\", variable)\n l.warning(\"Please use a leaf AST as the preconstraining variable instead.\")\n\n constraint = variable == value\n l.debug(\"Preconstraint: %s\", constraint)\n\n # add the constraint for reconstraining later\n self.variable_map[next(iter(variable.variables))] = constraint\n self.preconstraints.append(constraint)\n if o.REPLACEMENT_SOLVER in self.state.options:\n self.state.solver._solver.add_replacement(variable, value, invalidate_cache=False)\n else:\n self.state.add_constraints(*self.preconstraints)\n if not self.state.satisfiable():\n l.warning(\"State went unsat while adding preconstraints\")\n\n def preconstrain_file(self, content, simfile, set_length=False):\n \"\"\"\n Preconstrain the contents of a file.\n\n :param content: The content to preconstrain the file to. Can be a bytestring or a list thereof.\n :param simfile: The actual simfile to preconstrain\n \"\"\"\n repair_entry_state_opts = False\n if o.TRACK_ACTION_HISTORY in self.state.options:\n repair_entry_state_opts = True\n self.state.options -= {o.TRACK_ACTION_HISTORY}\n\n if set_length: # disable read bounds\n simfile.has_end = False\n\n pos = 0\n for write in content:\n if type(write) is int:\n write = bytes([write])\n data, length, pos = simfile.read(pos, len(write), disable_actions=True, inspect=False, short_reads=False)\n if not claripy.is_true(length == len(write)):\n raise AngrError(\"Bug in either SimFile or in usage of preconstrainer: couldn't get requested data from file\")\n self.preconstrain(write, data)\n\n # if the file is a stream, reset its position\n if simfile.pos is not None:\n simfile.pos = 0\n\n if set_length: # enable read bounds; size is now maximum size\n simfile.has_end = True\n\n if repair_entry_state_opts:\n self.state.options |= {o.TRACK_ACTION_HISTORY}\n\n def preconstrain_flag_page(self, magic_content):\n \"\"\"\n Preconstrain the data in the flag page.\n\n :param magic_content: The content of the magic page as a bytestring.\n \"\"\"\n for m, v in zip(magic_content, self.state.cgc.flag_bytes):\n self.preconstrain(m, v)\n\n def remove_preconstraints(self, to_composite_solver=True, simplify=True):\n \"\"\"\n Remove the preconstraints from the state.\n\n If you are using the zen plugin, this will also use that to filter the constraints.\n\n :param to_composite_solver: Whether to convert the replacement solver to a composite solver. You probably\n want this if you're switching from tracing to symbolic analysis.\n :param simplify: Whether to simplify the resulting set of constraints.\n \"\"\"\n if not self.preconstraints:\n return\n\n # cache key set creation\n precon_cache_keys = set()\n\n for con in self.preconstraints:\n precon_cache_keys.add(con.cache_key)\n\n # if we used the replacement solver we didn't add constraints we need to remove so keep all constraints\n if o.REPLACEMENT_SOLVER in self.state.options:\n new_constraints = self.state.solver.constraints\n else:\n new_constraints = list(filter(lambda x: x.cache_key not in precon_cache_keys, self.state.solver.constraints))\n\n\n if self.state.has_plugin(\"zen_plugin\"):\n new_constraints = self.state.get_plugin(\"zen_plugin\").filter_constraints(new_constraints)\n\n if to_composite_solver:\n self.state.options.discard(o.REPLACEMENT_SOLVER)\n self.state.options.add(o.COMPOSITE_SOLVER)\n\n # clear the solver's internal memory and replace it with the new solver options and constraints\n self.state.solver.reload_solver(new_constraints)\n\n if simplify:\n l.debug(\"simplifying solver...\")\n self.state.solver.simplify()\n l.debug(\"...simplification done\")\n\n def reconstrain(self):\n \"\"\"\n Split the solver. If any of the subsolvers time out after a short timeout (10 seconds), re-add the\n preconstraints associated with each of its variables. Hopefully these constraints still allow us to do\n meaningful things to the state.\n \"\"\"\n\n # test all solver splits\n subsolvers = self.state.solver._solver.split()\n\n for solver in subsolvers:\n solver.timeout = 1000 * 10 # 10 seconds\n if not solver.satisfiable():\n for var in solver.variables:\n if var in self.variable_map:\n self.state.add_constraints(self.variable_map[var])\n else:\n l.warning(\"var %s not found in self.variable_map\", var)\n\n\nfrom angr.sim_state import SimState\nSimState.register_default('preconstrainer', SimStatePreconstrainer)\n", "path": "angr/state_plugins/preconstrainer.py"}]}
| 2,933 | 225 |
gh_patches_debug_19020
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-5888
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
list: Add --show-json (or similar flag)
In the vs code project we have a view that uses `dvc list . --dvc-only` to show all paths that are tracked by DVC in a tree view. Reasons for this view, some discussion around it and a short demo are shown here: https://github.com/iterative/vscode-dvc/issues/318.
At the moment we take the stdout from the command, split the string into a list (using `\n` as a delimiter) and then post process to work out whether or not the paths relate to files or directories. I can see from the output of the command that directories are already highlighted:

From the above I assume that the work to determine what the path is (file or dir) has already been done by the cli. Rather than working out this information again it would be ideal if the cli could pass us json that contains the aforementioned information.
This will reduce the amount of code required in the extension and should increase performance (ever so slightly).
Please let me know if any of the above is unclear.
Thanks
</issue>
<code>
[start of dvc/command/ls/__init__.py]
1 import argparse
2 import logging
3 import sys
4
5 from dvc.command import completion
6 from dvc.command.base import CmdBaseNoRepo, append_doc_link
7 from dvc.command.ls.ls_colors import LsColors
8 from dvc.exceptions import DvcException
9
10 logger = logging.getLogger(__name__)
11
12
13 def _prettify(entries, with_color=False):
14 if with_color:
15 ls_colors = LsColors()
16 fmt = ls_colors.format
17 else:
18
19 def fmt(entry):
20 return entry["path"]
21
22 return [fmt(entry) for entry in entries]
23
24
25 class CmdList(CmdBaseNoRepo):
26 def run(self):
27 from dvc.repo import Repo
28
29 try:
30 entries = Repo.ls(
31 self.args.url,
32 self.args.path,
33 rev=self.args.rev,
34 recursive=self.args.recursive,
35 dvc_only=self.args.dvc_only,
36 )
37 if entries:
38 entries = _prettify(entries, sys.stdout.isatty())
39 logger.info("\n".join(entries))
40 return 0
41 except DvcException:
42 logger.exception(f"failed to list '{self.args.url}'")
43 return 1
44
45
46 def add_parser(subparsers, parent_parser):
47 LIST_HELP = (
48 "List repository contents, including files"
49 " and directories tracked by DVC and by Git."
50 )
51 list_parser = subparsers.add_parser(
52 "list",
53 parents=[parent_parser],
54 description=append_doc_link(LIST_HELP, "list"),
55 help=LIST_HELP,
56 formatter_class=argparse.RawTextHelpFormatter,
57 )
58 list_parser.add_argument("url", help="Location of DVC repository to list")
59 list_parser.add_argument(
60 "-R",
61 "--recursive",
62 action="store_true",
63 help="Recursively list files.",
64 )
65 list_parser.add_argument(
66 "--dvc-only", action="store_true", help="Show only DVC outputs."
67 )
68 list_parser.add_argument(
69 "--rev",
70 nargs="?",
71 help="Git revision (e.g. SHA, branch, tag)",
72 metavar="<commit>",
73 )
74 list_parser.add_argument(
75 "path",
76 nargs="?",
77 help="Path to directory within the repository to list outputs for",
78 ).complete = completion.DIR
79 list_parser.set_defaults(func=CmdList)
80
[end of dvc/command/ls/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/command/ls/__init__.py b/dvc/command/ls/__init__.py
--- a/dvc/command/ls/__init__.py
+++ b/dvc/command/ls/__init__.py
@@ -34,7 +34,11 @@
recursive=self.args.recursive,
dvc_only=self.args.dvc_only,
)
- if entries:
+ if self.args.show_json:
+ import json
+
+ logger.info(json.dumps(entries))
+ elif entries:
entries = _prettify(entries, sys.stdout.isatty())
logger.info("\n".join(entries))
return 0
@@ -65,6 +69,9 @@
list_parser.add_argument(
"--dvc-only", action="store_true", help="Show only DVC outputs."
)
+ list_parser.add_argument(
+ "--show-json", action="store_true", help="Show output in JSON format."
+ )
list_parser.add_argument(
"--rev",
nargs="?",
|
{"golden_diff": "diff --git a/dvc/command/ls/__init__.py b/dvc/command/ls/__init__.py\n--- a/dvc/command/ls/__init__.py\n+++ b/dvc/command/ls/__init__.py\n@@ -34,7 +34,11 @@\n recursive=self.args.recursive,\n dvc_only=self.args.dvc_only,\n )\n- if entries:\n+ if self.args.show_json:\n+ import json\n+\n+ logger.info(json.dumps(entries))\n+ elif entries:\n entries = _prettify(entries, sys.stdout.isatty())\n logger.info(\"\\n\".join(entries))\n return 0\n@@ -65,6 +69,9 @@\n list_parser.add_argument(\n \"--dvc-only\", action=\"store_true\", help=\"Show only DVC outputs.\"\n )\n+ list_parser.add_argument(\n+ \"--show-json\", action=\"store_true\", help=\"Show output in JSON format.\"\n+ )\n list_parser.add_argument(\n \"--rev\",\n nargs=\"?\",\n", "issue": "list: Add --show-json (or similar flag)\nIn the vs code project we have a view that uses `dvc list . --dvc-only` to show all paths that are tracked by DVC in a tree view. Reasons for this view, some discussion around it and a short demo are shown here: https://github.com/iterative/vscode-dvc/issues/318.\r\n\r\nAt the moment we take the stdout from the command, split the string into a list (using `\\n` as a delimiter) and then post process to work out whether or not the paths relate to files or directories. I can see from the output of the command that directories are already highlighted: \r\n\r\n\r\n\r\nFrom the above I assume that the work to determine what the path is (file or dir) has already been done by the cli. Rather than working out this information again it would be ideal if the cli could pass us json that contains the aforementioned information.\r\n\r\nThis will reduce the amount of code required in the extension and should increase performance (ever so slightly).\r\n\r\nPlease let me know if any of the above is unclear.\r\n\r\nThanks\n", "before_files": [{"content": "import argparse\nimport logging\nimport sys\n\nfrom dvc.command import completion\nfrom dvc.command.base import CmdBaseNoRepo, append_doc_link\nfrom dvc.command.ls.ls_colors import LsColors\nfrom dvc.exceptions import DvcException\n\nlogger = logging.getLogger(__name__)\n\n\ndef _prettify(entries, with_color=False):\n if with_color:\n ls_colors = LsColors()\n fmt = ls_colors.format\n else:\n\n def fmt(entry):\n return entry[\"path\"]\n\n return [fmt(entry) for entry in entries]\n\n\nclass CmdList(CmdBaseNoRepo):\n def run(self):\n from dvc.repo import Repo\n\n try:\n entries = Repo.ls(\n self.args.url,\n self.args.path,\n rev=self.args.rev,\n recursive=self.args.recursive,\n dvc_only=self.args.dvc_only,\n )\n if entries:\n entries = _prettify(entries, sys.stdout.isatty())\n logger.info(\"\\n\".join(entries))\n return 0\n except DvcException:\n logger.exception(f\"failed to list '{self.args.url}'\")\n return 1\n\n\ndef add_parser(subparsers, parent_parser):\n LIST_HELP = (\n \"List repository contents, including files\"\n \" and directories tracked by DVC and by Git.\"\n )\n list_parser = subparsers.add_parser(\n \"list\",\n parents=[parent_parser],\n description=append_doc_link(LIST_HELP, \"list\"),\n help=LIST_HELP,\n formatter_class=argparse.RawTextHelpFormatter,\n )\n list_parser.add_argument(\"url\", help=\"Location of DVC repository to list\")\n list_parser.add_argument(\n \"-R\",\n \"--recursive\",\n action=\"store_true\",\n help=\"Recursively list files.\",\n )\n list_parser.add_argument(\n \"--dvc-only\", action=\"store_true\", help=\"Show only DVC outputs.\"\n )\n list_parser.add_argument(\n \"--rev\",\n nargs=\"?\",\n help=\"Git revision (e.g. SHA, branch, tag)\",\n metavar=\"<commit>\",\n )\n list_parser.add_argument(\n \"path\",\n nargs=\"?\",\n help=\"Path to directory within the repository to list outputs for\",\n ).complete = completion.DIR\n list_parser.set_defaults(func=CmdList)\n", "path": "dvc/command/ls/__init__.py"}]}
| 1,478 | 222 |
gh_patches_debug_3062
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1281
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release new version of Hydra
# 🚀 Feature Request
I would like you to release Hydra that includes this PR: https://github.com/facebookresearch/hydra/pull/1197
## Motivation
currently I am using python 3.9 and I can't run Hydra due to a bug that is solved in above PR
</issue>
<code>
[start of hydra/__init__.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2
3 # Source of truth for Hydra's version
4 __version__ = "1.0.4"
5 from hydra import utils
6 from hydra.errors import MissingConfigException
7 from hydra.main import main
8 from hydra.types import TaskFunction
9
10 __all__ = ["__version__", "MissingConfigException", "main", "utils", "TaskFunction"]
11
[end of hydra/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/__init__.py b/hydra/__init__.py
--- a/hydra/__init__.py
+++ b/hydra/__init__.py
@@ -1,7 +1,7 @@
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
# Source of truth for Hydra's version
-__version__ = "1.0.4"
+__version__ = "1.0.5"
from hydra import utils
from hydra.errors import MissingConfigException
from hydra.main import main
|
{"golden_diff": "diff --git a/hydra/__init__.py b/hydra/__init__.py\n--- a/hydra/__init__.py\n+++ b/hydra/__init__.py\n@@ -1,7 +1,7 @@\n # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n \n # Source of truth for Hydra's version\n-__version__ = \"1.0.4\"\n+__version__ = \"1.0.5\"\n from hydra import utils\n from hydra.errors import MissingConfigException\n from hydra.main import main\n", "issue": "Release new version of Hydra\n# \ud83d\ude80 Feature Request\r\n\r\nI would like you to release Hydra that includes this PR: https://github.com/facebookresearch/hydra/pull/1197\r\n\r\n## Motivation\r\n\r\ncurrently I am using python 3.9 and I can't run Hydra due to a bug that is solved in above PR\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\n# Source of truth for Hydra's version\n__version__ = \"1.0.4\"\nfrom hydra import utils\nfrom hydra.errors import MissingConfigException\nfrom hydra.main import main\nfrom hydra.types import TaskFunction\n\n__all__ = [\"__version__\", \"MissingConfigException\", \"main\", \"utils\", \"TaskFunction\"]\n", "path": "hydra/__init__.py"}]}
| 717 | 122 |
gh_patches_debug_47930
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-614
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
project page header: more vertical space for byline
The byline in the project page’s header area, which show’s the project’s organization is vertically too close to the headline of the project.

</issue>
<code>
[start of euth/organisations/views.py]
1 from django.views import generic
2
3 from . import models
4
5
6 class OrganisationDetailView(generic.DetailView):
7 model = models.Organisation
8
9 def visible_projects(self):
10 if self.request.user in self.object.initiators.all():
11 return self.object.project_set.all()
12 else:
13 return self.object.project_set.filter(is_draft=False)
14
15
16 class OrganisationListView(generic.ListView):
17 model = models.Organisation
18 paginate_by = 10
19
[end of euth/organisations/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/euth/organisations/views.py b/euth/organisations/views.py
--- a/euth/organisations/views.py
+++ b/euth/organisations/views.py
@@ -15,4 +15,4 @@
class OrganisationListView(generic.ListView):
model = models.Organisation
- paginate_by = 10
+ paginate_by = 12
|
{"golden_diff": "diff --git a/euth/organisations/views.py b/euth/organisations/views.py\n--- a/euth/organisations/views.py\n+++ b/euth/organisations/views.py\n@@ -15,4 +15,4 @@\n \n class OrganisationListView(generic.ListView):\n model = models.Organisation\n- paginate_by = 10\n+ paginate_by = 12\n", "issue": "project page header: more vertical space for byline\nThe byline in the project page\u2019s header area, which show\u2019s the project\u2019s organization is vertically too close to the headline of the project. \r\n\r\n\n", "before_files": [{"content": "from django.views import generic\n\nfrom . import models\n\n\nclass OrganisationDetailView(generic.DetailView):\n model = models.Organisation\n\n def visible_projects(self):\n if self.request.user in self.object.initiators.all():\n return self.object.project_set.all()\n else:\n return self.object.project_set.filter(is_draft=False)\n\n\nclass OrganisationListView(generic.ListView):\n model = models.Organisation\n paginate_by = 10\n", "path": "euth/organisations/views.py"}]}
| 790 | 86 |
gh_patches_debug_13811
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-1674
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add new method to return the columns for PostgreSQL datasources :electric_plug: :1234:
When MindsDB creates a new PostgreSQL datasource we get information for columns by fetching all datasources. The problem here is that if datasource is big it takes a lot of time. We need a new get_columns method to return the columns name per datasource. The PR should include this method inside the PostgreSQL class .
## Steps :male_detective: :female_detective:
- Implement in https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/integrations/postgres/postgres.py#L37
- Push to staging branch
## Additional rewards :1st_place_medal:
Each code PR brings :three: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/
</issue>
<code>
[start of mindsdb/integrations/postgres/postgres.py]
1 from contextlib import closing
2 import pg8000
3
4 from lightwood.api import dtype
5 from mindsdb.integrations.base import Integration
6 from mindsdb.utilities.log import log
7
8
9 class PostgreSQLConnectionChecker:
10 def __init__(self, **kwargs):
11 self.host = kwargs.get('host')
12 self.port = kwargs.get('port')
13 self.user = kwargs.get('user')
14 self.password = kwargs.get('password')
15 self.database = kwargs.get('database', 'postgres')
16
17 def _get_connection(self):
18 return pg8000.connect(
19 database=self.database,
20 user=self.user,
21 password=self.password,
22 host=self.host,
23 port=self.port
24 )
25
26 def check_connection(self):
27 try:
28 con = self._get_connection()
29 with closing(con) as con:
30 con.run('select 1;')
31 connected = True
32 except Exception:
33 connected = False
34 return connected
35
36
37 class PostgreSQL(Integration, PostgreSQLConnectionChecker):
38 def __init__(self, config, name, db_info):
39 super().__init__(config, name)
40 self.user = db_info.get('user')
41 self.password = db_info.get('password')
42 self.host = db_info.get('host')
43 self.port = db_info.get('port')
44 self.database = db_info.get('database', 'postgres')
45
46 def _to_postgres_table(self, dtype_dict, predicted_cols, columns):
47 subtype_map = {
48 dtype.integer: ' int8',
49 dtype.float: 'float8',
50 dtype.binary: 'bool',
51 dtype.date: 'date',
52 dtype.datetime: 'timestamp',
53 dtype.binary: 'text',
54 dtype.categorical: 'text',
55 dtype.tags: 'text',
56 dtype.image: 'text',
57 dtype.video: 'text',
58 dtype.audio: 'text',
59 dtype.short_text: 'text',
60 dtype.rich_text: 'text',
61 dtype.array: 'text'
62 }
63
64 column_declaration = []
65 for name in columns:
66 try:
67 col_subtype = dtype_dict[name]
68 new_type = subtype_map[col_subtype]
69 column_declaration.append(f' "{name}" {new_type} ')
70 if name in predicted_cols:
71 column_declaration.append(f' "{name}_original" {new_type} ')
72 except Exception as e:
73 log.error(f'Error: can not determine postgres data type for column {name}: {e}')
74
75 return column_declaration
76
77 def _escape_table_name(self, name):
78 return '"' + name.replace('"', '""') + '"'
79
80 def _query(self, query):
81 con = self._get_connection()
82 with closing(con) as con:
83
84 cur = con.cursor()
85 res = True
86 cur.execute(query)
87
88 try:
89 rows = cur.fetchall()
90 keys = [k[0] if isinstance(k[0], str) else k[0].decode('ascii') for k in cur.description]
91 res = [dict(zip(keys, row)) for row in rows]
92 except Exception:
93 pass
94
95 con.commit()
96
97 return res
98
99 def setup(self):
100 user = f"{self.config['api']['mysql']['user']}_{self.name}"
101 password = self.config['api']['mysql']['password']
102 host = self.config['api']['mysql']['host']
103 port = self.config['api']['mysql']['port']
104
105 try:
106 self._query('''
107 DO $$
108 begin
109 if not exists (SELECT 1 FROM pg_extension where extname = 'mysql_fdw') then
110 CREATE EXTENSION mysql_fdw;
111 end if;
112 END
113 $$;
114 ''')
115 except Exception:
116 print('Error: cant find or activate mysql_fdw extension for PostgreSQL.')
117
118 self._query(f'DROP SCHEMA IF EXISTS {self.mindsdb_database} CASCADE')
119
120 self._query(f"DROP USER MAPPING IF EXISTS FOR {self.user} SERVER server_{self.mindsdb_database}")
121
122 self._query(f'DROP SERVER IF EXISTS server_{self.mindsdb_database} CASCADE')
123
124 self._query(f'''
125 CREATE SERVER server_{self.mindsdb_database}
126 FOREIGN DATA WRAPPER mysql_fdw
127 OPTIONS (host '{host}', port '{port}');
128 ''')
129
130 self._query(f'''
131 CREATE USER MAPPING FOR {self.user}
132 SERVER server_{self.mindsdb_database}
133 OPTIONS (username '{user}', password '{password}');
134 ''')
135
136 self._query(f'CREATE SCHEMA {self.mindsdb_database}')
137
138 q = f"""
139 CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (
140 name text,
141 status text,
142 accuracy text,
143 predict text,
144 select_data_query text,
145 external_datasource text,
146 training_options text
147 )
148 SERVER server_{self.mindsdb_database}
149 OPTIONS (dbname 'mindsdb', table_name 'predictors');
150 """
151 self._query(q)
152
153 q = f"""
154 CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.commands (
155 command text
156 ) SERVER server_{self.mindsdb_database}
157 OPTIONS (dbname 'mindsdb', table_name 'commands');
158 """
159 self._query(q)
160
161 def register_predictors(self, model_data_arr):
162 for model_meta in model_data_arr:
163 name = model_meta['name']
164 predict = model_meta['predict']
165 if not isinstance(predict, list):
166 predict = [predict]
167 columns_sql = ','.join(self._to_postgres_table(
168 model_meta['dtype_dict'],
169 predict,
170 list(model_meta['dtype_dict'].keys())
171 ))
172 columns_sql += ',"select_data_query" text'
173 columns_sql += ',"external_datasource" text'
174 for col in predict:
175 columns_sql += f',"{col}_confidence" float8'
176 if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):
177 columns_sql += f',"{col}_min" float8'
178 columns_sql += f',"{col}_max" float8'
179 columns_sql += f',"{col}_explain" text'
180
181 self.unregister_predictor(name)
182 q = f"""
183 CREATE FOREIGN TABLE {self.mindsdb_database}.{self._escape_table_name(name)} (
184 {columns_sql}
185 ) SERVER server_{self.mindsdb_database}
186 OPTIONS (dbname 'mindsdb', table_name '{name}');
187 """
188 self._query(q)
189
190 def unregister_predictor(self, name):
191 q = f"""
192 DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};
193 """
194 self._query(q)
195
196 def get_row_count(self, query):
197 q = f"""
198 SELECT COUNT(*) as count
199 FROM ({query}) as query;"""
200 result = self._query(q)
201 return result[0]['count']
202
203 def get_tables_list(self):
204 q = f""" SELECT table_schema, table_name
205 FROM information_schema.tables
206 WHERE table_schema != 'pg_catalog'
207 AND table_schema != 'information_schema'
208 ORDER BY table_schema, table_name"""
209 tables_list = self._query(q)
210 tables= [f"{table['table_schema']}.{table['table_name']}" for table in tables_list]
211 return tables
212
213 def get_columns(self):
214 q = f"""SELECT column_name, table_name
215 FROM information_schema.columns
216 WHERE table_schema NOT IN ('information_schema', 'pg_catalog')
217 ORDER BY column_name, table_name;"""
218 columns_list = self._query(q)
219 columns = [f"{columns[0]}.{columns[1]}" for columns in columns_list]
220 return columns
[end of mindsdb/integrations/postgres/postgres.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mindsdb/integrations/postgres/postgres.py b/mindsdb/integrations/postgres/postgres.py
--- a/mindsdb/integrations/postgres/postgres.py
+++ b/mindsdb/integrations/postgres/postgres.py
@@ -210,11 +210,11 @@
tables= [f"{table['table_schema']}.{table['table_name']}" for table in tables_list]
return tables
- def get_columns(self):
- q = f"""SELECT column_name, table_name
- FROM information_schema.columns
- WHERE table_schema NOT IN ('information_schema', 'pg_catalog')
- ORDER BY column_name, table_name;"""
- columns_list = self._query(q)
- columns = [f"{columns[0]}.{columns[1]}" for columns in columns_list]
- return columns
\ No newline at end of file
+ def get_columns(self,query):
+ q = f"""SELECT * from ({query}) LIMIT 1;"""
+ query_response = self._query(q)
+ if len(query_response) > 0:
+ columns = list(query_response[0].keys())
+ return columns
+ else:
+ return []
\ No newline at end of file
|
{"golden_diff": "diff --git a/mindsdb/integrations/postgres/postgres.py b/mindsdb/integrations/postgres/postgres.py\n--- a/mindsdb/integrations/postgres/postgres.py\n+++ b/mindsdb/integrations/postgres/postgres.py\n@@ -210,11 +210,11 @@\n tables= [f\"{table['table_schema']}.{table['table_name']}\" for table in tables_list]\n return tables\n \n- def get_columns(self):\n- q = f\"\"\"SELECT column_name, table_name\n-\t\tFROM information_schema.columns\n-\t\tWHERE table_schema NOT IN ('information_schema', 'pg_catalog')\n-\t\tORDER BY column_name, table_name;\"\"\"\n- columns_list = self._query(q)\n- columns = [f\"{columns[0]}.{columns[1]}\" for columns in columns_list]\n- return columns\n\\ No newline at end of file\n+ def get_columns(self,query):\n+ q = f\"\"\"SELECT * from ({query}) LIMIT 1;\"\"\"\n+ query_response = self._query(q)\n+ if len(query_response) > 0:\n+ columns = list(query_response[0].keys())\n+ return columns\n+ else:\n+ return []\n\\ No newline at end of file\n", "issue": "Add new method to return the columns for PostgreSQL datasources :electric_plug: :1234: \nWhen MindsDB creates a new PostgreSQL datasource we get information for columns by fetching all datasources. The problem here is that if datasource is big it takes a lot of time. We need a new get_columns method to return the columns name per datasource. The PR should include this method inside the PostgreSQL class .\r\n\r\n## Steps :male_detective: :female_detective: \r\n\r\n- Implement in https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/integrations/postgres/postgres.py#L37\r\n- Push to staging branch\r\n\r\n## Additional rewards :1st_place_medal: \r\n\r\nEach code PR brings :three: point for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/\r\n \r\n\r\n\n", "before_files": [{"content": "from contextlib import closing\nimport pg8000\n\nfrom lightwood.api import dtype\nfrom mindsdb.integrations.base import Integration\nfrom mindsdb.utilities.log import log\n\n\nclass PostgreSQLConnectionChecker:\n def __init__(self, **kwargs):\n self.host = kwargs.get('host')\n self.port = kwargs.get('port')\n self.user = kwargs.get('user')\n self.password = kwargs.get('password')\n self.database = kwargs.get('database', 'postgres')\n\n def _get_connection(self):\n return pg8000.connect(\n database=self.database,\n user=self.user,\n password=self.password,\n host=self.host,\n port=self.port\n )\n\n def check_connection(self):\n try:\n con = self._get_connection()\n with closing(con) as con:\n con.run('select 1;')\n connected = True\n except Exception:\n connected = False\n return connected\n\n\nclass PostgreSQL(Integration, PostgreSQLConnectionChecker):\n def __init__(self, config, name, db_info):\n super().__init__(config, name)\n self.user = db_info.get('user')\n self.password = db_info.get('password')\n self.host = db_info.get('host')\n self.port = db_info.get('port')\n self.database = db_info.get('database', 'postgres')\n\n def _to_postgres_table(self, dtype_dict, predicted_cols, columns):\n subtype_map = {\n dtype.integer: ' int8',\n dtype.float: 'float8',\n dtype.binary: 'bool',\n dtype.date: 'date',\n dtype.datetime: 'timestamp',\n dtype.binary: 'text',\n dtype.categorical: 'text',\n dtype.tags: 'text',\n dtype.image: 'text',\n dtype.video: 'text',\n dtype.audio: 'text',\n dtype.short_text: 'text',\n dtype.rich_text: 'text',\n dtype.array: 'text'\n }\n\n column_declaration = []\n for name in columns:\n try:\n col_subtype = dtype_dict[name]\n new_type = subtype_map[col_subtype]\n column_declaration.append(f' \"{name}\" {new_type} ')\n if name in predicted_cols:\n column_declaration.append(f' \"{name}_original\" {new_type} ')\n except Exception as e:\n log.error(f'Error: can not determine postgres data type for column {name}: {e}')\n\n return column_declaration\n\n def _escape_table_name(self, name):\n return '\"' + name.replace('\"', '\"\"') + '\"'\n\n def _query(self, query):\n con = self._get_connection()\n with closing(con) as con:\n\n cur = con.cursor()\n res = True\n cur.execute(query)\n\n try:\n rows = cur.fetchall()\n keys = [k[0] if isinstance(k[0], str) else k[0].decode('ascii') for k in cur.description]\n res = [dict(zip(keys, row)) for row in rows]\n except Exception:\n pass\n\n con.commit()\n\n return res\n\n def setup(self):\n user = f\"{self.config['api']['mysql']['user']}_{self.name}\"\n password = self.config['api']['mysql']['password']\n host = self.config['api']['mysql']['host']\n port = self.config['api']['mysql']['port']\n\n try:\n self._query('''\n DO $$\n begin\n if not exists (SELECT 1 FROM pg_extension where extname = 'mysql_fdw') then\n CREATE EXTENSION mysql_fdw;\n end if;\n END\n $$;\n ''')\n except Exception:\n print('Error: cant find or activate mysql_fdw extension for PostgreSQL.')\n\n self._query(f'DROP SCHEMA IF EXISTS {self.mindsdb_database} CASCADE')\n\n self._query(f\"DROP USER MAPPING IF EXISTS FOR {self.user} SERVER server_{self.mindsdb_database}\")\n\n self._query(f'DROP SERVER IF EXISTS server_{self.mindsdb_database} CASCADE')\n\n self._query(f'''\n CREATE SERVER server_{self.mindsdb_database}\n FOREIGN DATA WRAPPER mysql_fdw\n OPTIONS (host '{host}', port '{port}');\n ''')\n\n self._query(f'''\n CREATE USER MAPPING FOR {self.user}\n SERVER server_{self.mindsdb_database}\n OPTIONS (username '{user}', password '{password}');\n ''')\n\n self._query(f'CREATE SCHEMA {self.mindsdb_database}')\n\n q = f\"\"\"\n CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.predictors (\n name text,\n status text,\n accuracy text,\n predict text,\n select_data_query text,\n external_datasource text,\n training_options text\n )\n SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name 'predictors');\n \"\"\"\n self._query(q)\n\n q = f\"\"\"\n CREATE FOREIGN TABLE IF NOT EXISTS {self.mindsdb_database}.commands (\n command text\n ) SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name 'commands');\n \"\"\"\n self._query(q)\n\n def register_predictors(self, model_data_arr):\n for model_meta in model_data_arr:\n name = model_meta['name']\n predict = model_meta['predict']\n if not isinstance(predict, list):\n predict = [predict]\n columns_sql = ','.join(self._to_postgres_table(\n model_meta['dtype_dict'],\n predict,\n list(model_meta['dtype_dict'].keys())\n ))\n columns_sql += ',\"select_data_query\" text'\n columns_sql += ',\"external_datasource\" text'\n for col in predict:\n columns_sql += f',\"{col}_confidence\" float8'\n if model_meta['dtype_dict'][col] in (dtype.integer, dtype.float):\n columns_sql += f',\"{col}_min\" float8'\n columns_sql += f',\"{col}_max\" float8'\n columns_sql += f',\"{col}_explain\" text'\n\n self.unregister_predictor(name)\n q = f\"\"\"\n CREATE FOREIGN TABLE {self.mindsdb_database}.{self._escape_table_name(name)} (\n {columns_sql}\n ) SERVER server_{self.mindsdb_database}\n OPTIONS (dbname 'mindsdb', table_name '{name}');\n \"\"\"\n self._query(q)\n\n def unregister_predictor(self, name):\n q = f\"\"\"\n DROP FOREIGN TABLE IF EXISTS {self.mindsdb_database}.{self._escape_table_name(name)};\n \"\"\"\n self._query(q)\n\n def get_row_count(self, query):\n q = f\"\"\" \n SELECT COUNT(*) as count\n FROM ({query}) as query;\"\"\"\n result = self._query(q)\n return result[0]['count']\n \n def get_tables_list(self):\n q = f\"\"\" SELECT table_schema, table_name\n FROM information_schema.tables\n WHERE table_schema != 'pg_catalog'\n AND table_schema != 'information_schema'\n ORDER BY table_schema, table_name\"\"\"\n tables_list = self._query(q)\n tables= [f\"{table['table_schema']}.{table['table_name']}\" for table in tables_list]\n return tables\n\n def get_columns(self):\n q = f\"\"\"SELECT column_name, table_name\n\t\tFROM information_schema.columns\n\t\tWHERE table_schema NOT IN ('information_schema', 'pg_catalog')\n\t\tORDER BY column_name, table_name;\"\"\"\n columns_list = self._query(q)\n columns = [f\"{columns[0]}.{columns[1]}\" for columns in columns_list]\n return columns", "path": "mindsdb/integrations/postgres/postgres.py"}]}
| 2,952 | 278 |
gh_patches_debug_41669
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-5621
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
streamlit.runtime.secrets.AttrDict no longer returns True for isinstance() against dict in streamlit 1.14.0
### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
Hi.
With the latest streamlit version `streamlit.runtime.secrets.AttrDict` seems to inherit from `UserDict` instead of `dict` in previous version.
Many libraries I use check that their configuration is `isinstance` against `dict` and are now failing when I pass my config from st.secrets to them.
I can't see any documentation changes related to this and am not familiar with `UserDict`, do I have to go through my code and wrap all st.secrets access in a `dict()` conversion call now?
### Reproducible Code Example
```Python
import streamlit as st
print(isinstance(st.secrets["my_secret_dict"], dict)) # False on streamlit 1.14.0 - was True prior to that
```
### Steps To Reproduce
_No response_
### Expected Behavior
_No response_
### Current Behavior
_No response_
### Is this a regression?
- [X] Yes, this used to work in a previous version.
### Debug info
- Streamlit version: 1.14.0
- Python version: 3.100
- Operating System: Linux
- Browser: Firefox
- Virtual environment: None
### Additional Information
_No response_
### Are you willing to submit a PR?
- [ ] Yes, I am willing to submit a PR!
</issue>
<code>
[start of lib/streamlit/runtime/secrets.py]
1 # Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import threading
17 from collections import UserDict
18 from typing import Any, ItemsView, Iterator, KeysView, Mapping, Optional, ValuesView
19
20 import toml
21 from blinker import Signal
22 from typing_extensions import Final
23
24 import streamlit as st
25 import streamlit.watcher.path_watcher
26 from streamlit.logger import get_logger
27
28 _LOGGER = get_logger(__name__)
29 SECRETS_FILE_LOC = os.path.abspath(os.path.join(".", ".streamlit", "secrets.toml"))
30
31
32 def _missing_attr_error_message(attr_name: str) -> str:
33 return (
34 f'st.secrets has no attribute "{attr_name}". '
35 f"Did you forget to add it to secrets.toml or the app settings on Streamlit Cloud? "
36 f"More info: https://docs.streamlit.io/streamlit-cloud/get-started/deploy-an-app/connect-to-data-sources/secrets-management"
37 )
38
39
40 def _missing_key_error_message(key: str) -> str:
41 return (
42 f'st.secrets has no key "{key}". '
43 f"Did you forget to add it to secrets.toml or the app settings on Streamlit Cloud? "
44 f"More info: https://docs.streamlit.io/streamlit-cloud/get-started/deploy-an-app/connect-to-data-sources/secrets-management"
45 )
46
47
48 class AttrDict(UserDict): # type: ignore[type-arg]
49 """
50 We use AttrDict to wrap up dictionary values from secrets
51 to provide dot access to nested secrets
52 """
53
54 @staticmethod
55 def _maybe_wrap_in_attr_dict(value) -> Any:
56 if not isinstance(value, dict):
57 return value
58 else:
59 return AttrDict(**value)
60
61 def __getattr__(self, attr_name: str) -> Any:
62 try:
63 value = super().__getitem__(attr_name)
64 return self._maybe_wrap_in_attr_dict(value)
65 except KeyError:
66 raise AttributeError(_missing_attr_error_message(attr_name))
67
68 def __getitem__(self, key: str) -> Any:
69 try:
70 value = super().__getitem__(key)
71 return self._maybe_wrap_in_attr_dict(value)
72 except KeyError:
73 raise KeyError(_missing_key_error_message(key))
74
75
76 class Secrets(Mapping[str, Any]):
77 """A dict-like class that stores secrets.
78 Parses secrets.toml on-demand. Cannot be externally mutated.
79
80 Safe to use from multiple threads.
81 """
82
83 def __init__(self, file_path: str):
84 # Our secrets dict.
85 self._secrets: Optional[Mapping[str, Any]] = None
86 self._lock = threading.RLock()
87 self._file_watcher_installed = False
88 self._file_path = file_path
89 self._file_change_listener = Signal(
90 doc="Emitted when the `secrets.toml` file has been changed."
91 )
92
93 def load_if_toml_exists(self) -> None:
94 """Load secrets.toml from disk if it exists. If it doesn't exist,
95 no exception will be raised. (If the file exists but is malformed,
96 an exception *will* be raised.)
97
98 Thread-safe.
99 """
100 try:
101 self._parse(print_exceptions=False)
102 except FileNotFoundError:
103 # No secrets.toml file exists. That's fine.
104 pass
105
106 def _reset(self) -> None:
107 """Clear the secrets dictionary and remove any secrets that were
108 added to os.environ.
109
110 Thread-safe.
111 """
112 with self._lock:
113 if self._secrets is None:
114 return
115
116 for k, v in self._secrets.items():
117 self._maybe_delete_environment_variable(k, v)
118 self._secrets = None
119
120 def _parse(self, print_exceptions: bool) -> Mapping[str, Any]:
121 """Parse our secrets.toml file if it's not already parsed.
122 This function is safe to call from multiple threads.
123
124 Parameters
125 ----------
126 print_exceptions : bool
127 If True, then exceptions will be printed with `st.error` before
128 being re-raised.
129
130 Raises
131 ------
132 FileNotFoundError
133 Raised if secrets.toml doesn't exist.
134
135 """
136 # Avoid taking a lock for the common case where secrets are already
137 # loaded.
138 secrets = self._secrets
139 if secrets is not None:
140 return secrets
141
142 with self._lock:
143 if self._secrets is not None:
144 return self._secrets
145
146 try:
147 with open(self._file_path, encoding="utf-8") as f:
148 secrets_file_str = f.read()
149 except FileNotFoundError:
150 if print_exceptions:
151 st.error(f"Secrets file not found. Expected at: {self._file_path}")
152 raise
153
154 try:
155 secrets = toml.loads(secrets_file_str)
156 except:
157 if print_exceptions:
158 st.error("Error parsing Secrets file.")
159 raise
160
161 for k, v in secrets.items():
162 self._maybe_set_environment_variable(k, v)
163
164 self._secrets = secrets
165 self._maybe_install_file_watcher()
166
167 return self._secrets
168
169 @staticmethod
170 def _maybe_set_environment_variable(k: Any, v: Any) -> None:
171 """Add the given key/value pair to os.environ if the value
172 is a string, int, or float."""
173 value_type = type(v)
174 if value_type in (str, int, float):
175 os.environ[k] = str(v)
176
177 @staticmethod
178 def _maybe_delete_environment_variable(k: Any, v: Any) -> None:
179 """Remove the given key/value pair from os.environ if the value
180 is a string, int, or float."""
181 value_type = type(v)
182 if value_type in (str, int, float) and os.environ.get(k) == v:
183 del os.environ[k]
184
185 def _maybe_install_file_watcher(self) -> None:
186 with self._lock:
187 if self._file_watcher_installed:
188 return
189
190 # We force our watcher_type to 'poll' because Streamlit Cloud
191 # stores `secrets.toml` in a virtual filesystem that is
192 # incompatible with watchdog.
193 streamlit.watcher.path_watcher.watch_file(
194 self._file_path,
195 self._on_secrets_file_changed,
196 watcher_type="poll",
197 )
198
199 # We set file_watcher_installed to True even if watch_file
200 # returns False to avoid repeatedly trying to install it.
201 self._file_watcher_installed = True
202
203 def _on_secrets_file_changed(self, _) -> None:
204 with self._lock:
205 _LOGGER.debug("Secrets file %s changed, reloading", self._file_path)
206 self._reset()
207 self._parse(print_exceptions=True)
208
209 # Emit a signal to notify receivers that the `secrets.toml` file
210 # has been changed.
211 self._file_change_listener.send()
212
213 def __getattr__(self, key: str) -> Any:
214 """Return the value with the given key. If no such key
215 exists, raise an AttributeError.
216
217 Thread-safe.
218 """
219 try:
220 value = self._parse(True)[key]
221 if not isinstance(value, dict):
222 return value
223 else:
224 return AttrDict(**value)
225 # We add FileNotFoundError since __getattr__ is expected to only raise
226 # AttributeError. Without handling FileNotFoundError, unittests.mocks
227 # fails during mock creation on Python3.9
228 except (KeyError, FileNotFoundError):
229 raise AttributeError(_missing_attr_error_message(key))
230
231 def __getitem__(self, key: str) -> Any:
232 """Return the value with the given key. If no such key
233 exists, raise a KeyError.
234
235 Thread-safe.
236 """
237 try:
238 value = self._parse(True)[key]
239 if not isinstance(value, dict):
240 return value
241 else:
242 return AttrDict(**value)
243 except KeyError:
244 raise KeyError(_missing_key_error_message(key))
245
246 def __repr__(self) -> str:
247 """A string representation of the contents of the dict. Thread-safe."""
248 return repr(self._parse(True))
249
250 def __len__(self) -> int:
251 """The number of entries in the dict. Thread-safe."""
252 return len(self._parse(True))
253
254 def has_key(self, k: str) -> bool:
255 """True if the given key is in the dict. Thread-safe."""
256 return k in self._parse(True)
257
258 def keys(self) -> KeysView[str]:
259 """A view of the keys in the dict. Thread-safe."""
260 return self._parse(True).keys()
261
262 def values(self) -> ValuesView[Any]:
263 """A view of the values in the dict. Thread-safe."""
264 return self._parse(True).values()
265
266 def items(self) -> ItemsView[str, Any]:
267 """A view of the key-value items in the dict. Thread-safe."""
268 return self._parse(True).items()
269
270 def __contains__(self, key: Any) -> bool:
271 """True if the given key is in the dict. Thread-safe."""
272 return key in self._parse(True)
273
274 def __iter__(self) -> Iterator[str]:
275 """An iterator over the keys in the dict. Thread-safe."""
276 return iter(self._parse(True))
277
278
279 secrets_singleton: Final = Secrets(SECRETS_FILE_LOC)
280
[end of lib/streamlit/runtime/secrets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/runtime/secrets.py b/lib/streamlit/runtime/secrets.py
--- a/lib/streamlit/runtime/secrets.py
+++ b/lib/streamlit/runtime/secrets.py
@@ -14,8 +14,16 @@
import os
import threading
-from collections import UserDict
-from typing import Any, ItemsView, Iterator, KeysView, Mapping, Optional, ValuesView
+from typing import (
+ Any,
+ ItemsView,
+ Iterator,
+ KeysView,
+ Mapping,
+ NoReturn,
+ Optional,
+ ValuesView,
+)
import toml
from blinker import Signal
@@ -45,32 +53,50 @@
)
-class AttrDict(UserDict): # type: ignore[type-arg]
+class AttrDict(Mapping[str, Any]):
"""
We use AttrDict to wrap up dictionary values from secrets
to provide dot access to nested secrets
"""
+ def __init__(self, value):
+ self.__dict__["__nested_secrets__"] = dict(value)
+
@staticmethod
def _maybe_wrap_in_attr_dict(value) -> Any:
- if not isinstance(value, dict):
+ if not isinstance(value, Mapping):
return value
else:
- return AttrDict(**value)
+ return AttrDict(value)
- def __getattr__(self, attr_name: str) -> Any:
+ def __len__(self) -> int:
+ return len(self.__nested_secrets__)
+
+ def __iter__(self) -> Iterator[str]:
+ return iter(self.__nested_secrets__)
+
+ def __getitem__(self, key: str) -> Any:
try:
- value = super().__getitem__(attr_name)
+ value = self.__nested_secrets__[key]
return self._maybe_wrap_in_attr_dict(value)
except KeyError:
- raise AttributeError(_missing_attr_error_message(attr_name))
+ raise KeyError(_missing_key_error_message(key))
- def __getitem__(self, key: str) -> Any:
+ def __getattr__(self, attr_name: str) -> Any:
try:
- value = super().__getitem__(key)
+ value = self.__nested_secrets__[attr_name]
return self._maybe_wrap_in_attr_dict(value)
except KeyError:
- raise KeyError(_missing_key_error_message(key))
+ raise AttributeError(_missing_attr_error_message(attr_name))
+
+ def __repr__(self):
+ return repr(self.__nested_secrets__)
+
+ def __setitem__(self, key, value) -> NoReturn:
+ raise TypeError("Secrets does not support item assignment.")
+
+ def __setattr__(self, key, value) -> NoReturn:
+ raise TypeError("Secrets does not support attribute assignment.")
class Secrets(Mapping[str, Any]):
@@ -218,10 +244,10 @@
"""
try:
value = self._parse(True)[key]
- if not isinstance(value, dict):
+ if not isinstance(value, Mapping):
return value
else:
- return AttrDict(**value)
+ return AttrDict(value)
# We add FileNotFoundError since __getattr__ is expected to only raise
# AttributeError. Without handling FileNotFoundError, unittests.mocks
# fails during mock creation on Python3.9
@@ -236,10 +262,10 @@
"""
try:
value = self._parse(True)[key]
- if not isinstance(value, dict):
+ if not isinstance(value, Mapping):
return value
else:
- return AttrDict(**value)
+ return AttrDict(value)
except KeyError:
raise KeyError(_missing_key_error_message(key))
|
{"golden_diff": "diff --git a/lib/streamlit/runtime/secrets.py b/lib/streamlit/runtime/secrets.py\n--- a/lib/streamlit/runtime/secrets.py\n+++ b/lib/streamlit/runtime/secrets.py\n@@ -14,8 +14,16 @@\n \n import os\n import threading\n-from collections import UserDict\n-from typing import Any, ItemsView, Iterator, KeysView, Mapping, Optional, ValuesView\n+from typing import (\n+ Any,\n+ ItemsView,\n+ Iterator,\n+ KeysView,\n+ Mapping,\n+ NoReturn,\n+ Optional,\n+ ValuesView,\n+)\n \n import toml\n from blinker import Signal\n@@ -45,32 +53,50 @@\n )\n \n \n-class AttrDict(UserDict): # type: ignore[type-arg]\n+class AttrDict(Mapping[str, Any]):\n \"\"\"\n We use AttrDict to wrap up dictionary values from secrets\n to provide dot access to nested secrets\n \"\"\"\n \n+ def __init__(self, value):\n+ self.__dict__[\"__nested_secrets__\"] = dict(value)\n+\n @staticmethod\n def _maybe_wrap_in_attr_dict(value) -> Any:\n- if not isinstance(value, dict):\n+ if not isinstance(value, Mapping):\n return value\n else:\n- return AttrDict(**value)\n+ return AttrDict(value)\n \n- def __getattr__(self, attr_name: str) -> Any:\n+ def __len__(self) -> int:\n+ return len(self.__nested_secrets__)\n+\n+ def __iter__(self) -> Iterator[str]:\n+ return iter(self.__nested_secrets__)\n+\n+ def __getitem__(self, key: str) -> Any:\n try:\n- value = super().__getitem__(attr_name)\n+ value = self.__nested_secrets__[key]\n return self._maybe_wrap_in_attr_dict(value)\n except KeyError:\n- raise AttributeError(_missing_attr_error_message(attr_name))\n+ raise KeyError(_missing_key_error_message(key))\n \n- def __getitem__(self, key: str) -> Any:\n+ def __getattr__(self, attr_name: str) -> Any:\n try:\n- value = super().__getitem__(key)\n+ value = self.__nested_secrets__[attr_name]\n return self._maybe_wrap_in_attr_dict(value)\n except KeyError:\n- raise KeyError(_missing_key_error_message(key))\n+ raise AttributeError(_missing_attr_error_message(attr_name))\n+\n+ def __repr__(self):\n+ return repr(self.__nested_secrets__)\n+\n+ def __setitem__(self, key, value) -> NoReturn:\n+ raise TypeError(\"Secrets does not support item assignment.\")\n+\n+ def __setattr__(self, key, value) -> NoReturn:\n+ raise TypeError(\"Secrets does not support attribute assignment.\")\n \n \n class Secrets(Mapping[str, Any]):\n@@ -218,10 +244,10 @@\n \"\"\"\n try:\n value = self._parse(True)[key]\n- if not isinstance(value, dict):\n+ if not isinstance(value, Mapping):\n return value\n else:\n- return AttrDict(**value)\n+ return AttrDict(value)\n # We add FileNotFoundError since __getattr__ is expected to only raise\n # AttributeError. Without handling FileNotFoundError, unittests.mocks\n # fails during mock creation on Python3.9\n@@ -236,10 +262,10 @@\n \"\"\"\n try:\n value = self._parse(True)[key]\n- if not isinstance(value, dict):\n+ if not isinstance(value, Mapping):\n return value\n else:\n- return AttrDict(**value)\n+ return AttrDict(value)\n except KeyError:\n raise KeyError(_missing_key_error_message(key))\n", "issue": "streamlit.runtime.secrets.AttrDict no longer returns True for isinstance() against dict in streamlit 1.14.0\n### Checklist\r\n\r\n- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.\r\n- [X] I added a very descriptive title to this issue.\r\n- [X] I have provided sufficient information below to help reproduce this issue.\r\n\r\n### Summary\r\n\r\nHi.\r\n\r\nWith the latest streamlit version `streamlit.runtime.secrets.AttrDict` seems to inherit from `UserDict` instead of `dict` in previous version.\r\n\r\nMany libraries I use check that their configuration is `isinstance` against `dict` and are now failing when I pass my config from st.secrets to them.\r\n\r\nI can't see any documentation changes related to this and am not familiar with `UserDict`, do I have to go through my code and wrap all st.secrets access in a `dict()` conversion call now?\r\n\r\n### Reproducible Code Example\r\n\r\n```Python\r\nimport streamlit as st\r\n\r\nprint(isinstance(st.secrets[\"my_secret_dict\"], dict)) # False on streamlit 1.14.0 - was True prior to that\r\n```\r\n\r\n\r\n### Steps To Reproduce\r\n\r\n_No response_\r\n\r\n### Expected Behavior\r\n\r\n_No response_\r\n\r\n### Current Behavior\r\n\r\n_No response_\r\n\r\n### Is this a regression?\r\n\r\n- [X] Yes, this used to work in a previous version.\r\n\r\n### Debug info\r\n\r\n- Streamlit version: 1.14.0\r\n- Python version: 3.100\r\n- Operating System: Linux\r\n- Browser: Firefox\r\n- Virtual environment: None\r\n\r\n\r\n### Additional Information\r\n\r\n_No response_\r\n\r\n### Are you willing to submit a PR?\r\n\r\n- [ ] Yes, I am willing to submit a PR!\n", "before_files": [{"content": "# Copyright (c) Streamlit Inc. (2018-2022) Snowflake Inc. (2022)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport threading\nfrom collections import UserDict\nfrom typing import Any, ItemsView, Iterator, KeysView, Mapping, Optional, ValuesView\n\nimport toml\nfrom blinker import Signal\nfrom typing_extensions import Final\n\nimport streamlit as st\nimport streamlit.watcher.path_watcher\nfrom streamlit.logger import get_logger\n\n_LOGGER = get_logger(__name__)\nSECRETS_FILE_LOC = os.path.abspath(os.path.join(\".\", \".streamlit\", \"secrets.toml\"))\n\n\ndef _missing_attr_error_message(attr_name: str) -> str:\n return (\n f'st.secrets has no attribute \"{attr_name}\". '\n f\"Did you forget to add it to secrets.toml or the app settings on Streamlit Cloud? \"\n f\"More info: https://docs.streamlit.io/streamlit-cloud/get-started/deploy-an-app/connect-to-data-sources/secrets-management\"\n )\n\n\ndef _missing_key_error_message(key: str) -> str:\n return (\n f'st.secrets has no key \"{key}\". '\n f\"Did you forget to add it to secrets.toml or the app settings on Streamlit Cloud? \"\n f\"More info: https://docs.streamlit.io/streamlit-cloud/get-started/deploy-an-app/connect-to-data-sources/secrets-management\"\n )\n\n\nclass AttrDict(UserDict): # type: ignore[type-arg]\n \"\"\"\n We use AttrDict to wrap up dictionary values from secrets\n to provide dot access to nested secrets\n \"\"\"\n\n @staticmethod\n def _maybe_wrap_in_attr_dict(value) -> Any:\n if not isinstance(value, dict):\n return value\n else:\n return AttrDict(**value)\n\n def __getattr__(self, attr_name: str) -> Any:\n try:\n value = super().__getitem__(attr_name)\n return self._maybe_wrap_in_attr_dict(value)\n except KeyError:\n raise AttributeError(_missing_attr_error_message(attr_name))\n\n def __getitem__(self, key: str) -> Any:\n try:\n value = super().__getitem__(key)\n return self._maybe_wrap_in_attr_dict(value)\n except KeyError:\n raise KeyError(_missing_key_error_message(key))\n\n\nclass Secrets(Mapping[str, Any]):\n \"\"\"A dict-like class that stores secrets.\n Parses secrets.toml on-demand. Cannot be externally mutated.\n\n Safe to use from multiple threads.\n \"\"\"\n\n def __init__(self, file_path: str):\n # Our secrets dict.\n self._secrets: Optional[Mapping[str, Any]] = None\n self._lock = threading.RLock()\n self._file_watcher_installed = False\n self._file_path = file_path\n self._file_change_listener = Signal(\n doc=\"Emitted when the `secrets.toml` file has been changed.\"\n )\n\n def load_if_toml_exists(self) -> None:\n \"\"\"Load secrets.toml from disk if it exists. If it doesn't exist,\n no exception will be raised. (If the file exists but is malformed,\n an exception *will* be raised.)\n\n Thread-safe.\n \"\"\"\n try:\n self._parse(print_exceptions=False)\n except FileNotFoundError:\n # No secrets.toml file exists. That's fine.\n pass\n\n def _reset(self) -> None:\n \"\"\"Clear the secrets dictionary and remove any secrets that were\n added to os.environ.\n\n Thread-safe.\n \"\"\"\n with self._lock:\n if self._secrets is None:\n return\n\n for k, v in self._secrets.items():\n self._maybe_delete_environment_variable(k, v)\n self._secrets = None\n\n def _parse(self, print_exceptions: bool) -> Mapping[str, Any]:\n \"\"\"Parse our secrets.toml file if it's not already parsed.\n This function is safe to call from multiple threads.\n\n Parameters\n ----------\n print_exceptions : bool\n If True, then exceptions will be printed with `st.error` before\n being re-raised.\n\n Raises\n ------\n FileNotFoundError\n Raised if secrets.toml doesn't exist.\n\n \"\"\"\n # Avoid taking a lock for the common case where secrets are already\n # loaded.\n secrets = self._secrets\n if secrets is not None:\n return secrets\n\n with self._lock:\n if self._secrets is not None:\n return self._secrets\n\n try:\n with open(self._file_path, encoding=\"utf-8\") as f:\n secrets_file_str = f.read()\n except FileNotFoundError:\n if print_exceptions:\n st.error(f\"Secrets file not found. Expected at: {self._file_path}\")\n raise\n\n try:\n secrets = toml.loads(secrets_file_str)\n except:\n if print_exceptions:\n st.error(\"Error parsing Secrets file.\")\n raise\n\n for k, v in secrets.items():\n self._maybe_set_environment_variable(k, v)\n\n self._secrets = secrets\n self._maybe_install_file_watcher()\n\n return self._secrets\n\n @staticmethod\n def _maybe_set_environment_variable(k: Any, v: Any) -> None:\n \"\"\"Add the given key/value pair to os.environ if the value\n is a string, int, or float.\"\"\"\n value_type = type(v)\n if value_type in (str, int, float):\n os.environ[k] = str(v)\n\n @staticmethod\n def _maybe_delete_environment_variable(k: Any, v: Any) -> None:\n \"\"\"Remove the given key/value pair from os.environ if the value\n is a string, int, or float.\"\"\"\n value_type = type(v)\n if value_type in (str, int, float) and os.environ.get(k) == v:\n del os.environ[k]\n\n def _maybe_install_file_watcher(self) -> None:\n with self._lock:\n if self._file_watcher_installed:\n return\n\n # We force our watcher_type to 'poll' because Streamlit Cloud\n # stores `secrets.toml` in a virtual filesystem that is\n # incompatible with watchdog.\n streamlit.watcher.path_watcher.watch_file(\n self._file_path,\n self._on_secrets_file_changed,\n watcher_type=\"poll\",\n )\n\n # We set file_watcher_installed to True even if watch_file\n # returns False to avoid repeatedly trying to install it.\n self._file_watcher_installed = True\n\n def _on_secrets_file_changed(self, _) -> None:\n with self._lock:\n _LOGGER.debug(\"Secrets file %s changed, reloading\", self._file_path)\n self._reset()\n self._parse(print_exceptions=True)\n\n # Emit a signal to notify receivers that the `secrets.toml` file\n # has been changed.\n self._file_change_listener.send()\n\n def __getattr__(self, key: str) -> Any:\n \"\"\"Return the value with the given key. If no such key\n exists, raise an AttributeError.\n\n Thread-safe.\n \"\"\"\n try:\n value = self._parse(True)[key]\n if not isinstance(value, dict):\n return value\n else:\n return AttrDict(**value)\n # We add FileNotFoundError since __getattr__ is expected to only raise\n # AttributeError. Without handling FileNotFoundError, unittests.mocks\n # fails during mock creation on Python3.9\n except (KeyError, FileNotFoundError):\n raise AttributeError(_missing_attr_error_message(key))\n\n def __getitem__(self, key: str) -> Any:\n \"\"\"Return the value with the given key. If no such key\n exists, raise a KeyError.\n\n Thread-safe.\n \"\"\"\n try:\n value = self._parse(True)[key]\n if not isinstance(value, dict):\n return value\n else:\n return AttrDict(**value)\n except KeyError:\n raise KeyError(_missing_key_error_message(key))\n\n def __repr__(self) -> str:\n \"\"\"A string representation of the contents of the dict. Thread-safe.\"\"\"\n return repr(self._parse(True))\n\n def __len__(self) -> int:\n \"\"\"The number of entries in the dict. Thread-safe.\"\"\"\n return len(self._parse(True))\n\n def has_key(self, k: str) -> bool:\n \"\"\"True if the given key is in the dict. Thread-safe.\"\"\"\n return k in self._parse(True)\n\n def keys(self) -> KeysView[str]:\n \"\"\"A view of the keys in the dict. Thread-safe.\"\"\"\n return self._parse(True).keys()\n\n def values(self) -> ValuesView[Any]:\n \"\"\"A view of the values in the dict. Thread-safe.\"\"\"\n return self._parse(True).values()\n\n def items(self) -> ItemsView[str, Any]:\n \"\"\"A view of the key-value items in the dict. Thread-safe.\"\"\"\n return self._parse(True).items()\n\n def __contains__(self, key: Any) -> bool:\n \"\"\"True if the given key is in the dict. Thread-safe.\"\"\"\n return key in self._parse(True)\n\n def __iter__(self) -> Iterator[str]:\n \"\"\"An iterator over the keys in the dict. Thread-safe.\"\"\"\n return iter(self._parse(True))\n\n\nsecrets_singleton: Final = Secrets(SECRETS_FILE_LOC)\n", "path": "lib/streamlit/runtime/secrets.py"}]}
| 3,802 | 815 |
gh_patches_debug_41453
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-7592
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`kolibri manage provisiondevice` converts user-provided facility name to lower-case
### Observed behavior
In #7493, it was noted that `provisiondevice` converts facility names to lower-case, which might not be desirable.
This is probably because of this line in the code
https://github.com/learningequality/kolibri/blob/bf91a09cb7ea666f013f3488ea28d8391cefa1d1/kolibri/core/device/management/commands/provisiondevice.py#L78-L82
where `get_user_response` is the code that tries to normalize user input in the terminal (which includes converting to lower case).
### Expected behavior
When a user provides a facility name in the `provisiondevice` CLI tool, the eventual facility name matches the user's inputted facility name character-by-character. E.g. if I type "Jonathan's Facility", it doesn't convert it to "jonathan's facility"
### User-facing consequences
Facility name does not match what was provided in CLI, and admin will need to edit the name.
### Steps to reproduce
1. Use `kolibri manage provisiondevice`
1. At the new facility step, provide a name like "MY FACILITY"
1. When you actually view the Facility in Kolibri, it will have the name "my facility"
</issue>
<code>
[start of kolibri/core/device/management/commands/provisiondevice.py]
1 import json
2 import logging
3 import os
4 import sys
5
6 from django.conf import settings
7 from django.core.exceptions import ValidationError
8 from django.core.management.base import BaseCommand
9 from django.core.management.base import CommandError
10 from django.db import transaction
11 from django.utils import six
12
13 from kolibri.core.auth.constants.facility_presets import mappings
14 from kolibri.core.auth.constants.facility_presets import presets
15 from kolibri.core.auth.models import Facility
16 from kolibri.core.auth.models import FacilityUser
17 from kolibri.core.device.utils import provision_device
18
19 logger = logging.getLogger(__name__)
20
21
22 def _check_setting(name, available, msg):
23 if name not in available:
24 raise CommandError(msg.format(name))
25
26
27 def check_facility_setting(name):
28 AVAILABLE_SETTINGS = [
29 "learner_can_edit_username",
30 "learner_can_edit_name",
31 "learner_can_edit_password",
32 "learner_can_sign_up",
33 "learner_can_delete_account",
34 "learner_can_login_with_no_password",
35 "show_download_button_in_learn",
36 ]
37 _check_setting(
38 name,
39 AVAILABLE_SETTINGS,
40 "'{}' is not a facility setting that can be changed by this command",
41 )
42
43
44 def check_device_setting(name):
45 AVAILABLE_SETTINGS = [
46 "language_id",
47 "landing_page",
48 "allow_guest_access",
49 "allow_peer_unlisted_channel_import",
50 "allow_learner_unassigned_resource_access",
51 "name",
52 "allow_other_browsers_to_connect",
53 ]
54 _check_setting(
55 name,
56 AVAILABLE_SETTINGS,
57 "'{}' is not a device setting that can be changed by this command",
58 )
59
60
61 def get_user_response(prompt, valid_answers=None):
62 answer = None
63 while not answer or (
64 valid_answers is not None and answer.lower() not in valid_answers
65 ):
66 answer = six.moves.input(prompt)
67 return answer.lower()
68
69
70 languages = dict(settings.LANGUAGES)
71
72
73 def create_facility(facility_name=None, preset=None, interactive=False):
74 if facility_name is None and interactive:
75 answer = get_user_response(
76 "Do you wish to create a facility? [y/n] ", ["y", "n"]
77 )
78 if answer == "y":
79 facility_name = get_user_response(
80 "What do you wish to name your facility? "
81 )
82 else:
83 sys.exit(1)
84
85 if facility_name:
86 facility, created = Facility.objects.get_or_create(name=facility_name)
87
88 if not created:
89 logger.warn(
90 "Facility with name {name} already exists, not modifying preset.".format(
91 name=facility_name
92 )
93 )
94 return facility
95
96 logger.info("Facility with name {name} created.".format(name=facility_name))
97
98 if preset is None and interactive:
99 preset = get_user_response(
100 "Which preset do you wish to use? [{presets}]: ".format(
101 presets="/".join(presets.keys())
102 ),
103 valid_answers=presets,
104 )
105
106 # Only set preset data if we have created the facility, otherwise leave previous data intact
107 if preset:
108 dataset_data = mappings[preset]
109 facility.dataset.preset = preset
110 for key, value in dataset_data.items():
111 check_facility_setting(key)
112 setattr(facility.dataset, key, value)
113 facility.dataset.save()
114 logger.info("Facility preset changed to {preset}.".format(preset=preset))
115 else:
116 facility = Facility.get_default_facility() or Facility.objects.first()
117 if not facility:
118 raise CommandError("No facility exists")
119 return facility
120
121
122 def update_facility_settings(facility, new_settings):
123 # Override any settings passed in
124 for key, value in new_settings.items():
125 check_facility_setting(key)
126 setattr(facility.dataset, key, value)
127 facility.dataset.save()
128 logger.info("Facility settings updated with {}".format(new_settings))
129
130
131 def create_superuser(username=None, password=None, interactive=False, facility=None):
132 if username is None and interactive:
133 username = get_user_response("Enter a username for the super user: ")
134
135 if password is None and interactive:
136 confirm = ""
137 while password != confirm:
138 password = get_user_response("Enter a password for the super user: ")
139 confirm = get_user_response("Confirm password for the super user: ")
140
141 if username and password:
142 try:
143 FacilityUser.objects.create_superuser(username, password, facility=facility)
144 logger.info(
145 "Superuser created with username {username} in facility {facility}.".format(
146 username=username, facility=facility
147 )
148 )
149 except ValidationError:
150 logger.warn(
151 "An account with username {username} already exists in facility {facility}, not creating user account.".format(
152 username=username, facility=facility
153 )
154 )
155
156
157 def create_device_settings(
158 language_id=None, facility=None, interactive=False, new_settings={}
159 ):
160 if language_id is None and interactive:
161 language_id = get_user_response(
162 "Enter a default language code [{langs}]: ".format(
163 langs=",".join(languages.keys())
164 ),
165 valid_answers=languages,
166 )
167 # Override any settings passed in
168 for key in new_settings:
169 check_device_setting(key)
170
171 settings_to_set = dict(new_settings)
172 settings_to_set["language_id"] = language_id
173 settings_to_set["default_facility"] = facility
174
175 provision_device(**settings_to_set)
176 logger.info("Device settings updated with {}".format(settings_to_set))
177
178
179 def json_file_contents(parser, arg):
180 if not os.path.exists(arg) or not os.path.isfile(arg):
181 return parser.error("The file '{}' does not exist".format(arg))
182 with open(arg, "r") as f:
183 try:
184 output = json.load(f)
185 except json.decoder.JSONDecodeError as e:
186 return parser.error("The file '{}' is not valid JSON:\n{}".format(arg, e))
187 return output
188
189
190 class Command(BaseCommand):
191 help = "Provision a device for use"
192
193 def add_arguments(self, parser):
194 parser.add_argument(
195 "--facility", action="store", type=str, help="Facility name to create"
196 )
197 parser.add_argument(
198 "--superusername",
199 action="store",
200 type=str,
201 help="Superuser username to create",
202 )
203 parser.add_argument(
204 "--superuserpassword",
205 action="store",
206 type=str,
207 help="Superuser password to create",
208 )
209 parser.add_argument(
210 "--preset",
211 action="store",
212 type=str,
213 help="Facility preset to use",
214 choices=presets,
215 )
216 parser.add_argument(
217 "--language_id",
218 action="store",
219 type=str,
220 help="Language id for default language",
221 choices=languages,
222 )
223 parser.add_argument(
224 "--noinput",
225 "--no-input",
226 action="store_false",
227 dest="interactive",
228 default=True,
229 help="Tells Django to NOT prompt the user for input of any kind.",
230 )
231 parser.add_argument(
232 "--facility_settings",
233 action="store",
234 help="JSON file containing facility settings",
235 type=lambda arg: json_file_contents(parser, arg),
236 default={},
237 )
238 parser.add_argument(
239 "--device_settings",
240 action="store",
241 help="JSON file containing device settings",
242 type=lambda arg: json_file_contents(parser, arg),
243 default={},
244 )
245
246 def handle(self, *args, **options):
247
248 logger.warn(
249 "The 'provisiondevice' command is experimental, and the API and behavior will change in a future release"
250 )
251
252 with transaction.atomic():
253 facility = create_facility(
254 facility_name=options["facility"],
255 preset=options["preset"],
256 interactive=options["interactive"],
257 )
258
259 update_facility_settings(facility, options["facility_settings"])
260
261 create_device_settings(
262 language_id=options["language_id"],
263 facility=facility,
264 interactive=options["interactive"],
265 new_settings=options["device_settings"],
266 )
267
268 create_superuser(
269 username=options["superusername"],
270 password=options["superuserpassword"],
271 interactive=options["interactive"],
272 facility=facility,
273 )
274
[end of kolibri/core/device/management/commands/provisiondevice.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/device/management/commands/provisiondevice.py b/kolibri/core/device/management/commands/provisiondevice.py
--- a/kolibri/core/device/management/commands/provisiondevice.py
+++ b/kolibri/core/device/management/commands/provisiondevice.py
@@ -58,13 +58,16 @@
)
-def get_user_response(prompt, valid_answers=None):
+def get_user_response(prompt, valid_answers=None, to_lower_case=True):
answer = None
while not answer or (
valid_answers is not None and answer.lower() not in valid_answers
):
answer = six.moves.input(prompt)
- return answer.lower()
+ if to_lower_case:
+ return answer.lower()
+ else:
+ return answer
languages = dict(settings.LANGUAGES)
@@ -77,23 +80,27 @@
)
if answer == "y":
facility_name = get_user_response(
- "What do you wish to name your facility? "
+ "What do you wish to name your facility? ", to_lower_case=False
)
else:
sys.exit(1)
if facility_name:
- facility, created = Facility.objects.get_or_create(name=facility_name)
+ facility_query = Facility.objects.filter(name__iexact=facility_name)
- if not created:
+ if facility_query.exists():
+ facility = facility_query.get()
logger.warn(
- "Facility with name {name} already exists, not modifying preset.".format(
- name=facility_name
+ "Facility with name '{name}' already exists, not modifying preset.".format(
+ name=facility.name
)
)
return facility
-
- logger.info("Facility with name {name} created.".format(name=facility_name))
+ else:
+ facility = Facility.objects.create(name=facility_name)
+ logger.info(
+ "Facility with name '{name}' created.".format(name=facility.name)
+ )
if preset is None and interactive:
preset = get_user_response(
@@ -125,7 +132,9 @@
check_facility_setting(key)
setattr(facility.dataset, key, value)
facility.dataset.save()
- logger.info("Facility settings updated with {}".format(new_settings))
+
+ if new_settings:
+ logger.info("Facility settings updated with {}".format(new_settings))
def create_superuser(username=None, password=None, interactive=False, facility=None):
@@ -142,13 +151,13 @@
try:
FacilityUser.objects.create_superuser(username, password, facility=facility)
logger.info(
- "Superuser created with username {username} in facility {facility}.".format(
+ "Superuser created with username '{username}' in facility '{facility}'.".format(
username=username, facility=facility
)
)
except ValidationError:
logger.warn(
- "An account with username {username} already exists in facility {facility}, not creating user account.".format(
+ "An account with username '{username}' already exists in facility '{facility}', not creating user account.".format(
username=username, facility=facility
)
)
|
{"golden_diff": "diff --git a/kolibri/core/device/management/commands/provisiondevice.py b/kolibri/core/device/management/commands/provisiondevice.py\n--- a/kolibri/core/device/management/commands/provisiondevice.py\n+++ b/kolibri/core/device/management/commands/provisiondevice.py\n@@ -58,13 +58,16 @@\n )\n \n \n-def get_user_response(prompt, valid_answers=None):\n+def get_user_response(prompt, valid_answers=None, to_lower_case=True):\n answer = None\n while not answer or (\n valid_answers is not None and answer.lower() not in valid_answers\n ):\n answer = six.moves.input(prompt)\n- return answer.lower()\n+ if to_lower_case:\n+ return answer.lower()\n+ else:\n+ return answer\n \n \n languages = dict(settings.LANGUAGES)\n@@ -77,23 +80,27 @@\n )\n if answer == \"y\":\n facility_name = get_user_response(\n- \"What do you wish to name your facility? \"\n+ \"What do you wish to name your facility? \", to_lower_case=False\n )\n else:\n sys.exit(1)\n \n if facility_name:\n- facility, created = Facility.objects.get_or_create(name=facility_name)\n+ facility_query = Facility.objects.filter(name__iexact=facility_name)\n \n- if not created:\n+ if facility_query.exists():\n+ facility = facility_query.get()\n logger.warn(\n- \"Facility with name {name} already exists, not modifying preset.\".format(\n- name=facility_name\n+ \"Facility with name '{name}' already exists, not modifying preset.\".format(\n+ name=facility.name\n )\n )\n return facility\n-\n- logger.info(\"Facility with name {name} created.\".format(name=facility_name))\n+ else:\n+ facility = Facility.objects.create(name=facility_name)\n+ logger.info(\n+ \"Facility with name '{name}' created.\".format(name=facility.name)\n+ )\n \n if preset is None and interactive:\n preset = get_user_response(\n@@ -125,7 +132,9 @@\n check_facility_setting(key)\n setattr(facility.dataset, key, value)\n facility.dataset.save()\n- logger.info(\"Facility settings updated with {}\".format(new_settings))\n+\n+ if new_settings:\n+ logger.info(\"Facility settings updated with {}\".format(new_settings))\n \n \n def create_superuser(username=None, password=None, interactive=False, facility=None):\n@@ -142,13 +151,13 @@\n try:\n FacilityUser.objects.create_superuser(username, password, facility=facility)\n logger.info(\n- \"Superuser created with username {username} in facility {facility}.\".format(\n+ \"Superuser created with username '{username}' in facility '{facility}'.\".format(\n username=username, facility=facility\n )\n )\n except ValidationError:\n logger.warn(\n- \"An account with username {username} already exists in facility {facility}, not creating user account.\".format(\n+ \"An account with username '{username}' already exists in facility '{facility}', not creating user account.\".format(\n username=username, facility=facility\n )\n )\n", "issue": "`kolibri manage provisiondevice` converts user-provided facility name to lower-case\n### Observed behavior\r\n\r\nIn #7493, it was noted that `provisiondevice` converts facility names to lower-case, which might not be desirable.\r\n\r\nThis is probably because of this line in the code\r\n\r\nhttps://github.com/learningequality/kolibri/blob/bf91a09cb7ea666f013f3488ea28d8391cefa1d1/kolibri/core/device/management/commands/provisiondevice.py#L78-L82\r\n\r\nwhere `get_user_response` is the code that tries to normalize user input in the terminal (which includes converting to lower case).\r\n\r\n### Expected behavior\r\n\r\nWhen a user provides a facility name in the `provisiondevice` CLI tool, the eventual facility name matches the user's inputted facility name character-by-character. E.g. if I type \"Jonathan's Facility\", it doesn't convert it to \"jonathan's facility\"\r\n\r\n\r\n### User-facing consequences\r\n\r\nFacility name does not match what was provided in CLI, and admin will need to edit the name.\r\n\r\n### Steps to reproduce\r\n\r\n\r\n1. Use `kolibri manage provisiondevice`\r\n1. At the new facility step, provide a name like \"MY FACILITY\"\r\n1. When you actually view the Facility in Kolibri, it will have the name \"my facility\"\n", "before_files": [{"content": "import json\nimport logging\nimport os\nimport sys\n\nfrom django.conf import settings\nfrom django.core.exceptions import ValidationError\nfrom django.core.management.base import BaseCommand\nfrom django.core.management.base import CommandError\nfrom django.db import transaction\nfrom django.utils import six\n\nfrom kolibri.core.auth.constants.facility_presets import mappings\nfrom kolibri.core.auth.constants.facility_presets import presets\nfrom kolibri.core.auth.models import Facility\nfrom kolibri.core.auth.models import FacilityUser\nfrom kolibri.core.device.utils import provision_device\n\nlogger = logging.getLogger(__name__)\n\n\ndef _check_setting(name, available, msg):\n if name not in available:\n raise CommandError(msg.format(name))\n\n\ndef check_facility_setting(name):\n AVAILABLE_SETTINGS = [\n \"learner_can_edit_username\",\n \"learner_can_edit_name\",\n \"learner_can_edit_password\",\n \"learner_can_sign_up\",\n \"learner_can_delete_account\",\n \"learner_can_login_with_no_password\",\n \"show_download_button_in_learn\",\n ]\n _check_setting(\n name,\n AVAILABLE_SETTINGS,\n \"'{}' is not a facility setting that can be changed by this command\",\n )\n\n\ndef check_device_setting(name):\n AVAILABLE_SETTINGS = [\n \"language_id\",\n \"landing_page\",\n \"allow_guest_access\",\n \"allow_peer_unlisted_channel_import\",\n \"allow_learner_unassigned_resource_access\",\n \"name\",\n \"allow_other_browsers_to_connect\",\n ]\n _check_setting(\n name,\n AVAILABLE_SETTINGS,\n \"'{}' is not a device setting that can be changed by this command\",\n )\n\n\ndef get_user_response(prompt, valid_answers=None):\n answer = None\n while not answer or (\n valid_answers is not None and answer.lower() not in valid_answers\n ):\n answer = six.moves.input(prompt)\n return answer.lower()\n\n\nlanguages = dict(settings.LANGUAGES)\n\n\ndef create_facility(facility_name=None, preset=None, interactive=False):\n if facility_name is None and interactive:\n answer = get_user_response(\n \"Do you wish to create a facility? [y/n] \", [\"y\", \"n\"]\n )\n if answer == \"y\":\n facility_name = get_user_response(\n \"What do you wish to name your facility? \"\n )\n else:\n sys.exit(1)\n\n if facility_name:\n facility, created = Facility.objects.get_or_create(name=facility_name)\n\n if not created:\n logger.warn(\n \"Facility with name {name} already exists, not modifying preset.\".format(\n name=facility_name\n )\n )\n return facility\n\n logger.info(\"Facility with name {name} created.\".format(name=facility_name))\n\n if preset is None and interactive:\n preset = get_user_response(\n \"Which preset do you wish to use? [{presets}]: \".format(\n presets=\"/\".join(presets.keys())\n ),\n valid_answers=presets,\n )\n\n # Only set preset data if we have created the facility, otherwise leave previous data intact\n if preset:\n dataset_data = mappings[preset]\n facility.dataset.preset = preset\n for key, value in dataset_data.items():\n check_facility_setting(key)\n setattr(facility.dataset, key, value)\n facility.dataset.save()\n logger.info(\"Facility preset changed to {preset}.\".format(preset=preset))\n else:\n facility = Facility.get_default_facility() or Facility.objects.first()\n if not facility:\n raise CommandError(\"No facility exists\")\n return facility\n\n\ndef update_facility_settings(facility, new_settings):\n # Override any settings passed in\n for key, value in new_settings.items():\n check_facility_setting(key)\n setattr(facility.dataset, key, value)\n facility.dataset.save()\n logger.info(\"Facility settings updated with {}\".format(new_settings))\n\n\ndef create_superuser(username=None, password=None, interactive=False, facility=None):\n if username is None and interactive:\n username = get_user_response(\"Enter a username for the super user: \")\n\n if password is None and interactive:\n confirm = \"\"\n while password != confirm:\n password = get_user_response(\"Enter a password for the super user: \")\n confirm = get_user_response(\"Confirm password for the super user: \")\n\n if username and password:\n try:\n FacilityUser.objects.create_superuser(username, password, facility=facility)\n logger.info(\n \"Superuser created with username {username} in facility {facility}.\".format(\n username=username, facility=facility\n )\n )\n except ValidationError:\n logger.warn(\n \"An account with username {username} already exists in facility {facility}, not creating user account.\".format(\n username=username, facility=facility\n )\n )\n\n\ndef create_device_settings(\n language_id=None, facility=None, interactive=False, new_settings={}\n):\n if language_id is None and interactive:\n language_id = get_user_response(\n \"Enter a default language code [{langs}]: \".format(\n langs=\",\".join(languages.keys())\n ),\n valid_answers=languages,\n )\n # Override any settings passed in\n for key in new_settings:\n check_device_setting(key)\n\n settings_to_set = dict(new_settings)\n settings_to_set[\"language_id\"] = language_id\n settings_to_set[\"default_facility\"] = facility\n\n provision_device(**settings_to_set)\n logger.info(\"Device settings updated with {}\".format(settings_to_set))\n\n\ndef json_file_contents(parser, arg):\n if not os.path.exists(arg) or not os.path.isfile(arg):\n return parser.error(\"The file '{}' does not exist\".format(arg))\n with open(arg, \"r\") as f:\n try:\n output = json.load(f)\n except json.decoder.JSONDecodeError as e:\n return parser.error(\"The file '{}' is not valid JSON:\\n{}\".format(arg, e))\n return output\n\n\nclass Command(BaseCommand):\n help = \"Provision a device for use\"\n\n def add_arguments(self, parser):\n parser.add_argument(\n \"--facility\", action=\"store\", type=str, help=\"Facility name to create\"\n )\n parser.add_argument(\n \"--superusername\",\n action=\"store\",\n type=str,\n help=\"Superuser username to create\",\n )\n parser.add_argument(\n \"--superuserpassword\",\n action=\"store\",\n type=str,\n help=\"Superuser password to create\",\n )\n parser.add_argument(\n \"--preset\",\n action=\"store\",\n type=str,\n help=\"Facility preset to use\",\n choices=presets,\n )\n parser.add_argument(\n \"--language_id\",\n action=\"store\",\n type=str,\n help=\"Language id for default language\",\n choices=languages,\n )\n parser.add_argument(\n \"--noinput\",\n \"--no-input\",\n action=\"store_false\",\n dest=\"interactive\",\n default=True,\n help=\"Tells Django to NOT prompt the user for input of any kind.\",\n )\n parser.add_argument(\n \"--facility_settings\",\n action=\"store\",\n help=\"JSON file containing facility settings\",\n type=lambda arg: json_file_contents(parser, arg),\n default={},\n )\n parser.add_argument(\n \"--device_settings\",\n action=\"store\",\n help=\"JSON file containing device settings\",\n type=lambda arg: json_file_contents(parser, arg),\n default={},\n )\n\n def handle(self, *args, **options):\n\n logger.warn(\n \"The 'provisiondevice' command is experimental, and the API and behavior will change in a future release\"\n )\n\n with transaction.atomic():\n facility = create_facility(\n facility_name=options[\"facility\"],\n preset=options[\"preset\"],\n interactive=options[\"interactive\"],\n )\n\n update_facility_settings(facility, options[\"facility_settings\"])\n\n create_device_settings(\n language_id=options[\"language_id\"],\n facility=facility,\n interactive=options[\"interactive\"],\n new_settings=options[\"device_settings\"],\n )\n\n create_superuser(\n username=options[\"superusername\"],\n password=options[\"superuserpassword\"],\n interactive=options[\"interactive\"],\n facility=facility,\n )\n", "path": "kolibri/core/device/management/commands/provisiondevice.py"}]}
| 3,314 | 712 |
gh_patches_debug_18975
|
rasdani/github-patches
|
git_diff
|
projectmesa__mesa-465
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Feature Request]: Agent data on mouse over visualization
Is it possible to bundle agent data into the web browser side json so that when I mouse over an agent I can view that agent's data? Seems like it would mean adding some more fields to the portrayal method to include data that would only available on a mouse over. And of course javascript code to display that data on a mouse over. I don't know if the performance penalty would be too great? This would be particularly useful in early stages of model debugging and perhaps even later. If performance is an issue, it could be feature invoked only if needed.
Thanks
</issue>
<code>
[start of mesa/visualization/modules/CanvasGridVisualization.py]
1 # -*- coding: utf-8 -*-
2 """
3 Modular Canvas Rendering
4 ========================
5
6 Module for visualizing model objects in grid cells.
7
8 """
9 from collections import defaultdict
10 from mesa.visualization.ModularVisualization import VisualizationElement
11
12
13 class CanvasGrid(VisualizationElement):
14 """ A CanvasGrid object uses a user-provided portrayal method to generate a
15 portrayal for each object. A portrayal is a JSON-ready dictionary which
16 tells the relevant JavaScript code (GridDraw.js) where to draw what shape.
17
18 The render method returns a dictionary, keyed on layers, with values as
19 lists of portrayals to draw. Portrayals themselves are generated by the
20 user-provided portrayal_method, which accepts an object as an input and
21 produces a portrayal of it.
22
23 A portrayal as a dictionary with the following structure:
24 "x", "y": Coordinates for the cell in which the object is placed.
25 "Shape": Can be either "circle", "rect" or "arrowHead"
26 For Circles:
27 "r": The radius, defined as a fraction of cell size. r=1 will
28 fill the entire cell.
29 For Rectangles:
30 "w", "h": The width and height of the rectangle, which are in
31 fractions of cell width and height.
32 For arrowHead:
33 "scale": Proportion scaling as a fraction of cell size.
34 "heading_x": represents x direction unit vector.
35 "heading_y": represents y direction unit vector.
36 "Color": The color to draw the shape in; needs to be a valid HTML
37 color, e.g."Red" or "#AA08F8"
38 "Filled": either "true" or "false", and determines whether the shape is
39 filled or not.
40 "Layer": Layer number of 0 or above; higher-numbered layers are drawn
41 above lower-numbered layers.
42 "text": The text to be inscribed inside the Shape. Normally useful for
43 showing the unique_id of the agent.
44 "text_color": The color to draw the inscribed text. Should be given in
45 conjunction of "text" property.
46
47
48 Attributes:
49 portrayal_method: Function which generates portrayals from objects, as
50 described above.
51 grid_height, grid_width: Size of the grid to visualize, in cells.
52 canvas_height, canvas_width: Size, in pixels, of the grid visualization
53 to draw on the client.
54 template: "canvas_module.html" stores the module's HTML template.
55
56 """
57 package_includes = ["GridDraw.js", "CanvasModule.js"]
58
59 def __init__(self, portrayal_method, grid_width, grid_height,
60 canvas_width=500, canvas_height=500):
61 """ Instantiate a new CanvasGrid.
62
63 Args:
64 portrayal_method: function to convert each object on the grid to
65 a portrayal, as described above.
66 grid_width, grid_height: Size of the grid, in cells.
67 canvas_height, canvas_width: Size of the canvas to draw in the
68 client, in pixels. (default: 500x500)
69
70 """
71 self.portrayal_method = portrayal_method
72 self.grid_width = grid_width
73 self.grid_height = grid_height
74 self.canvas_width = canvas_width
75 self.canvas_height = canvas_height
76
77 new_element = ("new CanvasModule({}, {}, {}, {})"
78 .format(self.canvas_width, self.canvas_height,
79 self.grid_width, self.grid_height))
80
81 self.js_code = "elements.push(" + new_element + ");"
82
83 def render(self, model):
84 grid_state = defaultdict(list)
85 for x in range(model.grid.width):
86 for y in range(model.grid.height):
87 cell_objects = model.grid.get_cell_list_contents([(x, y)])
88 for obj in cell_objects:
89 portrayal = self.portrayal_method(obj)
90 if portrayal:
91 portrayal["x"] = x
92 portrayal["y"] = y
93 grid_state[portrayal["Layer"]].append(portrayal)
94
95 return grid_state
96
[end of mesa/visualization/modules/CanvasGridVisualization.py]
[start of mesa/visualization/modules/HexGridVisualization.py]
1 # -*- coding: utf-8 -*-
2 """
3 Modular Canvas Rendering
4 ========================
5
6 Module for visualizing model objects in hexagonal grid cells.
7
8 """
9 from collections import defaultdict
10 from mesa.visualization.ModularVisualization import VisualizationElement
11
12
13 class CanvasHexGrid(VisualizationElement):
14 """ A CanvasHexGrid object functions similarly to a CanvasGrid object. It takes a portrayal dictionary and talks to HexDraw.js to draw that shape.
15
16 A portrayal as a dictionary with the following structure:
17 "x", "y": Coordinates for the cell in which the object is placed.
18 "Shape": Can be either "hex" or "circle"
19 "r": The radius, defined as a fraction of cell size. r=1 will
20 fill the entire cell.
21 "Color": The color to draw the shape in; needs to be a valid HTML
22 color, e.g."Red" or "#AA08F8"
23 "Filled": either "true" or "false", and determines whether the shape is
24 filled or not.
25 "Layer": Layer number of 0 or above; higher-numbered layers are drawn
26 above lower-numbered layers.
27 "text": The text to be inscribed inside the Shape. Normally useful for
28 showing the unique_id of the agent.
29 "text_color": The color to draw the inscribed text. Should be given in
30 conjunction of "text" property.
31
32
33 Attributes:
34 portrayal_method: Function which generates portrayals from objects, as
35 described above.
36 grid_height, grid_width: Size of the grid to visualize, in cells.
37 canvas_height, canvas_width: Size, in pixels, of the grid visualization
38 to draw on the client.
39 template: "canvas_module.html" stores the module's HTML template.
40
41 """
42 package_includes = ["HexDraw.js", "CanvasHexModule.js"]
43 portrayal_method = None # Portrayal function
44 canvas_width = 500
45 canvas_height = 500
46
47 def __init__(self, portrayal_method, grid_width, grid_height,
48 canvas_width=500, canvas_height=500):
49 """ Instantiate a new CanvasGrid.
50
51 Args:
52 portrayal_method: function to convert each object on the grid to
53 a portrayal, as described above.
54 grid_width, grid_height: Size of the grid, in cells.
55 canvas_height, canvas_width: Size of the canvas to draw in the
56 client, in pixels. (default: 500x500)
57
58 """
59 self.portrayal_method = portrayal_method
60 self.grid_width = grid_width
61 self.grid_height = grid_height
62 self.canvas_width = canvas_width
63 self.canvas_height = canvas_height
64
65 new_element = ("new CanvasHexModule({}, {}, {}, {})"
66 .format(self.canvas_width, self.canvas_height,
67 self.grid_width, self.grid_height))
68
69 self.js_code = "elements.push(" + new_element + ");"
70
71 def render(self, model):
72 grid_state = defaultdict(list)
73 for x in range(model.grid.width):
74 for y in range(model.grid.height):
75 cell_objects = model.grid.get_cell_list_contents([(x, y)])
76 for obj in cell_objects:
77 portrayal = self.portrayal_method(obj)
78 if portrayal:
79 portrayal["x"] = x
80 portrayal["y"] = y
81 grid_state[portrayal["Layer"]].append(portrayal)
82
83 return grid_state
84
[end of mesa/visualization/modules/HexGridVisualization.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mesa/visualization/modules/CanvasGridVisualization.py b/mesa/visualization/modules/CanvasGridVisualization.py
--- a/mesa/visualization/modules/CanvasGridVisualization.py
+++ b/mesa/visualization/modules/CanvasGridVisualization.py
@@ -54,7 +54,7 @@
template: "canvas_module.html" stores the module's HTML template.
"""
- package_includes = ["GridDraw.js", "CanvasModule.js"]
+ package_includes = ["GridDraw.js", "CanvasModule.js", "InteractionHandler.js"]
def __init__(self, portrayal_method, grid_width, grid_height,
canvas_width=500, canvas_height=500):
diff --git a/mesa/visualization/modules/HexGridVisualization.py b/mesa/visualization/modules/HexGridVisualization.py
--- a/mesa/visualization/modules/HexGridVisualization.py
+++ b/mesa/visualization/modules/HexGridVisualization.py
@@ -39,7 +39,7 @@
template: "canvas_module.html" stores the module's HTML template.
"""
- package_includes = ["HexDraw.js", "CanvasHexModule.js"]
+ package_includes = ["HexDraw.js", "CanvasHexModule.js", "InteractionHandler.js"]
portrayal_method = None # Portrayal function
canvas_width = 500
canvas_height = 500
|
{"golden_diff": "diff --git a/mesa/visualization/modules/CanvasGridVisualization.py b/mesa/visualization/modules/CanvasGridVisualization.py\n--- a/mesa/visualization/modules/CanvasGridVisualization.py\n+++ b/mesa/visualization/modules/CanvasGridVisualization.py\n@@ -54,7 +54,7 @@\n template: \"canvas_module.html\" stores the module's HTML template.\n \n \"\"\"\n- package_includes = [\"GridDraw.js\", \"CanvasModule.js\"]\n+ package_includes = [\"GridDraw.js\", \"CanvasModule.js\", \"InteractionHandler.js\"]\n \n def __init__(self, portrayal_method, grid_width, grid_height,\n canvas_width=500, canvas_height=500):\ndiff --git a/mesa/visualization/modules/HexGridVisualization.py b/mesa/visualization/modules/HexGridVisualization.py\n--- a/mesa/visualization/modules/HexGridVisualization.py\n+++ b/mesa/visualization/modules/HexGridVisualization.py\n@@ -39,7 +39,7 @@\n template: \"canvas_module.html\" stores the module's HTML template.\n \n \"\"\"\n- package_includes = [\"HexDraw.js\", \"CanvasHexModule.js\"]\n+ package_includes = [\"HexDraw.js\", \"CanvasHexModule.js\", \"InteractionHandler.js\"]\n portrayal_method = None # Portrayal function\n canvas_width = 500\n canvas_height = 500\n", "issue": "[Feature Request]: Agent data on mouse over visualization\nIs it possible to bundle agent data into the web browser side json so that when I mouse over an agent I can view that agent's data? Seems like it would mean adding some more fields to the portrayal method to include data that would only available on a mouse over. And of course javascript code to display that data on a mouse over. I don't know if the performance penalty would be too great? This would be particularly useful in early stages of model debugging and perhaps even later. If performance is an issue, it could be feature invoked only if needed.\r\nThanks\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nModular Canvas Rendering\n========================\n\nModule for visualizing model objects in grid cells.\n\n\"\"\"\nfrom collections import defaultdict\nfrom mesa.visualization.ModularVisualization import VisualizationElement\n\n\nclass CanvasGrid(VisualizationElement):\n \"\"\" A CanvasGrid object uses a user-provided portrayal method to generate a\n portrayal for each object. A portrayal is a JSON-ready dictionary which\n tells the relevant JavaScript code (GridDraw.js) where to draw what shape.\n\n The render method returns a dictionary, keyed on layers, with values as\n lists of portrayals to draw. Portrayals themselves are generated by the\n user-provided portrayal_method, which accepts an object as an input and\n produces a portrayal of it.\n\n A portrayal as a dictionary with the following structure:\n \"x\", \"y\": Coordinates for the cell in which the object is placed.\n \"Shape\": Can be either \"circle\", \"rect\" or \"arrowHead\"\n For Circles:\n \"r\": The radius, defined as a fraction of cell size. r=1 will\n fill the entire cell.\n For Rectangles:\n \"w\", \"h\": The width and height of the rectangle, which are in\n fractions of cell width and height.\n For arrowHead:\n \"scale\": Proportion scaling as a fraction of cell size.\n \"heading_x\": represents x direction unit vector.\n \"heading_y\": represents y direction unit vector.\n \"Color\": The color to draw the shape in; needs to be a valid HTML\n color, e.g.\"Red\" or \"#AA08F8\"\n \"Filled\": either \"true\" or \"false\", and determines whether the shape is\n filled or not.\n \"Layer\": Layer number of 0 or above; higher-numbered layers are drawn\n above lower-numbered layers.\n \"text\": The text to be inscribed inside the Shape. Normally useful for\n showing the unique_id of the agent.\n \"text_color\": The color to draw the inscribed text. Should be given in\n conjunction of \"text\" property.\n\n\n Attributes:\n portrayal_method: Function which generates portrayals from objects, as\n described above.\n grid_height, grid_width: Size of the grid to visualize, in cells.\n canvas_height, canvas_width: Size, in pixels, of the grid visualization\n to draw on the client.\n template: \"canvas_module.html\" stores the module's HTML template.\n\n \"\"\"\n package_includes = [\"GridDraw.js\", \"CanvasModule.js\"]\n\n def __init__(self, portrayal_method, grid_width, grid_height,\n canvas_width=500, canvas_height=500):\n \"\"\" Instantiate a new CanvasGrid.\n\n Args:\n portrayal_method: function to convert each object on the grid to\n a portrayal, as described above.\n grid_width, grid_height: Size of the grid, in cells.\n canvas_height, canvas_width: Size of the canvas to draw in the\n client, in pixels. (default: 500x500)\n\n \"\"\"\n self.portrayal_method = portrayal_method\n self.grid_width = grid_width\n self.grid_height = grid_height\n self.canvas_width = canvas_width\n self.canvas_height = canvas_height\n\n new_element = (\"new CanvasModule({}, {}, {}, {})\"\n .format(self.canvas_width, self.canvas_height,\n self.grid_width, self.grid_height))\n\n self.js_code = \"elements.push(\" + new_element + \");\"\n\n def render(self, model):\n grid_state = defaultdict(list)\n for x in range(model.grid.width):\n for y in range(model.grid.height):\n cell_objects = model.grid.get_cell_list_contents([(x, y)])\n for obj in cell_objects:\n portrayal = self.portrayal_method(obj)\n if portrayal:\n portrayal[\"x\"] = x\n portrayal[\"y\"] = y\n grid_state[portrayal[\"Layer\"]].append(portrayal)\n\n return grid_state\n", "path": "mesa/visualization/modules/CanvasGridVisualization.py"}, {"content": "# -*- coding: utf-8 -*-\n\"\"\"\nModular Canvas Rendering\n========================\n\nModule for visualizing model objects in hexagonal grid cells.\n\n\"\"\"\nfrom collections import defaultdict\nfrom mesa.visualization.ModularVisualization import VisualizationElement\n\n\nclass CanvasHexGrid(VisualizationElement):\n \"\"\" A CanvasHexGrid object functions similarly to a CanvasGrid object. It takes a portrayal dictionary and talks to HexDraw.js to draw that shape.\n\n A portrayal as a dictionary with the following structure:\n \"x\", \"y\": Coordinates for the cell in which the object is placed.\n \"Shape\": Can be either \"hex\" or \"circle\"\n \"r\": The radius, defined as a fraction of cell size. r=1 will\n fill the entire cell.\n \"Color\": The color to draw the shape in; needs to be a valid HTML\n color, e.g.\"Red\" or \"#AA08F8\"\n \"Filled\": either \"true\" or \"false\", and determines whether the shape is\n filled or not.\n \"Layer\": Layer number of 0 or above; higher-numbered layers are drawn\n above lower-numbered layers.\n \"text\": The text to be inscribed inside the Shape. Normally useful for\n showing the unique_id of the agent.\n \"text_color\": The color to draw the inscribed text. Should be given in\n conjunction of \"text\" property.\n\n\n Attributes:\n portrayal_method: Function which generates portrayals from objects, as\n described above.\n grid_height, grid_width: Size of the grid to visualize, in cells.\n canvas_height, canvas_width: Size, in pixels, of the grid visualization\n to draw on the client.\n template: \"canvas_module.html\" stores the module's HTML template.\n\n \"\"\"\n package_includes = [\"HexDraw.js\", \"CanvasHexModule.js\"]\n portrayal_method = None # Portrayal function\n canvas_width = 500\n canvas_height = 500\n\n def __init__(self, portrayal_method, grid_width, grid_height,\n canvas_width=500, canvas_height=500):\n \"\"\" Instantiate a new CanvasGrid.\n\n Args:\n portrayal_method: function to convert each object on the grid to\n a portrayal, as described above.\n grid_width, grid_height: Size of the grid, in cells.\n canvas_height, canvas_width: Size of the canvas to draw in the\n client, in pixels. (default: 500x500)\n\n \"\"\"\n self.portrayal_method = portrayal_method\n self.grid_width = grid_width\n self.grid_height = grid_height\n self.canvas_width = canvas_width\n self.canvas_height = canvas_height\n\n new_element = (\"new CanvasHexModule({}, {}, {}, {})\"\n .format(self.canvas_width, self.canvas_height,\n self.grid_width, self.grid_height))\n\n self.js_code = \"elements.push(\" + new_element + \");\"\n\n def render(self, model):\n grid_state = defaultdict(list)\n for x in range(model.grid.width):\n for y in range(model.grid.height):\n cell_objects = model.grid.get_cell_list_contents([(x, y)])\n for obj in cell_objects:\n portrayal = self.portrayal_method(obj)\n if portrayal:\n portrayal[\"x\"] = x\n portrayal[\"y\"] = y\n grid_state[portrayal[\"Layer\"]].append(portrayal)\n\n return grid_state\n", "path": "mesa/visualization/modules/HexGridVisualization.py"}]}
| 2,637 | 302 |
gh_patches_debug_2543
|
rasdani/github-patches
|
git_diff
|
mlflow__mlflow-7504
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Convert `. code-block:: python` to `.. test-code-block:: python` in `mlflow/tracking/_model_registry/fluent.py`
See #7457 for more information.
</issue>
<code>
[start of mlflow/tracking/_model_registry/fluent.py]
1 from mlflow.tracking.client import MlflowClient
2 from mlflow.exceptions import MlflowException
3 from mlflow.entities.model_registry import ModelVersion
4 from mlflow.entities.model_registry import RegisteredModel
5 from mlflow.protos.databricks_pb2 import RESOURCE_ALREADY_EXISTS, ErrorCode
6 from mlflow.store.artifact.runs_artifact_repo import RunsArtifactRepository
7 from mlflow.utils.logging_utils import eprint
8 from mlflow.utils import get_results_from_paginated_fn
9 from mlflow.tracking._model_registry import DEFAULT_AWAIT_MAX_SLEEP_SECONDS
10 from mlflow.store.model_registry import SEARCH_REGISTERED_MODEL_MAX_RESULTS_DEFAULT
11 from typing import Any, Dict, Optional, List
12
13
14 def register_model(
15 model_uri,
16 name,
17 await_registration_for=DEFAULT_AWAIT_MAX_SLEEP_SECONDS,
18 *,
19 tags: Optional[Dict[str, Any]] = None,
20 ) -> ModelVersion:
21 """
22 Create a new model version in model registry for the model files specified by ``model_uri``.
23 Note that this method assumes the model registry backend URI is the same as that of the
24 tracking backend.
25
26 :param model_uri: URI referring to the MLmodel directory. Use a ``runs:/`` URI if you want to
27 record the run ID with the model in model registry. ``models:/`` URIs are
28 currently not supported.
29 :param name: Name of the registered model under which to create a new model version. If a
30 registered model with the given name does not exist, it will be created
31 automatically.
32 :param await_registration_for: Number of seconds to wait for the model version to finish
33 being created and is in ``READY`` status. By default, the function
34 waits for five minutes. Specify 0 or None to skip waiting.
35 :param tags: A dictionary of key-value pairs that are converted into
36 :py:class:`mlflow.entities.model_registry.ModelVersionTag` objects.
37 :return: Single :py:class:`mlflow.entities.model_registry.ModelVersion` object created by
38 backend.
39
40 .. code-block:: python
41 :caption: Example
42
43 import mlflow.sklearn
44 from sklearn.ensemble import RandomForestRegressor
45
46 mlflow.set_tracking_uri("sqlite:////tmp/mlruns.db")
47 params = {"n_estimators": 3, "random_state": 42}
48
49 # Log MLflow entities
50 with mlflow.start_run() as run:
51 rfr = RandomForestRegressor(**params).fit([[0, 1]], [1])
52 mlflow.log_params(params)
53 mlflow.sklearn.log_model(rfr, artifact_path="sklearn-model")
54
55 model_uri = "runs:/{}/sklearn-model".format(run.info.run_id)
56 mv = mlflow.register_model(model_uri, "RandomForestRegressionModel")
57 print("Name: {}".format(mv.name))
58 print("Version: {}".format(mv.version))
59
60 .. code-block:: text
61 :caption: Output
62
63 Name: RandomForestRegressionModel
64 Version: 1
65 """
66 client = MlflowClient()
67 try:
68 create_model_response = client.create_registered_model(name)
69 eprint("Successfully registered model '%s'." % create_model_response.name)
70 except MlflowException as e:
71 if e.error_code == ErrorCode.Name(RESOURCE_ALREADY_EXISTS):
72 eprint(
73 "Registered model '%s' already exists. Creating a new version of this model..."
74 % name
75 )
76 else:
77 raise e
78
79 if RunsArtifactRepository.is_runs_uri(model_uri):
80 source = RunsArtifactRepository.get_underlying_uri(model_uri)
81 (run_id, _) = RunsArtifactRepository.parse_runs_uri(model_uri)
82 create_version_response = client.create_model_version(
83 name, source, run_id, tags=tags, await_creation_for=await_registration_for
84 )
85 else:
86 create_version_response = client.create_model_version(
87 name,
88 source=model_uri,
89 run_id=None,
90 tags=tags,
91 await_creation_for=await_registration_for,
92 )
93 eprint(
94 "Created version '{version}' of model '{model_name}'.".format(
95 version=create_version_response.version, model_name=create_version_response.name
96 )
97 )
98 return create_version_response
99
100
101 def search_registered_models(
102 max_results: Optional[int] = None,
103 filter_string: Optional[str] = None,
104 order_by: Optional[List[str]] = None,
105 ) -> List[RegisteredModel]:
106 """
107 Search for registered models that satisfy the filter criteria.
108
109 :param filter_string: Filter query string
110 (e.g., ``"name = 'a_model_name' and tag.key = 'value1'"``),
111 defaults to searching for all registered models. The following identifiers, comparators,
112 and logical operators are supported.
113
114 Identifiers
115 - ``name``: registered model name.
116 - ``tags.<tag_key>``: registered model tag. If ``tag_key`` contains spaces, it must be
117 wrapped with backticks (e.g., ``"tags.`extra key`"``).
118
119 Comparators
120 - ``=``: Equal to.
121 - ``!=``: Not equal to.
122 - ``LIKE``: Case-sensitive pattern match.
123 - ``ILIKE``: Case-insensitive pattern match.
124
125 Logical operators
126 - ``AND``: Combines two sub-queries and returns True if both of them are True.
127
128 :param max_results: If passed, specifies the maximum number of models desired. If not
129 passed, all models will be returned.
130 :param order_by: List of column names with ASC|DESC annotation, to be used for ordering
131 matching search results.
132 :return: A list of :py:class:`mlflow.entities.model_registry.RegisteredModel` objects
133 that satisfy the search expressions.
134
135 .. test-code-block:: python
136 :caption: Example
137
138 import mlflow
139 from sklearn.linear_model import LogisticRegression
140
141 with mlflow.start_run():
142 mlflow.sklearn.log_model(
143 LogisticRegression(),
144 "Cordoba",
145 registered_model_name="CordobaWeatherForecastModel",
146 )
147 mlflow.sklearn.log_model(
148 LogisticRegression(),
149 "Boston",
150 registered_model_name="BostonWeatherForecastModel",
151 )
152
153 # Get search results filtered by the registered model name
154 filter_string = "name = 'CordobaWeatherForecastModel'"
155 results = mlflow.search_registered_models(filter_string=filter_string)
156 print("-" * 80)
157 for res in results:
158 for mv in res.latest_versions:
159 print("name={}; run_id={}; version={}".format(mv.name, mv.run_id, mv.version))
160
161 # Get search results filtered by the registered model name that matches
162 # prefix pattern
163 filter_string = "name LIKE 'Boston%'"
164 results = mlflow.search_registered_models(filter_string=filter_string)
165 print("-" * 80)
166 for res in results:
167 for mv in res.latest_versions:
168 print("name={}; run_id={}; version={}".format(mv.name, mv.run_id, mv.version))
169
170 # Get all registered models and order them by ascending order of the names
171 results = mlflow.search_registered_models(order_by=["name ASC"])
172 print("-" * 80)
173 for res in results:
174 for mv in res.latest_versions:
175 print("name={}; run_id={}; version={}".format(mv.name, mv.run_id, mv.version))
176
177 .. code-block:: text
178 :caption: Output
179
180 --------------------------------------------------------------------------------
181 name=CordobaWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1
182 --------------------------------------------------------------------------------
183 name=BostonWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1
184 --------------------------------------------------------------------------------
185 name=BostonWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1
186 name=CordobaWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1
187
188 """
189
190 def pagination_wrapper_func(number_to_get, next_page_token):
191 return MlflowClient().search_registered_models(
192 max_results=number_to_get,
193 filter_string=filter_string,
194 order_by=order_by,
195 page_token=next_page_token,
196 )
197
198 return get_results_from_paginated_fn(
199 pagination_wrapper_func,
200 SEARCH_REGISTERED_MODEL_MAX_RESULTS_DEFAULT,
201 max_results,
202 )
203
[end of mlflow/tracking/_model_registry/fluent.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlflow/tracking/_model_registry/fluent.py b/mlflow/tracking/_model_registry/fluent.py
--- a/mlflow/tracking/_model_registry/fluent.py
+++ b/mlflow/tracking/_model_registry/fluent.py
@@ -37,7 +37,7 @@
:return: Single :py:class:`mlflow.entities.model_registry.ModelVersion` object created by
backend.
- .. code-block:: python
+ .. test-code-block:: python
:caption: Example
import mlflow.sklearn
|
{"golden_diff": "diff --git a/mlflow/tracking/_model_registry/fluent.py b/mlflow/tracking/_model_registry/fluent.py\n--- a/mlflow/tracking/_model_registry/fluent.py\n+++ b/mlflow/tracking/_model_registry/fluent.py\n@@ -37,7 +37,7 @@\n :return: Single :py:class:`mlflow.entities.model_registry.ModelVersion` object created by\n backend.\n \n- .. code-block:: python\n+ .. test-code-block:: python\n :caption: Example\n \n import mlflow.sklearn\n", "issue": "Convert `. code-block:: python` to `.. test-code-block:: python` in `mlflow/tracking/_model_registry/fluent.py`\nSee #7457 for more information.\n", "before_files": [{"content": "from mlflow.tracking.client import MlflowClient\nfrom mlflow.exceptions import MlflowException\nfrom mlflow.entities.model_registry import ModelVersion\nfrom mlflow.entities.model_registry import RegisteredModel\nfrom mlflow.protos.databricks_pb2 import RESOURCE_ALREADY_EXISTS, ErrorCode\nfrom mlflow.store.artifact.runs_artifact_repo import RunsArtifactRepository\nfrom mlflow.utils.logging_utils import eprint\nfrom mlflow.utils import get_results_from_paginated_fn\nfrom mlflow.tracking._model_registry import DEFAULT_AWAIT_MAX_SLEEP_SECONDS\nfrom mlflow.store.model_registry import SEARCH_REGISTERED_MODEL_MAX_RESULTS_DEFAULT\nfrom typing import Any, Dict, Optional, List\n\n\ndef register_model(\n model_uri,\n name,\n await_registration_for=DEFAULT_AWAIT_MAX_SLEEP_SECONDS,\n *,\n tags: Optional[Dict[str, Any]] = None,\n) -> ModelVersion:\n \"\"\"\n Create a new model version in model registry for the model files specified by ``model_uri``.\n Note that this method assumes the model registry backend URI is the same as that of the\n tracking backend.\n\n :param model_uri: URI referring to the MLmodel directory. Use a ``runs:/`` URI if you want to\n record the run ID with the model in model registry. ``models:/`` URIs are\n currently not supported.\n :param name: Name of the registered model under which to create a new model version. If a\n registered model with the given name does not exist, it will be created\n automatically.\n :param await_registration_for: Number of seconds to wait for the model version to finish\n being created and is in ``READY`` status. By default, the function\n waits for five minutes. Specify 0 or None to skip waiting.\n :param tags: A dictionary of key-value pairs that are converted into\n :py:class:`mlflow.entities.model_registry.ModelVersionTag` objects.\n :return: Single :py:class:`mlflow.entities.model_registry.ModelVersion` object created by\n backend.\n\n .. code-block:: python\n :caption: Example\n\n import mlflow.sklearn\n from sklearn.ensemble import RandomForestRegressor\n\n mlflow.set_tracking_uri(\"sqlite:////tmp/mlruns.db\")\n params = {\"n_estimators\": 3, \"random_state\": 42}\n\n # Log MLflow entities\n with mlflow.start_run() as run:\n rfr = RandomForestRegressor(**params).fit([[0, 1]], [1])\n mlflow.log_params(params)\n mlflow.sklearn.log_model(rfr, artifact_path=\"sklearn-model\")\n\n model_uri = \"runs:/{}/sklearn-model\".format(run.info.run_id)\n mv = mlflow.register_model(model_uri, \"RandomForestRegressionModel\")\n print(\"Name: {}\".format(mv.name))\n print(\"Version: {}\".format(mv.version))\n\n .. code-block:: text\n :caption: Output\n\n Name: RandomForestRegressionModel\n Version: 1\n \"\"\"\n client = MlflowClient()\n try:\n create_model_response = client.create_registered_model(name)\n eprint(\"Successfully registered model '%s'.\" % create_model_response.name)\n except MlflowException as e:\n if e.error_code == ErrorCode.Name(RESOURCE_ALREADY_EXISTS):\n eprint(\n \"Registered model '%s' already exists. Creating a new version of this model...\"\n % name\n )\n else:\n raise e\n\n if RunsArtifactRepository.is_runs_uri(model_uri):\n source = RunsArtifactRepository.get_underlying_uri(model_uri)\n (run_id, _) = RunsArtifactRepository.parse_runs_uri(model_uri)\n create_version_response = client.create_model_version(\n name, source, run_id, tags=tags, await_creation_for=await_registration_for\n )\n else:\n create_version_response = client.create_model_version(\n name,\n source=model_uri,\n run_id=None,\n tags=tags,\n await_creation_for=await_registration_for,\n )\n eprint(\n \"Created version '{version}' of model '{model_name}'.\".format(\n version=create_version_response.version, model_name=create_version_response.name\n )\n )\n return create_version_response\n\n\ndef search_registered_models(\n max_results: Optional[int] = None,\n filter_string: Optional[str] = None,\n order_by: Optional[List[str]] = None,\n) -> List[RegisteredModel]:\n \"\"\"\n Search for registered models that satisfy the filter criteria.\n\n :param filter_string: Filter query string\n (e.g., ``\"name = 'a_model_name' and tag.key = 'value1'\"``),\n defaults to searching for all registered models. The following identifiers, comparators,\n and logical operators are supported.\n\n Identifiers\n - ``name``: registered model name.\n - ``tags.<tag_key>``: registered model tag. If ``tag_key`` contains spaces, it must be\n wrapped with backticks (e.g., ``\"tags.`extra key`\"``).\n\n Comparators\n - ``=``: Equal to.\n - ``!=``: Not equal to.\n - ``LIKE``: Case-sensitive pattern match.\n - ``ILIKE``: Case-insensitive pattern match.\n\n Logical operators\n - ``AND``: Combines two sub-queries and returns True if both of them are True.\n\n :param max_results: If passed, specifies the maximum number of models desired. If not\n passed, all models will be returned.\n :param order_by: List of column names with ASC|DESC annotation, to be used for ordering\n matching search results.\n :return: A list of :py:class:`mlflow.entities.model_registry.RegisteredModel` objects\n that satisfy the search expressions.\n\n .. test-code-block:: python\n :caption: Example\n\n import mlflow\n from sklearn.linear_model import LogisticRegression\n\n with mlflow.start_run():\n mlflow.sklearn.log_model(\n LogisticRegression(),\n \"Cordoba\",\n registered_model_name=\"CordobaWeatherForecastModel\",\n )\n mlflow.sklearn.log_model(\n LogisticRegression(),\n \"Boston\",\n registered_model_name=\"BostonWeatherForecastModel\",\n )\n\n # Get search results filtered by the registered model name\n filter_string = \"name = 'CordobaWeatherForecastModel'\"\n results = mlflow.search_registered_models(filter_string=filter_string)\n print(\"-\" * 80)\n for res in results:\n for mv in res.latest_versions:\n print(\"name={}; run_id={}; version={}\".format(mv.name, mv.run_id, mv.version))\n\n # Get search results filtered by the registered model name that matches\n # prefix pattern\n filter_string = \"name LIKE 'Boston%'\"\n results = mlflow.search_registered_models(filter_string=filter_string)\n print(\"-\" * 80)\n for res in results:\n for mv in res.latest_versions:\n print(\"name={}; run_id={}; version={}\".format(mv.name, mv.run_id, mv.version))\n\n # Get all registered models and order them by ascending order of the names\n results = mlflow.search_registered_models(order_by=[\"name ASC\"])\n print(\"-\" * 80)\n for res in results:\n for mv in res.latest_versions:\n print(\"name={}; run_id={}; version={}\".format(mv.name, mv.run_id, mv.version))\n\n .. code-block:: text\n :caption: Output\n\n --------------------------------------------------------------------------------\n name=CordobaWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1\n --------------------------------------------------------------------------------\n name=BostonWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1\n --------------------------------------------------------------------------------\n name=BostonWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1\n name=CordobaWeatherForecastModel; run_id=248c66a666744b4887bdeb2f9cf7f1c6; version=1\n\n \"\"\"\n\n def pagination_wrapper_func(number_to_get, next_page_token):\n return MlflowClient().search_registered_models(\n max_results=number_to_get,\n filter_string=filter_string,\n order_by=order_by,\n page_token=next_page_token,\n )\n\n return get_results_from_paginated_fn(\n pagination_wrapper_func,\n SEARCH_REGISTERED_MODEL_MAX_RESULTS_DEFAULT,\n max_results,\n )\n", "path": "mlflow/tracking/_model_registry/fluent.py"}]}
| 2,974 | 119 |
gh_patches_debug_26170
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-22270
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
management: `rename_stream` management command does not work
`rename_stream` uses the `do_rename_stream` function to rename the stream. However, it accesses a non-existent attribute when calling it.
```
do_rename_stream(stream, new_name, self.user_profile) # self.user_profile does not exist
```
To replicate this, run:
```
python manage.py rename_stream Denmark bar -r zulip
```
and you should see:
```
AttributeError: 'Command' object has no attribute 'user_profile'
```
You might want to look at `zerver/management/commands/rename_stream.py` and `zerver/actions/streams.py`.
The fix should refactor `do_rename_stream` to accept `user_profile: Optional[UserProfile]` with the `None` default, and correctly handle what should happen for the notification message that might be sent when the stream is renamed (which currently mentions the name of the acting user that renames it).
</issue>
<code>
[start of zerver/management/commands/rename_stream.py]
1 from argparse import ArgumentParser
2 from typing import Any
3
4 from zerver.actions.streams import do_rename_stream
5 from zerver.lib.management import ZulipBaseCommand
6 from zerver.models import get_stream
7
8
9 class Command(ZulipBaseCommand):
10 help = """Change the stream name for a realm."""
11
12 def add_arguments(self, parser: ArgumentParser) -> None:
13 parser.add_argument("old_name", metavar="<old name>", help="name of stream to be renamed")
14 parser.add_argument(
15 "new_name", metavar="<new name>", help="new name to rename the stream to"
16 )
17 self.add_realm_args(parser, required=True)
18
19 def handle(self, *args: Any, **options: str) -> None:
20 realm = self.get_realm(options)
21 assert realm is not None # Should be ensured by parser
22 old_name = options["old_name"]
23 new_name = options["new_name"]
24
25 stream = get_stream(old_name, realm)
26 do_rename_stream(stream, new_name, self.user_profile)
27
[end of zerver/management/commands/rename_stream.py]
[start of zilencer/management/commands/migrate_stream_notifications.py]
1 from typing import Any
2
3 from django.core.management.base import BaseCommand
4
5 from zerver.models import Subscription
6
7
8 class Command(BaseCommand):
9 help = """One-off script to migration users' stream notification settings."""
10
11 def handle(self, *args: Any, **options: Any) -> None:
12 for subscription in Subscription.objects.all():
13 subscription.desktop_notifications = subscription.notifications
14 subscription.audible_notifications = subscription.notifications
15 subscription.save(update_fields=["desktop_notifications", "audible_notifications"])
16
[end of zilencer/management/commands/migrate_stream_notifications.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zerver/management/commands/rename_stream.py b/zerver/management/commands/rename_stream.py
deleted file mode 100644
--- a/zerver/management/commands/rename_stream.py
+++ /dev/null
@@ -1,26 +0,0 @@
-from argparse import ArgumentParser
-from typing import Any
-
-from zerver.actions.streams import do_rename_stream
-from zerver.lib.management import ZulipBaseCommand
-from zerver.models import get_stream
-
-
-class Command(ZulipBaseCommand):
- help = """Change the stream name for a realm."""
-
- def add_arguments(self, parser: ArgumentParser) -> None:
- parser.add_argument("old_name", metavar="<old name>", help="name of stream to be renamed")
- parser.add_argument(
- "new_name", metavar="<new name>", help="new name to rename the stream to"
- )
- self.add_realm_args(parser, required=True)
-
- def handle(self, *args: Any, **options: str) -> None:
- realm = self.get_realm(options)
- assert realm is not None # Should be ensured by parser
- old_name = options["old_name"]
- new_name = options["new_name"]
-
- stream = get_stream(old_name, realm)
- do_rename_stream(stream, new_name, self.user_profile)
diff --git a/zilencer/management/commands/migrate_stream_notifications.py b/zilencer/management/commands/migrate_stream_notifications.py
deleted file mode 100644
--- a/zilencer/management/commands/migrate_stream_notifications.py
+++ /dev/null
@@ -1,15 +0,0 @@
-from typing import Any
-
-from django.core.management.base import BaseCommand
-
-from zerver.models import Subscription
-
-
-class Command(BaseCommand):
- help = """One-off script to migration users' stream notification settings."""
-
- def handle(self, *args: Any, **options: Any) -> None:
- for subscription in Subscription.objects.all():
- subscription.desktop_notifications = subscription.notifications
- subscription.audible_notifications = subscription.notifications
- subscription.save(update_fields=["desktop_notifications", "audible_notifications"])
|
{"golden_diff": "diff --git a/zerver/management/commands/rename_stream.py b/zerver/management/commands/rename_stream.py\ndeleted file mode 100644\n--- a/zerver/management/commands/rename_stream.py\n+++ /dev/null\n@@ -1,26 +0,0 @@\n-from argparse import ArgumentParser\n-from typing import Any\n-\n-from zerver.actions.streams import do_rename_stream\n-from zerver.lib.management import ZulipBaseCommand\n-from zerver.models import get_stream\n-\n-\n-class Command(ZulipBaseCommand):\n- help = \"\"\"Change the stream name for a realm.\"\"\"\n-\n- def add_arguments(self, parser: ArgumentParser) -> None:\n- parser.add_argument(\"old_name\", metavar=\"<old name>\", help=\"name of stream to be renamed\")\n- parser.add_argument(\n- \"new_name\", metavar=\"<new name>\", help=\"new name to rename the stream to\"\n- )\n- self.add_realm_args(parser, required=True)\n-\n- def handle(self, *args: Any, **options: str) -> None:\n- realm = self.get_realm(options)\n- assert realm is not None # Should be ensured by parser\n- old_name = options[\"old_name\"]\n- new_name = options[\"new_name\"]\n-\n- stream = get_stream(old_name, realm)\n- do_rename_stream(stream, new_name, self.user_profile)\ndiff --git a/zilencer/management/commands/migrate_stream_notifications.py b/zilencer/management/commands/migrate_stream_notifications.py\ndeleted file mode 100644\n--- a/zilencer/management/commands/migrate_stream_notifications.py\n+++ /dev/null\n@@ -1,15 +0,0 @@\n-from typing import Any\n-\n-from django.core.management.base import BaseCommand\n-\n-from zerver.models import Subscription\n-\n-\n-class Command(BaseCommand):\n- help = \"\"\"One-off script to migration users' stream notification settings.\"\"\"\n-\n- def handle(self, *args: Any, **options: Any) -> None:\n- for subscription in Subscription.objects.all():\n- subscription.desktop_notifications = subscription.notifications\n- subscription.audible_notifications = subscription.notifications\n- subscription.save(update_fields=[\"desktop_notifications\", \"audible_notifications\"])\n", "issue": "management: `rename_stream` management command does not work\n`rename_stream` uses the `do_rename_stream` function to rename the stream. However, it accesses a non-existent attribute when calling it.\r\n\r\n```\r\ndo_rename_stream(stream, new_name, self.user_profile) # self.user_profile does not exist\r\n```\r\n\r\nTo replicate this, run:\r\n```\r\npython manage.py rename_stream Denmark bar -r zulip\r\n```\r\nand you should see:\r\n```\r\nAttributeError: 'Command' object has no attribute 'user_profile'\r\n```\r\nYou might want to look at `zerver/management/commands/rename_stream.py` and `zerver/actions/streams.py`.\r\n\r\nThe fix should refactor `do_rename_stream` to accept `user_profile: Optional[UserProfile]` with the `None` default, and correctly handle what should happen for the notification message that might be sent when the stream is renamed (which currently mentions the name of the acting user that renames it).\n", "before_files": [{"content": "from argparse import ArgumentParser\nfrom typing import Any\n\nfrom zerver.actions.streams import do_rename_stream\nfrom zerver.lib.management import ZulipBaseCommand\nfrom zerver.models import get_stream\n\n\nclass Command(ZulipBaseCommand):\n help = \"\"\"Change the stream name for a realm.\"\"\"\n\n def add_arguments(self, parser: ArgumentParser) -> None:\n parser.add_argument(\"old_name\", metavar=\"<old name>\", help=\"name of stream to be renamed\")\n parser.add_argument(\n \"new_name\", metavar=\"<new name>\", help=\"new name to rename the stream to\"\n )\n self.add_realm_args(parser, required=True)\n\n def handle(self, *args: Any, **options: str) -> None:\n realm = self.get_realm(options)\n assert realm is not None # Should be ensured by parser\n old_name = options[\"old_name\"]\n new_name = options[\"new_name\"]\n\n stream = get_stream(old_name, realm)\n do_rename_stream(stream, new_name, self.user_profile)\n", "path": "zerver/management/commands/rename_stream.py"}, {"content": "from typing import Any\n\nfrom django.core.management.base import BaseCommand\n\nfrom zerver.models import Subscription\n\n\nclass Command(BaseCommand):\n help = \"\"\"One-off script to migration users' stream notification settings.\"\"\"\n\n def handle(self, *args: Any, **options: Any) -> None:\n for subscription in Subscription.objects.all():\n subscription.desktop_notifications = subscription.notifications\n subscription.audible_notifications = subscription.notifications\n subscription.save(update_fields=[\"desktop_notifications\", \"audible_notifications\"])\n", "path": "zilencer/management/commands/migrate_stream_notifications.py"}]}
| 1,173 | 486 |
gh_patches_debug_12810
|
rasdani/github-patches
|
git_diff
|
joke2k__faker-626
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Uk mobile number
It seems like the uk mobile number is not in the right format
it's completely not valid
some examples of them:
+44(0)9128 405119
(01414) 35336
01231052134
Uk mobile number
It seems like the uk mobile number is not in the right format
it's completely not valid
some examples of them:
+44(0)9128 405119
(01414) 35336
01231052134
</issue>
<code>
[start of faker/providers/phone_number/en_GB/__init__.py]
1 from __future__ import unicode_literals
2 from .. import Provider as PhoneNumberProvider
3
4
5 class Provider(PhoneNumberProvider):
6 formats = (
7 '+44(0)##########',
8 '+44(0)#### ######',
9 '+44(0)#########',
10 '+44(0)#### #####',
11 '0##########',
12 '0#########',
13 '0#### ######',
14 '0#### #####',
15 '(0####) ######',
16 '(0####) #####',
17 )
18
[end of faker/providers/phone_number/en_GB/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/faker/providers/phone_number/en_GB/__init__.py b/faker/providers/phone_number/en_GB/__init__.py
--- a/faker/providers/phone_number/en_GB/__init__.py
+++ b/faker/providers/phone_number/en_GB/__init__.py
@@ -3,6 +3,15 @@
class Provider(PhoneNumberProvider):
+ # Source: https://en.wikipedia.org/wiki/Telephone_numbers_in_the_United_Kingdom
+
+ cellphone_formats = (
+ '+44 7### ######',
+ '+44 7#########',
+ '07### ######',
+ '07#########',
+ )
+
formats = (
'+44(0)##########',
'+44(0)#### ######',
@@ -15,3 +24,7 @@
'(0####) ######',
'(0####) #####',
)
+
+ def cellphone_number(self):
+ pattern = self.random_element(self.cellphone_formats)
+ return self.numerify(self.generator.parse(pattern))
|
{"golden_diff": "diff --git a/faker/providers/phone_number/en_GB/__init__.py b/faker/providers/phone_number/en_GB/__init__.py\n--- a/faker/providers/phone_number/en_GB/__init__.py\n+++ b/faker/providers/phone_number/en_GB/__init__.py\n@@ -3,6 +3,15 @@\n \n \n class Provider(PhoneNumberProvider):\n+ # Source: https://en.wikipedia.org/wiki/Telephone_numbers_in_the_United_Kingdom\n+\n+ cellphone_formats = (\n+ '+44 7### ######',\n+ '+44 7#########',\n+ '07### ######',\n+ '07#########',\n+ )\n+\n formats = (\n '+44(0)##########',\n '+44(0)#### ######',\n@@ -15,3 +24,7 @@\n '(0####) ######',\n '(0####) #####',\n )\n+\n+ def cellphone_number(self):\n+ pattern = self.random_element(self.cellphone_formats)\n+ return self.numerify(self.generator.parse(pattern))\n", "issue": "Uk mobile number\nIt seems like the uk mobile number is not in the right format \r\nit's completely not valid\r\nsome examples of them: \r\n+44(0)9128 405119\r\n(01414) 35336\r\n01231052134\nUk mobile number\nIt seems like the uk mobile number is not in the right format \r\nit's completely not valid\r\nsome examples of them: \r\n+44(0)9128 405119\r\n(01414) 35336\r\n01231052134\n", "before_files": [{"content": "from __future__ import unicode_literals\nfrom .. import Provider as PhoneNumberProvider\n\n\nclass Provider(PhoneNumberProvider):\n formats = (\n '+44(0)##########',\n '+44(0)#### ######',\n '+44(0)#########',\n '+44(0)#### #####',\n '0##########',\n '0#########',\n '0#### ######',\n '0#### #####',\n '(0####) ######',\n '(0####) #####',\n )\n", "path": "faker/providers/phone_number/en_GB/__init__.py"}]}
| 835 | 235 |
gh_patches_debug_29327
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-24183
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
createuser: Error when trying to --force-update user
`createuser` fails when run against an existing user.
```
$ sudo docker-compose run --rm web sentry --version
sentry, version 10.1.0.dev0 (0bf9ffa08ff2)
$ sudo docker-compose run --rm web sentry createuser --email [email protected] --password pass1 --no-superuser --no-input --force-update
21:32:17 [WARNING] sentry.utils.geo: settings.GEOIP_PATH_MMDB not configured.
21:32:21 [INFO] sentry.plugins.github: apps-not-configured
User created: [email protected]
Added to organization: sentry
$ sudo docker-compose run --rm web sentry createuser --email [email protected] --password pass2 --no-superuser --no-input --force-update
21:33:46 [WARNING] sentry.utils.geo: settings.GEOIP_PATH_MMDB not configured.
21:33:49 [INFO] sentry.plugins.github: apps-not-configured
Traceback (most recent call last):
File "/usr/local/bin/sentry", line 8, in <module>
sys.exit(main())
File "/usr/local/lib/python2.7/site-packages/sentry/runner/__init__.py", line 166, in main
cli(prog_name=get_prog(), obj={}, max_content_width=100)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 722, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 697, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 1066, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 895, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 535, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/click/decorators.py", line 17, in new_func
return f(get_current_context(), *args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/sentry/runner/decorators.py", line 30, in inner
return ctx.invoke(f, *args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/click/core.py", line 535, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/sentry/runner/commands/createuser.py", line 83, in createuser
user.save(force_update=force_update)
File "/usr/local/lib/python2.7/site-packages/sentry/models/user.py", line 141, in save
return super(User, self).save(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/django/contrib/auth/base_user.py", line 80, in save
super(AbstractBaseUser, self).save(*args, **kwargs)
File "/usr/local/lib/python2.7/site-packages/django/db/models/base.py", line 808, in save
force_update=force_update, update_fields=update_fields)
File "/usr/local/lib/python2.7/site-packages/django/db/models/base.py", line 838, in save_base
updated = self._save_table(raw, cls, force_insert, force_update, using, update_fields)
File "/usr/local/lib/python2.7/site-packages/django/db/models/base.py", line 896, in _save_table
raise ValueError("Cannot force an update in save() with no primary key.")
ValueError: Cannot force an update in save() with no primary key.
```
</issue>
<code>
[start of src/sentry/runner/commands/createuser.py]
1 import click
2 import sys
3 from sentry.runner.decorators import configuration
4
5
6 def _get_field(field_name):
7 from sentry.models import User
8
9 return User._meta.get_field(field_name)
10
11
12 def _get_email():
13 from django.core.exceptions import ValidationError
14
15 rv = click.prompt("Email")
16 field = _get_field("email")
17 try:
18 return field.clean(rv, None)
19 except ValidationError as e:
20 raise click.ClickException("; ".join(e.messages))
21
22
23 def _get_password():
24 from django.core.exceptions import ValidationError
25
26 rv = click.prompt("Password", hide_input=True, confirmation_prompt=True)
27 field = _get_field("password")
28 try:
29 return field.clean(rv, None)
30 except ValidationError as e:
31 raise click.ClickException("; ".join(e.messages))
32
33
34 def _get_superuser():
35 return click.confirm("Should this user be a superuser?", default=False)
36
37
38 @click.command()
39 @click.option("--email")
40 @click.option("--password")
41 @click.option("--superuser/--no-superuser", default=None, is_flag=True)
42 @click.option("--no-password", default=False, is_flag=True)
43 @click.option("--no-input", default=False, is_flag=True)
44 @click.option("--force-update", default=False, is_flag=True)
45 @configuration
46 def createuser(email, password, superuser, no_password, no_input, force_update):
47 "Create a new user."
48 if not no_input:
49 if not email:
50 email = _get_email()
51
52 if not (password or no_password):
53 password = _get_password()
54
55 if superuser is None:
56 superuser = _get_superuser()
57
58 if superuser is None:
59 superuser = False
60
61 if not email:
62 raise click.ClickException("Invalid or missing email address.")
63
64 # TODO(mattrobenolt): Accept password over stdin?
65 if not no_password and not password:
66 raise click.ClickException("No password set and --no-password not passed.")
67
68 from sentry import roles
69 from sentry.models import User
70 from django.conf import settings
71
72 user = User(
73 email=email, username=email, is_superuser=superuser, is_staff=superuser, is_active=True
74 )
75
76 if password:
77 user.set_password(password)
78
79 if User.objects.filter(username=email).exists():
80 if force_update:
81 user.save(force_update=force_update)
82 click.echo(f"User updated: {email}")
83 else:
84 click.echo(f"User: {email} exists, use --force-update to force")
85 sys.exit(3)
86 else:
87 user.save()
88 click.echo(f"User created: {email}")
89
90 # TODO(dcramer): kill this when we improve flows
91 if settings.SENTRY_SINGLE_ORGANIZATION:
92 from sentry.models import Organization, OrganizationMember, OrganizationMemberTeam, Team
93
94 org = Organization.get_default()
95 if superuser:
96 role = roles.get_top_dog().id
97 else:
98 role = org.default_role
99 member = OrganizationMember.objects.create(organization=org, user=user, role=role)
100
101 # if we've only got a single team let's go ahead and give
102 # access to that team as its likely the desired outcome
103 teams = list(Team.objects.filter(organization=org)[0:2])
104 if len(teams) == 1:
105 OrganizationMemberTeam.objects.create(team=teams[0], organizationmember=member)
106 click.echo(f"Added to organization: {org.slug}")
107
[end of src/sentry/runner/commands/createuser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/runner/commands/createuser.py b/src/sentry/runner/commands/createuser.py
--- a/src/sentry/runner/commands/createuser.py
+++ b/src/sentry/runner/commands/createuser.py
@@ -69,23 +69,26 @@
from sentry.models import User
from django.conf import settings
- user = User(
+ fields = dict(
email=email, username=email, is_superuser=superuser, is_staff=superuser, is_active=True
)
- if password:
- user.set_password(password)
+ verb = None
+ try:
+ user = User.objects.get(username=email)
+ except User.DoesNotExist:
+ user = None
- if User.objects.filter(username=email).exists():
+ if user is not None:
if force_update:
- user.save(force_update=force_update)
- click.echo(f"User updated: {email}")
+ user.update(**fields)
+ verb = "updated"
else:
click.echo(f"User: {email} exists, use --force-update to force")
sys.exit(3)
else:
- user.save()
- click.echo(f"User created: {email}")
+ user = User.objects.create(**fields)
+ verb = "created"
# TODO(dcramer): kill this when we improve flows
if settings.SENTRY_SINGLE_ORGANIZATION:
@@ -104,3 +107,9 @@
if len(teams) == 1:
OrganizationMemberTeam.objects.create(team=teams[0], organizationmember=member)
click.echo(f"Added to organization: {org.slug}")
+
+ if password:
+ user.set_password(password)
+ user.save()
+
+ click.echo(f"User {verb}: {email}")
|
{"golden_diff": "diff --git a/src/sentry/runner/commands/createuser.py b/src/sentry/runner/commands/createuser.py\n--- a/src/sentry/runner/commands/createuser.py\n+++ b/src/sentry/runner/commands/createuser.py\n@@ -69,23 +69,26 @@\n from sentry.models import User\n from django.conf import settings\n \n- user = User(\n+ fields = dict(\n email=email, username=email, is_superuser=superuser, is_staff=superuser, is_active=True\n )\n \n- if password:\n- user.set_password(password)\n+ verb = None\n+ try:\n+ user = User.objects.get(username=email)\n+ except User.DoesNotExist:\n+ user = None\n \n- if User.objects.filter(username=email).exists():\n+ if user is not None:\n if force_update:\n- user.save(force_update=force_update)\n- click.echo(f\"User updated: {email}\")\n+ user.update(**fields)\n+ verb = \"updated\"\n else:\n click.echo(f\"User: {email} exists, use --force-update to force\")\n sys.exit(3)\n else:\n- user.save()\n- click.echo(f\"User created: {email}\")\n+ user = User.objects.create(**fields)\n+ verb = \"created\"\n \n # TODO(dcramer): kill this when we improve flows\n if settings.SENTRY_SINGLE_ORGANIZATION:\n@@ -104,3 +107,9 @@\n if len(teams) == 1:\n OrganizationMemberTeam.objects.create(team=teams[0], organizationmember=member)\n click.echo(f\"Added to organization: {org.slug}\")\n+\n+ if password:\n+ user.set_password(password)\n+ user.save()\n+\n+ click.echo(f\"User {verb}: {email}\")\n", "issue": "createuser: Error when trying to --force-update user\n`createuser` fails when run against an existing user. \r\n\r\n```\r\n$ sudo docker-compose run --rm web sentry --version\r\nsentry, version 10.1.0.dev0 (0bf9ffa08ff2)\r\n$ sudo docker-compose run --rm web sentry createuser --email [email protected] --password pass1 --no-superuser --no-input --force-update \r\n21:32:17 [WARNING] sentry.utils.geo: settings.GEOIP_PATH_MMDB not configured.\r\n21:32:21 [INFO] sentry.plugins.github: apps-not-configured\r\nUser created: [email protected]\r\nAdded to organization: sentry\r\n$ sudo docker-compose run --rm web sentry createuser --email [email protected] --password pass2 --no-superuser --no-input --force-update \r\n21:33:46 [WARNING] sentry.utils.geo: settings.GEOIP_PATH_MMDB not configured.\r\n21:33:49 [INFO] sentry.plugins.github: apps-not-configured\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/sentry\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/usr/local/lib/python2.7/site-packages/sentry/runner/__init__.py\", line 166, in main\r\n cli(prog_name=get_prog(), obj={}, max_content_width=100)\r\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 722, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 697, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 1066, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 895, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 535, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/click/decorators.py\", line 17, in new_func\r\n return f(get_current_context(), *args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/sentry/runner/decorators.py\", line 30, in inner\r\n return ctx.invoke(f, *args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/click/core.py\", line 535, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/sentry/runner/commands/createuser.py\", line 83, in createuser\r\n user.save(force_update=force_update)\r\n File \"/usr/local/lib/python2.7/site-packages/sentry/models/user.py\", line 141, in save\r\n return super(User, self).save(*args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/django/contrib/auth/base_user.py\", line 80, in save\r\n super(AbstractBaseUser, self).save(*args, **kwargs)\r\n File \"/usr/local/lib/python2.7/site-packages/django/db/models/base.py\", line 808, in save\r\n force_update=force_update, update_fields=update_fields)\r\n File \"/usr/local/lib/python2.7/site-packages/django/db/models/base.py\", line 838, in save_base\r\n updated = self._save_table(raw, cls, force_insert, force_update, using, update_fields)\r\n File \"/usr/local/lib/python2.7/site-packages/django/db/models/base.py\", line 896, in _save_table\r\n raise ValueError(\"Cannot force an update in save() with no primary key.\")\r\nValueError: Cannot force an update in save() with no primary key.\r\n```\n", "before_files": [{"content": "import click\nimport sys\nfrom sentry.runner.decorators import configuration\n\n\ndef _get_field(field_name):\n from sentry.models import User\n\n return User._meta.get_field(field_name)\n\n\ndef _get_email():\n from django.core.exceptions import ValidationError\n\n rv = click.prompt(\"Email\")\n field = _get_field(\"email\")\n try:\n return field.clean(rv, None)\n except ValidationError as e:\n raise click.ClickException(\"; \".join(e.messages))\n\n\ndef _get_password():\n from django.core.exceptions import ValidationError\n\n rv = click.prompt(\"Password\", hide_input=True, confirmation_prompt=True)\n field = _get_field(\"password\")\n try:\n return field.clean(rv, None)\n except ValidationError as e:\n raise click.ClickException(\"; \".join(e.messages))\n\n\ndef _get_superuser():\n return click.confirm(\"Should this user be a superuser?\", default=False)\n\n\[email protected]()\[email protected](\"--email\")\[email protected](\"--password\")\[email protected](\"--superuser/--no-superuser\", default=None, is_flag=True)\[email protected](\"--no-password\", default=False, is_flag=True)\[email protected](\"--no-input\", default=False, is_flag=True)\[email protected](\"--force-update\", default=False, is_flag=True)\n@configuration\ndef createuser(email, password, superuser, no_password, no_input, force_update):\n \"Create a new user.\"\n if not no_input:\n if not email:\n email = _get_email()\n\n if not (password or no_password):\n password = _get_password()\n\n if superuser is None:\n superuser = _get_superuser()\n\n if superuser is None:\n superuser = False\n\n if not email:\n raise click.ClickException(\"Invalid or missing email address.\")\n\n # TODO(mattrobenolt): Accept password over stdin?\n if not no_password and not password:\n raise click.ClickException(\"No password set and --no-password not passed.\")\n\n from sentry import roles\n from sentry.models import User\n from django.conf import settings\n\n user = User(\n email=email, username=email, is_superuser=superuser, is_staff=superuser, is_active=True\n )\n\n if password:\n user.set_password(password)\n\n if User.objects.filter(username=email).exists():\n if force_update:\n user.save(force_update=force_update)\n click.echo(f\"User updated: {email}\")\n else:\n click.echo(f\"User: {email} exists, use --force-update to force\")\n sys.exit(3)\n else:\n user.save()\n click.echo(f\"User created: {email}\")\n\n # TODO(dcramer): kill this when we improve flows\n if settings.SENTRY_SINGLE_ORGANIZATION:\n from sentry.models import Organization, OrganizationMember, OrganizationMemberTeam, Team\n\n org = Organization.get_default()\n if superuser:\n role = roles.get_top_dog().id\n else:\n role = org.default_role\n member = OrganizationMember.objects.create(organization=org, user=user, role=role)\n\n # if we've only got a single team let's go ahead and give\n # access to that team as its likely the desired outcome\n teams = list(Team.objects.filter(organization=org)[0:2])\n if len(teams) == 1:\n OrganizationMemberTeam.objects.create(team=teams[0], organizationmember=member)\n click.echo(f\"Added to organization: {org.slug}\")\n", "path": "src/sentry/runner/commands/createuser.py"}]}
| 2,409 | 398 |
gh_patches_debug_2835
|
rasdani/github-patches
|
git_diff
|
Cloud-CV__EvalAI-2012
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect Fields in Jobs serializer
*Observed code:* [here](https://github.com/Cloud-CV/EvalAI/blob/master/apps/jobs/serializers.py/#L54)
```
class Meta:
model = LeaderboardData
fields = "__all__"
fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')
```
*Expected Code:*
```
class Meta:
model = LeaderboardData
fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')
```
</issue>
<code>
[start of apps/jobs/serializers.py]
1 from django.contrib.auth.models import User
2
3 from rest_framework import serializers
4
5 from challenges.models import LeaderboardData
6 from participants.models import Participant, ParticipantTeam
7
8 from .models import Submission
9
10
11 class SubmissionSerializer(serializers.ModelSerializer):
12
13 participant_team_name = serializers.SerializerMethodField()
14 execution_time = serializers.SerializerMethodField()
15
16 def __init__(self, *args, **kwargs):
17 context = kwargs.get('context')
18 if context and context.get('request').method == 'POST':
19 created_by = context.get('request').user
20 kwargs['data']['created_by'] = created_by.pk
21
22 participant_team = context.get('participant_team').pk
23 kwargs['data']['participant_team'] = participant_team
24
25 challenge_phase = context.get('challenge_phase').pk
26 kwargs['data']['challenge_phase'] = challenge_phase
27
28 super(SubmissionSerializer, self).__init__(*args, **kwargs)
29
30 class Meta:
31 model = Submission
32 fields = ('id', 'participant_team', 'participant_team_name', 'execution_time', 'challenge_phase',
33 'created_by', 'status', 'input_file', 'stdout_file', 'stderr_file', 'submitted_at',
34 'method_name', 'method_description', 'project_url', 'publication_url', 'is_public',
35 'submission_result_file', 'when_made_public',)
36
37 def get_participant_team_name(self, obj):
38 return obj.participant_team.team_name
39
40 def get_execution_time(self, obj):
41 return obj.execution_time
42
43
44 class LeaderboardDataSerializer(serializers.ModelSerializer):
45
46 participant_team_name = serializers.SerializerMethodField()
47 leaderboard_schema = serializers.SerializerMethodField()
48
49 def __init__(self, *args, **kwargs):
50 super(LeaderboardDataSerializer, self).__init__(*args, **kwargs)
51
52 class Meta:
53 model = LeaderboardData
54 fields = "__all__"
55 fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')
56
57 def get_participant_team_name(self, obj):
58 return obj.submission.participant_team.team_name
59
60 def get_leaderboard_schema(self, obj):
61 return obj.leaderboard.schema
62
63
64 class ChallengeSubmissionManagementSerializer(serializers.ModelSerializer):
65
66 participant_team = serializers.SerializerMethodField()
67 challenge_phase = serializers.SerializerMethodField()
68 created_by = serializers.SerializerMethodField()
69 participant_team_members_email_ids = serializers.SerializerMethodField()
70 created_at = serializers.SerializerMethodField()
71 participant_team_members = serializers.SerializerMethodField()
72
73 class Meta:
74 model = Submission
75 fields = ('id', 'participant_team', 'challenge_phase', 'created_by', 'status', 'is_public',
76 'submission_number', 'submitted_at', 'execution_time', 'input_file', 'stdout_file',
77 'stderr_file', 'submission_result_file', 'submission_metadata_file',
78 'participant_team_members_email_ids', 'created_at', 'method_name', 'participant_team_members',)
79
80 def get_participant_team(self, obj):
81 return obj.participant_team.team_name
82
83 def get_challenge_phase(self, obj):
84 return obj.challenge_phase.name
85
86 def get_created_by(self, obj):
87 return obj.created_by.username
88
89 def get_participant_team_members_email_ids(self, obj):
90 try:
91 participant_team = ParticipantTeam.objects.get(team_name=obj.participant_team.team_name)
92 except ParticipantTeam.DoesNotExist:
93 return 'Participant team does not exist'
94
95 participant_ids = Participant.objects.filter(team=participant_team).values_list('user_id', flat=True)
96 return list(User.objects.filter(id__in=participant_ids).values_list('email', flat=True))
97
98 def get_created_at(self, obj):
99 return obj.created_at
100
101 def get_participant_team_members(self, obj):
102 try:
103 participant_team = ParticipantTeam.objects.get(team_name=obj.participant_team.team_name)
104 except ParticipantTeam.DoesNotExist:
105 return 'Participant team does not exist'
106
107 participant_ids = Participant.objects.filter(team=participant_team).values_list('user_id', flat=True)
108 return list(User.objects.filter(id__in=participant_ids).values('username', 'email'))
109
110
111 class SubmissionCount(object):
112 def __init__(self, submission_count):
113 self.submission_count = submission_count
114
115
116 class SubmissionCountSerializer(serializers.Serializer):
117 submission_count = serializers.IntegerField()
118
119
120 class LastSubmissionDateTime(object):
121 def __init__(self, last_submission_datetime):
122 self.last_submission_datetime = last_submission_datetime
123
124
125 class LastSubmissionDateTimeSerializer(serializers.Serializer):
126 last_submission_datetime = serializers.DateTimeField()
127
128
129 class CreateLeaderboardDataSerializer(serializers.ModelSerializer):
130
131 def __init__(self, *args, **kwargs):
132 context = kwargs.get('context')
133 if context and context.get('request').method == 'PUT':
134 challenge_phase_split = context.get('challenge_phase_split')
135 kwargs['data']['challenge_phase_split'] = challenge_phase_split.pk
136
137 submission = context.get('submission').pk
138 kwargs['data']['submission'] = submission
139
140 kwargs['data']['leaderboard'] = challenge_phase_split.leaderboard.pk
141
142 super(CreateLeaderboardDataSerializer, self).__init__(*args, **kwargs)
143
144 class Meta:
145 model = LeaderboardData
146 fields = ('challenge_phase_split', 'submission', 'result', 'leaderboard')
147
[end of apps/jobs/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/jobs/serializers.py b/apps/jobs/serializers.py
--- a/apps/jobs/serializers.py
+++ b/apps/jobs/serializers.py
@@ -51,7 +51,6 @@
class Meta:
model = LeaderboardData
- fields = "__all__"
fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')
def get_participant_team_name(self, obj):
|
{"golden_diff": "diff --git a/apps/jobs/serializers.py b/apps/jobs/serializers.py\n--- a/apps/jobs/serializers.py\n+++ b/apps/jobs/serializers.py\n@@ -51,7 +51,6 @@\n \n class Meta:\n model = LeaderboardData\n- fields = \"__all__\"\n fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')\n \n def get_participant_team_name(self, obj):\n", "issue": "Incorrect Fields in Jobs serializer\n*Observed code:* [here](https://github.com/Cloud-CV/EvalAI/blob/master/apps/jobs/serializers.py/#L54)\r\n```\r\nclass Meta:\r\n model = LeaderboardData\r\n fields = \"__all__\"\r\n fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')\r\n```\r\n*Expected Code:*\r\n```\r\nclass Meta:\r\n model = LeaderboardData\r\n fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')\r\n```\n", "before_files": [{"content": "from django.contrib.auth.models import User\n\nfrom rest_framework import serializers\n\nfrom challenges.models import LeaderboardData\nfrom participants.models import Participant, ParticipantTeam\n\nfrom .models import Submission\n\n\nclass SubmissionSerializer(serializers.ModelSerializer):\n\n participant_team_name = serializers.SerializerMethodField()\n execution_time = serializers.SerializerMethodField()\n\n def __init__(self, *args, **kwargs):\n context = kwargs.get('context')\n if context and context.get('request').method == 'POST':\n created_by = context.get('request').user\n kwargs['data']['created_by'] = created_by.pk\n\n participant_team = context.get('participant_team').pk\n kwargs['data']['participant_team'] = participant_team\n\n challenge_phase = context.get('challenge_phase').pk\n kwargs['data']['challenge_phase'] = challenge_phase\n\n super(SubmissionSerializer, self).__init__(*args, **kwargs)\n\n class Meta:\n model = Submission\n fields = ('id', 'participant_team', 'participant_team_name', 'execution_time', 'challenge_phase',\n 'created_by', 'status', 'input_file', 'stdout_file', 'stderr_file', 'submitted_at',\n 'method_name', 'method_description', 'project_url', 'publication_url', 'is_public',\n 'submission_result_file', 'when_made_public',)\n\n def get_participant_team_name(self, obj):\n return obj.participant_team.team_name\n\n def get_execution_time(self, obj):\n return obj.execution_time\n\n\nclass LeaderboardDataSerializer(serializers.ModelSerializer):\n\n participant_team_name = serializers.SerializerMethodField()\n leaderboard_schema = serializers.SerializerMethodField()\n\n def __init__(self, *args, **kwargs):\n super(LeaderboardDataSerializer, self).__init__(*args, **kwargs)\n\n class Meta:\n model = LeaderboardData\n fields = \"__all__\"\n fields = ('id', 'participant_team_name', 'challenge_phase_split', 'leaderboard_schema', 'result')\n\n def get_participant_team_name(self, obj):\n return obj.submission.participant_team.team_name\n\n def get_leaderboard_schema(self, obj):\n return obj.leaderboard.schema\n\n\nclass ChallengeSubmissionManagementSerializer(serializers.ModelSerializer):\n\n participant_team = serializers.SerializerMethodField()\n challenge_phase = serializers.SerializerMethodField()\n created_by = serializers.SerializerMethodField()\n participant_team_members_email_ids = serializers.SerializerMethodField()\n created_at = serializers.SerializerMethodField()\n participant_team_members = serializers.SerializerMethodField()\n\n class Meta:\n model = Submission\n fields = ('id', 'participant_team', 'challenge_phase', 'created_by', 'status', 'is_public',\n 'submission_number', 'submitted_at', 'execution_time', 'input_file', 'stdout_file',\n 'stderr_file', 'submission_result_file', 'submission_metadata_file',\n 'participant_team_members_email_ids', 'created_at', 'method_name', 'participant_team_members',)\n\n def get_participant_team(self, obj):\n return obj.participant_team.team_name\n\n def get_challenge_phase(self, obj):\n return obj.challenge_phase.name\n\n def get_created_by(self, obj):\n return obj.created_by.username\n\n def get_participant_team_members_email_ids(self, obj):\n try:\n participant_team = ParticipantTeam.objects.get(team_name=obj.participant_team.team_name)\n except ParticipantTeam.DoesNotExist:\n return 'Participant team does not exist'\n\n participant_ids = Participant.objects.filter(team=participant_team).values_list('user_id', flat=True)\n return list(User.objects.filter(id__in=participant_ids).values_list('email', flat=True))\n\n def get_created_at(self, obj):\n return obj.created_at\n\n def get_participant_team_members(self, obj):\n try:\n participant_team = ParticipantTeam.objects.get(team_name=obj.participant_team.team_name)\n except ParticipantTeam.DoesNotExist:\n return 'Participant team does not exist'\n\n participant_ids = Participant.objects.filter(team=participant_team).values_list('user_id', flat=True)\n return list(User.objects.filter(id__in=participant_ids).values('username', 'email'))\n\n\nclass SubmissionCount(object):\n def __init__(self, submission_count):\n self.submission_count = submission_count\n\n\nclass SubmissionCountSerializer(serializers.Serializer):\n submission_count = serializers.IntegerField()\n\n\nclass LastSubmissionDateTime(object):\n def __init__(self, last_submission_datetime):\n self.last_submission_datetime = last_submission_datetime\n\n\nclass LastSubmissionDateTimeSerializer(serializers.Serializer):\n last_submission_datetime = serializers.DateTimeField()\n\n\nclass CreateLeaderboardDataSerializer(serializers.ModelSerializer):\n\n def __init__(self, *args, **kwargs):\n context = kwargs.get('context')\n if context and context.get('request').method == 'PUT':\n challenge_phase_split = context.get('challenge_phase_split')\n kwargs['data']['challenge_phase_split'] = challenge_phase_split.pk\n\n submission = context.get('submission').pk\n kwargs['data']['submission'] = submission\n\n kwargs['data']['leaderboard'] = challenge_phase_split.leaderboard.pk\n\n super(CreateLeaderboardDataSerializer, self).__init__(*args, **kwargs)\n\n class Meta:\n model = LeaderboardData\n fields = ('challenge_phase_split', 'submission', 'result', 'leaderboard')\n", "path": "apps/jobs/serializers.py"}]}
| 2,129 | 108 |
gh_patches_debug_10611
|
rasdani/github-patches
|
git_diff
|
pretix__pretix-862
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add event name to admin notification
When recieving an admin notification, e.g. when an order is placed, only the order number is displayed in the mail. It would be great to also see the event, right now you have to look it up in the "Detail" button url.
I thought this could be an easy task by adding `n.add_attribute(_('Event'), order.event.name)` to `src/pretix/base/notifications.py`, but unfortunately I was not successful.
Thanks for your work!
</issue>
<code>
[start of src/pretix/base/notifications.py]
1 import logging
2 from collections import OrderedDict, namedtuple
3
4 from django.dispatch import receiver
5 from django.utils.formats import date_format
6 from django.utils.translation import ugettext_lazy as _
7
8 from pretix.base.models import Event, LogEntry
9 from pretix.base.signals import register_notification_types
10 from pretix.base.templatetags.money import money_filter
11 from pretix.helpers.urls import build_absolute_uri
12
13 logger = logging.getLogger(__name__)
14 _ALL_TYPES = None
15
16
17 NotificationAttribute = namedtuple('NotificationAttribute', ('title', 'value'))
18 NotificationAction = namedtuple('NotificationAction', ('label', 'url'))
19
20
21 class Notification:
22 """
23 Represents a notification that is sent/shown to a user. A notification consists of:
24
25 * one ``event`` reference
26 * one ``title`` text that is shown e.g. in the email subject or in a headline
27 * optionally one ``detail`` text that may or may not be shown depending on the notification method
28 * optionally one ``url`` that should be absolute and point to the context of an notification (e.g. an order)
29 * optionally a number of attributes consisting of a title and a value that can be used to add additional details
30 to the notification (e.g. "Customer: ABC")
31 * optionally a number of actions that may or may not be shown as buttons depending on the notification method,
32 each consisting of a button label and an absolute URL to point to.
33 """
34
35 def __init__(self, event: Event, title: str, detail: str=None, url: str=None):
36 self.title = title
37 self.event = event
38 self.detail = detail
39 self.url = url
40 self.attributes = []
41 self.actions = []
42
43 def add_action(self, label, url):
44 """
45 Add an action to the notification, defined by a label and an url. An example could be a label of "View order"
46 and an url linking to the order detail page.
47 """
48 self.actions.append(NotificationAction(label, url))
49
50 def add_attribute(self, title, value):
51 """
52 Add an attribute to the notification, defined by a title and a value. An example could be a title of
53 "Date" and a value of "2017-12-14".
54 """
55 self.attributes.append(NotificationAttribute(title, value))
56
57
58 class NotificationType:
59 def __init__(self, event: Event = None):
60 self.event = event
61
62 def __repr__(self):
63 return '<NotificationType: {}>'.format(self.action_type)
64
65 @property
66 def action_type(self) -> str:
67 """
68 The action_type string that this notification handles, for example
69 ``"pretix.event.order.paid"``. Only one notification type should be registered
70 per action type.
71 """
72 raise NotImplementedError() # NOQA
73
74 @property
75 def verbose_name(self) -> str:
76 """
77 A human-readable name of this notification type.
78 """
79 raise NotImplementedError() # NOQA
80
81 @property
82 def required_permission(self) -> str:
83 """
84 The permission a user needs to hold for the related event to receive this
85 notification.
86 """
87 raise NotImplementedError() # NOQA
88
89 def build_notification(self, logentry: LogEntry) -> Notification:
90 """
91 This is the main function that you should override. It is supposed to turn a log entry
92 object into a notification object that can then be rendered e.g. into an email.
93 """
94 return Notification(
95 logentry.event,
96 logentry.display()
97 )
98
99
100 def get_all_notification_types(event=None):
101 global _ALL_TYPES
102
103 if event is None and _ALL_TYPES:
104 return _ALL_TYPES
105
106 types = OrderedDict()
107 for recv, ret in register_notification_types.send(event):
108 if isinstance(ret, (list, tuple)):
109 for r in ret:
110 types[r.action_type] = r
111 else:
112 types[ret.action_type] = ret
113 if event is None:
114 _ALL_TYPES = types
115 return types
116
117
118 class ActionRequiredNotificationType(NotificationType):
119 required_permission = "can_change_orders"
120 action_type = "pretix.event.action_required"
121 verbose_name = _("Administrative action required")
122
123 def build_notification(self, logentry: LogEntry):
124 control_url = build_absolute_uri(
125 'control:event.requiredactions',
126 kwargs={
127 'organizer': logentry.event.organizer.slug,
128 'event': logentry.event.slug,
129 }
130 )
131
132 n = Notification(
133 event=logentry.event,
134 title=_('Administrative action required'),
135 detail=_('Something happened in your event that our system cannot handle automatically, e.g. an external '
136 'refund. You need to resolve it manually or choose to ignore it, depending on the issue at hand.'),
137 url=control_url
138 )
139 n.add_action(_('View all unresolved problems'), control_url)
140 return n
141
142
143 class ParametrizedOrderNotificationType(NotificationType):
144 required_permission = "can_view_orders"
145
146 def __init__(self, event, action_type, verbose_name, title):
147 self._action_type = action_type
148 self._verbose_name = verbose_name
149 self._title = title
150 super().__init__(event)
151
152 @property
153 def action_type(self):
154 return self._action_type
155
156 @property
157 def verbose_name(self):
158 return self._verbose_name
159
160 def build_notification(self, logentry: LogEntry):
161 order = logentry.content_object
162
163 order_url = build_absolute_uri(
164 'control:event.order',
165 kwargs={
166 'organizer': logentry.event.organizer.slug,
167 'event': logentry.event.slug,
168 'code': order.code
169 }
170 )
171
172 n = Notification(
173 event=logentry.event,
174 title=self._title.format(order=order, event=logentry.event),
175 url=order_url
176 )
177 n.add_attribute(_('Order code'), order.code)
178 n.add_attribute(_('Order total'), money_filter(order.total, logentry.event.currency))
179 n.add_attribute(_('Order date'), date_format(order.datetime, 'SHORT_DATETIME_FORMAT'))
180 n.add_attribute(_('Order status'), order.get_status_display())
181 n.add_attribute(_('Order positions'), str(order.positions.count()))
182 n.add_action(_('View order details'), order_url)
183 return n
184
185
186 @receiver(register_notification_types, dispatch_uid="base_register_default_notification_types")
187 def register_default_notification_types(sender, **kwargs):
188 return (
189 ParametrizedOrderNotificationType(
190 sender,
191 'pretix.event.order.placed',
192 _('New order placed'),
193 _('A new order has been placed: {order.code}'),
194 ),
195 ParametrizedOrderNotificationType(
196 sender,
197 'pretix.event.order.paid',
198 _('Order marked as paid'),
199 _('Order {order.code} has been marked as paid.')
200 ),
201 ParametrizedOrderNotificationType(
202 sender,
203 'pretix.event.order.canceled',
204 _('Order canceled'),
205 _('Order {order.code} has been canceled.')
206 ),
207 ParametrizedOrderNotificationType(
208 sender,
209 'pretix.event.order.expired',
210 _('Order expired'),
211 _('Order {order.code} has been marked as expired.'),
212 ),
213 ParametrizedOrderNotificationType(
214 sender,
215 'pretix.event.order.modified',
216 _('Order information changed'),
217 _('The ticket information of order {order.code} has been changed.')
218 ),
219 ParametrizedOrderNotificationType(
220 sender,
221 'pretix.event.order.contact.changed',
222 _('Order contact address changed'),
223 _('The contact address of order {order.code} has been changed.')
224 ),
225 ParametrizedOrderNotificationType(
226 sender,
227 'pretix.event.order.changed',
228 _('Order changed'),
229 _('Order {order.code} has been changed.')
230 ),
231 ParametrizedOrderNotificationType(
232 sender,
233 'pretix.event.order.refunded',
234 _('Order refunded'),
235 _('Order {order.code} has been refunded.')
236 ),
237 ActionRequiredNotificationType(
238 sender,
239 )
240 )
241
[end of src/pretix/base/notifications.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pretix/base/notifications.py b/src/pretix/base/notifications.py
--- a/src/pretix/base/notifications.py
+++ b/src/pretix/base/notifications.py
@@ -174,6 +174,7 @@
title=self._title.format(order=order, event=logentry.event),
url=order_url
)
+ n.add_attribute(_('Event'), order.event.name)
n.add_attribute(_('Order code'), order.code)
n.add_attribute(_('Order total'), money_filter(order.total, logentry.event.currency))
n.add_attribute(_('Order date'), date_format(order.datetime, 'SHORT_DATETIME_FORMAT'))
|
{"golden_diff": "diff --git a/src/pretix/base/notifications.py b/src/pretix/base/notifications.py\n--- a/src/pretix/base/notifications.py\n+++ b/src/pretix/base/notifications.py\n@@ -174,6 +174,7 @@\n title=self._title.format(order=order, event=logentry.event),\n url=order_url\n )\n+ n.add_attribute(_('Event'), order.event.name)\n n.add_attribute(_('Order code'), order.code)\n n.add_attribute(_('Order total'), money_filter(order.total, logentry.event.currency))\n n.add_attribute(_('Order date'), date_format(order.datetime, 'SHORT_DATETIME_FORMAT'))\n", "issue": "Add event name to admin notification\nWhen recieving an admin notification, e.g. when an order is placed, only the order number is displayed in the mail. It would be great to also see the event, right now you have to look it up in the \"Detail\" button url.\r\n\r\nI thought this could be an easy task by adding `n.add_attribute(_('Event'), order.event.name)` to `src/pretix/base/notifications.py`, but unfortunately I was not successful.\r\n\r\nThanks for your work!\n", "before_files": [{"content": "import logging\nfrom collections import OrderedDict, namedtuple\n\nfrom django.dispatch import receiver\nfrom django.utils.formats import date_format\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom pretix.base.models import Event, LogEntry\nfrom pretix.base.signals import register_notification_types\nfrom pretix.base.templatetags.money import money_filter\nfrom pretix.helpers.urls import build_absolute_uri\n\nlogger = logging.getLogger(__name__)\n_ALL_TYPES = None\n\n\nNotificationAttribute = namedtuple('NotificationAttribute', ('title', 'value'))\nNotificationAction = namedtuple('NotificationAction', ('label', 'url'))\n\n\nclass Notification:\n \"\"\"\n Represents a notification that is sent/shown to a user. A notification consists of:\n\n * one ``event`` reference\n * one ``title`` text that is shown e.g. in the email subject or in a headline\n * optionally one ``detail`` text that may or may not be shown depending on the notification method\n * optionally one ``url`` that should be absolute and point to the context of an notification (e.g. an order)\n * optionally a number of attributes consisting of a title and a value that can be used to add additional details\n to the notification (e.g. \"Customer: ABC\")\n * optionally a number of actions that may or may not be shown as buttons depending on the notification method,\n each consisting of a button label and an absolute URL to point to.\n \"\"\"\n\n def __init__(self, event: Event, title: str, detail: str=None, url: str=None):\n self.title = title\n self.event = event\n self.detail = detail\n self.url = url\n self.attributes = []\n self.actions = []\n\n def add_action(self, label, url):\n \"\"\"\n Add an action to the notification, defined by a label and an url. An example could be a label of \"View order\"\n and an url linking to the order detail page.\n \"\"\"\n self.actions.append(NotificationAction(label, url))\n\n def add_attribute(self, title, value):\n \"\"\"\n Add an attribute to the notification, defined by a title and a value. An example could be a title of\n \"Date\" and a value of \"2017-12-14\".\n \"\"\"\n self.attributes.append(NotificationAttribute(title, value))\n\n\nclass NotificationType:\n def __init__(self, event: Event = None):\n self.event = event\n\n def __repr__(self):\n return '<NotificationType: {}>'.format(self.action_type)\n\n @property\n def action_type(self) -> str:\n \"\"\"\n The action_type string that this notification handles, for example\n ``\"pretix.event.order.paid\"``. Only one notification type should be registered\n per action type.\n \"\"\"\n raise NotImplementedError() # NOQA\n\n @property\n def verbose_name(self) -> str:\n \"\"\"\n A human-readable name of this notification type.\n \"\"\"\n raise NotImplementedError() # NOQA\n\n @property\n def required_permission(self) -> str:\n \"\"\"\n The permission a user needs to hold for the related event to receive this\n notification.\n \"\"\"\n raise NotImplementedError() # NOQA\n\n def build_notification(self, logentry: LogEntry) -> Notification:\n \"\"\"\n This is the main function that you should override. It is supposed to turn a log entry\n object into a notification object that can then be rendered e.g. into an email.\n \"\"\"\n return Notification(\n logentry.event,\n logentry.display()\n )\n\n\ndef get_all_notification_types(event=None):\n global _ALL_TYPES\n\n if event is None and _ALL_TYPES:\n return _ALL_TYPES\n\n types = OrderedDict()\n for recv, ret in register_notification_types.send(event):\n if isinstance(ret, (list, tuple)):\n for r in ret:\n types[r.action_type] = r\n else:\n types[ret.action_type] = ret\n if event is None:\n _ALL_TYPES = types\n return types\n\n\nclass ActionRequiredNotificationType(NotificationType):\n required_permission = \"can_change_orders\"\n action_type = \"pretix.event.action_required\"\n verbose_name = _(\"Administrative action required\")\n\n def build_notification(self, logentry: LogEntry):\n control_url = build_absolute_uri(\n 'control:event.requiredactions',\n kwargs={\n 'organizer': logentry.event.organizer.slug,\n 'event': logentry.event.slug,\n }\n )\n\n n = Notification(\n event=logentry.event,\n title=_('Administrative action required'),\n detail=_('Something happened in your event that our system cannot handle automatically, e.g. an external '\n 'refund. You need to resolve it manually or choose to ignore it, depending on the issue at hand.'),\n url=control_url\n )\n n.add_action(_('View all unresolved problems'), control_url)\n return n\n\n\nclass ParametrizedOrderNotificationType(NotificationType):\n required_permission = \"can_view_orders\"\n\n def __init__(self, event, action_type, verbose_name, title):\n self._action_type = action_type\n self._verbose_name = verbose_name\n self._title = title\n super().__init__(event)\n\n @property\n def action_type(self):\n return self._action_type\n\n @property\n def verbose_name(self):\n return self._verbose_name\n\n def build_notification(self, logentry: LogEntry):\n order = logentry.content_object\n\n order_url = build_absolute_uri(\n 'control:event.order',\n kwargs={\n 'organizer': logentry.event.organizer.slug,\n 'event': logentry.event.slug,\n 'code': order.code\n }\n )\n\n n = Notification(\n event=logentry.event,\n title=self._title.format(order=order, event=logentry.event),\n url=order_url\n )\n n.add_attribute(_('Order code'), order.code)\n n.add_attribute(_('Order total'), money_filter(order.total, logentry.event.currency))\n n.add_attribute(_('Order date'), date_format(order.datetime, 'SHORT_DATETIME_FORMAT'))\n n.add_attribute(_('Order status'), order.get_status_display())\n n.add_attribute(_('Order positions'), str(order.positions.count()))\n n.add_action(_('View order details'), order_url)\n return n\n\n\n@receiver(register_notification_types, dispatch_uid=\"base_register_default_notification_types\")\ndef register_default_notification_types(sender, **kwargs):\n return (\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.placed',\n _('New order placed'),\n _('A new order has been placed: {order.code}'),\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.paid',\n _('Order marked as paid'),\n _('Order {order.code} has been marked as paid.')\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.canceled',\n _('Order canceled'),\n _('Order {order.code} has been canceled.')\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.expired',\n _('Order expired'),\n _('Order {order.code} has been marked as expired.'),\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.modified',\n _('Order information changed'),\n _('The ticket information of order {order.code} has been changed.')\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.contact.changed',\n _('Order contact address changed'),\n _('The contact address of order {order.code} has been changed.')\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.changed',\n _('Order changed'),\n _('Order {order.code} has been changed.')\n ),\n ParametrizedOrderNotificationType(\n sender,\n 'pretix.event.order.refunded',\n _('Order refunded'),\n _('Order {order.code} has been refunded.')\n ),\n ActionRequiredNotificationType(\n sender,\n )\n )\n", "path": "src/pretix/base/notifications.py"}]}
| 2,983 | 141 |
gh_patches_debug_12061
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-3033
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ansible Reports Twilio Failure Yet SMS Sent Successfullly
<!--- Verify first that your issue/request is not already reported in GitHub -->
##### ISSUE TYPE
<!--- Pick one below and delete the rest: -->
- Bug Report
##### COMPONENT NAME
<!--- Name of the plugin/module/task -->
Twilio
##### ANSIBLE VERSION
<!--- Paste verbatim output from “ansible --version” between quotes below -->
```
ansible 2.1.1.0
config file = /home/douglas/repos/ansible/ansible.cfg
configured module search path = Default w/o overrides
```
##### CONFIGURATION
<!---
Mention any settings you have changed/added/removed in ansible.cfg
(or using the ANSIBLE_* environment variables).
-->
```
Pipelining and threads but nothing else
```
##### OS / ENVIRONMENT
<!---
Mention the OS you are running Ansible from, and the OS you are
managing, or say “N/A” for anything that is not platform-specific.
-->
```
Linux Mint
```
##### SUMMARY
<!--- Explain the problem briefly -->
```
TASK [accounts : send sms challenge] *******************************************
fatal: [pascal -> localhost]: FAILED! => {"changed": false, "failed": true, "msg": "unable to send message to +15163205079"}
...ignoring
Yet Twilio console shows SMS delivered while recipient confirms SMS
```
##### STEPS TO REPRODUCE
<!---
For bugs, show exactly how to reproduce the problem.
For new features, show how the feature would be used.
-->
<!--- Paste example playbooks or commands between quotes below -->
```
ansible-playbook accounts.yml "-e hosts=server -e csms=[] -e number=+blah -e user=blah" -t csms --sudo -K --ask-vault-pass
cat accounts.yml
---
- hosts: "{{ hosts }}"
roles:
- accounts
gather_facts: True
cat roles/accounts/tasks/main.yml
- include: create_user.yml
when: create is defined
- include: remove_user.yml
when: remove is defined
- include: xfs.yml
when: ansible_hostname == "blah" or "blah"
- include: lab_email.yml
when: lab is defined
- include: challenge.yml
when: csms is defined
cat roles/accounts/tasks/challenge.yml
- name: send sms challenge
tags: csms
twilio:
msg: "{{ challenge }}"
account_sid: "SID"
auth_token: "TOKEN"
from_number: "+BLAH"
to_number: "{{ number }}"
delegate_to: localhost
ignore_errors: True
```
<!--- You can also paste gist.github.com links for larger files -->
##### EXPECTED RESULTS
<!--- What did you expect to happen when running the steps above? -->
SMS works without reported error
##### ACTUAL RESULTS
<!--- What actually happened? If possible run with high verbosity (-vvvv) -->
SMS works but module reports error
<!--- Paste verbatim command output between quotes below -->
```
ansible-playbook accounts.yml "-e hosts=host -e csms=[] -e number=+blah -e user=blah" -t csms --sudo -K --ask-vault-pass -vvv
Using /home/user/repos/ansible/ansible.cfg as config file
SUDO password:
Vault password:
PLAYBOOK: accounts.yml *********************************************************
1 plays in accounts.yml
PLAY [pascal] ******************************************************************
TASK [setup] *******************************************************************
<pascal> ESTABLISH SSH CONNECTION FOR USER: None
<pascal> SSH: EXEC ssh -C -q -o ControlMaster=auto -o ControlPersist=60s -o Port=22 -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o ConnectTimeout=20 -o ControlPath=/home/user/.ansible/cp/ansible-ssh-%h-%p-%r host '/bin/sh -c '"'"'sudo -H -S -p "[sudo via ansible, key=dovdppgsmmkpysizwmmmanqpnsnbhkbn] password: " -u root /bin/sh -c '"'"'"'"'"'"'"'"'echo BECOME-SUCCESS-dovdppgsmmkpysizwmmmanqpnsnbhkbn; LANG=C LC_ALL=C LC_MESSAGES=C /usr/bin/python'"'"'"'"'"'"'"'"' && sleep 0'"'"''
ok: [pascal]
TASK [accounts : send sms challenge] *******************************************
task path: /home/user/repos/ansible/playbooks/roles/accounts/tasks/challenge.yml:11
<localhost> ESTABLISH LOCAL CONNECTION FOR USER: user
<localhost> EXEC /bin/sh -c 'sudo -H -S -p "[sudo via ansible, key=pgyfxtpxffqiposwtecseosepacqessa] password: " -u root /bin/sh -c '"'"'echo BECOME-SUCCESS-pgyfxtpxffqiposwtecseosepacqessa; LANG=C LC_ALL=C LC_MESSAGES=C /usr/bin/python'"'"' && sleep 0'
fatal: [user -> localhost]: FAILED! => {"changed": false, "failed": true, "invocation": {"module_args": {"account_sid": "blah", "auth_token": "VALUE_SPECIFIED_IN_NO_LOG_PARAMETER", "from_number": "+blah", "media_url": null, "msg": "challenge", "to_number": "+blahblah", "url_password": "VALUE_SPECIFIED_IN_NO_LOG_PARAMETER", "url_username": "blah"}, "module_name": "twilio"}, "msg": "unable to send message to +blah"}
...ignoring
PLAY RECAP *********************************************************************
host : ok=2 changed=0 unreachable=0 failed=0
```
</issue>
<code>
[start of notification/twilio.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2015, Matt Makai <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 DOCUMENTATION = '''
22 ---
23 version_added: "1.6"
24 module: twilio
25 short_description: Sends a text message to a mobile phone through Twilio.
26 description:
27 - Sends a text message to a phone number through the Twilio messaging API.
28 notes:
29 - This module is non-idempotent because it sends an email through the
30 external API. It is idempotent only in the case that the module fails.
31 - Like the other notification modules, this one requires an external
32 dependency to work. In this case, you'll need a Twilio account with
33 a purchased or verified phone number to send the text message.
34 options:
35 account_sid:
36 description:
37 user's Twilio account token found on the account page
38 required: true
39 auth_token:
40 description: user's Twilio authentication token
41 required: true
42 msg:
43 description:
44 the body of the text message
45 required: true
46 to_number:
47 description:
48 one or more phone numbers to send the text message to,
49 format +15551112222
50 required: true
51 from_number:
52 description:
53 the Twilio number to send the text message from, format +15551112222
54 required: true
55 media_url:
56 description:
57 a URL with a picture, video or sound clip to send with an MMS
58 (multimedia message) instead of a plain SMS
59 required: false
60
61 author: "Matt Makai (@makaimc)"
62 '''
63
64 EXAMPLES = '''
65 # send an SMS about the build status to (555) 303 5681
66 # note: replace account_sid and auth_token values with your credentials
67 # and you have to have the 'from_number' on your Twilio account
68 - twilio:
69 msg: "All servers with webserver role are now configured."
70 account_sid: "ACXXXXXXXXXXXXXXXXX"
71 auth_token: "ACXXXXXXXXXXXXXXXXX"
72 from_number: "+15552014545"
73 to_number: "+15553035681"
74 delegate_to: localhost
75
76 # send an SMS to multiple phone numbers about the deployment
77 # note: replace account_sid and auth_token values with your credentials
78 # and you have to have the 'from_number' on your Twilio account
79 - twilio:
80 msg: "This server's configuration is now complete."
81 account_sid: "ACXXXXXXXXXXXXXXXXX"
82 auth_token: "ACXXXXXXXXXXXXXXXXX"
83 from_number: "+15553258899"
84 to_number:
85 - "+15551113232"
86 - "+12025551235"
87 - "+19735559010"
88 delegate_to: localhost
89
90 # send an MMS to a single recipient with an update on the deployment
91 # and an image of the results
92 # note: replace account_sid and auth_token values with your credentials
93 # and you have to have the 'from_number' on your Twilio account
94 - twilio:
95 msg: "Deployment complete!"
96 account_sid: "ACXXXXXXXXXXXXXXXXX"
97 auth_token: "ACXXXXXXXXXXXXXXXXX"
98 from_number: "+15552014545"
99 to_number: "+15553035681"
100 media_url: "https://demo.twilio.com/logo.png"
101 delegate_to: localhost
102 '''
103
104 # =======================================
105 # twilio module support methods
106 #
107 import urllib
108
109
110 def post_twilio_api(module, account_sid, auth_token, msg, from_number,
111 to_number, media_url=None):
112 URI = "https://api.twilio.com/2010-04-01/Accounts/%s/Messages.json" \
113 % (account_sid,)
114 AGENT = "Ansible"
115
116 data = {'From':from_number, 'To':to_number, 'Body':msg}
117 if media_url:
118 data['MediaUrl'] = media_url
119 encoded_data = urllib.urlencode(data)
120
121 headers = {'User-Agent': AGENT,
122 'Content-type': 'application/x-www-form-urlencoded',
123 'Accept': 'application/json',
124 }
125
126 # Hack module params to have the Basic auth params that fetch_url expects
127 module.params['url_username'] = account_sid.replace('\n', '')
128 module.params['url_password'] = auth_token.replace('\n', '')
129
130 return fetch_url(module, URI, data=encoded_data, headers=headers)
131
132
133 # =======================================
134 # Main
135 #
136
137 def main():
138
139 module = AnsibleModule(
140 argument_spec=dict(
141 account_sid=dict(required=True),
142 auth_token=dict(required=True, no_log=True),
143 msg=dict(required=True),
144 from_number=dict(required=True),
145 to_number=dict(required=True),
146 media_url=dict(default=None, required=False),
147 ),
148 supports_check_mode=True
149 )
150
151 account_sid = module.params['account_sid']
152 auth_token = module.params['auth_token']
153 msg = module.params['msg']
154 from_number = module.params['from_number']
155 to_number = module.params['to_number']
156 media_url = module.params['media_url']
157
158 if not isinstance(to_number, list):
159 to_number = [to_number]
160
161 for number in to_number:
162 r, info = post_twilio_api(module, account_sid, auth_token, msg,
163 from_number, number, media_url)
164 if info['status'] != 200:
165 module.fail_json(msg="unable to send message to %s" % number)
166
167 module.exit_json(msg=msg, changed=False)
168
169 # import module snippets
170 from ansible.module_utils.basic import *
171 from ansible.module_utils.urls import *
172 if __name__ == '__main__':
173 main()
174
[end of notification/twilio.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/notification/twilio.py b/notification/twilio.py
--- a/notification/twilio.py
+++ b/notification/twilio.py
@@ -161,8 +161,12 @@
for number in to_number:
r, info = post_twilio_api(module, account_sid, auth_token, msg,
from_number, number, media_url)
- if info['status'] != 200:
- module.fail_json(msg="unable to send message to %s" % number)
+ if info['status'] not in [200, 201]:
+ body_message = "unknown error"
+ if 'body' in info:
+ body = json.loads(info['body'])
+ body_message = body['message']
+ module.fail_json(msg="unable to send message to %s: %s" % (number, body_message))
module.exit_json(msg=msg, changed=False)
|
{"golden_diff": "diff --git a/notification/twilio.py b/notification/twilio.py\n--- a/notification/twilio.py\n+++ b/notification/twilio.py\n@@ -161,8 +161,12 @@\n for number in to_number:\n r, info = post_twilio_api(module, account_sid, auth_token, msg,\n from_number, number, media_url)\n- if info['status'] != 200:\n- module.fail_json(msg=\"unable to send message to %s\" % number)\n+ if info['status'] not in [200, 201]:\n+ body_message = \"unknown error\"\n+ if 'body' in info:\n+ body = json.loads(info['body'])\n+ body_message = body['message']\n+ module.fail_json(msg=\"unable to send message to %s: %s\" % (number, body_message))\n \n module.exit_json(msg=msg, changed=False)\n", "issue": "Ansible Reports Twilio Failure Yet SMS Sent Successfullly\n<!--- Verify first that your issue/request is not already reported in GitHub -->\n##### ISSUE TYPE\n\n<!--- Pick one below and delete the rest: -->\n- Bug Report\n##### COMPONENT NAME\n\n<!--- Name of the plugin/module/task -->\n\nTwilio\n##### ANSIBLE VERSION\n\n<!--- Paste verbatim output from \u201cansible --version\u201d between quotes below -->\n\n```\nansible 2.1.1.0\n config file = /home/douglas/repos/ansible/ansible.cfg\n configured module search path = Default w/o overrides\n```\n##### CONFIGURATION\n\n<!---\nMention any settings you have changed/added/removed in ansible.cfg\n(or using the ANSIBLE_* environment variables).\n-->\n\n```\nPipelining and threads but nothing else\n\n```\n##### OS / ENVIRONMENT\n\n<!---\nMention the OS you are running Ansible from, and the OS you are\nmanaging, or say \u201cN/A\u201d for anything that is not platform-specific.\n-->\n\n```\nLinux Mint\n\n```\n##### SUMMARY\n\n<!--- Explain the problem briefly -->\n\n```\n\nTASK [accounts : send sms challenge] *******************************************\nfatal: [pascal -> localhost]: FAILED! => {\"changed\": false, \"failed\": true, \"msg\": \"unable to send message to +15163205079\"}\n...ignoring\n\nYet Twilio console shows SMS delivered while recipient confirms SMS \n\n```\n##### STEPS TO REPRODUCE\n\n<!---\nFor bugs, show exactly how to reproduce the problem.\nFor new features, show how the feature would be used.\n-->\n\n<!--- Paste example playbooks or commands between quotes below -->\n\n```\nansible-playbook accounts.yml \"-e hosts=server -e csms=[] -e number=+blah -e user=blah\" -t csms --sudo -K --ask-vault-pass\n\ncat accounts.yml \n\n---\n- hosts: \"{{ hosts }}\"\n roles: \n - accounts\n gather_facts: True\n\n\ncat roles/accounts/tasks/main.yml \n\n- include: create_user.yml\n when: create is defined\n\n- include: remove_user.yml\n when: remove is defined\n\n- include: xfs.yml\n when: ansible_hostname == \"blah\" or \"blah\"\n\n- include: lab_email.yml\n when: lab is defined\n\n- include: challenge.yml\n when: csms is defined\n\ncat roles/accounts/tasks/challenge.yml \n\n- name: send sms challenge\n tags: csms \n twilio:\n msg: \"{{ challenge }}\"\n account_sid: \"SID\"\n auth_token: \"TOKEN\"\n from_number: \"+BLAH\"\n to_number: \"{{ number }}\"\n delegate_to: localhost \n ignore_errors: True\n\n```\n\n<!--- You can also paste gist.github.com links for larger files -->\n##### EXPECTED RESULTS\n\n<!--- What did you expect to happen when running the steps above? -->\n\nSMS works without reported error\n##### ACTUAL RESULTS\n\n<!--- What actually happened? If possible run with high verbosity (-vvvv) -->\n\nSMS works but module reports error \n\n<!--- Paste verbatim command output between quotes below -->\n\n```\n\n ansible-playbook accounts.yml \"-e hosts=host -e csms=[] -e number=+blah -e user=blah\" -t csms --sudo -K --ask-vault-pass -vvv\nUsing /home/user/repos/ansible/ansible.cfg as config file\nSUDO password: \nVault password: \n\nPLAYBOOK: accounts.yml *********************************************************\n1 plays in accounts.yml\n\nPLAY [pascal] ******************************************************************\n\nTASK [setup] *******************************************************************\n<pascal> ESTABLISH SSH CONNECTION FOR USER: None\n<pascal> SSH: EXEC ssh -C -q -o ControlMaster=auto -o ControlPersist=60s -o Port=22 -o KbdInteractiveAuthentication=no -o PreferredAuthentications=gssapi-with-mic,gssapi-keyex,hostbased,publickey -o PasswordAuthentication=no -o ConnectTimeout=20 -o ControlPath=/home/user/.ansible/cp/ansible-ssh-%h-%p-%r host '/bin/sh -c '\"'\"'sudo -H -S -p \"[sudo via ansible, key=dovdppgsmmkpysizwmmmanqpnsnbhkbn] password: \" -u root /bin/sh -c '\"'\"'\"'\"'\"'\"'\"'\"'echo BECOME-SUCCESS-dovdppgsmmkpysizwmmmanqpnsnbhkbn; LANG=C LC_ALL=C LC_MESSAGES=C /usr/bin/python'\"'\"'\"'\"'\"'\"'\"'\"' && sleep 0'\"'\"''\nok: [pascal]\n\nTASK [accounts : send sms challenge] *******************************************\ntask path: /home/user/repos/ansible/playbooks/roles/accounts/tasks/challenge.yml:11\n<localhost> ESTABLISH LOCAL CONNECTION FOR USER: user\n<localhost> EXEC /bin/sh -c 'sudo -H -S -p \"[sudo via ansible, key=pgyfxtpxffqiposwtecseosepacqessa] password: \" -u root /bin/sh -c '\"'\"'echo BECOME-SUCCESS-pgyfxtpxffqiposwtecseosepacqessa; LANG=C LC_ALL=C LC_MESSAGES=C /usr/bin/python'\"'\"' && sleep 0'\nfatal: [user -> localhost]: FAILED! => {\"changed\": false, \"failed\": true, \"invocation\": {\"module_args\": {\"account_sid\": \"blah\", \"auth_token\": \"VALUE_SPECIFIED_IN_NO_LOG_PARAMETER\", \"from_number\": \"+blah\", \"media_url\": null, \"msg\": \"challenge\", \"to_number\": \"+blahblah\", \"url_password\": \"VALUE_SPECIFIED_IN_NO_LOG_PARAMETER\", \"url_username\": \"blah\"}, \"module_name\": \"twilio\"}, \"msg\": \"unable to send message to +blah\"}\n...ignoring\n\nPLAY RECAP *********************************************************************\nhost : ok=2 changed=0 unreachable=0 failed=0 \n\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2015, Matt Makai <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nversion_added: \"1.6\"\nmodule: twilio\nshort_description: Sends a text message to a mobile phone through Twilio.\ndescription:\n - Sends a text message to a phone number through the Twilio messaging API.\nnotes:\n - This module is non-idempotent because it sends an email through the\n external API. It is idempotent only in the case that the module fails.\n - Like the other notification modules, this one requires an external\n dependency to work. In this case, you'll need a Twilio account with\n a purchased or verified phone number to send the text message.\noptions:\n account_sid:\n description:\n user's Twilio account token found on the account page\n required: true\n auth_token:\n description: user's Twilio authentication token\n required: true\n msg:\n description:\n the body of the text message\n required: true\n to_number:\n description:\n one or more phone numbers to send the text message to,\n format +15551112222\n required: true\n from_number:\n description:\n the Twilio number to send the text message from, format +15551112222\n required: true\n media_url:\n description:\n a URL with a picture, video or sound clip to send with an MMS\n (multimedia message) instead of a plain SMS\n required: false\n\nauthor: \"Matt Makai (@makaimc)\"\n'''\n\nEXAMPLES = '''\n# send an SMS about the build status to (555) 303 5681\n# note: replace account_sid and auth_token values with your credentials\n# and you have to have the 'from_number' on your Twilio account\n- twilio:\n msg: \"All servers with webserver role are now configured.\"\n account_sid: \"ACXXXXXXXXXXXXXXXXX\"\n auth_token: \"ACXXXXXXXXXXXXXXXXX\"\n from_number: \"+15552014545\"\n to_number: \"+15553035681\"\n delegate_to: localhost\n\n# send an SMS to multiple phone numbers about the deployment\n# note: replace account_sid and auth_token values with your credentials\n# and you have to have the 'from_number' on your Twilio account\n- twilio:\n msg: \"This server's configuration is now complete.\"\n account_sid: \"ACXXXXXXXXXXXXXXXXX\"\n auth_token: \"ACXXXXXXXXXXXXXXXXX\"\n from_number: \"+15553258899\"\n to_number:\n - \"+15551113232\"\n - \"+12025551235\"\n - \"+19735559010\"\n delegate_to: localhost\n\n# send an MMS to a single recipient with an update on the deployment\n# and an image of the results\n# note: replace account_sid and auth_token values with your credentials\n# and you have to have the 'from_number' on your Twilio account\n- twilio:\n msg: \"Deployment complete!\"\n account_sid: \"ACXXXXXXXXXXXXXXXXX\"\n auth_token: \"ACXXXXXXXXXXXXXXXXX\"\n from_number: \"+15552014545\"\n to_number: \"+15553035681\"\n media_url: \"https://demo.twilio.com/logo.png\"\n delegate_to: localhost\n'''\n\n# =======================================\n# twilio module support methods\n#\nimport urllib\n\n\ndef post_twilio_api(module, account_sid, auth_token, msg, from_number,\n to_number, media_url=None):\n URI = \"https://api.twilio.com/2010-04-01/Accounts/%s/Messages.json\" \\\n % (account_sid,)\n AGENT = \"Ansible\"\n\n data = {'From':from_number, 'To':to_number, 'Body':msg}\n if media_url:\n data['MediaUrl'] = media_url\n encoded_data = urllib.urlencode(data)\n\n headers = {'User-Agent': AGENT,\n 'Content-type': 'application/x-www-form-urlencoded',\n 'Accept': 'application/json',\n }\n\n # Hack module params to have the Basic auth params that fetch_url expects\n module.params['url_username'] = account_sid.replace('\\n', '')\n module.params['url_password'] = auth_token.replace('\\n', '')\n\n return fetch_url(module, URI, data=encoded_data, headers=headers)\n\n\n# =======================================\n# Main\n#\n\ndef main():\n\n module = AnsibleModule(\n argument_spec=dict(\n account_sid=dict(required=True),\n auth_token=dict(required=True, no_log=True),\n msg=dict(required=True),\n from_number=dict(required=True),\n to_number=dict(required=True),\n media_url=dict(default=None, required=False),\n ),\n supports_check_mode=True\n )\n\n account_sid = module.params['account_sid']\n auth_token = module.params['auth_token']\n msg = module.params['msg']\n from_number = module.params['from_number']\n to_number = module.params['to_number']\n media_url = module.params['media_url']\n\n if not isinstance(to_number, list):\n to_number = [to_number]\n\n for number in to_number:\n r, info = post_twilio_api(module, account_sid, auth_token, msg,\n from_number, number, media_url)\n if info['status'] != 200:\n module.fail_json(msg=\"unable to send message to %s\" % number)\n\n module.exit_json(msg=msg, changed=False)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nfrom ansible.module_utils.urls import *\nif __name__ == '__main__':\n main()\n", "path": "notification/twilio.py"}]}
| 3,664 | 205 |
gh_patches_debug_3977
|
rasdani/github-patches
|
git_diff
|
activeloopai__deeplake-1513
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Pytorch dataloader because of transforms and shuffle=false
## 🐛🐛 Bug Report
### ⚗️ Current Behavior
A clear and concise description of the behavior.
```python
import hub
ds = hub.load("hub://activeloop/mnist-test")
dataloader = ds.pytorch(batch_size=2, num_workers=2, shuffle=False, transform={"images": None, "labels": None})
for (images, labels) in dataloader:
print(images.shape, labels.shape)
break
```
```
Opening dataset in read-only mode as you don't have write permissions.
hub://activeloop/mnist-test loaded successfully.
This dataset can be visualized at https://app.activeloop.ai/activeloop/mnist-test.
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
[<ipython-input-21-22b652d8dbed>](https://localhost:8080/#) in <module>()
4 dataloader = ds.pytorch(batch_size=2, num_workers=2, shuffle=False, transform={"images": None, "labels": None})
5 for (images, labels) in dataloader:
----> 6 print(images.shape, labels.shape)
7 break
AttributeError: 'str' object has no attribute 'shape'
```
but when you remove the argument `transform` from dataloader that script works.
### ⚙️ Environment
- Google colab
</issue>
<code>
[start of hub/integrations/pytorch/common.py]
1 from typing import Callable, Dict, List, Optional
2 from hub.util.iterable_ordered_dict import IterableOrderedDict
3 import numpy as np
4
5
6 def collate_fn(batch):
7 import torch
8
9 elem = batch[0]
10
11 if isinstance(elem, IterableOrderedDict):
12 return IterableOrderedDict(
13 (key, collate_fn([d[key] for d in batch])) for key in elem.keys()
14 )
15
16 if isinstance(elem, np.ndarray) and elem.size > 0 and isinstance(elem[0], str):
17 batch = [it[0] for it in batch]
18 return torch.utils.data._utils.collate.default_collate(batch)
19
20
21 def convert_fn(data):
22 import torch
23
24 if isinstance(data, IterableOrderedDict):
25 return IterableOrderedDict((k, convert_fn(v)) for k, v in data.items())
26 if isinstance(data, np.ndarray) and data.size > 0 and isinstance(data[0], str):
27 data = data[0]
28
29 return torch.utils.data._utils.collate.default_convert(data)
30
31
32 class PytorchTransformFunction:
33 def __init__(
34 self,
35 transform_dict: Optional[Dict[str, Optional[Callable]]] = None,
36 composite_transform: Optional[Callable] = None,
37 tensors: List[str] = None,
38 ) -> None:
39 self.composite_transform = composite_transform
40 self.transform_dict = transform_dict
41 tensors = tensors or []
42
43 if transform_dict is not None:
44 for tensor in transform_dict:
45 if tensor not in tensors:
46 raise ValueError(f"Invalid transform. Tensor {tensor} not found.")
47
48 def __call__(self, data_in: Dict) -> Dict:
49 if self.composite_transform is not None:
50 return self.composite_transform(data_in)
51 elif self.transform_dict is not None:
52 data_out = {}
53 for tensor, fn in self.transform_dict.items():
54 value = data_in[tensor]
55 data_out[tensor] = value if fn is None else fn(value)
56 return data_out
57 return data_in
58
[end of hub/integrations/pytorch/common.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hub/integrations/pytorch/common.py b/hub/integrations/pytorch/common.py
--- a/hub/integrations/pytorch/common.py
+++ b/hub/integrations/pytorch/common.py
@@ -53,5 +53,6 @@
for tensor, fn in self.transform_dict.items():
value = data_in[tensor]
data_out[tensor] = value if fn is None else fn(value)
+ data_out = IterableOrderedDict(data_out)
return data_out
return data_in
|
{"golden_diff": "diff --git a/hub/integrations/pytorch/common.py b/hub/integrations/pytorch/common.py\n--- a/hub/integrations/pytorch/common.py\n+++ b/hub/integrations/pytorch/common.py\n@@ -53,5 +53,6 @@\n for tensor, fn in self.transform_dict.items():\n value = data_in[tensor]\n data_out[tensor] = value if fn is None else fn(value)\n+ data_out = IterableOrderedDict(data_out)\n return data_out\n return data_in\n", "issue": "[BUG] Pytorch dataloader because of transforms and shuffle=false\n## \ud83d\udc1b\ud83d\udc1b Bug Report\r\n\r\n\r\n### \u2697\ufe0f Current Behavior\r\nA clear and concise description of the behavior.\r\n\r\n```python\r\nimport hub\r\nds = hub.load(\"hub://activeloop/mnist-test\")\r\n\r\ndataloader = ds.pytorch(batch_size=2, num_workers=2, shuffle=False, transform={\"images\": None, \"labels\": None})\r\nfor (images, labels) in dataloader:\r\n print(images.shape, labels.shape)\r\n break\r\n```\r\n\r\n```\r\nOpening dataset in read-only mode as you don't have write permissions.\r\nhub://activeloop/mnist-test loaded successfully.\r\nThis dataset can be visualized at https://app.activeloop.ai/activeloop/mnist-test.\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n[<ipython-input-21-22b652d8dbed>](https://localhost:8080/#) in <module>()\r\n 4 dataloader = ds.pytorch(batch_size=2, num_workers=2, shuffle=False, transform={\"images\": None, \"labels\": None})\r\n 5 for (images, labels) in dataloader:\r\n----> 6 print(images.shape, labels.shape)\r\n 7 break\r\n\r\nAttributeError: 'str' object has no attribute 'shape'\r\n```\r\n\r\nbut when you remove the argument `transform` from dataloader that script works.\r\n\r\n### \u2699\ufe0f Environment\r\n\r\n- Google colab\r\n\n", "before_files": [{"content": "from typing import Callable, Dict, List, Optional\nfrom hub.util.iterable_ordered_dict import IterableOrderedDict\nimport numpy as np\n\n\ndef collate_fn(batch):\n import torch\n\n elem = batch[0]\n\n if isinstance(elem, IterableOrderedDict):\n return IterableOrderedDict(\n (key, collate_fn([d[key] for d in batch])) for key in elem.keys()\n )\n\n if isinstance(elem, np.ndarray) and elem.size > 0 and isinstance(elem[0], str):\n batch = [it[0] for it in batch]\n return torch.utils.data._utils.collate.default_collate(batch)\n\n\ndef convert_fn(data):\n import torch\n\n if isinstance(data, IterableOrderedDict):\n return IterableOrderedDict((k, convert_fn(v)) for k, v in data.items())\n if isinstance(data, np.ndarray) and data.size > 0 and isinstance(data[0], str):\n data = data[0]\n\n return torch.utils.data._utils.collate.default_convert(data)\n\n\nclass PytorchTransformFunction:\n def __init__(\n self,\n transform_dict: Optional[Dict[str, Optional[Callable]]] = None,\n composite_transform: Optional[Callable] = None,\n tensors: List[str] = None,\n ) -> None:\n self.composite_transform = composite_transform\n self.transform_dict = transform_dict\n tensors = tensors or []\n\n if transform_dict is not None:\n for tensor in transform_dict:\n if tensor not in tensors:\n raise ValueError(f\"Invalid transform. Tensor {tensor} not found.\")\n\n def __call__(self, data_in: Dict) -> Dict:\n if self.composite_transform is not None:\n return self.composite_transform(data_in)\n elif self.transform_dict is not None:\n data_out = {}\n for tensor, fn in self.transform_dict.items():\n value = data_in[tensor]\n data_out[tensor] = value if fn is None else fn(value)\n return data_out\n return data_in\n", "path": "hub/integrations/pytorch/common.py"}]}
| 1,406 | 116 |
gh_patches_debug_2155
|
rasdani/github-patches
|
git_diff
|
wright-group__WrightTools-878
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pcov TypeError in kit._leastsq
In kit._leastsq, if the line 62 if statement is not passed, the consequent else statement makes pcov data type float, triggering"TypeError: 'int' object is not subscriptable" in line 72-73:
72: try:
73: error.append(np.absolute(pcov[i][i]) ** 0.5)
Line 74 picks up index out of bound errors, not sure if it was meant to catch the type error.
74: except IndexError:
75: error.append(0.00)
Error is bypassed if I put a 2D array into line 68, but have not spent the time considering what this array should look like.
</issue>
<code>
[start of WrightTools/kit/_leastsq.py]
1 """Least-square fitting tools."""
2
3
4 # --- import --------------------------------------------------------------------------------------
5
6
7 from ._utilities import Timer
8
9 import numpy as np
10
11 from scipy import optimize as scipy_optimize
12
13
14 # --- define --------------------------------------------------------------------------------------
15
16
17 __all__ = ["leastsqfitter"]
18
19
20 # --- functions -----------------------------------------------------------------------------------
21
22
23 def leastsqfitter(p0, datax, datay, function, verbose=False, cov_verbose=False):
24 """Conveniently call scipy.optmize.leastsq().
25
26 Returns fit parameters and their errors.
27
28 Parameters
29 ----------
30 p0 : list
31 list of guess parameters to pass to function
32 datax : array
33 array of independent values
34 datay : array
35 array of dependent values
36 function : function
37 function object to fit data to. Must be of the callable form function(p, x)
38 verbose : bool
39 toggles printing of fit time, fit params, and fit param errors
40 cov_verbose : bool
41 toggles printing of covarience matrix
42
43 Returns
44 -------
45 pfit_leastsq : list
46 list of fit parameters. s.t. the error between datay and function(p, datax) is minimized
47 perr_leastsq : list
48 list of fit parameter errors (1 std)
49 """
50 timer = Timer(verbose=False)
51 with timer:
52 # define error function
53 def errfunc(p, x, y):
54 return y - function(p, x)
55
56 # run optimization
57 pfit_leastsq, pcov, infodict, errmsg, success = scipy_optimize.leastsq(
58 errfunc, p0, args=(datax, datay), full_output=1, epsfcn=0.0001
59 )
60 # calculate covarience matrix
61 # original idea https://stackoverflow.com/a/21844726
62 if (len(datay) > len(p0)) and pcov is not None:
63 s_sq = (errfunc(pfit_leastsq, datax, datay) ** 2).sum() / (len(datay) - len(p0))
64 pcov = pcov * s_sq
65 if cov_verbose:
66 print(pcov)
67 else:
68 pcov = np.inf
69 # calculate and write errors
70 error = []
71 for i in range(len(pfit_leastsq)):
72 try:
73 error.append(np.absolute(pcov[i][i]) ** 0.5)
74 except IndexError:
75 error.append(0.00)
76 perr_leastsq = np.array(error)
77 # exit
78 if verbose:
79 print("fit params: ", pfit_leastsq)
80 print("fit params error: ", perr_leastsq)
81 print("fitting done in %f seconds" % timer.interval)
82 return pfit_leastsq, perr_leastsq
83
[end of WrightTools/kit/_leastsq.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/WrightTools/kit/_leastsq.py b/WrightTools/kit/_leastsq.py
--- a/WrightTools/kit/_leastsq.py
+++ b/WrightTools/kit/_leastsq.py
@@ -65,7 +65,7 @@
if cov_verbose:
print(pcov)
else:
- pcov = np.inf
+ pcov = np.array(np.inf)
# calculate and write errors
error = []
for i in range(len(pfit_leastsq)):
|
{"golden_diff": "diff --git a/WrightTools/kit/_leastsq.py b/WrightTools/kit/_leastsq.py\n--- a/WrightTools/kit/_leastsq.py\n+++ b/WrightTools/kit/_leastsq.py\n@@ -65,7 +65,7 @@\n if cov_verbose:\n print(pcov)\n else:\n- pcov = np.inf\n+ pcov = np.array(np.inf)\n # calculate and write errors\n error = []\n for i in range(len(pfit_leastsq)):\n", "issue": "pcov TypeError in kit._leastsq\nIn kit._leastsq, if the line 62 if statement is not passed, the consequent else statement makes pcov data type float, triggering\"TypeError: 'int' object is not subscriptable\" in line 72-73:\r\n\r\n72: try:\r\n73: error.append(np.absolute(pcov[i][i]) ** 0.5)\r\n\r\nLine 74 picks up index out of bound errors, not sure if it was meant to catch the type error.\r\n\r\n74: except IndexError:\r\n75: error.append(0.00)\r\n\r\nError is bypassed if I put a 2D array into line 68, but have not spent the time considering what this array should look like.\n", "before_files": [{"content": "\"\"\"Least-square fitting tools.\"\"\"\n\n\n# --- import --------------------------------------------------------------------------------------\n\n\nfrom ._utilities import Timer\n\nimport numpy as np\n\nfrom scipy import optimize as scipy_optimize\n\n\n# --- define --------------------------------------------------------------------------------------\n\n\n__all__ = [\"leastsqfitter\"]\n\n\n# --- functions -----------------------------------------------------------------------------------\n\n\ndef leastsqfitter(p0, datax, datay, function, verbose=False, cov_verbose=False):\n \"\"\"Conveniently call scipy.optmize.leastsq().\n\n Returns fit parameters and their errors.\n\n Parameters\n ----------\n p0 : list\n list of guess parameters to pass to function\n datax : array\n array of independent values\n datay : array\n array of dependent values\n function : function\n function object to fit data to. Must be of the callable form function(p, x)\n verbose : bool\n toggles printing of fit time, fit params, and fit param errors\n cov_verbose : bool\n toggles printing of covarience matrix\n\n Returns\n -------\n pfit_leastsq : list\n list of fit parameters. s.t. the error between datay and function(p, datax) is minimized\n perr_leastsq : list\n list of fit parameter errors (1 std)\n \"\"\"\n timer = Timer(verbose=False)\n with timer:\n # define error function\n def errfunc(p, x, y):\n return y - function(p, x)\n\n # run optimization\n pfit_leastsq, pcov, infodict, errmsg, success = scipy_optimize.leastsq(\n errfunc, p0, args=(datax, datay), full_output=1, epsfcn=0.0001\n )\n # calculate covarience matrix\n # original idea https://stackoverflow.com/a/21844726\n if (len(datay) > len(p0)) and pcov is not None:\n s_sq = (errfunc(pfit_leastsq, datax, datay) ** 2).sum() / (len(datay) - len(p0))\n pcov = pcov * s_sq\n if cov_verbose:\n print(pcov)\n else:\n pcov = np.inf\n # calculate and write errors\n error = []\n for i in range(len(pfit_leastsq)):\n try:\n error.append(np.absolute(pcov[i][i]) ** 0.5)\n except IndexError:\n error.append(0.00)\n perr_leastsq = np.array(error)\n # exit\n if verbose:\n print(\"fit params: \", pfit_leastsq)\n print(\"fit params error: \", perr_leastsq)\n print(\"fitting done in %f seconds\" % timer.interval)\n return pfit_leastsq, perr_leastsq\n", "path": "WrightTools/kit/_leastsq.py"}]}
| 1,486 | 118 |
gh_patches_debug_1593
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-3090
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add `eth_chainId` to retry middleware whitelist
### What was wrong?
I enabled the `http_retry_request_middleware`, but an idempotent method that is called frequently (`eth_chainId`) is missing from the retry whitelist
### How can it be fixed?
Add this method to the retry method whitelist in the code
</issue>
<code>
[start of web3/middleware/exception_retry_request.py]
1 import asyncio
2 from typing import (
3 TYPE_CHECKING,
4 Any,
5 Callable,
6 Collection,
7 Optional,
8 Type,
9 )
10
11 import aiohttp
12 from requests.exceptions import (
13 ConnectionError,
14 HTTPError,
15 Timeout,
16 TooManyRedirects,
17 )
18
19 from web3.types import (
20 AsyncMiddlewareCoroutine,
21 RPCEndpoint,
22 RPCResponse,
23 )
24
25 if TYPE_CHECKING:
26 from web3 import ( # noqa: F401
27 AsyncWeb3,
28 Web3,
29 )
30
31 whitelist = [
32 "admin",
33 "miner",
34 "net",
35 "txpool",
36 "testing",
37 "evm",
38 "eth_protocolVersion",
39 "eth_syncing",
40 "eth_coinbase",
41 "eth_mining",
42 "eth_hashrate",
43 "eth_chainId",
44 "eth_gasPrice",
45 "eth_accounts",
46 "eth_blockNumber",
47 "eth_getBalance",
48 "eth_getStorageAt",
49 "eth_getProof",
50 "eth_getCode",
51 "eth_getBlockByNumber",
52 "eth_getBlockByHash",
53 "eth_getBlockTransactionCountByNumber",
54 "eth_getBlockTransactionCountByHash",
55 "eth_getUncleCountByBlockNumber",
56 "eth_getUncleCountByBlockHash",
57 "eth_getTransactionByHash",
58 "eth_getTransactionByBlockHashAndIndex",
59 "eth_getTransactionByBlockNumberAndIndex",
60 "eth_getTransactionReceipt",
61 "eth_getTransactionCount",
62 "eth_getRawTransactionByHash",
63 "eth_call",
64 "eth_estimateGas",
65 "eth_newBlockFilter",
66 "eth_newPendingTransactionFilter",
67 "eth_newFilter",
68 "eth_getFilterChanges",
69 "eth_getFilterLogs",
70 "eth_getLogs",
71 "eth_uninstallFilter",
72 "eth_getCompilers",
73 "eth_getWork",
74 "eth_sign",
75 "eth_signTypedData",
76 "eth_sendRawTransaction",
77 "personal_importRawKey",
78 "personal_newAccount",
79 "personal_listAccounts",
80 "personal_listWallets",
81 "personal_lockAccount",
82 "personal_unlockAccount",
83 "personal_ecRecover",
84 "personal_sign",
85 "personal_signTypedData",
86 ]
87
88
89 def check_if_retry_on_failure(method: RPCEndpoint) -> bool:
90 root = method.split("_")[0]
91 if root in whitelist:
92 return True
93 elif method in whitelist:
94 return True
95 else:
96 return False
97
98
99 def exception_retry_middleware(
100 make_request: Callable[[RPCEndpoint, Any], RPCResponse],
101 _w3: "Web3",
102 errors: Collection[Type[BaseException]],
103 retries: int = 5,
104 ) -> Callable[[RPCEndpoint, Any], RPCResponse]:
105 """
106 Creates middleware that retries failed HTTP requests. Is a default
107 middleware for HTTPProvider.
108 """
109
110 def middleware(method: RPCEndpoint, params: Any) -> Optional[RPCResponse]:
111 if check_if_retry_on_failure(method):
112 for i in range(retries):
113 try:
114 return make_request(method, params)
115 except tuple(errors):
116 if i < retries - 1:
117 continue
118 else:
119 raise
120 return None
121 else:
122 return make_request(method, params)
123
124 return middleware
125
126
127 def http_retry_request_middleware(
128 make_request: Callable[[RPCEndpoint, Any], Any], w3: "Web3"
129 ) -> Callable[[RPCEndpoint, Any], Any]:
130 return exception_retry_middleware(
131 make_request, w3, (ConnectionError, HTTPError, Timeout, TooManyRedirects)
132 )
133
134
135 async def async_exception_retry_middleware(
136 make_request: Callable[[RPCEndpoint, Any], Any],
137 _async_w3: "AsyncWeb3",
138 errors: Collection[Type[BaseException]],
139 retries: int = 5,
140 backoff_factor: float = 0.3,
141 ) -> AsyncMiddlewareCoroutine:
142 """
143 Creates middleware that retries failed HTTP requests.
144 Is a default middleware for AsyncHTTPProvider.
145 """
146
147 async def middleware(method: RPCEndpoint, params: Any) -> Optional[RPCResponse]:
148 if check_if_retry_on_failure(method):
149 for i in range(retries):
150 try:
151 return await make_request(method, params)
152 except tuple(errors):
153 if i < retries - 1:
154 await asyncio.sleep(backoff_factor)
155 continue
156 else:
157 raise
158 return None
159 else:
160 return await make_request(method, params)
161
162 return middleware
163
164
165 async def async_http_retry_request_middleware(
166 make_request: Callable[[RPCEndpoint, Any], Any], async_w3: "AsyncWeb3"
167 ) -> Callable[[RPCEndpoint, Any], Any]:
168 return await async_exception_retry_middleware(
169 make_request,
170 async_w3,
171 (TimeoutError, aiohttp.ClientError),
172 )
173
[end of web3/middleware/exception_retry_request.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/web3/middleware/exception_retry_request.py b/web3/middleware/exception_retry_request.py
--- a/web3/middleware/exception_retry_request.py
+++ b/web3/middleware/exception_retry_request.py
@@ -62,6 +62,7 @@
"eth_getRawTransactionByHash",
"eth_call",
"eth_estimateGas",
+ "eth_maxPriorityFeePerGas",
"eth_newBlockFilter",
"eth_newPendingTransactionFilter",
"eth_newFilter",
|
{"golden_diff": "diff --git a/web3/middleware/exception_retry_request.py b/web3/middleware/exception_retry_request.py\n--- a/web3/middleware/exception_retry_request.py\n+++ b/web3/middleware/exception_retry_request.py\n@@ -62,6 +62,7 @@\n \"eth_getRawTransactionByHash\",\n \"eth_call\",\n \"eth_estimateGas\",\n+ \"eth_maxPriorityFeePerGas\",\n \"eth_newBlockFilter\",\n \"eth_newPendingTransactionFilter\",\n \"eth_newFilter\",\n", "issue": "Add `eth_chainId` to retry middleware whitelist\n### What was wrong?\r\n\r\nI enabled the `http_retry_request_middleware`, but an idempotent method that is called frequently (`eth_chainId`) is missing from the retry whitelist\r\n\r\n\r\n### How can it be fixed?\r\n\r\nAdd this method to the retry method whitelist in the code\r\n\n", "before_files": [{"content": "import asyncio\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Callable,\n Collection,\n Optional,\n Type,\n)\n\nimport aiohttp\nfrom requests.exceptions import (\n ConnectionError,\n HTTPError,\n Timeout,\n TooManyRedirects,\n)\n\nfrom web3.types import (\n AsyncMiddlewareCoroutine,\n RPCEndpoint,\n RPCResponse,\n)\n\nif TYPE_CHECKING:\n from web3 import ( # noqa: F401\n AsyncWeb3,\n Web3,\n )\n\nwhitelist = [\n \"admin\",\n \"miner\",\n \"net\",\n \"txpool\",\n \"testing\",\n \"evm\",\n \"eth_protocolVersion\",\n \"eth_syncing\",\n \"eth_coinbase\",\n \"eth_mining\",\n \"eth_hashrate\",\n \"eth_chainId\",\n \"eth_gasPrice\",\n \"eth_accounts\",\n \"eth_blockNumber\",\n \"eth_getBalance\",\n \"eth_getStorageAt\",\n \"eth_getProof\",\n \"eth_getCode\",\n \"eth_getBlockByNumber\",\n \"eth_getBlockByHash\",\n \"eth_getBlockTransactionCountByNumber\",\n \"eth_getBlockTransactionCountByHash\",\n \"eth_getUncleCountByBlockNumber\",\n \"eth_getUncleCountByBlockHash\",\n \"eth_getTransactionByHash\",\n \"eth_getTransactionByBlockHashAndIndex\",\n \"eth_getTransactionByBlockNumberAndIndex\",\n \"eth_getTransactionReceipt\",\n \"eth_getTransactionCount\",\n \"eth_getRawTransactionByHash\",\n \"eth_call\",\n \"eth_estimateGas\",\n \"eth_newBlockFilter\",\n \"eth_newPendingTransactionFilter\",\n \"eth_newFilter\",\n \"eth_getFilterChanges\",\n \"eth_getFilterLogs\",\n \"eth_getLogs\",\n \"eth_uninstallFilter\",\n \"eth_getCompilers\",\n \"eth_getWork\",\n \"eth_sign\",\n \"eth_signTypedData\",\n \"eth_sendRawTransaction\",\n \"personal_importRawKey\",\n \"personal_newAccount\",\n \"personal_listAccounts\",\n \"personal_listWallets\",\n \"personal_lockAccount\",\n \"personal_unlockAccount\",\n \"personal_ecRecover\",\n \"personal_sign\",\n \"personal_signTypedData\",\n]\n\n\ndef check_if_retry_on_failure(method: RPCEndpoint) -> bool:\n root = method.split(\"_\")[0]\n if root in whitelist:\n return True\n elif method in whitelist:\n return True\n else:\n return False\n\n\ndef exception_retry_middleware(\n make_request: Callable[[RPCEndpoint, Any], RPCResponse],\n _w3: \"Web3\",\n errors: Collection[Type[BaseException]],\n retries: int = 5,\n) -> Callable[[RPCEndpoint, Any], RPCResponse]:\n \"\"\"\n Creates middleware that retries failed HTTP requests. Is a default\n middleware for HTTPProvider.\n \"\"\"\n\n def middleware(method: RPCEndpoint, params: Any) -> Optional[RPCResponse]:\n if check_if_retry_on_failure(method):\n for i in range(retries):\n try:\n return make_request(method, params)\n except tuple(errors):\n if i < retries - 1:\n continue\n else:\n raise\n return None\n else:\n return make_request(method, params)\n\n return middleware\n\n\ndef http_retry_request_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any], w3: \"Web3\"\n) -> Callable[[RPCEndpoint, Any], Any]:\n return exception_retry_middleware(\n make_request, w3, (ConnectionError, HTTPError, Timeout, TooManyRedirects)\n )\n\n\nasync def async_exception_retry_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any],\n _async_w3: \"AsyncWeb3\",\n errors: Collection[Type[BaseException]],\n retries: int = 5,\n backoff_factor: float = 0.3,\n) -> AsyncMiddlewareCoroutine:\n \"\"\"\n Creates middleware that retries failed HTTP requests.\n Is a default middleware for AsyncHTTPProvider.\n \"\"\"\n\n async def middleware(method: RPCEndpoint, params: Any) -> Optional[RPCResponse]:\n if check_if_retry_on_failure(method):\n for i in range(retries):\n try:\n return await make_request(method, params)\n except tuple(errors):\n if i < retries - 1:\n await asyncio.sleep(backoff_factor)\n continue\n else:\n raise\n return None\n else:\n return await make_request(method, params)\n\n return middleware\n\n\nasync def async_http_retry_request_middleware(\n make_request: Callable[[RPCEndpoint, Any], Any], async_w3: \"AsyncWeb3\"\n) -> Callable[[RPCEndpoint, Any], Any]:\n return await async_exception_retry_middleware(\n make_request,\n async_w3,\n (TimeoutError, aiohttp.ClientError),\n )\n", "path": "web3/middleware/exception_retry_request.py"}]}
| 2,087 | 111 |
gh_patches_debug_27418
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-4322
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support latest PyTorch lightning
### Expected behavior
Optuna works with the latest PyTorch-Lightning (1.6.0).
### Environment
- Optuna version: 3.0.0b0.dev
- Python version:
- OS: Independent
- (Optional) Other libraries and their versions: PyTorch-Lightning 1.6.0
### Error messages, stack traces, or logs
```shell
tests/integration_tests/test_pytorch_lightning.py:158:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
optuna/study/study.py:399: in optimize
_optimize(
optuna/study/_optimize.py:68: in _optimize
_optimize_sequential(
optuna/study/_optimize.py:162: in _optimize_sequential
trial = _run_trial(study, func, catch)
optuna/study/_optimize.py:262: in _run_trial
raise func_err
optuna/study/_optimize.py:211: in _run_trial
value_or_values = func(trial)
tests/integration_tests/test_pytorch_lightning.py:143: in objective
trainer = pl.Trainer(
/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/utilities/argparse.py:339: in insert_env_defaults
return fn(self, **kwargs)
/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:561: in __init__
self._call_callback_hooks("on_init_start")
/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:1617: in _call_callback_hooks
fn(self, *args, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <optuna.integration.pytorch_lightning.PyTorchLightningPruningCallback object at 0x7f892c1c5730>
trainer = <pytorch_lightning.trainer.trainer.Trainer object at 0x7f892c1c5040>
def on_init_start(self, trainer: Trainer) -> None:
> self.is_ddp_backend = trainer._accelerator_connector.distributed_backend is not None
E AttributeError: 'AcceleratorConnector' object has no attribute 'distributed_backend'
optuna/integration/pytorch_lightning.py:60: AttributeError
```
https://github.com/optuna/optuna/runs/5745775785?check_suite_focus=true
```
tests/integration_tests/test_pytorch_lightning.py:6: in <module>
import pytorch_lightning as pl
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/__init__.py:30: in <module>
from pytorch_lightning.callbacks import Callback # noqa: E402
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/callbacks/__init__.py:26: in <module>
from pytorch_lightning.callbacks.pruning import ModelPruning
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/callbacks/pruning.py:31: in <module>
from pytorch_lightning.core.lightning import LightningModule
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/core/__init__.py:16: in <module>
from pytorch_lightning.core.lightning import LightningModule
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/core/lightning.py:40: in <module>
from pytorch_lightning.loggers import LightningLoggerBase
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/loggers/__init__.py:18: in <module>
from pytorch_lightning.loggers.tensorboard import TensorBoardLogger
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/loggers/tensorboard.py:26: in <module>
from torch.utils.tensorboard import SummaryWriter
../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py:4: in <module>
LooseVersion = distutils.version.LooseVersion
E AttributeError: module 'distutils' has no attribute 'version'
```
https://github.com/optuna/optuna/runs/5745734509?check_suite_focus=true
### Steps to reproduce
See our CI failures.
### Additional context (optional)
It may be the simplest way to support PyTorch v1.11.0 (https://github.com/PyTorchLightning/pytorch-lightning/issues/12324).
🔗 https://github.com/optuna/optuna/pull/3417
</issue>
<code>
[start of optuna/integration/pytorch_lightning.py]
1 import warnings
2
3 from packaging import version
4
5 import optuna
6 from optuna.storages._cached_storage import _CachedStorage
7 from optuna.storages._rdb.storage import RDBStorage
8
9
10 # Define key names of `Trial.system_attrs`.
11 _PRUNED_KEY = "ddp_pl:pruned"
12 _EPOCH_KEY = "ddp_pl:epoch"
13
14
15 with optuna._imports.try_import() as _imports:
16 import pytorch_lightning as pl
17 from pytorch_lightning import LightningModule
18 from pytorch_lightning import Trainer
19 from pytorch_lightning.callbacks import Callback
20
21 if not _imports.is_successful():
22 Callback = object # type: ignore # NOQA
23 LightningModule = object # type: ignore # NOQA
24 Trainer = object # type: ignore # NOQA
25
26
27 class PyTorchLightningPruningCallback(Callback):
28 """PyTorch Lightning callback to prune unpromising trials.
29
30 See `the example <https://github.com/optuna/optuna-examples/blob/
31 main/pytorch/pytorch_lightning_simple.py>`__
32 if you want to add a pruning callback which observes accuracy.
33
34 Args:
35 trial:
36 A :class:`~optuna.trial.Trial` corresponding to the current evaluation of the
37 objective function.
38 monitor:
39 An evaluation metric for pruning, e.g., ``val_loss`` or
40 ``val_acc``. The metrics are obtained from the returned dictionaries from e.g.
41 ``pytorch_lightning.LightningModule.training_step`` or
42 ``pytorch_lightning.LightningModule.validation_epoch_end`` and the names thus depend on
43 how this dictionary is formatted.
44
45 .. note::
46 For the distributed data parallel training, the version of PyTorchLightning needs to be
47 higher than or equal to v1.5.0. In addition, :class:`~optuna.study.Study` should be
48 instantiated with RDB storage.
49 """
50
51 def __init__(self, trial: optuna.trial.Trial, monitor: str) -> None:
52 _imports.check()
53 super().__init__()
54
55 self._trial = trial
56 self.monitor = monitor
57 self.is_ddp_backend = False
58
59 def on_init_start(self, trainer: Trainer) -> None:
60 self.is_ddp_backend = (
61 trainer._accelerator_connector.distributed_backend is not None # type: ignore
62 )
63 if self.is_ddp_backend:
64 if version.parse(pl.__version__) < version.parse("1.5.0"): # type: ignore
65 raise ValueError("PyTorch Lightning>=1.5.0 is required in DDP.")
66 if not (
67 isinstance(self._trial.study._storage, _CachedStorage)
68 and isinstance(self._trial.study._storage._backend, RDBStorage)
69 ):
70 raise ValueError(
71 "optuna.integration.PyTorchLightningPruningCallback"
72 " supports only optuna.storages.RDBStorage in DDP."
73 )
74
75 def on_validation_end(self, trainer: Trainer, pl_module: LightningModule) -> None:
76 # When the trainer calls `on_validation_end` for sanity check,
77 # do not call `trial.report` to avoid calling `trial.report` multiple times
78 # at epoch 0. The related page is
79 # https://github.com/PyTorchLightning/pytorch-lightning/issues/1391.
80 if trainer.sanity_checking:
81 return
82
83 epoch = pl_module.current_epoch
84
85 current_score = trainer.callback_metrics.get(self.monitor)
86 if current_score is None:
87 message = (
88 "The metric '{}' is not in the evaluation logs for pruning. "
89 "Please make sure you set the correct metric name.".format(self.monitor)
90 )
91 warnings.warn(message)
92 return
93
94 should_stop = False
95 if trainer.is_global_zero:
96 self._trial.report(current_score.item(), step=epoch)
97 should_stop = self._trial.should_prune()
98 should_stop = trainer.training_type_plugin.broadcast(should_stop)
99 if not should_stop:
100 return
101
102 if not self.is_ddp_backend:
103 message = "Trial was pruned at epoch {}.".format(epoch)
104 raise optuna.TrialPruned(message)
105 else:
106 # Stop every DDP process if global rank 0 process decides to stop.
107 trainer.should_stop = True
108 if trainer.is_global_zero:
109 self._trial.storage.set_trial_system_attr(self._trial._trial_id, _PRUNED_KEY, True)
110 self._trial.storage.set_trial_system_attr(self._trial._trial_id, _EPOCH_KEY, epoch)
111
112 def on_fit_end(self, trainer: Trainer, pl_module: LightningModule) -> None:
113 if not self.is_ddp_backend:
114 return
115
116 # Because on_validation_end is executed in spawned processes,
117 # _trial.report is necessary to update the memory in main process, not to update the RDB.
118 _trial_id = self._trial._trial_id
119 _study = self._trial.study
120 _trial = _study._storage._backend.get_trial(_trial_id) # type: ignore
121 _trial_system_attrs = _study._storage.get_trial_system_attrs(_trial_id)
122 is_pruned = _trial_system_attrs.get(_PRUNED_KEY)
123 epoch = _trial_system_attrs.get(_EPOCH_KEY)
124 intermediate_values = _trial.intermediate_values
125 for step, value in intermediate_values.items():
126 self._trial.report(value, step=step)
127
128 if is_pruned:
129 message = "Trial was pruned at epoch {}.".format(epoch)
130 raise optuna.TrialPruned(message)
131
[end of optuna/integration/pytorch_lightning.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/optuna/integration/pytorch_lightning.py b/optuna/integration/pytorch_lightning.py
--- a/optuna/integration/pytorch_lightning.py
+++ b/optuna/integration/pytorch_lightning.py
@@ -56,13 +56,11 @@
self.monitor = monitor
self.is_ddp_backend = False
- def on_init_start(self, trainer: Trainer) -> None:
- self.is_ddp_backend = (
- trainer._accelerator_connector.distributed_backend is not None # type: ignore
- )
+ def on_fit_start(self, trainer: Trainer, pl_module: "pl.LightningModule") -> None:
+ self.is_ddp_backend = trainer._accelerator_connector.is_distributed
if self.is_ddp_backend:
- if version.parse(pl.__version__) < version.parse("1.5.0"): # type: ignore
- raise ValueError("PyTorch Lightning>=1.5.0 is required in DDP.")
+ if version.parse(pl.__version__) < version.parse("1.6.0"): # type: ignore
+ raise ValueError("PyTorch Lightning>=1.6.0 is required in DDP.")
if not (
isinstance(self._trial.study._storage, _CachedStorage)
and isinstance(self._trial.study._storage._backend, RDBStorage)
@@ -95,7 +93,7 @@
if trainer.is_global_zero:
self._trial.report(current_score.item(), step=epoch)
should_stop = self._trial.should_prune()
- should_stop = trainer.training_type_plugin.broadcast(should_stop)
+ should_stop = trainer.strategy.broadcast(should_stop)
if not should_stop:
return
|
{"golden_diff": "diff --git a/optuna/integration/pytorch_lightning.py b/optuna/integration/pytorch_lightning.py\n--- a/optuna/integration/pytorch_lightning.py\n+++ b/optuna/integration/pytorch_lightning.py\n@@ -56,13 +56,11 @@\n self.monitor = monitor\n self.is_ddp_backend = False\n \n- def on_init_start(self, trainer: Trainer) -> None:\n- self.is_ddp_backend = (\n- trainer._accelerator_connector.distributed_backend is not None # type: ignore\n- )\n+ def on_fit_start(self, trainer: Trainer, pl_module: \"pl.LightningModule\") -> None:\n+ self.is_ddp_backend = trainer._accelerator_connector.is_distributed\n if self.is_ddp_backend:\n- if version.parse(pl.__version__) < version.parse(\"1.5.0\"): # type: ignore\n- raise ValueError(\"PyTorch Lightning>=1.5.0 is required in DDP.\")\n+ if version.parse(pl.__version__) < version.parse(\"1.6.0\"): # type: ignore\n+ raise ValueError(\"PyTorch Lightning>=1.6.0 is required in DDP.\")\n if not (\n isinstance(self._trial.study._storage, _CachedStorage)\n and isinstance(self._trial.study._storage._backend, RDBStorage)\n@@ -95,7 +93,7 @@\n if trainer.is_global_zero:\n self._trial.report(current_score.item(), step=epoch)\n should_stop = self._trial.should_prune()\n- should_stop = trainer.training_type_plugin.broadcast(should_stop)\n+ should_stop = trainer.strategy.broadcast(should_stop)\n if not should_stop:\n return\n", "issue": "Support latest PyTorch lightning\n### Expected behavior\r\n\r\nOptuna works with the latest PyTorch-Lightning (1.6.0).\r\n\r\n### Environment\r\n\r\n- Optuna version: 3.0.0b0.dev\r\n- Python version: \r\n- OS: Independent\r\n- (Optional) Other libraries and their versions: PyTorch-Lightning 1.6.0\r\n\r\n\r\n### Error messages, stack traces, or logs\r\n\r\n```shell\r\ntests/integration_tests/test_pytorch_lightning.py:158: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\noptuna/study/study.py:399: in optimize\r\n _optimize(\r\noptuna/study/_optimize.py:68: in _optimize\r\n _optimize_sequential(\r\noptuna/study/_optimize.py:162: in _optimize_sequential\r\n trial = _run_trial(study, func, catch)\r\noptuna/study/_optimize.py:262: in _run_trial\r\n raise func_err\r\noptuna/study/_optimize.py:211: in _run_trial\r\n value_or_values = func(trial)\r\ntests/integration_tests/test_pytorch_lightning.py:143: in objective\r\n trainer = pl.Trainer(\r\n/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/utilities/argparse.py:339: in insert_env_defaults\r\n return fn(self, **kwargs)\r\n/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:561: in __init__\r\n self._call_callback_hooks(\"on_init_start\")\r\n/opt/hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/trainer/trainer.py:1617: in _call_callback_hooks\r\n fn(self, *args, **kwargs)\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\n\r\nself = <optuna.integration.pytorch_lightning.PyTorchLightningPruningCallback object at 0x7f892c1c5730>\r\ntrainer = <pytorch_lightning.trainer.trainer.Trainer object at 0x7f892c1c5040>\r\n\r\n def on_init_start(self, trainer: Trainer) -> None:\r\n> self.is_ddp_backend = trainer._accelerator_connector.distributed_backend is not None\r\nE AttributeError: 'AcceleratorConnector' object has no attribute 'distributed_backend'\r\n\r\noptuna/integration/pytorch_lightning.py:60: AttributeError\r\n```\r\n\r\nhttps://github.com/optuna/optuna/runs/5745775785?check_suite_focus=true\r\n\r\n```\r\ntests/integration_tests/test_pytorch_lightning.py:6: in <module>\r\n import pytorch_lightning as pl\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/__init__.py:30: in <module>\r\n from pytorch_lightning.callbacks import Callback # noqa: E402\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/callbacks/__init__.py:26: in <module>\r\n from pytorch_lightning.callbacks.pruning import ModelPruning\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/callbacks/pruning.py:31: in <module>\r\n from pytorch_lightning.core.lightning import LightningModule\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/core/__init__.py:16: in <module>\r\n from pytorch_lightning.core.lightning import LightningModule\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/core/lightning.py:40: in <module>\r\n from pytorch_lightning.loggers import LightningLoggerBase\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/loggers/__init__.py:18: in <module>\r\n from pytorch_lightning.loggers.tensorboard import TensorBoardLogger\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/pytorch_lightning/loggers/tensorboard.py:26: in <module>\r\n from torch.utils.tensorboard import SummaryWriter\r\n../../../hostedtoolcache/Python/3.8.12/x64/lib/python3.8/site-packages/torch/utils/tensorboard/__init__.py:4: in <module>\r\n LooseVersion = distutils.version.LooseVersion\r\nE AttributeError: module 'distutils' has no attribute 'version'\r\n```\r\n\r\nhttps://github.com/optuna/optuna/runs/5745734509?check_suite_focus=true\r\n\r\n\r\n### Steps to reproduce\r\n\r\nSee our CI failures.\r\n\r\n### Additional context (optional)\r\n\r\nIt may be the simplest way to support PyTorch v1.11.0 (https://github.com/PyTorchLightning/pytorch-lightning/issues/12324).\r\n\r\n\ud83d\udd17 https://github.com/optuna/optuna/pull/3417\n", "before_files": [{"content": "import warnings\n\nfrom packaging import version\n\nimport optuna\nfrom optuna.storages._cached_storage import _CachedStorage\nfrom optuna.storages._rdb.storage import RDBStorage\n\n\n# Define key names of `Trial.system_attrs`.\n_PRUNED_KEY = \"ddp_pl:pruned\"\n_EPOCH_KEY = \"ddp_pl:epoch\"\n\n\nwith optuna._imports.try_import() as _imports:\n import pytorch_lightning as pl\n from pytorch_lightning import LightningModule\n from pytorch_lightning import Trainer\n from pytorch_lightning.callbacks import Callback\n\nif not _imports.is_successful():\n Callback = object # type: ignore # NOQA\n LightningModule = object # type: ignore # NOQA\n Trainer = object # type: ignore # NOQA\n\n\nclass PyTorchLightningPruningCallback(Callback):\n \"\"\"PyTorch Lightning callback to prune unpromising trials.\n\n See `the example <https://github.com/optuna/optuna-examples/blob/\n main/pytorch/pytorch_lightning_simple.py>`__\n if you want to add a pruning callback which observes accuracy.\n\n Args:\n trial:\n A :class:`~optuna.trial.Trial` corresponding to the current evaluation of the\n objective function.\n monitor:\n An evaluation metric for pruning, e.g., ``val_loss`` or\n ``val_acc``. The metrics are obtained from the returned dictionaries from e.g.\n ``pytorch_lightning.LightningModule.training_step`` or\n ``pytorch_lightning.LightningModule.validation_epoch_end`` and the names thus depend on\n how this dictionary is formatted.\n\n .. note::\n For the distributed data parallel training, the version of PyTorchLightning needs to be\n higher than or equal to v1.5.0. In addition, :class:`~optuna.study.Study` should be\n instantiated with RDB storage.\n \"\"\"\n\n def __init__(self, trial: optuna.trial.Trial, monitor: str) -> None:\n _imports.check()\n super().__init__()\n\n self._trial = trial\n self.monitor = monitor\n self.is_ddp_backend = False\n\n def on_init_start(self, trainer: Trainer) -> None:\n self.is_ddp_backend = (\n trainer._accelerator_connector.distributed_backend is not None # type: ignore\n )\n if self.is_ddp_backend:\n if version.parse(pl.__version__) < version.parse(\"1.5.0\"): # type: ignore\n raise ValueError(\"PyTorch Lightning>=1.5.0 is required in DDP.\")\n if not (\n isinstance(self._trial.study._storage, _CachedStorage)\n and isinstance(self._trial.study._storage._backend, RDBStorage)\n ):\n raise ValueError(\n \"optuna.integration.PyTorchLightningPruningCallback\"\n \" supports only optuna.storages.RDBStorage in DDP.\"\n )\n\n def on_validation_end(self, trainer: Trainer, pl_module: LightningModule) -> None:\n # When the trainer calls `on_validation_end` for sanity check,\n # do not call `trial.report` to avoid calling `trial.report` multiple times\n # at epoch 0. The related page is\n # https://github.com/PyTorchLightning/pytorch-lightning/issues/1391.\n if trainer.sanity_checking:\n return\n\n epoch = pl_module.current_epoch\n\n current_score = trainer.callback_metrics.get(self.monitor)\n if current_score is None:\n message = (\n \"The metric '{}' is not in the evaluation logs for pruning. \"\n \"Please make sure you set the correct metric name.\".format(self.monitor)\n )\n warnings.warn(message)\n return\n\n should_stop = False\n if trainer.is_global_zero:\n self._trial.report(current_score.item(), step=epoch)\n should_stop = self._trial.should_prune()\n should_stop = trainer.training_type_plugin.broadcast(should_stop)\n if not should_stop:\n return\n\n if not self.is_ddp_backend:\n message = \"Trial was pruned at epoch {}.\".format(epoch)\n raise optuna.TrialPruned(message)\n else:\n # Stop every DDP process if global rank 0 process decides to stop.\n trainer.should_stop = True\n if trainer.is_global_zero:\n self._trial.storage.set_trial_system_attr(self._trial._trial_id, _PRUNED_KEY, True)\n self._trial.storage.set_trial_system_attr(self._trial._trial_id, _EPOCH_KEY, epoch)\n\n def on_fit_end(self, trainer: Trainer, pl_module: LightningModule) -> None:\n if not self.is_ddp_backend:\n return\n\n # Because on_validation_end is executed in spawned processes,\n # _trial.report is necessary to update the memory in main process, not to update the RDB.\n _trial_id = self._trial._trial_id\n _study = self._trial.study\n _trial = _study._storage._backend.get_trial(_trial_id) # type: ignore\n _trial_system_attrs = _study._storage.get_trial_system_attrs(_trial_id)\n is_pruned = _trial_system_attrs.get(_PRUNED_KEY)\n epoch = _trial_system_attrs.get(_EPOCH_KEY)\n intermediate_values = _trial.intermediate_values\n for step, value in intermediate_values.items():\n self._trial.report(value, step=step)\n\n if is_pruned:\n message = \"Trial was pruned at epoch {}.\".format(epoch)\n raise optuna.TrialPruned(message)\n", "path": "optuna/integration/pytorch_lightning.py"}]}
| 3,294 | 375 |
gh_patches_debug_30810
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-686
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support reading from BytesIO/StringIO
I'm trying to write a GIF to memory and use panel to read from memory rather than storage.
`ValueError: GIF pane does not support objects of type 'BytesIO'`
```
from io import BytesIO
import imageio
memory = BytesIO()
save_fps = [..]
with imageio.get_writer(memory, mode='I', format='gif', fps=8) as writer:
for fp in save_fps:
image = imageio.imread(fp)
writer.append_data(image)
memory.seek(0)
pn.pane.GIF(memory)
```
</issue>
<code>
[start of panel/pane/image.py]
1 """
2 Contains Image panes including renderers for PNG, SVG, GIF and JPG
3 file types.
4 """
5 from __future__ import absolute_import, division, unicode_literals
6
7 import base64
8 import os
9
10 from io import BytesIO
11 from six import string_types
12
13 import param
14
15 from .markup import DivPaneBase
16
17
18 class ImageBase(DivPaneBase):
19 """
20 Encodes an image as base64 and wraps it in a Bokeh Div model.
21 This is an abstract base class that needs the image type
22 to be specified and specific code for determining the image shape.
23
24 The imgtype determines the filetype, extension, and MIME type for
25 this image. Each image type (png,jpg,gif) has a base class that
26 supports anything with a `_repr_X_` method (where X is `png`,
27 `gif`, etc.), a local file with the given file extension, or a
28 HTTP(S) url with the given extension. Subclasses of each type can
29 provide their own way of obtaining or generating a PNG.
30 """
31
32 embed = param.Boolean(default=True, doc="""
33 Whether to embed the image as base64.""")
34
35 imgtype = 'None'
36
37 __abstract = True
38
39 @classmethod
40 def applies(cls, obj):
41 imgtype = cls.imgtype
42 return (hasattr(obj, '_repr_'+imgtype+'_') or
43 (isinstance(obj, string_types) and
44 ((os.path.isfile(obj) and obj.endswith('.'+imgtype)) or
45 cls._is_url(obj))))
46
47 @classmethod
48 def _is_url(cls, obj):
49 return (isinstance(obj, string_types) and
50 (obj.startswith('http://') or obj.startswith('https://'))
51 and obj.endswith('.'+cls.imgtype))
52
53 def _img(self):
54 if not isinstance(self.object, string_types):
55 return getattr(self.object, '_repr_'+self.imgtype+'_')()
56 elif os.path.isfile(self.object):
57 with open(self.object, 'rb') as f:
58 return f.read()
59 else:
60 import requests
61 r = requests.request(url=self.object, method='GET')
62 return r.content
63
64 def _imgshape(self, data):
65 """Calculate and return image width,height"""
66 raise NotImplementedError
67
68 def _get_properties(self):
69 p = super(ImageBase, self)._get_properties()
70 if self.object is None:
71 return dict(p, text='<img></img>')
72 data = self._img()
73 if not isinstance(data, bytes):
74 data = base64.b64decode(data)
75 width, height = self._imgshape(data)
76 if self.width is not None:
77 if self.height is None:
78 height = int((self.width/width)*height)
79 else:
80 height = self.height
81 width = self.width
82 elif self.height is not None:
83 width = int((self.height/height)*width)
84 height = self.height
85 if not self.embed:
86 src = self.object
87 else:
88 b64 = base64.b64encode(data).decode("utf-8")
89 src = "data:image/"+self.imgtype+";base64,{b64}".format(b64=b64)
90
91 smode = self.sizing_mode
92 if smode in ['fixed', None]:
93 w, h = '%spx' % width, '%spx' % height
94 elif smode == 'stretch_both':
95 w, h = '100%', '100%'
96 elif smode == 'stretch_height':
97 w, h = '%spx' % width, '100%'
98 elif smode == 'stretch_height':
99 w, h = '100%', '%spx' % height
100 elif smode == 'scale_height':
101 w, h = 'auto', '100%'
102 else:
103 w, h = '100%', 'auto'
104
105 html = "<img src='{src}' width='{width}' height='{height}'></img>".format(
106 src=src, width=w, height=h)
107
108 return dict(p, width=width, height=height, text=html)
109
110
111 class PNG(ImageBase):
112
113 imgtype = 'png'
114
115 @classmethod
116 def _imgshape(cls, data):
117 import struct
118 w, h = struct.unpack('>LL', data[16:24])
119 return int(w), int(h)
120
121
122 class GIF(ImageBase):
123
124 imgtype = 'gif'
125
126 @classmethod
127 def _imgshape(cls, data):
128 import struct
129 w, h = struct.unpack("<HH", data[6:10])
130 return int(w), int(h)
131
132
133 class JPG(ImageBase):
134
135 imgtype = 'jpg'
136
137 @classmethod
138 def _imgshape(cls, data):
139 import struct
140 b = BytesIO(data)
141 b.read(2)
142 c = b.read(1)
143 while (c and ord(c) != 0xDA):
144 while (ord(c) != 0xFF): c = b.read(1)
145 while (ord(c) == 0xFF): c = b.read(1)
146 if (ord(c) >= 0xC0 and ord(c) <= 0xC3):
147 b.read(3)
148 h, w = struct.unpack(">HH", b.read(4))
149 break
150 else:
151 b.read(int(struct.unpack(">H", b.read(2))[0])-2)
152 c = b.read(1)
153 return int(w), int(h)
154
155
156 class SVG(ImageBase):
157
158 imgtype = 'svg'
159
160 @classmethod
161 def applies(cls, obj):
162 return (super(SVG, cls).applies(obj) or
163 (isinstance(obj, string_types) and obj.lstrip().startswith('<svg')))
164
165 def _img(self):
166 if (isinstance(self.object, string_types) and
167 self.object.lstrip().startswith('<svg')):
168 return self.object
169 return super(SVG, self)._img()
170
171 def _imgshape(self, data):
172 return (self.width, self.height)
173
174 def _get_properties(self):
175 p = super(ImageBase, self)._get_properties()
176 if self.object is None:
177 return dict(p, text='<img></img>')
178 data = self._img()
179 width, height = self._imgshape(data)
180 if not isinstance(data, bytes):
181 data = data.encode('utf-8')
182 b64 = base64.b64encode(data).decode("utf-8")
183 src = "data:image/svg+xml;base64,{b64}".format(b64=b64)
184 html = "<img src='{src}' width={width} height={height}></img>".format(
185 src=src, width=width, height=height
186 )
187 return dict(p, width=width, height=height, text=html)
188
[end of panel/pane/image.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/pane/image.py b/panel/pane/image.py
--- a/panel/pane/image.py
+++ b/panel/pane/image.py
@@ -39,24 +39,37 @@
@classmethod
def applies(cls, obj):
imgtype = cls.imgtype
- return (hasattr(obj, '_repr_'+imgtype+'_') or
- (isinstance(obj, string_types) and
- ((os.path.isfile(obj) and obj.endswith('.'+imgtype)) or
- cls._is_url(obj))))
+ if hasattr(obj, '_repr_{}_'.format(imgtype)):
+ return True
+ if isinstance(obj, string_types):
+ if os.path.isfile(obj) and obj.endswith('.'+imgtype):
+ return True
+ if cls._is_url(obj):
+ return True
+ if hasattr(obj, 'read'): # Check for file like object
+ return True
+ return False
@classmethod
def _is_url(cls, obj):
- return (isinstance(obj, string_types) and
- (obj.startswith('http://') or obj.startswith('https://'))
- and obj.endswith('.'+cls.imgtype))
+ if isinstance(obj, string_types):
+ lower_string = obj.lower()
+ return (
+ lower_string.startswith('http://')
+ or lower_string.startswith('https://')
+ ) and lower_string.endswith('.'+cls.imgtype)
+ return False
def _img(self):
- if not isinstance(self.object, string_types):
- return getattr(self.object, '_repr_'+self.imgtype+'_')()
- elif os.path.isfile(self.object):
- with open(self.object, 'rb') as f:
- return f.read()
- else:
+ if hasattr(self.object, '_repr_{}_'.format(self.imgtype)):
+ return getattr(self.object, '_repr_' + self.imgtype + '_')()
+ if isinstance(self.object, string_types):
+ if os.path.isfile(self.object):
+ with open(self.object, 'rb') as f:
+ return f.read()
+ if hasattr(self.object, 'read'):
+ return self.object.read()
+ if self._is_url(self.object):
import requests
r = requests.request(url=self.object, method='GET')
return r.content
|
{"golden_diff": "diff --git a/panel/pane/image.py b/panel/pane/image.py\n--- a/panel/pane/image.py\n+++ b/panel/pane/image.py\n@@ -39,24 +39,37 @@\n @classmethod\n def applies(cls, obj):\n imgtype = cls.imgtype\n- return (hasattr(obj, '_repr_'+imgtype+'_') or\n- (isinstance(obj, string_types) and\n- ((os.path.isfile(obj) and obj.endswith('.'+imgtype)) or\n- cls._is_url(obj))))\n+ if hasattr(obj, '_repr_{}_'.format(imgtype)):\n+ return True\n+ if isinstance(obj, string_types):\n+ if os.path.isfile(obj) and obj.endswith('.'+imgtype):\n+ return True\n+ if cls._is_url(obj):\n+ return True\n+ if hasattr(obj, 'read'): # Check for file like object\n+ return True\n+ return False\n \n @classmethod\n def _is_url(cls, obj):\n- return (isinstance(obj, string_types) and\n- (obj.startswith('http://') or obj.startswith('https://'))\n- and obj.endswith('.'+cls.imgtype))\n+ if isinstance(obj, string_types):\n+ lower_string = obj.lower()\n+ return (\n+ lower_string.startswith('http://')\n+ or lower_string.startswith('https://')\n+ ) and lower_string.endswith('.'+cls.imgtype)\n+ return False\n \n def _img(self):\n- if not isinstance(self.object, string_types):\n- return getattr(self.object, '_repr_'+self.imgtype+'_')()\n- elif os.path.isfile(self.object):\n- with open(self.object, 'rb') as f:\n- return f.read()\n- else:\n+ if hasattr(self.object, '_repr_{}_'.format(self.imgtype)):\n+ return getattr(self.object, '_repr_' + self.imgtype + '_')()\n+ if isinstance(self.object, string_types):\n+ if os.path.isfile(self.object):\n+ with open(self.object, 'rb') as f:\n+ return f.read()\n+ if hasattr(self.object, 'read'):\n+ return self.object.read()\n+ if self._is_url(self.object):\n import requests\n r = requests.request(url=self.object, method='GET')\n return r.content\n", "issue": "Support reading from BytesIO/StringIO\nI'm trying to write a GIF to memory and use panel to read from memory rather than storage.\r\n`ValueError: GIF pane does not support objects of type 'BytesIO'`\r\n\r\n```\r\nfrom io import BytesIO\r\nimport imageio\r\n\r\nmemory = BytesIO()\r\n\r\nsave_fps = [..]\r\n\r\nwith imageio.get_writer(memory, mode='I', format='gif', fps=8) as writer:\r\n for fp in save_fps:\r\n image = imageio.imread(fp)\r\n writer.append_data(image)\r\n\r\nmemory.seek(0)\r\npn.pane.GIF(memory)\r\n```\n", "before_files": [{"content": "\"\"\"\nContains Image panes including renderers for PNG, SVG, GIF and JPG\nfile types.\n\"\"\"\nfrom __future__ import absolute_import, division, unicode_literals\n\nimport base64\nimport os\n\nfrom io import BytesIO\nfrom six import string_types\n\nimport param\n\nfrom .markup import DivPaneBase\n\n\nclass ImageBase(DivPaneBase):\n \"\"\"\n Encodes an image as base64 and wraps it in a Bokeh Div model.\n This is an abstract base class that needs the image type\n to be specified and specific code for determining the image shape.\n\n The imgtype determines the filetype, extension, and MIME type for\n this image. Each image type (png,jpg,gif) has a base class that\n supports anything with a `_repr_X_` method (where X is `png`,\n `gif`, etc.), a local file with the given file extension, or a\n HTTP(S) url with the given extension. Subclasses of each type can\n provide their own way of obtaining or generating a PNG.\n \"\"\"\n\n embed = param.Boolean(default=True, doc=\"\"\"\n Whether to embed the image as base64.\"\"\")\n\n imgtype = 'None'\n\n __abstract = True\n\n @classmethod\n def applies(cls, obj):\n imgtype = cls.imgtype\n return (hasattr(obj, '_repr_'+imgtype+'_') or\n (isinstance(obj, string_types) and\n ((os.path.isfile(obj) and obj.endswith('.'+imgtype)) or\n cls._is_url(obj))))\n\n @classmethod\n def _is_url(cls, obj):\n return (isinstance(obj, string_types) and\n (obj.startswith('http://') or obj.startswith('https://'))\n and obj.endswith('.'+cls.imgtype))\n\n def _img(self):\n if not isinstance(self.object, string_types):\n return getattr(self.object, '_repr_'+self.imgtype+'_')()\n elif os.path.isfile(self.object):\n with open(self.object, 'rb') as f:\n return f.read()\n else:\n import requests\n r = requests.request(url=self.object, method='GET')\n return r.content\n\n def _imgshape(self, data):\n \"\"\"Calculate and return image width,height\"\"\"\n raise NotImplementedError\n\n def _get_properties(self):\n p = super(ImageBase, self)._get_properties()\n if self.object is None:\n return dict(p, text='<img></img>')\n data = self._img()\n if not isinstance(data, bytes):\n data = base64.b64decode(data)\n width, height = self._imgshape(data)\n if self.width is not None:\n if self.height is None:\n height = int((self.width/width)*height)\n else:\n height = self.height\n width = self.width\n elif self.height is not None:\n width = int((self.height/height)*width)\n height = self.height\n if not self.embed:\n src = self.object\n else:\n b64 = base64.b64encode(data).decode(\"utf-8\")\n src = \"data:image/\"+self.imgtype+\";base64,{b64}\".format(b64=b64)\n\n smode = self.sizing_mode\n if smode in ['fixed', None]:\n w, h = '%spx' % width, '%spx' % height\n elif smode == 'stretch_both':\n w, h = '100%', '100%'\n elif smode == 'stretch_height':\n w, h = '%spx' % width, '100%'\n elif smode == 'stretch_height':\n w, h = '100%', '%spx' % height\n elif smode == 'scale_height':\n w, h = 'auto', '100%'\n else:\n w, h = '100%', 'auto'\n\n html = \"<img src='{src}' width='{width}' height='{height}'></img>\".format(\n src=src, width=w, height=h)\n\n return dict(p, width=width, height=height, text=html)\n\n\nclass PNG(ImageBase):\n\n imgtype = 'png'\n\n @classmethod\n def _imgshape(cls, data):\n import struct\n w, h = struct.unpack('>LL', data[16:24])\n return int(w), int(h)\n\n\nclass GIF(ImageBase):\n\n imgtype = 'gif'\n\n @classmethod\n def _imgshape(cls, data):\n import struct\n w, h = struct.unpack(\"<HH\", data[6:10])\n return int(w), int(h)\n\n\nclass JPG(ImageBase):\n\n imgtype = 'jpg'\n\n @classmethod\n def _imgshape(cls, data):\n import struct\n b = BytesIO(data)\n b.read(2)\n c = b.read(1)\n while (c and ord(c) != 0xDA):\n while (ord(c) != 0xFF): c = b.read(1)\n while (ord(c) == 0xFF): c = b.read(1)\n if (ord(c) >= 0xC0 and ord(c) <= 0xC3):\n b.read(3)\n h, w = struct.unpack(\">HH\", b.read(4))\n break\n else:\n b.read(int(struct.unpack(\">H\", b.read(2))[0])-2)\n c = b.read(1)\n return int(w), int(h)\n\n\nclass SVG(ImageBase):\n\n imgtype = 'svg'\n\n @classmethod\n def applies(cls, obj):\n return (super(SVG, cls).applies(obj) or\n (isinstance(obj, string_types) and obj.lstrip().startswith('<svg')))\n\n def _img(self):\n if (isinstance(self.object, string_types) and\n self.object.lstrip().startswith('<svg')):\n return self.object\n return super(SVG, self)._img()\n\n def _imgshape(self, data):\n return (self.width, self.height)\n\n def _get_properties(self):\n p = super(ImageBase, self)._get_properties()\n if self.object is None:\n return dict(p, text='<img></img>')\n data = self._img()\n width, height = self._imgshape(data)\n if not isinstance(data, bytes):\n data = data.encode('utf-8')\n b64 = base64.b64encode(data).decode(\"utf-8\")\n src = \"data:image/svg+xml;base64,{b64}\".format(b64=b64)\n html = \"<img src='{src}' width={width} height={height}></img>\".format(\n src=src, width=width, height=height\n )\n return dict(p, width=width, height=height, text=html)\n", "path": "panel/pane/image.py"}]}
| 2,622 | 513 |
gh_patches_debug_20829
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-1114
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation: "older version" warning present on latest
Every page under https://starlite-api.github.io/starlite/latest/ has the "You are viewing the documentation for an older version of Starlite. Click here to get to the latest version" warning, which links back to the welcome page.
The message is not present in https://starlite-api.github.io/starlite/1.50/, https://starlite-api.github.io/starlite/1.49/, or https://starlite-api.github.io/starlite/1.47/.
Documentation: "older version" warning present on latest
Every page under https://starlite-api.github.io/starlite/latest/ has the "You are viewing the documentation for an older version of Starlite. Click here to get to the latest version" warning, which links back to the welcome page.
The message is not present in https://starlite-api.github.io/starlite/1.50/, https://starlite-api.github.io/starlite/1.49/, or https://starlite-api.github.io/starlite/1.47/.
</issue>
<code>
[start of tools/publish_docs.py]
1 import importlib.metadata
2 import json
3 import shutil
4 import subprocess
5 from pathlib import Path
6 import argparse
7 import shutil
8
9 parser = argparse.ArgumentParser()
10 parser.add_argument("--version", required=False)
11 parser.add_argument("--push", action="store_true")
12 parser.add_argument("--latest", action="store_true")
13
14
15 def update_versions_file(version: str) -> None:
16 versions_file = Path("versions.json")
17 versions = []
18 if versions_file.exists():
19 versions = json.loads(versions_file.read_text())
20
21 new_version_spec = {"version": version, "title": version, "aliases": []}
22 if any(v["version"] == version for v in versions):
23 versions = [v if v["version"] != version else new_version_spec for v in versions]
24 else:
25 versions.insert(0, new_version_spec)
26
27 versions_file.write_text(json.dumps(versions))
28
29
30 def make_version(version: str, push: bool, latest: bool) -> None:
31 subprocess.run(["make", "docs"], check=True)
32
33 subprocess.run(["git", "checkout", "gh-pages"], check=True)
34
35 update_versions_file(version)
36
37 docs_src_path = Path("docs/_build/html")
38 docs_dest_path = Path(version)
39 docs_dest_path_latest = Path("latest")
40 if docs_dest_path.exists():
41 shutil.rmtree(docs_dest_path)
42
43 docs_src_path.rename(docs_dest_path)
44 if latest:
45 if docs_dest_path_latest.exists():
46 shutil.rmtree(docs_dest_path_latest)
47 shutil.copytree(docs_dest_path, docs_dest_path_latest)
48 subprocess.run(["git", "add", "latest"], check=True)
49
50 subprocess.run(["git", "add", version], check=True)
51 subprocess.run(["git", "add", "versions.json"], check=True)
52 subprocess.run(["git", "commit", "-m", f"automated docs build: {version}"], check=True)
53 if push:
54 subprocess.run(["git", "push"], check=True)
55 subprocess.run(["git", "checkout", "-"], check=True)
56
57
58 def main() -> None:
59 args = parser.parse_args()
60 version = args.version or importlib.metadata.version("starlite").rsplit(".", 1)[0]
61 make_version(version=version, push=args.push, latest=args.latest)
62
63
64 if __name__ == "__main__":
65 main()
66
[end of tools/publish_docs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/publish_docs.py b/tools/publish_docs.py
--- a/tools/publish_docs.py
+++ b/tools/publish_docs.py
@@ -12,7 +12,7 @@
parser.add_argument("--latest", action="store_true")
-def update_versions_file(version: str) -> None:
+def add_to_versions_file(version: str, latest: bool) -> None:
versions_file = Path("versions.json")
versions = []
if versions_file.exists():
@@ -24,6 +24,11 @@
else:
versions.insert(0, new_version_spec)
+ if latest:
+ for version in versions:
+ version["aliases"] = []
+ versions[0]["aliases"] = ["latest"]
+
versions_file.write_text(json.dumps(versions))
@@ -32,7 +37,7 @@
subprocess.run(["git", "checkout", "gh-pages"], check=True)
- update_versions_file(version)
+ add_to_versions_file(version, latest)
docs_src_path = Path("docs/_build/html")
docs_dest_path = Path(version)
|
{"golden_diff": "diff --git a/tools/publish_docs.py b/tools/publish_docs.py\n--- a/tools/publish_docs.py\n+++ b/tools/publish_docs.py\n@@ -12,7 +12,7 @@\n parser.add_argument(\"--latest\", action=\"store_true\")\n \n \n-def update_versions_file(version: str) -> None:\n+def add_to_versions_file(version: str, latest: bool) -> None:\n versions_file = Path(\"versions.json\")\n versions = []\n if versions_file.exists():\n@@ -24,6 +24,11 @@\n else:\n versions.insert(0, new_version_spec)\n \n+ if latest:\n+ for version in versions:\n+ version[\"aliases\"] = []\n+ versions[0][\"aliases\"] = [\"latest\"]\n+\n versions_file.write_text(json.dumps(versions))\n \n \n@@ -32,7 +37,7 @@\n \n subprocess.run([\"git\", \"checkout\", \"gh-pages\"], check=True)\n \n- update_versions_file(version)\n+ add_to_versions_file(version, latest)\n \n docs_src_path = Path(\"docs/_build/html\")\n docs_dest_path = Path(version)\n", "issue": "Documentation: \"older version\" warning present on latest\nEvery page under https://starlite-api.github.io/starlite/latest/ has the \"You are viewing the documentation for an older version of Starlite. Click here to get to the latest version\" warning, which links back to the welcome page. \r\n\r\nThe message is not present in https://starlite-api.github.io/starlite/1.50/, https://starlite-api.github.io/starlite/1.49/, or https://starlite-api.github.io/starlite/1.47/.\nDocumentation: \"older version\" warning present on latest\nEvery page under https://starlite-api.github.io/starlite/latest/ has the \"You are viewing the documentation for an older version of Starlite. Click here to get to the latest version\" warning, which links back to the welcome page. \r\n\r\nThe message is not present in https://starlite-api.github.io/starlite/1.50/, https://starlite-api.github.io/starlite/1.49/, or https://starlite-api.github.io/starlite/1.47/.\n", "before_files": [{"content": "import importlib.metadata\nimport json\nimport shutil\nimport subprocess\nfrom pathlib import Path\nimport argparse\nimport shutil\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\"--version\", required=False)\nparser.add_argument(\"--push\", action=\"store_true\")\nparser.add_argument(\"--latest\", action=\"store_true\")\n\n\ndef update_versions_file(version: str) -> None:\n versions_file = Path(\"versions.json\")\n versions = []\n if versions_file.exists():\n versions = json.loads(versions_file.read_text())\n\n new_version_spec = {\"version\": version, \"title\": version, \"aliases\": []}\n if any(v[\"version\"] == version for v in versions):\n versions = [v if v[\"version\"] != version else new_version_spec for v in versions]\n else:\n versions.insert(0, new_version_spec)\n\n versions_file.write_text(json.dumps(versions))\n\n\ndef make_version(version: str, push: bool, latest: bool) -> None:\n subprocess.run([\"make\", \"docs\"], check=True)\n\n subprocess.run([\"git\", \"checkout\", \"gh-pages\"], check=True)\n\n update_versions_file(version)\n\n docs_src_path = Path(\"docs/_build/html\")\n docs_dest_path = Path(version)\n docs_dest_path_latest = Path(\"latest\")\n if docs_dest_path.exists():\n shutil.rmtree(docs_dest_path)\n\n docs_src_path.rename(docs_dest_path)\n if latest:\n if docs_dest_path_latest.exists():\n shutil.rmtree(docs_dest_path_latest)\n shutil.copytree(docs_dest_path, docs_dest_path_latest)\n subprocess.run([\"git\", \"add\", \"latest\"], check=True)\n\n subprocess.run([\"git\", \"add\", version], check=True)\n subprocess.run([\"git\", \"add\", \"versions.json\"], check=True)\n subprocess.run([\"git\", \"commit\", \"-m\", f\"automated docs build: {version}\"], check=True)\n if push:\n subprocess.run([\"git\", \"push\"], check=True)\n subprocess.run([\"git\", \"checkout\", \"-\"], check=True)\n\n\ndef main() -> None:\n args = parser.parse_args()\n version = args.version or importlib.metadata.version(\"starlite\").rsplit(\".\", 1)[0]\n make_version(version=version, push=args.push, latest=args.latest)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "tools/publish_docs.py"}]}
| 1,380 | 242 |
gh_patches_debug_16074
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-645
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DEP: Depcrated `utm_crs`
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [ ] closes #xxxx
- [x] whatsnew entry
`pyproj.database.query_utm_crs_info` too slow to query all data.
For 1 point will cost 200ms but for 2000 points will cost 200s.
Even try `parallelize` to `utm_crs`, but the speed is still so lower.
</issue>
<code>
[start of dtoolkit/geoaccessor/geoseries/utm_crs.py]
1 import geopandas as gpd
2 import pandas as pd
3 from pyproj.aoi import AreaOfInterest
4 from pyproj.database import query_utm_crs_info
5
6 from dtoolkit.geoaccessor.register import register_geoseries_method
7 from dtoolkit.util._decorator import warning
8
9
10 @register_geoseries_method
11 @warning(
12 "The 'utm_crs' is deprecated and will be removed in 0.0.17. "
13 "(Warning added DToolKit 0.0.16)",
14 DeprecationWarning,
15 stacklevel=3,
16 )
17 def utm_crs(s: gpd.GeoSeries, /, datum_name: str = "WGS 84") -> pd.Series:
18 """
19 Returns the estimated UTM CRS based on the bounds of each geometry.
20
21 .. deprecated:: 0.0.17
22 The 'utm_crs' is deprecated and will be removed in 0.0.17.
23 (Warning added DToolKit 0.0.16)
24
25 Parameters
26 ----------
27 datum_name : str, default 'WGS 84'
28 The name of the datum in the CRS name ('NAD27', 'NAD83', 'WGS 84', …).
29
30 Returns
31 -------
32 Series
33 The element type is :class:`~pyproj.database.CRSInfo`.
34
35 See Also
36 --------
37 dtoolkit.geoaccessor.geoseries.utm_crs
38 Returns the estimated UTM CRS based on the bounds of each geometry.
39
40 dtoolkit.geoaccessor.geodataframe.utm_crs
41 Returns the estimated UTM CRS based on the bounds of each geometry.
42
43 geopandas.GeoSeries.estimate_utm_crs
44 Returns the estimated UTM CRS based on the bounds of the dataset.
45
46 geopandas.GeoDataFrame.estimate_utm_crs
47 Returns the estimated UTM CRS based on the bounds of the dataset.
48
49 Examples
50 --------
51 >>> import dtoolkit.accessor
52 >>> import dtoolkit.geoaccessor
53 >>> import geopandas as gpd
54 >>> s = gpd.GeoSeries.from_wkt(["Point (120 50)", "Point (100 1)"], crs="epsg:4326")
55 >>> s.utm_crs()
56 0 (EPSG, 32650, WGS 84 / UTM zone 50N, PJType.PR...
57 1 (EPSG, 32647, WGS 84 / UTM zone 47N, PJType.PR...
58 dtype: object
59
60 Same operate for GeoDataFrame.
61
62 >>> s.to_frame("geometry").utm_crs()
63 0 (EPSG, 32650, WGS 84 / UTM zone 50N, PJType.PR...
64 1 (EPSG, 32647, WGS 84 / UTM zone 47N, PJType.PR...
65 dtype: object
66
67 Get the EPSG code.
68
69 >>> s.utm_crs().getattr("code")
70 0 32650
71 1 32647
72 dtype: object
73 """
74
75 return s.bounds.apply(
76 lambda bound: None
77 if bound.isna().all()
78 else query_utm_crs_info(
79 datum_name=datum_name,
80 area_of_interest=AreaOfInterest(
81 west_lon_degree=bound["minx"],
82 south_lat_degree=bound["miny"],
83 east_lon_degree=bound["maxx"],
84 north_lat_degree=bound["maxy"],
85 ),
86 )[0],
87 axis=1,
88 )
89
[end of dtoolkit/geoaccessor/geoseries/utm_crs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dtoolkit/geoaccessor/geoseries/utm_crs.py b/dtoolkit/geoaccessor/geoseries/utm_crs.py
--- a/dtoolkit/geoaccessor/geoseries/utm_crs.py
+++ b/dtoolkit/geoaccessor/geoseries/utm_crs.py
@@ -9,8 +9,8 @@
@register_geoseries_method
@warning(
- "The 'utm_crs' is deprecated and will be removed in 0.0.17. "
- "(Warning added DToolKit 0.0.16)",
+ "The 'utm_crs' is deprecated and will be removed in 0.0.18. "
+ "(Warning added DToolKit 0.0.17)",
DeprecationWarning,
stacklevel=3,
)
@@ -18,9 +18,9 @@
"""
Returns the estimated UTM CRS based on the bounds of each geometry.
- .. deprecated:: 0.0.17
- The 'utm_crs' is deprecated and will be removed in 0.0.17.
- (Warning added DToolKit 0.0.16)
+ .. deprecated:: 0.0.18
+ The 'utm_crs' is deprecated and will be removed in 0.0.18.
+ (Warning added DToolKit 0.0.17)
Parameters
----------
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geoseries/utm_crs.py b/dtoolkit/geoaccessor/geoseries/utm_crs.py\n--- a/dtoolkit/geoaccessor/geoseries/utm_crs.py\n+++ b/dtoolkit/geoaccessor/geoseries/utm_crs.py\n@@ -9,8 +9,8 @@\n \n @register_geoseries_method\n @warning(\n- \"The 'utm_crs' is deprecated and will be removed in 0.0.17. \"\n- \"(Warning added DToolKit 0.0.16)\",\n+ \"The 'utm_crs' is deprecated and will be removed in 0.0.18. \"\n+ \"(Warning added DToolKit 0.0.17)\",\n DeprecationWarning,\n stacklevel=3,\n )\n@@ -18,9 +18,9 @@\n \"\"\"\n Returns the estimated UTM CRS based on the bounds of each geometry.\n \n- .. deprecated:: 0.0.17\n- The 'utm_crs' is deprecated and will be removed in 0.0.17.\n- (Warning added DToolKit 0.0.16)\n+ .. deprecated:: 0.0.18\n+ The 'utm_crs' is deprecated and will be removed in 0.0.18.\n+ (Warning added DToolKit 0.0.17)\n \n Parameters\n ----------\n", "issue": "DEP: Depcrated `utm_crs`\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [ ] closes #xxxx\r\n- [x] whatsnew entry\r\n\r\n`pyproj.database.query_utm_crs_info` too slow to query all data.\r\nFor 1 point will cost 200ms but for 2000 points will cost 200s.\r\nEven try `parallelize` to `utm_crs`, but the speed is still so lower.\n", "before_files": [{"content": "import geopandas as gpd\nimport pandas as pd\nfrom pyproj.aoi import AreaOfInterest\nfrom pyproj.database import query_utm_crs_info\n\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\nfrom dtoolkit.util._decorator import warning\n\n\n@register_geoseries_method\n@warning(\n \"The 'utm_crs' is deprecated and will be removed in 0.0.17. \"\n \"(Warning added DToolKit 0.0.16)\",\n DeprecationWarning,\n stacklevel=3,\n)\ndef utm_crs(s: gpd.GeoSeries, /, datum_name: str = \"WGS 84\") -> pd.Series:\n \"\"\"\n Returns the estimated UTM CRS based on the bounds of each geometry.\n\n .. deprecated:: 0.0.17\n The 'utm_crs' is deprecated and will be removed in 0.0.17.\n (Warning added DToolKit 0.0.16)\n\n Parameters\n ----------\n datum_name : str, default 'WGS 84'\n The name of the datum in the CRS name ('NAD27', 'NAD83', 'WGS 84', \u2026).\n\n Returns\n -------\n Series\n The element type is :class:`~pyproj.database.CRSInfo`.\n\n See Also\n --------\n dtoolkit.geoaccessor.geoseries.utm_crs\n Returns the estimated UTM CRS based on the bounds of each geometry.\n\n dtoolkit.geoaccessor.geodataframe.utm_crs\n Returns the estimated UTM CRS based on the bounds of each geometry.\n\n geopandas.GeoSeries.estimate_utm_crs\n Returns the estimated UTM CRS based on the bounds of the dataset.\n\n geopandas.GeoDataFrame.estimate_utm_crs\n Returns the estimated UTM CRS based on the bounds of the dataset.\n\n Examples\n --------\n >>> import dtoolkit.accessor\n >>> import dtoolkit.geoaccessor\n >>> import geopandas as gpd\n >>> s = gpd.GeoSeries.from_wkt([\"Point (120 50)\", \"Point (100 1)\"], crs=\"epsg:4326\")\n >>> s.utm_crs()\n 0 (EPSG, 32650, WGS 84 / UTM zone 50N, PJType.PR...\n 1 (EPSG, 32647, WGS 84 / UTM zone 47N, PJType.PR...\n dtype: object\n\n Same operate for GeoDataFrame.\n\n >>> s.to_frame(\"geometry\").utm_crs()\n 0 (EPSG, 32650, WGS 84 / UTM zone 50N, PJType.PR...\n 1 (EPSG, 32647, WGS 84 / UTM zone 47N, PJType.PR...\n dtype: object\n\n Get the EPSG code.\n\n >>> s.utm_crs().getattr(\"code\")\n 0 32650\n 1 32647\n dtype: object\n \"\"\"\n\n return s.bounds.apply(\n lambda bound: None\n if bound.isna().all()\n else query_utm_crs_info(\n datum_name=datum_name,\n area_of_interest=AreaOfInterest(\n west_lon_degree=bound[\"minx\"],\n south_lat_degree=bound[\"miny\"],\n east_lon_degree=bound[\"maxx\"],\n north_lat_degree=bound[\"maxy\"],\n ),\n )[0],\n axis=1,\n )\n", "path": "dtoolkit/geoaccessor/geoseries/utm_crs.py"}]}
| 1,805 | 328 |
gh_patches_debug_38481
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-2788
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Routes with duplicate parameter names are not shown in OpenAPI rendering
### Description
OpenAPI schema fails to generate if there's 2 parameters present with identical name, route is subsequently removed from OpenAPI schema.
### URL to code causing the issue
_No response_
### MCVE
```python
from typing import Annotated
from litestar import Litestar, post
from litestar.params import Parameter
@post("/test")
async def route(
name: Annotated[str | None, Parameter(cookie="name")] = None,
name_header: Annotated[str | None, Parameter(header="name")] = None,
) -> str:
return name or name_header or ""
app = Litestar(
route_handlers=[route],
)
```
### Steps to reproduce
```bash
1. Launch uvicorn server `uvicorn app:app`
2. Go to http://127.0.0.1:8000/schema/swagger
3. See error
```
### Screenshots
_No response_
### Logs
```bash
$ uvicorn app:app
INFO: Started server process [8376]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: 127.0.0.1:54807 - "GET /schema/swagger HTTP/1.1" 500 Internal Server Error
INFO: 127.0.0.1:54807 - "GET /schema/swagger HTTP/1.1" 200 OK
```
### Litestar Version
2.3.2
### Platform
- [ ] Linux
- [ ] Mac
- [X] Windows
- [ ] Other (Please specify in the description above)
</issue>
<code>
[start of litestar/_openapi/parameters.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING
4
5 from litestar._openapi.schema_generation.utils import get_formatted_examples
6 from litestar.constants import RESERVED_KWARGS
7 from litestar.enums import ParamType
8 from litestar.exceptions import ImproperlyConfiguredException
9 from litestar.openapi.spec.parameter import Parameter
10 from litestar.openapi.spec.schema import Schema
11 from litestar.params import DependencyKwarg, ParameterKwarg
12 from litestar.types import Empty
13
14 __all__ = ("create_parameter_for_handler",)
15
16 from litestar.typing import FieldDefinition
17
18 if TYPE_CHECKING:
19 from litestar._openapi.schema_generation import SchemaCreator
20 from litestar.di import Provide
21 from litestar.handlers.base import BaseRouteHandler
22 from litestar.openapi.spec import Reference
23 from litestar.types.internal_types import PathParameterDefinition
24
25
26 class ParameterCollection:
27 """Facilitates conditional deduplication of parameters.
28
29 If multiple parameters with the same name are produced for a handler, the condition is ignored if the two
30 ``Parameter`` instances are the same (the first is retained and any duplicates are ignored). If the ``Parameter``
31 instances are not the same, an exception is raised.
32 """
33
34 def __init__(self, route_handler: BaseRouteHandler) -> None:
35 """Initialize ``ParameterCollection``.
36
37 Args:
38 route_handler: Associated route handler
39 """
40 self.route_handler = route_handler
41 self._parameters: dict[str, Parameter] = {}
42
43 def add(self, parameter: Parameter) -> None:
44 """Add a ``Parameter`` to the collection.
45
46 If an existing parameter with the same name and type already exists, the
47 parameter is ignored.
48
49 If an existing parameter with the same name but different type exists, raises
50 ``ImproperlyConfiguredException``.
51 """
52
53 if parameter.name not in self._parameters:
54 # because we are defining routes as unique per path, we have to handle here a situation when there is an optional
55 # path parameter. e.g. get(path=["/", "/{param:str}"]). When parsing the parameter for path, the route handler
56 # would still have a kwarg called param:
57 # def handler(param: str | None) -> ...
58 if parameter.param_in != ParamType.QUERY or all(
59 "{" + parameter.name + ":" not in path for path in self.route_handler.paths
60 ):
61 self._parameters[parameter.name] = parameter
62 return
63
64 pre_existing = self._parameters[parameter.name]
65 if parameter == pre_existing:
66 return
67
68 raise ImproperlyConfiguredException(
69 f"OpenAPI schema generation for handler `{self.route_handler}` detected multiple parameters named "
70 f"'{parameter.name}' with different types."
71 )
72
73 def list(self) -> list[Parameter]:
74 """Return a list of all ``Parameter``'s in the collection."""
75 return list(self._parameters.values())
76
77
78 def create_parameter(
79 field_definition: FieldDefinition,
80 parameter_name: str,
81 path_parameters: tuple[PathParameterDefinition, ...],
82 schema_creator: SchemaCreator,
83 ) -> Parameter:
84 """Create an OpenAPI Parameter instance."""
85
86 result: Schema | Reference | None = None
87 kwarg_definition = (
88 field_definition.kwarg_definition if isinstance(field_definition.kwarg_definition, ParameterKwarg) else None
89 )
90
91 if any(path_param.name == parameter_name for path_param in path_parameters):
92 param_in = ParamType.PATH
93 is_required = True
94 result = schema_creator.for_field_definition(field_definition)
95 elif kwarg_definition and kwarg_definition.header:
96 parameter_name = kwarg_definition.header
97 param_in = ParamType.HEADER
98 is_required = field_definition.is_required
99 elif kwarg_definition and kwarg_definition.cookie:
100 parameter_name = kwarg_definition.cookie
101 param_in = ParamType.COOKIE
102 is_required = field_definition.is_required
103 else:
104 is_required = field_definition.is_required
105 param_in = ParamType.QUERY
106 parameter_name = kwarg_definition.query if kwarg_definition and kwarg_definition.query else parameter_name
107
108 if not result:
109 result = schema_creator.for_field_definition(field_definition)
110
111 schema = result if isinstance(result, Schema) else schema_creator.schemas[result.value]
112
113 examples_list = kwarg_definition.examples or [] if kwarg_definition else []
114 examples = get_formatted_examples(field_definition, examples_list)
115
116 return Parameter(
117 description=schema.description,
118 name=parameter_name,
119 param_in=param_in,
120 required=is_required,
121 schema=result,
122 examples=examples or None,
123 )
124
125
126 def get_recursive_handler_parameters(
127 field_name: str,
128 field_definition: FieldDefinition,
129 dependency_providers: dict[str, Provide],
130 route_handler: BaseRouteHandler,
131 path_parameters: tuple[PathParameterDefinition, ...],
132 schema_creator: SchemaCreator,
133 ) -> list[Parameter]:
134 """Create and return parameters for a handler.
135
136 If the provided field is not a dependency, a normal parameter is created and returned as a list, otherwise
137 `create_parameter_for_handler()` is called to generate parameters for the dependency.
138 """
139
140 if field_name not in dependency_providers:
141 return [
142 create_parameter(
143 field_definition=field_definition,
144 parameter_name=field_name,
145 path_parameters=path_parameters,
146 schema_creator=schema_creator,
147 )
148 ]
149
150 dependency_fields = dependency_providers[field_name].signature_model._fields
151 return create_parameter_for_handler(
152 route_handler=route_handler,
153 handler_fields=dependency_fields,
154 path_parameters=path_parameters,
155 schema_creator=schema_creator,
156 )
157
158
159 def get_layered_parameter(
160 field_name: str,
161 field_definition: FieldDefinition,
162 layered_parameters: dict[str, FieldDefinition],
163 path_parameters: tuple[PathParameterDefinition, ...],
164 schema_creator: SchemaCreator,
165 ) -> Parameter:
166 """Create a layered parameter for a given signature model field.
167
168 Layer info is extracted from the provided ``layered_parameters`` dict and set as the field's ``field_info`` attribute.
169 """
170 layer_field = layered_parameters[field_name]
171
172 field = field_definition if field_definition.is_parameter_field else layer_field
173 default = layer_field.default if field_definition.has_default else field_definition.default
174 annotation = field_definition.annotation if field_definition is not Empty else layer_field.annotation
175
176 parameter_name = field_name
177 if isinstance(field.kwarg_definition, ParameterKwarg):
178 parameter_name = (
179 field.kwarg_definition.query or field.kwarg_definition.header or field.kwarg_definition.cookie or field_name
180 )
181
182 field_definition = FieldDefinition.from_kwarg(
183 inner_types=field.inner_types,
184 default=default,
185 extra=field.extra,
186 annotation=annotation,
187 kwarg_definition=field.kwarg_definition,
188 name=field_name,
189 )
190 return create_parameter(
191 field_definition=field_definition,
192 parameter_name=parameter_name,
193 path_parameters=path_parameters,
194 schema_creator=schema_creator,
195 )
196
197
198 def create_parameter_for_handler(
199 route_handler: BaseRouteHandler,
200 handler_fields: dict[str, FieldDefinition],
201 path_parameters: tuple[PathParameterDefinition, ...],
202 schema_creator: SchemaCreator,
203 ) -> list[Parameter]:
204 """Create a list of path/query/header Parameter models for the given PathHandler."""
205 parameters = ParameterCollection(route_handler=route_handler)
206 dependency_providers = route_handler.resolve_dependencies()
207 layered_parameters = route_handler.resolve_layered_parameters()
208
209 unique_handler_fields = tuple(
210 (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k not in layered_parameters
211 )
212 unique_layered_fields = tuple(
213 (k, v) for k, v in layered_parameters.items() if k not in RESERVED_KWARGS and k not in handler_fields
214 )
215 intersection_fields = tuple(
216 (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k in layered_parameters
217 )
218
219 for field_name, field_definition in unique_handler_fields:
220 if isinstance(field_definition.kwarg_definition, DependencyKwarg) and field_name not in dependency_providers:
221 # never document explicit dependencies
222 continue
223
224 for parameter in get_recursive_handler_parameters(
225 field_name=field_name,
226 field_definition=field_definition,
227 dependency_providers=dependency_providers,
228 route_handler=route_handler,
229 path_parameters=path_parameters,
230 schema_creator=schema_creator,
231 ):
232 parameters.add(parameter)
233
234 for field_name, field_definition in unique_layered_fields:
235 parameters.add(
236 create_parameter(
237 field_definition=field_definition,
238 parameter_name=field_name,
239 path_parameters=path_parameters,
240 schema_creator=schema_creator,
241 )
242 )
243
244 for field_name, field_definition in intersection_fields:
245 parameters.add(
246 get_layered_parameter(
247 field_name=field_name,
248 field_definition=field_definition,
249 layered_parameters=layered_parameters,
250 path_parameters=path_parameters,
251 schema_creator=schema_creator,
252 )
253 )
254
255 return parameters.list()
256
[end of litestar/_openapi/parameters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/litestar/_openapi/parameters.py b/litestar/_openapi/parameters.py
--- a/litestar/_openapi/parameters.py
+++ b/litestar/_openapi/parameters.py
@@ -38,7 +38,7 @@
route_handler: Associated route handler
"""
self.route_handler = route_handler
- self._parameters: dict[str, Parameter] = {}
+ self._parameters: dict[tuple[str, str], Parameter] = {}
def add(self, parameter: Parameter) -> None:
"""Add a ``Parameter`` to the collection.
@@ -50,18 +50,18 @@
``ImproperlyConfiguredException``.
"""
- if parameter.name not in self._parameters:
+ if (parameter.name, parameter.param_in) not in self._parameters:
# because we are defining routes as unique per path, we have to handle here a situation when there is an optional
# path parameter. e.g. get(path=["/", "/{param:str}"]). When parsing the parameter for path, the route handler
# would still have a kwarg called param:
# def handler(param: str | None) -> ...
if parameter.param_in != ParamType.QUERY or all(
- "{" + parameter.name + ":" not in path for path in self.route_handler.paths
+ f"{{{parameter.name}:" not in path for path in self.route_handler.paths
):
- self._parameters[parameter.name] = parameter
+ self._parameters[(parameter.name, parameter.param_in)] = parameter
return
- pre_existing = self._parameters[parameter.name]
+ pre_existing = self._parameters[(parameter.name, parameter.param_in)]
if parameter == pre_existing:
return
@@ -206,13 +206,13 @@
dependency_providers = route_handler.resolve_dependencies()
layered_parameters = route_handler.resolve_layered_parameters()
- unique_handler_fields = tuple(
+ unique_handler_fields = (
(k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k not in layered_parameters
)
- unique_layered_fields = tuple(
+ unique_layered_fields = (
(k, v) for k, v in layered_parameters.items() if k not in RESERVED_KWARGS and k not in handler_fields
)
- intersection_fields = tuple(
+ intersection_fields = (
(k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k in layered_parameters
)
|
{"golden_diff": "diff --git a/litestar/_openapi/parameters.py b/litestar/_openapi/parameters.py\n--- a/litestar/_openapi/parameters.py\n+++ b/litestar/_openapi/parameters.py\n@@ -38,7 +38,7 @@\n route_handler: Associated route handler\n \"\"\"\n self.route_handler = route_handler\n- self._parameters: dict[str, Parameter] = {}\n+ self._parameters: dict[tuple[str, str], Parameter] = {}\n \n def add(self, parameter: Parameter) -> None:\n \"\"\"Add a ``Parameter`` to the collection.\n@@ -50,18 +50,18 @@\n ``ImproperlyConfiguredException``.\n \"\"\"\n \n- if parameter.name not in self._parameters:\n+ if (parameter.name, parameter.param_in) not in self._parameters:\n # because we are defining routes as unique per path, we have to handle here a situation when there is an optional\n # path parameter. e.g. get(path=[\"/\", \"/{param:str}\"]). When parsing the parameter for path, the route handler\n # would still have a kwarg called param:\n # def handler(param: str | None) -> ...\n if parameter.param_in != ParamType.QUERY or all(\n- \"{\" + parameter.name + \":\" not in path for path in self.route_handler.paths\n+ f\"{{{parameter.name}:\" not in path for path in self.route_handler.paths\n ):\n- self._parameters[parameter.name] = parameter\n+ self._parameters[(parameter.name, parameter.param_in)] = parameter\n return\n \n- pre_existing = self._parameters[parameter.name]\n+ pre_existing = self._parameters[(parameter.name, parameter.param_in)]\n if parameter == pre_existing:\n return\n \n@@ -206,13 +206,13 @@\n dependency_providers = route_handler.resolve_dependencies()\n layered_parameters = route_handler.resolve_layered_parameters()\n \n- unique_handler_fields = tuple(\n+ unique_handler_fields = (\n (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k not in layered_parameters\n )\n- unique_layered_fields = tuple(\n+ unique_layered_fields = (\n (k, v) for k, v in layered_parameters.items() if k not in RESERVED_KWARGS and k not in handler_fields\n )\n- intersection_fields = tuple(\n+ intersection_fields = (\n (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k in layered_parameters\n )\n", "issue": "Bug: Routes with duplicate parameter names are not shown in OpenAPI rendering\n### Description\r\n\r\nOpenAPI schema fails to generate if there's 2 parameters present with identical name, route is subsequently removed from OpenAPI schema.\r\n\r\n### URL to code causing the issue\r\n\r\n_No response_\r\n\r\n### MCVE\r\n\r\n```python\r\nfrom typing import Annotated\r\n\r\nfrom litestar import Litestar, post\r\nfrom litestar.params import Parameter\r\n\r\n\r\n@post(\"/test\")\r\nasync def route(\r\n name: Annotated[str | None, Parameter(cookie=\"name\")] = None,\r\n name_header: Annotated[str | None, Parameter(header=\"name\")] = None,\r\n) -> str:\r\n return name or name_header or \"\"\r\n\r\n\r\napp = Litestar(\r\n route_handlers=[route],\r\n)\r\n```\r\n\r\n\r\n### Steps to reproduce\r\n\r\n```bash\r\n1. Launch uvicorn server `uvicorn app:app`\r\n2. Go to http://127.0.0.1:8000/schema/swagger\r\n3. See error\r\n```\r\n\r\n\r\n### Screenshots\r\n\r\n_No response_\r\n\r\n### Logs\r\n\r\n```bash\r\n$ uvicorn app:app\r\nINFO: Started server process [8376]\r\nINFO: Waiting for application startup.\r\nINFO: Application startup complete.\r\nINFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)\r\nINFO: 127.0.0.1:54807 - \"GET /schema/swagger HTTP/1.1\" 500 Internal Server Error\r\nINFO: 127.0.0.1:54807 - \"GET /schema/swagger HTTP/1.1\" 200 OK\r\n```\r\n\r\n\r\n### Litestar Version\r\n\r\n2.3.2\r\n\r\n### Platform\r\n\r\n- [ ] Linux\r\n- [ ] Mac\r\n- [X] Windows\r\n- [ ] Other (Please specify in the description above)\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING\n\nfrom litestar._openapi.schema_generation.utils import get_formatted_examples\nfrom litestar.constants import RESERVED_KWARGS\nfrom litestar.enums import ParamType\nfrom litestar.exceptions import ImproperlyConfiguredException\nfrom litestar.openapi.spec.parameter import Parameter\nfrom litestar.openapi.spec.schema import Schema\nfrom litestar.params import DependencyKwarg, ParameterKwarg\nfrom litestar.types import Empty\n\n__all__ = (\"create_parameter_for_handler\",)\n\nfrom litestar.typing import FieldDefinition\n\nif TYPE_CHECKING:\n from litestar._openapi.schema_generation import SchemaCreator\n from litestar.di import Provide\n from litestar.handlers.base import BaseRouteHandler\n from litestar.openapi.spec import Reference\n from litestar.types.internal_types import PathParameterDefinition\n\n\nclass ParameterCollection:\n \"\"\"Facilitates conditional deduplication of parameters.\n\n If multiple parameters with the same name are produced for a handler, the condition is ignored if the two\n ``Parameter`` instances are the same (the first is retained and any duplicates are ignored). If the ``Parameter``\n instances are not the same, an exception is raised.\n \"\"\"\n\n def __init__(self, route_handler: BaseRouteHandler) -> None:\n \"\"\"Initialize ``ParameterCollection``.\n\n Args:\n route_handler: Associated route handler\n \"\"\"\n self.route_handler = route_handler\n self._parameters: dict[str, Parameter] = {}\n\n def add(self, parameter: Parameter) -> None:\n \"\"\"Add a ``Parameter`` to the collection.\n\n If an existing parameter with the same name and type already exists, the\n parameter is ignored.\n\n If an existing parameter with the same name but different type exists, raises\n ``ImproperlyConfiguredException``.\n \"\"\"\n\n if parameter.name not in self._parameters:\n # because we are defining routes as unique per path, we have to handle here a situation when there is an optional\n # path parameter. e.g. get(path=[\"/\", \"/{param:str}\"]). When parsing the parameter for path, the route handler\n # would still have a kwarg called param:\n # def handler(param: str | None) -> ...\n if parameter.param_in != ParamType.QUERY or all(\n \"{\" + parameter.name + \":\" not in path for path in self.route_handler.paths\n ):\n self._parameters[parameter.name] = parameter\n return\n\n pre_existing = self._parameters[parameter.name]\n if parameter == pre_existing:\n return\n\n raise ImproperlyConfiguredException(\n f\"OpenAPI schema generation for handler `{self.route_handler}` detected multiple parameters named \"\n f\"'{parameter.name}' with different types.\"\n )\n\n def list(self) -> list[Parameter]:\n \"\"\"Return a list of all ``Parameter``'s in the collection.\"\"\"\n return list(self._parameters.values())\n\n\ndef create_parameter(\n field_definition: FieldDefinition,\n parameter_name: str,\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> Parameter:\n \"\"\"Create an OpenAPI Parameter instance.\"\"\"\n\n result: Schema | Reference | None = None\n kwarg_definition = (\n field_definition.kwarg_definition if isinstance(field_definition.kwarg_definition, ParameterKwarg) else None\n )\n\n if any(path_param.name == parameter_name for path_param in path_parameters):\n param_in = ParamType.PATH\n is_required = True\n result = schema_creator.for_field_definition(field_definition)\n elif kwarg_definition and kwarg_definition.header:\n parameter_name = kwarg_definition.header\n param_in = ParamType.HEADER\n is_required = field_definition.is_required\n elif kwarg_definition and kwarg_definition.cookie:\n parameter_name = kwarg_definition.cookie\n param_in = ParamType.COOKIE\n is_required = field_definition.is_required\n else:\n is_required = field_definition.is_required\n param_in = ParamType.QUERY\n parameter_name = kwarg_definition.query if kwarg_definition and kwarg_definition.query else parameter_name\n\n if not result:\n result = schema_creator.for_field_definition(field_definition)\n\n schema = result if isinstance(result, Schema) else schema_creator.schemas[result.value]\n\n examples_list = kwarg_definition.examples or [] if kwarg_definition else []\n examples = get_formatted_examples(field_definition, examples_list)\n\n return Parameter(\n description=schema.description,\n name=parameter_name,\n param_in=param_in,\n required=is_required,\n schema=result,\n examples=examples or None,\n )\n\n\ndef get_recursive_handler_parameters(\n field_name: str,\n field_definition: FieldDefinition,\n dependency_providers: dict[str, Provide],\n route_handler: BaseRouteHandler,\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> list[Parameter]:\n \"\"\"Create and return parameters for a handler.\n\n If the provided field is not a dependency, a normal parameter is created and returned as a list, otherwise\n `create_parameter_for_handler()` is called to generate parameters for the dependency.\n \"\"\"\n\n if field_name not in dependency_providers:\n return [\n create_parameter(\n field_definition=field_definition,\n parameter_name=field_name,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n ]\n\n dependency_fields = dependency_providers[field_name].signature_model._fields\n return create_parameter_for_handler(\n route_handler=route_handler,\n handler_fields=dependency_fields,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n\n\ndef get_layered_parameter(\n field_name: str,\n field_definition: FieldDefinition,\n layered_parameters: dict[str, FieldDefinition],\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> Parameter:\n \"\"\"Create a layered parameter for a given signature model field.\n\n Layer info is extracted from the provided ``layered_parameters`` dict and set as the field's ``field_info`` attribute.\n \"\"\"\n layer_field = layered_parameters[field_name]\n\n field = field_definition if field_definition.is_parameter_field else layer_field\n default = layer_field.default if field_definition.has_default else field_definition.default\n annotation = field_definition.annotation if field_definition is not Empty else layer_field.annotation\n\n parameter_name = field_name\n if isinstance(field.kwarg_definition, ParameterKwarg):\n parameter_name = (\n field.kwarg_definition.query or field.kwarg_definition.header or field.kwarg_definition.cookie or field_name\n )\n\n field_definition = FieldDefinition.from_kwarg(\n inner_types=field.inner_types,\n default=default,\n extra=field.extra,\n annotation=annotation,\n kwarg_definition=field.kwarg_definition,\n name=field_name,\n )\n return create_parameter(\n field_definition=field_definition,\n parameter_name=parameter_name,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n\n\ndef create_parameter_for_handler(\n route_handler: BaseRouteHandler,\n handler_fields: dict[str, FieldDefinition],\n path_parameters: tuple[PathParameterDefinition, ...],\n schema_creator: SchemaCreator,\n) -> list[Parameter]:\n \"\"\"Create a list of path/query/header Parameter models for the given PathHandler.\"\"\"\n parameters = ParameterCollection(route_handler=route_handler)\n dependency_providers = route_handler.resolve_dependencies()\n layered_parameters = route_handler.resolve_layered_parameters()\n\n unique_handler_fields = tuple(\n (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k not in layered_parameters\n )\n unique_layered_fields = tuple(\n (k, v) for k, v in layered_parameters.items() if k not in RESERVED_KWARGS and k not in handler_fields\n )\n intersection_fields = tuple(\n (k, v) for k, v in handler_fields.items() if k not in RESERVED_KWARGS and k in layered_parameters\n )\n\n for field_name, field_definition in unique_handler_fields:\n if isinstance(field_definition.kwarg_definition, DependencyKwarg) and field_name not in dependency_providers:\n # never document explicit dependencies\n continue\n\n for parameter in get_recursive_handler_parameters(\n field_name=field_name,\n field_definition=field_definition,\n dependency_providers=dependency_providers,\n route_handler=route_handler,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n ):\n parameters.add(parameter)\n\n for field_name, field_definition in unique_layered_fields:\n parameters.add(\n create_parameter(\n field_definition=field_definition,\n parameter_name=field_name,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n )\n\n for field_name, field_definition in intersection_fields:\n parameters.add(\n get_layered_parameter(\n field_name=field_name,\n field_definition=field_definition,\n layered_parameters=layered_parameters,\n path_parameters=path_parameters,\n schema_creator=schema_creator,\n )\n )\n\n return parameters.list()\n", "path": "litestar/_openapi/parameters.py"}]}
| 3,555 | 565 |
gh_patches_debug_5539
|
rasdani/github-patches
|
git_diff
|
acl-org__acl-anthology-2313
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ingestion request: Generation challenges at INLG 2022
This is to complete the ingestions of all papers from INLG; the Generation Challenges papers still needed to be uploaded. See #1897 for the other papers.
Here are the papers and metadata from the INLG generation challenges, as generated using ACLPUB2: https://drive.google.com/file/d/1518aAVuvtbvHgw_6FREzJl0kip_lkqNg/view?usp=share_link
I think this matches the Anthology format, but I'm not sure as I added everything manually. (Export didn't work.) Could you check whether everything is OK to ingest in the Anthology? Many thanks!
</issue>
<code>
[start of bin/volumes_from_diff.py]
1 #!/usr/bin/env python3
2
3 """
4 Takes a list of XML files on STDIN, and prints all the volumes
5 within each of those files. e.g.,
6
7 git diff --name-only master | ./bin/volumes_from_xml.py https://preview.aclanthology.org/BRANCH
8
9 Used to find the list of volumes to generate previews for.
10 """
11
12 import sys
13 import argparse
14 import lxml.etree as etree
15 import subprocess
16
17
18 parser = argparse.ArgumentParser()
19 parser.add_argument("url_root")
20 args = parser.parse_args()
21
22 volumes = []
23 for filepath in sys.stdin:
24 try:
25 tree = etree.parse(filepath.rstrip())
26 except Exception as e:
27 continue
28 root = tree.getroot()
29 collection_id = root.attrib["id"]
30 for volume in root:
31 volume_name = volume.attrib["id"]
32 volume_id = f"{collection_id}-{volume_name}"
33 volumes.append(f"[{volume_id}]({args.url_root}/{volume_id})")
34
35 if len(volumes) > 50:
36 volumes = volumes[0:50] + [f"(plus {len(volumes)-50} more...)"]
37
38 print(", ".join(volumes))
39
[end of bin/volumes_from_diff.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bin/volumes_from_diff.py b/bin/volumes_from_diff.py
--- a/bin/volumes_from_diff.py
+++ b/bin/volumes_from_diff.py
@@ -27,7 +27,7 @@
continue
root = tree.getroot()
collection_id = root.attrib["id"]
- for volume in root:
+ for volume in root.findall("./volume"):
volume_name = volume.attrib["id"]
volume_id = f"{collection_id}-{volume_name}"
volumes.append(f"[{volume_id}]({args.url_root}/{volume_id})")
|
{"golden_diff": "diff --git a/bin/volumes_from_diff.py b/bin/volumes_from_diff.py\n--- a/bin/volumes_from_diff.py\n+++ b/bin/volumes_from_diff.py\n@@ -27,7 +27,7 @@\n continue\n root = tree.getroot()\n collection_id = root.attrib[\"id\"]\n- for volume in root:\n+ for volume in root.findall(\"./volume\"):\n volume_name = volume.attrib[\"id\"]\n volume_id = f\"{collection_id}-{volume_name}\"\n volumes.append(f\"[{volume_id}]({args.url_root}/{volume_id})\")\n", "issue": "Ingestion request: Generation challenges at INLG 2022\nThis is to complete the ingestions of all papers from INLG; the Generation Challenges papers still needed to be uploaded. See #1897 for the other papers. \r\n\r\nHere are the papers and metadata from the INLG generation challenges, as generated using ACLPUB2: https://drive.google.com/file/d/1518aAVuvtbvHgw_6FREzJl0kip_lkqNg/view?usp=share_link\r\n\r\nI think this matches the Anthology format, but I'm not sure as I added everything manually. (Export didn't work.) Could you check whether everything is OK to ingest in the Anthology? Many thanks!\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n\"\"\"\nTakes a list of XML files on STDIN, and prints all the volumes\nwithin each of those files. e.g.,\n\n git diff --name-only master | ./bin/volumes_from_xml.py https://preview.aclanthology.org/BRANCH\n\nUsed to find the list of volumes to generate previews for.\n\"\"\"\n\nimport sys\nimport argparse\nimport lxml.etree as etree\nimport subprocess\n\n\nparser = argparse.ArgumentParser()\nparser.add_argument(\"url_root\")\nargs = parser.parse_args()\n\nvolumes = []\nfor filepath in sys.stdin:\n try:\n tree = etree.parse(filepath.rstrip())\n except Exception as e:\n continue\n root = tree.getroot()\n collection_id = root.attrib[\"id\"]\n for volume in root:\n volume_name = volume.attrib[\"id\"]\n volume_id = f\"{collection_id}-{volume_name}\"\n volumes.append(f\"[{volume_id}]({args.url_root}/{volume_id})\")\n\nif len(volumes) > 50:\n volumes = volumes[0:50] + [f\"(plus {len(volumes)-50} more...)\"]\n\nprint(\", \".join(volumes))\n", "path": "bin/volumes_from_diff.py"}]}
| 1,011 | 123 |
gh_patches_debug_9119
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-786
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrade PyTorch requirement from `2.1.0` to `2.1.2`
**Is your feature request related to a problem? Please describe.**
The new `2.1` versions have significant bugfixes [[ref](https://github.com/pytorch/pytorch/releases/tag/v2.1.1),[ref](https://github.com/pytorch/pytorch/releases/tag/v2.1.2)], and it would be good to enable these.
**Describe the solution you'd like**
Update `setup.py`
**Describe alternatives you've considered**
N.A.
**Additional context**
N.A.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 """The setup script."""
4
5
6 import sys, re, os
7 from setuptools import setup, find_packages
8 from setuptools.command.install import install
9 from setuptools.command.develop import develop
10 from setuptools.command.egg_info import egg_info
11
12 try:
13 with open("README.md") as readme_file:
14 readme = readme_file.read()
15 except Exception as error:
16 readme = "No README information found."
17 sys.stderr.write(
18 "Warning: Could not open '%s' due %s\n" % ("README.md", error)
19 )
20
21
22 class CustomInstallCommand(install):
23 def run(self):
24 install.run(self)
25
26
27 class CustomDevelopCommand(develop):
28 def run(self):
29 develop.run(self)
30
31
32 class CustomEggInfoCommand(egg_info):
33 def run(self):
34 egg_info.run(self)
35
36
37 try:
38 filepath = "GANDLF/version.py"
39 version_file = open(filepath)
40 (__version__,) = re.findall('__version__ = "(.*)"', version_file.read())
41
42 except Exception as error:
43 __version__ = "0.0.1"
44 sys.stderr.write(
45 "Warning: Could not open '%s' due %s\n" % (filepath, error)
46 )
47
48 # Handle cases where specific files need to be bundled into the final package as installed via PyPI
49 dockerfiles = [
50 item
51 for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))
52 if (os.path.isfile(item) and item.startswith("Dockerfile-"))
53 ]
54 entrypoint_files = [
55 item
56 for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))
57 if (os.path.isfile(item) and item.startswith("gandlf_"))
58 ]
59 setup_files = ["setup.py", ".dockerignore", "pyproject.toml", "MANIFEST.in"]
60 all_extra_files = dockerfiles + entrypoint_files + setup_files
61 all_extra_files_pathcorrected = [
62 os.path.join("../", item) for item in all_extra_files
63 ]
64 # find_packages should only ever find these as subpackages of gandlf, not as top-level packages
65 # generate this dynamically?
66 # GANDLF.GANDLF is needed to prevent recursion madness in deployments
67 toplevel_package_excludes = [
68 "GANDLF.GANDLF",
69 "anonymize",
70 "cli",
71 "compute",
72 "data",
73 "grad_clipping",
74 "losses",
75 "metrics",
76 "models",
77 "optimizers",
78 "schedulers",
79 "utils",
80 ]
81
82
83 requirements = [
84 "torch==2.1.0",
85 "black==23.11.0",
86 "numpy==1.25.0",
87 "scipy",
88 "SimpleITK!=2.0.*",
89 "SimpleITK!=2.2.1", # https://github.com/mlcommons/GaNDLF/issues/536
90 "torchvision",
91 "tqdm",
92 "torchio==0.19.3",
93 "pandas>=2.0.0",
94 "scikit-learn>=0.23.2",
95 "scikit-image>=0.19.1",
96 "setuptools",
97 "seaborn",
98 "pyyaml",
99 "tiffslide",
100 "matplotlib",
101 "gdown==4.6.3",
102 "pytest",
103 "coverage",
104 "pytest-cov",
105 "psutil",
106 "medcam",
107 "opencv-python",
108 "torchmetrics==1.1.2",
109 "zarr==2.10.3",
110 "pydicom",
111 "onnx",
112 "torchinfo==1.7.0",
113 "segmentation-models-pytorch==0.3.3",
114 "ACSConv==0.1.1",
115 "docker",
116 "dicom-anonymizer",
117 "twine",
118 "zarr",
119 "keyring",
120 "monai==1.3.0",
121 ]
122
123 if __name__ == "__main__":
124 setup(
125 name="GANDLF",
126 version=__version__,
127 author="MLCommons",
128 author_email="[email protected]",
129 python_requires=">3.8, <3.12",
130 packages=find_packages(
131 where=os.path.dirname(os.path.abspath(__file__)),
132 exclude=toplevel_package_excludes,
133 ),
134 cmdclass={
135 "install": CustomInstallCommand,
136 "develop": CustomDevelopCommand,
137 "egg_info": CustomEggInfoCommand,
138 },
139 scripts=[
140 "gandlf_run",
141 "gandlf_constructCSV",
142 "gandlf_collectStats",
143 "gandlf_patchMiner",
144 "gandlf_preprocess",
145 "gandlf_anonymizer",
146 "gandlf_verifyInstall",
147 "gandlf_configGenerator",
148 "gandlf_recoverConfig",
149 "gandlf_deploy",
150 "gandlf_optimizeModel",
151 "gandlf_generateMetrics",
152 ],
153 classifiers=[
154 "Development Status :: 3 - Alpha",
155 "Intended Audience :: Science/Research",
156 "License :: OSI Approved :: Apache Software License",
157 "Natural Language :: English",
158 "Operating System :: OS Independent",
159 "Programming Language :: Python :: 3.9",
160 "Programming Language :: Python :: 3.10",
161 "Programming Language :: Python :: 3.11",
162 "Topic :: Scientific/Engineering :: Medical Science Apps.",
163 ],
164 description=(
165 "PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging."
166 ),
167 install_requires=requirements,
168 license="Apache-2.0",
169 long_description=readme,
170 long_description_content_type="text/markdown",
171 include_package_data=True,
172 package_data={"GANDLF": all_extra_files_pathcorrected},
173 keywords="semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch",
174 zip_safe=False,
175 )
176
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -81,7 +81,7 @@
requirements = [
- "torch==2.1.0",
+ "torch==2.1.2",
"black==23.11.0",
"numpy==1.25.0",
"scipy",
@@ -89,7 +89,7 @@
"SimpleITK!=2.2.1", # https://github.com/mlcommons/GaNDLF/issues/536
"torchvision",
"tqdm",
- "torchio==0.19.3",
+ "torchio==0.19.5",
"pandas>=2.0.0",
"scikit-learn>=0.23.2",
"scikit-image>=0.19.1",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -81,7 +81,7 @@\n \n \n requirements = [\n- \"torch==2.1.0\",\n+ \"torch==2.1.2\",\n \"black==23.11.0\",\n \"numpy==1.25.0\",\n \"scipy\",\n@@ -89,7 +89,7 @@\n \"SimpleITK!=2.2.1\", # https://github.com/mlcommons/GaNDLF/issues/536\n \"torchvision\",\n \"tqdm\",\n- \"torchio==0.19.3\",\n+ \"torchio==0.19.5\",\n \"pandas>=2.0.0\",\n \"scikit-learn>=0.23.2\",\n \"scikit-image>=0.19.1\",\n", "issue": "Upgrade PyTorch requirement from `2.1.0` to `2.1.2`\n**Is your feature request related to a problem? Please describe.**\r\nThe new `2.1` versions have significant bugfixes [[ref](https://github.com/pytorch/pytorch/releases/tag/v2.1.1),[ref](https://github.com/pytorch/pytorch/releases/tag/v2.1.2)], and it would be good to enable these.\r\n\r\n**Describe the solution you'd like**\r\nUpdate `setup.py`\r\n\r\n**Describe alternatives you've considered**\r\nN.A.\r\n\r\n**Additional context**\r\nN.A.\n", "before_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"The setup script.\"\"\"\n\n\nimport sys, re, os\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\nfrom setuptools.command.egg_info import egg_info\n\ntry:\n with open(\"README.md\") as readme_file:\n readme = readme_file.read()\nexcept Exception as error:\n readme = \"No README information found.\"\n sys.stderr.write(\n \"Warning: Could not open '%s' due %s\\n\" % (\"README.md\", error)\n )\n\n\nclass CustomInstallCommand(install):\n def run(self):\n install.run(self)\n\n\nclass CustomDevelopCommand(develop):\n def run(self):\n develop.run(self)\n\n\nclass CustomEggInfoCommand(egg_info):\n def run(self):\n egg_info.run(self)\n\n\ntry:\n filepath = \"GANDLF/version.py\"\n version_file = open(filepath)\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\n\nexcept Exception as error:\n __version__ = \"0.0.1\"\n sys.stderr.write(\n \"Warning: Could not open '%s' due %s\\n\" % (filepath, error)\n )\n\n# Handle cases where specific files need to be bundled into the final package as installed via PyPI\ndockerfiles = [\n item\n for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))\n if (os.path.isfile(item) and item.startswith(\"Dockerfile-\"))\n]\nentrypoint_files = [\n item\n for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))\n if (os.path.isfile(item) and item.startswith(\"gandlf_\"))\n]\nsetup_files = [\"setup.py\", \".dockerignore\", \"pyproject.toml\", \"MANIFEST.in\"]\nall_extra_files = dockerfiles + entrypoint_files + setup_files\nall_extra_files_pathcorrected = [\n os.path.join(\"../\", item) for item in all_extra_files\n]\n# find_packages should only ever find these as subpackages of gandlf, not as top-level packages\n# generate this dynamically?\n# GANDLF.GANDLF is needed to prevent recursion madness in deployments\ntoplevel_package_excludes = [\n \"GANDLF.GANDLF\",\n \"anonymize\",\n \"cli\",\n \"compute\",\n \"data\",\n \"grad_clipping\",\n \"losses\",\n \"metrics\",\n \"models\",\n \"optimizers\",\n \"schedulers\",\n \"utils\",\n]\n\n\nrequirements = [\n \"torch==2.1.0\",\n \"black==23.11.0\",\n \"numpy==1.25.0\",\n \"scipy\",\n \"SimpleITK!=2.0.*\",\n \"SimpleITK!=2.2.1\", # https://github.com/mlcommons/GaNDLF/issues/536\n \"torchvision\",\n \"tqdm\",\n \"torchio==0.19.3\",\n \"pandas>=2.0.0\",\n \"scikit-learn>=0.23.2\",\n \"scikit-image>=0.19.1\",\n \"setuptools\",\n \"seaborn\",\n \"pyyaml\",\n \"tiffslide\",\n \"matplotlib\",\n \"gdown==4.6.3\",\n \"pytest\",\n \"coverage\",\n \"pytest-cov\",\n \"psutil\",\n \"medcam\",\n \"opencv-python\",\n \"torchmetrics==1.1.2\",\n \"zarr==2.10.3\",\n \"pydicom\",\n \"onnx\",\n \"torchinfo==1.7.0\",\n \"segmentation-models-pytorch==0.3.3\",\n \"ACSConv==0.1.1\",\n \"docker\",\n \"dicom-anonymizer\",\n \"twine\",\n \"zarr\",\n \"keyring\",\n \"monai==1.3.0\",\n]\n\nif __name__ == \"__main__\":\n setup(\n name=\"GANDLF\",\n version=__version__,\n author=\"MLCommons\",\n author_email=\"[email protected]\",\n python_requires=\">3.8, <3.12\",\n packages=find_packages(\n where=os.path.dirname(os.path.abspath(__file__)),\n exclude=toplevel_package_excludes,\n ),\n cmdclass={\n \"install\": CustomInstallCommand,\n \"develop\": CustomDevelopCommand,\n \"egg_info\": CustomEggInfoCommand,\n },\n scripts=[\n \"gandlf_run\",\n \"gandlf_constructCSV\",\n \"gandlf_collectStats\",\n \"gandlf_patchMiner\",\n \"gandlf_preprocess\",\n \"gandlf_anonymizer\",\n \"gandlf_verifyInstall\",\n \"gandlf_configGenerator\",\n \"gandlf_recoverConfig\",\n \"gandlf_deploy\",\n \"gandlf_optimizeModel\",\n \"gandlf_generateMetrics\",\n ],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Topic :: Scientific/Engineering :: Medical Science Apps.\",\n ],\n description=(\n \"PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging.\"\n ),\n install_requires=requirements,\n license=\"Apache-2.0\",\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n package_data={\"GANDLF\": all_extra_files_pathcorrected},\n keywords=\"semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch\",\n zip_safe=False,\n )\n", "path": "setup.py"}]}
| 2,378 | 203 |
gh_patches_debug_42398
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-1461
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Could you add following command: "Show all occurrences and rename symbol"
Hi!
I would like to see all occurrences of symbol before renaming.
It would be nice to have this command.
Thanks!
</issue>
<code>
[start of plugin/core/panels.py]
1 from .typing import Dict, Optional, List, Generator, Tuple
2 from .types import debounced
3 from contextlib import contextmanager
4 import sublime
5 import sublime_plugin
6
7
8 # about 80 chars per line implies maintaining a buffer of about 40kb per window
9 SERVER_PANEL_MAX_LINES = 500
10
11 # If nothing else shows up after 80ms, actually print the messages to the panel
12 SERVER_PANEL_DEBOUNCE_TIME_MS = 80
13
14 OUTPUT_PANEL_SETTINGS = {
15 "auto_indent": False,
16 "draw_indent_guides": False,
17 "draw_unicode_white_space": "none",
18 "draw_white_space": "none",
19 "fold_buttons": True,
20 "gutter": True,
21 "is_widget": True,
22 "line_numbers": False,
23 "lsp_active": True,
24 "margin": 3,
25 "match_brackets": False,
26 "rulers": [],
27 "scroll_past_end": False,
28 "show_definitions": False,
29 "tab_size": 4,
30 "translate_tabs_to_spaces": False,
31 "word_wrap": False
32 }
33
34
35 class PanelName:
36 Diagnostics = "diagnostics"
37 References = "references"
38 LanguageServers = "language servers"
39
40
41 @contextmanager
42 def mutable(view: sublime.View) -> Generator:
43 view.set_read_only(False)
44 yield
45 view.set_read_only(True)
46
47
48 def create_output_panel(window: sublime.Window, name: str) -> Optional[sublime.View]:
49 panel = window.create_output_panel(name)
50 settings = panel.settings()
51 for key, value in OUTPUT_PANEL_SETTINGS.items():
52 settings.set(key, value)
53 return panel
54
55
56 def destroy_output_panels(window: sublime.Window) -> None:
57 for field in filter(lambda a: not a.startswith('__'), PanelName.__dict__.keys()):
58 panel_name = getattr(PanelName, field)
59 panel = window.find_output_panel(panel_name)
60 if panel and panel.is_valid():
61 panel.settings().set("syntax", "Packages/Text/Plain text.tmLanguage")
62 window.destroy_output_panel(panel_name)
63
64
65 def create_panel(window: sublime.Window, name: str, result_file_regex: str, result_line_regex: str,
66 syntax: str) -> Optional[sublime.View]:
67 panel = create_output_panel(window, name)
68 if not panel:
69 return None
70 if result_file_regex:
71 panel.settings().set("result_file_regex", result_file_regex)
72 if result_line_regex:
73 panel.settings().set("result_line_regex", result_line_regex)
74 panel.assign_syntax(syntax)
75 # Call create_output_panel a second time after assigning the above
76 # settings, so that it'll be picked up as a result buffer
77 # see: Packages/Default/exec.py#L228-L230
78 panel = window.create_output_panel(name)
79 # All our panels are read-only
80 panel.set_read_only(True)
81 return panel
82
83
84 def ensure_panel(window: sublime.Window, name: str, result_file_regex: str, result_line_regex: str,
85 syntax: str) -> Optional[sublime.View]:
86 return window.find_output_panel(name) or create_panel(window, name, result_file_regex, result_line_regex, syntax)
87
88
89 class LspClearPanelCommand(sublime_plugin.TextCommand):
90 """
91 A clear_panel command to clear the error panel.
92 """
93
94 def run(self, edit: sublime.Edit) -> None:
95 with mutable(self.view):
96 self.view.erase(edit, sublime.Region(0, self.view.size()))
97
98
99 class LspUpdatePanelCommand(sublime_plugin.TextCommand):
100 """
101 A update_panel command to update the error panel with new text.
102 """
103
104 def run(self, edit: sublime.Edit, characters: Optional[str] = "") -> None:
105 # Clear folds
106 self.view.unfold(sublime.Region(0, self.view.size()))
107
108 with mutable(self.view):
109 self.view.replace(edit, sublime.Region(0, self.view.size()), characters or "")
110
111 # Clear the selection
112 selection = self.view.sel()
113 selection.clear()
114
115
116 def ensure_server_panel(window: sublime.Window) -> Optional[sublime.View]:
117 return ensure_panel(window, PanelName.LanguageServers, "", "", "Packages/LSP/Syntaxes/ServerLog.sublime-syntax")
118
119
120 def update_server_panel(window: sublime.Window, prefix: str, message: str) -> None:
121 if not window.is_valid():
122 return
123 window_id = window.id()
124 panel = ensure_server_panel(window)
125 if not panel:
126 return
127 LspUpdateServerPanelCommand.to_be_processed.setdefault(window_id, []).append((prefix, message))
128 previous_length = len(LspUpdateServerPanelCommand.to_be_processed[window_id])
129
130 def condition() -> bool:
131 if not panel:
132 return False
133 if not panel.is_valid():
134 return False
135 to_process = LspUpdateServerPanelCommand.to_be_processed.get(window_id)
136 if to_process is None:
137 return False
138 current_length = len(to_process)
139 if current_length >= 10:
140 # Do not let the queue grow large.
141 return True
142 # If the queue remains stable, flush the messages.
143 return current_length == previous_length
144
145 debounced(
146 lambda: panel.run_command("lsp_update_server_panel", {"window_id": window_id}) if panel else None,
147 SERVER_PANEL_DEBOUNCE_TIME_MS,
148 condition
149 )
150
151
152 class LspUpdateServerPanelCommand(sublime_plugin.TextCommand):
153
154 to_be_processed = {} # type: Dict[int, List[Tuple[str, str]]]
155
156 def run(self, edit: sublime.Edit, window_id: int) -> None:
157 to_process = self.to_be_processed.pop(window_id)
158 with mutable(self.view):
159 for prefix, message in to_process:
160 message = message.replace("\r\n", "\n") # normalize Windows eol
161 self.view.insert(edit, self.view.size(), "{}: {}\n".format(prefix, message))
162 total_lines, _ = self.view.rowcol(self.view.size())
163 point = 0 # Starting from point 0 in the panel ...
164 regions = [] # type: List[sublime.Region]
165 for _ in range(0, max(0, total_lines - SERVER_PANEL_MAX_LINES)):
166 # ... collect all regions that span an entire line ...
167 region = self.view.full_line(point)
168 regions.append(region)
169 point = region.b
170 for region in reversed(regions):
171 # ... and erase them in reverse order
172 self.view.erase(edit, region)
173
[end of plugin/core/panels.py]
[start of plugin/rename.py]
1 import sublime
2 import sublime_plugin
3 from .core.edit import apply_workspace_edit
4 from .core.edit import parse_workspace_edit
5 from .core.protocol import Range
6 from .core.protocol import Request
7 from .core.registry import get_position
8 from .core.registry import LspTextCommand
9 from .core.typing import Any, Optional
10 from .core.views import range_to_region
11 from .core.views import text_document_position_params
12
13
14 class RenameSymbolInputHandler(sublime_plugin.TextInputHandler):
15 def __init__(self, view: sublime.View, placeholder: str) -> None:
16 self.view = view
17 self._placeholder = placeholder
18
19 def name(self) -> str:
20 return "new_name"
21
22 def placeholder(self) -> str:
23 return self._placeholder
24
25 def initial_text(self) -> str:
26 return self.placeholder()
27
28 def validate(self, name: str) -> bool:
29 return len(name) > 0
30
31
32 class LspSymbolRenameCommand(LspTextCommand):
33
34 capability = 'renameProvider'
35
36 # mypy: Signature of "is_enabled" incompatible with supertype "LspTextCommand"
37 def is_enabled( # type: ignore
38 self,
39 new_name: str = "",
40 placeholder: str = "",
41 position: Optional[int] = None,
42 event: Optional[dict] = None,
43 point: Optional[int] = None
44 ) -> bool:
45 if self.best_session("renameProvider.prepareProvider"):
46 # The language server will tell us if the selection is on a valid token.
47 return True
48 return super().is_enabled(event, point)
49
50 def input(self, args: dict) -> Optional[sublime_plugin.TextInputHandler]:
51 if "new_name" not in args:
52 placeholder = args.get("placeholder", "")
53 if not placeholder:
54 point = args.get("point")
55 # guess the symbol name
56 if not isinstance(point, int):
57 point = self.view.sel()[0].b
58 placeholder = self.view.substr(self.view.word(point))
59 return RenameSymbolInputHandler(self.view, placeholder)
60 else:
61 return None
62
63 def run(
64 self,
65 edit: sublime.Edit,
66 new_name: str = "",
67 placeholder: str = "",
68 position: Optional[int] = None,
69 event: Optional[dict] = None,
70 point: Optional[int] = None
71 ) -> None:
72 if position is None:
73 pos = get_position(self.view, event, point)
74 if new_name:
75 return self._do_rename(pos, new_name)
76 else:
77 session = self.best_session("{}.prepareProvider".format(self.capability))
78 if session:
79 params = text_document_position_params(self.view, pos)
80 request = Request.prepareRename(params, self.view)
81 self.event = event
82 session.send_request(request, lambda r: self.on_prepare_result(r, pos), self.on_prepare_error)
83 else:
84 # trigger InputHandler manually
85 raise TypeError("required positional argument")
86 else:
87 if new_name:
88 return self._do_rename(position, new_name)
89 else:
90 # trigger InputHandler manually
91 raise TypeError("required positional argument")
92
93 def _do_rename(self, position: int, new_name: str) -> None:
94 session = self.best_session(self.capability)
95 if session:
96 params = text_document_position_params(self.view, position)
97 params["newName"] = new_name
98 session.send_request(
99 Request.rename(params, self.view),
100 # This has to run on the main thread due to calling apply_workspace_edit
101 lambda r: sublime.set_timeout(lambda: self.on_rename_result(r))
102 )
103
104 def on_rename_result(self, response: Any) -> None:
105 window = self.view.window()
106 if window:
107 if response:
108 apply_workspace_edit(window, parse_workspace_edit(response))
109 else:
110 window.status_message('Nothing to rename')
111
112 def on_prepare_result(self, response: Any, pos: int) -> None:
113 if response is None:
114 sublime.error_message("The current selection cannot be renamed")
115 return
116 # It must be a dict at this point.
117 if "placeholder" in response:
118 placeholder = response["placeholder"]
119 r = response["range"]
120 else:
121 placeholder = self.view.substr(self.view.word(pos))
122 r = response
123 region = range_to_region(Range.from_lsp(r), self.view)
124 args = {"placeholder": placeholder, "position": region.a, "event": self.event}
125 self.view.run_command("lsp_symbol_rename", args)
126
127 def on_prepare_error(self, error: Any) -> None:
128 sublime.error_message("Rename error: {}".format(error["message"]))
129
[end of plugin/rename.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/core/panels.py b/plugin/core/panels.py
--- a/plugin/core/panels.py
+++ b/plugin/core/panels.py
@@ -35,6 +35,7 @@
class PanelName:
Diagnostics = "diagnostics"
References = "references"
+ Rename = "rename"
LanguageServers = "language servers"
diff --git a/plugin/rename.py b/plugin/rename.py
--- a/plugin/rename.py
+++ b/plugin/rename.py
@@ -1,14 +1,19 @@
-import sublime
-import sublime_plugin
from .core.edit import apply_workspace_edit
from .core.edit import parse_workspace_edit
+from .core.edit import TextEdit
+from .core.panels import ensure_panel
+from .core.panels import PanelName
from .core.protocol import Range
from .core.protocol import Request
from .core.registry import get_position
from .core.registry import LspTextCommand
-from .core.typing import Any, Optional
+from .core.registry import windows
+from .core.typing import Any, Optional, Dict, List
from .core.views import range_to_region
from .core.views import text_document_position_params
+import os
+import sublime
+import sublime_plugin
class RenameSymbolInputHandler(sublime_plugin.TextInputHandler):
@@ -105,7 +110,18 @@
window = self.view.window()
if window:
if response:
- apply_workspace_edit(window, parse_workspace_edit(response))
+ changes = parse_workspace_edit(response)
+ file_count = len(changes.keys())
+ if file_count > 1:
+ total_changes = sum(map(len, changes.values()))
+ message = "Replace {} occurrences across {} files?".format(total_changes, file_count)
+ choice = sublime.yes_no_cancel_dialog(message, "Replace", "Dry Run")
+ if choice == sublime.DIALOG_YES:
+ apply_workspace_edit(window, changes)
+ elif choice == sublime.DIALOG_NO:
+ self._render_rename_panel(changes, total_changes, file_count)
+ else:
+ apply_workspace_edit(window, changes)
else:
window.status_message('Nothing to rename')
@@ -126,3 +142,49 @@
def on_prepare_error(self, error: Any) -> None:
sublime.error_message("Rename error: {}".format(error["message"]))
+
+ def _get_relative_path(self, file_path: str) -> str:
+ window = self.view.window()
+ if not window:
+ return file_path
+ base_dir = windows.lookup(window).get_project_path(file_path)
+ if base_dir:
+ return os.path.relpath(file_path, base_dir)
+ else:
+ return file_path
+
+ def _render_rename_panel(self, changes: Dict[str, List[TextEdit]], total_changes: int, file_count: int) -> None:
+ window = self.view.window()
+ if not window:
+ return
+ panel = ensure_rename_panel(window)
+ if not panel:
+ return
+ text = ''
+ for file, file_changes in changes.items():
+ text += '◌ {}:\n'.format(self._get_relative_path(file))
+ for edit in file_changes:
+ start = edit[0]
+ text += '\t{:>8}:{}\n'.format(start[0] + 1, start[1] + 1)
+ # append a new line after each file name
+ text += '\n'
+ base_dir = windows.lookup(window).get_project_path(self.view.file_name() or "")
+ panel.settings().set("result_base_dir", base_dir)
+ panel.run_command("lsp_clear_panel")
+ window.run_command("show_panel", {"panel": "output.rename"})
+ fmt = "{} changes across {} files. Double-click on a row:col number to jump to that location.\n\n{}"
+ panel.run_command('append', {
+ 'characters': fmt.format(total_changes, file_count, text),
+ 'force': True,
+ 'scroll_to_end': False
+ })
+
+
+def ensure_rename_panel(window: sublime.Window) -> Optional[sublime.View]:
+ return ensure_panel(
+ window=window,
+ name=PanelName.Rename,
+ result_file_regex=r"^\s*\S\s+(\S.*):$",
+ result_line_regex=r"^\s*([0-9]+):([0-9]+)\s*$",
+ syntax="Packages/LSP/Syntaxes/Rename.sublime-syntax"
+ )
|
{"golden_diff": "diff --git a/plugin/core/panels.py b/plugin/core/panels.py\n--- a/plugin/core/panels.py\n+++ b/plugin/core/panels.py\n@@ -35,6 +35,7 @@\n class PanelName:\n Diagnostics = \"diagnostics\"\n References = \"references\"\n+ Rename = \"rename\"\n LanguageServers = \"language servers\"\n \n \ndiff --git a/plugin/rename.py b/plugin/rename.py\n--- a/plugin/rename.py\n+++ b/plugin/rename.py\n@@ -1,14 +1,19 @@\n-import sublime\n-import sublime_plugin\n from .core.edit import apply_workspace_edit\n from .core.edit import parse_workspace_edit\n+from .core.edit import TextEdit\n+from .core.panels import ensure_panel\n+from .core.panels import PanelName\n from .core.protocol import Range\n from .core.protocol import Request\n from .core.registry import get_position\n from .core.registry import LspTextCommand\n-from .core.typing import Any, Optional\n+from .core.registry import windows\n+from .core.typing import Any, Optional, Dict, List\n from .core.views import range_to_region\n from .core.views import text_document_position_params\n+import os\n+import sublime\n+import sublime_plugin\n \n \n class RenameSymbolInputHandler(sublime_plugin.TextInputHandler):\n@@ -105,7 +110,18 @@\n window = self.view.window()\n if window:\n if response:\n- apply_workspace_edit(window, parse_workspace_edit(response))\n+ changes = parse_workspace_edit(response)\n+ file_count = len(changes.keys())\n+ if file_count > 1:\n+ total_changes = sum(map(len, changes.values()))\n+ message = \"Replace {} occurrences across {} files?\".format(total_changes, file_count)\n+ choice = sublime.yes_no_cancel_dialog(message, \"Replace\", \"Dry Run\")\n+ if choice == sublime.DIALOG_YES:\n+ apply_workspace_edit(window, changes)\n+ elif choice == sublime.DIALOG_NO:\n+ self._render_rename_panel(changes, total_changes, file_count)\n+ else:\n+ apply_workspace_edit(window, changes)\n else:\n window.status_message('Nothing to rename')\n \n@@ -126,3 +142,49 @@\n \n def on_prepare_error(self, error: Any) -> None:\n sublime.error_message(\"Rename error: {}\".format(error[\"message\"]))\n+\n+ def _get_relative_path(self, file_path: str) -> str:\n+ window = self.view.window()\n+ if not window:\n+ return file_path\n+ base_dir = windows.lookup(window).get_project_path(file_path)\n+ if base_dir:\n+ return os.path.relpath(file_path, base_dir)\n+ else:\n+ return file_path\n+\n+ def _render_rename_panel(self, changes: Dict[str, List[TextEdit]], total_changes: int, file_count: int) -> None:\n+ window = self.view.window()\n+ if not window:\n+ return\n+ panel = ensure_rename_panel(window)\n+ if not panel:\n+ return\n+ text = ''\n+ for file, file_changes in changes.items():\n+ text += '\u25cc {}:\\n'.format(self._get_relative_path(file))\n+ for edit in file_changes:\n+ start = edit[0]\n+ text += '\\t{:>8}:{}\\n'.format(start[0] + 1, start[1] + 1)\n+ # append a new line after each file name\n+ text += '\\n'\n+ base_dir = windows.lookup(window).get_project_path(self.view.file_name() or \"\")\n+ panel.settings().set(\"result_base_dir\", base_dir)\n+ panel.run_command(\"lsp_clear_panel\")\n+ window.run_command(\"show_panel\", {\"panel\": \"output.rename\"})\n+ fmt = \"{} changes across {} files. Double-click on a row:col number to jump to that location.\\n\\n{}\"\n+ panel.run_command('append', {\n+ 'characters': fmt.format(total_changes, file_count, text),\n+ 'force': True,\n+ 'scroll_to_end': False\n+ })\n+\n+\n+def ensure_rename_panel(window: sublime.Window) -> Optional[sublime.View]:\n+ return ensure_panel(\n+ window=window,\n+ name=PanelName.Rename,\n+ result_file_regex=r\"^\\s*\\S\\s+(\\S.*):$\",\n+ result_line_regex=r\"^\\s*([0-9]+):([0-9]+)\\s*$\",\n+ syntax=\"Packages/LSP/Syntaxes/Rename.sublime-syntax\"\n+ )\n", "issue": "Could you add following command: \"Show all occurrences and rename symbol\"\nHi!\r\n\r\nI would like to see all occurrences of symbol before renaming.\r\nIt would be nice to have this command.\r\n\r\nThanks!\n", "before_files": [{"content": "from .typing import Dict, Optional, List, Generator, Tuple\nfrom .types import debounced\nfrom contextlib import contextmanager\nimport sublime\nimport sublime_plugin\n\n\n# about 80 chars per line implies maintaining a buffer of about 40kb per window\nSERVER_PANEL_MAX_LINES = 500\n\n# If nothing else shows up after 80ms, actually print the messages to the panel\nSERVER_PANEL_DEBOUNCE_TIME_MS = 80\n\nOUTPUT_PANEL_SETTINGS = {\n \"auto_indent\": False,\n \"draw_indent_guides\": False,\n \"draw_unicode_white_space\": \"none\",\n \"draw_white_space\": \"none\",\n \"fold_buttons\": True,\n \"gutter\": True,\n \"is_widget\": True,\n \"line_numbers\": False,\n \"lsp_active\": True,\n \"margin\": 3,\n \"match_brackets\": False,\n \"rulers\": [],\n \"scroll_past_end\": False,\n \"show_definitions\": False,\n \"tab_size\": 4,\n \"translate_tabs_to_spaces\": False,\n \"word_wrap\": False\n}\n\n\nclass PanelName:\n Diagnostics = \"diagnostics\"\n References = \"references\"\n LanguageServers = \"language servers\"\n\n\n@contextmanager\ndef mutable(view: sublime.View) -> Generator:\n view.set_read_only(False)\n yield\n view.set_read_only(True)\n\n\ndef create_output_panel(window: sublime.Window, name: str) -> Optional[sublime.View]:\n panel = window.create_output_panel(name)\n settings = panel.settings()\n for key, value in OUTPUT_PANEL_SETTINGS.items():\n settings.set(key, value)\n return panel\n\n\ndef destroy_output_panels(window: sublime.Window) -> None:\n for field in filter(lambda a: not a.startswith('__'), PanelName.__dict__.keys()):\n panel_name = getattr(PanelName, field)\n panel = window.find_output_panel(panel_name)\n if panel and panel.is_valid():\n panel.settings().set(\"syntax\", \"Packages/Text/Plain text.tmLanguage\")\n window.destroy_output_panel(panel_name)\n\n\ndef create_panel(window: sublime.Window, name: str, result_file_regex: str, result_line_regex: str,\n syntax: str) -> Optional[sublime.View]:\n panel = create_output_panel(window, name)\n if not panel:\n return None\n if result_file_regex:\n panel.settings().set(\"result_file_regex\", result_file_regex)\n if result_line_regex:\n panel.settings().set(\"result_line_regex\", result_line_regex)\n panel.assign_syntax(syntax)\n # Call create_output_panel a second time after assigning the above\n # settings, so that it'll be picked up as a result buffer\n # see: Packages/Default/exec.py#L228-L230\n panel = window.create_output_panel(name)\n # All our panels are read-only\n panel.set_read_only(True)\n return panel\n\n\ndef ensure_panel(window: sublime.Window, name: str, result_file_regex: str, result_line_regex: str,\n syntax: str) -> Optional[sublime.View]:\n return window.find_output_panel(name) or create_panel(window, name, result_file_regex, result_line_regex, syntax)\n\n\nclass LspClearPanelCommand(sublime_plugin.TextCommand):\n \"\"\"\n A clear_panel command to clear the error panel.\n \"\"\"\n\n def run(self, edit: sublime.Edit) -> None:\n with mutable(self.view):\n self.view.erase(edit, sublime.Region(0, self.view.size()))\n\n\nclass LspUpdatePanelCommand(sublime_plugin.TextCommand):\n \"\"\"\n A update_panel command to update the error panel with new text.\n \"\"\"\n\n def run(self, edit: sublime.Edit, characters: Optional[str] = \"\") -> None:\n # Clear folds\n self.view.unfold(sublime.Region(0, self.view.size()))\n\n with mutable(self.view):\n self.view.replace(edit, sublime.Region(0, self.view.size()), characters or \"\")\n\n # Clear the selection\n selection = self.view.sel()\n selection.clear()\n\n\ndef ensure_server_panel(window: sublime.Window) -> Optional[sublime.View]:\n return ensure_panel(window, PanelName.LanguageServers, \"\", \"\", \"Packages/LSP/Syntaxes/ServerLog.sublime-syntax\")\n\n\ndef update_server_panel(window: sublime.Window, prefix: str, message: str) -> None:\n if not window.is_valid():\n return\n window_id = window.id()\n panel = ensure_server_panel(window)\n if not panel:\n return\n LspUpdateServerPanelCommand.to_be_processed.setdefault(window_id, []).append((prefix, message))\n previous_length = len(LspUpdateServerPanelCommand.to_be_processed[window_id])\n\n def condition() -> bool:\n if not panel:\n return False\n if not panel.is_valid():\n return False\n to_process = LspUpdateServerPanelCommand.to_be_processed.get(window_id)\n if to_process is None:\n return False\n current_length = len(to_process)\n if current_length >= 10:\n # Do not let the queue grow large.\n return True\n # If the queue remains stable, flush the messages.\n return current_length == previous_length\n\n debounced(\n lambda: panel.run_command(\"lsp_update_server_panel\", {\"window_id\": window_id}) if panel else None,\n SERVER_PANEL_DEBOUNCE_TIME_MS,\n condition\n )\n\n\nclass LspUpdateServerPanelCommand(sublime_plugin.TextCommand):\n\n to_be_processed = {} # type: Dict[int, List[Tuple[str, str]]]\n\n def run(self, edit: sublime.Edit, window_id: int) -> None:\n to_process = self.to_be_processed.pop(window_id)\n with mutable(self.view):\n for prefix, message in to_process:\n message = message.replace(\"\\r\\n\", \"\\n\") # normalize Windows eol\n self.view.insert(edit, self.view.size(), \"{}: {}\\n\".format(prefix, message))\n total_lines, _ = self.view.rowcol(self.view.size())\n point = 0 # Starting from point 0 in the panel ...\n regions = [] # type: List[sublime.Region]\n for _ in range(0, max(0, total_lines - SERVER_PANEL_MAX_LINES)):\n # ... collect all regions that span an entire line ...\n region = self.view.full_line(point)\n regions.append(region)\n point = region.b\n for region in reversed(regions):\n # ... and erase them in reverse order\n self.view.erase(edit, region)\n", "path": "plugin/core/panels.py"}, {"content": "import sublime\nimport sublime_plugin\nfrom .core.edit import apply_workspace_edit\nfrom .core.edit import parse_workspace_edit\nfrom .core.protocol import Range\nfrom .core.protocol import Request\nfrom .core.registry import get_position\nfrom .core.registry import LspTextCommand\nfrom .core.typing import Any, Optional\nfrom .core.views import range_to_region\nfrom .core.views import text_document_position_params\n\n\nclass RenameSymbolInputHandler(sublime_plugin.TextInputHandler):\n def __init__(self, view: sublime.View, placeholder: str) -> None:\n self.view = view\n self._placeholder = placeholder\n\n def name(self) -> str:\n return \"new_name\"\n\n def placeholder(self) -> str:\n return self._placeholder\n\n def initial_text(self) -> str:\n return self.placeholder()\n\n def validate(self, name: str) -> bool:\n return len(name) > 0\n\n\nclass LspSymbolRenameCommand(LspTextCommand):\n\n capability = 'renameProvider'\n\n # mypy: Signature of \"is_enabled\" incompatible with supertype \"LspTextCommand\"\n def is_enabled( # type: ignore\n self,\n new_name: str = \"\",\n placeholder: str = \"\",\n position: Optional[int] = None,\n event: Optional[dict] = None,\n point: Optional[int] = None\n ) -> bool:\n if self.best_session(\"renameProvider.prepareProvider\"):\n # The language server will tell us if the selection is on a valid token.\n return True\n return super().is_enabled(event, point)\n\n def input(self, args: dict) -> Optional[sublime_plugin.TextInputHandler]:\n if \"new_name\" not in args:\n placeholder = args.get(\"placeholder\", \"\")\n if not placeholder:\n point = args.get(\"point\")\n # guess the symbol name\n if not isinstance(point, int):\n point = self.view.sel()[0].b\n placeholder = self.view.substr(self.view.word(point))\n return RenameSymbolInputHandler(self.view, placeholder)\n else:\n return None\n\n def run(\n self,\n edit: sublime.Edit,\n new_name: str = \"\",\n placeholder: str = \"\",\n position: Optional[int] = None,\n event: Optional[dict] = None,\n point: Optional[int] = None\n ) -> None:\n if position is None:\n pos = get_position(self.view, event, point)\n if new_name:\n return self._do_rename(pos, new_name)\n else:\n session = self.best_session(\"{}.prepareProvider\".format(self.capability))\n if session:\n params = text_document_position_params(self.view, pos)\n request = Request.prepareRename(params, self.view)\n self.event = event\n session.send_request(request, lambda r: self.on_prepare_result(r, pos), self.on_prepare_error)\n else:\n # trigger InputHandler manually\n raise TypeError(\"required positional argument\")\n else:\n if new_name:\n return self._do_rename(position, new_name)\n else:\n # trigger InputHandler manually\n raise TypeError(\"required positional argument\")\n\n def _do_rename(self, position: int, new_name: str) -> None:\n session = self.best_session(self.capability)\n if session:\n params = text_document_position_params(self.view, position)\n params[\"newName\"] = new_name\n session.send_request(\n Request.rename(params, self.view),\n # This has to run on the main thread due to calling apply_workspace_edit\n lambda r: sublime.set_timeout(lambda: self.on_rename_result(r))\n )\n\n def on_rename_result(self, response: Any) -> None:\n window = self.view.window()\n if window:\n if response:\n apply_workspace_edit(window, parse_workspace_edit(response))\n else:\n window.status_message('Nothing to rename')\n\n def on_prepare_result(self, response: Any, pos: int) -> None:\n if response is None:\n sublime.error_message(\"The current selection cannot be renamed\")\n return\n # It must be a dict at this point.\n if \"placeholder\" in response:\n placeholder = response[\"placeholder\"]\n r = response[\"range\"]\n else:\n placeholder = self.view.substr(self.view.word(pos))\n r = response\n region = range_to_region(Range.from_lsp(r), self.view)\n args = {\"placeholder\": placeholder, \"position\": region.a, \"event\": self.event}\n self.view.run_command(\"lsp_symbol_rename\", args)\n\n def on_prepare_error(self, error: Any) -> None:\n sublime.error_message(\"Rename error: {}\".format(error[\"message\"]))\n", "path": "plugin/rename.py"}]}
| 3,682 | 997 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.