
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_4842
|
rasdani/github-patches
|
git_diff
|
plone__Products.CMFPlone-3972
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TypeError thrown when during groups lookup
The offending code is [here](https://github.com/plone/Products.CMFPlone/blob/308aa4d03ee6c0ce9d8119ce4c37955153f0bc6f/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py#L66). The traceback looks like this:
```
Traceback (innermost last):
Module ZPublisher.WSGIPublisher, line 176, in transaction_pubevents
Module ZPublisher.WSGIPublisher, line 385, in publish_module
Module ZPublisher.WSGIPublisher, line 280, in publish
Module ZPublisher.mapply, line 85, in mapply
Module ZPublisher.WSGIPublisher, line 63, in call_object
Module Products.CMFPlone.controlpanel.browser.usergroups_usermembership, line 57, in __call__
Module Products.CMFPlone.controlpanel.browser.usergroups_usermembership, line 54, in update
Module Products.CMFPlone.controlpanel.browser.usergroups_usermembership, line 63, in getGroups
TypeError: '<' not supported between instances of 'bool' and 'str'
```
The issue is that when there's a `None` value in the `groupResults` (which is anticipated in the sort code) the lambda returns `False` which fails to compare against the group title/name strings under Python 3. The list comprehension that defines `groupResults` should probably just filter out `None` values to avoid this issue. I'm not entirely sure what circumstances result in a `None` group value, but I am seeing it occur in a real world use case.
</issue>
<code>
[start of Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py]
1 from plone.base import PloneMessageFactory as _
2 from Products.CMFCore.utils import getToolByName
3 from Products.CMFPlone.controlpanel.browser.usergroups import (
4 UsersGroupsControlPanelView,
5 )
6 from Products.CMFPlone.utils import normalizeString
7 from zExceptions import Forbidden
8
9
10 class UserMembershipControlPanel(UsersGroupsControlPanelView):
11 def update(self):
12 self.userid = getattr(self.request, "userid")
13 self.gtool = getToolByName(self, "portal_groups")
14 self.mtool = getToolByName(self, "portal_membership")
15 self.member = self.mtool.getMemberById(self.userid)
16
17 form = self.request.form
18
19 self.searchResults = []
20 self.searchString = ""
21 self.newSearch = False
22
23 if form.get("form.submitted", False):
24 delete = form.get("delete", [])
25 if delete:
26 for groupname in delete:
27 self.gtool.removePrincipalFromGroup(
28 self.userid, groupname, self.request
29 )
30 self.context.plone_utils.addPortalMessage(_("Changes made."))
31
32 add = form.get("add", [])
33 if add:
34 for groupname in add:
35 group = self.gtool.getGroupById(groupname)
36 if "Manager" in group.getRoles() and not self.is_zope_manager:
37 raise Forbidden
38
39 self.gtool.addPrincipalToGroup(self.userid, groupname, self.request)
40 self.context.plone_utils.addPortalMessage(_("Changes made."))
41
42 search = form.get("form.button.Search", None) is not None
43 findAll = (
44 form.get("form.button.FindAll", None) is not None and not self.many_groups
45 )
46 self.searchString = not findAll and form.get("searchstring", "") or ""
47
48 if findAll or not self.many_groups or self.searchString != "":
49 self.searchResults = self.getPotentialGroups(self.searchString)
50
51 if search or findAll:
52 self.newSearch = True
53
54 self.groups = self.getGroups()
55
56 def __call__(self):
57 self.update()
58 return self.index()
59
60 def getGroups(self):
61 groupResults = [
62 self.gtool.getGroupById(m)
63 for m in self.gtool.getGroupsForPrincipal(self.member)
64 ]
65 groupResults.sort(
66 key=lambda x: x is not None and normalizeString(x.getGroupTitleOrName())
67 )
68 return [i for i in groupResults if i]
69
70 def getPotentialGroups(self, searchString):
71 ignoredGroups = [x.id for x in self.getGroups() if x is not None]
72 return self.membershipSearch(
73 searchString, searchUsers=False, ignore=ignoredGroups
74 )
75
[end of Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py b/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py
--- a/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py
+++ b/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py
@@ -63,7 +63,7 @@
for m in self.gtool.getGroupsForPrincipal(self.member)
]
groupResults.sort(
- key=lambda x: x is not None and normalizeString(x.getGroupTitleOrName())
+ key=lambda x: normalizeString(x.getGroupTitleOrName()) if x else ''
)
return [i for i in groupResults if i]
|
{"golden_diff": "diff --git a/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py b/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py\n--- a/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py\n+++ b/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py\n@@ -63,7 +63,7 @@\n for m in self.gtool.getGroupsForPrincipal(self.member)\n ]\n groupResults.sort(\n- key=lambda x: x is not None and normalizeString(x.getGroupTitleOrName())\n+ key=lambda x: normalizeString(x.getGroupTitleOrName()) if x else ''\n )\n return [i for i in groupResults if i]\n", "issue": "TypeError thrown when during groups lookup\nThe offending code is [here](https://github.com/plone/Products.CMFPlone/blob/308aa4d03ee6c0ce9d8119ce4c37955153f0bc6f/Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py#L66). The traceback looks like this:\r\n```\r\nTraceback (innermost last):\r\n Module ZPublisher.WSGIPublisher, line 176, in transaction_pubevents\r\n Module ZPublisher.WSGIPublisher, line 385, in publish_module\r\n Module ZPublisher.WSGIPublisher, line 280, in publish\r\n Module ZPublisher.mapply, line 85, in mapply\r\n Module ZPublisher.WSGIPublisher, line 63, in call_object\r\n Module Products.CMFPlone.controlpanel.browser.usergroups_usermembership, line 57, in __call__\r\n Module Products.CMFPlone.controlpanel.browser.usergroups_usermembership, line 54, in update\r\n Module Products.CMFPlone.controlpanel.browser.usergroups_usermembership, line 63, in getGroups\r\nTypeError: '<' not supported between instances of 'bool' and 'str'\r\n```\r\n\r\nThe issue is that when there's a `None` value in the `groupResults` (which is anticipated in the sort code) the lambda returns `False` which fails to compare against the group title/name strings under Python 3. The list comprehension that defines `groupResults` should probably just filter out `None` values to avoid this issue. I'm not entirely sure what circumstances result in a `None` group value, but I am seeing it occur in a real world use case.\n", "before_files": [{"content": "from plone.base import PloneMessageFactory as _\nfrom Products.CMFCore.utils import getToolByName\nfrom Products.CMFPlone.controlpanel.browser.usergroups import (\n UsersGroupsControlPanelView,\n)\nfrom Products.CMFPlone.utils import normalizeString\nfrom zExceptions import Forbidden\n\n\nclass UserMembershipControlPanel(UsersGroupsControlPanelView):\n def update(self):\n self.userid = getattr(self.request, \"userid\")\n self.gtool = getToolByName(self, \"portal_groups\")\n self.mtool = getToolByName(self, \"portal_membership\")\n self.member = self.mtool.getMemberById(self.userid)\n\n form = self.request.form\n\n self.searchResults = []\n self.searchString = \"\"\n self.newSearch = False\n\n if form.get(\"form.submitted\", False):\n delete = form.get(\"delete\", [])\n if delete:\n for groupname in delete:\n self.gtool.removePrincipalFromGroup(\n self.userid, groupname, self.request\n )\n self.context.plone_utils.addPortalMessage(_(\"Changes made.\"))\n\n add = form.get(\"add\", [])\n if add:\n for groupname in add:\n group = self.gtool.getGroupById(groupname)\n if \"Manager\" in group.getRoles() and not self.is_zope_manager:\n raise Forbidden\n\n self.gtool.addPrincipalToGroup(self.userid, groupname, self.request)\n self.context.plone_utils.addPortalMessage(_(\"Changes made.\"))\n\n search = form.get(\"form.button.Search\", None) is not None\n findAll = (\n form.get(\"form.button.FindAll\", None) is not None and not self.many_groups\n )\n self.searchString = not findAll and form.get(\"searchstring\", \"\") or \"\"\n\n if findAll or not self.many_groups or self.searchString != \"\":\n self.searchResults = self.getPotentialGroups(self.searchString)\n\n if search or findAll:\n self.newSearch = True\n\n self.groups = self.getGroups()\n\n def __call__(self):\n self.update()\n return self.index()\n\n def getGroups(self):\n groupResults = [\n self.gtool.getGroupById(m)\n for m in self.gtool.getGroupsForPrincipal(self.member)\n ]\n groupResults.sort(\n key=lambda x: x is not None and normalizeString(x.getGroupTitleOrName())\n )\n return [i for i in groupResults if i]\n\n def getPotentialGroups(self, searchString):\n ignoredGroups = [x.id for x in self.getGroups() if x is not None]\n return self.membershipSearch(\n searchString, searchUsers=False, ignore=ignoredGroups\n )\n", "path": "Products/CMFPlone/controlpanel/browser/usergroups_usermembership.py"}]}
| 1,641 | 158 |
gh_patches_debug_19305
|
rasdani/github-patches
|
git_diff
|
fail2ban__fail2ban-940
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
WARNING 'ignoreregex' not defined
Hello there
I'm seeing this error each time I restart fail2ban:
```
WARNING 'ignoreregex' not defined in 'Definition'. Using default one: ''
```
No idea to which one filter this is referring to. Any ideas?
Here more information. Thanks!
```
$ fail2ban-client -d -v
INFO Using socket file /var/run/fail2ban/fail2ban.sock
WARNING 'ignoreregex' not defined in 'Definition'. Using default one: ''
['set', 'loglevel', 3]
['set', 'logtarget', '/var/log/fail2ban.log']
...
```
```
$ fail2ban-client -V
Fail2Ban v0.8.11
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/python
2 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-
3 # vi: set ft=python sts=4 ts=4 sw=4 noet :
4
5 # This file is part of Fail2Ban.
6 #
7 # Fail2Ban is free software; you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation; either version 2 of the License, or
10 # (at your option) any later version.
11 #
12 # Fail2Ban is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with Fail2Ban; if not, write to the Free Software
19 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
20
21 __author__ = "Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko"
22 __copyright__ = "Copyright (c) 2004 Cyril Jaquier, 2008-2013 Fail2Ban Contributors"
23 __license__ = "GPL"
24
25 try:
26 import setuptools
27 from setuptools import setup
28 except ImportError:
29 setuptools = None
30 from distutils.core import setup
31
32 try:
33 # python 3.x
34 from distutils.command.build_py import build_py_2to3 as build_py
35 from distutils.command.build_scripts \
36 import build_scripts_2to3 as build_scripts
37 except ImportError:
38 # python 2.x
39 from distutils.command.build_py import build_py
40 from distutils.command.build_scripts import build_scripts
41 import os
42 from os.path import isfile, join, isdir
43 import sys, warnings
44 from glob import glob
45
46 if setuptools and "test" in sys.argv:
47 import logging
48 logSys = logging.getLogger("fail2ban")
49 hdlr = logging.StreamHandler(sys.stdout)
50 fmt = logging.Formatter("%(asctime)-15s %(message)s")
51 hdlr.setFormatter(fmt)
52 logSys.addHandler(hdlr)
53 if set(["-q", "--quiet"]) & set(sys.argv):
54 logSys.setLevel(logging.CRITICAL)
55 warnings.simplefilter("ignore")
56 sys.warnoptions.append("ignore")
57 elif set(["-v", "--verbose"]) & set(sys.argv):
58 logSys.setLevel(logging.DEBUG)
59 else:
60 logSys.setLevel(logging.INFO)
61 elif "test" in sys.argv:
62 print("python distribute required to execute fail2ban tests")
63 print("")
64
65 longdesc = '''
66 Fail2Ban scans log files like /var/log/pwdfail or
67 /var/log/apache/error_log and bans IP that makes
68 too many password failures. It updates firewall rules
69 to reject the IP address or executes user defined
70 commands.'''
71
72 if setuptools:
73 setup_extra = {
74 'test_suite': "fail2ban.tests.utils.gatherTests",
75 'use_2to3': True,
76 }
77 else:
78 setup_extra = {}
79
80 # Get version number, avoiding importing fail2ban.
81 # This is due to tests not functioning for python3 as 2to3 takes place later
82 exec(open(join("fail2ban", "version.py")).read())
83
84 setup(
85 name = "fail2ban",
86 version = version,
87 description = "Ban IPs that make too many password failures",
88 long_description = longdesc,
89 author = "Cyril Jaquier & Fail2Ban Contributors",
90 author_email = "[email protected]",
91 url = "http://www.fail2ban.org",
92 license = "GPL",
93 platforms = "Posix",
94 cmdclass = {'build_py': build_py, 'build_scripts': build_scripts},
95 scripts = [
96 'bin/fail2ban-client',
97 'bin/fail2ban-server',
98 'bin/fail2ban-regex',
99 'bin/fail2ban-testcases',
100 ],
101 packages = [
102 'fail2ban',
103 'fail2ban.client',
104 'fail2ban.server',
105 'fail2ban.tests',
106 'fail2ban.tests.action_d',
107 ],
108 package_data = {
109 'fail2ban.tests':
110 [ join(w[0], f).replace("fail2ban/tests/", "", 1)
111 for w in os.walk('fail2ban/tests/files')
112 for f in w[2]] +
113 [ join(w[0], f).replace("fail2ban/tests/", "", 1)
114 for w in os.walk('fail2ban/tests/config')
115 for f in w[2]] +
116 [ join(w[0], f).replace("fail2ban/tests/", "", 1)
117 for w in os.walk('fail2ban/tests/action_d')
118 for f in w[2]]
119 },
120 data_files = [
121 ('/etc/fail2ban',
122 glob("config/*.conf")
123 ),
124 ('/etc/fail2ban/filter.d',
125 glob("config/filter.d/*.conf")
126 ),
127 ('/etc/fail2ban/action.d',
128 glob("config/action.d/*.conf") +
129 glob("config/action.d/*.py")
130 ),
131 ('/etc/fail2ban/fail2ban.d',
132 ''
133 ),
134 ('/etc/fail2ban/jail.d',
135 ''
136 ),
137 ('/var/lib/fail2ban',
138 ''
139 ),
140 ('/usr/share/doc/fail2ban',
141 ['README.md', 'README.Solaris', 'DEVELOP', 'FILTERS',
142 'doc/run-rootless.txt']
143 )
144 ],
145 **setup_extra
146 )
147
148 # Do some checks after installation
149 # Search for obsolete files.
150 obsoleteFiles = []
151 elements = {
152 "/etc/":
153 [
154 "fail2ban.conf"
155 ],
156 "/usr/bin/":
157 [
158 "fail2ban.py"
159 ],
160 "/usr/lib/fail2ban/":
161 [
162 "version.py",
163 "protocol.py"
164 ]
165 }
166
167 for directory in elements:
168 for f in elements[directory]:
169 path = join(directory, f)
170 if isfile(path):
171 obsoleteFiles.append(path)
172
173 if obsoleteFiles:
174 print("")
175 print("Obsolete files from previous Fail2Ban versions were found on "
176 "your system.")
177 print("Please delete them:")
178 print("")
179 for f in obsoleteFiles:
180 print("\t" + f)
181 print("")
182
183 if isdir("/usr/lib/fail2ban"):
184 print("")
185 print("Fail2ban is not installed under /usr/lib anymore. The new "
186 "location is under /usr/share. Please remove the directory "
187 "/usr/lib/fail2ban and everything under this directory.")
188 print("")
189
190 # Update config file
191 if sys.argv[1] == "install":
192 print("")
193 print("Please do not forget to update your configuration files.")
194 print("They are in /etc/fail2ban/.")
195 print("")
196
[end of setup.py]
[start of fail2ban/client/filterreader.py]
1 # emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-
2 # vi: set ft=python sts=4 ts=4 sw=4 noet :
3
4 # This file is part of Fail2Ban.
5 #
6 # Fail2Ban is free software; you can redistribute it and/or modify
7 # it under the terms of the GNU General Public License as published by
8 # the Free Software Foundation; either version 2 of the License, or
9 # (at your option) any later version.
10 #
11 # Fail2Ban is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with Fail2Ban; if not, write to the Free Software
18 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
19
20 # Author: Cyril Jaquier
21 #
22
23 __author__ = "Cyril Jaquier"
24 __copyright__ = "Copyright (c) 2004 Cyril Jaquier"
25 __license__ = "GPL"
26
27 import os, shlex
28
29 from .configreader import DefinitionInitConfigReader
30 from ..server.action import CommandAction
31 from ..helpers import getLogger
32
33 # Gets the instance of the logger.
34 logSys = getLogger(__name__)
35
36 class FilterReader(DefinitionInitConfigReader):
37
38 _configOpts = [
39 ["string", "ignoreregex", None],
40 ["string", "failregex", ""],
41 ]
42
43 def setFile(self, fileName):
44 self.__file = fileName
45 DefinitionInitConfigReader.setFile(self, os.path.join("filter.d", fileName))
46
47 def getFile(self):
48 return self.__file
49
50 def getCombined(self):
51 combinedopts = dict(list(self._opts.items()) + list(self._initOpts.items()))
52 if not len(combinedopts):
53 return {};
54 opts = CommandAction.substituteRecursiveTags(combinedopts)
55 if not opts:
56 raise ValueError('recursive tag definitions unable to be resolved')
57 return opts;
58
59 def convert(self):
60 stream = list()
61 opts = self.getCombined()
62 if not len(opts):
63 return stream;
64 for opt, value in opts.iteritems():
65 if opt == "failregex":
66 for regex in value.split('\n'):
67 # Do not send a command if the rule is empty.
68 if regex != '':
69 stream.append(["set", self._jailName, "addfailregex", regex])
70 elif opt == "ignoreregex":
71 for regex in value.split('\n'):
72 # Do not send a command if the rule is empty.
73 if regex != '':
74 stream.append(["set", self._jailName, "addignoreregex", regex])
75 if self._initOpts:
76 if 'maxlines' in self._initOpts:
77 # We warn when multiline regex is used without maxlines > 1
78 # therefore keep sure we set this option first.
79 stream.insert(0, ["set", self._jailName, "maxlines", self._initOpts["maxlines"]])
80 if 'datepattern' in self._initOpts:
81 stream.append(["set", self._jailName, "datepattern", self._initOpts["datepattern"]])
82 # Do not send a command if the match is empty.
83 if self._initOpts.get("journalmatch", '') != '':
84 for match in self._initOpts["journalmatch"].split("\n"):
85 stream.append(
86 ["set", self._jailName, "addjournalmatch"] +
87 shlex.split(match))
88 return stream
89
90
[end of fail2ban/client/filterreader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fail2ban/client/filterreader.py b/fail2ban/client/filterreader.py
--- a/fail2ban/client/filterreader.py
+++ b/fail2ban/client/filterreader.py
@@ -71,7 +71,7 @@
for regex in value.split('\n'):
# Do not send a command if the rule is empty.
if regex != '':
- stream.append(["set", self._jailName, "addignoreregex", regex])
+ stream.append(["set", self._jailName, "addignoreregex", regex])
if self._initOpts:
if 'maxlines' in self._initOpts:
# We warn when multiline regex is used without maxlines > 1
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -124,6 +124,9 @@
('/etc/fail2ban/filter.d',
glob("config/filter.d/*.conf")
),
+ ('/etc/fail2ban/filter.d/ignorecommands',
+ glob("config/filter.d/ignorecommands/*")
+ ),
('/etc/fail2ban/action.d',
glob("config/action.d/*.conf") +
glob("config/action.d/*.py")
|
{"golden_diff": "diff --git a/fail2ban/client/filterreader.py b/fail2ban/client/filterreader.py\n--- a/fail2ban/client/filterreader.py\n+++ b/fail2ban/client/filterreader.py\n@@ -71,7 +71,7 @@\n \t\t\t\tfor regex in value.split('\\n'):\n \t\t\t\t\t# Do not send a command if the rule is empty.\n \t\t\t\t\tif regex != '':\n-\t\t\t\t\t\tstream.append([\"set\", self._jailName, \"addignoreregex\", regex])\t\t\n+\t\t\t\t\t\tstream.append([\"set\", self._jailName, \"addignoreregex\", regex])\n \t\tif self._initOpts:\n \t\t\tif 'maxlines' in self._initOpts:\n \t\t\t\t# We warn when multiline regex is used without maxlines > 1\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -124,6 +124,9 @@\n \t\t('/etc/fail2ban/filter.d',\n \t\t\tglob(\"config/filter.d/*.conf\")\n \t\t),\n+\t\t('/etc/fail2ban/filter.d/ignorecommands',\n+\t\t\tglob(\"config/filter.d/ignorecommands/*\")\n+\t\t),\n \t\t('/etc/fail2ban/action.d',\n \t\t\tglob(\"config/action.d/*.conf\") +\n \t\t\tglob(\"config/action.d/*.py\")\n", "issue": "WARNING 'ignoreregex' not defined\nHello there\n\nI'm seeing this error each time I restart fail2ban:\n\n```\nWARNING 'ignoreregex' not defined in 'Definition'. Using default one: ''\n```\n\nNo idea to which one filter this is referring to. Any ideas?\n\nHere more information. Thanks!\n\n```\n$ fail2ban-client -d -v\nINFO Using socket file /var/run/fail2ban/fail2ban.sock\nWARNING 'ignoreregex' not defined in 'Definition'. Using default one: ''\n['set', 'loglevel', 3]\n['set', 'logtarget', '/var/log/fail2ban.log']\n...\n```\n\n```\n$ fail2ban-client -V\nFail2Ban v0.8.11\n```\n\n", "before_files": [{"content": "#!/usr/bin/python\n# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-\n# vi: set ft=python sts=4 ts=4 sw=4 noet :\n\n# This file is part of Fail2Ban.\n#\n# Fail2Ban is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# Fail2Ban is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Fail2Ban; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n__author__ = \"Cyril Jaquier, Steven Hiscocks, Yaroslav Halchenko\"\n__copyright__ = \"Copyright (c) 2004 Cyril Jaquier, 2008-2013 Fail2Ban Contributors\"\n__license__ = \"GPL\"\n\ntry:\n\timport setuptools\n\tfrom setuptools import setup\nexcept ImportError:\n\tsetuptools = None\n\tfrom distutils.core import setup\n\ntry:\n\t# python 3.x\n\tfrom distutils.command.build_py import build_py_2to3 as build_py\n\tfrom distutils.command.build_scripts \\\n\t\timport build_scripts_2to3 as build_scripts\nexcept ImportError:\n\t# python 2.x\n\tfrom distutils.command.build_py import build_py\n\tfrom distutils.command.build_scripts import build_scripts\nimport os\nfrom os.path import isfile, join, isdir\nimport sys, warnings\nfrom glob import glob\n\nif setuptools and \"test\" in sys.argv:\n\timport logging\n\tlogSys = logging.getLogger(\"fail2ban\")\n\thdlr = logging.StreamHandler(sys.stdout)\n\tfmt = logging.Formatter(\"%(asctime)-15s %(message)s\")\n\thdlr.setFormatter(fmt)\n\tlogSys.addHandler(hdlr)\n\tif set([\"-q\", \"--quiet\"]) & set(sys.argv):\n\t\tlogSys.setLevel(logging.CRITICAL)\n\t\twarnings.simplefilter(\"ignore\")\n\t\tsys.warnoptions.append(\"ignore\")\n\telif set([\"-v\", \"--verbose\"]) & set(sys.argv):\n\t\tlogSys.setLevel(logging.DEBUG)\n\telse:\n\t\tlogSys.setLevel(logging.INFO)\nelif \"test\" in sys.argv:\n\tprint(\"python distribute required to execute fail2ban tests\")\n\tprint(\"\")\n\nlongdesc = '''\nFail2Ban scans log files like /var/log/pwdfail or\n/var/log/apache/error_log and bans IP that makes\ntoo many password failures. It updates firewall rules\nto reject the IP address or executes user defined\ncommands.'''\n\nif setuptools:\n\tsetup_extra = {\n\t\t'test_suite': \"fail2ban.tests.utils.gatherTests\",\n\t\t'use_2to3': True,\n\t}\nelse:\n\tsetup_extra = {}\n\n# Get version number, avoiding importing fail2ban.\n# This is due to tests not functioning for python3 as 2to3 takes place later\nexec(open(join(\"fail2ban\", \"version.py\")).read())\n\nsetup(\n\tname = \"fail2ban\",\n\tversion = version,\n\tdescription = \"Ban IPs that make too many password failures\",\n\tlong_description = longdesc,\n\tauthor = \"Cyril Jaquier & Fail2Ban Contributors\",\n\tauthor_email = \"[email protected]\",\n\turl = \"http://www.fail2ban.org\",\n\tlicense = \"GPL\",\n\tplatforms = \"Posix\",\n\tcmdclass = {'build_py': build_py, 'build_scripts': build_scripts},\n\tscripts = [\n\t\t'bin/fail2ban-client',\n\t\t'bin/fail2ban-server',\n\t\t'bin/fail2ban-regex',\n\t\t'bin/fail2ban-testcases',\n\t],\n\tpackages = [\n\t\t'fail2ban',\n\t\t'fail2ban.client',\n\t\t'fail2ban.server',\n\t\t'fail2ban.tests',\n\t\t'fail2ban.tests.action_d',\n\t],\n\tpackage_data = {\n\t\t'fail2ban.tests':\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/files')\n\t\t\t\tfor f in w[2]] +\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/config')\n\t\t\t\tfor f in w[2]] +\n\t\t\t[ join(w[0], f).replace(\"fail2ban/tests/\", \"\", 1)\n\t\t\t\tfor w in os.walk('fail2ban/tests/action_d')\n\t\t\t\tfor f in w[2]]\n\t},\n\tdata_files = [\n\t\t('/etc/fail2ban',\n\t\t\tglob(\"config/*.conf\")\n\t\t),\n\t\t('/etc/fail2ban/filter.d',\n\t\t\tglob(\"config/filter.d/*.conf\")\n\t\t),\n\t\t('/etc/fail2ban/action.d',\n\t\t\tglob(\"config/action.d/*.conf\") +\n\t\t\tglob(\"config/action.d/*.py\")\n\t\t),\n\t\t('/etc/fail2ban/fail2ban.d',\n\t\t\t''\n\t\t),\n\t\t('/etc/fail2ban/jail.d',\n\t\t\t''\n\t\t),\n\t\t('/var/lib/fail2ban',\n\t\t\t''\n\t\t),\n\t\t('/usr/share/doc/fail2ban',\n\t\t\t['README.md', 'README.Solaris', 'DEVELOP', 'FILTERS',\n\t\t\t 'doc/run-rootless.txt']\n\t\t)\n\t],\n\t**setup_extra\n)\n\n# Do some checks after installation\n# Search for obsolete files.\nobsoleteFiles = []\nelements = {\n\t\"/etc/\":\n\t\t[\n\t\t\t\"fail2ban.conf\"\n\t\t],\n\t\"/usr/bin/\":\n\t\t[\n\t\t\t\"fail2ban.py\"\n\t\t],\n\t\"/usr/lib/fail2ban/\":\n\t\t[\n\t\t\t\"version.py\",\n\t\t\t\"protocol.py\"\n\t\t]\n}\n\nfor directory in elements:\n\tfor f in elements[directory]:\n\t\tpath = join(directory, f)\n\t\tif isfile(path):\n\t\t\tobsoleteFiles.append(path)\n\nif obsoleteFiles:\n\tprint(\"\")\n\tprint(\"Obsolete files from previous Fail2Ban versions were found on \"\n\t\t \"your system.\")\n\tprint(\"Please delete them:\")\n\tprint(\"\")\n\tfor f in obsoleteFiles:\n\t\tprint(\"\\t\" + f)\n\tprint(\"\")\n\nif isdir(\"/usr/lib/fail2ban\"):\n\tprint(\"\")\n\tprint(\"Fail2ban is not installed under /usr/lib anymore. The new \"\n\t\t \"location is under /usr/share. Please remove the directory \"\n\t\t \"/usr/lib/fail2ban and everything under this directory.\")\n\tprint(\"\")\n\n# Update config file\nif sys.argv[1] == \"install\":\n\tprint(\"\")\n\tprint(\"Please do not forget to update your configuration files.\")\n\tprint(\"They are in /etc/fail2ban/.\")\n\tprint(\"\")\n", "path": "setup.py"}, {"content": "# emacs: -*- mode: python; py-indent-offset: 4; indent-tabs-mode: t -*-\n# vi: set ft=python sts=4 ts=4 sw=4 noet :\n\n# This file is part of Fail2Ban.\n#\n# Fail2Ban is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# Fail2Ban is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Fail2Ban; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n# Author: Cyril Jaquier\n# \n\n__author__ = \"Cyril Jaquier\"\n__copyright__ = \"Copyright (c) 2004 Cyril Jaquier\"\n__license__ = \"GPL\"\n\nimport os, shlex\n\nfrom .configreader import DefinitionInitConfigReader\nfrom ..server.action import CommandAction\nfrom ..helpers import getLogger\n\n# Gets the instance of the logger.\nlogSys = getLogger(__name__)\n\nclass FilterReader(DefinitionInitConfigReader):\n\n\t_configOpts = [\n\t\t[\"string\", \"ignoreregex\", None],\n\t\t[\"string\", \"failregex\", \"\"],\n\t]\n\n\tdef setFile(self, fileName):\n\t\tself.__file = fileName\n\t\tDefinitionInitConfigReader.setFile(self, os.path.join(\"filter.d\", fileName))\n\t\n\tdef getFile(self):\n\t\treturn self.__file\n\n\tdef getCombined(self):\n\t\tcombinedopts = dict(list(self._opts.items()) + list(self._initOpts.items()))\n\t\tif not len(combinedopts):\n\t\t\treturn {};\n\t\topts = CommandAction.substituteRecursiveTags(combinedopts)\n\t\tif not opts:\n\t\t\traise ValueError('recursive tag definitions unable to be resolved')\n\t\treturn opts;\n\t\n\tdef convert(self):\n\t\tstream = list()\n\t\topts = self.getCombined()\n\t\tif not len(opts):\n\t\t\treturn stream;\n\t\tfor opt, value in opts.iteritems():\n\t\t\tif opt == \"failregex\":\n\t\t\t\tfor regex in value.split('\\n'):\n\t\t\t\t\t# Do not send a command if the rule is empty.\n\t\t\t\t\tif regex != '':\n\t\t\t\t\t\tstream.append([\"set\", self._jailName, \"addfailregex\", regex])\n\t\t\telif opt == \"ignoreregex\":\n\t\t\t\tfor regex in value.split('\\n'):\n\t\t\t\t\t# Do not send a command if the rule is empty.\n\t\t\t\t\tif regex != '':\n\t\t\t\t\t\tstream.append([\"set\", self._jailName, \"addignoreregex\", regex])\t\t\n\t\tif self._initOpts:\n\t\t\tif 'maxlines' in self._initOpts:\n\t\t\t\t# We warn when multiline regex is used without maxlines > 1\n\t\t\t\t# therefore keep sure we set this option first.\n\t\t\t\tstream.insert(0, [\"set\", self._jailName, \"maxlines\", self._initOpts[\"maxlines\"]])\n\t\t\tif 'datepattern' in self._initOpts:\n\t\t\t\tstream.append([\"set\", self._jailName, \"datepattern\", self._initOpts[\"datepattern\"]])\n\t\t\t# Do not send a command if the match is empty.\n\t\t\tif self._initOpts.get(\"journalmatch\", '') != '':\n\t\t\t\tfor match in self._initOpts[\"journalmatch\"].split(\"\\n\"):\n\t\t\t\t\tstream.append(\n\t\t\t\t\t\t[\"set\", self._jailName, \"addjournalmatch\"] +\n shlex.split(match))\n\t\treturn stream\n\t\t\n", "path": "fail2ban/client/filterreader.py"}]}
| 3,782 | 287 |
gh_patches_debug_29390
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-6302
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG ]At new splitting: "QuerySet' object has no attribute 'extend'" - Workflow adding a custom field on adding new document leads to the error message
### Description
When trying out the new splitting functionality I get the error message:
'QuerySet' object has no attribute 'extend'
A Workflow for adding a custom field on adding new document leads to the error message.
Anybody with the same issue?
### Steps to reproduce
1. Go to Documents
2. Edit Document
3. Split
4. Split Pages 1 and 2
5. Error message
### Webserver logs
```bash
[2024-04-06 11:18:26,873] [DEBUG] [paperless.tasks] Executing plugin WorkflowTriggerPlugin
[2024-04-06 11:18:26,905] [INFO] [paperless.matching] Document matched WorkflowTrigger 3 from Workflow: Benutzerdefinierte Felder hinzufügen
[2024-04-06 11:18:26,910] [ERROR] [paperless.tasks] WorkflowTriggerPlugin failed: 'QuerySet' object has no attribute 'extend'
Traceback (most recent call last):
File "/usr/src/paperless/src/documents/tasks.py", line 144, in consume_file
msg = plugin.run()
^^^^^^^^^^^^
File "/usr/src/paperless/src/documents/consumer.py", line 223, in run
self.metadata.update(overrides)
File "/usr/src/paperless/src/documents/data_models.py", line 64, in update
self.view_users.extend(other.view_users)
^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'QuerySet' object has no attribute 'extend'
```
### Browser logs
_No response_
### Paperless-ngx version
2.7.0
### Host OS
Docker on Synology NAS - DSM 7.2
### Installation method
Docker - official image
### Browser
Firefox
### Configuration changes
_No response_
### Other
_No response_
### Please confirm the following
- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.
- [X] I have already searched for relevant existing issues and discussions before opening this report.
- [X] I have updated the title field above with a concise description.
</issue>
<code>
[start of src/documents/data_models.py]
1 import dataclasses
2 import datetime
3 from enum import IntEnum
4 from pathlib import Path
5 from typing import Optional
6
7 import magic
8 from guardian.shortcuts import get_groups_with_perms
9 from guardian.shortcuts import get_users_with_perms
10
11
12 @dataclasses.dataclass
13 class DocumentMetadataOverrides:
14 """
15 Manages overrides for document fields which normally would
16 be set from content or matching. All fields default to None,
17 meaning no override is happening
18 """
19
20 filename: Optional[str] = None
21 title: Optional[str] = None
22 correspondent_id: Optional[int] = None
23 document_type_id: Optional[int] = None
24 tag_ids: Optional[list[int]] = None
25 storage_path_id: Optional[int] = None
26 created: Optional[datetime.datetime] = None
27 asn: Optional[int] = None
28 owner_id: Optional[int] = None
29 view_users: Optional[list[int]] = None
30 view_groups: Optional[list[int]] = None
31 change_users: Optional[list[int]] = None
32 change_groups: Optional[list[int]] = None
33 custom_field_ids: Optional[list[int]] = None
34
35 def update(self, other: "DocumentMetadataOverrides") -> "DocumentMetadataOverrides":
36 """
37 Merges two DocumentMetadataOverrides objects such that object B's overrides
38 are applied to object A or merged if multiple are accepted.
39
40 The update is an in-place modification of self
41 """
42 # only if empty
43 if other.title is not None:
44 self.title = other.title
45 if other.correspondent_id is not None:
46 self.correspondent_id = other.correspondent_id
47 if other.document_type_id is not None:
48 self.document_type_id = other.document_type_id
49 if other.storage_path_id is not None:
50 self.storage_path_id = other.storage_path_id
51 if other.owner_id is not None:
52 self.owner_id = other.owner_id
53
54 # merge
55 if self.tag_ids is None:
56 self.tag_ids = other.tag_ids
57 elif other.tag_ids is not None:
58 self.tag_ids.extend(other.tag_ids)
59 self.tag_ids = list(set(self.tag_ids))
60
61 if self.view_users is None:
62 self.view_users = other.view_users
63 elif other.view_users is not None:
64 self.view_users.extend(other.view_users)
65 self.view_users = list(set(self.view_users))
66
67 if self.view_groups is None:
68 self.view_groups = other.view_groups
69 elif other.view_groups is not None:
70 self.view_groups.extend(other.view_groups)
71 self.view_groups = list(set(self.view_groups))
72
73 if self.change_users is None:
74 self.change_users = other.change_users
75 elif other.change_users is not None:
76 self.change_users.extend(other.change_users)
77 self.change_users = list(set(self.change_users))
78
79 if self.change_groups is None:
80 self.change_groups = other.change_groups
81 elif other.change_groups is not None:
82 self.change_groups.extend(other.change_groups)
83 self.change_groups = list(set(self.change_groups))
84
85 if self.custom_field_ids is None:
86 self.custom_field_ids = other.custom_field_ids
87 elif other.custom_field_ids is not None:
88 self.custom_field_ids.extend(other.custom_field_ids)
89 self.custom_field_ids = list(set(self.custom_field_ids))
90
91 return self
92
93 @staticmethod
94 def from_document(doc) -> "DocumentMetadataOverrides":
95 """
96 Fills in the overrides from a document object
97 """
98 overrides = DocumentMetadataOverrides()
99 overrides.title = doc.title
100 overrides.correspondent_id = doc.correspondent.id if doc.correspondent else None
101 overrides.document_type_id = doc.document_type.id if doc.document_type else None
102 overrides.storage_path_id = doc.storage_path.id if doc.storage_path else None
103 overrides.owner_id = doc.owner.id if doc.owner else None
104 overrides.tag_ids = list(doc.tags.values_list("id", flat=True))
105
106 overrides.view_users = get_users_with_perms(
107 doc,
108 only_with_perms_in=["view_document"],
109 ).values_list("id", flat=True)
110 overrides.change_users = get_users_with_perms(
111 doc,
112 only_with_perms_in=["change_document"],
113 ).values_list("id", flat=True)
114 overrides.custom_field_ids = list(
115 doc.custom_fields.values_list("id", flat=True),
116 )
117
118 groups_with_perms = get_groups_with_perms(
119 doc,
120 attach_perms=True,
121 )
122 overrides.view_groups = [
123 group.id for group, perms in groups_with_perms if "view_document" in perms
124 ]
125 overrides.change_groups = [
126 group.id for group, perms in groups_with_perms if "change_document" in perms
127 ]
128
129 return overrides
130
131
132 class DocumentSource(IntEnum):
133 """
134 The source of an incoming document. May have other uses in the future
135 """
136
137 ConsumeFolder = 1
138 ApiUpload = 2
139 MailFetch = 3
140
141
142 @dataclasses.dataclass
143 class ConsumableDocument:
144 """
145 Encapsulates an incoming document, either from consume folder, API upload
146 or mail fetching and certain useful operations on it.
147 """
148
149 source: DocumentSource
150 original_file: Path
151 mailrule_id: Optional[int] = None
152 mime_type: str = dataclasses.field(init=False, default=None)
153
154 def __post_init__(self):
155 """
156 After a dataclass is initialized, this is called to finalize some data
157 1. Make sure the original path is an absolute, fully qualified path
158 2. Get the mime type of the file
159 """
160 # Always fully qualify the path first thing
161 # Just in case, convert to a path if it's a str
162 self.original_file = Path(self.original_file).resolve()
163
164 # Get the file type once at init
165 # Note this function isn't called when the object is unpickled
166 self.mime_type = magic.from_file(self.original_file, mime=True)
167
[end of src/documents/data_models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/documents/data_models.py b/src/documents/data_models.py
--- a/src/documents/data_models.py
+++ b/src/documents/data_models.py
@@ -103,14 +103,18 @@
overrides.owner_id = doc.owner.id if doc.owner else None
overrides.tag_ids = list(doc.tags.values_list("id", flat=True))
- overrides.view_users = get_users_with_perms(
- doc,
- only_with_perms_in=["view_document"],
- ).values_list("id", flat=True)
- overrides.change_users = get_users_with_perms(
- doc,
- only_with_perms_in=["change_document"],
- ).values_list("id", flat=True)
+ overrides.view_users = list(
+ get_users_with_perms(
+ doc,
+ only_with_perms_in=["view_document"],
+ ).values_list("id", flat=True),
+ )
+ overrides.change_users = list(
+ get_users_with_perms(
+ doc,
+ only_with_perms_in=["change_document"],
+ ).values_list("id", flat=True),
+ )
overrides.custom_field_ids = list(
doc.custom_fields.values_list("id", flat=True),
)
@@ -120,10 +124,14 @@
attach_perms=True,
)
overrides.view_groups = [
- group.id for group, perms in groups_with_perms if "view_document" in perms
+ group.id
+ for group in groups_with_perms
+ if "view_document" in groups_with_perms[group]
]
overrides.change_groups = [
- group.id for group, perms in groups_with_perms if "change_document" in perms
+ group.id
+ for group in groups_with_perms
+ if "change_document" in groups_with_perms[group]
]
return overrides
|
{"golden_diff": "diff --git a/src/documents/data_models.py b/src/documents/data_models.py\n--- a/src/documents/data_models.py\n+++ b/src/documents/data_models.py\n@@ -103,14 +103,18 @@\n overrides.owner_id = doc.owner.id if doc.owner else None\n overrides.tag_ids = list(doc.tags.values_list(\"id\", flat=True))\n \n- overrides.view_users = get_users_with_perms(\n- doc,\n- only_with_perms_in=[\"view_document\"],\n- ).values_list(\"id\", flat=True)\n- overrides.change_users = get_users_with_perms(\n- doc,\n- only_with_perms_in=[\"change_document\"],\n- ).values_list(\"id\", flat=True)\n+ overrides.view_users = list(\n+ get_users_with_perms(\n+ doc,\n+ only_with_perms_in=[\"view_document\"],\n+ ).values_list(\"id\", flat=True),\n+ )\n+ overrides.change_users = list(\n+ get_users_with_perms(\n+ doc,\n+ only_with_perms_in=[\"change_document\"],\n+ ).values_list(\"id\", flat=True),\n+ )\n overrides.custom_field_ids = list(\n doc.custom_fields.values_list(\"id\", flat=True),\n )\n@@ -120,10 +124,14 @@\n attach_perms=True,\n )\n overrides.view_groups = [\n- group.id for group, perms in groups_with_perms if \"view_document\" in perms\n+ group.id\n+ for group in groups_with_perms\n+ if \"view_document\" in groups_with_perms[group]\n ]\n overrides.change_groups = [\n- group.id for group, perms in groups_with_perms if \"change_document\" in perms\n+ group.id\n+ for group in groups_with_perms\n+ if \"change_document\" in groups_with_perms[group]\n ]\n \n return overrides\n", "issue": "[BUG ]At new splitting: \"QuerySet' object has no attribute 'extend'\" - Workflow adding a custom field on adding new document leads to the error message\n### Description\n\nWhen trying out the new splitting functionality I get the error message: \r\n\r\n 'QuerySet' object has no attribute 'extend'\r\n\r\nA Workflow for adding a custom field on adding new document leads to the error message.\r\n\r\nAnybody with the same issue?\r\n\n\n### Steps to reproduce\n\n1. Go to Documents\r\n2. Edit Document\r\n3. Split\r\n4. Split Pages 1 and 2\r\n5. Error message\n\n### Webserver logs\n\n```bash\n[2024-04-06 11:18:26,873] [DEBUG] [paperless.tasks] Executing plugin WorkflowTriggerPlugin\r\n\r\n[2024-04-06 11:18:26,905] [INFO] [paperless.matching] Document matched WorkflowTrigger 3 from Workflow: Benutzerdefinierte Felder hinzuf\u00fcgen\r\n\r\n[2024-04-06 11:18:26,910] [ERROR] [paperless.tasks] WorkflowTriggerPlugin failed: 'QuerySet' object has no attribute 'extend'\r\n\r\nTraceback (most recent call last):\r\n\r\n File \"/usr/src/paperless/src/documents/tasks.py\", line 144, in consume_file\r\n\r\n msg = plugin.run()\r\n\r\n ^^^^^^^^^^^^\r\n\r\n File \"/usr/src/paperless/src/documents/consumer.py\", line 223, in run\r\n\r\n self.metadata.update(overrides)\r\n\r\n File \"/usr/src/paperless/src/documents/data_models.py\", line 64, in update\r\n\r\n self.view_users.extend(other.view_users)\r\n\r\n ^^^^^^^^^^^^^^^^^^^^^^\r\n\r\nAttributeError: 'QuerySet' object has no attribute 'extend'\n```\n\n\n### Browser logs\n\n_No response_\n\n### Paperless-ngx version\n\n2.7.0\n\n### Host OS\n\nDocker on Synology NAS - DSM 7.2\n\n### Installation method\n\nDocker - official image\n\n### Browser\n\nFirefox\n\n### Configuration changes\n\n_No response_\n\n### Other\n\n_No response_\n\n### Please confirm the following\n\n- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.\n- [X] I have already searched for relevant existing issues and discussions before opening this report.\n- [X] I have updated the title field above with a concise description.\n", "before_files": [{"content": "import dataclasses\nimport datetime\nfrom enum import IntEnum\nfrom pathlib import Path\nfrom typing import Optional\n\nimport magic\nfrom guardian.shortcuts import get_groups_with_perms\nfrom guardian.shortcuts import get_users_with_perms\n\n\[email protected]\nclass DocumentMetadataOverrides:\n \"\"\"\n Manages overrides for document fields which normally would\n be set from content or matching. All fields default to None,\n meaning no override is happening\n \"\"\"\n\n filename: Optional[str] = None\n title: Optional[str] = None\n correspondent_id: Optional[int] = None\n document_type_id: Optional[int] = None\n tag_ids: Optional[list[int]] = None\n storage_path_id: Optional[int] = None\n created: Optional[datetime.datetime] = None\n asn: Optional[int] = None\n owner_id: Optional[int] = None\n view_users: Optional[list[int]] = None\n view_groups: Optional[list[int]] = None\n change_users: Optional[list[int]] = None\n change_groups: Optional[list[int]] = None\n custom_field_ids: Optional[list[int]] = None\n\n def update(self, other: \"DocumentMetadataOverrides\") -> \"DocumentMetadataOverrides\":\n \"\"\"\n Merges two DocumentMetadataOverrides objects such that object B's overrides\n are applied to object A or merged if multiple are accepted.\n\n The update is an in-place modification of self\n \"\"\"\n # only if empty\n if other.title is not None:\n self.title = other.title\n if other.correspondent_id is not None:\n self.correspondent_id = other.correspondent_id\n if other.document_type_id is not None:\n self.document_type_id = other.document_type_id\n if other.storage_path_id is not None:\n self.storage_path_id = other.storage_path_id\n if other.owner_id is not None:\n self.owner_id = other.owner_id\n\n # merge\n if self.tag_ids is None:\n self.tag_ids = other.tag_ids\n elif other.tag_ids is not None:\n self.tag_ids.extend(other.tag_ids)\n self.tag_ids = list(set(self.tag_ids))\n\n if self.view_users is None:\n self.view_users = other.view_users\n elif other.view_users is not None:\n self.view_users.extend(other.view_users)\n self.view_users = list(set(self.view_users))\n\n if self.view_groups is None:\n self.view_groups = other.view_groups\n elif other.view_groups is not None:\n self.view_groups.extend(other.view_groups)\n self.view_groups = list(set(self.view_groups))\n\n if self.change_users is None:\n self.change_users = other.change_users\n elif other.change_users is not None:\n self.change_users.extend(other.change_users)\n self.change_users = list(set(self.change_users))\n\n if self.change_groups is None:\n self.change_groups = other.change_groups\n elif other.change_groups is not None:\n self.change_groups.extend(other.change_groups)\n self.change_groups = list(set(self.change_groups))\n\n if self.custom_field_ids is None:\n self.custom_field_ids = other.custom_field_ids\n elif other.custom_field_ids is not None:\n self.custom_field_ids.extend(other.custom_field_ids)\n self.custom_field_ids = list(set(self.custom_field_ids))\n\n return self\n\n @staticmethod\n def from_document(doc) -> \"DocumentMetadataOverrides\":\n \"\"\"\n Fills in the overrides from a document object\n \"\"\"\n overrides = DocumentMetadataOverrides()\n overrides.title = doc.title\n overrides.correspondent_id = doc.correspondent.id if doc.correspondent else None\n overrides.document_type_id = doc.document_type.id if doc.document_type else None\n overrides.storage_path_id = doc.storage_path.id if doc.storage_path else None\n overrides.owner_id = doc.owner.id if doc.owner else None\n overrides.tag_ids = list(doc.tags.values_list(\"id\", flat=True))\n\n overrides.view_users = get_users_with_perms(\n doc,\n only_with_perms_in=[\"view_document\"],\n ).values_list(\"id\", flat=True)\n overrides.change_users = get_users_with_perms(\n doc,\n only_with_perms_in=[\"change_document\"],\n ).values_list(\"id\", flat=True)\n overrides.custom_field_ids = list(\n doc.custom_fields.values_list(\"id\", flat=True),\n )\n\n groups_with_perms = get_groups_with_perms(\n doc,\n attach_perms=True,\n )\n overrides.view_groups = [\n group.id for group, perms in groups_with_perms if \"view_document\" in perms\n ]\n overrides.change_groups = [\n group.id for group, perms in groups_with_perms if \"change_document\" in perms\n ]\n\n return overrides\n\n\nclass DocumentSource(IntEnum):\n \"\"\"\n The source of an incoming document. May have other uses in the future\n \"\"\"\n\n ConsumeFolder = 1\n ApiUpload = 2\n MailFetch = 3\n\n\[email protected]\nclass ConsumableDocument:\n \"\"\"\n Encapsulates an incoming document, either from consume folder, API upload\n or mail fetching and certain useful operations on it.\n \"\"\"\n\n source: DocumentSource\n original_file: Path\n mailrule_id: Optional[int] = None\n mime_type: str = dataclasses.field(init=False, default=None)\n\n def __post_init__(self):\n \"\"\"\n After a dataclass is initialized, this is called to finalize some data\n 1. Make sure the original path is an absolute, fully qualified path\n 2. Get the mime type of the file\n \"\"\"\n # Always fully qualify the path first thing\n # Just in case, convert to a path if it's a str\n self.original_file = Path(self.original_file).resolve()\n\n # Get the file type once at init\n # Note this function isn't called when the object is unpickled\n self.mime_type = magic.from_file(self.original_file, mime=True)\n", "path": "src/documents/data_models.py"}]}
| 2,749 | 397 |
gh_patches_debug_649
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1997
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.116
On the docket:
+ [x] The --resolve-local-platforms option does not work with --complete-platforms #1899
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.115"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.115"
+__version__ = "2.1.116"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.115\"\n+__version__ = \"2.1.116\"\n", "issue": "Release 2.1.116\nOn the docket:\r\n+ [x] The --resolve-local-platforms option does not work with --complete-platforms #1899\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.115\"\n", "path": "pex/version.py"}]}
| 623 | 98 |
gh_patches_debug_14330
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-5825
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Version Scheme Change
We've talked on and off for quite a few years about our versioning scheme for `cryptography`, but #5771 made it very clear that despite our [versioning documentation](https://cryptography.io/en/latest/api-stability.html#versioning) some users still assume it's [SemVer](https://semver.org) and are caught off guard by changes. I propose that we **switch to a [CalVer](https://calver.org) scheme** for the thirty fifth feature release (which we currently would call 3.5). This has the advantage of being unambiguously not semantic versioning but encoding some vaguely useful information (the year of release) in it.
### Alternate Choices
**Stay the course**
We've successfully used our versioning scheme for a bit over 7 years now and the probability of another monumental shift like this is low. There is, however, a constant (but low) background radiation of people who are tripped up by making assumptions about our versioning so I would argue against this choice.
**SemVer**
Switch to using an actual semantic versioning scheme. Without re-litigating years of conversations, I don't believe either @alex or myself are interested in this option. (See https://github.com/pyca/cryptography/issues/5801#issuecomment-776067787 for a bit of elaboration on our position)
**Firefox/Chrome Versioning**
(From @alex)
"Its merits are that it's technically semver compatible, it's fairly predictable, and it communicates at least a little info on the relative age of the project.
Its demerits are that it probably won't solve the real problem here, which was that folks were surprised a major change happened at all."
</issue>
<code>
[start of src/cryptography/__about__.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5
6 __all__ = [
7 "__title__",
8 "__summary__",
9 "__uri__",
10 "__version__",
11 "__author__",
12 "__email__",
13 "__license__",
14 "__copyright__",
15 ]
16
17 __title__ = "cryptography"
18 __summary__ = (
19 "cryptography is a package which provides cryptographic recipes"
20 " and primitives to Python developers."
21 )
22 __uri__ = "https://github.com/pyca/cryptography"
23
24 __version__ = "3.5.dev1"
25
26 __author__ = "The Python Cryptographic Authority and individual contributors"
27 __email__ = "[email protected]"
28
29 __license__ = "BSD or Apache License, Version 2.0"
30 __copyright__ = "Copyright 2013-2021 {}".format(__author__)
31
[end of src/cryptography/__about__.py]
[start of vectors/cryptography_vectors/__about__.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 __all__ = [
6 "__title__",
7 "__summary__",
8 "__uri__",
9 "__version__",
10 "__author__",
11 "__email__",
12 "__license__",
13 "__copyright__",
14 ]
15
16 __title__ = "cryptography_vectors"
17 __summary__ = "Test vectors for the cryptography package."
18
19 __uri__ = "https://github.com/pyca/cryptography"
20
21 __version__ = "3.5.dev1"
22
23 __author__ = "The Python Cryptographic Authority and individual contributors"
24 __email__ = "[email protected]"
25
26 __license__ = "BSD or Apache License, Version 2.0"
27 __copyright__ = "Copyright 2013-2021 %s" % __author__
28
[end of vectors/cryptography_vectors/__about__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/__about__.py b/src/cryptography/__about__.py
--- a/src/cryptography/__about__.py
+++ b/src/cryptography/__about__.py
@@ -21,7 +21,7 @@
)
__uri__ = "https://github.com/pyca/cryptography"
-__version__ = "3.5.dev1"
+__version__ = "35.0.0.dev1"
__author__ = "The Python Cryptographic Authority and individual contributors"
__email__ = "[email protected]"
diff --git a/vectors/cryptography_vectors/__about__.py b/vectors/cryptography_vectors/__about__.py
--- a/vectors/cryptography_vectors/__about__.py
+++ b/vectors/cryptography_vectors/__about__.py
@@ -18,7 +18,7 @@
__uri__ = "https://github.com/pyca/cryptography"
-__version__ = "3.5.dev1"
+__version__ = "35.0.0.dev1"
__author__ = "The Python Cryptographic Authority and individual contributors"
__email__ = "[email protected]"
|
{"golden_diff": "diff --git a/src/cryptography/__about__.py b/src/cryptography/__about__.py\n--- a/src/cryptography/__about__.py\n+++ b/src/cryptography/__about__.py\n@@ -21,7 +21,7 @@\n )\n __uri__ = \"https://github.com/pyca/cryptography\"\n \n-__version__ = \"3.5.dev1\"\n+__version__ = \"35.0.0.dev1\"\n \n __author__ = \"The Python Cryptographic Authority and individual contributors\"\n __email__ = \"[email protected]\"\ndiff --git a/vectors/cryptography_vectors/__about__.py b/vectors/cryptography_vectors/__about__.py\n--- a/vectors/cryptography_vectors/__about__.py\n+++ b/vectors/cryptography_vectors/__about__.py\n@@ -18,7 +18,7 @@\n \n __uri__ = \"https://github.com/pyca/cryptography\"\n \n-__version__ = \"3.5.dev1\"\n+__version__ = \"35.0.0.dev1\"\n \n __author__ = \"The Python Cryptographic Authority and individual contributors\"\n __email__ = \"[email protected]\"\n", "issue": "Version Scheme Change\nWe've talked on and off for quite a few years about our versioning scheme for `cryptography`, but #5771 made it very clear that despite our [versioning documentation](https://cryptography.io/en/latest/api-stability.html#versioning) some users still assume it's [SemVer](https://semver.org) and are caught off guard by changes. I propose that we **switch to a [CalVer](https://calver.org) scheme** for the thirty fifth feature release (which we currently would call 3.5). This has the advantage of being unambiguously not semantic versioning but encoding some vaguely useful information (the year of release) in it.\r\n\r\n### Alternate Choices\r\n**Stay the course**\r\nWe've successfully used our versioning scheme for a bit over 7 years now and the probability of another monumental shift like this is low. There is, however, a constant (but low) background radiation of people who are tripped up by making assumptions about our versioning so I would argue against this choice.\r\n\r\n**SemVer**\r\nSwitch to using an actual semantic versioning scheme. Without re-litigating years of conversations, I don't believe either @alex or myself are interested in this option. (See https://github.com/pyca/cryptography/issues/5801#issuecomment-776067787 for a bit of elaboration on our position)\r\n\r\n**Firefox/Chrome Versioning**\r\n(From @alex)\r\n\"Its merits are that it's technically semver compatible, it's fairly predictable, and it communicates at least a little info on the relative age of the project.\r\n\r\nIts demerits are that it probably won't solve the real problem here, which was that folks were surprised a major change happened at all.\"\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n\n__all__ = [\n \"__title__\",\n \"__summary__\",\n \"__uri__\",\n \"__version__\",\n \"__author__\",\n \"__email__\",\n \"__license__\",\n \"__copyright__\",\n]\n\n__title__ = \"cryptography\"\n__summary__ = (\n \"cryptography is a package which provides cryptographic recipes\"\n \" and primitives to Python developers.\"\n)\n__uri__ = \"https://github.com/pyca/cryptography\"\n\n__version__ = \"3.5.dev1\"\n\n__author__ = \"The Python Cryptographic Authority and individual contributors\"\n__email__ = \"[email protected]\"\n\n__license__ = \"BSD or Apache License, Version 2.0\"\n__copyright__ = \"Copyright 2013-2021 {}\".format(__author__)\n", "path": "src/cryptography/__about__.py"}, {"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\n__all__ = [\n \"__title__\",\n \"__summary__\",\n \"__uri__\",\n \"__version__\",\n \"__author__\",\n \"__email__\",\n \"__license__\",\n \"__copyright__\",\n]\n\n__title__ = \"cryptography_vectors\"\n__summary__ = \"Test vectors for the cryptography package.\"\n\n__uri__ = \"https://github.com/pyca/cryptography\"\n\n__version__ = \"3.5.dev1\"\n\n__author__ = \"The Python Cryptographic Authority and individual contributors\"\n__email__ = \"[email protected]\"\n\n__license__ = \"BSD or Apache License, Version 2.0\"\n__copyright__ = \"Copyright 2013-2021 %s\" % __author__\n", "path": "vectors/cryptography_vectors/__about__.py"}]}
| 1,457 | 252 |
gh_patches_debug_4829
|
rasdani/github-patches
|
git_diff
|
archlinux__archinstall-2178
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reset in locales menu causes crash
Using reset in the _Locales_ menu will cause a crash.
```
Traceback (most recent call last):
File "/home/scripttest/archinstall/.venv/bin/archinstall", line 8, in <module>
sys.exit(run_as_a_module())
^^^^^^^^^^^^^^^^^
File "/home/scripttest/archinstall/archinstall/__init__.py", line 291, in run_as_a_module
importlib.import_module(mod_name)
File "/usr/lib/python3.11/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<frozen importlib._bootstrap>", line 1204, in _gcd_import
File "<frozen importlib._bootstrap>", line 1176, in _find_and_load
File "<frozen importlib._bootstrap>", line 1147, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 690, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 940, in exec_module
File "<frozen importlib._bootstrap>", line 241, in _call_with_frames_removed
File "/home/scripttest/archinstall/archinstall/scripts/guided.py", line 234, in <module>
ask_user_questions()
File "/home/scripttest/archinstall/archinstall/scripts/guided.py", line 99, in ask_user_questions
global_menu.run()
File "/home/scripttest/archinstall/archinstall/lib/menu/abstract_menu.py", line 348, in run
if not self._process_selection(value):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/scripttest/archinstall/archinstall/lib/menu/abstract_menu.py", line 365, in _process_selection
return self.exec_option(config_name, selector)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/scripttest/archinstall/archinstall/lib/menu/abstract_menu.py", line 386, in exec_option
result = selector.func(presel_val)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/scripttest/archinstall/archinstall/lib/global_menu.py", line 53, in <lambda>
lambda preset: self._locale_selection(preset),
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/scripttest/archinstall/archinstall/lib/global_menu.py", line 246, in _locale_selection
locale_config = LocaleMenu(data_store, preset).run()
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/scripttest/archinstall/archinstall/lib/locale/locale_menu.py", line 84, in run
self._data_store['keyboard-layout'],
~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^
KeyError: 'keyboard-layout'
```
</issue>
<code>
[start of archinstall/lib/locale/locale_menu.py]
1 from dataclasses import dataclass
2 from typing import Dict, Any, TYPE_CHECKING, Optional
3
4 from .utils import list_keyboard_languages, list_locales, set_kb_layout
5 from ..menu import Selector, AbstractSubMenu, MenuSelectionType, Menu
6
7 if TYPE_CHECKING:
8 _: Any
9
10
11 @dataclass
12 class LocaleConfiguration:
13 kb_layout: str
14 sys_lang: str
15 sys_enc: str
16
17 @staticmethod
18 def default() -> 'LocaleConfiguration':
19 return LocaleConfiguration('us', 'en_US', 'UTF-8')
20
21 def json(self) -> Dict[str, str]:
22 return {
23 'kb_layout': self.kb_layout,
24 'sys_lang': self.sys_lang,
25 'sys_enc': self.sys_enc
26 }
27
28 @classmethod
29 def _load_config(cls, config: 'LocaleConfiguration', args: Dict[str, Any]) -> 'LocaleConfiguration':
30 if 'sys_lang' in args:
31 config.sys_lang = args['sys_lang']
32 if 'sys_enc' in args:
33 config.sys_enc = args['sys_enc']
34 if 'kb_layout' in args:
35 config.kb_layout = args['kb_layout']
36
37 return config
38
39 @classmethod
40 def parse_arg(cls, args: Dict[str, Any]) -> 'LocaleConfiguration':
41 default = cls.default()
42
43 if 'locale_config' in args:
44 default = cls._load_config(default, args['locale_config'])
45 else:
46 default = cls._load_config(default, args)
47
48 return default
49
50
51 class LocaleMenu(AbstractSubMenu):
52 def __init__(
53 self,
54 data_store: Dict[str, Any],
55 locale_conf: LocaleConfiguration
56 ):
57 self._preset = locale_conf
58 super().__init__(data_store=data_store)
59
60 def setup_selection_menu_options(self):
61 self._menu_options['keyboard-layout'] = \
62 Selector(
63 _('Keyboard layout'),
64 lambda preset: self._select_kb_layout(preset),
65 default=self._preset.kb_layout,
66 enabled=True)
67 self._menu_options['sys-language'] = \
68 Selector(
69 _('Locale language'),
70 lambda preset: select_locale_lang(preset),
71 default=self._preset.sys_lang,
72 enabled=True)
73 self._menu_options['sys-encoding'] = \
74 Selector(
75 _('Locale encoding'),
76 lambda preset: select_locale_enc(preset),
77 default=self._preset.sys_enc,
78 enabled=True)
79
80 def run(self, allow_reset: bool = True) -> LocaleConfiguration:
81 super().run(allow_reset=allow_reset)
82
83 return LocaleConfiguration(
84 self._data_store['keyboard-layout'],
85 self._data_store['sys-language'],
86 self._data_store['sys-encoding']
87 )
88
89 def _select_kb_layout(self, preset: Optional[str]) -> Optional[str]:
90 kb_lang = select_kb_layout(preset)
91 if kb_lang:
92 set_kb_layout(kb_lang)
93 return kb_lang
94
95
96 def select_locale_lang(preset: Optional[str] = None) -> Optional[str]:
97 locales = list_locales()
98 locale_lang = set([locale.split()[0] for locale in locales])
99
100 choice = Menu(
101 _('Choose which locale language to use'),
102 list(locale_lang),
103 sort=True,
104 preset_values=preset
105 ).run()
106
107 match choice.type_:
108 case MenuSelectionType.Selection: return choice.single_value
109 case MenuSelectionType.Skip: return preset
110
111 return None
112
113
114 def select_locale_enc(preset: Optional[str] = None) -> Optional[str]:
115 locales = list_locales()
116 locale_enc = set([locale.split()[1] for locale in locales])
117
118 choice = Menu(
119 _('Choose which locale encoding to use'),
120 list(locale_enc),
121 sort=True,
122 preset_values=preset
123 ).run()
124
125 match choice.type_:
126 case MenuSelectionType.Selection: return choice.single_value
127 case MenuSelectionType.Skip: return preset
128
129 return None
130
131
132 def select_kb_layout(preset: Optional[str] = None) -> Optional[str]:
133 """
134 Asks the user to select a language
135 Usually this is combined with :ref:`archinstall.list_keyboard_languages`.
136
137 :return: The language/dictionary key of the selected language
138 :rtype: str
139 """
140 kb_lang = list_keyboard_languages()
141 # sort alphabetically and then by length
142 sorted_kb_lang = sorted(kb_lang, key=lambda x: (len(x), x))
143
144 choice = Menu(
145 _('Select keyboard layout'),
146 sorted_kb_lang,
147 preset_values=preset,
148 sort=False
149 ).run()
150
151 match choice.type_:
152 case MenuSelectionType.Skip: return preset
153 case MenuSelectionType.Selection: return choice.single_value
154
155 return None
156
[end of archinstall/lib/locale/locale_menu.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/archinstall/lib/locale/locale_menu.py b/archinstall/lib/locale/locale_menu.py
--- a/archinstall/lib/locale/locale_menu.py
+++ b/archinstall/lib/locale/locale_menu.py
@@ -80,6 +80,9 @@
def run(self, allow_reset: bool = True) -> LocaleConfiguration:
super().run(allow_reset=allow_reset)
+ if not self._data_store:
+ return LocaleConfiguration.default()
+
return LocaleConfiguration(
self._data_store['keyboard-layout'],
self._data_store['sys-language'],
|
{"golden_diff": "diff --git a/archinstall/lib/locale/locale_menu.py b/archinstall/lib/locale/locale_menu.py\n--- a/archinstall/lib/locale/locale_menu.py\n+++ b/archinstall/lib/locale/locale_menu.py\n@@ -80,6 +80,9 @@\n \tdef run(self, allow_reset: bool = True) -> LocaleConfiguration:\n \t\tsuper().run(allow_reset=allow_reset)\n \n+\t\tif not self._data_store:\n+\t\t\treturn LocaleConfiguration.default()\n+\n \t\treturn LocaleConfiguration(\n \t\t\tself._data_store['keyboard-layout'],\n \t\t\tself._data_store['sys-language'],\n", "issue": "Reset in locales menu causes crash\nUsing reset in the _Locales_ menu will cause a crash.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/scripttest/archinstall/.venv/bin/archinstall\", line 8, in <module>\r\n sys.exit(run_as_a_module())\r\n ^^^^^^^^^^^^^^^^^\r\n File \"/home/scripttest/archinstall/archinstall/__init__.py\", line 291, in run_as_a_module\r\n importlib.import_module(mod_name)\r\n File \"/usr/lib/python3.11/importlib/__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"<frozen importlib._bootstrap>\", line 1204, in _gcd_import\r\n File \"<frozen importlib._bootstrap>\", line 1176, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 1147, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 690, in _load_unlocked\r\n File \"<frozen importlib._bootstrap_external>\", line 940, in exec_module\r\n File \"<frozen importlib._bootstrap>\", line 241, in _call_with_frames_removed\r\n File \"/home/scripttest/archinstall/archinstall/scripts/guided.py\", line 234, in <module>\r\n ask_user_questions()\r\n File \"/home/scripttest/archinstall/archinstall/scripts/guided.py\", line 99, in ask_user_questions\r\n global_menu.run()\r\n File \"/home/scripttest/archinstall/archinstall/lib/menu/abstract_menu.py\", line 348, in run\r\n if not self._process_selection(value):\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/scripttest/archinstall/archinstall/lib/menu/abstract_menu.py\", line 365, in _process_selection\r\n return self.exec_option(config_name, selector)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/scripttest/archinstall/archinstall/lib/menu/abstract_menu.py\", line 386, in exec_option\r\n result = selector.func(presel_val)\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/scripttest/archinstall/archinstall/lib/global_menu.py\", line 53, in <lambda>\r\n lambda preset: self._locale_selection(preset),\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/scripttest/archinstall/archinstall/lib/global_menu.py\", line 246, in _locale_selection\r\n locale_config = LocaleMenu(data_store, preset).run()\r\n ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^\r\n File \"/home/scripttest/archinstall/archinstall/lib/locale/locale_menu.py\", line 84, in run\r\n self._data_store['keyboard-layout'],\r\n ~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^\r\nKeyError: 'keyboard-layout'\r\n```\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import Dict, Any, TYPE_CHECKING, Optional\n\nfrom .utils import list_keyboard_languages, list_locales, set_kb_layout\nfrom ..menu import Selector, AbstractSubMenu, MenuSelectionType, Menu\n\nif TYPE_CHECKING:\n\t_: Any\n\n\n@dataclass\nclass LocaleConfiguration:\n\tkb_layout: str\n\tsys_lang: str\n\tsys_enc: str\n\n\t@staticmethod\n\tdef default() -> 'LocaleConfiguration':\n\t\treturn LocaleConfiguration('us', 'en_US', 'UTF-8')\n\n\tdef json(self) -> Dict[str, str]:\n\t\treturn {\n\t\t\t'kb_layout': self.kb_layout,\n\t\t\t'sys_lang': self.sys_lang,\n\t\t\t'sys_enc': self.sys_enc\n\t\t}\n\n\t@classmethod\n\tdef _load_config(cls, config: 'LocaleConfiguration', args: Dict[str, Any]) -> 'LocaleConfiguration':\n\t\tif 'sys_lang' in args:\n\t\t\tconfig.sys_lang = args['sys_lang']\n\t\tif 'sys_enc' in args:\n\t\t\tconfig.sys_enc = args['sys_enc']\n\t\tif 'kb_layout' in args:\n\t\t\tconfig.kb_layout = args['kb_layout']\n\n\t\treturn config\n\n\t@classmethod\n\tdef parse_arg(cls, args: Dict[str, Any]) -> 'LocaleConfiguration':\n\t\tdefault = cls.default()\n\n\t\tif 'locale_config' in args:\n\t\t\tdefault = cls._load_config(default, args['locale_config'])\n\t\telse:\n\t\t\tdefault = cls._load_config(default, args)\n\n\t\treturn default\n\n\nclass LocaleMenu(AbstractSubMenu):\n\tdef __init__(\n\t\tself,\n\t\tdata_store: Dict[str, Any],\n\t\tlocale_conf: LocaleConfiguration\n\t):\n\t\tself._preset = locale_conf\n\t\tsuper().__init__(data_store=data_store)\n\n\tdef setup_selection_menu_options(self):\n\t\tself._menu_options['keyboard-layout'] = \\\n\t\t\tSelector(\n\t\t\t\t_('Keyboard layout'),\n\t\t\t\tlambda preset: self._select_kb_layout(preset),\n\t\t\t\tdefault=self._preset.kb_layout,\n\t\t\t\tenabled=True)\n\t\tself._menu_options['sys-language'] = \\\n\t\t\tSelector(\n\t\t\t\t_('Locale language'),\n\t\t\t\tlambda preset: select_locale_lang(preset),\n\t\t\t\tdefault=self._preset.sys_lang,\n\t\t\t\tenabled=True)\n\t\tself._menu_options['sys-encoding'] = \\\n\t\t\tSelector(\n\t\t\t\t_('Locale encoding'),\n\t\t\t\tlambda preset: select_locale_enc(preset),\n\t\t\t\tdefault=self._preset.sys_enc,\n\t\t\t\tenabled=True)\n\n\tdef run(self, allow_reset: bool = True) -> LocaleConfiguration:\n\t\tsuper().run(allow_reset=allow_reset)\n\n\t\treturn LocaleConfiguration(\n\t\t\tself._data_store['keyboard-layout'],\n\t\t\tself._data_store['sys-language'],\n\t\t\tself._data_store['sys-encoding']\n\t\t)\n\n\tdef _select_kb_layout(self, preset: Optional[str]) -> Optional[str]:\n\t\tkb_lang = select_kb_layout(preset)\n\t\tif kb_lang:\n\t\t\tset_kb_layout(kb_lang)\n\t\treturn kb_lang\n\n\ndef select_locale_lang(preset: Optional[str] = None) -> Optional[str]:\n\tlocales = list_locales()\n\tlocale_lang = set([locale.split()[0] for locale in locales])\n\n\tchoice = Menu(\n\t\t_('Choose which locale language to use'),\n\t\tlist(locale_lang),\n\t\tsort=True,\n\t\tpreset_values=preset\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\t\tcase MenuSelectionType.Skip: return preset\n\n\treturn None\n\n\ndef select_locale_enc(preset: Optional[str] = None) -> Optional[str]:\n\tlocales = list_locales()\n\tlocale_enc = set([locale.split()[1] for locale in locales])\n\n\tchoice = Menu(\n\t\t_('Choose which locale encoding to use'),\n\t\tlist(locale_enc),\n\t\tsort=True,\n\t\tpreset_values=preset\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\t\tcase MenuSelectionType.Skip: return preset\n\n\treturn None\n\n\ndef select_kb_layout(preset: Optional[str] = None) -> Optional[str]:\n\t\"\"\"\n\tAsks the user to select a language\n\tUsually this is combined with :ref:`archinstall.list_keyboard_languages`.\n\n\t:return: The language/dictionary key of the selected language\n\t:rtype: str\n\t\"\"\"\n\tkb_lang = list_keyboard_languages()\n\t# sort alphabetically and then by length\n\tsorted_kb_lang = sorted(kb_lang, key=lambda x: (len(x), x))\n\n\tchoice = Menu(\n\t\t_('Select keyboard layout'),\n\t\tsorted_kb_lang,\n\t\tpreset_values=preset,\n\t\tsort=False\n\t).run()\n\n\tmatch choice.type_:\n\t\tcase MenuSelectionType.Skip: return preset\n\t\tcase MenuSelectionType.Selection: return choice.single_value\n\n\treturn None\n", "path": "archinstall/lib/locale/locale_menu.py"}]}
| 2,625 | 120 |
gh_patches_debug_34172
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-5943
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Parsing GBM files for GBMSummaryTimeSeries takes too long
### Describe the performance issue
When reading in the Fermi GBM CSPEC and CTIME fits files to create a timeseries, the parsing takes a very long time.
This can be up to 3 minutes for the CTIME files 😱 which have a very high cadence.
This is due to t he nested loop here:
https://github.com/sunpy/sunpy/blob/main/sunpy/timeseries/sources/fermi_gbm.py#L215
It loops over the time index which is really inefficient.
### To Reproduce
```python
>>> from sunpy import timeseries as ts
>>> import time
>>> t1 = time.time()
>>> gbm_cspec = ts.TimeSeries("glg_cspec_n0_220120_v00.pha")
>>> print("Time taken to read file", time.time() - t1)
Time taken to read file 11.445274829864502
>>> t1 = time.time()
>>> gbm_ctime = ts.TimeSeries("glg_ctime_n0_220120_v00.pha")
>>> print("Time taken to read file", time.time() - t1)
Time taken to read file 188.96947813034058 😱
```
### Proposed fix
array divisions rather than looping, I'll make a PR now
</issue>
<code>
[start of sunpy/timeseries/sources/fermi_gbm.py]
1 """
2 This module FERMI GBM `~sunpy.timeseries.TimeSeries` source.
3 """
4 from collections import OrderedDict
5
6 import matplotlib.pyplot as plt
7 import numpy as np
8 import pandas as pd
9
10 import astropy.units as u
11 from astropy.time import TimeDelta
12
13 import sunpy.io
14 from sunpy.time import parse_time
15 from sunpy.timeseries.timeseriesbase import GenericTimeSeries
16 from sunpy.util.metadata import MetaDict
17 from sunpy.visualization import peek_show
18
19 __all__ = ['GBMSummaryTimeSeries']
20
21
22 class GBMSummaryTimeSeries(GenericTimeSeries):
23 """
24 Fermi/GBM Summary lightcurve TimeSeries.
25
26 The Gamma-ray Burst Monitor (GBM) is an instrument on board Fermi.
27 It is meant to detect gamma-ray bursts but also detects solar flares.
28 It consists of 12 Sodium Iodide (NaI) scintillation detectors and 2 Bismuth Germanate (BGO) scintillation detectors.
29 The NaI detectors cover from a few keV to about 1 MeV and provide burst triggers and locations.
30 The BGO detectors cover the energy range from about 150 keV to about 30 MeV.
31
32 This summary lightcurve makes use of the CSPEC (daily version) data set which consists of the counts
33 accumulated every 4.096 seconds in 128 energy channels for each of the 14 detectors.
34 Note that the data is re-binned from the original 128 into the following 8 pre-determined energy channels.
35
36 * 4-15 keV
37 * 15-25 keV
38 * 25-50 keV
39 * 50-100 keV
40 * 100-300 keV
41 * 300-800 keV
42 * 800-2000 keV
43
44 Examples
45 --------
46 >>> import sunpy.timeseries
47 >>> import sunpy.data.sample # doctest: +REMOTE_DATA
48 >>> gbm = sunpy.timeseries.TimeSeries(sunpy.data.sample.GBM_TIMESERIES, source='GBMSummary') # doctest: +REMOTE_DATA
49 >>> gbm.peek() # doctest: +SKIP
50
51 References
52 ----------
53 * `Fermi Mission Homepage <https://fermi.gsfc.nasa.gov>`_
54 * `Fermi GBM Homepage <https://fermi.gsfc.nasa.gov/science/instruments/gbm.html>`_
55 * `Fermi Science Support Center <https://fermi.gsfc.nasa.gov/ssc/>`_
56 * `Fermi Data Product <https://fermi.gsfc.nasa.gov/ssc/data/access/>`_
57 * `GBM Instrument Papers <https://gammaray.nsstc.nasa.gov/gbm/publications/instrument_journal_gbm.html>`_
58 """
59 # Class attribute used to specify the source class of the TimeSeries.
60 _source = 'gbmsummary'
61
62 def plot(self, axes=None, **kwargs):
63 """
64 Plots the GBM timeseries.
65
66 Parameters
67 ----------
68 axes : `matplotlib.axes.Axes`, optional
69 The axes on which to plot the TimeSeries. Defaults to current axes.
70 **kwargs : `dict`
71 Additional plot keyword arguments that are handed to `~matplotlib.axes.Axes.plot`
72 functions.
73
74 Returns
75 -------
76 `~matplotlib.axes.Axes`
77 The plot axes.
78 """
79 self._validate_data_for_plotting()
80 if axes is None:
81 axes = plt.gca()
82 data_lab = self.to_dataframe().columns.values
83 for d in data_lab:
84 axes.plot(self.to_dataframe().index, self.to_dataframe()[d], label=d, **kwargs)
85 axes.set_yscale("log")
86 axes.set_xlabel('Start time: ' + self.to_dataframe().index[0].strftime('%Y-%m-%d %H:%M:%S UT'))
87 axes.set_ylabel('Counts/s/keV')
88 axes.legend()
89 return axes
90
91 @peek_show
92 def peek(self, title=None, **kwargs):
93 """
94 Displays the GBM timeseries by calling
95 `~sunpy.timeseries.sources.fermi_gbm.GBMSummaryTimeSeries.plot`.
96
97 .. plot::
98
99 import sunpy.timeseries
100 import sunpy.data.sample
101 gbm = sunpy.timeseries.TimeSeries(sunpy.data.sample.GBM_TIMESERIES, source='GBMSummary')
102 gbm.peek()
103
104 Parameters
105 ----------
106 title : `str`, optional
107 The title of the plot.
108 **kwargs : `dict`
109 Additional plot keyword arguments that are handed to `~matplotlib.axes.Axes.plot`
110 functions.
111 """
112 if title is None:
113 title = 'Fermi GBM Summary data ' + str(self.meta.get('DETNAM').values())
114 fig, ax = plt.subplots()
115 axes = self.plot(axes=ax, **kwargs)
116 axes.set_title(title)
117 fig.autofmt_xdate()
118 return fig
119
120 @classmethod
121 def _parse_file(cls, filepath):
122 """
123 Parses a GBM CSPEC FITS file.
124
125 Parameters
126 ----------
127 filepath : `str`
128 The path to the file you want to parse.
129 """
130 hdus = sunpy.io.read_file(filepath)
131 return cls._parse_hdus(hdus)
132
133 @classmethod
134 def _parse_hdus(cls, hdulist):
135 """
136 Parses a GBM CSPEC `astropy.io.fits.HDUList`.
137
138 Parameters
139 ----------
140 hdulist : `str`
141 The path to the file you want to parse.
142 """
143 header = MetaDict(OrderedDict(hdulist[0].header))
144 # these GBM files have three FITS extensions.
145 # extn1 - this gives the energy range for each of the 128 energy bins
146 # extn2 - this contains the data, e.g. counts, exposure time, time of observation
147 # extn3 - eclipse times?
148 energy_bins = hdulist[1].data
149 count_data = hdulist[2].data
150
151 # rebin the 128 energy channels into some summary ranges
152 # 4-15 keV, 15 - 25 keV, 25-50 keV, 50-100 keV, 100-300 keV, 300-800 keV, 800 - 2000 keV
153 # put the data in the units of counts/s/keV
154 summary_counts = _bin_data_for_summary(energy_bins, count_data)
155
156 # get the time information in datetime format with the correct MET adjustment
157 met_ref_time = parse_time('2001-01-01 00:00') # Mission elapsed time
158 gbm_times = met_ref_time + TimeDelta(count_data['time'], format='sec')
159 gbm_times.precision = 9
160 gbm_times = gbm_times.isot.astype('datetime64')
161
162 column_labels = ['4-15 keV', '15-25 keV', '25-50 keV', '50-100 keV',
163 '100-300 keV', '300-800 keV', '800-2000 keV']
164
165 # Add the units data
166 units = OrderedDict([('4-15 keV', u.ct / u.s / u.keV), ('15-25 keV', u.ct / u.s / u.keV),
167 ('25-50 keV', u.ct / u.s / u.keV), ('50-100 keV', u.ct / u.s / u.keV),
168 ('100-300 keV', u.ct / u.s / u.keV), ('300-800 keV', u.ct / u.s / u.keV),
169 ('800-2000 keV', u.ct / u.s / u.keV)])
170 return pd.DataFrame(summary_counts, columns=column_labels, index=gbm_times), header, units
171
172 @classmethod
173 def is_datasource_for(cls, **kwargs):
174 """
175 Determines if the file corresponds to a GBM summary lightcurve
176 `~sunpy.timeseries.TimeSeries`.
177 """
178 # Check if source is explicitly assigned
179 if 'source' in kwargs.keys():
180 if kwargs.get('source', ''):
181 return kwargs.get('source', '').lower().startswith(cls._source)
182 # Check if HDU defines the source instrument
183 if 'meta' in kwargs.keys():
184 return kwargs['meta'].get('INSTRUME', '').startswith('GBM')
185
186
187 def _bin_data_for_summary(energy_bins, count_data):
188 """
189 Rebin the 128 energy channels into some summary ranges and put the data in
190 the units of counts/s/keV.
191
192 Bin ranges used:
193 * 4-15 keV
194 * 15-25 keV
195 * 25-50 keV
196 * 50-100 keV
197 * 100-300 keV
198 * 300-800 keV
199 * 800-2000 keV
200
201 Parameters
202 ----------
203 energy_bins : `numpy.ndarray`
204 The array of energy bins to rebin.
205 count_data : `numpy.ndarray`
206 The array of count data to rebin.
207 """
208 # find the indices corresponding to some standard summary energy bins
209 ebands = [4, 15, 25, 50, 100, 300, 800, 2000]
210 indices = []
211 for e in ebands:
212 indices.append(np.searchsorted(energy_bins['e_max'], e))
213
214 summary_counts = []
215 for i in range(0, len(count_data['counts'])):
216 counts_in_bands = []
217 for j in range(1, len(ebands)):
218 counts_in_bands.append(
219 np.sum(count_data['counts'][i][indices[j - 1]:indices[j]]) /
220 (count_data['exposure'][i] *
221 (energy_bins['e_max'][indices[j]] -
222 energy_bins['e_min'][indices[j - 1]])))
223
224 summary_counts.append(counts_in_bands)
225
226 return summary_counts
227
228
229 def _parse_detector(detector):
230 """
231 Check and fix detector name strings.
232
233 Parameters
234 ----------
235 detector : `str`
236 The detector name to check.
237 """
238 oklist = ['n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9',
239 'n10', 'n11']
240 altlist = [str(i) for i in range(12)]
241 if detector in oklist:
242 return detector
243 elif detector in altlist:
244 return 'n' + detector
245 else:
246 raise ValueError('Detector string could not be interpreted')
247
[end of sunpy/timeseries/sources/fermi_gbm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/timeseries/sources/fermi_gbm.py b/sunpy/timeseries/sources/fermi_gbm.py
--- a/sunpy/timeseries/sources/fermi_gbm.py
+++ b/sunpy/timeseries/sources/fermi_gbm.py
@@ -31,7 +31,12 @@
This summary lightcurve makes use of the CSPEC (daily version) data set which consists of the counts
accumulated every 4.096 seconds in 128 energy channels for each of the 14 detectors.
+
Note that the data is re-binned from the original 128 into the following 8 pre-determined energy channels.
+ The rebinning method treats the counts in each of the original 128 channels as
+ all having the energy of the average energy of that channel. For example, the
+ counts in an 14.5--15.6 keV original channel would all be accumulated into the
+ 15--25 keV rebinned channel.
* 4-15 keV
* 15-25 keV
@@ -205,25 +210,20 @@
count_data : `numpy.ndarray`
The array of count data to rebin.
"""
- # find the indices corresponding to some standard summary energy bins
+
+ # list of energy bands to sum between
ebands = [4, 15, 25, 50, 100, 300, 800, 2000]
- indices = []
- for e in ebands:
- indices.append(np.searchsorted(energy_bins['e_max'], e))
+ e_center = (energy_bins['e_min'] + energy_bins['e_max']) / 2
+ indices = [np.searchsorted(e_center, e) for e in ebands]
summary_counts = []
- for i in range(0, len(count_data['counts'])):
- counts_in_bands = []
- for j in range(1, len(ebands)):
- counts_in_bands.append(
- np.sum(count_data['counts'][i][indices[j - 1]:indices[j]]) /
- (count_data['exposure'][i] *
- (energy_bins['e_max'][indices[j]] -
- energy_bins['e_min'][indices[j - 1]])))
-
- summary_counts.append(counts_in_bands)
-
- return summary_counts
+ for ind_start, ind_end in zip(indices[:-1], indices[1:]):
+ # sum the counts in the energy bands, and find counts/s/keV
+ summed_counts = np.sum(count_data["counts"][:, ind_start:ind_end], axis=1)
+ energy_width = (energy_bins["e_max"][ind_end - 1] - energy_bins["e_min"][ind_start])
+ summary_counts.append(summed_counts/energy_width/count_data["exposure"])
+
+ return np.array(summary_counts).T
def _parse_detector(detector):
|
{"golden_diff": "diff --git a/sunpy/timeseries/sources/fermi_gbm.py b/sunpy/timeseries/sources/fermi_gbm.py\n--- a/sunpy/timeseries/sources/fermi_gbm.py\n+++ b/sunpy/timeseries/sources/fermi_gbm.py\n@@ -31,7 +31,12 @@\n \n This summary lightcurve makes use of the CSPEC (daily version) data set which consists of the counts\n accumulated every 4.096 seconds in 128 energy channels for each of the 14 detectors.\n+\n Note that the data is re-binned from the original 128 into the following 8 pre-determined energy channels.\n+ The rebinning method treats the counts in each of the original 128 channels as\n+ all having the energy of the average energy of that channel. For example, the\n+ counts in an 14.5--15.6 keV original channel would all be accumulated into the\n+ 15--25 keV rebinned channel.\n \n * 4-15 keV\n * 15-25 keV\n@@ -205,25 +210,20 @@\n count_data : `numpy.ndarray`\n The array of count data to rebin.\n \"\"\"\n- # find the indices corresponding to some standard summary energy bins\n+\n+ # list of energy bands to sum between\n ebands = [4, 15, 25, 50, 100, 300, 800, 2000]\n- indices = []\n- for e in ebands:\n- indices.append(np.searchsorted(energy_bins['e_max'], e))\n+ e_center = (energy_bins['e_min'] + energy_bins['e_max']) / 2\n+ indices = [np.searchsorted(e_center, e) for e in ebands]\n \n summary_counts = []\n- for i in range(0, len(count_data['counts'])):\n- counts_in_bands = []\n- for j in range(1, len(ebands)):\n- counts_in_bands.append(\n- np.sum(count_data['counts'][i][indices[j - 1]:indices[j]]) /\n- (count_data['exposure'][i] *\n- (energy_bins['e_max'][indices[j]] -\n- energy_bins['e_min'][indices[j - 1]])))\n-\n- summary_counts.append(counts_in_bands)\n-\n- return summary_counts\n+ for ind_start, ind_end in zip(indices[:-1], indices[1:]):\n+ # sum the counts in the energy bands, and find counts/s/keV\n+ summed_counts = np.sum(count_data[\"counts\"][:, ind_start:ind_end], axis=1)\n+ energy_width = (energy_bins[\"e_max\"][ind_end - 1] - energy_bins[\"e_min\"][ind_start])\n+ summary_counts.append(summed_counts/energy_width/count_data[\"exposure\"])\n+\n+ return np.array(summary_counts).T\n \n \n def _parse_detector(detector):\n", "issue": "Parsing GBM files for GBMSummaryTimeSeries takes too long\n### Describe the performance issue\n\nWhen reading in the Fermi GBM CSPEC and CTIME fits files to create a timeseries, the parsing takes a very long time. \r\nThis can be up to 3 minutes for the CTIME files \ud83d\ude31 which have a very high cadence.\r\n\r\nThis is due to t he nested loop here:\r\n\r\nhttps://github.com/sunpy/sunpy/blob/main/sunpy/timeseries/sources/fermi_gbm.py#L215\r\n\r\n\r\nIt loops over the time index which is really inefficient.\n\n### To Reproduce\n\n```python\r\n>>> from sunpy import timeseries as ts\r\n>>> import time\r\n\r\n>>> t1 = time.time()\r\n>>> gbm_cspec = ts.TimeSeries(\"glg_cspec_n0_220120_v00.pha\")\r\n>>> print(\"Time taken to read file\", time.time() - t1)\r\nTime taken to read file 11.445274829864502\r\n\r\n>>> t1 = time.time()\r\n>>> gbm_ctime = ts.TimeSeries(\"glg_ctime_n0_220120_v00.pha\")\r\n>>> print(\"Time taken to read file\", time.time() - t1)\r\nTime taken to read file 188.96947813034058 \ud83d\ude31 \r\n```\r\n\r\n\n\n### Proposed fix\n\narray divisions rather than looping, I'll make a PR now\n", "before_files": [{"content": "\"\"\"\nThis module FERMI GBM `~sunpy.timeseries.TimeSeries` source.\n\"\"\"\nfrom collections import OrderedDict\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n\nimport astropy.units as u\nfrom astropy.time import TimeDelta\n\nimport sunpy.io\nfrom sunpy.time import parse_time\nfrom sunpy.timeseries.timeseriesbase import GenericTimeSeries\nfrom sunpy.util.metadata import MetaDict\nfrom sunpy.visualization import peek_show\n\n__all__ = ['GBMSummaryTimeSeries']\n\n\nclass GBMSummaryTimeSeries(GenericTimeSeries):\n \"\"\"\n Fermi/GBM Summary lightcurve TimeSeries.\n\n The Gamma-ray Burst Monitor (GBM) is an instrument on board Fermi.\n It is meant to detect gamma-ray bursts but also detects solar flares.\n It consists of 12 Sodium Iodide (NaI) scintillation detectors and 2 Bismuth Germanate (BGO) scintillation detectors.\n The NaI detectors cover from a few keV to about 1 MeV and provide burst triggers and locations.\n The BGO detectors cover the energy range from about 150 keV to about 30 MeV.\n\n This summary lightcurve makes use of the CSPEC (daily version) data set which consists of the counts\n accumulated every 4.096 seconds in 128 energy channels for each of the 14 detectors.\n Note that the data is re-binned from the original 128 into the following 8 pre-determined energy channels.\n\n * 4-15 keV\n * 15-25 keV\n * 25-50 keV\n * 50-100 keV\n * 100-300 keV\n * 300-800 keV\n * 800-2000 keV\n\n Examples\n --------\n >>> import sunpy.timeseries\n >>> import sunpy.data.sample # doctest: +REMOTE_DATA\n >>> gbm = sunpy.timeseries.TimeSeries(sunpy.data.sample.GBM_TIMESERIES, source='GBMSummary') # doctest: +REMOTE_DATA\n >>> gbm.peek() # doctest: +SKIP\n\n References\n ----------\n * `Fermi Mission Homepage <https://fermi.gsfc.nasa.gov>`_\n * `Fermi GBM Homepage <https://fermi.gsfc.nasa.gov/science/instruments/gbm.html>`_\n * `Fermi Science Support Center <https://fermi.gsfc.nasa.gov/ssc/>`_\n * `Fermi Data Product <https://fermi.gsfc.nasa.gov/ssc/data/access/>`_\n * `GBM Instrument Papers <https://gammaray.nsstc.nasa.gov/gbm/publications/instrument_journal_gbm.html>`_\n \"\"\"\n # Class attribute used to specify the source class of the TimeSeries.\n _source = 'gbmsummary'\n\n def plot(self, axes=None, **kwargs):\n \"\"\"\n Plots the GBM timeseries.\n\n Parameters\n ----------\n axes : `matplotlib.axes.Axes`, optional\n The axes on which to plot the TimeSeries. Defaults to current axes.\n **kwargs : `dict`\n Additional plot keyword arguments that are handed to `~matplotlib.axes.Axes.plot`\n functions.\n\n Returns\n -------\n `~matplotlib.axes.Axes`\n The plot axes.\n \"\"\"\n self._validate_data_for_plotting()\n if axes is None:\n axes = plt.gca()\n data_lab = self.to_dataframe().columns.values\n for d in data_lab:\n axes.plot(self.to_dataframe().index, self.to_dataframe()[d], label=d, **kwargs)\n axes.set_yscale(\"log\")\n axes.set_xlabel('Start time: ' + self.to_dataframe().index[0].strftime('%Y-%m-%d %H:%M:%S UT'))\n axes.set_ylabel('Counts/s/keV')\n axes.legend()\n return axes\n\n @peek_show\n def peek(self, title=None, **kwargs):\n \"\"\"\n Displays the GBM timeseries by calling\n `~sunpy.timeseries.sources.fermi_gbm.GBMSummaryTimeSeries.plot`.\n\n .. plot::\n\n import sunpy.timeseries\n import sunpy.data.sample\n gbm = sunpy.timeseries.TimeSeries(sunpy.data.sample.GBM_TIMESERIES, source='GBMSummary')\n gbm.peek()\n\n Parameters\n ----------\n title : `str`, optional\n The title of the plot.\n **kwargs : `dict`\n Additional plot keyword arguments that are handed to `~matplotlib.axes.Axes.plot`\n functions.\n \"\"\"\n if title is None:\n title = 'Fermi GBM Summary data ' + str(self.meta.get('DETNAM').values())\n fig, ax = plt.subplots()\n axes = self.plot(axes=ax, **kwargs)\n axes.set_title(title)\n fig.autofmt_xdate()\n return fig\n\n @classmethod\n def _parse_file(cls, filepath):\n \"\"\"\n Parses a GBM CSPEC FITS file.\n\n Parameters\n ----------\n filepath : `str`\n The path to the file you want to parse.\n \"\"\"\n hdus = sunpy.io.read_file(filepath)\n return cls._parse_hdus(hdus)\n\n @classmethod\n def _parse_hdus(cls, hdulist):\n \"\"\"\n Parses a GBM CSPEC `astropy.io.fits.HDUList`.\n\n Parameters\n ----------\n hdulist : `str`\n The path to the file you want to parse.\n \"\"\"\n header = MetaDict(OrderedDict(hdulist[0].header))\n # these GBM files have three FITS extensions.\n # extn1 - this gives the energy range for each of the 128 energy bins\n # extn2 - this contains the data, e.g. counts, exposure time, time of observation\n # extn3 - eclipse times?\n energy_bins = hdulist[1].data\n count_data = hdulist[2].data\n\n # rebin the 128 energy channels into some summary ranges\n # 4-15 keV, 15 - 25 keV, 25-50 keV, 50-100 keV, 100-300 keV, 300-800 keV, 800 - 2000 keV\n # put the data in the units of counts/s/keV\n summary_counts = _bin_data_for_summary(energy_bins, count_data)\n\n # get the time information in datetime format with the correct MET adjustment\n met_ref_time = parse_time('2001-01-01 00:00') # Mission elapsed time\n gbm_times = met_ref_time + TimeDelta(count_data['time'], format='sec')\n gbm_times.precision = 9\n gbm_times = gbm_times.isot.astype('datetime64')\n\n column_labels = ['4-15 keV', '15-25 keV', '25-50 keV', '50-100 keV',\n '100-300 keV', '300-800 keV', '800-2000 keV']\n\n # Add the units data\n units = OrderedDict([('4-15 keV', u.ct / u.s / u.keV), ('15-25 keV', u.ct / u.s / u.keV),\n ('25-50 keV', u.ct / u.s / u.keV), ('50-100 keV', u.ct / u.s / u.keV),\n ('100-300 keV', u.ct / u.s / u.keV), ('300-800 keV', u.ct / u.s / u.keV),\n ('800-2000 keV', u.ct / u.s / u.keV)])\n return pd.DataFrame(summary_counts, columns=column_labels, index=gbm_times), header, units\n\n @classmethod\n def is_datasource_for(cls, **kwargs):\n \"\"\"\n Determines if the file corresponds to a GBM summary lightcurve\n `~sunpy.timeseries.TimeSeries`.\n \"\"\"\n # Check if source is explicitly assigned\n if 'source' in kwargs.keys():\n if kwargs.get('source', ''):\n return kwargs.get('source', '').lower().startswith(cls._source)\n # Check if HDU defines the source instrument\n if 'meta' in kwargs.keys():\n return kwargs['meta'].get('INSTRUME', '').startswith('GBM')\n\n\ndef _bin_data_for_summary(energy_bins, count_data):\n \"\"\"\n Rebin the 128 energy channels into some summary ranges and put the data in\n the units of counts/s/keV.\n\n Bin ranges used:\n * 4-15 keV\n * 15-25 keV\n * 25-50 keV\n * 50-100 keV\n * 100-300 keV\n * 300-800 keV\n * 800-2000 keV\n\n Parameters\n ----------\n energy_bins : `numpy.ndarray`\n The array of energy bins to rebin.\n count_data : `numpy.ndarray`\n The array of count data to rebin.\n \"\"\"\n # find the indices corresponding to some standard summary energy bins\n ebands = [4, 15, 25, 50, 100, 300, 800, 2000]\n indices = []\n for e in ebands:\n indices.append(np.searchsorted(energy_bins['e_max'], e))\n\n summary_counts = []\n for i in range(0, len(count_data['counts'])):\n counts_in_bands = []\n for j in range(1, len(ebands)):\n counts_in_bands.append(\n np.sum(count_data['counts'][i][indices[j - 1]:indices[j]]) /\n (count_data['exposure'][i] *\n (energy_bins['e_max'][indices[j]] -\n energy_bins['e_min'][indices[j - 1]])))\n\n summary_counts.append(counts_in_bands)\n\n return summary_counts\n\n\ndef _parse_detector(detector):\n \"\"\"\n Check and fix detector name strings.\n\n Parameters\n ----------\n detector : `str`\n The detector name to check.\n \"\"\"\n oklist = ['n0', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9',\n 'n10', 'n11']\n altlist = [str(i) for i in range(12)]\n if detector in oklist:\n return detector\n elif detector in altlist:\n return 'n' + detector\n else:\n raise ValueError('Detector string could not be interpreted')\n", "path": "sunpy/timeseries/sources/fermi_gbm.py"}]}
| 3,977 | 688 |
gh_patches_debug_25043
|
rasdani/github-patches
|
git_diff
|
sktime__sktime-3541
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] TapNet test failures and long test times
TapNet is currently failing the macOS 3.7 test (`Install and test / test-unix (3.7, macOS-11) (pull_request)`) in PR #3523. The PR makes no changes relevant to TapNet or DL estimators, and the test times are extremely high.
https://github.com/sktime/sktime/actions/runs/3174214839/jobs/5170841022
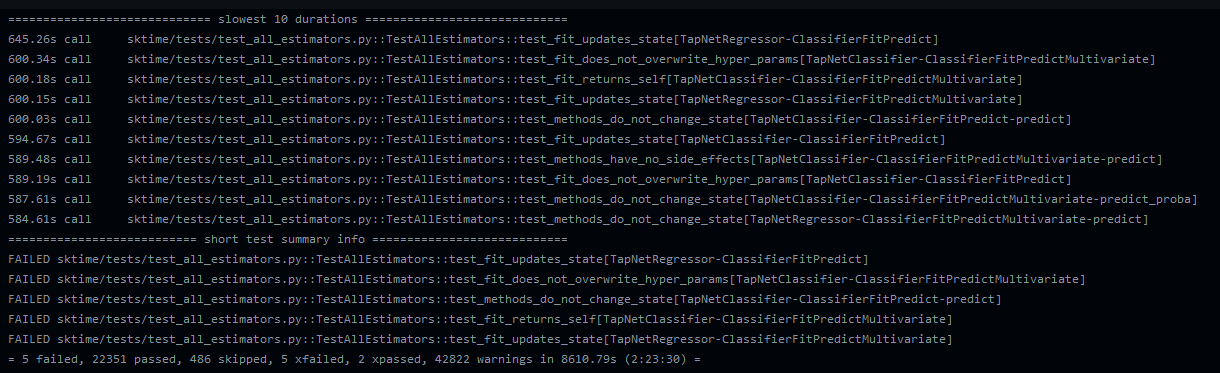
</issue>
<code>
[start of sktime/classification/deep_learning/tapnet.py]
1 # -*- coding: utf-8 -*-
2 """Time Convolutional Neural Network (CNN) for classification."""
3
4 __author__ = [
5 "Jack Russon",
6 ]
7 __all__ = [
8 "TapNetClassifier",
9 ]
10
11 from sklearn.utils import check_random_state
12
13 from sktime.classification.deep_learning.base import BaseDeepClassifier
14 from sktime.networks.tapnet import TapNetNetwork
15 from sktime.utils.validation._dependencies import _check_dl_dependencies
16
17 _check_dl_dependencies(severity="warning")
18
19
20 class TapNetClassifier(BaseDeepClassifier):
21 """Implementation of TapNetClassifier, as described in [1].
22
23 Parameters
24 ----------
25 filter_sizes : array of int, default = (256, 256, 128)
26 sets the kernel size argument for each convolutional block.
27 Controls number of convolutional filters
28 and number of neurons in attention dense layers.
29 kernel_sizes : array of int, default = (8, 5, 3)
30 controls the size of the convolutional kernels
31 layers : array of int, default = (500, 300)
32 size of dense layers
33 reduction : int, default = 16
34 divides the number of dense neurons in the first layer of the attention block.
35 n_epochs : int, default = 2000
36 number of epochs to train the model
37 batch_size : int, default = 16
38 number of samples per update
39 dropout : float, default = 0.5
40 dropout rate, in the range [0, 1)
41 dilation : int, default = 1
42 dilation value
43 activation : str, default = "sigmoid"
44 activation function for the last output layer
45 loss : str, default = "binary_crossentropy"
46 loss function for the classifier
47 optimizer : str or None, default = "Adam(lr=0.01)"
48 gradient updating function for the classifer
49 use_bias : bool, default = True
50 whether to use bias in the output dense layer
51 use_rp : bool, default = True
52 whether to use random projections
53 use_att : bool, default = True
54 whether to use self attention
55 use_lstm : bool, default = True
56 whether to use an LSTM layer
57 use_cnn : bool, default = True
58 whether to use a CNN layer
59 verbose : bool, default = False
60 whether to output extra information
61 random_state : int or None, default = None
62 seed for random
63
64 Attributes
65 ----------
66 n_classes : int
67 number of classes extracted from the data
68
69 References
70 ----------
71 .. [1] Zhang et al. Tapnet: Multivariate time series classification with
72 attentional prototypical network,
73 Proceedings of the AAAI Conference on Artificial Intelligence
74 34(4), 6845-6852, 2020
75
76 Examples
77 --------
78 >>> from sktime.classification.deep_learning.tapnet import TapNetClassifier
79 >>> from sktime.datasets import load_unit_test
80 >>> X_train, y_train = load_unit_test(split="train", return_X_y=True)
81 >>> X_test, y_test = load_unit_test(split="test", return_X_y=True)
82 >>> tapnet = TapNetClassifier() # doctest: +SKIP
83 >>> tapnet.fit(X_train, y_train) # doctest: +SKIP
84 TapNetClassifier(...)
85 """
86
87 _tags = {"python_dependencies": "tensorflow"}
88
89 def __init__(
90 self,
91 n_epochs=2000,
92 batch_size=16,
93 dropout=0.5,
94 filter_sizes=(256, 256, 128),
95 kernel_size=(8, 5, 3),
96 dilation=1,
97 layers=(500, 300),
98 use_rp=True,
99 rp_params=(-1, 3),
100 activation="sigmoid",
101 use_bias=True,
102 use_att=True,
103 use_lstm=True,
104 use_cnn=True,
105 random_state=None,
106 padding="same",
107 loss="binary_crossentropy",
108 optimizer=None,
109 metrics=None,
110 callbacks=None,
111 verbose=False,
112 ):
113 _check_dl_dependencies(severity="error")
114 super(TapNetClassifier, self).__init__()
115
116 self.batch_size = batch_size
117 self.random_state = random_state
118 self.kernel_size = kernel_size
119 self.layers = layers
120 self.rp_params = rp_params
121 self.filter_sizes = filter_sizes
122 self.activation = activation
123 self.use_att = use_att
124 self.use_bias = use_bias
125
126 self.dilation = dilation
127 self.padding = padding
128 self.n_epochs = n_epochs
129 self.loss = loss
130 self.optimizer = optimizer
131 self.metrics = metrics
132 self.callbacks = callbacks
133 self.verbose = verbose
134
135 self._is_fitted = False
136
137 self.dropout = dropout
138 self.use_lstm = use_lstm
139 self.use_cnn = use_cnn
140
141 # parameters for random projection
142 self.use_rp = use_rp
143 self.rp_params = rp_params
144
145 self._network = TapNetNetwork()
146
147 def build_model(self, input_shape, n_classes, **kwargs):
148 """Construct a complied, un-trained, keras model that is ready for training.
149
150 In sktime, time series are stored in numpy arrays of shape (d,m), where d
151 is the number of dimensions, m is the series length. Keras/tensorflow assume
152 data is in shape (m,d). This method also assumes (m,d). Transpose should
153 happen in fit.
154
155 Parameters
156 ----------
157 input_shape : tuple
158 The shape of the data fed into the input layer, should be (m, d)
159 n_classes : int
160 The number of classes, which becomes the size of the output layer
161
162 Returns
163 -------
164 output: a compiled Keras model
165 """
166 import tensorflow as tf
167 from tensorflow import keras
168
169 tf.random.set_seed(self.random_state)
170
171 if self.metrics is None:
172 metrics = ["accuracy"]
173 else:
174 metrics = self.metrics
175
176 input_layer, output_layer = self._network.build_network(input_shape, **kwargs)
177
178 output_layer = keras.layers.Dense(
179 units=n_classes, activation=self.activation, use_bias=self.use_bias
180 )(output_layer)
181
182 self.optimizer_ = (
183 keras.optimizers.Adam(learning_rate=0.01)
184 if self.optimizer is None
185 else self.optimizer
186 )
187
188 model = keras.models.Model(inputs=input_layer, outputs=output_layer)
189 model.compile(
190 loss=self.loss,
191 optimizer=self.optimizer_,
192 metrics=metrics,
193 )
194
195 return model
196
197 def _fit(self, X, y):
198 """Fit the classifier on the training set (X, y).
199
200 Parameters
201 ----------
202 X : np.ndarray of shape = (n_instances(n), n_dimensions(d), series_length(m))
203 Input training samples
204 y : np.ndarray of shape n
205 Input training class labels
206
207 Returns
208 -------
209 self: object
210 """
211 if self.callbacks is None:
212 self._callbacks = []
213
214 y_onehot = self.convert_y_to_keras(y)
215 # Transpose to conform to expectation format by keras
216 X = X.transpose(0, 2, 1)
217
218 check_random_state(self.random_state)
219 self.input_shape = X.shape[1:]
220 self.model_ = self.build_model(self.input_shape, self.n_classes_)
221 if self.verbose:
222 self.model_.summary()
223 self.history = self.model_.fit(
224 X,
225 y_onehot,
226 batch_size=self.batch_size,
227 epochs=self.n_epochs,
228 verbose=self.verbose,
229 callbacks=self._callbacks,
230 )
231
232 return self
233
[end of sktime/classification/deep_learning/tapnet.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sktime/classification/deep_learning/tapnet.py b/sktime/classification/deep_learning/tapnet.py
--- a/sktime/classification/deep_learning/tapnet.py
+++ b/sktime/classification/deep_learning/tapnet.py
@@ -3,6 +3,8 @@
__author__ = [
"Jack Russon",
+ "TonyBagnall",
+ "achieveordie",
]
__all__ = [
"TapNetClassifier",
@@ -230,3 +232,33 @@
)
return self
+
+ @classmethod
+ def get_test_params(cls, parameter_set="default"):
+ """Return testing parameter settings for the estimator.
+
+ Parameters
+ ----------
+ parameter_set : str, default="default"
+ Name of the set of test parameters to return, for use in tests. If no
+ special parameters are defined for a value, will return `"default"` set.
+ For classifiers, a "default" set of parameters should be provided for
+ general testing, and a "results_comparison" set for comparing against
+ previously recorded results if the general set does not produce suitable
+ probabilities to compare against.
+
+ Returns
+ -------
+ params : dict or list of dict, default={}
+ Parameters to create testing instances of the class.
+ Each dict are parameters to construct an "interesting" test instance, i.e.,
+ `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.
+ `create_test_instance` uses the first (or only) dictionary in `params`.
+ """
+ return {
+ "n_epochs": 50,
+ "batch_size": 32,
+ "filter_sizes": (128, 128, 64),
+ "dilation": 2,
+ "layers": (200, 100),
+ }
|
{"golden_diff": "diff --git a/sktime/classification/deep_learning/tapnet.py b/sktime/classification/deep_learning/tapnet.py\n--- a/sktime/classification/deep_learning/tapnet.py\n+++ b/sktime/classification/deep_learning/tapnet.py\n@@ -3,6 +3,8 @@\n \n __author__ = [\n \"Jack Russon\",\n+ \"TonyBagnall\",\n+ \"achieveordie\",\n ]\n __all__ = [\n \"TapNetClassifier\",\n@@ -230,3 +232,33 @@\n )\n \n return self\n+\n+ @classmethod\n+ def get_test_params(cls, parameter_set=\"default\"):\n+ \"\"\"Return testing parameter settings for the estimator.\n+\n+ Parameters\n+ ----------\n+ parameter_set : str, default=\"default\"\n+ Name of the set of test parameters to return, for use in tests. If no\n+ special parameters are defined for a value, will return `\"default\"` set.\n+ For classifiers, a \"default\" set of parameters should be provided for\n+ general testing, and a \"results_comparison\" set for comparing against\n+ previously recorded results if the general set does not produce suitable\n+ probabilities to compare against.\n+\n+ Returns\n+ -------\n+ params : dict or list of dict, default={}\n+ Parameters to create testing instances of the class.\n+ Each dict are parameters to construct an \"interesting\" test instance, i.e.,\n+ `MyClass(**params)` or `MyClass(**params[i])` creates a valid test instance.\n+ `create_test_instance` uses the first (or only) dictionary in `params`.\n+ \"\"\"\n+ return {\n+ \"n_epochs\": 50,\n+ \"batch_size\": 32,\n+ \"filter_sizes\": (128, 128, 64),\n+ \"dilation\": 2,\n+ \"layers\": (200, 100),\n+ }\n", "issue": "[BUG] TapNet test failures and long test times\nTapNet is currently failing the macOS 3.7 test (`Install and test / test-unix (3.7, macOS-11) (pull_request)`) in PR #3523. The PR makes no changes relevant to TapNet or DL estimators, and the test times are extremely high.\r\n\r\nhttps://github.com/sktime/sktime/actions/runs/3174214839/jobs/5170841022\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Time Convolutional Neural Network (CNN) for classification.\"\"\"\n\n__author__ = [\n \"Jack Russon\",\n]\n__all__ = [\n \"TapNetClassifier\",\n]\n\nfrom sklearn.utils import check_random_state\n\nfrom sktime.classification.deep_learning.base import BaseDeepClassifier\nfrom sktime.networks.tapnet import TapNetNetwork\nfrom sktime.utils.validation._dependencies import _check_dl_dependencies\n\n_check_dl_dependencies(severity=\"warning\")\n\n\nclass TapNetClassifier(BaseDeepClassifier):\n \"\"\"Implementation of TapNetClassifier, as described in [1].\n\n Parameters\n ----------\n filter_sizes : array of int, default = (256, 256, 128)\n sets the kernel size argument for each convolutional block.\n Controls number of convolutional filters\n and number of neurons in attention dense layers.\n kernel_sizes : array of int, default = (8, 5, 3)\n controls the size of the convolutional kernels\n layers : array of int, default = (500, 300)\n size of dense layers\n reduction : int, default = 16\n divides the number of dense neurons in the first layer of the attention block.\n n_epochs : int, default = 2000\n number of epochs to train the model\n batch_size : int, default = 16\n number of samples per update\n dropout : float, default = 0.5\n dropout rate, in the range [0, 1)\n dilation : int, default = 1\n dilation value\n activation : str, default = \"sigmoid\"\n activation function for the last output layer\n loss : str, default = \"binary_crossentropy\"\n loss function for the classifier\n optimizer : str or None, default = \"Adam(lr=0.01)\"\n gradient updating function for the classifer\n use_bias : bool, default = True\n whether to use bias in the output dense layer\n use_rp : bool, default = True\n whether to use random projections\n use_att : bool, default = True\n whether to use self attention\n use_lstm : bool, default = True\n whether to use an LSTM layer\n use_cnn : bool, default = True\n whether to use a CNN layer\n verbose : bool, default = False\n whether to output extra information\n random_state : int or None, default = None\n seed for random\n\n Attributes\n ----------\n n_classes : int\n number of classes extracted from the data\n\n References\n ----------\n .. [1] Zhang et al. Tapnet: Multivariate time series classification with\n attentional prototypical network,\n Proceedings of the AAAI Conference on Artificial Intelligence\n 34(4), 6845-6852, 2020\n\n Examples\n --------\n >>> from sktime.classification.deep_learning.tapnet import TapNetClassifier\n >>> from sktime.datasets import load_unit_test\n >>> X_train, y_train = load_unit_test(split=\"train\", return_X_y=True)\n >>> X_test, y_test = load_unit_test(split=\"test\", return_X_y=True)\n >>> tapnet = TapNetClassifier() # doctest: +SKIP\n >>> tapnet.fit(X_train, y_train) # doctest: +SKIP\n TapNetClassifier(...)\n \"\"\"\n\n _tags = {\"python_dependencies\": \"tensorflow\"}\n\n def __init__(\n self,\n n_epochs=2000,\n batch_size=16,\n dropout=0.5,\n filter_sizes=(256, 256, 128),\n kernel_size=(8, 5, 3),\n dilation=1,\n layers=(500, 300),\n use_rp=True,\n rp_params=(-1, 3),\n activation=\"sigmoid\",\n use_bias=True,\n use_att=True,\n use_lstm=True,\n use_cnn=True,\n random_state=None,\n padding=\"same\",\n loss=\"binary_crossentropy\",\n optimizer=None,\n metrics=None,\n callbacks=None,\n verbose=False,\n ):\n _check_dl_dependencies(severity=\"error\")\n super(TapNetClassifier, self).__init__()\n\n self.batch_size = batch_size\n self.random_state = random_state\n self.kernel_size = kernel_size\n self.layers = layers\n self.rp_params = rp_params\n self.filter_sizes = filter_sizes\n self.activation = activation\n self.use_att = use_att\n self.use_bias = use_bias\n\n self.dilation = dilation\n self.padding = padding\n self.n_epochs = n_epochs\n self.loss = loss\n self.optimizer = optimizer\n self.metrics = metrics\n self.callbacks = callbacks\n self.verbose = verbose\n\n self._is_fitted = False\n\n self.dropout = dropout\n self.use_lstm = use_lstm\n self.use_cnn = use_cnn\n\n # parameters for random projection\n self.use_rp = use_rp\n self.rp_params = rp_params\n\n self._network = TapNetNetwork()\n\n def build_model(self, input_shape, n_classes, **kwargs):\n \"\"\"Construct a complied, un-trained, keras model that is ready for training.\n\n In sktime, time series are stored in numpy arrays of shape (d,m), where d\n is the number of dimensions, m is the series length. Keras/tensorflow assume\n data is in shape (m,d). This method also assumes (m,d). Transpose should\n happen in fit.\n\n Parameters\n ----------\n input_shape : tuple\n The shape of the data fed into the input layer, should be (m, d)\n n_classes : int\n The number of classes, which becomes the size of the output layer\n\n Returns\n -------\n output: a compiled Keras model\n \"\"\"\n import tensorflow as tf\n from tensorflow import keras\n\n tf.random.set_seed(self.random_state)\n\n if self.metrics is None:\n metrics = [\"accuracy\"]\n else:\n metrics = self.metrics\n\n input_layer, output_layer = self._network.build_network(input_shape, **kwargs)\n\n output_layer = keras.layers.Dense(\n units=n_classes, activation=self.activation, use_bias=self.use_bias\n )(output_layer)\n\n self.optimizer_ = (\n keras.optimizers.Adam(learning_rate=0.01)\n if self.optimizer is None\n else self.optimizer\n )\n\n model = keras.models.Model(inputs=input_layer, outputs=output_layer)\n model.compile(\n loss=self.loss,\n optimizer=self.optimizer_,\n metrics=metrics,\n )\n\n return model\n\n def _fit(self, X, y):\n \"\"\"Fit the classifier on the training set (X, y).\n\n Parameters\n ----------\n X : np.ndarray of shape = (n_instances(n), n_dimensions(d), series_length(m))\n Input training samples\n y : np.ndarray of shape n\n Input training class labels\n\n Returns\n -------\n self: object\n \"\"\"\n if self.callbacks is None:\n self._callbacks = []\n\n y_onehot = self.convert_y_to_keras(y)\n # Transpose to conform to expectation format by keras\n X = X.transpose(0, 2, 1)\n\n check_random_state(self.random_state)\n self.input_shape = X.shape[1:]\n self.model_ = self.build_model(self.input_shape, self.n_classes_)\n if self.verbose:\n self.model_.summary()\n self.history = self.model_.fit(\n X,\n y_onehot,\n batch_size=self.batch_size,\n epochs=self.n_epochs,\n verbose=self.verbose,\n callbacks=self._callbacks,\n )\n\n return self\n", "path": "sktime/classification/deep_learning/tapnet.py"}]}
| 3,033 | 437 |
gh_patches_debug_12120
|
rasdani/github-patches
|
git_diff
|
numpy__numpy-13177
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong std for implicitly complex input
<!-- Please describe the issue in detail here, and fill in the fields below -->
Standart deviation formula could give unexpected result (e.g. imaginary values) when input is implicitly complex.
### Reproducing code example:
<!-- A short code example that reproduces the problem/missing feature. It should be
self-contained, i.e., possible to run as-is via 'python myproblem.py' -->
```python
import numpy as np
a = np.array([None, 0])
a[0] = 1j
b = np.array([1j, 0])
print(f'res={np.std(a)}, dtype={a.dtype}') # gives imaginary std
print(f'res={np.std(b)}, dtype={b.dtype}')
```
<!-- Remove these sections for a feature request -->
### Error message:
<!-- If you are reporting a segfault please include a GDB traceback, which you
can generate by following
https://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging -->
<!-- Full error message, if any (starting from line Traceback: ...) -->
### Numpy/Python version information:
numpy 1.16.2
python 3.7
<!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' -->
res=0.5j, dtype=object
res=0.5, dtype=complex128
</issue>
<code>
[start of numpy/core/_methods.py]
1 """
2 Array methods which are called by both the C-code for the method
3 and the Python code for the NumPy-namespace function
4
5 """
6 from __future__ import division, absolute_import, print_function
7
8 import warnings
9
10 from numpy.core import multiarray as mu
11 from numpy.core import umath as um
12 from numpy.core.numeric import asanyarray
13 from numpy.core import numerictypes as nt
14 from numpy._globals import _NoValue
15
16 # save those O(100) nanoseconds!
17 umr_maximum = um.maximum.reduce
18 umr_minimum = um.minimum.reduce
19 umr_sum = um.add.reduce
20 umr_prod = um.multiply.reduce
21 umr_any = um.logical_or.reduce
22 umr_all = um.logical_and.reduce
23
24 # avoid keyword arguments to speed up parsing, saves about 15%-20% for very
25 # small reductions
26 def _amax(a, axis=None, out=None, keepdims=False,
27 initial=_NoValue, where=True):
28 return umr_maximum(a, axis, None, out, keepdims, initial, where)
29
30 def _amin(a, axis=None, out=None, keepdims=False,
31 initial=_NoValue, where=True):
32 return umr_minimum(a, axis, None, out, keepdims, initial, where)
33
34 def _sum(a, axis=None, dtype=None, out=None, keepdims=False,
35 initial=_NoValue, where=True):
36 return umr_sum(a, axis, dtype, out, keepdims, initial, where)
37
38 def _prod(a, axis=None, dtype=None, out=None, keepdims=False,
39 initial=_NoValue, where=True):
40 return umr_prod(a, axis, dtype, out, keepdims, initial, where)
41
42 def _any(a, axis=None, dtype=None, out=None, keepdims=False):
43 return umr_any(a, axis, dtype, out, keepdims)
44
45 def _all(a, axis=None, dtype=None, out=None, keepdims=False):
46 return umr_all(a, axis, dtype, out, keepdims)
47
48 def _count_reduce_items(arr, axis):
49 if axis is None:
50 axis = tuple(range(arr.ndim))
51 if not isinstance(axis, tuple):
52 axis = (axis,)
53 items = 1
54 for ax in axis:
55 items *= arr.shape[ax]
56 return items
57
58 def _mean(a, axis=None, dtype=None, out=None, keepdims=False):
59 arr = asanyarray(a)
60
61 is_float16_result = False
62 rcount = _count_reduce_items(arr, axis)
63 # Make this warning show up first
64 if rcount == 0:
65 warnings.warn("Mean of empty slice.", RuntimeWarning, stacklevel=2)
66
67 # Cast bool, unsigned int, and int to float64 by default
68 if dtype is None:
69 if issubclass(arr.dtype.type, (nt.integer, nt.bool_)):
70 dtype = mu.dtype('f8')
71 elif issubclass(arr.dtype.type, nt.float16):
72 dtype = mu.dtype('f4')
73 is_float16_result = True
74
75 ret = umr_sum(arr, axis, dtype, out, keepdims)
76 if isinstance(ret, mu.ndarray):
77 ret = um.true_divide(
78 ret, rcount, out=ret, casting='unsafe', subok=False)
79 if is_float16_result and out is None:
80 ret = arr.dtype.type(ret)
81 elif hasattr(ret, 'dtype'):
82 if is_float16_result:
83 ret = arr.dtype.type(ret / rcount)
84 else:
85 ret = ret.dtype.type(ret / rcount)
86 else:
87 ret = ret / rcount
88
89 return ret
90
91 def _var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False):
92 arr = asanyarray(a)
93
94 rcount = _count_reduce_items(arr, axis)
95 # Make this warning show up on top.
96 if ddof >= rcount:
97 warnings.warn("Degrees of freedom <= 0 for slice", RuntimeWarning,
98 stacklevel=2)
99
100 # Cast bool, unsigned int, and int to float64 by default
101 if dtype is None and issubclass(arr.dtype.type, (nt.integer, nt.bool_)):
102 dtype = mu.dtype('f8')
103
104 # Compute the mean.
105 # Note that if dtype is not of inexact type then arraymean will
106 # not be either.
107 arrmean = umr_sum(arr, axis, dtype, keepdims=True)
108 if isinstance(arrmean, mu.ndarray):
109 arrmean = um.true_divide(
110 arrmean, rcount, out=arrmean, casting='unsafe', subok=False)
111 else:
112 arrmean = arrmean.dtype.type(arrmean / rcount)
113
114 # Compute sum of squared deviations from mean
115 # Note that x may not be inexact and that we need it to be an array,
116 # not a scalar.
117 x = asanyarray(arr - arrmean)
118 if issubclass(arr.dtype.type, nt.complexfloating):
119 x = um.multiply(x, um.conjugate(x), out=x).real
120 else:
121 x = um.multiply(x, x, out=x)
122 ret = umr_sum(x, axis, dtype, out, keepdims)
123
124 # Compute degrees of freedom and make sure it is not negative.
125 rcount = max([rcount - ddof, 0])
126
127 # divide by degrees of freedom
128 if isinstance(ret, mu.ndarray):
129 ret = um.true_divide(
130 ret, rcount, out=ret, casting='unsafe', subok=False)
131 elif hasattr(ret, 'dtype'):
132 ret = ret.dtype.type(ret / rcount)
133 else:
134 ret = ret / rcount
135
136 return ret
137
138 def _std(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False):
139 ret = _var(a, axis=axis, dtype=dtype, out=out, ddof=ddof,
140 keepdims=keepdims)
141
142 if isinstance(ret, mu.ndarray):
143 ret = um.sqrt(ret, out=ret)
144 elif hasattr(ret, 'dtype'):
145 ret = ret.dtype.type(um.sqrt(ret))
146 else:
147 ret = um.sqrt(ret)
148
149 return ret
150
151 def _ptp(a, axis=None, out=None, keepdims=False):
152 return um.subtract(
153 umr_maximum(a, axis, None, out, keepdims),
154 umr_minimum(a, axis, None, None, keepdims),
155 out
156 )
157
[end of numpy/core/_methods.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/numpy/core/_methods.py b/numpy/core/_methods.py
--- a/numpy/core/_methods.py
+++ b/numpy/core/_methods.py
@@ -115,10 +115,11 @@
# Note that x may not be inexact and that we need it to be an array,
# not a scalar.
x = asanyarray(arr - arrmean)
- if issubclass(arr.dtype.type, nt.complexfloating):
- x = um.multiply(x, um.conjugate(x), out=x).real
- else:
+ if issubclass(arr.dtype.type, (nt.floating, nt.integer)):
x = um.multiply(x, x, out=x)
+ else:
+ x = um.multiply(x, um.conjugate(x), out=x).real
+
ret = umr_sum(x, axis, dtype, out, keepdims)
# Compute degrees of freedom and make sure it is not negative.
|
{"golden_diff": "diff --git a/numpy/core/_methods.py b/numpy/core/_methods.py\n--- a/numpy/core/_methods.py\n+++ b/numpy/core/_methods.py\n@@ -115,10 +115,11 @@\n # Note that x may not be inexact and that we need it to be an array,\n # not a scalar.\n x = asanyarray(arr - arrmean)\n- if issubclass(arr.dtype.type, nt.complexfloating):\n- x = um.multiply(x, um.conjugate(x), out=x).real\n- else:\n+ if issubclass(arr.dtype.type, (nt.floating, nt.integer)):\n x = um.multiply(x, x, out=x)\n+ else:\n+ x = um.multiply(x, um.conjugate(x), out=x).real\n+\n ret = umr_sum(x, axis, dtype, out, keepdims)\n \n # Compute degrees of freedom and make sure it is not negative.\n", "issue": "Wrong std for implicitly complex input\n<!-- Please describe the issue in detail here, and fill in the fields below -->\r\n\r\nStandart deviation formula could give unexpected result (e.g. imaginary values) when input is implicitly complex.\r\n\r\n### Reproducing code example:\r\n\r\n<!-- A short code example that reproduces the problem/missing feature. It should be\r\nself-contained, i.e., possible to run as-is via 'python myproblem.py' -->\r\n\r\n```python\r\nimport numpy as np\r\na = np.array([None, 0])\r\na[0] = 1j\r\nb = np.array([1j, 0])\r\n\r\nprint(f'res={np.std(a)}, dtype={a.dtype}') # gives imaginary std\r\nprint(f'res={np.std(b)}, dtype={b.dtype}')\r\n\r\n```\r\n\r\n<!-- Remove these sections for a feature request -->\r\n\r\n### Error message:\r\n\r\n<!-- If you are reporting a segfault please include a GDB traceback, which you\r\ncan generate by following\r\nhttps://github.com/numpy/numpy/blob/master/doc/source/dev/development_environment.rst#debugging -->\r\n\r\n<!-- Full error message, if any (starting from line Traceback: ...) -->\r\n\r\n### Numpy/Python version information:\r\nnumpy 1.16.2\r\npython 3.7\r\n\r\n<!-- Output from 'import sys, numpy; print(numpy.__version__, sys.version)' -->\r\nres=0.5j, dtype=object\r\nres=0.5, dtype=complex128\r\n\n", "before_files": [{"content": "\"\"\"\nArray methods which are called by both the C-code for the method\nand the Python code for the NumPy-namespace function\n\n\"\"\"\nfrom __future__ import division, absolute_import, print_function\n\nimport warnings\n\nfrom numpy.core import multiarray as mu\nfrom numpy.core import umath as um\nfrom numpy.core.numeric import asanyarray\nfrom numpy.core import numerictypes as nt\nfrom numpy._globals import _NoValue\n\n# save those O(100) nanoseconds!\numr_maximum = um.maximum.reduce\numr_minimum = um.minimum.reduce\numr_sum = um.add.reduce\numr_prod = um.multiply.reduce\numr_any = um.logical_or.reduce\numr_all = um.logical_and.reduce\n\n# avoid keyword arguments to speed up parsing, saves about 15%-20% for very\n# small reductions\ndef _amax(a, axis=None, out=None, keepdims=False,\n initial=_NoValue, where=True):\n return umr_maximum(a, axis, None, out, keepdims, initial, where)\n\ndef _amin(a, axis=None, out=None, keepdims=False,\n initial=_NoValue, where=True):\n return umr_minimum(a, axis, None, out, keepdims, initial, where)\n\ndef _sum(a, axis=None, dtype=None, out=None, keepdims=False,\n initial=_NoValue, where=True):\n return umr_sum(a, axis, dtype, out, keepdims, initial, where)\n\ndef _prod(a, axis=None, dtype=None, out=None, keepdims=False,\n initial=_NoValue, where=True):\n return umr_prod(a, axis, dtype, out, keepdims, initial, where)\n\ndef _any(a, axis=None, dtype=None, out=None, keepdims=False):\n return umr_any(a, axis, dtype, out, keepdims)\n\ndef _all(a, axis=None, dtype=None, out=None, keepdims=False):\n return umr_all(a, axis, dtype, out, keepdims)\n\ndef _count_reduce_items(arr, axis):\n if axis is None:\n axis = tuple(range(arr.ndim))\n if not isinstance(axis, tuple):\n axis = (axis,)\n items = 1\n for ax in axis:\n items *= arr.shape[ax]\n return items\n\ndef _mean(a, axis=None, dtype=None, out=None, keepdims=False):\n arr = asanyarray(a)\n\n is_float16_result = False\n rcount = _count_reduce_items(arr, axis)\n # Make this warning show up first\n if rcount == 0:\n warnings.warn(\"Mean of empty slice.\", RuntimeWarning, stacklevel=2)\n\n # Cast bool, unsigned int, and int to float64 by default\n if dtype is None:\n if issubclass(arr.dtype.type, (nt.integer, nt.bool_)):\n dtype = mu.dtype('f8')\n elif issubclass(arr.dtype.type, nt.float16):\n dtype = mu.dtype('f4')\n is_float16_result = True\n\n ret = umr_sum(arr, axis, dtype, out, keepdims)\n if isinstance(ret, mu.ndarray):\n ret = um.true_divide(\n ret, rcount, out=ret, casting='unsafe', subok=False)\n if is_float16_result and out is None:\n ret = arr.dtype.type(ret)\n elif hasattr(ret, 'dtype'):\n if is_float16_result:\n ret = arr.dtype.type(ret / rcount)\n else:\n ret = ret.dtype.type(ret / rcount)\n else:\n ret = ret / rcount\n\n return ret\n\ndef _var(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False):\n arr = asanyarray(a)\n\n rcount = _count_reduce_items(arr, axis)\n # Make this warning show up on top.\n if ddof >= rcount:\n warnings.warn(\"Degrees of freedom <= 0 for slice\", RuntimeWarning,\n stacklevel=2)\n\n # Cast bool, unsigned int, and int to float64 by default\n if dtype is None and issubclass(arr.dtype.type, (nt.integer, nt.bool_)):\n dtype = mu.dtype('f8')\n\n # Compute the mean.\n # Note that if dtype is not of inexact type then arraymean will\n # not be either.\n arrmean = umr_sum(arr, axis, dtype, keepdims=True)\n if isinstance(arrmean, mu.ndarray):\n arrmean = um.true_divide(\n arrmean, rcount, out=arrmean, casting='unsafe', subok=False)\n else:\n arrmean = arrmean.dtype.type(arrmean / rcount)\n\n # Compute sum of squared deviations from mean\n # Note that x may not be inexact and that we need it to be an array,\n # not a scalar.\n x = asanyarray(arr - arrmean)\n if issubclass(arr.dtype.type, nt.complexfloating):\n x = um.multiply(x, um.conjugate(x), out=x).real\n else:\n x = um.multiply(x, x, out=x)\n ret = umr_sum(x, axis, dtype, out, keepdims)\n\n # Compute degrees of freedom and make sure it is not negative.\n rcount = max([rcount - ddof, 0])\n\n # divide by degrees of freedom\n if isinstance(ret, mu.ndarray):\n ret = um.true_divide(\n ret, rcount, out=ret, casting='unsafe', subok=False)\n elif hasattr(ret, 'dtype'):\n ret = ret.dtype.type(ret / rcount)\n else:\n ret = ret / rcount\n\n return ret\n\ndef _std(a, axis=None, dtype=None, out=None, ddof=0, keepdims=False):\n ret = _var(a, axis=axis, dtype=dtype, out=out, ddof=ddof,\n keepdims=keepdims)\n\n if isinstance(ret, mu.ndarray):\n ret = um.sqrt(ret, out=ret)\n elif hasattr(ret, 'dtype'):\n ret = ret.dtype.type(um.sqrt(ret))\n else:\n ret = um.sqrt(ret)\n\n return ret\n\ndef _ptp(a, axis=None, out=None, keepdims=False):\n return um.subtract(\n umr_maximum(a, axis, None, out, keepdims),\n umr_minimum(a, axis, None, None, keepdims),\n out\n )\n", "path": "numpy/core/_methods.py"}]}
| 2,611 | 212 |
gh_patches_debug_26390
|
rasdani/github-patches
|
git_diff
|
jupyterhub__jupyterhub-835
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove or edit unreachable code block
@minrk It looks like `_check_user_model` has a few code lines that don't seem to be reachable. Should we remove the lines after the return statement? https://github.com/jupyterhub/jupyterhub/blob/master/jupyterhub/apihandlers/base.py#L144
</issue>
<code>
[start of jupyterhub/apihandlers/base.py]
1 """Base API handlers"""
2 # Copyright (c) Jupyter Development Team.
3 # Distributed under the terms of the Modified BSD License.
4
5 import json
6
7 from http.client import responses
8
9 from tornado import web
10
11 from ..handlers import BaseHandler
12 from ..utils import url_path_join
13
14 class APIHandler(BaseHandler):
15
16 def check_referer(self):
17 """Check Origin for cross-site API requests.
18
19 Copied from WebSocket with changes:
20
21 - allow unspecified host/referer (e.g. scripts)
22 """
23 host = self.request.headers.get("Host")
24 referer = self.request.headers.get("Referer")
25
26 # If no header is provided, assume it comes from a script/curl.
27 # We are only concerned with cross-site browser stuff here.
28 if not host:
29 self.log.warning("Blocking API request with no host")
30 return False
31 if not referer:
32 self.log.warning("Blocking API request with no referer")
33 return False
34
35 host_path = url_path_join(host, self.hub.server.base_url)
36 referer_path = referer.split('://', 1)[-1]
37 if not (referer_path + '/').startswith(host_path):
38 self.log.warning("Blocking Cross Origin API request. Referer: %s, Host: %s",
39 referer, host_path)
40 return False
41 return True
42
43 def get_current_user_cookie(self):
44 """Override get_user_cookie to check Referer header"""
45 cookie_user = super().get_current_user_cookie()
46 # check referer only if there is a cookie user,
47 # avoiding misleading "Blocking Cross Origin" messages
48 # when there's no cookie set anyway.
49 if cookie_user and not self.check_referer():
50 return None
51 return cookie_user
52
53 def get_json_body(self):
54 """Return the body of the request as JSON data."""
55 if not self.request.body:
56 return None
57 body = self.request.body.strip().decode('utf-8')
58 try:
59 model = json.loads(body)
60 except Exception:
61 self.log.debug("Bad JSON: %r", body)
62 self.log.error("Couldn't parse JSON", exc_info=True)
63 raise web.HTTPError(400, 'Invalid JSON in body of request')
64 return model
65
66 def write_error(self, status_code, **kwargs):
67 """Write JSON errors instead of HTML"""
68 exc_info = kwargs.get('exc_info')
69 message = ''
70 status_message = responses.get(status_code, 'Unknown Error')
71 if exc_info:
72 exception = exc_info[1]
73 # get the custom message, if defined
74 try:
75 message = exception.log_message % exception.args
76 except Exception:
77 pass
78
79 # construct the custom reason, if defined
80 reason = getattr(exception, 'reason', '')
81 if reason:
82 status_message = reason
83 self.set_header('Content-Type', 'application/json')
84 self.write(json.dumps({
85 'status': status_code,
86 'message': message or status_message,
87 }))
88
89 def user_model(self, user):
90 """Get the JSON model for a User object"""
91 model = {
92 'name': user.name,
93 'admin': user.admin,
94 'groups': [ g.name for g in user.groups ],
95 'server': user.url if user.running else None,
96 'pending': None,
97 'last_activity': user.last_activity.isoformat(),
98 }
99 if user.spawn_pending:
100 model['pending'] = 'spawn'
101 elif user.stop_pending:
102 model['pending'] = 'stop'
103 return model
104
105 def group_model(self, group):
106 """Get the JSON model for a Group object"""
107 return {
108 'name': group.name,
109 'users': [ u.name for u in group.users ]
110 }
111
112 _user_model_types = {
113 'name': str,
114 'admin': bool,
115 'groups': list,
116 }
117
118 _group_model_types = {
119 'name': str,
120 'users': list,
121 }
122
123 def _check_model(self, model, model_types, name):
124 """Check a model provided by a REST API request
125
126 Args:
127 model (dict): user-provided model
128 model_types (dict): dict of key:type used to validate types and keys
129 name (str): name of the model, used in error messages
130 """
131 if not isinstance(model, dict):
132 raise web.HTTPError(400, "Invalid JSON data: %r" % model)
133 if not set(model).issubset(set(model_types)):
134 raise web.HTTPError(400, "Invalid JSON keys: %r" % model)
135 for key, value in model.items():
136 if not isinstance(value, model_types[key]):
137 raise web.HTTPError(400, "%s.%s must be %s, not: %r" % (
138 name, key, model_types[key], type(value)
139 ))
140
141 def _check_user_model(self, model):
142 """Check a request-provided user model from a REST API"""
143 return self._check_model(model, self._user_model_types, 'user')
144 for groupname in model.get('groups', []):
145 if not isinstance(groupname, str):
146 raise web.HTTPError(400, "group names must be str, not %r" % type(groupname))
147
148 def _check_group_model(self, model):
149 """Check a request-provided user model from a REST API"""
150 self._check_model(model, self._group_model_types, 'group')
151 for username in model.get('users', []):
152 if not isinstance(username, str):
153 raise web.HTTPError(400, "usernames must be str, not %r" % type(groupname))
154
155 def options(self, *args, **kwargs):
156 self.set_header('Access-Control-Allow-Headers', 'accept, content-type')
157 self.finish()
158
[end of jupyterhub/apihandlers/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/jupyterhub/apihandlers/base.py b/jupyterhub/apihandlers/base.py
--- a/jupyterhub/apihandlers/base.py
+++ b/jupyterhub/apihandlers/base.py
@@ -140,19 +140,18 @@
def _check_user_model(self, model):
"""Check a request-provided user model from a REST API"""
- return self._check_model(model, self._user_model_types, 'user')
- for groupname in model.get('groups', []):
- if not isinstance(groupname, str):
- raise web.HTTPError(400, "group names must be str, not %r" % type(groupname))
+ self._check_model(model, self._user_model_types, 'user')
+ for username in model.get('users', []):
+ if not isinstance(username, str):
+ raise web.HTTPError(400, ("usernames must be str, not %r", type(username)))
def _check_group_model(self, model):
- """Check a request-provided user model from a REST API"""
+ """Check a request-provided group model from a REST API"""
self._check_model(model, self._group_model_types, 'group')
- for username in model.get('users', []):
- if not isinstance(username, str):
- raise web.HTTPError(400, "usernames must be str, not %r" % type(groupname))
+ for groupname in model.get('groups', []):
+ if not isinstance(groupname, str):
+ raise web.HTTPError(400, ("group names must be str, not %r", type(groupname)))
def options(self, *args, **kwargs):
self.set_header('Access-Control-Allow-Headers', 'accept, content-type')
self.finish()
-
\ No newline at end of file
|
{"golden_diff": "diff --git a/jupyterhub/apihandlers/base.py b/jupyterhub/apihandlers/base.py\n--- a/jupyterhub/apihandlers/base.py\n+++ b/jupyterhub/apihandlers/base.py\n@@ -140,19 +140,18 @@\n \n def _check_user_model(self, model):\n \"\"\"Check a request-provided user model from a REST API\"\"\"\n- return self._check_model(model, self._user_model_types, 'user')\n- for groupname in model.get('groups', []):\n- if not isinstance(groupname, str):\n- raise web.HTTPError(400, \"group names must be str, not %r\" % type(groupname))\n+ self._check_model(model, self._user_model_types, 'user')\n+ for username in model.get('users', []):\n+ if not isinstance(username, str):\n+ raise web.HTTPError(400, (\"usernames must be str, not %r\", type(username)))\n \n def _check_group_model(self, model):\n- \"\"\"Check a request-provided user model from a REST API\"\"\"\n+ \"\"\"Check a request-provided group model from a REST API\"\"\"\n self._check_model(model, self._group_model_types, 'group')\n- for username in model.get('users', []):\n- if not isinstance(username, str):\n- raise web.HTTPError(400, \"usernames must be str, not %r\" % type(groupname))\n+ for groupname in model.get('groups', []):\n+ if not isinstance(groupname, str):\n+ raise web.HTTPError(400, (\"group names must be str, not %r\", type(groupname)))\n \n def options(self, *args, **kwargs):\n self.set_header('Access-Control-Allow-Headers', 'accept, content-type')\n self.finish()\n- \n\\ No newline at end of file\n", "issue": "Remove or edit unreachable code block\n@minrk It looks like `_check_user_model` has a few code lines that don't seem to be reachable. Should we remove the lines after the return statement? https://github.com/jupyterhub/jupyterhub/blob/master/jupyterhub/apihandlers/base.py#L144\n\n", "before_files": [{"content": "\"\"\"Base API handlers\"\"\"\n# Copyright (c) Jupyter Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport json\n\nfrom http.client import responses\n\nfrom tornado import web\n\nfrom ..handlers import BaseHandler\nfrom ..utils import url_path_join\n\nclass APIHandler(BaseHandler):\n\n def check_referer(self):\n \"\"\"Check Origin for cross-site API requests.\n \n Copied from WebSocket with changes:\n \n - allow unspecified host/referer (e.g. scripts)\n \"\"\"\n host = self.request.headers.get(\"Host\")\n referer = self.request.headers.get(\"Referer\")\n\n # If no header is provided, assume it comes from a script/curl.\n # We are only concerned with cross-site browser stuff here.\n if not host:\n self.log.warning(\"Blocking API request with no host\")\n return False\n if not referer:\n self.log.warning(\"Blocking API request with no referer\")\n return False\n \n host_path = url_path_join(host, self.hub.server.base_url)\n referer_path = referer.split('://', 1)[-1]\n if not (referer_path + '/').startswith(host_path):\n self.log.warning(\"Blocking Cross Origin API request. Referer: %s, Host: %s\",\n referer, host_path)\n return False\n return True\n \n def get_current_user_cookie(self):\n \"\"\"Override get_user_cookie to check Referer header\"\"\"\n cookie_user = super().get_current_user_cookie()\n # check referer only if there is a cookie user,\n # avoiding misleading \"Blocking Cross Origin\" messages\n # when there's no cookie set anyway.\n if cookie_user and not self.check_referer():\n return None\n return cookie_user\n\n def get_json_body(self):\n \"\"\"Return the body of the request as JSON data.\"\"\"\n if not self.request.body:\n return None\n body = self.request.body.strip().decode('utf-8')\n try:\n model = json.loads(body)\n except Exception:\n self.log.debug(\"Bad JSON: %r\", body)\n self.log.error(\"Couldn't parse JSON\", exc_info=True)\n raise web.HTTPError(400, 'Invalid JSON in body of request')\n return model\n \n def write_error(self, status_code, **kwargs):\n \"\"\"Write JSON errors instead of HTML\"\"\"\n exc_info = kwargs.get('exc_info')\n message = ''\n status_message = responses.get(status_code, 'Unknown Error')\n if exc_info:\n exception = exc_info[1]\n # get the custom message, if defined\n try:\n message = exception.log_message % exception.args\n except Exception:\n pass\n\n # construct the custom reason, if defined\n reason = getattr(exception, 'reason', '')\n if reason:\n status_message = reason\n self.set_header('Content-Type', 'application/json')\n self.write(json.dumps({\n 'status': status_code,\n 'message': message or status_message,\n }))\n\n def user_model(self, user):\n \"\"\"Get the JSON model for a User object\"\"\"\n model = {\n 'name': user.name,\n 'admin': user.admin,\n 'groups': [ g.name for g in user.groups ],\n 'server': user.url if user.running else None,\n 'pending': None,\n 'last_activity': user.last_activity.isoformat(),\n }\n if user.spawn_pending:\n model['pending'] = 'spawn'\n elif user.stop_pending:\n model['pending'] = 'stop'\n return model\n\n def group_model(self, group):\n \"\"\"Get the JSON model for a Group object\"\"\"\n return {\n 'name': group.name,\n 'users': [ u.name for u in group.users ]\n }\n\n _user_model_types = {\n 'name': str,\n 'admin': bool,\n 'groups': list,\n }\n\n _group_model_types = {\n 'name': str,\n 'users': list,\n }\n\n def _check_model(self, model, model_types, name):\n \"\"\"Check a model provided by a REST API request\n \n Args:\n model (dict): user-provided model\n model_types (dict): dict of key:type used to validate types and keys\n name (str): name of the model, used in error messages\n \"\"\"\n if not isinstance(model, dict):\n raise web.HTTPError(400, \"Invalid JSON data: %r\" % model)\n if not set(model).issubset(set(model_types)):\n raise web.HTTPError(400, \"Invalid JSON keys: %r\" % model)\n for key, value in model.items():\n if not isinstance(value, model_types[key]):\n raise web.HTTPError(400, \"%s.%s must be %s, not: %r\" % (\n name, key, model_types[key], type(value)\n ))\n\n def _check_user_model(self, model):\n \"\"\"Check a request-provided user model from a REST API\"\"\"\n return self._check_model(model, self._user_model_types, 'user')\n for groupname in model.get('groups', []):\n if not isinstance(groupname, str):\n raise web.HTTPError(400, \"group names must be str, not %r\" % type(groupname))\n\n def _check_group_model(self, model):\n \"\"\"Check a request-provided user model from a REST API\"\"\"\n self._check_model(model, self._group_model_types, 'group')\n for username in model.get('users', []):\n if not isinstance(username, str):\n raise web.HTTPError(400, \"usernames must be str, not %r\" % type(groupname))\n\n def options(self, *args, **kwargs):\n self.set_header('Access-Control-Allow-Headers', 'accept, content-type')\n self.finish()\n ", "path": "jupyterhub/apihandlers/base.py"}]}
| 2,230 | 408 |
gh_patches_debug_25209
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-516
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support body param in RequestMethods.request
Easiest way to do this is by avoiding defining a body kw when no fields are given, then if both are given it will naturally raise a "passed twice" error.
</issue>
<code>
[start of urllib3/request.py]
1 try:
2 from urllib.parse import urlencode
3 except ImportError:
4 from urllib import urlencode
5
6 from .filepost import encode_multipart_formdata
7
8
9 __all__ = ['RequestMethods']
10
11
12 class RequestMethods(object):
13 """
14 Convenience mixin for classes who implement a :meth:`urlopen` method, such
15 as :class:`~urllib3.connectionpool.HTTPConnectionPool` and
16 :class:`~urllib3.poolmanager.PoolManager`.
17
18 Provides behavior for making common types of HTTP request methods and
19 decides which type of request field encoding to use.
20
21 Specifically,
22
23 :meth:`.request_encode_url` is for sending requests whose fields are
24 encoded in the URL (such as GET, HEAD, DELETE).
25
26 :meth:`.request_encode_body` is for sending requests whose fields are
27 encoded in the *body* of the request using multipart or www-form-urlencoded
28 (such as for POST, PUT, PATCH).
29
30 :meth:`.request` is for making any kind of request, it will look up the
31 appropriate encoding format and use one of the above two methods to make
32 the request.
33
34 Initializer parameters:
35
36 :param headers:
37 Headers to include with all requests, unless other headers are given
38 explicitly.
39 """
40
41 _encode_url_methods = set(['DELETE', 'GET', 'HEAD', 'OPTIONS'])
42
43 def __init__(self, headers=None):
44 self.headers = headers or {}
45
46 def urlopen(self, method, url, body=None, headers=None,
47 encode_multipart=True, multipart_boundary=None,
48 **kw): # Abstract
49 raise NotImplemented("Classes extending RequestMethods must implement "
50 "their own ``urlopen`` method.")
51
52 def request(self, method, url, fields=None, headers=None, **urlopen_kw):
53 """
54 Make a request using :meth:`urlopen` with the appropriate encoding of
55 ``fields`` based on the ``method`` used.
56
57 This is a convenience method that requires the least amount of manual
58 effort. It can be used in most situations, while still having the
59 option to drop down to more specific methods when necessary, such as
60 :meth:`request_encode_url`, :meth:`request_encode_body`,
61 or even the lowest level :meth:`urlopen`.
62 """
63 method = method.upper()
64
65 if method in self._encode_url_methods:
66 return self.request_encode_url(method, url, fields=fields,
67 headers=headers,
68 **urlopen_kw)
69 else:
70 return self.request_encode_body(method, url, fields=fields,
71 headers=headers,
72 **urlopen_kw)
73
74 def request_encode_url(self, method, url, fields=None, **urlopen_kw):
75 """
76 Make a request using :meth:`urlopen` with the ``fields`` encoded in
77 the url. This is useful for request methods like GET, HEAD, DELETE, etc.
78 """
79 if fields:
80 url += '?' + urlencode(fields)
81 return self.urlopen(method, url, **urlopen_kw)
82
83 def request_encode_body(self, method, url, fields=None, headers=None,
84 encode_multipart=True, multipart_boundary=None,
85 **urlopen_kw):
86 """
87 Make a request using :meth:`urlopen` with the ``fields`` encoded in
88 the body. This is useful for request methods like POST, PUT, PATCH, etc.
89
90 When ``encode_multipart=True`` (default), then
91 :meth:`urllib3.filepost.encode_multipart_formdata` is used to encode
92 the payload with the appropriate content type. Otherwise
93 :meth:`urllib.urlencode` is used with the
94 'application/x-www-form-urlencoded' content type.
95
96 Multipart encoding must be used when posting files, and it's reasonably
97 safe to use it in other times too. However, it may break request
98 signing, such as with OAuth.
99
100 Supports an optional ``fields`` parameter of key/value strings AND
101 key/filetuple. A filetuple is a (filename, data, MIME type) tuple where
102 the MIME type is optional. For example::
103
104 fields = {
105 'foo': 'bar',
106 'fakefile': ('foofile.txt', 'contents of foofile'),
107 'realfile': ('barfile.txt', open('realfile').read()),
108 'typedfile': ('bazfile.bin', open('bazfile').read(),
109 'image/jpeg'),
110 'nonamefile': 'contents of nonamefile field',
111 }
112
113 When uploading a file, providing a filename (the first parameter of the
114 tuple) is optional but recommended to best mimick behavior of browsers.
115
116 Note that if ``headers`` are supplied, the 'Content-Type' header will
117 be overwritten because it depends on the dynamic random boundary string
118 which is used to compose the body of the request. The random boundary
119 string can be explicitly set with the ``multipart_boundary`` parameter.
120 """
121 if encode_multipart:
122 body, content_type = encode_multipart_formdata(
123 fields or {}, boundary=multipart_boundary)
124 else:
125 body, content_type = (urlencode(fields or {}),
126 'application/x-www-form-urlencoded')
127
128 if headers is None:
129 headers = self.headers
130
131 headers_ = {'Content-Type': content_type}
132 headers_.update(headers)
133
134 return self.urlopen(method, url, body=body, headers=headers_,
135 **urlopen_kw)
136
[end of urllib3/request.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/urllib3/request.py b/urllib3/request.py
--- a/urllib3/request.py
+++ b/urllib3/request.py
@@ -118,18 +118,24 @@
which is used to compose the body of the request. The random boundary
string can be explicitly set with the ``multipart_boundary`` parameter.
"""
- if encode_multipart:
- body, content_type = encode_multipart_formdata(
- fields or {}, boundary=multipart_boundary)
- else:
- body, content_type = (urlencode(fields or {}),
- 'application/x-www-form-urlencoded')
-
if headers is None:
headers = self.headers
- headers_ = {'Content-Type': content_type}
- headers_.update(headers)
+ extra_kw = {'headers': {}}
+
+ if fields:
+ if 'body' in urlopen_kw:
+ raise TypeError('request got values for both \'fields\' and \'body\', can only specify one.')
+
+ if encode_multipart:
+ body, content_type = encode_multipart_formdata(fields, boundary=multipart_boundary)
+ else:
+ body, content_type = urlencode(fields), 'application/x-www-form-urlencoded'
+
+ extra_kw['body'] = body
+ extra_kw['headers'] = {'Content-Type': content_type}
+
+ extra_kw['headers'].update(headers)
+ extra_kw.update(urlopen_kw)
- return self.urlopen(method, url, body=body, headers=headers_,
- **urlopen_kw)
+ return self.urlopen(method, url, **extra_kw)
|
{"golden_diff": "diff --git a/urllib3/request.py b/urllib3/request.py\n--- a/urllib3/request.py\n+++ b/urllib3/request.py\n@@ -118,18 +118,24 @@\n which is used to compose the body of the request. The random boundary\n string can be explicitly set with the ``multipart_boundary`` parameter.\n \"\"\"\n- if encode_multipart:\n- body, content_type = encode_multipart_formdata(\n- fields or {}, boundary=multipart_boundary)\n- else:\n- body, content_type = (urlencode(fields or {}),\n- 'application/x-www-form-urlencoded')\n-\n if headers is None:\n headers = self.headers\n \n- headers_ = {'Content-Type': content_type}\n- headers_.update(headers)\n+ extra_kw = {'headers': {}}\n+\n+ if fields:\n+ if 'body' in urlopen_kw:\n+ raise TypeError('request got values for both \\'fields\\' and \\'body\\', can only specify one.')\n+\n+ if encode_multipart:\n+ body, content_type = encode_multipart_formdata(fields, boundary=multipart_boundary)\n+ else:\n+ body, content_type = urlencode(fields), 'application/x-www-form-urlencoded'\n+\n+ extra_kw['body'] = body\n+ extra_kw['headers'] = {'Content-Type': content_type}\n+\n+ extra_kw['headers'].update(headers)\n+ extra_kw.update(urlopen_kw)\n \n- return self.urlopen(method, url, body=body, headers=headers_,\n- **urlopen_kw)\n+ return self.urlopen(method, url, **extra_kw)\n", "issue": "Support body param in RequestMethods.request\nEasiest way to do this is by avoiding defining a body kw when no fields are given, then if both are given it will naturally raise a \"passed twice\" error.\n\n", "before_files": [{"content": "try:\n from urllib.parse import urlencode\nexcept ImportError:\n from urllib import urlencode\n\nfrom .filepost import encode_multipart_formdata\n\n\n__all__ = ['RequestMethods']\n\n\nclass RequestMethods(object):\n \"\"\"\n Convenience mixin for classes who implement a :meth:`urlopen` method, such\n as :class:`~urllib3.connectionpool.HTTPConnectionPool` and\n :class:`~urllib3.poolmanager.PoolManager`.\n\n Provides behavior for making common types of HTTP request methods and\n decides which type of request field encoding to use.\n\n Specifically,\n\n :meth:`.request_encode_url` is for sending requests whose fields are\n encoded in the URL (such as GET, HEAD, DELETE).\n\n :meth:`.request_encode_body` is for sending requests whose fields are\n encoded in the *body* of the request using multipart or www-form-urlencoded\n (such as for POST, PUT, PATCH).\n\n :meth:`.request` is for making any kind of request, it will look up the\n appropriate encoding format and use one of the above two methods to make\n the request.\n\n Initializer parameters:\n\n :param headers:\n Headers to include with all requests, unless other headers are given\n explicitly.\n \"\"\"\n\n _encode_url_methods = set(['DELETE', 'GET', 'HEAD', 'OPTIONS'])\n\n def __init__(self, headers=None):\n self.headers = headers or {}\n\n def urlopen(self, method, url, body=None, headers=None,\n encode_multipart=True, multipart_boundary=None,\n **kw): # Abstract\n raise NotImplemented(\"Classes extending RequestMethods must implement \"\n \"their own ``urlopen`` method.\")\n\n def request(self, method, url, fields=None, headers=None, **urlopen_kw):\n \"\"\"\n Make a request using :meth:`urlopen` with the appropriate encoding of\n ``fields`` based on the ``method`` used.\n\n This is a convenience method that requires the least amount of manual\n effort. It can be used in most situations, while still having the\n option to drop down to more specific methods when necessary, such as\n :meth:`request_encode_url`, :meth:`request_encode_body`,\n or even the lowest level :meth:`urlopen`.\n \"\"\"\n method = method.upper()\n\n if method in self._encode_url_methods:\n return self.request_encode_url(method, url, fields=fields,\n headers=headers,\n **urlopen_kw)\n else:\n return self.request_encode_body(method, url, fields=fields,\n headers=headers,\n **urlopen_kw)\n\n def request_encode_url(self, method, url, fields=None, **urlopen_kw):\n \"\"\"\n Make a request using :meth:`urlopen` with the ``fields`` encoded in\n the url. This is useful for request methods like GET, HEAD, DELETE, etc.\n \"\"\"\n if fields:\n url += '?' + urlencode(fields)\n return self.urlopen(method, url, **urlopen_kw)\n\n def request_encode_body(self, method, url, fields=None, headers=None,\n encode_multipart=True, multipart_boundary=None,\n **urlopen_kw):\n \"\"\"\n Make a request using :meth:`urlopen` with the ``fields`` encoded in\n the body. This is useful for request methods like POST, PUT, PATCH, etc.\n\n When ``encode_multipart=True`` (default), then\n :meth:`urllib3.filepost.encode_multipart_formdata` is used to encode\n the payload with the appropriate content type. Otherwise\n :meth:`urllib.urlencode` is used with the\n 'application/x-www-form-urlencoded' content type.\n\n Multipart encoding must be used when posting files, and it's reasonably\n safe to use it in other times too. However, it may break request\n signing, such as with OAuth.\n\n Supports an optional ``fields`` parameter of key/value strings AND\n key/filetuple. A filetuple is a (filename, data, MIME type) tuple where\n the MIME type is optional. For example::\n\n fields = {\n 'foo': 'bar',\n 'fakefile': ('foofile.txt', 'contents of foofile'),\n 'realfile': ('barfile.txt', open('realfile').read()),\n 'typedfile': ('bazfile.bin', open('bazfile').read(),\n 'image/jpeg'),\n 'nonamefile': 'contents of nonamefile field',\n }\n\n When uploading a file, providing a filename (the first parameter of the\n tuple) is optional but recommended to best mimick behavior of browsers.\n\n Note that if ``headers`` are supplied, the 'Content-Type' header will\n be overwritten because it depends on the dynamic random boundary string\n which is used to compose the body of the request. The random boundary\n string can be explicitly set with the ``multipart_boundary`` parameter.\n \"\"\"\n if encode_multipart:\n body, content_type = encode_multipart_formdata(\n fields or {}, boundary=multipart_boundary)\n else:\n body, content_type = (urlencode(fields or {}),\n 'application/x-www-form-urlencoded')\n\n if headers is None:\n headers = self.headers\n\n headers_ = {'Content-Type': content_type}\n headers_.update(headers)\n\n return self.urlopen(method, url, body=body, headers=headers_,\n **urlopen_kw)\n", "path": "urllib3/request.py"}]}
| 2,040 | 351 |
gh_patches_debug_38491
|
rasdani/github-patches
|
git_diff
|
cleanlab__cleanlab-423
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Token Classification: given_labels -> labels
Rename argument `given_labels` to just `labels` throughout the module to be more consistent with rest of package.
Example: https://github.com/cleanlab/cleanlab/blob/master/cleanlab/token_classification/summary.py#L33
Need to correspondingly update tutorial notebook as well, possibly also example notebook but I don't think so.
</issue>
<code>
[start of cleanlab/token_classification/summary.py]
1 # Copyright (C) 2017-2022 Cleanlab Inc.
2 # This file is part of cleanlab.
3 #
4 # cleanlab is free software: you can redistribute it and/or modify
5 # it under the terms of the GNU Affero General Public License as published
6 # by the Free Software Foundation, either version 3 of the License, or
7 # (at your option) any later version.
8 #
9 # cleanlab is distributed in the hope that it will be useful,
10 # but WITHOUT ANY WARRANTY; without even the implied warranty of
11 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
12 # GNU Affero General Public License for more details.
13 #
14 # You should have received a copy of the GNU Affero General Public License
15 # along with cleanlab. If not, see <https://www.gnu.org/licenses/>.
16
17 """
18 Methods to display sentences and their label issues in a token classification dataset (text data), as well as summarize the types of issues identified.
19 """
20
21 import numpy as np
22 import pandas as pd
23 from typing import List, Optional, Tuple, Dict, Any
24
25 from cleanlab.internal.token_classification_utils import get_sentence, color_sentence
26
27
28 def display_issues(
29 issues: list,
30 given_words: List[List[str]],
31 *,
32 pred_probs: Optional[list] = None,
33 given_labels: Optional[list] = None,
34 exclude: List[Tuple[int, int]] = [],
35 class_names: Optional[List[str]] = None,
36 top: int = 20
37 ) -> None:
38 """
39 Display issues, including sentence with issue token highlighted. Also shows given and predicted label
40 if possible.
41
42 Parameters
43 ----------
44 issues:
45 list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.
46
47 given_words:
48 tokens in a nested-list format, such that `given_words[i]` contains the words of the i'th sentence from
49 the original file.
50
51 pred_probs:
52 list of model-predicted probability, such that `pred_probs[i]` contains the model-predicted probability of
53 the tokens in the i'th sentence, and has shape `(N, K)`, where `N` is the number of given tokens of the i'th
54 sentence, and `K` is the number of classes predicted by the model. If provided, also displays the predicted
55 label of the token.
56
57 given_labels:
58 list of given labels, such that `given_labels[i]` is a list containing the given labels of the tokens in the
59 i'th sentence, and has length equal to the number of given tokens of the i'th sentence. If provided, also
60 displays the given label of the token.
61
62 exclude:
63 list of given/predicted label swaps to be excluded. For example, if `exclude=[(0, 1), (1, 0)]`, swaps between
64 class 0 and 1 are not displayed.
65
66 class_names:
67 name of classes. If not provided, display the integer index for predicted and given labels.
68
69 top: int, default=20
70 maximum number of outputs to be printed.
71
72 """
73 if not class_names:
74 print(
75 "Classes will be printed in terms of their integer index since `class_names` was not provided. "
76 )
77 print("Specify this argument to see the string names of each class. \n")
78
79 shown = 0
80 is_tuple = isinstance(issues[0], tuple)
81
82 for issue in issues:
83 if is_tuple:
84 i, j = issue
85 sentence = get_sentence(given_words[i])
86 word = given_words[i][j]
87
88 if pred_probs:
89 prediction = pred_probs[i][j].argmax()
90 if given_labels:
91 given = given_labels[i][j]
92 if pred_probs and given_labels:
93 if (given, prediction) in exclude:
94 continue
95
96 if pred_probs and class_names:
97 prediction = class_names[prediction]
98 if given_labels and class_names:
99 given = class_names[given]
100
101 shown += 1
102 print("Sentence %d, token %d: \n%s" % (i, j, color_sentence(sentence, word)))
103 if given_labels and not pred_probs:
104 print("Given label: %s\n" % str(given))
105 elif not given_labels and pred_probs:
106 print("Predicted label according to provided pred_probs: %s\n" % str(prediction))
107 elif given_labels and pred_probs:
108 print(
109 "Given label: %s, predicted label according to provided pred_probs: %s\n"
110 % (str(given), str(prediction))
111 )
112 else:
113 print()
114 else:
115 shown += 1
116 sentence = get_sentence(given_words[issue])
117 print("Sentence %d: %s\n" % (issue, sentence))
118 if shown == top:
119 break
120
121
122 def common_label_issues(
123 issues: List[Tuple[int, int]],
124 given_words: List[List[str]],
125 *,
126 labels: Optional[list] = None,
127 pred_probs: Optional[list] = None,
128 class_names: Optional[List[str]] = None,
129 top: int = 10,
130 exclude: List[Tuple[int, int]] = [],
131 verbose: bool = True
132 ) -> pd.DataFrame:
133 """
134 Display the most common tokens that are potentially mislabeled.
135
136 Parameters
137 ----------
138 issues:
139 list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.
140
141 given_words:
142 tokens in a nested-list format, such that `given_words[i]` contains the words of the i'th sentence from
143 the original file.
144
145 labels:
146 list of given labels, such that `labels[i]` is a list containing the given labels of the tokens in the i'th
147 sentence, and has length equal to the number of given tokens of the i'th sentence. If provided, also
148 displays the given label of the token.
149
150 pred_probs:
151 list of model-predicted probability, such that `pred_probs[i]` contains the model-predicted probability of
152 the tokens in the i'th sentence, and has shape `(N, K)`, where `N` is the number of given tokens of the i'th
153 sentence, and `K` is the number of classes predicted by the model. If both `labels` and `pred_probs` are
154 provided, also evaluate each type of given/predicted label swap.
155
156 class_names:
157 name of classes. If not provided, display the integer index for predicted and given labels.
158
159 top:
160 maximum number of outputs to be printed.
161
162 exclude:
163 list of given/predicted label swaps to be excluded. For example, if `exclude=[(0, 1), (1, 0)]`, swaps between
164 class 0 and 1 are not displayed.
165
166 verbose:
167 if set to True, also display each type of given/predicted label swap for each token.
168
169 Returns
170 ---------
171 df:
172 if both `labels` and `pred_probs` are provided, return a data frame with columns ['token', 'given_label',
173 'predicted_label', 'num_label_issues'], and each row contains the information for a specific token and
174 given/predicted label swap, ordered by the number of label issues in descending order. Otherwise, return
175 a data frame with columns ['token', 'num_label_issues'], and each row contains the information for a specific
176 token, ordered by the number of label issues in descending order.
177
178 """
179 count: Dict[str, Any] = {}
180 if not labels or not pred_probs:
181 for issue in issues:
182 i, j = issue
183 word = given_words[i][j]
184 if word not in count:
185 count[word] = 0
186 count[word] += 1
187
188 words = [word for word in count.keys()]
189 freq = [count[word] for word in words]
190 rank = np.argsort(freq)[::-1][:top]
191
192 for r in rank:
193 print(
194 "Token '%s' is potentially mislabeled %d times throughout the dataset\n"
195 % (words[r], freq[r])
196 )
197
198 info = [[word, f] for word, f in zip(words, freq)]
199 info = sorted(info, key=lambda x: x[1], reverse=True)
200 return pd.DataFrame(info, columns=["token", "num_label_issues"])
201
202 if not class_names:
203 print(
204 "Classes will be printed in terms of their integer index since `class_names` was not provided. "
205 )
206 print("Specify this argument to see the string names of each class. \n")
207
208 n = pred_probs[0].shape[1]
209 for issue in issues:
210 i, j = issue
211 word = given_words[i][j]
212 label = labels[i][j]
213 pred = pred_probs[i][j].argmax()
214 if word not in count:
215 count[word] = np.zeros([n, n], dtype=int)
216 if (label, pred) not in exclude:
217 count[word][label][pred] += 1
218 words = [word for word in count.keys()]
219 freq = [np.sum(count[word]) for word in words]
220 rank = np.argsort(freq)[::-1][:top]
221
222 for r in rank:
223 matrix = count[words[r]]
224 most_frequent = np.argsort(count[words[r]].flatten())[::-1]
225 print(
226 "Token '%s' is potentially mislabeled %d times throughout the dataset"
227 % (words[r], freq[r])
228 )
229 if verbose:
230 print(
231 "---------------------------------------------------------------------------------------"
232 )
233 for f in most_frequent:
234 i, j = f // n, f % n
235 if matrix[i][j] == 0:
236 break
237 if class_names:
238 print(
239 "labeled as class `%s` but predicted to actually be class `%s` %d times"
240 % (class_names[i], class_names[j], matrix[i][j])
241 )
242 else:
243 print(
244 "labeled as class %d but predicted to actually be class %d %d times"
245 % (i, j, matrix[i][j])
246 )
247 print()
248 info = []
249 for word in words:
250 for i in range(n):
251 for j in range(n):
252 num = count[word][i][j]
253 if num > 0:
254 if not class_names:
255 info.append([word, i, j, num])
256 else:
257 info.append([word, class_names[i], class_names[j], num])
258 info = sorted(info, key=lambda x: x[3], reverse=True)
259 return pd.DataFrame(
260 info, columns=["token", "given_label", "predicted_label", "num_label_issues"]
261 )
262
263
264 def filter_by_token(
265 token: str, issues: List[Tuple[int, int]], given_words: List[List[str]]
266 ) -> List[Tuple[int, int]]:
267 """
268 Searches a specific token within all issue tokens
269
270 Parameters
271 ----------
272 token:
273 the specific token the user is looking for
274
275 issues:
276 list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.
277
278 given_words:
279 tokens in a nested-list format, such that `given_words[i]` contains the words of the i'th sentence from
280 the original file.
281
282 Returns
283 ----------
284 returned_issues:
285 list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.
286
287 """
288 returned_issues = []
289 for issue in issues:
290 i, j = issue
291 if token.lower() == given_words[i][j].lower():
292 returned_issues.append(issue)
293 return returned_issues
294
[end of cleanlab/token_classification/summary.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cleanlab/token_classification/summary.py b/cleanlab/token_classification/summary.py
--- a/cleanlab/token_classification/summary.py
+++ b/cleanlab/token_classification/summary.py
@@ -9,7 +9,7 @@
given_words: List[List[str]],
*,
pred_probs: Optional[list] = None,
- given_labels: Optional[list] = None,
+ labels: Optional[list] = None,
exclude: List[Tuple[int, int]] = [],
class_names: Optional[List[str]] = None,
top: int = 20
@@ -33,8 +33,8 @@
sentence, and `K` is the number of classes predicted by the model. If provided, also displays the predicted
label of the token.
- given_labels:
- list of given labels, such that `given_labels[i]` is a list containing the given labels of the tokens in the
+ labels:
+ list of given labels, such that `labels[i]` is a list containing the given labels of the tokens in the
i'th sentence, and has length equal to the number of given tokens of the i'th sentence. If provided, also
displays the given label of the token.
@@ -66,24 +66,24 @@
if pred_probs:
prediction = pred_probs[i][j].argmax()
- if given_labels:
- given = given_labels[i][j]
- if pred_probs and given_labels:
+ if labels:
+ given = labels[i][j]
+ if pred_probs and labels:
if (given, prediction) in exclude:
continue
if pred_probs and class_names:
prediction = class_names[prediction]
- if given_labels and class_names:
+ if labels and class_names:
given = class_names[given]
shown += 1
print("Sentence %d, token %d: \n%s" % (i, j, color_sentence(sentence, word)))
- if given_labels and not pred_probs:
+ if labels and not pred_probs:
print("Given label: %s\n" % str(given))
- elif not given_labels and pred_probs:
+ elif not labels and pred_probs:
print("Predicted label according to provided pred_probs: %s\n" % str(prediction))
- elif given_labels and pred_probs:
+ elif labels and pred_probs:
print(
"Given label: %s, predicted label according to provided pred_probs: %s\n"
% (str(given), str(prediction))
|
{"golden_diff": "diff --git a/cleanlab/token_classification/summary.py b/cleanlab/token_classification/summary.py\n--- a/cleanlab/token_classification/summary.py\n+++ b/cleanlab/token_classification/summary.py\n@@ -9,7 +9,7 @@\n given_words: List[List[str]],\n *,\n pred_probs: Optional[list] = None,\n- given_labels: Optional[list] = None,\n+ labels: Optional[list] = None,\n exclude: List[Tuple[int, int]] = [],\n class_names: Optional[List[str]] = None,\n top: int = 20\n@@ -33,8 +33,8 @@\n sentence, and `K` is the number of classes predicted by the model. If provided, also displays the predicted\n label of the token.\n \n- given_labels:\n- list of given labels, such that `given_labels[i]` is a list containing the given labels of the tokens in the\n+ labels:\n+ list of given labels, such that `labels[i]` is a list containing the given labels of the tokens in the\n i'th sentence, and has length equal to the number of given tokens of the i'th sentence. If provided, also\n displays the given label of the token.\n \n@@ -66,24 +66,24 @@\n \n if pred_probs:\n prediction = pred_probs[i][j].argmax()\n- if given_labels:\n- given = given_labels[i][j]\n- if pred_probs and given_labels:\n+ if labels:\n+ given = labels[i][j]\n+ if pred_probs and labels:\n if (given, prediction) in exclude:\n continue\n \n if pred_probs and class_names:\n prediction = class_names[prediction]\n- if given_labels and class_names:\n+ if labels and class_names:\n given = class_names[given]\n \n shown += 1\n print(\"Sentence %d, token %d: \\n%s\" % (i, j, color_sentence(sentence, word)))\n- if given_labels and not pred_probs:\n+ if labels and not pred_probs:\n print(\"Given label: %s\\n\" % str(given))\n- elif not given_labels and pred_probs:\n+ elif not labels and pred_probs:\n print(\"Predicted label according to provided pred_probs: %s\\n\" % str(prediction))\n- elif given_labels and pred_probs:\n+ elif labels and pred_probs:\n print(\n \"Given label: %s, predicted label according to provided pred_probs: %s\\n\"\n % (str(given), str(prediction))\n", "issue": "Token Classification: given_labels -> labels\nRename argument `given_labels` to just `labels` throughout the module to be more consistent with rest of package.\n\nExample: https://github.com/cleanlab/cleanlab/blob/master/cleanlab/token_classification/summary.py#L33\n\nNeed to correspondingly update tutorial notebook as well, possibly also example notebook but I don't think so.\n", "before_files": [{"content": "# Copyright (C) 2017-2022 Cleanlab Inc.\n# This file is part of cleanlab.\n#\n# cleanlab is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as published\n# by the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# cleanlab is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with cleanlab. If not, see <https://www.gnu.org/licenses/>.\n\n\"\"\"\nMethods to display sentences and their label issues in a token classification dataset (text data), as well as summarize the types of issues identified.\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nfrom typing import List, Optional, Tuple, Dict, Any\n\nfrom cleanlab.internal.token_classification_utils import get_sentence, color_sentence\n\n\ndef display_issues(\n issues: list,\n given_words: List[List[str]],\n *,\n pred_probs: Optional[list] = None,\n given_labels: Optional[list] = None,\n exclude: List[Tuple[int, int]] = [],\n class_names: Optional[List[str]] = None,\n top: int = 20\n) -> None:\n \"\"\"\n Display issues, including sentence with issue token highlighted. Also shows given and predicted label\n if possible.\n\n Parameters\n ----------\n issues:\n list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.\n\n given_words:\n tokens in a nested-list format, such that `given_words[i]` contains the words of the i'th sentence from\n the original file.\n\n pred_probs:\n list of model-predicted probability, such that `pred_probs[i]` contains the model-predicted probability of\n the tokens in the i'th sentence, and has shape `(N, K)`, where `N` is the number of given tokens of the i'th\n sentence, and `K` is the number of classes predicted by the model. If provided, also displays the predicted\n label of the token.\n\n given_labels:\n list of given labels, such that `given_labels[i]` is a list containing the given labels of the tokens in the\n i'th sentence, and has length equal to the number of given tokens of the i'th sentence. If provided, also\n displays the given label of the token.\n\n exclude:\n list of given/predicted label swaps to be excluded. For example, if `exclude=[(0, 1), (1, 0)]`, swaps between\n class 0 and 1 are not displayed.\n\n class_names:\n name of classes. If not provided, display the integer index for predicted and given labels.\n\n top: int, default=20\n maximum number of outputs to be printed.\n\n \"\"\"\n if not class_names:\n print(\n \"Classes will be printed in terms of their integer index since `class_names` was not provided. \"\n )\n print(\"Specify this argument to see the string names of each class. \\n\")\n\n shown = 0\n is_tuple = isinstance(issues[0], tuple)\n\n for issue in issues:\n if is_tuple:\n i, j = issue\n sentence = get_sentence(given_words[i])\n word = given_words[i][j]\n\n if pred_probs:\n prediction = pred_probs[i][j].argmax()\n if given_labels:\n given = given_labels[i][j]\n if pred_probs and given_labels:\n if (given, prediction) in exclude:\n continue\n\n if pred_probs and class_names:\n prediction = class_names[prediction]\n if given_labels and class_names:\n given = class_names[given]\n\n shown += 1\n print(\"Sentence %d, token %d: \\n%s\" % (i, j, color_sentence(sentence, word)))\n if given_labels and not pred_probs:\n print(\"Given label: %s\\n\" % str(given))\n elif not given_labels and pred_probs:\n print(\"Predicted label according to provided pred_probs: %s\\n\" % str(prediction))\n elif given_labels and pred_probs:\n print(\n \"Given label: %s, predicted label according to provided pred_probs: %s\\n\"\n % (str(given), str(prediction))\n )\n else:\n print()\n else:\n shown += 1\n sentence = get_sentence(given_words[issue])\n print(\"Sentence %d: %s\\n\" % (issue, sentence))\n if shown == top:\n break\n\n\ndef common_label_issues(\n issues: List[Tuple[int, int]],\n given_words: List[List[str]],\n *,\n labels: Optional[list] = None,\n pred_probs: Optional[list] = None,\n class_names: Optional[List[str]] = None,\n top: int = 10,\n exclude: List[Tuple[int, int]] = [],\n verbose: bool = True\n) -> pd.DataFrame:\n \"\"\"\n Display the most common tokens that are potentially mislabeled.\n\n Parameters\n ----------\n issues:\n list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.\n\n given_words:\n tokens in a nested-list format, such that `given_words[i]` contains the words of the i'th sentence from\n the original file.\n\n labels:\n list of given labels, such that `labels[i]` is a list containing the given labels of the tokens in the i'th\n sentence, and has length equal to the number of given tokens of the i'th sentence. If provided, also\n displays the given label of the token.\n\n pred_probs:\n list of model-predicted probability, such that `pred_probs[i]` contains the model-predicted probability of\n the tokens in the i'th sentence, and has shape `(N, K)`, where `N` is the number of given tokens of the i'th\n sentence, and `K` is the number of classes predicted by the model. If both `labels` and `pred_probs` are\n provided, also evaluate each type of given/predicted label swap.\n\n class_names:\n name of classes. If not provided, display the integer index for predicted and given labels.\n\n top:\n maximum number of outputs to be printed.\n\n exclude:\n list of given/predicted label swaps to be excluded. For example, if `exclude=[(0, 1), (1, 0)]`, swaps between\n class 0 and 1 are not displayed.\n\n verbose:\n if set to True, also display each type of given/predicted label swap for each token.\n\n Returns\n ---------\n df:\n if both `labels` and `pred_probs` are provided, return a data frame with columns ['token', 'given_label',\n 'predicted_label', 'num_label_issues'], and each row contains the information for a specific token and\n given/predicted label swap, ordered by the number of label issues in descending order. Otherwise, return\n a data frame with columns ['token', 'num_label_issues'], and each row contains the information for a specific\n token, ordered by the number of label issues in descending order.\n\n \"\"\"\n count: Dict[str, Any] = {}\n if not labels or not pred_probs:\n for issue in issues:\n i, j = issue\n word = given_words[i][j]\n if word not in count:\n count[word] = 0\n count[word] += 1\n\n words = [word for word in count.keys()]\n freq = [count[word] for word in words]\n rank = np.argsort(freq)[::-1][:top]\n\n for r in rank:\n print(\n \"Token '%s' is potentially mislabeled %d times throughout the dataset\\n\"\n % (words[r], freq[r])\n )\n\n info = [[word, f] for word, f in zip(words, freq)]\n info = sorted(info, key=lambda x: x[1], reverse=True)\n return pd.DataFrame(info, columns=[\"token\", \"num_label_issues\"])\n\n if not class_names:\n print(\n \"Classes will be printed in terms of their integer index since `class_names` was not provided. \"\n )\n print(\"Specify this argument to see the string names of each class. \\n\")\n\n n = pred_probs[0].shape[1]\n for issue in issues:\n i, j = issue\n word = given_words[i][j]\n label = labels[i][j]\n pred = pred_probs[i][j].argmax()\n if word not in count:\n count[word] = np.zeros([n, n], dtype=int)\n if (label, pred) not in exclude:\n count[word][label][pred] += 1\n words = [word for word in count.keys()]\n freq = [np.sum(count[word]) for word in words]\n rank = np.argsort(freq)[::-1][:top]\n\n for r in rank:\n matrix = count[words[r]]\n most_frequent = np.argsort(count[words[r]].flatten())[::-1]\n print(\n \"Token '%s' is potentially mislabeled %d times throughout the dataset\"\n % (words[r], freq[r])\n )\n if verbose:\n print(\n \"---------------------------------------------------------------------------------------\"\n )\n for f in most_frequent:\n i, j = f // n, f % n\n if matrix[i][j] == 0:\n break\n if class_names:\n print(\n \"labeled as class `%s` but predicted to actually be class `%s` %d times\"\n % (class_names[i], class_names[j], matrix[i][j])\n )\n else:\n print(\n \"labeled as class %d but predicted to actually be class %d %d times\"\n % (i, j, matrix[i][j])\n )\n print()\n info = []\n for word in words:\n for i in range(n):\n for j in range(n):\n num = count[word][i][j]\n if num > 0:\n if not class_names:\n info.append([word, i, j, num])\n else:\n info.append([word, class_names[i], class_names[j], num])\n info = sorted(info, key=lambda x: x[3], reverse=True)\n return pd.DataFrame(\n info, columns=[\"token\", \"given_label\", \"predicted_label\", \"num_label_issues\"]\n )\n\n\ndef filter_by_token(\n token: str, issues: List[Tuple[int, int]], given_words: List[List[str]]\n) -> List[Tuple[int, int]]:\n \"\"\"\n Searches a specific token within all issue tokens\n\n Parameters\n ----------\n token:\n the specific token the user is looking for\n\n issues:\n list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.\n\n given_words:\n tokens in a nested-list format, such that `given_words[i]` contains the words of the i'th sentence from\n the original file.\n\n Returns\n ----------\n returned_issues:\n list of tuples `(i, j)`, which represents the j'th token of the i'th sentence.\n\n \"\"\"\n returned_issues = []\n for issue in issues:\n i, j = issue\n if token.lower() == given_words[i][j].lower():\n returned_issues.append(issue)\n return returned_issues\n", "path": "cleanlab/token_classification/summary.py"}]}
| 3,954 | 564 |
gh_patches_debug_23347
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-15758
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove the `annotated_date()` and `annotated_now()` template filters
### Proposed Changes
Remove the following template filters from `utilities.templatetags.helpers`:
- `annotated_date()`
- `annotated_now()`
### Justification
With the shift to using ISO 8601-formatted dates & times everywhere in #15735, these filters are no longer needed.
### Impact
All uses of these filters must be updated. These can generally be replaced with the new `isodatetime()` template filter.
</issue>
<code>
[start of netbox/utilities/templatetags/helpers.py]
1 import datetime
2 import json
3 from typing import Dict, Any
4 from urllib.parse import quote
5
6 from django import template
7 from django.conf import settings
8 from django.template.defaultfilters import date
9 from django.urls import NoReverseMatch, reverse
10 from django.utils import timezone
11 from django.utils.safestring import mark_safe
12
13 from core.models import ObjectType
14 from utilities.forms import get_selected_values, TableConfigForm
15 from utilities.views import get_viewname
16
17 __all__ = (
18 'annotated_date',
19 'annotated_now',
20 'applied_filters',
21 'as_range',
22 'divide',
23 'get_item',
24 'get_key',
25 'humanize_megabytes',
26 'humanize_speed',
27 'icon_from_status',
28 'kg_to_pounds',
29 'meters_to_feet',
30 'percentage',
31 'querystring',
32 'startswith',
33 'status_from_tag',
34 'table_config_form',
35 'utilization_graph',
36 'validated_viewname',
37 'viewname',
38 )
39
40 register = template.Library()
41
42
43 #
44 # Filters
45 #
46
47
48 @register.filter()
49 def viewname(model, action):
50 """
51 Return the view name for the given model and action. Does not perform any validation.
52 """
53 return get_viewname(model, action)
54
55
56 @register.filter()
57 def validated_viewname(model, action):
58 """
59 Return the view name for the given model and action if valid, or None if invalid.
60 """
61 viewname = get_viewname(model, action)
62
63 # Validate the view name
64 try:
65 reverse(viewname)
66 return viewname
67 except NoReverseMatch:
68 return None
69
70
71 @register.filter()
72 def humanize_speed(speed):
73 """
74 Humanize speeds given in Kbps. Examples:
75
76 1544 => "1.544 Mbps"
77 100000 => "100 Mbps"
78 10000000 => "10 Gbps"
79 """
80 if not speed:
81 return ''
82 if speed >= 1000000000 and speed % 1000000000 == 0:
83 return '{} Tbps'.format(int(speed / 1000000000))
84 elif speed >= 1000000 and speed % 1000000 == 0:
85 return '{} Gbps'.format(int(speed / 1000000))
86 elif speed >= 1000 and speed % 1000 == 0:
87 return '{} Mbps'.format(int(speed / 1000))
88 elif speed >= 1000:
89 return '{} Mbps'.format(float(speed) / 1000)
90 else:
91 return '{} Kbps'.format(speed)
92
93
94 @register.filter()
95 def humanize_megabytes(mb):
96 """
97 Express a number of megabytes in the most suitable unit (e.g. gigabytes or terabytes).
98 """
99 if not mb:
100 return ''
101 if not mb % 1048576: # 1024^2
102 return f'{int(mb / 1048576)} TB'
103 if not mb % 1024:
104 return f'{int(mb / 1024)} GB'
105 return f'{mb} MB'
106
107
108 @register.filter(expects_localtime=True)
109 def annotated_date(date_value):
110 """
111 Returns date as HTML span with short date format as the content and the
112 (long) date format as the title.
113 """
114 if not date_value:
115 return ''
116
117 if type(date_value) is datetime.date:
118 long_ts = date(date_value, 'DATE_FORMAT')
119 short_ts = date(date_value, 'SHORT_DATE_FORMAT')
120 else:
121 long_ts = date(date_value, 'DATETIME_FORMAT')
122 short_ts = date(date_value, 'SHORT_DATETIME_FORMAT')
123
124 return mark_safe(f'<span title="{long_ts}">{short_ts}</span>')
125
126
127 @register.simple_tag
128 def annotated_now():
129 """
130 Returns the current date piped through the annotated_date filter.
131 """
132 tzinfo = timezone.get_current_timezone() if settings.USE_TZ else None
133 return annotated_date(datetime.datetime.now(tz=tzinfo))
134
135
136 @register.filter()
137 def divide(x, y):
138 """
139 Return x/y (rounded).
140 """
141 if x is None or y is None:
142 return None
143 return round(x / y)
144
145
146 @register.filter()
147 def percentage(x, y):
148 """
149 Return x/y as a percentage.
150 """
151 if x is None or y is None:
152 return None
153
154 return round(x / y * 100, 1)
155
156
157 @register.filter()
158 def as_range(n):
159 """
160 Return a range of n items.
161 """
162 try:
163 int(n)
164 except TypeError:
165 return list()
166 return range(n)
167
168
169 @register.filter()
170 def meters_to_feet(n):
171 """
172 Convert a length from meters to feet.
173 """
174 return float(n) * 3.28084
175
176
177 @register.filter()
178 def kg_to_pounds(n):
179 """
180 Convert a weight from kilograms to pounds.
181 """
182 return float(n) * 2.204623
183
184
185 @register.filter("startswith")
186 def startswith(text: str, starts: str) -> bool:
187 """
188 Template implementation of `str.startswith()`.
189 """
190 if isinstance(text, str):
191 return text.startswith(starts)
192 return False
193
194
195 @register.filter
196 def get_key(value: Dict, arg: str) -> Any:
197 """
198 Template implementation of `dict.get()`, for accessing dict values
199 by key when the key is not able to be used in a template. For
200 example, `{"ui.colormode": "dark"}`.
201 """
202 return value.get(arg, None)
203
204
205 @register.filter
206 def get_item(value: object, attr: str) -> Any:
207 """
208 Template implementation of `__getitem__`, for accessing the `__getitem__` method
209 of a class from a template.
210 """
211 return value[attr]
212
213
214 @register.filter
215 def status_from_tag(tag: str = "info") -> str:
216 """
217 Determine Bootstrap theme status/level from Django's Message.level_tag.
218 """
219 status_map = {
220 'warning': 'warning',
221 'success': 'success',
222 'error': 'danger',
223 'danger': 'danger',
224 'debug': 'info',
225 'info': 'info',
226 }
227 return status_map.get(tag.lower(), 'info')
228
229
230 @register.filter
231 def icon_from_status(status: str = "info") -> str:
232 """
233 Determine icon class name from Bootstrap theme status/level.
234 """
235 icon_map = {
236 'warning': 'alert',
237 'success': 'check-circle',
238 'danger': 'alert',
239 'info': 'information',
240 }
241 return icon_map.get(status.lower(), 'information')
242
243
244 #
245 # Tags
246 #
247
248 @register.simple_tag()
249 def querystring(request, **kwargs):
250 """
251 Append or update the page number in a querystring.
252 """
253 querydict = request.GET.copy()
254 for k, v in kwargs.items():
255 if v is not None:
256 querydict[k] = str(v)
257 elif k in querydict:
258 querydict.pop(k)
259 querystring = querydict.urlencode(safe='/')
260 if querystring:
261 return '?' + querystring
262 else:
263 return ''
264
265
266 @register.inclusion_tag('helpers/utilization_graph.html')
267 def utilization_graph(utilization, warning_threshold=75, danger_threshold=90):
268 """
269 Display a horizontal bar graph indicating a percentage of utilization.
270 """
271 if utilization == 100:
272 bar_class = 'bg-secondary'
273 elif danger_threshold and utilization >= danger_threshold:
274 bar_class = 'bg-danger'
275 elif warning_threshold and utilization >= warning_threshold:
276 bar_class = 'bg-warning'
277 elif warning_threshold or danger_threshold:
278 bar_class = 'bg-success'
279 else:
280 bar_class = 'bg-gray'
281 return {
282 'utilization': utilization,
283 'bar_class': bar_class,
284 }
285
286
287 @register.inclusion_tag('helpers/table_config_form.html')
288 def table_config_form(table, table_name=None):
289 return {
290 'table_name': table_name or table.__class__.__name__,
291 'form': TableConfigForm(table=table),
292 }
293
294
295 @register.inclusion_tag('helpers/applied_filters.html', takes_context=True)
296 def applied_filters(context, model, form, query_params):
297 """
298 Display the active filters for a given filter form.
299 """
300 user = context['request'].user
301 form.is_valid() # Ensure cleaned_data has been set
302
303 applied_filters = []
304 for filter_name in form.changed_data:
305 if filter_name not in form.cleaned_data:
306 continue
307
308 querydict = query_params.copy()
309 if filter_name not in querydict:
310 continue
311
312 bound_field = form.fields[filter_name].get_bound_field(form, filter_name)
313 querydict.pop(filter_name)
314 display_value = ', '.join([str(v) for v in get_selected_values(form, filter_name)])
315
316 applied_filters.append({
317 'name': filter_name,
318 'value': form.cleaned_data[filter_name],
319 'link_url': f'?{querydict.urlencode()}',
320 'link_text': f'{bound_field.label}: {display_value}',
321 })
322
323 save_link = None
324 if user.has_perm('extras.add_savedfilter') and 'filter_id' not in context['request'].GET:
325 object_type = ObjectType.objects.get_for_model(model).pk
326 parameters = json.dumps(dict(context['request'].GET.lists()))
327 url = reverse('extras:savedfilter_add')
328 save_link = f"{url}?object_types={object_type}¶meters={quote(parameters)}"
329
330 return {
331 'applied_filters': applied_filters,
332 'save_link': save_link,
333 }
334
[end of netbox/utilities/templatetags/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/utilities/templatetags/helpers.py b/netbox/utilities/templatetags/helpers.py
--- a/netbox/utilities/templatetags/helpers.py
+++ b/netbox/utilities/templatetags/helpers.py
@@ -15,8 +15,6 @@
from utilities.views import get_viewname
__all__ = (
- 'annotated_date',
- 'annotated_now',
'applied_filters',
'as_range',
'divide',
@@ -105,34 +103,6 @@
return f'{mb} MB'
[email protected](expects_localtime=True)
-def annotated_date(date_value):
- """
- Returns date as HTML span with short date format as the content and the
- (long) date format as the title.
- """
- if not date_value:
- return ''
-
- if type(date_value) is datetime.date:
- long_ts = date(date_value, 'DATE_FORMAT')
- short_ts = date(date_value, 'SHORT_DATE_FORMAT')
- else:
- long_ts = date(date_value, 'DATETIME_FORMAT')
- short_ts = date(date_value, 'SHORT_DATETIME_FORMAT')
-
- return mark_safe(f'<span title="{long_ts}">{short_ts}</span>')
-
-
[email protected]_tag
-def annotated_now():
- """
- Returns the current date piped through the annotated_date filter.
- """
- tzinfo = timezone.get_current_timezone() if settings.USE_TZ else None
- return annotated_date(datetime.datetime.now(tz=tzinfo))
-
-
@register.filter()
def divide(x, y):
"""
|
{"golden_diff": "diff --git a/netbox/utilities/templatetags/helpers.py b/netbox/utilities/templatetags/helpers.py\n--- a/netbox/utilities/templatetags/helpers.py\n+++ b/netbox/utilities/templatetags/helpers.py\n@@ -15,8 +15,6 @@\n from utilities.views import get_viewname\n \n __all__ = (\n- 'annotated_date',\n- 'annotated_now',\n 'applied_filters',\n 'as_range',\n 'divide',\n@@ -105,34 +103,6 @@\n return f'{mb} MB'\n \n \[email protected](expects_localtime=True)\n-def annotated_date(date_value):\n- \"\"\"\n- Returns date as HTML span with short date format as the content and the\n- (long) date format as the title.\n- \"\"\"\n- if not date_value:\n- return ''\n-\n- if type(date_value) is datetime.date:\n- long_ts = date(date_value, 'DATE_FORMAT')\n- short_ts = date(date_value, 'SHORT_DATE_FORMAT')\n- else:\n- long_ts = date(date_value, 'DATETIME_FORMAT')\n- short_ts = date(date_value, 'SHORT_DATETIME_FORMAT')\n-\n- return mark_safe(f'<span title=\"{long_ts}\">{short_ts}</span>')\n-\n-\[email protected]_tag\n-def annotated_now():\n- \"\"\"\n- Returns the current date piped through the annotated_date filter.\n- \"\"\"\n- tzinfo = timezone.get_current_timezone() if settings.USE_TZ else None\n- return annotated_date(datetime.datetime.now(tz=tzinfo))\n-\n-\n @register.filter()\n def divide(x, y):\n \"\"\"\n", "issue": "Remove the `annotated_date()` and `annotated_now()` template filters\n### Proposed Changes\n\nRemove the following template filters from `utilities.templatetags.helpers`:\r\n\r\n- `annotated_date()`\r\n- `annotated_now()`\n\n### Justification\n\nWith the shift to using ISO 8601-formatted dates & times everywhere in #15735, these filters are no longer needed.\n\n### Impact\n\nAll uses of these filters must be updated. These can generally be replaced with the new `isodatetime()` template filter.\n", "before_files": [{"content": "import datetime\nimport json\nfrom typing import Dict, Any\nfrom urllib.parse import quote\n\nfrom django import template\nfrom django.conf import settings\nfrom django.template.defaultfilters import date\nfrom django.urls import NoReverseMatch, reverse\nfrom django.utils import timezone\nfrom django.utils.safestring import mark_safe\n\nfrom core.models import ObjectType\nfrom utilities.forms import get_selected_values, TableConfigForm\nfrom utilities.views import get_viewname\n\n__all__ = (\n 'annotated_date',\n 'annotated_now',\n 'applied_filters',\n 'as_range',\n 'divide',\n 'get_item',\n 'get_key',\n 'humanize_megabytes',\n 'humanize_speed',\n 'icon_from_status',\n 'kg_to_pounds',\n 'meters_to_feet',\n 'percentage',\n 'querystring',\n 'startswith',\n 'status_from_tag',\n 'table_config_form',\n 'utilization_graph',\n 'validated_viewname',\n 'viewname',\n)\n\nregister = template.Library()\n\n\n#\n# Filters\n#\n\n\[email protected]()\ndef viewname(model, action):\n \"\"\"\n Return the view name for the given model and action. Does not perform any validation.\n \"\"\"\n return get_viewname(model, action)\n\n\[email protected]()\ndef validated_viewname(model, action):\n \"\"\"\n Return the view name for the given model and action if valid, or None if invalid.\n \"\"\"\n viewname = get_viewname(model, action)\n\n # Validate the view name\n try:\n reverse(viewname)\n return viewname\n except NoReverseMatch:\n return None\n\n\[email protected]()\ndef humanize_speed(speed):\n \"\"\"\n Humanize speeds given in Kbps. Examples:\n\n 1544 => \"1.544 Mbps\"\n 100000 => \"100 Mbps\"\n 10000000 => \"10 Gbps\"\n \"\"\"\n if not speed:\n return ''\n if speed >= 1000000000 and speed % 1000000000 == 0:\n return '{} Tbps'.format(int(speed / 1000000000))\n elif speed >= 1000000 and speed % 1000000 == 0:\n return '{} Gbps'.format(int(speed / 1000000))\n elif speed >= 1000 and speed % 1000 == 0:\n return '{} Mbps'.format(int(speed / 1000))\n elif speed >= 1000:\n return '{} Mbps'.format(float(speed) / 1000)\n else:\n return '{} Kbps'.format(speed)\n\n\[email protected]()\ndef humanize_megabytes(mb):\n \"\"\"\n Express a number of megabytes in the most suitable unit (e.g. gigabytes or terabytes).\n \"\"\"\n if not mb:\n return ''\n if not mb % 1048576: # 1024^2\n return f'{int(mb / 1048576)} TB'\n if not mb % 1024:\n return f'{int(mb / 1024)} GB'\n return f'{mb} MB'\n\n\[email protected](expects_localtime=True)\ndef annotated_date(date_value):\n \"\"\"\n Returns date as HTML span with short date format as the content and the\n (long) date format as the title.\n \"\"\"\n if not date_value:\n return ''\n\n if type(date_value) is datetime.date:\n long_ts = date(date_value, 'DATE_FORMAT')\n short_ts = date(date_value, 'SHORT_DATE_FORMAT')\n else:\n long_ts = date(date_value, 'DATETIME_FORMAT')\n short_ts = date(date_value, 'SHORT_DATETIME_FORMAT')\n\n return mark_safe(f'<span title=\"{long_ts}\">{short_ts}</span>')\n\n\[email protected]_tag\ndef annotated_now():\n \"\"\"\n Returns the current date piped through the annotated_date filter.\n \"\"\"\n tzinfo = timezone.get_current_timezone() if settings.USE_TZ else None\n return annotated_date(datetime.datetime.now(tz=tzinfo))\n\n\[email protected]()\ndef divide(x, y):\n \"\"\"\n Return x/y (rounded).\n \"\"\"\n if x is None or y is None:\n return None\n return round(x / y)\n\n\[email protected]()\ndef percentage(x, y):\n \"\"\"\n Return x/y as a percentage.\n \"\"\"\n if x is None or y is None:\n return None\n\n return round(x / y * 100, 1)\n\n\[email protected]()\ndef as_range(n):\n \"\"\"\n Return a range of n items.\n \"\"\"\n try:\n int(n)\n except TypeError:\n return list()\n return range(n)\n\n\[email protected]()\ndef meters_to_feet(n):\n \"\"\"\n Convert a length from meters to feet.\n \"\"\"\n return float(n) * 3.28084\n\n\[email protected]()\ndef kg_to_pounds(n):\n \"\"\"\n Convert a weight from kilograms to pounds.\n \"\"\"\n return float(n) * 2.204623\n\n\[email protected](\"startswith\")\ndef startswith(text: str, starts: str) -> bool:\n \"\"\"\n Template implementation of `str.startswith()`.\n \"\"\"\n if isinstance(text, str):\n return text.startswith(starts)\n return False\n\n\[email protected]\ndef get_key(value: Dict, arg: str) -> Any:\n \"\"\"\n Template implementation of `dict.get()`, for accessing dict values\n by key when the key is not able to be used in a template. For\n example, `{\"ui.colormode\": \"dark\"}`.\n \"\"\"\n return value.get(arg, None)\n\n\[email protected]\ndef get_item(value: object, attr: str) -> Any:\n \"\"\"\n Template implementation of `__getitem__`, for accessing the `__getitem__` method\n of a class from a template.\n \"\"\"\n return value[attr]\n\n\[email protected]\ndef status_from_tag(tag: str = \"info\") -> str:\n \"\"\"\n Determine Bootstrap theme status/level from Django's Message.level_tag.\n \"\"\"\n status_map = {\n 'warning': 'warning',\n 'success': 'success',\n 'error': 'danger',\n 'danger': 'danger',\n 'debug': 'info',\n 'info': 'info',\n }\n return status_map.get(tag.lower(), 'info')\n\n\[email protected]\ndef icon_from_status(status: str = \"info\") -> str:\n \"\"\"\n Determine icon class name from Bootstrap theme status/level.\n \"\"\"\n icon_map = {\n 'warning': 'alert',\n 'success': 'check-circle',\n 'danger': 'alert',\n 'info': 'information',\n }\n return icon_map.get(status.lower(), 'information')\n\n\n#\n# Tags\n#\n\[email protected]_tag()\ndef querystring(request, **kwargs):\n \"\"\"\n Append or update the page number in a querystring.\n \"\"\"\n querydict = request.GET.copy()\n for k, v in kwargs.items():\n if v is not None:\n querydict[k] = str(v)\n elif k in querydict:\n querydict.pop(k)\n querystring = querydict.urlencode(safe='/')\n if querystring:\n return '?' + querystring\n else:\n return ''\n\n\[email protected]_tag('helpers/utilization_graph.html')\ndef utilization_graph(utilization, warning_threshold=75, danger_threshold=90):\n \"\"\"\n Display a horizontal bar graph indicating a percentage of utilization.\n \"\"\"\n if utilization == 100:\n bar_class = 'bg-secondary'\n elif danger_threshold and utilization >= danger_threshold:\n bar_class = 'bg-danger'\n elif warning_threshold and utilization >= warning_threshold:\n bar_class = 'bg-warning'\n elif warning_threshold or danger_threshold:\n bar_class = 'bg-success'\n else:\n bar_class = 'bg-gray'\n return {\n 'utilization': utilization,\n 'bar_class': bar_class,\n }\n\n\[email protected]_tag('helpers/table_config_form.html')\ndef table_config_form(table, table_name=None):\n return {\n 'table_name': table_name or table.__class__.__name__,\n 'form': TableConfigForm(table=table),\n }\n\n\[email protected]_tag('helpers/applied_filters.html', takes_context=True)\ndef applied_filters(context, model, form, query_params):\n \"\"\"\n Display the active filters for a given filter form.\n \"\"\"\n user = context['request'].user\n form.is_valid() # Ensure cleaned_data has been set\n\n applied_filters = []\n for filter_name in form.changed_data:\n if filter_name not in form.cleaned_data:\n continue\n\n querydict = query_params.copy()\n if filter_name not in querydict:\n continue\n\n bound_field = form.fields[filter_name].get_bound_field(form, filter_name)\n querydict.pop(filter_name)\n display_value = ', '.join([str(v) for v in get_selected_values(form, filter_name)])\n\n applied_filters.append({\n 'name': filter_name,\n 'value': form.cleaned_data[filter_name],\n 'link_url': f'?{querydict.urlencode()}',\n 'link_text': f'{bound_field.label}: {display_value}',\n })\n\n save_link = None\n if user.has_perm('extras.add_savedfilter') and 'filter_id' not in context['request'].GET:\n object_type = ObjectType.objects.get_for_model(model).pk\n parameters = json.dumps(dict(context['request'].GET.lists()))\n url = reverse('extras:savedfilter_add')\n save_link = f\"{url}?object_types={object_type}¶meters={quote(parameters)}\"\n\n return {\n 'applied_filters': applied_filters,\n 'save_link': save_link,\n }\n", "path": "netbox/utilities/templatetags/helpers.py"}]}
| 3,724 | 366 |
gh_patches_debug_23722
|
rasdani/github-patches
|
git_diff
|
intel__dffml-585
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docs: source: New File source tutorial
The question of how to make a new data source came up [recently](https://gitter.im/dffml/community?at=5e0e4bfbfd580457e7b3e26a). We should have multiple tutorials for sources.
We're going to use https://github.com/intel/dffml/issues/551 as the example for this tutorial, so that issue needs to be closed first.
You'll want to make a
`docs/tutorials/sources/index.rst`
Then take this exist tutorial and move it under
`docs/tutoirials/sources/complex.rst`
You're new one will go under
`sources/file.rst`
Te idea here is just to explain how you can write a source which reads data from some new filetype, with our example being the `.ini`
Try to follow the new model tutorial format, where we do `literalinclude` and `:lines:` to talk about individual sections of the files we're writing.
</issue>
<code>
[start of dffml/source/ini.py]
1 from configparser import ConfigParser
2
3 from ..base import config
4 from ..record import Record
5 from .file import FileSource
6 from .memory import MemorySource
7 from ..util.data import parser_helper
8 from ..util.entrypoint import entrypoint
9
10
11 @config
12 class INISourceConfig:
13 filename: str
14 readwrite: bool = False
15 allowempty: bool = False
16
17
18 @entrypoint("ini")
19 class INISource(FileSource, MemorySource):
20 """
21 Source to read files in .ini format.
22 """
23
24 CONFIG = INISourceConfig
25
26 async def load_fd(self, ifile):
27 # Creating an instance of configparser
28 parser = ConfigParser()
29 # Read from a file object
30 parser.read_file(ifile)
31 # Get all the sections present in the file
32 sections = parser.sections()
33
34 self.mem = {}
35
36 # Go over each section
37 for section in sections:
38 # Get data under each section as a dict
39 temp_dict = {}
40 for k, v in parser.items(section):
41 temp_dict[k] = parser_helper(v)
42 # Each section used as a record
43 self.mem[str(section)] = Record(
44 str(section), data={"features": temp_dict},
45 )
46
47 self.logger.debug("%r loaded %d sections", self, len(self.mem))
48
49 async def dump_fd(self, fd):
50 # Create an instance of configparser
51 parser = ConfigParser()
52
53 # Go over each section and record in mem
54 for section, record in self.mem.items():
55 # Get each section data as a dict
56 section_data = record.features()
57 if section not in parser.keys():
58 # If section does not exist add new section
59 parser.add_section(section)
60 # Set section data
61 parser[section] = section_data
62
63 # Write to the fileobject
64 parser.write(fd)
65
66 self.logger.debug("%r saved %d sections", self, len(self.mem))
67
[end of dffml/source/ini.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dffml/source/ini.py b/dffml/source/ini.py
--- a/dffml/source/ini.py
+++ b/dffml/source/ini.py
@@ -23,11 +23,11 @@
CONFIG = INISourceConfig
- async def load_fd(self, ifile):
+ async def load_fd(self, fileobj):
# Creating an instance of configparser
parser = ConfigParser()
# Read from a file object
- parser.read_file(ifile)
+ parser.read_file(fileobj)
# Get all the sections present in the file
sections = parser.sections()
@@ -46,7 +46,7 @@
self.logger.debug("%r loaded %d sections", self, len(self.mem))
- async def dump_fd(self, fd):
+ async def dump_fd(self, fileobj):
# Create an instance of configparser
parser = ConfigParser()
@@ -61,6 +61,6 @@
parser[section] = section_data
# Write to the fileobject
- parser.write(fd)
+ parser.write(fileobj)
self.logger.debug("%r saved %d sections", self, len(self.mem))
|
{"golden_diff": "diff --git a/dffml/source/ini.py b/dffml/source/ini.py\n--- a/dffml/source/ini.py\n+++ b/dffml/source/ini.py\n@@ -23,11 +23,11 @@\n \n CONFIG = INISourceConfig\n \n- async def load_fd(self, ifile):\n+ async def load_fd(self, fileobj):\n # Creating an instance of configparser\n parser = ConfigParser()\n # Read from a file object\n- parser.read_file(ifile)\n+ parser.read_file(fileobj)\n # Get all the sections present in the file\n sections = parser.sections()\n \n@@ -46,7 +46,7 @@\n \n self.logger.debug(\"%r loaded %d sections\", self, len(self.mem))\n \n- async def dump_fd(self, fd):\n+ async def dump_fd(self, fileobj):\n # Create an instance of configparser\n parser = ConfigParser()\n \n@@ -61,6 +61,6 @@\n parser[section] = section_data\n \n # Write to the fileobject\n- parser.write(fd)\n+ parser.write(fileobj)\n \n self.logger.debug(\"%r saved %d sections\", self, len(self.mem))\n", "issue": "docs: source: New File source tutorial\nThe question of how to make a new data source came up [recently](https://gitter.im/dffml/community?at=5e0e4bfbfd580457e7b3e26a). We should have multiple tutorials for sources.\r\n\r\nWe're going to use https://github.com/intel/dffml/issues/551 as the example for this tutorial, so that issue needs to be closed first.\r\n\r\nYou'll want to make a\r\n\r\n`docs/tutorials/sources/index.rst`\r\n\r\nThen take this exist tutorial and move it under\r\n\r\n`docs/tutoirials/sources/complex.rst`\r\n\r\nYou're new one will go under \r\n\r\n`sources/file.rst`\r\n\r\nTe idea here is just to explain how you can write a source which reads data from some new filetype, with our example being the `.ini`\r\n\r\nTry to follow the new model tutorial format, where we do `literalinclude` and `:lines:` to talk about individual sections of the files we're writing.\n", "before_files": [{"content": "from configparser import ConfigParser\n\nfrom ..base import config\nfrom ..record import Record\nfrom .file import FileSource\nfrom .memory import MemorySource\nfrom ..util.data import parser_helper\nfrom ..util.entrypoint import entrypoint\n\n\n@config\nclass INISourceConfig:\n filename: str\n readwrite: bool = False\n allowempty: bool = False\n\n\n@entrypoint(\"ini\")\nclass INISource(FileSource, MemorySource):\n \"\"\"\n Source to read files in .ini format.\n \"\"\"\n\n CONFIG = INISourceConfig\n\n async def load_fd(self, ifile):\n # Creating an instance of configparser\n parser = ConfigParser()\n # Read from a file object\n parser.read_file(ifile)\n # Get all the sections present in the file\n sections = parser.sections()\n\n self.mem = {}\n\n # Go over each section\n for section in sections:\n # Get data under each section as a dict\n temp_dict = {}\n for k, v in parser.items(section):\n temp_dict[k] = parser_helper(v)\n # Each section used as a record\n self.mem[str(section)] = Record(\n str(section), data={\"features\": temp_dict},\n )\n\n self.logger.debug(\"%r loaded %d sections\", self, len(self.mem))\n\n async def dump_fd(self, fd):\n # Create an instance of configparser\n parser = ConfigParser()\n\n # Go over each section and record in mem\n for section, record in self.mem.items():\n # Get each section data as a dict\n section_data = record.features()\n if section not in parser.keys():\n # If section does not exist add new section\n parser.add_section(section)\n # Set section data\n parser[section] = section_data\n\n # Write to the fileobject\n parser.write(fd)\n\n self.logger.debug(\"%r saved %d sections\", self, len(self.mem))\n", "path": "dffml/source/ini.py"}]}
| 1,304 | 267 |
gh_patches_debug_28113
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-1835
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Container tile does not show number of projects
</issue>
<code>
[start of meinberlin/apps/plans/serializers.py]
1 from django.utils.translation import ugettext as _
2 from easy_thumbnails.files import get_thumbnailer
3 from rest_framework import serializers
4
5 from adhocracy4.projects.models import Project
6 from meinberlin.apps.projects import get_project_type
7
8 from .models import Plan
9
10
11 class CommonFields:
12
13 def get_district(self, instance):
14 city_wide = _('City wide')
15 district_name = str(city_wide)
16 if instance.administrative_district:
17 district_name = instance.administrative_district.name
18 return district_name
19
20 def get_point(self, instance):
21 point = instance.point
22 if not point:
23 point = ''
24 return point
25
26
27 class ProjectSerializer(serializers.ModelSerializer, CommonFields):
28 type = serializers.SerializerMethodField()
29 subtype = serializers.SerializerMethodField()
30 title = serializers.SerializerMethodField()
31 url = serializers.SerializerMethodField()
32 organisation = serializers.SerializerMethodField()
33 point = serializers.SerializerMethodField()
34 point_label = serializers.SerializerMethodField()
35 cost = serializers.SerializerMethodField()
36 district = serializers.SerializerMethodField()
37 status = serializers.SerializerMethodField()
38 participation = serializers.SerializerMethodField()
39 participation_active = serializers.SerializerMethodField()
40 participation_string = serializers.SerializerMethodField()
41 participation_display = serializers.SerializerMethodField()
42 future_phase = serializers.SerializerMethodField()
43 active_phase = serializers.SerializerMethodField()
44 past_phase = serializers.SerializerMethodField()
45 tile_image = serializers.SerializerMethodField()
46 plan_url = serializers.SerializerMethodField()
47 plan_title = serializers.SerializerMethodField()
48
49 class Meta:
50 model = Project
51 fields = ['type', 'subtype', 'title', 'url',
52 'organisation', 'tile_image',
53 'tile_image_copyright',
54 'point', 'point_label', 'cost',
55 'district', 'topic',
56 'status',
57 'participation_string',
58 'participation_active',
59 'participation', 'participation_display', 'description',
60 'future_phase', 'active_phase',
61 'past_phase', 'plan_url', 'plan_title']
62
63 def _get_participation_status_project(self, instance):
64 if instance.phases.active_phases():
65 return _('running'), True
66 elif instance.phases.future_phases():
67 try:
68 return (_('starts at {}').format
69 (instance.phases.future_phases().first().
70 start_date.date()),
71 True)
72 except AttributeError:
73 return (_('starts in the future'),
74 True)
75 else:
76 return _('done'), False
77
78 def get_type(self, instance):
79 return 'project'
80
81 def get_subtype(self, instance):
82 subtype = get_project_type(instance)
83 if subtype in ('external', 'bplan'):
84 return 'external'
85 return subtype
86
87 def get_title(self, instance):
88 return instance.name
89
90 def get_url(self, instance):
91 if get_project_type(instance) in ('external', 'bplan'):
92 return instance.externalproject.url
93 return instance.get_absolute_url()
94
95 def get_organisation(self, instance):
96 return instance.organisation.name
97
98 def get_tile_image(self, instance):
99 image_url = ''
100 if instance.tile_image:
101 image = get_thumbnailer(instance.tile_image)['project_tile']
102 image_url = image.url
103 return image_url
104
105 def get_point_label(self, instance):
106 return ''
107
108 def get_cost(self, instance):
109 return ''
110
111 def get_status(self, instance):
112 if instance.phases.active_phases() or instance.phases.future_phases():
113 return 2
114 return 3
115
116 def get_participation(self, instance):
117 return 1
118
119 def get_participation_display(self, instance):
120 return _('Yes')
121
122 def get_future_phase(self, instance):
123 if (instance.future_phases and
124 instance.future_phases.first().start_date):
125 return str(
126 instance.future_phases.first().start_date.date())
127 return False
128
129 def get_active_phase(self, instance):
130 if instance.active_phase:
131 progress = instance.active_phase_progress
132 time_left = instance.time_left
133 return [progress, time_left]
134 return False
135
136 def get_past_phase(self, instance):
137 if instance.phases.past_phases():
138 return True
139 return False
140
141 def get_participation_string(self, instance):
142 participation_string, participation_active = \
143 self._get_participation_status_project(instance)
144 return str(participation_string)
145
146 def get_participation_active(self, instance):
147 participation_string, participation_active = \
148 self._get_participation_status_project(instance)
149 return participation_active
150
151 def get_plan_url(self, instance):
152 if instance.plans.exists():
153 return instance.plans.first().get_absolute_url()
154 return None
155
156 def get_plan_title(self, instance):
157 if instance.plans.exists():
158 return instance.plans.first().title
159 return None
160
161
162 class PlanSerializer(serializers.ModelSerializer, CommonFields):
163 type = serializers.SerializerMethodField()
164 subtype = serializers.SerializerMethodField()
165 url = serializers.SerializerMethodField()
166 district = serializers.SerializerMethodField()
167 point = serializers.SerializerMethodField()
168 participation_active = serializers.SerializerMethodField()
169 participation_string = serializers.SerializerMethodField()
170 published_projects_count = serializers.SerializerMethodField()
171
172 class Meta:
173 model = Plan
174 fields = ['type', 'subtype', 'title', 'url',
175 'organisation', 'point',
176 'point_label', 'cost',
177 'district', 'topic', 'status',
178 'participation',
179 'participation_string',
180 'participation_active',
181 'published_projects_count']
182
183 def get_subtype(self, instance):
184 return 'plan'
185
186 def _get_participation_string(self, projects):
187 future_phase = None
188 for project in projects:
189 phases = project.phases
190 if phases.active_phases():
191 return _('running')
192 if phases.future_phases() and \
193 phases.future_phases().first().start_date:
194 date = phases.future_phases().first().start_date
195 if not future_phase:
196 future_phase = date
197 else:
198 if date < future_phase:
199 future_phase = date
200
201 if future_phase:
202 return _('starts at {}').format(future_phase.date())
203
204 def _get_participation_status_plan(self, item):
205 projects = item.projects.all() \
206 .filter(is_draft=False,
207 is_archived=False,
208 is_public=True)
209 if not projects:
210 return item.get_participation_display(), False
211 else:
212 participation_string = self._get_participation_string(projects)
213 if participation_string:
214 return participation_string, True
215 else:
216 return item.get_participation_display(), False
217
218 def get_type(self, instance):
219 return 'plan'
220
221 def get_url(self, instance):
222 return instance.get_absolute_url()
223
224 def get_published_projects_count(self, instance):
225 return instance.published_projects.count()
226
227 def get_participation_string(self, instance):
228 participation_string, participation_active = \
229 self._get_participation_status_plan(instance)
230 return str(participation_string)
231
232 def get_participation_active(self, instance):
233 participation_string, participation_active = \
234 self._get_participation_status_plan(instance)
235 return participation_active
236
[end of meinberlin/apps/plans/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/plans/serializers.py b/meinberlin/apps/plans/serializers.py
--- a/meinberlin/apps/plans/serializers.py
+++ b/meinberlin/apps/plans/serializers.py
@@ -45,6 +45,7 @@
tile_image = serializers.SerializerMethodField()
plan_url = serializers.SerializerMethodField()
plan_title = serializers.SerializerMethodField()
+ published_projects_count = serializers.SerializerMethodField()
class Meta:
model = Project
@@ -58,7 +59,8 @@
'participation_active',
'participation', 'participation_display', 'description',
'future_phase', 'active_phase',
- 'past_phase', 'plan_url', 'plan_title']
+ 'past_phase', 'plan_url', 'plan_title',
+ 'published_projects_count']
def _get_participation_status_project(self, instance):
if instance.phases.active_phases():
@@ -158,6 +160,10 @@
return instance.plans.first().title
return None
+ def get_published_projects_count(self, instance):
+ if hasattr(instance, 'projectcontainer') and instance.projectcontainer:
+ return instance.projectcontainer.active_project_count
+
class PlanSerializer(serializers.ModelSerializer, CommonFields):
type = serializers.SerializerMethodField()
|
{"golden_diff": "diff --git a/meinberlin/apps/plans/serializers.py b/meinberlin/apps/plans/serializers.py\n--- a/meinberlin/apps/plans/serializers.py\n+++ b/meinberlin/apps/plans/serializers.py\n@@ -45,6 +45,7 @@\n tile_image = serializers.SerializerMethodField()\n plan_url = serializers.SerializerMethodField()\n plan_title = serializers.SerializerMethodField()\n+ published_projects_count = serializers.SerializerMethodField()\n \n class Meta:\n model = Project\n@@ -58,7 +59,8 @@\n 'participation_active',\n 'participation', 'participation_display', 'description',\n 'future_phase', 'active_phase',\n- 'past_phase', 'plan_url', 'plan_title']\n+ 'past_phase', 'plan_url', 'plan_title',\n+ 'published_projects_count']\n \n def _get_participation_status_project(self, instance):\n if instance.phases.active_phases():\n@@ -158,6 +160,10 @@\n return instance.plans.first().title\n return None\n \n+ def get_published_projects_count(self, instance):\n+ if hasattr(instance, 'projectcontainer') and instance.projectcontainer:\n+ return instance.projectcontainer.active_project_count\n+\n \n class PlanSerializer(serializers.ModelSerializer, CommonFields):\n type = serializers.SerializerMethodField()\n", "issue": "Container tile does not show number of projects \n\n", "before_files": [{"content": "from django.utils.translation import ugettext as _\nfrom easy_thumbnails.files import get_thumbnailer\nfrom rest_framework import serializers\n\nfrom adhocracy4.projects.models import Project\nfrom meinberlin.apps.projects import get_project_type\n\nfrom .models import Plan\n\n\nclass CommonFields:\n\n def get_district(self, instance):\n city_wide = _('City wide')\n district_name = str(city_wide)\n if instance.administrative_district:\n district_name = instance.administrative_district.name\n return district_name\n\n def get_point(self, instance):\n point = instance.point\n if not point:\n point = ''\n return point\n\n\nclass ProjectSerializer(serializers.ModelSerializer, CommonFields):\n type = serializers.SerializerMethodField()\n subtype = serializers.SerializerMethodField()\n title = serializers.SerializerMethodField()\n url = serializers.SerializerMethodField()\n organisation = serializers.SerializerMethodField()\n point = serializers.SerializerMethodField()\n point_label = serializers.SerializerMethodField()\n cost = serializers.SerializerMethodField()\n district = serializers.SerializerMethodField()\n status = serializers.SerializerMethodField()\n participation = serializers.SerializerMethodField()\n participation_active = serializers.SerializerMethodField()\n participation_string = serializers.SerializerMethodField()\n participation_display = serializers.SerializerMethodField()\n future_phase = serializers.SerializerMethodField()\n active_phase = serializers.SerializerMethodField()\n past_phase = serializers.SerializerMethodField()\n tile_image = serializers.SerializerMethodField()\n plan_url = serializers.SerializerMethodField()\n plan_title = serializers.SerializerMethodField()\n\n class Meta:\n model = Project\n fields = ['type', 'subtype', 'title', 'url',\n 'organisation', 'tile_image',\n 'tile_image_copyright',\n 'point', 'point_label', 'cost',\n 'district', 'topic',\n 'status',\n 'participation_string',\n 'participation_active',\n 'participation', 'participation_display', 'description',\n 'future_phase', 'active_phase',\n 'past_phase', 'plan_url', 'plan_title']\n\n def _get_participation_status_project(self, instance):\n if instance.phases.active_phases():\n return _('running'), True\n elif instance.phases.future_phases():\n try:\n return (_('starts at {}').format\n (instance.phases.future_phases().first().\n start_date.date()),\n True)\n except AttributeError:\n return (_('starts in the future'),\n True)\n else:\n return _('done'), False\n\n def get_type(self, instance):\n return 'project'\n\n def get_subtype(self, instance):\n subtype = get_project_type(instance)\n if subtype in ('external', 'bplan'):\n return 'external'\n return subtype\n\n def get_title(self, instance):\n return instance.name\n\n def get_url(self, instance):\n if get_project_type(instance) in ('external', 'bplan'):\n return instance.externalproject.url\n return instance.get_absolute_url()\n\n def get_organisation(self, instance):\n return instance.organisation.name\n\n def get_tile_image(self, instance):\n image_url = ''\n if instance.tile_image:\n image = get_thumbnailer(instance.tile_image)['project_tile']\n image_url = image.url\n return image_url\n\n def get_point_label(self, instance):\n return ''\n\n def get_cost(self, instance):\n return ''\n\n def get_status(self, instance):\n if instance.phases.active_phases() or instance.phases.future_phases():\n return 2\n return 3\n\n def get_participation(self, instance):\n return 1\n\n def get_participation_display(self, instance):\n return _('Yes')\n\n def get_future_phase(self, instance):\n if (instance.future_phases and\n instance.future_phases.first().start_date):\n return str(\n instance.future_phases.first().start_date.date())\n return False\n\n def get_active_phase(self, instance):\n if instance.active_phase:\n progress = instance.active_phase_progress\n time_left = instance.time_left\n return [progress, time_left]\n return False\n\n def get_past_phase(self, instance):\n if instance.phases.past_phases():\n return True\n return False\n\n def get_participation_string(self, instance):\n participation_string, participation_active = \\\n self._get_participation_status_project(instance)\n return str(participation_string)\n\n def get_participation_active(self, instance):\n participation_string, participation_active = \\\n self._get_participation_status_project(instance)\n return participation_active\n\n def get_plan_url(self, instance):\n if instance.plans.exists():\n return instance.plans.first().get_absolute_url()\n return None\n\n def get_plan_title(self, instance):\n if instance.plans.exists():\n return instance.plans.first().title\n return None\n\n\nclass PlanSerializer(serializers.ModelSerializer, CommonFields):\n type = serializers.SerializerMethodField()\n subtype = serializers.SerializerMethodField()\n url = serializers.SerializerMethodField()\n district = serializers.SerializerMethodField()\n point = serializers.SerializerMethodField()\n participation_active = serializers.SerializerMethodField()\n participation_string = serializers.SerializerMethodField()\n published_projects_count = serializers.SerializerMethodField()\n\n class Meta:\n model = Plan\n fields = ['type', 'subtype', 'title', 'url',\n 'organisation', 'point',\n 'point_label', 'cost',\n 'district', 'topic', 'status',\n 'participation',\n 'participation_string',\n 'participation_active',\n 'published_projects_count']\n\n def get_subtype(self, instance):\n return 'plan'\n\n def _get_participation_string(self, projects):\n future_phase = None\n for project in projects:\n phases = project.phases\n if phases.active_phases():\n return _('running')\n if phases.future_phases() and \\\n phases.future_phases().first().start_date:\n date = phases.future_phases().first().start_date\n if not future_phase:\n future_phase = date\n else:\n if date < future_phase:\n future_phase = date\n\n if future_phase:\n return _('starts at {}').format(future_phase.date())\n\n def _get_participation_status_plan(self, item):\n projects = item.projects.all() \\\n .filter(is_draft=False,\n is_archived=False,\n is_public=True)\n if not projects:\n return item.get_participation_display(), False\n else:\n participation_string = self._get_participation_string(projects)\n if participation_string:\n return participation_string, True\n else:\n return item.get_participation_display(), False\n\n def get_type(self, instance):\n return 'plan'\n\n def get_url(self, instance):\n return instance.get_absolute_url()\n\n def get_published_projects_count(self, instance):\n return instance.published_projects.count()\n\n def get_participation_string(self, instance):\n participation_string, participation_active = \\\n self._get_participation_status_plan(instance)\n return str(participation_string)\n\n def get_participation_active(self, instance):\n participation_string, participation_active = \\\n self._get_participation_status_plan(instance)\n return participation_active\n", "path": "meinberlin/apps/plans/serializers.py"}]}
| 2,691 | 296 |
gh_patches_debug_13070
|
rasdani/github-patches
|
git_diff
|
kartoza__prj.app-116
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong links to images from entry page
If I open an entry page, for example
http://changelog.linfiniti.com/qgis/2.8/entry/more-responsive-browser/ and then click on the image I get server error 404 because the link is pointing to
/qgis/2.8/entry/<entry name>/images/entries/<hash>.<ext>
instead of
/media/images/entries/<hash>.<ext>
</issue>
<code>
[start of django_project/core/settings/base.py]
1 # coding=utf-8
2 """
3 core.settings.base
4 """
5 # Django settings for projecta project.
6
7 from .utils import absolute_path
8
9 ADMINS = (
10 ('Tim Sutton', '[email protected]'),
11 )
12 SERVER_EMAIL = '[email protected]'
13 EMAIL_HOST = 'localhost'
14 DEFAULT_FROM_EMAIL = '[email protected]'
15
16 MANAGERS = ADMINS
17
18 # Local time zone for this installation. Choices can be found here:
19 # http://en.wikipedia.org/wiki/List_of_tz_zones_by_name
20 # although not all choices may be available on all operating systems.
21 # In a Windows environment this must be set to your system time zone.
22 TIME_ZONE = 'America/Chicago'
23
24 # Language code for this installation. All choices can be found here:
25 # http://www.i18nguy.com/unicode/language-identifiers.html
26 LANGUAGE_CODE = 'en-us'
27
28 SITE_ID = 1
29
30 # If you set this to False, Django will make some optimizations so as not
31 # to load the internationalization machinery.
32 USE_I18N = True
33
34 # If you set this to False, Django will not format dates, numbers and
35 # calendars according to the current locale.
36 USE_L10N = True
37
38 # If you set this to False, Django will not use timezone-aware datetimes.
39 USE_TZ = True
40
41 # Absolute filesystem path to the directory that will hold user-uploaded files.
42 # Example: "/var/www/example.com/media/"
43 MEDIA_ROOT = absolute_path('media')
44
45 # URL that handles the media served from MEDIA_ROOT. Make sure to use a
46 # trailing slash.
47 # Examples: "http://example.com/media/", "http://media.example.com/"
48 # MEDIA_URL = '/media/'
49 # setting full MEDIA_URL to be able to use it for the feeds
50 MEDIA_URL = '/media/'
51
52 # Absolute path to the directory static files should be collected to.
53 # Don't put anything in this directory yourself; store your static files
54 # in apps' "static/" subdirectories and in STATICFILES_DIRS.
55 # Example: "/var/www/example.com/static/"
56 STATIC_ROOT = absolute_path('static')
57
58 # URL prefix for static files.
59 # Example: "http://example.com/static/", "http://static.example.com/"
60 STATIC_URL = '/static/'
61
62 # Additional locations of static files
63 STATICFILES_DIRS = (
64 # Put strings here, like "/home/html/static" or "C:/www/django/static".
65 # Always use forward slashes, even on Windows.
66 # Don't forget to use absolute paths, not relative paths.
67 absolute_path('core', 'base_static'),
68 )
69
70 # List of finder classes that know how to find static files in
71 # various locations.
72 STATICFILES_FINDERS = (
73 'django.contrib.staticfiles.finders.FileSystemFinder',
74 'django.contrib.staticfiles.finders.AppDirectoriesFinder',
75 # 'django.contrib.staticfiles.finders.DefaultStorageFinder',
76 )
77
78 # import SECRET_KEY into current namespace
79 # noinspection PyUnresolvedReferences
80 from .secret import SECRET_KEY # noqa
81
82 # List of callables that know how to import templates from various sources.
83 TEMPLATE_LOADERS = (
84 'django.template.loaders.filesystem.Loader',
85 'django.template.loaders.app_directories.Loader',
86 # 'django.template.loaders.eggs.Loader',
87 )
88
89 TEMPLATE_CONTEXT_PROCESSORS = (
90 'django.contrib.auth.context_processors.auth',
91 'django.core.context_processors.request',
92 'core.context_processors.add_intercom_app_id'
93 )
94
95 MIDDLEWARE_CLASSES = (
96 'django.middleware.common.CommonMiddleware',
97 'django.contrib.sessions.middleware.SessionMiddleware',
98 'django.middleware.csrf.CsrfViewMiddleware',
99 'django.contrib.auth.middleware.AuthenticationMiddleware',
100 'django.contrib.messages.middleware.MessageMiddleware',
101 # Uncomment the next line for simple clickjacking protection:
102 # 'django.middleware.clickjacking.XFrameOptionsMiddleware',
103 'core.custom_middleware.NavContextMiddleware'
104 )
105
106 ROOT_URLCONF = 'core.urls'
107
108 # Python dotted path to the WSGI application used by Django's runserver.
109 WSGI_APPLICATION = 'core.wsgi.application'
110
111 TEMPLATE_DIRS = (
112 # project level templates
113 absolute_path('core', 'base_templates'),
114 absolute_path('vota', 'templates'),
115 absolute_path('changes', 'templates'),
116
117 )
118
119 INSTALLED_APPS = (
120 'django.contrib.auth',
121 'django.contrib.contenttypes',
122 'django.contrib.sessions',
123 'django.contrib.sites',
124 'django.contrib.messages',
125 'django.contrib.staticfiles',
126 'django.contrib.admin',
127 'django.contrib.syndication',
128 )
129
130 # A sample logging configuration. The only tangible logging
131 # performed by this configuration is to send an email to
132 # the site admins on every HTTP 500 error when DEBUG=False.
133 # See http://docs.djangoproject.com/en/dev/topics/logging for
134 # more details on how to customize your logging configuration.
135 LOGGING = {
136 'version': 1,
137 'disable_existing_loggers': False,
138 'filters': {
139 'require_debug_false': {
140 '()': 'django.utils.log.RequireDebugFalse'
141 }
142 },
143 'handlers': {
144 'mail_admins': {
145 'level': 'ERROR',
146 'filters': ['require_debug_false'],
147 'class': 'django.utils.log.AdminEmailHandler'
148 }
149 },
150 'loggers': {
151 'django.request': {
152 'handlers': ['mail_admins'],
153 'level': 'ERROR',
154 'propagate': True,
155 },
156 }
157 }
158
[end of django_project/core/settings/base.py]
[start of django_project/vota/models/ballot.py]
1 """
2 This model is to create "ballots" i.e. questions/proposals/changes which a
3 Committee can vote on.
4
5 After voting is complete, a ballot should be marked as either Denied or Passed.
6
7 If no quorum is reached, no_quorum should be True
8
9 A ballot has one Committee.
10 """
11 from django.core.urlresolvers import reverse
12 from django.utils.text import slugify
13 import logging
14 from core.settings.contrib import STOP_WORDS
15
16 logger = logging.getLogger(__name__)
17 from django.db import models
18 from audited_models.models import AuditedModel
19 from django.utils.translation import ugettext_lazy as _
20 from django.utils import timezone
21 from vota.models.vote import Vote
22 import datetime
23 from django.contrib.auth.models import User
24
25
26 class ApprovedCategoryManager(models.Manager):
27 """Custom category manager that shows only approved ballots."""
28
29 def get_query_set(self):
30 """Query set generator"""
31 return super(
32 ApprovedCategoryManager, self).get_query_set().filter(
33 approved=True)
34
35
36 class DeniedCategoryManager(models.Manager):
37 """Custom version manager that shows only denied ballots."""
38
39 def get_query_set(self):
40 """Query set generator"""
41 return super(
42 DeniedCategoryManager, self).get_query_set().filter(
43 denied=True)
44
45
46 class OpenBallotManager(models.Manager):
47 """Custom version manager that shows only open ballots."""
48
49 def get_query_set(self):
50 """Query set generator"""
51 return super(
52 OpenBallotManager, self).get_query_set().filter(
53 open_from__lt=timezone.now()).filter(closes__gt=timezone.now())
54
55
56 class ClosedBallotManager(models.Manager):
57 """Custom version manager that shows only closed ballots."""
58
59 def get_query_set(self):
60 """Query set generator"""
61 return super(
62 ClosedBallotManager, self).get_query_set().filter(
63 closes__gt=timezone.now())
64
65
66 class Ballot(AuditedModel):
67 """A category model e.g. gui, backend, web site etc."""
68 name = models.CharField(
69 help_text=_('Name of this ballot.'),
70 max_length=255,
71 null=False,
72 blank=False,
73 unique=False
74 ) # there is a unique together rule in meta class below
75
76 summary = models.CharField(
77 help_text=_('A brief overview of the ballot.'),
78 max_length=250,
79 blank=False,
80 null=False
81 )
82
83 description = models.TextField(
84 help_text=_('A full description of the proposal if a summary is not '
85 'enough!'),
86 max_length=3000,
87 null=True,
88 blank=True,
89 )
90
91 approved = models.BooleanField(
92 help_text=_(
93 'Whether this ballot has been approved.'),
94 default=False
95 )
96
97 denied = models.BooleanField(
98 help_text=_(
99 'Whether this ballot has been denied.'),
100 default=False
101 )
102
103 no_quorum = models.BooleanField(
104 help_text=_('Whether the ballot was denied because no quorum was '
105 'reached'),
106 default=False
107 )
108
109 open_from = models.DateTimeField(
110 help_text=_('Date the ballot opens'),
111 default=timezone.now()
112 )
113
114 closes = models.DateTimeField(
115 help_text=_('Date the ballot closes'),
116 default=timezone.now() + datetime.timedelta(days=7)
117 )
118
119 private = models.BooleanField(
120 help_text=_('Should members be prevented from viewing results before '
121 'voting?'),
122 default=False
123 )
124
125 proposer = models.ForeignKey(User)
126 # noinspection PyUnresolvedReferences
127 committee = models.ForeignKey('Committee')
128 slug = models.SlugField()
129 objects = models.Manager()
130 approved_objects = ApprovedCategoryManager()
131 denied_objects = DeniedCategoryManager()
132 open_objects = OpenBallotManager()
133 closed_objects = ClosedBallotManager()
134
135 # noinspection PyClassicStyleClass
136 class Meta:
137 """Meta options for the category class."""
138 unique_together = (
139 ('name', 'committee'),
140 ('committee', 'slug')
141 )
142 app_label = 'vota'
143
144 def save(self, *args, **kwargs):
145 if not self.pk:
146 words = self.name.split()
147 filtered_words = [t for t in words if t.lower() not in STOP_WORDS]
148 new_list = ' '.join(filtered_words)
149 self.slug = slugify(new_list)[:50]
150 super(Ballot, self).save(*args, **kwargs)
151
152 def __unicode__(self):
153 return u'%s : %s' % (self.committee.name, self.name)
154
155 def get_absolute_url(self):
156 return reverse('ballot-detail', kwargs={
157 'project_slug': self.committee.project.slug,
158 'committee_slug': self.committee.slug,
159 'slug': self.slug
160 })
161
162 def get_user_voted(self, user=None):
163 voted = False
164 if Vote.objects.filter(ballot=self).filter(user=user).exists():
165 voted = True
166 return voted
167
168 def get_positive_vote_count(self):
169 votes = Vote.objects.filter(ballot=self).filter(choice='y').count()
170 return votes
171
172 def get_negative_vote_count(self):
173 votes = Vote.objects.filter(ballot=self).filter(choice='n').count()
174 return votes
175
176 def get_abstainer_count(self):
177 votes = Vote.objects.filter(ballot=self).filter(choice='-').count()
178 return votes
179
180 def get_current_tally(self):
181 positive = self.get_positive_vote_count()
182 negative = self.get_negative_vote_count()
183 tally = 0
184 tally += positive
185 tally -= negative
186 return tally
187
188 def get_total_vote_count(self):
189 vote_count = Vote.objects.filter(ballot=self).count()
190 return vote_count
191
192 def has_quorum(self):
193 vote_count = self.get_total_vote_count()
194 committee_user_count = self.committee.users.all().count()
195 if committee_user_count != 0:
196 quorum_percent = self.committee.quorum_setting
197 percentage = 100 * float(vote_count) / float(committee_user_count)
198 if percentage > quorum_percent:
199 return True
200 else:
201 return False
202
203 def is_open(self):
204 open_date = self.open_from
205 close_date = self.closes
206 if open_date < timezone.now() < close_date:
207 return True
208 return False
209
[end of django_project/vota/models/ballot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/django_project/core/settings/base.py b/django_project/core/settings/base.py
--- a/django_project/core/settings/base.py
+++ b/django_project/core/settings/base.py
@@ -89,6 +89,7 @@
TEMPLATE_CONTEXT_PROCESSORS = (
'django.contrib.auth.context_processors.auth',
'django.core.context_processors.request',
+ 'django.core.context_processors.media',
'core.context_processors.add_intercom_app_id'
)
diff --git a/django_project/vota/models/ballot.py b/django_project/vota/models/ballot.py
--- a/django_project/vota/models/ballot.py
+++ b/django_project/vota/models/ballot.py
@@ -108,7 +108,7 @@
open_from = models.DateTimeField(
help_text=_('Date the ballot opens'),
- default=timezone.now()
+ default=timezone.now
)
closes = models.DateTimeField(
|
{"golden_diff": "diff --git a/django_project/core/settings/base.py b/django_project/core/settings/base.py\n--- a/django_project/core/settings/base.py\n+++ b/django_project/core/settings/base.py\n@@ -89,6 +89,7 @@\n TEMPLATE_CONTEXT_PROCESSORS = (\n 'django.contrib.auth.context_processors.auth',\n 'django.core.context_processors.request',\n+ 'django.core.context_processors.media',\n 'core.context_processors.add_intercom_app_id'\n )\n \ndiff --git a/django_project/vota/models/ballot.py b/django_project/vota/models/ballot.py\n--- a/django_project/vota/models/ballot.py\n+++ b/django_project/vota/models/ballot.py\n@@ -108,7 +108,7 @@\n \n open_from = models.DateTimeField(\n help_text=_('Date the ballot opens'),\n- default=timezone.now()\n+ default=timezone.now\n )\n \n closes = models.DateTimeField(\n", "issue": "Wrong links to images from entry page\nIf I open an entry page, for example \n http://changelog.linfiniti.com/qgis/2.8/entry/more-responsive-browser/ and then click on the image I get server error 404 because the link is pointing to \n /qgis/2.8/entry/<entry name>/images/entries/<hash>.<ext>\ninstead of \n /media/images/entries/<hash>.<ext>\n\n", "before_files": [{"content": "# coding=utf-8\n\"\"\"\ncore.settings.base\n\"\"\"\n# Django settings for projecta project.\n\nfrom .utils import absolute_path\n\nADMINS = (\n ('Tim Sutton', '[email protected]'),\n)\nSERVER_EMAIL = '[email protected]'\nEMAIL_HOST = 'localhost'\nDEFAULT_FROM_EMAIL = '[email protected]'\n\nMANAGERS = ADMINS\n\n# Local time zone for this installation. Choices can be found here:\n# http://en.wikipedia.org/wiki/List_of_tz_zones_by_name\n# although not all choices may be available on all operating systems.\n# In a Windows environment this must be set to your system time zone.\nTIME_ZONE = 'America/Chicago'\n\n# Language code for this installation. All choices can be found here:\n# http://www.i18nguy.com/unicode/language-identifiers.html\nLANGUAGE_CODE = 'en-us'\n\nSITE_ID = 1\n\n# If you set this to False, Django will make some optimizations so as not\n# to load the internationalization machinery.\nUSE_I18N = True\n\n# If you set this to False, Django will not format dates, numbers and\n# calendars according to the current locale.\nUSE_L10N = True\n\n# If you set this to False, Django will not use timezone-aware datetimes.\nUSE_TZ = True\n\n# Absolute filesystem path to the directory that will hold user-uploaded files.\n# Example: \"/var/www/example.com/media/\"\nMEDIA_ROOT = absolute_path('media')\n\n# URL that handles the media served from MEDIA_ROOT. Make sure to use a\n# trailing slash.\n# Examples: \"http://example.com/media/\", \"http://media.example.com/\"\n# MEDIA_URL = '/media/'\n# setting full MEDIA_URL to be able to use it for the feeds\nMEDIA_URL = '/media/'\n\n# Absolute path to the directory static files should be collected to.\n# Don't put anything in this directory yourself; store your static files\n# in apps' \"static/\" subdirectories and in STATICFILES_DIRS.\n# Example: \"/var/www/example.com/static/\"\nSTATIC_ROOT = absolute_path('static')\n\n# URL prefix for static files.\n# Example: \"http://example.com/static/\", \"http://static.example.com/\"\nSTATIC_URL = '/static/'\n\n# Additional locations of static files\nSTATICFILES_DIRS = (\n # Put strings here, like \"/home/html/static\" or \"C:/www/django/static\".\n # Always use forward slashes, even on Windows.\n # Don't forget to use absolute paths, not relative paths.\n absolute_path('core', 'base_static'),\n)\n\n# List of finder classes that know how to find static files in\n# various locations.\nSTATICFILES_FINDERS = (\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n # 'django.contrib.staticfiles.finders.DefaultStorageFinder',\n)\n\n# import SECRET_KEY into current namespace\n# noinspection PyUnresolvedReferences\nfrom .secret import SECRET_KEY # noqa\n\n# List of callables that know how to import templates from various sources.\nTEMPLATE_LOADERS = (\n 'django.template.loaders.filesystem.Loader',\n 'django.template.loaders.app_directories.Loader',\n # 'django.template.loaders.eggs.Loader',\n)\n\nTEMPLATE_CONTEXT_PROCESSORS = (\n 'django.contrib.auth.context_processors.auth',\n 'django.core.context_processors.request',\n 'core.context_processors.add_intercom_app_id'\n)\n\nMIDDLEWARE_CLASSES = (\n 'django.middleware.common.CommonMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n # Uncomment the next line for simple clickjacking protection:\n # 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n 'core.custom_middleware.NavContextMiddleware'\n)\n\nROOT_URLCONF = 'core.urls'\n\n# Python dotted path to the WSGI application used by Django's runserver.\nWSGI_APPLICATION = 'core.wsgi.application'\n\nTEMPLATE_DIRS = (\n # project level templates\n absolute_path('core', 'base_templates'),\n absolute_path('vota', 'templates'),\n absolute_path('changes', 'templates'),\n\n)\n\nINSTALLED_APPS = (\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.sites',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.admin',\n 'django.contrib.syndication',\n)\n\n# A sample logging configuration. The only tangible logging\n# performed by this configuration is to send an email to\n# the site admins on every HTTP 500 error when DEBUG=False.\n# See http://docs.djangoproject.com/en/dev/topics/logging for\n# more details on how to customize your logging configuration.\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse'\n }\n },\n 'handlers': {\n 'mail_admins': {\n 'level': 'ERROR',\n 'filters': ['require_debug_false'],\n 'class': 'django.utils.log.AdminEmailHandler'\n }\n },\n 'loggers': {\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': True,\n },\n }\n}\n", "path": "django_project/core/settings/base.py"}, {"content": "\"\"\"\nThis model is to create \"ballots\" i.e. questions/proposals/changes which a\nCommittee can vote on.\n\nAfter voting is complete, a ballot should be marked as either Denied or Passed.\n\nIf no quorum is reached, no_quorum should be True\n\nA ballot has one Committee.\n\"\"\"\nfrom django.core.urlresolvers import reverse\nfrom django.utils.text import slugify\nimport logging\nfrom core.settings.contrib import STOP_WORDS\n\nlogger = logging.getLogger(__name__)\nfrom django.db import models\nfrom audited_models.models import AuditedModel\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.utils import timezone\nfrom vota.models.vote import Vote\nimport datetime\nfrom django.contrib.auth.models import User\n\n\nclass ApprovedCategoryManager(models.Manager):\n \"\"\"Custom category manager that shows only approved ballots.\"\"\"\n\n def get_query_set(self):\n \"\"\"Query set generator\"\"\"\n return super(\n ApprovedCategoryManager, self).get_query_set().filter(\n approved=True)\n\n\nclass DeniedCategoryManager(models.Manager):\n \"\"\"Custom version manager that shows only denied ballots.\"\"\"\n\n def get_query_set(self):\n \"\"\"Query set generator\"\"\"\n return super(\n DeniedCategoryManager, self).get_query_set().filter(\n denied=True)\n\n\nclass OpenBallotManager(models.Manager):\n \"\"\"Custom version manager that shows only open ballots.\"\"\"\n\n def get_query_set(self):\n \"\"\"Query set generator\"\"\"\n return super(\n OpenBallotManager, self).get_query_set().filter(\n open_from__lt=timezone.now()).filter(closes__gt=timezone.now())\n\n\nclass ClosedBallotManager(models.Manager):\n \"\"\"Custom version manager that shows only closed ballots.\"\"\"\n\n def get_query_set(self):\n \"\"\"Query set generator\"\"\"\n return super(\n ClosedBallotManager, self).get_query_set().filter(\n closes__gt=timezone.now())\n\n\nclass Ballot(AuditedModel):\n \"\"\"A category model e.g. gui, backend, web site etc.\"\"\"\n name = models.CharField(\n help_text=_('Name of this ballot.'),\n max_length=255,\n null=False,\n blank=False,\n unique=False\n ) # there is a unique together rule in meta class below\n\n summary = models.CharField(\n help_text=_('A brief overview of the ballot.'),\n max_length=250,\n blank=False,\n null=False\n )\n\n description = models.TextField(\n help_text=_('A full description of the proposal if a summary is not '\n 'enough!'),\n max_length=3000,\n null=True,\n blank=True,\n )\n\n approved = models.BooleanField(\n help_text=_(\n 'Whether this ballot has been approved.'),\n default=False\n )\n\n denied = models.BooleanField(\n help_text=_(\n 'Whether this ballot has been denied.'),\n default=False\n )\n\n no_quorum = models.BooleanField(\n help_text=_('Whether the ballot was denied because no quorum was '\n 'reached'),\n default=False\n )\n\n open_from = models.DateTimeField(\n help_text=_('Date the ballot opens'),\n default=timezone.now()\n )\n\n closes = models.DateTimeField(\n help_text=_('Date the ballot closes'),\n default=timezone.now() + datetime.timedelta(days=7)\n )\n\n private = models.BooleanField(\n help_text=_('Should members be prevented from viewing results before '\n 'voting?'),\n default=False\n )\n\n proposer = models.ForeignKey(User)\n # noinspection PyUnresolvedReferences\n committee = models.ForeignKey('Committee')\n slug = models.SlugField()\n objects = models.Manager()\n approved_objects = ApprovedCategoryManager()\n denied_objects = DeniedCategoryManager()\n open_objects = OpenBallotManager()\n closed_objects = ClosedBallotManager()\n\n # noinspection PyClassicStyleClass\n class Meta:\n \"\"\"Meta options for the category class.\"\"\"\n unique_together = (\n ('name', 'committee'),\n ('committee', 'slug')\n )\n app_label = 'vota'\n\n def save(self, *args, **kwargs):\n if not self.pk:\n words = self.name.split()\n filtered_words = [t for t in words if t.lower() not in STOP_WORDS]\n new_list = ' '.join(filtered_words)\n self.slug = slugify(new_list)[:50]\n super(Ballot, self).save(*args, **kwargs)\n\n def __unicode__(self):\n return u'%s : %s' % (self.committee.name, self.name)\n\n def get_absolute_url(self):\n return reverse('ballot-detail', kwargs={\n 'project_slug': self.committee.project.slug,\n 'committee_slug': self.committee.slug,\n 'slug': self.slug\n })\n\n def get_user_voted(self, user=None):\n voted = False\n if Vote.objects.filter(ballot=self).filter(user=user).exists():\n voted = True\n return voted\n\n def get_positive_vote_count(self):\n votes = Vote.objects.filter(ballot=self).filter(choice='y').count()\n return votes\n\n def get_negative_vote_count(self):\n votes = Vote.objects.filter(ballot=self).filter(choice='n').count()\n return votes\n\n def get_abstainer_count(self):\n votes = Vote.objects.filter(ballot=self).filter(choice='-').count()\n return votes\n\n def get_current_tally(self):\n positive = self.get_positive_vote_count()\n negative = self.get_negative_vote_count()\n tally = 0\n tally += positive\n tally -= negative\n return tally\n\n def get_total_vote_count(self):\n vote_count = Vote.objects.filter(ballot=self).count()\n return vote_count\n\n def has_quorum(self):\n vote_count = self.get_total_vote_count()\n committee_user_count = self.committee.users.all().count()\n if committee_user_count != 0:\n quorum_percent = self.committee.quorum_setting\n percentage = 100 * float(vote_count) / float(committee_user_count)\n if percentage > quorum_percent:\n return True\n else:\n return False\n\n def is_open(self):\n open_date = self.open_from\n close_date = self.closes\n if open_date < timezone.now() < close_date:\n return True\n return False\n", "path": "django_project/vota/models/ballot.py"}]}
| 4,065 | 203 |
gh_patches_debug_35267
|
rasdani/github-patches
|
git_diff
|
pyinstaller__pyinstaller-6952
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`hook-pkg_resources.py` is including hidden imports that are not available
https://github.com/pyinstaller/pyinstaller/blob/3b5d233d02472ad9d589a798d19ad3d3df645223/PyInstaller/hooks/hook-pkg_resources.py#L20
and
https://github.com/pyinstaller/pyinstaller/blob/3b5d233d02472ad9d589a798d19ad3d3df645223/PyInstaller/hooks/hook-pkg_resources.py#L30
Refer to https://github.com/pypa/setuptools/issues/1963 for the past need for including `py2_warn` and [the subsequent removal of py2_warn from setuptools](https://github.com/pypa/setuptools/pull/2238).
The `pkg_resources.py2_warn` submodule was introduced in v45.0.0 and removed in v49.1.1. Therefore, an check for those versions would look like this:
```python
if is_module_satisfies("setuptools >= 45.0.0, < 49.1.1"):
hiddenimports.append('pkg_resources.py2_warn')
```
As for `pkg_resources.markers`, I haven't found any references to any `pkg_resources.markers` packages through Google searches. I'm not convinced that it ever existed at any point. Perhaps it was being confused for (or just a typo of) `packaging.markers`, which does exist. Since `hook-pkg_resources.py` already collects the submodules of `packaging`, there doesn't need to be an extra hidden import added for `packaging.markers`. Therefore, I think that the `pkg_resources.markers` hidden import line can be removed completely.
Another module that it is trying to include is `pkg_resources._vendor.pyparsing.diagrams`. This module can only be used when the `railroad` module is available. Therefore, a check should be added to make sure that the `railroad` module is available, and filter out the diagrams module when it isn't.
For example:
```python
from PyInstaller.utils.hooks import (
collect_submodules,
is_module_satisfies,
can_import_module,
is_module_or_submodule
)
hiddenimports = []
# pkg_resources keeps vendored modules in its _vendor subpackage and does sys.meta_path based import magic to expose
# them as pkg_resources.extern.*
if not can_import_module('railroad'):
# The `railroad` package is an optional requirement for `pyparsing`. `pyparsing.diagrams` depends on `railroad`, so
# filter it out when `railroad` is not available.
hiddenimports += collect_submodules(
'pkg_resources._vendor',
lambda name: is_module_or_submodule(name, 'pkg_resources._vendor.pyparsing.diagrams'))
else:
hiddenimports += collect_submodules('pkg_resources._vendor')
```
PyInstaller: v5.1
</issue>
<code>
[start of PyInstaller/hooks/hook-pkg_resources.py]
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2005-2022, PyInstaller Development Team.
3 #
4 # Distributed under the terms of the GNU General Public License (version 2
5 # or later) with exception for distributing the bootloader.
6 #
7 # The full license is in the file COPYING.txt, distributed with this software.
8 #
9 # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
10 #-----------------------------------------------------------------------------
11
12 from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies
13
14 # pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose
15 # them as pkg_resources.extern.*
16 hiddenimports = collect_submodules('pkg_resources._vendor')
17
18 # pkg_resources v45.0 dropped support for Python 2 and added this module printing a warning. We could save some bytes if
19 # we would replace this by a fake module.
20 hiddenimports.append('pkg_resources.py2_warn')
21
22 excludedimports = ['__main__']
23
24 # Some more hidden imports. See:
25 # https://github.com/pyinstaller/pyinstaller-hooks-contrib/issues/15#issuecomment-663699288 `packaging` can either be
26 # its own package, or embedded in `pkg_resources._vendor.packaging`, or both. Assume the worst and include both if
27 # present.
28 hiddenimports += collect_submodules('packaging')
29
30 hiddenimports += ['pkg_resources.markers']
31
32 # As of v60.7, setuptools vendored jaraco and has pkg_resources use it. Currently, the pkg_resources._vendor.jaraco
33 # namespace package cannot be automatically scanned due to limited support for pure namespace packages in our hook
34 # utilities.
35 #
36 # In setuptools 60.7.0, the vendored jaraco.text package included "Lorem Ipsum.txt" data file, which also has to be
37 # collected. However, the presence of the data file (and the resulting directory hierarchy) confuses the importer's
38 # redirection logic; instead of trying to work-around that, tell user to upgrade or downgrade their setuptools.
39 if is_module_satisfies("setuptools == 60.7.0"):
40 raise SystemExit(
41 "ERROR: Setuptools 60.7.0 is incompatible with PyInstaller. "
42 "Downgrade to an earlier version or upgrade to a later version."
43 )
44 # In setuptools 60.7.1, the "Lorem Ipsum.txt" data file was dropped from the vendored jaraco.text package, so we can
45 # accommodate it with couple of hidden imports.
46 elif is_module_satisfies("setuptools >= 60.7.1"):
47 hiddenimports += [
48 'pkg_resources._vendor.jaraco.functools',
49 'pkg_resources._vendor.jaraco.context',
50 'pkg_resources._vendor.jaraco.text',
51 ]
52
[end of PyInstaller/hooks/hook-pkg_resources.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/PyInstaller/hooks/hook-pkg_resources.py b/PyInstaller/hooks/hook-pkg_resources.py
--- a/PyInstaller/hooks/hook-pkg_resources.py
+++ b/PyInstaller/hooks/hook-pkg_resources.py
@@ -9,26 +9,32 @@
# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)
#-----------------------------------------------------------------------------
-from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies
+from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies, can_import_module
# pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose
# them as pkg_resources.extern.*
-hiddenimports = collect_submodules('pkg_resources._vendor')
+
+# The `railroad` package is an optional requirement for `pyparsing`. `pyparsing.diagrams` depends on `railroad`, so
+# filter it out when `railroad` is not available.
+if can_import_module('railroad'):
+ hiddenimports = collect_submodules('pkg_resources._vendor')
+else:
+ hiddenimports = collect_submodules(
+ 'pkg_resources._vendor', filter=lambda name: 'pkg_resources._vendor.pyparsing.diagram' not in name
+ )
# pkg_resources v45.0 dropped support for Python 2 and added this module printing a warning. We could save some bytes if
# we would replace this by a fake module.
-hiddenimports.append('pkg_resources.py2_warn')
+if is_module_satisfies('setuptools >= 45.0.0, < 49.1.1'):
+ hiddenimports.append('pkg_resources.py2_warn')
excludedimports = ['__main__']
# Some more hidden imports. See:
# https://github.com/pyinstaller/pyinstaller-hooks-contrib/issues/15#issuecomment-663699288 `packaging` can either be
-# its own package, or embedded in `pkg_resources._vendor.packaging`, or both. Assume the worst and include both if
-# present.
+# its own package, or embedded in `pkg_resources._vendor.packaging`, or both.
hiddenimports += collect_submodules('packaging')
-hiddenimports += ['pkg_resources.markers']
-
# As of v60.7, setuptools vendored jaraco and has pkg_resources use it. Currently, the pkg_resources._vendor.jaraco
# namespace package cannot be automatically scanned due to limited support for pure namespace packages in our hook
# utilities.
|
{"golden_diff": "diff --git a/PyInstaller/hooks/hook-pkg_resources.py b/PyInstaller/hooks/hook-pkg_resources.py\n--- a/PyInstaller/hooks/hook-pkg_resources.py\n+++ b/PyInstaller/hooks/hook-pkg_resources.py\n@@ -9,26 +9,32 @@\n # SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n #-----------------------------------------------------------------------------\n \n-from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies\n+from PyInstaller.utils.hooks import collect_submodules, is_module_satisfies, can_import_module\n \n # pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose\n # them as pkg_resources.extern.*\n-hiddenimports = collect_submodules('pkg_resources._vendor')\n+\n+# The `railroad` package is an optional requirement for `pyparsing`. `pyparsing.diagrams` depends on `railroad`, so\n+# filter it out when `railroad` is not available.\n+if can_import_module('railroad'):\n+ hiddenimports = collect_submodules('pkg_resources._vendor')\n+else:\n+ hiddenimports = collect_submodules(\n+ 'pkg_resources._vendor', filter=lambda name: 'pkg_resources._vendor.pyparsing.diagram' not in name\n+ )\n \n # pkg_resources v45.0 dropped support for Python 2 and added this module printing a warning. We could save some bytes if\n # we would replace this by a fake module.\n-hiddenimports.append('pkg_resources.py2_warn')\n+if is_module_satisfies('setuptools >= 45.0.0, < 49.1.1'):\n+ hiddenimports.append('pkg_resources.py2_warn')\n \n excludedimports = ['__main__']\n \n # Some more hidden imports. See:\n # https://github.com/pyinstaller/pyinstaller-hooks-contrib/issues/15#issuecomment-663699288 `packaging` can either be\n-# its own package, or embedded in `pkg_resources._vendor.packaging`, or both. Assume the worst and include both if\n-# present.\n+# its own package, or embedded in `pkg_resources._vendor.packaging`, or both.\n hiddenimports += collect_submodules('packaging')\n \n-hiddenimports += ['pkg_resources.markers']\n-\n # As of v60.7, setuptools vendored jaraco and has pkg_resources use it. Currently, the pkg_resources._vendor.jaraco\n # namespace package cannot be automatically scanned due to limited support for pure namespace packages in our hook\n # utilities.\n", "issue": "`hook-pkg_resources.py` is including hidden imports that are not available\nhttps://github.com/pyinstaller/pyinstaller/blob/3b5d233d02472ad9d589a798d19ad3d3df645223/PyInstaller/hooks/hook-pkg_resources.py#L20\r\n\r\nand\r\n\r\nhttps://github.com/pyinstaller/pyinstaller/blob/3b5d233d02472ad9d589a798d19ad3d3df645223/PyInstaller/hooks/hook-pkg_resources.py#L30\r\n\r\nRefer to https://github.com/pypa/setuptools/issues/1963 for the past need for including `py2_warn` and [the subsequent removal of py2_warn from setuptools](https://github.com/pypa/setuptools/pull/2238).\r\n\r\nThe `pkg_resources.py2_warn` submodule was introduced in v45.0.0 and removed in v49.1.1. Therefore, an check for those versions would look like this:\r\n```python\r\nif is_module_satisfies(\"setuptools >= 45.0.0, < 49.1.1\"):\r\n hiddenimports.append('pkg_resources.py2_warn')\r\n```\r\n\r\nAs for `pkg_resources.markers`, I haven't found any references to any `pkg_resources.markers` packages through Google searches. I'm not convinced that it ever existed at any point. Perhaps it was being confused for (or just a typo of) `packaging.markers`, which does exist. Since `hook-pkg_resources.py` already collects the submodules of `packaging`, there doesn't need to be an extra hidden import added for `packaging.markers`. Therefore, I think that the `pkg_resources.markers` hidden import line can be removed completely.\r\n\r\nAnother module that it is trying to include is `pkg_resources._vendor.pyparsing.diagrams`. This module can only be used when the `railroad` module is available. Therefore, a check should be added to make sure that the `railroad` module is available, and filter out the diagrams module when it isn't.\r\n\r\nFor example:\r\n```python\r\nfrom PyInstaller.utils.hooks import (\r\n collect_submodules,\r\n is_module_satisfies,\r\n can_import_module,\r\n is_module_or_submodule\r\n)\r\n\r\nhiddenimports = []\r\n\r\n# pkg_resources keeps vendored modules in its _vendor subpackage and does sys.meta_path based import magic to expose\r\n# them as pkg_resources.extern.*\r\nif not can_import_module('railroad'):\r\n # The `railroad` package is an optional requirement for `pyparsing`. `pyparsing.diagrams` depends on `railroad`, so\r\n # filter it out when `railroad` is not available.\r\n hiddenimports += collect_submodules(\r\n 'pkg_resources._vendor',\r\n lambda name: is_module_or_submodule(name, 'pkg_resources._vendor.pyparsing.diagrams'))\r\nelse:\r\n hiddenimports += collect_submodules('pkg_resources._vendor')\r\n```\r\n\r\nPyInstaller: v5.1\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2005-2022, PyInstaller Development Team.\n#\n# Distributed under the terms of the GNU General Public License (version 2\n# or later) with exception for distributing the bootloader.\n#\n# The full license is in the file COPYING.txt, distributed with this software.\n#\n# SPDX-License-Identifier: (GPL-2.0-or-later WITH Bootloader-exception)\n#-----------------------------------------------------------------------------\n\nfrom PyInstaller.utils.hooks import collect_submodules, is_module_satisfies\n\n# pkg_resources keeps vendored modules in its _vendor subpackage, and does sys.meta_path based import magic to expose\n# them as pkg_resources.extern.*\nhiddenimports = collect_submodules('pkg_resources._vendor')\n\n# pkg_resources v45.0 dropped support for Python 2 and added this module printing a warning. We could save some bytes if\n# we would replace this by a fake module.\nhiddenimports.append('pkg_resources.py2_warn')\n\nexcludedimports = ['__main__']\n\n# Some more hidden imports. See:\n# https://github.com/pyinstaller/pyinstaller-hooks-contrib/issues/15#issuecomment-663699288 `packaging` can either be\n# its own package, or embedded in `pkg_resources._vendor.packaging`, or both. Assume the worst and include both if\n# present.\nhiddenimports += collect_submodules('packaging')\n\nhiddenimports += ['pkg_resources.markers']\n\n# As of v60.7, setuptools vendored jaraco and has pkg_resources use it. Currently, the pkg_resources._vendor.jaraco\n# namespace package cannot be automatically scanned due to limited support for pure namespace packages in our hook\n# utilities.\n#\n# In setuptools 60.7.0, the vendored jaraco.text package included \"Lorem Ipsum.txt\" data file, which also has to be\n# collected. However, the presence of the data file (and the resulting directory hierarchy) confuses the importer's\n# redirection logic; instead of trying to work-around that, tell user to upgrade or downgrade their setuptools.\nif is_module_satisfies(\"setuptools == 60.7.0\"):\n raise SystemExit(\n \"ERROR: Setuptools 60.7.0 is incompatible with PyInstaller. \"\n \"Downgrade to an earlier version or upgrade to a later version.\"\n )\n# In setuptools 60.7.1, the \"Lorem Ipsum.txt\" data file was dropped from the vendored jaraco.text package, so we can\n# accommodate it with couple of hidden imports.\nelif is_module_satisfies(\"setuptools >= 60.7.1\"):\n hiddenimports += [\n 'pkg_resources._vendor.jaraco.functools',\n 'pkg_resources._vendor.jaraco.context',\n 'pkg_resources._vendor.jaraco.text',\n ]\n", "path": "PyInstaller/hooks/hook-pkg_resources.py"}]}
| 1,904 | 551 |
gh_patches_debug_4257
|
rasdani/github-patches
|
git_diff
|
keras-team__autokeras-1312
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tuner use previous layer's output to adapt the next
<!-- STEP 1: Give the pull request a meaningful title. -->
### Which issue(s) does this Pull Request fix?
<!-- STEP 2: Replace the "000" with the issue ID this pull request resolves. -->
resolves #1312
### Details of the Pull Request
<!-- STEP 3: Add details/comments on the pull request. -->
<!-- STEP 4: If the pull request is in progress, click the down green arrow to select "Create Draft Pull Request", and click the button. If the pull request is ready to be reviewed, click "Create Pull Request" button directly. -->
</issue>
<code>
[start of autokeras/engine/tuner.py]
1 # Copyright 2020 The AutoKeras Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import copy
16 import os
17
18 import kerastuner
19 import tensorflow as tf
20 from kerastuner.engine import hypermodel as hm_module
21 from tensorflow.keras import callbacks as tf_callbacks
22 from tensorflow.keras.layers.experimental import preprocessing
23 from tensorflow.python.util import nest
24
25 from autokeras.utils import utils
26
27
28 class AutoTuner(kerastuner.engine.tuner.Tuner):
29 """A Tuner class based on KerasTuner for AutoKeras.
30
31 Different from KerasTuner's Tuner class. AutoTuner's not only tunes the
32 Hypermodel which can be directly built into a Keras model, but also the
33 preprocessors. Therefore, a HyperGraph stores the overall search space containing
34 both the Preprocessors and Hypermodel. For every trial, the HyperGraph build the
35 PreprocessGraph and KerasGraph with the provided HyperParameters.
36
37 The AutoTuner uses EarlyStopping for acceleration during the search and fully
38 train the model with full epochs and with both training and validation data.
39 The fully trained model is the best model to be used by AutoModel.
40
41 # Arguments
42 preprocessors: An instance or list of `Preprocessor` objects corresponding to
43 each AutoModel input, to preprocess a `tf.data.Dataset` before passing it
44 to the model. Defaults to None (no external preprocessing).
45 **kwargs: The args supported by KerasTuner.
46 """
47
48 def __init__(self, oracle, hypermodel, preprocessors=None, **kwargs):
49 # Initialize before super() for reload to work.
50 self._finished = False
51 super().__init__(oracle, hypermodel, **kwargs)
52 self.preprocessors = nest.flatten(preprocessors)
53 # Save or load the HyperModel.
54 self.hypermodel.hypermodel.save(os.path.join(self.project_dir, "graph"))
55
56 # Override the function to prevent building the model during initialization.
57 def _populate_initial_space(self):
58 pass
59
60 def get_best_model(self):
61 model = self._build_best_model()
62 with hm_module.maybe_distribute(self.distribution_strategy):
63 model.load_weights(self.best_model_path)
64 return model
65
66 def _on_train_begin(self, model, hp, x, *args, **kwargs):
67 """Adapt the preprocessing layers and tune the fit arguments."""
68 self.adapt(model, x)
69
70 @staticmethod
71 def adapt(model, dataset):
72 """Adapt the preprocessing layers in the model."""
73 # Currently, only support using the original dataset to adapt all the
74 # preprocessing layers before the first non-preprocessing layer.
75 # TODO: Use PreprocessingStage for preprocessing layers adapt.
76 # TODO: Use Keras Tuner for preprocessing layers adapt.
77 x = dataset.map(lambda x, y: x)
78
79 def get_output_layer(tensor):
80 tensor = nest.flatten(tensor)[0]
81 for layer in model.layers:
82 if isinstance(layer, tf.keras.layers.InputLayer):
83 continue
84 input_node = nest.flatten(layer.input)[0]
85 if input_node is tensor:
86 return layer
87 return None
88
89 for index, input_node in enumerate(nest.flatten(model.input)):
90 temp_x = x.map(lambda *args: nest.flatten(args)[index])
91 layer = get_output_layer(input_node)
92 while isinstance(layer, preprocessing.PreprocessingLayer):
93 layer.adapt(temp_x)
94 layer = get_output_layer(layer.output)
95 return model
96
97 def search(
98 self, epochs=None, callbacks=None, fit_on_val_data=False, **fit_kwargs
99 ):
100 """Search for the best HyperParameters.
101
102 If there is not early-stopping in the callbacks, the early-stopping callback
103 is injected to accelerate the search process. At the end of the search, the
104 best model will be fully trained with the specified number of epochs.
105
106 # Arguments
107 callbacks: A list of callback functions. Defaults to None.
108 fit_on_val_data: Boolean. Use the training set and validation set for the
109 final fit of the best model.
110 """
111 if self._finished:
112 return
113
114 if callbacks is None:
115 callbacks = []
116
117 # Insert early-stopping for adaptive number of epochs.
118 epochs_provided = True
119 if epochs is None:
120 epochs_provided = False
121 epochs = 1000
122 if not utils.contain_instance(callbacks, tf_callbacks.EarlyStopping):
123 callbacks.append(tf_callbacks.EarlyStopping(patience=10))
124
125 # Insert early-stopping for acceleration.
126 early_stopping_inserted = False
127 new_callbacks = self._deepcopy_callbacks(callbacks)
128 if not utils.contain_instance(callbacks, tf_callbacks.EarlyStopping):
129 early_stopping_inserted = True
130 new_callbacks.append(tf_callbacks.EarlyStopping(patience=10))
131
132 # Populate initial search space.
133 hp = self.oracle.get_space()
134 self.hypermodel.build(hp)
135 self.oracle.update_space(hp)
136
137 super().search(epochs=epochs, callbacks=new_callbacks, **fit_kwargs)
138
139 # Train the best model use validation data.
140 # Train the best model with enought number of epochs.
141 if fit_on_val_data or early_stopping_inserted:
142 copied_fit_kwargs = copy.copy(fit_kwargs)
143
144 # Remove early-stopping since no validation data.
145 # Remove early-stopping since it is inserted.
146 copied_fit_kwargs["callbacks"] = self._remove_early_stopping(callbacks)
147
148 # Decide the number of epochs.
149 copied_fit_kwargs["epochs"] = epochs
150 if not epochs_provided:
151 copied_fit_kwargs["epochs"] = self._get_best_trial_epochs()
152
153 # Concatenate training and validation data.
154 if fit_on_val_data:
155 copied_fit_kwargs["x"] = copied_fit_kwargs["x"].concatenate(
156 fit_kwargs["validation_data"]
157 )
158 copied_fit_kwargs.pop("validation_data")
159
160 model = self.final_fit(**copied_fit_kwargs)
161 else:
162 model = self.get_best_models()[0]
163
164 model.save_weights(self.best_model_path)
165 self._finished = True
166
167 def get_state(self):
168 state = super().get_state()
169 state.update({"finished": self._finished})
170 return state
171
172 def set_state(self, state):
173 super().set_state(state)
174 self._finished = state.get("finished")
175
176 @staticmethod
177 def _remove_early_stopping(callbacks):
178 return [
179 copy.deepcopy(callbacks)
180 for callback in callbacks
181 if not isinstance(callback, tf_callbacks.EarlyStopping)
182 ]
183
184 def _get_best_trial_epochs(self):
185 best_trial = self.oracle.get_best_trials(1)[0]
186 return self.oracle.get_trial(best_trial.trial_id).best_step
187
188 def _build_best_model(self):
189 best_trial = self.oracle.get_best_trials(1)[0]
190 best_hp = best_trial.hyperparameters
191 return self.hypermodel.build(best_hp)
192
193 def final_fit(self, x=None, **fit_kwargs):
194 model = self._build_best_model()
195 self.adapt(model, x)
196 model.fit(x, **fit_kwargs)
197 return model
198
199 @property
200 def best_model_path(self):
201 return os.path.join(self.project_dir, "best_model")
202
203 @property
204 def objective(self):
205 return self.oracle.objective
206
207 @property
208 def max_trials(self):
209 return self.oracle.max_trials
210
[end of autokeras/engine/tuner.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/autokeras/engine/tuner.py b/autokeras/engine/tuner.py
--- a/autokeras/engine/tuner.py
+++ b/autokeras/engine/tuner.py
@@ -91,6 +91,7 @@
layer = get_output_layer(input_node)
while isinstance(layer, preprocessing.PreprocessingLayer):
layer.adapt(temp_x)
+ temp_x = temp_x.map(layer)
layer = get_output_layer(layer.output)
return model
|
{"golden_diff": "diff --git a/autokeras/engine/tuner.py b/autokeras/engine/tuner.py\n--- a/autokeras/engine/tuner.py\n+++ b/autokeras/engine/tuner.py\n@@ -91,6 +91,7 @@\n layer = get_output_layer(input_node)\n while isinstance(layer, preprocessing.PreprocessingLayer):\n layer.adapt(temp_x)\n+ temp_x = temp_x.map(layer)\n layer = get_output_layer(layer.output)\n return model\n", "issue": "tuner use previous layer's output to adapt the next\n<!-- STEP 1: Give the pull request a meaningful title. -->\r\n### Which issue(s) does this Pull Request fix?\r\n<!-- STEP 2: Replace the \"000\" with the issue ID this pull request resolves. -->\r\nresolves #1312 \r\n\r\n### Details of the Pull Request\r\n<!-- STEP 3: Add details/comments on the pull request. -->\r\n\r\n<!-- STEP 4: If the pull request is in progress, click the down green arrow to select \"Create Draft Pull Request\", and click the button. If the pull request is ready to be reviewed, click \"Create Pull Request\" button directly. -->\r\n\n", "before_files": [{"content": "# Copyright 2020 The AutoKeras Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport copy\nimport os\n\nimport kerastuner\nimport tensorflow as tf\nfrom kerastuner.engine import hypermodel as hm_module\nfrom tensorflow.keras import callbacks as tf_callbacks\nfrom tensorflow.keras.layers.experimental import preprocessing\nfrom tensorflow.python.util import nest\n\nfrom autokeras.utils import utils\n\n\nclass AutoTuner(kerastuner.engine.tuner.Tuner):\n \"\"\"A Tuner class based on KerasTuner for AutoKeras.\n\n Different from KerasTuner's Tuner class. AutoTuner's not only tunes the\n Hypermodel which can be directly built into a Keras model, but also the\n preprocessors. Therefore, a HyperGraph stores the overall search space containing\n both the Preprocessors and Hypermodel. For every trial, the HyperGraph build the\n PreprocessGraph and KerasGraph with the provided HyperParameters.\n\n The AutoTuner uses EarlyStopping for acceleration during the search and fully\n train the model with full epochs and with both training and validation data.\n The fully trained model is the best model to be used by AutoModel.\n\n # Arguments\n preprocessors: An instance or list of `Preprocessor` objects corresponding to\n each AutoModel input, to preprocess a `tf.data.Dataset` before passing it\n to the model. Defaults to None (no external preprocessing).\n **kwargs: The args supported by KerasTuner.\n \"\"\"\n\n def __init__(self, oracle, hypermodel, preprocessors=None, **kwargs):\n # Initialize before super() for reload to work.\n self._finished = False\n super().__init__(oracle, hypermodel, **kwargs)\n self.preprocessors = nest.flatten(preprocessors)\n # Save or load the HyperModel.\n self.hypermodel.hypermodel.save(os.path.join(self.project_dir, \"graph\"))\n\n # Override the function to prevent building the model during initialization.\n def _populate_initial_space(self):\n pass\n\n def get_best_model(self):\n model = self._build_best_model()\n with hm_module.maybe_distribute(self.distribution_strategy):\n model.load_weights(self.best_model_path)\n return model\n\n def _on_train_begin(self, model, hp, x, *args, **kwargs):\n \"\"\"Adapt the preprocessing layers and tune the fit arguments.\"\"\"\n self.adapt(model, x)\n\n @staticmethod\n def adapt(model, dataset):\n \"\"\"Adapt the preprocessing layers in the model.\"\"\"\n # Currently, only support using the original dataset to adapt all the\n # preprocessing layers before the first non-preprocessing layer.\n # TODO: Use PreprocessingStage for preprocessing layers adapt.\n # TODO: Use Keras Tuner for preprocessing layers adapt.\n x = dataset.map(lambda x, y: x)\n\n def get_output_layer(tensor):\n tensor = nest.flatten(tensor)[0]\n for layer in model.layers:\n if isinstance(layer, tf.keras.layers.InputLayer):\n continue\n input_node = nest.flatten(layer.input)[0]\n if input_node is tensor:\n return layer\n return None\n\n for index, input_node in enumerate(nest.flatten(model.input)):\n temp_x = x.map(lambda *args: nest.flatten(args)[index])\n layer = get_output_layer(input_node)\n while isinstance(layer, preprocessing.PreprocessingLayer):\n layer.adapt(temp_x)\n layer = get_output_layer(layer.output)\n return model\n\n def search(\n self, epochs=None, callbacks=None, fit_on_val_data=False, **fit_kwargs\n ):\n \"\"\"Search for the best HyperParameters.\n\n If there is not early-stopping in the callbacks, the early-stopping callback\n is injected to accelerate the search process. At the end of the search, the\n best model will be fully trained with the specified number of epochs.\n\n # Arguments\n callbacks: A list of callback functions. Defaults to None.\n fit_on_val_data: Boolean. Use the training set and validation set for the\n final fit of the best model.\n \"\"\"\n if self._finished:\n return\n\n if callbacks is None:\n callbacks = []\n\n # Insert early-stopping for adaptive number of epochs.\n epochs_provided = True\n if epochs is None:\n epochs_provided = False\n epochs = 1000\n if not utils.contain_instance(callbacks, tf_callbacks.EarlyStopping):\n callbacks.append(tf_callbacks.EarlyStopping(patience=10))\n\n # Insert early-stopping for acceleration.\n early_stopping_inserted = False\n new_callbacks = self._deepcopy_callbacks(callbacks)\n if not utils.contain_instance(callbacks, tf_callbacks.EarlyStopping):\n early_stopping_inserted = True\n new_callbacks.append(tf_callbacks.EarlyStopping(patience=10))\n\n # Populate initial search space.\n hp = self.oracle.get_space()\n self.hypermodel.build(hp)\n self.oracle.update_space(hp)\n\n super().search(epochs=epochs, callbacks=new_callbacks, **fit_kwargs)\n\n # Train the best model use validation data.\n # Train the best model with enought number of epochs.\n if fit_on_val_data or early_stopping_inserted:\n copied_fit_kwargs = copy.copy(fit_kwargs)\n\n # Remove early-stopping since no validation data.\n # Remove early-stopping since it is inserted.\n copied_fit_kwargs[\"callbacks\"] = self._remove_early_stopping(callbacks)\n\n # Decide the number of epochs.\n copied_fit_kwargs[\"epochs\"] = epochs\n if not epochs_provided:\n copied_fit_kwargs[\"epochs\"] = self._get_best_trial_epochs()\n\n # Concatenate training and validation data.\n if fit_on_val_data:\n copied_fit_kwargs[\"x\"] = copied_fit_kwargs[\"x\"].concatenate(\n fit_kwargs[\"validation_data\"]\n )\n copied_fit_kwargs.pop(\"validation_data\")\n\n model = self.final_fit(**copied_fit_kwargs)\n else:\n model = self.get_best_models()[0]\n\n model.save_weights(self.best_model_path)\n self._finished = True\n\n def get_state(self):\n state = super().get_state()\n state.update({\"finished\": self._finished})\n return state\n\n def set_state(self, state):\n super().set_state(state)\n self._finished = state.get(\"finished\")\n\n @staticmethod\n def _remove_early_stopping(callbacks):\n return [\n copy.deepcopy(callbacks)\n for callback in callbacks\n if not isinstance(callback, tf_callbacks.EarlyStopping)\n ]\n\n def _get_best_trial_epochs(self):\n best_trial = self.oracle.get_best_trials(1)[0]\n return self.oracle.get_trial(best_trial.trial_id).best_step\n\n def _build_best_model(self):\n best_trial = self.oracle.get_best_trials(1)[0]\n best_hp = best_trial.hyperparameters\n return self.hypermodel.build(best_hp)\n\n def final_fit(self, x=None, **fit_kwargs):\n model = self._build_best_model()\n self.adapt(model, x)\n model.fit(x, **fit_kwargs)\n return model\n\n @property\n def best_model_path(self):\n return os.path.join(self.project_dir, \"best_model\")\n\n @property\n def objective(self):\n return self.oracle.objective\n\n @property\n def max_trials(self):\n return self.oracle.max_trials\n", "path": "autokeras/engine/tuner.py"}]}
| 2,920 | 105 |
gh_patches_debug_2753
|
rasdani/github-patches
|
git_diff
|
SeldonIO__MLServer-1172
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Star imports from `mlserver.codecs` not working
For example:
```python
from mlserver.codecs import *
```
Throws an error:
```python
Traceback (most recent call last):
File "/home/janis/.conda/envs/py310/lib/python3.10/site-packages/IPython/core/interactiveshell.py", line 3460, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-2-b8cc62508f29>", line 1, in <module>
from mlserver.codecs import *
AttributeError: module 'mlserver.codecs' has no attribute 'StringRequestCodec'
```
This is likely because `__all__` is out-of-date with the actual imports. I haven't tested other sub-packages, but it might be worth looking at these.
P.S. I'm not a big fan of `__all__` and star imports in particular, the main issue is that the existence of `__all__` gives rise to two public APIs which may diverge (as it has in this case).
</issue>
<code>
[start of mlserver/codecs/__init__.py]
1 from .numpy import NumpyCodec, NumpyRequestCodec
2 from .pandas import PandasCodec
3 from .string import StringCodec
4 from .base64 import Base64Codec
5 from .datetime import DatetimeCodec
6 from .errors import CodecError
7 from .decorator import decode_args
8 from .base import (
9 InputCodec,
10 RequestCodec,
11 register_input_codec,
12 register_request_codec,
13 InputCodecLike,
14 RequestCodecLike,
15 )
16 from .utils import (
17 DecodedParameterName,
18 has_decoded,
19 get_decoded,
20 get_decoded_or_raw,
21 encode_inference_response,
22 encode_response_output,
23 decode_request_input,
24 decode_inference_request,
25 )
26
27 __all__ = [
28 "CodecError",
29 "NumpyCodec",
30 "NumpyRequestCodec",
31 "StringCodec",
32 "StringRequestCodec",
33 "Base64Codec",
34 "DatetimeCodec",
35 "PandasCodec",
36 "InputCodec",
37 "InputCodecLike",
38 "RequestCodec",
39 "RequestCodecLike",
40 "DecodedParameterName",
41 "register_input_codec",
42 "register_request_codec",
43 "has_decoded",
44 "get_decoded",
45 "get_decoded_or_raw",
46 "encode_inference_response",
47 "encode_response_output",
48 "decode_request_input",
49 "decode_inference_request",
50 "decode_args",
51 ]
52
[end of mlserver/codecs/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mlserver/codecs/__init__.py b/mlserver/codecs/__init__.py
--- a/mlserver/codecs/__init__.py
+++ b/mlserver/codecs/__init__.py
@@ -1,6 +1,6 @@
from .numpy import NumpyCodec, NumpyRequestCodec
from .pandas import PandasCodec
-from .string import StringCodec
+from .string import StringCodec, StringRequestCodec
from .base64 import Base64Codec
from .datetime import DatetimeCodec
from .errors import CodecError
|
{"golden_diff": "diff --git a/mlserver/codecs/__init__.py b/mlserver/codecs/__init__.py\n--- a/mlserver/codecs/__init__.py\n+++ b/mlserver/codecs/__init__.py\n@@ -1,6 +1,6 @@\n from .numpy import NumpyCodec, NumpyRequestCodec\n from .pandas import PandasCodec\n-from .string import StringCodec\n+from .string import StringCodec, StringRequestCodec\n from .base64 import Base64Codec\n from .datetime import DatetimeCodec\n from .errors import CodecError\n", "issue": "Star imports from `mlserver.codecs` not working\nFor example:\r\n\r\n```python\r\nfrom mlserver.codecs import *\r\n```\r\nThrows an error:\r\n```python\r\nTraceback (most recent call last):\r\n File \"/home/janis/.conda/envs/py310/lib/python3.10/site-packages/IPython/core/interactiveshell.py\", line 3460, in run_code\r\n exec(code_obj, self.user_global_ns, self.user_ns)\r\n File \"<ipython-input-2-b8cc62508f29>\", line 1, in <module>\r\n from mlserver.codecs import *\r\nAttributeError: module 'mlserver.codecs' has no attribute 'StringRequestCodec'\r\n```\r\n\r\nThis is likely because `__all__` is out-of-date with the actual imports. I haven't tested other sub-packages, but it might be worth looking at these.\r\n\r\nP.S. I'm not a big fan of `__all__` and star imports in particular, the main issue is that the existence of `__all__` gives rise to two public APIs which may diverge (as it has in this case).\n", "before_files": [{"content": "from .numpy import NumpyCodec, NumpyRequestCodec\nfrom .pandas import PandasCodec\nfrom .string import StringCodec\nfrom .base64 import Base64Codec\nfrom .datetime import DatetimeCodec\nfrom .errors import CodecError\nfrom .decorator import decode_args\nfrom .base import (\n InputCodec,\n RequestCodec,\n register_input_codec,\n register_request_codec,\n InputCodecLike,\n RequestCodecLike,\n)\nfrom .utils import (\n DecodedParameterName,\n has_decoded,\n get_decoded,\n get_decoded_or_raw,\n encode_inference_response,\n encode_response_output,\n decode_request_input,\n decode_inference_request,\n)\n\n__all__ = [\n \"CodecError\",\n \"NumpyCodec\",\n \"NumpyRequestCodec\",\n \"StringCodec\",\n \"StringRequestCodec\",\n \"Base64Codec\",\n \"DatetimeCodec\",\n \"PandasCodec\",\n \"InputCodec\",\n \"InputCodecLike\",\n \"RequestCodec\",\n \"RequestCodecLike\",\n \"DecodedParameterName\",\n \"register_input_codec\",\n \"register_request_codec\",\n \"has_decoded\",\n \"get_decoded\",\n \"get_decoded_or_raw\",\n \"encode_inference_response\",\n \"encode_response_output\",\n \"decode_request_input\",\n \"decode_inference_request\",\n \"decode_args\",\n]\n", "path": "mlserver/codecs/__init__.py"}]}
| 1,174 | 121 |
gh_patches_debug_19124
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-664
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
errors in balanced_parentheses.py
https://github.com/TheAlgorithms/Python/blob/6a95bf9ad8090a1280abf76752a52ab9ee2420b7/data_structures/stacks/balanced_parentheses.py#L13-L17
`Line 16` returns wrong result due to `not`
`Line 15` can cause error for inputs like **))**. before calling _pop_ it should be checked if stack is empty.
https://github.com/TheAlgorithms/Python/blob/6a95bf9ad8090a1280abf76752a52ab9ee2420b7/data_structures/stacks/balanced_parentheses.py#L3
there is no module named **.Stack**. it should be
_from **s**tack import Stack_
</issue>
<code>
[start of data_structures/stacks/balanced_parentheses.py]
1 from __future__ import print_function
2 from __future__ import absolute_import
3 from .Stack import Stack
4
5 __author__ = 'Omkar Pathak'
6
7
8 def balanced_parentheses(parentheses):
9 """ Use a stack to check if a string of parentheses is balanced."""
10 stack = Stack(len(parentheses))
11 for parenthesis in parentheses:
12 if parenthesis == '(':
13 stack.push(parenthesis)
14 elif parenthesis == ')':
15 stack.pop()
16 return not stack.is_empty()
17
18
19 if __name__ == '__main__':
20 examples = ['((()))', '((())']
21 print('Balanced parentheses demonstration:\n')
22 for example in examples:
23 print(example + ': ' + str(balanced_parentheses(example)))
24
[end of data_structures/stacks/balanced_parentheses.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/data_structures/stacks/balanced_parentheses.py b/data_structures/stacks/balanced_parentheses.py
--- a/data_structures/stacks/balanced_parentheses.py
+++ b/data_structures/stacks/balanced_parentheses.py
@@ -1,6 +1,6 @@
from __future__ import print_function
from __future__ import absolute_import
-from .Stack import Stack
+from stack import Stack
__author__ = 'Omkar Pathak'
@@ -12,12 +12,14 @@
if parenthesis == '(':
stack.push(parenthesis)
elif parenthesis == ')':
+ if stack.is_empty():
+ return False
stack.pop()
- return not stack.is_empty()
+ return stack.is_empty()
if __name__ == '__main__':
- examples = ['((()))', '((())']
+ examples = ['((()))', '((())', '(()))']
print('Balanced parentheses demonstration:\n')
for example in examples:
print(example + ': ' + str(balanced_parentheses(example)))
|
{"golden_diff": "diff --git a/data_structures/stacks/balanced_parentheses.py b/data_structures/stacks/balanced_parentheses.py\n--- a/data_structures/stacks/balanced_parentheses.py\n+++ b/data_structures/stacks/balanced_parentheses.py\n@@ -1,6 +1,6 @@\n from __future__ import print_function\n from __future__ import absolute_import\n-from .Stack import Stack\n+from stack import Stack\n \n __author__ = 'Omkar Pathak'\n \n@@ -12,12 +12,14 @@\n if parenthesis == '(':\n stack.push(parenthesis)\n elif parenthesis == ')':\n+ if stack.is_empty():\n+ return False\n stack.pop()\n- return not stack.is_empty()\n+ return stack.is_empty()\n \n \n if __name__ == '__main__':\n- examples = ['((()))', '((())']\n+ examples = ['((()))', '((())', '(()))']\n print('Balanced parentheses demonstration:\\n')\n for example in examples:\n print(example + ': ' + str(balanced_parentheses(example)))\n", "issue": "errors in balanced_parentheses.py\nhttps://github.com/TheAlgorithms/Python/blob/6a95bf9ad8090a1280abf76752a52ab9ee2420b7/data_structures/stacks/balanced_parentheses.py#L13-L17\r\n\r\n`Line 16` returns wrong result due to `not`\r\n\r\n`Line 15` can cause error for inputs like **))**. before calling _pop_ it should be checked if stack is empty.\r\n\r\nhttps://github.com/TheAlgorithms/Python/blob/6a95bf9ad8090a1280abf76752a52ab9ee2420b7/data_structures/stacks/balanced_parentheses.py#L3\r\n\r\nthere is no module named **.Stack**. it should be\r\n _from **s**tack import Stack_\n", "before_files": [{"content": "from __future__ import print_function\nfrom __future__ import absolute_import\nfrom .Stack import Stack\n\n__author__ = 'Omkar Pathak'\n\n\ndef balanced_parentheses(parentheses):\n \"\"\" Use a stack to check if a string of parentheses is balanced.\"\"\"\n stack = Stack(len(parentheses))\n for parenthesis in parentheses:\n if parenthesis == '(':\n stack.push(parenthesis)\n elif parenthesis == ')':\n stack.pop()\n return not stack.is_empty()\n\n\nif __name__ == '__main__':\n examples = ['((()))', '((())']\n print('Balanced parentheses demonstration:\\n')\n for example in examples:\n print(example + ': ' + str(balanced_parentheses(example)))\n", "path": "data_structures/stacks/balanced_parentheses.py"}]}
| 951 | 244 |
gh_patches_debug_26805
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Kanal7 Plugin defective!
Hi there,
can you have a look on the kanal7.py please?
"error: No playable streams found on this URL"
Greetings
</issue>
<code>
[start of src/streamlink/plugins/kanal7.py]
1 from __future__ import print_function
2 import re
3
4 from streamlink.plugin import Plugin
5 from streamlink.plugin.api import http
6 from streamlink.plugin.api import validate
7 from streamlink.stream import HLSStream
8
9
10 class Kanal7(Plugin):
11 url_re = re.compile(r"https?://(?:www.)?kanal7.com/canli-izle")
12 iframe_re = re.compile(r'iframe .*?src="(http://[^"]*?)"')
13 stream_re = re.compile(r'src: "(http[^"]*?)"')
14
15 @classmethod
16 def can_handle_url(cls, url):
17 return cls.url_re.match(url) is not None
18
19 def find_iframe(self, url):
20 res = http.get(url)
21 # find iframe url
22 iframe = self.iframe_re.search(res.text)
23 iframe_url = iframe and iframe.group(1)
24 if iframe_url:
25 self.logger.debug("Found iframe: {}", iframe_url)
26 return iframe_url
27
28 def _get_streams(self):
29 iframe1 = self.find_iframe(self.url)
30 if iframe1:
31 iframe2 = self.find_iframe(iframe1)
32 if iframe2:
33 ires = http.get(iframe2)
34 stream_m = self.stream_re.search(ires.text)
35 stream_url = stream_m and stream_m.group(1)
36 if stream_url:
37 yield "live", HLSStream(self.session, stream_url)
38 else:
39 self.logger.error("Could not find second iframe, has the page layout changed?")
40 else:
41 self.logger.error("Could not find iframe, has the page layout changed?")
42
43
44 __plugin__ = Kanal7
45
[end of src/streamlink/plugins/kanal7.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/kanal7.py b/src/streamlink/plugins/kanal7.py
--- a/src/streamlink/plugins/kanal7.py
+++ b/src/streamlink/plugins/kanal7.py
@@ -3,6 +3,7 @@
from streamlink.plugin import Plugin
from streamlink.plugin.api import http
+from streamlink.plugin.api import useragents
from streamlink.plugin.api import validate
from streamlink.stream import HLSStream
@@ -10,7 +11,7 @@
class Kanal7(Plugin):
url_re = re.compile(r"https?://(?:www.)?kanal7.com/canli-izle")
iframe_re = re.compile(r'iframe .*?src="(http://[^"]*?)"')
- stream_re = re.compile(r'src: "(http[^"]*?)"')
+ stream_re = re.compile(r'src="(http[^"]*?)"')
@classmethod
def can_handle_url(cls, url):
@@ -34,7 +35,7 @@
stream_m = self.stream_re.search(ires.text)
stream_url = stream_m and stream_m.group(1)
if stream_url:
- yield "live", HLSStream(self.session, stream_url)
+ yield "live", HLSStream(self.session, stream_url, headers={"Referer": iframe2})
else:
self.logger.error("Could not find second iframe, has the page layout changed?")
else:
|
{"golden_diff": "diff --git a/src/streamlink/plugins/kanal7.py b/src/streamlink/plugins/kanal7.py\n--- a/src/streamlink/plugins/kanal7.py\n+++ b/src/streamlink/plugins/kanal7.py\n@@ -3,6 +3,7 @@\n \n from streamlink.plugin import Plugin\n from streamlink.plugin.api import http\n+from streamlink.plugin.api import useragents\n from streamlink.plugin.api import validate\n from streamlink.stream import HLSStream\n \n@@ -10,7 +11,7 @@\n class Kanal7(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?kanal7.com/canli-izle\")\n iframe_re = re.compile(r'iframe .*?src=\"(http://[^\"]*?)\"')\n- stream_re = re.compile(r'src: \"(http[^\"]*?)\"')\n+ stream_re = re.compile(r'src=\"(http[^\"]*?)\"')\n \n @classmethod\n def can_handle_url(cls, url):\n@@ -34,7 +35,7 @@\n stream_m = self.stream_re.search(ires.text)\n stream_url = stream_m and stream_m.group(1)\n if stream_url:\n- yield \"live\", HLSStream(self.session, stream_url)\n+ yield \"live\", HLSStream(self.session, stream_url, headers={\"Referer\": iframe2})\n else:\n self.logger.error(\"Could not find second iframe, has the page layout changed?\")\n else:\n", "issue": "Kanal7 Plugin defective!\nHi there,\r\n\r\ncan you have a look on the kanal7.py please?\r\n\r\n\"error: No playable streams found on this URL\"\r\n\r\nGreetings\n", "before_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\n\n\nclass Kanal7(Plugin):\n url_re = re.compile(r\"https?://(?:www.)?kanal7.com/canli-izle\")\n iframe_re = re.compile(r'iframe .*?src=\"(http://[^\"]*?)\"')\n stream_re = re.compile(r'src: \"(http[^\"]*?)\"')\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def find_iframe(self, url):\n res = http.get(url)\n # find iframe url\n iframe = self.iframe_re.search(res.text)\n iframe_url = iframe and iframe.group(1)\n if iframe_url:\n self.logger.debug(\"Found iframe: {}\", iframe_url)\n return iframe_url\n\n def _get_streams(self):\n iframe1 = self.find_iframe(self.url)\n if iframe1:\n iframe2 = self.find_iframe(iframe1)\n if iframe2:\n ires = http.get(iframe2)\n stream_m = self.stream_re.search(ires.text)\n stream_url = stream_m and stream_m.group(1)\n if stream_url:\n yield \"live\", HLSStream(self.session, stream_url)\n else:\n self.logger.error(\"Could not find second iframe, has the page layout changed?\")\n else:\n self.logger.error(\"Could not find iframe, has the page layout changed?\")\n\n\n__plugin__ = Kanal7\n", "path": "src/streamlink/plugins/kanal7.py"}]}
| 1,012 | 317 |
gh_patches_debug_24443
|
rasdani/github-patches
|
git_diff
|
tensorflow__addons-2345
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ValueError: Tensor conversion requested dtype float32 for Tensor with dtype uint8 when using losses.SigmoidFocalCrossEntropy
**System information**
- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04
- TensorFlow version and how it was installed (source or binary): 2.4.0, pip
- TensorFlow-Addons version and how it was installed (source or binary): 0.11.2, pip
- Python version: 3.8
- Is GPU used? (yes/no): yes
```
ValueError: in user code:
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py:805 train_function *
return step_function(self, iterator)
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow_addons/utils/keras_utils.py:61 call *
return self.fn(y_true, y_pred, **self._fn_kwargs)
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow_addons/losses/focal_loss.py:122 sigmoid_focal_crossentropy *
y_true = tf.convert_to_tensor(y_true, dtype=y_pred.dtype)
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/util/dispatch.py:201 wrapper **
return target(*args, **kwargs)
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1404 convert_to_tensor_v2_with_dispatch
return convert_to_tensor_v2(
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1410 convert_to_tensor_v2
return convert_to_tensor(
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/profiler/trace.py:163 wrapped
return func(*args, **kwargs)
/home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1507 convert_to_tensor
raise ValueError(
ValueError: Tensor conversion requested dtype float32 for Tensor with dtype uint8: <tf.Tensor 'y_true:0' shape=(None, None, None, 1) dtype=uint8>
```
When y_true had dtype of uint8 and y_pred had dtype float32, `tf.conver_to_tensor(y_true, y_pred.dtype)` in focal loss function failed.
Is it intended that y_true and y_pred have the same dtype when passed to the loss function? Do I need to convert y_true into float32 tensor in data processing step?
</issue>
<code>
[start of tensorflow_addons/losses/focal_loss.py]
1 # Copyright 2019 The TensorFlow Authors. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 # ==============================================================================
15 """Implements Focal loss."""
16
17 import tensorflow as tf
18 import tensorflow.keras.backend as K
19 from typeguard import typechecked
20
21 from tensorflow_addons.utils.keras_utils import LossFunctionWrapper
22 from tensorflow_addons.utils.types import FloatTensorLike, TensorLike
23
24
25 @tf.keras.utils.register_keras_serializable(package="Addons")
26 class SigmoidFocalCrossEntropy(LossFunctionWrapper):
27 """Implements the focal loss function.
28
29 Focal loss was first introduced in the RetinaNet paper
30 (https://arxiv.org/pdf/1708.02002.pdf). Focal loss is extremely useful for
31 classification when you have highly imbalanced classes. It down-weights
32 well-classified examples and focuses on hard examples. The loss value is
33 much high for a sample which is misclassified by the classifier as compared
34 to the loss value corresponding to a well-classified example. One of the
35 best use-cases of focal loss is its usage in object detection where the
36 imbalance between the background class and other classes is extremely high.
37
38 Usage:
39
40 >>> fl = tfa.losses.SigmoidFocalCrossEntropy()
41 >>> loss = fl(
42 ... y_true = [[1.0], [1.0], [0.0]],y_pred = [[0.97], [0.91], [0.03]])
43 >>> loss
44 <tf.Tensor: shape=(3,), dtype=float32, numpy=array([6.8532745e-06, 1.9097870e-04, 2.0559824e-05],
45 dtype=float32)>
46
47 Usage with `tf.keras` API:
48
49 >>> model = tf.keras.Model()
50 >>> model.compile('sgd', loss=tfa.losses.SigmoidFocalCrossEntropy())
51
52 Args:
53 alpha: balancing factor, default value is 0.25.
54 gamma: modulating factor, default value is 2.0.
55
56 Returns:
57 Weighted loss float `Tensor`. If `reduction` is `NONE`, this has the same
58 shape as `y_true`; otherwise, it is scalar.
59
60 Raises:
61 ValueError: If the shape of `sample_weight` is invalid or value of
62 `gamma` is less than zero.
63 """
64
65 @typechecked
66 def __init__(
67 self,
68 from_logits: bool = False,
69 alpha: FloatTensorLike = 0.25,
70 gamma: FloatTensorLike = 2.0,
71 reduction: str = tf.keras.losses.Reduction.NONE,
72 name: str = "sigmoid_focal_crossentropy",
73 ):
74 super().__init__(
75 sigmoid_focal_crossentropy,
76 name=name,
77 reduction=reduction,
78 from_logits=from_logits,
79 alpha=alpha,
80 gamma=gamma,
81 )
82
83
84 @tf.keras.utils.register_keras_serializable(package="Addons")
85 @tf.function
86 def sigmoid_focal_crossentropy(
87 y_true: TensorLike,
88 y_pred: TensorLike,
89 alpha: FloatTensorLike = 0.25,
90 gamma: FloatTensorLike = 2.0,
91 from_logits: bool = False,
92 ) -> tf.Tensor:
93 """Implements the focal loss function.
94
95 Focal loss was first introduced in the RetinaNet paper
96 (https://arxiv.org/pdf/1708.02002.pdf). Focal loss is extremely useful for
97 classification when you have highly imbalanced classes. It down-weights
98 well-classified examples and focuses on hard examples. The loss value is
99 much high for a sample which is misclassified by the classifier as compared
100 to the loss value corresponding to a well-classified example. One of the
101 best use-cases of focal loss is its usage in object detection where the
102 imbalance between the background class and other classes is extremely high.
103
104 Args:
105 y_true: true targets tensor.
106 y_pred: predictions tensor.
107 alpha: balancing factor.
108 gamma: modulating factor.
109
110 Returns:
111 Weighted loss float `Tensor`. If `reduction` is `NONE`,this has the
112 same shape as `y_true`; otherwise, it is scalar.
113 """
114 if gamma and gamma < 0:
115 raise ValueError("Value of gamma should be greater than or equal to zero")
116
117 y_pred = tf.convert_to_tensor(y_pred)
118 y_true = tf.convert_to_tensor(y_true, dtype=y_pred.dtype)
119
120 # Get the cross_entropy for each entry
121 ce = K.binary_crossentropy(y_true, y_pred, from_logits=from_logits)
122
123 # If logits are provided then convert the predictions into probabilities
124 if from_logits:
125 pred_prob = tf.sigmoid(y_pred)
126 else:
127 pred_prob = y_pred
128
129 p_t = (y_true * pred_prob) + ((1 - y_true) * (1 - pred_prob))
130 alpha_factor = 1.0
131 modulating_factor = 1.0
132
133 if alpha:
134 alpha = tf.convert_to_tensor(alpha, dtype=K.floatx())
135 alpha_factor = y_true * alpha + (1 - y_true) * (1 - alpha)
136
137 if gamma:
138 gamma = tf.convert_to_tensor(gamma, dtype=K.floatx())
139 modulating_factor = tf.pow((1.0 - p_t), gamma)
140
141 # compute the final loss and return
142 return tf.reduce_sum(alpha_factor * modulating_factor * ce, axis=-1)
143
[end of tensorflow_addons/losses/focal_loss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tensorflow_addons/losses/focal_loss.py b/tensorflow_addons/losses/focal_loss.py
--- a/tensorflow_addons/losses/focal_loss.py
+++ b/tensorflow_addons/losses/focal_loss.py
@@ -112,10 +112,10 @@
same shape as `y_true`; otherwise, it is scalar.
"""
if gamma and gamma < 0:
- raise ValueError("Value of gamma should be greater than or equal to zero")
+ raise ValueError("Value of gamma should be greater than or equal to zero.")
y_pred = tf.convert_to_tensor(y_pred)
- y_true = tf.convert_to_tensor(y_true, dtype=y_pred.dtype)
+ y_true = tf.cast(y_true, dtype=y_pred.dtype)
# Get the cross_entropy for each entry
ce = K.binary_crossentropy(y_true, y_pred, from_logits=from_logits)
@@ -131,11 +131,11 @@
modulating_factor = 1.0
if alpha:
- alpha = tf.convert_to_tensor(alpha, dtype=K.floatx())
+ alpha = tf.cast(alpha, dtype=y_true.dtype)
alpha_factor = y_true * alpha + (1 - y_true) * (1 - alpha)
if gamma:
- gamma = tf.convert_to_tensor(gamma, dtype=K.floatx())
+ gamma = tf.cast(gamma, dtype=y_true.dtype)
modulating_factor = tf.pow((1.0 - p_t), gamma)
# compute the final loss and return
|
{"golden_diff": "diff --git a/tensorflow_addons/losses/focal_loss.py b/tensorflow_addons/losses/focal_loss.py\n--- a/tensorflow_addons/losses/focal_loss.py\n+++ b/tensorflow_addons/losses/focal_loss.py\n@@ -112,10 +112,10 @@\n same shape as `y_true`; otherwise, it is scalar.\n \"\"\"\n if gamma and gamma < 0:\n- raise ValueError(\"Value of gamma should be greater than or equal to zero\")\n+ raise ValueError(\"Value of gamma should be greater than or equal to zero.\")\n \n y_pred = tf.convert_to_tensor(y_pred)\n- y_true = tf.convert_to_tensor(y_true, dtype=y_pred.dtype)\n+ y_true = tf.cast(y_true, dtype=y_pred.dtype)\n \n # Get the cross_entropy for each entry\n ce = K.binary_crossentropy(y_true, y_pred, from_logits=from_logits)\n@@ -131,11 +131,11 @@\n modulating_factor = 1.0\n \n if alpha:\n- alpha = tf.convert_to_tensor(alpha, dtype=K.floatx())\n+ alpha = tf.cast(alpha, dtype=y_true.dtype)\n alpha_factor = y_true * alpha + (1 - y_true) * (1 - alpha)\n \n if gamma:\n- gamma = tf.convert_to_tensor(gamma, dtype=K.floatx())\n+ gamma = tf.cast(gamma, dtype=y_true.dtype)\n modulating_factor = tf.pow((1.0 - p_t), gamma)\n \n # compute the final loss and return\n", "issue": " ValueError: Tensor conversion requested dtype float32 for Tensor with dtype uint8 when using losses.SigmoidFocalCrossEntropy\n**System information**\r\n- OS Platform and Distribution (e.g., Linux Ubuntu 16.04): Ubuntu 20.04\r\n- TensorFlow version and how it was installed (source or binary): 2.4.0, pip\r\n- TensorFlow-Addons version and how it was installed (source or binary): 0.11.2, pip\r\n- Python version: 3.8\r\n- Is GPU used? (yes/no): yes\r\n\r\n```\r\nValueError: in user code:\r\n\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py:805 train_function *\r\n return step_function(self, iterator)\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow_addons/utils/keras_utils.py:61 call *\r\n return self.fn(y_true, y_pred, **self._fn_kwargs)\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow_addons/losses/focal_loss.py:122 sigmoid_focal_crossentropy *\r\n y_true = tf.convert_to_tensor(y_true, dtype=y_pred.dtype)\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/util/dispatch.py:201 wrapper **\r\n return target(*args, **kwargs)\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1404 convert_to_tensor_v2_with_dispatch\r\n return convert_to_tensor_v2(\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1410 convert_to_tensor_v2\r\n return convert_to_tensor(\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/profiler/trace.py:163 wrapped\r\n return func(*args, **kwargs)\r\n /home/eck/software/anaconda3/envs/hk2/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1507 convert_to_tensor\r\n raise ValueError(\r\n\r\n ValueError: Tensor conversion requested dtype float32 for Tensor with dtype uint8: <tf.Tensor 'y_true:0' shape=(None, None, None, 1) dtype=uint8>\r\n```\r\n\r\n\r\nWhen y_true had dtype of uint8 and y_pred had dtype float32, `tf.conver_to_tensor(y_true, y_pred.dtype)` in focal loss function failed.\r\n\r\nIs it intended that y_true and y_pred have the same dtype when passed to the loss function? Do I need to convert y_true into float32 tensor in data processing step?\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright 2019 The TensorFlow Authors. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n# ==============================================================================\n\"\"\"Implements Focal loss.\"\"\"\n\nimport tensorflow as tf\nimport tensorflow.keras.backend as K\nfrom typeguard import typechecked\n\nfrom tensorflow_addons.utils.keras_utils import LossFunctionWrapper\nfrom tensorflow_addons.utils.types import FloatTensorLike, TensorLike\n\n\[email protected]_keras_serializable(package=\"Addons\")\nclass SigmoidFocalCrossEntropy(LossFunctionWrapper):\n \"\"\"Implements the focal loss function.\n\n Focal loss was first introduced in the RetinaNet paper\n (https://arxiv.org/pdf/1708.02002.pdf). Focal loss is extremely useful for\n classification when you have highly imbalanced classes. It down-weights\n well-classified examples and focuses on hard examples. The loss value is\n much high for a sample which is misclassified by the classifier as compared\n to the loss value corresponding to a well-classified example. One of the\n best use-cases of focal loss is its usage in object detection where the\n imbalance between the background class and other classes is extremely high.\n\n Usage:\n\n >>> fl = tfa.losses.SigmoidFocalCrossEntropy()\n >>> loss = fl(\n ... y_true = [[1.0], [1.0], [0.0]],y_pred = [[0.97], [0.91], [0.03]])\n >>> loss\n <tf.Tensor: shape=(3,), dtype=float32, numpy=array([6.8532745e-06, 1.9097870e-04, 2.0559824e-05],\n dtype=float32)>\n\n Usage with `tf.keras` API:\n\n >>> model = tf.keras.Model()\n >>> model.compile('sgd', loss=tfa.losses.SigmoidFocalCrossEntropy())\n\n Args:\n alpha: balancing factor, default value is 0.25.\n gamma: modulating factor, default value is 2.0.\n\n Returns:\n Weighted loss float `Tensor`. If `reduction` is `NONE`, this has the same\n shape as `y_true`; otherwise, it is scalar.\n\n Raises:\n ValueError: If the shape of `sample_weight` is invalid or value of\n `gamma` is less than zero.\n \"\"\"\n\n @typechecked\n def __init__(\n self,\n from_logits: bool = False,\n alpha: FloatTensorLike = 0.25,\n gamma: FloatTensorLike = 2.0,\n reduction: str = tf.keras.losses.Reduction.NONE,\n name: str = \"sigmoid_focal_crossentropy\",\n ):\n super().__init__(\n sigmoid_focal_crossentropy,\n name=name,\n reduction=reduction,\n from_logits=from_logits,\n alpha=alpha,\n gamma=gamma,\n )\n\n\[email protected]_keras_serializable(package=\"Addons\")\[email protected]\ndef sigmoid_focal_crossentropy(\n y_true: TensorLike,\n y_pred: TensorLike,\n alpha: FloatTensorLike = 0.25,\n gamma: FloatTensorLike = 2.0,\n from_logits: bool = False,\n) -> tf.Tensor:\n \"\"\"Implements the focal loss function.\n\n Focal loss was first introduced in the RetinaNet paper\n (https://arxiv.org/pdf/1708.02002.pdf). Focal loss is extremely useful for\n classification when you have highly imbalanced classes. It down-weights\n well-classified examples and focuses on hard examples. The loss value is\n much high for a sample which is misclassified by the classifier as compared\n to the loss value corresponding to a well-classified example. One of the\n best use-cases of focal loss is its usage in object detection where the\n imbalance between the background class and other classes is extremely high.\n\n Args:\n y_true: true targets tensor.\n y_pred: predictions tensor.\n alpha: balancing factor.\n gamma: modulating factor.\n\n Returns:\n Weighted loss float `Tensor`. If `reduction` is `NONE`,this has the\n same shape as `y_true`; otherwise, it is scalar.\n \"\"\"\n if gamma and gamma < 0:\n raise ValueError(\"Value of gamma should be greater than or equal to zero\")\n\n y_pred = tf.convert_to_tensor(y_pred)\n y_true = tf.convert_to_tensor(y_true, dtype=y_pred.dtype)\n\n # Get the cross_entropy for each entry\n ce = K.binary_crossentropy(y_true, y_pred, from_logits=from_logits)\n\n # If logits are provided then convert the predictions into probabilities\n if from_logits:\n pred_prob = tf.sigmoid(y_pred)\n else:\n pred_prob = y_pred\n\n p_t = (y_true * pred_prob) + ((1 - y_true) * (1 - pred_prob))\n alpha_factor = 1.0\n modulating_factor = 1.0\n\n if alpha:\n alpha = tf.convert_to_tensor(alpha, dtype=K.floatx())\n alpha_factor = y_true * alpha + (1 - y_true) * (1 - alpha)\n\n if gamma:\n gamma = tf.convert_to_tensor(gamma, dtype=K.floatx())\n modulating_factor = tf.pow((1.0 - p_t), gamma)\n\n # compute the final loss and return\n return tf.reduce_sum(alpha_factor * modulating_factor * ce, axis=-1)\n", "path": "tensorflow_addons/losses/focal_loss.py"}]}
| 2,849 | 351 |
gh_patches_debug_23275
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-3304
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
draft and live action labels are unclear

I don't think it's clear what the 'draft' and 'live' buttons will do. Could we include the full labels 'Preview draft' and 'View live'?
</issue>
<code>
[start of wagtail/wagtailadmin/wagtail_hooks.py]
1 from __future__ import absolute_import, unicode_literals
2
3 from django import forms
4 from django.contrib.auth.models import Permission
5 from django.contrib.staticfiles.templatetags.staticfiles import static
6 from django.core.urlresolvers import reverse
7 from django.utils.translation import ugettext_lazy as _
8 from wagtail.wagtailadmin.menu import MenuItem, SubmenuMenuItem, settings_menu
9 from wagtail.wagtailadmin.search import SearchArea
10 from wagtail.wagtailadmin.widgets import Button, ButtonWithDropdownFromHook, PageListingButton
11 from wagtail.wagtailcore import hooks
12 from wagtail.wagtailcore.permissions import collection_permission_policy
13
14
15 class ExplorerMenuItem(MenuItem):
16 @property
17 def media(self):
18 return forms.Media(js=[static('wagtailadmin/js/explorer-menu.js')])
19
20
21 @hooks.register('register_admin_menu_item')
22 def register_explorer_menu_item():
23 return ExplorerMenuItem(
24 _('Explorer'), reverse('wagtailadmin_explore_root'),
25 name='explorer',
26 classnames='icon icon-folder-open-inverse dl-trigger',
27 attrs={'data-explorer-menu-url': reverse('wagtailadmin_explorer_nav')},
28 order=100)
29
30
31 class SettingsMenuItem(SubmenuMenuItem):
32 template = 'wagtailadmin/shared/menu_settings_menu_item.html'
33
34
35 @hooks.register('register_admin_menu_item')
36 def register_settings_menu():
37 return SettingsMenuItem(
38 _('Settings'), settings_menu, classnames='icon icon-cogs', order=10000)
39
40
41 @hooks.register('register_permissions')
42 def register_permissions():
43 return Permission.objects.filter(content_type__app_label='wagtailadmin', codename='access_admin')
44
45
46 @hooks.register('register_admin_search_area')
47 def register_pages_search_area():
48 return SearchArea(
49 _('Pages'), reverse('wagtailadmin_pages:search'),
50 name='pages',
51 classnames='icon icon-folder-open-inverse',
52 order=100)
53
54
55 class CollectionsMenuItem(MenuItem):
56 def is_shown(self, request):
57 return collection_permission_policy.user_has_any_permission(
58 request.user, ['add', 'change', 'delete']
59 )
60
61
62 @hooks.register('register_settings_menu_item')
63 def register_collections_menu_item():
64 return CollectionsMenuItem(_('Collections'), reverse('wagtailadmin_collections:index'), classnames='icon icon-folder-open-1', order=700)
65
66
67 @hooks.register('register_page_listing_buttons')
68 def page_listing_buttons(page, page_perms, is_parent=False):
69 if page_perms.can_edit():
70 yield PageListingButton(_('Edit'), reverse('wagtailadmin_pages:edit', args=[page.id]),
71 attrs={'title': _('Edit this page')}, priority=10)
72 if page.has_unpublished_changes:
73 yield PageListingButton(_('Draft'), reverse('wagtailadmin_pages:view_draft', args=[page.id]),
74 attrs={'title': _('Preview draft'), 'target': '_blank'}, priority=20)
75 if page.live and page.url:
76 yield PageListingButton(_('Live'), page.url, attrs={'target': "_blank", 'title': _('View live')}, priority=30)
77 if page_perms.can_add_subpage():
78 if is_parent:
79 yield Button(_('Add child page'), reverse('wagtailadmin_pages:add_subpage', args=[page.id]),
80 attrs={'title': _("Add a child page to '{0}' ").format(page.get_admin_display_title())}, classes={'button', 'button-small', 'bicolor', 'icon', 'white', 'icon-plus'}, priority=40)
81 else:
82 yield PageListingButton(_('Add child page'), reverse('wagtailadmin_pages:add_subpage', args=[page.id]),
83 attrs={'title': _("Add a child page to '{0}' ").format(page.get_admin_display_title())}, priority=40)
84
85 yield ButtonWithDropdownFromHook(
86 _('More'),
87 hook_name='register_page_listing_more_buttons',
88 page=page,
89 page_perms=page_perms,
90 is_parent=is_parent,
91 attrs={'target': '_blank', 'title': _('View more options')}, priority=50)
92
93
94 @hooks.register('register_page_listing_more_buttons')
95 def page_listing_more_buttons(page, page_perms, is_parent=False):
96 if page_perms.can_move():
97 yield Button(_('Move'), reverse('wagtailadmin_pages:move', args=[page.id]),
98 attrs={"title": _('Move this page')}, priority=10)
99 if not page.is_root():
100 yield Button(_('Copy'), reverse('wagtailadmin_pages:copy', args=[page.id]),
101 attrs={'title': _('Copy this page')}, priority=20)
102 if page_perms.can_delete():
103 yield Button(_('Delete'), reverse('wagtailadmin_pages:delete', args=[page.id]),
104 attrs={'title': _('Delete this page')}, priority=30)
105 if page_perms.can_unpublish():
106 yield Button(_('Unpublish'), reverse('wagtailadmin_pages:unpublish', args=[page.id]),
107 attrs={'title': _('Unpublish this page')}, priority=40)
108 if not page.is_root():
109 yield Button(_('Revisions'), reverse('wagtailadmin_pages:revisions_index', args=[page.id]),
110 attrs={'title': _("View this page's revision history")}, priority=50)
111
[end of wagtail/wagtailadmin/wagtail_hooks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/wagtailadmin/wagtail_hooks.py b/wagtail/wagtailadmin/wagtail_hooks.py
--- a/wagtail/wagtailadmin/wagtail_hooks.py
+++ b/wagtail/wagtailadmin/wagtail_hooks.py
@@ -70,10 +70,10 @@
yield PageListingButton(_('Edit'), reverse('wagtailadmin_pages:edit', args=[page.id]),
attrs={'title': _('Edit this page')}, priority=10)
if page.has_unpublished_changes:
- yield PageListingButton(_('Draft'), reverse('wagtailadmin_pages:view_draft', args=[page.id]),
+ yield PageListingButton(_('View draft'), reverse('wagtailadmin_pages:view_draft', args=[page.id]),
attrs={'title': _('Preview draft'), 'target': '_blank'}, priority=20)
if page.live and page.url:
- yield PageListingButton(_('Live'), page.url, attrs={'target': "_blank", 'title': _('View live')}, priority=30)
+ yield PageListingButton(_('View live'), page.url, attrs={'target': "_blank", 'title': _('View live')}, priority=30)
if page_perms.can_add_subpage():
if is_parent:
yield Button(_('Add child page'), reverse('wagtailadmin_pages:add_subpage', args=[page.id]),
|
{"golden_diff": "diff --git a/wagtail/wagtailadmin/wagtail_hooks.py b/wagtail/wagtailadmin/wagtail_hooks.py\n--- a/wagtail/wagtailadmin/wagtail_hooks.py\n+++ b/wagtail/wagtailadmin/wagtail_hooks.py\n@@ -70,10 +70,10 @@\n yield PageListingButton(_('Edit'), reverse('wagtailadmin_pages:edit', args=[page.id]),\n attrs={'title': _('Edit this page')}, priority=10)\n if page.has_unpublished_changes:\n- yield PageListingButton(_('Draft'), reverse('wagtailadmin_pages:view_draft', args=[page.id]),\n+ yield PageListingButton(_('View draft'), reverse('wagtailadmin_pages:view_draft', args=[page.id]),\n attrs={'title': _('Preview draft'), 'target': '_blank'}, priority=20)\n if page.live and page.url:\n- yield PageListingButton(_('Live'), page.url, attrs={'target': \"_blank\", 'title': _('View live')}, priority=30)\n+ yield PageListingButton(_('View live'), page.url, attrs={'target': \"_blank\", 'title': _('View live')}, priority=30)\n if page_perms.can_add_subpage():\n if is_parent:\n yield Button(_('Add child page'), reverse('wagtailadmin_pages:add_subpage', args=[page.id]),\n", "issue": "draft and live action labels are unclear \n\r\n\r\nI don't think it's clear what the 'draft' and 'live' buttons will do. Could we include the full labels 'Preview draft' and 'View live'? \n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\n\nfrom django import forms\nfrom django.contrib.auth.models import Permission\nfrom django.contrib.staticfiles.templatetags.staticfiles import static\nfrom django.core.urlresolvers import reverse\nfrom django.utils.translation import ugettext_lazy as _\nfrom wagtail.wagtailadmin.menu import MenuItem, SubmenuMenuItem, settings_menu\nfrom wagtail.wagtailadmin.search import SearchArea\nfrom wagtail.wagtailadmin.widgets import Button, ButtonWithDropdownFromHook, PageListingButton\nfrom wagtail.wagtailcore import hooks\nfrom wagtail.wagtailcore.permissions import collection_permission_policy\n\n\nclass ExplorerMenuItem(MenuItem):\n @property\n def media(self):\n return forms.Media(js=[static('wagtailadmin/js/explorer-menu.js')])\n\n\[email protected]('register_admin_menu_item')\ndef register_explorer_menu_item():\n return ExplorerMenuItem(\n _('Explorer'), reverse('wagtailadmin_explore_root'),\n name='explorer',\n classnames='icon icon-folder-open-inverse dl-trigger',\n attrs={'data-explorer-menu-url': reverse('wagtailadmin_explorer_nav')},\n order=100)\n\n\nclass SettingsMenuItem(SubmenuMenuItem):\n template = 'wagtailadmin/shared/menu_settings_menu_item.html'\n\n\[email protected]('register_admin_menu_item')\ndef register_settings_menu():\n return SettingsMenuItem(\n _('Settings'), settings_menu, classnames='icon icon-cogs', order=10000)\n\n\[email protected]('register_permissions')\ndef register_permissions():\n return Permission.objects.filter(content_type__app_label='wagtailadmin', codename='access_admin')\n\n\[email protected]('register_admin_search_area')\ndef register_pages_search_area():\n return SearchArea(\n _('Pages'), reverse('wagtailadmin_pages:search'),\n name='pages',\n classnames='icon icon-folder-open-inverse',\n order=100)\n\n\nclass CollectionsMenuItem(MenuItem):\n def is_shown(self, request):\n return collection_permission_policy.user_has_any_permission(\n request.user, ['add', 'change', 'delete']\n )\n\n\[email protected]('register_settings_menu_item')\ndef register_collections_menu_item():\n return CollectionsMenuItem(_('Collections'), reverse('wagtailadmin_collections:index'), classnames='icon icon-folder-open-1', order=700)\n\n\[email protected]('register_page_listing_buttons')\ndef page_listing_buttons(page, page_perms, is_parent=False):\n if page_perms.can_edit():\n yield PageListingButton(_('Edit'), reverse('wagtailadmin_pages:edit', args=[page.id]),\n attrs={'title': _('Edit this page')}, priority=10)\n if page.has_unpublished_changes:\n yield PageListingButton(_('Draft'), reverse('wagtailadmin_pages:view_draft', args=[page.id]),\n attrs={'title': _('Preview draft'), 'target': '_blank'}, priority=20)\n if page.live and page.url:\n yield PageListingButton(_('Live'), page.url, attrs={'target': \"_blank\", 'title': _('View live')}, priority=30)\n if page_perms.can_add_subpage():\n if is_parent:\n yield Button(_('Add child page'), reverse('wagtailadmin_pages:add_subpage', args=[page.id]),\n attrs={'title': _(\"Add a child page to '{0}' \").format(page.get_admin_display_title())}, classes={'button', 'button-small', 'bicolor', 'icon', 'white', 'icon-plus'}, priority=40)\n else:\n yield PageListingButton(_('Add child page'), reverse('wagtailadmin_pages:add_subpage', args=[page.id]),\n attrs={'title': _(\"Add a child page to '{0}' \").format(page.get_admin_display_title())}, priority=40)\n\n yield ButtonWithDropdownFromHook(\n _('More'),\n hook_name='register_page_listing_more_buttons',\n page=page,\n page_perms=page_perms,\n is_parent=is_parent,\n attrs={'target': '_blank', 'title': _('View more options')}, priority=50)\n\n\[email protected]('register_page_listing_more_buttons')\ndef page_listing_more_buttons(page, page_perms, is_parent=False):\n if page_perms.can_move():\n yield Button(_('Move'), reverse('wagtailadmin_pages:move', args=[page.id]),\n attrs={\"title\": _('Move this page')}, priority=10)\n if not page.is_root():\n yield Button(_('Copy'), reverse('wagtailadmin_pages:copy', args=[page.id]),\n attrs={'title': _('Copy this page')}, priority=20)\n if page_perms.can_delete():\n yield Button(_('Delete'), reverse('wagtailadmin_pages:delete', args=[page.id]),\n attrs={'title': _('Delete this page')}, priority=30)\n if page_perms.can_unpublish():\n yield Button(_('Unpublish'), reverse('wagtailadmin_pages:unpublish', args=[page.id]),\n attrs={'title': _('Unpublish this page')}, priority=40)\n if not page.is_root():\n yield Button(_('Revisions'), reverse('wagtailadmin_pages:revisions_index', args=[page.id]),\n attrs={'title': _(\"View this page's revision history\")}, priority=50)\n", "path": "wagtail/wagtailadmin/wagtail_hooks.py"}]}
| 2,021 | 301 |
gh_patches_debug_14487
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-2853
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make API redirects respect query params
<!--
Please add the appropriate label for what change should be made:
docs: changes to the documentation)
refactor: refactoring production code, eg. renaming a variable or rewriting a function
test: adding missing tests, refactoring tests; no production code change
chore: updating poetry etc; no production code change
-->
### Describe the change
As seen in #2828 and #2821, some old API endpoints are redirected to their new replacements. This redirection does not propagate any query parameters. It would be nice to pass query parameters along when redirecting to a replacement API endpoint to prevent breaking consumers.
### Motivation
#2828 #2821
</issue>
<code>
[start of website/partners/api/v2/urls.py]
1 """Partners app API v2 urls."""
2 from django.urls import path
3 from django.views.generic import RedirectView
4
5 from partners.api.v2.views import (
6 PartnerDetailView,
7 PartnerListView,
8 VacancyCategoryListView,
9 VacancyDetailView,
10 VacancyListView,
11 )
12
13 app_name = "partners"
14
15 urlpatterns = [
16 path(
17 "partners/events/",
18 RedirectView.as_view(
19 pattern_name="api:v2:events:external-events-list", permanent=False
20 ),
21 name="partner-events-list",
22 ),
23 path(
24 "partners/events/<int:pk>/",
25 RedirectView.as_view(
26 pattern_name="api:v2:events:external-event-detail", permanent=False
27 ),
28 name="partner-events-detail",
29 ),
30 path("partners/vacancies/", VacancyListView.as_view(), name="vacancies-list"),
31 path(
32 "partners/vacancies/categories/",
33 VacancyCategoryListView.as_view(),
34 name="vacancy-categories-list",
35 ),
36 path(
37 "partners/vacancies/<int:pk>/",
38 VacancyDetailView.as_view(),
39 name="vacancies-detail",
40 ),
41 path("partners/", PartnerListView.as_view(), name="partners-list"),
42 path("partners/<int:pk>/", PartnerDetailView.as_view(), name="partners-detail"),
43 ]
44
[end of website/partners/api/v2/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/partners/api/v2/urls.py b/website/partners/api/v2/urls.py
--- a/website/partners/api/v2/urls.py
+++ b/website/partners/api/v2/urls.py
@@ -16,14 +16,18 @@
path(
"partners/events/",
RedirectView.as_view(
- pattern_name="api:v2:events:external-events-list", permanent=False
+ pattern_name="api:v2:events:external-events-list",
+ permanent=False,
+ query_string=True,
),
name="partner-events-list",
),
path(
"partners/events/<int:pk>/",
RedirectView.as_view(
- pattern_name="api:v2:events:external-event-detail", permanent=False
+ pattern_name="api:v2:events:external-event-detail",
+ permanent=False,
+ query_string=True,
),
name="partner-events-detail",
),
|
{"golden_diff": "diff --git a/website/partners/api/v2/urls.py b/website/partners/api/v2/urls.py\n--- a/website/partners/api/v2/urls.py\n+++ b/website/partners/api/v2/urls.py\n@@ -16,14 +16,18 @@\n path(\n \"partners/events/\",\n RedirectView.as_view(\n- pattern_name=\"api:v2:events:external-events-list\", permanent=False\n+ pattern_name=\"api:v2:events:external-events-list\",\n+ permanent=False,\n+ query_string=True,\n ),\n name=\"partner-events-list\",\n ),\n path(\n \"partners/events/<int:pk>/\",\n RedirectView.as_view(\n- pattern_name=\"api:v2:events:external-event-detail\", permanent=False\n+ pattern_name=\"api:v2:events:external-event-detail\",\n+ permanent=False,\n+ query_string=True,\n ),\n name=\"partner-events-detail\",\n ),\n", "issue": "Make API redirects respect query params\n<!--\n\nPlease add the appropriate label for what change should be made:\ndocs: changes to the documentation)\nrefactor: refactoring production code, eg. renaming a variable or rewriting a function\ntest: adding missing tests, refactoring tests; no production code change\nchore: updating poetry etc; no production code change\n\n-->\n\n### Describe the change\nAs seen in #2828 and #2821, some old API endpoints are redirected to their new replacements. This redirection does not propagate any query parameters. It would be nice to pass query parameters along when redirecting to a replacement API endpoint to prevent breaking consumers.\n\n### Motivation\n#2828 #2821\n", "before_files": [{"content": "\"\"\"Partners app API v2 urls.\"\"\"\nfrom django.urls import path\nfrom django.views.generic import RedirectView\n\nfrom partners.api.v2.views import (\n PartnerDetailView,\n PartnerListView,\n VacancyCategoryListView,\n VacancyDetailView,\n VacancyListView,\n)\n\napp_name = \"partners\"\n\nurlpatterns = [\n path(\n \"partners/events/\",\n RedirectView.as_view(\n pattern_name=\"api:v2:events:external-events-list\", permanent=False\n ),\n name=\"partner-events-list\",\n ),\n path(\n \"partners/events/<int:pk>/\",\n RedirectView.as_view(\n pattern_name=\"api:v2:events:external-event-detail\", permanent=False\n ),\n name=\"partner-events-detail\",\n ),\n path(\"partners/vacancies/\", VacancyListView.as_view(), name=\"vacancies-list\"),\n path(\n \"partners/vacancies/categories/\",\n VacancyCategoryListView.as_view(),\n name=\"vacancy-categories-list\",\n ),\n path(\n \"partners/vacancies/<int:pk>/\",\n VacancyDetailView.as_view(),\n name=\"vacancies-detail\",\n ),\n path(\"partners/\", PartnerListView.as_view(), name=\"partners-list\"),\n path(\"partners/<int:pk>/\", PartnerDetailView.as_view(), name=\"partners-detail\"),\n]\n", "path": "website/partners/api/v2/urls.py"}]}
| 1,043 | 208 |
gh_patches_debug_8139
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-5957
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve msg error for submodules with invalid url schemas
We only support `http` schemas, but the error message isn't clear about that. Here is a good suggestion: https://github.com/readthedocs/readthedocs.org/issues/5928#issuecomment-511708197
</issue>
<code>
[start of readthedocs/projects/exceptions.py]
1 # -*- coding: utf-8 -*-
2
3 """Project exceptions."""
4
5 from django.conf import settings
6 from django.utils.translation import ugettext_noop as _
7
8 from readthedocs.doc_builder.exceptions import BuildEnvironmentError
9
10
11 class ProjectConfigurationError(BuildEnvironmentError):
12
13 """Error raised trying to configure a project for build."""
14
15 NOT_FOUND = _(
16 'A configuration file was not found. '
17 'Make sure you have a conf.py file in your repository.',
18 )
19
20 MULTIPLE_CONF_FILES = _(
21 'We found more than one conf.py and are not sure which one to use. '
22 'Please, specify the correct file under the Advanced settings tab '
23 "in the project's Admin.",
24 )
25
26
27 class RepositoryError(BuildEnvironmentError):
28
29 """Failure during repository operation."""
30
31 PRIVATE_ALLOWED = _(
32 'There was a problem connecting to your repository, '
33 'ensure that your repository URL is correct.',
34 )
35 PRIVATE_NOT_ALLOWED = _(
36 'There was a problem connecting to your repository, '
37 'ensure that your repository URL is correct and your repository is public. '
38 'Private repositories are not supported.',
39 )
40
41 INVALID_SUBMODULES = _('One or more submodule URLs are not valid: {}.')
42 INVALID_SUBMODULES_PATH = _(
43 'One or more submodule paths are not valid. '
44 'Check that all your submodules in .gitmodules are used.'
45 )
46
47 DUPLICATED_RESERVED_VERSIONS = _(
48 'You can not have two versions with the name latest or stable.',
49 )
50
51 FAILED_TO_CHECKOUT = _('Failed to checkout revision: {}')
52
53 def get_default_message(self):
54 if settings.ALLOW_PRIVATE_REPOS:
55 return self.PRIVATE_ALLOWED
56 return self.PRIVATE_NOT_ALLOWED
57
58
59 class ProjectSpamError(Exception):
60
61 """
62 Error raised when a project field has detected spam.
63
64 This error is not raised to users, we use this for banning users in the
65 background.
66 """
67
[end of readthedocs/projects/exceptions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/projects/exceptions.py b/readthedocs/projects/exceptions.py
--- a/readthedocs/projects/exceptions.py
+++ b/readthedocs/projects/exceptions.py
@@ -38,7 +38,10 @@
'Private repositories are not supported.',
)
- INVALID_SUBMODULES = _('One or more submodule URLs are not valid: {}.')
+ INVALID_SUBMODULES = _(
+ 'One or more submodule URLs are not valid: {}, '
+ 'git/ssh URL schemas for submodules are not supported.'
+ )
INVALID_SUBMODULES_PATH = _(
'One or more submodule paths are not valid. '
'Check that all your submodules in .gitmodules are used.'
|
{"golden_diff": "diff --git a/readthedocs/projects/exceptions.py b/readthedocs/projects/exceptions.py\n--- a/readthedocs/projects/exceptions.py\n+++ b/readthedocs/projects/exceptions.py\n@@ -38,7 +38,10 @@\n 'Private repositories are not supported.',\n )\n \n- INVALID_SUBMODULES = _('One or more submodule URLs are not valid: {}.')\n+ INVALID_SUBMODULES = _(\n+ 'One or more submodule URLs are not valid: {}, '\n+ 'git/ssh URL schemas for submodules are not supported.'\n+ )\n INVALID_SUBMODULES_PATH = _(\n 'One or more submodule paths are not valid. '\n 'Check that all your submodules in .gitmodules are used.'\n", "issue": "Improve msg error for submodules with invalid url schemas\nWe only support `http` schemas, but the error message isn't clear about that. Here is a good suggestion: https://github.com/readthedocs/readthedocs.org/issues/5928#issuecomment-511708197\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"Project exceptions.\"\"\"\n\nfrom django.conf import settings\nfrom django.utils.translation import ugettext_noop as _\n\nfrom readthedocs.doc_builder.exceptions import BuildEnvironmentError\n\n\nclass ProjectConfigurationError(BuildEnvironmentError):\n\n \"\"\"Error raised trying to configure a project for build.\"\"\"\n\n NOT_FOUND = _(\n 'A configuration file was not found. '\n 'Make sure you have a conf.py file in your repository.',\n )\n\n MULTIPLE_CONF_FILES = _(\n 'We found more than one conf.py and are not sure which one to use. '\n 'Please, specify the correct file under the Advanced settings tab '\n \"in the project's Admin.\",\n )\n\n\nclass RepositoryError(BuildEnvironmentError):\n\n \"\"\"Failure during repository operation.\"\"\"\n\n PRIVATE_ALLOWED = _(\n 'There was a problem connecting to your repository, '\n 'ensure that your repository URL is correct.',\n )\n PRIVATE_NOT_ALLOWED = _(\n 'There was a problem connecting to your repository, '\n 'ensure that your repository URL is correct and your repository is public. '\n 'Private repositories are not supported.',\n )\n\n INVALID_SUBMODULES = _('One or more submodule URLs are not valid: {}.')\n INVALID_SUBMODULES_PATH = _(\n 'One or more submodule paths are not valid. '\n 'Check that all your submodules in .gitmodules are used.'\n )\n\n DUPLICATED_RESERVED_VERSIONS = _(\n 'You can not have two versions with the name latest or stable.',\n )\n\n FAILED_TO_CHECKOUT = _('Failed to checkout revision: {}')\n\n def get_default_message(self):\n if settings.ALLOW_PRIVATE_REPOS:\n return self.PRIVATE_ALLOWED\n return self.PRIVATE_NOT_ALLOWED\n\n\nclass ProjectSpamError(Exception):\n\n \"\"\"\n Error raised when a project field has detected spam.\n\n This error is not raised to users, we use this for banning users in the\n background.\n \"\"\"\n", "path": "readthedocs/projects/exceptions.py"}]}
| 1,155 | 160 |
gh_patches_debug_16298
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-python-612
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DeprecationWarning in sqlalchemy integration
At integrations/sqlalchemy.py line 28 - integration is listening for dbapi_error, this was deprecated in sqlalchemy a long time ago and should be replaced with handle_error event
</issue>
<code>
[start of sentry_sdk/integrations/sqlalchemy.py]
1 from __future__ import absolute_import
2
3 from sentry_sdk._types import MYPY
4 from sentry_sdk.hub import Hub
5 from sentry_sdk.integrations import Integration
6 from sentry_sdk.tracing import record_sql_queries
7
8 from sqlalchemy.engine import Engine # type: ignore
9 from sqlalchemy.event import listen # type: ignore
10
11 if MYPY:
12 from typing import Any
13 from typing import ContextManager
14 from typing import Optional
15
16 from sentry_sdk.tracing import Span
17
18
19 class SqlalchemyIntegration(Integration):
20 identifier = "sqlalchemy"
21
22 @staticmethod
23 def setup_once():
24 # type: () -> None
25
26 listen(Engine, "before_cursor_execute", _before_cursor_execute)
27 listen(Engine, "after_cursor_execute", _after_cursor_execute)
28 listen(Engine, "dbapi_error", _dbapi_error)
29
30
31 def _before_cursor_execute(
32 conn, cursor, statement, parameters, context, executemany, *args
33 ):
34 # type: (Any, Any, Any, Any, Any, bool, *Any) -> None
35 hub = Hub.current
36 if hub.get_integration(SqlalchemyIntegration) is None:
37 return
38
39 ctx_mgr = record_sql_queries(
40 hub,
41 cursor,
42 statement,
43 parameters,
44 paramstyle=context and context.dialect and context.dialect.paramstyle or None,
45 executemany=executemany,
46 )
47 conn._sentry_sql_span_manager = ctx_mgr
48
49 span = ctx_mgr.__enter__()
50
51 if span is not None:
52 conn._sentry_sql_span = span
53
54
55 def _after_cursor_execute(conn, cursor, statement, *args):
56 # type: (Any, Any, Any, *Any) -> None
57 ctx_mgr = getattr(
58 conn, "_sentry_sql_span_manager", None
59 ) # type: ContextManager[Any]
60
61 if ctx_mgr is not None:
62 conn._sentry_sql_span_manager = None
63 ctx_mgr.__exit__(None, None, None)
64
65
66 def _dbapi_error(conn, *args):
67 # type: (Any, *Any) -> None
68 span = getattr(conn, "_sentry_sql_span", None) # type: Optional[Span]
69
70 if span is not None:
71 span.set_status("internal_error")
72
[end of sentry_sdk/integrations/sqlalchemy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sentry_sdk/integrations/sqlalchemy.py b/sentry_sdk/integrations/sqlalchemy.py
--- a/sentry_sdk/integrations/sqlalchemy.py
+++ b/sentry_sdk/integrations/sqlalchemy.py
@@ -25,7 +25,7 @@
listen(Engine, "before_cursor_execute", _before_cursor_execute)
listen(Engine, "after_cursor_execute", _after_cursor_execute)
- listen(Engine, "dbapi_error", _dbapi_error)
+ listen(Engine, "handle_error", _handle_error)
def _before_cursor_execute(
@@ -63,8 +63,9 @@
ctx_mgr.__exit__(None, None, None)
-def _dbapi_error(conn, *args):
+def _handle_error(context, *args):
# type: (Any, *Any) -> None
+ conn = context.connection
span = getattr(conn, "_sentry_sql_span", None) # type: Optional[Span]
if span is not None:
|
{"golden_diff": "diff --git a/sentry_sdk/integrations/sqlalchemy.py b/sentry_sdk/integrations/sqlalchemy.py\n--- a/sentry_sdk/integrations/sqlalchemy.py\n+++ b/sentry_sdk/integrations/sqlalchemy.py\n@@ -25,7 +25,7 @@\n \n listen(Engine, \"before_cursor_execute\", _before_cursor_execute)\n listen(Engine, \"after_cursor_execute\", _after_cursor_execute)\n- listen(Engine, \"dbapi_error\", _dbapi_error)\n+ listen(Engine, \"handle_error\", _handle_error)\n \n \n def _before_cursor_execute(\n@@ -63,8 +63,9 @@\n ctx_mgr.__exit__(None, None, None)\n \n \n-def _dbapi_error(conn, *args):\n+def _handle_error(context, *args):\n # type: (Any, *Any) -> None\n+ conn = context.connection\n span = getattr(conn, \"_sentry_sql_span\", None) # type: Optional[Span]\n \n if span is not None:\n", "issue": "DeprecationWarning in sqlalchemy integration\nAt integrations/sqlalchemy.py line 28 - integration is listening for dbapi_error, this was deprecated in sqlalchemy a long time ago and should be replaced with handle_error event\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom sentry_sdk._types import MYPY\nfrom sentry_sdk.hub import Hub\nfrom sentry_sdk.integrations import Integration\nfrom sentry_sdk.tracing import record_sql_queries\n\nfrom sqlalchemy.engine import Engine # type: ignore\nfrom sqlalchemy.event import listen # type: ignore\n\nif MYPY:\n from typing import Any\n from typing import ContextManager\n from typing import Optional\n\n from sentry_sdk.tracing import Span\n\n\nclass SqlalchemyIntegration(Integration):\n identifier = \"sqlalchemy\"\n\n @staticmethod\n def setup_once():\n # type: () -> None\n\n listen(Engine, \"before_cursor_execute\", _before_cursor_execute)\n listen(Engine, \"after_cursor_execute\", _after_cursor_execute)\n listen(Engine, \"dbapi_error\", _dbapi_error)\n\n\ndef _before_cursor_execute(\n conn, cursor, statement, parameters, context, executemany, *args\n):\n # type: (Any, Any, Any, Any, Any, bool, *Any) -> None\n hub = Hub.current\n if hub.get_integration(SqlalchemyIntegration) is None:\n return\n\n ctx_mgr = record_sql_queries(\n hub,\n cursor,\n statement,\n parameters,\n paramstyle=context and context.dialect and context.dialect.paramstyle or None,\n executemany=executemany,\n )\n conn._sentry_sql_span_manager = ctx_mgr\n\n span = ctx_mgr.__enter__()\n\n if span is not None:\n conn._sentry_sql_span = span\n\n\ndef _after_cursor_execute(conn, cursor, statement, *args):\n # type: (Any, Any, Any, *Any) -> None\n ctx_mgr = getattr(\n conn, \"_sentry_sql_span_manager\", None\n ) # type: ContextManager[Any]\n\n if ctx_mgr is not None:\n conn._sentry_sql_span_manager = None\n ctx_mgr.__exit__(None, None, None)\n\n\ndef _dbapi_error(conn, *args):\n # type: (Any, *Any) -> None\n span = getattr(conn, \"_sentry_sql_span\", None) # type: Optional[Span]\n\n if span is not None:\n span.set_status(\"internal_error\")\n", "path": "sentry_sdk/integrations/sqlalchemy.py"}]}
| 1,228 | 223 |
gh_patches_debug_1197
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-nlp-1166
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add compute_output_shape method to WordPieceTokenizer
When we run Pretraining Transformer from Scratch guide with PyTorch and JAX backend, it raises
```
RuntimeError: Exception encountered when calling WordPieceTokenizer.call().
Could not automatically infer the output shape / dtype of 'word_piece_tokenizer_1' (of type WordPieceTokenizer). Either the `WordPieceTokenizer.call()` method is incorrect, or you need to implement the `WordPieceTokenizer.compute_output_spec() / compute_output_shape()` method. Error encountered:
'string'
Arguments received by WordPieceTokenizer.call():
• args=('<KerasTensor shape=(None,), dtype=string, name=keras_tensor_59>',)
• kwargs=<class 'inspect._empty'>
```
cc: @mattdangerw
</issue>
<code>
[start of keras_nlp/tokenizers/tokenizer.py]
1 # Copyright 2023 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import List
16
17 from keras_nlp.api_export import keras_nlp_export
18 from keras_nlp.layers.preprocessing.preprocessing_layer import (
19 PreprocessingLayer,
20 )
21
22
23 @keras_nlp_export("keras_nlp.tokenizers.Tokenizer")
24 class Tokenizer(PreprocessingLayer):
25 """A base class for tokenizer layers.
26
27 Tokenizers in the KerasNLP library should all subclass this layer.
28 The class provides two core methods `tokenize()` and `detokenize()` for
29 going from plain text to sequences and back. A tokenizer is a subclass of
30 `keras.layers.Layer` and can be combined into a `keras.Model`.
31
32 Subclassers should always implement the `tokenize()` method, which will also
33 be the default when calling the layer directly on inputs.
34
35 Subclassers can optionally implement the `detokenize()` method if the
36 tokenization is reversible. Otherwise, this can be skipped.
37
38 Subclassers should implement `get_vocabulary()`, `vocabulary_size()`,
39 `token_to_id()` and `id_to_token()` if applicable. For some simple
40 "vocab free" tokenizers, such as a whitespace splitter show below, these
41 methods do not apply and can be skipped.
42
43 Examples:
44
45 ```python
46 class WhitespaceSplitterTokenizer(keras_nlp.tokenizers.Tokenizer):
47 def tokenize(self, inputs):
48 return tf.strings.split(inputs)
49
50 def detokenize(self, inputs):
51 return tf.strings.reduce_join(inputs, separator=" ", axis=-1)
52
53 tokenizer = WhitespaceSplitterTokenizer()
54
55 # Tokenize some inputs.
56 tokenizer.tokenize("This is a test")
57
58 # Shorthard for `tokenize()`.
59 tokenizer("This is a test")
60
61 # Detokenize some outputs.
62 tokenizer.detokenize(["This", "is", "a", "test"])
63 ```
64 """
65
66 def __init__(self, *args, **kwargs):
67 super().__init__(*args, **kwargs)
68
69 def tokenize(self, inputs, *args, **kwargs):
70 """Transform input tensors of strings into output tokens.
71
72 Args:
73 inputs: Input tensor, or dict/list/tuple of input tensors.
74 *args: Additional positional arguments.
75 **kwargs: Additional keyword arguments.
76 """
77 raise NotImplementedError(
78 "No implementation of `tokenize()` was found for "
79 f"{self.__class__.__name__}. All tokenizers should implement "
80 "`tokenize()`."
81 )
82
83 def detokenize(self, inputs, *args, **kwargs):
84 """Transform tokens back into strings.
85
86 Args:
87 inputs: Input tensor, or dict/list/tuple of input tensors.
88 *args: Additional positional arguments.
89 **kwargs: Additional keyword arguments.
90 """
91 raise NotImplementedError(
92 "No implementation of `detokenize()` was found for "
93 f"{self.__class__.__name__}."
94 )
95
96 def get_vocabulary(self) -> List[str]:
97 """Get the tokenizer vocabulary as a list of strings terms."""
98 raise NotImplementedError(
99 "No implementation of `get_vocabulary()` was found for "
100 f"{self.__class__.__name__}."
101 )
102
103 def vocabulary_size(self) -> int:
104 """Returns the total size of the token id space."""
105 raise NotImplementedError(
106 "No implementation of `vocabulary_size()` was found for "
107 f"{self.__class__.__name__}."
108 )
109
110 def id_to_token(self, id: int) -> str:
111 """Convert an integer id to a string token."""
112 raise NotImplementedError(
113 "No implementation of `id_to_token()` was found for "
114 f"{self.__class__.__name__}."
115 )
116
117 def token_to_id(self, token: str) -> int:
118 """Convert an integer id to a string token."""
119 raise NotImplementedError(
120 "No implementation of `id_to_token()` was found for "
121 f"{self.__class__.__name__}."
122 )
123
124 def call(self, inputs, *args, training=None, **kwargs):
125 return self.tokenize(inputs, *args, **kwargs)
126
[end of keras_nlp/tokenizers/tokenizer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras_nlp/tokenizers/tokenizer.py b/keras_nlp/tokenizers/tokenizer.py
--- a/keras_nlp/tokenizers/tokenizer.py
+++ b/keras_nlp/tokenizers/tokenizer.py
@@ -123,3 +123,6 @@
def call(self, inputs, *args, training=None, **kwargs):
return self.tokenize(inputs, *args, **kwargs)
+
+ def compute_output_shape(self, inputs_shape):
+ return tuple(inputs_shape) + (self.sequence_length,)
|
{"golden_diff": "diff --git a/keras_nlp/tokenizers/tokenizer.py b/keras_nlp/tokenizers/tokenizer.py\n--- a/keras_nlp/tokenizers/tokenizer.py\n+++ b/keras_nlp/tokenizers/tokenizer.py\n@@ -123,3 +123,6 @@\n \n def call(self, inputs, *args, training=None, **kwargs):\n return self.tokenize(inputs, *args, **kwargs)\n+\n+ def compute_output_shape(self, inputs_shape):\n+ return tuple(inputs_shape) + (self.sequence_length,)\n", "issue": "Add compute_output_shape method to WordPieceTokenizer\nWhen we run Pretraining Transformer from Scratch guide with PyTorch and JAX backend, it raises\r\n\r\n```\r\n\r\nRuntimeError: Exception encountered when calling WordPieceTokenizer.call().\r\n\r\nCould not automatically infer the output shape / dtype of 'word_piece_tokenizer_1' (of type WordPieceTokenizer). Either the `WordPieceTokenizer.call()` method is incorrect, or you need to implement the `WordPieceTokenizer.compute_output_spec() / compute_output_shape()` method. Error encountered:\r\n\r\n'string'\r\n\r\nArguments received by WordPieceTokenizer.call():\r\n \u2022 args=('<KerasTensor shape=(None,), dtype=string, name=keras_tensor_59>',)\r\n \u2022 kwargs=<class 'inspect._empty'>\r\n```\r\n\r\ncc: @mattdangerw \n", "before_files": [{"content": "# Copyright 2023 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import List\n\nfrom keras_nlp.api_export import keras_nlp_export\nfrom keras_nlp.layers.preprocessing.preprocessing_layer import (\n PreprocessingLayer,\n)\n\n\n@keras_nlp_export(\"keras_nlp.tokenizers.Tokenizer\")\nclass Tokenizer(PreprocessingLayer):\n \"\"\"A base class for tokenizer layers.\n\n Tokenizers in the KerasNLP library should all subclass this layer.\n The class provides two core methods `tokenize()` and `detokenize()` for\n going from plain text to sequences and back. A tokenizer is a subclass of\n `keras.layers.Layer` and can be combined into a `keras.Model`.\n\n Subclassers should always implement the `tokenize()` method, which will also\n be the default when calling the layer directly on inputs.\n\n Subclassers can optionally implement the `detokenize()` method if the\n tokenization is reversible. Otherwise, this can be skipped.\n\n Subclassers should implement `get_vocabulary()`, `vocabulary_size()`,\n `token_to_id()` and `id_to_token()` if applicable. For some simple\n \"vocab free\" tokenizers, such as a whitespace splitter show below, these\n methods do not apply and can be skipped.\n\n Examples:\n\n ```python\n class WhitespaceSplitterTokenizer(keras_nlp.tokenizers.Tokenizer):\n def tokenize(self, inputs):\n return tf.strings.split(inputs)\n\n def detokenize(self, inputs):\n return tf.strings.reduce_join(inputs, separator=\" \", axis=-1)\n\n tokenizer = WhitespaceSplitterTokenizer()\n\n # Tokenize some inputs.\n tokenizer.tokenize(\"This is a test\")\n\n # Shorthard for `tokenize()`.\n tokenizer(\"This is a test\")\n\n # Detokenize some outputs.\n tokenizer.detokenize([\"This\", \"is\", \"a\", \"test\"])\n ```\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n def tokenize(self, inputs, *args, **kwargs):\n \"\"\"Transform input tensors of strings into output tokens.\n\n Args:\n inputs: Input tensor, or dict/list/tuple of input tensors.\n *args: Additional positional arguments.\n **kwargs: Additional keyword arguments.\n \"\"\"\n raise NotImplementedError(\n \"No implementation of `tokenize()` was found for \"\n f\"{self.__class__.__name__}. All tokenizers should implement \"\n \"`tokenize()`.\"\n )\n\n def detokenize(self, inputs, *args, **kwargs):\n \"\"\"Transform tokens back into strings.\n\n Args:\n inputs: Input tensor, or dict/list/tuple of input tensors.\n *args: Additional positional arguments.\n **kwargs: Additional keyword arguments.\n \"\"\"\n raise NotImplementedError(\n \"No implementation of `detokenize()` was found for \"\n f\"{self.__class__.__name__}.\"\n )\n\n def get_vocabulary(self) -> List[str]:\n \"\"\"Get the tokenizer vocabulary as a list of strings terms.\"\"\"\n raise NotImplementedError(\n \"No implementation of `get_vocabulary()` was found for \"\n f\"{self.__class__.__name__}.\"\n )\n\n def vocabulary_size(self) -> int:\n \"\"\"Returns the total size of the token id space.\"\"\"\n raise NotImplementedError(\n \"No implementation of `vocabulary_size()` was found for \"\n f\"{self.__class__.__name__}.\"\n )\n\n def id_to_token(self, id: int) -> str:\n \"\"\"Convert an integer id to a string token.\"\"\"\n raise NotImplementedError(\n \"No implementation of `id_to_token()` was found for \"\n f\"{self.__class__.__name__}.\"\n )\n\n def token_to_id(self, token: str) -> int:\n \"\"\"Convert an integer id to a string token.\"\"\"\n raise NotImplementedError(\n \"No implementation of `id_to_token()` was found for \"\n f\"{self.__class__.__name__}.\"\n )\n\n def call(self, inputs, *args, training=None, **kwargs):\n return self.tokenize(inputs, *args, **kwargs)\n", "path": "keras_nlp/tokenizers/tokenizer.py"}]}
| 1,990 | 120 |
gh_patches_debug_56864
|
rasdani/github-patches
|
git_diff
|
bentoml__BentoML-2300
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Files are read as Models
**Describe the bug**
<!--- A clear and concise description of what the bug is. -->
When a .DS_Store file is created in the `bentoml/models` folder, I think `store.py`'s `list` method tries loading it. I think the check for directories isn't working as intended (https://github.com/bentoml/BentoML/blob/4308c67f327d9524025e5c348ded22553824c1d4/bentoml/_internal/store.py#L69), but I'm not sure. Additionally, this happens when any file is created in the models folder, but not when folders are created.
**To Reproduce**
Steps to reproduce the issue:
1. Go to `~/bentoml/models/`
2. Create a `.DS_Store` file
3. Run `bentoml models list`
4. See error
**Expected behavior**
<!--- A clear and concise description of what you expected to happen. -->
All files should be skipped when scanning for models.
**Screenshots/Logs**
```shell
[19:12:41] WARNING [boot] converting .DS_Store to lowercase: .ds_store
Traceback (most recent call last):
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/__main__.py", line 4, in <module>
create_bentoml_cli()()
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1128, in __call__
return self.main(*args, **kwargs)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1053, in main
rv = self.invoke(ctx)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1659, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py", line 1395, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py", line 754, in invoke
return __callback(*args, **kwargs)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/cli/model_management.py", line 90, in list_models
models = model_store.list(model_name)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/store.py", line 63, in list
return [
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/store.py", line 64, in <listcomp>
ver for _d in sorted(self._fs.listdir("/")) for ver in self.list(_d)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/store.py", line 67, in list
_tag = Tag.from_taglike(tag)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/types.py", line 221, in from_taglike
return cls.from_str(taglike)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/types.py", line 226, in from_str
return cls(tag_str, None)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/types.py", line 180, in __init__
validate_tag_str(lname)
File "/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/utils/validation.py", line 29, in validate_tag_str
raise InvalidArgument(f"{value} is not a valid tag: " + ", and ".join(errors))
bentoml.exceptions.InvalidArgument: .ds_store is not a valid tag: a tag's name or version must consist of alphanumeric characters, '_', '-', or '.', and must start and end with an alphanumeric character
```
**Environment:**
- OS: MacOS 12.2.1
- Python 3.8.9
- BentoML 1.0.0a4
**Additional context**
MacOS creates .DS_Store files automatically, so I ran into this bug after opening the folder and sorting the files 😅
</issue>
<code>
[start of bentoml/_internal/store.py]
1 import os
2 import typing as t
3 import datetime
4 from abc import ABC
5 from abc import abstractmethod
6 from contextlib import contextmanager
7
8 import fs
9 import fs.errors
10 from fs.base import FS
11
12 from .types import Tag
13 from .types import PathType
14 from ..exceptions import NotFound
15 from ..exceptions import BentoMLException
16
17 T = t.TypeVar("T")
18
19
20 class StoreItem(ABC):
21 @property
22 @abstractmethod
23 def tag(self) -> Tag:
24 raise NotImplementedError
25
26 @classmethod
27 @abstractmethod
28 def from_fs(cls: t.Type[T], item_fs: FS) -> T:
29 raise NotImplementedError
30
31 @property
32 @abstractmethod
33 def creation_time(self) -> datetime.datetime:
34 raise NotImplementedError
35
36 def __repr__(self):
37 return f'{self.__class__.__name__}(tag="{self.tag}")'
38
39
40 Item = t.TypeVar("Item", bound=StoreItem)
41
42
43 class Store(ABC, t.Generic[Item]):
44 """An FsStore manages items under the given base filesystem.
45
46 Note that FsStore has no consistency checks; it assumes that no direct modification
47 of the files in its directory has occurred.
48
49 """
50
51 _fs: FS
52 _item_type: t.Type[Item]
53
54 @abstractmethod
55 def __init__(self, base_path: t.Union[PathType, FS], item_type: t.Type[Item]):
56 self._item_type = item_type
57 if isinstance(base_path, os.PathLike):
58 base_path = base_path.__fspath__()
59 self._fs = fs.open_fs(base_path)
60
61 def list(self, tag: t.Optional[t.Union[Tag, str]] = None) -> t.List[Item]:
62 if not tag:
63 return [
64 ver for _d in sorted(self._fs.listdir("/")) for ver in self.list(_d)
65 ]
66
67 _tag = Tag.from_taglike(tag)
68 if _tag.version is None:
69 if not self._fs.isdir(_tag.name):
70 raise NotFound(
71 f"no {self._item_type.__name__}s with name '{_tag.name}' found"
72 )
73
74 tags = sorted(
75 [
76 Tag(_tag.name, f.name)
77 for f in self._fs.scandir(_tag.name)
78 if f.is_dir
79 ]
80 )
81 return [self._get_item(t) for t in tags]
82 else:
83 return [self._get_item(_tag)] if self._fs.isdir(_tag.path()) else []
84
85 def _get_item(self, tag: Tag) -> Item:
86 """
87 Creates a new instance of Item that represents the item with tag `tag`.
88 """
89 return self._item_type.from_fs(self._fs.opendir(tag.path()))
90
91 def get(self, tag: t.Union[Tag, str]) -> Item:
92 """
93 store.get("my_bento")
94 store.get("my_bento:v1.0.0")
95 store.get(Tag("my_bento", "latest"))
96 """
97 _tag = Tag.from_taglike(tag)
98 if _tag.version is None or _tag.version == "latest":
99 try:
100 _tag.version = self._fs.readtext(_tag.latest_path())
101 except fs.errors.ResourceNotFound:
102 raise NotFound(
103 f"no {self._item_type.__name__}s with name '{_tag.name}' exist in BentoML store {self._fs}"
104 )
105
106 path = _tag.path()
107 if self._fs.exists(path):
108 return self._get_item(_tag)
109
110 matches = self._fs.glob(f"{path}*/")
111 counts = matches.count().directories
112 if counts == 0:
113 raise NotFound(
114 f"{self._item_type.__name__} '{tag}' is not found in BentoML store {self._fs}"
115 )
116 elif counts == 1:
117 match = next(iter(matches))
118 return self._get_item(Tag(_tag.name, match.info.name))
119 else:
120 vers: t.List[str] = []
121 for match in matches:
122 vers += match.info.name
123 raise BentoMLException(
124 f"multiple versions matched by {_tag.version}: {vers}"
125 )
126
127 @contextmanager
128 def register(self, tag: t.Union[str, Tag]):
129 _tag = Tag.from_taglike(tag)
130
131 item_path = _tag.path()
132 if self._fs.exists(item_path):
133 raise BentoMLException(
134 f"Item '{_tag}' already exists in the store {self._fs}"
135 )
136 self._fs.makedirs(item_path)
137 try:
138 yield self._fs.getsyspath(item_path)
139 finally:
140 # item generation is most likely successful, link latest path
141 if (
142 not self._fs.exists(_tag.latest_path())
143 or self.get(_tag).creation_time > self.get(_tag.name).creation_time
144 ):
145 with self._fs.open(_tag.latest_path(), "w") as latest_file:
146 latest_file.write(_tag.version)
147
148 def delete(self, tag: t.Union[str, Tag]) -> None:
149 _tag = Tag.from_taglike(tag)
150
151 if not self._fs.exists(_tag.path()):
152 raise NotFound(f"{self._item_type.__name__} '{tag}' not found")
153
154 self._fs.removetree(_tag.path())
155 if self._fs.isdir(_tag.name):
156 versions = self.list(_tag.name)
157 if len(versions) == 0:
158 # if we've removed all versions, remove the directory
159 self._fs.removetree(_tag.name)
160 else:
161 new_latest = sorted(versions, key=lambda x: x.creation_time)[-1]
162 # otherwise, update the latest version
163 assert new_latest.tag.version is not None
164 self._fs.writetext(_tag.latest_path(), new_latest.tag.version)
165
[end of bentoml/_internal/store.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bentoml/_internal/store.py b/bentoml/_internal/store.py
--- a/bentoml/_internal/store.py
+++ b/bentoml/_internal/store.py
@@ -61,7 +61,10 @@
def list(self, tag: t.Optional[t.Union[Tag, str]] = None) -> t.List[Item]:
if not tag:
return [
- ver for _d in sorted(self._fs.listdir("/")) for ver in self.list(_d)
+ ver
+ for _d in sorted(self._fs.listdir("/"))
+ if self._fs.isdir(_d)
+ for ver in self.list(_d)
]
_tag = Tag.from_taglike(tag)
|
{"golden_diff": "diff --git a/bentoml/_internal/store.py b/bentoml/_internal/store.py\n--- a/bentoml/_internal/store.py\n+++ b/bentoml/_internal/store.py\n@@ -61,7 +61,10 @@\n def list(self, tag: t.Optional[t.Union[Tag, str]] = None) -> t.List[Item]:\n if not tag:\n return [\n- ver for _d in sorted(self._fs.listdir(\"/\")) for ver in self.list(_d)\n+ ver\n+ for _d in sorted(self._fs.listdir(\"/\"))\n+ if self._fs.isdir(_d)\n+ for ver in self.list(_d)\n ]\n \n _tag = Tag.from_taglike(tag)\n", "issue": "Files are read as Models\n**Describe the bug**\r\n\r\n<!--- A clear and concise description of what the bug is. -->\r\nWhen a .DS_Store file is created in the `bentoml/models` folder, I think `store.py`'s `list` method tries loading it. I think the check for directories isn't working as intended (https://github.com/bentoml/BentoML/blob/4308c67f327d9524025e5c348ded22553824c1d4/bentoml/_internal/store.py#L69), but I'm not sure. Additionally, this happens when any file is created in the models folder, but not when folders are created.\r\n\r\n\r\n**To Reproduce**\r\n\r\nSteps to reproduce the issue:\r\n1. Go to `~/bentoml/models/`\r\n2. Create a `.DS_Store` file\r\n3. Run `bentoml models list`\r\n4. See error\r\n\r\n\r\n**Expected behavior**\r\n\r\n<!--- A clear and concise description of what you expected to happen. -->\r\nAll files should be skipped when scanning for models.\r\n\r\n\r\n**Screenshots/Logs**\r\n\r\n```shell\r\n[19:12:41] WARNING [boot] converting .DS_Store to lowercase: .ds_store \r\nTraceback (most recent call last):\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/runpy.py\", line 194, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.8/lib/python3.8/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/__main__.py\", line 4, in <module>\r\n create_bentoml_cli()()\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py\", line 1128, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py\", line 1053, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py\", line 1659, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py\", line 1659, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py\", line 1395, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/click/core.py\", line 754, in invoke\r\n return __callback(*args, **kwargs)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/cli/model_management.py\", line 90, in list_models\r\n models = model_store.list(model_name)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/store.py\", line 63, in list\r\n return [\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/store.py\", line 64, in <listcomp>\r\n ver for _d in sorted(self._fs.listdir(\"/\")) for ver in self.list(_d)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/store.py\", line 67, in list\r\n _tag = Tag.from_taglike(tag)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/types.py\", line 221, in from_taglike\r\n return cls.from_str(taglike)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/types.py\", line 226, in from_str\r\n return cls(tag_str, None)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/types.py\", line 180, in __init__\r\n validate_tag_str(lname)\r\n File \"/Users/spence/Library/Python/3.8/lib/python/site-packages/bentoml/_internal/utils/validation.py\", line 29, in validate_tag_str\r\n raise InvalidArgument(f\"{value} is not a valid tag: \" + \", and \".join(errors))\r\nbentoml.exceptions.InvalidArgument: .ds_store is not a valid tag: a tag's name or version must consist of alphanumeric characters, '_', '-', or '.', and must start and end with an alphanumeric character\r\n```\r\n\r\n\r\n**Environment:**\r\n - OS: MacOS 12.2.1\r\n - Python 3.8.9\r\n - BentoML 1.0.0a4\r\n\r\n\r\n**Additional context**\r\n\r\nMacOS creates .DS_Store files automatically, so I ran into this bug after opening the folder and sorting the files \ud83d\ude05\r\n\n", "before_files": [{"content": "import os\nimport typing as t\nimport datetime\nfrom abc import ABC\nfrom abc import abstractmethod\nfrom contextlib import contextmanager\n\nimport fs\nimport fs.errors\nfrom fs.base import FS\n\nfrom .types import Tag\nfrom .types import PathType\nfrom ..exceptions import NotFound\nfrom ..exceptions import BentoMLException\n\nT = t.TypeVar(\"T\")\n\n\nclass StoreItem(ABC):\n @property\n @abstractmethod\n def tag(self) -> Tag:\n raise NotImplementedError\n\n @classmethod\n @abstractmethod\n def from_fs(cls: t.Type[T], item_fs: FS) -> T:\n raise NotImplementedError\n\n @property\n @abstractmethod\n def creation_time(self) -> datetime.datetime:\n raise NotImplementedError\n\n def __repr__(self):\n return f'{self.__class__.__name__}(tag=\"{self.tag}\")'\n\n\nItem = t.TypeVar(\"Item\", bound=StoreItem)\n\n\nclass Store(ABC, t.Generic[Item]):\n \"\"\"An FsStore manages items under the given base filesystem.\n\n Note that FsStore has no consistency checks; it assumes that no direct modification\n of the files in its directory has occurred.\n\n \"\"\"\n\n _fs: FS\n _item_type: t.Type[Item]\n\n @abstractmethod\n def __init__(self, base_path: t.Union[PathType, FS], item_type: t.Type[Item]):\n self._item_type = item_type\n if isinstance(base_path, os.PathLike):\n base_path = base_path.__fspath__()\n self._fs = fs.open_fs(base_path)\n\n def list(self, tag: t.Optional[t.Union[Tag, str]] = None) -> t.List[Item]:\n if not tag:\n return [\n ver for _d in sorted(self._fs.listdir(\"/\")) for ver in self.list(_d)\n ]\n\n _tag = Tag.from_taglike(tag)\n if _tag.version is None:\n if not self._fs.isdir(_tag.name):\n raise NotFound(\n f\"no {self._item_type.__name__}s with name '{_tag.name}' found\"\n )\n\n tags = sorted(\n [\n Tag(_tag.name, f.name)\n for f in self._fs.scandir(_tag.name)\n if f.is_dir\n ]\n )\n return [self._get_item(t) for t in tags]\n else:\n return [self._get_item(_tag)] if self._fs.isdir(_tag.path()) else []\n\n def _get_item(self, tag: Tag) -> Item:\n \"\"\"\n Creates a new instance of Item that represents the item with tag `tag`.\n \"\"\"\n return self._item_type.from_fs(self._fs.opendir(tag.path()))\n\n def get(self, tag: t.Union[Tag, str]) -> Item:\n \"\"\"\n store.get(\"my_bento\")\n store.get(\"my_bento:v1.0.0\")\n store.get(Tag(\"my_bento\", \"latest\"))\n \"\"\"\n _tag = Tag.from_taglike(tag)\n if _tag.version is None or _tag.version == \"latest\":\n try:\n _tag.version = self._fs.readtext(_tag.latest_path())\n except fs.errors.ResourceNotFound:\n raise NotFound(\n f\"no {self._item_type.__name__}s with name '{_tag.name}' exist in BentoML store {self._fs}\"\n )\n\n path = _tag.path()\n if self._fs.exists(path):\n return self._get_item(_tag)\n\n matches = self._fs.glob(f\"{path}*/\")\n counts = matches.count().directories\n if counts == 0:\n raise NotFound(\n f\"{self._item_type.__name__} '{tag}' is not found in BentoML store {self._fs}\"\n )\n elif counts == 1:\n match = next(iter(matches))\n return self._get_item(Tag(_tag.name, match.info.name))\n else:\n vers: t.List[str] = []\n for match in matches:\n vers += match.info.name\n raise BentoMLException(\n f\"multiple versions matched by {_tag.version}: {vers}\"\n )\n\n @contextmanager\n def register(self, tag: t.Union[str, Tag]):\n _tag = Tag.from_taglike(tag)\n\n item_path = _tag.path()\n if self._fs.exists(item_path):\n raise BentoMLException(\n f\"Item '{_tag}' already exists in the store {self._fs}\"\n )\n self._fs.makedirs(item_path)\n try:\n yield self._fs.getsyspath(item_path)\n finally:\n # item generation is most likely successful, link latest path\n if (\n not self._fs.exists(_tag.latest_path())\n or self.get(_tag).creation_time > self.get(_tag.name).creation_time\n ):\n with self._fs.open(_tag.latest_path(), \"w\") as latest_file:\n latest_file.write(_tag.version)\n\n def delete(self, tag: t.Union[str, Tag]) -> None:\n _tag = Tag.from_taglike(tag)\n\n if not self._fs.exists(_tag.path()):\n raise NotFound(f\"{self._item_type.__name__} '{tag}' not found\")\n\n self._fs.removetree(_tag.path())\n if self._fs.isdir(_tag.name):\n versions = self.list(_tag.name)\n if len(versions) == 0:\n # if we've removed all versions, remove the directory\n self._fs.removetree(_tag.name)\n else:\n new_latest = sorted(versions, key=lambda x: x.creation_time)[-1]\n # otherwise, update the latest version\n assert new_latest.tag.version is not None\n self._fs.writetext(_tag.latest_path(), new_latest.tag.version)\n", "path": "bentoml/_internal/store.py"}]}
| 3,369 | 163 |
gh_patches_debug_9283
|
rasdani/github-patches
|
git_diff
|
locustio__locust-1918
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
the report cant show the right time
<!--
If you have a general question about how to use Locust, please check Stack Overflow first https://stackoverflow.com/questions/tagged/locust
You can also ask new questions on SO, https://stackoverflow.com/questions/ask just remember to tag your question with "locust". Do not immediately post your issue here after posting to SO, wait for an answer there instead.
Use this form only for reporting actual bugs in Locust. Remember, the developers of Locust are unpaid volunteers, so make sure you have tried everything you can think of before filing a bug :)
Always make sure you are running an up to date Locust version (pip3 install -U locust)
-->
### Describe the bug
<!-- A clear and concise description of what the bug is -->


this picture is right time i am in china
### Expected behavior
<!-- Tell us what you think should happen -->
Wrong time zone reported
### Actual behavior
<!-- Tell us what happens instead. Include screenshots if this an issue with the GUI. -->
### Steps to reproduce
<!-- Please provide a minimal reproducible code example (https://stackoverflow.com/help/minimal-reproducible-example) -->
### Environment
- OS:
- Python version:
- Locust version: (please dont file issues for anything but the most recent release or prerelease builds)
- Locust command line that you ran:
- Locust file contents (anonymized if necessary):
</issue>
<code>
[start of locust/html.py]
1 from jinja2 import Environment, FileSystemLoader
2 import os
3 import pathlib
4 import datetime
5 from itertools import chain
6 from .stats import sort_stats
7 from .user.inspectuser import get_task_ratio_dict
8 from html import escape
9 from json import dumps
10
11
12 def render_template(file, **kwargs):
13 templates_path = os.path.join(pathlib.Path(__file__).parent.absolute(), "templates")
14 env = Environment(loader=FileSystemLoader(templates_path), extensions=["jinja2.ext.do"])
15 template = env.get_template(file)
16 return template.render(**kwargs)
17
18
19 def get_html_report(environment, show_download_link=True):
20 stats = environment.runner.stats
21
22 start_ts = stats.start_time
23 start_time = datetime.datetime.fromtimestamp(start_ts).strftime("%Y-%m-%d %H:%M:%S")
24
25 end_ts = stats.last_request_timestamp
26 if end_ts:
27 end_time = datetime.datetime.fromtimestamp(end_ts).strftime("%Y-%m-%d %H:%M:%S")
28 else:
29 end_time = start_time
30
31 host = None
32 if environment.host:
33 host = environment.host
34 elif environment.runner.user_classes:
35 all_hosts = set([l.host for l in environment.runner.user_classes])
36 if len(all_hosts) == 1:
37 host = list(all_hosts)[0]
38
39 requests_statistics = list(chain(sort_stats(stats.entries), [stats.total]))
40 failures_statistics = sort_stats(stats.errors)
41 exceptions_statistics = [
42 {**exc, "nodes": ", ".join(exc["nodes"])} for exc in environment.runner.exceptions.values()
43 ]
44
45 history = stats.history
46
47 static_js = []
48 js_files = ["jquery-1.11.3.min.js", "echarts.common.min.js", "vintage.js", "chart.js", "tasks.js"]
49 for js_file in js_files:
50 path = os.path.join(os.path.dirname(__file__), "static", js_file)
51 static_js.append("// " + js_file)
52 with open(path, encoding="utf8") as f:
53 static_js.append(f.read())
54 static_js.extend(["", ""])
55
56 static_css = []
57 css_files = ["tables.css"]
58 for css_file in css_files:
59 path = os.path.join(os.path.dirname(__file__), "static", "css", css_file)
60 static_css.append("/* " + css_file + " */")
61 with open(path, encoding="utf8") as f:
62 static_css.append(f.read())
63 static_css.extend(["", ""])
64
65 task_data = {
66 "per_class": get_task_ratio_dict(environment.user_classes),
67 "total": get_task_ratio_dict(environment.user_classes, total=True),
68 }
69
70 res = render_template(
71 "report.html",
72 int=int,
73 round=round,
74 requests_statistics=requests_statistics,
75 failures_statistics=failures_statistics,
76 exceptions_statistics=exceptions_statistics,
77 start_time=start_time,
78 end_time=end_time,
79 host=host,
80 history=history,
81 static_js="\n".join(static_js),
82 static_css="\n".join(static_css),
83 show_download_link=show_download_link,
84 locustfile=environment.locustfile,
85 tasks=escape(dumps(task_data)),
86 )
87
88 return res
89
[end of locust/html.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locust/html.py b/locust/html.py
--- a/locust/html.py
+++ b/locust/html.py
@@ -20,11 +20,11 @@
stats = environment.runner.stats
start_ts = stats.start_time
- start_time = datetime.datetime.fromtimestamp(start_ts).strftime("%Y-%m-%d %H:%M:%S")
+ start_time = datetime.datetime.utcfromtimestamp(start_ts).strftime("%Y-%m-%d %H:%M:%S")
end_ts = stats.last_request_timestamp
if end_ts:
- end_time = datetime.datetime.fromtimestamp(end_ts).strftime("%Y-%m-%d %H:%M:%S")
+ end_time = datetime.datetime.utcfromtimestamp(end_ts).strftime("%Y-%m-%d %H:%M:%S")
else:
end_time = start_time
|
{"golden_diff": "diff --git a/locust/html.py b/locust/html.py\n--- a/locust/html.py\n+++ b/locust/html.py\n@@ -20,11 +20,11 @@\n stats = environment.runner.stats\n \n start_ts = stats.start_time\n- start_time = datetime.datetime.fromtimestamp(start_ts).strftime(\"%Y-%m-%d %H:%M:%S\")\n+ start_time = datetime.datetime.utcfromtimestamp(start_ts).strftime(\"%Y-%m-%d %H:%M:%S\")\n \n end_ts = stats.last_request_timestamp\n if end_ts:\n- end_time = datetime.datetime.fromtimestamp(end_ts).strftime(\"%Y-%m-%d %H:%M:%S\")\n+ end_time = datetime.datetime.utcfromtimestamp(end_ts).strftime(\"%Y-%m-%d %H:%M:%S\")\n else:\n end_time = start_time\n", "issue": "the report cant show the right time\n<!-- \r\nIf you have a general question about how to use Locust, please check Stack Overflow first https://stackoverflow.com/questions/tagged/locust\r\n\r\nYou can also ask new questions on SO, https://stackoverflow.com/questions/ask just remember to tag your question with \"locust\". Do not immediately post your issue here after posting to SO, wait for an answer there instead.\r\n\r\nUse this form only for reporting actual bugs in Locust. Remember, the developers of Locust are unpaid volunteers, so make sure you have tried everything you can think of before filing a bug :) \r\n\r\nAlways make sure you are running an up to date Locust version (pip3 install -U locust)\r\n-->\r\n\r\n### Describe the bug\r\n<!-- A clear and concise description of what the bug is -->\r\n\r\n\r\nthis picture is right time i am in china\r\n\r\n\r\n### Expected behavior\r\n<!-- Tell us what you think should happen -->\r\nWrong time zone reported\r\n### Actual behavior\r\n<!-- Tell us what happens instead. Include screenshots if this an issue with the GUI. -->\r\n\r\n### Steps to reproduce\r\n<!-- Please provide a minimal reproducible code example (https://stackoverflow.com/help/minimal-reproducible-example) --> \r\n\r\n### Environment\r\n\r\n- OS:\r\n- Python version:\r\n- Locust version: (please dont file issues for anything but the most recent release or prerelease builds)\r\n- Locust command line that you ran:\r\n- Locust file contents (anonymized if necessary):\n", "before_files": [{"content": "from jinja2 import Environment, FileSystemLoader\nimport os\nimport pathlib\nimport datetime\nfrom itertools import chain\nfrom .stats import sort_stats\nfrom .user.inspectuser import get_task_ratio_dict\nfrom html import escape\nfrom json import dumps\n\n\ndef render_template(file, **kwargs):\n templates_path = os.path.join(pathlib.Path(__file__).parent.absolute(), \"templates\")\n env = Environment(loader=FileSystemLoader(templates_path), extensions=[\"jinja2.ext.do\"])\n template = env.get_template(file)\n return template.render(**kwargs)\n\n\ndef get_html_report(environment, show_download_link=True):\n stats = environment.runner.stats\n\n start_ts = stats.start_time\n start_time = datetime.datetime.fromtimestamp(start_ts).strftime(\"%Y-%m-%d %H:%M:%S\")\n\n end_ts = stats.last_request_timestamp\n if end_ts:\n end_time = datetime.datetime.fromtimestamp(end_ts).strftime(\"%Y-%m-%d %H:%M:%S\")\n else:\n end_time = start_time\n\n host = None\n if environment.host:\n host = environment.host\n elif environment.runner.user_classes:\n all_hosts = set([l.host for l in environment.runner.user_classes])\n if len(all_hosts) == 1:\n host = list(all_hosts)[0]\n\n requests_statistics = list(chain(sort_stats(stats.entries), [stats.total]))\n failures_statistics = sort_stats(stats.errors)\n exceptions_statistics = [\n {**exc, \"nodes\": \", \".join(exc[\"nodes\"])} for exc in environment.runner.exceptions.values()\n ]\n\n history = stats.history\n\n static_js = []\n js_files = [\"jquery-1.11.3.min.js\", \"echarts.common.min.js\", \"vintage.js\", \"chart.js\", \"tasks.js\"]\n for js_file in js_files:\n path = os.path.join(os.path.dirname(__file__), \"static\", js_file)\n static_js.append(\"// \" + js_file)\n with open(path, encoding=\"utf8\") as f:\n static_js.append(f.read())\n static_js.extend([\"\", \"\"])\n\n static_css = []\n css_files = [\"tables.css\"]\n for css_file in css_files:\n path = os.path.join(os.path.dirname(__file__), \"static\", \"css\", css_file)\n static_css.append(\"/* \" + css_file + \" */\")\n with open(path, encoding=\"utf8\") as f:\n static_css.append(f.read())\n static_css.extend([\"\", \"\"])\n\n task_data = {\n \"per_class\": get_task_ratio_dict(environment.user_classes),\n \"total\": get_task_ratio_dict(environment.user_classes, total=True),\n }\n\n res = render_template(\n \"report.html\",\n int=int,\n round=round,\n requests_statistics=requests_statistics,\n failures_statistics=failures_statistics,\n exceptions_statistics=exceptions_statistics,\n start_time=start_time,\n end_time=end_time,\n host=host,\n history=history,\n static_js=\"\\n\".join(static_js),\n static_css=\"\\n\".join(static_css),\n show_download_link=show_download_link,\n locustfile=environment.locustfile,\n tasks=escape(dumps(task_data)),\n )\n\n return res\n", "path": "locust/html.py"}]}
| 1,811 | 192 |
gh_patches_debug_15430
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-7097
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Weight based rates not working as expected
### What I'm trying to achieve
…
Hi there 😃 I think there is a bug when setting up shipping methods.
### Steps to reproduce the problem
1. Setup a "Weight Based Rate" and check the "There are no value limits" checkbox.
2. Go to the storefront checkout and see that the shipping method is not shown.
### What I expected to happen
I would expect "DHL Express" to show up when the "no value limits" is enabled instead of giving me an empty "availableShippingMethods" list?
### Screenshots
--- WITH "no value limits" DISABLED ---
--- WITH "no value limits" ENABLED ---
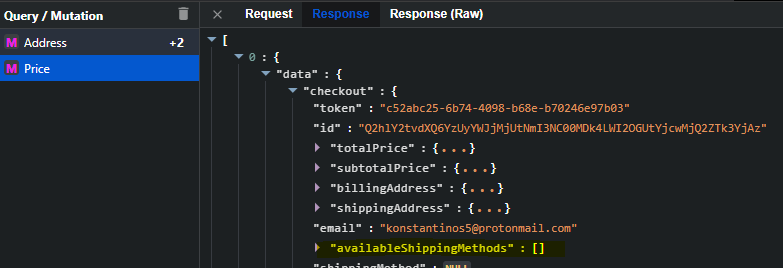
**System information**
Operating system: Windows 10 (WSL2)
Saleor/Saleor-storefront/Saleor-Dashboard version: 2.11
Apologies if I'm misunderstanding something or if this has already been raised - couldn't find it as an issue in any of the repos.
</issue>
<code>
[start of saleor/shipping/models.py]
1 from typing import TYPE_CHECKING, Union
2
3 from django.conf import settings
4 from django.db import models
5 from django.db.models import Q
6 from django_countries.fields import CountryField
7 from django_measurement.models import MeasurementField
8 from django_prices.models import MoneyField
9 from measurement.measures import Weight
10 from prices import Money, MoneyRange
11
12 from ..core.permissions import ShippingPermissions
13 from ..core.utils.translations import TranslationProxy
14 from ..core.weight import (
15 WeightUnits,
16 convert_weight,
17 get_default_weight_unit,
18 zero_weight,
19 )
20 from . import ShippingMethodType
21
22 if TYPE_CHECKING:
23 # flake8: noqa
24 from ..checkout.models import Checkout
25 from ..order.models import Order
26
27
28 def _applicable_weight_based_methods(weight, qs):
29 """Return weight based shipping methods that are applicable for the total weight."""
30 qs = qs.weight_based()
31 min_weight_matched = Q(minimum_order_weight__lte=weight)
32 no_weight_limit = Q(maximum_order_weight__isnull=True)
33 max_weight_matched = Q(maximum_order_weight__gte=weight)
34 return qs.filter(min_weight_matched & (no_weight_limit | max_weight_matched))
35
36
37 def _applicable_price_based_methods(price: Money, qs):
38 """Return price based shipping methods that are applicable for the given total."""
39 qs = qs.price_based()
40 min_price_matched = Q(minimum_order_price_amount__lte=price.amount)
41 no_price_limit = Q(maximum_order_price_amount__isnull=True)
42 max_price_matched = Q(maximum_order_price_amount__gte=price.amount)
43 return qs.filter(min_price_matched & (no_price_limit | max_price_matched))
44
45
46 def _get_weight_type_display(min_weight, max_weight):
47 default_unit = get_default_weight_unit()
48
49 if min_weight.unit != default_unit:
50 min_weight = convert_weight(min_weight, default_unit)
51 if max_weight and max_weight.unit != default_unit:
52 max_weight = convert_weight(max_weight, default_unit)
53
54 if max_weight is None:
55 return ("%(min_weight)s and up" % {"min_weight": min_weight},)
56 return "%(min_weight)s to %(max_weight)s" % {
57 "min_weight": min_weight,
58 "max_weight": max_weight,
59 }
60
61
62 class ShippingZone(models.Model):
63 name = models.CharField(max_length=100)
64 countries = CountryField(multiple=True, default=[], blank=True)
65 default = models.BooleanField(default=False)
66
67 def __str__(self):
68 return self.name
69
70 @property
71 def price_range(self):
72 prices = [
73 shipping_method.get_total()
74 for shipping_method in self.shipping_methods.all()
75 ]
76 if prices:
77 return MoneyRange(min(prices), max(prices))
78 return None
79
80 class Meta:
81 permissions = (
82 (ShippingPermissions.MANAGE_SHIPPING.codename, "Manage shipping."),
83 )
84
85
86 class ShippingMethodQueryset(models.QuerySet):
87 def price_based(self):
88 return self.filter(type=ShippingMethodType.PRICE_BASED)
89
90 def weight_based(self):
91 return self.filter(type=ShippingMethodType.WEIGHT_BASED)
92
93 def applicable_shipping_methods(self, price: Money, weight, country_code):
94 """Return the ShippingMethods that can be used on an order with shipment.
95
96 It is based on the given country code, and by shipping methods that are
97 applicable to the given price & weight total.
98 """
99 qs = self.filter(
100 shipping_zone__countries__contains=country_code, currency=price.currency,
101 )
102 qs = qs.prefetch_related("shipping_zone").order_by("price_amount")
103 price_based_methods = _applicable_price_based_methods(price, qs)
104 weight_based_methods = _applicable_weight_based_methods(weight, qs)
105 return price_based_methods | weight_based_methods
106
107 def applicable_shipping_methods_for_instance(
108 self, instance: Union["Checkout", "Order"], price: Money, country_code=None
109 ):
110 if not instance.is_shipping_required():
111 return None
112 if not instance.shipping_address:
113 return None
114
115 return self.applicable_shipping_methods(
116 price=price,
117 weight=instance.get_total_weight(),
118 country_code=country_code or instance.shipping_address.country.code,
119 )
120
121
122 class ShippingMethod(models.Model):
123 name = models.CharField(max_length=100)
124 type = models.CharField(max_length=30, choices=ShippingMethodType.CHOICES)
125 currency = models.CharField(
126 max_length=settings.DEFAULT_CURRENCY_CODE_LENGTH,
127 default=settings.DEFAULT_CURRENCY,
128 )
129 price_amount = models.DecimalField(
130 max_digits=settings.DEFAULT_MAX_DIGITS,
131 decimal_places=settings.DEFAULT_DECIMAL_PLACES,
132 default=0,
133 )
134 price = MoneyField(amount_field="price_amount", currency_field="currency")
135 shipping_zone = models.ForeignKey(
136 ShippingZone, related_name="shipping_methods", on_delete=models.CASCADE
137 )
138
139 minimum_order_price_amount = models.DecimalField(
140 max_digits=settings.DEFAULT_MAX_DIGITS,
141 decimal_places=settings.DEFAULT_DECIMAL_PLACES,
142 default=0,
143 blank=True,
144 null=True,
145 )
146 minimum_order_price = MoneyField(
147 amount_field="minimum_order_price_amount", currency_field="currency"
148 )
149
150 maximum_order_price_amount = models.DecimalField(
151 max_digits=settings.DEFAULT_MAX_DIGITS,
152 decimal_places=settings.DEFAULT_DECIMAL_PLACES,
153 blank=True,
154 null=True,
155 )
156 maximum_order_price = MoneyField(
157 amount_field="maximum_order_price_amount", currency_field="currency"
158 )
159
160 minimum_order_weight = MeasurementField(
161 measurement=Weight,
162 unit_choices=WeightUnits.CHOICES,
163 default=zero_weight,
164 blank=True,
165 null=True,
166 )
167 maximum_order_weight = MeasurementField(
168 measurement=Weight, unit_choices=WeightUnits.CHOICES, blank=True, null=True
169 )
170
171 objects = ShippingMethodQueryset.as_manager()
172 translated = TranslationProxy()
173
174 class Meta:
175 ordering = ("pk",)
176
177 def __str__(self):
178 return self.name
179
180 def __repr__(self):
181 if self.type == ShippingMethodType.PRICE_BASED:
182 minimum = "%s%s" % (
183 self.minimum_order_price.amount,
184 self.minimum_order_price.currency,
185 )
186 max_price = self.maximum_order_price
187 maximum = (
188 "%s%s" % (max_price.amount, max_price.currency)
189 if max_price
190 else "no limit"
191 )
192 return "ShippingMethod(type=%s min=%s, max=%s)" % (
193 self.type,
194 minimum,
195 maximum,
196 )
197 return "ShippingMethod(type=%s weight_range=(%s)" % (
198 self.type,
199 _get_weight_type_display(
200 self.minimum_order_weight, self.maximum_order_weight
201 ),
202 )
203
204 def get_total(self):
205 return self.price
206
207
208 class ShippingMethodTranslation(models.Model):
209 language_code = models.CharField(max_length=10)
210 name = models.CharField(max_length=255, null=True, blank=True)
211 shipping_method = models.ForeignKey(
212 ShippingMethod, related_name="translations", on_delete=models.CASCADE
213 )
214
215 class Meta:
216 unique_together = (("language_code", "shipping_method"),)
217
[end of saleor/shipping/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/shipping/models.py b/saleor/shipping/models.py
--- a/saleor/shipping/models.py
+++ b/saleor/shipping/models.py
@@ -28,10 +28,13 @@
def _applicable_weight_based_methods(weight, qs):
"""Return weight based shipping methods that are applicable for the total weight."""
qs = qs.weight_based()
- min_weight_matched = Q(minimum_order_weight__lte=weight)
- no_weight_limit = Q(maximum_order_weight__isnull=True)
- max_weight_matched = Q(maximum_order_weight__gte=weight)
- return qs.filter(min_weight_matched & (no_weight_limit | max_weight_matched))
+ min_weight_matched = Q(minimum_order_weight__lte=weight) | Q(
+ minimum_order_weight__isnull=True
+ )
+ max_weight_matched = Q(maximum_order_weight__gte=weight) | Q(
+ maximum_order_weight__isnull=True
+ )
+ return qs.filter(min_weight_matched & max_weight_matched)
def _applicable_price_based_methods(price: Money, qs):
|
{"golden_diff": "diff --git a/saleor/shipping/models.py b/saleor/shipping/models.py\n--- a/saleor/shipping/models.py\n+++ b/saleor/shipping/models.py\n@@ -28,10 +28,13 @@\n def _applicable_weight_based_methods(weight, qs):\n \"\"\"Return weight based shipping methods that are applicable for the total weight.\"\"\"\n qs = qs.weight_based()\n- min_weight_matched = Q(minimum_order_weight__lte=weight)\n- no_weight_limit = Q(maximum_order_weight__isnull=True)\n- max_weight_matched = Q(maximum_order_weight__gte=weight)\n- return qs.filter(min_weight_matched & (no_weight_limit | max_weight_matched))\n+ min_weight_matched = Q(minimum_order_weight__lte=weight) | Q(\n+ minimum_order_weight__isnull=True\n+ )\n+ max_weight_matched = Q(maximum_order_weight__gte=weight) | Q(\n+ maximum_order_weight__isnull=True\n+ )\n+ return qs.filter(min_weight_matched & max_weight_matched)\n \n \n def _applicable_price_based_methods(price: Money, qs):\n", "issue": "Weight based rates not working as expected\n### What I'm trying to achieve\r\n\u2026\r\nHi there \ud83d\ude03 I think there is a bug when setting up shipping methods. \r\n### Steps to reproduce the problem\r\n1. Setup a \"Weight Based Rate\" and check the \"There are no value limits\" checkbox.\r\n2. Go to the storefront checkout and see that the shipping method is not shown.\r\n\r\n### What I expected to happen\r\nI would expect \"DHL Express\" to show up when the \"no value limits\" is enabled instead of giving me an empty \"availableShippingMethods\" list?\r\n\r\n### Screenshots\r\n--- WITH \"no value limits\" DISABLED ---\r\n\r\n\r\n\r\n\r\n\r\n--- WITH \"no value limits\" ENABLED ---\r\n\r\n\r\n\r\n\r\n\r\n\r\n**System information**\r\nOperating system: Windows 10 (WSL2)\r\nSaleor/Saleor-storefront/Saleor-Dashboard version: 2.11\r\n\r\nApologies if I'm misunderstanding something or if this has already been raised - couldn't find it as an issue in any of the repos.\n", "before_files": [{"content": "from typing import TYPE_CHECKING, Union\n\nfrom django.conf import settings\nfrom django.db import models\nfrom django.db.models import Q\nfrom django_countries.fields import CountryField\nfrom django_measurement.models import MeasurementField\nfrom django_prices.models import MoneyField\nfrom measurement.measures import Weight\nfrom prices import Money, MoneyRange\n\nfrom ..core.permissions import ShippingPermissions\nfrom ..core.utils.translations import TranslationProxy\nfrom ..core.weight import (\n WeightUnits,\n convert_weight,\n get_default_weight_unit,\n zero_weight,\n)\nfrom . import ShippingMethodType\n\nif TYPE_CHECKING:\n # flake8: noqa\n from ..checkout.models import Checkout\n from ..order.models import Order\n\n\ndef _applicable_weight_based_methods(weight, qs):\n \"\"\"Return weight based shipping methods that are applicable for the total weight.\"\"\"\n qs = qs.weight_based()\n min_weight_matched = Q(minimum_order_weight__lte=weight)\n no_weight_limit = Q(maximum_order_weight__isnull=True)\n max_weight_matched = Q(maximum_order_weight__gte=weight)\n return qs.filter(min_weight_matched & (no_weight_limit | max_weight_matched))\n\n\ndef _applicable_price_based_methods(price: Money, qs):\n \"\"\"Return price based shipping methods that are applicable for the given total.\"\"\"\n qs = qs.price_based()\n min_price_matched = Q(minimum_order_price_amount__lte=price.amount)\n no_price_limit = Q(maximum_order_price_amount__isnull=True)\n max_price_matched = Q(maximum_order_price_amount__gte=price.amount)\n return qs.filter(min_price_matched & (no_price_limit | max_price_matched))\n\n\ndef _get_weight_type_display(min_weight, max_weight):\n default_unit = get_default_weight_unit()\n\n if min_weight.unit != default_unit:\n min_weight = convert_weight(min_weight, default_unit)\n if max_weight and max_weight.unit != default_unit:\n max_weight = convert_weight(max_weight, default_unit)\n\n if max_weight is None:\n return (\"%(min_weight)s and up\" % {\"min_weight\": min_weight},)\n return \"%(min_weight)s to %(max_weight)s\" % {\n \"min_weight\": min_weight,\n \"max_weight\": max_weight,\n }\n\n\nclass ShippingZone(models.Model):\n name = models.CharField(max_length=100)\n countries = CountryField(multiple=True, default=[], blank=True)\n default = models.BooleanField(default=False)\n\n def __str__(self):\n return self.name\n\n @property\n def price_range(self):\n prices = [\n shipping_method.get_total()\n for shipping_method in self.shipping_methods.all()\n ]\n if prices:\n return MoneyRange(min(prices), max(prices))\n return None\n\n class Meta:\n permissions = (\n (ShippingPermissions.MANAGE_SHIPPING.codename, \"Manage shipping.\"),\n )\n\n\nclass ShippingMethodQueryset(models.QuerySet):\n def price_based(self):\n return self.filter(type=ShippingMethodType.PRICE_BASED)\n\n def weight_based(self):\n return self.filter(type=ShippingMethodType.WEIGHT_BASED)\n\n def applicable_shipping_methods(self, price: Money, weight, country_code):\n \"\"\"Return the ShippingMethods that can be used on an order with shipment.\n\n It is based on the given country code, and by shipping methods that are\n applicable to the given price & weight total.\n \"\"\"\n qs = self.filter(\n shipping_zone__countries__contains=country_code, currency=price.currency,\n )\n qs = qs.prefetch_related(\"shipping_zone\").order_by(\"price_amount\")\n price_based_methods = _applicable_price_based_methods(price, qs)\n weight_based_methods = _applicable_weight_based_methods(weight, qs)\n return price_based_methods | weight_based_methods\n\n def applicable_shipping_methods_for_instance(\n self, instance: Union[\"Checkout\", \"Order\"], price: Money, country_code=None\n ):\n if not instance.is_shipping_required():\n return None\n if not instance.shipping_address:\n return None\n\n return self.applicable_shipping_methods(\n price=price,\n weight=instance.get_total_weight(),\n country_code=country_code or instance.shipping_address.country.code,\n )\n\n\nclass ShippingMethod(models.Model):\n name = models.CharField(max_length=100)\n type = models.CharField(max_length=30, choices=ShippingMethodType.CHOICES)\n currency = models.CharField(\n max_length=settings.DEFAULT_CURRENCY_CODE_LENGTH,\n default=settings.DEFAULT_CURRENCY,\n )\n price_amount = models.DecimalField(\n max_digits=settings.DEFAULT_MAX_DIGITS,\n decimal_places=settings.DEFAULT_DECIMAL_PLACES,\n default=0,\n )\n price = MoneyField(amount_field=\"price_amount\", currency_field=\"currency\")\n shipping_zone = models.ForeignKey(\n ShippingZone, related_name=\"shipping_methods\", on_delete=models.CASCADE\n )\n\n minimum_order_price_amount = models.DecimalField(\n max_digits=settings.DEFAULT_MAX_DIGITS,\n decimal_places=settings.DEFAULT_DECIMAL_PLACES,\n default=0,\n blank=True,\n null=True,\n )\n minimum_order_price = MoneyField(\n amount_field=\"minimum_order_price_amount\", currency_field=\"currency\"\n )\n\n maximum_order_price_amount = models.DecimalField(\n max_digits=settings.DEFAULT_MAX_DIGITS,\n decimal_places=settings.DEFAULT_DECIMAL_PLACES,\n blank=True,\n null=True,\n )\n maximum_order_price = MoneyField(\n amount_field=\"maximum_order_price_amount\", currency_field=\"currency\"\n )\n\n minimum_order_weight = MeasurementField(\n measurement=Weight,\n unit_choices=WeightUnits.CHOICES,\n default=zero_weight,\n blank=True,\n null=True,\n )\n maximum_order_weight = MeasurementField(\n measurement=Weight, unit_choices=WeightUnits.CHOICES, blank=True, null=True\n )\n\n objects = ShippingMethodQueryset.as_manager()\n translated = TranslationProxy()\n\n class Meta:\n ordering = (\"pk\",)\n\n def __str__(self):\n return self.name\n\n def __repr__(self):\n if self.type == ShippingMethodType.PRICE_BASED:\n minimum = \"%s%s\" % (\n self.minimum_order_price.amount,\n self.minimum_order_price.currency,\n )\n max_price = self.maximum_order_price\n maximum = (\n \"%s%s\" % (max_price.amount, max_price.currency)\n if max_price\n else \"no limit\"\n )\n return \"ShippingMethod(type=%s min=%s, max=%s)\" % (\n self.type,\n minimum,\n maximum,\n )\n return \"ShippingMethod(type=%s weight_range=(%s)\" % (\n self.type,\n _get_weight_type_display(\n self.minimum_order_weight, self.maximum_order_weight\n ),\n )\n\n def get_total(self):\n return self.price\n\n\nclass ShippingMethodTranslation(models.Model):\n language_code = models.CharField(max_length=10)\n name = models.CharField(max_length=255, null=True, blank=True)\n shipping_method = models.ForeignKey(\n ShippingMethod, related_name=\"translations\", on_delete=models.CASCADE\n )\n\n class Meta:\n unique_together = ((\"language_code\", \"shipping_method\"),)\n", "path": "saleor/shipping/models.py"}]}
| 3,076 | 244 |
gh_patches_debug_5677
|
rasdani/github-patches
|
git_diff
|
huggingface__diffusers-5115
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
convert_original_stable_diffison script have issue
https://github.com/huggingface/diffusers/blob/8263cf00f832399bca215e29fa7572e0b0bde4da/scripts/convert_original_stable_diffusion_to_diffusers.py#L157C9-L157C40
config_files command line argment is not include in this script.
I think we need to add this code
parser.add_argument(
"--config_files",
default=None,
type=str,
help="The YAML config file corresponding to the original architecture.",
)
</issue>
<code>
[start of scripts/convert_original_stable_diffusion_to_diffusers.py]
1 # coding=utf-8
2 # Copyright 2023 The HuggingFace Inc. team.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """ Conversion script for the LDM checkpoints. """
16
17 import argparse
18 import importlib
19
20 import torch
21
22 from diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt
23
24
25 if __name__ == "__main__":
26 parser = argparse.ArgumentParser()
27
28 parser.add_argument(
29 "--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
30 )
31 # !wget https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml
32 parser.add_argument(
33 "--original_config_file",
34 default=None,
35 type=str,
36 help="The YAML config file corresponding to the original architecture.",
37 )
38 parser.add_argument(
39 "--num_in_channels",
40 default=None,
41 type=int,
42 help="The number of input channels. If `None` number of input channels will be automatically inferred.",
43 )
44 parser.add_argument(
45 "--scheduler_type",
46 default="pndm",
47 type=str,
48 help="Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']",
49 )
50 parser.add_argument(
51 "--pipeline_type",
52 default=None,
53 type=str,
54 help=(
55 "The pipeline type. One of 'FrozenOpenCLIPEmbedder', 'FrozenCLIPEmbedder', 'PaintByExample'"
56 ". If `None` pipeline will be automatically inferred."
57 ),
58 )
59 parser.add_argument(
60 "--image_size",
61 default=None,
62 type=int,
63 help=(
64 "The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Siffusion v2"
65 " Base. Use 768 for Stable Diffusion v2."
66 ),
67 )
68 parser.add_argument(
69 "--prediction_type",
70 default=None,
71 type=str,
72 help=(
73 "The prediction type that the model was trained on. Use 'epsilon' for Stable Diffusion v1.X and Stable"
74 " Diffusion v2 Base. Use 'v_prediction' for Stable Diffusion v2."
75 ),
76 )
77 parser.add_argument(
78 "--extract_ema",
79 action="store_true",
80 help=(
81 "Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
82 " or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
83 " higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
84 ),
85 )
86 parser.add_argument(
87 "--upcast_attention",
88 action="store_true",
89 help=(
90 "Whether the attention computation should always be upcasted. This is necessary when running stable"
91 " diffusion 2.1."
92 ),
93 )
94 parser.add_argument(
95 "--from_safetensors",
96 action="store_true",
97 help="If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.",
98 )
99 parser.add_argument(
100 "--to_safetensors",
101 action="store_true",
102 help="Whether to store pipeline in safetensors format or not.",
103 )
104 parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
105 parser.add_argument("--device", type=str, help="Device to use (e.g. cpu, cuda:0, cuda:1, etc.)")
106 parser.add_argument(
107 "--stable_unclip",
108 type=str,
109 default=None,
110 required=False,
111 help="Set if this is a stable unCLIP model. One of 'txt2img' or 'img2img'.",
112 )
113 parser.add_argument(
114 "--stable_unclip_prior",
115 type=str,
116 default=None,
117 required=False,
118 help="Set if this is a stable unCLIP txt2img model. Selects which prior to use. If `--stable_unclip` is set to `txt2img`, the karlo prior (https://huggingface.co/kakaobrain/karlo-v1-alpha/tree/main/prior) is selected by default.",
119 )
120 parser.add_argument(
121 "--clip_stats_path",
122 type=str,
123 help="Path to the clip stats file. Only required if the stable unclip model's config specifies `model.params.noise_aug_config.params.clip_stats_path`.",
124 required=False,
125 )
126 parser.add_argument(
127 "--controlnet", action="store_true", default=None, help="Set flag if this is a controlnet checkpoint."
128 )
129 parser.add_argument("--half", action="store_true", help="Save weights in half precision.")
130 parser.add_argument(
131 "--vae_path",
132 type=str,
133 default=None,
134 required=False,
135 help="Set to a path, hub id to an already converted vae to not convert it again.",
136 )
137 parser.add_argument(
138 "--pipeline_class_name",
139 type=str,
140 default=None,
141 required=False,
142 help="Specify the pipeline class name",
143 )
144
145 args = parser.parse_args()
146
147 if args.pipeline_class_name is not None:
148 library = importlib.import_module("diffusers")
149 class_obj = getattr(library, args.pipeline_class_name)
150 pipeline_class = class_obj
151 else:
152 pipeline_class = None
153
154 pipe = download_from_original_stable_diffusion_ckpt(
155 checkpoint_path_or_dict=args.checkpoint_path,
156 original_config_file=args.original_config_file,
157 config_files=args.config_files,
158 image_size=args.image_size,
159 prediction_type=args.prediction_type,
160 model_type=args.pipeline_type,
161 extract_ema=args.extract_ema,
162 scheduler_type=args.scheduler_type,
163 num_in_channels=args.num_in_channels,
164 upcast_attention=args.upcast_attention,
165 from_safetensors=args.from_safetensors,
166 device=args.device,
167 stable_unclip=args.stable_unclip,
168 stable_unclip_prior=args.stable_unclip_prior,
169 clip_stats_path=args.clip_stats_path,
170 controlnet=args.controlnet,
171 vae_path=args.vae_path,
172 pipeline_class=pipeline_class,
173 )
174
175 if args.half:
176 pipe.to(torch_dtype=torch.float16)
177
178 if args.controlnet:
179 # only save the controlnet model
180 pipe.controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
181 else:
182 pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)
183
[end of scripts/convert_original_stable_diffusion_to_diffusers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/convert_original_stable_diffusion_to_diffusers.py b/scripts/convert_original_stable_diffusion_to_diffusers.py
--- a/scripts/convert_original_stable_diffusion_to_diffusers.py
+++ b/scripts/convert_original_stable_diffusion_to_diffusers.py
@@ -35,6 +35,12 @@
type=str,
help="The YAML config file corresponding to the original architecture.",
)
+ parser.add_argument(
+ "--config_files",
+ default=None,
+ type=str,
+ help="The YAML config file corresponding to the architecture.",
+ )
parser.add_argument(
"--num_in_channels",
default=None,
|
{"golden_diff": "diff --git a/scripts/convert_original_stable_diffusion_to_diffusers.py b/scripts/convert_original_stable_diffusion_to_diffusers.py\n--- a/scripts/convert_original_stable_diffusion_to_diffusers.py\n+++ b/scripts/convert_original_stable_diffusion_to_diffusers.py\n@@ -35,6 +35,12 @@\n type=str,\n help=\"The YAML config file corresponding to the original architecture.\",\n )\n+ parser.add_argument(\n+ \"--config_files\",\n+ default=None,\n+ type=str,\n+ help=\"The YAML config file corresponding to the architecture.\",\n+ )\n parser.add_argument(\n \"--num_in_channels\",\n default=None,\n", "issue": "convert_original_stable_diffison script have issue\nhttps://github.com/huggingface/diffusers/blob/8263cf00f832399bca215e29fa7572e0b0bde4da/scripts/convert_original_stable_diffusion_to_diffusers.py#L157C9-L157C40\r\n\r\nconfig_files command line argment is not include in this script.\r\nI think we need to add this code\r\n\r\nparser.add_argument(\r\n \"--config_files\",\r\n default=None,\r\n type=str,\r\n help=\"The YAML config file corresponding to the original architecture.\",\r\n )\n", "before_files": [{"content": "# coding=utf-8\n# Copyright 2023 The HuggingFace Inc. team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\" Conversion script for the LDM checkpoints. \"\"\"\n\nimport argparse\nimport importlib\n\nimport torch\n\nfrom diffusers.pipelines.stable_diffusion.convert_from_ckpt import download_from_original_stable_diffusion_ckpt\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser()\n\n parser.add_argument(\n \"--checkpoint_path\", default=None, type=str, required=True, help=\"Path to the checkpoint to convert.\"\n )\n # !wget https://raw.githubusercontent.com/CompVis/stable-diffusion/main/configs/stable-diffusion/v1-inference.yaml\n parser.add_argument(\n \"--original_config_file\",\n default=None,\n type=str,\n help=\"The YAML config file corresponding to the original architecture.\",\n )\n parser.add_argument(\n \"--num_in_channels\",\n default=None,\n type=int,\n help=\"The number of input channels. If `None` number of input channels will be automatically inferred.\",\n )\n parser.add_argument(\n \"--scheduler_type\",\n default=\"pndm\",\n type=str,\n help=\"Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']\",\n )\n parser.add_argument(\n \"--pipeline_type\",\n default=None,\n type=str,\n help=(\n \"The pipeline type. One of 'FrozenOpenCLIPEmbedder', 'FrozenCLIPEmbedder', 'PaintByExample'\"\n \". If `None` pipeline will be automatically inferred.\"\n ),\n )\n parser.add_argument(\n \"--image_size\",\n default=None,\n type=int,\n help=(\n \"The image size that the model was trained on. Use 512 for Stable Diffusion v1.X and Stable Siffusion v2\"\n \" Base. Use 768 for Stable Diffusion v2.\"\n ),\n )\n parser.add_argument(\n \"--prediction_type\",\n default=None,\n type=str,\n help=(\n \"The prediction type that the model was trained on. Use 'epsilon' for Stable Diffusion v1.X and Stable\"\n \" Diffusion v2 Base. Use 'v_prediction' for Stable Diffusion v2.\"\n ),\n )\n parser.add_argument(\n \"--extract_ema\",\n action=\"store_true\",\n help=(\n \"Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights\"\n \" or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield\"\n \" higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning.\"\n ),\n )\n parser.add_argument(\n \"--upcast_attention\",\n action=\"store_true\",\n help=(\n \"Whether the attention computation should always be upcasted. This is necessary when running stable\"\n \" diffusion 2.1.\"\n ),\n )\n parser.add_argument(\n \"--from_safetensors\",\n action=\"store_true\",\n help=\"If `--checkpoint_path` is in `safetensors` format, load checkpoint with safetensors instead of PyTorch.\",\n )\n parser.add_argument(\n \"--to_safetensors\",\n action=\"store_true\",\n help=\"Whether to store pipeline in safetensors format or not.\",\n )\n parser.add_argument(\"--dump_path\", default=None, type=str, required=True, help=\"Path to the output model.\")\n parser.add_argument(\"--device\", type=str, help=\"Device to use (e.g. cpu, cuda:0, cuda:1, etc.)\")\n parser.add_argument(\n \"--stable_unclip\",\n type=str,\n default=None,\n required=False,\n help=\"Set if this is a stable unCLIP model. One of 'txt2img' or 'img2img'.\",\n )\n parser.add_argument(\n \"--stable_unclip_prior\",\n type=str,\n default=None,\n required=False,\n help=\"Set if this is a stable unCLIP txt2img model. Selects which prior to use. If `--stable_unclip` is set to `txt2img`, the karlo prior (https://huggingface.co/kakaobrain/karlo-v1-alpha/tree/main/prior) is selected by default.\",\n )\n parser.add_argument(\n \"--clip_stats_path\",\n type=str,\n help=\"Path to the clip stats file. Only required if the stable unclip model's config specifies `model.params.noise_aug_config.params.clip_stats_path`.\",\n required=False,\n )\n parser.add_argument(\n \"--controlnet\", action=\"store_true\", default=None, help=\"Set flag if this is a controlnet checkpoint.\"\n )\n parser.add_argument(\"--half\", action=\"store_true\", help=\"Save weights in half precision.\")\n parser.add_argument(\n \"--vae_path\",\n type=str,\n default=None,\n required=False,\n help=\"Set to a path, hub id to an already converted vae to not convert it again.\",\n )\n parser.add_argument(\n \"--pipeline_class_name\",\n type=str,\n default=None,\n required=False,\n help=\"Specify the pipeline class name\",\n )\n\n args = parser.parse_args()\n\n if args.pipeline_class_name is not None:\n library = importlib.import_module(\"diffusers\")\n class_obj = getattr(library, args.pipeline_class_name)\n pipeline_class = class_obj\n else:\n pipeline_class = None\n\n pipe = download_from_original_stable_diffusion_ckpt(\n checkpoint_path_or_dict=args.checkpoint_path,\n original_config_file=args.original_config_file,\n config_files=args.config_files,\n image_size=args.image_size,\n prediction_type=args.prediction_type,\n model_type=args.pipeline_type,\n extract_ema=args.extract_ema,\n scheduler_type=args.scheduler_type,\n num_in_channels=args.num_in_channels,\n upcast_attention=args.upcast_attention,\n from_safetensors=args.from_safetensors,\n device=args.device,\n stable_unclip=args.stable_unclip,\n stable_unclip_prior=args.stable_unclip_prior,\n clip_stats_path=args.clip_stats_path,\n controlnet=args.controlnet,\n vae_path=args.vae_path,\n pipeline_class=pipeline_class,\n )\n\n if args.half:\n pipe.to(torch_dtype=torch.float16)\n\n if args.controlnet:\n # only save the controlnet model\n pipe.controlnet.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)\n else:\n pipe.save_pretrained(args.dump_path, safe_serialization=args.to_safetensors)\n", "path": "scripts/convert_original_stable_diffusion_to_diffusers.py"}]}
| 2,682 | 145 |
gh_patches_debug_38322
|
rasdani/github-patches
|
git_diff
|
pyodide__pyodide-3533
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CSS broken in latest docs
## 🐛 Bug

It seems like the versionwarning banner is not displayed correctly in latest docs.
</issue>
<code>
[start of docs/conf.py]
1 # Configuration file for the Sphinx documentation builder.
2
3 # -- Path setup --------------------------------------------------------------
4
5 import atexit
6 import os
7 import shutil
8 import subprocess
9 import sys
10 from pathlib import Path
11 from typing import Any
12 from unittest import mock
13
14 import micropip
15
16 panels_add_bootstrap_css = False
17
18 # -- Project information -----------------------------------------------------
19
20 project = "Pyodide"
21 copyright = "2019-2022, Pyodide contributors and Mozilla"
22
23 # -- General configuration ---------------------------------------------------
24
25 # If your documentation needs a minimal Sphinx version, state it here.
26 #
27 # needs_sphinx = '1.0'
28
29 extensions = [
30 "sphinx.ext.autodoc",
31 "sphinx.ext.autosummary",
32 "sphinx.ext.intersphinx",
33 "sphinx.ext.napoleon",
34 "myst_parser",
35 "sphinx_js",
36 "sphinx_click",
37 "autodocsumm",
38 "sphinx_pyodide",
39 "sphinx_argparse_cli",
40 "versionwarning.extension",
41 "sphinx_issues",
42 "sphinx_autodoc_typehints",
43 "sphinx_design", # Used for tabs in building-from-sources.md
44 ]
45
46
47 myst_enable_extensions = ["substitution"]
48
49 js_language = "typescript"
50 jsdoc_config_path = "../src/js/tsconfig.json"
51 root_for_relative_js_paths = "../src/"
52 issues_github_path = "pyodide/pyodide"
53
54 versionwarning_messages = {
55 "latest": (
56 "This is the development version of the documentation. "
57 'See <a href="https://pyodide.org/">here</a> for latest stable '
58 "documentation. Please do not use Pyodide with non "
59 "versioned (`dev`) URLs from the CDN for deployed applications!"
60 )
61 }
62 versionwarning_body_selector = "#main-content > div"
63
64 autosummary_generate = True
65 autodoc_default_flags = ["members", "inherited-members"]
66
67 intersphinx_mapping = {
68 "python": ("https://docs.python.org/3.10", None),
69 "micropip": (f"https://micropip.pyodide.org/en/v{micropip.__version__}/", None),
70 "numpy": ("https://numpy.org/doc/stable/", None),
71 }
72
73 # Add modules to be mocked.
74 mock_modules = ["tomli"]
75
76 # Add any paths that contain templates here, relative to this directory.
77 templates_path = ["_templates"]
78
79 # The suffix(es) of source filenames.
80 source_suffix = [".rst", ".md"]
81
82 # The master toctree document.
83 master_doc = "index"
84
85 # List of patterns, relative to source directory, that match files and
86 # directories to ignore when looking for source files.
87 exclude_patterns = [
88 "_build",
89 "Thumbs.db",
90 ".DS_Store",
91 "README.md",
92 "sphinx_pyodide",
93 ".*",
94 ]
95
96 # The name of the Pygments (syntax highlighting) style to use.
97 pygments_style = None
98
99 # -- Options for HTML output -------------------------------------------------
100
101 # The theme to use for HTML and HTML Help pages. See the documentation for
102 # a list of builtin themes.
103 #
104 html_theme = "sphinx_book_theme"
105 html_logo = "_static/img/pyodide-logo.png"
106
107 # theme-specific options
108 html_theme_options: dict[str, Any] = {}
109
110 # paths that contain custom static files (such as style sheets)
111 html_static_path = ["_static"]
112
113
114 html_css_files = [
115 "css/pyodide.css",
116 ]
117
118 # Custom sidebar templates, must be a dictionary that maps document names
119 # to template names.
120 # html_sidebars = {}
121
122 # -- Options for HTMLHelp output ---------------------------------------------
123
124 # Output file base name for HTML help builder.
125 htmlhelp_basename = "Pyodidedoc"
126
127 # A list of files that should not be packed into the epub file.
128 epub_exclude_files = ["search.html"]
129
130 # Try not to cause side effects if we are imported incidentally.
131
132 IN_SPHINX = "sphinx" in sys.modules and hasattr(sys.modules["sphinx"], "application")
133 IN_READTHEDOCS = "READTHEDOCS" in os.environ
134
135
136 base_dir = Path(__file__).resolve().parent.parent
137 extra_sys_path_dirs = [
138 str(base_dir),
139 str(base_dir / "pyodide-build"),
140 str(base_dir / "src/py"),
141 str(base_dir / "packages/micropip/src"),
142 ]
143
144
145 if IN_SPHINX:
146 # sphinx_pyodide is imported before setup() is called because it's a sphinx
147 # extension, so we need it to be on the path early. Everything else can be
148 # added to the path in setup().
149 #
150 # TODO: pip install -e sphinx-pyodide instead.
151 sys.path = [str(base_dir / "docs/sphinx_pyodide")] + sys.path
152
153
154 def patch_docs_argspec():
155 import builtins
156
157 from sphinx_pyodide.util import docs_argspec
158
159 # override docs_argspec, _pyodide.docs_argspec will read this value back.
160 # Must do this before importing pyodide!
161 setattr(builtins, "--docs_argspec--", docs_argspec)
162
163
164 def patch_inspect():
165 # Monkey patch for python3.11 incompatible code
166 import inspect
167
168 if not hasattr(inspect, "getargspec"):
169 inspect.getargspec = inspect.getfullargspec # type: ignore[assignment]
170
171
172 def prevent_parens_after_js_class_xrefs():
173 from sphinx.domains.javascript import JavaScriptDomain, JSXRefRole
174
175 JavaScriptDomain.roles["class"] = JSXRefRole()
176
177
178 def apply_patches():
179 patch_docs_argspec()
180 patch_inspect()
181 prevent_parens_after_js_class_xrefs()
182
183
184 def calculate_pyodide_version(app):
185 import pyodide
186
187 config = app.config
188
189 # The full version, including alpha/beta/rc tags.
190 config.release = config.version = version = pyodide.__version__
191
192 if ".dev" in version or os.environ.get("READTHEDOCS_VERSION") == "latest":
193 CDN_URL = "https://cdn.jsdelivr.net/pyodide/dev/full/"
194 else:
195 CDN_URL = f"https://cdn.jsdelivr.net/pyodide/v{version}/full/"
196
197 app.config.CDN_URL = CDN_URL
198 app.config.html_title = f"Version {version}"
199
200 app.config.global_replacements = {
201 "{{PYODIDE_CDN_URL}}": CDN_URL,
202 "{{VERSION}}": version,
203 }
204
205
206 def write_console_html(app):
207 # Make console.html file
208 env = {"PYODIDE_BASE_URL": app.config.CDN_URL}
209 os.makedirs(app.outdir, exist_ok=True)
210 os.makedirs("../dist", exist_ok=True)
211 res = subprocess.check_output(
212 ["make", "-C", "..", "dist/console.html"],
213 env=env,
214 stderr=subprocess.STDOUT,
215 encoding="utf-8",
216 )
217 print(res)
218
219 # insert the Plausible analytics script to console.html
220 console_html_lines = (
221 Path("../dist/console.html").read_text().splitlines(keepends=True)
222 )
223 for idx, line in enumerate(list(console_html_lines)):
224 if 'pyodide.js">' in line:
225 # insert the analytics script after the `pyodide.js` script
226 console_html_lines.insert(
227 idx,
228 '<script defer data-domain="pyodide.org" src="https://plausible.io/js/plausible.js"></script>\n',
229 )
230 break
231 else:
232 raise ValueError("Could not find pyodide.js in the <head> section")
233 output_path = Path(app.outdir) / "console.html"
234 output_path.write_text("".join(console_html_lines))
235
236
237 def ensure_typedoc_on_path():
238 if shutil.which("typedoc"):
239 return
240 os.environ["PATH"] += f':{str(Path("../src/js/node_modules/.bin").resolve())}'
241 print(os.environ["PATH"])
242 if shutil.which("typedoc"):
243 return
244 if IN_READTHEDOCS:
245 subprocess.run(["npm", "ci"], cwd="../src/js")
246 if shutil.which("typedoc"):
247 return
248 raise Exception(
249 "Before building the Pyodide docs you must run 'npm install' in 'src/js'."
250 )
251
252
253 def create_generated_typescript_files(app):
254 shutil.copy("../src/core/pyproxy.ts", "../src/js/pyproxy.gen.ts")
255 shutil.copy("../src/core/error_handling.ts", "../src/js/error_handling.gen.ts")
256 app.config.js_source_path = [str(x) for x in Path("../src/js").glob("*.ts")]
257
258 def remove_pyproxy_gen_ts():
259 Path("../src/js/pyproxy.gen.ts").unlink(missing_ok=True)
260
261 atexit.register(remove_pyproxy_gen_ts)
262
263
264 def prune_webloop_docs():
265 # Prevent API docs for webloop methods: they are the same as for base event loop
266 # and it clutters api docs too much
267 from sphinx_pyodide.util import delete_attrs
268
269 import pyodide.console
270 import pyodide.webloop
271
272 delete_attrs(pyodide.webloop.WebLoop)
273 delete_attrs(pyodide.webloop.WebLoopPolicy)
274 delete_attrs(pyodide.console.PyodideConsole)
275
276 for module in mock_modules:
277 sys.modules[module] = mock.Mock()
278
279
280 def prune_jsproxy_constructor_docs():
281 from pyodide.ffi import JsProxy
282
283 del JsProxy.__new__
284
285
286 def prune_docs():
287 prune_webloop_docs()
288 prune_jsproxy_constructor_docs()
289
290
291 # https://github.com/sphinx-doc/sphinx/issues/4054
292 def global_replace(app, docname, source):
293 result = source[0]
294 for key in app.config.global_replacements:
295 result = result.replace(key, app.config.global_replacements[key])
296 source[0] = result
297
298
299 always_document_param_types = True
300
301
302 def typehints_formatter(annotation, config):
303 """Adjust the rendering of various types that sphinx_autodoc_typehints mishandles"""
304 from sphinx_autodoc_typehints import (
305 get_annotation_class_name,
306 get_annotation_module,
307 )
308
309 try:
310 module = get_annotation_module(annotation)
311 class_name = get_annotation_class_name(annotation, module)
312 except ValueError:
313 return None
314 full_name = f"{module}.{class_name}"
315 if full_name == "typing.TypeVar":
316 # The way sphinx-autodoc-typehints renders TypeVar is too noisy for my
317 # taste
318 return f"``{annotation.__name__}``"
319 if full_name == "ast.Module":
320 return "`Module <https://docs.python.org/3/library/ast.html#module-ast>`_"
321 return None
322
323
324 def setup(app):
325 sys.path = extra_sys_path_dirs + sys.path
326 app.add_config_value("global_replacements", {}, True)
327 app.add_config_value("CDN_URL", "", True)
328 app.connect("source-read", global_replace)
329
330 apply_patches()
331 calculate_pyodide_version(app)
332 ensure_typedoc_on_path()
333 create_generated_typescript_files(app)
334 write_console_html(app)
335 prune_docs()
336
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -37,7 +37,6 @@
"autodocsumm",
"sphinx_pyodide",
"sphinx_argparse_cli",
- "versionwarning.extension",
"sphinx_issues",
"sphinx_autodoc_typehints",
"sphinx_design", # Used for tabs in building-from-sources.md
@@ -51,15 +50,12 @@
root_for_relative_js_paths = "../src/"
issues_github_path = "pyodide/pyodide"
-versionwarning_messages = {
- "latest": (
- "This is the development version of the documentation. "
- 'See <a href="https://pyodide.org/">here</a> for latest stable '
- "documentation. Please do not use Pyodide with non "
- "versioned (`dev`) URLs from the CDN for deployed applications!"
- )
-}
-versionwarning_body_selector = "#main-content > div"
+versionwarning_message = (
+ "This is the development version of the documentation. "
+ 'See <a href="https://pyodide.org/">here</a> for latest stable '
+ "documentation. Please do not use Pyodide with non "
+ "versioned (`dev`) URLs from the CDN for deployed applications!"
+)
autosummary_generate = True
autodoc_default_flags = ["members", "inherited-members"]
@@ -105,7 +101,9 @@
html_logo = "_static/img/pyodide-logo.png"
# theme-specific options
-html_theme_options: dict[str, Any] = {}
+html_theme_options: dict[str, Any] = {
+ "announcement": "",
+}
# paths that contain custom static files (such as style sheets)
html_static_path = ["_static"]
@@ -131,6 +129,9 @@
IN_SPHINX = "sphinx" in sys.modules and hasattr(sys.modules["sphinx"], "application")
IN_READTHEDOCS = "READTHEDOCS" in os.environ
+IN_READTHEDOCS_LATEST = (
+ IN_READTHEDOCS and os.environ.get("READTHEDOCS_VERSION") == "latest"
+)
base_dir = Path(__file__).resolve().parent.parent
@@ -203,6 +204,12 @@
}
+def set_announcement_message():
+ html_theme_options["announcement"] = (
+ versionwarning_message if IN_READTHEDOCS_LATEST else ""
+ )
+
+
def write_console_html(app):
# Make console.html file
env = {"PYODIDE_BASE_URL": app.config.CDN_URL}
@@ -327,6 +334,7 @@
app.add_config_value("CDN_URL", "", True)
app.connect("source-read", global_replace)
+ set_announcement_message()
apply_patches()
calculate_pyodide_version(app)
ensure_typedoc_on_path()
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -37,7 +37,6 @@\n \"autodocsumm\",\n \"sphinx_pyodide\",\n \"sphinx_argparse_cli\",\n- \"versionwarning.extension\",\n \"sphinx_issues\",\n \"sphinx_autodoc_typehints\",\n \"sphinx_design\", # Used for tabs in building-from-sources.md\n@@ -51,15 +50,12 @@\n root_for_relative_js_paths = \"../src/\"\n issues_github_path = \"pyodide/pyodide\"\n \n-versionwarning_messages = {\n- \"latest\": (\n- \"This is the development version of the documentation. \"\n- 'See <a href=\"https://pyodide.org/\">here</a> for latest stable '\n- \"documentation. Please do not use Pyodide with non \"\n- \"versioned (`dev`) URLs from the CDN for deployed applications!\"\n- )\n-}\n-versionwarning_body_selector = \"#main-content > div\"\n+versionwarning_message = (\n+ \"This is the development version of the documentation. \"\n+ 'See <a href=\"https://pyodide.org/\">here</a> for latest stable '\n+ \"documentation. Please do not use Pyodide with non \"\n+ \"versioned (`dev`) URLs from the CDN for deployed applications!\"\n+)\n \n autosummary_generate = True\n autodoc_default_flags = [\"members\", \"inherited-members\"]\n@@ -105,7 +101,9 @@\n html_logo = \"_static/img/pyodide-logo.png\"\n \n # theme-specific options\n-html_theme_options: dict[str, Any] = {}\n+html_theme_options: dict[str, Any] = {\n+ \"announcement\": \"\",\n+}\n \n # paths that contain custom static files (such as style sheets)\n html_static_path = [\"_static\"]\n@@ -131,6 +129,9 @@\n \n IN_SPHINX = \"sphinx\" in sys.modules and hasattr(sys.modules[\"sphinx\"], \"application\")\n IN_READTHEDOCS = \"READTHEDOCS\" in os.environ\n+IN_READTHEDOCS_LATEST = (\n+ IN_READTHEDOCS and os.environ.get(\"READTHEDOCS_VERSION\") == \"latest\"\n+)\n \n \n base_dir = Path(__file__).resolve().parent.parent\n@@ -203,6 +204,12 @@\n }\n \n \n+def set_announcement_message():\n+ html_theme_options[\"announcement\"] = (\n+ versionwarning_message if IN_READTHEDOCS_LATEST else \"\"\n+ )\n+\n+\n def write_console_html(app):\n # Make console.html file\n env = {\"PYODIDE_BASE_URL\": app.config.CDN_URL}\n@@ -327,6 +334,7 @@\n app.add_config_value(\"CDN_URL\", \"\", True)\n app.connect(\"source-read\", global_replace)\n \n+ set_announcement_message()\n apply_patches()\n calculate_pyodide_version(app)\n ensure_typedoc_on_path()\n", "issue": "CSS broken in latest docs\n## \ud83d\udc1b Bug\r\n\r\n\r\n\r\nIt seems like the versionwarning banner is not displayed correctly in latest docs.\r\n\n", "before_files": [{"content": "# Configuration file for the Sphinx documentation builder.\n\n# -- Path setup --------------------------------------------------------------\n\nimport atexit\nimport os\nimport shutil\nimport subprocess\nimport sys\nfrom pathlib import Path\nfrom typing import Any\nfrom unittest import mock\n\nimport micropip\n\npanels_add_bootstrap_css = False\n\n# -- Project information -----------------------------------------------------\n\nproject = \"Pyodide\"\ncopyright = \"2019-2022, Pyodide contributors and Mozilla\"\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.autosummary\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.napoleon\",\n \"myst_parser\",\n \"sphinx_js\",\n \"sphinx_click\",\n \"autodocsumm\",\n \"sphinx_pyodide\",\n \"sphinx_argparse_cli\",\n \"versionwarning.extension\",\n \"sphinx_issues\",\n \"sphinx_autodoc_typehints\",\n \"sphinx_design\", # Used for tabs in building-from-sources.md\n]\n\n\nmyst_enable_extensions = [\"substitution\"]\n\njs_language = \"typescript\"\njsdoc_config_path = \"../src/js/tsconfig.json\"\nroot_for_relative_js_paths = \"../src/\"\nissues_github_path = \"pyodide/pyodide\"\n\nversionwarning_messages = {\n \"latest\": (\n \"This is the development version of the documentation. \"\n 'See <a href=\"https://pyodide.org/\">here</a> for latest stable '\n \"documentation. Please do not use Pyodide with non \"\n \"versioned (`dev`) URLs from the CDN for deployed applications!\"\n )\n}\nversionwarning_body_selector = \"#main-content > div\"\n\nautosummary_generate = True\nautodoc_default_flags = [\"members\", \"inherited-members\"]\n\nintersphinx_mapping = {\n \"python\": (\"https://docs.python.org/3.10\", None),\n \"micropip\": (f\"https://micropip.pyodide.org/en/v{micropip.__version__}/\", None),\n \"numpy\": (\"https://numpy.org/doc/stable/\", None),\n}\n\n# Add modules to be mocked.\nmock_modules = [\"tomli\"]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\nsource_suffix = [\".rst\", \".md\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = [\n \"_build\",\n \"Thumbs.db\",\n \".DS_Store\",\n \"README.md\",\n \"sphinx_pyodide\",\n \".*\",\n]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = None\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"sphinx_book_theme\"\nhtml_logo = \"_static/img/pyodide-logo.png\"\n\n# theme-specific options\nhtml_theme_options: dict[str, Any] = {}\n\n# paths that contain custom static files (such as style sheets)\nhtml_static_path = [\"_static\"]\n\n\nhtml_css_files = [\n \"css/pyodide.css\",\n]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n# html_sidebars = {}\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"Pyodidedoc\"\n\n# A list of files that should not be packed into the epub file.\nepub_exclude_files = [\"search.html\"]\n\n# Try not to cause side effects if we are imported incidentally.\n\nIN_SPHINX = \"sphinx\" in sys.modules and hasattr(sys.modules[\"sphinx\"], \"application\")\nIN_READTHEDOCS = \"READTHEDOCS\" in os.environ\n\n\nbase_dir = Path(__file__).resolve().parent.parent\nextra_sys_path_dirs = [\n str(base_dir),\n str(base_dir / \"pyodide-build\"),\n str(base_dir / \"src/py\"),\n str(base_dir / \"packages/micropip/src\"),\n]\n\n\nif IN_SPHINX:\n # sphinx_pyodide is imported before setup() is called because it's a sphinx\n # extension, so we need it to be on the path early. Everything else can be\n # added to the path in setup().\n #\n # TODO: pip install -e sphinx-pyodide instead.\n sys.path = [str(base_dir / \"docs/sphinx_pyodide\")] + sys.path\n\n\ndef patch_docs_argspec():\n import builtins\n\n from sphinx_pyodide.util import docs_argspec\n\n # override docs_argspec, _pyodide.docs_argspec will read this value back.\n # Must do this before importing pyodide!\n setattr(builtins, \"--docs_argspec--\", docs_argspec)\n\n\ndef patch_inspect():\n # Monkey patch for python3.11 incompatible code\n import inspect\n\n if not hasattr(inspect, \"getargspec\"):\n inspect.getargspec = inspect.getfullargspec # type: ignore[assignment]\n\n\ndef prevent_parens_after_js_class_xrefs():\n from sphinx.domains.javascript import JavaScriptDomain, JSXRefRole\n\n JavaScriptDomain.roles[\"class\"] = JSXRefRole()\n\n\ndef apply_patches():\n patch_docs_argspec()\n patch_inspect()\n prevent_parens_after_js_class_xrefs()\n\n\ndef calculate_pyodide_version(app):\n import pyodide\n\n config = app.config\n\n # The full version, including alpha/beta/rc tags.\n config.release = config.version = version = pyodide.__version__\n\n if \".dev\" in version or os.environ.get(\"READTHEDOCS_VERSION\") == \"latest\":\n CDN_URL = \"https://cdn.jsdelivr.net/pyodide/dev/full/\"\n else:\n CDN_URL = f\"https://cdn.jsdelivr.net/pyodide/v{version}/full/\"\n\n app.config.CDN_URL = CDN_URL\n app.config.html_title = f\"Version {version}\"\n\n app.config.global_replacements = {\n \"{{PYODIDE_CDN_URL}}\": CDN_URL,\n \"{{VERSION}}\": version,\n }\n\n\ndef write_console_html(app):\n # Make console.html file\n env = {\"PYODIDE_BASE_URL\": app.config.CDN_URL}\n os.makedirs(app.outdir, exist_ok=True)\n os.makedirs(\"../dist\", exist_ok=True)\n res = subprocess.check_output(\n [\"make\", \"-C\", \"..\", \"dist/console.html\"],\n env=env,\n stderr=subprocess.STDOUT,\n encoding=\"utf-8\",\n )\n print(res)\n\n # insert the Plausible analytics script to console.html\n console_html_lines = (\n Path(\"../dist/console.html\").read_text().splitlines(keepends=True)\n )\n for idx, line in enumerate(list(console_html_lines)):\n if 'pyodide.js\">' in line:\n # insert the analytics script after the `pyodide.js` script\n console_html_lines.insert(\n idx,\n '<script defer data-domain=\"pyodide.org\" src=\"https://plausible.io/js/plausible.js\"></script>\\n',\n )\n break\n else:\n raise ValueError(\"Could not find pyodide.js in the <head> section\")\n output_path = Path(app.outdir) / \"console.html\"\n output_path.write_text(\"\".join(console_html_lines))\n\n\ndef ensure_typedoc_on_path():\n if shutil.which(\"typedoc\"):\n return\n os.environ[\"PATH\"] += f':{str(Path(\"../src/js/node_modules/.bin\").resolve())}'\n print(os.environ[\"PATH\"])\n if shutil.which(\"typedoc\"):\n return\n if IN_READTHEDOCS:\n subprocess.run([\"npm\", \"ci\"], cwd=\"../src/js\")\n if shutil.which(\"typedoc\"):\n return\n raise Exception(\n \"Before building the Pyodide docs you must run 'npm install' in 'src/js'.\"\n )\n\n\ndef create_generated_typescript_files(app):\n shutil.copy(\"../src/core/pyproxy.ts\", \"../src/js/pyproxy.gen.ts\")\n shutil.copy(\"../src/core/error_handling.ts\", \"../src/js/error_handling.gen.ts\")\n app.config.js_source_path = [str(x) for x in Path(\"../src/js\").glob(\"*.ts\")]\n\n def remove_pyproxy_gen_ts():\n Path(\"../src/js/pyproxy.gen.ts\").unlink(missing_ok=True)\n\n atexit.register(remove_pyproxy_gen_ts)\n\n\ndef prune_webloop_docs():\n # Prevent API docs for webloop methods: they are the same as for base event loop\n # and it clutters api docs too much\n from sphinx_pyodide.util import delete_attrs\n\n import pyodide.console\n import pyodide.webloop\n\n delete_attrs(pyodide.webloop.WebLoop)\n delete_attrs(pyodide.webloop.WebLoopPolicy)\n delete_attrs(pyodide.console.PyodideConsole)\n\n for module in mock_modules:\n sys.modules[module] = mock.Mock()\n\n\ndef prune_jsproxy_constructor_docs():\n from pyodide.ffi import JsProxy\n\n del JsProxy.__new__\n\n\ndef prune_docs():\n prune_webloop_docs()\n prune_jsproxy_constructor_docs()\n\n\n# https://github.com/sphinx-doc/sphinx/issues/4054\ndef global_replace(app, docname, source):\n result = source[0]\n for key in app.config.global_replacements:\n result = result.replace(key, app.config.global_replacements[key])\n source[0] = result\n\n\nalways_document_param_types = True\n\n\ndef typehints_formatter(annotation, config):\n \"\"\"Adjust the rendering of various types that sphinx_autodoc_typehints mishandles\"\"\"\n from sphinx_autodoc_typehints import (\n get_annotation_class_name,\n get_annotation_module,\n )\n\n try:\n module = get_annotation_module(annotation)\n class_name = get_annotation_class_name(annotation, module)\n except ValueError:\n return None\n full_name = f\"{module}.{class_name}\"\n if full_name == \"typing.TypeVar\":\n # The way sphinx-autodoc-typehints renders TypeVar is too noisy for my\n # taste\n return f\"``{annotation.__name__}``\"\n if full_name == \"ast.Module\":\n return \"`Module <https://docs.python.org/3/library/ast.html#module-ast>`_\"\n return None\n\n\ndef setup(app):\n sys.path = extra_sys_path_dirs + sys.path\n app.add_config_value(\"global_replacements\", {}, True)\n app.add_config_value(\"CDN_URL\", \"\", True)\n app.connect(\"source-read\", global_replace)\n\n apply_patches()\n calculate_pyodide_version(app)\n ensure_typedoc_on_path()\n create_generated_typescript_files(app)\n write_console_html(app)\n prune_docs()\n", "path": "docs/conf.py"}]}
| 3,951 | 670 |
gh_patches_debug_5105
|
rasdani/github-patches
|
git_diff
|
encode__httpx-2442
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support httpcore>=0.16.0
Hi,
I have a project that uses `fastapi` and `uvicorn` which demands `h11>=0.8`. Latest version of `fastapi` changed their test suite from `requests` to `httpx`. So I had to add `httpx` to my tests requirements.
Now the problem is, that `httpx` requires `httpcore`, which since version `0.16.0` allows for `h11==0.14.0`, but the current version of `httpcore` required by `httpx` doesn't, so I end up having to downgrade the `h11==0.14.0` which I have to `0.12.0`.
Can the constraint for `httpcore` be updated to `>=0.16.0` here?
</issue>
<code>
[start of setup.py]
1 import sys
2
3 from setuptools import setup
4
5 sys.stderr.write(
6 """
7 ===============================
8 Unsupported installation method
9 ===============================
10 httpx no longer supports installation with `python setup.py install`.
11 Please use `python -m pip install .` instead.
12 """
13 )
14 sys.exit(1)
15
16
17 # The below code will never execute, however GitHub is particularly
18 # picky about where it finds Python packaging metadata.
19 # See: https://github.com/github/feedback/discussions/6456
20 #
21 # To be removed once GitHub catches up.
22
23 setup(
24 name="httpx",
25 install_requires=[
26 "certifi",
27 "sniffio",
28 "rfc3986[idna2008]>=1.3,<2",
29 "httpcore>=0.15.0,<0.16.0",
30 ],
31 )
32
[end of setup.py]
[start of httpx/__version__.py]
1 __title__ = "httpx"
2 __description__ = "A next generation HTTP client, for Python 3."
3 __version__ = "0.23.0"
4
[end of httpx/__version__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/httpx/__version__.py b/httpx/__version__.py
--- a/httpx/__version__.py
+++ b/httpx/__version__.py
@@ -1,3 +1,3 @@
__title__ = "httpx"
__description__ = "A next generation HTTP client, for Python 3."
-__version__ = "0.23.0"
+__version__ = "0.23.1"
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -26,6 +26,6 @@
"certifi",
"sniffio",
"rfc3986[idna2008]>=1.3,<2",
- "httpcore>=0.15.0,<0.16.0",
+ "httpcore>=0.15.0,<0.17.0",
],
)
|
{"golden_diff": "diff --git a/httpx/__version__.py b/httpx/__version__.py\n--- a/httpx/__version__.py\n+++ b/httpx/__version__.py\n@@ -1,3 +1,3 @@\n __title__ = \"httpx\"\n __description__ = \"A next generation HTTP client, for Python 3.\"\n-__version__ = \"0.23.0\"\n+__version__ = \"0.23.1\"\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -26,6 +26,6 @@\n \"certifi\",\n \"sniffio\",\n \"rfc3986[idna2008]>=1.3,<2\",\n- \"httpcore>=0.15.0,<0.16.0\",\n+ \"httpcore>=0.15.0,<0.17.0\",\n ],\n )\n", "issue": "Support httpcore>=0.16.0\nHi,\r\n\r\nI have a project that uses `fastapi` and `uvicorn` which demands `h11>=0.8`. Latest version of `fastapi` changed their test suite from `requests` to `httpx`. So I had to add `httpx` to my tests requirements.\r\n\r\nNow the problem is, that `httpx` requires `httpcore`, which since version `0.16.0` allows for `h11==0.14.0`, but the current version of `httpcore` required by `httpx` doesn't, so I end up having to downgrade the `h11==0.14.0` which I have to `0.12.0`.\r\n\r\nCan the constraint for `httpcore` be updated to `>=0.16.0` here?\n", "before_files": [{"content": "import sys\n\nfrom setuptools import setup\n\nsys.stderr.write(\n \"\"\"\n===============================\nUnsupported installation method\n===============================\nhttpx no longer supports installation with `python setup.py install`.\nPlease use `python -m pip install .` instead.\n\"\"\"\n)\nsys.exit(1)\n\n\n# The below code will never execute, however GitHub is particularly\n# picky about where it finds Python packaging metadata.\n# See: https://github.com/github/feedback/discussions/6456\n#\n# To be removed once GitHub catches up.\n\nsetup(\n name=\"httpx\",\n install_requires=[\n \"certifi\",\n \"sniffio\",\n \"rfc3986[idna2008]>=1.3,<2\",\n \"httpcore>=0.15.0,<0.16.0\",\n ],\n)\n", "path": "setup.py"}, {"content": "__title__ = \"httpx\"\n__description__ = \"A next generation HTTP client, for Python 3.\"\n__version__ = \"0.23.0\"\n", "path": "httpx/__version__.py"}]}
| 1,006 | 203 |
gh_patches_debug_18193
|
rasdani/github-patches
|
git_diff
|
DataBiosphere__toil-3626
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add type hints to toilDebugJob.py
Add type hints to src/toil/utils/toilDebugJob.py so it can be checked by mypy during linting.
Refers to #3568.
┆Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-906)
┆Issue Number: TOIL-906
</issue>
<code>
[start of src/toil/utils/toilDebugJob.py]
1 # Copyright (C) 2015-2021 Regents of the University of California
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Debug tool for running a toil job locally."""
15 import logging
16
17 from toil.common import Config, Toil, parser_with_common_options
18 from toil.statsAndLogging import set_logging_from_options
19 from toil.utils.toilDebugFile import printContentsOfJobStore
20 from toil.worker import workerScript
21
22 logger = logging.getLogger(__name__)
23
24
25 def main():
26 parser = parser_with_common_options(jobstore_option=True)
27 parser.add_argument("jobID", nargs=1,
28 help="The job store id of a job within the provided jobstore to run by itself.")
29 parser.add_argument("--printJobInfo", nargs=1,
30 help="Return information about this job to the user including preceding jobs, "
31 "inputs, outputs, and runtime from the last known run.")
32
33 options = parser.parse_args()
34 set_logging_from_options(options)
35 config = Config()
36 config.setOptions(options)
37
38 jobStore = Toil.resumeJobStore(config.jobStore)
39
40 if options.printJobInfo:
41 printContentsOfJobStore(jobStorePath=config.jobStore, nameOfJob=options.printJobInfo)
42
43 # TODO: Option to print list of successor jobs
44 # TODO: Option to run job within python debugger, allowing step through of arguments
45 # idea would be to have option to import pdb and set breakpoint at the start of the user's code
46
47 jobID = options.jobID[0]
48 logger.debug(f"Running the following job locally: {jobID}")
49 workerScript(jobStore, config, jobID, jobID, redirectOutputToLogFile=False)
50 logger.debug(f"Finished running: {jobID}")
51
[end of src/toil/utils/toilDebugJob.py]
[start of contrib/admin/mypy-with-ignore.py]
1 #!/usr/bin/env python3
2 """
3 Runs mypy and ignores files that do not yet have passing type hints.
4
5 Does not type check test files (any path including "src/toil/test").
6 """
7 import os
8 import subprocess
9 import sys
10
11 pkg_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')) # noqa
12 sys.path.insert(0, pkg_root) # noqa
13
14 from src.toil.lib.resources import glob # type: ignore
15
16
17 def main():
18 all_files_to_check = []
19 for d in ['dashboard', 'docker', 'docs', 'src']:
20 all_files_to_check += glob(glob_pattern='*.py', directoryname=os.path.join(pkg_root, d))
21
22 # TODO: Remove these paths as typing is added and mypy conflicts are addressed
23 ignore_paths = [os.path.abspath(f) for f in [
24 'docker/Dockerfile.py',
25 'docs/conf.py',
26 'docs/vendor/sphinxcontrib/fulltoc.py',
27 'docs/vendor/sphinxcontrib/__init__.py',
28 'src/toil/job.py',
29 'src/toil/leader.py',
30 'src/toil/statsAndLogging.py',
31 'src/toil/common.py',
32 'src/toil/realtimeLogger.py',
33 'src/toil/worker.py',
34 'src/toil/serviceManager.py',
35 'src/toil/toilState.py',
36 'src/toil/__init__.py',
37 'src/toil/resource.py',
38 'src/toil/deferred.py',
39 'src/toil/version.py',
40 'src/toil/wdl/utils.py',
41 'src/toil/wdl/wdl_types.py',
42 'src/toil/wdl/wdl_synthesis.py',
43 'src/toil/wdl/wdl_analysis.py',
44 'src/toil/wdl/wdl_functions.py',
45 'src/toil/wdl/toilwdl.py',
46 'src/toil/wdl/versions/draft2.py',
47 'src/toil/wdl/versions/v1.py',
48 'src/toil/wdl/versions/dev.py',
49 'src/toil/provisioners/clusterScaler.py',
50 'src/toil/provisioners/abstractProvisioner.py',
51 'src/toil/provisioners/gceProvisioner.py',
52 'src/toil/provisioners/__init__.py',
53 'src/toil/provisioners/node.py',
54 'src/toil/provisioners/aws/boto2Context.py',
55 'src/toil/provisioners/aws/awsProvisioner.py',
56 'src/toil/provisioners/aws/__init__.py',
57 'src/toil/batchSystems/slurm.py',
58 'src/toil/batchSystems/gridengine.py',
59 'src/toil/batchSystems/singleMachine.py',
60 'src/toil/batchSystems/abstractBatchSystem.py',
61 'src/toil/batchSystems/parasol.py',
62 'src/toil/batchSystems/kubernetes.py',
63 'src/toil/batchSystems/torque.py',
64 'src/toil/batchSystems/options.py',
65 'src/toil/batchSystems/registry.py',
66 'src/toil/batchSystems/lsf.py',
67 'src/toil/batchSystems/__init__.py',
68 'src/toil/batchSystems/abstractGridEngineBatchSystem.py',
69 'src/toil/batchSystems/lsfHelper.py',
70 'src/toil/batchSystems/htcondor.py',
71 'src/toil/batchSystems/mesos/batchSystem.py',
72 'src/toil/batchSystems/mesos/executor.py',
73 'src/toil/batchSystems/mesos/conftest.py',
74 'src/toil/batchSystems/mesos/__init__.py',
75 'src/toil/batchSystems/mesos/test/__init__.py',
76 'src/toil/cwl/conftest.py',
77 'src/toil/cwl/__init__.py',
78 'src/toil/cwl/cwltoil.py',
79 'src/toil/fileStores/cachingFileStore.py',
80 'src/toil/fileStores/abstractFileStore.py',
81 'src/toil/fileStores/nonCachingFileStore.py',
82 'src/toil/fileStores/__init__.py',
83 'src/toil/jobStores/utils.py',
84 'src/toil/jobStores/abstractJobStore.py',
85 'src/toil/jobStores/conftest.py',
86 'src/toil/jobStores/fileJobStore.py',
87 'src/toil/jobStores/__init__.py',
88 'src/toil/jobStores/googleJobStore.py',
89 'src/toil/jobStores/aws/utils.py',
90 'src/toil/jobStores/aws/jobStore.py',
91 'src/toil/jobStores/aws/__init__.py',
92 'src/toil/utils/toilDebugFile.py',
93 'src/toil/utils/toilUpdateEC2Instances.py',
94 'src/toil/utils/toilStatus.py',
95 'src/toil/utils/toilStats.py',
96 'src/toil/utils/toilSshCluster.py',
97 'src/toil/utils/toilMain.py',
98 'src/toil/utils/__init__.py',
99 'src/toil/utils/toilDebugJob.py',
100 'src/toil/utils/toilLaunchCluster.py',
101 'src/toil/lib/memoize.py',
102 'src/toil/lib/throttle.py',
103 'src/toil/lib/humanize.py',
104 'src/toil/lib/compatibility.py',
105 'src/toil/lib/iterables.py',
106 'src/toil/lib/bioio.py',
107 'src/toil/lib/ec2.py',
108 # 'src/toil/lib/conversions.py',
109 'src/toil/lib/ec2nodes.py',
110 # 'src/toil/lib/misc.py',
111 'src/toil/lib/expando.py',
112 'src/toil/lib/threading.py',
113 'src/toil/lib/exceptions.py',
114 'src/toil/lib/__init__.py',
115 'src/toil/lib/generatedEC2Lists.py',
116 'src/toil/lib/retry.py',
117 'src/toil/lib/objects.py',
118 'src/toil/lib/io.py',
119 'src/toil/lib/docker.py',
120 'src/toil/lib/encryption/_nacl.py',
121 'src/toil/lib/encryption/_dummy.py',
122 'src/toil/lib/encryption/conftest.py',
123 'src/toil/lib/encryption/__init__.py',
124 'src/toil/lib/aws/utils.py',
125 'src/toil/lib/aws/__init__.py'
126 ]]
127
128 filtered_files_to_check = []
129 for file_path in all_files_to_check:
130 if file_path not in ignore_paths and 'src/toil/test' not in file_path:
131 filtered_files_to_check.append(file_path)
132 # follow-imports type checks pypi projects we don't control, so we skip it; why is this their default?
133 args = ['mypy', '--follow-imports=skip'] + filtered_files_to_check
134 p = subprocess.run(args=args, stdout=subprocess.PIPE)
135 result = p.stdout.decode()
136 print(result)
137 if 'Success: no issues found' not in result:
138 exit(1)
139
140
141 if __name__ == '__main__':
142 main()
143
[end of contrib/admin/mypy-with-ignore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/contrib/admin/mypy-with-ignore.py b/contrib/admin/mypy-with-ignore.py
--- a/contrib/admin/mypy-with-ignore.py
+++ b/contrib/admin/mypy-with-ignore.py
@@ -96,7 +96,6 @@
'src/toil/utils/toilSshCluster.py',
'src/toil/utils/toilMain.py',
'src/toil/utils/__init__.py',
- 'src/toil/utils/toilDebugJob.py',
'src/toil/utils/toilLaunchCluster.py',
'src/toil/lib/memoize.py',
'src/toil/lib/throttle.py',
diff --git a/src/toil/utils/toilDebugJob.py b/src/toil/utils/toilDebugJob.py
--- a/src/toil/utils/toilDebugJob.py
+++ b/src/toil/utils/toilDebugJob.py
@@ -22,7 +22,7 @@
logger = logging.getLogger(__name__)
-def main():
+def main() -> None:
parser = parser_with_common_options(jobstore_option=True)
parser.add_argument("jobID", nargs=1,
help="The job store id of a job within the provided jobstore to run by itself.")
|
{"golden_diff": "diff --git a/contrib/admin/mypy-with-ignore.py b/contrib/admin/mypy-with-ignore.py\n--- a/contrib/admin/mypy-with-ignore.py\n+++ b/contrib/admin/mypy-with-ignore.py\n@@ -96,7 +96,6 @@\n 'src/toil/utils/toilSshCluster.py',\n 'src/toil/utils/toilMain.py',\n 'src/toil/utils/__init__.py',\n- 'src/toil/utils/toilDebugJob.py',\n 'src/toil/utils/toilLaunchCluster.py',\n 'src/toil/lib/memoize.py',\n 'src/toil/lib/throttle.py',\ndiff --git a/src/toil/utils/toilDebugJob.py b/src/toil/utils/toilDebugJob.py\n--- a/src/toil/utils/toilDebugJob.py\n+++ b/src/toil/utils/toilDebugJob.py\n@@ -22,7 +22,7 @@\n logger = logging.getLogger(__name__)\n \n \n-def main():\n+def main() -> None:\n parser = parser_with_common_options(jobstore_option=True)\n parser.add_argument(\"jobID\", nargs=1,\n help=\"The job store id of a job within the provided jobstore to run by itself.\")\n", "issue": "Add type hints to toilDebugJob.py\nAdd type hints to src/toil/utils/toilDebugJob.py so it can be checked by mypy during linting.\n\nRefers to #3568.\n\n\u2506Issue is synchronized with this [Jira Task](https://ucsc-cgl.atlassian.net/browse/TOIL-906)\n\u2506Issue Number: TOIL-906\n\n", "before_files": [{"content": "# Copyright (C) 2015-2021 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Debug tool for running a toil job locally.\"\"\"\nimport logging\n\nfrom toil.common import Config, Toil, parser_with_common_options\nfrom toil.statsAndLogging import set_logging_from_options\nfrom toil.utils.toilDebugFile import printContentsOfJobStore\nfrom toil.worker import workerScript\n\nlogger = logging.getLogger(__name__)\n\n\ndef main():\n parser = parser_with_common_options(jobstore_option=True)\n parser.add_argument(\"jobID\", nargs=1,\n help=\"The job store id of a job within the provided jobstore to run by itself.\")\n parser.add_argument(\"--printJobInfo\", nargs=1,\n help=\"Return information about this job to the user including preceding jobs, \"\n \"inputs, outputs, and runtime from the last known run.\")\n\n options = parser.parse_args()\n set_logging_from_options(options)\n config = Config()\n config.setOptions(options)\n\n jobStore = Toil.resumeJobStore(config.jobStore)\n\n if options.printJobInfo:\n printContentsOfJobStore(jobStorePath=config.jobStore, nameOfJob=options.printJobInfo)\n\n # TODO: Option to print list of successor jobs\n # TODO: Option to run job within python debugger, allowing step through of arguments\n # idea would be to have option to import pdb and set breakpoint at the start of the user's code\n\n jobID = options.jobID[0]\n logger.debug(f\"Running the following job locally: {jobID}\")\n workerScript(jobStore, config, jobID, jobID, redirectOutputToLogFile=False)\n logger.debug(f\"Finished running: {jobID}\")\n", "path": "src/toil/utils/toilDebugJob.py"}, {"content": "#!/usr/bin/env python3\n\"\"\"\nRuns mypy and ignores files that do not yet have passing type hints.\n\nDoes not type check test files (any path including \"src/toil/test\").\n\"\"\"\nimport os\nimport subprocess\nimport sys\n\npkg_root = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')) # noqa\nsys.path.insert(0, pkg_root) # noqa\n\nfrom src.toil.lib.resources import glob # type: ignore\n\n\ndef main():\n all_files_to_check = []\n for d in ['dashboard', 'docker', 'docs', 'src']:\n all_files_to_check += glob(glob_pattern='*.py', directoryname=os.path.join(pkg_root, d))\n\n # TODO: Remove these paths as typing is added and mypy conflicts are addressed\n ignore_paths = [os.path.abspath(f) for f in [\n 'docker/Dockerfile.py',\n 'docs/conf.py',\n 'docs/vendor/sphinxcontrib/fulltoc.py',\n 'docs/vendor/sphinxcontrib/__init__.py',\n 'src/toil/job.py',\n 'src/toil/leader.py',\n 'src/toil/statsAndLogging.py',\n 'src/toil/common.py',\n 'src/toil/realtimeLogger.py',\n 'src/toil/worker.py',\n 'src/toil/serviceManager.py',\n 'src/toil/toilState.py',\n 'src/toil/__init__.py',\n 'src/toil/resource.py',\n 'src/toil/deferred.py',\n 'src/toil/version.py',\n 'src/toil/wdl/utils.py',\n 'src/toil/wdl/wdl_types.py',\n 'src/toil/wdl/wdl_synthesis.py',\n 'src/toil/wdl/wdl_analysis.py',\n 'src/toil/wdl/wdl_functions.py',\n 'src/toil/wdl/toilwdl.py',\n 'src/toil/wdl/versions/draft2.py',\n 'src/toil/wdl/versions/v1.py',\n 'src/toil/wdl/versions/dev.py',\n 'src/toil/provisioners/clusterScaler.py',\n 'src/toil/provisioners/abstractProvisioner.py',\n 'src/toil/provisioners/gceProvisioner.py',\n 'src/toil/provisioners/__init__.py',\n 'src/toil/provisioners/node.py',\n 'src/toil/provisioners/aws/boto2Context.py',\n 'src/toil/provisioners/aws/awsProvisioner.py',\n 'src/toil/provisioners/aws/__init__.py',\n 'src/toil/batchSystems/slurm.py',\n 'src/toil/batchSystems/gridengine.py',\n 'src/toil/batchSystems/singleMachine.py',\n 'src/toil/batchSystems/abstractBatchSystem.py',\n 'src/toil/batchSystems/parasol.py',\n 'src/toil/batchSystems/kubernetes.py',\n 'src/toil/batchSystems/torque.py',\n 'src/toil/batchSystems/options.py',\n 'src/toil/batchSystems/registry.py',\n 'src/toil/batchSystems/lsf.py',\n 'src/toil/batchSystems/__init__.py',\n 'src/toil/batchSystems/abstractGridEngineBatchSystem.py',\n 'src/toil/batchSystems/lsfHelper.py',\n 'src/toil/batchSystems/htcondor.py',\n 'src/toil/batchSystems/mesos/batchSystem.py',\n 'src/toil/batchSystems/mesos/executor.py',\n 'src/toil/batchSystems/mesos/conftest.py',\n 'src/toil/batchSystems/mesos/__init__.py',\n 'src/toil/batchSystems/mesos/test/__init__.py',\n 'src/toil/cwl/conftest.py',\n 'src/toil/cwl/__init__.py',\n 'src/toil/cwl/cwltoil.py',\n 'src/toil/fileStores/cachingFileStore.py',\n 'src/toil/fileStores/abstractFileStore.py',\n 'src/toil/fileStores/nonCachingFileStore.py',\n 'src/toil/fileStores/__init__.py',\n 'src/toil/jobStores/utils.py',\n 'src/toil/jobStores/abstractJobStore.py',\n 'src/toil/jobStores/conftest.py',\n 'src/toil/jobStores/fileJobStore.py',\n 'src/toil/jobStores/__init__.py',\n 'src/toil/jobStores/googleJobStore.py',\n 'src/toil/jobStores/aws/utils.py',\n 'src/toil/jobStores/aws/jobStore.py',\n 'src/toil/jobStores/aws/__init__.py',\n 'src/toil/utils/toilDebugFile.py',\n 'src/toil/utils/toilUpdateEC2Instances.py',\n 'src/toil/utils/toilStatus.py',\n 'src/toil/utils/toilStats.py',\n 'src/toil/utils/toilSshCluster.py',\n 'src/toil/utils/toilMain.py',\n 'src/toil/utils/__init__.py',\n 'src/toil/utils/toilDebugJob.py',\n 'src/toil/utils/toilLaunchCluster.py',\n 'src/toil/lib/memoize.py',\n 'src/toil/lib/throttle.py',\n 'src/toil/lib/humanize.py',\n 'src/toil/lib/compatibility.py',\n 'src/toil/lib/iterables.py',\n 'src/toil/lib/bioio.py',\n 'src/toil/lib/ec2.py',\n # 'src/toil/lib/conversions.py',\n 'src/toil/lib/ec2nodes.py',\n # 'src/toil/lib/misc.py',\n 'src/toil/lib/expando.py',\n 'src/toil/lib/threading.py',\n 'src/toil/lib/exceptions.py',\n 'src/toil/lib/__init__.py',\n 'src/toil/lib/generatedEC2Lists.py',\n 'src/toil/lib/retry.py',\n 'src/toil/lib/objects.py',\n 'src/toil/lib/io.py',\n 'src/toil/lib/docker.py',\n 'src/toil/lib/encryption/_nacl.py',\n 'src/toil/lib/encryption/_dummy.py',\n 'src/toil/lib/encryption/conftest.py',\n 'src/toil/lib/encryption/__init__.py',\n 'src/toil/lib/aws/utils.py',\n 'src/toil/lib/aws/__init__.py'\n ]]\n\n filtered_files_to_check = []\n for file_path in all_files_to_check:\n if file_path not in ignore_paths and 'src/toil/test' not in file_path:\n filtered_files_to_check.append(file_path)\n # follow-imports type checks pypi projects we don't control, so we skip it; why is this their default?\n args = ['mypy', '--follow-imports=skip'] + filtered_files_to_check\n p = subprocess.run(args=args, stdout=subprocess.PIPE)\n result = p.stdout.decode()\n print(result)\n if 'Success: no issues found' not in result:\n exit(1)\n\n\nif __name__ == '__main__':\n main()\n", "path": "contrib/admin/mypy-with-ignore.py"}]}
| 3,091 | 259 |
gh_patches_debug_33100
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5406
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix SMTP STARTTLS for Twisted >= 21.2.0
## Summary
The [Mail settings](https://docs.scrapy.org/en/latest/topics/email.html#topics-email-settings) don't have an option to choose a TLS version. Only to enforce upgrading connections to use SSL/TLS.
Mail servers like smtp.office365.com dropped support for TLS1.0 and TLS1.1 and now require TLS1.2: https://techcommunity.microsoft.com/t5/exchange-team-blog/new-opt-in-endpoint-available-for-smtp-auth-clients-still/ba-p/2659652
It seems that scrapy mail doesn't support TLS1.2. The error message (with `MAIL_TLS = True`):
`[scrapy.mail] Unable to send mail: To=['[email protected]'] Cc=[] Subject="Test" Attachs=0- 421 b'4.7.66 TLS 1.0 and 1.1 are not supported. Please upgrade/update your client to support TLS 1.2. Visit https://aka.ms/smtp_auth_tls. [AM6P194CA0047.EURP194.PROD.OUTLOOK.COM]'`
## Motivation
Without TLS1.2 it's not possible anymore to send mails via smtp.office365.com. An option to use TLS1.2 would fix this issue
</issue>
<code>
[start of scrapy/mail.py]
1 """
2 Mail sending helpers
3
4 See documentation in docs/topics/email.rst
5 """
6 import logging
7 from email import encoders as Encoders
8 from email.mime.base import MIMEBase
9 from email.mime.multipart import MIMEMultipart
10 from email.mime.nonmultipart import MIMENonMultipart
11 from email.mime.text import MIMEText
12 from email.utils import formatdate
13 from io import BytesIO
14
15 from twisted.internet import defer, ssl
16
17 from scrapy.utils.misc import arg_to_iter
18 from scrapy.utils.python import to_bytes
19
20
21 logger = logging.getLogger(__name__)
22
23
24 # Defined in the email.utils module, but undocumented:
25 # https://github.com/python/cpython/blob/v3.9.0/Lib/email/utils.py#L42
26 COMMASPACE = ", "
27
28
29 def _to_bytes_or_none(text):
30 if text is None:
31 return None
32 return to_bytes(text)
33
34
35 class MailSender:
36 def __init__(
37 self, smtphost='localhost', mailfrom='scrapy@localhost', smtpuser=None,
38 smtppass=None, smtpport=25, smtptls=False, smtpssl=False, debug=False
39 ):
40 self.smtphost = smtphost
41 self.smtpport = smtpport
42 self.smtpuser = _to_bytes_or_none(smtpuser)
43 self.smtppass = _to_bytes_or_none(smtppass)
44 self.smtptls = smtptls
45 self.smtpssl = smtpssl
46 self.mailfrom = mailfrom
47 self.debug = debug
48
49 @classmethod
50 def from_settings(cls, settings):
51 return cls(
52 smtphost=settings['MAIL_HOST'],
53 mailfrom=settings['MAIL_FROM'],
54 smtpuser=settings['MAIL_USER'],
55 smtppass=settings['MAIL_PASS'],
56 smtpport=settings.getint('MAIL_PORT'),
57 smtptls=settings.getbool('MAIL_TLS'),
58 smtpssl=settings.getbool('MAIL_SSL'),
59 )
60
61 def send(self, to, subject, body, cc=None, attachs=(), mimetype='text/plain', charset=None, _callback=None):
62 from twisted.internet import reactor
63 if attachs:
64 msg = MIMEMultipart()
65 else:
66 msg = MIMENonMultipart(*mimetype.split('/', 1))
67
68 to = list(arg_to_iter(to))
69 cc = list(arg_to_iter(cc))
70
71 msg['From'] = self.mailfrom
72 msg['To'] = COMMASPACE.join(to)
73 msg['Date'] = formatdate(localtime=True)
74 msg['Subject'] = subject
75 rcpts = to[:]
76 if cc:
77 rcpts.extend(cc)
78 msg['Cc'] = COMMASPACE.join(cc)
79
80 if charset:
81 msg.set_charset(charset)
82
83 if attachs:
84 msg.attach(MIMEText(body, 'plain', charset or 'us-ascii'))
85 for attach_name, mimetype, f in attachs:
86 part = MIMEBase(*mimetype.split('/'))
87 part.set_payload(f.read())
88 Encoders.encode_base64(part)
89 part.add_header('Content-Disposition', 'attachment', filename=attach_name)
90 msg.attach(part)
91 else:
92 msg.set_payload(body)
93
94 if _callback:
95 _callback(to=to, subject=subject, body=body, cc=cc, attach=attachs, msg=msg)
96
97 if self.debug:
98 logger.debug('Debug mail sent OK: To=%(mailto)s Cc=%(mailcc)s '
99 'Subject="%(mailsubject)s" Attachs=%(mailattachs)d',
100 {'mailto': to, 'mailcc': cc, 'mailsubject': subject,
101 'mailattachs': len(attachs)})
102 return
103
104 dfd = self._sendmail(rcpts, msg.as_string().encode(charset or 'utf-8'))
105 dfd.addCallbacks(
106 callback=self._sent_ok,
107 errback=self._sent_failed,
108 callbackArgs=[to, cc, subject, len(attachs)],
109 errbackArgs=[to, cc, subject, len(attachs)],
110 )
111 reactor.addSystemEventTrigger('before', 'shutdown', lambda: dfd)
112 return dfd
113
114 def _sent_ok(self, result, to, cc, subject, nattachs):
115 logger.info('Mail sent OK: To=%(mailto)s Cc=%(mailcc)s '
116 'Subject="%(mailsubject)s" Attachs=%(mailattachs)d',
117 {'mailto': to, 'mailcc': cc, 'mailsubject': subject,
118 'mailattachs': nattachs})
119
120 def _sent_failed(self, failure, to, cc, subject, nattachs):
121 errstr = str(failure.value)
122 logger.error('Unable to send mail: To=%(mailto)s Cc=%(mailcc)s '
123 'Subject="%(mailsubject)s" Attachs=%(mailattachs)d'
124 '- %(mailerr)s',
125 {'mailto': to, 'mailcc': cc, 'mailsubject': subject,
126 'mailattachs': nattachs, 'mailerr': errstr})
127
128 def _sendmail(self, to_addrs, msg):
129 # Import twisted.mail here because it is not available in python3
130 from twisted.internet import reactor
131 from twisted.mail.smtp import ESMTPSenderFactory
132 msg = BytesIO(msg)
133 d = defer.Deferred()
134 factory = ESMTPSenderFactory(
135 self.smtpuser, self.smtppass, self.mailfrom, to_addrs, msg, d,
136 heloFallback=True, requireAuthentication=False, requireTransportSecurity=self.smtptls,
137 )
138 factory.noisy = False
139
140 if self.smtpssl:
141 reactor.connectSSL(self.smtphost, self.smtpport, factory, ssl.ClientContextFactory())
142 else:
143 reactor.connectTCP(self.smtphost, self.smtpport, factory)
144
145 return d
146
[end of scrapy/mail.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/mail.py b/scrapy/mail.py
--- a/scrapy/mail.py
+++ b/scrapy/mail.py
@@ -12,7 +12,9 @@
from email.utils import formatdate
from io import BytesIO
+from twisted.python.versions import Version
from twisted.internet import defer, ssl
+from twisted import version as twisted_version
from scrapy.utils.misc import arg_to_iter
from scrapy.utils.python import to_bytes
@@ -126,16 +128,11 @@
'mailattachs': nattachs, 'mailerr': errstr})
def _sendmail(self, to_addrs, msg):
- # Import twisted.mail here because it is not available in python3
from twisted.internet import reactor
- from twisted.mail.smtp import ESMTPSenderFactory
msg = BytesIO(msg)
d = defer.Deferred()
- factory = ESMTPSenderFactory(
- self.smtpuser, self.smtppass, self.mailfrom, to_addrs, msg, d,
- heloFallback=True, requireAuthentication=False, requireTransportSecurity=self.smtptls,
- )
- factory.noisy = False
+
+ factory = self._create_sender_factory(to_addrs, msg, d)
if self.smtpssl:
reactor.connectSSL(self.smtphost, self.smtpport, factory, ssl.ClientContextFactory())
@@ -143,3 +140,20 @@
reactor.connectTCP(self.smtphost, self.smtpport, factory)
return d
+
+ def _create_sender_factory(self, to_addrs, msg, d):
+ from twisted.mail.smtp import ESMTPSenderFactory
+
+ factory_keywords = {
+ 'heloFallback': True,
+ 'requireAuthentication': False,
+ 'requireTransportSecurity': self.smtptls
+ }
+
+ # Newer versions of twisted require the hostname to use STARTTLS
+ if twisted_version >= Version('twisted', 21, 2, 0):
+ factory_keywords['hostname'] = self.smtphost
+
+ factory = ESMTPSenderFactory(self.smtpuser, self.smtppass, self.mailfrom, to_addrs, msg, d, **factory_keywords)
+ factory.noisy = False
+ return factory
|
{"golden_diff": "diff --git a/scrapy/mail.py b/scrapy/mail.py\n--- a/scrapy/mail.py\n+++ b/scrapy/mail.py\n@@ -12,7 +12,9 @@\n from email.utils import formatdate\n from io import BytesIO\n \n+from twisted.python.versions import Version\n from twisted.internet import defer, ssl\n+from twisted import version as twisted_version\n \n from scrapy.utils.misc import arg_to_iter\n from scrapy.utils.python import to_bytes\n@@ -126,16 +128,11 @@\n 'mailattachs': nattachs, 'mailerr': errstr})\n \n def _sendmail(self, to_addrs, msg):\n- # Import twisted.mail here because it is not available in python3\n from twisted.internet import reactor\n- from twisted.mail.smtp import ESMTPSenderFactory\n msg = BytesIO(msg)\n d = defer.Deferred()\n- factory = ESMTPSenderFactory(\n- self.smtpuser, self.smtppass, self.mailfrom, to_addrs, msg, d,\n- heloFallback=True, requireAuthentication=False, requireTransportSecurity=self.smtptls,\n- )\n- factory.noisy = False\n+\n+ factory = self._create_sender_factory(to_addrs, msg, d)\n \n if self.smtpssl:\n reactor.connectSSL(self.smtphost, self.smtpport, factory, ssl.ClientContextFactory())\n@@ -143,3 +140,20 @@\n reactor.connectTCP(self.smtphost, self.smtpport, factory)\n \n return d\n+\n+ def _create_sender_factory(self, to_addrs, msg, d):\n+ from twisted.mail.smtp import ESMTPSenderFactory\n+\n+ factory_keywords = {\n+ 'heloFallback': True,\n+ 'requireAuthentication': False,\n+ 'requireTransportSecurity': self.smtptls\n+ }\n+\n+ # Newer versions of twisted require the hostname to use STARTTLS\n+ if twisted_version >= Version('twisted', 21, 2, 0):\n+ factory_keywords['hostname'] = self.smtphost\n+\n+ factory = ESMTPSenderFactory(self.smtpuser, self.smtppass, self.mailfrom, to_addrs, msg, d, **factory_keywords)\n+ factory.noisy = False\n+ return factory\n", "issue": "Fix SMTP STARTTLS for Twisted >= 21.2.0\n## Summary\r\n\r\nThe [Mail settings](https://docs.scrapy.org/en/latest/topics/email.html#topics-email-settings) don't have an option to choose a TLS version. Only to enforce upgrading connections to use SSL/TLS.\r\nMail servers like smtp.office365.com dropped support for TLS1.0 and TLS1.1 and now require TLS1.2: https://techcommunity.microsoft.com/t5/exchange-team-blog/new-opt-in-endpoint-available-for-smtp-auth-clients-still/ba-p/2659652 \r\n\r\nIt seems that scrapy mail doesn't support TLS1.2. The error message (with `MAIL_TLS = True`):\r\n\r\n`[scrapy.mail] Unable to send mail: To=['[email protected]'] Cc=[] Subject=\"Test\" Attachs=0- 421 b'4.7.66 TLS 1.0 and 1.1 are not supported. Please upgrade/update your client to support TLS 1.2. Visit https://aka.ms/smtp_auth_tls. [AM6P194CA0047.EURP194.PROD.OUTLOOK.COM]'` \r\n\r\n## Motivation\r\n\r\nWithout TLS1.2 it's not possible anymore to send mails via smtp.office365.com. An option to use TLS1.2 would fix this issue\r\n\n", "before_files": [{"content": "\"\"\"\nMail sending helpers\n\nSee documentation in docs/topics/email.rst\n\"\"\"\nimport logging\nfrom email import encoders as Encoders\nfrom email.mime.base import MIMEBase\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.nonmultipart import MIMENonMultipart\nfrom email.mime.text import MIMEText\nfrom email.utils import formatdate\nfrom io import BytesIO\n\nfrom twisted.internet import defer, ssl\n\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.python import to_bytes\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Defined in the email.utils module, but undocumented:\n# https://github.com/python/cpython/blob/v3.9.0/Lib/email/utils.py#L42\nCOMMASPACE = \", \"\n\n\ndef _to_bytes_or_none(text):\n if text is None:\n return None\n return to_bytes(text)\n\n\nclass MailSender:\n def __init__(\n self, smtphost='localhost', mailfrom='scrapy@localhost', smtpuser=None,\n smtppass=None, smtpport=25, smtptls=False, smtpssl=False, debug=False\n ):\n self.smtphost = smtphost\n self.smtpport = smtpport\n self.smtpuser = _to_bytes_or_none(smtpuser)\n self.smtppass = _to_bytes_or_none(smtppass)\n self.smtptls = smtptls\n self.smtpssl = smtpssl\n self.mailfrom = mailfrom\n self.debug = debug\n\n @classmethod\n def from_settings(cls, settings):\n return cls(\n smtphost=settings['MAIL_HOST'],\n mailfrom=settings['MAIL_FROM'],\n smtpuser=settings['MAIL_USER'],\n smtppass=settings['MAIL_PASS'],\n smtpport=settings.getint('MAIL_PORT'),\n smtptls=settings.getbool('MAIL_TLS'),\n smtpssl=settings.getbool('MAIL_SSL'),\n )\n\n def send(self, to, subject, body, cc=None, attachs=(), mimetype='text/plain', charset=None, _callback=None):\n from twisted.internet import reactor\n if attachs:\n msg = MIMEMultipart()\n else:\n msg = MIMENonMultipart(*mimetype.split('/', 1))\n\n to = list(arg_to_iter(to))\n cc = list(arg_to_iter(cc))\n\n msg['From'] = self.mailfrom\n msg['To'] = COMMASPACE.join(to)\n msg['Date'] = formatdate(localtime=True)\n msg['Subject'] = subject\n rcpts = to[:]\n if cc:\n rcpts.extend(cc)\n msg['Cc'] = COMMASPACE.join(cc)\n\n if charset:\n msg.set_charset(charset)\n\n if attachs:\n msg.attach(MIMEText(body, 'plain', charset or 'us-ascii'))\n for attach_name, mimetype, f in attachs:\n part = MIMEBase(*mimetype.split('/'))\n part.set_payload(f.read())\n Encoders.encode_base64(part)\n part.add_header('Content-Disposition', 'attachment', filename=attach_name)\n msg.attach(part)\n else:\n msg.set_payload(body)\n\n if _callback:\n _callback(to=to, subject=subject, body=body, cc=cc, attach=attachs, msg=msg)\n\n if self.debug:\n logger.debug('Debug mail sent OK: To=%(mailto)s Cc=%(mailcc)s '\n 'Subject=\"%(mailsubject)s\" Attachs=%(mailattachs)d',\n {'mailto': to, 'mailcc': cc, 'mailsubject': subject,\n 'mailattachs': len(attachs)})\n return\n\n dfd = self._sendmail(rcpts, msg.as_string().encode(charset or 'utf-8'))\n dfd.addCallbacks(\n callback=self._sent_ok,\n errback=self._sent_failed,\n callbackArgs=[to, cc, subject, len(attachs)],\n errbackArgs=[to, cc, subject, len(attachs)],\n )\n reactor.addSystemEventTrigger('before', 'shutdown', lambda: dfd)\n return dfd\n\n def _sent_ok(self, result, to, cc, subject, nattachs):\n logger.info('Mail sent OK: To=%(mailto)s Cc=%(mailcc)s '\n 'Subject=\"%(mailsubject)s\" Attachs=%(mailattachs)d',\n {'mailto': to, 'mailcc': cc, 'mailsubject': subject,\n 'mailattachs': nattachs})\n\n def _sent_failed(self, failure, to, cc, subject, nattachs):\n errstr = str(failure.value)\n logger.error('Unable to send mail: To=%(mailto)s Cc=%(mailcc)s '\n 'Subject=\"%(mailsubject)s\" Attachs=%(mailattachs)d'\n '- %(mailerr)s',\n {'mailto': to, 'mailcc': cc, 'mailsubject': subject,\n 'mailattachs': nattachs, 'mailerr': errstr})\n\n def _sendmail(self, to_addrs, msg):\n # Import twisted.mail here because it is not available in python3\n from twisted.internet import reactor\n from twisted.mail.smtp import ESMTPSenderFactory\n msg = BytesIO(msg)\n d = defer.Deferred()\n factory = ESMTPSenderFactory(\n self.smtpuser, self.smtppass, self.mailfrom, to_addrs, msg, d,\n heloFallback=True, requireAuthentication=False, requireTransportSecurity=self.smtptls,\n )\n factory.noisy = False\n\n if self.smtpssl:\n reactor.connectSSL(self.smtphost, self.smtpport, factory, ssl.ClientContextFactory())\n else:\n reactor.connectTCP(self.smtphost, self.smtpport, factory)\n\n return d\n", "path": "scrapy/mail.py"}]}
| 2,425 | 508 |
gh_patches_debug_9050
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-3910
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[runtimeconfig] typo: "config.get_variable(...)"
https://github.com/GoogleCloudPlatform/google-cloud-python/blob/bee32c0ae68b1e6cf224f9017c758a8e31e8be83/runtimeconfig/google/cloud/runtimeconfig/config.py#L190
[runtimeconfig] Should be "client.config(...)" not "client.get_config(...)
https://github.com/GoogleCloudPlatform/google-cloud-python/blob/bee32c0ae68b1e6cf224f9017c758a8e31e8be83/runtimeconfig/google/cloud/runtimeconfig/config.py#L189
</issue>
<code>
[start of runtimeconfig/google/cloud/runtimeconfig/config.py]
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Create / interact with Google Cloud RuntimeConfig configs."""
16
17 from google.api.core import page_iterator
18 from google.cloud.exceptions import NotFound
19 from google.cloud.runtimeconfig._helpers import config_name_from_full_name
20 from google.cloud.runtimeconfig.variable import Variable
21
22
23 class Config(object):
24 """A Config resource in the Cloud RuntimeConfig service.
25
26 This consists of metadata and a hierarchy of variables.
27
28 See
29 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs
30
31 :type client: :class:`google.cloud.runtimeconfig.client.Client`
32 :param client: A client which holds credentials and project configuration
33 for the config (which requires a project).
34
35 :type name: str
36 :param name: The name of the config.
37 """
38
39 def __init__(self, client, name):
40 self._client = client
41 self.name = name
42 self._properties = {}
43
44 def __repr__(self):
45 return '<Config: %s>' % (self.name,)
46
47 @property
48 def client(self):
49 """The client bound to this config."""
50 return self._client
51
52 @property
53 def description(self):
54 """Description of the config object.
55
56 See
57 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs#resource-runtimeconfig
58
59 :rtype: str, or ``NoneType``
60 :returns: the description (None until set from the server).
61 """
62 return self._properties.get('description')
63
64 @property
65 def project(self):
66 """Project bound to the config.
67
68 :rtype: str
69 :returns: the project (derived from the client).
70 """
71 return self._client.project
72
73 @property
74 def full_name(self):
75 """Fully-qualified name of this variable.
76
77 Example:
78 ``projects/my-project/configs/my-config``
79
80 :rtype: str
81 :returns: The full name based on project and config names.
82
83 :raises: :class:`ValueError` if the config is missing a name.
84 """
85 if not self.name:
86 raise ValueError('Missing config name.')
87 return 'projects/%s/configs/%s' % (self._client.project, self.name)
88
89 @property
90 def path(self):
91 """URL path for the config's APIs.
92
93 :rtype: str
94 :returns: The URL path based on project and config names.
95 """
96 return '/%s' % (self.full_name,)
97
98 def variable(self, variable_name):
99 """Factory constructor for variable object.
100
101 .. note::
102 This will not make an HTTP request; it simply instantiates
103 a variable object owned by this config.
104
105 :type variable_name: str
106 :param variable_name: The name of the variable to be instantiated.
107
108 :rtype: :class:`google.cloud.runtimeconfig.variable.Variable`
109 :returns: The variable object created.
110 """
111 return Variable(name=variable_name, config=self)
112
113 def _require_client(self, client):
114 """Check client or verify over-ride.
115
116 :type client: :class:`google.cloud.runtimconfig.client.Client`
117 :param client:
118 (Optional) The client to use. If not passed, falls back to the
119 ``client`` stored on the current zone.
120
121 :rtype: :class:`google.cloud.runtimeconfig.client.Client`
122 :returns: The client passed in or the currently bound client.
123 """
124 if client is None:
125 client = self._client
126 return client
127
128 def _set_properties(self, api_response):
129 """Update properties from resource in body of ``api_response``
130
131 :type api_response: dict
132 :param api_response: response returned from an API call
133 """
134 self._properties.clear()
135 cleaned = api_response.copy()
136 if 'name' in cleaned:
137 self.name = config_name_from_full_name(cleaned.pop('name'))
138 self._properties.update(cleaned)
139
140 def exists(self, client=None):
141 """Determines whether or not this config exists.
142
143 :type client: :class:`~google.cloud.runtimeconfig.client.Client`
144 :param client:
145 (Optional) The client to use. If not passed, falls back to the
146 ``client`` stored on the current config.
147
148 :rtype: bool
149 :returns: True if the config exists in Cloud Runtime Configurator.
150 """
151 client = self._require_client(client)
152 try:
153 # We only need the status code (200 or not) so we seek to
154 # minimize the returned payload.
155 query_params = {'fields': 'name'}
156 client._connection.api_request(
157 method='GET', path=self.path, query_params=query_params)
158 return True
159 except NotFound:
160 return False
161
162 def reload(self, client=None):
163 """API call: reload the config via a ``GET`` request.
164
165 This method will reload the newest data for the config.
166
167 See
168 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs/get
169
170 :type client: :class:`google.cloud.runtimeconfig.client.Client`
171 :param client:
172 (Optional) The client to use. If not passed, falls back to the
173 client stored on the current config.
174 """
175 client = self._require_client(client)
176
177 # We assume the config exists. If it doesn't it will raise a NotFound
178 # exception.
179 resp = client._connection.api_request(method='GET', path=self.path)
180 self._set_properties(api_response=resp)
181
182 def get_variable(self, variable_name, client=None):
183 """API call: get a variable via a ``GET`` request.
184
185 This will return None if the variable doesn't exist::
186
187 >>> from google.cloud import runtimeconfig
188 >>> client = runtimeconfig.Client()
189 >>> config = client.get_config('my-config')
190 >>> print(config.get_varialbe('variable-name'))
191 <Variable: my-config, variable-name>
192 >>> print(config.get_variable('does-not-exist'))
193 None
194
195 :type variable_name: str
196 :param variable_name: The name of the variable to retrieve.
197
198 :type client: :class:`~google.cloud.runtimeconfig.client.Client`
199 :param client:
200 (Optional) The client to use. If not passed, falls back to the
201 ``client`` stored on the current config.
202
203 :rtype: :class:`google.cloud.runtimeconfig.variable.Variable` or None
204 :returns: The variable object if it exists, otherwise None.
205 """
206 client = self._require_client(client)
207 variable = Variable(config=self, name=variable_name)
208 try:
209 variable.reload(client=client)
210 return variable
211 except NotFound:
212 return None
213
214 def list_variables(self, page_size=None, page_token=None, client=None):
215 """API call: list variables for this config.
216
217 This only lists variable names, not the values.
218
219 See
220 https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/list
221
222 :type page_size: int
223 :param page_size:
224 (Optional) Maximum number of variables to return per page.
225
226 :type page_token: str
227 :param page_token: opaque marker for the next "page" of variables. If
228 not passed, will return the first page of variables.
229
230 :type client: :class:`~google.cloud.runtimeconfig.client.Client`
231 :param client:
232 (Optional) The client to use. If not passed, falls back to the
233 ``client`` stored on the current config.
234
235 :rtype: :class:`~google.api.core.page_iterator.Iterator`
236 :returns:
237 Iterator of :class:`~google.cloud.runtimeconfig.variable.Variable`
238 belonging to this project.
239 """
240 path = '%s/variables' % (self.path,)
241 client = self._require_client(client)
242 iterator = page_iterator.HTTPIterator(
243 client=client,
244 api_request=client._connection.api_request,
245 path=path,
246 item_to_value=_item_to_variable,
247 items_key='variables',
248 page_token=page_token,
249 max_results=page_size)
250 iterator._MAX_RESULTS = 'pageSize'
251 iterator.config = self
252 return iterator
253
254
255 def _item_to_variable(iterator, resource):
256 """Convert a JSON variable to the native object.
257
258 :type iterator: :class:`~google.api.core.page_iterator.Iterator`
259 :param iterator: The iterator that has retrieved the item.
260
261 :type resource: dict
262 :param resource: An item to be converted to a variable.
263
264 :rtype: :class:`.Variable`
265 :returns: The next variable in the page.
266 """
267 return Variable.from_api_repr(resource, iterator.config)
268
[end of runtimeconfig/google/cloud/runtimeconfig/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/runtimeconfig/google/cloud/runtimeconfig/config.py b/runtimeconfig/google/cloud/runtimeconfig/config.py
--- a/runtimeconfig/google/cloud/runtimeconfig/config.py
+++ b/runtimeconfig/google/cloud/runtimeconfig/config.py
@@ -186,8 +186,8 @@
>>> from google.cloud import runtimeconfig
>>> client = runtimeconfig.Client()
- >>> config = client.get_config('my-config')
- >>> print(config.get_varialbe('variable-name'))
+ >>> config = client.config('my-config')
+ >>> print(config.get_variable('variable-name'))
<Variable: my-config, variable-name>
>>> print(config.get_variable('does-not-exist'))
None
|
{"golden_diff": "diff --git a/runtimeconfig/google/cloud/runtimeconfig/config.py b/runtimeconfig/google/cloud/runtimeconfig/config.py\n--- a/runtimeconfig/google/cloud/runtimeconfig/config.py\n+++ b/runtimeconfig/google/cloud/runtimeconfig/config.py\n@@ -186,8 +186,8 @@\n \n >>> from google.cloud import runtimeconfig\n >>> client = runtimeconfig.Client()\n- >>> config = client.get_config('my-config')\n- >>> print(config.get_varialbe('variable-name'))\n+ >>> config = client.config('my-config')\n+ >>> print(config.get_variable('variable-name'))\n <Variable: my-config, variable-name>\n >>> print(config.get_variable('does-not-exist'))\n None\n", "issue": "[runtimeconfig] typo: \"config.get_variable(...)\"\nhttps://github.com/GoogleCloudPlatform/google-cloud-python/blob/bee32c0ae68b1e6cf224f9017c758a8e31e8be83/runtimeconfig/google/cloud/runtimeconfig/config.py#L190\n[runtimeconfig] Should be \"client.config(...)\" not \"client.get_config(...)\nhttps://github.com/GoogleCloudPlatform/google-cloud-python/blob/bee32c0ae68b1e6cf224f9017c758a8e31e8be83/runtimeconfig/google/cloud/runtimeconfig/config.py#L189\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Create / interact with Google Cloud RuntimeConfig configs.\"\"\"\n\nfrom google.api.core import page_iterator\nfrom google.cloud.exceptions import NotFound\nfrom google.cloud.runtimeconfig._helpers import config_name_from_full_name\nfrom google.cloud.runtimeconfig.variable import Variable\n\n\nclass Config(object):\n \"\"\"A Config resource in the Cloud RuntimeConfig service.\n\n This consists of metadata and a hierarchy of variables.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs\n\n :type client: :class:`google.cloud.runtimeconfig.client.Client`\n :param client: A client which holds credentials and project configuration\n for the config (which requires a project).\n\n :type name: str\n :param name: The name of the config.\n \"\"\"\n\n def __init__(self, client, name):\n self._client = client\n self.name = name\n self._properties = {}\n\n def __repr__(self):\n return '<Config: %s>' % (self.name,)\n\n @property\n def client(self):\n \"\"\"The client bound to this config.\"\"\"\n return self._client\n\n @property\n def description(self):\n \"\"\"Description of the config object.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs#resource-runtimeconfig\n\n :rtype: str, or ``NoneType``\n :returns: the description (None until set from the server).\n \"\"\"\n return self._properties.get('description')\n\n @property\n def project(self):\n \"\"\"Project bound to the config.\n\n :rtype: str\n :returns: the project (derived from the client).\n \"\"\"\n return self._client.project\n\n @property\n def full_name(self):\n \"\"\"Fully-qualified name of this variable.\n\n Example:\n ``projects/my-project/configs/my-config``\n\n :rtype: str\n :returns: The full name based on project and config names.\n\n :raises: :class:`ValueError` if the config is missing a name.\n \"\"\"\n if not self.name:\n raise ValueError('Missing config name.')\n return 'projects/%s/configs/%s' % (self._client.project, self.name)\n\n @property\n def path(self):\n \"\"\"URL path for the config's APIs.\n\n :rtype: str\n :returns: The URL path based on project and config names.\n \"\"\"\n return '/%s' % (self.full_name,)\n\n def variable(self, variable_name):\n \"\"\"Factory constructor for variable object.\n\n .. note::\n This will not make an HTTP request; it simply instantiates\n a variable object owned by this config.\n\n :type variable_name: str\n :param variable_name: The name of the variable to be instantiated.\n\n :rtype: :class:`google.cloud.runtimeconfig.variable.Variable`\n :returns: The variable object created.\n \"\"\"\n return Variable(name=variable_name, config=self)\n\n def _require_client(self, client):\n \"\"\"Check client or verify over-ride.\n\n :type client: :class:`google.cloud.runtimconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the current zone.\n\n :rtype: :class:`google.cloud.runtimeconfig.client.Client`\n :returns: The client passed in or the currently bound client.\n \"\"\"\n if client is None:\n client = self._client\n return client\n\n def _set_properties(self, api_response):\n \"\"\"Update properties from resource in body of ``api_response``\n\n :type api_response: dict\n :param api_response: response returned from an API call\n \"\"\"\n self._properties.clear()\n cleaned = api_response.copy()\n if 'name' in cleaned:\n self.name = config_name_from_full_name(cleaned.pop('name'))\n self._properties.update(cleaned)\n\n def exists(self, client=None):\n \"\"\"Determines whether or not this config exists.\n\n :type client: :class:`~google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the current config.\n\n :rtype: bool\n :returns: True if the config exists in Cloud Runtime Configurator.\n \"\"\"\n client = self._require_client(client)\n try:\n # We only need the status code (200 or not) so we seek to\n # minimize the returned payload.\n query_params = {'fields': 'name'}\n client._connection.api_request(\n method='GET', path=self.path, query_params=query_params)\n return True\n except NotFound:\n return False\n\n def reload(self, client=None):\n \"\"\"API call: reload the config via a ``GET`` request.\n\n This method will reload the newest data for the config.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs/get\n\n :type client: :class:`google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n client stored on the current config.\n \"\"\"\n client = self._require_client(client)\n\n # We assume the config exists. If it doesn't it will raise a NotFound\n # exception.\n resp = client._connection.api_request(method='GET', path=self.path)\n self._set_properties(api_response=resp)\n\n def get_variable(self, variable_name, client=None):\n \"\"\"API call: get a variable via a ``GET`` request.\n\n This will return None if the variable doesn't exist::\n\n >>> from google.cloud import runtimeconfig\n >>> client = runtimeconfig.Client()\n >>> config = client.get_config('my-config')\n >>> print(config.get_varialbe('variable-name'))\n <Variable: my-config, variable-name>\n >>> print(config.get_variable('does-not-exist'))\n None\n\n :type variable_name: str\n :param variable_name: The name of the variable to retrieve.\n\n :type client: :class:`~google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the current config.\n\n :rtype: :class:`google.cloud.runtimeconfig.variable.Variable` or None\n :returns: The variable object if it exists, otherwise None.\n \"\"\"\n client = self._require_client(client)\n variable = Variable(config=self, name=variable_name)\n try:\n variable.reload(client=client)\n return variable\n except NotFound:\n return None\n\n def list_variables(self, page_size=None, page_token=None, client=None):\n \"\"\"API call: list variables for this config.\n\n This only lists variable names, not the values.\n\n See\n https://cloud.google.com/deployment-manager/runtime-configurator/reference/rest/v1beta1/projects.configs.variables/list\n\n :type page_size: int\n :param page_size:\n (Optional) Maximum number of variables to return per page.\n\n :type page_token: str\n :param page_token: opaque marker for the next \"page\" of variables. If\n not passed, will return the first page of variables.\n\n :type client: :class:`~google.cloud.runtimeconfig.client.Client`\n :param client:\n (Optional) The client to use. If not passed, falls back to the\n ``client`` stored on the current config.\n\n :rtype: :class:`~google.api.core.page_iterator.Iterator`\n :returns:\n Iterator of :class:`~google.cloud.runtimeconfig.variable.Variable`\n belonging to this project.\n \"\"\"\n path = '%s/variables' % (self.path,)\n client = self._require_client(client)\n iterator = page_iterator.HTTPIterator(\n client=client,\n api_request=client._connection.api_request,\n path=path,\n item_to_value=_item_to_variable,\n items_key='variables',\n page_token=page_token,\n max_results=page_size)\n iterator._MAX_RESULTS = 'pageSize'\n iterator.config = self\n return iterator\n\n\ndef _item_to_variable(iterator, resource):\n \"\"\"Convert a JSON variable to the native object.\n\n :type iterator: :class:`~google.api.core.page_iterator.Iterator`\n :param iterator: The iterator that has retrieved the item.\n\n :type resource: dict\n :param resource: An item to be converted to a variable.\n\n :rtype: :class:`.Variable`\n :returns: The next variable in the page.\n \"\"\"\n return Variable.from_api_repr(resource, iterator.config)\n", "path": "runtimeconfig/google/cloud/runtimeconfig/config.py"}]}
| 3,425 | 148 |
gh_patches_debug_210
|
rasdani/github-patches
|
git_diff
|
xonsh__xonsh-3049
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exception on startup (pygments_cache)
<!--- Provide a general summary of the issue in the Title above -->
<!--- If you have a question along the lines of "How do I do this Bash command in xonsh"
please first look over the Bash to Xonsh translation guide: http://xon.sh/bash_to_xsh.html
If you don't find an answer there, please do open an issue! -->
## xonfig
<!--- Please post the output of the `xonfig` command (run from inside xonsh) so we know more about your current setup -->
## Expected Behavior
<!--- Tell us what should happen -->
## Current Behavior
<!--- Tell us what happens instead of the expected behavior -->
<!--- If part of your bug report is a traceback, please first enter debug mode before triggering the error
To enter debug mode, set the environment variable `XONSH_DEBUG=1` _before_ starting `xonsh`.
On Linux and OSX, an easy way to to do this is to run `env XONSH_DEBUG=1 xonsh` -->
## Steps to Reproduce
<!--- Please try to write out a minimal reproducible snippet to trigger the bug, it will help us fix it! -->
</issue>
<code>
[start of xonsh/ptk2/__init__.py]
1 # must come before ptk / pygments imports
2 from xonsh.lazyasd import load_module_in_background
3
4 load_module_in_background(
5 "pkg_resources",
6 debug="XONSH_DEBUG",
7 replacements={"pygments.plugin": "pkg_resources"},
8 )
9
[end of xonsh/ptk2/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xonsh/ptk2/__init__.py b/xonsh/ptk2/__init__.py
--- a/xonsh/ptk2/__init__.py
+++ b/xonsh/ptk2/__init__.py
@@ -1,8 +0,0 @@
-# must come before ptk / pygments imports
-from xonsh.lazyasd import load_module_in_background
-
-load_module_in_background(
- "pkg_resources",
- debug="XONSH_DEBUG",
- replacements={"pygments.plugin": "pkg_resources"},
-)
|
{"golden_diff": "diff --git a/xonsh/ptk2/__init__.py b/xonsh/ptk2/__init__.py\n--- a/xonsh/ptk2/__init__.py\n+++ b/xonsh/ptk2/__init__.py\n@@ -1,8 +0,0 @@\n-# must come before ptk / pygments imports\n-from xonsh.lazyasd import load_module_in_background\n-\n-load_module_in_background(\n- \"pkg_resources\",\n- debug=\"XONSH_DEBUG\",\n- replacements={\"pygments.plugin\": \"pkg_resources\"},\n-)\n", "issue": "Exception on startup (pygments_cache)\n<!--- Provide a general summary of the issue in the Title above -->\r\n<!--- If you have a question along the lines of \"How do I do this Bash command in xonsh\"\r\nplease first look over the Bash to Xonsh translation guide: http://xon.sh/bash_to_xsh.html\r\nIf you don't find an answer there, please do open an issue! -->\r\n\r\n## xonfig\r\n<!--- Please post the output of the `xonfig` command (run from inside xonsh) so we know more about your current setup -->\r\n\r\n## Expected Behavior\r\n<!--- Tell us what should happen -->\r\n\r\n## Current Behavior\r\n<!--- Tell us what happens instead of the expected behavior -->\r\n<!--- If part of your bug report is a traceback, please first enter debug mode before triggering the error\r\nTo enter debug mode, set the environment variable `XONSH_DEBUG=1` _before_ starting `xonsh`. \r\nOn Linux and OSX, an easy way to to do this is to run `env XONSH_DEBUG=1 xonsh` -->\r\n\r\n## Steps to Reproduce\r\n<!--- Please try to write out a minimal reproducible snippet to trigger the bug, it will help us fix it! -->\r\n\n", "before_files": [{"content": "# must come before ptk / pygments imports\nfrom xonsh.lazyasd import load_module_in_background\n\nload_module_in_background(\n \"pkg_resources\",\n debug=\"XONSH_DEBUG\",\n replacements={\"pygments.plugin\": \"pkg_resources\"},\n)\n", "path": "xonsh/ptk2/__init__.py"}]}
| 867 | 125 |
gh_patches_debug_19926
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-4432
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Running into TypeError exception with `batch_predict` component
### What steps did you take:
I am using batch_predict component to schedule prediction job on AI platform. I was referring to steps here. https://github.com/kubeflow/pipelines/tree/master/components/gcp/ml_engine/batch_predict
- I downloaded the component from https://raw.githubusercontent.com/kubeflow/pipelines/1.0.0/components/gcp/ml_engine/batch_predict/component.yaml.
- loaded the component with `ml_op = load_component_from_file(<local-path>)`
- created pipeline component with `ml_op(<attributes-mentioned-below>)`
- scheduled the pipeline on kubeflow
Job Parameters:
```
prediction_input: {'runtimeVersion': '2.1'}
project_id: <gcs-project>
region: <region-name>
model_path: <gcs-path>
input_paths: [<list-of-input-paths>]
input_data_format: TF_RECORD_GZIP
output_path: <gcs-path>
output_data_format: JSON
```
### What happened:
Running into type error while generating the job_id.
Issue:
It is raising an exception while generating id to schedule the job. This line is failing https://github.com/kubeflow/pipelines/blob/1.0.0/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py#L44 with this error `TypeError: expected string or buffer`. I am not passing any job_id and job_id_prefix. It is using the default values for generating the name.
Error trace:
```
INFO:root:Start KFP context with ID: 858b3ff01cdeed5c0b0b7fd9d2655641.
Traceback (most recent call last):
File "/usr/local/lib/python2.7/runpy.py", line 174, in _run_module_as_main
"__main__", fname, loader, pkg_name)
File "/usr/local/lib/python2.7/runpy.py", line 72, in _run_code
exec code in run_globals
File "/ml/kfp_component/launcher/__main__.py", line 45, in <module>
main()
File "/ml/kfp_component/launcher/__main__.py", line 42, in main
launch(args.file_or_module, args.args)
File "kfp_component/launcher/launcher.py", line 45, in launch
return fire.Fire(module, command=args, name=module.__name__)
File "/usr/local/lib/python2.7/site-packages/fire/core.py", line 127, in Fire
component_trace = _Fire(component, args, context, name)
File "/usr/local/lib/python2.7/site-packages/fire/core.py", line 366, in _Fire
component, remaining_args)
File "/usr/local/lib/python2.7/site-packages/fire/core.py", line 542, in _CallCallable
result = fn(*varargs, **kwargs)
File "kfp_component/google/ml_engine/_batch_predict.py", line 70, in batch_predict
create_job(project_id, job, job_id_prefix, wait_interval)
File "kfp_component/google/ml_engine/_create_job.py", line 48, in create_job
return CreateJobOp(project_id, job, job_id_prefix, job_id, wait_interval
File "kfp_component/google/ml_engine/_create_job.py", line 63, in execute_and_wait
self._set_job_id(ctx.context_id())
File "kfp_component/google/ml_engine/_create_job.py", line 74, in _set_job_id
job_id = gcp_common.normalize_name(job_id)
File "kfp_component/google/common/_utils.py", line 45, in normalize_name
invalid_char_placeholder, name)
File "/usr/local/lib/python2.7/re.py", line 155, in sub
return _compile(pattern, flags).sub(repl, string, count)
TypeError: expected string or buffer
```
### What did you expect to happen:
I was expecting the component to schedule the job with auto generated job id.
### Environment:
<!-- Please fill in those that seem relevant. -->
How did you deploy Kubeflow Pipelines (KFP)?
- I used Kustomize to deploy standalone kubeflow pipeline manifests on GKE.
<!-- If you are not sure, here's [an introduction of all options](https://www.kubeflow.org/docs/pipelines/installation/overview/). -->
KFP version: <!-- If you are not sure, build commit shows on bottom of KFP UI left sidenav. -->
1.0.0
KFP SDK version: <!-- Please attach the output of this shell command: $pip list | grep kfp -->
kfp==0.5.1
### Anything else you would like to add:
[Miscellaneous information that will assist in solving the issue.]
/kind bug
<!-- Please include labels by uncommenting them to help us better triage issues, choose from the following -->
<!--
// /area frontend
/area backend
// /area sdk
// /area testing
/area engprod
-->
</issue>
<code>
[start of components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from fire import decorators
16 from ._create_job import create_job
17
18 @decorators.SetParseFns(python_version=str, runtime_version=str)
19 def train(project_id, job_id_output_path, python_module=None, package_uris=None,
20 region=None, args=None, job_dir=None, python_version=None,
21 runtime_version=None, master_image_uri=None, worker_image_uri=None,
22 training_input=None, job_id_prefix=None, job_id=None, wait_interval=30):
23 """Creates a MLEngine training job.
24
25 Args:
26 project_id (str): Required. The ID of the parent project of the job.
27 python_module (str): Required. The Python module name to run after
28 installing the packages.
29 package_uris (list): Required. The Google Cloud Storage location of
30 the packages with the training program and any additional
31 dependencies. The maximum number of package URIs is 100.
32 region (str): Required. The Google Compute Engine region to run the
33 training job in
34 args (list): Command line arguments to pass to the program.
35 job_dir (str): A Google Cloud Storage path in which to store training
36 outputs and other data needed for training. This path is passed
37 to your TensorFlow program as the '--job-dir' command-line
38 argument. The benefit of specifying this field is that Cloud ML
39 validates the path for use in training.
40 python_version (str): Optional. The version of Python used in training.
41 If not set, the default version is '2.7'. Python '3.5' is
42 available when runtimeVersion is set to '1.4' and above.
43 Python '2.7' works with all supported runtime versions.
44 runtime_version (str): Optional. The Cloud ML Engine runtime version
45 to use for training. If not set, Cloud ML Engine uses the
46 default stable version, 1.0.
47 master_image_uri (str): The Docker image to run on the master replica.
48 This image must be in Container Registry.
49 worker_image_uri (str): The Docker image to run on the worker replica.
50 This image must be in Container Registry.
51 training_input (dict): Input parameters to create a training job.
52 job_id_prefix (str): the prefix of the generated job id.
53 job_id (str): the created job_id, takes precedence over generated job
54 id if set.
55 wait_interval (int): optional wait interval between calls
56 to get job status. Defaults to 30.
57 """
58 if not training_input:
59 training_input = {}
60 if python_module:
61 training_input['pythonModule'] = python_module
62 if package_uris:
63 training_input['packageUris'] = package_uris
64 if region:
65 training_input['region'] = region
66 if args:
67 training_input['args'] = args
68 if job_dir:
69 training_input['jobDir'] = job_dir
70 if python_version:
71 training_input['pythonVersion'] = python_version
72 if runtime_version:
73 training_input['runtimeVersion'] = runtime_version
74 if master_image_uri:
75 if 'masterConfig' not in training_input:
76 training_input['masterConfig'] = {}
77 training_input['masterConfig']['imageUri'] = master_image_uri
78 if worker_image_uri:
79 if 'workerConfig' not in training_input:
80 training_input['workerConfig'] = {}
81 training_input['workerConfig']['imageUri'] = worker_image_uri
82 job = {
83 'trainingInput': training_input
84 }
85 return create_job(project_id, job, job_id_prefix, job_id, wait_interval, job_id_output_path=job_id_output_path)
[end of components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py]
[start of components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py]
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import re
16
17 from ._create_job import create_job
18
19 def batch_predict(project_id, model_path, input_paths, input_data_format,
20 output_path, region, job_id_output_path, output_data_format=None, prediction_input=None, job_id_prefix=None,
21 wait_interval=30):
22 """Creates a MLEngine batch prediction job.
23
24 Args:
25 project_id (str): Required. The ID of the parent project of the job.
26 model_path (str): Required. The path to the model. It can be either:
27 `projects/[PROJECT_ID]/models/[MODEL_ID]` or
28 `projects/[PROJECT_ID]/models/[MODEL_ID]/versions/[VERSION_ID]`
29 or a GCS path of a model file.
30 input_paths (list): Required. The Google Cloud Storage location of
31 the input data files. May contain wildcards.
32 input_data_format (str): Required. The format of the input data files.
33 See https://cloud.google.com/ml-engine/reference/rest/v1/projects.jobs#DataFormat.
34 output_path (str): Required. The output Google Cloud Storage location.
35 region (str): Required. The Google Compute Engine region to run the
36 prediction job in.
37 output_data_format (str): Optional. Format of the output data files,
38 defaults to JSON.
39 prediction_input (dict): Input parameters to create a prediction job.
40 job_id_prefix (str): the prefix of the generated job id.
41 wait_interval (int): optional wait interval between calls
42 to get job status. Defaults to 30.
43 """
44 if not prediction_input:
45 prediction_input = {}
46 if not model_path:
47 raise ValueError('model_path must be provided.')
48 if _is_model_name(model_path):
49 prediction_input['modelName'] = model_path
50 elif _is_model_version_name(model_path):
51 prediction_input['versionName'] = model_path
52 elif _is_gcs_path(model_path):
53 prediction_input['uri'] = model_path
54 else:
55 raise ValueError('model_path value is invalid.')
56
57 if input_paths:
58 prediction_input['inputPaths'] = input_paths
59 if input_data_format:
60 prediction_input['dataFormat'] = input_data_format
61 if output_path:
62 prediction_input['outputPath'] = output_path
63 if output_data_format:
64 prediction_input['outputDataFormat'] = output_data_format
65 if region:
66 prediction_input['region'] = region
67 job = {
68 'predictionInput': prediction_input
69 }
70 create_job(project_id, job, job_id_prefix, wait_interval, job_id_output_path=job_id_output_path)
71
72 def _is_model_name(name):
73 return re.match(r'/projects/[^/]+/models/[^/]+$', name)
74
75 def _is_model_version_name(name):
76 return re.match(r'/projects/[^/]+/models/[^/]+/versions/[^/]+$', name)
77
78 def _is_gcs_path(name):
79 return name.startswith('gs://')
[end of components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py
--- a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py
+++ b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py
@@ -67,7 +67,13 @@
job = {
'predictionInput': prediction_input
}
- create_job(project_id, job, job_id_prefix, wait_interval, job_id_output_path=job_id_output_path)
+ create_job(
+ project_id=project_id,
+ job=job,
+ job_id_prefix=job_id_prefix,
+ wait_interval=wait_interval,
+ job_id_output_path=job_id_output_path,
+ )
def _is_model_name(name):
return re.match(r'/projects/[^/]+/models/[^/]+$', name)
diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py
--- a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py
+++ b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py
@@ -82,4 +82,11 @@
job = {
'trainingInput': training_input
}
- return create_job(project_id, job, job_id_prefix, job_id, wait_interval, job_id_output_path=job_id_output_path)
\ No newline at end of file
+ return create_job(
+ project_id=project_id,
+ job=job,
+ job_id_prefix=job_id_prefix,
+ job_id=job_id,
+ wait_interval=wait_interval,
+ job_id_output_path=job_id_output_path,
+ )
\ No newline at end of file
|
{"golden_diff": "diff --git a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py\n--- a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py\n+++ b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py\n@@ -67,7 +67,13 @@\n job = {\n 'predictionInput': prediction_input\n }\n- create_job(project_id, job, job_id_prefix, wait_interval, job_id_output_path=job_id_output_path)\n+ create_job(\n+ project_id=project_id,\n+ job=job,\n+ job_id_prefix=job_id_prefix,\n+ wait_interval=wait_interval,\n+ job_id_output_path=job_id_output_path,\n+ )\n \n def _is_model_name(name):\n return re.match(r'/projects/[^/]+/models/[^/]+$', name)\ndiff --git a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py\n--- a/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py\n+++ b/components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py\n@@ -82,4 +82,11 @@\n job = {\n 'trainingInput': training_input\n }\n- return create_job(project_id, job, job_id_prefix, job_id, wait_interval, job_id_output_path=job_id_output_path)\n\\ No newline at end of file\n+ return create_job(\n+ project_id=project_id,\n+ job=job,\n+ job_id_prefix=job_id_prefix,\n+ job_id=job_id,\n+ wait_interval=wait_interval,\n+ job_id_output_path=job_id_output_path,\n+ )\n\\ No newline at end of file\n", "issue": "Running into TypeError exception with `batch_predict` component\n### What steps did you take:\r\nI am using batch_predict component to schedule prediction job on AI platform. I was referring to steps here. https://github.com/kubeflow/pipelines/tree/master/components/gcp/ml_engine/batch_predict\r\n- I downloaded the component from https://raw.githubusercontent.com/kubeflow/pipelines/1.0.0/components/gcp/ml_engine/batch_predict/component.yaml. \r\n- loaded the component with `ml_op = load_component_from_file(<local-path>)`\r\n- created pipeline component with `ml_op(<attributes-mentioned-below>)`\r\n- scheduled the pipeline on kubeflow\r\n\r\nJob Parameters:\r\n\r\n```\r\nprediction_input: {'runtimeVersion': '2.1'}\r\nproject_id: <gcs-project>\r\nregion: <region-name>\r\nmodel_path: <gcs-path>\r\ninput_paths: [<list-of-input-paths>]\r\ninput_data_format: TF_RECORD_GZIP\r\noutput_path: <gcs-path>\r\noutput_data_format: JSON\r\n```\r\n\r\n### What happened:\r\n\r\nRunning into type error while generating the job_id.\r\n\r\nIssue:\r\n\r\nIt is raising an exception while generating id to schedule the job. This line is failing https://github.com/kubeflow/pipelines/blob/1.0.0/components/gcp/container/component_sdk/python/kfp_component/google/common/_utils.py#L44 with this error `TypeError: expected string or buffer`. I am not passing any job_id and job_id_prefix. It is using the default values for generating the name.\r\n\r\nError trace:\r\n\r\n```\r\nINFO:root:Start KFP context with ID: 858b3ff01cdeed5c0b0b7fd9d2655641.\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python2.7/runpy.py\", line 174, in _run_module_as_main\r\n \"__main__\", fname, loader, pkg_name)\r\n File \"/usr/local/lib/python2.7/runpy.py\", line 72, in _run_code\r\n exec code in run_globals\r\n File \"/ml/kfp_component/launcher/__main__.py\", line 45, in <module>\r\n main()\r\n File \"/ml/kfp_component/launcher/__main__.py\", line 42, in main\r\n launch(args.file_or_module, args.args)\r\n File \"kfp_component/launcher/launcher.py\", line 45, in launch\r\n return fire.Fire(module, command=args, name=module.__name__)\r\n File \"/usr/local/lib/python2.7/site-packages/fire/core.py\", line 127, in Fire\r\n component_trace = _Fire(component, args, context, name)\r\n File \"/usr/local/lib/python2.7/site-packages/fire/core.py\", line 366, in _Fire\r\n component, remaining_args)\r\n File \"/usr/local/lib/python2.7/site-packages/fire/core.py\", line 542, in _CallCallable\r\n result = fn(*varargs, **kwargs)\r\n File \"kfp_component/google/ml_engine/_batch_predict.py\", line 70, in batch_predict\r\n create_job(project_id, job, job_id_prefix, wait_interval)\r\n File \"kfp_component/google/ml_engine/_create_job.py\", line 48, in create_job\r\n return CreateJobOp(project_id, job, job_id_prefix, job_id, wait_interval\r\n File \"kfp_component/google/ml_engine/_create_job.py\", line 63, in execute_and_wait\r\n self._set_job_id(ctx.context_id())\r\n File \"kfp_component/google/ml_engine/_create_job.py\", line 74, in _set_job_id\r\n job_id = gcp_common.normalize_name(job_id)\r\n File \"kfp_component/google/common/_utils.py\", line 45, in normalize_name\r\n invalid_char_placeholder, name)\r\n File \"/usr/local/lib/python2.7/re.py\", line 155, in sub\r\n return _compile(pattern, flags).sub(repl, string, count)\r\nTypeError: expected string or buffer\r\n\r\n```\r\n\r\n### What did you expect to happen:\r\n\r\nI was expecting the component to schedule the job with auto generated job id.\r\n\r\n### Environment:\r\n<!-- Please fill in those that seem relevant. -->\r\n\r\nHow did you deploy Kubeflow Pipelines (KFP)?\r\n- I used Kustomize to deploy standalone kubeflow pipeline manifests on GKE.\r\n\r\n<!-- If you are not sure, here's [an introduction of all options](https://www.kubeflow.org/docs/pipelines/installation/overview/). -->\r\n\r\nKFP version: <!-- If you are not sure, build commit shows on bottom of KFP UI left sidenav. -->\r\n1.0.0\r\n\r\nKFP SDK version: <!-- Please attach the output of this shell command: $pip list | grep kfp -->\r\nkfp==0.5.1\r\n\r\n### Anything else you would like to add:\r\n[Miscellaneous information that will assist in solving the issue.]\r\n\r\n/kind bug\r\n<!-- Please include labels by uncommenting them to help us better triage issues, choose from the following -->\r\n<!--\r\n// /area frontend\r\n /area backend\r\n// /area sdk\r\n// /area testing\r\n /area engprod\r\n-->\r\n\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom fire import decorators\nfrom ._create_job import create_job\n\[email protected](python_version=str, runtime_version=str)\ndef train(project_id, job_id_output_path, python_module=None, package_uris=None, \n region=None, args=None, job_dir=None, python_version=None, \n runtime_version=None, master_image_uri=None, worker_image_uri=None, \n training_input=None, job_id_prefix=None, job_id=None, wait_interval=30):\n \"\"\"Creates a MLEngine training job.\n\n Args:\n project_id (str): Required. The ID of the parent project of the job.\n python_module (str): Required. The Python module name to run after \n installing the packages.\n package_uris (list): Required. The Google Cloud Storage location of \n the packages with the training program and any additional \n dependencies. The maximum number of package URIs is 100.\n region (str): Required. The Google Compute Engine region to run the \n training job in\n args (list): Command line arguments to pass to the program.\n job_dir (str): A Google Cloud Storage path in which to store training \n outputs and other data needed for training. This path is passed \n to your TensorFlow program as the '--job-dir' command-line \n argument. The benefit of specifying this field is that Cloud ML \n validates the path for use in training.\n python_version (str): Optional. The version of Python used in training. \n If not set, the default version is '2.7'. Python '3.5' is \n available when runtimeVersion is set to '1.4' and above. \n Python '2.7' works with all supported runtime versions.\n runtime_version (str): Optional. The Cloud ML Engine runtime version \n to use for training. If not set, Cloud ML Engine uses the \n default stable version, 1.0. \n master_image_uri (str): The Docker image to run on the master replica. \n This image must be in Container Registry.\n worker_image_uri (str): The Docker image to run on the worker replica. \n This image must be in Container Registry.\n training_input (dict): Input parameters to create a training job.\n job_id_prefix (str): the prefix of the generated job id.\n job_id (str): the created job_id, takes precedence over generated job\n id if set.\n wait_interval (int): optional wait interval between calls\n to get job status. Defaults to 30.\n \"\"\"\n if not training_input:\n training_input = {}\n if python_module:\n training_input['pythonModule'] = python_module\n if package_uris:\n training_input['packageUris'] = package_uris\n if region:\n training_input['region'] = region\n if args:\n training_input['args'] = args\n if job_dir:\n training_input['jobDir'] = job_dir\n if python_version:\n training_input['pythonVersion'] = python_version\n if runtime_version:\n training_input['runtimeVersion'] = runtime_version\n if master_image_uri:\n if 'masterConfig' not in training_input:\n training_input['masterConfig'] = {}\n training_input['masterConfig']['imageUri'] = master_image_uri\n if worker_image_uri:\n if 'workerConfig' not in training_input:\n training_input['workerConfig'] = {}\n training_input['workerConfig']['imageUri'] = worker_image_uri\n job = {\n 'trainingInput': training_input\n }\n return create_job(project_id, job, job_id_prefix, job_id, wait_interval, job_id_output_path=job_id_output_path)", "path": "components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_train.py"}, {"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport re\n\nfrom ._create_job import create_job\n\ndef batch_predict(project_id, model_path, input_paths, input_data_format, \n output_path, region, job_id_output_path, output_data_format=None, prediction_input=None, job_id_prefix=None,\n wait_interval=30):\n \"\"\"Creates a MLEngine batch prediction job.\n\n Args:\n project_id (str): Required. The ID of the parent project of the job.\n model_path (str): Required. The path to the model. It can be either:\n `projects/[PROJECT_ID]/models/[MODEL_ID]` or \n `projects/[PROJECT_ID]/models/[MODEL_ID]/versions/[VERSION_ID]`\n or a GCS path of a model file.\n input_paths (list): Required. The Google Cloud Storage location of \n the input data files. May contain wildcards.\n input_data_format (str): Required. The format of the input data files.\n See https://cloud.google.com/ml-engine/reference/rest/v1/projects.jobs#DataFormat.\n output_path (str): Required. The output Google Cloud Storage location.\n region (str): Required. The Google Compute Engine region to run the \n prediction job in.\n output_data_format (str): Optional. Format of the output data files, \n defaults to JSON.\n prediction_input (dict): Input parameters to create a prediction job.\n job_id_prefix (str): the prefix of the generated job id.\n wait_interval (int): optional wait interval between calls\n to get job status. Defaults to 30.\n \"\"\"\n if not prediction_input:\n prediction_input = {}\n if not model_path:\n raise ValueError('model_path must be provided.')\n if _is_model_name(model_path):\n prediction_input['modelName'] = model_path\n elif _is_model_version_name(model_path):\n prediction_input['versionName'] = model_path\n elif _is_gcs_path(model_path):\n prediction_input['uri'] = model_path\n else:\n raise ValueError('model_path value is invalid.')\n \n if input_paths:\n prediction_input['inputPaths'] = input_paths\n if input_data_format:\n prediction_input['dataFormat'] = input_data_format\n if output_path:\n prediction_input['outputPath'] = output_path\n if output_data_format:\n prediction_input['outputDataFormat'] = output_data_format\n if region:\n prediction_input['region'] = region\n job = {\n 'predictionInput': prediction_input\n }\n create_job(project_id, job, job_id_prefix, wait_interval, job_id_output_path=job_id_output_path)\n \ndef _is_model_name(name):\n return re.match(r'/projects/[^/]+/models/[^/]+$', name)\n\ndef _is_model_version_name(name):\n return re.match(r'/projects/[^/]+/models/[^/]+/versions/[^/]+$', name)\n\ndef _is_gcs_path(name):\n return name.startswith('gs://')", "path": "components/gcp/container/component_sdk/python/kfp_component/google/ml_engine/_batch_predict.py"}]}
| 3,705 | 423 |
gh_patches_debug_33044
|
rasdani/github-patches
|
git_diff
|
vispy__vispy-2135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove warning on import about missing networkx dependency
Currently, importing vispy (or some submodule) without networkx installed results in a warning about installing networkx, even if the user/downstream library has no intention of using the graph layout. The warning should be delayed and turned into an error, as noted by @djhoese [here](https://github.com/napari/napari/issues/2979#issuecomment-874159877).
xref napari/napari#2979
</issue>
<code>
[start of vispy/visuals/graphs/layouts/networkx_layout.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Vispy Development Team. All Rights Reserved.
3 # Distributed under the (new) BSD License. See LICENSE.txt for more info.#!/usr/bin/env python3
4 from ..util import _straight_line_vertices, issparse
5 import numpy as np
6 try:
7 import networkx as nx
8 except ModuleNotFoundError:
9 import warnings
10 warnings.warn(
11 "Networkx not found, please install network to use its layouts")
12 nx = None
13
14
15 class NetworkxCoordinates:
16 def __init__(self, graph=None, layout=None, **kwargs):
17 """
18 Converts :graph: into a layout. Can be used in conjunction with networkx layouts or using raw 2D-numpy arrays.
19
20 Parameters
21 ----------
22 graph : a networkx graph.
23 layout : str or dict or iterable-object of float32, optional
24 - When :layout: is s string, a lookup will be performed in the networkx avaiable layouts.
25 - When :layout: is a dict, it will be assumed that it takes the shape (key, value) = (node_id, 2D-coordinate).
26 - When :layout: is numpy array it is assumed it takes the shape (number_of_nodes, 2).
27 kwargs: dict, optional
28 when layout is :str: :kwargs: will act as a setting dictionary for the layout function of networkx
29 """
30 if isinstance(graph, type(None)):
31 raise ValueError("Requires networkx input")
32 self.graph = graph
33 self.positions = np.zeros((len(graph), 2), dtype=np.float32)
34 # default random positions
35 if isinstance(layout, type(None)):
36 self.positions = np.random.rand(*self.positions.shape)
37
38 # check for networkx
39 elif isinstance(layout, str):
40 if nx:
41 if not layout.endswith("_layout"):
42 layout += "_layout" # append for nx
43 layout_function = getattr(nx, layout)
44 if layout_function:
45 self.positions = np.asarray(
46 [i for i in dict(layout_function(graph, **kwargs)).values()])
47 else:
48 raise ValueError("Check networkx for layouts")
49 else:
50 raise ValueError("networkx not found")
51 # assume dict from networkx; values are 2-array
52 elif isinstance(layout, dict):
53 self.positions = np.asarray([i for i in layout.values()])
54
55 # assume given values
56 elif isinstance(layout, np.ndarray):
57 assert layout.ndim == 2
58 assert layout.shape[0] == len(graph)
59 self.positions = layout
60 else:
61 raise ValueError("Input not understood")
62
63 # normalize coordinates
64 self.positions = (self.positions - self.positions.min()) / \
65 (self.positions.max() - self.positions.min())
66 self.positions = self.positions.astype(np.float32)
67
68 def __call__(self, adjacency_mat, directed=False):
69 """
70 Parameters
71 ----------
72 adjacency_mat : sparse adjacency matrix.
73 directed : bool, default False
74
75 Returns
76 ---------
77 (node_vertices, line_vertices, arrow_vertices) : tuple
78 Yields the node and line vertices in a tuple. This layout only yields a
79 single time, and has no builtin animation
80 """
81 if issparse(adjacency_mat):
82 adjacency_mat = adjacency_mat.tocoo()
83 line_vertices, arrows = _straight_line_vertices(
84 adjacency_mat, self.positions, directed)
85
86 yield self.positions, line_vertices, arrows
87
88 @property
89 def adj(self):
90 """Convenient storage and holder of the adjacency matrix for the :scene.visuals.Graph: function."""
91 return nx.adjacency_matrix(self.graph)
92
[end of vispy/visuals/graphs/layouts/networkx_layout.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vispy/visuals/graphs/layouts/networkx_layout.py b/vispy/visuals/graphs/layouts/networkx_layout.py
--- a/vispy/visuals/graphs/layouts/networkx_layout.py
+++ b/vispy/visuals/graphs/layouts/networkx_layout.py
@@ -6,9 +6,6 @@
try:
import networkx as nx
except ModuleNotFoundError:
- import warnings
- warnings.warn(
- "Networkx not found, please install network to use its layouts")
nx = None
@@ -27,6 +24,8 @@
kwargs: dict, optional
when layout is :str: :kwargs: will act as a setting dictionary for the layout function of networkx
"""
+ if nx is None:
+ raise ValueError("networkx not found, please install networkx to use its layouts")
if isinstance(graph, type(None)):
raise ValueError("Requires networkx input")
self.graph = graph
@@ -37,17 +36,14 @@
# check for networkx
elif isinstance(layout, str):
- if nx:
- if not layout.endswith("_layout"):
- layout += "_layout" # append for nx
- layout_function = getattr(nx, layout)
- if layout_function:
- self.positions = np.asarray(
- [i for i in dict(layout_function(graph, **kwargs)).values()])
- else:
- raise ValueError("Check networkx for layouts")
+ if not layout.endswith("_layout"):
+ layout += "_layout" # append for nx
+ layout_function = getattr(nx, layout)
+ if layout_function:
+ self.positions = np.asarray(
+ [i for i in dict(layout_function(graph, **kwargs)).values()])
else:
- raise ValueError("networkx not found")
+ raise ValueError("Check networkx for layouts")
# assume dict from networkx; values are 2-array
elif isinstance(layout, dict):
self.positions = np.asarray([i for i in layout.values()])
|
{"golden_diff": "diff --git a/vispy/visuals/graphs/layouts/networkx_layout.py b/vispy/visuals/graphs/layouts/networkx_layout.py\n--- a/vispy/visuals/graphs/layouts/networkx_layout.py\n+++ b/vispy/visuals/graphs/layouts/networkx_layout.py\n@@ -6,9 +6,6 @@\n try:\n import networkx as nx\n except ModuleNotFoundError:\n- import warnings\n- warnings.warn(\n- \"Networkx not found, please install network to use its layouts\")\n nx = None\n \n \n@@ -27,6 +24,8 @@\n kwargs: dict, optional\n when layout is :str: :kwargs: will act as a setting dictionary for the layout function of networkx\n \"\"\"\n+ if nx is None:\n+ raise ValueError(\"networkx not found, please install networkx to use its layouts\")\n if isinstance(graph, type(None)):\n raise ValueError(\"Requires networkx input\")\n self.graph = graph\n@@ -37,17 +36,14 @@\n \n # check for networkx\n elif isinstance(layout, str):\n- if nx:\n- if not layout.endswith(\"_layout\"):\n- layout += \"_layout\" # append for nx\n- layout_function = getattr(nx, layout)\n- if layout_function:\n- self.positions = np.asarray(\n- [i for i in dict(layout_function(graph, **kwargs)).values()])\n- else:\n- raise ValueError(\"Check networkx for layouts\")\n+ if not layout.endswith(\"_layout\"):\n+ layout += \"_layout\" # append for nx\n+ layout_function = getattr(nx, layout)\n+ if layout_function:\n+ self.positions = np.asarray(\n+ [i for i in dict(layout_function(graph, **kwargs)).values()])\n else:\n- raise ValueError(\"networkx not found\")\n+ raise ValueError(\"Check networkx for layouts\")\n # assume dict from networkx; values are 2-array\n elif isinstance(layout, dict):\n self.positions = np.asarray([i for i in layout.values()])\n", "issue": "Remove warning on import about missing networkx dependency\nCurrently, importing vispy (or some submodule) without networkx installed results in a warning about installing networkx, even if the user/downstream library has no intention of using the graph layout. The warning should be delayed and turned into an error, as noted by @djhoese [here](https://github.com/napari/napari/issues/2979#issuecomment-874159877).\r\n\r\nxref napari/napari#2979\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Vispy Development Team. All Rights Reserved.\n# Distributed under the (new) BSD License. See LICENSE.txt for more info.#!/usr/bin/env python3\nfrom ..util import _straight_line_vertices, issparse\nimport numpy as np\ntry:\n import networkx as nx\nexcept ModuleNotFoundError:\n import warnings\n warnings.warn(\n \"Networkx not found, please install network to use its layouts\")\n nx = None\n\n\nclass NetworkxCoordinates:\n def __init__(self, graph=None, layout=None, **kwargs):\n \"\"\"\n Converts :graph: into a layout. Can be used in conjunction with networkx layouts or using raw 2D-numpy arrays.\n\n Parameters\n ----------\n graph : a networkx graph.\n layout : str or dict or iterable-object of float32, optional\n - When :layout: is s string, a lookup will be performed in the networkx avaiable layouts.\n - When :layout: is a dict, it will be assumed that it takes the shape (key, value) = (node_id, 2D-coordinate).\n - When :layout: is numpy array it is assumed it takes the shape (number_of_nodes, 2).\n kwargs: dict, optional\n when layout is :str: :kwargs: will act as a setting dictionary for the layout function of networkx\n \"\"\"\n if isinstance(graph, type(None)):\n raise ValueError(\"Requires networkx input\")\n self.graph = graph\n self.positions = np.zeros((len(graph), 2), dtype=np.float32)\n # default random positions\n if isinstance(layout, type(None)):\n self.positions = np.random.rand(*self.positions.shape)\n\n # check for networkx\n elif isinstance(layout, str):\n if nx:\n if not layout.endswith(\"_layout\"):\n layout += \"_layout\" # append for nx\n layout_function = getattr(nx, layout)\n if layout_function:\n self.positions = np.asarray(\n [i for i in dict(layout_function(graph, **kwargs)).values()])\n else:\n raise ValueError(\"Check networkx for layouts\")\n else:\n raise ValueError(\"networkx not found\")\n # assume dict from networkx; values are 2-array\n elif isinstance(layout, dict):\n self.positions = np.asarray([i for i in layout.values()])\n\n # assume given values\n elif isinstance(layout, np.ndarray):\n assert layout.ndim == 2\n assert layout.shape[0] == len(graph)\n self.positions = layout\n else:\n raise ValueError(\"Input not understood\")\n\n # normalize coordinates\n self.positions = (self.positions - self.positions.min()) / \\\n (self.positions.max() - self.positions.min())\n self.positions = self.positions.astype(np.float32)\n\n def __call__(self, adjacency_mat, directed=False):\n \"\"\"\n Parameters\n ----------\n adjacency_mat : sparse adjacency matrix.\n directed : bool, default False\n\n Returns\n ---------\n (node_vertices, line_vertices, arrow_vertices) : tuple\n Yields the node and line vertices in a tuple. This layout only yields a\n single time, and has no builtin animation\n \"\"\"\n if issparse(adjacency_mat):\n adjacency_mat = adjacency_mat.tocoo()\n line_vertices, arrows = _straight_line_vertices(\n adjacency_mat, self.positions, directed)\n\n yield self.positions, line_vertices, arrows\n\n @property\n def adj(self):\n \"\"\"Convenient storage and holder of the adjacency matrix for the :scene.visuals.Graph: function.\"\"\"\n return nx.adjacency_matrix(self.graph)\n", "path": "vispy/visuals/graphs/layouts/networkx_layout.py"}]}
| 1,616 | 447 |
gh_patches_debug_59198
|
rasdani/github-patches
|
git_diff
|
Nitrate__Nitrate-319
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix filter calls
Similar with the calls to `map`, these calls must be fixed as well.
</issue>
<code>
[start of tcms/testplans/helpers/email.py]
1 # -*- coding: utf-8 -*-
2 from django.conf import settings
3
4 from tcms.core.utils.mailto import send_email_using_threading
5
6
7 def email_plan_update(plan):
8 recipients = get_plan_notification_recipients(plan)
9 if len(recipients) == 0:
10 return
11 subject = u'TestPlan %s has been updated.' % plan.pk
12 send_email_using_threading(settings.PLAN_EMAIL_TEMPLATE, subject,
13 recipients, {'plan': plan})
14
15
16 def email_plan_deletion(plan):
17 recipients = get_plan_notification_recipients(plan)
18 if len(recipients) == 0:
19 return
20 subject = u'TestPlan %s has been deleted.' % plan.pk
21 send_email_using_threading(settings.PLAN_DELELE_EMAIL_TEMPLATE, subject,
22 recipients, {'plan': plan})
23
24
25 def get_plan_notification_recipients(plan):
26 recipients = set()
27 if plan.owner:
28 if plan.email_settings.auto_to_plan_owner:
29 recipients.add(plan.owner.email)
30 if plan.email_settings.auto_to_plan_author:
31 recipients.add(plan.author.email)
32 if plan.email_settings.auto_to_case_owner:
33 case_authors = plan.case.values_list('author__email', flat=True)
34 recipients.update(case_authors)
35 if plan.email_settings.auto_to_case_default_tester:
36 case_testers = plan.case.values_list('default_tester__email',
37 flat=True)
38 recipients.update(case_testers)
39 return filter(lambda e: bool(e), recipients)
40
[end of tcms/testplans/helpers/email.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tcms/testplans/helpers/email.py b/tcms/testplans/helpers/email.py
--- a/tcms/testplans/helpers/email.py
+++ b/tcms/testplans/helpers/email.py
@@ -36,4 +36,4 @@
case_testers = plan.case.values_list('default_tester__email',
flat=True)
recipients.update(case_testers)
- return filter(lambda e: bool(e), recipients)
+ return [r for r in recipients if r]
|
{"golden_diff": "diff --git a/tcms/testplans/helpers/email.py b/tcms/testplans/helpers/email.py\n--- a/tcms/testplans/helpers/email.py\n+++ b/tcms/testplans/helpers/email.py\n@@ -36,4 +36,4 @@\n case_testers = plan.case.values_list('default_tester__email',\n flat=True)\n recipients.update(case_testers)\n- return filter(lambda e: bool(e), recipients)\n+ return [r for r in recipients if r]\n", "issue": "Fix filter calls\nSimilar with the calls to `map`, these calls must be fixed as well.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom django.conf import settings\n\nfrom tcms.core.utils.mailto import send_email_using_threading\n\n\ndef email_plan_update(plan):\n recipients = get_plan_notification_recipients(plan)\n if len(recipients) == 0:\n return\n subject = u'TestPlan %s has been updated.' % plan.pk\n send_email_using_threading(settings.PLAN_EMAIL_TEMPLATE, subject,\n recipients, {'plan': plan})\n\n\ndef email_plan_deletion(plan):\n recipients = get_plan_notification_recipients(plan)\n if len(recipients) == 0:\n return\n subject = u'TestPlan %s has been deleted.' % plan.pk\n send_email_using_threading(settings.PLAN_DELELE_EMAIL_TEMPLATE, subject,\n recipients, {'plan': plan})\n\n\ndef get_plan_notification_recipients(plan):\n recipients = set()\n if plan.owner:\n if plan.email_settings.auto_to_plan_owner:\n recipients.add(plan.owner.email)\n if plan.email_settings.auto_to_plan_author:\n recipients.add(plan.author.email)\n if plan.email_settings.auto_to_case_owner:\n case_authors = plan.case.values_list('author__email', flat=True)\n recipients.update(case_authors)\n if plan.email_settings.auto_to_case_default_tester:\n case_testers = plan.case.values_list('default_tester__email',\n flat=True)\n recipients.update(case_testers)\n return filter(lambda e: bool(e), recipients)\n", "path": "tcms/testplans/helpers/email.py"}]}
| 941 | 103 |
gh_patches_debug_33011
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-3176
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
System Package manager should not update package index if CONAN_SYSREQUIRES_MODE=verify
Currently the SystemPackageManager.update() performs an update (which needs sudo rights!) if CONAN_SYSREQUIRES_MODE is anything else than "disabled". "verify" should also not update, I think.
</issue>
<code>
[start of conans/client/tools/system_pm.py]
1 import os
2 from conans.client.runner import ConanRunner
3 from conans.client.tools.oss import OSInfo
4 from conans.errors import ConanException
5 from conans.util.env_reader import get_env
6
7 _global_output = None
8
9
10 class SystemPackageTool(object):
11
12 def __init__(self, runner=None, os_info=None, tool=None, recommends=False):
13 os_info = os_info or OSInfo()
14 self._is_up_to_date = False
15 self._tool = tool or self._create_tool(os_info)
16 self._tool._sudo_str = "sudo " if self._is_sudo_enabled() else ""
17 self._tool._runner = runner or ConanRunner()
18 self._tool._recommends = recommends
19
20 @staticmethod
21 def _is_sudo_enabled():
22 if "CONAN_SYSREQUIRES_SUDO" not in os.environ:
23 if os.name == 'posix' and os.geteuid() == 0:
24 return False
25 if os.name == 'nt':
26 return False
27 return get_env("CONAN_SYSREQUIRES_SUDO", True)
28
29 @staticmethod
30 def _get_sysrequire_mode():
31 allowed_modes= ("enabled", "verify", "disabled")
32 mode = get_env("CONAN_SYSREQUIRES_MODE", "enabled")
33 mode_lower = mode.lower()
34 if mode_lower not in allowed_modes:
35 raise ConanException("CONAN_SYSREQUIRES_MODE=%s is not allowed, allowed modes=%r" % (mode, allowed_modes))
36 return mode_lower
37
38 @staticmethod
39 def _create_tool(os_info):
40 if os_info.with_apt:
41 return AptTool()
42 elif os_info.with_yum:
43 return YumTool()
44 elif os_info.with_pacman:
45 return PacManTool()
46 elif os_info.is_macos:
47 return BrewTool()
48 elif os_info.is_freebsd:
49 return PkgTool()
50 elif os_info.is_solaris:
51 return PkgUtilTool()
52 elif os_info.with_zypper:
53 return ZypperTool()
54 else:
55 return NullTool()
56
57 def update(self):
58 """
59 Get the system package tool update command
60 """
61 mode = self._get_sysrequire_mode()
62 if mode == "disabled":
63 _global_output.info("Not updating system_requirements. CONAN_SYSREQUIRES_MODE=Disabled")
64 return
65 self._is_up_to_date = True
66 self._tool.update()
67
68 def install(self, packages, update=True, force=False):
69 """
70 Get the system package tool install command.
71 '"""
72 packages = [packages] if isinstance(packages, str) else list(packages)
73
74 mode = self._get_sysrequire_mode()
75
76 if mode in ("verify", "disabled"):
77 # Report to output packages need to be installed
78 if mode == "disabled":
79 _global_output.info("The following packages need to be installed:\n %s" % "\n".join(packages))
80 return
81
82 if mode == "verify" and not self._installed(packages):
83 _global_output.error("The following packages need to be installed:\n %s" % "\n".join(packages))
84 raise ConanException(
85 "Aborted due to CONAN_SYSREQUIRES_MODE=%s. Some system packages need to be installed" % mode
86 )
87
88 if not force and self._installed(packages):
89 return
90
91 # From here system packages can be updated/modified
92 if update and not self._is_up_to_date:
93 self.update()
94 self._install_any(packages)
95
96 def _installed(self, packages):
97 if not packages:
98 return True
99
100 for pkg in packages:
101 if self._tool.installed(pkg):
102 _global_output.info("Package already installed: %s" % pkg)
103 return True
104 return False
105
106 def _install_any(self, packages):
107 if len(packages) == 1:
108 return self._tool.install(packages[0])
109 for pkg in packages:
110 try:
111 return self._tool.install(pkg)
112 except ConanException:
113 pass
114 raise ConanException("Could not install any of %s" % packages)
115
116
117 class NullTool(object):
118 def update(self):
119 pass
120
121 def install(self, package_name):
122 _global_output.warn("Only available for linux with apt-get, yum, or pacman or OSX with brew or "
123 "FreeBSD with pkg or Solaris with pkgutil")
124
125 def installed(self, package_name):
126 return False
127
128
129 class AptTool(object):
130 def update(self):
131 _run(self._runner, "%sapt-get update" % self._sudo_str)
132
133 def install(self, package_name):
134 recommends_str = '' if self._recommends else '--no-install-recommends '
135 _run(self._runner, "%sapt-get install -y %s%s" % (self._sudo_str, recommends_str, package_name))
136
137 def installed(self, package_name):
138 exit_code = self._runner("dpkg -s %s" % package_name, None)
139 return exit_code == 0
140
141
142 class YumTool(object):
143 def update(self):
144 _run(self._runner, "%syum check-update" % self._sudo_str, accepted_returns=[0, 100])
145
146 def install(self, package_name):
147 _run(self._runner, "%syum install -y %s" % (self._sudo_str, package_name))
148
149 def installed(self, package_name):
150 exit_code = self._runner("rpm -q %s" % package_name, None)
151 return exit_code == 0
152
153
154 class BrewTool(object):
155 def update(self):
156 _run(self._runner, "brew update")
157
158 def install(self, package_name):
159 _run(self._runner, "brew install %s" % package_name)
160
161 def installed(self, package_name):
162 exit_code = self._runner('test -n "$(brew ls --versions %s)"' % package_name, None)
163 return exit_code == 0
164
165
166 class PkgTool(object):
167 def update(self):
168 _run(self._runner, "%spkg update" % self._sudo_str)
169
170 def install(self, package_name):
171 _run(self._runner, "%spkg install -y %s" % (self._sudo_str, package_name))
172
173 def installed(self, package_name):
174 exit_code = self._runner("pkg info %s" % package_name, None)
175 return exit_code == 0
176
177
178 class PkgUtilTool(object):
179 def update(self):
180 _run(self._runner, "%spkgutil --catalog" % self._sudo_str)
181
182 def install(self, package_name):
183 _run(self._runner, "%spkgutil --install --yes %s" % (self._sudo_str, package_name))
184
185 def installed(self, package_name):
186 exit_code = self._runner('test -n "`pkgutil --list %s`"' % package_name, None)
187 return exit_code == 0
188
189
190 class ChocolateyTool(object):
191 def update(self):
192 _run(self._runner, "choco outdated")
193
194 def install(self, package_name):
195 _run(self._runner, "choco install --yes %s" % package_name)
196
197 def installed(self, package_name):
198 exit_code = self._runner('choco search --local-only --exact %s | findstr /c:"1 packages installed."' % package_name, None)
199 return exit_code == 0
200
201
202 class PacManTool(object):
203 def update(self):
204 _run(self._runner, "%spacman -Syyu --noconfirm" % self._sudo_str)
205
206 def install(self, package_name):
207 _run(self._runner, "%spacman -S --noconfirm %s" % (self._sudo_str, package_name))
208
209 def installed(self, package_name):
210 exit_code = self._runner("pacman -Qi %s" % package_name, None)
211 return exit_code == 0
212
213
214 class ZypperTool(object):
215 def update(self):
216 _run(self._runner, "%szypper --non-interactive ref" % self._sudo_str)
217
218 def install(self, package_name):
219 _run(self._runner, "%szypper --non-interactive in %s" % (self._sudo_str, package_name))
220
221 def installed(self, package_name):
222 exit_code = self._runner("rpm -q %s" % package_name, None)
223 return exit_code == 0
224
225 def _run(runner, command, accepted_returns=None):
226 accepted_returns = accepted_returns or [0, ]
227 _global_output.info("Running: %s" % command)
228 if runner(command, True) not in accepted_returns:
229 raise ConanException("Command '%s' failed" % command)
230
[end of conans/client/tools/system_pm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/tools/system_pm.py b/conans/client/tools/system_pm.py
--- a/conans/client/tools/system_pm.py
+++ b/conans/client/tools/system_pm.py
@@ -28,7 +28,7 @@
@staticmethod
def _get_sysrequire_mode():
- allowed_modes= ("enabled", "verify", "disabled")
+ allowed_modes = ("enabled", "verify", "disabled")
mode = get_env("CONAN_SYSREQUIRES_MODE", "enabled")
mode_lower = mode.lower()
if mode_lower not in allowed_modes:
@@ -59,8 +59,8 @@
Get the system package tool update command
"""
mode = self._get_sysrequire_mode()
- if mode == "disabled":
- _global_output.info("Not updating system_requirements. CONAN_SYSREQUIRES_MODE=Disabled")
+ if mode in ("disabled", "verify"):
+ _global_output.info("Not updating system_requirements. CONAN_SYSREQUIRES_MODE=%s" % mode)
return
self._is_up_to_date = True
self._tool.update()
@@ -195,7 +195,8 @@
_run(self._runner, "choco install --yes %s" % package_name)
def installed(self, package_name):
- exit_code = self._runner('choco search --local-only --exact %s | findstr /c:"1 packages installed."' % package_name, None)
+ exit_code = self._runner('choco search --local-only --exact %s | '
+ 'findstr /c:"1 packages installed."' % package_name, None)
return exit_code == 0
@@ -222,6 +223,7 @@
exit_code = self._runner("rpm -q %s" % package_name, None)
return exit_code == 0
+
def _run(runner, command, accepted_returns=None):
accepted_returns = accepted_returns or [0, ]
_global_output.info("Running: %s" % command)
|
{"golden_diff": "diff --git a/conans/client/tools/system_pm.py b/conans/client/tools/system_pm.py\n--- a/conans/client/tools/system_pm.py\n+++ b/conans/client/tools/system_pm.py\n@@ -28,7 +28,7 @@\n \n @staticmethod\n def _get_sysrequire_mode():\n- allowed_modes= (\"enabled\", \"verify\", \"disabled\")\n+ allowed_modes = (\"enabled\", \"verify\", \"disabled\")\n mode = get_env(\"CONAN_SYSREQUIRES_MODE\", \"enabled\")\n mode_lower = mode.lower()\n if mode_lower not in allowed_modes:\n@@ -59,8 +59,8 @@\n Get the system package tool update command\n \"\"\"\n mode = self._get_sysrequire_mode()\n- if mode == \"disabled\":\n- _global_output.info(\"Not updating system_requirements. CONAN_SYSREQUIRES_MODE=Disabled\")\n+ if mode in (\"disabled\", \"verify\"):\n+ _global_output.info(\"Not updating system_requirements. CONAN_SYSREQUIRES_MODE=%s\" % mode)\n return\n self._is_up_to_date = True\n self._tool.update()\n@@ -195,7 +195,8 @@\n _run(self._runner, \"choco install --yes %s\" % package_name)\n \n def installed(self, package_name):\n- exit_code = self._runner('choco search --local-only --exact %s | findstr /c:\"1 packages installed.\"' % package_name, None)\n+ exit_code = self._runner('choco search --local-only --exact %s | '\n+ 'findstr /c:\"1 packages installed.\"' % package_name, None)\n return exit_code == 0\n \n \n@@ -222,6 +223,7 @@\n exit_code = self._runner(\"rpm -q %s\" % package_name, None)\n return exit_code == 0\n \n+\n def _run(runner, command, accepted_returns=None):\n accepted_returns = accepted_returns or [0, ]\n _global_output.info(\"Running: %s\" % command)\n", "issue": "System Package manager should not update package index if CONAN_SYSREQUIRES_MODE=verify\nCurrently the SystemPackageManager.update() performs an update (which needs sudo rights!) if CONAN_SYSREQUIRES_MODE is anything else than \"disabled\". \"verify\" should also not update, I think.\r\n\r\n\n", "before_files": [{"content": "import os\nfrom conans.client.runner import ConanRunner\nfrom conans.client.tools.oss import OSInfo\nfrom conans.errors import ConanException\nfrom conans.util.env_reader import get_env\n\n_global_output = None\n\n\nclass SystemPackageTool(object):\n\n def __init__(self, runner=None, os_info=None, tool=None, recommends=False):\n os_info = os_info or OSInfo()\n self._is_up_to_date = False\n self._tool = tool or self._create_tool(os_info)\n self._tool._sudo_str = \"sudo \" if self._is_sudo_enabled() else \"\"\n self._tool._runner = runner or ConanRunner()\n self._tool._recommends = recommends\n\n @staticmethod\n def _is_sudo_enabled():\n if \"CONAN_SYSREQUIRES_SUDO\" not in os.environ:\n if os.name == 'posix' and os.geteuid() == 0:\n return False\n if os.name == 'nt':\n return False\n return get_env(\"CONAN_SYSREQUIRES_SUDO\", True)\n\n @staticmethod\n def _get_sysrequire_mode():\n allowed_modes= (\"enabled\", \"verify\", \"disabled\")\n mode = get_env(\"CONAN_SYSREQUIRES_MODE\", \"enabled\")\n mode_lower = mode.lower()\n if mode_lower not in allowed_modes:\n raise ConanException(\"CONAN_SYSREQUIRES_MODE=%s is not allowed, allowed modes=%r\" % (mode, allowed_modes))\n return mode_lower\n\n @staticmethod\n def _create_tool(os_info):\n if os_info.with_apt:\n return AptTool()\n elif os_info.with_yum:\n return YumTool()\n elif os_info.with_pacman:\n return PacManTool()\n elif os_info.is_macos:\n return BrewTool()\n elif os_info.is_freebsd:\n return PkgTool()\n elif os_info.is_solaris:\n return PkgUtilTool()\n elif os_info.with_zypper:\n return ZypperTool()\n else:\n return NullTool()\n\n def update(self):\n \"\"\"\n Get the system package tool update command\n \"\"\"\n mode = self._get_sysrequire_mode()\n if mode == \"disabled\":\n _global_output.info(\"Not updating system_requirements. CONAN_SYSREQUIRES_MODE=Disabled\")\n return\n self._is_up_to_date = True\n self._tool.update()\n\n def install(self, packages, update=True, force=False):\n \"\"\"\n Get the system package tool install command.\n '\"\"\"\n packages = [packages] if isinstance(packages, str) else list(packages)\n\n mode = self._get_sysrequire_mode()\n\n if mode in (\"verify\", \"disabled\"):\n # Report to output packages need to be installed\n if mode == \"disabled\":\n _global_output.info(\"The following packages need to be installed:\\n %s\" % \"\\n\".join(packages))\n return\n\n if mode == \"verify\" and not self._installed(packages):\n _global_output.error(\"The following packages need to be installed:\\n %s\" % \"\\n\".join(packages))\n raise ConanException(\n \"Aborted due to CONAN_SYSREQUIRES_MODE=%s. Some system packages need to be installed\" % mode\n )\n\n if not force and self._installed(packages):\n return\n\n # From here system packages can be updated/modified\n if update and not self._is_up_to_date:\n self.update()\n self._install_any(packages)\n\n def _installed(self, packages):\n if not packages:\n return True\n\n for pkg in packages:\n if self._tool.installed(pkg):\n _global_output.info(\"Package already installed: %s\" % pkg)\n return True\n return False\n\n def _install_any(self, packages):\n if len(packages) == 1:\n return self._tool.install(packages[0])\n for pkg in packages:\n try:\n return self._tool.install(pkg)\n except ConanException:\n pass\n raise ConanException(\"Could not install any of %s\" % packages)\n\n\nclass NullTool(object):\n def update(self):\n pass\n\n def install(self, package_name):\n _global_output.warn(\"Only available for linux with apt-get, yum, or pacman or OSX with brew or \"\n \"FreeBSD with pkg or Solaris with pkgutil\")\n\n def installed(self, package_name):\n return False\n\n\nclass AptTool(object):\n def update(self):\n _run(self._runner, \"%sapt-get update\" % self._sudo_str)\n\n def install(self, package_name):\n recommends_str = '' if self._recommends else '--no-install-recommends '\n _run(self._runner, \"%sapt-get install -y %s%s\" % (self._sudo_str, recommends_str, package_name))\n\n def installed(self, package_name):\n exit_code = self._runner(\"dpkg -s %s\" % package_name, None)\n return exit_code == 0\n\n\nclass YumTool(object):\n def update(self):\n _run(self._runner, \"%syum check-update\" % self._sudo_str, accepted_returns=[0, 100])\n\n def install(self, package_name):\n _run(self._runner, \"%syum install -y %s\" % (self._sudo_str, package_name))\n\n def installed(self, package_name):\n exit_code = self._runner(\"rpm -q %s\" % package_name, None)\n return exit_code == 0\n\n\nclass BrewTool(object):\n def update(self):\n _run(self._runner, \"brew update\")\n\n def install(self, package_name):\n _run(self._runner, \"brew install %s\" % package_name)\n\n def installed(self, package_name):\n exit_code = self._runner('test -n \"$(brew ls --versions %s)\"' % package_name, None)\n return exit_code == 0\n\n\nclass PkgTool(object):\n def update(self):\n _run(self._runner, \"%spkg update\" % self._sudo_str)\n\n def install(self, package_name):\n _run(self._runner, \"%spkg install -y %s\" % (self._sudo_str, package_name))\n\n def installed(self, package_name):\n exit_code = self._runner(\"pkg info %s\" % package_name, None)\n return exit_code == 0\n\n\nclass PkgUtilTool(object):\n def update(self):\n _run(self._runner, \"%spkgutil --catalog\" % self._sudo_str)\n\n def install(self, package_name):\n _run(self._runner, \"%spkgutil --install --yes %s\" % (self._sudo_str, package_name))\n\n def installed(self, package_name):\n exit_code = self._runner('test -n \"`pkgutil --list %s`\"' % package_name, None)\n return exit_code == 0\n\n\nclass ChocolateyTool(object):\n def update(self):\n _run(self._runner, \"choco outdated\")\n\n def install(self, package_name):\n _run(self._runner, \"choco install --yes %s\" % package_name)\n\n def installed(self, package_name):\n exit_code = self._runner('choco search --local-only --exact %s | findstr /c:\"1 packages installed.\"' % package_name, None)\n return exit_code == 0\n\n\nclass PacManTool(object):\n def update(self):\n _run(self._runner, \"%spacman -Syyu --noconfirm\" % self._sudo_str)\n\n def install(self, package_name):\n _run(self._runner, \"%spacman -S --noconfirm %s\" % (self._sudo_str, package_name))\n\n def installed(self, package_name):\n exit_code = self._runner(\"pacman -Qi %s\" % package_name, None)\n return exit_code == 0\n\n\nclass ZypperTool(object):\n def update(self):\n _run(self._runner, \"%szypper --non-interactive ref\" % self._sudo_str)\n\n def install(self, package_name):\n _run(self._runner, \"%szypper --non-interactive in %s\" % (self._sudo_str, package_name))\n\n def installed(self, package_name):\n exit_code = self._runner(\"rpm -q %s\" % package_name, None)\n return exit_code == 0\n\ndef _run(runner, command, accepted_returns=None):\n accepted_returns = accepted_returns or [0, ]\n _global_output.info(\"Running: %s\" % command)\n if runner(command, True) not in accepted_returns:\n raise ConanException(\"Command '%s' failed\" % command)\n", "path": "conans/client/tools/system_pm.py"}]}
| 3,089 | 447 |
gh_patches_debug_23803
|
rasdani/github-patches
|
git_diff
|
MycroftAI__mycroft-core-782
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Report errors while installing default skills
Installing default skills may fail quietly in some conditions, ideally some feedback to the user should be given.
</issue>
<code>
[start of mycroft/skills/main.py]
1 # Copyright 2016 Mycroft AI, Inc.
2 #
3 # This file is part of Mycroft Core.
4 #
5 # Mycroft Core is free software: you can redistribute it and/or modify
6 # it under the terms of the GNU General Public License as published by
7 # the Free Software Foundation, either version 3 of the License, or
8 # (at your option) any later version.
9 #
10 # Mycroft Core is distributed in the hope that it will be useful,
11 # but WITHOUT ANY WARRANTY; without even the implied warranty of
12 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
13 # GNU General Public License for more details.
14 #
15 # You should have received a copy of the GNU General Public License
16 # along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.
17
18
19 import json
20 import os
21 import subprocess
22 import sys
23 import time
24 from os.path import exists, join
25 from threading import Timer
26
27 from mycroft import MYCROFT_ROOT_PATH
28 from mycroft.configuration import ConfigurationManager
29 from mycroft.lock import Lock # Creates PID file for single instance
30 from mycroft.messagebus.client.ws import WebsocketClient
31 from mycroft.messagebus.message import Message
32 from mycroft.skills.core import load_skill, create_skill_descriptor, \
33 MainModule, SKILLS_DIR
34 from mycroft.skills.intent_service import IntentService
35 from mycroft.util import connected
36 from mycroft.util.log import getLogger
37 import mycroft.dialog
38
39 logger = getLogger("Skills")
40
41 __author__ = 'seanfitz'
42
43 ws = None
44 loaded_skills = {}
45 last_modified_skill = 0
46 skills_directories = []
47 skill_reload_thread = None
48 skills_manager_timer = None
49
50 installer_config = ConfigurationManager.instance().get("SkillInstallerSkill")
51 MSM_BIN = installer_config.get("path", join(MYCROFT_ROOT_PATH, 'msm', 'msm'))
52
53
54 def connect():
55 global ws
56 ws.run_forever()
57
58
59 def install_default_skills(speak=True):
60 if exists(MSM_BIN):
61 p = subprocess.Popen(MSM_BIN + " default", stderr=subprocess.STDOUT,
62 stdout=subprocess.PIPE, shell=True)
63 t = p.communicate()[0]
64 if t.splitlines()[-1] == "Installed!" and speak:
65 ws.emit(Message("speak", {
66 'utterance': mycroft.dialog.get("skills updated")}))
67 elif not connected():
68 ws.emit(Message("speak", {
69 'utterance': mycroft.dialog.get("no network connection")}))
70
71 else:
72 logger.error("Unable to invoke Mycroft Skill Manager: " + MSM_BIN)
73
74
75 def skills_manager(message):
76 global skills_manager_timer, ws
77
78 if connected():
79 if skills_manager_timer is None:
80 ws.emit(
81 Message("speak", {'utterance':
82 mycroft.dialog.get("checking for updates")}))
83
84 # Install default skills and look for updates via Github
85 logger.debug("==== Invoking Mycroft Skill Manager: " + MSM_BIN)
86 install_default_skills(False)
87
88 # Perform check again once and hour
89 skills_manager_timer = Timer(3600, _skills_manager_dispatch)
90 skills_manager_timer.daemon = True
91 skills_manager_timer.start()
92
93
94 def _skills_manager_dispatch():
95 ws.emit(Message("skill_manager", {}))
96
97
98 def _load_skills():
99 global ws, loaded_skills, last_modified_skill, skills_directories, \
100 skill_reload_thread
101
102 check_connection()
103
104 # Create skill_manager listener and invoke the first time
105 ws.on('skill_manager', skills_manager)
106 ws.on('mycroft.internet.connected', install_default_skills)
107 ws.emit(Message('skill_manager', {}))
108
109 # Create the Intent manager, which converts utterances to intents
110 # This is the heart of the voice invoked skill system
111 IntentService(ws)
112
113 # Create a thread that monitors the loaded skills, looking for updates
114 skill_reload_thread = Timer(0, _watch_skills)
115 skill_reload_thread.daemon = True
116 skill_reload_thread.start()
117
118
119 def check_connection():
120 if connected():
121 ws.emit(Message('mycroft.internet.connected'))
122 else:
123 thread = Timer(1, check_connection)
124 thread.daemon = True
125 thread.start()
126
127
128 def _get_last_modified_date(path):
129 last_date = 0
130 # getting all recursive paths
131 for root, _, _ in os.walk(path):
132 f = root.replace(path, "")
133 # checking if is a hidden path
134 if not f.startswith(".") and not f.startswith("/."):
135 last_date = max(last_date, os.path.getmtime(path + f))
136
137 return last_date
138
139
140 def _watch_skills():
141 global ws, loaded_skills, last_modified_skill, \
142 id_counter
143
144 # Scan the file folder that contains Skills. If a Skill is updated,
145 # unload the existing version from memory and reload from the disk.
146 while True:
147 if exists(SKILLS_DIR):
148 # checking skills dir and getting all skills there
149 list = filter(lambda x: os.path.isdir(
150 os.path.join(SKILLS_DIR, x)), os.listdir(SKILLS_DIR))
151
152 for skill_folder in list:
153 if skill_folder not in loaded_skills:
154 loaded_skills[skill_folder] = {}
155 skill = loaded_skills.get(skill_folder)
156 skill["path"] = os.path.join(SKILLS_DIR, skill_folder)
157 # checking if is a skill
158 if not MainModule + ".py" in os.listdir(skill["path"]):
159 continue
160 # getting the newest modified date of skill
161 skill["last_modified"] = _get_last_modified_date(skill["path"])
162 modified = skill.get("last_modified", 0)
163 # checking if skill is loaded and wasn't modified
164 if skill.get(
165 "loaded") and modified <= last_modified_skill:
166 continue
167 # checking if skill was modified
168 elif skill.get(
169 "instance") and modified > last_modified_skill:
170 # checking if skill should be reloaded
171 if not skill["instance"].reload_skill:
172 continue
173 logger.debug("Reloading Skill: " + skill_folder)
174 # removing listeners and stopping threads
175 skill["instance"].shutdown()
176 del skill["instance"]
177 skill["loaded"] = True
178 skill["instance"] = load_skill(
179 create_skill_descriptor(skill["path"]), ws)
180 # get the last modified skill
181 modified_dates = map(lambda x: x.get("last_modified"),
182 loaded_skills.values())
183 if len(modified_dates) > 0:
184 last_modified_skill = max(modified_dates)
185
186 # Pause briefly before beginning next scan
187 time.sleep(2)
188
189
190 def main():
191 global ws
192 lock = Lock('skills') # prevent multiple instances of this service
193
194 # Connect this Skill management process to the websocket
195 ws = WebsocketClient()
196 ConfigurationManager.init(ws)
197
198 ignore_logs = ConfigurationManager.instance().get("ignore_logs")
199
200 # Listen for messages and echo them for logging
201 def _echo(message):
202 try:
203 _message = json.loads(message)
204
205 if _message.get("type") in ignore_logs:
206 return
207
208 if _message.get("type") == "registration":
209 # do not log tokens from registration messages
210 _message["data"]["token"] = None
211 message = json.dumps(_message)
212 except:
213 pass
214 logger.debug(message)
215
216 ws.on('message', _echo)
217
218 # Kick off loading of skills
219 ws.once('open', _load_skills)
220 ws.run_forever()
221
222
223 if __name__ == "__main__":
224 try:
225 main()
226 except KeyboardInterrupt:
227 skills_manager_timer.cancel()
228 for skill in loaded_skills:
229 skill.shutdown()
230 if skill_reload_thread:
231 skill_reload_thread.cancel()
232
233 finally:
234 sys.exit()
235
[end of mycroft/skills/main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mycroft/skills/main.py b/mycroft/skills/main.py
--- a/mycroft/skills/main.py
+++ b/mycroft/skills/main.py
@@ -57,16 +57,25 @@
def install_default_skills(speak=True):
+ """
+ Install default skill set using msm.
+
+ Args:
+ speak (optional): Enable response for success. Default True
+ """
if exists(MSM_BIN):
- p = subprocess.Popen(MSM_BIN + " default", stderr=subprocess.STDOUT,
- stdout=subprocess.PIPE, shell=True)
- t = p.communicate()[0]
- if t.splitlines()[-1] == "Installed!" and speak:
+ res = subprocess.call(MSM_BIN + " default", stderr=subprocess.STDOUT,
+ stdout=subprocess.PIPE, shell=True)
+ if res == 0 and speak:
ws.emit(Message("speak", {
'utterance': mycroft.dialog.get("skills updated")}))
elif not connected():
ws.emit(Message("speak", {
'utterance': mycroft.dialog.get("no network connection")}))
+ elif res != 0:
+ ws.emit(Message("speak", {
+ 'utterance': mycroft.dialog.get(
+ "sorry I couldn't install default skills")}))
else:
logger.error("Unable to invoke Mycroft Skill Manager: " + MSM_BIN)
|
{"golden_diff": "diff --git a/mycroft/skills/main.py b/mycroft/skills/main.py\n--- a/mycroft/skills/main.py\n+++ b/mycroft/skills/main.py\n@@ -57,16 +57,25 @@\n \n \n def install_default_skills(speak=True):\n+ \"\"\"\n+ Install default skill set using msm.\n+\n+ Args:\n+ speak (optional): Enable response for success. Default True\n+ \"\"\"\n if exists(MSM_BIN):\n- p = subprocess.Popen(MSM_BIN + \" default\", stderr=subprocess.STDOUT,\n- stdout=subprocess.PIPE, shell=True)\n- t = p.communicate()[0]\n- if t.splitlines()[-1] == \"Installed!\" and speak:\n+ res = subprocess.call(MSM_BIN + \" default\", stderr=subprocess.STDOUT,\n+ stdout=subprocess.PIPE, shell=True)\n+ if res == 0 and speak:\n ws.emit(Message(\"speak\", {\n 'utterance': mycroft.dialog.get(\"skills updated\")}))\n elif not connected():\n ws.emit(Message(\"speak\", {\n 'utterance': mycroft.dialog.get(\"no network connection\")}))\n+ elif res != 0:\n+ ws.emit(Message(\"speak\", {\n+ 'utterance': mycroft.dialog.get(\n+ \"sorry I couldn't install default skills\")}))\n \n else:\n logger.error(\"Unable to invoke Mycroft Skill Manager: \" + MSM_BIN)\n", "issue": "Report errors while installing default skills\nInstalling default skills may fail quietly in some conditions, ideally some feedback to the user should be given.\n", "before_files": [{"content": "# Copyright 2016 Mycroft AI, Inc.\n#\n# This file is part of Mycroft Core.\n#\n# Mycroft Core is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Mycroft Core is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Mycroft Core. If not, see <http://www.gnu.org/licenses/>.\n\n\nimport json\nimport os\nimport subprocess\nimport sys\nimport time\nfrom os.path import exists, join\nfrom threading import Timer\n\nfrom mycroft import MYCROFT_ROOT_PATH\nfrom mycroft.configuration import ConfigurationManager\nfrom mycroft.lock import Lock # Creates PID file for single instance\nfrom mycroft.messagebus.client.ws import WebsocketClient\nfrom mycroft.messagebus.message import Message\nfrom mycroft.skills.core import load_skill, create_skill_descriptor, \\\n MainModule, SKILLS_DIR\nfrom mycroft.skills.intent_service import IntentService\nfrom mycroft.util import connected\nfrom mycroft.util.log import getLogger\nimport mycroft.dialog\n\nlogger = getLogger(\"Skills\")\n\n__author__ = 'seanfitz'\n\nws = None\nloaded_skills = {}\nlast_modified_skill = 0\nskills_directories = []\nskill_reload_thread = None\nskills_manager_timer = None\n\ninstaller_config = ConfigurationManager.instance().get(\"SkillInstallerSkill\")\nMSM_BIN = installer_config.get(\"path\", join(MYCROFT_ROOT_PATH, 'msm', 'msm'))\n\n\ndef connect():\n global ws\n ws.run_forever()\n\n\ndef install_default_skills(speak=True):\n if exists(MSM_BIN):\n p = subprocess.Popen(MSM_BIN + \" default\", stderr=subprocess.STDOUT,\n stdout=subprocess.PIPE, shell=True)\n t = p.communicate()[0]\n if t.splitlines()[-1] == \"Installed!\" and speak:\n ws.emit(Message(\"speak\", {\n 'utterance': mycroft.dialog.get(\"skills updated\")}))\n elif not connected():\n ws.emit(Message(\"speak\", {\n 'utterance': mycroft.dialog.get(\"no network connection\")}))\n\n else:\n logger.error(\"Unable to invoke Mycroft Skill Manager: \" + MSM_BIN)\n\n\ndef skills_manager(message):\n global skills_manager_timer, ws\n\n if connected():\n if skills_manager_timer is None:\n ws.emit(\n Message(\"speak\", {'utterance':\n mycroft.dialog.get(\"checking for updates\")}))\n\n # Install default skills and look for updates via Github\n logger.debug(\"==== Invoking Mycroft Skill Manager: \" + MSM_BIN)\n install_default_skills(False)\n\n # Perform check again once and hour\n skills_manager_timer = Timer(3600, _skills_manager_dispatch)\n skills_manager_timer.daemon = True\n skills_manager_timer.start()\n\n\ndef _skills_manager_dispatch():\n ws.emit(Message(\"skill_manager\", {}))\n\n\ndef _load_skills():\n global ws, loaded_skills, last_modified_skill, skills_directories, \\\n skill_reload_thread\n\n check_connection()\n\n # Create skill_manager listener and invoke the first time\n ws.on('skill_manager', skills_manager)\n ws.on('mycroft.internet.connected', install_default_skills)\n ws.emit(Message('skill_manager', {}))\n\n # Create the Intent manager, which converts utterances to intents\n # This is the heart of the voice invoked skill system\n IntentService(ws)\n\n # Create a thread that monitors the loaded skills, looking for updates\n skill_reload_thread = Timer(0, _watch_skills)\n skill_reload_thread.daemon = True\n skill_reload_thread.start()\n\n\ndef check_connection():\n if connected():\n ws.emit(Message('mycroft.internet.connected'))\n else:\n thread = Timer(1, check_connection)\n thread.daemon = True\n thread.start()\n\n\ndef _get_last_modified_date(path):\n last_date = 0\n # getting all recursive paths\n for root, _, _ in os.walk(path):\n f = root.replace(path, \"\")\n # checking if is a hidden path\n if not f.startswith(\".\") and not f.startswith(\"/.\"):\n last_date = max(last_date, os.path.getmtime(path + f))\n\n return last_date\n\n\ndef _watch_skills():\n global ws, loaded_skills, last_modified_skill, \\\n id_counter\n\n # Scan the file folder that contains Skills. If a Skill is updated,\n # unload the existing version from memory and reload from the disk.\n while True:\n if exists(SKILLS_DIR):\n # checking skills dir and getting all skills there\n list = filter(lambda x: os.path.isdir(\n os.path.join(SKILLS_DIR, x)), os.listdir(SKILLS_DIR))\n\n for skill_folder in list:\n if skill_folder not in loaded_skills:\n loaded_skills[skill_folder] = {}\n skill = loaded_skills.get(skill_folder)\n skill[\"path\"] = os.path.join(SKILLS_DIR, skill_folder)\n # checking if is a skill\n if not MainModule + \".py\" in os.listdir(skill[\"path\"]):\n continue\n # getting the newest modified date of skill\n skill[\"last_modified\"] = _get_last_modified_date(skill[\"path\"])\n modified = skill.get(\"last_modified\", 0)\n # checking if skill is loaded and wasn't modified\n if skill.get(\n \"loaded\") and modified <= last_modified_skill:\n continue\n # checking if skill was modified\n elif skill.get(\n \"instance\") and modified > last_modified_skill:\n # checking if skill should be reloaded\n if not skill[\"instance\"].reload_skill:\n continue\n logger.debug(\"Reloading Skill: \" + skill_folder)\n # removing listeners and stopping threads\n skill[\"instance\"].shutdown()\n del skill[\"instance\"]\n skill[\"loaded\"] = True\n skill[\"instance\"] = load_skill(\n create_skill_descriptor(skill[\"path\"]), ws)\n # get the last modified skill\n modified_dates = map(lambda x: x.get(\"last_modified\"),\n loaded_skills.values())\n if len(modified_dates) > 0:\n last_modified_skill = max(modified_dates)\n\n # Pause briefly before beginning next scan\n time.sleep(2)\n\n\ndef main():\n global ws\n lock = Lock('skills') # prevent multiple instances of this service\n\n # Connect this Skill management process to the websocket\n ws = WebsocketClient()\n ConfigurationManager.init(ws)\n\n ignore_logs = ConfigurationManager.instance().get(\"ignore_logs\")\n\n # Listen for messages and echo them for logging\n def _echo(message):\n try:\n _message = json.loads(message)\n\n if _message.get(\"type\") in ignore_logs:\n return\n\n if _message.get(\"type\") == \"registration\":\n # do not log tokens from registration messages\n _message[\"data\"][\"token\"] = None\n message = json.dumps(_message)\n except:\n pass\n logger.debug(message)\n\n ws.on('message', _echo)\n\n # Kick off loading of skills\n ws.once('open', _load_skills)\n ws.run_forever()\n\n\nif __name__ == \"__main__\":\n try:\n main()\n except KeyboardInterrupt:\n skills_manager_timer.cancel()\n for skill in loaded_skills:\n skill.shutdown()\n if skill_reload_thread:\n skill_reload_thread.cancel()\n\n finally:\n sys.exit()\n", "path": "mycroft/skills/main.py"}]}
| 2,824 | 307 |
gh_patches_debug_2599
|
rasdani/github-patches
|
git_diff
|
hpcaitech__ColossalAI-3323
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
</issue>
<code>
[start of colossalai/fx/tracer/_tracer_utils.py]
1 from typing import List, Union, Any
2 from ..proxy import ColoProxy, ColoAttribute
3 import torch
4 from .meta_patch import meta_patched_function, meta_patched_module
5
6 __all__ = ['is_element_in_list', 'extract_meta']
7
8
9 def is_element_in_list(elements: Union[List[Any], Any], list_: List[Any]):
10 if isinstance(elements, (tuple, list, set)):
11 for ele in elements:
12 if ele not in list_:
13 return False, ele
14 else:
15 if elements not in list_:
16 return False, elements
17
18 return True, None
19
20
21 def extract_meta(*args, **kwargs):
22
23 def _convert(val):
24 if isinstance(val, ColoProxy):
25 return val.meta_data
26 elif isinstance(val, (list, tuple)):
27 return type(val)([_convert(ele) for ele in val])
28
29 return val
30
31 new_args = [_convert(val) for val in args]
32 new_kwargs = {k: _convert(v) for k, v in kwargs.items()}
33 return new_args, new_kwargs
34
35
36 def compute_meta_data_for_functions_proxy(target, args, kwargs):
37 args_metas, kwargs_metas = extract_meta(*args, **kwargs)
38
39 # fetch patched function
40 if meta_patched_function.has(target):
41 meta_target = meta_patched_function.get(target)
42 elif meta_patched_function.has(target.__name__):
43 meta_target = meta_patched_function.get(target.__name__)
44 else:
45 meta_target = target
46 meta_out = meta_target(*args_metas, **kwargs_metas)
47 if isinstance(meta_out, torch.Tensor):
48 meta_out = meta_out.to(device="meta")
49
50 return meta_out
51
[end of colossalai/fx/tracer/_tracer_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/colossalai/fx/tracer/_tracer_utils.py b/colossalai/fx/tracer/_tracer_utils.py
--- a/colossalai/fx/tracer/_tracer_utils.py
+++ b/colossalai/fx/tracer/_tracer_utils.py
@@ -1,6 +1,8 @@
-from typing import List, Union, Any
-from ..proxy import ColoProxy, ColoAttribute
+from typing import Any, List, Union
+
import torch
+
+from ..proxy import ColoAttribute, ColoProxy
from .meta_patch import meta_patched_function, meta_patched_module
__all__ = ['is_element_in_list', 'extract_meta']
|
{"golden_diff": "diff --git a/colossalai/fx/tracer/_tracer_utils.py b/colossalai/fx/tracer/_tracer_utils.py\n--- a/colossalai/fx/tracer/_tracer_utils.py\n+++ b/colossalai/fx/tracer/_tracer_utils.py\n@@ -1,6 +1,8 @@\n-from typing import List, Union, Any\n-from ..proxy import ColoProxy, ColoAttribute\n+from typing import Any, List, Union\n+\n import torch\n+\n+from ..proxy import ColoAttribute, ColoProxy\n from .meta_patch import meta_patched_function, meta_patched_module\n \n __all__ = ['is_element_in_list', 'extract_meta']\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n", "before_files": [{"content": "from typing import List, Union, Any\nfrom ..proxy import ColoProxy, ColoAttribute\nimport torch\nfrom .meta_patch import meta_patched_function, meta_patched_module\n\n__all__ = ['is_element_in_list', 'extract_meta']\n\n\ndef is_element_in_list(elements: Union[List[Any], Any], list_: List[Any]):\n if isinstance(elements, (tuple, list, set)):\n for ele in elements:\n if ele not in list_:\n return False, ele\n else:\n if elements not in list_:\n return False, elements\n\n return True, None\n\n\ndef extract_meta(*args, **kwargs):\n\n def _convert(val):\n if isinstance(val, ColoProxy):\n return val.meta_data\n elif isinstance(val, (list, tuple)):\n return type(val)([_convert(ele) for ele in val])\n\n return val\n\n new_args = [_convert(val) for val in args]\n new_kwargs = {k: _convert(v) for k, v in kwargs.items()}\n return new_args, new_kwargs\n\n\ndef compute_meta_data_for_functions_proxy(target, args, kwargs):\n args_metas, kwargs_metas = extract_meta(*args, **kwargs)\n\n # fetch patched function\n if meta_patched_function.has(target):\n meta_target = meta_patched_function.get(target)\n elif meta_patched_function.has(target.__name__):\n meta_target = meta_patched_function.get(target.__name__)\n else:\n meta_target = target\n meta_out = meta_target(*args_metas, **kwargs_metas)\n if isinstance(meta_out, torch.Tensor):\n meta_out = meta_out.to(device=\"meta\")\n\n return meta_out\n", "path": "colossalai/fx/tracer/_tracer_utils.py"}]}
| 1,027 | 144 |
gh_patches_debug_4707
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-747
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add publisher as a book field
Currently, the only way to distinguish editions is by their cover and their publication date. It would be nice if editions were also referred to by their publisher.
This is especially useful as part of the alt text of a cover for screen reader users, but also great for people who would like to catalog which edition is by which publisher. I believe OpenLibrary provides a publisher field as well, so this could be automagically filled during an import.
</issue>
<code>
[start of bookwyrm/models/book.py]
1 """ database schema for books and shelves """
2 import re
3
4 from django.db import models
5 from model_utils.managers import InheritanceManager
6
7 from bookwyrm import activitypub
8 from bookwyrm.settings import DOMAIN
9
10 from .activitypub_mixin import OrderedCollectionPageMixin, ObjectMixin
11 from .base_model import BookWyrmModel
12 from . import fields
13
14
15 class BookDataModel(ObjectMixin, BookWyrmModel):
16 """ fields shared between editable book data (books, works, authors) """
17
18 origin_id = models.CharField(max_length=255, null=True, blank=True)
19 openlibrary_key = fields.CharField(
20 max_length=255, blank=True, null=True, deduplication_field=True
21 )
22 librarything_key = fields.CharField(
23 max_length=255, blank=True, null=True, deduplication_field=True
24 )
25 goodreads_key = fields.CharField(
26 max_length=255, blank=True, null=True, deduplication_field=True
27 )
28
29 last_edited_by = models.ForeignKey("User", on_delete=models.PROTECT, null=True)
30
31 class Meta:
32 """ can't initialize this model, that wouldn't make sense """
33
34 abstract = True
35
36 def save(self, *args, **kwargs):
37 """ ensure that the remote_id is within this instance """
38 if self.id:
39 self.remote_id = self.get_remote_id()
40 else:
41 self.origin_id = self.remote_id
42 self.remote_id = None
43 return super().save(*args, **kwargs)
44
45 def broadcast(self, activity, sender, software="bookwyrm"):
46 """ only send book data updates to other bookwyrm instances """
47 super().broadcast(activity, sender, software=software)
48
49
50 class Book(BookDataModel):
51 """ a generic book, which can mean either an edition or a work """
52
53 connector = models.ForeignKey("Connector", on_delete=models.PROTECT, null=True)
54
55 # book/work metadata
56 title = fields.CharField(max_length=255)
57 sort_title = fields.CharField(max_length=255, blank=True, null=True)
58 subtitle = fields.CharField(max_length=255, blank=True, null=True)
59 description = fields.HtmlField(blank=True, null=True)
60 languages = fields.ArrayField(
61 models.CharField(max_length=255), blank=True, default=list
62 )
63 series = fields.CharField(max_length=255, blank=True, null=True)
64 series_number = fields.CharField(max_length=255, blank=True, null=True)
65 subjects = fields.ArrayField(
66 models.CharField(max_length=255), blank=True, null=True, default=list
67 )
68 subject_places = fields.ArrayField(
69 models.CharField(max_length=255), blank=True, null=True, default=list
70 )
71 authors = fields.ManyToManyField("Author")
72 cover = fields.ImageField(
73 upload_to="covers/", blank=True, null=True, alt_field="alt_text"
74 )
75 first_published_date = fields.DateTimeField(blank=True, null=True)
76 published_date = fields.DateTimeField(blank=True, null=True)
77
78 objects = InheritanceManager()
79
80 @property
81 def author_text(self):
82 """ format a list of authors """
83 return ", ".join(a.name for a in self.authors.all())
84
85 @property
86 def latest_readthrough(self):
87 """ most recent readthrough activity """
88 return self.readthrough_set.order_by("-updated_date").first()
89
90 @property
91 def edition_info(self):
92 """ properties of this edition, as a string """
93 items = [
94 self.physical_format if hasattr(self, "physical_format") else None,
95 self.languages[0] + " language"
96 if self.languages and self.languages[0] != "English"
97 else None,
98 str(self.published_date.year) if self.published_date else None,
99 ]
100 return ", ".join(i for i in items if i)
101
102 @property
103 def alt_text(self):
104 """ image alt test """
105 text = "%s" % self.title
106 if self.edition_info:
107 text += " (%s)" % self.edition_info
108 return text
109
110 def save(self, *args, **kwargs):
111 """ can't be abstract for query reasons, but you shouldn't USE it """
112 if not isinstance(self, Edition) and not isinstance(self, Work):
113 raise ValueError("Books should be added as Editions or Works")
114 return super().save(*args, **kwargs)
115
116 def get_remote_id(self):
117 """ editions and works both use "book" instead of model_name """
118 return "https://%s/book/%d" % (DOMAIN, self.id)
119
120 def __repr__(self):
121 return "<{} key={!r} title={!r}>".format(
122 self.__class__,
123 self.openlibrary_key,
124 self.title,
125 )
126
127
128 class Work(OrderedCollectionPageMixin, Book):
129 """ a work (an abstract concept of a book that manifests in an edition) """
130
131 # library of congress catalog control number
132 lccn = fields.CharField(
133 max_length=255, blank=True, null=True, deduplication_field=True
134 )
135 # this has to be nullable but should never be null
136 default_edition = fields.ForeignKey(
137 "Edition", on_delete=models.PROTECT, null=True, load_remote=False
138 )
139
140 def save(self, *args, **kwargs):
141 """ set some fields on the edition object """
142 # set rank
143 for edition in self.editions.all():
144 edition.save()
145 return super().save(*args, **kwargs)
146
147 def get_default_edition(self):
148 """ in case the default edition is not set """
149 return self.default_edition or self.editions.order_by("-edition_rank").first()
150
151 def to_edition_list(self, **kwargs):
152 """ an ordered collection of editions """
153 return self.to_ordered_collection(
154 self.editions.order_by("-edition_rank").all(),
155 remote_id="%s/editions" % self.remote_id,
156 **kwargs
157 )
158
159 activity_serializer = activitypub.Work
160 serialize_reverse_fields = [("editions", "editions", "-edition_rank")]
161 deserialize_reverse_fields = [("editions", "editions")]
162
163
164 class Edition(Book):
165 """ an edition of a book """
166
167 # these identifiers only apply to editions, not works
168 isbn_10 = fields.CharField(
169 max_length=255, blank=True, null=True, deduplication_field=True
170 )
171 isbn_13 = fields.CharField(
172 max_length=255, blank=True, null=True, deduplication_field=True
173 )
174 oclc_number = fields.CharField(
175 max_length=255, blank=True, null=True, deduplication_field=True
176 )
177 asin = fields.CharField(
178 max_length=255, blank=True, null=True, deduplication_field=True
179 )
180 pages = fields.IntegerField(blank=True, null=True)
181 physical_format = fields.CharField(max_length=255, blank=True, null=True)
182 publishers = fields.ArrayField(
183 models.CharField(max_length=255), blank=True, default=list
184 )
185 shelves = models.ManyToManyField(
186 "Shelf",
187 symmetrical=False,
188 through="ShelfBook",
189 through_fields=("book", "shelf"),
190 )
191 parent_work = fields.ForeignKey(
192 "Work",
193 on_delete=models.PROTECT,
194 null=True,
195 related_name="editions",
196 activitypub_field="work",
197 )
198 edition_rank = fields.IntegerField(default=0)
199
200 activity_serializer = activitypub.Edition
201 name_field = "title"
202
203 def get_rank(self):
204 """ calculate how complete the data is on this edition """
205 if self.parent_work and self.parent_work.default_edition == self:
206 # default edition has the highest rank
207 return 20
208 rank = 0
209 rank += int(bool(self.cover)) * 3
210 rank += int(bool(self.isbn_13))
211 rank += int(bool(self.isbn_10))
212 rank += int(bool(self.oclc_number))
213 rank += int(bool(self.pages))
214 rank += int(bool(self.physical_format))
215 rank += int(bool(self.description))
216 # max rank is 9
217 return rank
218
219 def save(self, *args, **kwargs):
220 """ set some fields on the edition object """
221 # calculate isbn 10/13
222 if self.isbn_13 and self.isbn_13[:3] == "978" and not self.isbn_10:
223 self.isbn_10 = isbn_13_to_10(self.isbn_13)
224 if self.isbn_10 and not self.isbn_13:
225 self.isbn_13 = isbn_10_to_13(self.isbn_10)
226
227 # set rank
228 self.edition_rank = self.get_rank()
229
230 return super().save(*args, **kwargs)
231
232
233 def isbn_10_to_13(isbn_10):
234 """ convert an isbn 10 into an isbn 13 """
235 isbn_10 = re.sub(r"[^0-9X]", "", isbn_10)
236 # drop the last character of the isbn 10 number (the original checkdigit)
237 converted = isbn_10[:9]
238 # add "978" to the front
239 converted = "978" + converted
240 # add a check digit to the end
241 # multiply the odd digits by 1 and the even digits by 3 and sum them
242 try:
243 checksum = sum(int(i) for i in converted[::2]) + sum(
244 int(i) * 3 for i in converted[1::2]
245 )
246 except ValueError:
247 return None
248 # add the checksum mod 10 to the end
249 checkdigit = checksum % 10
250 if checkdigit != 0:
251 checkdigit = 10 - checkdigit
252 return converted + str(checkdigit)
253
254
255 def isbn_13_to_10(isbn_13):
256 """ convert isbn 13 to 10, if possible """
257 if isbn_13[:3] != "978":
258 return None
259
260 isbn_13 = re.sub(r"[^0-9X]", "", isbn_13)
261
262 # remove '978' and old checkdigit
263 converted = isbn_13[3:-1]
264 # calculate checkdigit
265 # multiple each digit by 10,9,8.. successively and sum them
266 try:
267 checksum = sum(int(d) * (10 - idx) for (idx, d) in enumerate(converted))
268 except ValueError:
269 return None
270 checkdigit = checksum % 11
271 checkdigit = 11 - checkdigit
272 if checkdigit == 10:
273 checkdigit = "X"
274 return converted + str(checkdigit)
275
[end of bookwyrm/models/book.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/models/book.py b/bookwyrm/models/book.py
--- a/bookwyrm/models/book.py
+++ b/bookwyrm/models/book.py
@@ -96,6 +96,7 @@
if self.languages and self.languages[0] != "English"
else None,
str(self.published_date.year) if self.published_date else None,
+ ", ".join(self.publishers) if hasattr(self, "publishers") else None,
]
return ", ".join(i for i in items if i)
|
{"golden_diff": "diff --git a/bookwyrm/models/book.py b/bookwyrm/models/book.py\n--- a/bookwyrm/models/book.py\n+++ b/bookwyrm/models/book.py\n@@ -96,6 +96,7 @@\n if self.languages and self.languages[0] != \"English\"\n else None,\n str(self.published_date.year) if self.published_date else None,\n+ \", \".join(self.publishers) if hasattr(self, \"publishers\") else None,\n ]\n return \", \".join(i for i in items if i)\n", "issue": "Add publisher as a book field\nCurrently, the only way to distinguish editions is by their cover and their publication date. It would be nice if editions were also referred to by their publisher.\r\n\r\nThis is especially useful as part of the alt text of a cover for screen reader users, but also great for people who would like to catalog which edition is by which publisher. I believe OpenLibrary provides a publisher field as well, so this could be automagically filled during an import.\n", "before_files": [{"content": "\"\"\" database schema for books and shelves \"\"\"\nimport re\n\nfrom django.db import models\nfrom model_utils.managers import InheritanceManager\n\nfrom bookwyrm import activitypub\nfrom bookwyrm.settings import DOMAIN\n\nfrom .activitypub_mixin import OrderedCollectionPageMixin, ObjectMixin\nfrom .base_model import BookWyrmModel\nfrom . import fields\n\n\nclass BookDataModel(ObjectMixin, BookWyrmModel):\n \"\"\" fields shared between editable book data (books, works, authors) \"\"\"\n\n origin_id = models.CharField(max_length=255, null=True, blank=True)\n openlibrary_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n librarything_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n goodreads_key = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n\n last_edited_by = models.ForeignKey(\"User\", on_delete=models.PROTECT, null=True)\n\n class Meta:\n \"\"\" can't initialize this model, that wouldn't make sense \"\"\"\n\n abstract = True\n\n def save(self, *args, **kwargs):\n \"\"\" ensure that the remote_id is within this instance \"\"\"\n if self.id:\n self.remote_id = self.get_remote_id()\n else:\n self.origin_id = self.remote_id\n self.remote_id = None\n return super().save(*args, **kwargs)\n\n def broadcast(self, activity, sender, software=\"bookwyrm\"):\n \"\"\" only send book data updates to other bookwyrm instances \"\"\"\n super().broadcast(activity, sender, software=software)\n\n\nclass Book(BookDataModel):\n \"\"\" a generic book, which can mean either an edition or a work \"\"\"\n\n connector = models.ForeignKey(\"Connector\", on_delete=models.PROTECT, null=True)\n\n # book/work metadata\n title = fields.CharField(max_length=255)\n sort_title = fields.CharField(max_length=255, blank=True, null=True)\n subtitle = fields.CharField(max_length=255, blank=True, null=True)\n description = fields.HtmlField(blank=True, null=True)\n languages = fields.ArrayField(\n models.CharField(max_length=255), blank=True, default=list\n )\n series = fields.CharField(max_length=255, blank=True, null=True)\n series_number = fields.CharField(max_length=255, blank=True, null=True)\n subjects = fields.ArrayField(\n models.CharField(max_length=255), blank=True, null=True, default=list\n )\n subject_places = fields.ArrayField(\n models.CharField(max_length=255), blank=True, null=True, default=list\n )\n authors = fields.ManyToManyField(\"Author\")\n cover = fields.ImageField(\n upload_to=\"covers/\", blank=True, null=True, alt_field=\"alt_text\"\n )\n first_published_date = fields.DateTimeField(blank=True, null=True)\n published_date = fields.DateTimeField(blank=True, null=True)\n\n objects = InheritanceManager()\n\n @property\n def author_text(self):\n \"\"\" format a list of authors \"\"\"\n return \", \".join(a.name for a in self.authors.all())\n\n @property\n def latest_readthrough(self):\n \"\"\" most recent readthrough activity \"\"\"\n return self.readthrough_set.order_by(\"-updated_date\").first()\n\n @property\n def edition_info(self):\n \"\"\" properties of this edition, as a string \"\"\"\n items = [\n self.physical_format if hasattr(self, \"physical_format\") else None,\n self.languages[0] + \" language\"\n if self.languages and self.languages[0] != \"English\"\n else None,\n str(self.published_date.year) if self.published_date else None,\n ]\n return \", \".join(i for i in items if i)\n\n @property\n def alt_text(self):\n \"\"\" image alt test \"\"\"\n text = \"%s\" % self.title\n if self.edition_info:\n text += \" (%s)\" % self.edition_info\n return text\n\n def save(self, *args, **kwargs):\n \"\"\" can't be abstract for query reasons, but you shouldn't USE it \"\"\"\n if not isinstance(self, Edition) and not isinstance(self, Work):\n raise ValueError(\"Books should be added as Editions or Works\")\n return super().save(*args, **kwargs)\n\n def get_remote_id(self):\n \"\"\" editions and works both use \"book\" instead of model_name \"\"\"\n return \"https://%s/book/%d\" % (DOMAIN, self.id)\n\n def __repr__(self):\n return \"<{} key={!r} title={!r}>\".format(\n self.__class__,\n self.openlibrary_key,\n self.title,\n )\n\n\nclass Work(OrderedCollectionPageMixin, Book):\n \"\"\" a work (an abstract concept of a book that manifests in an edition) \"\"\"\n\n # library of congress catalog control number\n lccn = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n # this has to be nullable but should never be null\n default_edition = fields.ForeignKey(\n \"Edition\", on_delete=models.PROTECT, null=True, load_remote=False\n )\n\n def save(self, *args, **kwargs):\n \"\"\" set some fields on the edition object \"\"\"\n # set rank\n for edition in self.editions.all():\n edition.save()\n return super().save(*args, **kwargs)\n\n def get_default_edition(self):\n \"\"\" in case the default edition is not set \"\"\"\n return self.default_edition or self.editions.order_by(\"-edition_rank\").first()\n\n def to_edition_list(self, **kwargs):\n \"\"\" an ordered collection of editions \"\"\"\n return self.to_ordered_collection(\n self.editions.order_by(\"-edition_rank\").all(),\n remote_id=\"%s/editions\" % self.remote_id,\n **kwargs\n )\n\n activity_serializer = activitypub.Work\n serialize_reverse_fields = [(\"editions\", \"editions\", \"-edition_rank\")]\n deserialize_reverse_fields = [(\"editions\", \"editions\")]\n\n\nclass Edition(Book):\n \"\"\" an edition of a book \"\"\"\n\n # these identifiers only apply to editions, not works\n isbn_10 = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n isbn_13 = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n oclc_number = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n asin = fields.CharField(\n max_length=255, blank=True, null=True, deduplication_field=True\n )\n pages = fields.IntegerField(blank=True, null=True)\n physical_format = fields.CharField(max_length=255, blank=True, null=True)\n publishers = fields.ArrayField(\n models.CharField(max_length=255), blank=True, default=list\n )\n shelves = models.ManyToManyField(\n \"Shelf\",\n symmetrical=False,\n through=\"ShelfBook\",\n through_fields=(\"book\", \"shelf\"),\n )\n parent_work = fields.ForeignKey(\n \"Work\",\n on_delete=models.PROTECT,\n null=True,\n related_name=\"editions\",\n activitypub_field=\"work\",\n )\n edition_rank = fields.IntegerField(default=0)\n\n activity_serializer = activitypub.Edition\n name_field = \"title\"\n\n def get_rank(self):\n \"\"\" calculate how complete the data is on this edition \"\"\"\n if self.parent_work and self.parent_work.default_edition == self:\n # default edition has the highest rank\n return 20\n rank = 0\n rank += int(bool(self.cover)) * 3\n rank += int(bool(self.isbn_13))\n rank += int(bool(self.isbn_10))\n rank += int(bool(self.oclc_number))\n rank += int(bool(self.pages))\n rank += int(bool(self.physical_format))\n rank += int(bool(self.description))\n # max rank is 9\n return rank\n\n def save(self, *args, **kwargs):\n \"\"\" set some fields on the edition object \"\"\"\n # calculate isbn 10/13\n if self.isbn_13 and self.isbn_13[:3] == \"978\" and not self.isbn_10:\n self.isbn_10 = isbn_13_to_10(self.isbn_13)\n if self.isbn_10 and not self.isbn_13:\n self.isbn_13 = isbn_10_to_13(self.isbn_10)\n\n # set rank\n self.edition_rank = self.get_rank()\n\n return super().save(*args, **kwargs)\n\n\ndef isbn_10_to_13(isbn_10):\n \"\"\" convert an isbn 10 into an isbn 13 \"\"\"\n isbn_10 = re.sub(r\"[^0-9X]\", \"\", isbn_10)\n # drop the last character of the isbn 10 number (the original checkdigit)\n converted = isbn_10[:9]\n # add \"978\" to the front\n converted = \"978\" + converted\n # add a check digit to the end\n # multiply the odd digits by 1 and the even digits by 3 and sum them\n try:\n checksum = sum(int(i) for i in converted[::2]) + sum(\n int(i) * 3 for i in converted[1::2]\n )\n except ValueError:\n return None\n # add the checksum mod 10 to the end\n checkdigit = checksum % 10\n if checkdigit != 0:\n checkdigit = 10 - checkdigit\n return converted + str(checkdigit)\n\n\ndef isbn_13_to_10(isbn_13):\n \"\"\" convert isbn 13 to 10, if possible \"\"\"\n if isbn_13[:3] != \"978\":\n return None\n\n isbn_13 = re.sub(r\"[^0-9X]\", \"\", isbn_13)\n\n # remove '978' and old checkdigit\n converted = isbn_13[3:-1]\n # calculate checkdigit\n # multiple each digit by 10,9,8.. successively and sum them\n try:\n checksum = sum(int(d) * (10 - idx) for (idx, d) in enumerate(converted))\n except ValueError:\n return None\n checkdigit = checksum % 11\n checkdigit = 11 - checkdigit\n if checkdigit == 10:\n checkdigit = \"X\"\n return converted + str(checkdigit)\n", "path": "bookwyrm/models/book.py"}]}
| 3,721 | 115 |
gh_patches_debug_5791
|
rasdani/github-patches
|
git_diff
|
paperless-ngx__paperless-ngx-195
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Other] Update name to paperless-ngx in docs
https://github.com/paperless-ngx/paperless-ngx/issues/4#issuecomment-1039890021
> I would go through the places where the project name is mentioned and add the x to it. Only actually code (variable names) could remain unchanged for backwards compatibility.
</issue>
<code>
[start of src/paperless/urls.py]
1 from django.conf.urls import include
2 from django.contrib import admin
3 from django.contrib.auth.decorators import login_required
4 from django.urls import path, re_path
5 from django.views.decorators.csrf import csrf_exempt
6 from django.views.generic import RedirectView
7 from rest_framework.authtoken import views
8 from rest_framework.routers import DefaultRouter
9
10 from django.utils.translation import gettext_lazy as _
11
12 from django.conf import settings
13
14 from paperless.consumers import StatusConsumer
15 from documents.views import (
16 CorrespondentViewSet,
17 UnifiedSearchViewSet,
18 LogViewSet,
19 TagViewSet,
20 DocumentTypeViewSet,
21 IndexView,
22 SearchAutoCompleteView,
23 StatisticsView,
24 PostDocumentView,
25 SavedViewViewSet,
26 BulkEditView,
27 SelectionDataView,
28 BulkDownloadView,
29 )
30 from paperless.views import FaviconView
31
32 api_router = DefaultRouter()
33 api_router.register(r"correspondents", CorrespondentViewSet)
34 api_router.register(r"document_types", DocumentTypeViewSet)
35 api_router.register(r"documents", UnifiedSearchViewSet)
36 api_router.register(r"logs", LogViewSet, basename="logs")
37 api_router.register(r"tags", TagViewSet)
38 api_router.register(r"saved_views", SavedViewViewSet)
39
40
41 urlpatterns = [
42 re_path(
43 r"^api/",
44 include(
45 [
46 re_path(
47 r"^auth/",
48 include(
49 ("rest_framework.urls", "rest_framework"),
50 namespace="rest_framework",
51 ),
52 ),
53 re_path(
54 r"^search/autocomplete/",
55 SearchAutoCompleteView.as_view(),
56 name="autocomplete",
57 ),
58 re_path(r"^statistics/", StatisticsView.as_view(), name="statistics"),
59 re_path(
60 r"^documents/post_document/",
61 PostDocumentView.as_view(),
62 name="post_document",
63 ),
64 re_path(
65 r"^documents/bulk_edit/", BulkEditView.as_view(), name="bulk_edit"
66 ),
67 re_path(
68 r"^documents/selection_data/",
69 SelectionDataView.as_view(),
70 name="selection_data",
71 ),
72 re_path(
73 r"^documents/bulk_download/",
74 BulkDownloadView.as_view(),
75 name="bulk_download",
76 ),
77 path("token/", views.obtain_auth_token),
78 ]
79 + api_router.urls
80 ),
81 ),
82 re_path(r"^favicon.ico$", FaviconView.as_view(), name="favicon"),
83 re_path(r"admin/", admin.site.urls),
84 re_path(
85 r"^fetch/",
86 include(
87 [
88 re_path(
89 r"^doc/(?P<pk>\d+)$",
90 RedirectView.as_view(
91 url=settings.BASE_URL + "api/documents/%(pk)s/download/"
92 ),
93 ),
94 re_path(
95 r"^thumb/(?P<pk>\d+)$",
96 RedirectView.as_view(
97 url=settings.BASE_URL + "api/documents/%(pk)s/thumb/"
98 ),
99 ),
100 re_path(
101 r"^preview/(?P<pk>\d+)$",
102 RedirectView.as_view(
103 url=settings.BASE_URL + "api/documents/%(pk)s/preview/"
104 ),
105 ),
106 ]
107 ),
108 ),
109 re_path(
110 r"^push$",
111 csrf_exempt(
112 RedirectView.as_view(url=settings.BASE_URL + "api/documents/post_document/")
113 ),
114 ),
115 # Frontend assets TODO: this is pretty bad, but it works.
116 path(
117 "assets/<path:path>",
118 RedirectView.as_view(
119 url=settings.STATIC_URL + "frontend/en-US/assets/%(path)s"
120 ),
121 ),
122 # TODO: with localization, this is even worse! :/
123 # login, logout
124 path("accounts/", include("django.contrib.auth.urls")),
125 # Root of the Frontent
126 re_path(r".*", login_required(IndexView.as_view()), name="base"),
127 ]
128
129
130 websocket_urlpatterns = [
131 re_path(r"ws/status/$", StatusConsumer.as_asgi()),
132 ]
133
134 # Text in each page's <h1> (and above login form).
135 admin.site.site_header = "Paperless-ng"
136 # Text at the end of each page's <title>.
137 admin.site.site_title = "Paperless-ng"
138 # Text at the top of the admin index page.
139 admin.site.index_title = _("Paperless-ng administration")
140
[end of src/paperless/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/paperless/urls.py b/src/paperless/urls.py
--- a/src/paperless/urls.py
+++ b/src/paperless/urls.py
@@ -132,8 +132,8 @@
]
# Text in each page's <h1> (and above login form).
-admin.site.site_header = "Paperless-ng"
+admin.site.site_header = "Paperless-ngx"
# Text at the end of each page's <title>.
-admin.site.site_title = "Paperless-ng"
+admin.site.site_title = "Paperless-ngx"
# Text at the top of the admin index page.
-admin.site.index_title = _("Paperless-ng administration")
+admin.site.index_title = _("Paperless-ngx administration")
|
{"golden_diff": "diff --git a/src/paperless/urls.py b/src/paperless/urls.py\n--- a/src/paperless/urls.py\n+++ b/src/paperless/urls.py\n@@ -132,8 +132,8 @@\n ]\n \n # Text in each page's <h1> (and above login form).\n-admin.site.site_header = \"Paperless-ng\"\n+admin.site.site_header = \"Paperless-ngx\"\n # Text at the end of each page's <title>.\n-admin.site.site_title = \"Paperless-ng\"\n+admin.site.site_title = \"Paperless-ngx\"\n # Text at the top of the admin index page.\n-admin.site.index_title = _(\"Paperless-ng administration\")\n+admin.site.index_title = _(\"Paperless-ngx administration\")\n", "issue": "[Other] Update name to paperless-ngx in docs\nhttps://github.com/paperless-ngx/paperless-ngx/issues/4#issuecomment-1039890021\r\n\r\n> I would go through the places where the project name is mentioned and add the x to it. Only actually code (variable names) could remain unchanged for backwards compatibility.\n", "before_files": [{"content": "from django.conf.urls import include\nfrom django.contrib import admin\nfrom django.contrib.auth.decorators import login_required\nfrom django.urls import path, re_path\nfrom django.views.decorators.csrf import csrf_exempt\nfrom django.views.generic import RedirectView\nfrom rest_framework.authtoken import views\nfrom rest_framework.routers import DefaultRouter\n\nfrom django.utils.translation import gettext_lazy as _\n\nfrom django.conf import settings\n\nfrom paperless.consumers import StatusConsumer\nfrom documents.views import (\n CorrespondentViewSet,\n UnifiedSearchViewSet,\n LogViewSet,\n TagViewSet,\n DocumentTypeViewSet,\n IndexView,\n SearchAutoCompleteView,\n StatisticsView,\n PostDocumentView,\n SavedViewViewSet,\n BulkEditView,\n SelectionDataView,\n BulkDownloadView,\n)\nfrom paperless.views import FaviconView\n\napi_router = DefaultRouter()\napi_router.register(r\"correspondents\", CorrespondentViewSet)\napi_router.register(r\"document_types\", DocumentTypeViewSet)\napi_router.register(r\"documents\", UnifiedSearchViewSet)\napi_router.register(r\"logs\", LogViewSet, basename=\"logs\")\napi_router.register(r\"tags\", TagViewSet)\napi_router.register(r\"saved_views\", SavedViewViewSet)\n\n\nurlpatterns = [\n re_path(\n r\"^api/\",\n include(\n [\n re_path(\n r\"^auth/\",\n include(\n (\"rest_framework.urls\", \"rest_framework\"),\n namespace=\"rest_framework\",\n ),\n ),\n re_path(\n r\"^search/autocomplete/\",\n SearchAutoCompleteView.as_view(),\n name=\"autocomplete\",\n ),\n re_path(r\"^statistics/\", StatisticsView.as_view(), name=\"statistics\"),\n re_path(\n r\"^documents/post_document/\",\n PostDocumentView.as_view(),\n name=\"post_document\",\n ),\n re_path(\n r\"^documents/bulk_edit/\", BulkEditView.as_view(), name=\"bulk_edit\"\n ),\n re_path(\n r\"^documents/selection_data/\",\n SelectionDataView.as_view(),\n name=\"selection_data\",\n ),\n re_path(\n r\"^documents/bulk_download/\",\n BulkDownloadView.as_view(),\n name=\"bulk_download\",\n ),\n path(\"token/\", views.obtain_auth_token),\n ]\n + api_router.urls\n ),\n ),\n re_path(r\"^favicon.ico$\", FaviconView.as_view(), name=\"favicon\"),\n re_path(r\"admin/\", admin.site.urls),\n re_path(\n r\"^fetch/\",\n include(\n [\n re_path(\n r\"^doc/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/download/\"\n ),\n ),\n re_path(\n r\"^thumb/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/thumb/\"\n ),\n ),\n re_path(\n r\"^preview/(?P<pk>\\d+)$\",\n RedirectView.as_view(\n url=settings.BASE_URL + \"api/documents/%(pk)s/preview/\"\n ),\n ),\n ]\n ),\n ),\n re_path(\n r\"^push$\",\n csrf_exempt(\n RedirectView.as_view(url=settings.BASE_URL + \"api/documents/post_document/\")\n ),\n ),\n # Frontend assets TODO: this is pretty bad, but it works.\n path(\n \"assets/<path:path>\",\n RedirectView.as_view(\n url=settings.STATIC_URL + \"frontend/en-US/assets/%(path)s\"\n ),\n ),\n # TODO: with localization, this is even worse! :/\n # login, logout\n path(\"accounts/\", include(\"django.contrib.auth.urls\")),\n # Root of the Frontent\n re_path(r\".*\", login_required(IndexView.as_view()), name=\"base\"),\n]\n\n\nwebsocket_urlpatterns = [\n re_path(r\"ws/status/$\", StatusConsumer.as_asgi()),\n]\n\n# Text in each page's <h1> (and above login form).\nadmin.site.site_header = \"Paperless-ng\"\n# Text at the end of each page's <title>.\nadmin.site.site_title = \"Paperless-ng\"\n# Text at the top of the admin index page.\nadmin.site.index_title = _(\"Paperless-ng administration\")\n", "path": "src/paperless/urls.py"}]}
| 1,815 | 163 |
gh_patches_debug_34903
|
rasdani/github-patches
|
git_diff
|
data-for-change__anyway-731
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Move load_discussions into main
I can't figure out what's the purpose of this file
</issue>
<code>
[start of anyway/load_discussions.py]
1 # -*- coding: utf-8 -*-
2 import argparse
3 from .models import DiscussionMarker
4 import re
5 from .database import db_session
6 import sys
7 import logging
8
9 def main():
10 parser = argparse.ArgumentParser()
11 parser.add_argument('identifiers', type=str, nargs='*',
12 help='Disqus identifiers to create markers for')
13 args = parser.parse_args()
14
15 identifiers = args.identifiers if args.identifiers else sys.stdin
16
17 for identifier in identifiers:
18 m = re.match(r'\((\d+\.\d+),\s*(\d+\.\d+)\)', identifier)
19 if not m:
20 logging.error("Failed processing: " + identifier)
21 continue
22 (latitude, longitude) = m.group(1, 2)
23 marker = DiscussionMarker.parse({
24 'latitude': latitude,
25 'longitude': longitude,
26 'title': identifier,
27 'identifier': identifier
28 })
29 try:
30 db_session.add(marker)
31 db_session.commit()
32 logging.info("Added: " + identifier, end="")
33 except:
34 db_session.rollback()
35 logging.warn("Failed: " + identifier, end="")
36
37
38 if __name__ == "__main__":
39 main()
40
[end of anyway/load_discussions.py]
[start of main.py]
1 #!/usr/bin/env python
2
3 import os
4 import click
5 import logging
6
7 @click.group()
8 def cli():
9 pass
10
11
12 @cli.command()
13 @click.option('--open', 'open_server', is_flag=True,
14 help='Open the server for communication from outside', default=False)
15 def testserver(open_server):
16 from anyway import app, united
17 from apscheduler.scheduler import Scheduler
18
19 sched = Scheduler()
20
21 @sched.interval_schedule(hours=12)
22 def scheduled_import():
23 united.main()
24 sched.start()
25
26 logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(message)s')
27
28 default_host = '0.0.0.0' if open_server else '127.0.0.1'
29 app.run(debug=True, host=os.getenv('IP', default_host),
30 port=int(os.getenv('PORT', 5000)))
31
32
33 @cli.command()
34 def init_db():
35 from anyway.models import init_db
36 init_db()
37
38
39 @cli.command()
40 @click.option('--specific_folder', is_flag=True, default=False)
41 @click.option('--delete_all', is_flag=True)
42 @click.option('--path', type=str, default="static/data/lms")
43 @click.option('--batch_size', type=int, default=100)
44 @click.option('--provider_code', type=int)
45 def process_data(specific_folder, delete_all, path, batch_size, provider_code):
46 from anyway.process import main
47
48 return main(specific_folder=specific_folder, delete_all=delete_all, path=path,
49 batch_size=batch_size, provider_code=provider_code)
50
51
52 @cli.command()
53 @click.option('--light', is_flag=True, help='Import without downloading any new files')
54 @click.option('--username', default='')
55 @click.option('--password', default='')
56 @click.option('--lastmail', is_flag=True)
57 def import_united_data(light, username, password, lastmail):
58 from anyway.united import main
59
60 return main(light=light, username=username, password=password, lastmail=lastmail)
61
62 if __name__ == '__main__':
63 cli()
64
[end of main.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/anyway/load_discussions.py b/anyway/load_discussions.py
deleted file mode 100755
--- a/anyway/load_discussions.py
+++ /dev/null
@@ -1,39 +0,0 @@
-# -*- coding: utf-8 -*-
-import argparse
-from .models import DiscussionMarker
-import re
-from .database import db_session
-import sys
-import logging
-
-def main():
- parser = argparse.ArgumentParser()
- parser.add_argument('identifiers', type=str, nargs='*',
- help='Disqus identifiers to create markers for')
- args = parser.parse_args()
-
- identifiers = args.identifiers if args.identifiers else sys.stdin
-
- for identifier in identifiers:
- m = re.match(r'\((\d+\.\d+),\s*(\d+\.\d+)\)', identifier)
- if not m:
- logging.error("Failed processing: " + identifier)
- continue
- (latitude, longitude) = m.group(1, 2)
- marker = DiscussionMarker.parse({
- 'latitude': latitude,
- 'longitude': longitude,
- 'title': identifier,
- 'identifier': identifier
- })
- try:
- db_session.add(marker)
- db_session.commit()
- logging.info("Added: " + identifier, end="")
- except:
- db_session.rollback()
- logging.warn("Failed: " + identifier, end="")
-
-
-if __name__ == "__main__":
- main()
diff --git a/main.py b/main.py
--- a/main.py
+++ b/main.py
@@ -1,8 +1,10 @@
#!/usr/bin/env python
-
-import os
import click
import logging
+import os
+import re
+import sys
+
@click.group()
def cli():
@@ -59,5 +61,36 @@
return main(light=light, username=username, password=password, lastmail=lastmail)
+
[email protected]()
[email protected]('identifiers', nargs=-1)
+def load_discussions(identifiers):
+ from anyway.database import db_session
+ from anyway.models import DiscussionMarker
+
+ identifiers = identifiers or sys.stdin
+
+ for identifier in identifiers:
+ identifier = identifier.strip()
+ m = re.match(r'\((\d+\.\d+),\s*(\d+\.\d+)\)', identifier)
+ if not m:
+ logging.error("Failed processing: " + identifier)
+ continue
+ (latitude, longitude) = m.group(1, 2)
+ marker = DiscussionMarker.parse({
+ 'latitude': latitude,
+ 'longitude': longitude,
+ 'title': identifier,
+ 'identifier': identifier
+ })
+ try:
+ db_session.add(marker)
+ db_session.commit()
+ logging.info("Added: " + identifier)
+ except Exception as e:
+ db_session.rollback()
+ logging.warn("Failed: " + identifier + ": " + e.message)
+
+
if __name__ == '__main__':
cli()
|
{"golden_diff": "diff --git a/anyway/load_discussions.py b/anyway/load_discussions.py\ndeleted file mode 100755\n--- a/anyway/load_discussions.py\n+++ /dev/null\n@@ -1,39 +0,0 @@\n-# -*- coding: utf-8 -*-\n-import argparse\n-from .models import DiscussionMarker\n-import re\n-from .database import db_session\n-import sys\n-import logging\n-\n-def main():\n- parser = argparse.ArgumentParser()\n- parser.add_argument('identifiers', type=str, nargs='*',\n- help='Disqus identifiers to create markers for')\n- args = parser.parse_args()\n-\n- identifiers = args.identifiers if args.identifiers else sys.stdin\n-\n- for identifier in identifiers:\n- m = re.match(r'\\((\\d+\\.\\d+),\\s*(\\d+\\.\\d+)\\)', identifier)\n- if not m:\n- logging.error(\"Failed processing: \" + identifier)\n- continue\n- (latitude, longitude) = m.group(1, 2)\n- marker = DiscussionMarker.parse({\n- 'latitude': latitude,\n- 'longitude': longitude,\n- 'title': identifier,\n- 'identifier': identifier\n- })\n- try:\n- db_session.add(marker)\n- db_session.commit()\n- logging.info(\"Added: \" + identifier, end=\"\")\n- except:\n- db_session.rollback()\n- logging.warn(\"Failed: \" + identifier, end=\"\")\n-\n-\n-if __name__ == \"__main__\":\n- main()\ndiff --git a/main.py b/main.py\n--- a/main.py\n+++ b/main.py\n@@ -1,8 +1,10 @@\n #!/usr/bin/env python\n-\n-import os\n import click\n import logging\n+import os\n+import re\n+import sys\n+\n \n @click.group()\n def cli():\n@@ -59,5 +61,36 @@\n \n return main(light=light, username=username, password=password, lastmail=lastmail)\n \n+\[email protected]()\[email protected]('identifiers', nargs=-1)\n+def load_discussions(identifiers):\n+ from anyway.database import db_session\n+ from anyway.models import DiscussionMarker\n+\n+ identifiers = identifiers or sys.stdin\n+\n+ for identifier in identifiers:\n+ identifier = identifier.strip()\n+ m = re.match(r'\\((\\d+\\.\\d+),\\s*(\\d+\\.\\d+)\\)', identifier)\n+ if not m:\n+ logging.error(\"Failed processing: \" + identifier)\n+ continue\n+ (latitude, longitude) = m.group(1, 2)\n+ marker = DiscussionMarker.parse({\n+ 'latitude': latitude,\n+ 'longitude': longitude,\n+ 'title': identifier,\n+ 'identifier': identifier\n+ })\n+ try:\n+ db_session.add(marker)\n+ db_session.commit()\n+ logging.info(\"Added: \" + identifier)\n+ except Exception as e:\n+ db_session.rollback()\n+ logging.warn(\"Failed: \" + identifier + \": \" + e.message)\n+\n+\n if __name__ == '__main__':\n cli()\n", "issue": "Move load_discussions into main\nI can't figure out what's the purpose of this file\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport argparse\nfrom .models import DiscussionMarker\nimport re\nfrom .database import db_session\nimport sys\nimport logging\n\ndef main():\n parser = argparse.ArgumentParser()\n parser.add_argument('identifiers', type=str, nargs='*',\n help='Disqus identifiers to create markers for')\n args = parser.parse_args()\n\n identifiers = args.identifiers if args.identifiers else sys.stdin\n\n for identifier in identifiers:\n m = re.match(r'\\((\\d+\\.\\d+),\\s*(\\d+\\.\\d+)\\)', identifier)\n if not m:\n logging.error(\"Failed processing: \" + identifier)\n continue\n (latitude, longitude) = m.group(1, 2)\n marker = DiscussionMarker.parse({\n 'latitude': latitude,\n 'longitude': longitude,\n 'title': identifier,\n 'identifier': identifier\n })\n try:\n db_session.add(marker)\n db_session.commit()\n logging.info(\"Added: \" + identifier, end=\"\")\n except:\n db_session.rollback()\n logging.warn(\"Failed: \" + identifier, end=\"\")\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "anyway/load_discussions.py"}, {"content": "#!/usr/bin/env python\n\nimport os\nimport click\nimport logging\n\[email protected]()\ndef cli():\n pass\n\n\[email protected]()\[email protected]('--open', 'open_server', is_flag=True,\n help='Open the server for communication from outside', default=False)\ndef testserver(open_server):\n from anyway import app, united\n from apscheduler.scheduler import Scheduler\n\n sched = Scheduler()\n\n @sched.interval_schedule(hours=12)\n def scheduled_import():\n united.main()\n sched.start()\n\n logging.basicConfig(level=logging.DEBUG, format='%(asctime)s %(message)s')\n\n default_host = '0.0.0.0' if open_server else '127.0.0.1'\n app.run(debug=True, host=os.getenv('IP', default_host),\n port=int(os.getenv('PORT', 5000)))\n\n\[email protected]()\ndef init_db():\n from anyway.models import init_db\n init_db()\n\n\[email protected]()\[email protected]('--specific_folder', is_flag=True, default=False)\[email protected]('--delete_all', is_flag=True)\[email protected]('--path', type=str, default=\"static/data/lms\")\[email protected]('--batch_size', type=int, default=100)\[email protected]('--provider_code', type=int)\ndef process_data(specific_folder, delete_all, path, batch_size, provider_code):\n from anyway.process import main\n\n return main(specific_folder=specific_folder, delete_all=delete_all, path=path,\n batch_size=batch_size, provider_code=provider_code)\n\n\[email protected]()\[email protected]('--light', is_flag=True, help='Import without downloading any new files')\[email protected]('--username', default='')\[email protected]('--password', default='')\[email protected]('--lastmail', is_flag=True)\ndef import_united_data(light, username, password, lastmail):\n from anyway.united import main\n\n return main(light=light, username=username, password=password, lastmail=lastmail)\n\nif __name__ == '__main__':\n cli()\n", "path": "main.py"}]}
| 1,456 | 685 |
gh_patches_debug_367
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-1305
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add `GetMetadataItem` like method
Ref: https://github.com/mapbox/rasterio/issues/1077,
I'm proposing to add a new method in https://github.com/mapbox/rasterio/blob/master/rasterio/_base.pyx to replicate GDAL GetMetadataItem
**Method Name:** `get_metadata_item` or `get_metadata`
**Why:** I need to be able to get TIFF metadata like `band.GetMetadataItem('IFD_OFFSET', 'TIFF')`
**Code:**
```cython
def get_metadata(self, bidx, ns, dm=None, ovr=None):
"""Returns metadata item
Parameters
----------
bidx: int
Band index, starting with 1.
name: str
The key for the metadata item to fetch.
domain: str
The domain to fetch for.
ovr: int
Overview level
Returns
-------
str
"""
cdef GDALMajorObjectH b = NULL
cdef GDALMajorObjectH obj = NULL
cdef char *value = NULL
cdef const char *name = NULL
cdef const char *domain = NULL
ns = ns.encode('utf-8')
name = ns
if dm:
dm = dm.encode('utf-8')
domain = dm
b = self.band(bidx)
if ovr:
b = GDALGetOverview(b, ovr)
obj = b
value = GDALGetMetadataItem(obj, name, domain)
if value == NULL:
return None
else:
return value
```
@sgillies I'm happy to submit a PR for that :-)
</issue>
<code>
[start of rasterio/errors.py]
1 """Errors and Warnings."""
2
3 from click import FileError
4
5
6 class RasterioError(Exception):
7 """Root exception class"""
8
9
10 class WindowError(RasterioError):
11 """Raised when errors occur during window operations"""
12
13
14 class CRSError(ValueError):
15 """Raised when a CRS string or mapping is invalid or cannot serve
16 to define a coordinate transformation."""
17
18
19 class EnvError(RasterioError):
20 """Raised when the state of GDAL/AWS environment cannot be created
21 or modified."""
22
23
24 class DriverRegistrationError(ValueError):
25 """Raised when a format driver is requested but is not registered."""
26
27
28 class FileOverwriteError(FileError):
29 """Raised when Rasterio's CLI refuses to clobber output files."""
30
31 def __init__(self, message):
32 """Raise FileOverwriteError with message as hint."""
33 super(FileOverwriteError, self).__init__('', hint=message)
34
35
36 class RasterioIOError(IOError):
37 """Raised when a dataset cannot be opened using one of the
38 registered format drivers."""
39
40
41 class NodataShadowWarning(UserWarning):
42 """Warn that a dataset's nodata attribute is shadowing its alpha band."""
43
44 def __str__(self):
45 return ("The dataset's nodata attribute is shadowing "
46 "the alpha band. All masks will be determined "
47 "by the nodata attribute")
48
49
50 class NotGeoreferencedWarning(UserWarning):
51 """Warn that a dataset isn't georeferenced."""
52
53
54 class GDALBehaviorChangeException(RuntimeError):
55 """Raised when GDAL's behavior differs from the given arguments. For
56 example, antimeridian cutting is always on as of GDAL 2.2.0. Users
57 expecting it to be off will be presented with a MultiPolygon when the
58 rest of their code expects a Polygon.
59
60 # Raises an exception on GDAL >= 2.2.0
61 rasterio.warp.transform_geometry(
62 src_crs, dst_crs, antimeridian_cutting=False)
63 """
64
65
66 class GDALOptionNotImplementedError(RasterioError):
67 """A dataset opening or dataset creation option can't be supported
68
69 This will be raised from Rasterio's shim modules. For example, when
70 a user passes arguments to open_dataset() that can't be evaluated
71 by GDAL 1.x.
72 """
73
74 class GDALVersionError(RasterioError):
75 """Raised if the runtime version of GDAL does not meet the required
76 version of GDAL."""
77
78
79 class WindowEvaluationError(ValueError):
80 """Raised when window evaluation fails"""
81
82
83 class RasterioDeprecationWarning(UserWarning):
84 """Rasterio module deprecations"""
85
86
87 class RasterBlockError(RasterioError):
88 """Raised when raster block access fails"""
89
[end of rasterio/errors.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/errors.py b/rasterio/errors.py
--- a/rasterio/errors.py
+++ b/rasterio/errors.py
@@ -86,3 +86,7 @@
class RasterBlockError(RasterioError):
"""Raised when raster block access fails"""
+
+
+class BandOverviewError(UserWarning):
+ """Raised when a band overview access fails."""
|
{"golden_diff": "diff --git a/rasterio/errors.py b/rasterio/errors.py\n--- a/rasterio/errors.py\n+++ b/rasterio/errors.py\n@@ -86,3 +86,7 @@\n \n class RasterBlockError(RasterioError):\n \"\"\"Raised when raster block access fails\"\"\"\n+\n+\n+class BandOverviewError(UserWarning):\n+ \"\"\"Raised when a band overview access fails.\"\"\"\n", "issue": "Add `GetMetadataItem` like method \nRef: https://github.com/mapbox/rasterio/issues/1077, \r\n\r\nI'm proposing to add a new method in https://github.com/mapbox/rasterio/blob/master/rasterio/_base.pyx to replicate GDAL GetMetadataItem\r\n\r\n\r\n**Method Name:** `get_metadata_item` or `get_metadata`\r\n**Why:** I need to be able to get TIFF metadata like `band.GetMetadataItem('IFD_OFFSET', 'TIFF')`\r\n\r\n**Code:**\r\n\r\n```cython\r\n def get_metadata(self, bidx, ns, dm=None, ovr=None):\r\n \"\"\"Returns metadata item\r\n\r\n Parameters\r\n ----------\r\n bidx: int\r\n Band index, starting with 1.\r\n name: str\r\n The key for the metadata item to fetch.\r\n domain: str\r\n The domain to fetch for.\r\n ovr: int\r\n Overview level\r\n\r\n Returns\r\n -------\r\n str\r\n \"\"\"\r\n cdef GDALMajorObjectH b = NULL\r\n cdef GDALMajorObjectH obj = NULL\r\n cdef char *value = NULL\r\n cdef const char *name = NULL\r\n cdef const char *domain = NULL\r\n\r\n ns = ns.encode('utf-8')\r\n name = ns\r\n\r\n if dm:\r\n dm = dm.encode('utf-8')\r\n domain = dm\r\n\r\n b = self.band(bidx)\r\n if ovr:\r\n b = GDALGetOverview(b, ovr)\r\n\r\n obj = b\r\n\r\n value = GDALGetMetadataItem(obj, name, domain)\r\n if value == NULL:\r\n return None\r\n else:\r\n return value\r\n```\r\n\r\n@sgillies I'm happy to submit a PR for that :-) \n", "before_files": [{"content": "\"\"\"Errors and Warnings.\"\"\"\n\nfrom click import FileError\n\n\nclass RasterioError(Exception):\n \"\"\"Root exception class\"\"\"\n\n\nclass WindowError(RasterioError):\n \"\"\"Raised when errors occur during window operations\"\"\"\n\n\nclass CRSError(ValueError):\n \"\"\"Raised when a CRS string or mapping is invalid or cannot serve\n to define a coordinate transformation.\"\"\"\n\n\nclass EnvError(RasterioError):\n \"\"\"Raised when the state of GDAL/AWS environment cannot be created\n or modified.\"\"\"\n\n\nclass DriverRegistrationError(ValueError):\n \"\"\"Raised when a format driver is requested but is not registered.\"\"\"\n\n\nclass FileOverwriteError(FileError):\n \"\"\"Raised when Rasterio's CLI refuses to clobber output files.\"\"\"\n\n def __init__(self, message):\n \"\"\"Raise FileOverwriteError with message as hint.\"\"\"\n super(FileOverwriteError, self).__init__('', hint=message)\n\n\nclass RasterioIOError(IOError):\n \"\"\"Raised when a dataset cannot be opened using one of the\n registered format drivers.\"\"\"\n\n\nclass NodataShadowWarning(UserWarning):\n \"\"\"Warn that a dataset's nodata attribute is shadowing its alpha band.\"\"\"\n\n def __str__(self):\n return (\"The dataset's nodata attribute is shadowing \"\n \"the alpha band. All masks will be determined \"\n \"by the nodata attribute\")\n\n\nclass NotGeoreferencedWarning(UserWarning):\n \"\"\"Warn that a dataset isn't georeferenced.\"\"\"\n\n\nclass GDALBehaviorChangeException(RuntimeError):\n \"\"\"Raised when GDAL's behavior differs from the given arguments. For\n example, antimeridian cutting is always on as of GDAL 2.2.0. Users\n expecting it to be off will be presented with a MultiPolygon when the\n rest of their code expects a Polygon.\n\n # Raises an exception on GDAL >= 2.2.0\n rasterio.warp.transform_geometry(\n src_crs, dst_crs, antimeridian_cutting=False)\n \"\"\"\n\n\nclass GDALOptionNotImplementedError(RasterioError):\n \"\"\"A dataset opening or dataset creation option can't be supported\n\n This will be raised from Rasterio's shim modules. For example, when\n a user passes arguments to open_dataset() that can't be evaluated\n by GDAL 1.x.\n \"\"\"\n\nclass GDALVersionError(RasterioError):\n \"\"\"Raised if the runtime version of GDAL does not meet the required\n version of GDAL.\"\"\"\n\n\nclass WindowEvaluationError(ValueError):\n \"\"\"Raised when window evaluation fails\"\"\"\n\n\nclass RasterioDeprecationWarning(UserWarning):\n \"\"\"Rasterio module deprecations\"\"\"\n\n\nclass RasterBlockError(RasterioError):\n \"\"\"Raised when raster block access fails\"\"\"\n", "path": "rasterio/errors.py"}]}
| 1,673 | 85 |
gh_patches_debug_33879
|
rasdani/github-patches
|
git_diff
|
TheAlgorithms__Python-9068
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Delete base85 algorithm
### Describe your change:
Re #6216
Normally, I'm not in favour of just deleting algorithms, but I would make the argument that this is not an algorithm, rather just a snippet of code that utilises another library.
Per `CONTRIBTUING.md`
> Algorithms in this repo should not be how-to examples for existing Python packages. Instead, they should perform internal calculations or manipulations to convert input values into different output values
This `base85` algorithm has essentially got two lines of code that purely utilise a singular library. The doctests only test an external library
This repository should not contains examples on how to use a certain library, that would be the library documentation here
https://docs.python.org/3/library/base64.html
* [ ] Add an algorithm?
* [ ] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
* [x] Delete an algorithm
### Checklist:
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.
* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): "Fixes #ISSUE-NUMBER".
</issue>
<code>
[start of ciphers/base32.py]
1 import base64
2
3
4 def base32_encode(string: str) -> bytes:
5 """
6 Encodes a given string to base32, returning a bytes-like object
7 >>> base32_encode("Hello World!")
8 b'JBSWY3DPEBLW64TMMQQQ===='
9 >>> base32_encode("123456")
10 b'GEZDGNBVGY======'
11 >>> base32_encode("some long complex string")
12 b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='
13 """
14
15 # encoded the input (we need a bytes like object)
16 # then, b32encoded the bytes-like object
17 return base64.b32encode(string.encode("utf-8"))
18
19
20 def base32_decode(encoded_bytes: bytes) -> str:
21 """
22 Decodes a given bytes-like object to a string, returning a string
23 >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')
24 'Hello World!'
25 >>> base32_decode(b'GEZDGNBVGY======')
26 '123456'
27 >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')
28 'some long complex string'
29 """
30
31 # decode the bytes from base32
32 # then, decode the bytes-like object to return as a string
33 return base64.b32decode(encoded_bytes).decode("utf-8")
34
35
36 if __name__ == "__main__":
37 test = "Hello World!"
38 encoded = base32_encode(test)
39 print(encoded)
40
41 decoded = base32_decode(encoded)
42 print(decoded)
43
[end of ciphers/base32.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ciphers/base32.py b/ciphers/base32.py
--- a/ciphers/base32.py
+++ b/ciphers/base32.py
@@ -1,42 +1,45 @@
-import base64
+"""
+Base32 encoding and decoding
+https://en.wikipedia.org/wiki/Base32
+"""
+B32_CHARSET = "ABCDEFGHIJKLMNOPQRSTUVWXYZ234567"
-def base32_encode(string: str) -> bytes:
+
+def base32_encode(data: bytes) -> bytes:
"""
- Encodes a given string to base32, returning a bytes-like object
- >>> base32_encode("Hello World!")
+ >>> base32_encode(b"Hello World!")
b'JBSWY3DPEBLW64TMMQQQ===='
- >>> base32_encode("123456")
+ >>> base32_encode(b"123456")
b'GEZDGNBVGY======'
- >>> base32_encode("some long complex string")
+ >>> base32_encode(b"some long complex string")
b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='
"""
-
- # encoded the input (we need a bytes like object)
- # then, b32encoded the bytes-like object
- return base64.b32encode(string.encode("utf-8"))
+ binary_data = "".join(bin(ord(d))[2:].zfill(8) for d in data.decode("utf-8"))
+ binary_data = binary_data.ljust(5 * ((len(binary_data) // 5) + 1), "0")
+ b32_chunks = map("".join, zip(*[iter(binary_data)] * 5))
+ b32_result = "".join(B32_CHARSET[int(chunk, 2)] for chunk in b32_chunks)
+ return bytes(b32_result.ljust(8 * ((len(b32_result) // 8) + 1), "="), "utf-8")
-def base32_decode(encoded_bytes: bytes) -> str:
+def base32_decode(data: bytes) -> bytes:
"""
- Decodes a given bytes-like object to a string, returning a string
>>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')
- 'Hello World!'
+ b'Hello World!'
>>> base32_decode(b'GEZDGNBVGY======')
- '123456'
+ b'123456'
>>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')
- 'some long complex string'
+ b'some long complex string'
"""
-
- # decode the bytes from base32
- # then, decode the bytes-like object to return as a string
- return base64.b32decode(encoded_bytes).decode("utf-8")
+ binary_chunks = "".join(
+ bin(B32_CHARSET.index(_d))[2:].zfill(5)
+ for _d in data.decode("utf-8").strip("=")
+ )
+ binary_data = list(map("".join, zip(*[iter(binary_chunks)] * 8)))
+ return bytes("".join([chr(int(_d, 2)) for _d in binary_data]), "utf-8")
if __name__ == "__main__":
- test = "Hello World!"
- encoded = base32_encode(test)
- print(encoded)
+ import doctest
- decoded = base32_decode(encoded)
- print(decoded)
+ doctest.testmod()
|
{"golden_diff": "diff --git a/ciphers/base32.py b/ciphers/base32.py\n--- a/ciphers/base32.py\n+++ b/ciphers/base32.py\n@@ -1,42 +1,45 @@\n-import base64\n+\"\"\"\n+Base32 encoding and decoding\n \n+https://en.wikipedia.org/wiki/Base32\n+\"\"\"\n+B32_CHARSET = \"ABCDEFGHIJKLMNOPQRSTUVWXYZ234567\"\n \n-def base32_encode(string: str) -> bytes:\n+\n+def base32_encode(data: bytes) -> bytes:\n \"\"\"\n- Encodes a given string to base32, returning a bytes-like object\n- >>> base32_encode(\"Hello World!\")\n+ >>> base32_encode(b\"Hello World!\")\n b'JBSWY3DPEBLW64TMMQQQ===='\n- >>> base32_encode(\"123456\")\n+ >>> base32_encode(b\"123456\")\n b'GEZDGNBVGY======'\n- >>> base32_encode(\"some long complex string\")\n+ >>> base32_encode(b\"some long complex string\")\n b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='\n \"\"\"\n-\n- # encoded the input (we need a bytes like object)\n- # then, b32encoded the bytes-like object\n- return base64.b32encode(string.encode(\"utf-8\"))\n+ binary_data = \"\".join(bin(ord(d))[2:].zfill(8) for d in data.decode(\"utf-8\"))\n+ binary_data = binary_data.ljust(5 * ((len(binary_data) // 5) + 1), \"0\")\n+ b32_chunks = map(\"\".join, zip(*[iter(binary_data)] * 5))\n+ b32_result = \"\".join(B32_CHARSET[int(chunk, 2)] for chunk in b32_chunks)\n+ return bytes(b32_result.ljust(8 * ((len(b32_result) // 8) + 1), \"=\"), \"utf-8\")\n \n \n-def base32_decode(encoded_bytes: bytes) -> str:\n+def base32_decode(data: bytes) -> bytes:\n \"\"\"\n- Decodes a given bytes-like object to a string, returning a string\n >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')\n- 'Hello World!'\n+ b'Hello World!'\n >>> base32_decode(b'GEZDGNBVGY======')\n- '123456'\n+ b'123456'\n >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')\n- 'some long complex string'\n+ b'some long complex string'\n \"\"\"\n-\n- # decode the bytes from base32\n- # then, decode the bytes-like object to return as a string\n- return base64.b32decode(encoded_bytes).decode(\"utf-8\")\n+ binary_chunks = \"\".join(\n+ bin(B32_CHARSET.index(_d))[2:].zfill(5)\n+ for _d in data.decode(\"utf-8\").strip(\"=\")\n+ )\n+ binary_data = list(map(\"\".join, zip(*[iter(binary_chunks)] * 8)))\n+ return bytes(\"\".join([chr(int(_d, 2)) for _d in binary_data]), \"utf-8\")\n \n \n if __name__ == \"__main__\":\n- test = \"Hello World!\"\n- encoded = base32_encode(test)\n- print(encoded)\n+ import doctest\n \n- decoded = base32_decode(encoded)\n- print(decoded)\n+ doctest.testmod()\n", "issue": "Delete base85 algorithm\n### Describe your change:\r\nRe #6216\r\n\r\nNormally, I'm not in favour of just deleting algorithms, but I would make the argument that this is not an algorithm, rather just a snippet of code that utilises another library.\r\n\r\nPer `CONTRIBTUING.md`\r\n> Algorithms in this repo should not be how-to examples for existing Python packages. Instead, they should perform internal calculations or manipulations to convert input values into different output values\r\nThis `base85` algorithm has essentially got two lines of code that purely utilise a singular library. The doctests only test an external library\r\n\r\nThis repository should not contains examples on how to use a certain library, that would be the library documentation here\r\nhttps://docs.python.org/3/library/base64.html\r\n\r\n\r\n* [ ] Add an algorithm?\r\n* [ ] Fix a bug or typo in an existing algorithm?\r\n* [ ] Documentation change?\r\n* [x] Delete an algorithm\r\n\r\n### Checklist:\r\n* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).\r\n* [x] This pull request is all my own work -- I have not plagiarized.\r\n* [x] I know that pull requests will not be merged if they fail the automated tests.\r\n* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.\r\n* [x] All new Python files are placed inside an existing directory.\r\n* [x] All filenames are in all lowercase characters with no spaces or dashes.\r\n* [x] All functions and variable names follow Python naming conventions.\r\n* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).\r\n* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.\r\n* [x] All new algorithms include at least one URL that points to Wikipedia or another similar explanation.\r\n* [x] If this pull request resolves one or more open issues then the description above includes the issue number(s) with a [closing keyword](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue): \"Fixes #ISSUE-NUMBER\".\r\n\n", "before_files": [{"content": "import base64\n\n\ndef base32_encode(string: str) -> bytes:\n \"\"\"\n Encodes a given string to base32, returning a bytes-like object\n >>> base32_encode(\"Hello World!\")\n b'JBSWY3DPEBLW64TMMQQQ===='\n >>> base32_encode(\"123456\")\n b'GEZDGNBVGY======'\n >>> base32_encode(\"some long complex string\")\n b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY='\n \"\"\"\n\n # encoded the input (we need a bytes like object)\n # then, b32encoded the bytes-like object\n return base64.b32encode(string.encode(\"utf-8\"))\n\n\ndef base32_decode(encoded_bytes: bytes) -> str:\n \"\"\"\n Decodes a given bytes-like object to a string, returning a string\n >>> base32_decode(b'JBSWY3DPEBLW64TMMQQQ====')\n 'Hello World!'\n >>> base32_decode(b'GEZDGNBVGY======')\n '123456'\n >>> base32_decode(b'ONXW2ZJANRXW4ZZAMNXW24DMMV4CA43UOJUW4ZY=')\n 'some long complex string'\n \"\"\"\n\n # decode the bytes from base32\n # then, decode the bytes-like object to return as a string\n return base64.b32decode(encoded_bytes).decode(\"utf-8\")\n\n\nif __name__ == \"__main__\":\n test = \"Hello World!\"\n encoded = base32_encode(test)\n print(encoded)\n\n decoded = base32_decode(encoded)\n print(decoded)\n", "path": "ciphers/base32.py"}]}
| 1,516 | 855 |
gh_patches_debug_20056
|
rasdani/github-patches
|
git_diff
|
xorbitsai__inference-400
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: wrong arguments for ChatGLM
Code:
```
from xinference.client import RESTfulClient
endpoint = 'http://localhost:9997'
client = RESTfulClient(endpoint)
uid = client.launch_model(model_name='chatglm2', model_format='ggmlv3')
model = client.get_model(model_uid=uid)
model.chat('What is the largest animal in the world?')
```
Response:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
Cell In[2], line 2
1 model = client.get_model(model_uid=uid)
----> 2 model.chat('What is the largest animal in the world?')
File ~/Desktop/cs/inference/xinference/client.py:463, in RESTfulChatglmCppChatModelHandle.chat(self, prompt, chat_history, generate_config)
460 response = requests.post(url, json=request_body, stream=stream)
462 if response.status_code != 200:
--> 463 raise RuntimeError(
464 f"Failed to generate chat completion, detail: {response.json()['detail']}"
465 )
467 if stream:
468 return chat_streaming_response_iterator(response.iter_lines())
RuntimeError: Failed to generate chat completion, detail: [address=127.0.0.1:63785, pid=63229] Pipeline.chat() got an unexpected keyword argument 'mirostat_mode'
```
Seems like the default arguments passed in the `chat` function are customized for Llama.cpp models, causing an error.
</issue>
<code>
[start of xinference/model/llm/ggml/chatglm.py]
1 # Copyright 2022-2023 XProbe Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 import os
17 import time
18 import uuid
19 from pathlib import Path
20 from typing import TYPE_CHECKING, Iterator, List, Optional, TypedDict, Union
21
22 from ....types import ChatCompletion, ChatCompletionChunk, ChatCompletionMessage
23 from .. import LLMFamilyV1, LLMSpecV1
24 from ..core import LLM
25
26 if TYPE_CHECKING:
27 from chatglm_cpp import Pipeline
28
29
30 logger = logging.getLogger(__name__)
31
32
33 class ChatglmCppModelConfig(TypedDict, total=False):
34 pass
35
36
37 class ChatglmCppGenerateConfig(TypedDict, total=False):
38 max_tokens: int
39 top_p: float
40 temperature: float
41 stream: bool
42
43
44 class ChatglmCppChatModel(LLM):
45 def __init__(
46 self,
47 model_uid: str,
48 model_family: "LLMFamilyV1",
49 model_spec: "LLMSpecV1",
50 quantization: str,
51 model_path: str,
52 model_config: Optional[ChatglmCppModelConfig] = None,
53 ):
54 super().__init__(model_uid, model_family, model_spec, quantization, model_path)
55 self._llm: Optional["Pipeline"] = None
56
57 # just a placeholder for now as the chatglm_cpp repo doesn't support model config.
58 self._model_config = model_config
59
60 @classmethod
61 def _sanitize_generate_config(
62 cls,
63 chatglmcpp_generate_config: Optional[ChatglmCppGenerateConfig],
64 ) -> ChatglmCppGenerateConfig:
65 if chatglmcpp_generate_config is None:
66 chatglmcpp_generate_config = ChatglmCppGenerateConfig()
67 chatglmcpp_generate_config.setdefault("stream", False)
68 return chatglmcpp_generate_config
69
70 def load(self):
71 try:
72 import chatglm_cpp
73 except ImportError:
74 error_message = "Failed to import module 'chatglm_cpp'"
75 installation_guide = [
76 "Please make sure 'chatglm_cpp' is installed. ",
77 "You can install it by running the following command in the terminal:\n",
78 "pip install git+https://github.com/li-plus/chatglm.cpp.git@main\n\n",
79 "Or visit the original git repo if the above command fails:\n",
80 "https://github.com/li-plus/chatglm.cpp",
81 ]
82
83 raise ImportError(f"{error_message}\n\n{''.join(installation_guide)}")
84
85 model_file_path = os.path.join(
86 self.model_path,
87 self.model_spec.model_file_name_template.format(
88 quantization=self.quantization
89 ),
90 )
91
92 # handle legacy cache.
93 legacy_model_file_path = os.path.join(self.model_path, "model.bin")
94 if os.path.exists(legacy_model_file_path):
95 model_file_path = legacy_model_file_path
96
97 self._llm = chatglm_cpp.Pipeline(Path(model_file_path))
98
99 @classmethod
100 def match(cls, llm_family: "LLMFamilyV1", llm_spec: "LLMSpecV1") -> bool:
101 if llm_spec.model_format != "ggmlv3":
102 return False
103 if "chatglm" not in llm_family.model_name:
104 return False
105 if "chat" not in llm_family.model_ability:
106 return False
107 return True
108
109 @staticmethod
110 def _convert_raw_text_chunks_to_chat(
111 tokens: Iterator[str], model_name: str
112 ) -> Iterator[ChatCompletionChunk]:
113 yield {
114 "id": "chat" + f"cmpl-{str(uuid.uuid4())}",
115 "model": model_name,
116 "object": "chat.completion.chunk",
117 "created": int(time.time()),
118 "choices": [
119 {
120 "index": 0,
121 "delta": {
122 "role": "assistant",
123 },
124 "finish_reason": None,
125 }
126 ],
127 }
128 for token in enumerate(tokens):
129 yield {
130 "id": "chat" + f"cmpl-{str(uuid.uuid4())}",
131 "model": model_name,
132 "object": "chat.completion.chunk",
133 "created": int(time.time()),
134 "choices": [
135 {
136 "index": 0,
137 "delta": {
138 "content": token[1],
139 },
140 "finish_reason": None,
141 }
142 ],
143 }
144
145 @staticmethod
146 def _convert_raw_text_completion_to_chat(
147 text: str, model_name: str
148 ) -> ChatCompletion:
149 return {
150 "id": "chat" + f"cmpl-{str(uuid.uuid4())}",
151 "model": model_name,
152 "object": "chat.completion",
153 "created": int(time.time()),
154 "choices": [
155 {
156 "index": 0,
157 "message": {
158 "role": "assistant",
159 "content": text,
160 },
161 "finish_reason": None,
162 }
163 ],
164 "usage": {
165 "prompt_tokens": -1,
166 "completion_tokens": -1,
167 "total_tokens": -1,
168 },
169 }
170
171 def chat(
172 self,
173 prompt: str,
174 chat_history: Optional[List[ChatCompletionMessage]] = None,
175 generate_config: Optional[ChatglmCppGenerateConfig] = None,
176 ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:
177 if chat_history is not None:
178 chat_history_list = [message["content"] for message in chat_history]
179 else:
180 chat_history_list = []
181
182 chat_history_list.append(prompt)
183 logger.debug("Full conversation history:\n%s", str(chat_history_list))
184
185 generate_config = self._sanitize_generate_config(generate_config)
186 params = dict(generate_config)
187 if "max_tokens" in params:
188 params["max_length"] = params.pop("max_tokens")
189
190 assert self._llm is not None
191
192 if params.pop("stream", False):
193 it = self._llm.stream_chat(
194 chat_history_list,
195 **params,
196 )
197 assert not isinstance(it, str)
198 return self._convert_raw_text_chunks_to_chat(it, self.model_uid)
199 else:
200 c = self._llm.chat(
201 chat_history_list,
202 **params,
203 )
204 assert not isinstance(c, Iterator)
205 return self._convert_raw_text_completion_to_chat(c, self.model_uid)
206
[end of xinference/model/llm/ggml/chatglm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/xinference/model/llm/ggml/chatglm.py b/xinference/model/llm/ggml/chatglm.py
--- a/xinference/model/llm/ggml/chatglm.py
+++ b/xinference/model/llm/ggml/chatglm.py
@@ -183,13 +183,21 @@
logger.debug("Full conversation history:\n%s", str(chat_history_list))
generate_config = self._sanitize_generate_config(generate_config)
- params = dict(generate_config)
- if "max_tokens" in params:
- params["max_length"] = params.pop("max_tokens")
+
+ params = {
+ "max_length": generate_config.get("max_tokens"),
+ "max_context_length": generate_config.get("max_tokens"),
+ "top_k": generate_config.get("top_k"),
+ "top_p": generate_config.get("top_p"),
+ "temperature": generate_config.get("temperature"),
+ }
+
+ # Remove None values to exclude missing keys from params
+ params = {k: v for k, v in params.items() if v is not None}
assert self._llm is not None
- if params.pop("stream", False):
+ if generate_config["stream"]:
it = self._llm.stream_chat(
chat_history_list,
**params,
|
{"golden_diff": "diff --git a/xinference/model/llm/ggml/chatglm.py b/xinference/model/llm/ggml/chatglm.py\n--- a/xinference/model/llm/ggml/chatglm.py\n+++ b/xinference/model/llm/ggml/chatglm.py\n@@ -183,13 +183,21 @@\n logger.debug(\"Full conversation history:\\n%s\", str(chat_history_list))\n \n generate_config = self._sanitize_generate_config(generate_config)\n- params = dict(generate_config)\n- if \"max_tokens\" in params:\n- params[\"max_length\"] = params.pop(\"max_tokens\")\n+\n+ params = {\n+ \"max_length\": generate_config.get(\"max_tokens\"),\n+ \"max_context_length\": generate_config.get(\"max_tokens\"),\n+ \"top_k\": generate_config.get(\"top_k\"),\n+ \"top_p\": generate_config.get(\"top_p\"),\n+ \"temperature\": generate_config.get(\"temperature\"),\n+ }\n+\n+ # Remove None values to exclude missing keys from params\n+ params = {k: v for k, v in params.items() if v is not None}\n \n assert self._llm is not None\n \n- if params.pop(\"stream\", False):\n+ if generate_config[\"stream\"]:\n it = self._llm.stream_chat(\n chat_history_list,\n **params,\n", "issue": "BUG: wrong arguments for ChatGLM\nCode:\r\n\r\n```\r\nfrom xinference.client import RESTfulClient\r\nendpoint = 'http://localhost:9997'\r\nclient = RESTfulClient(endpoint)\r\nuid = client.launch_model(model_name='chatglm2', model_format='ggmlv3')\r\nmodel = client.get_model(model_uid=uid)\r\nmodel.chat('What is the largest animal in the world?')\r\n```\r\n\r\nResponse:\r\n\r\n```\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\nCell In[2], line 2\r\n 1 model = client.get_model(model_uid=uid)\r\n----> 2 model.chat('What is the largest animal in the world?')\r\n\r\nFile ~/Desktop/cs/inference/xinference/client.py:463, in RESTfulChatglmCppChatModelHandle.chat(self, prompt, chat_history, generate_config)\r\n 460 response = requests.post(url, json=request_body, stream=stream)\r\n 462 if response.status_code != 200:\r\n--> 463 raise RuntimeError(\r\n 464 f\"Failed to generate chat completion, detail: {response.json()['detail']}\"\r\n 465 )\r\n 467 if stream:\r\n 468 return chat_streaming_response_iterator(response.iter_lines())\r\n\r\nRuntimeError: Failed to generate chat completion, detail: [address=127.0.0.1:63785, pid=63229] Pipeline.chat() got an unexpected keyword argument 'mirostat_mode'\r\n```\r\n\r\nSeems like the default arguments passed in the `chat` function are customized for Llama.cpp models, causing an error.\n", "before_files": [{"content": "# Copyright 2022-2023 XProbe Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nimport os\nimport time\nimport uuid\nfrom pathlib import Path\nfrom typing import TYPE_CHECKING, Iterator, List, Optional, TypedDict, Union\n\nfrom ....types import ChatCompletion, ChatCompletionChunk, ChatCompletionMessage\nfrom .. import LLMFamilyV1, LLMSpecV1\nfrom ..core import LLM\n\nif TYPE_CHECKING:\n from chatglm_cpp import Pipeline\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass ChatglmCppModelConfig(TypedDict, total=False):\n pass\n\n\nclass ChatglmCppGenerateConfig(TypedDict, total=False):\n max_tokens: int\n top_p: float\n temperature: float\n stream: bool\n\n\nclass ChatglmCppChatModel(LLM):\n def __init__(\n self,\n model_uid: str,\n model_family: \"LLMFamilyV1\",\n model_spec: \"LLMSpecV1\",\n quantization: str,\n model_path: str,\n model_config: Optional[ChatglmCppModelConfig] = None,\n ):\n super().__init__(model_uid, model_family, model_spec, quantization, model_path)\n self._llm: Optional[\"Pipeline\"] = None\n\n # just a placeholder for now as the chatglm_cpp repo doesn't support model config.\n self._model_config = model_config\n\n @classmethod\n def _sanitize_generate_config(\n cls,\n chatglmcpp_generate_config: Optional[ChatglmCppGenerateConfig],\n ) -> ChatglmCppGenerateConfig:\n if chatglmcpp_generate_config is None:\n chatglmcpp_generate_config = ChatglmCppGenerateConfig()\n chatglmcpp_generate_config.setdefault(\"stream\", False)\n return chatglmcpp_generate_config\n\n def load(self):\n try:\n import chatglm_cpp\n except ImportError:\n error_message = \"Failed to import module 'chatglm_cpp'\"\n installation_guide = [\n \"Please make sure 'chatglm_cpp' is installed. \",\n \"You can install it by running the following command in the terminal:\\n\",\n \"pip install git+https://github.com/li-plus/chatglm.cpp.git@main\\n\\n\",\n \"Or visit the original git repo if the above command fails:\\n\",\n \"https://github.com/li-plus/chatglm.cpp\",\n ]\n\n raise ImportError(f\"{error_message}\\n\\n{''.join(installation_guide)}\")\n\n model_file_path = os.path.join(\n self.model_path,\n self.model_spec.model_file_name_template.format(\n quantization=self.quantization\n ),\n )\n\n # handle legacy cache.\n legacy_model_file_path = os.path.join(self.model_path, \"model.bin\")\n if os.path.exists(legacy_model_file_path):\n model_file_path = legacy_model_file_path\n\n self._llm = chatglm_cpp.Pipeline(Path(model_file_path))\n\n @classmethod\n def match(cls, llm_family: \"LLMFamilyV1\", llm_spec: \"LLMSpecV1\") -> bool:\n if llm_spec.model_format != \"ggmlv3\":\n return False\n if \"chatglm\" not in llm_family.model_name:\n return False\n if \"chat\" not in llm_family.model_ability:\n return False\n return True\n\n @staticmethod\n def _convert_raw_text_chunks_to_chat(\n tokens: Iterator[str], model_name: str\n ) -> Iterator[ChatCompletionChunk]:\n yield {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion.chunk\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"delta\": {\n \"role\": \"assistant\",\n },\n \"finish_reason\": None,\n }\n ],\n }\n for token in enumerate(tokens):\n yield {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion.chunk\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"delta\": {\n \"content\": token[1],\n },\n \"finish_reason\": None,\n }\n ],\n }\n\n @staticmethod\n def _convert_raw_text_completion_to_chat(\n text: str, model_name: str\n ) -> ChatCompletion:\n return {\n \"id\": \"chat\" + f\"cmpl-{str(uuid.uuid4())}\",\n \"model\": model_name,\n \"object\": \"chat.completion\",\n \"created\": int(time.time()),\n \"choices\": [\n {\n \"index\": 0,\n \"message\": {\n \"role\": \"assistant\",\n \"content\": text,\n },\n \"finish_reason\": None,\n }\n ],\n \"usage\": {\n \"prompt_tokens\": -1,\n \"completion_tokens\": -1,\n \"total_tokens\": -1,\n },\n }\n\n def chat(\n self,\n prompt: str,\n chat_history: Optional[List[ChatCompletionMessage]] = None,\n generate_config: Optional[ChatglmCppGenerateConfig] = None,\n ) -> Union[ChatCompletion, Iterator[ChatCompletionChunk]]:\n if chat_history is not None:\n chat_history_list = [message[\"content\"] for message in chat_history]\n else:\n chat_history_list = []\n\n chat_history_list.append(prompt)\n logger.debug(\"Full conversation history:\\n%s\", str(chat_history_list))\n\n generate_config = self._sanitize_generate_config(generate_config)\n params = dict(generate_config)\n if \"max_tokens\" in params:\n params[\"max_length\"] = params.pop(\"max_tokens\")\n\n assert self._llm is not None\n\n if params.pop(\"stream\", False):\n it = self._llm.stream_chat(\n chat_history_list,\n **params,\n )\n assert not isinstance(it, str)\n return self._convert_raw_text_chunks_to_chat(it, self.model_uid)\n else:\n c = self._llm.chat(\n chat_history_list,\n **params,\n )\n assert not isinstance(c, Iterator)\n return self._convert_raw_text_completion_to_chat(c, self.model_uid)\n", "path": "xinference/model/llm/ggml/chatglm.py"}]}
| 2,898 | 300 |
gh_patches_debug_1834
|
rasdani/github-patches
|
git_diff
|
mozilla__pontoon-3003
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
GetText check fails incorrectly on newline
https://pontoon.mozilla.org/en-GB/all-projects/all-resources/?string=286055
If you copy the source string, an extra line is added at the back, and that fails the checks for GetText.
</issue>
<code>
[start of pontoon/translations/forms.py]
1 from django import forms
2 from django.contrib.postgres.forms import SimpleArrayField
3
4 from pontoon.base.models import (
5 Entity,
6 Locale,
7 )
8
9
10 class CreateTranslationForm(forms.Form):
11 """
12 Form for parameters to the `entities` view.
13 """
14
15 entity = forms.IntegerField()
16 locale = forms.CharField()
17 plural_form = forms.CharField()
18
19 # Some file formats allow empty original strings and translations.
20 # We must allow both here. Validation is handled in pontoon.checks module.
21 original = forms.CharField(required=False)
22 translation = forms.CharField(required=False)
23
24 ignore_warnings = forms.BooleanField(required=False)
25 approve = forms.BooleanField(required=False)
26 force_suggestions = forms.BooleanField(required=False)
27 paths = forms.MultipleChoiceField(required=False)
28 machinery_sources = SimpleArrayField(forms.CharField(max_length=30), required=False)
29
30 def clean_paths(self):
31 try:
32 return self.data.getlist("paths[]")
33 except AttributeError:
34 # If the data source is not a QueryDict, it won't have a `getlist` method.
35 return self.data.get("paths[]") or []
36
37 def clean_entity(self):
38 try:
39 return Entity.objects.get(pk=self.cleaned_data["entity"])
40 except Entity.DoesNotExist:
41 raise forms.ValidationError(f"Entity `{self.entity}` could not be found")
42
43 def clean_locale(self):
44 try:
45 return Locale.objects.get(code=self.cleaned_data["locale"])
46 except Locale.DoesNotExist:
47 raise forms.ValidationError(f"Locale `{self.entity}` could not be found")
48
49 def clean_plural_form(self):
50 if self.cleaned_data["plural_form"] == "-1":
51 return None
52 return self.cleaned_data["plural_form"]
53
54 def clean_translation(self):
55 return self.data.get("translation", "")
56
[end of pontoon/translations/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pontoon/translations/forms.py b/pontoon/translations/forms.py
--- a/pontoon/translations/forms.py
+++ b/pontoon/translations/forms.py
@@ -51,5 +51,8 @@
return None
return self.cleaned_data["plural_form"]
+ def clean_original(self):
+ return self.data.get("original", "")
+
def clean_translation(self):
return self.data.get("translation", "")
|
{"golden_diff": "diff --git a/pontoon/translations/forms.py b/pontoon/translations/forms.py\n--- a/pontoon/translations/forms.py\n+++ b/pontoon/translations/forms.py\n@@ -51,5 +51,8 @@\n return None\n return self.cleaned_data[\"plural_form\"]\n \n+ def clean_original(self):\n+ return self.data.get(\"original\", \"\")\n+\n def clean_translation(self):\n return self.data.get(\"translation\", \"\")\n", "issue": "GetText check fails incorrectly on newline\nhttps://pontoon.mozilla.org/en-GB/all-projects/all-resources/?string=286055\r\n\r\nIf you copy the source string, an extra line is added at the back, and that fails the checks for GetText.\n", "before_files": [{"content": "from django import forms\nfrom django.contrib.postgres.forms import SimpleArrayField\n\nfrom pontoon.base.models import (\n Entity,\n Locale,\n)\n\n\nclass CreateTranslationForm(forms.Form):\n \"\"\"\n Form for parameters to the `entities` view.\n \"\"\"\n\n entity = forms.IntegerField()\n locale = forms.CharField()\n plural_form = forms.CharField()\n\n # Some file formats allow empty original strings and translations.\n # We must allow both here. Validation is handled in pontoon.checks module.\n original = forms.CharField(required=False)\n translation = forms.CharField(required=False)\n\n ignore_warnings = forms.BooleanField(required=False)\n approve = forms.BooleanField(required=False)\n force_suggestions = forms.BooleanField(required=False)\n paths = forms.MultipleChoiceField(required=False)\n machinery_sources = SimpleArrayField(forms.CharField(max_length=30), required=False)\n\n def clean_paths(self):\n try:\n return self.data.getlist(\"paths[]\")\n except AttributeError:\n # If the data source is not a QueryDict, it won't have a `getlist` method.\n return self.data.get(\"paths[]\") or []\n\n def clean_entity(self):\n try:\n return Entity.objects.get(pk=self.cleaned_data[\"entity\"])\n except Entity.DoesNotExist:\n raise forms.ValidationError(f\"Entity `{self.entity}` could not be found\")\n\n def clean_locale(self):\n try:\n return Locale.objects.get(code=self.cleaned_data[\"locale\"])\n except Locale.DoesNotExist:\n raise forms.ValidationError(f\"Locale `{self.entity}` could not be found\")\n\n def clean_plural_form(self):\n if self.cleaned_data[\"plural_form\"] == \"-1\":\n return None\n return self.cleaned_data[\"plural_form\"]\n\n def clean_translation(self):\n return self.data.get(\"translation\", \"\")\n", "path": "pontoon/translations/forms.py"}]}
| 1,071 | 99 |
gh_patches_debug_8461
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-7603
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add e2e tests for pipeline evaluation for 2.x
Test eval for 2.x with tiny dataset, check dataframes, isolated, integrated eval (migrate existing integration tests to e2e tests for 2.x)
</issue>
<code>
[start of haystack/evaluation/eval_run_result.py]
1 from abc import ABC, abstractmethod
2 from copy import deepcopy
3 from typing import Any, Dict, List
4 from warnings import warn
5
6 from pandas import DataFrame
7 from pandas import concat as pd_concat
8
9
10 class BaseEvaluationRunResult(ABC):
11 """
12 Represents the results of an evaluation run.
13 """
14
15 @abstractmethod
16 def to_pandas(self) -> "DataFrame":
17 """
18 Creates a Pandas DataFrame containing the scores of each metric for every input sample.
19
20 :returns:
21 Pandas DataFrame with the scores.
22 """
23
24 @abstractmethod
25 def score_report(self) -> "DataFrame":
26 """
27 Transforms the results into a Pandas DataFrame with the aggregated scores for each metric.
28
29 :returns:
30 Pandas DataFrame with the aggregated scores.
31 """
32
33 @abstractmethod
34 def comparative_individual_scores_report(self, other: "BaseEvaluationRunResult") -> "DataFrame":
35 """
36 Creates a Pandas DataFrame with the scores for each metric in the results of two different evaluation runs.
37
38 The inputs to both evaluation runs is assumed to be the same.
39
40 :param other:
41 Results of another evaluation run to compare with.
42 :returns:
43 Pandas DataFrame with the score comparison.
44 """
45
46
47 class EvaluationRunResult(BaseEvaluationRunResult):
48 """
49 Contains the inputs and the outputs of an evaluation pipeline and provides methods to inspect them.
50 """
51
52 def __init__(self, run_name: str, inputs: Dict[str, List[Any]], results: Dict[str, Dict[str, Any]]):
53 """
54 Initialize a new evaluation run result.
55
56 :param run_name:
57 Name of the evaluation run.
58 :param inputs:
59 Dictionary containing the inputs used for the run.
60 Each key is the name of the input and its value is
61 a list of input values. The length of the lists should
62 be the same.
63 :param results:
64 Dictionary containing the results of the evaluators
65 used in the evaluation pipeline. Each key is the name
66 of the metric and its value is dictionary with the following
67 keys:
68 - 'score': The aggregated score for the metric.
69 - 'individual_scores': A list of scores for each input sample.
70 """
71 self.run_name = run_name
72 self.inputs = deepcopy(inputs)
73 self.results = deepcopy(results)
74
75 if len(inputs) == 0:
76 raise ValueError("No inputs provided.")
77 if len({len(l) for l in inputs.values()}) != 1:
78 raise ValueError("Lengths of the inputs should be the same.")
79
80 expected_len = len(next(iter(inputs.values())))
81
82 for metric, outputs in results.items():
83 if "score" not in outputs:
84 raise ValueError(f"Aggregate score missing for {metric}.")
85 if "individual_scores" not in outputs:
86 raise ValueError(f"Individual scores missing for {metric}.")
87
88 if len(outputs["individual_scores"]) != expected_len:
89 raise ValueError(
90 f"Length of individual scores for '{metric}' should be the same as the inputs. "
91 f"Got {len(outputs['individual_scores'])} but expected {expected_len}."
92 )
93
94 def score_report(self) -> DataFrame: # noqa: D102
95 results = {k: v["score"] for k, v in self.results.items()}
96 return DataFrame.from_dict(results, orient="index", columns=["score"])
97
98 def to_pandas(self) -> DataFrame: # noqa: D102
99 inputs_columns = list(self.inputs.keys())
100 inputs_values = list(self.inputs.values())
101 inputs_values = list(map(list, zip(*inputs_values))) # transpose the values
102 df_inputs = DataFrame(inputs_values, columns=inputs_columns)
103
104 scores_columns = list(self.results.keys())
105 scores_values = [v["individual_scores"] for v in self.results.values()]
106 scores_values = list(map(list, zip(*scores_values))) # transpose the values
107 df_scores = DataFrame(scores_values, columns=scores_columns)
108
109 return df_inputs.join(df_scores)
110
111 def comparative_individual_scores_report(self, other: "BaseEvaluationRunResult") -> DataFrame: # noqa: D102
112 if not isinstance(other, EvaluationRunResult):
113 raise ValueError("Comparative scores can only be computed between EvaluationRunResults.")
114
115 this_name = self.run_name
116 other_name = other.run_name
117 if this_name == other_name:
118 warn(f"The run names of the two evaluation results are the same ('{this_name}')")
119 this_name = f"{this_name}_first"
120 other_name = f"{other_name}_second"
121
122 if self.inputs != other.inputs:
123 warn(f"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.")
124
125 pipe_a_df = self.to_pandas()
126 pipe_b_df = other.to_pandas()
127
128 ignore = list(self.inputs.keys())
129 pipe_b_df.drop(columns=ignore, inplace=True, errors="ignore")
130 pipe_b_df.columns = [f"{other_name}_{column}" for column in pipe_b_df.columns] # type: ignore
131 pipe_a_df.columns = [
132 f"{this_name}_{col}" if col not in ignore else col for col in pipe_a_df.columns
133 ] # type: ignore
134
135 results_df = pd_concat([pipe_a_df, pipe_b_df], axis=1)
136 return results_df
137
[end of haystack/evaluation/eval_run_result.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/haystack/evaluation/eval_run_result.py b/haystack/evaluation/eval_run_result.py
--- a/haystack/evaluation/eval_run_result.py
+++ b/haystack/evaluation/eval_run_result.py
@@ -119,8 +119,8 @@
this_name = f"{this_name}_first"
other_name = f"{other_name}_second"
- if self.inputs != other.inputs:
- warn(f"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.")
+ if self.inputs.keys() != other.inputs.keys():
+ warn(f"The input columns differ between the results; using the input columns of '{this_name}'.")
pipe_a_df = self.to_pandas()
pipe_b_df = other.to_pandas()
|
{"golden_diff": "diff --git a/haystack/evaluation/eval_run_result.py b/haystack/evaluation/eval_run_result.py\n--- a/haystack/evaluation/eval_run_result.py\n+++ b/haystack/evaluation/eval_run_result.py\n@@ -119,8 +119,8 @@\n this_name = f\"{this_name}_first\"\n other_name = f\"{other_name}_second\"\n \n- if self.inputs != other.inputs:\n- warn(f\"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.\")\n+ if self.inputs.keys() != other.inputs.keys():\n+ warn(f\"The input columns differ between the results; using the input columns of '{this_name}'.\")\n \n pipe_a_df = self.to_pandas()\n pipe_b_df = other.to_pandas()\n", "issue": "Add e2e tests for pipeline evaluation for 2.x\nTest eval for 2.x with tiny dataset, check dataframes, isolated, integrated eval (migrate existing integration tests to e2e tests for 2.x)\n", "before_files": [{"content": "from abc import ABC, abstractmethod\nfrom copy import deepcopy\nfrom typing import Any, Dict, List\nfrom warnings import warn\n\nfrom pandas import DataFrame\nfrom pandas import concat as pd_concat\n\n\nclass BaseEvaluationRunResult(ABC):\n \"\"\"\n Represents the results of an evaluation run.\n \"\"\"\n\n @abstractmethod\n def to_pandas(self) -> \"DataFrame\":\n \"\"\"\n Creates a Pandas DataFrame containing the scores of each metric for every input sample.\n\n :returns:\n Pandas DataFrame with the scores.\n \"\"\"\n\n @abstractmethod\n def score_report(self) -> \"DataFrame\":\n \"\"\"\n Transforms the results into a Pandas DataFrame with the aggregated scores for each metric.\n\n :returns:\n Pandas DataFrame with the aggregated scores.\n \"\"\"\n\n @abstractmethod\n def comparative_individual_scores_report(self, other: \"BaseEvaluationRunResult\") -> \"DataFrame\":\n \"\"\"\n Creates a Pandas DataFrame with the scores for each metric in the results of two different evaluation runs.\n\n The inputs to both evaluation runs is assumed to be the same.\n\n :param other:\n Results of another evaluation run to compare with.\n :returns:\n Pandas DataFrame with the score comparison.\n \"\"\"\n\n\nclass EvaluationRunResult(BaseEvaluationRunResult):\n \"\"\"\n Contains the inputs and the outputs of an evaluation pipeline and provides methods to inspect them.\n \"\"\"\n\n def __init__(self, run_name: str, inputs: Dict[str, List[Any]], results: Dict[str, Dict[str, Any]]):\n \"\"\"\n Initialize a new evaluation run result.\n\n :param run_name:\n Name of the evaluation run.\n :param inputs:\n Dictionary containing the inputs used for the run.\n Each key is the name of the input and its value is\n a list of input values. The length of the lists should\n be the same.\n :param results:\n Dictionary containing the results of the evaluators\n used in the evaluation pipeline. Each key is the name\n of the metric and its value is dictionary with the following\n keys:\n - 'score': The aggregated score for the metric.\n - 'individual_scores': A list of scores for each input sample.\n \"\"\"\n self.run_name = run_name\n self.inputs = deepcopy(inputs)\n self.results = deepcopy(results)\n\n if len(inputs) == 0:\n raise ValueError(\"No inputs provided.\")\n if len({len(l) for l in inputs.values()}) != 1:\n raise ValueError(\"Lengths of the inputs should be the same.\")\n\n expected_len = len(next(iter(inputs.values())))\n\n for metric, outputs in results.items():\n if \"score\" not in outputs:\n raise ValueError(f\"Aggregate score missing for {metric}.\")\n if \"individual_scores\" not in outputs:\n raise ValueError(f\"Individual scores missing for {metric}.\")\n\n if len(outputs[\"individual_scores\"]) != expected_len:\n raise ValueError(\n f\"Length of individual scores for '{metric}' should be the same as the inputs. \"\n f\"Got {len(outputs['individual_scores'])} but expected {expected_len}.\"\n )\n\n def score_report(self) -> DataFrame: # noqa: D102\n results = {k: v[\"score\"] for k, v in self.results.items()}\n return DataFrame.from_dict(results, orient=\"index\", columns=[\"score\"])\n\n def to_pandas(self) -> DataFrame: # noqa: D102\n inputs_columns = list(self.inputs.keys())\n inputs_values = list(self.inputs.values())\n inputs_values = list(map(list, zip(*inputs_values))) # transpose the values\n df_inputs = DataFrame(inputs_values, columns=inputs_columns)\n\n scores_columns = list(self.results.keys())\n scores_values = [v[\"individual_scores\"] for v in self.results.values()]\n scores_values = list(map(list, zip(*scores_values))) # transpose the values\n df_scores = DataFrame(scores_values, columns=scores_columns)\n\n return df_inputs.join(df_scores)\n\n def comparative_individual_scores_report(self, other: \"BaseEvaluationRunResult\") -> DataFrame: # noqa: D102\n if not isinstance(other, EvaluationRunResult):\n raise ValueError(\"Comparative scores can only be computed between EvaluationRunResults.\")\n\n this_name = self.run_name\n other_name = other.run_name\n if this_name == other_name:\n warn(f\"The run names of the two evaluation results are the same ('{this_name}')\")\n this_name = f\"{this_name}_first\"\n other_name = f\"{other_name}_second\"\n\n if self.inputs != other.inputs:\n warn(f\"The inputs to the two evaluation results differ; using the inputs of '{this_name}'.\")\n\n pipe_a_df = self.to_pandas()\n pipe_b_df = other.to_pandas()\n\n ignore = list(self.inputs.keys())\n pipe_b_df.drop(columns=ignore, inplace=True, errors=\"ignore\")\n pipe_b_df.columns = [f\"{other_name}_{column}\" for column in pipe_b_df.columns] # type: ignore\n pipe_a_df.columns = [\n f\"{this_name}_{col}\" if col not in ignore else col for col in pipe_a_df.columns\n ] # type: ignore\n\n results_df = pd_concat([pipe_a_df, pipe_b_df], axis=1)\n return results_df\n", "path": "haystack/evaluation/eval_run_result.py"}]}
| 2,036 | 175 |
gh_patches_debug_13129
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-613
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
datetimepicker unique ids
<img width="980" alt="screen shot 2017-06-01 at 15 59 21" src="https://cloud.githubusercontent.com/assets/16354712/26683219/61f8eb4c-46e3-11e7-851b-148bff927bd4.png">
</issue>
<code>
[start of apps/contrib/widgets.py]
1 import datetime
2 from itertools import chain
3
4 import django_filters
5 from django.contrib.staticfiles.storage import staticfiles_storage
6 from django.db.models.fields import BLANK_CHOICE_DASH
7 from django.forms import widgets as form_widgets
8 from django.forms.widgets import flatatt
9 from django.template.loader import render_to_string
10 from django.utils import formats
11 from django.utils.timezone import localtime
12 from django.utils.translation import ugettext as _
13
14
15 class DropdownLinkWidget(django_filters.widgets.LinkWidget):
16 label = None
17 right = False
18 template = 'meinberlin_contrib/widgets/dropdown_link.html'
19
20 def get_option_label(self, value, choices=()):
21 option_label = BLANK_CHOICE_DASH[0][1]
22
23 for v, label in chain(self.choices, choices):
24 if str(v) == value:
25 option_label = label
26 break
27
28 if option_label == BLANK_CHOICE_DASH[0][1]:
29 option_label = _('All')
30
31 return option_label
32
33 def render(self, name, value, attrs=None, choices=()):
34 all_choices = list(chain(self.choices, choices))
35
36 if len(all_choices) <= 1:
37 return ''
38
39 if value is None:
40 value = all_choices[0][0]
41
42 _id = attrs.pop('id')
43 final_attrs = flatatt(self.build_attrs(attrs))
44 value_label = self.get_option_label(value, choices=choices)
45
46 options = super().render(name, value, attrs={
47 'class': 'dropdown-menu',
48 'aria-labelledby': _id,
49 }, choices=choices)
50
51 return render_to_string(self.template, {
52 'options': options,
53 'id': _id,
54 'attrs': final_attrs,
55 'value_label': value_label,
56 'label': self.label,
57 'right': self.right,
58 })
59
60
61 class DateTimeInput(form_widgets.SplitDateTimeWidget):
62 class Media:
63 js = (
64 staticfiles_storage.url('datepicker.js'),
65 )
66 css = {'all': [
67 staticfiles_storage.url('datepicker.css'),
68 ]}
69
70 def render(self, name, value, attrs=None):
71 date_attrs = self.build_attrs(attrs)
72 date_attrs.update({
73 'class': 'datepicker',
74 'placeholder': formats.localize_input(datetime.date.today())
75 })
76 time_attrs = self.build_attrs(attrs)
77 time_attrs.update({
78 'class': 'timepicker',
79 'placeholder': '00:00',
80 })
81
82 if isinstance(value, datetime.datetime):
83 value = localtime(value)
84 date = value.date()
85 time = value.time()
86 else:
87 # value's just a list in case of an error
88 date = value[0] if value else None
89 time = value[1] if value else '00:00'
90
91 return render_to_string('datetime_input.html', {
92 'date': self.widgets[0].render(
93 name + '_0',
94 date,
95 date_attrs
96 ),
97 'time': self.widgets[1].render(
98 name + '_1',
99 time,
100 time_attrs
101 )
102 })
103
[end of apps/contrib/widgets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/contrib/widgets.py b/apps/contrib/widgets.py
--- a/apps/contrib/widgets.py
+++ b/apps/contrib/widgets.py
@@ -71,12 +71,14 @@
date_attrs = self.build_attrs(attrs)
date_attrs.update({
'class': 'datepicker',
- 'placeholder': formats.localize_input(datetime.date.today())
+ 'placeholder': formats.localize_input(datetime.date.today()),
+ 'id': name + '_date'
})
time_attrs = self.build_attrs(attrs)
time_attrs.update({
'class': 'timepicker',
'placeholder': '00:00',
+ 'id': name + '_time'
})
if isinstance(value, datetime.datetime):
|
{"golden_diff": "diff --git a/apps/contrib/widgets.py b/apps/contrib/widgets.py\n--- a/apps/contrib/widgets.py\n+++ b/apps/contrib/widgets.py\n@@ -71,12 +71,14 @@\n date_attrs = self.build_attrs(attrs)\n date_attrs.update({\n 'class': 'datepicker',\n- 'placeholder': formats.localize_input(datetime.date.today())\n+ 'placeholder': formats.localize_input(datetime.date.today()),\n+ 'id': name + '_date'\n })\n time_attrs = self.build_attrs(attrs)\n time_attrs.update({\n 'class': 'timepicker',\n 'placeholder': '00:00',\n+ 'id': name + '_time'\n })\n \n if isinstance(value, datetime.datetime):\n", "issue": "datetimepicker unique ids\n<img width=\"980\" alt=\"screen shot 2017-06-01 at 15 59 21\" src=\"https://cloud.githubusercontent.com/assets/16354712/26683219/61f8eb4c-46e3-11e7-851b-148bff927bd4.png\">\r\n\n", "before_files": [{"content": "import datetime\nfrom itertools import chain\n\nimport django_filters\nfrom django.contrib.staticfiles.storage import staticfiles_storage\nfrom django.db.models.fields import BLANK_CHOICE_DASH\nfrom django.forms import widgets as form_widgets\nfrom django.forms.widgets import flatatt\nfrom django.template.loader import render_to_string\nfrom django.utils import formats\nfrom django.utils.timezone import localtime\nfrom django.utils.translation import ugettext as _\n\n\nclass DropdownLinkWidget(django_filters.widgets.LinkWidget):\n label = None\n right = False\n template = 'meinberlin_contrib/widgets/dropdown_link.html'\n\n def get_option_label(self, value, choices=()):\n option_label = BLANK_CHOICE_DASH[0][1]\n\n for v, label in chain(self.choices, choices):\n if str(v) == value:\n option_label = label\n break\n\n if option_label == BLANK_CHOICE_DASH[0][1]:\n option_label = _('All')\n\n return option_label\n\n def render(self, name, value, attrs=None, choices=()):\n all_choices = list(chain(self.choices, choices))\n\n if len(all_choices) <= 1:\n return ''\n\n if value is None:\n value = all_choices[0][0]\n\n _id = attrs.pop('id')\n final_attrs = flatatt(self.build_attrs(attrs))\n value_label = self.get_option_label(value, choices=choices)\n\n options = super().render(name, value, attrs={\n 'class': 'dropdown-menu',\n 'aria-labelledby': _id,\n }, choices=choices)\n\n return render_to_string(self.template, {\n 'options': options,\n 'id': _id,\n 'attrs': final_attrs,\n 'value_label': value_label,\n 'label': self.label,\n 'right': self.right,\n })\n\n\nclass DateTimeInput(form_widgets.SplitDateTimeWidget):\n class Media:\n js = (\n staticfiles_storage.url('datepicker.js'),\n )\n css = {'all': [\n staticfiles_storage.url('datepicker.css'),\n ]}\n\n def render(self, name, value, attrs=None):\n date_attrs = self.build_attrs(attrs)\n date_attrs.update({\n 'class': 'datepicker',\n 'placeholder': formats.localize_input(datetime.date.today())\n })\n time_attrs = self.build_attrs(attrs)\n time_attrs.update({\n 'class': 'timepicker',\n 'placeholder': '00:00',\n })\n\n if isinstance(value, datetime.datetime):\n value = localtime(value)\n date = value.date()\n time = value.time()\n else:\n # value's just a list in case of an error\n date = value[0] if value else None\n time = value[1] if value else '00:00'\n\n return render_to_string('datetime_input.html', {\n 'date': self.widgets[0].render(\n name + '_0',\n date,\n date_attrs\n ),\n 'time': self.widgets[1].render(\n name + '_1',\n time,\n time_attrs\n )\n })\n", "path": "apps/contrib/widgets.py"}]}
| 1,499 | 159 |
gh_patches_debug_17569
|
rasdani/github-patches
|
git_diff
|
python-discord__site-304
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make newlines visible in the deleted messages front-end
The deleted messages front-end currently doesn't display newlines if they're consecutive, i.e., if the lines are otherwise empty (`"\n\n\n\n\n\n\n\n\n"`). This makes it difficult to interpret what actually happened in chat. A good solution to this would be to make newlines character visible using the `↵` character, printed in a light gray color (similar to how IDEs do it).
**before**

**proposed after**

</issue>
<code>
[start of pydis_site/apps/staff/templatetags/deletedmessage_filters.py]
1 from datetime import datetime
2
3 from django import template
4
5 register = template.Library()
6
7
8 @register.filter
9 def hex_colour(color: int) -> str:
10 """Converts an integer representation of a colour to the RGB hex value."""
11 return f"#{color:0>6X}"
12
13
14 @register.filter
15 def footer_datetime(timestamp: str) -> datetime:
16 """Takes an embed timestamp and returns a timezone-aware datetime object."""
17 return datetime.fromisoformat(timestamp)
18
[end of pydis_site/apps/staff/templatetags/deletedmessage_filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
--- a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
+++ b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py
@@ -7,11 +7,22 @@
@register.filter
def hex_colour(color: int) -> str:
- """Converts an integer representation of a colour to the RGB hex value."""
- return f"#{color:0>6X}"
+ """
+ Converts an integer representation of a colour to the RGB hex value.
+
+ As we are using a Discord dark theme analogue, black colours are returned as white instead.
+ """
+ colour = f"#{color:0>6X}"
+ return colour if colour != "#000000" else "#FFFFFF"
@register.filter
def footer_datetime(timestamp: str) -> datetime:
"""Takes an embed timestamp and returns a timezone-aware datetime object."""
return datetime.fromisoformat(timestamp)
+
+
[email protected]
+def visible_newlines(text: str) -> str:
+ """Takes an embed timestamp and returns a timezone-aware datetime object."""
+ return text.replace("\n", " <span class='has-text-grey'>↵</span><br>")
|
{"golden_diff": "diff --git a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n--- a/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n+++ b/pydis_site/apps/staff/templatetags/deletedmessage_filters.py\n@@ -7,11 +7,22 @@\n \n @register.filter\n def hex_colour(color: int) -> str:\n- \"\"\"Converts an integer representation of a colour to the RGB hex value.\"\"\"\n- return f\"#{color:0>6X}\"\n+ \"\"\"\n+ Converts an integer representation of a colour to the RGB hex value.\n+\n+ As we are using a Discord dark theme analogue, black colours are returned as white instead.\n+ \"\"\"\n+ colour = f\"#{color:0>6X}\"\n+ return colour if colour != \"#000000\" else \"#FFFFFF\"\n \n \n @register.filter\n def footer_datetime(timestamp: str) -> datetime:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return datetime.fromisoformat(timestamp)\n+\n+\[email protected]\n+def visible_newlines(text: str) -> str:\n+ \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n+ return text.replace(\"\\n\", \" <span class='has-text-grey'>\u21b5</span><br>\")\n", "issue": "Make newlines visible in the deleted messages front-end\nThe deleted messages front-end currently doesn't display newlines if they're consecutive, i.e., if the lines are otherwise empty (`\"\\n\\n\\n\\n\\n\\n\\n\\n\\n\"`). This makes it difficult to interpret what actually happened in chat. A good solution to this would be to make newlines character visible using the `\u21b5` character, printed in a light gray color (similar to how IDEs do it).\r\n\r\n**before**\r\n\r\n\r\n**proposed after**\r\n\r\n\n", "before_files": [{"content": "from datetime import datetime\n\nfrom django import template\n\nregister = template.Library()\n\n\[email protected]\ndef hex_colour(color: int) -> str:\n \"\"\"Converts an integer representation of a colour to the RGB hex value.\"\"\"\n return f\"#{color:0>6X}\"\n\n\[email protected]\ndef footer_datetime(timestamp: str) -> datetime:\n \"\"\"Takes an embed timestamp and returns a timezone-aware datetime object.\"\"\"\n return datetime.fromisoformat(timestamp)\n", "path": "pydis_site/apps/staff/templatetags/deletedmessage_filters.py"}]}
| 946 | 304 |
gh_patches_debug_18377
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection-4300
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Empirical attention with ResNext backbone
In mmdetectiom v1 I used ResNext backbone with empirical attention 0010_dcn but in v2 I got an error.
Any ideas how to fix this?
My updated config file:
```
_base_ = '../faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'
model = dict(
pretrained='open-mmlab://resnext50_32x4d',
backbone=dict(
type='ResNeXt',
depth=50,
groups=32,
base_width=4,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='BN', requires_grad=True),
style='pytorch',
plugins=[
dict(
cfg=dict(
type='GeneralizedAttention',
spatial_range=-1,
num_heads=8,
attention_type='0010',
kv_stride=2),
stages=(False, False, True, True),
position='after_conv2')
],
dcn=dict(type='DCN', deform_groups=1, fallback_on_stride=False),
stage_with_dcn=(False, True, True, True)))
```
Error:
```
RuntimeError: Given groups=1, weight of size [256, 256, 1, 1], expected input[2, 512, 41, 73] to have 256 channels, but got 512 channels instead
```
</issue>
<code>
[start of mmdet/models/backbones/resnext.py]
1 import math
2
3 from mmcv.cnn import build_conv_layer, build_norm_layer
4
5 from ..builder import BACKBONES
6 from ..utils import ResLayer
7 from .resnet import Bottleneck as _Bottleneck
8 from .resnet import ResNet
9
10
11 class Bottleneck(_Bottleneck):
12 expansion = 4
13
14 def __init__(self,
15 inplanes,
16 planes,
17 groups=1,
18 base_width=4,
19 base_channels=64,
20 **kwargs):
21 """Bottleneck block for ResNeXt.
22
23 If style is "pytorch", the stride-two layer is the 3x3 conv layer, if
24 it is "caffe", the stride-two layer is the first 1x1 conv layer.
25 """
26 super(Bottleneck, self).__init__(inplanes, planes, **kwargs)
27
28 if groups == 1:
29 width = self.planes
30 else:
31 width = math.floor(self.planes *
32 (base_width / base_channels)) * groups
33
34 self.norm1_name, norm1 = build_norm_layer(
35 self.norm_cfg, width, postfix=1)
36 self.norm2_name, norm2 = build_norm_layer(
37 self.norm_cfg, width, postfix=2)
38 self.norm3_name, norm3 = build_norm_layer(
39 self.norm_cfg, self.planes * self.expansion, postfix=3)
40
41 self.conv1 = build_conv_layer(
42 self.conv_cfg,
43 self.inplanes,
44 width,
45 kernel_size=1,
46 stride=self.conv1_stride,
47 bias=False)
48 self.add_module(self.norm1_name, norm1)
49 fallback_on_stride = False
50 self.with_modulated_dcn = False
51 if self.with_dcn:
52 fallback_on_stride = self.dcn.pop('fallback_on_stride', False)
53 if not self.with_dcn or fallback_on_stride:
54 self.conv2 = build_conv_layer(
55 self.conv_cfg,
56 width,
57 width,
58 kernel_size=3,
59 stride=self.conv2_stride,
60 padding=self.dilation,
61 dilation=self.dilation,
62 groups=groups,
63 bias=False)
64 else:
65 assert self.conv_cfg is None, 'conv_cfg must be None for DCN'
66 self.conv2 = build_conv_layer(
67 self.dcn,
68 width,
69 width,
70 kernel_size=3,
71 stride=self.conv2_stride,
72 padding=self.dilation,
73 dilation=self.dilation,
74 groups=groups,
75 bias=False)
76
77 self.add_module(self.norm2_name, norm2)
78 self.conv3 = build_conv_layer(
79 self.conv_cfg,
80 width,
81 self.planes * self.expansion,
82 kernel_size=1,
83 bias=False)
84 self.add_module(self.norm3_name, norm3)
85
86
87 @BACKBONES.register_module()
88 class ResNeXt(ResNet):
89 """ResNeXt backbone.
90
91 Args:
92 depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.
93 in_channels (int): Number of input image channels. Default: 3.
94 num_stages (int): Resnet stages. Default: 4.
95 groups (int): Group of resnext.
96 base_width (int): Base width of resnext.
97 strides (Sequence[int]): Strides of the first block of each stage.
98 dilations (Sequence[int]): Dilation of each stage.
99 out_indices (Sequence[int]): Output from which stages.
100 style (str): `pytorch` or `caffe`. If set to "pytorch", the stride-two
101 layer is the 3x3 conv layer, otherwise the stride-two layer is
102 the first 1x1 conv layer.
103 frozen_stages (int): Stages to be frozen (all param fixed). -1 means
104 not freezing any parameters.
105 norm_cfg (dict): dictionary to construct and config norm layer.
106 norm_eval (bool): Whether to set norm layers to eval mode, namely,
107 freeze running stats (mean and var). Note: Effect on Batch Norm
108 and its variants only.
109 with_cp (bool): Use checkpoint or not. Using checkpoint will save some
110 memory while slowing down the training speed.
111 zero_init_residual (bool): whether to use zero init for last norm layer
112 in resblocks to let them behave as identity.
113 """
114
115 arch_settings = {
116 50: (Bottleneck, (3, 4, 6, 3)),
117 101: (Bottleneck, (3, 4, 23, 3)),
118 152: (Bottleneck, (3, 8, 36, 3))
119 }
120
121 def __init__(self, groups=1, base_width=4, **kwargs):
122 self.groups = groups
123 self.base_width = base_width
124 super(ResNeXt, self).__init__(**kwargs)
125
126 def make_res_layer(self, **kwargs):
127 """Pack all blocks in a stage into a ``ResLayer``"""
128 return ResLayer(
129 groups=self.groups,
130 base_width=self.base_width,
131 base_channels=self.base_channels,
132 **kwargs)
133
[end of mmdet/models/backbones/resnext.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmdet/models/backbones/resnext.py b/mmdet/models/backbones/resnext.py
--- a/mmdet/models/backbones/resnext.py
+++ b/mmdet/models/backbones/resnext.py
@@ -83,6 +83,27 @@
bias=False)
self.add_module(self.norm3_name, norm3)
+ if self.with_plugins:
+ self._del_block_plugins(self.after_conv1_plugin_names +
+ self.after_conv2_plugin_names +
+ self.after_conv3_plugin_names)
+ self.after_conv1_plugin_names = self.make_block_plugins(
+ width, self.after_conv1_plugins)
+ self.after_conv2_plugin_names = self.make_block_plugins(
+ width, self.after_conv2_plugins)
+ self.after_conv3_plugin_names = self.make_block_plugins(
+ self.planes * self.expansion, self.after_conv3_plugins)
+
+ def _del_block_plugins(self, plugin_names):
+ """delete plugins for block if exist.
+
+ Args:
+ plugin_names (list[str]): List of plugins name to delete.
+ """
+ assert isinstance(plugin_names, list)
+ for plugin_name in plugin_names:
+ del self._modules[plugin_name]
+
@BACKBONES.register_module()
class ResNeXt(ResNet):
|
{"golden_diff": "diff --git a/mmdet/models/backbones/resnext.py b/mmdet/models/backbones/resnext.py\n--- a/mmdet/models/backbones/resnext.py\n+++ b/mmdet/models/backbones/resnext.py\n@@ -83,6 +83,27 @@\n bias=False)\n self.add_module(self.norm3_name, norm3)\n \n+ if self.with_plugins:\n+ self._del_block_plugins(self.after_conv1_plugin_names +\n+ self.after_conv2_plugin_names +\n+ self.after_conv3_plugin_names)\n+ self.after_conv1_plugin_names = self.make_block_plugins(\n+ width, self.after_conv1_plugins)\n+ self.after_conv2_plugin_names = self.make_block_plugins(\n+ width, self.after_conv2_plugins)\n+ self.after_conv3_plugin_names = self.make_block_plugins(\n+ self.planes * self.expansion, self.after_conv3_plugins)\n+\n+ def _del_block_plugins(self, plugin_names):\n+ \"\"\"delete plugins for block if exist.\n+\n+ Args:\n+ plugin_names (list[str]): List of plugins name to delete.\n+ \"\"\"\n+ assert isinstance(plugin_names, list)\n+ for plugin_name in plugin_names:\n+ del self._modules[plugin_name]\n+\n \n @BACKBONES.register_module()\n class ResNeXt(ResNet):\n", "issue": "Empirical attention with ResNext backbone\nIn mmdetectiom v1 I used ResNext backbone with empirical attention 0010_dcn but in v2 I got an error.\r\nAny ideas how to fix this?\r\n\r\nMy updated config file:\r\n```\r\n_base_ = '../faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py'\r\nmodel = dict(\r\n\r\n pretrained='open-mmlab://resnext50_32x4d',\r\n backbone=dict(\r\n type='ResNeXt',\r\n depth=50,\r\n groups=32,\r\n base_width=4,\r\n num_stages=4,\r\n out_indices=(0, 1, 2, 3),\r\n frozen_stages=1,\r\n norm_cfg=dict(type='BN', requires_grad=True),\r\n style='pytorch',\r\n plugins=[\r\n dict(\r\n cfg=dict(\r\n type='GeneralizedAttention',\r\n spatial_range=-1,\r\n num_heads=8,\r\n attention_type='0010',\r\n kv_stride=2),\r\n stages=(False, False, True, True),\r\n position='after_conv2')\r\n ],\r\n dcn=dict(type='DCN', deform_groups=1, fallback_on_stride=False),\r\n stage_with_dcn=(False, True, True, True)))\r\n```\r\n\r\nError:\r\n```\r\nRuntimeError: Given groups=1, weight of size [256, 256, 1, 1], expected input[2, 512, 41, 73] to have 256 channels, but got 512 channels instead\r\n```\n", "before_files": [{"content": "import math\n\nfrom mmcv.cnn import build_conv_layer, build_norm_layer\n\nfrom ..builder import BACKBONES\nfrom ..utils import ResLayer\nfrom .resnet import Bottleneck as _Bottleneck\nfrom .resnet import ResNet\n\n\nclass Bottleneck(_Bottleneck):\n expansion = 4\n\n def __init__(self,\n inplanes,\n planes,\n groups=1,\n base_width=4,\n base_channels=64,\n **kwargs):\n \"\"\"Bottleneck block for ResNeXt.\n\n If style is \"pytorch\", the stride-two layer is the 3x3 conv layer, if\n it is \"caffe\", the stride-two layer is the first 1x1 conv layer.\n \"\"\"\n super(Bottleneck, self).__init__(inplanes, planes, **kwargs)\n\n if groups == 1:\n width = self.planes\n else:\n width = math.floor(self.planes *\n (base_width / base_channels)) * groups\n\n self.norm1_name, norm1 = build_norm_layer(\n self.norm_cfg, width, postfix=1)\n self.norm2_name, norm2 = build_norm_layer(\n self.norm_cfg, width, postfix=2)\n self.norm3_name, norm3 = build_norm_layer(\n self.norm_cfg, self.planes * self.expansion, postfix=3)\n\n self.conv1 = build_conv_layer(\n self.conv_cfg,\n self.inplanes,\n width,\n kernel_size=1,\n stride=self.conv1_stride,\n bias=False)\n self.add_module(self.norm1_name, norm1)\n fallback_on_stride = False\n self.with_modulated_dcn = False\n if self.with_dcn:\n fallback_on_stride = self.dcn.pop('fallback_on_stride', False)\n if not self.with_dcn or fallback_on_stride:\n self.conv2 = build_conv_layer(\n self.conv_cfg,\n width,\n width,\n kernel_size=3,\n stride=self.conv2_stride,\n padding=self.dilation,\n dilation=self.dilation,\n groups=groups,\n bias=False)\n else:\n assert self.conv_cfg is None, 'conv_cfg must be None for DCN'\n self.conv2 = build_conv_layer(\n self.dcn,\n width,\n width,\n kernel_size=3,\n stride=self.conv2_stride,\n padding=self.dilation,\n dilation=self.dilation,\n groups=groups,\n bias=False)\n\n self.add_module(self.norm2_name, norm2)\n self.conv3 = build_conv_layer(\n self.conv_cfg,\n width,\n self.planes * self.expansion,\n kernel_size=1,\n bias=False)\n self.add_module(self.norm3_name, norm3)\n\n\[email protected]_module()\nclass ResNeXt(ResNet):\n \"\"\"ResNeXt backbone.\n\n Args:\n depth (int): Depth of resnet, from {18, 34, 50, 101, 152}.\n in_channels (int): Number of input image channels. Default: 3.\n num_stages (int): Resnet stages. Default: 4.\n groups (int): Group of resnext.\n base_width (int): Base width of resnext.\n strides (Sequence[int]): Strides of the first block of each stage.\n dilations (Sequence[int]): Dilation of each stage.\n out_indices (Sequence[int]): Output from which stages.\n style (str): `pytorch` or `caffe`. If set to \"pytorch\", the stride-two\n layer is the 3x3 conv layer, otherwise the stride-two layer is\n the first 1x1 conv layer.\n frozen_stages (int): Stages to be frozen (all param fixed). -1 means\n not freezing any parameters.\n norm_cfg (dict): dictionary to construct and config norm layer.\n norm_eval (bool): Whether to set norm layers to eval mode, namely,\n freeze running stats (mean and var). Note: Effect on Batch Norm\n and its variants only.\n with_cp (bool): Use checkpoint or not. Using checkpoint will save some\n memory while slowing down the training speed.\n zero_init_residual (bool): whether to use zero init for last norm layer\n in resblocks to let them behave as identity.\n \"\"\"\n\n arch_settings = {\n 50: (Bottleneck, (3, 4, 6, 3)),\n 101: (Bottleneck, (3, 4, 23, 3)),\n 152: (Bottleneck, (3, 8, 36, 3))\n }\n\n def __init__(self, groups=1, base_width=4, **kwargs):\n self.groups = groups\n self.base_width = base_width\n super(ResNeXt, self).__init__(**kwargs)\n\n def make_res_layer(self, **kwargs):\n \"\"\"Pack all blocks in a stage into a ``ResLayer``\"\"\"\n return ResLayer(\n groups=self.groups,\n base_width=self.base_width,\n base_channels=self.base_channels,\n **kwargs)\n", "path": "mmdet/models/backbones/resnext.py"}]}
| 2,304 | 287 |
gh_patches_debug_1191
|
rasdani/github-patches
|
git_diff
|
huggingface__dataset-viewer-2409
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Retry jobs that finish with `ClientConnection` error?
Maybe here: https://github.com/huggingface/datasets-server/blob/f311a9212aaa91dd0373e5c2d4f5da9b6bdabcb5/chart/env/prod.yaml#L209
Internal conversation on Slack: https://huggingface.slack.com/archives/C0311GZ7R6K/p1698224875005729
Anyway: I'm wondering if we can have the error now that the dataset scripts are disabled by default.
</issue>
<code>
[start of libs/libcommon/src/libcommon/constants.py]
1 # SPDX-License-Identifier: Apache-2.0
2 # Copyright 2022 The HuggingFace Authors.
3
4 CACHE_COLLECTION_RESPONSES = "cachedResponsesBlue"
5 CACHE_MONGOENGINE_ALIAS = "cache"
6 HF_DATASETS_CACHE_APPNAME = "hf_datasets_cache"
7 PARQUET_METADATA_CACHE_APPNAME = "datasets_server_parquet_metadata"
8 DESCRIPTIVE_STATISTICS_CACHE_APPNAME = "datasets_server_descriptive_statistics"
9 DUCKDB_INDEX_CACHE_APPNAME = "datasets_server_duckdb_index"
10 DUCKDB_INDEX_DOWNLOADS_SUBDIRECTORY = "downloads"
11 DUCKDB_INDEX_JOB_RUNNER_SUBDIRECTORY = "job_runner"
12 CACHE_METRICS_COLLECTION = "cacheTotalMetric"
13 QUEUE_METRICS_COLLECTION = "jobTotalMetric"
14 METRICS_MONGOENGINE_ALIAS = "metrics"
15 QUEUE_COLLECTION_JOBS = "jobsBlue"
16 QUEUE_COLLECTION_LOCKS = "locks"
17 QUEUE_MONGOENGINE_ALIAS = "queue"
18 QUEUE_TTL_SECONDS = 600 # 10 minutes
19 LOCK_TTL_SECONDS_NO_OWNER = 600 # 10 minutes
20 LOCK_TTL_SECONDS_TO_START_JOB = 600 # 10 minutes
21 LOCK_TTL_SECONDS_TO_WRITE_ON_GIT_BRANCH = 3600 # 1 hour
22
23 MAX_FAILED_RUNS = 3
24 DATASET_SEPARATOR = "--"
25 DEFAULT_DIFFICULTY = 50
26 DEFAULT_DIFFICULTY_MAX = 100
27 DEFAULT_DIFFICULTY_MIN = 0
28 DEFAULT_INPUT_TYPE = "dataset"
29 DEFAULT_JOB_RUNNER_VERSION = 1
30 DIFFICULTY_BONUS_BY_FAILED_RUNS = 20
31 MIN_BYTES_FOR_BONUS_DIFFICULTY = 3_000_000_000
32
33 PROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_AUDIO_DATASETS = 100
34 PROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_IMAGE_DATASETS = 100
35 PROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_BINARY_DATASETS = 100
36 PARQUET_REVISION = "refs/convert/parquet"
37
38 ERROR_CODES_TO_RETRY = {
39 "CreateCommitError",
40 "ExternalServerError",
41 "JobManagerCrashedError",
42 "LockedDatasetTimeoutError",
43 "StreamingRowsError",
44 }
45
46 EXTERNAL_DATASET_SCRIPT_PATTERN = "datasets_modules/datasets"
47
48 # Arrays are not immutable, we have to take care of not modifying them
49 # Anyway: in all this file, we allow constant reassignment (no use of Final)
50 CONFIG_HAS_VIEWER_KINDS = ["config-size"]
51 CONFIG_INFO_KINDS = ["config-info"]
52 CONFIG_PARQUET_METADATA_KINDS = ["config-parquet-metadata"]
53 CONFIG_PARQUET_AND_METADATA_KINDS = ["config-parquet", "config-parquet-metadata"]
54 CONFIG_SPLIT_NAMES_KINDS = ["config-split-names-from-info", "config-split-names-from-streaming"]
55 DATASET_CONFIG_NAMES_KINDS = ["dataset-config-names"]
56 DATASET_INFO_KINDS = ["dataset-info"]
57 SPLIT_DUCKDB_INDEX_KINDS = ["split-duckdb-index"]
58 SPLIT_HAS_PREVIEW_KINDS = ["split-first-rows-from-streaming", "split-first-rows-from-parquet"]
59 SPLIT_HAS_SEARCH_KINDS = ["split-duckdb-index"]
60 PARALLEL_STEPS_LISTS = [
61 CONFIG_SPLIT_NAMES_KINDS,
62 SPLIT_HAS_PREVIEW_KINDS,
63 ]
64
65 CROISSANT_MAX_CONFIGS = 100
66 MAX_NUM_ROWS_PER_PAGE = 100
67
[end of libs/libcommon/src/libcommon/constants.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libs/libcommon/src/libcommon/constants.py b/libs/libcommon/src/libcommon/constants.py
--- a/libs/libcommon/src/libcommon/constants.py
+++ b/libs/libcommon/src/libcommon/constants.py
@@ -36,6 +36,7 @@
PARQUET_REVISION = "refs/convert/parquet"
ERROR_CODES_TO_RETRY = {
+ "ConnectionError",
"CreateCommitError",
"ExternalServerError",
"JobManagerCrashedError",
|
{"golden_diff": "diff --git a/libs/libcommon/src/libcommon/constants.py b/libs/libcommon/src/libcommon/constants.py\n--- a/libs/libcommon/src/libcommon/constants.py\n+++ b/libs/libcommon/src/libcommon/constants.py\n@@ -36,6 +36,7 @@\n PARQUET_REVISION = \"refs/convert/parquet\"\n \n ERROR_CODES_TO_RETRY = {\n+ \"ConnectionError\",\n \"CreateCommitError\",\n \"ExternalServerError\",\n \"JobManagerCrashedError\",\n", "issue": "Retry jobs that finish with `ClientConnection` error?\nMaybe here: https://github.com/huggingface/datasets-server/blob/f311a9212aaa91dd0373e5c2d4f5da9b6bdabcb5/chart/env/prod.yaml#L209\r\n\r\nInternal conversation on Slack: https://huggingface.slack.com/archives/C0311GZ7R6K/p1698224875005729\r\n\r\nAnyway: I'm wondering if we can have the error now that the dataset scripts are disabled by default.\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n# Copyright 2022 The HuggingFace Authors.\n\nCACHE_COLLECTION_RESPONSES = \"cachedResponsesBlue\"\nCACHE_MONGOENGINE_ALIAS = \"cache\"\nHF_DATASETS_CACHE_APPNAME = \"hf_datasets_cache\"\nPARQUET_METADATA_CACHE_APPNAME = \"datasets_server_parquet_metadata\"\nDESCRIPTIVE_STATISTICS_CACHE_APPNAME = \"datasets_server_descriptive_statistics\"\nDUCKDB_INDEX_CACHE_APPNAME = \"datasets_server_duckdb_index\"\nDUCKDB_INDEX_DOWNLOADS_SUBDIRECTORY = \"downloads\"\nDUCKDB_INDEX_JOB_RUNNER_SUBDIRECTORY = \"job_runner\"\nCACHE_METRICS_COLLECTION = \"cacheTotalMetric\"\nQUEUE_METRICS_COLLECTION = \"jobTotalMetric\"\nMETRICS_MONGOENGINE_ALIAS = \"metrics\"\nQUEUE_COLLECTION_JOBS = \"jobsBlue\"\nQUEUE_COLLECTION_LOCKS = \"locks\"\nQUEUE_MONGOENGINE_ALIAS = \"queue\"\nQUEUE_TTL_SECONDS = 600 # 10 minutes\nLOCK_TTL_SECONDS_NO_OWNER = 600 # 10 minutes\nLOCK_TTL_SECONDS_TO_START_JOB = 600 # 10 minutes\nLOCK_TTL_SECONDS_TO_WRITE_ON_GIT_BRANCH = 3600 # 1 hour\n\nMAX_FAILED_RUNS = 3\nDATASET_SEPARATOR = \"--\"\nDEFAULT_DIFFICULTY = 50\nDEFAULT_DIFFICULTY_MAX = 100\nDEFAULT_DIFFICULTY_MIN = 0\nDEFAULT_INPUT_TYPE = \"dataset\"\nDEFAULT_JOB_RUNNER_VERSION = 1\nDIFFICULTY_BONUS_BY_FAILED_RUNS = 20\nMIN_BYTES_FOR_BONUS_DIFFICULTY = 3_000_000_000\n\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_AUDIO_DATASETS = 100\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_IMAGE_DATASETS = 100\nPROCESSING_STEP_CONFIG_PARQUET_AND_INFO_ROW_GROUP_SIZE_FOR_BINARY_DATASETS = 100\nPARQUET_REVISION = \"refs/convert/parquet\"\n\nERROR_CODES_TO_RETRY = {\n \"CreateCommitError\",\n \"ExternalServerError\",\n \"JobManagerCrashedError\",\n \"LockedDatasetTimeoutError\",\n \"StreamingRowsError\",\n}\n\nEXTERNAL_DATASET_SCRIPT_PATTERN = \"datasets_modules/datasets\"\n\n# Arrays are not immutable, we have to take care of not modifying them\n# Anyway: in all this file, we allow constant reassignment (no use of Final)\nCONFIG_HAS_VIEWER_KINDS = [\"config-size\"]\nCONFIG_INFO_KINDS = [\"config-info\"]\nCONFIG_PARQUET_METADATA_KINDS = [\"config-parquet-metadata\"]\nCONFIG_PARQUET_AND_METADATA_KINDS = [\"config-parquet\", \"config-parquet-metadata\"]\nCONFIG_SPLIT_NAMES_KINDS = [\"config-split-names-from-info\", \"config-split-names-from-streaming\"]\nDATASET_CONFIG_NAMES_KINDS = [\"dataset-config-names\"]\nDATASET_INFO_KINDS = [\"dataset-info\"]\nSPLIT_DUCKDB_INDEX_KINDS = [\"split-duckdb-index\"]\nSPLIT_HAS_PREVIEW_KINDS = [\"split-first-rows-from-streaming\", \"split-first-rows-from-parquet\"]\nSPLIT_HAS_SEARCH_KINDS = [\"split-duckdb-index\"]\nPARALLEL_STEPS_LISTS = [\n CONFIG_SPLIT_NAMES_KINDS,\n SPLIT_HAS_PREVIEW_KINDS,\n]\n\nCROISSANT_MAX_CONFIGS = 100\nMAX_NUM_ROWS_PER_PAGE = 100\n", "path": "libs/libcommon/src/libcommon/constants.py"}]}
| 1,539 | 102 |
gh_patches_debug_8293
|
rasdani/github-patches
|
git_diff
|
wandb__wandb-963
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fastai WandbCallback with multilabel datasets
* Weights and Biases version: 0.8.9
* Python version: 3.6.9
* Operating System: Linux-4.14.133-88.112.amzn1.x86_64-x86_64-with-Ubuntu-16.04-xenial
### Description
I'm trying to see prediction samples for fastai image classification, where the images are multilabel. I'd like it to be ran on the validation data at the end of each epoch and to see captions of ground truth/predictions.
When I use a multilabel dataset, instead of ground truth/prediction captions for each image, I get a three copies of each image side by side, where each is labeled, "Input data", "Prediction", "Ground Truth" (but not the actual categories)
### What I Did
`callback_fns += [partial(WandbCallback, input_type='images', monitor='acc_thresholded')]`
</issue>
<code>
[start of wandb/fastai/__init__.py]
1 '''
2 This module hooks fast.ai Learners to Weights & Biases through a callback.
3 Requested logged data can be configured through the callback constructor.
4
5 Examples:
6 WandbCallback can be used when initializing the Learner::
7
8 ```
9 from wandb.fastai import WandbCallback
10 [...]
11 learn = Learner(data, ..., callback_fns=WandbCallback)
12 learn.fit(epochs)
13 ```
14
15 Custom parameters can be given using functools.partial::
16
17 ```
18 from wandb.fastai import WandbCallback
19 from functools import partial
20 [...]
21 learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))
22 learn.fit(epochs)
23 ```
24
25 Finally, it is possible to use WandbCallback only when starting
26 training. In this case it must be instantiated::
27
28 ```
29 learn.fit(..., callbacks=WandbCallback(learn))
30 ```
31
32 or, with custom parameters::
33
34 ```
35 learn.fit(..., callbacks=WandbCallback(learn, ...))
36 ```
37 '''
38 import wandb
39 import fastai
40 from fastai.callbacks import TrackerCallback
41 from pathlib import Path
42 import random
43 try:
44 import matplotlib
45 matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)
46 import matplotlib.pyplot as plt
47 except:
48 print('Warning: matplotlib required if logging sample image predictions')
49
50
51 class WandbCallback(TrackerCallback):
52 """
53 Automatically saves model topology, losses & metrics.
54 Optionally logs weights, gradients, sample predictions and best trained model.
55
56 Args:
57 learn (fastai.basic_train.Learner): the fast.ai learner to hook.
58 log (str): "gradients", "parameters", "all", or None. Losses & metrics are always logged.
59 save_model (bool): save model at the end of each epoch. It will also load best model at the end of training.
60 monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.
61 mode (str): "auto", "min" or "max" to compare "monitor" values and define best model.
62 input_type (str): "images" or None. Used to display sample predictions.
63 validation_data (list): data used for sample predictions if input_type is set.
64 predictions (int): number of predictions to make if input_type is set and validation_data is None.
65 seed (int): initialize random generator for sample predictions if input_type is set and validation_data is None.
66 """
67
68 # Record if watch has been called previously (even in another instance)
69 _watch_called = False
70
71 def __init__(self,
72 learn,
73 log="gradients",
74 save_model=True,
75 monitor=None,
76 mode='auto',
77 input_type=None,
78 validation_data=None,
79 predictions=36,
80 seed=12345):
81
82 # Check if wandb.init has been called
83 if wandb.run is None:
84 raise ValueError(
85 'You must call wandb.init() before WandbCallback()')
86
87 # Adapted from fast.ai "SaveModelCallback"
88 if monitor is None:
89 # use default TrackerCallback monitor value
90 super().__init__(learn, mode=mode)
91 else:
92 super().__init__(learn, monitor=monitor, mode=mode)
93 self.save_model = save_model
94 self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'
95
96 self.log = log
97 self.input_type = input_type
98 self.best = None
99
100 # Select items for sample predictions to see evolution along training
101 self.validation_data = validation_data
102 if input_type and not self.validation_data:
103 wandbRandom = random.Random(seed) # For repeatability
104 predictions = min(predictions, len(learn.data.valid_ds))
105 indices = wandbRandom.sample(range(len(learn.data.valid_ds)),
106 predictions)
107 self.validation_data = [learn.data.valid_ds[i] for i in indices]
108
109 def on_train_begin(self, **kwargs):
110 "Call watch method to log model topology, gradients & weights"
111
112 # Set self.best, method inherited from "TrackerCallback" by "SaveModelCallback"
113 super().on_train_begin()
114
115 # Ensure we don't call "watch" multiple times
116 if not WandbCallback._watch_called:
117 WandbCallback._watch_called = True
118
119 # Logs model topology and optionally gradients and weights
120 wandb.watch(self.learn.model, log=self.log)
121
122 def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):
123 "Logs training loss, validation loss and custom metrics & log prediction samples & save model"
124
125 if self.save_model:
126 # Adapted from fast.ai "SaveModelCallback"
127 current = self.get_monitor_value()
128 if current is not None and self.operator(current, self.best):
129 print(
130 'Better model found at epoch {} with {} value: {}.'.format(
131 epoch, self.monitor, current))
132 self.best = current
133
134 # Save within wandb folder
135 with self.model_path.open('wb') as model_file:
136 self.learn.save(model_file)
137
138 # Log sample predictions if learn.predict is available
139 if self.validation_data:
140 try:
141 self._wandb_log_predictions()
142 except FastaiError as e:
143 wandb.termwarn(e.message)
144 self.validation_data = None # prevent from trying again on next loop
145 except Exception as e:
146 wandb.termwarn("Unable to log prediction samples.\n{}".format(e))
147 self.validation_data=None # prevent from trying again on next loop
148
149 # Log losses & metrics
150 # Adapted from fast.ai "CSVLogger"
151 logs = {
152 name: stat
153 for name, stat in list(
154 zip(self.learn.recorder.names, [epoch, smooth_loss] +
155 last_metrics))
156 }
157 wandb.log(logs)
158
159 def on_train_end(self, **kwargs):
160 "Load the best model."
161
162 if self.save_model:
163 # Adapted from fast.ai "SaveModelCallback"
164 if self.model_path.is_file():
165 with self.model_path.open('rb') as model_file:
166 self.learn.load(model_file, purge=False)
167 print('Loaded best saved model from {}'.format(
168 self.model_path))
169
170 def _wandb_log_predictions(self):
171 "Log prediction samples"
172
173 pred_log = []
174
175 for x, y in self.validation_data:
176 try:
177 pred=self.learn.predict(x)
178 except:
179 raise FastaiError('Unable to run "predict" method from Learner to log prediction samples.')
180
181 # scalar -> likely to be a category
182 if not pred[1].shape:
183 pred_log.append(
184 wandb.Image(
185 x.data,
186 caption='Ground Truth: {}\nPrediction: {}'.format(
187 y, pred[0])))
188
189 # most vision datasets have a "show" function we can use
190 elif hasattr(x, "show"):
191 # log input data
192 pred_log.append(
193 wandb.Image(x.data, caption='Input data', grouping=3))
194
195 # log label and prediction
196 for im, capt in ((pred[0], "Prediction"),
197 (y, "Ground Truth")):
198 # Resize plot to image resolution
199 # from https://stackoverflow.com/a/13714915
200 my_dpi = 100
201 fig = plt.figure(frameon=False, dpi=my_dpi)
202 h, w = x.size
203 fig.set_size_inches(w / my_dpi, h / my_dpi)
204 ax = plt.Axes(fig, [0., 0., 1., 1.])
205 ax.set_axis_off()
206 fig.add_axes(ax)
207
208 # Superpose label or prediction to input image
209 x.show(ax=ax, y=im)
210 pred_log.append(wandb.Image(fig, caption=capt))
211 plt.close(fig)
212
213 # likely to be an image
214 elif hasattr(y, "shape") and (
215 (len(y.shape) == 2) or
216 (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):
217
218 pred_log.extend([
219 wandb.Image(x.data, caption='Input data', grouping=3),
220 wandb.Image(pred[0].data, caption='Prediction'),
221 wandb.Image(y.data, caption='Ground Truth')
222 ])
223
224 # we just log input data
225 else:
226 pred_log.append(wandb.Image(x.data, caption='Input data'))
227
228 wandb.log({"Prediction Samples": pred_log}, commit=False)
229
230
231 class FastaiError(wandb.Error):
232 pass
233
[end of wandb/fastai/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wandb/fastai/__init__.py b/wandb/fastai/__init__.py
--- a/wandb/fastai/__init__.py
+++ b/wandb/fastai/__init__.py
@@ -179,7 +179,8 @@
raise FastaiError('Unable to run "predict" method from Learner to log prediction samples.')
# scalar -> likely to be a category
- if not pred[1].shape:
+ # tensor of dim 1 -> likely to be multicategory
+ if not pred[1].shape or pred[1].dim() == 1:
pred_log.append(
wandb.Image(
x.data,
|
{"golden_diff": "diff --git a/wandb/fastai/__init__.py b/wandb/fastai/__init__.py\n--- a/wandb/fastai/__init__.py\n+++ b/wandb/fastai/__init__.py\n@@ -179,7 +179,8 @@\n raise FastaiError('Unable to run \"predict\" method from Learner to log prediction samples.')\n \n # scalar -> likely to be a category\n- if not pred[1].shape:\n+ # tensor of dim 1 -> likely to be multicategory\n+ if not pred[1].shape or pred[1].dim() == 1:\n pred_log.append(\n wandb.Image(\n x.data,\n", "issue": "Fastai WandbCallback with multilabel datasets\n* Weights and Biases version: 0.8.9\r\n* Python version: 3.6.9\r\n* Operating System: Linux-4.14.133-88.112.amzn1.x86_64-x86_64-with-Ubuntu-16.04-xenial\r\n\r\n### Description\r\n\r\nI'm trying to see prediction samples for fastai image classification, where the images are multilabel. I'd like it to be ran on the validation data at the end of each epoch and to see captions of ground truth/predictions.\r\n\r\nWhen I use a multilabel dataset, instead of ground truth/prediction captions for each image, I get a three copies of each image side by side, where each is labeled, \"Input data\", \"Prediction\", \"Ground Truth\" (but not the actual categories)\r\n\r\n### What I Did\r\n\r\n`callback_fns += [partial(WandbCallback, input_type='images', monitor='acc_thresholded')]`\r\n\r\n\n", "before_files": [{"content": "'''\nThis module hooks fast.ai Learners to Weights & Biases through a callback.\nRequested logged data can be configured through the callback constructor.\n\nExamples:\n WandbCallback can be used when initializing the Learner::\n\n ```\n from wandb.fastai import WandbCallback\n [...]\n learn = Learner(data, ..., callback_fns=WandbCallback)\n learn.fit(epochs)\n ```\n\n Custom parameters can be given using functools.partial::\n\n ```\n from wandb.fastai import WandbCallback\n from functools import partial\n [...]\n learn = Learner(data, ..., callback_fns=partial(WandbCallback, ...))\n learn.fit(epochs)\n ```\n\n Finally, it is possible to use WandbCallback only when starting\n training. In this case it must be instantiated::\n\n ```\n learn.fit(..., callbacks=WandbCallback(learn))\n ```\n\n or, with custom parameters::\n\n ```\n learn.fit(..., callbacks=WandbCallback(learn, ...))\n ```\n'''\nimport wandb\nimport fastai\nfrom fastai.callbacks import TrackerCallback\nfrom pathlib import Path\nimport random\ntry:\n import matplotlib\n matplotlib.use('Agg') # non-interactive backend (avoid tkinter issues)\n import matplotlib.pyplot as plt\nexcept:\n print('Warning: matplotlib required if logging sample image predictions')\n\n\nclass WandbCallback(TrackerCallback):\n \"\"\"\n Automatically saves model topology, losses & metrics.\n Optionally logs weights, gradients, sample predictions and best trained model.\n\n Args:\n learn (fastai.basic_train.Learner): the fast.ai learner to hook.\n log (str): \"gradients\", \"parameters\", \"all\", or None. Losses & metrics are always logged.\n save_model (bool): save model at the end of each epoch. It will also load best model at the end of training.\n monitor (str): metric to monitor for saving best model. None uses default TrackerCallback monitor value.\n mode (str): \"auto\", \"min\" or \"max\" to compare \"monitor\" values and define best model.\n input_type (str): \"images\" or None. Used to display sample predictions.\n validation_data (list): data used for sample predictions if input_type is set.\n predictions (int): number of predictions to make if input_type is set and validation_data is None.\n seed (int): initialize random generator for sample predictions if input_type is set and validation_data is None.\n \"\"\"\n\n # Record if watch has been called previously (even in another instance)\n _watch_called = False\n\n def __init__(self,\n learn,\n log=\"gradients\",\n save_model=True,\n monitor=None,\n mode='auto',\n input_type=None,\n validation_data=None,\n predictions=36,\n seed=12345):\n\n # Check if wandb.init has been called\n if wandb.run is None:\n raise ValueError(\n 'You must call wandb.init() before WandbCallback()')\n\n # Adapted from fast.ai \"SaveModelCallback\"\n if monitor is None:\n # use default TrackerCallback monitor value\n super().__init__(learn, mode=mode)\n else:\n super().__init__(learn, monitor=monitor, mode=mode)\n self.save_model = save_model\n self.model_path = Path(wandb.run.dir) / 'bestmodel.pth'\n\n self.log = log\n self.input_type = input_type\n self.best = None\n\n # Select items for sample predictions to see evolution along training\n self.validation_data = validation_data\n if input_type and not self.validation_data:\n wandbRandom = random.Random(seed) # For repeatability\n predictions = min(predictions, len(learn.data.valid_ds))\n indices = wandbRandom.sample(range(len(learn.data.valid_ds)),\n predictions)\n self.validation_data = [learn.data.valid_ds[i] for i in indices]\n\n def on_train_begin(self, **kwargs):\n \"Call watch method to log model topology, gradients & weights\"\n\n # Set self.best, method inherited from \"TrackerCallback\" by \"SaveModelCallback\"\n super().on_train_begin()\n\n # Ensure we don't call \"watch\" multiple times\n if not WandbCallback._watch_called:\n WandbCallback._watch_called = True\n\n # Logs model topology and optionally gradients and weights\n wandb.watch(self.learn.model, log=self.log)\n\n def on_epoch_end(self, epoch, smooth_loss, last_metrics, **kwargs):\n \"Logs training loss, validation loss and custom metrics & log prediction samples & save model\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n current = self.get_monitor_value()\n if current is not None and self.operator(current, self.best):\n print(\n 'Better model found at epoch {} with {} value: {}.'.format(\n epoch, self.monitor, current))\n self.best = current\n\n # Save within wandb folder\n with self.model_path.open('wb') as model_file:\n self.learn.save(model_file)\n\n # Log sample predictions if learn.predict is available\n if self.validation_data:\n try:\n self._wandb_log_predictions()\n except FastaiError as e:\n wandb.termwarn(e.message)\n self.validation_data = None # prevent from trying again on next loop\n except Exception as e:\n wandb.termwarn(\"Unable to log prediction samples.\\n{}\".format(e))\n self.validation_data=None # prevent from trying again on next loop\n\n # Log losses & metrics\n # Adapted from fast.ai \"CSVLogger\"\n logs = {\n name: stat\n for name, stat in list(\n zip(self.learn.recorder.names, [epoch, smooth_loss] +\n last_metrics))\n }\n wandb.log(logs)\n\n def on_train_end(self, **kwargs):\n \"Load the best model.\"\n\n if self.save_model:\n # Adapted from fast.ai \"SaveModelCallback\"\n if self.model_path.is_file():\n with self.model_path.open('rb') as model_file:\n self.learn.load(model_file, purge=False)\n print('Loaded best saved model from {}'.format(\n self.model_path))\n\n def _wandb_log_predictions(self):\n \"Log prediction samples\"\n\n pred_log = []\n\n for x, y in self.validation_data:\n try:\n pred=self.learn.predict(x)\n except:\n raise FastaiError('Unable to run \"predict\" method from Learner to log prediction samples.')\n\n # scalar -> likely to be a category\n if not pred[1].shape:\n pred_log.append(\n wandb.Image(\n x.data,\n caption='Ground Truth: {}\\nPrediction: {}'.format(\n y, pred[0])))\n\n # most vision datasets have a \"show\" function we can use\n elif hasattr(x, \"show\"):\n # log input data\n pred_log.append(\n wandb.Image(x.data, caption='Input data', grouping=3))\n\n # log label and prediction\n for im, capt in ((pred[0], \"Prediction\"),\n (y, \"Ground Truth\")):\n # Resize plot to image resolution\n # from https://stackoverflow.com/a/13714915\n my_dpi = 100\n fig = plt.figure(frameon=False, dpi=my_dpi)\n h, w = x.size\n fig.set_size_inches(w / my_dpi, h / my_dpi)\n ax = plt.Axes(fig, [0., 0., 1., 1.])\n ax.set_axis_off()\n fig.add_axes(ax)\n\n # Superpose label or prediction to input image\n x.show(ax=ax, y=im)\n pred_log.append(wandb.Image(fig, caption=capt))\n plt.close(fig)\n\n # likely to be an image\n elif hasattr(y, \"shape\") and (\n (len(y.shape) == 2) or\n (len(y.shape) == 3 and y.shape[0] in [1, 3, 4])):\n\n pred_log.extend([\n wandb.Image(x.data, caption='Input data', grouping=3),\n wandb.Image(pred[0].data, caption='Prediction'),\n wandb.Image(y.data, caption='Ground Truth')\n ])\n\n # we just log input data\n else:\n pred_log.append(wandb.Image(x.data, caption='Input data'))\n\n wandb.log({\"Prediction Samples\": pred_log}, commit=False)\n\n\nclass FastaiError(wandb.Error):\n pass\n", "path": "wandb/fastai/__init__.py"}]}
| 3,221 | 153 |
gh_patches_debug_812
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__codeforlife-portal-412
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update models search field values in admin
</issue>
<code>
[start of portal/models.py]
1 # -*- coding: utf-8 -*-
2 # Code for Life
3 #
4 # Copyright (C) 2016, Ocado Innovation Limited
5 #
6 # This program is free software: you can redistribute it and/or modify
7 # it under the terms of the GNU Affero General Public License as
8 # published by the Free Software Foundation, either version 3 of the
9 # License, or (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU Affero General Public License for more details.
15 #
16 # You should have received a copy of the GNU Affero General Public License
17 # along with this program. If not, see <http://www.gnu.org/licenses/>.
18 #
19 # ADDITIONAL TERMS – Section 7 GNU General Public Licence
20 #
21 # This licence does not grant any right, title or interest in any “Ocado” logos,
22 # trade names or the trademark “Ocado” or any other trademarks or domain names
23 # owned by Ocado Innovation Limited or the Ocado group of companies or any other
24 # distinctive brand features of “Ocado” as may be secured from time to time. You
25 # must not distribute any modification of this program using the trademark
26 # “Ocado” or claim any affiliation or association with Ocado or its employees.
27 #
28 # You are not authorised to use the name Ocado (or any of its trade names) or
29 # the names of any author or contributor in advertising or for publicity purposes
30 # pertaining to the distribution of this program, without the prior written
31 # authorisation of Ocado.
32 #
33 # Any propagation, distribution or conveyance of this program must include this
34 # copyright notice and these terms. You must not misrepresent the origins of this
35 # program; modified versions of the program must be marked as such and not
36 # identified as the original program.
37 from __future__ import absolute_import
38
39 import re
40 import datetime
41
42 from django.contrib.auth.models import User
43 from django.db import models
44 from django_countries.fields import CountryField
45 from django.core.cache import cache
46 from django.utils import timezone
47
48 from online_status.status import CACHE_USERS
49
50
51 class UserProfile(models.Model):
52 user = models.OneToOneField(User)
53 can_view_aggregated_data = models.BooleanField(default=False)
54 developer = models.BooleanField(default=False)
55
56 awaiting_email_verification = models.BooleanField(default=False)
57
58 def __unicode__(self):
59 return self.user.username
60
61 def joined_recently(self):
62 now = timezone.now()
63 return now - datetime.timedelta(days=7) <= self.user.date_joined
64
65
66 class School(models.Model):
67 name = models.CharField(max_length=200)
68 postcode = models.CharField(max_length=10)
69 town = models.CharField(max_length=200)
70 latitude = models.CharField(max_length=20)
71 longitude = models.CharField(max_length=20)
72 country = CountryField(blank_label='(select country)')
73
74 class Meta:
75 permissions = (
76 ('view_aggregated_data', "Can see available aggregated data"),
77 ('view_map_data', "Can see schools' location displayed on map")
78 )
79
80 def __unicode__(self):
81 return self.name
82
83
84 class TeacherModelManager(models.Manager):
85 def factory(self, title, first_name, last_name, email, password):
86 from portal.helpers.generators import get_random_username
87
88 user = User.objects.create_user(
89 username=email,
90 email=email,
91 password=password,
92 first_name=first_name,
93 last_name=last_name)
94
95 user_profile = UserProfile.objects.create(user=user)
96
97 return Teacher.objects.create(user=user_profile, new_user=user, title=title)
98
99
100 class Teacher(models.Model):
101 title = models.CharField(max_length=35)
102 user = models.OneToOneField(UserProfile)
103 new_user = models.OneToOneField(User, related_name='new_teacher', null=True, blank=True)
104 school = models.ForeignKey(School, related_name='teacher_school', null=True)
105 is_admin = models.BooleanField(default=False)
106 pending_join_request = models.ForeignKey(School, related_name='join_request', null=True)
107
108 objects = TeacherModelManager()
109
110 def teaches(self, userprofile):
111 if hasattr(userprofile, 'student'):
112 student = userprofile.student
113 return not student.is_independent() and student.class_field.teacher == self
114
115 def has_school(self):
116 return self.school is not (None or "")
117
118 def has_class(self):
119 classes = self.class_teacher.all()
120 return classes.count() != 0
121
122 def class_(self):
123 if self.has_class():
124 classes = self.class_teacher.all()
125 return classes[0]
126 return None
127
128 def __unicode__(self):
129 return '%s %s' % (self.user.first_name, self.user.last_name)
130
131
132 class Class(models.Model):
133 name = models.CharField(max_length=200)
134 teacher = models.ForeignKey(Teacher, related_name='class_teacher')
135 access_code = models.CharField(max_length=5)
136 classmates_data_viewable = models.BooleanField(default=False)
137 always_accept_requests = models.BooleanField(default=False)
138 accept_requests_until = models.DateTimeField(null=True)
139
140 def __unicode__(self):
141 return self.name
142
143 def has_students(self):
144 students = self.students.all()
145 return students.count() != 0
146
147 def get_logged_in_students(self):
148 ONLINE = 1
149
150 """This gets all the students who are logged in."""
151 users_status = cache.get(CACHE_USERS)
152 online_users_status = filter(lambda status: status.status == ONLINE, users_status)
153 online_user_ids = map(lambda status: status.user.id, online_users_status)
154
155 # Query all logged in users based on id list
156 return Student.objects.filter(class_field=self).filter(new_user__id__in=online_user_ids)
157
158 class Meta:
159 verbose_name_plural = "classes"
160
161
162 class StudentModelManager(models.Manager):
163 def schoolFactory(self, klass, name, password):
164 from portal.helpers.generators import get_random_username
165
166 user = User.objects.create_user(
167 username=get_random_username(),
168 password=password,
169 first_name=name)
170
171 user_profile = UserProfile.objects.create(user=user)
172 return Student.objects.create(class_field=klass, user=user_profile, new_user=user)
173
174 def independentStudentFactory(self, username, name, email, password):
175 user = User.objects.create_user(
176 username=username,
177 email=email,
178 password=password,
179 first_name=name)
180
181 user_profile = UserProfile.objects.create(user=user)
182
183 return Student.objects.create(user=user_profile, new_user=user)
184
185
186 class Student(models.Model):
187 class_field = models.ForeignKey(Class, related_name='students', null=True)
188 user = models.OneToOneField(UserProfile)
189 new_user = models.OneToOneField(User, related_name='new_student', null=True, blank=True)
190 pending_class_request = models.ForeignKey(Class, related_name='class_request', null=True)
191
192 objects = StudentModelManager()
193
194 def is_independent(self):
195 return not self.class_field
196
197 def __unicode__(self):
198 return '%s %s' % (self.new_user.first_name, self.new_user.last_name)
199
200
201 def stripStudentName(name):
202 return re.sub('[ \t]+', ' ', name.strip())
203
204
205 class Guardian(models.Model):
206 name = models.CharField(max_length=200)
207 children = models.ManyToManyField(Student)
208 user = models.OneToOneField(UserProfile)
209 new_user = models.OneToOneField(User, related_name='new_guardian', null=True, blank=True)
210
211 def __unicode__(self):
212 return '%s %s' % (self.new_user.first_name, self.new_user.last_name)
213
214
215 class EmailVerification(models.Model):
216 user = models.ForeignKey(User, related_name='email_verifications', null=True, blank=True)
217 token = models.CharField(max_length=30)
218 email = models.CharField(max_length=200, null=True, default=None, blank=True)
219 expiry = models.DateTimeField()
220 verified = models.BooleanField(default=False)
221
222
223 class FrontPageNews(models.Model):
224 title = models.CharField(max_length=200)
225 text = models.CharField(max_length=1000)
226 link = models.CharField(max_length=500)
227 link_text = models.CharField(max_length=200)
228 added_dstamp = models.DateTimeField()
229
230 class Meta:
231 verbose_name_plural = "front page news"
232
233 def __unicode__(self):
234 return self.title
235
236
237 from . import handlers # noqa
238
[end of portal/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/portal/models.py b/portal/models.py
--- a/portal/models.py
+++ b/portal/models.py
@@ -126,7 +126,7 @@
return None
def __unicode__(self):
- return '%s %s' % (self.user.first_name, self.user.last_name)
+ return '%s %s' % (self.new_user.first_name, self.new_user.last_name)
class Class(models.Model):
|
{"golden_diff": "diff --git a/portal/models.py b/portal/models.py\n--- a/portal/models.py\n+++ b/portal/models.py\n@@ -126,7 +126,7 @@\n return None\n \n def __unicode__(self):\n- return '%s %s' % (self.user.first_name, self.user.last_name)\n+ return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n \n \n class Class(models.Model):\n", "issue": "Update models search field values in admin\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Code for Life\n#\n# Copyright (C) 2016, Ocado Innovation Limited\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU Affero General Public License as\n# published by the Free Software Foundation, either version 3 of the\n# License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n# ADDITIONAL TERMS \u2013 Section 7 GNU General Public Licence\n#\n# This licence does not grant any right, title or interest in any \u201cOcado\u201d logos,\n# trade names or the trademark \u201cOcado\u201d or any other trademarks or domain names\n# owned by Ocado Innovation Limited or the Ocado group of companies or any other\n# distinctive brand features of \u201cOcado\u201d as may be secured from time to time. You\n# must not distribute any modification of this program using the trademark\n# \u201cOcado\u201d or claim any affiliation or association with Ocado or its employees.\n#\n# You are not authorised to use the name Ocado (or any of its trade names) or\n# the names of any author or contributor in advertising or for publicity purposes\n# pertaining to the distribution of this program, without the prior written\n# authorisation of Ocado.\n#\n# Any propagation, distribution or conveyance of this program must include this\n# copyright notice and these terms. You must not misrepresent the origins of this\n# program; modified versions of the program must be marked as such and not\n# identified as the original program.\nfrom __future__ import absolute_import\n\nimport re\nimport datetime\n\nfrom django.contrib.auth.models import User\nfrom django.db import models\nfrom django_countries.fields import CountryField\nfrom django.core.cache import cache\nfrom django.utils import timezone\n\nfrom online_status.status import CACHE_USERS\n\n\nclass UserProfile(models.Model):\n user = models.OneToOneField(User)\n can_view_aggregated_data = models.BooleanField(default=False)\n developer = models.BooleanField(default=False)\n\n awaiting_email_verification = models.BooleanField(default=False)\n\n def __unicode__(self):\n return self.user.username\n\n def joined_recently(self):\n now = timezone.now()\n return now - datetime.timedelta(days=7) <= self.user.date_joined\n\n\nclass School(models.Model):\n name = models.CharField(max_length=200)\n postcode = models.CharField(max_length=10)\n town = models.CharField(max_length=200)\n latitude = models.CharField(max_length=20)\n longitude = models.CharField(max_length=20)\n country = CountryField(blank_label='(select country)')\n\n class Meta:\n permissions = (\n ('view_aggregated_data', \"Can see available aggregated data\"),\n ('view_map_data', \"Can see schools' location displayed on map\")\n )\n\n def __unicode__(self):\n return self.name\n\n\nclass TeacherModelManager(models.Manager):\n def factory(self, title, first_name, last_name, email, password):\n from portal.helpers.generators import get_random_username\n\n user = User.objects.create_user(\n username=email,\n email=email,\n password=password,\n first_name=first_name,\n last_name=last_name)\n\n user_profile = UserProfile.objects.create(user=user)\n\n return Teacher.objects.create(user=user_profile, new_user=user, title=title)\n\n\nclass Teacher(models.Model):\n title = models.CharField(max_length=35)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_teacher', null=True, blank=True)\n school = models.ForeignKey(School, related_name='teacher_school', null=True)\n is_admin = models.BooleanField(default=False)\n pending_join_request = models.ForeignKey(School, related_name='join_request', null=True)\n\n objects = TeacherModelManager()\n\n def teaches(self, userprofile):\n if hasattr(userprofile, 'student'):\n student = userprofile.student\n return not student.is_independent() and student.class_field.teacher == self\n\n def has_school(self):\n return self.school is not (None or \"\")\n\n def has_class(self):\n classes = self.class_teacher.all()\n return classes.count() != 0\n\n def class_(self):\n if self.has_class():\n classes = self.class_teacher.all()\n return classes[0]\n return None\n\n def __unicode__(self):\n return '%s %s' % (self.user.first_name, self.user.last_name)\n\n\nclass Class(models.Model):\n name = models.CharField(max_length=200)\n teacher = models.ForeignKey(Teacher, related_name='class_teacher')\n access_code = models.CharField(max_length=5)\n classmates_data_viewable = models.BooleanField(default=False)\n always_accept_requests = models.BooleanField(default=False)\n accept_requests_until = models.DateTimeField(null=True)\n\n def __unicode__(self):\n return self.name\n\n def has_students(self):\n students = self.students.all()\n return students.count() != 0\n\n def get_logged_in_students(self):\n ONLINE = 1\n\n \"\"\"This gets all the students who are logged in.\"\"\"\n users_status = cache.get(CACHE_USERS)\n online_users_status = filter(lambda status: status.status == ONLINE, users_status)\n online_user_ids = map(lambda status: status.user.id, online_users_status)\n\n # Query all logged in users based on id list\n return Student.objects.filter(class_field=self).filter(new_user__id__in=online_user_ids)\n\n class Meta:\n verbose_name_plural = \"classes\"\n\n\nclass StudentModelManager(models.Manager):\n def schoolFactory(self, klass, name, password):\n from portal.helpers.generators import get_random_username\n\n user = User.objects.create_user(\n username=get_random_username(),\n password=password,\n first_name=name)\n\n user_profile = UserProfile.objects.create(user=user)\n return Student.objects.create(class_field=klass, user=user_profile, new_user=user)\n\n def independentStudentFactory(self, username, name, email, password):\n user = User.objects.create_user(\n username=username,\n email=email,\n password=password,\n first_name=name)\n\n user_profile = UserProfile.objects.create(user=user)\n\n return Student.objects.create(user=user_profile, new_user=user)\n\n\nclass Student(models.Model):\n class_field = models.ForeignKey(Class, related_name='students', null=True)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_student', null=True, blank=True)\n pending_class_request = models.ForeignKey(Class, related_name='class_request', null=True)\n\n objects = StudentModelManager()\n\n def is_independent(self):\n return not self.class_field\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\ndef stripStudentName(name):\n return re.sub('[ \\t]+', ' ', name.strip())\n\n\nclass Guardian(models.Model):\n name = models.CharField(max_length=200)\n children = models.ManyToManyField(Student)\n user = models.OneToOneField(UserProfile)\n new_user = models.OneToOneField(User, related_name='new_guardian', null=True, blank=True)\n\n def __unicode__(self):\n return '%s %s' % (self.new_user.first_name, self.new_user.last_name)\n\n\nclass EmailVerification(models.Model):\n user = models.ForeignKey(User, related_name='email_verifications', null=True, blank=True)\n token = models.CharField(max_length=30)\n email = models.CharField(max_length=200, null=True, default=None, blank=True)\n expiry = models.DateTimeField()\n verified = models.BooleanField(default=False)\n\n\nclass FrontPageNews(models.Model):\n title = models.CharField(max_length=200)\n text = models.CharField(max_length=1000)\n link = models.CharField(max_length=500)\n link_text = models.CharField(max_length=200)\n added_dstamp = models.DateTimeField()\n\n class Meta:\n verbose_name_plural = \"front page news\"\n\n def __unicode__(self):\n return self.title\n\n\nfrom . import handlers # noqa\n", "path": "portal/models.py"}]}
| 2,972 | 101 |
gh_patches_debug_35411
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1394
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ParentBased sampler ignores sample decision of parent when creating span via implicit Context
When having a `ParentBased` sampler setup and creating a span via `tracer.start_span` without explicitly providing a `context` as parent, possible parent spans in the current `Context` are ignored [ignored](https://github.com/open-telemetry/opentelemetry-python/blob/v0.15b0/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py#L230).
Since for implicit parents the passed `context` is always `None` the `ParentBased` sampler needs to consider also parent Spans in the current `Context` and, if available, respect their sampling flag instead of forwarding to the delegate sampler.
</issue>
<code>
[start of opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 For general information about sampling, see `the specification <https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/sdk.md#sampling>`_.
17
18 OpenTelemetry provides two types of samplers:
19
20 - `StaticSampler`
21 - `TraceIdRatioBased`
22
23 A `StaticSampler` always returns the same sampling result regardless of the conditions. Both possible StaticSamplers are already created:
24
25 - Always sample spans: ALWAYS_ON
26 - Never sample spans: ALWAYS_OFF
27
28 A `TraceIdRatioBased` sampler makes a random sampling result based on the sampling probability given.
29
30 If the span being sampled has a parent, `ParentBased` will respect the parent span's sampling result. Otherwise, it returns the sampling result from the given delegate sampler.
31
32 Currently, sampling results are always made during the creation of the span. However, this might not always be the case in the future (see `OTEP #115 <https://github.com/open-telemetry/oteps/pull/115>`_).
33
34 Custom samplers can be created by subclassing `Sampler` and implementing `Sampler.should_sample` as well as `Sampler.get_description`.
35
36 To use a sampler, pass it into the tracer provider constructor. For example:
37
38 .. code:: python
39
40 from opentelemetry import trace
41 from opentelemetry.sdk.trace import TracerProvider
42 from opentelemetry.sdk.trace.export import (
43 ConsoleSpanExporter,
44 SimpleExportSpanProcessor,
45 )
46 from opentelemetry.sdk.trace.sampling import TraceIdRatioBased
47
48 # sample 1 in every 1000 traces
49 sampler = TraceIdRatioBased(1/1000)
50
51 # set the sampler onto the global tracer provider
52 trace.set_tracer_provider(TracerProvider(sampler=sampler))
53
54 # set up an exporter for sampled spans
55 trace.get_tracer_provider().add_span_processor(
56 SimpleExportSpanProcessor(ConsoleSpanExporter())
57 )
58
59 # created spans will now be sampled by the TraceIdRatioBased sampler
60 with trace.get_tracer(__name__).start_as_current_span("Test Span"):
61 ...
62 """
63 import abc
64 import enum
65 from types import MappingProxyType
66 from typing import Optional, Sequence
67
68 # pylint: disable=unused-import
69 from opentelemetry.context import Context
70 from opentelemetry.trace import Link, get_current_span
71 from opentelemetry.trace.span import TraceState
72 from opentelemetry.util.types import Attributes
73
74
75 class Decision(enum.Enum):
76 # IsRecording() == false, span will not be recorded and all events and attributes will be dropped.
77 DROP = 0
78 # IsRecording() == true, but Sampled flag MUST NOT be set.
79 RECORD_ONLY = 1
80 # IsRecording() == true AND Sampled flag` MUST be set.
81 RECORD_AND_SAMPLE = 2
82
83 def is_recording(self):
84 return self in (Decision.RECORD_ONLY, Decision.RECORD_AND_SAMPLE)
85
86 def is_sampled(self):
87 return self is Decision.RECORD_AND_SAMPLE
88
89
90 class SamplingResult:
91 """A sampling result as applied to a newly-created Span.
92
93 Args:
94 decision: A sampling decision based off of whether the span is recorded
95 and the sampled flag in trace flags in the span context.
96 attributes: Attributes to add to the `opentelemetry.trace.Span`.
97 trace_state: The tracestate used for the `opentelemetry.trace.Span`.
98 Could possibly have been modified by the sampler.
99 """
100
101 def __repr__(self) -> str:
102 return "{}({}, attributes={})".format(
103 type(self).__name__, str(self.decision), str(self.attributes)
104 )
105
106 def __init__(
107 self,
108 decision: Decision,
109 attributes: "Attributes" = None,
110 trace_state: "TraceState" = None,
111 ) -> None:
112 self.decision = decision
113 if attributes is None:
114 self.attributes = MappingProxyType({})
115 else:
116 self.attributes = MappingProxyType(attributes)
117 self.trace_state = trace_state
118
119
120 class Sampler(abc.ABC):
121 @abc.abstractmethod
122 def should_sample(
123 self,
124 parent_context: Optional["Context"],
125 trace_id: int,
126 name: str,
127 attributes: Attributes = None,
128 links: Sequence["Link"] = None,
129 trace_state: "TraceState" = None,
130 ) -> "SamplingResult":
131 pass
132
133 @abc.abstractmethod
134 def get_description(self) -> str:
135 pass
136
137
138 class StaticSampler(Sampler):
139 """Sampler that always returns the same decision."""
140
141 def __init__(self, decision: "Decision"):
142 self._decision = decision
143
144 def should_sample(
145 self,
146 parent_context: Optional["Context"],
147 trace_id: int,
148 name: str,
149 attributes: Attributes = None,
150 links: Sequence["Link"] = None,
151 trace_state: "TraceState" = None,
152 ) -> "SamplingResult":
153 if self._decision is Decision.DROP:
154 return SamplingResult(self._decision)
155 return SamplingResult(self._decision, attributes, trace_state)
156
157 def get_description(self) -> str:
158 if self._decision is Decision.DROP:
159 return "AlwaysOffSampler"
160 return "AlwaysOnSampler"
161
162
163 class TraceIdRatioBased(Sampler):
164 """
165 Sampler that makes sampling decisions probabalistically based on `rate`,
166 while also respecting the parent span sampling decision.
167
168 Args:
169 rate: Probability (between 0 and 1) that a span will be sampled
170 """
171
172 def __init__(self, rate: float):
173 if rate < 0.0 or rate > 1.0:
174 raise ValueError("Probability must be in range [0.0, 1.0].")
175 self._rate = rate
176 self._bound = self.get_bound_for_rate(self._rate)
177
178 # For compatibility with 64 bit trace IDs, the sampler checks the 64
179 # low-order bits of the trace ID to decide whether to sample a given trace.
180 TRACE_ID_LIMIT = (1 << 64) - 1
181
182 @classmethod
183 def get_bound_for_rate(cls, rate: float) -> int:
184 return round(rate * (cls.TRACE_ID_LIMIT + 1))
185
186 @property
187 def rate(self) -> float:
188 return self._rate
189
190 @rate.setter
191 def rate(self, new_rate: float) -> None:
192 self._rate = new_rate
193 self._bound = self.get_bound_for_rate(self._rate)
194
195 @property
196 def bound(self) -> int:
197 return self._bound
198
199 def should_sample(
200 self,
201 parent_context: Optional["Context"],
202 trace_id: int,
203 name: str,
204 attributes: Attributes = None,
205 links: Sequence["Link"] = None,
206 trace_state: "TraceState" = None,
207 ) -> "SamplingResult":
208 decision = Decision.DROP
209 if trace_id & self.TRACE_ID_LIMIT < self.bound:
210 decision = Decision.RECORD_AND_SAMPLE
211 if decision is Decision.DROP:
212 return SamplingResult(decision)
213 return SamplingResult(decision, attributes)
214
215 def get_description(self) -> str:
216 return "TraceIdRatioBased{{{}}}".format(self._rate)
217
218
219 class ParentBased(Sampler):
220 """
221 If a parent is set, follows the same sampling decision as the parent.
222 Otherwise, uses the delegate provided at initialization to make a
223 decision.
224
225 Args:
226 delegate: The delegate sampler to use if parent is not set.
227 """
228
229 def __init__(self, delegate: Sampler):
230 self._delegate = delegate
231
232 def should_sample(
233 self,
234 parent_context: Optional["Context"],
235 trace_id: int,
236 name: str,
237 attributes: Attributes = None,
238 links: Sequence["Link"] = None,
239 trace_state: "TraceState" = None,
240 ) -> "SamplingResult":
241 if parent_context is not None:
242 parent_span_context = get_current_span(
243 parent_context
244 ).get_span_context()
245 # only drop if parent exists and is not a root span
246 if (
247 parent_span_context is not None
248 and parent_span_context.is_valid
249 and not parent_span_context.trace_flags.sampled
250 ):
251 return SamplingResult(Decision.DROP)
252 return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)
253
254 return self._delegate.should_sample(
255 parent_context=parent_context,
256 trace_id=trace_id,
257 name=name,
258 attributes=attributes,
259 links=links,
260 trace_state=trace_state,
261 )
262
263 def get_description(self):
264 return "ParentBased{{{}}}".format(self._delegate.get_description())
265
266
267 ALWAYS_OFF = StaticSampler(Decision.DROP)
268 """Sampler that never samples spans, regardless of the parent span's sampling decision."""
269
270 ALWAYS_ON = StaticSampler(Decision.RECORD_AND_SAMPLE)
271 """Sampler that always samples spans, regardless of the parent span's sampling decision."""
272
273 DEFAULT_OFF = ParentBased(ALWAYS_OFF)
274 """Sampler that respects its parent span's sampling decision, but otherwise never samples."""
275
276 DEFAULT_ON = ParentBased(ALWAYS_ON)
277 """Sampler that respects its parent span's sampling decision, but otherwise always samples."""
278
[end of opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py
@@ -151,7 +151,7 @@
trace_state: "TraceState" = None,
) -> "SamplingResult":
if self._decision is Decision.DROP:
- return SamplingResult(self._decision)
+ attributes = None
return SamplingResult(self._decision, attributes, trace_state)
def get_description(self) -> str:
@@ -209,8 +209,8 @@
if trace_id & self.TRACE_ID_LIMIT < self.bound:
decision = Decision.RECORD_AND_SAMPLE
if decision is Decision.DROP:
- return SamplingResult(decision)
- return SamplingResult(decision, attributes)
+ attributes = None
+ return SamplingResult(decision, attributes, trace_state)
def get_description(self) -> str:
return "TraceIdRatioBased{{{}}}".format(self._rate)
@@ -238,18 +238,16 @@
links: Sequence["Link"] = None,
trace_state: "TraceState" = None,
) -> "SamplingResult":
- if parent_context is not None:
- parent_span_context = get_current_span(
- parent_context
- ).get_span_context()
- # only drop if parent exists and is not a root span
- if (
- parent_span_context is not None
- and parent_span_context.is_valid
- and not parent_span_context.trace_flags.sampled
- ):
- return SamplingResult(Decision.DROP)
- return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)
+ parent_span_context = get_current_span(
+ parent_context
+ ).get_span_context()
+ # respect the sampling flag of the parent if present
+ if parent_span_context is not None and parent_span_context.is_valid:
+ decision = Decision.RECORD_AND_SAMPLE
+ if not parent_span_context.trace_flags.sampled:
+ decision = Decision.DROP
+ attributes = None
+ return SamplingResult(decision, attributes, trace_state)
return self._delegate.should_sample(
parent_context=parent_context,
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py\n@@ -151,7 +151,7 @@\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if self._decision is Decision.DROP:\n- return SamplingResult(self._decision)\n+ attributes = None\n return SamplingResult(self._decision, attributes, trace_state)\n \n def get_description(self) -> str:\n@@ -209,8 +209,8 @@\n if trace_id & self.TRACE_ID_LIMIT < self.bound:\n decision = Decision.RECORD_AND_SAMPLE\n if decision is Decision.DROP:\n- return SamplingResult(decision)\n- return SamplingResult(decision, attributes)\n+ attributes = None\n+ return SamplingResult(decision, attributes, trace_state)\n \n def get_description(self) -> str:\n return \"TraceIdRatioBased{{{}}}\".format(self._rate)\n@@ -238,18 +238,16 @@\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n- if parent_context is not None:\n- parent_span_context = get_current_span(\n- parent_context\n- ).get_span_context()\n- # only drop if parent exists and is not a root span\n- if (\n- parent_span_context is not None\n- and parent_span_context.is_valid\n- and not parent_span_context.trace_flags.sampled\n- ):\n- return SamplingResult(Decision.DROP)\n- return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)\n+ parent_span_context = get_current_span(\n+ parent_context\n+ ).get_span_context()\n+ # respect the sampling flag of the parent if present\n+ if parent_span_context is not None and parent_span_context.is_valid:\n+ decision = Decision.RECORD_AND_SAMPLE\n+ if not parent_span_context.trace_flags.sampled:\n+ decision = Decision.DROP\n+ attributes = None\n+ return SamplingResult(decision, attributes, trace_state)\n \n return self._delegate.should_sample(\n parent_context=parent_context,\n", "issue": "ParentBased sampler ignores sample decision of parent when creating span via implicit Context\nWhen having a `ParentBased` sampler setup and creating a span via `tracer.start_span` without explicitly providing a `context` as parent, possible parent spans in the current `Context` are ignored [ignored](https://github.com/open-telemetry/opentelemetry-python/blob/v0.15b0/opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py#L230). \r\nSince for implicit parents the passed `context` is always `None` the `ParentBased` sampler needs to consider also parent Spans in the current `Context` and, if available, respect their sampling flag instead of forwarding to the delegate sampler.\r\n\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nFor general information about sampling, see `the specification <https://github.com/open-telemetry/opentelemetry-specification/blob/master/specification/trace/sdk.md#sampling>`_.\n\nOpenTelemetry provides two types of samplers:\n\n- `StaticSampler`\n- `TraceIdRatioBased`\n\nA `StaticSampler` always returns the same sampling result regardless of the conditions. Both possible StaticSamplers are already created:\n\n- Always sample spans: ALWAYS_ON\n- Never sample spans: ALWAYS_OFF\n\nA `TraceIdRatioBased` sampler makes a random sampling result based on the sampling probability given.\n\nIf the span being sampled has a parent, `ParentBased` will respect the parent span's sampling result. Otherwise, it returns the sampling result from the given delegate sampler.\n\nCurrently, sampling results are always made during the creation of the span. However, this might not always be the case in the future (see `OTEP #115 <https://github.com/open-telemetry/oteps/pull/115>`_).\n\nCustom samplers can be created by subclassing `Sampler` and implementing `Sampler.should_sample` as well as `Sampler.get_description`.\n\nTo use a sampler, pass it into the tracer provider constructor. For example:\n\n.. code:: python\n\n from opentelemetry import trace\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleExportSpanProcessor,\n )\n from opentelemetry.sdk.trace.sampling import TraceIdRatioBased\n\n # sample 1 in every 1000 traces\n sampler = TraceIdRatioBased(1/1000)\n\n # set the sampler onto the global tracer provider\n trace.set_tracer_provider(TracerProvider(sampler=sampler))\n\n # set up an exporter for sampled spans\n trace.get_tracer_provider().add_span_processor(\n SimpleExportSpanProcessor(ConsoleSpanExporter())\n )\n\n # created spans will now be sampled by the TraceIdRatioBased sampler\n with trace.get_tracer(__name__).start_as_current_span(\"Test Span\"):\n ...\n\"\"\"\nimport abc\nimport enum\nfrom types import MappingProxyType\nfrom typing import Optional, Sequence\n\n# pylint: disable=unused-import\nfrom opentelemetry.context import Context\nfrom opentelemetry.trace import Link, get_current_span\nfrom opentelemetry.trace.span import TraceState\nfrom opentelemetry.util.types import Attributes\n\n\nclass Decision(enum.Enum):\n # IsRecording() == false, span will not be recorded and all events and attributes will be dropped.\n DROP = 0\n # IsRecording() == true, but Sampled flag MUST NOT be set.\n RECORD_ONLY = 1\n # IsRecording() == true AND Sampled flag` MUST be set.\n RECORD_AND_SAMPLE = 2\n\n def is_recording(self):\n return self in (Decision.RECORD_ONLY, Decision.RECORD_AND_SAMPLE)\n\n def is_sampled(self):\n return self is Decision.RECORD_AND_SAMPLE\n\n\nclass SamplingResult:\n \"\"\"A sampling result as applied to a newly-created Span.\n\n Args:\n decision: A sampling decision based off of whether the span is recorded\n and the sampled flag in trace flags in the span context.\n attributes: Attributes to add to the `opentelemetry.trace.Span`.\n trace_state: The tracestate used for the `opentelemetry.trace.Span`.\n Could possibly have been modified by the sampler.\n \"\"\"\n\n def __repr__(self) -> str:\n return \"{}({}, attributes={})\".format(\n type(self).__name__, str(self.decision), str(self.attributes)\n )\n\n def __init__(\n self,\n decision: Decision,\n attributes: \"Attributes\" = None,\n trace_state: \"TraceState\" = None,\n ) -> None:\n self.decision = decision\n if attributes is None:\n self.attributes = MappingProxyType({})\n else:\n self.attributes = MappingProxyType(attributes)\n self.trace_state = trace_state\n\n\nclass Sampler(abc.ABC):\n @abc.abstractmethod\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n pass\n\n @abc.abstractmethod\n def get_description(self) -> str:\n pass\n\n\nclass StaticSampler(Sampler):\n \"\"\"Sampler that always returns the same decision.\"\"\"\n\n def __init__(self, decision: \"Decision\"):\n self._decision = decision\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if self._decision is Decision.DROP:\n return SamplingResult(self._decision)\n return SamplingResult(self._decision, attributes, trace_state)\n\n def get_description(self) -> str:\n if self._decision is Decision.DROP:\n return \"AlwaysOffSampler\"\n return \"AlwaysOnSampler\"\n\n\nclass TraceIdRatioBased(Sampler):\n \"\"\"\n Sampler that makes sampling decisions probabalistically based on `rate`,\n while also respecting the parent span sampling decision.\n\n Args:\n rate: Probability (between 0 and 1) that a span will be sampled\n \"\"\"\n\n def __init__(self, rate: float):\n if rate < 0.0 or rate > 1.0:\n raise ValueError(\"Probability must be in range [0.0, 1.0].\")\n self._rate = rate\n self._bound = self.get_bound_for_rate(self._rate)\n\n # For compatibility with 64 bit trace IDs, the sampler checks the 64\n # low-order bits of the trace ID to decide whether to sample a given trace.\n TRACE_ID_LIMIT = (1 << 64) - 1\n\n @classmethod\n def get_bound_for_rate(cls, rate: float) -> int:\n return round(rate * (cls.TRACE_ID_LIMIT + 1))\n\n @property\n def rate(self) -> float:\n return self._rate\n\n @rate.setter\n def rate(self, new_rate: float) -> None:\n self._rate = new_rate\n self._bound = self.get_bound_for_rate(self._rate)\n\n @property\n def bound(self) -> int:\n return self._bound\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n decision = Decision.DROP\n if trace_id & self.TRACE_ID_LIMIT < self.bound:\n decision = Decision.RECORD_AND_SAMPLE\n if decision is Decision.DROP:\n return SamplingResult(decision)\n return SamplingResult(decision, attributes)\n\n def get_description(self) -> str:\n return \"TraceIdRatioBased{{{}}}\".format(self._rate)\n\n\nclass ParentBased(Sampler):\n \"\"\"\n If a parent is set, follows the same sampling decision as the parent.\n Otherwise, uses the delegate provided at initialization to make a\n decision.\n\n Args:\n delegate: The delegate sampler to use if parent is not set.\n \"\"\"\n\n def __init__(self, delegate: Sampler):\n self._delegate = delegate\n\n def should_sample(\n self,\n parent_context: Optional[\"Context\"],\n trace_id: int,\n name: str,\n attributes: Attributes = None,\n links: Sequence[\"Link\"] = None,\n trace_state: \"TraceState\" = None,\n ) -> \"SamplingResult\":\n if parent_context is not None:\n parent_span_context = get_current_span(\n parent_context\n ).get_span_context()\n # only drop if parent exists and is not a root span\n if (\n parent_span_context is not None\n and parent_span_context.is_valid\n and not parent_span_context.trace_flags.sampled\n ):\n return SamplingResult(Decision.DROP)\n return SamplingResult(Decision.RECORD_AND_SAMPLE, attributes)\n\n return self._delegate.should_sample(\n parent_context=parent_context,\n trace_id=trace_id,\n name=name,\n attributes=attributes,\n links=links,\n trace_state=trace_state,\n )\n\n def get_description(self):\n return \"ParentBased{{{}}}\".format(self._delegate.get_description())\n\n\nALWAYS_OFF = StaticSampler(Decision.DROP)\n\"\"\"Sampler that never samples spans, regardless of the parent span's sampling decision.\"\"\"\n\nALWAYS_ON = StaticSampler(Decision.RECORD_AND_SAMPLE)\n\"\"\"Sampler that always samples spans, regardless of the parent span's sampling decision.\"\"\"\n\nDEFAULT_OFF = ParentBased(ALWAYS_OFF)\n\"\"\"Sampler that respects its parent span's sampling decision, but otherwise never samples.\"\"\"\n\nDEFAULT_ON = ParentBased(ALWAYS_ON)\n\"\"\"Sampler that respects its parent span's sampling decision, but otherwise always samples.\"\"\"\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/trace/sampling.py"}]}
| 3,541 | 523 |
gh_patches_debug_10313
|
rasdani/github-patches
|
git_diff
|
nilearn__nilearn-4049
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[DOC] Fix Sphinx issues related to adding new experimental module and typing
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe your proposed suggestion in detail.
1. Linkcode extension error https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739213117 and related workaround: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/sphinxext/github_link.py#L43-L44
2. See Sphinx warning https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739630179 and related hotfix of remving sphinx role here: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/modules/experimental.rst?plain=1#L10
3. Sphinx autodoc has an issue with resolving external libraries like numpy when using typehints. It seems to be a bug similar to what is reported here https://github.com/sphinx-doc/sphinx/issues/10785. For now this autodoc argument is added to hide the typehints from the integrated typing https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/conf.py#L57
And if we have both docstrings and the typehints we have double rendering in the docs of the description of a e.g. class and this is redundant and looks ugly so we should also discuss how we want to approach adding docstrings + typing and how to configure what will be displayed. I'll post an example once the dev docs are built
### List any pages that would be impacted.
_No response_
</issue>
<code>
[start of doc/sphinxext/github_link.py]
1 import inspect
2 import os
3 import subprocess
4 import sys
5 from functools import partial
6 from operator import attrgetter
7
8 REVISION_CMD = "git rev-parse --short HEAD"
9
10
11 def _get_git_revision():
12 try:
13 revision = subprocess.check_output(REVISION_CMD.split()).strip()
14 except (subprocess.CalledProcessError, OSError):
15 print("Failed to execute git to get revision")
16 return None
17 return revision.decode("utf-8")
18
19
20 def _linkcode_resolve(domain, info, package, url_fmt, revision):
21 """Determine a link to online source for a class/method/function.
22
23 This is called by sphinx.ext.linkcode
24
25 An example with a long-untouched module that everyone has
26 >>> _linkcode_resolve('py', {'module': 'tty',
27 ... 'fullname': 'setraw'},
28 ... package='tty',
29 ... url_fmt='http://hg.python.org/cpython/file/'
30 ... '{revision}/Lib/{package}/{path}#L{lineno}',
31 ... revision='xxxx')
32 'http://hg.python.org/cpython/file/xxxx/Lib/tty/tty.py#L18'
33 """
34 if revision is None:
35 return
36 if domain not in ("py", "pyx"):
37 return
38 if not info.get("module") or not info.get("fullname"):
39 return
40
41 class_name = info["fullname"].split(".")[0]
42 module = __import__(info["module"], fromlist=[class_name])
43 if info["module"] == "nilearn.experimental.surface":
44 return
45 obj = attrgetter(info["fullname"])(module)
46
47 # Unwrap the object to get the correct source
48 # file in case that is wrapped by a decorator
49 obj = inspect.unwrap(obj)
50
51 try:
52 fn = inspect.getsourcefile(obj)
53 except Exception:
54 fn = None
55 if not fn:
56 try:
57 fn = inspect.getsourcefile(sys.modules[obj.__module__])
58 except Exception:
59 fn = None
60 if not fn:
61 return
62
63 # Don't include filenames from outside this package's tree
64 if os.path.dirname(__import__(package).__file__) not in fn:
65 return
66
67 fn = os.path.relpath(
68 fn, start=os.path.dirname(__import__(package).__file__)
69 )
70 try:
71 lineno = inspect.getsourcelines(obj)[1]
72 except Exception:
73 lineno = ""
74 return url_fmt.format(
75 revision=revision, package=package, path=fn, lineno=lineno
76 )
77
78
79 def make_linkcode_resolve(package, url_fmt):
80 """Return a linkcode_resolve function for the given URL format.
81
82 revision is a git commit reference (hash or name)
83
84 package is the name of the root module of the package
85
86 url_fmt is along the lines of ('https://github.com/USER/PROJECT/'
87 'blob/{revision}/{package}/'
88 '{path}#L{lineno}')
89 """
90 revision = _get_git_revision()
91 return partial(
92 _linkcode_resolve, revision=revision, package=package, url_fmt=url_fmt
93 )
94
[end of doc/sphinxext/github_link.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/doc/sphinxext/github_link.py b/doc/sphinxext/github_link.py
--- a/doc/sphinxext/github_link.py
+++ b/doc/sphinxext/github_link.py
@@ -40,9 +40,12 @@
class_name = info["fullname"].split(".")[0]
module = __import__(info["module"], fromlist=[class_name])
- if info["module"] == "nilearn.experimental.surface":
+ # For typed parameters, this will try to get uninitialized attributes
+ # and fail
+ try:
+ obj = attrgetter(info["fullname"])(module)
+ except AttributeError:
return
- obj = attrgetter(info["fullname"])(module)
# Unwrap the object to get the correct source
# file in case that is wrapped by a decorator
|
{"golden_diff": "diff --git a/doc/sphinxext/github_link.py b/doc/sphinxext/github_link.py\n--- a/doc/sphinxext/github_link.py\n+++ b/doc/sphinxext/github_link.py\n@@ -40,9 +40,12 @@\n \n class_name = info[\"fullname\"].split(\".\")[0]\n module = __import__(info[\"module\"], fromlist=[class_name])\n- if info[\"module\"] == \"nilearn.experimental.surface\":\n+ # For typed parameters, this will try to get uninitialized attributes\n+ # and fail\n+ try:\n+ obj = attrgetter(info[\"fullname\"])(module)\n+ except AttributeError:\n return\n- obj = attrgetter(info[\"fullname\"])(module)\n \n # Unwrap the object to get the correct source\n # file in case that is wrapped by a decorator\n", "issue": "[DOC] Fix Sphinx issues related to adding new experimental module and typing\n### Is there an existing issue for this?\r\n\r\n- [X] I have searched the existing issues\r\n\r\n### Describe your proposed suggestion in detail.\r\n\r\n1. Linkcode extension error https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739213117 and related workaround: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/sphinxext/github_link.py#L43-L44\r\n\r\n2. See Sphinx warning https://github.com/nilearn/nilearn/pull/4017#issuecomment-1739630179 and related hotfix of remving sphinx role here: https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/modules/experimental.rst?plain=1#L10\r\n\r\n3. Sphinx autodoc has an issue with resolving external libraries like numpy when using typehints. It seems to be a bug similar to what is reported here https://github.com/sphinx-doc/sphinx/issues/10785. For now this autodoc argument is added to hide the typehints from the integrated typing https://github.com/nilearn/nilearn/blob/9133bd98ddc085e14d545fd0439be621c8679f91/doc/conf.py#L57\r\nAnd if we have both docstrings and the typehints we have double rendering in the docs of the description of a e.g. class and this is redundant and looks ugly so we should also discuss how we want to approach adding docstrings + typing and how to configure what will be displayed. I'll post an example once the dev docs are built\r\n\r\n### List any pages that would be impacted.\r\n\r\n_No response_\n", "before_files": [{"content": "import inspect\nimport os\nimport subprocess\nimport sys\nfrom functools import partial\nfrom operator import attrgetter\n\nREVISION_CMD = \"git rev-parse --short HEAD\"\n\n\ndef _get_git_revision():\n try:\n revision = subprocess.check_output(REVISION_CMD.split()).strip()\n except (subprocess.CalledProcessError, OSError):\n print(\"Failed to execute git to get revision\")\n return None\n return revision.decode(\"utf-8\")\n\n\ndef _linkcode_resolve(domain, info, package, url_fmt, revision):\n \"\"\"Determine a link to online source for a class/method/function.\n\n This is called by sphinx.ext.linkcode\n\n An example with a long-untouched module that everyone has\n >>> _linkcode_resolve('py', {'module': 'tty',\n ... 'fullname': 'setraw'},\n ... package='tty',\n ... url_fmt='http://hg.python.org/cpython/file/'\n ... '{revision}/Lib/{package}/{path}#L{lineno}',\n ... revision='xxxx')\n 'http://hg.python.org/cpython/file/xxxx/Lib/tty/tty.py#L18'\n \"\"\"\n if revision is None:\n return\n if domain not in (\"py\", \"pyx\"):\n return\n if not info.get(\"module\") or not info.get(\"fullname\"):\n return\n\n class_name = info[\"fullname\"].split(\".\")[0]\n module = __import__(info[\"module\"], fromlist=[class_name])\n if info[\"module\"] == \"nilearn.experimental.surface\":\n return\n obj = attrgetter(info[\"fullname\"])(module)\n\n # Unwrap the object to get the correct source\n # file in case that is wrapped by a decorator\n obj = inspect.unwrap(obj)\n\n try:\n fn = inspect.getsourcefile(obj)\n except Exception:\n fn = None\n if not fn:\n try:\n fn = inspect.getsourcefile(sys.modules[obj.__module__])\n except Exception:\n fn = None\n if not fn:\n return\n\n # Don't include filenames from outside this package's tree\n if os.path.dirname(__import__(package).__file__) not in fn:\n return\n\n fn = os.path.relpath(\n fn, start=os.path.dirname(__import__(package).__file__)\n )\n try:\n lineno = inspect.getsourcelines(obj)[1]\n except Exception:\n lineno = \"\"\n return url_fmt.format(\n revision=revision, package=package, path=fn, lineno=lineno\n )\n\n\ndef make_linkcode_resolve(package, url_fmt):\n \"\"\"Return a linkcode_resolve function for the given URL format.\n\n revision is a git commit reference (hash or name)\n\n package is the name of the root module of the package\n\n url_fmt is along the lines of ('https://github.com/USER/PROJECT/'\n 'blob/{revision}/{package}/'\n '{path}#L{lineno}')\n \"\"\"\n revision = _get_git_revision()\n return partial(\n _linkcode_resolve, revision=revision, package=package, url_fmt=url_fmt\n )\n", "path": "doc/sphinxext/github_link.py"}]}
| 1,858 | 182 |
gh_patches_debug_31327
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-8162
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Resources loading on Windows (follow-up from #8159)
## Observed behavior
After Promise.polyfill issue was fixed to restore IE11 compatibility in #8159, resources (HTML5, videos) are not loading on all browsers on Windows, but those on Ubuntu Linux are not affected.
HTML on IE11 | HTML on Firefox | videos on FF & Chrome
--- | --- | ---
 |  |  <br> 
## Errors and logs
…
## Expected behavior
Resources loading correctly on IE11, Firefox and Chrome on Windows.
## User-facing consequences
...
## Steps to reproduce
…
## Context
* Kolibri version: 0.15/develop
* Operating system: Windows 7
* Browser: all
cc @rtibbles
</issue>
<code>
[start of kolibri/utils/kolibri_whitenoise.py]
1 import os
2 import re
3 import stat
4 from collections import OrderedDict
5
6 from django.contrib.staticfiles import finders
7 from django.core.files.storage import FileSystemStorage
8 from whitenoise import WhiteNoise
9 from whitenoise.string_utils import decode_path_info
10
11
12 class FileFinder(finders.FileSystemFinder):
13 """
14 A modified version of the Django FileSystemFinder class
15 which allows us to pass in arbitrary locations to find files
16 """
17
18 def __init__(self, locations):
19 # List of locations with static files
20 self.locations = []
21 self.prefixes = set()
22 # Maps dir paths to an appropriate storage instance
23 self.storages = OrderedDict()
24 if not isinstance(locations, (list, tuple)):
25 raise TypeError("locations argument is not a tuple or list")
26 for root in locations:
27 prefix, root = root
28 # Django requires paths, even on Windows, to use forward slashes
29 # do this substitution that will be idempotent on Unix
30 root = root.replace(os.sep, "/")
31 if not prefix:
32 raise ValueError(
33 "Cannot use unprefixed locations for dynamic locations"
34 )
35 else:
36 prefix = prefix.rstrip("/")
37 if (prefix, root) not in self.locations:
38 self.locations.append((prefix, root))
39 self.prefixes.add(prefix)
40 for prefix, root in self.locations:
41 filesystem_storage = FileSystemStorage(location=root)
42 filesystem_storage.prefix = prefix
43 self.storages[root] = filesystem_storage
44
45 def find(self, path, all=False):
46 path = path.replace("/", os.sep)
47 return super(FileFinder, self).find(path, all=all)
48
49
50 class DynamicWhiteNoise(WhiteNoise):
51 def __init__(self, application, dynamic_locations=None, **kwargs):
52 whitenoise_settings = {
53 # Use 1 day as the default cache time for static assets
54 "max_age": 24 * 60 * 60,
55 # Add a test for any file name that contains a semantic version number
56 # or a 32 digit number (assumed to be a file hash)
57 # these files will be cached indefinitely
58 "immutable_file_test": r"((0|[1-9]\d*)\.(0|[1-9]\d*)\.(0|[1-9]\d*)|[a-f0-9]{32})",
59 "autorefresh": os.environ.get("KOLIBRI_DEVELOPER_MODE", False),
60 }
61 kwargs.update(whitenoise_settings)
62 super(DynamicWhiteNoise, self).__init__(application, **kwargs)
63 self.dynamic_finder = FileFinder(dynamic_locations or [])
64 # Generate a regex to check if a path matches one of our dynamic
65 # location prefixes
66 self.dynamic_check = (
67 re.compile("^({})".format("|".join(self.dynamic_finder.prefixes)))
68 if self.dynamic_finder.prefixes
69 else None
70 )
71
72 def __call__(self, environ, start_response):
73 path = decode_path_info(environ.get("PATH_INFO", ""))
74 if self.autorefresh:
75 static_file = self.find_file(path)
76 else:
77 static_file = self.files.get(path)
78 if static_file is None:
79 static_file = self.find_and_cache_dynamic_file(path)
80 if static_file is None:
81 return self.application(environ, start_response)
82 else:
83 return self.serve(static_file, environ, start_response)
84
85 def find_and_cache_dynamic_file(self, url):
86 path = self.get_dynamic_path(url)
87 if path:
88 file_stat = os.stat(path)
89 # Only try to do matches for regular files.
90 if stat.S_ISREG(file_stat.st_mode):
91 stat_cache = {path: os.stat(path)}
92 self.add_file_to_dictionary(url, path, stat_cache=stat_cache)
93 return self.files.get(url)
94
95 def get_dynamic_path(self, url):
96 if self.dynamic_check is not None and self.dynamic_check.match(url):
97 return self.dynamic_finder.find(url)
98
99 def candidate_paths_for_url(self, url):
100 paths = super(DynamicWhiteNoise, self).candidate_paths_for_url(url)
101 for path in paths:
102 yield path
103 path = self.get_dynamic_path(url)
104 if path:
105 yield path
106
107
108 class DjangoWhiteNoise(DynamicWhiteNoise):
109 def __init__(self, application, static_prefix=None, **kwargs):
110 super(DjangoWhiteNoise, self).__init__(application, **kwargs)
111 self.static_prefix = static_prefix
112 if not self.autorefresh and self.static_prefix:
113 self.add_files_from_finders()
114
115 def add_files_from_finders(self):
116 files = {}
117 for finder in finders.get_finders():
118 for path, storage in finder.list(None):
119 prefix = (getattr(storage, "prefix", None) or "").strip("/")
120 url = u"".join(
121 (
122 self.static_prefix,
123 prefix,
124 "/" if prefix else "",
125 path.replace("\\", "/"),
126 )
127 )
128 # Use setdefault as only first matching file should be used
129 files.setdefault(url, storage.path(path))
130 stat_cache = {path: os.stat(path) for path in files.values()}
131 for url, path in files.items():
132 self.add_file_to_dictionary(url, path, stat_cache=stat_cache)
133
134 def candidate_paths_for_url(self, url):
135 paths = super(DjangoWhiteNoise, self).candidate_paths_for_url(url)
136 for path in paths:
137 yield path
138 if self.autorefresh and url.startswith(self.static_prefix):
139 path = finders.find(url[len(self.static_prefix) :])
140 if path:
141 yield path
142
[end of kolibri/utils/kolibri_whitenoise.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/utils/kolibri_whitenoise.py b/kolibri/utils/kolibri_whitenoise.py
--- a/kolibri/utils/kolibri_whitenoise.py
+++ b/kolibri/utils/kolibri_whitenoise.py
@@ -5,6 +5,7 @@
from django.contrib.staticfiles import finders
from django.core.files.storage import FileSystemStorage
+from django.utils._os import safe_join
from whitenoise import WhiteNoise
from whitenoise.string_utils import decode_path_info
@@ -25,9 +26,6 @@
raise TypeError("locations argument is not a tuple or list")
for root in locations:
prefix, root = root
- # Django requires paths, even on Windows, to use forward slashes
- # do this substitution that will be idempotent on Unix
- root = root.replace(os.sep, "/")
if not prefix:
raise ValueError(
"Cannot use unprefixed locations for dynamic locations"
@@ -42,9 +40,20 @@
filesystem_storage.prefix = prefix
self.storages[root] = filesystem_storage
- def find(self, path, all=False):
- path = path.replace("/", os.sep)
- return super(FileFinder, self).find(path, all=all)
+ def find_location(self, root, path, prefix=None):
+ """
+ Finds a requested static file in a location, returning the found
+ absolute path (or ``None`` if no match).
+ Vendored from Django to handle being passed a URL path instead of a file path.
+ """
+ if prefix:
+ prefix = prefix + "/"
+ if not path.startswith(prefix):
+ return None
+ path = path[len(prefix) :]
+ path = safe_join(root, path)
+ if os.path.exists(path):
+ return path
class DynamicWhiteNoise(WhiteNoise):
|
{"golden_diff": "diff --git a/kolibri/utils/kolibri_whitenoise.py b/kolibri/utils/kolibri_whitenoise.py\n--- a/kolibri/utils/kolibri_whitenoise.py\n+++ b/kolibri/utils/kolibri_whitenoise.py\n@@ -5,6 +5,7 @@\n \n from django.contrib.staticfiles import finders\n from django.core.files.storage import FileSystemStorage\n+from django.utils._os import safe_join\n from whitenoise import WhiteNoise\n from whitenoise.string_utils import decode_path_info\n \n@@ -25,9 +26,6 @@\n raise TypeError(\"locations argument is not a tuple or list\")\n for root in locations:\n prefix, root = root\n- # Django requires paths, even on Windows, to use forward slashes\n- # do this substitution that will be idempotent on Unix\n- root = root.replace(os.sep, \"/\")\n if not prefix:\n raise ValueError(\n \"Cannot use unprefixed locations for dynamic locations\"\n@@ -42,9 +40,20 @@\n filesystem_storage.prefix = prefix\n self.storages[root] = filesystem_storage\n \n- def find(self, path, all=False):\n- path = path.replace(\"/\", os.sep)\n- return super(FileFinder, self).find(path, all=all)\n+ def find_location(self, root, path, prefix=None):\n+ \"\"\"\n+ Finds a requested static file in a location, returning the found\n+ absolute path (or ``None`` if no match).\n+ Vendored from Django to handle being passed a URL path instead of a file path.\n+ \"\"\"\n+ if prefix:\n+ prefix = prefix + \"/\"\n+ if not path.startswith(prefix):\n+ return None\n+ path = path[len(prefix) :]\n+ path = safe_join(root, path)\n+ if os.path.exists(path):\n+ return path\n \n \n class DynamicWhiteNoise(WhiteNoise):\n", "issue": "Resources loading on Windows (follow-up from #8159)\n\r\n## Observed behavior\r\nAfter Promise.polyfill issue was fixed to restore IE11 compatibility in #8159, resources (HTML5, videos) are not loading on all browsers on Windows, but those on Ubuntu Linux are not affected.\r\n\r\nHTML on IE11 | HTML on Firefox | videos on FF & Chrome\r\n--- | --- | --- \r\n |  |  <br> \r\n\r\n## Errors and logs\r\n\u2026\r\n\r\n## Expected behavior\r\nResources loading correctly on IE11, Firefox and Chrome on Windows.\r\n\r\n## User-facing consequences\r\n...\r\n\r\n## Steps to reproduce\r\n\u2026\r\n\r\n## Context\r\n * Kolibri version: 0.15/develop\r\n * Operating system: Windows 7\r\n * Browser: all\r\n\r\ncc @rtibbles \r\n\n", "before_files": [{"content": "import os\nimport re\nimport stat\nfrom collections import OrderedDict\n\nfrom django.contrib.staticfiles import finders\nfrom django.core.files.storage import FileSystemStorage\nfrom whitenoise import WhiteNoise\nfrom whitenoise.string_utils import decode_path_info\n\n\nclass FileFinder(finders.FileSystemFinder):\n \"\"\"\n A modified version of the Django FileSystemFinder class\n which allows us to pass in arbitrary locations to find files\n \"\"\"\n\n def __init__(self, locations):\n # List of locations with static files\n self.locations = []\n self.prefixes = set()\n # Maps dir paths to an appropriate storage instance\n self.storages = OrderedDict()\n if not isinstance(locations, (list, tuple)):\n raise TypeError(\"locations argument is not a tuple or list\")\n for root in locations:\n prefix, root = root\n # Django requires paths, even on Windows, to use forward slashes\n # do this substitution that will be idempotent on Unix\n root = root.replace(os.sep, \"/\")\n if not prefix:\n raise ValueError(\n \"Cannot use unprefixed locations for dynamic locations\"\n )\n else:\n prefix = prefix.rstrip(\"/\")\n if (prefix, root) not in self.locations:\n self.locations.append((prefix, root))\n self.prefixes.add(prefix)\n for prefix, root in self.locations:\n filesystem_storage = FileSystemStorage(location=root)\n filesystem_storage.prefix = prefix\n self.storages[root] = filesystem_storage\n\n def find(self, path, all=False):\n path = path.replace(\"/\", os.sep)\n return super(FileFinder, self).find(path, all=all)\n\n\nclass DynamicWhiteNoise(WhiteNoise):\n def __init__(self, application, dynamic_locations=None, **kwargs):\n whitenoise_settings = {\n # Use 1 day as the default cache time for static assets\n \"max_age\": 24 * 60 * 60,\n # Add a test for any file name that contains a semantic version number\n # or a 32 digit number (assumed to be a file hash)\n # these files will be cached indefinitely\n \"immutable_file_test\": r\"((0|[1-9]\\d*)\\.(0|[1-9]\\d*)\\.(0|[1-9]\\d*)|[a-f0-9]{32})\",\n \"autorefresh\": os.environ.get(\"KOLIBRI_DEVELOPER_MODE\", False),\n }\n kwargs.update(whitenoise_settings)\n super(DynamicWhiteNoise, self).__init__(application, **kwargs)\n self.dynamic_finder = FileFinder(dynamic_locations or [])\n # Generate a regex to check if a path matches one of our dynamic\n # location prefixes\n self.dynamic_check = (\n re.compile(\"^({})\".format(\"|\".join(self.dynamic_finder.prefixes)))\n if self.dynamic_finder.prefixes\n else None\n )\n\n def __call__(self, environ, start_response):\n path = decode_path_info(environ.get(\"PATH_INFO\", \"\"))\n if self.autorefresh:\n static_file = self.find_file(path)\n else:\n static_file = self.files.get(path)\n if static_file is None:\n static_file = self.find_and_cache_dynamic_file(path)\n if static_file is None:\n return self.application(environ, start_response)\n else:\n return self.serve(static_file, environ, start_response)\n\n def find_and_cache_dynamic_file(self, url):\n path = self.get_dynamic_path(url)\n if path:\n file_stat = os.stat(path)\n # Only try to do matches for regular files.\n if stat.S_ISREG(file_stat.st_mode):\n stat_cache = {path: os.stat(path)}\n self.add_file_to_dictionary(url, path, stat_cache=stat_cache)\n return self.files.get(url)\n\n def get_dynamic_path(self, url):\n if self.dynamic_check is not None and self.dynamic_check.match(url):\n return self.dynamic_finder.find(url)\n\n def candidate_paths_for_url(self, url):\n paths = super(DynamicWhiteNoise, self).candidate_paths_for_url(url)\n for path in paths:\n yield path\n path = self.get_dynamic_path(url)\n if path:\n yield path\n\n\nclass DjangoWhiteNoise(DynamicWhiteNoise):\n def __init__(self, application, static_prefix=None, **kwargs):\n super(DjangoWhiteNoise, self).__init__(application, **kwargs)\n self.static_prefix = static_prefix\n if not self.autorefresh and self.static_prefix:\n self.add_files_from_finders()\n\n def add_files_from_finders(self):\n files = {}\n for finder in finders.get_finders():\n for path, storage in finder.list(None):\n prefix = (getattr(storage, \"prefix\", None) or \"\").strip(\"/\")\n url = u\"\".join(\n (\n self.static_prefix,\n prefix,\n \"/\" if prefix else \"\",\n path.replace(\"\\\\\", \"/\"),\n )\n )\n # Use setdefault as only first matching file should be used\n files.setdefault(url, storage.path(path))\n stat_cache = {path: os.stat(path) for path in files.values()}\n for url, path in files.items():\n self.add_file_to_dictionary(url, path, stat_cache=stat_cache)\n\n def candidate_paths_for_url(self, url):\n paths = super(DjangoWhiteNoise, self).candidate_paths_for_url(url)\n for path in paths:\n yield path\n if self.autorefresh and url.startswith(self.static_prefix):\n path = finders.find(url[len(self.static_prefix) :])\n if path:\n yield path\n", "path": "kolibri/utils/kolibri_whitenoise.py"}]}
| 2,531 | 419 |
gh_patches_debug_451
|
rasdani/github-patches
|
git_diff
|
ros__ros_comm-683
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
unregister() method to message_filter.Subscriber on python
Do you have plan to implement this?
Or there is other way to achieve this?
</issue>
<code>
[start of utilities/message_filters/src/message_filters/__init__.py]
1 # Copyright (c) 2009, Willow Garage, Inc.
2 # All rights reserved.
3 #
4 # Redistribution and use in source and binary forms, with or without
5 # modification, are permitted provided that the following conditions are met:
6 #
7 # * Redistributions of source code must retain the above copyright
8 # notice, this list of conditions and the following disclaimer.
9 # * Redistributions in binary form must reproduce the above copyright
10 # notice, this list of conditions and the following disclaimer in the
11 # documentation and/or other materials provided with the distribution.
12 # * Neither the name of the Willow Garage, Inc. nor the names of its
13 # contributors may be used to endorse or promote products derived from
14 # this software without specific prior written permission.
15 #
16 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
17 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
18 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
19 # ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE
20 # LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
21 # CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
22 # SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
23 # INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
24 # CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
25 # ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
26 # POSSIBILITY OF SUCH DAMAGE.
27
28 """
29 Message Filter Objects
30 ======================
31 """
32
33 import itertools
34 import threading
35 import rospy
36
37 class SimpleFilter:
38
39 def __init__(self):
40 self.callbacks = {}
41
42 def registerCallback(self, cb, *args):
43 """
44 Register a callback function `cb` to be called when this filter
45 has output.
46 The filter calls the function ``cb`` with a filter-dependent list of arguments,
47 followed by the call-supplied arguments ``args``.
48 """
49
50 conn = len(self.callbacks)
51 self.callbacks[conn] = (cb, args)
52 return conn
53
54 def signalMessage(self, *msg):
55 for (cb, args) in self.callbacks.values():
56 cb(*(msg + args))
57
58 class Subscriber(SimpleFilter):
59
60 """
61 ROS subscription filter. Identical arguments as :class:`rospy.Subscriber`.
62
63 This class acts as a highest-level filter, simply passing messages
64 from a ROS subscription through to the filters which have connected
65 to it.
66 """
67 def __init__(self, *args, **kwargs):
68 SimpleFilter.__init__(self)
69 self.topic = args[0]
70 kwargs['callback'] = self.callback
71 self.sub = rospy.Subscriber(*args, **kwargs)
72
73 def callback(self, msg):
74 self.signalMessage(msg)
75
76 def getTopic(self):
77 return self.topic
78
79 class Cache(SimpleFilter):
80
81 """
82 Stores a time history of messages.
83
84 Given a stream of messages, the most recent ``cache_size`` messages
85 are cached in a ring buffer, from which time intervals of the cache
86 can then be retrieved by the client.
87 """
88
89 def __init__(self, f, cache_size = 1):
90 SimpleFilter.__init__(self)
91 self.connectInput(f)
92 self.cache_size = cache_size
93 # Array to store messages
94 self.cache_msgs = []
95 # Array to store msgs times, auxiliary structure to facilitate
96 # sorted insertion
97 self.cache_times = []
98
99 def connectInput(self, f):
100 self.incoming_connection = f.registerCallback(self.add)
101
102 def add(self, msg):
103 # Cannot use message filters with non-stamped messages
104 if not hasattr(msg, 'header') or not hasattr(msg.header, 'stamp'):
105 rospy.logwarn("Cannot use message filters with non-stamped messages")
106 return
107
108 # Insert sorted
109 stamp = msg.header.stamp
110 self.cache_times.append(stamp)
111 self.cache_msgs.append(msg)
112
113 # Implement a ring buffer, discard older if oversized
114 if (len(self.cache_msgs) > self.cache_size):
115 del self.cache_msgs[0]
116 del self.cache_times[0]
117
118 # Signal new input
119 self.signalMessage(msg)
120
121 def getInterval(self, from_stamp, to_stamp):
122 """Query the current cache content between from_stamp to to_stamp."""
123 assert from_stamp <= to_stamp
124 return [m for m in self.cache_msgs
125 if m.header.stamp >= from_stamp and m.header.stamp <= to_stamp]
126
127 def getElemAfterTime(self, stamp):
128 """Return the oldest element after or equal the passed time stamp."""
129 newer = [m for m in self.cache_msgs if m.header.stamp >= stamp]
130 if not newer:
131 return None
132 return newer[0]
133
134 def getElemBeforeTime(self, stamp):
135 """Return the newest element before or equal the passed time stamp."""
136 older = [m for m in self.cache_msgs if m.header.stamp <= stamp]
137 if not older:
138 return None
139 return older[-1]
140
141 def getLastestTime(self):
142 """Return the newest recorded timestamp."""
143 if not self.cache_times:
144 return None
145 return self.cache_times[-1]
146
147 def getOldestTime(self):
148 """Return the oldest recorded timestamp."""
149 if not self.cache_times:
150 return None
151 return self.cache_times[0]
152
153
154 class TimeSynchronizer(SimpleFilter):
155
156 """
157 Synchronizes messages by their timestamps.
158
159 :class:`TimeSynchronizer` synchronizes incoming message filters by the
160 timestamps contained in their messages' headers. TimeSynchronizer
161 listens on multiple input message filters ``fs``, and invokes the callback
162 when it has a collection of messages with matching timestamps.
163
164 The signature of the callback function is::
165
166 def callback(msg1, ... msgN):
167
168 where N is the number of input message filters, and each message is
169 the output of the corresponding filter in ``fs``.
170 The required ``queue size`` parameter specifies how many sets of
171 messages it should store from each input filter (by timestamp)
172 while waiting for messages to arrive and complete their "set".
173 """
174
175 def __init__(self, fs, queue_size):
176 SimpleFilter.__init__(self)
177 self.connectInput(fs)
178 self.queue_size = queue_size
179 self.lock = threading.Lock()
180
181 def connectInput(self, fs):
182 self.queues = [{} for f in fs]
183 self.input_connections = [f.registerCallback(self.add, q) for (f, q) in zip(fs, self.queues)]
184
185 def add(self, msg, my_queue):
186 self.lock.acquire()
187 my_queue[msg.header.stamp] = msg
188 while len(my_queue) > self.queue_size:
189 del my_queue[min(my_queue)]
190 # common is the set of timestamps that occur in all queues
191 common = reduce(set.intersection, [set(q) for q in self.queues])
192 for t in sorted(common):
193 # msgs is list of msgs (one from each queue) with stamp t
194 msgs = [q[t] for q in self.queues]
195 self.signalMessage(*msgs)
196 for q in self.queues:
197 del q[t]
198 self.lock.release()
199
200 class ApproximateTimeSynchronizer(TimeSynchronizer):
201
202 """
203 Approximately synchronizes messages by their timestamps.
204
205 :class:`ApproximateTimeSynchronizer` synchronizes incoming message filters by the
206 timestamps contained in their messages' headers. The API is the same as TimeSynchronizer
207 except for an extra `slop` parameter in the constructor that defines the delay (in seconds)
208 with which messages can be synchronized
209 """
210
211 def __init__(self, fs, queue_size, slop):
212 TimeSynchronizer.__init__(self, fs, queue_size)
213 self.slop = rospy.Duration.from_sec(slop)
214
215 def add(self, msg, my_queue):
216 self.lock.acquire()
217 my_queue[msg.header.stamp] = msg
218 while len(my_queue) > self.queue_size:
219 del my_queue[min(my_queue)]
220 for vv in itertools.product(*[list(q.keys()) for q in self.queues]):
221 qt = list(zip(self.queues, vv))
222 if ( ((max(vv) - min(vv)) < self.slop) and
223 (len([1 for q,t in qt if t not in q]) == 0) ):
224 msgs = [q[t] for q,t in qt]
225 self.signalMessage(*msgs)
226 for q,t in qt:
227 del q[t]
228 self.lock.release()
229
[end of utilities/message_filters/src/message_filters/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/utilities/message_filters/src/message_filters/__init__.py b/utilities/message_filters/src/message_filters/__init__.py
--- a/utilities/message_filters/src/message_filters/__init__.py
+++ b/utilities/message_filters/src/message_filters/__init__.py
@@ -76,6 +76,9 @@
def getTopic(self):
return self.topic
+ def unregister(self):
+ self.sub.unregister()
+
class Cache(SimpleFilter):
"""
|
{"golden_diff": "diff --git a/utilities/message_filters/src/message_filters/__init__.py b/utilities/message_filters/src/message_filters/__init__.py\n--- a/utilities/message_filters/src/message_filters/__init__.py\n+++ b/utilities/message_filters/src/message_filters/__init__.py\n@@ -76,6 +76,9 @@\n def getTopic(self):\n return self.topic\n \n+ def unregister(self):\n+ self.sub.unregister()\n+\n class Cache(SimpleFilter):\n \n \"\"\"\n", "issue": "unregister() method to message_filter.Subscriber on python\nDo you have plan to implement this?\nOr there is other way to achieve this?\n\n", "before_files": [{"content": "# Copyright (c) 2009, Willow Garage, Inc.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of the Willow Garage, Inc. nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE\n# ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE\n# LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR\n# CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF\n# SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS\n# INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN\n# CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)\n# ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n# POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nMessage Filter Objects\n======================\n\"\"\"\n\nimport itertools\nimport threading\nimport rospy\n\nclass SimpleFilter:\n\n def __init__(self):\n self.callbacks = {}\n\n def registerCallback(self, cb, *args):\n \"\"\"\n Register a callback function `cb` to be called when this filter\n has output.\n The filter calls the function ``cb`` with a filter-dependent list of arguments,\n followed by the call-supplied arguments ``args``.\n \"\"\"\n\n conn = len(self.callbacks)\n self.callbacks[conn] = (cb, args)\n return conn\n\n def signalMessage(self, *msg):\n for (cb, args) in self.callbacks.values():\n cb(*(msg + args))\n\nclass Subscriber(SimpleFilter):\n \n \"\"\"\n ROS subscription filter. Identical arguments as :class:`rospy.Subscriber`.\n\n This class acts as a highest-level filter, simply passing messages\n from a ROS subscription through to the filters which have connected\n to it.\n \"\"\"\n def __init__(self, *args, **kwargs):\n SimpleFilter.__init__(self)\n self.topic = args[0]\n kwargs['callback'] = self.callback\n self.sub = rospy.Subscriber(*args, **kwargs)\n\n def callback(self, msg):\n self.signalMessage(msg)\n\n def getTopic(self):\n return self.topic\n\nclass Cache(SimpleFilter):\n\n \"\"\"\n Stores a time history of messages.\n\n Given a stream of messages, the most recent ``cache_size`` messages\n are cached in a ring buffer, from which time intervals of the cache\n can then be retrieved by the client.\n \"\"\"\n\n def __init__(self, f, cache_size = 1):\n SimpleFilter.__init__(self)\n self.connectInput(f)\n self.cache_size = cache_size\n # Array to store messages\n self.cache_msgs = []\n # Array to store msgs times, auxiliary structure to facilitate\n # sorted insertion\n self.cache_times = []\n\n def connectInput(self, f):\n self.incoming_connection = f.registerCallback(self.add)\n\n def add(self, msg):\n # Cannot use message filters with non-stamped messages\n if not hasattr(msg, 'header') or not hasattr(msg.header, 'stamp'):\n rospy.logwarn(\"Cannot use message filters with non-stamped messages\")\n return\n\n # Insert sorted\n stamp = msg.header.stamp\n self.cache_times.append(stamp)\n self.cache_msgs.append(msg)\n\n # Implement a ring buffer, discard older if oversized\n if (len(self.cache_msgs) > self.cache_size):\n del self.cache_msgs[0]\n del self.cache_times[0]\n\n # Signal new input\n self.signalMessage(msg)\n\n def getInterval(self, from_stamp, to_stamp):\n \"\"\"Query the current cache content between from_stamp to to_stamp.\"\"\"\n assert from_stamp <= to_stamp\n return [m for m in self.cache_msgs\n if m.header.stamp >= from_stamp and m.header.stamp <= to_stamp]\n\n def getElemAfterTime(self, stamp):\n \"\"\"Return the oldest element after or equal the passed time stamp.\"\"\"\n newer = [m for m in self.cache_msgs if m.header.stamp >= stamp]\n if not newer:\n return None\n return newer[0]\n\n def getElemBeforeTime(self, stamp):\n \"\"\"Return the newest element before or equal the passed time stamp.\"\"\"\n older = [m for m in self.cache_msgs if m.header.stamp <= stamp]\n if not older:\n return None\n return older[-1]\n\n def getLastestTime(self):\n \"\"\"Return the newest recorded timestamp.\"\"\"\n if not self.cache_times:\n return None\n return self.cache_times[-1]\n\n def getOldestTime(self):\n \"\"\"Return the oldest recorded timestamp.\"\"\"\n if not self.cache_times:\n return None\n return self.cache_times[0]\n\n\nclass TimeSynchronizer(SimpleFilter):\n\n \"\"\"\n Synchronizes messages by their timestamps.\n\n :class:`TimeSynchronizer` synchronizes incoming message filters by the\n timestamps contained in their messages' headers. TimeSynchronizer\n listens on multiple input message filters ``fs``, and invokes the callback\n when it has a collection of messages with matching timestamps.\n\n The signature of the callback function is::\n\n def callback(msg1, ... msgN):\n\n where N is the number of input message filters, and each message is\n the output of the corresponding filter in ``fs``.\n The required ``queue size`` parameter specifies how many sets of\n messages it should store from each input filter (by timestamp)\n while waiting for messages to arrive and complete their \"set\".\n \"\"\"\n\n def __init__(self, fs, queue_size):\n SimpleFilter.__init__(self)\n self.connectInput(fs)\n self.queue_size = queue_size\n self.lock = threading.Lock()\n\n def connectInput(self, fs):\n self.queues = [{} for f in fs]\n self.input_connections = [f.registerCallback(self.add, q) for (f, q) in zip(fs, self.queues)]\n\n def add(self, msg, my_queue):\n self.lock.acquire()\n my_queue[msg.header.stamp] = msg\n while len(my_queue) > self.queue_size:\n del my_queue[min(my_queue)]\n # common is the set of timestamps that occur in all queues\n common = reduce(set.intersection, [set(q) for q in self.queues])\n for t in sorted(common):\n # msgs is list of msgs (one from each queue) with stamp t\n msgs = [q[t] for q in self.queues]\n self.signalMessage(*msgs)\n for q in self.queues:\n del q[t]\n self.lock.release()\n\nclass ApproximateTimeSynchronizer(TimeSynchronizer):\n\n \"\"\"\n Approximately synchronizes messages by their timestamps.\n\n :class:`ApproximateTimeSynchronizer` synchronizes incoming message filters by the\n timestamps contained in their messages' headers. The API is the same as TimeSynchronizer\n except for an extra `slop` parameter in the constructor that defines the delay (in seconds)\n with which messages can be synchronized\n \"\"\"\n\n def __init__(self, fs, queue_size, slop):\n TimeSynchronizer.__init__(self, fs, queue_size)\n self.slop = rospy.Duration.from_sec(slop)\n\n def add(self, msg, my_queue):\n self.lock.acquire()\n my_queue[msg.header.stamp] = msg\n while len(my_queue) > self.queue_size:\n del my_queue[min(my_queue)]\n for vv in itertools.product(*[list(q.keys()) for q in self.queues]):\n qt = list(zip(self.queues, vv))\n if ( ((max(vv) - min(vv)) < self.slop) and\n (len([1 for q,t in qt if t not in q]) == 0) ):\n msgs = [q[t] for q,t in qt]\n self.signalMessage(*msgs)\n for q,t in qt:\n del q[t]\n self.lock.release()\n", "path": "utilities/message_filters/src/message_filters/__init__.py"}]}
| 3,010 | 101 |
gh_patches_debug_39543
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-2009
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Accordion's active does not work correctly
#### ALL software version info
Python 3.7.6, panel==0.10.3
#### Description of expected behavior and the observed behavior
1. I would expect `accordion.active` to return list of active cards. Now it returns an empty list even if some card is open.
2. Also setting values to `accordion.active` I would expect to open only selected cards. Now it opens selected cards, but does not close the ones that were not selected.
#### Complete, minimal, self-contained example code that reproduces the issue
```python
# based on https://panel.holoviz.org/reference/layouts/Accordion.html
import panel as pn
pn.extension()
from bokeh.plotting import figure
p1 = figure(width=300, height=80, name='Scatter', margin=5)
p1.scatter([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])
p2 = figure(width=300, height=80, name='Line', margin=5)
p2.line([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])
accordion = pn.Accordion(p1, p2)
accordion
```
```
accordion.active
```
```
accordion.active = [0]
```
#### Screenshots or screencasts of the bug in action

</issue>
<code>
[start of panel/layout/card.py]
1 import param
2
3 from ..models import Card as BkCard
4 from .base import Column, Row, ListPanel
5
6
7 class Card(Column):
8 """
9 A Card layout allows arranging multiple panel objects in a
10 collapsible, vertical container with a header bar.
11 """
12
13 active_header_background = param.String(doc="""
14 A valid CSS color for the header background when not collapsed.""")
15
16 button_css_classes = param.List(['card-button'], doc="""
17 CSS classes to apply to the button element.""")
18
19 collapsible = param.Boolean(default=True, doc="""
20 Whether the Card should be expandable and collapsible.""")
21
22 collapsed = param.Boolean(default=False, doc="""
23 Whether the contents of the Card are collapsed.""")
24
25 css_classes = param.List(['card'], doc="""
26 CSS classes to apply to the overall Card.""")
27
28 header = param.Parameter(doc="""
29 A Panel component to display in the header bar of the Card.
30 Will override the given title if defined.""")
31
32 header_background = param.String(doc="""
33 A valid CSS color for the header background.""")
34
35 header_color = param.String(doc="""
36 A valid CSS color to apply to the header text.""")
37
38 header_css_classes = param.List(['card-header'], doc="""
39 CSS classes to apply to the header element.""")
40
41 title_css_classes = param.List(['card-title'], doc="""
42 CSS classes to apply to the header title.""")
43
44 margin = param.Parameter(default=5)
45
46 title = param.String(doc="""
47 A title to be displayed in the Card header, will be overridden
48 by the header if defined.""")
49
50 _bokeh_model = BkCard
51
52 _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)
53
54 def __init__(self, *objects, **params):
55 self._header_layout = Row(css_classes=['card-header-row'],
56 sizing_mode='stretch_width')
57 super().__init__(*objects, **params)
58 self.param.watch(self._update_header, ['title', 'header', 'title_css_classes'])
59 self._update_header()
60
61 def _cleanup(self, root):
62 super()._cleanup(root)
63 self._header_layout._cleanup(root)
64
65 def _process_param_change(self, params):
66 scroll = params.pop('scroll', None)
67 css_classes = self.css_classes or []
68 if scroll:
69 params['css_classes'] = css_classes + ['scrollable']
70 elif scroll == False:
71 params['css_classes'] = css_classes
72 return super(ListPanel, self)._process_param_change(params)
73
74 def _update_header(self, *events):
75 from ..pane import HTML, panel
76 if self.header is None:
77 item = HTML('%s' % (self.title or "​"),
78 css_classes=self.title_css_classes,
79 sizing_mode='stretch_width',
80 margin=(2, 5))
81 else:
82 item = panel(self.header)
83 self._header_layout[:] = [item]
84
85 def _get_objects(self, model, old_objects, doc, root, comm=None):
86 ref = root.ref['id']
87 if ref in self._header_layout._models:
88 header = self._header_layout._models[ref][0]
89 else:
90 header = self._header_layout._get_model(doc, root, model, comm)
91 objects = super()._get_objects(model, old_objects, doc, root, comm)
92 return [header]+objects
93
[end of panel/layout/card.py]
[start of panel/layout/accordion.py]
1 import param
2
3 from bokeh.models import Column as BkColumn, CustomJS
4
5 from .base import NamedListPanel
6 from .card import Card
7
8
9 class Accordion(NamedListPanel):
10
11 active_header_background = param.String(default='#ccc', doc="""
12 Color for currently active headers.""")
13
14 active = param.List(default=[], doc="""
15 List of indexes of active cards.""")
16
17 header_color = param.String(doc="""
18 A valid CSS color to apply to the expand button.""")
19
20 header_background = param.String(doc="""
21 A valid CSS color for the header background.""")
22
23 toggle = param.Boolean(default=False, doc="""
24 Whether to toggle between active cards or allow multiple cards""")
25
26 _bokeh_model = BkColumn
27
28 _rename = {'active': None, 'active_header_background': None,
29 'header_background': None, 'objects': 'children',
30 'dynamic': None, 'toggle': None, 'header_color': None}
31
32 _toggle = """
33 for (var child of accordion.children) {
34 if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {
35 child.collapsed = !cb_obj.collapsed
36 }
37 }
38 """
39
40 _synced_properties = [
41 'active_header_background', 'header_background', 'width',
42 'sizing_mode', 'width_policy', 'height_policy', 'header_color'
43 ]
44
45 def __init__(self, *objects, **params):
46 super().__init__(*objects, **params)
47 self.param.watch(self._update_active, ['active'])
48 self.param.watch(self._update_cards, self._synced_properties)
49
50 def _get_objects(self, model, old_objects, doc, root, comm=None):
51 """
52 Returns new child models for the layout while reusing unchanged
53 models and cleaning up any dropped objects.
54 """
55 from panel.pane.base import RerenderError, panel
56 new_models = []
57 if len(self._names) != len(self):
58 raise ValueError('Accordion names do not match objects, ensure '
59 'that the Tabs.objects are not modified '
60 'directly. Found %d names, expected %d.' %
61 (len(self._names), len(self)))
62 for i, (name, pane) in enumerate(zip(self._names, self)):
63 pane = panel(pane, name=name)
64 self.objects[i] = pane
65
66 for obj in old_objects:
67 if obj not in self.objects:
68 self._panels[id(obj)]._cleanup(root)
69
70 params = {k: v for k, v in self.param.get_param_values()
71 if k in self._synced_properties}
72
73 ref = root.ref['id']
74 current_objects = list(self)
75 for i, (name, pane) in enumerate(zip(self._names, self)):
76 params.update(self._apply_style(i))
77 if id(pane) in self._panels:
78 card = self._panels[id(pane)]
79 else:
80 card = Card(
81 pane, title=name, css_classes=['accordion'],
82 header_css_classes=['accordion-header'],
83 margin=self.margin
84 )
85 self._panels[id(pane)] = card
86 card.param.set_param(**params)
87 if ref in card._models:
88 panel = card._models[ref][0]
89 else:
90 try:
91 panel = card._get_model(doc, root, model, comm)
92 if self.toggle:
93 cb = CustomJS(args={'accordion': model}, code=self._toggle)
94 panel.js_on_change('collapsed', cb)
95 except RerenderError:
96 return self._get_objects(model, current_objects[:i], doc, root, comm)
97
98 new_models.append(panel)
99 self._update_cards()
100 self._update_active()
101 return new_models
102
103 def _cleanup(self, root):
104 for panel in self._panels.values():
105 panel._cleanup(root)
106 super()._cleanup(root)
107
108 def _apply_style(self, i):
109 if i == 0:
110 margin = (5, 5, 0, 5)
111 elif i == (len(self)-1):
112 margin = (0, 5, 5, 5)
113 else:
114 margin = (0, 5, 0, 5)
115 return dict(margin=margin, collapsed = i not in self.active)
116
117 def _update_active(self, *events):
118 for i, pane in enumerate(self.objects):
119 if id(pane) not in self._panels:
120 continue
121 self._panels[id(pane)].collapsed = i not in self.active
122
123 def _update_cards(self, *events):
124 params = {k: v for k, v in self.param.get_param_values()
125 if k in self._synced_properties}
126 for panel in self._panels.values():
127 panel.param.set_param(**params)
128
[end of panel/layout/accordion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/layout/accordion.py b/panel/layout/accordion.py
--- a/panel/layout/accordion.py
+++ b/panel/layout/accordion.py
@@ -44,6 +44,7 @@
def __init__(self, *objects, **params):
super().__init__(*objects, **params)
+ self._updating_active = False
self.param.watch(self._update_active, ['active'])
self.param.watch(self._update_cards, self._synced_properties)
@@ -82,6 +83,7 @@
header_css_classes=['accordion-header'],
margin=self.margin
)
+ card.param.watch(self._set_active, ['collapsed'])
self._panels[id(pane)] = card
card.param.set_param(**params)
if ref in card._models:
@@ -94,7 +96,6 @@
panel.js_on_change('collapsed', cb)
except RerenderError:
return self._get_objects(model, current_objects[:i], doc, root, comm)
-
new_models.append(panel)
self._update_cards()
self._update_active()
@@ -114,11 +115,32 @@
margin = (0, 5, 0, 5)
return dict(margin=margin, collapsed = i not in self.active)
+ def _set_active(self, *events):
+ if self._updating_active:
+ return
+ active = []
+ self._updating_active = True
+ try:
+ for i, pane in enumerate(self.objects):
+ if id(pane) not in self._panels:
+ continue
+ elif not self._panels[id(pane)].collapsed:
+ active.append(i)
+ self.active = active
+ finally:
+ self._updating_active = False
+
def _update_active(self, *events):
- for i, pane in enumerate(self.objects):
- if id(pane) not in self._panels:
- continue
- self._panels[id(pane)].collapsed = i not in self.active
+ if self._updating_active:
+ return
+ self._updating_active = True
+ try:
+ for i, pane in enumerate(self.objects):
+ if id(pane) not in self._panels:
+ continue
+ self._panels[id(pane)].collapsed = i not in self.active
+ finally:
+ self._updating_active = False
def _update_cards(self, *events):
params = {k: v for k, v in self.param.get_param_values()
diff --git a/panel/layout/card.py b/panel/layout/card.py
--- a/panel/layout/card.py
+++ b/panel/layout/card.py
@@ -49,6 +49,8 @@
_bokeh_model = BkCard
+ _linked_props = ['collapsed']
+
_rename = dict(Column._rename, title=None, header=None, title_css_classes=None)
def __init__(self, *objects, **params):
|
{"golden_diff": "diff --git a/panel/layout/accordion.py b/panel/layout/accordion.py\n--- a/panel/layout/accordion.py\n+++ b/panel/layout/accordion.py\n@@ -44,6 +44,7 @@\n \n def __init__(self, *objects, **params):\n super().__init__(*objects, **params)\n+ self._updating_active = False\n self.param.watch(self._update_active, ['active'])\n self.param.watch(self._update_cards, self._synced_properties)\n \n@@ -82,6 +83,7 @@\n header_css_classes=['accordion-header'],\n margin=self.margin\n )\n+ card.param.watch(self._set_active, ['collapsed'])\n self._panels[id(pane)] = card\n card.param.set_param(**params)\n if ref in card._models:\n@@ -94,7 +96,6 @@\n panel.js_on_change('collapsed', cb)\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n- \n new_models.append(panel)\n self._update_cards()\n self._update_active()\n@@ -114,11 +115,32 @@\n margin = (0, 5, 0, 5)\n return dict(margin=margin, collapsed = i not in self.active)\n \n+ def _set_active(self, *events):\n+ if self._updating_active:\n+ return\n+ active = []\n+ self._updating_active = True\n+ try:\n+ for i, pane in enumerate(self.objects):\n+ if id(pane) not in self._panels:\n+ continue\n+ elif not self._panels[id(pane)].collapsed:\n+ active.append(i)\n+ self.active = active\n+ finally:\n+ self._updating_active = False\n+\n def _update_active(self, *events):\n- for i, pane in enumerate(self.objects):\n- if id(pane) not in self._panels:\n- continue\n- self._panels[id(pane)].collapsed = i not in self.active\n+ if self._updating_active:\n+ return\n+ self._updating_active = True\n+ try:\n+ for i, pane in enumerate(self.objects):\n+ if id(pane) not in self._panels:\n+ continue\n+ self._panels[id(pane)].collapsed = i not in self.active\n+ finally:\n+ self._updating_active = False\n \n def _update_cards(self, *events):\n params = {k: v for k, v in self.param.get_param_values()\ndiff --git a/panel/layout/card.py b/panel/layout/card.py\n--- a/panel/layout/card.py\n+++ b/panel/layout/card.py\n@@ -49,6 +49,8 @@\n \n _bokeh_model = BkCard\n \n+ _linked_props = ['collapsed']\n+\n _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)\n \n def __init__(self, *objects, **params):\n", "issue": "Accordion's active does not work correctly\n#### ALL software version info\r\nPython 3.7.6, panel==0.10.3\r\n\r\n#### Description of expected behavior and the observed behavior\r\n1. I would expect `accordion.active` to return list of active cards. Now it returns an empty list even if some card is open.\r\n2. Also setting values to `accordion.active` I would expect to open only selected cards. Now it opens selected cards, but does not close the ones that were not selected.\r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\n```python\r\n# based on https://panel.holoviz.org/reference/layouts/Accordion.html\r\nimport panel as pn\r\npn.extension()\r\n\r\nfrom bokeh.plotting import figure\r\n\r\np1 = figure(width=300, height=80, name='Scatter', margin=5)\r\np1.scatter([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])\r\n\r\np2 = figure(width=300, height=80, name='Line', margin=5)\r\np2.line([0, 1, 2, 3, 4, 5, 6], [0, 1, 2, 3, 2, 1, 0])\r\n\r\naccordion = pn.Accordion(p1, p2)\r\naccordion\r\n\r\n```\r\n\r\n```\r\naccordion.active\r\n```\r\n\r\n```\r\naccordion.active = [0]\r\n```\r\n\r\n#### Screenshots or screencasts of the bug in action\r\n\r\n\n", "before_files": [{"content": "import param\n\nfrom ..models import Card as BkCard\nfrom .base import Column, Row, ListPanel\n\n\nclass Card(Column):\n \"\"\"\n A Card layout allows arranging multiple panel objects in a\n collapsible, vertical container with a header bar.\n \"\"\"\n\n active_header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background when not collapsed.\"\"\")\n\n button_css_classes = param.List(['card-button'], doc=\"\"\"\n CSS classes to apply to the button element.\"\"\")\n\n collapsible = param.Boolean(default=True, doc=\"\"\"\n Whether the Card should be expandable and collapsible.\"\"\")\n\n collapsed = param.Boolean(default=False, doc=\"\"\"\n Whether the contents of the Card are collapsed.\"\"\")\n\n css_classes = param.List(['card'], doc=\"\"\"\n CSS classes to apply to the overall Card.\"\"\")\n\n header = param.Parameter(doc=\"\"\"\n A Panel component to display in the header bar of the Card.\n Will override the given title if defined.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the header text.\"\"\")\n\n header_css_classes = param.List(['card-header'], doc=\"\"\"\n CSS classes to apply to the header element.\"\"\")\n\n title_css_classes = param.List(['card-title'], doc=\"\"\"\n CSS classes to apply to the header title.\"\"\")\n\n margin = param.Parameter(default=5)\n\n title = param.String(doc=\"\"\"\n A title to be displayed in the Card header, will be overridden\n by the header if defined.\"\"\")\n\n _bokeh_model = BkCard\n \n _rename = dict(Column._rename, title=None, header=None, title_css_classes=None)\n\n def __init__(self, *objects, **params):\n self._header_layout = Row(css_classes=['card-header-row'],\n sizing_mode='stretch_width')\n super().__init__(*objects, **params)\n self.param.watch(self._update_header, ['title', 'header', 'title_css_classes'])\n self._update_header()\n\n def _cleanup(self, root):\n super()._cleanup(root)\n self._header_layout._cleanup(root)\n\n def _process_param_change(self, params):\n scroll = params.pop('scroll', None)\n css_classes = self.css_classes or []\n if scroll:\n params['css_classes'] = css_classes + ['scrollable']\n elif scroll == False:\n params['css_classes'] = css_classes\n return super(ListPanel, self)._process_param_change(params)\n\n def _update_header(self, *events):\n from ..pane import HTML, panel\n if self.header is None:\n item = HTML('%s' % (self.title or \"​\"),\n css_classes=self.title_css_classes,\n sizing_mode='stretch_width',\n margin=(2, 5))\n else:\n item = panel(self.header)\n self._header_layout[:] = [item]\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n ref = root.ref['id']\n if ref in self._header_layout._models:\n header = self._header_layout._models[ref][0]\n else:\n header = self._header_layout._get_model(doc, root, model, comm)\n objects = super()._get_objects(model, old_objects, doc, root, comm)\n return [header]+objects\n", "path": "panel/layout/card.py"}, {"content": "import param\n\nfrom bokeh.models import Column as BkColumn, CustomJS\n\nfrom .base import NamedListPanel\nfrom .card import Card\n\n\nclass Accordion(NamedListPanel):\n \n active_header_background = param.String(default='#ccc', doc=\"\"\"\n Color for currently active headers.\"\"\")\n\n active = param.List(default=[], doc=\"\"\"\n List of indexes of active cards.\"\"\")\n\n header_color = param.String(doc=\"\"\"\n A valid CSS color to apply to the expand button.\"\"\")\n\n header_background = param.String(doc=\"\"\"\n A valid CSS color for the header background.\"\"\")\n\n toggle = param.Boolean(default=False, doc=\"\"\"\n Whether to toggle between active cards or allow multiple cards\"\"\")\n\n _bokeh_model = BkColumn\n \n _rename = {'active': None, 'active_header_background': None,\n 'header_background': None, 'objects': 'children',\n 'dynamic': None, 'toggle': None, 'header_color': None}\n\n _toggle = \"\"\"\n for (var child of accordion.children) {\n if ((child.id !== cb_obj.id) && (child.collapsed == cb_obj.collapsed) && !cb_obj.collapsed) {\n child.collapsed = !cb_obj.collapsed\n }\n }\n \"\"\"\n\n _synced_properties = [\n 'active_header_background', 'header_background', 'width',\n 'sizing_mode', 'width_policy', 'height_policy', 'header_color'\n ]\n\n def __init__(self, *objects, **params):\n super().__init__(*objects, **params)\n self.param.watch(self._update_active, ['active'])\n self.param.watch(self._update_cards, self._synced_properties)\n\n def _get_objects(self, model, old_objects, doc, root, comm=None):\n \"\"\"\n Returns new child models for the layout while reusing unchanged\n models and cleaning up any dropped objects.\n \"\"\"\n from panel.pane.base import RerenderError, panel\n new_models = []\n if len(self._names) != len(self):\n raise ValueError('Accordion names do not match objects, ensure '\n 'that the Tabs.objects are not modified '\n 'directly. Found %d names, expected %d.' %\n (len(self._names), len(self)))\n for i, (name, pane) in enumerate(zip(self._names, self)):\n pane = panel(pane, name=name)\n self.objects[i] = pane\n\n for obj in old_objects:\n if obj not in self.objects:\n self._panels[id(obj)]._cleanup(root)\n\n params = {k: v for k, v in self.param.get_param_values()\n if k in self._synced_properties}\n\n ref = root.ref['id']\n current_objects = list(self)\n for i, (name, pane) in enumerate(zip(self._names, self)):\n params.update(self._apply_style(i))\n if id(pane) in self._panels:\n card = self._panels[id(pane)]\n else:\n card = Card(\n pane, title=name, css_classes=['accordion'],\n header_css_classes=['accordion-header'],\n margin=self.margin\n )\n self._panels[id(pane)] = card\n card.param.set_param(**params)\n if ref in card._models:\n panel = card._models[ref][0]\n else:\n try:\n panel = card._get_model(doc, root, model, comm)\n if self.toggle:\n cb = CustomJS(args={'accordion': model}, code=self._toggle)\n panel.js_on_change('collapsed', cb)\n except RerenderError:\n return self._get_objects(model, current_objects[:i], doc, root, comm)\n \n new_models.append(panel)\n self._update_cards()\n self._update_active()\n return new_models\n\n def _cleanup(self, root):\n for panel in self._panels.values():\n panel._cleanup(root)\n super()._cleanup(root)\n\n def _apply_style(self, i):\n if i == 0:\n margin = (5, 5, 0, 5)\n elif i == (len(self)-1):\n margin = (0, 5, 5, 5)\n else:\n margin = (0, 5, 0, 5)\n return dict(margin=margin, collapsed = i not in self.active)\n\n def _update_active(self, *events):\n for i, pane in enumerate(self.objects):\n if id(pane) not in self._panels:\n continue\n self._panels[id(pane)].collapsed = i not in self.active\n\n def _update_cards(self, *events):\n params = {k: v for k, v in self.param.get_param_values()\n if k in self._synced_properties}\n for panel in self._panels.values():\n panel.param.set_param(**params)\n", "path": "panel/layout/accordion.py"}]}
| 3,220 | 666 |
gh_patches_debug_14871
|
rasdani/github-patches
|
git_diff
|
liqd__a4-meinberlin-2610
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
preview in text commenting does not work
URL: https://meinberlin-dev.liqd.net/dashboard/projects/textkommentierung/basic/
user: initiator
expected behaviour: should be able to see preview
behaviour: get 405 error
Comment/Question: I checked brainstorming and it works. After I enter content for the document it also works, so I guess it has to do with the module text commenting. We also have the problem on prod, so I guess we need a hot fix.
</issue>
<code>
[start of meinberlin/apps/documents/views.py]
1 from django.http import Http404
2 from django.urls import reverse
3 from django.utils.functional import cached_property
4 from django.utils.translation import ugettext_lazy as _
5 from django.views import generic
6
7 from adhocracy4.dashboard import mixins as dashboard_mixins
8 from adhocracy4.projects.mixins import DisplayProjectOrModuleMixin
9 from adhocracy4.projects.mixins import ProjectMixin
10 from adhocracy4.rules import mixins as rules_mixins
11 from meinberlin.apps.exports.views import DashboardExportView
12
13 from . import models
14
15
16 class DocumentDashboardView(ProjectMixin,
17 dashboard_mixins.DashboardBaseMixin,
18 dashboard_mixins.DashboardComponentMixin,
19 generic.TemplateView):
20 template_name = 'meinberlin_documents/document_dashboard.html'
21 permission_required = 'a4projects.change_project'
22
23 def get_permission_object(self):
24 return self.project
25
26
27 class ChapterDetailView(ProjectMixin,
28 rules_mixins.PermissionRequiredMixin,
29 generic.DetailView,
30 DisplayProjectOrModuleMixin):
31 model = models.Chapter
32 permission_required = 'meinberlin_documents.view_chapter'
33 get_context_from_object = True
34
35 def get_context_data(self, **kwargs):
36 context = super().get_context_data(**kwargs)
37 context['chapter_list'] = self.chapter_list
38 return context
39
40 @property
41 def chapter_list(self):
42 return models.Chapter.objects.filter(module=self.module)
43
44 @cached_property
45 def extends(self):
46 if self.url_name == 'module-detail':
47 return 'a4modules/module_detail.html'
48 if self.url_name == 'chapter-detail':
49 if self.module.is_in_module_cluster:
50 return 'a4modules/module_detail.html'
51 return 'a4projects/project_detail.html'
52
53
54 class DocumentDetailView(ChapterDetailView):
55 get_context_from_object = False
56
57 def get_object(self):
58 first_chapter = models.Chapter.objects \
59 .filter(module=self.module) \
60 .first()
61
62 if not first_chapter:
63 raise Http404(_('Document has no chapters defined.'))
64 return first_chapter
65
66
67 class ParagraphDetailView(ProjectMixin,
68 rules_mixins.PermissionRequiredMixin,
69 generic.DetailView):
70 model = models.Paragraph
71 permission_required = 'meinberlin_documents.view_paragraph'
72
73
74 class DocumentDashboardExportView(DashboardExportView):
75 template_name = 'meinberlin_exports/export_dashboard.html'
76
77 def get_context_data(self, **kwargs):
78 context = super().get_context_data(**kwargs)
79 context['comment_export'] = reverse(
80 'a4dashboard:document-comment-export',
81 kwargs={'module_slug': self.module.slug})
82 return context
83
[end of meinberlin/apps/documents/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/meinberlin/apps/documents/views.py b/meinberlin/apps/documents/views.py
--- a/meinberlin/apps/documents/views.py
+++ b/meinberlin/apps/documents/views.py
@@ -1,7 +1,5 @@
-from django.http import Http404
from django.urls import reverse
from django.utils.functional import cached_property
-from django.utils.translation import ugettext_lazy as _
from django.views import generic
from adhocracy4.dashboard import mixins as dashboard_mixins
@@ -58,9 +56,6 @@
first_chapter = models.Chapter.objects \
.filter(module=self.module) \
.first()
-
- if not first_chapter:
- raise Http404(_('Document has no chapters defined.'))
return first_chapter
|
{"golden_diff": "diff --git a/meinberlin/apps/documents/views.py b/meinberlin/apps/documents/views.py\n--- a/meinberlin/apps/documents/views.py\n+++ b/meinberlin/apps/documents/views.py\n@@ -1,7 +1,5 @@\n-from django.http import Http404\n from django.urls import reverse\n from django.utils.functional import cached_property\n-from django.utils.translation import ugettext_lazy as _\n from django.views import generic\n \n from adhocracy4.dashboard import mixins as dashboard_mixins\n@@ -58,9 +56,6 @@\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n-\n- if not first_chapter:\n- raise Http404(_('Document has no chapters defined.'))\n return first_chapter\n", "issue": "preview in text commenting does not work\nURL: https://meinberlin-dev.liqd.net/dashboard/projects/textkommentierung/basic/\r\nuser: initiator\r\nexpected behaviour: should be able to see preview\r\nbehaviour: get 405 error\r\nComment/Question: I checked brainstorming and it works. After I enter content for the document it also works, so I guess it has to do with the module text commenting. We also have the problem on prod, so I guess we need a hot fix.\n", "before_files": [{"content": "from django.http import Http404\nfrom django.urls import reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views import generic\n\nfrom adhocracy4.dashboard import mixins as dashboard_mixins\nfrom adhocracy4.projects.mixins import DisplayProjectOrModuleMixin\nfrom adhocracy4.projects.mixins import ProjectMixin\nfrom adhocracy4.rules import mixins as rules_mixins\nfrom meinberlin.apps.exports.views import DashboardExportView\n\nfrom . import models\n\n\nclass DocumentDashboardView(ProjectMixin,\n dashboard_mixins.DashboardBaseMixin,\n dashboard_mixins.DashboardComponentMixin,\n generic.TemplateView):\n template_name = 'meinberlin_documents/document_dashboard.html'\n permission_required = 'a4projects.change_project'\n\n def get_permission_object(self):\n return self.project\n\n\nclass ChapterDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView,\n DisplayProjectOrModuleMixin):\n model = models.Chapter\n permission_required = 'meinberlin_documents.view_chapter'\n get_context_from_object = True\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['chapter_list'] = self.chapter_list\n return context\n\n @property\n def chapter_list(self):\n return models.Chapter.objects.filter(module=self.module)\n\n @cached_property\n def extends(self):\n if self.url_name == 'module-detail':\n return 'a4modules/module_detail.html'\n if self.url_name == 'chapter-detail':\n if self.module.is_in_module_cluster:\n return 'a4modules/module_detail.html'\n return 'a4projects/project_detail.html'\n\n\nclass DocumentDetailView(ChapterDetailView):\n get_context_from_object = False\n\n def get_object(self):\n first_chapter = models.Chapter.objects \\\n .filter(module=self.module) \\\n .first()\n\n if not first_chapter:\n raise Http404(_('Document has no chapters defined.'))\n return first_chapter\n\n\nclass ParagraphDetailView(ProjectMixin,\n rules_mixins.PermissionRequiredMixin,\n generic.DetailView):\n model = models.Paragraph\n permission_required = 'meinberlin_documents.view_paragraph'\n\n\nclass DocumentDashboardExportView(DashboardExportView):\n template_name = 'meinberlin_exports/export_dashboard.html'\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['comment_export'] = reverse(\n 'a4dashboard:document-comment-export',\n kwargs={'module_slug': self.module.slug})\n return context\n", "path": "meinberlin/apps/documents/views.py"}]}
| 1,362 | 170 |
gh_patches_debug_8603
|
rasdani/github-patches
|
git_diff
|
pulp__pulpcore-272
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update CI files for branch 3.22
</issue>
<code>
[start of pulpcore/app/settings.py]
1 """
2 Django settings for the Pulp Platform application
3
4 Never import this module directly, instead `from django.conf import settings`, see
5 https://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code
6
7 For the full list of settings and their values, see
8 https://docs.djangoproject.com/en/1.11/ref/settings/
9 """
10
11 import os
12 from contextlib import suppress
13 from importlib import import_module
14 from pkg_resources import iter_entry_points
15
16 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
17 BASE_DIR = os.path.dirname(os.path.abspath(__file__))
18
19 # Quick-start development settings - unsuitable for production
20 # See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/
21
22 # SECURITY WARNING: don't run with debug turned on in production!
23 DEBUG = False
24
25 ALLOWED_HOSTS = ['*']
26
27 MEDIA_ROOT = '/var/lib/pulp/'
28 STATIC_ROOT = os.path.join(MEDIA_ROOT, 'static/')
29
30 DEFAULT_FILE_STORAGE = 'pulpcore.app.models.storage.FileSystem'
31
32 FILE_UPLOAD_TEMP_DIR = os.path.join(MEDIA_ROOT, 'tmp/')
33 WORKING_DIRECTORY = os.path.join(MEDIA_ROOT, 'tmp/')
34
35 # List of upload handler classes to be applied in order.
36 FILE_UPLOAD_HANDLERS = ('pulpcore.app.files.HashingFileUploadHandler',)
37
38 SECRET_KEY = True
39
40 # Application definition
41
42 INSTALLED_APPS = [
43 # django stuff
44 'django.contrib.admin',
45 'django.contrib.auth',
46 'django.contrib.contenttypes',
47 'django.contrib.sessions',
48 'django.contrib.messages',
49 'django.contrib.staticfiles',
50 # third-party
51 'django_filters',
52 'drf_yasg',
53 'rest_framework',
54 # pulp core app
55 'pulpcore.app',
56 ]
57
58 # Enumerate the installed Pulp plugins during the loading process for use in the status API
59 INSTALLED_PULP_PLUGINS = []
60
61 for entry_point in iter_entry_points('pulpcore.plugin'):
62 plugin_app_config = entry_point.load()
63 INSTALLED_PULP_PLUGINS.append(entry_point.module_name)
64 INSTALLED_APPS.append(plugin_app_config)
65
66 # Optional apps that help with development, or augment Pulp in some non-critical way
67 OPTIONAL_APPS = [
68 'crispy_forms',
69 'django_extensions',
70 'storages',
71 ]
72
73 for app in OPTIONAL_APPS:
74 # only import if app is installed
75 with suppress(ImportError):
76 import_module(app)
77 INSTALLED_APPS.append(app)
78
79 MIDDLEWARE = [
80 'django.middleware.security.SecurityMiddleware',
81 'whitenoise.middleware.WhiteNoiseMiddleware',
82 'django.contrib.sessions.middleware.SessionMiddleware',
83 'django.middleware.common.CommonMiddleware',
84 'django.middleware.csrf.CsrfViewMiddleware',
85 'django.contrib.auth.middleware.AuthenticationMiddleware',
86 'pulpcore.app.middleware.PulpRemoteUserMiddleware',
87 'django.contrib.messages.middleware.MessageMiddleware',
88 'django.middleware.clickjacking.XFrameOptionsMiddleware',
89 ]
90
91 AUTHENTICATION_BACKENDS = [
92 'django.contrib.auth.backends.ModelBackend',
93 'django.contrib.auth.backends.RemoteUserBackend',
94 ]
95
96 ROOT_URLCONF = 'pulpcore.app.urls'
97
98 TEMPLATES = [
99 {
100 'BACKEND': 'django.template.backends.django.DjangoTemplates',
101 'DIRS': [os.path.join(BASE_DIR, 'templates')],
102 'APP_DIRS': True,
103 'OPTIONS': {
104 'context_processors': [
105 'django.template.context_processors.debug',
106 'django.template.context_processors.request',
107 'django.contrib.auth.context_processors.auth',
108 'django.contrib.messages.context_processors.messages',
109 ],
110 },
111 },
112 ]
113
114 WSGI_APPLICATION = 'pulpcore.app.wsgi.application'
115
116 REST_FRAMEWORK = {
117 'URL_FIELD_NAME': '_href',
118 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),
119 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
120 'PAGE_SIZE': 100,
121 'DEFAULT_PERMISSION_CLASSES': ('rest_framework.permissions.IsAuthenticated',),
122 'DEFAULT_AUTHENTICATION_CLASSES': (
123 'rest_framework.authentication.SessionAuthentication',
124 'rest_framework.authentication.RemoteUserAuthentication',
125 'rest_framework.authentication.BasicAuthentication',
126 ),
127 'UPLOADED_FILES_USE_URL': False,
128 'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',
129 }
130
131 # Password validation
132 # https://docs.djangoproject.com/en/dev/ref/settings/#auth-password-validators
133
134 AUTH_PASSWORD_VALIDATORS = [
135 {
136 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',
137 },
138 {
139 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',
140 },
141 {
142 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',
143 },
144 {
145 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',
146 },
147 ]
148
149
150 # Internationalization
151 # https://docs.djangoproject.com/en/1.11/topics/i18n/
152
153 LANGUAGE_CODE = 'en-us'
154
155 TIME_ZONE = 'UTC'
156
157 USE_I18N = 'USE_I18N', True
158
159 USE_L10N = True
160
161 USE_TZ = True
162
163
164 # Static files (CSS, JavaScript, Images)
165 # https://docs.djangoproject.com/en/1.11/howto/static-files/
166
167 STATIC_URL = '/static/'
168
169 # A set of default settings to use if the configuration file in
170 # /etc/pulp/ is missing or if it does not have values for every setting
171
172 # https://docs.djangoproject.com/en/1.11/ref/settings/#databases
173 DATABASES = {
174 'default': {
175 'ENGINE': 'django.db.backends.postgresql_psycopg2',
176 'NAME': 'pulp',
177 'USER': 'pulp',
178 'CONN_MAX_AGE': 0,
179 },
180 }
181 # https://docs.djangoproject.com/en/1.11/ref/settings/#logging and
182 # https://docs.python.org/3/library/logging.config.html
183 LOGGING = {
184 'version': 1,
185 'disable_existing_loggers': False,
186 'formatters': {
187 'simple': {'format': 'pulp: %(name)s:%(levelname)s: %(message)s'},
188 },
189 'handlers': {
190 'console': {
191 'class': 'logging.StreamHandler',
192 'formatter': 'simple'
193 }
194 },
195 'loggers': {
196 '': {
197 # The root logger
198 'handlers': ['console'],
199 'level': 'INFO'
200 },
201 }
202 }
203
204 CONTENT_HOST = ''
205 CONTENT_PATH_PREFIX = '/pulp/content/'
206 CONTENT_APP_TTL = 30
207
208 REMOTE_USER_ENVIRON_NAME = "REMOTE_USER"
209
210 PROFILE_STAGES_API = False
211
212 SWAGGER_SETTINGS = {
213 'DEFAULT_GENERATOR_CLASS': 'pulpcore.app.openapigenerator.PulpOpenAPISchemaGenerator',
214 'DEFAULT_AUTO_SCHEMA_CLASS': 'pulpcore.app.openapigenerator.PulpAutoSchema',
215 'DEFAULT_INFO': 'pulpcore.app.urls.api_info',
216 }
217
218 # HERE STARTS DYNACONF EXTENSION LOAD (Keep at the very bottom of settings.py)
219 # Read more at https://dynaconf.readthedocs.io/en/latest/guides/django.html
220 import dynaconf # noqa
221 settings = dynaconf.DjangoDynaconf(
222 __name__,
223 GLOBAL_ENV_FOR_DYNACONF='PULP',
224 ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',
225 SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',
226 INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],
227 ENVVAR_FOR_DYNACONF='PULP_SETTINGS',
228 )
229 # HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)
230
[end of pulpcore/app/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pulpcore/app/settings.py b/pulpcore/app/settings.py
--- a/pulpcore/app/settings.py
+++ b/pulpcore/app/settings.py
@@ -223,7 +223,10 @@
GLOBAL_ENV_FOR_DYNACONF='PULP',
ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',
SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',
- INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],
+ INCLUDES_FOR_DYNACONF=[
+ '{}.app.settings'.format(plugin_name)
+ for plugin_name in INSTALLED_PULP_PLUGINS
+ ],
ENVVAR_FOR_DYNACONF='PULP_SETTINGS',
)
# HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)
|
{"golden_diff": "diff --git a/pulpcore/app/settings.py b/pulpcore/app/settings.py\n--- a/pulpcore/app/settings.py\n+++ b/pulpcore/app/settings.py\n@@ -223,7 +223,10 @@\n GLOBAL_ENV_FOR_DYNACONF='PULP',\n ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',\n SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',\n- INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],\n+ INCLUDES_FOR_DYNACONF=[\n+ '{}.app.settings'.format(plugin_name)\n+ for plugin_name in INSTALLED_PULP_PLUGINS\n+ ],\n ENVVAR_FOR_DYNACONF='PULP_SETTINGS',\n )\n # HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)\n", "issue": "Update CI files for branch 3.22\n\n", "before_files": [{"content": "\"\"\"\nDjango settings for the Pulp Platform application\n\nNever import this module directly, instead `from django.conf import settings`, see\nhttps://docs.djangoproject.com/en/1.11/topics/settings/#using-settings-in-python-code\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/1.11/ref/settings/\n\"\"\"\n\nimport os\nfrom contextlib import suppress\nfrom importlib import import_module\nfrom pkg_resources import iter_entry_points\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/1.11/howto/deployment/checklist/\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = False\n\nALLOWED_HOSTS = ['*']\n\nMEDIA_ROOT = '/var/lib/pulp/'\nSTATIC_ROOT = os.path.join(MEDIA_ROOT, 'static/')\n\nDEFAULT_FILE_STORAGE = 'pulpcore.app.models.storage.FileSystem'\n\nFILE_UPLOAD_TEMP_DIR = os.path.join(MEDIA_ROOT, 'tmp/')\nWORKING_DIRECTORY = os.path.join(MEDIA_ROOT, 'tmp/')\n\n# List of upload handler classes to be applied in order.\nFILE_UPLOAD_HANDLERS = ('pulpcore.app.files.HashingFileUploadHandler',)\n\nSECRET_KEY = True\n\n# Application definition\n\nINSTALLED_APPS = [\n # django stuff\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n # third-party\n 'django_filters',\n 'drf_yasg',\n 'rest_framework',\n # pulp core app\n 'pulpcore.app',\n]\n\n# Enumerate the installed Pulp plugins during the loading process for use in the status API\nINSTALLED_PULP_PLUGINS = []\n\nfor entry_point in iter_entry_points('pulpcore.plugin'):\n plugin_app_config = entry_point.load()\n INSTALLED_PULP_PLUGINS.append(entry_point.module_name)\n INSTALLED_APPS.append(plugin_app_config)\n\n# Optional apps that help with development, or augment Pulp in some non-critical way\nOPTIONAL_APPS = [\n 'crispy_forms',\n 'django_extensions',\n 'storages',\n]\n\nfor app in OPTIONAL_APPS:\n # only import if app is installed\n with suppress(ImportError):\n import_module(app)\n INSTALLED_APPS.append(app)\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'whitenoise.middleware.WhiteNoiseMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'pulpcore.app.middleware.PulpRemoteUserMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nAUTHENTICATION_BACKENDS = [\n 'django.contrib.auth.backends.ModelBackend',\n 'django.contrib.auth.backends.RemoteUserBackend',\n]\n\nROOT_URLCONF = 'pulpcore.app.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [os.path.join(BASE_DIR, 'templates')],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'pulpcore.app.wsgi.application'\n\nREST_FRAMEWORK = {\n 'URL_FIELD_NAME': '_href',\n 'DEFAULT_FILTER_BACKENDS': ('django_filters.rest_framework.DjangoFilterBackend',),\n 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',\n 'PAGE_SIZE': 100,\n 'DEFAULT_PERMISSION_CLASSES': ('rest_framework.permissions.IsAuthenticated',),\n 'DEFAULT_AUTHENTICATION_CLASSES': (\n 'rest_framework.authentication.SessionAuthentication',\n 'rest_framework.authentication.RemoteUserAuthentication',\n 'rest_framework.authentication.BasicAuthentication',\n ),\n 'UPLOADED_FILES_USE_URL': False,\n 'DEFAULT_VERSIONING_CLASS': 'rest_framework.versioning.URLPathVersioning',\n}\n\n# Password validation\n# https://docs.djangoproject.com/en/dev/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n# https://docs.djangoproject.com/en/1.11/topics/i18n/\n\nLANGUAGE_CODE = 'en-us'\n\nTIME_ZONE = 'UTC'\n\nUSE_I18N = 'USE_I18N', True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/1.11/howto/static-files/\n\nSTATIC_URL = '/static/'\n\n# A set of default settings to use if the configuration file in\n# /etc/pulp/ is missing or if it does not have values for every setting\n\n# https://docs.djangoproject.com/en/1.11/ref/settings/#databases\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.postgresql_psycopg2',\n 'NAME': 'pulp',\n 'USER': 'pulp',\n 'CONN_MAX_AGE': 0,\n },\n}\n# https://docs.djangoproject.com/en/1.11/ref/settings/#logging and\n# https://docs.python.org/3/library/logging.config.html\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'formatters': {\n 'simple': {'format': 'pulp: %(name)s:%(levelname)s: %(message)s'},\n },\n 'handlers': {\n 'console': {\n 'class': 'logging.StreamHandler',\n 'formatter': 'simple'\n }\n },\n 'loggers': {\n '': {\n # The root logger\n 'handlers': ['console'],\n 'level': 'INFO'\n },\n }\n}\n\nCONTENT_HOST = ''\nCONTENT_PATH_PREFIX = '/pulp/content/'\nCONTENT_APP_TTL = 30\n\nREMOTE_USER_ENVIRON_NAME = \"REMOTE_USER\"\n\nPROFILE_STAGES_API = False\n\nSWAGGER_SETTINGS = {\n 'DEFAULT_GENERATOR_CLASS': 'pulpcore.app.openapigenerator.PulpOpenAPISchemaGenerator',\n 'DEFAULT_AUTO_SCHEMA_CLASS': 'pulpcore.app.openapigenerator.PulpAutoSchema',\n 'DEFAULT_INFO': 'pulpcore.app.urls.api_info',\n}\n\n# HERE STARTS DYNACONF EXTENSION LOAD (Keep at the very bottom of settings.py)\n# Read more at https://dynaconf.readthedocs.io/en/latest/guides/django.html\nimport dynaconf # noqa\nsettings = dynaconf.DjangoDynaconf(\n __name__,\n GLOBAL_ENV_FOR_DYNACONF='PULP',\n ENV_SWITCHER_FOR_DYNACONF='PULP_ENV',\n SETTINGS_MODULE_FOR_DYNACONF='/etc/pulp/settings.py',\n INCLUDES_FOR_DYNACONF=['/etc/pulp/plugins/*'],\n ENVVAR_FOR_DYNACONF='PULP_SETTINGS',\n)\n# HERE ENDS DYNACONF EXTENSION LOAD (No more code below this line)\n", "path": "pulpcore/app/settings.py"}]}
| 2,790 | 190 |
gh_patches_debug_598
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1733
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.82
On the docket:
+ [x] Pex resolve checking does not allow resolved pre-releases when --no-pre. #1730
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.81"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.81"
+__version__ = "2.1.82"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.81\"\n+__version__ = \"2.1.82\"\n", "issue": "Release 2.1.82\nOn the docket:\r\n+ [x] Pex resolve checking does not allow resolved pre-releases when --no-pre. #1730 \n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.81\"\n", "path": "pex/version.py"}]}
| 622 | 96 |
gh_patches_debug_66995
|
rasdani/github-patches
|
git_diff
|
spack__spack-12972
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Automatically use Python 3 if available
As discussed during today's BoF, some people would like Spack to use Python 3 if available. Since we cannot depend on any version of Python being available on all systems, this needs a slightly complex approach: The spack binary is moved to spack-real and replaced by a shell script that checks for available versions of Python (preferring Python 3) and invokes spack-real accordingly.
This should also take care of the situation where no python binary is available (as will be on RHEL 8 by default).
Not sure if this is really the best way to go but I have been meaning to take a stab at this for a while now. (Only tested on Linux.)
@tgamblin @alalazo @becker33 @adamjstewart
</issue>
<code>
[start of lib/spack/spack/cmd/license.py]
1 # Copyright 2013-2019 Lawrence Livermore National Security, LLC and other
2 # Spack Project Developers. See the top-level COPYRIGHT file for details.
3 #
4 # SPDX-License-Identifier: (Apache-2.0 OR MIT)
5
6 from __future__ import print_function
7
8 import os
9 import re
10 from collections import defaultdict
11
12 import llnl.util.tty as tty
13
14 import spack.paths
15 from spack.util.executable import which
16
17 description = 'list and check license headers on files in spack'
18 section = "developer"
19 level = "long"
20
21 #: need the git command to check new files
22 git = which('git')
23
24 #: SPDX license id must appear in the first <license_lines> lines of a file
25 license_lines = 6
26
27 #: Spack's license identifier
28 apache2_mit_spdx = "(Apache-2.0 OR MIT)"
29
30 #: regular expressions for licensed files.
31 licensed_files = [
32 # spack scripts
33 r'^bin/spack$',
34 r'^bin/spack-python$',
35 r'^bin/sbang$',
36
37 # all of spack core
38 r'^lib/spack/spack/.*\.py$',
39 r'^lib/spack/spack/.*\.sh$',
40 r'^lib/spack/llnl/.*\.py$',
41 r'^lib/spack/env/cc$',
42
43 # rst files in documentation
44 r'^lib/spack/docs/(?!command_index|spack|llnl).*\.rst$',
45 r'^lib/spack/docs/.*\.py$',
46
47 # 2 files in external
48 r'^lib/spack/external/__init__.py$',
49 r'^lib/spack/external/ordereddict_backport.py$',
50
51 # shell scripts in share
52 r'^share/spack/.*\.sh$',
53 r'^share/spack/.*\.bash$',
54 r'^share/spack/.*\.csh$',
55 r'^share/spack/qa/run-[^/]*$',
56
57 # all packages
58 r'^var/spack/repos/.*/package.py$'
59 ]
60
61 #: licensed files that can have LGPL language in them
62 #: so far, just this command -- so it can find LGPL things elsewhere
63 lgpl_exceptions = [
64 r'lib/spack/spack/cmd/license.py',
65 r'lib/spack/spack/test/cmd/license.py',
66 ]
67
68
69 def _all_spack_files(root=spack.paths.prefix):
70 """Generates root-relative paths of all files in the spack repository."""
71 visited = set()
72 for cur_root, folders, files in os.walk(root):
73 for filename in files:
74 path = os.path.realpath(os.path.join(cur_root, filename))
75
76 if path not in visited:
77 yield os.path.relpath(path, root)
78 visited.add(path)
79
80
81 def _licensed_files(root=spack.paths.prefix):
82 for relpath in _all_spack_files(root):
83 if any(regex.match(relpath) for regex in licensed_files):
84 yield relpath
85
86
87 def list_files(args):
88 """list files in spack that should have license headers"""
89 for relpath in sorted(_licensed_files()):
90 print(os.path.join(spack.paths.spack_root, relpath))
91
92
93 # Error codes for license verification. All values are chosen such that
94 # bool(value) evaluates to True
95 OLD_LICENSE, SPDX_MISMATCH, GENERAL_MISMATCH = range(1, 4)
96
97
98 class LicenseError(object):
99 def __init__(self):
100 self.error_counts = defaultdict(int)
101
102 def add_error(self, error):
103 self.error_counts[error] += 1
104
105 def has_errors(self):
106 return sum(self.error_counts.values()) > 0
107
108 def error_messages(self):
109 total = sum(self.error_counts.values())
110 missing = self.error_counts[GENERAL_MISMATCH]
111 spdx_mismatch = self.error_counts[SPDX_MISMATCH]
112 old_license = self.error_counts[OLD_LICENSE]
113 return (
114 '%d improperly licensed files' % (total),
115 'files with wrong SPDX-License-Identifier: %d' % spdx_mismatch,
116 'files with old license header: %d' % old_license,
117 'files not containing expected license: %d' % missing)
118
119
120 def _check_license(lines, path):
121 license_lines = [
122 r'Copyright 2013-(?:201[789]|202\d) Lawrence Livermore National Security, LLC and other', # noqa: E501
123 r'Spack Project Developers\. See the top-level COPYRIGHT file for details.', # noqa: E501
124 r'SPDX-License-Identifier: \(Apache-2\.0 OR MIT\)'
125 ]
126
127 strict_date = r'Copyright 2013-2019'
128
129 found = []
130
131 for line in lines:
132 line = re.sub(r'^[\s#\.]*', '', line)
133 line = line.rstrip()
134 for i, license_line in enumerate(license_lines):
135 if re.match(license_line, line):
136 # The first line of the license contains the copyright date.
137 # We allow it to be out of date but print a warning if it is
138 # out of date.
139 if i == 0:
140 if not re.search(strict_date, line):
141 tty.debug('{0}: copyright date mismatch'.format(path))
142 found.append(i)
143
144 if len(found) == len(license_lines) and found == list(sorted(found)):
145 return
146
147 def old_license(line, path):
148 if re.search('This program is free software', line):
149 print('{0}: has old LGPL license header'.format(path))
150 return OLD_LICENSE
151
152 # If the SPDX identifier is present, then there is a mismatch (since it
153 # did not match the above regex)
154 def wrong_spdx_identifier(line, path):
155 m = re.search(r'SPDX-License-Identifier: ([^\n]*)', line)
156 if m and m.group(1) != apache2_mit_spdx:
157 print('{0}: SPDX license identifier mismatch'
158 '(expecting {1}, found {2})'
159 .format(path, apache2_mit_spdx, m.group(1)))
160 return SPDX_MISMATCH
161
162 checks = [old_license, wrong_spdx_identifier]
163
164 for line in lines:
165 for check in checks:
166 error = check(line, path)
167 if error:
168 return error
169
170 print('{0}: the license does not match the expected format'.format(path))
171 return GENERAL_MISMATCH
172
173
174 def verify(args):
175 """verify that files in spack have the right license header"""
176
177 license_errors = LicenseError()
178
179 for relpath in _licensed_files(args.root):
180 path = os.path.join(args.root, relpath)
181 with open(path) as f:
182 lines = [line for line in f][:license_lines]
183
184 error = _check_license(lines, path)
185 if error:
186 license_errors.add_error(error)
187
188 if license_errors.has_errors():
189 tty.die(*license_errors.error_messages())
190 else:
191 tty.msg('No license issues found.')
192
193
194 def setup_parser(subparser):
195 sp = subparser.add_subparsers(metavar='SUBCOMMAND', dest='license_command')
196 sp.add_parser('list-files', help=list_files.__doc__)
197
198 verify_parser = sp.add_parser('verify', help=verify.__doc__)
199 verify_parser.add_argument(
200 '--root', action='store', default=spack.paths.prefix,
201 help='scan a different prefix for license issues')
202
203
204 def license(parser, args):
205 if not git:
206 tty.die('spack license requires git in your environment')
207
208 licensed_files[:] = [re.compile(regex) for regex in licensed_files]
209
210 commands = {
211 'list-files': list_files,
212 'verify': verify,
213 }
214 return commands[args.license_command](args)
215
[end of lib/spack/spack/cmd/license.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/spack/spack/cmd/license.py b/lib/spack/spack/cmd/license.py
--- a/lib/spack/spack/cmd/license.py
+++ b/lib/spack/spack/cmd/license.py
@@ -22,7 +22,7 @@
git = which('git')
#: SPDX license id must appear in the first <license_lines> lines of a file
-license_lines = 6
+license_lines = 7
#: Spack's license identifier
apache2_mit_spdx = "(Apache-2.0 OR MIT)"
|
{"golden_diff": "diff --git a/lib/spack/spack/cmd/license.py b/lib/spack/spack/cmd/license.py\n--- a/lib/spack/spack/cmd/license.py\n+++ b/lib/spack/spack/cmd/license.py\n@@ -22,7 +22,7 @@\n git = which('git')\n \n #: SPDX license id must appear in the first <license_lines> lines of a file\n-license_lines = 6\n+license_lines = 7\n \n #: Spack's license identifier\n apache2_mit_spdx = \"(Apache-2.0 OR MIT)\"\n", "issue": "Automatically use Python 3 if available\nAs discussed during today's BoF, some people would like Spack to use Python 3 if available. Since we cannot depend on any version of Python being available on all systems, this needs a slightly complex approach: The spack binary is moved to spack-real and replaced by a shell script that checks for available versions of Python (preferring Python 3) and invokes spack-real accordingly.\r\n\r\nThis should also take care of the situation where no python binary is available (as will be on RHEL 8 by default).\r\n\r\nNot sure if this is really the best way to go but I have been meaning to take a stab at this for a while now. (Only tested on Linux.)\r\n@tgamblin @alalazo @becker33 @adamjstewart\n", "before_files": [{"content": "# Copyright 2013-2019 Lawrence Livermore National Security, LLC and other\n# Spack Project Developers. See the top-level COPYRIGHT file for details.\n#\n# SPDX-License-Identifier: (Apache-2.0 OR MIT)\n\nfrom __future__ import print_function\n\nimport os\nimport re\nfrom collections import defaultdict\n\nimport llnl.util.tty as tty\n\nimport spack.paths\nfrom spack.util.executable import which\n\ndescription = 'list and check license headers on files in spack'\nsection = \"developer\"\nlevel = \"long\"\n\n#: need the git command to check new files\ngit = which('git')\n\n#: SPDX license id must appear in the first <license_lines> lines of a file\nlicense_lines = 6\n\n#: Spack's license identifier\napache2_mit_spdx = \"(Apache-2.0 OR MIT)\"\n\n#: regular expressions for licensed files.\nlicensed_files = [\n # spack scripts\n r'^bin/spack$',\n r'^bin/spack-python$',\n r'^bin/sbang$',\n\n # all of spack core\n r'^lib/spack/spack/.*\\.py$',\n r'^lib/spack/spack/.*\\.sh$',\n r'^lib/spack/llnl/.*\\.py$',\n r'^lib/spack/env/cc$',\n\n # rst files in documentation\n r'^lib/spack/docs/(?!command_index|spack|llnl).*\\.rst$',\n r'^lib/spack/docs/.*\\.py$',\n\n # 2 files in external\n r'^lib/spack/external/__init__.py$',\n r'^lib/spack/external/ordereddict_backport.py$',\n\n # shell scripts in share\n r'^share/spack/.*\\.sh$',\n r'^share/spack/.*\\.bash$',\n r'^share/spack/.*\\.csh$',\n r'^share/spack/qa/run-[^/]*$',\n\n # all packages\n r'^var/spack/repos/.*/package.py$'\n]\n\n#: licensed files that can have LGPL language in them\n#: so far, just this command -- so it can find LGPL things elsewhere\nlgpl_exceptions = [\n r'lib/spack/spack/cmd/license.py',\n r'lib/spack/spack/test/cmd/license.py',\n]\n\n\ndef _all_spack_files(root=spack.paths.prefix):\n \"\"\"Generates root-relative paths of all files in the spack repository.\"\"\"\n visited = set()\n for cur_root, folders, files in os.walk(root):\n for filename in files:\n path = os.path.realpath(os.path.join(cur_root, filename))\n\n if path not in visited:\n yield os.path.relpath(path, root)\n visited.add(path)\n\n\ndef _licensed_files(root=spack.paths.prefix):\n for relpath in _all_spack_files(root):\n if any(regex.match(relpath) for regex in licensed_files):\n yield relpath\n\n\ndef list_files(args):\n \"\"\"list files in spack that should have license headers\"\"\"\n for relpath in sorted(_licensed_files()):\n print(os.path.join(spack.paths.spack_root, relpath))\n\n\n# Error codes for license verification. All values are chosen such that\n# bool(value) evaluates to True\nOLD_LICENSE, SPDX_MISMATCH, GENERAL_MISMATCH = range(1, 4)\n\n\nclass LicenseError(object):\n def __init__(self):\n self.error_counts = defaultdict(int)\n\n def add_error(self, error):\n self.error_counts[error] += 1\n\n def has_errors(self):\n return sum(self.error_counts.values()) > 0\n\n def error_messages(self):\n total = sum(self.error_counts.values())\n missing = self.error_counts[GENERAL_MISMATCH]\n spdx_mismatch = self.error_counts[SPDX_MISMATCH]\n old_license = self.error_counts[OLD_LICENSE]\n return (\n '%d improperly licensed files' % (total),\n 'files with wrong SPDX-License-Identifier: %d' % spdx_mismatch,\n 'files with old license header: %d' % old_license,\n 'files not containing expected license: %d' % missing)\n\n\ndef _check_license(lines, path):\n license_lines = [\n r'Copyright 2013-(?:201[789]|202\\d) Lawrence Livermore National Security, LLC and other', # noqa: E501\n r'Spack Project Developers\\. See the top-level COPYRIGHT file for details.', # noqa: E501\n r'SPDX-License-Identifier: \\(Apache-2\\.0 OR MIT\\)'\n ]\n\n strict_date = r'Copyright 2013-2019'\n\n found = []\n\n for line in lines:\n line = re.sub(r'^[\\s#\\.]*', '', line)\n line = line.rstrip()\n for i, license_line in enumerate(license_lines):\n if re.match(license_line, line):\n # The first line of the license contains the copyright date.\n # We allow it to be out of date but print a warning if it is\n # out of date.\n if i == 0:\n if not re.search(strict_date, line):\n tty.debug('{0}: copyright date mismatch'.format(path))\n found.append(i)\n\n if len(found) == len(license_lines) and found == list(sorted(found)):\n return\n\n def old_license(line, path):\n if re.search('This program is free software', line):\n print('{0}: has old LGPL license header'.format(path))\n return OLD_LICENSE\n\n # If the SPDX identifier is present, then there is a mismatch (since it\n # did not match the above regex)\n def wrong_spdx_identifier(line, path):\n m = re.search(r'SPDX-License-Identifier: ([^\\n]*)', line)\n if m and m.group(1) != apache2_mit_spdx:\n print('{0}: SPDX license identifier mismatch'\n '(expecting {1}, found {2})'\n .format(path, apache2_mit_spdx, m.group(1)))\n return SPDX_MISMATCH\n\n checks = [old_license, wrong_spdx_identifier]\n\n for line in lines:\n for check in checks:\n error = check(line, path)\n if error:\n return error\n\n print('{0}: the license does not match the expected format'.format(path))\n return GENERAL_MISMATCH\n\n\ndef verify(args):\n \"\"\"verify that files in spack have the right license header\"\"\"\n\n license_errors = LicenseError()\n\n for relpath in _licensed_files(args.root):\n path = os.path.join(args.root, relpath)\n with open(path) as f:\n lines = [line for line in f][:license_lines]\n\n error = _check_license(lines, path)\n if error:\n license_errors.add_error(error)\n\n if license_errors.has_errors():\n tty.die(*license_errors.error_messages())\n else:\n tty.msg('No license issues found.')\n\n\ndef setup_parser(subparser):\n sp = subparser.add_subparsers(metavar='SUBCOMMAND', dest='license_command')\n sp.add_parser('list-files', help=list_files.__doc__)\n\n verify_parser = sp.add_parser('verify', help=verify.__doc__)\n verify_parser.add_argument(\n '--root', action='store', default=spack.paths.prefix,\n help='scan a different prefix for license issues')\n\n\ndef license(parser, args):\n if not git:\n tty.die('spack license requires git in your environment')\n\n licensed_files[:] = [re.compile(regex) for regex in licensed_files]\n\n commands = {\n 'list-files': list_files,\n 'verify': verify,\n }\n return commands[args.license_command](args)\n", "path": "lib/spack/spack/cmd/license.py"}]}
| 2,955 | 117 |
gh_patches_debug_31030
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2468
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Checkout process improvements
During my work on PR #2206 I found out few things that may improve checkout process.
#### Going forward/back between steps
Although we can go back to shipping address step from choosing shipping method, we can't go back from summary step, where billing address is set. I think that passing between steps should be allowed.
#### Clearing cart
We can remove every single item from cart, but there is no button like `Clear cart`. It would be useful, when customer wants to cancel all cart lines at once.
</issue>
<code>
[start of saleor/checkout/urls.py]
1 from django.conf.urls import url
2
3 from . import views
4 from .views.discount import remove_voucher_view
5
6 checkout_urlpatterns = [
7 url(r'^$', views.checkout_index, name='index'),
8 url(r'^shipping-address/', views.checkout_shipping_address,
9 name='shipping-address'),
10 url(r'^shipping-method/', views.checkout_shipping_method,
11 name='shipping-method'),
12 url(r'^summary/', views.checkout_summary, name='summary'),
13 url(r'^remove_voucher/', remove_voucher_view,
14 name='remove-voucher'),
15 url(r'^login/', views.checkout_login, name='login')]
16
17
18 cart_urlpatterns = [
19 url(r'^$', views.cart_index, name='index'),
20 url(r'^update/(?P<variant_id>\d+)/$',
21 views.update_cart_line, name='update-line'),
22 url(r'^summary/$', views.cart_summary, name='summary'),
23 url(r'^shipping-options/$', views.cart_shipping_options,
24 name='shipping-options')]
25
[end of saleor/checkout/urls.py]
[start of saleor/checkout/views/__init__.py]
1 """Cart and checkout related views."""
2 from django.http import JsonResponse
3 from django.shortcuts import get_object_or_404, redirect, render
4 from django.template.response import TemplateResponse
5
6 from ...account.forms import LoginForm
7 from ...core.utils import (
8 format_money, get_user_shipping_country, to_local_currency)
9 from ...product.models import ProductVariant
10 from ...shipping.utils import get_shipment_options
11 from ..forms import CartShippingMethodForm, CountryForm, ReplaceCartLineForm
12 from ..models import Cart
13 from ..utils import (
14 check_product_availability_and_warn, check_shipping_method, get_cart_data,
15 get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)
16 from .discount import add_voucher_form, validate_voucher
17 from .shipping import (
18 anonymous_user_shipping_address_view, user_shipping_address_view)
19 from .summary import (
20 anonymous_summary_without_shipping, summary_with_shipping_view,
21 summary_without_shipping)
22 from .validators import (
23 validate_cart, validate_is_shipping_required, validate_shipping_address,
24 validate_shipping_method)
25
26
27 @get_or_empty_db_cart(Cart.objects.for_display())
28 @validate_cart
29 def checkout_login(request, cart):
30 """Allow the user to log in prior to checkout."""
31 if request.user.is_authenticated:
32 return redirect('checkout:index')
33 ctx = {'form': LoginForm()}
34 return TemplateResponse(request, 'checkout/login.html', ctx)
35
36
37 @get_or_empty_db_cart(Cart.objects.for_display())
38 @validate_cart
39 @validate_is_shipping_required
40 def checkout_index(request, cart):
41 """Redirect to the initial step of checkout."""
42 return redirect('checkout:shipping-address')
43
44
45 @get_or_empty_db_cart(Cart.objects.for_display())
46 @validate_voucher
47 @validate_cart
48 @validate_is_shipping_required
49 @add_voucher_form
50 def checkout_shipping_address(request, cart):
51 """Display the correct shipping address step."""
52 if request.user.is_authenticated:
53 return user_shipping_address_view(request, cart)
54 return anonymous_user_shipping_address_view(request, cart)
55
56
57 @get_or_empty_db_cart(Cart.objects.for_display())
58 @validate_voucher
59 @validate_cart
60 @validate_is_shipping_required
61 @validate_shipping_address
62 @add_voucher_form
63 def checkout_shipping_method(request, cart):
64 """Display the shipping method selection step."""
65 taxes = get_taxes_for_cart(cart, request.taxes)
66 check_shipping_method(cart)
67 form = CartShippingMethodForm(
68 request.POST or None, taxes=taxes, instance=cart,
69 initial={'shipping_method': cart.shipping_method})
70
71 if form.is_valid():
72 form.save()
73 return redirect('checkout:summary')
74
75 ctx = get_cart_data_for_checkout(cart, request.discounts, taxes)
76 ctx.update({'shipping_method_form': form})
77 return TemplateResponse(request, 'checkout/shipping_method.html', ctx)
78
79
80 @get_or_empty_db_cart(Cart.objects.for_display())
81 @validate_voucher
82 @validate_cart
83 @add_voucher_form
84 def checkout_summary(request, cart):
85 """Display the correct order summary."""
86 if cart.is_shipping_required():
87 view = validate_shipping_method(summary_with_shipping_view)
88 view = validate_shipping_address(view)
89 return view(request, cart)
90 if request.user.is_authenticated:
91 return summary_without_shipping(request, cart)
92 return anonymous_summary_without_shipping(request, cart)
93
94
95 @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
96 def cart_index(request, cart):
97 """Display cart details."""
98 discounts = request.discounts
99 taxes = request.taxes
100 cart_lines = []
101 check_product_availability_and_warn(request, cart)
102
103 # refresh required to get updated cart lines and it's quantity
104 try:
105 cart = Cart.objects.prefetch_related(
106 'lines__variant__product__category').get(pk=cart.pk)
107 except Cart.DoesNotExist:
108 pass
109
110 lines = cart.lines.select_related(
111 'variant__product__product_type',
112 'variant__product__category')
113 lines = lines.prefetch_related(
114 'variant__product__collections',
115 'variant__product__images',
116 'variant__product__product_type__variant_attributes')
117 for line in lines:
118 initial = {'quantity': line.quantity}
119 form = ReplaceCartLineForm(
120 None, cart=cart, variant=line.variant, initial=initial,
121 discounts=discounts, taxes=taxes)
122 cart_lines.append({
123 'variant': line.variant,
124 'get_price': line.variant.get_price(discounts, taxes),
125 'get_total': line.get_total(discounts, taxes),
126 'form': form})
127
128 default_country = get_user_shipping_country(request)
129 country_form = CountryForm(initial={'country': default_country})
130 default_country_options = get_shipment_options(default_country, taxes)
131
132 cart_data = get_cart_data(
133 cart, default_country_options, request.currency, discounts, taxes)
134 ctx = {
135 'cart_lines': cart_lines,
136 'country_form': country_form,
137 'default_country_options': default_country_options}
138 ctx.update(cart_data)
139
140 return TemplateResponse(request, 'checkout/index.html', ctx)
141
142
143 @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
144 def cart_shipping_options(request, cart):
145 """Display shipping options to get a price estimate."""
146 country_form = CountryForm(request.POST or None, taxes=request.taxes)
147 if country_form.is_valid():
148 shipments = country_form.get_shipment_options()
149 else:
150 shipments = None
151 ctx = {
152 'default_country_options': shipments,
153 'country_form': country_form}
154 cart_data = get_cart_data(
155 cart, shipments, request.currency, request.discounts, request.taxes)
156 ctx.update(cart_data)
157 return TemplateResponse(request, 'checkout/_subtotal_table.html', ctx)
158
159
160 @get_or_empty_db_cart()
161 def update_cart_line(request, cart, variant_id):
162 """Update the line quantities."""
163 if not request.is_ajax():
164 return redirect('cart:index')
165 variant = get_object_or_404(ProductVariant, pk=variant_id)
166 discounts = request.discounts
167 taxes = request.taxes
168 status = None
169 form = ReplaceCartLineForm(
170 request.POST, cart=cart, variant=variant, discounts=discounts,
171 taxes=taxes)
172 if form.is_valid():
173 form.save()
174 response = {
175 'variantId': variant_id,
176 'subtotal': 0,
177 'total': 0,
178 'cart': {
179 'numItems': cart.quantity,
180 'numLines': len(cart)}}
181 updated_line = cart.get_line(form.cart_line.variant)
182 if updated_line:
183 response['subtotal'] = format_money(
184 updated_line.get_total(discounts, taxes).gross)
185 if cart:
186 cart_total = cart.get_subtotal(discounts, taxes)
187 response['total'] = format_money(cart_total.gross)
188 local_cart_total = to_local_currency(cart_total, request.currency)
189 if local_cart_total is not None:
190 response['localTotal'] = format_money(local_cart_total.gross)
191 status = 200
192 elif request.POST is not None:
193 response = {'error': form.errors}
194 status = 400
195 return JsonResponse(response, status=status)
196
197
198 @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
199 def cart_summary(request, cart):
200 """Display a cart summary suitable for displaying on all pages."""
201 discounts = request.discounts
202 taxes = request.taxes
203
204 def prepare_line_data(line):
205 first_image = line.variant.get_first_image()
206 return {
207 'product': line.variant.product,
208 'variant': line.variant.name,
209 'quantity': line.quantity,
210 'image': first_image,
211 'line_total': line.get_total(discounts, taxes),
212 'variant_url': line.variant.get_absolute_url()}
213
214 if cart.quantity == 0:
215 data = {'quantity': 0}
216 else:
217 data = {
218 'quantity': cart.quantity,
219 'total': cart.get_subtotal(discounts, taxes),
220 'lines': [prepare_line_data(line) for line in cart]}
221
222 return render(request, 'cart_dropdown.html', data)
223
[end of saleor/checkout/views/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/checkout/urls.py b/saleor/checkout/urls.py
--- a/saleor/checkout/urls.py
+++ b/saleor/checkout/urls.py
@@ -19,6 +19,7 @@
url(r'^$', views.cart_index, name='index'),
url(r'^update/(?P<variant_id>\d+)/$',
views.update_cart_line, name='update-line'),
+ url(r'^clear-cart/$', views.clear_cart, name='clear-cart'),
url(r'^summary/$', views.cart_summary, name='summary'),
url(r'^shipping-options/$', views.cart_shipping_options,
name='shipping-options')]
diff --git a/saleor/checkout/views/__init__.py b/saleor/checkout/views/__init__.py
--- a/saleor/checkout/views/__init__.py
+++ b/saleor/checkout/views/__init__.py
@@ -12,7 +12,8 @@
from ..models import Cart
from ..utils import (
check_product_availability_and_warn, check_shipping_method, get_cart_data,
- get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)
+ get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart,
+ update_cart_quantity)
from .discount import add_voucher_form, validate_voucher
from .shipping import (
anonymous_user_shipping_address_view, user_shipping_address_view)
@@ -195,6 +196,17 @@
return JsonResponse(response, status=status)
+@get_or_empty_db_cart()
+def clear_cart(request, cart):
+ """Clear cart"""
+ if not request.is_ajax():
+ return redirect('cart:index')
+ cart.lines.all().delete()
+ update_cart_quantity(cart)
+ response = {'numItems': 0}
+ return JsonResponse(response)
+
+
@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())
def cart_summary(request, cart):
"""Display a cart summary suitable for displaying on all pages."""
|
{"golden_diff": "diff --git a/saleor/checkout/urls.py b/saleor/checkout/urls.py\n--- a/saleor/checkout/urls.py\n+++ b/saleor/checkout/urls.py\n@@ -19,6 +19,7 @@\n url(r'^$', views.cart_index, name='index'),\n url(r'^update/(?P<variant_id>\\d+)/$',\n views.update_cart_line, name='update-line'),\n+ url(r'^clear-cart/$', views.clear_cart, name='clear-cart'),\n url(r'^summary/$', views.cart_summary, name='summary'),\n url(r'^shipping-options/$', views.cart_shipping_options,\n name='shipping-options')]\ndiff --git a/saleor/checkout/views/__init__.py b/saleor/checkout/views/__init__.py\n--- a/saleor/checkout/views/__init__.py\n+++ b/saleor/checkout/views/__init__.py\n@@ -12,7 +12,8 @@\n from ..models import Cart\n from ..utils import (\n check_product_availability_and_warn, check_shipping_method, get_cart_data,\n- get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)\n+ get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart,\n+ update_cart_quantity)\n from .discount import add_voucher_form, validate_voucher\n from .shipping import (\n anonymous_user_shipping_address_view, user_shipping_address_view)\n@@ -195,6 +196,17 @@\n return JsonResponse(response, status=status)\n \n \n+@get_or_empty_db_cart()\n+def clear_cart(request, cart):\n+ \"\"\"Clear cart\"\"\"\n+ if not request.is_ajax():\n+ return redirect('cart:index')\n+ cart.lines.all().delete()\n+ update_cart_quantity(cart)\n+ response = {'numItems': 0}\n+ return JsonResponse(response)\n+\n+\n @get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\n def cart_summary(request, cart):\n \"\"\"Display a cart summary suitable for displaying on all pages.\"\"\"\n", "issue": "Checkout process improvements\nDuring my work on PR #2206 I found out few things that may improve checkout process.\r\n\r\n#### Going forward/back between steps\r\n\r\nAlthough we can go back to shipping address step from choosing shipping method, we can't go back from summary step, where billing address is set. I think that passing between steps should be allowed.\r\n\r\n#### Clearing cart\r\n\r\nWe can remove every single item from cart, but there is no button like `Clear cart`. It would be useful, when customer wants to cancel all cart lines at once.\n", "before_files": [{"content": "from django.conf.urls import url\n\nfrom . import views\nfrom .views.discount import remove_voucher_view\n\ncheckout_urlpatterns = [\n url(r'^$', views.checkout_index, name='index'),\n url(r'^shipping-address/', views.checkout_shipping_address,\n name='shipping-address'),\n url(r'^shipping-method/', views.checkout_shipping_method,\n name='shipping-method'),\n url(r'^summary/', views.checkout_summary, name='summary'),\n url(r'^remove_voucher/', remove_voucher_view,\n name='remove-voucher'),\n url(r'^login/', views.checkout_login, name='login')]\n\n\ncart_urlpatterns = [\n url(r'^$', views.cart_index, name='index'),\n url(r'^update/(?P<variant_id>\\d+)/$',\n views.update_cart_line, name='update-line'),\n url(r'^summary/$', views.cart_summary, name='summary'),\n url(r'^shipping-options/$', views.cart_shipping_options,\n name='shipping-options')]\n", "path": "saleor/checkout/urls.py"}, {"content": "\"\"\"Cart and checkout related views.\"\"\"\nfrom django.http import JsonResponse\nfrom django.shortcuts import get_object_or_404, redirect, render\nfrom django.template.response import TemplateResponse\n\nfrom ...account.forms import LoginForm\nfrom ...core.utils import (\n format_money, get_user_shipping_country, to_local_currency)\nfrom ...product.models import ProductVariant\nfrom ...shipping.utils import get_shipment_options\nfrom ..forms import CartShippingMethodForm, CountryForm, ReplaceCartLineForm\nfrom ..models import Cart\nfrom ..utils import (\n check_product_availability_and_warn, check_shipping_method, get_cart_data,\n get_cart_data_for_checkout, get_or_empty_db_cart, get_taxes_for_cart)\nfrom .discount import add_voucher_form, validate_voucher\nfrom .shipping import (\n anonymous_user_shipping_address_view, user_shipping_address_view)\nfrom .summary import (\n anonymous_summary_without_shipping, summary_with_shipping_view,\n summary_without_shipping)\nfrom .validators import (\n validate_cart, validate_is_shipping_required, validate_shipping_address,\n validate_shipping_method)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_cart\ndef checkout_login(request, cart):\n \"\"\"Allow the user to log in prior to checkout.\"\"\"\n if request.user.is_authenticated:\n return redirect('checkout:index')\n ctx = {'form': LoginForm()}\n return TemplateResponse(request, 'checkout/login.html', ctx)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_cart\n@validate_is_shipping_required\ndef checkout_index(request, cart):\n \"\"\"Redirect to the initial step of checkout.\"\"\"\n return redirect('checkout:shipping-address')\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@validate_is_shipping_required\n@add_voucher_form\ndef checkout_shipping_address(request, cart):\n \"\"\"Display the correct shipping address step.\"\"\"\n if request.user.is_authenticated:\n return user_shipping_address_view(request, cart)\n return anonymous_user_shipping_address_view(request, cart)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@validate_is_shipping_required\n@validate_shipping_address\n@add_voucher_form\ndef checkout_shipping_method(request, cart):\n \"\"\"Display the shipping method selection step.\"\"\"\n taxes = get_taxes_for_cart(cart, request.taxes)\n check_shipping_method(cart)\n form = CartShippingMethodForm(\n request.POST or None, taxes=taxes, instance=cart,\n initial={'shipping_method': cart.shipping_method})\n\n if form.is_valid():\n form.save()\n return redirect('checkout:summary')\n\n ctx = get_cart_data_for_checkout(cart, request.discounts, taxes)\n ctx.update({'shipping_method_form': form})\n return TemplateResponse(request, 'checkout/shipping_method.html', ctx)\n\n\n@get_or_empty_db_cart(Cart.objects.for_display())\n@validate_voucher\n@validate_cart\n@add_voucher_form\ndef checkout_summary(request, cart):\n \"\"\"Display the correct order summary.\"\"\"\n if cart.is_shipping_required():\n view = validate_shipping_method(summary_with_shipping_view)\n view = validate_shipping_address(view)\n return view(request, cart)\n if request.user.is_authenticated:\n return summary_without_shipping(request, cart)\n return anonymous_summary_without_shipping(request, cart)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_index(request, cart):\n \"\"\"Display cart details.\"\"\"\n discounts = request.discounts\n taxes = request.taxes\n cart_lines = []\n check_product_availability_and_warn(request, cart)\n\n # refresh required to get updated cart lines and it's quantity\n try:\n cart = Cart.objects.prefetch_related(\n 'lines__variant__product__category').get(pk=cart.pk)\n except Cart.DoesNotExist:\n pass\n\n lines = cart.lines.select_related(\n 'variant__product__product_type',\n 'variant__product__category')\n lines = lines.prefetch_related(\n 'variant__product__collections',\n 'variant__product__images',\n 'variant__product__product_type__variant_attributes')\n for line in lines:\n initial = {'quantity': line.quantity}\n form = ReplaceCartLineForm(\n None, cart=cart, variant=line.variant, initial=initial,\n discounts=discounts, taxes=taxes)\n cart_lines.append({\n 'variant': line.variant,\n 'get_price': line.variant.get_price(discounts, taxes),\n 'get_total': line.get_total(discounts, taxes),\n 'form': form})\n\n default_country = get_user_shipping_country(request)\n country_form = CountryForm(initial={'country': default_country})\n default_country_options = get_shipment_options(default_country, taxes)\n\n cart_data = get_cart_data(\n cart, default_country_options, request.currency, discounts, taxes)\n ctx = {\n 'cart_lines': cart_lines,\n 'country_form': country_form,\n 'default_country_options': default_country_options}\n ctx.update(cart_data)\n\n return TemplateResponse(request, 'checkout/index.html', ctx)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_shipping_options(request, cart):\n \"\"\"Display shipping options to get a price estimate.\"\"\"\n country_form = CountryForm(request.POST or None, taxes=request.taxes)\n if country_form.is_valid():\n shipments = country_form.get_shipment_options()\n else:\n shipments = None\n ctx = {\n 'default_country_options': shipments,\n 'country_form': country_form}\n cart_data = get_cart_data(\n cart, shipments, request.currency, request.discounts, request.taxes)\n ctx.update(cart_data)\n return TemplateResponse(request, 'checkout/_subtotal_table.html', ctx)\n\n\n@get_or_empty_db_cart()\ndef update_cart_line(request, cart, variant_id):\n \"\"\"Update the line quantities.\"\"\"\n if not request.is_ajax():\n return redirect('cart:index')\n variant = get_object_or_404(ProductVariant, pk=variant_id)\n discounts = request.discounts\n taxes = request.taxes\n status = None\n form = ReplaceCartLineForm(\n request.POST, cart=cart, variant=variant, discounts=discounts,\n taxes=taxes)\n if form.is_valid():\n form.save()\n response = {\n 'variantId': variant_id,\n 'subtotal': 0,\n 'total': 0,\n 'cart': {\n 'numItems': cart.quantity,\n 'numLines': len(cart)}}\n updated_line = cart.get_line(form.cart_line.variant)\n if updated_line:\n response['subtotal'] = format_money(\n updated_line.get_total(discounts, taxes).gross)\n if cart:\n cart_total = cart.get_subtotal(discounts, taxes)\n response['total'] = format_money(cart_total.gross)\n local_cart_total = to_local_currency(cart_total, request.currency)\n if local_cart_total is not None:\n response['localTotal'] = format_money(local_cart_total.gross)\n status = 200\n elif request.POST is not None:\n response = {'error': form.errors}\n status = 400\n return JsonResponse(response, status=status)\n\n\n@get_or_empty_db_cart(cart_queryset=Cart.objects.for_display())\ndef cart_summary(request, cart):\n \"\"\"Display a cart summary suitable for displaying on all pages.\"\"\"\n discounts = request.discounts\n taxes = request.taxes\n\n def prepare_line_data(line):\n first_image = line.variant.get_first_image()\n return {\n 'product': line.variant.product,\n 'variant': line.variant.name,\n 'quantity': line.quantity,\n 'image': first_image,\n 'line_total': line.get_total(discounts, taxes),\n 'variant_url': line.variant.get_absolute_url()}\n\n if cart.quantity == 0:\n data = {'quantity': 0}\n else:\n data = {\n 'quantity': cart.quantity,\n 'total': cart.get_subtotal(discounts, taxes),\n 'lines': [prepare_line_data(line) for line in cart]}\n\n return render(request, 'cart_dropdown.html', data)\n", "path": "saleor/checkout/views/__init__.py"}]}
| 3,210 | 440 |
gh_patches_debug_16210
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3291
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pagination of projects is incorrect
On the home page, the pagination is off for large sets of projects.
#### Example
Select the EU trust fund for Africa in the organisations filter. The pagination widget shows that there are 22 pages of projects, but the last [two are empty](https://rsr.akvo.org/en/projects/?organisation=3394&page=22)!
</issue>
<code>
[start of akvo/rest/views/project.py]
1 # -*- coding: utf-8 -*-
2 """Akvo RSR is covered by the GNU Affero General Public License.
3
4 See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6 """
7
8 from django.db.models import Q
9 from rest_framework.decorators import api_view
10 from rest_framework.response import Response
11
12 from akvo.codelists.store.codelists_v202 import SECTOR_CATEGORY
13 from akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,
14 ProjectExtraDeepSerializer,
15 ProjectIatiExportSerializer,
16 ProjectUpSerializer,
17 ProjectDirectorySerializer,
18 TypeaheadOrganisationSerializer,
19 TypeaheadSectorSerializer,)
20 from akvo.rest.views.utils import (
21 int_or_none, get_cached_data, get_qs_elements_for_page, set_cached_data
22 )
23 from akvo.rsr.models import Project
24 from akvo.rsr.filters import location_choices, get_m49_filter
25 from akvo.utils import codelist_choices
26 from ..viewsets import PublicProjectViewSet
27
28
29 class ProjectViewSet(PublicProjectViewSet):
30
31 """
32 Viewset providing Project data.
33 """
34 queryset = Project.objects.select_related(
35 'categories',
36 'keywords',
37 'partners',
38 ).prefetch_related(
39 'publishingstatus',
40 )
41 serializer_class = ProjectSerializer
42 project_relation = ''
43
44 def get_queryset(self):
45 """
46 Allow custom filter for sync_owner, since this field has been replaced by the
47 reporting org partnership.
48 """
49
50 sync_owner = self.request.query_params.get('sync_owner', None)
51 reporting_org = self.request.query_params.get('reporting_org', None)
52
53 reporting_org = reporting_org or sync_owner
54 if reporting_org:
55 self.queryset = self.queryset.filter(
56 partnerships__iati_organisation_role=101,
57 partnerships__organisation__pk=reporting_org
58 ).distinct()
59 return super(ProjectViewSet, self).get_queryset()
60
61
62 class ProjectIatiExportViewSet(PublicProjectViewSet):
63 """Lean viewset for project data, as used in the My IATI section of RSR."""
64 queryset = Project.objects.only(
65 'id',
66 'title',
67 'is_public',
68 'status',
69 ).select_related(
70 'partners',
71 ).prefetch_related(
72 'iati_checks',
73 'publishingstatus',
74 'partnerships',
75 )
76 serializer_class = ProjectIatiExportSerializer
77 project_relation = ''
78 paginate_by_param = 'limit'
79 max_paginate_by = 50
80
81 def get_queryset(self):
82 """
83 Allow custom filter for sync_owner, since this field has been replaced by the
84 reporting org partnership.
85 """
86 reporting_org = self.request.query_params.get('reporting_org', None)
87 if reporting_org:
88 self.queryset = self.queryset.filter(
89 partnerships__iati_organisation_role=101,
90 partnerships__organisation__pk=reporting_org
91 ).distinct()
92 return super(ProjectIatiExportViewSet, self).get_queryset()
93
94
95 class ProjectExtraViewSet(ProjectViewSet):
96
97 """
98 Viewset providing extra Project data.
99
100 Allowed parameters are:
101 __limit__ (default 10, max 30),
102 __partnerships\__organisation__ (filter on organisation ID), and
103 __publishingstatus\__status__ (filter on publishing status)
104 """
105
106 queryset = Project.objects.prefetch_related(
107 'publishingstatus',
108 'sectors',
109 'partnerships',
110 'budget_items',
111 'legacy_data',
112 'links',
113 'locations',
114 'locations__country',
115 'planned_disbursements',
116 'policy_markers',
117 'documents',
118 'comments',
119 'conditions',
120 'contacts',
121 'project_updates',
122 'recipient_countries',
123 'recipient_regions',
124 'related_projects',
125 'results',
126 'sectors',
127 'transactions',
128 )
129 serializer_class = ProjectExtraSerializer
130 paginate_by_param = 'limit'
131 paginate_by = 10
132 max_paginate_by = 30
133
134
135 class ProjectExtraDeepViewSet(ProjectViewSet):
136
137 """
138 Viewset providing extra deep (depth=2 or bigger) Project data.
139
140 Allowed parameters are:
141 __limit__ (default 5, max 10),
142 __partnerships\__organisation__ (filter on organisation ID), and
143 __publishingstatus\__status__ (filter on publishing status)
144 """
145
146 queryset = Project.objects.prefetch_related(
147 'publishingstatus',
148 'sectors',
149 'partnerships',
150 'budget_items',
151 'legacy_data',
152 'links',
153 'locations',
154 'locations__country',
155 'planned_disbursements',
156 'policy_markers',
157 'documents',
158 'comments',
159 'conditions',
160 'contacts',
161 'project_updates',
162 'recipient_countries',
163 'recipient_regions',
164 'related_projects',
165 'results',
166 'sectors',
167 'transactions',
168 )
169 serializer_class = ProjectExtraDeepSerializer
170 paginate_by_param = 'limit'
171 paginate_by = 5
172 max_paginate_by = 10
173
174
175 class ProjectUpViewSet(ProjectViewSet):
176
177 """
178 Viewset providing extra data and limited filtering for Up in one go.
179
180 Allowed parameters are:
181 __limit__ (default 30, max 100),
182 __partnerships\__organisation__ (filter on organisation ID), and
183 __publishingstatus\__status__ (filter on publishing status)
184 """
185
186 queryset = Project.objects.select_related(
187 'primary_location',
188 'categories',
189 'keywords',
190 'partners',
191 ).prefetch_related(
192 'publishingstatus',
193 'project_updates',
194 )
195 serializer_class = ProjectUpSerializer
196 paginate_by_param = 'limit'
197 max_paginate_by = 100
198
199
200 ###############################################################################
201 # Project directory
202 ###############################################################################
203
204 @api_view(['GET'])
205 def project_directory(request):
206 """Return the values for various project filters.
207
208 Based on the current filters, it returns new options for all the (other)
209 filters. This is used to generate dynamic filters.
210
211 """
212
213 # Fetch projects based on whether we are an Akvo site or RSR main site
214 page = request.rsr_page
215 projects = page.projects() if page else Project.objects.all().public().published()
216
217 # Exclude projects which don't have an image or a title
218 # FIXME: This happens silently and may be confusing?
219 projects = projects.exclude(Q(title='') | Q(current_image=''))
220
221 # Filter projects based on query parameters
222 filter_, text_filter = _create_filters_query(request)
223 projects = projects.filter(filter_).distinct() if filter_ is not None else projects
224 # NOTE: The text filter is handled differently/separately from the other filters.
225 # The text filter allows users to enter free form text, which could result in no
226 # projects being found for the given text. Other fields only allow selecting from
227 # a list of options, and for every combination that is shown to users and
228 # selectable by them, at least one project exists.
229 # When no projects are returned for a given search string, if the text search is
230 # not handled separately, the options for all the other filters are empty, and
231 # this causes the filters to get cleared automatically. This is very weird UX.
232 projects_text_filtered = (
233 projects.filter(text_filter) if text_filter is not None else projects
234 )
235 if projects_text_filtered.exists():
236 projects = projects_text_filtered
237
238 # Pre-fetch related fields to make things faster
239 projects = projects.select_related(
240 'primary_location',
241 'primary_organisation',
242 ).prefetch_related(
243 'locations',
244 'locations__country',
245 'recipient_countries',
246 'recipient_countries__country',
247 )
248
249 # Get the relevant data for typeaheads based on filtered projects (minus
250 # text filtering, if no projects were found)
251 cached_locations, _ = get_cached_data(request, 'locations', None, None)
252 if cached_locations is None:
253 cached_locations = [
254 {'id': choice[0], 'name': choice[1]}
255 for choice in location_choices(projects)
256 ]
257 set_cached_data(request, 'locations', cached_locations)
258
259 organisations = projects.all_partners().values('id', 'name', 'long_name')
260
261 # FIXME: Currently only vocabulary 2 is supported (as was the case with
262 # static filters). This could be extended to other vocabularies, in future.
263 valid_sectors = dict(codelist_choices(SECTOR_CATEGORY))
264 sectors = projects.sectors().filter(
265 vocabulary='2', sector_code__in=valid_sectors
266 ).values('sector_code').distinct()
267
268 # NOTE: We use projects_text_filtered for displaying projects
269 count = projects_text_filtered.count()
270 display_projects = get_qs_elements_for_page(projects_text_filtered, request).select_related(
271 'primary_organisation'
272 )
273
274 # NOTE: We use the _get_cached_data function to individually cache small
275 # bits of data to avoid the response from never getting saved in the cache,
276 # because the response is larger than the max size of data that can be
277 # saved in the cache.
278 cached_projects, showing_cached_projects = get_cached_data(
279 request, 'projects', display_projects, ProjectDirectorySerializer
280 )
281 cached_organisations, _ = get_cached_data(
282 request, 'organisations', organisations, TypeaheadOrganisationSerializer
283 )
284
285 response = {
286 'project_count': count,
287 'projects': cached_projects,
288 'showing_cached_projects': showing_cached_projects,
289 'organisation': cached_organisations,
290 'sector': TypeaheadSectorSerializer(sectors, many=True).data,
291 'location': cached_locations,
292 }
293
294 return Response(response)
295
296
297 def _create_filters_query(request):
298 """Returns a Q object expression based on query parameters."""
299 keyword_param = int_or_none(request.GET.get('keyword'))
300 location_param = int_or_none(request.GET.get('location'))
301 status_param = int_or_none(request.GET.get('status'))
302 organisation_param = int_or_none(request.GET.get('organisation'))
303 sector_param = int_or_none(request.GET.get('sector'))
304 title_or_subtitle_param = request.GET.get('title_or_subtitle')
305
306 keyword_filter = Q(keywords__id=keyword_param) if keyword_param else None
307 location_filter = get_m49_filter(location_param) if location_param else None
308 status_filter = Q(iati_status=status_param) if status_param else None
309 organisation_filter = Q(partners__id=organisation_param) if organisation_param else None
310 sector_filter = (
311 Q(sectors__sector_code=sector_param, sectors__vocabulary='2')
312 if sector_param else None
313 )
314 title_or_subtitle_filter = (
315 Q(title__icontains=title_or_subtitle_param) | Q(subtitle__icontains=title_or_subtitle_param)
316 ) if title_or_subtitle_param else None
317 all_filters = [
318 keyword_filter,
319 location_filter,
320 status_filter,
321 organisation_filter,
322 sector_filter,
323 ]
324 filters = filter(None, all_filters)
325 return reduce(lambda x, y: x & y, filters) if filters else None, title_or_subtitle_filter
326
[end of akvo/rest/views/project.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/views/project.py b/akvo/rest/views/project.py
--- a/akvo/rest/views/project.py
+++ b/akvo/rest/views/project.py
@@ -5,6 +5,7 @@
For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
"""
+from django.conf import settings
from django.db.models import Q
from rest_framework.decorators import api_view
from rest_framework.response import Response
@@ -289,6 +290,7 @@
'organisation': cached_organisations,
'sector': TypeaheadSectorSerializer(sectors, many=True).data,
'location': cached_locations,
+ 'page_size_default': settings.PROJECT_DIRECTORY_PAGE_SIZES[0],
}
return Response(response)
|
{"golden_diff": "diff --git a/akvo/rest/views/project.py b/akvo/rest/views/project.py\n--- a/akvo/rest/views/project.py\n+++ b/akvo/rest/views/project.py\n@@ -5,6 +5,7 @@\n For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n \"\"\"\n \n+from django.conf import settings\n from django.db.models import Q\n from rest_framework.decorators import api_view\n from rest_framework.response import Response\n@@ -289,6 +290,7 @@\n 'organisation': cached_organisations,\n 'sector': TypeaheadSectorSerializer(sectors, many=True).data,\n 'location': cached_locations,\n+ 'page_size_default': settings.PROJECT_DIRECTORY_PAGE_SIZES[0],\n }\n \n return Response(response)\n", "issue": "Pagination of projects is incorrect\nOn the home page, the pagination is off for large sets of projects. \r\n\r\n#### Example\r\nSelect the EU trust fund for Africa in the organisations filter. The pagination widget shows that there are 22 pages of projects, but the last [two are empty](https://rsr.akvo.org/en/projects/?organisation=3394&page=22)!\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Akvo RSR is covered by the GNU Affero General Public License.\n\nSee more details in the license.txt file located at the root folder of the Akvo RSR module.\nFor additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\"\"\"\n\nfrom django.db.models import Q\nfrom rest_framework.decorators import api_view\nfrom rest_framework.response import Response\n\nfrom akvo.codelists.store.codelists_v202 import SECTOR_CATEGORY\nfrom akvo.rest.serializers import (ProjectSerializer, ProjectExtraSerializer,\n ProjectExtraDeepSerializer,\n ProjectIatiExportSerializer,\n ProjectUpSerializer,\n ProjectDirectorySerializer,\n TypeaheadOrganisationSerializer,\n TypeaheadSectorSerializer,)\nfrom akvo.rest.views.utils import (\n int_or_none, get_cached_data, get_qs_elements_for_page, set_cached_data\n)\nfrom akvo.rsr.models import Project\nfrom akvo.rsr.filters import location_choices, get_m49_filter\nfrom akvo.utils import codelist_choices\nfrom ..viewsets import PublicProjectViewSet\n\n\nclass ProjectViewSet(PublicProjectViewSet):\n\n \"\"\"\n Viewset providing Project data.\n \"\"\"\n queryset = Project.objects.select_related(\n 'categories',\n 'keywords',\n 'partners',\n ).prefetch_related(\n 'publishingstatus',\n )\n serializer_class = ProjectSerializer\n project_relation = ''\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n\n sync_owner = self.request.query_params.get('sync_owner', None)\n reporting_org = self.request.query_params.get('reporting_org', None)\n\n reporting_org = reporting_org or sync_owner\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectViewSet, self).get_queryset()\n\n\nclass ProjectIatiExportViewSet(PublicProjectViewSet):\n \"\"\"Lean viewset for project data, as used in the My IATI section of RSR.\"\"\"\n queryset = Project.objects.only(\n 'id',\n 'title',\n 'is_public',\n 'status',\n ).select_related(\n 'partners',\n ).prefetch_related(\n 'iati_checks',\n 'publishingstatus',\n 'partnerships',\n )\n serializer_class = ProjectIatiExportSerializer\n project_relation = ''\n paginate_by_param = 'limit'\n max_paginate_by = 50\n\n def get_queryset(self):\n \"\"\"\n Allow custom filter for sync_owner, since this field has been replaced by the\n reporting org partnership.\n \"\"\"\n reporting_org = self.request.query_params.get('reporting_org', None)\n if reporting_org:\n self.queryset = self.queryset.filter(\n partnerships__iati_organisation_role=101,\n partnerships__organisation__pk=reporting_org\n ).distinct()\n return super(ProjectIatiExportViewSet, self).get_queryset()\n\n\nclass ProjectExtraViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra Project data.\n\n Allowed parameters are:\n __limit__ (default 10, max 30),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'comments',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraSerializer\n paginate_by_param = 'limit'\n paginate_by = 10\n max_paginate_by = 30\n\n\nclass ProjectExtraDeepViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra deep (depth=2 or bigger) Project data.\n\n Allowed parameters are:\n __limit__ (default 5, max 10),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.prefetch_related(\n 'publishingstatus',\n 'sectors',\n 'partnerships',\n 'budget_items',\n 'legacy_data',\n 'links',\n 'locations',\n 'locations__country',\n 'planned_disbursements',\n 'policy_markers',\n 'documents',\n 'comments',\n 'conditions',\n 'contacts',\n 'project_updates',\n 'recipient_countries',\n 'recipient_regions',\n 'related_projects',\n 'results',\n 'sectors',\n 'transactions',\n )\n serializer_class = ProjectExtraDeepSerializer\n paginate_by_param = 'limit'\n paginate_by = 5\n max_paginate_by = 10\n\n\nclass ProjectUpViewSet(ProjectViewSet):\n\n \"\"\"\n Viewset providing extra data and limited filtering for Up in one go.\n\n Allowed parameters are:\n __limit__ (default 30, max 100),\n __partnerships\\__organisation__ (filter on organisation ID), and\n __publishingstatus\\__status__ (filter on publishing status)\n \"\"\"\n\n queryset = Project.objects.select_related(\n 'primary_location',\n 'categories',\n 'keywords',\n 'partners',\n ).prefetch_related(\n 'publishingstatus',\n 'project_updates',\n )\n serializer_class = ProjectUpSerializer\n paginate_by_param = 'limit'\n max_paginate_by = 100\n\n\n###############################################################################\n# Project directory\n###############################################################################\n\n@api_view(['GET'])\ndef project_directory(request):\n \"\"\"Return the values for various project filters.\n\n Based on the current filters, it returns new options for all the (other)\n filters. This is used to generate dynamic filters.\n\n \"\"\"\n\n # Fetch projects based on whether we are an Akvo site or RSR main site\n page = request.rsr_page\n projects = page.projects() if page else Project.objects.all().public().published()\n\n # Exclude projects which don't have an image or a title\n # FIXME: This happens silently and may be confusing?\n projects = projects.exclude(Q(title='') | Q(current_image=''))\n\n # Filter projects based on query parameters\n filter_, text_filter = _create_filters_query(request)\n projects = projects.filter(filter_).distinct() if filter_ is not None else projects\n # NOTE: The text filter is handled differently/separately from the other filters.\n # The text filter allows users to enter free form text, which could result in no\n # projects being found for the given text. Other fields only allow selecting from\n # a list of options, and for every combination that is shown to users and\n # selectable by them, at least one project exists.\n # When no projects are returned for a given search string, if the text search is\n # not handled separately, the options for all the other filters are empty, and\n # this causes the filters to get cleared automatically. This is very weird UX.\n projects_text_filtered = (\n projects.filter(text_filter) if text_filter is not None else projects\n )\n if projects_text_filtered.exists():\n projects = projects_text_filtered\n\n # Pre-fetch related fields to make things faster\n projects = projects.select_related(\n 'primary_location',\n 'primary_organisation',\n ).prefetch_related(\n 'locations',\n 'locations__country',\n 'recipient_countries',\n 'recipient_countries__country',\n )\n\n # Get the relevant data for typeaheads based on filtered projects (minus\n # text filtering, if no projects were found)\n cached_locations, _ = get_cached_data(request, 'locations', None, None)\n if cached_locations is None:\n cached_locations = [\n {'id': choice[0], 'name': choice[1]}\n for choice in location_choices(projects)\n ]\n set_cached_data(request, 'locations', cached_locations)\n\n organisations = projects.all_partners().values('id', 'name', 'long_name')\n\n # FIXME: Currently only vocabulary 2 is supported (as was the case with\n # static filters). This could be extended to other vocabularies, in future.\n valid_sectors = dict(codelist_choices(SECTOR_CATEGORY))\n sectors = projects.sectors().filter(\n vocabulary='2', sector_code__in=valid_sectors\n ).values('sector_code').distinct()\n\n # NOTE: We use projects_text_filtered for displaying projects\n count = projects_text_filtered.count()\n display_projects = get_qs_elements_for_page(projects_text_filtered, request).select_related(\n 'primary_organisation'\n )\n\n # NOTE: We use the _get_cached_data function to individually cache small\n # bits of data to avoid the response from never getting saved in the cache,\n # because the response is larger than the max size of data that can be\n # saved in the cache.\n cached_projects, showing_cached_projects = get_cached_data(\n request, 'projects', display_projects, ProjectDirectorySerializer\n )\n cached_organisations, _ = get_cached_data(\n request, 'organisations', organisations, TypeaheadOrganisationSerializer\n )\n\n response = {\n 'project_count': count,\n 'projects': cached_projects,\n 'showing_cached_projects': showing_cached_projects,\n 'organisation': cached_organisations,\n 'sector': TypeaheadSectorSerializer(sectors, many=True).data,\n 'location': cached_locations,\n }\n\n return Response(response)\n\n\ndef _create_filters_query(request):\n \"\"\"Returns a Q object expression based on query parameters.\"\"\"\n keyword_param = int_or_none(request.GET.get('keyword'))\n location_param = int_or_none(request.GET.get('location'))\n status_param = int_or_none(request.GET.get('status'))\n organisation_param = int_or_none(request.GET.get('organisation'))\n sector_param = int_or_none(request.GET.get('sector'))\n title_or_subtitle_param = request.GET.get('title_or_subtitle')\n\n keyword_filter = Q(keywords__id=keyword_param) if keyword_param else None\n location_filter = get_m49_filter(location_param) if location_param else None\n status_filter = Q(iati_status=status_param) if status_param else None\n organisation_filter = Q(partners__id=organisation_param) if organisation_param else None\n sector_filter = (\n Q(sectors__sector_code=sector_param, sectors__vocabulary='2')\n if sector_param else None\n )\n title_or_subtitle_filter = (\n Q(title__icontains=title_or_subtitle_param) | Q(subtitle__icontains=title_or_subtitle_param)\n ) if title_or_subtitle_param else None\n all_filters = [\n keyword_filter,\n location_filter,\n status_filter,\n organisation_filter,\n sector_filter,\n ]\n filters = filter(None, all_filters)\n return reduce(lambda x, y: x & y, filters) if filters else None, title_or_subtitle_filter\n", "path": "akvo/rest/views/project.py"}]}
| 3,921 | 174 |
gh_patches_debug_20220
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-4984
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Stable builds are triggered recursively
On Sunday we found that a build for the `stable` version was triggered constantly (Example, http://readthedocs.org/projects/bugzilla/builds/)
@ericholscher hotfixed this with this commit https://github.com/rtfd/readthedocs.org/commit/83caf8fe8 to avoid the "Sunday problem", but we need to research and fix it properly.
We suspect that this could be introduced on #4433 and/or #4876.
</issue>
<code>
[start of readthedocs/vcs_support/backends/git.py]
1 # -*- coding: utf-8 -*-
2 """Git-related utilities."""
3
4 from __future__ import (
5 absolute_import,
6 division,
7 print_function,
8 unicode_literals,
9 )
10
11 import logging
12 import os
13 import re
14
15 import git
16 from builtins import str
17 from django.core.exceptions import ValidationError
18 from git.exc import BadName
19
20 from readthedocs.config import ALL
21 from readthedocs.projects.exceptions import RepositoryError
22 from readthedocs.projects.validators import validate_submodule_url
23 from readthedocs.vcs_support.base import BaseVCS, VCSVersion
24
25 log = logging.getLogger(__name__)
26
27
28 class Backend(BaseVCS):
29
30 """Git VCS backend."""
31
32 supports_tags = True
33 supports_branches = True
34 supports_submodules = True
35 fallback_branch = 'master' # default branch
36 repo_depth = 50
37
38 def __init__(self, *args, **kwargs):
39 super(Backend, self).__init__(*args, **kwargs)
40 self.token = kwargs.get('token', None)
41 self.repo_url = self._get_clone_url()
42
43 def _get_clone_url(self):
44 if '://' in self.repo_url:
45 hacked_url = self.repo_url.split('://')[1]
46 hacked_url = re.sub('.git$', '', hacked_url)
47 clone_url = 'https://%s' % hacked_url
48 if self.token:
49 clone_url = 'https://%s@%s' % (self.token, hacked_url)
50 return clone_url
51 # Don't edit URL because all hosts aren't the same
52 # else:
53 # clone_url = 'git://%s' % (hacked_url)
54 return self.repo_url
55
56 def set_remote_url(self, url):
57 return self.run('git', 'remote', 'set-url', 'origin', url)
58
59 def update(self):
60 """Clone or update the repository."""
61 super(Backend, self).update()
62 if self.repo_exists():
63 self.set_remote_url(self.repo_url)
64 return self.fetch()
65 self.make_clean_working_dir()
66 return self.clone()
67
68 def repo_exists(self):
69 code, _, _ = self.run('git', 'status', record=False)
70 return code == 0
71
72 def are_submodules_available(self, config):
73 """Test whether git submodule checkout step should be performed."""
74 # TODO remove this after users migrate to a config file
75 from readthedocs.projects.models import Feature
76 submodules_in_config = (
77 config.submodules.exclude != ALL or
78 config.submodules.include
79 )
80 if (self.project.has_feature(Feature.SKIP_SUBMODULES) or
81 not submodules_in_config):
82 return False
83
84 # Keep compatibility with previous projects
85 code, out, _ = self.run('git', 'submodule', 'status', record=False)
86 return code == 0 and bool(out)
87
88 def validate_submodules(self, config):
89 """
90 Returns the submodules and check that its URLs are valid.
91
92 .. note::
93
94 Allways call after `self.are_submodules_available`.
95
96 :returns: tuple(bool, list)
97
98 Returns true if all required submodules URLs are valid.
99 Returns a list of all required submodules:
100 - Include is `ALL`, returns all submodules avaliable.
101 - Include is a list, returns just those.
102 - Exclude is `ALL` - this should never happen.
103 - Exlude is a list, returns all avaliable submodules
104 but those from the list.
105 """
106 repo = git.Repo(self.working_dir)
107 submodules = {
108 sub.path: sub
109 for sub in repo.submodules
110 }
111
112 for sub_path in config.submodules.exclude:
113 path = sub_path.rstrip('/')
114 if path in submodules:
115 del submodules[path]
116
117 if config.submodules.include != ALL and config.submodules.include:
118 submodules_include = {}
119 for sub_path in config.submodules.include:
120 path = sub_path.rstrip('/')
121 submodules_include[path] = submodules[path]
122 submodules = submodules_include
123
124 for path, submodule in submodules.items():
125 try:
126 validate_submodule_url(submodule.url)
127 except ValidationError:
128 return False, []
129 return True, submodules.keys()
130
131 def fetch(self):
132 code, stdout, stderr = self.run(
133 'git', 'fetch', '--depth', str(self.repo_depth),
134 '--tags', '--prune', '--prune-tags',
135 )
136 if code != 0:
137 raise RepositoryError
138 return code, stdout, stderr
139
140 def checkout_revision(self, revision=None):
141 if not revision:
142 branch = self.default_branch or self.fallback_branch
143 revision = 'origin/%s' % branch
144
145 code, out, err = self.run('git', 'checkout', '--force', revision)
146 if code != 0:
147 log.warning("Failed to checkout revision '%s': %s", revision, code)
148 return [code, out, err]
149
150 def clone(self):
151 """Clones the repository."""
152 code, stdout, stderr = self.run(
153 'git', 'clone', '--depth', str(self.repo_depth),
154 '--no-single-branch', self.repo_url, '.'
155 )
156 if code != 0:
157 raise RepositoryError
158 return code, stdout, stderr
159
160 @property
161 def tags(self):
162 versions = []
163 repo = git.Repo(self.working_dir)
164 for tag in repo.tags:
165 try:
166 versions.append(VCSVersion(self, str(tag.commit), str(tag)))
167 except ValueError as e:
168 # ValueError: Cannot resolve commit as tag TAGNAME points to a
169 # blob object - use the `.object` property instead to access it
170 # This is not a real tag for us, so we skip it
171 # https://github.com/rtfd/readthedocs.org/issues/4440
172 log.warning('Git tag skipped: %s', tag, exc_info=True)
173 continue
174 return versions
175
176 @property
177 def branches(self):
178 repo = git.Repo(self.working_dir)
179 versions = []
180
181 # ``repo.branches`` returns local branches and
182 branches = repo.branches
183 # ``repo.remotes.origin.refs`` returns remote branches
184 if repo.remotes:
185 branches += repo.remotes.origin.refs
186
187 for branch in branches:
188 verbose_name = branch.name
189 if verbose_name.startswith('origin/'):
190 verbose_name = verbose_name.replace('origin/', '')
191 if verbose_name == 'HEAD':
192 continue
193 versions.append(VCSVersion(self, str(branch), verbose_name))
194 return versions
195
196 @property
197 def commit(self):
198 _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')
199 return stdout.strip()
200
201 def checkout(self, identifier=None):
202 """Checkout to identifier or latest."""
203 super(Backend, self).checkout()
204 # Find proper identifier
205 if not identifier:
206 identifier = self.default_branch or self.fallback_branch
207
208 identifier = self.find_ref(identifier)
209
210 # Checkout the correct identifier for this branch.
211 code, out, err = self.checkout_revision(identifier)
212 if code != 0:
213 return code, out, err
214
215 # Clean any remains of previous checkouts
216 self.run('git', 'clean', '-d', '-f', '-f')
217 return code, out, err
218
219 def update_submodules(self, config):
220 if self.are_submodules_available(config):
221 valid, submodules = self.validate_submodules(config)
222 if valid:
223 self.checkout_submodules(submodules, config)
224 else:
225 raise RepositoryError(RepositoryError.INVALID_SUBMODULES)
226
227 def checkout_submodules(self, submodules, config):
228 """Checkout all repository submodules."""
229 self.run('git', 'submodule', 'sync')
230 cmd = [
231 'git',
232 'submodule',
233 'update',
234 '--init',
235 '--force',
236 ]
237 if config.submodules.recursive:
238 cmd.append('--recursive')
239 cmd += submodules
240 self.run(*cmd)
241
242 def find_ref(self, ref):
243 # Check if ref starts with 'origin/'
244 if ref.startswith('origin/'):
245 return ref
246
247 # Check if ref is a branch of the origin remote
248 if self.ref_exists('remotes/origin/' + ref):
249 return 'origin/' + ref
250
251 return ref
252
253 def ref_exists(self, ref):
254 try:
255 r = git.Repo(self.working_dir)
256 if r.commit(ref):
257 return True
258 except (BadName, ValueError):
259 return False
260 return False
261
262 @property
263 def env(self):
264 env = super(Backend, self).env
265 env['GIT_DIR'] = os.path.join(self.working_dir, '.git')
266 # Don't prompt for username, this requires Git 2.3+
267 env['GIT_TERMINAL_PROMPT'] = '0'
268 return env
269
[end of readthedocs/vcs_support/backends/git.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py
--- a/readthedocs/vcs_support/backends/git.py
+++ b/readthedocs/vcs_support/backends/git.py
@@ -15,6 +15,7 @@
import git
from builtins import str
from django.core.exceptions import ValidationError
+from django.conf import settings
from git.exc import BadName
from readthedocs.config import ALL
@@ -177,12 +178,13 @@
def branches(self):
repo = git.Repo(self.working_dir)
versions = []
+ branches = []
- # ``repo.branches`` returns local branches and
- branches = repo.branches
# ``repo.remotes.origin.refs`` returns remote branches
if repo.remotes:
branches += repo.remotes.origin.refs
+ if getattr(settings, 'LOCAL_GIT_BRANCHES', False):
+ branches += repo.branches
for branch in branches:
verbose_name = branch.name
|
{"golden_diff": "diff --git a/readthedocs/vcs_support/backends/git.py b/readthedocs/vcs_support/backends/git.py\n--- a/readthedocs/vcs_support/backends/git.py\n+++ b/readthedocs/vcs_support/backends/git.py\n@@ -15,6 +15,7 @@\n import git\n from builtins import str\n from django.core.exceptions import ValidationError\n+from django.conf import settings\n from git.exc import BadName\n \n from readthedocs.config import ALL\n@@ -177,12 +178,13 @@\n def branches(self):\n repo = git.Repo(self.working_dir)\n versions = []\n+ branches = []\n \n- # ``repo.branches`` returns local branches and\n- branches = repo.branches\n # ``repo.remotes.origin.refs`` returns remote branches\n if repo.remotes:\n branches += repo.remotes.origin.refs\n+ if getattr(settings, 'LOCAL_GIT_BRANCHES', False):\n+ branches += repo.branches\n \n for branch in branches:\n verbose_name = branch.name\n", "issue": "Stable builds are triggered recursively\nOn Sunday we found that a build for the `stable` version was triggered constantly (Example, http://readthedocs.org/projects/bugzilla/builds/)\r\n\r\n@ericholscher hotfixed this with this commit https://github.com/rtfd/readthedocs.org/commit/83caf8fe8 to avoid the \"Sunday problem\", but we need to research and fix it properly.\r\n\r\nWe suspect that this could be introduced on #4433 and/or #4876.\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"Git-related utilities.\"\"\"\n\nfrom __future__ import (\n absolute_import,\n division,\n print_function,\n unicode_literals,\n)\n\nimport logging\nimport os\nimport re\n\nimport git\nfrom builtins import str\nfrom django.core.exceptions import ValidationError\nfrom git.exc import BadName\n\nfrom readthedocs.config import ALL\nfrom readthedocs.projects.exceptions import RepositoryError\nfrom readthedocs.projects.validators import validate_submodule_url\nfrom readthedocs.vcs_support.base import BaseVCS, VCSVersion\n\nlog = logging.getLogger(__name__)\n\n\nclass Backend(BaseVCS):\n\n \"\"\"Git VCS backend.\"\"\"\n\n supports_tags = True\n supports_branches = True\n supports_submodules = True\n fallback_branch = 'master' # default branch\n repo_depth = 50\n\n def __init__(self, *args, **kwargs):\n super(Backend, self).__init__(*args, **kwargs)\n self.token = kwargs.get('token', None)\n self.repo_url = self._get_clone_url()\n\n def _get_clone_url(self):\n if '://' in self.repo_url:\n hacked_url = self.repo_url.split('://')[1]\n hacked_url = re.sub('.git$', '', hacked_url)\n clone_url = 'https://%s' % hacked_url\n if self.token:\n clone_url = 'https://%s@%s' % (self.token, hacked_url)\n return clone_url\n # Don't edit URL because all hosts aren't the same\n # else:\n # clone_url = 'git://%s' % (hacked_url)\n return self.repo_url\n\n def set_remote_url(self, url):\n return self.run('git', 'remote', 'set-url', 'origin', url)\n\n def update(self):\n \"\"\"Clone or update the repository.\"\"\"\n super(Backend, self).update()\n if self.repo_exists():\n self.set_remote_url(self.repo_url)\n return self.fetch()\n self.make_clean_working_dir()\n return self.clone()\n\n def repo_exists(self):\n code, _, _ = self.run('git', 'status', record=False)\n return code == 0\n\n def are_submodules_available(self, config):\n \"\"\"Test whether git submodule checkout step should be performed.\"\"\"\n # TODO remove this after users migrate to a config file\n from readthedocs.projects.models import Feature\n submodules_in_config = (\n config.submodules.exclude != ALL or\n config.submodules.include\n )\n if (self.project.has_feature(Feature.SKIP_SUBMODULES) or\n not submodules_in_config):\n return False\n\n # Keep compatibility with previous projects\n code, out, _ = self.run('git', 'submodule', 'status', record=False)\n return code == 0 and bool(out)\n\n def validate_submodules(self, config):\n \"\"\"\n Returns the submodules and check that its URLs are valid.\n\n .. note::\n\n Allways call after `self.are_submodules_available`.\n\n :returns: tuple(bool, list)\n\n Returns true if all required submodules URLs are valid.\n Returns a list of all required submodules:\n - Include is `ALL`, returns all submodules avaliable.\n - Include is a list, returns just those.\n - Exclude is `ALL` - this should never happen.\n - Exlude is a list, returns all avaliable submodules\n but those from the list.\n \"\"\"\n repo = git.Repo(self.working_dir)\n submodules = {\n sub.path: sub\n for sub in repo.submodules\n }\n\n for sub_path in config.submodules.exclude:\n path = sub_path.rstrip('/')\n if path in submodules:\n del submodules[path]\n\n if config.submodules.include != ALL and config.submodules.include:\n submodules_include = {}\n for sub_path in config.submodules.include:\n path = sub_path.rstrip('/')\n submodules_include[path] = submodules[path]\n submodules = submodules_include\n\n for path, submodule in submodules.items():\n try:\n validate_submodule_url(submodule.url)\n except ValidationError:\n return False, []\n return True, submodules.keys()\n\n def fetch(self):\n code, stdout, stderr = self.run(\n 'git', 'fetch', '--depth', str(self.repo_depth),\n '--tags', '--prune', '--prune-tags',\n )\n if code != 0:\n raise RepositoryError\n return code, stdout, stderr\n\n def checkout_revision(self, revision=None):\n if not revision:\n branch = self.default_branch or self.fallback_branch\n revision = 'origin/%s' % branch\n\n code, out, err = self.run('git', 'checkout', '--force', revision)\n if code != 0:\n log.warning(\"Failed to checkout revision '%s': %s\", revision, code)\n return [code, out, err]\n\n def clone(self):\n \"\"\"Clones the repository.\"\"\"\n code, stdout, stderr = self.run(\n 'git', 'clone', '--depth', str(self.repo_depth),\n '--no-single-branch', self.repo_url, '.'\n )\n if code != 0:\n raise RepositoryError\n return code, stdout, stderr\n\n @property\n def tags(self):\n versions = []\n repo = git.Repo(self.working_dir)\n for tag in repo.tags:\n try:\n versions.append(VCSVersion(self, str(tag.commit), str(tag)))\n except ValueError as e:\n # ValueError: Cannot resolve commit as tag TAGNAME points to a\n # blob object - use the `.object` property instead to access it\n # This is not a real tag for us, so we skip it\n # https://github.com/rtfd/readthedocs.org/issues/4440\n log.warning('Git tag skipped: %s', tag, exc_info=True)\n continue\n return versions\n\n @property\n def branches(self):\n repo = git.Repo(self.working_dir)\n versions = []\n\n # ``repo.branches`` returns local branches and\n branches = repo.branches\n # ``repo.remotes.origin.refs`` returns remote branches\n if repo.remotes:\n branches += repo.remotes.origin.refs\n\n for branch in branches:\n verbose_name = branch.name\n if verbose_name.startswith('origin/'):\n verbose_name = verbose_name.replace('origin/', '')\n if verbose_name == 'HEAD':\n continue\n versions.append(VCSVersion(self, str(branch), verbose_name))\n return versions\n\n @property\n def commit(self):\n _, stdout, _ = self.run('git', 'rev-parse', 'HEAD')\n return stdout.strip()\n\n def checkout(self, identifier=None):\n \"\"\"Checkout to identifier or latest.\"\"\"\n super(Backend, self).checkout()\n # Find proper identifier\n if not identifier:\n identifier = self.default_branch or self.fallback_branch\n\n identifier = self.find_ref(identifier)\n\n # Checkout the correct identifier for this branch.\n code, out, err = self.checkout_revision(identifier)\n if code != 0:\n return code, out, err\n\n # Clean any remains of previous checkouts\n self.run('git', 'clean', '-d', '-f', '-f')\n return code, out, err\n\n def update_submodules(self, config):\n if self.are_submodules_available(config):\n valid, submodules = self.validate_submodules(config)\n if valid:\n self.checkout_submodules(submodules, config)\n else:\n raise RepositoryError(RepositoryError.INVALID_SUBMODULES)\n\n def checkout_submodules(self, submodules, config):\n \"\"\"Checkout all repository submodules.\"\"\"\n self.run('git', 'submodule', 'sync')\n cmd = [\n 'git',\n 'submodule',\n 'update',\n '--init',\n '--force',\n ]\n if config.submodules.recursive:\n cmd.append('--recursive')\n cmd += submodules\n self.run(*cmd)\n\n def find_ref(self, ref):\n # Check if ref starts with 'origin/'\n if ref.startswith('origin/'):\n return ref\n\n # Check if ref is a branch of the origin remote\n if self.ref_exists('remotes/origin/' + ref):\n return 'origin/' + ref\n\n return ref\n\n def ref_exists(self, ref):\n try:\n r = git.Repo(self.working_dir)\n if r.commit(ref):\n return True\n except (BadName, ValueError):\n return False\n return False\n\n @property\n def env(self):\n env = super(Backend, self).env\n env['GIT_DIR'] = os.path.join(self.working_dir, '.git')\n # Don't prompt for username, this requires Git 2.3+\n env['GIT_TERMINAL_PROMPT'] = '0'\n return env\n", "path": "readthedocs/vcs_support/backends/git.py"}]}
| 3,291 | 229 |
gh_patches_debug_60634
|
rasdani/github-patches
|
git_diff
|
facebookresearch__fairscale-881
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Auto wrapping Huggingface models with FullyShardedDataParallel can break them
## 🐛 Bug
If you auto wrap a HuggingFace model with `FullyShardedDataParallel`, depending on what sub-modules are wrapped, and how the output of the modules are accessed in the model, calling `forward` can result in exceptions.
## What happens
Some sub-modules of the HuggingFace model output a child implementation of [`ModelOutput`](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/file_utils.py#L1884), which is itself a descendent of `OrderedDict`.
An example is, for instance, [`CausalLMOutputWithCrossAttentions` ](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/modeling_outputs.py#L375).
You can access attributes of `ModelOutput` instance derivatives in three ways, e.g. like this:
- `hidden_states = transformer_outputs[0]`
- `hidden_states = transformer_outputs.hidden_states`
- `hidden_states = transformer_outputs["hidden_states"]`
In the HuggingFace library these three types of accessing attributes are used interchangeably.
Now, when a sub-module, which outputs a `ModelOutput` derived instance, is wrapped with `FullyShardedDataParallel`, this output instance is converted in to an `OrderedDict`, in the [`apply_to_tensors`](https://github.com/facebookresearch/fairscale/blob/fecb665b812b6bfc38442e1fb1557e21508917f4/fairscale/utils/containers.py#L21) function, in `utils/containers.py`, since the `ModelOutput` derives from `OrderedDict`! :
```
elif isinstance(x, OrderedDict):
od = OrderedDict()
for key, value in x.items():
od[key] = _apply(value)
return od
```
After it has been converted into a plain `OrderedDict` by `FullyShardedDataParallel`, when the output of the submodule is, for instance, accessed using an index (`transformer_outputs[0]`) or attribute accessor (`transformer_outputs. hidden_states`), an exception is thrown, because the `OrderedDict` instance doesn't know how to handle that.
## A simple solution
A simple solution is to replace the `OrderedDict` instantiation above with `od = x.__class__()`, thus:
```
elif isinstance(x, OrderedDict):
od = x.__class__()
for key, value in x.items():
od[key] = _apply(value)
return od
```
In this way we keep on using the original class, with its extended means to access attributes, which is used in the HuggingFace library.
## To Reproduce
Steps to reproduce the behavior:
1. Use a HuggingFace model, e.g. `GPT2LMHeadModel`
```
from transformers import GPT2Config, GPT2LMHeadModel
```
2. Build the model
```
# You could also try, e.g. "gpt2-large"
model_config = GPT2Config.from_pretrained("gpt2")
self._model = GPT2LMHeadModel(model_config)
self._model.to(self._device)
```
3. Auto wrap the model
```
wrap_policy = functools.partial(default_auto_wrap_policy,
min_num_params=1e8)
fsdp_params = {
"mixed_precision": False,
"move_params_to_cpu": False
}
with enable_wrap(wrapper_cls=FullyShardedDDP, auto_wrap_policy=wrap_policy, **fsdp_params):
self._training_model = auto_wrap(self._model)
# Finally wrap root module
self._training_model = FullyShardedDDP(self._training_model, **fsdp_params)
```
4. Use this in a training loop
This results in errors similar to this one where the `OrderedDict` accessed in invalid ways:
```
... transformers/models/gpt2/modeling_gpt2.py", line 1057, in forward
hidden_states = transformer_outputs[0]
KeyError: 0
```
## Expected behavior
No exception should occur, `FullyShardedDataParallel` should not break calling the HuggingFace model.
## Environment
```
$ pip show fairscale
Name: fairscale
Version: 0.4.3
$ pip show transformers
Name: transformers
Version: 4.12.5
$ pip show torch
Name: torch
Version: 1.10.0
$ python --version
Python 3.7.4
```
</issue>
<code>
[start of fairscale/utils/containers.py]
1 # Copyright (c) Facebook, Inc. and its affiliates.
2 #
3 # This source code is licensed under the BSD license found in the
4 # LICENSE file in the root directory of this source tree.
5
6 from collections import OrderedDict
7 from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
8
9 import torch
10 from torch.nn.utils.rnn import PackedSequence
11
12 """Useful functions to deal with tensor types with other python container types."""
13
14
15 def apply_to_tensors(fn: Callable, container: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:
16 """Recursively apply to all tensor in different kinds of container types."""
17
18 def _apply(x: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:
19 if torch.is_tensor(x):
20 return fn(x)
21 elif isinstance(x, OrderedDict):
22 od = OrderedDict()
23 for key, value in x.items():
24 od[key] = _apply(value)
25 return od
26 elif isinstance(x, PackedSequence):
27 _apply(x.data)
28 return x
29 elif isinstance(x, dict):
30 return {key: _apply(value) for key, value in x.items()}
31 elif isinstance(x, list):
32 return [_apply(x) for x in x]
33 elif isinstance(x, tuple):
34 return tuple(_apply(x) for x in x)
35 elif isinstance(x, set):
36 return {_apply(x) for x in x}
37 else:
38 return x
39
40 return _apply(container)
41
42
43 def pack_kwargs(*args: Any, **kwargs: Any) -> Tuple[Tuple[str, ...], Tuple[Any, ...]]:
44 """
45 Turn argument list into separate key list and value list (unpack_kwargs does the opposite)
46
47 Usage::
48
49 kwarg_keys, flat_args = pack_kwargs(1, 2, a=3, b=4)
50 assert kwarg_keys == ("a", "b")
51 assert flat_args == (1, 2, 3, 4)
52 args, kwargs = unpack_kwargs(kwarg_keys, flat_args)
53 assert args == (1, 2)
54 assert kwargs == {"a": 3, "b": 4}
55 """
56 kwarg_keys: List[str] = []
57 flat_args: List[Any] = list(args)
58 for k, v in kwargs.items():
59 kwarg_keys.append(k)
60 flat_args.append(v)
61 return tuple(kwarg_keys), tuple(flat_args)
62
63
64 def unpack_kwargs(kwarg_keys: Tuple[str, ...], flat_args: Tuple[Any, ...]) -> Tuple[Tuple[Any, ...], Dict[str, Any]]:
65 """See pack_kwargs."""
66 assert len(kwarg_keys) <= len(flat_args), f"too many keys {len(kwarg_keys)} vs. {len(flat_args)}"
67 if len(kwarg_keys) == 0:
68 return flat_args, {}
69 args = flat_args[: -len(kwarg_keys)]
70 kwargs = {k: v for k, v in zip(kwarg_keys, flat_args[-len(kwarg_keys) :])}
71 return args, kwargs
72
73
74 def split_non_tensors(
75 mixed: Union[torch.Tensor, Tuple[Any, ...]]
76 ) -> Tuple[Tuple[torch.Tensor, ...], Optional[Dict[str, List[Any]]]]:
77 """
78 Split a tuple into a list of tensors and the rest with information
79 for later reconstruction.
80
81 Usage::
82
83 x = torch.Tensor([1])
84 y = torch.Tensor([2])
85 tensors, packed_non_tensors = split_non_tensors((x, y, None, 3))
86 assert tensors == (x, y)
87 assert packed_non_tensors == {
88 "is_tensor": [True, True, False, False],
89 "objects": [None, 3],
90 }
91 recon = unpack_non_tensors(tensors, packed_non_tensors)
92 assert recon == (x, y, None, 3)
93 """
94 if isinstance(mixed, torch.Tensor):
95 return (mixed,), None
96 tensors: List[torch.Tensor] = []
97 packed_non_tensors: Dict[str, List[Any]] = {"is_tensor": [], "objects": []}
98 for o in mixed:
99 if isinstance(o, torch.Tensor):
100 packed_non_tensors["is_tensor"].append(True)
101 tensors.append(o)
102 else:
103 packed_non_tensors["is_tensor"].append(False)
104 packed_non_tensors["objects"].append(o)
105 return tuple(tensors), packed_non_tensors
106
107
108 def unpack_non_tensors(
109 tensors: Tuple[torch.Tensor, ...], packed_non_tensors: Optional[Dict[str, List[Any]]]
110 ) -> Tuple[Any, ...]:
111 """See split_non_tensors."""
112 if packed_non_tensors is None:
113 return tensors
114 assert isinstance(packed_non_tensors, dict), type(packed_non_tensors)
115 mixed: List[Any] = []
116 is_tensor_list = packed_non_tensors["is_tensor"]
117 objects = packed_non_tensors["objects"]
118 assert len(tensors) + len(objects) == len(is_tensor_list), (
119 f"len(tensors) {len(tensors)} len(objects) {len(objects)} " f"len(is_tensor_list) {len(is_tensor_list)}"
120 )
121 obj_i = tnsr_i = 0
122 for is_tensor in is_tensor_list:
123 if is_tensor:
124 mixed.append(tensors[tnsr_i])
125 tnsr_i += 1
126 else:
127 mixed.append(objects[obj_i])
128 obj_i += 1
129 return tuple(mixed)
130
[end of fairscale/utils/containers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/fairscale/utils/containers.py b/fairscale/utils/containers.py
--- a/fairscale/utils/containers.py
+++ b/fairscale/utils/containers.py
@@ -19,7 +19,7 @@
if torch.is_tensor(x):
return fn(x)
elif isinstance(x, OrderedDict):
- od = OrderedDict()
+ od = x.__class__()
for key, value in x.items():
od[key] = _apply(value)
return od
|
{"golden_diff": "diff --git a/fairscale/utils/containers.py b/fairscale/utils/containers.py\n--- a/fairscale/utils/containers.py\n+++ b/fairscale/utils/containers.py\n@@ -19,7 +19,7 @@\n if torch.is_tensor(x):\n return fn(x)\n elif isinstance(x, OrderedDict):\n- od = OrderedDict()\n+ od = x.__class__()\n for key, value in x.items():\n od[key] = _apply(value)\n return od\n", "issue": "Auto wrapping Huggingface models with FullyShardedDataParallel can break them\n## \ud83d\udc1b Bug\r\n\r\nIf you auto wrap a HuggingFace model with `FullyShardedDataParallel`, depending on what sub-modules are wrapped, and how the output of the modules are accessed in the model, calling `forward` can result in exceptions. \r\n\r\n## What happens\r\n\r\nSome sub-modules of the HuggingFace model output a child implementation of [`ModelOutput`](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/file_utils.py#L1884), which is itself a descendent of `OrderedDict`.\r\n\r\nAn example is, for instance, [`CausalLMOutputWithCrossAttentions` ](https://github.com/huggingface/transformers/blob/8b240a06617455eae59e1116af6a1a016664e963/src/transformers/modeling_outputs.py#L375).\r\n\r\nYou can access attributes of `ModelOutput` instance derivatives in three ways, e.g. like this:\r\n\r\n- `hidden_states = transformer_outputs[0]`\r\n- `hidden_states = transformer_outputs.hidden_states`\r\n- `hidden_states = transformer_outputs[\"hidden_states\"]`\r\n\r\nIn the HuggingFace library these three types of accessing attributes are used interchangeably.\r\n\r\nNow, when a sub-module, which outputs a `ModelOutput` derived instance, is wrapped with `FullyShardedDataParallel`, this output instance is converted in to an `OrderedDict`, in the [`apply_to_tensors`](https://github.com/facebookresearch/fairscale/blob/fecb665b812b6bfc38442e1fb1557e21508917f4/fairscale/utils/containers.py#L21) function, in `utils/containers.py`, since the `ModelOutput` derives from `OrderedDict`! :\r\n\r\n```\r\n elif isinstance(x, OrderedDict):\r\n od = OrderedDict()\r\n for key, value in x.items():\r\n od[key] = _apply(value)\r\n return od\r\n```\r\n\r\nAfter it has been converted into a plain `OrderedDict` by `FullyShardedDataParallel`, when the output of the submodule is, for instance, accessed using an index (`transformer_outputs[0]`) or attribute accessor (`transformer_outputs. hidden_states`), an exception is thrown, because the `OrderedDict` instance doesn't know how to handle that. \r\n\r\n## A simple solution\r\n\r\nA simple solution is to replace the `OrderedDict` instantiation above with `od = x.__class__()`, thus:\r\n\r\n```\r\n elif isinstance(x, OrderedDict):\r\n od = x.__class__()\r\n for key, value in x.items():\r\n od[key] = _apply(value)\r\n return od\r\n```\r\n\r\nIn this way we keep on using the original class, with its extended means to access attributes, which is used in the HuggingFace library.\r\n\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Use a HuggingFace model, e.g. `GPT2LMHeadModel`\r\n```\r\nfrom transformers import GPT2Config, GPT2LMHeadModel\r\n```\r\n\r\n2. Build the model \r\n```\r\n # You could also try, e.g. \"gpt2-large\"\r\n model_config = GPT2Config.from_pretrained(\"gpt2\")\r\n self._model = GPT2LMHeadModel(model_config)\r\n\r\n self._model.to(self._device)\r\n```\r\n\r\n3. Auto wrap the model\r\n```\r\n wrap_policy = functools.partial(default_auto_wrap_policy,\r\n min_num_params=1e8)\r\n\r\n fsdp_params = {\r\n \"mixed_precision\": False,\r\n \"move_params_to_cpu\": False\r\n }\r\n\r\n with enable_wrap(wrapper_cls=FullyShardedDDP, auto_wrap_policy=wrap_policy, **fsdp_params):\r\n self._training_model = auto_wrap(self._model)\r\n\r\n # Finally wrap root module\r\n self._training_model = FullyShardedDDP(self._training_model, **fsdp_params)\r\n```\r\n\r\n4. Use this in a training loop\r\n\r\nThis results in errors similar to this one where the `OrderedDict` accessed in invalid ways:\r\n```\r\n... transformers/models/gpt2/modeling_gpt2.py\", line 1057, in forward\r\n hidden_states = transformer_outputs[0]\r\nKeyError: 0\r\n```\r\n\r\n## Expected behavior\r\n\r\nNo exception should occur, `FullyShardedDataParallel` should not break calling the HuggingFace model.\r\n\r\n## Environment\r\n\r\n```\r\n$ pip show fairscale\r\nName: fairscale\r\nVersion: 0.4.3\r\n\r\n$ pip show transformers\r\nName: transformers\r\nVersion: 4.12.5\r\n\r\n$ pip show torch\r\nName: torch\r\nVersion: 1.10.0\r\n\r\n$ python --version\r\nPython 3.7.4\r\n```\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates.\n#\n# This source code is licensed under the BSD license found in the\n# LICENSE file in the root directory of this source tree.\n\nfrom collections import OrderedDict\nfrom typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union\n\nimport torch\nfrom torch.nn.utils.rnn import PackedSequence\n\n\"\"\"Useful functions to deal with tensor types with other python container types.\"\"\"\n\n\ndef apply_to_tensors(fn: Callable, container: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:\n \"\"\"Recursively apply to all tensor in different kinds of container types.\"\"\"\n\n def _apply(x: Union[torch.Tensor, Dict, List, Tuple, Set]) -> Any:\n if torch.is_tensor(x):\n return fn(x)\n elif isinstance(x, OrderedDict):\n od = OrderedDict()\n for key, value in x.items():\n od[key] = _apply(value)\n return od\n elif isinstance(x, PackedSequence):\n _apply(x.data)\n return x\n elif isinstance(x, dict):\n return {key: _apply(value) for key, value in x.items()}\n elif isinstance(x, list):\n return [_apply(x) for x in x]\n elif isinstance(x, tuple):\n return tuple(_apply(x) for x in x)\n elif isinstance(x, set):\n return {_apply(x) for x in x}\n else:\n return x\n\n return _apply(container)\n\n\ndef pack_kwargs(*args: Any, **kwargs: Any) -> Tuple[Tuple[str, ...], Tuple[Any, ...]]:\n \"\"\"\n Turn argument list into separate key list and value list (unpack_kwargs does the opposite)\n\n Usage::\n\n kwarg_keys, flat_args = pack_kwargs(1, 2, a=3, b=4)\n assert kwarg_keys == (\"a\", \"b\")\n assert flat_args == (1, 2, 3, 4)\n args, kwargs = unpack_kwargs(kwarg_keys, flat_args)\n assert args == (1, 2)\n assert kwargs == {\"a\": 3, \"b\": 4}\n \"\"\"\n kwarg_keys: List[str] = []\n flat_args: List[Any] = list(args)\n for k, v in kwargs.items():\n kwarg_keys.append(k)\n flat_args.append(v)\n return tuple(kwarg_keys), tuple(flat_args)\n\n\ndef unpack_kwargs(kwarg_keys: Tuple[str, ...], flat_args: Tuple[Any, ...]) -> Tuple[Tuple[Any, ...], Dict[str, Any]]:\n \"\"\"See pack_kwargs.\"\"\"\n assert len(kwarg_keys) <= len(flat_args), f\"too many keys {len(kwarg_keys)} vs. {len(flat_args)}\"\n if len(kwarg_keys) == 0:\n return flat_args, {}\n args = flat_args[: -len(kwarg_keys)]\n kwargs = {k: v for k, v in zip(kwarg_keys, flat_args[-len(kwarg_keys) :])}\n return args, kwargs\n\n\ndef split_non_tensors(\n mixed: Union[torch.Tensor, Tuple[Any, ...]]\n) -> Tuple[Tuple[torch.Tensor, ...], Optional[Dict[str, List[Any]]]]:\n \"\"\"\n Split a tuple into a list of tensors and the rest with information\n for later reconstruction.\n\n Usage::\n\n x = torch.Tensor([1])\n y = torch.Tensor([2])\n tensors, packed_non_tensors = split_non_tensors((x, y, None, 3))\n assert tensors == (x, y)\n assert packed_non_tensors == {\n \"is_tensor\": [True, True, False, False],\n \"objects\": [None, 3],\n }\n recon = unpack_non_tensors(tensors, packed_non_tensors)\n assert recon == (x, y, None, 3)\n \"\"\"\n if isinstance(mixed, torch.Tensor):\n return (mixed,), None\n tensors: List[torch.Tensor] = []\n packed_non_tensors: Dict[str, List[Any]] = {\"is_tensor\": [], \"objects\": []}\n for o in mixed:\n if isinstance(o, torch.Tensor):\n packed_non_tensors[\"is_tensor\"].append(True)\n tensors.append(o)\n else:\n packed_non_tensors[\"is_tensor\"].append(False)\n packed_non_tensors[\"objects\"].append(o)\n return tuple(tensors), packed_non_tensors\n\n\ndef unpack_non_tensors(\n tensors: Tuple[torch.Tensor, ...], packed_non_tensors: Optional[Dict[str, List[Any]]]\n) -> Tuple[Any, ...]:\n \"\"\"See split_non_tensors.\"\"\"\n if packed_non_tensors is None:\n return tensors\n assert isinstance(packed_non_tensors, dict), type(packed_non_tensors)\n mixed: List[Any] = []\n is_tensor_list = packed_non_tensors[\"is_tensor\"]\n objects = packed_non_tensors[\"objects\"]\n assert len(tensors) + len(objects) == len(is_tensor_list), (\n f\"len(tensors) {len(tensors)} len(objects) {len(objects)} \" f\"len(is_tensor_list) {len(is_tensor_list)}\"\n )\n obj_i = tnsr_i = 0\n for is_tensor in is_tensor_list:\n if is_tensor:\n mixed.append(tensors[tnsr_i])\n tnsr_i += 1\n else:\n mixed.append(objects[obj_i])\n obj_i += 1\n return tuple(mixed)\n", "path": "fairscale/utils/containers.py"}]}
| 3,075 | 107 |
gh_patches_debug_15476
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-trace-py-4196
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
aioredis raises CancelledError in _finish_span
### Which version of dd-trace-py are you using?
~~0.53.0~~ 0.58.0
### Which version of pip are you using?
21.3.1
### Which version of the libraries are you using?
django==3.2.11
django-redis==5.0.0
channels==3.0.4
daphne==3.0.2
### How can we reproduce your problem?
I am using code similar to the following:
asgi.py
```
import django
from channels.routing import get_default_application
from ddtrace.contrib.asgi import TraceMiddleware
django.setup()
application = TraceMiddleware(get_default_application())
```
routing.py
```
from django.urls import re_path
import my_app.consumers
websocket_urlpatterns = [
re_path(r"^ws/test/$", consumers.TestConsumer.as_asgi()),
]
```
my_app/consumers.py
```
from channels.generic.websocket import WebsocketConsumer
class TestConsumer(WebsocketConsumer):
groups = ["broadcast"]
def connect(self):
self.accept()
def receive(self, text_data=None, bytes_data=None):
raise Exception("An test exception")
```
I am running the application with: `ddtrace-run daphne asgi:application --bind 0.0.0.0 --port 8001`
### What is the result that you get?
I don't get any traces at all, and my logs show this:
```
handle: <Handle traced_13_execute_command.<locals>._finish_span(<Future cancelled>) at /usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py:140>
Traceback (most recent call last):
File "/usr/local/lib/python3.10/asyncio/events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "/usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py", line 146, in _finish_span
future.result()
asyncio.exceptions.CancelledError
```
### What is the result that you expected?
No errors
</issue>
<code>
[start of ddtrace/contrib/aioredis/patch.py]
1 import asyncio
2 import sys
3
4 import aioredis
5
6 from ddtrace import config
7 from ddtrace.internal.utils.wrappers import unwrap as _u
8 from ddtrace.pin import Pin
9 from ddtrace.vendor.wrapt import wrap_function_wrapper as _w
10
11 from .. import trace_utils
12 from ...constants import ANALYTICS_SAMPLE_RATE_KEY
13 from ...constants import SPAN_MEASURED_KEY
14 from ...ext import SpanTypes
15 from ...ext import net
16 from ...ext import redis as redisx
17 from ...internal.utils.formats import stringify_cache_args
18 from ..redis.util import _trace_redis_cmd
19 from ..redis.util import _trace_redis_execute_pipeline
20
21
22 try:
23 from aioredis.commands.transaction import _RedisBuffer
24 except ImportError:
25 _RedisBuffer = None
26
27 config._add("aioredis", dict(_default_service="redis"))
28
29 aioredis_version_str = getattr(aioredis, "__version__", "0.0.0")
30 aioredis_version = tuple([int(i) for i in aioredis_version_str.split(".")])
31
32
33 def patch():
34 if getattr(aioredis, "_datadog_patch", False):
35 return
36 setattr(aioredis, "_datadog_patch", True)
37 pin = Pin()
38 if aioredis_version >= (2, 0):
39 _w("aioredis.client", "Redis.execute_command", traced_execute_command)
40 _w("aioredis.client", "Redis.pipeline", traced_pipeline)
41 _w("aioredis.client", "Pipeline.execute", traced_execute_pipeline)
42 pin.onto(aioredis.client.Redis)
43 else:
44 _w("aioredis", "Redis.execute", traced_13_execute_command)
45 _w("aioredis", "Redis.pipeline", traced_13_pipeline)
46 _w("aioredis.commands.transaction", "Pipeline.execute", traced_13_execute_pipeline)
47 pin.onto(aioredis.Redis)
48
49
50 def unpatch():
51 if not getattr(aioredis, "_datadog_patch", False):
52 return
53
54 setattr(aioredis, "_datadog_patch", False)
55 if aioredis_version >= (2, 0):
56 _u(aioredis.client.Redis, "execute_command")
57 _u(aioredis.client.Redis, "pipeline")
58 _u(aioredis.client.Pipeline, "execute")
59 else:
60 _u(aioredis.Redis, "execute")
61 _u(aioredis.Redis, "pipeline")
62 _u(aioredis.commands.transaction.Pipeline, "execute")
63
64
65 async def traced_execute_command(func, instance, args, kwargs):
66 pin = Pin.get_from(instance)
67 if not pin or not pin.enabled():
68 return await func(*args, **kwargs)
69
70 with _trace_redis_cmd(pin, config.aioredis, instance, args):
71 return await func(*args, **kwargs)
72
73
74 def traced_pipeline(func, instance, args, kwargs):
75 pipeline = func(*args, **kwargs)
76 pin = Pin.get_from(instance)
77 if pin:
78 pin.onto(pipeline)
79 return pipeline
80
81
82 async def traced_execute_pipeline(func, instance, args, kwargs):
83 pin = Pin.get_from(instance)
84 if not pin or not pin.enabled():
85 return await func(*args, **kwargs)
86
87 cmds = [stringify_cache_args(c) for c, _ in instance.command_stack]
88 resource = "\n".join(cmds)
89 with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):
90 return await func(*args, **kwargs)
91
92
93 def traced_13_pipeline(func, instance, args, kwargs):
94 pipeline = func(*args, **kwargs)
95 pin = Pin.get_from(instance)
96 if pin:
97 pin.onto(pipeline)
98 return pipeline
99
100
101 def traced_13_execute_command(func, instance, args, kwargs):
102 # If we have a _RedisBuffer then we are in a pipeline
103 if isinstance(instance.connection, _RedisBuffer):
104 return func(*args, **kwargs)
105
106 pin = Pin.get_from(instance)
107 if not pin or not pin.enabled():
108 return func(*args, **kwargs)
109
110 # Don't activate the span since this operation is performed as a future which concludes sometime later on in
111 # execution so subsequent operations in the stack are not necessarily semantically related
112 # (we don't want this span to be the parent of all other spans created before the future is resolved)
113 parent = pin.tracer.current_span()
114 span = pin.tracer.start_span(
115 redisx.CMD,
116 service=trace_utils.ext_service(pin, config.aioredis),
117 span_type=SpanTypes.REDIS,
118 activate=False,
119 child_of=parent,
120 )
121
122 span.set_tag(SPAN_MEASURED_KEY)
123 query = stringify_cache_args(args)
124 span.resource = query
125 span.set_tag(redisx.RAWCMD, query)
126 if pin.tags:
127 span.set_tags(pin.tags)
128
129 span.set_tags(
130 {
131 net.TARGET_HOST: instance.address[0],
132 net.TARGET_PORT: instance.address[1],
133 redisx.DB: instance.db or 0,
134 }
135 )
136 span.set_metric(redisx.ARGS_LEN, len(args))
137 # set analytics sample rate if enabled
138 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())
139
140 def _finish_span(future):
141 try:
142 # Accessing the result will raise an exception if:
143 # - The future was cancelled
144 # - There was an error executing the future (`future.exception()`)
145 # - The future is in an invalid state
146 future.result()
147 except Exception:
148 span.set_exc_info(*sys.exc_info())
149 finally:
150 span.finish()
151
152 task = func(*args, **kwargs)
153 # Execute command returns a coroutine when no free connections are available
154 # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191
155 task = asyncio.ensure_future(task)
156 task.add_done_callback(_finish_span)
157 return task
158
159
160 async def traced_13_execute_pipeline(func, instance, args, kwargs):
161 pin = Pin.get_from(instance)
162 if not pin or not pin.enabled():
163 return await func(*args, **kwargs)
164
165 cmds = []
166 for _, cmd, cmd_args, _ in instance._pipeline:
167 parts = [cmd]
168 parts.extend(cmd_args)
169 cmds.append(stringify_cache_args(parts))
170 resource = "\n".join(cmds)
171 with pin.tracer.trace(
172 redisx.CMD,
173 resource=resource,
174 service=trace_utils.ext_service(pin, config.aioredis),
175 span_type=SpanTypes.REDIS,
176 ) as span:
177
178 span.set_tags(
179 {
180 net.TARGET_HOST: instance._pool_or_conn.address[0],
181 net.TARGET_PORT: instance._pool_or_conn.address[1],
182 redisx.DB: instance._pool_or_conn.db or 0,
183 }
184 )
185
186 span.set_tag(SPAN_MEASURED_KEY)
187 span.set_tag(redisx.RAWCMD, resource)
188 span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))
189 # set analytics sample rate if enabled
190 span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())
191
192 return await func(*args, **kwargs)
193
[end of ddtrace/contrib/aioredis/patch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ddtrace/contrib/aioredis/patch.py b/ddtrace/contrib/aioredis/patch.py
--- a/ddtrace/contrib/aioredis/patch.py
+++ b/ddtrace/contrib/aioredis/patch.py
@@ -140,11 +140,12 @@
def _finish_span(future):
try:
# Accessing the result will raise an exception if:
- # - The future was cancelled
+ # - The future was cancelled (CancelledError)
# - There was an error executing the future (`future.exception()`)
# - The future is in an invalid state
future.result()
- except Exception:
+ # CancelledError exceptions extend from BaseException as of Python 3.8, instead of usual Exception
+ except BaseException:
span.set_exc_info(*sys.exc_info())
finally:
span.finish()
|
{"golden_diff": "diff --git a/ddtrace/contrib/aioredis/patch.py b/ddtrace/contrib/aioredis/patch.py\n--- a/ddtrace/contrib/aioredis/patch.py\n+++ b/ddtrace/contrib/aioredis/patch.py\n@@ -140,11 +140,12 @@\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n- # - The future was cancelled\n+ # - The future was cancelled (CancelledError)\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n- except Exception:\n+ # CancelledError exceptions extend from BaseException as of Python 3.8, instead of usual Exception\n+ except BaseException:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n", "issue": "aioredis raises CancelledError in _finish_span \n### Which version of dd-trace-py are you using?\r\n\r\n~~0.53.0~~ 0.58.0\r\n\r\n### Which version of pip are you using?\r\n\r\n21.3.1\r\n\r\n### Which version of the libraries are you using?\r\n\r\ndjango==3.2.11\r\ndjango-redis==5.0.0\r\nchannels==3.0.4\r\ndaphne==3.0.2\r\n\r\n### How can we reproduce your problem?\r\n\r\nI am using code similar to the following:\r\n\r\nasgi.py\r\n\r\n```\r\nimport django\r\nfrom channels.routing import get_default_application\r\nfrom ddtrace.contrib.asgi import TraceMiddleware\r\n\r\ndjango.setup()\r\napplication = TraceMiddleware(get_default_application())\r\n```\r\n\r\nrouting.py\r\n\r\n```\r\nfrom django.urls import re_path\r\nimport my_app.consumers\r\n\r\nwebsocket_urlpatterns = [\r\n re_path(r\"^ws/test/$\", consumers.TestConsumer.as_asgi()),\r\n]\r\n```\r\n\r\nmy_app/consumers.py\r\n\r\n```\r\nfrom channels.generic.websocket import WebsocketConsumer\r\n\r\nclass TestConsumer(WebsocketConsumer):\r\n groups = [\"broadcast\"]\r\n\r\n def connect(self):\r\n self.accept()\r\n\r\n def receive(self, text_data=None, bytes_data=None):\r\n raise Exception(\"An test exception\")\r\n```\r\n\r\nI am running the application with: `ddtrace-run daphne asgi:application --bind 0.0.0.0 --port 8001`\r\n\r\n### What is the result that you get?\r\n\r\nI don't get any traces at all, and my logs show this:\r\n\r\n```\r\nhandle: <Handle traced_13_execute_command.<locals>._finish_span(<Future cancelled>) at /usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py:140>\r\n\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.10/asyncio/events.py\", line 80, in _run\r\n self._context.run(self._callback, *self._args)\r\n File \"/usr/local/lib/python3.10/site-packages/ddtrace/contrib/aioredis/patch.py\", line 146, in _finish_span\r\n future.result()\r\nasyncio.exceptions.CancelledError\r\n```\r\n\r\n\r\n### What is the result that you expected?\r\n\r\nNo errors\r\n\n", "before_files": [{"content": "import asyncio\nimport sys\n\nimport aioredis\n\nfrom ddtrace import config\nfrom ddtrace.internal.utils.wrappers import unwrap as _u\nfrom ddtrace.pin import Pin\nfrom ddtrace.vendor.wrapt import wrap_function_wrapper as _w\n\nfrom .. import trace_utils\nfrom ...constants import ANALYTICS_SAMPLE_RATE_KEY\nfrom ...constants import SPAN_MEASURED_KEY\nfrom ...ext import SpanTypes\nfrom ...ext import net\nfrom ...ext import redis as redisx\nfrom ...internal.utils.formats import stringify_cache_args\nfrom ..redis.util import _trace_redis_cmd\nfrom ..redis.util import _trace_redis_execute_pipeline\n\n\ntry:\n from aioredis.commands.transaction import _RedisBuffer\nexcept ImportError:\n _RedisBuffer = None\n\nconfig._add(\"aioredis\", dict(_default_service=\"redis\"))\n\naioredis_version_str = getattr(aioredis, \"__version__\", \"0.0.0\")\naioredis_version = tuple([int(i) for i in aioredis_version_str.split(\".\")])\n\n\ndef patch():\n if getattr(aioredis, \"_datadog_patch\", False):\n return\n setattr(aioredis, \"_datadog_patch\", True)\n pin = Pin()\n if aioredis_version >= (2, 0):\n _w(\"aioredis.client\", \"Redis.execute_command\", traced_execute_command)\n _w(\"aioredis.client\", \"Redis.pipeline\", traced_pipeline)\n _w(\"aioredis.client\", \"Pipeline.execute\", traced_execute_pipeline)\n pin.onto(aioredis.client.Redis)\n else:\n _w(\"aioredis\", \"Redis.execute\", traced_13_execute_command)\n _w(\"aioredis\", \"Redis.pipeline\", traced_13_pipeline)\n _w(\"aioredis.commands.transaction\", \"Pipeline.execute\", traced_13_execute_pipeline)\n pin.onto(aioredis.Redis)\n\n\ndef unpatch():\n if not getattr(aioredis, \"_datadog_patch\", False):\n return\n\n setattr(aioredis, \"_datadog_patch\", False)\n if aioredis_version >= (2, 0):\n _u(aioredis.client.Redis, \"execute_command\")\n _u(aioredis.client.Redis, \"pipeline\")\n _u(aioredis.client.Pipeline, \"execute\")\n else:\n _u(aioredis.Redis, \"execute\")\n _u(aioredis.Redis, \"pipeline\")\n _u(aioredis.commands.transaction.Pipeline, \"execute\")\n\n\nasync def traced_execute_command(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n with _trace_redis_cmd(pin, config.aioredis, instance, args):\n return await func(*args, **kwargs)\n\n\ndef traced_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\nasync def traced_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = [stringify_cache_args(c) for c, _ in instance.command_stack]\n resource = \"\\n\".join(cmds)\n with _trace_redis_execute_pipeline(pin, config.aioredis, resource, instance):\n return await func(*args, **kwargs)\n\n\ndef traced_13_pipeline(func, instance, args, kwargs):\n pipeline = func(*args, **kwargs)\n pin = Pin.get_from(instance)\n if pin:\n pin.onto(pipeline)\n return pipeline\n\n\ndef traced_13_execute_command(func, instance, args, kwargs):\n # If we have a _RedisBuffer then we are in a pipeline\n if isinstance(instance.connection, _RedisBuffer):\n return func(*args, **kwargs)\n\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return func(*args, **kwargs)\n\n # Don't activate the span since this operation is performed as a future which concludes sometime later on in\n # execution so subsequent operations in the stack are not necessarily semantically related\n # (we don't want this span to be the parent of all other spans created before the future is resolved)\n parent = pin.tracer.current_span()\n span = pin.tracer.start_span(\n redisx.CMD,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n activate=False,\n child_of=parent,\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n query = stringify_cache_args(args)\n span.resource = query\n span.set_tag(redisx.RAWCMD, query)\n if pin.tags:\n span.set_tags(pin.tags)\n\n span.set_tags(\n {\n net.TARGET_HOST: instance.address[0],\n net.TARGET_PORT: instance.address[1],\n redisx.DB: instance.db or 0,\n }\n )\n span.set_metric(redisx.ARGS_LEN, len(args))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n def _finish_span(future):\n try:\n # Accessing the result will raise an exception if:\n # - The future was cancelled\n # - There was an error executing the future (`future.exception()`)\n # - The future is in an invalid state\n future.result()\n except Exception:\n span.set_exc_info(*sys.exc_info())\n finally:\n span.finish()\n\n task = func(*args, **kwargs)\n # Execute command returns a coroutine when no free connections are available\n # https://github.com/aio-libs/aioredis-py/blob/v1.3.1/aioredis/pool.py#L191\n task = asyncio.ensure_future(task)\n task.add_done_callback(_finish_span)\n return task\n\n\nasync def traced_13_execute_pipeline(func, instance, args, kwargs):\n pin = Pin.get_from(instance)\n if not pin or not pin.enabled():\n return await func(*args, **kwargs)\n\n cmds = []\n for _, cmd, cmd_args, _ in instance._pipeline:\n parts = [cmd]\n parts.extend(cmd_args)\n cmds.append(stringify_cache_args(parts))\n resource = \"\\n\".join(cmds)\n with pin.tracer.trace(\n redisx.CMD,\n resource=resource,\n service=trace_utils.ext_service(pin, config.aioredis),\n span_type=SpanTypes.REDIS,\n ) as span:\n\n span.set_tags(\n {\n net.TARGET_HOST: instance._pool_or_conn.address[0],\n net.TARGET_PORT: instance._pool_or_conn.address[1],\n redisx.DB: instance._pool_or_conn.db or 0,\n }\n )\n\n span.set_tag(SPAN_MEASURED_KEY)\n span.set_tag(redisx.RAWCMD, resource)\n span.set_metric(redisx.PIPELINE_LEN, len(instance._pipeline))\n # set analytics sample rate if enabled\n span.set_tag(ANALYTICS_SAMPLE_RATE_KEY, config.aioredis.get_analytics_sample_rate())\n\n return await func(*args, **kwargs)\n", "path": "ddtrace/contrib/aioredis/patch.py"}]}
| 3,106 | 202 |
gh_patches_debug_4478
|
rasdani/github-patches
|
git_diff
|
python-telegram-bot__python-telegram-bot-2168
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mypy doesn't pick up type hints[BUG]
<!--
Thanks for reporting issues of python-telegram-bot!
Use this template to notify us if you found a bug.
To make it easier for us to help you please enter detailed information below.
Please note, we only support the latest version of python-telegram-bot and
master branch. Please make sure to upgrade & recreate the issue on the latest
version prior to opening an issue.
-->
### Steps to reproduce
1. import python-telegram-bot modules into your `test.py` file (e.g. `from telegram import InlineKeyboardMarkup`)
2. run `mypy test.py`
3. receive the following output `error: Skipping analyzing 'telegram': found module but no type hints or library stubs`
### Expected behaviour
mypy should pickup the typehints as they've been added in the latest release (version `13` )
### Actual behaviour
mypy doesn't pickup the typehints.
I'm confident this can be solved by either
1. adding `python-telegram-bot` to `typeshed`
2. adding a `py.typed` file
More information can be found [here.](https://stackoverflow.com/questions/60856237/mypy-cant-find-type-hints-for-black)
### Configuration
**Operating System:**
Ubuntu 18.04
**Version of Python, python-telegram-bot & dependencies:**
``$ python -m telegram``
python-telegram-bot 13.0
certifi 2020.06.20
Python 3.8.0 (default, Oct 30 2020, 19:06:04) [GCC 7.5.0]
### Logs
```
error: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs
note: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports
error: Skipping analyzing 'telegram': found module but no type hints or library stubs
error: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs
error: Skipping analyzing 'telegram': found module but no type hints or library stubs
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 """The setup and build script for the python-telegram-bot library."""
3
4 import codecs
5 import os
6 import sys
7
8 from setuptools import setup, find_packages
9
10
11 def requirements():
12 """Build the requirements list for this project"""
13 requirements_list = []
14
15 with open('requirements.txt') as requirements:
16 for install in requirements:
17 requirements_list.append(install.strip())
18
19 return requirements_list
20
21
22 packages = find_packages(exclude=['tests*'])
23 requirements = requirements()
24
25 # Allow for a package install to not use the vendored urllib3
26 UPSTREAM_URLLIB3_FLAG = '--with-upstream-urllib3'
27 if UPSTREAM_URLLIB3_FLAG in sys.argv:
28 sys.argv.remove(UPSTREAM_URLLIB3_FLAG)
29 requirements.append('urllib3 >= 1.19.1')
30 packages = [x for x in packages if not x.startswith('telegram.vendor.ptb_urllib3')]
31
32 with codecs.open('README.rst', 'r', 'utf-8') as fd:
33 fn = os.path.join('telegram', 'version.py')
34 with open(fn) as fh:
35 code = compile(fh.read(), fn, 'exec')
36 exec(code)
37
38 setup(name='python-telegram-bot',
39 version=__version__,
40 author='Leandro Toledo',
41 author_email='[email protected]',
42 license='LGPLv3',
43 url='https://python-telegram-bot.org/',
44 keywords='python telegram bot api wrapper',
45 description="We have made you a wrapper you can't refuse",
46 long_description=fd.read(),
47 packages=packages,
48 install_requires=requirements,
49 extras_require={
50 'json': 'ujson',
51 'socks': 'PySocks'
52 },
53 include_package_data=True,
54 classifiers=[
55 'Development Status :: 5 - Production/Stable',
56 'Intended Audience :: Developers',
57 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',
58 'Operating System :: OS Independent',
59 'Topic :: Software Development :: Libraries :: Python Modules',
60 'Topic :: Communications :: Chat',
61 'Topic :: Internet',
62 'Programming Language :: Python',
63 'Programming Language :: Python :: 3',
64 'Programming Language :: Python :: 3.6',
65 'Programming Language :: Python :: 3.7',
66 'Programming Language :: Python :: 3.8',
67 'Programming Language :: Python :: 3.9',
68 ],)
69
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -45,6 +45,7 @@
description="We have made you a wrapper you can't refuse",
long_description=fd.read(),
packages=packages,
+ package_data={'telegram': ['py.typed']},
install_requires=requirements,
extras_require={
'json': 'ujson',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -45,6 +45,7 @@\n description=\"We have made you a wrapper you can't refuse\",\n long_description=fd.read(),\n packages=packages,\n+ package_data={'telegram': ['py.typed']},\n install_requires=requirements,\n extras_require={\n 'json': 'ujson',\n", "issue": "mypy doesn't pick up type hints[BUG]\n<!--\r\nThanks for reporting issues of python-telegram-bot!\r\n\r\nUse this template to notify us if you found a bug.\r\n\r\nTo make it easier for us to help you please enter detailed information below.\r\n\r\nPlease note, we only support the latest version of python-telegram-bot and\r\nmaster branch. Please make sure to upgrade & recreate the issue on the latest\r\nversion prior to opening an issue.\r\n-->\r\n### Steps to reproduce\r\n1. import python-telegram-bot modules into your `test.py` file (e.g. `from telegram import InlineKeyboardMarkup`)\r\n\r\n2. run `mypy test.py`\r\n\r\n3. receive the following output `error: Skipping analyzing 'telegram': found module but no type hints or library stubs`\r\n\r\n### Expected behaviour\r\nmypy should pickup the typehints as they've been added in the latest release (version `13` )\r\n\r\n### Actual behaviour\r\nmypy doesn't pickup the typehints.\r\n\r\nI'm confident this can be solved by either\r\n\r\n1. adding `python-telegram-bot` to `typeshed` \r\n2. adding a `py.typed` file\r\n\r\nMore information can be found [here.](https://stackoverflow.com/questions/60856237/mypy-cant-find-type-hints-for-black)\r\n\r\n### Configuration\r\n**Operating System:**\r\nUbuntu 18.04\r\n\r\n**Version of Python, python-telegram-bot & dependencies:**\r\n\r\n``$ python -m telegram``\r\npython-telegram-bot 13.0\r\ncertifi 2020.06.20\r\nPython 3.8.0 (default, Oct 30 2020, 19:06:04) [GCC 7.5.0]\r\n### Logs\r\n```\r\nerror: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs\r\nnote: See https://mypy.readthedocs.io/en/latest/running_mypy.html#missing-imports\r\nerror: Skipping analyzing 'telegram': found module but no type hints or library stubs\r\nerror: Skipping analyzing 'telegram.ext': found module but no type hints or library stubs\r\nerror: Skipping analyzing 'telegram': found module but no type hints or library stubs\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"The setup and build script for the python-telegram-bot library.\"\"\"\n\nimport codecs\nimport os\nimport sys\n\nfrom setuptools import setup, find_packages\n\n\ndef requirements():\n \"\"\"Build the requirements list for this project\"\"\"\n requirements_list = []\n\n with open('requirements.txt') as requirements:\n for install in requirements:\n requirements_list.append(install.strip())\n\n return requirements_list\n\n\npackages = find_packages(exclude=['tests*'])\nrequirements = requirements()\n\n# Allow for a package install to not use the vendored urllib3\nUPSTREAM_URLLIB3_FLAG = '--with-upstream-urllib3'\nif UPSTREAM_URLLIB3_FLAG in sys.argv:\n sys.argv.remove(UPSTREAM_URLLIB3_FLAG)\n requirements.append('urllib3 >= 1.19.1')\n packages = [x for x in packages if not x.startswith('telegram.vendor.ptb_urllib3')]\n\nwith codecs.open('README.rst', 'r', 'utf-8') as fd:\n fn = os.path.join('telegram', 'version.py')\n with open(fn) as fh:\n code = compile(fh.read(), fn, 'exec')\n exec(code)\n\n setup(name='python-telegram-bot',\n version=__version__,\n author='Leandro Toledo',\n author_email='[email protected]',\n license='LGPLv3',\n url='https://python-telegram-bot.org/',\n keywords='python telegram bot api wrapper',\n description=\"We have made you a wrapper you can't refuse\",\n long_description=fd.read(),\n packages=packages,\n install_requires=requirements,\n extras_require={\n 'json': 'ujson',\n 'socks': 'PySocks'\n },\n include_package_data=True,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: GNU Lesser General Public License v3 (LGPLv3)',\n 'Operating System :: OS Independent',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n 'Topic :: Communications :: Chat',\n 'Topic :: Internet',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],)\n", "path": "setup.py"}]}
| 1,660 | 88 |
gh_patches_debug_3769
|
rasdani/github-patches
|
git_diff
|
lmfit__lmfit-py-949
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sys.module needs to be copied before being iterated over
#### Description
According to https://docs.python.org/3/library/sys.html#sys.modules, one needs to copy `sys.module` to iterate over it. This function [in this file](https://github.com/lmfit/lmfit-py/blob/8781a2dc33288b25fae6f3139595402155e4968b/lmfit/jsonutils.py#L27) does not follow this advice.
It should be replaced by:
```
def find_importer(obj):
"""Find importer of an object."""
oname = obj.__name__
for modname, module in sys.modules.copy().items():
if modname.startswith('__main__'):
continue
t = getattr(module, oname, None)
if t is obj:
return modname
return None
```
Please note `sys.modules.items()` -> `sys.modules.copy().items()`
###### A Minimal, Complete, and Verifiable example
I ran into `RuntimeError: dictionary changed size during iteration` with a large project using lmfit. The solution indicated in the python docs solves it. It is not immediate to create an MVE and I hope the python docs is enough to convince to implement the change.
###### Error message:
<!-- If any, paste the *full* error message inside a code block (starting from line Traceback) -->
```
...
obj = <function test_serde_lmfit_modelresult_with_error.<locals>.custom_error at 0x308a292d0>
def find_importer(obj):
"""Find importer of an object."""
oname = obj.__name__
> for modname, module in sys.modules.items():
E RuntimeError: dictionary changed size during iteration
/.../lib/python3.10/site-packages/lmfit/jsonutils.py:27: RuntimeError
```
###### Version information
Python: 3.10.14 (main, Mar 19 2024, 21:46:16) [Clang 15.0.0 (clang-1500.3.9.4)]
lmfit: 1.3.0, scipy: 1.11.4, numpy: 1.26.3,asteval: 0.9.32, uncertainties: 3.1.6###### Link(s)
<!-- If you started a discussion on the lmfit mailing list, discussion page, or Stack Overflow, please provide the relevant link(s) -->
</issue>
<code>
[start of lmfit/jsonutils.py]
1 """JSON utilities."""
2
3 from base64 import b64decode, b64encode
4 from io import StringIO
5 import sys
6 import warnings
7
8 import dill
9 import numpy as np
10 import uncertainties
11
12 HAS_DILL = True
13
14 try:
15 from pandas import DataFrame, Series, read_json
16 except ImportError:
17 DataFrame = Series = type(NotImplemented)
18 read_json = None
19
20
21 pyvers = f'{sys.version_info.major}.{sys.version_info.minor}'
22
23
24 def find_importer(obj):
25 """Find importer of an object."""
26 oname = obj.__name__
27 for modname, module in sys.modules.items():
28 if modname.startswith('__main__'):
29 continue
30 t = getattr(module, oname, None)
31 if t is obj:
32 return modname
33 return None
34
35
36 def import_from(modulepath, objectname):
37 """Wrapper for __import__ for nested objects."""
38 path = modulepath.split('.')
39 top = path.pop(0)
40 parent = __import__(top)
41 while len(path) > 0:
42 parent = getattr(parent, path.pop(0))
43 return getattr(parent, objectname)
44
45
46 def encode4js(obj):
47 """Prepare an object for JSON encoding.
48
49 It has special handling for many Python types, including:
50 - pandas DataFrames and Series
51 - NumPy ndarrays
52 - complex numbers
53
54 """
55 if isinstance(obj, DataFrame):
56 return dict(__class__='PDataFrame', value=obj.to_json())
57 if isinstance(obj, Series):
58 return dict(__class__='PSeries', value=obj.to_json())
59 if isinstance(obj, uncertainties.core.AffineScalarFunc):
60 return dict(__class__='UFloat', val=obj.nominal_value, err=obj.std_dev)
61 if isinstance(obj, np.ndarray):
62 if 'complex' in obj.dtype.name:
63 val = [(obj.real).tolist(), (obj.imag).tolist()]
64 elif obj.dtype.name == 'object':
65 val = [encode4js(item) for item in obj]
66 else:
67 val = obj.flatten().tolist()
68 return dict(__class__='NDArray', __shape__=obj.shape,
69 __dtype__=obj.dtype.name, value=val)
70 if isinstance(obj, float):
71 return float(obj)
72 if isinstance(obj, int):
73 return int(obj)
74 if isinstance(obj, str):
75 try:
76 return str(obj)
77 except UnicodeError:
78 return obj
79 if isinstance(obj, complex):
80 return dict(__class__='Complex', value=(obj.real, obj.imag))
81 if isinstance(obj, (tuple, list)):
82 ctype = 'List'
83 if isinstance(obj, tuple):
84 ctype = 'Tuple'
85 val = [encode4js(item) for item in obj]
86 return dict(__class__=ctype, value=val)
87 if isinstance(obj, dict):
88 out = dict(__class__='Dict')
89 for key, val in obj.items():
90 out[encode4js(key)] = encode4js(val)
91 return out
92 if callable(obj):
93 value = str(b64encode(dill.dumps(obj)), 'utf-8')
94 return dict(__class__='Callable', __name__=obj.__name__,
95 pyversion=pyvers, value=value,
96 importer=find_importer(obj))
97 return obj
98
99
100 def decode4js(obj):
101 """Return decoded Python object from encoded object."""
102 if not isinstance(obj, dict):
103 return obj
104 out = obj
105 classname = obj.pop('__class__', None)
106 if classname is None and isinstance(obj, dict):
107 classname = 'dict'
108 if classname is None:
109 return obj
110 if classname == 'Complex':
111 out = obj['value'][0] + 1j*obj['value'][1]
112 elif classname in ('List', 'Tuple'):
113 out = []
114 for item in obj['value']:
115 out.append(decode4js(item))
116 if classname == 'Tuple':
117 out = tuple(out)
118 elif classname == 'NDArray':
119 if obj['__dtype__'].startswith('complex'):
120 re = np.fromiter(obj['value'][0], dtype='double')
121 im = np.fromiter(obj['value'][1], dtype='double')
122 out = re + 1j*im
123 elif obj['__dtype__'].startswith('object'):
124 val = [decode4js(v) for v in obj['value']]
125 out = np.array(val, dtype=obj['__dtype__'])
126 else:
127 out = np.fromiter(obj['value'], dtype=obj['__dtype__'])
128 out.shape = obj['__shape__']
129 elif classname == 'PDataFrame' and read_json is not None:
130 out = read_json(StringIO(obj['value']))
131 elif classname == 'PSeries' and read_json is not None:
132 out = read_json(StringIO(obj['value']), typ='series')
133 elif classname == 'UFloat':
134 out = uncertainties.ufloat(obj['val'], obj['err'])
135 elif classname == 'Callable':
136 out = obj['__name__']
137 try:
138 out = import_from(obj['importer'], out)
139 unpacked = True
140 except (ImportError, AttributeError):
141 unpacked = False
142 if not unpacked:
143 spyvers = obj.get('pyversion', '?')
144 if not pyvers == spyvers:
145 msg = f"Could not unpack dill-encoded callable '{out}', saved with Python version {spyvers}"
146 warnings.warn(msg)
147
148 try:
149 out = dill.loads(b64decode(obj['value']))
150 except RuntimeError:
151 msg = f"Could not unpack dill-encoded callable '{out}`, saved with Python version {spyvers}"
152 warnings.warn(msg)
153
154 elif classname in ('Dict', 'dict'):
155 out = {}
156 for key, val in obj.items():
157 out[key] = decode4js(val)
158 return out
159
[end of lmfit/jsonutils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lmfit/jsonutils.py b/lmfit/jsonutils.py
--- a/lmfit/jsonutils.py
+++ b/lmfit/jsonutils.py
@@ -24,7 +24,7 @@
def find_importer(obj):
"""Find importer of an object."""
oname = obj.__name__
- for modname, module in sys.modules.items():
+ for modname, module in sys.modules.copy().items():
if modname.startswith('__main__'):
continue
t = getattr(module, oname, None)
|
{"golden_diff": "diff --git a/lmfit/jsonutils.py b/lmfit/jsonutils.py\n--- a/lmfit/jsonutils.py\n+++ b/lmfit/jsonutils.py\n@@ -24,7 +24,7 @@\n def find_importer(obj):\n \"\"\"Find importer of an object.\"\"\"\n oname = obj.__name__\n- for modname, module in sys.modules.items():\n+ for modname, module in sys.modules.copy().items():\n if modname.startswith('__main__'):\n continue\n t = getattr(module, oname, None)\n", "issue": "Sys.module needs to be copied before being iterated over\n#### Description\r\nAccording to https://docs.python.org/3/library/sys.html#sys.modules, one needs to copy `sys.module` to iterate over it. This function [in this file](https://github.com/lmfit/lmfit-py/blob/8781a2dc33288b25fae6f3139595402155e4968b/lmfit/jsonutils.py#L27) does not follow this advice.\r\n\r\nIt should be replaced by:\r\n```\r\ndef find_importer(obj):\r\n \"\"\"Find importer of an object.\"\"\"\r\n oname = obj.__name__\r\n for modname, module in sys.modules.copy().items():\r\n if modname.startswith('__main__'):\r\n continue\r\n t = getattr(module, oname, None)\r\n if t is obj:\r\n return modname\r\n return None\r\n```\r\n\r\nPlease note `sys.modules.items()` -> `sys.modules.copy().items()`\r\n\r\n###### A Minimal, Complete, and Verifiable example\r\nI ran into `RuntimeError: dictionary changed size during iteration` with a large project using lmfit. The solution indicated in the python docs solves it. It is not immediate to create an MVE and I hope the python docs is enough to convince to implement the change.\r\n\r\n###### Error message:\r\n<!-- If any, paste the *full* error message inside a code block (starting from line Traceback) -->\r\n\r\n```\r\n...\r\n\r\nobj = <function test_serde_lmfit_modelresult_with_error.<locals>.custom_error at 0x308a292d0>\r\n\r\n def find_importer(obj):\r\n \"\"\"Find importer of an object.\"\"\"\r\n oname = obj.__name__\r\n> for modname, module in sys.modules.items():\r\nE RuntimeError: dictionary changed size during iteration\r\n\r\n/.../lib/python3.10/site-packages/lmfit/jsonutils.py:27: RuntimeError\r\n```\r\n\r\n###### Version information\r\nPython: 3.10.14 (main, Mar 19 2024, 21:46:16) [Clang 15.0.0 (clang-1500.3.9.4)]\r\n\r\nlmfit: 1.3.0, scipy: 1.11.4, numpy: 1.26.3,asteval: 0.9.32, uncertainties: 3.1.6###### Link(s)\r\n<!-- If you started a discussion on the lmfit mailing list, discussion page, or Stack Overflow, please provide the relevant link(s) -->\r\n\n", "before_files": [{"content": "\"\"\"JSON utilities.\"\"\"\n\nfrom base64 import b64decode, b64encode\nfrom io import StringIO\nimport sys\nimport warnings\n\nimport dill\nimport numpy as np\nimport uncertainties\n\nHAS_DILL = True\n\ntry:\n from pandas import DataFrame, Series, read_json\nexcept ImportError:\n DataFrame = Series = type(NotImplemented)\n read_json = None\n\n\npyvers = f'{sys.version_info.major}.{sys.version_info.minor}'\n\n\ndef find_importer(obj):\n \"\"\"Find importer of an object.\"\"\"\n oname = obj.__name__\n for modname, module in sys.modules.items():\n if modname.startswith('__main__'):\n continue\n t = getattr(module, oname, None)\n if t is obj:\n return modname\n return None\n\n\ndef import_from(modulepath, objectname):\n \"\"\"Wrapper for __import__ for nested objects.\"\"\"\n path = modulepath.split('.')\n top = path.pop(0)\n parent = __import__(top)\n while len(path) > 0:\n parent = getattr(parent, path.pop(0))\n return getattr(parent, objectname)\n\n\ndef encode4js(obj):\n \"\"\"Prepare an object for JSON encoding.\n\n It has special handling for many Python types, including:\n - pandas DataFrames and Series\n - NumPy ndarrays\n - complex numbers\n\n \"\"\"\n if isinstance(obj, DataFrame):\n return dict(__class__='PDataFrame', value=obj.to_json())\n if isinstance(obj, Series):\n return dict(__class__='PSeries', value=obj.to_json())\n if isinstance(obj, uncertainties.core.AffineScalarFunc):\n return dict(__class__='UFloat', val=obj.nominal_value, err=obj.std_dev)\n if isinstance(obj, np.ndarray):\n if 'complex' in obj.dtype.name:\n val = [(obj.real).tolist(), (obj.imag).tolist()]\n elif obj.dtype.name == 'object':\n val = [encode4js(item) for item in obj]\n else:\n val = obj.flatten().tolist()\n return dict(__class__='NDArray', __shape__=obj.shape,\n __dtype__=obj.dtype.name, value=val)\n if isinstance(obj, float):\n return float(obj)\n if isinstance(obj, int):\n return int(obj)\n if isinstance(obj, str):\n try:\n return str(obj)\n except UnicodeError:\n return obj\n if isinstance(obj, complex):\n return dict(__class__='Complex', value=(obj.real, obj.imag))\n if isinstance(obj, (tuple, list)):\n ctype = 'List'\n if isinstance(obj, tuple):\n ctype = 'Tuple'\n val = [encode4js(item) for item in obj]\n return dict(__class__=ctype, value=val)\n if isinstance(obj, dict):\n out = dict(__class__='Dict')\n for key, val in obj.items():\n out[encode4js(key)] = encode4js(val)\n return out\n if callable(obj):\n value = str(b64encode(dill.dumps(obj)), 'utf-8')\n return dict(__class__='Callable', __name__=obj.__name__,\n pyversion=pyvers, value=value,\n importer=find_importer(obj))\n return obj\n\n\ndef decode4js(obj):\n \"\"\"Return decoded Python object from encoded object.\"\"\"\n if not isinstance(obj, dict):\n return obj\n out = obj\n classname = obj.pop('__class__', None)\n if classname is None and isinstance(obj, dict):\n classname = 'dict'\n if classname is None:\n return obj\n if classname == 'Complex':\n out = obj['value'][0] + 1j*obj['value'][1]\n elif classname in ('List', 'Tuple'):\n out = []\n for item in obj['value']:\n out.append(decode4js(item))\n if classname == 'Tuple':\n out = tuple(out)\n elif classname == 'NDArray':\n if obj['__dtype__'].startswith('complex'):\n re = np.fromiter(obj['value'][0], dtype='double')\n im = np.fromiter(obj['value'][1], dtype='double')\n out = re + 1j*im\n elif obj['__dtype__'].startswith('object'):\n val = [decode4js(v) for v in obj['value']]\n out = np.array(val, dtype=obj['__dtype__'])\n else:\n out = np.fromiter(obj['value'], dtype=obj['__dtype__'])\n out.shape = obj['__shape__']\n elif classname == 'PDataFrame' and read_json is not None:\n out = read_json(StringIO(obj['value']))\n elif classname == 'PSeries' and read_json is not None:\n out = read_json(StringIO(obj['value']), typ='series')\n elif classname == 'UFloat':\n out = uncertainties.ufloat(obj['val'], obj['err'])\n elif classname == 'Callable':\n out = obj['__name__']\n try:\n out = import_from(obj['importer'], out)\n unpacked = True\n except (ImportError, AttributeError):\n unpacked = False\n if not unpacked:\n spyvers = obj.get('pyversion', '?')\n if not pyvers == spyvers:\n msg = f\"Could not unpack dill-encoded callable '{out}', saved with Python version {spyvers}\"\n warnings.warn(msg)\n\n try:\n out = dill.loads(b64decode(obj['value']))\n except RuntimeError:\n msg = f\"Could not unpack dill-encoded callable '{out}`, saved with Python version {spyvers}\"\n warnings.warn(msg)\n\n elif classname in ('Dict', 'dict'):\n out = {}\n for key, val in obj.items():\n out[key] = decode4js(val)\n return out\n", "path": "lmfit/jsonutils.py"}]}
| 2,720 | 119 |
gh_patches_debug_23377
|
rasdani/github-patches
|
git_diff
|
mdn__kuma-5665
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Reindex dangerously excludes slugs
The reindexing exludes these slugs: https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L30-L31
But [the way it does it](https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L228) is that it uses `icontains` instead of `startswith` which is more inefficient and it's also potentially excluding slugs that contain any of those strings later. E.g. `Learn/HTML/user:prefixing`
</issue>
<code>
[start of kuma/wiki/search.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import division
3
4 import logging
5 import operator
6 from math import ceil
7
8 from celery import chain
9 from django.conf import settings
10 from django.db.models import Q
11 from django.utils.html import strip_tags
12 from django.utils.translation import ugettext_lazy as _
13 from elasticsearch.helpers import bulk
14 from elasticsearch_dsl import document, field
15 from elasticsearch_dsl.connections import connections
16 from elasticsearch_dsl.mapping import Mapping
17 from elasticsearch_dsl.search import Search
18 from six.moves import reduce
19
20 from kuma.core.utils import chord_flow, chunked
21
22 from .constants import EXPERIMENT_TITLE_PREFIX
23
24
25 log = logging.getLogger('kuma.wiki.search')
26
27
28 class WikiDocumentType(document.Document):
29 excerpt_fields = ['summary', 'content']
30 exclude_slugs = ['Talk:', 'User:', 'User_talk:', 'Template_talk:',
31 'Project_talk:', EXPERIMENT_TITLE_PREFIX]
32
33 boost = field.Float(null_value=1.0)
34 content = field.Text(analyzer='kuma_content',
35 term_vector='with_positions_offsets')
36 css_classnames = field.Keyword()
37 html_attributes = field.Keyword()
38 id = field.Long()
39 kumascript_macros = field.Keyword()
40 locale = field.Keyword()
41 modified = field.Date()
42 parent = field.Object(properties={
43 'id': field.Long(),
44 'title': field.Text(analyzer='kuma_title'),
45 'slug': field.Keyword(),
46 'locale': field.Keyword(),
47 })
48 slug = field.Keyword()
49 summary = field.Text(analyzer='kuma_content',
50 term_vector='with_positions_offsets')
51 tags = field.Keyword()
52 title = field.Text(analyzer='kuma_title')
53
54 class Meta(object):
55 mapping = Mapping('wiki_document')
56 mapping.meta('_all', enabled=False)
57
58 @classmethod
59 def get_connection(cls, alias='default'):
60 return connections.get_connection(alias)
61
62 @classmethod
63 def get_doc_type(cls):
64 return cls._doc_type.name
65
66 @classmethod
67 def case_insensitive_keywords(cls, keywords):
68 '''Create a unique list of lowercased keywords.'''
69 return sorted(set([keyword.lower() for keyword in keywords]))
70
71 @classmethod
72 def from_django(cls, obj):
73 is_root_document = obj.slug.count('/') == 1
74 doc = {
75 'id': obj.id,
76 'boost': 4.0 if is_root_document else 1.0,
77 'title': obj.title,
78 'slug': obj.slug,
79 'summary': obj.get_summary_text(),
80 'locale': obj.locale,
81 'modified': obj.modified,
82 'content': strip_tags(obj.rendered_html or ''),
83 'tags': [o.name for o in obj.tags.all()],
84 'kumascript_macros': cls.case_insensitive_keywords(
85 obj.extract.macro_names()),
86 'css_classnames': cls.case_insensitive_keywords(
87 obj.extract.css_classnames()),
88 'html_attributes': cls.case_insensitive_keywords(
89 obj.extract.html_attributes()),
90 }
91
92 if obj.parent:
93 doc['parent'] = {
94 'id': obj.parent.id,
95 'title': obj.parent.title,
96 'locale': obj.parent.locale,
97 'slug': obj.parent.slug,
98 }
99 else:
100 doc['parent'] = {}
101
102 return doc
103
104 @classmethod
105 def get_mapping(cls):
106 return cls._doc_type.mapping.to_dict()
107
108 @classmethod
109 def get_analysis(cls):
110 return {
111 'filter': {
112 'kuma_word_delimiter': {
113 'type': 'word_delimiter',
114 'preserve_original': True, # hi-fi -> hifi, hi-fi
115 'catenate_words': True, # hi-fi -> hifi
116 'catenate_numbers': True, # 90-210 -> 90210
117 }
118 },
119 'analyzer': {
120 'default': {
121 'tokenizer': 'standard',
122 'filter': ['standard', 'elision']
123 },
124 # a custom analyzer that strips html and uses our own
125 # word delimiter filter and the elision filter
126 # (e.g. L'attribut -> attribut). The rest is the same as
127 # the snowball analyzer
128 'kuma_content': {
129 'type': 'custom',
130 'tokenizer': 'standard',
131 'char_filter': ['html_strip'],
132 'filter': [
133 'elision',
134 'kuma_word_delimiter',
135 'lowercase',
136 'standard',
137 'stop',
138 'snowball',
139 ],
140 },
141 'kuma_title': {
142 'type': 'custom',
143 'tokenizer': 'standard',
144 'filter': [
145 'elision',
146 'kuma_word_delimiter',
147 'lowercase',
148 'standard',
149 'snowball',
150 ],
151 },
152 },
153 }
154
155 @classmethod
156 def get_settings(cls):
157 return {
158 'mappings': cls.get_mapping(),
159 'settings': {
160 'analysis': cls.get_analysis(),
161 'number_of_replicas': settings.ES_DEFAULT_NUM_REPLICAS,
162 'number_of_shards': settings.ES_DEFAULT_NUM_SHARDS,
163 }
164 }
165
166 @classmethod
167 def bulk_index(cls, documents, id_field='id', es=None, index=None):
168 """Index of a bunch of documents."""
169 es = es or cls.get_connection()
170 index = index or cls.get_index()
171 type = cls.get_doc_type()
172
173 actions = [
174 {'_index': index, '_type': type, '_id': d['id'], '_source': d}
175 for d in documents]
176
177 bulk(es, actions)
178
179 @classmethod
180 def bulk_delete(cls, ids, es=None, index=None):
181 """Index of a bunch of documents."""
182 es = es or cls.get_connection()
183 index = index or cls.get_index()
184 type = cls.get_doc_type()
185
186 actions = [
187 {'_op_type': 'delete', '_index': index, '_type': type, '_id': _id}
188 for _id in ids]
189
190 bulk(es, actions)
191
192 @classmethod
193 def get_index(cls):
194 from kuma.search.models import Index
195 return Index.objects.get_current().prefixed_name
196
197 @classmethod
198 def search(cls, **kwargs):
199 options = {
200 'using': connections.get_connection(),
201 'index': cls.get_index(),
202 'doc_type': {cls._doc_type.name: cls.from_es},
203 }
204 options.update(kwargs)
205 sq = Search(**options)
206
207 return sq
208
209 @classmethod
210 def get_model(cls):
211 from kuma.wiki.models import Document
212 return Document
213
214 @classmethod
215 def get_indexable(cls, percent=100):
216 """
217 For this mapping type return a list of model IDs that should be
218 indexed with the management command, in a full reindex.
219
220 WARNING: When changing this code make sure to update the
221 ``should_update`` method below, too!
222
223 """
224 model = cls.get_model()
225
226 excludes = []
227 for exclude in cls.exclude_slugs:
228 excludes.append(Q(slug__icontains=exclude))
229
230 qs = (model.objects
231 .filter(is_redirect=False, deleted=False)
232 .exclude(reduce(operator.or_, excludes)))
233
234 percent = percent / 100
235 if percent < 1:
236 qs = qs[:int(qs.count() * percent)]
237
238 return qs.values_list('id', flat=True)
239
240 @classmethod
241 def should_update(cls, obj):
242 """
243 Given a Document instance should return boolean value
244 whether the instance should be indexed or not.
245
246 WARNING: This *must* mirror the logic of the ``get_indexable``
247 method above!
248 """
249 return (not obj.is_redirect and not obj.deleted and
250 not any([exclude in obj.slug
251 for exclude in cls.exclude_slugs]))
252
253 def get_excerpt(self):
254 highlighted = getattr(self.meta, 'highlight', None)
255 if highlighted:
256 for excerpt_field in self.excerpt_fields:
257 if excerpt_field in highlighted:
258 return u'…'.join(highlighted[excerpt_field])
259 return self.summary
260
261 @classmethod
262 def reindex_all(cls, chunk_size=500, index=None, percent=100):
263 """Rebuild ElasticSearch indexes.
264
265 :arg chunk_size: how many documents to bulk index as a single chunk.
266 :arg index: the `Index` object to reindex into. Uses the current
267 promoted index if none provided.
268 :arg percent: 1 to 100--the percentage of the db to index.
269
270 """
271 from kuma.search.models import Index
272 from kuma.search.tasks import prepare_index, finalize_index
273 from kuma.wiki.tasks import index_documents
274
275 index = index or Index.objects.get_current()
276
277 # Get the list of document IDs to index.
278 indexable = WikiDocumentType.get_indexable(percent)
279
280 total = len(indexable)
281 total_chunks = int(ceil(total / chunk_size))
282
283 pre_task = prepare_index.si(index.pk)
284 post_task = finalize_index.si(index.pk)
285
286 if not total:
287 # If there's no data we still create the index and finalize it.
288 chain(pre_task, post_task).apply_async()
289 else:
290 index_tasks = [index_documents.si(chunk, index.pk)
291 for chunk in chunked(indexable, chunk_size)]
292 chord_flow(pre_task, index_tasks, post_task).apply_async()
293
294 message = _(
295 'Indexing %(total)d documents into %(total_chunks)d chunks of '
296 'size %(size)d into index %(index)s.' % {
297 'total': total,
298 'total_chunks': total_chunks,
299 'size': chunk_size,
300 'index': index.prefixed_name
301 }
302 )
303 return message
304
[end of kuma/wiki/search.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kuma/wiki/search.py b/kuma/wiki/search.py
--- a/kuma/wiki/search.py
+++ b/kuma/wiki/search.py
@@ -2,7 +2,6 @@
from __future__ import division
import logging
-import operator
from math import ceil
from celery import chain
@@ -15,7 +14,6 @@
from elasticsearch_dsl.connections import connections
from elasticsearch_dsl.mapping import Mapping
from elasticsearch_dsl.search import Search
-from six.moves import reduce
from kuma.core.utils import chord_flow, chunked
@@ -223,13 +221,11 @@
"""
model = cls.get_model()
- excludes = []
+ excludes = Q()
for exclude in cls.exclude_slugs:
- excludes.append(Q(slug__icontains=exclude))
+ excludes |= Q(slug__startswith=exclude)
- qs = (model.objects
- .filter(is_redirect=False, deleted=False)
- .exclude(reduce(operator.or_, excludes)))
+ qs = model.objects.filter(is_redirect=False).exclude(excludes)
percent = percent / 100
if percent < 1:
|
{"golden_diff": "diff --git a/kuma/wiki/search.py b/kuma/wiki/search.py\n--- a/kuma/wiki/search.py\n+++ b/kuma/wiki/search.py\n@@ -2,7 +2,6 @@\n from __future__ import division\n \n import logging\n-import operator\n from math import ceil\n \n from celery import chain\n@@ -15,7 +14,6 @@\n from elasticsearch_dsl.connections import connections\n from elasticsearch_dsl.mapping import Mapping\n from elasticsearch_dsl.search import Search\n-from six.moves import reduce\n \n from kuma.core.utils import chord_flow, chunked\n \n@@ -223,13 +221,11 @@\n \"\"\"\n model = cls.get_model()\n \n- excludes = []\n+ excludes = Q()\n for exclude in cls.exclude_slugs:\n- excludes.append(Q(slug__icontains=exclude))\n+ excludes |= Q(slug__startswith=exclude)\n \n- qs = (model.objects\n- .filter(is_redirect=False, deleted=False)\n- .exclude(reduce(operator.or_, excludes)))\n+ qs = model.objects.filter(is_redirect=False).exclude(excludes)\n \n percent = percent / 100\n if percent < 1:\n", "issue": "Reindex dangerously excludes slugs\nThe reindexing exludes these slugs: https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L30-L31\r\nBut [the way it does it](https://github.com/mozilla/kuma/blob/71816ee9280238aa5460bd3f7e12eaad9589abb5/kuma/wiki/search.py#L228) is that it uses `icontains` instead of `startswith` which is more inefficient and it's also potentially excluding slugs that contain any of those strings later. E.g. `Learn/HTML/user:prefixing`\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import division\n\nimport logging\nimport operator\nfrom math import ceil\n\nfrom celery import chain\nfrom django.conf import settings\nfrom django.db.models import Q\nfrom django.utils.html import strip_tags\nfrom django.utils.translation import ugettext_lazy as _\nfrom elasticsearch.helpers import bulk\nfrom elasticsearch_dsl import document, field\nfrom elasticsearch_dsl.connections import connections\nfrom elasticsearch_dsl.mapping import Mapping\nfrom elasticsearch_dsl.search import Search\nfrom six.moves import reduce\n\nfrom kuma.core.utils import chord_flow, chunked\n\nfrom .constants import EXPERIMENT_TITLE_PREFIX\n\n\nlog = logging.getLogger('kuma.wiki.search')\n\n\nclass WikiDocumentType(document.Document):\n excerpt_fields = ['summary', 'content']\n exclude_slugs = ['Talk:', 'User:', 'User_talk:', 'Template_talk:',\n 'Project_talk:', EXPERIMENT_TITLE_PREFIX]\n\n boost = field.Float(null_value=1.0)\n content = field.Text(analyzer='kuma_content',\n term_vector='with_positions_offsets')\n css_classnames = field.Keyword()\n html_attributes = field.Keyword()\n id = field.Long()\n kumascript_macros = field.Keyword()\n locale = field.Keyword()\n modified = field.Date()\n parent = field.Object(properties={\n 'id': field.Long(),\n 'title': field.Text(analyzer='kuma_title'),\n 'slug': field.Keyword(),\n 'locale': field.Keyword(),\n })\n slug = field.Keyword()\n summary = field.Text(analyzer='kuma_content',\n term_vector='with_positions_offsets')\n tags = field.Keyword()\n title = field.Text(analyzer='kuma_title')\n\n class Meta(object):\n mapping = Mapping('wiki_document')\n mapping.meta('_all', enabled=False)\n\n @classmethod\n def get_connection(cls, alias='default'):\n return connections.get_connection(alias)\n\n @classmethod\n def get_doc_type(cls):\n return cls._doc_type.name\n\n @classmethod\n def case_insensitive_keywords(cls, keywords):\n '''Create a unique list of lowercased keywords.'''\n return sorted(set([keyword.lower() for keyword in keywords]))\n\n @classmethod\n def from_django(cls, obj):\n is_root_document = obj.slug.count('/') == 1\n doc = {\n 'id': obj.id,\n 'boost': 4.0 if is_root_document else 1.0,\n 'title': obj.title,\n 'slug': obj.slug,\n 'summary': obj.get_summary_text(),\n 'locale': obj.locale,\n 'modified': obj.modified,\n 'content': strip_tags(obj.rendered_html or ''),\n 'tags': [o.name for o in obj.tags.all()],\n 'kumascript_macros': cls.case_insensitive_keywords(\n obj.extract.macro_names()),\n 'css_classnames': cls.case_insensitive_keywords(\n obj.extract.css_classnames()),\n 'html_attributes': cls.case_insensitive_keywords(\n obj.extract.html_attributes()),\n }\n\n if obj.parent:\n doc['parent'] = {\n 'id': obj.parent.id,\n 'title': obj.parent.title,\n 'locale': obj.parent.locale,\n 'slug': obj.parent.slug,\n }\n else:\n doc['parent'] = {}\n\n return doc\n\n @classmethod\n def get_mapping(cls):\n return cls._doc_type.mapping.to_dict()\n\n @classmethod\n def get_analysis(cls):\n return {\n 'filter': {\n 'kuma_word_delimiter': {\n 'type': 'word_delimiter',\n 'preserve_original': True, # hi-fi -> hifi, hi-fi\n 'catenate_words': True, # hi-fi -> hifi\n 'catenate_numbers': True, # 90-210 -> 90210\n }\n },\n 'analyzer': {\n 'default': {\n 'tokenizer': 'standard',\n 'filter': ['standard', 'elision']\n },\n # a custom analyzer that strips html and uses our own\n # word delimiter filter and the elision filter\n # (e.g. L'attribut -> attribut). The rest is the same as\n # the snowball analyzer\n 'kuma_content': {\n 'type': 'custom',\n 'tokenizer': 'standard',\n 'char_filter': ['html_strip'],\n 'filter': [\n 'elision',\n 'kuma_word_delimiter',\n 'lowercase',\n 'standard',\n 'stop',\n 'snowball',\n ],\n },\n 'kuma_title': {\n 'type': 'custom',\n 'tokenizer': 'standard',\n 'filter': [\n 'elision',\n 'kuma_word_delimiter',\n 'lowercase',\n 'standard',\n 'snowball',\n ],\n },\n },\n }\n\n @classmethod\n def get_settings(cls):\n return {\n 'mappings': cls.get_mapping(),\n 'settings': {\n 'analysis': cls.get_analysis(),\n 'number_of_replicas': settings.ES_DEFAULT_NUM_REPLICAS,\n 'number_of_shards': settings.ES_DEFAULT_NUM_SHARDS,\n }\n }\n\n @classmethod\n def bulk_index(cls, documents, id_field='id', es=None, index=None):\n \"\"\"Index of a bunch of documents.\"\"\"\n es = es or cls.get_connection()\n index = index or cls.get_index()\n type = cls.get_doc_type()\n\n actions = [\n {'_index': index, '_type': type, '_id': d['id'], '_source': d}\n for d in documents]\n\n bulk(es, actions)\n\n @classmethod\n def bulk_delete(cls, ids, es=None, index=None):\n \"\"\"Index of a bunch of documents.\"\"\"\n es = es or cls.get_connection()\n index = index or cls.get_index()\n type = cls.get_doc_type()\n\n actions = [\n {'_op_type': 'delete', '_index': index, '_type': type, '_id': _id}\n for _id in ids]\n\n bulk(es, actions)\n\n @classmethod\n def get_index(cls):\n from kuma.search.models import Index\n return Index.objects.get_current().prefixed_name\n\n @classmethod\n def search(cls, **kwargs):\n options = {\n 'using': connections.get_connection(),\n 'index': cls.get_index(),\n 'doc_type': {cls._doc_type.name: cls.from_es},\n }\n options.update(kwargs)\n sq = Search(**options)\n\n return sq\n\n @classmethod\n def get_model(cls):\n from kuma.wiki.models import Document\n return Document\n\n @classmethod\n def get_indexable(cls, percent=100):\n \"\"\"\n For this mapping type return a list of model IDs that should be\n indexed with the management command, in a full reindex.\n\n WARNING: When changing this code make sure to update the\n ``should_update`` method below, too!\n\n \"\"\"\n model = cls.get_model()\n\n excludes = []\n for exclude in cls.exclude_slugs:\n excludes.append(Q(slug__icontains=exclude))\n\n qs = (model.objects\n .filter(is_redirect=False, deleted=False)\n .exclude(reduce(operator.or_, excludes)))\n\n percent = percent / 100\n if percent < 1:\n qs = qs[:int(qs.count() * percent)]\n\n return qs.values_list('id', flat=True)\n\n @classmethod\n def should_update(cls, obj):\n \"\"\"\n Given a Document instance should return boolean value\n whether the instance should be indexed or not.\n\n WARNING: This *must* mirror the logic of the ``get_indexable``\n method above!\n \"\"\"\n return (not obj.is_redirect and not obj.deleted and\n not any([exclude in obj.slug\n for exclude in cls.exclude_slugs]))\n\n def get_excerpt(self):\n highlighted = getattr(self.meta, 'highlight', None)\n if highlighted:\n for excerpt_field in self.excerpt_fields:\n if excerpt_field in highlighted:\n return u'\u2026'.join(highlighted[excerpt_field])\n return self.summary\n\n @classmethod\n def reindex_all(cls, chunk_size=500, index=None, percent=100):\n \"\"\"Rebuild ElasticSearch indexes.\n\n :arg chunk_size: how many documents to bulk index as a single chunk.\n :arg index: the `Index` object to reindex into. Uses the current\n promoted index if none provided.\n :arg percent: 1 to 100--the percentage of the db to index.\n\n \"\"\"\n from kuma.search.models import Index\n from kuma.search.tasks import prepare_index, finalize_index\n from kuma.wiki.tasks import index_documents\n\n index = index or Index.objects.get_current()\n\n # Get the list of document IDs to index.\n indexable = WikiDocumentType.get_indexable(percent)\n\n total = len(indexable)\n total_chunks = int(ceil(total / chunk_size))\n\n pre_task = prepare_index.si(index.pk)\n post_task = finalize_index.si(index.pk)\n\n if not total:\n # If there's no data we still create the index and finalize it.\n chain(pre_task, post_task).apply_async()\n else:\n index_tasks = [index_documents.si(chunk, index.pk)\n for chunk in chunked(indexable, chunk_size)]\n chord_flow(pre_task, index_tasks, post_task).apply_async()\n\n message = _(\n 'Indexing %(total)d documents into %(total_chunks)d chunks of '\n 'size %(size)d into index %(index)s.' % {\n 'total': total,\n 'total_chunks': total_chunks,\n 'size': chunk_size,\n 'index': index.prefixed_name\n }\n )\n return message\n", "path": "kuma/wiki/search.py"}]}
| 3,643 | 254 |
gh_patches_debug_4094
|
rasdani/github-patches
|
git_diff
|
urllib3__urllib3-841
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PyOpenSSL: Fails to import after installation with the provided instructions
The [Security documentation page](https://urllib3.readthedocs.org/en/latest/security.html#openssl-pyopenssl) indicates that to use PyOpenSSL that you must first install:
- pip3 install pyopenssl ndg-httpsclient pyasn1
And then in a Python interpreter run:
- import urllib3.contrib.pyopenssl
- urllib3.contrib.pyopenssl.inject_into_urllib3()
However on Python 3.4.4 (the latest 3.4.x) on OS X 10.11 (the latest OS X) I get the following traceback when executing `import urllib3.contrib.pyopenssl`:
```
Traceback (most recent call last):
File "/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py", line 60, in <module>
from socket import _fileobject
ImportError: cannot import name '_fileobject'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py", line 63, in <module>
from urllib3.packages.backports.makefile import backport_makefile
ImportError: No module named 'urllib3.packages.backports'
```
Perhaps there is some missing step in the documentation?
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 from setuptools import setup
4
5 import os
6 import re
7 import codecs
8
9 base_path = os.path.dirname(__file__)
10
11 # Get the version (borrowed from SQLAlchemy)
12 fp = open(os.path.join(base_path, 'urllib3', '__init__.py'))
13 VERSION = re.compile(r".*__version__ = '(.*?)'",
14 re.S).match(fp.read()).group(1)
15 fp.close()
16
17 readme = codecs.open('README.rst', encoding='utf-8').read()
18 changes = codecs.open('CHANGES.rst', encoding='utf-8').read()
19 version = VERSION
20
21 setup(name='urllib3',
22 version=version,
23 description="HTTP library with thread-safe connection pooling, file post, and more.",
24 long_description=u'\n\n'.join([readme, changes]),
25 classifiers=[
26 'Environment :: Web Environment',
27 'Intended Audience :: Developers',
28 'License :: OSI Approved :: MIT License',
29 'Operating System :: OS Independent',
30 'Programming Language :: Python',
31 'Programming Language :: Python :: 2',
32 'Programming Language :: Python :: 3',
33 'Topic :: Internet :: WWW/HTTP',
34 'Topic :: Software Development :: Libraries',
35 ],
36 keywords='urllib httplib threadsafe filepost http https ssl pooling',
37 author='Andrey Petrov',
38 author_email='[email protected]',
39 url='http://urllib3.readthedocs.org/',
40 license='MIT',
41 packages=['urllib3',
42 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
43 'urllib3.contrib', 'urllib3.util',
44 ],
45 requires=[],
46 tests_require=[
47 # These are a less-specific subset of dev-requirements.txt, for the
48 # convenience of distro package maintainers.
49 'nose',
50 'mock',
51 'tornado',
52 ],
53 test_suite='test',
54 extras_require={
55 'secure': [
56 'pyOpenSSL>=0.13',
57 'ndg-httpsclient',
58 'pyasn1',
59 'certifi',
60 ],
61 'socks': [
62 'PySocks>=1.5.6,<2.0',
63 ]
64 },
65 )
66
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -40,7 +40,8 @@
license='MIT',
packages=['urllib3',
'urllib3.packages', 'urllib3.packages.ssl_match_hostname',
- 'urllib3.contrib', 'urllib3.util',
+ 'urllib3.packages.backports', 'urllib3.contrib',
+ 'urllib3.util',
],
requires=[],
tests_require=[
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -40,7 +40,8 @@\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n- 'urllib3.contrib', 'urllib3.util',\n+ 'urllib3.packages.backports', 'urllib3.contrib',\n+ 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n", "issue": "PyOpenSSL: Fails to import after installation with the provided instructions\nThe [Security documentation page](https://urllib3.readthedocs.org/en/latest/security.html#openssl-pyopenssl) indicates that to use PyOpenSSL that you must first install:\n- pip3 install pyopenssl ndg-httpsclient pyasn1\n\nAnd then in a Python interpreter run:\n- import urllib3.contrib.pyopenssl\n- urllib3.contrib.pyopenssl.inject_into_urllib3()\n\nHowever on Python 3.4.4 (the latest 3.4.x) on OS X 10.11 (the latest OS X) I get the following traceback when executing `import urllib3.contrib.pyopenssl`:\n\n```\nTraceback (most recent call last):\n File \"/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py\", line 60, in <module>\n from socket import _fileobject\nImportError: cannot import name '_fileobject'\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"<stdin>\", line 1, in <module>\n File \"/Users/davidf/Projects/webcrystal/venv/lib/python3.4/site-packages/urllib3/contrib/pyopenssl.py\", line 63, in <module>\n from urllib3.packages.backports.makefile import backport_makefile\nImportError: No module named 'urllib3.packages.backports'\n```\n\nPerhaps there is some missing step in the documentation?\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nfrom setuptools import setup\n\nimport os\nimport re\nimport codecs\n\nbase_path = os.path.dirname(__file__)\n\n# Get the version (borrowed from SQLAlchemy)\nfp = open(os.path.join(base_path, 'urllib3', '__init__.py'))\nVERSION = re.compile(r\".*__version__ = '(.*?)'\",\n re.S).match(fp.read()).group(1)\nfp.close()\n\nreadme = codecs.open('README.rst', encoding='utf-8').read()\nchanges = codecs.open('CHANGES.rst', encoding='utf-8').read()\nversion = VERSION\n\nsetup(name='urllib3',\n version=version,\n description=\"HTTP library with thread-safe connection pooling, file post, and more.\",\n long_description=u'\\n\\n'.join([readme, changes]),\n classifiers=[\n 'Environment :: Web Environment',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 3',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries',\n ],\n keywords='urllib httplib threadsafe filepost http https ssl pooling',\n author='Andrey Petrov',\n author_email='[email protected]',\n url='http://urllib3.readthedocs.org/',\n license='MIT',\n packages=['urllib3',\n 'urllib3.packages', 'urllib3.packages.ssl_match_hostname',\n 'urllib3.contrib', 'urllib3.util',\n ],\n requires=[],\n tests_require=[\n # These are a less-specific subset of dev-requirements.txt, for the\n # convenience of distro package maintainers.\n 'nose',\n 'mock',\n 'tornado',\n ],\n test_suite='test',\n extras_require={\n 'secure': [\n 'pyOpenSSL>=0.13',\n 'ndg-httpsclient',\n 'pyasn1',\n 'certifi',\n ],\n 'socks': [\n 'PySocks>=1.5.6,<2.0',\n ]\n },\n )\n", "path": "setup.py"}]}
| 1,466 | 111 |
gh_patches_debug_30146
|
rasdani/github-patches
|
git_diff
|
beetbox__beets-4807
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plugins: add markunmatched
## Description
Add a plugin useful for bulk importers.
## To Do
- [x] Documentation. (If you've add a new command-line flag, for example, find the appropriate page under `docs/` to describe it.)
- [x] Changelog. (Add an entry to `docs/changelog.rst` near the top of the document.)
- [ ] Tests. (Encouraged but not strictly required.)
</issue>
<code>
[start of beetsplug/mbsubmit.py]
1 # This file is part of beets.
2 # Copyright 2016, Adrian Sampson and Diego Moreda.
3 #
4 # Permission is hereby granted, free of charge, to any person obtaining
5 # a copy of this software and associated documentation files (the
6 # "Software"), to deal in the Software without restriction, including
7 # without limitation the rights to use, copy, modify, merge, publish,
8 # distribute, sublicense, and/or sell copies of the Software, and to
9 # permit persons to whom the Software is furnished to do so, subject to
10 # the following conditions:
11 #
12 # The above copyright notice and this permission notice shall be
13 # included in all copies or substantial portions of the Software.
14
15 """Aid in submitting information to MusicBrainz.
16
17 This plugin allows the user to print track information in a format that is
18 parseable by the MusicBrainz track parser [1]. Programmatic submitting is not
19 implemented by MusicBrainz yet.
20
21 [1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings
22 """
23
24
25 from beets import ui
26 from beets.autotag import Recommendation
27 from beets.plugins import BeetsPlugin
28 from beets.ui.commands import PromptChoice
29 from beetsplug.info import print_data
30
31
32 class MBSubmitPlugin(BeetsPlugin):
33 def __init__(self):
34 super().__init__()
35
36 self.config.add(
37 {
38 "format": "$track. $title - $artist ($length)",
39 "threshold": "medium",
40 }
41 )
42
43 # Validate and store threshold.
44 self.threshold = self.config["threshold"].as_choice(
45 {
46 "none": Recommendation.none,
47 "low": Recommendation.low,
48 "medium": Recommendation.medium,
49 "strong": Recommendation.strong,
50 }
51 )
52
53 self.register_listener(
54 "before_choose_candidate", self.before_choose_candidate_event
55 )
56
57 def before_choose_candidate_event(self, session, task):
58 if task.rec <= self.threshold:
59 return [PromptChoice("p", "Print tracks", self.print_tracks)]
60
61 def print_tracks(self, session, task):
62 for i in sorted(task.items, key=lambda i: i.track):
63 print_data(None, i, self.config["format"].as_str())
64
65 def commands(self):
66 """Add beet UI commands for mbsubmit."""
67 mbsubmit_cmd = ui.Subcommand(
68 "mbsubmit", help="Submit Tracks to MusicBrainz"
69 )
70
71 def func(lib, opts, args):
72 items = lib.items(ui.decargs(args))
73 self._mbsubmit(items)
74
75 mbsubmit_cmd.func = func
76
77 return [mbsubmit_cmd]
78
79 def _mbsubmit(self, items):
80 """Print track information to be submitted to MusicBrainz."""
81 for i in sorted(items, key=lambda i: i.track):
82 print_data(None, i, self.config["format"].as_str())
83
[end of beetsplug/mbsubmit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/beetsplug/mbsubmit.py b/beetsplug/mbsubmit.py
--- a/beetsplug/mbsubmit.py
+++ b/beetsplug/mbsubmit.py
@@ -21,11 +21,13 @@
[1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings
"""
+import subprocess
from beets import ui
from beets.autotag import Recommendation
from beets.plugins import BeetsPlugin
from beets.ui.commands import PromptChoice
+from beets.util import displayable_path
from beetsplug.info import print_data
@@ -37,6 +39,7 @@
{
"format": "$track. $title - $artist ($length)",
"threshold": "medium",
+ "picard_path": "picard",
}
)
@@ -56,7 +59,21 @@
def before_choose_candidate_event(self, session, task):
if task.rec <= self.threshold:
- return [PromptChoice("p", "Print tracks", self.print_tracks)]
+ return [
+ PromptChoice("p", "Print tracks", self.print_tracks),
+ PromptChoice("o", "Open files with Picard", self.picard),
+ ]
+
+ def picard(self, session, task):
+ paths = []
+ for p in task.paths:
+ paths.append(displayable_path(p))
+ try:
+ picard_path = self.config["picard_path"].as_str()
+ subprocess.Popen([picard_path] + paths)
+ self._log.info("launched picard from\n{}", picard_path)
+ except OSError as exc:
+ self._log.error(f"Could not open picard, got error:\n{exc}")
def print_tracks(self, session, task):
for i in sorted(task.items, key=lambda i: i.track):
|
{"golden_diff": "diff --git a/beetsplug/mbsubmit.py b/beetsplug/mbsubmit.py\n--- a/beetsplug/mbsubmit.py\n+++ b/beetsplug/mbsubmit.py\n@@ -21,11 +21,13 @@\n [1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings\n \"\"\"\n \n+import subprocess\n \n from beets import ui\n from beets.autotag import Recommendation\n from beets.plugins import BeetsPlugin\n from beets.ui.commands import PromptChoice\n+from beets.util import displayable_path\n from beetsplug.info import print_data\n \n \n@@ -37,6 +39,7 @@\n {\n \"format\": \"$track. $title - $artist ($length)\",\n \"threshold\": \"medium\",\n+ \"picard_path\": \"picard\",\n }\n )\n \n@@ -56,7 +59,21 @@\n \n def before_choose_candidate_event(self, session, task):\n if task.rec <= self.threshold:\n- return [PromptChoice(\"p\", \"Print tracks\", self.print_tracks)]\n+ return [\n+ PromptChoice(\"p\", \"Print tracks\", self.print_tracks),\n+ PromptChoice(\"o\", \"Open files with Picard\", self.picard),\n+ ]\n+\n+ def picard(self, session, task):\n+ paths = []\n+ for p in task.paths:\n+ paths.append(displayable_path(p))\n+ try:\n+ picard_path = self.config[\"picard_path\"].as_str()\n+ subprocess.Popen([picard_path] + paths)\n+ self._log.info(\"launched picard from\\n{}\", picard_path)\n+ except OSError as exc:\n+ self._log.error(f\"Could not open picard, got error:\\n{exc}\")\n \n def print_tracks(self, session, task):\n for i in sorted(task.items, key=lambda i: i.track):\n", "issue": "plugins: add markunmatched\n## Description\r\n\r\nAdd a plugin useful for bulk importers.\r\n\r\n## To Do\r\n\r\n- [x] Documentation. (If you've add a new command-line flag, for example, find the appropriate page under `docs/` to describe it.)\r\n- [x] Changelog. (Add an entry to `docs/changelog.rst` near the top of the document.)\r\n- [ ] Tests. (Encouraged but not strictly required.)\r\n\n", "before_files": [{"content": "# This file is part of beets.\n# Copyright 2016, Adrian Sampson and Diego Moreda.\n#\n# Permission is hereby granted, free of charge, to any person obtaining\n# a copy of this software and associated documentation files (the\n# \"Software\"), to deal in the Software without restriction, including\n# without limitation the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the Software, and to\n# permit persons to whom the Software is furnished to do so, subject to\n# the following conditions:\n#\n# The above copyright notice and this permission notice shall be\n# included in all copies or substantial portions of the Software.\n\n\"\"\"Aid in submitting information to MusicBrainz.\n\nThis plugin allows the user to print track information in a format that is\nparseable by the MusicBrainz track parser [1]. Programmatic submitting is not\nimplemented by MusicBrainz yet.\n\n[1] https://wiki.musicbrainz.org/History:How_To_Parse_Track_Listings\n\"\"\"\n\n\nfrom beets import ui\nfrom beets.autotag import Recommendation\nfrom beets.plugins import BeetsPlugin\nfrom beets.ui.commands import PromptChoice\nfrom beetsplug.info import print_data\n\n\nclass MBSubmitPlugin(BeetsPlugin):\n def __init__(self):\n super().__init__()\n\n self.config.add(\n {\n \"format\": \"$track. $title - $artist ($length)\",\n \"threshold\": \"medium\",\n }\n )\n\n # Validate and store threshold.\n self.threshold = self.config[\"threshold\"].as_choice(\n {\n \"none\": Recommendation.none,\n \"low\": Recommendation.low,\n \"medium\": Recommendation.medium,\n \"strong\": Recommendation.strong,\n }\n )\n\n self.register_listener(\n \"before_choose_candidate\", self.before_choose_candidate_event\n )\n\n def before_choose_candidate_event(self, session, task):\n if task.rec <= self.threshold:\n return [PromptChoice(\"p\", \"Print tracks\", self.print_tracks)]\n\n def print_tracks(self, session, task):\n for i in sorted(task.items, key=lambda i: i.track):\n print_data(None, i, self.config[\"format\"].as_str())\n\n def commands(self):\n \"\"\"Add beet UI commands for mbsubmit.\"\"\"\n mbsubmit_cmd = ui.Subcommand(\n \"mbsubmit\", help=\"Submit Tracks to MusicBrainz\"\n )\n\n def func(lib, opts, args):\n items = lib.items(ui.decargs(args))\n self._mbsubmit(items)\n\n mbsubmit_cmd.func = func\n\n return [mbsubmit_cmd]\n\n def _mbsubmit(self, items):\n \"\"\"Print track information to be submitted to MusicBrainz.\"\"\"\n for i in sorted(items, key=lambda i: i.track):\n print_data(None, i, self.config[\"format\"].as_str())\n", "path": "beetsplug/mbsubmit.py"}]}
| 1,416 | 415 |
gh_patches_debug_2187
|
rasdani/github-patches
|
git_diff
|
projectmesa__mesa-989
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Color patches takes a long time to load
When you hit "reset" to load the color patches example, it takes a long time to load.
Not sure why. As a result, I thought it was broken.
To recreate...
```
cd examples/color_patches
python run.py
```
Wait for patches to load when browser window pops up.
OR hit reset and wait for color patches to load.
This is what it should look something like...
<img width="407" alt="screen shot 2018-04-01 at 10 03 33 pm" src="https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png">
Color patches takes a long time to load
When you hit "reset" to load the color patches example, it takes a long time to load.
Not sure why. As a result, I thought it was broken.
To recreate...
```
cd examples/color_patches
python run.py
```
Wait for patches to load when browser window pops up.
OR hit reset and wait for color patches to load.
This is what it should look something like...
<img width="407" alt="screen shot 2018-04-01 at 10 03 33 pm" src="https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png">
</issue>
<code>
[start of examples/color_patches/color_patches/server.py]
1 """
2 handles the definition of the canvas parameters and
3 the drawing of the model representation on the canvas
4 """
5 # import webbrowser
6
7 from mesa.visualization.modules import CanvasGrid
8 from mesa.visualization.ModularVisualization import ModularServer
9
10 from .model import ColorPatches
11
12 _COLORS = [
13 "Aqua",
14 "Blue",
15 "Fuchsia",
16 "Gray",
17 "Green",
18 "Lime",
19 "Maroon",
20 "Navy",
21 "Olive",
22 "Orange",
23 "Purple",
24 "Red",
25 "Silver",
26 "Teal",
27 "White",
28 "Yellow",
29 ]
30
31
32 grid_rows = 50
33 grid_cols = 25
34 cell_size = 10
35 canvas_width = grid_rows * cell_size
36 canvas_height = grid_cols * cell_size
37
38
39 def color_patch_draw(cell):
40 """
41 This function is registered with the visualization server to be called
42 each tick to indicate how to draw the cell in its current state.
43
44 :param cell: the cell in the simulation
45
46 :return: the portrayal dictionary.
47
48 """
49 assert cell is not None
50 portrayal = {"Shape": "rect", "w": 1, "h": 1, "Filled": "true", "Layer": 0}
51 portrayal["x"] = cell.get_row()
52 portrayal["y"] = cell.get_col()
53 portrayal["Color"] = _COLORS[cell.get_state()]
54 return portrayal
55
56
57 canvas_element = CanvasGrid(
58 color_patch_draw, grid_rows, grid_cols, canvas_width, canvas_height
59 )
60
61 server = ModularServer(
62 ColorPatches,
63 [canvas_element],
64 "Color Patches",
65 {"width": canvas_width, "height": canvas_height},
66 )
67
68 # webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable
69
[end of examples/color_patches/color_patches/server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/color_patches/color_patches/server.py b/examples/color_patches/color_patches/server.py
--- a/examples/color_patches/color_patches/server.py
+++ b/examples/color_patches/color_patches/server.py
@@ -62,7 +62,7 @@
ColorPatches,
[canvas_element],
"Color Patches",
- {"width": canvas_width, "height": canvas_height},
+ {"width": grid_rows, "height": grid_cols},
)
# webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable
|
{"golden_diff": "diff --git a/examples/color_patches/color_patches/server.py b/examples/color_patches/color_patches/server.py\n--- a/examples/color_patches/color_patches/server.py\n+++ b/examples/color_patches/color_patches/server.py\n@@ -62,7 +62,7 @@\n ColorPatches,\n [canvas_element],\n \"Color Patches\",\n- {\"width\": canvas_width, \"height\": canvas_height},\n+ {\"width\": grid_rows, \"height\": grid_cols},\n )\n \n # webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable\n", "issue": "Color patches takes a long time to load\nWhen you hit \"reset\" to load the color patches example, it takes a long time to load.\r\nNot sure why. As a result, I thought it was broken.\r\n\r\nTo recreate... \r\n```\r\ncd examples/color_patches\r\npython run.py\r\n```\r\n\r\nWait for patches to load when browser window pops up. \r\nOR hit reset and wait for color patches to load.\r\n\r\nThis is what it should look something like...\r\n<img width=\"407\" alt=\"screen shot 2018-04-01 at 10 03 33 pm\" src=\"https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png\">\nColor patches takes a long time to load\nWhen you hit \"reset\" to load the color patches example, it takes a long time to load.\r\nNot sure why. As a result, I thought it was broken.\r\n\r\nTo recreate... \r\n```\r\ncd examples/color_patches\r\npython run.py\r\n```\r\n\r\nWait for patches to load when browser window pops up. \r\nOR hit reset and wait for color patches to load.\r\n\r\nThis is what it should look something like...\r\n<img width=\"407\" alt=\"screen shot 2018-04-01 at 10 03 33 pm\" src=\"https://user-images.githubusercontent.com/166734/38180194-95c2acb0-35f8-11e8-8c1b-8bd7a6d25098.png\">\n", "before_files": [{"content": "\"\"\"\nhandles the definition of the canvas parameters and\nthe drawing of the model representation on the canvas\n\"\"\"\n# import webbrowser\n\nfrom mesa.visualization.modules import CanvasGrid\nfrom mesa.visualization.ModularVisualization import ModularServer\n\nfrom .model import ColorPatches\n\n_COLORS = [\n \"Aqua\",\n \"Blue\",\n \"Fuchsia\",\n \"Gray\",\n \"Green\",\n \"Lime\",\n \"Maroon\",\n \"Navy\",\n \"Olive\",\n \"Orange\",\n \"Purple\",\n \"Red\",\n \"Silver\",\n \"Teal\",\n \"White\",\n \"Yellow\",\n]\n\n\ngrid_rows = 50\ngrid_cols = 25\ncell_size = 10\ncanvas_width = grid_rows * cell_size\ncanvas_height = grid_cols * cell_size\n\n\ndef color_patch_draw(cell):\n \"\"\"\n This function is registered with the visualization server to be called\n each tick to indicate how to draw the cell in its current state.\n\n :param cell: the cell in the simulation\n\n :return: the portrayal dictionary.\n\n \"\"\"\n assert cell is not None\n portrayal = {\"Shape\": \"rect\", \"w\": 1, \"h\": 1, \"Filled\": \"true\", \"Layer\": 0}\n portrayal[\"x\"] = cell.get_row()\n portrayal[\"y\"] = cell.get_col()\n portrayal[\"Color\"] = _COLORS[cell.get_state()]\n return portrayal\n\n\ncanvas_element = CanvasGrid(\n color_patch_draw, grid_rows, grid_cols, canvas_width, canvas_height\n)\n\nserver = ModularServer(\n ColorPatches,\n [canvas_element],\n \"Color Patches\",\n {\"width\": canvas_width, \"height\": canvas_height},\n)\n\n# webbrowser.open('http://127.0.0.1:8521') # TODO: make this configurable\n", "path": "examples/color_patches/color_patches/server.py"}]}
| 1,448 | 128 |
gh_patches_debug_15770
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1793
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documentation references old propagators module
`propagators.inject` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blob/main/docs/examples/auto-instrumentation/client.py#L40), `propagators.extract` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blame/main/docs/examples/auto-instrumentation/README.rst#L40). They should use `propagate` instead.
</issue>
<code>
[start of docs/examples/auto-instrumentation/client.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from sys import argv
16
17 from requests import get
18
19 from opentelemetry import propagators, trace
20 from opentelemetry.sdk.trace import TracerProvider
21 from opentelemetry.sdk.trace.export import (
22 ConsoleSpanExporter,
23 SimpleSpanProcessor,
24 )
25
26 trace.set_tracer_provider(TracerProvider())
27 tracer = trace.get_tracer_provider().get_tracer(__name__)
28
29 trace.get_tracer_provider().add_span_processor(
30 SimpleSpanProcessor(ConsoleSpanExporter())
31 )
32
33
34 assert len(argv) == 2
35
36 with tracer.start_as_current_span("client"):
37
38 with tracer.start_as_current_span("client-server"):
39 headers = {}
40 propagators.inject(headers)
41 requested = get(
42 "http://localhost:8082/server_request",
43 params={"param": argv[1]},
44 headers=headers,
45 )
46
47 assert requested.status_code == 200
48
[end of docs/examples/auto-instrumentation/client.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/examples/auto-instrumentation/client.py b/docs/examples/auto-instrumentation/client.py
--- a/docs/examples/auto-instrumentation/client.py
+++ b/docs/examples/auto-instrumentation/client.py
@@ -16,7 +16,8 @@
from requests import get
-from opentelemetry import propagators, trace
+from opentelemetry import trace
+from opentelemetry.propagate import inject
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import (
ConsoleSpanExporter,
@@ -37,7 +38,7 @@
with tracer.start_as_current_span("client-server"):
headers = {}
- propagators.inject(headers)
+ inject(headers)
requested = get(
"http://localhost:8082/server_request",
params={"param": argv[1]},
|
{"golden_diff": "diff --git a/docs/examples/auto-instrumentation/client.py b/docs/examples/auto-instrumentation/client.py\n--- a/docs/examples/auto-instrumentation/client.py\n+++ b/docs/examples/auto-instrumentation/client.py\n@@ -16,7 +16,8 @@\n \n from requests import get\n \n-from opentelemetry import propagators, trace\n+from opentelemetry import trace\n+from opentelemetry.propagate import inject\n from opentelemetry.sdk.trace import TracerProvider\n from opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n@@ -37,7 +38,7 @@\n \n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n- propagators.inject(headers)\n+ inject(headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n", "issue": "Documentation references old propagators module\n`propagators.inject` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blob/main/docs/examples/auto-instrumentation/client.py#L40), `propagators.extract` is being used [here](https://github.com/open-telemetry/opentelemetry-python/blame/main/docs/examples/auto-instrumentation/README.rst#L40). They should use `propagate` instead.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom sys import argv\n\nfrom requests import get\n\nfrom opentelemetry import propagators, trace\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import (\n ConsoleSpanExporter,\n SimpleSpanProcessor,\n)\n\ntrace.set_tracer_provider(TracerProvider())\ntracer = trace.get_tracer_provider().get_tracer(__name__)\n\ntrace.get_tracer_provider().add_span_processor(\n SimpleSpanProcessor(ConsoleSpanExporter())\n)\n\n\nassert len(argv) == 2\n\nwith tracer.start_as_current_span(\"client\"):\n\n with tracer.start_as_current_span(\"client-server\"):\n headers = {}\n propagators.inject(headers)\n requested = get(\n \"http://localhost:8082/server_request\",\n params={\"param\": argv[1]},\n headers=headers,\n )\n\n assert requested.status_code == 200\n", "path": "docs/examples/auto-instrumentation/client.py"}]}
| 1,037 | 182 |
gh_patches_debug_28717
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-1953
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SBMTD: Update agency card name in user-facing text
SBMTD is renaming its agency card to avoid confusion for riders about the purpose of its various passes. Their agency card is currently named `Mobility Pass` but will change to `Reduced Fare Mobility ID`. We need update our Benefits application copy to display the updated name.
## Acceptance Criteria
<!-- Remember to consider edge cases -->
- [x] There are no instances of `Mobility Pass` in user-facing copy in the Benefits application.
- [x] All references to SBMTD's agency card in user-facing copy in the Benefits application are `Reduced Fare Mobility ID`.
- [ ] ~Design files reflect the two criteria above.~
- [x] [Cal-ITP Benefits Application Copy](https://docs.google.com/spreadsheets/d/1_Gi_YbJr4ZuXCOsnOWaewvHqUO1nC1nKqiVDHvw0118/edit?usp=sharing) master includes the updated name.
## Additional context
A larger research and scoping effort to determine all non-user-facing instances of `Mobility Pass` is being tracked in #1922
</issue>
<code>
[start of benefits/eligibility/forms.py]
1 """
2 The eligibility application: Form definition for the eligibility verification flow.
3 """
4
5 import logging
6
7 from django import forms
8 from django.utils.translation import gettext_lazy as _
9
10 from benefits.core import models, recaptcha, widgets
11
12
13 logger = logging.getLogger(__name__)
14
15
16 class EligibilityVerifierSelectionForm(forms.Form):
17 """Form to capture eligibility verifier selection."""
18
19 action_url = "eligibility:index"
20 id = "form-verifier-selection"
21 method = "POST"
22
23 verifier = forms.ChoiceField(label="", widget=widgets.VerifierRadioSelect)
24 # sets label to empty string so the radio_select template can override the label style
25 submit_value = _("Choose this Benefit")
26
27 def __init__(self, agency: models.TransitAgency, *args, **kwargs):
28 super().__init__(*args, **kwargs)
29 verifiers = agency.eligibility_verifiers.filter(active=True)
30
31 self.classes = "col-lg-8"
32 # second element is not used since we render the whole label using selection_label_template,
33 # therefore set to None
34 self.fields["verifier"].choices = [(v.id, None) for v in verifiers]
35 self.fields["verifier"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}
36
37 def clean(self):
38 if not recaptcha.verify(self.data):
39 raise forms.ValidationError("reCAPTCHA failed")
40
41
42 class EligibilityVerificationForm(forms.Form):
43 """Form to collect eligibility verification details."""
44
45 action_url = "eligibility:confirm"
46 id = "form-eligibility-verification"
47 method = "POST"
48
49 submit_value = _("Check eligibility")
50 submitting_value = _("Checking")
51
52 _error_messages = {
53 "invalid": _("Check your input. The format looks wrong."),
54 "missing": _("This field is required."),
55 }
56
57 def __init__(
58 self,
59 title,
60 headline,
61 blurb,
62 name_label,
63 name_placeholder,
64 name_help_text,
65 sub_label,
66 sub_placeholder,
67 sub_help_text,
68 name_max_length=None,
69 sub_input_mode=None,
70 sub_max_length=None,
71 sub_pattern=None,
72 *args,
73 **kwargs,
74 ):
75 """Initialize a new EligibilityVerifier form.
76
77 Args:
78 title (str): The page (i.e. tab) title for the form's page.
79
80 headline (str): The <h1> on the form's page.
81
82 blurb (str): Intro <p> on the form's page.
83
84 name_label (str): Label for the name form field.
85
86 name_placeholder (str): Field placeholder for the name form field.
87
88 name_help_text (str): Extra help text for the name form field.
89
90 sub_label (str): Label for the sub form field.
91
92 sub_placeholder (str): Field placeholder for the sub form field.
93
94 sub_help_text (str): Extra help text for the sub form field.
95
96 name_max_length (int): The maximum length accepted for the 'name' API field before sending to this verifier
97
98 sub_input_mode (str): Input mode can be "numeric", "tel", "search", etc. to override default "text" keyboard on
99 mobile devices
100
101 sub_max_length (int): The maximum length accepted for the 'sub' API field before sending to this verifier
102
103 sub_pattern (str): A regular expression used to validate the 'sub' API field before sending to this verifier
104
105 Extra args and kwargs are passed through to the underlying django.forms.Form.
106 """
107 super().__init__(auto_id=True, label_suffix="", *args, **kwargs)
108
109 self.title = title
110 self.headline = headline
111 self.blurb = blurb
112
113 self.classes = "col-lg-6"
114 sub_widget = widgets.FormControlTextInput(placeholder=sub_placeholder)
115 if sub_pattern:
116 sub_widget.attrs.update({"pattern": sub_pattern})
117 if sub_input_mode:
118 sub_widget.attrs.update({"inputmode": sub_input_mode})
119 if sub_max_length:
120 sub_widget.attrs.update({"maxlength": sub_max_length})
121
122 self.fields["sub"] = forms.CharField(
123 label=sub_label,
124 widget=sub_widget,
125 help_text=sub_help_text,
126 )
127
128 name_widget = widgets.FormControlTextInput(placeholder=name_placeholder)
129 if name_max_length:
130 name_widget.attrs.update({"maxlength": name_max_length})
131
132 self.fields["name"] = forms.CharField(label=name_label, widget=name_widget, help_text=name_help_text)
133
134 def clean(self):
135 if not recaptcha.verify(self.data):
136 raise forms.ValidationError("reCAPTCHA failed")
137
138
139 class MSTCourtesyCard(EligibilityVerificationForm):
140 """EligibilityVerification form for the MST Courtesy Card."""
141
142 def __init__(self, *args, **kwargs):
143 super().__init__(
144 title=_("Agency card information"),
145 headline=_("Let’s see if we can confirm your eligibility."),
146 blurb=_("Please input your Courtesy Card number and last name below to confirm your eligibility."),
147 name_label=_("Last name (as it appears on Courtesy Card)"),
148 name_placeholder="Garcia",
149 name_help_text=_("We use this to help confirm your Courtesy Card."),
150 sub_label=_("MST Courtesy Card number"),
151 sub_help_text=_("This is a 5-digit number on the front and back of your card."),
152 sub_placeholder="12345",
153 name_max_length=255,
154 sub_input_mode="numeric",
155 sub_max_length=5,
156 sub_pattern=r"\d{5}",
157 *args,
158 **kwargs,
159 )
160
161
162 class SBMTDMobilityPass(EligibilityVerificationForm):
163 """EligibilityVerification form for the SBMTD Mobility Pass."""
164
165 def __init__(self, *args, **kwargs):
166 super().__init__(
167 title=_("Agency card information"),
168 headline=_("Let’s see if we can confirm your eligibility."),
169 blurb=_("Please input your Mobility Pass number and last name below to confirm your eligibility."),
170 name_label=_("Last name (as it appears on Mobility Pass card)"),
171 name_placeholder="Garcia",
172 name_help_text=_("We use this to help confirm your Mobility Pass."),
173 sub_label=_("SBMTD Mobility Pass number"),
174 sub_help_text=_("This is a 4-digit number on the back of your card."),
175 sub_placeholder="1234",
176 name_max_length=255,
177 sub_input_mode="numeric",
178 sub_max_length=4,
179 sub_pattern=r"\d{4}",
180 *args,
181 **kwargs,
182 )
183
[end of benefits/eligibility/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/eligibility/forms.py b/benefits/eligibility/forms.py
--- a/benefits/eligibility/forms.py
+++ b/benefits/eligibility/forms.py
@@ -9,7 +9,6 @@
from benefits.core import models, recaptcha, widgets
-
logger = logging.getLogger(__name__)
@@ -160,17 +159,17 @@
class SBMTDMobilityPass(EligibilityVerificationForm):
- """EligibilityVerification form for the SBMTD Mobility Pass."""
+ """EligibilityVerification form for the SBMTD Reduced Fare Mobility ID."""
def __init__(self, *args, **kwargs):
super().__init__(
title=_("Agency card information"),
headline=_("Let’s see if we can confirm your eligibility."),
- blurb=_("Please input your Mobility Pass number and last name below to confirm your eligibility."),
- name_label=_("Last name (as it appears on Mobility Pass card)"),
+ blurb=_("Please input your Reduced Fare Mobility ID number and last name below to confirm your eligibility."),
+ name_label=_("Last name (as it appears on Reduced Fare Mobility ID card)"),
name_placeholder="Garcia",
- name_help_text=_("We use this to help confirm your Mobility Pass."),
- sub_label=_("SBMTD Mobility Pass number"),
+ name_help_text=_("We use this to help confirm your Reduced Fare Mobility ID."),
+ sub_label=_("SBMTD Reduced Fare Mobility ID number"),
sub_help_text=_("This is a 4-digit number on the back of your card."),
sub_placeholder="1234",
name_max_length=255,
|
{"golden_diff": "diff --git a/benefits/eligibility/forms.py b/benefits/eligibility/forms.py\n--- a/benefits/eligibility/forms.py\n+++ b/benefits/eligibility/forms.py\n@@ -9,7 +9,6 @@\n \n from benefits.core import models, recaptcha, widgets\n \n-\n logger = logging.getLogger(__name__)\n \n \n@@ -160,17 +159,17 @@\n \n \n class SBMTDMobilityPass(EligibilityVerificationForm):\n- \"\"\"EligibilityVerification form for the SBMTD Mobility Pass.\"\"\"\n+ \"\"\"EligibilityVerification form for the SBMTD Reduced Fare Mobility ID.\"\"\"\n \n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n- blurb=_(\"Please input your Mobility Pass number and last name below to confirm your eligibility.\"),\n- name_label=_(\"Last name (as it appears on Mobility Pass card)\"),\n+ blurb=_(\"Please input your Reduced Fare Mobility ID number and last name below to confirm your eligibility.\"),\n+ name_label=_(\"Last name (as it appears on Reduced Fare Mobility ID card)\"),\n name_placeholder=\"Garcia\",\n- name_help_text=_(\"We use this to help confirm your Mobility Pass.\"),\n- sub_label=_(\"SBMTD Mobility Pass number\"),\n+ name_help_text=_(\"We use this to help confirm your Reduced Fare Mobility ID.\"),\n+ sub_label=_(\"SBMTD Reduced Fare Mobility ID number\"),\n sub_help_text=_(\"This is a 4-digit number on the back of your card.\"),\n sub_placeholder=\"1234\",\n name_max_length=255,\n", "issue": "SBMTD: Update agency card name in user-facing text\nSBMTD is renaming its agency card to avoid confusion for riders about the purpose of its various passes. Their agency card is currently named `Mobility Pass` but will change to `Reduced Fare Mobility ID`. We need update our Benefits application copy to display the updated name.\r\n\r\n## Acceptance Criteria\r\n\r\n<!-- Remember to consider edge cases -->\r\n\r\n- [x] There are no instances of `Mobility Pass` in user-facing copy in the Benefits application.\r\n- [x] All references to SBMTD's agency card in user-facing copy in the Benefits application are `Reduced Fare Mobility ID`.\r\n- [ ] ~Design files reflect the two criteria above.~\r\n- [x] [Cal-ITP Benefits Application Copy](https://docs.google.com/spreadsheets/d/1_Gi_YbJr4ZuXCOsnOWaewvHqUO1nC1nKqiVDHvw0118/edit?usp=sharing) master includes the updated name.\r\n\r\n## Additional context\r\n\r\nA larger research and scoping effort to determine all non-user-facing instances of `Mobility Pass` is being tracked in #1922\n", "before_files": [{"content": "\"\"\"\nThe eligibility application: Form definition for the eligibility verification flow.\n\"\"\"\n\nimport logging\n\nfrom django import forms\nfrom django.utils.translation import gettext_lazy as _\n\nfrom benefits.core import models, recaptcha, widgets\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass EligibilityVerifierSelectionForm(forms.Form):\n \"\"\"Form to capture eligibility verifier selection.\"\"\"\n\n action_url = \"eligibility:index\"\n id = \"form-verifier-selection\"\n method = \"POST\"\n\n verifier = forms.ChoiceField(label=\"\", widget=widgets.VerifierRadioSelect)\n # sets label to empty string so the radio_select template can override the label style\n submit_value = _(\"Choose this Benefit\")\n\n def __init__(self, agency: models.TransitAgency, *args, **kwargs):\n super().__init__(*args, **kwargs)\n verifiers = agency.eligibility_verifiers.filter(active=True)\n\n self.classes = \"col-lg-8\"\n # second element is not used since we render the whole label using selection_label_template,\n # therefore set to None\n self.fields[\"verifier\"].choices = [(v.id, None) for v in verifiers]\n self.fields[\"verifier\"].widget.selection_label_templates = {v.id: v.selection_label_template for v in verifiers}\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass EligibilityVerificationForm(forms.Form):\n \"\"\"Form to collect eligibility verification details.\"\"\"\n\n action_url = \"eligibility:confirm\"\n id = \"form-eligibility-verification\"\n method = \"POST\"\n\n submit_value = _(\"Check eligibility\")\n submitting_value = _(\"Checking\")\n\n _error_messages = {\n \"invalid\": _(\"Check your input. The format looks wrong.\"),\n \"missing\": _(\"This field is required.\"),\n }\n\n def __init__(\n self,\n title,\n headline,\n blurb,\n name_label,\n name_placeholder,\n name_help_text,\n sub_label,\n sub_placeholder,\n sub_help_text,\n name_max_length=None,\n sub_input_mode=None,\n sub_max_length=None,\n sub_pattern=None,\n *args,\n **kwargs,\n ):\n \"\"\"Initialize a new EligibilityVerifier form.\n\n Args:\n title (str): The page (i.e. tab) title for the form's page.\n\n headline (str): The <h1> on the form's page.\n\n blurb (str): Intro <p> on the form's page.\n\n name_label (str): Label for the name form field.\n\n name_placeholder (str): Field placeholder for the name form field.\n\n name_help_text (str): Extra help text for the name form field.\n\n sub_label (str): Label for the sub form field.\n\n sub_placeholder (str): Field placeholder for the sub form field.\n\n sub_help_text (str): Extra help text for the sub form field.\n\n name_max_length (int): The maximum length accepted for the 'name' API field before sending to this verifier\n\n sub_input_mode (str): Input mode can be \"numeric\", \"tel\", \"search\", etc. to override default \"text\" keyboard on\n mobile devices\n\n sub_max_length (int): The maximum length accepted for the 'sub' API field before sending to this verifier\n\n sub_pattern (str): A regular expression used to validate the 'sub' API field before sending to this verifier\n\n Extra args and kwargs are passed through to the underlying django.forms.Form.\n \"\"\"\n super().__init__(auto_id=True, label_suffix=\"\", *args, **kwargs)\n\n self.title = title\n self.headline = headline\n self.blurb = blurb\n\n self.classes = \"col-lg-6\"\n sub_widget = widgets.FormControlTextInput(placeholder=sub_placeholder)\n if sub_pattern:\n sub_widget.attrs.update({\"pattern\": sub_pattern})\n if sub_input_mode:\n sub_widget.attrs.update({\"inputmode\": sub_input_mode})\n if sub_max_length:\n sub_widget.attrs.update({\"maxlength\": sub_max_length})\n\n self.fields[\"sub\"] = forms.CharField(\n label=sub_label,\n widget=sub_widget,\n help_text=sub_help_text,\n )\n\n name_widget = widgets.FormControlTextInput(placeholder=name_placeholder)\n if name_max_length:\n name_widget.attrs.update({\"maxlength\": name_max_length})\n\n self.fields[\"name\"] = forms.CharField(label=name_label, widget=name_widget, help_text=name_help_text)\n\n def clean(self):\n if not recaptcha.verify(self.data):\n raise forms.ValidationError(\"reCAPTCHA failed\")\n\n\nclass MSTCourtesyCard(EligibilityVerificationForm):\n \"\"\"EligibilityVerification form for the MST Courtesy Card.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n blurb=_(\"Please input your Courtesy Card number and last name below to confirm your eligibility.\"),\n name_label=_(\"Last name (as it appears on Courtesy Card)\"),\n name_placeholder=\"Garcia\",\n name_help_text=_(\"We use this to help confirm your Courtesy Card.\"),\n sub_label=_(\"MST Courtesy Card number\"),\n sub_help_text=_(\"This is a 5-digit number on the front and back of your card.\"),\n sub_placeholder=\"12345\",\n name_max_length=255,\n sub_input_mode=\"numeric\",\n sub_max_length=5,\n sub_pattern=r\"\\d{5}\",\n *args,\n **kwargs,\n )\n\n\nclass SBMTDMobilityPass(EligibilityVerificationForm):\n \"\"\"EligibilityVerification form for the SBMTD Mobility Pass.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(\n title=_(\"Agency card information\"),\n headline=_(\"Let\u2019s see if we can confirm your eligibility.\"),\n blurb=_(\"Please input your Mobility Pass number and last name below to confirm your eligibility.\"),\n name_label=_(\"Last name (as it appears on Mobility Pass card)\"),\n name_placeholder=\"Garcia\",\n name_help_text=_(\"We use this to help confirm your Mobility Pass.\"),\n sub_label=_(\"SBMTD Mobility Pass number\"),\n sub_help_text=_(\"This is a 4-digit number on the back of your card.\"),\n sub_placeholder=\"1234\",\n name_max_length=255,\n sub_input_mode=\"numeric\",\n sub_max_length=4,\n sub_pattern=r\"\\d{4}\",\n *args,\n **kwargs,\n )\n", "path": "benefits/eligibility/forms.py"}]}
| 2,632 | 362 |
gh_patches_debug_17971
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-630
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The DB API Binary function should accept bytes.
```
(3.8) jim@ds9:~/p/g/python-bigquery-sqlalchemy$ python
Python 3.8.5 (default, Jan 27 2021, 15:41:15)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import google.cloud.bigquery.dbapi
>>> google.cloud.bigquery.dbapi.Binary(b'x')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jim/p/g/python-bigquery/google/cloud/bigquery/dbapi/types.py", line 42, in Binary
return string.encode("utf-8")
AttributeError: 'bytes' object has no attribute 'encode'
```
Bytes are the most common way to represent binary data. Accepting strings, as it does now seems at best to be a convenience and at worst a bug magnet.
In SQLAlchemy, if you defined a model that has a binary attribute, you'd store bytes data in it, but that would break for bigquery, di to this issue.
Sqlite's `Binary` function requires bytes data.
I propose to change the function to accept bytes. For the sake of backward compatibility, I propose to continue to accept strings.
</issue>
<code>
[start of google/cloud/bigquery/dbapi/types.py]
1 # Copyright 2017 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Types used in the Google BigQuery DB-API.
16
17 See `PEP-249`_ for details.
18
19 .. _PEP-249:
20 https://www.python.org/dev/peps/pep-0249/#type-objects-and-constructors
21 """
22
23 import datetime
24
25
26 Date = datetime.date
27 Time = datetime.time
28 Timestamp = datetime.datetime
29 DateFromTicks = datetime.date.fromtimestamp
30 TimestampFromTicks = datetime.datetime.fromtimestamp
31
32
33 def Binary(string):
34 """Contruct a DB-API binary value.
35
36 Args:
37 string (str): A string to encode as a binary value.
38
39 Returns:
40 bytes: The UTF-8 encoded bytes representing the string.
41 """
42 return string.encode("utf-8")
43
44
45 def TimeFromTicks(ticks, tz=None):
46 """Construct a DB-API time value from the given ticks value.
47
48 Args:
49 ticks (float):
50 a number of seconds since the epoch; see the documentation of the
51 standard Python time module for details.
52
53 tz (datetime.tzinfo): (Optional) time zone to use for conversion
54
55 Returns:
56 datetime.time: time represented by ticks.
57 """
58 dt = datetime.datetime.fromtimestamp(ticks, tz=tz)
59 return dt.timetz()
60
61
62 class _DBAPITypeObject(object):
63 """DB-API type object which compares equal to many different strings.
64
65 See `PEP-249`_ for details.
66
67 .. _PEP-249:
68 https://www.python.org/dev/peps/pep-0249/#implementation-hints-for-module-authors
69 """
70
71 def __init__(self, *values):
72 self.values = values
73
74 def __eq__(self, other):
75 return other in self.values
76
77
78 STRING = "STRING"
79 BINARY = _DBAPITypeObject("BYTES", "RECORD", "STRUCT")
80 NUMBER = _DBAPITypeObject(
81 "INTEGER", "INT64", "FLOAT", "FLOAT64", "NUMERIC", "BIGNUMERIC", "BOOLEAN", "BOOL"
82 )
83 DATETIME = _DBAPITypeObject("TIMESTAMP", "DATE", "TIME", "DATETIME")
84 ROWID = "ROWID"
85
[end of google/cloud/bigquery/dbapi/types.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/google/cloud/bigquery/dbapi/types.py b/google/cloud/bigquery/dbapi/types.py
--- a/google/cloud/bigquery/dbapi/types.py
+++ b/google/cloud/bigquery/dbapi/types.py
@@ -30,16 +30,28 @@
TimestampFromTicks = datetime.datetime.fromtimestamp
-def Binary(string):
+def Binary(data):
"""Contruct a DB-API binary value.
Args:
- string (str): A string to encode as a binary value.
+ data (bytes-like): An object containing binary data and that
+ can be converted to bytes with the `bytes` builtin.
Returns:
- bytes: The UTF-8 encoded bytes representing the string.
+ bytes: The binary data as a bytes object.
"""
- return string.encode("utf-8")
+ if isinstance(data, int):
+ # This is not the conversion we're looking for, because it
+ # will simply create a bytes object of the given size.
+ raise TypeError("cannot convert `int` object to binary")
+
+ try:
+ return bytes(data)
+ except TypeError:
+ if isinstance(data, str):
+ return data.encode("utf-8")
+ else:
+ raise
def TimeFromTicks(ticks, tz=None):
|
{"golden_diff": "diff --git a/google/cloud/bigquery/dbapi/types.py b/google/cloud/bigquery/dbapi/types.py\n--- a/google/cloud/bigquery/dbapi/types.py\n+++ b/google/cloud/bigquery/dbapi/types.py\n@@ -30,16 +30,28 @@\n TimestampFromTicks = datetime.datetime.fromtimestamp\n \n \n-def Binary(string):\n+def Binary(data):\n \"\"\"Contruct a DB-API binary value.\n \n Args:\n- string (str): A string to encode as a binary value.\n+ data (bytes-like): An object containing binary data and that\n+ can be converted to bytes with the `bytes` builtin.\n \n Returns:\n- bytes: The UTF-8 encoded bytes representing the string.\n+ bytes: The binary data as a bytes object.\n \"\"\"\n- return string.encode(\"utf-8\")\n+ if isinstance(data, int):\n+ # This is not the conversion we're looking for, because it\n+ # will simply create a bytes object of the given size.\n+ raise TypeError(\"cannot convert `int` object to binary\")\n+\n+ try:\n+ return bytes(data)\n+ except TypeError:\n+ if isinstance(data, str):\n+ return data.encode(\"utf-8\")\n+ else:\n+ raise\n \n \n def TimeFromTicks(ticks, tz=None):\n", "issue": "The DB API Binary function should accept bytes.\n```\r\n(3.8) jim@ds9:~/p/g/python-bigquery-sqlalchemy$ python\r\nPython 3.8.5 (default, Jan 27 2021, 15:41:15) \r\n[GCC 9.3.0] on linux\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import google.cloud.bigquery.dbapi\r\n>>> google.cloud.bigquery.dbapi.Binary(b'x')\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/jim/p/g/python-bigquery/google/cloud/bigquery/dbapi/types.py\", line 42, in Binary\r\n return string.encode(\"utf-8\")\r\nAttributeError: 'bytes' object has no attribute 'encode'\r\n```\r\nBytes are the most common way to represent binary data. Accepting strings, as it does now seems at best to be a convenience and at worst a bug magnet.\r\n\r\nIn SQLAlchemy, if you defined a model that has a binary attribute, you'd store bytes data in it, but that would break for bigquery, di to this issue.\r\n\r\nSqlite's `Binary` function requires bytes data.\r\n\r\nI propose to change the function to accept bytes. For the sake of backward compatibility, I propose to continue to accept strings.\r\n\n", "before_files": [{"content": "# Copyright 2017 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Types used in the Google BigQuery DB-API.\n\nSee `PEP-249`_ for details.\n\n.. _PEP-249:\n https://www.python.org/dev/peps/pep-0249/#type-objects-and-constructors\n\"\"\"\n\nimport datetime\n\n\nDate = datetime.date\nTime = datetime.time\nTimestamp = datetime.datetime\nDateFromTicks = datetime.date.fromtimestamp\nTimestampFromTicks = datetime.datetime.fromtimestamp\n\n\ndef Binary(string):\n \"\"\"Contruct a DB-API binary value.\n\n Args:\n string (str): A string to encode as a binary value.\n\n Returns:\n bytes: The UTF-8 encoded bytes representing the string.\n \"\"\"\n return string.encode(\"utf-8\")\n\n\ndef TimeFromTicks(ticks, tz=None):\n \"\"\"Construct a DB-API time value from the given ticks value.\n\n Args:\n ticks (float):\n a number of seconds since the epoch; see the documentation of the\n standard Python time module for details.\n\n tz (datetime.tzinfo): (Optional) time zone to use for conversion\n\n Returns:\n datetime.time: time represented by ticks.\n \"\"\"\n dt = datetime.datetime.fromtimestamp(ticks, tz=tz)\n return dt.timetz()\n\n\nclass _DBAPITypeObject(object):\n \"\"\"DB-API type object which compares equal to many different strings.\n\n See `PEP-249`_ for details.\n\n .. _PEP-249:\n https://www.python.org/dev/peps/pep-0249/#implementation-hints-for-module-authors\n \"\"\"\n\n def __init__(self, *values):\n self.values = values\n\n def __eq__(self, other):\n return other in self.values\n\n\nSTRING = \"STRING\"\nBINARY = _DBAPITypeObject(\"BYTES\", \"RECORD\", \"STRUCT\")\nNUMBER = _DBAPITypeObject(\n \"INTEGER\", \"INT64\", \"FLOAT\", \"FLOAT64\", \"NUMERIC\", \"BIGNUMERIC\", \"BOOLEAN\", \"BOOL\"\n)\nDATETIME = _DBAPITypeObject(\"TIMESTAMP\", \"DATE\", \"TIME\", \"DATETIME\")\nROWID = \"ROWID\"\n", "path": "google/cloud/bigquery/dbapi/types.py"}]}
| 1,619 | 282 |
gh_patches_debug_27461
|
rasdani/github-patches
|
git_diff
|
napari__napari-745
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Show logo during startup
## 🚀 Feature
Right now napari takes a long time to launch the viewer. People can get discouraged as they wait, unsure if napari is loading, or if their data is loading, or if it is just hanging. Showing the napari logo, possibly with / without some text during that time might make it feel better.
</issue>
<code>
[start of napari/_qt/event_loop.py]
1 import sys
2 from contextlib import contextmanager
3
4 from qtpy.QtWidgets import QApplication
5
6
7 @contextmanager
8 def gui_qt():
9 """Start a Qt event loop in which to run the application.
10
11 Notes
12 -----
13 This context manager is not needed if running napari within an interactive
14 IPython session. In this case, use the ``%gui qt`` magic command, or start
15 IPython with the Qt GUI event loop enabled by default by using
16 ``ipython --gui=qt``.
17 """
18 app = QApplication.instance() or QApplication(sys.argv)
19 yield
20 app.exec_()
21
[end of napari/_qt/event_loop.py]
[start of napari/__main__.py]
1 """
2 napari command line viewer.
3 """
4 import argparse
5 import sys
6
7 import numpy as np
8
9 from .util import io
10 from . import Viewer, gui_qt
11
12
13 def main():
14 parser = argparse.ArgumentParser(usage=__doc__)
15 parser.add_argument('images', nargs='*', help='Images to view.')
16 parser.add_argument(
17 '--layers',
18 action='store_true',
19 help='Treat multiple input images as layers.',
20 )
21 parser.add_argument(
22 '-r',
23 '--rgb',
24 help='Treat images as RGB.',
25 action='store_true',
26 default=None,
27 )
28 parser.add_argument(
29 '-g',
30 '--grayscale',
31 dest='rgb',
32 action='store_false',
33 help='interpret all dimensions in the image as spatial',
34 )
35 parser.add_argument(
36 '-D',
37 '--use-dask',
38 action='store_true',
39 help='Use dask to read in images. This conserves memory. This option '
40 'does nothing if a single image is given.',
41 default=None,
42 )
43 parser.add_argument(
44 '-N',
45 '--use-numpy',
46 action='store_false',
47 dest='use_dask',
48 help='Use NumPy to read in images. This can be more performant than '
49 'dask if all the images fit in RAM. This option does nothing if '
50 'only a single image is given.',
51 )
52 args = parser.parse_args()
53 with gui_qt():
54 v = Viewer()
55 if len(args.images) > 0:
56 images = io.magic_imread(
57 args.images, use_dask=args.use_dask, stack=not args.layers
58 )
59 if args.layers:
60 for layer in images:
61 if layer.dtype in (
62 np.int32,
63 np.uint32,
64 np.int64,
65 np.uint64,
66 ):
67 v.add_labels(layer)
68 else:
69 v.add_image(layer, rgb=args.rgb)
70 else:
71 v.add_image(images, rgb=args.rgb)
72
73
74 if __name__ == '__main__':
75 sys.exit(main())
76
[end of napari/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/napari/__main__.py b/napari/__main__.py
--- a/napari/__main__.py
+++ b/napari/__main__.py
@@ -50,7 +50,7 @@
'only a single image is given.',
)
args = parser.parse_args()
- with gui_qt():
+ with gui_qt(startup_logo=True):
v = Viewer()
if len(args.images) > 0:
images = io.magic_imread(
diff --git a/napari/_qt/event_loop.py b/napari/_qt/event_loop.py
--- a/napari/_qt/event_loop.py
+++ b/napari/_qt/event_loop.py
@@ -1,13 +1,20 @@
import sys
from contextlib import contextmanager
+from os.path import dirname, join
-from qtpy.QtWidgets import QApplication
+from qtpy.QtGui import QPixmap
+from qtpy.QtWidgets import QApplication, QSplashScreen
@contextmanager
-def gui_qt():
+def gui_qt(*, startup_logo=False):
"""Start a Qt event loop in which to run the application.
+ Parameters
+ ----------
+ startup_logo : bool
+ Show a splash screen with the napari logo during startup.
+
Notes
-----
This context manager is not needed if running napari within an interactive
@@ -16,5 +23,11 @@
``ipython --gui=qt``.
"""
app = QApplication.instance() or QApplication(sys.argv)
+ if startup_logo:
+ logopath = join(dirname(__file__), '..', 'resources', 'logo.png')
+ splash_widget = QSplashScreen(QPixmap(logopath).scaled(400, 400))
+ splash_widget.show()
yield
+ if startup_logo:
+ splash_widget.close()
app.exec_()
|
{"golden_diff": "diff --git a/napari/__main__.py b/napari/__main__.py\n--- a/napari/__main__.py\n+++ b/napari/__main__.py\n@@ -50,7 +50,7 @@\n 'only a single image is given.',\n )\n args = parser.parse_args()\n- with gui_qt():\n+ with gui_qt(startup_logo=True):\n v = Viewer()\n if len(args.images) > 0:\n images = io.magic_imread(\ndiff --git a/napari/_qt/event_loop.py b/napari/_qt/event_loop.py\n--- a/napari/_qt/event_loop.py\n+++ b/napari/_qt/event_loop.py\n@@ -1,13 +1,20 @@\n import sys\n from contextlib import contextmanager\n+from os.path import dirname, join\n \n-from qtpy.QtWidgets import QApplication\n+from qtpy.QtGui import QPixmap\n+from qtpy.QtWidgets import QApplication, QSplashScreen\n \n \n @contextmanager\n-def gui_qt():\n+def gui_qt(*, startup_logo=False):\n \"\"\"Start a Qt event loop in which to run the application.\n \n+ Parameters\n+ ----------\n+ startup_logo : bool\n+ Show a splash screen with the napari logo during startup.\n+\n Notes\n -----\n This context manager is not needed if running napari within an interactive\n@@ -16,5 +23,11 @@\n ``ipython --gui=qt``.\n \"\"\"\n app = QApplication.instance() or QApplication(sys.argv)\n+ if startup_logo:\n+ logopath = join(dirname(__file__), '..', 'resources', 'logo.png')\n+ splash_widget = QSplashScreen(QPixmap(logopath).scaled(400, 400))\n+ splash_widget.show()\n yield\n+ if startup_logo:\n+ splash_widget.close()\n app.exec_()\n", "issue": "Show logo during startup\n## \ud83d\ude80 Feature\r\nRight now napari takes a long time to launch the viewer. People can get discouraged as they wait, unsure if napari is loading, or if their data is loading, or if it is just hanging. Showing the napari logo, possibly with / without some text during that time might make it feel better.\n", "before_files": [{"content": "import sys\nfrom contextlib import contextmanager\n\nfrom qtpy.QtWidgets import QApplication\n\n\n@contextmanager\ndef gui_qt():\n \"\"\"Start a Qt event loop in which to run the application.\n\n Notes\n -----\n This context manager is not needed if running napari within an interactive\n IPython session. In this case, use the ``%gui qt`` magic command, or start\n IPython with the Qt GUI event loop enabled by default by using\n ``ipython --gui=qt``.\n \"\"\"\n app = QApplication.instance() or QApplication(sys.argv)\n yield\n app.exec_()\n", "path": "napari/_qt/event_loop.py"}, {"content": "\"\"\"\nnapari command line viewer.\n\"\"\"\nimport argparse\nimport sys\n\nimport numpy as np\n\nfrom .util import io\nfrom . import Viewer, gui_qt\n\n\ndef main():\n parser = argparse.ArgumentParser(usage=__doc__)\n parser.add_argument('images', nargs='*', help='Images to view.')\n parser.add_argument(\n '--layers',\n action='store_true',\n help='Treat multiple input images as layers.',\n )\n parser.add_argument(\n '-r',\n '--rgb',\n help='Treat images as RGB.',\n action='store_true',\n default=None,\n )\n parser.add_argument(\n '-g',\n '--grayscale',\n dest='rgb',\n action='store_false',\n help='interpret all dimensions in the image as spatial',\n )\n parser.add_argument(\n '-D',\n '--use-dask',\n action='store_true',\n help='Use dask to read in images. This conserves memory. This option '\n 'does nothing if a single image is given.',\n default=None,\n )\n parser.add_argument(\n '-N',\n '--use-numpy',\n action='store_false',\n dest='use_dask',\n help='Use NumPy to read in images. This can be more performant than '\n 'dask if all the images fit in RAM. This option does nothing if '\n 'only a single image is given.',\n )\n args = parser.parse_args()\n with gui_qt():\n v = Viewer()\n if len(args.images) > 0:\n images = io.magic_imread(\n args.images, use_dask=args.use_dask, stack=not args.layers\n )\n if args.layers:\n for layer in images:\n if layer.dtype in (\n np.int32,\n np.uint32,\n np.int64,\n np.uint64,\n ):\n v.add_labels(layer)\n else:\n v.add_image(layer, rgb=args.rgb)\n else:\n v.add_image(images, rgb=args.rgb)\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "napari/__main__.py"}]}
| 1,388 | 413 |
gh_patches_debug_9652
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-19512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
f
numpy.random.f function
</issue>
<code>
[start of ivy/functional/frontends/numpy/random/functions.py]
1 # local
2 import ivy
3 from ivy.functional.frontends.numpy.func_wrapper import (
4 to_ivy_arrays_and_back,
5 from_zero_dim_arrays_to_scalar,
6 )
7
8
9 @to_ivy_arrays_and_back
10 @from_zero_dim_arrays_to_scalar
11 def random_sample(size=None):
12 return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
13
14
15 @to_ivy_arrays_and_back
16 @from_zero_dim_arrays_to_scalar
17 def dirichlet(alpha, size=None):
18 return ivy.dirichlet(alpha, size=size)
19
20
21 @to_ivy_arrays_and_back
22 @from_zero_dim_arrays_to_scalar
23 def uniform(low=0.0, high=1.0, size=None):
24 return ivy.random_uniform(low=low, high=high, shape=size, dtype="float64")
25
26
27 @to_ivy_arrays_and_back
28 @from_zero_dim_arrays_to_scalar
29 def geometric(p, size=None):
30 if p < 0 or p > 1:
31 raise ValueError("p must be in the interval [0, 1]")
32 oneMinusP = ivy.subtract(1, p)
33 sizeMinusOne = ivy.subtract(size, 1)
34
35 return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)
36
37
38 @to_ivy_arrays_and_back
39 @from_zero_dim_arrays_to_scalar
40 def normal(loc=0.0, scale=1.0, size=None):
41 return ivy.random_normal(mean=loc, std=scale, shape=size, dtype="float64")
42
43
44 @to_ivy_arrays_and_back
45 @from_zero_dim_arrays_to_scalar
46 def poisson(lam=1.0, size=None):
47 return ivy.poisson(lam=lam, shape=size)
48
49
50 @to_ivy_arrays_and_back
51 @from_zero_dim_arrays_to_scalar
52 def multinomial(n, pvals, size=None):
53 assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)
54 batch_size = 1
55 if ivy.exists(size):
56 if len(size) == 2:
57 batch_size = size[0]
58 num_samples = size[1]
59 else:
60 num_samples = size[0]
61 else:
62 num_samples = len(pvals)
63 return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)
64
65
66 @to_ivy_arrays_and_back
67 @from_zero_dim_arrays_to_scalar
68 def permutation(x, /):
69 if isinstance(x, int):
70 x = ivy.arange(x)
71 return ivy.shuffle(x)
72
73
74 @to_ivy_arrays_and_back
75 @from_zero_dim_arrays_to_scalar
76 def beta(a, b, size=None):
77 return ivy.beta(a, b, shape=size)
78
79
80 @to_ivy_arrays_and_back
81 @from_zero_dim_arrays_to_scalar
82 def shuffle(x, axis=0, /):
83 if isinstance(x, int):
84 x = ivy.arange(x)
85 return ivy.shuffle(x, axis)
86
87
88 @to_ivy_arrays_and_back
89 @from_zero_dim_arrays_to_scalar
90 def standard_normal(size=None):
91 return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype="float64")
92
93
94 @to_ivy_arrays_and_back
95 @from_zero_dim_arrays_to_scalar
96 def standard_gamma(shape, size=None):
97 return ivy.gamma(shape, 1.0, shape=size, dtype="float64")
98
99
100 @to_ivy_arrays_and_back
101 @from_zero_dim_arrays_to_scalar
102 def binomial(n, p, size=None):
103 if p < 0 or p > 1:
104 raise ValueError("p must be in the interval (0, 1)")
105 if n < 0:
106 raise ValueError("n must be strictly positive")
107 if size is None:
108 size = 1
109 else:
110 size = size
111 if isinstance(size, int):
112 size = (size,)
113 lambda_ = ivy.multiply(n, p)
114 return ivy.poisson(lambda_, shape=size)
115
116
117 @to_ivy_arrays_and_back
118 @from_zero_dim_arrays_to_scalar
119 def chisquare(df, size=None):
120 df = ivy.array(df) # scalar ints and floats are also array_like
121 if ivy.any(df <= 0):
122 raise ValueError("df <= 0")
123
124 # ivy.gamma() throws an error if both alpha is an array and a shape is passed
125 # so this part broadcasts df into the shape of `size`` first to keep it happy.
126 if size is not None:
127 df = df * ivy.ones(size)
128
129 return ivy.gamma(df / 2, 2, dtype="float64")
130
131
132 @to_ivy_arrays_and_back
133 @from_zero_dim_arrays_to_scalar
134 def lognormal(mean=0.0, sigma=1.0, size=None):
135 ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype="float64"))
136 return ret
137
138
139 @to_ivy_arrays_and_back
140 @from_zero_dim_arrays_to_scalar
141 def negative_binomial(n, p, size=None):
142 if p <= 0 or p >= 1:
143 raise ValueError("p must be in the interval (0, 1)")
144 if n <= 0:
145 raise ValueError("n must be strictly positive")
146 # numpy implementation uses scale = (1 - p) / p
147 scale = (1 - p) / p
148 # poisson requires shape to be a tuple
149 if isinstance(size, int):
150 size = (size,)
151 lambda_ = ivy.gamma(n, scale, shape=size)
152 return ivy.poisson(lam=lambda_, shape=size)
153
154
155 @to_ivy_arrays_and_back
156 @from_zero_dim_arrays_to_scalar
157 def weibull(a, size=None):
158 if a < 0:
159 return 0
160 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
161 return ivy.pow(-ivy.log(1 - u), 1 / a)
162
163
164 @to_ivy_arrays_and_back
165 @from_zero_dim_arrays_to_scalar
166 def standard_cauchy(size=None):
167 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
168 return ivy.tan(ivy.pi * (u - 0.5))
169
170
171 @to_ivy_arrays_and_back
172 @from_zero_dim_arrays_to_scalar
173 def rayleigh(scale, size=None):
174 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
175 log_u = ivy.log(u)
176 x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))
177 return x
178
179
180 @to_ivy_arrays_and_back
181 @from_zero_dim_arrays_to_scalar
182 def gumbel(loc=0.0, scale=1.0, size=None):
183 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
184 x = loc - scale * ivy.log(-ivy.log(u))
185 return x
186
187
188 @to_ivy_arrays_and_back
189 @from_zero_dim_arrays_to_scalar
190 def gamma(shape, scale=1.0, size=None):
191 return ivy.gamma(shape, scale, shape=size, dtype="float64")
192
193
194 @to_ivy_arrays_and_back
195 @from_zero_dim_arrays_to_scalar
196 def logistic(loc=0.0, scale=1.0, size=None):
197 u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype="float64")
198 x = loc + scale * ivy.log(u / (1 - u))
199 return x
200
201
202 @to_ivy_arrays_and_back
203 @from_zero_dim_arrays_to_scalar
204 def triangular(left, mode, right, size=None):
205 if left > mode or mode > right or left == right:
206 raise ivy.utils.exceptions.IvyValueError(
207 "left < mode < right is not being followed"
208 )
209 u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype="float64")
210 condition = u <= (mode - left) / (right - left)
211 values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5
212 values2 = (
213 right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5
214 )
215 return ivy.where(condition, values1, values2)
216
[end of ivy/functional/frontends/numpy/random/functions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py
--- a/ivy/functional/frontends/numpy/random/functions.py
+++ b/ivy/functional/frontends/numpy/random/functions.py
@@ -185,6 +185,17 @@
return x
+@to_ivy_arrays_and_back
+@from_zero_dim_arrays_to_scalar
+def f(dfn, dfd, size=None):
+ # Generate samples from the uniform distribution
+ x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype="float64")
+ x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype="float64")
+ # Calculate the F-distributed samples
+ samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))
+ return samples
+
+
@to_ivy_arrays_and_back
@from_zero_dim_arrays_to_scalar
def gamma(shape, scale=1.0, size=None):
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/random/functions.py b/ivy/functional/frontends/numpy/random/functions.py\n--- a/ivy/functional/frontends/numpy/random/functions.py\n+++ b/ivy/functional/frontends/numpy/random/functions.py\n@@ -185,6 +185,17 @@\n return x\n \n \n+@to_ivy_arrays_and_back\n+@from_zero_dim_arrays_to_scalar\n+def f(dfn, dfd, size=None):\n+ # Generate samples from the uniform distribution\n+ x1 = ivy.gamma(ivy.to_scalar(ivy.divide(dfn, 2)), 2.0, shape=size, dtype=\"float64\")\n+ x2 = ivy.gamma(ivy.to_scalar(ivy.divide(dfd, 2)), 2.0, shape=size, dtype=\"float64\")\n+ # Calculate the F-distributed samples\n+ samples = ivy.divide(ivy.divide(x1, ivy.array(dfn)), ivy.divide(x2, ivy.array(dfd)))\n+ return samples\n+\n+\n @to_ivy_arrays_and_back\n @from_zero_dim_arrays_to_scalar\n def gamma(shape, scale=1.0, size=None):\n", "issue": "f\nnumpy.random.f function\n", "before_files": [{"content": "# local\nimport ivy\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n from_zero_dim_arrays_to_scalar,\n)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef random_sample(size=None):\n return ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef dirichlet(alpha, size=None):\n return ivy.dirichlet(alpha, size=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef uniform(low=0.0, high=1.0, size=None):\n return ivy.random_uniform(low=low, high=high, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef geometric(p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval [0, 1]\")\n oneMinusP = ivy.subtract(1, p)\n sizeMinusOne = ivy.subtract(size, 1)\n\n return ivy.multiply(ivy.pow(oneMinusP, sizeMinusOne), p)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef normal(loc=0.0, scale=1.0, size=None):\n return ivy.random_normal(mean=loc, std=scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef poisson(lam=1.0, size=None):\n return ivy.poisson(lam=lam, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef multinomial(n, pvals, size=None):\n assert not ivy.exists(size) or (len(size) > 0 and len(size) < 3)\n batch_size = 1\n if ivy.exists(size):\n if len(size) == 2:\n batch_size = size[0]\n num_samples = size[1]\n else:\n num_samples = size[0]\n else:\n num_samples = len(pvals)\n return ivy.multinomial(n, num_samples, batch_size=batch_size, probs=pvals)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef permutation(x, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef beta(a, b, size=None):\n return ivy.beta(a, b, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef shuffle(x, axis=0, /):\n if isinstance(x, int):\n x = ivy.arange(x)\n return ivy.shuffle(x, axis)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_normal(size=None):\n return ivy.random_normal(mean=0.0, std=1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_gamma(shape, size=None):\n return ivy.gamma(shape, 1.0, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef binomial(n, p, size=None):\n if p < 0 or p > 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n < 0:\n raise ValueError(\"n must be strictly positive\")\n if size is None:\n size = 1\n else:\n size = size\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.multiply(n, p)\n return ivy.poisson(lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef chisquare(df, size=None):\n df = ivy.array(df) # scalar ints and floats are also array_like\n if ivy.any(df <= 0):\n raise ValueError(\"df <= 0\")\n\n # ivy.gamma() throws an error if both alpha is an array and a shape is passed\n # so this part broadcasts df into the shape of `size`` first to keep it happy.\n if size is not None:\n df = df * ivy.ones(size)\n\n return ivy.gamma(df / 2, 2, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef lognormal(mean=0.0, sigma=1.0, size=None):\n ret = ivy.exp(ivy.random_normal(mean=mean, std=sigma, shape=size, dtype=\"float64\"))\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef negative_binomial(n, p, size=None):\n if p <= 0 or p >= 1:\n raise ValueError(\"p must be in the interval (0, 1)\")\n if n <= 0:\n raise ValueError(\"n must be strictly positive\")\n # numpy implementation uses scale = (1 - p) / p\n scale = (1 - p) / p\n # poisson requires shape to be a tuple\n if isinstance(size, int):\n size = (size,)\n lambda_ = ivy.gamma(n, scale, shape=size)\n return ivy.poisson(lam=lambda_, shape=size)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef weibull(a, size=None):\n if a < 0:\n return 0\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.pow(-ivy.log(1 - u), 1 / a)\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef standard_cauchy(size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n return ivy.tan(ivy.pi * (u - 0.5))\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef rayleigh(scale, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n log_u = ivy.log(u)\n x = ivy.multiply(scale, ivy.sqrt(ivy.multiply(-2, log_u)))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gumbel(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n x = loc - scale * ivy.log(-ivy.log(u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef gamma(shape, scale=1.0, size=None):\n return ivy.gamma(shape, scale, shape=size, dtype=\"float64\")\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef logistic(loc=0.0, scale=1.0, size=None):\n u = ivy.random_uniform(low=0.0, high=0.0, shape=size, dtype=\"float64\")\n x = loc + scale * ivy.log(u / (1 - u))\n return x\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef triangular(left, mode, right, size=None):\n if left > mode or mode > right or left == right:\n raise ivy.utils.exceptions.IvyValueError(\n \"left < mode < right is not being followed\"\n )\n u = ivy.random_uniform(low=0.0, high=1.0, shape=size, dtype=\"float64\")\n condition = u <= (mode - left) / (right - left)\n values1 = left + (right - left) * (u * (mode - left) / (right - left)) ** 0.5\n values2 = (\n right - (right - mode) * ((1 - u) * (right - mode) / (right - left)) ** 0.5\n )\n return ivy.where(condition, values1, values2)\n", "path": "ivy/functional/frontends/numpy/random/functions.py"}]}
| 2,998 | 263 |
gh_patches_debug_31614
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-1306
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TRAIL filters
Add "communes, secteurs, type physique, type foncier..." for TRAILS filters as it is in other modules.
</issue>
<code>
[start of geotrek/land/filters.py]
1 from django.utils.translation import ugettext_lazy as _
2
3 from mapentity.filters import MapEntityFilterSet
4
5 from geotrek.common.models import Organism
6 from geotrek.common.filters import StructureRelatedFilterSet
7
8 from geotrek.core.filters import TopologyFilter, PathFilterSet
9 from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
10 from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
11 from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
12 from geotrek.zoning.filters import * # NOQA
13
14 from .models import (
15 CompetenceEdge, LandEdge, LandType, PhysicalEdge, PhysicalType,
16 SignageManagementEdge, WorkManagementEdge,
17 )
18
19
20 class PhysicalEdgeFilterSet(MapEntityFilterSet):
21 class Meta:
22 model = PhysicalEdge
23 fields = ['physical_type']
24
25
26 class LandEdgeFilterSet(StructureRelatedFilterSet):
27 class Meta:
28 model = LandEdge
29 fields = ['land_type']
30
31
32 class OrganismFilterSet(MapEntityFilterSet):
33 class Meta:
34 fields = ['organization']
35
36
37 class CompetenceEdgeFilterSet(OrganismFilterSet):
38 class Meta(OrganismFilterSet.Meta):
39 model = CompetenceEdge
40
41
42 class WorkManagementEdgeFilterSet(OrganismFilterSet):
43 class Meta(OrganismFilterSet.Meta):
44 model = WorkManagementEdge
45
46
47 class SignageManagementEdgeFilterSet(OrganismFilterSet):
48 class Meta(OrganismFilterSet.Meta):
49 model = SignageManagementEdge
50
51
52 """
53
54 Injected filter fields
55
56 """
57
58
59 class TopologyFilterPhysicalType(TopologyFilter):
60 model = PhysicalType
61
62 def value_to_edges(self, value):
63 return value.physicaledge_set.all()
64
65
66 class TopologyFilterLandType(TopologyFilter):
67 model = LandType
68
69 def value_to_edges(self, value):
70 return value.landedge_set.all()
71
72
73 class TopologyFilterCompetenceEdge(TopologyFilter):
74 model = Organism
75
76 def value_to_edges(self, value):
77 return value.competenceedge_set.select_related('organization').all()
78
79
80 class TopologyFilterSignageManagementEdge(TopologyFilter):
81 model = Organism
82
83 def value_to_edges(self, value):
84 return value.signagemanagementedge_set.select_related('organization').all()
85
86
87 class TopologyFilterWorkManagementEdge(TopologyFilter):
88 model = Organism
89
90 def value_to_edges(self, value):
91 return value.workmanagementedge_set.select_related('organization').all()
92
93
94 def add_edge_filters(filter_set):
95 filter_set.add_filters({
96 'physical_type': TopologyFilterPhysicalType(label=_('Physical type'), required=False),
97 'land_type': TopologyFilterLandType(label=_('Land type'), required=False),
98 'competence': TopologyFilterCompetenceEdge(label=_('Competence'), required=False),
99 'signage': TopologyFilterSignageManagementEdge(label=_('Signage management'), required=False),
100 'work': TopologyFilterWorkManagementEdge(label=_('Work management'), required=False),
101 })
102
103
104 add_edge_filters(TrekFilterSet)
105 add_edge_filters(POIFilterSet)
106 add_edge_filters(InterventionFilterSet)
107 add_edge_filters(ProjectFilterSet)
108 add_edge_filters(PathFilterSet)
109 add_edge_filters(InfrastructureFilterSet)
110 add_edge_filters(SignageFilterSet)
111
[end of geotrek/land/filters.py]
[start of geotrek/zoning/filters.py]
1 from django.utils.translation import ugettext_lazy as _
2
3 from geotrek.core.filters import TopologyFilter, PathFilterSet
4 from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
5 from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
6 from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
7 from geotrek.tourism.filters import TouristicContentFilterSet, TouristicEventFilterSet
8 from geotrek.zoning.models import City, District
9
10
11 class TopologyFilterCity(TopologyFilter):
12 model = City
13
14 def value_to_edges(self, value):
15 return value.cityedge_set.all()
16
17
18 class TopologyFilterDistrict(TopologyFilter):
19 model = District
20
21 def value_to_edges(self, value):
22 return value.districtedge_set.all()
23
24
25 def add_edge_filters(filter_set):
26 filter_set.add_filters({
27 'city': TopologyFilterCity(label=_('City'), required=False),
28 'district': TopologyFilterDistrict(label=_('District'), required=False),
29 })
30
31
32 add_edge_filters(TrekFilterSet)
33 add_edge_filters(POIFilterSet)
34 add_edge_filters(InterventionFilterSet)
35 add_edge_filters(ProjectFilterSet)
36 add_edge_filters(PathFilterSet)
37 add_edge_filters(InfrastructureFilterSet)
38 add_edge_filters(SignageFilterSet)
39
40
41 class IntersectionFilter(TopologyFilter):
42 """Inherit from ``TopologyFilter``, just to make sure the widgets
43 will be initialized the same way.
44 """
45 def filter(self, qs, value):
46 if not value:
47 return qs
48 return qs.filter(geom__intersects=value.geom)
49
50
51 class IntersectionFilterCity(IntersectionFilter):
52 model = City
53
54
55 class IntersectionFilterDistrict(IntersectionFilter):
56 model = District
57
58
59 TouristicContentFilterSet.add_filters({
60 'city': IntersectionFilterCity(label=_('City'), required=False),
61 'district': IntersectionFilterDistrict(label=_('District'), required=False),
62 })
63
64 TouristicEventFilterSet.add_filters({
65 'city': IntersectionFilterCity(label=_('City'), required=False),
66 'district': IntersectionFilterDistrict(label=_('District'), required=False),
67 })
68
[end of geotrek/zoning/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/geotrek/land/filters.py b/geotrek/land/filters.py
--- a/geotrek/land/filters.py
+++ b/geotrek/land/filters.py
@@ -5,7 +5,7 @@
from geotrek.common.models import Organism
from geotrek.common.filters import StructureRelatedFilterSet
-from geotrek.core.filters import TopologyFilter, PathFilterSet
+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet
from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
@@ -108,3 +108,4 @@
add_edge_filters(PathFilterSet)
add_edge_filters(InfrastructureFilterSet)
add_edge_filters(SignageFilterSet)
+add_edge_filters(TrailFilterSet)
diff --git a/geotrek/zoning/filters.py b/geotrek/zoning/filters.py
--- a/geotrek/zoning/filters.py
+++ b/geotrek/zoning/filters.py
@@ -1,6 +1,6 @@
from django.utils.translation import ugettext_lazy as _
-from geotrek.core.filters import TopologyFilter, PathFilterSet
+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet
from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet
from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet
from geotrek.trekking.filters import TrekFilterSet, POIFilterSet
@@ -36,6 +36,7 @@
add_edge_filters(PathFilterSet)
add_edge_filters(InfrastructureFilterSet)
add_edge_filters(SignageFilterSet)
+add_edge_filters(TrailFilterSet)
class IntersectionFilter(TopologyFilter):
|
{"golden_diff": "diff --git a/geotrek/land/filters.py b/geotrek/land/filters.py\n--- a/geotrek/land/filters.py\n+++ b/geotrek/land/filters.py\n@@ -5,7 +5,7 @@\n from geotrek.common.models import Organism\n from geotrek.common.filters import StructureRelatedFilterSet\n \n-from geotrek.core.filters import TopologyFilter, PathFilterSet\n+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet\n from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\n from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\n from geotrek.trekking.filters import TrekFilterSet, POIFilterSet\n@@ -108,3 +108,4 @@\n add_edge_filters(PathFilterSet)\n add_edge_filters(InfrastructureFilterSet)\n add_edge_filters(SignageFilterSet)\n+add_edge_filters(TrailFilterSet)\ndiff --git a/geotrek/zoning/filters.py b/geotrek/zoning/filters.py\n--- a/geotrek/zoning/filters.py\n+++ b/geotrek/zoning/filters.py\n@@ -1,6 +1,6 @@\n from django.utils.translation import ugettext_lazy as _\n \n-from geotrek.core.filters import TopologyFilter, PathFilterSet\n+from geotrek.core.filters import TopologyFilter, PathFilterSet, TrailFilterSet\n from geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\n from geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\n from geotrek.trekking.filters import TrekFilterSet, POIFilterSet\n@@ -36,6 +36,7 @@\n add_edge_filters(PathFilterSet)\n add_edge_filters(InfrastructureFilterSet)\n add_edge_filters(SignageFilterSet)\n+add_edge_filters(TrailFilterSet)\n \n \n class IntersectionFilter(TopologyFilter):\n", "issue": "TRAIL filters\nAdd \"communes, secteurs, type physique, type foncier...\" for TRAILS filters as it is in other modules.\n\n", "before_files": [{"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom mapentity.filters import MapEntityFilterSet\n\nfrom geotrek.common.models import Organism\nfrom geotrek.common.filters import StructureRelatedFilterSet\n\nfrom geotrek.core.filters import TopologyFilter, PathFilterSet\nfrom geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\nfrom geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\nfrom geotrek.trekking.filters import TrekFilterSet, POIFilterSet\nfrom geotrek.zoning.filters import * # NOQA\n\nfrom .models import (\n CompetenceEdge, LandEdge, LandType, PhysicalEdge, PhysicalType,\n SignageManagementEdge, WorkManagementEdge,\n)\n\n\nclass PhysicalEdgeFilterSet(MapEntityFilterSet):\n class Meta:\n model = PhysicalEdge\n fields = ['physical_type']\n\n\nclass LandEdgeFilterSet(StructureRelatedFilterSet):\n class Meta:\n model = LandEdge\n fields = ['land_type']\n\n\nclass OrganismFilterSet(MapEntityFilterSet):\n class Meta:\n fields = ['organization']\n\n\nclass CompetenceEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = CompetenceEdge\n\n\nclass WorkManagementEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = WorkManagementEdge\n\n\nclass SignageManagementEdgeFilterSet(OrganismFilterSet):\n class Meta(OrganismFilterSet.Meta):\n model = SignageManagementEdge\n\n\n\"\"\"\n\n Injected filter fields\n\n\"\"\"\n\n\nclass TopologyFilterPhysicalType(TopologyFilter):\n model = PhysicalType\n\n def value_to_edges(self, value):\n return value.physicaledge_set.all()\n\n\nclass TopologyFilterLandType(TopologyFilter):\n model = LandType\n\n def value_to_edges(self, value):\n return value.landedge_set.all()\n\n\nclass TopologyFilterCompetenceEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.competenceedge_set.select_related('organization').all()\n\n\nclass TopologyFilterSignageManagementEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.signagemanagementedge_set.select_related('organization').all()\n\n\nclass TopologyFilterWorkManagementEdge(TopologyFilter):\n model = Organism\n\n def value_to_edges(self, value):\n return value.workmanagementedge_set.select_related('organization').all()\n\n\ndef add_edge_filters(filter_set):\n filter_set.add_filters({\n 'physical_type': TopologyFilterPhysicalType(label=_('Physical type'), required=False),\n 'land_type': TopologyFilterLandType(label=_('Land type'), required=False),\n 'competence': TopologyFilterCompetenceEdge(label=_('Competence'), required=False),\n 'signage': TopologyFilterSignageManagementEdge(label=_('Signage management'), required=False),\n 'work': TopologyFilterWorkManagementEdge(label=_('Work management'), required=False),\n })\n\n\nadd_edge_filters(TrekFilterSet)\nadd_edge_filters(POIFilterSet)\nadd_edge_filters(InterventionFilterSet)\nadd_edge_filters(ProjectFilterSet)\nadd_edge_filters(PathFilterSet)\nadd_edge_filters(InfrastructureFilterSet)\nadd_edge_filters(SignageFilterSet)\n", "path": "geotrek/land/filters.py"}, {"content": "from django.utils.translation import ugettext_lazy as _\n\nfrom geotrek.core.filters import TopologyFilter, PathFilterSet\nfrom geotrek.infrastructure.filters import InfrastructureFilterSet, SignageFilterSet\nfrom geotrek.maintenance.filters import InterventionFilterSet, ProjectFilterSet\nfrom geotrek.trekking.filters import TrekFilterSet, POIFilterSet\nfrom geotrek.tourism.filters import TouristicContentFilterSet, TouristicEventFilterSet\nfrom geotrek.zoning.models import City, District\n\n\nclass TopologyFilterCity(TopologyFilter):\n model = City\n\n def value_to_edges(self, value):\n return value.cityedge_set.all()\n\n\nclass TopologyFilterDistrict(TopologyFilter):\n model = District\n\n def value_to_edges(self, value):\n return value.districtedge_set.all()\n\n\ndef add_edge_filters(filter_set):\n filter_set.add_filters({\n 'city': TopologyFilterCity(label=_('City'), required=False),\n 'district': TopologyFilterDistrict(label=_('District'), required=False),\n })\n\n\nadd_edge_filters(TrekFilterSet)\nadd_edge_filters(POIFilterSet)\nadd_edge_filters(InterventionFilterSet)\nadd_edge_filters(ProjectFilterSet)\nadd_edge_filters(PathFilterSet)\nadd_edge_filters(InfrastructureFilterSet)\nadd_edge_filters(SignageFilterSet)\n\n\nclass IntersectionFilter(TopologyFilter):\n \"\"\"Inherit from ``TopologyFilter``, just to make sure the widgets\n will be initialized the same way.\n \"\"\"\n def filter(self, qs, value):\n if not value:\n return qs\n return qs.filter(geom__intersects=value.geom)\n\n\nclass IntersectionFilterCity(IntersectionFilter):\n model = City\n\n\nclass IntersectionFilterDistrict(IntersectionFilter):\n model = District\n\n\nTouristicContentFilterSet.add_filters({\n 'city': IntersectionFilterCity(label=_('City'), required=False),\n 'district': IntersectionFilterDistrict(label=_('District'), required=False),\n})\n\nTouristicEventFilterSet.add_filters({\n 'city': IntersectionFilterCity(label=_('City'), required=False),\n 'district': IntersectionFilterDistrict(label=_('District'), required=False),\n})\n", "path": "geotrek/zoning/filters.py"}]}
| 2,135 | 414 |
gh_patches_debug_47458
|
rasdani/github-patches
|
git_diff
|
awslabs__gluonts-1132
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update pandas dependency
As documented in #967, pandas will be fixing the breaking change that led us to fix the dependency to `<1.1`, see pandas-dev/pandas#37267
Once that is resolved, we could remove the constraint.
*Edit:* we should also make sure to find a solution to #965 first
</issue>
<code>
[start of src/gluonts/time_feature/_base.py]
1 # Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License").
4 # You may not use this file except in compliance with the License.
5 # A copy of the License is located at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # or in the "license" file accompanying this file. This file is distributed
10 # on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either
11 # express or implied. See the License for the specific language governing
12 # permissions and limitations under the License.
13
14 from typing import List
15
16 # Third-party imports
17 import numpy as np
18 import pandas as pd
19 from pandas.tseries import offsets
20 from pandas.tseries.frequencies import to_offset
21
22 # First-party imports
23 from gluonts.core.component import validated
24
25
26 class TimeFeature:
27 """
28 Base class for features that only depend on time.
29 """
30
31 @validated()
32 def __init__(self, normalized: bool = True):
33 self.normalized = normalized
34
35 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
36 pass
37
38 def __repr__(self):
39 return self.__class__.__name__ + "()"
40
41
42 class MinuteOfHour(TimeFeature):
43 """
44 Minute of hour encoded as value between [-0.5, 0.5]
45 """
46
47 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
48 if self.normalized:
49 return index.minute / 59.0 - 0.5
50 else:
51 return index.minute.map(float)
52
53
54 class HourOfDay(TimeFeature):
55 """
56 Hour of day encoded as value between [-0.5, 0.5]
57 """
58
59 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
60 if self.normalized:
61 return index.hour / 23.0 - 0.5
62 else:
63 return index.hour.map(float)
64
65
66 class DayOfWeek(TimeFeature):
67 """
68 Hour of day encoded as value between [-0.5, 0.5]
69 """
70
71 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
72 if self.normalized:
73 return index.dayofweek / 6.0 - 0.5
74 else:
75 return index.dayofweek.map(float)
76
77
78 class DayOfMonth(TimeFeature):
79 """
80 Day of month encoded as value between [-0.5, 0.5]
81 """
82
83 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
84 if self.normalized:
85 return index.day / 30.0 - 0.5
86 else:
87 return index.day.map(float)
88
89
90 class DayOfYear(TimeFeature):
91 """
92 Day of year encoded as value between [-0.5, 0.5]
93 """
94
95 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
96 if self.normalized:
97 return index.dayofyear / 364.0 - 0.5
98 else:
99 return index.dayofyear.map(float)
100
101
102 class MonthOfYear(TimeFeature):
103 """
104 Month of year encoded as value between [-0.5, 0.5]
105 """
106
107 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
108 if self.normalized:
109 return index.month / 11.0 - 0.5
110 else:
111 return index.month.map(float)
112
113
114 class WeekOfYear(TimeFeature):
115 """
116 Week of year encoded as value between [-0.5, 0.5]
117 """
118
119 def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:
120 if self.normalized:
121 return index.weekofyear / 51.0 - 0.5
122 else:
123 return index.weekofyear.map(float)
124
125
126 def time_features_from_frequency_str(freq_str: str) -> List[TimeFeature]:
127 """
128 Returns a list of time features that will be appropriate for the given frequency string.
129
130 Parameters
131 ----------
132
133 freq_str
134 Frequency string of the form [multiple][granularity] such as "12H", "5min", "1D" etc.
135
136 """
137
138 features_by_offsets = {
139 offsets.YearOffset: [],
140 offsets.MonthOffset: [MonthOfYear],
141 offsets.Week: [DayOfMonth, WeekOfYear],
142 offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],
143 offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],
144 offsets.Hour: [HourOfDay, DayOfWeek, DayOfMonth, DayOfYear],
145 offsets.Minute: [
146 MinuteOfHour,
147 HourOfDay,
148 DayOfWeek,
149 DayOfMonth,
150 DayOfYear,
151 ],
152 }
153
154 offset = to_offset(freq_str)
155
156 for offset_type, feature_classes in features_by_offsets.items():
157 if isinstance(offset, offset_type):
158 return [cls() for cls in feature_classes]
159
160 supported_freq_msg = f"""
161 Unsupported frequency {freq_str}
162
163 The following frequencies are supported:
164
165 Y - yearly
166 alias: A
167 M - monthly
168 W - weekly
169 D - daily
170 B - business days
171 H - hourly
172 T - minutely
173 alias: min
174 """
175 raise RuntimeError(supported_freq_msg)
176
[end of src/gluonts/time_feature/_base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/gluonts/time_feature/_base.py b/src/gluonts/time_feature/_base.py
--- a/src/gluonts/time_feature/_base.py
+++ b/src/gluonts/time_feature/_base.py
@@ -136,8 +136,8 @@
"""
features_by_offsets = {
- offsets.YearOffset: [],
- offsets.MonthOffset: [MonthOfYear],
+ offsets.YearEnd: [],
+ offsets.MonthEnd: [MonthOfYear],
offsets.Week: [DayOfMonth, WeekOfYear],
offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],
offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],
|
{"golden_diff": "diff --git a/src/gluonts/time_feature/_base.py b/src/gluonts/time_feature/_base.py\n--- a/src/gluonts/time_feature/_base.py\n+++ b/src/gluonts/time_feature/_base.py\n@@ -136,8 +136,8 @@\n \"\"\"\n \n features_by_offsets = {\n- offsets.YearOffset: [],\n- offsets.MonthOffset: [MonthOfYear],\n+ offsets.YearEnd: [],\n+ offsets.MonthEnd: [MonthOfYear],\n offsets.Week: [DayOfMonth, WeekOfYear],\n offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],\n", "issue": "Update pandas dependency\nAs documented in #967, pandas will be fixing the breaking change that led us to fix the dependency to `<1.1`, see pandas-dev/pandas#37267\r\n\r\nOnce that is resolved, we could remove the constraint.\r\n\r\n*Edit:* we should also make sure to find a solution to #965 first\n", "before_files": [{"content": "# Copyright 2018 Amazon.com, Inc. or its affiliates. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\").\n# You may not use this file except in compliance with the License.\n# A copy of the License is located at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# or in the \"license\" file accompanying this file. This file is distributed\n# on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either\n# express or implied. See the License for the specific language governing\n# permissions and limitations under the License.\n\nfrom typing import List\n\n# Third-party imports\nimport numpy as np\nimport pandas as pd\nfrom pandas.tseries import offsets\nfrom pandas.tseries.frequencies import to_offset\n\n# First-party imports\nfrom gluonts.core.component import validated\n\n\nclass TimeFeature:\n \"\"\"\n Base class for features that only depend on time.\n \"\"\"\n\n @validated()\n def __init__(self, normalized: bool = True):\n self.normalized = normalized\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n pass\n\n def __repr__(self):\n return self.__class__.__name__ + \"()\"\n\n\nclass MinuteOfHour(TimeFeature):\n \"\"\"\n Minute of hour encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.minute / 59.0 - 0.5\n else:\n return index.minute.map(float)\n\n\nclass HourOfDay(TimeFeature):\n \"\"\"\n Hour of day encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.hour / 23.0 - 0.5\n else:\n return index.hour.map(float)\n\n\nclass DayOfWeek(TimeFeature):\n \"\"\"\n Hour of day encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.dayofweek / 6.0 - 0.5\n else:\n return index.dayofweek.map(float)\n\n\nclass DayOfMonth(TimeFeature):\n \"\"\"\n Day of month encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.day / 30.0 - 0.5\n else:\n return index.day.map(float)\n\n\nclass DayOfYear(TimeFeature):\n \"\"\"\n Day of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.dayofyear / 364.0 - 0.5\n else:\n return index.dayofyear.map(float)\n\n\nclass MonthOfYear(TimeFeature):\n \"\"\"\n Month of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.month / 11.0 - 0.5\n else:\n return index.month.map(float)\n\n\nclass WeekOfYear(TimeFeature):\n \"\"\"\n Week of year encoded as value between [-0.5, 0.5]\n \"\"\"\n\n def __call__(self, index: pd.DatetimeIndex) -> np.ndarray:\n if self.normalized:\n return index.weekofyear / 51.0 - 0.5\n else:\n return index.weekofyear.map(float)\n\n\ndef time_features_from_frequency_str(freq_str: str) -> List[TimeFeature]:\n \"\"\"\n Returns a list of time features that will be appropriate for the given frequency string.\n\n Parameters\n ----------\n\n freq_str\n Frequency string of the form [multiple][granularity] such as \"12H\", \"5min\", \"1D\" etc.\n\n \"\"\"\n\n features_by_offsets = {\n offsets.YearOffset: [],\n offsets.MonthOffset: [MonthOfYear],\n offsets.Week: [DayOfMonth, WeekOfYear],\n offsets.Day: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.BusinessDay: [DayOfWeek, DayOfMonth, DayOfYear],\n offsets.Hour: [HourOfDay, DayOfWeek, DayOfMonth, DayOfYear],\n offsets.Minute: [\n MinuteOfHour,\n HourOfDay,\n DayOfWeek,\n DayOfMonth,\n DayOfYear,\n ],\n }\n\n offset = to_offset(freq_str)\n\n for offset_type, feature_classes in features_by_offsets.items():\n if isinstance(offset, offset_type):\n return [cls() for cls in feature_classes]\n\n supported_freq_msg = f\"\"\"\n Unsupported frequency {freq_str}\n\n The following frequencies are supported:\n\n Y - yearly\n alias: A\n M - monthly\n W - weekly\n D - daily\n B - business days\n H - hourly\n T - minutely\n alias: min\n \"\"\"\n raise RuntimeError(supported_freq_msg)\n", "path": "src/gluonts/time_feature/_base.py"}]}
| 2,209 | 150 |
gh_patches_debug_12149
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-813
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add endpoint for mindsdb version
Add HTTP route to get a version of mindsdb: /util/version/
That should return as mindsb version in JSON view:
```
{
"mindsdb": "2.11.2"
}
```
The new endpoint needs to be added in [Utils](https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/api/http/namespaces/util.py).
</issue>
<code>
[start of mindsdb/api/http/namespaces/util.py]
1 from flask import request
2 from flask_restx import Resource, abort
3
4 from mindsdb.api.http.namespaces.configs.util import ns_conf
5
6
7 @ns_conf.route('/ping')
8 class Ping(Resource):
9 @ns_conf.doc('get_ping')
10 def get(self):
11 '''Checks server avaliable'''
12 return {'status': 'ok'}
13
14
15 @ns_conf.route('/shutdown')
16 class Shutdown(Resource):
17 @ns_conf.doc('get_shutdown')
18 def get(self):
19 '''Shutdown server'''
20 if request.host.startswith('127.0.0.1') or request.host.startswith('localhost'):
21 func = request.environ.get('werkzeug.server.shutdown')
22 if func is None:
23 return '', 500
24 func()
25 return '', 200
26 abort(403, "")
27
[end of mindsdb/api/http/namespaces/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mindsdb/api/http/namespaces/util.py b/mindsdb/api/http/namespaces/util.py
--- a/mindsdb/api/http/namespaces/util.py
+++ b/mindsdb/api/http/namespaces/util.py
@@ -2,7 +2,7 @@
from flask_restx import Resource, abort
from mindsdb.api.http.namespaces.configs.util import ns_conf
-
+from mindsdb import __about__
@ns_conf.route('/ping')
class Ping(Resource):
@@ -24,3 +24,12 @@
func()
return '', 200
abort(403, "")
+
+
+@ns_conf.route('/util/version')
+class Version(Resource):
+ @ns_conf.doc('get_endpoint')
+ def get(self):
+ '''Check endpoint'''
+ return {'mindsdb': "{__about__.__version__}"}
+
|
{"golden_diff": "diff --git a/mindsdb/api/http/namespaces/util.py b/mindsdb/api/http/namespaces/util.py\n--- a/mindsdb/api/http/namespaces/util.py\n+++ b/mindsdb/api/http/namespaces/util.py\n@@ -2,7 +2,7 @@\n from flask_restx import Resource, abort\n \n from mindsdb.api.http.namespaces.configs.util import ns_conf\n-\n+from mindsdb import __about__\n \n @ns_conf.route('/ping')\n class Ping(Resource):\n@@ -24,3 +24,12 @@\n func()\n return '', 200\n abort(403, \"\")\n+\n+ \n+@ns_conf.route('/util/version')\n+class Version(Resource):\n+ @ns_conf.doc('get_endpoint')\n+ def get(self):\n+ '''Check endpoint'''\n+ return {'mindsdb': \"{__about__.__version__}\"}\n+\n", "issue": "Add endpoint for mindsdb version\nAdd HTTP route to get a version of mindsdb: /util/version/\r\nThat should return as mindsb version in JSON view:\r\n```\r\n{\r\n \"mindsdb\": \"2.11.2\"\r\n}\r\n```\r\nThe new endpoint needs to be added in [Utils](https://github.com/mindsdb/mindsdb/blob/staging/mindsdb/api/http/namespaces/util.py).\n", "before_files": [{"content": "from flask import request\nfrom flask_restx import Resource, abort\n\nfrom mindsdb.api.http.namespaces.configs.util import ns_conf\n\n\n@ns_conf.route('/ping')\nclass Ping(Resource):\n @ns_conf.doc('get_ping')\n def get(self):\n '''Checks server avaliable'''\n return {'status': 'ok'}\n\n\n@ns_conf.route('/shutdown')\nclass Shutdown(Resource):\n @ns_conf.doc('get_shutdown')\n def get(self):\n '''Shutdown server'''\n if request.host.startswith('127.0.0.1') or request.host.startswith('localhost'):\n func = request.environ.get('werkzeug.server.shutdown')\n if func is None:\n return '', 500\n func()\n return '', 200\n abort(403, \"\")\n", "path": "mindsdb/api/http/namespaces/util.py"}]}
| 847 | 194 |
gh_patches_debug_38899
|
rasdani/github-patches
|
git_diff
|
kubeflow__pipelines-10550
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[sdk] Missing optional parameter to v2 `use_config_map_as_volume` and `use_secret_as_volume`
In kfp v1 the config map or secret can be marked as optional when used as a volume source, as shown in the example below.
This capability is missing in the recent added `use_config_map_as_volume` and `use_secret_as_volume` v2 sdk functions. (https://github.com/kubeflow/pipelines/pull/10400, https://github.com/kubeflow/pipelines/pull/10483)
```bash
vol = k8s_client.V1Volume(
name='dummy',
config_map=k8s_client.V1ConfigMapVolumeSource(name='name', optional=True),
)
component.add_pvolumes({mountPoint: vol})
vol = k8s_client.V1Volume(
name='dummy',
secret=k8s_client.V1SecretVolumeSource(secret_name='name', optional=False),
)
component.add_pvolumes({mountPoint: vol})
```
What is the use case or pain point?
Making the secret or config map an optional resource allows the KFP component to function without failing even if those resources are not present.
</issue>
<code>
[start of kubernetes_platform/python/kfp/kubernetes/secret.py]
1 # Copyright 2023 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Dict
16
17 from google.protobuf import json_format
18 from kfp.dsl import PipelineTask
19 from kfp.kubernetes import common
20 from kfp.kubernetes import kubernetes_executor_config_pb2 as pb
21
22
23 def use_secret_as_env(
24 task: PipelineTask,
25 secret_name: str,
26 secret_key_to_env: Dict[str, str],
27 ) -> PipelineTask:
28 """Use a Kubernetes Secret as an environment variable as described by the `Kubernetes documentation
29 https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-environment-variables `_.
30
31 Args:
32 task: Pipeline task.
33 secret_name: Name of the Secret.
34 secret_key_to_env: Dictionary of Secret data key to environment variable name. For example, ``{'password': 'PASSWORD'}`` sets the data of the Secret's password field to the environment variable ``PASSWORD``.
35
36 Returns:
37 Task object with updated secret configuration.
38 """
39
40 msg = common.get_existing_kubernetes_config_as_message(task)
41
42 key_to_env = [
43 pb.SecretAsEnv.SecretKeyToEnvMap(
44 secret_key=secret_key,
45 env_var=env_var,
46 ) for secret_key, env_var in secret_key_to_env.items()
47 ]
48 secret_as_env = pb.SecretAsEnv(
49 secret_name=secret_name,
50 key_to_env=key_to_env,
51 )
52
53 msg.secret_as_env.append(secret_as_env)
54
55 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
56
57 return task
58
59
60 def use_secret_as_volume(
61 task: PipelineTask,
62 secret_name: str,
63 mount_path: str,
64 ) -> PipelineTask:
65 """Use a Kubernetes Secret by mounting its data to the task's container as
66 described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.
67
68 Args:
69 task: Pipeline task.
70 secret_name: Name of the Secret.
71 mount_path: Path to which to mount the Secret data.
72
73 Returns:
74 Task object with updated secret configuration.
75 """
76
77 msg = common.get_existing_kubernetes_config_as_message(task)
78
79 secret_as_vol = pb.SecretAsVolume(
80 secret_name=secret_name,
81 mount_path=mount_path,
82 )
83
84 msg.secret_as_volume.append(secret_as_vol)
85
86 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
87
88 return task
89
[end of kubernetes_platform/python/kfp/kubernetes/secret.py]
[start of kubernetes_platform/python/kfp/kubernetes/config_map.py]
1 # Copyright 2024 The Kubeflow Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Dict
16
17 from google.protobuf import json_format
18 from kfp.dsl import PipelineTask
19 from kfp.kubernetes import common
20 from kfp.kubernetes import kubernetes_executor_config_pb2 as pb
21
22
23 def use_config_map_as_env(
24 task: PipelineTask,
25 config_map_name: str,
26 config_map_key_to_env: Dict[str, str],
27 ) -> PipelineTask:
28 """Use a Kubernetes ConfigMap as an environment variable as described by the `Kubernetes documentation
29 https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#define-container-environment-variables-using-configmap-data` _.
30
31 Args:
32 task: Pipeline task.
33 config_map_name: Name of the ConfigMap.
34 config_map_key_to_env: Dictionary of ConfigMap key to environment variable name. For example, ``{'foo': 'FOO'}`` sets the value of the ConfigMap's foo field to the environment variable ``FOO``.
35
36 Returns:
37 Task object with updated ConfigMap configuration.
38 """
39
40 msg = common.get_existing_kubernetes_config_as_message(task)
41
42 key_to_env = [
43 pb.ConfigMapAsEnv.ConfigMapKeyToEnvMap(
44 config_map_key=config_map_key,
45 env_var=env_var,
46 ) for config_map_key, env_var in config_map_key_to_env.items()
47 ]
48 config_map_as_env = pb.ConfigMapAsEnv(
49 config_map_name=config_map_name,
50 key_to_env=key_to_env,
51 )
52
53 msg.config_map_as_env.append(config_map_as_env)
54
55 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
56
57 return task
58
59
60 def use_config_map_as_volume(
61 task: PipelineTask,
62 config_map_name: str,
63 mount_path: str,
64 ) -> PipelineTask:
65 """Use a Kubernetes ConfigMap by mounting its data to the task's container as
66 described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.
67
68 Args:
69 task: Pipeline task.
70 config_map_name: Name of the ConfigMap.
71 mount_path: Path to which to mount the ConfigMap data.
72
73 Returns:
74 Task object with updated ConfigMap configuration.
75 """
76
77 msg = common.get_existing_kubernetes_config_as_message(task)
78
79 config_map_as_vol = pb.ConfigMapAsVolume(
80 config_map_name=config_map_name,
81 mount_path=mount_path,
82 )
83 msg.config_map_as_volume.append(config_map_as_vol)
84
85 task.platform_config['kubernetes'] = json_format.MessageToDict(msg)
86
87 return task
88
[end of kubernetes_platform/python/kfp/kubernetes/config_map.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kubernetes_platform/python/kfp/kubernetes/config_map.py b/kubernetes_platform/python/kfp/kubernetes/config_map.py
--- a/kubernetes_platform/python/kfp/kubernetes/config_map.py
+++ b/kubernetes_platform/python/kfp/kubernetes/config_map.py
@@ -61,6 +61,7 @@
task: PipelineTask,
config_map_name: str,
mount_path: str,
+ optional: bool = False,
) -> PipelineTask:
"""Use a Kubernetes ConfigMap by mounting its data to the task's container as
described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.
@@ -69,6 +70,7 @@
task: Pipeline task.
config_map_name: Name of the ConfigMap.
mount_path: Path to which to mount the ConfigMap data.
+ optional: Optional field specifying whether the ConfigMap must be defined.
Returns:
Task object with updated ConfigMap configuration.
@@ -79,6 +81,7 @@
config_map_as_vol = pb.ConfigMapAsVolume(
config_map_name=config_map_name,
mount_path=mount_path,
+ optional=optional,
)
msg.config_map_as_volume.append(config_map_as_vol)
diff --git a/kubernetes_platform/python/kfp/kubernetes/secret.py b/kubernetes_platform/python/kfp/kubernetes/secret.py
--- a/kubernetes_platform/python/kfp/kubernetes/secret.py
+++ b/kubernetes_platform/python/kfp/kubernetes/secret.py
@@ -61,6 +61,7 @@
task: PipelineTask,
secret_name: str,
mount_path: str,
+ optional: bool = False,
) -> PipelineTask:
"""Use a Kubernetes Secret by mounting its data to the task's container as
described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.
@@ -69,6 +70,7 @@
task: Pipeline task.
secret_name: Name of the Secret.
mount_path: Path to which to mount the Secret data.
+ optional: Optional field specifying whether the Secret must be defined.
Returns:
Task object with updated secret configuration.
@@ -79,6 +81,7 @@
secret_as_vol = pb.SecretAsVolume(
secret_name=secret_name,
mount_path=mount_path,
+ optional=optional,
)
msg.secret_as_volume.append(secret_as_vol)
|
{"golden_diff": "diff --git a/kubernetes_platform/python/kfp/kubernetes/config_map.py b/kubernetes_platform/python/kfp/kubernetes/config_map.py\n--- a/kubernetes_platform/python/kfp/kubernetes/config_map.py\n+++ b/kubernetes_platform/python/kfp/kubernetes/config_map.py\n@@ -61,6 +61,7 @@\n task: PipelineTask,\n config_map_name: str,\n mount_path: str,\n+ optional: bool = False,\n ) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.\n@@ -69,6 +70,7 @@\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n mount_path: Path to which to mount the ConfigMap data.\n+ optional: Optional field specifying whether the ConfigMap must be defined.\n \n Returns:\n Task object with updated ConfigMap configuration.\n@@ -79,6 +81,7 @@\n config_map_as_vol = pb.ConfigMapAsVolume(\n config_map_name=config_map_name,\n mount_path=mount_path,\n+ optional=optional,\n )\n msg.config_map_as_volume.append(config_map_as_vol)\n \ndiff --git a/kubernetes_platform/python/kfp/kubernetes/secret.py b/kubernetes_platform/python/kfp/kubernetes/secret.py\n--- a/kubernetes_platform/python/kfp/kubernetes/secret.py\n+++ b/kubernetes_platform/python/kfp/kubernetes/secret.py\n@@ -61,6 +61,7 @@\n task: PipelineTask,\n secret_name: str,\n mount_path: str,\n+ optional: bool = False,\n ) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.\n@@ -69,6 +70,7 @@\n task: Pipeline task.\n secret_name: Name of the Secret.\n mount_path: Path to which to mount the Secret data.\n+ optional: Optional field specifying whether the Secret must be defined.\n \n Returns:\n Task object with updated secret configuration.\n@@ -79,6 +81,7 @@\n secret_as_vol = pb.SecretAsVolume(\n secret_name=secret_name,\n mount_path=mount_path,\n+ optional=optional,\n )\n \n msg.secret_as_volume.append(secret_as_vol)\n", "issue": "[sdk] Missing optional parameter to v2 `use_config_map_as_volume` and `use_secret_as_volume` \nIn kfp v1 the config map or secret can be marked as optional when used as a volume source, as shown in the example below.\r\n\r\nThis capability is missing in the recent added `use_config_map_as_volume` and `use_secret_as_volume` v2 sdk functions. (https://github.com/kubeflow/pipelines/pull/10400, https://github.com/kubeflow/pipelines/pull/10483)\r\n\r\n```bash\r\nvol = k8s_client.V1Volume(\r\n name='dummy',\r\n config_map=k8s_client.V1ConfigMapVolumeSource(name='name', optional=True),\r\n )\r\n component.add_pvolumes({mountPoint: vol})\r\n\r\n\r\nvol = k8s_client.V1Volume(\r\n name='dummy',\r\n secret=k8s_client.V1SecretVolumeSource(secret_name='name', optional=False),\r\n )\r\n component.add_pvolumes({mountPoint: vol})\r\n\r\n```\r\n\r\n\r\nWhat is the use case or pain point?\r\n\r\nMaking the secret or config map an optional resource allows the KFP component to function without failing even if those resources are not present.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2023 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Dict\n\nfrom google.protobuf import json_format\nfrom kfp.dsl import PipelineTask\nfrom kfp.kubernetes import common\nfrom kfp.kubernetes import kubernetes_executor_config_pb2 as pb\n\n\ndef use_secret_as_env(\n task: PipelineTask,\n secret_name: str,\n secret_key_to_env: Dict[str, str],\n) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret as an environment variable as described by the `Kubernetes documentation\n https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-environment-variables `_.\n\n Args:\n task: Pipeline task.\n secret_name: Name of the Secret.\n secret_key_to_env: Dictionary of Secret data key to environment variable name. For example, ``{'password': 'PASSWORD'}`` sets the data of the Secret's password field to the environment variable ``PASSWORD``.\n\n Returns:\n Task object with updated secret configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n key_to_env = [\n pb.SecretAsEnv.SecretKeyToEnvMap(\n secret_key=secret_key,\n env_var=env_var,\n ) for secret_key, env_var in secret_key_to_env.items()\n ]\n secret_as_env = pb.SecretAsEnv(\n secret_name=secret_name,\n key_to_env=key_to_env,\n )\n\n msg.secret_as_env.append(secret_as_env)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n\n\ndef use_secret_as_volume(\n task: PipelineTask,\n secret_name: str,\n mount_path: str,\n) -> PipelineTask:\n \"\"\"Use a Kubernetes Secret by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/concepts/configuration/secret/#using-secrets-as-files-from-a-pod>`_.\n\n Args:\n task: Pipeline task.\n secret_name: Name of the Secret.\n mount_path: Path to which to mount the Secret data.\n\n Returns:\n Task object with updated secret configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n secret_as_vol = pb.SecretAsVolume(\n secret_name=secret_name,\n mount_path=mount_path,\n )\n\n msg.secret_as_volume.append(secret_as_vol)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n", "path": "kubernetes_platform/python/kfp/kubernetes/secret.py"}, {"content": "# Copyright 2024 The Kubeflow Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Dict\n\nfrom google.protobuf import json_format\nfrom kfp.dsl import PipelineTask\nfrom kfp.kubernetes import common\nfrom kfp.kubernetes import kubernetes_executor_config_pb2 as pb\n\n\ndef use_config_map_as_env(\n task: PipelineTask,\n config_map_name: str,\n config_map_key_to_env: Dict[str, str],\n) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap as an environment variable as described by the `Kubernetes documentation\n https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#define-container-environment-variables-using-configmap-data` _.\n\n Args:\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n config_map_key_to_env: Dictionary of ConfigMap key to environment variable name. For example, ``{'foo': 'FOO'}`` sets the value of the ConfigMap's foo field to the environment variable ``FOO``.\n\n Returns:\n Task object with updated ConfigMap configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n key_to_env = [\n pb.ConfigMapAsEnv.ConfigMapKeyToEnvMap(\n config_map_key=config_map_key,\n env_var=env_var,\n ) for config_map_key, env_var in config_map_key_to_env.items()\n ]\n config_map_as_env = pb.ConfigMapAsEnv(\n config_map_name=config_map_name,\n key_to_env=key_to_env,\n )\n\n msg.config_map_as_env.append(config_map_as_env)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n\n\ndef use_config_map_as_volume(\n task: PipelineTask,\n config_map_name: str,\n mount_path: str,\n) -> PipelineTask:\n \"\"\"Use a Kubernetes ConfigMap by mounting its data to the task's container as\n described by the `Kubernetes documentation <https://kubernetes.io/docs/tasks/configure-pod-container/configure-pod-configmap/#add-configmap-data-to-a-volume>`_.\n\n Args:\n task: Pipeline task.\n config_map_name: Name of the ConfigMap.\n mount_path: Path to which to mount the ConfigMap data.\n\n Returns:\n Task object with updated ConfigMap configuration.\n \"\"\"\n\n msg = common.get_existing_kubernetes_config_as_message(task)\n\n config_map_as_vol = pb.ConfigMapAsVolume(\n config_map_name=config_map_name,\n mount_path=mount_path,\n )\n msg.config_map_as_volume.append(config_map_as_vol)\n\n task.platform_config['kubernetes'] = json_format.MessageToDict(msg)\n\n return task\n", "path": "kubernetes_platform/python/kfp/kubernetes/config_map.py"}]}
| 2,531 | 541 |
gh_patches_debug_11524
|
rasdani/github-patches
|
git_diff
|
Cog-Creators__Red-DiscordBot-1374
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[V3/Config] Clearing a registered data group when no data has been set results in a KeyError.
Please be sure to read through other issues as well to make sure what you are suggesting/reporting has not already
been suggested/reported
### Type:
- [ ] Suggestion
- [x] Bug
### Brief description of the problem
When attempting to use methods such as `.clear_all_members` and `.clear_all_globals`, when no data has been set, will result in a KeyError being raised.
### Expected behavior
Silently passes
### Actual behavior
Key Error is raised.
### Steps to reproduce
1. register some data
2. try to clear all data from that scope
3. Key error is raised
4. You cry
</issue>
<code>
[start of redbot/core/drivers/red_json.py]
1 from pathlib import Path
2 from typing import Tuple
3
4 from ..json_io import JsonIO
5
6 from .red_base import BaseDriver
7
8 __all__ = ["JSON"]
9
10
11 class JSON(BaseDriver):
12 """
13 Subclass of :py:class:`.red_base.BaseDriver`.
14
15 .. py:attribute:: file_name
16
17 The name of the file in which to store JSON data.
18
19 .. py:attribute:: data_path
20
21 The path in which to store the file indicated by :py:attr:`file_name`.
22 """
23 def __init__(self, cog_name, *, data_path_override: Path=None,
24 file_name_override: str="settings.json"):
25 super().__init__(cog_name)
26 self.file_name = file_name_override
27 if data_path_override:
28 self.data_path = data_path_override
29 else:
30 self.data_path = Path.cwd() / 'cogs' / '.data' / self.cog_name
31
32 self.data_path.mkdir(parents=True, exist_ok=True)
33
34 self.data_path = self.data_path / self.file_name
35
36 self.jsonIO = JsonIO(self.data_path)
37
38 try:
39 self.data = self.jsonIO._load_json()
40 except FileNotFoundError:
41 self.data = {}
42 self.jsonIO._save_json(self.data)
43
44 async def get(self, *identifiers: Tuple[str]):
45 partial = self.data
46 full_identifiers = (self.unique_cog_identifier, *identifiers)
47 for i in full_identifiers:
48 partial = partial[i]
49 return partial
50
51 async def set(self, *identifiers: str, value=None):
52 partial = self.data
53 full_identifiers = (self.unique_cog_identifier, *identifiers)
54 for i in full_identifiers[:-1]:
55 if i not in partial:
56 partial[i] = {}
57 partial = partial[i]
58
59 partial[full_identifiers[-1]] = value
60 await self.jsonIO._threadsafe_save_json(self.data)
61
62 async def clear(self, *identifiers: str):
63 partial = self.data
64 full_identifiers = (self.unique_cog_identifier, *identifiers)
65 for i in full_identifiers[:-1]:
66 if i not in partial:
67 break
68 partial = partial[i]
69 else:
70 del partial[identifiers[-1]]
71 await self.jsonIO._threadsafe_save_json(self.data)
72
[end of redbot/core/drivers/red_json.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redbot/core/drivers/red_json.py b/redbot/core/drivers/red_json.py
--- a/redbot/core/drivers/red_json.py
+++ b/redbot/core/drivers/red_json.py
@@ -62,10 +62,11 @@
async def clear(self, *identifiers: str):
partial = self.data
full_identifiers = (self.unique_cog_identifier, *identifiers)
- for i in full_identifiers[:-1]:
- if i not in partial:
- break
- partial = partial[i]
- else:
+ try:
+ for i in full_identifiers[:-1]:
+ partial = partial[i]
del partial[identifiers[-1]]
- await self.jsonIO._threadsafe_save_json(self.data)
+ except KeyError:
+ pass
+ else:
+ await self.jsonIO._threadsafe_save_json(self.data)
|
{"golden_diff": "diff --git a/redbot/core/drivers/red_json.py b/redbot/core/drivers/red_json.py\n--- a/redbot/core/drivers/red_json.py\n+++ b/redbot/core/drivers/red_json.py\n@@ -62,10 +62,11 @@\n async def clear(self, *identifiers: str):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n- for i in full_identifiers[:-1]:\n- if i not in partial:\n- break\n- partial = partial[i]\n- else:\n+ try:\n+ for i in full_identifiers[:-1]:\n+ partial = partial[i]\n del partial[identifiers[-1]]\n- await self.jsonIO._threadsafe_save_json(self.data)\n+ except KeyError:\n+ pass\n+ else:\n+ await self.jsonIO._threadsafe_save_json(self.data)\n", "issue": "[V3/Config] Clearing a registered data group when no data has been set results in a KeyError.\nPlease be sure to read through other issues as well to make sure what you are suggesting/reporting has not already\r\nbeen suggested/reported\r\n\r\n### Type:\r\n\r\n- [ ] Suggestion\r\n- [x] Bug\r\n\r\n### Brief description of the problem\r\nWhen attempting to use methods such as `.clear_all_members` and `.clear_all_globals`, when no data has been set, will result in a KeyError being raised.\r\n### Expected behavior\r\nSilently passes\r\n### Actual behavior\r\nKey Error is raised.\r\n### Steps to reproduce\r\n\r\n1. register some data\r\n2. try to clear all data from that scope\r\n3. Key error is raised\r\n4. You cry\r\n\n", "before_files": [{"content": "from pathlib import Path\nfrom typing import Tuple\n\nfrom ..json_io import JsonIO\n\nfrom .red_base import BaseDriver\n\n__all__ = [\"JSON\"]\n\n\nclass JSON(BaseDriver):\n \"\"\"\n Subclass of :py:class:`.red_base.BaseDriver`.\n\n .. py:attribute:: file_name\n\n The name of the file in which to store JSON data.\n\n .. py:attribute:: data_path\n\n The path in which to store the file indicated by :py:attr:`file_name`.\n \"\"\"\n def __init__(self, cog_name, *, data_path_override: Path=None,\n file_name_override: str=\"settings.json\"):\n super().__init__(cog_name)\n self.file_name = file_name_override\n if data_path_override:\n self.data_path = data_path_override\n else:\n self.data_path = Path.cwd() / 'cogs' / '.data' / self.cog_name\n\n self.data_path.mkdir(parents=True, exist_ok=True)\n\n self.data_path = self.data_path / self.file_name\n\n self.jsonIO = JsonIO(self.data_path)\n\n try:\n self.data = self.jsonIO._load_json()\n except FileNotFoundError:\n self.data = {}\n self.jsonIO._save_json(self.data)\n\n async def get(self, *identifiers: Tuple[str]):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers:\n partial = partial[i]\n return partial\n\n async def set(self, *identifiers: str, value=None):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers[:-1]:\n if i not in partial:\n partial[i] = {}\n partial = partial[i]\n\n partial[full_identifiers[-1]] = value\n await self.jsonIO._threadsafe_save_json(self.data)\n\n async def clear(self, *identifiers: str):\n partial = self.data\n full_identifiers = (self.unique_cog_identifier, *identifiers)\n for i in full_identifiers[:-1]:\n if i not in partial:\n break\n partial = partial[i]\n else:\n del partial[identifiers[-1]]\n await self.jsonIO._threadsafe_save_json(self.data)\n", "path": "redbot/core/drivers/red_json.py"}]}
| 1,342 | 194 |
gh_patches_debug_31804
|
rasdani/github-patches
|
git_diff
|
opensearch-project__opensearch-build-3161
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Resolving RPM/DEB IntegTest having config modify issues.
Hi,
There are issues modifying the config yml files in RPM/DEB if you dont use sudo/root to run test.sh.
However, the issue being that certain OS process and integTest cannot run on root, thus catch 22.
This issue would be resolved if we assume the current running user of test.sh has sudo permission, while still able to change settings without using root.
Thanks.
------
Even when you have everything on root seems like integTest class is still asking the gradle run to happen on non-root:
```
» ↓ errors and warnings from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log ↓
» ERROR][o.o.b.OpenSearchUncaughtExceptionHandler] [integTest-0] uncaught exception in thread [main]
» org.opensearch.bootstrap.StartupException: java.lang.RuntimeException: can not run opensearch as root
» at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:184) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.execute(OpenSearch.java:171) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:104) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.cli.Command.mainWithoutErrorHandling(Command.java:138) ~[opensearch-cli-2.5.0.jar:2.5.0]
» at org.opensearch.cli.Command.main(Command.java:101) ~[opensearch-cli-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:137) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:103) ~[opensearch-2.5.0.jar:2.5.0]
» Caused by: java.lang.RuntimeException: can not run opensearch as root
» at org.opensearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:124) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.Bootstrap.setup(Bootstrap.java:191) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.Bootstrap.init(Bootstrap.java:404) ~[opensearch-2.5.0.jar:2.5.0]
» at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:180) ~[opensearch-2.5.0.jar:2.5.0]
» ... 6 more
» ↓ last 40 non error or warning messages from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log ↓
» [2023-01-30T20:10:26.670011235Z] [BUILD] Configuring custom cluster specific distro directory: /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE
» [2023-01-30T20:10:26.710573952Z] [BUILD] Copying additional config files from distro [/tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/log4j2.properties, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options.d, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/opensearch.yml, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options]
» [2023-01-30T20:10:26.711812308Z] [BUILD] installing 1 plugins in a single transaction
» [2023-01-30T20:10:28.341404943Z] [BUILD] installed plugins
» [2023-01-30T20:10:28.341674400Z] [BUILD] Creating opensearch keystore with password set to []
» [2023-01-30T20:10:29.386451250Z] [BUILD] Starting OpenSearch process
» [2023-01-30T20:10:31.909907707Z] [BUILD] Stopping node
```
------
Part of #2994.
</issue>
<code>
[start of src/system/process.py]
1 # Copyright OpenSearch Contributors
2 # SPDX-License-Identifier: Apache-2.0
3 #
4 # The OpenSearch Contributors require contributions made to
5 # this file be licensed under the Apache-2.0 license or a
6 # compatible open source license.
7 import logging
8 import os
9 import subprocess
10 import tempfile
11 from typing import Any
12
13 import psutil
14
15
16 class Process:
17 def __init__(self) -> None:
18 self.process: subprocess.Popen[bytes] = None
19 self.stdout: Any = None
20 self.stderr: Any = None
21 self.__stdout_data__: str = None
22 self.__stderr_data__: str = None
23
24 def start(self, command: str, cwd: str) -> None:
25 if self.started:
26 raise ProcessStartedError(self.pid)
27
28 self.stdout = tempfile.NamedTemporaryFile(mode="r+", delete=False)
29 self.stderr = tempfile.NamedTemporaryFile(mode="r+", delete=False)
30
31 self.process = subprocess.Popen(
32 command,
33 cwd=cwd,
34 shell=True,
35 stdout=self.stdout,
36 stderr=self.stderr,
37 )
38
39 def terminate(self) -> int:
40 if not self.started:
41 raise ProcessNotStartedError()
42
43 parent = psutil.Process(self.process.pid)
44 logging.debug("Checking for child processes")
45 child_processes = parent.children(recursive=True)
46 for child in child_processes:
47 logging.debug(f"Found child process with pid {child.pid}")
48 if child.pid != self.process.pid:
49 logging.debug(f"Sending SIGKILL to {child.pid} ")
50 child.kill()
51 logging.info(f"Sending SIGKILL to PID {self.process.pid}")
52
53 self.process.kill()
54
55 logging.info(f"Process killed with exit code {self.process.returncode}")
56
57 if self.stdout:
58 self.__stdout_data__ = open(self.stdout.name, 'r').read()
59 self.stdout.close()
60 os.remove(self.stdout.name)
61 self.stdout = None
62
63 if self.stderr:
64 self.__stderr_data__ = open(self.stderr.name, 'r').read()
65 self.stderr.close()
66 os.remove(self.stderr.name)
67 self.stderr = None
68
69 self.return_code = self.process.returncode
70 self.process = None
71
72 return self.return_code
73
74 @property
75 def started(self) -> bool:
76 return True if self.process else False
77
78 @property
79 def pid(self) -> int:
80 return self.process.pid if self.started else None
81
82 @property
83 def stdout_data(self) -> Any:
84 return self.stdout.read() if self.stdout else self.__stdout_data__
85
86 @property
87 def stderr_data(self) -> Any:
88 return self.stderr.read() if self.stderr else self.__stderr_data__
89
90
91 class ProcessStartedError(Exception):
92 """
93 Indicates that process already started.
94 """
95
96 def __init__(self, pid: int) -> None:
97 self.pid = pid
98 super().__init__(f"Process already started, pid: {pid}")
99
100
101 class ProcessNotStartedError(Exception):
102 """
103 Indicates that process has not started.
104 """
105
106 def __init__(self) -> None:
107 super().__init__("Process has not started")
108
[end of src/system/process.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/system/process.py b/src/system/process.py
--- a/src/system/process.py
+++ b/src/system/process.py
@@ -16,18 +16,21 @@
class Process:
def __init__(self) -> None:
self.process: subprocess.Popen[bytes] = None
+ self.require_sudo: bool = False
self.stdout: Any = None
self.stderr: Any = None
self.__stdout_data__: str = None
self.__stderr_data__: str = None
- def start(self, command: str, cwd: str) -> None:
+ def start(self, command: str, cwd: str, require_sudo: bool = False) -> None:
if self.started:
raise ProcessStartedError(self.pid)
self.stdout = tempfile.NamedTemporaryFile(mode="r+", delete=False)
self.stderr = tempfile.NamedTemporaryFile(mode="r+", delete=False)
+ self.require_sudo = require_sudo
+
self.process = subprocess.Popen(
command,
cwd=cwd,
@@ -47,10 +50,10 @@
logging.debug(f"Found child process with pid {child.pid}")
if child.pid != self.process.pid:
logging.debug(f"Sending SIGKILL to {child.pid} ")
- child.kill()
+ child.kill() if self.require_sudo is False else subprocess.check_call(f"sudo kill -9 {child.pid}", shell=True)
logging.info(f"Sending SIGKILL to PID {self.process.pid}")
- self.process.kill()
+ self.process.kill() if self.require_sudo is False else subprocess.check_call(f"sudo kill -9 {self.process.pid}", shell=True)
logging.info(f"Process killed with exit code {self.process.returncode}")
|
{"golden_diff": "diff --git a/src/system/process.py b/src/system/process.py\n--- a/src/system/process.py\n+++ b/src/system/process.py\n@@ -16,18 +16,21 @@\n class Process:\n def __init__(self) -> None:\n self.process: subprocess.Popen[bytes] = None\n+ self.require_sudo: bool = False\n self.stdout: Any = None\n self.stderr: Any = None\n self.__stdout_data__: str = None\n self.__stderr_data__: str = None\n \n- def start(self, command: str, cwd: str) -> None:\n+ def start(self, command: str, cwd: str, require_sudo: bool = False) -> None:\n if self.started:\n raise ProcessStartedError(self.pid)\n \n self.stdout = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n self.stderr = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n \n+ self.require_sudo = require_sudo\n+\n self.process = subprocess.Popen(\n command,\n cwd=cwd,\n@@ -47,10 +50,10 @@\n logging.debug(f\"Found child process with pid {child.pid}\")\n if child.pid != self.process.pid:\n logging.debug(f\"Sending SIGKILL to {child.pid} \")\n- child.kill()\n+ child.kill() if self.require_sudo is False else subprocess.check_call(f\"sudo kill -9 {child.pid}\", shell=True)\n logging.info(f\"Sending SIGKILL to PID {self.process.pid}\")\n \n- self.process.kill()\n+ self.process.kill() if self.require_sudo is False else subprocess.check_call(f\"sudo kill -9 {self.process.pid}\", shell=True)\n \n logging.info(f\"Process killed with exit code {self.process.returncode}\")\n", "issue": "Resolving RPM/DEB IntegTest having config modify issues.\nHi,\r\n\r\nThere are issues modifying the config yml files in RPM/DEB if you dont use sudo/root to run test.sh.\r\nHowever, the issue being that certain OS process and integTest cannot run on root, thus catch 22.\r\n\r\nThis issue would be resolved if we assume the current running user of test.sh has sudo permission, while still able to change settings without using root.\r\n\r\nThanks.\r\n\r\n------\r\n\r\nEven when you have everything on root seems like integTest class is still asking the gradle run to happen on non-root:\r\n```\r\n\r\n\u00bb \u2193 errors and warnings from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log \u2193\r\n\u00bb ERROR][o.o.b.OpenSearchUncaughtExceptionHandler] [integTest-0] uncaught exception in thread [main]\r\n\u00bb org.opensearch.bootstrap.StartupException: java.lang.RuntimeException: can not run opensearch as root\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:184) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.execute(OpenSearch.java:171) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand.java:104) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.cli.Command.mainWithoutErrorHandling(Command.java:138) ~[opensearch-cli-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.cli.Command.main(Command.java:101) ~[opensearch-cli-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:137) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.main(OpenSearch.java:103) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb Caused by: java.lang.RuntimeException: can not run opensearch as root\r\n\u00bb at org.opensearch.bootstrap.Bootstrap.initializeNatives(Bootstrap.java:124) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.Bootstrap.setup(Bootstrap.java:191) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.Bootstrap.init(Bootstrap.java:404) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb at org.opensearch.bootstrap.OpenSearch.init(OpenSearch.java:180) ~[opensearch-2.5.0.jar:2.5.0]\r\n\u00bb ... 6 more\r\n\u00bb \u2193 last 40 non error or warning messages from /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/logs/opensearch.stdout.log \u2193\r\n\u00bb [2023-01-30T20:10:26.670011235Z] [BUILD] Configuring custom cluster specific distro directory: /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE\r\n\u00bb [2023-01-30T20:10:26.710573952Z] [BUILD] Copying additional config files from distro [/tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/log4j2.properties, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options.d, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/opensearch.yml, /tmp/tmp9niemi8p/geospatial/build/testclusters/integTest-0/distro/2.5.0-ARCHIVE/config/jvm.options]\r\n\u00bb [2023-01-30T20:10:26.711812308Z] [BUILD] installing 1 plugins in a single transaction\r\n\u00bb [2023-01-30T20:10:28.341404943Z] [BUILD] installed plugins\r\n\u00bb [2023-01-30T20:10:28.341674400Z] [BUILD] Creating opensearch keystore with password set to []\r\n\u00bb [2023-01-30T20:10:29.386451250Z] [BUILD] Starting OpenSearch process\r\n\u00bb [2023-01-30T20:10:31.909907707Z] [BUILD] Stopping node\r\n```\r\n\r\n------\r\n\r\nPart of #2994.\n", "before_files": [{"content": "# Copyright OpenSearch Contributors\n# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\nimport logging\nimport os\nimport subprocess\nimport tempfile\nfrom typing import Any\n\nimport psutil\n\n\nclass Process:\n def __init__(self) -> None:\n self.process: subprocess.Popen[bytes] = None\n self.stdout: Any = None\n self.stderr: Any = None\n self.__stdout_data__: str = None\n self.__stderr_data__: str = None\n\n def start(self, command: str, cwd: str) -> None:\n if self.started:\n raise ProcessStartedError(self.pid)\n\n self.stdout = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n self.stderr = tempfile.NamedTemporaryFile(mode=\"r+\", delete=False)\n\n self.process = subprocess.Popen(\n command,\n cwd=cwd,\n shell=True,\n stdout=self.stdout,\n stderr=self.stderr,\n )\n\n def terminate(self) -> int:\n if not self.started:\n raise ProcessNotStartedError()\n\n parent = psutil.Process(self.process.pid)\n logging.debug(\"Checking for child processes\")\n child_processes = parent.children(recursive=True)\n for child in child_processes:\n logging.debug(f\"Found child process with pid {child.pid}\")\n if child.pid != self.process.pid:\n logging.debug(f\"Sending SIGKILL to {child.pid} \")\n child.kill()\n logging.info(f\"Sending SIGKILL to PID {self.process.pid}\")\n\n self.process.kill()\n\n logging.info(f\"Process killed with exit code {self.process.returncode}\")\n\n if self.stdout:\n self.__stdout_data__ = open(self.stdout.name, 'r').read()\n self.stdout.close()\n os.remove(self.stdout.name)\n self.stdout = None\n\n if self.stderr:\n self.__stderr_data__ = open(self.stderr.name, 'r').read()\n self.stderr.close()\n os.remove(self.stderr.name)\n self.stderr = None\n\n self.return_code = self.process.returncode\n self.process = None\n\n return self.return_code\n\n @property\n def started(self) -> bool:\n return True if self.process else False\n\n @property\n def pid(self) -> int:\n return self.process.pid if self.started else None\n\n @property\n def stdout_data(self) -> Any:\n return self.stdout.read() if self.stdout else self.__stdout_data__\n\n @property\n def stderr_data(self) -> Any:\n return self.stderr.read() if self.stderr else self.__stderr_data__\n\n\nclass ProcessStartedError(Exception):\n \"\"\"\n Indicates that process already started.\n \"\"\"\n\n def __init__(self, pid: int) -> None:\n self.pid = pid\n super().__init__(f\"Process already started, pid: {pid}\")\n\n\nclass ProcessNotStartedError(Exception):\n \"\"\"\n Indicates that process has not started.\n \"\"\"\n\n def __init__(self) -> None:\n super().__init__(\"Process has not started\")\n", "path": "src/system/process.py"}]}
| 2,617 | 385 |
gh_patches_debug_5046
|
rasdani/github-patches
|
git_diff
|
ansible__ansible-modules-extras-204
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
rabbitmq_user fails when no password provided
Even though the `password` param is specified as optional, the `rabbitmq_user` module fails when it is not provided.
```
Stacktrace:
File "<stdin>", line 1595, in <module>
File "<stdin>", line 240, in main
File "<stdin>", line 165, in add
File "<stdin>", line 131, in _exec
File "<stdin>", line 1448, in run_command
File "/usr/lib/python2.7/posixpath.py", line 261, in expanduser
if not path.startswith('~'):
AttributeError: 'NoneType' object has no attribute 'startswith'
```
The bug is [right here](https://github.com/ansible/ansible-modules-extras/blob/a0df36c6ab257281cbaae00b8a4590200802f571/messaging/rabbitmq_user.py#L165). I might send a PR when I get the time to fork and test.
</issue>
<code>
[start of messaging/rabbitmq_user.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # (c) 2013, Chatham Financial <[email protected]>
5 #
6 # This file is part of Ansible
7 #
8 # Ansible is free software: you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation, either version 3 of the License, or
11 # (at your option) any later version.
12 #
13 # Ansible is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with Ansible. If not, see <http://www.gnu.org/licenses/>.
20
21 DOCUMENTATION = '''
22 ---
23 module: rabbitmq_user
24 short_description: Adds or removes users to RabbitMQ
25 description:
26 - Add or remove users to RabbitMQ and assign permissions
27 version_added: "1.1"
28 author: Chris Hoffman
29 options:
30 user:
31 description:
32 - Name of user to add
33 required: true
34 default: null
35 aliases: [username, name]
36 password:
37 description:
38 - Password of user to add.
39 - To change the password of an existing user, you must also specify
40 C(force=yes).
41 required: false
42 default: null
43 tags:
44 description:
45 - User tags specified as comma delimited
46 required: false
47 default: null
48 vhost:
49 description:
50 - vhost to apply access privileges.
51 required: false
52 default: /
53 node:
54 description:
55 - erlang node name of the rabbit we wish to configure
56 required: false
57 default: rabbit
58 version_added: "1.2"
59 configure_priv:
60 description:
61 - Regular expression to restrict configure actions on a resource
62 for the specified vhost.
63 - By default all actions are restricted.
64 required: false
65 default: ^$
66 write_priv:
67 description:
68 - Regular expression to restrict configure actions on a resource
69 for the specified vhost.
70 - By default all actions are restricted.
71 required: false
72 default: ^$
73 read_priv:
74 description:
75 - Regular expression to restrict configure actions on a resource
76 for the specified vhost.
77 - By default all actions are restricted.
78 required: false
79 default: ^$
80 force:
81 description:
82 - Deletes and recreates the user.
83 required: false
84 default: "no"
85 choices: [ "yes", "no" ]
86 state:
87 description:
88 - Specify if user is to be added or removed
89 required: false
90 default: present
91 choices: [present, absent]
92 '''
93
94 EXAMPLES = '''
95 # Add user to server and assign full access control
96 - rabbitmq_user: user=joe
97 password=changeme
98 vhost=/
99 configure_priv=.*
100 read_priv=.*
101 write_priv=.*
102 state=present
103 '''
104
105 class RabbitMqUser(object):
106 def __init__(self, module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node):
107 self.module = module
108 self.username = username
109 self.password = password
110 self.node = node
111 if tags is None:
112 self.tags = list()
113 else:
114 self.tags = tags.split(',')
115
116 permissions = dict(
117 vhost=vhost,
118 configure_priv=configure_priv,
119 write_priv=write_priv,
120 read_priv=read_priv
121 )
122 self.permissions = permissions
123
124 self._tags = None
125 self._permissions = None
126 self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)
127
128 def _exec(self, args, run_in_check_mode=False):
129 if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):
130 cmd = [self._rabbitmqctl, '-q', '-n', self.node]
131 rc, out, err = self.module.run_command(cmd + args, check_rc=True)
132 return out.splitlines()
133 return list()
134
135 def get(self):
136 users = self._exec(['list_users'], True)
137
138 for user_tag in users:
139 user, tags = user_tag.split('\t')
140
141 if user == self.username:
142 for c in ['[',']',' ']:
143 tags = tags.replace(c, '')
144
145 if tags != '':
146 self._tags = tags.split(',')
147 else:
148 self._tags = list()
149
150 self._permissions = self._get_permissions()
151 return True
152 return False
153
154 def _get_permissions(self):
155 perms_out = self._exec(['list_user_permissions', self.username], True)
156
157 for perm in perms_out:
158 vhost, configure_priv, write_priv, read_priv = perm.split('\t')
159 if vhost == self.permissions['vhost']:
160 return dict(vhost=vhost, configure_priv=configure_priv, write_priv=write_priv, read_priv=read_priv)
161
162 return dict()
163
164 def add(self):
165 self._exec(['add_user', self.username, self.password])
166
167 def delete(self):
168 self._exec(['delete_user', self.username])
169
170 def set_tags(self):
171 self._exec(['set_user_tags', self.username] + self.tags)
172
173 def set_permissions(self):
174 cmd = ['set_permissions']
175 cmd.append('-p')
176 cmd.append(self.permissions['vhost'])
177 cmd.append(self.username)
178 cmd.append(self.permissions['configure_priv'])
179 cmd.append(self.permissions['write_priv'])
180 cmd.append(self.permissions['read_priv'])
181 self._exec(cmd)
182
183 def has_tags_modifications(self):
184 return set(self.tags) != set(self._tags)
185
186 def has_permissions_modifications(self):
187 return self._permissions != self.permissions
188
189 def main():
190 arg_spec = dict(
191 user=dict(required=True, aliases=['username', 'name']),
192 password=dict(default=None),
193 tags=dict(default=None),
194 vhost=dict(default='/'),
195 configure_priv=dict(default='^$'),
196 write_priv=dict(default='^$'),
197 read_priv=dict(default='^$'),
198 force=dict(default='no', type='bool'),
199 state=dict(default='present', choices=['present', 'absent']),
200 node=dict(default='rabbit')
201 )
202 module = AnsibleModule(
203 argument_spec=arg_spec,
204 supports_check_mode=True
205 )
206
207 username = module.params['user']
208 password = module.params['password']
209 tags = module.params['tags']
210 vhost = module.params['vhost']
211 configure_priv = module.params['configure_priv']
212 write_priv = module.params['write_priv']
213 read_priv = module.params['read_priv']
214 force = module.params['force']
215 state = module.params['state']
216 node = module.params['node']
217
218 rabbitmq_user = RabbitMqUser(module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node)
219
220 changed = False
221 if rabbitmq_user.get():
222 if state == 'absent':
223 rabbitmq_user.delete()
224 changed = True
225 else:
226 if force:
227 rabbitmq_user.delete()
228 rabbitmq_user.add()
229 rabbitmq_user.get()
230 changed = True
231
232 if rabbitmq_user.has_tags_modifications():
233 rabbitmq_user.set_tags()
234 changed = True
235
236 if rabbitmq_user.has_permissions_modifications():
237 rabbitmq_user.set_permissions()
238 changed = True
239 elif state == 'present':
240 rabbitmq_user.add()
241 rabbitmq_user.set_tags()
242 rabbitmq_user.set_permissions()
243 changed = True
244
245 module.exit_json(changed=changed, user=username, state=state)
246
247 # import module snippets
248 from ansible.module_utils.basic import *
249 main()
250
[end of messaging/rabbitmq_user.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/messaging/rabbitmq_user.py b/messaging/rabbitmq_user.py
--- a/messaging/rabbitmq_user.py
+++ b/messaging/rabbitmq_user.py
@@ -162,7 +162,11 @@
return dict()
def add(self):
- self._exec(['add_user', self.username, self.password])
+ if self.password is not None:
+ self._exec(['add_user', self.username, self.password])
+ else
+ self._exec(['add_user', self.username, ''])
+ self._exec(['clear_password', self.username])
def delete(self):
self._exec(['delete_user', self.username])
|
{"golden_diff": "diff --git a/messaging/rabbitmq_user.py b/messaging/rabbitmq_user.py\n--- a/messaging/rabbitmq_user.py\n+++ b/messaging/rabbitmq_user.py\n@@ -162,7 +162,11 @@\n return dict()\n \n def add(self):\n- self._exec(['add_user', self.username, self.password])\n+ if self.password is not None:\n+ self._exec(['add_user', self.username, self.password])\n+ else\n+ self._exec(['add_user', self.username, ''])\n+ self._exec(['clear_password', self.username])\n \n def delete(self):\n self._exec(['delete_user', self.username])\n", "issue": "rabbitmq_user fails when no password provided\nEven though the `password` param is specified as optional, the `rabbitmq_user` module fails when it is not provided.\n\n```\nStacktrace:\n File \"<stdin>\", line 1595, in <module>\n File \"<stdin>\", line 240, in main\n File \"<stdin>\", line 165, in add\n File \"<stdin>\", line 131, in _exec\n File \"<stdin>\", line 1448, in run_command\n File \"/usr/lib/python2.7/posixpath.py\", line 261, in expanduser\n if not path.startswith('~'):\nAttributeError: 'NoneType' object has no attribute 'startswith'\n```\n\nThe bug is [right here](https://github.com/ansible/ansible-modules-extras/blob/a0df36c6ab257281cbaae00b8a4590200802f571/messaging/rabbitmq_user.py#L165). I might send a PR when I get the time to fork and test.\n\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# (c) 2013, Chatham Financial <[email protected]>\n#\n# This file is part of Ansible\n#\n# Ansible is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# Ansible is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Ansible. If not, see <http://www.gnu.org/licenses/>.\n\nDOCUMENTATION = '''\n---\nmodule: rabbitmq_user\nshort_description: Adds or removes users to RabbitMQ\ndescription:\n - Add or remove users to RabbitMQ and assign permissions\nversion_added: \"1.1\"\nauthor: Chris Hoffman\noptions:\n user:\n description:\n - Name of user to add\n required: true\n default: null\n aliases: [username, name]\n password:\n description:\n - Password of user to add.\n - To change the password of an existing user, you must also specify\n C(force=yes).\n required: false\n default: null\n tags:\n description:\n - User tags specified as comma delimited\n required: false\n default: null\n vhost:\n description:\n - vhost to apply access privileges.\n required: false\n default: /\n node:\n description:\n - erlang node name of the rabbit we wish to configure\n required: false\n default: rabbit\n version_added: \"1.2\"\n configure_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n write_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n read_priv:\n description:\n - Regular expression to restrict configure actions on a resource\n for the specified vhost.\n - By default all actions are restricted.\n required: false\n default: ^$\n force:\n description:\n - Deletes and recreates the user.\n required: false\n default: \"no\"\n choices: [ \"yes\", \"no\" ]\n state:\n description:\n - Specify if user is to be added or removed\n required: false\n default: present\n choices: [present, absent]\n'''\n\nEXAMPLES = '''\n# Add user to server and assign full access control\n- rabbitmq_user: user=joe\n password=changeme\n vhost=/\n configure_priv=.*\n read_priv=.*\n write_priv=.*\n state=present\n'''\n\nclass RabbitMqUser(object):\n def __init__(self, module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node):\n self.module = module\n self.username = username\n self.password = password\n self.node = node\n if tags is None:\n self.tags = list()\n else:\n self.tags = tags.split(',')\n\n permissions = dict(\n vhost=vhost,\n configure_priv=configure_priv,\n write_priv=write_priv,\n read_priv=read_priv\n )\n self.permissions = permissions\n\n self._tags = None\n self._permissions = None\n self._rabbitmqctl = module.get_bin_path('rabbitmqctl', True)\n\n def _exec(self, args, run_in_check_mode=False):\n if not self.module.check_mode or (self.module.check_mode and run_in_check_mode):\n cmd = [self._rabbitmqctl, '-q', '-n', self.node]\n rc, out, err = self.module.run_command(cmd + args, check_rc=True)\n return out.splitlines()\n return list()\n\n def get(self):\n users = self._exec(['list_users'], True)\n\n for user_tag in users:\n user, tags = user_tag.split('\\t')\n\n if user == self.username:\n for c in ['[',']',' ']:\n tags = tags.replace(c, '')\n\n if tags != '':\n self._tags = tags.split(',')\n else:\n self._tags = list()\n\n self._permissions = self._get_permissions()\n return True\n return False\n\n def _get_permissions(self):\n perms_out = self._exec(['list_user_permissions', self.username], True)\n\n for perm in perms_out:\n vhost, configure_priv, write_priv, read_priv = perm.split('\\t')\n if vhost == self.permissions['vhost']:\n return dict(vhost=vhost, configure_priv=configure_priv, write_priv=write_priv, read_priv=read_priv)\n\n return dict()\n\n def add(self):\n self._exec(['add_user', self.username, self.password])\n\n def delete(self):\n self._exec(['delete_user', self.username])\n\n def set_tags(self):\n self._exec(['set_user_tags', self.username] + self.tags)\n\n def set_permissions(self):\n cmd = ['set_permissions']\n cmd.append('-p')\n cmd.append(self.permissions['vhost'])\n cmd.append(self.username)\n cmd.append(self.permissions['configure_priv'])\n cmd.append(self.permissions['write_priv'])\n cmd.append(self.permissions['read_priv'])\n self._exec(cmd)\n\n def has_tags_modifications(self):\n return set(self.tags) != set(self._tags)\n\n def has_permissions_modifications(self):\n return self._permissions != self.permissions\n\ndef main():\n arg_spec = dict(\n user=dict(required=True, aliases=['username', 'name']),\n password=dict(default=None),\n tags=dict(default=None),\n vhost=dict(default='/'),\n configure_priv=dict(default='^$'),\n write_priv=dict(default='^$'),\n read_priv=dict(default='^$'),\n force=dict(default='no', type='bool'),\n state=dict(default='present', choices=['present', 'absent']),\n node=dict(default='rabbit')\n )\n module = AnsibleModule(\n argument_spec=arg_spec,\n supports_check_mode=True\n )\n\n username = module.params['user']\n password = module.params['password']\n tags = module.params['tags']\n vhost = module.params['vhost']\n configure_priv = module.params['configure_priv']\n write_priv = module.params['write_priv']\n read_priv = module.params['read_priv']\n force = module.params['force']\n state = module.params['state']\n node = module.params['node']\n\n rabbitmq_user = RabbitMqUser(module, username, password, tags, vhost, configure_priv, write_priv, read_priv, node)\n\n changed = False\n if rabbitmq_user.get():\n if state == 'absent':\n rabbitmq_user.delete()\n changed = True\n else:\n if force:\n rabbitmq_user.delete()\n rabbitmq_user.add()\n rabbitmq_user.get()\n changed = True\n\n if rabbitmq_user.has_tags_modifications():\n rabbitmq_user.set_tags()\n changed = True\n\n if rabbitmq_user.has_permissions_modifications():\n rabbitmq_user.set_permissions()\n changed = True\n elif state == 'present':\n rabbitmq_user.add()\n rabbitmq_user.set_tags()\n rabbitmq_user.set_permissions()\n changed = True\n\n module.exit_json(changed=changed, user=username, state=state)\n\n# import module snippets\nfrom ansible.module_utils.basic import *\nmain()\n", "path": "messaging/rabbitmq_user.py"}]}
| 3,119 | 151 |
gh_patches_debug_7462
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-644
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
add api docs for plot_energy
https://arviz-devs.github.io/arviz/generated/arviz.plot_energy.html#arviz.plot_energy
See Posterior Docs for example
https://arviz-devs.github.io/arviz/generated/arviz.plot_posterior.html#arviz.plot_posterior
</issue>
<code>
[start of arviz/plots/energyplot.py]
1 """Plot energy transition distribution in HMC inference."""
2 import numpy as np
3 import matplotlib.pyplot as plt
4
5 from ..data import convert_to_dataset
6 from ..stats import bfmi as e_bfmi
7 from .kdeplot import plot_kde
8 from .plot_utils import _scale_fig_size
9
10
11 def plot_energy(
12 data,
13 kind="kde",
14 bfmi=True,
15 figsize=None,
16 legend=True,
17 fill_alpha=(1, 0.75),
18 fill_color=("C0", "C5"),
19 bw=4.5,
20 textsize=None,
21 fill_kwargs=None,
22 plot_kwargs=None,
23 ax=None,
24 ):
25 """Plot energy transition distribution and marginal energy distribution in HMC algorithms.
26
27 This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.
28
29 Parameters
30 ----------
31 data : xarray dataset, or object that can be converted (must represent
32 `sample_stats` and have an `energy` variable)
33 kind : str
34 Type of plot to display (kde or histogram)
35 bfmi : bool
36 If True add to the plot the value of the estimated Bayesian fraction of missing information
37 figsize : tuple
38 Figure size. If None it will be defined automatically.
39 legend : bool
40 Flag for plotting legend (defaults to True)
41 fill_alpha : tuple of floats
42 Alpha blending value for the shaded area under the curve, between 0
43 (no shade) and 1 (opaque). Defaults to (1, .75)
44 fill_color : tuple of valid matplotlib color
45 Color for Marginal energy distribution and Energy transition distribution.
46 Defaults to ('C0', 'C5')
47 bw : float
48 Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the
49 smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule
50 of thumb (the default rule used by SciPy). Only works if `kind='kde'`
51 textsize: float
52 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
53 on figsize.
54 fill_kwargs : dicts, optional
55 Additional keywords passed to `arviz.plot_kde` (to control the shade)
56 plot_kwargs : dicts, optional
57 Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')
58 ax : axes
59 Matplotlib axes.
60
61 Returns
62 -------
63 ax : matplotlib axes
64 """
65 energy = convert_to_dataset(data, group="sample_stats").energy.values
66
67 if ax is None:
68 _, ax = plt.subplots(figsize=figsize, constrained_layout=True)
69
70 if fill_kwargs is None:
71 fill_kwargs = {}
72
73 if plot_kwargs is None:
74 plot_kwargs = {}
75
76 figsize, _, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)
77
78 series = zip(
79 fill_alpha,
80 fill_color,
81 ("Marginal Energy", "Energy transition"),
82 (energy - energy.mean(), np.diff(energy)),
83 )
84
85 if kind == "kde":
86 for alpha, color, label, value in series:
87 fill_kwargs["alpha"] = alpha
88 fill_kwargs["color"] = color
89 plot_kwargs.setdefault("color", color)
90 plot_kwargs.setdefault("alpha", 0)
91 plot_kwargs.setdefault("linewidth", linewidth)
92 plot_kde(
93 value,
94 bw=bw,
95 label=label,
96 textsize=xt_labelsize,
97 plot_kwargs=plot_kwargs,
98 fill_kwargs=fill_kwargs,
99 ax=ax,
100 )
101
102 elif kind == "hist":
103 for alpha, color, label, value in series:
104 ax.hist(
105 value.flatten(),
106 bins="auto",
107 density=True,
108 alpha=alpha,
109 label=label,
110 color=color,
111 **plot_kwargs
112 )
113
114 else:
115 raise ValueError("Plot type {} not recognized.".format(kind))
116
117 if bfmi:
118 for idx, val in enumerate(e_bfmi(energy)):
119 ax.plot([], label="chain {:>2} BFMI = {:.2f}".format(idx, val), alpha=0)
120
121 ax.set_xticks([])
122 ax.set_yticks([])
123
124 if legend:
125 ax.legend()
126
127 return ax
128
[end of arviz/plots/energyplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/plots/energyplot.py b/arviz/plots/energyplot.py
--- a/arviz/plots/energyplot.py
+++ b/arviz/plots/energyplot.py
@@ -61,6 +61,25 @@
Returns
-------
ax : matplotlib axes
+
+ Examples
+ --------
+ Plot a default energy plot
+
+ .. plot::
+ :context: close-figs
+
+ >>> import arviz as az
+ >>> data = az.load_arviz_data('centered_eight')
+ >>> az.plot_energy(data)
+
+ Represent energy plot via histograms
+
+ .. plot::
+ :context: close-figs
+
+ >>> az.plot_energy(data, kind='hist')
+
"""
energy = convert_to_dataset(data, group="sample_stats").energy.values
|
{"golden_diff": "diff --git a/arviz/plots/energyplot.py b/arviz/plots/energyplot.py\n--- a/arviz/plots/energyplot.py\n+++ b/arviz/plots/energyplot.py\n@@ -61,6 +61,25 @@\n Returns\n -------\n ax : matplotlib axes\n+\n+ Examples\n+ --------\n+ Plot a default energy plot\n+\n+ .. plot::\n+ :context: close-figs\n+\n+ >>> import arviz as az\n+ >>> data = az.load_arviz_data('centered_eight')\n+ >>> az.plot_energy(data)\n+\n+ Represent energy plot via histograms\n+\n+ .. plot::\n+ :context: close-figs\n+\n+ >>> az.plot_energy(data, kind='hist')\n+\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n", "issue": "add api docs for plot_energy\nhttps://arviz-devs.github.io/arviz/generated/arviz.plot_energy.html#arviz.plot_energy\r\n\r\nSee Posterior Docs for example\r\nhttps://arviz-devs.github.io/arviz/generated/arviz.plot_posterior.html#arviz.plot_posterior\n", "before_files": [{"content": "\"\"\"Plot energy transition distribution in HMC inference.\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom ..data import convert_to_dataset\nfrom ..stats import bfmi as e_bfmi\nfrom .kdeplot import plot_kde\nfrom .plot_utils import _scale_fig_size\n\n\ndef plot_energy(\n data,\n kind=\"kde\",\n bfmi=True,\n figsize=None,\n legend=True,\n fill_alpha=(1, 0.75),\n fill_color=(\"C0\", \"C5\"),\n bw=4.5,\n textsize=None,\n fill_kwargs=None,\n plot_kwargs=None,\n ax=None,\n):\n \"\"\"Plot energy transition distribution and marginal energy distribution in HMC algorithms.\n\n This may help to diagnose poor exploration by gradient-based algorithms like HMC or NUTS.\n\n Parameters\n ----------\n data : xarray dataset, or object that can be converted (must represent\n `sample_stats` and have an `energy` variable)\n kind : str\n Type of plot to display (kde or histogram)\n bfmi : bool\n If True add to the plot the value of the estimated Bayesian fraction of missing information\n figsize : tuple\n Figure size. If None it will be defined automatically.\n legend : bool\n Flag for plotting legend (defaults to True)\n fill_alpha : tuple of floats\n Alpha blending value for the shaded area under the curve, between 0\n (no shade) and 1 (opaque). Defaults to (1, .75)\n fill_color : tuple of valid matplotlib color\n Color for Marginal energy distribution and Energy transition distribution.\n Defaults to ('C0', 'C5')\n bw : float\n Bandwidth scaling factor for the KDE. Should be larger than 0. The higher this number the\n smoother the KDE will be. Defaults to 4.5 which is essentially the same as the Scott's rule\n of thumb (the default rule used by SciPy). Only works if `kind='kde'`\n textsize: float\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\n on figsize.\n fill_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` (to control the shade)\n plot_kwargs : dicts, optional\n Additional keywords passed to `arviz.plot_kde` or `plt.hist` (if type='hist')\n ax : axes\n Matplotlib axes.\n\n Returns\n -------\n ax : matplotlib axes\n \"\"\"\n energy = convert_to_dataset(data, group=\"sample_stats\").energy.values\n\n if ax is None:\n _, ax = plt.subplots(figsize=figsize, constrained_layout=True)\n\n if fill_kwargs is None:\n fill_kwargs = {}\n\n if plot_kwargs is None:\n plot_kwargs = {}\n\n figsize, _, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)\n\n series = zip(\n fill_alpha,\n fill_color,\n (\"Marginal Energy\", \"Energy transition\"),\n (energy - energy.mean(), np.diff(energy)),\n )\n\n if kind == \"kde\":\n for alpha, color, label, value in series:\n fill_kwargs[\"alpha\"] = alpha\n fill_kwargs[\"color\"] = color\n plot_kwargs.setdefault(\"color\", color)\n plot_kwargs.setdefault(\"alpha\", 0)\n plot_kwargs.setdefault(\"linewidth\", linewidth)\n plot_kde(\n value,\n bw=bw,\n label=label,\n textsize=xt_labelsize,\n plot_kwargs=plot_kwargs,\n fill_kwargs=fill_kwargs,\n ax=ax,\n )\n\n elif kind == \"hist\":\n for alpha, color, label, value in series:\n ax.hist(\n value.flatten(),\n bins=\"auto\",\n density=True,\n alpha=alpha,\n label=label,\n color=color,\n **plot_kwargs\n )\n\n else:\n raise ValueError(\"Plot type {} not recognized.\".format(kind))\n\n if bfmi:\n for idx, val in enumerate(e_bfmi(energy)):\n ax.plot([], label=\"chain {:>2} BFMI = {:.2f}\".format(idx, val), alpha=0)\n\n ax.set_xticks([])\n ax.set_yticks([])\n\n if legend:\n ax.legend()\n\n return ax\n", "path": "arviz/plots/energyplot.py"}]}
| 1,815 | 191 |
gh_patches_debug_16849
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-4514
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IonQ Job should throw TimeoutError when wait time exceeded
**Description of the issue**
Currently, `Job.results()` throws a `RuntimeError` when the job execution exceeds the `timeout_seconds` wait time. It would be more accurate to throw a `TimeoutError` instead.
see cirq-ionq/cirq_ionq/job.py:
https://github.com/quantumlib/Cirq/blob/7759c05fd71673ca58559307c220b5b779bf5bb6/cirq-ionq/cirq_ionq/job.py#L202
**How to reproduce the issue**
```
import cirq
import cirq.ionq as ionq
API_KEY = 'tomyheart' # Replace with your IonQ API key
service = ionq.Service(api_key=API_KEY,
default_target='simulator')
q0, q1 = cirq.LineQubit.range(2)
circuit = cirq.Circuit(
cirq.X(q0)**0.5, # Square root of X
cirq.CX(q0, q1), # CNOT
cirq.measure(q0, q1, key='b') # Measure both qubits
)
# create a job
job = service.create_job(circuit, repetitions=100)
job.results(timeout_seconds=0.1) # trigger a timeout
```
<details>
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_6204/2129298043.py in <module>
----> 1 job.results(timeout_seconds=0.01)
~/anaconda3/envs/my-env/lib/python3.7/site-packages/cirq_ionq/job.py in results(self, timeout_seconds, polling_seconds)
199 raise RuntimeError(f'Job failed. Error message: {error}')
200 raise RuntimeError(
--> 201 f'Job was not completed successful. Instead had status: {self.status()}'
202 )
203 # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.
RuntimeError: Job was not completed successful. Instead had status: ready
</details>
**Cirq version**
0.12.0
</issue>
<code>
[start of cirq-ionq/cirq_ionq/job.py]
1 # Copyright 2020 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """Represents a job created via the IonQ API."""
15
16 import time
17 from typing import Dict, Sequence, Union, TYPE_CHECKING
18
19 from cirq_ionq import ionq_exceptions, results
20 from cirq._doc import document
21
22 import cirq
23
24 if TYPE_CHECKING:
25 import cirq_ionq
26
27
28 def _little_endian_to_big(value: int, bit_count: int) -> int:
29 return cirq.big_endian_bits_to_int(
30 cirq.big_endian_int_to_bits(value, bit_count=bit_count)[::-1]
31 )
32
33
34 class Job:
35 """A job created on the IonQ API.
36
37 Note that this is mutable, when calls to get status or results are made
38 the job updates itself to the results returned from the API.
39
40 If a job is canceled or deleted, only the job id and the status remain
41 valid.
42 """
43
44 TERMINAL_STATES = ('completed', 'canceled', 'failed', 'deleted')
45 document(
46 TERMINAL_STATES,
47 'States of the IonQ API job from which the job cannot transition. '
48 'Note that deleted can only exist in a return call from a delete '
49 '(subsequent calls will return not found).',
50 )
51
52 NON_TERMINAL_STATES = ('ready', 'submitted', 'running')
53 document(
54 NON_TERMINAL_STATES, 'States of the IonQ API job which can transition to other states.'
55 )
56
57 ALL_STATES = TERMINAL_STATES + NON_TERMINAL_STATES
58 document(ALL_STATES, 'All states that an IonQ API job can exist in.')
59
60 UNSUCCESSFUL_STATES = ('canceled', 'failed', 'deleted')
61 document(
62 UNSUCCESSFUL_STATES,
63 'States of the IonQ API job when it was not successful and so does not have any '
64 'data associated with it beyond an id and a status.',
65 )
66
67 def __init__(self, client: 'cirq_ionq.ionq_client._IonQClient', job_dict: dict):
68 """Construct an IonQJob.
69
70 Users should not call this themselves. If you only know the `job_id`, use `get_job`
71 on `cirq_ionq.Service`.
72
73 Args:
74 client: The client used for calling the API.
75 job_dict: A dict representing the response from a call to get_job on the client.
76 """
77 self._client = client
78 self._job = job_dict
79
80 def _refresh_job(self):
81 """If the last fetched job is not terminal, gets the job from the API."""
82 if self._job['status'] not in self.TERMINAL_STATES:
83 self._job = self._client.get_job(self.job_id())
84
85 def _check_if_unsuccessful(self):
86 if self.status() in self.UNSUCCESSFUL_STATES:
87 raise ionq_exceptions.IonQUnsuccessfulJobException(self.job_id(), self.status())
88
89 def job_id(self) -> str:
90 """Returns the job id (UID) for the job.
91
92 This is the id used for identifying the job by the API.
93 """
94 return self._job['id']
95
96 def status(self) -> str:
97 """Gets the current status of the job.
98
99 This will get a new job if the status of the job previously was determined to not be in
100 a terminal state. A full list of states is given in `cirq_ionq.IonQJob.ALL_STATES`.
101
102 Raises:
103 IonQException: If the API is not able to get the status of the job.
104
105 Returns:
106 The job status.
107 """
108 self._refresh_job()
109 return self._job['status']
110
111 def target(self) -> str:
112 """Returns the target where the job is to be run, or was run.
113
114 Returns:
115 'qpu' or 'simulator' depending on where the job was run or is running.
116
117 Raises:
118 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
119 IonQException: If unable to get the status of the job from the API.
120 """
121 self._check_if_unsuccessful()
122 return self._job['target']
123
124 def name(self) -> str:
125 """Returns the name of the job which was supplied during job creation.
126
127 This is different than the `job_id`.
128
129 Raises:
130 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
131 IonQException: If unable to get the status of the job from the API.
132 """
133 self._check_if_unsuccessful()
134 return self._job['name']
135
136 def num_qubits(self) -> int:
137 """Returns the number of qubits for the job.
138
139 Raises:
140 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
141 IonQException: If unable to get the status of the job from the API.
142 """
143 self._check_if_unsuccessful()
144 return int(self._job['qubits'])
145
146 def repetitions(self) -> int:
147 """Returns the number of repetitions for the job.
148
149 Raises:
150 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
151 IonQException: If unable to get the status of the job from the API.
152 """
153 self._check_if_unsuccessful()
154 return int(self._job['metadata']['shots'])
155
156 def measurement_dict(self) -> Dict[str, Sequence[int]]:
157 """Returns a dictionary of measurement keys to target qubit index."""
158 measurement_dict: Dict[str, Sequence[int]] = {}
159 if 'metadata' in self._job:
160 full_str = ''.join(
161 value
162 for key, value in self._job['metadata'].items()
163 if key.startswith('measurement')
164 )
165 if full_str == '':
166 return measurement_dict
167 for key_value in full_str.split(chr(30)):
168 key, value = key_value.split(chr(31))
169 measurement_dict[key] = [int(t) for t in value.split(',')]
170 return measurement_dict
171
172 # TODO(#3388) Add documentation for Raises.
173 # pylint: disable=missing-raises-doc
174 def results(
175 self, timeout_seconds: int = 7200, polling_seconds: int = 1
176 ) -> Union[results.QPUResult, results.SimulatorResult]:
177 """Polls the IonQ api for results.
178
179 Args:
180 timeout_seconds: The total number of seconds to poll for.
181 polling_seconds: The interval with which to poll.
182
183 Returns:
184 Either a `cirq_ionq.QPUResults` or `cirq_ionq.SimulatorResults` depending on whether
185 the job was running on an actual quantum processor or a simulator.
186
187 Raises:
188 IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.
189 IonQException: If unable to get the results from the API.
190 """
191 time_waited_seconds = 0
192 while time_waited_seconds < timeout_seconds:
193 # Status does a refresh.
194 if self.status() in self.TERMINAL_STATES:
195 break
196 time.sleep(polling_seconds)
197 time_waited_seconds += polling_seconds
198 if self.status() != 'completed':
199 if 'failure' in self._job and 'error' in self._job['failure']:
200 error = self._job['failure']['error']
201 raise RuntimeError(f'Job failed. Error message: {error}')
202 raise RuntimeError(
203 f'Job was not completed successful. Instead had status: {self.status()}'
204 )
205 # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.
206 if self.target() == 'qpu':
207 repetitions = self.repetitions()
208 counts = {
209 _little_endian_to_big(int(k), self.num_qubits()): int(repetitions * float(v))
210 for k, v in self._job['data']['histogram'].items()
211 }
212 return results.QPUResult(
213 counts=counts,
214 num_qubits=self.num_qubits(),
215 measurement_dict=self.measurement_dict(),
216 )
217 else:
218 probabilities = {
219 _little_endian_to_big(int(k), self.num_qubits()): float(v)
220 for k, v in self._job['data']['histogram'].items()
221 }
222 return results.SimulatorResult(
223 probabilities=probabilities,
224 num_qubits=self.num_qubits(),
225 measurement_dict=self.measurement_dict(),
226 repetitions=self.repetitions(),
227 )
228
229 # pylint: enable=missing-raises-doc
230 def cancel(self):
231 """Cancel the given job.
232
233 This mutates the job to only have a job id and status `canceled`.
234 """
235 self._job = self._client.cancel_job(job_id=self.job_id())
236
237 def delete(self):
238 """Delete the given job.
239
240 This mutates the job to only have a job id and status `deleted`. Subsequence attempts to
241 get the job with this job id will return not found.
242 """
243 self._job = self._client.delete_job(job_id=self.job_id())
244
245 def __str__(self) -> str:
246 return f'cirq_ionq.Job(job_id={self.job_id()})'
247
[end of cirq-ionq/cirq_ionq/job.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq-ionq/cirq_ionq/job.py b/cirq-ionq/cirq_ionq/job.py
--- a/cirq-ionq/cirq_ionq/job.py
+++ b/cirq-ionq/cirq_ionq/job.py
@@ -199,8 +199,10 @@
if 'failure' in self._job and 'error' in self._job['failure']:
error = self._job['failure']['error']
raise RuntimeError(f'Job failed. Error message: {error}')
+ if time_waited_seconds >= timeout_seconds:
+ raise TimeoutError(f'Job timed out after waiting {time_waited_seconds} seconds.')
raise RuntimeError(
- f'Job was not completed successful. Instead had status: {self.status()}'
+ f'Job was not completed successfully. Instead had status: {self.status()}'
)
# IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.
if self.target() == 'qpu':
|
{"golden_diff": "diff --git a/cirq-ionq/cirq_ionq/job.py b/cirq-ionq/cirq_ionq/job.py\n--- a/cirq-ionq/cirq_ionq/job.py\n+++ b/cirq-ionq/cirq_ionq/job.py\n@@ -199,8 +199,10 @@\n if 'failure' in self._job and 'error' in self._job['failure']:\n error = self._job['failure']['error']\n raise RuntimeError(f'Job failed. Error message: {error}')\n+ if time_waited_seconds >= timeout_seconds:\n+ raise TimeoutError(f'Job timed out after waiting {time_waited_seconds} seconds.')\n raise RuntimeError(\n- f'Job was not completed successful. Instead had status: {self.status()}'\n+ f'Job was not completed successfully. Instead had status: {self.status()}'\n )\n # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\n if self.target() == 'qpu':\n", "issue": "IonQ Job should throw TimeoutError when wait time exceeded\n**Description of the issue**\r\n\r\nCurrently, `Job.results()` throws a `RuntimeError` when the job execution exceeds the `timeout_seconds` wait time. It would be more accurate to throw a `TimeoutError` instead.\r\n\r\nsee cirq-ionq/cirq_ionq/job.py:\r\n\r\nhttps://github.com/quantumlib/Cirq/blob/7759c05fd71673ca58559307c220b5b779bf5bb6/cirq-ionq/cirq_ionq/job.py#L202\r\n\r\n**How to reproduce the issue**\r\n\r\n```\r\nimport cirq\r\nimport cirq.ionq as ionq\r\n\r\nAPI_KEY = 'tomyheart' # Replace with your IonQ API key\r\n\r\nservice = ionq.Service(api_key=API_KEY, \r\n default_target='simulator')\r\n\r\nq0, q1 = cirq.LineQubit.range(2)\r\ncircuit = cirq.Circuit(\r\n cirq.X(q0)**0.5, # Square root of X\r\n cirq.CX(q0, q1), # CNOT\r\n cirq.measure(q0, q1, key='b') # Measure both qubits\r\n)\r\n\r\n# create a job\r\njob = service.create_job(circuit, repetitions=100)\r\njob.results(timeout_seconds=0.1) # trigger a timeout\r\n```\r\n\r\n<details>\r\n\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n/tmp/ipykernel_6204/2129298043.py in <module>\r\n----> 1 job.results(timeout_seconds=0.01)\r\n\r\n~/anaconda3/envs/my-env/lib/python3.7/site-packages/cirq_ionq/job.py in results(self, timeout_seconds, polling_seconds)\r\n 199 raise RuntimeError(f'Job failed. Error message: {error}')\r\n 200 raise RuntimeError(\r\n--> 201 f'Job was not completed successful. Instead had status: {self.status()}'\r\n 202 )\r\n 203 # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\r\n\r\nRuntimeError: Job was not completed successful. Instead had status: ready\r\n\r\n</details>\r\n\r\n**Cirq version**\r\n\r\n0.12.0\n", "before_files": [{"content": "# Copyright 2020 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Represents a job created via the IonQ API.\"\"\"\n\nimport time\nfrom typing import Dict, Sequence, Union, TYPE_CHECKING\n\nfrom cirq_ionq import ionq_exceptions, results\nfrom cirq._doc import document\n\nimport cirq\n\nif TYPE_CHECKING:\n import cirq_ionq\n\n\ndef _little_endian_to_big(value: int, bit_count: int) -> int:\n return cirq.big_endian_bits_to_int(\n cirq.big_endian_int_to_bits(value, bit_count=bit_count)[::-1]\n )\n\n\nclass Job:\n \"\"\"A job created on the IonQ API.\n\n Note that this is mutable, when calls to get status or results are made\n the job updates itself to the results returned from the API.\n\n If a job is canceled or deleted, only the job id and the status remain\n valid.\n \"\"\"\n\n TERMINAL_STATES = ('completed', 'canceled', 'failed', 'deleted')\n document(\n TERMINAL_STATES,\n 'States of the IonQ API job from which the job cannot transition. '\n 'Note that deleted can only exist in a return call from a delete '\n '(subsequent calls will return not found).',\n )\n\n NON_TERMINAL_STATES = ('ready', 'submitted', 'running')\n document(\n NON_TERMINAL_STATES, 'States of the IonQ API job which can transition to other states.'\n )\n\n ALL_STATES = TERMINAL_STATES + NON_TERMINAL_STATES\n document(ALL_STATES, 'All states that an IonQ API job can exist in.')\n\n UNSUCCESSFUL_STATES = ('canceled', 'failed', 'deleted')\n document(\n UNSUCCESSFUL_STATES,\n 'States of the IonQ API job when it was not successful and so does not have any '\n 'data associated with it beyond an id and a status.',\n )\n\n def __init__(self, client: 'cirq_ionq.ionq_client._IonQClient', job_dict: dict):\n \"\"\"Construct an IonQJob.\n\n Users should not call this themselves. If you only know the `job_id`, use `get_job`\n on `cirq_ionq.Service`.\n\n Args:\n client: The client used for calling the API.\n job_dict: A dict representing the response from a call to get_job on the client.\n \"\"\"\n self._client = client\n self._job = job_dict\n\n def _refresh_job(self):\n \"\"\"If the last fetched job is not terminal, gets the job from the API.\"\"\"\n if self._job['status'] not in self.TERMINAL_STATES:\n self._job = self._client.get_job(self.job_id())\n\n def _check_if_unsuccessful(self):\n if self.status() in self.UNSUCCESSFUL_STATES:\n raise ionq_exceptions.IonQUnsuccessfulJobException(self.job_id(), self.status())\n\n def job_id(self) -> str:\n \"\"\"Returns the job id (UID) for the job.\n\n This is the id used for identifying the job by the API.\n \"\"\"\n return self._job['id']\n\n def status(self) -> str:\n \"\"\"Gets the current status of the job.\n\n This will get a new job if the status of the job previously was determined to not be in\n a terminal state. A full list of states is given in `cirq_ionq.IonQJob.ALL_STATES`.\n\n Raises:\n IonQException: If the API is not able to get the status of the job.\n\n Returns:\n The job status.\n \"\"\"\n self._refresh_job()\n return self._job['status']\n\n def target(self) -> str:\n \"\"\"Returns the target where the job is to be run, or was run.\n\n Returns:\n 'qpu' or 'simulator' depending on where the job was run or is running.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return self._job['target']\n\n def name(self) -> str:\n \"\"\"Returns the name of the job which was supplied during job creation.\n\n This is different than the `job_id`.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return self._job['name']\n\n def num_qubits(self) -> int:\n \"\"\"Returns the number of qubits for the job.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return int(self._job['qubits'])\n\n def repetitions(self) -> int:\n \"\"\"Returns the number of repetitions for the job.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the status of the job from the API.\n \"\"\"\n self._check_if_unsuccessful()\n return int(self._job['metadata']['shots'])\n\n def measurement_dict(self) -> Dict[str, Sequence[int]]:\n \"\"\"Returns a dictionary of measurement keys to target qubit index.\"\"\"\n measurement_dict: Dict[str, Sequence[int]] = {}\n if 'metadata' in self._job:\n full_str = ''.join(\n value\n for key, value in self._job['metadata'].items()\n if key.startswith('measurement')\n )\n if full_str == '':\n return measurement_dict\n for key_value in full_str.split(chr(30)):\n key, value = key_value.split(chr(31))\n measurement_dict[key] = [int(t) for t in value.split(',')]\n return measurement_dict\n\n # TODO(#3388) Add documentation for Raises.\n # pylint: disable=missing-raises-doc\n def results(\n self, timeout_seconds: int = 7200, polling_seconds: int = 1\n ) -> Union[results.QPUResult, results.SimulatorResult]:\n \"\"\"Polls the IonQ api for results.\n\n Args:\n timeout_seconds: The total number of seconds to poll for.\n polling_seconds: The interval with which to poll.\n\n Returns:\n Either a `cirq_ionq.QPUResults` or `cirq_ionq.SimulatorResults` depending on whether\n the job was running on an actual quantum processor or a simulator.\n\n Raises:\n IonQUnsuccessfulJob: If the job has failed, been canceled, or deleted.\n IonQException: If unable to get the results from the API.\n \"\"\"\n time_waited_seconds = 0\n while time_waited_seconds < timeout_seconds:\n # Status does a refresh.\n if self.status() in self.TERMINAL_STATES:\n break\n time.sleep(polling_seconds)\n time_waited_seconds += polling_seconds\n if self.status() != 'completed':\n if 'failure' in self._job and 'error' in self._job['failure']:\n error = self._job['failure']['error']\n raise RuntimeError(f'Job failed. Error message: {error}')\n raise RuntimeError(\n f'Job was not completed successful. Instead had status: {self.status()}'\n )\n # IonQ returns results in little endian, Cirq prefers to use big endian, so we convert.\n if self.target() == 'qpu':\n repetitions = self.repetitions()\n counts = {\n _little_endian_to_big(int(k), self.num_qubits()): int(repetitions * float(v))\n for k, v in self._job['data']['histogram'].items()\n }\n return results.QPUResult(\n counts=counts,\n num_qubits=self.num_qubits(),\n measurement_dict=self.measurement_dict(),\n )\n else:\n probabilities = {\n _little_endian_to_big(int(k), self.num_qubits()): float(v)\n for k, v in self._job['data']['histogram'].items()\n }\n return results.SimulatorResult(\n probabilities=probabilities,\n num_qubits=self.num_qubits(),\n measurement_dict=self.measurement_dict(),\n repetitions=self.repetitions(),\n )\n\n # pylint: enable=missing-raises-doc\n def cancel(self):\n \"\"\"Cancel the given job.\n\n This mutates the job to only have a job id and status `canceled`.\n \"\"\"\n self._job = self._client.cancel_job(job_id=self.job_id())\n\n def delete(self):\n \"\"\"Delete the given job.\n\n This mutates the job to only have a job id and status `deleted`. Subsequence attempts to\n get the job with this job id will return not found.\n \"\"\"\n self._job = self._client.delete_job(job_id=self.job_id())\n\n def __str__(self) -> str:\n return f'cirq_ionq.Job(job_id={self.job_id()})'\n", "path": "cirq-ionq/cirq_ionq/job.py"}]}
| 3,807 | 223 |
gh_patches_debug_10892
|
rasdani/github-patches
|
git_diff
|
NVIDIA__TransformerEngine-627
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The version v1.2 has compatibility issues with PyTorch 2.0.1, causing errors during execution.
Hello,
I encountered the following error while using version v1.2 of Transformer Engine:
`no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive). The error message is TypeError: disable() got an unexpected keyword argument 'recursive'.
`
My environment setup is as follows: CUDA 11.8, PyTorch 2.0.1, and Python 3.10. I am experiencing this issue specifically in the context of using MegatronLM at commit fab0bd6 for Large Language Model (LLM) training. The error occurs right at the start of the training.
Possible cause of the issue:
The `disable` function in PyTorch 2.0.1 is defined as `def disable(f)`, and the recursive parameter was introduced only in later versions starting from PyTorch 2.1.0.
</issue>
<code>
[start of transformer_engine/pytorch/jit.py]
1 # Copyright (c) 2022-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
2 #
3 # See LICENSE for license information.
4
5 """NVFuser functions and JIT utilities"""
6 import os
7 from typing import Callable, Optional, Tuple
8
9 import torch
10
11 jit_fuser = torch.jit.script
12 if torch.__version__ >= "2" and bool(int(os.getenv("NVTE_TORCH_COMPILE", "1"))):
13 jit_fuser = torch.compile
14
15 # See: https://github.com/NVIDIA/TransformerEngine/issues/597
16 dropout_fuser = torch.jit.script
17 if torch.__version__ >= "2.2" and bool(int(os.getenv("NVTE_TORCH_COMPILE", "1"))):
18 dropout_fuser = torch.compile
19
20 # Decorator to disable Torch Dynamo
21 # See: https://github.com/NVIDIA/TransformerEngine/issues/308
22 no_torch_dynamo = lambda recursive=True: lambda func: func
23 if torch.__version__ >= "2":
24 import torch._dynamo
25 no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)
26
27
28 def set_jit_fusion_options() -> None:
29 """Set PyTorch JIT layer fusion options."""
30 # flags required to enable jit fusion kernels
31 TORCH_MAJOR = int(torch.__version__.split(".")[0])
32 TORCH_MINOR = int(torch.__version__.split(".")[1])
33 if (TORCH_MAJOR > 1) or (TORCH_MAJOR == 1 and TORCH_MINOR >= 10):
34 # nvfuser
35 torch._C._jit_set_profiling_executor(True)
36 torch._C._jit_set_profiling_mode(True)
37 torch._C._jit_override_can_fuse_on_cpu(False)
38 torch._C._jit_override_can_fuse_on_gpu(False)
39 torch._C._jit_set_texpr_fuser_enabled(False)
40 torch._C._jit_set_nvfuser_enabled(True)
41 torch._C._debug_set_autodiff_subgraph_inlining(False)
42 else:
43 # legacy pytorch fuser
44 torch._C._jit_set_profiling_mode(False)
45 torch._C._jit_set_profiling_executor(False)
46 torch._C._jit_override_can_fuse_on_cpu(True)
47 torch._C._jit_override_can_fuse_on_gpu(True)
48
49
50 @jit_fuser
51 def bias_gelu_fused_(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
52 """Bias-GeLU fused"""
53 x = inp + bias
54 return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
55
56
57 @jit_fuser
58 def gelu_fused_(inp: torch.Tensor) -> torch.Tensor:
59 """
60 GeLU fused, this is copy of bias_gelu_fused cause jit fusion doesn't allow conditioning.
61 """
62 x = inp
63 return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))
64
65
66 # gradient of tanh approximation of gelu
67 # gradient of actual gelu is:
68 # 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)
69 @jit_fuser
70 def bgrad_dgelu_fused_(
71 grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor
72 ) -> Tuple[torch.Tensor, torch.Tensor]:
73 """Bgrad-Dgelu fused"""
74 x = inp + bias
75 tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))
76 # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243
77 ff = 0.5 * x * (
78 (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)
79 ) + 0.5 * (1 + tanh_out)
80 dgelu = ff * grad_output
81 bgrad = dgelu.sum(dim=0)
82 return bgrad, dgelu
83
84
85 @jit_fuser
86 def dgelu_fused_(
87 grad_output: torch.Tensor, inp: torch.Tensor
88 ) -> torch.Tensor:
89 """
90 Dgelu fused, this is copy of bgrad_dgelu_fused_ cause jit fusion doesn't allow conditioning.
91 """
92 x = inp
93 tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))
94 # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243
95 ff = 0.5 * x * (
96 (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)
97 ) + 0.5 * (1 + tanh_out)
98 dgelu = ff * grad_output
99 return dgelu
100
101
102 def bias_gelu_fused(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:
103 """Disable native AMP for bias_gelu_fused_"""
104 with torch.cuda.amp.autocast(enabled=False):
105 if bias.numel() != 0:
106 return bias_gelu_fused_(inp, bias)
107 return gelu_fused_(inp)
108
109
110 def bgrad_dgelu_fused(
111 grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor
112 ) -> Tuple[Optional[torch.Tensor], torch.Tensor]:
113 """Disable native AMP for `bgrad_dgelu_fused_`"""
114 with torch.cuda.amp.autocast(enabled=False):
115 if bias.numel() != 0:
116 return bgrad_dgelu_fused_(grad_output, inp, bias)
117 return None, dgelu_fused_(grad_output, inp)
118
119
120 def bias_dropout_add(
121 x: torch.Tensor,
122 bias: torch.Tensor,
123 residual: torch.Tensor,
124 prob: float,
125 training: bool,
126 ) -> torch.Tensor:
127 """dropout(inp + bias) + residual"""
128 out = torch.nn.functional.dropout(x + bias, p=prob, training=training)
129 out = residual + out
130 return out
131
132
133 def get_bias_dropout_add(training: bool) -> Callable:
134 """bias_dropout_add based on training or not"""
135
136 def _bias_dropout_add(x, bias, residual, prob):
137 return bias_dropout_add(x, bias, residual, prob, training)
138
139 return _bias_dropout_add
140
141
142 @dropout_fuser
143 def bias_dropout_add_fused_train_(
144 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
145 ) -> torch.Tensor:
146 """Jit fused bias_dropout_add for training"""
147 return bias_dropout_add(x, bias, residual, prob, True)
148
149
150 def bias_dropout_add_fused_train(
151 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
152 ) -> torch.Tensor:
153 """Disable native AMP and enable grad for BDA"""
154 with torch.enable_grad():
155 with torch.cuda.amp.autocast(enabled=False):
156 return bias_dropout_add_fused_train_(x, bias, residual, prob)
157
158
159 @dropout_fuser
160 def bias_dropout_add_fused_inference_(
161 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
162 ) -> torch.Tensor:
163 """Jit fused bias_dropout_add for inference"""
164 return bias_dropout_add(x, bias, residual, prob, False)
165
166
167 def bias_dropout_add_fused_inference(
168 x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float
169 ) -> torch.Tensor:
170 """Disable native AMP for BDA"""
171 with torch.cuda.amp.autocast(enabled=False):
172 return bias_dropout_add_fused_inference_(x, bias, residual, prob)
173
174
175 def warmup_jit_bias_dropout_add(
176 hidden_size: int, dtype: torch.dtype, seq_length: int, micro_batch_size: int
177 ) -> None:
178 """Compile BDA JIT function before the main training steps"""
179
180 # Save cuda RNG state to ensure warmup does not affect reproducibility.
181 rng_state = torch.cuda.get_rng_state()
182
183 inp = torch.rand(
184 (seq_length, micro_batch_size, hidden_size), dtype=dtype, device="cuda"
185 )
186 residual = torch.rand(
187 (seq_length, micro_batch_size, hidden_size), dtype=dtype, device="cuda"
188 )
189 bias = torch.rand((hidden_size), dtype=dtype, device="cuda")
190 dropout_rate = 0.1
191 # Warmup JIT fusions with the input grad_enable state of both forward
192 # prop and recomputation
193 for input_grad, bias_grad, residual_grad in zip(
194 [False, True], [True, True], [True, True]
195 ):
196 inp.requires_grad = input_grad
197 bias.requires_grad = bias_grad
198 residual.requires_grad = residual_grad
199 for _ in range(5):
200 output = bias_dropout_add_fused_train(inp, bias, residual, dropout_rate)
201 del bias, inp, residual, output
202
203 torch.cuda.empty_cache()
204 torch.cuda.set_rng_state(rng_state)
205
206
207 def warmup_jit_bias_dropout_add_all_dtypes(
208 hidden_size: int, seq_length: int, micro_batch_size: int
209 ) -> None:
210 """Call `warmup_jit_bias_dropout_add` for all training dtypes"""
211 for dtype in [torch.float32, torch.bfloat16, torch.float16]:
212 warmup_jit_bias_dropout_add(hidden_size, dtype, seq_length, micro_batch_size)
213
214
215 def warmup_jit_bias_gelu(
216 ffn_hidden_size_per_partition: int,
217 dtype: torch.dtype,
218 seq_length: int,
219 micro_batch_size: int,
220 ) -> None:
221 """Compile bias-gelu JIT function before the main training steps"""
222
223 # Save cuda RNG state to ensure warmup does not affect reproducibility.
224 rng_state = torch.cuda.get_rng_state()
225
226 bias = torch.rand(ffn_hidden_size_per_partition, dtype=dtype, device="cuda")
227 inp = torch.rand(
228 (seq_length * micro_batch_size, ffn_hidden_size_per_partition),
229 dtype=dtype,
230 device="cuda",
231 )
232 # Warmup JIT fusions with the input grad_enable state of both forward
233 # prop and recomputation
234 for bias_grad, input_grad in zip([True, True], [False, True]):
235 bias.requires_grad, inp.requires_grad = bias_grad, input_grad
236 for _ in range(5):
237 _ = bias_gelu_fused_(inp, bias)
238 _ = gelu_fused_(inp)
239 del bias, inp
240
241 torch.cuda.empty_cache()
242 torch.cuda.set_rng_state(rng_state)
243
244
245 def warmup_jit_bias_gelu_all_dtypes(
246 ffn_hidden_size: int, seq_length: int, micro_batch_size: int
247 ) -> None:
248 """Call `warmup_jit_bias_gelu` for all training dtypes"""
249 for dtype in [torch.float32, torch.bfloat16, torch.float16]:
250 warmup_jit_bias_gelu(ffn_hidden_size, dtype, seq_length, micro_batch_size)
251
[end of transformer_engine/pytorch/jit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/transformer_engine/pytorch/jit.py b/transformer_engine/pytorch/jit.py
--- a/transformer_engine/pytorch/jit.py
+++ b/transformer_engine/pytorch/jit.py
@@ -22,7 +22,12 @@
no_torch_dynamo = lambda recursive=True: lambda func: func
if torch.__version__ >= "2":
import torch._dynamo
- no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)
+ if torch.__version__ >= "2.1":
+ no_torch_dynamo = lambda recursive=True: lambda f: \
+ torch._dynamo.disable(f, recursive=recursive)
+ else:
+ # no "recursive" option in pyTorch 2.0 - it acts as if recursive was True
+ no_torch_dynamo = lambda recursive=True: torch._dynamo.disable
def set_jit_fusion_options() -> None:
|
{"golden_diff": "diff --git a/transformer_engine/pytorch/jit.py b/transformer_engine/pytorch/jit.py\n--- a/transformer_engine/pytorch/jit.py\n+++ b/transformer_engine/pytorch/jit.py\n@@ -22,7 +22,12 @@\n no_torch_dynamo = lambda recursive=True: lambda func: func\n if torch.__version__ >= \"2\":\n import torch._dynamo\n- no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)\n+ if torch.__version__ >= \"2.1\":\n+ no_torch_dynamo = lambda recursive=True: lambda f: \\\n+ torch._dynamo.disable(f, recursive=recursive)\n+ else:\n+ # no \"recursive\" option in pyTorch 2.0 - it acts as if recursive was True\n+ no_torch_dynamo = lambda recursive=True: torch._dynamo.disable\n \n \n def set_jit_fusion_options() -> None:\n", "issue": "The version v1.2 has compatibility issues with PyTorch 2.0.1, causing errors during execution.\nHello,\r\n\r\nI encountered the following error while using version v1.2 of Transformer Engine: \r\n\r\n`no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive). The error message is TypeError: disable() got an unexpected keyword argument 'recursive'.\r\n`\r\n\r\nMy environment setup is as follows: CUDA 11.8, PyTorch 2.0.1, and Python 3.10. I am experiencing this issue specifically in the context of using MegatronLM at commit fab0bd6 for Large Language Model (LLM) training. The error occurs right at the start of the training.\r\n\r\nPossible cause of the issue:\r\nThe `disable` function in PyTorch 2.0.1 is defined as `def disable(f)`, and the recursive parameter was introduced only in later versions starting from PyTorch 2.1.0.\n", "before_files": [{"content": "# Copyright (c) 2022-2024, NVIDIA CORPORATION & AFFILIATES. All rights reserved.\n#\n# See LICENSE for license information.\n\n\"\"\"NVFuser functions and JIT utilities\"\"\"\nimport os\nfrom typing import Callable, Optional, Tuple\n\nimport torch\n\njit_fuser = torch.jit.script\nif torch.__version__ >= \"2\" and bool(int(os.getenv(\"NVTE_TORCH_COMPILE\", \"1\"))):\n jit_fuser = torch.compile\n\n# See: https://github.com/NVIDIA/TransformerEngine/issues/597\ndropout_fuser = torch.jit.script\nif torch.__version__ >= \"2.2\" and bool(int(os.getenv(\"NVTE_TORCH_COMPILE\", \"1\"))):\n dropout_fuser = torch.compile\n\n# Decorator to disable Torch Dynamo\n# See: https://github.com/NVIDIA/TransformerEngine/issues/308\nno_torch_dynamo = lambda recursive=True: lambda func: func\nif torch.__version__ >= \"2\":\n import torch._dynamo\n no_torch_dynamo = lambda recursive=True: lambda f: torch._dynamo.disable(f, recursive=recursive)\n\n\ndef set_jit_fusion_options() -> None:\n \"\"\"Set PyTorch JIT layer fusion options.\"\"\"\n # flags required to enable jit fusion kernels\n TORCH_MAJOR = int(torch.__version__.split(\".\")[0])\n TORCH_MINOR = int(torch.__version__.split(\".\")[1])\n if (TORCH_MAJOR > 1) or (TORCH_MAJOR == 1 and TORCH_MINOR >= 10):\n # nvfuser\n torch._C._jit_set_profiling_executor(True)\n torch._C._jit_set_profiling_mode(True)\n torch._C._jit_override_can_fuse_on_cpu(False)\n torch._C._jit_override_can_fuse_on_gpu(False)\n torch._C._jit_set_texpr_fuser_enabled(False)\n torch._C._jit_set_nvfuser_enabled(True)\n torch._C._debug_set_autodiff_subgraph_inlining(False)\n else:\n # legacy pytorch fuser\n torch._C._jit_set_profiling_mode(False)\n torch._C._jit_set_profiling_executor(False)\n torch._C._jit_override_can_fuse_on_cpu(True)\n torch._C._jit_override_can_fuse_on_gpu(True)\n\n\n@jit_fuser\ndef bias_gelu_fused_(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:\n \"\"\"Bias-GeLU fused\"\"\"\n x = inp + bias\n return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))\n\n\n@jit_fuser\ndef gelu_fused_(inp: torch.Tensor) -> torch.Tensor:\n \"\"\"\n GeLU fused, this is copy of bias_gelu_fused cause jit fusion doesn't allow conditioning.\n \"\"\"\n x = inp\n return x * 0.5 * (1.0 + torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x)))\n\n\n# gradient of tanh approximation of gelu\n# gradient of actual gelu is:\n# 0.5 * (1. + torch.erf(x * 0.70710678)) + 0.3989423 * x * torch.exp(-0.5 * x * x)\n@jit_fuser\ndef bgrad_dgelu_fused_(\n grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor\n) -> Tuple[torch.Tensor, torch.Tensor]:\n \"\"\"Bgrad-Dgelu fused\"\"\"\n x = inp + bias\n tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))\n # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243\n ff = 0.5 * x * (\n (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)\n ) + 0.5 * (1 + tanh_out)\n dgelu = ff * grad_output\n bgrad = dgelu.sum(dim=0)\n return bgrad, dgelu\n\n\n@jit_fuser\ndef dgelu_fused_(\n grad_output: torch.Tensor, inp: torch.Tensor\n) -> torch.Tensor:\n \"\"\"\n Dgelu fused, this is copy of bgrad_dgelu_fused_ cause jit fusion doesn't allow conditioning.\n \"\"\"\n x = inp\n tanh_out = torch.tanh(0.79788456 * x * (1 + 0.044715 * x * x))\n # sqrt(2/pi) * 3 * 0.044715 -> 0.1070322243\n ff = 0.5 * x * (\n (1 - tanh_out * tanh_out) * (0.79788456 + 0.1070322243 * x * x)\n ) + 0.5 * (1 + tanh_out)\n dgelu = ff * grad_output\n return dgelu\n\n\ndef bias_gelu_fused(inp: torch.Tensor, bias: torch.Tensor) -> torch.Tensor:\n \"\"\"Disable native AMP for bias_gelu_fused_\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n if bias.numel() != 0:\n return bias_gelu_fused_(inp, bias)\n return gelu_fused_(inp)\n\n\ndef bgrad_dgelu_fused(\n grad_output: torch.Tensor, inp: torch.Tensor, bias: torch.Tensor\n) -> Tuple[Optional[torch.Tensor], torch.Tensor]:\n \"\"\"Disable native AMP for `bgrad_dgelu_fused_`\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n if bias.numel() != 0:\n return bgrad_dgelu_fused_(grad_output, inp, bias)\n return None, dgelu_fused_(grad_output, inp)\n\n\ndef bias_dropout_add(\n x: torch.Tensor,\n bias: torch.Tensor,\n residual: torch.Tensor,\n prob: float,\n training: bool,\n) -> torch.Tensor:\n \"\"\"dropout(inp + bias) + residual\"\"\"\n out = torch.nn.functional.dropout(x + bias, p=prob, training=training)\n out = residual + out\n return out\n\n\ndef get_bias_dropout_add(training: bool) -> Callable:\n \"\"\"bias_dropout_add based on training or not\"\"\"\n\n def _bias_dropout_add(x, bias, residual, prob):\n return bias_dropout_add(x, bias, residual, prob, training)\n\n return _bias_dropout_add\n\n\n@dropout_fuser\ndef bias_dropout_add_fused_train_(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Jit fused bias_dropout_add for training\"\"\"\n return bias_dropout_add(x, bias, residual, prob, True)\n\n\ndef bias_dropout_add_fused_train(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Disable native AMP and enable grad for BDA\"\"\"\n with torch.enable_grad():\n with torch.cuda.amp.autocast(enabled=False):\n return bias_dropout_add_fused_train_(x, bias, residual, prob)\n\n\n@dropout_fuser\ndef bias_dropout_add_fused_inference_(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Jit fused bias_dropout_add for inference\"\"\"\n return bias_dropout_add(x, bias, residual, prob, False)\n\n\ndef bias_dropout_add_fused_inference(\n x: torch.Tensor, bias: torch.Tensor, residual: torch.Tensor, prob: float\n) -> torch.Tensor:\n \"\"\"Disable native AMP for BDA\"\"\"\n with torch.cuda.amp.autocast(enabled=False):\n return bias_dropout_add_fused_inference_(x, bias, residual, prob)\n\n\ndef warmup_jit_bias_dropout_add(\n hidden_size: int, dtype: torch.dtype, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Compile BDA JIT function before the main training steps\"\"\"\n\n # Save cuda RNG state to ensure warmup does not affect reproducibility.\n rng_state = torch.cuda.get_rng_state()\n\n inp = torch.rand(\n (seq_length, micro_batch_size, hidden_size), dtype=dtype, device=\"cuda\"\n )\n residual = torch.rand(\n (seq_length, micro_batch_size, hidden_size), dtype=dtype, device=\"cuda\"\n )\n bias = torch.rand((hidden_size), dtype=dtype, device=\"cuda\")\n dropout_rate = 0.1\n # Warmup JIT fusions with the input grad_enable state of both forward\n # prop and recomputation\n for input_grad, bias_grad, residual_grad in zip(\n [False, True], [True, True], [True, True]\n ):\n inp.requires_grad = input_grad\n bias.requires_grad = bias_grad\n residual.requires_grad = residual_grad\n for _ in range(5):\n output = bias_dropout_add_fused_train(inp, bias, residual, dropout_rate)\n del bias, inp, residual, output\n\n torch.cuda.empty_cache()\n torch.cuda.set_rng_state(rng_state)\n\n\ndef warmup_jit_bias_dropout_add_all_dtypes(\n hidden_size: int, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Call `warmup_jit_bias_dropout_add` for all training dtypes\"\"\"\n for dtype in [torch.float32, torch.bfloat16, torch.float16]:\n warmup_jit_bias_dropout_add(hidden_size, dtype, seq_length, micro_batch_size)\n\n\ndef warmup_jit_bias_gelu(\n ffn_hidden_size_per_partition: int,\n dtype: torch.dtype,\n seq_length: int,\n micro_batch_size: int,\n) -> None:\n \"\"\"Compile bias-gelu JIT function before the main training steps\"\"\"\n\n # Save cuda RNG state to ensure warmup does not affect reproducibility.\n rng_state = torch.cuda.get_rng_state()\n\n bias = torch.rand(ffn_hidden_size_per_partition, dtype=dtype, device=\"cuda\")\n inp = torch.rand(\n (seq_length * micro_batch_size, ffn_hidden_size_per_partition),\n dtype=dtype,\n device=\"cuda\",\n )\n # Warmup JIT fusions with the input grad_enable state of both forward\n # prop and recomputation\n for bias_grad, input_grad in zip([True, True], [False, True]):\n bias.requires_grad, inp.requires_grad = bias_grad, input_grad\n for _ in range(5):\n _ = bias_gelu_fused_(inp, bias)\n _ = gelu_fused_(inp)\n del bias, inp\n\n torch.cuda.empty_cache()\n torch.cuda.set_rng_state(rng_state)\n\n\ndef warmup_jit_bias_gelu_all_dtypes(\n ffn_hidden_size: int, seq_length: int, micro_batch_size: int\n) -> None:\n \"\"\"Call `warmup_jit_bias_gelu` for all training dtypes\"\"\"\n for dtype in [torch.float32, torch.bfloat16, torch.float16]:\n warmup_jit_bias_gelu(ffn_hidden_size, dtype, seq_length, micro_batch_size)\n", "path": "transformer_engine/pytorch/jit.py"}]}
| 3,986 | 219 |
gh_patches_debug_5140
|
rasdani/github-patches
|
git_diff
|
abey79__vpype-144
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Doesn't have support for outputting a2 to a0 paper sizes
I was hoping to output some large paper sizes to plot.
the error messages were the same for paper sizes a2 to a0
```
Traceback (most recent call last):
File "/usr/local/bin/vpype", line 8, in <module>
sys.exit(cli())
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py", line 74, in main
return super().main(args=preprocess_argument_list(args), **extra)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 1290, in invoke
return _process_result(rv)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 1224, in _process_result
value = ctx.invoke(self.result_callback, value, **ctx.params)
File "/usr/local/lib/python3.8/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py", line 128, in process_pipeline
execute_processors(processors)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py", line 212, in execute_processors
state = proc(state)
File "/usr/local/lib/python3.8/site-packages/vpype/decorators.py", line 150, in global_processor
state.document = f(state.document, *args, **kwargs)
File "/usr/local/lib/python3.8/site-packages/vpype_cli/write.py", line 199, in write
page_size_px = convert_page_size(page_size)
File "/usr/local/lib/python3.8/site-packages/vpype/utils.py", line 154, in convert_page_size
raise ValueError(f"page size '{value}' unknown")
ValueError: page size 'a2' unknown
```
</issue>
<code>
[start of vpype/utils.py]
1 import logging
2 import math
3 import re
4 from typing import Callable, Dict, List, Tuple, Union
5
6 import click
7 import numpy as np
8
9 # REMINDER: anything added here must be added to docs/api.rst
10 __all__ = [
11 "UNITS",
12 "ANGLE_UNITS",
13 "PAGE_SIZES",
14 "LengthType",
15 "AngleType",
16 "PageSizeType",
17 "convert_length",
18 "convert_angle",
19 "convert_page_size",
20 "union",
21 # deprecated:
22 "PAGE_FORMATS",
23 "convert",
24 "convert_page_format",
25 "Length",
26 ]
27
28
29 def _mm_to_px(x: float, y: float) -> Tuple[float, float]:
30 return x * 96.0 / 25.4, y * 96.0 / 25.4
31
32
33 UNITS = {
34 "px": 1.0,
35 "in": 96.0,
36 "mm": 96.0 / 25.4,
37 "cm": 96.0 / 2.54,
38 "pc": 16.0,
39 "pt": 96.0 / 72.0,
40 }
41
42 ANGLE_UNITS = {
43 "deg": 1.0,
44 "grad": 9.0 / 10.0, # note: must be before "rad"!
45 "rad": 180.0 / math.pi,
46 "turn": 360.0,
47 }
48
49 # page sizes in pixel
50 PAGE_SIZES = {
51 "tight": _mm_to_px(0, 0),
52 "a6": _mm_to_px(105.0, 148.0),
53 "a5": _mm_to_px(148.0, 210.0),
54 "a4": _mm_to_px(210.0, 297.0),
55 "a3": _mm_to_px(297.0, 420.0),
56 "letter": _mm_to_px(215.9, 279.4),
57 "legal": _mm_to_px(215.9, 355.6),
58 "executive": _mm_to_px(185.15, 266.7),
59 "tabloid": _mm_to_px(279.4, 431.8),
60 }
61
62 # deprecated
63 PAGE_FORMATS = PAGE_SIZES
64
65
66 def _convert_unit(value: Union[str, float], units: Dict[str, float]) -> float:
67 """Converts a string with unit to a value"""
68 if isinstance(value, str):
69 value = value.strip().lower()
70 for unit, factor in units.items():
71 if value.endswith(unit):
72 num = value.strip(unit)
73 return (float(num) if len(num) > 0 else 1.0) * factor
74
75 return float(value)
76
77
78 def convert_length(value: Union[str, float]) -> float:
79 """Convert a length optionally expressed as a string with unit to px value.
80
81 Args:
82 value: value to convert
83
84 Returns:
85 converted value
86
87 Raises:
88 :class:`ValueError`
89 """
90 return _convert_unit(value, UNITS)
91
92
93 def convert(value: Union[str, float]) -> float: # pragma: no cover
94 """Deprecated, use convert_length."""
95 logging.warning(
96 "!!! `vpype.convert()` is deprecated, use `vpype.convert_length()` instead."
97 )
98 return convert_length(value)
99
100
101 def convert_angle(value: Union[str, float]) -> float:
102 """Convert an angle optionally expressed as a string with unit to degrees.
103
104 Args:
105 value: angle to convert
106
107 Returns:
108 converted angle in degree
109
110 Raises:
111 :class:`ValueError`
112 """
113 return _convert_unit(value, ANGLE_UNITS)
114
115
116 def convert_page_size(value: str) -> Tuple[float, float]:
117 """Converts a string with page size to dimension in pixels.
118
119 The input can be either a known page size (see ``vpype write --help`` for a list) or
120 a page size descriptor in the form of "WxH" where both W and H can have units.
121
122 Examples:
123
124 Using a know page size::
125
126 >>> import vpype
127 >>> vpype.convert_page_size("a3")
128 (1122.5196850393702, 1587.4015748031497)
129
130 Using page size descriptor (no units, pixels are assumed)::
131
132 >>> vpype.convert_page_size("100x200")
133 (100.0, 200.0)
134
135 Using page size descriptor (explicit units)::
136
137 >>> vpype.convert_page_size("1inx2in")
138 (96.0, 192.0)
139
140 Args:
141 value: page size descriptor
142
143 Returns:
144 the page size in CSS pixels
145 """
146 if value in PAGE_SIZES:
147 return PAGE_SIZES[value]
148
149 match = re.match(
150 r"^(\d+\.?\d*)({0})?x(\d+\.?\d*)({0})?$".format("|".join(UNITS.keys())), value
151 )
152
153 if not match:
154 raise ValueError(f"page size '{value}' unknown")
155
156 x, x_unit, y, y_unit = match.groups()
157
158 if not x_unit:
159 x_unit = y_unit if y_unit else "px"
160 if not y_unit:
161 y_unit = x_unit
162
163 return float(x) * convert_length(x_unit), float(y) * convert_length(y_unit)
164
165
166 def convert_page_format(value: str) -> Tuple[float, float]: # pragma: no cover
167 """Deprecated, use convert_page_size."""
168 logging.warning(
169 "!!! `vpype.convert_page_format()` is deprecated, use `vpype.convert_page_size()` "
170 "instead."
171 )
172 return convert_page_size(value)
173
174
175 class LengthType(click.ParamType):
176 """:class:`click.ParamType` sub-class to automatically converts a user-provided length
177 string (which may contain units) into a value in CSS pixel units. This class uses
178 :func:`convert_length` internally.
179
180 Example::
181
182 >>> import click
183 >>> import vpype_cli
184 >>> import vpype
185 >>> @vpype_cli.cli.command(group="my commands")
186 ... @click.argument("x", type=vpype.LengthType())
187 ... @click.option("-o", "--option", type=vpype.LengthType(), default="1mm")
188 ... @vpype.generator
189 ... def my_command(x: float, option: float):
190 ... pass
191 """
192
193 name = "length"
194
195 def convert(self, value, param, ctx):
196 try:
197 return convert_length(value)
198 except ValueError:
199 self.fail(f"parameter {value} is an incorrect length")
200
201
202 class Length(LengthType): # pragma: no cover
203 """Deprecated, use LengthType."""
204
205 def __init__(self, *args, **kwargs):
206 super().__init__(*args, **kwargs)
207 logging.warning("!!! `vpype.Length` is deprecated, use `vpype.LengthType` instead.")
208
209
210 class AngleType(click.ParamType):
211 """:class:`click.ParamType` sub-class to automatically converts a user-provided angle
212 string (which may contain units) into a value in degrees. This class uses
213 :func:`convert_angle` internally.
214
215 Example::
216
217 >>> import click
218 >>> import vpype_cli
219 >>> import vpype
220 >>> @vpype_cli.cli.command(group="my commands")
221 ... @click.argument("angle", type=vpype.AngleType())
222 ... @vpype.generator
223 ... def my_command(angle: float):
224 ... pass
225 """
226
227 name = "angle"
228
229 def convert(self, value, param, ctx):
230 try:
231 return convert_angle(value)
232 except ValueError:
233 self.fail(f"parameter {value} is an incorrect angle")
234
235
236 class PageSizeType(click.ParamType):
237 """:class:`click.ParamType` sub-class to automatically converts a user-provided page size
238 string into a tuple of float in CSS pixel units. See :func:`convert_page_size` for
239 information on the page size descriptor syntax.
240
241 Example::
242
243 >>> import click
244 >>> import vpype_cli
245 >>> import vpype
246 >>> @vpype_cli.cli.command(group="my commands")
247 ... @click.argument("fmt", type=vpype.PageSizeType())
248 ... @vpype.generator
249 ... def my_command(fmt: Tuple[float, float]):
250 ... pass
251 """
252
253 name = "PAGESIZE"
254
255 def convert(self, value, param, ctx) -> Tuple[float, float]:
256 try:
257 return convert_page_size(value)
258 except ValueError:
259 self.fail(f"parameter {value} is not a valid page size")
260
261
262 def union(line: np.ndarray, keys: List[Callable[[np.ndarray], bool]]) -> bool:
263 """Returns True if every callables in ``keys`` return True (similar to ``all()``. This
264 function is typically used with :meth:`LineCollection.filter`.
265
266 Args:
267 line: line to test
268 keys: list of callables
269
270 Returns:
271 True if every callables return True
272 """
273 for key in keys:
274 if not key(line):
275 return False
276 return True
277
[end of vpype/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vpype/utils.py b/vpype/utils.py
--- a/vpype/utils.py
+++ b/vpype/utils.py
@@ -53,6 +53,9 @@
"a5": _mm_to_px(148.0, 210.0),
"a4": _mm_to_px(210.0, 297.0),
"a3": _mm_to_px(297.0, 420.0),
+ "a2": _mm_to_px(420.0, 594.0),
+ "a1": _mm_to_px(594.0, 841.0),
+ "a0": _mm_to_px(841.0, 1189.0),
"letter": _mm_to_px(215.9, 279.4),
"legal": _mm_to_px(215.9, 355.6),
"executive": _mm_to_px(185.15, 266.7),
|
{"golden_diff": "diff --git a/vpype/utils.py b/vpype/utils.py\n--- a/vpype/utils.py\n+++ b/vpype/utils.py\n@@ -53,6 +53,9 @@\n \"a5\": _mm_to_px(148.0, 210.0),\n \"a4\": _mm_to_px(210.0, 297.0),\n \"a3\": _mm_to_px(297.0, 420.0),\n+ \"a2\": _mm_to_px(420.0, 594.0),\n+ \"a1\": _mm_to_px(594.0, 841.0),\n+ \"a0\": _mm_to_px(841.0, 1189.0),\n \"letter\": _mm_to_px(215.9, 279.4),\n \"legal\": _mm_to_px(215.9, 355.6),\n \"executive\": _mm_to_px(185.15, 266.7),\n", "issue": "Doesn't have support for outputting a2 to a0 paper sizes\nI was hoping to output some large paper sizes to plot.\r\n\r\nthe error messages were the same for paper sizes a2 to a0\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/usr/local/bin/vpype\", line 8, in <module>\r\n sys.exit(cli())\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py\", line 74, in main\r\n return super().main(args=preprocess_argument_list(args), **extra)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 1290, in invoke\r\n return _process_result(rv)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 1224, in _process_result\r\n value = ctx.invoke(self.result_callback, value, **ctx.params)\r\n File \"/usr/local/lib/python3.8/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py\", line 128, in process_pipeline\r\n execute_processors(processors)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/cli.py\", line 212, in execute_processors\r\n state = proc(state)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype/decorators.py\", line 150, in global_processor\r\n state.document = f(state.document, *args, **kwargs)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype_cli/write.py\", line 199, in write\r\n page_size_px = convert_page_size(page_size)\r\n File \"/usr/local/lib/python3.8/site-packages/vpype/utils.py\", line 154, in convert_page_size\r\n raise ValueError(f\"page size '{value}' unknown\")\r\nValueError: page size 'a2' unknown\r\n```\n", "before_files": [{"content": "import logging\nimport math\nimport re\nfrom typing import Callable, Dict, List, Tuple, Union\n\nimport click\nimport numpy as np\n\n# REMINDER: anything added here must be added to docs/api.rst\n__all__ = [\n \"UNITS\",\n \"ANGLE_UNITS\",\n \"PAGE_SIZES\",\n \"LengthType\",\n \"AngleType\",\n \"PageSizeType\",\n \"convert_length\",\n \"convert_angle\",\n \"convert_page_size\",\n \"union\",\n # deprecated:\n \"PAGE_FORMATS\",\n \"convert\",\n \"convert_page_format\",\n \"Length\",\n]\n\n\ndef _mm_to_px(x: float, y: float) -> Tuple[float, float]:\n return x * 96.0 / 25.4, y * 96.0 / 25.4\n\n\nUNITS = {\n \"px\": 1.0,\n \"in\": 96.0,\n \"mm\": 96.0 / 25.4,\n \"cm\": 96.0 / 2.54,\n \"pc\": 16.0,\n \"pt\": 96.0 / 72.0,\n}\n\nANGLE_UNITS = {\n \"deg\": 1.0,\n \"grad\": 9.0 / 10.0, # note: must be before \"rad\"!\n \"rad\": 180.0 / math.pi,\n \"turn\": 360.0,\n}\n\n# page sizes in pixel\nPAGE_SIZES = {\n \"tight\": _mm_to_px(0, 0),\n \"a6\": _mm_to_px(105.0, 148.0),\n \"a5\": _mm_to_px(148.0, 210.0),\n \"a4\": _mm_to_px(210.0, 297.0),\n \"a3\": _mm_to_px(297.0, 420.0),\n \"letter\": _mm_to_px(215.9, 279.4),\n \"legal\": _mm_to_px(215.9, 355.6),\n \"executive\": _mm_to_px(185.15, 266.7),\n \"tabloid\": _mm_to_px(279.4, 431.8),\n}\n\n# deprecated\nPAGE_FORMATS = PAGE_SIZES\n\n\ndef _convert_unit(value: Union[str, float], units: Dict[str, float]) -> float:\n \"\"\"Converts a string with unit to a value\"\"\"\n if isinstance(value, str):\n value = value.strip().lower()\n for unit, factor in units.items():\n if value.endswith(unit):\n num = value.strip(unit)\n return (float(num) if len(num) > 0 else 1.0) * factor\n\n return float(value)\n\n\ndef convert_length(value: Union[str, float]) -> float:\n \"\"\"Convert a length optionally expressed as a string with unit to px value.\n\n Args:\n value: value to convert\n\n Returns:\n converted value\n\n Raises:\n :class:`ValueError`\n \"\"\"\n return _convert_unit(value, UNITS)\n\n\ndef convert(value: Union[str, float]) -> float: # pragma: no cover\n \"\"\"Deprecated, use convert_length.\"\"\"\n logging.warning(\n \"!!! `vpype.convert()` is deprecated, use `vpype.convert_length()` instead.\"\n )\n return convert_length(value)\n\n\ndef convert_angle(value: Union[str, float]) -> float:\n \"\"\"Convert an angle optionally expressed as a string with unit to degrees.\n\n Args:\n value: angle to convert\n\n Returns:\n converted angle in degree\n\n Raises:\n :class:`ValueError`\n \"\"\"\n return _convert_unit(value, ANGLE_UNITS)\n\n\ndef convert_page_size(value: str) -> Tuple[float, float]:\n \"\"\"Converts a string with page size to dimension in pixels.\n\n The input can be either a known page size (see ``vpype write --help`` for a list) or\n a page size descriptor in the form of \"WxH\" where both W and H can have units.\n\n Examples:\n\n Using a know page size::\n\n >>> import vpype\n >>> vpype.convert_page_size(\"a3\")\n (1122.5196850393702, 1587.4015748031497)\n\n Using page size descriptor (no units, pixels are assumed)::\n\n >>> vpype.convert_page_size(\"100x200\")\n (100.0, 200.0)\n\n Using page size descriptor (explicit units)::\n\n >>> vpype.convert_page_size(\"1inx2in\")\n (96.0, 192.0)\n\n Args:\n value: page size descriptor\n\n Returns:\n the page size in CSS pixels\n \"\"\"\n if value in PAGE_SIZES:\n return PAGE_SIZES[value]\n\n match = re.match(\n r\"^(\\d+\\.?\\d*)({0})?x(\\d+\\.?\\d*)({0})?$\".format(\"|\".join(UNITS.keys())), value\n )\n\n if not match:\n raise ValueError(f\"page size '{value}' unknown\")\n\n x, x_unit, y, y_unit = match.groups()\n\n if not x_unit:\n x_unit = y_unit if y_unit else \"px\"\n if not y_unit:\n y_unit = x_unit\n\n return float(x) * convert_length(x_unit), float(y) * convert_length(y_unit)\n\n\ndef convert_page_format(value: str) -> Tuple[float, float]: # pragma: no cover\n \"\"\"Deprecated, use convert_page_size.\"\"\"\n logging.warning(\n \"!!! `vpype.convert_page_format()` is deprecated, use `vpype.convert_page_size()` \"\n \"instead.\"\n )\n return convert_page_size(value)\n\n\nclass LengthType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided length\n string (which may contain units) into a value in CSS pixel units. This class uses\n :func:`convert_length` internally.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"x\", type=vpype.LengthType())\n ... @click.option(\"-o\", \"--option\", type=vpype.LengthType(), default=\"1mm\")\n ... @vpype.generator\n ... def my_command(x: float, option: float):\n ... pass\n \"\"\"\n\n name = \"length\"\n\n def convert(self, value, param, ctx):\n try:\n return convert_length(value)\n except ValueError:\n self.fail(f\"parameter {value} is an incorrect length\")\n\n\nclass Length(LengthType): # pragma: no cover\n \"\"\"Deprecated, use LengthType.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n logging.warning(\"!!! `vpype.Length` is deprecated, use `vpype.LengthType` instead.\")\n\n\nclass AngleType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided angle\n string (which may contain units) into a value in degrees. This class uses\n :func:`convert_angle` internally.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"angle\", type=vpype.AngleType())\n ... @vpype.generator\n ... def my_command(angle: float):\n ... pass\n \"\"\"\n\n name = \"angle\"\n\n def convert(self, value, param, ctx):\n try:\n return convert_angle(value)\n except ValueError:\n self.fail(f\"parameter {value} is an incorrect angle\")\n\n\nclass PageSizeType(click.ParamType):\n \"\"\":class:`click.ParamType` sub-class to automatically converts a user-provided page size\n string into a tuple of float in CSS pixel units. See :func:`convert_page_size` for\n information on the page size descriptor syntax.\n\n Example::\n\n >>> import click\n >>> import vpype_cli\n >>> import vpype\n >>> @vpype_cli.cli.command(group=\"my commands\")\n ... @click.argument(\"fmt\", type=vpype.PageSizeType())\n ... @vpype.generator\n ... def my_command(fmt: Tuple[float, float]):\n ... pass\n \"\"\"\n\n name = \"PAGESIZE\"\n\n def convert(self, value, param, ctx) -> Tuple[float, float]:\n try:\n return convert_page_size(value)\n except ValueError:\n self.fail(f\"parameter {value} is not a valid page size\")\n\n\ndef union(line: np.ndarray, keys: List[Callable[[np.ndarray], bool]]) -> bool:\n \"\"\"Returns True if every callables in ``keys`` return True (similar to ``all()``. This\n function is typically used with :meth:`LineCollection.filter`.\n\n Args:\n line: line to test\n keys: list of callables\n\n Returns:\n True if every callables return True\n \"\"\"\n for key in keys:\n if not key(line):\n return False\n return True\n", "path": "vpype/utils.py"}]}
| 3,867 | 254 |
gh_patches_debug_42818
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1807
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rename CompositeHTTPPropagator
[`CompositeHTTPPropagator`](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23) has nothing to do with HTTP so this name is confusing. It should be renamed to probably just `CompositePropagator`, but we need to keep an alias of the old name for backward compatibility.
[Relevant section of spec](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23)
</issue>
<code>
[start of docs/examples/datadog_exporter/server.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from flask import Flask, request
16
17 from opentelemetry import trace
18 from opentelemetry.exporter.datadog import (
19 DatadogExportSpanProcessor,
20 DatadogSpanExporter,
21 )
22 from opentelemetry.exporter.datadog.propagator import DatadogFormat
23 from opentelemetry.propagate import get_global_textmap, set_global_textmap
24 from opentelemetry.propagators.composite import CompositeHTTPPropagator
25 from opentelemetry.sdk.trace import TracerProvider
26
27 app = Flask(__name__)
28
29 trace.set_tracer_provider(TracerProvider())
30
31 trace.get_tracer_provider().add_span_processor(
32 DatadogExportSpanProcessor(
33 DatadogSpanExporter(
34 agent_url="http://localhost:8126", service="example-server"
35 )
36 )
37 )
38
39 # append Datadog format for propagation to and from Datadog instrumented services
40 global_textmap = get_global_textmap()
41 if isinstance(global_textmap, CompositeHTTPPropagator) and not any(
42 isinstance(p, DatadogFormat) for p in global_textmap._propagators
43 ):
44 set_global_textmap(
45 CompositeHTTPPropagator(
46 global_textmap._propagators + [DatadogFormat()]
47 )
48 )
49 else:
50 set_global_textmap(DatadogFormat())
51
52 tracer = trace.get_tracer(__name__)
53
54
55 @app.route("/server_request")
56 def server_request():
57 param = request.args.get("param")
58 with tracer.start_as_current_span("server-inner"):
59 if param == "error":
60 raise ValueError("forced server error")
61 return "served: {}".format(param)
62
63
64 if __name__ == "__main__":
65 app.run(port=8082)
66
[end of docs/examples/datadog_exporter/server.py]
[start of opentelemetry-api/src/opentelemetry/propagate/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 API for propagation of context.
17
18 The propagators for the
19 ``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined
20 via configuration in the ``OTEL_PROPAGATORS`` environment variable. This
21 variable should be set to a comma-separated string of names of values for the
22 ``opentelemetry_propagator`` entry point. For example, setting
23 ``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)
24 would instantiate
25 ``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2
26 propagators, one of type
27 ``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``
28 and other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.
29 Notice that these propagator classes are defined as
30 ``opentelemetry_propagator`` entry points in the ``setup.cfg`` file of
31 ``opentelemetry``.
32
33 Example::
34
35 import flask
36 import requests
37 from opentelemetry import propagators
38
39
40 PROPAGATOR = propagators.get_global_textmap()
41
42
43 def get_header_from_flask_request(request, key):
44 return request.headers.get_all(key)
45
46 def set_header_into_requests_request(request: requests.Request,
47 key: str, value: str):
48 request.headers[key] = value
49
50 def example_route():
51 context = PROPAGATOR.extract(
52 get_header_from_flask_request,
53 flask.request
54 )
55 request_to_downstream = requests.Request(
56 "GET", "http://httpbin.org/get"
57 )
58 PROPAGATOR.inject(
59 set_header_into_requests_request,
60 request_to_downstream,
61 context=context
62 )
63 session = requests.Session()
64 session.send(request_to_downstream.prepare())
65
66
67 .. _Propagation API Specification:
68 https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md
69 """
70
71 import typing
72 from logging import getLogger
73 from os import environ
74
75 from pkg_resources import iter_entry_points
76
77 from opentelemetry.context.context import Context
78 from opentelemetry.environment_variables import OTEL_PROPAGATORS
79 from opentelemetry.propagators import composite, textmap
80
81 logger = getLogger(__name__)
82
83
84 def extract(
85 carrier: textmap.CarrierT,
86 context: typing.Optional[Context] = None,
87 getter: textmap.Getter = textmap.default_getter,
88 ) -> Context:
89 """Uses the configured propagator to extract a Context from the carrier.
90
91 Args:
92 getter: an object which contains a get function that can retrieve zero
93 or more values from the carrier and a keys function that can get all the keys
94 from carrier.
95 carrier: and object which contains values that are
96 used to construct a Context. This object
97 must be paired with an appropriate getter
98 which understands how to extract a value from it.
99 context: an optional Context to use. Defaults to current
100 context if not set.
101 """
102 return get_global_textmap().extract(carrier, context, getter=getter)
103
104
105 def inject(
106 carrier: textmap.CarrierT,
107 context: typing.Optional[Context] = None,
108 setter: textmap.Setter = textmap.default_setter,
109 ) -> None:
110 """Uses the configured propagator to inject a Context into the carrier.
111
112 Args:
113 carrier: An object that contains a representation of HTTP
114 headers. Should be paired with setter, which
115 should know how to set header values on the carrier.
116 context: An optional Context to use. Defaults to current
117 context if not set.
118 setter: An optional `Setter` object that can set values
119 on the carrier.
120 """
121 get_global_textmap().inject(carrier, context=context, setter=setter)
122
123
124 try:
125
126 propagators = []
127
128 # Single use variable here to hack black and make lint pass
129 environ_propagators = environ.get(
130 OTEL_PROPAGATORS,
131 "tracecontext,baggage",
132 )
133
134 for propagator in environ_propagators.split(","):
135 propagators.append( # type: ignore
136 next( # type: ignore
137 iter_entry_points("opentelemetry_propagator", propagator)
138 ).load()()
139 )
140
141 except Exception: # pylint: disable=broad-except
142 logger.exception("Failed to load configured propagators")
143 raise
144
145 _HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore
146
147
148 def get_global_textmap() -> textmap.TextMapPropagator:
149 return _HTTP_TEXT_FORMAT
150
151
152 def set_global_textmap(
153 http_text_format: textmap.TextMapPropagator,
154 ) -> None:
155 global _HTTP_TEXT_FORMAT # pylint:disable=global-statement
156 _HTTP_TEXT_FORMAT = http_text_format # type: ignore
157
[end of opentelemetry-api/src/opentelemetry/propagate/__init__.py]
[start of opentelemetry-api/src/opentelemetry/propagators/composite.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import logging
15 import typing
16
17 from opentelemetry.context.context import Context
18 from opentelemetry.propagators import textmap
19
20 logger = logging.getLogger(__name__)
21
22
23 class CompositeHTTPPropagator(textmap.TextMapPropagator):
24 """CompositeHTTPPropagator provides a mechanism for combining multiple
25 propagators into a single one.
26
27 Args:
28 propagators: the list of propagators to use
29 """
30
31 def __init__(
32 self, propagators: typing.Sequence[textmap.TextMapPropagator]
33 ) -> None:
34 self._propagators = propagators
35
36 def extract(
37 self,
38 carrier: textmap.CarrierT,
39 context: typing.Optional[Context] = None,
40 getter: textmap.Getter = textmap.default_getter,
41 ) -> Context:
42 """Run each of the configured propagators with the given context and carrier.
43 Propagators are run in the order they are configured, if multiple
44 propagators write the same context key, the propagator later in the list
45 will override previous propagators.
46
47 See `opentelemetry.propagators.textmap.TextMapPropagator.extract`
48 """
49 for propagator in self._propagators:
50 context = propagator.extract(carrier, context, getter=getter)
51 return context # type: ignore
52
53 def inject(
54 self,
55 carrier: textmap.CarrierT,
56 context: typing.Optional[Context] = None,
57 setter: textmap.Setter = textmap.default_setter,
58 ) -> None:
59 """Run each of the configured propagators with the given context and carrier.
60 Propagators are run in the order they are configured, if multiple
61 propagators write the same carrier key, the propagator later in the list
62 will override previous propagators.
63
64 See `opentelemetry.propagators.textmap.TextMapPropagator.inject`
65 """
66 for propagator in self._propagators:
67 propagator.inject(carrier, context, setter=setter)
68
69 @property
70 def fields(self) -> typing.Set[str]:
71 """Returns a set with the fields set in `inject`.
72
73 See
74 `opentelemetry.propagators.textmap.TextMapPropagator.fields`
75 """
76 composite_fields = set()
77
78 for propagator in self._propagators:
79 for field in propagator.fields:
80 composite_fields.add(field)
81
82 return composite_fields
83
[end of opentelemetry-api/src/opentelemetry/propagators/composite.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/examples/datadog_exporter/server.py b/docs/examples/datadog_exporter/server.py
--- a/docs/examples/datadog_exporter/server.py
+++ b/docs/examples/datadog_exporter/server.py
@@ -21,7 +21,7 @@
)
from opentelemetry.exporter.datadog.propagator import DatadogFormat
from opentelemetry.propagate import get_global_textmap, set_global_textmap
-from opentelemetry.propagators.composite import CompositeHTTPPropagator
+from opentelemetry.propagators.composite import CompositePropagator
from opentelemetry.sdk.trace import TracerProvider
app = Flask(__name__)
@@ -38,13 +38,11 @@
# append Datadog format for propagation to and from Datadog instrumented services
global_textmap = get_global_textmap()
-if isinstance(global_textmap, CompositeHTTPPropagator) and not any(
+if isinstance(global_textmap, CompositePropagator) and not any(
isinstance(p, DatadogFormat) for p in global_textmap._propagators
):
set_global_textmap(
- CompositeHTTPPropagator(
- global_textmap._propagators + [DatadogFormat()]
- )
+ CompositePropagator(global_textmap._propagators + [DatadogFormat()])
)
else:
set_global_textmap(DatadogFormat())
diff --git a/opentelemetry-api/src/opentelemetry/propagate/__init__.py b/opentelemetry-api/src/opentelemetry/propagate/__init__.py
--- a/opentelemetry-api/src/opentelemetry/propagate/__init__.py
+++ b/opentelemetry-api/src/opentelemetry/propagate/__init__.py
@@ -16,13 +16,13 @@
API for propagation of context.
The propagators for the
-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined
+``opentelemetry.propagators.composite.CompositePropagator`` can be defined
via configuration in the ``OTEL_PROPAGATORS`` environment variable. This
variable should be set to a comma-separated string of names of values for the
``opentelemetry_propagator`` entry point. For example, setting
``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)
would instantiate
-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2
+``opentelemetry.propagators.composite.CompositePropagator`` with 2
propagators, one of type
``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``
and other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.
@@ -142,7 +142,7 @@
logger.exception("Failed to load configured propagators")
raise
-_HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore
+_HTTP_TEXT_FORMAT = composite.CompositePropagator(propagators) # type: ignore
def get_global_textmap() -> textmap.TextMapPropagator:
diff --git a/opentelemetry-api/src/opentelemetry/propagators/composite.py b/opentelemetry-api/src/opentelemetry/propagators/composite.py
--- a/opentelemetry-api/src/opentelemetry/propagators/composite.py
+++ b/opentelemetry-api/src/opentelemetry/propagators/composite.py
@@ -14,14 +14,16 @@
import logging
import typing
+from deprecated import deprecated
+
from opentelemetry.context.context import Context
from opentelemetry.propagators import textmap
logger = logging.getLogger(__name__)
-class CompositeHTTPPropagator(textmap.TextMapPropagator):
- """CompositeHTTPPropagator provides a mechanism for combining multiple
+class CompositePropagator(textmap.TextMapPropagator):
+ """CompositePropagator provides a mechanism for combining multiple
propagators into a single one.
Args:
@@ -80,3 +82,10 @@
composite_fields.add(field)
return composite_fields
+
+
+@deprecated(version="1.2.0", reason="You should use CompositePropagator") # type: ignore
+class CompositeHTTPPropagator(CompositePropagator):
+ """CompositeHTTPPropagator provides a mechanism for combining multiple
+ propagators into a single one.
+ """
|
{"golden_diff": "diff --git a/docs/examples/datadog_exporter/server.py b/docs/examples/datadog_exporter/server.py\n--- a/docs/examples/datadog_exporter/server.py\n+++ b/docs/examples/datadog_exporter/server.py\n@@ -21,7 +21,7 @@\n )\n from opentelemetry.exporter.datadog.propagator import DatadogFormat\n from opentelemetry.propagate import get_global_textmap, set_global_textmap\n-from opentelemetry.propagators.composite import CompositeHTTPPropagator\n+from opentelemetry.propagators.composite import CompositePropagator\n from opentelemetry.sdk.trace import TracerProvider\n \n app = Flask(__name__)\n@@ -38,13 +38,11 @@\n \n # append Datadog format for propagation to and from Datadog instrumented services\n global_textmap = get_global_textmap()\n-if isinstance(global_textmap, CompositeHTTPPropagator) and not any(\n+if isinstance(global_textmap, CompositePropagator) and not any(\n isinstance(p, DatadogFormat) for p in global_textmap._propagators\n ):\n set_global_textmap(\n- CompositeHTTPPropagator(\n- global_textmap._propagators + [DatadogFormat()]\n- )\n+ CompositePropagator(global_textmap._propagators + [DatadogFormat()])\n )\n else:\n set_global_textmap(DatadogFormat())\ndiff --git a/opentelemetry-api/src/opentelemetry/propagate/__init__.py b/opentelemetry-api/src/opentelemetry/propagate/__init__.py\n--- a/opentelemetry-api/src/opentelemetry/propagate/__init__.py\n+++ b/opentelemetry-api/src/opentelemetry/propagate/__init__.py\n@@ -16,13 +16,13 @@\n API for propagation of context.\n \n The propagators for the\n-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined\n+``opentelemetry.propagators.composite.CompositePropagator`` can be defined\n via configuration in the ``OTEL_PROPAGATORS`` environment variable. This\n variable should be set to a comma-separated string of names of values for the\n ``opentelemetry_propagator`` entry point. For example, setting\n ``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)\n would instantiate\n-``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2\n+``opentelemetry.propagators.composite.CompositePropagator`` with 2\n propagators, one of type\n ``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``\n and other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.\n@@ -142,7 +142,7 @@\n logger.exception(\"Failed to load configured propagators\")\n raise\n \n-_HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore\n+_HTTP_TEXT_FORMAT = composite.CompositePropagator(propagators) # type: ignore\n \n \n def get_global_textmap() -> textmap.TextMapPropagator:\ndiff --git a/opentelemetry-api/src/opentelemetry/propagators/composite.py b/opentelemetry-api/src/opentelemetry/propagators/composite.py\n--- a/opentelemetry-api/src/opentelemetry/propagators/composite.py\n+++ b/opentelemetry-api/src/opentelemetry/propagators/composite.py\n@@ -14,14 +14,16 @@\n import logging\n import typing\n \n+from deprecated import deprecated\n+\n from opentelemetry.context.context import Context\n from opentelemetry.propagators import textmap\n \n logger = logging.getLogger(__name__)\n \n \n-class CompositeHTTPPropagator(textmap.TextMapPropagator):\n- \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n+class CompositePropagator(textmap.TextMapPropagator):\n+ \"\"\"CompositePropagator provides a mechanism for combining multiple\n propagators into a single one.\n \n Args:\n@@ -80,3 +82,10 @@\n composite_fields.add(field)\n \n return composite_fields\n+\n+\n+@deprecated(version=\"1.2.0\", reason=\"You should use CompositePropagator\") # type: ignore\n+class CompositeHTTPPropagator(CompositePropagator):\n+ \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n+ propagators into a single one.\n+ \"\"\"\n", "issue": "Rename CompositeHTTPPropagator\n[`CompositeHTTPPropagator`](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23) has nothing to do with HTTP so this name is confusing. It should be renamed to probably just `CompositePropagator`, but we need to keep an alias of the old name for backward compatibility.\r\n\r\n[Relevant section of spec](https://github.com/open-telemetry/opentelemetry-python/blob/b73d8009904fc1693b2ba3a1e0656af376f859cf/opentelemetry-api/src/opentelemetry/propagators/composite.py#L23)\r\n\r\n\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom flask import Flask, request\n\nfrom opentelemetry import trace\nfrom opentelemetry.exporter.datadog import (\n DatadogExportSpanProcessor,\n DatadogSpanExporter,\n)\nfrom opentelemetry.exporter.datadog.propagator import DatadogFormat\nfrom opentelemetry.propagate import get_global_textmap, set_global_textmap\nfrom opentelemetry.propagators.composite import CompositeHTTPPropagator\nfrom opentelemetry.sdk.trace import TracerProvider\n\napp = Flask(__name__)\n\ntrace.set_tracer_provider(TracerProvider())\n\ntrace.get_tracer_provider().add_span_processor(\n DatadogExportSpanProcessor(\n DatadogSpanExporter(\n agent_url=\"http://localhost:8126\", service=\"example-server\"\n )\n )\n)\n\n# append Datadog format for propagation to and from Datadog instrumented services\nglobal_textmap = get_global_textmap()\nif isinstance(global_textmap, CompositeHTTPPropagator) and not any(\n isinstance(p, DatadogFormat) for p in global_textmap._propagators\n):\n set_global_textmap(\n CompositeHTTPPropagator(\n global_textmap._propagators + [DatadogFormat()]\n )\n )\nelse:\n set_global_textmap(DatadogFormat())\n\ntracer = trace.get_tracer(__name__)\n\n\[email protected](\"/server_request\")\ndef server_request():\n param = request.args.get(\"param\")\n with tracer.start_as_current_span(\"server-inner\"):\n if param == \"error\":\n raise ValueError(\"forced server error\")\n return \"served: {}\".format(param)\n\n\nif __name__ == \"__main__\":\n app.run(port=8082)\n", "path": "docs/examples/datadog_exporter/server.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nAPI for propagation of context.\n\nThe propagators for the\n``opentelemetry.propagators.composite.CompositeHTTPPropagator`` can be defined\nvia configuration in the ``OTEL_PROPAGATORS`` environment variable. This\nvariable should be set to a comma-separated string of names of values for the\n``opentelemetry_propagator`` entry point. For example, setting\n``OTEL_PROPAGATORS`` to ``tracecontext,baggage`` (which is the default value)\nwould instantiate\n``opentelemetry.propagators.composite.CompositeHTTPPropagator`` with 2\npropagators, one of type\n``opentelemetry.trace.propagation.tracecontext.TraceContextTextMapPropagator``\nand other of type ``opentelemetry.baggage.propagation.W3CBaggagePropagator``.\nNotice that these propagator classes are defined as\n``opentelemetry_propagator`` entry points in the ``setup.cfg`` file of\n``opentelemetry``.\n\nExample::\n\n import flask\n import requests\n from opentelemetry import propagators\n\n\n PROPAGATOR = propagators.get_global_textmap()\n\n\n def get_header_from_flask_request(request, key):\n return request.headers.get_all(key)\n\n def set_header_into_requests_request(request: requests.Request,\n key: str, value: str):\n request.headers[key] = value\n\n def example_route():\n context = PROPAGATOR.extract(\n get_header_from_flask_request,\n flask.request\n )\n request_to_downstream = requests.Request(\n \"GET\", \"http://httpbin.org/get\"\n )\n PROPAGATOR.inject(\n set_header_into_requests_request,\n request_to_downstream,\n context=context\n )\n session = requests.Session()\n session.send(request_to_downstream.prepare())\n\n\n.. _Propagation API Specification:\n https://github.com/open-telemetry/opentelemetry-specification/blob/main/specification/context/api-propagators.md\n\"\"\"\n\nimport typing\nfrom logging import getLogger\nfrom os import environ\n\nfrom pkg_resources import iter_entry_points\n\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.environment_variables import OTEL_PROPAGATORS\nfrom opentelemetry.propagators import composite, textmap\n\nlogger = getLogger(__name__)\n\n\ndef extract(\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n getter: textmap.Getter = textmap.default_getter,\n) -> Context:\n \"\"\"Uses the configured propagator to extract a Context from the carrier.\n\n Args:\n getter: an object which contains a get function that can retrieve zero\n or more values from the carrier and a keys function that can get all the keys\n from carrier.\n carrier: and object which contains values that are\n used to construct a Context. This object\n must be paired with an appropriate getter\n which understands how to extract a value from it.\n context: an optional Context to use. Defaults to current\n context if not set.\n \"\"\"\n return get_global_textmap().extract(carrier, context, getter=getter)\n\n\ndef inject(\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n setter: textmap.Setter = textmap.default_setter,\n) -> None:\n \"\"\"Uses the configured propagator to inject a Context into the carrier.\n\n Args:\n carrier: An object that contains a representation of HTTP\n headers. Should be paired with setter, which\n should know how to set header values on the carrier.\n context: An optional Context to use. Defaults to current\n context if not set.\n setter: An optional `Setter` object that can set values\n on the carrier.\n \"\"\"\n get_global_textmap().inject(carrier, context=context, setter=setter)\n\n\ntry:\n\n propagators = []\n\n # Single use variable here to hack black and make lint pass\n environ_propagators = environ.get(\n OTEL_PROPAGATORS,\n \"tracecontext,baggage\",\n )\n\n for propagator in environ_propagators.split(\",\"):\n propagators.append( # type: ignore\n next( # type: ignore\n iter_entry_points(\"opentelemetry_propagator\", propagator)\n ).load()()\n )\n\nexcept Exception: # pylint: disable=broad-except\n logger.exception(\"Failed to load configured propagators\")\n raise\n\n_HTTP_TEXT_FORMAT = composite.CompositeHTTPPropagator(propagators) # type: ignore\n\n\ndef get_global_textmap() -> textmap.TextMapPropagator:\n return _HTTP_TEXT_FORMAT\n\n\ndef set_global_textmap(\n http_text_format: textmap.TextMapPropagator,\n) -> None:\n global _HTTP_TEXT_FORMAT # pylint:disable=global-statement\n _HTTP_TEXT_FORMAT = http_text_format # type: ignore\n", "path": "opentelemetry-api/src/opentelemetry/propagate/__init__.py"}, {"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport logging\nimport typing\n\nfrom opentelemetry.context.context import Context\nfrom opentelemetry.propagators import textmap\n\nlogger = logging.getLogger(__name__)\n\n\nclass CompositeHTTPPropagator(textmap.TextMapPropagator):\n \"\"\"CompositeHTTPPropagator provides a mechanism for combining multiple\n propagators into a single one.\n\n Args:\n propagators: the list of propagators to use\n \"\"\"\n\n def __init__(\n self, propagators: typing.Sequence[textmap.TextMapPropagator]\n ) -> None:\n self._propagators = propagators\n\n def extract(\n self,\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n getter: textmap.Getter = textmap.default_getter,\n ) -> Context:\n \"\"\"Run each of the configured propagators with the given context and carrier.\n Propagators are run in the order they are configured, if multiple\n propagators write the same context key, the propagator later in the list\n will override previous propagators.\n\n See `opentelemetry.propagators.textmap.TextMapPropagator.extract`\n \"\"\"\n for propagator in self._propagators:\n context = propagator.extract(carrier, context, getter=getter)\n return context # type: ignore\n\n def inject(\n self,\n carrier: textmap.CarrierT,\n context: typing.Optional[Context] = None,\n setter: textmap.Setter = textmap.default_setter,\n ) -> None:\n \"\"\"Run each of the configured propagators with the given context and carrier.\n Propagators are run in the order they are configured, if multiple\n propagators write the same carrier key, the propagator later in the list\n will override previous propagators.\n\n See `opentelemetry.propagators.textmap.TextMapPropagator.inject`\n \"\"\"\n for propagator in self._propagators:\n propagator.inject(carrier, context, setter=setter)\n\n @property\n def fields(self) -> typing.Set[str]:\n \"\"\"Returns a set with the fields set in `inject`.\n\n See\n `opentelemetry.propagators.textmap.TextMapPropagator.fields`\n \"\"\"\n composite_fields = set()\n\n for propagator in self._propagators:\n for field in propagator.fields:\n composite_fields.add(field)\n\n return composite_fields\n", "path": "opentelemetry-api/src/opentelemetry/propagators/composite.py"}]}
| 3,788 | 986 |
gh_patches_debug_12018
|
rasdani/github-patches
|
git_diff
|
gwastro__pycbc-2107
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PyCBC can't import its own version
It seems that a broken relative import means pycbc can't actually import its own version, from `ldas-pcdev1.ligo.caltech.edu`:
```bash
$ . /cvmfs/oasis.opensciencegrid.org/ligo/sw/pycbc/x86_64_rhel_7/virtualenv/pycbc-v1.9.2/bin/activate
(pycbc-v1.9.2) $ python -c "import pycbc; print(pycbc.pycbc_version)"
none
```
The fix is pretty trivial, I will post a PR shortly.
</issue>
<code>
[start of pycbc/__init__.py]
1 # Copyright (C) 2012 Alex Nitz, Josh Willis
2 #
3 # This program is free software; you can redistribute it and/or modify it
4 # under the terms of the GNU General Public License as published by the
5 # Free Software Foundation; either version 3 of the License, or (at your
6 # option) any later version.
7 #
8 # This program is distributed in the hope that it will be useful, but
9 # WITHOUT ANY WARRANTY; without even the implied warranty of
10 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General
11 # Public License for more details.
12 #
13 # You should have received a copy of the GNU General Public License along
14 # with this program; if not, write to the Free Software Foundation, Inc.,
15 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
16
17
18 #
19 # =============================================================================
20 #
21 # Preamble
22 #
23 # =============================================================================
24 #
25 """PyCBC contains a toolkit for CBC gravitational wave analysis
26 """
27 from __future__ import (absolute_import, print_function)
28 import subprocess, os, sys, tempfile
29 import logging
30 import signal
31
32 try:
33 # This will fail when pycbc is imported during the build process,
34 # before version.py has been generated.
35 from version import git_hash
36 from version import version as pycbc_version
37 except:
38 git_hash = 'none'
39 pycbc_version = 'none'
40
41 def init_logging(verbose=False, format='%(asctime)s %(message)s'):
42 """ Common utility for setting up logging in PyCBC.
43
44 Installs a signal handler such that verbosity can be activated at
45 run-time by sending a SIGUSR1 to the process.
46 """
47 def sig_handler(signum, frame):
48 logger = logging.getLogger()
49 log_level = logger.level
50 if log_level == logging.DEBUG:
51 log_level = logging.WARN
52 else:
53 log_level = logging.DEBUG
54 logging.warn('Got signal %d, setting log level to %d',
55 signum, log_level)
56 logger.setLevel(log_level)
57
58 signal.signal(signal.SIGUSR1, sig_handler)
59
60 if verbose:
61 initial_level = logging.DEBUG
62 else:
63 initial_level = logging.WARN
64 logging.getLogger().setLevel(initial_level)
65 logging.basicConfig(format=format, level=initial_level)
66
67
68 # Check for optional components of the PyCBC Package
69 try:
70 # This is a crude check to make sure that the driver is installed
71 try:
72 loaded_modules = subprocess.Popen(['lsmod'], stdout=subprocess.PIPE).communicate()[0]
73 loaded_modules = loaded_modules.decode()
74 if 'nvidia' not in loaded_modules:
75 raise ImportError("nvidia driver may not be installed correctly")
76 except OSError:
77 pass
78
79 # Check that pycuda is installed and can talk to the driver
80 import pycuda.driver as _pycudadrv
81
82 HAVE_CUDA=True
83 except ImportError:
84 HAVE_CUDA=False
85
86 # Check for openmp suppport, currently we pressume it exists, unless on
87 # platforms (mac) that are silly and don't use the standard gcc.
88 if sys.platform == 'darwin':
89 HAVE_OMP = False
90 else:
91 HAVE_OMP = True
92
93 # PyCBC-Specific Constants
94
95 # Set the value we want any aligned memory calls to use
96 # N.B.: *Not* all pycbc memory will be aligned to multiples
97 # of this value
98
99 PYCBC_ALIGNMENT = 32
100
101 # Dynamic range factor: a large constant for rescaling
102 # GW strains. This is 2**69 rounded to 17 sig.fig.
103
104 DYN_RANGE_FAC = 5.9029581035870565e+20
105
106 if os.environ.get("INITIAL_LOG_LEVEL", None):
107 logging.basicConfig(format='%(asctime)s %(message)s',
108 level=int(os.environ["INITIAL_LOG_LEVEL"]))
109
110 # Make sure we use a user specific, machine specific compiled cache location
111 _python_name = "python%d%d_compiled" % tuple(sys.version_info[:2])
112 _tmp_dir = tempfile.gettempdir()
113 _cache_dir_name = repr(os.getuid()) + '_' + _python_name
114 _cache_dir_path = os.path.join(_tmp_dir, _cache_dir_name)
115 # Append the git hash to the cache path. This will ensure that cached
116 # files are correct even in cases where weave currently doesn't realize
117 # that a recompile is needed.
118 # FIXME: It would be better to find a way to trigger a recompile off
119 # of all the arguments to weave.
120 _cache_dir_path = os.path.join(_cache_dir_path, pycbc_version)
121 _cache_dir_path = os.path.join(_cache_dir_path, git_hash)
122 if os.environ.get("NO_TMPDIR", None):
123 if os.environ.get("INITIAL_LOG_LEVEL", 0) >= 10:
124 print("__init__: Skipped creating %s as NO_TEMPDIR is set"
125 % _cache_dir_path, file=sys.stderr)
126 else:
127 try: os.makedirs(_cache_dir_path)
128 except OSError: pass
129 if os.environ.get("INITIAL_LOG_LEVEL", 0) >= 10:
130 print("__init__: Setting weave cache to %s" % _cache_dir_path,
131 file=sys.stderr)
132 os.environ['PYTHONCOMPILED'] = _cache_dir_path
133
134 # Check for MKL capability
135 try:
136 import pycbc.fft.mkl
137 HAVE_MKL=True
138 except ImportError as e:
139 print(e)
140 HAVE_MKL=False
141
142
143 # Check for site-local flags to pass to gcc
144 WEAVE_FLAGS = '-march=native -O3 -w '
145 if 'WEAVE_FLAGS' in os.environ:
146 if '-march=' in os.environ['WEAVE_FLAGS']:
147 WEAVE_FLAGS = os.environ['WEAVE_FLAGS']
148 else:
149 WEAVE_FLAGS += os.environ['WEAVE_FLAGS']
150
151 def multiprocess_cache_dir():
152 import multiprocessing
153 cache_dir = os.path.join(_cache_dir_path, str(id(multiprocessing.current_process())))
154 os.environ['PYTHONCOMPILED'] = cache_dir
155 try: os.makedirs(cache_dir)
156 except OSError: pass
157
[end of pycbc/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pycbc/__init__.py b/pycbc/__init__.py
--- a/pycbc/__init__.py
+++ b/pycbc/__init__.py
@@ -32,12 +32,15 @@
try:
# This will fail when pycbc is imported during the build process,
# before version.py has been generated.
- from version import git_hash
- from version import version as pycbc_version
+ from .version import git_hash
+ from .version import version as pycbc_version
except:
git_hash = 'none'
pycbc_version = 'none'
+__version__ = pycbc_version
+
+
def init_logging(verbose=False, format='%(asctime)s %(message)s'):
""" Common utility for setting up logging in PyCBC.
|
{"golden_diff": "diff --git a/pycbc/__init__.py b/pycbc/__init__.py\n--- a/pycbc/__init__.py\n+++ b/pycbc/__init__.py\n@@ -32,12 +32,15 @@\n try:\n # This will fail when pycbc is imported during the build process,\n # before version.py has been generated.\n- from version import git_hash\n- from version import version as pycbc_version\n+ from .version import git_hash\n+ from .version import version as pycbc_version\n except:\n git_hash = 'none'\n pycbc_version = 'none'\n \n+__version__ = pycbc_version\n+\n+\n def init_logging(verbose=False, format='%(asctime)s %(message)s'):\n \"\"\" Common utility for setting up logging in PyCBC.\n", "issue": "PyCBC can't import its own version\nIt seems that a broken relative import means pycbc can't actually import its own version, from `ldas-pcdev1.ligo.caltech.edu`:\r\n\r\n```bash\r\n$ . /cvmfs/oasis.opensciencegrid.org/ligo/sw/pycbc/x86_64_rhel_7/virtualenv/pycbc-v1.9.2/bin/activate\r\n(pycbc-v1.9.2) $ python -c \"import pycbc; print(pycbc.pycbc_version)\"\r\nnone\r\n```\r\n\r\nThe fix is pretty trivial, I will post a PR shortly.\n", "before_files": [{"content": "# Copyright (C) 2012 Alex Nitz, Josh Willis\n#\n# This program is free software; you can redistribute it and/or modify it\n# under the terms of the GNU General Public License as published by the\n# Free Software Foundation; either version 3 of the License, or (at your\n# option) any later version.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General\n# Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n\n#\n# =============================================================================\n#\n# Preamble\n#\n# =============================================================================\n#\n\"\"\"PyCBC contains a toolkit for CBC gravitational wave analysis\n\"\"\"\nfrom __future__ import (absolute_import, print_function)\nimport subprocess, os, sys, tempfile\nimport logging\nimport signal\n\ntry:\n # This will fail when pycbc is imported during the build process,\n # before version.py has been generated.\n from version import git_hash\n from version import version as pycbc_version\nexcept:\n git_hash = 'none'\n pycbc_version = 'none'\n\ndef init_logging(verbose=False, format='%(asctime)s %(message)s'):\n \"\"\" Common utility for setting up logging in PyCBC.\n\n Installs a signal handler such that verbosity can be activated at\n run-time by sending a SIGUSR1 to the process.\n \"\"\"\n def sig_handler(signum, frame):\n logger = logging.getLogger()\n log_level = logger.level\n if log_level == logging.DEBUG:\n log_level = logging.WARN\n else:\n log_level = logging.DEBUG\n logging.warn('Got signal %d, setting log level to %d',\n signum, log_level)\n logger.setLevel(log_level)\n\n signal.signal(signal.SIGUSR1, sig_handler)\n\n if verbose:\n initial_level = logging.DEBUG\n else:\n initial_level = logging.WARN\n logging.getLogger().setLevel(initial_level)\n logging.basicConfig(format=format, level=initial_level)\n\n\n# Check for optional components of the PyCBC Package\ntry:\n # This is a crude check to make sure that the driver is installed\n try:\n loaded_modules = subprocess.Popen(['lsmod'], stdout=subprocess.PIPE).communicate()[0]\n loaded_modules = loaded_modules.decode()\n if 'nvidia' not in loaded_modules:\n raise ImportError(\"nvidia driver may not be installed correctly\")\n except OSError:\n pass\n\n # Check that pycuda is installed and can talk to the driver\n import pycuda.driver as _pycudadrv\n\n HAVE_CUDA=True \nexcept ImportError:\n HAVE_CUDA=False\n \n# Check for openmp suppport, currently we pressume it exists, unless on \n# platforms (mac) that are silly and don't use the standard gcc. \nif sys.platform == 'darwin':\n HAVE_OMP = False\nelse:\n HAVE_OMP = True\n\n# PyCBC-Specific Constants\n\n# Set the value we want any aligned memory calls to use\n# N.B.: *Not* all pycbc memory will be aligned to multiples\n# of this value\n\nPYCBC_ALIGNMENT = 32\n\n# Dynamic range factor: a large constant for rescaling\n# GW strains. This is 2**69 rounded to 17 sig.fig.\n\nDYN_RANGE_FAC = 5.9029581035870565e+20\n\nif os.environ.get(\"INITIAL_LOG_LEVEL\", None):\n logging.basicConfig(format='%(asctime)s %(message)s',\n level=int(os.environ[\"INITIAL_LOG_LEVEL\"]))\n\n# Make sure we use a user specific, machine specific compiled cache location\n_python_name = \"python%d%d_compiled\" % tuple(sys.version_info[:2])\n_tmp_dir = tempfile.gettempdir()\n_cache_dir_name = repr(os.getuid()) + '_' + _python_name\n_cache_dir_path = os.path.join(_tmp_dir, _cache_dir_name)\n# Append the git hash to the cache path. This will ensure that cached \n# files are correct even in cases where weave currently doesn't realize\n# that a recompile is needed.\n# FIXME: It would be better to find a way to trigger a recompile off\n# of all the arguments to weave.\n_cache_dir_path = os.path.join(_cache_dir_path, pycbc_version)\n_cache_dir_path = os.path.join(_cache_dir_path, git_hash)\nif os.environ.get(\"NO_TMPDIR\", None):\n if os.environ.get(\"INITIAL_LOG_LEVEL\", 0) >= 10:\n print(\"__init__: Skipped creating %s as NO_TEMPDIR is set\"\n % _cache_dir_path, file=sys.stderr)\nelse:\n try: os.makedirs(_cache_dir_path)\n except OSError: pass\n if os.environ.get(\"INITIAL_LOG_LEVEL\", 0) >= 10:\n print(\"__init__: Setting weave cache to %s\" % _cache_dir_path,\n file=sys.stderr)\nos.environ['PYTHONCOMPILED'] = _cache_dir_path\n\n# Check for MKL capability\ntry:\n import pycbc.fft.mkl\n HAVE_MKL=True\nexcept ImportError as e:\n print(e)\n HAVE_MKL=False\n \n\n# Check for site-local flags to pass to gcc\nWEAVE_FLAGS = '-march=native -O3 -w '\nif 'WEAVE_FLAGS' in os.environ:\n if '-march=' in os.environ['WEAVE_FLAGS']:\n WEAVE_FLAGS = os.environ['WEAVE_FLAGS']\n else:\n WEAVE_FLAGS += os.environ['WEAVE_FLAGS']\n\ndef multiprocess_cache_dir():\n import multiprocessing\n cache_dir = os.path.join(_cache_dir_path, str(id(multiprocessing.current_process())))\n os.environ['PYTHONCOMPILED'] = cache_dir\n try: os.makedirs(cache_dir)\n except OSError: pass\n", "path": "pycbc/__init__.py"}]}
| 2,374 | 177 |
gh_patches_debug_8207
|
rasdani/github-patches
|
git_diff
|
nautobot__nautobot-4976
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Install issue 2.0.1 -> collect static fails to create directories
<!--
NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.
This form is only for reporting reproducible bugs. If you need assistance
with Nautobot installation, or if you have a general question, please start a
discussion instead: https://github.com/nautobot/nautobot/discussions
Please describe the environment in which you are running Nautobot. Be sure
that you are running an unmodified instance of the latest stable release
before submitting a bug report, and that any plugins have been disabled.
-->
### Environment
* Nautobot version (Docker tag too if applicable): 2.0.1
* Python version: 3.10.12
* Database platform, version: postgres
* Middleware(s):none
<!--
Describe in detail the exact steps that someone else can take to reproduce
this bug using the current stable release of Nautobot. Begin with the
creation of any necessary database objects and call out every operation
being performed explicitly. If reporting a bug in the REST API, be sure to
reconstruct the raw HTTP request(s) being made: Don't rely on a client
library such as pynautobot.
-->
### Steps to Reproduce
1. New installation of nautobot
2. Following instructions at https://blog.networktocode.com/post/installing-nautobot/
3. Issue command nautobot-server collectstatic
<!-- What did you expect to happen? -->
### Expected Behavior
Expected directories to be created and static files to be collected
<!-- What happened instead? -->
Error occurred
nautobot@server:~$ nautobot-server collectstatic
16:21:56.992 ERROR nautobot.core.apps :
Error in link construction for Notes: Reverse for 'note_list' not found. 'note_list' is not a valid view function or pattern name.
Traceback (most recent call last):
File "/opt/nautobot/bin/nautobot-server", line 8, in <module>
sys.exit(main())
File "/opt/nautobot/lib/python3.10/site-packages/nautobot/core/cli/__init__.py", line 54, in main
run_app(
File "/opt/nautobot/lib/python3.10/site-packages/nautobot/core/runner/runner.py", line 297, in run_app
management.execute_from_command_line([runner_name, command] + command_args)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py", line 419, in execute_from_command_line
utility.execute()
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py", line 413, in execute
self.fetch_command(subcommand).run_from_argv(self.argv)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py", line 354, in run_from_argv
self.execute(*args, **cmd_options)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py", line 398, in execute
output = self.handle(*args, **options)
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py", line 187, in handle
collected = self.collect()
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py", line 105, in collect
for path, storage in finder.list(self.ignore_patterns):
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/finders.py", line 130, in list
for path in utils.get_files(storage, ignore_patterns):
File "/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/utils.py", line 23, in get_files
directories, files = storage.listdir(location)
File "/opt/nautobot/lib/python3.10/site-packages/django/core/files/storage.py", line 330, in listdir
for entry in os.scandir(path):
FileNotFoundError: [Errno 2] No such file or directory: '/opt/nautobot/ui/build/static'
As a workaround, I manually created /opt/nautobot/ui/build/static and re-ran collectstatic
</issue>
<code>
[start of nautobot/core/cli/__init__.py]
1 """
2 Utilities and primitives for the `nautobot-server` CLI command.
3 """
4
5 import os
6
7 from django.core.exceptions import ImproperlyConfigured
8 from django.core.management.utils import get_random_secret_key
9 from jinja2 import BaseLoader, Environment
10
11 from nautobot.core.runner import run_app
12 from nautobot.extras.plugins.utils import load_plugins
13
14
15 # Default file location for the generated config emitted by `init`
16 NAUTOBOT_ROOT = os.getenv("NAUTOBOT_ROOT", os.path.expanduser("~/.nautobot"))
17 DEFAULT_CONFIG_PATH = os.path.join(NAUTOBOT_ROOT, "nautobot_config.py")
18
19 # Default settings to use when building the config
20 DEFAULT_SETTINGS = "nautobot.core.settings"
21
22 # Name of the environment variable used to specify path of config
23 SETTINGS_ENVVAR = "NAUTOBOT_CONFIG"
24
25 # Base directory for this module
26 BASE_DIR = os.path.dirname(__file__)
27
28 # File path of template used to generate config emitted by `init`
29 CONFIG_TEMPLATE = os.path.join(BASE_DIR, "../templates/nautobot_config.py.j2")
30
31 DESCRIPTION = """
32 Nautobot server management utility.
33
34 Type '%(prog)s help' to display a list of included sub-commands.
35
36 Type '%(prog)s init' to generate a new configuration.
37 """
38
39
40 def main():
41 """
42 The main server CLI command that replaces `manage.py` and allows a
43 configuration file to be passed in.
44
45 How this works:
46
47 - Process CLI args
48 - Load default settings
49 - Read config file from path
50 - Overlay config settings on top of default settings
51 - Overlay special/conditional settings (see `_configure_settings`)
52 """
53 run_app(
54 project="nautobot",
55 description=DESCRIPTION,
56 default_config_path=DEFAULT_CONFIG_PATH,
57 default_settings=DEFAULT_SETTINGS,
58 settings_initializer=generate_settings,
59 settings_envvar=SETTINGS_ENVVAR,
60 initializer=_configure_settings, # Called after defaults
61 )
62
63
64 def generate_settings(config_template=CONFIG_TEMPLATE, **kwargs):
65 """
66 This command is ran when `default_config_path` doesn't exist, or `init` is
67 ran and returns a string representing the default data to put into the
68 settings file.
69 """
70 template_vars = {
71 "secret_key": get_random_secret_key(),
72 "installation_metrics_enabled": kwargs.get("installation_metrics_enabled", True),
73 }
74
75 with open(config_template) as fh:
76 environment = Environment(loader=BaseLoader, keep_trailing_newline=True)
77 config = environment.from_string(fh.read())
78
79 return config.render(**template_vars)
80
81
82 def _configure_settings(config):
83 """
84 Callback for processing conditional or special purpose settings.
85
86 Any specially prepared settings will be handled here, such as loading
87 plugins, enabling social auth, etc.
88
89 This is intended to be called by `run_app` and should not be invoked
90 directly.
91
92 :param config:
93 A dictionary of `config_path`, `project`, `settings`
94
95 Example::
96
97 {
98 'project': 'nautobot',
99 'config_path': '/path/to/nautobot_config.py',
100 'settings': <LazySettings "nautobot_config">
101 }
102 """
103
104 settings = config["settings"]
105
106 # Include the config path to the settings to align with builtin
107 # `settings.SETTINGS_MODULE`. Useful for debugging correct config path.
108 settings.SETTINGS_PATH = config["config_path"]
109
110 #
111 # Storage directories
112 #
113 os.makedirs(settings.GIT_ROOT, exist_ok=True)
114 os.makedirs(settings.JOBS_ROOT, exist_ok=True)
115 os.makedirs(settings.MEDIA_ROOT, exist_ok=True)
116 os.makedirs(os.path.join(settings.MEDIA_ROOT, "devicetype-images"), exist_ok=True)
117 os.makedirs(os.path.join(settings.MEDIA_ROOT, "image-attachments"), exist_ok=True)
118 os.makedirs(settings.STATIC_ROOT, exist_ok=True)
119
120 #
121 # Databases
122 #
123
124 # If metrics are enabled and postgres is the backend, set the driver to the
125 # one provided by django-prometheus.
126 if settings.METRICS_ENABLED and "postgres" in settings.DATABASES["default"]["ENGINE"]:
127 settings.DATABASES["default"]["ENGINE"] = "django_prometheus.db.backends.postgresql"
128
129 # Create secondary db connection for job logging. This still writes to the default db, but because it's a separate
130 # connection, it allows allows us to "escape" from transaction.atomic() and ensure that job log entries are saved
131 # to the database even when the rest of the job transaction is rolled back.
132 settings.DATABASES["job_logs"] = settings.DATABASES["default"].copy()
133 # When running unit tests, treat it as a mirror of the default test DB, not a separate test DB of its own
134 settings.DATABASES["job_logs"]["TEST"] = {"MIRROR": "default"}
135
136 #
137 # Media storage
138 #
139
140 if settings.STORAGE_BACKEND is not None:
141 settings.DEFAULT_FILE_STORAGE = settings.STORAGE_BACKEND
142
143 # django-storages
144 if settings.STORAGE_BACKEND.startswith("storages."):
145 try:
146 import storages.utils
147 except ModuleNotFoundError as e:
148 if getattr(e, "name") == "storages":
149 raise ImproperlyConfigured(
150 f"STORAGE_BACKEND is set to {settings.STORAGE_BACKEND} but django-storages is not present. It "
151 f"can be installed by running 'pip install django-storages'."
152 )
153 raise e
154
155 # Monkey-patch django-storages to fetch settings from STORAGE_CONFIG or fall back to settings
156 def _setting(name, default=None):
157 if name in settings.STORAGE_CONFIG:
158 return settings.STORAGE_CONFIG[name]
159 return getattr(settings, name, default)
160
161 storages.utils.setting = _setting
162
163 #
164 # Plugins
165 #
166
167 # Process the plugins and manipulate the specified config settings that are
168 # passed in.
169 load_plugins(settings)
170
171
172 if __name__ == "__main__":
173 main()
174
[end of nautobot/core/cli/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nautobot/core/cli/__init__.py b/nautobot/core/cli/__init__.py
--- a/nautobot/core/cli/__init__.py
+++ b/nautobot/core/cli/__init__.py
@@ -115,6 +115,7 @@
os.makedirs(settings.MEDIA_ROOT, exist_ok=True)
os.makedirs(os.path.join(settings.MEDIA_ROOT, "devicetype-images"), exist_ok=True)
os.makedirs(os.path.join(settings.MEDIA_ROOT, "image-attachments"), exist_ok=True)
+ os.makedirs(os.path.join(settings.NAUTOBOT_UI_DIR, "build", "static"), exist_ok=True)
os.makedirs(settings.STATIC_ROOT, exist_ok=True)
#
|
{"golden_diff": "diff --git a/nautobot/core/cli/__init__.py b/nautobot/core/cli/__init__.py\n--- a/nautobot/core/cli/__init__.py\n+++ b/nautobot/core/cli/__init__.py\n@@ -115,6 +115,7 @@\n os.makedirs(settings.MEDIA_ROOT, exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"devicetype-images\"), exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"image-attachments\"), exist_ok=True)\n+ os.makedirs(os.path.join(settings.NAUTOBOT_UI_DIR, \"build\", \"static\"), exist_ok=True)\n os.makedirs(settings.STATIC_ROOT, exist_ok=True)\n \n #\n", "issue": "Install issue 2.0.1 -> collect static fails to create directories\n<!--\r\n NOTE: IF YOUR ISSUE DOES NOT FOLLOW THIS TEMPLATE, IT WILL BE CLOSED.\r\n\r\n This form is only for reporting reproducible bugs. If you need assistance\r\n with Nautobot installation, or if you have a general question, please start a\r\n discussion instead: https://github.com/nautobot/nautobot/discussions\r\n\r\n Please describe the environment in which you are running Nautobot. Be sure\r\n that you are running an unmodified instance of the latest stable release\r\n before submitting a bug report, and that any plugins have been disabled.\r\n-->\r\n### Environment\r\n* Nautobot version (Docker tag too if applicable): 2.0.1\r\n* Python version: 3.10.12\r\n* Database platform, version: postgres\r\n* Middleware(s):none\r\n\r\n<!--\r\n Describe in detail the exact steps that someone else can take to reproduce\r\n this bug using the current stable release of Nautobot. Begin with the\r\n creation of any necessary database objects and call out every operation\r\n being performed explicitly. If reporting a bug in the REST API, be sure to\r\n reconstruct the raw HTTP request(s) being made: Don't rely on a client\r\n library such as pynautobot.\r\n-->\r\n### Steps to Reproduce\r\n1. New installation of nautobot\r\n2. Following instructions at https://blog.networktocode.com/post/installing-nautobot/\r\n3. Issue command nautobot-server collectstatic\r\n\r\n<!-- What did you expect to happen? -->\r\n### Expected Behavior\r\nExpected directories to be created and static files to be collected\r\n\r\n<!-- What happened instead? -->\r\nError occurred\r\n\r\nnautobot@server:~$ nautobot-server collectstatic\r\n16:21:56.992 ERROR nautobot.core.apps :\r\n Error in link construction for Notes: Reverse for 'note_list' not found. 'note_list' is not a valid view function or pattern name.\r\nTraceback (most recent call last):\r\n File \"/opt/nautobot/bin/nautobot-server\", line 8, in <module>\r\n sys.exit(main())\r\n File \"/opt/nautobot/lib/python3.10/site-packages/nautobot/core/cli/__init__.py\", line 54, in main\r\n run_app(\r\n File \"/opt/nautobot/lib/python3.10/site-packages/nautobot/core/runner/runner.py\", line 297, in run_app\r\n management.execute_from_command_line([runner_name, command] + command_args)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py\", line 419, in execute_from_command_line\r\n utility.execute()\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/__init__.py\", line 413, in execute\r\n self.fetch_command(subcommand).run_from_argv(self.argv)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py\", line 354, in run_from_argv\r\n self.execute(*args, **cmd_options)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/management/base.py\", line 398, in execute\r\n output = self.handle(*args, **options)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py\", line 187, in handle\r\n collected = self.collect()\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/management/commands/collectstatic.py\", line 105, in collect\r\n for path, storage in finder.list(self.ignore_patterns):\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/finders.py\", line 130, in list\r\n for path in utils.get_files(storage, ignore_patterns):\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/contrib/staticfiles/utils.py\", line 23, in get_files\r\n directories, files = storage.listdir(location)\r\n File \"/opt/nautobot/lib/python3.10/site-packages/django/core/files/storage.py\", line 330, in listdir\r\n for entry in os.scandir(path):\r\nFileNotFoundError: [Errno 2] No such file or directory: '/opt/nautobot/ui/build/static'\r\n\r\n\r\n\r\nAs a workaround, I manually created /opt/nautobot/ui/build/static and re-ran collectstatic\n", "before_files": [{"content": "\"\"\"\nUtilities and primitives for the `nautobot-server` CLI command.\n\"\"\"\n\nimport os\n\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.core.management.utils import get_random_secret_key\nfrom jinja2 import BaseLoader, Environment\n\nfrom nautobot.core.runner import run_app\nfrom nautobot.extras.plugins.utils import load_plugins\n\n\n# Default file location for the generated config emitted by `init`\nNAUTOBOT_ROOT = os.getenv(\"NAUTOBOT_ROOT\", os.path.expanduser(\"~/.nautobot\"))\nDEFAULT_CONFIG_PATH = os.path.join(NAUTOBOT_ROOT, \"nautobot_config.py\")\n\n# Default settings to use when building the config\nDEFAULT_SETTINGS = \"nautobot.core.settings\"\n\n# Name of the environment variable used to specify path of config\nSETTINGS_ENVVAR = \"NAUTOBOT_CONFIG\"\n\n# Base directory for this module\nBASE_DIR = os.path.dirname(__file__)\n\n# File path of template used to generate config emitted by `init`\nCONFIG_TEMPLATE = os.path.join(BASE_DIR, \"../templates/nautobot_config.py.j2\")\n\nDESCRIPTION = \"\"\"\nNautobot server management utility.\n\nType '%(prog)s help' to display a list of included sub-commands.\n\nType '%(prog)s init' to generate a new configuration.\n\"\"\"\n\n\ndef main():\n \"\"\"\n The main server CLI command that replaces `manage.py` and allows a\n configuration file to be passed in.\n\n How this works:\n\n - Process CLI args\n - Load default settings\n - Read config file from path\n - Overlay config settings on top of default settings\n - Overlay special/conditional settings (see `_configure_settings`)\n \"\"\"\n run_app(\n project=\"nautobot\",\n description=DESCRIPTION,\n default_config_path=DEFAULT_CONFIG_PATH,\n default_settings=DEFAULT_SETTINGS,\n settings_initializer=generate_settings,\n settings_envvar=SETTINGS_ENVVAR,\n initializer=_configure_settings, # Called after defaults\n )\n\n\ndef generate_settings(config_template=CONFIG_TEMPLATE, **kwargs):\n \"\"\"\n This command is ran when `default_config_path` doesn't exist, or `init` is\n ran and returns a string representing the default data to put into the\n settings file.\n \"\"\"\n template_vars = {\n \"secret_key\": get_random_secret_key(),\n \"installation_metrics_enabled\": kwargs.get(\"installation_metrics_enabled\", True),\n }\n\n with open(config_template) as fh:\n environment = Environment(loader=BaseLoader, keep_trailing_newline=True)\n config = environment.from_string(fh.read())\n\n return config.render(**template_vars)\n\n\ndef _configure_settings(config):\n \"\"\"\n Callback for processing conditional or special purpose settings.\n\n Any specially prepared settings will be handled here, such as loading\n plugins, enabling social auth, etc.\n\n This is intended to be called by `run_app` and should not be invoked\n directly.\n\n :param config:\n A dictionary of `config_path`, `project`, `settings`\n\n Example::\n\n {\n 'project': 'nautobot',\n 'config_path': '/path/to/nautobot_config.py',\n 'settings': <LazySettings \"nautobot_config\">\n }\n \"\"\"\n\n settings = config[\"settings\"]\n\n # Include the config path to the settings to align with builtin\n # `settings.SETTINGS_MODULE`. Useful for debugging correct config path.\n settings.SETTINGS_PATH = config[\"config_path\"]\n\n #\n # Storage directories\n #\n os.makedirs(settings.GIT_ROOT, exist_ok=True)\n os.makedirs(settings.JOBS_ROOT, exist_ok=True)\n os.makedirs(settings.MEDIA_ROOT, exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"devicetype-images\"), exist_ok=True)\n os.makedirs(os.path.join(settings.MEDIA_ROOT, \"image-attachments\"), exist_ok=True)\n os.makedirs(settings.STATIC_ROOT, exist_ok=True)\n\n #\n # Databases\n #\n\n # If metrics are enabled and postgres is the backend, set the driver to the\n # one provided by django-prometheus.\n if settings.METRICS_ENABLED and \"postgres\" in settings.DATABASES[\"default\"][\"ENGINE\"]:\n settings.DATABASES[\"default\"][\"ENGINE\"] = \"django_prometheus.db.backends.postgresql\"\n\n # Create secondary db connection for job logging. This still writes to the default db, but because it's a separate\n # connection, it allows allows us to \"escape\" from transaction.atomic() and ensure that job log entries are saved\n # to the database even when the rest of the job transaction is rolled back.\n settings.DATABASES[\"job_logs\"] = settings.DATABASES[\"default\"].copy()\n # When running unit tests, treat it as a mirror of the default test DB, not a separate test DB of its own\n settings.DATABASES[\"job_logs\"][\"TEST\"] = {\"MIRROR\": \"default\"}\n\n #\n # Media storage\n #\n\n if settings.STORAGE_BACKEND is not None:\n settings.DEFAULT_FILE_STORAGE = settings.STORAGE_BACKEND\n\n # django-storages\n if settings.STORAGE_BACKEND.startswith(\"storages.\"):\n try:\n import storages.utils\n except ModuleNotFoundError as e:\n if getattr(e, \"name\") == \"storages\":\n raise ImproperlyConfigured(\n f\"STORAGE_BACKEND is set to {settings.STORAGE_BACKEND} but django-storages is not present. It \"\n f\"can be installed by running 'pip install django-storages'.\"\n )\n raise e\n\n # Monkey-patch django-storages to fetch settings from STORAGE_CONFIG or fall back to settings\n def _setting(name, default=None):\n if name in settings.STORAGE_CONFIG:\n return settings.STORAGE_CONFIG[name]\n return getattr(settings, name, default)\n\n storages.utils.setting = _setting\n\n #\n # Plugins\n #\n\n # Process the plugins and manipulate the specified config settings that are\n # passed in.\n load_plugins(settings)\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "nautobot/core/cli/__init__.py"}]}
| 3,247 | 151 |
gh_patches_debug_8546
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-2567
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Choose more secure configuration defaults
The configuration for SMTP server, privacyIDEA server or LDAP resolvers default to not using TLS and no certificate verification.
Better defaults or additional documentation may reduce the chance of accidental misconfiguration by the admins.
We have the following occurances:
* [x] Config -> SMTP Server: ``Use TLS``, check it by default.
* [x] Config -> privacyIDEA Server ``Verify the certificate``, check it by default
* [x] Config -> SMS Gateways (HTTP Gateway), default ``Check_SSL`` to "yes".
* ~~Config->User->New LDAP server: already defaults to ``verify TLS``.~~
</issue>
<code>
[start of privacyidea/lib/smsprovider/HttpSMSProvider.py]
1 # -*- coding: utf-8 -*-
2 #
3 # E-mail: [email protected]
4 # Contact: www.privacyidea.org
5 #
6 # 2018-06-15 Pascal Fuks <[email protected]>
7 # Added REGEXP parameter on phone number
8 # 2018-01-10 Cornelius Kölbel <[email protected]>
9 # Fix type cast for timeout
10 # 2016-06-14 Cornelius Kölbel <[email protected]>
11 # Add properties for new SMS provider model
12 # 2016-04-08 Cornelius Kölbel <[email protected]>
13 # Remote "None" as redundant 2nd argument to get
14 # 2016-01-13 Cornelius Kölbel <[email protected]>
15 # omit data object in GET request
16 # omit params in POST request
17 #
18 # privacyIDEA is a fork of LinOTP
19 # May 28, 2014 Cornelius Kölbel
20 # 2015-01-30 Rewrite for migration to flask
21 # Cornelius Kölbel <[email protected]>
22 #
23 #
24 # Copyright (C) LinOTP: 2010 - 2014 LSE Leading Security Experts GmbH
25 #
26 # This program is free software: you can redistribute it and/or
27 # modify it under the terms of the GNU Affero General Public
28 # License, version 3, as published by the Free Software Foundation.
29 #
30 # This program is distributed in the hope that it will be useful,
31 # but WITHOUT ANY WARRANTY; without even the implied warranty of
32 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
33 # GNU Affero General Public License for more details.
34 #
35 # You should have received a copy of the
36 # GNU Affero General Public License
37 # along with this program. If not, see <http://www.gnu.org/licenses/>.
38 #
39 #
40
41 __doc__ = """This is the SMSClass to send SMS via HTTP Gateways
42 It can handle HTTP/HTTPS PUT and GET requests also with Proxy support
43
44 The code is tested in tests/test_lib_smsprovider
45 """
46
47 from privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider, SMSError)
48 from privacyidea.lib import _
49 import requests
50 from six.moves.urllib.parse import urlparse
51 import re
52 import logging
53 log = logging.getLogger(__name__)
54
55
56 class HttpSMSProvider(ISMSProvider):
57
58 @staticmethod
59 def _mangle_phone(phone, config):
60 regexp = config.get("REGEXP")
61 if regexp:
62 try:
63 m = re.match("^/(.*)/(.*)/$", regexp)
64 if m:
65 phone = re.sub(m.group(1), m.group(2), phone)
66 except re.error:
67 log.warning(u"Can not mangle phone number. "
68 u"Please check your REGEXP: {0!s}".format(regexp))
69
70 return phone
71
72 def submit_message(self, phone, message):
73 """
74 send a message to a phone via an http sms gateway
75
76 :param phone: the phone number
77 :param message: the message to submit to the phone
78 :return:
79 """
80 log.debug("submitting message {0!r} to {1!s}".format(message, phone))
81 parameter = {}
82 headers = {}
83 if self.smsgateway:
84 phone = self._mangle_phone(phone, self.smsgateway.option_dict)
85 url = self.smsgateway.option_dict.get("URL")
86 method = self.smsgateway.option_dict.get("HTTP_METHOD", "GET")
87 username = self.smsgateway.option_dict.get("USERNAME")
88 password = self.smsgateway.option_dict.get("PASSWORD")
89 ssl_verify = self.smsgateway.option_dict.get("CHECK_SSL",
90 "yes") == "yes"
91 # FIXME: The Proxy option is deprecated and will be removed a version > 2.21
92 proxy = self.smsgateway.option_dict.get("PROXY")
93 http_proxy = self.smsgateway.option_dict.get('HTTP_PROXY')
94 https_proxy = self.smsgateway.option_dict.get('HTTPS_PROXY')
95 timeout = self.smsgateway.option_dict.get("TIMEOUT") or 3
96 for k, v in self.smsgateway.option_dict.items():
97 if k not in self.parameters().get("parameters"):
98 # This is an additional option
99 parameter[k] = v.format(otp=message, phone=phone)
100 headers = self.smsgateway.header_dict
101 else:
102 phone = self._mangle_phone(phone, self.config)
103 url = self.config.get('URL')
104 method = self.config.get('HTTP_Method', 'GET')
105 username = self.config.get('USERNAME')
106 password = self.config.get('PASSWORD')
107 ssl_verify = self.config.get('CHECK_SSL', True)
108 # FIXME: The Proxy option is deprecated and will be removed a version > 2.21
109 proxy = self.config.get('PROXY')
110 http_proxy = self.config.get('HTTP_PROXY')
111 https_proxy = self.config.get('HTTPS_PROXY')
112 parameter = self._get_parameters(message, phone)
113 timeout = self.config.get("TIMEOUT") or 3
114
115 if url is None:
116 log.warning("can not submit message. URL is missing.")
117 raise SMSError(-1, "No URL specified in the provider config.")
118 basic_auth = None
119
120 # there might be the basic authentication in the request url
121 # like http://user:passw@hostname:port/path
122 if password is None and username is None:
123 parsed_url = urlparse(url)
124 if "@" in parsed_url[1]:
125 puser, server = parsed_url[1].split('@')
126 username, password = puser.split(':')
127
128 if username and password is not None:
129 basic_auth = (username, password)
130
131 proxies = {}
132 if http_proxy:
133 proxies["http"] = http_proxy
134 if https_proxy:
135 proxies["https"] = https_proxy
136 if not proxies and proxy:
137 # No new proxy config but only the old one.
138 protocol = proxy.split(":")[0]
139 proxies = {protocol: proxy}
140
141 # url, parameter, username, password, method
142 requestor = requests.get
143 params = parameter
144 data = {}
145 if method == "POST":
146 requestor = requests.post
147 params = {}
148 data = parameter
149
150 log.debug(u"issuing request with parameters {0!s} headers {1!s} and method {2!s} and"
151 "authentication {3!s} to url {4!s}.".format(params, headers, method,
152 basic_auth, url))
153 # Todo: drop basic auth if Authorization-Header is given?
154 r = requestor(url, params=params, headers=headers,
155 data=data,
156 verify=ssl_verify,
157 auth=basic_auth,
158 timeout=float(timeout),
159 proxies=proxies)
160 log.debug("queued SMS on the HTTP gateway. status code returned: {0!s}".format(
161 r.status_code))
162
163 # We assume, that all gateways return with HTTP Status Code 200,
164 # 201 or 202
165 if r.status_code not in [200, 201, 202]:
166 raise SMSError(r.status_code, "SMS could not be "
167 "sent: %s" % r.status_code)
168 success = self._check_success(r)
169 return success
170
171 def _get_parameters(self, message, phone):
172
173 urldata = {}
174 # transfer the phone key
175 phoneKey = self.config.get('SMS_PHONENUMBER_KEY', "phone")
176 urldata[phoneKey] = phone
177 # transfer the sms key
178 messageKey = self.config.get('SMS_TEXT_KEY', "sms")
179 urldata[messageKey] = message
180 params = self.config.get('PARAMETER', {})
181 urldata.update(params)
182 log.debug("[getParameters] urldata: {0!s}".format(urldata))
183 return urldata
184
185 def _check_success(self, response):
186 """
187 Check the success according to the reply
188 1. if RETURN_SUCCESS is defined
189 2. if RETURN_FAIL is defined
190 :response reply: A response object.
191 """
192 reply = response.text
193 ret = False
194 if self.smsgateway:
195 return_success = self.smsgateway.option_dict.get("RETURN_SUCCESS")
196 return_fail = self.smsgateway.option_dict.get("RETURN_FAIL")
197 else:
198 return_success = self.config.get("RETURN_SUCCESS")
199 return_fail = self.config.get("RETURN_FAIL")
200
201 if return_success:
202 if return_success in reply:
203 log.debug("sending sms success")
204 ret = True
205 else:
206 log.warning("failed to send sms. Reply %s does not match "
207 "the RETURN_SUCCESS definition" % reply)
208 raise SMSError(response.status_code,
209 "We received a none success reply from the "
210 "SMS Gateway: {0!s} ({1!s})".format(reply,
211 return_success))
212
213 elif return_fail:
214 if return_fail in reply:
215 log.warning("sending sms failed. %s was not found "
216 "in %s" % (return_fail, reply))
217 raise SMSError(response.status_code,
218 "We received the predefined error from the "
219 "SMS Gateway.")
220 else:
221 log.debug("sending sms success")
222 ret = True
223 else:
224 ret = True
225 return ret
226
227 @classmethod
228 def parameters(cls):
229 """
230 Return a dictionary, that describes the parameters and options for the
231 SMS provider.
232 Parameters are required keys to values.
233
234 :return: dict
235 """
236 params = {"options_allowed": True,
237 "headers_allowed": True,
238 "parameters": {
239 "URL": {
240 "required": True,
241 "description": _("The base URL of the HTTP Gateway")},
242 "HTTP_METHOD": {
243 "required": True,
244 "description": _("Should the HTTP Gateway be "
245 "connected via an HTTP GET or POST "
246 "request."),
247 "values": ["GET", "POST"]},
248 "RETURN_SUCCESS": {
249 "description": _("Specify a substring, "
250 "that indicates, that the SMS was "
251 "delivered successfully.")},
252 "RETURN_FAIL": {
253 "description": _("Specify a substring, "
254 "that indicates, that the SMS "
255 "failed to be delivered.")},
256 "USERNAME": {
257 "description": _("Username in case of basic "
258 "authentication.")
259 },
260 "PASSWORD": {
261 "description": _("Password in case of basic "
262 "authentication.")
263 },
264 "CHECK_SSL": {
265 "description": _("Should the SSL certificate be "
266 "verified."),
267 "values": ["yes", "no"]
268 },
269 "REGEXP": {
270 "description": _("Regular expression to modify the phone number "
271 "to make it compatible with provider. "
272 "Enter something like '/[\\+/]//' to remove "
273 "pluses and slashes.")
274 },
275 "PROXY": {"description": _("An optional proxy string. DEPRECATED. Do not use "
276 "this anymore. Rather use HTTP_PROXY for http "
277 "connections and HTTPS_PROXY for https "
278 "connection. The PROXY option will be removed in "
279 "future.")},
280 "HTTP_PROXY": {"description": _("Proxy setting for HTTP connections.")},
281 "HTTPS_PROXY": {"description": _("Proxy setting for HTTPS connections.")},
282 "TIMEOUT": {"description": _("The timeout in seconds.")}
283 }
284 }
285 return params
286
[end of privacyidea/lib/smsprovider/HttpSMSProvider.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/privacyidea/lib/smsprovider/HttpSMSProvider.py b/privacyidea/lib/smsprovider/HttpSMSProvider.py
--- a/privacyidea/lib/smsprovider/HttpSMSProvider.py
+++ b/privacyidea/lib/smsprovider/HttpSMSProvider.py
@@ -262,6 +262,7 @@
"authentication.")
},
"CHECK_SSL": {
+ "required": True,
"description": _("Should the SSL certificate be "
"verified."),
"values": ["yes", "no"]
|
{"golden_diff": "diff --git a/privacyidea/lib/smsprovider/HttpSMSProvider.py b/privacyidea/lib/smsprovider/HttpSMSProvider.py\n--- a/privacyidea/lib/smsprovider/HttpSMSProvider.py\n+++ b/privacyidea/lib/smsprovider/HttpSMSProvider.py\n@@ -262,6 +262,7 @@\n \"authentication.\")\n },\n \"CHECK_SSL\": {\n+ \"required\": True,\n \"description\": _(\"Should the SSL certificate be \"\n \"verified.\"),\n \"values\": [\"yes\", \"no\"]\n", "issue": "Choose more secure configuration defaults\nThe configuration for SMTP server, privacyIDEA server or LDAP resolvers default to not using TLS and no certificate verification.\r\nBetter defaults or additional documentation may reduce the chance of accidental misconfiguration by the admins.\r\n\r\nWe have the following occurances:\r\n\r\n* [x] Config -> SMTP Server: ``Use TLS``, check it by default.\r\n* [x] Config -> privacyIDEA Server ``Verify the certificate``, check it by default\r\n* [x] Config -> SMS Gateways (HTTP Gateway), default ``Check_SSL`` to \"yes\".\r\n* ~~Config->User->New LDAP server: already defaults to ``verify TLS``.~~\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# E-mail: [email protected]\n# Contact: www.privacyidea.org\n#\n# 2018-06-15 Pascal Fuks <[email protected]>\n# Added REGEXP parameter on phone number\n# 2018-01-10 Cornelius K\u00f6lbel <[email protected]>\n# Fix type cast for timeout\n# 2016-06-14 Cornelius K\u00f6lbel <[email protected]>\n# Add properties for new SMS provider model\n# 2016-04-08 Cornelius K\u00f6lbel <[email protected]>\n# Remote \"None\" as redundant 2nd argument to get\n# 2016-01-13 Cornelius K\u00f6lbel <[email protected]>\n# omit data object in GET request\n# omit params in POST request\n#\n# privacyIDEA is a fork of LinOTP\n# May 28, 2014 Cornelius K\u00f6lbel\n# 2015-01-30 Rewrite for migration to flask\n# Cornelius K\u00f6lbel <[email protected]>\n#\n#\n# Copyright (C) LinOTP: 2010 - 2014 LSE Leading Security Experts GmbH\n#\n# This program is free software: you can redistribute it and/or\n# modify it under the terms of the GNU Affero General Public\n# License, version 3, as published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU Affero General Public License for more details.\n#\n# You should have received a copy of the\n# GNU Affero General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n#\n#\n\n__doc__ = \"\"\"This is the SMSClass to send SMS via HTTP Gateways\nIt can handle HTTP/HTTPS PUT and GET requests also with Proxy support\n\nThe code is tested in tests/test_lib_smsprovider\n\"\"\"\n\nfrom privacyidea.lib.smsprovider.SMSProvider import (ISMSProvider, SMSError)\nfrom privacyidea.lib import _\nimport requests\nfrom six.moves.urllib.parse import urlparse\nimport re\nimport logging\nlog = logging.getLogger(__name__)\n\n\nclass HttpSMSProvider(ISMSProvider):\n\n @staticmethod\n def _mangle_phone(phone, config):\n regexp = config.get(\"REGEXP\")\n if regexp:\n try:\n m = re.match(\"^/(.*)/(.*)/$\", regexp)\n if m:\n phone = re.sub(m.group(1), m.group(2), phone)\n except re.error:\n log.warning(u\"Can not mangle phone number. \"\n u\"Please check your REGEXP: {0!s}\".format(regexp))\n\n return phone\n\n def submit_message(self, phone, message):\n \"\"\"\n send a message to a phone via an http sms gateway\n\n :param phone: the phone number\n :param message: the message to submit to the phone\n :return:\n \"\"\"\n log.debug(\"submitting message {0!r} to {1!s}\".format(message, phone))\n parameter = {}\n headers = {}\n if self.smsgateway:\n phone = self._mangle_phone(phone, self.smsgateway.option_dict)\n url = self.smsgateway.option_dict.get(\"URL\")\n method = self.smsgateway.option_dict.get(\"HTTP_METHOD\", \"GET\")\n username = self.smsgateway.option_dict.get(\"USERNAME\")\n password = self.smsgateway.option_dict.get(\"PASSWORD\")\n ssl_verify = self.smsgateway.option_dict.get(\"CHECK_SSL\",\n \"yes\") == \"yes\"\n # FIXME: The Proxy option is deprecated and will be removed a version > 2.21\n proxy = self.smsgateway.option_dict.get(\"PROXY\")\n http_proxy = self.smsgateway.option_dict.get('HTTP_PROXY')\n https_proxy = self.smsgateway.option_dict.get('HTTPS_PROXY')\n timeout = self.smsgateway.option_dict.get(\"TIMEOUT\") or 3\n for k, v in self.smsgateway.option_dict.items():\n if k not in self.parameters().get(\"parameters\"):\n # This is an additional option\n parameter[k] = v.format(otp=message, phone=phone)\n headers = self.smsgateway.header_dict\n else:\n phone = self._mangle_phone(phone, self.config)\n url = self.config.get('URL')\n method = self.config.get('HTTP_Method', 'GET')\n username = self.config.get('USERNAME')\n password = self.config.get('PASSWORD')\n ssl_verify = self.config.get('CHECK_SSL', True)\n # FIXME: The Proxy option is deprecated and will be removed a version > 2.21\n proxy = self.config.get('PROXY')\n http_proxy = self.config.get('HTTP_PROXY')\n https_proxy = self.config.get('HTTPS_PROXY')\n parameter = self._get_parameters(message, phone)\n timeout = self.config.get(\"TIMEOUT\") or 3\n\n if url is None:\n log.warning(\"can not submit message. URL is missing.\")\n raise SMSError(-1, \"No URL specified in the provider config.\")\n basic_auth = None\n\n # there might be the basic authentication in the request url\n # like http://user:passw@hostname:port/path\n if password is None and username is None:\n parsed_url = urlparse(url)\n if \"@\" in parsed_url[1]:\n puser, server = parsed_url[1].split('@')\n username, password = puser.split(':')\n\n if username and password is not None:\n basic_auth = (username, password)\n\n proxies = {}\n if http_proxy:\n proxies[\"http\"] = http_proxy\n if https_proxy:\n proxies[\"https\"] = https_proxy\n if not proxies and proxy:\n # No new proxy config but only the old one.\n protocol = proxy.split(\":\")[0]\n proxies = {protocol: proxy}\n\n # url, parameter, username, password, method\n requestor = requests.get\n params = parameter\n data = {}\n if method == \"POST\":\n requestor = requests.post\n params = {}\n data = parameter\n\n log.debug(u\"issuing request with parameters {0!s} headers {1!s} and method {2!s} and\"\n \"authentication {3!s} to url {4!s}.\".format(params, headers, method,\n basic_auth, url))\n # Todo: drop basic auth if Authorization-Header is given?\n r = requestor(url, params=params, headers=headers,\n data=data,\n verify=ssl_verify,\n auth=basic_auth,\n timeout=float(timeout),\n proxies=proxies)\n log.debug(\"queued SMS on the HTTP gateway. status code returned: {0!s}\".format(\n r.status_code))\n\n # We assume, that all gateways return with HTTP Status Code 200,\n # 201 or 202\n if r.status_code not in [200, 201, 202]:\n raise SMSError(r.status_code, \"SMS could not be \"\n \"sent: %s\" % r.status_code)\n success = self._check_success(r)\n return success\n\n def _get_parameters(self, message, phone):\n\n urldata = {}\n # transfer the phone key\n phoneKey = self.config.get('SMS_PHONENUMBER_KEY', \"phone\")\n urldata[phoneKey] = phone\n # transfer the sms key\n messageKey = self.config.get('SMS_TEXT_KEY', \"sms\")\n urldata[messageKey] = message\n params = self.config.get('PARAMETER', {})\n urldata.update(params)\n log.debug(\"[getParameters] urldata: {0!s}\".format(urldata))\n return urldata\n\n def _check_success(self, response):\n \"\"\"\n Check the success according to the reply\n 1. if RETURN_SUCCESS is defined\n 2. if RETURN_FAIL is defined\n :response reply: A response object.\n \"\"\"\n reply = response.text\n ret = False\n if self.smsgateway:\n return_success = self.smsgateway.option_dict.get(\"RETURN_SUCCESS\")\n return_fail = self.smsgateway.option_dict.get(\"RETURN_FAIL\")\n else:\n return_success = self.config.get(\"RETURN_SUCCESS\")\n return_fail = self.config.get(\"RETURN_FAIL\")\n\n if return_success:\n if return_success in reply:\n log.debug(\"sending sms success\")\n ret = True\n else:\n log.warning(\"failed to send sms. Reply %s does not match \"\n \"the RETURN_SUCCESS definition\" % reply)\n raise SMSError(response.status_code,\n \"We received a none success reply from the \"\n \"SMS Gateway: {0!s} ({1!s})\".format(reply,\n return_success))\n\n elif return_fail:\n if return_fail in reply:\n log.warning(\"sending sms failed. %s was not found \"\n \"in %s\" % (return_fail, reply))\n raise SMSError(response.status_code,\n \"We received the predefined error from the \"\n \"SMS Gateway.\")\n else:\n log.debug(\"sending sms success\")\n ret = True\n else:\n ret = True\n return ret\n\n @classmethod\n def parameters(cls):\n \"\"\"\n Return a dictionary, that describes the parameters and options for the\n SMS provider.\n Parameters are required keys to values.\n\n :return: dict\n \"\"\"\n params = {\"options_allowed\": True,\n \"headers_allowed\": True,\n \"parameters\": {\n \"URL\": {\n \"required\": True,\n \"description\": _(\"The base URL of the HTTP Gateway\")},\n \"HTTP_METHOD\": {\n \"required\": True,\n \"description\": _(\"Should the HTTP Gateway be \"\n \"connected via an HTTP GET or POST \"\n \"request.\"),\n \"values\": [\"GET\", \"POST\"]},\n \"RETURN_SUCCESS\": {\n \"description\": _(\"Specify a substring, \"\n \"that indicates, that the SMS was \"\n \"delivered successfully.\")},\n \"RETURN_FAIL\": {\n \"description\": _(\"Specify a substring, \"\n \"that indicates, that the SMS \"\n \"failed to be delivered.\")},\n \"USERNAME\": {\n \"description\": _(\"Username in case of basic \"\n \"authentication.\")\n },\n \"PASSWORD\": {\n \"description\": _(\"Password in case of basic \"\n \"authentication.\")\n },\n \"CHECK_SSL\": {\n \"description\": _(\"Should the SSL certificate be \"\n \"verified.\"),\n \"values\": [\"yes\", \"no\"]\n },\n \"REGEXP\": {\n \"description\": _(\"Regular expression to modify the phone number \" \n \"to make it compatible with provider. \"\n \"Enter something like '/[\\\\+/]//' to remove \"\n \"pluses and slashes.\")\n },\n \"PROXY\": {\"description\": _(\"An optional proxy string. DEPRECATED. Do not use \"\n \"this anymore. Rather use HTTP_PROXY for http \"\n \"connections and HTTPS_PROXY for https \"\n \"connection. The PROXY option will be removed in \"\n \"future.\")},\n \"HTTP_PROXY\": {\"description\": _(\"Proxy setting for HTTP connections.\")},\n \"HTTPS_PROXY\": {\"description\": _(\"Proxy setting for HTTPS connections.\")},\n \"TIMEOUT\": {\"description\": _(\"The timeout in seconds.\")}\n }\n }\n return params\n", "path": "privacyidea/lib/smsprovider/HttpSMSProvider.py"}]}
| 3,977 | 118 |
gh_patches_debug_26757
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-532
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Nondeterministic "invalid command 'bdist_wheel'" resulting in "Untranslateable" exception
I just started using pex. About half of the time I run it, it works great. The other half of the time, it fails like this.
```
> pex --python python2.7 abc.zip -v
**** Failed to install enum34-1.0.4. stdout: :: Packaging enum34
**** Failed to install enum34-1.0.4. stderr:
usage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]
or: setup.py --help [cmd1 cmd2 ...]
or: setup.py --help-commands
or: setup.py cmd --help
error: invalid command 'bdist_wheel'
pex: Failed to install package at /tmp/tmppcotrf/enum34-1.0.4: Failed to install /tmp/tmppcotrf/enum34-1.0.4
Traceback (most recent call last):
File "/bin/pex", line 9, in <module>
load_entry_point('pex==1.0.3', 'console_scripts', 'pex')()
File "/usr/lib/python3.3/site-packages/pex/bin/pex.py", line 509, in main
pex_builder = build_pex(reqs, options, resolver_options_builder)
File "/usr/lib/python3.3/site-packages/pex/bin/pex.py", line 471, in build_pex
resolveds = resolver.resolve(resolvables)
File "/usr/lib/python3.3/site-packages/pex/resolver.py", line 191, in resolve
dist = self.build(package, resolvable.options)
File "/usr/lib/python3.3/site-packages/pex/resolver.py", line 248, in build
dist = super(CachingResolver, self).build(package, options)
File "/usr/lib/python3.3/site-packages/pex/resolver.py", line 160, in build
raise Untranslateable('Package %s is not translateable by %s' % (package, translator))
pex.resolver.Untranslateable: Package SourcePackage('file:///home/chris/.pex/build/enum34-1.0.4.zip') is not translateable by ChainedTranslator(WheelTranslator, EggTranslator, SourceTranslator)
```
In the above example it failed on `enum34`, but which dependency it fails on appears random as well.
</issue>
<code>
[start of pex/installer.py]
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import absolute_import, print_function
5
6 import os
7 import sys
8 import tempfile
9
10 from pkg_resources import Distribution, PathMetadata
11
12 from .common import safe_mkdtemp, safe_rmtree
13 from .compatibility import WINDOWS
14 from .executor import Executor
15 from .interpreter import PythonInterpreter
16 from .tracer import TRACER
17 from .version import SETUPTOOLS_REQUIREMENT, WHEEL_REQUIREMENT
18
19 __all__ = (
20 'Installer',
21 'Packager'
22 )
23
24
25 def after_installation(function):
26 def function_wrapper(self, *args, **kw):
27 self._installed = self.run()
28 if not self._installed:
29 raise Installer.InstallFailure('Failed to install %s' % self._source_dir)
30 return function(self, *args, **kw)
31 return function_wrapper
32
33
34 class InstallerBase(object):
35 SETUP_BOOTSTRAP_HEADER = "import sys"
36 SETUP_BOOTSTRAP_MODULE = "sys.path.insert(0, %(path)r); import %(module)s"
37 SETUP_BOOTSTRAP_FOOTER = """
38 __file__ = 'setup.py'
39 sys.argv[0] = 'setup.py'
40 exec(compile(open(__file__, 'rb').read(), __file__, 'exec'))
41 """
42
43 class Error(Exception): pass
44 class InstallFailure(Error): pass
45 class IncapableInterpreter(Error): pass
46
47 def __init__(self, source_dir, strict=True, interpreter=None, install_dir=None):
48 """
49 Create an installer from an unpacked source distribution in source_dir.
50
51 If strict=True, fail if any installation dependencies (e.g. distribute)
52 are missing.
53 """
54 self._source_dir = source_dir
55 self._install_tmp = install_dir or safe_mkdtemp()
56 self._installed = None
57 self._strict = strict
58 self._interpreter = interpreter or PythonInterpreter.get()
59 if not self._interpreter.satisfies(self.capability) and strict:
60 raise self.IncapableInterpreter('Interpreter %s not capable of running %s' % (
61 self._interpreter.binary, self.__class__.__name__))
62
63 def mixins(self):
64 """Return a map from import name to requirement to load into setup script prior to invocation.
65
66 May be subclassed.
67 """
68 return {}
69
70 @property
71 def install_tmp(self):
72 return self._install_tmp
73
74 def _setup_command(self):
75 """the setup command-line to run, to be implemented by subclasses."""
76 raise NotImplementedError
77
78 def _postprocess(self):
79 """a post-processing function to run following setup.py invocation."""
80
81 @property
82 def capability(self):
83 """returns the list of requirements for the interpreter to run this installer."""
84 return list(self.mixins().values())
85
86 @property
87 def bootstrap_script(self):
88 bootstrap_modules = []
89 for module, requirement in self.mixins().items():
90 path = self._interpreter.get_location(requirement)
91 if not path:
92 assert not self._strict # This should be caught by validation
93 continue
94 bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})
95 return '\n'.join(
96 [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])
97
98 def run(self):
99 if self._installed is not None:
100 return self._installed
101
102 with TRACER.timed('Installing %s' % self._install_tmp, V=2):
103 command = [self._interpreter.binary, '-'] + self._setup_command()
104 try:
105 Executor.execute(command,
106 env=self._interpreter.sanitized_environment(),
107 cwd=self._source_dir,
108 stdin_payload=self.bootstrap_script.encode('ascii'))
109 self._installed = True
110 except Executor.NonZeroExit as e:
111 self._installed = False
112 name = os.path.basename(self._source_dir)
113 print('**** Failed to install %s (caused by: %r\n):' % (name, e), file=sys.stderr)
114 print('stdout:\n%s\nstderr:\n%s\n' % (e.stdout, e.stderr), file=sys.stderr)
115 return self._installed
116
117 self._postprocess()
118 return self._installed
119
120 def cleanup(self):
121 safe_rmtree(self._install_tmp)
122
123
124 class Installer(InstallerBase):
125 """Install an unpacked distribution with a setup.py."""
126
127 def __init__(self, source_dir, strict=True, interpreter=None):
128 """
129 Create an installer from an unpacked source distribution in source_dir.
130
131 If strict=True, fail if any installation dependencies (e.g. setuptools)
132 are missing.
133 """
134 super(Installer, self).__init__(source_dir, strict=strict, interpreter=interpreter)
135 self._egg_info = None
136 fd, self._install_record = tempfile.mkstemp()
137 os.close(fd)
138
139 def _setup_command(self):
140 return ['install',
141 '--root=%s' % self._install_tmp,
142 '--prefix=',
143 '--single-version-externally-managed',
144 '--record', self._install_record]
145
146 def _postprocess(self):
147 installed_files = []
148 egg_info = None
149 with open(self._install_record) as fp:
150 installed_files = fp.read().splitlines()
151 for line in installed_files:
152 if line.endswith('.egg-info'):
153 assert line.startswith('/'), 'Expect .egg-info to be within install_tmp!'
154 egg_info = line
155 break
156
157 if not egg_info:
158 self._installed = False
159 return self._installed
160
161 installed_files = [os.path.relpath(fn, egg_info) for fn in installed_files if fn != egg_info]
162
163 self._egg_info = os.path.join(self._install_tmp, egg_info[1:])
164 with open(os.path.join(self._egg_info, 'installed-files.txt'), 'w') as fp:
165 fp.write('\n'.join(installed_files))
166 fp.write('\n')
167
168 return self._installed
169
170 @after_installation
171 def egg_info(self):
172 return self._egg_info
173
174 @after_installation
175 def root(self):
176 egg_info = self.egg_info()
177 assert egg_info
178 return os.path.realpath(os.path.dirname(egg_info))
179
180 @after_installation
181 def distribution(self):
182 base_dir = self.root()
183 egg_info = self.egg_info()
184 metadata = PathMetadata(base_dir, egg_info)
185 return Distribution.from_location(base_dir, os.path.basename(egg_info), metadata=metadata)
186
187
188 class DistributionPackager(InstallerBase):
189 def mixins(self):
190 mixins = super(DistributionPackager, self).mixins().copy()
191 mixins.update(setuptools=SETUPTOOLS_REQUIREMENT)
192 return mixins
193
194 def find_distribution(self):
195 dists = os.listdir(self.install_tmp)
196 if len(dists) == 0:
197 raise self.InstallFailure('No distributions were produced!')
198 elif len(dists) > 1:
199 raise self.InstallFailure('Ambiguous source distributions found: %s' % (' '.join(dists)))
200 else:
201 return os.path.join(self.install_tmp, dists[0])
202
203
204 class Packager(DistributionPackager):
205 """
206 Create a source distribution from an unpacked setup.py-based project.
207 """
208
209 def _setup_command(self):
210 if WINDOWS:
211 return ['sdist', '--formats=zip', '--dist-dir=%s' % self._install_tmp]
212 else:
213 return ['sdist', '--formats=gztar', '--dist-dir=%s' % self._install_tmp]
214
215 @after_installation
216 def sdist(self):
217 return self.find_distribution()
218
219
220 class EggInstaller(DistributionPackager):
221 """
222 Create a source distribution from an unpacked setup.py-based project.
223 """
224
225 def _setup_command(self):
226 return ['bdist_egg', '--dist-dir=%s' % self._install_tmp]
227
228 @after_installation
229 def bdist(self):
230 return self.find_distribution()
231
232
233 class WheelInstaller(DistributionPackager):
234 """
235 Create a source distribution from an unpacked setup.py-based project.
236 """
237 MIXINS = {
238 'setuptools': SETUPTOOLS_REQUIREMENT,
239 'wheel': WHEEL_REQUIREMENT,
240 }
241
242 def mixins(self):
243 mixins = super(WheelInstaller, self).mixins().copy()
244 mixins.update(self.MIXINS)
245 return mixins
246
247 def _setup_command(self):
248 return ['bdist_wheel', '--dist-dir=%s' % self._install_tmp]
249
250 @after_installation
251 def bdist(self):
252 return self.find_distribution()
253
[end of pex/installer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/installer.py b/pex/installer.py
--- a/pex/installer.py
+++ b/pex/installer.py
@@ -33,7 +33,8 @@
class InstallerBase(object):
SETUP_BOOTSTRAP_HEADER = "import sys"
- SETUP_BOOTSTRAP_MODULE = "sys.path.insert(0, %(path)r); import %(module)s"
+ SETUP_BOOTSTRAP_PYPATH = "sys.path.insert(0, %(path)r)"
+ SETUP_BOOTSTRAP_MODULE = "import %(module)s"
SETUP_BOOTSTRAP_FOOTER = """
__file__ = 'setup.py'
sys.argv[0] = 'setup.py'
@@ -85,15 +86,21 @@
@property
def bootstrap_script(self):
+ bootstrap_sys_paths = []
bootstrap_modules = []
for module, requirement in self.mixins().items():
path = self._interpreter.get_location(requirement)
if not path:
assert not self._strict # This should be caught by validation
continue
- bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})
+ bootstrap_sys_paths.append(self.SETUP_BOOTSTRAP_PYPATH % {'path': path})
+ bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'module': module})
return '\n'.join(
- [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])
+ [self.SETUP_BOOTSTRAP_HEADER] +
+ bootstrap_sys_paths +
+ bootstrap_modules +
+ [self.SETUP_BOOTSTRAP_FOOTER]
+ )
def run(self):
if self._installed is not None:
|
{"golden_diff": "diff --git a/pex/installer.py b/pex/installer.py\n--- a/pex/installer.py\n+++ b/pex/installer.py\n@@ -33,7 +33,8 @@\n \n class InstallerBase(object):\n SETUP_BOOTSTRAP_HEADER = \"import sys\"\n- SETUP_BOOTSTRAP_MODULE = \"sys.path.insert(0, %(path)r); import %(module)s\"\n+ SETUP_BOOTSTRAP_PYPATH = \"sys.path.insert(0, %(path)r)\"\n+ SETUP_BOOTSTRAP_MODULE = \"import %(module)s\"\n SETUP_BOOTSTRAP_FOOTER = \"\"\"\n __file__ = 'setup.py'\n sys.argv[0] = 'setup.py'\n@@ -85,15 +86,21 @@\n \n @property\n def bootstrap_script(self):\n+ bootstrap_sys_paths = []\n bootstrap_modules = []\n for module, requirement in self.mixins().items():\n path = self._interpreter.get_location(requirement)\n if not path:\n assert not self._strict # This should be caught by validation\n continue\n- bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})\n+ bootstrap_sys_paths.append(self.SETUP_BOOTSTRAP_PYPATH % {'path': path})\n+ bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'module': module})\n return '\\n'.join(\n- [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])\n+ [self.SETUP_BOOTSTRAP_HEADER] +\n+ bootstrap_sys_paths +\n+ bootstrap_modules +\n+ [self.SETUP_BOOTSTRAP_FOOTER]\n+ )\n \n def run(self):\n if self._installed is not None:\n", "issue": "Nondeterministic \"invalid command 'bdist_wheel'\" resulting in \"Untranslateable\" exception\nI just started using pex. About half of the time I run it, it works great. The other half of the time, it fails like this.\n\n```\n> pex --python python2.7 abc.zip -v\n**** Failed to install enum34-1.0.4. stdout: :: Packaging enum34\n\n**** Failed to install enum34-1.0.4. stderr:\nusage: setup.py [global_opts] cmd1 [cmd1_opts] [cmd2 [cmd2_opts] ...]\n or: setup.py --help [cmd1 cmd2 ...]\n or: setup.py --help-commands\n or: setup.py cmd --help\n\nerror: invalid command 'bdist_wheel'\n\npex: Failed to install package at /tmp/tmppcotrf/enum34-1.0.4: Failed to install /tmp/tmppcotrf/enum34-1.0.4\nTraceback (most recent call last):\n File \"/bin/pex\", line 9, in <module>\n load_entry_point('pex==1.0.3', 'console_scripts', 'pex')()\n File \"/usr/lib/python3.3/site-packages/pex/bin/pex.py\", line 509, in main\n pex_builder = build_pex(reqs, options, resolver_options_builder)\n File \"/usr/lib/python3.3/site-packages/pex/bin/pex.py\", line 471, in build_pex\n resolveds = resolver.resolve(resolvables)\n File \"/usr/lib/python3.3/site-packages/pex/resolver.py\", line 191, in resolve\n dist = self.build(package, resolvable.options)\n File \"/usr/lib/python3.3/site-packages/pex/resolver.py\", line 248, in build\n dist = super(CachingResolver, self).build(package, options)\n File \"/usr/lib/python3.3/site-packages/pex/resolver.py\", line 160, in build\n raise Untranslateable('Package %s is not translateable by %s' % (package, translator))\npex.resolver.Untranslateable: Package SourcePackage('file:///home/chris/.pex/build/enum34-1.0.4.zip') is not translateable by ChainedTranslator(WheelTranslator, EggTranslator, SourceTranslator)\n```\n\nIn the above example it failed on `enum34`, but which dependency it fails on appears random as well.\n\n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import, print_function\n\nimport os\nimport sys\nimport tempfile\n\nfrom pkg_resources import Distribution, PathMetadata\n\nfrom .common import safe_mkdtemp, safe_rmtree\nfrom .compatibility import WINDOWS\nfrom .executor import Executor\nfrom .interpreter import PythonInterpreter\nfrom .tracer import TRACER\nfrom .version import SETUPTOOLS_REQUIREMENT, WHEEL_REQUIREMENT\n\n__all__ = (\n 'Installer',\n 'Packager'\n)\n\n\ndef after_installation(function):\n def function_wrapper(self, *args, **kw):\n self._installed = self.run()\n if not self._installed:\n raise Installer.InstallFailure('Failed to install %s' % self._source_dir)\n return function(self, *args, **kw)\n return function_wrapper\n\n\nclass InstallerBase(object):\n SETUP_BOOTSTRAP_HEADER = \"import sys\"\n SETUP_BOOTSTRAP_MODULE = \"sys.path.insert(0, %(path)r); import %(module)s\"\n SETUP_BOOTSTRAP_FOOTER = \"\"\"\n__file__ = 'setup.py'\nsys.argv[0] = 'setup.py'\nexec(compile(open(__file__, 'rb').read(), __file__, 'exec'))\n\"\"\"\n\n class Error(Exception): pass\n class InstallFailure(Error): pass\n class IncapableInterpreter(Error): pass\n\n def __init__(self, source_dir, strict=True, interpreter=None, install_dir=None):\n \"\"\"\n Create an installer from an unpacked source distribution in source_dir.\n\n If strict=True, fail if any installation dependencies (e.g. distribute)\n are missing.\n \"\"\"\n self._source_dir = source_dir\n self._install_tmp = install_dir or safe_mkdtemp()\n self._installed = None\n self._strict = strict\n self._interpreter = interpreter or PythonInterpreter.get()\n if not self._interpreter.satisfies(self.capability) and strict:\n raise self.IncapableInterpreter('Interpreter %s not capable of running %s' % (\n self._interpreter.binary, self.__class__.__name__))\n\n def mixins(self):\n \"\"\"Return a map from import name to requirement to load into setup script prior to invocation.\n\n May be subclassed.\n \"\"\"\n return {}\n\n @property\n def install_tmp(self):\n return self._install_tmp\n\n def _setup_command(self):\n \"\"\"the setup command-line to run, to be implemented by subclasses.\"\"\"\n raise NotImplementedError\n\n def _postprocess(self):\n \"\"\"a post-processing function to run following setup.py invocation.\"\"\"\n\n @property\n def capability(self):\n \"\"\"returns the list of requirements for the interpreter to run this installer.\"\"\"\n return list(self.mixins().values())\n\n @property\n def bootstrap_script(self):\n bootstrap_modules = []\n for module, requirement in self.mixins().items():\n path = self._interpreter.get_location(requirement)\n if not path:\n assert not self._strict # This should be caught by validation\n continue\n bootstrap_modules.append(self.SETUP_BOOTSTRAP_MODULE % {'path': path, 'module': module})\n return '\\n'.join(\n [self.SETUP_BOOTSTRAP_HEADER] + bootstrap_modules + [self.SETUP_BOOTSTRAP_FOOTER])\n\n def run(self):\n if self._installed is not None:\n return self._installed\n\n with TRACER.timed('Installing %s' % self._install_tmp, V=2):\n command = [self._interpreter.binary, '-'] + self._setup_command()\n try:\n Executor.execute(command,\n env=self._interpreter.sanitized_environment(),\n cwd=self._source_dir,\n stdin_payload=self.bootstrap_script.encode('ascii'))\n self._installed = True\n except Executor.NonZeroExit as e:\n self._installed = False\n name = os.path.basename(self._source_dir)\n print('**** Failed to install %s (caused by: %r\\n):' % (name, e), file=sys.stderr)\n print('stdout:\\n%s\\nstderr:\\n%s\\n' % (e.stdout, e.stderr), file=sys.stderr)\n return self._installed\n\n self._postprocess()\n return self._installed\n\n def cleanup(self):\n safe_rmtree(self._install_tmp)\n\n\nclass Installer(InstallerBase):\n \"\"\"Install an unpacked distribution with a setup.py.\"\"\"\n\n def __init__(self, source_dir, strict=True, interpreter=None):\n \"\"\"\n Create an installer from an unpacked source distribution in source_dir.\n\n If strict=True, fail if any installation dependencies (e.g. setuptools)\n are missing.\n \"\"\"\n super(Installer, self).__init__(source_dir, strict=strict, interpreter=interpreter)\n self._egg_info = None\n fd, self._install_record = tempfile.mkstemp()\n os.close(fd)\n\n def _setup_command(self):\n return ['install',\n '--root=%s' % self._install_tmp,\n '--prefix=',\n '--single-version-externally-managed',\n '--record', self._install_record]\n\n def _postprocess(self):\n installed_files = []\n egg_info = None\n with open(self._install_record) as fp:\n installed_files = fp.read().splitlines()\n for line in installed_files:\n if line.endswith('.egg-info'):\n assert line.startswith('/'), 'Expect .egg-info to be within install_tmp!'\n egg_info = line\n break\n\n if not egg_info:\n self._installed = False\n return self._installed\n\n installed_files = [os.path.relpath(fn, egg_info) for fn in installed_files if fn != egg_info]\n\n self._egg_info = os.path.join(self._install_tmp, egg_info[1:])\n with open(os.path.join(self._egg_info, 'installed-files.txt'), 'w') as fp:\n fp.write('\\n'.join(installed_files))\n fp.write('\\n')\n\n return self._installed\n\n @after_installation\n def egg_info(self):\n return self._egg_info\n\n @after_installation\n def root(self):\n egg_info = self.egg_info()\n assert egg_info\n return os.path.realpath(os.path.dirname(egg_info))\n\n @after_installation\n def distribution(self):\n base_dir = self.root()\n egg_info = self.egg_info()\n metadata = PathMetadata(base_dir, egg_info)\n return Distribution.from_location(base_dir, os.path.basename(egg_info), metadata=metadata)\n\n\nclass DistributionPackager(InstallerBase):\n def mixins(self):\n mixins = super(DistributionPackager, self).mixins().copy()\n mixins.update(setuptools=SETUPTOOLS_REQUIREMENT)\n return mixins\n\n def find_distribution(self):\n dists = os.listdir(self.install_tmp)\n if len(dists) == 0:\n raise self.InstallFailure('No distributions were produced!')\n elif len(dists) > 1:\n raise self.InstallFailure('Ambiguous source distributions found: %s' % (' '.join(dists)))\n else:\n return os.path.join(self.install_tmp, dists[0])\n\n\nclass Packager(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n\n def _setup_command(self):\n if WINDOWS:\n return ['sdist', '--formats=zip', '--dist-dir=%s' % self._install_tmp]\n else:\n return ['sdist', '--formats=gztar', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def sdist(self):\n return self.find_distribution()\n\n\nclass EggInstaller(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n\n def _setup_command(self):\n return ['bdist_egg', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def bdist(self):\n return self.find_distribution()\n\n\nclass WheelInstaller(DistributionPackager):\n \"\"\"\n Create a source distribution from an unpacked setup.py-based project.\n \"\"\"\n MIXINS = {\n 'setuptools': SETUPTOOLS_REQUIREMENT,\n 'wheel': WHEEL_REQUIREMENT,\n }\n\n def mixins(self):\n mixins = super(WheelInstaller, self).mixins().copy()\n mixins.update(self.MIXINS)\n return mixins\n\n def _setup_command(self):\n return ['bdist_wheel', '--dist-dir=%s' % self._install_tmp]\n\n @after_installation\n def bdist(self):\n return self.find_distribution()\n", "path": "pex/installer.py"}]}
| 3,625 | 380 |
gh_patches_debug_18826
|
rasdani/github-patches
|
git_diff
|
LMFDB__lmfdb-4276
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Some Dirichlet character pages are failing to load
The page https://www.lmfdb.org/Character/Dirichlet/947/934 is timing out. Some similar pages such as https://www.lmfdb.org/Character/Dirichlet/947/933 and https://www.lmfdb.org/Character/Dirichlet/947/935 work but are slow too load and the knowl for the fixed field does not work. I believe this is due to some of the recent changes that were made #4231 -- @BarinderBanwait can you take a look at this?
Below is the trace back from the page that is failing to load. the failure is inside the call to "zeta_order" on line 156 of https://github.com/LMFDB/lmfdb/blob/master/lmfdb/characters/TinyConrey.py. I don't think that call should be taking any time, but if Sage is doing something silly we should just compute zeta_order directly. I confess it's not clear to me why we are using Sage DirichletGroup and Sage characters at all (it appears they are being used in just 2 places).
```
Traceback (most recent call last):
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 2447, in wsgi_app
response = self.full_dispatch_request()
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1952, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1821, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/_compat.py", line 39, in reraise
raise value
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py", line 367, in render_Dirichletwebpage
webchar = make_webchar(args)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py", line 313, in make_webchar
return WebDBDirichletCharacter(**args)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 925, in __init__
WebDBDirichlet.__init__(self, **kwargs)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 568, in __init__
self._compute()
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 575, in _compute
self._populate_from_db()
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 589, in _populate_from_db
self._set_generators_and_genvalues(values_data)
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py", line 615, in _set_generators_and_genvalues
self._genvalues_for_code = get_sage_genvalues(self.modulus, self.order, vals, self.chi.sage_zeta_order(self.order))
File "/home/lmfdb/lmfdb-git-web/lmfdb/characters/TinyConrey.py", line 156, in sage_zeta_order
return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()
File "sage/misc/cachefunc.pyx", line 2310, in sage.misc.cachefunc.CachedMethodCallerNoArgs.__call__ (build/cythonized/sage/misc/cachefunc.c:12712)
self.cache = f(self._instance)
File "/home/sage/sage-9.1/local/lib/python3.7/site-packages/sage/modular/dirichlet.py", line 2880, in zeta_order
order = self.zeta().multiplicative_order()
File "sage/rings/number_field/number_field_element.pyx", line 3229, in sage.rings.number_field.number_field_element.NumberFieldElement.multiplicative_order (build/cythonized/sage/rings/number_field/number_field_element.cpp:27976)
elif not (self.is_integral() and self.norm().is_one()):
File "sage/rings/number_field/number_field_element.pyx", line 3576, in sage.rings.number_field.number_field_element.NumberFieldElement.is_integral (build/cythonized/sage/rings/number_field/number_field_element.cpp:30234)
return all(a in ZZ for a in self.absolute_minpoly())
File "sage/rings/number_field/number_field_element.pyx", line 3576, in genexpr (build/cythonized/sage/rings/number_field/number_field_element.cpp:30109)
return all(a in ZZ for a in self.absolute_minpoly())
File "sage/rings/number_field/number_field_element.pyx", line 4488, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.absolute_minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37507)
return self.minpoly(var)
File "sage/rings/number_field/number_field_element.pyx", line 4576, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:38144)
return self.charpoly(var, algorithm).radical() # square free part of charpoly
File "sage/rings/number_field/number_field_element.pyx", line 4543, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.charpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37945)
return R(self.matrix().charpoly())
File "sage/matrix/matrix_rational_dense.pyx", line 1034, in sage.matrix.matrix_rational_dense.Matrix_rational_dense.charpoly (build/cythonized/sage/matrix/matrix_rational_dense.c:10660)
f = A.charpoly(var, algorithm=algorithm)
File "sage/matrix/matrix_integer_dense.pyx", line 1336, in sage.matrix.matrix_integer_dense.Matrix_integer_dense.charpoly (build/cythonized/sage/matrix/matrix_integer_dense.c:12941)
sig_on()
```
</issue>
<code>
[start of lmfdb/characters/TinyConrey.py]
1 from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,
2 DirichletGroup, CyclotomicField, euler_phi)
3 from sage.misc.cachefunc import cached_method
4 from sage.modular.dirichlet import DirichletCharacter
5
6 def symbol_numerator(cond, parity):
7 # Reference: Sect. 9.3, Montgomery, Hugh L; Vaughan, Robert C. (2007).
8 # Multiplicative number theory. I. Classical theory. Cambridge Studies in
9 # Advanced Mathematics 97
10 #
11 # Let F = Q(\sqrt(d)) with d a non zero squarefree integer then a real
12 # Dirichlet character \chi(n) can be represented as a Kronecker symbol
13 # (m / n) where { m = d if # d = 1 mod 4 else m = 4d if d = 2,3 (mod) 4 }
14 # and m is the discriminant of F. The conductor of \chi is |m|.
15 #
16 # symbol_numerator returns the appropriate Kronecker symbol depending on
17 # the conductor of \chi.
18 m = cond
19 if cond % 2 == 1:
20 if cond % 4 == 3:
21 m = -cond
22 elif cond % 8 == 4:
23 # Fixed cond % 16 == 4 and cond % 16 == 12 were switched in the
24 # previous version of the code.
25 #
26 # Let d be a non zero squarefree integer. If d = 2,3 (mod) 4 and if
27 # cond = 4d = 4 ( 4n + 2) or 4 (4n + 3) = 16 n + 8 or 16n + 12 then we
28 # set m = cond. On the other hand if d = 1 (mod) 4 and cond = 4d = 4
29 # (4n +1) = 16n + 4 then we set m = -cond.
30 if cond % 16 == 4:
31 m = -cond
32 elif cond % 16 == 8:
33 if parity == 1:
34 m = -cond
35 else:
36 return None
37 return m
38
39
40 def kronecker_symbol(m):
41 if m:
42 return r'\(\displaystyle\left(\frac{%s}{\bullet}\right)\)' % (m)
43 else:
44 return None
45
46 ###############################################################################
47 ## Conrey character with no call to Jonathan's code
48 ## in order to handle big moduli
49 ##
50
51 def get_sage_genvalues(modulus, order, genvalues, zeta_order):
52 """
53 Helper method for computing correct genvalues when constructing
54 the sage character
55 """
56 phi_mod = euler_phi(modulus)
57 exponent_factor = phi_mod / order
58 genvalues_exponent = [x * exponent_factor for x in genvalues]
59 return [x * zeta_order / phi_mod for x in genvalues_exponent]
60
61
62 class PariConreyGroup(object):
63
64 def __init__(self, modulus):
65 self.modulus = int(modulus)
66 self.G = Pari("znstar({},1)".format(modulus))
67
68 def gens(self):
69 return Integers(self.modulus).unit_gens()
70
71 def invariants(self):
72 return pari("znstar({},1).cyc".format(self.modulus))
73
74
75 class ConreyCharacter(object):
76 """
77 tiny implementation on Conrey index only
78 """
79
80 def __init__(self, modulus, number):
81 assert gcd(modulus, number)==1
82 self.modulus = Integer(modulus)
83 self.number = Integer(number)
84 self.G = Pari("znstar({},1)".format(modulus))
85 self.chi_pari = pari("znconreylog(%s,%d)"%(self.G,self.number))
86 self.chi_0 = None
87 self.indlabel = None
88
89 @property
90 def texname(self):
91 from lmfdb.characters.web_character import WebDirichlet
92 return WebDirichlet.char2tex(self.modulus, self.number)
93
94 @cached_method
95 def modfactor(self):
96 return self.modulus.factor()
97
98 @cached_method
99 def conductor(self):
100 B = pari("znconreyconductor(%s,%s,&chi0)"%(self.G, self.chi_pari))
101 if B.type() == 't_INT':
102 # means chi is primitive
103 self.chi_0 = self.chi_pari
104 self.indlabel = self.number
105 return int(B)
106 else:
107 self.chi_0 = pari("chi0")
108 G_0 = Pari("znstar({},1)".format(B))
109 self.indlabel = int(pari("znconreyexp(%s,%s)"%(G_0,self.chi_0)))
110 return int(B[0])
111
112 def is_primitive(self):
113 return self.conductor() == self.modulus
114
115 @cached_method
116 def parity(self):
117 number = self.number
118 par = 0
119 for p,e in self.modfactor():
120 if p == 2:
121 if number % 4 == 3:
122 par = 1 - par
123 else:
124 phi2 = (p-1)/Integer(2) * p **(e-1)
125 if Mod(number, p ** e)**phi2 != 1:
126 par = 1 - par
127 return par
128
129 def is_odd(self):
130 return self.parity() == 1
131
132 def is_even(self):
133 return self.parity() == 0
134
135 @cached_method
136 def multiplicative_order(self):
137 return Mod(self.number, self.modulus).multiplicative_order()
138
139 @property
140 def order(self):
141 return self.multiplicative_order()
142
143 @cached_method
144 def kronecker_symbol(self):
145 c = self.conductor()
146 p = self.parity()
147 return kronecker_symbol(symbol_numerator(c, p))
148
149 def conreyangle(self,x):
150 return Rational(pari("chareval(%s,znconreylog(%s,%d),%d)"%(self.G,self.G,self.number,x)))
151
152 def gauss_sum_numerical(self, a):
153 return pari("znchargauss(%s,%s,a=%d)"%(self.G,self.chi_pari,a))
154
155 def sage_zeta_order(self, order):
156 return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()
157
158 def sage_character(self, order, genvalues):
159 H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))
160 M = H._module
161 order_corrected_genvalues = get_sage_genvalues(self.modulus, order, genvalues, H.zeta_order())
162 return DirichletCharacter(H,M(order_corrected_genvalues))
163
[end of lmfdb/characters/TinyConrey.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lmfdb/characters/TinyConrey.py b/lmfdb/characters/TinyConrey.py
--- a/lmfdb/characters/TinyConrey.py
+++ b/lmfdb/characters/TinyConrey.py
@@ -1,5 +1,5 @@
from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,
- DirichletGroup, CyclotomicField, euler_phi)
+ DirichletGroup, CyclotomicField, euler_phi, lcm)
from sage.misc.cachefunc import cached_method
from sage.modular.dirichlet import DirichletCharacter
@@ -153,7 +153,7 @@
return pari("znchargauss(%s,%s,a=%d)"%(self.G,self.chi_pari,a))
def sage_zeta_order(self, order):
- return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()
+ return 1 if self.modulus <= 2 else lcm(2,order)
def sage_character(self, order, genvalues):
H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))
|
{"golden_diff": "diff --git a/lmfdb/characters/TinyConrey.py b/lmfdb/characters/TinyConrey.py\n--- a/lmfdb/characters/TinyConrey.py\n+++ b/lmfdb/characters/TinyConrey.py\n@@ -1,5 +1,5 @@\n from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,\n- DirichletGroup, CyclotomicField, euler_phi)\n+ DirichletGroup, CyclotomicField, euler_phi, lcm)\n from sage.misc.cachefunc import cached_method\n from sage.modular.dirichlet import DirichletCharacter\n \n@@ -153,7 +153,7 @@\n return pari(\"znchargauss(%s,%s,a=%d)\"%(self.G,self.chi_pari,a))\n \n def sage_zeta_order(self, order):\n- return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()\n+ return 1 if self.modulus <= 2 else lcm(2,order)\n \n def sage_character(self, order, genvalues):\n H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))\n", "issue": "Some Dirichlet character pages are failing to load\nThe page https://www.lmfdb.org/Character/Dirichlet/947/934 is timing out. Some similar pages such as https://www.lmfdb.org/Character/Dirichlet/947/933 and https://www.lmfdb.org/Character/Dirichlet/947/935 work but are slow too load and the knowl for the fixed field does not work. I believe this is due to some of the recent changes that were made #4231 -- @BarinderBanwait can you take a look at this?\r\n\r\nBelow is the trace back from the page that is failing to load. the failure is inside the call to \"zeta_order\" on line 156 of https://github.com/LMFDB/lmfdb/blob/master/lmfdb/characters/TinyConrey.py. I don't think that call should be taking any time, but if Sage is doing something silly we should just compute zeta_order directly. I confess it's not clear to me why we are using Sage DirichletGroup and Sage characters at all (it appears they are being used in just 2 places).\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 2447, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1952, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1821, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/_compat.py\", line 39, in reraise\r\n raise value\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1950, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/flask/app.py\", line 1936, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py\", line 367, in render_Dirichletwebpage\r\n webchar = make_webchar(args)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/main.py\", line 313, in make_webchar\r\n return WebDBDirichletCharacter(**args)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 925, in __init__\r\n WebDBDirichlet.__init__(self, **kwargs)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 568, in __init__\r\n self._compute()\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 575, in _compute\r\n self._populate_from_db()\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 589, in _populate_from_db\r\n self._set_generators_and_genvalues(values_data)\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/web_character.py\", line 615, in _set_generators_and_genvalues\r\n self._genvalues_for_code = get_sage_genvalues(self.modulus, self.order, vals, self.chi.sage_zeta_order(self.order))\r\n File \"/home/lmfdb/lmfdb-git-web/lmfdb/characters/TinyConrey.py\", line 156, in sage_zeta_order\r\n return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()\r\n File \"sage/misc/cachefunc.pyx\", line 2310, in sage.misc.cachefunc.CachedMethodCallerNoArgs.__call__ (build/cythonized/sage/misc/cachefunc.c:12712)\r\n self.cache = f(self._instance)\r\n File \"/home/sage/sage-9.1/local/lib/python3.7/site-packages/sage/modular/dirichlet.py\", line 2880, in zeta_order\r\n order = self.zeta().multiplicative_order()\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 3229, in sage.rings.number_field.number_field_element.NumberFieldElement.multiplicative_order (build/cythonized/sage/rings/number_field/number_field_element.cpp:27976)\r\n elif not (self.is_integral() and self.norm().is_one()):\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 3576, in sage.rings.number_field.number_field_element.NumberFieldElement.is_integral (build/cythonized/sage/rings/number_field/number_field_element.cpp:30234)\r\n return all(a in ZZ for a in self.absolute_minpoly())\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 3576, in genexpr (build/cythonized/sage/rings/number_field/number_field_element.cpp:30109)\r\n return all(a in ZZ for a in self.absolute_minpoly())\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 4488, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.absolute_minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37507)\r\n return self.minpoly(var)\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 4576, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.minpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:38144)\r\n return self.charpoly(var, algorithm).radical() # square free part of charpoly\r\n File \"sage/rings/number_field/number_field_element.pyx\", line 4543, in sage.rings.number_field.number_field_element.NumberFieldElement_absolute.charpoly (build/cythonized/sage/rings/number_field/number_field_element.cpp:37945)\r\n return R(self.matrix().charpoly())\r\n File \"sage/matrix/matrix_rational_dense.pyx\", line 1034, in sage.matrix.matrix_rational_dense.Matrix_rational_dense.charpoly (build/cythonized/sage/matrix/matrix_rational_dense.c:10660)\r\n f = A.charpoly(var, algorithm=algorithm)\r\n File \"sage/matrix/matrix_integer_dense.pyx\", line 1336, in sage.matrix.matrix_integer_dense.Matrix_integer_dense.charpoly (build/cythonized/sage/matrix/matrix_integer_dense.c:12941)\r\n sig_on()\r\n```\n", "before_files": [{"content": "from sage.all import (gcd, Mod, Integer, Integers, Rational, pari, Pari,\n DirichletGroup, CyclotomicField, euler_phi)\nfrom sage.misc.cachefunc import cached_method\nfrom sage.modular.dirichlet import DirichletCharacter\n\ndef symbol_numerator(cond, parity):\n # Reference: Sect. 9.3, Montgomery, Hugh L; Vaughan, Robert C. (2007).\n # Multiplicative number theory. I. Classical theory. Cambridge Studies in\n # Advanced Mathematics 97\n #\n # Let F = Q(\\sqrt(d)) with d a non zero squarefree integer then a real\n # Dirichlet character \\chi(n) can be represented as a Kronecker symbol\n # (m / n) where { m = d if # d = 1 mod 4 else m = 4d if d = 2,3 (mod) 4 }\n # and m is the discriminant of F. The conductor of \\chi is |m|.\n #\n # symbol_numerator returns the appropriate Kronecker symbol depending on\n # the conductor of \\chi.\n m = cond\n if cond % 2 == 1:\n if cond % 4 == 3:\n m = -cond\n elif cond % 8 == 4:\n # Fixed cond % 16 == 4 and cond % 16 == 12 were switched in the\n # previous version of the code.\n #\n # Let d be a non zero squarefree integer. If d = 2,3 (mod) 4 and if\n # cond = 4d = 4 ( 4n + 2) or 4 (4n + 3) = 16 n + 8 or 16n + 12 then we\n # set m = cond. On the other hand if d = 1 (mod) 4 and cond = 4d = 4\n # (4n +1) = 16n + 4 then we set m = -cond.\n if cond % 16 == 4:\n m = -cond\n elif cond % 16 == 8:\n if parity == 1:\n m = -cond\n else:\n return None\n return m\n\n\ndef kronecker_symbol(m):\n if m:\n return r'\\(\\displaystyle\\left(\\frac{%s}{\\bullet}\\right)\\)' % (m)\n else:\n return None\n\n###############################################################################\n## Conrey character with no call to Jonathan's code\n## in order to handle big moduli\n##\n\ndef get_sage_genvalues(modulus, order, genvalues, zeta_order):\n \"\"\"\n Helper method for computing correct genvalues when constructing\n the sage character\n \"\"\"\n phi_mod = euler_phi(modulus)\n exponent_factor = phi_mod / order\n genvalues_exponent = [x * exponent_factor for x in genvalues]\n return [x * zeta_order / phi_mod for x in genvalues_exponent]\n\n\nclass PariConreyGroup(object):\n\n def __init__(self, modulus):\n self.modulus = int(modulus)\n self.G = Pari(\"znstar({},1)\".format(modulus))\n\n def gens(self):\n return Integers(self.modulus).unit_gens()\n\n def invariants(self):\n return pari(\"znstar({},1).cyc\".format(self.modulus))\n\n\nclass ConreyCharacter(object):\n \"\"\"\n tiny implementation on Conrey index only\n \"\"\"\n\n def __init__(self, modulus, number):\n assert gcd(modulus, number)==1\n self.modulus = Integer(modulus)\n self.number = Integer(number)\n self.G = Pari(\"znstar({},1)\".format(modulus))\n self.chi_pari = pari(\"znconreylog(%s,%d)\"%(self.G,self.number))\n self.chi_0 = None\n self.indlabel = None\n\n @property\n def texname(self):\n from lmfdb.characters.web_character import WebDirichlet\n return WebDirichlet.char2tex(self.modulus, self.number)\n\n @cached_method\n def modfactor(self):\n return self.modulus.factor()\n\n @cached_method\n def conductor(self):\n B = pari(\"znconreyconductor(%s,%s,&chi0)\"%(self.G, self.chi_pari))\n if B.type() == 't_INT':\n # means chi is primitive\n self.chi_0 = self.chi_pari\n self.indlabel = self.number\n return int(B)\n else:\n self.chi_0 = pari(\"chi0\")\n G_0 = Pari(\"znstar({},1)\".format(B))\n self.indlabel = int(pari(\"znconreyexp(%s,%s)\"%(G_0,self.chi_0)))\n return int(B[0])\n\n def is_primitive(self):\n return self.conductor() == self.modulus\n\n @cached_method\n def parity(self):\n number = self.number\n par = 0\n for p,e in self.modfactor():\n if p == 2:\n if number % 4 == 3:\n par = 1 - par\n else:\n phi2 = (p-1)/Integer(2) * p **(e-1)\n if Mod(number, p ** e)**phi2 != 1:\n par = 1 - par\n return par\n\n def is_odd(self):\n return self.parity() == 1\n\n def is_even(self):\n return self.parity() == 0\n\n @cached_method\n def multiplicative_order(self):\n return Mod(self.number, self.modulus).multiplicative_order()\n\n @property\n def order(self):\n return self.multiplicative_order()\n\n @cached_method\n def kronecker_symbol(self):\n c = self.conductor()\n p = self.parity()\n return kronecker_symbol(symbol_numerator(c, p))\n\n def conreyangle(self,x):\n return Rational(pari(\"chareval(%s,znconreylog(%s,%d),%d)\"%(self.G,self.G,self.number,x)))\n\n def gauss_sum_numerical(self, a):\n return pari(\"znchargauss(%s,%s,a=%d)\"%(self.G,self.chi_pari,a))\n\n def sage_zeta_order(self, order):\n return DirichletGroup(self.modulus, base_ring=CyclotomicField(order)).zeta_order()\n\n def sage_character(self, order, genvalues):\n H = DirichletGroup(self.modulus, base_ring=CyclotomicField(order))\n M = H._module\n order_corrected_genvalues = get_sage_genvalues(self.modulus, order, genvalues, H.zeta_order())\n return DirichletCharacter(H,M(order_corrected_genvalues))\n", "path": "lmfdb/characters/TinyConrey.py"}]}
| 4,061 | 264 |
gh_patches_debug_14517
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-862
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make interactive visualizations default for Jupyter
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues to confirm this idea does not exist. -->
### What is the expected enhancement?
The interactive visualizations contributed in PR #765 are much better than the static ones, and should be default when the environment is a Jupyter notebook. This is related to Epic #707 for providing better jupyter tools.
Several issues must be solved first:
- These visualizations need internet connection. Can we eliminate that?
- The interface of the static and interactive visualizations are all the same, except for `plot_histogram` vs `iplot_histogram`. These should be made similar for consistency. But the interactive visualization is able to plot multiple histograms in one plot.
- How "heavy" is it to run these interactive visualizations? I hear my laptop fan.
</issue>
<code>
[start of qiskit/tools/visualization/__init__.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright 2018, IBM.
4 #
5 # This source code is licensed under the Apache License, Version 2.0 found in
6 # the LICENSE.txt file in the root directory of this source tree.
7
8 """Main QISKit visualization methods."""
9
10 from ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\
11 latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme
12 from ._state_visualization import plot_state
13 from ._counts_visualization import plot_histogram
14
[end of qiskit/tools/visualization/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/tools/visualization/__init__.py b/qiskit/tools/visualization/__init__.py
--- a/qiskit/tools/visualization/__init__.py
+++ b/qiskit/tools/visualization/__init__.py
@@ -7,7 +7,18 @@
"""Main QISKit visualization methods."""
+import sys
+
from ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\
latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme
-from ._state_visualization import plot_state
from ._counts_visualization import plot_histogram
+
+if ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):
+ import requests
+ if requests.get(
+ 'https://qvisualization.mybluemix.net/').status_code == 200:
+ from .interactive._iplot_state import iplot_state as plot_state
+ else:
+ from ._state_visualization import plot_state
+else:
+ from ._state_visualization import plot_state
|
{"golden_diff": "diff --git a/qiskit/tools/visualization/__init__.py b/qiskit/tools/visualization/__init__.py\n--- a/qiskit/tools/visualization/__init__.py\n+++ b/qiskit/tools/visualization/__init__.py\n@@ -7,7 +7,18 @@\n \n \"\"\"Main QISKit visualization methods.\"\"\"\n \n+import sys\n+\n from ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\\\n latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme\n-from ._state_visualization import plot_state\n from ._counts_visualization import plot_histogram\n+\n+if ('ipykernel' in sys.modules) and ('spyder' not in sys.modules):\n+ import requests\n+ if requests.get(\n+ 'https://qvisualization.mybluemix.net/').status_code == 200:\n+ from .interactive._iplot_state import iplot_state as plot_state\n+ else:\n+ from ._state_visualization import plot_state\n+else:\n+ from ._state_visualization import plot_state\n", "issue": "Make interactive visualizations default for Jupyter\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues to confirm this idea does not exist. -->\r\n\r\n### What is the expected enhancement?\r\nThe interactive visualizations contributed in PR #765 are much better than the static ones, and should be default when the environment is a Jupyter notebook. This is related to Epic #707 for providing better jupyter tools.\r\n\r\nSeveral issues must be solved first:\r\n- These visualizations need internet connection. Can we eliminate that?\r\n- The interface of the static and interactive visualizations are all the same, except for `plot_histogram` vs `iplot_histogram`. These should be made similar for consistency. But the interactive visualization is able to plot multiple histograms in one plot.\r\n- How \"heavy\" is it to run these interactive visualizations? I hear my laptop fan.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n\"\"\"Main QISKit visualization methods.\"\"\"\n\nfrom ._circuit_visualization import circuit_drawer, plot_circuit, generate_latex_source,\\\n latex_circuit_drawer, matplotlib_circuit_drawer, qx_color_scheme\nfrom ._state_visualization import plot_state\nfrom ._counts_visualization import plot_histogram\n", "path": "qiskit/tools/visualization/__init__.py"}]}
| 874 | 230 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.