
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_31158
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-3189
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CSV export does not include read date
**Describe the bug**
When exporting data into a CSV file, several fields are exported, but `read date` is not one of them, despite being exremelly valuable.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'Profile'
2. Click on 'Export to CSV'
3. Download CSV file
4. Open CSV file
**Expected behavior**
A column containing read date should be included among the current ones
**Instance**
bookwyrm.social
---
**Desktop (please complete the following information):**
- OS: KDE Neon
- Browser Firefox, Chromium
- Version
</issue>
<code>
[start of bookwyrm/views/preferences/export.py]
1 """ Let users export their book data """
2 from datetime import timedelta
3 import csv
4 import io
5
6 from django.contrib.auth.decorators import login_required
7 from django.core.paginator import Paginator
8 from django.db.models import Q
9 from django.http import HttpResponse
10 from django.template.response import TemplateResponse
11 from django.utils import timezone
12 from django.views import View
13 from django.utils.decorators import method_decorator
14 from django.shortcuts import redirect
15
16 from bookwyrm import models
17 from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob
18 from bookwyrm.settings import PAGE_LENGTH
19
20 # pylint: disable=no-self-use
21 @method_decorator(login_required, name="dispatch")
22 class Export(View):
23 """Let users export data"""
24
25 def get(self, request):
26 """Request csv file"""
27 return TemplateResponse(request, "preferences/export.html")
28
29 def post(self, request):
30 """Download the csv file of a user's book data"""
31 books = models.Edition.viewer_aware_objects(request.user)
32 books_shelves = books.filter(Q(shelves__user=request.user)).distinct()
33 books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()
34 books_review = books.filter(Q(review__user=request.user)).distinct()
35 books_comment = books.filter(Q(comment__user=request.user)).distinct()
36 books_quotation = books.filter(Q(quotation__user=request.user)).distinct()
37
38 books = set(
39 list(books_shelves)
40 + list(books_readthrough)
41 + list(books_review)
42 + list(books_comment)
43 + list(books_quotation)
44 )
45
46 csv_string = io.StringIO()
47 writer = csv.writer(csv_string)
48
49 deduplication_fields = [
50 f.name
51 for f in models.Edition._meta.get_fields() # pylint: disable=protected-access
52 if getattr(f, "deduplication_field", False)
53 ]
54 fields = (
55 ["title", "author_text"]
56 + deduplication_fields
57 + ["rating", "review_name", "review_cw", "review_content"]
58 )
59 writer.writerow(fields)
60
61 for book in books:
62 # I think this is more efficient than doing a subquery in the view? but idk
63 review_rating = (
64 models.Review.objects.filter(
65 user=request.user, book=book, rating__isnull=False
66 )
67 .order_by("-published_date")
68 .first()
69 )
70
71 book.rating = review_rating.rating if review_rating else None
72
73 review = (
74 models.Review.objects.filter(
75 user=request.user, book=book, content__isnull=False
76 )
77 .order_by("-published_date")
78 .first()
79 )
80 if review:
81 book.review_name = review.name
82 book.review_cw = review.content_warning
83 book.review_content = review.raw_content
84 writer.writerow([getattr(book, field, "") or "" for field in fields])
85
86 return HttpResponse(
87 csv_string.getvalue(),
88 content_type="text/csv",
89 headers={
90 "Content-Disposition": 'attachment; filename="bookwyrm-export.csv"'
91 },
92 )
93
94
95 # pylint: disable=no-self-use
96 @method_decorator(login_required, name="dispatch")
97 class ExportUser(View):
98 """Let users export user data to import into another Bookwyrm instance"""
99
100 def get(self, request):
101 """Request tar file"""
102
103 jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(
104 "-created_date"
105 )
106 site = models.SiteSettings.objects.get()
107 hours = site.user_import_time_limit
108 allowed = (
109 jobs.first().created_date < timezone.now() - timedelta(hours=hours)
110 if jobs.first()
111 else True
112 )
113 next_available = (
114 jobs.first().created_date + timedelta(hours=hours) if not allowed else False
115 )
116 paginated = Paginator(jobs, PAGE_LENGTH)
117 page = paginated.get_page(request.GET.get("page"))
118 data = {
119 "jobs": page,
120 "next_available": next_available,
121 "page_range": paginated.get_elided_page_range(
122 page.number, on_each_side=2, on_ends=1
123 ),
124 }
125
126 return TemplateResponse(request, "preferences/export-user.html", data)
127
128 def post(self, request):
129 """Download the json file of a user's data"""
130
131 job = BookwyrmExportJob.objects.create(user=request.user)
132 job.start_job()
133
134 return redirect("prefs-user-export")
135
136
137 @method_decorator(login_required, name="dispatch")
138 class ExportArchive(View):
139 """Serve the archive file"""
140
141 def get(self, request, archive_id):
142 """download user export file"""
143 export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)
144 return HttpResponse(
145 export.export_data,
146 content_type="application/gzip",
147 headers={
148 "Content-Disposition": 'attachment; filename="bookwyrm-account-export.tar.gz"' # pylint: disable=line-too-long
149 },
150 )
151
[end of bookwyrm/views/preferences/export.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/views/preferences/export.py b/bookwyrm/views/preferences/export.py
--- a/bookwyrm/views/preferences/export.py
+++ b/bookwyrm/views/preferences/export.py
@@ -17,7 +17,7 @@
from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob
from bookwyrm.settings import PAGE_LENGTH
-# pylint: disable=no-self-use
+# pylint: disable=no-self-use,too-many-locals
@method_decorator(login_required, name="dispatch")
class Export(View):
"""Let users export data"""
@@ -54,6 +54,7 @@
fields = (
["title", "author_text"]
+ deduplication_fields
+ + ["start_date", "finish_date", "stopped_date"]
+ ["rating", "review_name", "review_cw", "review_content"]
)
writer.writerow(fields)
@@ -70,6 +71,24 @@
book.rating = review_rating.rating if review_rating else None
+ readthrough = (
+ models.ReadThrough.objects.filter(user=request.user, book=book)
+ .order_by("-start_date", "-finish_date")
+ .first()
+ )
+ if readthrough:
+ book.start_date = (
+ readthrough.start_date.date() if readthrough.start_date else None
+ )
+ book.finish_date = (
+ readthrough.finish_date.date() if readthrough.finish_date else None
+ )
+ book.stopped_date = (
+ readthrough.stopped_date.date()
+ if readthrough.stopped_date
+ else None
+ )
+
review = (
models.Review.objects.filter(
user=request.user, book=book, content__isnull=False
|
{"golden_diff": "diff --git a/bookwyrm/views/preferences/export.py b/bookwyrm/views/preferences/export.py\n--- a/bookwyrm/views/preferences/export.py\n+++ b/bookwyrm/views/preferences/export.py\n@@ -17,7 +17,7 @@\n from bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\n from bookwyrm.settings import PAGE_LENGTH\n \n-# pylint: disable=no-self-use\n+# pylint: disable=no-self-use,too-many-locals\n @method_decorator(login_required, name=\"dispatch\")\n class Export(View):\n \"\"\"Let users export data\"\"\"\n@@ -54,6 +54,7 @@\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n+ + [\"start_date\", \"finish_date\", \"stopped_date\"]\n + [\"rating\", \"review_name\", \"review_cw\", \"review_content\"]\n )\n writer.writerow(fields)\n@@ -70,6 +71,24 @@\n \n book.rating = review_rating.rating if review_rating else None\n \n+ readthrough = (\n+ models.ReadThrough.objects.filter(user=request.user, book=book)\n+ .order_by(\"-start_date\", \"-finish_date\")\n+ .first()\n+ )\n+ if readthrough:\n+ book.start_date = (\n+ readthrough.start_date.date() if readthrough.start_date else None\n+ )\n+ book.finish_date = (\n+ readthrough.finish_date.date() if readthrough.finish_date else None\n+ )\n+ book.stopped_date = (\n+ readthrough.stopped_date.date()\n+ if readthrough.stopped_date\n+ else None\n+ )\n+\n review = (\n models.Review.objects.filter(\n user=request.user, book=book, content__isnull=False\n", "issue": "CSV export does not include read date\n**Describe the bug**\r\nWhen exporting data into a CSV file, several fields are exported, but `read date` is not one of them, despite being exremelly valuable.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to 'Profile'\r\n2. Click on 'Export to CSV'\r\n3. Download CSV file\r\n4. Open CSV file\r\n\r\n**Expected behavior**\r\nA column containing read date should be included among the current ones\r\n\r\n**Instance**\r\nbookwyrm.social\r\n\r\n\r\n\r\n---\r\n\r\n**Desktop (please complete the following information):**\r\n - OS: KDE Neon\r\n - Browser Firefox, Chromium\r\n - Version \r\n\n", "before_files": [{"content": "\"\"\" Let users export their book data \"\"\"\nfrom datetime import timedelta\nimport csv\nimport io\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.paginator import Paginator\nfrom django.db.models import Q\nfrom django.http import HttpResponse\nfrom django.template.response import TemplateResponse\nfrom django.utils import timezone\nfrom django.views import View\nfrom django.utils.decorators import method_decorator\nfrom django.shortcuts import redirect\n\nfrom bookwyrm import models\nfrom bookwyrm.models.bookwyrm_export_job import BookwyrmExportJob\nfrom bookwyrm.settings import PAGE_LENGTH\n\n# pylint: disable=no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass Export(View):\n \"\"\"Let users export data\"\"\"\n\n def get(self, request):\n \"\"\"Request csv file\"\"\"\n return TemplateResponse(request, \"preferences/export.html\")\n\n def post(self, request):\n \"\"\"Download the csv file of a user's book data\"\"\"\n books = models.Edition.viewer_aware_objects(request.user)\n books_shelves = books.filter(Q(shelves__user=request.user)).distinct()\n books_readthrough = books.filter(Q(readthrough__user=request.user)).distinct()\n books_review = books.filter(Q(review__user=request.user)).distinct()\n books_comment = books.filter(Q(comment__user=request.user)).distinct()\n books_quotation = books.filter(Q(quotation__user=request.user)).distinct()\n\n books = set(\n list(books_shelves)\n + list(books_readthrough)\n + list(books_review)\n + list(books_comment)\n + list(books_quotation)\n )\n\n csv_string = io.StringIO()\n writer = csv.writer(csv_string)\n\n deduplication_fields = [\n f.name\n for f in models.Edition._meta.get_fields() # pylint: disable=protected-access\n if getattr(f, \"deduplication_field\", False)\n ]\n fields = (\n [\"title\", \"author_text\"]\n + deduplication_fields\n + [\"rating\", \"review_name\", \"review_cw\", \"review_content\"]\n )\n writer.writerow(fields)\n\n for book in books:\n # I think this is more efficient than doing a subquery in the view? but idk\n review_rating = (\n models.Review.objects.filter(\n user=request.user, book=book, rating__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n\n book.rating = review_rating.rating if review_rating else None\n\n review = (\n models.Review.objects.filter(\n user=request.user, book=book, content__isnull=False\n )\n .order_by(\"-published_date\")\n .first()\n )\n if review:\n book.review_name = review.name\n book.review_cw = review.content_warning\n book.review_content = review.raw_content\n writer.writerow([getattr(book, field, \"\") or \"\" for field in fields])\n\n return HttpResponse(\n csv_string.getvalue(),\n content_type=\"text/csv\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-export.csv\"'\n },\n )\n\n\n# pylint: disable=no-self-use\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportUser(View):\n \"\"\"Let users export user data to import into another Bookwyrm instance\"\"\"\n\n def get(self, request):\n \"\"\"Request tar file\"\"\"\n\n jobs = BookwyrmExportJob.objects.filter(user=request.user).order_by(\n \"-created_date\"\n )\n site = models.SiteSettings.objects.get()\n hours = site.user_import_time_limit\n allowed = (\n jobs.first().created_date < timezone.now() - timedelta(hours=hours)\n if jobs.first()\n else True\n )\n next_available = (\n jobs.first().created_date + timedelta(hours=hours) if not allowed else False\n )\n paginated = Paginator(jobs, PAGE_LENGTH)\n page = paginated.get_page(request.GET.get(\"page\"))\n data = {\n \"jobs\": page,\n \"next_available\": next_available,\n \"page_range\": paginated.get_elided_page_range(\n page.number, on_each_side=2, on_ends=1\n ),\n }\n\n return TemplateResponse(request, \"preferences/export-user.html\", data)\n\n def post(self, request):\n \"\"\"Download the json file of a user's data\"\"\"\n\n job = BookwyrmExportJob.objects.create(user=request.user)\n job.start_job()\n\n return redirect(\"prefs-user-export\")\n\n\n@method_decorator(login_required, name=\"dispatch\")\nclass ExportArchive(View):\n \"\"\"Serve the archive file\"\"\"\n\n def get(self, request, archive_id):\n \"\"\"download user export file\"\"\"\n export = BookwyrmExportJob.objects.get(task_id=archive_id, user=request.user)\n return HttpResponse(\n export.export_data,\n content_type=\"application/gzip\",\n headers={\n \"Content-Disposition\": 'attachment; filename=\"bookwyrm-account-export.tar.gz\"' # pylint: disable=line-too-long\n },\n )\n", "path": "bookwyrm/views/preferences/export.py"}]}
| 2,086 | 380 |
gh_patches_debug_5570
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-40
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ModuleNotFoundError: No module named '_lzma'
I've tried to test lightwood with [home rentals
example](https://github.com/mindsdb/lightwood/blob/master/docs/examples/home_rentals.py) but got ModuleNotFoundError: No module named '_lzma'.
Screenshot:

It looks like _lzma is a dependency to pandas, but it should be included with Python 3.x version.
</issue>
<code>
[start of lightwood/__about__.py]
1 __title__ = 'lightwood'
2 __package_name__ = 'mindsdb'
3 __version__ = '0.9.0'
4 __description__ = "Lightwood's goal is to make it very simple for developers to use the power of artificial neural networks in their projects."
5 __email__ = "[email protected]"
6 __author__ = 'MindsDB Inc'
7 __github__ = 'https://github.com/mindsdb/lightwood'
8 __pypi__ = 'https://pypi.org/project/lightwood'
9 __license__ = 'MIT'
10 __copyright__ = 'Copyright 2019- mindsdb'
11
[end of lightwood/__about__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lightwood/__about__.py b/lightwood/__about__.py
--- a/lightwood/__about__.py
+++ b/lightwood/__about__.py
@@ -1,6 +1,6 @@
__title__ = 'lightwood'
__package_name__ = 'mindsdb'
-__version__ = '0.9.0'
+__version__ = '0.9.1'
__description__ = "Lightwood's goal is to make it very simple for developers to use the power of artificial neural networks in their projects."
__email__ = "[email protected]"
__author__ = 'MindsDB Inc'
|
{"golden_diff": "diff --git a/lightwood/__about__.py b/lightwood/__about__.py\n--- a/lightwood/__about__.py\n+++ b/lightwood/__about__.py\n@@ -1,6 +1,6 @@\n __title__ = 'lightwood'\n __package_name__ = 'mindsdb'\n-__version__ = '0.9.0'\n+__version__ = '0.9.1'\n __description__ = \"Lightwood's goal is to make it very simple for developers to use the power of artificial neural networks in their projects.\"\n __email__ = \"[email protected]\"\n __author__ = 'MindsDB Inc'\n", "issue": "ModuleNotFoundError: No module named '_lzma'\nI've tried to test lightwood with [home rentals\r\n example](https://github.com/mindsdb/lightwood/blob/master/docs/examples/home_rentals.py) but got ModuleNotFoundError: No module named '_lzma'.\r\n\r\nScreenshot:\r\n\r\n\r\nIt looks like _lzma is a dependency to pandas, but it should be included with Python 3.x version.\r\n\r\n\n", "before_files": [{"content": "__title__ = 'lightwood'\n__package_name__ = 'mindsdb'\n__version__ = '0.9.0'\n__description__ = \"Lightwood's goal is to make it very simple for developers to use the power of artificial neural networks in their projects.\"\n__email__ = \"[email protected]\"\n__author__ = 'MindsDB Inc'\n__github__ = 'https://github.com/mindsdb/lightwood'\n__pypi__ = 'https://pypi.org/project/lightwood'\n__license__ = 'MIT'\n__copyright__ = 'Copyright 2019- mindsdb'\n", "path": "lightwood/__about__.py"}]}
| 848 | 139 |
gh_patches_debug_19383
|
rasdani/github-patches
|
git_diff
|
ckan__ckan-7387
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
datatablesview: show columns feature bug
## CKAN version
master, 2.10 (earlier?)
## Describe the bug
If any columns are unselected when creating a view, the view will not appear.
### Steps to reproduce
When creating or editing a datatablesview (not viewing an existing one) un-check some columns and save the view.
### Expected behavior
Those columns should be excluded but view should still work.
### Additional details
</issue>
<code>
[start of ckanext/datastore/helpers.py]
1 # encoding: utf-8
2 from __future__ import annotations
3
4 import json
5 import logging
6 from typing import (
7 Any, Iterable, Optional, Sequence, Union, cast, overload
8 )
9 from typing_extensions import Literal
10
11 import sqlparse
12 import six
13
14 import ckan.common as converters
15 import ckan.plugins.toolkit as tk
16 from ckan.types import Context
17
18
19 log = logging.getLogger(__name__)
20
21
22 def is_single_statement(sql: str):
23 '''Returns True if received SQL string contains at most one statement'''
24 return len(sqlparse.split(sql)) <= 1
25
26
27 def is_valid_field_name(name: str):
28 '''
29 Check that field name is valid:
30 * can't start or end with whitespace characters
31 * can't start with underscore
32 * can't contain double quote (")
33 * can't be empty
34 '''
35 return (name and name == name.strip() and
36 not name.startswith('_') and
37 '"' not in name)
38
39
40 def is_valid_table_name(name: str):
41 if '%' in name:
42 return False
43 return is_valid_field_name(name)
44
45
46 @overload
47 def get_list(input: Literal[None], strip_values: bool = ...) -> Literal[None]:
48 ...
49
50
51 @overload
52 def get_list(input: Union[str, "Sequence[Any]"],
53 strip_values: bool = ...) -> list[str]:
54 ...
55
56
57 def get_list(input: Any, strip_values: bool = True) -> Optional[list[str]]:
58 '''Transforms a string or list to a list'''
59 if input is None:
60 return
61 if input == '':
62 return []
63
64 converters_list = converters.aslist(input, ',', True)
65 if strip_values:
66 return [_strip(x) for x in converters_list]
67 else:
68 return converters_list
69
70
71 def validate_int(i: Any, non_negative: bool = False):
72 try:
73 i = int(i)
74 except ValueError:
75 return False
76 return i >= 0 or not non_negative
77
78
79 def _strip(s: Any):
80 if isinstance(s, str) and len(s) and s[0] == s[-1]:
81 return s.strip().strip('"')
82 return s
83
84
85 def should_fts_index_field_type(field_type: str):
86 return field_type.lower() in ['tsvector', 'text', 'number']
87
88
89 def get_table_and_function_names_from_sql(context: Context, sql: str):
90 '''Parses the output of EXPLAIN (FORMAT JSON) looking for table and
91 function names
92
93 It performs an EXPLAIN query against the provided SQL, and parses
94 the output recusively.
95
96 Note that this requires Postgres 9.x.
97
98 :param context: a CKAN context dict. It must contain a 'connection' key
99 with the current DB connection.
100 :type context: dict
101 :param sql: the SQL statement to parse for table and function names
102 :type sql: string
103
104 :rtype: a tuple with two list of strings, one for table and one for
105 function names
106 '''
107
108 queries = [sql]
109 table_names: list[str] = []
110 function_names: list[str] = []
111
112 while queries:
113 sql = queries.pop()
114
115 function_names.extend(_get_function_names_from_sql(sql))
116
117 result = context['connection'].execute(
118 'EXPLAIN (VERBOSE, FORMAT JSON) {0}'.format(
119 six.ensure_str(sql))).fetchone()
120
121 try:
122 query_plan = json.loads(result['QUERY PLAN'])
123 plan = query_plan[0]['Plan']
124
125 t, q, f = _parse_query_plan(plan)
126 table_names.extend(t)
127 queries.extend(q)
128
129 function_names = list(set(function_names) | set(f))
130
131 except ValueError:
132 log.error('Could not parse query plan')
133 raise
134
135 return table_names, function_names
136
137
138 def _parse_query_plan(
139 plan: dict[str, Any]) -> tuple[list[str], list[str], list[str]]:
140 '''
141 Given a Postgres Query Plan object (parsed from the output of an EXPLAIN
142 query), returns a tuple with three items:
143
144 * A list of tables involved
145 * A list of remaining queries to parse
146 * A list of function names involved
147 '''
148
149 table_names: list[str] = []
150 queries: list[str] = []
151 functions: list[str] = []
152
153 if plan.get('Relation Name'):
154 table_names.append(plan['Relation Name'])
155 if 'Function Name' in plan:
156 if plan['Function Name'].startswith(
157 'crosstab'):
158 try:
159 queries.append(_get_subquery_from_crosstab_call(
160 plan['Function Call']))
161 except ValueError:
162 table_names.append('_unknown_crosstab_sql')
163 else:
164 functions.append(plan['Function Name'])
165
166 if 'Plans' in plan:
167 for child_plan in plan['Plans']:
168 t, q, f = _parse_query_plan(child_plan)
169 table_names.extend(t)
170 queries.extend(q)
171 functions.extend(f)
172
173 return table_names, queries, functions
174
175
176 def _get_function_names_from_sql(sql: str):
177 function_names: list[str] = []
178
179 def _get_function_names(tokens: Iterable[Any]):
180 for token in tokens:
181 if isinstance(token, sqlparse.sql.Function):
182 function_name = cast(str, token.get_name())
183 if function_name not in function_names:
184 function_names.append(function_name)
185 if hasattr(token, 'tokens'):
186 _get_function_names(token.tokens)
187
188 parsed = sqlparse.parse(sql)[0]
189 _get_function_names(parsed.tokens)
190
191 return function_names
192
193
194 def _get_subquery_from_crosstab_call(ct: str):
195 """
196 Crosstabs are a useful feature some sites choose to enable on
197 their datastore databases. To support the sql parameter passed
198 safely we accept only the simple crosstab(text) form where text
199 is a literal SQL string, otherwise raise ValueError
200 """
201 if not ct.startswith("crosstab('") or not ct.endswith("'::text)"):
202 raise ValueError('only simple crosstab calls supported')
203 ct = ct[10:-8]
204 if "'" in ct.replace("''", ""):
205 raise ValueError('only escaped single quotes allowed in query')
206 return ct.replace("''", "'")
207
208
209 def datastore_dictionary(resource_id: str):
210 """
211 Return the data dictionary info for a resource
212 """
213 try:
214 return [
215 f for f in tk.get_action('datastore_search')(
216 {}, {
217 u'resource_id': resource_id,
218 u'limit': 0,
219 u'include_total': False})['fields']
220 if not f['id'].startswith(u'_')]
221 except (tk.ObjectNotFound, tk.NotAuthorized):
222 return []
223
[end of ckanext/datastore/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ckanext/datastore/helpers.py b/ckanext/datastore/helpers.py
--- a/ckanext/datastore/helpers.py
+++ b/ckanext/datastore/helpers.py
@@ -206,9 +206,13 @@
return ct.replace("''", "'")
-def datastore_dictionary(resource_id: str):
+def datastore_dictionary(
+ resource_id: str, include_columns: Optional[list[str]] = None):
"""
- Return the data dictionary info for a resource
+ Return the data dictionary info for a resource, optionally filtering
+ columns returned.
+
+ include_columns is a list of column ids to include in the output
"""
try:
return [
@@ -217,6 +221,8 @@
u'resource_id': resource_id,
u'limit': 0,
u'include_total': False})['fields']
- if not f['id'].startswith(u'_')]
+ if not f['id'].startswith(u'_') and (
+ include_columns is None or f['id'] in include_columns)
+ ]
except (tk.ObjectNotFound, tk.NotAuthorized):
return []
|
{"golden_diff": "diff --git a/ckanext/datastore/helpers.py b/ckanext/datastore/helpers.py\n--- a/ckanext/datastore/helpers.py\n+++ b/ckanext/datastore/helpers.py\n@@ -206,9 +206,13 @@\n return ct.replace(\"''\", \"'\")\n \n \n-def datastore_dictionary(resource_id: str):\n+def datastore_dictionary(\n+ resource_id: str, include_columns: Optional[list[str]] = None):\n \"\"\"\n- Return the data dictionary info for a resource\n+ Return the data dictionary info for a resource, optionally filtering\n+ columns returned.\n+\n+ include_columns is a list of column ids to include in the output\n \"\"\"\n try:\n return [\n@@ -217,6 +221,8 @@\n u'resource_id': resource_id,\n u'limit': 0,\n u'include_total': False})['fields']\n- if not f['id'].startswith(u'_')]\n+ if not f['id'].startswith(u'_') and (\n+ include_columns is None or f['id'] in include_columns)\n+ ]\n except (tk.ObjectNotFound, tk.NotAuthorized):\n return []\n", "issue": "datatablesview: show columns feature bug\n## CKAN version\r\nmaster, 2.10 (earlier?)\r\n\r\n## Describe the bug\r\nIf any columns are unselected when creating a view, the view will not appear.\r\n\r\n### Steps to reproduce\r\nWhen creating or editing a datatablesview (not viewing an existing one) un-check some columns and save the view.\r\n\r\n### Expected behavior\r\nThose columns should be excluded but view should still work.\r\n\r\n### Additional details\r\n\r\n\r\n\n", "before_files": [{"content": "# encoding: utf-8\nfrom __future__ import annotations\n\nimport json\nimport logging\nfrom typing import (\n Any, Iterable, Optional, Sequence, Union, cast, overload\n)\nfrom typing_extensions import Literal\n\nimport sqlparse\nimport six\n\nimport ckan.common as converters\nimport ckan.plugins.toolkit as tk\nfrom ckan.types import Context\n\n\nlog = logging.getLogger(__name__)\n\n\ndef is_single_statement(sql: str):\n '''Returns True if received SQL string contains at most one statement'''\n return len(sqlparse.split(sql)) <= 1\n\n\ndef is_valid_field_name(name: str):\n '''\n Check that field name is valid:\n * can't start or end with whitespace characters\n * can't start with underscore\n * can't contain double quote (\")\n * can't be empty\n '''\n return (name and name == name.strip() and\n not name.startswith('_') and\n '\"' not in name)\n\n\ndef is_valid_table_name(name: str):\n if '%' in name:\n return False\n return is_valid_field_name(name)\n\n\n@overload\ndef get_list(input: Literal[None], strip_values: bool = ...) -> Literal[None]:\n ...\n\n\n@overload\ndef get_list(input: Union[str, \"Sequence[Any]\"],\n strip_values: bool = ...) -> list[str]:\n ...\n\n\ndef get_list(input: Any, strip_values: bool = True) -> Optional[list[str]]:\n '''Transforms a string or list to a list'''\n if input is None:\n return\n if input == '':\n return []\n\n converters_list = converters.aslist(input, ',', True)\n if strip_values:\n return [_strip(x) for x in converters_list]\n else:\n return converters_list\n\n\ndef validate_int(i: Any, non_negative: bool = False):\n try:\n i = int(i)\n except ValueError:\n return False\n return i >= 0 or not non_negative\n\n\ndef _strip(s: Any):\n if isinstance(s, str) and len(s) and s[0] == s[-1]:\n return s.strip().strip('\"')\n return s\n\n\ndef should_fts_index_field_type(field_type: str):\n return field_type.lower() in ['tsvector', 'text', 'number']\n\n\ndef get_table_and_function_names_from_sql(context: Context, sql: str):\n '''Parses the output of EXPLAIN (FORMAT JSON) looking for table and\n function names\n\n It performs an EXPLAIN query against the provided SQL, and parses\n the output recusively.\n\n Note that this requires Postgres 9.x.\n\n :param context: a CKAN context dict. It must contain a 'connection' key\n with the current DB connection.\n :type context: dict\n :param sql: the SQL statement to parse for table and function names\n :type sql: string\n\n :rtype: a tuple with two list of strings, one for table and one for\n function names\n '''\n\n queries = [sql]\n table_names: list[str] = []\n function_names: list[str] = []\n\n while queries:\n sql = queries.pop()\n\n function_names.extend(_get_function_names_from_sql(sql))\n\n result = context['connection'].execute(\n 'EXPLAIN (VERBOSE, FORMAT JSON) {0}'.format(\n six.ensure_str(sql))).fetchone()\n\n try:\n query_plan = json.loads(result['QUERY PLAN'])\n plan = query_plan[0]['Plan']\n\n t, q, f = _parse_query_plan(plan)\n table_names.extend(t)\n queries.extend(q)\n\n function_names = list(set(function_names) | set(f))\n\n except ValueError:\n log.error('Could not parse query plan')\n raise\n\n return table_names, function_names\n\n\ndef _parse_query_plan(\n plan: dict[str, Any]) -> tuple[list[str], list[str], list[str]]:\n '''\n Given a Postgres Query Plan object (parsed from the output of an EXPLAIN\n query), returns a tuple with three items:\n\n * A list of tables involved\n * A list of remaining queries to parse\n * A list of function names involved\n '''\n\n table_names: list[str] = []\n queries: list[str] = []\n functions: list[str] = []\n\n if plan.get('Relation Name'):\n table_names.append(plan['Relation Name'])\n if 'Function Name' in plan:\n if plan['Function Name'].startswith(\n 'crosstab'):\n try:\n queries.append(_get_subquery_from_crosstab_call(\n plan['Function Call']))\n except ValueError:\n table_names.append('_unknown_crosstab_sql')\n else:\n functions.append(plan['Function Name'])\n\n if 'Plans' in plan:\n for child_plan in plan['Plans']:\n t, q, f = _parse_query_plan(child_plan)\n table_names.extend(t)\n queries.extend(q)\n functions.extend(f)\n\n return table_names, queries, functions\n\n\ndef _get_function_names_from_sql(sql: str):\n function_names: list[str] = []\n\n def _get_function_names(tokens: Iterable[Any]):\n for token in tokens:\n if isinstance(token, sqlparse.sql.Function):\n function_name = cast(str, token.get_name())\n if function_name not in function_names:\n function_names.append(function_name)\n if hasattr(token, 'tokens'):\n _get_function_names(token.tokens)\n\n parsed = sqlparse.parse(sql)[0]\n _get_function_names(parsed.tokens)\n\n return function_names\n\n\ndef _get_subquery_from_crosstab_call(ct: str):\n \"\"\"\n Crosstabs are a useful feature some sites choose to enable on\n their datastore databases. To support the sql parameter passed\n safely we accept only the simple crosstab(text) form where text\n is a literal SQL string, otherwise raise ValueError\n \"\"\"\n if not ct.startswith(\"crosstab('\") or not ct.endswith(\"'::text)\"):\n raise ValueError('only simple crosstab calls supported')\n ct = ct[10:-8]\n if \"'\" in ct.replace(\"''\", \"\"):\n raise ValueError('only escaped single quotes allowed in query')\n return ct.replace(\"''\", \"'\")\n\n\ndef datastore_dictionary(resource_id: str):\n \"\"\"\n Return the data dictionary info for a resource\n \"\"\"\n try:\n return [\n f for f in tk.get_action('datastore_search')(\n {}, {\n u'resource_id': resource_id,\n u'limit': 0,\n u'include_total': False})['fields']\n if not f['id'].startswith(u'_')]\n except (tk.ObjectNotFound, tk.NotAuthorized):\n return []\n", "path": "ckanext/datastore/helpers.py"}]}
| 2,661 | 256 |
gh_patches_debug_30214
|
rasdani/github-patches
|
git_diff
|
DataDog__dd-agent-1709
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[etcd] `/stats/leader` from a follower returns a 403
The `/stats/leader` endpoint is only available on the leader etcd host.
On the followers, it returns a 403: it is illegitimately logged as an exception in the agent and triggers a CRITICAL service check.
`#0[ERROR]: 'Http status code 403 on url http://localhost:4002/v2/stats/leader`
Full stacktrace:
```
2015-06-17 16:41:46 UTC | ERROR | dd.collector | checks.etcd(__init__.py:678) | Check 'etcd' instance #0 failed
Traceback (most recent call last):
File "/opt/datadog-agent/agent/checks/__init__.py", line 661, in run
self.check(copy.deepcopy(instance))
File "/opt/datadog-agent/agent/checks.d/etcd.py", line 114, in check
leader_response = self._get_leader_metrics(url, timeout)
File "/opt/datadog-agent/agent/checks.d/etcd.py", line 143, in _get_leader_metrics
return self._get_json(url + "/v2/stats/leader", timeout)
File "/opt/datadog-agent/agent/checks.d/etcd.py", line 159, in _get_json
raise Exception("Http status code {0} on url {1}".format(r.status_code, url))
Exception: Http status code 403 on url http://localhost:4002/v2/stats/leader
```
</issue>
<code>
[start of checks.d/etcd.py]
1 # project
2 from checks import AgentCheck
3 from util import headers
4
5 # 3rd party
6 import requests
7
8
9 class Etcd(AgentCheck):
10
11 DEFAULT_TIMEOUT = 5
12
13 SERVICE_CHECK_NAME = 'etcd.can_connect'
14
15 STORE_RATES = {
16 'getsSuccess': 'etcd.store.gets.success',
17 'getsFail': 'etcd.store.gets.fail',
18 'setsSuccess': 'etcd.store.sets.success',
19 'setsFail': 'etcd.store.sets.fail',
20 'deleteSuccess': 'etcd.store.delete.success',
21 'deleteFail': 'etcd.store.delete.fail',
22 'updateSuccess': 'etcd.store.update.success',
23 'updateFail': 'etcd.store.update.fail',
24 'createSuccess': 'etcd.store.create.success',
25 'createFail': 'etcd.store.create.fail',
26 'compareAndSwapSuccess': 'etcd.store.compareandswap.success',
27 'compareAndSwapFail': 'etcd.store.compareandswap.fail',
28 'compareAndDeleteSuccess': 'etcd.store.compareanddelete.success',
29 'compareAndDeleteFail': 'etcd.store.compareanddelete.fail',
30 'expireCount': 'etcd.store.expire.count'
31 }
32
33 STORE_GAUGES = {
34 'watchers': 'etcd.store.watchers'
35 }
36
37 SELF_GAUGES = {
38 'sendPkgRate': 'etcd.self.send.pkgrate',
39 'sendBandwidthRate': 'etcd.self.send.bandwidthrate',
40 'recvPkgRate': 'etcd.self.recv.pkgrate',
41 'recvBandwidthRate': 'etcd.self.recv.bandwidthrate'
42 }
43
44 SELF_RATES = {
45 'recvAppendRequestCnt': 'etcd.self.recv.appendrequest.count',
46 'sendAppendRequestCnt': 'etcd.self.send.appendrequest.count'
47 }
48
49 LEADER_COUNTS = {
50 # Rates
51 'fail': 'etcd.leader.counts.fail',
52 'success': 'etcd.leader.counts.success',
53 }
54
55 LEADER_LATENCY = {
56 # Gauges
57 'current': 'etcd.leader.latency.current',
58 'average': 'etcd.leader.latency.avg',
59 'minimum': 'etcd.leader.latency.min',
60 'maximum': 'etcd.leader.latency.max',
61 'standardDeviation': 'etcd.leader.latency.stddev',
62 }
63
64 def check(self, instance):
65 if 'url' not in instance:
66 raise Exception('etcd instance missing "url" value.')
67
68 # Load values from the instance config
69 url = instance['url']
70 instance_tags = instance.get('tags', [])
71 # Append the instance's URL in case there are more than one, that
72 # way they can tell the difference!
73 instance_tags.append("url:{0}".format(url))
74 timeout = float(instance.get('timeout', self.DEFAULT_TIMEOUT))
75 is_leader = False
76
77 # Gather self metrics
78 self_response = self._get_self_metrics(url, timeout)
79 if self_response is not None:
80 if self_response['state'] == 'StateLeader':
81 is_leader = True
82 instance_tags.append('etcd_state:leader')
83 else:
84 instance_tags.append('etcd_state:follower')
85
86 for key in self.SELF_RATES:
87 if key in self_response:
88 self.rate(self.SELF_RATES[key], self_response[key], tags=instance_tags)
89 else:
90 self.log.warn("Missing key {0} in stats.".format(key))
91
92 for key in self.SELF_GAUGES:
93 if key in self_response:
94 self.gauge(self.SELF_GAUGES[key], self_response[key], tags=instance_tags)
95 else:
96 self.log.warn("Missing key {0} in stats.".format(key))
97
98 # Gather store metrics
99 store_response = self._get_store_metrics(url, timeout)
100 if store_response is not None:
101 for key in self.STORE_RATES:
102 if key in store_response:
103 self.rate(self.STORE_RATES[key], store_response[key], tags=instance_tags)
104 else:
105 self.log.warn("Missing key {0} in stats.".format(key))
106
107 for key in self.STORE_GAUGES:
108 if key in store_response:
109 self.gauge(self.STORE_GAUGES[key], store_response[key], tags=instance_tags)
110 else:
111 self.log.warn("Missing key {0} in stats.".format(key))
112
113 # Gather leader metrics
114 leader_response = self._get_leader_metrics(url, timeout)
115 if leader_response is not None and is_leader \
116 and len(leader_response.get("followers", {})) > 0:
117 # Get the followers
118 followers = leader_response.get("followers")
119 for fol in followers:
120 # counts
121 for key in self.LEADER_COUNTS:
122 self.rate(self.LEADER_COUNTS[key],
123 followers[fol].get("counts").get(key),
124 tags=instance_tags + ['follower:{0}'.format(fol)])
125 # latency
126 for key in self.LEADER_LATENCY:
127 self.gauge(self.LEADER_LATENCY[key],
128 followers[fol].get("latency").get(key),
129 tags=instance_tags + ['follower:{0}'.format(fol)])
130
131 # Service check
132 if self_response is not None and store_response is not None:
133 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK,
134 tags=["url:{0}".format(url)])
135
136 def _get_self_metrics(self, url, timeout):
137 return self._get_json(url + "/v2/stats/self", timeout)
138
139 def _get_store_metrics(self, url, timeout):
140 return self._get_json(url + "/v2/stats/store", timeout)
141
142 def _get_leader_metrics(self, url, timeout):
143 return self._get_json(url + "/v2/stats/leader", timeout)
144
145 def _get_json(self, url, timeout):
146 try:
147 r = requests.get(url, timeout=timeout, headers=headers(self.agentConfig))
148 except requests.exceptions.Timeout:
149 # If there's a timeout
150 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,
151 message="Timeout when hitting %s" % url,
152 tags=["url:{0}".format(url)])
153 raise
154
155 if r.status_code != 200:
156 self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,
157 message="Got %s when hitting %s" % (r.status_code, url),
158 tags=["url:{0}".format(url)])
159 raise Exception("Http status code {0} on url {1}".format(r.status_code, url))
160
161 return r.json()
162
[end of checks.d/etcd.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checks.d/etcd.py b/checks.d/etcd.py
--- a/checks.d/etcd.py
+++ b/checks.d/etcd.py
@@ -111,22 +111,22 @@
self.log.warn("Missing key {0} in stats.".format(key))
# Gather leader metrics
- leader_response = self._get_leader_metrics(url, timeout)
- if leader_response is not None and is_leader \
- and len(leader_response.get("followers", {})) > 0:
- # Get the followers
- followers = leader_response.get("followers")
- for fol in followers:
- # counts
- for key in self.LEADER_COUNTS:
- self.rate(self.LEADER_COUNTS[key],
- followers[fol].get("counts").get(key),
- tags=instance_tags + ['follower:{0}'.format(fol)])
- # latency
- for key in self.LEADER_LATENCY:
- self.gauge(self.LEADER_LATENCY[key],
- followers[fol].get("latency").get(key),
- tags=instance_tags + ['follower:{0}'.format(fol)])
+ if is_leader:
+ leader_response = self._get_leader_metrics(url, timeout)
+ if leader_response is not None and len(leader_response.get("followers", {})) > 0:
+ # Get the followers
+ followers = leader_response.get("followers")
+ for fol in followers:
+ # counts
+ for key in self.LEADER_COUNTS:
+ self.rate(self.LEADER_COUNTS[key],
+ followers[fol].get("counts").get(key),
+ tags=instance_tags + ['follower:{0}'.format(fol)])
+ # latency
+ for key in self.LEADER_LATENCY:
+ self.gauge(self.LEADER_LATENCY[key],
+ followers[fol].get("latency").get(key),
+ tags=instance_tags + ['follower:{0}'.format(fol)])
# Service check
if self_response is not None and store_response is not None:
|
{"golden_diff": "diff --git a/checks.d/etcd.py b/checks.d/etcd.py\n--- a/checks.d/etcd.py\n+++ b/checks.d/etcd.py\n@@ -111,22 +111,22 @@\n self.log.warn(\"Missing key {0} in stats.\".format(key))\n \n # Gather leader metrics\n- leader_response = self._get_leader_metrics(url, timeout)\n- if leader_response is not None and is_leader \\\n- and len(leader_response.get(\"followers\", {})) > 0:\n- # Get the followers\n- followers = leader_response.get(\"followers\")\n- for fol in followers:\n- # counts\n- for key in self.LEADER_COUNTS:\n- self.rate(self.LEADER_COUNTS[key],\n- followers[fol].get(\"counts\").get(key),\n- tags=instance_tags + ['follower:{0}'.format(fol)])\n- # latency\n- for key in self.LEADER_LATENCY:\n- self.gauge(self.LEADER_LATENCY[key],\n- followers[fol].get(\"latency\").get(key),\n- tags=instance_tags + ['follower:{0}'.format(fol)])\n+ if is_leader:\n+ leader_response = self._get_leader_metrics(url, timeout)\n+ if leader_response is not None and len(leader_response.get(\"followers\", {})) > 0:\n+ # Get the followers\n+ followers = leader_response.get(\"followers\")\n+ for fol in followers:\n+ # counts\n+ for key in self.LEADER_COUNTS:\n+ self.rate(self.LEADER_COUNTS[key],\n+ followers[fol].get(\"counts\").get(key),\n+ tags=instance_tags + ['follower:{0}'.format(fol)])\n+ # latency\n+ for key in self.LEADER_LATENCY:\n+ self.gauge(self.LEADER_LATENCY[key],\n+ followers[fol].get(\"latency\").get(key),\n+ tags=instance_tags + ['follower:{0}'.format(fol)])\n \n # Service check\n if self_response is not None and store_response is not None:\n", "issue": "[etcd] `/stats/leader` from a follower returns a 403\nThe `/stats/leader` endpoint is only available on the leader etcd host.\nOn the followers, it returns a 403: it is illegitimately logged as an exception in the agent and triggers a CRITICAL service check.\n\n`#0[ERROR]: 'Http status code 403 on url http://localhost:4002/v2/stats/leader`\n\nFull stacktrace: \n\n```\n2015-06-17 16:41:46 UTC | ERROR | dd.collector | checks.etcd(__init__.py:678) | Check 'etcd' instance #0 failed\nTraceback (most recent call last):\n File \"/opt/datadog-agent/agent/checks/__init__.py\", line 661, in run\n self.check(copy.deepcopy(instance))\n File \"/opt/datadog-agent/agent/checks.d/etcd.py\", line 114, in check\n leader_response = self._get_leader_metrics(url, timeout)\n File \"/opt/datadog-agent/agent/checks.d/etcd.py\", line 143, in _get_leader_metrics\n return self._get_json(url + \"/v2/stats/leader\", timeout)\n File \"/opt/datadog-agent/agent/checks.d/etcd.py\", line 159, in _get_json\n raise Exception(\"Http status code {0} on url {1}\".format(r.status_code, url))\nException: Http status code 403 on url http://localhost:4002/v2/stats/leader\n```\n\n", "before_files": [{"content": "# project\nfrom checks import AgentCheck\nfrom util import headers\n\n# 3rd party\nimport requests\n\n\nclass Etcd(AgentCheck):\n\n DEFAULT_TIMEOUT = 5\n\n SERVICE_CHECK_NAME = 'etcd.can_connect'\n\n STORE_RATES = {\n 'getsSuccess': 'etcd.store.gets.success',\n 'getsFail': 'etcd.store.gets.fail',\n 'setsSuccess': 'etcd.store.sets.success',\n 'setsFail': 'etcd.store.sets.fail',\n 'deleteSuccess': 'etcd.store.delete.success',\n 'deleteFail': 'etcd.store.delete.fail',\n 'updateSuccess': 'etcd.store.update.success',\n 'updateFail': 'etcd.store.update.fail',\n 'createSuccess': 'etcd.store.create.success',\n 'createFail': 'etcd.store.create.fail',\n 'compareAndSwapSuccess': 'etcd.store.compareandswap.success',\n 'compareAndSwapFail': 'etcd.store.compareandswap.fail',\n 'compareAndDeleteSuccess': 'etcd.store.compareanddelete.success',\n 'compareAndDeleteFail': 'etcd.store.compareanddelete.fail',\n 'expireCount': 'etcd.store.expire.count'\n }\n\n STORE_GAUGES = {\n 'watchers': 'etcd.store.watchers'\n }\n\n SELF_GAUGES = {\n 'sendPkgRate': 'etcd.self.send.pkgrate',\n 'sendBandwidthRate': 'etcd.self.send.bandwidthrate',\n 'recvPkgRate': 'etcd.self.recv.pkgrate',\n 'recvBandwidthRate': 'etcd.self.recv.bandwidthrate'\n }\n\n SELF_RATES = {\n 'recvAppendRequestCnt': 'etcd.self.recv.appendrequest.count',\n 'sendAppendRequestCnt': 'etcd.self.send.appendrequest.count'\n }\n\n LEADER_COUNTS = {\n # Rates\n 'fail': 'etcd.leader.counts.fail',\n 'success': 'etcd.leader.counts.success',\n }\n\n LEADER_LATENCY = {\n # Gauges\n 'current': 'etcd.leader.latency.current',\n 'average': 'etcd.leader.latency.avg',\n 'minimum': 'etcd.leader.latency.min',\n 'maximum': 'etcd.leader.latency.max',\n 'standardDeviation': 'etcd.leader.latency.stddev',\n }\n\n def check(self, instance):\n if 'url' not in instance:\n raise Exception('etcd instance missing \"url\" value.')\n\n # Load values from the instance config\n url = instance['url']\n instance_tags = instance.get('tags', [])\n # Append the instance's URL in case there are more than one, that\n # way they can tell the difference!\n instance_tags.append(\"url:{0}\".format(url))\n timeout = float(instance.get('timeout', self.DEFAULT_TIMEOUT))\n is_leader = False\n\n # Gather self metrics\n self_response = self._get_self_metrics(url, timeout)\n if self_response is not None:\n if self_response['state'] == 'StateLeader':\n is_leader = True\n instance_tags.append('etcd_state:leader')\n else:\n instance_tags.append('etcd_state:follower')\n\n for key in self.SELF_RATES:\n if key in self_response:\n self.rate(self.SELF_RATES[key], self_response[key], tags=instance_tags)\n else:\n self.log.warn(\"Missing key {0} in stats.\".format(key))\n\n for key in self.SELF_GAUGES:\n if key in self_response:\n self.gauge(self.SELF_GAUGES[key], self_response[key], tags=instance_tags)\n else:\n self.log.warn(\"Missing key {0} in stats.\".format(key))\n\n # Gather store metrics\n store_response = self._get_store_metrics(url, timeout)\n if store_response is not None:\n for key in self.STORE_RATES:\n if key in store_response:\n self.rate(self.STORE_RATES[key], store_response[key], tags=instance_tags)\n else:\n self.log.warn(\"Missing key {0} in stats.\".format(key))\n\n for key in self.STORE_GAUGES:\n if key in store_response:\n self.gauge(self.STORE_GAUGES[key], store_response[key], tags=instance_tags)\n else:\n self.log.warn(\"Missing key {0} in stats.\".format(key))\n\n # Gather leader metrics\n leader_response = self._get_leader_metrics(url, timeout)\n if leader_response is not None and is_leader \\\n and len(leader_response.get(\"followers\", {})) > 0:\n # Get the followers\n followers = leader_response.get(\"followers\")\n for fol in followers:\n # counts\n for key in self.LEADER_COUNTS:\n self.rate(self.LEADER_COUNTS[key],\n followers[fol].get(\"counts\").get(key),\n tags=instance_tags + ['follower:{0}'.format(fol)])\n # latency\n for key in self.LEADER_LATENCY:\n self.gauge(self.LEADER_LATENCY[key],\n followers[fol].get(\"latency\").get(key),\n tags=instance_tags + ['follower:{0}'.format(fol)])\n\n # Service check\n if self_response is not None and store_response is not None:\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.OK,\n tags=[\"url:{0}\".format(url)])\n\n def _get_self_metrics(self, url, timeout):\n return self._get_json(url + \"/v2/stats/self\", timeout)\n\n def _get_store_metrics(self, url, timeout):\n return self._get_json(url + \"/v2/stats/store\", timeout)\n\n def _get_leader_metrics(self, url, timeout):\n return self._get_json(url + \"/v2/stats/leader\", timeout)\n\n def _get_json(self, url, timeout):\n try:\n r = requests.get(url, timeout=timeout, headers=headers(self.agentConfig))\n except requests.exceptions.Timeout:\n # If there's a timeout\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,\n message=\"Timeout when hitting %s\" % url,\n tags=[\"url:{0}\".format(url)])\n raise\n\n if r.status_code != 200:\n self.service_check(self.SERVICE_CHECK_NAME, AgentCheck.CRITICAL,\n message=\"Got %s when hitting %s\" % (r.status_code, url),\n tags=[\"url:{0}\".format(url)])\n raise Exception(\"Http status code {0} on url {1}\".format(r.status_code, url))\n\n return r.json()\n", "path": "checks.d/etcd.py"}]}
| 2,725 | 461 |
gh_patches_debug_713
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-1826
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Agate type inference is too clever
### Describe the bug
We’re trying to set a value from a {% call statement %} and within the call, one line is SELECT 0 AS my_value...and it then treats it as a boolean (false) in the returned values.
The same happens if we try SELECT 1 AS my_value, but as soon as we do SELECT 2 AS my_value it treats it like a number (as it should).
### Steps To Reproduce
Create a call statement that selects 0, or 1. false, and true respectively will be returned.
### Expected behavior
0, or 1 to be returned, as integers.
### Screenshots and log output
### System information
**Which database are you using dbt with?**
- [ ] postgres
- [ ] redshift
- [x] bigquery
- [ ] snowflake
- [ ] other (specify: ____________)
**The output of `dbt --version`:**
```
installed version: 0.15.0-a1
latest version: 0.14.2
Your version of dbt is ahead of the latest release!
```
FYI, we run a fork, but that shouldn't have affected anything here.
**The operating system you're using:**
Mojave
**The output of `python --version`:**
Python 3.7.1
### Additional context
We'd love a quick fix for this, even if it's ugly!
</issue>
<code>
[start of core/dbt/clients/agate_helper.py]
1 from codecs import BOM_UTF8
2
3 import agate
4 import json
5
6
7 BOM = BOM_UTF8.decode('utf-8') # '\ufeff'
8
9 DEFAULT_TYPE_TESTER = agate.TypeTester(types=[
10 agate.data_types.Number(null_values=('null', '')),
11 agate.data_types.TimeDelta(null_values=('null', '')),
12 agate.data_types.Date(null_values=('null', '')),
13 agate.data_types.DateTime(null_values=('null', '')),
14 agate.data_types.Boolean(true_values=('true',),
15 false_values=('false',),
16 null_values=('null', '')),
17 agate.data_types.Text(null_values=('null', ''))
18 ])
19
20
21 def table_from_data(data, column_names):
22 "Convert list of dictionaries into an Agate table"
23
24 # The agate table is generated from a list of dicts, so the column order
25 # from `data` is not preserved. We can use `select` to reorder the columns
26 #
27 # If there is no data, create an empty table with the specified columns
28
29 if len(data) == 0:
30 return agate.Table([], column_names=column_names)
31 else:
32 table = agate.Table.from_object(data, column_types=DEFAULT_TYPE_TESTER)
33 return table.select(column_names)
34
35
36 def table_from_data_flat(data, column_names):
37 "Convert list of dictionaries into an Agate table"
38
39 rows = []
40 for _row in data:
41 row = []
42 for value in list(_row.values()):
43 if isinstance(value, (dict, list, tuple)):
44 row.append(json.dumps(value))
45 else:
46 row.append(value)
47 rows.append(row)
48
49 return agate.Table(rows, column_names)
50
51
52 def empty_table():
53 "Returns an empty Agate table. To be used in place of None"
54
55 return agate.Table(rows=[])
56
57
58 def as_matrix(table):
59 "Return an agate table as a matrix of data sans columns"
60
61 return [r.values() for r in table.rows.values()]
62
63
64 def from_csv(abspath):
65 with open(abspath, encoding='utf-8') as fp:
66 if fp.read(1) != BOM:
67 fp.seek(0)
68 return agate.Table.from_csv(fp, column_types=DEFAULT_TYPE_TESTER)
69
[end of core/dbt/clients/agate_helper.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/dbt/clients/agate_helper.py b/core/dbt/clients/agate_helper.py
--- a/core/dbt/clients/agate_helper.py
+++ b/core/dbt/clients/agate_helper.py
@@ -46,7 +46,7 @@
row.append(value)
rows.append(row)
- return agate.Table(rows, column_names)
+ return agate.Table(rows, column_names, column_types=DEFAULT_TYPE_TESTER)
def empty_table():
|
{"golden_diff": "diff --git a/core/dbt/clients/agate_helper.py b/core/dbt/clients/agate_helper.py\n--- a/core/dbt/clients/agate_helper.py\n+++ b/core/dbt/clients/agate_helper.py\n@@ -46,7 +46,7 @@\n row.append(value)\n rows.append(row)\n \n- return agate.Table(rows, column_names)\n+ return agate.Table(rows, column_names, column_types=DEFAULT_TYPE_TESTER)\n \n \n def empty_table():\n", "issue": "Agate type inference is too clever\n### Describe the bug\r\nWe\u2019re trying to set a value from a {% call statement %} and within the call, one line is SELECT 0 AS my_value...and it then treats it as a boolean (false) in the returned values. \r\n\r\nThe same happens if we try SELECT 1 AS my_value, but as soon as we do SELECT 2 AS my_value it treats it like a number (as it should).\r\n\r\n### Steps To Reproduce\r\nCreate a call statement that selects 0, or 1. false, and true respectively will be returned.\r\n\r\n### Expected behavior\r\n0, or 1 to be returned, as integers.\r\n\r\n### Screenshots and log output\r\n\r\n### System information\r\n**Which database are you using dbt with?**\r\n- [ ] postgres\r\n- [ ] redshift\r\n- [x] bigquery\r\n- [ ] snowflake\r\n- [ ] other (specify: ____________)\r\n\r\n\r\n**The output of `dbt --version`:**\r\n```\r\ninstalled version: 0.15.0-a1\r\n latest version: 0.14.2\r\nYour version of dbt is ahead of the latest release!\r\n```\r\n\r\nFYI, we run a fork, but that shouldn't have affected anything here.\r\n\r\n**The operating system you're using:**\r\n\r\nMojave\r\n\r\n**The output of `python --version`:**\r\n\r\nPython 3.7.1\r\n\r\n### Additional context\r\nWe'd love a quick fix for this, even if it's ugly!\r\n\n", "before_files": [{"content": "from codecs import BOM_UTF8\n\nimport agate\nimport json\n\n\nBOM = BOM_UTF8.decode('utf-8') # '\\ufeff'\n\nDEFAULT_TYPE_TESTER = agate.TypeTester(types=[\n agate.data_types.Number(null_values=('null', '')),\n agate.data_types.TimeDelta(null_values=('null', '')),\n agate.data_types.Date(null_values=('null', '')),\n agate.data_types.DateTime(null_values=('null', '')),\n agate.data_types.Boolean(true_values=('true',),\n false_values=('false',),\n null_values=('null', '')),\n agate.data_types.Text(null_values=('null', ''))\n])\n\n\ndef table_from_data(data, column_names):\n \"Convert list of dictionaries into an Agate table\"\n\n # The agate table is generated from a list of dicts, so the column order\n # from `data` is not preserved. We can use `select` to reorder the columns\n #\n # If there is no data, create an empty table with the specified columns\n\n if len(data) == 0:\n return agate.Table([], column_names=column_names)\n else:\n table = agate.Table.from_object(data, column_types=DEFAULT_TYPE_TESTER)\n return table.select(column_names)\n\n\ndef table_from_data_flat(data, column_names):\n \"Convert list of dictionaries into an Agate table\"\n\n rows = []\n for _row in data:\n row = []\n for value in list(_row.values()):\n if isinstance(value, (dict, list, tuple)):\n row.append(json.dumps(value))\n else:\n row.append(value)\n rows.append(row)\n\n return agate.Table(rows, column_names)\n\n\ndef empty_table():\n \"Returns an empty Agate table. To be used in place of None\"\n\n return agate.Table(rows=[])\n\n\ndef as_matrix(table):\n \"Return an agate table as a matrix of data sans columns\"\n\n return [r.values() for r in table.rows.values()]\n\n\ndef from_csv(abspath):\n with open(abspath, encoding='utf-8') as fp:\n if fp.read(1) != BOM:\n fp.seek(0)\n return agate.Table.from_csv(fp, column_types=DEFAULT_TYPE_TESTER)\n", "path": "core/dbt/clients/agate_helper.py"}]}
| 1,485 | 106 |
gh_patches_debug_1031
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-3857
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[beta][v20] S'inscrire/se connecter/chercher avec un emoji provoque une 500
Serveur : Beta
Version : v20-RC3/d3fd8af
Système : Mac OS X
Navigateur : 52.0.2743.116 (64-bit)
---
1. Rendez-vous à la page d'inscription et renseigner un pseudo du type : 👚 test
2. Remplissez les autres champs.
3. Soumettez le formulaire.
4. Constatez une erreur 500.
Note : Vous pouvez reproduire la même erreur en tentant de vous connecter avec le même pseudo ou en faisant une recherche sur le pseudo d'un membre.
</issue>
<code>
[start of zds/utils/misc.py]
1 # coding: utf-8
2 import hashlib
3 import re
4
5 THUMB_MAX_WIDTH = 80
6 THUMB_MAX_HEIGHT = 80
7
8 MEDIUM_MAX_WIDTH = 200
9 MEDIUM_MAX_HEIGHT = 200
10
11
12 def compute_hash(filenames):
13 """returns a md5 hexdigest of group of files to check if they have change"""
14 md5_hash = hashlib.md5()
15 for filename in filenames:
16 if filename:
17 file_handle = open(filename, 'rb')
18 must_continue = True
19 while must_continue:
20 read_bytes = file_handle.read(8096)
21 if not read_bytes:
22 must_continue = False
23 else:
24 md5_hash.update(read_bytes)
25 return md5_hash.hexdigest()
26
27
28 def content_has_changed(filenames, md5):
29 return md5 != compute_hash(filenames)
30
31
32 def has_changed(instance, field, manager='objects'):
33 """Returns true if a field has changed in a model May be used in a
34 model.save() method."""
35 if not instance.pk:
36 return True
37 manager = getattr(instance.__class__, manager)
38 old = getattr(manager.get(pk=instance.pk), field)
39 return not getattr(instance, field) == old
40
41
42 def convert_camel_to_underscore(camel_case):
43 """
44 Converts a name in camel case to underscore.
45 """
46 s1 = re.sub('(.)([A-Z][a-z]+)', r'\1_\2', camel_case)
47 return re.sub('([a-z0-9])([A-Z])', r'\1_\2', s1).lower()
48
49
50 def contains_utf8mb4(s):
51 """
52 This string contains at least one character of more than 3 bytes
53 """
54 if not isinstance(s, unicode):
55 s = unicode(s, 'utf-8')
56 return not all(len(c.encode('utf-8')) <= 3 for c in s)
57
[end of zds/utils/misc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/utils/misc.py b/zds/utils/misc.py
--- a/zds/utils/misc.py
+++ b/zds/utils/misc.py
@@ -53,4 +53,5 @@
"""
if not isinstance(s, unicode):
s = unicode(s, 'utf-8')
- return not all(len(c.encode('utf-8')) <= 3 for c in s)
+ re_pattern = re.compile(u'[^\u0000-\uD7FF\uE000-\uFFFF]', re.UNICODE)
+ return s != re_pattern.sub(u'\uFFFD', s)
|
{"golden_diff": "diff --git a/zds/utils/misc.py b/zds/utils/misc.py\n--- a/zds/utils/misc.py\n+++ b/zds/utils/misc.py\n@@ -53,4 +53,5 @@\n \"\"\"\n if not isinstance(s, unicode):\n s = unicode(s, 'utf-8')\n- return not all(len(c.encode('utf-8')) <= 3 for c in s)\n+ re_pattern = re.compile(u'[^\\u0000-\\uD7FF\\uE000-\\uFFFF]', re.UNICODE)\n+ return s != re_pattern.sub(u'\\uFFFD', s)\n", "issue": "[beta][v20] S'inscrire/se connecter/chercher avec un emoji provoque une 500\nServeur : Beta\nVersion : v20-RC3/d3fd8af\nSyst\u00e8me : Mac OS X\nNavigateur : 52.0.2743.116 (64-bit)\n\n---\n1. Rendez-vous \u00e0 la page d'inscription et renseigner un pseudo du type : \ud83d\udc5a test\n2. Remplissez les autres champs.\n3. Soumettez le formulaire.\n4. Constatez une erreur 500.\n\nNote : Vous pouvez reproduire la m\u00eame erreur en tentant de vous connecter avec le m\u00eame pseudo ou en faisant une recherche sur le pseudo d'un membre.\n\n", "before_files": [{"content": "# coding: utf-8\nimport hashlib\nimport re\n\nTHUMB_MAX_WIDTH = 80\nTHUMB_MAX_HEIGHT = 80\n\nMEDIUM_MAX_WIDTH = 200\nMEDIUM_MAX_HEIGHT = 200\n\n\ndef compute_hash(filenames):\n \"\"\"returns a md5 hexdigest of group of files to check if they have change\"\"\"\n md5_hash = hashlib.md5()\n for filename in filenames:\n if filename:\n file_handle = open(filename, 'rb')\n must_continue = True\n while must_continue:\n read_bytes = file_handle.read(8096)\n if not read_bytes:\n must_continue = False\n else:\n md5_hash.update(read_bytes)\n return md5_hash.hexdigest()\n\n\ndef content_has_changed(filenames, md5):\n return md5 != compute_hash(filenames)\n\n\ndef has_changed(instance, field, manager='objects'):\n \"\"\"Returns true if a field has changed in a model May be used in a\n model.save() method.\"\"\"\n if not instance.pk:\n return True\n manager = getattr(instance.__class__, manager)\n old = getattr(manager.get(pk=instance.pk), field)\n return not getattr(instance, field) == old\n\n\ndef convert_camel_to_underscore(camel_case):\n \"\"\"\n Converts a name in camel case to underscore.\n \"\"\"\n s1 = re.sub('(.)([A-Z][a-z]+)', r'\\1_\\2', camel_case)\n return re.sub('([a-z0-9])([A-Z])', r'\\1_\\2', s1).lower()\n\n\ndef contains_utf8mb4(s):\n \"\"\"\n This string contains at least one character of more than 3 bytes\n \"\"\"\n if not isinstance(s, unicode):\n s = unicode(s, 'utf-8')\n return not all(len(c.encode('utf-8')) <= 3 for c in s)\n", "path": "zds/utils/misc.py"}]}
| 1,223 | 134 |
gh_patches_debug_10873
|
rasdani/github-patches
|
git_diff
|
ietf-tools__datatracker-6268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
xml parsing heuristics crash if a reference has anchor "STD", "FYI", "RFC", or "BCP"
### Describe the issue
I'm trying to submit a draft. On my first attempt, I realized that I tagged the wrong commit and missed some important changes from a co-author. So when I received the email, I cancelled the submission.
I have since tried twice (with the right commit). Both have gotten to the point where I receive an email and both have failed when I requested that the draft be published.
For my second retry attempt, the failed submission was apparently still in progress, so that failed. I then cancelled the first retry and tried a third time. That has also failed. I will leave things in that state for now.
https://datatracker.ietf.org/submit/status/136389/ (original, cancelled)
https://datatracker.ietf.org/submit/status/136390/ (retry 1, failed, also cancelled)
https://datatracker.ietf.org/submit/status/136403/ (retry 3, failed)
### Code of Conduct
- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)
</issue>
<code>
[start of ietf/utils/xmldraft.py]
1 # Copyright The IETF Trust 2022, All Rights Reserved
2 # -*- coding: utf-8 -*-
3 import datetime
4 import io
5 import re
6 import xml2rfc
7
8 import debug # pyflakes: ignore
9
10 from contextlib import ExitStack
11 from xml2rfc.util.date import augment_date, extract_date
12 from ietf.utils.timezone import date_today
13
14 from .draft import Draft
15
16
17 class XMLDraft(Draft):
18 """Draft from XML source
19
20 Not all methods from the superclass are implemented yet.
21 """
22 def __init__(self, xml_file):
23 """Initialize XMLDraft instance
24
25 :parameter xml_file: path to file containing XML source
26 """
27 super().__init__()
28 # cast xml_file to str so, e.g., this will work with a Path
29 self.xmltree, self.xml_version = self.parse_xml(str(xml_file))
30 self.xmlroot = self.xmltree.getroot()
31 self.filename, self.revision = self._parse_docname()
32
33 @staticmethod
34 def parse_xml(filename):
35 """Parse XML draft
36
37 Converts to xml2rfc v3 schema, then returns the root of the v3 tree and the original
38 xml version.
39 """
40 orig_write_out = xml2rfc.log.write_out
41 orig_write_err = xml2rfc.log.write_err
42 parser_out = io.StringIO()
43 parser_err = io.StringIO()
44
45 with ExitStack() as stack:
46 @stack.callback
47 def cleanup(): # called when context exited, even if there's an exception
48 xml2rfc.log.write_out = orig_write_out
49 xml2rfc.log.write_err = orig_write_err
50
51 xml2rfc.log.write_out = parser_out
52 xml2rfc.log.write_err = parser_err
53
54 parser = xml2rfc.XmlRfcParser(filename, quiet=True)
55 try:
56 tree = parser.parse()
57 except Exception as e:
58 raise XMLParseError(parser_out.getvalue(), parser_err.getvalue()) from e
59
60 xml_version = tree.getroot().get('version', '2')
61 if xml_version == '2':
62 v2v3 = xml2rfc.V2v3XmlWriter(tree)
63 tree.tree = v2v3.convert2to3()
64 return tree, xml_version
65
66 def _document_name(self, ref):
67 """Get document name from reference."""
68 series = ["rfc", "bcp", "fyi", "std"]
69 # handle xinclude first
70 # FIXME: this assumes the xinclude is a bibxml href; if it isn't, there can
71 # still be false negatives. it would be better to expand the xinclude and parse
72 # its seriesInfo.
73 if ref.tag.endswith("}include"):
74 name = re.search(
75 rf"reference\.({'|'.join(series).upper()})\.(\d{{4}})\.xml",
76 ref.attrib["href"],
77 )
78 if name:
79 return f"{name.group(1)}{int(name.group(2))}".lower()
80 name = re.search(
81 r"reference\.I-D\.(?:draft-)?(.*)\.xml", ref.attrib["href"]
82 )
83 if name:
84 return f"draft-{name.group(1)}"
85 # can't extract the name, give up
86 return ""
87
88 # check the anchor next
89 anchor = ref.get("anchor").lower() # always give back lowercase
90 label = anchor.rstrip("0123456789") # remove trailing digits
91 if label in series:
92 number = int(anchor[len(label) :])
93 return f"{label}{number}"
94
95 # if we couldn't find a match so far, try the seriesInfo
96 series_query = " or ".join(f"@name='{x.upper()}'" for x in series)
97 for info in ref.xpath(
98 f"./seriesInfo[{series_query} or @name='Internet-Draft']"
99 ):
100 if not info.attrib["value"]:
101 continue
102 if info.attrib["name"] == "Internet-Draft":
103 return info.attrib["value"]
104 else:
105 return f'{info.attrib["name"].lower()}{info.attrib["value"]}'
106 return ""
107
108 def _reference_section_type(self, section_name):
109 """Determine reference type from name of references section"""
110 if section_name:
111 section_name = section_name.lower()
112 if 'normative' in section_name:
113 return self.REF_TYPE_NORMATIVE
114 elif 'informative' in section_name:
115 return self.REF_TYPE_INFORMATIVE
116 return self.REF_TYPE_UNKNOWN
117
118 def _reference_section_name(self, section_elt):
119 section_name = section_elt.findtext('name')
120 if section_name is None and 'title' in section_elt.keys():
121 section_name = section_elt.get('title') # fall back to title if we have it
122 return section_name
123
124 def _parse_docname(self):
125 docname = self.xmlroot.attrib.get('docName')
126 revmatch = re.match(
127 r'^(?P<filename>.+?)(?:-(?P<rev>[0-9][0-9]))?$',
128 docname,
129
130 )
131 if revmatch is None:
132 raise ValueError('Unable to parse docName')
133 # If a group had no match it is None
134 return revmatch.group('filename'), revmatch.group('rev')
135
136 def get_title(self):
137 return self.xmlroot.findtext('front/title').strip()
138
139 @staticmethod
140 def parse_creation_date(date_elt):
141 if date_elt is None:
142 return None
143 today = date_today()
144 # ths mimics handling of date elements in the xml2rfc text/html writers
145 year, month, day = extract_date(date_elt, today)
146 year, month, day = augment_date(year, month, day, today)
147 if not day:
148 # Must choose a day for a datetime.date. Per RFC 7991 sect 2.17, we use
149 # today's date if it is consistent with the rest of the date. Otherwise,
150 # arbitrariy (and consistent with the text parser) assume the 15th.
151 if year == today.year and month == today.month:
152 day = today.day
153 else:
154 day = 15
155 return datetime.date(year, month, day)
156
157 def get_creation_date(self):
158 return self.parse_creation_date(self.xmlroot.find("front/date"))
159
160 # todo fix the implementation of XMLDraft.get_abstract()
161 #
162 # This code was pulled from ietf.submit.forms where it existed for some time.
163 # It does not work, at least with modern xml2rfc. This assumes that the abstract
164 # is simply text in the front/abstract node, but the XML schema wraps the actual
165 # abstract text in <t> elements (and allows <dl>, <ol>, and <ul> as well). As a
166 # result, this method normally returns an empty string, which is later replaced by
167 # the abstract parsed from the rendered text. For now, I a commenting this out
168 # and making it explicit that the abstract always comes from the text format.
169 #
170 # def get_abstract(self):
171 # """Extract the abstract"""
172 # abstract = self.xmlroot.findtext('front/abstract')
173 # return abstract.strip() if abstract else ''
174
175 def get_author_list(self):
176 """Get detailed author list
177
178 Returns a list of dicts with the following keys:
179 name, first_name, middle_initial, last_name,
180 name_suffix, email, country, affiliation
181 Values will be None if not available
182 """
183 result = []
184 empty_author = {
185 k: None for k in [
186 'name', 'first_name', 'middle_initial', 'last_name',
187 'name_suffix', 'email', 'country', 'affiliation',
188 ]
189 }
190
191 for author in self.xmlroot.findall('front/author'):
192 info = {
193 'name': author.attrib.get('fullname'),
194 'email': author.findtext('address/email'),
195 'affiliation': author.findtext('organization'),
196 }
197 elem = author.find('address/postal/country')
198 if elem is not None:
199 ascii_country = elem.get('ascii', None)
200 info['country'] = ascii_country if ascii_country else elem.text
201 for item in info:
202 if info[item]:
203 info[item] = info[item].strip()
204 result.append(empty_author | info) # merge, preferring info
205 return result
206
207 def get_refs(self):
208 """Extract references from the draft"""
209 refs = {}
210 # accept nested <references> sections
211 for section in self.xmlroot.findall("back//references"):
212 ref_type = self._reference_section_type(
213 self._reference_section_name(section)
214 )
215 for ref in (
216 section.findall("./reference")
217 + section.findall("./referencegroup")
218 + section.findall(
219 "./xi:include", {"xi": "http://www.w3.org/2001/XInclude"}
220 )
221 ):
222 name = self._document_name(ref)
223 if name:
224 refs[name] = ref_type
225 return refs
226
227
228 class XMLParseError(Exception):
229 """An error occurred while parsing"""
230 def __init__(self, out: str, err: str, *args):
231 super().__init__(*args)
232 self._out = out
233 self._err = err
234
235 def parser_msgs(self):
236 return self._out.splitlines() + self._err.splitlines()
237
[end of ietf/utils/xmldraft.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ietf/utils/xmldraft.py b/ietf/utils/xmldraft.py
--- a/ietf/utils/xmldraft.py
+++ b/ietf/utils/xmldraft.py
@@ -88,8 +88,9 @@
# check the anchor next
anchor = ref.get("anchor").lower() # always give back lowercase
label = anchor.rstrip("0123456789") # remove trailing digits
- if label in series:
- number = int(anchor[len(label) :])
+ maybe_number = anchor[len(label) :]
+ if label in series and maybe_number.isdigit():
+ number = int(maybe_number)
return f"{label}{number}"
# if we couldn't find a match so far, try the seriesInfo
|
{"golden_diff": "diff --git a/ietf/utils/xmldraft.py b/ietf/utils/xmldraft.py\n--- a/ietf/utils/xmldraft.py\n+++ b/ietf/utils/xmldraft.py\n@@ -88,8 +88,9 @@\n # check the anchor next\n anchor = ref.get(\"anchor\").lower() # always give back lowercase\n label = anchor.rstrip(\"0123456789\") # remove trailing digits\n- if label in series:\n- number = int(anchor[len(label) :])\n+ maybe_number = anchor[len(label) :]\n+ if label in series and maybe_number.isdigit():\n+ number = int(maybe_number)\n return f\"{label}{number}\"\n \n # if we couldn't find a match so far, try the seriesInfo\n", "issue": "xml parsing heuristics crash if a reference has anchor \"STD\", \"FYI\", \"RFC\", or \"BCP\"\n### Describe the issue\n\nI'm trying to submit a draft. On my first attempt, I realized that I tagged the wrong commit and missed some important changes from a co-author. So when I received the email, I cancelled the submission.\r\n\r\nI have since tried twice (with the right commit). Both have gotten to the point where I receive an email and both have failed when I requested that the draft be published.\r\n\r\nFor my second retry attempt, the failed submission was apparently still in progress, so that failed. I then cancelled the first retry and tried a third time. That has also failed. I will leave things in that state for now.\r\n\r\nhttps://datatracker.ietf.org/submit/status/136389/ (original, cancelled)\r\nhttps://datatracker.ietf.org/submit/status/136390/ (retry 1, failed, also cancelled)\r\nhttps://datatracker.ietf.org/submit/status/136403/ (retry 3, failed)\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the [IETF's Code of Conduct](https://github.com/ietf-tools/.github/blob/main/CODE_OF_CONDUCT.md)\n", "before_files": [{"content": "# Copyright The IETF Trust 2022, All Rights Reserved\n# -*- coding: utf-8 -*-\nimport datetime\nimport io\nimport re\nimport xml2rfc\n\nimport debug # pyflakes: ignore\n\nfrom contextlib import ExitStack\nfrom xml2rfc.util.date import augment_date, extract_date\nfrom ietf.utils.timezone import date_today\n\nfrom .draft import Draft\n\n\nclass XMLDraft(Draft):\n \"\"\"Draft from XML source\n\n Not all methods from the superclass are implemented yet.\n \"\"\"\n def __init__(self, xml_file):\n \"\"\"Initialize XMLDraft instance\n\n :parameter xml_file: path to file containing XML source\n \"\"\"\n super().__init__()\n # cast xml_file to str so, e.g., this will work with a Path\n self.xmltree, self.xml_version = self.parse_xml(str(xml_file))\n self.xmlroot = self.xmltree.getroot()\n self.filename, self.revision = self._parse_docname()\n\n @staticmethod\n def parse_xml(filename):\n \"\"\"Parse XML draft\n\n Converts to xml2rfc v3 schema, then returns the root of the v3 tree and the original\n xml version.\n \"\"\"\n orig_write_out = xml2rfc.log.write_out\n orig_write_err = xml2rfc.log.write_err\n parser_out = io.StringIO()\n parser_err = io.StringIO()\n\n with ExitStack() as stack:\n @stack.callback\n def cleanup(): # called when context exited, even if there's an exception\n xml2rfc.log.write_out = orig_write_out\n xml2rfc.log.write_err = orig_write_err\n\n xml2rfc.log.write_out = parser_out\n xml2rfc.log.write_err = parser_err\n\n parser = xml2rfc.XmlRfcParser(filename, quiet=True)\n try:\n tree = parser.parse()\n except Exception as e:\n raise XMLParseError(parser_out.getvalue(), parser_err.getvalue()) from e\n\n xml_version = tree.getroot().get('version', '2')\n if xml_version == '2':\n v2v3 = xml2rfc.V2v3XmlWriter(tree)\n tree.tree = v2v3.convert2to3()\n return tree, xml_version\n\n def _document_name(self, ref):\n \"\"\"Get document name from reference.\"\"\"\n series = [\"rfc\", \"bcp\", \"fyi\", \"std\"]\n # handle xinclude first\n # FIXME: this assumes the xinclude is a bibxml href; if it isn't, there can\n # still be false negatives. it would be better to expand the xinclude and parse\n # its seriesInfo.\n if ref.tag.endswith(\"}include\"):\n name = re.search(\n rf\"reference\\.({'|'.join(series).upper()})\\.(\\d{{4}})\\.xml\",\n ref.attrib[\"href\"],\n )\n if name:\n return f\"{name.group(1)}{int(name.group(2))}\".lower()\n name = re.search(\n r\"reference\\.I-D\\.(?:draft-)?(.*)\\.xml\", ref.attrib[\"href\"]\n )\n if name:\n return f\"draft-{name.group(1)}\"\n # can't extract the name, give up\n return \"\"\n\n # check the anchor next\n anchor = ref.get(\"anchor\").lower() # always give back lowercase\n label = anchor.rstrip(\"0123456789\") # remove trailing digits\n if label in series:\n number = int(anchor[len(label) :])\n return f\"{label}{number}\"\n\n # if we couldn't find a match so far, try the seriesInfo\n series_query = \" or \".join(f\"@name='{x.upper()}'\" for x in series)\n for info in ref.xpath(\n f\"./seriesInfo[{series_query} or @name='Internet-Draft']\"\n ):\n if not info.attrib[\"value\"]:\n continue\n if info.attrib[\"name\"] == \"Internet-Draft\":\n return info.attrib[\"value\"]\n else:\n return f'{info.attrib[\"name\"].lower()}{info.attrib[\"value\"]}'\n return \"\"\n\n def _reference_section_type(self, section_name):\n \"\"\"Determine reference type from name of references section\"\"\"\n if section_name:\n section_name = section_name.lower()\n if 'normative' in section_name:\n return self.REF_TYPE_NORMATIVE\n elif 'informative' in section_name:\n return self.REF_TYPE_INFORMATIVE\n return self.REF_TYPE_UNKNOWN\n\n def _reference_section_name(self, section_elt):\n section_name = section_elt.findtext('name')\n if section_name is None and 'title' in section_elt.keys():\n section_name = section_elt.get('title') # fall back to title if we have it\n return section_name\n\n def _parse_docname(self):\n docname = self.xmlroot.attrib.get('docName')\n revmatch = re.match(\n r'^(?P<filename>.+?)(?:-(?P<rev>[0-9][0-9]))?$',\n docname,\n\n )\n if revmatch is None:\n raise ValueError('Unable to parse docName')\n # If a group had no match it is None\n return revmatch.group('filename'), revmatch.group('rev')\n\n def get_title(self):\n return self.xmlroot.findtext('front/title').strip()\n\n @staticmethod\n def parse_creation_date(date_elt):\n if date_elt is None:\n return None\n today = date_today()\n # ths mimics handling of date elements in the xml2rfc text/html writers\n year, month, day = extract_date(date_elt, today)\n year, month, day = augment_date(year, month, day, today)\n if not day:\n # Must choose a day for a datetime.date. Per RFC 7991 sect 2.17, we use\n # today's date if it is consistent with the rest of the date. Otherwise,\n # arbitrariy (and consistent with the text parser) assume the 15th.\n if year == today.year and month == today.month:\n day = today.day\n else:\n day = 15\n return datetime.date(year, month, day)\n\n def get_creation_date(self):\n return self.parse_creation_date(self.xmlroot.find(\"front/date\"))\n\n # todo fix the implementation of XMLDraft.get_abstract()\n #\n # This code was pulled from ietf.submit.forms where it existed for some time.\n # It does not work, at least with modern xml2rfc. This assumes that the abstract\n # is simply text in the front/abstract node, but the XML schema wraps the actual\n # abstract text in <t> elements (and allows <dl>, <ol>, and <ul> as well). As a\n # result, this method normally returns an empty string, which is later replaced by\n # the abstract parsed from the rendered text. For now, I a commenting this out\n # and making it explicit that the abstract always comes from the text format.\n #\n # def get_abstract(self):\n # \"\"\"Extract the abstract\"\"\"\n # abstract = self.xmlroot.findtext('front/abstract')\n # return abstract.strip() if abstract else ''\n\n def get_author_list(self):\n \"\"\"Get detailed author list\n\n Returns a list of dicts with the following keys:\n name, first_name, middle_initial, last_name,\n name_suffix, email, country, affiliation\n Values will be None if not available\n \"\"\"\n result = []\n empty_author = {\n k: None for k in [\n 'name', 'first_name', 'middle_initial', 'last_name',\n 'name_suffix', 'email', 'country', 'affiliation',\n ]\n }\n\n for author in self.xmlroot.findall('front/author'):\n info = {\n 'name': author.attrib.get('fullname'),\n 'email': author.findtext('address/email'),\n 'affiliation': author.findtext('organization'),\n }\n elem = author.find('address/postal/country')\n if elem is not None:\n ascii_country = elem.get('ascii', None)\n info['country'] = ascii_country if ascii_country else elem.text\n for item in info:\n if info[item]:\n info[item] = info[item].strip()\n result.append(empty_author | info) # merge, preferring info\n return result\n\n def get_refs(self):\n \"\"\"Extract references from the draft\"\"\"\n refs = {}\n # accept nested <references> sections\n for section in self.xmlroot.findall(\"back//references\"):\n ref_type = self._reference_section_type(\n self._reference_section_name(section)\n )\n for ref in (\n section.findall(\"./reference\")\n + section.findall(\"./referencegroup\")\n + section.findall(\n \"./xi:include\", {\"xi\": \"http://www.w3.org/2001/XInclude\"}\n )\n ):\n name = self._document_name(ref)\n if name:\n refs[name] = ref_type\n return refs\n\n\nclass XMLParseError(Exception):\n \"\"\"An error occurred while parsing\"\"\"\n def __init__(self, out: str, err: str, *args):\n super().__init__(*args)\n self._out = out\n self._err = err\n\n def parser_msgs(self):\n return self._out.splitlines() + self._err.splitlines()\n", "path": "ietf/utils/xmldraft.py"}]}
| 3,495 | 177 |
gh_patches_debug_39012
|
rasdani/github-patches
|
git_diff
|
chainer__chainer-6031
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Orthogonal initializer dimensions error
Orthogonal Initializer throws an error whenever the first dimension is larger than the second. This could be fixed by transposing the array rather than throwing an error.
e.g. 1. ` dense = L.Linear(64,128, initialW=initializers.Orthogonal())`

e.g. 2 `initializers.generate_array(initializers.Orthogonal(), (20,10), numpy, 'f')`

System Info:
Chainer: 5.0.0rc1
NumPy: 1.14.2
CuPy:
CuPy Version : 5.0.0rc1
CUDA Root : /usr/local/cuda
CUDA Build Version : 8000
CUDA Driver Version : 9020
CUDA Runtime Version : 8000
cuDNN Build Version : 7102
cuDNN Version : 7102
NCCL Build Version : 2213
</issue>
<code>
[start of chainer/initializers/orthogonal.py]
1 import numpy
2
3 from chainer import backend
4 from chainer import initializer
5 from chainer import utils
6
7
8 # Original code forked from MIT licensed keras project
9 # https://github.com/fchollet/keras/blob/master/keras/initializations.py
10
11 class Orthogonal(initializer.Initializer):
12 """Initializes array with an orthogonal system.
13
14 This initializer first makes a matrix of the same shape as the
15 array to be initialized whose elements are drawn independently from
16 standard Gaussian distribution.
17 Next, it applies QR decomposition to (the transpose of) the matrix.
18 To make the decomposition (almost surely) unique, we require the diagonal
19 of the triangular matrix R to be non-negative (see e.g. Edelman & Rao,
20 https://web.eecs.umich.edu/~rajnrao/Acta05rmt.pdf).
21 Then, it initializes the array with the (semi-)orthogonal matrix Q.
22 Finally, the array is multiplied by the constant ``scale``.
23
24 If the ``ndim`` of the input array is more than 2, we consider the array
25 to be a matrix by concatenating all axes except the first one.
26
27 The number of vectors consisting of the orthogonal system
28 (i.e. first element of the shape of the array) must be equal to or smaller
29 than the dimension of each vector (i.e. second element of the shape of
30 the array).
31
32 Attributes:
33 scale (float): A constant to be multiplied by.
34 dtype: Data type specifier.
35
36 Reference: Saxe et al., https://arxiv.org/abs/1312.6120
37
38 """
39
40 def __init__(self, scale=1.1, dtype=None):
41 self.scale = scale
42 super(Orthogonal, self).__init__(dtype)
43
44 # TODO(Kenta Oono)
45 # How do we treat overcomplete base-system case?
46 def __call__(self, array):
47 if self.dtype is not None:
48 assert array.dtype == self.dtype
49 xp = backend.get_array_module(array)
50 if not array.shape: # 0-dim case
51 array[...] = self.scale * (2 * numpy.random.randint(2) - 1)
52 elif not array.size:
53 raise ValueError('Array to be initialized must be non-empty.')
54 else:
55 # numpy.prod returns float value when the argument is empty.
56 flat_shape = (len(array), utils.size_of_shape(array.shape[1:]))
57 if flat_shape[0] > flat_shape[1]:
58 raise ValueError('Cannot make orthogonal system because'
59 ' # of vectors ({}) is larger than'
60 ' that of dimensions ({})'.format(
61 flat_shape[0], flat_shape[1]))
62 a = numpy.random.normal(size=flat_shape)
63 # cupy.linalg.qr requires cusolver in CUDA 8+
64 q, r = numpy.linalg.qr(a.T)
65 q *= numpy.copysign(self.scale, numpy.diag(r))
66 array[...] = xp.asarray(q.T.reshape(array.shape))
67
[end of chainer/initializers/orthogonal.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/chainer/initializers/orthogonal.py b/chainer/initializers/orthogonal.py
--- a/chainer/initializers/orthogonal.py
+++ b/chainer/initializers/orthogonal.py
@@ -5,6 +5,14 @@
from chainer import utils
+_orthogonal_constraints = { # (assert emb., assert proj.)
+ 'auto': (False, False),
+ 'projection': (False, True),
+ 'embedding': (True, False),
+ 'basis': (True, True),
+}
+
+
# Original code forked from MIT licensed keras project
# https://github.com/fchollet/keras/blob/master/keras/initializations.py
@@ -32,13 +40,24 @@
Attributes:
scale (float): A constant to be multiplied by.
dtype: Data type specifier.
+ mode (str): Assertion on the initialized shape.
+ ``'auto'`` (default), ``'projection'`` (before v7),
+ ``'embedding'``, or ``'basis'``.
Reference: Saxe et al., https://arxiv.org/abs/1312.6120
"""
- def __init__(self, scale=1.1, dtype=None):
+ def __init__(self, scale=1.1, dtype=None, mode='auto'):
self.scale = scale
+ self.mode = mode
+ try:
+ self._checks = _orthogonal_constraints[mode]
+ except KeyError:
+ raise ValueError(
+ 'Invalid mode: {}. Choose from {}.'.format(
+ repr(mode),
+ ', '.join(repr(m) for m in _orthogonal_constraints)))
super(Orthogonal, self).__init__(dtype)
# TODO(Kenta Oono)
@@ -53,14 +72,22 @@
raise ValueError('Array to be initialized must be non-empty.')
else:
# numpy.prod returns float value when the argument is empty.
- flat_shape = (len(array), utils.size_of_shape(array.shape[1:]))
- if flat_shape[0] > flat_shape[1]:
- raise ValueError('Cannot make orthogonal system because'
- ' # of vectors ({}) is larger than'
- ' that of dimensions ({})'.format(
- flat_shape[0], flat_shape[1]))
- a = numpy.random.normal(size=flat_shape)
+ out_dim = len(array)
+ in_dim = utils.size_of_shape(array.shape[1:])
+ if (in_dim > out_dim and self._checks[0]) or (
+ in_dim < out_dim and self._checks[1]):
+ raise ValueError(
+ 'Cannot make orthogonal {}.'
+ 'shape = {}, interpreted as '
+ '{}-dim input and {}-dim output.'.format(
+ self.mode, array.shape, in_dim, out_dim))
+ transpose = in_dim > out_dim
+ a = numpy.random.normal(size=(out_dim, in_dim))
+ if transpose:
+ a = a.T
# cupy.linalg.qr requires cusolver in CUDA 8+
- q, r = numpy.linalg.qr(a.T)
+ q, r = numpy.linalg.qr(a)
q *= numpy.copysign(self.scale, numpy.diag(r))
- array[...] = xp.asarray(q.T.reshape(array.shape))
+ if transpose:
+ q = q.T
+ array[...] = xp.asarray(q.reshape(array.shape))
|
{"golden_diff": "diff --git a/chainer/initializers/orthogonal.py b/chainer/initializers/orthogonal.py\n--- a/chainer/initializers/orthogonal.py\n+++ b/chainer/initializers/orthogonal.py\n@@ -5,6 +5,14 @@\n from chainer import utils\n \n \n+_orthogonal_constraints = { # (assert emb., assert proj.)\n+ 'auto': (False, False),\n+ 'projection': (False, True),\n+ 'embedding': (True, False),\n+ 'basis': (True, True),\n+}\n+\n+\n # Original code forked from MIT licensed keras project\n # https://github.com/fchollet/keras/blob/master/keras/initializations.py\n \n@@ -32,13 +40,24 @@\n Attributes:\n scale (float): A constant to be multiplied by.\n dtype: Data type specifier.\n+ mode (str): Assertion on the initialized shape.\n+ ``'auto'`` (default), ``'projection'`` (before v7),\n+ ``'embedding'``, or ``'basis'``.\n \n Reference: Saxe et al., https://arxiv.org/abs/1312.6120\n \n \"\"\"\n \n- def __init__(self, scale=1.1, dtype=None):\n+ def __init__(self, scale=1.1, dtype=None, mode='auto'):\n self.scale = scale\n+ self.mode = mode\n+ try:\n+ self._checks = _orthogonal_constraints[mode]\n+ except KeyError:\n+ raise ValueError(\n+ 'Invalid mode: {}. Choose from {}.'.format(\n+ repr(mode),\n+ ', '.join(repr(m) for m in _orthogonal_constraints)))\n super(Orthogonal, self).__init__(dtype)\n \n # TODO(Kenta Oono)\n@@ -53,14 +72,22 @@\n raise ValueError('Array to be initialized must be non-empty.')\n else:\n # numpy.prod returns float value when the argument is empty.\n- flat_shape = (len(array), utils.size_of_shape(array.shape[1:]))\n- if flat_shape[0] > flat_shape[1]:\n- raise ValueError('Cannot make orthogonal system because'\n- ' # of vectors ({}) is larger than'\n- ' that of dimensions ({})'.format(\n- flat_shape[0], flat_shape[1]))\n- a = numpy.random.normal(size=flat_shape)\n+ out_dim = len(array)\n+ in_dim = utils.size_of_shape(array.shape[1:])\n+ if (in_dim > out_dim and self._checks[0]) or (\n+ in_dim < out_dim and self._checks[1]):\n+ raise ValueError(\n+ 'Cannot make orthogonal {}.'\n+ 'shape = {}, interpreted as '\n+ '{}-dim input and {}-dim output.'.format(\n+ self.mode, array.shape, in_dim, out_dim))\n+ transpose = in_dim > out_dim\n+ a = numpy.random.normal(size=(out_dim, in_dim))\n+ if transpose:\n+ a = a.T\n # cupy.linalg.qr requires cusolver in CUDA 8+\n- q, r = numpy.linalg.qr(a.T)\n+ q, r = numpy.linalg.qr(a)\n q *= numpy.copysign(self.scale, numpy.diag(r))\n- array[...] = xp.asarray(q.T.reshape(array.shape))\n+ if transpose:\n+ q = q.T\n+ array[...] = xp.asarray(q.reshape(array.shape))\n", "issue": "Orthogonal initializer dimensions error\nOrthogonal Initializer throws an error whenever the first dimension is larger than the second. This could be fixed by transposing the array rather than throwing an error.\r\n\r\n\r\ne.g. 1. ` dense = L.Linear(64,128, initialW=initializers.Orthogonal())`\r\n\r\n\r\n\r\n\r\ne.g. 2 `initializers.generate_array(initializers.Orthogonal(), (20,10), numpy, 'f')`\r\n\r\n\r\n\r\n\r\nSystem Info:\r\nChainer: 5.0.0rc1\r\nNumPy: 1.14.2\r\nCuPy:\r\n CuPy Version : 5.0.0rc1\r\n CUDA Root : /usr/local/cuda\r\n CUDA Build Version : 8000\r\n CUDA Driver Version : 9020\r\n CUDA Runtime Version : 8000\r\n cuDNN Build Version : 7102\r\n cuDNN Version : 7102\r\n NCCL Build Version : 2213\r\n\n", "before_files": [{"content": "import numpy\n\nfrom chainer import backend\nfrom chainer import initializer\nfrom chainer import utils\n\n\n# Original code forked from MIT licensed keras project\n# https://github.com/fchollet/keras/blob/master/keras/initializations.py\n\nclass Orthogonal(initializer.Initializer):\n \"\"\"Initializes array with an orthogonal system.\n\n This initializer first makes a matrix of the same shape as the\n array to be initialized whose elements are drawn independently from\n standard Gaussian distribution.\n Next, it applies QR decomposition to (the transpose of) the matrix.\n To make the decomposition (almost surely) unique, we require the diagonal\n of the triangular matrix R to be non-negative (see e.g. Edelman & Rao,\n https://web.eecs.umich.edu/~rajnrao/Acta05rmt.pdf).\n Then, it initializes the array with the (semi-)orthogonal matrix Q.\n Finally, the array is multiplied by the constant ``scale``.\n\n If the ``ndim`` of the input array is more than 2, we consider the array\n to be a matrix by concatenating all axes except the first one.\n\n The number of vectors consisting of the orthogonal system\n (i.e. first element of the shape of the array) must be equal to or smaller\n than the dimension of each vector (i.e. second element of the shape of\n the array).\n\n Attributes:\n scale (float): A constant to be multiplied by.\n dtype: Data type specifier.\n\n Reference: Saxe et al., https://arxiv.org/abs/1312.6120\n\n \"\"\"\n\n def __init__(self, scale=1.1, dtype=None):\n self.scale = scale\n super(Orthogonal, self).__init__(dtype)\n\n # TODO(Kenta Oono)\n # How do we treat overcomplete base-system case?\n def __call__(self, array):\n if self.dtype is not None:\n assert array.dtype == self.dtype\n xp = backend.get_array_module(array)\n if not array.shape: # 0-dim case\n array[...] = self.scale * (2 * numpy.random.randint(2) - 1)\n elif not array.size:\n raise ValueError('Array to be initialized must be non-empty.')\n else:\n # numpy.prod returns float value when the argument is empty.\n flat_shape = (len(array), utils.size_of_shape(array.shape[1:]))\n if flat_shape[0] > flat_shape[1]:\n raise ValueError('Cannot make orthogonal system because'\n ' # of vectors ({}) is larger than'\n ' that of dimensions ({})'.format(\n flat_shape[0], flat_shape[1]))\n a = numpy.random.normal(size=flat_shape)\n # cupy.linalg.qr requires cusolver in CUDA 8+\n q, r = numpy.linalg.qr(a.T)\n q *= numpy.copysign(self.scale, numpy.diag(r))\n array[...] = xp.asarray(q.T.reshape(array.shape))\n", "path": "chainer/initializers/orthogonal.py"}]}
| 1,682 | 773 |
gh_patches_debug_2430
|
rasdani/github-patches
|
git_diff
|
pypa__pip-1390
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pip doesn't detect a venv created virtual environment as a virtual environment
The venv integration in Python 3.4 fails if PIP_REQUIREVIRTUALENV is set (http://bugs.python.org/issue19734)
I'm currently working around this by forcibly clearing the setting in the test, but the PIP_REQUIREVIRTUALENV check should pass when sys.prefix and sys.base_prefix are different.
</issue>
<code>
[start of pip/locations.py]
1 """Locations where we look for configs, install stuff, etc"""
2
3 import sys
4 import site
5 import os
6 import tempfile
7 from distutils.command.install import install, SCHEME_KEYS
8 import getpass
9 from pip.backwardcompat import get_python_lib, get_path_uid, user_site
10 import pip.exceptions
11
12
13 DELETE_MARKER_MESSAGE = '''\
14 This file is placed here by pip to indicate the source was put
15 here by pip.
16
17 Once this package is successfully installed this source code will be
18 deleted (unless you remove this file).
19 '''
20 PIP_DELETE_MARKER_FILENAME = 'pip-delete-this-directory.txt'
21
22 def write_delete_marker_file(directory):
23 """
24 Write the pip delete marker file into this directory.
25 """
26 filepath = os.path.join(directory, PIP_DELETE_MARKER_FILENAME)
27 marker_fp = open(filepath, 'w')
28 marker_fp.write(DELETE_MARKER_MESSAGE)
29 marker_fp.close()
30
31
32 def running_under_virtualenv():
33 """
34 Return True if we're running inside a virtualenv, False otherwise.
35
36 """
37 return hasattr(sys, 'real_prefix')
38
39
40 def virtualenv_no_global():
41 """
42 Return True if in a venv and no system site packages.
43 """
44 #this mirrors the logic in virtualenv.py for locating the no-global-site-packages.txt file
45 site_mod_dir = os.path.dirname(os.path.abspath(site.__file__))
46 no_global_file = os.path.join(site_mod_dir, 'no-global-site-packages.txt')
47 if running_under_virtualenv() and os.path.isfile(no_global_file):
48 return True
49
50 def __get_username():
51 """ Returns the effective username of the current process. """
52 if sys.platform == 'win32':
53 return getpass.getuser()
54 import pwd
55 return pwd.getpwuid(os.geteuid()).pw_name
56
57 def _get_build_prefix():
58 """ Returns a safe build_prefix """
59 path = os.path.join(tempfile.gettempdir(), 'pip_build_%s' %
60 __get_username())
61 if sys.platform == 'win32':
62 """ on windows(tested on 7) temp dirs are isolated """
63 return path
64 try:
65 os.mkdir(path)
66 write_delete_marker_file(path)
67 except OSError:
68 file_uid = None
69 try:
70 # raises OSError for symlinks
71 # https://github.com/pypa/pip/pull/935#discussion_r5307003
72 file_uid = get_path_uid(path)
73 except OSError:
74 file_uid = None
75
76 if file_uid != os.geteuid():
77 msg = "The temporary folder for building (%s) is either not owned by you, or is a symlink." \
78 % path
79 print (msg)
80 print("pip will not work until the temporary folder is " + \
81 "either deleted or is a real directory owned by your user account.")
82 raise pip.exceptions.InstallationError(msg)
83 return path
84
85 if running_under_virtualenv():
86 build_prefix = os.path.join(sys.prefix, 'build')
87 src_prefix = os.path.join(sys.prefix, 'src')
88 else:
89 # Note: intentionally NOT using mkdtemp
90 # See https://github.com/pypa/pip/issues/906 for plan to move to mkdtemp
91 build_prefix = _get_build_prefix()
92
93 ## FIXME: keep src in cwd for now (it is not a temporary folder)
94 try:
95 src_prefix = os.path.join(os.getcwd(), 'src')
96 except OSError:
97 # In case the current working directory has been renamed or deleted
98 sys.exit("The folder you are executing pip from can no longer be found.")
99
100 # under Mac OS X + virtualenv sys.prefix is not properly resolved
101 # it is something like /path/to/python/bin/..
102 # Note: using realpath due to tmp dirs on OSX being symlinks
103 build_prefix = os.path.abspath(os.path.realpath(build_prefix))
104 src_prefix = os.path.abspath(src_prefix)
105
106 # FIXME doesn't account for venv linked to global site-packages
107
108 site_packages = get_python_lib()
109 user_dir = os.path.expanduser('~')
110 if sys.platform == 'win32':
111 bin_py = os.path.join(sys.prefix, 'Scripts')
112 bin_user = os.path.join(user_site, 'Scripts') if user_site else None
113 # buildout uses 'bin' on Windows too?
114 if not os.path.exists(bin_py):
115 bin_py = os.path.join(sys.prefix, 'bin')
116 bin_user = os.path.join(user_site, 'bin') if user_site else None
117 default_storage_dir = os.path.join(user_dir, 'pip')
118 default_config_file = os.path.join(default_storage_dir, 'pip.ini')
119 default_log_file = os.path.join(default_storage_dir, 'pip.log')
120 else:
121 bin_py = os.path.join(sys.prefix, 'bin')
122 bin_user = os.path.join(user_site, 'bin') if user_site else None
123 default_storage_dir = os.path.join(user_dir, '.pip')
124 default_config_file = os.path.join(default_storage_dir, 'pip.conf')
125 default_log_file = os.path.join(default_storage_dir, 'pip.log')
126
127 # Forcing to use /usr/local/bin for standard Mac OS X framework installs
128 # Also log to ~/Library/Logs/ for use with the Console.app log viewer
129 if sys.platform[:6] == 'darwin' and sys.prefix[:16] == '/System/Library/':
130 bin_py = '/usr/local/bin'
131 default_log_file = os.path.join(user_dir, 'Library/Logs/pip.log')
132
133
134 def distutils_scheme(dist_name, user=False, home=None, root=None):
135 """
136 Return a distutils install scheme
137 """
138 from distutils.dist import Distribution
139
140 scheme = {}
141 d = Distribution({'name': dist_name})
142 d.parse_config_files()
143 i = d.get_command_obj('install', create=True)
144 # NOTE: setting user or home has the side-effect of creating the home dir or
145 # user base for installations during finalize_options()
146 # ideally, we'd prefer a scheme class that has no side-effects.
147 i.user = user or i.user
148 i.home = home or i.home
149 i.root = root or i.root
150 i.finalize_options()
151 for key in SCHEME_KEYS:
152 scheme[key] = getattr(i, 'install_'+key)
153
154 if running_under_virtualenv():
155 scheme['headers'] = os.path.join(sys.prefix,
156 'include',
157 'site',
158 'python' + sys.version[:3],
159 dist_name)
160
161 if root is not None:
162 scheme["headers"] = os.path.join(
163 root,
164 os.path.abspath(scheme["headers"])[1:],
165 )
166
167 return scheme
168
[end of pip/locations.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pip/locations.py b/pip/locations.py
--- a/pip/locations.py
+++ b/pip/locations.py
@@ -34,7 +34,12 @@
Return True if we're running inside a virtualenv, False otherwise.
"""
- return hasattr(sys, 'real_prefix')
+ if hasattr(sys, 'real_prefix'):
+ return True
+ elif sys.prefix != getattr(sys, "base_prefix", sys.prefix):
+ return True
+
+ return False
def virtualenv_no_global():
|
{"golden_diff": "diff --git a/pip/locations.py b/pip/locations.py\n--- a/pip/locations.py\n+++ b/pip/locations.py\n@@ -34,7 +34,12 @@\n Return True if we're running inside a virtualenv, False otherwise.\n \n \"\"\"\n- return hasattr(sys, 'real_prefix')\n+ if hasattr(sys, 'real_prefix'):\n+ return True\n+ elif sys.prefix != getattr(sys, \"base_prefix\", sys.prefix):\n+ return True\n+\n+ return False\n \n \n def virtualenv_no_global():\n", "issue": "pip doesn't detect a venv created virtual environment as a virtual environment\nThe venv integration in Python 3.4 fails if PIP_REQUIREVIRTUALENV is set (http://bugs.python.org/issue19734)\n\nI'm currently working around this by forcibly clearing the setting in the test, but the PIP_REQUIREVIRTUALENV check should pass when sys.prefix and sys.base_prefix are different.\n\n", "before_files": [{"content": "\"\"\"Locations where we look for configs, install stuff, etc\"\"\"\n\nimport sys\nimport site\nimport os\nimport tempfile\nfrom distutils.command.install import install, SCHEME_KEYS\nimport getpass\nfrom pip.backwardcompat import get_python_lib, get_path_uid, user_site\nimport pip.exceptions\n\n\nDELETE_MARKER_MESSAGE = '''\\\nThis file is placed here by pip to indicate the source was put\nhere by pip.\n\nOnce this package is successfully installed this source code will be\ndeleted (unless you remove this file).\n'''\nPIP_DELETE_MARKER_FILENAME = 'pip-delete-this-directory.txt'\n\ndef write_delete_marker_file(directory):\n \"\"\"\n Write the pip delete marker file into this directory.\n \"\"\"\n filepath = os.path.join(directory, PIP_DELETE_MARKER_FILENAME)\n marker_fp = open(filepath, 'w')\n marker_fp.write(DELETE_MARKER_MESSAGE)\n marker_fp.close()\n\n\ndef running_under_virtualenv():\n \"\"\"\n Return True if we're running inside a virtualenv, False otherwise.\n\n \"\"\"\n return hasattr(sys, 'real_prefix')\n\n\ndef virtualenv_no_global():\n \"\"\"\n Return True if in a venv and no system site packages.\n \"\"\"\n #this mirrors the logic in virtualenv.py for locating the no-global-site-packages.txt file\n site_mod_dir = os.path.dirname(os.path.abspath(site.__file__))\n no_global_file = os.path.join(site_mod_dir, 'no-global-site-packages.txt')\n if running_under_virtualenv() and os.path.isfile(no_global_file):\n return True\n\ndef __get_username():\n \"\"\" Returns the effective username of the current process. \"\"\"\n if sys.platform == 'win32':\n return getpass.getuser()\n import pwd\n return pwd.getpwuid(os.geteuid()).pw_name\n\ndef _get_build_prefix():\n \"\"\" Returns a safe build_prefix \"\"\"\n path = os.path.join(tempfile.gettempdir(), 'pip_build_%s' %\n __get_username())\n if sys.platform == 'win32':\n \"\"\" on windows(tested on 7) temp dirs are isolated \"\"\"\n return path\n try:\n os.mkdir(path)\n write_delete_marker_file(path)\n except OSError:\n file_uid = None\n try:\n # raises OSError for symlinks\n # https://github.com/pypa/pip/pull/935#discussion_r5307003\n file_uid = get_path_uid(path)\n except OSError:\n file_uid = None\n\n if file_uid != os.geteuid():\n msg = \"The temporary folder for building (%s) is either not owned by you, or is a symlink.\" \\\n % path\n print (msg)\n print(\"pip will not work until the temporary folder is \" + \\\n \"either deleted or is a real directory owned by your user account.\")\n raise pip.exceptions.InstallationError(msg)\n return path\n\nif running_under_virtualenv():\n build_prefix = os.path.join(sys.prefix, 'build')\n src_prefix = os.path.join(sys.prefix, 'src')\nelse:\n # Note: intentionally NOT using mkdtemp\n # See https://github.com/pypa/pip/issues/906 for plan to move to mkdtemp\n build_prefix = _get_build_prefix()\n\n ## FIXME: keep src in cwd for now (it is not a temporary folder)\n try:\n src_prefix = os.path.join(os.getcwd(), 'src')\n except OSError:\n # In case the current working directory has been renamed or deleted\n sys.exit(\"The folder you are executing pip from can no longer be found.\")\n\n# under Mac OS X + virtualenv sys.prefix is not properly resolved\n# it is something like /path/to/python/bin/..\n# Note: using realpath due to tmp dirs on OSX being symlinks\nbuild_prefix = os.path.abspath(os.path.realpath(build_prefix))\nsrc_prefix = os.path.abspath(src_prefix)\n\n# FIXME doesn't account for venv linked to global site-packages\n\nsite_packages = get_python_lib()\nuser_dir = os.path.expanduser('~')\nif sys.platform == 'win32':\n bin_py = os.path.join(sys.prefix, 'Scripts')\n bin_user = os.path.join(user_site, 'Scripts') if user_site else None\n # buildout uses 'bin' on Windows too?\n if not os.path.exists(bin_py):\n bin_py = os.path.join(sys.prefix, 'bin')\n bin_user = os.path.join(user_site, 'bin') if user_site else None\n default_storage_dir = os.path.join(user_dir, 'pip')\n default_config_file = os.path.join(default_storage_dir, 'pip.ini')\n default_log_file = os.path.join(default_storage_dir, 'pip.log')\nelse:\n bin_py = os.path.join(sys.prefix, 'bin')\n bin_user = os.path.join(user_site, 'bin') if user_site else None\n default_storage_dir = os.path.join(user_dir, '.pip')\n default_config_file = os.path.join(default_storage_dir, 'pip.conf')\n default_log_file = os.path.join(default_storage_dir, 'pip.log')\n\n # Forcing to use /usr/local/bin for standard Mac OS X framework installs\n # Also log to ~/Library/Logs/ for use with the Console.app log viewer\n if sys.platform[:6] == 'darwin' and sys.prefix[:16] == '/System/Library/':\n bin_py = '/usr/local/bin'\n default_log_file = os.path.join(user_dir, 'Library/Logs/pip.log')\n\n\ndef distutils_scheme(dist_name, user=False, home=None, root=None):\n \"\"\"\n Return a distutils install scheme\n \"\"\"\n from distutils.dist import Distribution\n\n scheme = {}\n d = Distribution({'name': dist_name})\n d.parse_config_files()\n i = d.get_command_obj('install', create=True)\n # NOTE: setting user or home has the side-effect of creating the home dir or\n # user base for installations during finalize_options()\n # ideally, we'd prefer a scheme class that has no side-effects.\n i.user = user or i.user\n i.home = home or i.home\n i.root = root or i.root\n i.finalize_options()\n for key in SCHEME_KEYS:\n scheme[key] = getattr(i, 'install_'+key)\n\n if running_under_virtualenv():\n scheme['headers'] = os.path.join(sys.prefix,\n 'include',\n 'site',\n 'python' + sys.version[:3],\n dist_name)\n\n if root is not None:\n scheme[\"headers\"] = os.path.join(\n root,\n os.path.abspath(scheme[\"headers\"])[1:],\n )\n\n return scheme\n", "path": "pip/locations.py"}]}
| 2,444 | 122 |
gh_patches_debug_22931
|
rasdani/github-patches
|
git_diff
|
GPflow__GPflow-1071
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
print summary fails for sum kernel
System information:
* Python version: 3.7
* TensorFlow installed from pip tf2 nightly
* TensorFlow version (use command below):'2.0.0-dev20190930'
* GPflow installed from (source or binary): python setup.py develop
* GPflow version: awav/gpflow-2.0
... _Describe the current behavior_
MWE:
```
k = gpflow.kernels.SquaredExponential() + gpflow.kernels.SquaredExponential()
print_summary(k)
Output:
name class transform trainable shape dtype value
------ ------- ----------- ----------- ------- ------- -------
```
... _Describe the expected behavior_
should print the values of the summed kernel's parameters.
</issue>
<code>
[start of gpflow/utilities/utilities.py]
1 import re
2 from functools import lru_cache
3 from typing import Callable, Dict, List, Optional, Union
4
5 import numpy as np
6 import tensorflow as tf
7 from tabulate import tabulate
8 from tensorflow.python.training.tracking.data_structures import ListWrapper, _DictWrapper
9
10 from ..base import Parameter
11 from ..config import summary_fmt
12
13 __all__ = [
14 "set_trainable",
15 "multiple_assign",
16 "training_loop",
17 "print_summary",
18 ]
19
20
21 def set_trainable(model: tf.Module, flag: bool = False):
22 """
23 Set trainable flag for all `tf.Variable`s and `gpflow.Parameter`s in a module.
24 """
25 for variable in model.trainable_variables:
26 variable._trainable = flag
27
28
29 def multiple_assign(input: tf.Module, vars_dict: Dict[str, tf.Tensor]):
30 """
31 Multiple assign takes a dictionary with new values. Dictionary keys are paths to the
32 `tf.Variable`s or `gpflow.Parameters` of the input module.
33
34 :param input: `tf.Module`.
35 :param vars_dict: a dictionary with keys of the form "module.path.to.variable" and new value tensors.
36 """
37 reference_var_dict = leaf_components(input)
38 for path, value in vars_dict.items():
39 reference_var_dict[path].assign(value)
40
41
42 def training_loop(closure: Callable[..., tf.Tensor],
43 optimizer: Optional[tf.optimizers.Optimizer] = None,
44 var_list: List[tf.Variable] = None,
45 maxiter=1e3,
46 jit=False):
47 """
48 Simple generic training loop. At each iteration uses a GradientTape to compute
49 the gradients of a loss function with respect to a set of variables.
50
51 :param closure: Callable that constructs a loss function based on data and model being trained
52 :param optimizer: tf.optimizers or tf.keras.optimizers that updates variables by applying the
53 corresponding loss gradients. Adam is a default optimizer with default settings.
54 :param var_list: List of model variables to be learnt during training
55 :param maxiter: Maximum number of
56 :return:
57 """
58
59 optimizer = tf.optimizers.Adam() if optimizer is None else optimizer
60
61 def optimization_step():
62 with tf.GradientTape() as tape:
63 tape.watch(var_list)
64 loss = closure()
65 grads = tape.gradient(loss, var_list)
66 optimizer.apply_gradients(zip(grads, var_list))
67
68 if jit:
69 optimization_step = tf.function(optimization_step)
70
71 for _ in range(int(maxiter)):
72 optimization_step()
73
74
75 def print_summary(module: tf.Module, fmt: str = None):
76 """
77 Prints a summary of the parameters and variables contained in a tf.Module.
78 """
79
80 fmt = fmt if fmt is not None else summary_fmt()
81 column_names = ['name', 'class', 'transform', 'trainable', 'shape', 'dtype', 'value']
82
83 def get_name(v):
84 return v.__class__.__name__
85
86 def get_transform(v):
87 if hasattr(v, "transform") and v.transform is not None:
88 return v.transform.__class__.__name__
89 return None
90
91 merged_leaf_components = _merge_leaf_components(leaf_components(module))
92
93 column_values = [[
94 path,
95 get_name(variable),
96 get_transform(variable),
97 variable.trainable,
98 variable.shape,
99 variable.dtype.name,
100 _str_tensor_value(variable.numpy())
101 ] for path, variable in merged_leaf_components.items()]
102
103 if fmt == "notebook":
104 from IPython.core.display import display, HTML
105 tab = tabulate(column_values, headers=column_names, tablefmt="html")
106 display(HTML(tab))
107 else:
108 print(tabulate(column_values, headers=column_names, tablefmt=fmt))
109
110
111 def leaf_components(input: tf.Module):
112 return _get_leaf_components(input)
113
114
115 def _merge_leaf_components(
116 input: Dict[str, Union[tf.Tensor, Parameter]]) -> Dict[str, Union[tf.Tensor, Parameter]]:
117 if len(set(input.values())) == len(input):
118 return input
119 tmp_dict = dict()
120 for key, item in input.items():
121 if item in tmp_dict:
122 tmp_dict[item] = f"{tmp_dict[item]}\n{key}"
123 else:
124 tmp_dict[item] = key
125 return {key: item for item, key in tmp_dict.items()}
126
127
128 def _get_leaf_components(input: tf.Module, prefix: Optional[str] = None):
129 """
130 Returns a list of tuples each corresponding to a gpflow.Parameter or tf.Variable in the each
131 submodules of a given tf.Module. Each tuple consists of an specific Parameter (or Variable) and
132 its relative path inside the module, which is constructed recursively by adding a prefix with
133 the path to the current module. Designed to be used as a helper for the method 'print_summary'.
134
135 :param module: tf.Module including keras.Model, keras.layers.Layer and gpflow.Module.
136 :param prefix: string containing the relative path to module, by default set to None.
137 :return:
138 """
139 if not isinstance(input, tf.Module):
140 raise TypeError("Input object expected to have `tf.Module` type")
141
142 prefix = input.__class__.__name__ if prefix is None else prefix
143 var_dict = dict()
144
145 for key, submodule in vars(input).items():
146 if key in tf.Module._TF_MODULE_IGNORED_PROPERTIES:
147 continue
148 elif isinstance(submodule, Parameter) or isinstance(submodule, tf.Variable):
149 var_dict[f"{prefix}.{key}"] = submodule
150 elif isinstance(submodule, tf.Module):
151 submodule_var = _get_leaf_components(submodule, prefix=f"{prefix}.{key}")
152 var_dict.update(submodule_var)
153 elif isinstance(submodule, ListWrapper):
154 submodule_name = input.__class__.__name__
155 for term_idx, subterm in enumerate(submodule):
156 subterm_key = f"{submodule_name}_{key}[{term_idx}]"
157 if isinstance(subterm, Parameter):
158 subterm_var = _get_leaf_components(subterm, prefix=f"{prefix}.{subterm_key}")
159 var_dict.update(subterm_var)
160 elif isinstance(submodule, _DictWrapper):
161 submodule_name = input.__class__.__name__
162 for term_key, subterm in submodule.items():
163 subterm_key = f"{submodule_name}_{key}[{term_key}]"
164 subterm_var = _get_leaf_components(subterm, prefix=f"{prefix}.{subterm_key}")
165 var_dict.update(subterm_var)
166 return var_dict
167
168
169 @lru_cache()
170 def _first_three_elements_regexp():
171 num_re = r"[+\-]?(?:0|[1-9]\d*)(?:\.\d*)?(?:[eE][+\-]?\d+)?"
172 pat_re = rf"^(?:(\[+)\s*)?({num_re})(?:\s+({num_re})(?:\s+({num_re}))?)?.*?"
173 return re.compile(pat_re)
174
175
176 def _str_tensor_value(value: np.ndarray):
177 value_str = str(value)
178 if value.size <= 3:
179 return value_str
180
181 max_chars = 500
182 value_str = value_str[:max_chars]
183 regexp = _first_three_elements_regexp()
184 match = regexp.match(value_str)
185 assert match is not None
186 brackets, elem1, elem2, elem3 = match.groups()
187
188 out = f"{elem1}"
189 if elem2 is not None:
190 out = f"{out}{f', {elem2}'}"
191 if elem3 is not None:
192 out = f"{out}{f', {elem3}'}"
193 if brackets is not None:
194 out = f"{brackets}{out}..."
195
196 return out
197
[end of gpflow/utilities/utilities.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpflow/utilities/utilities.py b/gpflow/utilities/utilities.py
--- a/gpflow/utilities/utilities.py
+++ b/gpflow/utilities/utilities.py
@@ -100,6 +100,7 @@
_str_tensor_value(variable.numpy())
] for path, variable in merged_leaf_components.items()]
+
if fmt == "notebook":
from IPython.core.display import display, HTML
tab = tabulate(column_values, headers=column_names, tablefmt="html")
@@ -154,7 +155,7 @@
submodule_name = input.__class__.__name__
for term_idx, subterm in enumerate(submodule):
subterm_key = f"{submodule_name}_{key}[{term_idx}]"
- if isinstance(subterm, Parameter):
+ if isinstance(subterm, tf.Module):
subterm_var = _get_leaf_components(subterm, prefix=f"{prefix}.{subterm_key}")
var_dict.update(subterm_var)
elif isinstance(submodule, _DictWrapper):
|
{"golden_diff": "diff --git a/gpflow/utilities/utilities.py b/gpflow/utilities/utilities.py\n--- a/gpflow/utilities/utilities.py\n+++ b/gpflow/utilities/utilities.py\n@@ -100,6 +100,7 @@\n _str_tensor_value(variable.numpy())\n ] for path, variable in merged_leaf_components.items()]\n \n+\n if fmt == \"notebook\":\n from IPython.core.display import display, HTML\n tab = tabulate(column_values, headers=column_names, tablefmt=\"html\")\n@@ -154,7 +155,7 @@\n submodule_name = input.__class__.__name__\n for term_idx, subterm in enumerate(submodule):\n subterm_key = f\"{submodule_name}_{key}[{term_idx}]\"\n- if isinstance(subterm, Parameter):\n+ if isinstance(subterm, tf.Module):\n subterm_var = _get_leaf_components(subterm, prefix=f\"{prefix}.{subterm_key}\")\n var_dict.update(subterm_var)\n elif isinstance(submodule, _DictWrapper):\n", "issue": "print summary fails for sum kernel\n\r\nSystem information:\r\n\r\n* Python version: 3.7\r\n* TensorFlow installed from pip tf2 nightly\r\n* TensorFlow version (use command below):'2.0.0-dev20190930'\r\n* GPflow installed from (source or binary): python setup.py develop\r\n* GPflow version: awav/gpflow-2.0\r\n\r\n\r\n\r\n... _Describe the current behavior_\r\nMWE:\r\n```\r\nk = gpflow.kernels.SquaredExponential() + gpflow.kernels.SquaredExponential()\r\nprint_summary(k)\r\n\r\nOutput:\r\nname class transform trainable shape dtype value\r\n------ ------- ----------- ----------- ------- ------- -------\r\n```\r\n... _Describe the expected behavior_\r\nshould print the values of the summed kernel's parameters.\r\n\n", "before_files": [{"content": "import re\nfrom functools import lru_cache\nfrom typing import Callable, Dict, List, Optional, Union\n\nimport numpy as np\nimport tensorflow as tf\nfrom tabulate import tabulate\nfrom tensorflow.python.training.tracking.data_structures import ListWrapper, _DictWrapper\n\nfrom ..base import Parameter\nfrom ..config import summary_fmt\n\n__all__ = [\n \"set_trainable\",\n \"multiple_assign\",\n \"training_loop\",\n \"print_summary\",\n]\n\n\ndef set_trainable(model: tf.Module, flag: bool = False):\n \"\"\"\n Set trainable flag for all `tf.Variable`s and `gpflow.Parameter`s in a module.\n \"\"\"\n for variable in model.trainable_variables:\n variable._trainable = flag\n\n\ndef multiple_assign(input: tf.Module, vars_dict: Dict[str, tf.Tensor]):\n \"\"\"\n Multiple assign takes a dictionary with new values. Dictionary keys are paths to the\n `tf.Variable`s or `gpflow.Parameters` of the input module.\n\n :param input: `tf.Module`.\n :param vars_dict: a dictionary with keys of the form \"module.path.to.variable\" and new value tensors.\n \"\"\"\n reference_var_dict = leaf_components(input)\n for path, value in vars_dict.items():\n reference_var_dict[path].assign(value)\n\n\ndef training_loop(closure: Callable[..., tf.Tensor],\n optimizer: Optional[tf.optimizers.Optimizer] = None,\n var_list: List[tf.Variable] = None,\n maxiter=1e3,\n jit=False):\n \"\"\"\n Simple generic training loop. At each iteration uses a GradientTape to compute\n the gradients of a loss function with respect to a set of variables.\n\n :param closure: Callable that constructs a loss function based on data and model being trained\n :param optimizer: tf.optimizers or tf.keras.optimizers that updates variables by applying the\n corresponding loss gradients. Adam is a default optimizer with default settings.\n :param var_list: List of model variables to be learnt during training\n :param maxiter: Maximum number of\n :return:\n \"\"\"\n\n optimizer = tf.optimizers.Adam() if optimizer is None else optimizer\n\n def optimization_step():\n with tf.GradientTape() as tape:\n tape.watch(var_list)\n loss = closure()\n grads = tape.gradient(loss, var_list)\n optimizer.apply_gradients(zip(grads, var_list))\n\n if jit:\n optimization_step = tf.function(optimization_step)\n\n for _ in range(int(maxiter)):\n optimization_step()\n\n\ndef print_summary(module: tf.Module, fmt: str = None):\n \"\"\"\n Prints a summary of the parameters and variables contained in a tf.Module.\n \"\"\"\n\n fmt = fmt if fmt is not None else summary_fmt()\n column_names = ['name', 'class', 'transform', 'trainable', 'shape', 'dtype', 'value']\n\n def get_name(v):\n return v.__class__.__name__\n\n def get_transform(v):\n if hasattr(v, \"transform\") and v.transform is not None:\n return v.transform.__class__.__name__\n return None\n\n merged_leaf_components = _merge_leaf_components(leaf_components(module))\n\n column_values = [[\n path,\n get_name(variable),\n get_transform(variable),\n variable.trainable,\n variable.shape,\n variable.dtype.name,\n _str_tensor_value(variable.numpy())\n ] for path, variable in merged_leaf_components.items()]\n\n if fmt == \"notebook\":\n from IPython.core.display import display, HTML\n tab = tabulate(column_values, headers=column_names, tablefmt=\"html\")\n display(HTML(tab))\n else:\n print(tabulate(column_values, headers=column_names, tablefmt=fmt))\n\n\ndef leaf_components(input: tf.Module):\n return _get_leaf_components(input)\n\n\ndef _merge_leaf_components(\n input: Dict[str, Union[tf.Tensor, Parameter]]) -> Dict[str, Union[tf.Tensor, Parameter]]:\n if len(set(input.values())) == len(input):\n return input\n tmp_dict = dict()\n for key, item in input.items():\n if item in tmp_dict:\n tmp_dict[item] = f\"{tmp_dict[item]}\\n{key}\"\n else:\n tmp_dict[item] = key\n return {key: item for item, key in tmp_dict.items()}\n\n\ndef _get_leaf_components(input: tf.Module, prefix: Optional[str] = None):\n \"\"\"\n Returns a list of tuples each corresponding to a gpflow.Parameter or tf.Variable in the each\n submodules of a given tf.Module. Each tuple consists of an specific Parameter (or Variable) and\n its relative path inside the module, which is constructed recursively by adding a prefix with\n the path to the current module. Designed to be used as a helper for the method 'print_summary'.\n\n :param module: tf.Module including keras.Model, keras.layers.Layer and gpflow.Module.\n :param prefix: string containing the relative path to module, by default set to None.\n :return:\n \"\"\"\n if not isinstance(input, tf.Module):\n raise TypeError(\"Input object expected to have `tf.Module` type\")\n\n prefix = input.__class__.__name__ if prefix is None else prefix\n var_dict = dict()\n\n for key, submodule in vars(input).items():\n if key in tf.Module._TF_MODULE_IGNORED_PROPERTIES:\n continue\n elif isinstance(submodule, Parameter) or isinstance(submodule, tf.Variable):\n var_dict[f\"{prefix}.{key}\"] = submodule\n elif isinstance(submodule, tf.Module):\n submodule_var = _get_leaf_components(submodule, prefix=f\"{prefix}.{key}\")\n var_dict.update(submodule_var)\n elif isinstance(submodule, ListWrapper):\n submodule_name = input.__class__.__name__\n for term_idx, subterm in enumerate(submodule):\n subterm_key = f\"{submodule_name}_{key}[{term_idx}]\"\n if isinstance(subterm, Parameter):\n subterm_var = _get_leaf_components(subterm, prefix=f\"{prefix}.{subterm_key}\")\n var_dict.update(subterm_var)\n elif isinstance(submodule, _DictWrapper):\n submodule_name = input.__class__.__name__\n for term_key, subterm in submodule.items():\n subterm_key = f\"{submodule_name}_{key}[{term_key}]\"\n subterm_var = _get_leaf_components(subterm, prefix=f\"{prefix}.{subterm_key}\")\n var_dict.update(subterm_var)\n return var_dict\n\n\n@lru_cache()\ndef _first_three_elements_regexp():\n num_re = r\"[+\\-]?(?:0|[1-9]\\d*)(?:\\.\\d*)?(?:[eE][+\\-]?\\d+)?\"\n pat_re = rf\"^(?:(\\[+)\\s*)?({num_re})(?:\\s+({num_re})(?:\\s+({num_re}))?)?.*?\"\n return re.compile(pat_re)\n\n\ndef _str_tensor_value(value: np.ndarray):\n value_str = str(value)\n if value.size <= 3:\n return value_str\n\n max_chars = 500\n value_str = value_str[:max_chars]\n regexp = _first_three_elements_regexp()\n match = regexp.match(value_str)\n assert match is not None\n brackets, elem1, elem2, elem3 = match.groups()\n\n out = f\"{elem1}\"\n if elem2 is not None:\n out = f\"{out}{f', {elem2}'}\"\n if elem3 is not None:\n out = f\"{out}{f', {elem3}'}\"\n if brackets is not None:\n out = f\"{brackets}{out}...\"\n\n return out\n", "path": "gpflow/utilities/utilities.py"}]}
| 2,849 | 229 |
gh_patches_debug_41470
|
rasdani/github-patches
|
git_diff
|
PennyLaneAI__pennylane-1761
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add batching support to the AmplitudeEmbedding template
### Feature details
A recent PR, #1710, added support for creating PennyLane QNodes with *batches* of input parameters via [`@qml.batch_params`](https://pennylane.readthedocs.io/en/latest/code/api/pennylane.batch_params.html). Under the hood, a separate circuit per batch dimension is created, and as a result this approach is both hardware and simulator compatible:
```python
dev = qml.device("default.qubit", wires=2)
@qml.batch_params
@qml.beta.qnode(dev)
def circuit(x, weights):
qml.RX(x, wires=0)
qml.RY(0.2, wires=1)
qml.templates.StronglyEntanglingLayers(weights, wires=[0, 1, 2])
return qml.expval(qml.Hadamard(0))
def cost(x, weights):
return np.sum(circuit(x, weights))
batch_size = 3
x = np.linspace(0.1, 0.5, batch_size)
weights = np.random.random((batch_size, 10, 3, 3))
>>> circuit(x, weights)
[-0.30773348 0.23135516 0.13086565]
>>> cost_fn(x, weights)
-0.8581269507766536
>>> qml.grad(cost_fn)(x, weights)[0]
[ 0.23235464 0.00928953 -0.30083487]
```
One such template that would be great to support in batch mode is [`qml.templates.AmplitudeEmbedding`](https://pennylane.readthedocs.io/en/stable/code/api/pennylane.templates.embeddings.AmplitudeEmbedding.html). In order to add support, this template needs to be modified to recognize the first dimension of the input parameter as a _batch_ dimension.
### Implementation
We would like to support the following example:
```python
dev = qml.device("default.qubit", wires=3)
@qml.batch_params
@qml.beta.qnode(dev)
def circuit(data, weights):
qml.templates.AmplitudeEmbedding(data, wires=[0, 1, 2])
qml.templates.StronglyEntanglingLayers(weights, wires=[0, 1, 2])
return qml.expval(qml.PauliX(0))
batch_size = 3
# create a batched input statevector
data = np.random.random((batch_size, 8))
data /= np.linalg.norm(data, axis=1).reshape(-1, 1) # normalize
weights = np.random.random((batch_size, 10, 3, 3))
circuit(data, weights)
```
This can be done by modifying the `AmplitudeEmbedding` source code as needed. In addition, a test should be added to `tests/transforms/test_batch_params.py`.
Note that some hardware devices do not support `AmplitudeEmbedding` directly, and instead decompose via the [`qml.templates.MottonenStatePreparation`](https://pennylane.readthedocs.io/en/stable/code/api/pennylane.templates.state_preparations.MottonenStatePreparation.html) template, so adding support to this template would also be an added bonus.
### How important would you say this feature is?
2: Somewhat important. Needed this quarter.
### Additional information
_No response_
</issue>
<code>
[start of pennylane/templates/embeddings/amplitude.py]
1 # Copyright 2018-2021 Xanadu Quantum Technologies Inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 r"""
15 Contains the AmplitudeEmbedding template.
16 """
17 # pylint: disable-msg=too-many-branches,too-many-arguments,protected-access
18 import warnings
19 import numpy as np
20
21 import pennylane as qml
22 from pennylane.operation import Operation, AnyWires
23 from pennylane.ops import QubitStateVector
24 from pennylane.wires import Wires
25
26 # tolerance for normalization
27 TOLERANCE = 1e-10
28
29
30 class AmplitudeEmbedding(Operation):
31 r"""Encodes :math:`2^n` features into the amplitude vector of :math:`n` qubits.
32
33 By setting ``pad_with`` to a real or complex number, ``features`` is automatically padded to dimension
34 :math:`2^n` where :math:`n` is the number of qubits used in the embedding.
35
36 To represent a valid quantum state vector, the L2-norm of ``features`` must be one.
37 The argument ``normalize`` can be set to ``True`` to automatically normalize the features.
38
39 If both automatic padding and normalization are used, padding is executed *before* normalizing.
40
41 .. note::
42
43 On some devices, ``AmplitudeEmbedding`` must be the first operation of a quantum circuit.
44
45 .. warning::
46
47 At the moment, the ``features`` argument is **not differentiable** when using the template, and
48 gradients with respect to the features cannot be computed by PennyLane.
49
50 Args:
51 features (tensor_like): input tensor of dimension ``(2^n,)``, or less if `pad_with` is specified
52 wires (Iterable): wires that the template acts on
53 pad_with (float or complex): if not None, the input is padded with this constant to size :math:`2^n`
54 normalize (bool): whether to automatically normalize the features
55 pad (float or complex): same as `pad`, to be deprecated
56
57 Example:
58
59 Amplitude embedding encodes a normalized :math:`2^n`-dimensional feature vector into the state
60 of :math:`n` qubits:
61
62 .. code-block:: python
63
64 import pennylane as qml
65 from pennylane.templates import AmplitudeEmbedding
66
67 dev = qml.device('default.qubit', wires=2)
68
69 @qml.qnode(dev)
70 def circuit(f=None):
71 AmplitudeEmbedding(features=f, wires=range(2))
72 return qml.expval(qml.PauliZ(0))
73
74 circuit(f=[1/2, 1/2, 1/2, 1/2])
75
76 The final state of the device is - up to a global phase - equivalent to the input passed to the circuit:
77
78 >>> dev.state
79 [0.5+0.j 0.5+0.j 0.5+0.j 0.5+0.j]
80
81 **Differentiating with respect to the features**
82
83 Due to non-trivial classical processing to construct the state preparation circuit,
84 the features argument is in general **not differentiable**.
85
86 **Normalization**
87
88 The template will raise an error if the feature input is not normalized.
89 One can set ``normalize=True`` to automatically normalize it:
90
91 .. code-block:: python
92
93 @qml.qnode(dev)
94 def circuit(f=None):
95 AmplitudeEmbedding(features=f, wires=range(2), normalize=True)
96 return qml.expval(qml.PauliZ(0))
97
98 circuit(f=[15, 15, 15, 15])
99
100 >>> dev.state
101 [0.5 + 0.j, 0.5 + 0.j, 0.5 + 0.j, 0.5 + 0.j]
102
103 **Padding**
104
105 If the dimension of the feature vector is smaller than the number of amplitudes,
106 one can automatically pad it with a constant for the missing dimensions using the ``pad_with`` option:
107
108 .. code-block:: python
109
110 from math import sqrt
111
112 @qml.qnode(dev)
113 def circuit(f=None):
114 AmplitudeEmbedding(features=f, wires=range(2), pad_with=0.)
115 return qml.expval(qml.PauliZ(0))
116
117 circuit(f=[1/sqrt(2), 1/sqrt(2)])
118
119 >>> dev.state
120 [0.70710678 + 0.j, 0.70710678 + 0.j, 0.0 + 0.j, 0.0 + 0.j]
121
122 """
123
124 num_params = 1
125 num_wires = AnyWires
126 par_domain = "A"
127 grad_method = None
128
129 def __init__(
130 self, features, wires, pad_with=None, normalize=False, pad=None, do_queue=True, id=None
131 ):
132
133 # pad is replaced with the more verbose pad_with
134 if pad is not None:
135 warnings.warn(
136 "The pad argument will be replaced by the pad_with option in future versions of PennyLane.",
137 UserWarning,
138 )
139 if pad_with is None:
140 pad_with = pad
141
142 wires = Wires(wires)
143 self.pad_with = pad_with
144 self.normalize = normalize
145
146 features = self._preprocess(features, wires, pad_with, normalize)
147 super().__init__(features, wires=wires, do_queue=do_queue, id=id)
148
149 def adjoint(self): # pylint: disable=arguments-differ
150 return qml.adjoint(qml.templates.MottonenStatePreparation)(
151 self.parameters[0], wires=self.wires
152 )
153
154 def expand(self):
155
156 with qml.tape.QuantumTape() as tape:
157 QubitStateVector(self.parameters[0], wires=self.wires)
158
159 return tape
160
161 @staticmethod
162 def _preprocess(features, wires, pad_with, normalize):
163 """Validate and pre-process inputs as follows:
164
165 * Check that the features tensor is one-dimensional.
166 * If pad_with is None, check that the first dimension of the features tensor
167 has length :math:`2^n` where :math:`n` is the number of qubits. Else check that the
168 first dimension of the features tensor is not larger than :math:`2^n` and pad features with value if necessary.
169 * If normalize is false, check that first dimension of features is normalised to one. Else, normalise the
170 features tensor.
171 """
172
173 shape = qml.math.shape(features)
174
175 # check shape
176 if len(shape) != 1:
177 raise ValueError(f"Features must be a one-dimensional tensor; got shape {shape}.")
178
179 n_features = shape[0]
180 if pad_with is None and n_features != 2 ** len(wires):
181 raise ValueError(
182 f"Features must be of length {2 ** len(wires)}; got length {n_features}. "
183 f"Use the 'pad' argument for automated padding."
184 )
185
186 if pad_with is not None and n_features > 2 ** len(wires):
187 raise ValueError(
188 f"Features must be of length {2 ** len(wires)} or "
189 f"smaller to be padded; got length {n_features}."
190 )
191
192 # pad
193 if pad_with is not None and n_features < 2 ** len(wires):
194 padding = [pad_with] * (2 ** len(wires) - n_features)
195 features = qml.math.concatenate([features, padding], axis=0)
196
197 # normalize
198 norm = qml.math.sum(qml.math.abs(features) ** 2)
199
200 if not qml.math.allclose(norm, 1.0, atol=TOLERANCE):
201 if normalize or pad_with:
202 features = features / np.sqrt(norm)
203 else:
204 raise ValueError(
205 f"Features must be a vector of length 1.0; got length {norm}."
206 "Use 'normalize=True' to automatically normalize."
207 )
208
209 features = qml.math.cast(features, np.complex128)
210 return features
211
[end of pennylane/templates/embeddings/amplitude.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pennylane/templates/embeddings/amplitude.py b/pennylane/templates/embeddings/amplitude.py
--- a/pennylane/templates/embeddings/amplitude.py
+++ b/pennylane/templates/embeddings/amplitude.py
@@ -162,6 +162,7 @@
def _preprocess(features, wires, pad_with, normalize):
"""Validate and pre-process inputs as follows:
+ * If features is batched, the processing that follows is applied to each feature set in the batch.
* Check that the features tensor is one-dimensional.
* If pad_with is None, check that the first dimension of the features tensor
has length :math:`2^n` where :math:`n` is the number of qubits. Else check that the
@@ -170,41 +171,49 @@
features tensor.
"""
- shape = qml.math.shape(features)
+ # check if features is batched
+ batched = len(qml.math.shape(features)) > 1
- # check shape
- if len(shape) != 1:
- raise ValueError(f"Features must be a one-dimensional tensor; got shape {shape}.")
+ features_batch = features if batched else [features]
- n_features = shape[0]
- if pad_with is None and n_features != 2 ** len(wires):
- raise ValueError(
- f"Features must be of length {2 ** len(wires)}; got length {n_features}. "
- f"Use the 'pad' argument for automated padding."
- )
-
- if pad_with is not None and n_features > 2 ** len(wires):
- raise ValueError(
- f"Features must be of length {2 ** len(wires)} or "
- f"smaller to be padded; got length {n_features}."
- )
+ # apply pre-processing to each features tensor in the batch
+ for i, feature_set in enumerate(features_batch):
+ shape = qml.math.shape(feature_set)
- # pad
- if pad_with is not None and n_features < 2 ** len(wires):
- padding = [pad_with] * (2 ** len(wires) - n_features)
- features = qml.math.concatenate([features, padding], axis=0)
+ # check shape
+ if len(shape) != 1:
+ raise ValueError(f"Features must be a one-dimensional tensor; got shape {shape}.")
- # normalize
- norm = qml.math.sum(qml.math.abs(features) ** 2)
+ n_features = shape[0]
+ if pad_with is None and n_features != 2 ** len(wires):
+ raise ValueError(
+ f"Features must be of length {2 ** len(wires)}; got length {n_features}. "
+ f"Use the 'pad' argument for automated padding."
+ )
- if not qml.math.allclose(norm, 1.0, atol=TOLERANCE):
- if normalize or pad_with:
- features = features / np.sqrt(norm)
- else:
+ if pad_with is not None and n_features > 2 ** len(wires):
raise ValueError(
- f"Features must be a vector of length 1.0; got length {norm}."
- "Use 'normalize=True' to automatically normalize."
+ f"Features must be of length {2 ** len(wires)} or "
+ f"smaller to be padded; got length {n_features}."
)
- features = qml.math.cast(features, np.complex128)
- return features
+ # pad
+ if pad_with is not None and n_features < 2 ** len(wires):
+ padding = [pad_with] * (2 ** len(wires) - n_features)
+ feature_set = qml.math.concatenate([feature_set, padding], axis=0)
+
+ # normalize
+ norm = qml.math.sum(qml.math.abs(feature_set) ** 2)
+
+ if not qml.math.allclose(norm, 1.0, atol=TOLERANCE):
+ if normalize or pad_with:
+ feature_set = feature_set / np.sqrt(norm)
+ else:
+ raise ValueError(
+ f"Features must be a vector of norm 1.0; got norm {norm}."
+ "Use 'normalize=True' to automatically normalize."
+ )
+
+ features_batch[i] = qml.math.cast(feature_set, np.complex128)
+
+ return features_batch if batched else features_batch[0]
|
{"golden_diff": "diff --git a/pennylane/templates/embeddings/amplitude.py b/pennylane/templates/embeddings/amplitude.py\n--- a/pennylane/templates/embeddings/amplitude.py\n+++ b/pennylane/templates/embeddings/amplitude.py\n@@ -162,6 +162,7 @@\n def _preprocess(features, wires, pad_with, normalize):\n \"\"\"Validate and pre-process inputs as follows:\n \n+ * If features is batched, the processing that follows is applied to each feature set in the batch.\n * Check that the features tensor is one-dimensional.\n * If pad_with is None, check that the first dimension of the features tensor\n has length :math:`2^n` where :math:`n` is the number of qubits. Else check that the\n@@ -170,41 +171,49 @@\n features tensor.\n \"\"\"\n \n- shape = qml.math.shape(features)\n+ # check if features is batched\n+ batched = len(qml.math.shape(features)) > 1\n \n- # check shape\n- if len(shape) != 1:\n- raise ValueError(f\"Features must be a one-dimensional tensor; got shape {shape}.\")\n+ features_batch = features if batched else [features]\n \n- n_features = shape[0]\n- if pad_with is None and n_features != 2 ** len(wires):\n- raise ValueError(\n- f\"Features must be of length {2 ** len(wires)}; got length {n_features}. \"\n- f\"Use the 'pad' argument for automated padding.\"\n- )\n-\n- if pad_with is not None and n_features > 2 ** len(wires):\n- raise ValueError(\n- f\"Features must be of length {2 ** len(wires)} or \"\n- f\"smaller to be padded; got length {n_features}.\"\n- )\n+ # apply pre-processing to each features tensor in the batch\n+ for i, feature_set in enumerate(features_batch):\n+ shape = qml.math.shape(feature_set)\n \n- # pad\n- if pad_with is not None and n_features < 2 ** len(wires):\n- padding = [pad_with] * (2 ** len(wires) - n_features)\n- features = qml.math.concatenate([features, padding], axis=0)\n+ # check shape\n+ if len(shape) != 1:\n+ raise ValueError(f\"Features must be a one-dimensional tensor; got shape {shape}.\")\n \n- # normalize\n- norm = qml.math.sum(qml.math.abs(features) ** 2)\n+ n_features = shape[0]\n+ if pad_with is None and n_features != 2 ** len(wires):\n+ raise ValueError(\n+ f\"Features must be of length {2 ** len(wires)}; got length {n_features}. \"\n+ f\"Use the 'pad' argument for automated padding.\"\n+ )\n \n- if not qml.math.allclose(norm, 1.0, atol=TOLERANCE):\n- if normalize or pad_with:\n- features = features / np.sqrt(norm)\n- else:\n+ if pad_with is not None and n_features > 2 ** len(wires):\n raise ValueError(\n- f\"Features must be a vector of length 1.0; got length {norm}.\"\n- \"Use 'normalize=True' to automatically normalize.\"\n+ f\"Features must be of length {2 ** len(wires)} or \"\n+ f\"smaller to be padded; got length {n_features}.\"\n )\n \n- features = qml.math.cast(features, np.complex128)\n- return features\n+ # pad\n+ if pad_with is not None and n_features < 2 ** len(wires):\n+ padding = [pad_with] * (2 ** len(wires) - n_features)\n+ feature_set = qml.math.concatenate([feature_set, padding], axis=0)\n+\n+ # normalize\n+ norm = qml.math.sum(qml.math.abs(feature_set) ** 2)\n+\n+ if not qml.math.allclose(norm, 1.0, atol=TOLERANCE):\n+ if normalize or pad_with:\n+ feature_set = feature_set / np.sqrt(norm)\n+ else:\n+ raise ValueError(\n+ f\"Features must be a vector of norm 1.0; got norm {norm}.\"\n+ \"Use 'normalize=True' to automatically normalize.\"\n+ )\n+\n+ features_batch[i] = qml.math.cast(feature_set, np.complex128)\n+\n+ return features_batch if batched else features_batch[0]\n", "issue": "Add batching support to the AmplitudeEmbedding template\n### Feature details\r\n\r\nA recent PR, #1710, added support for creating PennyLane QNodes with *batches* of input parameters via [`@qml.batch_params`](https://pennylane.readthedocs.io/en/latest/code/api/pennylane.batch_params.html). Under the hood, a separate circuit per batch dimension is created, and as a result this approach is both hardware and simulator compatible:\r\n\r\n```python\r\ndev = qml.device(\"default.qubit\", wires=2)\r\n\r\[email protected]_params\r\[email protected](dev)\r\ndef circuit(x, weights):\r\n qml.RX(x, wires=0)\r\n qml.RY(0.2, wires=1)\r\n qml.templates.StronglyEntanglingLayers(weights, wires=[0, 1, 2])\r\n return qml.expval(qml.Hadamard(0))\r\n\r\ndef cost(x, weights):\r\n return np.sum(circuit(x, weights))\r\n\r\nbatch_size = 3\r\nx = np.linspace(0.1, 0.5, batch_size)\r\nweights = np.random.random((batch_size, 10, 3, 3))\r\n\r\n>>> circuit(x, weights)\r\n[-0.30773348 0.23135516 0.13086565]\r\n>>> cost_fn(x, weights)\r\n-0.8581269507766536\r\n>>> qml.grad(cost_fn)(x, weights)[0]\r\n[ 0.23235464 0.00928953 -0.30083487]\r\n```\r\n\r\nOne such template that would be great to support in batch mode is [`qml.templates.AmplitudeEmbedding`](https://pennylane.readthedocs.io/en/stable/code/api/pennylane.templates.embeddings.AmplitudeEmbedding.html). In order to add support, this template needs to be modified to recognize the first dimension of the input parameter as a _batch_ dimension.\r\n\r\n### Implementation\r\n\r\nWe would like to support the following example:\r\n\r\n```python\r\ndev = qml.device(\"default.qubit\", wires=3)\r\n\r\[email protected]_params\r\[email protected](dev)\r\ndef circuit(data, weights):\r\n qml.templates.AmplitudeEmbedding(data, wires=[0, 1, 2])\r\n qml.templates.StronglyEntanglingLayers(weights, wires=[0, 1, 2])\r\n return qml.expval(qml.PauliX(0))\r\n\r\nbatch_size = 3\r\n\r\n# create a batched input statevector\r\ndata = np.random.random((batch_size, 8))\r\ndata /= np.linalg.norm(data, axis=1).reshape(-1, 1) # normalize\r\n\r\nweights = np.random.random((batch_size, 10, 3, 3))\r\ncircuit(data, weights)\r\n```\r\n\r\nThis can be done by modifying the `AmplitudeEmbedding` source code as needed. In addition, a test should be added to `tests/transforms/test_batch_params.py`.\r\n\r\nNote that some hardware devices do not support `AmplitudeEmbedding` directly, and instead decompose via the [`qml.templates.MottonenStatePreparation`](https://pennylane.readthedocs.io/en/stable/code/api/pennylane.templates.state_preparations.MottonenStatePreparation.html) template, so adding support to this template would also be an added bonus.\r\n\r\n### How important would you say this feature is?\r\n\r\n2: Somewhat important. Needed this quarter.\r\n\r\n### Additional information\r\n\r\n_No response_\n", "before_files": [{"content": "# Copyright 2018-2021 Xanadu Quantum Technologies Inc.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nr\"\"\"\nContains the AmplitudeEmbedding template.\n\"\"\"\n# pylint: disable-msg=too-many-branches,too-many-arguments,protected-access\nimport warnings\nimport numpy as np\n\nimport pennylane as qml\nfrom pennylane.operation import Operation, AnyWires\nfrom pennylane.ops import QubitStateVector\nfrom pennylane.wires import Wires\n\n# tolerance for normalization\nTOLERANCE = 1e-10\n\n\nclass AmplitudeEmbedding(Operation):\n r\"\"\"Encodes :math:`2^n` features into the amplitude vector of :math:`n` qubits.\n\n By setting ``pad_with`` to a real or complex number, ``features`` is automatically padded to dimension\n :math:`2^n` where :math:`n` is the number of qubits used in the embedding.\n\n To represent a valid quantum state vector, the L2-norm of ``features`` must be one.\n The argument ``normalize`` can be set to ``True`` to automatically normalize the features.\n\n If both automatic padding and normalization are used, padding is executed *before* normalizing.\n\n .. note::\n\n On some devices, ``AmplitudeEmbedding`` must be the first operation of a quantum circuit.\n\n .. warning::\n\n At the moment, the ``features`` argument is **not differentiable** when using the template, and\n gradients with respect to the features cannot be computed by PennyLane.\n\n Args:\n features (tensor_like): input tensor of dimension ``(2^n,)``, or less if `pad_with` is specified\n wires (Iterable): wires that the template acts on\n pad_with (float or complex): if not None, the input is padded with this constant to size :math:`2^n`\n normalize (bool): whether to automatically normalize the features\n pad (float or complex): same as `pad`, to be deprecated\n\n Example:\n\n Amplitude embedding encodes a normalized :math:`2^n`-dimensional feature vector into the state\n of :math:`n` qubits:\n\n .. code-block:: python\n\n import pennylane as qml\n from pennylane.templates import AmplitudeEmbedding\n\n dev = qml.device('default.qubit', wires=2)\n\n @qml.qnode(dev)\n def circuit(f=None):\n AmplitudeEmbedding(features=f, wires=range(2))\n return qml.expval(qml.PauliZ(0))\n\n circuit(f=[1/2, 1/2, 1/2, 1/2])\n\n The final state of the device is - up to a global phase - equivalent to the input passed to the circuit:\n\n >>> dev.state\n [0.5+0.j 0.5+0.j 0.5+0.j 0.5+0.j]\n\n **Differentiating with respect to the features**\n\n Due to non-trivial classical processing to construct the state preparation circuit,\n the features argument is in general **not differentiable**.\n\n **Normalization**\n\n The template will raise an error if the feature input is not normalized.\n One can set ``normalize=True`` to automatically normalize it:\n\n .. code-block:: python\n\n @qml.qnode(dev)\n def circuit(f=None):\n AmplitudeEmbedding(features=f, wires=range(2), normalize=True)\n return qml.expval(qml.PauliZ(0))\n\n circuit(f=[15, 15, 15, 15])\n\n >>> dev.state\n [0.5 + 0.j, 0.5 + 0.j, 0.5 + 0.j, 0.5 + 0.j]\n\n **Padding**\n\n If the dimension of the feature vector is smaller than the number of amplitudes,\n one can automatically pad it with a constant for the missing dimensions using the ``pad_with`` option:\n\n .. code-block:: python\n\n from math import sqrt\n\n @qml.qnode(dev)\n def circuit(f=None):\n AmplitudeEmbedding(features=f, wires=range(2), pad_with=0.)\n return qml.expval(qml.PauliZ(0))\n\n circuit(f=[1/sqrt(2), 1/sqrt(2)])\n\n >>> dev.state\n [0.70710678 + 0.j, 0.70710678 + 0.j, 0.0 + 0.j, 0.0 + 0.j]\n\n \"\"\"\n\n num_params = 1\n num_wires = AnyWires\n par_domain = \"A\"\n grad_method = None\n\n def __init__(\n self, features, wires, pad_with=None, normalize=False, pad=None, do_queue=True, id=None\n ):\n\n # pad is replaced with the more verbose pad_with\n if pad is not None:\n warnings.warn(\n \"The pad argument will be replaced by the pad_with option in future versions of PennyLane.\",\n UserWarning,\n )\n if pad_with is None:\n pad_with = pad\n\n wires = Wires(wires)\n self.pad_with = pad_with\n self.normalize = normalize\n\n features = self._preprocess(features, wires, pad_with, normalize)\n super().__init__(features, wires=wires, do_queue=do_queue, id=id)\n\n def adjoint(self): # pylint: disable=arguments-differ\n return qml.adjoint(qml.templates.MottonenStatePreparation)(\n self.parameters[0], wires=self.wires\n )\n\n def expand(self):\n\n with qml.tape.QuantumTape() as tape:\n QubitStateVector(self.parameters[0], wires=self.wires)\n\n return tape\n\n @staticmethod\n def _preprocess(features, wires, pad_with, normalize):\n \"\"\"Validate and pre-process inputs as follows:\n\n * Check that the features tensor is one-dimensional.\n * If pad_with is None, check that the first dimension of the features tensor\n has length :math:`2^n` where :math:`n` is the number of qubits. Else check that the\n first dimension of the features tensor is not larger than :math:`2^n` and pad features with value if necessary.\n * If normalize is false, check that first dimension of features is normalised to one. Else, normalise the\n features tensor.\n \"\"\"\n\n shape = qml.math.shape(features)\n\n # check shape\n if len(shape) != 1:\n raise ValueError(f\"Features must be a one-dimensional tensor; got shape {shape}.\")\n\n n_features = shape[0]\n if pad_with is None and n_features != 2 ** len(wires):\n raise ValueError(\n f\"Features must be of length {2 ** len(wires)}; got length {n_features}. \"\n f\"Use the 'pad' argument for automated padding.\"\n )\n\n if pad_with is not None and n_features > 2 ** len(wires):\n raise ValueError(\n f\"Features must be of length {2 ** len(wires)} or \"\n f\"smaller to be padded; got length {n_features}.\"\n )\n\n # pad\n if pad_with is not None and n_features < 2 ** len(wires):\n padding = [pad_with] * (2 ** len(wires) - n_features)\n features = qml.math.concatenate([features, padding], axis=0)\n\n # normalize\n norm = qml.math.sum(qml.math.abs(features) ** 2)\n\n if not qml.math.allclose(norm, 1.0, atol=TOLERANCE):\n if normalize or pad_with:\n features = features / np.sqrt(norm)\n else:\n raise ValueError(\n f\"Features must be a vector of length 1.0; got length {norm}.\"\n \"Use 'normalize=True' to automatically normalize.\"\n )\n\n features = qml.math.cast(features, np.complex128)\n return features\n", "path": "pennylane/templates/embeddings/amplitude.py"}]}
| 3,742 | 1,021 |
gh_patches_debug_18049
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-9390
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Filter by work pool not filtering the "dot" graph
### First check
- [X] I added a descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the Prefect documentation for this issue.
- [X] I checked that this issue is related to Prefect and not one of its dependencies.
### Bug summary
When filtering by "work pool" in the flows screen, the "dots graph" is not filtered.
The "main-pool" is a pool I've just created, and there are no runs associated to it.

### Reproduction
```python3
Create a new "work flow".
Make sure it's empty and has no runs in it.
Go to the flows screen, and filter by this work pool.
You'll see that all the dots on the graph remain although they are not related to that work pool.
```
### Error
_No response_
### Versions
```Text
Prefect cloud
```
### Additional context
_No response_
</issue>
<code>
[start of src/prefect/server/api/ui/flow_runs.py]
1 import datetime
2 from typing import List
3 from uuid import UUID
4
5 from fastapi import Body, Depends
6 from pydantic import Field
7
8 import prefect.server.schemas as schemas
9 from prefect.logging import get_logger
10 from prefect.server import models
11 from prefect.server.database.dependencies import provide_database_interface
12 from prefect.server.database.interface import PrefectDBInterface
13 from prefect.server.utilities.schemas import DateTimeTZ, PrefectBaseModel
14 from prefect.server.utilities.server import PrefectRouter
15
16 logger = get_logger("server.api.ui.flow_runs")
17
18 router = PrefectRouter(prefix="/ui/flow_runs", tags=["Flow Runs", "UI"])
19
20
21 class SimpleFlowRun(PrefectBaseModel):
22 id: UUID = Field(default=..., description="The flow run id.")
23 state_type: schemas.states.StateType = Field(
24 default=..., description="The state type."
25 )
26 timestamp: DateTimeTZ = Field(
27 default=...,
28 description=(
29 "The start time of the run, or the expected start time "
30 "if it hasn't run yet."
31 ),
32 )
33 duration: datetime.timedelta = Field(
34 default=..., description="The total run time of the run."
35 )
36 lateness: datetime.timedelta = Field(
37 default=..., description="The delay between the expected and actual start time."
38 )
39
40
41 @router.post("/history")
42 async def read_flow_run_history(
43 sort: schemas.sorting.FlowRunSort = Body(
44 schemas.sorting.FlowRunSort.EXPECTED_START_TIME_DESC
45 ),
46 limit: int = Body(1000, le=1000),
47 offset: int = Body(0, ge=0),
48 flows: schemas.filters.FlowFilter = None,
49 flow_runs: schemas.filters.FlowRunFilter = None,
50 task_runs: schemas.filters.TaskRunFilter = None,
51 deployments: schemas.filters.DeploymentFilter = None,
52 db: PrefectDBInterface = Depends(provide_database_interface),
53 ) -> List[SimpleFlowRun]:
54 columns = [
55 db.FlowRun.id,
56 db.FlowRun.state_type,
57 db.FlowRun.start_time,
58 db.FlowRun.expected_start_time,
59 db.FlowRun.total_run_time,
60 # Although it isn't returned, we need to select
61 # this field in order to compute `estimated_run_time`
62 db.FlowRun.state_timestamp,
63 ]
64 async with db.session_context() as session:
65 result = await models.flow_runs.read_flow_runs(
66 columns=columns,
67 flow_filter=flows,
68 flow_run_filter=flow_runs,
69 task_run_filter=task_runs,
70 deployment_filter=deployments,
71 sort=sort,
72 limit=limit,
73 offset=offset,
74 session=session,
75 )
76 return [
77 SimpleFlowRun(
78 id=r.id,
79 state_type=r.state_type,
80 timestamp=r.start_time or r.expected_start_time,
81 duration=r.estimated_run_time,
82 lateness=r.estimated_start_time_delta,
83 )
84 for r in result
85 ]
86
[end of src/prefect/server/api/ui/flow_runs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/server/api/ui/flow_runs.py b/src/prefect/server/api/ui/flow_runs.py
--- a/src/prefect/server/api/ui/flow_runs.py
+++ b/src/prefect/server/api/ui/flow_runs.py
@@ -49,6 +49,7 @@
flow_runs: schemas.filters.FlowRunFilter = None,
task_runs: schemas.filters.TaskRunFilter = None,
deployments: schemas.filters.DeploymentFilter = None,
+ work_pools: schemas.filters.WorkPoolFilter = None,
db: PrefectDBInterface = Depends(provide_database_interface),
) -> List[SimpleFlowRun]:
columns = [
@@ -68,6 +69,7 @@
flow_run_filter=flow_runs,
task_run_filter=task_runs,
deployment_filter=deployments,
+ work_pool_filter=work_pools,
sort=sort,
limit=limit,
offset=offset,
|
{"golden_diff": "diff --git a/src/prefect/server/api/ui/flow_runs.py b/src/prefect/server/api/ui/flow_runs.py\n--- a/src/prefect/server/api/ui/flow_runs.py\n+++ b/src/prefect/server/api/ui/flow_runs.py\n@@ -49,6 +49,7 @@\n flow_runs: schemas.filters.FlowRunFilter = None,\n task_runs: schemas.filters.TaskRunFilter = None,\n deployments: schemas.filters.DeploymentFilter = None,\n+ work_pools: schemas.filters.WorkPoolFilter = None,\n db: PrefectDBInterface = Depends(provide_database_interface),\n ) -> List[SimpleFlowRun]:\n columns = [\n@@ -68,6 +69,7 @@\n flow_run_filter=flow_runs,\n task_run_filter=task_runs,\n deployment_filter=deployments,\n+ work_pool_filter=work_pools,\n sort=sort,\n limit=limit,\n offset=offset,\n", "issue": "Filter by work pool not filtering the \"dot\" graph\n### First check\n\n- [X] I added a descriptive title to this issue.\n- [X] I used the GitHub search to find a similar issue and didn't find it.\n- [X] I searched the Prefect documentation for this issue.\n- [X] I checked that this issue is related to Prefect and not one of its dependencies.\n\n### Bug summary\n\nWhen filtering by \"work pool\" in the flows screen, the \"dots graph\" is not filtered.\r\nThe \"main-pool\" is a pool I've just created, and there are no runs associated to it.\r\n\r\n\r\n\r\n\n\n### Reproduction\n\n```python3\nCreate a new \"work flow\".\r\nMake sure it's empty and has no runs in it.\r\nGo to the flows screen, and filter by this work pool.\r\nYou'll see that all the dots on the graph remain although they are not related to that work pool.\n```\n\n\n### Error\n\n_No response_\n\n### Versions\n\n```Text\nPrefect cloud\n```\n\n\n### Additional context\n\n_No response_\n", "before_files": [{"content": "import datetime\nfrom typing import List\nfrom uuid import UUID\n\nfrom fastapi import Body, Depends\nfrom pydantic import Field\n\nimport prefect.server.schemas as schemas\nfrom prefect.logging import get_logger\nfrom prefect.server import models\nfrom prefect.server.database.dependencies import provide_database_interface\nfrom prefect.server.database.interface import PrefectDBInterface\nfrom prefect.server.utilities.schemas import DateTimeTZ, PrefectBaseModel\nfrom prefect.server.utilities.server import PrefectRouter\n\nlogger = get_logger(\"server.api.ui.flow_runs\")\n\nrouter = PrefectRouter(prefix=\"/ui/flow_runs\", tags=[\"Flow Runs\", \"UI\"])\n\n\nclass SimpleFlowRun(PrefectBaseModel):\n id: UUID = Field(default=..., description=\"The flow run id.\")\n state_type: schemas.states.StateType = Field(\n default=..., description=\"The state type.\"\n )\n timestamp: DateTimeTZ = Field(\n default=...,\n description=(\n \"The start time of the run, or the expected start time \"\n \"if it hasn't run yet.\"\n ),\n )\n duration: datetime.timedelta = Field(\n default=..., description=\"The total run time of the run.\"\n )\n lateness: datetime.timedelta = Field(\n default=..., description=\"The delay between the expected and actual start time.\"\n )\n\n\[email protected](\"/history\")\nasync def read_flow_run_history(\n sort: schemas.sorting.FlowRunSort = Body(\n schemas.sorting.FlowRunSort.EXPECTED_START_TIME_DESC\n ),\n limit: int = Body(1000, le=1000),\n offset: int = Body(0, ge=0),\n flows: schemas.filters.FlowFilter = None,\n flow_runs: schemas.filters.FlowRunFilter = None,\n task_runs: schemas.filters.TaskRunFilter = None,\n deployments: schemas.filters.DeploymentFilter = None,\n db: PrefectDBInterface = Depends(provide_database_interface),\n) -> List[SimpleFlowRun]:\n columns = [\n db.FlowRun.id,\n db.FlowRun.state_type,\n db.FlowRun.start_time,\n db.FlowRun.expected_start_time,\n db.FlowRun.total_run_time,\n # Although it isn't returned, we need to select\n # this field in order to compute `estimated_run_time`\n db.FlowRun.state_timestamp,\n ]\n async with db.session_context() as session:\n result = await models.flow_runs.read_flow_runs(\n columns=columns,\n flow_filter=flows,\n flow_run_filter=flow_runs,\n task_run_filter=task_runs,\n deployment_filter=deployments,\n sort=sort,\n limit=limit,\n offset=offset,\n session=session,\n )\n return [\n SimpleFlowRun(\n id=r.id,\n state_type=r.state_type,\n timestamp=r.start_time or r.expected_start_time,\n duration=r.estimated_run_time,\n lateness=r.estimated_start_time_delta,\n )\n for r in result\n ]\n", "path": "src/prefect/server/api/ui/flow_runs.py"}]}
| 1,651 | 203 |
gh_patches_debug_4840
|
rasdani/github-patches
|
git_diff
|
vega__altair-1192
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect description of an example
https://altair-viz.github.io/gallery/scatter_linked_brush.html
The title of the page says "Faceted Scatter Plot with Linked Brushing".
But the example is a concatenated view, not a faceted view.
(The data points are shown twice in the visualization, not split by a category.)
</issue>
<code>
[start of altair/vegalite/v2/examples/scatter_linked_brush.py]
1 """
2 Faceted Scatter Plot with Linked Brushing
3 -----------------------------------------
4 This is an example of using an interval selection to control the color of
5 points across multiple facets.
6 """
7 # category: interactive charts
8 import altair as alt
9 from vega_datasets import data
10
11 cars = data.cars()
12
13 brush = alt.selection(type='interval', resolve='global')
14
15 base = alt.Chart(cars).mark_point().encode(
16 y='Miles_per_Gallon',
17 color=alt.condition(brush, 'Origin', alt.ColorValue('gray'))
18 ).add_selection(
19 brush
20 ).properties(
21 width=250,
22 height=250
23 )
24
25 base.encode(x='Horsepower') | base.encode(x='Acceleration')
26
[end of altair/vegalite/v2/examples/scatter_linked_brush.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/altair/vegalite/v2/examples/scatter_linked_brush.py b/altair/vegalite/v2/examples/scatter_linked_brush.py
--- a/altair/vegalite/v2/examples/scatter_linked_brush.py
+++ b/altair/vegalite/v2/examples/scatter_linked_brush.py
@@ -1,8 +1,8 @@
"""
-Faceted Scatter Plot with Linked Brushing
------------------------------------------
+Multi-panel Scatter Plot with Linked Brushing
+---------------------------------------------
This is an example of using an interval selection to control the color of
-points across multiple facets.
+points across multiple panels.
"""
# category: interactive charts
import altair as alt
|
{"golden_diff": "diff --git a/altair/vegalite/v2/examples/scatter_linked_brush.py b/altair/vegalite/v2/examples/scatter_linked_brush.py\n--- a/altair/vegalite/v2/examples/scatter_linked_brush.py\n+++ b/altair/vegalite/v2/examples/scatter_linked_brush.py\n@@ -1,8 +1,8 @@\n \"\"\"\n-Faceted Scatter Plot with Linked Brushing\n------------------------------------------\n+Multi-panel Scatter Plot with Linked Brushing\n+---------------------------------------------\n This is an example of using an interval selection to control the color of\n-points across multiple facets.\n+points across multiple panels.\n \"\"\"\n # category: interactive charts\n import altair as alt\n", "issue": "Incorrect description of an example\nhttps://altair-viz.github.io/gallery/scatter_linked_brush.html\r\n\r\nThe title of the page says \"Faceted Scatter Plot with Linked Brushing\".\r\nBut the example is a concatenated view, not a faceted view. \r\n(The data points are shown twice in the visualization, not split by a category.) \n", "before_files": [{"content": "\"\"\"\nFaceted Scatter Plot with Linked Brushing\n-----------------------------------------\nThis is an example of using an interval selection to control the color of\npoints across multiple facets.\n\"\"\"\n# category: interactive charts\nimport altair as alt\nfrom vega_datasets import data\n\ncars = data.cars()\n\nbrush = alt.selection(type='interval', resolve='global')\n\nbase = alt.Chart(cars).mark_point().encode(\n y='Miles_per_Gallon',\n color=alt.condition(brush, 'Origin', alt.ColorValue('gray'))\n).add_selection(\n brush\n).properties(\n width=250,\n height=250\n)\n\nbase.encode(x='Horsepower') | base.encode(x='Acceleration')\n", "path": "altair/vegalite/v2/examples/scatter_linked_brush.py"}]}
| 821 | 151 |
gh_patches_debug_109
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-747
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Porting to PyTorch 2.0
**Is your feature request related to a problem? Please describe.**
As PyTorch 2.0 is approaching its release and promising significant benefits, particularly in model compilation, it would be beneficial for GaNDLF to migrate to the platform once it becomes stable. To learn more about PyTorch 2.0, visit [here](https://pytorch.org/get-started/pytorch-2.0/).
**Describe the solution you'd like**
A transition after *tagging* GaNDLF to move to pytorch 2.0
**Describe alternatives you've considered**
N.A.
**Additional context**
N.A.
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 """The setup script."""
4
5
6 import sys, re, os
7 from setuptools import setup, find_packages
8 from setuptools.command.install import install
9 from setuptools.command.develop import develop
10 from setuptools.command.egg_info import egg_info
11
12 try:
13 with open("README.md") as readme_file:
14 readme = readme_file.read()
15 except Exception as error:
16 readme = "No README information found."
17 sys.stderr.write(
18 "Warning: Could not open '%s' due %s\n" % ("README.md", error)
19 )
20
21
22 class CustomInstallCommand(install):
23 def run(self):
24 install.run(self)
25
26
27 class CustomDevelopCommand(develop):
28 def run(self):
29 develop.run(self)
30
31
32 class CustomEggInfoCommand(egg_info):
33 def run(self):
34 egg_info.run(self)
35
36
37 try:
38 filepath = "GANDLF/version.py"
39 version_file = open(filepath)
40 (__version__,) = re.findall('__version__ = "(.*)"', version_file.read())
41
42 except Exception as error:
43 __version__ = "0.0.1"
44 sys.stderr.write(
45 "Warning: Could not open '%s' due %s\n" % (filepath, error)
46 )
47
48 # Handle cases where specific files need to be bundled into the final package as installed via PyPI
49 dockerfiles = [
50 item
51 for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))
52 if (os.path.isfile(item) and item.startswith("Dockerfile-"))
53 ]
54 entrypoint_files = [
55 item
56 for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))
57 if (os.path.isfile(item) and item.startswith("gandlf_"))
58 ]
59 setup_files = ["setup.py", ".dockerignore", "pyproject.toml", "MANIFEST.in"]
60 all_extra_files = dockerfiles + entrypoint_files + setup_files
61 all_extra_files_pathcorrected = [
62 os.path.join("../", item) for item in all_extra_files
63 ]
64 # find_packages should only ever find these as subpackages of gandlf, not as top-level packages
65 # generate this dynamically?
66 # GANDLF.GANDLF is needed to prevent recursion madness in deployments
67 toplevel_package_excludes = [
68 "GANDLF.GANDLF",
69 "anonymize",
70 "cli",
71 "compute",
72 "data",
73 "grad_clipping",
74 "losses",
75 "metrics",
76 "models",
77 "optimizers",
78 "schedulers",
79 "utils",
80 ]
81
82
83 requirements = [
84 "torch==1.13.1",
85 "black==23.11.0",
86 "numpy==1.25.0",
87 "scipy",
88 "SimpleITK!=2.0.*",
89 "SimpleITK!=2.2.1", # https://github.com/mlcommons/GaNDLF/issues/536
90 "torchvision",
91 "tqdm",
92 "torchio==0.18.75",
93 "pandas>=2.0.0",
94 "scikit-learn>=0.23.2",
95 "scikit-image>=0.19.1",
96 "setuptools",
97 "seaborn",
98 "pyyaml",
99 "tiffslide",
100 "matplotlib",
101 "gdown",
102 "pytest",
103 "coverage",
104 "pytest-cov",
105 "psutil",
106 "medcam",
107 "opencv-python",
108 "torchmetrics==1.1.2",
109 "zarr==2.10.3",
110 "pydicom",
111 "onnx",
112 "torchinfo==1.7.0",
113 "segmentation-models-pytorch==0.3.2",
114 "ACSConv==0.1.1",
115 "docker",
116 "dicom-anonymizer",
117 "twine",
118 "zarr",
119 "keyring",
120 ]
121
122 if __name__ == "__main__":
123 setup(
124 name="GANDLF",
125 version=__version__,
126 author="MLCommons",
127 author_email="[email protected]",
128 python_requires=">=3.9, <3.11",
129 packages=find_packages(
130 where=os.path.dirname(os.path.abspath(__file__)),
131 exclude=toplevel_package_excludes,
132 ),
133 cmdclass={
134 "install": CustomInstallCommand,
135 "develop": CustomDevelopCommand,
136 "egg_info": CustomEggInfoCommand,
137 },
138 scripts=[
139 "gandlf_run",
140 "gandlf_constructCSV",
141 "gandlf_collectStats",
142 "gandlf_patchMiner",
143 "gandlf_preprocess",
144 "gandlf_anonymizer",
145 "gandlf_verifyInstall",
146 "gandlf_configGenerator",
147 "gandlf_recoverConfig",
148 "gandlf_deploy",
149 "gandlf_optimizeModel",
150 "gandlf_generateMetrics",
151 ],
152 classifiers=[
153 "Development Status :: 3 - Alpha",
154 "Intended Audience :: Science/Research",
155 "License :: OSI Approved :: Apache Software License",
156 "Natural Language :: English",
157 "Operating System :: OS Independent",
158 "Programming Language :: Python :: 3.9",
159 "Programming Language :: Python :: 3.10",
160 "Topic :: Scientific/Engineering :: Medical Science Apps.",
161 ],
162 description=(
163 "PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging."
164 ),
165 install_requires=requirements,
166 license="Apache-2.0",
167 long_description=readme,
168 long_description_content_type="text/markdown",
169 include_package_data=True,
170 package_data={"GANDLF": all_extra_files_pathcorrected},
171 keywords="semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch",
172 zip_safe=False,
173 )
174
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -81,7 +81,7 @@
requirements = [
- "torch==1.13.1",
+ "torch==2.1.0",
"black==23.11.0",
"numpy==1.25.0",
"scipy",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -81,7 +81,7 @@\n \n \n requirements = [\n- \"torch==1.13.1\",\n+ \"torch==2.1.0\",\n \"black==23.11.0\",\n \"numpy==1.25.0\",\n \"scipy\",\n", "issue": "Porting to PyTorch 2.0\n**Is your feature request related to a problem? Please describe.**\r\nAs PyTorch 2.0 is approaching its release and promising significant benefits, particularly in model compilation, it would be beneficial for GaNDLF to migrate to the platform once it becomes stable. To learn more about PyTorch 2.0, visit [here](https://pytorch.org/get-started/pytorch-2.0/).\r\n\r\n**Describe the solution you'd like**\r\nA transition after *tagging* GaNDLF to move to pytorch 2.0\r\n\r\n**Describe alternatives you've considered**\r\nN.A.\r\n\r\n**Additional context**\r\nN.A.\n", "before_files": [{"content": "#!/usr/bin/env python\n\n\"\"\"The setup script.\"\"\"\n\n\nimport sys, re, os\nfrom setuptools import setup, find_packages\nfrom setuptools.command.install import install\nfrom setuptools.command.develop import develop\nfrom setuptools.command.egg_info import egg_info\n\ntry:\n with open(\"README.md\") as readme_file:\n readme = readme_file.read()\nexcept Exception as error:\n readme = \"No README information found.\"\n sys.stderr.write(\n \"Warning: Could not open '%s' due %s\\n\" % (\"README.md\", error)\n )\n\n\nclass CustomInstallCommand(install):\n def run(self):\n install.run(self)\n\n\nclass CustomDevelopCommand(develop):\n def run(self):\n develop.run(self)\n\n\nclass CustomEggInfoCommand(egg_info):\n def run(self):\n egg_info.run(self)\n\n\ntry:\n filepath = \"GANDLF/version.py\"\n version_file = open(filepath)\n (__version__,) = re.findall('__version__ = \"(.*)\"', version_file.read())\n\nexcept Exception as error:\n __version__ = \"0.0.1\"\n sys.stderr.write(\n \"Warning: Could not open '%s' due %s\\n\" % (filepath, error)\n )\n\n# Handle cases where specific files need to be bundled into the final package as installed via PyPI\ndockerfiles = [\n item\n for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))\n if (os.path.isfile(item) and item.startswith(\"Dockerfile-\"))\n]\nentrypoint_files = [\n item\n for item in os.listdir(os.path.dirname(os.path.abspath(__file__)))\n if (os.path.isfile(item) and item.startswith(\"gandlf_\"))\n]\nsetup_files = [\"setup.py\", \".dockerignore\", \"pyproject.toml\", \"MANIFEST.in\"]\nall_extra_files = dockerfiles + entrypoint_files + setup_files\nall_extra_files_pathcorrected = [\n os.path.join(\"../\", item) for item in all_extra_files\n]\n# find_packages should only ever find these as subpackages of gandlf, not as top-level packages\n# generate this dynamically?\n# GANDLF.GANDLF is needed to prevent recursion madness in deployments\ntoplevel_package_excludes = [\n \"GANDLF.GANDLF\",\n \"anonymize\",\n \"cli\",\n \"compute\",\n \"data\",\n \"grad_clipping\",\n \"losses\",\n \"metrics\",\n \"models\",\n \"optimizers\",\n \"schedulers\",\n \"utils\",\n]\n\n\nrequirements = [\n \"torch==1.13.1\",\n \"black==23.11.0\",\n \"numpy==1.25.0\",\n \"scipy\",\n \"SimpleITK!=2.0.*\",\n \"SimpleITK!=2.2.1\", # https://github.com/mlcommons/GaNDLF/issues/536\n \"torchvision\",\n \"tqdm\",\n \"torchio==0.18.75\",\n \"pandas>=2.0.0\",\n \"scikit-learn>=0.23.2\",\n \"scikit-image>=0.19.1\",\n \"setuptools\",\n \"seaborn\",\n \"pyyaml\",\n \"tiffslide\",\n \"matplotlib\",\n \"gdown\",\n \"pytest\",\n \"coverage\",\n \"pytest-cov\",\n \"psutil\",\n \"medcam\",\n \"opencv-python\",\n \"torchmetrics==1.1.2\",\n \"zarr==2.10.3\",\n \"pydicom\",\n \"onnx\",\n \"torchinfo==1.7.0\",\n \"segmentation-models-pytorch==0.3.2\",\n \"ACSConv==0.1.1\",\n \"docker\",\n \"dicom-anonymizer\",\n \"twine\",\n \"zarr\",\n \"keyring\",\n]\n\nif __name__ == \"__main__\":\n setup(\n name=\"GANDLF\",\n version=__version__,\n author=\"MLCommons\",\n author_email=\"[email protected]\",\n python_requires=\">=3.9, <3.11\",\n packages=find_packages(\n where=os.path.dirname(os.path.abspath(__file__)),\n exclude=toplevel_package_excludes,\n ),\n cmdclass={\n \"install\": CustomInstallCommand,\n \"develop\": CustomDevelopCommand,\n \"egg_info\": CustomEggInfoCommand,\n },\n scripts=[\n \"gandlf_run\",\n \"gandlf_constructCSV\",\n \"gandlf_collectStats\",\n \"gandlf_patchMiner\",\n \"gandlf_preprocess\",\n \"gandlf_anonymizer\",\n \"gandlf_verifyInstall\",\n \"gandlf_configGenerator\",\n \"gandlf_recoverConfig\",\n \"gandlf_deploy\",\n \"gandlf_optimizeModel\",\n \"gandlf_generateMetrics\",\n ],\n classifiers=[\n \"Development Status :: 3 - Alpha\",\n \"Intended Audience :: Science/Research\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Topic :: Scientific/Engineering :: Medical Science Apps.\",\n ],\n description=(\n \"PyTorch-based framework that handles segmentation/regression/classification using various DL architectures for medical imaging.\"\n ),\n install_requires=requirements,\n license=\"Apache-2.0\",\n long_description=readme,\n long_description_content_type=\"text/markdown\",\n include_package_data=True,\n package_data={\"GANDLF\": all_extra_files_pathcorrected},\n keywords=\"semantic, segmentation, regression, classification, data-augmentation, medical-imaging, clinical-workflows, deep-learning, pytorch\",\n zip_safe=False,\n )\n", "path": "setup.py"}]}
| 2,359 | 87 |
gh_patches_debug_44424
|
rasdani/github-patches
|
git_diff
|
deepset-ai__haystack-2048
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Ranker scores shouldn't be discarded
**Is your feature request related to a problem? Please describe.**
The reason for using a ranker is that the scores should be more accurate than the retriever scores. For this reason, in that use case you would also want to use the ranker scores later on instead of the retriever score (e.g. when defining a threshold). You currently cannot do that as the ranker scores aren't saved anywhere (see [here](https://github.com/deepset-ai/haystack/blob/b87c0c950b2243f47fb249aa3865d4c46edb16df/haystack/nodes/ranker/sentence_transformers.py)) as the reader only updates the order and not the score. Having the order of documents not dependent on the scores is also unintuitive.
**Describe the solution you'd like**
Replace retriever scores with ranker scores.
**Describe alternatives you've considered**
Having an additional field to save ranker scores.
</issue>
<code>
[start of haystack/nodes/ranker/sentence_transformers.py]
1 from typing import List, Optional, Union, Tuple, Iterator
2 import logging
3 from pathlib import Path
4
5 import torch
6 from torch.nn import DataParallel
7 from transformers import AutoModelForSequenceClassification, AutoTokenizer
8
9 from haystack.errors import HaystackError
10 from haystack.schema import Document
11 from haystack.nodes.ranker.base import BaseRanker
12 from haystack.modeling.utils import initialize_device_settings
13
14 logger = logging.getLogger(__name__)
15
16
17 class SentenceTransformersRanker(BaseRanker):
18 """
19 Sentence Transformer based pre-trained Cross-Encoder model for Document Re-ranking (https://huggingface.co/cross-encoder).
20 Re-Ranking can be used on top of a retriever to boost the performance for document search. This is particularly useful if the retriever has a high recall but is bad in sorting the documents by relevance.
21
22 SentenceTransformerRanker handles Cross-Encoder models
23 - use a single logit as similarity score e.g. cross-encoder/ms-marco-MiniLM-L-12-v2
24 - use two output logits (no_answer, has_answer) e.g. deepset/gbert-base-germandpr-reranking
25 https://www.sbert.net/docs/pretrained-models/ce-msmarco.html#usage-with-transformers
26
27 | With a SentenceTransformersRanker, you can:
28 - directly get predictions via predict()
29
30 Usage example:
31 ...
32 retriever = BM25Retriever(document_store=document_store)
33 ranker = SentenceTransformersRanker(model_name_or_path="cross-encoder/ms-marco-MiniLM-L-12-v2")
34 p = Pipeline()
35 p.add_node(component=retriever, name="ESRetriever", inputs=["Query"])
36 p.add_node(component=ranker, name="Ranker", inputs=["ESRetriever"])
37 """
38
39 def __init__(
40 self,
41 model_name_or_path: Union[str, Path],
42 model_version: Optional[str] = None,
43 top_k: int = 10,
44 use_gpu: bool = True,
45 devices: Optional[List[Union[str, torch.device]]] = None,
46 batch_size: Optional[int] = None,
47 ):
48 """
49 :param model_name_or_path: Directory of a saved model or the name of a public model e.g.
50 'cross-encoder/ms-marco-MiniLM-L-12-v2'.
51 See https://huggingface.co/cross-encoder for full list of available models
52 :param model_version: The version of model to use from the HuggingFace model hub. Can be tag name, branch name, or commit hash.
53 :param top_k: The maximum number of documents to return
54 :param use_gpu: Whether to use all available GPUs or the CPU. Falls back on CPU if no GPU is available.
55 :param devices: List of GPU (or CPU) devices, to limit inference to certain GPUs and not use all available ones
56 The strings will be converted into pytorch devices, so use the string notation described here:
57 https://pytorch.org/docs/stable/tensor_attributes.html?highlight=torch%20device#torch.torch.device
58 (e.g. ["cuda:0"]).
59 :param batch_size: Number of documents to process at a time.
60 """
61 super().__init__()
62
63 self.top_k = top_k
64
65 if devices is not None:
66 self.devices = [torch.device(device) for device in devices]
67 else:
68 self.devices, _ = initialize_device_settings(use_cuda=use_gpu, multi_gpu=True)
69
70 self.transformer_model = AutoModelForSequenceClassification.from_pretrained(
71 pretrained_model_name_or_path=model_name_or_path, revision=model_version
72 )
73 self.transformer_model.to(str(self.devices[0]))
74 self.transformer_tokenizer = AutoTokenizer.from_pretrained(
75 pretrained_model_name_or_path=model_name_or_path, revision=model_version
76 )
77 self.transformer_model.eval()
78
79 if len(self.devices) > 1:
80 self.model = DataParallel(self.transformer_model, device_ids=self.devices)
81
82 self.batch_size = batch_size
83
84 def predict(self, query: str, documents: List[Document], top_k: Optional[int] = None) -> List[Document]:
85 """
86 Use loaded ranker model to re-rank the supplied list of Document.
87
88 Returns list of Document sorted by (desc.) similarity with the query.
89
90 :param query: Query string
91 :param documents: List of Document to be re-ranked
92 :param top_k: The maximum number of documents to return
93 :return: List of Document
94 """
95 if top_k is None:
96 top_k = self.top_k
97
98 features = self.transformer_tokenizer(
99 [query for doc in documents],
100 [doc.content for doc in documents],
101 padding=True,
102 truncation=True,
103 return_tensors="pt",
104 ).to(self.devices[0])
105
106 # SentenceTransformerRanker uses:
107 # 1. the logit as similarity score/answerable classification
108 # 2. the logits as answerable classification (no_answer / has_answer)
109 # https://www.sbert.net/docs/pretrained-models/ce-msmarco.html#usage-with-transformers
110 with torch.no_grad():
111 similarity_scores = self.transformer_model(**features).logits
112
113 logits_dim = similarity_scores.shape[1] # [batch_size, logits_dim]
114 sorted_scores_and_documents = sorted(
115 zip(similarity_scores, documents),
116 key=lambda similarity_document_tuple:
117 # assume the last element in logits represents the `has_answer` label
118 similarity_document_tuple[0][-1] if logits_dim >= 2 else similarity_document_tuple[0],
119 reverse=True,
120 )
121
122 # rank documents according to scores
123 sorted_documents = [doc for _, doc in sorted_scores_and_documents]
124 return sorted_documents[:top_k]
125
126 def predict_batch(
127 self,
128 queries: List[str],
129 documents: Union[List[Document], List[List[Document]]],
130 top_k: Optional[int] = None,
131 batch_size: Optional[int] = None,
132 ) -> Union[List[Document], List[List[Document]]]:
133 """
134 Use loaded ranker model to re-rank the supplied lists of Documents.
135
136 Returns lists of Documents sorted by (desc.) similarity with the corresponding queries.
137
138
139 - If you provide a list containing a single query...
140
141 - ... and a single list of Documents, the single list of Documents will be re-ranked based on the
142 supplied query.
143 - ... and a list of lists of Documents, each list of Documents will be re-ranked individually based on the
144 supplied query.
145
146
147 - If you provide a list of multiple queries...
148
149 - ... you need to provide a list of lists of Documents. Each list of Documents will be re-ranked based on
150 its corresponding query.
151
152 :param queries: Single query string or list of queries
153 :param documents: Single list of Documents or list of lists of Documents to be reranked.
154 :param top_k: The maximum number of documents to return per Document list.
155 :param batch_size: Number of Documents to process at a time.
156 """
157 if top_k is None:
158 top_k = self.top_k
159
160 if batch_size is None:
161 batch_size = self.batch_size
162
163 number_of_docs, all_queries, all_docs, single_list_of_docs = self._preprocess_batch_queries_and_docs(
164 queries=queries, documents=documents
165 )
166
167 batches = self._get_batches(all_queries=all_queries, all_docs=all_docs, batch_size=batch_size)
168 preds = []
169 for cur_queries, cur_docs in batches:
170 features = self.transformer_tokenizer(
171 cur_queries, [doc.content for doc in cur_docs], padding=True, truncation=True, return_tensors="pt"
172 ).to(self.devices[0])
173
174 with torch.no_grad():
175 similarity_scores = self.transformer_model(**features).logits
176 preds.extend(similarity_scores)
177
178 logits_dim = similarity_scores.shape[1] # [batch_size, logits_dim]
179 if single_list_of_docs:
180 sorted_scores_and_documents = sorted(
181 zip(similarity_scores, documents),
182 key=lambda similarity_document_tuple:
183 # assume the last element in logits represents the `has_answer` label
184 similarity_document_tuple[0][-1] if logits_dim >= 2 else similarity_document_tuple[0],
185 reverse=True,
186 )
187
188 # rank documents according to scores
189 sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)]
190 return sorted_documents[:top_k]
191 else:
192 # Group predictions together
193 grouped_predictions = []
194 left_idx = 0
195 right_idx = 0
196 for number in number_of_docs:
197 right_idx = left_idx + number
198 grouped_predictions.append(similarity_scores[left_idx:right_idx])
199 left_idx = right_idx
200
201 result = []
202 for pred_group, doc_group in zip(grouped_predictions, documents):
203 sorted_scores_and_documents = sorted(
204 zip(pred_group, doc_group), # type: ignore
205 key=lambda similarity_document_tuple:
206 # assume the last element in logits represents the `has_answer` label
207 similarity_document_tuple[0][-1] if logits_dim >= 2 else similarity_document_tuple[0],
208 reverse=True,
209 )
210
211 # rank documents according to scores
212 sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)][:top_k]
213 result.append(sorted_documents)
214
215 return result
216
217 def _preprocess_batch_queries_and_docs(
218 self, queries: List[str], documents: Union[List[Document], List[List[Document]]]
219 ) -> Tuple[List[int], List[str], List[Document], bool]:
220 number_of_docs = []
221 all_queries = []
222 all_docs: List[Document] = []
223 single_list_of_docs = False
224
225 # Docs case 1: single list of Documents -> rerank single list of Documents based on single query
226 if len(documents) > 0 and isinstance(documents[0], Document):
227 if len(queries) != 1:
228 raise HaystackError("Number of queries must be 1 if a single list of Documents is provided.")
229 query = queries[0]
230 number_of_docs = [len(documents)]
231 all_queries = [query] * len(documents)
232 all_docs = documents # type: ignore
233 single_list_of_docs = True
234
235 # Docs case 2: list of lists of Documents -> rerank each list of Documents based on corresponding query
236 # If queries contains a single query, apply it to each list of Documents
237 if len(documents) > 0 and isinstance(documents[0], list):
238 if len(queries) == 1:
239 queries = queries * len(documents)
240 if len(queries) != len(documents):
241 raise HaystackError("Number of queries must be equal to number of provided Document lists.")
242 for query, cur_docs in zip(queries, documents):
243 if not isinstance(cur_docs, list):
244 raise HaystackError(f"cur_docs was of type {type(cur_docs)}, but expected a list of Documents.")
245 number_of_docs.append(len(cur_docs))
246 all_queries.extend([query] * len(cur_docs))
247 all_docs.extend(cur_docs)
248
249 return number_of_docs, all_queries, all_docs, single_list_of_docs
250
251 @staticmethod
252 def _get_batches(
253 all_queries: List[str], all_docs: List[Document], batch_size: Optional[int]
254 ) -> Iterator[Tuple[List[str], List[Document]]]:
255 if batch_size is None:
256 yield all_queries, all_docs
257 return
258 else:
259 for index in range(0, len(all_queries), batch_size):
260 yield all_queries[index : index + batch_size], all_docs[index : index + batch_size]
261
[end of haystack/nodes/ranker/sentence_transformers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/haystack/nodes/ranker/sentence_transformers.py b/haystack/nodes/ranker/sentence_transformers.py
--- a/haystack/nodes/ranker/sentence_transformers.py
+++ b/haystack/nodes/ranker/sentence_transformers.py
@@ -1,4 +1,4 @@
-from typing import List, Optional, Union, Tuple, Iterator
+from typing import List, Optional, Union, Tuple, Iterator, Any
import logging
from pathlib import Path
@@ -44,6 +44,7 @@
use_gpu: bool = True,
devices: Optional[List[Union[str, torch.device]]] = None,
batch_size: Optional[int] = None,
+ scale_score: bool = True,
):
"""
:param model_name_or_path: Directory of a saved model or the name of a public model e.g.
@@ -57,6 +58,9 @@
https://pytorch.org/docs/stable/tensor_attributes.html?highlight=torch%20device#torch.torch.device
(e.g. ["cuda:0"]).
:param batch_size: Number of documents to process at a time.
+ :param scale_score: The raw predictions will be transformed using a Sigmoid activation function in case the model
+ only predicts a single label. For multi-label predictions, no scaling is applied. Set this
+ to False if you do not want any scaling of the raw predictions.
"""
super().__init__()
@@ -76,6 +80,15 @@
)
self.transformer_model.eval()
+ # we use sigmoid activation function to scale the score in case there is only a single label
+ # we do not apply any scaling when scale_score is set to False
+ num_labels = self.transformer_model.num_labels
+ self.activation_function: torch.nn.Module
+ if num_labels == 1 and scale_score:
+ self.activation_function = torch.nn.Sigmoid()
+ else:
+ self.activation_function = torch.nn.Identity()
+
if len(self.devices) > 1:
self.model = DataParallel(self.transformer_model, device_ids=self.devices)
@@ -119,9 +132,31 @@
reverse=True,
)
- # rank documents according to scores
- sorted_documents = [doc for _, doc in sorted_scores_and_documents]
- return sorted_documents[:top_k]
+ # add normalized scores to documents
+ sorted_documents = self._add_scores_to_documents(sorted_scores_and_documents[:top_k], logits_dim)
+
+ return sorted_documents
+
+ def _add_scores_to_documents(
+ self, sorted_scores_and_documents: List[Tuple[Any, Document]], logits_dim: int
+ ) -> List[Document]:
+ """
+ Normalize and add scores to retrieved result documents.
+
+ :param sorted_scores_and_documents: List of score, Document Tuples.
+ :param logits_dim: Dimensionality of the returned scores.
+ """
+ sorted_documents = []
+ for raw_score, doc in sorted_scores_and_documents:
+ if logits_dim >= 2:
+ score = self.activation_function(raw_score)[-1]
+ else:
+ score = self.activation_function(raw_score)[0]
+
+ doc.score = score.detach().cpu().numpy().tolist()
+ sorted_documents.append(doc)
+
+ return sorted_documents
def predict_batch(
self,
@@ -185,9 +220,11 @@
reverse=True,
)
- # rank documents according to scores
- sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)]
- return sorted_documents[:top_k]
+ # is this step needed?
+ sorted_documents = [(score, doc) for score, doc in sorted_scores_and_documents if isinstance(doc, Document)]
+ sorted_documents_with_scores = self._add_scores_to_documents(sorted_documents[:top_k], logits_dim)
+
+ return sorted_documents_with_scores
else:
# Group predictions together
grouped_predictions = []
@@ -209,8 +246,12 @@
)
# rank documents according to scores
- sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)][:top_k]
- result.append(sorted_documents)
+ sorted_documents = [
+ (score, doc) for score, doc in sorted_scores_and_documents if isinstance(doc, Document)
+ ]
+ sorted_documents_with_scores = self._add_scores_to_documents(sorted_documents[:top_k], logits_dim)
+
+ result.append(sorted_documents_with_scores)
return result
|
{"golden_diff": "diff --git a/haystack/nodes/ranker/sentence_transformers.py b/haystack/nodes/ranker/sentence_transformers.py\n--- a/haystack/nodes/ranker/sentence_transformers.py\n+++ b/haystack/nodes/ranker/sentence_transformers.py\n@@ -1,4 +1,4 @@\n-from typing import List, Optional, Union, Tuple, Iterator\n+from typing import List, Optional, Union, Tuple, Iterator, Any\n import logging\n from pathlib import Path\n \n@@ -44,6 +44,7 @@\n use_gpu: bool = True,\n devices: Optional[List[Union[str, torch.device]]] = None,\n batch_size: Optional[int] = None,\n+ scale_score: bool = True,\n ):\n \"\"\"\n :param model_name_or_path: Directory of a saved model or the name of a public model e.g.\n@@ -57,6 +58,9 @@\n https://pytorch.org/docs/stable/tensor_attributes.html?highlight=torch%20device#torch.torch.device\n (e.g. [\"cuda:0\"]).\n :param batch_size: Number of documents to process at a time.\n+ :param scale_score: The raw predictions will be transformed using a Sigmoid activation function in case the model\n+ only predicts a single label. For multi-label predictions, no scaling is applied. Set this\n+ to False if you do not want any scaling of the raw predictions.\n \"\"\"\n super().__init__()\n \n@@ -76,6 +80,15 @@\n )\n self.transformer_model.eval()\n \n+ # we use sigmoid activation function to scale the score in case there is only a single label\n+ # we do not apply any scaling when scale_score is set to False\n+ num_labels = self.transformer_model.num_labels\n+ self.activation_function: torch.nn.Module\n+ if num_labels == 1 and scale_score:\n+ self.activation_function = torch.nn.Sigmoid()\n+ else:\n+ self.activation_function = torch.nn.Identity()\n+\n if len(self.devices) > 1:\n self.model = DataParallel(self.transformer_model, device_ids=self.devices)\n \n@@ -119,9 +132,31 @@\n reverse=True,\n )\n \n- # rank documents according to scores\n- sorted_documents = [doc for _, doc in sorted_scores_and_documents]\n- return sorted_documents[:top_k]\n+ # add normalized scores to documents\n+ sorted_documents = self._add_scores_to_documents(sorted_scores_and_documents[:top_k], logits_dim)\n+\n+ return sorted_documents\n+\n+ def _add_scores_to_documents(\n+ self, sorted_scores_and_documents: List[Tuple[Any, Document]], logits_dim: int\n+ ) -> List[Document]:\n+ \"\"\"\n+ Normalize and add scores to retrieved result documents.\n+\n+ :param sorted_scores_and_documents: List of score, Document Tuples.\n+ :param logits_dim: Dimensionality of the returned scores.\n+ \"\"\"\n+ sorted_documents = []\n+ for raw_score, doc in sorted_scores_and_documents:\n+ if logits_dim >= 2:\n+ score = self.activation_function(raw_score)[-1]\n+ else:\n+ score = self.activation_function(raw_score)[0]\n+\n+ doc.score = score.detach().cpu().numpy().tolist()\n+ sorted_documents.append(doc)\n+\n+ return sorted_documents\n \n def predict_batch(\n self,\n@@ -185,9 +220,11 @@\n reverse=True,\n )\n \n- # rank documents according to scores\n- sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)]\n- return sorted_documents[:top_k]\n+ # is this step needed?\n+ sorted_documents = [(score, doc) for score, doc in sorted_scores_and_documents if isinstance(doc, Document)]\n+ sorted_documents_with_scores = self._add_scores_to_documents(sorted_documents[:top_k], logits_dim)\n+\n+ return sorted_documents_with_scores\n else:\n # Group predictions together\n grouped_predictions = []\n@@ -209,8 +246,12 @@\n )\n \n # rank documents according to scores\n- sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)][:top_k]\n- result.append(sorted_documents)\n+ sorted_documents = [\n+ (score, doc) for score, doc in sorted_scores_and_documents if isinstance(doc, Document)\n+ ]\n+ sorted_documents_with_scores = self._add_scores_to_documents(sorted_documents[:top_k], logits_dim)\n+\n+ result.append(sorted_documents_with_scores)\n \n return result\n", "issue": "Ranker scores shouldn't be discarded\n**Is your feature request related to a problem? Please describe.**\r\nThe reason for using a ranker is that the scores should be more accurate than the retriever scores. For this reason, in that use case you would also want to use the ranker scores later on instead of the retriever score (e.g. when defining a threshold). You currently cannot do that as the ranker scores aren't saved anywhere (see [here](https://github.com/deepset-ai/haystack/blob/b87c0c950b2243f47fb249aa3865d4c46edb16df/haystack/nodes/ranker/sentence_transformers.py)) as the reader only updates the order and not the score. Having the order of documents not dependent on the scores is also unintuitive.\r\n\r\n**Describe the solution you'd like**\r\nReplace retriever scores with ranker scores.\r\n\r\n**Describe alternatives you've considered**\r\nHaving an additional field to save ranker scores.\n", "before_files": [{"content": "from typing import List, Optional, Union, Tuple, Iterator\nimport logging\nfrom pathlib import Path\n\nimport torch\nfrom torch.nn import DataParallel\nfrom transformers import AutoModelForSequenceClassification, AutoTokenizer\n\nfrom haystack.errors import HaystackError\nfrom haystack.schema import Document\nfrom haystack.nodes.ranker.base import BaseRanker\nfrom haystack.modeling.utils import initialize_device_settings\n\nlogger = logging.getLogger(__name__)\n\n\nclass SentenceTransformersRanker(BaseRanker):\n \"\"\"\n Sentence Transformer based pre-trained Cross-Encoder model for Document Re-ranking (https://huggingface.co/cross-encoder).\n Re-Ranking can be used on top of a retriever to boost the performance for document search. This is particularly useful if the retriever has a high recall but is bad in sorting the documents by relevance.\n\n SentenceTransformerRanker handles Cross-Encoder models\n - use a single logit as similarity score e.g. cross-encoder/ms-marco-MiniLM-L-12-v2\n - use two output logits (no_answer, has_answer) e.g. deepset/gbert-base-germandpr-reranking\n https://www.sbert.net/docs/pretrained-models/ce-msmarco.html#usage-with-transformers\n\n | With a SentenceTransformersRanker, you can:\n - directly get predictions via predict()\n\n Usage example:\n ...\n retriever = BM25Retriever(document_store=document_store)\n ranker = SentenceTransformersRanker(model_name_or_path=\"cross-encoder/ms-marco-MiniLM-L-12-v2\")\n p = Pipeline()\n p.add_node(component=retriever, name=\"ESRetriever\", inputs=[\"Query\"])\n p.add_node(component=ranker, name=\"Ranker\", inputs=[\"ESRetriever\"])\n \"\"\"\n\n def __init__(\n self,\n model_name_or_path: Union[str, Path],\n model_version: Optional[str] = None,\n top_k: int = 10,\n use_gpu: bool = True,\n devices: Optional[List[Union[str, torch.device]]] = None,\n batch_size: Optional[int] = None,\n ):\n \"\"\"\n :param model_name_or_path: Directory of a saved model or the name of a public model e.g.\n 'cross-encoder/ms-marco-MiniLM-L-12-v2'.\n See https://huggingface.co/cross-encoder for full list of available models\n :param model_version: The version of model to use from the HuggingFace model hub. Can be tag name, branch name, or commit hash.\n :param top_k: The maximum number of documents to return\n :param use_gpu: Whether to use all available GPUs or the CPU. Falls back on CPU if no GPU is available.\n :param devices: List of GPU (or CPU) devices, to limit inference to certain GPUs and not use all available ones\n The strings will be converted into pytorch devices, so use the string notation described here:\n https://pytorch.org/docs/stable/tensor_attributes.html?highlight=torch%20device#torch.torch.device\n (e.g. [\"cuda:0\"]).\n :param batch_size: Number of documents to process at a time.\n \"\"\"\n super().__init__()\n\n self.top_k = top_k\n\n if devices is not None:\n self.devices = [torch.device(device) for device in devices]\n else:\n self.devices, _ = initialize_device_settings(use_cuda=use_gpu, multi_gpu=True)\n\n self.transformer_model = AutoModelForSequenceClassification.from_pretrained(\n pretrained_model_name_or_path=model_name_or_path, revision=model_version\n )\n self.transformer_model.to(str(self.devices[0]))\n self.transformer_tokenizer = AutoTokenizer.from_pretrained(\n pretrained_model_name_or_path=model_name_or_path, revision=model_version\n )\n self.transformer_model.eval()\n\n if len(self.devices) > 1:\n self.model = DataParallel(self.transformer_model, device_ids=self.devices)\n\n self.batch_size = batch_size\n\n def predict(self, query: str, documents: List[Document], top_k: Optional[int] = None) -> List[Document]:\n \"\"\"\n Use loaded ranker model to re-rank the supplied list of Document.\n\n Returns list of Document sorted by (desc.) similarity with the query.\n\n :param query: Query string\n :param documents: List of Document to be re-ranked\n :param top_k: The maximum number of documents to return\n :return: List of Document\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n features = self.transformer_tokenizer(\n [query for doc in documents],\n [doc.content for doc in documents],\n padding=True,\n truncation=True,\n return_tensors=\"pt\",\n ).to(self.devices[0])\n\n # SentenceTransformerRanker uses:\n # 1. the logit as similarity score/answerable classification\n # 2. the logits as answerable classification (no_answer / has_answer)\n # https://www.sbert.net/docs/pretrained-models/ce-msmarco.html#usage-with-transformers\n with torch.no_grad():\n similarity_scores = self.transformer_model(**features).logits\n\n logits_dim = similarity_scores.shape[1] # [batch_size, logits_dim]\n sorted_scores_and_documents = sorted(\n zip(similarity_scores, documents),\n key=lambda similarity_document_tuple:\n # assume the last element in logits represents the `has_answer` label\n similarity_document_tuple[0][-1] if logits_dim >= 2 else similarity_document_tuple[0],\n reverse=True,\n )\n\n # rank documents according to scores\n sorted_documents = [doc for _, doc in sorted_scores_and_documents]\n return sorted_documents[:top_k]\n\n def predict_batch(\n self,\n queries: List[str],\n documents: Union[List[Document], List[List[Document]]],\n top_k: Optional[int] = None,\n batch_size: Optional[int] = None,\n ) -> Union[List[Document], List[List[Document]]]:\n \"\"\"\n Use loaded ranker model to re-rank the supplied lists of Documents.\n\n Returns lists of Documents sorted by (desc.) similarity with the corresponding queries.\n\n\n - If you provide a list containing a single query...\n\n - ... and a single list of Documents, the single list of Documents will be re-ranked based on the\n supplied query.\n - ... and a list of lists of Documents, each list of Documents will be re-ranked individually based on the\n supplied query.\n\n\n - If you provide a list of multiple queries...\n\n - ... you need to provide a list of lists of Documents. Each list of Documents will be re-ranked based on\n its corresponding query.\n\n :param queries: Single query string or list of queries\n :param documents: Single list of Documents or list of lists of Documents to be reranked.\n :param top_k: The maximum number of documents to return per Document list.\n :param batch_size: Number of Documents to process at a time.\n \"\"\"\n if top_k is None:\n top_k = self.top_k\n\n if batch_size is None:\n batch_size = self.batch_size\n\n number_of_docs, all_queries, all_docs, single_list_of_docs = self._preprocess_batch_queries_and_docs(\n queries=queries, documents=documents\n )\n\n batches = self._get_batches(all_queries=all_queries, all_docs=all_docs, batch_size=batch_size)\n preds = []\n for cur_queries, cur_docs in batches:\n features = self.transformer_tokenizer(\n cur_queries, [doc.content for doc in cur_docs], padding=True, truncation=True, return_tensors=\"pt\"\n ).to(self.devices[0])\n\n with torch.no_grad():\n similarity_scores = self.transformer_model(**features).logits\n preds.extend(similarity_scores)\n\n logits_dim = similarity_scores.shape[1] # [batch_size, logits_dim]\n if single_list_of_docs:\n sorted_scores_and_documents = sorted(\n zip(similarity_scores, documents),\n key=lambda similarity_document_tuple:\n # assume the last element in logits represents the `has_answer` label\n similarity_document_tuple[0][-1] if logits_dim >= 2 else similarity_document_tuple[0],\n reverse=True,\n )\n\n # rank documents according to scores\n sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)]\n return sorted_documents[:top_k]\n else:\n # Group predictions together\n grouped_predictions = []\n left_idx = 0\n right_idx = 0\n for number in number_of_docs:\n right_idx = left_idx + number\n grouped_predictions.append(similarity_scores[left_idx:right_idx])\n left_idx = right_idx\n\n result = []\n for pred_group, doc_group in zip(grouped_predictions, documents):\n sorted_scores_and_documents = sorted(\n zip(pred_group, doc_group), # type: ignore\n key=lambda similarity_document_tuple:\n # assume the last element in logits represents the `has_answer` label\n similarity_document_tuple[0][-1] if logits_dim >= 2 else similarity_document_tuple[0],\n reverse=True,\n )\n\n # rank documents according to scores\n sorted_documents = [doc for _, doc in sorted_scores_and_documents if isinstance(doc, Document)][:top_k]\n result.append(sorted_documents)\n\n return result\n\n def _preprocess_batch_queries_and_docs(\n self, queries: List[str], documents: Union[List[Document], List[List[Document]]]\n ) -> Tuple[List[int], List[str], List[Document], bool]:\n number_of_docs = []\n all_queries = []\n all_docs: List[Document] = []\n single_list_of_docs = False\n\n # Docs case 1: single list of Documents -> rerank single list of Documents based on single query\n if len(documents) > 0 and isinstance(documents[0], Document):\n if len(queries) != 1:\n raise HaystackError(\"Number of queries must be 1 if a single list of Documents is provided.\")\n query = queries[0]\n number_of_docs = [len(documents)]\n all_queries = [query] * len(documents)\n all_docs = documents # type: ignore\n single_list_of_docs = True\n\n # Docs case 2: list of lists of Documents -> rerank each list of Documents based on corresponding query\n # If queries contains a single query, apply it to each list of Documents\n if len(documents) > 0 and isinstance(documents[0], list):\n if len(queries) == 1:\n queries = queries * len(documents)\n if len(queries) != len(documents):\n raise HaystackError(\"Number of queries must be equal to number of provided Document lists.\")\n for query, cur_docs in zip(queries, documents):\n if not isinstance(cur_docs, list):\n raise HaystackError(f\"cur_docs was of type {type(cur_docs)}, but expected a list of Documents.\")\n number_of_docs.append(len(cur_docs))\n all_queries.extend([query] * len(cur_docs))\n all_docs.extend(cur_docs)\n\n return number_of_docs, all_queries, all_docs, single_list_of_docs\n\n @staticmethod\n def _get_batches(\n all_queries: List[str], all_docs: List[Document], batch_size: Optional[int]\n ) -> Iterator[Tuple[List[str], List[Document]]]:\n if batch_size is None:\n yield all_queries, all_docs\n return\n else:\n for index in range(0, len(all_queries), batch_size):\n yield all_queries[index : index + batch_size], all_docs[index : index + batch_size]\n", "path": "haystack/nodes/ranker/sentence_transformers.py"}]}
| 3,985 | 1,010 |
gh_patches_debug_39588
|
rasdani/github-patches
|
git_diff
|
google__turbinia-1002
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve exception handling in FileSystemTimelineJob
Under certain conditions, dfvfs may throw exceptions that are not currently being handked:
```
dfvfs.lib.errors.BackEndError: Unable to open file system with error: pyfsext_volume_open_file_object: unable to open volume. libfsext_superblock_read_data: unsupported read-only compatible features flags: 0xff000003. libfsext_superblock_read_file_io_handle: unable to read superblock at offset: 1024 (0x00000400). libfsext_internal_volume_read_block_groups: unable to read superblock: 0 at offset: 1024 (0x00000400). libfsext_internal_volume_open_read: unable to read block groups. libfsext_volume_open_file_io_handle: unable to read from file IO handle.
```
</issue>
<code>
[start of turbinia/workers/file_system_timeline.py]
1 # -*- coding: utf-8 -*-
2 # Copyright 2022 Google Inc.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Task to run dfimagetools FileEntryLister on disk partitions."""
16
17 from __future__ import unicode_literals
18
19 import os
20
21 from turbinia import TurbiniaException
22 from turbinia.workers import TurbiniaTask
23 from turbinia.evidence import EvidenceState as state
24 from turbinia.evidence import BodyFile
25
26 if TurbiniaTask.check_worker_role():
27 try:
28 from dfvfs.helpers import volume_scanner
29 from dfvfs.lib import errors as dfvfs_errors
30 from dfimagetools import file_entry_lister
31 except ImportError as exception:
32 message = 'Could not import libraries: {0!s}'.format(exception)
33 raise TurbiniaException(message)
34
35
36 class FileSystemTimelineTask(TurbiniaTask):
37
38 REQUIRED_STATES = [state.ATTACHED]
39
40 TASK_CONFIG = {'partitions': ['all']}
41
42 def run(self, evidence, result):
43 """Task to execute (dfimagetools) FileEntryLister.
44
45 Args:
46 evidence (Evidence object): The evidence we will process.
47 result (TurbiniaTaskResult): The object to place task results into.
48
49 Returns:
50 TurbiniaTaskResult object.
51 """
52 bodyfile_output = os.path.join(self.output_dir, 'file_system.bodyfile')
53 output_evidence = BodyFile(source_path=bodyfile_output)
54 number_of_entries = 0
55
56 # Set things up for the FileEntryLister client. We will scan all
57 # partitions in the volume.
58 volume_scanner_options = volume_scanner.VolumeScannerOptions()
59 volume_scanner_options.partitions = self.task_config.get('partitions')
60
61 # Create the FileEntryLister client and generate the path specs
62 # for all available partitions.
63 entry_lister = file_entry_lister.FileEntryLister()
64 base_path_specs = entry_lister.GetBasePathSpecs(
65 evidence.device_path, options=volume_scanner_options)
66
67 # Iterate over all file entries and generate the output in bodyfile
68 # format.
69 try:
70 with open(bodyfile_output, 'w') as file_object:
71 for file_entry, path_segments in entry_lister.ListFileEntries(
72 base_path_specs):
73 bodyfile_entries = entry_lister.GetBodyfileEntries(
74 file_entry, path_segments)
75 for bodyfile_entry in bodyfile_entries:
76 file_object.write(bodyfile_entry)
77 file_object.write('\n')
78 number_of_entries += 1
79 output_evidence.number_of_entries = number_of_entries
80 result.add_evidence(output_evidence, evidence.config)
81 status = 'Generated file system timeline containing [{0:d}] entries'.format(
82 number_of_entries)
83 result.close(self, success=True, status=status)
84 except dfvfs_errors.ScannerError as exception:
85 result.log('Error generating bodyfile {0!s}'.format(exception))
86 status = 'Unable to generate bodyfile using provided evidence data.'
87 result.close(self, success=False, status=status)
88 raise TurbiniaException(
89 'Could not process volume: {0!s}'.format(exception))
90
91 return result
92
[end of turbinia/workers/file_system_timeline.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/turbinia/workers/file_system_timeline.py b/turbinia/workers/file_system_timeline.py
--- a/turbinia/workers/file_system_timeline.py
+++ b/turbinia/workers/file_system_timeline.py
@@ -34,6 +34,7 @@
class FileSystemTimelineTask(TurbiniaTask):
+ """Task to generate file system timelines. """
REQUIRED_STATES = [state.ATTACHED]
@@ -61,31 +62,49 @@
# Create the FileEntryLister client and generate the path specs
# for all available partitions.
entry_lister = file_entry_lister.FileEntryLister()
- base_path_specs = entry_lister.GetBasePathSpecs(
- evidence.device_path, options=volume_scanner_options)
+ try:
+ base_path_specs = entry_lister.GetBasePathSpecs(
+ evidence.device_path, options=volume_scanner_options)
+ except dfvfs_errors.ScannerError as exception:
+ status = 'Unable to open evidence: {0!s}'.format(exception)
+ result.close(self, success=False, status=status)
# Iterate over all file entries and generate the output in bodyfile
# format.
try:
- with open(bodyfile_output, 'w') as file_object:
- for file_entry, path_segments in entry_lister.ListFileEntries(
- base_path_specs):
- bodyfile_entries = entry_lister.GetBodyfileEntries(
- file_entry, path_segments)
- for bodyfile_entry in bodyfile_entries:
- file_object.write(bodyfile_entry)
- file_object.write('\n')
- number_of_entries += 1
- output_evidence.number_of_entries = number_of_entries
- result.add_evidence(output_evidence, evidence.config)
- status = 'Generated file system timeline containing [{0:d}] entries'.format(
- number_of_entries)
- result.close(self, success=True, status=status)
- except dfvfs_errors.ScannerError as exception:
- result.log('Error generating bodyfile {0!s}'.format(exception))
- status = 'Unable to generate bodyfile using provided evidence data.'
+ file_entries = None
+ with open(bodyfile_output, 'w', encoding='utf-8') as file_object:
+ file_entries = enumerate(entry_lister.ListFileEntries(base_path_specs))
+ while file_entries:
+ try:
+ _, (file_entry, path_segments) = next(file_entries)
+ bodyfile_entries = entry_lister.GetBodyfileEntries(
+ file_entry, path_segments)
+ for bodyfile_entry in bodyfile_entries:
+ file_object.write(bodyfile_entry)
+ file_object.write('\n')
+ number_of_entries += 1
+ except StopIteration:
+ break
+ except (dfvfs_errors.AccessError, dfvfs_errors.BackEndError,
+ dfvfs_errors.MountPointError,
+ dfvfs_errors.PathSpecError) as exception:
+ status = 'Unable to process file entry: {0!s}'.format(exception)
+ result.log(status)
+
+ if number_of_entries > 0:
+ output_evidence.number_of_entries = number_of_entries
+ result.add_evidence(output_evidence, evidence.config)
+ status = 'Generated file system timeline containing [{0:d}] entries'.format(
+ number_of_entries)
+ result.close(self, success=True, status=status)
+ else:
+ status = 'Unable to process any file entries.'
+ result.close(self, success=False, status=status)
+
+ except IOError as exception:
+ status = 'Unable to create bodyfile local output file: {0!s}'.format(
+ exception)
result.close(self, success=False, status=status)
- raise TurbiniaException(
- 'Could not process volume: {0!s}'.format(exception))
return result
|
{"golden_diff": "diff --git a/turbinia/workers/file_system_timeline.py b/turbinia/workers/file_system_timeline.py\n--- a/turbinia/workers/file_system_timeline.py\n+++ b/turbinia/workers/file_system_timeline.py\n@@ -34,6 +34,7 @@\n \n \n class FileSystemTimelineTask(TurbiniaTask):\n+ \"\"\"Task to generate file system timelines. \"\"\"\n \n REQUIRED_STATES = [state.ATTACHED]\n \n@@ -61,31 +62,49 @@\n # Create the FileEntryLister client and generate the path specs\n # for all available partitions.\n entry_lister = file_entry_lister.FileEntryLister()\n- base_path_specs = entry_lister.GetBasePathSpecs(\n- evidence.device_path, options=volume_scanner_options)\n+ try:\n+ base_path_specs = entry_lister.GetBasePathSpecs(\n+ evidence.device_path, options=volume_scanner_options)\n+ except dfvfs_errors.ScannerError as exception:\n+ status = 'Unable to open evidence: {0!s}'.format(exception)\n+ result.close(self, success=False, status=status)\n \n # Iterate over all file entries and generate the output in bodyfile\n # format.\n try:\n- with open(bodyfile_output, 'w') as file_object:\n- for file_entry, path_segments in entry_lister.ListFileEntries(\n- base_path_specs):\n- bodyfile_entries = entry_lister.GetBodyfileEntries(\n- file_entry, path_segments)\n- for bodyfile_entry in bodyfile_entries:\n- file_object.write(bodyfile_entry)\n- file_object.write('\\n')\n- number_of_entries += 1\n- output_evidence.number_of_entries = number_of_entries\n- result.add_evidence(output_evidence, evidence.config)\n- status = 'Generated file system timeline containing [{0:d}] entries'.format(\n- number_of_entries)\n- result.close(self, success=True, status=status)\n- except dfvfs_errors.ScannerError as exception:\n- result.log('Error generating bodyfile {0!s}'.format(exception))\n- status = 'Unable to generate bodyfile using provided evidence data.'\n+ file_entries = None\n+ with open(bodyfile_output, 'w', encoding='utf-8') as file_object:\n+ file_entries = enumerate(entry_lister.ListFileEntries(base_path_specs))\n+ while file_entries:\n+ try:\n+ _, (file_entry, path_segments) = next(file_entries)\n+ bodyfile_entries = entry_lister.GetBodyfileEntries(\n+ file_entry, path_segments)\n+ for bodyfile_entry in bodyfile_entries:\n+ file_object.write(bodyfile_entry)\n+ file_object.write('\\n')\n+ number_of_entries += 1\n+ except StopIteration:\n+ break\n+ except (dfvfs_errors.AccessError, dfvfs_errors.BackEndError,\n+ dfvfs_errors.MountPointError,\n+ dfvfs_errors.PathSpecError) as exception:\n+ status = 'Unable to process file entry: {0!s}'.format(exception)\n+ result.log(status)\n+\n+ if number_of_entries > 0:\n+ output_evidence.number_of_entries = number_of_entries\n+ result.add_evidence(output_evidence, evidence.config)\n+ status = 'Generated file system timeline containing [{0:d}] entries'.format(\n+ number_of_entries)\n+ result.close(self, success=True, status=status)\n+ else:\n+ status = 'Unable to process any file entries.'\n+ result.close(self, success=False, status=status)\n+\n+ except IOError as exception:\n+ status = 'Unable to create bodyfile local output file: {0!s}'.format(\n+ exception)\n result.close(self, success=False, status=status)\n- raise TurbiniaException(\n- 'Could not process volume: {0!s}'.format(exception))\n \n return result\n", "issue": "Improve exception handling in FileSystemTimelineJob\nUnder certain conditions, dfvfs may throw exceptions that are not currently being handked:\r\n\r\n```\r\ndfvfs.lib.errors.BackEndError: Unable to open file system with error: pyfsext_volume_open_file_object: unable to open volume. libfsext_superblock_read_data: unsupported read-only compatible features flags: 0xff000003. libfsext_superblock_read_file_io_handle: unable to read superblock at offset: 1024 (0x00000400). libfsext_internal_volume_read_block_groups: unable to read superblock: 0 at offset: 1024 (0x00000400). libfsext_internal_volume_open_read: unable to read block groups. libfsext_volume_open_file_io_handle: unable to read from file IO handle.\r\n```\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright 2022 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Task to run dfimagetools FileEntryLister on disk partitions.\"\"\"\n\nfrom __future__ import unicode_literals\n\nimport os\n\nfrom turbinia import TurbiniaException\nfrom turbinia.workers import TurbiniaTask\nfrom turbinia.evidence import EvidenceState as state\nfrom turbinia.evidence import BodyFile\n\nif TurbiniaTask.check_worker_role():\n try:\n from dfvfs.helpers import volume_scanner\n from dfvfs.lib import errors as dfvfs_errors\n from dfimagetools import file_entry_lister\n except ImportError as exception:\n message = 'Could not import libraries: {0!s}'.format(exception)\n raise TurbiniaException(message)\n\n\nclass FileSystemTimelineTask(TurbiniaTask):\n\n REQUIRED_STATES = [state.ATTACHED]\n\n TASK_CONFIG = {'partitions': ['all']}\n\n def run(self, evidence, result):\n \"\"\"Task to execute (dfimagetools) FileEntryLister.\n\n Args:\n evidence (Evidence object): The evidence we will process.\n result (TurbiniaTaskResult): The object to place task results into.\n\n Returns:\n TurbiniaTaskResult object.\n \"\"\"\n bodyfile_output = os.path.join(self.output_dir, 'file_system.bodyfile')\n output_evidence = BodyFile(source_path=bodyfile_output)\n number_of_entries = 0\n\n # Set things up for the FileEntryLister client. We will scan all\n # partitions in the volume.\n volume_scanner_options = volume_scanner.VolumeScannerOptions()\n volume_scanner_options.partitions = self.task_config.get('partitions')\n\n # Create the FileEntryLister client and generate the path specs\n # for all available partitions.\n entry_lister = file_entry_lister.FileEntryLister()\n base_path_specs = entry_lister.GetBasePathSpecs(\n evidence.device_path, options=volume_scanner_options)\n\n # Iterate over all file entries and generate the output in bodyfile\n # format.\n try:\n with open(bodyfile_output, 'w') as file_object:\n for file_entry, path_segments in entry_lister.ListFileEntries(\n base_path_specs):\n bodyfile_entries = entry_lister.GetBodyfileEntries(\n file_entry, path_segments)\n for bodyfile_entry in bodyfile_entries:\n file_object.write(bodyfile_entry)\n file_object.write('\\n')\n number_of_entries += 1\n output_evidence.number_of_entries = number_of_entries\n result.add_evidence(output_evidence, evidence.config)\n status = 'Generated file system timeline containing [{0:d}] entries'.format(\n number_of_entries)\n result.close(self, success=True, status=status)\n except dfvfs_errors.ScannerError as exception:\n result.log('Error generating bodyfile {0!s}'.format(exception))\n status = 'Unable to generate bodyfile using provided evidence data.'\n result.close(self, success=False, status=status)\n raise TurbiniaException(\n 'Could not process volume: {0!s}'.format(exception))\n\n return result\n", "path": "turbinia/workers/file_system_timeline.py"}]}
| 1,714 | 849 |
gh_patches_debug_24183
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-6460
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tifffile deprecation warning on test_tifffile.py
## Description
<!--
(Note: for guidance on how to use `scikit-image`, please post instead on https://forum.image.sc/tag/scikit-image)
-->
## Way to reproduce
```python
run pytest on skimage/io/tests/test_tifffile.py
```
Will show deprecation warning issues
```bash
skimage/io/tests/test_tifffile.py ................................... [100%]
=============================== warnings summary ===============================
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float32-shape1]
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float32-shape1]
/scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 3) and dtype 'float32' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.
result = tif.write(
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float32-shape2]
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float32-shape2]
/scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 4) and dtype 'float32' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.
result = tif.write(
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-int16-shape1]
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-int16-shape1]
/scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 3) and dtype 'int16' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.
result = tif.write(
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-int16-shape2]
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-int16-shape2]
/scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 4) and dtype 'int16' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.
result = tif.write(
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float64-shape1]
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float64-shape1]
/scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 3) and dtype 'float64' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.
result = tif.write(
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float64-shape2]
skimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float64-shape2]
/scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 4) and dtype 'float64' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.
result = tif.write(
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
```
</issue>
<code>
[start of skimage/io/_plugins/tifffile_plugin.py]
1 __all__ = ['imread', 'imsave']
2
3 from tifffile import imwrite as imsave, imread as tifffile_imread
4
5
6 def imread(fname, **kwargs):
7 """Load a tiff image from file.
8
9 Parameters
10 ----------
11 fname : str or file
12 File name or file-like-object.
13 kwargs : keyword pairs, optional
14 Additional keyword arguments to pass through (see ``tifffile``'s
15 ``imread`` function).
16
17 Notes
18 -----
19 Provided by the tifffile library [1]_, and supports many
20 advanced image types including multi-page and floating point.
21
22 References
23 ----------
24 .. [1] https://pypi.org/project/tifffile/
25
26 """
27 if 'img_num' in kwargs:
28 kwargs['key'] = kwargs.pop('img_num')
29
30 return tifffile_imread(fname, **kwargs)
31
[end of skimage/io/_plugins/tifffile_plugin.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/io/_plugins/tifffile_plugin.py b/skimage/io/_plugins/tifffile_plugin.py
--- a/skimage/io/_plugins/tifffile_plugin.py
+++ b/skimage/io/_plugins/tifffile_plugin.py
@@ -1,6 +1,50 @@
+from tifffile import imread as tifffile_imread
+from tifffile import imwrite as tifffile_imwrite
+
__all__ = ['imread', 'imsave']
-from tifffile import imwrite as imsave, imread as tifffile_imread
+
+def imsave(fname, arr, **kwargs):
+ """Load a tiff image to file.
+
+ Parameters
+ ----------
+ fname : str or file
+ File name or file-like object.
+ arr : ndarray
+ The array to write.
+ kwargs : keyword pairs, optional
+ Additional keyword arguments to pass through (see ``tifffile``'s
+ ``imwrite`` function).
+
+ Notes
+ -----
+ Provided by the tifffile library [1]_, and supports many
+ advanced image types including multi-page and floating-point.
+
+ This implementation will set ``photometric='RGB'`` when writing if the first
+ or last axis of `arr` has length 3 or 4. To override this, explicitly
+ pass the ``photometric`` kwarg.
+
+ This implementation will set ``planarconfig='SEPARATE'`` when writing if the
+ first axis of arr has length 3 or 4. To override this, explicitly
+ specify the ``planarconfig`` kwarg.
+
+ References
+ ----------
+ .. [1] https://pypi.org/project/tifffile/
+
+ """
+ if arr.shape[0] in [3, 4]:
+ if 'planarconfig' not in kwargs:
+ kwargs['planarconfig'] = 'SEPARATE'
+ rgb = True
+ else:
+ rgb = arr.shape[-1] in [3, 4]
+ if rgb and 'photometric' not in kwargs:
+ kwargs['photometric'] = 'RGB'
+
+ return tifffile_imwrite(fname, arr, **kwargs)
def imread(fname, **kwargs):
|
{"golden_diff": "diff --git a/skimage/io/_plugins/tifffile_plugin.py b/skimage/io/_plugins/tifffile_plugin.py\n--- a/skimage/io/_plugins/tifffile_plugin.py\n+++ b/skimage/io/_plugins/tifffile_plugin.py\n@@ -1,6 +1,50 @@\n+from tifffile import imread as tifffile_imread\n+from tifffile import imwrite as tifffile_imwrite\n+\n __all__ = ['imread', 'imsave']\n \n-from tifffile import imwrite as imsave, imread as tifffile_imread\n+\n+def imsave(fname, arr, **kwargs):\n+ \"\"\"Load a tiff image to file.\n+\n+ Parameters\n+ ----------\n+ fname : str or file\n+ File name or file-like object.\n+ arr : ndarray\n+ The array to write.\n+ kwargs : keyword pairs, optional\n+ Additional keyword arguments to pass through (see ``tifffile``'s\n+ ``imwrite`` function).\n+\n+ Notes\n+ -----\n+ Provided by the tifffile library [1]_, and supports many\n+ advanced image types including multi-page and floating-point.\n+\n+ This implementation will set ``photometric='RGB'`` when writing if the first\n+ or last axis of `arr` has length 3 or 4. To override this, explicitly\n+ pass the ``photometric`` kwarg.\n+\n+ This implementation will set ``planarconfig='SEPARATE'`` when writing if the\n+ first axis of arr has length 3 or 4. To override this, explicitly\n+ specify the ``planarconfig`` kwarg.\n+\n+ References\n+ ----------\n+ .. [1] https://pypi.org/project/tifffile/\n+\n+ \"\"\"\n+ if arr.shape[0] in [3, 4]:\n+ if 'planarconfig' not in kwargs:\n+ kwargs['planarconfig'] = 'SEPARATE'\n+ rgb = True\n+ else:\n+ rgb = arr.shape[-1] in [3, 4]\n+ if rgb and 'photometric' not in kwargs:\n+ kwargs['photometric'] = 'RGB'\n+\n+ return tifffile_imwrite(fname, arr, **kwargs)\n \n \n def imread(fname, **kwargs):\n", "issue": "tifffile deprecation warning on test_tifffile.py\n## Description\r\n\r\n<!--\r\n(Note: for guidance on how to use `scikit-image`, please post instead on https://forum.image.sc/tag/scikit-image)\r\n-->\r\n\r\n## Way to reproduce\r\n```python\r\nrun pytest on skimage/io/tests/test_tifffile.py\r\n```\r\nWill show deprecation warning issues\r\n```bash\r\nskimage/io/tests/test_tifffile.py ................................... [100%]\r\n\r\n=============================== warnings summary ===============================\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float32-shape1]\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float32-shape1]\r\n /scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 3) and dtype 'float32' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.\r\n result = tif.write(\r\n\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float32-shape2]\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float32-shape2]\r\n /scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 4) and dtype 'float32' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.\r\n result = tif.write(\r\n\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-int16-shape1]\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-int16-shape1]\r\n /scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 3) and dtype 'int16' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.\r\n result = tif.write(\r\n\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-int16-shape2]\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-int16-shape2]\r\n /scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 4) and dtype 'int16' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.\r\n result = tif.write(\r\n\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float64-shape1]\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float64-shape1]\r\n /scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 3) and dtype 'float64' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.\r\n result = tif.write(\r\n\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[False-float64-shape2]\r\nskimage/io/tests/test_tifffile.py::TestSave::test_imsave_roundtrip[True-float64-shape2]\r\n /scikit-image/.venv/lib/python3.10/site-packages/tifffile/tifffile.py:1155: DeprecationWarning: <tifffile.TiffWriter.write> data with shape (10, 10, 4) and dtype 'float64' are stored as RGB with contiguous samples. Future versions will store such data as MINISBLACK in separate pages by default, unless the 'photometric' parameter is specified.\r\n result = tif.write(\r\n\r\n-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html\r\n\r\n```\r\n\r\n\n", "before_files": [{"content": "__all__ = ['imread', 'imsave']\n\nfrom tifffile import imwrite as imsave, imread as tifffile_imread\n\n\ndef imread(fname, **kwargs):\n \"\"\"Load a tiff image from file.\n\n Parameters\n ----------\n fname : str or file\n File name or file-like-object.\n kwargs : keyword pairs, optional\n Additional keyword arguments to pass through (see ``tifffile``'s\n ``imread`` function).\n\n Notes\n -----\n Provided by the tifffile library [1]_, and supports many\n advanced image types including multi-page and floating point.\n\n References\n ----------\n .. [1] https://pypi.org/project/tifffile/\n\n \"\"\"\n if 'img_num' in kwargs:\n kwargs['key'] = kwargs.pop('img_num')\n\n return tifffile_imread(fname, **kwargs)\n", "path": "skimage/io/_plugins/tifffile_plugin.py"}]}
| 1,933 | 526 |
gh_patches_debug_21682
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-7409
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
kernel_blacklist - Error while setting attributes: /tmp/xyz: Operation not supported
### Summary
I wanted to blacklist some kernel modules using the ready-made kernel_blacklist in Ansible.
My sample code:
```yaml
- name: Remove potentially affected (and unused) modules
community.general.kernel_blacklist:
name: "{{ line_item }}"
state: present
blacklist_file: "/etc/modprobe.d/{{ line_item }}-blacklist.conf"
with_items:
- cifs
- cls_rsvp
loop_control:
loop_var: line_item
```
As I understand it, the module should create such a file and add content to it.
As a result, when you run the playbook, the files are created but their contents are empty:
```bash
$ find /etc/modprobe.d/ -size 0 -ls
6030631 0 -rw-r--r-- 1 root root 0 paź 7 12:19 /etc/modprobe.d/cls_rsvp-blacklist.conf
6029638 0 -rw-r--r-- 1 root root 0 paź 7 12:19 /etc/modprobe.d/cifs-blacklist.conf
```
Additionally, when launching the playbook, I receive a failure message. Below traceback ( -vvv)
```
The full traceback is:
Traceback (most recent call last):
File "/tmp/ansible_community.general.kernel_blacklist_payload_rk2m8l96/ansible_community.general.kernel_blacklist_payload.zip/ansible/module_utils/basic.py", line 1003, in set_attributes_if_different
raise Exception("Error while setting attributes: %s" % (out + err))
Exception: Error while setting attributes: /tmp/tmpnholykn5: Operation not supported
failed: [local] (item=cls_rsvp) => {
"ansible_loop_var": "line_item",
"changed": false,
"details": "Error while setting attributes: /tmp/tmpnholykn5: Operation not supported\n",
"gid": 0,
"group": "root",
"invocation": {
"module_args": {
"blacklist_file": "/etc/modprobe.d/cls_rsvp-blacklist.conf",
"name": "cls_rsvp",
"state": "present"
}
},
"line_item": "cls_rsvp",
"mode": "0644",
"msg": "chattr failed",
"owner": "root",
"path": "/tmp/tmpnholykn5",
"size": 0,
"state": "file",
"uid": 0
}
```
I don't know why module display `Error while setting attributes: /tmp/tmpwn_d8ybv: Operation not supported`.
In bash shell work perfect:
```bash
# rm -fv /etc/modprobe.d/cifs-blacklist.conf
removed '/etc/modprobe.d/cifs-blacklist.conf'
# touch /etc/modprobe.d/cifs-blacklist.conf
# echo 'test test' > /etc/modprobe.d/cifs-blacklist.conf
```
### Issue Type
Bug Report
### Component Name
kernel_blacklist
### Ansible Version
```bash
$ ansible --version
ansible [core 2.14.10]
config file = /etc/ansible/ansible.cfg
configured module search path = ['/home/bkida/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']
ansible python module location = /usr/lib/python3.11/site-packages/ansible
ansible collection location = /home/bkida/.ansible/collections:/usr/share/ansible/collections
executable location = /usr/bin/ansible
python version = 3.11.5 (main, Aug 28 2023, 00:00:00) [GCC 13.2.1 20230728 (Red Hat 13.2.1-1)] (/usr/bin/python3)
jinja version = 3.0.3
libyaml = True
```
### Community.general Version
```bash
$ ansible-galaxy collection list community.general
# /usr/lib/python3.11/site-packages/ansible_collections
Collection Version
----------------- -------
community.general 6.6.2
# /usr/share/ansible/collections/ansible_collections
Collection Version
----------------- -------
community.general 6.6.0
```
### Configuration
```bash
$ ansible-config dump --only-changed
CONFIG_FILE() = /etc/ansible/ansible.cfg
```
### OS / Environment
Fedora 38
### Steps to Reproduce
Copy example code from summary description and run on the same ansible / community.general version
### Expected Results
Working module ;)
### Actual Results
`Error while setting attributes: /tmp/tmpwn_d8ybv: Operation not supported`
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/modules/kernel_blacklist.py]
1 #!/usr/bin/python
2 # -*- coding: utf-8 -*-
3
4 # Copyright (c) 2021, Alexei Znamensky (@russoz) <[email protected]>
5 # Copyright (c) 2013, Matthias Vogelgesang <[email protected]>
6 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
7 # SPDX-License-Identifier: GPL-3.0-or-later
8
9 from __future__ import absolute_import, division, print_function
10 __metaclass__ = type
11
12 DOCUMENTATION = '''
13 ---
14 module: kernel_blacklist
15 author:
16 - Matthias Vogelgesang (@matze)
17 short_description: Blacklist kernel modules
18 description:
19 - Add or remove kernel modules from blacklist.
20 extends_documentation_fragment:
21 - community.general.attributes
22 attributes:
23 check_mode:
24 support: full
25 diff_mode:
26 support: full
27 options:
28 name:
29 type: str
30 description:
31 - Name of kernel module to black- or whitelist.
32 required: true
33 state:
34 type: str
35 description:
36 - Whether the module should be present in the blacklist or absent.
37 choices: [ absent, present ]
38 default: present
39 blacklist_file:
40 type: str
41 description:
42 - If specified, use this blacklist file instead of
43 C(/etc/modprobe.d/blacklist-ansible.conf).
44 default: /etc/modprobe.d/blacklist-ansible.conf
45 '''
46
47 EXAMPLES = '''
48 - name: Blacklist the nouveau driver module
49 community.general.kernel_blacklist:
50 name: nouveau
51 state: present
52 '''
53
54 import os
55 import re
56 import tempfile
57
58 from ansible_collections.community.general.plugins.module_utils.module_helper import StateModuleHelper
59
60
61 class Blacklist(StateModuleHelper):
62 output_params = ('name', 'state')
63 module = dict(
64 argument_spec=dict(
65 name=dict(type='str', required=True),
66 state=dict(type='str', default='present', choices=['absent', 'present']),
67 blacklist_file=dict(type='str', default='/etc/modprobe.d/blacklist-ansible.conf'),
68 ),
69 supports_check_mode=True,
70 )
71
72 def __init_module__(self):
73 self.pattern = re.compile(r'^blacklist\s+{0}$'.format(re.escape(self.vars.name)))
74 self.vars.filename = self.vars.blacklist_file
75 self.vars.set('file_exists', os.path.exists(self.vars.filename), output=False, change=True)
76 if not self.vars.file_exists:
77 with open(self.vars.filename, 'a'):
78 pass
79 self.vars.file_exists = True
80 self.vars.set('lines', [], change=True, diff=True)
81 else:
82 with open(self.vars.filename) as fd:
83 self.vars.set('lines', [x.rstrip() for x in fd.readlines()], change=True, diff=True)
84 self.vars.set('is_blacklisted', self._is_module_blocked(), change=True)
85
86 def _is_module_blocked(self):
87 for line in self.vars.lines:
88 stripped = line.strip()
89 if stripped.startswith('#'):
90 continue
91 if self.pattern.match(stripped):
92 return True
93 return False
94
95 def state_absent(self):
96 if not self.vars.is_blacklisted:
97 return
98 self.vars.is_blacklisted = False
99 self.vars.lines = [line for line in self.vars.lines if not self.pattern.match(line.strip())]
100
101 def state_present(self):
102 if self.vars.is_blacklisted:
103 return
104 self.vars.is_blacklisted = True
105 self.vars.lines = self.vars.lines + ['blacklist %s' % self.vars.name]
106
107 def __quit_module__(self):
108 if self.has_changed() and not self.module.check_mode:
109 dummy, tmpfile = tempfile.mkstemp()
110 try:
111 os.remove(tmpfile)
112 self.module.preserved_copy(self.vars.filename, tmpfile) # ensure right perms/ownership
113 with open(tmpfile, 'w') as fd:
114 fd.writelines(["{0}\n".format(x) for x in self.vars.lines])
115 self.module.atomic_move(tmpfile, self.vars.filename)
116 finally:
117 if os.path.exists(tmpfile):
118 os.remove(tmpfile)
119
120
121 def main():
122 Blacklist.execute()
123
124
125 if __name__ == '__main__':
126 main()
127
[end of plugins/modules/kernel_blacklist.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/modules/kernel_blacklist.py b/plugins/modules/kernel_blacklist.py
--- a/plugins/modules/kernel_blacklist.py
+++ b/plugins/modules/kernel_blacklist.py
@@ -53,7 +53,6 @@
import os
import re
-import tempfile
from ansible_collections.community.general.plugins.module_utils.module_helper import StateModuleHelper
@@ -106,16 +105,10 @@
def __quit_module__(self):
if self.has_changed() and not self.module.check_mode:
- dummy, tmpfile = tempfile.mkstemp()
- try:
- os.remove(tmpfile)
- self.module.preserved_copy(self.vars.filename, tmpfile) # ensure right perms/ownership
- with open(tmpfile, 'w') as fd:
- fd.writelines(["{0}\n".format(x) for x in self.vars.lines])
- self.module.atomic_move(tmpfile, self.vars.filename)
- finally:
- if os.path.exists(tmpfile):
- os.remove(tmpfile)
+ bkp = self.module.backup_local(self.vars.filename)
+ with open(self.vars.filename, "w") as fd:
+ fd.writelines(["{0}\n".format(x) for x in self.vars.lines])
+ self.module.add_cleanup_file(bkp)
def main():
|
{"golden_diff": "diff --git a/plugins/modules/kernel_blacklist.py b/plugins/modules/kernel_blacklist.py\n--- a/plugins/modules/kernel_blacklist.py\n+++ b/plugins/modules/kernel_blacklist.py\n@@ -53,7 +53,6 @@\n \n import os\n import re\n-import tempfile\n \n from ansible_collections.community.general.plugins.module_utils.module_helper import StateModuleHelper\n \n@@ -106,16 +105,10 @@\n \n def __quit_module__(self):\n if self.has_changed() and not self.module.check_mode:\n- dummy, tmpfile = tempfile.mkstemp()\n- try:\n- os.remove(tmpfile)\n- self.module.preserved_copy(self.vars.filename, tmpfile) # ensure right perms/ownership\n- with open(tmpfile, 'w') as fd:\n- fd.writelines([\"{0}\\n\".format(x) for x in self.vars.lines])\n- self.module.atomic_move(tmpfile, self.vars.filename)\n- finally:\n- if os.path.exists(tmpfile):\n- os.remove(tmpfile)\n+ bkp = self.module.backup_local(self.vars.filename)\n+ with open(self.vars.filename, \"w\") as fd:\n+ fd.writelines([\"{0}\\n\".format(x) for x in self.vars.lines])\n+ self.module.add_cleanup_file(bkp)\n \n \n def main():\n", "issue": "kernel_blacklist - Error while setting attributes: /tmp/xyz: Operation not supported\n### Summary\n\nI wanted to blacklist some kernel modules using the ready-made kernel_blacklist in Ansible.\r\n\r\nMy sample code:\r\n```yaml\r\n- name: Remove potentially affected (and unused) modules\r\n community.general.kernel_blacklist:\r\n name: \"{{ line_item }}\"\r\n state: present\r\n blacklist_file: \"/etc/modprobe.d/{{ line_item }}-blacklist.conf\"\r\n with_items:\r\n - cifs\r\n - cls_rsvp\r\n loop_control:\r\n loop_var: line_item\r\n```\r\n\r\nAs I understand it, the module should create such a file and add content to it.\r\n\r\nAs a result, when you run the playbook, the files are created but their contents are empty:\r\n```bash\r\n$ find /etc/modprobe.d/ -size 0 -ls\r\n 6030631 0 -rw-r--r-- 1 root root 0 pa\u017a 7 12:19 /etc/modprobe.d/cls_rsvp-blacklist.conf\r\n 6029638 0 -rw-r--r-- 1 root root 0 pa\u017a 7 12:19 /etc/modprobe.d/cifs-blacklist.conf\r\n```\r\n\r\nAdditionally, when launching the playbook, I receive a failure message. Below traceback ( -vvv)\r\n```\r\nThe full traceback is:\r\nTraceback (most recent call last):\r\n File \"/tmp/ansible_community.general.kernel_blacklist_payload_rk2m8l96/ansible_community.general.kernel_blacklist_payload.zip/ansible/module_utils/basic.py\", line 1003, in set_attributes_if_different\r\n raise Exception(\"Error while setting attributes: %s\" % (out + err))\r\nException: Error while setting attributes: /tmp/tmpnholykn5: Operation not supported\r\n\r\nfailed: [local] (item=cls_rsvp) => {\r\n \"ansible_loop_var\": \"line_item\",\r\n \"changed\": false,\r\n \"details\": \"Error while setting attributes: /tmp/tmpnholykn5: Operation not supported\\n\",\r\n \"gid\": 0,\r\n \"group\": \"root\",\r\n \"invocation\": {\r\n \"module_args\": {\r\n \"blacklist_file\": \"/etc/modprobe.d/cls_rsvp-blacklist.conf\",\r\n \"name\": \"cls_rsvp\",\r\n \"state\": \"present\"\r\n }\r\n },\r\n \"line_item\": \"cls_rsvp\",\r\n \"mode\": \"0644\",\r\n \"msg\": \"chattr failed\",\r\n \"owner\": \"root\",\r\n \"path\": \"/tmp/tmpnholykn5\",\r\n \"size\": 0,\r\n \"state\": \"file\",\r\n \"uid\": 0\r\n}\r\n```\r\n\r\nI don't know why module display `Error while setting attributes: /tmp/tmpwn_d8ybv: Operation not supported`. \r\nIn bash shell work perfect:\r\n```bash\r\n# rm -fv /etc/modprobe.d/cifs-blacklist.conf\r\nremoved '/etc/modprobe.d/cifs-blacklist.conf'\r\n# touch /etc/modprobe.d/cifs-blacklist.conf\r\n# echo 'test test' > /etc/modprobe.d/cifs-blacklist.conf\r\n```\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\nkernel_blacklist\n\n### Ansible Version\n\n```bash\r\n$ ansible --version\r\nansible [core 2.14.10]\r\n config file = /etc/ansible/ansible.cfg\r\n configured module search path = ['/home/bkida/.ansible/plugins/modules', '/usr/share/ansible/plugins/modules']\r\n ansible python module location = /usr/lib/python3.11/site-packages/ansible\r\n ansible collection location = /home/bkida/.ansible/collections:/usr/share/ansible/collections\r\n executable location = /usr/bin/ansible\r\n python version = 3.11.5 (main, Aug 28 2023, 00:00:00) [GCC 13.2.1 20230728 (Red Hat 13.2.1-1)] (/usr/bin/python3)\r\n jinja version = 3.0.3\r\n libyaml = True\r\n```\r\n\n\n### Community.general Version\n\n```bash\r\n$ ansible-galaxy collection list community.general\r\n\r\n# /usr/lib/python3.11/site-packages/ansible_collections\r\nCollection Version\r\n----------------- -------\r\ncommunity.general 6.6.2 \r\n\r\n# /usr/share/ansible/collections/ansible_collections\r\nCollection Version\r\n----------------- -------\r\ncommunity.general 6.6.0 \r\n\r\n```\r\n\n\n### Configuration\n\n```bash\r\n$ ansible-config dump --only-changed\r\nCONFIG_FILE() = /etc/ansible/ansible.cfg\r\n```\r\n\n\n### OS / Environment\n\nFedora 38\n\n### Steps to Reproduce\n\nCopy example code from summary description and run on the same ansible / community.general version\n\n### Expected Results\n\nWorking module ;)\n\n### Actual Results\n\n`Error while setting attributes: /tmp/tmpwn_d8ybv: Operation not supported`\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# Copyright (c) 2021, Alexei Znamensky (@russoz) <[email protected]>\n# Copyright (c) 2013, Matthias Vogelgesang <[email protected]>\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import absolute_import, division, print_function\n__metaclass__ = type\n\nDOCUMENTATION = '''\n---\nmodule: kernel_blacklist\nauthor:\n - Matthias Vogelgesang (@matze)\nshort_description: Blacklist kernel modules\ndescription:\n - Add or remove kernel modules from blacklist.\nextends_documentation_fragment:\n - community.general.attributes\nattributes:\n check_mode:\n support: full\n diff_mode:\n support: full\noptions:\n name:\n type: str\n description:\n - Name of kernel module to black- or whitelist.\n required: true\n state:\n type: str\n description:\n - Whether the module should be present in the blacklist or absent.\n choices: [ absent, present ]\n default: present\n blacklist_file:\n type: str\n description:\n - If specified, use this blacklist file instead of\n C(/etc/modprobe.d/blacklist-ansible.conf).\n default: /etc/modprobe.d/blacklist-ansible.conf\n'''\n\nEXAMPLES = '''\n- name: Blacklist the nouveau driver module\n community.general.kernel_blacklist:\n name: nouveau\n state: present\n'''\n\nimport os\nimport re\nimport tempfile\n\nfrom ansible_collections.community.general.plugins.module_utils.module_helper import StateModuleHelper\n\n\nclass Blacklist(StateModuleHelper):\n output_params = ('name', 'state')\n module = dict(\n argument_spec=dict(\n name=dict(type='str', required=True),\n state=dict(type='str', default='present', choices=['absent', 'present']),\n blacklist_file=dict(type='str', default='/etc/modprobe.d/blacklist-ansible.conf'),\n ),\n supports_check_mode=True,\n )\n\n def __init_module__(self):\n self.pattern = re.compile(r'^blacklist\\s+{0}$'.format(re.escape(self.vars.name)))\n self.vars.filename = self.vars.blacklist_file\n self.vars.set('file_exists', os.path.exists(self.vars.filename), output=False, change=True)\n if not self.vars.file_exists:\n with open(self.vars.filename, 'a'):\n pass\n self.vars.file_exists = True\n self.vars.set('lines', [], change=True, diff=True)\n else:\n with open(self.vars.filename) as fd:\n self.vars.set('lines', [x.rstrip() for x in fd.readlines()], change=True, diff=True)\n self.vars.set('is_blacklisted', self._is_module_blocked(), change=True)\n\n def _is_module_blocked(self):\n for line in self.vars.lines:\n stripped = line.strip()\n if stripped.startswith('#'):\n continue\n if self.pattern.match(stripped):\n return True\n return False\n\n def state_absent(self):\n if not self.vars.is_blacklisted:\n return\n self.vars.is_blacklisted = False\n self.vars.lines = [line for line in self.vars.lines if not self.pattern.match(line.strip())]\n\n def state_present(self):\n if self.vars.is_blacklisted:\n return\n self.vars.is_blacklisted = True\n self.vars.lines = self.vars.lines + ['blacklist %s' % self.vars.name]\n\n def __quit_module__(self):\n if self.has_changed() and not self.module.check_mode:\n dummy, tmpfile = tempfile.mkstemp()\n try:\n os.remove(tmpfile)\n self.module.preserved_copy(self.vars.filename, tmpfile) # ensure right perms/ownership\n with open(tmpfile, 'w') as fd:\n fd.writelines([\"{0}\\n\".format(x) for x in self.vars.lines])\n self.module.atomic_move(tmpfile, self.vars.filename)\n finally:\n if os.path.exists(tmpfile):\n os.remove(tmpfile)\n\n\ndef main():\n Blacklist.execute()\n\n\nif __name__ == '__main__':\n main()\n", "path": "plugins/modules/kernel_blacklist.py"}]}
| 2,854 | 285 |
gh_patches_debug_34329
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-1417
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Documents: This backend doesn't support absolute paths. (Update to 1.0b2)
## 1. Bug since Wagtail update
I recently upgraded to 1.0b2 (from 1.0b1) and now, when I try to access I document I uploaded via a `wagtaildocs.Document` field, I get the following error:
```
NotImplementedError at /documents/3/headphones.svg
This backend doesn't support absolute paths.
```
The field is specified as:
```
svg_mask = models.ForeignKey(
verbose_name=u"Mask (SVG)",
to='wagtaildocs.Document',
null=True,
blank=True,
on_delete=models.SET_NULL,
related_name='+'
)
```
Is this a wagtail bug or a configuration error?
## 2. Unexpected behaviour
I would like to serve the svg as a `image/svg+xml`, not as a stream (which was the case in 1.0b1). I set the mimetype in my settings as follows:
```
mimetypes.add_type("image/svg+xml", ".svg", True)
mimetypes.add_type("image/svg+xml", ".svgz", True)
```
Yet (in 1.0b1) it always got served as a stream. I couldn't test it in 1.0b2 yet, because of the above problem.
Thank you in advance.
</issue>
<code>
[start of wagtail/wagtaildocs/views/serve.py]
1 from django.shortcuts import get_object_or_404
2 from django.conf import settings
3
4 from wagtail.utils.sendfile import sendfile
5 from wagtail.utils import sendfile_streaming_backend
6
7 from wagtail.wagtaildocs.models import Document, document_served
8
9
10 def serve(request, document_id, document_filename):
11 doc = get_object_or_404(Document, id=document_id)
12
13 # Send document_served signal
14 document_served.send(sender=Document, instance=doc, request=request)
15
16 if hasattr(settings, 'SENDFILE_BACKEND'):
17 return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename)
18 else:
19 # Fallback to streaming backend if user hasn't specified SENDFILE_BACKEND
20 return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename, backend=sendfile_streaming_backend.sendfile)
21
[end of wagtail/wagtaildocs/views/serve.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/wagtaildocs/views/serve.py b/wagtail/wagtaildocs/views/serve.py
--- a/wagtail/wagtaildocs/views/serve.py
+++ b/wagtail/wagtaildocs/views/serve.py
@@ -1,5 +1,9 @@
from django.shortcuts import get_object_or_404
from django.conf import settings
+from django.http import StreamingHttpResponse, BadHeaderError
+
+from unidecode import unidecode
+from wsgiref.util import FileWrapper
from wagtail.utils.sendfile import sendfile
from wagtail.utils import sendfile_streaming_backend
@@ -13,8 +17,40 @@
# Send document_served signal
document_served.send(sender=Document, instance=doc, request=request)
- if hasattr(settings, 'SENDFILE_BACKEND'):
- return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename)
+ try:
+ local_path = doc.file.path
+ except NotImplementedError:
+ local_path = None
+
+ if local_path:
+
+ # Use wagtail.utils.sendfile to serve the file;
+ # this provides support for mimetypes, if-modified-since and django-sendfile backends
+
+ if hasattr(settings, 'SENDFILE_BACKEND'):
+ return sendfile(request, local_path, attachment=True, attachment_filename=doc.filename)
+ else:
+ # Fallback to streaming backend if user hasn't specified SENDFILE_BACKEND
+ return sendfile(request, local_path, attachment=True, attachment_filename=doc.filename, backend=sendfile_streaming_backend.sendfile)
+
else:
- # Fallback to streaming backend if user hasn't specified SENDFILE_BACKEND
- return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename, backend=sendfile_streaming_backend.sendfile)
+
+ # We are using a storage backend which does not expose filesystem paths
+ # (e.g. storages.backends.s3boto.S3BotoStorage).
+ # Fall back on pre-sendfile behaviour of reading the file content and serving it
+ # as a StreamingHttpResponse
+
+ wrapper = FileWrapper(doc.file)
+ response = StreamingHttpResponse(wrapper, content_type='application/octet-stream')
+
+ try:
+ response['Content-Disposition'] = 'attachment; filename=%s' % doc.filename
+ except BadHeaderError:
+ # Unicode filenames can fail on Django <1.8, Python 2 due to
+ # https://code.djangoproject.com/ticket/20889 - try with an ASCIIfied version of the name
+ response['Content-Disposition'] = 'attachment; filename=%s' % unidecode(doc.filename)
+
+ # FIXME: storage backends are not guaranteed to implement 'size'
+ response['Content-Length'] = doc.file.size
+
+ return response
|
{"golden_diff": "diff --git a/wagtail/wagtaildocs/views/serve.py b/wagtail/wagtaildocs/views/serve.py\n--- a/wagtail/wagtaildocs/views/serve.py\n+++ b/wagtail/wagtaildocs/views/serve.py\n@@ -1,5 +1,9 @@\n from django.shortcuts import get_object_or_404\n from django.conf import settings\n+from django.http import StreamingHttpResponse, BadHeaderError\n+\n+from unidecode import unidecode\n+from wsgiref.util import FileWrapper\n \n from wagtail.utils.sendfile import sendfile\n from wagtail.utils import sendfile_streaming_backend\n@@ -13,8 +17,40 @@\n # Send document_served signal\n document_served.send(sender=Document, instance=doc, request=request)\n \n- if hasattr(settings, 'SENDFILE_BACKEND'):\n- return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename)\n+ try:\n+ local_path = doc.file.path\n+ except NotImplementedError:\n+ local_path = None\n+\n+ if local_path:\n+\n+ # Use wagtail.utils.sendfile to serve the file;\n+ # this provides support for mimetypes, if-modified-since and django-sendfile backends\n+\n+ if hasattr(settings, 'SENDFILE_BACKEND'):\n+ return sendfile(request, local_path, attachment=True, attachment_filename=doc.filename)\n+ else:\n+ # Fallback to streaming backend if user hasn't specified SENDFILE_BACKEND\n+ return sendfile(request, local_path, attachment=True, attachment_filename=doc.filename, backend=sendfile_streaming_backend.sendfile)\n+\n else:\n- # Fallback to streaming backend if user hasn't specified SENDFILE_BACKEND\n- return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename, backend=sendfile_streaming_backend.sendfile)\n+\n+ # We are using a storage backend which does not expose filesystem paths\n+ # (e.g. storages.backends.s3boto.S3BotoStorage).\n+ # Fall back on pre-sendfile behaviour of reading the file content and serving it\n+ # as a StreamingHttpResponse\n+\n+ wrapper = FileWrapper(doc.file)\n+ response = StreamingHttpResponse(wrapper, content_type='application/octet-stream')\n+\n+ try:\n+ response['Content-Disposition'] = 'attachment; filename=%s' % doc.filename\n+ except BadHeaderError:\n+ # Unicode filenames can fail on Django <1.8, Python 2 due to\n+ # https://code.djangoproject.com/ticket/20889 - try with an ASCIIfied version of the name\n+ response['Content-Disposition'] = 'attachment; filename=%s' % unidecode(doc.filename)\n+\n+ # FIXME: storage backends are not guaranteed to implement 'size'\n+ response['Content-Length'] = doc.file.size\n+\n+ return response\n", "issue": "Documents: This backend doesn't support absolute paths. (Update to 1.0b2)\n## 1. Bug since Wagtail update\n\nI recently upgraded to 1.0b2 (from 1.0b1) and now, when I try to access I document I uploaded via a `wagtaildocs.Document` field, I get the following error:\n\n```\nNotImplementedError at /documents/3/headphones.svg\nThis backend doesn't support absolute paths.\n```\n\nThe field is specified as:\n\n```\nsvg_mask = models.ForeignKey(\n verbose_name=u\"Mask (SVG)\",\n to='wagtaildocs.Document',\n null=True,\n blank=True,\n on_delete=models.SET_NULL,\n related_name='+'\n)\n```\n\nIs this a wagtail bug or a configuration error?\n## 2. Unexpected behaviour\n\nI would like to serve the svg as a `image/svg+xml`, not as a stream (which was the case in 1.0b1). I set the mimetype in my settings as follows:\n\n```\nmimetypes.add_type(\"image/svg+xml\", \".svg\", True)\nmimetypes.add_type(\"image/svg+xml\", \".svgz\", True)\n```\n\nYet (in 1.0b1) it always got served as a stream. I couldn't test it in 1.0b2 yet, because of the above problem.\n\nThank you in advance.\n\n", "before_files": [{"content": "from django.shortcuts import get_object_or_404\nfrom django.conf import settings\n\nfrom wagtail.utils.sendfile import sendfile\nfrom wagtail.utils import sendfile_streaming_backend\n\nfrom wagtail.wagtaildocs.models import Document, document_served\n\n\ndef serve(request, document_id, document_filename):\n doc = get_object_or_404(Document, id=document_id)\n\n # Send document_served signal\n document_served.send(sender=Document, instance=doc, request=request)\n\n if hasattr(settings, 'SENDFILE_BACKEND'):\n return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename)\n else:\n # Fallback to streaming backend if user hasn't specified SENDFILE_BACKEND\n return sendfile(request, doc.file.path, attachment=True, attachment_filename=doc.filename, backend=sendfile_streaming_backend.sendfile)\n", "path": "wagtail/wagtaildocs/views/serve.py"}]}
| 1,060 | 637 |
gh_patches_debug_5789
|
rasdani/github-patches
|
git_diff
|
weni-ai__bothub-engine-145
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Just email console backend in development mode
When EMAIL_HOST is setted and DEBUG is True email continue on console
</issue>
<code>
[start of bothub/settings.py]
1 import os
2 import dj_database_url
3
4 from decouple import config
5
6
7 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
8 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
9
10
11 # SECURITY WARNING: keep the secret key used in production secret!
12 SECRET_KEY = config('SECRET_KEY')
13
14 # SECURITY WARNING: don't run with debug turned on in production!
15 DEBUG = config('DEBUG', default=False, cast=bool)
16
17 ALLOWED_HOSTS = config(
18 'ALLOWED_HOSTS',
19 default='*',
20 cast=lambda v: [s.strip() for s in v.split(',')])
21
22
23 # Application definition
24
25 INSTALLED_APPS = [
26 'django.contrib.admin',
27 'django.contrib.auth',
28 'django.contrib.contenttypes',
29 'django.contrib.sessions',
30 'django.contrib.messages',
31 'django.contrib.staticfiles',
32 'rest_framework',
33 'rest_framework.authtoken',
34 'django_filters',
35 'corsheaders',
36 'bothub.authentication',
37 'bothub.common',
38 'bothub.api',
39 ]
40
41 MIDDLEWARE = [
42 'django.middleware.security.SecurityMiddleware',
43 'whitenoise.middleware.WhiteNoiseMiddleware',
44 'django.contrib.sessions.middleware.SessionMiddleware',
45 'corsheaders.middleware.CorsMiddleware',
46 'django.middleware.common.CommonMiddleware',
47 'django.middleware.csrf.CsrfViewMiddleware',
48 'django.contrib.auth.middleware.AuthenticationMiddleware',
49 'django.contrib.messages.middleware.MessageMiddleware',
50 'django.middleware.clickjacking.XFrameOptionsMiddleware',
51 ]
52
53 ROOT_URLCONF = 'bothub.urls'
54
55 TEMPLATES = [
56 {
57 'BACKEND': 'django.template.backends.django.DjangoTemplates',
58 'DIRS': [],
59 'APP_DIRS': True,
60 'OPTIONS': {
61 'context_processors': [
62 'django.template.context_processors.debug',
63 'django.template.context_processors.request',
64 'django.contrib.auth.context_processors.auth',
65 'django.contrib.messages.context_processors.messages',
66 ],
67 },
68 },
69 ]
70
71 WSGI_APPLICATION = 'bothub.wsgi.application'
72
73
74 # Database
75
76 DATABASES = {}
77 DATABASES['default'] = dj_database_url.parse(
78 config(
79 'DEFAULT_DATABASE',
80 default='sqlite:///db.sqlite3'))
81
82
83 # Auth
84
85 AUTH_USER_MODEL = 'authentication.User'
86
87
88 # Password validation
89
90 AUTH_PASSWORD_VALIDATORS = [
91 {
92 'NAME': 'django.contrib.auth.password_validation.' +
93 'UserAttributeSimilarityValidator',
94 },
95 {
96 'NAME': 'django.contrib.auth.password_validation.' +
97 'MinimumLengthValidator',
98 },
99 {
100 'NAME': 'django.contrib.auth.password_validation.' +
101 'CommonPasswordValidator',
102 },
103 {
104 'NAME': 'django.contrib.auth.password_validation.' +
105 'NumericPasswordValidator',
106 },
107 ]
108
109
110 # Internationalization
111
112 LANGUAGE_CODE = config('LANGUAGE_CODE', default='en-us')
113
114 TIME_ZONE = config('TIME_ZONE', default='UTC')
115
116 USE_I18N = True
117
118 USE_L10N = True
119
120 USE_TZ = True
121
122
123 # Static files (CSS, JavaScript, Images)
124
125 STATIC_URL = '/static/'
126
127 STATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')
128
129 STATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'
130
131
132 # rest framework
133
134 REST_FRAMEWORK = {
135 'DEFAULT_AUTHENTICATION_CLASSES': [
136 'rest_framework.authentication.TokenAuthentication',
137 ],
138 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.' +
139 'LimitOffsetPagination',
140 'PAGE_SIZE': 20,
141 'DEFAULT_FILTER_BACKENDS': [
142 'django_filters.rest_framework.DjangoFilterBackend',
143 ],
144 'DEFAULT_METADATA_CLASS': 'bothub.api.metadata.Metadata',
145 }
146
147
148 # cors headers
149
150 CORS_ORIGIN_ALLOW_ALL = True
151 CORS_URLS_REGEX = r'^/api/.*$'
152
153
154 # mail
155
156 envvar_EMAIL_HOST = config('EMAIL_HOST', default=None)
157
158 ADMINS = config(
159 'ADMINS',
160 default='',
161 cast=lambda v: [
162 (
163 s.strip().split('|')[0],
164 s.strip().split('|')[1],
165 ) for s in v.split(',')] if v else [])
166 EMAIL_SUBJECT_PREFIX = '[bothub] '
167 DEFAULT_FROM_EMAIL = config(
168 'DEFAULT_FROM_EMAIL',
169 default='webmaster@localhost')
170 SERVER_EMAIL = config('SERVER_EMAIL', default='root@localhost')
171
172 if not DEBUG and envvar_EMAIL_HOST:
173 EMAIL_HOST = envvar_EMAIL_HOST
174 EMAIL_PORT = config('EMAIL_PORT', default=25, cast=int)
175 EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')
176 EMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')
177 EMAIL_USE_SSL = config('EMAIL_USE_SSL', default=False, cast=bool)
178 EMAIL_USE_TLS = config('EMAIL_USE_TLS', default=False, cast=bool)
179 else:
180 EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'
181
182
183 # webapp
184
185 BOTHUB_WEBAPP_BASE_URL = config(
186 'BOTHUB_WEBAPP_BASE_URL',
187 default='http://localhost:8080/')
188
189
190 # NLP
191
192 BOTHUB_NLP_BASE_URL = config(
193 'BOTHUB_NLP_BASE_URL',
194 default='http://localhost:8001/')
195
196
197 # CSRF
198
199 CSRF_COOKIE_DOMAIN = config(
200 'CSRF_COOKIE_DOMAIN',
201 default=None)
202
203 CSRF_COOKIE_SECURE = config(
204 'CSRF_COOKIE_SECURE',
205 default=False,
206 cast=bool)
207
[end of bothub/settings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bothub/settings.py b/bothub/settings.py
--- a/bothub/settings.py
+++ b/bothub/settings.py
@@ -169,7 +169,7 @@
default='webmaster@localhost')
SERVER_EMAIL = config('SERVER_EMAIL', default='root@localhost')
-if not DEBUG and envvar_EMAIL_HOST:
+if envvar_EMAIL_HOST:
EMAIL_HOST = envvar_EMAIL_HOST
EMAIL_PORT = config('EMAIL_PORT', default=25, cast=int)
EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')
|
{"golden_diff": "diff --git a/bothub/settings.py b/bothub/settings.py\n--- a/bothub/settings.py\n+++ b/bothub/settings.py\n@@ -169,7 +169,7 @@\n default='webmaster@localhost')\n SERVER_EMAIL = config('SERVER_EMAIL', default='root@localhost')\n \n-if not DEBUG and envvar_EMAIL_HOST:\n+if envvar_EMAIL_HOST:\n EMAIL_HOST = envvar_EMAIL_HOST\n EMAIL_PORT = config('EMAIL_PORT', default=25, cast=int)\n EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')\n", "issue": "Just email console backend in development mode\nWhen EMAIL_HOST is setted and DEBUG is True email continue on console\n", "before_files": [{"content": "import os\nimport dj_database_url\n\nfrom decouple import config\n\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = config('SECRET_KEY')\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = config('DEBUG', default=False, cast=bool)\n\nALLOWED_HOSTS = config(\n 'ALLOWED_HOSTS',\n default='*',\n cast=lambda v: [s.strip() for s in v.split(',')])\n\n\n# Application definition\n\nINSTALLED_APPS = [\n 'django.contrib.admin',\n 'django.contrib.auth',\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'rest_framework',\n 'rest_framework.authtoken',\n 'django_filters',\n 'corsheaders',\n 'bothub.authentication',\n 'bothub.common',\n 'bothub.api',\n]\n\nMIDDLEWARE = [\n 'django.middleware.security.SecurityMiddleware',\n 'whitenoise.middleware.WhiteNoiseMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'corsheaders.middleware.CorsMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'django.middleware.clickjacking.XFrameOptionsMiddleware',\n]\n\nROOT_URLCONF = 'bothub.urls'\n\nTEMPLATES = [\n {\n 'BACKEND': 'django.template.backends.django.DjangoTemplates',\n 'DIRS': [],\n 'APP_DIRS': True,\n 'OPTIONS': {\n 'context_processors': [\n 'django.template.context_processors.debug',\n 'django.template.context_processors.request',\n 'django.contrib.auth.context_processors.auth',\n 'django.contrib.messages.context_processors.messages',\n ],\n },\n },\n]\n\nWSGI_APPLICATION = 'bothub.wsgi.application'\n\n\n# Database\n\nDATABASES = {}\nDATABASES['default'] = dj_database_url.parse(\n config(\n 'DEFAULT_DATABASE',\n default='sqlite:///db.sqlite3'))\n\n\n# Auth\n\nAUTH_USER_MODEL = 'authentication.User'\n\n\n# Password validation\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'UserAttributeSimilarityValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'MinimumLengthValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'CommonPasswordValidator',\n },\n {\n 'NAME': 'django.contrib.auth.password_validation.' +\n 'NumericPasswordValidator',\n },\n]\n\n\n# Internationalization\n\nLANGUAGE_CODE = config('LANGUAGE_CODE', default='en-us')\n\nTIME_ZONE = config('TIME_ZONE', default='UTC')\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n\n# Static files (CSS, JavaScript, Images)\n\nSTATIC_URL = '/static/'\n\nSTATIC_ROOT = os.path.join(BASE_DIR, 'staticfiles')\n\nSTATICFILES_STORAGE = 'whitenoise.storage.CompressedManifestStaticFilesStorage'\n\n\n# rest framework\n\nREST_FRAMEWORK = {\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.TokenAuthentication',\n ],\n 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.' +\n 'LimitOffsetPagination',\n 'PAGE_SIZE': 20,\n 'DEFAULT_FILTER_BACKENDS': [\n 'django_filters.rest_framework.DjangoFilterBackend',\n ],\n 'DEFAULT_METADATA_CLASS': 'bothub.api.metadata.Metadata',\n}\n\n\n# cors headers\n\nCORS_ORIGIN_ALLOW_ALL = True\nCORS_URLS_REGEX = r'^/api/.*$'\n\n\n# mail\n\nenvvar_EMAIL_HOST = config('EMAIL_HOST', default=None)\n\nADMINS = config(\n 'ADMINS',\n default='',\n cast=lambda v: [\n (\n s.strip().split('|')[0],\n s.strip().split('|')[1],\n ) for s in v.split(',')] if v else [])\nEMAIL_SUBJECT_PREFIX = '[bothub] '\nDEFAULT_FROM_EMAIL = config(\n 'DEFAULT_FROM_EMAIL',\n default='webmaster@localhost')\nSERVER_EMAIL = config('SERVER_EMAIL', default='root@localhost')\n\nif not DEBUG and envvar_EMAIL_HOST:\n EMAIL_HOST = envvar_EMAIL_HOST\n EMAIL_PORT = config('EMAIL_PORT', default=25, cast=int)\n EMAIL_HOST_USER = config('EMAIL_HOST_USER', default='')\n EMAIL_HOST_PASSWORD = config('EMAIL_HOST_PASSWORD', default='')\n EMAIL_USE_SSL = config('EMAIL_USE_SSL', default=False, cast=bool)\n EMAIL_USE_TLS = config('EMAIL_USE_TLS', default=False, cast=bool)\nelse:\n EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\n\n# webapp\n\nBOTHUB_WEBAPP_BASE_URL = config(\n 'BOTHUB_WEBAPP_BASE_URL',\n default='http://localhost:8080/')\n\n\n# NLP\n\nBOTHUB_NLP_BASE_URL = config(\n 'BOTHUB_NLP_BASE_URL',\n default='http://localhost:8001/')\n\n\n# CSRF\n\nCSRF_COOKIE_DOMAIN = config(\n 'CSRF_COOKIE_DOMAIN',\n default=None)\n\nCSRF_COOKIE_SECURE = config(\n 'CSRF_COOKIE_SECURE',\n default=False,\n cast=bool)\n", "path": "bothub/settings.py"}]}
| 2,233 | 124 |
gh_patches_debug_35844
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-1205
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecate htmlparser link extractor
Let's add a deprecation warning like we did for SGML Link extractor
</issue>
<code>
[start of scrapy/linkextractors/sgml.py]
1 """
2 SGMLParser-based Link extractors
3 """
4 from six.moves.urllib.parse import urljoin
5 import warnings
6 from sgmllib import SGMLParser
7
8 from w3lib.url import safe_url_string
9 from scrapy.selector import Selector
10 from scrapy.link import Link
11 from scrapy.linkextractor import FilteringLinkExtractor
12 from scrapy.utils.misc import arg_to_iter
13 from scrapy.utils.python import unique as unique_list, str_to_unicode
14 from scrapy.utils.response import get_base_url
15 from scrapy.exceptions import ScrapyDeprecationWarning
16
17
18 class BaseSgmlLinkExtractor(SGMLParser):
19
20 def __init__(self, tag="a", attr="href", unique=False, process_value=None):
21 warnings.warn(
22 "BaseSgmlLinkExtractor is deprecated and will be removed in future releases. "
23 "Please use scrapy.linkextractors.LinkExtractor",
24 ScrapyDeprecationWarning
25 )
26 SGMLParser.__init__(self)
27 self.scan_tag = tag if callable(tag) else lambda t: t == tag
28 self.scan_attr = attr if callable(attr) else lambda a: a == attr
29 self.process_value = (lambda v: v) if process_value is None else process_value
30 self.current_link = None
31 self.unique = unique
32
33 def _extract_links(self, response_text, response_url, response_encoding, base_url=None):
34 """ Do the real extraction work """
35 self.reset()
36 self.feed(response_text)
37 self.close()
38
39 ret = []
40 if base_url is None:
41 base_url = urljoin(response_url, self.base_url) if self.base_url else response_url
42 for link in self.links:
43 if isinstance(link.url, unicode):
44 link.url = link.url.encode(response_encoding)
45 link.url = urljoin(base_url, link.url)
46 link.url = safe_url_string(link.url, response_encoding)
47 link.text = str_to_unicode(link.text, response_encoding, errors='replace').strip()
48 ret.append(link)
49
50 return ret
51
52 def _process_links(self, links):
53 """ Normalize and filter extracted links
54
55 The subclass should override it if necessary
56 """
57 links = unique_list(links, key=lambda link: link.url) if self.unique else links
58 return links
59
60 def extract_links(self, response):
61 # wrapper needed to allow to work directly with text
62 links = self._extract_links(response.body, response.url, response.encoding)
63 links = self._process_links(links)
64 return links
65
66 def reset(self):
67 SGMLParser.reset(self)
68 self.links = []
69 self.base_url = None
70 self.current_link = None
71
72 def unknown_starttag(self, tag, attrs):
73 if tag == 'base':
74 self.base_url = dict(attrs).get('href')
75 if self.scan_tag(tag):
76 for attr, value in attrs:
77 if self.scan_attr(attr):
78 url = self.process_value(value)
79 if url is not None:
80 link = Link(url=url, nofollow=True if dict(attrs).get('rel') == 'nofollow' else False)
81 self.links.append(link)
82 self.current_link = link
83
84 def unknown_endtag(self, tag):
85 if self.scan_tag(tag):
86 self.current_link = None
87
88 def handle_data(self, data):
89 if self.current_link:
90 self.current_link.text = self.current_link.text + data
91
92 def matches(self, url):
93 """This extractor matches with any url, since
94 it doesn't contain any patterns"""
95 return True
96
97
98 class SgmlLinkExtractor(FilteringLinkExtractor):
99
100 def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),
101 tags=('a', 'area'), attrs=('href',), canonicalize=True, unique=True,
102 process_value=None, deny_extensions=None, restrict_css=()):
103
104 warnings.warn(
105 "SgmlLinkExtractor is deprecated and will be removed in future releases. "
106 "Please use scrapy.linkextractors.LinkExtractor",
107 ScrapyDeprecationWarning
108 )
109
110 tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))
111 tag_func = lambda x: x in tags
112 attr_func = lambda x: x in attrs
113
114 with warnings.catch_warnings(record=True):
115 lx = BaseSgmlLinkExtractor(tag=tag_func, attr=attr_func,
116 unique=unique, process_value=process_value)
117
118 super(SgmlLinkExtractor, self).__init__(lx, allow=allow, deny=deny,
119 allow_domains=allow_domains, deny_domains=deny_domains,
120 restrict_xpaths=restrict_xpaths, restrict_css=restrict_css,
121 canonicalize=canonicalize, deny_extensions=deny_extensions)
122
123 # FIXME: was added to fix a RegexLinkExtractor testcase
124 self.base_url = None
125
126 def extract_links(self, response):
127 base_url = None
128 if self.restrict_xpaths:
129 sel = Selector(response)
130 base_url = get_base_url(response)
131 body = u''.join(f
132 for x in self.restrict_xpaths
133 for f in sel.xpath(x).extract()
134 ).encode(response.encoding, errors='xmlcharrefreplace')
135 else:
136 body = response.body
137
138 links = self._extract_links(body, response.url, response.encoding, base_url)
139 links = self._process_links(links)
140 return links
141
[end of scrapy/linkextractors/sgml.py]
[start of scrapy/linkextractors/htmlparser.py]
1 """
2 HTMLParser-based link extractor
3 """
4
5 from HTMLParser import HTMLParser
6 from six.moves.urllib.parse import urljoin
7
8 from w3lib.url import safe_url_string
9
10 from scrapy.link import Link
11 from scrapy.utils.python import unique as unique_list
12
13 class HtmlParserLinkExtractor(HTMLParser):
14
15 def __init__(self, tag="a", attr="href", process=None, unique=False):
16 HTMLParser.__init__(self)
17
18 self.scan_tag = tag if callable(tag) else lambda t: t == tag
19 self.scan_attr = attr if callable(attr) else lambda a: a == attr
20 self.process_attr = process if callable(process) else lambda v: v
21 self.unique = unique
22
23 def _extract_links(self, response_text, response_url, response_encoding):
24 self.reset()
25 self.feed(response_text)
26 self.close()
27
28 links = unique_list(self.links, key=lambda link: link.url) if self.unique else self.links
29
30 ret = []
31 base_url = urljoin(response_url, self.base_url) if self.base_url else response_url
32 for link in links:
33 if isinstance(link.url, unicode):
34 link.url = link.url.encode(response_encoding)
35 link.url = urljoin(base_url, link.url)
36 link.url = safe_url_string(link.url, response_encoding)
37 link.text = link.text.decode(response_encoding)
38 ret.append(link)
39
40 return ret
41
42 def extract_links(self, response):
43 # wrapper needed to allow to work directly with text
44 return self._extract_links(response.body, response.url, response.encoding)
45
46 def reset(self):
47 HTMLParser.reset(self)
48
49 self.base_url = None
50 self.current_link = None
51 self.links = []
52
53 def handle_starttag(self, tag, attrs):
54 if tag == 'base':
55 self.base_url = dict(attrs).get('href')
56 if self.scan_tag(tag):
57 for attr, value in attrs:
58 if self.scan_attr(attr):
59 url = self.process_attr(value)
60 link = Link(url=url)
61 self.links.append(link)
62 self.current_link = link
63
64 def handle_endtag(self, tag):
65 if self.scan_tag(tag):
66 self.current_link = None
67
68 def handle_data(self, data):
69 if self.current_link:
70 self.current_link.text = self.current_link.text + data
71
72 def matches(self, url):
73 """This extractor matches with any url, since
74 it doesn't contain any patterns"""
75 return True
76
[end of scrapy/linkextractors/htmlparser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/linkextractors/htmlparser.py b/scrapy/linkextractors/htmlparser.py
--- a/scrapy/linkextractors/htmlparser.py
+++ b/scrapy/linkextractors/htmlparser.py
@@ -2,6 +2,7 @@
HTMLParser-based link extractor
"""
+import warnings
from HTMLParser import HTMLParser
from six.moves.urllib.parse import urljoin
@@ -9,12 +10,20 @@
from scrapy.link import Link
from scrapy.utils.python import unique as unique_list
+from scrapy.exceptions import ScrapyDeprecationWarning
+
class HtmlParserLinkExtractor(HTMLParser):
def __init__(self, tag="a", attr="href", process=None, unique=False):
HTMLParser.__init__(self)
+ warnings.warn(
+ "HtmlParserLinkExtractor is deprecated and will be removed in "
+ "future releases. Please use scrapy.linkextractors.LinkExtractor",
+ ScrapyDeprecationWarning, stacklevel=2,
+ )
+
self.scan_tag = tag if callable(tag) else lambda t: t == tag
self.scan_attr = attr if callable(attr) else lambda a: a == attr
self.process_attr = process if callable(process) else lambda v: v
diff --git a/scrapy/linkextractors/sgml.py b/scrapy/linkextractors/sgml.py
--- a/scrapy/linkextractors/sgml.py
+++ b/scrapy/linkextractors/sgml.py
@@ -21,7 +21,7 @@
warnings.warn(
"BaseSgmlLinkExtractor is deprecated and will be removed in future releases. "
"Please use scrapy.linkextractors.LinkExtractor",
- ScrapyDeprecationWarning
+ ScrapyDeprecationWarning, stacklevel=2,
)
SGMLParser.__init__(self)
self.scan_tag = tag if callable(tag) else lambda t: t == tag
@@ -104,7 +104,7 @@
warnings.warn(
"SgmlLinkExtractor is deprecated and will be removed in future releases. "
"Please use scrapy.linkextractors.LinkExtractor",
- ScrapyDeprecationWarning
+ ScrapyDeprecationWarning, stacklevel=2,
)
tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))
|
{"golden_diff": "diff --git a/scrapy/linkextractors/htmlparser.py b/scrapy/linkextractors/htmlparser.py\n--- a/scrapy/linkextractors/htmlparser.py\n+++ b/scrapy/linkextractors/htmlparser.py\n@@ -2,6 +2,7 @@\n HTMLParser-based link extractor\n \"\"\"\n \n+import warnings\n from HTMLParser import HTMLParser\n from six.moves.urllib.parse import urljoin\n \n@@ -9,12 +10,20 @@\n \n from scrapy.link import Link\n from scrapy.utils.python import unique as unique_list\n+from scrapy.exceptions import ScrapyDeprecationWarning\n+\n \n class HtmlParserLinkExtractor(HTMLParser):\n \n def __init__(self, tag=\"a\", attr=\"href\", process=None, unique=False):\n HTMLParser.__init__(self)\n \n+ warnings.warn(\n+ \"HtmlParserLinkExtractor is deprecated and will be removed in \"\n+ \"future releases. Please use scrapy.linkextractors.LinkExtractor\",\n+ ScrapyDeprecationWarning, stacklevel=2,\n+ )\n+\n self.scan_tag = tag if callable(tag) else lambda t: t == tag\n self.scan_attr = attr if callable(attr) else lambda a: a == attr\n self.process_attr = process if callable(process) else lambda v: v\ndiff --git a/scrapy/linkextractors/sgml.py b/scrapy/linkextractors/sgml.py\n--- a/scrapy/linkextractors/sgml.py\n+++ b/scrapy/linkextractors/sgml.py\n@@ -21,7 +21,7 @@\n warnings.warn(\n \"BaseSgmlLinkExtractor is deprecated and will be removed in future releases. \"\n \"Please use scrapy.linkextractors.LinkExtractor\",\n- ScrapyDeprecationWarning\n+ ScrapyDeprecationWarning, stacklevel=2,\n )\n SGMLParser.__init__(self)\n self.scan_tag = tag if callable(tag) else lambda t: t == tag\n@@ -104,7 +104,7 @@\n warnings.warn(\n \"SgmlLinkExtractor is deprecated and will be removed in future releases. \"\n \"Please use scrapy.linkextractors.LinkExtractor\",\n- ScrapyDeprecationWarning\n+ ScrapyDeprecationWarning, stacklevel=2,\n )\n \n tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))\n", "issue": "Deprecate htmlparser link extractor\nLet's add a deprecation warning like we did for SGML Link extractor\n\n", "before_files": [{"content": "\"\"\"\nSGMLParser-based Link extractors\n\"\"\"\nfrom six.moves.urllib.parse import urljoin\nimport warnings\nfrom sgmllib import SGMLParser\n\nfrom w3lib.url import safe_url_string\nfrom scrapy.selector import Selector\nfrom scrapy.link import Link\nfrom scrapy.linkextractor import FilteringLinkExtractor\nfrom scrapy.utils.misc import arg_to_iter\nfrom scrapy.utils.python import unique as unique_list, str_to_unicode\nfrom scrapy.utils.response import get_base_url\nfrom scrapy.exceptions import ScrapyDeprecationWarning\n\n\nclass BaseSgmlLinkExtractor(SGMLParser):\n\n def __init__(self, tag=\"a\", attr=\"href\", unique=False, process_value=None):\n warnings.warn(\n \"BaseSgmlLinkExtractor is deprecated and will be removed in future releases. \"\n \"Please use scrapy.linkextractors.LinkExtractor\",\n ScrapyDeprecationWarning\n )\n SGMLParser.__init__(self)\n self.scan_tag = tag if callable(tag) else lambda t: t == tag\n self.scan_attr = attr if callable(attr) else lambda a: a == attr\n self.process_value = (lambda v: v) if process_value is None else process_value\n self.current_link = None\n self.unique = unique\n\n def _extract_links(self, response_text, response_url, response_encoding, base_url=None):\n \"\"\" Do the real extraction work \"\"\"\n self.reset()\n self.feed(response_text)\n self.close()\n\n ret = []\n if base_url is None:\n base_url = urljoin(response_url, self.base_url) if self.base_url else response_url\n for link in self.links:\n if isinstance(link.url, unicode):\n link.url = link.url.encode(response_encoding)\n link.url = urljoin(base_url, link.url)\n link.url = safe_url_string(link.url, response_encoding)\n link.text = str_to_unicode(link.text, response_encoding, errors='replace').strip()\n ret.append(link)\n\n return ret\n\n def _process_links(self, links):\n \"\"\" Normalize and filter extracted links\n\n The subclass should override it if necessary\n \"\"\"\n links = unique_list(links, key=lambda link: link.url) if self.unique else links\n return links\n\n def extract_links(self, response):\n # wrapper needed to allow to work directly with text\n links = self._extract_links(response.body, response.url, response.encoding)\n links = self._process_links(links)\n return links\n\n def reset(self):\n SGMLParser.reset(self)\n self.links = []\n self.base_url = None\n self.current_link = None\n\n def unknown_starttag(self, tag, attrs):\n if tag == 'base':\n self.base_url = dict(attrs).get('href')\n if self.scan_tag(tag):\n for attr, value in attrs:\n if self.scan_attr(attr):\n url = self.process_value(value)\n if url is not None:\n link = Link(url=url, nofollow=True if dict(attrs).get('rel') == 'nofollow' else False)\n self.links.append(link)\n self.current_link = link\n\n def unknown_endtag(self, tag):\n if self.scan_tag(tag):\n self.current_link = None\n\n def handle_data(self, data):\n if self.current_link:\n self.current_link.text = self.current_link.text + data\n\n def matches(self, url):\n \"\"\"This extractor matches with any url, since\n it doesn't contain any patterns\"\"\"\n return True\n\n\nclass SgmlLinkExtractor(FilteringLinkExtractor):\n\n def __init__(self, allow=(), deny=(), allow_domains=(), deny_domains=(), restrict_xpaths=(),\n tags=('a', 'area'), attrs=('href',), canonicalize=True, unique=True,\n process_value=None, deny_extensions=None, restrict_css=()):\n\n warnings.warn(\n \"SgmlLinkExtractor is deprecated and will be removed in future releases. \"\n \"Please use scrapy.linkextractors.LinkExtractor\",\n ScrapyDeprecationWarning\n )\n\n tags, attrs = set(arg_to_iter(tags)), set(arg_to_iter(attrs))\n tag_func = lambda x: x in tags\n attr_func = lambda x: x in attrs\n\n with warnings.catch_warnings(record=True):\n lx = BaseSgmlLinkExtractor(tag=tag_func, attr=attr_func,\n unique=unique, process_value=process_value)\n\n super(SgmlLinkExtractor, self).__init__(lx, allow=allow, deny=deny,\n allow_domains=allow_domains, deny_domains=deny_domains,\n restrict_xpaths=restrict_xpaths, restrict_css=restrict_css,\n canonicalize=canonicalize, deny_extensions=deny_extensions)\n\n # FIXME: was added to fix a RegexLinkExtractor testcase\n self.base_url = None\n\n def extract_links(self, response):\n base_url = None\n if self.restrict_xpaths:\n sel = Selector(response)\n base_url = get_base_url(response)\n body = u''.join(f\n for x in self.restrict_xpaths\n for f in sel.xpath(x).extract()\n ).encode(response.encoding, errors='xmlcharrefreplace')\n else:\n body = response.body\n\n links = self._extract_links(body, response.url, response.encoding, base_url)\n links = self._process_links(links)\n return links\n", "path": "scrapy/linkextractors/sgml.py"}, {"content": "\"\"\"\nHTMLParser-based link extractor\n\"\"\"\n\nfrom HTMLParser import HTMLParser\nfrom six.moves.urllib.parse import urljoin\n\nfrom w3lib.url import safe_url_string\n\nfrom scrapy.link import Link\nfrom scrapy.utils.python import unique as unique_list\n\nclass HtmlParserLinkExtractor(HTMLParser):\n\n def __init__(self, tag=\"a\", attr=\"href\", process=None, unique=False):\n HTMLParser.__init__(self)\n\n self.scan_tag = tag if callable(tag) else lambda t: t == tag\n self.scan_attr = attr if callable(attr) else lambda a: a == attr\n self.process_attr = process if callable(process) else lambda v: v\n self.unique = unique\n\n def _extract_links(self, response_text, response_url, response_encoding):\n self.reset()\n self.feed(response_text)\n self.close()\n\n links = unique_list(self.links, key=lambda link: link.url) if self.unique else self.links\n\n ret = []\n base_url = urljoin(response_url, self.base_url) if self.base_url else response_url\n for link in links:\n if isinstance(link.url, unicode):\n link.url = link.url.encode(response_encoding)\n link.url = urljoin(base_url, link.url)\n link.url = safe_url_string(link.url, response_encoding)\n link.text = link.text.decode(response_encoding)\n ret.append(link)\n\n return ret\n\n def extract_links(self, response):\n # wrapper needed to allow to work directly with text\n return self._extract_links(response.body, response.url, response.encoding)\n\n def reset(self):\n HTMLParser.reset(self)\n\n self.base_url = None\n self.current_link = None\n self.links = []\n\n def handle_starttag(self, tag, attrs):\n if tag == 'base':\n self.base_url = dict(attrs).get('href')\n if self.scan_tag(tag):\n for attr, value in attrs:\n if self.scan_attr(attr):\n url = self.process_attr(value)\n link = Link(url=url)\n self.links.append(link)\n self.current_link = link\n\n def handle_endtag(self, tag):\n if self.scan_tag(tag):\n self.current_link = None\n\n def handle_data(self, data):\n if self.current_link:\n self.current_link.text = self.current_link.text + data\n\n def matches(self, url):\n \"\"\"This extractor matches with any url, since\n it doesn't contain any patterns\"\"\"\n return True\n", "path": "scrapy/linkextractors/htmlparser.py"}]}
| 2,727 | 508 |
gh_patches_debug_34719
|
rasdani/github-patches
|
git_diff
|
aio-libs-abandoned__aioredis-py-311
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
aioredis.pubsub.Receiver has no iter() method
The example code (below) references an iter() method on Receiver (here is the [implementation](https://github.com/aio-libs/aioredis/blob/master/aioredis/pubsub.py#L200)).
There is no iter() method on Receiver. What is the correct implementation of listening on all Receiver's subscribed channels?
code:
```
>>> from aioredis.pubsub import Receiver
>>> from aioredis.abc import AbcChannel
>>> mpsc = Receiver(loop=loop)
>>> async def reader(mpsc):
... async for channel, msg in mpsc.iter():
... assert isinstance(channel, AbcChannel)
... print("Got {!r} in channel {!r}".format(msg, channel))
>>> asyncio.ensure_future(reader(mpsc))
>>> await redis.subscribe(mpsc.channel('channel:1'),
... mpsc.channel('channel:3'))
... mpsc.channel('channel:5'))
>>> await redis.psubscribe(mpsc.pattern('hello'))
>>> # publishing 'Hello world' into 'hello-channel'
>>> # will print this message:
Got b'Hello world' in channel b'hello-channel'
>>> # when all is done:
>>> await redis.unsubscribe('channel:1', 'channel:3', 'channel:5')
>>> await redis.punsubscribe('hello')
>>> mpsc.stop()
>>> # any message received after stop() will be ignored.
```
</issue>
<code>
[start of aioredis/commands/__init__.py]
1 import asyncio
2 import warnings
3
4 from aioredis.connection import create_connection
5 from aioredis.pool import create_pool
6 from aioredis.util import _NOTSET
7 from .generic import GenericCommandsMixin
8 from .string import StringCommandsMixin
9 from .hash import HashCommandsMixin
10 from .hyperloglog import HyperLogLogCommandsMixin
11 from .set import SetCommandsMixin
12 from .sorted_set import SortedSetCommandsMixin
13 from .transaction import TransactionsCommandsMixin, Pipeline, MultiExec
14 from .list import ListCommandsMixin
15 from .scripting import ScriptingCommandsMixin
16 from .server import ServerCommandsMixin
17 from .pubsub import PubSubCommandsMixin
18 from .cluster import ClusterCommandsMixin
19 from .geo import GeoCommandsMixin, GeoPoint, GeoMember
20
21 __all__ = [
22 'create_redis',
23 'create_redis_pool',
24 'Redis',
25 'Pipeline',
26 'MultiExec',
27 'GeoPoint',
28 'GeoMember',
29 ]
30
31
32 class Redis(GenericCommandsMixin, StringCommandsMixin,
33 HyperLogLogCommandsMixin, SetCommandsMixin,
34 HashCommandsMixin, TransactionsCommandsMixin,
35 SortedSetCommandsMixin, ListCommandsMixin,
36 ScriptingCommandsMixin, ServerCommandsMixin,
37 PubSubCommandsMixin, ClusterCommandsMixin,
38 GeoCommandsMixin):
39 """High-level Redis interface.
40
41 Gathers in one place Redis commands implemented in mixins.
42
43 For commands details see: http://redis.io/commands/#connection
44 """
45 def __init__(self, pool_or_conn):
46 self._pool_or_conn = pool_or_conn
47
48 def __repr__(self):
49 return '<Redis {!r}>'.format(self._pool_or_conn)
50
51 def execute(self, command, *args, **kwargs):
52 return self._pool_or_conn.execute(command, *args, **kwargs)
53
54 def close(self):
55 """Close client connections."""
56 self._pool_or_conn.close()
57
58 @asyncio.coroutine
59 def wait_closed(self):
60 """Coroutine waiting until underlying connections are closed."""
61 yield from self._pool_or_conn.wait_closed()
62
63 @property
64 def db(self):
65 """Currently selected db index."""
66 return self._pool_or_conn.db
67
68 @property
69 def encoding(self):
70 """Current set codec or None."""
71 return self._pool_or_conn.encoding
72
73 @property
74 def connection(self):
75 """Either :class:`aioredis.RedisConnection`,
76 or :class:`aioredis.ConnectionsPool` instance.
77 """
78 return self._pool_or_conn
79
80 @property
81 def address(self):
82 """Redis connection address (if applicable)."""
83 return self._pool_or_conn.address
84
85 @property
86 def in_transaction(self):
87 """Set to True when MULTI command was issued."""
88 # XXX: this must be bound to real connection
89 return self._pool_or_conn.in_transaction
90
91 @property
92 def closed(self):
93 """True if connection is closed."""
94 return self._pool_or_conn.closed
95
96 def auth(self, password):
97 """Authenticate to server.
98
99 This method wraps call to :meth:`aioredis.RedisConnection.auth()`
100 """
101 return self._pool_or_conn.auth(password)
102
103 def echo(self, message, *, encoding=_NOTSET):
104 """Echo the given string."""
105 return self.execute('ECHO', message, encoding=encoding)
106
107 def ping(self, message=_NOTSET, *, encoding=_NOTSET):
108 """Ping the server.
109
110 Accept optional echo message.
111 """
112 if message is not _NOTSET:
113 args = (message,)
114 else:
115 args = ()
116 return self.execute('PING', *args, encoding=encoding)
117
118 def quit(self):
119 """Close the connection."""
120 # TODO: warn when using pool
121 return self.execute('QUIT')
122
123 def select(self, db):
124 """Change the selected database for the current connection.
125
126 This method wraps call to :meth:`aioredis.RedisConnection.select()`
127 """
128 return self._pool_or_conn.select(db)
129
130 def __enter__(self):
131 # TODO: warn it is obsolete way
132 warnings.warn("It is not recommended way to use Redis instance"
133 " as a context manager. Use Redis.<command> directly")
134 return self
135
136 def __exit__(self, *args):
137 pass
138
139 def __iter__(self):
140 return self
141 yield
142
143
144 @asyncio.coroutine
145 def create_redis(address, *, db=None, password=None, ssl=None,
146 encoding=None, commands_factory=Redis,
147 parser=None, timeout=None,
148 connection_cls=None, loop=None):
149 """Creates high-level Redis interface.
150
151 This function is a coroutine.
152 """
153 conn = yield from create_connection(address, db=db,
154 password=password,
155 ssl=ssl,
156 encoding=encoding,
157 parser=parser,
158 timeout=timeout,
159 connection_cls=connection_cls,
160 loop=loop)
161 return commands_factory(conn)
162
163
164 @asyncio.coroutine
165 def create_redis_pool(address, *, db=None, password=None, ssl=None,
166 encoding=None, commands_factory=Redis,
167 minsize=1, maxsize=10, parser=None,
168 timeout=None, pool_cls=None,
169 connection_cls=None, loop=None):
170 """Creates high-level Redis interface.
171
172 This function is a coroutine.
173 """
174 pool = yield from create_pool(address, db=db,
175 password=password,
176 ssl=ssl,
177 encoding=encoding,
178 minsize=minsize,
179 maxsize=maxsize,
180 parser=parser,
181 create_connection_timeout=timeout,
182 pool_cls=pool_cls,
183 connection_cls=connection_cls,
184 loop=loop)
185 return commands_factory(pool)
186
[end of aioredis/commands/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aioredis/commands/__init__.py b/aioredis/commands/__init__.py
--- a/aioredis/commands/__init__.py
+++ b/aioredis/commands/__init__.py
@@ -1,9 +1,10 @@
import asyncio
-import warnings
+# import warnings
from aioredis.connection import create_connection
from aioredis.pool import create_pool
from aioredis.util import _NOTSET
+from aioredis.abc import AbcPool
from .generic import GenericCommandsMixin
from .string import StringCommandsMixin
from .hash import HashCommandsMixin
@@ -46,7 +47,7 @@
self._pool_or_conn = pool_or_conn
def __repr__(self):
- return '<Redis {!r}>'.format(self._pool_or_conn)
+ return '<{} {!r}>'.format(self.__class__.__name__, self._pool_or_conn)
def execute(self, command, *args, **kwargs):
return self._pool_or_conn.execute(command, *args, **kwargs)
@@ -127,18 +128,38 @@
"""
return self._pool_or_conn.select(db)
+ def __await__(self):
+ if isinstance(self._pool_or_conn, AbcPool):
+ conn = yield from self._pool_or_conn.acquire()
+ release = self._pool_or_conn.release
+ else:
+ # TODO: probably a lock is needed here if _pool_or_conn
+ # is Connection instance.
+ conn = self._pool_or_conn
+ release = None
+ return ContextRedis(conn, release)
+ __iter__ = __await__
+
+
+class ContextRedis(Redis):
+ """An instance of Redis class bound to single connection."""
+
+ def __init__(self, conn, release_cb=None):
+ super().__init__(conn)
+ self._release_callback = release_cb
+
def __enter__(self):
- # TODO: warn it is obsolete way
- warnings.warn("It is not recommended way to use Redis instance"
- " as a context manager. Use Redis.<command> directly")
return self
- def __exit__(self, *args):
- pass
+ def __exit__(self, *exc_info):
+ if self._release_callback is not None:
+ conn, self._pool_or_conn = self._pool_or_conn, None
+ self._release_callback(conn)
- def __iter__(self):
- return self
+ def __await__(self):
+ return ContextRedis(self._pool_or_conn)
yield
+ __iter__ = __await__
@asyncio.coroutine
|
{"golden_diff": "diff --git a/aioredis/commands/__init__.py b/aioredis/commands/__init__.py\n--- a/aioredis/commands/__init__.py\n+++ b/aioredis/commands/__init__.py\n@@ -1,9 +1,10 @@\n import asyncio\n-import warnings\n+# import warnings\n \n from aioredis.connection import create_connection\n from aioredis.pool import create_pool\n from aioredis.util import _NOTSET\n+from aioredis.abc import AbcPool\n from .generic import GenericCommandsMixin\n from .string import StringCommandsMixin\n from .hash import HashCommandsMixin\n@@ -46,7 +47,7 @@\n self._pool_or_conn = pool_or_conn\n \n def __repr__(self):\n- return '<Redis {!r}>'.format(self._pool_or_conn)\n+ return '<{} {!r}>'.format(self.__class__.__name__, self._pool_or_conn)\n \n def execute(self, command, *args, **kwargs):\n return self._pool_or_conn.execute(command, *args, **kwargs)\n@@ -127,18 +128,38 @@\n \"\"\"\n return self._pool_or_conn.select(db)\n \n+ def __await__(self):\n+ if isinstance(self._pool_or_conn, AbcPool):\n+ conn = yield from self._pool_or_conn.acquire()\n+ release = self._pool_or_conn.release\n+ else:\n+ # TODO: probably a lock is needed here if _pool_or_conn\n+ # is Connection instance.\n+ conn = self._pool_or_conn\n+ release = None\n+ return ContextRedis(conn, release)\n+ __iter__ = __await__\n+\n+\n+class ContextRedis(Redis):\n+ \"\"\"An instance of Redis class bound to single connection.\"\"\"\n+\n+ def __init__(self, conn, release_cb=None):\n+ super().__init__(conn)\n+ self._release_callback = release_cb\n+\n def __enter__(self):\n- # TODO: warn it is obsolete way\n- warnings.warn(\"It is not recommended way to use Redis instance\"\n- \" as a context manager. Use Redis.<command> directly\")\n return self\n \n- def __exit__(self, *args):\n- pass\n+ def __exit__(self, *exc_info):\n+ if self._release_callback is not None:\n+ conn, self._pool_or_conn = self._pool_or_conn, None\n+ self._release_callback(conn)\n \n- def __iter__(self):\n- return self\n+ def __await__(self):\n+ return ContextRedis(self._pool_or_conn)\n yield\n+ __iter__ = __await__\n \n \n @asyncio.coroutine\n", "issue": "aioredis.pubsub.Receiver has no iter() method\nThe example code (below) references an iter() method on Receiver (here is the [implementation](https://github.com/aio-libs/aioredis/blob/master/aioredis/pubsub.py#L200)).\r\n\r\nThere is no iter() method on Receiver. What is the correct implementation of listening on all Receiver's subscribed channels?\r\n\r\ncode:\r\n```\r\n>>> from aioredis.pubsub import Receiver\r\n>>> from aioredis.abc import AbcChannel\r\n>>> mpsc = Receiver(loop=loop)\r\n>>> async def reader(mpsc):\r\n... async for channel, msg in mpsc.iter():\r\n... assert isinstance(channel, AbcChannel)\r\n... print(\"Got {!r} in channel {!r}\".format(msg, channel))\r\n>>> asyncio.ensure_future(reader(mpsc))\r\n>>> await redis.subscribe(mpsc.channel('channel:1'),\r\n... mpsc.channel('channel:3'))\r\n... mpsc.channel('channel:5'))\r\n>>> await redis.psubscribe(mpsc.pattern('hello'))\r\n>>> # publishing 'Hello world' into 'hello-channel'\r\n>>> # will print this message:\r\nGot b'Hello world' in channel b'hello-channel'\r\n>>> # when all is done:\r\n>>> await redis.unsubscribe('channel:1', 'channel:3', 'channel:5')\r\n>>> await redis.punsubscribe('hello')\r\n>>> mpsc.stop()\r\n>>> # any message received after stop() will be ignored.\r\n```\n", "before_files": [{"content": "import asyncio\nimport warnings\n\nfrom aioredis.connection import create_connection\nfrom aioredis.pool import create_pool\nfrom aioredis.util import _NOTSET\nfrom .generic import GenericCommandsMixin\nfrom .string import StringCommandsMixin\nfrom .hash import HashCommandsMixin\nfrom .hyperloglog import HyperLogLogCommandsMixin\nfrom .set import SetCommandsMixin\nfrom .sorted_set import SortedSetCommandsMixin\nfrom .transaction import TransactionsCommandsMixin, Pipeline, MultiExec\nfrom .list import ListCommandsMixin\nfrom .scripting import ScriptingCommandsMixin\nfrom .server import ServerCommandsMixin\nfrom .pubsub import PubSubCommandsMixin\nfrom .cluster import ClusterCommandsMixin\nfrom .geo import GeoCommandsMixin, GeoPoint, GeoMember\n\n__all__ = [\n 'create_redis',\n 'create_redis_pool',\n 'Redis',\n 'Pipeline',\n 'MultiExec',\n 'GeoPoint',\n 'GeoMember',\n]\n\n\nclass Redis(GenericCommandsMixin, StringCommandsMixin,\n HyperLogLogCommandsMixin, SetCommandsMixin,\n HashCommandsMixin, TransactionsCommandsMixin,\n SortedSetCommandsMixin, ListCommandsMixin,\n ScriptingCommandsMixin, ServerCommandsMixin,\n PubSubCommandsMixin, ClusterCommandsMixin,\n GeoCommandsMixin):\n \"\"\"High-level Redis interface.\n\n Gathers in one place Redis commands implemented in mixins.\n\n For commands details see: http://redis.io/commands/#connection\n \"\"\"\n def __init__(self, pool_or_conn):\n self._pool_or_conn = pool_or_conn\n\n def __repr__(self):\n return '<Redis {!r}>'.format(self._pool_or_conn)\n\n def execute(self, command, *args, **kwargs):\n return self._pool_or_conn.execute(command, *args, **kwargs)\n\n def close(self):\n \"\"\"Close client connections.\"\"\"\n self._pool_or_conn.close()\n\n @asyncio.coroutine\n def wait_closed(self):\n \"\"\"Coroutine waiting until underlying connections are closed.\"\"\"\n yield from self._pool_or_conn.wait_closed()\n\n @property\n def db(self):\n \"\"\"Currently selected db index.\"\"\"\n return self._pool_or_conn.db\n\n @property\n def encoding(self):\n \"\"\"Current set codec or None.\"\"\"\n return self._pool_or_conn.encoding\n\n @property\n def connection(self):\n \"\"\"Either :class:`aioredis.RedisConnection`,\n or :class:`aioredis.ConnectionsPool` instance.\n \"\"\"\n return self._pool_or_conn\n\n @property\n def address(self):\n \"\"\"Redis connection address (if applicable).\"\"\"\n return self._pool_or_conn.address\n\n @property\n def in_transaction(self):\n \"\"\"Set to True when MULTI command was issued.\"\"\"\n # XXX: this must be bound to real connection\n return self._pool_or_conn.in_transaction\n\n @property\n def closed(self):\n \"\"\"True if connection is closed.\"\"\"\n return self._pool_or_conn.closed\n\n def auth(self, password):\n \"\"\"Authenticate to server.\n\n This method wraps call to :meth:`aioredis.RedisConnection.auth()`\n \"\"\"\n return self._pool_or_conn.auth(password)\n\n def echo(self, message, *, encoding=_NOTSET):\n \"\"\"Echo the given string.\"\"\"\n return self.execute('ECHO', message, encoding=encoding)\n\n def ping(self, message=_NOTSET, *, encoding=_NOTSET):\n \"\"\"Ping the server.\n\n Accept optional echo message.\n \"\"\"\n if message is not _NOTSET:\n args = (message,)\n else:\n args = ()\n return self.execute('PING', *args, encoding=encoding)\n\n def quit(self):\n \"\"\"Close the connection.\"\"\"\n # TODO: warn when using pool\n return self.execute('QUIT')\n\n def select(self, db):\n \"\"\"Change the selected database for the current connection.\n\n This method wraps call to :meth:`aioredis.RedisConnection.select()`\n \"\"\"\n return self._pool_or_conn.select(db)\n\n def __enter__(self):\n # TODO: warn it is obsolete way\n warnings.warn(\"It is not recommended way to use Redis instance\"\n \" as a context manager. Use Redis.<command> directly\")\n return self\n\n def __exit__(self, *args):\n pass\n\n def __iter__(self):\n return self\n yield\n\n\[email protected]\ndef create_redis(address, *, db=None, password=None, ssl=None,\n encoding=None, commands_factory=Redis,\n parser=None, timeout=None,\n connection_cls=None, loop=None):\n \"\"\"Creates high-level Redis interface.\n\n This function is a coroutine.\n \"\"\"\n conn = yield from create_connection(address, db=db,\n password=password,\n ssl=ssl,\n encoding=encoding,\n parser=parser,\n timeout=timeout,\n connection_cls=connection_cls,\n loop=loop)\n return commands_factory(conn)\n\n\[email protected]\ndef create_redis_pool(address, *, db=None, password=None, ssl=None,\n encoding=None, commands_factory=Redis,\n minsize=1, maxsize=10, parser=None,\n timeout=None, pool_cls=None,\n connection_cls=None, loop=None):\n \"\"\"Creates high-level Redis interface.\n\n This function is a coroutine.\n \"\"\"\n pool = yield from create_pool(address, db=db,\n password=password,\n ssl=ssl,\n encoding=encoding,\n minsize=minsize,\n maxsize=maxsize,\n parser=parser,\n create_connection_timeout=timeout,\n pool_cls=pool_cls,\n connection_cls=connection_cls,\n loop=loop)\n return commands_factory(pool)\n", "path": "aioredis/commands/__init__.py"}]}
| 2,511 | 597 |
gh_patches_debug_9375
|
rasdani/github-patches
|
git_diff
|
readthedocs__readthedocs.org-2304
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MkDocs's media url shouldn't be hardcode with media_url = 'http://localhost:8000' + media_url
In file `readthedocs.org/readthedocs/doc_builder/backends/mkdocs.py`:
``` python
55 # Set mkdocs config values
56
57 media_url = getattr(settings, 'MEDIA_URL', 'https://media.readthedocs.org')
58
59 # Mkdocs needs a full domain here because it tries to link to local media files
60 if not media_url.startswith('http'):
61 media_url = 'http://localhost:8000' + media_url
```
Can u please to replace it with `SITE_URL` as the follows:
``` python
59 # Mkdocs needs a full domain here because it tries to link to local media files
60 if not media_url.startswith('http'):
61 media_url = getattr(settings, 'SITE_URL', None) + media_url
```
</issue>
<code>
[start of readthedocs/doc_builder/backends/mkdocs.py]
1 import os
2 import logging
3 import json
4 import yaml
5
6 from django.conf import settings
7 from django.template import Context, loader as template_loader
8
9 from readthedocs.doc_builder.base import BaseBuilder
10
11 log = logging.getLogger(__name__)
12
13 TEMPLATE_DIR = '%s/readthedocs/templates/mkdocs/readthedocs' % settings.SITE_ROOT
14 OVERRIDE_TEMPLATE_DIR = '%s/readthedocs/templates/mkdocs/overrides' % settings.SITE_ROOT
15
16
17 class BaseMkdocs(BaseBuilder):
18
19 """
20 Mkdocs builder
21 """
22 use_theme = True
23
24 def __init__(self, *args, **kwargs):
25 super(BaseMkdocs, self).__init__(*args, **kwargs)
26 self.old_artifact_path = os.path.join(
27 self.version.project.checkout_path(self.version.slug),
28 self.build_dir)
29 self.root_path = self.version.project.checkout_path(self.version.slug)
30
31 def append_conf(self, **kwargs):
32 """
33 Set mkdocs config values
34 """
35
36 # Pull mkdocs config data
37 try:
38 user_config = yaml.safe_load(
39 open(os.path.join(self.root_path, 'mkdocs.yml'), 'r')
40 )
41 except IOError:
42 user_config = {
43 'site_name': self.version.project.name,
44 }
45
46 # Handle custom docs dirs
47
48 user_docs_dir = user_config.get('docs_dir')
49 if user_docs_dir:
50 user_docs_dir = os.path.join(self.root_path, user_docs_dir)
51 docs_dir = self.docs_dir(docs_dir=user_docs_dir)
52 self.create_index(extension='md')
53 user_config['docs_dir'] = docs_dir
54
55 # Set mkdocs config values
56
57 media_url = getattr(settings, 'MEDIA_URL', 'https://media.readthedocs.org')
58
59 # Mkdocs needs a full domain here because it tries to link to local media files
60 if not media_url.startswith('http'):
61 media_url = 'http://localhost:8000' + media_url
62
63 if 'extra_javascript' in user_config:
64 user_config['extra_javascript'].append('readthedocs-data.js')
65 user_config['extra_javascript'].append(
66 'readthedocs-dynamic-include.js')
67 user_config['extra_javascript'].append(
68 '%sjavascript/readthedocs-doc-embed.js' % media_url)
69 else:
70 user_config['extra_javascript'] = [
71 'readthedocs-data.js',
72 'readthedocs-dynamic-include.js',
73 '%sjavascript/readthedocs-doc-embed.js' % media_url,
74 ]
75
76 if 'extra_css' in user_config:
77 user_config['extra_css'].append(
78 '%s/css/badge_only.css' % media_url)
79 user_config['extra_css'].append(
80 '%s/css/readthedocs-doc-embed.css' % media_url)
81 else:
82 user_config['extra_css'] = [
83 '%scss/badge_only.css' % media_url,
84 '%scss/readthedocs-doc-embed.css' % media_url,
85 ]
86
87 # Set our custom theme dir for mkdocs
88 if 'theme_dir' not in user_config and self.use_theme:
89 user_config['theme_dir'] = TEMPLATE_DIR
90
91 yaml.dump(
92 user_config,
93 open(os.path.join(self.root_path, 'mkdocs.yml'), 'w')
94 )
95
96 # RTD javascript writing
97
98 # Will be available in the JavaScript as READTHEDOCS_DATA.
99 readthedocs_data = {
100 'project': self.version.project.slug,
101 'version': self.version.slug,
102 'language': self.version.project.language,
103 'page': None,
104 'theme': "readthedocs",
105 'builder': "mkdocs",
106 'docroot': docs_dir,
107 'source_suffix': ".md",
108 'api_host': getattr(settings, 'PUBLIC_API_URL',
109 'https://readthedocs.org'),
110 'commit': self.version.project.vcs_repo(self.version.slug).commit,
111 }
112 data_json = json.dumps(readthedocs_data, indent=4)
113 data_ctx = {
114 'data_json': data_json,
115 'current_version': readthedocs_data['version'],
116 'slug': readthedocs_data['project'],
117 'html_theme': readthedocs_data['theme'],
118 'pagename': None,
119 }
120 data_string = template_loader.get_template(
121 'doc_builder/data.js.tmpl'
122 ).render(data_ctx)
123
124 data_file = open(os.path.join(self.root_path, docs_dir, 'readthedocs-data.js'), 'w+')
125 data_file.write(data_string)
126 data_file.write('''
127 READTHEDOCS_DATA["page"] = mkdocs_page_input_path.substr(
128 0, mkdocs_page_input_path.lastIndexOf(READTHEDOCS_DATA.source_suffix));
129 ''')
130 data_file.close()
131
132 include_ctx = {
133 'global_analytics_code': getattr(settings, 'GLOBAL_ANALYTICS_CODE', 'UA-17997319-1'),
134 'user_analytics_code': self.version.project.analytics_code,
135 }
136 include_string = template_loader.get_template(
137 'doc_builder/include.js.tmpl'
138 ).render(include_ctx)
139 include_file = open(
140 os.path.join(self.root_path, docs_dir, 'readthedocs-dynamic-include.js'),
141 'w+'
142 )
143 include_file.write(include_string)
144 include_file.close()
145
146 def build(self, **kwargs):
147 checkout_path = self.project.checkout_path(self.version.slug)
148 build_command = [
149 'python',
150 self.python_env.venv_bin(filename='mkdocs'),
151 self.builder,
152 '--clean',
153 '--site-dir', self.build_dir,
154 ]
155 if self.use_theme:
156 build_command.extend(['--theme', 'readthedocs'])
157 cmd_ret = self.run(
158 *build_command,
159 cwd=checkout_path,
160 bin_path=self.python_env.venv_bin()
161 )
162 return cmd_ret.successful
163
164
165 class MkdocsHTML(BaseMkdocs):
166 type = 'mkdocs'
167 builder = 'build'
168 build_dir = '_build/html'
169
170
171 class MkdocsJSON(BaseMkdocs):
172 type = 'mkdocs_json'
173 builder = 'json'
174 build_dir = '_build/json'
175 use_theme = False
176
177 def build(self, **kwargs):
178 user_config = yaml.safe_load(
179 open(os.path.join(self.root_path, 'mkdocs.yml'), 'r')
180 )
181 if user_config['theme_dir'] == TEMPLATE_DIR:
182 del user_config['theme_dir']
183 yaml.dump(
184 user_config,
185 open(os.path.join(self.root_path, 'mkdocs.yml'), 'w')
186 )
187 super(MkdocsJSON, self).build(**kwargs)
188
[end of readthedocs/doc_builder/backends/mkdocs.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/readthedocs/doc_builder/backends/mkdocs.py b/readthedocs/doc_builder/backends/mkdocs.py
--- a/readthedocs/doc_builder/backends/mkdocs.py
+++ b/readthedocs/doc_builder/backends/mkdocs.py
@@ -58,7 +58,8 @@
# Mkdocs needs a full domain here because it tries to link to local media files
if not media_url.startswith('http'):
- media_url = 'http://localhost:8000' + media_url
+ domain = getattr(settings, 'PRODUCTION_DOMAIN')
+ media_url = 'http://{}/{}'.format(domain, media_url)
if 'extra_javascript' in user_config:
user_config['extra_javascript'].append('readthedocs-data.js')
|
{"golden_diff": "diff --git a/readthedocs/doc_builder/backends/mkdocs.py b/readthedocs/doc_builder/backends/mkdocs.py\n--- a/readthedocs/doc_builder/backends/mkdocs.py\n+++ b/readthedocs/doc_builder/backends/mkdocs.py\n@@ -58,7 +58,8 @@\n \n # Mkdocs needs a full domain here because it tries to link to local media files\n if not media_url.startswith('http'):\n- media_url = 'http://localhost:8000' + media_url\n+ domain = getattr(settings, 'PRODUCTION_DOMAIN')\n+ media_url = 'http://{}/{}'.format(domain, media_url)\n \n if 'extra_javascript' in user_config:\n user_config['extra_javascript'].append('readthedocs-data.js')\n", "issue": "MkDocs's media url shouldn't be hardcode with media_url = 'http://localhost:8000' + media_url\nIn file `readthedocs.org/readthedocs/doc_builder/backends/mkdocs.py`:\n\n``` python\n55 # Set mkdocs config values\n56\n57 media_url = getattr(settings, 'MEDIA_URL', 'https://media.readthedocs.org')\n58\n59 # Mkdocs needs a full domain here because it tries to link to local media files\n60 if not media_url.startswith('http'):\n61 media_url = 'http://localhost:8000' + media_url\n```\n\nCan u please to replace it with `SITE_URL` as the follows:\n\n``` python\n59 # Mkdocs needs a full domain here because it tries to link to local media files\n60 if not media_url.startswith('http'):\n61 media_url = getattr(settings, 'SITE_URL', None) + media_url\n```\n\n", "before_files": [{"content": "import os\nimport logging\nimport json\nimport yaml\n\nfrom django.conf import settings\nfrom django.template import Context, loader as template_loader\n\nfrom readthedocs.doc_builder.base import BaseBuilder\n\nlog = logging.getLogger(__name__)\n\nTEMPLATE_DIR = '%s/readthedocs/templates/mkdocs/readthedocs' % settings.SITE_ROOT\nOVERRIDE_TEMPLATE_DIR = '%s/readthedocs/templates/mkdocs/overrides' % settings.SITE_ROOT\n\n\nclass BaseMkdocs(BaseBuilder):\n\n \"\"\"\n Mkdocs builder\n \"\"\"\n use_theme = True\n\n def __init__(self, *args, **kwargs):\n super(BaseMkdocs, self).__init__(*args, **kwargs)\n self.old_artifact_path = os.path.join(\n self.version.project.checkout_path(self.version.slug),\n self.build_dir)\n self.root_path = self.version.project.checkout_path(self.version.slug)\n\n def append_conf(self, **kwargs):\n \"\"\"\n Set mkdocs config values\n \"\"\"\n\n # Pull mkdocs config data\n try:\n user_config = yaml.safe_load(\n open(os.path.join(self.root_path, 'mkdocs.yml'), 'r')\n )\n except IOError:\n user_config = {\n 'site_name': self.version.project.name,\n }\n\n # Handle custom docs dirs\n\n user_docs_dir = user_config.get('docs_dir')\n if user_docs_dir:\n user_docs_dir = os.path.join(self.root_path, user_docs_dir)\n docs_dir = self.docs_dir(docs_dir=user_docs_dir)\n self.create_index(extension='md')\n user_config['docs_dir'] = docs_dir\n\n # Set mkdocs config values\n\n media_url = getattr(settings, 'MEDIA_URL', 'https://media.readthedocs.org')\n\n # Mkdocs needs a full domain here because it tries to link to local media files\n if not media_url.startswith('http'):\n media_url = 'http://localhost:8000' + media_url\n\n if 'extra_javascript' in user_config:\n user_config['extra_javascript'].append('readthedocs-data.js')\n user_config['extra_javascript'].append(\n 'readthedocs-dynamic-include.js')\n user_config['extra_javascript'].append(\n '%sjavascript/readthedocs-doc-embed.js' % media_url)\n else:\n user_config['extra_javascript'] = [\n 'readthedocs-data.js',\n 'readthedocs-dynamic-include.js',\n '%sjavascript/readthedocs-doc-embed.js' % media_url,\n ]\n\n if 'extra_css' in user_config:\n user_config['extra_css'].append(\n '%s/css/badge_only.css' % media_url)\n user_config['extra_css'].append(\n '%s/css/readthedocs-doc-embed.css' % media_url)\n else:\n user_config['extra_css'] = [\n '%scss/badge_only.css' % media_url,\n '%scss/readthedocs-doc-embed.css' % media_url,\n ]\n\n # Set our custom theme dir for mkdocs\n if 'theme_dir' not in user_config and self.use_theme:\n user_config['theme_dir'] = TEMPLATE_DIR\n\n yaml.dump(\n user_config,\n open(os.path.join(self.root_path, 'mkdocs.yml'), 'w')\n )\n\n # RTD javascript writing\n\n # Will be available in the JavaScript as READTHEDOCS_DATA.\n readthedocs_data = {\n 'project': self.version.project.slug,\n 'version': self.version.slug,\n 'language': self.version.project.language,\n 'page': None,\n 'theme': \"readthedocs\",\n 'builder': \"mkdocs\",\n 'docroot': docs_dir,\n 'source_suffix': \".md\",\n 'api_host': getattr(settings, 'PUBLIC_API_URL',\n 'https://readthedocs.org'),\n 'commit': self.version.project.vcs_repo(self.version.slug).commit,\n }\n data_json = json.dumps(readthedocs_data, indent=4)\n data_ctx = {\n 'data_json': data_json,\n 'current_version': readthedocs_data['version'],\n 'slug': readthedocs_data['project'],\n 'html_theme': readthedocs_data['theme'],\n 'pagename': None,\n }\n data_string = template_loader.get_template(\n 'doc_builder/data.js.tmpl'\n ).render(data_ctx)\n\n data_file = open(os.path.join(self.root_path, docs_dir, 'readthedocs-data.js'), 'w+')\n data_file.write(data_string)\n data_file.write('''\nREADTHEDOCS_DATA[\"page\"] = mkdocs_page_input_path.substr(\n 0, mkdocs_page_input_path.lastIndexOf(READTHEDOCS_DATA.source_suffix));\n''')\n data_file.close()\n\n include_ctx = {\n 'global_analytics_code': getattr(settings, 'GLOBAL_ANALYTICS_CODE', 'UA-17997319-1'),\n 'user_analytics_code': self.version.project.analytics_code,\n }\n include_string = template_loader.get_template(\n 'doc_builder/include.js.tmpl'\n ).render(include_ctx)\n include_file = open(\n os.path.join(self.root_path, docs_dir, 'readthedocs-dynamic-include.js'),\n 'w+'\n )\n include_file.write(include_string)\n include_file.close()\n\n def build(self, **kwargs):\n checkout_path = self.project.checkout_path(self.version.slug)\n build_command = [\n 'python',\n self.python_env.venv_bin(filename='mkdocs'),\n self.builder,\n '--clean',\n '--site-dir', self.build_dir,\n ]\n if self.use_theme:\n build_command.extend(['--theme', 'readthedocs'])\n cmd_ret = self.run(\n *build_command,\n cwd=checkout_path,\n bin_path=self.python_env.venv_bin()\n )\n return cmd_ret.successful\n\n\nclass MkdocsHTML(BaseMkdocs):\n type = 'mkdocs'\n builder = 'build'\n build_dir = '_build/html'\n\n\nclass MkdocsJSON(BaseMkdocs):\n type = 'mkdocs_json'\n builder = 'json'\n build_dir = '_build/json'\n use_theme = False\n\n def build(self, **kwargs):\n user_config = yaml.safe_load(\n open(os.path.join(self.root_path, 'mkdocs.yml'), 'r')\n )\n if user_config['theme_dir'] == TEMPLATE_DIR:\n del user_config['theme_dir']\n yaml.dump(\n user_config,\n open(os.path.join(self.root_path, 'mkdocs.yml'), 'w')\n )\n super(MkdocsJSON, self).build(**kwargs)\n", "path": "readthedocs/doc_builder/backends/mkdocs.py"}]}
| 2,660 | 172 |
gh_patches_debug_4929
|
rasdani/github-patches
|
git_diff
|
carpentries__amy-1283
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add search by github handle to API persons endpoint
Would it be possible to add the functionality to search for people using their github handle through the API? i.e. `https://amy.software-carpentry.org/api/v1/persons/?github=fmichonneau`
</issue>
<code>
[start of api/filters.py]
1 from django_filters import rest_framework as filters
2
3 from workshops.filters import AMYFilterSet
4 from workshops.models import Event, Task, Tag, Person, Badge
5
6
7 def filter_tag_by_name(queryset, name, values):
8 tags = Tag.objects.filter(name__in=values)
9 for tag in tags:
10 queryset = queryset.filter(tags=tag)
11 return queryset
12
13
14 class EventFilter(filters.FilterSet):
15 start_after = filters.DateFilter(name='start', lookup_expr='gte')
16 start_before = filters.DateFilter(name='start', lookup_expr='lte')
17 end_after = filters.DateFilter(name='end', lookup_expr='gte')
18 end_before = filters.DateFilter(name='end', lookup_expr='lte')
19 TAG_CHOICES = Tag.objects.all().values_list('name', 'name')
20 tag = filters.MultipleChoiceFilter(
21 choices=TAG_CHOICES, name='tags', method=filter_tag_by_name,
22 )
23
24 class Meta:
25 model = Event
26 fields = (
27 'completed', 'tag',
28 'start', 'start_before', 'start_after',
29 'end', 'end_before', 'end_after',
30 )
31 order_by = ('-slug', 'slug', 'start', '-start', 'end', '-end')
32
33
34 class TaskFilter(filters.FilterSet):
35 role = filters.CharFilter(name='role__name')
36
37 class Meta:
38 model = Task
39 fields = (
40 'role',
41 )
42
43
44 def filter_instructors(queryset, name, value):
45 instructor_badges = Badge.objects.instructor_badges()
46 if value is True:
47 return queryset.filter(badges__in=instructor_badges)
48 elif value is False:
49 return queryset.exclude(badges__in=instructor_badges)
50 else:
51 return queryset
52
53
54 class PersonFilter(filters.FilterSet):
55 is_instructor = filters.BooleanFilter(method=filter_instructors,
56 label='Is instructor?')
57
58 class Meta:
59 model = Person
60 fields = (
61 'badges', 'username', 'personal', 'middle', 'family', 'email',
62 'may_contact', 'publish_profile',
63 )
64 order_by = (
65 'lastname', '-lastname', 'firstname', '-firstname', 'email',
66 '-email',
67 )
68
69 def get_order_by(self, order_value):
70 if order_value == 'firstname':
71 return ['personal', 'middle', 'family']
72 elif order_value == '-firstname':
73 return ['-personal', '-middle', '-family']
74 elif order_value == 'lastname':
75 return ['family', 'middle', 'personal']
76 elif order_value == '-lastname':
77 return ['-family', '-middle', '-personal']
78 return super().get_order_by(order_value)
79
80
81 class InstructorsOverTimeFilter(AMYFilterSet):
82 badges = filters.ModelMultipleChoiceFilter(
83 queryset=Badge.objects.instructor_badges(),
84 label='Badges',
85 lookup_expr='in',
86 )
87
88 class Meta:
89 model = Person
90 fields = [
91 'badges',
92 ]
93
94
95 class WorkshopsOverTimeFilter(AMYFilterSet):
96 tags = filters.ModelMultipleChoiceFilter(
97 queryset=Tag.objects.all(),
98 label='Events with at least one of the following tags:',
99 )
100
101 class Meta:
102 model = Event
103 fields = [
104 'tags',
105 ]
106
107
108 class LearnersOverTimeFilter(AMYFilterSet):
109 tags = filters.ModelMultipleChoiceFilter(
110 queryset=Tag.objects.all(),
111 label='Events with all the following tags:',
112 conjoined=True,
113 )
114
115 class Meta:
116 model = Event
117 fields = [
118 'tags',
119 ]
120
[end of api/filters.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/api/filters.py b/api/filters.py
--- a/api/filters.py
+++ b/api/filters.py
@@ -59,7 +59,7 @@
model = Person
fields = (
'badges', 'username', 'personal', 'middle', 'family', 'email',
- 'may_contact', 'publish_profile',
+ 'may_contact', 'publish_profile', 'github',
)
order_by = (
'lastname', '-lastname', 'firstname', '-firstname', 'email',
|
{"golden_diff": "diff --git a/api/filters.py b/api/filters.py\n--- a/api/filters.py\n+++ b/api/filters.py\n@@ -59,7 +59,7 @@\n model = Person\n fields = (\n 'badges', 'username', 'personal', 'middle', 'family', 'email',\n- 'may_contact', 'publish_profile',\n+ 'may_contact', 'publish_profile', 'github',\n )\n order_by = (\n 'lastname', '-lastname', 'firstname', '-firstname', 'email',\n", "issue": "Add search by github handle to API persons endpoint\nWould it be possible to add the functionality to search for people using their github handle through the API? i.e. `https://amy.software-carpentry.org/api/v1/persons/?github=fmichonneau`\n", "before_files": [{"content": "from django_filters import rest_framework as filters\n\nfrom workshops.filters import AMYFilterSet\nfrom workshops.models import Event, Task, Tag, Person, Badge\n\n\ndef filter_tag_by_name(queryset, name, values):\n tags = Tag.objects.filter(name__in=values)\n for tag in tags:\n queryset = queryset.filter(tags=tag)\n return queryset\n\n\nclass EventFilter(filters.FilterSet):\n start_after = filters.DateFilter(name='start', lookup_expr='gte')\n start_before = filters.DateFilter(name='start', lookup_expr='lte')\n end_after = filters.DateFilter(name='end', lookup_expr='gte')\n end_before = filters.DateFilter(name='end', lookup_expr='lte')\n TAG_CHOICES = Tag.objects.all().values_list('name', 'name')\n tag = filters.MultipleChoiceFilter(\n choices=TAG_CHOICES, name='tags', method=filter_tag_by_name,\n )\n\n class Meta:\n model = Event\n fields = (\n 'completed', 'tag',\n 'start', 'start_before', 'start_after',\n 'end', 'end_before', 'end_after',\n )\n order_by = ('-slug', 'slug', 'start', '-start', 'end', '-end')\n\n\nclass TaskFilter(filters.FilterSet):\n role = filters.CharFilter(name='role__name')\n\n class Meta:\n model = Task\n fields = (\n 'role',\n )\n\n\ndef filter_instructors(queryset, name, value):\n instructor_badges = Badge.objects.instructor_badges()\n if value is True:\n return queryset.filter(badges__in=instructor_badges)\n elif value is False:\n return queryset.exclude(badges__in=instructor_badges)\n else:\n return queryset\n\n\nclass PersonFilter(filters.FilterSet):\n is_instructor = filters.BooleanFilter(method=filter_instructors,\n label='Is instructor?')\n\n class Meta:\n model = Person\n fields = (\n 'badges', 'username', 'personal', 'middle', 'family', 'email',\n 'may_contact', 'publish_profile',\n )\n order_by = (\n 'lastname', '-lastname', 'firstname', '-firstname', 'email',\n '-email',\n )\n\n def get_order_by(self, order_value):\n if order_value == 'firstname':\n return ['personal', 'middle', 'family']\n elif order_value == '-firstname':\n return ['-personal', '-middle', '-family']\n elif order_value == 'lastname':\n return ['family', 'middle', 'personal']\n elif order_value == '-lastname':\n return ['-family', '-middle', '-personal']\n return super().get_order_by(order_value)\n\n\nclass InstructorsOverTimeFilter(AMYFilterSet):\n badges = filters.ModelMultipleChoiceFilter(\n queryset=Badge.objects.instructor_badges(),\n label='Badges',\n lookup_expr='in',\n )\n\n class Meta:\n model = Person\n fields = [\n 'badges',\n ]\n\n\nclass WorkshopsOverTimeFilter(AMYFilterSet):\n tags = filters.ModelMultipleChoiceFilter(\n queryset=Tag.objects.all(),\n label='Events with at least one of the following tags:',\n )\n\n class Meta:\n model = Event\n fields = [\n 'tags',\n ]\n\n\nclass LearnersOverTimeFilter(AMYFilterSet):\n tags = filters.ModelMultipleChoiceFilter(\n queryset=Tag.objects.all(),\n label='Events with all the following tags:',\n conjoined=True,\n )\n\n class Meta:\n model = Event\n fields = [\n 'tags',\n ]\n", "path": "api/filters.py"}]}
| 1,615 | 115 |
gh_patches_debug_14474
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__aimmo-512
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make logout button on AI:MMO
</issue>
<code>
[start of players/urls.py]
1 from django.conf.urls import url
2 from django.contrib.auth import views as auth_views
3 from django.contrib.auth.decorators import login_required
4 from django.views.generic import TemplateView
5 from django.views.generic import RedirectView
6
7 from players import views
8
9 urlpatterns = [
10 url(r'^$', TemplateView.as_view(template_name='players/home.html'), name='aimmo/home'),
11
12 url(r'^accounts/login/$', auth_views.login),
13
14 url(r'^program/(?P<id>[0-9]+)/$', login_required(views.ProgramView.as_view()), name='aimmo/program'),
15 url(r'^program_level/(?P<num>[0-9]+)/$', login_required(views.program_level), name='aimmo/program_level'),
16 url(r'^watch/(?P<id>[0-9]+)/$', login_required(views.watch_game), name='aimmo/watch'),
17 url(r'^watch_level/(?P<num>[0-9]+)/$', login_required(views.watch_level), name='aimmo/watch_level'),
18 url(r'^statistics/$', TemplateView.as_view(template_name='players/statistics.html'), name='aimmo/statistics'),
19 url(r'^game_ide/$', TemplateView.as_view(template_name='players/game_ide.html'), name='aimmo/game_ide'),
20
21 url(r'^api/code/(?P<id>[0-9]+)/$', views.code, name='aimmo/code'),
22 url(r'^api/games/$', views.list_games, name='aimmo/games'),
23 url(r'^api/games/(?P<id>[0-9]+)/$', views.get_game, name='aimmo/game_details'),
24 url(r'^api/games/(?P<id>[0-9]+)/complete/$', views.mark_game_complete, name='aimmo/complete_game'),
25 url(r'^api/games/(?P<game_id>[0-9]+)/current_avatar/$', views.current_avatar_in_game, name='aimmo/current_avatar_in_game'),
26
27 url(r'^jsreverse/$', 'django_js_reverse.views.urls_js', name='aimmo/js_reverse'), # TODO: Pull request to make django_js_reverse.urls
28 url(r'^games/new/$', views.add_game, name='aimmo/new_game'),
29
30 # TODO: this is a quickfix for redirecting for the Unity resources
31 url(r'^watch/(?P<id>[0-9]+)/(?P<resource>.[0-9A-Za-z/.]+)$',
32 RedirectView.as_view(url='/static/unity/%(resource)s', permanent=False)),
33
34 url(r'^socket.io/socket.io.js',
35 RedirectView.as_view(url='https://cdnjs.cloudflare.com/ajax/libs/socket.io/1.7.4/socket.io.min.js', permanent=False)),
36 ]
37
[end of players/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/players/urls.py b/players/urls.py
--- a/players/urls.py
+++ b/players/urls.py
@@ -10,6 +10,8 @@
url(r'^$', TemplateView.as_view(template_name='players/home.html'), name='aimmo/home'),
url(r'^accounts/login/$', auth_views.login),
+ url(r'^accounts/logout/$', auth_views.logout, {'next_page' : 'aimmo/logout_success'}, name='aimmo/logout'),
+ url(r'^accounts/logout_success/$', TemplateView.as_view(template_name='registration/success_logout.html'), name='aimmo/logout_success'),
url(r'^program/(?P<id>[0-9]+)/$', login_required(views.ProgramView.as_view()), name='aimmo/program'),
url(r'^program_level/(?P<num>[0-9]+)/$', login_required(views.program_level), name='aimmo/program_level'),
|
{"golden_diff": "diff --git a/players/urls.py b/players/urls.py\n--- a/players/urls.py\n+++ b/players/urls.py\n@@ -10,6 +10,8 @@\n url(r'^$', TemplateView.as_view(template_name='players/home.html'), name='aimmo/home'),\n \n url(r'^accounts/login/$', auth_views.login),\n+ url(r'^accounts/logout/$', auth_views.logout, {'next_page' : 'aimmo/logout_success'}, name='aimmo/logout'),\n+ url(r'^accounts/logout_success/$', TemplateView.as_view(template_name='registration/success_logout.html'), name='aimmo/logout_success'),\n \n url(r'^program/(?P<id>[0-9]+)/$', login_required(views.ProgramView.as_view()), name='aimmo/program'),\n url(r'^program_level/(?P<num>[0-9]+)/$', login_required(views.program_level), name='aimmo/program_level'),\n", "issue": "Make logout button on AI:MMO\n\n", "before_files": [{"content": "from django.conf.urls import url\nfrom django.contrib.auth import views as auth_views\nfrom django.contrib.auth.decorators import login_required\nfrom django.views.generic import TemplateView\nfrom django.views.generic import RedirectView\n\nfrom players import views\n\nurlpatterns = [\n url(r'^$', TemplateView.as_view(template_name='players/home.html'), name='aimmo/home'),\n\n url(r'^accounts/login/$', auth_views.login),\n\n url(r'^program/(?P<id>[0-9]+)/$', login_required(views.ProgramView.as_view()), name='aimmo/program'),\n url(r'^program_level/(?P<num>[0-9]+)/$', login_required(views.program_level), name='aimmo/program_level'),\n url(r'^watch/(?P<id>[0-9]+)/$', login_required(views.watch_game), name='aimmo/watch'),\n url(r'^watch_level/(?P<num>[0-9]+)/$', login_required(views.watch_level), name='aimmo/watch_level'),\n url(r'^statistics/$', TemplateView.as_view(template_name='players/statistics.html'), name='aimmo/statistics'),\n url(r'^game_ide/$', TemplateView.as_view(template_name='players/game_ide.html'), name='aimmo/game_ide'),\n\n url(r'^api/code/(?P<id>[0-9]+)/$', views.code, name='aimmo/code'),\n url(r'^api/games/$', views.list_games, name='aimmo/games'),\n url(r'^api/games/(?P<id>[0-9]+)/$', views.get_game, name='aimmo/game_details'),\n url(r'^api/games/(?P<id>[0-9]+)/complete/$', views.mark_game_complete, name='aimmo/complete_game'),\n url(r'^api/games/(?P<game_id>[0-9]+)/current_avatar/$', views.current_avatar_in_game, name='aimmo/current_avatar_in_game'),\n\n url(r'^jsreverse/$', 'django_js_reverse.views.urls_js', name='aimmo/js_reverse'), # TODO: Pull request to make django_js_reverse.urls\n url(r'^games/new/$', views.add_game, name='aimmo/new_game'),\n\n # TODO: this is a quickfix for redirecting for the Unity resources\n url(r'^watch/(?P<id>[0-9]+)/(?P<resource>.[0-9A-Za-z/.]+)$',\n RedirectView.as_view(url='/static/unity/%(resource)s', permanent=False)),\n\n url(r'^socket.io/socket.io.js',\n RedirectView.as_view(url='https://cdnjs.cloudflare.com/ajax/libs/socket.io/1.7.4/socket.io.min.js', permanent=False)),\n]\n", "path": "players/urls.py"}]}
| 1,162 | 197 |
gh_patches_debug_173
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-2038
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Parsl v1.1.0 Release Checklist
## Checklist
Please edit the checklist if I've missed any items.
### Documentation updates :
- [x] Update docs to point at 1.1.0 as the latest
- [x] Make sure docs are not broken on readthedocs, since a broken doc build will stick on as stable till next release.
- [x] Update changelog with summary of changes since 0.9.0 [@benclifford to take a crack at this]
- [ ] Update Parsl tutorial repo with a 1.1.0 branch that folds in changes
- [x] Add `Beta` tags to components/features that are not yet stable.
### Testing :
- [ ] All testing should be green on Travis
- [x] Update all configs in `parsl/parsl/configs` to match current best practices
- [x] Update all test configs in `parsl/parsl/test/configs`
- [x] Test notebooks/tutorials and basic tests on a Mac
- [ ] Post news update on the website about release
- [x] Site testing:
- [x] Bridges2(PSC) [YY]
- [ ] ~~Comet (SDSC)~~ Machine is getting replaced by Expanse
- [x] Cori (NERSC) [YY/Yadu]
- [x] Stampede2 (TACC) [Yadu]
- [ ] ~~Frontera (TACC)~~ [Yadu, no access]
- [x] Theta (ALCF) [YY]
- [x] Bluewaters (NCSA) [ZZ]
- [x] Summit (ORNL) [Yadu]
- [ ] ~~CC-IN2P3 (French Grid)~~ [Yadu]
- [x] Midway (RCC, UChicago) [YY]
- [x] Open Science Grid
- [x] AWS
- [x] Kubernetes [ZZ]
- [x] NSCC Singapore [ZZ]
- [ ] Ad-Hoc clusters [YY]
### Release Tagging and pushing to PyPI
I'll make an updated alpha to smoothen installation and site testing.
</issue>
<code>
[start of parsl/version.py]
1 """Set module version.
2
3 <Major>.<Minor>.<maintenance>[alpha/beta/..]
4 Alphas will be numbered like this -> 0.4.0a0
5 """
6 VERSION = '1.1.0a1'
7
[end of parsl/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/version.py b/parsl/version.py
--- a/parsl/version.py
+++ b/parsl/version.py
@@ -3,4 +3,4 @@
<Major>.<Minor>.<maintenance>[alpha/beta/..]
Alphas will be numbered like this -> 0.4.0a0
"""
-VERSION = '1.1.0a1'
+VERSION = '1.1.0'
|
{"golden_diff": "diff --git a/parsl/version.py b/parsl/version.py\n--- a/parsl/version.py\n+++ b/parsl/version.py\n@@ -3,4 +3,4 @@\n <Major>.<Minor>.<maintenance>[alpha/beta/..]\n Alphas will be numbered like this -> 0.4.0a0\n \"\"\"\n-VERSION = '1.1.0a1'\n+VERSION = '1.1.0'\n", "issue": "Parsl v1.1.0 Release Checklist\n## Checklist\r\n\r\nPlease edit the checklist if I've missed any items. \r\n\r\n### Documentation updates :\r\n\r\n- [x] Update docs to point at 1.1.0 as the latest\r\n- [x] Make sure docs are not broken on readthedocs, since a broken doc build will stick on as stable till next release.\r\n- [x] Update changelog with summary of changes since 0.9.0 [@benclifford to take a crack at this]\r\n- [ ] Update Parsl tutorial repo with a 1.1.0 branch that folds in changes \r\n- [x] Add `Beta` tags to components/features that are not yet stable.\r\n\r\n\r\n### Testing :\r\n\r\n- [ ] All testing should be green on Travis\r\n- [x] Update all configs in `parsl/parsl/configs` to match current best practices\r\n- [x] Update all test configs in `parsl/parsl/test/configs`\r\n- [x] Test notebooks/tutorials and basic tests on a Mac\r\n- [ ] Post news update on the website about release\r\n\r\n- [x] Site testing:\r\n - [x] Bridges2(PSC) [YY]\r\n - [ ] ~~Comet (SDSC)~~ Machine is getting replaced by Expanse\r\n - [x] Cori (NERSC) [YY/Yadu]\r\n - [x] Stampede2 (TACC) [Yadu]\r\n - [ ] ~~Frontera (TACC)~~ [Yadu, no access]\r\n - [x] Theta (ALCF) [YY]\r\n - [x] Bluewaters (NCSA) [ZZ]\r\n - [x] Summit (ORNL) [Yadu]\r\n - [ ] ~~CC-IN2P3 (French Grid)~~ [Yadu]\r\n - [x] Midway (RCC, UChicago) [YY]\r\n - [x] Open Science Grid\r\n - [x] AWS\r\n - [x] Kubernetes [ZZ]\r\n - [x] NSCC Singapore [ZZ]\r\n - [ ] Ad-Hoc clusters [YY]\r\n\r\n### Release Tagging and pushing to PyPI\r\n\r\nI'll make an updated alpha to smoothen installation and site testing.\r\n\n", "before_files": [{"content": "\"\"\"Set module version.\n\n<Major>.<Minor>.<maintenance>[alpha/beta/..]\nAlphas will be numbered like this -> 0.4.0a0\n\"\"\"\nVERSION = '1.1.0a1'\n", "path": "parsl/version.py"}]}
| 1,074 | 97 |
gh_patches_debug_6931
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-28775
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Improve integrations documentation in help center
We should:
- Rename /help/bots-and-integrations to "Bots overview" everywhere (sidebar, page title, page URL).
- Add a copy of https://zulip.com/api/integrations-overview as the second page in the Bots & integrations section, titled "Integration overview"
- Cross-link as appropriate, both in related articles and in the content of the pages.
</issue>
<code>
[start of zerver/lib/url_redirects.py]
1 from dataclasses import dataclass
2 from typing import List
3
4
5 @dataclass
6 class URLRedirect:
7 old_url: str
8 new_url: str
9
10
11 API_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [
12 # Add URL redirects for REST API documentation here:
13 URLRedirect("/api/delete-stream", "/api/archive-stream"),
14 ]
15
16 POLICY_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [
17 # Add URL redirects for policy documentation here:
18 URLRedirect("/privacy/", "/policies/privacy"),
19 URLRedirect("/terms/", "/policies/terms"),
20 ]
21
22 HELP_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [
23 # Add URL redirects for help center documentation here:
24 URLRedirect("/help/pm-mention-alert-notifications", "/help/dm-mention-alert-notifications"),
25 URLRedirect("/help/restrict-private-messages", "/help/restrict-direct-messages"),
26 URLRedirect("/help/reading-pms", "/help/reading-dms"),
27 URLRedirect("/help/private-messages", "/help/direct-messages"),
28 URLRedirect("/help/configure-who-can-edit-topics", "/help/restrict-moving-messages"),
29 URLRedirect(
30 "/help/configure-message-editing-and-deletion",
31 "/help/restrict-message-editing-and-deletion",
32 ),
33 URLRedirect("/help/restrict-visibility-of-email-addresses", "/help/configure-email-visibility"),
34 URLRedirect("/help/change-default-view", "/help/configure-default-view"),
35 URLRedirect("/help/recent-topics", "/help/recent-conversations"),
36 URLRedirect(
37 "/help/add-custom-profile-fields",
38 "/help/custom-profile-fields",
39 ),
40 URLRedirect(
41 "/help/enable-enter-to-send",
42 "/help/mastering-the-compose-box#toggle-between-ctrl-enter-and-enter-to-send-a-message",
43 ),
44 URLRedirect(
45 "/help/change-the-default-language-for-your-organization",
46 "/help/configure-organization-language",
47 ),
48 URLRedirect("/help/delete-a-stream", "/help/archive-a-stream"),
49 URLRedirect("/help/change-the-topic-of-a-message", "/help/rename-a-topic"),
50 URLRedirect("/help/configure-missed-message-emails", "/help/email-notifications"),
51 URLRedirect("/help/add-an-alert-word", "/help/dm-mention-alert-notifications#alert-words"),
52 URLRedirect("/help/test-mobile-notifications", "/help/mobile-notifications"),
53 URLRedirect(
54 "/help/troubleshooting-desktop-notifications",
55 "/help/desktop-notifications#troubleshooting-desktop-notifications",
56 ),
57 URLRedirect(
58 "/help/change-notification-sound", "/help/desktop-notifications#change-notification-sound"
59 ),
60 URLRedirect("/help/configure-message-notification-emails", "/help/email-notifications"),
61 URLRedirect("/help/disable-new-login-emails", "/help/email-notifications#new-login-emails"),
62 # The `help/about-streams-and-topics` redirect is particularly important,
63 # because the old URL appears in links from Welcome Bot messages.
64 URLRedirect("/help/about-streams-and-topics", "/help/streams-and-topics"),
65 URLRedirect("/help/community-topic-edits", "/help/restrict-moving-messages"),
66 URLRedirect(
67 "/help/only-allow-admins-to-add-emoji", "/help/custom-emoji#change-who-can-add-custom-emoji"
68 ),
69 URLRedirect(
70 "/help/configure-who-can-add-custom-emoji",
71 "/help/custom-emoji#change-who-can-add-custom-emoji",
72 ),
73 URLRedirect("/help/add-custom-emoji", "/help/custom-emoji"),
74 URLRedirect("/help/night-mode", "/help/dark-theme"),
75 URLRedirect("/help/enable-emoticon-translations", "/help/configure-emoticon-translations"),
76 URLRedirect("/help/web-public-streams", "/help/public-access-option"),
77 URLRedirect("/help/starting-a-new-private-thread", "/help/starting-a-new-direct-message"),
78 URLRedirect("/help/edit-or-delete-a-message", "/help/delete-a-message"),
79 URLRedirect("/help/start-a-new-topic", "/help/starting-a-new-topic"),
80 URLRedirect("/help/configure-default-view", "/help/configure-home-view"),
81 URLRedirect("/help/reading-topics", "/help/reading-conversations"),
82 URLRedirect("/help/finding-a-topic-to-read", "/help/finding-a-conversation-to-read"),
83 URLRedirect("/help/view-and-browse-images", "/help/view-images-and-videos"),
84 ]
85
86 LANDING_PAGE_REDIRECTS = [
87 # Add URL redirects for corporate landing pages here.
88 URLRedirect("/new-user/", "/hello/"),
89 URLRedirect("/developer-community/", "/development-community"),
90 URLRedirect("/for/companies/", "/for/business"),
91 URLRedirect("/for/working-groups-and-communities/", "/for/communities"),
92 ]
93
94 DOCUMENTATION_REDIRECTS = (
95 API_DOCUMENTATION_REDIRECTS + POLICY_DOCUMENTATION_REDIRECTS + HELP_DOCUMENTATION_REDIRECTS
96 )
97
[end of zerver/lib/url_redirects.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zerver/lib/url_redirects.py b/zerver/lib/url_redirects.py
--- a/zerver/lib/url_redirects.py
+++ b/zerver/lib/url_redirects.py
@@ -81,6 +81,7 @@
URLRedirect("/help/reading-topics", "/help/reading-conversations"),
URLRedirect("/help/finding-a-topic-to-read", "/help/finding-a-conversation-to-read"),
URLRedirect("/help/view-and-browse-images", "/help/view-images-and-videos"),
+ URLRedirect("/help/bots-and-integrations", "/help/bots-overview"),
]
LANDING_PAGE_REDIRECTS = [
|
{"golden_diff": "diff --git a/zerver/lib/url_redirects.py b/zerver/lib/url_redirects.py\n--- a/zerver/lib/url_redirects.py\n+++ b/zerver/lib/url_redirects.py\n@@ -81,6 +81,7 @@\n URLRedirect(\"/help/reading-topics\", \"/help/reading-conversations\"),\n URLRedirect(\"/help/finding-a-topic-to-read\", \"/help/finding-a-conversation-to-read\"),\n URLRedirect(\"/help/view-and-browse-images\", \"/help/view-images-and-videos\"),\n+ URLRedirect(\"/help/bots-and-integrations\", \"/help/bots-overview\"),\n ]\n \n LANDING_PAGE_REDIRECTS = [\n", "issue": "Improve integrations documentation in help center\nWe should:\r\n- Rename /help/bots-and-integrations to \"Bots overview\" everywhere (sidebar, page title, page URL).\r\n- Add a copy of https://zulip.com/api/integrations-overview as the second page in the Bots & integrations section, titled \"Integration overview\"\r\n- Cross-link as appropriate, both in related articles and in the content of the pages.\n", "before_files": [{"content": "from dataclasses import dataclass\nfrom typing import List\n\n\n@dataclass\nclass URLRedirect:\n old_url: str\n new_url: str\n\n\nAPI_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [\n # Add URL redirects for REST API documentation here:\n URLRedirect(\"/api/delete-stream\", \"/api/archive-stream\"),\n]\n\nPOLICY_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [\n # Add URL redirects for policy documentation here:\n URLRedirect(\"/privacy/\", \"/policies/privacy\"),\n URLRedirect(\"/terms/\", \"/policies/terms\"),\n]\n\nHELP_DOCUMENTATION_REDIRECTS: List[URLRedirect] = [\n # Add URL redirects for help center documentation here:\n URLRedirect(\"/help/pm-mention-alert-notifications\", \"/help/dm-mention-alert-notifications\"),\n URLRedirect(\"/help/restrict-private-messages\", \"/help/restrict-direct-messages\"),\n URLRedirect(\"/help/reading-pms\", \"/help/reading-dms\"),\n URLRedirect(\"/help/private-messages\", \"/help/direct-messages\"),\n URLRedirect(\"/help/configure-who-can-edit-topics\", \"/help/restrict-moving-messages\"),\n URLRedirect(\n \"/help/configure-message-editing-and-deletion\",\n \"/help/restrict-message-editing-and-deletion\",\n ),\n URLRedirect(\"/help/restrict-visibility-of-email-addresses\", \"/help/configure-email-visibility\"),\n URLRedirect(\"/help/change-default-view\", \"/help/configure-default-view\"),\n URLRedirect(\"/help/recent-topics\", \"/help/recent-conversations\"),\n URLRedirect(\n \"/help/add-custom-profile-fields\",\n \"/help/custom-profile-fields\",\n ),\n URLRedirect(\n \"/help/enable-enter-to-send\",\n \"/help/mastering-the-compose-box#toggle-between-ctrl-enter-and-enter-to-send-a-message\",\n ),\n URLRedirect(\n \"/help/change-the-default-language-for-your-organization\",\n \"/help/configure-organization-language\",\n ),\n URLRedirect(\"/help/delete-a-stream\", \"/help/archive-a-stream\"),\n URLRedirect(\"/help/change-the-topic-of-a-message\", \"/help/rename-a-topic\"),\n URLRedirect(\"/help/configure-missed-message-emails\", \"/help/email-notifications\"),\n URLRedirect(\"/help/add-an-alert-word\", \"/help/dm-mention-alert-notifications#alert-words\"),\n URLRedirect(\"/help/test-mobile-notifications\", \"/help/mobile-notifications\"),\n URLRedirect(\n \"/help/troubleshooting-desktop-notifications\",\n \"/help/desktop-notifications#troubleshooting-desktop-notifications\",\n ),\n URLRedirect(\n \"/help/change-notification-sound\", \"/help/desktop-notifications#change-notification-sound\"\n ),\n URLRedirect(\"/help/configure-message-notification-emails\", \"/help/email-notifications\"),\n URLRedirect(\"/help/disable-new-login-emails\", \"/help/email-notifications#new-login-emails\"),\n # The `help/about-streams-and-topics` redirect is particularly important,\n # because the old URL appears in links from Welcome Bot messages.\n URLRedirect(\"/help/about-streams-and-topics\", \"/help/streams-and-topics\"),\n URLRedirect(\"/help/community-topic-edits\", \"/help/restrict-moving-messages\"),\n URLRedirect(\n \"/help/only-allow-admins-to-add-emoji\", \"/help/custom-emoji#change-who-can-add-custom-emoji\"\n ),\n URLRedirect(\n \"/help/configure-who-can-add-custom-emoji\",\n \"/help/custom-emoji#change-who-can-add-custom-emoji\",\n ),\n URLRedirect(\"/help/add-custom-emoji\", \"/help/custom-emoji\"),\n URLRedirect(\"/help/night-mode\", \"/help/dark-theme\"),\n URLRedirect(\"/help/enable-emoticon-translations\", \"/help/configure-emoticon-translations\"),\n URLRedirect(\"/help/web-public-streams\", \"/help/public-access-option\"),\n URLRedirect(\"/help/starting-a-new-private-thread\", \"/help/starting-a-new-direct-message\"),\n URLRedirect(\"/help/edit-or-delete-a-message\", \"/help/delete-a-message\"),\n URLRedirect(\"/help/start-a-new-topic\", \"/help/starting-a-new-topic\"),\n URLRedirect(\"/help/configure-default-view\", \"/help/configure-home-view\"),\n URLRedirect(\"/help/reading-topics\", \"/help/reading-conversations\"),\n URLRedirect(\"/help/finding-a-topic-to-read\", \"/help/finding-a-conversation-to-read\"),\n URLRedirect(\"/help/view-and-browse-images\", \"/help/view-images-and-videos\"),\n]\n\nLANDING_PAGE_REDIRECTS = [\n # Add URL redirects for corporate landing pages here.\n URLRedirect(\"/new-user/\", \"/hello/\"),\n URLRedirect(\"/developer-community/\", \"/development-community\"),\n URLRedirect(\"/for/companies/\", \"/for/business\"),\n URLRedirect(\"/for/working-groups-and-communities/\", \"/for/communities\"),\n]\n\nDOCUMENTATION_REDIRECTS = (\n API_DOCUMENTATION_REDIRECTS + POLICY_DOCUMENTATION_REDIRECTS + HELP_DOCUMENTATION_REDIRECTS\n)\n", "path": "zerver/lib/url_redirects.py"}]}
| 1,852 | 139 |
gh_patches_debug_20189
|
rasdani/github-patches
|
git_diff
|
plotly__dash-2856
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] set_props called multiple times only keep the last props.
For regular callbacks, when multiple call of `set_props` to the same component id, only the last call is saved.
Example:
```
from dash import Dash, Input, html, set_props
app = Dash()
app.layout = [
html.Button("start", id="start"),
html.Div("initial", id="output"),
]
@app.callback(
Input("start", "n_clicks"),
)
def on_click(_):
set_props("output", {"children": "changed"})
set_props("output", {"style": {"background": "red"}})
if __name__ == "__main__":
app.run(debug=True)
```
Clicking on the start button only set the background red, the text stays at "initial". The props should be merged and both updated.
</issue>
<code>
[start of dash/long_callback/_proxy_set_props.py]
1 class ProxySetProps(dict):
2 """
3 Defer dictionary item setter to run a custom function on change.
4 Used by background callback manager to save the `set_props` data.
5 """
6
7 def __init__(self, on_change):
8 super().__init__()
9 self.on_change = on_change
10
11 def __setitem__(self, key, value):
12 self.on_change(key, value)
13
[end of dash/long_callback/_proxy_set_props.py]
[start of dash/_callback_context.py]
1 import functools
2 import warnings
3 import json
4 import contextvars
5 import typing
6
7 import flask
8
9 from . import exceptions
10 from ._utils import AttributeDict, stringify_id
11
12
13 context_value = contextvars.ContextVar("callback_context")
14 context_value.set({})
15
16
17 def has_context(func):
18 @functools.wraps(func)
19 def assert_context(*args, **kwargs):
20 if not context_value.get():
21 raise exceptions.MissingCallbackContextException(
22 f"dash.callback_context.{getattr(func, '__name__')} is only available from a callback!"
23 )
24 return func(*args, **kwargs)
25
26 return assert_context
27
28
29 def _get_context_value():
30 return context_value.get()
31
32
33 class FalsyList(list):
34 def __bool__(self):
35 # for Python 3
36 return False
37
38 def __nonzero__(self):
39 # for Python 2
40 return False
41
42
43 falsy_triggered = FalsyList([{"prop_id": ".", "value": None}])
44
45
46 # pylint: disable=no-init
47 class CallbackContext:
48 @property
49 @has_context
50 def inputs(self):
51 return getattr(_get_context_value(), "input_values", {})
52
53 @property
54 @has_context
55 def states(self):
56 return getattr(_get_context_value(), "state_values", {})
57
58 @property
59 @has_context
60 def triggered(self):
61 """
62 Returns a list of all the Input props that changed and caused the callback to execute. It is empty when the
63 callback is called on initial load, unless an Input prop got its value from another initial callback.
64 Callbacks triggered by user actions typically have one item in triggered, unless the same action changes
65 two props at once or the callback has several Input props that are all modified by another callback based on
66 a single user action.
67
68 Example: To get the id of the component that triggered the callback:
69 `component_id = ctx.triggered[0]['prop_id'].split('.')[0]`
70
71 Example: To detect initial call, empty triggered is not really empty, it's falsy so that you can use:
72 `if ctx.triggered:`
73 """
74 # For backward compatibility: previously `triggered` always had a
75 # value - to avoid breaking existing apps, add a dummy item but
76 # make the list still look falsy. So `if ctx.triggered` will make it
77 # look empty, but you can still do `triggered[0]["prop_id"].split(".")`
78 return getattr(_get_context_value(), "triggered_inputs", []) or falsy_triggered
79
80 @property
81 @has_context
82 def triggered_prop_ids(self):
83 """
84 Returns a dictionary of all the Input props that changed and caused the callback to execute. It is empty when
85 the callback is called on initial load, unless an Input prop got its value from another initial callback.
86 Callbacks triggered by user actions typically have one item in triggered, unless the same action changes
87 two props at once or the callback has several Input props that are all modified by another callback based
88 on a single user action.
89
90 triggered_prop_ids (dict):
91 - keys (str) : the triggered "prop_id" composed of "component_id.component_property"
92 - values (str or dict): the id of the component that triggered the callback. Will be the dict id for pattern matching callbacks
93
94 Example - regular callback
95 {"btn-1.n_clicks": "btn-1"}
96
97 Example - pattern matching callbacks:
98 {'{"index":0,"type":"filter-dropdown"}.value': {"index":0,"type":"filter-dropdown"}}
99
100 Example usage:
101 `if "btn-1.n_clicks" in ctx.triggered_prop_ids:
102 do_something()`
103 """
104 triggered = getattr(_get_context_value(), "triggered_inputs", [])
105 ids = AttributeDict({})
106 for item in triggered:
107 component_id, _, _ = item["prop_id"].rpartition(".")
108 ids[item["prop_id"]] = component_id
109 if component_id.startswith("{"):
110 ids[item["prop_id"]] = AttributeDict(json.loads(component_id))
111 return ids
112
113 @property
114 @has_context
115 def triggered_id(self):
116 """
117 Returns the component id (str or dict) of the Input component that triggered the callback.
118
119 Note - use `triggered_prop_ids` if you need both the component id and the prop that triggered the callback or if
120 multiple Inputs triggered the callback.
121
122 Example usage:
123 `if "btn-1" == ctx.triggered_id:
124 do_something()`
125
126 """
127 component_id = None
128 if self.triggered:
129 prop_id = self.triggered_prop_ids.first()
130 component_id = self.triggered_prop_ids[prop_id]
131 return component_id
132
133 @property
134 @has_context
135 def args_grouping(self):
136 """
137 args_grouping is a dict of the inputs used with flexible callback signatures. The keys are the variable names
138 and the values are dictionaries containing:
139 - “id”: (string or dict) the component id. If it’s a pattern matching id, it will be a dict.
140 - “id_str”: (str) for pattern matching ids, it’s the stringified dict id with no white spaces.
141 - “property”: (str) The component property used in the callback.
142 - “value”: the value of the component property at the time the callback was fired.
143 - “triggered”: (bool)Whether this input triggered the callback.
144
145 Example usage:
146 @app.callback(
147 Output("container", "children"),
148 inputs=dict(btn1=Input("btn-1", "n_clicks"), btn2=Input("btn-2", "n_clicks")),
149 )
150 def display(btn1, btn2):
151 c = ctx.args_grouping
152 if c.btn1.triggered:
153 return f"Button 1 clicked {btn1} times"
154 elif c.btn2.triggered:
155 return f"Button 2 clicked {btn2} times"
156 else:
157 return "No clicks yet"
158
159 """
160 return getattr(_get_context_value(), "args_grouping", [])
161
162 @property
163 @has_context
164 def outputs_grouping(self):
165 return getattr(_get_context_value(), "outputs_grouping", [])
166
167 @property
168 @has_context
169 def outputs_list(self):
170 if self.using_outputs_grouping:
171 warnings.warn(
172 "outputs_list is deprecated, use outputs_grouping instead",
173 DeprecationWarning,
174 )
175
176 return getattr(_get_context_value(), "outputs_list", [])
177
178 @property
179 @has_context
180 def inputs_list(self):
181 if self.using_args_grouping:
182 warnings.warn(
183 "inputs_list is deprecated, use args_grouping instead",
184 DeprecationWarning,
185 )
186
187 return getattr(_get_context_value(), "inputs_list", [])
188
189 @property
190 @has_context
191 def states_list(self):
192 if self.using_args_grouping:
193 warnings.warn(
194 "states_list is deprecated, use args_grouping instead",
195 DeprecationWarning,
196 )
197 return getattr(_get_context_value(), "states_list", [])
198
199 @property
200 @has_context
201 def response(self):
202 return getattr(_get_context_value(), "dash_response")
203
204 @staticmethod
205 @has_context
206 def record_timing(name, duration=None, description=None):
207 """Records timing information for a server resource.
208
209 :param name: The name of the resource.
210 :type name: string
211
212 :param duration: The time in seconds to report. Internally, this
213 is rounded to the nearest millisecond.
214 :type duration: float or None
215
216 :param description: A description of the resource.
217 :type description: string or None
218 """
219 timing_information = getattr(flask.g, "timing_information", {})
220
221 if name in timing_information:
222 raise KeyError(f'Duplicate resource name "{name}" found.')
223
224 timing_information[name] = {"dur": round(duration * 1000), "desc": description}
225
226 setattr(flask.g, "timing_information", timing_information)
227
228 @property
229 @has_context
230 def using_args_grouping(self):
231 """
232 Return True if this callback is using dictionary or nested groupings for
233 Input/State dependencies, or if Input and State dependencies are interleaved
234 """
235 return getattr(_get_context_value(), "using_args_grouping", [])
236
237 @property
238 @has_context
239 def using_outputs_grouping(self):
240 """
241 Return True if this callback is using dictionary or nested groupings for
242 Output dependencies.
243 """
244 return getattr(_get_context_value(), "using_outputs_grouping", [])
245
246 @property
247 @has_context
248 def timing_information(self):
249 return getattr(flask.g, "timing_information", {})
250
251 @has_context
252 def set_props(self, component_id: typing.Union[str, dict], props: dict):
253 ctx_value = _get_context_value()
254 _id = stringify_id(component_id)
255 ctx_value.updated_props[_id] = props
256
257
258 callback_context = CallbackContext()
259
260
261 def set_props(component_id: typing.Union[str, dict], props: dict):
262 """
263 Set the props for a component not included in the callback outputs.
264 """
265 callback_context.set_props(component_id, props)
266
[end of dash/_callback_context.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dash/_callback_context.py b/dash/_callback_context.py
--- a/dash/_callback_context.py
+++ b/dash/_callback_context.py
@@ -252,7 +252,11 @@
def set_props(self, component_id: typing.Union[str, dict], props: dict):
ctx_value = _get_context_value()
_id = stringify_id(component_id)
- ctx_value.updated_props[_id] = props
+ existing = ctx_value.updated_props.get(_id)
+ if existing is not None:
+ ctx_value.updated_props[_id] = {**existing, **props}
+ else:
+ ctx_value.updated_props[_id] = props
callback_context = CallbackContext()
diff --git a/dash/long_callback/_proxy_set_props.py b/dash/long_callback/_proxy_set_props.py
--- a/dash/long_callback/_proxy_set_props.py
+++ b/dash/long_callback/_proxy_set_props.py
@@ -7,6 +7,12 @@
def __init__(self, on_change):
super().__init__()
self.on_change = on_change
+ self._data = {}
def __setitem__(self, key, value):
self.on_change(key, value)
+ self._data.setdefault(key, {})
+ self._data[key] = {**self._data[key], **value}
+
+ def get(self, key):
+ return self._data.get(key)
|
{"golden_diff": "diff --git a/dash/_callback_context.py b/dash/_callback_context.py\n--- a/dash/_callback_context.py\n+++ b/dash/_callback_context.py\n@@ -252,7 +252,11 @@\n def set_props(self, component_id: typing.Union[str, dict], props: dict):\n ctx_value = _get_context_value()\n _id = stringify_id(component_id)\n- ctx_value.updated_props[_id] = props\n+ existing = ctx_value.updated_props.get(_id)\n+ if existing is not None:\n+ ctx_value.updated_props[_id] = {**existing, **props}\n+ else:\n+ ctx_value.updated_props[_id] = props\n \n \n callback_context = CallbackContext()\ndiff --git a/dash/long_callback/_proxy_set_props.py b/dash/long_callback/_proxy_set_props.py\n--- a/dash/long_callback/_proxy_set_props.py\n+++ b/dash/long_callback/_proxy_set_props.py\n@@ -7,6 +7,12 @@\n def __init__(self, on_change):\n super().__init__()\n self.on_change = on_change\n+ self._data = {}\n \n def __setitem__(self, key, value):\n self.on_change(key, value)\n+ self._data.setdefault(key, {})\n+ self._data[key] = {**self._data[key], **value}\n+\n+ def get(self, key):\n+ return self._data.get(key)\n", "issue": "[BUG] set_props called multiple times only keep the last props.\nFor regular callbacks, when multiple call of `set_props` to the same component id, only the last call is saved.\r\n\r\nExample:\r\n```\r\nfrom dash import Dash, Input, html, set_props\r\n\r\napp = Dash()\r\n\r\napp.layout = [\r\n html.Button(\"start\", id=\"start\"),\r\n html.Div(\"initial\", id=\"output\"),\r\n]\r\n\r\[email protected](\r\n Input(\"start\", \"n_clicks\"),\r\n)\r\ndef on_click(_):\r\n set_props(\"output\", {\"children\": \"changed\"})\r\n set_props(\"output\", {\"style\": {\"background\": \"red\"}})\r\n\r\nif __name__ == \"__main__\":\r\n app.run(debug=True)\r\n\r\n```\r\n\r\nClicking on the start button only set the background red, the text stays at \"initial\". The props should be merged and both updated.\r\n\r\n\n", "before_files": [{"content": "class ProxySetProps(dict):\n \"\"\"\n Defer dictionary item setter to run a custom function on change.\n Used by background callback manager to save the `set_props` data.\n \"\"\"\n\n def __init__(self, on_change):\n super().__init__()\n self.on_change = on_change\n\n def __setitem__(self, key, value):\n self.on_change(key, value)\n", "path": "dash/long_callback/_proxy_set_props.py"}, {"content": "import functools\nimport warnings\nimport json\nimport contextvars\nimport typing\n\nimport flask\n\nfrom . import exceptions\nfrom ._utils import AttributeDict, stringify_id\n\n\ncontext_value = contextvars.ContextVar(\"callback_context\")\ncontext_value.set({})\n\n\ndef has_context(func):\n @functools.wraps(func)\n def assert_context(*args, **kwargs):\n if not context_value.get():\n raise exceptions.MissingCallbackContextException(\n f\"dash.callback_context.{getattr(func, '__name__')} is only available from a callback!\"\n )\n return func(*args, **kwargs)\n\n return assert_context\n\n\ndef _get_context_value():\n return context_value.get()\n\n\nclass FalsyList(list):\n def __bool__(self):\n # for Python 3\n return False\n\n def __nonzero__(self):\n # for Python 2\n return False\n\n\nfalsy_triggered = FalsyList([{\"prop_id\": \".\", \"value\": None}])\n\n\n# pylint: disable=no-init\nclass CallbackContext:\n @property\n @has_context\n def inputs(self):\n return getattr(_get_context_value(), \"input_values\", {})\n\n @property\n @has_context\n def states(self):\n return getattr(_get_context_value(), \"state_values\", {})\n\n @property\n @has_context\n def triggered(self):\n \"\"\"\n Returns a list of all the Input props that changed and caused the callback to execute. It is empty when the\n callback is called on initial load, unless an Input prop got its value from another initial callback.\n Callbacks triggered by user actions typically have one item in triggered, unless the same action changes\n two props at once or the callback has several Input props that are all modified by another callback based on\n a single user action.\n\n Example: To get the id of the component that triggered the callback:\n `component_id = ctx.triggered[0]['prop_id'].split('.')[0]`\n\n Example: To detect initial call, empty triggered is not really empty, it's falsy so that you can use:\n `if ctx.triggered:`\n \"\"\"\n # For backward compatibility: previously `triggered` always had a\n # value - to avoid breaking existing apps, add a dummy item but\n # make the list still look falsy. So `if ctx.triggered` will make it\n # look empty, but you can still do `triggered[0][\"prop_id\"].split(\".\")`\n return getattr(_get_context_value(), \"triggered_inputs\", []) or falsy_triggered\n\n @property\n @has_context\n def triggered_prop_ids(self):\n \"\"\"\n Returns a dictionary of all the Input props that changed and caused the callback to execute. It is empty when\n the callback is called on initial load, unless an Input prop got its value from another initial callback.\n Callbacks triggered by user actions typically have one item in triggered, unless the same action changes\n two props at once or the callback has several Input props that are all modified by another callback based\n on a single user action.\n\n triggered_prop_ids (dict):\n - keys (str) : the triggered \"prop_id\" composed of \"component_id.component_property\"\n - values (str or dict): the id of the component that triggered the callback. Will be the dict id for pattern matching callbacks\n\n Example - regular callback\n {\"btn-1.n_clicks\": \"btn-1\"}\n\n Example - pattern matching callbacks:\n {'{\"index\":0,\"type\":\"filter-dropdown\"}.value': {\"index\":0,\"type\":\"filter-dropdown\"}}\n\n Example usage:\n `if \"btn-1.n_clicks\" in ctx.triggered_prop_ids:\n do_something()`\n \"\"\"\n triggered = getattr(_get_context_value(), \"triggered_inputs\", [])\n ids = AttributeDict({})\n for item in triggered:\n component_id, _, _ = item[\"prop_id\"].rpartition(\".\")\n ids[item[\"prop_id\"]] = component_id\n if component_id.startswith(\"{\"):\n ids[item[\"prop_id\"]] = AttributeDict(json.loads(component_id))\n return ids\n\n @property\n @has_context\n def triggered_id(self):\n \"\"\"\n Returns the component id (str or dict) of the Input component that triggered the callback.\n\n Note - use `triggered_prop_ids` if you need both the component id and the prop that triggered the callback or if\n multiple Inputs triggered the callback.\n\n Example usage:\n `if \"btn-1\" == ctx.triggered_id:\n do_something()`\n\n \"\"\"\n component_id = None\n if self.triggered:\n prop_id = self.triggered_prop_ids.first()\n component_id = self.triggered_prop_ids[prop_id]\n return component_id\n\n @property\n @has_context\n def args_grouping(self):\n \"\"\"\n args_grouping is a dict of the inputs used with flexible callback signatures. The keys are the variable names\n and the values are dictionaries containing:\n - \u201cid\u201d: (string or dict) the component id. If it\u2019s a pattern matching id, it will be a dict.\n - \u201cid_str\u201d: (str) for pattern matching ids, it\u2019s the stringified dict id with no white spaces.\n - \u201cproperty\u201d: (str) The component property used in the callback.\n - \u201cvalue\u201d: the value of the component property at the time the callback was fired.\n - \u201ctriggered\u201d: (bool)Whether this input triggered the callback.\n\n Example usage:\n @app.callback(\n Output(\"container\", \"children\"),\n inputs=dict(btn1=Input(\"btn-1\", \"n_clicks\"), btn2=Input(\"btn-2\", \"n_clicks\")),\n )\n def display(btn1, btn2):\n c = ctx.args_grouping\n if c.btn1.triggered:\n return f\"Button 1 clicked {btn1} times\"\n elif c.btn2.triggered:\n return f\"Button 2 clicked {btn2} times\"\n else:\n return \"No clicks yet\"\n\n \"\"\"\n return getattr(_get_context_value(), \"args_grouping\", [])\n\n @property\n @has_context\n def outputs_grouping(self):\n return getattr(_get_context_value(), \"outputs_grouping\", [])\n\n @property\n @has_context\n def outputs_list(self):\n if self.using_outputs_grouping:\n warnings.warn(\n \"outputs_list is deprecated, use outputs_grouping instead\",\n DeprecationWarning,\n )\n\n return getattr(_get_context_value(), \"outputs_list\", [])\n\n @property\n @has_context\n def inputs_list(self):\n if self.using_args_grouping:\n warnings.warn(\n \"inputs_list is deprecated, use args_grouping instead\",\n DeprecationWarning,\n )\n\n return getattr(_get_context_value(), \"inputs_list\", [])\n\n @property\n @has_context\n def states_list(self):\n if self.using_args_grouping:\n warnings.warn(\n \"states_list is deprecated, use args_grouping instead\",\n DeprecationWarning,\n )\n return getattr(_get_context_value(), \"states_list\", [])\n\n @property\n @has_context\n def response(self):\n return getattr(_get_context_value(), \"dash_response\")\n\n @staticmethod\n @has_context\n def record_timing(name, duration=None, description=None):\n \"\"\"Records timing information for a server resource.\n\n :param name: The name of the resource.\n :type name: string\n\n :param duration: The time in seconds to report. Internally, this\n is rounded to the nearest millisecond.\n :type duration: float or None\n\n :param description: A description of the resource.\n :type description: string or None\n \"\"\"\n timing_information = getattr(flask.g, \"timing_information\", {})\n\n if name in timing_information:\n raise KeyError(f'Duplicate resource name \"{name}\" found.')\n\n timing_information[name] = {\"dur\": round(duration * 1000), \"desc\": description}\n\n setattr(flask.g, \"timing_information\", timing_information)\n\n @property\n @has_context\n def using_args_grouping(self):\n \"\"\"\n Return True if this callback is using dictionary or nested groupings for\n Input/State dependencies, or if Input and State dependencies are interleaved\n \"\"\"\n return getattr(_get_context_value(), \"using_args_grouping\", [])\n\n @property\n @has_context\n def using_outputs_grouping(self):\n \"\"\"\n Return True if this callback is using dictionary or nested groupings for\n Output dependencies.\n \"\"\"\n return getattr(_get_context_value(), \"using_outputs_grouping\", [])\n\n @property\n @has_context\n def timing_information(self):\n return getattr(flask.g, \"timing_information\", {})\n\n @has_context\n def set_props(self, component_id: typing.Union[str, dict], props: dict):\n ctx_value = _get_context_value()\n _id = stringify_id(component_id)\n ctx_value.updated_props[_id] = props\n\n\ncallback_context = CallbackContext()\n\n\ndef set_props(component_id: typing.Union[str, dict], props: dict):\n \"\"\"\n Set the props for a component not included in the callback outputs.\n \"\"\"\n callback_context.set_props(component_id, props)\n", "path": "dash/_callback_context.py"}]}
| 3,548 | 320 |
gh_patches_debug_3281
|
rasdani/github-patches
|
git_diff
|
bentoml__BentoML-951
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When I built a H2O-based image, the following error occurred
**Describe the bug**
When I built a H2O-based image, the following error occurred. From the Dockerfile generated by BentoML, the base image is bentoml/model-server:0.8.1, and JRE is indeed not installed
I used service.py to build a bentoML bundle
```python
import bentoml
from bentoml.adapters import DataframeInput
from bentoml.artifact import H2oModelArtifact
from customize import preprocessing, postprocessing
@bentoml.env(auto_pip_dependencies=True)
@bentoml.artifacts([H2oModelArtifact('model')])
class LoanDefaultPrediction(bentoml.BentoService):
@bentoml.api(input=DataframeInput())
def predict(self, df):
model_input = preprocessing(df)
model_output = self.artifacts.model.predict(model_input)
return postprocessing(model_output)
if __name__ == "__main__":
import h2o
h2o.init(strict_version_check=False)
model = h2o.load_model('H2O_AutoML_20200720_153457')
model_service = LoanDefaultPrediction()
model_service.pack("model", model)
saved_path = model_service.save()
```
And another customize.py to pre process
```python
import h2o
def preprocessing(model_input):
return h2o.H2OFrame(model_input, na_strings=['NaN'])
def postprocessing(model_output):
return model_output.as_data_frame()
```
Finally, After I build service image with this bundle, I run this docker image with below log:
```
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/gunicorn/arbiter.py", line 583, in spawn_worker
worker.init_process()
File "/opt/conda/lib/python3.7/site-packages/gunicorn/workers/base.py", line 119, in init_process
self.load_wsgi()
File "/opt/conda/lib/python3.7/site-packages/gunicorn/workers/base.py", line 144, in load_wsgi
self.wsgi = self.app.wsgi()
File "/opt/conda/lib/python3.7/site-packages/gunicorn/app/base.py", line 67, in wsgi
self.callable = self.load()
File "/opt/conda/lib/python3.7/site-packages/bentoml/server/gunicorn_server.py", line 92, in load
bento_service = load(self.bento_service_bundle_path)
File "/opt/conda/lib/python3.7/site-packages/bentoml/saved_bundle/loader.py", line 179, in load
svc = svc_cls()
File "/opt/conda/lib/python3.7/site-packages/bentoml/service.py", line 526, in __init__
self._load_artifacts(self._bento_service_bundle_path)
File "/opt/conda/lib/python3.7/site-packages/bentoml/service.py", line 734, in _load_artifacts
packed_artifact = artifact.load(artifacts_path)
File "/opt/conda/lib/python3.7/site-packages/bentoml/artifact/h2o_model_artifact.py", line 79, in load
h2o.init()
File "/opt/conda/lib/python3.7/site-packages/h2o/h2o.py", line 307, in init
bind_to_localhost=bind_to_localhost)
File "/opt/conda/lib/python3.7/site-packages/h2o/backend/server.py", line 143, in start
bind_to_localhost=bind_to_localhost, log_dir=log_dir, log_level=log_level, max_log_file_size=max_log_file_size)
File "/opt/conda/lib/python3.7/site-packages/h2o/backend/server.py", line 276, in _launch_server
java = self._find_java()
File "/opt/conda/lib/python3.7/site-packages/h2o/backend/server.py", line 441, in _find_java
raise H2OStartupError("Cannot find Java. Please install the latest JRE from\n"
h2o.exceptions.H2OStartupError: Cannot find Java. Please install the latest JRE from
http://www.oracle.com/technetwork/java/javase/downloads/index.html
```
</issue>
<code>
[start of bentoml/artifact/h2o_model_artifact.py]
1 # Copyright 2019 Atalaya Tech, Inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import os
16 import shutil
17
18 from bentoml.artifact import BentoServiceArtifact
19 from bentoml.exceptions import MissingDependencyException
20 from bentoml.service_env import BentoServiceEnv
21
22
23 class H2oModelArtifact(BentoServiceArtifact):
24 """Abstraction for saving/loading objects with h2o.save_model and h2o.load_model
25
26 Args:
27 name (str): Name for this h2o artifact..
28
29 Raises:
30 MissingDependencyException: h2o package is required to use H2o model artifact
31
32 Example usage:
33
34 >>> import h2o
35 >>> h2o.init()
36 >>>
37 >>> from h2o.estimators.deeplearning import H2ODeepLearningEstimator
38 >>> model_to_save = H2ODeepLearningEstimator(...)
39 >>> # train model with data
40 >>> data = h2o.import_file(...)
41 >>> model_to_save.train(...)
42 >>>
43 >>> import bentoml
44 >>> from bentoml.artifact import H2oModelArtifact
45 >>> from bentoml.adapters import DataframeInput
46 >>>
47 >>> @bentoml.artifacts([H2oModelArtifact('model')])
48 >>> @bentoml.env(auto_pip_dependencies=True)
49 >>> class H2oModelService(bentoml.BentoService):
50 >>>
51 >>> @bentoml.api(input=DataframeInput())
52 >>> def predict(self, df):
53 >>> hf = h2o.H2OFrame(df)
54 >>> predictions = self.artifacts.model.predict(hf)
55 >>> return predictions.as_data_frame()
56 >>>
57 >>> svc = H2oModelService()
58 >>>
59 >>> svc.pack('model', model_to_save)
60 """
61
62 def __init__(self, name):
63 super(H2oModelArtifact, self).__init__(name)
64
65 self._model = None
66
67 def set_dependencies(self, env: BentoServiceEnv):
68 env.add_pip_dependencies_if_missing(['h2o'])
69
70 def _model_file_path(self, base_path):
71 return os.path.join(base_path, self.name)
72
73 def pack(self, model): # pylint:disable=arguments-differ
74 self._model = model
75 return self
76
77 def load(self, path):
78 try:
79 import h2o
80 except ImportError:
81 raise MissingDependencyException(
82 "h2o package is required to use H2oModelArtifact"
83 )
84
85 h2o.init()
86 model = h2o.load_model(self._model_file_path(path))
87 self._model = model
88 return self
89
90 def save(self, dst):
91 try:
92 import h2o
93 except ImportError:
94 raise MissingDependencyException(
95 "h2o package is required to use H2oModelArtifact"
96 )
97
98 h2o_saved_path = h2o.save_model(model=self._model, path=dst, force=True)
99 shutil.move(h2o_saved_path, self._model_file_path(dst))
100 return
101
102 def get(self):
103 return self._model
104
[end of bentoml/artifact/h2o_model_artifact.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bentoml/artifact/h2o_model_artifact.py b/bentoml/artifact/h2o_model_artifact.py
--- a/bentoml/artifact/h2o_model_artifact.py
+++ b/bentoml/artifact/h2o_model_artifact.py
@@ -66,6 +66,7 @@
def set_dependencies(self, env: BentoServiceEnv):
env.add_pip_dependencies_if_missing(['h2o'])
+ env.add_conda_dependencies(['openjdk'])
def _model_file_path(self, base_path):
return os.path.join(base_path, self.name)
|
{"golden_diff": "diff --git a/bentoml/artifact/h2o_model_artifact.py b/bentoml/artifact/h2o_model_artifact.py\n--- a/bentoml/artifact/h2o_model_artifact.py\n+++ b/bentoml/artifact/h2o_model_artifact.py\n@@ -66,6 +66,7 @@\n \n def set_dependencies(self, env: BentoServiceEnv):\n env.add_pip_dependencies_if_missing(['h2o'])\n+ env.add_conda_dependencies(['openjdk'])\n \n def _model_file_path(self, base_path):\n return os.path.join(base_path, self.name)\n", "issue": "When I built a H2O-based image, the following error occurred\n**Describe the bug**\r\nWhen I built a H2O-based image, the following error occurred. From the Dockerfile generated by BentoML, the base image is bentoml/model-server:0.8.1, and JRE is indeed not installed\r\n\r\n\r\nI used service.py to build a bentoML bundle\r\n```python\r\nimport bentoml\r\nfrom bentoml.adapters import DataframeInput\r\nfrom bentoml.artifact import H2oModelArtifact\r\nfrom customize import preprocessing, postprocessing\r\n\r\n\r\[email protected](auto_pip_dependencies=True)\r\[email protected]([H2oModelArtifact('model')])\r\nclass LoanDefaultPrediction(bentoml.BentoService):\r\n @bentoml.api(input=DataframeInput())\r\n def predict(self, df):\r\n model_input = preprocessing(df)\r\n model_output = self.artifacts.model.predict(model_input)\r\n return postprocessing(model_output)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n import h2o\r\n h2o.init(strict_version_check=False)\r\n model = h2o.load_model('H2O_AutoML_20200720_153457')\r\n\r\n model_service = LoanDefaultPrediction()\r\n model_service.pack(\"model\", model)\r\n\r\n saved_path = model_service.save()\r\n```\r\nAnd another customize.py to pre process\r\n```python\r\nimport h2o\r\n\r\ndef preprocessing(model_input):\r\n return h2o.H2OFrame(model_input, na_strings=['NaN'])\r\n\r\n\r\ndef postprocessing(model_output):\r\n return model_output.as_data_frame()\r\n```\r\n\r\nFinally, After I build service image with this bundle, I run this docker image with below log:\r\n```\r\nTraceback (most recent call last):\r\n File \"/opt/conda/lib/python3.7/site-packages/gunicorn/arbiter.py\", line 583, in spawn_worker\r\n worker.init_process()\r\n File \"/opt/conda/lib/python3.7/site-packages/gunicorn/workers/base.py\", line 119, in init_process\r\n self.load_wsgi()\r\n File \"/opt/conda/lib/python3.7/site-packages/gunicorn/workers/base.py\", line 144, in load_wsgi\r\n self.wsgi = self.app.wsgi()\r\n File \"/opt/conda/lib/python3.7/site-packages/gunicorn/app/base.py\", line 67, in wsgi\r\n self.callable = self.load()\r\n File \"/opt/conda/lib/python3.7/site-packages/bentoml/server/gunicorn_server.py\", line 92, in load\r\n bento_service = load(self.bento_service_bundle_path)\r\n File \"/opt/conda/lib/python3.7/site-packages/bentoml/saved_bundle/loader.py\", line 179, in load\r\n svc = svc_cls()\r\n File \"/opt/conda/lib/python3.7/site-packages/bentoml/service.py\", line 526, in __init__\r\n self._load_artifacts(self._bento_service_bundle_path)\r\n File \"/opt/conda/lib/python3.7/site-packages/bentoml/service.py\", line 734, in _load_artifacts\r\n packed_artifact = artifact.load(artifacts_path)\r\n File \"/opt/conda/lib/python3.7/site-packages/bentoml/artifact/h2o_model_artifact.py\", line 79, in load\r\n h2o.init()\r\n File \"/opt/conda/lib/python3.7/site-packages/h2o/h2o.py\", line 307, in init\r\n bind_to_localhost=bind_to_localhost)\r\n File \"/opt/conda/lib/python3.7/site-packages/h2o/backend/server.py\", line 143, in start\r\n bind_to_localhost=bind_to_localhost, log_dir=log_dir, log_level=log_level, max_log_file_size=max_log_file_size)\r\n File \"/opt/conda/lib/python3.7/site-packages/h2o/backend/server.py\", line 276, in _launch_server\r\n java = self._find_java()\r\n File \"/opt/conda/lib/python3.7/site-packages/h2o/backend/server.py\", line 441, in _find_java\r\n raise H2OStartupError(\"Cannot find Java. Please install the latest JRE from\\n\"\r\nh2o.exceptions.H2OStartupError: Cannot find Java. Please install the latest JRE from\r\nhttp://www.oracle.com/technetwork/java/javase/downloads/index.html\r\n```\n", "before_files": [{"content": "# Copyright 2019 Atalaya Tech, Inc.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport shutil\n\nfrom bentoml.artifact import BentoServiceArtifact\nfrom bentoml.exceptions import MissingDependencyException\nfrom bentoml.service_env import BentoServiceEnv\n\n\nclass H2oModelArtifact(BentoServiceArtifact):\n \"\"\"Abstraction for saving/loading objects with h2o.save_model and h2o.load_model\n\n Args:\n name (str): Name for this h2o artifact..\n\n Raises:\n MissingDependencyException: h2o package is required to use H2o model artifact\n\n Example usage:\n\n >>> import h2o\n >>> h2o.init()\n >>>\n >>> from h2o.estimators.deeplearning import H2ODeepLearningEstimator\n >>> model_to_save = H2ODeepLearningEstimator(...)\n >>> # train model with data\n >>> data = h2o.import_file(...)\n >>> model_to_save.train(...)\n >>>\n >>> import bentoml\n >>> from bentoml.artifact import H2oModelArtifact\n >>> from bentoml.adapters import DataframeInput\n >>>\n >>> @bentoml.artifacts([H2oModelArtifact('model')])\n >>> @bentoml.env(auto_pip_dependencies=True)\n >>> class H2oModelService(bentoml.BentoService):\n >>>\n >>> @bentoml.api(input=DataframeInput())\n >>> def predict(self, df):\n >>> hf = h2o.H2OFrame(df)\n >>> predictions = self.artifacts.model.predict(hf)\n >>> return predictions.as_data_frame()\n >>>\n >>> svc = H2oModelService()\n >>>\n >>> svc.pack('model', model_to_save)\n \"\"\"\n\n def __init__(self, name):\n super(H2oModelArtifact, self).__init__(name)\n\n self._model = None\n\n def set_dependencies(self, env: BentoServiceEnv):\n env.add_pip_dependencies_if_missing(['h2o'])\n\n def _model_file_path(self, base_path):\n return os.path.join(base_path, self.name)\n\n def pack(self, model): # pylint:disable=arguments-differ\n self._model = model\n return self\n\n def load(self, path):\n try:\n import h2o\n except ImportError:\n raise MissingDependencyException(\n \"h2o package is required to use H2oModelArtifact\"\n )\n\n h2o.init()\n model = h2o.load_model(self._model_file_path(path))\n self._model = model\n return self\n\n def save(self, dst):\n try:\n import h2o\n except ImportError:\n raise MissingDependencyException(\n \"h2o package is required to use H2oModelArtifact\"\n )\n\n h2o_saved_path = h2o.save_model(model=self._model, path=dst, force=True)\n shutil.move(h2o_saved_path, self._model_file_path(dst))\n return\n\n def get(self):\n return self._model\n", "path": "bentoml/artifact/h2o_model_artifact.py"}]}
| 2,519 | 137 |
gh_patches_debug_5130
|
rasdani/github-patches
|
git_diff
|
obspy__obspy-1916
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Invalid version schema "0.0.0.dev+.gXXX" - may not work with newer versions of setuptools, pip, and PyPI
```C:\Miniconda-x64\envs\test\lib\site-packages\setuptools\dist.py:350: UserWarning: The version specified (u'0.0.0.dev+.g5c641b2cb1') is an invalid version, this may not work as expected with newer versions of setuptools, pip, and PyPI. Please see PEP 440 for more details.```
see also https://ci.appveyor.com/project/obspy/obspy/build/1.0.5140-warnings/job/rxhusf826vk5atia
</issue>
<code>
[start of obspy/core/util/version.py]
1 # -*- coding: utf-8 -*-
2 # Author: Douglas Creager <[email protected]>
3 # This file is placed into the public domain.
4
5 # Calculates the current version number. If possible, this is the
6 # output of “git describe”, modified to conform to the versioning
7 # scheme that setuptools uses. If “git describe” returns an error
8 # (most likely because we're in an unpacked copy of a release tarball,
9 # rather than in a git working copy), then we fall back on reading the
10 # contents of the RELEASE-VERSION file.
11 #
12 # To use this script, simply import it your setup.py file, and use the
13 # results of get_git_version() as your package version:
14 #
15 # from version import *
16 #
17 # setup(
18 # version=get_git_version(),
19 # .
20 # .
21 # .
22 # )
23 #
24 # This will automatically update the RELEASE-VERSION file, if
25 # necessary. Note that the RELEASE-VERSION file should *not* be
26 # checked into git; please add it to your top-level .gitignore file.
27 #
28 # You'll probably want to distribute the RELEASE-VERSION file in your
29 # sdist tarballs; to do this, just create a MANIFEST.in file that
30 # contains the following line:
31 #
32 # include RELEASE-VERSION
33
34 # NO IMPORTS FROM OBSPY OR FUTURE IN THIS FILE! (file gets used at
35 # installation time)
36 import inspect
37 import io
38 import os
39 import re
40 from subprocess import STDOUT, CalledProcessError, check_output
41
42
43 __all__ = ("get_git_version")
44
45 script_dir = os.path.abspath(os.path.dirname(inspect.getfile(
46 inspect.currentframe())))
47 OBSPY_ROOT = os.path.abspath(os.path.join(script_dir, os.pardir,
48 os.pardir, os.pardir))
49 VERSION_FILE = os.path.join(OBSPY_ROOT, "obspy", "RELEASE-VERSION")
50
51
52 def call_git_describe(abbrev=10, dirty=True,
53 append_remote_tracking_branch=True):
54 try:
55 p = check_output(['git', 'rev-parse', '--show-toplevel'],
56 cwd=OBSPY_ROOT, stderr=STDOUT)
57 path = p.decode().strip()
58 except (OSError, CalledProcessError):
59 return None
60
61 if os.path.normpath(path) != OBSPY_ROOT:
62 return None
63
64 command = ['git', 'describe', '--abbrev=%d' % abbrev, '--always', '--tags']
65 if dirty:
66 command.append("--dirty")
67 try:
68 p = check_output(['git', 'describe', '--dirty', '--abbrev=%d' % abbrev,
69 '--always', '--tags'],
70 cwd=OBSPY_ROOT, stderr=STDOUT)
71 line = p.decode().strip()
72 except (OSError, CalledProcessError):
73 return None
74
75 remote_tracking_branch = None
76 if append_remote_tracking_branch:
77 try:
78 # find out local alias of remote and name of remote tracking branch
79 p = check_output(['git', 'branch', '-vv'],
80 cwd=OBSPY_ROOT, stderr=STDOUT)
81 remote_info = [line_.rstrip()
82 for line_ in p.decode().splitlines()]
83 remote_info = [line_ for line_ in remote_info
84 if line_.startswith('*')][0]
85 remote_info = re.sub(r".*? \[([^ :]*).*?\] .*", r"\1", remote_info)
86 remote, branch = remote_info.split("/")
87 # find out real name of remote
88 p = check_output(['git', 'remote', '-v'],
89 cwd=OBSPY_ROOT, stderr=STDOUT)
90 stdout = [line_.strip() for line_ in p.decode().splitlines()]
91 remote = [line_ for line_ in stdout
92 if line_.startswith(remote)][0].split()[1]
93 if remote.startswith("[email protected]:"):
94 remote = re.sub(r"[email protected]:(.*?)/.*", r"\1", remote)
95 elif remote.startswith("https://github.com/"):
96 remote = re.sub(r"https://github.com/(.*?)/.*", r"\1", remote)
97 elif remote.startswith("git://github.com"):
98 remote = re.sub(r"git://github.com/(.*?)/.*", r"\1", remote)
99 else:
100 remote = None
101 if remote is not None:
102 remote_tracking_branch = re.sub(r'[^A-Za-z0-9._-]', r'_',
103 '%s-%s' % (remote, branch))
104 except (IndexError, OSError, ValueError, CalledProcessError):
105 pass
106
107 # (this line prevents official releases)
108 # should work again now, see #482 and obspy/obspy@b437f31
109 if "-" not in line and "." not in line:
110 version = "0.0.0.dev+.g%s" % line
111 else:
112 parts = line.split('-', 1)
113 version = parts[0]
114 try:
115 version += '.post+' + parts[1]
116 if remote_tracking_branch is not None:
117 version += '.' + remote_tracking_branch
118 # IndexError means we are at a release version tag cleanly,
119 # add nothing additional
120 except IndexError:
121 pass
122 return version
123
124
125 def read_release_version():
126 try:
127 with io.open(VERSION_FILE, "rt") as fh:
128 version = fh.readline()
129 return version.strip()
130 except IOError:
131 return None
132
133
134 def write_release_version(version):
135 with io.open(VERSION_FILE, "wb") as fh:
136 fh.write(("%s\n" % version).encode('ascii', 'strict'))
137
138
139 def get_git_version(abbrev=10, dirty=True, append_remote_tracking_branch=True):
140 # Read in the version that's currently in RELEASE-VERSION.
141 release_version = read_release_version()
142
143 # First try to get the current version using “git describe”.
144 version = call_git_describe(
145 abbrev, dirty=dirty,
146 append_remote_tracking_branch=append_remote_tracking_branch)
147
148 # If that doesn't work, fall back on the value that's in
149 # RELEASE-VERSION.
150 if version is None:
151 version = release_version
152
153 # If we still don't have anything, that's an error.
154 if version is None:
155 return '0.0.0+archive'
156
157 # pip uses its normalized version number (strict PEP440) instead of our
158 # original version number, so we bow to pip and use the normalized version
159 # number internally, too, to avoid discrepancies.
160 version = _normalize_version(version)
161
162 # If the current version is different from what's in the
163 # RELEASE-VERSION file, update the file to be current.
164 if version != release_version:
165 write_release_version(version)
166
167 # Finally, return the current version.
168 return version
169
170
171 def _normalize_version(version):
172 """
173 Normalize version number string to adhere with PEP440 strictly.
174 """
175 # we have a clean release version:
176 if re.match(r'^[0-9]+?\.[0-9]+?\.[0-9]+?$', version):
177 return version
178 # we have a release candidate version:
179 elif re.match(r'^[0-9]+?\.[0-9]+?\.[0-9]+?rc[0-9]+?$', version):
180 return version
181 # we have an old-style version (i.e. a git describe string), prepare it for
182 # the rest of clean up, i.e. put the '.post+' as separator for the local
183 # version number part
184 elif re.match(r'^[0-9]+?\.[0-9]+?\.[0-9]+?-[0-9]+?-g[0-9a-z]+?$', version):
185 version = re.sub(r'-', '.post+', version, count=1)
186 # only adapt local version part right
187 version = re.match(r'(.*?\+)(.*)', version)
188 # no upper case letters
189 local_version = version.group(2).lower()
190 # only alphanumeric and "." in local part
191 local_version = re.sub(r'[^A-Za-z0-9.]', r'.', local_version)
192 version = version.group(1) + local_version
193 # make sure there's a "0" after ".post"
194 version = re.sub(r'\.post\+', r'.post0+', version)
195 return version
196
197
198 if __name__ == "__main__":
199 print(get_git_version())
200
[end of obspy/core/util/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/obspy/core/util/version.py b/obspy/core/util/version.py
--- a/obspy/core/util/version.py
+++ b/obspy/core/util/version.py
@@ -107,7 +107,7 @@
# (this line prevents official releases)
# should work again now, see #482 and obspy/obspy@b437f31
if "-" not in line and "." not in line:
- version = "0.0.0.dev+.g%s" % line
+ version = "0.0.0.dev+0.g%s" % line
else:
parts = line.split('-', 1)
version = parts[0]
|
{"golden_diff": "diff --git a/obspy/core/util/version.py b/obspy/core/util/version.py\n--- a/obspy/core/util/version.py\n+++ b/obspy/core/util/version.py\n@@ -107,7 +107,7 @@\n # (this line prevents official releases)\n # should work again now, see #482 and obspy/obspy@b437f31\n if \"-\" not in line and \".\" not in line:\n- version = \"0.0.0.dev+.g%s\" % line\n+ version = \"0.0.0.dev+0.g%s\" % line\n else:\n parts = line.split('-', 1)\n version = parts[0]\n", "issue": "Invalid version schema \"0.0.0.dev+.gXXX\" - may not work with newer versions of setuptools, pip, and PyPI\n```C:\\Miniconda-x64\\envs\\test\\lib\\site-packages\\setuptools\\dist.py:350: UserWarning: The version specified (u'0.0.0.dev+.g5c641b2cb1') is an invalid version, this may not work as expected with newer versions of setuptools, pip, and PyPI. Please see PEP 440 for more details.```\r\n\r\nsee also https://ci.appveyor.com/project/obspy/obspy/build/1.0.5140-warnings/job/rxhusf826vk5atia\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Author: Douglas Creager <[email protected]>\n# This file is placed into the public domain.\n\n# Calculates the current version number. If possible, this is the\n# output of \u201cgit describe\u201d, modified to conform to the versioning\n# scheme that setuptools uses. If \u201cgit describe\u201d returns an error\n# (most likely because we're in an unpacked copy of a release tarball,\n# rather than in a git working copy), then we fall back on reading the\n# contents of the RELEASE-VERSION file.\n#\n# To use this script, simply import it your setup.py file, and use the\n# results of get_git_version() as your package version:\n#\n# from version import *\n#\n# setup(\n# version=get_git_version(),\n# .\n# .\n# .\n# )\n#\n# This will automatically update the RELEASE-VERSION file, if\n# necessary. Note that the RELEASE-VERSION file should *not* be\n# checked into git; please add it to your top-level .gitignore file.\n#\n# You'll probably want to distribute the RELEASE-VERSION file in your\n# sdist tarballs; to do this, just create a MANIFEST.in file that\n# contains the following line:\n#\n# include RELEASE-VERSION\n\n# NO IMPORTS FROM OBSPY OR FUTURE IN THIS FILE! (file gets used at\n# installation time)\nimport inspect\nimport io\nimport os\nimport re\nfrom subprocess import STDOUT, CalledProcessError, check_output\n\n\n__all__ = (\"get_git_version\")\n\nscript_dir = os.path.abspath(os.path.dirname(inspect.getfile(\n inspect.currentframe())))\nOBSPY_ROOT = os.path.abspath(os.path.join(script_dir, os.pardir,\n os.pardir, os.pardir))\nVERSION_FILE = os.path.join(OBSPY_ROOT, \"obspy\", \"RELEASE-VERSION\")\n\n\ndef call_git_describe(abbrev=10, dirty=True,\n append_remote_tracking_branch=True):\n try:\n p = check_output(['git', 'rev-parse', '--show-toplevel'],\n cwd=OBSPY_ROOT, stderr=STDOUT)\n path = p.decode().strip()\n except (OSError, CalledProcessError):\n return None\n\n if os.path.normpath(path) != OBSPY_ROOT:\n return None\n\n command = ['git', 'describe', '--abbrev=%d' % abbrev, '--always', '--tags']\n if dirty:\n command.append(\"--dirty\")\n try:\n p = check_output(['git', 'describe', '--dirty', '--abbrev=%d' % abbrev,\n '--always', '--tags'],\n cwd=OBSPY_ROOT, stderr=STDOUT)\n line = p.decode().strip()\n except (OSError, CalledProcessError):\n return None\n\n remote_tracking_branch = None\n if append_remote_tracking_branch:\n try:\n # find out local alias of remote and name of remote tracking branch\n p = check_output(['git', 'branch', '-vv'],\n cwd=OBSPY_ROOT, stderr=STDOUT)\n remote_info = [line_.rstrip()\n for line_ in p.decode().splitlines()]\n remote_info = [line_ for line_ in remote_info\n if line_.startswith('*')][0]\n remote_info = re.sub(r\".*? \\[([^ :]*).*?\\] .*\", r\"\\1\", remote_info)\n remote, branch = remote_info.split(\"/\")\n # find out real name of remote\n p = check_output(['git', 'remote', '-v'],\n cwd=OBSPY_ROOT, stderr=STDOUT)\n stdout = [line_.strip() for line_ in p.decode().splitlines()]\n remote = [line_ for line_ in stdout\n if line_.startswith(remote)][0].split()[1]\n if remote.startswith(\"[email protected]:\"):\n remote = re.sub(r\"[email protected]:(.*?)/.*\", r\"\\1\", remote)\n elif remote.startswith(\"https://github.com/\"):\n remote = re.sub(r\"https://github.com/(.*?)/.*\", r\"\\1\", remote)\n elif remote.startswith(\"git://github.com\"):\n remote = re.sub(r\"git://github.com/(.*?)/.*\", r\"\\1\", remote)\n else:\n remote = None\n if remote is not None:\n remote_tracking_branch = re.sub(r'[^A-Za-z0-9._-]', r'_',\n '%s-%s' % (remote, branch))\n except (IndexError, OSError, ValueError, CalledProcessError):\n pass\n\n # (this line prevents official releases)\n # should work again now, see #482 and obspy/obspy@b437f31\n if \"-\" not in line and \".\" not in line:\n version = \"0.0.0.dev+.g%s\" % line\n else:\n parts = line.split('-', 1)\n version = parts[0]\n try:\n version += '.post+' + parts[1]\n if remote_tracking_branch is not None:\n version += '.' + remote_tracking_branch\n # IndexError means we are at a release version tag cleanly,\n # add nothing additional\n except IndexError:\n pass\n return version\n\n\ndef read_release_version():\n try:\n with io.open(VERSION_FILE, \"rt\") as fh:\n version = fh.readline()\n return version.strip()\n except IOError:\n return None\n\n\ndef write_release_version(version):\n with io.open(VERSION_FILE, \"wb\") as fh:\n fh.write((\"%s\\n\" % version).encode('ascii', 'strict'))\n\n\ndef get_git_version(abbrev=10, dirty=True, append_remote_tracking_branch=True):\n # Read in the version that's currently in RELEASE-VERSION.\n release_version = read_release_version()\n\n # First try to get the current version using \u201cgit describe\u201d.\n version = call_git_describe(\n abbrev, dirty=dirty,\n append_remote_tracking_branch=append_remote_tracking_branch)\n\n # If that doesn't work, fall back on the value that's in\n # RELEASE-VERSION.\n if version is None:\n version = release_version\n\n # If we still don't have anything, that's an error.\n if version is None:\n return '0.0.0+archive'\n\n # pip uses its normalized version number (strict PEP440) instead of our\n # original version number, so we bow to pip and use the normalized version\n # number internally, too, to avoid discrepancies.\n version = _normalize_version(version)\n\n # If the current version is different from what's in the\n # RELEASE-VERSION file, update the file to be current.\n if version != release_version:\n write_release_version(version)\n\n # Finally, return the current version.\n return version\n\n\ndef _normalize_version(version):\n \"\"\"\n Normalize version number string to adhere with PEP440 strictly.\n \"\"\"\n # we have a clean release version:\n if re.match(r'^[0-9]+?\\.[0-9]+?\\.[0-9]+?$', version):\n return version\n # we have a release candidate version:\n elif re.match(r'^[0-9]+?\\.[0-9]+?\\.[0-9]+?rc[0-9]+?$', version):\n return version\n # we have an old-style version (i.e. a git describe string), prepare it for\n # the rest of clean up, i.e. put the '.post+' as separator for the local\n # version number part\n elif re.match(r'^[0-9]+?\\.[0-9]+?\\.[0-9]+?-[0-9]+?-g[0-9a-z]+?$', version):\n version = re.sub(r'-', '.post+', version, count=1)\n # only adapt local version part right\n version = re.match(r'(.*?\\+)(.*)', version)\n # no upper case letters\n local_version = version.group(2).lower()\n # only alphanumeric and \".\" in local part\n local_version = re.sub(r'[^A-Za-z0-9.]', r'.', local_version)\n version = version.group(1) + local_version\n # make sure there's a \"0\" after \".post\"\n version = re.sub(r'\\.post\\+', r'.post0+', version)\n return version\n\n\nif __name__ == \"__main__\":\n print(get_git_version())\n", "path": "obspy/core/util/version.py"}]}
| 3,044 | 158 |
gh_patches_debug_62126
|
rasdani/github-patches
|
git_diff
|
gratipay__gratipay.com-1975
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
/about/stats.json is broken
[stats.json](https://www.gittip.com/about/stats.json) is broken, I guess because of commit https://github.com/gittip/www.gittip.com/commit/892b1c28d127a18858032c88bd3d065cae973c34 by @clone1018.
</issue>
<code>
[start of configure-aspen.py]
1 from __future__ import division
2
3 from importlib import import_module
4 import os
5 import sys
6 import threading
7 import time
8 import traceback
9
10 import gittip
11 import gittip.wireup
12 from gittip import canonize, configure_payments
13 from gittip.security import authentication, csrf, x_frame_options
14 from gittip.utils import cache_static, timer
15 from gittip.elsewhere import platform_classes
16
17
18 from aspen import log_dammit
19
20 # Wireup Algorithm
21 # ================
22
23 version_file = os.path.join(website.www_root, 'version.txt')
24 __version__ = open(version_file).read().strip()
25 website.version = os.environ['__VERSION__'] = __version__
26
27
28 website.renderer_default = "jinja2"
29 website.default_renderers_by_media_type['application/json'] = 'stdlib_format'
30
31 website.renderer_factories['jinja2'].Renderer.global_context = {
32 'range': range,
33 'unicode': unicode,
34 'enumerate': enumerate,
35 'len': len,
36 'float': float,
37 'type': type,
38 'str': str
39 }
40
41
42 gittip.wireup.canonical()
43 website.db = gittip.wireup.db()
44 gittip.wireup.billing()
45 gittip.wireup.username_restrictions(website)
46 gittip.wireup.nanswers()
47 gittip.wireup.envvars(website)
48 tell_sentry = gittip.wireup.make_sentry_teller(website)
49
50 # this serves two purposes:
51 # 1) ensure all platform classes are created (and thus added to platform_classes)
52 # 2) keep the platform modules around to be added to the context below
53 platform_modules = {platform: import_module("gittip.elsewhere.%s" % platform)
54 for platform in platform_classes}
55
56 # The homepage wants expensive queries. Let's periodically select into an
57 # intermediate table.
58
59 UPDATE_HOMEPAGE_EVERY = int(os.environ['UPDATE_HOMEPAGE_EVERY'])
60 def update_homepage_queries():
61 from gittip import utils
62 while 1:
63 try:
64 utils.update_global_stats(website)
65 utils.update_homepage_queries_once(website.db)
66 website.db.self_check()
67 except:
68 exception = sys.exc_info()[0]
69 tell_sentry(exception)
70 tb = traceback.format_exc().strip()
71 log_dammit(tb)
72 time.sleep(UPDATE_HOMEPAGE_EVERY)
73
74 if UPDATE_HOMEPAGE_EVERY > 0:
75 homepage_updater = threading.Thread(target=update_homepage_queries)
76 homepage_updater.daemon = True
77 homepage_updater.start()
78 else:
79 from gittip import utils
80 utils.update_global_stats(website)
81
82
83 # Server Algorithm
84 # ================
85
86 def up_minthreads(website):
87 # https://github.com/gittip/www.gittip.com/issues/1098
88 # Discovered the following API by inspecting in pdb and browsing source.
89 # This requires network_engine.bind to have already been called.
90 request_queue = website.network_engine.cheroot_server.requests
91 request_queue.min = website.min_threads
92
93
94 def setup_busy_threads_logging(website):
95 # https://github.com/gittip/www.gittip.com/issues/1572
96 log_every = website.log_busy_threads_every
97 if log_every == 0:
98 return
99
100 pool = website.network_engine.cheroot_server.requests
101 def log_busy_threads():
102 time.sleep(0.5) # without this we get a single log message where all threads are busy
103 while 1:
104
105 # Use pool.min and not pool.max because of the semantics of these
106 # inside of Cheroot. (Max is a hard limit used only when pool.grow
107 # is called, and it's never called except when the pool starts up,
108 # when it's called with pool.min.)
109
110 nbusy_threads = pool.min - pool.idle
111 print("sample#aspen.busy_threads={}".format(nbusy_threads))
112 time.sleep(log_every)
113
114 thread = threading.Thread(target=log_busy_threads)
115 thread.daemon = True
116 thread.start()
117
118
119 website.server_algorithm.insert_before('start', up_minthreads)
120 website.server_algorithm.insert_before('start', setup_busy_threads_logging)
121
122
123 # Website Algorithm
124 # =================
125
126 def add_stuff_to_context(request):
127 request.context['username'] = None
128 request.context.update(platform_modules)
129
130 def scab_body_onto_response(response):
131
132 # This is a workaround for a Cheroot bug, where the connection is closed
133 # too early if there is no body:
134 #
135 # https://bitbucket.org/cherrypy/cheroot/issue/1/fail-if-passed-zero-bytes
136 #
137 # This Cheroot bug is manifesting because of a change in Aspen's behavior
138 # with the algorithm.py refactor in 0.27+: Aspen no longer sets a body for
139 # 302s as it used to. This means that all redirects are breaking
140 # intermittently (sometimes the client seems not to care that the
141 # connection is closed too early, so I guess there's some timing
142 # involved?), which is affecting a number of parts of Gittip, notably
143 # around logging in (#1859).
144
145 if not response.body:
146 response.body = '*sigh*'
147
148
149 algorithm = website.algorithm
150 algorithm.functions = [ timer.start
151 , algorithm['parse_environ_into_request']
152 , algorithm['tack_website_onto_request']
153 , algorithm['raise_200_for_OPTIONS']
154
155 , canonize
156 , configure_payments
157 , authentication.inbound
158 , csrf.inbound
159 , add_stuff_to_context
160
161 , algorithm['dispatch_request_to_filesystem']
162 , algorithm['apply_typecasters_to_path']
163
164 , cache_static.inbound
165
166 , algorithm['get_response_for_socket']
167 , algorithm['get_resource_for_request']
168 , algorithm['get_response_for_resource']
169
170 , tell_sentry
171 , algorithm['get_response_for_exception']
172
173 , gittip.outbound
174 , authentication.outbound
175 , csrf.outbound
176 , cache_static.outbound
177 , x_frame_options
178
179 , algorithm['log_traceback_for_5xx']
180 , algorithm['delegate_error_to_simplate']
181 , tell_sentry
182 , algorithm['log_traceback_for_exception']
183 , algorithm['log_result_of_request']
184
185 , scab_body_onto_response
186 , timer.end
187 , tell_sentry
188 ]
189
[end of configure-aspen.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/configure-aspen.py b/configure-aspen.py
--- a/configure-aspen.py
+++ b/configure-aspen.py
@@ -26,7 +26,6 @@
website.renderer_default = "jinja2"
-website.default_renderers_by_media_type['application/json'] = 'stdlib_format'
website.renderer_factories['jinja2'].Renderer.global_context = {
'range': range,
|
{"golden_diff": "diff --git a/configure-aspen.py b/configure-aspen.py\n--- a/configure-aspen.py\n+++ b/configure-aspen.py\n@@ -26,7 +26,6 @@\n \n \n website.renderer_default = \"jinja2\"\n-website.default_renderers_by_media_type['application/json'] = 'stdlib_format'\n \n website.renderer_factories['jinja2'].Renderer.global_context = {\n 'range': range,\n", "issue": "/about/stats.json is broken\n[stats.json](https://www.gittip.com/about/stats.json) is broken, I guess because of commit https://github.com/gittip/www.gittip.com/commit/892b1c28d127a18858032c88bd3d065cae973c34 by @clone1018.\n\n", "before_files": [{"content": "from __future__ import division\n\nfrom importlib import import_module\nimport os\nimport sys\nimport threading\nimport time\nimport traceback\n\nimport gittip\nimport gittip.wireup\nfrom gittip import canonize, configure_payments\nfrom gittip.security import authentication, csrf, x_frame_options\nfrom gittip.utils import cache_static, timer\nfrom gittip.elsewhere import platform_classes\n\n\nfrom aspen import log_dammit\n\n# Wireup Algorithm\n# ================\n\nversion_file = os.path.join(website.www_root, 'version.txt')\n__version__ = open(version_file).read().strip()\nwebsite.version = os.environ['__VERSION__'] = __version__\n\n\nwebsite.renderer_default = \"jinja2\"\nwebsite.default_renderers_by_media_type['application/json'] = 'stdlib_format'\n\nwebsite.renderer_factories['jinja2'].Renderer.global_context = {\n 'range': range,\n 'unicode': unicode,\n 'enumerate': enumerate,\n 'len': len,\n 'float': float,\n 'type': type,\n 'str': str\n}\n\n\ngittip.wireup.canonical()\nwebsite.db = gittip.wireup.db()\ngittip.wireup.billing()\ngittip.wireup.username_restrictions(website)\ngittip.wireup.nanswers()\ngittip.wireup.envvars(website)\ntell_sentry = gittip.wireup.make_sentry_teller(website)\n\n# this serves two purposes:\n# 1) ensure all platform classes are created (and thus added to platform_classes)\n# 2) keep the platform modules around to be added to the context below\nplatform_modules = {platform: import_module(\"gittip.elsewhere.%s\" % platform)\n for platform in platform_classes}\n\n# The homepage wants expensive queries. Let's periodically select into an\n# intermediate table.\n\nUPDATE_HOMEPAGE_EVERY = int(os.environ['UPDATE_HOMEPAGE_EVERY'])\ndef update_homepage_queries():\n from gittip import utils\n while 1:\n try:\n utils.update_global_stats(website)\n utils.update_homepage_queries_once(website.db)\n website.db.self_check()\n except:\n exception = sys.exc_info()[0]\n tell_sentry(exception)\n tb = traceback.format_exc().strip()\n log_dammit(tb)\n time.sleep(UPDATE_HOMEPAGE_EVERY)\n\nif UPDATE_HOMEPAGE_EVERY > 0:\n homepage_updater = threading.Thread(target=update_homepage_queries)\n homepage_updater.daemon = True\n homepage_updater.start()\nelse:\n from gittip import utils\n utils.update_global_stats(website)\n\n\n# Server Algorithm\n# ================\n\ndef up_minthreads(website):\n # https://github.com/gittip/www.gittip.com/issues/1098\n # Discovered the following API by inspecting in pdb and browsing source.\n # This requires network_engine.bind to have already been called.\n request_queue = website.network_engine.cheroot_server.requests\n request_queue.min = website.min_threads\n\n\ndef setup_busy_threads_logging(website):\n # https://github.com/gittip/www.gittip.com/issues/1572\n log_every = website.log_busy_threads_every\n if log_every == 0:\n return\n\n pool = website.network_engine.cheroot_server.requests\n def log_busy_threads():\n time.sleep(0.5) # without this we get a single log message where all threads are busy\n while 1:\n\n # Use pool.min and not pool.max because of the semantics of these\n # inside of Cheroot. (Max is a hard limit used only when pool.grow\n # is called, and it's never called except when the pool starts up,\n # when it's called with pool.min.)\n\n nbusy_threads = pool.min - pool.idle\n print(\"sample#aspen.busy_threads={}\".format(nbusy_threads))\n time.sleep(log_every)\n\n thread = threading.Thread(target=log_busy_threads)\n thread.daemon = True\n thread.start()\n\n\nwebsite.server_algorithm.insert_before('start', up_minthreads)\nwebsite.server_algorithm.insert_before('start', setup_busy_threads_logging)\n\n\n# Website Algorithm\n# =================\n\ndef add_stuff_to_context(request):\n request.context['username'] = None\n request.context.update(platform_modules)\n\ndef scab_body_onto_response(response):\n\n # This is a workaround for a Cheroot bug, where the connection is closed\n # too early if there is no body:\n #\n # https://bitbucket.org/cherrypy/cheroot/issue/1/fail-if-passed-zero-bytes\n #\n # This Cheroot bug is manifesting because of a change in Aspen's behavior\n # with the algorithm.py refactor in 0.27+: Aspen no longer sets a body for\n # 302s as it used to. This means that all redirects are breaking\n # intermittently (sometimes the client seems not to care that the\n # connection is closed too early, so I guess there's some timing\n # involved?), which is affecting a number of parts of Gittip, notably\n # around logging in (#1859).\n\n if not response.body:\n response.body = '*sigh*'\n\n\nalgorithm = website.algorithm\nalgorithm.functions = [ timer.start\n , algorithm['parse_environ_into_request']\n , algorithm['tack_website_onto_request']\n , algorithm['raise_200_for_OPTIONS']\n\n , canonize\n , configure_payments\n , authentication.inbound\n , csrf.inbound\n , add_stuff_to_context\n\n , algorithm['dispatch_request_to_filesystem']\n , algorithm['apply_typecasters_to_path']\n\n , cache_static.inbound\n\n , algorithm['get_response_for_socket']\n , algorithm['get_resource_for_request']\n , algorithm['get_response_for_resource']\n\n , tell_sentry\n , algorithm['get_response_for_exception']\n\n , gittip.outbound\n , authentication.outbound\n , csrf.outbound\n , cache_static.outbound\n , x_frame_options\n\n , algorithm['log_traceback_for_5xx']\n , algorithm['delegate_error_to_simplate']\n , tell_sentry\n , algorithm['log_traceback_for_exception']\n , algorithm['log_result_of_request']\n\n , scab_body_onto_response\n , timer.end\n , tell_sentry\n ]\n", "path": "configure-aspen.py"}]}
| 2,496 | 92 |
gh_patches_debug_11405
|
rasdani/github-patches
|
git_diff
|
aio-libs-abandoned__aioredis-py-1017
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[2.0] Lock class uses blocking sleep
aioredis/lock.py calls `time.sleep` instead of `asyncio.sleep`. Pull request on its way...
</issue>
<code>
[start of aioredis/lock.py]
1 import threading
2 import time as mod_time
3 import uuid
4 from types import SimpleNamespace
5 from typing import TYPE_CHECKING, Awaitable, NoReturn, Union
6
7 from aioredis.exceptions import LockError, LockNotOwnedError
8
9 if TYPE_CHECKING:
10 from aioredis import Redis
11
12
13 class Lock:
14 """
15 A shared, distributed Lock. Using Redis for locking allows the Lock
16 to be shared across processes and/or machines.
17
18 It's left to the user to resolve deadlock issues and make sure
19 multiple clients play nicely together.
20 """
21
22 lua_release = None
23 lua_extend = None
24 lua_reacquire = None
25
26 # KEYS[1] - lock name
27 # ARGV[1] - token
28 # return 1 if the lock was released, otherwise 0
29 LUA_RELEASE_SCRIPT = """
30 local token = redis.call('get', KEYS[1])
31 if not token or token ~= ARGV[1] then
32 return 0
33 end
34 redis.call('del', KEYS[1])
35 return 1
36 """
37
38 # KEYS[1] - lock name
39 # ARGV[1] - token
40 # ARGV[2] - additional milliseconds
41 # ARGV[3] - "0" if the additional time should be added to the lock's
42 # existing ttl or "1" if the existing ttl should be replaced
43 # return 1 if the locks time was extended, otherwise 0
44 LUA_EXTEND_SCRIPT = """
45 local token = redis.call('get', KEYS[1])
46 if not token or token ~= ARGV[1] then
47 return 0
48 end
49 local expiration = redis.call('pttl', KEYS[1])
50 if not expiration then
51 expiration = 0
52 end
53 if expiration < 0 then
54 return 0
55 end
56
57 local newttl = ARGV[2]
58 if ARGV[3] == "0" then
59 newttl = ARGV[2] + expiration
60 end
61 redis.call('pexpire', KEYS[1], newttl)
62 return 1
63 """
64
65 # KEYS[1] - lock name
66 # ARGV[1] - token
67 # ARGV[2] - milliseconds
68 # return 1 if the locks time was reacquired, otherwise 0
69 LUA_REACQUIRE_SCRIPT = """
70 local token = redis.call('get', KEYS[1])
71 if not token or token ~= ARGV[1] then
72 return 0
73 end
74 redis.call('pexpire', KEYS[1], ARGV[2])
75 return 1
76 """
77
78 def __init__(
79 self,
80 redis: "Redis",
81 name: str,
82 timeout: float = None,
83 sleep: float = 0.1,
84 blocking: bool = True,
85 blocking_timeout: float = None,
86 thread_local: bool = True,
87 ):
88 """
89 Create a new Lock instance named ``name`` using the Redis client
90 supplied by ``redis``.
91
92 ``timeout`` indicates a maximum life for the lock.
93 By default, it will remain locked until release() is called.
94 ``timeout`` can be specified as a float or integer, both representing
95 the number of seconds to wait.
96
97 ``sleep`` indicates the amount of time to sleep per loop iteration
98 when the lock is in blocking mode and another client is currently
99 holding the lock.
100
101 ``blocking`` indicates whether calling ``acquire`` should block until
102 the lock has been acquired or to fail immediately, causing ``acquire``
103 to return False and the lock not being acquired. Defaults to True.
104 Note this value can be overridden by passing a ``blocking``
105 argument to ``acquire``.
106
107 ``blocking_timeout`` indicates the maximum amount of time in seconds to
108 spend trying to acquire the lock. A value of ``None`` indicates
109 continue trying forever. ``blocking_timeout`` can be specified as a
110 float or integer, both representing the number of seconds to wait.
111
112 ``thread_local`` indicates whether the lock token is placed in
113 thread-local storage. By default, the token is placed in thread local
114 storage so that a thread only sees its token, not a token set by
115 another thread. Consider the following timeline:
116
117 time: 0, thread-1 acquires `my-lock`, with a timeout of 5 seconds.
118 thread-1 sets the token to "abc"
119 time: 1, thread-2 blocks trying to acquire `my-lock` using the
120 Lock instance.
121 time: 5, thread-1 has not yet completed. redis expires the lock
122 key.
123 time: 5, thread-2 acquired `my-lock` now that it's available.
124 thread-2 sets the token to "xyz"
125 time: 6, thread-1 finishes its work and calls release(). if the
126 token is *not* stored in thread local storage, then
127 thread-1 would see the token value as "xyz" and would be
128 able to successfully release the thread-2's lock.
129
130 In some use cases it's necessary to disable thread local storage. For
131 example, if you have code where one thread acquires a lock and passes
132 that lock instance to a worker thread to release later. If thread
133 local storage isn't disabled in this case, the worker thread won't see
134 the token set by the thread that acquired the lock. Our assumption
135 is that these cases aren't common and as such default to using
136 thread local storage.
137 """
138 self.redis = redis
139 self.name = name
140 self.timeout = timeout
141 self.sleep = sleep
142 self.blocking = blocking
143 self.blocking_timeout = blocking_timeout
144 self.thread_local = bool(thread_local)
145 self.local = threading.local() if self.thread_local else SimpleNamespace()
146 self.local.token = None
147 self.register_scripts()
148
149 def register_scripts(self):
150 cls = self.__class__
151 client = self.redis
152 if cls.lua_release is None:
153 cls.lua_release = client.register_script(cls.LUA_RELEASE_SCRIPT)
154 if cls.lua_extend is None:
155 cls.lua_extend = client.register_script(cls.LUA_EXTEND_SCRIPT)
156 if cls.lua_reacquire is None:
157 cls.lua_reacquire = client.register_script(cls.LUA_REACQUIRE_SCRIPT)
158
159 async def __aenter__(self):
160 # force blocking, as otherwise the user would have to check whether
161 # the lock was actually acquired or not.
162 if await self.acquire(blocking=True):
163 return self
164 raise LockError("Unable to acquire lock within the time specified")
165
166 async def __aexit__(self, exc_type, exc_value, traceback):
167 await self.release()
168
169 async def acquire(
170 self,
171 blocking: bool = None,
172 blocking_timeout: float = None,
173 token: Union[str, bytes] = None,
174 ):
175 """
176 Use Redis to hold a shared, distributed lock named ``name``.
177 Returns True once the lock is acquired.
178
179 If ``blocking`` is False, always return immediately. If the lock
180 was acquired, return True, otherwise return False.
181
182 ``blocking_timeout`` specifies the maximum number of seconds to
183 wait trying to acquire the lock.
184
185 ``token`` specifies the token value to be used. If provided, token
186 must be a bytes object or a string that can be encoded to a bytes
187 object with the default encoding. If a token isn't specified, a UUID
188 will be generated.
189 """
190 sleep = self.sleep
191 if token is None:
192 token = uuid.uuid1().hex.encode()
193 else:
194 encoder = self.redis.connection_pool.get_encoder()
195 token = encoder.encode(token)
196 if blocking is None:
197 blocking = self.blocking
198 if blocking_timeout is None:
199 blocking_timeout = self.blocking_timeout
200 stop_trying_at = None
201 if blocking_timeout is not None:
202 stop_trying_at = mod_time.monotonic() + blocking_timeout
203 while True:
204 if await self.do_acquire(token):
205 self.local.token = token
206 return True
207 if not blocking:
208 return False
209 next_try_at = mod_time.monotonic() + sleep
210 if stop_trying_at is not None and next_try_at > stop_trying_at:
211 return False
212 mod_time.sleep(sleep)
213
214 async def do_acquire(self, token: Union[str, bytes]) -> bool:
215 if self.timeout:
216 # convert to milliseconds
217 timeout = int(self.timeout * 1000)
218 else:
219 timeout = None
220 if await self.redis.set(self.name, token, nx=True, px=timeout):
221 return True
222 return False
223
224 async def locked(self) -> bool:
225 """
226 Returns True if this key is locked by any process, otherwise False.
227 """
228 return await self.redis.get(self.name) is not None
229
230 async def owned(self) -> bool:
231 """
232 Returns True if this key is locked by this lock, otherwise False.
233 """
234 stored_token = await self.redis.get(self.name)
235 # need to always compare bytes to bytes
236 # TODO: this can be simplified when the context manager is finished
237 if stored_token and not isinstance(stored_token, bytes):
238 encoder = self.redis.connection_pool.get_encoder()
239 stored_token = encoder.encode(stored_token)
240 return self.local.token is not None and stored_token == self.local.token
241
242 def release(self) -> Awaitable[NoReturn]:
243 """Releases the already acquired lock"""
244 expected_token = self.local.token
245 if expected_token is None:
246 raise LockError("Cannot release an unlocked lock")
247 self.local.token = None
248 return self.do_release(expected_token)
249
250 async def do_release(self, expected_token: bytes):
251 if not bool(
252 await self.lua_release(
253 keys=[self.name], args=[expected_token], client=self.redis
254 )
255 ):
256 raise LockNotOwnedError("Cannot release a lock" " that's no longer owned")
257
258 def extend(
259 self, additional_time: float, replace_ttl: bool = False
260 ) -> Awaitable[bool]:
261 """
262 Adds more time to an already acquired lock.
263
264 ``additional_time`` can be specified as an integer or a float, both
265 representing the number of seconds to add.
266
267 ``replace_ttl`` if False (the default), add `additional_time` to
268 the lock's existing ttl. If True, replace the lock's ttl with
269 `additional_time`.
270 """
271 if self.local.token is None:
272 raise LockError("Cannot extend an unlocked lock")
273 if self.timeout is None:
274 raise LockError("Cannot extend a lock with no timeout")
275 return self.do_extend(additional_time, replace_ttl)
276
277 async def do_extend(self, additional_time, replace_ttl) -> bool:
278 additional_time = int(additional_time * 1000)
279 if not bool(
280 await self.lua_extend(
281 keys=[self.name],
282 args=[self.local.token, additional_time, replace_ttl and "1" or "0"],
283 client=self.redis,
284 )
285 ):
286 raise LockNotOwnedError("Cannot extend a lock that's" " no longer owned")
287 return True
288
289 def reacquire(self) -> Awaitable[bool]:
290 """
291 Resets a TTL of an already acquired lock back to a timeout value.
292 """
293 if self.local.token is None:
294 raise LockError("Cannot reacquire an unlocked lock")
295 if self.timeout is None:
296 raise LockError("Cannot reacquire a lock with no timeout")
297 return self.do_reacquire()
298
299 async def do_reacquire(self) -> bool:
300 timeout = int(self.timeout * 1000)
301 if not bool(
302 await self.lua_reacquire(
303 keys=[self.name], args=[self.local.token, timeout], client=self.redis
304 )
305 ):
306 raise LockNotOwnedError("Cannot reacquire a lock that's" " no longer owned")
307 return True
308
[end of aioredis/lock.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aioredis/lock.py b/aioredis/lock.py
--- a/aioredis/lock.py
+++ b/aioredis/lock.py
@@ -1,3 +1,4 @@
+import asyncio
import threading
import time as mod_time
import uuid
@@ -209,7 +210,7 @@
next_try_at = mod_time.monotonic() + sleep
if stop_trying_at is not None and next_try_at > stop_trying_at:
return False
- mod_time.sleep(sleep)
+ await asyncio.sleep(sleep)
async def do_acquire(self, token: Union[str, bytes]) -> bool:
if self.timeout:
|
{"golden_diff": "diff --git a/aioredis/lock.py b/aioredis/lock.py\n--- a/aioredis/lock.py\n+++ b/aioredis/lock.py\n@@ -1,3 +1,4 @@\n+import asyncio\n import threading\n import time as mod_time\n import uuid\n@@ -209,7 +210,7 @@\n next_try_at = mod_time.monotonic() + sleep\n if stop_trying_at is not None and next_try_at > stop_trying_at:\n return False\n- mod_time.sleep(sleep)\n+ await asyncio.sleep(sleep)\n \n async def do_acquire(self, token: Union[str, bytes]) -> bool:\n if self.timeout:\n", "issue": "[2.0] Lock class uses blocking sleep\naioredis/lock.py calls `time.sleep` instead of `asyncio.sleep`. Pull request on its way...\n", "before_files": [{"content": "import threading\nimport time as mod_time\nimport uuid\nfrom types import SimpleNamespace\nfrom typing import TYPE_CHECKING, Awaitable, NoReturn, Union\n\nfrom aioredis.exceptions import LockError, LockNotOwnedError\n\nif TYPE_CHECKING:\n from aioredis import Redis\n\n\nclass Lock:\n \"\"\"\n A shared, distributed Lock. Using Redis for locking allows the Lock\n to be shared across processes and/or machines.\n\n It's left to the user to resolve deadlock issues and make sure\n multiple clients play nicely together.\n \"\"\"\n\n lua_release = None\n lua_extend = None\n lua_reacquire = None\n\n # KEYS[1] - lock name\n # ARGV[1] - token\n # return 1 if the lock was released, otherwise 0\n LUA_RELEASE_SCRIPT = \"\"\"\n local token = redis.call('get', KEYS[1])\n if not token or token ~= ARGV[1] then\n return 0\n end\n redis.call('del', KEYS[1])\n return 1\n \"\"\"\n\n # KEYS[1] - lock name\n # ARGV[1] - token\n # ARGV[2] - additional milliseconds\n # ARGV[3] - \"0\" if the additional time should be added to the lock's\n # existing ttl or \"1\" if the existing ttl should be replaced\n # return 1 if the locks time was extended, otherwise 0\n LUA_EXTEND_SCRIPT = \"\"\"\n local token = redis.call('get', KEYS[1])\n if not token or token ~= ARGV[1] then\n return 0\n end\n local expiration = redis.call('pttl', KEYS[1])\n if not expiration then\n expiration = 0\n end\n if expiration < 0 then\n return 0\n end\n\n local newttl = ARGV[2]\n if ARGV[3] == \"0\" then\n newttl = ARGV[2] + expiration\n end\n redis.call('pexpire', KEYS[1], newttl)\n return 1\n \"\"\"\n\n # KEYS[1] - lock name\n # ARGV[1] - token\n # ARGV[2] - milliseconds\n # return 1 if the locks time was reacquired, otherwise 0\n LUA_REACQUIRE_SCRIPT = \"\"\"\n local token = redis.call('get', KEYS[1])\n if not token or token ~= ARGV[1] then\n return 0\n end\n redis.call('pexpire', KEYS[1], ARGV[2])\n return 1\n \"\"\"\n\n def __init__(\n self,\n redis: \"Redis\",\n name: str,\n timeout: float = None,\n sleep: float = 0.1,\n blocking: bool = True,\n blocking_timeout: float = None,\n thread_local: bool = True,\n ):\n \"\"\"\n Create a new Lock instance named ``name`` using the Redis client\n supplied by ``redis``.\n\n ``timeout`` indicates a maximum life for the lock.\n By default, it will remain locked until release() is called.\n ``timeout`` can be specified as a float or integer, both representing\n the number of seconds to wait.\n\n ``sleep`` indicates the amount of time to sleep per loop iteration\n when the lock is in blocking mode and another client is currently\n holding the lock.\n\n ``blocking`` indicates whether calling ``acquire`` should block until\n the lock has been acquired or to fail immediately, causing ``acquire``\n to return False and the lock not being acquired. Defaults to True.\n Note this value can be overridden by passing a ``blocking``\n argument to ``acquire``.\n\n ``blocking_timeout`` indicates the maximum amount of time in seconds to\n spend trying to acquire the lock. A value of ``None`` indicates\n continue trying forever. ``blocking_timeout`` can be specified as a\n float or integer, both representing the number of seconds to wait.\n\n ``thread_local`` indicates whether the lock token is placed in\n thread-local storage. By default, the token is placed in thread local\n storage so that a thread only sees its token, not a token set by\n another thread. Consider the following timeline:\n\n time: 0, thread-1 acquires `my-lock`, with a timeout of 5 seconds.\n thread-1 sets the token to \"abc\"\n time: 1, thread-2 blocks trying to acquire `my-lock` using the\n Lock instance.\n time: 5, thread-1 has not yet completed. redis expires the lock\n key.\n time: 5, thread-2 acquired `my-lock` now that it's available.\n thread-2 sets the token to \"xyz\"\n time: 6, thread-1 finishes its work and calls release(). if the\n token is *not* stored in thread local storage, then\n thread-1 would see the token value as \"xyz\" and would be\n able to successfully release the thread-2's lock.\n\n In some use cases it's necessary to disable thread local storage. For\n example, if you have code where one thread acquires a lock and passes\n that lock instance to a worker thread to release later. If thread\n local storage isn't disabled in this case, the worker thread won't see\n the token set by the thread that acquired the lock. Our assumption\n is that these cases aren't common and as such default to using\n thread local storage.\n \"\"\"\n self.redis = redis\n self.name = name\n self.timeout = timeout\n self.sleep = sleep\n self.blocking = blocking\n self.blocking_timeout = blocking_timeout\n self.thread_local = bool(thread_local)\n self.local = threading.local() if self.thread_local else SimpleNamespace()\n self.local.token = None\n self.register_scripts()\n\n def register_scripts(self):\n cls = self.__class__\n client = self.redis\n if cls.lua_release is None:\n cls.lua_release = client.register_script(cls.LUA_RELEASE_SCRIPT)\n if cls.lua_extend is None:\n cls.lua_extend = client.register_script(cls.LUA_EXTEND_SCRIPT)\n if cls.lua_reacquire is None:\n cls.lua_reacquire = client.register_script(cls.LUA_REACQUIRE_SCRIPT)\n\n async def __aenter__(self):\n # force blocking, as otherwise the user would have to check whether\n # the lock was actually acquired or not.\n if await self.acquire(blocking=True):\n return self\n raise LockError(\"Unable to acquire lock within the time specified\")\n\n async def __aexit__(self, exc_type, exc_value, traceback):\n await self.release()\n\n async def acquire(\n self,\n blocking: bool = None,\n blocking_timeout: float = None,\n token: Union[str, bytes] = None,\n ):\n \"\"\"\n Use Redis to hold a shared, distributed lock named ``name``.\n Returns True once the lock is acquired.\n\n If ``blocking`` is False, always return immediately. If the lock\n was acquired, return True, otherwise return False.\n\n ``blocking_timeout`` specifies the maximum number of seconds to\n wait trying to acquire the lock.\n\n ``token`` specifies the token value to be used. If provided, token\n must be a bytes object or a string that can be encoded to a bytes\n object with the default encoding. If a token isn't specified, a UUID\n will be generated.\n \"\"\"\n sleep = self.sleep\n if token is None:\n token = uuid.uuid1().hex.encode()\n else:\n encoder = self.redis.connection_pool.get_encoder()\n token = encoder.encode(token)\n if blocking is None:\n blocking = self.blocking\n if blocking_timeout is None:\n blocking_timeout = self.blocking_timeout\n stop_trying_at = None\n if blocking_timeout is not None:\n stop_trying_at = mod_time.monotonic() + blocking_timeout\n while True:\n if await self.do_acquire(token):\n self.local.token = token\n return True\n if not blocking:\n return False\n next_try_at = mod_time.monotonic() + sleep\n if stop_trying_at is not None and next_try_at > stop_trying_at:\n return False\n mod_time.sleep(sleep)\n\n async def do_acquire(self, token: Union[str, bytes]) -> bool:\n if self.timeout:\n # convert to milliseconds\n timeout = int(self.timeout * 1000)\n else:\n timeout = None\n if await self.redis.set(self.name, token, nx=True, px=timeout):\n return True\n return False\n\n async def locked(self) -> bool:\n \"\"\"\n Returns True if this key is locked by any process, otherwise False.\n \"\"\"\n return await self.redis.get(self.name) is not None\n\n async def owned(self) -> bool:\n \"\"\"\n Returns True if this key is locked by this lock, otherwise False.\n \"\"\"\n stored_token = await self.redis.get(self.name)\n # need to always compare bytes to bytes\n # TODO: this can be simplified when the context manager is finished\n if stored_token and not isinstance(stored_token, bytes):\n encoder = self.redis.connection_pool.get_encoder()\n stored_token = encoder.encode(stored_token)\n return self.local.token is not None and stored_token == self.local.token\n\n def release(self) -> Awaitable[NoReturn]:\n \"\"\"Releases the already acquired lock\"\"\"\n expected_token = self.local.token\n if expected_token is None:\n raise LockError(\"Cannot release an unlocked lock\")\n self.local.token = None\n return self.do_release(expected_token)\n\n async def do_release(self, expected_token: bytes):\n if not bool(\n await self.lua_release(\n keys=[self.name], args=[expected_token], client=self.redis\n )\n ):\n raise LockNotOwnedError(\"Cannot release a lock\" \" that's no longer owned\")\n\n def extend(\n self, additional_time: float, replace_ttl: bool = False\n ) -> Awaitable[bool]:\n \"\"\"\n Adds more time to an already acquired lock.\n\n ``additional_time`` can be specified as an integer or a float, both\n representing the number of seconds to add.\n\n ``replace_ttl`` if False (the default), add `additional_time` to\n the lock's existing ttl. If True, replace the lock's ttl with\n `additional_time`.\n \"\"\"\n if self.local.token is None:\n raise LockError(\"Cannot extend an unlocked lock\")\n if self.timeout is None:\n raise LockError(\"Cannot extend a lock with no timeout\")\n return self.do_extend(additional_time, replace_ttl)\n\n async def do_extend(self, additional_time, replace_ttl) -> bool:\n additional_time = int(additional_time * 1000)\n if not bool(\n await self.lua_extend(\n keys=[self.name],\n args=[self.local.token, additional_time, replace_ttl and \"1\" or \"0\"],\n client=self.redis,\n )\n ):\n raise LockNotOwnedError(\"Cannot extend a lock that's\" \" no longer owned\")\n return True\n\n def reacquire(self) -> Awaitable[bool]:\n \"\"\"\n Resets a TTL of an already acquired lock back to a timeout value.\n \"\"\"\n if self.local.token is None:\n raise LockError(\"Cannot reacquire an unlocked lock\")\n if self.timeout is None:\n raise LockError(\"Cannot reacquire a lock with no timeout\")\n return self.do_reacquire()\n\n async def do_reacquire(self) -> bool:\n timeout = int(self.timeout * 1000)\n if not bool(\n await self.lua_reacquire(\n keys=[self.name], args=[self.local.token, timeout], client=self.redis\n )\n ):\n raise LockNotOwnedError(\"Cannot reacquire a lock that's\" \" no longer owned\")\n return True\n", "path": "aioredis/lock.py"}]}
| 4,011 | 156 |
gh_patches_debug_9141
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-720
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support multi-line feedback
### Motivation
<!-- A clear and concise description of what the motivation for the new feature is, and what problem it is solving. -->
When users sent multiple lines of feedback, the lines are shown wrapped in the backend list. It would make the feedback more readable if the feedback was shown exactly like the user submitted it.
### Proposed Solution
<!-- A clear and concise description of the feature you would like to add, and how it solves the motivating problem. -->
- Change `CharField` to `TextField`
- Use the css class `whitespace-pre-line` when rendering feedback
- Collapse feedback which has multiple lines
### Alternatives
<!-- A clear and concise description of any alternative solutions or features you've considered, and why you're proposed solution is better. -->
### Additional Context
<!-- Add any other information or screenshots about the feature request here. -->
</issue>
<code>
[start of src/cms/models/feedback/feedback.py]
1 from django.conf import settings
2 from django.db import models
3 from django.utils.text import capfirst
4 from django.utils.translation import ugettext_lazy as _
5
6 from ...constants import feedback_ratings
7 from ...utils.translation_utils import ugettext_many_lazy as __
8 from ..languages.language import Language
9 from ..regions.region import Region
10
11
12 class Feedback(models.Model):
13 """
14 Database model representing feedback from app-users.
15 Do not directly create instances of this base model, but of the submodels (e.g. PageFeedback) instead.
16 """
17
18 region = models.ForeignKey(
19 Region,
20 on_delete=models.CASCADE,
21 related_name="feedback",
22 verbose_name=_("region"),
23 )
24 language = models.ForeignKey(
25 Language,
26 on_delete=models.CASCADE,
27 related_name="feedback",
28 verbose_name=_("language"),
29 )
30 #: Manage choices in :mod:`cms.constants.feedback_ratings`
31 rating = models.BooleanField(
32 null=True,
33 blank=True,
34 default=feedback_ratings.NOT_STATED,
35 choices=feedback_ratings.CHOICES,
36 verbose_name=_("rating"),
37 help_text=_("Whether the feedback is positive or negative"),
38 )
39 comment = models.CharField(max_length=1000, blank=True, verbose_name=_("comment"))
40 is_technical = models.BooleanField(
41 verbose_name=_("technical"),
42 help_text=_("Whether or not the feedback is targeted at the developers"),
43 )
44 read_by = models.ForeignKey(
45 settings.AUTH_USER_MODEL,
46 null=True,
47 blank=True,
48 on_delete=models.SET_NULL,
49 related_name="feedback",
50 verbose_name=_("marked as read by"),
51 help_text=__(
52 _("The user who marked this feedback as read."),
53 _("If the feedback is unread, this field is empty."),
54 ),
55 )
56 created_date = models.DateTimeField(
57 auto_now_add=True,
58 verbose_name=_("creation date"),
59 )
60
61 @property
62 def submodel_instance(self):
63 """
64 This property returns the submodel instance (e.g. PageFeedback) of a Feedback instance.
65 """
66 # In this case we need type() instead of isinstance(), because we want to differ between inherited models
67 # pylint: disable=unidiomatic-typecheck
68 if type(self) != Feedback:
69 raise NotImplementedError(
70 "Use submodel_instance only on instances of the base Feedback model, not on submodels."
71 )
72 for submodel in Feedback.__subclasses__():
73 # Inherited models automatically get their name as lowercase assigned as reverse relationship from the base class
74 reverse_related_name = submodel.__name__.lower()
75 if hasattr(self, reverse_related_name):
76 return getattr(self, reverse_related_name)
77 raise TypeError(
78 "Do not directly create instances of the Feedback base model, but of the submodels (e.g. PageFeedback) instead."
79 )
80
81 @property
82 def category(self):
83 """
84 This property returns the category (verbose name of the submodel) of this feedback object.
85 """
86 return capfirst(type(self.submodel_instance)._meta.verbose_name)
87
88 @property
89 def object_name(self):
90 """
91 This property returns the name of the object this feedback comments on.
92 To be implemented in the inheriting model.
93 """
94 return self.submodel_instance.object_name
95
96 @property
97 def object_url(self):
98 """
99 This property returns the url to the object this feedback comments on.
100 To be implemented in the inheriting model.
101 """
102 return self.submodel_instance.object_url
103
104 @property
105 def related_feedback(self):
106 """
107 This property returns all feedback entries which relate to the same object and have the same is_technical value.
108
109 :return: The queryset of related feedback
110 :rtype: ~django.db.models.query.QuerySet [ ~cms.models.feedback.feedback.Feedback ]
111 """
112 return self.submodel_instance.related_feedback
113
114 @property
115 def rating_sum_positive(self):
116 """
117 This property returns the sum of the up-ratings of this object.
118
119 :return: The number of positive ratings on this feedback object
120 :rtype: int
121 """
122 # Enable this property on instances of the base Feedback model
123 # In this case we need type() instead of isinstance(), because we want to differ between inherited models
124 # pylint: disable=unidiomatic-typecheck
125 if type(self) == Feedback:
126 instance = self.submodel_instance
127 else:
128 instance = self
129 return instance.related_feedback.filter(
130 rating=feedback_ratings.POSITIVE
131 ).count()
132
133 @property
134 def rating_sum_negative(self):
135 """
136 This property returns the sum of the down-ratings of this object.
137
138 :return: The number of negative ratings on this feedback object
139 :rtype: int
140 """
141 # Enable this property on instances of the base Feedback model
142 # In this case we need type() instead of isinstance(), because we want to differ between inherited models
143 # pylint: disable=unidiomatic-typecheck
144 if type(self) == Feedback:
145 instance = self.submodel_instance
146 else:
147 instance = self
148 return instance.related_feedback.filter(
149 rating=feedback_ratings.NEGATIVE
150 ).count()
151
152 @property
153 def read(self):
154 """
155 This property returns whether or not the feedback is marked as read or not.
156 It is ``True`` if :attr:`~cms.models.feedback.feedback.Feedback.read_by` is set and ``False`` otherwise.
157 """
158 return bool(self.read_by)
159
160 class Meta:
161 #: The verbose name of the model
162 verbose_name = _("feedback")
163 #: The plural verbose name of the model
164 verbose_name_plural = _("feedback")
165 #: The fields which are used to sort the returned objects of a QuerySet
166 ordering = ["-created_date"]
167 #: The default permissions for this model
168 default_permissions = ()
169 #: The custom permissions for this model
170 permissions = (("manage_feedback", "Can manage feedback"),)
171
[end of src/cms/models/feedback/feedback.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cms/models/feedback/feedback.py b/src/cms/models/feedback/feedback.py
--- a/src/cms/models/feedback/feedback.py
+++ b/src/cms/models/feedback/feedback.py
@@ -36,7 +36,7 @@
verbose_name=_("rating"),
help_text=_("Whether the feedback is positive or negative"),
)
- comment = models.CharField(max_length=1000, blank=True, verbose_name=_("comment"))
+ comment = models.TextField(blank=True, verbose_name=_("comment"))
is_technical = models.BooleanField(
verbose_name=_("technical"),
help_text=_("Whether or not the feedback is targeted at the developers"),
|
{"golden_diff": "diff --git a/src/cms/models/feedback/feedback.py b/src/cms/models/feedback/feedback.py\n--- a/src/cms/models/feedback/feedback.py\n+++ b/src/cms/models/feedback/feedback.py\n@@ -36,7 +36,7 @@\n verbose_name=_(\"rating\"),\n help_text=_(\"Whether the feedback is positive or negative\"),\n )\n- comment = models.CharField(max_length=1000, blank=True, verbose_name=_(\"comment\"))\n+ comment = models.TextField(blank=True, verbose_name=_(\"comment\"))\n is_technical = models.BooleanField(\n verbose_name=_(\"technical\"),\n help_text=_(\"Whether or not the feedback is targeted at the developers\"),\n", "issue": "Support multi-line feedback\n### Motivation\r\n<!-- A clear and concise description of what the motivation for the new feature is, and what problem it is solving. -->\r\nWhen users sent multiple lines of feedback, the lines are shown wrapped in the backend list. It would make the feedback more readable if the feedback was shown exactly like the user submitted it.\r\n\r\n### Proposed Solution\r\n<!-- A clear and concise description of the feature you would like to add, and how it solves the motivating problem. -->\r\n- Change `CharField` to `TextField`\r\n- Use the css class `whitespace-pre-line` when rendering feedback\r\n- Collapse feedback which has multiple lines\r\n\r\n### Alternatives\r\n<!-- A clear and concise description of any alternative solutions or features you've considered, and why you're proposed solution is better. -->\r\n\r\n\r\n### Additional Context\r\n<!-- Add any other information or screenshots about the feature request here. -->\r\n\r\n\n", "before_files": [{"content": "from django.conf import settings\nfrom django.db import models\nfrom django.utils.text import capfirst\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom ...constants import feedback_ratings\nfrom ...utils.translation_utils import ugettext_many_lazy as __\nfrom ..languages.language import Language\nfrom ..regions.region import Region\n\n\nclass Feedback(models.Model):\n \"\"\"\n Database model representing feedback from app-users.\n Do not directly create instances of this base model, but of the submodels (e.g. PageFeedback) instead.\n \"\"\"\n\n region = models.ForeignKey(\n Region,\n on_delete=models.CASCADE,\n related_name=\"feedback\",\n verbose_name=_(\"region\"),\n )\n language = models.ForeignKey(\n Language,\n on_delete=models.CASCADE,\n related_name=\"feedback\",\n verbose_name=_(\"language\"),\n )\n #: Manage choices in :mod:`cms.constants.feedback_ratings`\n rating = models.BooleanField(\n null=True,\n blank=True,\n default=feedback_ratings.NOT_STATED,\n choices=feedback_ratings.CHOICES,\n verbose_name=_(\"rating\"),\n help_text=_(\"Whether the feedback is positive or negative\"),\n )\n comment = models.CharField(max_length=1000, blank=True, verbose_name=_(\"comment\"))\n is_technical = models.BooleanField(\n verbose_name=_(\"technical\"),\n help_text=_(\"Whether or not the feedback is targeted at the developers\"),\n )\n read_by = models.ForeignKey(\n settings.AUTH_USER_MODEL,\n null=True,\n blank=True,\n on_delete=models.SET_NULL,\n related_name=\"feedback\",\n verbose_name=_(\"marked as read by\"),\n help_text=__(\n _(\"The user who marked this feedback as read.\"),\n _(\"If the feedback is unread, this field is empty.\"),\n ),\n )\n created_date = models.DateTimeField(\n auto_now_add=True,\n verbose_name=_(\"creation date\"),\n )\n\n @property\n def submodel_instance(self):\n \"\"\"\n This property returns the submodel instance (e.g. PageFeedback) of a Feedback instance.\n \"\"\"\n # In this case we need type() instead of isinstance(), because we want to differ between inherited models\n # pylint: disable=unidiomatic-typecheck\n if type(self) != Feedback:\n raise NotImplementedError(\n \"Use submodel_instance only on instances of the base Feedback model, not on submodels.\"\n )\n for submodel in Feedback.__subclasses__():\n # Inherited models automatically get their name as lowercase assigned as reverse relationship from the base class\n reverse_related_name = submodel.__name__.lower()\n if hasattr(self, reverse_related_name):\n return getattr(self, reverse_related_name)\n raise TypeError(\n \"Do not directly create instances of the Feedback base model, but of the submodels (e.g. PageFeedback) instead.\"\n )\n\n @property\n def category(self):\n \"\"\"\n This property returns the category (verbose name of the submodel) of this feedback object.\n \"\"\"\n return capfirst(type(self.submodel_instance)._meta.verbose_name)\n\n @property\n def object_name(self):\n \"\"\"\n This property returns the name of the object this feedback comments on.\n To be implemented in the inheriting model.\n \"\"\"\n return self.submodel_instance.object_name\n\n @property\n def object_url(self):\n \"\"\"\n This property returns the url to the object this feedback comments on.\n To be implemented in the inheriting model.\n \"\"\"\n return self.submodel_instance.object_url\n\n @property\n def related_feedback(self):\n \"\"\"\n This property returns all feedback entries which relate to the same object and have the same is_technical value.\n\n :return: The queryset of related feedback\n :rtype: ~django.db.models.query.QuerySet [ ~cms.models.feedback.feedback.Feedback ]\n \"\"\"\n return self.submodel_instance.related_feedback\n\n @property\n def rating_sum_positive(self):\n \"\"\"\n This property returns the sum of the up-ratings of this object.\n\n :return: The number of positive ratings on this feedback object\n :rtype: int\n \"\"\"\n # Enable this property on instances of the base Feedback model\n # In this case we need type() instead of isinstance(), because we want to differ between inherited models\n # pylint: disable=unidiomatic-typecheck\n if type(self) == Feedback:\n instance = self.submodel_instance\n else:\n instance = self\n return instance.related_feedback.filter(\n rating=feedback_ratings.POSITIVE\n ).count()\n\n @property\n def rating_sum_negative(self):\n \"\"\"\n This property returns the sum of the down-ratings of this object.\n\n :return: The number of negative ratings on this feedback object\n :rtype: int\n \"\"\"\n # Enable this property on instances of the base Feedback model\n # In this case we need type() instead of isinstance(), because we want to differ between inherited models\n # pylint: disable=unidiomatic-typecheck\n if type(self) == Feedback:\n instance = self.submodel_instance\n else:\n instance = self\n return instance.related_feedback.filter(\n rating=feedback_ratings.NEGATIVE\n ).count()\n\n @property\n def read(self):\n \"\"\"\n This property returns whether or not the feedback is marked as read or not.\n It is ``True`` if :attr:`~cms.models.feedback.feedback.Feedback.read_by` is set and ``False`` otherwise.\n \"\"\"\n return bool(self.read_by)\n\n class Meta:\n #: The verbose name of the model\n verbose_name = _(\"feedback\")\n #: The plural verbose name of the model\n verbose_name_plural = _(\"feedback\")\n #: The fields which are used to sort the returned objects of a QuerySet\n ordering = [\"-created_date\"]\n #: The default permissions for this model\n default_permissions = ()\n #: The custom permissions for this model\n permissions = ((\"manage_feedback\", \"Can manage feedback\"),)\n", "path": "src/cms/models/feedback/feedback.py"}]}
| 2,382 | 142 |
gh_patches_debug_6451
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-5630
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Validator throws KeyError 'table.head' while interactively creating Expectation Suite on a BigQuery datasource
**Describe the bug**
I am getting the same error as described in #3540 when interactively creating an Expectation Suite on a BigQuery datasource via CLI. As requested in the discussion, I am opening a new issue for this.
In the "Edit Your Expectation Suite" notebook provided by `great_expectations suite new`, the following function call throws an error:
```python
validator.head(n_rows=5, fetch_all=False)
```
Thrown error:
```text
KeyError Traceback (most recent call last)
Input In [11], in <cell line: 1>()
----> 1 validator.head(n_rows=5, fetch_all=False)
File some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:2146, in Validator.head(self, n_rows, domain_kwargs, fetch_all)
2141 if domain_kwargs is None:
2142 domain_kwargs = {
2143 "batch_id": self.execution_engine.active_batch_data_id,
2144 }
-> 2146 data: Any = self.get_metric(
2147 metric=MetricConfiguration(
2148 metric_name="table.head",
2149 metric_domain_kwargs=domain_kwargs,
2150 metric_value_kwargs={
2151 "n_rows": n_rows,
2152 "fetch_all": fetch_all,
2153 },
2154 )
2155 )
2157 df: pd.DataFrame
2158 if isinstance(
2159 self.execution_engine, (PandasExecutionEngine, SqlAlchemyExecutionEngine)
2160 ):
File some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:891, in Validator.get_metric(self, metric)
889 def get_metric(self, metric: MetricConfiguration) -> Any:
890 """return the value of the requested metric."""
--> 891 return self.get_metrics(metrics={metric.metric_name: metric})[
892 metric.metric_name
893 ]
File some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:856, in Validator.get_metrics(self, metrics)
848 """
849 metrics: Dictionary of desired metrics to be resolved, with metric_name as key and MetricConfiguration as value.
850 Return Dictionary with requested metrics resolved, with metric_name as key and computed metric as value.
851 """
852 resolved_metrics: Dict[Tuple[str, str, str], Any] = self.compute_metrics(
853 metric_configurations=list(metrics.values())
854 )
--> 856 return {
857 metric_configuration.metric_name: resolved_metrics[metric_configuration.id]
858 for metric_configuration in metrics.values()
859 }
File some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:857, in <dictcomp>(.0)
848 """
849 metrics: Dictionary of desired metrics to be resolved, with metric_name as key and MetricConfiguration as value.
850 Return Dictionary with requested metrics resolved, with metric_name as key and computed metric as value.
851 """
852 resolved_metrics: Dict[Tuple[str, str, str], Any] = self.compute_metrics(
853 metric_configurations=list(metrics.values())
854 )
856 return {
--> 857 metric_configuration.metric_name: resolved_metrics[metric_configuration.id]
858 for metric_configuration in metrics.values()
859 }
KeyError: ('table.head', 'batch_id=15a077d486452b3e1c894458758b7972', '04166707abe073177c1dd922d3584468')
```
**To Reproduce**
Steps to reproduce the behavior:
1. Initialize GE project
2. Add a BigQuery datasource via `great_expectations datasource new`
3. Create a new Expectation Suite via `great_expectations suite new`
4. Choose Interactively and select your datasource and data asset
5. Execute notebook code including the _validator.head()_ call
6. See error above
**Expected behavior**
Calling validator.head() should not raise a KeyError.
**Environment**
- Operating System: MacOS 12.3.1
- Great Expectations Version: 0.15.11
**Additional context**
I have examined the GCP logs in the period of the call of the validator.head() function. I exclude a permission error, because the used service account has maximum rights on used GCP project during debugging. However, errors occur here in the BigQuery service with the JobService.InsertJob method, which are not due to insufficient permissions:
```json
"serviceName": "bigquery.googleapis.com",
"methodName": "google.cloud.bigquery.v2.JobService.InsertJob",
"authorizationInfo": [
{
"resource": "projects/my-project",
"permission": "bigquery.jobs.create",
"granted": true,
"resourceAttributes": {}
}
],
```
The error itself is reported in the response object _jobStatus_:
```json
"jobStatus": {
"errors": [
{
"code": 3,
"message": "Cannot access field id on a value with type ARRAY<STRUCT<id STRING>> at [1:4656]"
}
],
"errorResult": {
"message": "Cannot access field id on a value with type ARRAY<STRUCT<id STRING>> at [1:4656]",
"code": 3
},
"jobState": "DONE"
},
```
Some fields of the table I use are nested fields. Does the validator have problems with these?
</issue>
<code>
[start of great_expectations/expectations/metrics/table_metrics/table_head.py]
1 from typing import Any, Dict
2
3 import pandas as pd
4
5 from great_expectations.core.metric_domain_types import MetricDomainTypes
6 from great_expectations.execution_engine import (
7 PandasExecutionEngine,
8 SparkDFExecutionEngine,
9 SqlAlchemyExecutionEngine,
10 )
11 from great_expectations.expectations.metrics.import_manager import sa
12 from great_expectations.expectations.metrics.metric_provider import metric_value
13 from great_expectations.expectations.metrics.table_metric_provider import (
14 TableMetricProvider,
15 )
16 from great_expectations.validator.metric_configuration import MetricConfiguration
17 from great_expectations.validator.validator import Validator
18
19
20 class TableHead(TableMetricProvider):
21 metric_name = "table.head"
22 value_keys = ("n_rows", "fetch_all")
23 default_kwarg_values = {"n_rows": 5, "fetch_all": False}
24
25 @metric_value(engine=PandasExecutionEngine)
26 def _pandas(
27 cls,
28 execution_engine: PandasExecutionEngine,
29 metric_domain_kwargs: Dict,
30 metric_value_kwargs: Dict,
31 metrics: Dict[str, Any],
32 runtime_configuration: Dict,
33 ):
34 df, _, _ = execution_engine.get_compute_domain(
35 metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE
36 )
37 if metric_value_kwargs.get("fetch_all", cls.default_kwarg_values["fetch_all"]):
38 return df
39 return df.head(metric_value_kwargs["n_rows"])
40
41 @metric_value(engine=SqlAlchemyExecutionEngine)
42 def _sqlalchemy(
43 cls,
44 execution_engine: SqlAlchemyExecutionEngine,
45 metric_domain_kwargs: Dict,
46 metric_value_kwargs: Dict,
47 metrics: Dict[str, Any],
48 runtime_configuration: Dict,
49 ):
50 selectable, _, _ = execution_engine.get_compute_domain(
51 metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE
52 )
53 df = None
54 table_name = getattr(selectable, "name", None)
55 if table_name is None:
56 # if a custom query was passed
57 try:
58 if metric_value_kwargs["fetch_all"]:
59 df = pd.read_sql_query(
60 sql=selectable,
61 con=execution_engine.engine,
62 )
63 else:
64 df = next(
65 pd.read_sql_query(
66 sql=selectable,
67 con=execution_engine.engine,
68 chunksize=metric_value_kwargs["n_rows"],
69 )
70 )
71 except (ValueError, NotImplementedError):
72 # it looks like MetaData that is used by pd.read_sql_query
73 # cannot work on a temp table.
74 # If it fails, we are trying to get the data using read_sql
75 df = None
76 except StopIteration:
77 validator = Validator(execution_engine=execution_engine)
78 columns = validator.get_metric(
79 MetricConfiguration("table.columns", metric_domain_kwargs)
80 )
81 df = pd.DataFrame(columns=columns)
82 else:
83 try:
84 if metric_value_kwargs["fetch_all"]:
85 df = pd.read_sql_table(
86 table_name=getattr(selectable, "name", None),
87 schema=getattr(selectable, "schema", None),
88 con=execution_engine.engine,
89 )
90 else:
91 df = next(
92 pd.read_sql_table(
93 table_name=getattr(selectable, "name", None),
94 schema=getattr(selectable, "schema", None),
95 con=execution_engine.engine,
96 chunksize=metric_value_kwargs["n_rows"],
97 )
98 )
99 except (ValueError, NotImplementedError):
100 # it looks like MetaData that is used by pd.read_sql_table
101 # cannot work on a temp table.
102 # If it fails, we are trying to get the data using read_sql
103 df = None
104 except StopIteration:
105 validator = Validator(execution_engine=execution_engine)
106 columns = validator.get_metric(
107 MetricConfiguration("table.columns", metric_domain_kwargs)
108 )
109 df = pd.DataFrame(columns=columns)
110
111 if df is None:
112 # we want to compile our selectable
113 stmt = sa.select(["*"]).select_from(selectable)
114 if metric_value_kwargs["fetch_all"]:
115 sql = stmt.compile(
116 dialect=execution_engine.engine.dialect,
117 compile_kwargs={"literal_binds": True},
118 )
119 elif execution_engine.engine.dialect.name.lower() == "mssql":
120 # limit doesn't compile properly for mssql
121 sql = str(
122 stmt.compile(
123 dialect=execution_engine.engine.dialect,
124 compile_kwargs={"literal_binds": True},
125 )
126 )
127 sql = f"SELECT TOP {metric_value_kwargs['n_rows']}{sql[6:]}"
128 else:
129 stmt = stmt.limit(metric_value_kwargs["n_rows"])
130 sql = stmt.compile(
131 dialect=execution_engine.engine.dialect,
132 compile_kwargs={"literal_binds": True},
133 )
134
135 df = pd.read_sql(sql, con=execution_engine.engine)
136
137 return df
138
139 @metric_value(engine=SparkDFExecutionEngine)
140 def _spark(
141 cls,
142 execution_engine: SparkDFExecutionEngine,
143 metric_domain_kwargs: Dict,
144 metric_value_kwargs: Dict,
145 metrics: Dict[str, Any],
146 runtime_configuration: Dict,
147 ):
148 df, _, _ = execution_engine.get_compute_domain(
149 metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE
150 )
151 if metric_value_kwargs["fetch_all"]:
152 return df.collect()
153 return df.head(metric_value_kwargs["n_rows"])
154
[end of great_expectations/expectations/metrics/table_metrics/table_head.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/great_expectations/expectations/metrics/table_metrics/table_head.py b/great_expectations/expectations/metrics/table_metrics/table_head.py
--- a/great_expectations/expectations/metrics/table_metrics/table_head.py
+++ b/great_expectations/expectations/metrics/table_metrics/table_head.py
@@ -52,7 +52,10 @@
)
df = None
table_name = getattr(selectable, "name", None)
- if table_name is None:
+ if (
+ isinstance(table_name, sa.sql.elements._anonymous_label)
+ or table_name is None
+ ):
# if a custom query was passed
try:
if metric_value_kwargs["fetch_all"]:
|
{"golden_diff": "diff --git a/great_expectations/expectations/metrics/table_metrics/table_head.py b/great_expectations/expectations/metrics/table_metrics/table_head.py\n--- a/great_expectations/expectations/metrics/table_metrics/table_head.py\n+++ b/great_expectations/expectations/metrics/table_metrics/table_head.py\n@@ -52,7 +52,10 @@\n )\n df = None\n table_name = getattr(selectable, \"name\", None)\n- if table_name is None:\n+ if (\n+ isinstance(table_name, sa.sql.elements._anonymous_label)\n+ or table_name is None\n+ ):\n # if a custom query was passed\n try:\n if metric_value_kwargs[\"fetch_all\"]:\n", "issue": "Validator throws KeyError 'table.head' while interactively creating Expectation Suite on a BigQuery datasource\n**Describe the bug**\r\nI am getting the same error as described in #3540 when interactively creating an Expectation Suite on a BigQuery datasource via CLI. As requested in the discussion, I am opening a new issue for this.\r\n\r\nIn the \"Edit Your Expectation Suite\" notebook provided by `great_expectations suite new`, the following function call throws an error:\r\n\r\n```python\r\nvalidator.head(n_rows=5, fetch_all=False)\r\n```\r\n\r\nThrown error:\r\n\r\n```text\r\nKeyError Traceback (most recent call last)\r\nInput In [11], in <cell line: 1>()\r\n----> 1 validator.head(n_rows=5, fetch_all=False)\r\n\r\nFile some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:2146, in Validator.head(self, n_rows, domain_kwargs, fetch_all)\r\n 2141 if domain_kwargs is None:\r\n 2142 domain_kwargs = {\r\n 2143 \"batch_id\": self.execution_engine.active_batch_data_id,\r\n 2144 }\r\n-> 2146 data: Any = self.get_metric(\r\n 2147 metric=MetricConfiguration(\r\n 2148 metric_name=\"table.head\",\r\n 2149 metric_domain_kwargs=domain_kwargs,\r\n 2150 metric_value_kwargs={\r\n 2151 \"n_rows\": n_rows,\r\n 2152 \"fetch_all\": fetch_all,\r\n 2153 },\r\n 2154 )\r\n 2155 )\r\n 2157 df: pd.DataFrame\r\n 2158 if isinstance(\r\n 2159 self.execution_engine, (PandasExecutionEngine, SqlAlchemyExecutionEngine)\r\n 2160 ):\r\n\r\nFile some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:891, in Validator.get_metric(self, metric)\r\n 889 def get_metric(self, metric: MetricConfiguration) -> Any:\r\n 890 \"\"\"return the value of the requested metric.\"\"\"\r\n--> 891 return self.get_metrics(metrics={metric.metric_name: metric})[\r\n 892 metric.metric_name\r\n 893 ]\r\n\r\nFile some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:856, in Validator.get_metrics(self, metrics)\r\n 848 \"\"\"\r\n 849 metrics: Dictionary of desired metrics to be resolved, with metric_name as key and MetricConfiguration as value.\r\n 850 Return Dictionary with requested metrics resolved, with metric_name as key and computed metric as value.\r\n 851 \"\"\"\r\n 852 resolved_metrics: Dict[Tuple[str, str, str], Any] = self.compute_metrics(\r\n 853 metric_configurations=list(metrics.values())\r\n 854 )\r\n--> 856 return {\r\n 857 metric_configuration.metric_name: resolved_metrics[metric_configuration.id]\r\n 858 for metric_configuration in metrics.values()\r\n 859 }\r\n\r\nFile some-path/.venv/lib/python3.9/site-packages/great_expectations/validator/validator.py:857, in <dictcomp>(.0)\r\n 848 \"\"\"\r\n 849 metrics: Dictionary of desired metrics to be resolved, with metric_name as key and MetricConfiguration as value.\r\n 850 Return Dictionary with requested metrics resolved, with metric_name as key and computed metric as value.\r\n 851 \"\"\"\r\n 852 resolved_metrics: Dict[Tuple[str, str, str], Any] = self.compute_metrics(\r\n 853 metric_configurations=list(metrics.values())\r\n 854 )\r\n 856 return {\r\n--> 857 metric_configuration.metric_name: resolved_metrics[metric_configuration.id]\r\n 858 for metric_configuration in metrics.values()\r\n 859 }\r\n\r\nKeyError: ('table.head', 'batch_id=15a077d486452b3e1c894458758b7972', '04166707abe073177c1dd922d3584468')\r\n```\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n\r\n1. Initialize GE project\r\n2. Add a BigQuery datasource via `great_expectations datasource new`\r\n3. Create a new Expectation Suite via `great_expectations suite new`\r\n4. Choose Interactively and select your datasource and data asset\r\n5. Execute notebook code including the _validator.head()_ call\r\n6. See error above\r\n\r\n**Expected behavior**\r\nCalling validator.head() should not raise a KeyError.\r\n\r\n**Environment**\r\n - Operating System: MacOS 12.3.1\r\n - Great Expectations Version: 0.15.11\r\n\r\n**Additional context**\r\n\r\nI have examined the GCP logs in the period of the call of the validator.head() function. I exclude a permission error, because the used service account has maximum rights on used GCP project during debugging. However, errors occur here in the BigQuery service with the JobService.InsertJob method, which are not due to insufficient permissions:\r\n\r\n```json\r\n\"serviceName\": \"bigquery.googleapis.com\",\r\n\"methodName\": \"google.cloud.bigquery.v2.JobService.InsertJob\",\r\n\"authorizationInfo\": [\r\n {\r\n \"resource\": \"projects/my-project\",\r\n \"permission\": \"bigquery.jobs.create\",\r\n \"granted\": true,\r\n \"resourceAttributes\": {}\r\n }\r\n],\r\n```\r\n\r\nThe error itself is reported in the response object _jobStatus_:\r\n\r\n```json\r\n\"jobStatus\": {\r\n \"errors\": [\r\n {\r\n \"code\": 3,\r\n \"message\": \"Cannot access field id on a value with type ARRAY<STRUCT<id STRING>> at [1:4656]\"\r\n }\r\n ],\r\n \"errorResult\": {\r\n \"message\": \"Cannot access field id on a value with type ARRAY<STRUCT<id STRING>> at [1:4656]\",\r\n \"code\": 3\r\n },\r\n \"jobState\": \"DONE\"\r\n},\r\n```\r\n\r\nSome fields of the table I use are nested fields. Does the validator have problems with these?\n", "before_files": [{"content": "from typing import Any, Dict\n\nimport pandas as pd\n\nfrom great_expectations.core.metric_domain_types import MetricDomainTypes\nfrom great_expectations.execution_engine import (\n PandasExecutionEngine,\n SparkDFExecutionEngine,\n SqlAlchemyExecutionEngine,\n)\nfrom great_expectations.expectations.metrics.import_manager import sa\nfrom great_expectations.expectations.metrics.metric_provider import metric_value\nfrom great_expectations.expectations.metrics.table_metric_provider import (\n TableMetricProvider,\n)\nfrom great_expectations.validator.metric_configuration import MetricConfiguration\nfrom great_expectations.validator.validator import Validator\n\n\nclass TableHead(TableMetricProvider):\n metric_name = \"table.head\"\n value_keys = (\"n_rows\", \"fetch_all\")\n default_kwarg_values = {\"n_rows\": 5, \"fetch_all\": False}\n\n @metric_value(engine=PandasExecutionEngine)\n def _pandas(\n cls,\n execution_engine: PandasExecutionEngine,\n metric_domain_kwargs: Dict,\n metric_value_kwargs: Dict,\n metrics: Dict[str, Any],\n runtime_configuration: Dict,\n ):\n df, _, _ = execution_engine.get_compute_domain(\n metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE\n )\n if metric_value_kwargs.get(\"fetch_all\", cls.default_kwarg_values[\"fetch_all\"]):\n return df\n return df.head(metric_value_kwargs[\"n_rows\"])\n\n @metric_value(engine=SqlAlchemyExecutionEngine)\n def _sqlalchemy(\n cls,\n execution_engine: SqlAlchemyExecutionEngine,\n metric_domain_kwargs: Dict,\n metric_value_kwargs: Dict,\n metrics: Dict[str, Any],\n runtime_configuration: Dict,\n ):\n selectable, _, _ = execution_engine.get_compute_domain(\n metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE\n )\n df = None\n table_name = getattr(selectable, \"name\", None)\n if table_name is None:\n # if a custom query was passed\n try:\n if metric_value_kwargs[\"fetch_all\"]:\n df = pd.read_sql_query(\n sql=selectable,\n con=execution_engine.engine,\n )\n else:\n df = next(\n pd.read_sql_query(\n sql=selectable,\n con=execution_engine.engine,\n chunksize=metric_value_kwargs[\"n_rows\"],\n )\n )\n except (ValueError, NotImplementedError):\n # it looks like MetaData that is used by pd.read_sql_query\n # cannot work on a temp table.\n # If it fails, we are trying to get the data using read_sql\n df = None\n except StopIteration:\n validator = Validator(execution_engine=execution_engine)\n columns = validator.get_metric(\n MetricConfiguration(\"table.columns\", metric_domain_kwargs)\n )\n df = pd.DataFrame(columns=columns)\n else:\n try:\n if metric_value_kwargs[\"fetch_all\"]:\n df = pd.read_sql_table(\n table_name=getattr(selectable, \"name\", None),\n schema=getattr(selectable, \"schema\", None),\n con=execution_engine.engine,\n )\n else:\n df = next(\n pd.read_sql_table(\n table_name=getattr(selectable, \"name\", None),\n schema=getattr(selectable, \"schema\", None),\n con=execution_engine.engine,\n chunksize=metric_value_kwargs[\"n_rows\"],\n )\n )\n except (ValueError, NotImplementedError):\n # it looks like MetaData that is used by pd.read_sql_table\n # cannot work on a temp table.\n # If it fails, we are trying to get the data using read_sql\n df = None\n except StopIteration:\n validator = Validator(execution_engine=execution_engine)\n columns = validator.get_metric(\n MetricConfiguration(\"table.columns\", metric_domain_kwargs)\n )\n df = pd.DataFrame(columns=columns)\n\n if df is None:\n # we want to compile our selectable\n stmt = sa.select([\"*\"]).select_from(selectable)\n if metric_value_kwargs[\"fetch_all\"]:\n sql = stmt.compile(\n dialect=execution_engine.engine.dialect,\n compile_kwargs={\"literal_binds\": True},\n )\n elif execution_engine.engine.dialect.name.lower() == \"mssql\":\n # limit doesn't compile properly for mssql\n sql = str(\n stmt.compile(\n dialect=execution_engine.engine.dialect,\n compile_kwargs={\"literal_binds\": True},\n )\n )\n sql = f\"SELECT TOP {metric_value_kwargs['n_rows']}{sql[6:]}\"\n else:\n stmt = stmt.limit(metric_value_kwargs[\"n_rows\"])\n sql = stmt.compile(\n dialect=execution_engine.engine.dialect,\n compile_kwargs={\"literal_binds\": True},\n )\n\n df = pd.read_sql(sql, con=execution_engine.engine)\n\n return df\n\n @metric_value(engine=SparkDFExecutionEngine)\n def _spark(\n cls,\n execution_engine: SparkDFExecutionEngine,\n metric_domain_kwargs: Dict,\n metric_value_kwargs: Dict,\n metrics: Dict[str, Any],\n runtime_configuration: Dict,\n ):\n df, _, _ = execution_engine.get_compute_domain(\n metric_domain_kwargs, domain_type=MetricDomainTypes.TABLE\n )\n if metric_value_kwargs[\"fetch_all\"]:\n return df.collect()\n return df.head(metric_value_kwargs[\"n_rows\"])\n", "path": "great_expectations/expectations/metrics/table_metrics/table_head.py"}]}
| 3,409 | 158 |
gh_patches_debug_17179
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-1954
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Request access to admin (add fixtures for Riley Orr)
### Issue description
Add fixtures so Riley can access the sandboxes
### Acceptance criteria
- [ ] Fixtures added for Riley Orr
### Additional context
_No response_
### Links to other issues
_No response_
</issue>
<code>
[start of src/registrar/fixtures_users.py]
1 import logging
2 from faker import Faker
3 from django.db import transaction
4
5 from registrar.models import (
6 User,
7 UserGroup,
8 )
9
10 fake = Faker()
11 logger = logging.getLogger(__name__)
12
13
14 class UserFixture:
15 """
16 Load users into the database.
17
18 Make sure this class' `load` method is called from `handle`
19 in management/commands/load.py, then use `./manage.py load`
20 to run this code.
21 """
22
23 ADMINS = [
24 {
25 "username": "5f283494-31bd-49b5-b024-a7e7cae00848",
26 "first_name": "Rachid",
27 "last_name": "Mrad",
28 },
29 {
30 "username": "eb2214cd-fc0c-48c0-9dbd-bc4cd6820c74",
31 "first_name": "Alysia",
32 "last_name": "Broddrick",
33 },
34 {
35 "username": "8f8e7293-17f7-4716-889b-1990241cbd39",
36 "first_name": "Katherine",
37 "last_name": "Osos",
38 },
39 {
40 "username": "70488e0a-e937-4894-a28c-16f5949effd4",
41 "first_name": "Gaby",
42 "last_name": "DiSarli",
43 "email": "[email protected]",
44 },
45 {
46 "username": "83c2b6dd-20a2-4cac-bb40-e22a72d2955c",
47 "first_name": "Cameron",
48 "last_name": "Dixon",
49 },
50 {
51 "username": "0353607a-cbba-47d2-98d7-e83dcd5b90ea",
52 "first_name": "Ryan",
53 "last_name": "Brooks",
54 },
55 {
56 "username": "30001ee7-0467-4df2-8db2-786e79606060",
57 "first_name": "Zander",
58 "last_name": "Adkinson",
59 },
60 {
61 "username": "2bf518c2-485a-4c42-ab1a-f5a8b0a08484",
62 "first_name": "Paul",
63 "last_name": "Kuykendall",
64 },
65 {
66 "username": "2a88a97b-be96-4aad-b99e-0b605b492c78",
67 "first_name": "Rebecca",
68 "last_name": "Hsieh",
69 },
70 {
71 "username": "fa69c8e8-da83-4798-a4f2-263c9ce93f52",
72 "first_name": "David",
73 "last_name": "Kennedy",
74 },
75 {
76 "username": "f14433d8-f0e9-41bf-9c72-b99b110e665d",
77 "first_name": "Nicolle",
78 "last_name": "LeClair",
79 },
80 {
81 "username": "24840450-bf47-4d89-8aa9-c612fe68f9da",
82 "first_name": "Erin",
83 "last_name": "Song",
84 },
85 {
86 "username": "e0ea8b94-6e53-4430-814a-849a7ca45f21",
87 "first_name": "Kristina",
88 "last_name": "Yin",
89 },
90 {
91 "username": "ac49d7c1-368a-4e6b-8f1d-60250e20a16f",
92 "first_name": "Vicky",
93 "last_name": "Chin",
94 "email": "[email protected]",
95 },
96 ]
97
98 STAFF = [
99 {
100 "username": "319c490d-453b-43d9-bc4d-7d6cd8ff6844",
101 "first_name": "Rachid-Analyst",
102 "last_name": "Mrad-Analyst",
103 "email": "[email protected]",
104 },
105 {
106 "username": "b6a15987-5c88-4e26-8de2-ca71a0bdb2cd",
107 "first_name": "Alysia-Analyst",
108 "last_name": "Alysia-Analyst",
109 },
110 {
111 "username": "91a9b97c-bd0a-458d-9823-babfde7ebf44",
112 "first_name": "Katherine-Analyst",
113 "last_name": "Osos-Analyst",
114 "email": "[email protected]",
115 },
116 {
117 "username": "2cc0cde8-8313-4a50-99d8-5882e71443e8",
118 "first_name": "Zander-Analyst",
119 "last_name": "Adkinson-Analyst",
120 },
121 {
122 "username": "57ab5847-7789-49fe-a2f9-21d38076d699",
123 "first_name": "Paul-Analyst",
124 "last_name": "Kuykendall-Analyst",
125 },
126 {
127 "username": "e474e7a9-71ca-449d-833c-8a6e094dd117",
128 "first_name": "Rebecca-Analyst",
129 "last_name": "Hsieh-Analyst",
130 },
131 {
132 "username": "5dc6c9a6-61d9-42b4-ba54-4beff28bac3c",
133 "first_name": "David-Analyst",
134 "last_name": "Kennedy-Analyst",
135 },
136 {
137 "username": "0eb6f326-a3d4-410f-a521-aa4c1fad4e47",
138 "first_name": "Gaby-Analyst",
139 "last_name": "DiSarli-Analyst",
140 "email": "[email protected]",
141 },
142 {
143 "username": "cfe7c2fc-e24a-480e-8b78-28645a1459b3",
144 "first_name": "Nicolle-Analyst",
145 "last_name": "LeClair-Analyst",
146 "email": "[email protected]",
147 },
148 {
149 "username": "378d0bc4-d5a7-461b-bd84-3ae6f6864af9",
150 "first_name": "Erin-Analyst",
151 "last_name": "Song-Analyst",
152 "email": "[email protected]",
153 },
154 {
155 "username": "9a98e4c9-9409-479d-964e-4aec7799107f",
156 "first_name": "Kristina-Analyst",
157 "last_name": "Yin-Analyst",
158 "email": "[email protected]",
159 },
160 {
161 "username": "8f42302e-b83a-4c9e-8764-fc19e2cea576",
162 "first_name": "Vickster-Analyst",
163 "last_name": "Chin-Analyst",
164 "email": "[email protected]",
165 },
166 {
167 "username": "d9839768-0c17-4fa2-9c8e-36291eef5c11",
168 "first_name": "Alex-Analyst",
169 "last_name": "Mcelya-Analyst",
170 "email": "[email protected]",
171 },
172 ]
173
174 def load_users(cls, users, group_name):
175 logger.info(f"Going to load {len(users)} users in group {group_name}")
176 for user_data in users:
177 try:
178 user, _ = User.objects.get_or_create(username=user_data["username"])
179 user.is_superuser = False
180 user.first_name = user_data["first_name"]
181 user.last_name = user_data["last_name"]
182 if "email" in user_data:
183 user.email = user_data["email"]
184 user.is_staff = True
185 user.is_active = True
186 group = UserGroup.objects.get(name=group_name)
187 user.groups.add(group)
188 user.save()
189 logger.debug(f"User object created for {user_data['first_name']}")
190 except Exception as e:
191 logger.warning(e)
192 logger.info(f"All users in group {group_name} loaded.")
193
194 @classmethod
195 def load(cls):
196 # Lumped under .atomic to ensure we don't make redundant DB calls.
197 # This bundles them all together, and then saves it in a single call.
198 # This is slightly different then bulk_create or bulk_update, in that
199 # you still get the same behaviour of .save(), but those incremental
200 # steps now do not need to close/reopen a db connection,
201 # instead they share one.
202 with transaction.atomic():
203 cls.load_users(cls, cls.ADMINS, "full_access_group")
204 cls.load_users(cls, cls.STAFF, "cisa_analysts_group")
205
[end of src/registrar/fixtures_users.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/registrar/fixtures_users.py b/src/registrar/fixtures_users.py
--- a/src/registrar/fixtures_users.py
+++ b/src/registrar/fixtures_users.py
@@ -93,6 +93,12 @@
"last_name": "Chin",
"email": "[email protected]",
},
+ {
+ "username": "012f844d-8a0f-4225-9d82-cbf87bff1d3e",
+ "first_name": "Riley",
+ "last_name": "Orr",
+ "email": "[email protected]",
+ },
]
STAFF = [
@@ -169,6 +175,12 @@
"last_name": "Mcelya-Analyst",
"email": "[email protected]",
},
+ {
+ "username": "082a066f-e0a4-45f6-8672-4343a1208a36",
+ "first_name": "Riley-Analyst",
+ "last_name": "Orr-Analyst",
+ "email": "[email protected]",
+ },
]
def load_users(cls, users, group_name):
|
{"golden_diff": "diff --git a/src/registrar/fixtures_users.py b/src/registrar/fixtures_users.py\n--- a/src/registrar/fixtures_users.py\n+++ b/src/registrar/fixtures_users.py\n@@ -93,6 +93,12 @@\n \"last_name\": \"Chin\",\n \"email\": \"[email protected]\",\n },\n+ {\n+ \"username\": \"012f844d-8a0f-4225-9d82-cbf87bff1d3e\",\n+ \"first_name\": \"Riley\",\n+ \"last_name\": \"Orr\",\n+ \"email\": \"[email protected]\",\n+ },\n ]\n \n STAFF = [\n@@ -169,6 +175,12 @@\n \"last_name\": \"Mcelya-Analyst\",\n \"email\": \"[email protected]\",\n },\n+ {\n+ \"username\": \"082a066f-e0a4-45f6-8672-4343a1208a36\",\n+ \"first_name\": \"Riley-Analyst\",\n+ \"last_name\": \"Orr-Analyst\",\n+ \"email\": \"[email protected]\",\n+ },\n ]\n \n def load_users(cls, users, group_name):\n", "issue": "Request access to admin (add fixtures for Riley Orr)\n### Issue description\n\nAdd fixtures so Riley can access the sandboxes\n\n### Acceptance criteria\n\n- [ ] Fixtures added for Riley Orr\n\n### Additional context\n\n_No response_\n\n### Links to other issues\n\n_No response_\n", "before_files": [{"content": "import logging\nfrom faker import Faker\nfrom django.db import transaction\n\nfrom registrar.models import (\n User,\n UserGroup,\n)\n\nfake = Faker()\nlogger = logging.getLogger(__name__)\n\n\nclass UserFixture:\n \"\"\"\n Load users into the database.\n\n Make sure this class' `load` method is called from `handle`\n in management/commands/load.py, then use `./manage.py load`\n to run this code.\n \"\"\"\n\n ADMINS = [\n {\n \"username\": \"5f283494-31bd-49b5-b024-a7e7cae00848\",\n \"first_name\": \"Rachid\",\n \"last_name\": \"Mrad\",\n },\n {\n \"username\": \"eb2214cd-fc0c-48c0-9dbd-bc4cd6820c74\",\n \"first_name\": \"Alysia\",\n \"last_name\": \"Broddrick\",\n },\n {\n \"username\": \"8f8e7293-17f7-4716-889b-1990241cbd39\",\n \"first_name\": \"Katherine\",\n \"last_name\": \"Osos\",\n },\n {\n \"username\": \"70488e0a-e937-4894-a28c-16f5949effd4\",\n \"first_name\": \"Gaby\",\n \"last_name\": \"DiSarli\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"83c2b6dd-20a2-4cac-bb40-e22a72d2955c\",\n \"first_name\": \"Cameron\",\n \"last_name\": \"Dixon\",\n },\n {\n \"username\": \"0353607a-cbba-47d2-98d7-e83dcd5b90ea\",\n \"first_name\": \"Ryan\",\n \"last_name\": \"Brooks\",\n },\n {\n \"username\": \"30001ee7-0467-4df2-8db2-786e79606060\",\n \"first_name\": \"Zander\",\n \"last_name\": \"Adkinson\",\n },\n {\n \"username\": \"2bf518c2-485a-4c42-ab1a-f5a8b0a08484\",\n \"first_name\": \"Paul\",\n \"last_name\": \"Kuykendall\",\n },\n {\n \"username\": \"2a88a97b-be96-4aad-b99e-0b605b492c78\",\n \"first_name\": \"Rebecca\",\n \"last_name\": \"Hsieh\",\n },\n {\n \"username\": \"fa69c8e8-da83-4798-a4f2-263c9ce93f52\",\n \"first_name\": \"David\",\n \"last_name\": \"Kennedy\",\n },\n {\n \"username\": \"f14433d8-f0e9-41bf-9c72-b99b110e665d\",\n \"first_name\": \"Nicolle\",\n \"last_name\": \"LeClair\",\n },\n {\n \"username\": \"24840450-bf47-4d89-8aa9-c612fe68f9da\",\n \"first_name\": \"Erin\",\n \"last_name\": \"Song\",\n },\n {\n \"username\": \"e0ea8b94-6e53-4430-814a-849a7ca45f21\",\n \"first_name\": \"Kristina\",\n \"last_name\": \"Yin\",\n },\n {\n \"username\": \"ac49d7c1-368a-4e6b-8f1d-60250e20a16f\",\n \"first_name\": \"Vicky\",\n \"last_name\": \"Chin\",\n \"email\": \"[email protected]\",\n },\n ]\n\n STAFF = [\n {\n \"username\": \"319c490d-453b-43d9-bc4d-7d6cd8ff6844\",\n \"first_name\": \"Rachid-Analyst\",\n \"last_name\": \"Mrad-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"b6a15987-5c88-4e26-8de2-ca71a0bdb2cd\",\n \"first_name\": \"Alysia-Analyst\",\n \"last_name\": \"Alysia-Analyst\",\n },\n {\n \"username\": \"91a9b97c-bd0a-458d-9823-babfde7ebf44\",\n \"first_name\": \"Katherine-Analyst\",\n \"last_name\": \"Osos-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"2cc0cde8-8313-4a50-99d8-5882e71443e8\",\n \"first_name\": \"Zander-Analyst\",\n \"last_name\": \"Adkinson-Analyst\",\n },\n {\n \"username\": \"57ab5847-7789-49fe-a2f9-21d38076d699\",\n \"first_name\": \"Paul-Analyst\",\n \"last_name\": \"Kuykendall-Analyst\",\n },\n {\n \"username\": \"e474e7a9-71ca-449d-833c-8a6e094dd117\",\n \"first_name\": \"Rebecca-Analyst\",\n \"last_name\": \"Hsieh-Analyst\",\n },\n {\n \"username\": \"5dc6c9a6-61d9-42b4-ba54-4beff28bac3c\",\n \"first_name\": \"David-Analyst\",\n \"last_name\": \"Kennedy-Analyst\",\n },\n {\n \"username\": \"0eb6f326-a3d4-410f-a521-aa4c1fad4e47\",\n \"first_name\": \"Gaby-Analyst\",\n \"last_name\": \"DiSarli-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"cfe7c2fc-e24a-480e-8b78-28645a1459b3\",\n \"first_name\": \"Nicolle-Analyst\",\n \"last_name\": \"LeClair-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"378d0bc4-d5a7-461b-bd84-3ae6f6864af9\",\n \"first_name\": \"Erin-Analyst\",\n \"last_name\": \"Song-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"9a98e4c9-9409-479d-964e-4aec7799107f\",\n \"first_name\": \"Kristina-Analyst\",\n \"last_name\": \"Yin-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"8f42302e-b83a-4c9e-8764-fc19e2cea576\",\n \"first_name\": \"Vickster-Analyst\",\n \"last_name\": \"Chin-Analyst\",\n \"email\": \"[email protected]\",\n },\n {\n \"username\": \"d9839768-0c17-4fa2-9c8e-36291eef5c11\",\n \"first_name\": \"Alex-Analyst\",\n \"last_name\": \"Mcelya-Analyst\",\n \"email\": \"[email protected]\",\n },\n ]\n\n def load_users(cls, users, group_name):\n logger.info(f\"Going to load {len(users)} users in group {group_name}\")\n for user_data in users:\n try:\n user, _ = User.objects.get_or_create(username=user_data[\"username\"])\n user.is_superuser = False\n user.first_name = user_data[\"first_name\"]\n user.last_name = user_data[\"last_name\"]\n if \"email\" in user_data:\n user.email = user_data[\"email\"]\n user.is_staff = True\n user.is_active = True\n group = UserGroup.objects.get(name=group_name)\n user.groups.add(group)\n user.save()\n logger.debug(f\"User object created for {user_data['first_name']}\")\n except Exception as e:\n logger.warning(e)\n logger.info(f\"All users in group {group_name} loaded.\")\n\n @classmethod\n def load(cls):\n # Lumped under .atomic to ensure we don't make redundant DB calls.\n # This bundles them all together, and then saves it in a single call.\n # This is slightly different then bulk_create or bulk_update, in that\n # you still get the same behaviour of .save(), but those incremental\n # steps now do not need to close/reopen a db connection,\n # instead they share one.\n with transaction.atomic():\n cls.load_users(cls, cls.ADMINS, \"full_access_group\")\n cls.load_users(cls, cls.STAFF, \"cisa_analysts_group\")\n", "path": "src/registrar/fixtures_users.py"}]}
| 3,402 | 324 |
gh_patches_debug_1008
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-4892
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OSError: File /checkpoint/meganu/projects/safety_failures/recovery/model_templates/blender_3B/model.dict-vocab.json does not exist. --bpe-vocab must be pretrained.
**Bug description**
Please enter a clear and concise description of what the bug is.
When I execute:
```sh
$python -m parlai eval_model --task fromfile:parlaiformat\
--fromfile_datapath "${test_set_path}" \
-mf zoo:saferdialogues/model\
-bs 1\
--world-logs $test_set_path.SafeRDialog_parlai.jsonl\
--no-cuda
```
It report:
```sh
16:13:53 | Overriding opt["task"] to fromfile:parlaiformat (previously: internal:safety_failures_with_recovery,internal:bst_sf_modified)
16:13:53 | Overriding opt["no_cuda"] to True (previously: False)
>>>using / style agent path
>>>finally module name: parlai.agents.transformer.generator
16:13:53 | loading dictionary from /home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/data/models/saferdialogues/model.dict
16:13:53 | num words = 8008
Traceback (most recent call last):
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/__main__.py", line 18, in <module>
main()
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/__main__.py", line 14, in main
superscript_main()
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/script.py", line 325, in superscript_main
return SCRIPT_REGISTRY[cmd].klass._run_from_parser_and_opt(opt, parser)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/script.py", line 108, in _run_from_parser_and_opt
return script.run()
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/scripts/eval_model.py", line 265, in run
return eval_model(self.opt)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/scripts/eval_model.py", line 233, in eval_model
agent = create_agent(opt, requireModelExists=True)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/agents.py", line 468, in create_agent
model = create_agent_from_opt_file(opt)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/agents.py", line 421, in create_agent_from_opt_file
return model_class(opt_from_file)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/torch_generator_agent.py", line 462, in __init__
super().__init__(opt, shared)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/torch_agent.py", line 783, in __init__
self.dict = self.build_dictionary()
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/torch_agent.py", line 862, in build_dictionary
d = self.dictionary_class()(self.opt)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/dict.py", line 322, in __init__
self.bpe = bpe_factory(opt, shared)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/utils/bpe.py", line 68, in bpe_factory
bpe_helper = HuggingFaceBpeHelper(opt, shared)
File "/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/utils/bpe.py", line 841, in __init__
raise IOError(
OSError: File /checkpoint/meganu/projects/safety_failures/recovery/model_templates/blender_3B/model.dict-vocab.json does not exist. --bpe-vocab must be pretrained.
```
and the parlai version is: `1.6.0`.
**Reproduction steps**
Enter steps to reproduce the behavior.
**Expected behavior**
Give a clear and concise description of what you expected to happen.
**Logs**
Please paste the command line output:
```
Output goes here
```
**Additional context**
Add any other context about the problem here. (like proxy settings, network setup, overall goals, etc.)
</issue>
<code>
[start of parlai/zoo/saferdialogues/build.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6
7 """
8 Blender 2.7B model fine-tuned on the SaFeRDialogues and BST (without persona) tasks.
9 """
10
11 from parlai.core.build_data import download_models
12
13
14 def download(datapath):
15 opt = {'datapath': datapath}
16 version = 'v0.1'
17 fnames = [f'models_{version}.tar.gz']
18 download_models(
19 opt,
20 fnames,
21 model_folder='saferdialogues',
22 version=version,
23 use_model_type=False,
24 )
25
[end of parlai/zoo/saferdialogues/build.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parlai/zoo/saferdialogues/build.py b/parlai/zoo/saferdialogues/build.py
--- a/parlai/zoo/saferdialogues/build.py
+++ b/parlai/zoo/saferdialogues/build.py
@@ -13,7 +13,7 @@
def download(datapath):
opt = {'datapath': datapath}
- version = 'v0.1'
+ version = 'v0.2'
fnames = [f'models_{version}.tar.gz']
download_models(
opt,
|
{"golden_diff": "diff --git a/parlai/zoo/saferdialogues/build.py b/parlai/zoo/saferdialogues/build.py\n--- a/parlai/zoo/saferdialogues/build.py\n+++ b/parlai/zoo/saferdialogues/build.py\n@@ -13,7 +13,7 @@\n \n def download(datapath):\n opt = {'datapath': datapath}\n- version = 'v0.1'\n+ version = 'v0.2'\n fnames = [f'models_{version}.tar.gz']\n download_models(\n opt,\n", "issue": "OSError: File /checkpoint/meganu/projects/safety_failures/recovery/model_templates/blender_3B/model.dict-vocab.json does not exist. --bpe-vocab must be pretrained.\n**Bug description**\r\n\r\nPlease enter a clear and concise description of what the bug is.\r\n\r\nWhen I execute:\r\n```sh\r\n$python -m parlai eval_model --task fromfile:parlaiformat\\\r\n --fromfile_datapath \"${test_set_path}\" \\\r\n -mf zoo:saferdialogues/model\\\r\n -bs 1\\\r\n --world-logs $test_set_path.SafeRDialog_parlai.jsonl\\\r\n --no-cuda\r\n```\r\nIt report:\r\n\r\n```sh\r\n16:13:53 | Overriding opt[\"task\"] to fromfile:parlaiformat (previously: internal:safety_failures_with_recovery,internal:bst_sf_modified)\r\n16:13:53 | Overriding opt[\"no_cuda\"] to True (previously: False)\r\n>>>using / style agent path\r\n>>>finally module name: parlai.agents.transformer.generator\r\n16:13:53 | loading dictionary from /home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/data/models/saferdialogues/model.dict\r\n16:13:53 | num words = 8008\r\nTraceback (most recent call last):\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/runpy.py\", line 194, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/__main__.py\", line 18, in <module>\r\n main()\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/__main__.py\", line 14, in main\r\n superscript_main()\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/script.py\", line 325, in superscript_main\r\n return SCRIPT_REGISTRY[cmd].klass._run_from_parser_and_opt(opt, parser)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/script.py\", line 108, in _run_from_parser_and_opt\r\n return script.run()\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/scripts/eval_model.py\", line 265, in run\r\n return eval_model(self.opt)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/scripts/eval_model.py\", line 233, in eval_model\r\n agent = create_agent(opt, requireModelExists=True)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/agents.py\", line 468, in create_agent\r\n model = create_agent_from_opt_file(opt)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/agents.py\", line 421, in create_agent_from_opt_file\r\n return model_class(opt_from_file)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/torch_generator_agent.py\", line 462, in __init__\r\n super().__init__(opt, shared)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/torch_agent.py\", line 783, in __init__\r\n self.dict = self.build_dictionary()\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/torch_agent.py\", line 862, in build_dictionary\r\n d = self.dictionary_class()(self.opt)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/core/dict.py\", line 322, in __init__\r\n self.bpe = bpe_factory(opt, shared)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/utils/bpe.py\", line 68, in bpe_factory\r\n bpe_helper = HuggingFaceBpeHelper(opt, shared)\r\n File \"/home/liangzi/anaconda3/envs/opendomaindialogue/lib/python3.8/site-packages/parlai/utils/bpe.py\", line 841, in __init__\r\n raise IOError(\r\nOSError: File /checkpoint/meganu/projects/safety_failures/recovery/model_templates/blender_3B/model.dict-vocab.json does not exist. --bpe-vocab must be pretrained.\r\n```\r\n\r\nand the parlai version is: `1.6.0`.\r\n\r\n**Reproduction steps**\r\nEnter steps to reproduce the behavior.\r\n\r\n**Expected behavior**\r\nGive a clear and concise description of what you expected to happen.\r\n\r\n**Logs**\r\nPlease paste the command line output:\r\n\r\n```\r\nOutput goes here\r\n```\r\n\r\n**Additional context**\r\nAdd any other context about the problem here. (like proxy settings, network setup, overall goals, etc.)\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\"\"\"\nBlender 2.7B model fine-tuned on the SaFeRDialogues and BST (without persona) tasks.\n\"\"\"\n\nfrom parlai.core.build_data import download_models\n\n\ndef download(datapath):\n opt = {'datapath': datapath}\n version = 'v0.1'\n fnames = [f'models_{version}.tar.gz']\n download_models(\n opt,\n fnames,\n model_folder='saferdialogues',\n version=version,\n use_model_type=False,\n )\n", "path": "parlai/zoo/saferdialogues/build.py"}]}
| 2,032 | 135 |
gh_patches_debug_37035
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-4935
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
is_generator_with_return_value raises IndentationError with a flush left doc string
### Description
Code that is accepted by the python interpreter raises when fed through `textwrap.dedent`
### Steps to Reproduce
1. Create `is_generator_bug.py` with the content below (which I simplified from [the `is_generator_with_return_value` method body](https://github.com/scrapy/scrapy/blob/2.0.1/scrapy/utils/misc.py#L186-L187)
2. Run `python is_generator_bug.py`
3. Observe the kaboom
```python
import ast
import inspect
from textwrap import dedent
class Bob:
def doit(self):
"""
this line is flush left
"""
if True:
yield 1234
if __name__ == '__main__':
b = Bob()
c = b.doit
if inspect.isgeneratorfunction(c):
tree = ast.parse(dedent(inspect.getsource(c)))
```
**Expected behavior:** [What you expect to happen]
No Error
**Actual behavior:** [What actually happens]
```console
$ python3.7 is_generator_bug.py
Traceback (most recent call last):
File "is_generator_bug.py", line 16, in <module>
tree = ast.parse(dedent(inspect.getsource(c)))
File "/usr/local/Cellar/python/3.7.7/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ast.py", line 35, in parse
return compile(source, filename, mode, PyCF_ONLY_AST)
File "<unknown>", line 1
def doit(self):
^
IndentationError: unexpected indent
```
**Reproduces how often:** [What percentage of the time does it reproduce?]
100%
### Versions
```
Scrapy : 2.0.1
lxml : 4.5.0.0
libxml2 : 2.9.10
cssselect : 1.1.0
parsel : 1.5.2
w3lib : 1.21.0
Twisted : 20.3.0
Python : 3.7.7 (default, Mar 11 2020, 23:30:22) - [Clang 10.0.0 (clang-1000.11.45.5)]
pyOpenSSL : 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019)
cryptography : 2.8
Platform : Darwin-17.7.0-x86_64-i386-64bit
```
### Additional context
</issue>
<code>
[start of scrapy/utils/misc.py]
1 """Helper functions which don't fit anywhere else"""
2 import ast
3 import inspect
4 import os
5 import re
6 import hashlib
7 import warnings
8 from collections import deque
9 from contextlib import contextmanager
10 from importlib import import_module
11 from pkgutil import iter_modules
12 from textwrap import dedent
13
14 from w3lib.html import replace_entities
15
16 from scrapy.utils.datatypes import LocalWeakReferencedCache
17 from scrapy.utils.python import flatten, to_unicode
18 from scrapy.item import _BaseItem
19 from scrapy.utils.deprecate import ScrapyDeprecationWarning
20
21
22 _ITERABLE_SINGLE_VALUES = dict, _BaseItem, str, bytes
23
24
25 def arg_to_iter(arg):
26 """Convert an argument to an iterable. The argument can be a None, single
27 value, or an iterable.
28
29 Exception: if arg is a dict, [arg] will be returned
30 """
31 if arg is None:
32 return []
33 elif not isinstance(arg, _ITERABLE_SINGLE_VALUES) and hasattr(arg, '__iter__'):
34 return arg
35 else:
36 return [arg]
37
38
39 def load_object(path):
40 """Load an object given its absolute object path, and return it.
41
42 The object can be the import path of a class, function, variable or an
43 instance, e.g. 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'.
44
45 If ``path`` is not a string, but is a callable object, such as a class or
46 a function, then return it as is.
47 """
48
49 if not isinstance(path, str):
50 if callable(path):
51 return path
52 else:
53 raise TypeError("Unexpected argument type, expected string "
54 "or object, got: %s" % type(path))
55
56 try:
57 dot = path.rindex('.')
58 except ValueError:
59 raise ValueError(f"Error loading object '{path}': not a full path")
60
61 module, name = path[:dot], path[dot + 1:]
62 mod = import_module(module)
63
64 try:
65 obj = getattr(mod, name)
66 except AttributeError:
67 raise NameError(f"Module '{module}' doesn't define any object named '{name}'")
68
69 return obj
70
71
72 def walk_modules(path):
73 """Loads a module and all its submodules from the given module path and
74 returns them. If *any* module throws an exception while importing, that
75 exception is thrown back.
76
77 For example: walk_modules('scrapy.utils')
78 """
79
80 mods = []
81 mod = import_module(path)
82 mods.append(mod)
83 if hasattr(mod, '__path__'):
84 for _, subpath, ispkg in iter_modules(mod.__path__):
85 fullpath = path + '.' + subpath
86 if ispkg:
87 mods += walk_modules(fullpath)
88 else:
89 submod = import_module(fullpath)
90 mods.append(submod)
91 return mods
92
93
94 def extract_regex(regex, text, encoding='utf-8'):
95 """Extract a list of unicode strings from the given text/encoding using the following policies:
96
97 * if the regex contains a named group called "extract" that will be returned
98 * if the regex contains multiple numbered groups, all those will be returned (flattened)
99 * if the regex doesn't contain any group the entire regex matching is returned
100 """
101 warnings.warn(
102 "scrapy.utils.misc.extract_regex has moved to parsel.utils.extract_regex.",
103 ScrapyDeprecationWarning,
104 stacklevel=2
105 )
106
107 if isinstance(regex, str):
108 regex = re.compile(regex, re.UNICODE)
109
110 try:
111 strings = [regex.search(text).group('extract')] # named group
112 except Exception:
113 strings = regex.findall(text) # full regex or numbered groups
114 strings = flatten(strings)
115
116 if isinstance(text, str):
117 return [replace_entities(s, keep=['lt', 'amp']) for s in strings]
118 else:
119 return [replace_entities(to_unicode(s, encoding), keep=['lt', 'amp'])
120 for s in strings]
121
122
123 def md5sum(file):
124 """Calculate the md5 checksum of a file-like object without reading its
125 whole content in memory.
126
127 >>> from io import BytesIO
128 >>> md5sum(BytesIO(b'file content to hash'))
129 '784406af91dd5a54fbb9c84c2236595a'
130 """
131 m = hashlib.md5()
132 while True:
133 d = file.read(8096)
134 if not d:
135 break
136 m.update(d)
137 return m.hexdigest()
138
139
140 def rel_has_nofollow(rel):
141 """Return True if link rel attribute has nofollow type"""
142 return rel is not None and 'nofollow' in rel.split()
143
144
145 def create_instance(objcls, settings, crawler, *args, **kwargs):
146 """Construct a class instance using its ``from_crawler`` or
147 ``from_settings`` constructors, if available.
148
149 At least one of ``settings`` and ``crawler`` needs to be different from
150 ``None``. If ``settings `` is ``None``, ``crawler.settings`` will be used.
151 If ``crawler`` is ``None``, only the ``from_settings`` constructor will be
152 tried.
153
154 ``*args`` and ``**kwargs`` are forwarded to the constructors.
155
156 Raises ``ValueError`` if both ``settings`` and ``crawler`` are ``None``.
157
158 .. versionchanged:: 2.2
159 Raises ``TypeError`` if the resulting instance is ``None`` (e.g. if an
160 extension has not been implemented correctly).
161 """
162 if settings is None:
163 if crawler is None:
164 raise ValueError("Specify at least one of settings and crawler.")
165 settings = crawler.settings
166 if crawler and hasattr(objcls, 'from_crawler'):
167 instance = objcls.from_crawler(crawler, *args, **kwargs)
168 method_name = 'from_crawler'
169 elif hasattr(objcls, 'from_settings'):
170 instance = objcls.from_settings(settings, *args, **kwargs)
171 method_name = 'from_settings'
172 else:
173 instance = objcls(*args, **kwargs)
174 method_name = '__new__'
175 if instance is None:
176 raise TypeError(f"{objcls.__qualname__}.{method_name} returned None")
177 return instance
178
179
180 @contextmanager
181 def set_environ(**kwargs):
182 """Temporarily set environment variables inside the context manager and
183 fully restore previous environment afterwards
184 """
185
186 original_env = {k: os.environ.get(k) for k in kwargs}
187 os.environ.update(kwargs)
188 try:
189 yield
190 finally:
191 for k, v in original_env.items():
192 if v is None:
193 del os.environ[k]
194 else:
195 os.environ[k] = v
196
197
198 def walk_callable(node):
199 """Similar to ``ast.walk``, but walks only function body and skips nested
200 functions defined within the node.
201 """
202 todo = deque([node])
203 walked_func_def = False
204 while todo:
205 node = todo.popleft()
206 if isinstance(node, ast.FunctionDef):
207 if walked_func_def:
208 continue
209 walked_func_def = True
210 todo.extend(ast.iter_child_nodes(node))
211 yield node
212
213
214 _generator_callbacks_cache = LocalWeakReferencedCache(limit=128)
215
216
217 def is_generator_with_return_value(callable):
218 """
219 Returns True if a callable is a generator function which includes a
220 'return' statement with a value different than None, False otherwise
221 """
222 if callable in _generator_callbacks_cache:
223 return _generator_callbacks_cache[callable]
224
225 def returns_none(return_node):
226 value = return_node.value
227 return value is None or isinstance(value, ast.NameConstant) and value.value is None
228
229 if inspect.isgeneratorfunction(callable):
230 tree = ast.parse(dedent(inspect.getsource(callable)))
231 for node in walk_callable(tree):
232 if isinstance(node, ast.Return) and not returns_none(node):
233 _generator_callbacks_cache[callable] = True
234 return _generator_callbacks_cache[callable]
235
236 _generator_callbacks_cache[callable] = False
237 return _generator_callbacks_cache[callable]
238
239
240 def warn_on_generator_with_return_value(spider, callable):
241 """
242 Logs a warning if a callable is a generator function and includes
243 a 'return' statement with a value different than None
244 """
245 if is_generator_with_return_value(callable):
246 warnings.warn(
247 f'The "{spider.__class__.__name__}.{callable.__name__}" method is '
248 'a generator and includes a "return" statement with a value '
249 'different than None. This could lead to unexpected behaviour. Please see '
250 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '
251 'for details about the semantics of the "return" statement within generators',
252 stacklevel=2,
253 )
254
[end of scrapy/utils/misc.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scrapy/utils/misc.py b/scrapy/utils/misc.py
--- a/scrapy/utils/misc.py
+++ b/scrapy/utils/misc.py
@@ -9,7 +9,6 @@
from contextlib import contextmanager
from importlib import import_module
from pkgutil import iter_modules
-from textwrap import dedent
from w3lib.html import replace_entities
@@ -227,7 +226,8 @@
return value is None or isinstance(value, ast.NameConstant) and value.value is None
if inspect.isgeneratorfunction(callable):
- tree = ast.parse(dedent(inspect.getsource(callable)))
+ code = re.sub(r"^[\t ]+", "", inspect.getsource(callable))
+ tree = ast.parse(code)
for node in walk_callable(tree):
if isinstance(node, ast.Return) and not returns_none(node):
_generator_callbacks_cache[callable] = True
@@ -242,12 +242,23 @@
Logs a warning if a callable is a generator function and includes
a 'return' statement with a value different than None
"""
- if is_generator_with_return_value(callable):
+ try:
+ if is_generator_with_return_value(callable):
+ warnings.warn(
+ f'The "{spider.__class__.__name__}.{callable.__name__}" method is '
+ 'a generator and includes a "return" statement with a value '
+ 'different than None. This could lead to unexpected behaviour. Please see '
+ 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '
+ 'for details about the semantics of the "return" statement within generators',
+ stacklevel=2,
+ )
+ except IndentationError:
+ callable_name = spider.__class__.__name__ + "." + callable.__name__
warnings.warn(
- f'The "{spider.__class__.__name__}.{callable.__name__}" method is '
- 'a generator and includes a "return" statement with a value '
- 'different than None. This could lead to unexpected behaviour. Please see '
- 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '
- 'for details about the semantics of the "return" statement within generators',
+ f'Unable to determine whether or not "{callable_name}" is a generator with a return value. '
+ 'This will not prevent your code from working, but it prevents Scrapy from detecting '
+ f'potential issues in your implementation of "{callable_name}". Please, report this in the '
+ 'Scrapy issue tracker (https://github.com/scrapy/scrapy/issues), '
+ f'including the code of "{callable_name}"',
stacklevel=2,
)
|
{"golden_diff": "diff --git a/scrapy/utils/misc.py b/scrapy/utils/misc.py\n--- a/scrapy/utils/misc.py\n+++ b/scrapy/utils/misc.py\n@@ -9,7 +9,6 @@\n from contextlib import contextmanager\n from importlib import import_module\n from pkgutil import iter_modules\n-from textwrap import dedent\n \n from w3lib.html import replace_entities\n \n@@ -227,7 +226,8 @@\n return value is None or isinstance(value, ast.NameConstant) and value.value is None\n \n if inspect.isgeneratorfunction(callable):\n- tree = ast.parse(dedent(inspect.getsource(callable)))\n+ code = re.sub(r\"^[\\t ]+\", \"\", inspect.getsource(callable))\n+ tree = ast.parse(code)\n for node in walk_callable(tree):\n if isinstance(node, ast.Return) and not returns_none(node):\n _generator_callbacks_cache[callable] = True\n@@ -242,12 +242,23 @@\n Logs a warning if a callable is a generator function and includes\n a 'return' statement with a value different than None\n \"\"\"\n- if is_generator_with_return_value(callable):\n+ try:\n+ if is_generator_with_return_value(callable):\n+ warnings.warn(\n+ f'The \"{spider.__class__.__name__}.{callable.__name__}\" method is '\n+ 'a generator and includes a \"return\" statement with a value '\n+ 'different than None. This could lead to unexpected behaviour. Please see '\n+ 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '\n+ 'for details about the semantics of the \"return\" statement within generators',\n+ stacklevel=2,\n+ )\n+ except IndentationError:\n+ callable_name = spider.__class__.__name__ + \".\" + callable.__name__\n warnings.warn(\n- f'The \"{spider.__class__.__name__}.{callable.__name__}\" method is '\n- 'a generator and includes a \"return\" statement with a value '\n- 'different than None. This could lead to unexpected behaviour. Please see '\n- 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '\n- 'for details about the semantics of the \"return\" statement within generators',\n+ f'Unable to determine whether or not \"{callable_name}\" is a generator with a return value. '\n+ 'This will not prevent your code from working, but it prevents Scrapy from detecting '\n+ f'potential issues in your implementation of \"{callable_name}\". Please, report this in the '\n+ 'Scrapy issue tracker (https://github.com/scrapy/scrapy/issues), '\n+ f'including the code of \"{callable_name}\"',\n stacklevel=2,\n )\n", "issue": "is_generator_with_return_value raises IndentationError with a flush left doc string\n### Description\r\n\r\nCode that is accepted by the python interpreter raises when fed through `textwrap.dedent`\r\n\r\n### Steps to Reproduce\r\n\r\n1. Create `is_generator_bug.py` with the content below (which I simplified from [the `is_generator_with_return_value` method body](https://github.com/scrapy/scrapy/blob/2.0.1/scrapy/utils/misc.py#L186-L187)\r\n2. Run `python is_generator_bug.py`\r\n3. Observe the kaboom\r\n\r\n```python\r\nimport ast\r\nimport inspect\r\nfrom textwrap import dedent\r\nclass Bob:\r\n def doit(self):\r\n \"\"\"\r\nthis line is flush left\r\n \"\"\"\r\n if True:\r\n yield 1234\r\n\r\nif __name__ == '__main__':\r\n b = Bob()\r\n c = b.doit\r\n if inspect.isgeneratorfunction(c):\r\n tree = ast.parse(dedent(inspect.getsource(c)))\r\n```\r\n\r\n**Expected behavior:** [What you expect to happen]\r\n\r\nNo Error\r\n\r\n**Actual behavior:** [What actually happens]\r\n\r\n```console\r\n$ python3.7 is_generator_bug.py\r\nTraceback (most recent call last):\r\n File \"is_generator_bug.py\", line 16, in <module>\r\n tree = ast.parse(dedent(inspect.getsource(c)))\r\n File \"/usr/local/Cellar/python/3.7.7/Frameworks/Python.framework/Versions/3.7/lib/python3.7/ast.py\", line 35, in parse\r\n return compile(source, filename, mode, PyCF_ONLY_AST)\r\n File \"<unknown>\", line 1\r\n def doit(self):\r\n ^\r\nIndentationError: unexpected indent\r\n```\r\n\r\n**Reproduces how often:** [What percentage of the time does it reproduce?]\r\n\r\n100%\r\n\r\n### Versions\r\n\r\n```\r\nScrapy : 2.0.1\r\nlxml : 4.5.0.0\r\nlibxml2 : 2.9.10\r\ncssselect : 1.1.0\r\nparsel : 1.5.2\r\nw3lib : 1.21.0\r\nTwisted : 20.3.0\r\nPython : 3.7.7 (default, Mar 11 2020, 23:30:22) - [Clang 10.0.0 (clang-1000.11.45.5)]\r\npyOpenSSL : 19.1.0 (OpenSSL 1.1.1d 10 Sep 2019)\r\ncryptography : 2.8\r\nPlatform : Darwin-17.7.0-x86_64-i386-64bit\r\n```\r\n\r\n### Additional context\r\n\n", "before_files": [{"content": "\"\"\"Helper functions which don't fit anywhere else\"\"\"\nimport ast\nimport inspect\nimport os\nimport re\nimport hashlib\nimport warnings\nfrom collections import deque\nfrom contextlib import contextmanager\nfrom importlib import import_module\nfrom pkgutil import iter_modules\nfrom textwrap import dedent\n\nfrom w3lib.html import replace_entities\n\nfrom scrapy.utils.datatypes import LocalWeakReferencedCache\nfrom scrapy.utils.python import flatten, to_unicode\nfrom scrapy.item import _BaseItem\nfrom scrapy.utils.deprecate import ScrapyDeprecationWarning\n\n\n_ITERABLE_SINGLE_VALUES = dict, _BaseItem, str, bytes\n\n\ndef arg_to_iter(arg):\n \"\"\"Convert an argument to an iterable. The argument can be a None, single\n value, or an iterable.\n\n Exception: if arg is a dict, [arg] will be returned\n \"\"\"\n if arg is None:\n return []\n elif not isinstance(arg, _ITERABLE_SINGLE_VALUES) and hasattr(arg, '__iter__'):\n return arg\n else:\n return [arg]\n\n\ndef load_object(path):\n \"\"\"Load an object given its absolute object path, and return it.\n\n The object can be the import path of a class, function, variable or an\n instance, e.g. 'scrapy.downloadermiddlewares.redirect.RedirectMiddleware'.\n\n If ``path`` is not a string, but is a callable object, such as a class or\n a function, then return it as is.\n \"\"\"\n\n if not isinstance(path, str):\n if callable(path):\n return path\n else:\n raise TypeError(\"Unexpected argument type, expected string \"\n \"or object, got: %s\" % type(path))\n\n try:\n dot = path.rindex('.')\n except ValueError:\n raise ValueError(f\"Error loading object '{path}': not a full path\")\n\n module, name = path[:dot], path[dot + 1:]\n mod = import_module(module)\n\n try:\n obj = getattr(mod, name)\n except AttributeError:\n raise NameError(f\"Module '{module}' doesn't define any object named '{name}'\")\n\n return obj\n\n\ndef walk_modules(path):\n \"\"\"Loads a module and all its submodules from the given module path and\n returns them. If *any* module throws an exception while importing, that\n exception is thrown back.\n\n For example: walk_modules('scrapy.utils')\n \"\"\"\n\n mods = []\n mod = import_module(path)\n mods.append(mod)\n if hasattr(mod, '__path__'):\n for _, subpath, ispkg in iter_modules(mod.__path__):\n fullpath = path + '.' + subpath\n if ispkg:\n mods += walk_modules(fullpath)\n else:\n submod = import_module(fullpath)\n mods.append(submod)\n return mods\n\n\ndef extract_regex(regex, text, encoding='utf-8'):\n \"\"\"Extract a list of unicode strings from the given text/encoding using the following policies:\n\n * if the regex contains a named group called \"extract\" that will be returned\n * if the regex contains multiple numbered groups, all those will be returned (flattened)\n * if the regex doesn't contain any group the entire regex matching is returned\n \"\"\"\n warnings.warn(\n \"scrapy.utils.misc.extract_regex has moved to parsel.utils.extract_regex.\",\n ScrapyDeprecationWarning,\n stacklevel=2\n )\n\n if isinstance(regex, str):\n regex = re.compile(regex, re.UNICODE)\n\n try:\n strings = [regex.search(text).group('extract')] # named group\n except Exception:\n strings = regex.findall(text) # full regex or numbered groups\n strings = flatten(strings)\n\n if isinstance(text, str):\n return [replace_entities(s, keep=['lt', 'amp']) for s in strings]\n else:\n return [replace_entities(to_unicode(s, encoding), keep=['lt', 'amp'])\n for s in strings]\n\n\ndef md5sum(file):\n \"\"\"Calculate the md5 checksum of a file-like object without reading its\n whole content in memory.\n\n >>> from io import BytesIO\n >>> md5sum(BytesIO(b'file content to hash'))\n '784406af91dd5a54fbb9c84c2236595a'\n \"\"\"\n m = hashlib.md5()\n while True:\n d = file.read(8096)\n if not d:\n break\n m.update(d)\n return m.hexdigest()\n\n\ndef rel_has_nofollow(rel):\n \"\"\"Return True if link rel attribute has nofollow type\"\"\"\n return rel is not None and 'nofollow' in rel.split()\n\n\ndef create_instance(objcls, settings, crawler, *args, **kwargs):\n \"\"\"Construct a class instance using its ``from_crawler`` or\n ``from_settings`` constructors, if available.\n\n At least one of ``settings`` and ``crawler`` needs to be different from\n ``None``. If ``settings `` is ``None``, ``crawler.settings`` will be used.\n If ``crawler`` is ``None``, only the ``from_settings`` constructor will be\n tried.\n\n ``*args`` and ``**kwargs`` are forwarded to the constructors.\n\n Raises ``ValueError`` if both ``settings`` and ``crawler`` are ``None``.\n\n .. versionchanged:: 2.2\n Raises ``TypeError`` if the resulting instance is ``None`` (e.g. if an\n extension has not been implemented correctly).\n \"\"\"\n if settings is None:\n if crawler is None:\n raise ValueError(\"Specify at least one of settings and crawler.\")\n settings = crawler.settings\n if crawler and hasattr(objcls, 'from_crawler'):\n instance = objcls.from_crawler(crawler, *args, **kwargs)\n method_name = 'from_crawler'\n elif hasattr(objcls, 'from_settings'):\n instance = objcls.from_settings(settings, *args, **kwargs)\n method_name = 'from_settings'\n else:\n instance = objcls(*args, **kwargs)\n method_name = '__new__'\n if instance is None:\n raise TypeError(f\"{objcls.__qualname__}.{method_name} returned None\")\n return instance\n\n\n@contextmanager\ndef set_environ(**kwargs):\n \"\"\"Temporarily set environment variables inside the context manager and\n fully restore previous environment afterwards\n \"\"\"\n\n original_env = {k: os.environ.get(k) for k in kwargs}\n os.environ.update(kwargs)\n try:\n yield\n finally:\n for k, v in original_env.items():\n if v is None:\n del os.environ[k]\n else:\n os.environ[k] = v\n\n\ndef walk_callable(node):\n \"\"\"Similar to ``ast.walk``, but walks only function body and skips nested\n functions defined within the node.\n \"\"\"\n todo = deque([node])\n walked_func_def = False\n while todo:\n node = todo.popleft()\n if isinstance(node, ast.FunctionDef):\n if walked_func_def:\n continue\n walked_func_def = True\n todo.extend(ast.iter_child_nodes(node))\n yield node\n\n\n_generator_callbacks_cache = LocalWeakReferencedCache(limit=128)\n\n\ndef is_generator_with_return_value(callable):\n \"\"\"\n Returns True if a callable is a generator function which includes a\n 'return' statement with a value different than None, False otherwise\n \"\"\"\n if callable in _generator_callbacks_cache:\n return _generator_callbacks_cache[callable]\n\n def returns_none(return_node):\n value = return_node.value\n return value is None or isinstance(value, ast.NameConstant) and value.value is None\n\n if inspect.isgeneratorfunction(callable):\n tree = ast.parse(dedent(inspect.getsource(callable)))\n for node in walk_callable(tree):\n if isinstance(node, ast.Return) and not returns_none(node):\n _generator_callbacks_cache[callable] = True\n return _generator_callbacks_cache[callable]\n\n _generator_callbacks_cache[callable] = False\n return _generator_callbacks_cache[callable]\n\n\ndef warn_on_generator_with_return_value(spider, callable):\n \"\"\"\n Logs a warning if a callable is a generator function and includes\n a 'return' statement with a value different than None\n \"\"\"\n if is_generator_with_return_value(callable):\n warnings.warn(\n f'The \"{spider.__class__.__name__}.{callable.__name__}\" method is '\n 'a generator and includes a \"return\" statement with a value '\n 'different than None. This could lead to unexpected behaviour. Please see '\n 'https://docs.python.org/3/reference/simple_stmts.html#the-return-statement '\n 'for details about the semantics of the \"return\" statement within generators',\n stacklevel=2,\n )\n", "path": "scrapy/utils/misc.py"}]}
| 3,719 | 603 |
gh_patches_debug_43166
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-65417
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support measurement metrics in new metrics/traces sample endpoint
</issue>
<code>
[start of src/sentry/sentry_metrics/querying/samples_list.py]
1 from abc import ABC, abstractmethod
2 from datetime import datetime
3 from typing import Any
4
5 from snuba_sdk import And, Condition, Op, Or
6
7 from sentry import options
8 from sentry.search.events.builder import QueryBuilder, SpansIndexedQueryBuilder
9 from sentry.search.events.types import QueryBuilderConfig, SnubaParams
10 from sentry.snuba.dataset import Dataset
11 from sentry.snuba.metrics.naming_layer.mri import SpanMRI, TransactionMRI
12 from sentry.snuba.referrer import Referrer
13
14
15 class SamplesListExecutor(ABC):
16 def __init__(
17 self,
18 mri: str,
19 params: dict[str, Any],
20 snuba_params: SnubaParams,
21 fields: list[str],
22 query: str | None,
23 rollup: int,
24 referrer: Referrer,
25 ):
26 self.mri = mri
27 self.params = params
28 self.snuba_params = snuba_params
29 self.fields = fields
30 self.query = query
31 self.rollup = rollup
32 self.referrer = referrer
33
34 @classmethod
35 @abstractmethod
36 def supports(cls, metric_mri: str) -> bool:
37 raise NotImplementedError
38
39 @abstractmethod
40 def execute(self, offset, limit):
41 raise NotImplementedError
42
43 def get_spans_by_key(self, span_ids: list[tuple[str, str, str]]):
44 if not span_ids:
45 return {"data": []}
46
47 builder = SpansIndexedQueryBuilder(
48 Dataset.SpansIndexed,
49 self.params,
50 snuba_params=self.snuba_params,
51 selected_columns=self.fields,
52 limit=len(span_ids),
53 offset=0,
54 )
55
56 # Using `IN` sometimes does not use the bloomfilter index
57 # on the table. So we're explicitly writing the condition
58 # using `OR`s.
59 #
60 # May not be necessary because it's also filtering on the
61 # `span.group` as well which allows Clickhouse to filter
62 # via the primary key but this is a precaution.
63 conditions = [
64 And(
65 [
66 Condition(builder.column("span.group"), Op.EQ, group),
67 Condition(
68 builder.column("timestamp"), Op.EQ, datetime.fromisoformat(timestamp)
69 ),
70 Condition(builder.column("id"), Op.EQ, span_id),
71 ]
72 )
73 for (group, timestamp, span_id) in span_ids
74 ]
75
76 if len(conditions) == 1:
77 span_condition = conditions[0]
78 else:
79 span_condition = Or(conditions)
80
81 builder.add_conditions([span_condition])
82
83 query_results = builder.run_query(self.referrer.value)
84 return builder.process_results(query_results)
85
86
87 class SegmentsSamplesListExecutor(SamplesListExecutor):
88 @classmethod
89 def mri_to_column(cls, mri) -> str | None:
90 if mri == TransactionMRI.DURATION.value:
91 return "duration"
92 return None
93
94 @classmethod
95 def supports(cls, mri: str) -> bool:
96 return cls.mri_to_column(mri) is not None
97
98 def execute(self, offset, limit):
99 span_keys = self.get_span_keys(offset, limit)
100 return self.get_spans_by_key(span_keys)
101
102 def get_span_keys(self, offset: int, limit: int) -> list[tuple[str, str, str]]:
103 rounded_timestamp = f"rounded_timestamp({self.rollup})"
104
105 builder = QueryBuilder(
106 Dataset.Transactions,
107 self.params,
108 snuba_params=self.snuba_params,
109 query=self.query,
110 selected_columns=[rounded_timestamp, "example()"],
111 limit=limit,
112 offset=offset,
113 sample_rate=options.get("metrics.sample-list.sample-rate"),
114 config=QueryBuilderConfig(functions_acl=["rounded_timestamp", "example"]),
115 )
116
117 query_results = builder.run_query(self.referrer.value)
118 result = builder.process_results(query_results)
119
120 return [
121 (
122 "00", # all segments have a group of `00` currently
123 row["example"][0], # timestamp
124 row["example"][1], # span_id
125 )
126 for row in result["data"]
127 ]
128
129
130 class SpansSamplesListExecutor(SamplesListExecutor):
131 MRI_MAPPING = {
132 SpanMRI.DURATION.value: "span.duration",
133 SpanMRI.SELF_TIME.value: "span.self_time",
134 }
135
136 @classmethod
137 def mri_to_column(cls, mri) -> str | None:
138 return cls.MRI_MAPPING.get(mri)
139
140 @classmethod
141 def supports(cls, mri: str) -> bool:
142 return cls.mri_to_column(mri) is not None
143
144 def execute(self, offset, limit):
145 span_keys = self.get_span_keys(offset, limit)
146 return self.get_spans_by_key(span_keys)
147
148 def get_span_keys(self, offset: int, limit: int) -> list[tuple[str, str, str]]:
149 rounded_timestamp = f"rounded_timestamp({self.rollup})"
150
151 builder = SpansIndexedQueryBuilder(
152 Dataset.SpansIndexed,
153 self.params,
154 snuba_params=self.snuba_params,
155 query=self.query,
156 selected_columns=[rounded_timestamp, "example()"],
157 limit=limit,
158 offset=offset,
159 sample_rate=options.get("metrics.sample-list.sample-rate"),
160 config=QueryBuilderConfig(functions_acl=["rounded_timestamp", "example"]),
161 )
162
163 builder.add_conditions(
164 [
165 # The `00` group is used for spans not used within the
166 # new starfish experience. It's effectively the group
167 # for other. It is a massive group, so we've chosen
168 # to exclude it here.
169 #
170 # In the future, we will want to look into exposing them
171 Condition(builder.column("span.group"), Op.NEQ, "00")
172 ]
173 )
174
175 query_results = builder.run_query(self.referrer.value)
176 result = builder.process_results(query_results)
177
178 return [
179 (
180 row["example"][0], # group
181 row["example"][1], # timestamp
182 row["example"][2], # span_id
183 )
184 for row in result["data"]
185 ]
186
187
188 SAMPLE_LIST_EXECUTORS = [
189 SpansSamplesListExecutor,
190 SegmentsSamplesListExecutor,
191 ]
192
193
194 def get_sample_list_executor_cls(mri) -> type[SamplesListExecutor] | None:
195 for executor_cls in SAMPLE_LIST_EXECUTORS:
196 if executor_cls.supports(mri):
197 return executor_cls
198 return None
199
[end of src/sentry/sentry_metrics/querying/samples_list.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/sentry_metrics/querying/samples_list.py b/src/sentry/sentry_metrics/querying/samples_list.py
--- a/src/sentry/sentry_metrics/querying/samples_list.py
+++ b/src/sentry/sentry_metrics/querying/samples_list.py
@@ -2,13 +2,13 @@
from datetime import datetime
from typing import Any
-from snuba_sdk import And, Condition, Op, Or
+from snuba_sdk import And, Column, Condition, Function, Op, Or
from sentry import options
from sentry.search.events.builder import QueryBuilder, SpansIndexedQueryBuilder
from sentry.search.events.types import QueryBuilderConfig, SnubaParams
from sentry.snuba.dataset import Dataset
-from sentry.snuba.metrics.naming_layer.mri import SpanMRI, TransactionMRI
+from sentry.snuba.metrics.naming_layer.mri import SpanMRI, TransactionMRI, is_measurement, parse_mri
from sentry.snuba.referrer import Referrer
@@ -86,10 +86,9 @@
class SegmentsSamplesListExecutor(SamplesListExecutor):
@classmethod
+ @abstractmethod
def mri_to_column(cls, mri) -> str | None:
- if mri == TransactionMRI.DURATION.value:
- return "duration"
- return None
+ raise NotImplementedError
@classmethod
def supports(cls, mri: str) -> bool:
@@ -102,6 +101,16 @@
def get_span_keys(self, offset: int, limit: int) -> list[tuple[str, str, str]]:
rounded_timestamp = f"rounded_timestamp({self.rollup})"
+ """
+ When getting examples for a segment, it's actually much faster to read it
+ from the transactions dataset compared to the spans dataset as it's a much
+ smaller dataset.
+
+ One consideration here is that there is an one to one mapping between a
+ transaction to a segment today. If this relationship changes, we'll have to
+ rethink how to fetch segment samples a little as the transactions dataset
+ may not contain all the necessary data.
+ """
builder = QueryBuilder(
Dataset.Transactions,
self.params,
@@ -114,6 +123,8 @@
config=QueryBuilderConfig(functions_acl=["rounded_timestamp", "example"]),
)
+ builder.add_conditions(self.get_additional_conditions())
+
query_results = builder.run_query(self.referrer.value)
result = builder.process_results(query_results)
@@ -126,6 +137,42 @@
for row in result["data"]
]
+ @abstractmethod
+ def get_additional_conditions(self) -> list[Condition]:
+ raise NotImplementedError
+
+
+class TransactionDurationSamplesListExecutor(SegmentsSamplesListExecutor):
+ @classmethod
+ def mri_to_column(cls, mri) -> str | None:
+ if mri == TransactionMRI.DURATION.value:
+ return "duration"
+ return None
+
+ def get_additional_conditions(self) -> list[Condition]:
+ return []
+
+
+class MeasurementsSamplesListExecutor(SegmentsSamplesListExecutor):
+ @classmethod
+ def mri_to_column(cls, mri) -> str | None:
+ name = cls.measurement_name(mri)
+ if name is not None:
+ return f"measurements[{name}]"
+
+ return None
+
+ @classmethod
+ def measurement_name(cls, mri) -> str | None:
+ parsed_mri = parse_mri(mri)
+ if parsed_mri is not None and is_measurement(parsed_mri):
+ return parsed_mri.name[len("measurements:") :]
+ return None
+
+ def get_additional_conditions(self) -> list[Condition]:
+ name = self.measurement_name(self.mri)
+ return [Condition(Function("has", [Column("measurements.key"), name]), Op.EQ, 1)]
+
class SpansSamplesListExecutor(SamplesListExecutor):
MRI_MAPPING = {
@@ -187,7 +234,8 @@
SAMPLE_LIST_EXECUTORS = [
SpansSamplesListExecutor,
- SegmentsSamplesListExecutor,
+ TransactionDurationSamplesListExecutor,
+ MeasurementsSamplesListExecutor,
]
|
{"golden_diff": "diff --git a/src/sentry/sentry_metrics/querying/samples_list.py b/src/sentry/sentry_metrics/querying/samples_list.py\n--- a/src/sentry/sentry_metrics/querying/samples_list.py\n+++ b/src/sentry/sentry_metrics/querying/samples_list.py\n@@ -2,13 +2,13 @@\n from datetime import datetime\n from typing import Any\n \n-from snuba_sdk import And, Condition, Op, Or\n+from snuba_sdk import And, Column, Condition, Function, Op, Or\n \n from sentry import options\n from sentry.search.events.builder import QueryBuilder, SpansIndexedQueryBuilder\n from sentry.search.events.types import QueryBuilderConfig, SnubaParams\n from sentry.snuba.dataset import Dataset\n-from sentry.snuba.metrics.naming_layer.mri import SpanMRI, TransactionMRI\n+from sentry.snuba.metrics.naming_layer.mri import SpanMRI, TransactionMRI, is_measurement, parse_mri\n from sentry.snuba.referrer import Referrer\n \n \n@@ -86,10 +86,9 @@\n \n class SegmentsSamplesListExecutor(SamplesListExecutor):\n @classmethod\n+ @abstractmethod\n def mri_to_column(cls, mri) -> str | None:\n- if mri == TransactionMRI.DURATION.value:\n- return \"duration\"\n- return None\n+ raise NotImplementedError\n \n @classmethod\n def supports(cls, mri: str) -> bool:\n@@ -102,6 +101,16 @@\n def get_span_keys(self, offset: int, limit: int) -> list[tuple[str, str, str]]:\n rounded_timestamp = f\"rounded_timestamp({self.rollup})\"\n \n+ \"\"\"\n+ When getting examples for a segment, it's actually much faster to read it\n+ from the transactions dataset compared to the spans dataset as it's a much\n+ smaller dataset.\n+\n+ One consideration here is that there is an one to one mapping between a\n+ transaction to a segment today. If this relationship changes, we'll have to\n+ rethink how to fetch segment samples a little as the transactions dataset\n+ may not contain all the necessary data.\n+ \"\"\"\n builder = QueryBuilder(\n Dataset.Transactions,\n self.params,\n@@ -114,6 +123,8 @@\n config=QueryBuilderConfig(functions_acl=[\"rounded_timestamp\", \"example\"]),\n )\n \n+ builder.add_conditions(self.get_additional_conditions())\n+\n query_results = builder.run_query(self.referrer.value)\n result = builder.process_results(query_results)\n \n@@ -126,6 +137,42 @@\n for row in result[\"data\"]\n ]\n \n+ @abstractmethod\n+ def get_additional_conditions(self) -> list[Condition]:\n+ raise NotImplementedError\n+\n+\n+class TransactionDurationSamplesListExecutor(SegmentsSamplesListExecutor):\n+ @classmethod\n+ def mri_to_column(cls, mri) -> str | None:\n+ if mri == TransactionMRI.DURATION.value:\n+ return \"duration\"\n+ return None\n+\n+ def get_additional_conditions(self) -> list[Condition]:\n+ return []\n+\n+\n+class MeasurementsSamplesListExecutor(SegmentsSamplesListExecutor):\n+ @classmethod\n+ def mri_to_column(cls, mri) -> str | None:\n+ name = cls.measurement_name(mri)\n+ if name is not None:\n+ return f\"measurements[{name}]\"\n+\n+ return None\n+\n+ @classmethod\n+ def measurement_name(cls, mri) -> str | None:\n+ parsed_mri = parse_mri(mri)\n+ if parsed_mri is not None and is_measurement(parsed_mri):\n+ return parsed_mri.name[len(\"measurements:\") :]\n+ return None\n+\n+ def get_additional_conditions(self) -> list[Condition]:\n+ name = self.measurement_name(self.mri)\n+ return [Condition(Function(\"has\", [Column(\"measurements.key\"), name]), Op.EQ, 1)]\n+\n \n class SpansSamplesListExecutor(SamplesListExecutor):\n MRI_MAPPING = {\n@@ -187,7 +234,8 @@\n \n SAMPLE_LIST_EXECUTORS = [\n SpansSamplesListExecutor,\n- SegmentsSamplesListExecutor,\n+ TransactionDurationSamplesListExecutor,\n+ MeasurementsSamplesListExecutor,\n ]\n", "issue": "Support measurement metrics in new metrics/traces sample endpoint\n\n", "before_files": [{"content": "from abc import ABC, abstractmethod\nfrom datetime import datetime\nfrom typing import Any\n\nfrom snuba_sdk import And, Condition, Op, Or\n\nfrom sentry import options\nfrom sentry.search.events.builder import QueryBuilder, SpansIndexedQueryBuilder\nfrom sentry.search.events.types import QueryBuilderConfig, SnubaParams\nfrom sentry.snuba.dataset import Dataset\nfrom sentry.snuba.metrics.naming_layer.mri import SpanMRI, TransactionMRI\nfrom sentry.snuba.referrer import Referrer\n\n\nclass SamplesListExecutor(ABC):\n def __init__(\n self,\n mri: str,\n params: dict[str, Any],\n snuba_params: SnubaParams,\n fields: list[str],\n query: str | None,\n rollup: int,\n referrer: Referrer,\n ):\n self.mri = mri\n self.params = params\n self.snuba_params = snuba_params\n self.fields = fields\n self.query = query\n self.rollup = rollup\n self.referrer = referrer\n\n @classmethod\n @abstractmethod\n def supports(cls, metric_mri: str) -> bool:\n raise NotImplementedError\n\n @abstractmethod\n def execute(self, offset, limit):\n raise NotImplementedError\n\n def get_spans_by_key(self, span_ids: list[tuple[str, str, str]]):\n if not span_ids:\n return {\"data\": []}\n\n builder = SpansIndexedQueryBuilder(\n Dataset.SpansIndexed,\n self.params,\n snuba_params=self.snuba_params,\n selected_columns=self.fields,\n limit=len(span_ids),\n offset=0,\n )\n\n # Using `IN` sometimes does not use the bloomfilter index\n # on the table. So we're explicitly writing the condition\n # using `OR`s.\n #\n # May not be necessary because it's also filtering on the\n # `span.group` as well which allows Clickhouse to filter\n # via the primary key but this is a precaution.\n conditions = [\n And(\n [\n Condition(builder.column(\"span.group\"), Op.EQ, group),\n Condition(\n builder.column(\"timestamp\"), Op.EQ, datetime.fromisoformat(timestamp)\n ),\n Condition(builder.column(\"id\"), Op.EQ, span_id),\n ]\n )\n for (group, timestamp, span_id) in span_ids\n ]\n\n if len(conditions) == 1:\n span_condition = conditions[0]\n else:\n span_condition = Or(conditions)\n\n builder.add_conditions([span_condition])\n\n query_results = builder.run_query(self.referrer.value)\n return builder.process_results(query_results)\n\n\nclass SegmentsSamplesListExecutor(SamplesListExecutor):\n @classmethod\n def mri_to_column(cls, mri) -> str | None:\n if mri == TransactionMRI.DURATION.value:\n return \"duration\"\n return None\n\n @classmethod\n def supports(cls, mri: str) -> bool:\n return cls.mri_to_column(mri) is not None\n\n def execute(self, offset, limit):\n span_keys = self.get_span_keys(offset, limit)\n return self.get_spans_by_key(span_keys)\n\n def get_span_keys(self, offset: int, limit: int) -> list[tuple[str, str, str]]:\n rounded_timestamp = f\"rounded_timestamp({self.rollup})\"\n\n builder = QueryBuilder(\n Dataset.Transactions,\n self.params,\n snuba_params=self.snuba_params,\n query=self.query,\n selected_columns=[rounded_timestamp, \"example()\"],\n limit=limit,\n offset=offset,\n sample_rate=options.get(\"metrics.sample-list.sample-rate\"),\n config=QueryBuilderConfig(functions_acl=[\"rounded_timestamp\", \"example\"]),\n )\n\n query_results = builder.run_query(self.referrer.value)\n result = builder.process_results(query_results)\n\n return [\n (\n \"00\", # all segments have a group of `00` currently\n row[\"example\"][0], # timestamp\n row[\"example\"][1], # span_id\n )\n for row in result[\"data\"]\n ]\n\n\nclass SpansSamplesListExecutor(SamplesListExecutor):\n MRI_MAPPING = {\n SpanMRI.DURATION.value: \"span.duration\",\n SpanMRI.SELF_TIME.value: \"span.self_time\",\n }\n\n @classmethod\n def mri_to_column(cls, mri) -> str | None:\n return cls.MRI_MAPPING.get(mri)\n\n @classmethod\n def supports(cls, mri: str) -> bool:\n return cls.mri_to_column(mri) is not None\n\n def execute(self, offset, limit):\n span_keys = self.get_span_keys(offset, limit)\n return self.get_spans_by_key(span_keys)\n\n def get_span_keys(self, offset: int, limit: int) -> list[tuple[str, str, str]]:\n rounded_timestamp = f\"rounded_timestamp({self.rollup})\"\n\n builder = SpansIndexedQueryBuilder(\n Dataset.SpansIndexed,\n self.params,\n snuba_params=self.snuba_params,\n query=self.query,\n selected_columns=[rounded_timestamp, \"example()\"],\n limit=limit,\n offset=offset,\n sample_rate=options.get(\"metrics.sample-list.sample-rate\"),\n config=QueryBuilderConfig(functions_acl=[\"rounded_timestamp\", \"example\"]),\n )\n\n builder.add_conditions(\n [\n # The `00` group is used for spans not used within the\n # new starfish experience. It's effectively the group\n # for other. It is a massive group, so we've chosen\n # to exclude it here.\n #\n # In the future, we will want to look into exposing them\n Condition(builder.column(\"span.group\"), Op.NEQ, \"00\")\n ]\n )\n\n query_results = builder.run_query(self.referrer.value)\n result = builder.process_results(query_results)\n\n return [\n (\n row[\"example\"][0], # group\n row[\"example\"][1], # timestamp\n row[\"example\"][2], # span_id\n )\n for row in result[\"data\"]\n ]\n\n\nSAMPLE_LIST_EXECUTORS = [\n SpansSamplesListExecutor,\n SegmentsSamplesListExecutor,\n]\n\n\ndef get_sample_list_executor_cls(mri) -> type[SamplesListExecutor] | None:\n for executor_cls in SAMPLE_LIST_EXECUTORS:\n if executor_cls.supports(mri):\n return executor_cls\n return None\n", "path": "src/sentry/sentry_metrics/querying/samples_list.py"}]}
| 2,450 | 940 |
gh_patches_debug_17950
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-3346
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
intel-compiler fails sanity check on Debian/Ubuntu
With the recent changes to gcc easyblock #3254 and the older change to intel_compiler easyblock #1237 and its followups, intel-compiler now fails sanity check due to an incorrect module file being generated.
```
multiarch_inc_dir, ec = run_cmd("gcc -E -Wp,-v -xc /dev/null 2>&1 | grep %s$" % multiarch_out)
```
returns
```
easybuild@b-cn1615:~$ gcc -E -Wp,-v -xc /dev/null 2>&1 | grep x86_64-linux-gnu'$'
/cvmfs/ebsw.hpc2n.umu.se/amd64_ubuntu2204_icelake/software/GCCcore/13.2.0/bin/../lib/gcc/x86_64-pc-linux-gnu/13.2.0/include-fixed/x86_64-linux-gnu
/usr/include/x86_64-linux-gnu
```
resulting in an malformed CPATH being added to the module file:
```
append_path("CPATH", "/cvmfs/ebsw.hpc2n.umu.se/amd64_ubuntu2204_icelake/software/GCCcore/13.2.0/bin/../lib/gcc/x86_64-pc-linux-gnu/13.2.0/include-fixed/x86_64-linux-gnu
/usr/include/x86_64-linux-gnu")
```
Simple fix is to do ```grep -v GCCcore``` at the and of the command.
</issue>
<code>
[start of easybuild/easyblocks/i/intel_compilers.py]
1 # #
2 # Copyright 2021-2024 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 # #
25 """
26 EasyBuild support for installing Intel compilers, implemented as an easyblock
27
28 @author: Kenneth Hoste (Ghent University)
29 """
30 import os
31 from easybuild.tools import LooseVersion
32
33 from easybuild.easyblocks.generic.intelbase import IntelBase
34 from easybuild.easyblocks.t.tbb import get_tbb_gccprefix
35 from easybuild.tools.build_log import EasyBuildError, print_msg
36 from easybuild.tools.run import run_cmd
37
38
39 class EB_intel_minus_compilers(IntelBase):
40 """
41 Support for installing Intel compilers, starting with verion 2021.x (oneAPI)
42 """
43
44 def __init__(self, *args, **kwargs):
45 """
46 Easyblock constructor: check version
47 """
48 super(EB_intel_minus_compilers, self).__init__(*args, **kwargs)
49
50 # this easyblock is only valid for recent versions of the Intel compilers (2021.x, oneAPI)
51 if LooseVersion(self.version) < LooseVersion('2021'):
52 raise EasyBuildError("Invalid version %s, should be >= 2021.x" % self.version)
53
54 @property
55 def compilers_subdir(self):
56 compilers_subdir = self.get_versioned_subdir('compiler')
57 if LooseVersion(self.version) < LooseVersion('2024'):
58 compilers_subdir = os.path.join(compilers_subdir, 'linux')
59 return compilers_subdir
60
61 @property
62 def tbb_subdir(self):
63 return self.get_versioned_subdir('tbb')
64
65 def prepare_step(self, *args, **kwargs):
66 """
67 Prepare environment for installing.
68
69 Specify that oneAPI versions of Intel compilers don't require a runtime license.
70 """
71 # avoid that IntelBase trips over not having license info specified
72 kwargs['requires_runtime_license'] = False
73
74 super(EB_intel_minus_compilers, self).prepare_step(*args, **kwargs)
75
76 def configure_step(self):
77 """Configure installation."""
78
79 # redefine $HOME for install step, to avoid that anything is stored in $HOME/intel
80 # (like the 'installercache' database)
81 self.cfg['preinstallopts'] += " HOME=%s " % self.builddir
82
83 def install_step(self):
84 """
85 Install step: install each 'source file' one by one.
86 Installing the Intel compilers could be done via a single installation file (HPC Toolkit),
87 or with separate installation files (patch releases of the C++ and Fortran compilers).
88 """
89 srcs = self.src[:]
90 cnt = len(srcs)
91 for idx, src in enumerate(srcs):
92 print_msg("installing part %d/%s (%s)..." % (idx + 1, cnt, src['name']))
93 self.src = [src]
94 super(EB_intel_minus_compilers, self).install_step()
95
96 def sanity_check_step(self):
97 """
98 Custom sanity check for Intel compilers.
99 """
100
101 oneapi_compiler_cmds = [
102 'dpcpp', # Intel oneAPI Data Parallel C++ compiler
103 'icx', # oneAPI Intel C compiler
104 'icpx', # oneAPI Intel C++ compiler
105 'ifx', # oneAPI Intel Fortran compiler
106 ]
107 bindir = os.path.join(self.compilers_subdir, 'bin')
108 oneapi_compiler_paths = [os.path.join(bindir, x) for x in oneapi_compiler_cmds]
109 if LooseVersion(self.version) >= LooseVersion('2024'):
110 classic_compiler_cmds = ['ifort']
111 classic_bindir = bindir
112 else:
113 classic_compiler_cmds = ['icc', 'icpc', 'ifort']
114 classic_bindir = os.path.join(bindir, 'intel64')
115 classic_compiler_paths = [os.path.join(classic_bindir, x) for x in classic_compiler_cmds]
116
117 custom_paths = {
118 'files': classic_compiler_paths + oneapi_compiler_paths,
119 'dirs': [self.compilers_subdir],
120 }
121
122 all_compiler_cmds = classic_compiler_cmds + oneapi_compiler_cmds
123 custom_commands = ["which %s" % c for c in all_compiler_cmds]
124
125 # only for 2021.x versions do all compiler commands have the expected version;
126 # for example: for 2022.0.1, icc has version 2021.5.0, icpx has 2022.0.0
127 if LooseVersion(self.version) >= LooseVersion('2022.0'):
128 custom_commands.extend("%s --version" % c for c in all_compiler_cmds)
129 else:
130 custom_commands.extend("%s --version | grep %s" % (c, self.version) for c in all_compiler_cmds)
131
132 super(EB_intel_minus_compilers, self).sanity_check_step(custom_paths=custom_paths,
133 custom_commands=custom_commands)
134
135 def make_module_req_guess(self):
136 """
137 Paths to consider for prepend-paths statements in module file
138 """
139 libdirs = [
140 'lib',
141 os.path.join('lib', 'x64'),
142 os.path.join('compiler', 'lib', 'intel64_lin'),
143 ]
144 libdirs = [os.path.join(self.compilers_subdir, x) for x in libdirs]
145 tbb_subdir = self.tbb_subdir
146 tbb_libsubdir = os.path.join(tbb_subdir, 'lib', 'intel64')
147 libdirs.append(os.path.join(tbb_libsubdir,
148 get_tbb_gccprefix(os.path.join(self.installdir, tbb_libsubdir))))
149 guesses = {
150 'PATH': [
151 os.path.join(self.compilers_subdir, 'bin'),
152 os.path.join(self.compilers_subdir, 'bin', 'intel64'),
153 ],
154 'LD_LIBRARY_PATH': libdirs,
155 'LIBRARY_PATH': libdirs,
156 'MANPATH': [
157 os.path.join(os.path.dirname(self.compilers_subdir), 'documentation', 'en', 'man', 'common'),
158 os.path.join(self.compilers_subdir, 'share', 'man'),
159 ],
160 'OCL_ICD_FILENAMES': [
161 os.path.join(self.compilers_subdir, 'lib', 'x64', 'libintelocl.so'),
162 os.path.join(self.compilers_subdir, 'lib', 'libintelocl.so'),
163 ],
164 'CPATH': [
165 os.path.join(tbb_subdir, 'include'),
166 ],
167 'TBBROOT': [tbb_subdir],
168 }
169 return guesses
170
171 def make_module_extra(self):
172 """Additional custom variables for intel-compiler"""
173 txt = super(EB_intel_minus_compilers, self).make_module_extra()
174
175 # On Debian/Ubuntu, /usr/include/x86_64-linux-gnu, or whatever dir gcc uses, needs to be included
176 # in $CPATH for Intel C compiler
177 multiarch_out, ec = run_cmd("gcc -print-multiarch", simple=False)
178 multiarch_out = multiarch_out.strip()
179 if ec == 0 and multiarch_out:
180 multiarch_inc_dir, ec = run_cmd("gcc -E -Wp,-v -xc /dev/null 2>&1 | grep %s$" % multiarch_out)
181 if ec == 0 and multiarch_inc_dir:
182 multiarch_inc_dir = multiarch_inc_dir.strip()
183 self.log.info("Adding multiarch include path %s to $CPATH in generated module file", multiarch_inc_dir)
184 # system location must be appended at the end, so use append_paths
185 txt += self.module_generator.append_paths('CPATH', [multiarch_inc_dir], allow_abs=True)
186
187 return txt
188
[end of easybuild/easyblocks/i/intel_compilers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/easyblocks/i/intel_compilers.py b/easybuild/easyblocks/i/intel_compilers.py
--- a/easybuild/easyblocks/i/intel_compilers.py
+++ b/easybuild/easyblocks/i/intel_compilers.py
@@ -177,7 +177,12 @@
multiarch_out, ec = run_cmd("gcc -print-multiarch", simple=False)
multiarch_out = multiarch_out.strip()
if ec == 0 and multiarch_out:
- multiarch_inc_dir, ec = run_cmd("gcc -E -Wp,-v -xc /dev/null 2>&1 | grep %s$" % multiarch_out)
+ multi_arch_inc_dir_cmd = '|'.join([
+ "gcc -E -Wp,-v -xc /dev/null 2>&1",
+ "grep %s$" % multiarch_out,
+ "grep -v /include-fixed/",
+ ])
+ multiarch_inc_dir, ec = run_cmd(multi_arch_inc_dir_cmd)
if ec == 0 and multiarch_inc_dir:
multiarch_inc_dir = multiarch_inc_dir.strip()
self.log.info("Adding multiarch include path %s to $CPATH in generated module file", multiarch_inc_dir)
|
{"golden_diff": "diff --git a/easybuild/easyblocks/i/intel_compilers.py b/easybuild/easyblocks/i/intel_compilers.py\n--- a/easybuild/easyblocks/i/intel_compilers.py\n+++ b/easybuild/easyblocks/i/intel_compilers.py\n@@ -177,7 +177,12 @@\n multiarch_out, ec = run_cmd(\"gcc -print-multiarch\", simple=False)\n multiarch_out = multiarch_out.strip()\n if ec == 0 and multiarch_out:\n- multiarch_inc_dir, ec = run_cmd(\"gcc -E -Wp,-v -xc /dev/null 2>&1 | grep %s$\" % multiarch_out)\n+ multi_arch_inc_dir_cmd = '|'.join([\n+ \"gcc -E -Wp,-v -xc /dev/null 2>&1\",\n+ \"grep %s$\" % multiarch_out,\n+ \"grep -v /include-fixed/\",\n+ ])\n+ multiarch_inc_dir, ec = run_cmd(multi_arch_inc_dir_cmd)\n if ec == 0 and multiarch_inc_dir:\n multiarch_inc_dir = multiarch_inc_dir.strip()\n self.log.info(\"Adding multiarch include path %s to $CPATH in generated module file\", multiarch_inc_dir)\n", "issue": "intel-compiler fails sanity check on Debian/Ubuntu\nWith the recent changes to gcc easyblock #3254 and the older change to intel_compiler easyblock #1237 and its followups, intel-compiler now fails sanity check due to an incorrect module file being generated.\r\n\r\n```\r\nmultiarch_inc_dir, ec = run_cmd(\"gcc -E -Wp,-v -xc /dev/null 2>&1 | grep %s$\" % multiarch_out)\r\n```\r\nreturns\r\n```\r\neasybuild@b-cn1615:~$ gcc -E -Wp,-v -xc /dev/null 2>&1 | grep x86_64-linux-gnu'$'\r\n /cvmfs/ebsw.hpc2n.umu.se/amd64_ubuntu2204_icelake/software/GCCcore/13.2.0/bin/../lib/gcc/x86_64-pc-linux-gnu/13.2.0/include-fixed/x86_64-linux-gnu\r\n /usr/include/x86_64-linux-gnu\r\n```\r\n\r\nresulting in an malformed CPATH being added to the module file:\r\n```\r\nappend_path(\"CPATH\", \"/cvmfs/ebsw.hpc2n.umu.se/amd64_ubuntu2204_icelake/software/GCCcore/13.2.0/bin/../lib/gcc/x86_64-pc-linux-gnu/13.2.0/include-fixed/x86_64-linux-gnu\r\n /usr/include/x86_64-linux-gnu\")\r\n```\r\n\r\nSimple fix is to do ```grep -v GCCcore``` at the and of the command.\n", "before_files": [{"content": "# #\n# Copyright 2021-2024 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n# #\n\"\"\"\nEasyBuild support for installing Intel compilers, implemented as an easyblock\n\n@author: Kenneth Hoste (Ghent University)\n\"\"\"\nimport os\nfrom easybuild.tools import LooseVersion\n\nfrom easybuild.easyblocks.generic.intelbase import IntelBase\nfrom easybuild.easyblocks.t.tbb import get_tbb_gccprefix\nfrom easybuild.tools.build_log import EasyBuildError, print_msg\nfrom easybuild.tools.run import run_cmd\n\n\nclass EB_intel_minus_compilers(IntelBase):\n \"\"\"\n Support for installing Intel compilers, starting with verion 2021.x (oneAPI)\n \"\"\"\n\n def __init__(self, *args, **kwargs):\n \"\"\"\n Easyblock constructor: check version\n \"\"\"\n super(EB_intel_minus_compilers, self).__init__(*args, **kwargs)\n\n # this easyblock is only valid for recent versions of the Intel compilers (2021.x, oneAPI)\n if LooseVersion(self.version) < LooseVersion('2021'):\n raise EasyBuildError(\"Invalid version %s, should be >= 2021.x\" % self.version)\n\n @property\n def compilers_subdir(self):\n compilers_subdir = self.get_versioned_subdir('compiler')\n if LooseVersion(self.version) < LooseVersion('2024'):\n compilers_subdir = os.path.join(compilers_subdir, 'linux')\n return compilers_subdir\n\n @property\n def tbb_subdir(self):\n return self.get_versioned_subdir('tbb')\n\n def prepare_step(self, *args, **kwargs):\n \"\"\"\n Prepare environment for installing.\n\n Specify that oneAPI versions of Intel compilers don't require a runtime license.\n \"\"\"\n # avoid that IntelBase trips over not having license info specified\n kwargs['requires_runtime_license'] = False\n\n super(EB_intel_minus_compilers, self).prepare_step(*args, **kwargs)\n\n def configure_step(self):\n \"\"\"Configure installation.\"\"\"\n\n # redefine $HOME for install step, to avoid that anything is stored in $HOME/intel\n # (like the 'installercache' database)\n self.cfg['preinstallopts'] += \" HOME=%s \" % self.builddir\n\n def install_step(self):\n \"\"\"\n Install step: install each 'source file' one by one.\n Installing the Intel compilers could be done via a single installation file (HPC Toolkit),\n or with separate installation files (patch releases of the C++ and Fortran compilers).\n \"\"\"\n srcs = self.src[:]\n cnt = len(srcs)\n for idx, src in enumerate(srcs):\n print_msg(\"installing part %d/%s (%s)...\" % (idx + 1, cnt, src['name']))\n self.src = [src]\n super(EB_intel_minus_compilers, self).install_step()\n\n def sanity_check_step(self):\n \"\"\"\n Custom sanity check for Intel compilers.\n \"\"\"\n\n oneapi_compiler_cmds = [\n 'dpcpp', # Intel oneAPI Data Parallel C++ compiler\n 'icx', # oneAPI Intel C compiler\n 'icpx', # oneAPI Intel C++ compiler\n 'ifx', # oneAPI Intel Fortran compiler\n ]\n bindir = os.path.join(self.compilers_subdir, 'bin')\n oneapi_compiler_paths = [os.path.join(bindir, x) for x in oneapi_compiler_cmds]\n if LooseVersion(self.version) >= LooseVersion('2024'):\n classic_compiler_cmds = ['ifort']\n classic_bindir = bindir\n else:\n classic_compiler_cmds = ['icc', 'icpc', 'ifort']\n classic_bindir = os.path.join(bindir, 'intel64')\n classic_compiler_paths = [os.path.join(classic_bindir, x) for x in classic_compiler_cmds]\n\n custom_paths = {\n 'files': classic_compiler_paths + oneapi_compiler_paths,\n 'dirs': [self.compilers_subdir],\n }\n\n all_compiler_cmds = classic_compiler_cmds + oneapi_compiler_cmds\n custom_commands = [\"which %s\" % c for c in all_compiler_cmds]\n\n # only for 2021.x versions do all compiler commands have the expected version;\n # for example: for 2022.0.1, icc has version 2021.5.0, icpx has 2022.0.0\n if LooseVersion(self.version) >= LooseVersion('2022.0'):\n custom_commands.extend(\"%s --version\" % c for c in all_compiler_cmds)\n else:\n custom_commands.extend(\"%s --version | grep %s\" % (c, self.version) for c in all_compiler_cmds)\n\n super(EB_intel_minus_compilers, self).sanity_check_step(custom_paths=custom_paths,\n custom_commands=custom_commands)\n\n def make_module_req_guess(self):\n \"\"\"\n Paths to consider for prepend-paths statements in module file\n \"\"\"\n libdirs = [\n 'lib',\n os.path.join('lib', 'x64'),\n os.path.join('compiler', 'lib', 'intel64_lin'),\n ]\n libdirs = [os.path.join(self.compilers_subdir, x) for x in libdirs]\n tbb_subdir = self.tbb_subdir\n tbb_libsubdir = os.path.join(tbb_subdir, 'lib', 'intel64')\n libdirs.append(os.path.join(tbb_libsubdir,\n get_tbb_gccprefix(os.path.join(self.installdir, tbb_libsubdir))))\n guesses = {\n 'PATH': [\n os.path.join(self.compilers_subdir, 'bin'),\n os.path.join(self.compilers_subdir, 'bin', 'intel64'),\n ],\n 'LD_LIBRARY_PATH': libdirs,\n 'LIBRARY_PATH': libdirs,\n 'MANPATH': [\n os.path.join(os.path.dirname(self.compilers_subdir), 'documentation', 'en', 'man', 'common'),\n os.path.join(self.compilers_subdir, 'share', 'man'),\n ],\n 'OCL_ICD_FILENAMES': [\n os.path.join(self.compilers_subdir, 'lib', 'x64', 'libintelocl.so'),\n os.path.join(self.compilers_subdir, 'lib', 'libintelocl.so'),\n ],\n 'CPATH': [\n os.path.join(tbb_subdir, 'include'),\n ],\n 'TBBROOT': [tbb_subdir],\n }\n return guesses\n\n def make_module_extra(self):\n \"\"\"Additional custom variables for intel-compiler\"\"\"\n txt = super(EB_intel_minus_compilers, self).make_module_extra()\n\n # On Debian/Ubuntu, /usr/include/x86_64-linux-gnu, or whatever dir gcc uses, needs to be included\n # in $CPATH for Intel C compiler\n multiarch_out, ec = run_cmd(\"gcc -print-multiarch\", simple=False)\n multiarch_out = multiarch_out.strip()\n if ec == 0 and multiarch_out:\n multiarch_inc_dir, ec = run_cmd(\"gcc -E -Wp,-v -xc /dev/null 2>&1 | grep %s$\" % multiarch_out)\n if ec == 0 and multiarch_inc_dir:\n multiarch_inc_dir = multiarch_inc_dir.strip()\n self.log.info(\"Adding multiarch include path %s to $CPATH in generated module file\", multiarch_inc_dir)\n # system location must be appended at the end, so use append_paths\n txt += self.module_generator.append_paths('CPATH', [multiarch_inc_dir], allow_abs=True)\n\n return txt\n", "path": "easybuild/easyblocks/i/intel_compilers.py"}]}
| 3,300 | 280 |
gh_patches_debug_17633
|
rasdani/github-patches
|
git_diff
|
nextcloud__appstore-523
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
App Generator creates faulty info.xml when using umlauts (special characters äöü)
Problem: nextcloud/apps/foo/appinfo/info.xml misses the closing **</info>** tag. Just generates **</**
## Details
* Browser and browser version: Firefox 55.0.3
## Steps to reproduce
Steps to reproduce:
- visit https://apps.nextcloud.com/developer/apps/generate
- enter the required information; in summary and description enter "This is a test app äöü"
- click generate and download.
- look at the generated info.xml
App Generator creates faulty info.xml when using umlauts (special characters äöü)
Problem: nextcloud/apps/foo/appinfo/info.xml misses the closing **</info>** tag. Just generates **</**
## Details
* Browser and browser version: Firefox 55.0.3
## Steps to reproduce
Steps to reproduce:
- visit https://apps.nextcloud.com/developer/apps/generate
- enter the required information; in summary and description enter "This is a test app äöü"
- click generate and download.
- look at the generated info.xml
</issue>
<code>
[start of nextcloudappstore/scaffolding/archive.py]
1 import re
2 import tarfile
3 from io import BytesIO, StringIO
4 from typing import Dict
5 from os.path import join, isdir, relpath
6 from os import walk
7
8 from django.template import Context
9 from django.template import Template
10
11 from nextcloudappstore.core.facades import resolve_file_relative_path
12 from nextcloudappstore.settings.base import APP_SCAFFOLDING_PROFILES
13
14
15 def build_files(args: Dict[str, str]) -> Dict[str, str]:
16 platform = int(args['platform']) # prevent path traversal
17 vars = {
18 'id': args['name'].lower(),
19 'summary': args['summary'],
20 'description': args['description'],
21 'name': ' '.join(re.findall(r'[A-Z][^A-Z]*', args['name'])),
22 'namespace': args['name'],
23 'author_name': args['author_name'],
24 'author_mail': args['author_email'],
25 'author_homepage': args['author_homepage'],
26 'issue_tracker': args['issue_tracker'],
27 'categories': args['categories'],
28 'nextcloud_version': platform
29 }
30 vars.update(APP_SCAFFOLDING_PROFILES.get(platform, {}))
31 relative_base = 'app-templates/%i/app/' % platform
32 base = resolve_file_relative_path(__file__, relative_base)
33
34 context = Context({'app': vars})
35 result = {}
36 if isdir(base):
37 for root, dirs, files in walk(base):
38 for file in files:
39 file_path = join(root, file)
40 rel_file_path = '%s/%s' % (
41 vars['id'], relpath(file_path, base)
42 )
43 with open(file_path) as f:
44 t = Template(f.read())
45 result[rel_file_path] = t.render(context)
46
47 return result
48
49
50 def build_archive(parameters: Dict[str, str]) -> BytesIO:
51 buffer = BytesIO()
52 with tarfile.open(fileobj=buffer, mode='w:gz') as f:
53 files = build_files(parameters)
54 for path, contents in files.items():
55 info = tarfile.TarInfo(path)
56 info.size = len(contents)
57 f.addfile(info, BytesIO(contents.encode()))
58 buffer.seek(0)
59 return buffer
60
[end of nextcloudappstore/scaffolding/archive.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nextcloudappstore/scaffolding/archive.py b/nextcloudappstore/scaffolding/archive.py
--- a/nextcloudappstore/scaffolding/archive.py
+++ b/nextcloudappstore/scaffolding/archive.py
@@ -1,9 +1,9 @@
import re
import tarfile
-from io import BytesIO, StringIO
-from typing import Dict
-from os.path import join, isdir, relpath
+from io import BytesIO
from os import walk
+from os.path import join, isdir, relpath
+from typing import Dict
from django.template import Context
from django.template import Template
@@ -53,7 +53,8 @@
files = build_files(parameters)
for path, contents in files.items():
info = tarfile.TarInfo(path)
- info.size = len(contents)
- f.addfile(info, BytesIO(contents.encode()))
+ encoded_content = contents.encode()
+ info.size = len(encoded_content)
+ f.addfile(info, BytesIO(encoded_content))
buffer.seek(0)
return buffer
|
{"golden_diff": "diff --git a/nextcloudappstore/scaffolding/archive.py b/nextcloudappstore/scaffolding/archive.py\n--- a/nextcloudappstore/scaffolding/archive.py\n+++ b/nextcloudappstore/scaffolding/archive.py\n@@ -1,9 +1,9 @@\n import re\n import tarfile\n-from io import BytesIO, StringIO\n-from typing import Dict\n-from os.path import join, isdir, relpath\n+from io import BytesIO\n from os import walk\n+from os.path import join, isdir, relpath\n+from typing import Dict\n \n from django.template import Context\n from django.template import Template\n@@ -53,7 +53,8 @@\n files = build_files(parameters)\n for path, contents in files.items():\n info = tarfile.TarInfo(path)\n- info.size = len(contents)\n- f.addfile(info, BytesIO(contents.encode()))\n+ encoded_content = contents.encode()\n+ info.size = len(encoded_content)\n+ f.addfile(info, BytesIO(encoded_content))\n buffer.seek(0)\n return buffer\n", "issue": "App Generator creates faulty info.xml when using umlauts (special characters \u00e4\u00f6\u00fc)\nProblem: nextcloud/apps/foo/appinfo/info.xml misses the closing **</info>** tag. Just generates **</**\r\n\r\n## Details\r\n\r\n* Browser and browser version: Firefox 55.0.3\r\n\r\n## Steps to reproduce\r\n\r\nSteps to reproduce:\r\n\r\n- visit https://apps.nextcloud.com/developer/apps/generate\r\n- enter the required information; in summary and description enter \"This is a test app \u00e4\u00f6\u00fc\"\r\n- click generate and download.\r\n- look at the generated info.xml\r\n\r\n\nApp Generator creates faulty info.xml when using umlauts (special characters \u00e4\u00f6\u00fc)\nProblem: nextcloud/apps/foo/appinfo/info.xml misses the closing **</info>** tag. Just generates **</**\r\n\r\n## Details\r\n\r\n* Browser and browser version: Firefox 55.0.3\r\n\r\n## Steps to reproduce\r\n\r\nSteps to reproduce:\r\n\r\n- visit https://apps.nextcloud.com/developer/apps/generate\r\n- enter the required information; in summary and description enter \"This is a test app \u00e4\u00f6\u00fc\"\r\n- click generate and download.\r\n- look at the generated info.xml\r\n\r\n\n", "before_files": [{"content": "import re\nimport tarfile\nfrom io import BytesIO, StringIO\nfrom typing import Dict\nfrom os.path import join, isdir, relpath\nfrom os import walk\n\nfrom django.template import Context\nfrom django.template import Template\n\nfrom nextcloudappstore.core.facades import resolve_file_relative_path\nfrom nextcloudappstore.settings.base import APP_SCAFFOLDING_PROFILES\n\n\ndef build_files(args: Dict[str, str]) -> Dict[str, str]:\n platform = int(args['platform']) # prevent path traversal\n vars = {\n 'id': args['name'].lower(),\n 'summary': args['summary'],\n 'description': args['description'],\n 'name': ' '.join(re.findall(r'[A-Z][^A-Z]*', args['name'])),\n 'namespace': args['name'],\n 'author_name': args['author_name'],\n 'author_mail': args['author_email'],\n 'author_homepage': args['author_homepage'],\n 'issue_tracker': args['issue_tracker'],\n 'categories': args['categories'],\n 'nextcloud_version': platform\n }\n vars.update(APP_SCAFFOLDING_PROFILES.get(platform, {}))\n relative_base = 'app-templates/%i/app/' % platform\n base = resolve_file_relative_path(__file__, relative_base)\n\n context = Context({'app': vars})\n result = {}\n if isdir(base):\n for root, dirs, files in walk(base):\n for file in files:\n file_path = join(root, file)\n rel_file_path = '%s/%s' % (\n vars['id'], relpath(file_path, base)\n )\n with open(file_path) as f:\n t = Template(f.read())\n result[rel_file_path] = t.render(context)\n\n return result\n\n\ndef build_archive(parameters: Dict[str, str]) -> BytesIO:\n buffer = BytesIO()\n with tarfile.open(fileobj=buffer, mode='w:gz') as f:\n files = build_files(parameters)\n for path, contents in files.items():\n info = tarfile.TarInfo(path)\n info.size = len(contents)\n f.addfile(info, BytesIO(contents.encode()))\n buffer.seek(0)\n return buffer\n", "path": "nextcloudappstore/scaffolding/archive.py"}]}
| 1,379 | 234 |
gh_patches_debug_7203
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-2338
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Python error after pressing SPACE to pull up command-name input
**Small description**
The first time I press SPACE on a sheet, I often get the following Python error. It usually succeeds on the second press.
**Expected result**
Open command prompt.
**Actual result with screenshot**

[errors_recent.txt](https://github.com/saulpw/visidata/files/14471969/errors_recent.txt)
**Steps to reproduce with sample data and a .vd**
Open any sheet and press SPACE.
It may take a few attempts. It seems to only happen the first time it is entered on a sheet, and only some of the time.
**Additional context**
Python 3.8.0
VisiData 3.0.2
</issue>
<code>
[start of visidata/features/cmdpalette.py]
1 import collections
2 from functools import partial
3 from visidata import DrawablePane, BaseSheet, vd, VisiData, CompleteKey, clipdraw, HelpSheet, colors, AcceptInput, AttrDict, drawcache_property
4
5
6 vd.theme_option('color_cmdpalette', 'black on 72', 'base color of command palette')
7 vd.theme_option('disp_cmdpal_max', 10, 'max number of suggestions for command palette')
8
9 vd.help_longname = '''# Choose Command
10 Start typing a command longname or keyword in its helpstring.
11
12 - `Enter` to execute top command.
13 - `Tab` to highlight top command.
14
15 ## When Command Highlighted
16
17 - `Tab`/`Shift+Tab` to cycle highlighted command.
18 - `Enter` to execute highlighted command.
19 - `0-9` to execute numbered command.
20 '''
21
22 def add_to_input(v, i, value=''):
23 items = list(v.split())
24 if not v or v.endswith(' '):
25 items.append(value)
26 else:
27 items[-1] = value
28 v = ' '.join(items) + ' '
29 return v, len(v)
30
31
32 def accept_input(v, i, value=None):
33 raise AcceptInput(v if value is None else value)
34
35 def accept_input_if_subset(v, i, value=''):
36 # if no input, accept value under cmd palette cursor
37 if not v:
38 raise AcceptInput(value)
39
40 # if the last item is a partial match, replace it with the full value
41 parts = v.split()
42 if value and value.startswith(parts[-1]):
43 v = ' '.join(parts[:-1] + [value])
44
45 raise AcceptInput(v)
46
47 @VisiData.lazy_property
48 def usedInputs(vd):
49 return collections.defaultdict(int)
50
51 @DrawablePane.after
52 def execCommand2(sheet, cmd, *args, **kwargs):
53 vd.usedInputs[cmd.longname] += 1
54
55 @BaseSheet.api
56 def inputPalette(sheet, prompt, items,
57 value_key='key',
58 formatter=lambda m, item, trigger_key: f'{trigger_key} {item}',
59 multiple=False,
60 **kwargs):
61 bindings = dict()
62
63 tabitem = -1
64
65 def tab(n, nitems):
66 nonlocal tabitem
67 if not nitems: return None
68 tabitem = (tabitem + n) % nitems
69
70 def _draw_palette(value):
71 words = value.lower().split()
72
73 if multiple and words:
74 if value.endswith(' '):
75 finished_words = words
76 unfinished_words = []
77 else:
78 finished_words = words[:-1]
79 unfinished_words = [words[-1]]
80 else:
81 unfinished_words = words
82 finished_words = []
83
84 unuseditems = [item for item in items if item[value_key] not in finished_words]
85
86 matches = vd.fuzzymatch(unuseditems, unfinished_words)
87
88 h = sheet.windowHeight
89 w = min(100, sheet.windowWidth)
90 nitems = min(h-1, sheet.options.disp_cmdpal_max)
91
92 useditems = []
93 palrows = []
94
95 for m in matches[:nitems]:
96 useditems.append(m.match)
97 palrows.append((m, m.match))
98
99 favitems = sorted([item for item in unuseditems if item not in useditems],
100 key=lambda item: -vd.usedInputs.get(item[value_key], 0))
101
102 for item in favitems[:nitems-len(palrows)]:
103 palrows.append((None, item))
104
105 navailitems = min(len(palrows), nitems)
106
107 bindings['^I'] = lambda *args: tab(1, navailitems) or args
108 bindings['KEY_BTAB'] = lambda *args: tab(-1, navailitems) or args
109
110 for i in range(nitems-len(palrows)):
111 palrows.append((None, None))
112
113 used_triggers = set()
114 for i, (m, item) in enumerate(palrows):
115 trigger_key = ''
116 if tabitem >= 0 and item:
117 tkey = f'{i+1}'[-1]
118 if tkey not in used_triggers:
119 trigger_key = tkey
120 bindings[trigger_key] = partial(add_to_input if multiple else accept_input, value=item[value_key])
121 used_triggers.add(trigger_key)
122
123 attr = colors.color_cmdpalette
124
125 if tabitem < 0 and palrows:
126 _ , topitem = palrows[0]
127 if not topitem: return
128 if multiple:
129 bindings[' '] = partial(add_to_input, value=topitem[value_key])
130 bindings['^J'] = partial(accept_input_if_subset, value=topitem[value_key])
131 else:
132 bindings['^J'] = partial(accept_input, value=topitem[value_key])
133 elif item and i == tabitem:
134 if not item: return
135 if multiple:
136 bindings['^J'] = partial(accept_input_if_subset, value=item[value_key])
137 bindings[' '] = partial(add_to_input, value=item[value_key])
138 else:
139 bindings['^J'] = partial(accept_input, value=item[value_key])
140 attr = colors.color_menu_spec
141
142 match_summary = formatter(m, item, trigger_key) if item else ' '
143
144 clipdraw(sheet._scr, h-nitems-1+i, 0, match_summary, attr, w=w)
145
146 return None
147
148 completer = CompleteKey(sorted(item[value_key] for item in items))
149 return vd.input(prompt,
150 completer=completer,
151 updater=_draw_palette,
152 bindings=bindings,
153 **kwargs)
154
155
156 def cmdlist(sheet):
157 return [
158 AttrDict(longname=row.longname,
159 description=sheet.cmddict[(row.sheet, row.longname)].helpstr)
160 for row in sheet.rows
161 ]
162 HelpSheet.cmdlist = drawcache_property(cmdlist)
163
164
165 @BaseSheet.api
166 def inputLongname(sheet):
167 prompt = 'command name: '
168 # get set of commands possible in the sheet
169 this_sheets_help = HelpSheet('', source=sheet)
170 this_sheets_help.ensureLoaded()
171
172 def _fmt_cmdpal_summary(match, row, trigger_key):
173 keystrokes = this_sheets_help.revbinds.get(row.longname, [None])[0] or ' '
174 formatted_longname = match.formatted.get('longname', row.longname) if match else row.longname
175 formatted_name = f'[:bold][:onclick {row.longname}]{formatted_longname}[/][/]'
176 if vd.options.debug and match:
177 keystrokes = f'[{match.score}]'
178 r = f' [:keystrokes]{keystrokes.rjust(len(prompt)-5)}[/] '
179 if trigger_key:
180 r += f'[:keystrokes]{trigger_key}[/]'
181 else:
182 r += ' '
183
184 r += f' {formatted_name}'
185 if row.description:
186 formatted_desc = match.formatted.get('description', row.description) if match else row.description
187 r += f' - {formatted_desc}'
188 return r
189
190 return sheet.inputPalette(prompt, this_sheets_help.cmdlist,
191 value_key='longname',
192 formatter=_fmt_cmdpal_summary,
193 help=vd.help_longname,
194 type='longname')
195
196
197 @BaseSheet.api
198 def exec_longname(sheet, longname):
199 if not sheet.getCommand(longname):
200 vd.fail(f'no command {longname}')
201 sheet.execCommand(longname)
202
203
204 vd.addCommand('Space', 'exec-longname', 'exec_longname(inputLongname())', 'execute command by its longname')
205
[end of visidata/features/cmdpalette.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/visidata/features/cmdpalette.py b/visidata/features/cmdpalette.py
--- a/visidata/features/cmdpalette.py
+++ b/visidata/features/cmdpalette.py
@@ -167,7 +167,7 @@
prompt = 'command name: '
# get set of commands possible in the sheet
this_sheets_help = HelpSheet('', source=sheet)
- this_sheets_help.ensureLoaded()
+ vd.sync(this_sheets_help.ensureLoaded())
def _fmt_cmdpal_summary(match, row, trigger_key):
keystrokes = this_sheets_help.revbinds.get(row.longname, [None])[0] or ' '
|
{"golden_diff": "diff --git a/visidata/features/cmdpalette.py b/visidata/features/cmdpalette.py\n--- a/visidata/features/cmdpalette.py\n+++ b/visidata/features/cmdpalette.py\n@@ -167,7 +167,7 @@\n prompt = 'command name: '\n # get set of commands possible in the sheet\n this_sheets_help = HelpSheet('', source=sheet)\n- this_sheets_help.ensureLoaded()\n+ vd.sync(this_sheets_help.ensureLoaded())\n \n def _fmt_cmdpal_summary(match, row, trigger_key):\n keystrokes = this_sheets_help.revbinds.get(row.longname, [None])[0] or ' '\n", "issue": "Python error after pressing SPACE to pull up command-name input\n**Small description**\r\nThe first time I press SPACE on a sheet, I often get the following Python error. It usually succeeds on the second press.\r\n\r\n**Expected result**\r\nOpen command prompt.\r\n\r\n**Actual result with screenshot**\r\n\r\n[errors_recent.txt](https://github.com/saulpw/visidata/files/14471969/errors_recent.txt)\r\n\r\n**Steps to reproduce with sample data and a .vd**\r\nOpen any sheet and press SPACE.\r\nIt may take a few attempts. It seems to only happen the first time it is entered on a sheet, and only some of the time.\r\n\r\n**Additional context**\r\nPython 3.8.0\r\nVisiData 3.0.2\r\n\n", "before_files": [{"content": "import collections\nfrom functools import partial\nfrom visidata import DrawablePane, BaseSheet, vd, VisiData, CompleteKey, clipdraw, HelpSheet, colors, AcceptInput, AttrDict, drawcache_property\n\n\nvd.theme_option('color_cmdpalette', 'black on 72', 'base color of command palette')\nvd.theme_option('disp_cmdpal_max', 10, 'max number of suggestions for command palette')\n\nvd.help_longname = '''# Choose Command\nStart typing a command longname or keyword in its helpstring.\n\n- `Enter` to execute top command.\n- `Tab` to highlight top command.\n\n## When Command Highlighted\n\n- `Tab`/`Shift+Tab` to cycle highlighted command.\n- `Enter` to execute highlighted command.\n- `0-9` to execute numbered command.\n'''\n\ndef add_to_input(v, i, value=''):\n items = list(v.split())\n if not v or v.endswith(' '):\n items.append(value)\n else:\n items[-1] = value\n v = ' '.join(items) + ' '\n return v, len(v)\n\n\ndef accept_input(v, i, value=None):\n raise AcceptInput(v if value is None else value)\n\ndef accept_input_if_subset(v, i, value=''):\n # if no input, accept value under cmd palette cursor\n if not v:\n raise AcceptInput(value)\n\n # if the last item is a partial match, replace it with the full value\n parts = v.split()\n if value and value.startswith(parts[-1]):\n v = ' '.join(parts[:-1] + [value])\n\n raise AcceptInput(v)\n\[email protected]_property\ndef usedInputs(vd):\n return collections.defaultdict(int)\n\[email protected]\ndef execCommand2(sheet, cmd, *args, **kwargs):\n vd.usedInputs[cmd.longname] += 1\n\[email protected]\ndef inputPalette(sheet, prompt, items,\n value_key='key',\n formatter=lambda m, item, trigger_key: f'{trigger_key} {item}',\n multiple=False,\n **kwargs):\n bindings = dict()\n\n tabitem = -1\n\n def tab(n, nitems):\n nonlocal tabitem\n if not nitems: return None\n tabitem = (tabitem + n) % nitems\n\n def _draw_palette(value):\n words = value.lower().split()\n\n if multiple and words:\n if value.endswith(' '):\n finished_words = words\n unfinished_words = []\n else:\n finished_words = words[:-1]\n unfinished_words = [words[-1]]\n else:\n unfinished_words = words\n finished_words = []\n\n unuseditems = [item for item in items if item[value_key] not in finished_words]\n\n matches = vd.fuzzymatch(unuseditems, unfinished_words)\n\n h = sheet.windowHeight\n w = min(100, sheet.windowWidth)\n nitems = min(h-1, sheet.options.disp_cmdpal_max)\n\n useditems = []\n palrows = []\n\n for m in matches[:nitems]:\n useditems.append(m.match)\n palrows.append((m, m.match))\n\n favitems = sorted([item for item in unuseditems if item not in useditems],\n key=lambda item: -vd.usedInputs.get(item[value_key], 0))\n\n for item in favitems[:nitems-len(palrows)]:\n palrows.append((None, item))\n\n navailitems = min(len(palrows), nitems)\n\n bindings['^I'] = lambda *args: tab(1, navailitems) or args\n bindings['KEY_BTAB'] = lambda *args: tab(-1, navailitems) or args\n\n for i in range(nitems-len(palrows)):\n palrows.append((None, None))\n\n used_triggers = set()\n for i, (m, item) in enumerate(palrows):\n trigger_key = ''\n if tabitem >= 0 and item:\n tkey = f'{i+1}'[-1]\n if tkey not in used_triggers:\n trigger_key = tkey\n bindings[trigger_key] = partial(add_to_input if multiple else accept_input, value=item[value_key])\n used_triggers.add(trigger_key)\n\n attr = colors.color_cmdpalette\n\n if tabitem < 0 and palrows:\n _ , topitem = palrows[0]\n if not topitem: return\n if multiple:\n bindings[' '] = partial(add_to_input, value=topitem[value_key])\n bindings['^J'] = partial(accept_input_if_subset, value=topitem[value_key])\n else:\n bindings['^J'] = partial(accept_input, value=topitem[value_key])\n elif item and i == tabitem:\n if not item: return\n if multiple:\n bindings['^J'] = partial(accept_input_if_subset, value=item[value_key])\n bindings[' '] = partial(add_to_input, value=item[value_key])\n else:\n bindings['^J'] = partial(accept_input, value=item[value_key])\n attr = colors.color_menu_spec\n\n match_summary = formatter(m, item, trigger_key) if item else ' '\n\n clipdraw(sheet._scr, h-nitems-1+i, 0, match_summary, attr, w=w)\n\n return None\n\n completer = CompleteKey(sorted(item[value_key] for item in items))\n return vd.input(prompt,\n completer=completer,\n updater=_draw_palette,\n bindings=bindings,\n **kwargs)\n\n\ndef cmdlist(sheet):\n return [\n AttrDict(longname=row.longname,\n description=sheet.cmddict[(row.sheet, row.longname)].helpstr)\n for row in sheet.rows\n ]\nHelpSheet.cmdlist = drawcache_property(cmdlist)\n\n\[email protected]\ndef inputLongname(sheet):\n prompt = 'command name: '\n # get set of commands possible in the sheet\n this_sheets_help = HelpSheet('', source=sheet)\n this_sheets_help.ensureLoaded()\n\n def _fmt_cmdpal_summary(match, row, trigger_key):\n keystrokes = this_sheets_help.revbinds.get(row.longname, [None])[0] or ' '\n formatted_longname = match.formatted.get('longname', row.longname) if match else row.longname\n formatted_name = f'[:bold][:onclick {row.longname}]{formatted_longname}[/][/]'\n if vd.options.debug and match:\n keystrokes = f'[{match.score}]'\n r = f' [:keystrokes]{keystrokes.rjust(len(prompt)-5)}[/] '\n if trigger_key:\n r += f'[:keystrokes]{trigger_key}[/]'\n else:\n r += ' '\n\n r += f' {formatted_name}'\n if row.description:\n formatted_desc = match.formatted.get('description', row.description) if match else row.description\n r += f' - {formatted_desc}'\n return r\n\n return sheet.inputPalette(prompt, this_sheets_help.cmdlist,\n value_key='longname',\n formatter=_fmt_cmdpal_summary,\n help=vd.help_longname,\n type='longname')\n\n\[email protected]\ndef exec_longname(sheet, longname):\n if not sheet.getCommand(longname):\n vd.fail(f'no command {longname}')\n sheet.execCommand(longname)\n\n\nvd.addCommand('Space', 'exec-longname', 'exec_longname(inputLongname())', 'execute command by its longname')\n", "path": "visidata/features/cmdpalette.py"}]}
| 2,924 | 145 |
gh_patches_debug_3122
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1721
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bugs with save-all
I've a question about saving.
1. I load a two sheet notebook "responses-grades-cda.xlsx".
2. `g ctrl+s`
3. it gives me a blank line -- why not default to name of file without xlsx extension?
4. I type in file name without extension + `vds`: "responses-grades-cda.vds".
5. I get an error: "AttributeError: 'X1sxIndexSheet' object has no attribute 'join'"
_Originally posted by @reagle in https://github.com/saulpw/visidata/discussions/1266#discussioncomment-4870711_
</issue>
<code>
[start of visidata/save.py]
1 import collections
2
3 from visidata import *
4
5
6 vd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')
7 vd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)
8
9 @Sheet.api
10 def safe_trdict(vs):
11 'returns string.translate dictionary for replacing tabs and newlines'
12 if options.safety_first:
13 delim = vs.options.delimiter
14 return {
15 0: '', # strip NUL completely
16 ord(delim): vs.options.tsv_safe_tab, # \t
17 10: vs.options.tsv_safe_newline, # \n
18 13: vs.options.tsv_safe_newline, # \r
19 }
20 return {}
21
22
23 @Sheet.api
24 def iterdispvals(sheet, *cols, format=False):
25 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'
26 if not cols:
27 cols = sheet.visibleCols
28
29 transformers = collections.OrderedDict() # list of transformers for each column in order
30 for col in cols:
31 transformers[col] = [ col.type ]
32 if format:
33 formatMaker = getattr(col, 'formatter_'+(col.formatter or sheet.options.disp_formatter))
34 transformers[col].append(formatMaker(col._formatdict))
35 trdict = sheet.safe_trdict()
36 if trdict:
37 transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))
38
39 options_safe_error = options.safe_error
40 for r in Progress(sheet.rows):
41 dispvals = collections.OrderedDict() # [col] -> value
42 for col, transforms in transformers.items():
43 try:
44 dispval = col.getValue(r)
45
46 except Exception as e:
47 vd.exceptionCaught(e)
48 dispval = options_safe_error or str(e)
49
50 try:
51 for t in transforms:
52 if dispval is None:
53 break
54 elif isinstance(dispval, TypedExceptionWrapper):
55 dispval = options_safe_error or str(dispval)
56 break
57 else:
58 dispval = t(dispval)
59
60 if dispval is None and format:
61 dispval = ''
62 except Exception as e:
63 dispval = str(dispval)
64
65 dispvals[col] = dispval
66
67 yield dispvals
68
69
70 @Sheet.api
71 def itervals(sheet, *cols, format=False):
72 for row in sheet.iterdispvals(*cols, format=format):
73 yield [row[c] for c in cols]
74
75 @BaseSheet.api
76 def getDefaultSaveName(sheet):
77 src = getattr(sheet, 'source', None)
78 if hasattr(src, 'scheme') and src.scheme:
79 return src.name + src.suffix
80 if isinstance(src, Path):
81 if sheet.options.is_set('save_filetype', sheet):
82 # if save_filetype is over-ridden from default, use it as the extension
83 return str(src.with_suffix('')) + '.' + sheet.options.save_filetype
84 return str(src)
85 else:
86 return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)
87
88
89 @VisiData.api
90 def save_cols(vd, cols):
91 sheet = cols[0].sheet
92 vs = copy(sheet)
93 vs.columns = list(cols)
94 vs.rows = sheet.rows
95 if len(cols) == 1:
96 savedcoltxt = cols[0].name + ' column'
97 else:
98 savedcoltxt = '%s columns' % len(cols)
99 path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())
100 vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)
101
102
103 @VisiData.api
104 def saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):
105 'Save all *vsheets* to *givenpath*.'
106
107 filetype = givenpath.ext or options.save_filetype
108
109 vd.clearCaches()
110
111 savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)
112
113 if savefunc is None:
114 vd.fail(f'no function to save as {filetype}')
115
116 if givenpath.exists() and confirm_overwrite:
117 vd.confirm("%s already exists. overwrite? " % givenpath.given)
118
119 vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))
120
121 if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /
122 for vs in vsheets:
123 vs.hasBeenModified = False
124 # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)
125 # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)
126 if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:
127 vd.fail(f'cannot save multiple {filetype} sheets to non-dir')
128 return vd.execAsync(savefunc, givenpath, *vsheets)
129
130 # path is a dir
131
132 # save as individual files in the givenpath directory
133 try:
134 os.makedirs(givenpath, exist_ok=True)
135 except FileExistsError:
136 pass
137
138 if not givenpath.is_dir():
139 vd.fail(f'cannot save multiple {filetype} sheets to non-dir')
140
141 def _savefiles(vsheets, givenpath, savefunc, filetype):
142 for vs in vsheets:
143 p = Path((givenpath / vs.name).with_suffix('.'+filetype))
144 savefunc(p, vs)
145 vs.hasBeenModified = False
146 return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)
147
148
149 @VisiData.api
150 def save_zip(vd, p, *vsheets):
151 vd.clearCaches()
152
153 import tempfile
154 import zipfile
155 with tempfile.TemporaryDirectory() as tmpdir:
156 with zipfile.ZipFile(str(p), 'w', zipfile.ZIP_DEFLATED, allowZip64=True, compresslevel=9) as zfp:
157 for vs in Progress(vsheets):
158 filetype = vs.options.save_filetype
159 tmpp = Path(f'{tmpdir}{vs.name}.{filetype}')
160 savefunc = getattr(vs, 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)
161 savefunc(tmpp, vs)
162 zfp.write(tmpp, f'{vs.name}.{vs.options.save_filetype}')
163 vd.status('%s save finished' % p)
164
165
166 @VisiData.api
167 def save_txt(vd, p, *vsheets):
168 with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:
169 for vs in vsheets:
170 unitsep = vs.options.delimiter
171 rowsep = vs.options.row_delimiter
172 for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):
173 fp.write(unitsep.join(dispvals.values()))
174 fp.write(rowsep)
175 vd.status('%s save finished' % p)
176
177
178 @BaseSheet.api
179 def rootSheet(sheet):
180 r = sheet
181 while isinstance(r.source, BaseSheet):
182 r = r.source
183
184 return r
185
186 BaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath("save to: ", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')
187 BaseSheet.addCommand('', 'save-sheet-really', 'vd.saveSheets(Path(getDefaultSaveName()), sheet, confirm_overwrite=False)', 'save current sheet without asking for filename or confirmation')
188 BaseSheet.addCommand('', 'save-source', 'vd.saveSheets(rootSheet().source, rootSheet(), confirm_overwrite=options.confirm_overwrite)', 'save root sheet to its source')
189 BaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath("save all sheets to: "), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')
190 IndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath("save %d sheets to: " % nSelectedRows, value="_".join(getattr(vs, "name", None) or "blank" for vs in selectedRows)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')
191 Sheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')
192 Sheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')
193
[end of visidata/save.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/visidata/save.py b/visidata/save.py
--- a/visidata/save.py
+++ b/visidata/save.py
@@ -104,6 +104,10 @@
def saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):
'Save all *vsheets* to *givenpath*.'
+ if not vsheets: # blank tuple
+ vd.warning('no sheets to save')
+ return
+
filetype = givenpath.ext or options.save_filetype
vd.clearCaches()
|
{"golden_diff": "diff --git a/visidata/save.py b/visidata/save.py\n--- a/visidata/save.py\n+++ b/visidata/save.py\n@@ -104,6 +104,10 @@\n def saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):\n 'Save all *vsheets* to *givenpath*.'\n \n+ if not vsheets: # blank tuple\n+ vd.warning('no sheets to save')\n+ return\n+\n filetype = givenpath.ext or options.save_filetype\n \n vd.clearCaches()\n", "issue": "Bugs with save-all\n I've a question about saving.\r\n\r\n1. I load a two sheet notebook \"responses-grades-cda.xlsx\".\r\n2. `g ctrl+s`\r\n3. it gives me a blank line -- why not default to name of file without xlsx extension?\r\n4. I type in file name without extension + `vds`: \"responses-grades-cda.vds\".\r\n5. I get an error: \"AttributeError: 'X1sxIndexSheet' object has no attribute 'join'\"\r\n\r\n_Originally posted by @reagle in https://github.com/saulpw/visidata/discussions/1266#discussioncomment-4870711_\r\n \n", "before_files": [{"content": "import collections\n\nfrom visidata import *\n\n\nvd.option('confirm_overwrite', True, 'whether to prompt for overwrite confirmation on save')\nvd.option('safe_error', '#ERR', 'error string to use while saving', replay=True)\n\[email protected]\ndef safe_trdict(vs):\n 'returns string.translate dictionary for replacing tabs and newlines'\n if options.safety_first:\n delim = vs.options.delimiter\n return {\n 0: '', # strip NUL completely\n ord(delim): vs.options.tsv_safe_tab, # \\t\n 10: vs.options.tsv_safe_newline, # \\n\n 13: vs.options.tsv_safe_newline, # \\r\n }\n return {}\n\n\[email protected]\ndef iterdispvals(sheet, *cols, format=False):\n 'For each row in sheet, yield OrderedDict of values for given cols. Values are typed if format=False, or a formatted display string if format=True.'\n if not cols:\n cols = sheet.visibleCols\n\n transformers = collections.OrderedDict() # list of transformers for each column in order\n for col in cols:\n transformers[col] = [ col.type ]\n if format:\n formatMaker = getattr(col, 'formatter_'+(col.formatter or sheet.options.disp_formatter))\n transformers[col].append(formatMaker(col._formatdict))\n trdict = sheet.safe_trdict()\n if trdict:\n transformers[col].append(lambda v,trdict=trdict: v.translate(trdict))\n\n options_safe_error = options.safe_error\n for r in Progress(sheet.rows):\n dispvals = collections.OrderedDict() # [col] -> value\n for col, transforms in transformers.items():\n try:\n dispval = col.getValue(r)\n\n except Exception as e:\n vd.exceptionCaught(e)\n dispval = options_safe_error or str(e)\n\n try:\n for t in transforms:\n if dispval is None:\n break\n elif isinstance(dispval, TypedExceptionWrapper):\n dispval = options_safe_error or str(dispval)\n break\n else:\n dispval = t(dispval)\n\n if dispval is None and format:\n dispval = ''\n except Exception as e:\n dispval = str(dispval)\n\n dispvals[col] = dispval\n\n yield dispvals\n\n\[email protected]\ndef itervals(sheet, *cols, format=False):\n for row in sheet.iterdispvals(*cols, format=format):\n yield [row[c] for c in cols]\n\[email protected]\ndef getDefaultSaveName(sheet):\n src = getattr(sheet, 'source', None)\n if hasattr(src, 'scheme') and src.scheme:\n return src.name + src.suffix\n if isinstance(src, Path):\n if sheet.options.is_set('save_filetype', sheet):\n # if save_filetype is over-ridden from default, use it as the extension\n return str(src.with_suffix('')) + '.' + sheet.options.save_filetype\n return str(src)\n else:\n return sheet.name+'.'+getattr(sheet, 'filetype', options.save_filetype)\n\n\[email protected]\ndef save_cols(vd, cols):\n sheet = cols[0].sheet\n vs = copy(sheet)\n vs.columns = list(cols)\n vs.rows = sheet.rows\n if len(cols) == 1:\n savedcoltxt = cols[0].name + ' column'\n else:\n savedcoltxt = '%s columns' % len(cols)\n path = vd.inputPath('save %s to: ' % savedcoltxt, value=vs.getDefaultSaveName())\n vd.saveSheets(path, vs, confirm_overwrite=options.confirm_overwrite)\n\n\[email protected]\ndef saveSheets(vd, givenpath, *vsheets, confirm_overwrite=False):\n 'Save all *vsheets* to *givenpath*.'\n\n filetype = givenpath.ext or options.save_filetype\n\n vd.clearCaches()\n\n savefunc = getattr(vsheets[0], 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n\n if savefunc is None:\n vd.fail(f'no function to save as {filetype}')\n\n if givenpath.exists() and confirm_overwrite:\n vd.confirm(\"%s already exists. overwrite? \" % givenpath.given)\n\n vd.status('saving %s sheets to %s as %s' % (len(vsheets), givenpath.given, filetype))\n\n if not givenpath.given.endswith('/'): # forcibly specify save individual files into directory by ending path with /\n for vs in vsheets:\n vs.hasBeenModified = False\n # savefuncs(vd, p, *vsheets) will have 2 argcount (*vsheets does not get counted as an arg)\n # savefuncs(vd, p, vs) will have 3 argcount (vs counts as an arg, along with vd, path)\n if savefunc.__code__.co_argcount == 3 and len(vsheets) > 1:\n vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n return vd.execAsync(savefunc, givenpath, *vsheets)\n\n # path is a dir\n\n # save as individual files in the givenpath directory\n try:\n os.makedirs(givenpath, exist_ok=True)\n except FileExistsError:\n pass\n\n if not givenpath.is_dir():\n vd.fail(f'cannot save multiple {filetype} sheets to non-dir')\n\n def _savefiles(vsheets, givenpath, savefunc, filetype):\n for vs in vsheets:\n p = Path((givenpath / vs.name).with_suffix('.'+filetype))\n savefunc(p, vs)\n vs.hasBeenModified = False\n return vd.execAsync(_savefiles, vsheets, givenpath, savefunc, filetype)\n\n\[email protected]\ndef save_zip(vd, p, *vsheets):\n vd.clearCaches()\n\n import tempfile\n import zipfile\n with tempfile.TemporaryDirectory() as tmpdir:\n with zipfile.ZipFile(str(p), 'w', zipfile.ZIP_DEFLATED, allowZip64=True, compresslevel=9) as zfp:\n for vs in Progress(vsheets):\n filetype = vs.options.save_filetype\n tmpp = Path(f'{tmpdir}{vs.name}.{filetype}')\n savefunc = getattr(vs, 'save_' + filetype, None) or getattr(vd, 'save_' + filetype, None)\n savefunc(tmpp, vs)\n zfp.write(tmpp, f'{vs.name}.{vs.options.save_filetype}')\n vd.status('%s save finished' % p)\n\n\[email protected]\ndef save_txt(vd, p, *vsheets):\n with p.open_text(mode='w', encoding=vsheets[0].options.encoding) as fp:\n for vs in vsheets:\n unitsep = vs.options.delimiter\n rowsep = vs.options.row_delimiter\n for dispvals in vs.iterdispvals(*vs.visibleCols, format=True):\n fp.write(unitsep.join(dispvals.values()))\n fp.write(rowsep)\n vd.status('%s save finished' % p)\n\n\[email protected]\ndef rootSheet(sheet):\n r = sheet\n while isinstance(r.source, BaseSheet):\n r = r.source\n\n return r\n\nBaseSheet.addCommand('^S', 'save-sheet', 'vd.saveSheets(inputPath(\"save to: \", value=getDefaultSaveName()), sheet, confirm_overwrite=options.confirm_overwrite)', 'save current sheet to filename in format determined by extension (default .tsv)')\nBaseSheet.addCommand('', 'save-sheet-really', 'vd.saveSheets(Path(getDefaultSaveName()), sheet, confirm_overwrite=False)', 'save current sheet without asking for filename or confirmation')\nBaseSheet.addCommand('', 'save-source', 'vd.saveSheets(rootSheet().source, rootSheet(), confirm_overwrite=options.confirm_overwrite)', 'save root sheet to its source')\nBaseSheet.addCommand('g^S', 'save-all', 'vd.saveSheets(inputPath(\"save all sheets to: \"), *vd.stackedSheets, confirm_overwrite=options.confirm_overwrite)', 'save all sheets to given file or directory)')\nIndexSheet.addCommand('g^S', 'save-selected', 'vd.saveSheets(inputPath(\"save %d sheets to: \" % nSelectedRows, value=\"_\".join(getattr(vs, \"name\", None) or \"blank\" for vs in selectedRows)), *selectedRows, confirm_overwrite=options.confirm_overwrite)', 'save all selected sheets to given file or directory')\nSheet.addCommand('', 'save-col', 'save_cols([cursorCol])', 'save current column only to filename in format determined by extension (default .tsv)')\nSheet.addCommand('', 'save-col-keys', 'save_cols(keyCols + [cursorCol])', 'save key columns and current column to filename in format determined by extension (default .tsv)')\n", "path": "visidata/save.py"}]}
| 3,096 | 125 |
gh_patches_debug_41254
|
rasdani/github-patches
|
git_diff
|
Pylons__pyramid-3029
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remove request.exception if the excview tween fails to handle the exception
Pyramid 1.9 makes `request.exception` and `request.exc_info` a little more important as I've moved the pyramid_tm tween over the excview and in general would advocate to move most tweens over the excview. With that in mind it's currently not possible to test `request.exception` to see if the response was rendered in relation to that exception - the excview tween sets the exception even if it failed to squash it (attempted to render an excview and couldn't find one). Ideally the exception would be related to the response that was generated when it was squashed. This would be more explicit if we used `response.exception` to indicate the response is from a squashed exception but I think that's a larger change.
I'm proposing to remove `request.exception` and `request.exc_info` in the excview tween if it reraises the original exception. This makes introspection `request.exception` more reliable by upstream tweens that want to know what the squashed exception was... Of course any raised exception should be more interesting than the original `request.exception` but if the tween receives a response then they can see if it is a response generated by a squashed exception or if it is a "normal" response.
</issue>
<code>
[start of pyramid/tweens.py]
1 import sys
2
3 from pyramid.compat import reraise
4 from pyramid.exceptions import PredicateMismatch
5 from pyramid.interfaces import (
6 IExceptionViewClassifier,
7 IRequest,
8 )
9
10 from zope.interface import providedBy
11 from pyramid.view import _call_view
12
13 def excview_tween_factory(handler, registry):
14 """ A :term:`tween` factory which produces a tween that catches an
15 exception raised by downstream tweens (or the main Pyramid request
16 handler) and, if possible, converts it into a Response using an
17 :term:`exception view`."""
18
19 def excview_tween(request):
20 attrs = request.__dict__
21 try:
22 response = handler(request)
23 except Exception as exc:
24 # WARNING: do not assign the result of sys.exc_info() to a local
25 # var here, doing so will cause a leak. We used to actually
26 # explicitly delete both "exception" and "exc_info" from ``attrs``
27 # in a ``finally:`` clause below, but now we do not because these
28 # attributes are useful to upstream tweens. This actually still
29 # apparently causes a reference cycle, but it is broken
30 # successfully by the garbage collector (see
31 # https://github.com/Pylons/pyramid/issues/1223).
32 attrs['exc_info'] = sys.exc_info()
33 attrs['exception'] = exc
34 # clear old generated request.response, if any; it may
35 # have been mutated by the view, and its state is not
36 # sane (e.g. caching headers)
37 if 'response' in attrs:
38 del attrs['response']
39 # we use .get instead of .__getitem__ below due to
40 # https://github.com/Pylons/pyramid/issues/700
41 request_iface = attrs.get('request_iface', IRequest)
42 provides = providedBy(exc)
43 try:
44 response = _call_view(
45 registry,
46 request,
47 exc,
48 provides,
49 '',
50 view_classifier=IExceptionViewClassifier,
51 request_iface=request_iface.combined
52 )
53
54 # if views matched but did not pass predicates, squash the error
55 # and re-raise the original exception
56 except PredicateMismatch:
57 response = None
58
59 # re-raise the original exception as no exception views were
60 # able to handle the error
61 if response is None:
62 reraise(*attrs['exc_info'])
63
64 return response
65
66 return excview_tween
67
68 MAIN = 'MAIN'
69 INGRESS = 'INGRESS'
70 EXCVIEW = 'pyramid.tweens.excview_tween_factory'
71
[end of pyramid/tweens.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyramid/tweens.py b/pyramid/tweens.py
--- a/pyramid/tweens.py
+++ b/pyramid/tweens.py
@@ -10,6 +10,50 @@
from zope.interface import providedBy
from pyramid.view import _call_view
+def _error_handler(request, exc):
+ # NOTE: we do not need to delete exc_info because this function
+ # should never be in the call stack of the exception
+ exc_info = sys.exc_info()
+
+ attrs = request.__dict__
+ attrs['exc_info'] = exc_info
+ attrs['exception'] = exc
+ # clear old generated request.response, if any; it may
+ # have been mutated by the view, and its state is not
+ # sane (e.g. caching headers)
+ if 'response' in attrs:
+ del attrs['response']
+ # we use .get instead of .__getitem__ below due to
+ # https://github.com/Pylons/pyramid/issues/700
+ request_iface = attrs.get('request_iface', IRequest)
+ provides = providedBy(exc)
+ try:
+ response = _call_view(
+ request.registry,
+ request,
+ exc,
+ provides,
+ '',
+ view_classifier=IExceptionViewClassifier,
+ request_iface=request_iface.combined
+ )
+
+ # if views matched but did not pass predicates then treat the
+ # same as not finding any matching views
+ except PredicateMismatch:
+ response = None
+
+ # re-raise the original exception as no exception views were
+ # able to handle the error
+ if response is None:
+ if 'exception' in attrs:
+ del attrs['exception']
+ if 'exc_info' in attrs:
+ del attrs['exc_info']
+ reraise(*exc_info)
+
+ return response
+
def excview_tween_factory(handler, registry):
""" A :term:`tween` factory which produces a tween that catches an
exception raised by downstream tweens (or the main Pyramid request
@@ -17,50 +61,10 @@
:term:`exception view`."""
def excview_tween(request):
- attrs = request.__dict__
try:
response = handler(request)
except Exception as exc:
- # WARNING: do not assign the result of sys.exc_info() to a local
- # var here, doing so will cause a leak. We used to actually
- # explicitly delete both "exception" and "exc_info" from ``attrs``
- # in a ``finally:`` clause below, but now we do not because these
- # attributes are useful to upstream tweens. This actually still
- # apparently causes a reference cycle, but it is broken
- # successfully by the garbage collector (see
- # https://github.com/Pylons/pyramid/issues/1223).
- attrs['exc_info'] = sys.exc_info()
- attrs['exception'] = exc
- # clear old generated request.response, if any; it may
- # have been mutated by the view, and its state is not
- # sane (e.g. caching headers)
- if 'response' in attrs:
- del attrs['response']
- # we use .get instead of .__getitem__ below due to
- # https://github.com/Pylons/pyramid/issues/700
- request_iface = attrs.get('request_iface', IRequest)
- provides = providedBy(exc)
- try:
- response = _call_view(
- registry,
- request,
- exc,
- provides,
- '',
- view_classifier=IExceptionViewClassifier,
- request_iface=request_iface.combined
- )
-
- # if views matched but did not pass predicates, squash the error
- # and re-raise the original exception
- except PredicateMismatch:
- response = None
-
- # re-raise the original exception as no exception views were
- # able to handle the error
- if response is None:
- reraise(*attrs['exc_info'])
-
+ response = _error_handler(request, exc)
return response
return excview_tween
|
{"golden_diff": "diff --git a/pyramid/tweens.py b/pyramid/tweens.py\n--- a/pyramid/tweens.py\n+++ b/pyramid/tweens.py\n@@ -10,6 +10,50 @@\n from zope.interface import providedBy\n from pyramid.view import _call_view\n \n+def _error_handler(request, exc):\n+ # NOTE: we do not need to delete exc_info because this function\n+ # should never be in the call stack of the exception\n+ exc_info = sys.exc_info()\n+\n+ attrs = request.__dict__\n+ attrs['exc_info'] = exc_info\n+ attrs['exception'] = exc\n+ # clear old generated request.response, if any; it may\n+ # have been mutated by the view, and its state is not\n+ # sane (e.g. caching headers)\n+ if 'response' in attrs:\n+ del attrs['response']\n+ # we use .get instead of .__getitem__ below due to\n+ # https://github.com/Pylons/pyramid/issues/700\n+ request_iface = attrs.get('request_iface', IRequest)\n+ provides = providedBy(exc)\n+ try:\n+ response = _call_view(\n+ request.registry,\n+ request,\n+ exc,\n+ provides,\n+ '',\n+ view_classifier=IExceptionViewClassifier,\n+ request_iface=request_iface.combined\n+ )\n+\n+ # if views matched but did not pass predicates then treat the\n+ # same as not finding any matching views\n+ except PredicateMismatch:\n+ response = None\n+\n+ # re-raise the original exception as no exception views were\n+ # able to handle the error\n+ if response is None:\n+ if 'exception' in attrs:\n+ del attrs['exception']\n+ if 'exc_info' in attrs:\n+ del attrs['exc_info']\n+ reraise(*exc_info)\n+\n+ return response\n+\n def excview_tween_factory(handler, registry):\n \"\"\" A :term:`tween` factory which produces a tween that catches an\n exception raised by downstream tweens (or the main Pyramid request\n@@ -17,50 +61,10 @@\n :term:`exception view`.\"\"\"\n \n def excview_tween(request):\n- attrs = request.__dict__\n try:\n response = handler(request)\n except Exception as exc:\n- # WARNING: do not assign the result of sys.exc_info() to a local\n- # var here, doing so will cause a leak. We used to actually\n- # explicitly delete both \"exception\" and \"exc_info\" from ``attrs``\n- # in a ``finally:`` clause below, but now we do not because these\n- # attributes are useful to upstream tweens. This actually still\n- # apparently causes a reference cycle, but it is broken\n- # successfully by the garbage collector (see\n- # https://github.com/Pylons/pyramid/issues/1223).\n- attrs['exc_info'] = sys.exc_info()\n- attrs['exception'] = exc\n- # clear old generated request.response, if any; it may\n- # have been mutated by the view, and its state is not\n- # sane (e.g. caching headers)\n- if 'response' in attrs:\n- del attrs['response']\n- # we use .get instead of .__getitem__ below due to\n- # https://github.com/Pylons/pyramid/issues/700\n- request_iface = attrs.get('request_iface', IRequest)\n- provides = providedBy(exc)\n- try:\n- response = _call_view(\n- registry,\n- request,\n- exc,\n- provides,\n- '',\n- view_classifier=IExceptionViewClassifier,\n- request_iface=request_iface.combined\n- )\n-\n- # if views matched but did not pass predicates, squash the error\n- # and re-raise the original exception\n- except PredicateMismatch:\n- response = None\n-\n- # re-raise the original exception as no exception views were\n- # able to handle the error\n- if response is None:\n- reraise(*attrs['exc_info'])\n-\n+ response = _error_handler(request, exc)\n return response\n \n return excview_tween\n", "issue": "remove request.exception if the excview tween fails to handle the exception\nPyramid 1.9 makes `request.exception` and `request.exc_info` a little more important as I've moved the pyramid_tm tween over the excview and in general would advocate to move most tweens over the excview. With that in mind it's currently not possible to test `request.exception` to see if the response was rendered in relation to that exception - the excview tween sets the exception even if it failed to squash it (attempted to render an excview and couldn't find one). Ideally the exception would be related to the response that was generated when it was squashed. This would be more explicit if we used `response.exception` to indicate the response is from a squashed exception but I think that's a larger change.\r\n\r\nI'm proposing to remove `request.exception` and `request.exc_info` in the excview tween if it reraises the original exception. This makes introspection `request.exception` more reliable by upstream tweens that want to know what the squashed exception was... Of course any raised exception should be more interesting than the original `request.exception` but if the tween receives a response then they can see if it is a response generated by a squashed exception or if it is a \"normal\" response.\n", "before_files": [{"content": "import sys\n\nfrom pyramid.compat import reraise\nfrom pyramid.exceptions import PredicateMismatch\nfrom pyramid.interfaces import (\n IExceptionViewClassifier,\n IRequest,\n )\n\nfrom zope.interface import providedBy\nfrom pyramid.view import _call_view\n\ndef excview_tween_factory(handler, registry):\n \"\"\" A :term:`tween` factory which produces a tween that catches an\n exception raised by downstream tweens (or the main Pyramid request\n handler) and, if possible, converts it into a Response using an\n :term:`exception view`.\"\"\"\n\n def excview_tween(request):\n attrs = request.__dict__\n try:\n response = handler(request)\n except Exception as exc:\n # WARNING: do not assign the result of sys.exc_info() to a local\n # var here, doing so will cause a leak. We used to actually\n # explicitly delete both \"exception\" and \"exc_info\" from ``attrs``\n # in a ``finally:`` clause below, but now we do not because these\n # attributes are useful to upstream tweens. This actually still\n # apparently causes a reference cycle, but it is broken\n # successfully by the garbage collector (see\n # https://github.com/Pylons/pyramid/issues/1223).\n attrs['exc_info'] = sys.exc_info()\n attrs['exception'] = exc\n # clear old generated request.response, if any; it may\n # have been mutated by the view, and its state is not\n # sane (e.g. caching headers)\n if 'response' in attrs:\n del attrs['response']\n # we use .get instead of .__getitem__ below due to\n # https://github.com/Pylons/pyramid/issues/700\n request_iface = attrs.get('request_iface', IRequest)\n provides = providedBy(exc)\n try:\n response = _call_view(\n registry,\n request,\n exc,\n provides,\n '',\n view_classifier=IExceptionViewClassifier,\n request_iface=request_iface.combined\n )\n\n # if views matched but did not pass predicates, squash the error\n # and re-raise the original exception\n except PredicateMismatch:\n response = None\n\n # re-raise the original exception as no exception views were\n # able to handle the error\n if response is None:\n reraise(*attrs['exc_info'])\n\n return response\n\n return excview_tween\n\nMAIN = 'MAIN'\nINGRESS = 'INGRESS'\nEXCVIEW = 'pyramid.tweens.excview_tween_factory'\n", "path": "pyramid/tweens.py"}]}
| 1,500 | 960 |
gh_patches_debug_14765
|
rasdani/github-patches
|
git_diff
|
sunpy__sunpy-1158
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix for sunpy paper listing 3.7
</issue>
<code>
[start of sunpy/net/helio/parser.py]
1 # -*- coding: utf-8 -*-
2 # Author: Michael Malocha <[email protected]>
3 # Last Edit: September 22nd, 2013
4 #
5 # This module was developed with funding from the GSOC 2013 summer of code
6 #
7
8 """
9 This module is meant to parse the HELIO registry and return WSDL endpoints to
10 facilitate the interfacing between further modules and HELIO.
11 """
12 from __future__ import absolute_import
13 from urllib2 import urlopen, URLError
14 #import sunpy.util.etree as EL
15 import xml.etree.ElementTree as EL
16 from sunpy.net.helio import registry_links as RL
17 from bs4 import BeautifulSoup
18 from contextlib import closing
19
20 __author__ = 'Michael Malocha'
21 __version__ = 'September 22nd, 2013'
22
23 # Lifespan in seconds before a link times-out
24 LINK_TIMEOUT = 3
25
26
27 def webservice_parser(service='HEC'):
28 """
29 Quickly parses important contents from HELIO registry.
30
31 Uses the link contained in registry_links in with 'service' appended
32 and scrapes the web-service links contained on that webpage.
33
34 Parameters
35 ----------
36 service: str
37 Indicates which particular HELIO service is used. Defaults to HEC.
38
39 Returns
40 -------
41 links: list or NoneType
42 List of urls to registries containing WSDL endpoints.
43
44 Examples
45 --------
46 >>> from sunpy.net.helio import parser
47 >>> parser.webservice_parser()
48 ['http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService',
49 'http://festung3.oats.inaf.it:8080/helio-hec/HelioService',
50 'http://festung1.oats.inaf.it:8080/helio-hec/HelioService',
51 'http://hec.helio-vo.eu/helio_hec/HelioService',
52 'http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioLongQueryService',
53 'http://festung3.oats.inaf.it:8080/helio-hec/HelioLongQueryService',
54 'http://festung1.oats.inaf.it:8080/helio-hec/HelioLongQueryService',
55 'http://hec.helio-vo.eu/helio_hec/HelioLongQueryService']
56 """
57 link = RL.LINK + service.lower()
58 xml = link_test(link)
59 if xml is None:
60 return xml
61 root = EL.fromstring(xml)
62 links = []
63
64 #WARNING: getiterator is deprecated in Python 2.7+
65 #Fix for 3.x support
66 for interface in root.getiterator('interface'):
67 service_type = interface.attrib
68 key = service_type.keys()
69 if len(key) > 0:
70 value = service_type[key[0]]
71 if value == 'vr:WebService':
72 for url in interface.getiterator('accessURL'):
73 if url.text not in links:
74 links.append(url.text)
75 return links
76
77
78 def endpoint_parser(link):
79 """
80 Takes a link to a list of endpoints and parses the WSDL links.
81
82 Feeding 1 result from webservice_parser() into endpoint_parser() at a time
83 will return a list of WSDL endpoints that are contained on the page from
84 that link that was passed in.
85
86 Parameters
87 ----------
88 link: str
89 A url to a page containing links to WSDL files.
90
91 Returns
92 -------
93 endpoints: list or NoneType
94 A list containing all of the available WSDL endpoints from the passed
95 in url.
96
97 Examples
98 --------
99 >>> from sunpy.net.helio import parser
100 >>> parser.endpoint_parser('http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService')
101 ['http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioService?wsdl',
102 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioService1_0?wsdl',
103 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioService1_0b?wsdl',
104 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService?wsdl',
105 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService1_0?wsdl',
106 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService1_1?wsdl',
107 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService1_0b?wsdl',
108 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioTavernaService?wsdl']
109 """
110 endpoint_page = link_test(link)
111 if endpoint_page is None:
112 return None
113 soup = BeautifulSoup(endpoint_page)
114 endpoints = []
115 for web_link in soup.find_all('a'):
116 endpoints.append(web_link.get('href'))
117 return endpoints
118
119
120 def taverna_parser(link):
121 """
122 Takes a link to a list of endpoints and parses the taverna WSDL links.
123
124 Takes a url to a page containing a list of endpoints, then passes that url
125 to endpoint_parser(). Upon receiving the resulting list from the parser
126 taverna_parser() goes through the list and finds all the WSDL links for
127 the taverna web-service. It then returns a list containing the filtered
128 links.
129
130 Parameters
131 ----------
132 link: str
133 A url to a page containing links to WSDL files.
134
135 Returns
136 -------
137 taverna_links: list or NoneType
138 A list containing WSDL links for a taverna web-service
139
140 Examples
141 --------
142 >>> from sunpy.net.helio import parser
143 >>> parser.taverna_parser('http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService')
144 ['http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioTavernaService?wsdl']
145 """
146 endpoints = endpoint_parser(link)
147 taverna_links = []
148 if endpoints is None:
149 return None
150 for web_link in endpoints:
151 if 'Taverna' in web_link:
152 taverna_links.append(web_link)
153 if len(taverna_links) == 0:
154 return None
155 return taverna_links
156
157
158 def link_test(link):
159 """
160 Just a quick function to test a link.
161
162 Quickly checks to see if the URL is a valid link; if it is it returns the
163 downloaded contents of that page.
164
165 Parameters
166 ----------
167 link: str
168 A string containing a URL
169
170 Returns
171 -------
172 webpage: str or NoneType
173 String containing the webresults
174
175 Examples
176 --------
177 >>> from sunpy.net.helio import parser
178 >>> parser.link_test('http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService')
179 u'<html>\n<head>...</body>\n</html>\n'
180
181 >>> print parser.link_test('http://rrnx.invalid_url5523.com')
182 None
183 """
184 try:
185 with closing(urlopen(link)) as fd:
186 return fd.read()
187 except (ValueError, URLError):
188 return None
189
190
191 def wsdl_retriever(service='HEC'):
192 """
193 Retrieves a link to a taverna WSDL file
194
195 This is essentially the master method, from it all the other functions get
196 called and it essentially knits everything together. It gets a list of
197 service links via webservice_parser(), then filters the results via
198 taverna_parser(). Finally it tests all the returned taverna WSDL links
199 and returns the first live taverna endpoint.
200
201 Parameters
202 ----------
203 service: str
204 Indicates which particular HELIO service is used. Defaults to HEC.
205
206 Returns
207 -------
208 wsdl: str
209 URL to a single live taverna endpoint
210
211 Examples
212 --------
213 >>> from sunpy.net.helio import parser
214 >>> parser.wsdl_retriever()
215 'http://msslkz.mssl.ucl.ac.uk:80/helio_hec/HelioTavernaService?wsdl'
216
217 Notes
218 -----
219 * Currently only support for HEC exists, but it was designed so that it
220 could be expanded at a later date
221 * There is a 3 second timeout lifespan on links, so there is potential for
222 this function to take a while to return. Timeout duration can be
223 controlled through the LINK_TIMEOUT value
224 """
225 service_links = webservice_parser(service=service)
226 wsdl = None
227 wsdl_links = None
228 if service_links is None:
229 return None
230 for link in service_links:
231 wsdl_links = taverna_parser(link)
232 if wsdl_links is None:
233 return None
234 for end_point in wsdl_links:
235 if end_point is not None and link_test(end_point) is not None:
236 wsdl = end_point
237 break
238 return wsdl
239
[end of sunpy/net/helio/parser.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/sunpy/net/helio/parser.py b/sunpy/net/helio/parser.py
--- a/sunpy/net/helio/parser.py
+++ b/sunpy/net/helio/parser.py
@@ -54,7 +54,7 @@
'http://festung1.oats.inaf.it:8080/helio-hec/HelioLongQueryService',
'http://hec.helio-vo.eu/helio_hec/HelioLongQueryService']
"""
- link = RL.LINK + service.lower()
+ link = RL.LINK + '/' + service.lower()
xml = link_test(link)
if xml is None:
return xml
@@ -182,7 +182,7 @@
None
"""
try:
- with closing(urlopen(link)) as fd:
+ with closing(urlopen(link, timeout=LINK_TIMEOUT)) as fd:
return fd.read()
except (ValueError, URLError):
return None
|
{"golden_diff": "diff --git a/sunpy/net/helio/parser.py b/sunpy/net/helio/parser.py\n--- a/sunpy/net/helio/parser.py\n+++ b/sunpy/net/helio/parser.py\n@@ -54,7 +54,7 @@\n 'http://festung1.oats.inaf.it:8080/helio-hec/HelioLongQueryService',\n 'http://hec.helio-vo.eu/helio_hec/HelioLongQueryService']\n \"\"\"\n- link = RL.LINK + service.lower()\n+ link = RL.LINK + '/' + service.lower()\n xml = link_test(link)\n if xml is None:\n return xml\n@@ -182,7 +182,7 @@\n None\n \"\"\"\n try:\n- with closing(urlopen(link)) as fd:\n+ with closing(urlopen(link, timeout=LINK_TIMEOUT)) as fd:\n return fd.read()\n except (ValueError, URLError):\n return None\n", "issue": "Fix for sunpy paper listing 3.7\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Author: Michael Malocha <[email protected]>\n# Last Edit: September 22nd, 2013\n#\n# This module was developed with funding from the GSOC 2013 summer of code\n#\n\n\"\"\"\nThis module is meant to parse the HELIO registry and return WSDL endpoints to\nfacilitate the interfacing between further modules and HELIO.\n\"\"\"\nfrom __future__ import absolute_import\nfrom urllib2 import urlopen, URLError\n#import sunpy.util.etree as EL\nimport xml.etree.ElementTree as EL\nfrom sunpy.net.helio import registry_links as RL\nfrom bs4 import BeautifulSoup\nfrom contextlib import closing\n\n__author__ = 'Michael Malocha'\n__version__ = 'September 22nd, 2013'\n\n# Lifespan in seconds before a link times-out\nLINK_TIMEOUT = 3\n\n\ndef webservice_parser(service='HEC'):\n \"\"\"\n Quickly parses important contents from HELIO registry.\n\n Uses the link contained in registry_links in with 'service' appended\n and scrapes the web-service links contained on that webpage.\n\n Parameters\n ----------\n service: str\n Indicates which particular HELIO service is used. Defaults to HEC.\n\n Returns\n -------\n links: list or NoneType\n List of urls to registries containing WSDL endpoints.\n\n Examples\n --------\n >>> from sunpy.net.helio import parser\n >>> parser.webservice_parser()\n ['http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService',\n 'http://festung3.oats.inaf.it:8080/helio-hec/HelioService',\n 'http://festung1.oats.inaf.it:8080/helio-hec/HelioService',\n 'http://hec.helio-vo.eu/helio_hec/HelioService',\n 'http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioLongQueryService',\n 'http://festung3.oats.inaf.it:8080/helio-hec/HelioLongQueryService',\n 'http://festung1.oats.inaf.it:8080/helio-hec/HelioLongQueryService',\n 'http://hec.helio-vo.eu/helio_hec/HelioLongQueryService']\n \"\"\"\n link = RL.LINK + service.lower()\n xml = link_test(link)\n if xml is None:\n return xml\n root = EL.fromstring(xml)\n links = []\n\n #WARNING: getiterator is deprecated in Python 2.7+\n #Fix for 3.x support\n for interface in root.getiterator('interface'):\n service_type = interface.attrib\n key = service_type.keys()\n if len(key) > 0:\n value = service_type[key[0]]\n if value == 'vr:WebService':\n for url in interface.getiterator('accessURL'):\n if url.text not in links:\n links.append(url.text)\n return links\n\n\ndef endpoint_parser(link):\n \"\"\"\n Takes a link to a list of endpoints and parses the WSDL links.\n\n Feeding 1 result from webservice_parser() into endpoint_parser() at a time\n will return a list of WSDL endpoints that are contained on the page from\n that link that was passed in.\n\n Parameters\n ----------\n link: str\n A url to a page containing links to WSDL files.\n\n Returns\n -------\n endpoints: list or NoneType\n A list containing all of the available WSDL endpoints from the passed\n in url.\n\n Examples\n --------\n >>> from sunpy.net.helio import parser\n >>> parser.endpoint_parser('http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService')\n ['http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioService?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioService1_0?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioService1_0b?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService1_0?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService1_1?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioLongQueryService1_0b?wsdl',\n 'http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioTavernaService?wsdl']\n \"\"\"\n endpoint_page = link_test(link)\n if endpoint_page is None:\n return None\n soup = BeautifulSoup(endpoint_page)\n endpoints = []\n for web_link in soup.find_all('a'):\n endpoints.append(web_link.get('href'))\n return endpoints\n\n\ndef taverna_parser(link):\n \"\"\"\n Takes a link to a list of endpoints and parses the taverna WSDL links.\n\n Takes a url to a page containing a list of endpoints, then passes that url\n to endpoint_parser(). Upon receiving the resulting list from the parser\n taverna_parser() goes through the list and finds all the WSDL links for\n the taverna web-service. It then returns a list containing the filtered\n links.\n\n Parameters\n ----------\n link: str\n A url to a page containing links to WSDL files.\n\n Returns\n -------\n taverna_links: list or NoneType\n A list containing WSDL links for a taverna web-service\n\n Examples\n --------\n >>> from sunpy.net.helio import parser\n >>> parser.taverna_parser('http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService')\n ['http://msslkz.mssl.ucl.ac.uk:80/helio-hec/HelioTavernaService?wsdl']\n \"\"\"\n endpoints = endpoint_parser(link)\n taverna_links = []\n if endpoints is None:\n return None\n for web_link in endpoints:\n if 'Taverna' in web_link:\n taverna_links.append(web_link)\n if len(taverna_links) == 0:\n return None\n return taverna_links\n\n\ndef link_test(link):\n \"\"\"\n Just a quick function to test a link.\n\n Quickly checks to see if the URL is a valid link; if it is it returns the\n downloaded contents of that page.\n\n Parameters\n ----------\n link: str\n A string containing a URL\n\n Returns\n -------\n webpage: str or NoneType\n String containing the webresults\n\n Examples\n --------\n >>> from sunpy.net.helio import parser\n >>> parser.link_test('http://msslkz.mssl.ucl.ac.uk/helio-hec/HelioService')\n u'<html>\\n<head>...</body>\\n</html>\\n'\n\n >>> print parser.link_test('http://rrnx.invalid_url5523.com')\n None\n \"\"\"\n try:\n with closing(urlopen(link)) as fd:\n return fd.read()\n except (ValueError, URLError):\n return None\n\n\ndef wsdl_retriever(service='HEC'):\n \"\"\"\n Retrieves a link to a taverna WSDL file\n\n This is essentially the master method, from it all the other functions get\n called and it essentially knits everything together. It gets a list of\n service links via webservice_parser(), then filters the results via\n taverna_parser(). Finally it tests all the returned taverna WSDL links\n and returns the first live taverna endpoint.\n\n Parameters\n ----------\n service: str\n Indicates which particular HELIO service is used. Defaults to HEC.\n\n Returns\n -------\n wsdl: str\n URL to a single live taverna endpoint\n\n Examples\n --------\n >>> from sunpy.net.helio import parser\n >>> parser.wsdl_retriever()\n 'http://msslkz.mssl.ucl.ac.uk:80/helio_hec/HelioTavernaService?wsdl'\n\n Notes\n -----\n * Currently only support for HEC exists, but it was designed so that it\n could be expanded at a later date\n * There is a 3 second timeout lifespan on links, so there is potential for\n this function to take a while to return. Timeout duration can be\n controlled through the LINK_TIMEOUT value\n \"\"\"\n service_links = webservice_parser(service=service)\n wsdl = None\n wsdl_links = None\n if service_links is None:\n return None\n for link in service_links:\n wsdl_links = taverna_parser(link)\n if wsdl_links is None:\n return None\n for end_point in wsdl_links:\n if end_point is not None and link_test(end_point) is not None:\n wsdl = end_point\n break\n return wsdl\n", "path": "sunpy/net/helio/parser.py"}]}
| 3,246 | 222 |
gh_patches_debug_36756
|
rasdani/github-patches
|
git_diff
|
horovod__horovod-3245
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pytorch_lightning_mnist.py example is not working with GPU
**Environment:**
torch==1.7.1
pytorch-lightning==1.3.8
horovod==master branch
**Bug report:**
Reproduce with `horovodrun -np 1 -H agent11240-phx4:1 python pytorch_lightning_mnist.py --epochs 1`
It fails in test step since model weights are on cpu:
```
Epoch 0: 100% 946/948 [00:10<00:00, 86.76it/s, loss=0.438, v[[1,0]<stdout>:A epoch ended.
Epoch 0: 100% 948/948 [00:11<00:00, 84.24it/s, loss=0.438, v_[1,0]<stdout>:Training ends
Epoch 0: 100% 948/948 [00:11<00:00, 84.18it/s, loss=0.438, v_num=0][1,0]<stdout>:
[1,0]<stderr>:Traceback (most recent call last):
[1,0]<stderr>: File "pytorch_lightning_mnist.py", line 218, in <module>
[1,0]<stderr>: test()
[1,0]<stderr>: File "pytorch_lightning_mnist.py", line 101, in test
[1,0]<stderr>: output = model(data)
[1,0]<stderr>: File "/usr/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
[1,0]<stderr>: result = self.forward(*input, **kwargs)
[1,0]<stderr>: File "pytorch_lightning_mnist.py", line 59, in forward
[1,0]<stderr>: x = F.relu(F.max_pool2d(self.conv1(x), 2))
[1,0]<stderr>: File "/usr/lib/python3.6/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
[1,0]<stderr>: result = self.forward(*input, **kwargs)
[1,0]<stderr>: File "/usr/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 423, in forward
[1,0]<stderr>: return self._conv_forward(input, self.weight)
[1,0]<stderr>: File "/usr/lib/python3.6/site-packages/torch/nn/modules/conv.py", line 420, in _conv_forward
[1,0]<stderr>: self.padding, self.dilation, self.groups)
[1,0]<stderr>:RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
```
CPU version `horovodrun -np 1 -H agent11240-phx4:1 python pytorch_lightning_mnist.py --epochs 1 --no-cuda` is working.
Also, the example seems has wrong configuration for using GPUs:
The `gpus` for `trainer` should depend on `args.cuda`, instead of system default setting.
https://github.com/horovod/horovod/blob/master/examples/pytorch/pytorch_lightning_mnist.py#L208
</issue>
<code>
[start of examples/pytorch/pytorch_lightning_mnist.py]
1 import argparse
2 import os
3 from filelock import FileLock
4 import tempfile
5
6 import torch
7 import torch.multiprocessing as mp
8 import torch.nn as nn
9 import torch.nn.functional as F
10 import torch.optim as optim
11 from torchvision import datasets, transforms
12 # import torch.utils.data.distributed
13
14 from pytorch_lightning import LightningModule, Trainer
15 from pytorch_lightning.callbacks import ModelCheckpoint
16 from pytorch_lightning.loggers import TensorBoardLogger
17 import horovod.torch as hvd
18
19 # Training settings
20 parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
21 parser.add_argument('--batch-size', type=int, default=64, metavar='N',
22 help='input batch size for training (default: 64)')
23 parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
24 help='input batch size for testing (default: 1000)')
25 parser.add_argument('--epochs', type=int, default=10, metavar='N',
26 help='number of epochs to train (default: 10)')
27 parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
28 help='learning rate (default: 0.01)')
29 parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
30 help='SGD momentum (default: 0.5)')
31 parser.add_argument('--no-cuda', action='store_true', default=False,
32 help='disables CUDA training')
33 parser.add_argument('--seed', type=int, default=42, metavar='S',
34 help='random seed (default: 42)')
35 parser.add_argument('--log-interval', type=int, default=10, metavar='N',
36 help='how many batches to wait before logging training status')
37 parser.add_argument('--fp16-allreduce', action='store_true', default=False,
38 help='use fp16 compression during allreduce')
39 parser.add_argument('--use-adasum', action='store_true', default=False,
40 help='use adasum algorithm to do reduction')
41 parser.add_argument('--gradient-predivide-factor', type=float, default=1.0,
42 help='apply gradient predivide factor in optimizer (default: 1.0)')
43 parser.add_argument('--data-dir',
44 help='location of the training dataset in the local filesystem (will be downloaded if needed)')
45
46
47 # Define the PyTorch model without any Horovod-specific parameters
48 class Net(LightningModule):
49 def __init__(self):
50 super(Net, self).__init__()
51 self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
52 self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
53 self.conv2_drop = nn.Dropout2d()
54 self.fc1 = nn.Linear(320, 50)
55 self.fc2 = nn.Linear(50, 10)
56
57 def forward(self, x):
58 x = x.float()
59 x = F.relu(F.max_pool2d(self.conv1(x), 2))
60 x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
61 x = x.view(-1, 320)
62 x = F.relu(self.fc1(x))
63 x = F.dropout(x, training=self.training)
64 x = self.fc2(x)
65 return F.log_softmax(x, -1)
66
67 def configure_optimizers(self):
68 return optim.SGD(self.parameters(), lr=0.01, momentum=0.5)
69
70 def training_step(self, batch, batch_nb):
71 x, y = batch[0], batch[1]
72 y_hat = self(x)
73 loss = F.nll_loss(y_hat, y.long())
74 tensorboard_logs = {'train_loss': loss}
75 return {'loss': loss, 'log': tensorboard_logs}
76
77 def validation_step(self, batch, batch_nb):
78 x, y = batch[0], batch[1]
79 y_hat = self(x)
80 return {'val_loss': F.nll_loss(y_hat, y.long())}
81
82 def validation_epoch_end(self, outputs):
83 avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
84 tensorboard_logs = {'val_loss': avg_loss}
85 return {'avg_val_loss': avg_loss, 'log': tensorboard_logs}
86
87
88 def metric_average(val, name):
89 tensor = torch.tensor(val)
90 avg_tensor = hvd.allreduce(tensor, name=name)
91 return avg_tensor.item()
92
93
94 def test():
95 model.eval()
96 test_loss = 0.
97 test_accuracy = 0.
98 for data, target in test_loader:
99 if args.cuda:
100 data, target = data.cuda(), target.cuda()
101 output = model(data)
102 # sum up batch loss
103 test_loss += F.nll_loss(output, target, size_average=False).item()
104 # get the index of the max log-probability
105 pred = output.data.max(1, keepdim=True)[1]
106 test_accuracy += pred.eq(target.data.view_as(pred)).cpu().float().sum()
107
108 # Horovod: use test_sampler to determine the number of examples in
109 # this worker's partition.
110 test_loss /= len(test_sampler)
111 test_accuracy /= len(test_sampler)
112
113 # Horovod: average metric values across workers.
114 test_loss = metric_average(test_loss, 'avg_loss')
115 test_accuracy = metric_average(test_accuracy, 'avg_accuracy')
116
117 # Horovod: print output only on first rank.
118 if hvd.rank() == 0:
119 print('\nTest set: Average loss: {:.4f}, Accuracy: {:.2f}%\n'.format(
120 test_loss, 100. * test_accuracy))
121
122
123 if __name__ == '__main__':
124 args = parser.parse_args()
125 args.cuda = not args.no_cuda and torch.cuda.is_available()
126 hvd.init()
127
128 kwargs = {'num_workers': 2}
129 # When supported, use 'forkserver' to spawn dataloader workers instead of 'fork' to prevent
130 # issues with Infiniband implementations that are not fork-safe
131 if (kwargs.get('num_workers', 0) > 0 and hasattr(mp, '_supports_context') and
132 mp._supports_context and 'forkserver' in mp.get_all_start_methods()):
133 kwargs['multiprocessing_context'] = 'forkserver'
134
135 # get data
136 data_dir = args.data_dir or './data'
137 with FileLock(os.path.expanduser("~/.horovod_lock")):
138 train_dataset = \
139 datasets.MNIST(data_dir, train=True, download=True,
140 transform=transforms.Compose([
141 transforms.ToTensor(),
142 transforms.Normalize((0.1307,), (0.3081,))
143 ]))
144
145 # set training data loader
146 train_sampler = torch.utils.data.distributed.DistributedSampler(
147 train_dataset, num_replicas=hvd.size(), rank=hvd.rank())
148 train_loader = torch.utils.data.DataLoader(
149 train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs)
150
151 test_dataset = \
152 datasets.MNIST(data_dir, train=False, transform=transforms.Compose([
153 transforms.ToTensor(),
154 transforms.Normalize((0.1307,), (0.3081,))
155 ]))
156
157 # set validation data loader
158 test_sampler = torch.utils.data.distributed.DistributedSampler(
159 test_dataset, num_replicas=hvd.size(), rank=hvd.rank())
160 test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=args.test_batch_size,
161 sampler=test_sampler, **kwargs)
162
163 epochs = args.epochs
164 with tempfile.TemporaryDirectory() as run_output_dir:
165 ckpt_path = os.path.join(run_output_dir, "checkpoint")
166 os.makedirs(ckpt_path, exist_ok=True)
167
168 logs_path = os.path.join(run_output_dir, "logger")
169 os.makedirs(logs_path, exist_ok=True)
170 logger = TensorBoardLogger(logs_path)
171
172 train_percent = 1.0
173 val_percent = 1.0
174
175 model = Net()
176 setattr(model, 'train_dataloader', lambda: train_loader)
177 setattr(model, 'val_dataloader', lambda: test_loader)
178
179 from pytorch_lightning.callbacks import Callback
180
181 class MyDummyCallback(Callback):
182 def __init__(self):
183 self.epcoh_end_counter = 0
184 self.train_epcoh_end_counter = 0
185
186 def on_init_start(self, trainer):
187 print('Starting to init trainer!')
188
189 def on_init_end(self, trainer):
190 print('Trainer is initialized.')
191
192 def on_epoch_end(self, trainer, model):
193 print('A epoch ended.')
194 self.epcoh_end_counter += 1
195
196 def on_train_epoch_end(self, trainer, model, unused=None):
197 print('A train epoch ended.')
198 self.train_epcoh_end_counter += 1
199
200 def on_train_end(self, trainer, model):
201 print('Training ends')
202 assert self.epcoh_end_counter == 2 * epochs
203 assert self.train_epcoh_end_counter == epochs
204
205 callbacks = [MyDummyCallback(), ModelCheckpoint(dirpath=ckpt_path)]
206
207 trainer = Trainer(accelerator='horovod',
208 gpus=(1 if torch.cuda.is_available() else 0),
209 callbacks=callbacks,
210 max_epochs=epochs,
211 limit_train_batches=train_percent,
212 limit_val_batches=val_percent,
213 logger=logger,
214 num_sanity_val_steps=0)
215
216 trainer.fit(model)
217
218 test()
219
220
[end of examples/pytorch/pytorch_lightning_mnist.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/pytorch/pytorch_lightning_mnist.py b/examples/pytorch/pytorch_lightning_mnist.py
--- a/examples/pytorch/pytorch_lightning_mnist.py
+++ b/examples/pytorch/pytorch_lightning_mnist.py
@@ -24,22 +24,10 @@
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
-parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
- help='learning rate (default: 0.01)')
-parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
- help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=42, metavar='S',
help='random seed (default: 42)')
-parser.add_argument('--log-interval', type=int, default=10, metavar='N',
- help='how many batches to wait before logging training status')
-parser.add_argument('--fp16-allreduce', action='store_true', default=False,
- help='use fp16 compression during allreduce')
-parser.add_argument('--use-adasum', action='store_true', default=False,
- help='use adasum algorithm to do reduction')
-parser.add_argument('--gradient-predivide-factor', type=float, default=1.0,
- help='apply gradient predivide factor in optimizer (default: 1.0)')
parser.add_argument('--data-dir',
help='location of the training dataset in the local filesystem (will be downloaded if needed)')
@@ -205,7 +193,7 @@
callbacks = [MyDummyCallback(), ModelCheckpoint(dirpath=ckpt_path)]
trainer = Trainer(accelerator='horovod',
- gpus=(1 if torch.cuda.is_available() else 0),
+ gpus=(1 if args.cuda else 0),
callbacks=callbacks,
max_epochs=epochs,
limit_train_batches=train_percent,
@@ -214,6 +202,7 @@
num_sanity_val_steps=0)
trainer.fit(model)
-
+ if args.cuda:
+ model = model.cuda()
test()
|
{"golden_diff": "diff --git a/examples/pytorch/pytorch_lightning_mnist.py b/examples/pytorch/pytorch_lightning_mnist.py\n--- a/examples/pytorch/pytorch_lightning_mnist.py\n+++ b/examples/pytorch/pytorch_lightning_mnist.py\n@@ -24,22 +24,10 @@\n help='input batch size for testing (default: 1000)')\n parser.add_argument('--epochs', type=int, default=10, metavar='N',\n help='number of epochs to train (default: 10)')\n-parser.add_argument('--lr', type=float, default=0.01, metavar='LR',\n- help='learning rate (default: 0.01)')\n-parser.add_argument('--momentum', type=float, default=0.5, metavar='M',\n- help='SGD momentum (default: 0.5)')\n parser.add_argument('--no-cuda', action='store_true', default=False,\n help='disables CUDA training')\n parser.add_argument('--seed', type=int, default=42, metavar='S',\n help='random seed (default: 42)')\n-parser.add_argument('--log-interval', type=int, default=10, metavar='N',\n- help='how many batches to wait before logging training status')\n-parser.add_argument('--fp16-allreduce', action='store_true', default=False,\n- help='use fp16 compression during allreduce')\n-parser.add_argument('--use-adasum', action='store_true', default=False,\n- help='use adasum algorithm to do reduction')\n-parser.add_argument('--gradient-predivide-factor', type=float, default=1.0,\n- help='apply gradient predivide factor in optimizer (default: 1.0)')\n parser.add_argument('--data-dir',\n help='location of the training dataset in the local filesystem (will be downloaded if needed)')\n \n@@ -205,7 +193,7 @@\n callbacks = [MyDummyCallback(), ModelCheckpoint(dirpath=ckpt_path)]\n \n trainer = Trainer(accelerator='horovod',\n- gpus=(1 if torch.cuda.is_available() else 0),\n+ gpus=(1 if args.cuda else 0),\n callbacks=callbacks,\n max_epochs=epochs,\n limit_train_batches=train_percent,\n@@ -214,6 +202,7 @@\n num_sanity_val_steps=0)\n \n trainer.fit(model)\n-\n+ if args.cuda:\n+ model = model.cuda()\n test()\n", "issue": "pytorch_lightning_mnist.py example is not working with GPU\n**Environment:**\r\ntorch==1.7.1\r\npytorch-lightning==1.3.8\r\nhorovod==master branch\r\n\r\n**Bug report:**\r\nReproduce with `horovodrun -np 1 -H agent11240-phx4:1 python pytorch_lightning_mnist.py --epochs 1`\r\nIt fails in test step since model weights are on cpu:\r\n```\r\nEpoch 0: 100% 946/948 [00:10<00:00, 86.76it/s, loss=0.438, v[[1,0]<stdout>:A epoch ended.\r\nEpoch 0: 100% 948/948 [00:11<00:00, 84.24it/s, loss=0.438, v_[1,0]<stdout>:Training ends\r\nEpoch 0: 100% 948/948 [00:11<00:00, 84.18it/s, loss=0.438, v_num=0][1,0]<stdout>:\r\n[1,0]<stderr>:Traceback (most recent call last):\r\n[1,0]<stderr>: File \"pytorch_lightning_mnist.py\", line 218, in <module>\r\n[1,0]<stderr>: test()\r\n[1,0]<stderr>: File \"pytorch_lightning_mnist.py\", line 101, in test\r\n[1,0]<stderr>: output = model(data)\r\n[1,0]<stderr>: File \"/usr/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 727, in _call_impl\r\n[1,0]<stderr>: result = self.forward(*input, **kwargs)\r\n[1,0]<stderr>: File \"pytorch_lightning_mnist.py\", line 59, in forward\r\n[1,0]<stderr>: x = F.relu(F.max_pool2d(self.conv1(x), 2))\r\n[1,0]<stderr>: File \"/usr/lib/python3.6/site-packages/torch/nn/modules/module.py\", line 727, in _call_impl\r\n[1,0]<stderr>: result = self.forward(*input, **kwargs)\r\n[1,0]<stderr>: File \"/usr/lib/python3.6/site-packages/torch/nn/modules/conv.py\", line 423, in forward\r\n[1,0]<stderr>: return self._conv_forward(input, self.weight)\r\n[1,0]<stderr>: File \"/usr/lib/python3.6/site-packages/torch/nn/modules/conv.py\", line 420, in _conv_forward\r\n[1,0]<stderr>: self.padding, self.dilation, self.groups)\r\n[1,0]<stderr>:RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same\r\n```\r\n\r\nCPU version `horovodrun -np 1 -H agent11240-phx4:1 python pytorch_lightning_mnist.py --epochs 1 --no-cuda` is working.\r\n\r\nAlso, the example seems has wrong configuration for using GPUs:\r\nThe `gpus` for `trainer` should depend on `args.cuda`, instead of system default setting.\r\nhttps://github.com/horovod/horovod/blob/master/examples/pytorch/pytorch_lightning_mnist.py#L208\n", "before_files": [{"content": "import argparse\nimport os\nfrom filelock import FileLock\nimport tempfile\n\nimport torch\nimport torch.multiprocessing as mp\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nfrom torchvision import datasets, transforms\n# import torch.utils.data.distributed\n\nfrom pytorch_lightning import LightningModule, Trainer\nfrom pytorch_lightning.callbacks import ModelCheckpoint\nfrom pytorch_lightning.loggers import TensorBoardLogger\nimport horovod.torch as hvd\n\n# Training settings\nparser = argparse.ArgumentParser(description='PyTorch MNIST Example')\nparser.add_argument('--batch-size', type=int, default=64, metavar='N',\n help='input batch size for training (default: 64)')\nparser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',\n help='input batch size for testing (default: 1000)')\nparser.add_argument('--epochs', type=int, default=10, metavar='N',\n help='number of epochs to train (default: 10)')\nparser.add_argument('--lr', type=float, default=0.01, metavar='LR',\n help='learning rate (default: 0.01)')\nparser.add_argument('--momentum', type=float, default=0.5, metavar='M',\n help='SGD momentum (default: 0.5)')\nparser.add_argument('--no-cuda', action='store_true', default=False,\n help='disables CUDA training')\nparser.add_argument('--seed', type=int, default=42, metavar='S',\n help='random seed (default: 42)')\nparser.add_argument('--log-interval', type=int, default=10, metavar='N',\n help='how many batches to wait before logging training status')\nparser.add_argument('--fp16-allreduce', action='store_true', default=False,\n help='use fp16 compression during allreduce')\nparser.add_argument('--use-adasum', action='store_true', default=False,\n help='use adasum algorithm to do reduction')\nparser.add_argument('--gradient-predivide-factor', type=float, default=1.0,\n help='apply gradient predivide factor in optimizer (default: 1.0)')\nparser.add_argument('--data-dir',\n help='location of the training dataset in the local filesystem (will be downloaded if needed)')\n\n\n# Define the PyTorch model without any Horovod-specific parameters\nclass Net(LightningModule):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(1, 10, kernel_size=5)\n self.conv2 = nn.Conv2d(10, 20, kernel_size=5)\n self.conv2_drop = nn.Dropout2d()\n self.fc1 = nn.Linear(320, 50)\n self.fc2 = nn.Linear(50, 10)\n\n def forward(self, x):\n x = x.float()\n x = F.relu(F.max_pool2d(self.conv1(x), 2))\n x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))\n x = x.view(-1, 320)\n x = F.relu(self.fc1(x))\n x = F.dropout(x, training=self.training)\n x = self.fc2(x)\n return F.log_softmax(x, -1)\n\n def configure_optimizers(self):\n return optim.SGD(self.parameters(), lr=0.01, momentum=0.5)\n\n def training_step(self, batch, batch_nb):\n x, y = batch[0], batch[1]\n y_hat = self(x)\n loss = F.nll_loss(y_hat, y.long())\n tensorboard_logs = {'train_loss': loss}\n return {'loss': loss, 'log': tensorboard_logs}\n\n def validation_step(self, batch, batch_nb):\n x, y = batch[0], batch[1]\n y_hat = self(x)\n return {'val_loss': F.nll_loss(y_hat, y.long())}\n\n def validation_epoch_end(self, outputs):\n avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()\n tensorboard_logs = {'val_loss': avg_loss}\n return {'avg_val_loss': avg_loss, 'log': tensorboard_logs}\n\n\ndef metric_average(val, name):\n tensor = torch.tensor(val)\n avg_tensor = hvd.allreduce(tensor, name=name)\n return avg_tensor.item()\n\n\ndef test():\n model.eval()\n test_loss = 0.\n test_accuracy = 0.\n for data, target in test_loader:\n if args.cuda:\n data, target = data.cuda(), target.cuda()\n output = model(data)\n # sum up batch loss\n test_loss += F.nll_loss(output, target, size_average=False).item()\n # get the index of the max log-probability\n pred = output.data.max(1, keepdim=True)[1]\n test_accuracy += pred.eq(target.data.view_as(pred)).cpu().float().sum()\n\n # Horovod: use test_sampler to determine the number of examples in\n # this worker's partition.\n test_loss /= len(test_sampler)\n test_accuracy /= len(test_sampler)\n\n # Horovod: average metric values across workers.\n test_loss = metric_average(test_loss, 'avg_loss')\n test_accuracy = metric_average(test_accuracy, 'avg_accuracy')\n\n # Horovod: print output only on first rank.\n if hvd.rank() == 0:\n print('\\nTest set: Average loss: {:.4f}, Accuracy: {:.2f}%\\n'.format(\n test_loss, 100. * test_accuracy))\n\n\nif __name__ == '__main__':\n args = parser.parse_args()\n args.cuda = not args.no_cuda and torch.cuda.is_available()\n hvd.init()\n\n kwargs = {'num_workers': 2}\n # When supported, use 'forkserver' to spawn dataloader workers instead of 'fork' to prevent\n # issues with Infiniband implementations that are not fork-safe\n if (kwargs.get('num_workers', 0) > 0 and hasattr(mp, '_supports_context') and\n mp._supports_context and 'forkserver' in mp.get_all_start_methods()):\n kwargs['multiprocessing_context'] = 'forkserver'\n\n # get data\n data_dir = args.data_dir or './data'\n with FileLock(os.path.expanduser(\"~/.horovod_lock\")):\n train_dataset = \\\n datasets.MNIST(data_dir, train=True, download=True,\n transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.1307,), (0.3081,))\n ]))\n\n # set training data loader\n train_sampler = torch.utils.data.distributed.DistributedSampler(\n train_dataset, num_replicas=hvd.size(), rank=hvd.rank())\n train_loader = torch.utils.data.DataLoader(\n train_dataset, batch_size=args.batch_size, sampler=train_sampler, **kwargs)\n\n test_dataset = \\\n datasets.MNIST(data_dir, train=False, transform=transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize((0.1307,), (0.3081,))\n ]))\n\n # set validation data loader\n test_sampler = torch.utils.data.distributed.DistributedSampler(\n test_dataset, num_replicas=hvd.size(), rank=hvd.rank())\n test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=args.test_batch_size,\n sampler=test_sampler, **kwargs)\n\n epochs = args.epochs\n with tempfile.TemporaryDirectory() as run_output_dir:\n ckpt_path = os.path.join(run_output_dir, \"checkpoint\")\n os.makedirs(ckpt_path, exist_ok=True)\n\n logs_path = os.path.join(run_output_dir, \"logger\")\n os.makedirs(logs_path, exist_ok=True)\n logger = TensorBoardLogger(logs_path)\n\n train_percent = 1.0\n val_percent = 1.0\n\n model = Net()\n setattr(model, 'train_dataloader', lambda: train_loader)\n setattr(model, 'val_dataloader', lambda: test_loader)\n\n from pytorch_lightning.callbacks import Callback\n\n class MyDummyCallback(Callback):\n def __init__(self):\n self.epcoh_end_counter = 0\n self.train_epcoh_end_counter = 0\n\n def on_init_start(self, trainer):\n print('Starting to init trainer!')\n\n def on_init_end(self, trainer):\n print('Trainer is initialized.')\n\n def on_epoch_end(self, trainer, model):\n print('A epoch ended.')\n self.epcoh_end_counter += 1\n\n def on_train_epoch_end(self, trainer, model, unused=None):\n print('A train epoch ended.')\n self.train_epcoh_end_counter += 1\n\n def on_train_end(self, trainer, model):\n print('Training ends')\n assert self.epcoh_end_counter == 2 * epochs\n assert self.train_epcoh_end_counter == epochs\n\n callbacks = [MyDummyCallback(), ModelCheckpoint(dirpath=ckpt_path)]\n\n trainer = Trainer(accelerator='horovod',\n gpus=(1 if torch.cuda.is_available() else 0),\n callbacks=callbacks,\n max_epochs=epochs,\n limit_train_batches=train_percent,\n limit_val_batches=val_percent,\n logger=logger,\n num_sanity_val_steps=0)\n\n trainer.fit(model)\n\n test()\n\n", "path": "examples/pytorch/pytorch_lightning_mnist.py"}]}
| 3,945 | 535 |
gh_patches_debug_668
|
rasdani/github-patches
|
git_diff
|
liqd__a4-opin-388
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
timeline wrong way?
the phases in the timeline seem to be sorted in the wrong direction:


</issue>
<code>
[start of euth/phases/models.py]
1 from django.core.exceptions import ValidationError
2 from django.db import models
3 from django.utils import timezone
4 from django.utils.translation import ugettext as _
5
6 from euth.modules import models as modules_models
7
8 from . import content
9 from .validators import validate_content
10
11
12 class PhasesQuerySet(models.QuerySet):
13
14 def active_phases(self):
15 now = timezone.now()
16 return self.filter(start_date__lte=now, end_date__gt=now)
17
18
19 class Phase(models.Model):
20 name = models.CharField(max_length=80)
21 description = models.TextField(max_length=300)
22 type = models.CharField(max_length=128, validators=[validate_content])
23 module = models.ForeignKey(modules_models.Module, on_delete=models.CASCADE)
24 start_date = models.DateTimeField(blank=True, null=True)
25 end_date = models.DateTimeField(blank=True, null=True)
26
27 objects = PhasesQuerySet.as_manager()
28
29 def __str__(self):
30 return '{} ({})'.format(self.name, self.type)
31
32 def content(self):
33 return content[self.type]
34
35 def clean(self):
36 if self.end_date and self.start_date:
37 if self.end_date < self.start_date:
38 raise ValidationError({
39 'end_date': _('End date can not be smaller'
40 'than the start date.')
41 })
42 super().clean()
43
44 @property
45 def view(self):
46 return content[self.type].view
47
48 def has_feature(self, feature, model):
49 return content[self.type].has_feature(feature, model)
50
[end of euth/phases/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/euth/phases/models.py b/euth/phases/models.py
--- a/euth/phases/models.py
+++ b/euth/phases/models.py
@@ -26,6 +26,9 @@
objects = PhasesQuerySet.as_manager()
+ class Meta:
+ ordering = ['type']
+
def __str__(self):
return '{} ({})'.format(self.name, self.type)
|
{"golden_diff": "diff --git a/euth/phases/models.py b/euth/phases/models.py\n--- a/euth/phases/models.py\n+++ b/euth/phases/models.py\n@@ -26,6 +26,9 @@\n \n objects = PhasesQuerySet.as_manager()\n \n+ class Meta:\n+ ordering = ['type']\n+\n def __str__(self):\n return '{} ({})'.format(self.name, self.type)\n", "issue": "timeline wrong way?\nthe phases in the timeline seem to be sorted in the wrong direction:\n\n\n\n", "before_files": [{"content": "from django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext as _\n\nfrom euth.modules import models as modules_models\n\nfrom . import content\nfrom .validators import validate_content\n\n\nclass PhasesQuerySet(models.QuerySet):\n\n def active_phases(self):\n now = timezone.now()\n return self.filter(start_date__lte=now, end_date__gt=now)\n\n\nclass Phase(models.Model):\n name = models.CharField(max_length=80)\n description = models.TextField(max_length=300)\n type = models.CharField(max_length=128, validators=[validate_content])\n module = models.ForeignKey(modules_models.Module, on_delete=models.CASCADE)\n start_date = models.DateTimeField(blank=True, null=True)\n end_date = models.DateTimeField(blank=True, null=True)\n\n objects = PhasesQuerySet.as_manager()\n\n def __str__(self):\n return '{} ({})'.format(self.name, self.type)\n\n def content(self):\n return content[self.type]\n\n def clean(self):\n if self.end_date and self.start_date:\n if self.end_date < self.start_date:\n raise ValidationError({\n 'end_date': _('End date can not be smaller'\n 'than the start date.')\n })\n super().clean()\n\n @property\n def view(self):\n return content[self.type].view\n\n def has_feature(self, feature, model):\n return content[self.type].has_feature(feature, model)\n", "path": "euth/phases/models.py"}]}
| 1,140 | 93 |
gh_patches_debug_29172
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-4876
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fixed light/dark theme setting
Hello, is it possible to set the dark and light theme fixed? With the OS autodetection I have otherwise problems with my different logos that I use in my Tenants settings. Light logos are not visible to users on light platforms, dark logos are not visible to users on dark platforms.
Thanks in advanced
pupazze
</issue>
<code>
[start of authentik/tenants/api.py]
1 """Serializer for tenant models"""
2 from typing import Any
3
4 from drf_spectacular.utils import extend_schema
5 from rest_framework.decorators import action
6 from rest_framework.exceptions import ValidationError
7 from rest_framework.fields import CharField, ListField
8 from rest_framework.filters import OrderingFilter, SearchFilter
9 from rest_framework.permissions import AllowAny
10 from rest_framework.request import Request
11 from rest_framework.response import Response
12 from rest_framework.serializers import ModelSerializer
13 from rest_framework.viewsets import ModelViewSet
14
15 from authentik.api.authorization import SecretKeyFilter
16 from authentik.core.api.used_by import UsedByMixin
17 from authentik.core.api.utils import PassiveSerializer
18 from authentik.lib.config import CONFIG
19 from authentik.tenants.models import Tenant
20
21
22 class FooterLinkSerializer(PassiveSerializer):
23 """Links returned in Config API"""
24
25 href = CharField(read_only=True)
26 name = CharField(read_only=True)
27
28
29 class TenantSerializer(ModelSerializer):
30 """Tenant Serializer"""
31
32 def validate(self, attrs: dict[str, Any]) -> dict[str, Any]:
33 if attrs.get("default", False):
34 tenants = Tenant.objects.filter(default=True)
35 if self.instance:
36 tenants = tenants.exclude(pk=self.instance.pk)
37 if tenants.exists():
38 raise ValidationError("Only a single Tenant can be set as default.")
39 return super().validate(attrs)
40
41 class Meta:
42 model = Tenant
43 fields = [
44 "tenant_uuid",
45 "domain",
46 "default",
47 "branding_title",
48 "branding_logo",
49 "branding_favicon",
50 "flow_authentication",
51 "flow_invalidation",
52 "flow_recovery",
53 "flow_unenrollment",
54 "flow_user_settings",
55 "flow_device_code",
56 "event_retention",
57 "web_certificate",
58 "attributes",
59 ]
60
61
62 class CurrentTenantSerializer(PassiveSerializer):
63 """Partial tenant information for styling"""
64
65 matched_domain = CharField(source="domain")
66 branding_title = CharField()
67 branding_logo = CharField()
68 branding_favicon = CharField()
69 ui_footer_links = ListField(
70 child=FooterLinkSerializer(),
71 read_only=True,
72 default=CONFIG.y("footer_links", []),
73 )
74
75 flow_authentication = CharField(source="flow_authentication.slug", required=False)
76 flow_invalidation = CharField(source="flow_invalidation.slug", required=False)
77 flow_recovery = CharField(source="flow_recovery.slug", required=False)
78 flow_unenrollment = CharField(source="flow_unenrollment.slug", required=False)
79 flow_user_settings = CharField(source="flow_user_settings.slug", required=False)
80 flow_device_code = CharField(source="flow_device_code.slug", required=False)
81
82 default_locale = CharField(read_only=True)
83
84
85 class TenantViewSet(UsedByMixin, ModelViewSet):
86 """Tenant Viewset"""
87
88 queryset = Tenant.objects.all()
89 serializer_class = TenantSerializer
90 search_fields = [
91 "domain",
92 "branding_title",
93 "web_certificate__name",
94 ]
95 filterset_fields = [
96 "tenant_uuid",
97 "domain",
98 "default",
99 "branding_title",
100 "branding_logo",
101 "branding_favicon",
102 "flow_authentication",
103 "flow_invalidation",
104 "flow_recovery",
105 "flow_unenrollment",
106 "flow_user_settings",
107 "flow_device_code",
108 "event_retention",
109 "web_certificate",
110 ]
111 ordering = ["domain"]
112
113 filter_backends = [SecretKeyFilter, OrderingFilter, SearchFilter]
114
115 @extend_schema(
116 responses=CurrentTenantSerializer(many=False),
117 )
118 @action(methods=["GET"], detail=False, permission_classes=[AllowAny])
119 def current(self, request: Request) -> Response:
120 """Get current tenant"""
121 tenant: Tenant = request._request.tenant
122 return Response(CurrentTenantSerializer(tenant).data)
123
[end of authentik/tenants/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/authentik/tenants/api.py b/authentik/tenants/api.py
--- a/authentik/tenants/api.py
+++ b/authentik/tenants/api.py
@@ -1,10 +1,11 @@
"""Serializer for tenant models"""
from typing import Any
+from django.db import models
from drf_spectacular.utils import extend_schema
from rest_framework.decorators import action
from rest_framework.exceptions import ValidationError
-from rest_framework.fields import CharField, ListField
+from rest_framework.fields import CharField, ChoiceField, ListField
from rest_framework.filters import OrderingFilter, SearchFilter
from rest_framework.permissions import AllowAny
from rest_framework.request import Request
@@ -59,6 +60,14 @@
]
+class Themes(models.TextChoices):
+ """Themes"""
+
+ AUTOMATIC = "automatic"
+ LIGHT = "light"
+ DARK = "dark"
+
+
class CurrentTenantSerializer(PassiveSerializer):
"""Partial tenant information for styling"""
@@ -71,6 +80,12 @@
read_only=True,
default=CONFIG.y("footer_links", []),
)
+ ui_theme = ChoiceField(
+ choices=Themes.choices,
+ source="attributes.settings.theme.base",
+ default=Themes.AUTOMATIC,
+ read_only=True,
+ )
flow_authentication = CharField(source="flow_authentication.slug", required=False)
flow_invalidation = CharField(source="flow_invalidation.slug", required=False)
|
{"golden_diff": "diff --git a/authentik/tenants/api.py b/authentik/tenants/api.py\n--- a/authentik/tenants/api.py\n+++ b/authentik/tenants/api.py\n@@ -1,10 +1,11 @@\n \"\"\"Serializer for tenant models\"\"\"\n from typing import Any\n \n+from django.db import models\n from drf_spectacular.utils import extend_schema\n from rest_framework.decorators import action\n from rest_framework.exceptions import ValidationError\n-from rest_framework.fields import CharField, ListField\n+from rest_framework.fields import CharField, ChoiceField, ListField\n from rest_framework.filters import OrderingFilter, SearchFilter\n from rest_framework.permissions import AllowAny\n from rest_framework.request import Request\n@@ -59,6 +60,14 @@\n ]\n \n \n+class Themes(models.TextChoices):\n+ \"\"\"Themes\"\"\"\n+\n+ AUTOMATIC = \"automatic\"\n+ LIGHT = \"light\"\n+ DARK = \"dark\"\n+\n+\n class CurrentTenantSerializer(PassiveSerializer):\n \"\"\"Partial tenant information for styling\"\"\"\n \n@@ -71,6 +80,12 @@\n read_only=True,\n default=CONFIG.y(\"footer_links\", []),\n )\n+ ui_theme = ChoiceField(\n+ choices=Themes.choices,\n+ source=\"attributes.settings.theme.base\",\n+ default=Themes.AUTOMATIC,\n+ read_only=True,\n+ )\n \n flow_authentication = CharField(source=\"flow_authentication.slug\", required=False)\n flow_invalidation = CharField(source=\"flow_invalidation.slug\", required=False)\n", "issue": "Fixed light/dark theme setting\nHello, is it possible to set the dark and light theme fixed? With the OS autodetection I have otherwise problems with my different logos that I use in my Tenants settings. Light logos are not visible to users on light platforms, dark logos are not visible to users on dark platforms.\r\nThanks in advanced\r\npupazze\n", "before_files": [{"content": "\"\"\"Serializer for tenant models\"\"\"\nfrom typing import Any\n\nfrom drf_spectacular.utils import extend_schema\nfrom rest_framework.decorators import action\nfrom rest_framework.exceptions import ValidationError\nfrom rest_framework.fields import CharField, ListField\nfrom rest_framework.filters import OrderingFilter, SearchFilter\nfrom rest_framework.permissions import AllowAny\nfrom rest_framework.request import Request\nfrom rest_framework.response import Response\nfrom rest_framework.serializers import ModelSerializer\nfrom rest_framework.viewsets import ModelViewSet\n\nfrom authentik.api.authorization import SecretKeyFilter\nfrom authentik.core.api.used_by import UsedByMixin\nfrom authentik.core.api.utils import PassiveSerializer\nfrom authentik.lib.config import CONFIG\nfrom authentik.tenants.models import Tenant\n\n\nclass FooterLinkSerializer(PassiveSerializer):\n \"\"\"Links returned in Config API\"\"\"\n\n href = CharField(read_only=True)\n name = CharField(read_only=True)\n\n\nclass TenantSerializer(ModelSerializer):\n \"\"\"Tenant Serializer\"\"\"\n\n def validate(self, attrs: dict[str, Any]) -> dict[str, Any]:\n if attrs.get(\"default\", False):\n tenants = Tenant.objects.filter(default=True)\n if self.instance:\n tenants = tenants.exclude(pk=self.instance.pk)\n if tenants.exists():\n raise ValidationError(\"Only a single Tenant can be set as default.\")\n return super().validate(attrs)\n\n class Meta:\n model = Tenant\n fields = [\n \"tenant_uuid\",\n \"domain\",\n \"default\",\n \"branding_title\",\n \"branding_logo\",\n \"branding_favicon\",\n \"flow_authentication\",\n \"flow_invalidation\",\n \"flow_recovery\",\n \"flow_unenrollment\",\n \"flow_user_settings\",\n \"flow_device_code\",\n \"event_retention\",\n \"web_certificate\",\n \"attributes\",\n ]\n\n\nclass CurrentTenantSerializer(PassiveSerializer):\n \"\"\"Partial tenant information for styling\"\"\"\n\n matched_domain = CharField(source=\"domain\")\n branding_title = CharField()\n branding_logo = CharField()\n branding_favicon = CharField()\n ui_footer_links = ListField(\n child=FooterLinkSerializer(),\n read_only=True,\n default=CONFIG.y(\"footer_links\", []),\n )\n\n flow_authentication = CharField(source=\"flow_authentication.slug\", required=False)\n flow_invalidation = CharField(source=\"flow_invalidation.slug\", required=False)\n flow_recovery = CharField(source=\"flow_recovery.slug\", required=False)\n flow_unenrollment = CharField(source=\"flow_unenrollment.slug\", required=False)\n flow_user_settings = CharField(source=\"flow_user_settings.slug\", required=False)\n flow_device_code = CharField(source=\"flow_device_code.slug\", required=False)\n\n default_locale = CharField(read_only=True)\n\n\nclass TenantViewSet(UsedByMixin, ModelViewSet):\n \"\"\"Tenant Viewset\"\"\"\n\n queryset = Tenant.objects.all()\n serializer_class = TenantSerializer\n search_fields = [\n \"domain\",\n \"branding_title\",\n \"web_certificate__name\",\n ]\n filterset_fields = [\n \"tenant_uuid\",\n \"domain\",\n \"default\",\n \"branding_title\",\n \"branding_logo\",\n \"branding_favicon\",\n \"flow_authentication\",\n \"flow_invalidation\",\n \"flow_recovery\",\n \"flow_unenrollment\",\n \"flow_user_settings\",\n \"flow_device_code\",\n \"event_retention\",\n \"web_certificate\",\n ]\n ordering = [\"domain\"]\n\n filter_backends = [SecretKeyFilter, OrderingFilter, SearchFilter]\n\n @extend_schema(\n responses=CurrentTenantSerializer(many=False),\n )\n @action(methods=[\"GET\"], detail=False, permission_classes=[AllowAny])\n def current(self, request: Request) -> Response:\n \"\"\"Get current tenant\"\"\"\n tenant: Tenant = request._request.tenant\n return Response(CurrentTenantSerializer(tenant).data)\n", "path": "authentik/tenants/api.py"}]}
| 1,697 | 327 |
gh_patches_debug_10131
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-578
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
nodeenv try to download non existing tar.gz prebuilt under Cygwin
Hi,
Strange issue: I suspect a recent change broke this as it used to work last week, on another Windows computer with Cygwin.
Bug reproduction: `pre-commit run` using e.g. https://github.com/Lucas-C/pre-commit-hooks-html v1.1.0
`pre-commit` execute the following command under the hood, a command that also fails if I execute it manually:
```
nodeenv --prebuilt /cygdrive/c/Users/admin/.pre-commit/repoYHJ85q/node_env-default
```
The error is the following:
```
urllib2.HTTPError: HTTP Error 404: Not Found
```
The `tar.gz` it tries to install is https://nodejs.org/dist/v7.2.1/node-v7.2.1-cygwin_nt-6.1-x64.tar.gz, which does not exist. My guess is that `nodeenv` should use the Windows prebuilts instead: https://nodejs.org/dist/v7.2.1/node-v7.2.1-win-x64.zip This is because `platform.system()` is used: https://github.com/ekalinin/nodeenv/blob/master/nodeenv.py#L503
I'm going to ask for help on the https://github.com/ekalinin/nodeenv project, but do you have any hint at what the root cause could be here ?
</issue>
<code>
[start of pre_commit/languages/node.py]
1 from __future__ import unicode_literals
2
3 import contextlib
4 import os
5 import sys
6
7 from pre_commit.envcontext import envcontext
8 from pre_commit.envcontext import Var
9 from pre_commit.languages import helpers
10 from pre_commit.util import clean_path_on_failure
11 from pre_commit.xargs import xargs
12
13
14 ENVIRONMENT_DIR = 'node_env'
15 get_default_version = helpers.basic_get_default_version
16 healthy = helpers.basic_healthy
17
18
19 def get_env_patch(venv): # pragma: windows no cover
20 return (
21 ('NODE_VIRTUAL_ENV', venv),
22 ('NPM_CONFIG_PREFIX', venv),
23 ('npm_config_prefix', venv),
24 ('NODE_PATH', os.path.join(venv, 'lib', 'node_modules')),
25 ('PATH', (os.path.join(venv, 'bin'), os.pathsep, Var('PATH'))),
26 )
27
28
29 @contextlib.contextmanager
30 def in_env(repo_cmd_runner, language_version): # pragma: windows no cover
31 envdir = repo_cmd_runner.path(
32 helpers.environment_dir(ENVIRONMENT_DIR, language_version),
33 )
34 with envcontext(get_env_patch(envdir)):
35 yield
36
37
38 def install_environment(
39 repo_cmd_runner, version, additional_dependencies,
40 ): # pragma: windows no cover
41 additional_dependencies = tuple(additional_dependencies)
42 assert repo_cmd_runner.exists('package.json')
43 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
44
45 env_dir = repo_cmd_runner.path(directory)
46 with clean_path_on_failure(env_dir):
47 cmd = [
48 sys.executable, '-m', 'nodeenv', '--prebuilt',
49 '{{prefix}}{}'.format(directory),
50 ]
51
52 if version != 'default':
53 cmd.extend(['-n', version])
54
55 repo_cmd_runner.run(cmd)
56
57 with in_env(repo_cmd_runner, version):
58 helpers.run_setup_cmd(
59 repo_cmd_runner,
60 ('npm', 'install', '-g', '.') + additional_dependencies,
61 )
62
63
64 def run_hook(repo_cmd_runner, hook, file_args): # pragma: windows no cover
65 with in_env(repo_cmd_runner, hook['language_version']):
66 return xargs(helpers.to_cmd(hook), file_args)
67
[end of pre_commit/languages/node.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/node.py b/pre_commit/languages/node.py
--- a/pre_commit/languages/node.py
+++ b/pre_commit/languages/node.py
@@ -17,10 +17,11 @@
def get_env_patch(venv): # pragma: windows no cover
+ config = os.path.join(venv, 'bin') if sys.platform == 'cygwin' else venv
return (
('NODE_VIRTUAL_ENV', venv),
- ('NPM_CONFIG_PREFIX', venv),
- ('npm_config_prefix', venv),
+ ('NPM_CONFIG_PREFIX', config),
+ ('npm_config_prefix', config),
('NODE_PATH', os.path.join(venv, 'lib', 'node_modules')),
('PATH', (os.path.join(venv, 'bin'), os.pathsep, Var('PATH'))),
)
|
{"golden_diff": "diff --git a/pre_commit/languages/node.py b/pre_commit/languages/node.py\n--- a/pre_commit/languages/node.py\n+++ b/pre_commit/languages/node.py\n@@ -17,10 +17,11 @@\n \n \n def get_env_patch(venv): # pragma: windows no cover\n+ config = os.path.join(venv, 'bin') if sys.platform == 'cygwin' else venv\n return (\n ('NODE_VIRTUAL_ENV', venv),\n- ('NPM_CONFIG_PREFIX', venv),\n- ('npm_config_prefix', venv),\n+ ('NPM_CONFIG_PREFIX', config),\n+ ('npm_config_prefix', config),\n ('NODE_PATH', os.path.join(venv, 'lib', 'node_modules')),\n ('PATH', (os.path.join(venv, 'bin'), os.pathsep, Var('PATH'))),\n )\n", "issue": "nodeenv try to download non existing tar.gz prebuilt under Cygwin\nHi,\r\n\r\nStrange issue: I suspect a recent change broke this as it used to work last week, on another Windows computer with Cygwin.\r\n\r\nBug reproduction: `pre-commit run` using e.g. https://github.com/Lucas-C/pre-commit-hooks-html v1.1.0\r\n\r\n`pre-commit` execute the following command under the hood, a command that also fails if I execute it manually:\r\n```\r\nnodeenv --prebuilt /cygdrive/c/Users/admin/.pre-commit/repoYHJ85q/node_env-default\r\n```\r\nThe error is the following:\r\n```\r\nurllib2.HTTPError: HTTP Error 404: Not Found\r\n```\r\nThe `tar.gz` it tries to install is https://nodejs.org/dist/v7.2.1/node-v7.2.1-cygwin_nt-6.1-x64.tar.gz, which does not exist. My guess is that `nodeenv` should use the Windows prebuilts instead: https://nodejs.org/dist/v7.2.1/node-v7.2.1-win-x64.zip This is because `platform.system()` is used: https://github.com/ekalinin/nodeenv/blob/master/nodeenv.py#L503\r\n\r\nI'm going to ask for help on the https://github.com/ekalinin/nodeenv project, but do you have any hint at what the root cause could be here ?\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nimport contextlib\nimport os\nimport sys\n\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import Var\nfrom pre_commit.languages import helpers\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.xargs import xargs\n\n\nENVIRONMENT_DIR = 'node_env'\nget_default_version = helpers.basic_get_default_version\nhealthy = helpers.basic_healthy\n\n\ndef get_env_patch(venv): # pragma: windows no cover\n return (\n ('NODE_VIRTUAL_ENV', venv),\n ('NPM_CONFIG_PREFIX', venv),\n ('npm_config_prefix', venv),\n ('NODE_PATH', os.path.join(venv, 'lib', 'node_modules')),\n ('PATH', (os.path.join(venv, 'bin'), os.pathsep, Var('PATH'))),\n )\n\n\[email protected]\ndef in_env(repo_cmd_runner, language_version): # pragma: windows no cover\n envdir = repo_cmd_runner.path(\n helpers.environment_dir(ENVIRONMENT_DIR, language_version),\n )\n with envcontext(get_env_patch(envdir)):\n yield\n\n\ndef install_environment(\n repo_cmd_runner, version, additional_dependencies,\n): # pragma: windows no cover\n additional_dependencies = tuple(additional_dependencies)\n assert repo_cmd_runner.exists('package.json')\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n\n env_dir = repo_cmd_runner.path(directory)\n with clean_path_on_failure(env_dir):\n cmd = [\n sys.executable, '-m', 'nodeenv', '--prebuilt',\n '{{prefix}}{}'.format(directory),\n ]\n\n if version != 'default':\n cmd.extend(['-n', version])\n\n repo_cmd_runner.run(cmd)\n\n with in_env(repo_cmd_runner, version):\n helpers.run_setup_cmd(\n repo_cmd_runner,\n ('npm', 'install', '-g', '.') + additional_dependencies,\n )\n\n\ndef run_hook(repo_cmd_runner, hook, file_args): # pragma: windows no cover\n with in_env(repo_cmd_runner, hook['language_version']):\n return xargs(helpers.to_cmd(hook), file_args)\n", "path": "pre_commit/languages/node.py"}]}
| 1,440 | 191 |
gh_patches_debug_1913
|
rasdani/github-patches
|
git_diff
|
falconry__falcon-1946
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Deprecate falcon.api_helpers
See https://github.com/falconry/falcon/issues/1902.
Starting with 3.1, mark `falcon.api_helpers` as deprecated. We could employ module-level `__getattr__` or redecorate re-imported functions.
</issue>
<code>
[start of falcon/api_helpers.py]
1 from .app_helpers import * # NOQA
2
3 # TODO deprecate
4 # import warnings
5 # from .util.deprecation import DeprecatedWarning
6
7 # warnings.warn('The api_helpers module was renamed to app_helpers.', DeprecatedWarning)
8
[end of falcon/api_helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/falcon/api_helpers.py b/falcon/api_helpers.py
--- a/falcon/api_helpers.py
+++ b/falcon/api_helpers.py
@@ -1,7 +1,6 @@
-from .app_helpers import * # NOQA
+import warnings
-# TODO deprecate
-# import warnings
-# from .util.deprecation import DeprecatedWarning
+from .app_helpers import * # NOQA
+from .util.deprecation import DeprecatedWarning
-# warnings.warn('The api_helpers module was renamed to app_helpers.', DeprecatedWarning)
+warnings.warn('The api_helpers module was renamed to app_helpers.', DeprecatedWarning)
|
{"golden_diff": "diff --git a/falcon/api_helpers.py b/falcon/api_helpers.py\n--- a/falcon/api_helpers.py\n+++ b/falcon/api_helpers.py\n@@ -1,7 +1,6 @@\n-from .app_helpers import * # NOQA\n+import warnings\n \n-# TODO deprecate\n-# import warnings\n-# from .util.deprecation import DeprecatedWarning\n+from .app_helpers import * # NOQA\n+from .util.deprecation import DeprecatedWarning\n \n-# warnings.warn('The api_helpers module was renamed to app_helpers.', DeprecatedWarning)\n+warnings.warn('The api_helpers module was renamed to app_helpers.', DeprecatedWarning)\n", "issue": "Deprecate falcon.api_helpers\nSee https://github.com/falconry/falcon/issues/1902.\r\n\r\nStarting with 3.1, mark `falcon.api_helpers` as deprecated. We could employ module-level `__getattr__` or redecorate re-imported functions.\n", "before_files": [{"content": "from .app_helpers import * # NOQA\n\n# TODO deprecate\n# import warnings\n# from .util.deprecation import DeprecatedWarning\n\n# warnings.warn('The api_helpers module was renamed to app_helpers.', DeprecatedWarning)\n", "path": "falcon/api_helpers.py"}]}
| 654 | 137 |
gh_patches_debug_29346
|
rasdani/github-patches
|
git_diff
|
zulip__zulip-13789
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error with AWX 7.0.0
Hello.
I'm testing integration between **AWX 7.0.0** (Ansible Tower) by sending notifications in **Zulip 2.0.4**.
During testing, I encounter an error from Ansible :

And I immediatly receive an email warning from Zulip with the following content :
```Logger root, from module zerver.middleware line 291:
Error generated by Ansible (user42@zulip.******.**) on zulip.******.** deployment
Traceback (most recent call last):
File "/srv/zulip-venv-cache/ebe617662f96425113e5a75344bbe5a0593f634a/zulip-py3-venv/lib/python3.7/site-packages/django/core/handlers/base.py", line 185, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/srv/zulip-venv-cache/ebe617662f96425113e5a75344bbe5a0593f634a/zulip-py3-venv/lib/python3.7/site-packages/django/views/decorators/csrf.py", line 58, in wrapped_view
return view_func(*args, **kwargs)
File "./zerver/lib/request.py", line 289, in _wrapped_view_func
return view_func(request, *args, **kwargs)
File "./zerver/decorator.py", line 375, in _wrapped_func_arguments
raise err
File "./zerver/decorator.py", line 361, in _wrapped_func_arguments
return view_func(request, user_profile, *args, **kwargs)
File "./zerver/lib/request.py", line 289, in _wrapped_view_func
return view_func(request, *args, **kwargs)
File "./zerver/webhooks/ansibletower/view.py", line 27, in api_ansibletower_webhook
body = get_body(payload)
File "./zerver/webhooks/ansibletower/view.py", line 34, in get_body
if (payload['friendly_name'] == 'Job'):
KeyError: 'friendly_name'
Deployed code:
- git: 2.0.0-2546-ga1fa0b011
- ZULIP_VERSION: 2.0.4+git
Request info:
- path: /api/v1/external/ansibletower
- POST: {}
- REMOTE_ADDR: "['10.10.36.6']"
- QUERY_STRING: "['api_key=******&topic=******&stream=******&topic=******"
- SERVER_NAME: "['']"
```
I have already disable the "Disable SSL checking" but it seems also that the new version of AWX (the 7.0.0) contains new options for webhook like "HTTP Headers" and "HTTP Method".

Note that I have already notifications from GitLab so the notification service works in my self-hosted Zulip configuration.
</issue>
<code>
[start of zerver/webhooks/ansibletower/view.py]
1 import operator
2 from typing import Any, Dict, List
3
4 from django.http import HttpRequest, HttpResponse
5
6 from zerver.decorator import REQ, api_key_only_webhook_view, \
7 has_request_variables
8 from zerver.lib.response import json_success
9 from zerver.lib.webhooks.common import check_send_webhook_message
10 from zerver.models import UserProfile
11
12 ANSIBLETOWER_DEFAULT_MESSAGE_TEMPLATE = "{friendly_name}: [#{id} {name}]({url}) {status}."
13
14
15 ANSIBLETOWER_JOB_MESSAGE_TEMPLATE = """
16 {friendly_name}: [#{id} {name}]({url}) {status}:
17 {hosts_final_data}
18 """.strip()
19
20 ANSIBLETOWER_JOB_HOST_ROW_TEMPLATE = '* {hostname}: {status}\n'
21
22 @api_key_only_webhook_view('Ansibletower')
23 @has_request_variables
24 def api_ansibletower_webhook(request: HttpRequest, user_profile: UserProfile,
25 payload: Dict[str, Any]=REQ(argument_type='body')) -> HttpResponse:
26
27 body = get_body(payload)
28 subject = payload['name']
29
30 check_send_webhook_message(request, user_profile, subject, body)
31 return json_success()
32
33 def get_body(payload: Dict[str, Any]) -> str:
34 if (payload['friendly_name'] == 'Job'):
35 hosts_list_data = payload['hosts']
36 hosts_data = []
37 for host in payload['hosts']:
38 if (hosts_list_data[host].get('failed') is True):
39 hoststatus = 'Failed'
40 elif (hosts_list_data[host].get('failed') is False):
41 hoststatus = 'Success'
42 hosts_data.append({
43 'hostname': host,
44 'status': hoststatus
45 })
46
47 if (payload['status'] == "successful"):
48 status = 'was successful'
49 else:
50 status = 'failed'
51
52 return ANSIBLETOWER_JOB_MESSAGE_TEMPLATE.format(
53 name=payload['name'],
54 friendly_name=payload['friendly_name'],
55 id=payload['id'],
56 url=payload['url'],
57 status=status,
58 hosts_final_data=get_hosts_content(hosts_data)
59 )
60
61 else:
62
63 if (payload['status'] == "successful"):
64 status = 'was successful'
65 else:
66 status = 'failed'
67
68 data = {
69 "name": payload['name'],
70 "friendly_name": payload['friendly_name'],
71 "id": payload['id'],
72 "url": payload['url'],
73 "status": status
74 }
75
76 return ANSIBLETOWER_DEFAULT_MESSAGE_TEMPLATE.format(**data)
77
78 def get_hosts_content(hosts_data: List[Dict[str, Any]]) -> str:
79 hosts_data = sorted(hosts_data, key=operator.itemgetter('hostname'))
80 hosts_content = ''
81 for host in hosts_data:
82 hosts_content += ANSIBLETOWER_JOB_HOST_ROW_TEMPLATE.format(
83 hostname=host.get('hostname'),
84 status=host.get('status')
85 )
86 return hosts_content
87
[end of zerver/webhooks/ansibletower/view.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zerver/webhooks/ansibletower/view.py b/zerver/webhooks/ansibletower/view.py
--- a/zerver/webhooks/ansibletower/view.py
+++ b/zerver/webhooks/ansibletower/view.py
@@ -30,8 +30,19 @@
check_send_webhook_message(request, user_profile, subject, body)
return json_success()
+def extract_friendly_name(payload: Dict[str, Any]) -> str:
+ tentative_job_name = payload.get("friendly_name", "")
+ if not tentative_job_name:
+ url = payload["url"]
+ segments = url.split("/")
+ tentative_job_name = segments[-3]
+ if tentative_job_name == "jobs":
+ tentative_job_name = "Job"
+ return tentative_job_name
+
def get_body(payload: Dict[str, Any]) -> str:
- if (payload['friendly_name'] == 'Job'):
+ friendly_name = extract_friendly_name(payload)
+ if (friendly_name == 'Job'):
hosts_list_data = payload['hosts']
hosts_data = []
for host in payload['hosts']:
@@ -51,7 +62,7 @@
return ANSIBLETOWER_JOB_MESSAGE_TEMPLATE.format(
name=payload['name'],
- friendly_name=payload['friendly_name'],
+ friendly_name=friendly_name,
id=payload['id'],
url=payload['url'],
status=status,
@@ -67,7 +78,7 @@
data = {
"name": payload['name'],
- "friendly_name": payload['friendly_name'],
+ "friendly_name": friendly_name,
"id": payload['id'],
"url": payload['url'],
"status": status
|
{"golden_diff": "diff --git a/zerver/webhooks/ansibletower/view.py b/zerver/webhooks/ansibletower/view.py\n--- a/zerver/webhooks/ansibletower/view.py\n+++ b/zerver/webhooks/ansibletower/view.py\n@@ -30,8 +30,19 @@\n check_send_webhook_message(request, user_profile, subject, body)\n return json_success()\n \n+def extract_friendly_name(payload: Dict[str, Any]) -> str:\n+ tentative_job_name = payload.get(\"friendly_name\", \"\")\n+ if not tentative_job_name:\n+ url = payload[\"url\"]\n+ segments = url.split(\"/\")\n+ tentative_job_name = segments[-3]\n+ if tentative_job_name == \"jobs\":\n+ tentative_job_name = \"Job\"\n+ return tentative_job_name\n+\n def get_body(payload: Dict[str, Any]) -> str:\n- if (payload['friendly_name'] == 'Job'):\n+ friendly_name = extract_friendly_name(payload)\n+ if (friendly_name == 'Job'):\n hosts_list_data = payload['hosts']\n hosts_data = []\n for host in payload['hosts']:\n@@ -51,7 +62,7 @@\n \n return ANSIBLETOWER_JOB_MESSAGE_TEMPLATE.format(\n name=payload['name'],\n- friendly_name=payload['friendly_name'],\n+ friendly_name=friendly_name,\n id=payload['id'],\n url=payload['url'],\n status=status,\n@@ -67,7 +78,7 @@\n \n data = {\n \"name\": payload['name'],\n- \"friendly_name\": payload['friendly_name'],\n+ \"friendly_name\": friendly_name,\n \"id\": payload['id'],\n \"url\": payload['url'],\n \"status\": status\n", "issue": "Error with AWX 7.0.0\nHello.\r\nI'm testing integration between **AWX 7.0.0** (Ansible Tower) by sending notifications in **Zulip 2.0.4**.\r\nDuring testing, I encounter an error from Ansible :\r\n\r\n\r\n\r\nAnd I immediatly receive an email warning from Zulip with the following content :\r\n\r\n```Logger root, from module zerver.middleware line 291:\r\nError generated by Ansible (user42@zulip.******.**) on zulip.******.** deployment\r\n\r\nTraceback (most recent call last):\r\n File \"/srv/zulip-venv-cache/ebe617662f96425113e5a75344bbe5a0593f634a/zulip-py3-venv/lib/python3.7/site-packages/django/core/handlers/base.py\", line 185, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/srv/zulip-venv-cache/ebe617662f96425113e5a75344bbe5a0593f634a/zulip-py3-venv/lib/python3.7/site-packages/django/views/decorators/csrf.py\", line 58, in wrapped_view\r\n return view_func(*args, **kwargs)\r\n File \"./zerver/lib/request.py\", line 289, in _wrapped_view_func\r\n return view_func(request, *args, **kwargs)\r\n File \"./zerver/decorator.py\", line 375, in _wrapped_func_arguments\r\n raise err\r\n File \"./zerver/decorator.py\", line 361, in _wrapped_func_arguments\r\n return view_func(request, user_profile, *args, **kwargs)\r\n File \"./zerver/lib/request.py\", line 289, in _wrapped_view_func\r\n return view_func(request, *args, **kwargs)\r\n File \"./zerver/webhooks/ansibletower/view.py\", line 27, in api_ansibletower_webhook\r\n body = get_body(payload)\r\n File \"./zerver/webhooks/ansibletower/view.py\", line 34, in get_body\r\n if (payload['friendly_name'] == 'Job'):\r\nKeyError: 'friendly_name'\r\n\r\n\r\nDeployed code:\r\n- git: 2.0.0-2546-ga1fa0b011\r\n- ZULIP_VERSION: 2.0.4+git\r\n\r\n\r\nRequest info:\r\n- path: /api/v1/external/ansibletower\r\n- POST: {}\r\n- REMOTE_ADDR: \"['10.10.36.6']\"\r\n- QUERY_STRING: \"['api_key=******&topic=******&stream=******&topic=******\"\r\n- SERVER_NAME: \"['']\"\r\n```\r\n\r\nI have already disable the \"Disable SSL checking\" but it seems also that the new version of AWX (the 7.0.0) contains new options for webhook like \"HTTP Headers\" and \"HTTP Method\".\r\n\r\n\r\n\r\nNote that I have already notifications from GitLab so the notification service works in my self-hosted Zulip configuration.\n", "before_files": [{"content": "import operator\nfrom typing import Any, Dict, List\n\nfrom django.http import HttpRequest, HttpResponse\n\nfrom zerver.decorator import REQ, api_key_only_webhook_view, \\\n has_request_variables\nfrom zerver.lib.response import json_success\nfrom zerver.lib.webhooks.common import check_send_webhook_message\nfrom zerver.models import UserProfile\n\nANSIBLETOWER_DEFAULT_MESSAGE_TEMPLATE = \"{friendly_name}: [#{id} {name}]({url}) {status}.\"\n\n\nANSIBLETOWER_JOB_MESSAGE_TEMPLATE = \"\"\"\n{friendly_name}: [#{id} {name}]({url}) {status}:\n{hosts_final_data}\n\"\"\".strip()\n\nANSIBLETOWER_JOB_HOST_ROW_TEMPLATE = '* {hostname}: {status}\\n'\n\n@api_key_only_webhook_view('Ansibletower')\n@has_request_variables\ndef api_ansibletower_webhook(request: HttpRequest, user_profile: UserProfile,\n payload: Dict[str, Any]=REQ(argument_type='body')) -> HttpResponse:\n\n body = get_body(payload)\n subject = payload['name']\n\n check_send_webhook_message(request, user_profile, subject, body)\n return json_success()\n\ndef get_body(payload: Dict[str, Any]) -> str:\n if (payload['friendly_name'] == 'Job'):\n hosts_list_data = payload['hosts']\n hosts_data = []\n for host in payload['hosts']:\n if (hosts_list_data[host].get('failed') is True):\n hoststatus = 'Failed'\n elif (hosts_list_data[host].get('failed') is False):\n hoststatus = 'Success'\n hosts_data.append({\n 'hostname': host,\n 'status': hoststatus\n })\n\n if (payload['status'] == \"successful\"):\n status = 'was successful'\n else:\n status = 'failed'\n\n return ANSIBLETOWER_JOB_MESSAGE_TEMPLATE.format(\n name=payload['name'],\n friendly_name=payload['friendly_name'],\n id=payload['id'],\n url=payload['url'],\n status=status,\n hosts_final_data=get_hosts_content(hosts_data)\n )\n\n else:\n\n if (payload['status'] == \"successful\"):\n status = 'was successful'\n else:\n status = 'failed'\n\n data = {\n \"name\": payload['name'],\n \"friendly_name\": payload['friendly_name'],\n \"id\": payload['id'],\n \"url\": payload['url'],\n \"status\": status\n }\n\n return ANSIBLETOWER_DEFAULT_MESSAGE_TEMPLATE.format(**data)\n\ndef get_hosts_content(hosts_data: List[Dict[str, Any]]) -> str:\n hosts_data = sorted(hosts_data, key=operator.itemgetter('hostname'))\n hosts_content = ''\n for host in hosts_data:\n hosts_content += ANSIBLETOWER_JOB_HOST_ROW_TEMPLATE.format(\n hostname=host.get('hostname'),\n status=host.get('status')\n )\n return hosts_content\n", "path": "zerver/webhooks/ansibletower/view.py"}]}
| 2,180 | 383 |
gh_patches_debug_24613
|
rasdani/github-patches
|
git_diff
|
openshift__openshift-ansible-5619
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
docker_image_availability check fails, repo url divided into single character urls
#### Description
Looks to be a tokenizing error in the `docker_image_availability` check
```
Failure summary:
1. Hosts: infra.lab.variantweb.net, master.lab.variantweb.net, node1.lab.variantweb.net
Play: Verify Requirements
Task: openshift_health_check
Message: One or more checks failed
Details: check "docker_image_availability":
One or more required Docker images are not available:
openshift3/ose-deployer:v3.7.0-0.127.0,
openshift3/ose-docker-registry:v3.7.0-0.127.0,
openshift3/ose-haproxy-router:v3.7.0-0.127.0,
openshift3/ose-pod:v3.7.0-0.127.0
Configured registries: r (unreachable), e (unreachable), g (unreachable), i (unreachable), s (unreachable), t (unreachable), r (unreachable), y (unreachable), . (unreachable), o (unreachable), p (unreachable), s (unreachable), . (unreachable), o (unreachable), p (unreachable), e (unreachable), n (unreachable), s (unreachable), h (unreachable), i (unreachable), f (unreachable), t (unreachable), . (unreachable), c (unreachable), o (unreachable), m (unreachable), registry.access.redhat.com
Checked by: timeout 10 skopeo inspect --tls-verify=false docker://{registry}/{image}
```
##### Version
```
$ ansible --version
ansible 2.3.2.0
config file = /home/sjennings/projects/go/src/github.com/openshift/openshift-ansible/ansible.cfg
configured module search path = Default w/o overrides
python version = 2.7.13 (default, Jun 26 2017, 10:20:05) [GCC 7.1.1 20170622 (Red Hat 7.1.1-3)]
$ git describe
openshift-ansible-3.7.0-0.135.0-10-g62cb2a8d5
```
##### Steps To Reproduce
1. run playbook/byo/config.yml
2. playbook fails with above error
##### Expected Results
Installation check succeeds and each character of the `openshift_docker_additional_registries` is not treated as an individual repo url.
@sdodson
</issue>
<code>
[start of roles/openshift_health_checker/openshift_checks/docker_image_availability.py]
1 """Check that required Docker images are available."""
2
3 from openshift_checks import OpenShiftCheck
4 from openshift_checks.mixins import DockerHostMixin
5
6
7 NODE_IMAGE_SUFFIXES = ["haproxy-router", "docker-registry", "deployer", "pod"]
8 DEPLOYMENT_IMAGE_INFO = {
9 "origin": {
10 "namespace": "openshift",
11 "name": "origin",
12 "registry_console_image": "cockpit/kubernetes",
13 },
14 "openshift-enterprise": {
15 "namespace": "openshift3",
16 "name": "ose",
17 "registry_console_image": "registry.access.redhat.com/openshift3/registry-console",
18 },
19 }
20
21
22 class DockerImageAvailability(DockerHostMixin, OpenShiftCheck):
23 """Check that required Docker images are available.
24
25 Determine docker images that an install would require and check that they
26 are either present in the host's docker index, or available for the host to pull
27 with known registries as defined in our inventory file (or defaults).
28 """
29
30 name = "docker_image_availability"
31 tags = ["preflight"]
32 # we use python-docker-py to check local docker for images, and skopeo
33 # to look for images available remotely without waiting to pull them.
34 dependencies = ["python-docker-py", "skopeo"]
35 skopeo_img_check_command = "timeout 10 skopeo inspect --tls-verify=false docker://{registry}/{image}"
36
37 def __init__(self, *args, **kwargs):
38 super(DockerImageAvailability, self).__init__(*args, **kwargs)
39 # record whether we could reach a registry or not (and remember results)
40 self.reachable_registries = {}
41
42 def is_active(self):
43 """Skip hosts with unsupported deployment types."""
44 deployment_type = self.get_var("openshift_deployment_type")
45 has_valid_deployment_type = deployment_type in DEPLOYMENT_IMAGE_INFO
46
47 return super(DockerImageAvailability, self).is_active() and has_valid_deployment_type
48
49 def run(self):
50 msg, failed = self.ensure_dependencies()
51 if failed:
52 return {
53 "failed": True,
54 "msg": "Some dependencies are required in order to check Docker image availability.\n" + msg
55 }
56
57 required_images = self.required_images()
58 missing_images = set(required_images) - set(self.local_images(required_images))
59
60 # exit early if all images were found locally
61 if not missing_images:
62 return {}
63
64 registries = self.known_docker_registries()
65 if not registries:
66 return {"failed": True, "msg": "Unable to retrieve any docker registries."}
67
68 available_images = self.available_images(missing_images, registries)
69 unavailable_images = set(missing_images) - set(available_images)
70
71 if unavailable_images:
72 registries = [
73 reg if self.reachable_registries.get(reg, True) else reg + " (unreachable)"
74 for reg in registries
75 ]
76 msg = (
77 "One or more required Docker images are not available:\n {}\n"
78 "Configured registries: {}\n"
79 "Checked by: {}"
80 ).format(
81 ",\n ".join(sorted(unavailable_images)),
82 ", ".join(registries),
83 self.skopeo_img_check_command
84 )
85
86 return dict(failed=True, msg=msg)
87
88 return {}
89
90 def required_images(self):
91 """
92 Determine which images we expect to need for this host.
93 Returns: a set of required images like 'openshift/origin:v3.6'
94
95 The thorny issue of determining the image names from the variables is under consideration
96 via https://github.com/openshift/openshift-ansible/issues/4415
97
98 For now we operate as follows:
99 * For containerized components (master, node, ...) we look at the deployment type and
100 use openshift/origin or openshift3/ose as the base for those component images. The
101 version is openshift_image_tag as determined by the openshift_version role.
102 * For OpenShift-managed infrastructure (router, registry...) we use oreg_url if
103 it is defined; otherwise we again use the base that depends on the deployment type.
104 Registry is not included in constructed images. It may be in oreg_url or etcd image.
105 """
106 required = set()
107 deployment_type = self.get_var("openshift_deployment_type")
108 host_groups = self.get_var("group_names")
109 # containerized etcd may not have openshift_image_tag, see bz 1466622
110 image_tag = self.get_var("openshift_image_tag", default="latest")
111 image_info = DEPLOYMENT_IMAGE_INFO[deployment_type]
112
113 # template for images that run on top of OpenShift
114 image_url = "{}/{}-{}:{}".format(image_info["namespace"], image_info["name"], "${component}", "${version}")
115 image_url = self.get_var("oreg_url", default="") or image_url
116 if 'nodes' in host_groups:
117 for suffix in NODE_IMAGE_SUFFIXES:
118 required.add(image_url.replace("${component}", suffix).replace("${version}", image_tag))
119 # The registry-console is for some reason not prefixed with ose- like the other components.
120 # Nor is it versioned the same, so just look for latest.
121 # Also a completely different name is used for Origin.
122 required.add(image_info["registry_console_image"])
123
124 # images for containerized components
125 if self.get_var("openshift", "common", "is_containerized"):
126 components = set()
127 if 'nodes' in host_groups:
128 components.update(["node", "openvswitch"])
129 if 'masters' in host_groups: # name is "origin" or "ose"
130 components.add(image_info["name"])
131 for component in components:
132 required.add("{}/{}:{}".format(image_info["namespace"], component, image_tag))
133 if 'etcd' in host_groups: # special case, note it is the same for origin/enterprise
134 required.add("registry.access.redhat.com/rhel7/etcd") # and no image tag
135
136 return required
137
138 def local_images(self, images):
139 """Filter a list of images and return those available locally."""
140 registries = self.known_docker_registries()
141 found_images = []
142 for image in images:
143 # docker could have the image name as-is or prefixed with any registry
144 imglist = [image] + [reg + "/" + image for reg in registries]
145 if self.is_image_local(imglist):
146 found_images.append(image)
147 return found_images
148
149 def is_image_local(self, image):
150 """Check if image is already in local docker index."""
151 result = self.execute_module("docker_image_facts", {"name": image})
152 return bool(result.get("images")) and not result.get("failed")
153
154 def known_docker_registries(self):
155 """Build a list of docker registries available according to inventory vars."""
156 regs = list(self.get_var("openshift_docker_additional_registries", default=[]))
157
158 deployment_type = self.get_var("openshift_deployment_type")
159 if deployment_type == "origin" and "docker.io" not in regs:
160 regs.append("docker.io")
161 elif deployment_type == 'openshift-enterprise' and "registry.access.redhat.com" not in regs:
162 regs.append("registry.access.redhat.com")
163
164 return regs
165
166 def available_images(self, images, default_registries):
167 """Search remotely for images. Returns: list of images found."""
168 return [
169 image for image in images
170 if self.is_available_skopeo_image(image, default_registries)
171 ]
172
173 def is_available_skopeo_image(self, image, default_registries):
174 """Use Skopeo to determine if required image exists in known registry(s)."""
175 registries = default_registries
176
177 # If image already includes a registry, only use that.
178 # NOTE: This logic would incorrectly identify images that do not use a namespace, e.g.
179 # registry.access.redhat.com/rhel7 as if the registry were a namespace.
180 # It's not clear that there's any way to distinguish them, but fortunately
181 # the current set of images all look like [registry/]namespace/name[:version].
182 if image.count("/") > 1:
183 registry, image = image.split("/", 1)
184 registries = [registry]
185
186 for registry in registries:
187 if registry not in self.reachable_registries:
188 self.reachable_registries[registry] = self.connect_to_registry(registry)
189 if not self.reachable_registries[registry]:
190 continue
191
192 args = {"_raw_params": self.skopeo_img_check_command.format(registry=registry, image=image)}
193 result = self.execute_module_with_retries("command", args)
194 if result.get("rc", 0) == 0 and not result.get("failed"):
195 return True
196 if result.get("rc") == 124: # RC 124 == timed out; mark unreachable
197 self.reachable_registries[registry] = False
198
199 return False
200
201 def connect_to_registry(self, registry):
202 """Use ansible wait_for module to test connectivity from host to registry. Returns bool."""
203 # test a simple TCP connection
204 host, _, port = registry.partition(":")
205 port = port or 443
206 args = dict(host=host, port=port, state="started", timeout=30)
207 result = self.execute_module("wait_for", args)
208 return result.get("rc", 0) == 0 and not result.get("failed")
209
[end of roles/openshift_health_checker/openshift_checks/docker_image_availability.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/roles/openshift_health_checker/openshift_checks/docker_image_availability.py b/roles/openshift_health_checker/openshift_checks/docker_image_availability.py
--- a/roles/openshift_health_checker/openshift_checks/docker_image_availability.py
+++ b/roles/openshift_health_checker/openshift_checks/docker_image_availability.py
@@ -1,5 +1,6 @@
"""Check that required Docker images are available."""
+from ansible.module_utils import six
from openshift_checks import OpenShiftCheck
from openshift_checks.mixins import DockerHostMixin
@@ -153,7 +154,15 @@
def known_docker_registries(self):
"""Build a list of docker registries available according to inventory vars."""
- regs = list(self.get_var("openshift_docker_additional_registries", default=[]))
+ regs = self.get_var("openshift_docker_additional_registries", default=[])
+ # https://bugzilla.redhat.com/show_bug.cgi?id=1497274
+ # if the result was a string type, place it into a list. We must do this
+ # as using list() on a string will split the string into its characters.
+ if isinstance(regs, six.string_types):
+ regs = [regs]
+ else:
+ # Otherwise cast to a list as was done previously
+ regs = list(regs)
deployment_type = self.get_var("openshift_deployment_type")
if deployment_type == "origin" and "docker.io" not in regs:
|
{"golden_diff": "diff --git a/roles/openshift_health_checker/openshift_checks/docker_image_availability.py b/roles/openshift_health_checker/openshift_checks/docker_image_availability.py\n--- a/roles/openshift_health_checker/openshift_checks/docker_image_availability.py\n+++ b/roles/openshift_health_checker/openshift_checks/docker_image_availability.py\n@@ -1,5 +1,6 @@\n \"\"\"Check that required Docker images are available.\"\"\"\n \n+from ansible.module_utils import six\n from openshift_checks import OpenShiftCheck\n from openshift_checks.mixins import DockerHostMixin\n \n@@ -153,7 +154,15 @@\n \n def known_docker_registries(self):\n \"\"\"Build a list of docker registries available according to inventory vars.\"\"\"\n- regs = list(self.get_var(\"openshift_docker_additional_registries\", default=[]))\n+ regs = self.get_var(\"openshift_docker_additional_registries\", default=[])\n+ # https://bugzilla.redhat.com/show_bug.cgi?id=1497274\n+ # if the result was a string type, place it into a list. We must do this\n+ # as using list() on a string will split the string into its characters.\n+ if isinstance(regs, six.string_types):\n+ regs = [regs]\n+ else:\n+ # Otherwise cast to a list as was done previously\n+ regs = list(regs)\n \n deployment_type = self.get_var(\"openshift_deployment_type\")\n if deployment_type == \"origin\" and \"docker.io\" not in regs:\n", "issue": "docker_image_availability check fails, repo url divided into single character urls\n#### Description\r\n\r\nLooks to be a tokenizing error in the `docker_image_availability` check\r\n```\r\nFailure summary:\r\n\r\n\r\n 1. Hosts: infra.lab.variantweb.net, master.lab.variantweb.net, node1.lab.variantweb.net\r\n Play: Verify Requirements\r\n Task: openshift_health_check\r\n Message: One or more checks failed\r\n Details: check \"docker_image_availability\":\r\n One or more required Docker images are not available:\r\n openshift3/ose-deployer:v3.7.0-0.127.0,\r\n openshift3/ose-docker-registry:v3.7.0-0.127.0,\r\n openshift3/ose-haproxy-router:v3.7.0-0.127.0,\r\n openshift3/ose-pod:v3.7.0-0.127.0\r\n Configured registries: r (unreachable), e (unreachable), g (unreachable), i (unreachable), s (unreachable), t (unreachable), r (unreachable), y (unreachable), . (unreachable), o (unreachable), p (unreachable), s (unreachable), . (unreachable), o (unreachable), p (unreachable), e (unreachable), n (unreachable), s (unreachable), h (unreachable), i (unreachable), f (unreachable), t (unreachable), . (unreachable), c (unreachable), o (unreachable), m (unreachable), registry.access.redhat.com\r\n Checked by: timeout 10 skopeo inspect --tls-verify=false docker://{registry}/{image}\r\n```\r\n\r\n##### Version\r\n\r\n```\r\n$ ansible --version\r\nansible 2.3.2.0\r\n config file = /home/sjennings/projects/go/src/github.com/openshift/openshift-ansible/ansible.cfg\r\n configured module search path = Default w/o overrides\r\n python version = 2.7.13 (default, Jun 26 2017, 10:20:05) [GCC 7.1.1 20170622 (Red Hat 7.1.1-3)]\r\n\r\n$ git describe\r\nopenshift-ansible-3.7.0-0.135.0-10-g62cb2a8d5\r\n```\r\n\r\n##### Steps To Reproduce\r\n1. run playbook/byo/config.yml\r\n2. playbook fails with above error\r\n\r\n##### Expected Results\r\nInstallation check succeeds and each character of the `openshift_docker_additional_registries` is not treated as an individual repo url.\r\n\r\n@sdodson \n", "before_files": [{"content": "\"\"\"Check that required Docker images are available.\"\"\"\n\nfrom openshift_checks import OpenShiftCheck\nfrom openshift_checks.mixins import DockerHostMixin\n\n\nNODE_IMAGE_SUFFIXES = [\"haproxy-router\", \"docker-registry\", \"deployer\", \"pod\"]\nDEPLOYMENT_IMAGE_INFO = {\n \"origin\": {\n \"namespace\": \"openshift\",\n \"name\": \"origin\",\n \"registry_console_image\": \"cockpit/kubernetes\",\n },\n \"openshift-enterprise\": {\n \"namespace\": \"openshift3\",\n \"name\": \"ose\",\n \"registry_console_image\": \"registry.access.redhat.com/openshift3/registry-console\",\n },\n}\n\n\nclass DockerImageAvailability(DockerHostMixin, OpenShiftCheck):\n \"\"\"Check that required Docker images are available.\n\n Determine docker images that an install would require and check that they\n are either present in the host's docker index, or available for the host to pull\n with known registries as defined in our inventory file (or defaults).\n \"\"\"\n\n name = \"docker_image_availability\"\n tags = [\"preflight\"]\n # we use python-docker-py to check local docker for images, and skopeo\n # to look for images available remotely without waiting to pull them.\n dependencies = [\"python-docker-py\", \"skopeo\"]\n skopeo_img_check_command = \"timeout 10 skopeo inspect --tls-verify=false docker://{registry}/{image}\"\n\n def __init__(self, *args, **kwargs):\n super(DockerImageAvailability, self).__init__(*args, **kwargs)\n # record whether we could reach a registry or not (and remember results)\n self.reachable_registries = {}\n\n def is_active(self):\n \"\"\"Skip hosts with unsupported deployment types.\"\"\"\n deployment_type = self.get_var(\"openshift_deployment_type\")\n has_valid_deployment_type = deployment_type in DEPLOYMENT_IMAGE_INFO\n\n return super(DockerImageAvailability, self).is_active() and has_valid_deployment_type\n\n def run(self):\n msg, failed = self.ensure_dependencies()\n if failed:\n return {\n \"failed\": True,\n \"msg\": \"Some dependencies are required in order to check Docker image availability.\\n\" + msg\n }\n\n required_images = self.required_images()\n missing_images = set(required_images) - set(self.local_images(required_images))\n\n # exit early if all images were found locally\n if not missing_images:\n return {}\n\n registries = self.known_docker_registries()\n if not registries:\n return {\"failed\": True, \"msg\": \"Unable to retrieve any docker registries.\"}\n\n available_images = self.available_images(missing_images, registries)\n unavailable_images = set(missing_images) - set(available_images)\n\n if unavailable_images:\n registries = [\n reg if self.reachable_registries.get(reg, True) else reg + \" (unreachable)\"\n for reg in registries\n ]\n msg = (\n \"One or more required Docker images are not available:\\n {}\\n\"\n \"Configured registries: {}\\n\"\n \"Checked by: {}\"\n ).format(\n \",\\n \".join(sorted(unavailable_images)),\n \", \".join(registries),\n self.skopeo_img_check_command\n )\n\n return dict(failed=True, msg=msg)\n\n return {}\n\n def required_images(self):\n \"\"\"\n Determine which images we expect to need for this host.\n Returns: a set of required images like 'openshift/origin:v3.6'\n\n The thorny issue of determining the image names from the variables is under consideration\n via https://github.com/openshift/openshift-ansible/issues/4415\n\n For now we operate as follows:\n * For containerized components (master, node, ...) we look at the deployment type and\n use openshift/origin or openshift3/ose as the base for those component images. The\n version is openshift_image_tag as determined by the openshift_version role.\n * For OpenShift-managed infrastructure (router, registry...) we use oreg_url if\n it is defined; otherwise we again use the base that depends on the deployment type.\n Registry is not included in constructed images. It may be in oreg_url or etcd image.\n \"\"\"\n required = set()\n deployment_type = self.get_var(\"openshift_deployment_type\")\n host_groups = self.get_var(\"group_names\")\n # containerized etcd may not have openshift_image_tag, see bz 1466622\n image_tag = self.get_var(\"openshift_image_tag\", default=\"latest\")\n image_info = DEPLOYMENT_IMAGE_INFO[deployment_type]\n\n # template for images that run on top of OpenShift\n image_url = \"{}/{}-{}:{}\".format(image_info[\"namespace\"], image_info[\"name\"], \"${component}\", \"${version}\")\n image_url = self.get_var(\"oreg_url\", default=\"\") or image_url\n if 'nodes' in host_groups:\n for suffix in NODE_IMAGE_SUFFIXES:\n required.add(image_url.replace(\"${component}\", suffix).replace(\"${version}\", image_tag))\n # The registry-console is for some reason not prefixed with ose- like the other components.\n # Nor is it versioned the same, so just look for latest.\n # Also a completely different name is used for Origin.\n required.add(image_info[\"registry_console_image\"])\n\n # images for containerized components\n if self.get_var(\"openshift\", \"common\", \"is_containerized\"):\n components = set()\n if 'nodes' in host_groups:\n components.update([\"node\", \"openvswitch\"])\n if 'masters' in host_groups: # name is \"origin\" or \"ose\"\n components.add(image_info[\"name\"])\n for component in components:\n required.add(\"{}/{}:{}\".format(image_info[\"namespace\"], component, image_tag))\n if 'etcd' in host_groups: # special case, note it is the same for origin/enterprise\n required.add(\"registry.access.redhat.com/rhel7/etcd\") # and no image tag\n\n return required\n\n def local_images(self, images):\n \"\"\"Filter a list of images and return those available locally.\"\"\"\n registries = self.known_docker_registries()\n found_images = []\n for image in images:\n # docker could have the image name as-is or prefixed with any registry\n imglist = [image] + [reg + \"/\" + image for reg in registries]\n if self.is_image_local(imglist):\n found_images.append(image)\n return found_images\n\n def is_image_local(self, image):\n \"\"\"Check if image is already in local docker index.\"\"\"\n result = self.execute_module(\"docker_image_facts\", {\"name\": image})\n return bool(result.get(\"images\")) and not result.get(\"failed\")\n\n def known_docker_registries(self):\n \"\"\"Build a list of docker registries available according to inventory vars.\"\"\"\n regs = list(self.get_var(\"openshift_docker_additional_registries\", default=[]))\n\n deployment_type = self.get_var(\"openshift_deployment_type\")\n if deployment_type == \"origin\" and \"docker.io\" not in regs:\n regs.append(\"docker.io\")\n elif deployment_type == 'openshift-enterprise' and \"registry.access.redhat.com\" not in regs:\n regs.append(\"registry.access.redhat.com\")\n\n return regs\n\n def available_images(self, images, default_registries):\n \"\"\"Search remotely for images. Returns: list of images found.\"\"\"\n return [\n image for image in images\n if self.is_available_skopeo_image(image, default_registries)\n ]\n\n def is_available_skopeo_image(self, image, default_registries):\n \"\"\"Use Skopeo to determine if required image exists in known registry(s).\"\"\"\n registries = default_registries\n\n # If image already includes a registry, only use that.\n # NOTE: This logic would incorrectly identify images that do not use a namespace, e.g.\n # registry.access.redhat.com/rhel7 as if the registry were a namespace.\n # It's not clear that there's any way to distinguish them, but fortunately\n # the current set of images all look like [registry/]namespace/name[:version].\n if image.count(\"/\") > 1:\n registry, image = image.split(\"/\", 1)\n registries = [registry]\n\n for registry in registries:\n if registry not in self.reachable_registries:\n self.reachable_registries[registry] = self.connect_to_registry(registry)\n if not self.reachable_registries[registry]:\n continue\n\n args = {\"_raw_params\": self.skopeo_img_check_command.format(registry=registry, image=image)}\n result = self.execute_module_with_retries(\"command\", args)\n if result.get(\"rc\", 0) == 0 and not result.get(\"failed\"):\n return True\n if result.get(\"rc\") == 124: # RC 124 == timed out; mark unreachable\n self.reachable_registries[registry] = False\n\n return False\n\n def connect_to_registry(self, registry):\n \"\"\"Use ansible wait_for module to test connectivity from host to registry. Returns bool.\"\"\"\n # test a simple TCP connection\n host, _, port = registry.partition(\":\")\n port = port or 443\n args = dict(host=host, port=port, state=\"started\", timeout=30)\n result = self.execute_module(\"wait_for\", args)\n return result.get(\"rc\", 0) == 0 and not result.get(\"failed\")\n", "path": "roles/openshift_health_checker/openshift_checks/docker_image_availability.py"}]}
| 3,774 | 344 |
gh_patches_debug_28712
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-648
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New custom user statuses should appear in !user
Related to #620, we must moderate the new custom statuses, but they don't appear when we issue a !user command. These should be included to form part of the channel record for moderation purposes.
</issue>
<code>
[start of bot/cogs/information.py]
1 import colorsys
2 import logging
3 import pprint
4 import textwrap
5 import typing
6 from typing import Any, Mapping, Optional
7
8 import discord
9 from discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils
10 from discord.ext import commands
11 from discord.ext.commands import Bot, BucketType, Cog, Context, command, group
12
13 from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES
14 from bot.decorators import InChannelCheckFailure, in_channel, with_role
15 from bot.utils.checks import cooldown_with_role_bypass, with_role_check
16 from bot.utils.time import time_since
17
18 log = logging.getLogger(__name__)
19
20
21 class Information(Cog):
22 """A cog with commands for generating embeds with server info, such as server stats and user info."""
23
24 def __init__(self, bot: Bot):
25 self.bot = bot
26
27 @with_role(*MODERATION_ROLES)
28 @command(name="roles")
29 async def roles_info(self, ctx: Context) -> None:
30 """Returns a list of all roles and their corresponding IDs."""
31 # Sort the roles alphabetically and remove the @everyone role
32 roles = sorted(ctx.guild.roles, key=lambda role: role.name)
33 roles = [role for role in roles if role.name != "@everyone"]
34
35 # Build a string
36 role_string = ""
37 for role in roles:
38 role_string += f"`{role.id}` - {role.mention}\n"
39
40 # Build an embed
41 embed = Embed(
42 title="Role information",
43 colour=Colour.blurple(),
44 description=role_string
45 )
46
47 embed.set_footer(text=f"Total roles: {len(roles)}")
48
49 await ctx.send(embed=embed)
50
51 @with_role(*MODERATION_ROLES)
52 @command(name="role")
53 async def role_info(self, ctx: Context, *roles: typing.Union[Role, str]) -> None:
54 """
55 Return information on a role or list of roles.
56
57 To specify multiple roles just add to the arguments, delimit roles with spaces in them using quotation marks.
58 """
59 parsed_roles = []
60
61 for role_name in roles:
62 if isinstance(role_name, Role):
63 # Role conversion has already succeeded
64 parsed_roles.append(role_name)
65 continue
66
67 role = utils.find(lambda r: r.name.lower() == role_name.lower(), ctx.guild.roles)
68
69 if not role:
70 await ctx.send(f":x: Could not convert `{role_name}` to a role")
71 continue
72
73 parsed_roles.append(role)
74
75 for role in parsed_roles:
76 embed = Embed(
77 title=f"{role.name} info",
78 colour=role.colour,
79 )
80
81 embed.add_field(name="ID", value=role.id, inline=True)
82
83 embed.add_field(name="Colour (RGB)", value=f"#{role.colour.value:0>6x}", inline=True)
84
85 h, s, v = colorsys.rgb_to_hsv(*role.colour.to_rgb())
86
87 embed.add_field(name="Colour (HSV)", value=f"{h:.2f} {s:.2f} {v}", inline=True)
88
89 embed.add_field(name="Member count", value=len(role.members), inline=True)
90
91 embed.add_field(name="Position", value=role.position)
92
93 embed.add_field(name="Permission code", value=role.permissions.value, inline=True)
94
95 await ctx.send(embed=embed)
96
97 @command(name="server", aliases=["server_info", "guild", "guild_info"])
98 async def server_info(self, ctx: Context) -> None:
99 """Returns an embed full of server information."""
100 created = time_since(ctx.guild.created_at, precision="days")
101 features = ", ".join(ctx.guild.features)
102 region = ctx.guild.region
103
104 # How many of each type of channel?
105 roles = len(ctx.guild.roles)
106 channels = ctx.guild.channels
107 text_channels = 0
108 category_channels = 0
109 voice_channels = 0
110 for channel in channels:
111 if type(channel) == TextChannel:
112 text_channels += 1
113 elif type(channel) == CategoryChannel:
114 category_channels += 1
115 elif type(channel) == VoiceChannel:
116 voice_channels += 1
117
118 # How many of each user status?
119 member_count = ctx.guild.member_count
120 members = ctx.guild.members
121 online = 0
122 dnd = 0
123 idle = 0
124 offline = 0
125 for member in members:
126 if str(member.status) == "online":
127 online += 1
128 elif str(member.status) == "offline":
129 offline += 1
130 elif str(member.status) == "idle":
131 idle += 1
132 elif str(member.status) == "dnd":
133 dnd += 1
134
135 embed = Embed(
136 colour=Colour.blurple(),
137 description=textwrap.dedent(f"""
138 **Server information**
139 Created: {created}
140 Voice region: {region}
141 Features: {features}
142
143 **Counts**
144 Members: {member_count:,}
145 Roles: {roles}
146 Text: {text_channels}
147 Voice: {voice_channels}
148 Channel categories: {category_channels}
149
150 **Members**
151 {Emojis.status_online} {online}
152 {Emojis.status_idle} {idle}
153 {Emojis.status_dnd} {dnd}
154 {Emojis.status_offline} {offline}
155 """)
156 )
157
158 embed.set_thumbnail(url=ctx.guild.icon_url)
159
160 await ctx.send(embed=embed)
161
162 @command(name="user", aliases=["user_info", "member", "member_info"])
163 async def user_info(self, ctx: Context, user: Member = None, hidden: bool = False) -> None:
164 """Returns info about a user."""
165 if user is None:
166 user = ctx.author
167
168 # Do a role check if this is being executed on someone other than the caller
169 if user != ctx.author and not with_role_check(ctx, *MODERATION_ROLES):
170 await ctx.send("You may not use this command on users other than yourself.")
171 return
172
173 # Non-moderators may only do this in #bot-commands and can't see hidden infractions.
174 if not with_role_check(ctx, *STAFF_ROLES):
175 if not ctx.channel.id == Channels.bot:
176 raise InChannelCheckFailure(Channels.bot)
177 # Hide hidden infractions for users without a moderation role
178 hidden = False
179
180 # User information
181 created = time_since(user.created_at, max_units=3)
182
183 name = str(user)
184 if user.nick:
185 name = f"{user.nick} ({name})"
186
187 # Member information
188 joined = time_since(user.joined_at, precision="days")
189
190 # You're welcome, Volcyyyyyyyyyyyyyyyy
191 roles = ", ".join(role.mention for role in user.roles if role.name != "@everyone")
192
193 # Infractions
194 infractions = await self.bot.api_client.get(
195 'bot/infractions',
196 params={
197 'hidden': str(hidden),
198 'user__id': str(user.id)
199 }
200 )
201
202 infr_total = 0
203 infr_active = 0
204
205 # At least it's readable.
206 for infr in infractions:
207 if infr["active"]:
208 infr_active += 1
209
210 infr_total += 1
211
212 # Let's build the embed now
213 embed = Embed(
214 title=name,
215 description=textwrap.dedent(f"""
216 **User Information**
217 Created: {created}
218 Profile: {user.mention}
219 ID: {user.id}
220
221 **Member Information**
222 Joined: {joined}
223 Roles: {roles or None}
224
225 **Infractions**
226 Total: {infr_total}
227 Active: {infr_active}
228 """)
229 )
230
231 embed.set_thumbnail(url=user.avatar_url_as(format="png"))
232 embed.colour = user.top_role.colour if roles else Colour.blurple()
233
234 await ctx.send(embed=embed)
235
236 def format_fields(self, mapping: Mapping[str, Any], field_width: Optional[int] = None) -> str:
237 """Format a mapping to be readable to a human."""
238 # sorting is technically superfluous but nice if you want to look for a specific field
239 fields = sorted(mapping.items(), key=lambda item: item[0])
240
241 if field_width is None:
242 field_width = len(max(mapping.keys(), key=len))
243
244 out = ''
245
246 for key, val in fields:
247 if isinstance(val, dict):
248 # if we have dicts inside dicts we want to apply the same treatment to the inner dictionaries
249 inner_width = int(field_width * 1.6)
250 val = '\n' + self.format_fields(val, field_width=inner_width)
251
252 elif isinstance(val, str):
253 # split up text since it might be long
254 text = textwrap.fill(val, width=100, replace_whitespace=False)
255
256 # indent it, I guess you could do this with `wrap` and `join` but this is nicer
257 val = textwrap.indent(text, ' ' * (field_width + len(': ')))
258
259 # the first line is already indented so we `str.lstrip` it
260 val = val.lstrip()
261
262 if key == 'color':
263 # makes the base 10 representation of a hex number readable to humans
264 val = hex(val)
265
266 out += '{0:>{width}}: {1}\n'.format(key, val, width=field_width)
267
268 # remove trailing whitespace
269 return out.rstrip()
270
271 @cooldown_with_role_bypass(2, 60 * 3, BucketType.member, bypass_roles=STAFF_ROLES)
272 @group(invoke_without_command=True)
273 @in_channel(Channels.bot, bypass_roles=STAFF_ROLES)
274 async def raw(self, ctx: Context, *, message: discord.Message, json: bool = False) -> None:
275 """Shows information about the raw API response."""
276 # I *guess* it could be deleted right as the command is invoked but I felt like it wasn't worth handling
277 # doing this extra request is also much easier than trying to convert everything back into a dictionary again
278 raw_data = await ctx.bot.http.get_message(message.channel.id, message.id)
279
280 paginator = commands.Paginator()
281
282 def add_content(title: str, content: str) -> None:
283 paginator.add_line(f'== {title} ==\n')
284 # replace backticks as it breaks out of code blocks. Spaces seemed to be the most reasonable solution.
285 # we hope it's not close to 2000
286 paginator.add_line(content.replace('```', '`` `'))
287 paginator.close_page()
288
289 if message.content:
290 add_content('Raw message', message.content)
291
292 transformer = pprint.pformat if json else self.format_fields
293 for field_name in ('embeds', 'attachments'):
294 data = raw_data[field_name]
295
296 if not data:
297 continue
298
299 total = len(data)
300 for current, item in enumerate(data, start=1):
301 title = f'Raw {field_name} ({current}/{total})'
302 add_content(title, transformer(item))
303
304 for page in paginator.pages:
305 await ctx.send(page)
306
307 @raw.command()
308 async def json(self, ctx: Context, message: discord.Message) -> None:
309 """Shows information about the raw API response in a copy-pasteable Python format."""
310 await ctx.invoke(self.raw, message=message, json=True)
311
312
313 def setup(bot: Bot) -> None:
314 """Information cog load."""
315 bot.add_cog(Information(bot))
316 log.info("Cog loaded: Information")
317
[end of bot/cogs/information.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/information.py b/bot/cogs/information.py
--- a/bot/cogs/information.py
+++ b/bot/cogs/information.py
@@ -9,6 +9,7 @@
from discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils
from discord.ext import commands
from discord.ext.commands import Bot, BucketType, Cog, Context, command, group
+from discord.utils import escape_markdown
from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES
from bot.decorators import InChannelCheckFailure, in_channel, with_role
@@ -180,6 +181,13 @@
# User information
created = time_since(user.created_at, max_units=3)
+ # Custom status
+ custom_status = ''
+ for activity in user.activities:
+ if activity.name == 'Custom Status':
+ state = escape_markdown(activity.state)
+ custom_status = f'Status: {state}\n'
+
name = str(user)
if user.nick:
name = f"{user.nick} ({name})"
@@ -217,7 +225,7 @@
Created: {created}
Profile: {user.mention}
ID: {user.id}
-
+ {custom_status}
**Member Information**
Joined: {joined}
Roles: {roles or None}
|
{"golden_diff": "diff --git a/bot/cogs/information.py b/bot/cogs/information.py\n--- a/bot/cogs/information.py\n+++ b/bot/cogs/information.py\n@@ -9,6 +9,7 @@\n from discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils\n from discord.ext import commands\n from discord.ext.commands import Bot, BucketType, Cog, Context, command, group\n+from discord.utils import escape_markdown\n \n from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES\n from bot.decorators import InChannelCheckFailure, in_channel, with_role\n@@ -180,6 +181,13 @@\n # User information\n created = time_since(user.created_at, max_units=3)\n \n+ # Custom status\n+ custom_status = ''\n+ for activity in user.activities:\n+ if activity.name == 'Custom Status':\n+ state = escape_markdown(activity.state)\n+ custom_status = f'Status: {state}\\n'\n+\n name = str(user)\n if user.nick:\n name = f\"{user.nick} ({name})\"\n@@ -217,7 +225,7 @@\n Created: {created}\n Profile: {user.mention}\n ID: {user.id}\n-\n+ {custom_status}\n **Member Information**\n Joined: {joined}\n Roles: {roles or None}\n", "issue": "New custom user statuses should appear in !user\nRelated to #620, we must moderate the new custom statuses, but they don't appear when we issue a !user command. These should be included to form part of the channel record for moderation purposes.\n", "before_files": [{"content": "import colorsys\nimport logging\nimport pprint\nimport textwrap\nimport typing\nfrom typing import Any, Mapping, Optional\n\nimport discord\nfrom discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils\nfrom discord.ext import commands\nfrom discord.ext.commands import Bot, BucketType, Cog, Context, command, group\n\nfrom bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES\nfrom bot.decorators import InChannelCheckFailure, in_channel, with_role\nfrom bot.utils.checks import cooldown_with_role_bypass, with_role_check\nfrom bot.utils.time import time_since\n\nlog = logging.getLogger(__name__)\n\n\nclass Information(Cog):\n \"\"\"A cog with commands for generating embeds with server info, such as server stats and user info.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n @with_role(*MODERATION_ROLES)\n @command(name=\"roles\")\n async def roles_info(self, ctx: Context) -> None:\n \"\"\"Returns a list of all roles and their corresponding IDs.\"\"\"\n # Sort the roles alphabetically and remove the @everyone role\n roles = sorted(ctx.guild.roles, key=lambda role: role.name)\n roles = [role for role in roles if role.name != \"@everyone\"]\n\n # Build a string\n role_string = \"\"\n for role in roles:\n role_string += f\"`{role.id}` - {role.mention}\\n\"\n\n # Build an embed\n embed = Embed(\n title=\"Role information\",\n colour=Colour.blurple(),\n description=role_string\n )\n\n embed.set_footer(text=f\"Total roles: {len(roles)}\")\n\n await ctx.send(embed=embed)\n\n @with_role(*MODERATION_ROLES)\n @command(name=\"role\")\n async def role_info(self, ctx: Context, *roles: typing.Union[Role, str]) -> None:\n \"\"\"\n Return information on a role or list of roles.\n\n To specify multiple roles just add to the arguments, delimit roles with spaces in them using quotation marks.\n \"\"\"\n parsed_roles = []\n\n for role_name in roles:\n if isinstance(role_name, Role):\n # Role conversion has already succeeded\n parsed_roles.append(role_name)\n continue\n\n role = utils.find(lambda r: r.name.lower() == role_name.lower(), ctx.guild.roles)\n\n if not role:\n await ctx.send(f\":x: Could not convert `{role_name}` to a role\")\n continue\n\n parsed_roles.append(role)\n\n for role in parsed_roles:\n embed = Embed(\n title=f\"{role.name} info\",\n colour=role.colour,\n )\n\n embed.add_field(name=\"ID\", value=role.id, inline=True)\n\n embed.add_field(name=\"Colour (RGB)\", value=f\"#{role.colour.value:0>6x}\", inline=True)\n\n h, s, v = colorsys.rgb_to_hsv(*role.colour.to_rgb())\n\n embed.add_field(name=\"Colour (HSV)\", value=f\"{h:.2f} {s:.2f} {v}\", inline=True)\n\n embed.add_field(name=\"Member count\", value=len(role.members), inline=True)\n\n embed.add_field(name=\"Position\", value=role.position)\n\n embed.add_field(name=\"Permission code\", value=role.permissions.value, inline=True)\n\n await ctx.send(embed=embed)\n\n @command(name=\"server\", aliases=[\"server_info\", \"guild\", \"guild_info\"])\n async def server_info(self, ctx: Context) -> None:\n \"\"\"Returns an embed full of server information.\"\"\"\n created = time_since(ctx.guild.created_at, precision=\"days\")\n features = \", \".join(ctx.guild.features)\n region = ctx.guild.region\n\n # How many of each type of channel?\n roles = len(ctx.guild.roles)\n channels = ctx.guild.channels\n text_channels = 0\n category_channels = 0\n voice_channels = 0\n for channel in channels:\n if type(channel) == TextChannel:\n text_channels += 1\n elif type(channel) == CategoryChannel:\n category_channels += 1\n elif type(channel) == VoiceChannel:\n voice_channels += 1\n\n # How many of each user status?\n member_count = ctx.guild.member_count\n members = ctx.guild.members\n online = 0\n dnd = 0\n idle = 0\n offline = 0\n for member in members:\n if str(member.status) == \"online\":\n online += 1\n elif str(member.status) == \"offline\":\n offline += 1\n elif str(member.status) == \"idle\":\n idle += 1\n elif str(member.status) == \"dnd\":\n dnd += 1\n\n embed = Embed(\n colour=Colour.blurple(),\n description=textwrap.dedent(f\"\"\"\n **Server information**\n Created: {created}\n Voice region: {region}\n Features: {features}\n\n **Counts**\n Members: {member_count:,}\n Roles: {roles}\n Text: {text_channels}\n Voice: {voice_channels}\n Channel categories: {category_channels}\n\n **Members**\n {Emojis.status_online} {online}\n {Emojis.status_idle} {idle}\n {Emojis.status_dnd} {dnd}\n {Emojis.status_offline} {offline}\n \"\"\")\n )\n\n embed.set_thumbnail(url=ctx.guild.icon_url)\n\n await ctx.send(embed=embed)\n\n @command(name=\"user\", aliases=[\"user_info\", \"member\", \"member_info\"])\n async def user_info(self, ctx: Context, user: Member = None, hidden: bool = False) -> None:\n \"\"\"Returns info about a user.\"\"\"\n if user is None:\n user = ctx.author\n\n # Do a role check if this is being executed on someone other than the caller\n if user != ctx.author and not with_role_check(ctx, *MODERATION_ROLES):\n await ctx.send(\"You may not use this command on users other than yourself.\")\n return\n\n # Non-moderators may only do this in #bot-commands and can't see hidden infractions.\n if not with_role_check(ctx, *STAFF_ROLES):\n if not ctx.channel.id == Channels.bot:\n raise InChannelCheckFailure(Channels.bot)\n # Hide hidden infractions for users without a moderation role\n hidden = False\n\n # User information\n created = time_since(user.created_at, max_units=3)\n\n name = str(user)\n if user.nick:\n name = f\"{user.nick} ({name})\"\n\n # Member information\n joined = time_since(user.joined_at, precision=\"days\")\n\n # You're welcome, Volcyyyyyyyyyyyyyyyy\n roles = \", \".join(role.mention for role in user.roles if role.name != \"@everyone\")\n\n # Infractions\n infractions = await self.bot.api_client.get(\n 'bot/infractions',\n params={\n 'hidden': str(hidden),\n 'user__id': str(user.id)\n }\n )\n\n infr_total = 0\n infr_active = 0\n\n # At least it's readable.\n for infr in infractions:\n if infr[\"active\"]:\n infr_active += 1\n\n infr_total += 1\n\n # Let's build the embed now\n embed = Embed(\n title=name,\n description=textwrap.dedent(f\"\"\"\n **User Information**\n Created: {created}\n Profile: {user.mention}\n ID: {user.id}\n\n **Member Information**\n Joined: {joined}\n Roles: {roles or None}\n\n **Infractions**\n Total: {infr_total}\n Active: {infr_active}\n \"\"\")\n )\n\n embed.set_thumbnail(url=user.avatar_url_as(format=\"png\"))\n embed.colour = user.top_role.colour if roles else Colour.blurple()\n\n await ctx.send(embed=embed)\n\n def format_fields(self, mapping: Mapping[str, Any], field_width: Optional[int] = None) -> str:\n \"\"\"Format a mapping to be readable to a human.\"\"\"\n # sorting is technically superfluous but nice if you want to look for a specific field\n fields = sorted(mapping.items(), key=lambda item: item[0])\n\n if field_width is None:\n field_width = len(max(mapping.keys(), key=len))\n\n out = ''\n\n for key, val in fields:\n if isinstance(val, dict):\n # if we have dicts inside dicts we want to apply the same treatment to the inner dictionaries\n inner_width = int(field_width * 1.6)\n val = '\\n' + self.format_fields(val, field_width=inner_width)\n\n elif isinstance(val, str):\n # split up text since it might be long\n text = textwrap.fill(val, width=100, replace_whitespace=False)\n\n # indent it, I guess you could do this with `wrap` and `join` but this is nicer\n val = textwrap.indent(text, ' ' * (field_width + len(': ')))\n\n # the first line is already indented so we `str.lstrip` it\n val = val.lstrip()\n\n if key == 'color':\n # makes the base 10 representation of a hex number readable to humans\n val = hex(val)\n\n out += '{0:>{width}}: {1}\\n'.format(key, val, width=field_width)\n\n # remove trailing whitespace\n return out.rstrip()\n\n @cooldown_with_role_bypass(2, 60 * 3, BucketType.member, bypass_roles=STAFF_ROLES)\n @group(invoke_without_command=True)\n @in_channel(Channels.bot, bypass_roles=STAFF_ROLES)\n async def raw(self, ctx: Context, *, message: discord.Message, json: bool = False) -> None:\n \"\"\"Shows information about the raw API response.\"\"\"\n # I *guess* it could be deleted right as the command is invoked but I felt like it wasn't worth handling\n # doing this extra request is also much easier than trying to convert everything back into a dictionary again\n raw_data = await ctx.bot.http.get_message(message.channel.id, message.id)\n\n paginator = commands.Paginator()\n\n def add_content(title: str, content: str) -> None:\n paginator.add_line(f'== {title} ==\\n')\n # replace backticks as it breaks out of code blocks. Spaces seemed to be the most reasonable solution.\n # we hope it's not close to 2000\n paginator.add_line(content.replace('```', '`` `'))\n paginator.close_page()\n\n if message.content:\n add_content('Raw message', message.content)\n\n transformer = pprint.pformat if json else self.format_fields\n for field_name in ('embeds', 'attachments'):\n data = raw_data[field_name]\n\n if not data:\n continue\n\n total = len(data)\n for current, item in enumerate(data, start=1):\n title = f'Raw {field_name} ({current}/{total})'\n add_content(title, transformer(item))\n\n for page in paginator.pages:\n await ctx.send(page)\n\n @raw.command()\n async def json(self, ctx: Context, message: discord.Message) -> None:\n \"\"\"Shows information about the raw API response in a copy-pasteable Python format.\"\"\"\n await ctx.invoke(self.raw, message=message, json=True)\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Information cog load.\"\"\"\n bot.add_cog(Information(bot))\n log.info(\"Cog loaded: Information\")\n", "path": "bot/cogs/information.py"}]}
| 3,974 | 314 |
gh_patches_debug_29441
|
rasdani/github-patches
|
git_diff
|
goauthentik__authentik-3254
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
404 error for kubernetes depoyment
**Describe the bug**
/if/flow/initial-setup/ endpoint in the browser gives a 404 not found error
**To Reproduce**
Steps to reproduce the behavior:
1. Go to 'https://goauthentik.io/docs/installation/kubernetes'
2. Create Values.yaml
3. run helm commands
4. all pods are up and running
5. go to browser http://<ing-url>/if/flow/initial-setup/
**Expected behavior**
Page should load letting me setup ak-admin password
**Screenshots**
404 not found
**Logs**
{"event": "/api/v3/outposts/instances/", "host": "localhost:8000", "level": "info", "logger": "authentik.asgi", "method": "GET", "pid": 24, "remote": "127.0.0.1", "request_id": "454efe5b57f34713bf837681449b91a6", "runtime": 35, "scheme": "http", "status": 403, "timestamp": "2022-07-11T10:39:00.436171", "user": "", "user_agent": "goauthentik.io/outpost/2022.7.2"}
{"event": "Forbidden: /api/v3/outposts/instances/", "level": "warning", "logger": "django.request", "timestamp": 1657535940.437195}
{"error":"403 Forbidden","event":"Failed to fetch outpost configuration, retrying in 3 seconds","level":"error","logger":"authentik.outpost.ak-api-controller","timestamp":"2022-07-11T10:39:00Z"}
**Version and Deployment (please complete the following information):**
- authentik version: authentik-2022.7.2
- Deployment: [kubectl 1.21, helm v3.1.0]
**Additional context**
Add any other context about the problem here.
</issue>
<code>
[start of lifecycle/migrate.py]
1 #!/usr/bin/env python
2 """System Migration handler"""
3 import os
4 from importlib.util import module_from_spec, spec_from_file_location
5 from inspect import getmembers, isclass
6 from pathlib import Path
7 from typing import Any
8
9 from psycopg2 import connect
10 from structlog.stdlib import get_logger
11
12 from authentik.lib.config import CONFIG
13
14 LOGGER = get_logger()
15 ADV_LOCK_UID = 1000
16 LOCKED = False
17
18
19 class BaseMigration:
20 """Base System Migration"""
21
22 cur: Any
23 con: Any
24
25 def __init__(self, cur: Any, con: Any):
26 self.cur = cur
27 self.con = con
28
29 def needs_migration(self) -> bool:
30 """Return true if Migration needs to be run"""
31 return False
32
33 def run(self):
34 """Run the actual migration"""
35
36
37 def wait_for_lock():
38 """lock an advisory lock to prevent multiple instances from migrating at once"""
39 LOGGER.info("waiting to acquire database lock")
40 curr.execute("SELECT pg_advisory_lock(%s)", (ADV_LOCK_UID,))
41 # pylint: disable=global-statement
42 global LOCKED
43 LOCKED = True
44
45
46 def release_lock():
47 """Release database lock"""
48 if not LOCKED:
49 return
50 curr.execute("SELECT pg_advisory_unlock(%s)", (ADV_LOCK_UID,))
51
52
53 if __name__ == "__main__":
54
55 conn = connect(
56 dbname=CONFIG.y("postgresql.name"),
57 user=CONFIG.y("postgresql.user"),
58 password=CONFIG.y("postgresql.password"),
59 host=CONFIG.y("postgresql.host"),
60 port=int(CONFIG.y("postgresql.port")),
61 )
62 curr = conn.cursor()
63 try:
64 for migration in Path(__file__).parent.absolute().glob("system_migrations/*.py"):
65 spec = spec_from_file_location("lifecycle.system_migrations", migration)
66 mod = module_from_spec(spec)
67 # pyright: reportGeneralTypeIssues=false
68 spec.loader.exec_module(mod)
69
70 for name, sub in getmembers(mod, isclass):
71 if name != "Migration":
72 continue
73 migration = sub(curr, conn)
74 if migration.needs_migration():
75 wait_for_lock()
76 LOGGER.info("Migration needs to be applied", migration=sub)
77 migration.run()
78 LOGGER.info("Migration finished applying", migration=sub)
79 release_lock()
80 LOGGER.info("applying django migrations")
81 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "authentik.root.settings")
82 wait_for_lock()
83 try:
84 from django.core.management import execute_from_command_line
85 except ImportError as exc:
86 raise ImportError(
87 "Couldn't import Django. Are you sure it's installed and "
88 "available on your PYTHONPATH environment variable? Did you "
89 "forget to activate a virtual environment?"
90 ) from exc
91 execute_from_command_line(["", "migrate"])
92 finally:
93 release_lock()
94
[end of lifecycle/migrate.py]
[start of authentik/managed/tasks.py]
1 """managed tasks"""
2 from django.db import DatabaseError
3
4 from authentik.core.tasks import CELERY_APP
5 from authentik.events.monitored_tasks import (
6 MonitoredTask,
7 TaskResult,
8 TaskResultStatus,
9 prefill_task,
10 )
11 from authentik.managed.manager import ObjectManager
12
13
14 @CELERY_APP.task(bind=True, base=MonitoredTask)
15 @prefill_task
16 def managed_reconcile(self: MonitoredTask):
17 """Run ObjectManager to ensure objects are up-to-date"""
18 try:
19 ObjectManager().run()
20 self.set_status(
21 TaskResult(TaskResultStatus.SUCCESSFUL, ["Successfully updated managed models."])
22 )
23 except DatabaseError as exc: # pragma: no cover
24 self.set_status(TaskResult(TaskResultStatus.WARNING, [str(exc)]))
25
[end of authentik/managed/tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/authentik/managed/tasks.py b/authentik/managed/tasks.py
--- a/authentik/managed/tasks.py
+++ b/authentik/managed/tasks.py
@@ -11,7 +11,11 @@
from authentik.managed.manager import ObjectManager
-@CELERY_APP.task(bind=True, base=MonitoredTask)
+@CELERY_APP.task(
+ bind=True,
+ base=MonitoredTask,
+ retry_backoff=True,
+)
@prefill_task
def managed_reconcile(self: MonitoredTask):
"""Run ObjectManager to ensure objects are up-to-date"""
@@ -22,3 +26,4 @@
)
except DatabaseError as exc: # pragma: no cover
self.set_status(TaskResult(TaskResultStatus.WARNING, [str(exc)]))
+ self.retry()
diff --git a/lifecycle/migrate.py b/lifecycle/migrate.py
--- a/lifecycle/migrate.py
+++ b/lifecycle/migrate.py
@@ -1,6 +1,7 @@
#!/usr/bin/env python
"""System Migration handler"""
import os
+import sys
from importlib.util import module_from_spec, spec_from_file_location
from inspect import getmembers, isclass
from pathlib import Path
@@ -50,7 +51,16 @@
curr.execute("SELECT pg_advisory_unlock(%s)", (ADV_LOCK_UID,))
+def is_locked():
+ """Check if lock is currently active (used by worker to wait for migrations)"""
+ curr.executor("SELECT count(*) FROM pg_locks WHERE objid = %s", (ADV_LOCK_UID,))
+ return curr.rowcount
+
+
if __name__ == "__main__":
+ if len(sys.argv) > 1:
+ if sys.argv[1] == "check_lock":
+ sys.exit(is_locked())
conn = connect(
dbname=CONFIG.y("postgresql.name"),
|
{"golden_diff": "diff --git a/authentik/managed/tasks.py b/authentik/managed/tasks.py\n--- a/authentik/managed/tasks.py\n+++ b/authentik/managed/tasks.py\n@@ -11,7 +11,11 @@\n from authentik.managed.manager import ObjectManager\n \n \n-@CELERY_APP.task(bind=True, base=MonitoredTask)\n+@CELERY_APP.task(\n+ bind=True,\n+ base=MonitoredTask,\n+ retry_backoff=True,\n+)\n @prefill_task\n def managed_reconcile(self: MonitoredTask):\n \"\"\"Run ObjectManager to ensure objects are up-to-date\"\"\"\n@@ -22,3 +26,4 @@\n )\n except DatabaseError as exc: # pragma: no cover\n self.set_status(TaskResult(TaskResultStatus.WARNING, [str(exc)]))\n+ self.retry()\ndiff --git a/lifecycle/migrate.py b/lifecycle/migrate.py\n--- a/lifecycle/migrate.py\n+++ b/lifecycle/migrate.py\n@@ -1,6 +1,7 @@\n #!/usr/bin/env python\n \"\"\"System Migration handler\"\"\"\n import os\n+import sys\n from importlib.util import module_from_spec, spec_from_file_location\n from inspect import getmembers, isclass\n from pathlib import Path\n@@ -50,7 +51,16 @@\n curr.execute(\"SELECT pg_advisory_unlock(%s)\", (ADV_LOCK_UID,))\n \n \n+def is_locked():\n+ \"\"\"Check if lock is currently active (used by worker to wait for migrations)\"\"\"\n+ curr.executor(\"SELECT count(*) FROM pg_locks WHERE objid = %s\", (ADV_LOCK_UID,))\n+ return curr.rowcount\n+\n+\n if __name__ == \"__main__\":\n+ if len(sys.argv) > 1:\n+ if sys.argv[1] == \"check_lock\":\n+ sys.exit(is_locked())\n \n conn = connect(\n dbname=CONFIG.y(\"postgresql.name\"),\n", "issue": "404 error for kubernetes depoyment\n**Describe the bug**\r\n/if/flow/initial-setup/ endpoint in the browser gives a 404 not found error\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Go to 'https://goauthentik.io/docs/installation/kubernetes'\r\n2. Create Values.yaml\r\n3. run helm commands\r\n4. all pods are up and running\r\n5. go to browser http://<ing-url>/if/flow/initial-setup/\r\n\r\n**Expected behavior**\r\nPage should load letting me setup ak-admin password\r\n\r\n**Screenshots**\r\n404 not found\r\n\r\n**Logs**\r\n{\"event\": \"/api/v3/outposts/instances/\", \"host\": \"localhost:8000\", \"level\": \"info\", \"logger\": \"authentik.asgi\", \"method\": \"GET\", \"pid\": 24, \"remote\": \"127.0.0.1\", \"request_id\": \"454efe5b57f34713bf837681449b91a6\", \"runtime\": 35, \"scheme\": \"http\", \"status\": 403, \"timestamp\": \"2022-07-11T10:39:00.436171\", \"user\": \"\", \"user_agent\": \"goauthentik.io/outpost/2022.7.2\"}\r\n{\"event\": \"Forbidden: /api/v3/outposts/instances/\", \"level\": \"warning\", \"logger\": \"django.request\", \"timestamp\": 1657535940.437195}\r\n{\"error\":\"403 Forbidden\",\"event\":\"Failed to fetch outpost configuration, retrying in 3 seconds\",\"level\":\"error\",\"logger\":\"authentik.outpost.ak-api-controller\",\"timestamp\":\"2022-07-11T10:39:00Z\"}\r\n**Version and Deployment (please complete the following information):**\r\n - authentik version: authentik-2022.7.2 \r\n - Deployment: [kubectl 1.21, helm v3.1.0]\r\n\r\n**Additional context**\r\nAdd any other context about the problem here.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"System Migration handler\"\"\"\nimport os\nfrom importlib.util import module_from_spec, spec_from_file_location\nfrom inspect import getmembers, isclass\nfrom pathlib import Path\nfrom typing import Any\n\nfrom psycopg2 import connect\nfrom structlog.stdlib import get_logger\n\nfrom authentik.lib.config import CONFIG\n\nLOGGER = get_logger()\nADV_LOCK_UID = 1000\nLOCKED = False\n\n\nclass BaseMigration:\n \"\"\"Base System Migration\"\"\"\n\n cur: Any\n con: Any\n\n def __init__(self, cur: Any, con: Any):\n self.cur = cur\n self.con = con\n\n def needs_migration(self) -> bool:\n \"\"\"Return true if Migration needs to be run\"\"\"\n return False\n\n def run(self):\n \"\"\"Run the actual migration\"\"\"\n\n\ndef wait_for_lock():\n \"\"\"lock an advisory lock to prevent multiple instances from migrating at once\"\"\"\n LOGGER.info(\"waiting to acquire database lock\")\n curr.execute(\"SELECT pg_advisory_lock(%s)\", (ADV_LOCK_UID,))\n # pylint: disable=global-statement\n global LOCKED\n LOCKED = True\n\n\ndef release_lock():\n \"\"\"Release database lock\"\"\"\n if not LOCKED:\n return\n curr.execute(\"SELECT pg_advisory_unlock(%s)\", (ADV_LOCK_UID,))\n\n\nif __name__ == \"__main__\":\n\n conn = connect(\n dbname=CONFIG.y(\"postgresql.name\"),\n user=CONFIG.y(\"postgresql.user\"),\n password=CONFIG.y(\"postgresql.password\"),\n host=CONFIG.y(\"postgresql.host\"),\n port=int(CONFIG.y(\"postgresql.port\")),\n )\n curr = conn.cursor()\n try:\n for migration in Path(__file__).parent.absolute().glob(\"system_migrations/*.py\"):\n spec = spec_from_file_location(\"lifecycle.system_migrations\", migration)\n mod = module_from_spec(spec)\n # pyright: reportGeneralTypeIssues=false\n spec.loader.exec_module(mod)\n\n for name, sub in getmembers(mod, isclass):\n if name != \"Migration\":\n continue\n migration = sub(curr, conn)\n if migration.needs_migration():\n wait_for_lock()\n LOGGER.info(\"Migration needs to be applied\", migration=sub)\n migration.run()\n LOGGER.info(\"Migration finished applying\", migration=sub)\n release_lock()\n LOGGER.info(\"applying django migrations\")\n os.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"authentik.root.settings\")\n wait_for_lock()\n try:\n from django.core.management import execute_from_command_line\n except ImportError as exc:\n raise ImportError(\n \"Couldn't import Django. Are you sure it's installed and \"\n \"available on your PYTHONPATH environment variable? Did you \"\n \"forget to activate a virtual environment?\"\n ) from exc\n execute_from_command_line([\"\", \"migrate\"])\n finally:\n release_lock()\n", "path": "lifecycle/migrate.py"}, {"content": "\"\"\"managed tasks\"\"\"\nfrom django.db import DatabaseError\n\nfrom authentik.core.tasks import CELERY_APP\nfrom authentik.events.monitored_tasks import (\n MonitoredTask,\n TaskResult,\n TaskResultStatus,\n prefill_task,\n)\nfrom authentik.managed.manager import ObjectManager\n\n\n@CELERY_APP.task(bind=True, base=MonitoredTask)\n@prefill_task\ndef managed_reconcile(self: MonitoredTask):\n \"\"\"Run ObjectManager to ensure objects are up-to-date\"\"\"\n try:\n ObjectManager().run()\n self.set_status(\n TaskResult(TaskResultStatus.SUCCESSFUL, [\"Successfully updated managed models.\"])\n )\n except DatabaseError as exc: # pragma: no cover\n self.set_status(TaskResult(TaskResultStatus.WARNING, [str(exc)]))\n", "path": "authentik/managed/tasks.py"}]}
| 2,050 | 418 |
gh_patches_debug_22932
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-2568
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add type annontations
please add type annotations here
_Originally posted by @aabmass in https://github.com/open-telemetry/opentelemetry-python/pull/2400#discussion_r809406486_
</issue>
<code>
[start of opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py]
1 # Copyright The OpenTelemetry Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from logging import getLogger
17 from threading import Lock
18 from typing import TYPE_CHECKING, Iterable
19
20 from opentelemetry.sdk._metrics.aggregation import (
21 _convert_aggregation_temporality,
22 )
23 from opentelemetry.sdk._metrics.measurement import Measurement
24 from opentelemetry.sdk._metrics.point import AggregationTemporality, Metric
25 from opentelemetry.sdk._metrics.sdk_configuration import SdkConfiguration
26 from opentelemetry.sdk._metrics.view import View
27
28 if TYPE_CHECKING:
29 from opentelemetry.sdk._metrics.instrument import _Instrument
30
31 _logger = getLogger(__name__)
32
33
34 class _ViewInstrumentMatch:
35 def __init__(
36 self,
37 view: View,
38 instrument: "_Instrument",
39 sdk_config: SdkConfiguration,
40 ):
41 self._view = view
42 self._instrument = instrument
43 self._sdk_config = sdk_config
44 self._attributes_aggregation = {}
45 self._attributes_previous_point = {}
46 self._lock = Lock()
47
48 # pylint: disable=protected-access
49 def consume_measurement(self, measurement: Measurement) -> None:
50
51 if self._view._attribute_keys is not None:
52
53 attributes = {}
54
55 for key, value in (measurement.attributes or {}).items():
56 if key in self._view._attribute_keys:
57 attributes[key] = value
58 elif measurement.attributes is not None:
59 attributes = measurement.attributes
60 else:
61 attributes = {}
62
63 attributes = frozenset(attributes.items())
64
65 if attributes not in self._attributes_aggregation:
66 with self._lock:
67 if attributes not in self._attributes_aggregation:
68 if self._view._aggregation:
69 aggregation = (
70 self._view._aggregation._create_aggregation(
71 self._instrument
72 )
73 )
74 else:
75 aggregation = self._instrument._default_aggregation
76 self._attributes_aggregation[attributes] = aggregation
77
78 self._attributes_aggregation[attributes].aggregate(measurement)
79
80 def collect(self, temporality: int) -> Iterable[Metric]:
81
82 with self._lock:
83 for (
84 attributes,
85 aggregation,
86 ) in self._attributes_aggregation.items():
87
88 previous_point = self._attributes_previous_point.get(
89 attributes
90 )
91
92 current_point = aggregation.collect()
93
94 # pylint: disable=assignment-from-none
95 self._attributes_previous_point[
96 attributes
97 ] = _convert_aggregation_temporality(
98 previous_point,
99 current_point,
100 AggregationTemporality.CUMULATIVE,
101 )
102
103 if current_point is not None:
104
105 yield Metric(
106 attributes=dict(attributes),
107 description=(
108 self._view._description
109 or self._instrument.description
110 ),
111 instrumentation_info=self._instrument.instrumentation_info,
112 name=self._view._name or self._instrument.name,
113 resource=self._sdk_config.resource,
114 unit=self._instrument.unit,
115 point=_convert_aggregation_temporality(
116 previous_point,
117 current_point,
118 temporality,
119 ),
120 )
121
[end of opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py
--- a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py
+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py
@@ -15,10 +15,12 @@
from logging import getLogger
from threading import Lock
-from typing import TYPE_CHECKING, Iterable
+from typing import TYPE_CHECKING, Dict, Iterable
from opentelemetry.sdk._metrics.aggregation import (
+ _Aggregation,
_convert_aggregation_temporality,
+ _PointVarT,
)
from opentelemetry.sdk._metrics.measurement import Measurement
from opentelemetry.sdk._metrics.point import AggregationTemporality, Metric
@@ -41,8 +43,8 @@
self._view = view
self._instrument = instrument
self._sdk_config = sdk_config
- self._attributes_aggregation = {}
- self._attributes_previous_point = {}
+ self._attributes_aggregation: Dict[frozenset, _Aggregation] = {}
+ self._attributes_previous_point: Dict[frozenset, _PointVarT] = {}
self._lock = Lock()
# pylint: disable=protected-access
|
{"golden_diff": "diff --git a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py\n--- a/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py\n+++ b/opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py\n@@ -15,10 +15,12 @@\n \n from logging import getLogger\n from threading import Lock\n-from typing import TYPE_CHECKING, Iterable\n+from typing import TYPE_CHECKING, Dict, Iterable\n \n from opentelemetry.sdk._metrics.aggregation import (\n+ _Aggregation,\n _convert_aggregation_temporality,\n+ _PointVarT,\n )\n from opentelemetry.sdk._metrics.measurement import Measurement\n from opentelemetry.sdk._metrics.point import AggregationTemporality, Metric\n@@ -41,8 +43,8 @@\n self._view = view\n self._instrument = instrument\n self._sdk_config = sdk_config\n- self._attributes_aggregation = {}\n- self._attributes_previous_point = {}\n+ self._attributes_aggregation: Dict[frozenset, _Aggregation] = {}\n+ self._attributes_previous_point: Dict[frozenset, _PointVarT] = {}\n self._lock = Lock()\n \n # pylint: disable=protected-access\n", "issue": "Add type annontations\nplease add type annotations here\r\n\r\n_Originally posted by @aabmass in https://github.com/open-telemetry/opentelemetry-python/pull/2400#discussion_r809406486_\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom logging import getLogger\nfrom threading import Lock\nfrom typing import TYPE_CHECKING, Iterable\n\nfrom opentelemetry.sdk._metrics.aggregation import (\n _convert_aggregation_temporality,\n)\nfrom opentelemetry.sdk._metrics.measurement import Measurement\nfrom opentelemetry.sdk._metrics.point import AggregationTemporality, Metric\nfrom opentelemetry.sdk._metrics.sdk_configuration import SdkConfiguration\nfrom opentelemetry.sdk._metrics.view import View\n\nif TYPE_CHECKING:\n from opentelemetry.sdk._metrics.instrument import _Instrument\n\n_logger = getLogger(__name__)\n\n\nclass _ViewInstrumentMatch:\n def __init__(\n self,\n view: View,\n instrument: \"_Instrument\",\n sdk_config: SdkConfiguration,\n ):\n self._view = view\n self._instrument = instrument\n self._sdk_config = sdk_config\n self._attributes_aggregation = {}\n self._attributes_previous_point = {}\n self._lock = Lock()\n\n # pylint: disable=protected-access\n def consume_measurement(self, measurement: Measurement) -> None:\n\n if self._view._attribute_keys is not None:\n\n attributes = {}\n\n for key, value in (measurement.attributes or {}).items():\n if key in self._view._attribute_keys:\n attributes[key] = value\n elif measurement.attributes is not None:\n attributes = measurement.attributes\n else:\n attributes = {}\n\n attributes = frozenset(attributes.items())\n\n if attributes not in self._attributes_aggregation:\n with self._lock:\n if attributes not in self._attributes_aggregation:\n if self._view._aggregation:\n aggregation = (\n self._view._aggregation._create_aggregation(\n self._instrument\n )\n )\n else:\n aggregation = self._instrument._default_aggregation\n self._attributes_aggregation[attributes] = aggregation\n\n self._attributes_aggregation[attributes].aggregate(measurement)\n\n def collect(self, temporality: int) -> Iterable[Metric]:\n\n with self._lock:\n for (\n attributes,\n aggregation,\n ) in self._attributes_aggregation.items():\n\n previous_point = self._attributes_previous_point.get(\n attributes\n )\n\n current_point = aggregation.collect()\n\n # pylint: disable=assignment-from-none\n self._attributes_previous_point[\n attributes\n ] = _convert_aggregation_temporality(\n previous_point,\n current_point,\n AggregationTemporality.CUMULATIVE,\n )\n\n if current_point is not None:\n\n yield Metric(\n attributes=dict(attributes),\n description=(\n self._view._description\n or self._instrument.description\n ),\n instrumentation_info=self._instrument.instrumentation_info,\n name=self._view._name or self._instrument.name,\n resource=self._sdk_config.resource,\n unit=self._instrument.unit,\n point=_convert_aggregation_temporality(\n previous_point,\n current_point,\n temporality,\n ),\n )\n", "path": "opentelemetry-sdk/src/opentelemetry/sdk/_metrics/_view_instrument_match.py"}]}
| 1,629 | 300 |
gh_patches_debug_33550
|
rasdani/github-patches
|
git_diff
|
litestar-org__litestar-594
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: logging queue listener writing to in-memory stream
The handler for the `queue_listener` handler is created as `StreamHandler(StringIO())`. Explicitly passing the stream to the the handler means that the output is no longer logged to stderr.
</issue>
<code>
[start of starlite/logging/standard.py]
1 import atexit
2 from io import StringIO
3 from logging import StreamHandler
4 from logging.handlers import QueueHandler, QueueListener
5 from queue import Queue
6 from typing import Any, List, Optional
7
8 from starlite.logging.utils import resolve_handlers
9
10
11 class QueueListenerHandler(QueueHandler):
12 def __init__(self, handlers: Optional[List[Any]] = None) -> None:
13 """Configures queue listener and handler to support non-blocking
14 logging configuration.
15
16 Args:
17 handlers: Optional 'ConvertingList'
18 """
19 super().__init__(Queue(-1))
20 if handlers:
21 handlers = resolve_handlers(handlers)
22 else:
23 handlers = [StreamHandler(StringIO())]
24 self.listener = QueueListener(self.queue, *handlers)
25 self.listener.start()
26
27 atexit.register(self.listener.stop)
28
[end of starlite/logging/standard.py]
[start of starlite/logging/picologging.py]
1 import atexit
2 from io import StringIO
3 from logging import StreamHandler
4 from queue import Queue
5 from typing import Any, List, Optional
6
7 from starlite.exceptions import MissingDependencyException
8 from starlite.logging.utils import resolve_handlers
9
10 try:
11 from picologging.handlers import QueueHandler, QueueListener
12 except ImportError as e:
13 raise MissingDependencyException("picologging is not installed") from e
14
15
16 class QueueListenerHandler(QueueHandler): # type: ignore[misc]
17 def __init__(self, handlers: Optional[List[Any]] = None) -> None:
18 """Configures queue listener and handler to support non-blocking
19 logging configuration.
20
21 Args:
22 handlers: Optional 'ConvertingList'
23
24 Notes:
25 - Requires `picologging` to be installed.
26 """
27 super().__init__(Queue(-1))
28 if handlers:
29 handlers = resolve_handlers(handlers)
30 else:
31 handlers = [StreamHandler(StringIO())]
32 self.listener = QueueListener(self.queue, *handlers)
33 self.listener.start()
34
35 atexit.register(self.listener.stop)
36
[end of starlite/logging/picologging.py]
[start of starlite/config/logging.py]
1 from abc import ABC, abstractmethod
2 from importlib.util import find_spec
3 from logging import INFO
4 from typing import (
5 TYPE_CHECKING,
6 Any,
7 Callable,
8 Dict,
9 Iterable,
10 List,
11 Optional,
12 Type,
13 Union,
14 cast,
15 )
16
17 from orjson import dumps
18 from pydantic import BaseModel, Field, validator
19 from typing_extensions import Literal
20
21 from starlite.exceptions import (
22 ImproperlyConfiguredException,
23 MissingDependencyException,
24 )
25
26 if TYPE_CHECKING:
27 from starlite.types import Logger
28 from starlite.types.callable_types import GetLogger
29
30 try:
31 from structlog.types import BindableLogger, Processor, WrappedLogger
32 except ImportError:
33 BindableLogger = Any # type: ignore
34 Processor = Any # type: ignore
35 WrappedLogger = Any # type: ignore
36
37
38 default_handlers: Dict[str, Dict[str, Any]] = {
39 "console": {
40 "class": "logging.StreamHandler",
41 "level": "DEBUG",
42 "formatter": "standard",
43 },
44 "queue_listener": {
45 "class": "starlite.logging.standard.QueueListenerHandler",
46 "level": "DEBUG",
47 "formatter": "standard",
48 },
49 }
50
51 default_picologging_handlers: Dict[str, Dict[str, Any]] = {
52 "console": {
53 "class": "picologging.StreamHandler",
54 "level": "DEBUG",
55 "formatter": "standard",
56 },
57 "queue_listener": {
58 "class": "starlite.logging.picologging.QueueListenerHandler",
59 "level": "DEBUG",
60 "formatter": "standard",
61 },
62 }
63
64
65 def get_default_handlers() -> Dict[str, Dict[str, Any]]:
66 """
67
68 Returns:
69 The default handlers for the config.
70 """
71 if find_spec("picologging"):
72 return default_picologging_handlers
73 return default_handlers
74
75
76 def get_logger_placeholder(_: str) -> Any: # pragma: no cover
77 """
78 Raises:
79 ImproperlyConfiguredException
80 """
81 raise ImproperlyConfiguredException(
82 "To use 'app.get_logger', 'request.get_logger' or 'socket.get_logger' pass 'logging_config' to the Starlite constructor"
83 )
84
85
86 class BaseLoggingConfig(ABC): # pragma: no cover
87 """Abstract class that should be extended by logging configs."""
88
89 __slots__ = ()
90
91 @abstractmethod
92 def configure(self) -> "GetLogger":
93 """Configured logger with the given configuration.
94
95 Returns:
96 A 'logging.getLogger' like function.
97 """
98 raise NotImplementedError("abstract method")
99
100
101 class LoggingConfig(BaseLoggingConfig, BaseModel):
102 """Configuration class for standard logging.
103
104 Notes:
105 - If 'picologging' is installed it will be used by default.
106 """
107
108 version: Literal[1] = 1
109 """The only valid value at present is 1."""
110 incremental: bool = False
111 """Whether the configuration is to be interpreted as incremental to the existing configuration.
112
113 Notes:
114 - This option is ignored for 'picologging'
115 """
116 disable_existing_loggers: bool = False
117 """Whether any existing non-root loggers are to be disabled."""
118 filters: Optional[Dict[str, Dict[str, Any]]] = None
119 """A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance."""
120 propagate: bool = True
121 """If messages must propagate to handlers higher up the logger hierarchy from this logger."""
122 formatters: Dict[str, Dict[str, Any]] = {
123 "standard": {"format": "%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s"}
124 }
125 handlers: Dict[str, Dict[str, Any]] = Field(default_factory=get_default_handlers)
126 """A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance."""
127 loggers: Dict[str, Dict[str, Any]] = {
128 "starlite": {
129 "level": "INFO",
130 "handlers": ["queue_listener"],
131 },
132 }
133 """A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance."""
134 root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {
135 "handlers": ["queue_listener", "console"],
136 "level": "INFO",
137 }
138 """This will be the configuration for the root logger. Processing of the configuration will be as for any logger,
139 except that the propagate setting will not be applicable."""
140
141 @validator("handlers", always=True)
142 def validate_handlers( # pylint: disable=no-self-argument
143 cls, value: Dict[str, Dict[str, Any]]
144 ) -> Dict[str, Dict[str, Any]]:
145 """
146 Ensures that 'queue_listener' is always set
147 Args:
148 value: A dict of route handlers.
149
150 Returns:
151 A dict of route handlers.
152 """
153 if "queue_listener" not in value:
154 value["queue_listener"] = get_default_handlers()["queue_listener"]
155 return value
156
157 @validator("loggers", always=True)
158 def validate_loggers( # pylint: disable=no-self-argument
159 cls, value: Dict[str, Dict[str, Any]]
160 ) -> Dict[str, Dict[str, Any]]:
161 """Ensures that the 'starlite' logger is always set.
162
163 Args:
164 value: A dict of loggers.
165
166 Returns:
167 A dict of loggers.
168 """
169
170 if "starlite" not in value:
171 value["starlite"] = {
172 "level": "INFO",
173 "handlers": ["queue_listener"],
174 }
175 return value
176
177 def configure(self) -> "GetLogger":
178 """Configured logger with the given configuration.
179
180 Returns:
181 A 'logging.getLogger' like function.
182 """
183 try:
184 if "picologging" in str(dumps(self.handlers)):
185
186 from picologging import ( # pylint: disable=import-outside-toplevel
187 config,
188 getLogger,
189 )
190
191 values = self.dict(exclude_none=True, exclude={"incremental"})
192 else:
193 from logging import ( # type: ignore[no-redef] # pylint: disable=import-outside-toplevel
194 config,
195 getLogger,
196 )
197
198 values = self.dict(exclude_none=True)
199 config.dictConfig(values)
200 return cast("Callable[[str], Logger]", getLogger)
201 except ImportError as e: # pragma: no cover
202 raise MissingDependencyException("picologging is not installed") from e
203
204
205 def default_structlog_processors() -> Optional[Iterable[Processor]]: # pyright: ignore
206 """Sets the default processors for structlog.
207
208 Returns:
209 An optional list of processors.
210 """
211 try:
212 import structlog # pylint: disable=import-outside-toplevel
213
214 return [
215 structlog.contextvars.merge_contextvars,
216 structlog.processors.add_log_level,
217 structlog.processors.format_exc_info,
218 structlog.processors.TimeStamper(fmt="iso", utc=True),
219 structlog.processors.JSONRenderer(serializer=dumps),
220 ]
221 except ImportError: # pragma: no cover
222 return None
223
224
225 def default_wrapper_class() -> Optional[Type[BindableLogger]]: # pyright: ignore
226 """Sets the default wrapper class for structlog.
227
228 Returns:
229 An optional wrapper class.
230 """
231
232 try:
233 import structlog # pylint: disable=import-outside-toplevel
234
235 return structlog.make_filtering_bound_logger(INFO)
236 except ImportError: # pragma: no cover
237 return None
238
239
240 def default_logger_factory() -> Optional[Callable[..., WrappedLogger]]:
241 """Sets the default logger factory for structlog.
242
243 Returns:
244 An optional logger factory.
245 """
246 try:
247 import structlog # pylint: disable=import-outside-toplevel
248
249 return structlog.BytesLoggerFactory()
250 except ImportError: # pragma: no cover
251 return None
252
253
254 class StructLoggingConfig(BaseLoggingConfig, BaseModel):
255 """Configuration class for structlog.
256
257 Notes:
258 - requires 'structlog' to be installed.
259 """
260
261 processors: Optional[Iterable[Processor]] = Field(default_factory=default_structlog_processors) # pyright: ignore
262 """Iterable of structlog logging processors."""
263 wrapper_class: Optional[Type[BindableLogger]] = Field(default_factory=default_wrapper_class) # pyright: ignore
264 """Structlog bindable logger."""
265 context_class: Optional[Dict[str, Any]] = None
266 """Context class (a 'contextvar' context) for the logger"""
267 logger_factory: Optional[Callable[..., WrappedLogger]] = Field(default_factory=default_logger_factory)
268 """Logger factory to use."""
269 cache_logger_on_first_use: bool = True
270 """Whether to cache the logger configuration and reuse. """
271
272 def configure(self) -> "GetLogger":
273 """Configured logger with the given configuration.
274
275 Returns:
276 A 'logging.getLogger' like function.
277 """
278 try:
279 from structlog import ( # pylint: disable=import-outside-toplevel
280 configure,
281 get_logger,
282 )
283
284 # we now configure structlog
285 configure(**self.dict(exclude={"standard_lib_logging_config"}))
286 return get_logger
287 except ImportError as e: # pragma: no cover
288 raise MissingDependencyException("structlog is not installed") from e
289
[end of starlite/config/logging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlite/config/logging.py b/starlite/config/logging.py
--- a/starlite/config/logging.py
+++ b/starlite/config/logging.py
@@ -132,7 +132,7 @@
}
"""A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance."""
root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {
- "handlers": ["queue_listener", "console"],
+ "handlers": ["queue_listener"],
"level": "INFO",
}
"""This will be the configuration for the root logger. Processing of the configuration will be as for any logger,
diff --git a/starlite/logging/picologging.py b/starlite/logging/picologging.py
--- a/starlite/logging/picologging.py
+++ b/starlite/logging/picologging.py
@@ -1,5 +1,4 @@
import atexit
-from io import StringIO
from logging import StreamHandler
from queue import Queue
from typing import Any, List, Optional
@@ -28,7 +27,7 @@
if handlers:
handlers = resolve_handlers(handlers)
else:
- handlers = [StreamHandler(StringIO())]
+ handlers = [StreamHandler()]
self.listener = QueueListener(self.queue, *handlers)
self.listener.start()
diff --git a/starlite/logging/standard.py b/starlite/logging/standard.py
--- a/starlite/logging/standard.py
+++ b/starlite/logging/standard.py
@@ -1,5 +1,4 @@
import atexit
-from io import StringIO
from logging import StreamHandler
from logging.handlers import QueueHandler, QueueListener
from queue import Queue
@@ -20,7 +19,7 @@
if handlers:
handlers = resolve_handlers(handlers)
else:
- handlers = [StreamHandler(StringIO())]
+ handlers = [StreamHandler()]
self.listener = QueueListener(self.queue, *handlers)
self.listener.start()
|
{"golden_diff": "diff --git a/starlite/config/logging.py b/starlite/config/logging.py\n--- a/starlite/config/logging.py\n+++ b/starlite/config/logging.py\n@@ -132,7 +132,7 @@\n }\n \"\"\"A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance.\"\"\"\n root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {\n- \"handlers\": [\"queue_listener\", \"console\"],\n+ \"handlers\": [\"queue_listener\"],\n \"level\": \"INFO\",\n }\n \"\"\"This will be the configuration for the root logger. Processing of the configuration will be as for any logger,\ndiff --git a/starlite/logging/picologging.py b/starlite/logging/picologging.py\n--- a/starlite/logging/picologging.py\n+++ b/starlite/logging/picologging.py\n@@ -1,5 +1,4 @@\n import atexit\n-from io import StringIO\n from logging import StreamHandler\n from queue import Queue\n from typing import Any, List, Optional\n@@ -28,7 +27,7 @@\n if handlers:\n handlers = resolve_handlers(handlers)\n else:\n- handlers = [StreamHandler(StringIO())]\n+ handlers = [StreamHandler()]\n self.listener = QueueListener(self.queue, *handlers)\n self.listener.start()\n \ndiff --git a/starlite/logging/standard.py b/starlite/logging/standard.py\n--- a/starlite/logging/standard.py\n+++ b/starlite/logging/standard.py\n@@ -1,5 +1,4 @@\n import atexit\n-from io import StringIO\n from logging import StreamHandler\n from logging.handlers import QueueHandler, QueueListener\n from queue import Queue\n@@ -20,7 +19,7 @@\n if handlers:\n handlers = resolve_handlers(handlers)\n else:\n- handlers = [StreamHandler(StringIO())]\n+ handlers = [StreamHandler()]\n self.listener = QueueListener(self.queue, *handlers)\n self.listener.start()\n", "issue": "Bug: logging queue listener writing to in-memory stream\nThe handler for the `queue_listener` handler is created as `StreamHandler(StringIO())`. Explicitly passing the stream to the the handler means that the output is no longer logged to stderr.\r\n\n", "before_files": [{"content": "import atexit\nfrom io import StringIO\nfrom logging import StreamHandler\nfrom logging.handlers import QueueHandler, QueueListener\nfrom queue import Queue\nfrom typing import Any, List, Optional\n\nfrom starlite.logging.utils import resolve_handlers\n\n\nclass QueueListenerHandler(QueueHandler):\n def __init__(self, handlers: Optional[List[Any]] = None) -> None:\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Args:\n handlers: Optional 'ConvertingList'\n \"\"\"\n super().__init__(Queue(-1))\n if handlers:\n handlers = resolve_handlers(handlers)\n else:\n handlers = [StreamHandler(StringIO())]\n self.listener = QueueListener(self.queue, *handlers)\n self.listener.start()\n\n atexit.register(self.listener.stop)\n", "path": "starlite/logging/standard.py"}, {"content": "import atexit\nfrom io import StringIO\nfrom logging import StreamHandler\nfrom queue import Queue\nfrom typing import Any, List, Optional\n\nfrom starlite.exceptions import MissingDependencyException\nfrom starlite.logging.utils import resolve_handlers\n\ntry:\n from picologging.handlers import QueueHandler, QueueListener\nexcept ImportError as e:\n raise MissingDependencyException(\"picologging is not installed\") from e\n\n\nclass QueueListenerHandler(QueueHandler): # type: ignore[misc]\n def __init__(self, handlers: Optional[List[Any]] = None) -> None:\n \"\"\"Configures queue listener and handler to support non-blocking\n logging configuration.\n\n Args:\n handlers: Optional 'ConvertingList'\n\n Notes:\n - Requires `picologging` to be installed.\n \"\"\"\n super().__init__(Queue(-1))\n if handlers:\n handlers = resolve_handlers(handlers)\n else:\n handlers = [StreamHandler(StringIO())]\n self.listener = QueueListener(self.queue, *handlers)\n self.listener.start()\n\n atexit.register(self.listener.stop)\n", "path": "starlite/logging/picologging.py"}, {"content": "from abc import ABC, abstractmethod\nfrom importlib.util import find_spec\nfrom logging import INFO\nfrom typing import (\n TYPE_CHECKING,\n Any,\n Callable,\n Dict,\n Iterable,\n List,\n Optional,\n Type,\n Union,\n cast,\n)\n\nfrom orjson import dumps\nfrom pydantic import BaseModel, Field, validator\nfrom typing_extensions import Literal\n\nfrom starlite.exceptions import (\n ImproperlyConfiguredException,\n MissingDependencyException,\n)\n\nif TYPE_CHECKING:\n from starlite.types import Logger\n from starlite.types.callable_types import GetLogger\n\ntry:\n from structlog.types import BindableLogger, Processor, WrappedLogger\nexcept ImportError:\n BindableLogger = Any # type: ignore\n Processor = Any # type: ignore\n WrappedLogger = Any # type: ignore\n\n\ndefault_handlers: Dict[str, Dict[str, Any]] = {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n \"queue_listener\": {\n \"class\": \"starlite.logging.standard.QueueListenerHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n}\n\ndefault_picologging_handlers: Dict[str, Dict[str, Any]] = {\n \"console\": {\n \"class\": \"picologging.StreamHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n \"queue_listener\": {\n \"class\": \"starlite.logging.picologging.QueueListenerHandler\",\n \"level\": \"DEBUG\",\n \"formatter\": \"standard\",\n },\n}\n\n\ndef get_default_handlers() -> Dict[str, Dict[str, Any]]:\n \"\"\"\n\n Returns:\n The default handlers for the config.\n \"\"\"\n if find_spec(\"picologging\"):\n return default_picologging_handlers\n return default_handlers\n\n\ndef get_logger_placeholder(_: str) -> Any: # pragma: no cover\n \"\"\"\n Raises:\n ImproperlyConfiguredException\n \"\"\"\n raise ImproperlyConfiguredException(\n \"To use 'app.get_logger', 'request.get_logger' or 'socket.get_logger' pass 'logging_config' to the Starlite constructor\"\n )\n\n\nclass BaseLoggingConfig(ABC): # pragma: no cover\n \"\"\"Abstract class that should be extended by logging configs.\"\"\"\n\n __slots__ = ()\n\n @abstractmethod\n def configure(self) -> \"GetLogger\":\n \"\"\"Configured logger with the given configuration.\n\n Returns:\n A 'logging.getLogger' like function.\n \"\"\"\n raise NotImplementedError(\"abstract method\")\n\n\nclass LoggingConfig(BaseLoggingConfig, BaseModel):\n \"\"\"Configuration class for standard logging.\n\n Notes:\n - If 'picologging' is installed it will be used by default.\n \"\"\"\n\n version: Literal[1] = 1\n \"\"\"The only valid value at present is 1.\"\"\"\n incremental: bool = False\n \"\"\"Whether the configuration is to be interpreted as incremental to the existing configuration.\n\n Notes:\n - This option is ignored for 'picologging'\n \"\"\"\n disable_existing_loggers: bool = False\n \"\"\"Whether any existing non-root loggers are to be disabled.\"\"\"\n filters: Optional[Dict[str, Dict[str, Any]]] = None\n \"\"\"A dict in which each key is a filter id and each value is a dict describing how to configure the corresponding Filter instance.\"\"\"\n propagate: bool = True\n \"\"\"If messages must propagate to handlers higher up the logger hierarchy from this logger.\"\"\"\n formatters: Dict[str, Dict[str, Any]] = {\n \"standard\": {\"format\": \"%(levelname)s - %(asctime)s - %(name)s - %(module)s - %(message)s\"}\n }\n handlers: Dict[str, Dict[str, Any]] = Field(default_factory=get_default_handlers)\n \"\"\"A dict in which each key is a handler id and each value is a dict describing how to configure the corresponding Handler instance.\"\"\"\n loggers: Dict[str, Dict[str, Any]] = {\n \"starlite\": {\n \"level\": \"INFO\",\n \"handlers\": [\"queue_listener\"],\n },\n }\n \"\"\"A dict in which each key is a logger name and each value is a dict describing how to configure the corresponding Logger instance.\"\"\"\n root: Dict[str, Union[Dict[str, Any], List[Any], str]] = {\n \"handlers\": [\"queue_listener\", \"console\"],\n \"level\": \"INFO\",\n }\n \"\"\"This will be the configuration for the root logger. Processing of the configuration will be as for any logger,\n except that the propagate setting will not be applicable.\"\"\"\n\n @validator(\"handlers\", always=True)\n def validate_handlers( # pylint: disable=no-self-argument\n cls, value: Dict[str, Dict[str, Any]]\n ) -> Dict[str, Dict[str, Any]]:\n \"\"\"\n Ensures that 'queue_listener' is always set\n Args:\n value: A dict of route handlers.\n\n Returns:\n A dict of route handlers.\n \"\"\"\n if \"queue_listener\" not in value:\n value[\"queue_listener\"] = get_default_handlers()[\"queue_listener\"]\n return value\n\n @validator(\"loggers\", always=True)\n def validate_loggers( # pylint: disable=no-self-argument\n cls, value: Dict[str, Dict[str, Any]]\n ) -> Dict[str, Dict[str, Any]]:\n \"\"\"Ensures that the 'starlite' logger is always set.\n\n Args:\n value: A dict of loggers.\n\n Returns:\n A dict of loggers.\n \"\"\"\n\n if \"starlite\" not in value:\n value[\"starlite\"] = {\n \"level\": \"INFO\",\n \"handlers\": [\"queue_listener\"],\n }\n return value\n\n def configure(self) -> \"GetLogger\":\n \"\"\"Configured logger with the given configuration.\n\n Returns:\n A 'logging.getLogger' like function.\n \"\"\"\n try:\n if \"picologging\" in str(dumps(self.handlers)):\n\n from picologging import ( # pylint: disable=import-outside-toplevel\n config,\n getLogger,\n )\n\n values = self.dict(exclude_none=True, exclude={\"incremental\"})\n else:\n from logging import ( # type: ignore[no-redef] # pylint: disable=import-outside-toplevel\n config,\n getLogger,\n )\n\n values = self.dict(exclude_none=True)\n config.dictConfig(values)\n return cast(\"Callable[[str], Logger]\", getLogger)\n except ImportError as e: # pragma: no cover\n raise MissingDependencyException(\"picologging is not installed\") from e\n\n\ndef default_structlog_processors() -> Optional[Iterable[Processor]]: # pyright: ignore\n \"\"\"Sets the default processors for structlog.\n\n Returns:\n An optional list of processors.\n \"\"\"\n try:\n import structlog # pylint: disable=import-outside-toplevel\n\n return [\n structlog.contextvars.merge_contextvars,\n structlog.processors.add_log_level,\n structlog.processors.format_exc_info,\n structlog.processors.TimeStamper(fmt=\"iso\", utc=True),\n structlog.processors.JSONRenderer(serializer=dumps),\n ]\n except ImportError: # pragma: no cover\n return None\n\n\ndef default_wrapper_class() -> Optional[Type[BindableLogger]]: # pyright: ignore\n \"\"\"Sets the default wrapper class for structlog.\n\n Returns:\n An optional wrapper class.\n \"\"\"\n\n try:\n import structlog # pylint: disable=import-outside-toplevel\n\n return structlog.make_filtering_bound_logger(INFO)\n except ImportError: # pragma: no cover\n return None\n\n\ndef default_logger_factory() -> Optional[Callable[..., WrappedLogger]]:\n \"\"\"Sets the default logger factory for structlog.\n\n Returns:\n An optional logger factory.\n \"\"\"\n try:\n import structlog # pylint: disable=import-outside-toplevel\n\n return structlog.BytesLoggerFactory()\n except ImportError: # pragma: no cover\n return None\n\n\nclass StructLoggingConfig(BaseLoggingConfig, BaseModel):\n \"\"\"Configuration class for structlog.\n\n Notes:\n - requires 'structlog' to be installed.\n \"\"\"\n\n processors: Optional[Iterable[Processor]] = Field(default_factory=default_structlog_processors) # pyright: ignore\n \"\"\"Iterable of structlog logging processors.\"\"\"\n wrapper_class: Optional[Type[BindableLogger]] = Field(default_factory=default_wrapper_class) # pyright: ignore\n \"\"\"Structlog bindable logger.\"\"\"\n context_class: Optional[Dict[str, Any]] = None\n \"\"\"Context class (a 'contextvar' context) for the logger\"\"\"\n logger_factory: Optional[Callable[..., WrappedLogger]] = Field(default_factory=default_logger_factory)\n \"\"\"Logger factory to use.\"\"\"\n cache_logger_on_first_use: bool = True\n \"\"\"Whether to cache the logger configuration and reuse. \"\"\"\n\n def configure(self) -> \"GetLogger\":\n \"\"\"Configured logger with the given configuration.\n\n Returns:\n A 'logging.getLogger' like function.\n \"\"\"\n try:\n from structlog import ( # pylint: disable=import-outside-toplevel\n configure,\n get_logger,\n )\n\n # we now configure structlog\n configure(**self.dict(exclude={\"standard_lib_logging_config\"}))\n return get_logger\n except ImportError as e: # pragma: no cover\n raise MissingDependencyException(\"structlog is not installed\") from e\n", "path": "starlite/config/logging.py"}]}
| 3,952 | 434 |
gh_patches_debug_15669
|
rasdani/github-patches
|
git_diff
|
keras-team__autokeras-965
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tf.data.Dataset not support! [bug]
<!---
**If you are reporting a bug:**
* Verify that your issue is not being currently addressed by other issues or pull requests.
* Please note that Auto-Keras is only compatible with **Python 3.6**.
* Tag the issue with the `bug report` tag.
-->
### Bug Description
<!---
A clear and concise description of what the bug is.
-->
run with tensorflow_datasets 's mnist dataset, but show error message:
AttributeError: 'TakeDataset' object has no attribute 'shape'
### Reproducing Steps
```
# run codes:
import tensorflow_datasets as tfds
mnist_train = tfds.load('mnist', split="train", as_supervised=True)
import autokeras as ak
ak0 = ak.ImageClassifier(num_classes=10, max_trials=10)
ak0.fit(mnist_train, epochs=10)
```
### Expected Behavior
<!--
A clear and concise description of what you expected to happen.
-->
```
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
<ipython-input-4-a90e48684d55> in <module>
----> 1 ak0.fit(mnist_train, epochs=10)
~/anaconda3/lib/python3.7/site-packages/autokeras/tasks/image.py in fit(self, x, y, epochs, callbacks, validation_split, validation_data, **kwargs)
119 validation_split=validation_split,
120 validation_data=validation_data,
--> 121 **kwargs)
122
123
~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in fit(self, x, y, batch_size, epochs, callbacks, validation_split, validation_data, **kwargs)
229 y=y,
230 validation_data=validation_data,
--> 231 validation_split=validation_split)
232
233 # Process the args.
~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in _prepare_data(self, x, y, validation_data, validation_split)
303 # TODO: Handle other types of input, zip dataset, tensor, dict.
304 # Prepare the dataset.
--> 305 dataset = self._process_xy(x, y, True)
306 if validation_data:
307 self._split_dataset = False
~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in _process_xy(self, x, y, fit)
291
292 x = self._process_x(x, fit)
--> 293 y = self._process_y(y, fit)
294
295 return tf.data.Dataset.zip((x, y))
~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in _process_y(self, y, fit)
267 for data, head, adapter in zip(y, self._heads, self._output_adapters):
268 if fit:
--> 269 data = adapter.fit_transform(data)
270 else:
271 data = adapter.transform(data)
~/anaconda3/lib/python3.7/site-packages/autokeras/engine/adapter.py in fit_transform(self, dataset)
66 def fit_transform(self, dataset):
67 self.check(dataset)
---> 68 self.fit_before_convert(dataset)
69 dataset = self.convert_to_dataset(dataset)
70 self.fit(dataset)
~/anaconda3/lib/python3.7/site-packages/autokeras/adapters/output_adapter.py in fit_before_convert(self, dataset)
65 if isinstance(dataset, tf.data.Dataset):
66 if not self.num_classes:
---> 67 shape = dataset.take(1).shape[1]
68 if shape == 1:
69 self.num_classes = 2
AttributeError: 'TakeDataset' object has no attribute 'shape'
```
### Setup Details
Include the details about the versions of:
- OS type and version:
- Python:
- autokeras: 1.0.1
- scikit-learn:
- numpy:
- keras:
- scipy:
- tensorflow: 2.1.0
- pytorch:
### Additional context
<!---
Add any other context about the problem here.
-->
TakeDataset doesn't have attribute 'shape', so the code may be wrong. You can also find I have set num_classes=10, so there are several bugs, not just one.
</issue>
<code>
[start of autokeras/adapters/output_adapter.py]
1 import numpy as np
2 import pandas as pd
3 import tensorflow as tf
4
5 from autokeras import encoders
6 from autokeras.engine import adapter as adapter_module
7
8
9 class HeadAdapter(adapter_module.Adapter):
10
11 def __init__(self, name, **kwargs):
12 super().__init__(**kwargs)
13 self.name = name
14
15 def check(self, dataset):
16 supported_types = (tf.data.Dataset, np.ndarray, pd.DataFrame, pd.Series)
17 if not isinstance(dataset, supported_types):
18 raise TypeError('Expect the target data of {name} to be tf.data.Dataset,'
19 ' np.ndarray, pd.DataFrame or pd.Series, but got {type}.'
20 .format(name=self.name, type=type(dataset)))
21
22 def convert_to_dataset(self, dataset):
23 if isinstance(dataset, np.ndarray):
24 if len(dataset.shape) == 1:
25 dataset = dataset.reshape(-1, 1)
26 if isinstance(dataset, pd.DataFrame):
27 dataset = dataset.values
28 if isinstance(dataset, pd.Series):
29 dataset = dataset.values.reshape(-1, 1)
30 return super().convert_to_dataset(dataset)
31
32 def postprocess(self, y):
33 """Postprocess the output of the Keras Model."""
34 return y
35
36 def get_config(self):
37 config = super().get_config()
38 config.update({
39 'name': self.name,
40 })
41 return config
42
43
44 class ClassificationHeadAdapter(HeadAdapter):
45
46 def __init__(self, num_classes=None, **kwargs):
47 super().__init__(**kwargs)
48 self.num_classes = num_classes
49 self.label_encoder = None
50
51 def get_config(self):
52 config = super().get_config()
53 config.update({
54 'encoder': encoders.serialize(self.label_encoder),
55 })
56 return config
57
58 @classmethod
59 def from_config(cls, config):
60 obj = super().from_config(config)
61 obj.label_encoder = encoders.deserialize(config['encoder'])
62
63 def fit_before_convert(self, dataset):
64 # If in tf.data.Dataset, must be encoded already.
65 if isinstance(dataset, tf.data.Dataset):
66 if not self.num_classes:
67 shape = dataset.take(1).shape[1]
68 if shape == 1:
69 self.num_classes = 2
70 else:
71 self.num_classes = shape
72 return
73 if isinstance(dataset, pd.DataFrame):
74 dataset = dataset.values
75 if isinstance(dataset, pd.Series):
76 dataset = dataset.values.reshape(-1, 1)
77 # Not label.
78 if len(dataset.flatten()) != len(dataset):
79 self.num_classes = dataset.shape[1]
80 return
81 labels = set(dataset.flatten())
82 if self.num_classes is None:
83 self.num_classes = len(labels)
84 if self.num_classes == 2:
85 self.label_encoder = encoders.LabelEncoder()
86 elif self.num_classes > 2:
87 self.label_encoder = encoders.OneHotEncoder()
88 elif self.num_classes < 2:
89 raise ValueError('Expect the target data for {name} to have '
90 'at least 2 classes, but got {num_classes}.'
91 .format(name=self.name, num_classes=self.num_classes))
92 self.label_encoder.fit(dataset)
93
94 def convert_to_dataset(self, dataset):
95 if self.label_encoder:
96 dataset = self.label_encoder.encode(dataset)
97 return super().convert_to_dataset(dataset)
98
99 def postprocess(self, y):
100 if self.label_encoder:
101 y = self.label_encoder.decode(y)
102 return y
103
104
105 class RegressionHeadAdapter(HeadAdapter):
106 pass
107
[end of autokeras/adapters/output_adapter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/autokeras/adapters/output_adapter.py b/autokeras/adapters/output_adapter.py
--- a/autokeras/adapters/output_adapter.py
+++ b/autokeras/adapters/output_adapter.py
@@ -3,6 +3,7 @@
import tensorflow as tf
from autokeras import encoders
+from autokeras import utils
from autokeras.engine import adapter as adapter_module
@@ -64,7 +65,8 @@
# If in tf.data.Dataset, must be encoded already.
if isinstance(dataset, tf.data.Dataset):
if not self.num_classes:
- shape = dataset.take(1).shape[1]
+ shape = utils.dataset_shape(dataset)[0]
+ # Single column with 0s and 1s.
if shape == 1:
self.num_classes = 2
else:
|
{"golden_diff": "diff --git a/autokeras/adapters/output_adapter.py b/autokeras/adapters/output_adapter.py\n--- a/autokeras/adapters/output_adapter.py\n+++ b/autokeras/adapters/output_adapter.py\n@@ -3,6 +3,7 @@\n import tensorflow as tf\n \n from autokeras import encoders\n+from autokeras import utils\n from autokeras.engine import adapter as adapter_module\n \n \n@@ -64,7 +65,8 @@\n # If in tf.data.Dataset, must be encoded already.\n if isinstance(dataset, tf.data.Dataset):\n if not self.num_classes:\n- shape = dataset.take(1).shape[1]\n+ shape = utils.dataset_shape(dataset)[0]\n+ # Single column with 0s and 1s.\n if shape == 1:\n self.num_classes = 2\n else:\n", "issue": "tf.data.Dataset not support! [bug]\n<!---\r\n**If you are reporting a bug:**\r\n* Verify that your issue is not being currently addressed by other issues or pull requests.\r\n* Please note that Auto-Keras is only compatible with **Python 3.6**.\r\n* Tag the issue with the `bug report` tag.\r\n-->\r\n\r\n### Bug Description\r\n<!---\r\nA clear and concise description of what the bug is.\r\n-->\r\nrun with tensorflow_datasets 's mnist dataset, but show error message:\r\nAttributeError: 'TakeDataset' object has no attribute 'shape'\r\n\r\n### Reproducing Steps\r\n```\r\n# run codes:\r\nimport tensorflow_datasets as tfds\r\nmnist_train = tfds.load('mnist', split=\"train\", as_supervised=True)\r\nimport autokeras as ak\r\nak0 = ak.ImageClassifier(num_classes=10, max_trials=10)\r\nak0.fit(mnist_train, epochs=10)\r\n```\r\n### Expected Behavior\r\n<!--\r\nA clear and concise description of what you expected to happen.\r\n-->\r\n```\r\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n<ipython-input-4-a90e48684d55> in <module>\r\n----> 1 ak0.fit(mnist_train, epochs=10)\r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/tasks/image.py in fit(self, x, y, epochs, callbacks, validation_split, validation_data, **kwargs)\r\n 119 validation_split=validation_split,\r\n 120 validation_data=validation_data,\r\n--> 121 **kwargs)\r\n 122 \r\n 123 \r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in fit(self, x, y, batch_size, epochs, callbacks, validation_split, validation_data, **kwargs)\r\n 229 y=y,\r\n 230 validation_data=validation_data,\r\n--> 231 validation_split=validation_split)\r\n 232 \r\n 233 # Process the args.\r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in _prepare_data(self, x, y, validation_data, validation_split)\r\n 303 # TODO: Handle other types of input, zip dataset, tensor, dict.\r\n 304 # Prepare the dataset.\r\n--> 305 dataset = self._process_xy(x, y, True)\r\n 306 if validation_data:\r\n 307 self._split_dataset = False\r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in _process_xy(self, x, y, fit)\r\n 291 \r\n 292 x = self._process_x(x, fit)\r\n--> 293 y = self._process_y(y, fit)\r\n 294 \r\n 295 return tf.data.Dataset.zip((x, y))\r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/auto_model.py in _process_y(self, y, fit)\r\n 267 for data, head, adapter in zip(y, self._heads, self._output_adapters):\r\n 268 if fit:\r\n--> 269 data = adapter.fit_transform(data)\r\n 270 else:\r\n 271 data = adapter.transform(data)\r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/engine/adapter.py in fit_transform(self, dataset)\r\n 66 def fit_transform(self, dataset):\r\n 67 self.check(dataset)\r\n---> 68 self.fit_before_convert(dataset)\r\n 69 dataset = self.convert_to_dataset(dataset)\r\n 70 self.fit(dataset)\r\n\r\n~/anaconda3/lib/python3.7/site-packages/autokeras/adapters/output_adapter.py in fit_before_convert(self, dataset)\r\n 65 if isinstance(dataset, tf.data.Dataset):\r\n 66 if not self.num_classes:\r\n---> 67 shape = dataset.take(1).shape[1]\r\n 68 if shape == 1:\r\n 69 self.num_classes = 2\r\n\r\nAttributeError: 'TakeDataset' object has no attribute 'shape'\r\n```\r\n### Setup Details\r\nInclude the details about the versions of:\r\n - OS type and version:\r\n - Python: \r\n - autokeras: 1.0.1\r\n - scikit-learn:\r\n - numpy:\r\n - keras:\r\n - scipy:\r\n - tensorflow: 2.1.0\r\n - pytorch:\r\n\r\n### Additional context\r\n<!---\r\nAdd any other context about the problem here.\r\n-->\r\nTakeDataset doesn't have attribute 'shape', so the code may be wrong. You can also find I have set num_classes=10, so there are several bugs, not just one.\r\n\n", "before_files": [{"content": "import numpy as np\nimport pandas as pd\nimport tensorflow as tf\n\nfrom autokeras import encoders\nfrom autokeras.engine import adapter as adapter_module\n\n\nclass HeadAdapter(adapter_module.Adapter):\n\n def __init__(self, name, **kwargs):\n super().__init__(**kwargs)\n self.name = name\n\n def check(self, dataset):\n supported_types = (tf.data.Dataset, np.ndarray, pd.DataFrame, pd.Series)\n if not isinstance(dataset, supported_types):\n raise TypeError('Expect the target data of {name} to be tf.data.Dataset,'\n ' np.ndarray, pd.DataFrame or pd.Series, but got {type}.'\n .format(name=self.name, type=type(dataset)))\n\n def convert_to_dataset(self, dataset):\n if isinstance(dataset, np.ndarray):\n if len(dataset.shape) == 1:\n dataset = dataset.reshape(-1, 1)\n if isinstance(dataset, pd.DataFrame):\n dataset = dataset.values\n if isinstance(dataset, pd.Series):\n dataset = dataset.values.reshape(-1, 1)\n return super().convert_to_dataset(dataset)\n\n def postprocess(self, y):\n \"\"\"Postprocess the output of the Keras Model.\"\"\"\n return y\n\n def get_config(self):\n config = super().get_config()\n config.update({\n 'name': self.name,\n })\n return config\n\n\nclass ClassificationHeadAdapter(HeadAdapter):\n\n def __init__(self, num_classes=None, **kwargs):\n super().__init__(**kwargs)\n self.num_classes = num_classes\n self.label_encoder = None\n\n def get_config(self):\n config = super().get_config()\n config.update({\n 'encoder': encoders.serialize(self.label_encoder),\n })\n return config\n\n @classmethod\n def from_config(cls, config):\n obj = super().from_config(config)\n obj.label_encoder = encoders.deserialize(config['encoder'])\n\n def fit_before_convert(self, dataset):\n # If in tf.data.Dataset, must be encoded already.\n if isinstance(dataset, tf.data.Dataset):\n if not self.num_classes:\n shape = dataset.take(1).shape[1]\n if shape == 1:\n self.num_classes = 2\n else:\n self.num_classes = shape\n return\n if isinstance(dataset, pd.DataFrame):\n dataset = dataset.values\n if isinstance(dataset, pd.Series):\n dataset = dataset.values.reshape(-1, 1)\n # Not label.\n if len(dataset.flatten()) != len(dataset):\n self.num_classes = dataset.shape[1]\n return\n labels = set(dataset.flatten())\n if self.num_classes is None:\n self.num_classes = len(labels)\n if self.num_classes == 2:\n self.label_encoder = encoders.LabelEncoder()\n elif self.num_classes > 2:\n self.label_encoder = encoders.OneHotEncoder()\n elif self.num_classes < 2:\n raise ValueError('Expect the target data for {name} to have '\n 'at least 2 classes, but got {num_classes}.'\n .format(name=self.name, num_classes=self.num_classes))\n self.label_encoder.fit(dataset)\n\n def convert_to_dataset(self, dataset):\n if self.label_encoder:\n dataset = self.label_encoder.encode(dataset)\n return super().convert_to_dataset(dataset)\n\n def postprocess(self, y):\n if self.label_encoder:\n y = self.label_encoder.decode(y)\n return y\n\n\nclass RegressionHeadAdapter(HeadAdapter):\n pass\n", "path": "autokeras/adapters/output_adapter.py"}]}
| 2,550 | 188 |
gh_patches_debug_3773
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-860
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add Python 3.8 to CI
# Description
The branch [`ci/add-Python-3.8-to-CI`](https://github.com/diana-hep/pyhf/compare/ci/add-Python-3.8-to-CI) adds Python 3.8 to the CI. However, as [PyTorch won't have a Python 3.8 wheel until the next release](https://github.com/pytorch/pytorch/issues/21741#issuecomment-541242504) this won't be able to happen until around December 2019.
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 from pathlib import Path
3
4 this_directory = Path(__file__).parent.resolve()
5 with open(Path(this_directory).joinpath('README.rst'), encoding='utf-8') as readme_rst:
6 long_description = readme_rst.read()
7
8 extras_require = {
9 'tensorflow': ['tensorflow~=2.0', 'tensorflow-probability~=0.8'],
10 'torch': ['torch~=1.2'],
11 'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],
12 'xmlio': ['uproot'],
13 'minuit': ['iminuit'],
14 }
15 extras_require['backends'] = sorted(
16 set(
17 extras_require['tensorflow']
18 + extras_require['torch']
19 + extras_require['jax']
20 + extras_require['minuit']
21 )
22 )
23 extras_require['contrib'] = sorted(set(['matplotlib']))
24
25 extras_require['test'] = sorted(
26 set(
27 extras_require['backends']
28 + extras_require['xmlio']
29 + extras_require['contrib']
30 + [
31 'pyflakes',
32 'pytest~=3.5',
33 'pytest-cov>=2.5.1',
34 'pytest-mock',
35 'pytest-benchmark[histogram]',
36 'pytest-console-scripts',
37 'pytest-mpl',
38 'pydocstyle',
39 'coverage>=4.0', # coveralls
40 'papermill~=2.0',
41 'nteract-scrapbook~=0.2',
42 'check-manifest',
43 'jupyter',
44 'uproot~=3.3',
45 'graphviz',
46 'jsonpatch',
47 'black',
48 ]
49 )
50 )
51 extras_require['docs'] = sorted(
52 set(
53 [
54 'sphinx',
55 'sphinxcontrib-bibtex',
56 'sphinx-click',
57 'sphinx_rtd_theme',
58 'nbsphinx',
59 'ipywidgets',
60 'sphinx-issues',
61 'sphinx-copybutton>0.2.9',
62 ]
63 )
64 )
65 extras_require['develop'] = sorted(
66 set(
67 extras_require['docs']
68 + extras_require['test']
69 + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'twine']
70 )
71 )
72 extras_require['complete'] = sorted(set(sum(extras_require.values(), [])))
73
74
75 setup(
76 name='pyhf',
77 version='0.4.1',
78 description='(partial) pure python histfactory implementation',
79 long_description=long_description,
80 long_description_content_type='text/x-rst',
81 url='https://github.com/scikit-hep/pyhf',
82 author='Lukas Heinrich, Matthew Feickert, Giordon Stark',
83 author_email='[email protected], [email protected], [email protected]',
84 license='Apache',
85 keywords='physics fitting numpy scipy tensorflow pytorch',
86 classifiers=[
87 "Programming Language :: Python :: 3",
88 "Programming Language :: Python :: 3.6",
89 "Programming Language :: Python :: 3.7",
90 ],
91 package_dir={'': 'src'},
92 packages=find_packages(where='src'),
93 include_package_data=True,
94 python_requires=">=3.6",
95 install_requires=[
96 'scipy', # requires numpy, which is required by pyhf and tensorflow
97 'click>=6.0', # for console scripts,
98 'tqdm', # for readxml
99 'jsonschema>=3.2.0', # for utils
100 'jsonpatch',
101 'pyyaml', # for parsing CLI equal-delimited options
102 ],
103 extras_require=extras_require,
104 entry_points={'console_scripts': ['pyhf=pyhf.cli:cli']},
105 dependency_links=[],
106 use_scm_version=lambda: {'local_scheme': lambda version: ''},
107 )
108
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -87,6 +87,7 @@
"Programming Language :: Python :: 3",
"Programming Language :: Python :: 3.6",
"Programming Language :: Python :: 3.7",
+ "Programming Language :: Python :: 3.8",
],
package_dir={'': 'src'},
packages=find_packages(where='src'),
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -87,6 +87,7 @@\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n+ \"Programming Language :: Python :: 3.8\",\n ],\n package_dir={'': 'src'},\n packages=find_packages(where='src'),\n", "issue": "Add Python 3.8 to CI\n# Description\r\n\r\nThe branch [`ci/add-Python-3.8-to-CI`](https://github.com/diana-hep/pyhf/compare/ci/add-Python-3.8-to-CI) adds Python 3.8 to the CI. However, as [PyTorch won't have a Python 3.8 wheel until the next release](https://github.com/pytorch/pytorch/issues/21741#issuecomment-541242504) this won't be able to happen until around December 2019.\n", "before_files": [{"content": "from setuptools import setup, find_packages\nfrom pathlib import Path\n\nthis_directory = Path(__file__).parent.resolve()\nwith open(Path(this_directory).joinpath('README.rst'), encoding='utf-8') as readme_rst:\n long_description = readme_rst.read()\n\nextras_require = {\n 'tensorflow': ['tensorflow~=2.0', 'tensorflow-probability~=0.8'],\n 'torch': ['torch~=1.2'],\n 'jax': ['jax~=0.1,>0.1.51', 'jaxlib~=0.1,>0.1.33'],\n 'xmlio': ['uproot'],\n 'minuit': ['iminuit'],\n}\nextras_require['backends'] = sorted(\n set(\n extras_require['tensorflow']\n + extras_require['torch']\n + extras_require['jax']\n + extras_require['minuit']\n )\n)\nextras_require['contrib'] = sorted(set(['matplotlib']))\n\nextras_require['test'] = sorted(\n set(\n extras_require['backends']\n + extras_require['xmlio']\n + extras_require['contrib']\n + [\n 'pyflakes',\n 'pytest~=3.5',\n 'pytest-cov>=2.5.1',\n 'pytest-mock',\n 'pytest-benchmark[histogram]',\n 'pytest-console-scripts',\n 'pytest-mpl',\n 'pydocstyle',\n 'coverage>=4.0', # coveralls\n 'papermill~=2.0',\n 'nteract-scrapbook~=0.2',\n 'check-manifest',\n 'jupyter',\n 'uproot~=3.3',\n 'graphviz',\n 'jsonpatch',\n 'black',\n ]\n )\n)\nextras_require['docs'] = sorted(\n set(\n [\n 'sphinx',\n 'sphinxcontrib-bibtex',\n 'sphinx-click',\n 'sphinx_rtd_theme',\n 'nbsphinx',\n 'ipywidgets',\n 'sphinx-issues',\n 'sphinx-copybutton>0.2.9',\n ]\n )\n)\nextras_require['develop'] = sorted(\n set(\n extras_require['docs']\n + extras_require['test']\n + ['nbdime', 'bumpversion', 'ipython', 'pre-commit', 'twine']\n )\n)\nextras_require['complete'] = sorted(set(sum(extras_require.values(), [])))\n\n\nsetup(\n name='pyhf',\n version='0.4.1',\n description='(partial) pure python histfactory implementation',\n long_description=long_description,\n long_description_content_type='text/x-rst',\n url='https://github.com/scikit-hep/pyhf',\n author='Lukas Heinrich, Matthew Feickert, Giordon Stark',\n author_email='[email protected], [email protected], [email protected]',\n license='Apache',\n keywords='physics fitting numpy scipy tensorflow pytorch',\n classifiers=[\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n ],\n package_dir={'': 'src'},\n packages=find_packages(where='src'),\n include_package_data=True,\n python_requires=\">=3.6\",\n install_requires=[\n 'scipy', # requires numpy, which is required by pyhf and tensorflow\n 'click>=6.0', # for console scripts,\n 'tqdm', # for readxml\n 'jsonschema>=3.2.0', # for utils\n 'jsonpatch',\n 'pyyaml', # for parsing CLI equal-delimited options\n ],\n extras_require=extras_require,\n entry_points={'console_scripts': ['pyhf=pyhf.cli:cli']},\n dependency_links=[],\n use_scm_version=lambda: {'local_scheme': lambda version: ''},\n)\n", "path": "setup.py"}]}
| 1,719 | 97 |
gh_patches_debug_3061
|
rasdani/github-patches
|
git_diff
|
googleapis__python-bigquery-1567
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Warning on OpenTelemetry when some attributes are not set
#### Environment details
- OS type and version: Windows 10 21H2
- Python version: `3.9.4`
- pip version: `22.2.2`
- `google-cloud-bigquery` version: `3.3.5`
#### Steps to reproduce
1. Set up a query job with opentelemetry enabled
2. See warning in the console: `Invalid type NoneType for attribute value. Expected one of ['bool', 'str', 'bytes', 'int', 'float'] or a sequence of those types`
#### Code example
```python
import logging
from google.cloud import bigquery
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import (
SimpleSpanProcessor,
ConsoleSpanExporter,
)
provider = TracerProvider()
simple_processor = SimpleSpanProcessor(ConsoleSpanExporter())
provider.add_span_processor(simple_processor)
trace.set_tracer_provider(provider)
logging.basicConfig(level=10)
# Construct a BigQuery client object.
client = bigquery.Client()
query = "SELECT 1;"
query_job = client.query(query)
```
#### Stack trace
```
DEBUG:google.auth._default:Checking None for explicit credentials as part of auth process...
DEBUG:google.auth._default:Checking Cloud SDK credentials as part of auth process...
DEBUG:google.auth._default:Checking None for explicit credentials as part of auth process...
DEBUG:google.auth._default:Checking Cloud SDK credentials as part of auth process...
WARNING:opentelemetry.attributes:Invalid type NoneType for attribute value. Expected one of ['bool', 'str', 'bytes', 'int', 'float'] or a sequence of those types
WARNING:opentelemetry.attributes:Invalid type NoneType for attribute value. Expected one of ['bool', 'str', 'bytes', 'int', 'float'] or a sequence of those types
DEBUG:urllib3.util.retry:Converted retries value: 3 -> Retry(total=3, connect=None, read=None, redirect=None, status=None)
DEBUG:google.auth.transport.requests:Making request: POST https://oauth2.googleapis.com/token
DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): oauth2.googleapis.com:443
DEBUG:urllib3.connectionpool:https://oauth2.googleapis.com:443 "POST /token HTTP/1.1" 200 None
DEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): bigquery.googleapis.com:443
DEBUG:urllib3.connectionpool:https://bigquery.googleapis.com:443 "POST /bigquery/v2/projects/my-project/jobs?prettyPrint=false HTTP/1.1" 200 None
{
"name": "BigQuery.job.begin",
"context": {
"trace_id": "0x192a0e4ec554c63f68525922208fed88",
"span_id": "0xfa29f0363122c4c4",
"trace_state": "[]"
},
"kind": "SpanKind.INTERNAL",
"parent_id": null,
"start_time": "2022-10-12T09:41:57.259114Z",
"end_time": "2022-10-12T09:41:57.934410Z",
"status": {
"status_code": "UNSET"
},
"attributes": {
"db.system": "BigQuery",
"db.name": "my-project",
"job_id": "fc1581e3-708b-4b51-9a05-e3ad52c68dec",
"hasErrors": false,
"num_child_jobs": 0,
"path": "/projects/my-project/jobs"
},
"events": [],
"links": [],
"resource": {
"attributes": {
"telemetry.sdk.language": "python",
"telemetry.sdk.name": "opentelemetry",
"telemetry.sdk.version": "1.13.0",
"service.name": "unknown_service"
},
"schema_url": ""
}
}
```
#### Analysis
Warnings appear when `location` and job `state` attributes are not set.
</issue>
<code>
[start of google/cloud/bigquery/opentelemetry_tracing.py]
1 # Copyright 2020 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 from contextlib import contextmanager
17 from google.api_core.exceptions import GoogleAPICallError # type: ignore
18
19 logger = logging.getLogger(__name__)
20 try:
21 from opentelemetry import trace # type: ignore
22 from opentelemetry.instrumentation.utils import http_status_to_status_code # type: ignore
23 from opentelemetry.trace.status import Status # type: ignore
24
25 HAS_OPENTELEMETRY = True
26 _warned_telemetry = True
27
28 except ImportError:
29 HAS_OPENTELEMETRY = False
30 _warned_telemetry = False
31
32 _default_attributes = {
33 "db.system": "BigQuery"
34 } # static, default values assigned to all spans
35
36
37 @contextmanager
38 def create_span(name, attributes=None, client=None, job_ref=None):
39 """Creates a ContextManager for a Span to be exported to the configured exporter.
40 If no configuration exists yields None.
41
42 Args:
43 name (str): Name that will be set for the span being created
44 attributes (Optional[dict]):
45 Additional attributes that pertain to
46 the specific API call (i.e. not a default attribute)
47 client (Optional[google.cloud.bigquery.client.Client]):
48 Pass in a Client object to extract any attributes that may be
49 relevant to it and add them to the created spans.
50 job_ref (Optional[google.cloud.bigquery.job._AsyncJob])
51 Pass in a _AsyncJob object to extract any attributes that may be
52 relevant to it and add them to the created spans.
53
54 Yields:
55 opentelemetry.trace.Span: Yields the newly created Span.
56
57 Raises:
58 google.api_core.exceptions.GoogleAPICallError:
59 Raised if a span could not be yielded or issue with call to
60 OpenTelemetry.
61 """
62 global _warned_telemetry
63 final_attributes = _get_final_span_attributes(attributes, client, job_ref)
64 if not HAS_OPENTELEMETRY:
65 if not _warned_telemetry:
66 logger.debug(
67 "This service is instrumented using OpenTelemetry. "
68 "OpenTelemetry or one of its components could not be imported; "
69 "please add compatible versions of opentelemetry-api and "
70 "opentelemetry-instrumentation packages in order to get BigQuery "
71 "Tracing data."
72 )
73 _warned_telemetry = True
74
75 yield None
76 return
77 tracer = trace.get_tracer(__name__)
78
79 # yield new span value
80 with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:
81 try:
82 yield span
83 except GoogleAPICallError as error:
84 if error.code is not None:
85 span.set_status(Status(http_status_to_status_code(error.code)))
86 raise
87
88
89 def _get_final_span_attributes(attributes=None, client=None, job_ref=None):
90 final_attributes = {}
91 final_attributes.update(_default_attributes.copy())
92 if client:
93 client_attributes = _set_client_attributes(client)
94 final_attributes.update(client_attributes)
95 if job_ref:
96 job_attributes = _set_job_attributes(job_ref)
97 final_attributes.update(job_attributes)
98 if attributes:
99 final_attributes.update(attributes)
100 return final_attributes
101
102
103 def _set_client_attributes(client):
104 return {"db.name": client.project, "location": client.location}
105
106
107 def _set_job_attributes(job_ref):
108 job_attributes = {
109 "db.name": job_ref.project,
110 "job_id": job_ref.job_id,
111 "state": job_ref.state,
112 }
113
114 job_attributes["hasErrors"] = job_ref.error_result is not None
115
116 if job_ref.created is not None:
117 job_attributes["timeCreated"] = job_ref.created.isoformat()
118
119 if job_ref.started is not None:
120 job_attributes["timeStarted"] = job_ref.started.isoformat()
121
122 if job_ref.ended is not None:
123 job_attributes["timeEnded"] = job_ref.ended.isoformat()
124
125 if job_ref.location is not None:
126 job_attributes["location"] = job_ref.location
127
128 if job_ref.parent_job_id is not None:
129 job_attributes["parent_job_id"] = job_ref.parent_job_id
130
131 if job_ref.num_child_jobs is not None:
132 job_attributes["num_child_jobs"] = job_ref.num_child_jobs
133
134 return job_attributes
135
[end of google/cloud/bigquery/opentelemetry_tracing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/google/cloud/bigquery/opentelemetry_tracing.py b/google/cloud/bigquery/opentelemetry_tracing.py
--- a/google/cloud/bigquery/opentelemetry_tracing.py
+++ b/google/cloud/bigquery/opentelemetry_tracing.py
@@ -97,6 +97,11 @@
final_attributes.update(job_attributes)
if attributes:
final_attributes.update(attributes)
+
+ filtered = {k: v for k, v in final_attributes.items() if v is not None}
+ final_attributes.clear()
+ final_attributes.update(filtered)
+
return final_attributes
|
{"golden_diff": "diff --git a/google/cloud/bigquery/opentelemetry_tracing.py b/google/cloud/bigquery/opentelemetry_tracing.py\n--- a/google/cloud/bigquery/opentelemetry_tracing.py\n+++ b/google/cloud/bigquery/opentelemetry_tracing.py\n@@ -97,6 +97,11 @@\n final_attributes.update(job_attributes)\n if attributes:\n final_attributes.update(attributes)\n+\n+ filtered = {k: v for k, v in final_attributes.items() if v is not None}\n+ final_attributes.clear()\n+ final_attributes.update(filtered)\n+\n return final_attributes\n", "issue": "Warning on OpenTelemetry when some attributes are not set\n#### Environment details\r\n\r\n - OS type and version: Windows 10 21H2\r\n - Python version: `3.9.4`\r\n - pip version: `22.2.2`\r\n - `google-cloud-bigquery` version: `3.3.5`\r\n\r\n#### Steps to reproduce\r\n\r\n 1. Set up a query job with opentelemetry enabled\r\n 2. See warning in the console: `Invalid type NoneType for attribute value. Expected one of ['bool', 'str', 'bytes', 'int', 'float'] or a sequence of those types`\r\n\r\n#### Code example\r\n\r\n```python\r\nimport logging\r\nfrom google.cloud import bigquery\r\nfrom opentelemetry import trace\r\nfrom opentelemetry.sdk.trace import TracerProvider\r\nfrom opentelemetry.sdk.trace.export import (\r\n SimpleSpanProcessor,\r\n ConsoleSpanExporter,\r\n)\r\n\r\nprovider = TracerProvider()\r\nsimple_processor = SimpleSpanProcessor(ConsoleSpanExporter())\r\nprovider.add_span_processor(simple_processor)\r\ntrace.set_tracer_provider(provider)\r\n\r\nlogging.basicConfig(level=10)\r\n\r\n# Construct a BigQuery client object.\r\nclient = bigquery.Client()\r\n\r\nquery = \"SELECT 1;\"\r\n\r\nquery_job = client.query(query)\r\n```\r\n#### Stack trace\r\n```\r\nDEBUG:google.auth._default:Checking None for explicit credentials as part of auth process...\r\nDEBUG:google.auth._default:Checking Cloud SDK credentials as part of auth process...\r\nDEBUG:google.auth._default:Checking None for explicit credentials as part of auth process...\r\nDEBUG:google.auth._default:Checking Cloud SDK credentials as part of auth process...\r\nWARNING:opentelemetry.attributes:Invalid type NoneType for attribute value. Expected one of ['bool', 'str', 'bytes', 'int', 'float'] or a sequence of those types\r\nWARNING:opentelemetry.attributes:Invalid type NoneType for attribute value. Expected one of ['bool', 'str', 'bytes', 'int', 'float'] or a sequence of those types\r\nDEBUG:urllib3.util.retry:Converted retries value: 3 -> Retry(total=3, connect=None, read=None, redirect=None, status=None)\r\nDEBUG:google.auth.transport.requests:Making request: POST https://oauth2.googleapis.com/token\r\nDEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): oauth2.googleapis.com:443\r\nDEBUG:urllib3.connectionpool:https://oauth2.googleapis.com:443 \"POST /token HTTP/1.1\" 200 None\r\nDEBUG:urllib3.connectionpool:Starting new HTTPS connection (1): bigquery.googleapis.com:443\r\nDEBUG:urllib3.connectionpool:https://bigquery.googleapis.com:443 \"POST /bigquery/v2/projects/my-project/jobs?prettyPrint=false HTTP/1.1\" 200 None\r\n{\r\n \"name\": \"BigQuery.job.begin\",\r\n \"context\": {\r\n \"trace_id\": \"0x192a0e4ec554c63f68525922208fed88\",\r\n \"span_id\": \"0xfa29f0363122c4c4\",\r\n \"trace_state\": \"[]\"\r\n },\r\n \"kind\": \"SpanKind.INTERNAL\",\r\n \"parent_id\": null,\r\n \"start_time\": \"2022-10-12T09:41:57.259114Z\",\r\n \"end_time\": \"2022-10-12T09:41:57.934410Z\",\r\n \"status\": {\r\n \"status_code\": \"UNSET\"\r\n },\r\n \"attributes\": {\r\n \"db.system\": \"BigQuery\",\r\n \"db.name\": \"my-project\",\r\n \"job_id\": \"fc1581e3-708b-4b51-9a05-e3ad52c68dec\",\r\n \"hasErrors\": false,\r\n \"num_child_jobs\": 0,\r\n \"path\": \"/projects/my-project/jobs\"\r\n },\r\n \"events\": [],\r\n \"links\": [],\r\n \"resource\": {\r\n \"attributes\": {\r\n \"telemetry.sdk.language\": \"python\",\r\n \"telemetry.sdk.name\": \"opentelemetry\",\r\n \"telemetry.sdk.version\": \"1.13.0\",\r\n \"service.name\": \"unknown_service\"\r\n },\r\n \"schema_url\": \"\"\r\n }\r\n}\r\n```\r\n#### Analysis\r\n\r\nWarnings appear when `location` and job `state` attributes are not set.\r\n\r\n\n", "before_files": [{"content": "# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom contextlib import contextmanager\nfrom google.api_core.exceptions import GoogleAPICallError # type: ignore\n\nlogger = logging.getLogger(__name__)\ntry:\n from opentelemetry import trace # type: ignore\n from opentelemetry.instrumentation.utils import http_status_to_status_code # type: ignore\n from opentelemetry.trace.status import Status # type: ignore\n\n HAS_OPENTELEMETRY = True\n _warned_telemetry = True\n\nexcept ImportError:\n HAS_OPENTELEMETRY = False\n _warned_telemetry = False\n\n_default_attributes = {\n \"db.system\": \"BigQuery\"\n} # static, default values assigned to all spans\n\n\n@contextmanager\ndef create_span(name, attributes=None, client=None, job_ref=None):\n \"\"\"Creates a ContextManager for a Span to be exported to the configured exporter.\n If no configuration exists yields None.\n\n Args:\n name (str): Name that will be set for the span being created\n attributes (Optional[dict]):\n Additional attributes that pertain to\n the specific API call (i.e. not a default attribute)\n client (Optional[google.cloud.bigquery.client.Client]):\n Pass in a Client object to extract any attributes that may be\n relevant to it and add them to the created spans.\n job_ref (Optional[google.cloud.bigquery.job._AsyncJob])\n Pass in a _AsyncJob object to extract any attributes that may be\n relevant to it and add them to the created spans.\n\n Yields:\n opentelemetry.trace.Span: Yields the newly created Span.\n\n Raises:\n google.api_core.exceptions.GoogleAPICallError:\n Raised if a span could not be yielded or issue with call to\n OpenTelemetry.\n \"\"\"\n global _warned_telemetry\n final_attributes = _get_final_span_attributes(attributes, client, job_ref)\n if not HAS_OPENTELEMETRY:\n if not _warned_telemetry:\n logger.debug(\n \"This service is instrumented using OpenTelemetry. \"\n \"OpenTelemetry or one of its components could not be imported; \"\n \"please add compatible versions of opentelemetry-api and \"\n \"opentelemetry-instrumentation packages in order to get BigQuery \"\n \"Tracing data.\"\n )\n _warned_telemetry = True\n\n yield None\n return\n tracer = trace.get_tracer(__name__)\n\n # yield new span value\n with tracer.start_as_current_span(name=name, attributes=final_attributes) as span:\n try:\n yield span\n except GoogleAPICallError as error:\n if error.code is not None:\n span.set_status(Status(http_status_to_status_code(error.code)))\n raise\n\n\ndef _get_final_span_attributes(attributes=None, client=None, job_ref=None):\n final_attributes = {}\n final_attributes.update(_default_attributes.copy())\n if client:\n client_attributes = _set_client_attributes(client)\n final_attributes.update(client_attributes)\n if job_ref:\n job_attributes = _set_job_attributes(job_ref)\n final_attributes.update(job_attributes)\n if attributes:\n final_attributes.update(attributes)\n return final_attributes\n\n\ndef _set_client_attributes(client):\n return {\"db.name\": client.project, \"location\": client.location}\n\n\ndef _set_job_attributes(job_ref):\n job_attributes = {\n \"db.name\": job_ref.project,\n \"job_id\": job_ref.job_id,\n \"state\": job_ref.state,\n }\n\n job_attributes[\"hasErrors\"] = job_ref.error_result is not None\n\n if job_ref.created is not None:\n job_attributes[\"timeCreated\"] = job_ref.created.isoformat()\n\n if job_ref.started is not None:\n job_attributes[\"timeStarted\"] = job_ref.started.isoformat()\n\n if job_ref.ended is not None:\n job_attributes[\"timeEnded\"] = job_ref.ended.isoformat()\n\n if job_ref.location is not None:\n job_attributes[\"location\"] = job_ref.location\n\n if job_ref.parent_job_id is not None:\n job_attributes[\"parent_job_id\"] = job_ref.parent_job_id\n\n if job_ref.num_child_jobs is not None:\n job_attributes[\"num_child_jobs\"] = job_ref.num_child_jobs\n\n return job_attributes\n", "path": "google/cloud/bigquery/opentelemetry_tracing.py"}]}
| 2,880 | 125 |
gh_patches_debug_34144
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-3017
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Doesn't catch invalid `rate(1 hours)`
*cfn-lint version: (`cfn-lint --version`)*
0.44.7
*Description of issue.*
cfn-lint doesn't recognize that this ScheduledExpression is invalid (should be `rate(1 hour)`)
```yaml
ExampleRule:
Type: AWS::Events::Rule
Properties:
Description: desc
Name: name
ScheduleExpression: rate(1 hours)
State: ENABLED
```
But when building the cloudformation, I get the following error:
```
Parameter ScheduleExpression is not valid. (Service: AmazonCloudWatchEvents; Status Code: 400; Error Code: ValidationException; Request ID: ...; Proxy: null)
```
I saw #816, but since this is a `rate` issue, not a `cron` issue, I thought I should open a new ticket
</issue>
<code>
[start of src/cfnlint/rules/resources/events/RuleScheduleExpression.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 from cfnlint.rules import CloudFormationLintRule, RuleMatch
6
7
8 class RuleScheduleExpression(CloudFormationLintRule):
9 """Validate AWS Events Schedule expression format"""
10
11 id = "E3027"
12 shortdesc = "Validate AWS Event ScheduleExpression format"
13 description = "Validate the formation of the AWS::Event ScheduleExpression"
14 source_url = "https://docs.aws.amazon.com/AmazonCloudWatch/latest/events/ScheduledEvents.html"
15 tags = ["resources", "events"]
16
17 def initialize(self, cfn):
18 """Initialize the rule"""
19 self.resource_property_types = ["AWS::Events::Rule"]
20
21 def check_rate(self, value, path):
22 """Check Rate configuration"""
23 matches = []
24 # Extract the expression from rate(XXX)
25 rate_expression = value[value.find("(") + 1 : value.find(")")]
26
27 if not rate_expression:
28 matches.append(
29 RuleMatch(path, "Rate value of ScheduleExpression cannot be empty")
30 )
31 else:
32 # Rate format: rate(Value Unit)
33 items = rate_expression.split(" ")
34
35 if len(items) != 2:
36 message = "Rate expression must contain 2 elements (Value Unit), rate contains {} elements"
37 matches.append(RuleMatch(path, message.format(len(items))))
38 else:
39 # Check the Value
40 if not items[0].isdigit():
41 message = "Rate Value ({}) should be of type Integer."
42 extra_args = {
43 "actual_type": type(items[0]).__name__,
44 "expected_type": int.__name__,
45 }
46 matches.append(
47 RuleMatch(path, message.format(items[0]), **extra_args)
48 )
49
50 return matches
51
52 def check_cron(self, value, path):
53 """Check Cron configuration"""
54 matches = []
55 # Extract the expression from cron(XXX)
56 cron_expression = value[value.find("(") + 1 : value.find(")")]
57
58 if not cron_expression:
59 matches.append(
60 RuleMatch(path, "Cron value of ScheduleExpression cannot be empty")
61 )
62 else:
63 # Rate format: cron(Minutes Hours Day-of-month Month Day-of-week Year)
64 items = cron_expression.split(" ")
65
66 if len(items) != 6:
67 message = "Cron expression must contain 6 elements (Minutes Hours Day-of-month Month Day-of-week Year), cron contains {} elements"
68 matches.append(RuleMatch(path, message.format(len(items))))
69 return matches
70
71 _, _, day_of_month, _, day_of_week, _ = cron_expression.split(" ")
72 if day_of_month != "?" and day_of_week != "?":
73 matches.append(
74 RuleMatch(
75 path,
76 "Don't specify the Day-of-month and Day-of-week fields in the same cron expression",
77 )
78 )
79
80 return matches
81
82 def check_value(self, value, path):
83 """Count ScheduledExpression value"""
84 matches = []
85
86 # Value is either "cron()" or "rate()"
87 if value.startswith("rate(") and value.endswith(")"):
88 matches.extend(self.check_rate(value, path))
89 elif value.startswith("cron(") and value.endswith(")"):
90 matches.extend(self.check_cron(value, path))
91 else:
92 message = "Invalid ScheduledExpression specified ({}). Value has to be either cron() or rate()"
93 matches.append(RuleMatch(path, message.format(value)))
94
95 return matches
96
97 def match_resource_properties(self, properties, _, path, cfn):
98 """Check CloudFormation Properties"""
99 matches = []
100
101 matches.extend(
102 cfn.check_value(
103 obj=properties,
104 key="ScheduleExpression",
105 path=path[:],
106 check_value=self.check_value,
107 )
108 )
109
110 return matches
111
[end of src/cfnlint/rules/resources/events/RuleScheduleExpression.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/resources/events/RuleScheduleExpression.py b/src/cfnlint/rules/resources/events/RuleScheduleExpression.py
--- a/src/cfnlint/rules/resources/events/RuleScheduleExpression.py
+++ b/src/cfnlint/rules/resources/events/RuleScheduleExpression.py
@@ -25,29 +25,43 @@
rate_expression = value[value.find("(") + 1 : value.find(")")]
if not rate_expression:
- matches.append(
- RuleMatch(path, "Rate value of ScheduleExpression cannot be empty")
- )
- else:
- # Rate format: rate(Value Unit)
- items = rate_expression.split(" ")
-
- if len(items) != 2:
- message = "Rate expression must contain 2 elements (Value Unit), rate contains {} elements"
- matches.append(RuleMatch(path, message.format(len(items))))
- else:
- # Check the Value
- if not items[0].isdigit():
- message = "Rate Value ({}) should be of type Integer."
- extra_args = {
- "actual_type": type(items[0]).__name__,
- "expected_type": int.__name__,
- }
- matches.append(
- RuleMatch(path, message.format(items[0]), **extra_args)
- )
+ return [RuleMatch(path, "Rate value of ScheduleExpression cannot be empty")]
+
+ # Rate format: rate(Value Unit)
+ items = rate_expression.split(" ")
+
+ if len(items) != 2:
+ message = "Rate expression must contain 2 elements (Value Unit), rate contains {} elements"
+ matches.append(RuleMatch(path, message.format(len(items))))
+ return [RuleMatch(path, message.format(len(items)))]
+
+ # Check the Value
+ if not items[0].isdigit():
+ message = "Rate Value ({}) should be of type Integer."
+ extra_args = {
+ "actual_type": type(items[0]).__name__,
+ "expected_type": int.__name__,
+ }
+ return [RuleMatch(path, message.format(items[0]), **extra_args)]
+
+ if float(items[0]) <= 0:
+ return [
+ RuleMatch(path, f"Rate Value {items[0]!r} should be greater than 0.")
+ ]
+
+ if float(items[0]) <= 1:
+ valid_periods = ["minute", "hour", "day"]
+ elif float(items[0]) > 1:
+ valid_periods = ["minutes", "hours", "days"]
+ # Check the Unit
+ if items[1] not in valid_periods:
+ return [
+ RuleMatch(
+ path, f"Rate Unit {items[1]!r} should be one of {valid_periods!r}."
+ )
+ ]
- return matches
+ return []
def check_cron(self, value, path):
"""Check Cron configuration"""
|
{"golden_diff": "diff --git a/src/cfnlint/rules/resources/events/RuleScheduleExpression.py b/src/cfnlint/rules/resources/events/RuleScheduleExpression.py\n--- a/src/cfnlint/rules/resources/events/RuleScheduleExpression.py\n+++ b/src/cfnlint/rules/resources/events/RuleScheduleExpression.py\n@@ -25,29 +25,43 @@\n rate_expression = value[value.find(\"(\") + 1 : value.find(\")\")]\n \n if not rate_expression:\n- matches.append(\n- RuleMatch(path, \"Rate value of ScheduleExpression cannot be empty\")\n- )\n- else:\n- # Rate format: rate(Value Unit)\n- items = rate_expression.split(\" \")\n-\n- if len(items) != 2:\n- message = \"Rate expression must contain 2 elements (Value Unit), rate contains {} elements\"\n- matches.append(RuleMatch(path, message.format(len(items))))\n- else:\n- # Check the Value\n- if not items[0].isdigit():\n- message = \"Rate Value ({}) should be of type Integer.\"\n- extra_args = {\n- \"actual_type\": type(items[0]).__name__,\n- \"expected_type\": int.__name__,\n- }\n- matches.append(\n- RuleMatch(path, message.format(items[0]), **extra_args)\n- )\n+ return [RuleMatch(path, \"Rate value of ScheduleExpression cannot be empty\")]\n+\n+ # Rate format: rate(Value Unit)\n+ items = rate_expression.split(\" \")\n+\n+ if len(items) != 2:\n+ message = \"Rate expression must contain 2 elements (Value Unit), rate contains {} elements\"\n+ matches.append(RuleMatch(path, message.format(len(items))))\n+ return [RuleMatch(path, message.format(len(items)))]\n+\n+ # Check the Value\n+ if not items[0].isdigit():\n+ message = \"Rate Value ({}) should be of type Integer.\"\n+ extra_args = {\n+ \"actual_type\": type(items[0]).__name__,\n+ \"expected_type\": int.__name__,\n+ }\n+ return [RuleMatch(path, message.format(items[0]), **extra_args)]\n+\n+ if float(items[0]) <= 0:\n+ return [\n+ RuleMatch(path, f\"Rate Value {items[0]!r} should be greater than 0.\")\n+ ]\n+\n+ if float(items[0]) <= 1:\n+ valid_periods = [\"minute\", \"hour\", \"day\"]\n+ elif float(items[0]) > 1:\n+ valid_periods = [\"minutes\", \"hours\", \"days\"]\n+ # Check the Unit\n+ if items[1] not in valid_periods:\n+ return [\n+ RuleMatch(\n+ path, f\"Rate Unit {items[1]!r} should be one of {valid_periods!r}.\"\n+ )\n+ ]\n \n- return matches\n+ return []\n \n def check_cron(self, value, path):\n \"\"\"Check Cron configuration\"\"\"\n", "issue": "Doesn't catch invalid `rate(1 hours)`\n*cfn-lint version: (`cfn-lint --version`)*\r\n\r\n0.44.7\r\n\r\n*Description of issue.*\r\n\r\ncfn-lint doesn't recognize that this ScheduledExpression is invalid (should be `rate(1 hour)`)\r\n```yaml\r\n ExampleRule:\r\n Type: AWS::Events::Rule\r\n Properties:\r\n Description: desc\r\n Name: name\r\n ScheduleExpression: rate(1 hours)\r\n State: ENABLED\r\n```\r\n\r\nBut when building the cloudformation, I get the following error:\r\n\r\n```\r\nParameter ScheduleExpression is not valid. (Service: AmazonCloudWatchEvents; Status Code: 400; Error Code: ValidationException; Request ID: ...; Proxy: null)\r\n```\r\n\r\nI saw #816, but since this is a `rate` issue, not a `cron` issue, I thought I should open a new ticket\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\nfrom cfnlint.rules import CloudFormationLintRule, RuleMatch\n\n\nclass RuleScheduleExpression(CloudFormationLintRule):\n \"\"\"Validate AWS Events Schedule expression format\"\"\"\n\n id = \"E3027\"\n shortdesc = \"Validate AWS Event ScheduleExpression format\"\n description = \"Validate the formation of the AWS::Event ScheduleExpression\"\n source_url = \"https://docs.aws.amazon.com/AmazonCloudWatch/latest/events/ScheduledEvents.html\"\n tags = [\"resources\", \"events\"]\n\n def initialize(self, cfn):\n \"\"\"Initialize the rule\"\"\"\n self.resource_property_types = [\"AWS::Events::Rule\"]\n\n def check_rate(self, value, path):\n \"\"\"Check Rate configuration\"\"\"\n matches = []\n # Extract the expression from rate(XXX)\n rate_expression = value[value.find(\"(\") + 1 : value.find(\")\")]\n\n if not rate_expression:\n matches.append(\n RuleMatch(path, \"Rate value of ScheduleExpression cannot be empty\")\n )\n else:\n # Rate format: rate(Value Unit)\n items = rate_expression.split(\" \")\n\n if len(items) != 2:\n message = \"Rate expression must contain 2 elements (Value Unit), rate contains {} elements\"\n matches.append(RuleMatch(path, message.format(len(items))))\n else:\n # Check the Value\n if not items[0].isdigit():\n message = \"Rate Value ({}) should be of type Integer.\"\n extra_args = {\n \"actual_type\": type(items[0]).__name__,\n \"expected_type\": int.__name__,\n }\n matches.append(\n RuleMatch(path, message.format(items[0]), **extra_args)\n )\n\n return matches\n\n def check_cron(self, value, path):\n \"\"\"Check Cron configuration\"\"\"\n matches = []\n # Extract the expression from cron(XXX)\n cron_expression = value[value.find(\"(\") + 1 : value.find(\")\")]\n\n if not cron_expression:\n matches.append(\n RuleMatch(path, \"Cron value of ScheduleExpression cannot be empty\")\n )\n else:\n # Rate format: cron(Minutes Hours Day-of-month Month Day-of-week Year)\n items = cron_expression.split(\" \")\n\n if len(items) != 6:\n message = \"Cron expression must contain 6 elements (Minutes Hours Day-of-month Month Day-of-week Year), cron contains {} elements\"\n matches.append(RuleMatch(path, message.format(len(items))))\n return matches\n\n _, _, day_of_month, _, day_of_week, _ = cron_expression.split(\" \")\n if day_of_month != \"?\" and day_of_week != \"?\":\n matches.append(\n RuleMatch(\n path,\n \"Don't specify the Day-of-month and Day-of-week fields in the same cron expression\",\n )\n )\n\n return matches\n\n def check_value(self, value, path):\n \"\"\"Count ScheduledExpression value\"\"\"\n matches = []\n\n # Value is either \"cron()\" or \"rate()\"\n if value.startswith(\"rate(\") and value.endswith(\")\"):\n matches.extend(self.check_rate(value, path))\n elif value.startswith(\"cron(\") and value.endswith(\")\"):\n matches.extend(self.check_cron(value, path))\n else:\n message = \"Invalid ScheduledExpression specified ({}). Value has to be either cron() or rate()\"\n matches.append(RuleMatch(path, message.format(value)))\n\n return matches\n\n def match_resource_properties(self, properties, _, path, cfn):\n \"\"\"Check CloudFormation Properties\"\"\"\n matches = []\n\n matches.extend(\n cfn.check_value(\n obj=properties,\n key=\"ScheduleExpression\",\n path=path[:],\n check_value=self.check_value,\n )\n )\n\n return matches\n", "path": "src/cfnlint/rules/resources/events/RuleScheduleExpression.py"}]}
| 1,788 | 654 |
gh_patches_debug_10525
|
rasdani/github-patches
|
git_diff
|
easybuilders__easybuild-easyblocks-1924
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pylibdir of versionindependentpythonpackage.py is overwritten by pythonpackage.py
In 599869d `set_pylibdirs` of [pythonpackage.py](https://github.com/easybuilders/easybuild-easyblocks/blob/develop/easybuild/easyblocks/generic/pythonpackage.py) was changed to always set `self.pylibdir` (not only if its value is `UNKNOWN`). This seems to break the `prepare_step` of [versionindependentpythonpackage.py](https://github.com/easybuilders/easybuild-easyblocks/blob/develop/easybuild/easyblocks/generic/versionindependentpythonpackage.py) because pylibdir is now overwritten. This forces the `install_step` to crash afterwards due to missing subdirs within the `os.mkdir(full_pylibdir)` command.
</issue>
<code>
[start of easybuild/easyblocks/generic/versionindependentpythonpackage.py]
1 ##
2 # Copyright 2013-2020 Ghent University
3 #
4 # This file is part of EasyBuild,
5 # originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),
6 # with support of Ghent University (http://ugent.be/hpc),
7 # the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),
8 # Flemish Research Foundation (FWO) (http://www.fwo.be/en)
9 # and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).
10 #
11 # https://github.com/easybuilders/easybuild
12 #
13 # EasyBuild is free software: you can redistribute it and/or modify
14 # it under the terms of the GNU General Public License as published by
15 # the Free Software Foundation v2.
16 #
17 # EasyBuild is distributed in the hope that it will be useful,
18 # but WITHOUT ANY WARRANTY; without even the implied warranty of
19 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
20 # GNU General Public License for more details.
21 #
22 # You should have received a copy of the GNU General Public License
23 # along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.
24 ##
25 """
26 EasyBuild support for building and installing a Pythonpackage independend of a python version as an easyblock.
27
28 Python installs libraries by defailt in site-packages/python-xxx/
29 But packages that are not dependend on the python version can be installed in a different prefix, e.g. lib
30 as long as we add this folder to the pythonpath.
31
32 @author: Kenneth Hoste, Jens Timmerman (Ghent University)
33 """
34 import os
35 import re
36
37 import easybuild.tools.environment as env
38 from easybuild.easyblocks.generic.pythonpackage import PythonPackage
39 from easybuild.tools.build_log import EasyBuildError
40 from easybuild.tools.run import run_cmd
41
42
43 class VersionIndependentPythonPackage(PythonPackage):
44 """Support for building/installing python packages without requiring a specific python package."""
45
46 def build_step(self):
47 """No build procedure."""
48 pass
49
50 def prepare_step(self, *args, **kwargs):
51 """Set pylibdir"""
52 self.pylibdir = 'lib'
53 super(VersionIndependentPythonPackage, self).prepare_step(*args, **kwargs)
54
55 def install_step(self):
56 """Custom install procedure to skip selection of python package versions."""
57 full_pylibdir = os.path.join(self.installdir, self.pylibdir)
58
59 env.setvar('PYTHONPATH', '%s:%s' % (full_pylibdir, os.getenv('PYTHONPATH')))
60
61 try:
62 os.mkdir(full_pylibdir)
63 except OSError as err:
64 # this will raise an error and not return
65 raise EasyBuildError("Failed to install: %s", err)
66
67 if self.use_setup_py:
68 extra_installopts = [
69 '--install-lib=%s' % full_pylibdir,
70 '--single-version-externally-managed',
71 '--record %s' % os.path.join(self.builddir, 'record'),
72 '--no-compile',
73 ]
74 self.cfg.update('installopts', ' '.join(extra_installopts))
75 else:
76 # using easy_install or pip always results in installation that is specific to Python version
77 eb_name = self.__class__.__name__
78 raise EasyBuildError("%s easyblock is not compatible with using easy_install or pip", eb_name)
79
80 cmd = self.compose_install_command(self.installdir)
81 run_cmd(cmd, log_all=True, simple=True, log_output=True)
82
83 # setuptools stubbornly replaces the shebang line in scripts with
84 # the full path to the Python interpreter used to install;
85 # we change it (back) to '#!/usr/bin/env python' here
86 shebang_re = re.compile("^#!/.*python")
87 bindir = os.path.join(self.installdir, 'bin')
88 if os.path.exists(bindir):
89 for script in os.listdir(bindir):
90 script = os.path.join(bindir, script)
91 if os.path.isfile(script):
92 try:
93 txt = open(script, 'r').read()
94 if shebang_re.search(txt):
95 new_shebang = "#!/usr/bin/env python"
96 self.log.debug("Patching shebang header line in %s to '%s'" % (script, new_shebang))
97 txt = shebang_re.sub(new_shebang, txt)
98 open(script, 'w').write(txt)
99 except IOError as err:
100 raise EasyBuildError("Failed to patch shebang header line in %s: %s", script, err)
101
[end of easybuild/easyblocks/generic/versionindependentpythonpackage.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/easybuild/easyblocks/generic/versionindependentpythonpackage.py b/easybuild/easyblocks/generic/versionindependentpythonpackage.py
--- a/easybuild/easyblocks/generic/versionindependentpythonpackage.py
+++ b/easybuild/easyblocks/generic/versionindependentpythonpackage.py
@@ -47,10 +47,11 @@
"""No build procedure."""
pass
- def prepare_step(self, *args, **kwargs):
- """Set pylibdir"""
+ def set_pylibdirs(self):
+ """Set pylibdir."""
+ super(VersionIndependentPythonPackage, self).set_pylibdirs()
self.pylibdir = 'lib'
- super(VersionIndependentPythonPackage, self).prepare_step(*args, **kwargs)
+ self.all_pylibdirs = ['lib']
def install_step(self):
"""Custom install procedure to skip selection of python package versions."""
|
{"golden_diff": "diff --git a/easybuild/easyblocks/generic/versionindependentpythonpackage.py b/easybuild/easyblocks/generic/versionindependentpythonpackage.py\n--- a/easybuild/easyblocks/generic/versionindependentpythonpackage.py\n+++ b/easybuild/easyblocks/generic/versionindependentpythonpackage.py\n@@ -47,10 +47,11 @@\n \"\"\"No build procedure.\"\"\"\n pass\n \n- def prepare_step(self, *args, **kwargs):\n- \"\"\"Set pylibdir\"\"\"\n+ def set_pylibdirs(self):\n+ \"\"\"Set pylibdir.\"\"\"\n+ super(VersionIndependentPythonPackage, self).set_pylibdirs()\n self.pylibdir = 'lib'\n- super(VersionIndependentPythonPackage, self).prepare_step(*args, **kwargs)\n+ self.all_pylibdirs = ['lib']\n \n def install_step(self):\n \"\"\"Custom install procedure to skip selection of python package versions.\"\"\"\n", "issue": "pylibdir of versionindependentpythonpackage.py is overwritten by pythonpackage.py\nIn 599869d `set_pylibdirs` of [pythonpackage.py](https://github.com/easybuilders/easybuild-easyblocks/blob/develop/easybuild/easyblocks/generic/pythonpackage.py) was changed to always set `self.pylibdir` (not only if its value is `UNKNOWN`). This seems to break the `prepare_step` of [versionindependentpythonpackage.py](https://github.com/easybuilders/easybuild-easyblocks/blob/develop/easybuild/easyblocks/generic/versionindependentpythonpackage.py) because pylibdir is now overwritten. This forces the `install_step` to crash afterwards due to missing subdirs within the `os.mkdir(full_pylibdir)` command.\n", "before_files": [{"content": "##\n# Copyright 2013-2020 Ghent University\n#\n# This file is part of EasyBuild,\n# originally created by the HPC team of Ghent University (http://ugent.be/hpc/en),\n# with support of Ghent University (http://ugent.be/hpc),\n# the Flemish Supercomputer Centre (VSC) (https://www.vscentrum.be),\n# Flemish Research Foundation (FWO) (http://www.fwo.be/en)\n# and the Department of Economy, Science and Innovation (EWI) (http://www.ewi-vlaanderen.be/en).\n#\n# https://github.com/easybuilders/easybuild\n#\n# EasyBuild is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation v2.\n#\n# EasyBuild is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with EasyBuild. If not, see <http://www.gnu.org/licenses/>.\n##\n\"\"\"\nEasyBuild support for building and installing a Pythonpackage independend of a python version as an easyblock.\n\nPython installs libraries by defailt in site-packages/python-xxx/\nBut packages that are not dependend on the python version can be installed in a different prefix, e.g. lib\nas long as we add this folder to the pythonpath.\n\n@author: Kenneth Hoste, Jens Timmerman (Ghent University)\n\"\"\"\nimport os\nimport re\n\nimport easybuild.tools.environment as env\nfrom easybuild.easyblocks.generic.pythonpackage import PythonPackage\nfrom easybuild.tools.build_log import EasyBuildError\nfrom easybuild.tools.run import run_cmd\n\n\nclass VersionIndependentPythonPackage(PythonPackage):\n \"\"\"Support for building/installing python packages without requiring a specific python package.\"\"\"\n\n def build_step(self):\n \"\"\"No build procedure.\"\"\"\n pass\n\n def prepare_step(self, *args, **kwargs):\n \"\"\"Set pylibdir\"\"\"\n self.pylibdir = 'lib'\n super(VersionIndependentPythonPackage, self).prepare_step(*args, **kwargs)\n\n def install_step(self):\n \"\"\"Custom install procedure to skip selection of python package versions.\"\"\"\n full_pylibdir = os.path.join(self.installdir, self.pylibdir)\n\n env.setvar('PYTHONPATH', '%s:%s' % (full_pylibdir, os.getenv('PYTHONPATH')))\n\n try:\n os.mkdir(full_pylibdir)\n except OSError as err:\n # this will raise an error and not return\n raise EasyBuildError(\"Failed to install: %s\", err)\n\n if self.use_setup_py:\n extra_installopts = [\n '--install-lib=%s' % full_pylibdir,\n '--single-version-externally-managed',\n '--record %s' % os.path.join(self.builddir, 'record'),\n '--no-compile',\n ]\n self.cfg.update('installopts', ' '.join(extra_installopts))\n else:\n # using easy_install or pip always results in installation that is specific to Python version\n eb_name = self.__class__.__name__\n raise EasyBuildError(\"%s easyblock is not compatible with using easy_install or pip\", eb_name)\n\n cmd = self.compose_install_command(self.installdir)\n run_cmd(cmd, log_all=True, simple=True, log_output=True)\n\n # setuptools stubbornly replaces the shebang line in scripts with\n # the full path to the Python interpreter used to install;\n # we change it (back) to '#!/usr/bin/env python' here\n shebang_re = re.compile(\"^#!/.*python\")\n bindir = os.path.join(self.installdir, 'bin')\n if os.path.exists(bindir):\n for script in os.listdir(bindir):\n script = os.path.join(bindir, script)\n if os.path.isfile(script):\n try:\n txt = open(script, 'r').read()\n if shebang_re.search(txt):\n new_shebang = \"#!/usr/bin/env python\"\n self.log.debug(\"Patching shebang header line in %s to '%s'\" % (script, new_shebang))\n txt = shebang_re.sub(new_shebang, txt)\n open(script, 'w').write(txt)\n except IOError as err:\n raise EasyBuildError(\"Failed to patch shebang header line in %s: %s\", script, err)\n", "path": "easybuild/easyblocks/generic/versionindependentpythonpackage.py"}]}
| 1,915 | 204 |
gh_patches_debug_22476
|
rasdani/github-patches
|
git_diff
|
carpentries__amy-714
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Tokenize person lookup to work with "name last_name"
`lookups.PersonLookup` won't show 'Piotr Banaszkiewicz' for 'Piotr Ban' input – because it only looks up `personal` or `family` or `email`…
</issue>
<code>
[start of workshops/lookups.py]
1 from django.contrib.auth.models import Group
2 from django.db.models import Q
3
4 from selectable.base import ModelLookup
5 from selectable.registry import registry
6 from selectable.decorators import login_required
7
8 from workshops import models
9
10
11 @login_required
12 class EventLookup(ModelLookup):
13 model = models.Event
14 search_fields = ('slug__icontains', )
15
16
17 @login_required
18 class HostLookup(ModelLookup):
19 model = models.Host
20 search_fields = (
21 'domain__icontains',
22 'fullname__icontains'
23 )
24
25
26 @login_required
27 class PersonLookup(ModelLookup):
28 model = models.Person
29 search_fields = (
30 'personal__icontains',
31 'family__icontains',
32 'email__icontains',
33 'username__icontains'
34 )
35
36
37 @login_required
38 class AdminLookup(ModelLookup):
39 """The same as PersonLookup, but allows only to select administrators.
40
41 Administrator is anyone with superuser power or in "administrators" group.
42 """
43 model = models.Person
44 search_fields = (
45 'personal__icontains',
46 'family__icontains',
47 'email__icontains',
48 'username__icontains'
49 )
50
51 def get_query(self, request, term):
52 results = super().get_query(request, term)
53 admin_group = Group.objects.get(name='administrators')
54 results = results.filter(
55 Q(is_superuser=True) | Q(groups__in=[admin_group])
56 )
57 return results
58
59
60 @login_required
61 class AirportLookup(ModelLookup):
62 model = models.Airport
63 search_fields = (
64 'iata__icontains',
65 'fullname__icontains'
66 )
67
68
69 registry.register(EventLookup)
70 registry.register(HostLookup)
71 registry.register(PersonLookup)
72 registry.register(AdminLookup)
73 registry.register(AirportLookup)
74
[end of workshops/lookups.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/workshops/lookups.py b/workshops/lookups.py
--- a/workshops/lookups.py
+++ b/workshops/lookups.py
@@ -1,3 +1,7 @@
+from functools import reduce
+import operator
+import re
+
from django.contrib.auth.models import Group
from django.db.models import Q
@@ -33,6 +37,32 @@
'username__icontains'
)
+ def get_query(self, request, term):
+ """Override this method to allow for additional lookup method: """
+ # original code from selectable.base.ModelLookup.get_query:
+ qs = self.get_queryset()
+ if term:
+ search_filters = []
+ if self.search_fields:
+ for field in self.search_fields:
+ search_filters.append(Q(**{field: term}))
+
+ # tokenizing part
+ tokens = re.split('\s+', term)
+ if len(tokens) == 2:
+ name1, name2 = tokens
+ complex_q = (
+ Q(personal__icontains=name1) & Q(family__icontains=name2)
+ ) | (
+ Q(personal__icontains=name2) & Q(family__icontains=name1)
+ )
+ search_filters.append(complex_q)
+
+ # this is brilliant: it applies OR to all search filters
+ qs = qs.filter(reduce(operator.or_, search_filters))
+
+ return qs
+
@login_required
class AdminLookup(ModelLookup):
|
{"golden_diff": "diff --git a/workshops/lookups.py b/workshops/lookups.py\n--- a/workshops/lookups.py\n+++ b/workshops/lookups.py\n@@ -1,3 +1,7 @@\n+from functools import reduce\n+import operator\n+import re\n+\n from django.contrib.auth.models import Group\n from django.db.models import Q\n \n@@ -33,6 +37,32 @@\n 'username__icontains'\n )\n \n+ def get_query(self, request, term):\n+ \"\"\"Override this method to allow for additional lookup method: \"\"\"\n+ # original code from selectable.base.ModelLookup.get_query:\n+ qs = self.get_queryset()\n+ if term:\n+ search_filters = []\n+ if self.search_fields:\n+ for field in self.search_fields:\n+ search_filters.append(Q(**{field: term}))\n+\n+ # tokenizing part\n+ tokens = re.split('\\s+', term)\n+ if len(tokens) == 2:\n+ name1, name2 = tokens\n+ complex_q = (\n+ Q(personal__icontains=name1) & Q(family__icontains=name2)\n+ ) | (\n+ Q(personal__icontains=name2) & Q(family__icontains=name1)\n+ )\n+ search_filters.append(complex_q)\n+\n+ # this is brilliant: it applies OR to all search filters\n+ qs = qs.filter(reduce(operator.or_, search_filters))\n+\n+ return qs\n+\n \n @login_required\n class AdminLookup(ModelLookup):\n", "issue": "Tokenize person lookup to work with \"name last_name\"\n`lookups.PersonLookup` won't show 'Piotr Banaszkiewicz' for 'Piotr Ban' input \u2013 because it only looks up `personal` or `family` or `email`\u2026\n\n", "before_files": [{"content": "from django.contrib.auth.models import Group\nfrom django.db.models import Q\n\nfrom selectable.base import ModelLookup\nfrom selectable.registry import registry\nfrom selectable.decorators import login_required\n\nfrom workshops import models\n\n\n@login_required\nclass EventLookup(ModelLookup):\n model = models.Event\n search_fields = ('slug__icontains', )\n\n\n@login_required\nclass HostLookup(ModelLookup):\n model = models.Host\n search_fields = (\n 'domain__icontains',\n 'fullname__icontains'\n )\n\n\n@login_required\nclass PersonLookup(ModelLookup):\n model = models.Person\n search_fields = (\n 'personal__icontains',\n 'family__icontains',\n 'email__icontains',\n 'username__icontains'\n )\n\n\n@login_required\nclass AdminLookup(ModelLookup):\n \"\"\"The same as PersonLookup, but allows only to select administrators.\n\n Administrator is anyone with superuser power or in \"administrators\" group.\n \"\"\"\n model = models.Person\n search_fields = (\n 'personal__icontains',\n 'family__icontains',\n 'email__icontains',\n 'username__icontains'\n )\n\n def get_query(self, request, term):\n results = super().get_query(request, term)\n admin_group = Group.objects.get(name='administrators')\n results = results.filter(\n Q(is_superuser=True) | Q(groups__in=[admin_group])\n )\n return results\n\n\n@login_required\nclass AirportLookup(ModelLookup):\n model = models.Airport\n search_fields = (\n 'iata__icontains',\n 'fullname__icontains'\n )\n\n\nregistry.register(EventLookup)\nregistry.register(HostLookup)\nregistry.register(PersonLookup)\nregistry.register(AdminLookup)\nregistry.register(AirportLookup)\n", "path": "workshops/lookups.py"}]}
| 1,102 | 331 |
gh_patches_debug_8564
|
rasdani/github-patches
|
git_diff
|
comfyanonymous__ComfyUI-2859
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Perp-Neg implementation is wrong, parallel component not ignored
https://github.com/comfyanonymous/ComfyUI/blob/18c151b3e3f6838fab4028e7a8ba526e30e610d3/comfy_extras/nodes_perpneg.py#L38-L40
The Perp-Neg node does not match the [paper](https://arxiv.org/pdf/2304.04968.pdf) (pytorch code in Appendix A.1).
When positive and negative prompt are the same, the result should be the same as an empty negative prompt because the prompts are completely parallel (i.e. there is no perpendicular component).
Positive: "forest"
Negative: ""

Positive: "forest"
Negative: "forest"

I'll submit a PR in a bit.
</issue>
<code>
[start of comfy_extras/nodes_perpneg.py]
1 import torch
2 import comfy.model_management
3 import comfy.sample
4 import comfy.samplers
5 import comfy.utils
6
7
8 class PerpNeg:
9 @classmethod
10 def INPUT_TYPES(s):
11 return {"required": {"model": ("MODEL", ),
12 "empty_conditioning": ("CONDITIONING", ),
13 "neg_scale": ("FLOAT", {"default": 1.0, "min": 0.0, "max": 100.0}),
14 }}
15 RETURN_TYPES = ("MODEL",)
16 FUNCTION = "patch"
17
18 CATEGORY = "_for_testing"
19
20 def patch(self, model, empty_conditioning, neg_scale):
21 m = model.clone()
22 nocond = comfy.sample.convert_cond(empty_conditioning)
23
24 def cfg_function(args):
25 model = args["model"]
26 noise_pred_pos = args["cond_denoised"]
27 noise_pred_neg = args["uncond_denoised"]
28 cond_scale = args["cond_scale"]
29 x = args["input"]
30 sigma = args["sigma"]
31 model_options = args["model_options"]
32 nocond_processed = comfy.samplers.encode_model_conds(model.extra_conds, nocond, x, x.device, "negative")
33
34 (noise_pred_nocond, _) = comfy.samplers.calc_cond_uncond_batch(model, nocond_processed, None, x, sigma, model_options)
35
36 pos = noise_pred_pos - noise_pred_nocond
37 neg = noise_pred_neg - noise_pred_nocond
38 perp = ((torch.mul(pos, neg).sum())/(torch.norm(neg)**2)) * neg
39 perp_neg = perp * neg_scale
40 cfg_result = noise_pred_nocond + cond_scale*(pos - perp_neg)
41 cfg_result = x - cfg_result
42 return cfg_result
43
44 m.set_model_sampler_cfg_function(cfg_function)
45
46 return (m, )
47
48
49 NODE_CLASS_MAPPINGS = {
50 "PerpNeg": PerpNeg,
51 }
52
53 NODE_DISPLAY_NAME_MAPPINGS = {
54 "PerpNeg": "Perp-Neg",
55 }
56
[end of comfy_extras/nodes_perpneg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/comfy_extras/nodes_perpneg.py b/comfy_extras/nodes_perpneg.py
--- a/comfy_extras/nodes_perpneg.py
+++ b/comfy_extras/nodes_perpneg.py
@@ -35,7 +35,7 @@
pos = noise_pred_pos - noise_pred_nocond
neg = noise_pred_neg - noise_pred_nocond
- perp = ((torch.mul(pos, neg).sum())/(torch.norm(neg)**2)) * neg
+ perp = neg - ((torch.mul(neg, pos).sum())/(torch.norm(pos)**2)) * pos
perp_neg = perp * neg_scale
cfg_result = noise_pred_nocond + cond_scale*(pos - perp_neg)
cfg_result = x - cfg_result
|
{"golden_diff": "diff --git a/comfy_extras/nodes_perpneg.py b/comfy_extras/nodes_perpneg.py\n--- a/comfy_extras/nodes_perpneg.py\n+++ b/comfy_extras/nodes_perpneg.py\n@@ -35,7 +35,7 @@\n \n pos = noise_pred_pos - noise_pred_nocond\n neg = noise_pred_neg - noise_pred_nocond\n- perp = ((torch.mul(pos, neg).sum())/(torch.norm(neg)**2)) * neg\n+ perp = neg - ((torch.mul(neg, pos).sum())/(torch.norm(pos)**2)) * pos\n perp_neg = perp * neg_scale\n cfg_result = noise_pred_nocond + cond_scale*(pos - perp_neg)\n cfg_result = x - cfg_result\n", "issue": "Perp-Neg implementation is wrong, parallel component not ignored\nhttps://github.com/comfyanonymous/ComfyUI/blob/18c151b3e3f6838fab4028e7a8ba526e30e610d3/comfy_extras/nodes_perpneg.py#L38-L40\r\n\r\nThe Perp-Neg node does not match the [paper](https://arxiv.org/pdf/2304.04968.pdf) (pytorch code in Appendix A.1).\r\nWhen positive and negative prompt are the same, the result should be the same as an empty negative prompt because the prompts are completely parallel (i.e. there is no perpendicular component).\r\n\r\nPositive: \"forest\"\r\nNegative: \"\"\r\n\r\n\r\nPositive: \"forest\"\r\nNegative: \"forest\"\r\n\r\n\r\nI'll submit a PR in a bit.\n", "before_files": [{"content": "import torch\nimport comfy.model_management\nimport comfy.sample\nimport comfy.samplers\nimport comfy.utils\n\n\nclass PerpNeg:\n @classmethod\n def INPUT_TYPES(s):\n return {\"required\": {\"model\": (\"MODEL\", ),\n \"empty_conditioning\": (\"CONDITIONING\", ),\n \"neg_scale\": (\"FLOAT\", {\"default\": 1.0, \"min\": 0.0, \"max\": 100.0}),\n }}\n RETURN_TYPES = (\"MODEL\",)\n FUNCTION = \"patch\"\n\n CATEGORY = \"_for_testing\"\n\n def patch(self, model, empty_conditioning, neg_scale):\n m = model.clone()\n nocond = comfy.sample.convert_cond(empty_conditioning)\n\n def cfg_function(args):\n model = args[\"model\"]\n noise_pred_pos = args[\"cond_denoised\"]\n noise_pred_neg = args[\"uncond_denoised\"]\n cond_scale = args[\"cond_scale\"]\n x = args[\"input\"]\n sigma = args[\"sigma\"]\n model_options = args[\"model_options\"]\n nocond_processed = comfy.samplers.encode_model_conds(model.extra_conds, nocond, x, x.device, \"negative\")\n\n (noise_pred_nocond, _) = comfy.samplers.calc_cond_uncond_batch(model, nocond_processed, None, x, sigma, model_options)\n\n pos = noise_pred_pos - noise_pred_nocond\n neg = noise_pred_neg - noise_pred_nocond\n perp = ((torch.mul(pos, neg).sum())/(torch.norm(neg)**2)) * neg\n perp_neg = perp * neg_scale\n cfg_result = noise_pred_nocond + cond_scale*(pos - perp_neg)\n cfg_result = x - cfg_result\n return cfg_result\n\n m.set_model_sampler_cfg_function(cfg_function)\n\n return (m, )\n\n\nNODE_CLASS_MAPPINGS = {\n \"PerpNeg\": PerpNeg,\n}\n\nNODE_DISPLAY_NAME_MAPPINGS = {\n \"PerpNeg\": \"Perp-Neg\",\n}\n", "path": "comfy_extras/nodes_perpneg.py"}]}
| 1,406 | 179 |
gh_patches_debug_34384
|
rasdani/github-patches
|
git_diff
|
great-expectations__great_expectations-6877
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Use cleaner solution for non-truncating division in python 2
Prefer `from __future__ import division` to `1.*x/y`
</issue>
<code>
[start of great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py]
1 from typing import TYPE_CHECKING, Optional
2
3 from great_expectations.core import (
4 ExpectationConfiguration,
5 ExpectationValidationResult,
6 )
7 from great_expectations.expectations.expectation import (
8 ColumnMapExpectation,
9 InvalidExpectationConfigurationError,
10 render_evaluation_parameter_string,
11 )
12 from great_expectations.render import LegacyRendererType, RenderedStringTemplateContent
13 from great_expectations.render.renderer.renderer import renderer
14 from great_expectations.render.renderer_configuration import (
15 RendererConfiguration,
16 RendererValueType,
17 )
18 from great_expectations.render.util import (
19 num_to_str,
20 parse_row_condition_string_pandas_engine,
21 substitute_none_for_missing,
22 )
23
24 if TYPE_CHECKING:
25 from great_expectations.render.renderer_configuration import AddParamArgs
26
27
28 class ExpectColumnValuesToNotMatchRegexList(ColumnMapExpectation):
29 """Expect the column entries to be strings that do not match any of a list of regular expressions. Matches can be anywhere in the string.
30
31 expect_column_values_to_not_match_regex_list is a \
32 [Column Map Expectation](https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_column_map_expectations).
33
34 Args:
35 column (str): \
36 The column name.
37 regex_list (list): \
38 The list of regular expressions which the column entries should not match
39
40 Keyword Args:
41 mostly (None or a float between 0 and 1): \
42 Successful if at least mostly fraction of values match the expectation. \
43 For more detail, see [mostly](https://docs.greatexpectations.io/docs/reference/expectations/standard_arguments/#mostly).
44
45 Other Parameters:
46 result_format (str or None): \
47 Which output mode to use: BOOLEAN_ONLY, BASIC, COMPLETE, or SUMMARY. \
48 For more detail, see [result_format](https://docs.greatexpectations.io/docs/reference/expectations/result_format).
49 include_config (boolean): \
50 If True, then include the expectation config as part of the result object.
51 catch_exceptions (boolean or None): \
52 If True, then catch exceptions and include them as part of the result object. \
53 For more detail, see [catch_exceptions](https://docs.greatexpectations.io/docs/reference/expectations/standard_arguments/#catch_exceptions).
54 meta (dict or None): \
55 A JSON-serializable dictionary (nesting allowed) that will be included in the output without \
56 modification. For more detail, see [meta](https://docs.greatexpectations.io/docs/reference/expectations/standard_arguments/#meta).
57
58 Returns:
59 An [ExpectationSuiteValidationResult](https://docs.greatexpectations.io/docs/terms/validation_result)
60
61 Exact fields vary depending on the values passed to result_format, include_config, catch_exceptions, and meta.
62
63 See Also:
64 [expect_column_values_to_match_regex](https://greatexpectations.io/expectations/expect_column_values_to_match_regex)
65 [expect_column_values_to_match_regex_list](https://greatexpectations.io/expectations/expect_column_values_to_match_regex_list)
66 [expect_column_values_to_not_match_regex](https://greatexpectations.io/expectations/expect_column_values_to_not_match_regex)
67 [expect_column_values_to_match_like_pattern](https://greatexpectations.io/expectations/expect_column_values_to_match_like_pattern)
68 [expect_column_values_to_match_like_pattern_list](https://greatexpectations.io/expectations/expect_column_values_to_match_like_pattern_list)
69 [expect_column_values_to_not_match_like_pattern](https://greatexpectations.io/expectations/expect_column_values_to_not_match_like_pattern)
70 [expect_column_values_to_not_match_like_pattern_list](https://greatexpectations.io/expectations/expect_column_values_to_not_match_like_pattern_list)
71 """
72
73 library_metadata = {
74 "maturity": "production",
75 "tags": ["core expectation", "column map expectation"],
76 "contributors": [
77 "@great_expectations",
78 ],
79 "requirements": [],
80 "has_full_test_suite": True,
81 "manually_reviewed_code": True,
82 }
83
84 map_metric = "column_values.not_match_regex_list"
85 success_keys = (
86 "regex_list",
87 "mostly",
88 )
89 default_kwarg_values = {
90 "row_condition": None,
91 "condition_parser": None, # we expect this to be explicitly set whenever a row_condition is passed
92 "mostly": 1,
93 "result_format": "BASIC",
94 "include_config": True,
95 "catch_exceptions": True,
96 }
97 args_keys = (
98 "column",
99 "regex_list",
100 )
101
102 def validate_configuration(
103 self, configuration: Optional[ExpectationConfiguration] = None
104 ) -> None:
105 """Validates the configuration for the Expectation.
106
107 For `expect_column_values_to_match_regex_list`
108 we require that the `configuraton.kwargs` contain a `regex_list` key that is either
109 a non-empty `list[str]` or a `dict[list]` with `$PARAMETER` key with list of regexes.
110
111 Args:
112 configuration: The ExpectationConfiguration to be validated.
113
114 Raises:
115 InvalidExpectationConfigurationError: The configuraton does not contain the values required by the Expectation
116 """
117 super().validate_configuration(configuration)
118 configuration = configuration or self.configuration
119 try:
120 assert "regex_list" in configuration.kwargs, "regex_list is required"
121 assert isinstance(
122 configuration.kwargs["regex_list"], (list, dict)
123 ), "regex_list must be a list of regexes"
124 if (
125 not isinstance(configuration.kwargs["regex_list"], dict)
126 and len(configuration.kwargs["regex_list"]) > 0
127 ):
128 for i in configuration.kwargs["regex_list"]:
129 assert isinstance(i, str), "regexes in list must be strings"
130 if isinstance(configuration.kwargs["regex_list"], dict):
131 assert (
132 "$PARAMETER" in configuration.kwargs["regex_list"]
133 ), 'Evaluation Parameter dict for regex_list kwarg must have "$PARAMETER" key.'
134 except AssertionError as e:
135 raise InvalidExpectationConfigurationError(str(e))
136
137 @classmethod
138 def _prescriptive_template(
139 cls,
140 renderer_configuration: RendererConfiguration,
141 ) -> RendererConfiguration:
142 add_param_args: AddParamArgs = (
143 ("column", RendererValueType.STRING),
144 ("regex_list", RendererValueType.ARRAY),
145 ("mostly", RendererValueType.NUMBER),
146 )
147 for name, param_type in add_param_args:
148 renderer_configuration.add_param(name=name, param_type=param_type)
149
150 params = renderer_configuration.params
151
152 if not params.regex_list or not params.regex_list.value:
153 values_string = "[ ]"
154 else:
155 array_param_name = "regex_list"
156 param_prefix = "v__"
157 renderer_configuration = cls._add_array_params(
158 array_param_name=array_param_name,
159 param_prefix=param_prefix,
160 renderer_configuration=renderer_configuration,
161 )
162 values_string: str = cls._get_array_string(
163 array_param_name=array_param_name,
164 param_prefix=param_prefix,
165 renderer_configuration=renderer_configuration,
166 )
167
168 template_str = (
169 "values must not match any of the following regular expressions: "
170 + values_string
171 )
172
173 if params.mostly and params.mostly.value < 1.0:
174 renderer_configuration = cls._add_mostly_pct_param(
175 renderer_configuration=renderer_configuration
176 )
177 template_str += ", at least $mostly_pct % of the time."
178 else:
179 template_str += "."
180
181 if renderer_configuration.include_column_name:
182 template_str = f"$column {template_str}"
183
184 renderer_configuration.template_str = template_str
185
186 return renderer_configuration
187
188 @classmethod
189 @renderer(renderer_type=LegacyRendererType.PRESCRIPTIVE)
190 @render_evaluation_parameter_string
191 def _prescriptive_renderer(
192 cls,
193 configuration: Optional[ExpectationConfiguration] = None,
194 result: Optional[ExpectationValidationResult] = None,
195 runtime_configuration: Optional[dict] = None,
196 **kwargs,
197 ):
198 runtime_configuration = runtime_configuration or {}
199 include_column_name = (
200 False if runtime_configuration.get("include_column_name") is False else True
201 )
202 styling = runtime_configuration.get("styling")
203 params = substitute_none_for_missing(
204 configuration.kwargs,
205 ["column", "regex_list", "mostly", "row_condition", "condition_parser"],
206 )
207
208 if not params.get("regex_list") or len(params.get("regex_list")) == 0:
209 values_string = "[ ]"
210 else:
211 for i, v in enumerate(params["regex_list"]):
212 params[f"v__{str(i)}"] = v
213 values_string = " ".join(
214 [f"$v__{str(i)}" for i, v in enumerate(params["regex_list"])]
215 )
216
217 template_str = (
218 "values must not match any of the following regular expressions: "
219 + values_string
220 )
221
222 if params["mostly"] is not None and params["mostly"] < 1.0:
223 params["mostly_pct"] = num_to_str(
224 params["mostly"] * 100, precision=15, no_scientific=True
225 )
226 # params["mostly_pct"] = "{:.14f}".format(params["mostly"]*100).rstrip("0").rstrip(".")
227 template_str += ", at least $mostly_pct % of the time."
228 else:
229 template_str += "."
230
231 if include_column_name:
232 template_str = f"$column {template_str}"
233
234 if params["row_condition"] is not None:
235 (
236 conditional_template_str,
237 conditional_params,
238 ) = parse_row_condition_string_pandas_engine(params["row_condition"])
239 template_str = f"{conditional_template_str}, then {template_str}"
240 params.update(conditional_params)
241
242 return [
243 RenderedStringTemplateContent(
244 **{
245 "content_block_type": "string_template",
246 "string_template": {
247 "template": template_str,
248 "params": params,
249 "styling": styling,
250 },
251 }
252 )
253 ]
254
[end of great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py b/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py
--- a/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py
+++ b/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py
@@ -102,17 +102,20 @@
def validate_configuration(
self, configuration: Optional[ExpectationConfiguration] = None
) -> None:
- """Validates the configuration for the Expectation.
+ """Validates the configuration of an Expectation.
- For `expect_column_values_to_match_regex_list`
- we require that the `configuraton.kwargs` contain a `regex_list` key that is either
- a non-empty `list[str]` or a `dict[list]` with `$PARAMETER` key with list of regexes.
+ For `expect_column_values_to_not_match_regex_list` it is required that:
+ - 'regex_list' kwarg is of type list or dict
+ - if 'regex_list' is list, assert is non-empty and each entry is of type str
+ - if 'regex_list' is dict, assert a key "$PARAMETER" is present
Args:
- configuration: The ExpectationConfiguration to be validated.
+ configuration: An `ExpectationConfiguration` to validate. If no configuration is provided, it will be pulled
+ from the configuration attribute of the Expectation instance.
Raises:
- InvalidExpectationConfigurationError: The configuraton does not contain the values required by the Expectation
+ InvalidExpectationConfigurationError: The configuration does not contain the values required by the
+ Expectation.
"""
super().validate_configuration(configuration)
configuration = configuration or self.configuration
@@ -120,7 +123,7 @@
assert "regex_list" in configuration.kwargs, "regex_list is required"
assert isinstance(
configuration.kwargs["regex_list"], (list, dict)
- ), "regex_list must be a list of regexes"
+ ), "regex_list must be a list or dict of regexes"
if (
not isinstance(configuration.kwargs["regex_list"], dict)
and len(configuration.kwargs["regex_list"]) > 0
|
{"golden_diff": "diff --git a/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py b/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py\n--- a/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py\n+++ b/great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py\n@@ -102,17 +102,20 @@\n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration] = None\n ) -> None:\n- \"\"\"Validates the configuration for the Expectation.\n+ \"\"\"Validates the configuration of an Expectation.\n \n- For `expect_column_values_to_match_regex_list`\n- we require that the `configuraton.kwargs` contain a `regex_list` key that is either\n- a non-empty `list[str]` or a `dict[list]` with `$PARAMETER` key with list of regexes.\n+ For `expect_column_values_to_not_match_regex_list` it is required that:\n+ - 'regex_list' kwarg is of type list or dict\n+ - if 'regex_list' is list, assert is non-empty and each entry is of type str\n+ - if 'regex_list' is dict, assert a key \"$PARAMETER\" is present\n \n Args:\n- configuration: The ExpectationConfiguration to be validated.\n+ configuration: An `ExpectationConfiguration` to validate. If no configuration is provided, it will be pulled\n+ from the configuration attribute of the Expectation instance.\n \n Raises:\n- InvalidExpectationConfigurationError: The configuraton does not contain the values required by the Expectation\n+ InvalidExpectationConfigurationError: The configuration does not contain the values required by the\n+ Expectation.\n \"\"\"\n super().validate_configuration(configuration)\n configuration = configuration or self.configuration\n@@ -120,7 +123,7 @@\n assert \"regex_list\" in configuration.kwargs, \"regex_list is required\"\n assert isinstance(\n configuration.kwargs[\"regex_list\"], (list, dict)\n- ), \"regex_list must be a list of regexes\"\n+ ), \"regex_list must be a list or dict of regexes\"\n if (\n not isinstance(configuration.kwargs[\"regex_list\"], dict)\n and len(configuration.kwargs[\"regex_list\"]) > 0\n", "issue": "Use cleaner solution for non-truncating division in python 2\nPrefer `from __future__ import division` to `1.*x/y`\n", "before_files": [{"content": "from typing import TYPE_CHECKING, Optional\n\nfrom great_expectations.core import (\n ExpectationConfiguration,\n ExpectationValidationResult,\n)\nfrom great_expectations.expectations.expectation import (\n ColumnMapExpectation,\n InvalidExpectationConfigurationError,\n render_evaluation_parameter_string,\n)\nfrom great_expectations.render import LegacyRendererType, RenderedStringTemplateContent\nfrom great_expectations.render.renderer.renderer import renderer\nfrom great_expectations.render.renderer_configuration import (\n RendererConfiguration,\n RendererValueType,\n)\nfrom great_expectations.render.util import (\n num_to_str,\n parse_row_condition_string_pandas_engine,\n substitute_none_for_missing,\n)\n\nif TYPE_CHECKING:\n from great_expectations.render.renderer_configuration import AddParamArgs\n\n\nclass ExpectColumnValuesToNotMatchRegexList(ColumnMapExpectation):\n \"\"\"Expect the column entries to be strings that do not match any of a list of regular expressions. Matches can be anywhere in the string.\n\n expect_column_values_to_not_match_regex_list is a \\\n [Column Map Expectation](https://docs.greatexpectations.io/docs/guides/expectations/creating_custom_expectations/how_to_create_custom_column_map_expectations).\n\n Args:\n column (str): \\\n The column name.\n regex_list (list): \\\n The list of regular expressions which the column entries should not match\n\n Keyword Args:\n mostly (None or a float between 0 and 1): \\\n Successful if at least mostly fraction of values match the expectation. \\\n For more detail, see [mostly](https://docs.greatexpectations.io/docs/reference/expectations/standard_arguments/#mostly).\n\n Other Parameters:\n result_format (str or None): \\\n Which output mode to use: BOOLEAN_ONLY, BASIC, COMPLETE, or SUMMARY. \\\n For more detail, see [result_format](https://docs.greatexpectations.io/docs/reference/expectations/result_format).\n include_config (boolean): \\\n If True, then include the expectation config as part of the result object.\n catch_exceptions (boolean or None): \\\n If True, then catch exceptions and include them as part of the result object. \\\n For more detail, see [catch_exceptions](https://docs.greatexpectations.io/docs/reference/expectations/standard_arguments/#catch_exceptions).\n meta (dict or None): \\\n A JSON-serializable dictionary (nesting allowed) that will be included in the output without \\\n modification. For more detail, see [meta](https://docs.greatexpectations.io/docs/reference/expectations/standard_arguments/#meta).\n\n Returns:\n An [ExpectationSuiteValidationResult](https://docs.greatexpectations.io/docs/terms/validation_result)\n\n Exact fields vary depending on the values passed to result_format, include_config, catch_exceptions, and meta.\n\n See Also:\n [expect_column_values_to_match_regex](https://greatexpectations.io/expectations/expect_column_values_to_match_regex)\n [expect_column_values_to_match_regex_list](https://greatexpectations.io/expectations/expect_column_values_to_match_regex_list)\n [expect_column_values_to_not_match_regex](https://greatexpectations.io/expectations/expect_column_values_to_not_match_regex)\n [expect_column_values_to_match_like_pattern](https://greatexpectations.io/expectations/expect_column_values_to_match_like_pattern)\n [expect_column_values_to_match_like_pattern_list](https://greatexpectations.io/expectations/expect_column_values_to_match_like_pattern_list)\n [expect_column_values_to_not_match_like_pattern](https://greatexpectations.io/expectations/expect_column_values_to_not_match_like_pattern)\n [expect_column_values_to_not_match_like_pattern_list](https://greatexpectations.io/expectations/expect_column_values_to_not_match_like_pattern_list)\n \"\"\"\n\n library_metadata = {\n \"maturity\": \"production\",\n \"tags\": [\"core expectation\", \"column map expectation\"],\n \"contributors\": [\n \"@great_expectations\",\n ],\n \"requirements\": [],\n \"has_full_test_suite\": True,\n \"manually_reviewed_code\": True,\n }\n\n map_metric = \"column_values.not_match_regex_list\"\n success_keys = (\n \"regex_list\",\n \"mostly\",\n )\n default_kwarg_values = {\n \"row_condition\": None,\n \"condition_parser\": None, # we expect this to be explicitly set whenever a row_condition is passed\n \"mostly\": 1,\n \"result_format\": \"BASIC\",\n \"include_config\": True,\n \"catch_exceptions\": True,\n }\n args_keys = (\n \"column\",\n \"regex_list\",\n )\n\n def validate_configuration(\n self, configuration: Optional[ExpectationConfiguration] = None\n ) -> None:\n \"\"\"Validates the configuration for the Expectation.\n\n For `expect_column_values_to_match_regex_list`\n we require that the `configuraton.kwargs` contain a `regex_list` key that is either\n a non-empty `list[str]` or a `dict[list]` with `$PARAMETER` key with list of regexes.\n\n Args:\n configuration: The ExpectationConfiguration to be validated.\n\n Raises:\n InvalidExpectationConfigurationError: The configuraton does not contain the values required by the Expectation\n \"\"\"\n super().validate_configuration(configuration)\n configuration = configuration or self.configuration\n try:\n assert \"regex_list\" in configuration.kwargs, \"regex_list is required\"\n assert isinstance(\n configuration.kwargs[\"regex_list\"], (list, dict)\n ), \"regex_list must be a list of regexes\"\n if (\n not isinstance(configuration.kwargs[\"regex_list\"], dict)\n and len(configuration.kwargs[\"regex_list\"]) > 0\n ):\n for i in configuration.kwargs[\"regex_list\"]:\n assert isinstance(i, str), \"regexes in list must be strings\"\n if isinstance(configuration.kwargs[\"regex_list\"], dict):\n assert (\n \"$PARAMETER\" in configuration.kwargs[\"regex_list\"]\n ), 'Evaluation Parameter dict for regex_list kwarg must have \"$PARAMETER\" key.'\n except AssertionError as e:\n raise InvalidExpectationConfigurationError(str(e))\n\n @classmethod\n def _prescriptive_template(\n cls,\n renderer_configuration: RendererConfiguration,\n ) -> RendererConfiguration:\n add_param_args: AddParamArgs = (\n (\"column\", RendererValueType.STRING),\n (\"regex_list\", RendererValueType.ARRAY),\n (\"mostly\", RendererValueType.NUMBER),\n )\n for name, param_type in add_param_args:\n renderer_configuration.add_param(name=name, param_type=param_type)\n\n params = renderer_configuration.params\n\n if not params.regex_list or not params.regex_list.value:\n values_string = \"[ ]\"\n else:\n array_param_name = \"regex_list\"\n param_prefix = \"v__\"\n renderer_configuration = cls._add_array_params(\n array_param_name=array_param_name,\n param_prefix=param_prefix,\n renderer_configuration=renderer_configuration,\n )\n values_string: str = cls._get_array_string(\n array_param_name=array_param_name,\n param_prefix=param_prefix,\n renderer_configuration=renderer_configuration,\n )\n\n template_str = (\n \"values must not match any of the following regular expressions: \"\n + values_string\n )\n\n if params.mostly and params.mostly.value < 1.0:\n renderer_configuration = cls._add_mostly_pct_param(\n renderer_configuration=renderer_configuration\n )\n template_str += \", at least $mostly_pct % of the time.\"\n else:\n template_str += \".\"\n\n if renderer_configuration.include_column_name:\n template_str = f\"$column {template_str}\"\n\n renderer_configuration.template_str = template_str\n\n return renderer_configuration\n\n @classmethod\n @renderer(renderer_type=LegacyRendererType.PRESCRIPTIVE)\n @render_evaluation_parameter_string\n def _prescriptive_renderer(\n cls,\n configuration: Optional[ExpectationConfiguration] = None,\n result: Optional[ExpectationValidationResult] = None,\n runtime_configuration: Optional[dict] = None,\n **kwargs,\n ):\n runtime_configuration = runtime_configuration or {}\n include_column_name = (\n False if runtime_configuration.get(\"include_column_name\") is False else True\n )\n styling = runtime_configuration.get(\"styling\")\n params = substitute_none_for_missing(\n configuration.kwargs,\n [\"column\", \"regex_list\", \"mostly\", \"row_condition\", \"condition_parser\"],\n )\n\n if not params.get(\"regex_list\") or len(params.get(\"regex_list\")) == 0:\n values_string = \"[ ]\"\n else:\n for i, v in enumerate(params[\"regex_list\"]):\n params[f\"v__{str(i)}\"] = v\n values_string = \" \".join(\n [f\"$v__{str(i)}\" for i, v in enumerate(params[\"regex_list\"])]\n )\n\n template_str = (\n \"values must not match any of the following regular expressions: \"\n + values_string\n )\n\n if params[\"mostly\"] is not None and params[\"mostly\"] < 1.0:\n params[\"mostly_pct\"] = num_to_str(\n params[\"mostly\"] * 100, precision=15, no_scientific=True\n )\n # params[\"mostly_pct\"] = \"{:.14f}\".format(params[\"mostly\"]*100).rstrip(\"0\").rstrip(\".\")\n template_str += \", at least $mostly_pct % of the time.\"\n else:\n template_str += \".\"\n\n if include_column_name:\n template_str = f\"$column {template_str}\"\n\n if params[\"row_condition\"] is not None:\n (\n conditional_template_str,\n conditional_params,\n ) = parse_row_condition_string_pandas_engine(params[\"row_condition\"])\n template_str = f\"{conditional_template_str}, then {template_str}\"\n params.update(conditional_params)\n\n return [\n RenderedStringTemplateContent(\n **{\n \"content_block_type\": \"string_template\",\n \"string_template\": {\n \"template\": template_str,\n \"params\": params,\n \"styling\": styling,\n },\n }\n )\n ]\n", "path": "great_expectations/expectations/core/expect_column_values_to_not_match_regex_list.py"}]}
| 3,398 | 512 |
gh_patches_debug_15326
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-1192
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Page tree broken after searching and going back
### Describe the Bug
When using the back button of the browser after searching, the page tree is expanded. After that, the collapsing function is broken.
Can we tell the browser to reload the full page after using the back button? However, it would be the best solution to actually keep the status of the tree after using the back button.
~~This could be related to #1131~~
</issue>
<code>
[start of integreat_cms/cms/views/pages/page_tree_view.py]
1 import logging
2
3 from django.contrib import messages
4 from django.shortcuts import render, redirect
5 from django.utils.decorators import method_decorator
6 from django.utils.translation import ugettext as _
7 from django.views.generic import TemplateView
8
9 from ...constants import translation_status
10 from ...decorators import permission_required
11 from ...forms import PageFilterForm
12 from ...models import Language
13 from .page_context_mixin import PageContextMixin
14
15 logger = logging.getLogger(__name__)
16
17
18 @method_decorator(permission_required("cms.view_page"), name="dispatch")
19 class PageTreeView(TemplateView, PageContextMixin):
20 """
21 View for showing the page tree
22 """
23
24 #: Template for list of non-archived pages
25 template = "pages/page_tree.html"
26 #: Template for list of archived pages
27 template_archived = "pages/page_tree_archived.html"
28 #: Whether or not to show archived pages
29 archived = False
30
31 @property
32 def template_name(self):
33 """
34 Select correct HTML template, depending on :attr:`~integreat_cms.cms.views.pages.page_tree_view.PageTreeView.archived` flag
35 (see :class:`~django.views.generic.base.TemplateResponseMixin`)
36
37 :return: Path to HTML template
38 :rtype: str
39 """
40
41 return self.template_archived if self.archived else self.template
42
43 def get(self, request, *args, **kwargs):
44 r"""
45 Render page tree
46
47 :param request: The current request
48 :type request: ~django.http.HttpResponse
49
50 :param \*args: The supplied arguments
51 :type \*args: list
52
53 :param \**kwargs: The supplied keyword arguments
54 :type \**kwargs: dict
55
56 :return: The rendered template response
57 :rtype: ~django.template.response.TemplateResponse
58 """
59
60 # current region
61 region_slug = kwargs.get("region_slug")
62 region = request.region
63
64 # current language
65 language_slug = kwargs.get("language_slug")
66 if language_slug:
67 language = Language.objects.get(slug=language_slug)
68 elif region.default_language:
69 return redirect(
70 "pages",
71 **{
72 "region_slug": region_slug,
73 "language_slug": region.default_language.slug,
74 }
75 )
76 else:
77 messages.error(
78 request,
79 _("Please create at least one language node before creating pages."),
80 )
81 return redirect(
82 "language_tree",
83 **{
84 "region_slug": region_slug,
85 }
86 )
87
88 if not request.user.has_perm("cms.change_page"):
89 messages.warning(
90 request, _("You don't have the permission to edit or create pages.")
91 )
92
93 # Filter pages according to given filters, if any
94 filter_data = kwargs.get("filter_data")
95
96 if filter_data or self.archived:
97 page_queryset = region.pages.all()
98 else:
99 page_queryset = region.pages.filter(lft=1)
100 pages = page_queryset.cache_tree(archived=self.archived)[0]
101
102 if filter_data:
103 # Set data for filter form rendering
104 filter_form = PageFilterForm(data=filter_data)
105 pages = self.filter_pages(pages, language_slug, filter_form)
106 else:
107 filter_form = PageFilterForm()
108 filter_form.changed_data.clear()
109
110 return render(
111 request,
112 self.template_name,
113 {
114 **self.get_context_data(**kwargs),
115 "pages": pages,
116 "language": language,
117 "languages": region.active_languages,
118 "filter_form": filter_form,
119 },
120 )
121
122 def post(self, request, *args, **kwargs):
123 r"""
124 Apply page filters and render page tree
125
126 :param request: The current request
127 :type request: ~django.http.HttpResponse
128
129 :param \*args: The supplied arguments
130 :type \*args: list
131
132 :param \**kwargs: The supplied keyword arguments
133 :type \**kwargs: dict
134
135 :return: The rendered template response
136 :rtype: ~django.template.response.TemplateResponse
137 """
138 return self.get(request, *args, **kwargs, filter_data=request.POST)
139
140 @staticmethod
141 def filter_pages(pages, language_slug, filter_form):
142 """
143 Filter the pages list according to the given filter data
144
145 :param pages: The list of pages
146 :type pages: list
147
148 :param language_slug: The slug of the current language
149 :type language_slug: str
150
151 :param filter_form: The filter form
152 :type filter_form: integreat_cms.cms.forms.pages.page_filter_form.PageFilterForm
153
154 :return: The filtered page list
155 :rtype: list
156 """
157 if filter_form.is_valid():
158 query = filter_form.cleaned_data["query"]
159 if query:
160 # Buffer variable because the pages list should not be modified during iteration
161 filtered_pages = []
162 for page in pages:
163 translation = page.get_translation(language_slug)
164 if translation and (
165 query.lower() in translation.slug
166 or query.lower() in translation.title.lower()
167 ):
168 filtered_pages.append(page)
169 pages = filtered_pages
170
171 selected_status = filter_form.cleaned_data["translation_status"]
172 # Only filter if at least one checkbox but not all are checked
173 if 0 < len(selected_status) < len(translation_status.CHOICES):
174 # Buffer variable because the pages list should not be modified during iteration
175 filtered_pages = []
176 for page in pages:
177 translation_state = page.translation_states.get(language_slug)
178 if translation_state and translation_state[1] in selected_status:
179 filtered_pages.append(page)
180 pages = filtered_pages
181 return pages
182
[end of integreat_cms/cms/views/pages/page_tree_view.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/integreat_cms/cms/views/pages/page_tree_view.py b/integreat_cms/cms/views/pages/page_tree_view.py
--- a/integreat_cms/cms/views/pages/page_tree_view.py
+++ b/integreat_cms/cms/views/pages/page_tree_view.py
@@ -107,7 +107,7 @@
filter_form = PageFilterForm()
filter_form.changed_data.clear()
- return render(
+ response = render(
request,
self.template_name,
{
@@ -118,6 +118,9 @@
"filter_form": filter_form,
},
)
+ # Disable browser cache of page tree to prevent subpages from being expanded after using "back"-button
+ response["Cache-Control"] = "no-store, must-revalidate"
+ return response
def post(self, request, *args, **kwargs):
r"""
|
{"golden_diff": "diff --git a/integreat_cms/cms/views/pages/page_tree_view.py b/integreat_cms/cms/views/pages/page_tree_view.py\n--- a/integreat_cms/cms/views/pages/page_tree_view.py\n+++ b/integreat_cms/cms/views/pages/page_tree_view.py\n@@ -107,7 +107,7 @@\n filter_form = PageFilterForm()\n filter_form.changed_data.clear()\n \n- return render(\n+ response = render(\n request,\n self.template_name,\n {\n@@ -118,6 +118,9 @@\n \"filter_form\": filter_form,\n },\n )\n+ # Disable browser cache of page tree to prevent subpages from being expanded after using \"back\"-button\n+ response[\"Cache-Control\"] = \"no-store, must-revalidate\"\n+ return response\n \n def post(self, request, *args, **kwargs):\n r\"\"\"\n", "issue": "Page tree broken after searching and going back\n### Describe the Bug\r\nWhen using the back button of the browser after searching, the page tree is expanded. After that, the collapsing function is broken.\r\n\r\nCan we tell the browser to reload the full page after using the back button? However, it would be the best solution to actually keep the status of the tree after using the back button.\r\n\r\n~~This could be related to #1131~~\n", "before_files": [{"content": "import logging\n\nfrom django.contrib import messages\nfrom django.shortcuts import render, redirect\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import ugettext as _\nfrom django.views.generic import TemplateView\n\nfrom ...constants import translation_status\nfrom ...decorators import permission_required\nfrom ...forms import PageFilterForm\nfrom ...models import Language\nfrom .page_context_mixin import PageContextMixin\n\nlogger = logging.getLogger(__name__)\n\n\n@method_decorator(permission_required(\"cms.view_page\"), name=\"dispatch\")\nclass PageTreeView(TemplateView, PageContextMixin):\n \"\"\"\n View for showing the page tree\n \"\"\"\n\n #: Template for list of non-archived pages\n template = \"pages/page_tree.html\"\n #: Template for list of archived pages\n template_archived = \"pages/page_tree_archived.html\"\n #: Whether or not to show archived pages\n archived = False\n\n @property\n def template_name(self):\n \"\"\"\n Select correct HTML template, depending on :attr:`~integreat_cms.cms.views.pages.page_tree_view.PageTreeView.archived` flag\n (see :class:`~django.views.generic.base.TemplateResponseMixin`)\n\n :return: Path to HTML template\n :rtype: str\n \"\"\"\n\n return self.template_archived if self.archived else self.template\n\n def get(self, request, *args, **kwargs):\n r\"\"\"\n Render page tree\n\n :param request: The current request\n :type request: ~django.http.HttpResponse\n\n :param \\*args: The supplied arguments\n :type \\*args: list\n\n :param \\**kwargs: The supplied keyword arguments\n :type \\**kwargs: dict\n\n :return: The rendered template response\n :rtype: ~django.template.response.TemplateResponse\n \"\"\"\n\n # current region\n region_slug = kwargs.get(\"region_slug\")\n region = request.region\n\n # current language\n language_slug = kwargs.get(\"language_slug\")\n if language_slug:\n language = Language.objects.get(slug=language_slug)\n elif region.default_language:\n return redirect(\n \"pages\",\n **{\n \"region_slug\": region_slug,\n \"language_slug\": region.default_language.slug,\n }\n )\n else:\n messages.error(\n request,\n _(\"Please create at least one language node before creating pages.\"),\n )\n return redirect(\n \"language_tree\",\n **{\n \"region_slug\": region_slug,\n }\n )\n\n if not request.user.has_perm(\"cms.change_page\"):\n messages.warning(\n request, _(\"You don't have the permission to edit or create pages.\")\n )\n\n # Filter pages according to given filters, if any\n filter_data = kwargs.get(\"filter_data\")\n\n if filter_data or self.archived:\n page_queryset = region.pages.all()\n else:\n page_queryset = region.pages.filter(lft=1)\n pages = page_queryset.cache_tree(archived=self.archived)[0]\n\n if filter_data:\n # Set data for filter form rendering\n filter_form = PageFilterForm(data=filter_data)\n pages = self.filter_pages(pages, language_slug, filter_form)\n else:\n filter_form = PageFilterForm()\n filter_form.changed_data.clear()\n\n return render(\n request,\n self.template_name,\n {\n **self.get_context_data(**kwargs),\n \"pages\": pages,\n \"language\": language,\n \"languages\": region.active_languages,\n \"filter_form\": filter_form,\n },\n )\n\n def post(self, request, *args, **kwargs):\n r\"\"\"\n Apply page filters and render page tree\n\n :param request: The current request\n :type request: ~django.http.HttpResponse\n\n :param \\*args: The supplied arguments\n :type \\*args: list\n\n :param \\**kwargs: The supplied keyword arguments\n :type \\**kwargs: dict\n\n :return: The rendered template response\n :rtype: ~django.template.response.TemplateResponse\n \"\"\"\n return self.get(request, *args, **kwargs, filter_data=request.POST)\n\n @staticmethod\n def filter_pages(pages, language_slug, filter_form):\n \"\"\"\n Filter the pages list according to the given filter data\n\n :param pages: The list of pages\n :type pages: list\n\n :param language_slug: The slug of the current language\n :type language_slug: str\n\n :param filter_form: The filter form\n :type filter_form: integreat_cms.cms.forms.pages.page_filter_form.PageFilterForm\n\n :return: The filtered page list\n :rtype: list\n \"\"\"\n if filter_form.is_valid():\n query = filter_form.cleaned_data[\"query\"]\n if query:\n # Buffer variable because the pages list should not be modified during iteration\n filtered_pages = []\n for page in pages:\n translation = page.get_translation(language_slug)\n if translation and (\n query.lower() in translation.slug\n or query.lower() in translation.title.lower()\n ):\n filtered_pages.append(page)\n pages = filtered_pages\n\n selected_status = filter_form.cleaned_data[\"translation_status\"]\n # Only filter if at least one checkbox but not all are checked\n if 0 < len(selected_status) < len(translation_status.CHOICES):\n # Buffer variable because the pages list should not be modified during iteration\n filtered_pages = []\n for page in pages:\n translation_state = page.translation_states.get(language_slug)\n if translation_state and translation_state[1] in selected_status:\n filtered_pages.append(page)\n pages = filtered_pages\n return pages\n", "path": "integreat_cms/cms/views/pages/page_tree_view.py"}]}
| 2,283 | 197 |
gh_patches_debug_17579
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-7697
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
examples/howto/{js_events,events_app} contain bad CSS
* https://github.com/bokeh/bokeh/blob/master/examples/howto/js_events.py#L19
* https://github.com/bokeh/bokeh/blob/master/examples/howto/events_app.py#L21
* the same in user_guide
</issue>
<code>
[start of examples/howto/events_app.py]
1 """ Demonstration Bokeh app of how to register event callbacks in both
2 Javascript and Python using an adaptation of the color_scatter example
3 from the bokeh gallery. This example extends the js_events.py example
4 with corresponding Python event callbacks.
5 """
6
7 import numpy as np
8
9 from bokeh.io import curdoc
10 from bokeh.plotting import figure
11 from bokeh import events
12 from bokeh.models import CustomJS, Div, Button
13 from bokeh.layouts import column, row
14
15
16 def display_event(div, attributes=[]):
17 """
18 Function to build a suitable CustomJS to display the current event
19 in the div model.
20 """
21 style = 'float:left;clear:left;font_size=0.5pt'
22 return CustomJS(args=dict(div=div), code="""
23 var attrs = %s;
24 var args = [];
25 for (var i=0; i<attrs.length; i++ ) {
26 val = JSON.stringify(cb_obj[attrs[i]], function(key, val) {
27 return val.toFixed ? Number(val.toFixed(2)) : val;
28 })
29 args.push(attrs[i] + '=' + val)
30 }
31 var line = "<span style=%r><b>" + cb_obj.event_name + "</b>(" + args.join(", ") + ")</span>\\n";
32 var text = div.text.concat(line);
33 var lines = text.split("\\n")
34 if ( lines.length > 35 ) { lines.shift(); }
35 div.text = lines.join("\\n");
36 """ % (attributes, style))
37
38 def print_event(attributes=[]):
39 """
40 Function that returns a Python callback to pretty print the events.
41 """
42 def python_callback(event):
43 cls_name = event.__class__.__name__
44 attrs = ', '.join(['{attr}={val}'.format(attr=attr, val=event.__dict__[attr])
45 for attr in attributes])
46 print('{cls_name}({attrs})'.format(cls_name=cls_name, attrs=attrs))
47 return python_callback
48
49 # Follows the color_scatter gallery example
50
51 N = 4000
52 x = np.random.random(size=N) * 100
53 y = np.random.random(size=N) * 100
54 radii = np.random.random(size=N) * 1.5
55 colors = [
56 "#%02x%02x%02x" % (int(r), int(g), 150) for r, g in zip(50+2*x, 30+2*y)
57 ]
58
59 p = figure(tools="pan,wheel_zoom,zoom_in,zoom_out,reset,tap,lasso_select,box_select")
60
61 p.scatter(x, y, radius=radii,
62 fill_color=colors, fill_alpha=0.6,
63 line_color=None)
64
65 # Add a div to display events and a button to trigger button click events
66
67 div = Div(width=1000)
68 button = Button(label="Button", button_type="success")
69 layout = column(button, row(p, div))
70
71
72 point_attributes = ['x','y','sx','sy']
73 pan_attributes = point_attributes + ['delta_x', 'delta_y']
74 pinch_attributes = point_attributes + ['scale']
75 wheel_attributes = point_attributes+['delta']
76
77 ## Register Javascript event callbacks
78
79 # Button event
80 button.js_on_event(events.ButtonClick, display_event(div))
81
82 # LOD events
83 p.js_on_event(events.LODStart, display_event(div))
84 p.js_on_event(events.LODEnd, display_event(div))
85
86 # Point events
87
88 p.js_on_event(events.Tap, display_event(div, attributes=point_attributes))
89 p.js_on_event(events.DoubleTap, display_event(div, attributes=point_attributes))
90 p.js_on_event(events.Press, display_event(div, attributes=point_attributes))
91
92 # Mouse wheel event
93 p.js_on_event(events.MouseWheel, display_event(div,attributes=wheel_attributes))
94
95 # Mouse move, enter and leave
96 p.js_on_event(events.MouseMove, display_event(div, attributes=point_attributes))
97 p.js_on_event(events.MouseEnter, display_event(div, attributes=point_attributes))
98 p.js_on_event(events.MouseLeave, display_event(div, attributes=point_attributes))
99
100 # Pan events
101 p.js_on_event(events.Pan, display_event(div, attributes=pan_attributes))
102 p.js_on_event(events.PanStart, display_event(div, attributes=point_attributes))
103 p.js_on_event(events.PanEnd, display_event(div, attributes=point_attributes))
104
105 # Pinch events
106 p.js_on_event(events.Pinch, display_event(div, attributes=pinch_attributes))
107 p.js_on_event(events.PinchStart, display_event(div, attributes=point_attributes))
108 p.js_on_event(events.PinchEnd, display_event(div, attributes=point_attributes))
109
110 # Selection events
111 p.js_on_event(events.SelectionGeometry, display_event(div, attributes=['geometry', 'final']))
112
113 # Reset events
114 p.js_on_event(events.Reset, display_event(div))
115
116
117 ## Register Python event callbacks
118
119 # Button event
120 button.on_event(events.ButtonClick, print_event())
121
122 # LOD events
123 p.on_event(events.LODStart, print_event())
124 p.on_event(events.LODEnd, print_event())
125
126 # Point events
127
128 p.on_event(events.Tap, print_event(attributes=point_attributes))
129 p.on_event(events.DoubleTap, print_event(attributes=point_attributes))
130 p.on_event(events.Press, print_event(attributes=point_attributes))
131
132 # Mouse wheel event
133 p.on_event(events.MouseWheel, print_event(attributes=wheel_attributes))
134
135 # Mouse move, enter and leave
136 p.on_event(events.MouseMove, print_event(attributes=point_attributes))
137 p.on_event(events.MouseEnter, print_event(attributes=point_attributes))
138 p.on_event(events.MouseLeave, print_event(attributes=point_attributes))
139
140 # Pan events
141 p.on_event(events.Pan, print_event(attributes=pan_attributes))
142 p.on_event(events.PanStart, print_event(attributes=point_attributes))
143 p.on_event(events.PanEnd, print_event(attributes=point_attributes))
144
145 # Pinch events
146 p.on_event(events.Pinch, print_event(attributes=pinch_attributes))
147 p.on_event(events.PinchStart, print_event(attributes=point_attributes))
148 p.on_event(events.PinchEnd, print_event(attributes=point_attributes))
149
150 # Selection events
151 p.on_event(events.SelectionGeometry, print_event(attributes=['geometry', 'final']))
152
153 # Reset events
154 p.on_event(events.Reset, print_event())
155
156 curdoc().add_root(layout)
157
[end of examples/howto/events_app.py]
[start of examples/howto/js_events.py]
1 """ Demonstration of how to register event callbacks using an adaptation
2 of the color_scatter example from the bokeh gallery
3 """
4
5 import numpy as np
6
7 from bokeh.io import show, output_file
8 from bokeh.plotting import figure
9 from bokeh import events
10 from bokeh.models import CustomJS, Div, Button
11 from bokeh.layouts import column, row
12
13
14 def display_event(div, attributes=[]):
15 """
16 Function to build a suitable CustomJS to display the current event
17 in the div model.
18 """
19 style = 'float:left;clear:left;font_size=0.5pt'
20 return CustomJS(args=dict(div=div), code="""
21 var attrs = %s;
22 var args = [];
23 for (var i=0; i<attrs.length; i++ ) {
24 val = JSON.stringify(cb_obj[attrs[i]], function(key, val) {
25 return val.toFixed ? Number(val.toFixed(2)) : val;
26 })
27 args.push(attrs[i] + '=' + val)
28 }
29 var line = "<span style=%r><b>" + cb_obj.event_name + "</b>(" + args.join(", ") + ")</span>\\n";
30 var text = div.text.concat(line);
31 var lines = text.split("\\n")
32 if ( lines.length > 35 ) { lines.shift(); }
33 div.text = lines.join("\\n");
34 """ % (attributes, style))
35
36 # Follows the color_scatter gallery example
37
38 N = 4000
39 x = np.random.random(size=N) * 100
40 y = np.random.random(size=N) * 100
41 radii = np.random.random(size=N) * 1.5
42 colors = [
43 "#%02x%02x%02x" % (int(r), int(g), 150) for r, g in zip(50+2*x, 30+2*y)
44 ]
45
46 p = figure(tools="pan,wheel_zoom,zoom_in,zoom_out,reset,tap,lasso_select,box_select")
47
48 p.scatter(x, y, radius=radii,
49 fill_color=colors, fill_alpha=0.6,
50 line_color=None)
51
52 # Add a div to display events and a button to trigger button click events
53
54 div = Div(width=1000)
55 button = Button(label="Button", button_type="success")
56 layout = column(button, row(p, div))
57
58
59 ## Register event callbacks
60
61 # Button event
62 button.js_on_event(events.ButtonClick, display_event(div))
63
64 # LOD events
65 p.js_on_event(events.LODStart, display_event(div))
66 p.js_on_event(events.LODEnd, display_event(div))
67
68 # Point events
69 point_attributes = ['x','y','sx','sy']
70 p.js_on_event(events.Tap, display_event(div, attributes=point_attributes))
71 p.js_on_event(events.DoubleTap, display_event(div, attributes=point_attributes))
72 p.js_on_event(events.Press, display_event(div, attributes=point_attributes))
73
74 # Mouse wheel event
75 p.js_on_event(events.MouseWheel, display_event(div,attributes=point_attributes+['delta']))
76
77 # Mouse move, enter and leave
78 p.js_on_event(events.MouseMove, display_event(div, attributes=point_attributes))
79 p.js_on_event(events.MouseEnter, display_event(div, attributes=point_attributes))
80 p.js_on_event(events.MouseLeave, display_event(div, attributes=point_attributes))
81
82 # Pan events
83 pan_attributes = point_attributes + ['delta_x', 'delta_y']
84 p.js_on_event(events.Pan, display_event(div, attributes=pan_attributes))
85 p.js_on_event(events.PanStart, display_event(div, attributes=point_attributes))
86 p.js_on_event(events.PanEnd, display_event(div, attributes=point_attributes))
87
88 # Pinch events
89 pinch_attributes = point_attributes + ['scale']
90 p.js_on_event(events.Pinch, display_event(div, attributes=pinch_attributes))
91 p.js_on_event(events.PinchStart, display_event(div, attributes=point_attributes))
92 p.js_on_event(events.PinchEnd, display_event(div, attributes=point_attributes))
93
94 # Selection events
95 p.js_on_event(events.SelectionGeometry, display_event(div, attributes=['geometry', 'final']))
96
97 output_file("js_events.html", title="JS Events Example")
98 show(layout)
99
[end of examples/howto/js_events.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/howto/events_app.py b/examples/howto/events_app.py
--- a/examples/howto/events_app.py
+++ b/examples/howto/events_app.py
@@ -18,7 +18,7 @@
Function to build a suitable CustomJS to display the current event
in the div model.
"""
- style = 'float:left;clear:left;font_size=0.5pt'
+ style = 'float: left; clear: left; font-size: 0.5pt'
return CustomJS(args=dict(div=div), code="""
var attrs = %s;
var args = [];
diff --git a/examples/howto/js_events.py b/examples/howto/js_events.py
--- a/examples/howto/js_events.py
+++ b/examples/howto/js_events.py
@@ -16,7 +16,7 @@
Function to build a suitable CustomJS to display the current event
in the div model.
"""
- style = 'float:left;clear:left;font_size=0.5pt'
+ style = 'float: left; clear: left; font-size: 0.5pt'
return CustomJS(args=dict(div=div), code="""
var attrs = %s;
var args = [];
|
{"golden_diff": "diff --git a/examples/howto/events_app.py b/examples/howto/events_app.py\n--- a/examples/howto/events_app.py\n+++ b/examples/howto/events_app.py\n@@ -18,7 +18,7 @@\n Function to build a suitable CustomJS to display the current event\n in the div model.\n \"\"\"\n- style = 'float:left;clear:left;font_size=0.5pt'\n+ style = 'float: left; clear: left; font-size: 0.5pt'\n return CustomJS(args=dict(div=div), code=\"\"\"\n var attrs = %s;\n var args = [];\ndiff --git a/examples/howto/js_events.py b/examples/howto/js_events.py\n--- a/examples/howto/js_events.py\n+++ b/examples/howto/js_events.py\n@@ -16,7 +16,7 @@\n Function to build a suitable CustomJS to display the current event\n in the div model.\n \"\"\"\n- style = 'float:left;clear:left;font_size=0.5pt'\n+ style = 'float: left; clear: left; font-size: 0.5pt'\n return CustomJS(args=dict(div=div), code=\"\"\"\n var attrs = %s;\n var args = [];\n", "issue": "examples/howto/{js_events,events_app} contain bad CSS\n* https://github.com/bokeh/bokeh/blob/master/examples/howto/js_events.py#L19\r\n* https://github.com/bokeh/bokeh/blob/master/examples/howto/events_app.py#L21\r\n* the same in user_guide\n", "before_files": [{"content": "\"\"\" Demonstration Bokeh app of how to register event callbacks in both\nJavascript and Python using an adaptation of the color_scatter example\nfrom the bokeh gallery. This example extends the js_events.py example\nwith corresponding Python event callbacks.\n\"\"\"\n\nimport numpy as np\n\nfrom bokeh.io import curdoc\nfrom bokeh.plotting import figure\nfrom bokeh import events\nfrom bokeh.models import CustomJS, Div, Button\nfrom bokeh.layouts import column, row\n\n\ndef display_event(div, attributes=[]):\n \"\"\"\n Function to build a suitable CustomJS to display the current event\n in the div model.\n \"\"\"\n style = 'float:left;clear:left;font_size=0.5pt'\n return CustomJS(args=dict(div=div), code=\"\"\"\n var attrs = %s;\n var args = [];\n for (var i=0; i<attrs.length; i++ ) {\n val = JSON.stringify(cb_obj[attrs[i]], function(key, val) {\n return val.toFixed ? Number(val.toFixed(2)) : val;\n })\n args.push(attrs[i] + '=' + val)\n }\n var line = \"<span style=%r><b>\" + cb_obj.event_name + \"</b>(\" + args.join(\", \") + \")</span>\\\\n\";\n var text = div.text.concat(line);\n var lines = text.split(\"\\\\n\")\n if ( lines.length > 35 ) { lines.shift(); }\n div.text = lines.join(\"\\\\n\");\n \"\"\" % (attributes, style))\n\ndef print_event(attributes=[]):\n \"\"\"\n Function that returns a Python callback to pretty print the events.\n \"\"\"\n def python_callback(event):\n cls_name = event.__class__.__name__\n attrs = ', '.join(['{attr}={val}'.format(attr=attr, val=event.__dict__[attr])\n for attr in attributes])\n print('{cls_name}({attrs})'.format(cls_name=cls_name, attrs=attrs))\n return python_callback\n\n# Follows the color_scatter gallery example\n\nN = 4000\nx = np.random.random(size=N) * 100\ny = np.random.random(size=N) * 100\nradii = np.random.random(size=N) * 1.5\ncolors = [\n \"#%02x%02x%02x\" % (int(r), int(g), 150) for r, g in zip(50+2*x, 30+2*y)\n]\n\np = figure(tools=\"pan,wheel_zoom,zoom_in,zoom_out,reset,tap,lasso_select,box_select\")\n\np.scatter(x, y, radius=radii,\n fill_color=colors, fill_alpha=0.6,\n line_color=None)\n\n# Add a div to display events and a button to trigger button click events\n\ndiv = Div(width=1000)\nbutton = Button(label=\"Button\", button_type=\"success\")\nlayout = column(button, row(p, div))\n\n\npoint_attributes = ['x','y','sx','sy']\npan_attributes = point_attributes + ['delta_x', 'delta_y']\npinch_attributes = point_attributes + ['scale']\nwheel_attributes = point_attributes+['delta']\n\n## Register Javascript event callbacks\n\n# Button event\nbutton.js_on_event(events.ButtonClick, display_event(div))\n\n# LOD events\np.js_on_event(events.LODStart, display_event(div))\np.js_on_event(events.LODEnd, display_event(div))\n\n# Point events\n\np.js_on_event(events.Tap, display_event(div, attributes=point_attributes))\np.js_on_event(events.DoubleTap, display_event(div, attributes=point_attributes))\np.js_on_event(events.Press, display_event(div, attributes=point_attributes))\n\n# Mouse wheel event\np.js_on_event(events.MouseWheel, display_event(div,attributes=wheel_attributes))\n\n# Mouse move, enter and leave\np.js_on_event(events.MouseMove, display_event(div, attributes=point_attributes))\np.js_on_event(events.MouseEnter, display_event(div, attributes=point_attributes))\np.js_on_event(events.MouseLeave, display_event(div, attributes=point_attributes))\n\n# Pan events\np.js_on_event(events.Pan, display_event(div, attributes=pan_attributes))\np.js_on_event(events.PanStart, display_event(div, attributes=point_attributes))\np.js_on_event(events.PanEnd, display_event(div, attributes=point_attributes))\n\n# Pinch events\np.js_on_event(events.Pinch, display_event(div, attributes=pinch_attributes))\np.js_on_event(events.PinchStart, display_event(div, attributes=point_attributes))\np.js_on_event(events.PinchEnd, display_event(div, attributes=point_attributes))\n\n# Selection events\np.js_on_event(events.SelectionGeometry, display_event(div, attributes=['geometry', 'final']))\n\n# Reset events\np.js_on_event(events.Reset, display_event(div))\n\n\n## Register Python event callbacks\n\n# Button event\nbutton.on_event(events.ButtonClick, print_event())\n\n# LOD events\np.on_event(events.LODStart, print_event())\np.on_event(events.LODEnd, print_event())\n\n# Point events\n\np.on_event(events.Tap, print_event(attributes=point_attributes))\np.on_event(events.DoubleTap, print_event(attributes=point_attributes))\np.on_event(events.Press, print_event(attributes=point_attributes))\n\n# Mouse wheel event\np.on_event(events.MouseWheel, print_event(attributes=wheel_attributes))\n\n# Mouse move, enter and leave\np.on_event(events.MouseMove, print_event(attributes=point_attributes))\np.on_event(events.MouseEnter, print_event(attributes=point_attributes))\np.on_event(events.MouseLeave, print_event(attributes=point_attributes))\n\n# Pan events\np.on_event(events.Pan, print_event(attributes=pan_attributes))\np.on_event(events.PanStart, print_event(attributes=point_attributes))\np.on_event(events.PanEnd, print_event(attributes=point_attributes))\n\n# Pinch events\np.on_event(events.Pinch, print_event(attributes=pinch_attributes))\np.on_event(events.PinchStart, print_event(attributes=point_attributes))\np.on_event(events.PinchEnd, print_event(attributes=point_attributes))\n\n# Selection events\np.on_event(events.SelectionGeometry, print_event(attributes=['geometry', 'final']))\n\n# Reset events\np.on_event(events.Reset, print_event())\n\ncurdoc().add_root(layout)\n", "path": "examples/howto/events_app.py"}, {"content": "\"\"\" Demonstration of how to register event callbacks using an adaptation\nof the color_scatter example from the bokeh gallery\n\"\"\"\n\nimport numpy as np\n\nfrom bokeh.io import show, output_file\nfrom bokeh.plotting import figure\nfrom bokeh import events\nfrom bokeh.models import CustomJS, Div, Button\nfrom bokeh.layouts import column, row\n\n\ndef display_event(div, attributes=[]):\n \"\"\"\n Function to build a suitable CustomJS to display the current event\n in the div model.\n \"\"\"\n style = 'float:left;clear:left;font_size=0.5pt'\n return CustomJS(args=dict(div=div), code=\"\"\"\n var attrs = %s;\n var args = [];\n for (var i=0; i<attrs.length; i++ ) {\n val = JSON.stringify(cb_obj[attrs[i]], function(key, val) {\n return val.toFixed ? Number(val.toFixed(2)) : val;\n })\n args.push(attrs[i] + '=' + val)\n }\n var line = \"<span style=%r><b>\" + cb_obj.event_name + \"</b>(\" + args.join(\", \") + \")</span>\\\\n\";\n var text = div.text.concat(line);\n var lines = text.split(\"\\\\n\")\n if ( lines.length > 35 ) { lines.shift(); }\n div.text = lines.join(\"\\\\n\");\n \"\"\" % (attributes, style))\n\n# Follows the color_scatter gallery example\n\nN = 4000\nx = np.random.random(size=N) * 100\ny = np.random.random(size=N) * 100\nradii = np.random.random(size=N) * 1.5\ncolors = [\n \"#%02x%02x%02x\" % (int(r), int(g), 150) for r, g in zip(50+2*x, 30+2*y)\n]\n\np = figure(tools=\"pan,wheel_zoom,zoom_in,zoom_out,reset,tap,lasso_select,box_select\")\n\np.scatter(x, y, radius=radii,\n fill_color=colors, fill_alpha=0.6,\n line_color=None)\n\n# Add a div to display events and a button to trigger button click events\n\ndiv = Div(width=1000)\nbutton = Button(label=\"Button\", button_type=\"success\")\nlayout = column(button, row(p, div))\n\n\n## Register event callbacks\n\n# Button event\nbutton.js_on_event(events.ButtonClick, display_event(div))\n\n# LOD events\np.js_on_event(events.LODStart, display_event(div))\np.js_on_event(events.LODEnd, display_event(div))\n\n# Point events\npoint_attributes = ['x','y','sx','sy']\np.js_on_event(events.Tap, display_event(div, attributes=point_attributes))\np.js_on_event(events.DoubleTap, display_event(div, attributes=point_attributes))\np.js_on_event(events.Press, display_event(div, attributes=point_attributes))\n\n# Mouse wheel event\np.js_on_event(events.MouseWheel, display_event(div,attributes=point_attributes+['delta']))\n\n# Mouse move, enter and leave\np.js_on_event(events.MouseMove, display_event(div, attributes=point_attributes))\np.js_on_event(events.MouseEnter, display_event(div, attributes=point_attributes))\np.js_on_event(events.MouseLeave, display_event(div, attributes=point_attributes))\n\n# Pan events\npan_attributes = point_attributes + ['delta_x', 'delta_y']\np.js_on_event(events.Pan, display_event(div, attributes=pan_attributes))\np.js_on_event(events.PanStart, display_event(div, attributes=point_attributes))\np.js_on_event(events.PanEnd, display_event(div, attributes=point_attributes))\n\n# Pinch events\npinch_attributes = point_attributes + ['scale']\np.js_on_event(events.Pinch, display_event(div, attributes=pinch_attributes))\np.js_on_event(events.PinchStart, display_event(div, attributes=point_attributes))\np.js_on_event(events.PinchEnd, display_event(div, attributes=point_attributes))\n\n# Selection events\np.js_on_event(events.SelectionGeometry, display_event(div, attributes=['geometry', 'final']))\n\noutput_file(\"js_events.html\", title=\"JS Events Example\")\nshow(layout)\n", "path": "examples/howto/js_events.py"}]}
| 3,471 | 270 |
gh_patches_debug_6676
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-1513
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fox.com.tr not work with Streamlink
## **Checklist**
- [x] This is a bug report.
- [ ] This is a feature request.
- [ ] ] This is a plugin (improvement) request.
- [ ] I have read the contribution guidelines.
## **Description**
i cant see anything at fox.com.tr
i have test it with this links but i became black screen
## **Reproduction steps / Explicit stream URLs to test**
https://www.fox.com.tr/canli-yayin
</issue>
<code>
[start of src/streamlink/plugins/foxtr.py]
1 from __future__ import print_function
2 import re
3
4 from streamlink.plugin import Plugin
5 from streamlink.plugin.api import http
6 from streamlink.plugin.api import validate
7 from streamlink.stream import HLSStream
8
9
10 class FoxTR(Plugin):
11 """
12 Support for Turkish Fox live stream: http://www.fox.com.tr/canli-yayin
13 """
14 url_re = re.compile(r"https?://www.fox.com.tr/canli-yayin")
15 playervars_re = re.compile(r"desktop\s*:\s*\[\s*\{\s*src\s*:\s*'(.*?)'", re.DOTALL)
16
17 @classmethod
18 def can_handle_url(cls, url):
19 return cls.url_re.match(url) is not None
20
21 def _get_streams(self):
22 res = http.get(self.url)
23 match = self.playervars_re.search(res.text)
24 if match:
25 stream_url = match.group(1)
26 return HLSStream.parse_variant_playlist(self.session, stream_url)
27
28
29 __plugin__ = FoxTR
30
[end of src/streamlink/plugins/foxtr.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/foxtr.py b/src/streamlink/plugins/foxtr.py
--- a/src/streamlink/plugins/foxtr.py
+++ b/src/streamlink/plugins/foxtr.py
@@ -12,7 +12,7 @@
Support for Turkish Fox live stream: http://www.fox.com.tr/canli-yayin
"""
url_re = re.compile(r"https?://www.fox.com.tr/canli-yayin")
- playervars_re = re.compile(r"desktop\s*:\s*\[\s*\{\s*src\s*:\s*'(.*?)'", re.DOTALL)
+ playervars_re = re.compile(r"source\s*:\s*\[\s*\{\s*videoSrc\s*:\s*'(.*?)'", re.DOTALL)
@classmethod
def can_handle_url(cls, url):
|
{"golden_diff": "diff --git a/src/streamlink/plugins/foxtr.py b/src/streamlink/plugins/foxtr.py\n--- a/src/streamlink/plugins/foxtr.py\n+++ b/src/streamlink/plugins/foxtr.py\n@@ -12,7 +12,7 @@\n Support for Turkish Fox live stream: http://www.fox.com.tr/canli-yayin\n \"\"\"\n url_re = re.compile(r\"https?://www.fox.com.tr/canli-yayin\")\n- playervars_re = re.compile(r\"desktop\\s*:\\s*\\[\\s*\\{\\s*src\\s*:\\s*'(.*?)'\", re.DOTALL)\n+ playervars_re = re.compile(r\"source\\s*:\\s*\\[\\s*\\{\\s*videoSrc\\s*:\\s*'(.*?)'\", re.DOTALL)\n \n @classmethod\n def can_handle_url(cls, url):\n", "issue": "Fox.com.tr not work with Streamlink\n## **Checklist**\r\n\r\n- [x] This is a bug report.\r\n- [ ] This is a feature request.\r\n- [ ] ] This is a plugin (improvement) request.\r\n- [ ] I have read the contribution guidelines.\r\n\r\n## **Description**\r\n\r\n i cant see anything at fox.com.tr \r\n i have test it with this links but i became black screen \r\n\r\n## **Reproduction steps / Explicit stream URLs to test**\r\n\r\nhttps://www.fox.com.tr/canli-yayin\n", "before_files": [{"content": "from __future__ import print_function\nimport re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugin.api import http\nfrom streamlink.plugin.api import validate\nfrom streamlink.stream import HLSStream\n\n\nclass FoxTR(Plugin):\n \"\"\"\n Support for Turkish Fox live stream: http://www.fox.com.tr/canli-yayin\n \"\"\"\n url_re = re.compile(r\"https?://www.fox.com.tr/canli-yayin\")\n playervars_re = re.compile(r\"desktop\\s*:\\s*\\[\\s*\\{\\s*src\\s*:\\s*'(.*?)'\", re.DOTALL)\n\n @classmethod\n def can_handle_url(cls, url):\n return cls.url_re.match(url) is not None\n\n def _get_streams(self):\n res = http.get(self.url)\n match = self.playervars_re.search(res.text)\n if match:\n stream_url = match.group(1)\n return HLSStream.parse_variant_playlist(self.session, stream_url)\n\n\n__plugin__ = FoxTR\n", "path": "src/streamlink/plugins/foxtr.py"}]}
| 930 | 191 |
gh_patches_debug_66910
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-20200
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
randint_like
Add randint_like function to pytorch frontend
</issue>
<code>
[start of ivy/functional/frontends/torch/random_sampling.py]
1 import ivy
2 from ivy.func_wrapper import with_supported_dtypes
3 from ivy.functional.frontends.torch.func_wrapper import to_ivy_arrays_and_back
4
5
6 # ToDo: will need to create a Generator class to be able to fully test these functions
7
8
9 def seed() -> int:
10 """Return a 64 bit number used to seed the RNG."""
11 return int(ivy.randint(-(2**63), 2**63 - 1))
12
13
14 @to_ivy_arrays_and_back
15 def manual_seed(seed: int):
16 ivy.seed(seed_value=seed)
17 return None
18
19
20 @with_supported_dtypes(
21 {
22 "2.0.1 and below": (
23 "float32",
24 "float64",
25 )
26 },
27 "torch",
28 )
29 @to_ivy_arrays_and_back
30 def multinomial(input, num_samples, replacement=False, *, generator=None, out=None):
31 seed = generator.initial_seed() if generator is not None else None
32 return ivy.multinomial(
33 num_samples + 1, # doesn't matter because `probs` is provided, but should be
34 # greater than the number of samples
35 num_samples,
36 probs=input,
37 replace=replacement,
38 seed=seed,
39 out=out,
40 )
41
42
43 @with_supported_dtypes(
44 {
45 "2.0.1 and below": (
46 "float32",
47 "float64",
48 )
49 },
50 "torch",
51 )
52 @to_ivy_arrays_and_back
53 def poisson(input, generator=None):
54 seed = generator.initial_seed() if generator is not None else None
55 return ivy.poisson(input, seed=seed, shape=None)
56
57
58 @to_ivy_arrays_and_back
59 def randint(
60 low,
61 high,
62 size,
63 *,
64 generator=None,
65 out=None,
66 dtype=None,
67 layout=None,
68 device=None,
69 requires_grad=False,
70 ):
71 seed = generator.initial_seed() if generator is not None else None
72 return ivy.randint(
73 low,
74 high,
75 shape=size,
76 seed=seed,
77 out=out,
78 dtype=dtype,
79 device=device,
80 )
81
82
83 @to_ivy_arrays_and_back
84 def rand(
85 *size,
86 generator=None,
87 out=None,
88 dtype=None,
89 layout=None,
90 device=None,
91 requires_grad=False,
92 pin_memory=False,
93 **kwargs,
94 ):
95 if not size and "size" not in kwargs:
96 raise ValueError("Missing 1 required positional/keyword argument: size")
97 size = kwargs["size"] if not size else size
98 if (
99 isinstance(size, (list, tuple))
100 and len(size) == 1
101 and isinstance(size[0], (list, tuple))
102 ):
103 size = size[0]
104 seed = generator.initial_seed() if generator is not None else None
105 return ivy.random_uniform(
106 shape=size,
107 seed=seed,
108 out=out,
109 dtype=dtype,
110 device=device,
111 )
112
113
114 @with_supported_dtypes(
115 {
116 "2.0.1 and below": (
117 "float32",
118 "float64",
119 )
120 },
121 "torch",
122 )
123 @to_ivy_arrays_and_back
124 def normal(mean, std, *, generator=None, out=None):
125 seed = generator.initial_seed() if generator is not None else None
126 return ivy.random_normal(mean=mean, std=std, seed=seed, out=out)
127
128
129 @to_ivy_arrays_and_back
130 def rand_like(
131 input,
132 *,
133 dtype=None,
134 layout=None,
135 device=None,
136 requires_grad=False,
137 memory_format=False,
138 ):
139 shape = input.shape
140 if not dtype:
141 dtype = input.dtype
142
143 return ivy.random_uniform(
144 shape=shape,
145 dtype=dtype,
146 device=device,
147 )
148
149
150 @to_ivy_arrays_and_back
151 def randn(
152 *size,
153 generator=None,
154 out=None,
155 dtype=None,
156 layout=None,
157 device=None,
158 requires_grad=False,
159 pin_memory=False,
160 **kwargs,
161 ):
162 if not size and "size" not in kwargs:
163 raise ValueError("Missing 1 required positional/keyword argument: size")
164 size = kwargs["size"] if not size else size
165 if (
166 isinstance(size, (list, tuple))
167 and len(size) == 1
168 and isinstance(size[0], (list, tuple))
169 ):
170 size = size[0]
171 seed = generator.initial_seed() if generator is not None else None
172 return ivy.random_normal(
173 shape=size,
174 seed=seed,
175 out=out,
176 dtype=dtype,
177 device=device,
178 )
179
180
181 @to_ivy_arrays_and_back
182 def randn_like(
183 input,
184 *,
185 dtype=None,
186 layout=None,
187 device=None,
188 requires_grad=False,
189 memory_format=None,
190 ):
191 shape = input.shape
192 if not dtype:
193 dtype = input.dtype
194
195 return ivy.random_normal(
196 shape=shape,
197 dtype=dtype,
198 device=device,
199 )
200
201
202 @with_supported_dtypes(
203 {
204 "2.0.1 and below": (
205 "float32",
206 "float64",
207 )
208 },
209 "torch",
210 )
211 @to_ivy_arrays_and_back
212 def bernoulli(input, *, generator=None, out=None):
213 seed = generator.initial_seed() if generator is not None else None
214 return ivy.bernoulli(input, seed=seed, out=out)
215
216
217 @to_ivy_arrays_and_back
218 def randperm(
219 n,
220 *,
221 generator=None,
222 out=None,
223 dtype=ivy.int64,
224 layout=None,
225 device=None,
226 requires_grad=False,
227 pin_memory=False,
228 ):
229 seed = generator.initial_seed() if generator is not None else None
230 arr = ivy.arange(n, device=device, dtype=dtype)
231 ret = ivy.shuffle(arr, seed=seed, out=out)
232 return ret
233
[end of ivy/functional/frontends/torch/random_sampling.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/torch/random_sampling.py b/ivy/functional/frontends/torch/random_sampling.py
--- a/ivy/functional/frontends/torch/random_sampling.py
+++ b/ivy/functional/frontends/torch/random_sampling.py
@@ -230,3 +230,26 @@
arr = ivy.arange(n, device=device, dtype=dtype)
ret = ivy.shuffle(arr, seed=seed, out=out)
return ret
+
+
+@to_ivy_arrays_and_back
+def randint_like(
+ input,
+ low,
+ high,
+ *,
+ dtype=None,
+ layout=None,
+ device=None,
+ requires_grad=False,
+ memory_format=None,
+):
+ shape = input.shape
+
+ return ivy.randint(
+ low,
+ high,
+ shape=shape,
+ device=device,
+ dtype=dtype,
+ )
|
{"golden_diff": "diff --git a/ivy/functional/frontends/torch/random_sampling.py b/ivy/functional/frontends/torch/random_sampling.py\n--- a/ivy/functional/frontends/torch/random_sampling.py\n+++ b/ivy/functional/frontends/torch/random_sampling.py\n@@ -230,3 +230,26 @@\n arr = ivy.arange(n, device=device, dtype=dtype)\n ret = ivy.shuffle(arr, seed=seed, out=out)\n return ret\n+\n+\n+@to_ivy_arrays_and_back\n+def randint_like(\n+ input,\n+ low,\n+ high,\n+ *,\n+ dtype=None,\n+ layout=None,\n+ device=None,\n+ requires_grad=False,\n+ memory_format=None,\n+):\n+ shape = input.shape\n+\n+ return ivy.randint(\n+ low,\n+ high,\n+ shape=shape,\n+ device=device,\n+ dtype=dtype,\n+ )\n", "issue": "randint_like\nAdd randint_like function to pytorch frontend\n", "before_files": [{"content": "import ivy\nfrom ivy.func_wrapper import with_supported_dtypes\nfrom ivy.functional.frontends.torch.func_wrapper import to_ivy_arrays_and_back\n\n\n# ToDo: will need to create a Generator class to be able to fully test these functions\n\n\ndef seed() -> int:\n \"\"\"Return a 64 bit number used to seed the RNG.\"\"\"\n return int(ivy.randint(-(2**63), 2**63 - 1))\n\n\n@to_ivy_arrays_and_back\ndef manual_seed(seed: int):\n ivy.seed(seed_value=seed)\n return None\n\n\n@with_supported_dtypes(\n {\n \"2.0.1 and below\": (\n \"float32\",\n \"float64\",\n )\n },\n \"torch\",\n)\n@to_ivy_arrays_and_back\ndef multinomial(input, num_samples, replacement=False, *, generator=None, out=None):\n seed = generator.initial_seed() if generator is not None else None\n return ivy.multinomial(\n num_samples + 1, # doesn't matter because `probs` is provided, but should be\n # greater than the number of samples\n num_samples,\n probs=input,\n replace=replacement,\n seed=seed,\n out=out,\n )\n\n\n@with_supported_dtypes(\n {\n \"2.0.1 and below\": (\n \"float32\",\n \"float64\",\n )\n },\n \"torch\",\n)\n@to_ivy_arrays_and_back\ndef poisson(input, generator=None):\n seed = generator.initial_seed() if generator is not None else None\n return ivy.poisson(input, seed=seed, shape=None)\n\n\n@to_ivy_arrays_and_back\ndef randint(\n low,\n high,\n size,\n *,\n generator=None,\n out=None,\n dtype=None,\n layout=None,\n device=None,\n requires_grad=False,\n):\n seed = generator.initial_seed() if generator is not None else None\n return ivy.randint(\n low,\n high,\n shape=size,\n seed=seed,\n out=out,\n dtype=dtype,\n device=device,\n )\n\n\n@to_ivy_arrays_and_back\ndef rand(\n *size,\n generator=None,\n out=None,\n dtype=None,\n layout=None,\n device=None,\n requires_grad=False,\n pin_memory=False,\n **kwargs,\n):\n if not size and \"size\" not in kwargs:\n raise ValueError(\"Missing 1 required positional/keyword argument: size\")\n size = kwargs[\"size\"] if not size else size\n if (\n isinstance(size, (list, tuple))\n and len(size) == 1\n and isinstance(size[0], (list, tuple))\n ):\n size = size[0]\n seed = generator.initial_seed() if generator is not None else None\n return ivy.random_uniform(\n shape=size,\n seed=seed,\n out=out,\n dtype=dtype,\n device=device,\n )\n\n\n@with_supported_dtypes(\n {\n \"2.0.1 and below\": (\n \"float32\",\n \"float64\",\n )\n },\n \"torch\",\n)\n@to_ivy_arrays_and_back\ndef normal(mean, std, *, generator=None, out=None):\n seed = generator.initial_seed() if generator is not None else None\n return ivy.random_normal(mean=mean, std=std, seed=seed, out=out)\n\n\n@to_ivy_arrays_and_back\ndef rand_like(\n input,\n *,\n dtype=None,\n layout=None,\n device=None,\n requires_grad=False,\n memory_format=False,\n):\n shape = input.shape\n if not dtype:\n dtype = input.dtype\n\n return ivy.random_uniform(\n shape=shape,\n dtype=dtype,\n device=device,\n )\n\n\n@to_ivy_arrays_and_back\ndef randn(\n *size,\n generator=None,\n out=None,\n dtype=None,\n layout=None,\n device=None,\n requires_grad=False,\n pin_memory=False,\n **kwargs,\n):\n if not size and \"size\" not in kwargs:\n raise ValueError(\"Missing 1 required positional/keyword argument: size\")\n size = kwargs[\"size\"] if not size else size\n if (\n isinstance(size, (list, tuple))\n and len(size) == 1\n and isinstance(size[0], (list, tuple))\n ):\n size = size[0]\n seed = generator.initial_seed() if generator is not None else None\n return ivy.random_normal(\n shape=size,\n seed=seed,\n out=out,\n dtype=dtype,\n device=device,\n )\n\n\n@to_ivy_arrays_and_back\ndef randn_like(\n input,\n *,\n dtype=None,\n layout=None,\n device=None,\n requires_grad=False,\n memory_format=None,\n):\n shape = input.shape\n if not dtype:\n dtype = input.dtype\n\n return ivy.random_normal(\n shape=shape,\n dtype=dtype,\n device=device,\n )\n\n\n@with_supported_dtypes(\n {\n \"2.0.1 and below\": (\n \"float32\",\n \"float64\",\n )\n },\n \"torch\",\n)\n@to_ivy_arrays_and_back\ndef bernoulli(input, *, generator=None, out=None):\n seed = generator.initial_seed() if generator is not None else None\n return ivy.bernoulli(input, seed=seed, out=out)\n\n\n@to_ivy_arrays_and_back\ndef randperm(\n n,\n *,\n generator=None,\n out=None,\n dtype=ivy.int64,\n layout=None,\n device=None,\n requires_grad=False,\n pin_memory=False,\n):\n seed = generator.initial_seed() if generator is not None else None\n arr = ivy.arange(n, device=device, dtype=dtype)\n ret = ivy.shuffle(arr, seed=seed, out=out)\n return ret\n", "path": "ivy/functional/frontends/torch/random_sampling.py"}]}
| 2,442 | 208 |
gh_patches_debug_3272
|
rasdani/github-patches
|
git_diff
|
dbt-labs__dbt-core-4192
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Incompatible versions of `protobuf` required in sub-dependencies
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
It is not currently possible to install dbt through Pipenv because of incompatible versions of `protobuf` in sub-dependencies used in `dbt-bigquery`.
Specifically;
- `google-api-core[grpc]==1.31.3` requires `protobuf<3.18.0`
- `proto-plus==1.19.7` (used by `google-cloud-bigquery==2.29.0`) requires `protobuf>=3.19.0`
Alternatively, installing dbt through `pip` may appear successful, but the issue of incompatible versions remains -- pip simply installs the version of `protobuf` that satisfies whichever sub-dependency is installed last in the sequence, ignoring that previous sub-dependencies required an incompatible version.
### Expected Behavior
dbt should ideally use non-conflicting versions of `google-api-core[grpc]` and `google-cloud-bigquery` or allow installation of dbt without the `dbt-bigquery` extra.
### Steps To Reproduce
1. `pip install pipenv`
2. `pipenv install dbt`
### Relevant log output
```shell
[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.
First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.
Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.
Hint: try $ pipenv lock --pre if it is a pre-release dependency.
ERROR: Could not find a version that matches protobuf<3.18.0,<4,>=3.12.0,>=3.13.0,>=3.19.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
Tried: 2.0.3, 2.3.0, 2.4.1, 2.5.0, 2.6.0, 2.6.1, 3.0.0, 3.0.0, 3.1.0, 3.1.0.post1, 3.1.0.post1, 3.2.0, 3.2.0, 3.3.0, 3.4.0, 3.4.0, 3.5.0.post1, 3.5.0.post1, 3.5.1, 3.5.1, 3.5.2, 3.5.2, 3.5.2.post1, 3.5.2.post1, 3.6.0, 3.6.0, 3.6.1, 3.6.1, 3.7.0, 3.7.0, 3.7.1, 3.7.1, 3.8.0, 3.8.0, 3.9.0, 3.9.0, 3.9.1, 3.9.1, 3.9.2, 3.9.2, 3.10.0, 3.10.0, 3.11.0, 3.11.0, 3.11.1, 3.11.1, 3.11.2, 3.11.2, 3.11.3, 3.11.3, 3.12.2, 3.12.2, 3.12.4, 3.12.4, 3.13.0, 3.13.0, 3.14.0, 3.14.0, 3.15.0, 3.15.0, 3.15.0, 3.15.1, 3.15.1, 3.15.1, 3.15.2, 3.15.2, 3.15.2, 3.15.3, 3.15.3, 3.15.3, 3.15.4, 3.15.4, 3.15.4, 3.15.5, 3.15.5, 3.15.5, 3.15.6, 3.15.6, 3.15.6, 3.15.7, 3.15.7, 3.15.7, 3.15.8, 3.15.8, 3.15.8, 3.16.0, 3.16.0, 3.16.0, 3.17.0, 3.17.0, 3.17.0, 3.17.1, 3.17.1, 3.17.1, 3.17.2, 3.17.2, 3.17.2, 3.17.3, 3.17.3, 3.17.3, 3.18.0, 3.18.0, 3.18.0, 3.18.1, 3.18.1, 3.18.1, 3.19.0, 3.19.0, 3.19.0, 3.19.1, 3.19.1, 3.19.1
Skipped pre-versions: 2.0.0b0, 3.0.0a2, 3.0.0a3, 3.0.0b1, 3.0.0b1.post1, 3.0.0b1.post2, 3.0.0b2, 3.0.0b2, 3.0.0b2.post1, 3.0.0b2.post1, 3.0.0b2.post2, 3.0.0b2.post2, 3.0.0b3, 3.0.0b4, 3.0.0b4, 3.2.0rc1, 3.2.0rc1, 3.2.0rc1.post1, 3.2.0rc1.post1, 3.2.0rc2, 3.2.0rc2, 3.7.0rc2, 3.7.0rc2, 3.7.0rc3, 3.7.0rc3, 3.8.0rc1, 3.8.0rc1, 3.9.0rc1, 3.9.0rc1, 3.10.0rc1, 3.10.0rc1, 3.11.0rc1, 3.11.0rc1, 3.11.0rc2, 3.11.0rc2, 3.13.0rc3, 3.13.0rc3, 3.14.0rc1, 3.14.0rc1, 3.14.0rc2, 3.14.0rc2, 3.14.0rc3, 3.14.0rc3, 3.15.0rc1, 3.15.0rc1, 3.15.0rc1, 3.15.0rc2, 3.15.0rc2, 3.15.0rc2, 3.16.0rc1, 3.16.0rc1, 3.16.0rc1, 3.16.0rc2, 3.16.0rc2, 3.16.0rc2, 3.17.0rc1, 3.17.0rc1, 3.17.0rc1, 3.17.0rc2, 3.17.0rc2, 3.17.0rc2, 3.18.0rc1, 3.18.0rc1, 3.18.0rc1, 3.18.0rc2, 3.18.0rc2, 3.18.0rc2, 3.19.0rc1, 3.19.0rc1, 3.19.0rc1, 3.19.0rc2, 3.19.0rc2, 3.19.0rc2, 4.0.0rc1, 4.0.0rc1, 4.0.0rc2, 4.0.0rc2
There are incompatible versions in the resolved dependencies:
protobuf<3.18.0,>=3.12.0 (from google-api-core[grpc]==1.31.3->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf<4,>=3.13.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf>=3.12.0 (from google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf>=3.12.0 (from googleapis-common-protos==1.53.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
protobuf>=3.19.0 (from proto-plus==1.19.7->google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))
```
### Environment
```markdown
- OS: macOS 11.6
- Python: Python 3.7
- dbt: 0.21 (same error with 0.20)
```
### What database are you using dbt with?
_No response_
### Additional Context
_No response_
</issue>
<code>
[start of plugins/bigquery/setup.py]
1 #!/usr/bin/env python
2 import os
3 import sys
4
5 if sys.version_info < (3, 6):
6 print('Error: dbt does not support this version of Python.')
7 print('Please upgrade to Python 3.6 or higher.')
8 sys.exit(1)
9
10
11 from setuptools import setup
12 try:
13 from setuptools import find_namespace_packages
14 except ImportError:
15 # the user has a downlevel version of setuptools.
16 print('Error: dbt requires setuptools v40.1.0 or higher.')
17 print('Please upgrade setuptools with "pip install --upgrade setuptools" '
18 'and try again')
19 sys.exit(1)
20
21
22 package_name = "dbt-bigquery"
23 package_version = "0.21.0"
24 description = """The bigquery adapter plugin for dbt (data build tool)"""
25
26 this_directory = os.path.abspath(os.path.dirname(__file__))
27 with open(os.path.join(this_directory, 'README.md')) as f:
28 long_description = f.read()
29
30 setup(
31 name=package_name,
32 version=package_version,
33 description=description,
34 long_description=long_description,
35 long_description_content_type='text/markdown',
36 author="dbt Labs",
37 author_email="[email protected]",
38 url="https://github.com/dbt-labs/dbt",
39 packages=find_namespace_packages(include=['dbt', 'dbt.*']),
40 package_data={
41 'dbt': [
42 'include/bigquery/dbt_project.yml',
43 'include/bigquery/sample_profiles.yml',
44 'include/bigquery/macros/*.sql',
45 'include/bigquery/macros/**/*.sql',
46 ]
47 },
48 install_requires=[
49 'dbt-core=={}'.format(package_version),
50 'protobuf>=3.13.0,<4',
51 'google-cloud-core>=1.3.0,<2',
52 'google-cloud-bigquery>=1.25.0,<3',
53 'google-api-core>=1.16.0,<2',
54 'googleapis-common-protos>=1.6.0,<2',
55 'six>=1.14.0',
56 ],
57 zip_safe=False,
58 classifiers=[
59 'Development Status :: 5 - Production/Stable',
60
61 'License :: OSI Approved :: Apache Software License',
62
63 'Operating System :: Microsoft :: Windows',
64 'Operating System :: MacOS :: MacOS X',
65 'Operating System :: POSIX :: Linux',
66
67 'Programming Language :: Python :: 3.6',
68 'Programming Language :: Python :: 3.7',
69 'Programming Language :: Python :: 3.8',
70 'Programming Language :: Python :: 3.9',
71 ],
72 python_requires=">=3.6.2",
73 )
74
[end of plugins/bigquery/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/bigquery/setup.py b/plugins/bigquery/setup.py
--- a/plugins/bigquery/setup.py
+++ b/plugins/bigquery/setup.py
@@ -50,7 +50,7 @@
'protobuf>=3.13.0,<4',
'google-cloud-core>=1.3.0,<2',
'google-cloud-bigquery>=1.25.0,<3',
- 'google-api-core>=1.16.0,<2',
+ 'google-api-core>=1.16.0,<1.31.3',
'googleapis-common-protos>=1.6.0,<2',
'six>=1.14.0',
],
|
{"golden_diff": "diff --git a/plugins/bigquery/setup.py b/plugins/bigquery/setup.py\n--- a/plugins/bigquery/setup.py\n+++ b/plugins/bigquery/setup.py\n@@ -50,7 +50,7 @@\n 'protobuf>=3.13.0,<4',\n 'google-cloud-core>=1.3.0,<2',\n 'google-cloud-bigquery>=1.25.0,<3',\n- 'google-api-core>=1.16.0,<2',\n+ 'google-api-core>=1.16.0,<1.31.3',\n 'googleapis-common-protos>=1.6.0,<2',\n 'six>=1.14.0',\n ],\n", "issue": "[Bug] Incompatible versions of `protobuf` required in sub-dependencies\n### Is there an existing issue for this?\r\n\r\n- [X] I have searched the existing issues\r\n\r\n### Current Behavior\r\n\r\nIt is not currently possible to install dbt through Pipenv because of incompatible versions of `protobuf` in sub-dependencies used in `dbt-bigquery`. \r\n\r\nSpecifically;\r\n\r\n- `google-api-core[grpc]==1.31.3` requires `protobuf<3.18.0`\r\n- `proto-plus==1.19.7` (used by `google-cloud-bigquery==2.29.0`) requires `protobuf>=3.19.0`\r\n\r\nAlternatively, installing dbt through `pip` may appear successful, but the issue of incompatible versions remains -- pip simply installs the version of `protobuf` that satisfies whichever sub-dependency is installed last in the sequence, ignoring that previous sub-dependencies required an incompatible version.\r\n\r\n### Expected Behavior\r\n\r\ndbt should ideally use non-conflicting versions of `google-api-core[grpc]` and `google-cloud-bigquery` or allow installation of dbt without the `dbt-bigquery` extra.\r\n\r\n### Steps To Reproduce\r\n\r\n1. `pip install pipenv`\r\n2. `pipenv install dbt`\r\n\r\n### Relevant log output\r\n\r\n```shell\r\n[pipenv.exceptions.ResolutionFailure]: Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.\r\n First try clearing your dependency cache with $ pipenv lock --clear, then try the original command again.\r\n Alternatively, you can use $ pipenv install --skip-lock to bypass this mechanism, then run $ pipenv graph to inspect the situation.\r\n Hint: try $ pipenv lock --pre if it is a pre-release dependency.\r\nERROR: Could not find a version that matches protobuf<3.18.0,<4,>=3.12.0,>=3.13.0,>=3.19.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\nTried: 2.0.3, 2.3.0, 2.4.1, 2.5.0, 2.6.0, 2.6.1, 3.0.0, 3.0.0, 3.1.0, 3.1.0.post1, 3.1.0.post1, 3.2.0, 3.2.0, 3.3.0, 3.4.0, 3.4.0, 3.5.0.post1, 3.5.0.post1, 3.5.1, 3.5.1, 3.5.2, 3.5.2, 3.5.2.post1, 3.5.2.post1, 3.6.0, 3.6.0, 3.6.1, 3.6.1, 3.7.0, 3.7.0, 3.7.1, 3.7.1, 3.8.0, 3.8.0, 3.9.0, 3.9.0, 3.9.1, 3.9.1, 3.9.2, 3.9.2, 3.10.0, 3.10.0, 3.11.0, 3.11.0, 3.11.1, 3.11.1, 3.11.2, 3.11.2, 3.11.3, 3.11.3, 3.12.2, 3.12.2, 3.12.4, 3.12.4, 3.13.0, 3.13.0, 3.14.0, 3.14.0, 3.15.0, 3.15.0, 3.15.0, 3.15.1, 3.15.1, 3.15.1, 3.15.2, 3.15.2, 3.15.2, 3.15.3, 3.15.3, 3.15.3, 3.15.4, 3.15.4, 3.15.4, 3.15.5, 3.15.5, 3.15.5, 3.15.6, 3.15.6, 3.15.6, 3.15.7, 3.15.7, 3.15.7, 3.15.8, 3.15.8, 3.15.8, 3.16.0, 3.16.0, 3.16.0, 3.17.0, 3.17.0, 3.17.0, 3.17.1, 3.17.1, 3.17.1, 3.17.2, 3.17.2, 3.17.2, 3.17.3, 3.17.3, 3.17.3, 3.18.0, 3.18.0, 3.18.0, 3.18.1, 3.18.1, 3.18.1, 3.19.0, 3.19.0, 3.19.0, 3.19.1, 3.19.1, 3.19.1\r\nSkipped pre-versions: 2.0.0b0, 3.0.0a2, 3.0.0a3, 3.0.0b1, 3.0.0b1.post1, 3.0.0b1.post2, 3.0.0b2, 3.0.0b2, 3.0.0b2.post1, 3.0.0b2.post1, 3.0.0b2.post2, 3.0.0b2.post2, 3.0.0b3, 3.0.0b4, 3.0.0b4, 3.2.0rc1, 3.2.0rc1, 3.2.0rc1.post1, 3.2.0rc1.post1, 3.2.0rc2, 3.2.0rc2, 3.7.0rc2, 3.7.0rc2, 3.7.0rc3, 3.7.0rc3, 3.8.0rc1, 3.8.0rc1, 3.9.0rc1, 3.9.0rc1, 3.10.0rc1, 3.10.0rc1, 3.11.0rc1, 3.11.0rc1, 3.11.0rc2, 3.11.0rc2, 3.13.0rc3, 3.13.0rc3, 3.14.0rc1, 3.14.0rc1, 3.14.0rc2, 3.14.0rc2, 3.14.0rc3, 3.14.0rc3, 3.15.0rc1, 3.15.0rc1, 3.15.0rc1, 3.15.0rc2, 3.15.0rc2, 3.15.0rc2, 3.16.0rc1, 3.16.0rc1, 3.16.0rc1, 3.16.0rc2, 3.16.0rc2, 3.16.0rc2, 3.17.0rc1, 3.17.0rc1, 3.17.0rc1, 3.17.0rc2, 3.17.0rc2, 3.17.0rc2, 3.18.0rc1, 3.18.0rc1, 3.18.0rc1, 3.18.0rc2, 3.18.0rc2, 3.18.0rc2, 3.19.0rc1, 3.19.0rc1, 3.19.0rc1, 3.19.0rc2, 3.19.0rc2, 3.19.0rc2, 4.0.0rc1, 4.0.0rc1, 4.0.0rc2, 4.0.0rc2\r\nThere are incompatible versions in the resolved dependencies:\r\n protobuf<3.18.0,>=3.12.0 (from google-api-core[grpc]==1.31.3->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf<4,>=3.13.0 (from dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf>=3.12.0 (from google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf>=3.12.0 (from googleapis-common-protos==1.53.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n protobuf>=3.19.0 (from proto-plus==1.19.7->google-cloud-bigquery==2.29.0->dbt-bigquery==0.20.0->dbt==0.20->-r /var/folders/rq/bvjd2wms54j2m16rt180h5th0000gp/T/pipenvg3nqu30irequirements/pipenv-ng7tsiwu-constraints.txt (line 2))\r\n```\r\n\r\n\r\n### Environment\r\n\r\n```markdown\r\n- OS: macOS 11.6\r\n- Python: Python 3.7\r\n- dbt: 0.21 (same error with 0.20)\r\n```\r\n\r\n\r\n### What database are you using dbt with?\r\n\r\n_No response_\r\n\r\n### Additional Context\r\n\r\n_No response_\n", "before_files": [{"content": "#!/usr/bin/env python\nimport os\nimport sys\n\nif sys.version_info < (3, 6):\n print('Error: dbt does not support this version of Python.')\n print('Please upgrade to Python 3.6 or higher.')\n sys.exit(1)\n\n\nfrom setuptools import setup\ntry:\n from setuptools import find_namespace_packages\nexcept ImportError:\n # the user has a downlevel version of setuptools.\n print('Error: dbt requires setuptools v40.1.0 or higher.')\n print('Please upgrade setuptools with \"pip install --upgrade setuptools\" '\n 'and try again')\n sys.exit(1)\n\n\npackage_name = \"dbt-bigquery\"\npackage_version = \"0.21.0\"\ndescription = \"\"\"The bigquery adapter plugin for dbt (data build tool)\"\"\"\n\nthis_directory = os.path.abspath(os.path.dirname(__file__))\nwith open(os.path.join(this_directory, 'README.md')) as f:\n long_description = f.read()\n\nsetup(\n name=package_name,\n version=package_version,\n description=description,\n long_description=long_description,\n long_description_content_type='text/markdown',\n author=\"dbt Labs\",\n author_email=\"[email protected]\",\n url=\"https://github.com/dbt-labs/dbt\",\n packages=find_namespace_packages(include=['dbt', 'dbt.*']),\n package_data={\n 'dbt': [\n 'include/bigquery/dbt_project.yml',\n 'include/bigquery/sample_profiles.yml',\n 'include/bigquery/macros/*.sql',\n 'include/bigquery/macros/**/*.sql',\n ]\n },\n install_requires=[\n 'dbt-core=={}'.format(package_version),\n 'protobuf>=3.13.0,<4',\n 'google-cloud-core>=1.3.0,<2',\n 'google-cloud-bigquery>=1.25.0,<3',\n 'google-api-core>=1.16.0,<2',\n 'googleapis-common-protos>=1.6.0,<2',\n 'six>=1.14.0',\n ],\n zip_safe=False,\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n\n 'License :: OSI Approved :: Apache Software License',\n\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: MacOS :: MacOS X',\n 'Operating System :: POSIX :: Linux',\n\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n python_requires=\">=3.6.2\",\n)\n", "path": "plugins/bigquery/setup.py"}]}
| 3,986 | 154 |
gh_patches_debug_26755
|
rasdani/github-patches
|
git_diff
|
dask__dask-8213
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
⚠️ Upstream CI failed ⚠️
[Workflow Run URL](https://github.com/dask/dask/actions/runs/1304259797)
</issue>
<code>
[start of dask/dataframe/tseries/resample.py]
1 import numpy as np
2 import pandas as pd
3 from pandas.core.resample import Resampler as pd_Resampler
4
5 from ...base import tokenize
6 from ...highlevelgraph import HighLevelGraph
7 from ...utils import derived_from
8 from .. import methods
9 from ..core import DataFrame, Series
10
11
12 def getnanos(rule):
13 try:
14 return getattr(rule, "nanos", None)
15 except ValueError:
16 return None
17
18
19 def _resample_series(
20 series,
21 start,
22 end,
23 reindex_closed,
24 rule,
25 resample_kwargs,
26 how,
27 fill_value,
28 how_args,
29 how_kwargs,
30 ):
31 out = getattr(series.resample(rule, **resample_kwargs), how)(
32 *how_args, **how_kwargs
33 )
34
35 new_index = pd.date_range(
36 start.tz_localize(None),
37 end.tz_localize(None),
38 freq=rule,
39 closed=reindex_closed,
40 name=out.index.name,
41 ).tz_localize(start.tz, nonexistent="shift_forward")
42
43 if not out.index.isin(new_index).all():
44 raise ValueError(
45 "Index is not contained within new index. This can often be "
46 "resolved by using larger partitions, or unambiguous "
47 "frequencies: 'Q', 'A'..."
48 )
49
50 return out.reindex(new_index, fill_value=fill_value)
51
52
53 def _resample_bin_and_out_divs(divisions, rule, closed="left", label="left"):
54 rule = pd.tseries.frequencies.to_offset(rule)
55 g = pd.Grouper(freq=rule, how="count", closed=closed, label=label)
56
57 # Determine bins to apply `how` to. Disregard labeling scheme.
58 divs = pd.Series(range(len(divisions)), index=divisions)
59 temp = divs.resample(rule, closed=closed, label="left").count()
60 tempdivs = temp.loc[temp > 0].index
61
62 # Cleanup closed == 'right' and label == 'right'
63 res = pd.offsets.Nano() if hasattr(rule, "delta") else pd.offsets.Day()
64 if g.closed == "right":
65 newdivs = tempdivs + res
66 else:
67 newdivs = tempdivs
68 if g.label == "right":
69 outdivs = tempdivs + rule
70 else:
71 outdivs = tempdivs
72
73 newdivs = methods.tolist(newdivs)
74 outdivs = methods.tolist(outdivs)
75
76 # Adjust ends
77 if newdivs[0] < divisions[0]:
78 newdivs[0] = divisions[0]
79 if newdivs[-1] < divisions[-1]:
80 if len(newdivs) < len(divs):
81 setter = lambda a, val: a.append(val)
82 else:
83 setter = lambda a, val: a.__setitem__(-1, val)
84 setter(newdivs, divisions[-1] + res)
85 if outdivs[-1] > divisions[-1]:
86 setter(outdivs, outdivs[-1])
87 elif outdivs[-1] < divisions[-1]:
88 setter(outdivs, temp.index[-1])
89
90 return tuple(map(pd.Timestamp, newdivs)), tuple(map(pd.Timestamp, outdivs))
91
92
93 class Resampler:
94 """Class for resampling timeseries data.
95
96 This class is commonly encountered when using ``obj.resample(...)`` which
97 return ``Resampler`` objects.
98
99 Parameters
100 ----------
101 obj : Dask DataFrame or Series
102 Data to be resampled.
103 rule : str, tuple, datetime.timedelta, DateOffset or None
104 The offset string or object representing the target conversion.
105 kwargs : optional
106 Keyword arguments passed to underlying pandas resampling function.
107
108 Returns
109 -------
110 Resampler instance of the appropriate type
111 """
112
113 def __init__(self, obj, rule, **kwargs):
114 if not obj.known_divisions:
115 msg = (
116 "Can only resample dataframes with known divisions\n"
117 "See https://docs.dask.org/en/latest/dataframe-design.html#partitions\n"
118 "for more information."
119 )
120 raise ValueError(msg)
121 self.obj = obj
122 self._rule = pd.tseries.frequencies.to_offset(rule)
123 self._kwargs = kwargs
124
125 def _agg(self, how, meta=None, fill_value=np.nan, how_args=(), how_kwargs={}):
126 """Aggregate using one or more operations
127
128 Parameters
129 ----------
130 how : str
131 Name of aggregation operation
132 fill_value : scalar, optional
133 Value to use for missing values, applied during upsampling.
134 Default is NaN.
135 how_args : optional
136 Positional arguments for aggregation operation.
137 how_kwargs : optional
138 Keyword arguments for aggregation operation.
139
140 Returns
141 -------
142 Dask DataFrame or Series
143 """
144 rule = self._rule
145 kwargs = self._kwargs
146 name = "resample-" + tokenize(
147 self.obj, rule, kwargs, how, *how_args, **how_kwargs
148 )
149
150 # Create a grouper to determine closed and label conventions
151 newdivs, outdivs = _resample_bin_and_out_divs(
152 self.obj.divisions, rule, **kwargs
153 )
154
155 # Repartition divs into bins. These won't match labels after mapping
156 partitioned = self.obj.repartition(newdivs, force=True)
157
158 keys = partitioned.__dask_keys__()
159 dsk = {}
160
161 args = zip(keys, outdivs, outdivs[1:], ["left"] * (len(keys) - 1) + [None])
162 for i, (k, s, e, c) in enumerate(args):
163 dsk[(name, i)] = (
164 _resample_series,
165 k,
166 s,
167 e,
168 c,
169 rule,
170 kwargs,
171 how,
172 fill_value,
173 list(how_args),
174 how_kwargs,
175 )
176
177 # Infer output metadata
178 meta_r = self.obj._meta_nonempty.resample(self._rule, **self._kwargs)
179 meta = getattr(meta_r, how)(*how_args, **how_kwargs)
180
181 graph = HighLevelGraph.from_collections(name, dsk, dependencies=[partitioned])
182 if isinstance(meta, pd.DataFrame):
183 return DataFrame(graph, name, meta, outdivs)
184 return Series(graph, name, meta, outdivs)
185
186 @derived_from(pd_Resampler)
187 def agg(self, agg_funcs, *args, **kwargs):
188 return self._agg("agg", how_args=(agg_funcs,) + args, how_kwargs=kwargs)
189
190 @derived_from(pd_Resampler)
191 def count(self):
192 return self._agg("count", fill_value=0)
193
194 @derived_from(pd_Resampler)
195 def first(self):
196 return self._agg("first")
197
198 @derived_from(pd_Resampler)
199 def last(self):
200 return self._agg("last")
201
202 @derived_from(pd_Resampler)
203 def mean(self):
204 return self._agg("mean")
205
206 @derived_from(pd_Resampler)
207 def min(self):
208 return self._agg("min")
209
210 @derived_from(pd_Resampler)
211 def median(self):
212 return self._agg("median")
213
214 @derived_from(pd_Resampler)
215 def max(self):
216 return self._agg("max")
217
218 @derived_from(pd_Resampler)
219 def nunique(self):
220 return self._agg("nunique", fill_value=0)
221
222 @derived_from(pd_Resampler)
223 def ohlc(self):
224 return self._agg("ohlc")
225
226 @derived_from(pd_Resampler)
227 def prod(self):
228 return self._agg("prod")
229
230 @derived_from(pd_Resampler)
231 def sem(self):
232 return self._agg("sem")
233
234 @derived_from(pd_Resampler)
235 def std(self):
236 return self._agg("std")
237
238 @derived_from(pd_Resampler)
239 def size(self):
240 return self._agg("size", fill_value=0)
241
242 @derived_from(pd_Resampler)
243 def sum(self):
244 return self._agg("sum", fill_value=0)
245
246 @derived_from(pd_Resampler)
247 def var(self):
248 return self._agg("var")
249
250 @derived_from(pd_Resampler)
251 def quantile(self):
252 return self._agg("quantile")
253
[end of dask/dataframe/tseries/resample.py]
[start of dask/dataframe/_compat.py]
1 import string
2
3 import numpy as np
4 import pandas as pd
5 from packaging.version import parse as parse_version
6
7 PANDAS_VERSION = parse_version(pd.__version__)
8 PANDAS_GT_104 = PANDAS_VERSION >= parse_version("1.0.4")
9 PANDAS_GT_110 = PANDAS_VERSION >= parse_version("1.1.0")
10 PANDAS_GT_120 = PANDAS_VERSION >= parse_version("1.2.0")
11 PANDAS_GT_121 = PANDAS_VERSION >= parse_version("1.2.1")
12 PANDAS_GT_130 = PANDAS_VERSION >= parse_version("1.3.0")
13 PANDAS_GT_131 = PANDAS_VERSION >= parse_version("1.3.1")
14 PANDAS_GT_133 = PANDAS_VERSION >= parse_version("1.3.3")
15
16 import pandas.testing as tm
17
18
19 def assert_categorical_equal(left, right, *args, **kwargs):
20 tm.assert_extension_array_equal(left, right, *args, **kwargs)
21 assert pd.api.types.is_categorical_dtype(
22 left.dtype
23 ), "{} is not categorical dtype".format(left)
24 assert pd.api.types.is_categorical_dtype(
25 right.dtype
26 ), "{} is not categorical dtype".format(right)
27
28
29 def assert_numpy_array_equal(left, right):
30 left_na = pd.isna(left)
31 right_na = pd.isna(right)
32 np.testing.assert_array_equal(left_na, right_na)
33
34 left_valid = left[~left_na]
35 right_valid = right[~right_na]
36 np.testing.assert_array_equal(left_valid, right_valid)
37
38
39 def makeDataFrame():
40 data = np.random.randn(30, 4)
41 index = list(string.ascii_letters)[:30]
42 return pd.DataFrame(data, index=index, columns=list("ABCD"))
43
44
45 def makeTimeDataFrame():
46 data = makeDataFrame()
47 data.index = makeDateIndex()
48 return data
49
50
51 def makeTimeSeries():
52 return makeTimeDataFrame()["A"]
53
54
55 def makeDateIndex(k=30, freq="B"):
56 return pd.date_range("2000", periods=k, freq=freq)
57
58
59 def makeTimedeltaIndex(k=30, freq="D"):
60 return pd.timedelta_range("1 day", periods=k, freq=freq)
61
62
63 def makeMissingDataframe():
64 df = makeDataFrame()
65 data = df.values
66 data = np.where(data > 1, np.nan, data)
67 return pd.DataFrame(data, index=df.index, columns=df.columns)
68
69
70 def makeMixedDataFrame():
71 df = pd.DataFrame(
72 {
73 "A": [0.0, 1, 2, 3, 4],
74 "B": [0.0, 1, 0, 1, 0],
75 "C": ["foo{}".format(i) for i in range(5)],
76 "D": pd.date_range("2009-01-01", periods=5),
77 }
78 )
79 return df
80
[end of dask/dataframe/_compat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dask/dataframe/_compat.py b/dask/dataframe/_compat.py
--- a/dask/dataframe/_compat.py
+++ b/dask/dataframe/_compat.py
@@ -12,6 +12,7 @@
PANDAS_GT_130 = PANDAS_VERSION >= parse_version("1.3.0")
PANDAS_GT_131 = PANDAS_VERSION >= parse_version("1.3.1")
PANDAS_GT_133 = PANDAS_VERSION >= parse_version("1.3.3")
+PANDAS_GT_140 = PANDAS_VERSION.release == (1, 4, 0) # include pre-release
import pandas.testing as tm
diff --git a/dask/dataframe/tseries/resample.py b/dask/dataframe/tseries/resample.py
--- a/dask/dataframe/tseries/resample.py
+++ b/dask/dataframe/tseries/resample.py
@@ -6,6 +6,7 @@
from ...highlevelgraph import HighLevelGraph
from ...utils import derived_from
from .. import methods
+from .._compat import PANDAS_GT_140
from ..core import DataFrame, Series
@@ -32,11 +33,20 @@
*how_args, **how_kwargs
)
+ if PANDAS_GT_140:
+ if reindex_closed is None:
+ inclusive = "both"
+ else:
+ inclusive = reindex_closed
+ closed_kwargs = {"inclusive": inclusive}
+ else:
+ closed_kwargs = {"closed": reindex_closed}
+
new_index = pd.date_range(
start.tz_localize(None),
end.tz_localize(None),
freq=rule,
- closed=reindex_closed,
+ **closed_kwargs,
name=out.index.name,
).tz_localize(start.tz, nonexistent="shift_forward")
|
{"golden_diff": "diff --git a/dask/dataframe/_compat.py b/dask/dataframe/_compat.py\n--- a/dask/dataframe/_compat.py\n+++ b/dask/dataframe/_compat.py\n@@ -12,6 +12,7 @@\n PANDAS_GT_130 = PANDAS_VERSION >= parse_version(\"1.3.0\")\n PANDAS_GT_131 = PANDAS_VERSION >= parse_version(\"1.3.1\")\n PANDAS_GT_133 = PANDAS_VERSION >= parse_version(\"1.3.3\")\n+PANDAS_GT_140 = PANDAS_VERSION.release == (1, 4, 0) # include pre-release\n \n import pandas.testing as tm\n \ndiff --git a/dask/dataframe/tseries/resample.py b/dask/dataframe/tseries/resample.py\n--- a/dask/dataframe/tseries/resample.py\n+++ b/dask/dataframe/tseries/resample.py\n@@ -6,6 +6,7 @@\n from ...highlevelgraph import HighLevelGraph\n from ...utils import derived_from\n from .. import methods\n+from .._compat import PANDAS_GT_140\n from ..core import DataFrame, Series\n \n \n@@ -32,11 +33,20 @@\n *how_args, **how_kwargs\n )\n \n+ if PANDAS_GT_140:\n+ if reindex_closed is None:\n+ inclusive = \"both\"\n+ else:\n+ inclusive = reindex_closed\n+ closed_kwargs = {\"inclusive\": inclusive}\n+ else:\n+ closed_kwargs = {\"closed\": reindex_closed}\n+\n new_index = pd.date_range(\n start.tz_localize(None),\n end.tz_localize(None),\n freq=rule,\n- closed=reindex_closed,\n+ **closed_kwargs,\n name=out.index.name,\n ).tz_localize(start.tz, nonexistent=\"shift_forward\")\n", "issue": "\u26a0\ufe0f Upstream CI failed \u26a0\ufe0f\n[Workflow Run URL](https://github.com/dask/dask/actions/runs/1304259797)\n", "before_files": [{"content": "import numpy as np\nimport pandas as pd\nfrom pandas.core.resample import Resampler as pd_Resampler\n\nfrom ...base import tokenize\nfrom ...highlevelgraph import HighLevelGraph\nfrom ...utils import derived_from\nfrom .. import methods\nfrom ..core import DataFrame, Series\n\n\ndef getnanos(rule):\n try:\n return getattr(rule, \"nanos\", None)\n except ValueError:\n return None\n\n\ndef _resample_series(\n series,\n start,\n end,\n reindex_closed,\n rule,\n resample_kwargs,\n how,\n fill_value,\n how_args,\n how_kwargs,\n):\n out = getattr(series.resample(rule, **resample_kwargs), how)(\n *how_args, **how_kwargs\n )\n\n new_index = pd.date_range(\n start.tz_localize(None),\n end.tz_localize(None),\n freq=rule,\n closed=reindex_closed,\n name=out.index.name,\n ).tz_localize(start.tz, nonexistent=\"shift_forward\")\n\n if not out.index.isin(new_index).all():\n raise ValueError(\n \"Index is not contained within new index. This can often be \"\n \"resolved by using larger partitions, or unambiguous \"\n \"frequencies: 'Q', 'A'...\"\n )\n\n return out.reindex(new_index, fill_value=fill_value)\n\n\ndef _resample_bin_and_out_divs(divisions, rule, closed=\"left\", label=\"left\"):\n rule = pd.tseries.frequencies.to_offset(rule)\n g = pd.Grouper(freq=rule, how=\"count\", closed=closed, label=label)\n\n # Determine bins to apply `how` to. Disregard labeling scheme.\n divs = pd.Series(range(len(divisions)), index=divisions)\n temp = divs.resample(rule, closed=closed, label=\"left\").count()\n tempdivs = temp.loc[temp > 0].index\n\n # Cleanup closed == 'right' and label == 'right'\n res = pd.offsets.Nano() if hasattr(rule, \"delta\") else pd.offsets.Day()\n if g.closed == \"right\":\n newdivs = tempdivs + res\n else:\n newdivs = tempdivs\n if g.label == \"right\":\n outdivs = tempdivs + rule\n else:\n outdivs = tempdivs\n\n newdivs = methods.tolist(newdivs)\n outdivs = methods.tolist(outdivs)\n\n # Adjust ends\n if newdivs[0] < divisions[0]:\n newdivs[0] = divisions[0]\n if newdivs[-1] < divisions[-1]:\n if len(newdivs) < len(divs):\n setter = lambda a, val: a.append(val)\n else:\n setter = lambda a, val: a.__setitem__(-1, val)\n setter(newdivs, divisions[-1] + res)\n if outdivs[-1] > divisions[-1]:\n setter(outdivs, outdivs[-1])\n elif outdivs[-1] < divisions[-1]:\n setter(outdivs, temp.index[-1])\n\n return tuple(map(pd.Timestamp, newdivs)), tuple(map(pd.Timestamp, outdivs))\n\n\nclass Resampler:\n \"\"\"Class for resampling timeseries data.\n\n This class is commonly encountered when using ``obj.resample(...)`` which\n return ``Resampler`` objects.\n\n Parameters\n ----------\n obj : Dask DataFrame or Series\n Data to be resampled.\n rule : str, tuple, datetime.timedelta, DateOffset or None\n The offset string or object representing the target conversion.\n kwargs : optional\n Keyword arguments passed to underlying pandas resampling function.\n\n Returns\n -------\n Resampler instance of the appropriate type\n \"\"\"\n\n def __init__(self, obj, rule, **kwargs):\n if not obj.known_divisions:\n msg = (\n \"Can only resample dataframes with known divisions\\n\"\n \"See https://docs.dask.org/en/latest/dataframe-design.html#partitions\\n\"\n \"for more information.\"\n )\n raise ValueError(msg)\n self.obj = obj\n self._rule = pd.tseries.frequencies.to_offset(rule)\n self._kwargs = kwargs\n\n def _agg(self, how, meta=None, fill_value=np.nan, how_args=(), how_kwargs={}):\n \"\"\"Aggregate using one or more operations\n\n Parameters\n ----------\n how : str\n Name of aggregation operation\n fill_value : scalar, optional\n Value to use for missing values, applied during upsampling.\n Default is NaN.\n how_args : optional\n Positional arguments for aggregation operation.\n how_kwargs : optional\n Keyword arguments for aggregation operation.\n\n Returns\n -------\n Dask DataFrame or Series\n \"\"\"\n rule = self._rule\n kwargs = self._kwargs\n name = \"resample-\" + tokenize(\n self.obj, rule, kwargs, how, *how_args, **how_kwargs\n )\n\n # Create a grouper to determine closed and label conventions\n newdivs, outdivs = _resample_bin_and_out_divs(\n self.obj.divisions, rule, **kwargs\n )\n\n # Repartition divs into bins. These won't match labels after mapping\n partitioned = self.obj.repartition(newdivs, force=True)\n\n keys = partitioned.__dask_keys__()\n dsk = {}\n\n args = zip(keys, outdivs, outdivs[1:], [\"left\"] * (len(keys) - 1) + [None])\n for i, (k, s, e, c) in enumerate(args):\n dsk[(name, i)] = (\n _resample_series,\n k,\n s,\n e,\n c,\n rule,\n kwargs,\n how,\n fill_value,\n list(how_args),\n how_kwargs,\n )\n\n # Infer output metadata\n meta_r = self.obj._meta_nonempty.resample(self._rule, **self._kwargs)\n meta = getattr(meta_r, how)(*how_args, **how_kwargs)\n\n graph = HighLevelGraph.from_collections(name, dsk, dependencies=[partitioned])\n if isinstance(meta, pd.DataFrame):\n return DataFrame(graph, name, meta, outdivs)\n return Series(graph, name, meta, outdivs)\n\n @derived_from(pd_Resampler)\n def agg(self, agg_funcs, *args, **kwargs):\n return self._agg(\"agg\", how_args=(agg_funcs,) + args, how_kwargs=kwargs)\n\n @derived_from(pd_Resampler)\n def count(self):\n return self._agg(\"count\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def first(self):\n return self._agg(\"first\")\n\n @derived_from(pd_Resampler)\n def last(self):\n return self._agg(\"last\")\n\n @derived_from(pd_Resampler)\n def mean(self):\n return self._agg(\"mean\")\n\n @derived_from(pd_Resampler)\n def min(self):\n return self._agg(\"min\")\n\n @derived_from(pd_Resampler)\n def median(self):\n return self._agg(\"median\")\n\n @derived_from(pd_Resampler)\n def max(self):\n return self._agg(\"max\")\n\n @derived_from(pd_Resampler)\n def nunique(self):\n return self._agg(\"nunique\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def ohlc(self):\n return self._agg(\"ohlc\")\n\n @derived_from(pd_Resampler)\n def prod(self):\n return self._agg(\"prod\")\n\n @derived_from(pd_Resampler)\n def sem(self):\n return self._agg(\"sem\")\n\n @derived_from(pd_Resampler)\n def std(self):\n return self._agg(\"std\")\n\n @derived_from(pd_Resampler)\n def size(self):\n return self._agg(\"size\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def sum(self):\n return self._agg(\"sum\", fill_value=0)\n\n @derived_from(pd_Resampler)\n def var(self):\n return self._agg(\"var\")\n\n @derived_from(pd_Resampler)\n def quantile(self):\n return self._agg(\"quantile\")\n", "path": "dask/dataframe/tseries/resample.py"}, {"content": "import string\n\nimport numpy as np\nimport pandas as pd\nfrom packaging.version import parse as parse_version\n\nPANDAS_VERSION = parse_version(pd.__version__)\nPANDAS_GT_104 = PANDAS_VERSION >= parse_version(\"1.0.4\")\nPANDAS_GT_110 = PANDAS_VERSION >= parse_version(\"1.1.0\")\nPANDAS_GT_120 = PANDAS_VERSION >= parse_version(\"1.2.0\")\nPANDAS_GT_121 = PANDAS_VERSION >= parse_version(\"1.2.1\")\nPANDAS_GT_130 = PANDAS_VERSION >= parse_version(\"1.3.0\")\nPANDAS_GT_131 = PANDAS_VERSION >= parse_version(\"1.3.1\")\nPANDAS_GT_133 = PANDAS_VERSION >= parse_version(\"1.3.3\")\n\nimport pandas.testing as tm\n\n\ndef assert_categorical_equal(left, right, *args, **kwargs):\n tm.assert_extension_array_equal(left, right, *args, **kwargs)\n assert pd.api.types.is_categorical_dtype(\n left.dtype\n ), \"{} is not categorical dtype\".format(left)\n assert pd.api.types.is_categorical_dtype(\n right.dtype\n ), \"{} is not categorical dtype\".format(right)\n\n\ndef assert_numpy_array_equal(left, right):\n left_na = pd.isna(left)\n right_na = pd.isna(right)\n np.testing.assert_array_equal(left_na, right_na)\n\n left_valid = left[~left_na]\n right_valid = right[~right_na]\n np.testing.assert_array_equal(left_valid, right_valid)\n\n\ndef makeDataFrame():\n data = np.random.randn(30, 4)\n index = list(string.ascii_letters)[:30]\n return pd.DataFrame(data, index=index, columns=list(\"ABCD\"))\n\n\ndef makeTimeDataFrame():\n data = makeDataFrame()\n data.index = makeDateIndex()\n return data\n\n\ndef makeTimeSeries():\n return makeTimeDataFrame()[\"A\"]\n\n\ndef makeDateIndex(k=30, freq=\"B\"):\n return pd.date_range(\"2000\", periods=k, freq=freq)\n\n\ndef makeTimedeltaIndex(k=30, freq=\"D\"):\n return pd.timedelta_range(\"1 day\", periods=k, freq=freq)\n\n\ndef makeMissingDataframe():\n df = makeDataFrame()\n data = df.values\n data = np.where(data > 1, np.nan, data)\n return pd.DataFrame(data, index=df.index, columns=df.columns)\n\n\ndef makeMixedDataFrame():\n df = pd.DataFrame(\n {\n \"A\": [0.0, 1, 2, 3, 4],\n \"B\": [0.0, 1, 0, 1, 0],\n \"C\": [\"foo{}\".format(i) for i in range(5)],\n \"D\": pd.date_range(\"2009-01-01\", periods=5),\n }\n )\n return df\n", "path": "dask/dataframe/_compat.py"}]}
| 3,881 | 417 |
gh_patches_debug_26197
|
rasdani/github-patches
|
git_diff
|
automl__auto-sklearn-1508
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix timeouts related to metalearnings tests
</issue>
<code>
[start of scripts/03_calculate_metafeatures.py]
1 from argparse import ArgumentParser
2 from collections import defaultdict, OrderedDict
3 import copy
4 import logging
5 import os
6 import sys
7 import unittest.mock
8
9 import arff
10 import joblib
11 import numpy as np
12 import pandas as pd
13
14 from autosklearn.constants import (
15 BINARY_CLASSIFICATION,
16 MULTICLASS_CLASSIFICATION,
17 REGRESSION,
18 )
19 from autosklearn.metalearning.metafeatures import metafeatures
20 from autosklearn.smbo import (
21 _calculate_metafeatures,
22 _calculate_metafeatures_encoded,
23 EXCLUDE_META_FEATURES_REGRESSION,
24 EXCLUDE_META_FEATURES_CLASSIFICATION,
25 )
26 from autosklearn.util.stopwatch import StopWatch
27
28 sys.path.append(".")
29 from update_metadata_util import load_task, classification_tasks, regression_tasks
30
31 logger = logging.getLogger("03_calculate_metafeatures")
32
33
34 def calculate_metafeatures(task_id):
35 X_train, y_train, X_test, y_test, cat, task_type, dataset_name = load_task(task_id)
36 stopwatch = StopWatch()
37
38 if task_type == "classification":
39 if len(np.unique(y_train)) == 2:
40 task_type = BINARY_CLASSIFICATION
41 else:
42 task_type = MULTICLASS_CLASSIFICATION
43 else:
44 task_type = REGRESSION
45
46 _metafeatures_labels = _calculate_metafeatures(
47 x_train=X_train,
48 y_train=y_train,
49 data_feat_type=cat,
50 data_info_task=task_type,
51 basename=dataset_name,
52 logger_=logger,
53 stopwatch=stopwatch,
54 )
55
56 _metafeatures_encoded_labels = _calculate_metafeatures_encoded(
57 x_train=X_train,
58 y_train=y_train,
59 data_feat_type=cat,
60 task=task_type,
61 basename=dataset_name,
62 logger_=logger,
63 stopwatch=stopwatch,
64 )
65
66 mf = _metafeatures_labels
67 mf.metafeature_values.update(_metafeatures_encoded_labels.metafeature_values)
68
69 return mf
70
71
72 if __name__ == "__main__":
73 parser = ArgumentParser()
74 parser.add_argument("--working-directory", type=str, required=True)
75 parser.add_argument("--memory-limit", type=int, default=3072)
76 parser.add_argument("--test-mode", action="store_true")
77
78 args = parser.parse_args()
79 working_directory = args.working_directory
80 memory_limit = args.memory_limit
81 test_mode = args.test_mode
82
83 for task_type in ("classification", "regression"):
84 output_directory = os.path.join(working_directory, "metafeatures", task_type)
85 try:
86 os.makedirs(output_directory)
87 except:
88 pass
89
90 all_metafeatures = {}
91
92 if task_type == "classification":
93 tasks = classification_tasks
94 else:
95 tasks = regression_tasks
96
97 if test_mode:
98 tasks = [tasks[0]]
99
100 tasks = copy.deepcopy(tasks)
101 np.random.shuffle(tasks)
102
103 def producer():
104 for task_id in tasks:
105 yield task_id
106
107 memory = joblib.Memory(location="/tmp/joblib", verbose=10)
108 cached_calculate_metafeatures = memory.cache(calculate_metafeatures)
109 mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]
110
111 for mf in mfs:
112 if mf is not None:
113 all_metafeatures[mf.dataset_name] = mf
114
115 # Write the calculation times as a csv file to disc (can be viewed in
116 # LibreOffice calc afterwards)
117 calculation_times = defaultdict(dict)
118 metafeature_values = defaultdict(dict)
119 helperfunction_values = defaultdict(dict)
120
121 for i, task_id in enumerate(all_metafeatures):
122 calculation_times[task_id] = dict()
123 for metafeature_name in sorted(
124 all_metafeatures[task_id].metafeature_values
125 ):
126 metafeature_value = all_metafeatures[task_id].metafeature_values[
127 metafeature_name
128 ]
129 calculation_times[task_id][metafeature_name] = metafeature_value.time
130 if metafeature_value.type_ == "HELPERFUNCTION":
131 helperfunction_values[task_id][
132 metafeature_name
133 ] = metafeature_value.value
134 else:
135 metafeature_values[task_id][
136 metafeature_name
137 ] = metafeature_value.value
138
139 calculation_times = pd.DataFrame(calculation_times).transpose()
140 calculation_times = calculation_times.sort_index()
141 with open(os.path.join(output_directory, "calculation_times.csv"), "w") as fh:
142 fh.write(calculation_times.to_csv())
143
144 # Write all metafeatures in the aslib1.0 format
145 metafeature_values = metafeature_values = pd.DataFrame(
146 metafeature_values
147 ).transpose()
148 metafeature_values = metafeature_values.sort_index()
149 arff_object = dict()
150 arff_object["attributes"] = [
151 ("instance_id", "STRING"),
152 ("repetition", "NUMERIC"),
153 ] + [("%s" % name, "NUMERIC") for name in metafeature_values.columns]
154 arff_object["relation"] = "FEATURE_VALUES"
155 arff_object["description"] = ""
156
157 data = []
158 for idx in metafeature_values.index:
159 line = [idx, 1]
160 line += [
161 value if np.isfinite(value) else None
162 for value in metafeature_values.loc[idx, :].values
163 ]
164 data.append(line)
165 arff_object["data"] = data
166
167 with open(os.path.join(output_directory, "feature_values.arff"), "w") as fh:
168 arff.dump(arff_object, fh)
169
170 # Feature steps and runtimes according to the aslib1.0 format
171 feature_steps = defaultdict(list)
172 metafeature_names = list()
173
174 exclude_metafeatures = (
175 EXCLUDE_META_FEATURES_CLASSIFICATION
176 if task_type == "classification"
177 else EXCLUDE_META_FEATURES_REGRESSION
178 )
179
180 for metafeature_name in metafeatures.metafeatures.functions:
181
182 if metafeature_name in exclude_metafeatures:
183 continue
184
185 dependency = metafeatures.metafeatures.get_dependency(metafeature_name)
186 if dependency is not None:
187 feature_steps[dependency].append(metafeature_name)
188 feature_steps[metafeature_name].append(metafeature_name)
189
190 metafeature_names.append(metafeature_name)
191
192 # Write the feature runstatus in the aslib1.0 format
193 arff_object = dict()
194 arff_object["attributes"] = [
195 ("instance_id", "STRING"),
196 ("repetition", "NUMERIC"),
197 ] + [
198 ("%s" % name, ["ok", "timeout", "memout", "presolved", "crash", "other"])
199 for name in feature_steps
200 ]
201 arff_object["relation"] = "FEATURE_RUNSTATUS"
202 arff_object["description"] = ""
203
204 data = []
205 for idx in metafeature_values.index:
206 line = [idx, 1]
207 for feature_step in feature_steps:
208 if feature_step in helperfunction_values[idx]:
209 line.append(
210 "ok"
211 if helperfunction_values[feature_step] is not None
212 else "other"
213 )
214 elif feature_step in metafeature_values.loc[idx]:
215 line.append(
216 "ok"
217 if np.isfinite(metafeature_values.loc[idx][feature_step])
218 else "other"
219 )
220 else:
221 line.append("other")
222
223 data.append(line)
224 arff_object["data"] = data
225
226 with open(os.path.join(output_directory, "feature_runstatus.arff"), "w") as fh:
227 arff.dump(arff_object, fh)
228
229 arff_object = dict()
230 arff_object["attributes"] = [
231 ("instance_id", "STRING"),
232 ("repetition", "NUMERIC"),
233 ] + [("%s" % feature_step, "NUMERIC") for feature_step in feature_steps]
234 arff_object["relation"] = "FEATURE_COSTS"
235 arff_object["description"] = ""
236
237 data = []
238 for instance_id in calculation_times.index:
239 calculation_times_per_group = dict()
240 line = [instance_id, 1]
241 for feature_step in feature_steps:
242 time_ = 0.0
243 for feature in feature_steps[feature_step]:
244 time_ += calculation_times[feature][instance_id]
245 if not np.isfinite(time_):
246 raise ValueError(
247 "Feature cost %s for instance %s and feature "
248 "step %s not finite" % (time_, instance_id, feature)
249 )
250 line.append(time_)
251 data.append(line)
252 arff_object["data"] = data
253
254 with open(os.path.join(output_directory, "feature_costs.arff"), "w") as fh:
255 arff.dump(arff_object, fh)
256
257 # Write the features part of the description.txt to a file
258 description = OrderedDict()
259 description["features_cutoff_time"] = "3600"
260 description["features_cutoff_memory"] = args.memory_limit
261 description["number_of_feature_steps"] = str(len(feature_steps))
262
263 for feature_step in feature_steps:
264 description["feature_step %s" % feature_step] = ", ".join(
265 feature_steps[feature_step]
266 )
267 description["features_deterministic"] = ", ".join(
268 [metafeature_name for metafeature_name in metafeature_names]
269 )
270 description["features_stochastic"] = ""
271 description["default_steps"] = ", ".join(feature_steps)
272
273 with open(
274 os.path.join(output_directory, "description.features.txt"), "w"
275 ) as fh:
276 for entry in description:
277 fh.write("%s: %s\n" % (entry, description[entry]))
278
[end of scripts/03_calculate_metafeatures.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/03_calculate_metafeatures.py b/scripts/03_calculate_metafeatures.py
--- a/scripts/03_calculate_metafeatures.py
+++ b/scripts/03_calculate_metafeatures.py
@@ -5,6 +5,7 @@
import os
import sys
import unittest.mock
+import tempfile
import arff
import joblib
@@ -82,10 +83,7 @@
for task_type in ("classification", "regression"):
output_directory = os.path.join(working_directory, "metafeatures", task_type)
- try:
- os.makedirs(output_directory)
- except:
- pass
+ os.makedirs(output_directory, exist_ok=True)
all_metafeatures = {}
@@ -100,13 +98,10 @@
tasks = copy.deepcopy(tasks)
np.random.shuffle(tasks)
- def producer():
- for task_id in tasks:
- yield task_id
-
- memory = joblib.Memory(location="/tmp/joblib", verbose=10)
+ tmpdir = os.path.join(tempfile.gettempdir(), "joblib")
+ memory = joblib.Memory(location=tmpdir, verbose=10)
cached_calculate_metafeatures = memory.cache(calculate_metafeatures)
- mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]
+ mfs = [cached_calculate_metafeatures(task_id) for task_id in tasks]
for mf in mfs:
if mf is not None:
|
{"golden_diff": "diff --git a/scripts/03_calculate_metafeatures.py b/scripts/03_calculate_metafeatures.py\n--- a/scripts/03_calculate_metafeatures.py\n+++ b/scripts/03_calculate_metafeatures.py\n@@ -5,6 +5,7 @@\n import os\n import sys\n import unittest.mock\n+import tempfile\n \n import arff\n import joblib\n@@ -82,10 +83,7 @@\n \n for task_type in (\"classification\", \"regression\"):\n output_directory = os.path.join(working_directory, \"metafeatures\", task_type)\n- try:\n- os.makedirs(output_directory)\n- except:\n- pass\n+ os.makedirs(output_directory, exist_ok=True)\n \n all_metafeatures = {}\n \n@@ -100,13 +98,10 @@\n tasks = copy.deepcopy(tasks)\n np.random.shuffle(tasks)\n \n- def producer():\n- for task_id in tasks:\n- yield task_id\n-\n- memory = joblib.Memory(location=\"/tmp/joblib\", verbose=10)\n+ tmpdir = os.path.join(tempfile.gettempdir(), \"joblib\")\n+ memory = joblib.Memory(location=tmpdir, verbose=10)\n cached_calculate_metafeatures = memory.cache(calculate_metafeatures)\n- mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]\n+ mfs = [cached_calculate_metafeatures(task_id) for task_id in tasks]\n \n for mf in mfs:\n if mf is not None:\n", "issue": "Fix timeouts related to metalearnings tests\n\n", "before_files": [{"content": "from argparse import ArgumentParser\nfrom collections import defaultdict, OrderedDict\nimport copy\nimport logging\nimport os\nimport sys\nimport unittest.mock\n\nimport arff\nimport joblib\nimport numpy as np\nimport pandas as pd\n\nfrom autosklearn.constants import (\n BINARY_CLASSIFICATION,\n MULTICLASS_CLASSIFICATION,\n REGRESSION,\n)\nfrom autosklearn.metalearning.metafeatures import metafeatures\nfrom autosklearn.smbo import (\n _calculate_metafeatures,\n _calculate_metafeatures_encoded,\n EXCLUDE_META_FEATURES_REGRESSION,\n EXCLUDE_META_FEATURES_CLASSIFICATION,\n)\nfrom autosklearn.util.stopwatch import StopWatch\n\nsys.path.append(\".\")\nfrom update_metadata_util import load_task, classification_tasks, regression_tasks\n\nlogger = logging.getLogger(\"03_calculate_metafeatures\")\n\n\ndef calculate_metafeatures(task_id):\n X_train, y_train, X_test, y_test, cat, task_type, dataset_name = load_task(task_id)\n stopwatch = StopWatch()\n\n if task_type == \"classification\":\n if len(np.unique(y_train)) == 2:\n task_type = BINARY_CLASSIFICATION\n else:\n task_type = MULTICLASS_CLASSIFICATION\n else:\n task_type = REGRESSION\n\n _metafeatures_labels = _calculate_metafeatures(\n x_train=X_train,\n y_train=y_train,\n data_feat_type=cat,\n data_info_task=task_type,\n basename=dataset_name,\n logger_=logger,\n stopwatch=stopwatch,\n )\n\n _metafeatures_encoded_labels = _calculate_metafeatures_encoded(\n x_train=X_train,\n y_train=y_train,\n data_feat_type=cat,\n task=task_type,\n basename=dataset_name,\n logger_=logger,\n stopwatch=stopwatch,\n )\n\n mf = _metafeatures_labels\n mf.metafeature_values.update(_metafeatures_encoded_labels.metafeature_values)\n\n return mf\n\n\nif __name__ == \"__main__\":\n parser = ArgumentParser()\n parser.add_argument(\"--working-directory\", type=str, required=True)\n parser.add_argument(\"--memory-limit\", type=int, default=3072)\n parser.add_argument(\"--test-mode\", action=\"store_true\")\n\n args = parser.parse_args()\n working_directory = args.working_directory\n memory_limit = args.memory_limit\n test_mode = args.test_mode\n\n for task_type in (\"classification\", \"regression\"):\n output_directory = os.path.join(working_directory, \"metafeatures\", task_type)\n try:\n os.makedirs(output_directory)\n except:\n pass\n\n all_metafeatures = {}\n\n if task_type == \"classification\":\n tasks = classification_tasks\n else:\n tasks = regression_tasks\n\n if test_mode:\n tasks = [tasks[0]]\n\n tasks = copy.deepcopy(tasks)\n np.random.shuffle(tasks)\n\n def producer():\n for task_id in tasks:\n yield task_id\n\n memory = joblib.Memory(location=\"/tmp/joblib\", verbose=10)\n cached_calculate_metafeatures = memory.cache(calculate_metafeatures)\n mfs = [cached_calculate_metafeatures(task_id) for task_id in producer()]\n\n for mf in mfs:\n if mf is not None:\n all_metafeatures[mf.dataset_name] = mf\n\n # Write the calculation times as a csv file to disc (can be viewed in\n # LibreOffice calc afterwards)\n calculation_times = defaultdict(dict)\n metafeature_values = defaultdict(dict)\n helperfunction_values = defaultdict(dict)\n\n for i, task_id in enumerate(all_metafeatures):\n calculation_times[task_id] = dict()\n for metafeature_name in sorted(\n all_metafeatures[task_id].metafeature_values\n ):\n metafeature_value = all_metafeatures[task_id].metafeature_values[\n metafeature_name\n ]\n calculation_times[task_id][metafeature_name] = metafeature_value.time\n if metafeature_value.type_ == \"HELPERFUNCTION\":\n helperfunction_values[task_id][\n metafeature_name\n ] = metafeature_value.value\n else:\n metafeature_values[task_id][\n metafeature_name\n ] = metafeature_value.value\n\n calculation_times = pd.DataFrame(calculation_times).transpose()\n calculation_times = calculation_times.sort_index()\n with open(os.path.join(output_directory, \"calculation_times.csv\"), \"w\") as fh:\n fh.write(calculation_times.to_csv())\n\n # Write all metafeatures in the aslib1.0 format\n metafeature_values = metafeature_values = pd.DataFrame(\n metafeature_values\n ).transpose()\n metafeature_values = metafeature_values.sort_index()\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [(\"%s\" % name, \"NUMERIC\") for name in metafeature_values.columns]\n arff_object[\"relation\"] = \"FEATURE_VALUES\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for idx in metafeature_values.index:\n line = [idx, 1]\n line += [\n value if np.isfinite(value) else None\n for value in metafeature_values.loc[idx, :].values\n ]\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_values.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n # Feature steps and runtimes according to the aslib1.0 format\n feature_steps = defaultdict(list)\n metafeature_names = list()\n\n exclude_metafeatures = (\n EXCLUDE_META_FEATURES_CLASSIFICATION\n if task_type == \"classification\"\n else EXCLUDE_META_FEATURES_REGRESSION\n )\n\n for metafeature_name in metafeatures.metafeatures.functions:\n\n if metafeature_name in exclude_metafeatures:\n continue\n\n dependency = metafeatures.metafeatures.get_dependency(metafeature_name)\n if dependency is not None:\n feature_steps[dependency].append(metafeature_name)\n feature_steps[metafeature_name].append(metafeature_name)\n\n metafeature_names.append(metafeature_name)\n\n # Write the feature runstatus in the aslib1.0 format\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [\n (\"%s\" % name, [\"ok\", \"timeout\", \"memout\", \"presolved\", \"crash\", \"other\"])\n for name in feature_steps\n ]\n arff_object[\"relation\"] = \"FEATURE_RUNSTATUS\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for idx in metafeature_values.index:\n line = [idx, 1]\n for feature_step in feature_steps:\n if feature_step in helperfunction_values[idx]:\n line.append(\n \"ok\"\n if helperfunction_values[feature_step] is not None\n else \"other\"\n )\n elif feature_step in metafeature_values.loc[idx]:\n line.append(\n \"ok\"\n if np.isfinite(metafeature_values.loc[idx][feature_step])\n else \"other\"\n )\n else:\n line.append(\"other\")\n\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_runstatus.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n arff_object = dict()\n arff_object[\"attributes\"] = [\n (\"instance_id\", \"STRING\"),\n (\"repetition\", \"NUMERIC\"),\n ] + [(\"%s\" % feature_step, \"NUMERIC\") for feature_step in feature_steps]\n arff_object[\"relation\"] = \"FEATURE_COSTS\"\n arff_object[\"description\"] = \"\"\n\n data = []\n for instance_id in calculation_times.index:\n calculation_times_per_group = dict()\n line = [instance_id, 1]\n for feature_step in feature_steps:\n time_ = 0.0\n for feature in feature_steps[feature_step]:\n time_ += calculation_times[feature][instance_id]\n if not np.isfinite(time_):\n raise ValueError(\n \"Feature cost %s for instance %s and feature \"\n \"step %s not finite\" % (time_, instance_id, feature)\n )\n line.append(time_)\n data.append(line)\n arff_object[\"data\"] = data\n\n with open(os.path.join(output_directory, \"feature_costs.arff\"), \"w\") as fh:\n arff.dump(arff_object, fh)\n\n # Write the features part of the description.txt to a file\n description = OrderedDict()\n description[\"features_cutoff_time\"] = \"3600\"\n description[\"features_cutoff_memory\"] = args.memory_limit\n description[\"number_of_feature_steps\"] = str(len(feature_steps))\n\n for feature_step in feature_steps:\n description[\"feature_step %s\" % feature_step] = \", \".join(\n feature_steps[feature_step]\n )\n description[\"features_deterministic\"] = \", \".join(\n [metafeature_name for metafeature_name in metafeature_names]\n )\n description[\"features_stochastic\"] = \"\"\n description[\"default_steps\"] = \", \".join(feature_steps)\n\n with open(\n os.path.join(output_directory, \"description.features.txt\"), \"w\"\n ) as fh:\n for entry in description:\n fh.write(\"%s: %s\\n\" % (entry, description[entry]))\n", "path": "scripts/03_calculate_metafeatures.py"}]}
| 3,325 | 332 |
gh_patches_debug_2182
|
rasdani/github-patches
|
git_diff
|
modin-project__modin-4769
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
test_join_sort.py in CI failed by timeout with new Dask release - 2022.2.0
Error: https://github.com/modin-project/modin/runs/5195622251?check_suite_focus=true
Dask release - https://github.com/dask/dask/releases/tag/2022.02.0
Fastest option here - pin `dask<2022.2.0`, but it also requires an investigation into the cause.
</issue>
<code>
[start of setup.py]
1 from setuptools import setup, find_packages
2 import versioneer
3 import sys
4
5 PANDAS_VERSION = "1.4.3" if sys.version_info >= (3, 8) else "1.1.5"
6
7 with open("README.md", "r", encoding="utf-8") as fh:
8 long_description = fh.read()
9
10 dask_deps = ["dask>=2.22.0,<2022.2.0", "distributed>=2.22.0,<2022.2.0"]
11 if sys.version_info < (3, 8):
12 dask_deps.append("pickle5")
13
14 ray_deps = [
15 "ray[default]>=1.4.0",
16 "pyarrow>=4.0.1",
17 "redis>=3.5.0,<4.0.0",
18 ]
19 remote_deps = ["rpyc==4.1.5", "cloudpickle", "boto3"]
20 spreadsheet_deps = ["modin-spreadsheet>=0.1.0"]
21 sql_deps = ["dfsql>=0.4.2", "pyparsing<=2.4.7"]
22 all_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps
23
24 # Distribute 'modin-autoimport-pandas.pth' along with binary and source distributions.
25 # This file provides the "import pandas before Ray init" feature if specific
26 # environment variable is set (see https://github.com/modin-project/modin/issues/4564).
27 cmdclass = versioneer.get_cmdclass()
28 extra_files = ["modin-autoimport-pandas.pth"]
29
30
31 class AddPthFileBuild(cmdclass["build_py"]):
32 def _get_data_files(self):
33 return (super()._get_data_files() or []) + [
34 (".", ".", self.build_lib, extra_files)
35 ]
36
37
38 class AddPthFileSDist(cmdclass["sdist"]):
39 def make_distribution(self):
40 self.filelist.extend(extra_files)
41 return super().make_distribution()
42
43
44 cmdclass["build_py"] = AddPthFileBuild
45 cmdclass["sdist"] = AddPthFileSDist
46
47 setup(
48 name="modin",
49 version=versioneer.get_version(),
50 cmdclass=cmdclass,
51 description="Modin: Make your pandas code run faster by changing one line of code.",
52 packages=find_packages(exclude=["scripts", "scripts.*"]),
53 include_package_data=True,
54 license="Apache 2",
55 url="https://github.com/modin-project/modin",
56 long_description=long_description,
57 long_description_content_type="text/markdown",
58 install_requires=[f"pandas=={PANDAS_VERSION}", "packaging", "numpy>=1.18.5", "fsspec", "psutil"],
59 extras_require={
60 # can be installed by pip install modin[dask]
61 "dask": dask_deps,
62 "ray": ray_deps,
63 "remote": remote_deps,
64 "spreadsheet": spreadsheet_deps,
65 "sql": sql_deps,
66 "all": all_deps,
67 },
68 python_requires=">=3.6",
69 )
70
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -7,7 +7,7 @@
with open("README.md", "r", encoding="utf-8") as fh:
long_description = fh.read()
-dask_deps = ["dask>=2.22.0,<2022.2.0", "distributed>=2.22.0,<2022.2.0"]
+dask_deps = ["dask>=2.22.0", "distributed>=2.22.0"]
if sys.version_info < (3, 8):
dask_deps.append("pickle5")
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -7,7 +7,7 @@\n with open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n \n-dask_deps = [\"dask>=2.22.0,<2022.2.0\", \"distributed>=2.22.0,<2022.2.0\"]\n+dask_deps = [\"dask>=2.22.0\", \"distributed>=2.22.0\"]\n if sys.version_info < (3, 8):\n dask_deps.append(\"pickle5\")\n", "issue": "test_join_sort.py in CI failed by timeout with new Dask release - 2022.2.0\nError: https://github.com/modin-project/modin/runs/5195622251?check_suite_focus=true\r\n\r\nDask release - https://github.com/dask/dask/releases/tag/2022.02.0\r\n\r\nFastest option here - pin `dask<2022.2.0`, but it also requires an investigation into the cause.\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\nimport sys\n\nPANDAS_VERSION = \"1.4.3\" if sys.version_info >= (3, 8) else \"1.1.5\"\n\nwith open(\"README.md\", \"r\", encoding=\"utf-8\") as fh:\n long_description = fh.read()\n\ndask_deps = [\"dask>=2.22.0,<2022.2.0\", \"distributed>=2.22.0,<2022.2.0\"]\nif sys.version_info < (3, 8):\n dask_deps.append(\"pickle5\")\n\nray_deps = [\n \"ray[default]>=1.4.0\",\n \"pyarrow>=4.0.1\",\n \"redis>=3.5.0,<4.0.0\",\n]\nremote_deps = [\"rpyc==4.1.5\", \"cloudpickle\", \"boto3\"]\nspreadsheet_deps = [\"modin-spreadsheet>=0.1.0\"]\nsql_deps = [\"dfsql>=0.4.2\", \"pyparsing<=2.4.7\"]\nall_deps = dask_deps + ray_deps + remote_deps + spreadsheet_deps\n\n# Distribute 'modin-autoimport-pandas.pth' along with binary and source distributions.\n# This file provides the \"import pandas before Ray init\" feature if specific\n# environment variable is set (see https://github.com/modin-project/modin/issues/4564).\ncmdclass = versioneer.get_cmdclass()\nextra_files = [\"modin-autoimport-pandas.pth\"]\n\n\nclass AddPthFileBuild(cmdclass[\"build_py\"]):\n def _get_data_files(self):\n return (super()._get_data_files() or []) + [\n (\".\", \".\", self.build_lib, extra_files)\n ]\n\n\nclass AddPthFileSDist(cmdclass[\"sdist\"]):\n def make_distribution(self):\n self.filelist.extend(extra_files)\n return super().make_distribution()\n\n\ncmdclass[\"build_py\"] = AddPthFileBuild\ncmdclass[\"sdist\"] = AddPthFileSDist\n\nsetup(\n name=\"modin\",\n version=versioneer.get_version(),\n cmdclass=cmdclass,\n description=\"Modin: Make your pandas code run faster by changing one line of code.\",\n packages=find_packages(exclude=[\"scripts\", \"scripts.*\"]),\n include_package_data=True,\n license=\"Apache 2\",\n url=\"https://github.com/modin-project/modin\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n install_requires=[f\"pandas=={PANDAS_VERSION}\", \"packaging\", \"numpy>=1.18.5\", \"fsspec\", \"psutil\"],\n extras_require={\n # can be installed by pip install modin[dask]\n \"dask\": dask_deps,\n \"ray\": ray_deps,\n \"remote\": remote_deps,\n \"spreadsheet\": spreadsheet_deps,\n \"sql\": sql_deps,\n \"all\": all_deps,\n },\n python_requires=\">=3.6\",\n)\n", "path": "setup.py"}]}
| 1,437 | 144 |
gh_patches_debug_33208
|
rasdani/github-patches
|
git_diff
|
Azure__azure-cli-extensions-3135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Transition to GA: costmanagement
Command module `costmanagement` has been released for a long time and is using stable sdk version `2019-11-01`.
Please check [Extension GA guidelines](https://github.com/Azure/azure-cli/blob/dev/doc/onboarding_guide.md#preview-extension-to-ga-extension) and remove `experimental` tag if necessary.
</issue>
<code>
[start of src/costmanagement/setup.py]
1 #!/usr/bin/env python
2
3 # --------------------------------------------------------------------------------------------
4 # Copyright (c) Microsoft Corporation. All rights reserved.
5 # Licensed under the MIT License. See License.txt in the project root for license information.
6 # --------------------------------------------------------------------------------------------
7
8
9 from codecs import open
10 from setuptools import setup, find_packages
11
12 # TODO: Confirm this is the right version number you want and it matches your
13 # HISTORY.rst entry.
14 VERSION = '0.1.0'
15
16 # The full list of classifiers is available at
17 # https://pypi.python.org/pypi?%3Aaction=list_classifiers
18 CLASSIFIERS = [
19 'Development Status :: 4 - Beta',
20 'Intended Audience :: Developers',
21 'Intended Audience :: System Administrators',
22 'Programming Language :: Python',
23 'Programming Language :: Python :: 3',
24 'Programming Language :: Python :: 3.6',
25 'Programming Language :: Python :: 3.7',
26 'Programming Language :: Python :: 3.8',
27 'License :: OSI Approved :: MIT License',
28 ]
29
30 # TODO: Add any additional SDK dependencies here
31 DEPENDENCIES = []
32
33 with open('README.md', 'r', encoding='utf-8') as f:
34 README = f.read()
35 with open('HISTORY.rst', 'r', encoding='utf-8') as f:
36 HISTORY = f.read()
37
38 setup(
39 name='costmanagement',
40 version=VERSION,
41 description='Microsoft Azure Command-Line Tools CostManagementClient Extension',
42 # TODO: Update author and email, if applicable
43 author='Microsoft Corporation',
44 author_email='[email protected]',
45 url='https://github.com/Azure/azure-cli-extensions/tree/master/src/costmanagement',
46 long_description=README + '\n\n' + HISTORY,
47 license='MIT',
48 classifiers=CLASSIFIERS,
49 packages=find_packages(),
50 install_requires=DEPENDENCIES,
51 package_data={'azext_costmanagement': ['azext_metadata.json']},
52 )
53
[end of src/costmanagement/setup.py]
[start of src/costmanagement/azext_costmanagement/manual/commands.py]
1 # --------------------------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License. See License.txt in the project root for license information.
4 # --------------------------------------------------------------------------------------------
5
6 from azure.cli.core.commands import CliCommandType
7
8
9 def load_command_table(self, _):
10
11 from azext_costmanagement.generated._client_factory import cf_query
12 costmanagement_query = CliCommandType(
13 operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'
14 '_query_operations#QueryOperations.{}',
15 client_factory=cf_query)
16 with self.command_group('costmanagement', costmanagement_query,
17 client_factory=cf_query, is_experimental=True) as g:
18 g.custom_command('query', 'costmanagement_query')
19
20 from azext_costmanagement.generated._client_factory import cf_export
21 costmanagement_export = CliCommandType(
22 operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'
23 'ns.{}',
24 client_factory=cf_export)
25 with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,
26 is_experimental=True) as g:
27 g.custom_command('list', 'costmanagement_export_list')
28 g.custom_show_command('show', 'costmanagement_export_show')
29 g.custom_command('create', 'costmanagement_export_create')
30 g.custom_command('update', 'costmanagement_export_update')
31 g.custom_command('delete', 'costmanagement_export_delete', confirmation=True)
32
[end of src/costmanagement/azext_costmanagement/manual/commands.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/costmanagement/azext_costmanagement/manual/commands.py b/src/costmanagement/azext_costmanagement/manual/commands.py
--- a/src/costmanagement/azext_costmanagement/manual/commands.py
+++ b/src/costmanagement/azext_costmanagement/manual/commands.py
@@ -13,8 +13,7 @@
operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'
'_query_operations#QueryOperations.{}',
client_factory=cf_query)
- with self.command_group('costmanagement', costmanagement_query,
- client_factory=cf_query, is_experimental=True) as g:
+ with self.command_group('costmanagement', costmanagement_query, client_factory=cf_query) as g:
g.custom_command('query', 'costmanagement_query')
from azext_costmanagement.generated._client_factory import cf_export
@@ -22,8 +21,7 @@
operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'
'ns.{}',
client_factory=cf_export)
- with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,
- is_experimental=True) as g:
+ with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export) as g:
g.custom_command('list', 'costmanagement_export_list')
g.custom_show_command('show', 'costmanagement_export_show')
g.custom_command('create', 'costmanagement_export_create')
diff --git a/src/costmanagement/setup.py b/src/costmanagement/setup.py
--- a/src/costmanagement/setup.py
+++ b/src/costmanagement/setup.py
@@ -11,7 +11,7 @@
# TODO: Confirm this is the right version number you want and it matches your
# HISTORY.rst entry.
-VERSION = '0.1.0'
+VERSION = '0.1.1'
# The full list of classifiers is available at
# https://pypi.python.org/pypi?%3Aaction=list_classifiers
|
{"golden_diff": "diff --git a/src/costmanagement/azext_costmanagement/manual/commands.py b/src/costmanagement/azext_costmanagement/manual/commands.py\n--- a/src/costmanagement/azext_costmanagement/manual/commands.py\n+++ b/src/costmanagement/azext_costmanagement/manual/commands.py\n@@ -13,8 +13,7 @@\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'\n '_query_operations#QueryOperations.{}',\n client_factory=cf_query)\n- with self.command_group('costmanagement', costmanagement_query,\n- client_factory=cf_query, is_experimental=True) as g:\n+ with self.command_group('costmanagement', costmanagement_query, client_factory=cf_query) as g:\n g.custom_command('query', 'costmanagement_query')\n \n from azext_costmanagement.generated._client_factory import cf_export\n@@ -22,8 +21,7 @@\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'\n 'ns.{}',\n client_factory=cf_export)\n- with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,\n- is_experimental=True) as g:\n+ with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export) as g:\n g.custom_command('list', 'costmanagement_export_list')\n g.custom_show_command('show', 'costmanagement_export_show')\n g.custom_command('create', 'costmanagement_export_create')\ndiff --git a/src/costmanagement/setup.py b/src/costmanagement/setup.py\n--- a/src/costmanagement/setup.py\n+++ b/src/costmanagement/setup.py\n@@ -11,7 +11,7 @@\n \r\n # TODO: Confirm this is the right version number you want and it matches your\r\n # HISTORY.rst entry.\r\n-VERSION = '0.1.0'\r\n+VERSION = '0.1.1'\r\n \r\n # The full list of classifiers is available at\r\n # https://pypi.python.org/pypi?%3Aaction=list_classifiers\n", "issue": "Transition to GA: costmanagement\nCommand module `costmanagement` has been released for a long time and is using stable sdk version `2019-11-01`.\r\n\r\nPlease check [Extension GA guidelines](https://github.com/Azure/azure-cli/blob/dev/doc/onboarding_guide.md#preview-extension-to-ga-extension) and remove `experimental` tag if necessary.\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\r\n\r\n# --------------------------------------------------------------------------------------------\r\n# Copyright (c) Microsoft Corporation. All rights reserved.\r\n# Licensed under the MIT License. See License.txt in the project root for license information.\r\n# --------------------------------------------------------------------------------------------\r\n\r\n\r\nfrom codecs import open\r\nfrom setuptools import setup, find_packages\r\n\r\n# TODO: Confirm this is the right version number you want and it matches your\r\n# HISTORY.rst entry.\r\nVERSION = '0.1.0'\r\n\r\n# The full list of classifiers is available at\r\n# https://pypi.python.org/pypi?%3Aaction=list_classifiers\r\nCLASSIFIERS = [\r\n 'Development Status :: 4 - Beta',\r\n 'Intended Audience :: Developers',\r\n 'Intended Audience :: System Administrators',\r\n 'Programming Language :: Python',\r\n 'Programming Language :: Python :: 3',\r\n 'Programming Language :: Python :: 3.6',\r\n 'Programming Language :: Python :: 3.7',\r\n 'Programming Language :: Python :: 3.8',\r\n 'License :: OSI Approved :: MIT License',\r\n]\r\n\r\n# TODO: Add any additional SDK dependencies here\r\nDEPENDENCIES = []\r\n\r\nwith open('README.md', 'r', encoding='utf-8') as f:\r\n README = f.read()\r\nwith open('HISTORY.rst', 'r', encoding='utf-8') as f:\r\n HISTORY = f.read()\r\n\r\nsetup(\r\n name='costmanagement',\r\n version=VERSION,\r\n description='Microsoft Azure Command-Line Tools CostManagementClient Extension',\r\n # TODO: Update author and email, if applicable\r\n author='Microsoft Corporation',\r\n author_email='[email protected]',\r\n url='https://github.com/Azure/azure-cli-extensions/tree/master/src/costmanagement',\r\n long_description=README + '\\n\\n' + HISTORY,\r\n license='MIT',\r\n classifiers=CLASSIFIERS,\r\n packages=find_packages(),\r\n install_requires=DEPENDENCIES,\r\n package_data={'azext_costmanagement': ['azext_metadata.json']},\r\n)\r\n", "path": "src/costmanagement/setup.py"}, {"content": "# --------------------------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for license information.\n# --------------------------------------------------------------------------------------------\n\nfrom azure.cli.core.commands import CliCommandType\n\n\ndef load_command_table(self, _):\n\n from azext_costmanagement.generated._client_factory import cf_query\n costmanagement_query = CliCommandType(\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations.'\n '_query_operations#QueryOperations.{}',\n client_factory=cf_query)\n with self.command_group('costmanagement', costmanagement_query,\n client_factory=cf_query, is_experimental=True) as g:\n g.custom_command('query', 'costmanagement_query')\n\n from azext_costmanagement.generated._client_factory import cf_export\n costmanagement_export = CliCommandType(\n operations_tmpl='azext_costmanagement.vendored_sdks.costmanagement.operations._export_operations#ExportOperatio'\n 'ns.{}',\n client_factory=cf_export)\n with self.command_group('costmanagement export', costmanagement_export, client_factory=cf_export,\n is_experimental=True) as g:\n g.custom_command('list', 'costmanagement_export_list')\n g.custom_show_command('show', 'costmanagement_export_show')\n g.custom_command('create', 'costmanagement_export_create')\n g.custom_command('update', 'costmanagement_export_update')\n g.custom_command('delete', 'costmanagement_export_delete', confirmation=True)\n", "path": "src/costmanagement/azext_costmanagement/manual/commands.py"}]}
| 1,539 | 457 |
gh_patches_debug_38816
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-3454
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Spider valero is broken
During the global build at 2021-07-14-14-42-22, spider **valero** failed with **0 features** and **1 errors**.
Here's [the log](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/logs/valero.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson))
</issue>
<code>
[start of locations/spiders/valero.py]
1 # -*- coding: utf-8 -*-
2 import scrapy
3 import json
4 from locations.items import GeojsonPointItem
5
6
7 class ValeroSpider(scrapy.Spider):
8 name = "valero"
9 item_attributes = {'brand': "Valero", 'brand_wikidata': 'Q1283291'}
10 allowed_domains = ["valeromaps.valero.com"]
11
12 def start_requests(self):
13 yield scrapy.FormRequest(
14 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',
15 method='POST',
16 headers={
17 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'
18 },
19 formdata={
20 'NEBound_Lat': '90',
21 'NEBound_Long': '180',
22 'SWBound_Lat': '-90',
23 'SWBound_Long': '-180',
24 'center_Lat': '0',
25 'center_Long': '0'
26 }
27 )
28
29 def parse(self, response):
30 result = json.loads(response.body_as_unicode())
31 for store in result['StoreList']:
32 details = ', '.join([d['DetailName'] for d in store['Details']])
33 yield GeojsonPointItem(
34 lon=store['Longitude'],
35 lat=store['Latitude'],
36 ref=store['UniqueID'],
37 name=store['StationName'],
38 addr_full=store['Address'],
39 phone=store['Phone'],
40 opening_hours='24/7' if '24 Hours' in details else None,
41 extras={
42 'amenity:fuel': True,
43 'amenity:toilets': 'Restroom' in details or None,
44 'atm': 'ATM' in details,
45 'car_wash': 'Car Wash' in details,
46 'fuel:diesel': 'Diesel' in details or None,
47 'fuel:e85': 'E-85' in details or None,
48 }
49 )
50
[end of locations/spiders/valero.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/valero.py b/locations/spiders/valero.py
--- a/locations/spiders/valero.py
+++ b/locations/spiders/valero.py
@@ -1,49 +1,39 @@
# -*- coding: utf-8 -*-
import scrapy
import json
+
from locations.items import GeojsonPointItem
class ValeroSpider(scrapy.Spider):
name = "valero"
- item_attributes = {'brand': "Valero", 'brand_wikidata': 'Q1283291'}
- allowed_domains = ["valeromaps.valero.com"]
-
- def start_requests(self):
- yield scrapy.FormRequest(
- 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',
- method='POST',
- headers={
- 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'
- },
- formdata={
- 'NEBound_Lat': '90',
- 'NEBound_Long': '180',
- 'SWBound_Lat': '-90',
- 'SWBound_Long': '-180',
- 'center_Lat': '0',
- 'center_Long': '0'
- }
- )
+ item_attributes = {"brand": "Valero", "brand_wikidata": "Q1283291"}
+ allowed_domains = ["valero.com"]
+ start_urls = ["https://locations.valero.com/sitemap.xml"]
def parse(self, response):
- result = json.loads(response.body_as_unicode())
- for store in result['StoreList']:
- details = ', '.join([d['DetailName'] for d in store['Details']])
- yield GeojsonPointItem(
- lon=store['Longitude'],
- lat=store['Latitude'],
- ref=store['UniqueID'],
- name=store['StationName'],
- addr_full=store['Address'],
- phone=store['Phone'],
- opening_hours='24/7' if '24 Hours' in details else None,
- extras={
- 'amenity:fuel': True,
- 'amenity:toilets': 'Restroom' in details or None,
- 'atm': 'ATM' in details,
- 'car_wash': 'Car Wash' in details,
- 'fuel:diesel': 'Diesel' in details or None,
- 'fuel:e85': 'E-85' in details or None,
- }
- )
+ response.selector.remove_namespaces()
+ for url in response.xpath("//loc/text()").extract():
+ yield scrapy.Request(url, callback=self.parse_store)
+
+ def parse_store(self, response):
+ amenities = [s.strip() for s in response.xpath('//div[@class="amenityIconLabel"]/text()').extract()]
+ properties = {
+ "lat": response.xpath('//meta[@property="place:location:latitude"]/@content').get(),
+ "lon": response.xpath('//meta[@property="place:location:longitude"]/@content').get(),
+ "ref": response.url.rsplit("/", 1)[-1],
+ "website": response.url,
+ "name": response.xpath('normalize-space(//*[@id="pageTitleStoreName"])').get(),
+ "addr_full": response.xpath('normalize-space(//div[@class="locationDetailsContactRow"][1]//br/..)').get(),
+ "phone": response.xpath('//a[contains(@href,"tel:")]/text()').get(),
+ "opening_hours": "24/7" if "24 Hour" in amenities else None,
+ "extras": {
+ "atm": "ATM" in amenities,
+ "amenity:fuel": True,
+ "amenity:toilets": "Public Restroom" in amenities or None,
+ "car_wash": "Car Wash" in amenities,
+ "fuel:diesel": "Diesel" in amenities or None,
+ "fuel:e85": "E-85" in amenities or None,
+ },
+ }
+ yield GeojsonPointItem(**properties)
|
{"golden_diff": "diff --git a/locations/spiders/valero.py b/locations/spiders/valero.py\n--- a/locations/spiders/valero.py\n+++ b/locations/spiders/valero.py\n@@ -1,49 +1,39 @@\n # -*- coding: utf-8 -*-\n import scrapy\n import json\n+\n from locations.items import GeojsonPointItem\n \n \n class ValeroSpider(scrapy.Spider):\n name = \"valero\"\n- item_attributes = {'brand': \"Valero\", 'brand_wikidata': 'Q1283291'}\n- allowed_domains = [\"valeromaps.valero.com\"]\n-\n- def start_requests(self):\n- yield scrapy.FormRequest(\n- 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',\n- method='POST',\n- headers={\n- 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'\n- },\n- formdata={\n- 'NEBound_Lat': '90',\n- 'NEBound_Long': '180',\n- 'SWBound_Lat': '-90',\n- 'SWBound_Long': '-180',\n- 'center_Lat': '0',\n- 'center_Long': '0'\n- }\n- )\n+ item_attributes = {\"brand\": \"Valero\", \"brand_wikidata\": \"Q1283291\"}\n+ allowed_domains = [\"valero.com\"]\n+ start_urls = [\"https://locations.valero.com/sitemap.xml\"]\n \n def parse(self, response):\n- result = json.loads(response.body_as_unicode())\n- for store in result['StoreList']:\n- details = ', '.join([d['DetailName'] for d in store['Details']])\n- yield GeojsonPointItem(\n- lon=store['Longitude'],\n- lat=store['Latitude'],\n- ref=store['UniqueID'],\n- name=store['StationName'],\n- addr_full=store['Address'],\n- phone=store['Phone'],\n- opening_hours='24/7' if '24 Hours' in details else None,\n- extras={\n- 'amenity:fuel': True,\n- 'amenity:toilets': 'Restroom' in details or None,\n- 'atm': 'ATM' in details,\n- 'car_wash': 'Car Wash' in details,\n- 'fuel:diesel': 'Diesel' in details or None,\n- 'fuel:e85': 'E-85' in details or None,\n- }\n- )\n+ response.selector.remove_namespaces()\n+ for url in response.xpath(\"//loc/text()\").extract():\n+ yield scrapy.Request(url, callback=self.parse_store)\n+\n+ def parse_store(self, response):\n+ amenities = [s.strip() for s in response.xpath('//div[@class=\"amenityIconLabel\"]/text()').extract()]\n+ properties = {\n+ \"lat\": response.xpath('//meta[@property=\"place:location:latitude\"]/@content').get(),\n+ \"lon\": response.xpath('//meta[@property=\"place:location:longitude\"]/@content').get(),\n+ \"ref\": response.url.rsplit(\"/\", 1)[-1],\n+ \"website\": response.url,\n+ \"name\": response.xpath('normalize-space(//*[@id=\"pageTitleStoreName\"])').get(),\n+ \"addr_full\": response.xpath('normalize-space(//div[@class=\"locationDetailsContactRow\"][1]//br/..)').get(),\n+ \"phone\": response.xpath('//a[contains(@href,\"tel:\")]/text()').get(),\n+ \"opening_hours\": \"24/7\" if \"24 Hour\" in amenities else None,\n+ \"extras\": {\n+ \"atm\": \"ATM\" in amenities,\n+ \"amenity:fuel\": True,\n+ \"amenity:toilets\": \"Public Restroom\" in amenities or None,\n+ \"car_wash\": \"Car Wash\" in amenities,\n+ \"fuel:diesel\": \"Diesel\" in amenities or None,\n+ \"fuel:e85\": \"E-85\" in amenities or None,\n+ },\n+ }\n+ yield GeojsonPointItem(**properties)\n", "issue": "Spider valero is broken\nDuring the global build at 2021-07-14-14-42-22, spider **valero** failed with **0 features** and **1 errors**.\n\nHere's [the log](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/logs/valero.txt) and [the output](https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson) ([on a map](https://data.alltheplaces.xyz/map.html?show=https://data.alltheplaces.xyz/runs/2021-07-14-14-42-22/output/valero.geojson))\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport scrapy\nimport json\nfrom locations.items import GeojsonPointItem\n\n\nclass ValeroSpider(scrapy.Spider):\n name = \"valero\"\n item_attributes = {'brand': \"Valero\", 'brand_wikidata': 'Q1283291'}\n allowed_domains = [\"valeromaps.valero.com\"]\n\n def start_requests(self):\n yield scrapy.FormRequest(\n 'https://valeromaps.valero.com/Home/Search?SPHostUrl=https:%2F%2Fwww.valero.com%2Fen-us',\n method='POST',\n headers={\n 'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8'\n },\n formdata={\n 'NEBound_Lat': '90',\n 'NEBound_Long': '180',\n 'SWBound_Lat': '-90',\n 'SWBound_Long': '-180',\n 'center_Lat': '0',\n 'center_Long': '0'\n }\n )\n\n def parse(self, response):\n result = json.loads(response.body_as_unicode())\n for store in result['StoreList']:\n details = ', '.join([d['DetailName'] for d in store['Details']])\n yield GeojsonPointItem(\n lon=store['Longitude'],\n lat=store['Latitude'],\n ref=store['UniqueID'],\n name=store['StationName'],\n addr_full=store['Address'],\n phone=store['Phone'],\n opening_hours='24/7' if '24 Hours' in details else None,\n extras={\n 'amenity:fuel': True,\n 'amenity:toilets': 'Restroom' in details or None,\n 'atm': 'ATM' in details,\n 'car_wash': 'Car Wash' in details,\n 'fuel:diesel': 'Diesel' in details or None,\n 'fuel:e85': 'E-85' in details or None,\n }\n )\n", "path": "locations/spiders/valero.py"}]}
| 1,247 | 938 |
gh_patches_debug_14564
|
rasdani/github-patches
|
git_diff
|
WordPress__openverse-api-477
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Distinguish between staging & prod when sending data refresh slack updates
## Problem
<!-- Describe a problem solved by this feature; or delete the section entirely. -->
It's not easy to tell based on the slack messages produced by the ingestion server whether a given ingestion is being run in production or staging.
## Description
<!-- Describe the feature and how it solves the problem. -->
We should pre-pend the messages (or change the bot's name) based on which environment the data refresh is running in.
## Alternatives
<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->
We _could_ turn off messages altogether for staging (how it is currently) but that would make it harder for us to know when a staging data refresh is complete.
## Additional context
<!-- Add any other context about the feature here; or delete the section entirely. -->
## Implementation
<!-- Replace the [ ] with [x] to check the box. -->
- [x] 🙋 I would be interested in implementing this feature.
</issue>
<code>
[start of ingestion_server/ingestion_server/slack.py]
1 import logging
2 import os
3
4 import requests
5
6
7 log = logging.getLogger(__name__)
8 SLACK_WEBHOOK = "SLACK_WEBHOOK"
9
10
11 def message(text: str, summary: str = None) -> None:
12 """
13 Send a Slack message to a channel specified by a Slack webhook variable.
14
15 A message is only sent if the SLACK_WEBHOOK environment variable is undefined.
16 """
17 if not (webhook := os.getenv(SLACK_WEBHOOK)):
18 log.debug(
19 f"{SLACK_WEBHOOK} variable not defined, skipping slack message: {text}"
20 )
21 return
22 if not summary:
23 if "\n" in text:
24 summary = "Ingestion server message"
25 else:
26 summary = text
27
28 data = {
29 "blocks": [{"text": {"text": text, "type": "mrkdwn"}, "type": "section"}],
30 "text": summary,
31 "username": "Data Refresh Notification",
32 "icon_emoji": "arrows_counterclockwise",
33 }
34 try:
35 requests.post(webhook, json=data)
36 except Exception as err:
37 log.exception(f"Unable to issue slack message: {err}")
38 pass
39
[end of ingestion_server/ingestion_server/slack.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ingestion_server/ingestion_server/slack.py b/ingestion_server/ingestion_server/slack.py
--- a/ingestion_server/ingestion_server/slack.py
+++ b/ingestion_server/ingestion_server/slack.py
@@ -2,6 +2,7 @@
import os
import requests
+from decouple import config
log = logging.getLogger(__name__)
@@ -25,10 +26,12 @@
else:
summary = text
+ environment = config("ENVIRONMENT", default="local")
+
data = {
"blocks": [{"text": {"text": text, "type": "mrkdwn"}, "type": "section"}],
"text": summary,
- "username": "Data Refresh Notification",
+ "username": f"Data Refresh Notification | {environment.upper()}",
"icon_emoji": "arrows_counterclockwise",
}
try:
|
{"golden_diff": "diff --git a/ingestion_server/ingestion_server/slack.py b/ingestion_server/ingestion_server/slack.py\n--- a/ingestion_server/ingestion_server/slack.py\n+++ b/ingestion_server/ingestion_server/slack.py\n@@ -2,6 +2,7 @@\n import os\n \n import requests\n+from decouple import config\n \n \n log = logging.getLogger(__name__)\n@@ -25,10 +26,12 @@\n else:\n summary = text\n \n+ environment = config(\"ENVIRONMENT\", default=\"local\")\n+\n data = {\n \"blocks\": [{\"text\": {\"text\": text, \"type\": \"mrkdwn\"}, \"type\": \"section\"}],\n \"text\": summary,\n- \"username\": \"Data Refresh Notification\",\n+ \"username\": f\"Data Refresh Notification | {environment.upper()}\",\n \"icon_emoji\": \"arrows_counterclockwise\",\n }\n try:\n", "issue": "Distinguish between staging & prod when sending data refresh slack updates\n## Problem\r\n<!-- Describe a problem solved by this feature; or delete the section entirely. -->\r\nIt's not easy to tell based on the slack messages produced by the ingestion server whether a given ingestion is being run in production or staging.\r\n\r\n## Description\r\n<!-- Describe the feature and how it solves the problem. -->\r\nWe should pre-pend the messages (or change the bot's name) based on which environment the data refresh is running in. \r\n\r\n## Alternatives\r\n<!-- Describe any alternative solutions or features you have considered. How is this feature better? -->\r\nWe _could_ turn off messages altogether for staging (how it is currently) but that would make it harder for us to know when a staging data refresh is complete.\r\n\r\n## Additional context\r\n<!-- Add any other context about the feature here; or delete the section entirely. -->\r\n\r\n## Implementation\r\n<!-- Replace the [ ] with [x] to check the box. -->\r\n- [x] \ud83d\ude4b I would be interested in implementing this feature.\r\n\n", "before_files": [{"content": "import logging\nimport os\n\nimport requests\n\n\nlog = logging.getLogger(__name__)\nSLACK_WEBHOOK = \"SLACK_WEBHOOK\"\n\n\ndef message(text: str, summary: str = None) -> None:\n \"\"\"\n Send a Slack message to a channel specified by a Slack webhook variable.\n\n A message is only sent if the SLACK_WEBHOOK environment variable is undefined.\n \"\"\"\n if not (webhook := os.getenv(SLACK_WEBHOOK)):\n log.debug(\n f\"{SLACK_WEBHOOK} variable not defined, skipping slack message: {text}\"\n )\n return\n if not summary:\n if \"\\n\" in text:\n summary = \"Ingestion server message\"\n else:\n summary = text\n\n data = {\n \"blocks\": [{\"text\": {\"text\": text, \"type\": \"mrkdwn\"}, \"type\": \"section\"}],\n \"text\": summary,\n \"username\": \"Data Refresh Notification\",\n \"icon_emoji\": \"arrows_counterclockwise\",\n }\n try:\n requests.post(webhook, json=data)\n except Exception as err:\n log.exception(f\"Unable to issue slack message: {err}\")\n pass\n", "path": "ingestion_server/ingestion_server/slack.py"}]}
| 1,083 | 205 |
gh_patches_debug_26399
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-1503
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix `cirq.control` documentation talking about `__control__` instead of `controlled_by`
</issue>
<code>
[start of cirq/protocols/control.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Any, TYPE_CHECKING, TypeVar, Union, Sequence
16
17 import collections
18
19 from cirq.ops import op_tree
20
21 if TYPE_CHECKING:
22 # pylint: disable=unused-import
23 import cirq
24
25 # This is a special indicator value used by the control method to determine
26 # whether or not the caller provided a 'default' argument.
27 RaiseTypeErrorIfNotProvided = ([],) # type: Any
28
29
30 TDefault = TypeVar('TDefault')
31
32 def control(controllee: Union['cirq.Gate', op_tree.OP_TREE],
33 control_qubits: Sequence['cirq.Qid'] = None,
34 default: Any = RaiseTypeErrorIfNotProvided) -> Any:
35 """Returns a Controlled version of the given value, if defined.
36
37 Controllees define how to be controlled by defining a method
38 __control__(self, control_qubits). Note that the method may return
39 NotImplemented to indicate a particular controlling can't be done.
40
41 Args:
42 controllee: The gate, operation or iterable of operations to control.
43 control_qubits: A list of Qids that would control this controllee.
44 default: Determines the fallback behavior when `controllee` doesn't
45 have a controlling defined. If `default` is not set and the
46 fallback occurs, a TypeError is raised instead.
47
48 Returns:
49 If `controllee` has a __control__ method that returns something besides
50 NotImplemented, that result is returned. For an OP_TREE, transformation
51 is applied at the leaf. Otherwise, if a default value was specified,
52 the default value is returned.
53
54 Raises:
55 TypeError: `controllee` doesn't have a __control__ method (or that
56 method returned NotImplemented) and no `default` was specified.
57 """
58 if control_qubits is None:
59 control_qubits = []
60 controller = getattr(controllee, 'controlled_by', None)
61 result = NotImplemented if controller is None else controller(
62 *control_qubits)
63 if result is not NotImplemented:
64 return result
65
66 if isinstance(controllee, collections.Iterable):
67 return op_tree.transform_op_tree(controllee, op_transformation=
68 lambda op: control(op, control_qubits))
69
70 if default is not RaiseTypeErrorIfNotProvided:
71 return default
72
73 if controller is None:
74 raise TypeError("object of type '{}' has no controlled_by "
75 "method.".format(type(controllee)))
76 raise TypeError("object of type '{}' does have a controlled_by method, "
77 "but it returned NotImplemented.".format(type(controllee)))
78
[end of cirq/protocols/control.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq/protocols/control.py b/cirq/protocols/control.py
--- a/cirq/protocols/control.py
+++ b/cirq/protocols/control.py
@@ -35,7 +35,7 @@
"""Returns a Controlled version of the given value, if defined.
Controllees define how to be controlled by defining a method
- __control__(self, control_qubits). Note that the method may return
+ controlled_by(self, control_qubits). Note that the method may return
NotImplemented to indicate a particular controlling can't be done.
Args:
@@ -46,13 +46,13 @@
fallback occurs, a TypeError is raised instead.
Returns:
- If `controllee` has a __control__ method that returns something besides
- NotImplemented, that result is returned. For an OP_TREE, transformation
- is applied at the leaf. Otherwise, if a default value was specified,
- the default value is returned.
+ If `controllee` has a controlled_by method that returns something
+ besides NotImplemented, that result is returned. For an OP_TREE,
+ transformation is applied at the leaf. Otherwise, if a default value
+ was specified, the default value is returned.
Raises:
- TypeError: `controllee` doesn't have a __control__ method (or that
+ TypeError: `controllee` doesn't have a controlled_by method (or that
method returned NotImplemented) and no `default` was specified.
"""
if control_qubits is None:
|
{"golden_diff": "diff --git a/cirq/protocols/control.py b/cirq/protocols/control.py\n--- a/cirq/protocols/control.py\n+++ b/cirq/protocols/control.py\n@@ -35,7 +35,7 @@\n \"\"\"Returns a Controlled version of the given value, if defined.\n \n Controllees define how to be controlled by defining a method\n- __control__(self, control_qubits). Note that the method may return\n+ controlled_by(self, control_qubits). Note that the method may return\n NotImplemented to indicate a particular controlling can't be done.\n \n Args:\n@@ -46,13 +46,13 @@\n fallback occurs, a TypeError is raised instead.\n \n Returns:\n- If `controllee` has a __control__ method that returns something besides\n- NotImplemented, that result is returned. For an OP_TREE, transformation\n- is applied at the leaf. Otherwise, if a default value was specified,\n- the default value is returned.\n+ If `controllee` has a controlled_by method that returns something\n+ besides NotImplemented, that result is returned. For an OP_TREE,\n+ transformation is applied at the leaf. Otherwise, if a default value\n+ was specified, the default value is returned.\n \n Raises:\n- TypeError: `controllee` doesn't have a __control__ method (or that\n+ TypeError: `controllee` doesn't have a controlled_by method (or that\n method returned NotImplemented) and no `default` was specified.\n \"\"\"\n if control_qubits is None:\n", "issue": "Fix `cirq.control` documentation talking about `__control__` instead of `controlled_by`\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Any, TYPE_CHECKING, TypeVar, Union, Sequence\n\nimport collections\n\nfrom cirq.ops import op_tree\n\nif TYPE_CHECKING:\n # pylint: disable=unused-import\n import cirq\n\n# This is a special indicator value used by the control method to determine\n# whether or not the caller provided a 'default' argument.\nRaiseTypeErrorIfNotProvided = ([],) # type: Any\n\n\nTDefault = TypeVar('TDefault')\n\ndef control(controllee: Union['cirq.Gate', op_tree.OP_TREE],\n control_qubits: Sequence['cirq.Qid'] = None,\n default: Any = RaiseTypeErrorIfNotProvided) -> Any:\n \"\"\"Returns a Controlled version of the given value, if defined.\n\n Controllees define how to be controlled by defining a method\n __control__(self, control_qubits). Note that the method may return\n NotImplemented to indicate a particular controlling can't be done.\n\n Args:\n controllee: The gate, operation or iterable of operations to control.\n control_qubits: A list of Qids that would control this controllee.\n default: Determines the fallback behavior when `controllee` doesn't\n have a controlling defined. If `default` is not set and the\n fallback occurs, a TypeError is raised instead.\n\n Returns:\n If `controllee` has a __control__ method that returns something besides\n NotImplemented, that result is returned. For an OP_TREE, transformation\n is applied at the leaf. Otherwise, if a default value was specified,\n the default value is returned.\n\n Raises:\n TypeError: `controllee` doesn't have a __control__ method (or that\n method returned NotImplemented) and no `default` was specified.\n \"\"\"\n if control_qubits is None:\n control_qubits = []\n controller = getattr(controllee, 'controlled_by', None)\n result = NotImplemented if controller is None else controller(\n *control_qubits)\n if result is not NotImplemented:\n return result\n\n if isinstance(controllee, collections.Iterable):\n return op_tree.transform_op_tree(controllee, op_transformation=\n lambda op: control(op, control_qubits))\n\n if default is not RaiseTypeErrorIfNotProvided:\n return default\n\n if controller is None:\n raise TypeError(\"object of type '{}' has no controlled_by \"\n \"method.\".format(type(controllee)))\n raise TypeError(\"object of type '{}' does have a controlled_by method, \"\n \"but it returned NotImplemented.\".format(type(controllee)))\n", "path": "cirq/protocols/control.py"}]}
| 1,388 | 339 |
gh_patches_debug_12122
|
rasdani/github-patches
|
git_diff
|
google__fuzzbench-1466
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Write a validator to prevent issues requesting bug experiments
https://github.com/google/fuzzbench/commit/da5fab4dfcabcd856e0247b90122bb577f0c734e#diff-c89bd86bcf4447f199973358896b7a69d69d92f258653f28e77583ee8967dd13R49 has happened twice now, time to prevent it.
</issue>
<code>
[start of service/automatic_run_experiment.py]
1 #!/usr/bin/env python3
2 # Copyright 2020 Google LLC
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 """Reads experiment-requests.yaml and determines if there is a new experiment
16 and runs it if needed. Note that this code uses a config file for experiments
17 that is specific to the FuzzBench service. Therefore this code will break if
18 others try to run it."""
19 import argparse
20 import collections
21 import os
22 import re
23 import sys
24 from typing import Optional
25
26 from common import benchmark_utils
27 from common import logs
28 from common import utils
29 from common import yaml_utils
30 from database import models
31 from database import utils as db_utils
32 from experiment import run_experiment
33
34 logger = logs.Logger('automatic_run_experiment') # pylint: disable=invalid-name
35
36 EXPERIMENT_CONFIG_FILE = os.path.join(utils.ROOT_DIR, 'service',
37 'experiment-config.yaml')
38
39 REQUESTED_EXPERIMENTS_PATH = os.path.join(utils.ROOT_DIR, 'service',
40 'experiment-requests.yaml')
41
42 # Don't run an experiment if we have a "request" just containing this keyword.
43 # TODO(metzman): Look into replacing this mechanism for pausing the service.
44 PAUSE_SERVICE_KEYWORD = 'PAUSE_SERVICE'
45
46 EXPERIMENT_NAME_REGEX = re.compile(r'^\d{4}-\d{2}-\d{2}.*')
47
48
49 def _get_experiment_name(experiment_config: dict) -> str:
50 """Returns the name of the experiment described by |experiment_config| as a
51 string."""
52 # Use str because the yaml parser will parse things like `2020-05-06` as
53 # a datetime if not included in quotes.
54 return str(experiment_config['experiment'])
55
56
57 def _get_description(experiment_config: dict) -> Optional[str]:
58 """Returns the description of the experiment described by
59 |experiment_config| as a string."""
60 return experiment_config.get('description')
61
62
63 def _use_oss_fuzz_corpus(experiment_config: dict) -> bool:
64 """Returns the oss_fuzz_corpus flag of the experiment described by
65 |experiment_config| as a bool."""
66 return bool(experiment_config.get('oss_fuzz_corpus'))
67
68
69 def _get_requested_experiments():
70 """Return requested experiments."""
71 return yaml_utils.read(REQUESTED_EXPERIMENTS_PATH)
72
73
74 def validate_experiment_name(experiment_name):
75 """Returns True if |experiment_name| is valid."""
76 if EXPERIMENT_NAME_REGEX.match(experiment_name) is None:
77 logger.error('Experiment name: %s is not valid.', experiment_name)
78 return False
79 try:
80 run_experiment.validate_experiment_name(experiment_name)
81 return True
82 except run_experiment.ValidationError:
83 logger.error('Experiment name: %s is not valid.', experiment_name)
84 return False
85
86
87 def _validate_individual_experiment_requests(experiment_requests):
88 """Returns True if all requests in |experiment_request| are valid in
89 isolation. Does not account for PAUSE_SERVICE_KEYWORD or duplicates."""
90 valid = True
91 # Validate format.
92 for request in experiment_requests:
93 if not isinstance(request, dict):
94 logger.error('Request: %s is not a dict.', request)
95 experiment_requests.remove(request)
96 valid = False
97 continue
98
99 if 'experiment' not in request:
100 logger.error('Request: %s does not have field "experiment".',
101 request)
102 valid = False
103 continue
104
105 experiment = _get_experiment_name(request)
106 if not validate_experiment_name(experiment):
107 valid = False
108 # Request isn't so malformed that we can find other issues, if
109 # present.
110
111 fuzzers = request.get('fuzzers')
112 if not fuzzers:
113 logger.error('Request: %s does not specify any fuzzers.', request)
114 valid = False
115 continue
116
117 for fuzzer in fuzzers:
118 try:
119 run_experiment.validate_fuzzer(fuzzer)
120 except run_experiment.ValidationError:
121 logger.error('Fuzzer: %s is invalid.', fuzzer)
122 valid = False
123
124 description = request.get('description')
125 if description is not None and not isinstance(description, str):
126 logger.error(
127 'Request: %s "description" attribute is not a valid string.',
128 request)
129 valid = False
130
131 oss_fuzz_corpus = request.get('oss_fuzz_corpus')
132 if oss_fuzz_corpus is not None and not isinstance(
133 oss_fuzz_corpus, bool):
134 logger.error(
135 'Request: %s "oss_fuzz_corpus" attribute is not a valid bool.',
136 request)
137 valid = False
138
139 experiment_type = request.get('type',
140 benchmark_utils.BenchmarkType.CODE.value)
141 if experiment_type not in benchmark_utils.BENCHMARK_TYPE_STRS:
142 logger.error('Type: %s is invalid, must be one of %s',
143 experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)
144 valid = False
145
146 return valid
147
148
149 def validate_experiment_requests(experiment_requests):
150 """Returns True if all requests in |experiment_requests| are valid."""
151 # This function tries to find as many requests as possible.
152 if PAUSE_SERVICE_KEYWORD in experiment_requests:
153 # This is a special case where a string is used instead of an experiment
154 # to tell the service not to run experiments automatically. Remove it
155 # from the list because it fails validation.
156 experiment_requests = experiment_requests[:] # Don't mutate input.
157 experiment_requests.remove(PAUSE_SERVICE_KEYWORD)
158
159 if not _validate_individual_experiment_requests(experiment_requests):
160 # Don't try the next validation step if the previous failed, we might
161 # exception.
162 return False
163
164 # Make sure experiment requests have a unique name, we can't run the same
165 # experiment twice.
166 counts = collections.Counter(
167 [request['experiment'] for request in experiment_requests])
168
169 valid = True
170 for experiment_name, count in counts.items():
171 if count != 1:
172 logger.error('Experiment: "%s" appears %d times.',
173 str(experiment_name), count)
174 valid = False
175
176 return valid
177
178
179 def run_requested_experiment(dry_run):
180 """Run the oldest requested experiment that hasn't been run yet in
181 experiment-requests.yaml."""
182 requested_experiments = _get_requested_experiments()
183
184 # TODO(metzman): Look into supporting benchmarks as an optional parameter so
185 # that people can add fuzzers that don't support everything.
186
187 if PAUSE_SERVICE_KEYWORD in requested_experiments:
188 # Check if automated experiment service is paused.
189 logs.warning('Pause service requested, not running experiment.')
190 return
191
192 requested_experiment = None
193 for experiment_config in reversed(requested_experiments):
194 experiment_name = _get_experiment_name(experiment_config)
195 with db_utils.session_scope() as session:
196 is_new_experiment = session.query(models.Experiment).filter(
197 models.Experiment.name == experiment_name).first() is None
198 if is_new_experiment:
199 requested_experiment = experiment_config
200 break
201
202 if requested_experiment is None:
203 logs.info('No new experiment to run. Exiting.')
204 return
205
206 experiment_name = _get_experiment_name(requested_experiment)
207 if not validate_experiment_requests([requested_experiment]):
208 logs.error('Requested experiment: %s in %s is not valid.',
209 requested_experiment, REQUESTED_EXPERIMENTS_PATH)
210 return
211 fuzzers = requested_experiment['fuzzers']
212
213 benchmark_type = requested_experiment.get('type')
214 if benchmark_type == benchmark_utils.BenchmarkType.BUG.value:
215 valid_benchmarks = benchmark_utils.exclude_non_cpp(
216 benchmark_utils.get_bug_benchmarks())
217 else:
218 valid_benchmarks = benchmark_utils.exclude_non_cpp(
219 benchmark_utils.get_coverage_benchmarks())
220
221 benchmarks = requested_experiment.get('benchmarks')
222 if benchmarks is None:
223 benchmarks = valid_benchmarks
224 else:
225 errors = False
226 for benchmark in benchmarks:
227 if benchmark not in valid_benchmarks:
228 logs.error(
229 'Requested experiment:'
230 ' in %s, %s is not a valid %s benchmark.',
231 requested_experiment, benchmark, benchmark_type)
232 errors = True
233 if errors:
234 return
235
236 logs.info('Running experiment: %s with fuzzers: %s.', experiment_name,
237 ' '.join(fuzzers))
238 description = _get_description(requested_experiment)
239 oss_fuzz_corpus = _use_oss_fuzz_corpus(requested_experiment)
240 _run_experiment(experiment_name, fuzzers, benchmarks, description,
241 oss_fuzz_corpus, dry_run)
242
243
244 def _run_experiment( # pylint: disable=too-many-arguments
245 experiment_name,
246 fuzzers,
247 benchmarks,
248 description,
249 oss_fuzz_corpus,
250 dry_run=False):
251 """Run an experiment named |experiment_name| on |fuzzer_configs| and shut it
252 down once it terminates."""
253 logs.info('Starting experiment: %s.', experiment_name)
254 if dry_run:
255 logs.info('Dry run. Not actually running experiment.')
256 return
257 run_experiment.start_experiment(experiment_name,
258 EXPERIMENT_CONFIG_FILE,
259 benchmarks,
260 fuzzers,
261 description=description,
262 oss_fuzz_corpus=oss_fuzz_corpus)
263
264
265 def main():
266 """Run an experiment."""
267 logs.initialize()
268 parser = argparse.ArgumentParser(description='Run a requested experiment.')
269 # TODO(metzman): Add a way to exit immediately if there is already an
270 # experiment running. FuzzBench's scheduler isn't smart enough to deal with
271 # this properly.
272 parser.add_argument('-d',
273 '--dry-run',
274 help='Dry run, don\'t actually run the experiment',
275 default=False,
276 action='store_true')
277 args = parser.parse_args()
278 try:
279 run_requested_experiment(args.dry_run)
280 except Exception: # pylint: disable=broad-except
281 logger.error('Error running requested experiment.')
282 return 1
283 return 0
284
285
286 if __name__ == '__main__':
287 sys.exit(main())
288
[end of service/automatic_run_experiment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/service/automatic_run_experiment.py b/service/automatic_run_experiment.py
--- a/service/automatic_run_experiment.py
+++ b/service/automatic_run_experiment.py
@@ -143,6 +143,18 @@
experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)
valid = False
+ benchmarks = request.get('benchmarks', [])
+ for benchmark in benchmarks:
+ benchmark_type = benchmark_utils.get_type(benchmark)
+ if (benchmark_type == benchmark_utils.BenchmarkType.BUG.value and
+ experiment_type != benchmark_utils.BenchmarkType.BUG.value):
+ logger.error(
+ 'Benchmark %s is "type: bug". '
+ 'Experiment %s must be "type: bug" as well.', benchmark,
+ experiment)
+ valid = False
+ break
+
return valid
|
{"golden_diff": "diff --git a/service/automatic_run_experiment.py b/service/automatic_run_experiment.py\n--- a/service/automatic_run_experiment.py\n+++ b/service/automatic_run_experiment.py\n@@ -143,6 +143,18 @@\n experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)\n valid = False\n \n+ benchmarks = request.get('benchmarks', [])\n+ for benchmark in benchmarks:\n+ benchmark_type = benchmark_utils.get_type(benchmark)\n+ if (benchmark_type == benchmark_utils.BenchmarkType.BUG.value and\n+ experiment_type != benchmark_utils.BenchmarkType.BUG.value):\n+ logger.error(\n+ 'Benchmark %s is \"type: bug\". '\n+ 'Experiment %s must be \"type: bug\" as well.', benchmark,\n+ experiment)\n+ valid = False\n+ break\n+\n return valid\n", "issue": "Write a validator to prevent issues requesting bug experiments\nhttps://github.com/google/fuzzbench/commit/da5fab4dfcabcd856e0247b90122bb577f0c734e#diff-c89bd86bcf4447f199973358896b7a69d69d92f258653f28e77583ee8967dd13R49 has happened twice now, time to prevent it.\n", "before_files": [{"content": "#!/usr/bin/env python3\n# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"Reads experiment-requests.yaml and determines if there is a new experiment\nand runs it if needed. Note that this code uses a config file for experiments\nthat is specific to the FuzzBench service. Therefore this code will break if\nothers try to run it.\"\"\"\nimport argparse\nimport collections\nimport os\nimport re\nimport sys\nfrom typing import Optional\n\nfrom common import benchmark_utils\nfrom common import logs\nfrom common import utils\nfrom common import yaml_utils\nfrom database import models\nfrom database import utils as db_utils\nfrom experiment import run_experiment\n\nlogger = logs.Logger('automatic_run_experiment') # pylint: disable=invalid-name\n\nEXPERIMENT_CONFIG_FILE = os.path.join(utils.ROOT_DIR, 'service',\n 'experiment-config.yaml')\n\nREQUESTED_EXPERIMENTS_PATH = os.path.join(utils.ROOT_DIR, 'service',\n 'experiment-requests.yaml')\n\n# Don't run an experiment if we have a \"request\" just containing this keyword.\n# TODO(metzman): Look into replacing this mechanism for pausing the service.\nPAUSE_SERVICE_KEYWORD = 'PAUSE_SERVICE'\n\nEXPERIMENT_NAME_REGEX = re.compile(r'^\\d{4}-\\d{2}-\\d{2}.*')\n\n\ndef _get_experiment_name(experiment_config: dict) -> str:\n \"\"\"Returns the name of the experiment described by |experiment_config| as a\n string.\"\"\"\n # Use str because the yaml parser will parse things like `2020-05-06` as\n # a datetime if not included in quotes.\n return str(experiment_config['experiment'])\n\n\ndef _get_description(experiment_config: dict) -> Optional[str]:\n \"\"\"Returns the description of the experiment described by\n |experiment_config| as a string.\"\"\"\n return experiment_config.get('description')\n\n\ndef _use_oss_fuzz_corpus(experiment_config: dict) -> bool:\n \"\"\"Returns the oss_fuzz_corpus flag of the experiment described by\n |experiment_config| as a bool.\"\"\"\n return bool(experiment_config.get('oss_fuzz_corpus'))\n\n\ndef _get_requested_experiments():\n \"\"\"Return requested experiments.\"\"\"\n return yaml_utils.read(REQUESTED_EXPERIMENTS_PATH)\n\n\ndef validate_experiment_name(experiment_name):\n \"\"\"Returns True if |experiment_name| is valid.\"\"\"\n if EXPERIMENT_NAME_REGEX.match(experiment_name) is None:\n logger.error('Experiment name: %s is not valid.', experiment_name)\n return False\n try:\n run_experiment.validate_experiment_name(experiment_name)\n return True\n except run_experiment.ValidationError:\n logger.error('Experiment name: %s is not valid.', experiment_name)\n return False\n\n\ndef _validate_individual_experiment_requests(experiment_requests):\n \"\"\"Returns True if all requests in |experiment_request| are valid in\n isolation. Does not account for PAUSE_SERVICE_KEYWORD or duplicates.\"\"\"\n valid = True\n # Validate format.\n for request in experiment_requests:\n if not isinstance(request, dict):\n logger.error('Request: %s is not a dict.', request)\n experiment_requests.remove(request)\n valid = False\n continue\n\n if 'experiment' not in request:\n logger.error('Request: %s does not have field \"experiment\".',\n request)\n valid = False\n continue\n\n experiment = _get_experiment_name(request)\n if not validate_experiment_name(experiment):\n valid = False\n # Request isn't so malformed that we can find other issues, if\n # present.\n\n fuzzers = request.get('fuzzers')\n if not fuzzers:\n logger.error('Request: %s does not specify any fuzzers.', request)\n valid = False\n continue\n\n for fuzzer in fuzzers:\n try:\n run_experiment.validate_fuzzer(fuzzer)\n except run_experiment.ValidationError:\n logger.error('Fuzzer: %s is invalid.', fuzzer)\n valid = False\n\n description = request.get('description')\n if description is not None and not isinstance(description, str):\n logger.error(\n 'Request: %s \"description\" attribute is not a valid string.',\n request)\n valid = False\n\n oss_fuzz_corpus = request.get('oss_fuzz_corpus')\n if oss_fuzz_corpus is not None and not isinstance(\n oss_fuzz_corpus, bool):\n logger.error(\n 'Request: %s \"oss_fuzz_corpus\" attribute is not a valid bool.',\n request)\n valid = False\n\n experiment_type = request.get('type',\n benchmark_utils.BenchmarkType.CODE.value)\n if experiment_type not in benchmark_utils.BENCHMARK_TYPE_STRS:\n logger.error('Type: %s is invalid, must be one of %s',\n experiment_type, benchmark_utils.BENCHMARK_TYPE_STRS)\n valid = False\n\n return valid\n\n\ndef validate_experiment_requests(experiment_requests):\n \"\"\"Returns True if all requests in |experiment_requests| are valid.\"\"\"\n # This function tries to find as many requests as possible.\n if PAUSE_SERVICE_KEYWORD in experiment_requests:\n # This is a special case where a string is used instead of an experiment\n # to tell the service not to run experiments automatically. Remove it\n # from the list because it fails validation.\n experiment_requests = experiment_requests[:] # Don't mutate input.\n experiment_requests.remove(PAUSE_SERVICE_KEYWORD)\n\n if not _validate_individual_experiment_requests(experiment_requests):\n # Don't try the next validation step if the previous failed, we might\n # exception.\n return False\n\n # Make sure experiment requests have a unique name, we can't run the same\n # experiment twice.\n counts = collections.Counter(\n [request['experiment'] for request in experiment_requests])\n\n valid = True\n for experiment_name, count in counts.items():\n if count != 1:\n logger.error('Experiment: \"%s\" appears %d times.',\n str(experiment_name), count)\n valid = False\n\n return valid\n\n\ndef run_requested_experiment(dry_run):\n \"\"\"Run the oldest requested experiment that hasn't been run yet in\n experiment-requests.yaml.\"\"\"\n requested_experiments = _get_requested_experiments()\n\n # TODO(metzman): Look into supporting benchmarks as an optional parameter so\n # that people can add fuzzers that don't support everything.\n\n if PAUSE_SERVICE_KEYWORD in requested_experiments:\n # Check if automated experiment service is paused.\n logs.warning('Pause service requested, not running experiment.')\n return\n\n requested_experiment = None\n for experiment_config in reversed(requested_experiments):\n experiment_name = _get_experiment_name(experiment_config)\n with db_utils.session_scope() as session:\n is_new_experiment = session.query(models.Experiment).filter(\n models.Experiment.name == experiment_name).first() is None\n if is_new_experiment:\n requested_experiment = experiment_config\n break\n\n if requested_experiment is None:\n logs.info('No new experiment to run. Exiting.')\n return\n\n experiment_name = _get_experiment_name(requested_experiment)\n if not validate_experiment_requests([requested_experiment]):\n logs.error('Requested experiment: %s in %s is not valid.',\n requested_experiment, REQUESTED_EXPERIMENTS_PATH)\n return\n fuzzers = requested_experiment['fuzzers']\n\n benchmark_type = requested_experiment.get('type')\n if benchmark_type == benchmark_utils.BenchmarkType.BUG.value:\n valid_benchmarks = benchmark_utils.exclude_non_cpp(\n benchmark_utils.get_bug_benchmarks())\n else:\n valid_benchmarks = benchmark_utils.exclude_non_cpp(\n benchmark_utils.get_coverage_benchmarks())\n\n benchmarks = requested_experiment.get('benchmarks')\n if benchmarks is None:\n benchmarks = valid_benchmarks\n else:\n errors = False\n for benchmark in benchmarks:\n if benchmark not in valid_benchmarks:\n logs.error(\n 'Requested experiment:'\n ' in %s, %s is not a valid %s benchmark.',\n requested_experiment, benchmark, benchmark_type)\n errors = True\n if errors:\n return\n\n logs.info('Running experiment: %s with fuzzers: %s.', experiment_name,\n ' '.join(fuzzers))\n description = _get_description(requested_experiment)\n oss_fuzz_corpus = _use_oss_fuzz_corpus(requested_experiment)\n _run_experiment(experiment_name, fuzzers, benchmarks, description,\n oss_fuzz_corpus, dry_run)\n\n\ndef _run_experiment( # pylint: disable=too-many-arguments\n experiment_name,\n fuzzers,\n benchmarks,\n description,\n oss_fuzz_corpus,\n dry_run=False):\n \"\"\"Run an experiment named |experiment_name| on |fuzzer_configs| and shut it\n down once it terminates.\"\"\"\n logs.info('Starting experiment: %s.', experiment_name)\n if dry_run:\n logs.info('Dry run. Not actually running experiment.')\n return\n run_experiment.start_experiment(experiment_name,\n EXPERIMENT_CONFIG_FILE,\n benchmarks,\n fuzzers,\n description=description,\n oss_fuzz_corpus=oss_fuzz_corpus)\n\n\ndef main():\n \"\"\"Run an experiment.\"\"\"\n logs.initialize()\n parser = argparse.ArgumentParser(description='Run a requested experiment.')\n # TODO(metzman): Add a way to exit immediately if there is already an\n # experiment running. FuzzBench's scheduler isn't smart enough to deal with\n # this properly.\n parser.add_argument('-d',\n '--dry-run',\n help='Dry run, don\\'t actually run the experiment',\n default=False,\n action='store_true')\n args = parser.parse_args()\n try:\n run_requested_experiment(args.dry_run)\n except Exception: # pylint: disable=broad-except\n logger.error('Error running requested experiment.')\n return 1\n return 0\n\n\nif __name__ == '__main__':\n sys.exit(main())\n", "path": "service/automatic_run_experiment.py"}]}
| 3,673 | 184 |
gh_patches_debug_47731
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-5429
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Tune] Experiment Analysis get_best behaviour
Hi,
In their current version, the [`get_best_config`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L56) and [`get_best_logdir`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L70) methods of the `Analysis` object may consider different Trials as the best one:
- `get_best_config` will first retrieve the best row of each trial dataframe and then select the best trial from these rows.
- `get_best_logdir` will first retrieve the last row of each trial and then selects the best one.
Is it the expected behaviour ?
If it isn't, I think that the correct way of doing it is the first one. This could be done by simply passing the `metric` and `max` arguments to the [`self.dataframe`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L78) call in `get_best_dir`.
</issue>
<code>
[start of python/ray/tune/analysis/experiment_analysis.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 import json
6 import logging
7 import os
8
9 try:
10 import pandas as pd
11 except ImportError:
12 pd = None
13
14 from ray.tune.error import TuneError
15 from ray.tune.result import EXPR_PROGRESS_FILE, EXPR_PARAM_FILE, CONFIG_PREFIX
16
17 logger = logging.getLogger(__name__)
18
19
20 class Analysis(object):
21 """Analyze all results from a directory of experiments."""
22
23 def __init__(self, experiment_dir):
24 experiment_dir = os.path.expanduser(experiment_dir)
25 if not os.path.isdir(experiment_dir):
26 raise ValueError(
27 "{} is not a valid directory.".format(experiment_dir))
28 self._experiment_dir = experiment_dir
29 self._configs = {}
30 self._trial_dataframes = {}
31
32 if not pd:
33 logger.warning(
34 "pandas not installed. Run `pip install pandas` for "
35 "Analysis utilities.")
36 else:
37 self.fetch_trial_dataframes()
38
39 def dataframe(self, metric=None, mode=None):
40 """Returns a pandas.DataFrame object constructed from the trials.
41
42 Args:
43 metric (str): Key for trial info to order on.
44 If None, uses last result.
45 mode (str): One of [min, max].
46
47 """
48 rows = self._retrieve_rows(metric=metric, mode=mode)
49 all_configs = self.get_all_configs(prefix=True)
50 for path, config in all_configs.items():
51 if path in rows:
52 rows[path].update(config)
53 rows[path].update(logdir=path)
54 return pd.DataFrame(list(rows.values()))
55
56 def get_best_config(self, metric, mode="max"):
57 """Retrieve the best config corresponding to the trial.
58
59 Args:
60 metric (str): Key for trial info to order on.
61 mode (str): One of [min, max].
62
63 """
64 rows = self._retrieve_rows(metric=metric, mode=mode)
65 all_configs = self.get_all_configs()
66 compare_op = max if mode == "max" else min
67 best_path = compare_op(rows, key=lambda k: rows[k][metric])
68 return all_configs[best_path]
69
70 def get_best_logdir(self, metric, mode="max"):
71 """Retrieve the logdir corresponding to the best trial.
72
73 Args:
74 metric (str): Key for trial info to order on.
75 mode (str): One of [min, max].
76
77 """
78 df = self.dataframe()
79 if mode == "max":
80 return df.iloc[df[metric].idxmax()].logdir
81 elif mode == "min":
82 return df.iloc[df[metric].idxmin()].logdir
83
84 def fetch_trial_dataframes(self):
85 fail_count = 0
86 for path in self._get_trial_paths():
87 try:
88 self.trial_dataframes[path] = pd.read_csv(
89 os.path.join(path, EXPR_PROGRESS_FILE))
90 except Exception:
91 fail_count += 1
92
93 if fail_count:
94 logger.debug(
95 "Couldn't read results from {} paths".format(fail_count))
96 return self.trial_dataframes
97
98 def get_all_configs(self, prefix=False):
99 """Returns a list of all configurations.
100
101 Parameters:
102 prefix (bool): If True, flattens the config dict
103 and prepends `config/`.
104 """
105 fail_count = 0
106 for path in self._get_trial_paths():
107 try:
108 with open(os.path.join(path, EXPR_PARAM_FILE)) as f:
109 config = json.load(f)
110 if prefix:
111 for k in list(config):
112 config[CONFIG_PREFIX + k] = config.pop(k)
113 self._configs[path] = config
114 except Exception:
115 fail_count += 1
116
117 if fail_count:
118 logger.warning(
119 "Couldn't read config from {} paths".format(fail_count))
120 return self._configs
121
122 def _retrieve_rows(self, metric=None, mode=None):
123 assert mode is None or mode in ["max", "min"]
124 rows = {}
125 for path, df in self.trial_dataframes.items():
126 if mode == "max":
127 idx = df[metric].idxmax()
128 elif mode == "min":
129 idx = df[metric].idxmin()
130 else:
131 idx = -1
132 rows[path] = df.iloc[idx].to_dict()
133
134 return rows
135
136 def _get_trial_paths(self):
137 _trial_paths = []
138 for trial_path, _, files in os.walk(self._experiment_dir):
139 if EXPR_PROGRESS_FILE in files:
140 _trial_paths += [trial_path]
141
142 if not _trial_paths:
143 raise TuneError("No trials found in {}.".format(
144 self._experiment_dir))
145 return _trial_paths
146
147 @property
148 def trial_dataframes(self):
149 """List of all dataframes of the trials."""
150 return self._trial_dataframes
151
152
153 class ExperimentAnalysis(Analysis):
154 """Analyze results from a Tune experiment.
155
156 Parameters:
157 experiment_checkpoint_path (str): Path to a json file
158 representing an experiment state. Corresponds to
159 Experiment.local_dir/Experiment.name/experiment_state.json
160
161 Example:
162 >>> tune.run(my_trainable, name="my_exp", local_dir="~/tune_results")
163 >>> analysis = ExperimentAnalysis(
164 >>> experiment_checkpoint_path="~/tune_results/my_exp/state.json")
165 """
166
167 def __init__(self, experiment_checkpoint_path, trials=None):
168 """Initializer.
169
170 Args:
171 experiment_path (str): Path to where experiment is located.
172 trials (list|None): List of trials that can be accessed via
173 `analysis.trials`.
174 """
175 with open(experiment_checkpoint_path) as f:
176 _experiment_state = json.load(f)
177 self._experiment_state = _experiment_state
178
179 if "checkpoints" not in _experiment_state:
180 raise TuneError("Experiment state invalid; no checkpoints found.")
181 self._checkpoints = _experiment_state["checkpoints"]
182 self.trials = trials
183 super(ExperimentAnalysis, self).__init__(
184 os.path.dirname(experiment_checkpoint_path))
185
186 def stats(self):
187 """Returns a dictionary of the statistics of the experiment."""
188 return self._experiment_state.get("stats")
189
190 def runner_data(self):
191 """Returns a dictionary of the TrialRunner data."""
192 return self._experiment_state.get("runner_data")
193
194 def _get_trial_paths(self):
195 """Overwrites Analysis to only have trials of one experiment."""
196 if self.trials:
197 _trial_paths = [t.logdir for t in self.trials]
198 else:
199 logger.warning("No `self.trials`. Drawing logdirs from checkpoint "
200 "file. This may result in some information that is "
201 "out of sync, as checkpointing is periodic.")
202 _trial_paths = [
203 checkpoint["logdir"] for checkpoint in self._checkpoints
204 ]
205 if not _trial_paths:
206 raise TuneError("No trials found.")
207 return _trial_paths
208
[end of python/ray/tune/analysis/experiment_analysis.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/python/ray/tune/analysis/experiment_analysis.py b/python/ray/tune/analysis/experiment_analysis.py
--- a/python/ray/tune/analysis/experiment_analysis.py
+++ b/python/ray/tune/analysis/experiment_analysis.py
@@ -75,7 +75,7 @@
mode (str): One of [min, max].
"""
- df = self.dataframe()
+ df = self.dataframe(metric=metric, mode=mode)
if mode == "max":
return df.iloc[df[metric].idxmax()].logdir
elif mode == "min":
|
{"golden_diff": "diff --git a/python/ray/tune/analysis/experiment_analysis.py b/python/ray/tune/analysis/experiment_analysis.py\n--- a/python/ray/tune/analysis/experiment_analysis.py\n+++ b/python/ray/tune/analysis/experiment_analysis.py\n@@ -75,7 +75,7 @@\n mode (str): One of [min, max].\n \n \"\"\"\n- df = self.dataframe()\n+ df = self.dataframe(metric=metric, mode=mode)\n if mode == \"max\":\n return df.iloc[df[metric].idxmax()].logdir\n elif mode == \"min\":\n", "issue": "[Tune] Experiment Analysis get_best behaviour\nHi,\r\nIn their current version, the [`get_best_config`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L56) and [`get_best_logdir`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L70) methods of the `Analysis` object may consider different Trials as the best one:\r\n- `get_best_config` will first retrieve the best row of each trial dataframe and then select the best trial from these rows.\r\n- `get_best_logdir` will first retrieve the last row of each trial and then selects the best one.\r\n\r\nIs it the expected behaviour ? \r\nIf it isn't, I think that the correct way of doing it is the first one. This could be done by simply passing the `metric` and `max` arguments to the [`self.dataframe`](https://github.com/ray-project/ray/blob/ed89897a311fbe63afdd5fa05a4ef8b7576ca6a4/python/ray/tune/analysis/experiment_analysis.py#L78) call in `get_best_dir`.\r\n\r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport json\nimport logging\nimport os\n\ntry:\n import pandas as pd\nexcept ImportError:\n pd = None\n\nfrom ray.tune.error import TuneError\nfrom ray.tune.result import EXPR_PROGRESS_FILE, EXPR_PARAM_FILE, CONFIG_PREFIX\n\nlogger = logging.getLogger(__name__)\n\n\nclass Analysis(object):\n \"\"\"Analyze all results from a directory of experiments.\"\"\"\n\n def __init__(self, experiment_dir):\n experiment_dir = os.path.expanduser(experiment_dir)\n if not os.path.isdir(experiment_dir):\n raise ValueError(\n \"{} is not a valid directory.\".format(experiment_dir))\n self._experiment_dir = experiment_dir\n self._configs = {}\n self._trial_dataframes = {}\n\n if not pd:\n logger.warning(\n \"pandas not installed. Run `pip install pandas` for \"\n \"Analysis utilities.\")\n else:\n self.fetch_trial_dataframes()\n\n def dataframe(self, metric=None, mode=None):\n \"\"\"Returns a pandas.DataFrame object constructed from the trials.\n\n Args:\n metric (str): Key for trial info to order on.\n If None, uses last result.\n mode (str): One of [min, max].\n\n \"\"\"\n rows = self._retrieve_rows(metric=metric, mode=mode)\n all_configs = self.get_all_configs(prefix=True)\n for path, config in all_configs.items():\n if path in rows:\n rows[path].update(config)\n rows[path].update(logdir=path)\n return pd.DataFrame(list(rows.values()))\n\n def get_best_config(self, metric, mode=\"max\"):\n \"\"\"Retrieve the best config corresponding to the trial.\n\n Args:\n metric (str): Key for trial info to order on.\n mode (str): One of [min, max].\n\n \"\"\"\n rows = self._retrieve_rows(metric=metric, mode=mode)\n all_configs = self.get_all_configs()\n compare_op = max if mode == \"max\" else min\n best_path = compare_op(rows, key=lambda k: rows[k][metric])\n return all_configs[best_path]\n\n def get_best_logdir(self, metric, mode=\"max\"):\n \"\"\"Retrieve the logdir corresponding to the best trial.\n\n Args:\n metric (str): Key for trial info to order on.\n mode (str): One of [min, max].\n\n \"\"\"\n df = self.dataframe()\n if mode == \"max\":\n return df.iloc[df[metric].idxmax()].logdir\n elif mode == \"min\":\n return df.iloc[df[metric].idxmin()].logdir\n\n def fetch_trial_dataframes(self):\n fail_count = 0\n for path in self._get_trial_paths():\n try:\n self.trial_dataframes[path] = pd.read_csv(\n os.path.join(path, EXPR_PROGRESS_FILE))\n except Exception:\n fail_count += 1\n\n if fail_count:\n logger.debug(\n \"Couldn't read results from {} paths\".format(fail_count))\n return self.trial_dataframes\n\n def get_all_configs(self, prefix=False):\n \"\"\"Returns a list of all configurations.\n\n Parameters:\n prefix (bool): If True, flattens the config dict\n and prepends `config/`.\n \"\"\"\n fail_count = 0\n for path in self._get_trial_paths():\n try:\n with open(os.path.join(path, EXPR_PARAM_FILE)) as f:\n config = json.load(f)\n if prefix:\n for k in list(config):\n config[CONFIG_PREFIX + k] = config.pop(k)\n self._configs[path] = config\n except Exception:\n fail_count += 1\n\n if fail_count:\n logger.warning(\n \"Couldn't read config from {} paths\".format(fail_count))\n return self._configs\n\n def _retrieve_rows(self, metric=None, mode=None):\n assert mode is None or mode in [\"max\", \"min\"]\n rows = {}\n for path, df in self.trial_dataframes.items():\n if mode == \"max\":\n idx = df[metric].idxmax()\n elif mode == \"min\":\n idx = df[metric].idxmin()\n else:\n idx = -1\n rows[path] = df.iloc[idx].to_dict()\n\n return rows\n\n def _get_trial_paths(self):\n _trial_paths = []\n for trial_path, _, files in os.walk(self._experiment_dir):\n if EXPR_PROGRESS_FILE in files:\n _trial_paths += [trial_path]\n\n if not _trial_paths:\n raise TuneError(\"No trials found in {}.\".format(\n self._experiment_dir))\n return _trial_paths\n\n @property\n def trial_dataframes(self):\n \"\"\"List of all dataframes of the trials.\"\"\"\n return self._trial_dataframes\n\n\nclass ExperimentAnalysis(Analysis):\n \"\"\"Analyze results from a Tune experiment.\n\n Parameters:\n experiment_checkpoint_path (str): Path to a json file\n representing an experiment state. Corresponds to\n Experiment.local_dir/Experiment.name/experiment_state.json\n\n Example:\n >>> tune.run(my_trainable, name=\"my_exp\", local_dir=\"~/tune_results\")\n >>> analysis = ExperimentAnalysis(\n >>> experiment_checkpoint_path=\"~/tune_results/my_exp/state.json\")\n \"\"\"\n\n def __init__(self, experiment_checkpoint_path, trials=None):\n \"\"\"Initializer.\n\n Args:\n experiment_path (str): Path to where experiment is located.\n trials (list|None): List of trials that can be accessed via\n `analysis.trials`.\n \"\"\"\n with open(experiment_checkpoint_path) as f:\n _experiment_state = json.load(f)\n self._experiment_state = _experiment_state\n\n if \"checkpoints\" not in _experiment_state:\n raise TuneError(\"Experiment state invalid; no checkpoints found.\")\n self._checkpoints = _experiment_state[\"checkpoints\"]\n self.trials = trials\n super(ExperimentAnalysis, self).__init__(\n os.path.dirname(experiment_checkpoint_path))\n\n def stats(self):\n \"\"\"Returns a dictionary of the statistics of the experiment.\"\"\"\n return self._experiment_state.get(\"stats\")\n\n def runner_data(self):\n \"\"\"Returns a dictionary of the TrialRunner data.\"\"\"\n return self._experiment_state.get(\"runner_data\")\n\n def _get_trial_paths(self):\n \"\"\"Overwrites Analysis to only have trials of one experiment.\"\"\"\n if self.trials:\n _trial_paths = [t.logdir for t in self.trials]\n else:\n logger.warning(\"No `self.trials`. Drawing logdirs from checkpoint \"\n \"file. This may result in some information that is \"\n \"out of sync, as checkpointing is periodic.\")\n _trial_paths = [\n checkpoint[\"logdir\"] for checkpoint in self._checkpoints\n ]\n if not _trial_paths:\n raise TuneError(\"No trials found.\")\n return _trial_paths\n", "path": "python/ray/tune/analysis/experiment_analysis.py"}]}
| 2,900 | 134 |
gh_patches_debug_6636
|
rasdani/github-patches
|
git_diff
|
arviz-devs__arviz-801
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pm.compare seems not compatible with az.plot_compare
If I try to run two following commands
```python
df_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})
az.plot_compare(df_comp_WAIC);
```
I get the error:
```python
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-208-a89027c76a69> in <module>
3 df_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})
----> 4 az.plot_compare(df_comp_WAIC);
~/anaconda3/lib/python3.6/site-packages/arviz/plots/compareplot.py in plot_compare(comp_df, insample_dev, plot_standard_error, plot_ic_diff, figsize, textsize, plot_kwargs, ax)
99 raise ValueError(
100 "comp_df must contain one of the following"
--> 101 " information criterion: {}".format(_information_criterion)
102 )
103
ValueError: comp_df must contain one of the following information criterion: ['waic', 'loo']
```
Both pymc3 and arviz are the latest from github (using pip command)
</issue>
<code>
[start of arviz/plots/compareplot.py]
1 """Summary plot for model comparison."""
2 import numpy as np
3 import matplotlib.pyplot as plt
4 from .plot_utils import _scale_fig_size
5
6
7 def plot_compare(
8 comp_df,
9 insample_dev=True,
10 plot_standard_error=True,
11 plot_ic_diff=True,
12 order_by_rank=True,
13 figsize=None,
14 textsize=None,
15 plot_kwargs=None,
16 ax=None,
17 ):
18 """
19 Summary plot for model comparison.
20
21 This plot is in the style of the one used in the book Statistical Rethinking (Chapter 6)
22 by Richard McElreath.
23
24 Notes
25 -----
26 Defaults to comparing Widely Accepted Information Criterion (WAIC) if present in comp_df column,
27 otherwise compares Leave-one-out (loo)
28
29
30 Parameters
31 ----------
32 comp_df : pd.DataFrame
33 Result of the `az.compare()` method
34 insample_dev : bool, optional
35 Plot in-sample deviance, that is the value of the information criteria without the
36 penalization given by the effective number of parameters (pIC). Defaults to True
37 plot_standard_error : bool, optional
38 Plot the standard error of the information criteria estimate. Defaults to True
39 plot_ic_diff : bool, optional
40 Plot standard error of the difference in information criteria between each model
41 and the top-ranked model. Defaults to True
42 order_by_rank : bool
43 If True (default) ensure the best model is used as reference.
44 figsize : tuple, optional
45 If None, size is (6, num of models) inches
46 textsize: float
47 Text size scaling factor for labels, titles and lines. If None it will be autoscaled based
48 on figsize.
49 plot_kwargs : dict, optional
50 Optional arguments for plot elements. Currently accepts 'color_ic',
51 'marker_ic', 'color_insample_dev', 'marker_insample_dev', 'color_dse',
52 'marker_dse', 'ls_min_ic' 'color_ls_min_ic', 'fontsize'
53 ax : axes, optional
54 Matplotlib axes
55
56 Returns
57 -------
58 ax : matplotlib axes
59
60
61 Examples
62 --------
63 Show default compare plot
64
65 .. plot::
66 :context: close-figs
67
68 >>> import arviz as az
69 >>> model_compare = az.compare({'Centered 8 schools': az.load_arviz_data('centered_eight'),
70 >>> 'Non-centered 8 schools': az.load_arviz_data('non_centered_eight')})
71 >>> az.plot_compare(model_compare)
72
73 Plot standard error and information criteria difference only
74
75 .. plot::
76 :context: close-figs
77
78 >>> az.plot_compare(model_compare, insample_dev=False)
79
80 """
81 if figsize is None:
82 figsize = (6, len(comp_df))
83
84 figsize, ax_labelsize, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)
85
86 if ax is None:
87 _, ax = plt.subplots(figsize=figsize, constrained_layout=True)
88
89 if plot_kwargs is None:
90 plot_kwargs = {}
91
92 yticks_pos, step = np.linspace(0, -1, (comp_df.shape[0] * 2) - 1, retstep=True)
93 yticks_pos[1::2] = yticks_pos[1::2] + step / 2
94
95 yticks_labels = [""] * len(yticks_pos)
96
97 _information_criterion = ["waic", "loo"]
98 for information_criterion in _information_criterion:
99 if information_criterion in comp_df.columns:
100 break
101 else:
102 raise ValueError(
103 "comp_df must contain one of the following"
104 " information criterion: {}".format(_information_criterion)
105 )
106
107 if order_by_rank:
108 comp_df.sort_values(by="rank", inplace=True)
109
110 if plot_ic_diff:
111 yticks_labels[0] = comp_df.index[0]
112 yticks_labels[2::2] = comp_df.index[1:]
113 ax.set_yticks(yticks_pos)
114 ax.errorbar(
115 x=comp_df[information_criterion].iloc[1:],
116 y=yticks_pos[1::2],
117 xerr=comp_df.dse[1:],
118 color=plot_kwargs.get("color_dse", "grey"),
119 fmt=plot_kwargs.get("marker_dse", "^"),
120 mew=linewidth,
121 elinewidth=linewidth,
122 )
123
124 else:
125 yticks_labels = comp_df.index
126 ax.set_yticks(yticks_pos[::2])
127
128 if plot_standard_error:
129 ax.errorbar(
130 x=comp_df[information_criterion],
131 y=yticks_pos[::2],
132 xerr=comp_df.se,
133 color=plot_kwargs.get("color_ic", "k"),
134 fmt=plot_kwargs.get("marker_ic", "o"),
135 mfc="None",
136 mew=linewidth,
137 lw=linewidth,
138 )
139 else:
140 ax.plot(
141 comp_df[information_criterion],
142 yticks_pos[::2],
143 color=plot_kwargs.get("color_ic", "k"),
144 marker=plot_kwargs.get("marker_ic", "o"),
145 mfc="None",
146 mew=linewidth,
147 lw=0,
148 )
149
150 if insample_dev:
151 ax.plot(
152 comp_df[information_criterion] - (2 * comp_df["p_" + information_criterion]),
153 yticks_pos[::2],
154 color=plot_kwargs.get("color_insample_dev", "k"),
155 marker=plot_kwargs.get("marker_insample_dev", "o"),
156 mew=linewidth,
157 lw=0,
158 )
159
160 ax.axvline(
161 comp_df[information_criterion].iloc[0],
162 ls=plot_kwargs.get("ls_min_ic", "--"),
163 color=plot_kwargs.get("color_ls_min_ic", "grey"),
164 lw=linewidth,
165 )
166
167 scale_col = information_criterion + "_scale"
168 if scale_col in comp_df:
169 scale = comp_df[scale_col].iloc[0].capitalize()
170 else:
171 scale = "Deviance"
172 ax.set_xlabel(scale, fontsize=ax_labelsize)
173 ax.set_yticklabels(yticks_labels)
174 ax.set_ylim(-1 + step, 0 - step)
175 ax.tick_params(labelsize=xt_labelsize)
176
177 return ax
178
[end of arviz/plots/compareplot.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/arviz/plots/compareplot.py b/arviz/plots/compareplot.py
--- a/arviz/plots/compareplot.py
+++ b/arviz/plots/compareplot.py
@@ -95,8 +95,9 @@
yticks_labels = [""] * len(yticks_pos)
_information_criterion = ["waic", "loo"]
+ column_index = [c.lower() for c in comp_df.columns]
for information_criterion in _information_criterion:
- if information_criterion in comp_df.columns:
+ if information_criterion in column_index:
break
else:
raise ValueError(
|
{"golden_diff": "diff --git a/arviz/plots/compareplot.py b/arviz/plots/compareplot.py\n--- a/arviz/plots/compareplot.py\n+++ b/arviz/plots/compareplot.py\n@@ -95,8 +95,9 @@\n yticks_labels = [\"\"] * len(yticks_pos)\r\n \r\n _information_criterion = [\"waic\", \"loo\"]\r\n+ column_index = [c.lower() for c in comp_df.columns]\r\n for information_criterion in _information_criterion:\r\n- if information_criterion in comp_df.columns:\r\n+ if information_criterion in column_index:\r\n break\r\n else:\r\n raise ValueError(\n", "issue": "pm.compare seems not compatible with az.plot_compare\nIf I try to run two following commands\r\n```python\r\ndf_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})\r\naz.plot_compare(df_comp_WAIC);\r\n```\r\nI get the error:\r\n```python\r\n---------------------------------------------------------------------------\r\nValueError Traceback (most recent call last)\r\n<ipython-input-208-a89027c76a69> in <module>\r\n 3 df_comp_WAIC = pm.compare({models[0]: traces[0], models[1]: traces[1]})\r\n----> 4 az.plot_compare(df_comp_WAIC);\r\n\r\n~/anaconda3/lib/python3.6/site-packages/arviz/plots/compareplot.py in plot_compare(comp_df, insample_dev, plot_standard_error, plot_ic_diff, figsize, textsize, plot_kwargs, ax)\r\n 99 raise ValueError(\r\n 100 \"comp_df must contain one of the following\"\r\n--> 101 \" information criterion: {}\".format(_information_criterion)\r\n 102 )\r\n 103 \r\n\r\nValueError: comp_df must contain one of the following information criterion: ['waic', 'loo']\r\n```\r\n\r\nBoth pymc3 and arviz are the latest from github (using pip command)\n", "before_files": [{"content": "\"\"\"Summary plot for model comparison.\"\"\"\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom .plot_utils import _scale_fig_size\r\n\r\n\r\ndef plot_compare(\r\n comp_df,\r\n insample_dev=True,\r\n plot_standard_error=True,\r\n plot_ic_diff=True,\r\n order_by_rank=True,\r\n figsize=None,\r\n textsize=None,\r\n plot_kwargs=None,\r\n ax=None,\r\n):\r\n \"\"\"\r\n Summary plot for model comparison.\r\n\r\n This plot is in the style of the one used in the book Statistical Rethinking (Chapter 6)\r\n by Richard McElreath.\r\n\r\n Notes\r\n -----\r\n Defaults to comparing Widely Accepted Information Criterion (WAIC) if present in comp_df column,\r\n otherwise compares Leave-one-out (loo)\r\n\r\n\r\n Parameters\r\n ----------\r\n comp_df : pd.DataFrame\r\n Result of the `az.compare()` method\r\n insample_dev : bool, optional\r\n Plot in-sample deviance, that is the value of the information criteria without the\r\n penalization given by the effective number of parameters (pIC). Defaults to True\r\n plot_standard_error : bool, optional\r\n Plot the standard error of the information criteria estimate. Defaults to True\r\n plot_ic_diff : bool, optional\r\n Plot standard error of the difference in information criteria between each model\r\n and the top-ranked model. Defaults to True\r\n order_by_rank : bool\r\n If True (default) ensure the best model is used as reference.\r\n figsize : tuple, optional\r\n If None, size is (6, num of models) inches\r\n textsize: float\r\n Text size scaling factor for labels, titles and lines. If None it will be autoscaled based\r\n on figsize.\r\n plot_kwargs : dict, optional\r\n Optional arguments for plot elements. Currently accepts 'color_ic',\r\n 'marker_ic', 'color_insample_dev', 'marker_insample_dev', 'color_dse',\r\n 'marker_dse', 'ls_min_ic' 'color_ls_min_ic', 'fontsize'\r\n ax : axes, optional\r\n Matplotlib axes\r\n\r\n Returns\r\n -------\r\n ax : matplotlib axes\r\n\r\n\r\n Examples\r\n --------\r\n Show default compare plot\r\n\r\n .. plot::\r\n :context: close-figs\r\n\r\n >>> import arviz as az\r\n >>> model_compare = az.compare({'Centered 8 schools': az.load_arviz_data('centered_eight'),\r\n >>> 'Non-centered 8 schools': az.load_arviz_data('non_centered_eight')})\r\n >>> az.plot_compare(model_compare)\r\n\r\n Plot standard error and information criteria difference only\r\n\r\n .. plot::\r\n :context: close-figs\r\n\r\n >>> az.plot_compare(model_compare, insample_dev=False)\r\n\r\n \"\"\"\r\n if figsize is None:\r\n figsize = (6, len(comp_df))\r\n\r\n figsize, ax_labelsize, _, xt_labelsize, linewidth, _ = _scale_fig_size(figsize, textsize, 1, 1)\r\n\r\n if ax is None:\r\n _, ax = plt.subplots(figsize=figsize, constrained_layout=True)\r\n\r\n if plot_kwargs is None:\r\n plot_kwargs = {}\r\n\r\n yticks_pos, step = np.linspace(0, -1, (comp_df.shape[0] * 2) - 1, retstep=True)\r\n yticks_pos[1::2] = yticks_pos[1::2] + step / 2\r\n\r\n yticks_labels = [\"\"] * len(yticks_pos)\r\n\r\n _information_criterion = [\"waic\", \"loo\"]\r\n for information_criterion in _information_criterion:\r\n if information_criterion in comp_df.columns:\r\n break\r\n else:\r\n raise ValueError(\r\n \"comp_df must contain one of the following\"\r\n \" information criterion: {}\".format(_information_criterion)\r\n )\r\n\r\n if order_by_rank:\r\n comp_df.sort_values(by=\"rank\", inplace=True)\r\n\r\n if plot_ic_diff:\r\n yticks_labels[0] = comp_df.index[0]\r\n yticks_labels[2::2] = comp_df.index[1:]\r\n ax.set_yticks(yticks_pos)\r\n ax.errorbar(\r\n x=comp_df[information_criterion].iloc[1:],\r\n y=yticks_pos[1::2],\r\n xerr=comp_df.dse[1:],\r\n color=plot_kwargs.get(\"color_dse\", \"grey\"),\r\n fmt=plot_kwargs.get(\"marker_dse\", \"^\"),\r\n mew=linewidth,\r\n elinewidth=linewidth,\r\n )\r\n\r\n else:\r\n yticks_labels = comp_df.index\r\n ax.set_yticks(yticks_pos[::2])\r\n\r\n if plot_standard_error:\r\n ax.errorbar(\r\n x=comp_df[information_criterion],\r\n y=yticks_pos[::2],\r\n xerr=comp_df.se,\r\n color=plot_kwargs.get(\"color_ic\", \"k\"),\r\n fmt=plot_kwargs.get(\"marker_ic\", \"o\"),\r\n mfc=\"None\",\r\n mew=linewidth,\r\n lw=linewidth,\r\n )\r\n else:\r\n ax.plot(\r\n comp_df[information_criterion],\r\n yticks_pos[::2],\r\n color=plot_kwargs.get(\"color_ic\", \"k\"),\r\n marker=plot_kwargs.get(\"marker_ic\", \"o\"),\r\n mfc=\"None\",\r\n mew=linewidth,\r\n lw=0,\r\n )\r\n\r\n if insample_dev:\r\n ax.plot(\r\n comp_df[information_criterion] - (2 * comp_df[\"p_\" + information_criterion]),\r\n yticks_pos[::2],\r\n color=plot_kwargs.get(\"color_insample_dev\", \"k\"),\r\n marker=plot_kwargs.get(\"marker_insample_dev\", \"o\"),\r\n mew=linewidth,\r\n lw=0,\r\n )\r\n\r\n ax.axvline(\r\n comp_df[information_criterion].iloc[0],\r\n ls=plot_kwargs.get(\"ls_min_ic\", \"--\"),\r\n color=plot_kwargs.get(\"color_ls_min_ic\", \"grey\"),\r\n lw=linewidth,\r\n )\r\n\r\n scale_col = information_criterion + \"_scale\"\r\n if scale_col in comp_df:\r\n scale = comp_df[scale_col].iloc[0].capitalize()\r\n else:\r\n scale = \"Deviance\"\r\n ax.set_xlabel(scale, fontsize=ax_labelsize)\r\n ax.set_yticklabels(yticks_labels)\r\n ax.set_ylim(-1 + step, 0 - step)\r\n ax.tick_params(labelsize=xt_labelsize)\r\n\r\n return ax\r\n", "path": "arviz/plots/compareplot.py"}]}
| 2,634 | 141 |
gh_patches_debug_30853
|
rasdani/github-patches
|
git_diff
|
pymedusa__Medusa-4622
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Emby notifications not working
Branch: master
Commit: 7cfc79d5280b719c6288090fb805521dfc0402cd
Version: v0.2.6
Database: 44.11
Python Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]
SSL Version: | OpenSSL 1.0.1t 3 May 2016
OS: | Linux-4.9.61+-armv7l-with-debian-8.11
Locale: | en_GB.UTF-8
I haven't changed the IP, port or API of the Emby device but notifications no longer work.
This is in the log:
```
2018-07-05 22:43:11 WARNING Thread_34 :: [7cfc79d] EMBY: Warning: Unable to contact Emby at http://**********/emby/Notifications/Admin: 500 Server Error: Internal Server Error for url: http://**********/emby/Notifications/Admin
```
I think this has just started with the most recent update of Medusa. There haven't been any Emby updates for a couple of weeks. Restarting Emby - no difference.
Restated Medusa and it updated to:
Branch: master
Commit: e7c4ff3bc9a48b47c932b0e40a539d62e3a62f64
Version: v0.2.6
Database: 44.11
Python Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]
SSL Version: | OpenSSL 1.0.1t 3 May 2016
OS: | Linux-4.9.61+-armv7l-with-debian-8.11
Locale: | en_GB.UTF-8
But the problem persists.
Thanks for checking out.
</issue>
<code>
[start of medusa/notifiers/emby.py]
1 # coding=utf-8
2
3 """Emby notifier module."""
4 from __future__ import unicode_literals
5
6 import logging
7
8 from medusa import app
9 from medusa.helper.exceptions import ex
10 from medusa.indexers.indexer_config import INDEXER_TVDBV2, INDEXER_TVRAGE
11 from medusa.indexers.utils import indexer_id_to_name, mappings
12 from medusa.logger.adapters.style import BraceAdapter
13 from medusa.session.core import MedusaSession
14
15 from requests.exceptions import HTTPError, RequestException
16
17 from six import text_type as str
18
19 log = BraceAdapter(logging.getLogger(__name__))
20 log.logger.addHandler(logging.NullHandler())
21
22
23 class Notifier(object):
24 """Emby notifier class."""
25
26 def __init__(self):
27 self.session = MedusaSession()
28
29 def _notify_emby(self, message, host=None, emby_apikey=None):
30 """
31 Notify Emby host via HTTP API.
32
33 :return: True for no issue or False if there was an error
34 """
35 # fill in omitted parameters
36 if not host:
37 host = app.EMBY_HOST
38 if not emby_apikey:
39 emby_apikey = app.EMBY_APIKEY
40
41 url = 'http://{host}/emby/Notifications/Admin'.format(host=host)
42 try:
43 resp = self.session.post(
44 url=url,
45 data={
46 'Name': 'Medusa',
47 'Description': message,
48 'ImageUrl': app.LOGO_URL
49 },
50 headers={
51 'X-MediaBrowser-Token': emby_apikey,
52 'Content-Type': 'application/json'
53 }
54 )
55 resp.raise_for_status()
56
57 if resp.content:
58 log.debug('EMBY: HTTP response: {0}', resp.content.replace('\n', ''))
59
60 log.info('EMBY: Successfully sent a test notification.')
61 return True
62
63 except (HTTPError, RequestException) as error:
64 log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',
65 {'url': url, 'error': ex(error)})
66 return False
67
68
69 ##############################################################################
70 # Public functions
71 ##############################################################################
72
73 def test_notify(self, host, emby_apikey):
74 """
75 Sends a test notification.
76
77 :return: True for no issue or False if there was an error
78 """
79 return self._notify_emby('This is a test notification from Medusa', host, emby_apikey)
80
81 def update_library(self, show=None):
82 """
83 Update the Emby Media Server host via HTTP API.
84
85 :return: True for no issue or False if there was an error
86 """
87 if app.USE_EMBY:
88 if not app.EMBY_HOST:
89 log.debug('EMBY: No host specified, check your settings')
90 return False
91
92 if show:
93 # EMBY only supports TVDB ids
94 provider = 'tvdbid'
95 if show.indexer == INDEXER_TVDBV2:
96 tvdb_id = show.indexerid
97 else:
98 # Try using external ids to get a TVDB id
99 tvdb_id = show.externals.get(mappings[INDEXER_TVDBV2], None)
100
101 if tvdb_id is None:
102 if show.indexer == INDEXER_TVRAGE:
103 log.warning('EMBY: TVRage indexer no longer valid')
104 else:
105 log.warning(
106 'EMBY: Unable to find a TVDB ID for {series},'
107 ' and {indexer} indexer is unsupported',
108 {'series': show.name, 'indexer': indexer_id_to_name(show.indexer)}
109 )
110 return False
111
112 params = {
113 provider: str(tvdb_id)
114 }
115 else:
116 params = {}
117
118 url = 'http://{host}/emby/Library/Series/Updated'.format(host=app.EMBY_HOST)
119 try:
120 resp = self.session.post(
121 url=url,
122 params=params,
123 headers={
124 'X-MediaBrowser-Token': app.EMBY_APIKEY
125 }
126 )
127 resp.raise_for_status()
128
129 if resp.content:
130 log.debug('EMBY: HTTP response: {0}', resp.content.replace('\n', ''))
131
132 log.info('EMBY: Successfully sent a "Series Library Updated" command.')
133 return True
134
135 except (HTTPError, RequestException) as error:
136 log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',
137 {'url': url, 'error': ex(error)})
138 return False
139
[end of medusa/notifiers/emby.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/medusa/notifiers/emby.py b/medusa/notifiers/emby.py
--- a/medusa/notifiers/emby.py
+++ b/medusa/notifiers/emby.py
@@ -3,6 +3,7 @@
"""Emby notifier module."""
from __future__ import unicode_literals
+import json
import logging
from medusa import app
@@ -14,7 +15,7 @@
from requests.exceptions import HTTPError, RequestException
-from six import text_type as str
+from six import text_type
log = BraceAdapter(logging.getLogger(__name__))
log.logger.addHandler(logging.NullHandler())
@@ -39,14 +40,15 @@
emby_apikey = app.EMBY_APIKEY
url = 'http://{host}/emby/Notifications/Admin'.format(host=host)
+ data = json.dumps({
+ 'Name': 'Medusa',
+ 'Description': message,
+ 'ImageUrl': app.LOGO_URL
+ })
try:
resp = self.session.post(
url=url,
- data={
- 'Name': 'Medusa',
- 'Description': message,
- 'ImageUrl': app.LOGO_URL
- },
+ data=data,
headers={
'X-MediaBrowser-Token': emby_apikey,
'Content-Type': 'application/json'
@@ -110,7 +112,7 @@
return False
params = {
- provider: str(tvdb_id)
+ provider: text_type(tvdb_id)
}
else:
params = {}
|
{"golden_diff": "diff --git a/medusa/notifiers/emby.py b/medusa/notifiers/emby.py\n--- a/medusa/notifiers/emby.py\n+++ b/medusa/notifiers/emby.py\n@@ -3,6 +3,7 @@\n \"\"\"Emby notifier module.\"\"\"\n from __future__ import unicode_literals\n \n+import json\n import logging\n \n from medusa import app\n@@ -14,7 +15,7 @@\n \n from requests.exceptions import HTTPError, RequestException\n \n-from six import text_type as str\n+from six import text_type\n \n log = BraceAdapter(logging.getLogger(__name__))\n log.logger.addHandler(logging.NullHandler())\n@@ -39,14 +40,15 @@\n emby_apikey = app.EMBY_APIKEY\n \n url = 'http://{host}/emby/Notifications/Admin'.format(host=host)\n+ data = json.dumps({\n+ 'Name': 'Medusa',\n+ 'Description': message,\n+ 'ImageUrl': app.LOGO_URL\n+ })\n try:\n resp = self.session.post(\n url=url,\n- data={\n- 'Name': 'Medusa',\n- 'Description': message,\n- 'ImageUrl': app.LOGO_URL\n- },\n+ data=data,\n headers={\n 'X-MediaBrowser-Token': emby_apikey,\n 'Content-Type': 'application/json'\n@@ -110,7 +112,7 @@\n return False\n \n params = {\n- provider: str(tvdb_id)\n+ provider: text_type(tvdb_id)\n }\n else:\n params = {}\n", "issue": "Emby notifications not working\n\r\nBranch:\u00a0master\r\nCommit:\u00a07cfc79d5280b719c6288090fb805521dfc0402cd\r\nVersion:\u00a0v0.2.6\r\nDatabase:\u00a044.11\r\nPython Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]\r\nSSL Version: | OpenSSL 1.0.1t 3 May 2016\r\nOS: | Linux-4.9.61+-armv7l-with-debian-8.11\r\nLocale: | en_GB.UTF-8\r\n\r\nI haven't changed the IP, port or API of the Emby device but notifications no longer work. \r\n\r\nThis is in the log:\r\n```\r\n2018-07-05 22:43:11 WARNING Thread_34 :: [7cfc79d] EMBY: Warning: Unable to contact Emby at http://**********/emby/Notifications/Admin: 500 Server Error: Internal Server Error for url: http://**********/emby/Notifications/Admin\r\n```\r\n\r\nI think this has just started with the most recent update of Medusa. There haven't been any Emby updates for a couple of weeks. Restarting Emby - no difference. \r\n\r\nRestated Medusa and it updated to:\r\n\r\nBranch:\u00a0master\r\nCommit:\u00a0e7c4ff3bc9a48b47c932b0e40a539d62e3a62f64\r\nVersion:\u00a0v0.2.6\r\nDatabase:\u00a044.11\r\nPython Version: | 2.7.9 (default, Aug 13 2016, 17:56:53) [GCC 4.9.2]\r\nSSL Version: | OpenSSL 1.0.1t 3 May 2016\r\nOS: | Linux-4.9.61+-armv7l-with-debian-8.11\r\nLocale: | en_GB.UTF-8\r\n\r\nBut the problem persists.\r\n\r\nThanks for checking out.\r\n\n", "before_files": [{"content": "# coding=utf-8\n\n\"\"\"Emby notifier module.\"\"\"\nfrom __future__ import unicode_literals\n\nimport logging\n\nfrom medusa import app\nfrom medusa.helper.exceptions import ex\nfrom medusa.indexers.indexer_config import INDEXER_TVDBV2, INDEXER_TVRAGE\nfrom medusa.indexers.utils import indexer_id_to_name, mappings\nfrom medusa.logger.adapters.style import BraceAdapter\nfrom medusa.session.core import MedusaSession\n\nfrom requests.exceptions import HTTPError, RequestException\n\nfrom six import text_type as str\n\nlog = BraceAdapter(logging.getLogger(__name__))\nlog.logger.addHandler(logging.NullHandler())\n\n\nclass Notifier(object):\n \"\"\"Emby notifier class.\"\"\"\n\n def __init__(self):\n self.session = MedusaSession()\n\n def _notify_emby(self, message, host=None, emby_apikey=None):\n \"\"\"\n Notify Emby host via HTTP API.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n # fill in omitted parameters\n if not host:\n host = app.EMBY_HOST\n if not emby_apikey:\n emby_apikey = app.EMBY_APIKEY\n\n url = 'http://{host}/emby/Notifications/Admin'.format(host=host)\n try:\n resp = self.session.post(\n url=url,\n data={\n 'Name': 'Medusa',\n 'Description': message,\n 'ImageUrl': app.LOGO_URL\n },\n headers={\n 'X-MediaBrowser-Token': emby_apikey,\n 'Content-Type': 'application/json'\n }\n )\n resp.raise_for_status()\n\n if resp.content:\n log.debug('EMBY: HTTP response: {0}', resp.content.replace('\\n', ''))\n\n log.info('EMBY: Successfully sent a test notification.')\n return True\n\n except (HTTPError, RequestException) as error:\n log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',\n {'url': url, 'error': ex(error)})\n return False\n\n\n##############################################################################\n# Public functions\n##############################################################################\n\n def test_notify(self, host, emby_apikey):\n \"\"\"\n Sends a test notification.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n return self._notify_emby('This is a test notification from Medusa', host, emby_apikey)\n\n def update_library(self, show=None):\n \"\"\"\n Update the Emby Media Server host via HTTP API.\n\n :return: True for no issue or False if there was an error\n \"\"\"\n if app.USE_EMBY:\n if not app.EMBY_HOST:\n log.debug('EMBY: No host specified, check your settings')\n return False\n\n if show:\n # EMBY only supports TVDB ids\n provider = 'tvdbid'\n if show.indexer == INDEXER_TVDBV2:\n tvdb_id = show.indexerid\n else:\n # Try using external ids to get a TVDB id\n tvdb_id = show.externals.get(mappings[INDEXER_TVDBV2], None)\n\n if tvdb_id is None:\n if show.indexer == INDEXER_TVRAGE:\n log.warning('EMBY: TVRage indexer no longer valid')\n else:\n log.warning(\n 'EMBY: Unable to find a TVDB ID for {series},'\n ' and {indexer} indexer is unsupported',\n {'series': show.name, 'indexer': indexer_id_to_name(show.indexer)}\n )\n return False\n\n params = {\n provider: str(tvdb_id)\n }\n else:\n params = {}\n\n url = 'http://{host}/emby/Library/Series/Updated'.format(host=app.EMBY_HOST)\n try:\n resp = self.session.post(\n url=url,\n params=params,\n headers={\n 'X-MediaBrowser-Token': app.EMBY_APIKEY\n }\n )\n resp.raise_for_status()\n\n if resp.content:\n log.debug('EMBY: HTTP response: {0}', resp.content.replace('\\n', ''))\n\n log.info('EMBY: Successfully sent a \"Series Library Updated\" command.')\n return True\n\n except (HTTPError, RequestException) as error:\n log.warning('EMBY: Warning: Unable to contact Emby at {url}: {error}',\n {'url': url, 'error': ex(error)})\n return False\n", "path": "medusa/notifiers/emby.py"}]}
| 2,326 | 344 |
gh_patches_debug_20936
|
rasdani/github-patches
|
git_diff
|
Zeroto521__my-data-toolkit-706
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ENH: New geoaccessor to generate great circle distances matrix
<!--
Thanks for contributing a pull request!
Please follow these standard acronyms to start the commit message:
- ENH: enhancement
- BUG: bug fix
- DOC: documentation
- TYP: type annotations
- TST: addition or modification of tests
- MAINT: maintenance commit (refactoring, typos, etc.)
- BLD: change related to building
- REL: related to releasing
- API: an (incompatible) API change
- DEP: deprecate something, or remove a deprecated object
- DEV: development tool or utility
- REV: revert an earlier commit
- PERF: performance improvement
- BOT: always commit via a bot
- CI: related to CI or CD
- CLN: Code cleanup
-->
- [x] closes #699
- [ ] whatsnew entry
</issue>
<code>
[start of dtoolkit/geoaccessor/geoseries/geodistance_matrix.py]
1 from __future__ import annotations
2
3 import geopandas as gpd
4 import numpy as np
5 import pandas as pd
6
7 from dtoolkit.geoaccessor.register import register_geoseries_method
8
9
10 @register_geoseries_method
11 def geodistance_matrix(
12 s: gpd.GeoSeries,
13 /,
14 other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,
15 radius: float = 6371008.7714150598,
16 ) -> pd.DataFrame:
17 """
18 Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in
19 ``s`` and ``other`` via haversine formula.
20
21 __ https://en.wikipedia.org/wiki/Great-circle_distance
22
23 .. math::
24
25 D(x, y) = 2 \\arcsin [
26 \\sqrt{
27 \\sin^2 ((x_1 - y_1) / 2)
28 + \\cos(x_1) \\cos(y_1) \\sin^2 ((x_2 - y_2) / 2)
29 }
30 ]
31
32 Parameters
33 ----------
34 other : GeoSeries, or GeoDataFrame, default None
35 If None, uses ``other=s``.
36
37 radius : float, default 6371008.7714150598
38 Great-circle distance uses a spherical model of the earth, using the mean earth
39 radius as defined by the International Union of Geodesy and Geophysics,
40 (2\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.
41
42 Returns
43 -------
44 DataFrame
45 - The index and columns are the same as the index of ``s`` and ``other``.
46 - The values are the great-circle distances and its unit is meters.
47
48 Raises
49 ------
50 ModuleNotFoundError
51 If don't have module named 'sklearn'.
52
53 ValueError
54 If the CRS is not ``ESGP:4326``.
55
56 See Also
57 --------
58 sklearn.metrics.pairwise.haversine_distances
59 dtoolkit.geoaccessor.geoseries.geodistance
60 dtoolkit.geoaccessor.geoseries.geodistance_matrix
61 dtoolkit.geoaccessor.geodataframe.geodistance
62 dtoolkit.geoaccessor.geodataframe.geodistance_matrix
63
64 Notes
65 -----
66 - Currently, only supports Point geometry.
67 - The great-circle distance is the angular distance between two points on the
68 surface of a sphere. As the Earth is nearly spherical, the haversine formula
69 provides a good approximation of the distance between two points of the Earth
70 surface, with a less than 1% error on average.
71
72 Examples
73 --------
74 >>> import dtoolkit.geoaccessor
75 >>> df = pd.DataFrame(
76 ... {
77 ... "x": [120, 122, 100],
78 ... "y":[30, 55, 1],
79 ... },
80 ... ).from_xy("x", "y", crs=4326)
81 >>> df
82 x y geometry
83 0 120 30 POINT (120.00000 30.00000)
84 1 122 55 POINT (122.00000 55.00000)
85 2 100 1 POINT (100.00000 1.00000)
86 >>> other = pd.DataFrame(
87 ... {
88 ... "x": [120, 110],
89 ... "y":[30, 40],
90 ... },
91 ... ).from_xy("x", "y", crs=4326)
92 >>> other
93 x y geometry
94 0 120 30 POINT (120.00000 30.00000)
95 1 110 40 POINT (110.00000 40.00000)
96 >>> df.geodistance_matrix(other)
97 0 1
98 0 0.000000e+00 1.203540e+06
99 1 1.439971e+06 1.511958e+06
100 2 2.418544e+06 1.522752e+06
101 """
102 from sklearn.metrics.pairwise import haversine_distances
103
104 if s.crs != 4326:
105 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {s.crs!r}.")
106
107 if isinstance(other, gpd.base.GeoPandasBase):
108 if other.crs != 4326:
109 raise ValueError(f"Only support 'EPSG:4326' CRS, but got {other.crs!r}.")
110
111 # Force convert to GeoSeries
112 other = other.geometry
113
114 X = np.radians(np.stack((s.x, s.y), axis=1))
115 Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other
116 return pd.DataFrame(
117 radius * haversine_distances(X, Y),
118 index=s.index,
119 columns=other.index,
120 )
121
[end of dtoolkit/geoaccessor/geoseries/geodistance_matrix.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
--- a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
+++ b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py
@@ -95,9 +95,9 @@
1 110 40 POINT (110.00000 40.00000)
>>> df.geodistance_matrix(other)
0 1
- 0 0.000000e+00 1.203540e+06
- 1 1.439971e+06 1.511958e+06
- 2 2.418544e+06 1.522752e+06
+ 0 0.000000e+00 1.435335e+06
+ 1 2.784435e+06 1.889892e+06
+ 2 3.855604e+06 4.453100e+06
"""
from sklearn.metrics.pairwise import haversine_distances
@@ -111,8 +111,8 @@
# Force convert to GeoSeries
other = other.geometry
- X = np.radians(np.stack((s.x, s.y), axis=1))
- Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other
+ X = np.radians(np.stack((s.y, s.x), axis=1))
+ Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other
return pd.DataFrame(
radius * haversine_distances(X, Y),
index=s.index,
|
{"golden_diff": "diff --git a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n--- a/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n+++ b/dtoolkit/geoaccessor/geoseries/geodistance_matrix.py\n@@ -95,9 +95,9 @@\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n- 0 0.000000e+00 1.203540e+06\n- 1 1.439971e+06 1.511958e+06\n- 2 2.418544e+06 1.522752e+06\n+ 0 0.000000e+00 1.435335e+06\n+ 1 2.784435e+06 1.889892e+06\n+ 2 3.855604e+06 4.453100e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n \n@@ -111,8 +111,8 @@\n # Force convert to GeoSeries\n other = other.geometry\n \n- X = np.radians(np.stack((s.x, s.y), axis=1))\n- Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other\n+ X = np.radians(np.stack((s.y, s.x), axis=1))\n+ Y = np.radians(np.stack((other.y, other.x), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n", "issue": "ENH: New geoaccessor to generate great circle distances matrix\n<!--\r\nThanks for contributing a pull request!\r\n\r\nPlease follow these standard acronyms to start the commit message:\r\n\r\n- ENH: enhancement\r\n- BUG: bug fix\r\n- DOC: documentation\r\n- TYP: type annotations\r\n- TST: addition or modification of tests\r\n- MAINT: maintenance commit (refactoring, typos, etc.)\r\n- BLD: change related to building\r\n- REL: related to releasing\r\n- API: an (incompatible) API change\r\n- DEP: deprecate something, or remove a deprecated object\r\n- DEV: development tool or utility\r\n- REV: revert an earlier commit\r\n- PERF: performance improvement\r\n- BOT: always commit via a bot\r\n- CI: related to CI or CD\r\n- CLN: Code cleanup\r\n-->\r\n\r\n- [x] closes #699\r\n- [ ] whatsnew entry\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport geopandas as gpd\nimport numpy as np\nimport pandas as pd\n\nfrom dtoolkit.geoaccessor.register import register_geoseries_method\n\n\n@register_geoseries_method\ndef geodistance_matrix(\n s: gpd.GeoSeries,\n /,\n other: gpd.GeoSeries | gpd.GeoDataFrame | None = None,\n radius: float = 6371008.7714150598,\n) -> pd.DataFrame:\n \"\"\"\n Returns a ``DataFrame`` containing the `great-circle`__ distances matrix between in\n ``s`` and ``other`` via haversine formula.\n\n __ https://en.wikipedia.org/wiki/Great-circle_distance\n\n .. math::\n\n D(x, y) = 2 \\\\arcsin [\n \\\\sqrt{\n \\\\sin^2 ((x_1 - y_1) / 2)\n + \\\\cos(x_1) \\\\cos(y_1) \\\\sin^2 ((x_2 - y_2) / 2)\n }\n ]\n\n Parameters\n ----------\n other : GeoSeries, or GeoDataFrame, default None\n If None, uses ``other=s``.\n\n radius : float, default 6371008.7714150598\n Great-circle distance uses a spherical model of the earth, using the mean earth\n radius as defined by the International Union of Geodesy and Geophysics,\n (2\\\\ *a* + *b*)/3 = 6371008.7714150598 meters for WGS-84.\n\n Returns\n -------\n DataFrame\n - The index and columns are the same as the index of ``s`` and ``other``.\n - The values are the great-circle distances and its unit is meters.\n\n Raises\n ------\n ModuleNotFoundError\n If don't have module named 'sklearn'.\n\n ValueError\n If the CRS is not ``ESGP:4326``.\n\n See Also\n --------\n sklearn.metrics.pairwise.haversine_distances\n dtoolkit.geoaccessor.geoseries.geodistance\n dtoolkit.geoaccessor.geoseries.geodistance_matrix\n dtoolkit.geoaccessor.geodataframe.geodistance\n dtoolkit.geoaccessor.geodataframe.geodistance_matrix\n\n Notes\n -----\n - Currently, only supports Point geometry.\n - The great-circle distance is the angular distance between two points on the\n surface of a sphere. As the Earth is nearly spherical, the haversine formula\n provides a good approximation of the distance between two points of the Earth\n surface, with a less than 1% error on average.\n\n Examples\n --------\n >>> import dtoolkit.geoaccessor\n >>> df = pd.DataFrame(\n ... {\n ... \"x\": [120, 122, 100],\n ... \"y\":[30, 55, 1],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> df\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 122 55 POINT (122.00000 55.00000)\n 2 100 1 POINT (100.00000 1.00000)\n >>> other = pd.DataFrame(\n ... {\n ... \"x\": [120, 110],\n ... \"y\":[30, 40],\n ... },\n ... ).from_xy(\"x\", \"y\", crs=4326)\n >>> other\n x y geometry\n 0 120 30 POINT (120.00000 30.00000)\n 1 110 40 POINT (110.00000 40.00000)\n >>> df.geodistance_matrix(other)\n 0 1\n 0 0.000000e+00 1.203540e+06\n 1 1.439971e+06 1.511958e+06\n 2 2.418544e+06 1.522752e+06\n \"\"\"\n from sklearn.metrics.pairwise import haversine_distances\n\n if s.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {s.crs!r}.\")\n\n if isinstance(other, gpd.base.GeoPandasBase):\n if other.crs != 4326:\n raise ValueError(f\"Only support 'EPSG:4326' CRS, but got {other.crs!r}.\")\n\n # Force convert to GeoSeries\n other = other.geometry\n\n X = np.radians(np.stack((s.x, s.y), axis=1))\n Y = np.radians(np.stack((other.x, other.y), axis=1)) if other is not None else other\n return pd.DataFrame(\n radius * haversine_distances(X, Y),\n index=s.index,\n columns=other.index,\n )\n", "path": "dtoolkit/geoaccessor/geoseries/geodistance_matrix.py"}]}
| 2,272 | 487 |
gh_patches_debug_13663
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-493
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
New CSV imports use autogenerated column names.
## Description
<!-- A clear and concise description of what the bug is. -->
According to #459, newly imported CSVs are supposed to use the first row as headers by default. However, newly uploaded CSVs are showing autogenerated column names.
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
The first row of the CSV should be used as header names by default.
## To Reproduce
<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->
Upload a CSV from the Mathesar UI. Column names will be of the form `column_0`, etc.
</issue>
<code>
[start of mathesar/serializers.py]
1 from django.urls import reverse
2 from rest_framework import serializers
3
4 from mathesar.models import Table, Schema, DataFile, Database
5
6
7 class NestedTableSerializer(serializers.HyperlinkedModelSerializer):
8 url = serializers.SerializerMethodField()
9
10 class Meta:
11 model = Table
12 fields = ['id', 'name', 'url']
13
14 def get_url(self, obj):
15 request = self.context['request']
16 return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))
17
18
19 class ModelNameField(serializers.CharField):
20 """
21 De-serializes the request field as a string, but serializes the response field as
22 `model.name`. Required to support passing and returing a model name from the
23 endpoint, while also storing the model as a related field.
24 """
25 def to_representation(self, value):
26 return value.name
27
28
29 class SchemaSerializer(serializers.HyperlinkedModelSerializer):
30 tables = NestedTableSerializer(many=True, read_only=True)
31 name = serializers.CharField()
32 database = ModelNameField(max_length=128)
33
34 class Meta:
35 model = Schema
36 fields = ['id', 'name', 'tables', 'database', 'has_dependencies']
37
38
39 class SimpleColumnSerializer(serializers.Serializer):
40 name = serializers.CharField()
41 type = serializers.CharField()
42
43
44 class ColumnSerializer(SimpleColumnSerializer):
45 index = serializers.IntegerField(source='column_index', read_only=True)
46 nullable = serializers.BooleanField(default=True)
47 primary_key = serializers.BooleanField(default=False)
48 valid_target_types = serializers.ListField(read_only=True)
49
50
51 class TableSerializer(serializers.ModelSerializer):
52 columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')
53 records = serializers.SerializerMethodField()
54 name = serializers.CharField()
55 data_files = serializers.PrimaryKeyRelatedField(required=False, many=True, queryset=DataFile.objects.all())
56
57 class Meta:
58 model = Table
59 fields = ['id', 'name', 'schema', 'created_at', 'updated_at',
60 'columns', 'records', 'data_files', 'has_dependencies']
61
62 def get_records(self, obj):
63 if isinstance(obj, Table):
64 # Only get records if we are serializing an existing table
65 request = self.context['request']
66 return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))
67 else:
68 return None
69
70
71 class RecordSerializer(serializers.BaseSerializer):
72 def to_representation(self, instance):
73 return instance._asdict()
74
75
76 class RecordListParameterSerializer(serializers.Serializer):
77 filters = serializers.JSONField(required=False, default=[])
78 order_by = serializers.JSONField(required=False, default=[])
79 group_count_by = serializers.JSONField(required=False, default=[])
80
81
82 class DatabaseSerializer(serializers.ModelSerializer):
83 supported_types = serializers.ListField(child=serializers.CharField())
84
85 class Meta:
86 model = Database
87 fields = ['id', 'name', 'deleted', 'supported_types']
88 read_only_fields = ['id', 'name', 'deleted', 'supported_types']
89
90
91 class DataFileSerializer(serializers.ModelSerializer):
92 user = serializers.PrimaryKeyRelatedField(
93 default=serializers.CurrentUserDefault(), read_only=True
94 )
95
96 class Meta:
97 model = DataFile
98 fields = [
99 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter', 'escapechar', 'quotechar'
100 ]
101 extra_kwargs = {'delimiter': {'trim_whitespace': False},
102 'escapechar': {'trim_whitespace': False},
103 'quotechar': {'trim_whitespace': False}}
104 # We only currently support importing to a new table, so setting a table via API is invalid.
105 # User should be set automatically, not submitted via the API.
106 read_only_fields = ['table_imported_to']
107
108 def save(self, **kwargs):
109 """
110 Set user to current user while saving the data file.
111 """
112 current_user = self.fields['user'].get_default()
113 if current_user.is_authenticated:
114 kwargs['user'] = current_user
115 return super().save(**kwargs)
116
[end of mathesar/serializers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mathesar/serializers.py b/mathesar/serializers.py
--- a/mathesar/serializers.py
+++ b/mathesar/serializers.py
@@ -100,7 +100,8 @@
]
extra_kwargs = {'delimiter': {'trim_whitespace': False},
'escapechar': {'trim_whitespace': False},
- 'quotechar': {'trim_whitespace': False}}
+ 'quotechar': {'trim_whitespace': False},
+ 'header': {'required': True}}
# We only currently support importing to a new table, so setting a table via API is invalid.
# User should be set automatically, not submitted via the API.
read_only_fields = ['table_imported_to']
|
{"golden_diff": "diff --git a/mathesar/serializers.py b/mathesar/serializers.py\n--- a/mathesar/serializers.py\n+++ b/mathesar/serializers.py\n@@ -100,7 +100,8 @@\n ]\n extra_kwargs = {'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n- 'quotechar': {'trim_whitespace': False}}\n+ 'quotechar': {'trim_whitespace': False},\n+ 'header': {'required': True}}\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['table_imported_to']\n", "issue": "New CSV imports use autogenerated column names.\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\nAccording to #459, newly imported CSVs are supposed to use the first row as headers by default. However, newly uploaded CSVs are showing autogenerated column names.\r\n\r\n## Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe first row of the CSV should be used as header names by default.\r\n\r\n## To Reproduce\r\n<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->\r\nUpload a CSV from the Mathesar UI. Column names will be of the form `column_0`, etc.\n", "before_files": [{"content": "from django.urls import reverse\nfrom rest_framework import serializers\n\nfrom mathesar.models import Table, Schema, DataFile, Database\n\n\nclass NestedTableSerializer(serializers.HyperlinkedModelSerializer):\n url = serializers.SerializerMethodField()\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'url']\n\n def get_url(self, obj):\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-detail', kwargs={'pk': obj.pk}))\n\n\nclass ModelNameField(serializers.CharField):\n \"\"\"\n De-serializes the request field as a string, but serializes the response field as\n `model.name`. Required to support passing and returing a model name from the\n endpoint, while also storing the model as a related field.\n \"\"\"\n def to_representation(self, value):\n return value.name\n\n\nclass SchemaSerializer(serializers.HyperlinkedModelSerializer):\n tables = NestedTableSerializer(many=True, read_only=True)\n name = serializers.CharField()\n database = ModelNameField(max_length=128)\n\n class Meta:\n model = Schema\n fields = ['id', 'name', 'tables', 'database', 'has_dependencies']\n\n\nclass SimpleColumnSerializer(serializers.Serializer):\n name = serializers.CharField()\n type = serializers.CharField()\n\n\nclass ColumnSerializer(SimpleColumnSerializer):\n index = serializers.IntegerField(source='column_index', read_only=True)\n nullable = serializers.BooleanField(default=True)\n primary_key = serializers.BooleanField(default=False)\n valid_target_types = serializers.ListField(read_only=True)\n\n\nclass TableSerializer(serializers.ModelSerializer):\n columns = SimpleColumnSerializer(many=True, read_only=True, source='sa_columns')\n records = serializers.SerializerMethodField()\n name = serializers.CharField()\n data_files = serializers.PrimaryKeyRelatedField(required=False, many=True, queryset=DataFile.objects.all())\n\n class Meta:\n model = Table\n fields = ['id', 'name', 'schema', 'created_at', 'updated_at',\n 'columns', 'records', 'data_files', 'has_dependencies']\n\n def get_records(self, obj):\n if isinstance(obj, Table):\n # Only get records if we are serializing an existing table\n request = self.context['request']\n return request.build_absolute_uri(reverse('table-record-list', kwargs={'table_pk': obj.pk}))\n else:\n return None\n\n\nclass RecordSerializer(serializers.BaseSerializer):\n def to_representation(self, instance):\n return instance._asdict()\n\n\nclass RecordListParameterSerializer(serializers.Serializer):\n filters = serializers.JSONField(required=False, default=[])\n order_by = serializers.JSONField(required=False, default=[])\n group_count_by = serializers.JSONField(required=False, default=[])\n\n\nclass DatabaseSerializer(serializers.ModelSerializer):\n supported_types = serializers.ListField(child=serializers.CharField())\n\n class Meta:\n model = Database\n fields = ['id', 'name', 'deleted', 'supported_types']\n read_only_fields = ['id', 'name', 'deleted', 'supported_types']\n\n\nclass DataFileSerializer(serializers.ModelSerializer):\n user = serializers.PrimaryKeyRelatedField(\n default=serializers.CurrentUserDefault(), read_only=True\n )\n\n class Meta:\n model = DataFile\n fields = [\n 'id', 'file', 'table_imported_to', 'user', 'header', 'delimiter', 'escapechar', 'quotechar'\n ]\n extra_kwargs = {'delimiter': {'trim_whitespace': False},\n 'escapechar': {'trim_whitespace': False},\n 'quotechar': {'trim_whitespace': False}}\n # We only currently support importing to a new table, so setting a table via API is invalid.\n # User should be set automatically, not submitted via the API.\n read_only_fields = ['table_imported_to']\n\n def save(self, **kwargs):\n \"\"\"\n Set user to current user while saving the data file.\n \"\"\"\n current_user = self.fields['user'].get_default()\n if current_user.is_authenticated:\n kwargs['user'] = current_user\n return super().save(**kwargs)\n", "path": "mathesar/serializers.py"}]}
| 1,794 | 156 |
gh_patches_debug_4145
|
rasdani/github-patches
|
git_diff
|
benoitc__gunicorn-1414
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
gunicorn.pidfile.validate crashes gunicorn when PID exists but is from a different user
```
Traceback (most recent call last):
File "/opt/python2.7/bin/gunicorn", line 11, in <module>
sys.exit(run())
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py", line 74, in run
WSGIApplication("%(prog)s [OPTIONS] [APP_MODULE]").run()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py", line 189, in run
super(Application, self).run()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py", line 72, in run
Arbiter(self).run()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py", line 171, in run
self.start()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py", line 125, in start
self.pidfile.create(self.pid)
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py", line 23, in create
oldpid = self.validate()
File "/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py", line 75, in validate
os.kill(wpid, 0)
OSError: [Errno 1] Operation not permitted
```
This happens because the process identified by the pid-file exists, but belongs to a different user than the one starting gunicorn.
(This is with gunicorn 19.3.0)
</issue>
<code>
[start of gunicorn/pidfile.py]
1 # -*- coding: utf-8 -
2 #
3 # This file is part of gunicorn released under the MIT license.
4 # See the NOTICE for more information.
5
6 import errno
7 import os
8 import tempfile
9
10
11 class Pidfile(object):
12 """\
13 Manage a PID file. If a specific name is provided
14 it and '"%s.oldpid" % name' will be used. Otherwise
15 we create a temp file using os.mkstemp.
16 """
17
18 def __init__(self, fname):
19 self.fname = fname
20 self.pid = None
21
22 def create(self, pid):
23 oldpid = self.validate()
24 if oldpid:
25 if oldpid == os.getpid():
26 return
27 msg = "Already running on PID %s (or pid file '%s' is stale)"
28 raise RuntimeError(msg % (oldpid, self.fname))
29
30 self.pid = pid
31
32 # Write pidfile
33 fdir = os.path.dirname(self.fname)
34 if fdir and not os.path.isdir(fdir):
35 raise RuntimeError("%s doesn't exist. Can't create pidfile." % fdir)
36 fd, fname = tempfile.mkstemp(dir=fdir)
37 os.write(fd, ("%s\n" % self.pid).encode('utf-8'))
38 if self.fname:
39 os.rename(fname, self.fname)
40 else:
41 self.fname = fname
42 os.close(fd)
43
44 # set permissions to -rw-r--r--
45 os.chmod(self.fname, 420)
46
47 def rename(self, path):
48 self.unlink()
49 self.fname = path
50 self.create(self.pid)
51
52 def unlink(self):
53 """ delete pidfile"""
54 try:
55 with open(self.fname, "r") as f:
56 pid1 = int(f.read() or 0)
57
58 if pid1 == self.pid:
59 os.unlink(self.fname)
60 except:
61 pass
62
63 def validate(self):
64 """ Validate pidfile and make it stale if needed"""
65 if not self.fname:
66 return
67 try:
68 with open(self.fname, "r") as f:
69 try:
70 wpid = int(f.read())
71 except ValueError:
72 return
73
74 try:
75 os.kill(wpid, 0)
76 return wpid
77 except OSError as e:
78 if e.args[0] == errno.ESRCH:
79 return
80 raise
81 except IOError as e:
82 if e.args[0] == errno.ENOENT:
83 return
84 raise
85
[end of gunicorn/pidfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gunicorn/pidfile.py b/gunicorn/pidfile.py
--- a/gunicorn/pidfile.py
+++ b/gunicorn/pidfile.py
@@ -75,6 +75,8 @@
os.kill(wpid, 0)
return wpid
except OSError as e:
+ if e.args[0] == errno.EPERM:
+ return wpid
if e.args[0] == errno.ESRCH:
return
raise
|
{"golden_diff": "diff --git a/gunicorn/pidfile.py b/gunicorn/pidfile.py\n--- a/gunicorn/pidfile.py\n+++ b/gunicorn/pidfile.py\n@@ -75,6 +75,8 @@\n os.kill(wpid, 0)\n return wpid\n except OSError as e:\n+ if e.args[0] == errno.EPERM:\n+ return wpid\n if e.args[0] == errno.ESRCH:\n return\n raise\n", "issue": "gunicorn.pidfile.validate crashes gunicorn when PID exists but is from a different user\n```\nTraceback (most recent call last):\n File \"/opt/python2.7/bin/gunicorn\", line 11, in <module>\n sys.exit(run())\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/wsgiapp.py\", line 74, in run\n WSGIApplication(\"%(prog)s [OPTIONS] [APP_MODULE]\").run()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py\", line 189, in run\n super(Application, self).run()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/app/base.py\", line 72, in run\n Arbiter(self).run()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py\", line 171, in run\n self.start()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/arbiter.py\", line 125, in start\n self.pidfile.create(self.pid)\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py\", line 23, in create\n oldpid = self.validate()\n File \"/opt/python2.7/lib/python2.7/site-packages/gunicorn/pidfile.py\", line 75, in validate\n os.kill(wpid, 0)\nOSError: [Errno 1] Operation not permitted\n```\n\nThis happens because the process identified by the pid-file exists, but belongs to a different user than the one starting gunicorn.\n\n(This is with gunicorn 19.3.0)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -\n#\n# This file is part of gunicorn released under the MIT license.\n# See the NOTICE for more information.\n\nimport errno\nimport os\nimport tempfile\n\n\nclass Pidfile(object):\n \"\"\"\\\n Manage a PID file. If a specific name is provided\n it and '\"%s.oldpid\" % name' will be used. Otherwise\n we create a temp file using os.mkstemp.\n \"\"\"\n\n def __init__(self, fname):\n self.fname = fname\n self.pid = None\n\n def create(self, pid):\n oldpid = self.validate()\n if oldpid:\n if oldpid == os.getpid():\n return\n msg = \"Already running on PID %s (or pid file '%s' is stale)\"\n raise RuntimeError(msg % (oldpid, self.fname))\n\n self.pid = pid\n\n # Write pidfile\n fdir = os.path.dirname(self.fname)\n if fdir and not os.path.isdir(fdir):\n raise RuntimeError(\"%s doesn't exist. Can't create pidfile.\" % fdir)\n fd, fname = tempfile.mkstemp(dir=fdir)\n os.write(fd, (\"%s\\n\" % self.pid).encode('utf-8'))\n if self.fname:\n os.rename(fname, self.fname)\n else:\n self.fname = fname\n os.close(fd)\n\n # set permissions to -rw-r--r--\n os.chmod(self.fname, 420)\n\n def rename(self, path):\n self.unlink()\n self.fname = path\n self.create(self.pid)\n\n def unlink(self):\n \"\"\" delete pidfile\"\"\"\n try:\n with open(self.fname, \"r\") as f:\n pid1 = int(f.read() or 0)\n\n if pid1 == self.pid:\n os.unlink(self.fname)\n except:\n pass\n\n def validate(self):\n \"\"\" Validate pidfile and make it stale if needed\"\"\"\n if not self.fname:\n return\n try:\n with open(self.fname, \"r\") as f:\n try:\n wpid = int(f.read())\n except ValueError:\n return\n\n try:\n os.kill(wpid, 0)\n return wpid\n except OSError as e:\n if e.args[0] == errno.ESRCH:\n return\n raise\n except IOError as e:\n if e.args[0] == errno.ENOENT:\n return\n raise\n", "path": "gunicorn/pidfile.py"}]}
| 1,612 | 108 |
gh_patches_debug_64391
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-5886
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
name=Bankomat should not be added for amenity=atm
It is like `name=ATM`
The same goes for `name=Wpłatomat` (for ATM accepting cash)
https://www.alltheplaces.xyz/map/#16.82/50.072257/20.036549

</issue>
<code>
[start of locations/spiders/santander_pl.py]
1 import chompjs
2 from scrapy import Spider
3
4 from locations.categories import Categories, apply_category, apply_yes_no
5 from locations.dict_parser import DictParser
6 from locations.hours import DAYS, OpeningHours
7 from locations.items import Feature
8
9
10 class SantanderPLSpider(Spider):
11 name = "santander_pl"
12 item_attributes = {"brand": "Santander", "brand_wikidata": "Q806653"}
13 # The "20000000000000" needs to be a valid date time, but it seems it's just there to stop the page being cached by
14 # the CDN. We always get the same data.
15 start_urls = ["https://www.santander.pl/_js_places/time20000000000000/places.js"]
16
17 def parse(self, response, **kwargs):
18 data = chompjs.parse_js_object(response.text)
19 for ref, branch in data["atm"].items():
20 yield self.parse_item(ref, branch, Categories.ATM)
21 for ref, branch in data["branch"].items():
22 yield self.parse_item(ref, branch, Categories.BANK)
23 for ref, branch in data["cashin"].items():
24 item = self.parse_item(ref, branch, Categories.ATM)
25 apply_yes_no("cash_in", item, True)
26 yield item
27
28 @staticmethod
29 def parse_item(ref: str, data: dict, category) -> Feature:
30 data["basicParameters"]["street_address"] = data["basicParameters"].pop("street")
31 item = DictParser.parse(data["basicParameters"])
32 item["ref"] = ref
33
34 if data["open_24h"]:
35 item["opening_hours"] = "24/7"
36 else:
37 item["opening_hours"] = OpeningHours()
38 for day, hours in data["basicParameters"]["opening_hours"].items():
39 start_time, end_time = hours.split("-")
40 item["opening_hours"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())
41
42 apply_category(category, item)
43
44 return item
45
[end of locations/spiders/santander_pl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/santander_pl.py b/locations/spiders/santander_pl.py
--- a/locations/spiders/santander_pl.py
+++ b/locations/spiders/santander_pl.py
@@ -39,6 +39,9 @@
start_time, end_time = hours.split("-")
item["opening_hours"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())
+ if category == Categories.ATM:
+ item["name"] = None
+
apply_category(category, item)
return item
|
{"golden_diff": "diff --git a/locations/spiders/santander_pl.py b/locations/spiders/santander_pl.py\n--- a/locations/spiders/santander_pl.py\n+++ b/locations/spiders/santander_pl.py\n@@ -39,6 +39,9 @@\n start_time, end_time = hours.split(\"-\")\n item[\"opening_hours\"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())\n \n+ if category == Categories.ATM:\n+ item[\"name\"] = None\n+\n apply_category(category, item)\n \n return item\n", "issue": "name=Bankomat should not be added for amenity=atm\nIt is like `name=ATM`\r\n\r\nThe same goes for `name=Wp\u0142atomat` (for ATM accepting cash)\r\n\r\nhttps://www.alltheplaces.xyz/map/#16.82/50.072257/20.036549\r\n\r\n\r\n\n", "before_files": [{"content": "import chompjs\nfrom scrapy import Spider\n\nfrom locations.categories import Categories, apply_category, apply_yes_no\nfrom locations.dict_parser import DictParser\nfrom locations.hours import DAYS, OpeningHours\nfrom locations.items import Feature\n\n\nclass SantanderPLSpider(Spider):\n name = \"santander_pl\"\n item_attributes = {\"brand\": \"Santander\", \"brand_wikidata\": \"Q806653\"}\n # The \"20000000000000\" needs to be a valid date time, but it seems it's just there to stop the page being cached by\n # the CDN. We always get the same data.\n start_urls = [\"https://www.santander.pl/_js_places/time20000000000000/places.js\"]\n\n def parse(self, response, **kwargs):\n data = chompjs.parse_js_object(response.text)\n for ref, branch in data[\"atm\"].items():\n yield self.parse_item(ref, branch, Categories.ATM)\n for ref, branch in data[\"branch\"].items():\n yield self.parse_item(ref, branch, Categories.BANK)\n for ref, branch in data[\"cashin\"].items():\n item = self.parse_item(ref, branch, Categories.ATM)\n apply_yes_no(\"cash_in\", item, True)\n yield item\n\n @staticmethod\n def parse_item(ref: str, data: dict, category) -> Feature:\n data[\"basicParameters\"][\"street_address\"] = data[\"basicParameters\"].pop(\"street\")\n item = DictParser.parse(data[\"basicParameters\"])\n item[\"ref\"] = ref\n\n if data[\"open_24h\"]:\n item[\"opening_hours\"] = \"24/7\"\n else:\n item[\"opening_hours\"] = OpeningHours()\n for day, hours in data[\"basicParameters\"][\"opening_hours\"].items():\n start_time, end_time = hours.split(\"-\")\n item[\"opening_hours\"].add_range(DAYS[int(day) - 2], start_time.strip(), end_time.strip())\n\n apply_category(category, item)\n\n return item\n", "path": "locations/spiders/santander_pl.py"}]}
| 1,222 | 129 |
gh_patches_debug_20505
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-499
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Suite output text - fix first part
1. Add explanation for the “!” (warning) 2. add link to docs where written (or remove wording), where it says:"Suites, checks and conditions can all be modified (see tutorial [link])."
</issue>
<code>
[start of deepchecks/base/display_suite.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Handle display of suite result."""
12 from typing import List, Union
13
14 # pylint: disable=protected-access
15 import sys
16 import tqdm
17 import pandas as pd
18 from IPython.core.display import display_html
19 from IPython import get_ipython
20
21 from deepchecks import errors
22 from deepchecks.utils.ipython import is_widgets_enabled
23 from deepchecks.utils.strings import get_random_string
24 from deepchecks.base.check import CheckResult, CheckFailure
25 from deepchecks.base.display_pandas import dataframe_to_html, display_conditions_table
26
27
28 __all__ = ['display_suite_result', 'ProgressBar']
29
30
31 class ProgressBar:
32 """Progress bar for display while running suite."""
33
34 def __init__(self, name, length):
35 """Initialize progress bar."""
36 shared_args = {'total': length, 'desc': name, 'unit': ' Check', 'leave': False, 'file': sys.stdout}
37 if is_widgets_enabled():
38 self.pbar = tqdm.tqdm_notebook(**shared_args, colour='#9d60fb')
39 else:
40 # Normal tqdm with colour in notebooks produce bug that the cleanup doesn't remove all characters. so
41 # until bug fixed, doesn't add the colour to regular tqdm
42 self.pbar = tqdm.tqdm(**shared_args, bar_format=f'{{l_bar}}{{bar:{length}}}{{r_bar}}')
43
44 def set_text(self, text):
45 """Set current running check."""
46 self.pbar.set_postfix(Check=text)
47
48 def close(self):
49 """Close the progress bar."""
50 self.pbar.close()
51
52 def inc_progress(self):
53 """Increase progress bar value by 1."""
54 self.pbar.update(1)
55
56
57 def get_display_exists_icon(exists: bool):
58 if exists:
59 return '<div style="text-align: center">Yes</div>'
60 return '<div style="text-align: center">No</div>'
61
62
63 def display_suite_result(suite_name: str, results: List[Union[CheckResult, CheckFailure]]):
64 """Display results of suite in IPython."""
65 if len(results) == 0:
66 display_html(f"""<h1>{suite_name}</h1><p>Suite is empty.</p>""", raw=True)
67 return
68 if 'google.colab' in str(get_ipython()):
69 unique_id = ''
70 else:
71 unique_id = get_random_string()
72 checks_with_conditions = []
73 display_table: List[CheckResult] = []
74 others_table = []
75
76 for result in results:
77 if isinstance(result, CheckResult):
78 if result.have_conditions():
79 checks_with_conditions.append(result)
80 if result.have_display():
81 display_table.append(result)
82 else:
83 others_table.append([result.get_header(), 'Nothing found', 2])
84 elif isinstance(result, CheckFailure):
85 msg = result.exception.__class__.__name__ + ': ' + str(result.exception)
86 name = result.check.name()
87 others_table.append([name, msg, 1])
88 else:
89 # Should never reach here!
90 raise errors.DeepchecksValueError(
91 f"Expecting list of 'CheckResult'|'CheckFailure', but got {type(result)}."
92 )
93
94 display_table = sorted(display_table, key=lambda it: it.priority)
95
96 light_hr = '<hr style="background-color: #eee;border: 0 none;color: #eee;height: 1px;">'
97 bold_hr = '<hr style="background-color: black;border: 0 none;color: black;height: 1px;">'
98
99 icons = """
100 <span style="color: green;display:inline-block">\U00002713</span> /
101 <span style="color: red;display:inline-block">\U00002716</span> /
102 <span style="color: orange;font-weight:bold;display:inline-block">\U00000021</span>
103 """
104
105 check_names = list(set(it.check.name() for it in results))
106 prologue = (
107 f"The suite is composed of various checks such as: {', '.join(check_names[:3])}, etc..."
108 if len(check_names) > 3
109 else f"The suite is composed of the following checks: {', '.join(check_names)}."
110 )
111
112 display_html(
113 f"""
114 <h1 id="summary_{unique_id}">{suite_name}</h1>
115 <p>{prologue}<br>
116 Each check may contain conditions (which results in {icons}),
117 as well as other outputs such as plots or tables.<br>
118 Suites, checks and conditions can all be modified (see tutorial [link]).</p>
119 {bold_hr}<h2>Conditions Summary</h2>
120 """,
121 raw=True
122 )
123
124 if checks_with_conditions:
125 display_conditions_table(checks_with_conditions, unique_id)
126 else:
127 display_html('<p>No conditions defined on checks in the suite.</p>', raw=True)
128
129 display_html(f'{bold_hr}<h2>Additional Outputs</h2>', raw=True)
130 if display_table:
131 for i, r in enumerate(display_table):
132 r.show(show_conditions=False, unique_id=unique_id)
133 if i < len(display_table) - 1:
134 display_html(light_hr, raw=True)
135 else:
136 display_html('<p>No outputs to show.</p>', raw=True)
137
138 if others_table:
139 others_table = pd.DataFrame(data=others_table, columns=['Check', 'Reason', 'sort'])
140 others_table.sort_values(by=['sort'], inplace=True)
141 others_table.drop('sort', axis=1, inplace=True)
142 html = f"""{bold_hr}
143 <h2>Other Checks That Weren't Displayed</h2>
144 {dataframe_to_html(others_table.style.hide_index())}
145 """
146 display_html(html, raw=True)
147
148 display_html(f'<br><a href="#summary_{unique_id}" style="font-size: 14px">Go to top</a>', raw=True)
149
[end of deepchecks/base/display_suite.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/base/display_suite.py b/deepchecks/base/display_suite.py
--- a/deepchecks/base/display_suite.py
+++ b/deepchecks/base/display_suite.py
@@ -109,14 +109,20 @@
else f"The suite is composed of the following checks: {', '.join(check_names)}."
)
+ suite_creation_example_link = 'https://docs.deepchecks.com/en/stable/examples/guides/create_a_custom_suite.html'
+
display_html(
f"""
<h1 id="summary_{unique_id}">{suite_name}</h1>
- <p>{prologue}<br>
- Each check may contain conditions (which results in {icons}),
- as well as other outputs such as plots or tables.<br>
- Suites, checks and conditions can all be modified (see tutorial [link]).</p>
- {bold_hr}<h2>Conditions Summary</h2>
+ <p>
+ {prologue}<br>
+ Each check may contain conditions (which will result in pass / fail / warning, represented by {icons})
+ as well as other outputs such as plots or tables.<br>
+ Suites, checks and conditions can all be modified (see the
+ <a href={suite_creation_example_link}>Create a Custom Suite</a> tutorial).
+ </p>
+ {bold_hr}
+ <h2>Conditions Summary</h2>
""",
raw=True
)
|
{"golden_diff": "diff --git a/deepchecks/base/display_suite.py b/deepchecks/base/display_suite.py\n--- a/deepchecks/base/display_suite.py\n+++ b/deepchecks/base/display_suite.py\n@@ -109,14 +109,20 @@\n else f\"The suite is composed of the following checks: {', '.join(check_names)}.\"\n )\n \n+ suite_creation_example_link = 'https://docs.deepchecks.com/en/stable/examples/guides/create_a_custom_suite.html'\n+\n display_html(\n f\"\"\"\n <h1 id=\"summary_{unique_id}\">{suite_name}</h1>\n- <p>{prologue}<br>\n- Each check may contain conditions (which results in {icons}),\n- as well as other outputs such as plots or tables.<br>\n- Suites, checks and conditions can all be modified (see tutorial [link]).</p>\n- {bold_hr}<h2>Conditions Summary</h2>\n+ <p>\n+ {prologue}<br>\n+ Each check may contain conditions (which will result in pass / fail / warning, represented by {icons})\n+ as well as other outputs such as plots or tables.<br>\n+ Suites, checks and conditions can all be modified (see the\n+ <a href={suite_creation_example_link}>Create a Custom Suite</a> tutorial).\n+ </p>\n+ {bold_hr}\n+ <h2>Conditions Summary</h2>\n \"\"\",\n raw=True\n )\n", "issue": "Suite output text - fix first part\n1. Add explanation for the \u201c!\u201d (warning) 2. add link to docs where written (or remove wording), where it says:\"Suites, checks and conditions can all be modified (see tutorial [link]).\"\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Handle display of suite result.\"\"\"\nfrom typing import List, Union\n\n# pylint: disable=protected-access\nimport sys\nimport tqdm\nimport pandas as pd\nfrom IPython.core.display import display_html\nfrom IPython import get_ipython\n\nfrom deepchecks import errors\nfrom deepchecks.utils.ipython import is_widgets_enabled\nfrom deepchecks.utils.strings import get_random_string\nfrom deepchecks.base.check import CheckResult, CheckFailure\nfrom deepchecks.base.display_pandas import dataframe_to_html, display_conditions_table\n\n\n__all__ = ['display_suite_result', 'ProgressBar']\n\n\nclass ProgressBar:\n \"\"\"Progress bar for display while running suite.\"\"\"\n\n def __init__(self, name, length):\n \"\"\"Initialize progress bar.\"\"\"\n shared_args = {'total': length, 'desc': name, 'unit': ' Check', 'leave': False, 'file': sys.stdout}\n if is_widgets_enabled():\n self.pbar = tqdm.tqdm_notebook(**shared_args, colour='#9d60fb')\n else:\n # Normal tqdm with colour in notebooks produce bug that the cleanup doesn't remove all characters. so\n # until bug fixed, doesn't add the colour to regular tqdm\n self.pbar = tqdm.tqdm(**shared_args, bar_format=f'{{l_bar}}{{bar:{length}}}{{r_bar}}')\n\n def set_text(self, text):\n \"\"\"Set current running check.\"\"\"\n self.pbar.set_postfix(Check=text)\n\n def close(self):\n \"\"\"Close the progress bar.\"\"\"\n self.pbar.close()\n\n def inc_progress(self):\n \"\"\"Increase progress bar value by 1.\"\"\"\n self.pbar.update(1)\n\n\ndef get_display_exists_icon(exists: bool):\n if exists:\n return '<div style=\"text-align: center\">Yes</div>'\n return '<div style=\"text-align: center\">No</div>'\n\n\ndef display_suite_result(suite_name: str, results: List[Union[CheckResult, CheckFailure]]):\n \"\"\"Display results of suite in IPython.\"\"\"\n if len(results) == 0:\n display_html(f\"\"\"<h1>{suite_name}</h1><p>Suite is empty.</p>\"\"\", raw=True)\n return\n if 'google.colab' in str(get_ipython()):\n unique_id = ''\n else:\n unique_id = get_random_string()\n checks_with_conditions = []\n display_table: List[CheckResult] = []\n others_table = []\n\n for result in results:\n if isinstance(result, CheckResult):\n if result.have_conditions():\n checks_with_conditions.append(result)\n if result.have_display():\n display_table.append(result)\n else:\n others_table.append([result.get_header(), 'Nothing found', 2])\n elif isinstance(result, CheckFailure):\n msg = result.exception.__class__.__name__ + ': ' + str(result.exception)\n name = result.check.name()\n others_table.append([name, msg, 1])\n else:\n # Should never reach here!\n raise errors.DeepchecksValueError(\n f\"Expecting list of 'CheckResult'|'CheckFailure', but got {type(result)}.\"\n )\n\n display_table = sorted(display_table, key=lambda it: it.priority)\n\n light_hr = '<hr style=\"background-color: #eee;border: 0 none;color: #eee;height: 1px;\">'\n bold_hr = '<hr style=\"background-color: black;border: 0 none;color: black;height: 1px;\">'\n\n icons = \"\"\"\n <span style=\"color: green;display:inline-block\">\\U00002713</span> /\n <span style=\"color: red;display:inline-block\">\\U00002716</span> /\n <span style=\"color: orange;font-weight:bold;display:inline-block\">\\U00000021</span>\n \"\"\"\n\n check_names = list(set(it.check.name() for it in results))\n prologue = (\n f\"The suite is composed of various checks such as: {', '.join(check_names[:3])}, etc...\"\n if len(check_names) > 3\n else f\"The suite is composed of the following checks: {', '.join(check_names)}.\"\n )\n\n display_html(\n f\"\"\"\n <h1 id=\"summary_{unique_id}\">{suite_name}</h1>\n <p>{prologue}<br>\n Each check may contain conditions (which results in {icons}),\n as well as other outputs such as plots or tables.<br>\n Suites, checks and conditions can all be modified (see tutorial [link]).</p>\n {bold_hr}<h2>Conditions Summary</h2>\n \"\"\",\n raw=True\n )\n\n if checks_with_conditions:\n display_conditions_table(checks_with_conditions, unique_id)\n else:\n display_html('<p>No conditions defined on checks in the suite.</p>', raw=True)\n\n display_html(f'{bold_hr}<h2>Additional Outputs</h2>', raw=True)\n if display_table:\n for i, r in enumerate(display_table):\n r.show(show_conditions=False, unique_id=unique_id)\n if i < len(display_table) - 1:\n display_html(light_hr, raw=True)\n else:\n display_html('<p>No outputs to show.</p>', raw=True)\n\n if others_table:\n others_table = pd.DataFrame(data=others_table, columns=['Check', 'Reason', 'sort'])\n others_table.sort_values(by=['sort'], inplace=True)\n others_table.drop('sort', axis=1, inplace=True)\n html = f\"\"\"{bold_hr}\n <h2>Other Checks That Weren't Displayed</h2>\n {dataframe_to_html(others_table.style.hide_index())}\n \"\"\"\n display_html(html, raw=True)\n\n display_html(f'<br><a href=\"#summary_{unique_id}\" style=\"font-size: 14px\">Go to top</a>', raw=True)\n", "path": "deepchecks/base/display_suite.py"}]}
| 2,300 | 324 |
gh_patches_debug_24114
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-5188
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Program PDF report returns an XLS report
# What were you doing?
Follow the steps in test "Download PDF Program overview".
# What should've happened?
A PDF report should've been received in the email, but an XLS report was delivered.
</issue>
<code>
[start of akvo/rsr/views/py_reports/email_report.py]
1 import logging
2
3 from datetime import timedelta
4 from django.db.models import Q
5 from django.utils.timezone import now
6 from akvo.rsr.models import EmailReportJob
7
8 from . import (
9 program_overview_pdf_report,
10 program_overview_excel_report,
11 program_period_labels_overview_pdf_report,
12 results_indicators_with_map_pdf_reports,
13 nuffic_country_level_map_report,
14 )
15
16 TIMEOUT = timedelta(minutes=30)
17 MAX_ATTEMPTS = 3
18 HANDLER = {
19 program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
20 program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
21 program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,
22 results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,
23 nuffic_country_level_map_report.REPORT_NAME: nuffic_country_level_map_report.handle_email_report,
24 }
25
26 logger = logging.getLogger(__name__)
27
28
29 def run_job():
30 pending_jobs = _get_pending_jobs()
31 if not pending_jobs.exists():
32 return
33 job = pending_jobs.first()
34 job.mark_started()
35 try:
36 handler = HANDLER.get(job.report, None)
37 if handler:
38 handler(job.payload, job.recipient)
39 job.mark_finished()
40 except Exception:
41 logger.exception(f'Failed to genereate report {job.report} for {job.recipient}')
42
43
44 def _get_pending_jobs():
45 started_timeout = now() - TIMEOUT
46 return EmailReportJob.objects\
47 .order_by('created_at')\
48 .filter(finished_at__isnull=True)\
49 .exclude(Q(attempts__gte=MAX_ATTEMPTS) | Q(started_at__gte=started_timeout))
50
[end of akvo/rsr/views/py_reports/email_report.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rsr/views/py_reports/email_report.py b/akvo/rsr/views/py_reports/email_report.py
--- a/akvo/rsr/views/py_reports/email_report.py
+++ b/akvo/rsr/views/py_reports/email_report.py
@@ -16,7 +16,7 @@
TIMEOUT = timedelta(minutes=30)
MAX_ATTEMPTS = 3
HANDLER = {
- program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
+ program_overview_pdf_report.REPORT_NAME: program_overview_pdf_report.handle_email_report,
program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,
program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,
results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,
@@ -35,6 +35,7 @@
try:
handler = HANDLER.get(job.report, None)
if handler:
+ logger.info("Handling job %s for report %s with %s", job.id, job.report)
handler(job.payload, job.recipient)
job.mark_finished()
except Exception:
|
{"golden_diff": "diff --git a/akvo/rsr/views/py_reports/email_report.py b/akvo/rsr/views/py_reports/email_report.py\n--- a/akvo/rsr/views/py_reports/email_report.py\n+++ b/akvo/rsr/views/py_reports/email_report.py\n@@ -16,7 +16,7 @@\n TIMEOUT = timedelta(minutes=30)\n MAX_ATTEMPTS = 3\n HANDLER = {\n- program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n+ program_overview_pdf_report.REPORT_NAME: program_overview_pdf_report.handle_email_report,\n program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,\n results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,\n@@ -35,6 +35,7 @@\n try:\n handler = HANDLER.get(job.report, None)\n if handler:\n+ logger.info(\"Handling job %s for report %s with %s\", job.id, job.report)\n handler(job.payload, job.recipient)\n job.mark_finished()\n except Exception:\n", "issue": "Program PDF report returns an XLS report\n# What were you doing?\n\nFollow the steps in test \"Download PDF Program overview\".\n\n# What should've happened?\n\nA PDF report should've been received in the email, but an XLS report was delivered.\n", "before_files": [{"content": "import logging\n\nfrom datetime import timedelta\nfrom django.db.models import Q\nfrom django.utils.timezone import now\nfrom akvo.rsr.models import EmailReportJob\n\nfrom . import (\n program_overview_pdf_report,\n program_overview_excel_report,\n program_period_labels_overview_pdf_report,\n results_indicators_with_map_pdf_reports,\n nuffic_country_level_map_report,\n)\n\nTIMEOUT = timedelta(minutes=30)\nMAX_ATTEMPTS = 3\nHANDLER = {\n program_overview_pdf_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_overview_excel_report.REPORT_NAME: program_overview_excel_report.handle_email_report,\n program_period_labels_overview_pdf_report.REPORT_NAME: program_period_labels_overview_pdf_report.handle_email_report,\n results_indicators_with_map_pdf_reports.ORG_PROJECTS_REPORT_NAME: results_indicators_with_map_pdf_reports.handle_org_projects_email_report,\n nuffic_country_level_map_report.REPORT_NAME: nuffic_country_level_map_report.handle_email_report,\n}\n\nlogger = logging.getLogger(__name__)\n\n\ndef run_job():\n pending_jobs = _get_pending_jobs()\n if not pending_jobs.exists():\n return\n job = pending_jobs.first()\n job.mark_started()\n try:\n handler = HANDLER.get(job.report, None)\n if handler:\n handler(job.payload, job.recipient)\n job.mark_finished()\n except Exception:\n logger.exception(f'Failed to genereate report {job.report} for {job.recipient}')\n\n\ndef _get_pending_jobs():\n started_timeout = now() - TIMEOUT\n return EmailReportJob.objects\\\n .order_by('created_at')\\\n .filter(finished_at__isnull=True)\\\n .exclude(Q(attempts__gte=MAX_ATTEMPTS) | Q(started_at__gte=started_timeout))\n", "path": "akvo/rsr/views/py_reports/email_report.py"}]}
| 1,073 | 269 |
gh_patches_debug_5510
|
rasdani/github-patches
|
git_diff
|
pyca__cryptography-3215
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
HKDF key-length inconsistency
For too small key sizes, `HKDF.derive()` outputs an empty array instead of a small key:
Program:
```python
#!/usr/bin/env python3.5
import cryptography
from cryptography.hazmat.primitives import hashes
from cryptography.hazmat.primitives.kdf.hkdf import HKDF
from cryptography.hazmat.backends import default_backend
print("cryptography.io:{}".format(cryptography.__version__))
hkdf = HKDF(algorithm=hashes.SHA256(), length=4, salt=b"salt",
info=b"some-test", backend=default_backend())
key = hkdf.derive(b"my secret passphrase")
print("Derived key: {}".format(key))
```
Output:
```
cryptography.io:1.5.2
Derived key: b''
```
Suggested fix:
I am not quite sure why the division by 8 in the snippet below was added. The cumulative size of the output array is always `self._algorithm.digest_size * len(output)` and thus we can stop after `self._algorithm.digest_size * len(output) >= self._length`. At first I thought this might be a clever trick taken from the paper, but I didn't find it there. I guess there was a mixup between bits and bytes at some point.
```python
# class HKDFExpand
def _expand(self, key_material):
output = [b""]
counter = 1
while (self._algorithm.digest_size // 8) * len(output) < self._length:
h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
h.update(output[-1])
h.update(self._info)
h.update(six.int2byte(counter))
output.append(h.finalize())
counter += 1
return b"".join(output)[:self._length]
```
</issue>
<code>
[start of src/cryptography/hazmat/primitives/kdf/hkdf.py]
1 # This file is dual licensed under the terms of the Apache License, Version
2 # 2.0, and the BSD License. See the LICENSE file in the root of this repository
3 # for complete details.
4
5 from __future__ import absolute_import, division, print_function
6
7 import six
8
9 from cryptography import utils
10 from cryptography.exceptions import (
11 AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons
12 )
13 from cryptography.hazmat.backends.interfaces import HMACBackend
14 from cryptography.hazmat.primitives import constant_time, hmac
15 from cryptography.hazmat.primitives.kdf import KeyDerivationFunction
16
17
18 @utils.register_interface(KeyDerivationFunction)
19 class HKDF(object):
20 def __init__(self, algorithm, length, salt, info, backend):
21 if not isinstance(backend, HMACBackend):
22 raise UnsupportedAlgorithm(
23 "Backend object does not implement HMACBackend.",
24 _Reasons.BACKEND_MISSING_INTERFACE
25 )
26
27 self._algorithm = algorithm
28
29 if not (salt is None or isinstance(salt, bytes)):
30 raise TypeError("salt must be bytes.")
31
32 if salt is None:
33 salt = b"\x00" * (self._algorithm.digest_size // 8)
34
35 self._salt = salt
36
37 self._backend = backend
38
39 self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)
40
41 def _extract(self, key_material):
42 h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)
43 h.update(key_material)
44 return h.finalize()
45
46 def derive(self, key_material):
47 if not isinstance(key_material, bytes):
48 raise TypeError("key_material must be bytes.")
49
50 return self._hkdf_expand.derive(self._extract(key_material))
51
52 def verify(self, key_material, expected_key):
53 if not constant_time.bytes_eq(self.derive(key_material), expected_key):
54 raise InvalidKey
55
56
57 @utils.register_interface(KeyDerivationFunction)
58 class HKDFExpand(object):
59 def __init__(self, algorithm, length, info, backend):
60 if not isinstance(backend, HMACBackend):
61 raise UnsupportedAlgorithm(
62 "Backend object does not implement HMACBackend.",
63 _Reasons.BACKEND_MISSING_INTERFACE
64 )
65
66 self._algorithm = algorithm
67
68 self._backend = backend
69
70 max_length = 255 * (algorithm.digest_size // 8)
71
72 if length > max_length:
73 raise ValueError(
74 "Can not derive keys larger than {0} octets.".format(
75 max_length
76 ))
77
78 self._length = length
79
80 if not (info is None or isinstance(info, bytes)):
81 raise TypeError("info must be bytes.")
82
83 if info is None:
84 info = b""
85
86 self._info = info
87
88 self._used = False
89
90 def _expand(self, key_material):
91 output = [b""]
92 counter = 1
93
94 while (self._algorithm.digest_size // 8) * len(output) < self._length:
95 h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
96 h.update(output[-1])
97 h.update(self._info)
98 h.update(six.int2byte(counter))
99 output.append(h.finalize())
100 counter += 1
101
102 return b"".join(output)[:self._length]
103
104 def derive(self, key_material):
105 if not isinstance(key_material, bytes):
106 raise TypeError("key_material must be bytes.")
107
108 if self._used:
109 raise AlreadyFinalized
110
111 self._used = True
112 return self._expand(key_material)
113
114 def verify(self, key_material, expected_key):
115 if not constant_time.bytes_eq(self.derive(key_material), expected_key):
116 raise InvalidKey
117
[end of src/cryptography/hazmat/primitives/kdf/hkdf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cryptography/hazmat/primitives/kdf/hkdf.py b/src/cryptography/hazmat/primitives/kdf/hkdf.py
--- a/src/cryptography/hazmat/primitives/kdf/hkdf.py
+++ b/src/cryptography/hazmat/primitives/kdf/hkdf.py
@@ -91,7 +91,7 @@
output = [b""]
counter = 1
- while (self._algorithm.digest_size // 8) * len(output) < self._length:
+ while self._algorithm.digest_size * (len(output) - 1) < self._length:
h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)
h.update(output[-1])
h.update(self._info)
|
{"golden_diff": "diff --git a/src/cryptography/hazmat/primitives/kdf/hkdf.py b/src/cryptography/hazmat/primitives/kdf/hkdf.py\n--- a/src/cryptography/hazmat/primitives/kdf/hkdf.py\n+++ b/src/cryptography/hazmat/primitives/kdf/hkdf.py\n@@ -91,7 +91,7 @@\n output = [b\"\"]\n counter = 1\n \n- while (self._algorithm.digest_size // 8) * len(output) < self._length:\n+ while self._algorithm.digest_size * (len(output) - 1) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n", "issue": "HKDF key-length inconsistency\nFor too small key sizes, `HKDF.derive()` outputs an empty array instead of a small key:\r\n\r\nProgram:\r\n```python\r\n#!/usr/bin/env python3.5\r\nimport cryptography\r\nfrom cryptography.hazmat.primitives import hashes\r\nfrom cryptography.hazmat.primitives.kdf.hkdf import HKDF\r\nfrom cryptography.hazmat.backends import default_backend\r\n\r\nprint(\"cryptography.io:{}\".format(cryptography.__version__))\r\n\r\nhkdf = HKDF(algorithm=hashes.SHA256(), length=4, salt=b\"salt\",\r\n info=b\"some-test\", backend=default_backend())\r\n\r\nkey = hkdf.derive(b\"my secret passphrase\")\r\nprint(\"Derived key: {}\".format(key))\r\n```\r\n\r\nOutput:\r\n```\r\ncryptography.io:1.5.2\r\nDerived key: b''\r\n```\r\n\r\nSuggested fix:\r\n\r\nI am not quite sure why the division by 8 in the snippet below was added. The cumulative size of the output array is always `self._algorithm.digest_size * len(output)` and thus we can stop after `self._algorithm.digest_size * len(output) >= self._length`. At first I thought this might be a clever trick taken from the paper, but I didn't find it there. I guess there was a mixup between bits and bytes at some point.\r\n\r\n```python\r\n# class HKDFExpand\r\ndef _expand(self, key_material):\r\n output = [b\"\"]\r\n counter = 1\r\n\r\n while (self._algorithm.digest_size // 8) * len(output) < self._length:\r\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\r\n h.update(output[-1])\r\n h.update(self._info)\r\n h.update(six.int2byte(counter))\r\n output.append(h.finalize())\r\n counter += 1\r\n\r\n return b\"\".join(output)[:self._length]\r\n```\n", "before_files": [{"content": "# This file is dual licensed under the terms of the Apache License, Version\n# 2.0, and the BSD License. See the LICENSE file in the root of this repository\n# for complete details.\n\nfrom __future__ import absolute_import, division, print_function\n\nimport six\n\nfrom cryptography import utils\nfrom cryptography.exceptions import (\n AlreadyFinalized, InvalidKey, UnsupportedAlgorithm, _Reasons\n)\nfrom cryptography.hazmat.backends.interfaces import HMACBackend\nfrom cryptography.hazmat.primitives import constant_time, hmac\nfrom cryptography.hazmat.primitives.kdf import KeyDerivationFunction\n\n\[email protected]_interface(KeyDerivationFunction)\nclass HKDF(object):\n def __init__(self, algorithm, length, salt, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n if not (salt is None or isinstance(salt, bytes)):\n raise TypeError(\"salt must be bytes.\")\n\n if salt is None:\n salt = b\"\\x00\" * (self._algorithm.digest_size // 8)\n\n self._salt = salt\n\n self._backend = backend\n\n self._hkdf_expand = HKDFExpand(self._algorithm, length, info, backend)\n\n def _extract(self, key_material):\n h = hmac.HMAC(self._salt, self._algorithm, backend=self._backend)\n h.update(key_material)\n return h.finalize()\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n return self._hkdf_expand.derive(self._extract(key_material))\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n\n\[email protected]_interface(KeyDerivationFunction)\nclass HKDFExpand(object):\n def __init__(self, algorithm, length, info, backend):\n if not isinstance(backend, HMACBackend):\n raise UnsupportedAlgorithm(\n \"Backend object does not implement HMACBackend.\",\n _Reasons.BACKEND_MISSING_INTERFACE\n )\n\n self._algorithm = algorithm\n\n self._backend = backend\n\n max_length = 255 * (algorithm.digest_size // 8)\n\n if length > max_length:\n raise ValueError(\n \"Can not derive keys larger than {0} octets.\".format(\n max_length\n ))\n\n self._length = length\n\n if not (info is None or isinstance(info, bytes)):\n raise TypeError(\"info must be bytes.\")\n\n if info is None:\n info = b\"\"\n\n self._info = info\n\n self._used = False\n\n def _expand(self, key_material):\n output = [b\"\"]\n counter = 1\n\n while (self._algorithm.digest_size // 8) * len(output) < self._length:\n h = hmac.HMAC(key_material, self._algorithm, backend=self._backend)\n h.update(output[-1])\n h.update(self._info)\n h.update(six.int2byte(counter))\n output.append(h.finalize())\n counter += 1\n\n return b\"\".join(output)[:self._length]\n\n def derive(self, key_material):\n if not isinstance(key_material, bytes):\n raise TypeError(\"key_material must be bytes.\")\n\n if self._used:\n raise AlreadyFinalized\n\n self._used = True\n return self._expand(key_material)\n\n def verify(self, key_material, expected_key):\n if not constant_time.bytes_eq(self.derive(key_material), expected_key):\n raise InvalidKey\n", "path": "src/cryptography/hazmat/primitives/kdf/hkdf.py"}]}
| 1,998 | 169 |
gh_patches_debug_7796
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-1135
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Redis address parsing is done in init_app
This was added in #1107:
https://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L11-L12
While, `REDIS_ADDRESS` is now only resolved in `init_app`. (#940). We took care of that in:
https://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L116-L117
I believe DEFAULT_CONFIG should be like:
https://github.com/Mailu/Mailu/blob/4c25c83419be128fb12591721627a718ec23f69d/core/admin/mailu/configuration.py#L12-L13
We are now in the process of backporting #940 to 1.7. PR #1107 was not backported. Therefore 1.7 will look like the last snippet.
CC @mildred, @kaiyou
</issue>
<code>
[start of core/admin/mailu/configuration.py]
1 import os
2
3 from socrate import system
4
5 DEFAULT_CONFIG = {
6 # Specific to the admin UI
7 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',
8 'BABEL_DEFAULT_LOCALE': 'en',
9 'BABEL_DEFAULT_TIMEZONE': 'UTC',
10 'BOOTSTRAP_SERVE_LOCAL': True,
11 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv("REDIS_ADDRESS", "redis")),
12 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv("REDIS_ADDRESS", "redis")),
13 'DEBUG': False,
14 'DOMAIN_REGISTRATION': False,
15 'TEMPLATES_AUTO_RELOAD': True,
16 # Database settings
17 'DB_FLAVOR': None,
18 'DB_USER': 'mailu',
19 'DB_PW': None,
20 'DB_HOST': 'database',
21 'DB_NAME': 'mailu',
22 'SQLITE_DATABASE_FILE':'data/main.db',
23 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',
24 'SQLALCHEMY_TRACK_MODIFICATIONS': False,
25 # Statistics management
26 'INSTANCE_ID_PATH': '/data/instance',
27 'STATS_ENDPOINT': '0.{}.stats.mailu.io',
28 # Common configuration variables
29 'SECRET_KEY': 'changeMe',
30 'DOMAIN': 'mailu.io',
31 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',
32 'POSTMASTER': 'postmaster',
33 'TLS_FLAVOR': 'cert',
34 'AUTH_RATELIMIT': '10/minute;1000/hour',
35 'DISABLE_STATISTICS': False,
36 # Mail settings
37 'DMARC_RUA': None,
38 'DMARC_RUF': None,
39 'WELCOME': False,
40 'WELCOME_SUBJECT': 'Dummy welcome topic',
41 'WELCOME_BODY': 'Dummy welcome body',
42 'DKIM_SELECTOR': 'dkim',
43 'DKIM_PATH': '/dkim/{domain}.{selector}.key',
44 'DEFAULT_QUOTA': 1000000000,
45 # Web settings
46 'SITENAME': 'Mailu',
47 'WEBSITE': 'https://mailu.io',
48 'WEB_ADMIN': '/admin',
49 'WEB_WEBMAIL': '/webmail',
50 'WEBMAIL': 'none',
51 'RECAPTCHA_PUBLIC_KEY': '',
52 'RECAPTCHA_PRIVATE_KEY': '',
53 # Advanced settings
54 'PASSWORD_SCHEME': 'BLF-CRYPT',
55 'LOG_LEVEL': 'WARNING',
56 # Host settings
57 'HOST_IMAP': 'imap',
58 'HOST_LMTP': 'imap:2525',
59 'HOST_POP3': 'imap',
60 'HOST_SMTP': 'smtp',
61 'HOST_AUTHSMTP': 'smtp',
62 'HOST_ADMIN': 'admin',
63 'HOST_ANTISPAM': 'antispam:11334',
64 'HOST_WEBMAIL': 'webmail',
65 'HOST_WEBDAV': 'webdav:5232',
66 'HOST_REDIS': 'redis',
67 'HOST_FRONT': 'front',
68 'SUBNET': '192.168.203.0/24',
69 'POD_ADDRESS_RANGE': None
70 }
71
72 class ConfigManager(dict):
73 """ Naive configuration manager that uses environment only
74 """
75
76 DB_TEMPLATES = {
77 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',
78 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',
79 'mysql': 'mysql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'
80 }
81
82 HOSTS = ('IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS')
83 OPTIONAL_HOSTS = ('WEBMAIL', 'ANTISPAM')
84
85 def __init__(self):
86 self.config = dict()
87
88 def resolve_host(self):
89 optional = [item for item in self.OPTIONAL_HOSTS if item in self.config and self.config[item] != "none"]
90 for item in list(self.HOSTS) + optional:
91 host = 'HOST_' + item
92 address = item + '_ADDRESS'
93 self.config[address] = system.resolve_address(self.config[host])
94
95 def __coerce_value(self, value):
96 if isinstance(value, str) and value.lower() in ('true','yes'):
97 return True
98 elif isinstance(value, str) and value.lower() in ('false', 'no'):
99 return False
100 return value
101
102 def init_app(self, app):
103 self.config.update(app.config)
104 # get environment variables
105 self.config.update({
106 key: self.__coerce_value(os.environ.get(key, value))
107 for key, value in DEFAULT_CONFIG.items()
108 })
109 self.resolve_host()
110
111 # automatically set the sqlalchemy string
112 if self.config['DB_FLAVOR']:
113 template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]
114 self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)
115
116 self.config['RATELIMIT_STORAGE_URL'] = 'redis://{0}/2'.format(self.config['REDIS_ADDRESS'])
117 self.config['QUOTA_STORAGE_URL'] = 'redis://{0}/1'.format(self.config['REDIS_ADDRESS'])
118 # update the app config itself
119 app.config = self
120
121 def setdefault(self, key, value):
122 if key not in self.config:
123 self.config[key] = value
124 return self.config[key]
125
126 def get(self, *args):
127 return self.config.get(*args)
128
129 def keys(self):
130 return self.config.keys()
131
132 def __getitem__(self, key):
133 return self.config.get(key)
134
135 def __setitem__(self, key, value):
136 self.config[key] = value
137
138 def __contains__(self, key):
139 return key in self.config
140
[end of core/admin/mailu/configuration.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/core/admin/mailu/configuration.py b/core/admin/mailu/configuration.py
--- a/core/admin/mailu/configuration.py
+++ b/core/admin/mailu/configuration.py
@@ -8,8 +8,8 @@
'BABEL_DEFAULT_LOCALE': 'en',
'BABEL_DEFAULT_TIMEZONE': 'UTC',
'BOOTSTRAP_SERVE_LOCAL': True,
- 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv("REDIS_ADDRESS", "redis")),
- 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv("REDIS_ADDRESS", "redis")),
+ 'RATELIMIT_STORAGE_URL': '',
+ 'QUOTA_STORAGE_URL': '',
'DEBUG': False,
'DOMAIN_REGISTRATION': False,
'TEMPLATES_AUTO_RELOAD': True,
|
{"golden_diff": "diff --git a/core/admin/mailu/configuration.py b/core/admin/mailu/configuration.py\n--- a/core/admin/mailu/configuration.py\n+++ b/core/admin/mailu/configuration.py\n@@ -8,8 +8,8 @@\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n- 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n- 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n+ 'RATELIMIT_STORAGE_URL': '',\n+ 'QUOTA_STORAGE_URL': '',\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n", "issue": "Redis address parsing is done in init_app\nThis was added in #1107:\r\n\r\nhttps://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L11-L12\r\n\r\nWhile, `REDIS_ADDRESS` is now only resolved in `init_app`. (#940). We took care of that in:\r\n\r\nhttps://github.com/Mailu/Mailu/blob/f3f0c3190be9ab9b53a29c5b0326fc9a4602df46/core/admin/mailu/configuration.py#L116-L117\r\n\r\nI believe DEFAULT_CONFIG should be like:\r\n\r\nhttps://github.com/Mailu/Mailu/blob/4c25c83419be128fb12591721627a718ec23f69d/core/admin/mailu/configuration.py#L12-L13\r\n\r\nWe are now in the process of backporting #940 to 1.7. PR #1107 was not backported. Therefore 1.7 will look like the last snippet.\r\n\r\nCC @mildred, @kaiyou \n", "before_files": [{"content": "import os\n\nfrom socrate import system\n\nDEFAULT_CONFIG = {\n # Specific to the admin UI\n 'DOCKER_SOCKET': 'unix:///var/run/docker.sock',\n 'BABEL_DEFAULT_LOCALE': 'en',\n 'BABEL_DEFAULT_TIMEZONE': 'UTC',\n 'BOOTSTRAP_SERVE_LOCAL': True,\n 'RATELIMIT_STORAGE_URL': 'redis://%s/2' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n 'QUOTA_STORAGE_URL': 'redis://%s/1' % (os.getenv(\"REDIS_ADDRESS\", \"redis\")),\n 'DEBUG': False,\n 'DOMAIN_REGISTRATION': False,\n 'TEMPLATES_AUTO_RELOAD': True,\n # Database settings\n 'DB_FLAVOR': None,\n 'DB_USER': 'mailu',\n 'DB_PW': None,\n 'DB_HOST': 'database',\n 'DB_NAME': 'mailu',\n 'SQLITE_DATABASE_FILE':'data/main.db',\n 'SQLALCHEMY_DATABASE_URI': 'sqlite:////data/main.db',\n 'SQLALCHEMY_TRACK_MODIFICATIONS': False,\n # Statistics management\n 'INSTANCE_ID_PATH': '/data/instance',\n 'STATS_ENDPOINT': '0.{}.stats.mailu.io',\n # Common configuration variables\n 'SECRET_KEY': 'changeMe',\n 'DOMAIN': 'mailu.io',\n 'HOSTNAMES': 'mail.mailu.io,alternative.mailu.io,yetanother.mailu.io',\n 'POSTMASTER': 'postmaster',\n 'TLS_FLAVOR': 'cert',\n 'AUTH_RATELIMIT': '10/minute;1000/hour',\n 'DISABLE_STATISTICS': False,\n # Mail settings\n 'DMARC_RUA': None,\n 'DMARC_RUF': None,\n 'WELCOME': False,\n 'WELCOME_SUBJECT': 'Dummy welcome topic',\n 'WELCOME_BODY': 'Dummy welcome body',\n 'DKIM_SELECTOR': 'dkim',\n 'DKIM_PATH': '/dkim/{domain}.{selector}.key',\n 'DEFAULT_QUOTA': 1000000000,\n # Web settings\n 'SITENAME': 'Mailu',\n 'WEBSITE': 'https://mailu.io',\n 'WEB_ADMIN': '/admin',\n 'WEB_WEBMAIL': '/webmail',\n 'WEBMAIL': 'none',\n 'RECAPTCHA_PUBLIC_KEY': '',\n 'RECAPTCHA_PRIVATE_KEY': '',\n # Advanced settings\n 'PASSWORD_SCHEME': 'BLF-CRYPT',\n 'LOG_LEVEL': 'WARNING',\n # Host settings\n 'HOST_IMAP': 'imap',\n 'HOST_LMTP': 'imap:2525',\n 'HOST_POP3': 'imap',\n 'HOST_SMTP': 'smtp',\n 'HOST_AUTHSMTP': 'smtp',\n 'HOST_ADMIN': 'admin',\n 'HOST_ANTISPAM': 'antispam:11334',\n 'HOST_WEBMAIL': 'webmail',\n 'HOST_WEBDAV': 'webdav:5232',\n 'HOST_REDIS': 'redis',\n 'HOST_FRONT': 'front',\n 'SUBNET': '192.168.203.0/24',\n 'POD_ADDRESS_RANGE': None\n}\n\nclass ConfigManager(dict):\n \"\"\" Naive configuration manager that uses environment only\n \"\"\"\n\n DB_TEMPLATES = {\n 'sqlite': 'sqlite:////{SQLITE_DATABASE_FILE}',\n 'postgresql': 'postgresql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}',\n 'mysql': 'mysql://{DB_USER}:{DB_PW}@{DB_HOST}/{DB_NAME}'\n }\n\n HOSTS = ('IMAP', 'POP3', 'AUTHSMTP', 'SMTP', 'REDIS')\n OPTIONAL_HOSTS = ('WEBMAIL', 'ANTISPAM')\n\n def __init__(self):\n self.config = dict()\n\n def resolve_host(self):\n optional = [item for item in self.OPTIONAL_HOSTS if item in self.config and self.config[item] != \"none\"]\n for item in list(self.HOSTS) + optional:\n host = 'HOST_' + item\n address = item + '_ADDRESS'\n self.config[address] = system.resolve_address(self.config[host])\n\n def __coerce_value(self, value):\n if isinstance(value, str) and value.lower() in ('true','yes'):\n return True\n elif isinstance(value, str) and value.lower() in ('false', 'no'):\n return False\n return value\n\n def init_app(self, app):\n self.config.update(app.config)\n # get environment variables\n self.config.update({\n key: self.__coerce_value(os.environ.get(key, value))\n for key, value in DEFAULT_CONFIG.items()\n })\n self.resolve_host()\n\n # automatically set the sqlalchemy string\n if self.config['DB_FLAVOR']:\n template = self.DB_TEMPLATES[self.config['DB_FLAVOR']]\n self.config['SQLALCHEMY_DATABASE_URI'] = template.format(**self.config)\n\n self.config['RATELIMIT_STORAGE_URL'] = 'redis://{0}/2'.format(self.config['REDIS_ADDRESS'])\n self.config['QUOTA_STORAGE_URL'] = 'redis://{0}/1'.format(self.config['REDIS_ADDRESS'])\n # update the app config itself\n app.config = self\n\n def setdefault(self, key, value):\n if key not in self.config:\n self.config[key] = value\n return self.config[key]\n\n def get(self, *args):\n return self.config.get(*args)\n\n def keys(self):\n return self.config.keys()\n\n def __getitem__(self, key):\n return self.config.get(key)\n\n def __setitem__(self, key, value):\n self.config[key] = value\n\n def __contains__(self, key):\n return key in self.config\n", "path": "core/admin/mailu/configuration.py"}]}
| 2,404 | 173 |
gh_patches_debug_11975
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-1394
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Compile and execute use a progress bar even if a single circuit is passed.
<!-- ⚠️ If you do not respect this template, your issue will be closed -->
<!-- ⚠️ Make sure to browse the opened and closed issues -->
### Informations
- **Qiskit Terra version**: master
- **Python version**: 3.7
- **Operating system**: OSX
### What is the current behavior?
The `compile` and `execute` functions make use of a progress bar for a single circuit.
### Steps to reproduce the problem
```
from qiskit import *
from qiskit.tools.jupyter import TextProgressBar
q = QuantumRegister(2)
c = ClassicalRegister(2)
qc = QuantumCircuit(q, c)
qc.h(q[0])
qc.cx(q[0], q[1])
qc.measure(q, c)
backend = Aer.get_backend('qasm_simulator')
TextProgressBar()
qobj = compile([qc], backend)
```
### What is the expected behavior?
A progress bar should not be used for a single circuit.
### Suggested solutions
</issue>
<code>
[start of qiskit/transpiler/_parallel.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright 2018, IBM.
4 #
5 # This source code is licensed under the Apache License, Version 2.0 found in
6 # the LICENSE.txt file in the root directory of this source tree.
7
8 # This file is part of QuTiP: Quantum Toolbox in Python.
9 #
10 # Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.
11 # All rights reserved.
12 #
13 # Redistribution and use in source and binary forms, with or without
14 # modification, are permitted provided that the following conditions are
15 # met:
16 #
17 # 1. Redistributions of source code must retain the above copyright notice,
18 # this list of conditions and the following disclaimer.
19 #
20 # 2. Redistributions in binary form must reproduce the above copyright
21 # notice, this list of conditions and the following disclaimer in the
22 # documentation and/or other materials provided with the distribution.
23 #
24 # 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names
25 # of its contributors may be used to endorse or promote products derived
26 # from this software without specific prior written permission.
27 #
28 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
29 # "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
30 # LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A
31 # PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
32 # HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
33 # SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
34 # LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
35 # DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
36 # THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
37 # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
38 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
39 ###############################################################################
40
41 """
42 Routines for running Python functions in parallel using process pools
43 from the multiprocessing library.
44 """
45
46 import os
47 import platform
48 from multiprocessing import Pool
49 from qiskit._qiskiterror import QISKitError
50 from qiskit._util import local_hardware_info
51 from qiskit._pubsub import Publisher
52
53 # Number of local physical cpus
54 CPU_COUNT = local_hardware_info()['cpus']
55
56
57 def parallel_map(task, values, task_args=tuple(), task_kwargs={}, # pylint: disable=W0102
58 num_processes=CPU_COUNT):
59 """
60 Parallel execution of a mapping of `values` to the function `task`. This
61 is functionally equivalent to::
62
63 result = [task(value, *task_args, **task_kwargs) for value in values]
64
65 On Windows this function defaults to a serial implementation to avoid the
66 overhead from spawning processes in Windows.
67
68 Args:
69 task (func): Function that is to be called for each value in ``task_vec``.
70 values (array_like): List or array of values for which the ``task``
71 function is to be evaluated.
72 task_args (list): Optional additional arguments to the ``task`` function.
73 task_kwargs (dict): Optional additional keyword argument to the ``task`` function.
74 num_processes (int): Number of processes to spawn.
75
76 Returns:
77 result: The result list contains the value of
78 ``task(value, *task_args, **task_kwargs)`` for
79 each value in ``values``.
80
81 Raises:
82 QISKitError: If user interrupts via keyboard.
83
84 Events:
85 terra.transpiler.parallel.start: The collection of parallel tasks are about to start.
86 terra.transpiler.parallel.update: One of the parallel task has finished.
87 terra.transpiler.parallel.finish: All the parallel tasks have finished.
88 """
89 Publisher().publish("terra.transpiler.parallel.start", len(values))
90 if len(values) == 1:
91 Publisher().publish("terra.transpiler.parallel.finish")
92 return [task(values[0], *task_args, **task_kwargs)]
93
94 nfinished = [0]
95
96 def _callback(_):
97 nfinished[0] += 1
98 Publisher().publish("terra.transpiler.parallel.done", nfinished[0])
99
100 # Run in parallel if not Win and not in parallel already
101 if platform.system() != 'Windows' and num_processes > 1 \
102 and os.getenv('QISKIT_IN_PARALLEL') == 'FALSE':
103 os.environ['QISKIT_IN_PARALLEL'] = 'TRUE'
104 try:
105 pool = Pool(processes=num_processes)
106
107 async_res = [pool.apply_async(task, (value,) + task_args, task_kwargs,
108 _callback) for value in values]
109
110 while not all([item.ready() for item in async_res]):
111 for item in async_res:
112 item.wait(timeout=0.1)
113
114 pool.terminate()
115 pool.join()
116
117 except KeyboardInterrupt:
118 pool.terminate()
119 pool.join()
120 Publisher().publish("terra.parallel.parallel.finish")
121 raise QISKitError('Keyboard interrupt in parallel_map.')
122
123 Publisher().publish("terra.transpiler.parallel.finish")
124 os.environ['QISKIT_IN_PARALLEL'] = 'FALSE'
125 return [ar.get() for ar in async_res]
126
127 # Cannot do parallel on Windows , if another parallel_map is running in parallel,
128 # or len(values) == 1.
129 results = []
130 for _, value in enumerate(values):
131 result = task(value, *task_args, **task_kwargs)
132 results.append(result)
133 _callback(0)
134 Publisher().publish("terra.transpiler.parallel.finish")
135 return results
136
[end of qiskit/transpiler/_parallel.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/transpiler/_parallel.py b/qiskit/transpiler/_parallel.py
--- a/qiskit/transpiler/_parallel.py
+++ b/qiskit/transpiler/_parallel.py
@@ -86,11 +86,10 @@
terra.transpiler.parallel.update: One of the parallel task has finished.
terra.transpiler.parallel.finish: All the parallel tasks have finished.
"""
- Publisher().publish("terra.transpiler.parallel.start", len(values))
if len(values) == 1:
- Publisher().publish("terra.transpiler.parallel.finish")
return [task(values[0], *task_args, **task_kwargs)]
+ Publisher().publish("terra.transpiler.parallel.start", len(values))
nfinished = [0]
def _callback(_):
|
{"golden_diff": "diff --git a/qiskit/transpiler/_parallel.py b/qiskit/transpiler/_parallel.py\n--- a/qiskit/transpiler/_parallel.py\n+++ b/qiskit/transpiler/_parallel.py\n@@ -86,11 +86,10 @@\n terra.transpiler.parallel.update: One of the parallel task has finished.\n terra.transpiler.parallel.finish: All the parallel tasks have finished.\n \"\"\"\n- Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n if len(values) == 1:\n- Publisher().publish(\"terra.transpiler.parallel.finish\")\n return [task(values[0], *task_args, **task_kwargs)]\n \n+ Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n nfinished = [0]\n \n def _callback(_):\n", "issue": "Compile and execute use a progress bar even if a single circuit is passed.\n<!-- \u26a0\ufe0f If you do not respect this template, your issue will be closed -->\r\n<!-- \u26a0\ufe0f Make sure to browse the opened and closed issues -->\r\n\r\n### Informations\r\n\r\n- **Qiskit Terra version**: master\r\n- **Python version**: 3.7\r\n- **Operating system**: OSX\r\n\r\n### What is the current behavior?\r\nThe `compile` and `execute` functions make use of a progress bar for a single circuit.\r\n\r\n### Steps to reproduce the problem\r\n```\r\nfrom qiskit import *\r\nfrom qiskit.tools.jupyter import TextProgressBar\r\n\r\nq = QuantumRegister(2)\r\nc = ClassicalRegister(2)\r\nqc = QuantumCircuit(q, c)\r\n\r\nqc.h(q[0])\r\nqc.cx(q[0], q[1])\r\nqc.measure(q, c)\r\n\r\nbackend = Aer.get_backend('qasm_simulator')\r\nTextProgressBar()\r\nqobj = compile([qc], backend)\r\n```\r\n\r\n\r\n### What is the expected behavior?\r\nA progress bar should not be used for a single circuit.\r\n\r\n### Suggested solutions\r\n\r\n\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright 2018, IBM.\n#\n# This source code is licensed under the Apache License, Version 2.0 found in\n# the LICENSE.txt file in the root directory of this source tree.\n\n# This file is part of QuTiP: Quantum Toolbox in Python.\n#\n# Copyright (c) 2011 and later, Paul D. Nation and Robert J. Johansson.\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are\n# met:\n#\n# 1. Redistributions of source code must retain the above copyright notice,\n# this list of conditions and the following disclaimer.\n#\n# 2. Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n#\n# 3. Neither the name of the QuTiP: Quantum Toolbox in Python nor the names\n# of its contributors may be used to endorse or promote products derived\n# from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS\n# \"AS IS\" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT\n# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A\n# PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT\n# HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,\n# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT\n# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,\n# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY\n# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n###############################################################################\n\n\"\"\"\nRoutines for running Python functions in parallel using process pools\nfrom the multiprocessing library.\n\"\"\"\n\nimport os\nimport platform\nfrom multiprocessing import Pool\nfrom qiskit._qiskiterror import QISKitError\nfrom qiskit._util import local_hardware_info\nfrom qiskit._pubsub import Publisher\n\n# Number of local physical cpus\nCPU_COUNT = local_hardware_info()['cpus']\n\n\ndef parallel_map(task, values, task_args=tuple(), task_kwargs={}, # pylint: disable=W0102\n num_processes=CPU_COUNT):\n \"\"\"\n Parallel execution of a mapping of `values` to the function `task`. This\n is functionally equivalent to::\n\n result = [task(value, *task_args, **task_kwargs) for value in values]\n\n On Windows this function defaults to a serial implementation to avoid the\n overhead from spawning processes in Windows.\n\n Args:\n task (func): Function that is to be called for each value in ``task_vec``.\n values (array_like): List or array of values for which the ``task``\n function is to be evaluated.\n task_args (list): Optional additional arguments to the ``task`` function.\n task_kwargs (dict): Optional additional keyword argument to the ``task`` function.\n num_processes (int): Number of processes to spawn.\n\n Returns:\n result: The result list contains the value of\n ``task(value, *task_args, **task_kwargs)`` for\n each value in ``values``.\n\n Raises:\n QISKitError: If user interrupts via keyboard.\n\n Events:\n terra.transpiler.parallel.start: The collection of parallel tasks are about to start.\n terra.transpiler.parallel.update: One of the parallel task has finished.\n terra.transpiler.parallel.finish: All the parallel tasks have finished.\n \"\"\"\n Publisher().publish(\"terra.transpiler.parallel.start\", len(values))\n if len(values) == 1:\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n return [task(values[0], *task_args, **task_kwargs)]\n\n nfinished = [0]\n\n def _callback(_):\n nfinished[0] += 1\n Publisher().publish(\"terra.transpiler.parallel.done\", nfinished[0])\n\n # Run in parallel if not Win and not in parallel already\n if platform.system() != 'Windows' and num_processes > 1 \\\n and os.getenv('QISKIT_IN_PARALLEL') == 'FALSE':\n os.environ['QISKIT_IN_PARALLEL'] = 'TRUE'\n try:\n pool = Pool(processes=num_processes)\n\n async_res = [pool.apply_async(task, (value,) + task_args, task_kwargs,\n _callback) for value in values]\n\n while not all([item.ready() for item in async_res]):\n for item in async_res:\n item.wait(timeout=0.1)\n\n pool.terminate()\n pool.join()\n\n except KeyboardInterrupt:\n pool.terminate()\n pool.join()\n Publisher().publish(\"terra.parallel.parallel.finish\")\n raise QISKitError('Keyboard interrupt in parallel_map.')\n\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n os.environ['QISKIT_IN_PARALLEL'] = 'FALSE'\n return [ar.get() for ar in async_res]\n\n # Cannot do parallel on Windows , if another parallel_map is running in parallel,\n # or len(values) == 1.\n results = []\n for _, value in enumerate(values):\n result = task(value, *task_args, **task_kwargs)\n results.append(result)\n _callback(0)\n Publisher().publish(\"terra.transpiler.parallel.finish\")\n return results\n", "path": "qiskit/transpiler/_parallel.py"}]}
| 2,284 | 171 |
gh_patches_debug_37473
|
rasdani/github-patches
|
git_diff
|
OpenNMT__OpenNMT-py-1101
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Repeated check in code
https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L133, why is the layer_cache is not None check required again? Similarly will this be ever called? https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L158
</issue>
<code>
[start of onmt/modules/multi_headed_attn.py]
1 """ Multi-Head Attention module """
2 import math
3 import torch
4 import torch.nn as nn
5
6 # from onmt.utils.misc import aeq
7
8
9 class MultiHeadedAttention(nn.Module):
10 """
11 Multi-Head Attention module from
12 "Attention is All You Need"
13 :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.
14
15 Similar to standard `dot` attention but uses
16 multiple attention distributions simulataneously
17 to select relevant items.
18
19 .. mermaid::
20
21 graph BT
22 A[key]
23 B[value]
24 C[query]
25 O[output]
26 subgraph Attn
27 D[Attn 1]
28 E[Attn 2]
29 F[Attn N]
30 end
31 A --> D
32 C --> D
33 A --> E
34 C --> E
35 A --> F
36 C --> F
37 D --> O
38 E --> O
39 F --> O
40 B --> O
41
42 Also includes several additional tricks.
43
44 Args:
45 head_count (int): number of parallel heads
46 model_dim (int): the dimension of keys/values/queries,
47 must be divisible by head_count
48 dropout (float): dropout parameter
49 """
50
51 def __init__(self, head_count, model_dim, dropout=0.1):
52 assert model_dim % head_count == 0
53 self.dim_per_head = model_dim // head_count
54 self.model_dim = model_dim
55
56 super(MultiHeadedAttention, self).__init__()
57 self.head_count = head_count
58
59 self.linear_keys = nn.Linear(model_dim,
60 head_count * self.dim_per_head)
61 self.linear_values = nn.Linear(model_dim,
62 head_count * self.dim_per_head)
63 self.linear_query = nn.Linear(model_dim,
64 head_count * self.dim_per_head)
65 self.softmax = nn.Softmax(dim=-1)
66 self.dropout = nn.Dropout(dropout)
67 self.final_linear = nn.Linear(model_dim, model_dim)
68
69 def forward(self, key, value, query, mask=None,
70 layer_cache=None, type=None):
71 """
72 Compute the context vector and the attention vectors.
73
74 Args:
75 key (`FloatTensor`): set of `key_len`
76 key vectors `[batch, key_len, dim]`
77 value (`FloatTensor`): set of `key_len`
78 value vectors `[batch, key_len, dim]`
79 query (`FloatTensor`): set of `query_len`
80 query vectors `[batch, query_len, dim]`
81 mask: binary mask indicating which keys have
82 non-zero attention `[batch, query_len, key_len]`
83 Returns:
84 (`FloatTensor`, `FloatTensor`) :
85
86 * output context vectors `[batch, query_len, dim]`
87 * one of the attention vectors `[batch, query_len, key_len]`
88 """
89
90 # CHECKS
91 # batch, k_len, d = key.size()
92 # batch_, k_len_, d_ = value.size()
93 # aeq(batch, batch_)
94 # aeq(k_len, k_len_)
95 # aeq(d, d_)
96 # batch_, q_len, d_ = query.size()
97 # aeq(batch, batch_)
98 # aeq(d, d_)
99 # aeq(self.model_dim % 8, 0)
100 # if mask is not None:
101 # batch_, q_len_, k_len_ = mask.size()
102 # aeq(batch_, batch)
103 # aeq(k_len_, k_len)
104 # aeq(q_len_ == q_len)
105 # END CHECKS
106
107 batch_size = key.size(0)
108 dim_per_head = self.dim_per_head
109 head_count = self.head_count
110 key_len = key.size(1)
111 query_len = query.size(1)
112
113 def shape(x):
114 """ projection """
115 return x.view(batch_size, -1, head_count, dim_per_head) \
116 .transpose(1, 2)
117
118 def unshape(x):
119 """ compute context """
120 return x.transpose(1, 2).contiguous() \
121 .view(batch_size, -1, head_count * dim_per_head)
122
123 # 1) Project key, value, and query.
124 if layer_cache is not None:
125 if type == "self":
126 query, key, value = self.linear_query(query),\
127 self.linear_keys(query),\
128 self.linear_values(query)
129
130 key = shape(key)
131 value = shape(value)
132
133 if layer_cache is not None:
134 device = key.device
135 if layer_cache["self_keys"] is not None:
136 key = torch.cat(
137 (layer_cache["self_keys"].to(device), key),
138 dim=2)
139 if layer_cache["self_values"] is not None:
140 value = torch.cat(
141 (layer_cache["self_values"].to(device), value),
142 dim=2)
143 layer_cache["self_keys"] = key
144 layer_cache["self_values"] = value
145 elif type == "context":
146 query = self.linear_query(query)
147 if layer_cache is not None:
148 if layer_cache["memory_keys"] is None:
149 key, value = self.linear_keys(key),\
150 self.linear_values(value)
151 key = shape(key)
152 value = shape(value)
153 else:
154 key, value = layer_cache["memory_keys"],\
155 layer_cache["memory_values"]
156 layer_cache["memory_keys"] = key
157 layer_cache["memory_values"] = value
158 else:
159 key, value = self.linear_keys(key),\
160 self.linear_values(value)
161 key = shape(key)
162 value = shape(value)
163 else:
164 key = self.linear_keys(key)
165 value = self.linear_values(value)
166 query = self.linear_query(query)
167 key = shape(key)
168 value = shape(value)
169
170 query = shape(query)
171
172 key_len = key.size(2)
173 query_len = query.size(2)
174
175 # 2) Calculate and scale scores.
176 query = query / math.sqrt(dim_per_head)
177 scores = torch.matmul(query, key.transpose(2, 3))
178
179 if mask is not None:
180 mask = mask.unsqueeze(1) # [B, 1, 1, T_values]
181 scores = scores.masked_fill(mask, -1e18)
182
183 # 3) Apply attention dropout and compute context vectors.
184 attn = self.softmax(scores)
185 drop_attn = self.dropout(attn)
186 context = unshape(torch.matmul(drop_attn, value))
187
188 output = self.final_linear(context)
189 # CHECK
190 # batch_, q_len_, d_ = output.size()
191 # aeq(q_len, q_len_)
192 # aeq(batch, batch_)
193 # aeq(d, d_)
194
195 # Return one attn
196 top_attn = attn \
197 .view(batch_size, head_count,
198 query_len, key_len)[:, 0, :, :] \
199 .contiguous()
200
201 return output, top_attn
202
[end of onmt/modules/multi_headed_attn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/onmt/modules/multi_headed_attn.py b/onmt/modules/multi_headed_attn.py
--- a/onmt/modules/multi_headed_attn.py
+++ b/onmt/modules/multi_headed_attn.py
@@ -126,40 +126,31 @@
query, key, value = self.linear_query(query),\
self.linear_keys(query),\
self.linear_values(query)
-
key = shape(key)
value = shape(value)
-
- if layer_cache is not None:
- device = key.device
- if layer_cache["self_keys"] is not None:
- key = torch.cat(
- (layer_cache["self_keys"].to(device), key),
- dim=2)
- if layer_cache["self_values"] is not None:
- value = torch.cat(
- (layer_cache["self_values"].to(device), value),
- dim=2)
- layer_cache["self_keys"] = key
- layer_cache["self_values"] = value
+ device = key.device
+ if layer_cache["self_keys"] is not None:
+ key = torch.cat(
+ (layer_cache["self_keys"].to(device), key),
+ dim=2)
+ if layer_cache["self_values"] is not None:
+ value = torch.cat(
+ (layer_cache["self_values"].to(device), value),
+ dim=2)
+ layer_cache["self_keys"] = key
+ layer_cache["self_values"] = value
elif type == "context":
query = self.linear_query(query)
- if layer_cache is not None:
- if layer_cache["memory_keys"] is None:
- key, value = self.linear_keys(key),\
- self.linear_values(value)
- key = shape(key)
- value = shape(value)
- else:
- key, value = layer_cache["memory_keys"],\
- layer_cache["memory_values"]
- layer_cache["memory_keys"] = key
- layer_cache["memory_values"] = value
- else:
+ if layer_cache["memory_keys"] is None:
key, value = self.linear_keys(key),\
self.linear_values(value)
key = shape(key)
value = shape(value)
+ else:
+ key, value = layer_cache["memory_keys"],\
+ layer_cache["memory_values"]
+ layer_cache["memory_keys"] = key
+ layer_cache["memory_values"] = value
else:
key = self.linear_keys(key)
value = self.linear_values(value)
|
{"golden_diff": "diff --git a/onmt/modules/multi_headed_attn.py b/onmt/modules/multi_headed_attn.py\n--- a/onmt/modules/multi_headed_attn.py\n+++ b/onmt/modules/multi_headed_attn.py\n@@ -126,40 +126,31 @@\n query, key, value = self.linear_query(query),\\\n self.linear_keys(query),\\\n self.linear_values(query)\n-\n key = shape(key)\n value = shape(value)\n-\n- if layer_cache is not None:\n- device = key.device\n- if layer_cache[\"self_keys\"] is not None:\n- key = torch.cat(\n- (layer_cache[\"self_keys\"].to(device), key),\n- dim=2)\n- if layer_cache[\"self_values\"] is not None:\n- value = torch.cat(\n- (layer_cache[\"self_values\"].to(device), value),\n- dim=2)\n- layer_cache[\"self_keys\"] = key\n- layer_cache[\"self_values\"] = value\n+ device = key.device\n+ if layer_cache[\"self_keys\"] is not None:\n+ key = torch.cat(\n+ (layer_cache[\"self_keys\"].to(device), key),\n+ dim=2)\n+ if layer_cache[\"self_values\"] is not None:\n+ value = torch.cat(\n+ (layer_cache[\"self_values\"].to(device), value),\n+ dim=2)\n+ layer_cache[\"self_keys\"] = key\n+ layer_cache[\"self_values\"] = value\n elif type == \"context\":\n query = self.linear_query(query)\n- if layer_cache is not None:\n- if layer_cache[\"memory_keys\"] is None:\n- key, value = self.linear_keys(key),\\\n- self.linear_values(value)\n- key = shape(key)\n- value = shape(value)\n- else:\n- key, value = layer_cache[\"memory_keys\"],\\\n- layer_cache[\"memory_values\"]\n- layer_cache[\"memory_keys\"] = key\n- layer_cache[\"memory_values\"] = value\n- else:\n+ if layer_cache[\"memory_keys\"] is None:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n+ else:\n+ key, value = layer_cache[\"memory_keys\"],\\\n+ layer_cache[\"memory_values\"]\n+ layer_cache[\"memory_keys\"] = key\n+ layer_cache[\"memory_values\"] = value\n else:\n key = self.linear_keys(key)\n value = self.linear_values(value)\n", "issue": "Repeated check in code\nhttps://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L133, why is the layer_cache is not None check required again? Similarly will this be ever called? https://github.com/OpenNMT/OpenNMT-py/blob/master/onmt/modules/multi_headed_attn.py#L158 \n", "before_files": [{"content": "\"\"\" Multi-Head Attention module \"\"\"\nimport math\nimport torch\nimport torch.nn as nn\n\n# from onmt.utils.misc import aeq\n\n\nclass MultiHeadedAttention(nn.Module):\n \"\"\"\n Multi-Head Attention module from\n \"Attention is All You Need\"\n :cite:`DBLP:journals/corr/VaswaniSPUJGKP17`.\n\n Similar to standard `dot` attention but uses\n multiple attention distributions simulataneously\n to select relevant items.\n\n .. mermaid::\n\n graph BT\n A[key]\n B[value]\n C[query]\n O[output]\n subgraph Attn\n D[Attn 1]\n E[Attn 2]\n F[Attn N]\n end\n A --> D\n C --> D\n A --> E\n C --> E\n A --> F\n C --> F\n D --> O\n E --> O\n F --> O\n B --> O\n\n Also includes several additional tricks.\n\n Args:\n head_count (int): number of parallel heads\n model_dim (int): the dimension of keys/values/queries,\n must be divisible by head_count\n dropout (float): dropout parameter\n \"\"\"\n\n def __init__(self, head_count, model_dim, dropout=0.1):\n assert model_dim % head_count == 0\n self.dim_per_head = model_dim // head_count\n self.model_dim = model_dim\n\n super(MultiHeadedAttention, self).__init__()\n self.head_count = head_count\n\n self.linear_keys = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_values = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.linear_query = nn.Linear(model_dim,\n head_count * self.dim_per_head)\n self.softmax = nn.Softmax(dim=-1)\n self.dropout = nn.Dropout(dropout)\n self.final_linear = nn.Linear(model_dim, model_dim)\n\n def forward(self, key, value, query, mask=None,\n layer_cache=None, type=None):\n \"\"\"\n Compute the context vector and the attention vectors.\n\n Args:\n key (`FloatTensor`): set of `key_len`\n key vectors `[batch, key_len, dim]`\n value (`FloatTensor`): set of `key_len`\n value vectors `[batch, key_len, dim]`\n query (`FloatTensor`): set of `query_len`\n query vectors `[batch, query_len, dim]`\n mask: binary mask indicating which keys have\n non-zero attention `[batch, query_len, key_len]`\n Returns:\n (`FloatTensor`, `FloatTensor`) :\n\n * output context vectors `[batch, query_len, dim]`\n * one of the attention vectors `[batch, query_len, key_len]`\n \"\"\"\n\n # CHECKS\n # batch, k_len, d = key.size()\n # batch_, k_len_, d_ = value.size()\n # aeq(batch, batch_)\n # aeq(k_len, k_len_)\n # aeq(d, d_)\n # batch_, q_len, d_ = query.size()\n # aeq(batch, batch_)\n # aeq(d, d_)\n # aeq(self.model_dim % 8, 0)\n # if mask is not None:\n # batch_, q_len_, k_len_ = mask.size()\n # aeq(batch_, batch)\n # aeq(k_len_, k_len)\n # aeq(q_len_ == q_len)\n # END CHECKS\n\n batch_size = key.size(0)\n dim_per_head = self.dim_per_head\n head_count = self.head_count\n key_len = key.size(1)\n query_len = query.size(1)\n\n def shape(x):\n \"\"\" projection \"\"\"\n return x.view(batch_size, -1, head_count, dim_per_head) \\\n .transpose(1, 2)\n\n def unshape(x):\n \"\"\" compute context \"\"\"\n return x.transpose(1, 2).contiguous() \\\n .view(batch_size, -1, head_count * dim_per_head)\n\n # 1) Project key, value, and query.\n if layer_cache is not None:\n if type == \"self\":\n query, key, value = self.linear_query(query),\\\n self.linear_keys(query),\\\n self.linear_values(query)\n\n key = shape(key)\n value = shape(value)\n\n if layer_cache is not None:\n device = key.device\n if layer_cache[\"self_keys\"] is not None:\n key = torch.cat(\n (layer_cache[\"self_keys\"].to(device), key),\n dim=2)\n if layer_cache[\"self_values\"] is not None:\n value = torch.cat(\n (layer_cache[\"self_values\"].to(device), value),\n dim=2)\n layer_cache[\"self_keys\"] = key\n layer_cache[\"self_values\"] = value\n elif type == \"context\":\n query = self.linear_query(query)\n if layer_cache is not None:\n if layer_cache[\"memory_keys\"] is None:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n else:\n key, value = layer_cache[\"memory_keys\"],\\\n layer_cache[\"memory_values\"]\n layer_cache[\"memory_keys\"] = key\n layer_cache[\"memory_values\"] = value\n else:\n key, value = self.linear_keys(key),\\\n self.linear_values(value)\n key = shape(key)\n value = shape(value)\n else:\n key = self.linear_keys(key)\n value = self.linear_values(value)\n query = self.linear_query(query)\n key = shape(key)\n value = shape(value)\n\n query = shape(query)\n\n key_len = key.size(2)\n query_len = query.size(2)\n\n # 2) Calculate and scale scores.\n query = query / math.sqrt(dim_per_head)\n scores = torch.matmul(query, key.transpose(2, 3))\n\n if mask is not None:\n mask = mask.unsqueeze(1) # [B, 1, 1, T_values]\n scores = scores.masked_fill(mask, -1e18)\n\n # 3) Apply attention dropout and compute context vectors.\n attn = self.softmax(scores)\n drop_attn = self.dropout(attn)\n context = unshape(torch.matmul(drop_attn, value))\n\n output = self.final_linear(context)\n # CHECK\n # batch_, q_len_, d_ = output.size()\n # aeq(q_len, q_len_)\n # aeq(batch, batch_)\n # aeq(d, d_)\n\n # Return one attn\n top_attn = attn \\\n .view(batch_size, head_count,\n query_len, key_len)[:, 0, :, :] \\\n .contiguous()\n\n return output, top_attn\n", "path": "onmt/modules/multi_headed_attn.py"}]}
| 2,643 | 562 |
gh_patches_debug_21739
|
rasdani/github-patches
|
git_diff
|
holoviz__holoviews-3810
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
UserWarning: Config option `use_jedi` not recognized by `IPCompleter`.
This error is show when I'm trying to import bokeh:
`hv.extension('bokeh')`
Product versions:
- numpy 1.16.4
- pandas 0.24.4
- bokeh 1.2.0
- holoviews 1.12.3
- hvplot 0.4.0
</issue>
<code>
[start of holoviews/ipython/__init__.py]
1 import os
2 from unittest import SkipTest
3
4 import param
5 import holoviews
6 from pyviz_comms import nb_mime_js
7 from IPython import version_info
8 from param import ipython as param_ext
9 from IPython.display import HTML, publish_display_data
10
11 from ..core.dimension import LabelledData
12 from ..core.tree import AttrTree
13 from ..core.options import Store
14 from ..element.comparison import ComparisonTestCase
15 from ..util import extension
16 from ..plotting.renderer import Renderer, MIME_TYPES
17 from .magics import load_magics
18 from .display_hooks import display # noqa (API import)
19 from .display_hooks import pprint_display, png_display, svg_display
20
21
22 AttrTree._disabled_prefixes = ['_repr_','_ipython_canary_method_should_not_exist']
23
24 def show_traceback():
25 """
26 Display the full traceback after an abbreviated traceback has occurred.
27 """
28 from .display_hooks import FULL_TRACEBACK
29 print(FULL_TRACEBACK)
30
31
32 class IPTestCase(ComparisonTestCase):
33 """
34 This class extends ComparisonTestCase to handle IPython specific
35 objects and support the execution of cells and magic.
36 """
37
38 def setUp(self):
39 super(IPTestCase, self).setUp()
40 try:
41 import IPython
42 from IPython.display import HTML, SVG
43 self.ip = IPython.InteractiveShell()
44 if self.ip is None:
45 raise TypeError()
46 except Exception:
47 raise SkipTest("IPython could not be started")
48
49 self.addTypeEqualityFunc(HTML, self.skip_comparison)
50 self.addTypeEqualityFunc(SVG, self.skip_comparison)
51
52 def skip_comparison(self, obj1, obj2, msg): pass
53
54 def get_object(self, name):
55 obj = self.ip._object_find(name).obj
56 if obj is None:
57 raise self.failureException("Could not find object %s" % name)
58 return obj
59
60
61 def cell(self, line):
62 "Run an IPython cell"
63 self.ip.run_cell(line, silent=True)
64
65 def cell_magic(self, *args, **kwargs):
66 "Run an IPython cell magic"
67 self.ip.run_cell_magic(*args, **kwargs)
68
69
70 def line_magic(self, *args, **kwargs):
71 "Run an IPython line magic"
72 self.ip.run_line_magic(*args, **kwargs)
73
74
75 class notebook_extension(extension):
76 """
77 Notebook specific extension to hv.extension that offers options for
78 controlling the notebook environment.
79 """
80
81 css = param.String(default='', doc="Optional CSS rule set to apply to the notebook.")
82
83 logo = param.Boolean(default=True, doc="Toggles display of HoloViews logo")
84
85 inline = param.Boolean(default=True, doc="""
86 Whether to inline JS and CSS resources.
87 If disabled, resources are loaded from CDN if one is available.""")
88
89 width = param.Number(default=None, bounds=(0, 100), doc="""
90 Width of the notebook as a percentage of the browser screen window width.""")
91
92 display_formats = param.List(default=['html'], doc="""
93 A list of formats that are rendered to the notebook where
94 multiple formats may be selected at once (although only one
95 format will be displayed).
96
97 Although the 'html' format is supported across backends, other
98 formats supported by the current backend (e.g 'png' and 'svg'
99 using the matplotlib backend) may be used. This may be useful to
100 export figures to other formats such as PDF with nbconvert. """)
101
102 allow_jedi_completion = param.Boolean(default=False, doc="""
103 Whether to allow jedi tab-completion to be enabled in IPython.
104 Disabled by default because many HoloViews features rely on
105 tab-completion machinery not supported when using jedi.""")
106
107 case_sensitive_completion = param.Boolean(default=False, doc="""
108 Whether to monkey patch IPython to use the correct tab-completion
109 behavior. """)
110
111 _loaded = False
112
113 def __call__(self, *args, **params):
114 super(notebook_extension, self).__call__(*args, **params)
115 # Abort if IPython not found
116 try:
117 ip = params.pop('ip', None) or get_ipython() # noqa (get_ipython)
118 except:
119 return
120
121 # Notebook archive relies on display hooks being set to work.
122 try:
123 if version_info[0] >= 4:
124 import nbformat # noqa (ensures availability)
125 else:
126 from IPython import nbformat # noqa (ensures availability)
127 try:
128 from .archive import notebook_archive
129 holoviews.archive = notebook_archive
130 except AttributeError as e:
131 if str(e) != "module 'tornado.web' has no attribute 'asynchronous'":
132 raise
133
134 except ImportError:
135 pass
136
137 # Not quite right, should be set when switching backends
138 if 'matplotlib' in Store.renderers and not notebook_extension._loaded:
139 svg_exporter = Store.renderers['matplotlib'].instance(holomap=None,fig='svg')
140 holoviews.archive.exporters = [svg_exporter] + holoviews.archive.exporters
141
142 p = param.ParamOverrides(self, {k:v for k,v in params.items() if k!='config'})
143 if p.case_sensitive_completion:
144 from IPython.core import completer
145 completer.completions_sorting_key = self.completions_sorting_key
146 if not p.allow_jedi_completion:
147 ip.run_line_magic('config', 'IPCompleter.use_jedi = False')
148
149 resources = self._get_resources(args, params)
150
151 Store.display_formats = p.display_formats
152 if 'html' not in p.display_formats and len(p.display_formats) > 1:
153 msg = ('Output magic unable to control displayed format '
154 'as IPython notebook uses fixed precedence '
155 'between %r' % p.display_formats)
156 display(HTML('<b>Warning</b>: %s' % msg))
157
158 loaded = notebook_extension._loaded
159 if loaded == False:
160 param_ext.load_ipython_extension(ip, verbose=False)
161 load_magics(ip)
162 Store.output_settings.initialize(list(Store.renderers.keys()))
163 Store.set_display_hook('html+js', LabelledData, pprint_display)
164 Store.set_display_hook('png', LabelledData, png_display)
165 Store.set_display_hook('svg', LabelledData, svg_display)
166 notebook_extension._loaded = True
167
168 css = ''
169 if p.width is not None:
170 css += '<style>div.container { width: %s%% }</style>' % p.width
171 if p.css:
172 css += '<style>%s</style>' % p.css
173 if css:
174 display(HTML(css))
175
176 resources = list(resources)
177 if len(resources) == 0: return
178
179 Renderer.load_nb()
180 for r in [r for r in resources if r != 'holoviews']:
181 Store.renderers[r].load_nb(inline=p.inline)
182
183 if hasattr(ip, 'kernel') and not loaded:
184 Renderer.comm_manager.get_client_comm(notebook_extension._process_comm_msg,
185 "hv-extension-comm")
186
187 # Create a message for the logo (if shown)
188 self.load_hvjs(logo=p.logo,
189 bokeh_logo= p.logo and ('bokeh' in resources),
190 mpl_logo= p.logo and (('matplotlib' in resources)
191 or resources==['holoviews']),
192 plotly_logo= p.logo and ('plotly' in resources),
193 JS=('holoviews' in resources))
194
195 @classmethod
196 def completions_sorting_key(cls, word):
197 "Fixed version of IPyton.completer.completions_sorting_key"
198 prio1, prio2 = 0, 0
199 if word.startswith('__'): prio1 = 2
200 elif word.startswith('_'): prio1 = 1
201 if word.endswith('='): prio1 = -1
202 if word.startswith('%%'):
203 if not "%" in word[2:]:
204 word = word[2:]; prio2 = 2
205 elif word.startswith('%'):
206 if not "%" in word[1:]:
207 word = word[1:]; prio2 = 1
208 return prio1, word, prio2
209
210
211 def _get_resources(self, args, params):
212 """
213 Finds the list of resources from the keyword parameters and pops
214 them out of the params dictionary.
215 """
216 resources = []
217 disabled = []
218 for resource in ['holoviews'] + list(Store.renderers.keys()):
219 if resource in args:
220 resources.append(resource)
221
222 if resource in params:
223 setting = params.pop(resource)
224 if setting is True and resource != 'matplotlib':
225 if resource not in resources:
226 resources.append(resource)
227 if setting is False:
228 disabled.append(resource)
229
230 unmatched_args = set(args) - set(resources)
231 if unmatched_args:
232 display(HTML('<b>Warning:</b> Unrecognized resources %s'
233 % ', '.join(unmatched_args)))
234
235 resources = [r for r in resources if r not in disabled]
236 if ('holoviews' not in disabled) and ('holoviews' not in resources):
237 resources = ['holoviews'] + resources
238 return resources
239
240 @classmethod
241 def load_hvjs(cls, logo=False, bokeh_logo=False, mpl_logo=False, plotly_logo=False,
242 JS=True, message='HoloViewsJS successfully loaded.'):
243 """
244 Displays javascript and CSS to initialize HoloViews widgets.
245 """
246 import jinja2
247 # Evaluate load_notebook.html template with widgetjs code
248 if JS:
249 widgetjs, widgetcss = Renderer.html_assets(extras=False, backends=[], script=True)
250 else:
251 widgetjs, widgetcss = '', ''
252
253 # Add classic notebook MIME renderer
254 widgetjs += nb_mime_js
255
256 templateLoader = jinja2.FileSystemLoader(os.path.dirname(os.path.abspath(__file__)))
257 jinjaEnv = jinja2.Environment(loader=templateLoader)
258 template = jinjaEnv.get_template('load_notebook.html')
259 html = template.render({'widgetcss': widgetcss,
260 'logo': logo,
261 'bokeh_logo': bokeh_logo,
262 'mpl_logo': mpl_logo,
263 'plotly_logo': plotly_logo,
264 'message': message})
265 publish_display_data(data={'text/html': html})
266
267 # Vanilla JS mime type is only consumed by classic notebook
268 # Custom mime type is only consumed by JupyterLab
269 if JS:
270 mimebundle = {
271 MIME_TYPES['js'] : widgetjs,
272 MIME_TYPES['jlab-hv-load'] : widgetjs
273 }
274 publish_display_data(data=mimebundle)
275
276
277 @param.parameterized.bothmethod
278 def tab_completion_docstring(self_or_cls):
279 """
280 Generates a docstring that can be used to enable tab-completion
281 of resources.
282 """
283 elements = ['%s=Boolean' %k for k in list(Store.renderers.keys())]
284 for name, p in self_or_cls.param.objects().items():
285 param_type = p.__class__.__name__
286 elements.append("%s=%s" % (name, param_type))
287
288 return "params(%s)" % ', '.join(['holoviews=Boolean'] + elements)
289
290
291 notebook_extension.__doc__ = notebook_extension.tab_completion_docstring()
292 notebook_extension.add_delete_action(Renderer._delete_plot)
293
294
295 def load_ipython_extension(ip):
296 notebook_extension(ip=ip)
297
298 def unload_ipython_extension(ip):
299 notebook_extension._loaded = False
300
[end of holoviews/ipython/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/holoviews/ipython/__init__.py b/holoviews/ipython/__init__.py
--- a/holoviews/ipython/__init__.py
+++ b/holoviews/ipython/__init__.py
@@ -3,10 +3,12 @@
import param
import holoviews
-from pyviz_comms import nb_mime_js
+
from IPython import version_info
-from param import ipython as param_ext
+from IPython.core.completer import IPCompleter
from IPython.display import HTML, publish_display_data
+from param import ipython as param_ext
+from pyviz_comms import nb_mime_js
from ..core.dimension import LabelledData
from ..core.tree import AttrTree
@@ -143,7 +145,7 @@
if p.case_sensitive_completion:
from IPython.core import completer
completer.completions_sorting_key = self.completions_sorting_key
- if not p.allow_jedi_completion:
+ if not p.allow_jedi_completion and hasattr(IPCompleter, 'use_jedi'):
ip.run_line_magic('config', 'IPCompleter.use_jedi = False')
resources = self._get_resources(args, params)
|
{"golden_diff": "diff --git a/holoviews/ipython/__init__.py b/holoviews/ipython/__init__.py\n--- a/holoviews/ipython/__init__.py\n+++ b/holoviews/ipython/__init__.py\n@@ -3,10 +3,12 @@\n \n import param\n import holoviews\n-from pyviz_comms import nb_mime_js\n+\n from IPython import version_info\n-from param import ipython as param_ext\n+from IPython.core.completer import IPCompleter\n from IPython.display import HTML, publish_display_data\n+from param import ipython as param_ext\n+from pyviz_comms import nb_mime_js\n \n from ..core.dimension import LabelledData\n from ..core.tree import AttrTree\n@@ -143,7 +145,7 @@\n if p.case_sensitive_completion:\n from IPython.core import completer\n completer.completions_sorting_key = self.completions_sorting_key\n- if not p.allow_jedi_completion:\n+ if not p.allow_jedi_completion and hasattr(IPCompleter, 'use_jedi'):\n ip.run_line_magic('config', 'IPCompleter.use_jedi = False')\n \n resources = self._get_resources(args, params)\n", "issue": "UserWarning: Config option `use_jedi` not recognized by `IPCompleter`.\nThis error is show when I'm trying to import bokeh:\r\n`hv.extension('bokeh')`\r\n\r\nProduct versions:\r\n- numpy 1.16.4\r\n- pandas 0.24.4\r\n- bokeh 1.2.0\r\n- holoviews 1.12.3\r\n- hvplot 0.4.0\n", "before_files": [{"content": "import os\nfrom unittest import SkipTest\n\nimport param\nimport holoviews\nfrom pyviz_comms import nb_mime_js\nfrom IPython import version_info\nfrom param import ipython as param_ext\nfrom IPython.display import HTML, publish_display_data\n\nfrom ..core.dimension import LabelledData\nfrom ..core.tree import AttrTree\nfrom ..core.options import Store\nfrom ..element.comparison import ComparisonTestCase\nfrom ..util import extension\nfrom ..plotting.renderer import Renderer, MIME_TYPES\nfrom .magics import load_magics\nfrom .display_hooks import display # noqa (API import)\nfrom .display_hooks import pprint_display, png_display, svg_display\n\n\nAttrTree._disabled_prefixes = ['_repr_','_ipython_canary_method_should_not_exist']\n\ndef show_traceback():\n \"\"\"\n Display the full traceback after an abbreviated traceback has occurred.\n \"\"\"\n from .display_hooks import FULL_TRACEBACK\n print(FULL_TRACEBACK)\n\n\nclass IPTestCase(ComparisonTestCase):\n \"\"\"\n This class extends ComparisonTestCase to handle IPython specific\n objects and support the execution of cells and magic.\n \"\"\"\n\n def setUp(self):\n super(IPTestCase, self).setUp()\n try:\n import IPython\n from IPython.display import HTML, SVG\n self.ip = IPython.InteractiveShell()\n if self.ip is None:\n raise TypeError()\n except Exception:\n raise SkipTest(\"IPython could not be started\")\n\n self.addTypeEqualityFunc(HTML, self.skip_comparison)\n self.addTypeEqualityFunc(SVG, self.skip_comparison)\n\n def skip_comparison(self, obj1, obj2, msg): pass\n\n def get_object(self, name):\n obj = self.ip._object_find(name).obj\n if obj is None:\n raise self.failureException(\"Could not find object %s\" % name)\n return obj\n\n\n def cell(self, line):\n \"Run an IPython cell\"\n self.ip.run_cell(line, silent=True)\n\n def cell_magic(self, *args, **kwargs):\n \"Run an IPython cell magic\"\n self.ip.run_cell_magic(*args, **kwargs)\n\n\n def line_magic(self, *args, **kwargs):\n \"Run an IPython line magic\"\n self.ip.run_line_magic(*args, **kwargs)\n\n\nclass notebook_extension(extension):\n \"\"\"\n Notebook specific extension to hv.extension that offers options for\n controlling the notebook environment.\n \"\"\"\n\n css = param.String(default='', doc=\"Optional CSS rule set to apply to the notebook.\")\n\n logo = param.Boolean(default=True, doc=\"Toggles display of HoloViews logo\")\n\n inline = param.Boolean(default=True, doc=\"\"\"\n Whether to inline JS and CSS resources. \n If disabled, resources are loaded from CDN if one is available.\"\"\")\n\n width = param.Number(default=None, bounds=(0, 100), doc=\"\"\"\n Width of the notebook as a percentage of the browser screen window width.\"\"\")\n\n display_formats = param.List(default=['html'], doc=\"\"\"\n A list of formats that are rendered to the notebook where\n multiple formats may be selected at once (although only one\n format will be displayed).\n\n Although the 'html' format is supported across backends, other\n formats supported by the current backend (e.g 'png' and 'svg'\n using the matplotlib backend) may be used. This may be useful to\n export figures to other formats such as PDF with nbconvert. \"\"\")\n\n allow_jedi_completion = param.Boolean(default=False, doc=\"\"\"\n Whether to allow jedi tab-completion to be enabled in IPython.\n Disabled by default because many HoloViews features rely on\n tab-completion machinery not supported when using jedi.\"\"\")\n\n case_sensitive_completion = param.Boolean(default=False, doc=\"\"\"\n Whether to monkey patch IPython to use the correct tab-completion\n behavior. \"\"\")\n\n _loaded = False\n\n def __call__(self, *args, **params):\n super(notebook_extension, self).__call__(*args, **params)\n # Abort if IPython not found\n try:\n ip = params.pop('ip', None) or get_ipython() # noqa (get_ipython)\n except:\n return\n\n # Notebook archive relies on display hooks being set to work.\n try:\n if version_info[0] >= 4:\n import nbformat # noqa (ensures availability)\n else:\n from IPython import nbformat # noqa (ensures availability)\n try:\n from .archive import notebook_archive\n holoviews.archive = notebook_archive\n except AttributeError as e:\n if str(e) != \"module 'tornado.web' has no attribute 'asynchronous'\":\n raise\n\n except ImportError:\n pass\n\n # Not quite right, should be set when switching backends\n if 'matplotlib' in Store.renderers and not notebook_extension._loaded:\n svg_exporter = Store.renderers['matplotlib'].instance(holomap=None,fig='svg')\n holoviews.archive.exporters = [svg_exporter] + holoviews.archive.exporters\n\n p = param.ParamOverrides(self, {k:v for k,v in params.items() if k!='config'})\n if p.case_sensitive_completion:\n from IPython.core import completer\n completer.completions_sorting_key = self.completions_sorting_key\n if not p.allow_jedi_completion:\n ip.run_line_magic('config', 'IPCompleter.use_jedi = False')\n\n resources = self._get_resources(args, params)\n\n Store.display_formats = p.display_formats\n if 'html' not in p.display_formats and len(p.display_formats) > 1:\n msg = ('Output magic unable to control displayed format '\n 'as IPython notebook uses fixed precedence '\n 'between %r' % p.display_formats)\n display(HTML('<b>Warning</b>: %s' % msg))\n\n loaded = notebook_extension._loaded\n if loaded == False:\n param_ext.load_ipython_extension(ip, verbose=False)\n load_magics(ip)\n Store.output_settings.initialize(list(Store.renderers.keys()))\n Store.set_display_hook('html+js', LabelledData, pprint_display)\n Store.set_display_hook('png', LabelledData, png_display)\n Store.set_display_hook('svg', LabelledData, svg_display)\n notebook_extension._loaded = True\n\n css = ''\n if p.width is not None:\n css += '<style>div.container { width: %s%% }</style>' % p.width\n if p.css:\n css += '<style>%s</style>' % p.css\n if css:\n display(HTML(css))\n\n resources = list(resources)\n if len(resources) == 0: return\n\n Renderer.load_nb()\n for r in [r for r in resources if r != 'holoviews']:\n Store.renderers[r].load_nb(inline=p.inline)\n\n if hasattr(ip, 'kernel') and not loaded:\n Renderer.comm_manager.get_client_comm(notebook_extension._process_comm_msg,\n \"hv-extension-comm\")\n\n # Create a message for the logo (if shown)\n self.load_hvjs(logo=p.logo,\n bokeh_logo= p.logo and ('bokeh' in resources),\n mpl_logo= p.logo and (('matplotlib' in resources)\n or resources==['holoviews']),\n plotly_logo= p.logo and ('plotly' in resources),\n JS=('holoviews' in resources))\n\n @classmethod\n def completions_sorting_key(cls, word):\n \"Fixed version of IPyton.completer.completions_sorting_key\"\n prio1, prio2 = 0, 0\n if word.startswith('__'): prio1 = 2\n elif word.startswith('_'): prio1 = 1\n if word.endswith('='): prio1 = -1\n if word.startswith('%%'):\n if not \"%\" in word[2:]:\n word = word[2:]; prio2 = 2\n elif word.startswith('%'):\n if not \"%\" in word[1:]:\n word = word[1:]; prio2 = 1\n return prio1, word, prio2\n\n\n def _get_resources(self, args, params):\n \"\"\"\n Finds the list of resources from the keyword parameters and pops\n them out of the params dictionary.\n \"\"\"\n resources = []\n disabled = []\n for resource in ['holoviews'] + list(Store.renderers.keys()):\n if resource in args:\n resources.append(resource)\n\n if resource in params:\n setting = params.pop(resource)\n if setting is True and resource != 'matplotlib':\n if resource not in resources:\n resources.append(resource)\n if setting is False:\n disabled.append(resource)\n\n unmatched_args = set(args) - set(resources)\n if unmatched_args:\n display(HTML('<b>Warning:</b> Unrecognized resources %s'\n % ', '.join(unmatched_args)))\n\n resources = [r for r in resources if r not in disabled]\n if ('holoviews' not in disabled) and ('holoviews' not in resources):\n resources = ['holoviews'] + resources\n return resources\n\n @classmethod\n def load_hvjs(cls, logo=False, bokeh_logo=False, mpl_logo=False, plotly_logo=False,\n JS=True, message='HoloViewsJS successfully loaded.'):\n \"\"\"\n Displays javascript and CSS to initialize HoloViews widgets.\n \"\"\"\n import jinja2\n # Evaluate load_notebook.html template with widgetjs code\n if JS:\n widgetjs, widgetcss = Renderer.html_assets(extras=False, backends=[], script=True)\n else:\n widgetjs, widgetcss = '', ''\n\n # Add classic notebook MIME renderer\n widgetjs += nb_mime_js\n\n templateLoader = jinja2.FileSystemLoader(os.path.dirname(os.path.abspath(__file__)))\n jinjaEnv = jinja2.Environment(loader=templateLoader)\n template = jinjaEnv.get_template('load_notebook.html')\n html = template.render({'widgetcss': widgetcss,\n 'logo': logo,\n 'bokeh_logo': bokeh_logo,\n 'mpl_logo': mpl_logo,\n 'plotly_logo': plotly_logo,\n 'message': message})\n publish_display_data(data={'text/html': html})\n\n # Vanilla JS mime type is only consumed by classic notebook\n # Custom mime type is only consumed by JupyterLab\n if JS:\n mimebundle = {\n MIME_TYPES['js'] : widgetjs,\n MIME_TYPES['jlab-hv-load'] : widgetjs\n }\n publish_display_data(data=mimebundle)\n\n\n @param.parameterized.bothmethod\n def tab_completion_docstring(self_or_cls):\n \"\"\"\n Generates a docstring that can be used to enable tab-completion\n of resources.\n \"\"\"\n elements = ['%s=Boolean' %k for k in list(Store.renderers.keys())]\n for name, p in self_or_cls.param.objects().items():\n param_type = p.__class__.__name__\n elements.append(\"%s=%s\" % (name, param_type))\n\n return \"params(%s)\" % ', '.join(['holoviews=Boolean'] + elements)\n\n\nnotebook_extension.__doc__ = notebook_extension.tab_completion_docstring()\nnotebook_extension.add_delete_action(Renderer._delete_plot)\n\n\ndef load_ipython_extension(ip):\n notebook_extension(ip=ip)\n\ndef unload_ipython_extension(ip):\n notebook_extension._loaded = False\n", "path": "holoviews/ipython/__init__.py"}]}
| 3,948 | 279 |
gh_patches_debug_5996
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-2221
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
VA failing since at least 2018-03-21
VA has been failing since 2018-03-21
Based on automated runs it appears that VA has not run successfully in 3 days (2018-03-21).
```
00:06:18 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+062
00:06:20 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+068
00:06:21 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+063
00:06:23 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+064
00:06:24 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+026
00:06:26 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+065
00:06:27 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+lst+ALL
00:06:29 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5001
00:06:30 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5001
00:06:32 INFO pupa: save bill HB 5001 in 2018specialI as bill_f1ff8050-2e57-11e8-8346-0a58a9feac2a.json
00:06:32 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5002
00:06:33 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5002
00:06:35 INFO pupa: save bill HB 5002 in 2018specialI as bill_f3c89dd6-2e57-11e8-8346-0a58a9feac2a.json
00:06:35 INFO pupa: no session specified, using 2018specialI
00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/182/mbr/MBR.HTM
00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+S71
loaded Open States pupa settings...
va (scrape, import)
bills: {}
people: {}
Traceback (most recent call last):
File "/opt/openstates/venv-pupa//bin/pupa", line 11, in <module>
load_entry_point('pupa', 'console_scripts', 'pupa')()
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py", line 68, in main
subcommands[args.subcommand].handle(args, other)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 260, in handle
return self.do_handle(args, other, juris)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 305, in do_handle
report['scrape'] = self.do_scrape(juris, args, scrapers)
File "/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py", line 173, in do_scrape
report[scraper_name] = scraper.do_scrape(**scrape_args)
File "/opt/openstates/venv-pupa/src/pupa/pupa/scrape/base.py", line 111, in do_scrape
for obj in self.scrape(**kwargs) or []:
File "/opt/openstates/openstates/openstates/va/people.py", line 194, in scrape
SenateList, session=session, url=url, committees=committees)
File "/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py", line 11, in scrape_page_items
yield from page_type(self, url=url, **kwargs).handle_page()
File "/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py", line 69, in handle_page
yield from processed
File "/opt/openstates/openstates/openstates/va/people.py", line 135, in handle_list_item
obj=leg,
File "/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py", line 66, in handle_page
processed = self.handle_list_item(item)
File "/opt/openstates/openstates/openstates/va/people.py", line 36, in handle_list_item
self.get_committees(item)
File "/opt/openstates/openstates/openstates/va/people.py", line 79, in get_committees
end_date=maybe_date(self.kwargs['session'].get('end_date')),
File "/opt/openstates/openstates/openstates/va/people.py", line 203, in maybe_date
date = datetime.datetime.strptime(text, '%Y-%d-%m')
TypeError: strptime() argument 1 must be str, not None
```
Visit http://bobsled.openstates.org for more info.
</issue>
<code>
[start of openstates/va/people.py]
1 import re
2 import pytz
3 import datetime
4
5 import lxml.html
6 from pupa.scrape import Person
7 from pupa.scrape import Scraper
8 from pupa.scrape import Organization
9 from spatula import Page, Spatula
10
11 from .common import SESSION_SITE_IDS
12
13
14 CHAMBER_MOVES = {
15 "A. Benton \"Ben\" Chafin-Elect": "upper",
16 "A. Benton Chafin-Senate Elect": "upper",
17 }
18 PARTY_MAP = {
19 'R': 'Republican',
20 'D': 'Democratic',
21 'I': 'Independent',
22 }
23 TIMEZONE = pytz.timezone('US/Eastern')
24
25
26 class MemberDetail(Page):
27 list_xpath = '//body'
28
29 def handle_list_item(self, item):
30 party_district_text = item.xpath('//h3/font/text()')[0]
31 party, district = get_party_district(party_district_text)
32 self.obj.add_term(self.role, self.chamber, district=district)
33 self.obj.add_party(PARTY_MAP[party])
34
35 self.get_offices(item)
36 self.get_committees(item)
37
38 photo_url = self.get_photo_url()
39 if photo_url is not None:
40 self.obj.image = photo_url
41
42 def get_offices(self, item):
43 for ul in item.xpath('//ul[@class="linkNon" and normalize-space()]'):
44 address = []
45 phone = None
46 email = None
47 for li in ul.getchildren():
48 text = li.text_content()
49 if re.match('\(\d{3}\)', text):
50 phone = text.strip()
51 elif text.startswith('email:'):
52 email = text.strip('email: ').strip()
53 else:
54 address.append(text.strip())
55 office_type = ('Capitol Office' if 'Capitol Square' in address
56 else 'District Office')
57
58 self.obj.add_contact_detail(type='address', value='\n'.join(address), note=office_type)
59 if phone:
60 self.obj.add_contact_detail(type='voice', value=phone, note=office_type)
61 if email:
62 self.obj.add_contact_detail(type='email', value=email, note=office_type)
63
64 def get_committees(self, item):
65 for com in item.xpath('//ul[@class="linkSect"][1]/li/a/text()'):
66 key = (com, self.chamber)
67 if key not in self.kwargs['committees']:
68 org = Organization(
69 name=com,
70 chamber=self.chamber,
71 classification='committee',
72 )
73 org.add_source(self.url)
74 self.kwargs['committees'][key] = org
75
76 self.obj.add_membership(
77 self.kwargs['committees'][key],
78 start_date=maybe_date(self.kwargs['session'].get('start_date')),
79 end_date=maybe_date(self.kwargs['session'].get('end_date')),
80 )
81
82 def get_photo_url(self):
83 pass
84
85
86 class SenateDetail(MemberDetail):
87 role = 'Senator'
88 chamber = 'upper'
89
90 def get_photo_url(self):
91 lis_id = get_lis_id(self.chamber, self.url)
92 profile_url = 'http://apps.senate.virginia.gov/Senator/memberpage.php?id={}'.format(lis_id)
93 page = lxml.html.fromstring(self.scraper.get(profile_url).text)
94 src = page.xpath('.//img[@class="profile_pic"]/@src')
95 img = src[0] if src else None
96 if img.startswith('//'):
97 img = 'https:' + img
98 return img
99
100
101 class DelegateDetail(MemberDetail):
102 role = 'Delegate'
103 chamber = 'lower'
104
105 def get_photo_url(self):
106 lis_id = get_lis_id(self.chamber, self.url)
107 if lis_id:
108 lis_id = '{}{:04d}'.format(lis_id[0], int(lis_id[1:]))
109 return (
110 'http://memdata.virginiageneralassembly.gov'
111 '/images/display_image/{}'
112 ).format(lis_id)
113
114
115 class MemberList(Page):
116 def handle_list_item(self, item):
117 name = item.text
118
119 if 'resigned' in name.lower() or 'vacated' in name.lower():
120 return
121 if (name in CHAMBER_MOVES and(self.chamber != CHAMBER_MOVES[name])):
122 return
123
124 name, action, date = clean_name(name)
125
126 leg = Person(name=name)
127 leg.add_source(self.url)
128 leg.add_source(item.get('href'))
129 leg.add_link(item.get('href'))
130 yield from self.scrape_page(
131 self.detail_page,
132 item.get('href'),
133 session=self.kwargs['session'],
134 committees=self.kwargs['committees'],
135 obj=leg,
136 )
137 yield leg
138
139
140 party_district_pattern = re.compile(r'\((R|D|I)\) - (?:House|Senate) District\s+(\d+)')
141
142
143 def get_party_district(text):
144 return party_district_pattern.match(text).groups()
145
146
147 lis_id_patterns = {
148 'upper': re.compile(r'(S[0-9]+$)'),
149 'lower': re.compile(r'(H[0-9]+$)'),
150 }
151
152
153 def get_lis_id(chamber, url):
154 """Retrieve LIS ID of legislator from URL."""
155 match = re.search(lis_id_patterns[chamber], url)
156 if match.groups:
157 return match.group(1)
158
159
160 name_elect_pattern = re.compile(r'(- Elect)$')
161
162
163 def clean_name(name):
164 name = name_elect_pattern.sub('', name).strip()
165 action, date = (None, None)
166 match = re.search(r'-(Resigned|Member) (\d{1,2}/\d{1,2})?', name)
167 if match:
168 action, date = match.groups()
169 name = name.rsplit('-')[0]
170 return name, action, date
171
172
173 class SenateList(MemberList):
174 chamber = 'upper'
175 detail_page = SenateDetail
176 list_xpath = '//div[@class="lColRt"]/ul/li/a'
177
178
179 class DelegateList(MemberList):
180 chamber = 'lower'
181 detail_page = DelegateDetail
182 list_xpath = '//div[@class="lColLt"]/ul/li/a'
183
184
185 class VaPersonScraper(Scraper, Spatula):
186 def scrape(self, session=None):
187 if not session:
188 session = self.jurisdiction.legislative_sessions[-1]
189 self.info('no session specified, using %s', session['identifier'])
190 url = 'http://lis.virginia.gov/{}/mbr/MBR.HTM'.format(
191 SESSION_SITE_IDS[session['identifier']])
192 committees = {}
193 yield from self.scrape_page_items(
194 SenateList, session=session, url=url, committees=committees)
195 yield from self.scrape_page_items(
196 DelegateList, session=session, url=url, committees=committees)
197 for committee in committees.values():
198 yield committee
199
200
201 def maybe_date(text):
202 try:
203 date = datetime.datetime.strptime(text, '%Y-%d-%m')
204 return date.strftime('%Y-%m-%d')
205 except ValueError:
206 return ''
207
[end of openstates/va/people.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/va/people.py b/openstates/va/people.py
--- a/openstates/va/people.py
+++ b/openstates/va/people.py
@@ -76,7 +76,7 @@
self.obj.add_membership(
self.kwargs['committees'][key],
start_date=maybe_date(self.kwargs['session'].get('start_date')),
- end_date=maybe_date(self.kwargs['session'].get('end_date')),
+ end_date=maybe_date(self.kwargs['session'].get('end_date', '')),
)
def get_photo_url(self):
|
{"golden_diff": "diff --git a/openstates/va/people.py b/openstates/va/people.py\n--- a/openstates/va/people.py\n+++ b/openstates/va/people.py\n@@ -76,7 +76,7 @@\n self.obj.add_membership(\n self.kwargs['committees'][key],\n start_date=maybe_date(self.kwargs['session'].get('start_date')),\n- end_date=maybe_date(self.kwargs['session'].get('end_date')),\n+ end_date=maybe_date(self.kwargs['session'].get('end_date', '')),\n )\n \n def get_photo_url(self):\n", "issue": "VA failing since at least 2018-03-21\nVA has been failing since 2018-03-21\n\nBased on automated runs it appears that VA has not run successfully in 3 days (2018-03-21).\n\n\n```\n 00:06:18 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+062\n00:06:20 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+068\n00:06:21 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+063\n00:06:23 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+064\n00:06:24 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+026\n00:06:26 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sbj+065\n00:06:27 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+lst+ALL\n00:06:29 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5001\n00:06:30 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5001\n00:06:32 INFO pupa: save bill HB 5001 in 2018specialI as bill_f1ff8050-2e57-11e8-8346-0a58a9feac2a.json\n00:06:32 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+HB5002\n00:06:33 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+sum+HB5002\n00:06:35 INFO pupa: save bill HB 5002 in 2018specialI as bill_f3c89dd6-2e57-11e8-8346-0a58a9feac2a.json\n00:06:35 INFO pupa: no session specified, using 2018specialI\n00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/182/mbr/MBR.HTM\n00:06:35 INFO scrapelib: GET - http://lis.virginia.gov/cgi-bin/legp604.exe?182+mbr+S71\nloaded Open States pupa settings...\nva (scrape, import)\n bills: {}\n people: {}\nTraceback (most recent call last):\n File \"/opt/openstates/venv-pupa//bin/pupa\", line 11, in <module>\n load_entry_point('pupa', 'console_scripts', 'pupa')()\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/__main__.py\", line 68, in main\n subcommands[args.subcommand].handle(args, other)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 260, in handle\n return self.do_handle(args, other, juris)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 305, in do_handle\n report['scrape'] = self.do_scrape(juris, args, scrapers)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/cli/commands/update.py\", line 173, in do_scrape\n report[scraper_name] = scraper.do_scrape(**scrape_args)\n File \"/opt/openstates/venv-pupa/src/pupa/pupa/scrape/base.py\", line 111, in do_scrape\n for obj in self.scrape(**kwargs) or []:\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 194, in scrape\n SenateList, session=session, url=url, committees=committees)\n File \"/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py\", line 11, in scrape_page_items\n yield from page_type(self, url=url, **kwargs).handle_page()\n File \"/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py\", line 69, in handle_page\n yield from processed\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 135, in handle_list_item\n obj=leg,\n File \"/opt/openstates/venv-pupa/lib/python3.5/site-packages/spatula/base.py\", line 66, in handle_page\n processed = self.handle_list_item(item)\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 36, in handle_list_item\n self.get_committees(item)\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 79, in get_committees\n end_date=maybe_date(self.kwargs['session'].get('end_date')),\n File \"/opt/openstates/openstates/openstates/va/people.py\", line 203, in maybe_date\n date = datetime.datetime.strptime(text, '%Y-%d-%m')\nTypeError: strptime() argument 1 must be str, not None\n```\n\nVisit http://bobsled.openstates.org for more info.\n\n", "before_files": [{"content": "import re\nimport pytz\nimport datetime\n\nimport lxml.html\nfrom pupa.scrape import Person\nfrom pupa.scrape import Scraper\nfrom pupa.scrape import Organization\nfrom spatula import Page, Spatula\n\nfrom .common import SESSION_SITE_IDS\n\n\nCHAMBER_MOVES = {\n \"A. Benton \\\"Ben\\\" Chafin-Elect\": \"upper\",\n \"A. Benton Chafin-Senate Elect\": \"upper\",\n}\nPARTY_MAP = {\n 'R': 'Republican',\n 'D': 'Democratic',\n 'I': 'Independent',\n}\nTIMEZONE = pytz.timezone('US/Eastern')\n\n\nclass MemberDetail(Page):\n list_xpath = '//body'\n\n def handle_list_item(self, item):\n party_district_text = item.xpath('//h3/font/text()')[0]\n party, district = get_party_district(party_district_text)\n self.obj.add_term(self.role, self.chamber, district=district)\n self.obj.add_party(PARTY_MAP[party])\n\n self.get_offices(item)\n self.get_committees(item)\n\n photo_url = self.get_photo_url()\n if photo_url is not None:\n self.obj.image = photo_url\n\n def get_offices(self, item):\n for ul in item.xpath('//ul[@class=\"linkNon\" and normalize-space()]'):\n address = []\n phone = None\n email = None\n for li in ul.getchildren():\n text = li.text_content()\n if re.match('\\(\\d{3}\\)', text):\n phone = text.strip()\n elif text.startswith('email:'):\n email = text.strip('email: ').strip()\n else:\n address.append(text.strip())\n office_type = ('Capitol Office' if 'Capitol Square' in address\n else 'District Office')\n\n self.obj.add_contact_detail(type='address', value='\\n'.join(address), note=office_type)\n if phone:\n self.obj.add_contact_detail(type='voice', value=phone, note=office_type)\n if email:\n self.obj.add_contact_detail(type='email', value=email, note=office_type)\n\n def get_committees(self, item):\n for com in item.xpath('//ul[@class=\"linkSect\"][1]/li/a/text()'):\n key = (com, self.chamber)\n if key not in self.kwargs['committees']:\n org = Organization(\n name=com,\n chamber=self.chamber,\n classification='committee',\n )\n org.add_source(self.url)\n self.kwargs['committees'][key] = org\n\n self.obj.add_membership(\n self.kwargs['committees'][key],\n start_date=maybe_date(self.kwargs['session'].get('start_date')),\n end_date=maybe_date(self.kwargs['session'].get('end_date')),\n )\n\n def get_photo_url(self):\n pass\n\n\nclass SenateDetail(MemberDetail):\n role = 'Senator'\n chamber = 'upper'\n\n def get_photo_url(self):\n lis_id = get_lis_id(self.chamber, self.url)\n profile_url = 'http://apps.senate.virginia.gov/Senator/memberpage.php?id={}'.format(lis_id)\n page = lxml.html.fromstring(self.scraper.get(profile_url).text)\n src = page.xpath('.//img[@class=\"profile_pic\"]/@src')\n img = src[0] if src else None\n if img.startswith('//'):\n img = 'https:' + img\n return img\n\n\nclass DelegateDetail(MemberDetail):\n role = 'Delegate'\n chamber = 'lower'\n\n def get_photo_url(self):\n lis_id = get_lis_id(self.chamber, self.url)\n if lis_id:\n lis_id = '{}{:04d}'.format(lis_id[0], int(lis_id[1:]))\n return (\n 'http://memdata.virginiageneralassembly.gov'\n '/images/display_image/{}'\n ).format(lis_id)\n\n\nclass MemberList(Page):\n def handle_list_item(self, item):\n name = item.text\n\n if 'resigned' in name.lower() or 'vacated' in name.lower():\n return\n if (name in CHAMBER_MOVES and(self.chamber != CHAMBER_MOVES[name])):\n return\n\n name, action, date = clean_name(name)\n\n leg = Person(name=name)\n leg.add_source(self.url)\n leg.add_source(item.get('href'))\n leg.add_link(item.get('href'))\n yield from self.scrape_page(\n self.detail_page,\n item.get('href'),\n session=self.kwargs['session'],\n committees=self.kwargs['committees'],\n obj=leg,\n )\n yield leg\n\n\nparty_district_pattern = re.compile(r'\\((R|D|I)\\) - (?:House|Senate) District\\s+(\\d+)')\n\n\ndef get_party_district(text):\n return party_district_pattern.match(text).groups()\n\n\nlis_id_patterns = {\n 'upper': re.compile(r'(S[0-9]+$)'),\n 'lower': re.compile(r'(H[0-9]+$)'),\n}\n\n\ndef get_lis_id(chamber, url):\n \"\"\"Retrieve LIS ID of legislator from URL.\"\"\"\n match = re.search(lis_id_patterns[chamber], url)\n if match.groups:\n return match.group(1)\n\n\nname_elect_pattern = re.compile(r'(- Elect)$')\n\n\ndef clean_name(name):\n name = name_elect_pattern.sub('', name).strip()\n action, date = (None, None)\n match = re.search(r'-(Resigned|Member) (\\d{1,2}/\\d{1,2})?', name)\n if match:\n action, date = match.groups()\n name = name.rsplit('-')[0]\n return name, action, date\n\n\nclass SenateList(MemberList):\n chamber = 'upper'\n detail_page = SenateDetail\n list_xpath = '//div[@class=\"lColRt\"]/ul/li/a'\n\n\nclass DelegateList(MemberList):\n chamber = 'lower'\n detail_page = DelegateDetail\n list_xpath = '//div[@class=\"lColLt\"]/ul/li/a'\n\n\nclass VaPersonScraper(Scraper, Spatula):\n def scrape(self, session=None):\n if not session:\n session = self.jurisdiction.legislative_sessions[-1]\n self.info('no session specified, using %s', session['identifier'])\n url = 'http://lis.virginia.gov/{}/mbr/MBR.HTM'.format(\n SESSION_SITE_IDS[session['identifier']])\n committees = {}\n yield from self.scrape_page_items(\n SenateList, session=session, url=url, committees=committees)\n yield from self.scrape_page_items(\n DelegateList, session=session, url=url, committees=committees)\n for committee in committees.values():\n yield committee\n\n\ndef maybe_date(text):\n try:\n date = datetime.datetime.strptime(text, '%Y-%d-%m')\n return date.strftime('%Y-%m-%d')\n except ValueError:\n return ''\n", "path": "openstates/va/people.py"}]}
| 3,997 | 125 |
gh_patches_debug_14774
|
rasdani/github-patches
|
git_diff
|
speechbrain__speechbrain-124
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Replicability Issue
Every time I run the same experiment (e.,g minimal_examples/neural_networks/autoencoder) on the same machine I got slightly different results. Since we set up the seed, this shouldn't happen.
</issue>
<code>
[start of recipes/TIMIT/ASR_CTC/experiment.py]
1 #!/usr/bin/env python3
2 import os
3 import sys
4 import torch
5 import speechbrain as sb
6 import speechbrain.data_io.wer as wer_io
7 import speechbrain.utils.edit_distance as edit_distance
8 from speechbrain.data_io.data_io import convert_index_to_lab
9 from speechbrain.decoders.ctc import ctc_greedy_decode
10 from speechbrain.decoders.decoders import undo_padding
11 from speechbrain.utils.checkpoints import ckpt_recency
12 from speechbrain.utils.train_logger import summarize_error_rate
13
14 # This hack needed to import data preparation script from ..
15 current_dir = os.path.dirname(os.path.abspath(__file__))
16 sys.path.append(os.path.dirname(current_dir))
17 from timit_prepare import TIMITPreparer # noqa E402
18
19 # Load hyperparameters file with command-line overrides
20 params_file, overrides = sb.core.parse_arguments(sys.argv[1:])
21 if "seed" in overrides:
22 torch.manual_seed(overrides["seed"])
23 with open(params_file) as fin:
24 params = sb.yaml.load_extended_yaml(fin, overrides)
25
26 # Create experiment directory
27 sb.core.create_experiment_directory(
28 experiment_directory=params.output_folder,
29 params_to_save=params_file,
30 overrides=overrides,
31 )
32
33
34 # Define training procedure
35 class ASR(sb.core.Brain):
36 def compute_forward(self, x, train_mode=True, init_params=False):
37 ids, wavs, wav_lens = x
38 wavs, wav_lens = wavs.to(params.device), wav_lens.to(params.device)
39 if hasattr(params, "augmentation"):
40 wavs = params.augmentation(wavs, wav_lens, init_params)
41 feats = params.compute_features(wavs, init_params)
42 feats = params.normalize(feats, wav_lens)
43 out = params.model(feats, init_params)
44 out = params.output(out, init_params)
45 pout = params.log_softmax(out)
46 return pout, wav_lens
47
48 def compute_objectives(self, predictions, targets, train_mode=True):
49 pout, pout_lens = predictions
50 ids, phns, phn_lens = targets
51 phns, phn_lens = phns.to(params.device), phn_lens.to(params.device)
52 loss = params.compute_cost(pout, phns, [pout_lens, phn_lens])
53
54 if not train_mode:
55 ind2lab = params.train_loader.label_dict["phn"]["index2lab"]
56 sequence = ctc_greedy_decode(pout, pout_lens, blank_id=-1)
57 sequence = convert_index_to_lab(sequence, ind2lab)
58 phns = undo_padding(phns, phn_lens)
59 phns = convert_index_to_lab(phns, ind2lab)
60 stats = edit_distance.wer_details_for_batch(
61 ids, phns, sequence, compute_alignments=True
62 )
63 stats = {"PER": stats}
64 return loss, stats
65
66 return loss
67
68 def on_epoch_end(self, epoch, train_stats, valid_stats=None):
69 per = summarize_error_rate(valid_stats["PER"])
70 old_lr, new_lr = params.lr_annealing([params.optimizer], epoch, per)
71 epoch_stats = {"epoch": epoch, "lr": old_lr}
72 params.train_logger.log_stats(epoch_stats, train_stats, valid_stats)
73
74 params.checkpointer.save_and_keep_only(
75 meta={"PER": per},
76 importance_keys=[ckpt_recency, lambda c: -c.meta["PER"]],
77 )
78
79
80 # Prepare data
81 prepare = TIMITPreparer(
82 data_folder=params.data_folder,
83 splits=["train", "dev", "test"],
84 save_folder=params.data_folder,
85 )
86 prepare()
87 train_set = params.train_loader()
88 valid_set = params.valid_loader()
89 first_x, first_y = next(zip(*train_set))
90
91 # Modules are passed to optimizer and have train/eval called on them
92 modules = [params.model, params.output]
93 if hasattr(params, "augmentation"):
94 modules.append(params.augmentation)
95
96 # Create brain object for training
97 asr_brain = ASR(
98 modules=modules, optimizer=params.optimizer, first_inputs=[first_x],
99 )
100
101 # Load latest checkpoint to resume training
102 params.checkpointer.recover_if_possible()
103 asr_brain.fit(params.epoch_counter, train_set, valid_set)
104
105 # Load best checkpoint for evaluation
106 params.checkpointer.recover_if_possible(lambda c: -c.meta["PER"])
107 test_stats = asr_brain.evaluate(params.test_loader())
108 params.train_logger.log_stats(
109 stats_meta={"Epoch loaded": params.epoch_counter.current},
110 test_stats=test_stats,
111 )
112
113 # Write alignments to file
114 per_summary = edit_distance.wer_summary(test_stats["PER"])
115 with open(params.wer_file, "w") as fo:
116 wer_io.print_wer_summary(per_summary, fo)
117 wer_io.print_alignments(test_stats["PER"], fo)
118
[end of recipes/TIMIT/ASR_CTC/experiment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/TIMIT/ASR_CTC/experiment.py b/recipes/TIMIT/ASR_CTC/experiment.py
--- a/recipes/TIMIT/ASR_CTC/experiment.py
+++ b/recipes/TIMIT/ASR_CTC/experiment.py
@@ -1,7 +1,6 @@
#!/usr/bin/env python3
import os
import sys
-import torch
import speechbrain as sb
import speechbrain.data_io.wer as wer_io
import speechbrain.utils.edit_distance as edit_distance
@@ -18,8 +17,6 @@
# Load hyperparameters file with command-line overrides
params_file, overrides = sb.core.parse_arguments(sys.argv[1:])
-if "seed" in overrides:
- torch.manual_seed(overrides["seed"])
with open(params_file) as fin:
params = sb.yaml.load_extended_yaml(fin, overrides)
|
{"golden_diff": "diff --git a/recipes/TIMIT/ASR_CTC/experiment.py b/recipes/TIMIT/ASR_CTC/experiment.py\n--- a/recipes/TIMIT/ASR_CTC/experiment.py\n+++ b/recipes/TIMIT/ASR_CTC/experiment.py\n@@ -1,7 +1,6 @@\n #!/usr/bin/env python3\n import os\n import sys\n-import torch\n import speechbrain as sb\n import speechbrain.data_io.wer as wer_io\n import speechbrain.utils.edit_distance as edit_distance\n@@ -18,8 +17,6 @@\n \n # Load hyperparameters file with command-line overrides\n params_file, overrides = sb.core.parse_arguments(sys.argv[1:])\n-if \"seed\" in overrides:\n- torch.manual_seed(overrides[\"seed\"])\n with open(params_file) as fin:\n params = sb.yaml.load_extended_yaml(fin, overrides)\n", "issue": "Replicability Issue\nEvery time I run the same experiment (e.,g minimal_examples/neural_networks/autoencoder) on the same machine I got slightly different results. Since we set up the seed, this shouldn't happen. \n", "before_files": [{"content": "#!/usr/bin/env python3\nimport os\nimport sys\nimport torch\nimport speechbrain as sb\nimport speechbrain.data_io.wer as wer_io\nimport speechbrain.utils.edit_distance as edit_distance\nfrom speechbrain.data_io.data_io import convert_index_to_lab\nfrom speechbrain.decoders.ctc import ctc_greedy_decode\nfrom speechbrain.decoders.decoders import undo_padding\nfrom speechbrain.utils.checkpoints import ckpt_recency\nfrom speechbrain.utils.train_logger import summarize_error_rate\n\n# This hack needed to import data preparation script from ..\ncurrent_dir = os.path.dirname(os.path.abspath(__file__))\nsys.path.append(os.path.dirname(current_dir))\nfrom timit_prepare import TIMITPreparer # noqa E402\n\n# Load hyperparameters file with command-line overrides\nparams_file, overrides = sb.core.parse_arguments(sys.argv[1:])\nif \"seed\" in overrides:\n torch.manual_seed(overrides[\"seed\"])\nwith open(params_file) as fin:\n params = sb.yaml.load_extended_yaml(fin, overrides)\n\n# Create experiment directory\nsb.core.create_experiment_directory(\n experiment_directory=params.output_folder,\n params_to_save=params_file,\n overrides=overrides,\n)\n\n\n# Define training procedure\nclass ASR(sb.core.Brain):\n def compute_forward(self, x, train_mode=True, init_params=False):\n ids, wavs, wav_lens = x\n wavs, wav_lens = wavs.to(params.device), wav_lens.to(params.device)\n if hasattr(params, \"augmentation\"):\n wavs = params.augmentation(wavs, wav_lens, init_params)\n feats = params.compute_features(wavs, init_params)\n feats = params.normalize(feats, wav_lens)\n out = params.model(feats, init_params)\n out = params.output(out, init_params)\n pout = params.log_softmax(out)\n return pout, wav_lens\n\n def compute_objectives(self, predictions, targets, train_mode=True):\n pout, pout_lens = predictions\n ids, phns, phn_lens = targets\n phns, phn_lens = phns.to(params.device), phn_lens.to(params.device)\n loss = params.compute_cost(pout, phns, [pout_lens, phn_lens])\n\n if not train_mode:\n ind2lab = params.train_loader.label_dict[\"phn\"][\"index2lab\"]\n sequence = ctc_greedy_decode(pout, pout_lens, blank_id=-1)\n sequence = convert_index_to_lab(sequence, ind2lab)\n phns = undo_padding(phns, phn_lens)\n phns = convert_index_to_lab(phns, ind2lab)\n stats = edit_distance.wer_details_for_batch(\n ids, phns, sequence, compute_alignments=True\n )\n stats = {\"PER\": stats}\n return loss, stats\n\n return loss\n\n def on_epoch_end(self, epoch, train_stats, valid_stats=None):\n per = summarize_error_rate(valid_stats[\"PER\"])\n old_lr, new_lr = params.lr_annealing([params.optimizer], epoch, per)\n epoch_stats = {\"epoch\": epoch, \"lr\": old_lr}\n params.train_logger.log_stats(epoch_stats, train_stats, valid_stats)\n\n params.checkpointer.save_and_keep_only(\n meta={\"PER\": per},\n importance_keys=[ckpt_recency, lambda c: -c.meta[\"PER\"]],\n )\n\n\n# Prepare data\nprepare = TIMITPreparer(\n data_folder=params.data_folder,\n splits=[\"train\", \"dev\", \"test\"],\n save_folder=params.data_folder,\n)\nprepare()\ntrain_set = params.train_loader()\nvalid_set = params.valid_loader()\nfirst_x, first_y = next(zip(*train_set))\n\n# Modules are passed to optimizer and have train/eval called on them\nmodules = [params.model, params.output]\nif hasattr(params, \"augmentation\"):\n modules.append(params.augmentation)\n\n# Create brain object for training\nasr_brain = ASR(\n modules=modules, optimizer=params.optimizer, first_inputs=[first_x],\n)\n\n# Load latest checkpoint to resume training\nparams.checkpointer.recover_if_possible()\nasr_brain.fit(params.epoch_counter, train_set, valid_set)\n\n# Load best checkpoint for evaluation\nparams.checkpointer.recover_if_possible(lambda c: -c.meta[\"PER\"])\ntest_stats = asr_brain.evaluate(params.test_loader())\nparams.train_logger.log_stats(\n stats_meta={\"Epoch loaded\": params.epoch_counter.current},\n test_stats=test_stats,\n)\n\n# Write alignments to file\nper_summary = edit_distance.wer_summary(test_stats[\"PER\"])\nwith open(params.wer_file, \"w\") as fo:\n wer_io.print_wer_summary(per_summary, fo)\n wer_io.print_alignments(test_stats[\"PER\"], fo)\n", "path": "recipes/TIMIT/ASR_CTC/experiment.py"}]}
| 1,858 | 188 |
gh_patches_debug_5694
|
rasdani/github-patches
|
git_diff
|
saulpw__visidata-1558
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[zo] Give feedback when a file or URL is not found in the cell value
New users (and me when I have a few z related `open-cell-XYZ` commands 🙃) may get confused at the purpose of `zo`, when it is usually `zENTER` they want.
I propose the change, whereby a status is given to the user to tell them that a `file` or `URL` wasn't found (and therefore nothing happens). Also maybe suggest they want `zENTER`?
</issue>
<code>
[start of visidata/_open.py]
1 from visidata import *
2
3
4 vd.option('filetype', '', 'specify file type', replay=True)
5
6
7 @VisiData.api
8 def inputFilename(vd, prompt, *args, **kwargs):
9 return vd.input(prompt, type="filename", *args, completer=_completeFilename, **kwargs).strip()
10
11
12 @VisiData.api
13 def inputPath(vd, *args, **kwargs):
14 return Path(vd.inputFilename(*args, **kwargs))
15
16
17 def _completeFilename(val, state):
18 i = val.rfind('/')
19 if i < 0: # no /
20 base = ''
21 partial = val
22 elif i == 0: # root /
23 base = '/'
24 partial = val[1:]
25 else:
26 base = val[:i]
27 partial = val[i+1:]
28
29 files = []
30 for f in os.listdir(Path(base or '.')):
31 if f.startswith(partial):
32 files.append(os.path.join(base, f))
33
34 files.sort()
35 return files[state%len(files)]
36
37
38 @VisiData.api
39 def openPath(vd, p, filetype=None, create=False):
40 '''Call ``open_<filetype>(p)`` or ``openurl_<p.scheme>(p, filetype)``. Return constructed but unloaded sheet of appropriate type.
41 If True, *create* will return a new, blank **Sheet** if file does not exist.'''
42 if p.scheme and not p.has_fp():
43 schemes = p.scheme.split('+')
44 openfuncname = 'openurl_' + schemes[-1]
45
46 openfunc = getattr(vd, openfuncname, None) or vd.getGlobals().get(openfuncname, None)
47 if not openfunc:
48 vd.fail(f'no loader for url scheme: {p.scheme}')
49
50 return openfunc(p, filetype=filetype)
51
52 if not p.exists() and not create:
53 return None
54
55 if not filetype:
56 if p.is_dir():
57 filetype = 'dir'
58 else:
59 filetype = p.ext or options.filetype or 'txt'
60
61 filetype = filetype.lower()
62
63 if not p.exists():
64 if not create:
65 return None
66 newfunc = getattr(vd, 'new_' + filetype, vd.getGlobals().get('new_' + filetype))
67 if not newfunc:
68 vd.warning('%s does not exist, creating new sheet' % p)
69 return vd.newSheet(p.name, 1, source=p)
70
71 vd.status('creating blank %s' % (p.given))
72 return newfunc(p)
73
74 openfunc = getattr(vd, 'open_' + filetype, vd.getGlobals().get('open_' + filetype))
75 if not openfunc:
76 vd.warning('unknown "%s" filetype' % filetype)
77 filetype = 'txt'
78 openfunc = vd.open_txt
79
80 vd.status('opening %s as %s' % (p.given, filetype))
81
82 return openfunc(p)
83
84
85 @VisiData.api
86 def openSource(vd, p, filetype=None, create=False, **kwargs):
87 '''Return unloaded sheet object for *p* opened as the given *filetype* and with *kwargs* as option overrides. *p* can be a Path or a string (filename, url, or "-" for stdin).
88 when true, *create* will return a blank sheet, if file does not exist.'''
89 if not filetype:
90 filetype = options.getonly('filetype', 'global', '')
91
92 vs = None
93 if isinstance(p, str):
94 if '://' in p:
95 vs = vd.openPath(Path(p), filetype=filetype) # convert to Path and recurse
96 elif p == '-':
97 vs = vd.openPath(vd.stdinSource, filetype=filetype)
98 else:
99 vs = vd.openPath(Path(p), filetype=filetype, create=create) # convert to Path and recurse
100 else:
101 vs = vd.openPath(p, filetype=filetype, create=create)
102
103 for optname, optval in kwargs.items():
104 vs.options[optname] = optval
105
106 return vs
107
108
109 #### enable external addons
110 @VisiData.api
111 def open_txt(vd, p):
112 'Create sheet from `.txt` file at Path `p`, checking whether it is TSV.'
113 with p.open_text(encoding=vd.options.encoding) as fp:
114 try:
115 if options.delimiter in next(fp): # peek at the first line
116 return vd.open_tsv(p) # TSV often have .txt extension
117 except StopIteration:
118 return Sheet(p.name, columns=[SettableColumn()], source=p)
119 return TextSheet(p.name, source=p)
120
121
122 @VisiData.api
123 def loadInternalSheet(vd, cls, p, **kwargs):
124 'Load internal sheet of given class. Internal sheets are always tsv.'
125 vs = cls(p.name, source=p, **kwargs)
126 options._set('encoding', 'utf8', vs)
127 if p.exists():
128 vd.sheets.insert(0, vs)
129 vs.reload.__wrapped__(vs)
130 vd.sheets.pop(0)
131 return vs
132
133
134 BaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename("open: "), create=True))', 'Open file or URL')
135 TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')
136
[end of visidata/_open.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/visidata/_open.py b/visidata/_open.py
--- a/visidata/_open.py
+++ b/visidata/_open.py
@@ -132,4 +132,4 @@
BaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename("open: "), create=True))', 'Open file or URL')
-TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')
+TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay) or fail(f"file {cursorDisplay} does not exist"))', 'Open file or URL from path in current cell')
|
{"golden_diff": "diff --git a/visidata/_open.py b/visidata/_open.py\n--- a/visidata/_open.py\n+++ b/visidata/_open.py\n@@ -132,4 +132,4 @@\n \n \n BaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename(\"open: \"), create=True))', 'Open file or URL')\n-TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')\n+TableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay) or fail(f\"file {cursorDisplay} does not exist\"))', 'Open file or URL from path in current cell')\n", "issue": "[zo] Give feedback when a file or URL is not found in the cell value\nNew users (and me when I have a few z related `open-cell-XYZ` commands \ud83d\ude43) may get confused at the purpose of `zo`, when it is usually `zENTER` they want.\r\n\r\nI propose the change, whereby a status is given to the user to tell them that a `file` or `URL` wasn't found (and therefore nothing happens). Also maybe suggest they want `zENTER`?\n", "before_files": [{"content": "from visidata import *\n\n\nvd.option('filetype', '', 'specify file type', replay=True)\n\n\[email protected]\ndef inputFilename(vd, prompt, *args, **kwargs):\n return vd.input(prompt, type=\"filename\", *args, completer=_completeFilename, **kwargs).strip()\n\n\[email protected]\ndef inputPath(vd, *args, **kwargs):\n return Path(vd.inputFilename(*args, **kwargs))\n\n\ndef _completeFilename(val, state):\n i = val.rfind('/')\n if i < 0: # no /\n base = ''\n partial = val\n elif i == 0: # root /\n base = '/'\n partial = val[1:]\n else:\n base = val[:i]\n partial = val[i+1:]\n\n files = []\n for f in os.listdir(Path(base or '.')):\n if f.startswith(partial):\n files.append(os.path.join(base, f))\n\n files.sort()\n return files[state%len(files)]\n\n\[email protected]\ndef openPath(vd, p, filetype=None, create=False):\n '''Call ``open_<filetype>(p)`` or ``openurl_<p.scheme>(p, filetype)``. Return constructed but unloaded sheet of appropriate type.\n If True, *create* will return a new, blank **Sheet** if file does not exist.'''\n if p.scheme and not p.has_fp():\n schemes = p.scheme.split('+')\n openfuncname = 'openurl_' + schemes[-1]\n\n openfunc = getattr(vd, openfuncname, None) or vd.getGlobals().get(openfuncname, None)\n if not openfunc:\n vd.fail(f'no loader for url scheme: {p.scheme}')\n\n return openfunc(p, filetype=filetype)\n\n if not p.exists() and not create:\n return None\n\n if not filetype:\n if p.is_dir():\n filetype = 'dir'\n else:\n filetype = p.ext or options.filetype or 'txt'\n\n filetype = filetype.lower()\n\n if not p.exists():\n if not create:\n return None\n newfunc = getattr(vd, 'new_' + filetype, vd.getGlobals().get('new_' + filetype))\n if not newfunc:\n vd.warning('%s does not exist, creating new sheet' % p)\n return vd.newSheet(p.name, 1, source=p)\n\n vd.status('creating blank %s' % (p.given))\n return newfunc(p)\n\n openfunc = getattr(vd, 'open_' + filetype, vd.getGlobals().get('open_' + filetype))\n if not openfunc:\n vd.warning('unknown \"%s\" filetype' % filetype)\n filetype = 'txt'\n openfunc = vd.open_txt\n\n vd.status('opening %s as %s' % (p.given, filetype))\n\n return openfunc(p)\n\n\[email protected]\ndef openSource(vd, p, filetype=None, create=False, **kwargs):\n '''Return unloaded sheet object for *p* opened as the given *filetype* and with *kwargs* as option overrides. *p* can be a Path or a string (filename, url, or \"-\" for stdin).\n when true, *create* will return a blank sheet, if file does not exist.'''\n if not filetype:\n filetype = options.getonly('filetype', 'global', '')\n\n vs = None\n if isinstance(p, str):\n if '://' in p:\n vs = vd.openPath(Path(p), filetype=filetype) # convert to Path and recurse\n elif p == '-':\n vs = vd.openPath(vd.stdinSource, filetype=filetype)\n else:\n vs = vd.openPath(Path(p), filetype=filetype, create=create) # convert to Path and recurse\n else:\n vs = vd.openPath(p, filetype=filetype, create=create)\n\n for optname, optval in kwargs.items():\n vs.options[optname] = optval\n\n return vs\n\n\n#### enable external addons\[email protected]\ndef open_txt(vd, p):\n 'Create sheet from `.txt` file at Path `p`, checking whether it is TSV.'\n with p.open_text(encoding=vd.options.encoding) as fp:\n try:\n if options.delimiter in next(fp): # peek at the first line\n return vd.open_tsv(p) # TSV often have .txt extension\n except StopIteration:\n return Sheet(p.name, columns=[SettableColumn()], source=p)\n return TextSheet(p.name, source=p)\n\n\[email protected]\ndef loadInternalSheet(vd, cls, p, **kwargs):\n 'Load internal sheet of given class. Internal sheets are always tsv.'\n vs = cls(p.name, source=p, **kwargs)\n options._set('encoding', 'utf8', vs)\n if p.exists():\n vd.sheets.insert(0, vs)\n vs.reload.__wrapped__(vs)\n vd.sheets.pop(0)\n return vs\n\n\nBaseSheet.addCommand('o', 'open-file', 'vd.push(openSource(inputFilename(\"open: \"), create=True))', 'Open file or URL')\nTableSheet.addCommand('zo', 'open-cell-file', 'vd.push(openSource(cursorDisplay))', 'Open file or URL from path in current cell')\n", "path": "visidata/_open.py"}]}
| 2,111 | 162 |
gh_patches_debug_27186
|
rasdani/github-patches
|
git_diff
|
translate__pootle-3593
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Mitigate the risk of revision counter also being in 'default' Redis cache
The revision counter goes into the 'default' cache. This adds the risk of people clearing the default cache and also wiping out the revision counter — even if there's a way to restore it, we might want to prevent removal in the first place. This concern was raised in https://github.com/translate/pootle/issues/3500#issuecomment-73204160
</issue>
<code>
[start of pootle/core/models.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2013-2015 Evernote Corporation
5 #
6 # This file is part of Pootle.
7 #
8 # Pootle is free software; you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation; either version 2 of the License, or
11 # (at your option) any later version.
12 #
13 # translate is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with translate; if not, write to the Free Software
20 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
21
22
23 from .cache import get_cache
24 from .mixins import TreeItem
25
26
27 cache = get_cache()
28
29
30 class Revision(object):
31 """Wrapper around the revision counter stored in Redis."""
32
33 CACHE_KEY = 'pootle:revision'
34 INITIAL = 0
35
36 @classmethod
37 def initialize(cls, force=False):
38 """Initializes the revision with `cls.INITIAL`.
39
40 :param force: whether to overwrite the number if there's a
41 revision already set or not.
42 :return: `True` if the initial value was set, `False` otherwise.
43 """
44 if force:
45 return cls.set(cls.INITIAL)
46
47 return cls.add(cls.INITIAL)
48
49 @classmethod
50 def get(cls):
51 """Gets the current revision number.
52
53 :return: The current revision number, or the initial number if
54 there's no revision stored yet.
55 """
56 return cache.get(cls.CACHE_KEY, cls.INITIAL)
57
58 @classmethod
59 def set(cls, value):
60 """Sets the revision number to `value`, regardless of whether
61 there's a value previously set or not.
62
63 :return: `True` if the value was set, `False` otherwise.
64 """
65 return cache.set(cls.CACHE_KEY, value, None)
66
67 @classmethod
68 def add(cls, value):
69 """Sets the revision number to `value`, only if there's no
70 revision already set.
71
72 :return: `True` if the value was set, `False` otherwise.
73 """
74 return cache.add(cls.CACHE_KEY, value, None)
75
76 @classmethod
77 def incr(cls):
78 """Increments the revision number.
79
80 :return: the new revision number after incrementing it, or the
81 initial number if there's no revision stored yet.
82 """
83 try:
84 return cache.incr(cls.CACHE_KEY)
85 except ValueError:
86 return cls.INITIAL
87
88
89 class VirtualResource(TreeItem):
90 """An object representing a virtual resource.
91
92 A virtual resource doesn't live in the DB and has a unique
93 `pootle_path` of its own. It's a simple collection of actual
94 resources.
95
96 For instance, this can be used in projects to have cross-language
97 references.
98
99 Don't use this object as-is, rather subclass it and adapt the
100 implementation details for each context.
101 """
102 def __init__(self, resources, pootle_path, *args, **kwargs):
103 self.resources = resources #: Collection of underlying resources
104 self.pootle_path = pootle_path
105
106 super(VirtualResource, self).__init__(*args, **kwargs)
107
108 def __unicode__(self):
109 return self.pootle_path
110
111 ### TreeItem
112
113 def get_children(self):
114 return self.resources
115
116 def get_cachekey(self):
117 return self.pootle_path
118
119 ### /TreeItem
120
[end of pootle/core/models.py]
[start of pootle/core/cache.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 #
4 # Copyright 2013-2015 Evernote Corporation
5 #
6 # This file is part of Pootle.
7 #
8 # Pootle is free software; you can redistribute it and/or modify
9 # it under the terms of the GNU General Public License as published by
10 # the Free Software Foundation; either version 2 of the License, or
11 # (at your option) any later version.
12 #
13 # This program is distributed in the hope that it will be useful,
14 # but WITHOUT ANY WARRANTY; without even the implied warranty of
15 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
16 # GNU General Public License for more details.
17 #
18 # You should have received a copy of the GNU General Public License
19 # along with this program; if not, see <http://www.gnu.org/licenses/>.
20
21
22 from django.core.cache import caches, cache as default_cache
23 from django.core.cache.backends.base import InvalidCacheBackendError
24
25
26 def make_method_key(model, method, key):
27 """Creates a cache key for model's `method` method.
28
29 :param model: A model instance
30 :param method: Method name to cache
31 :param key: a unique key to identify the object to be cached
32 """
33 prefix = 'method-cache'
34
35 if isinstance(model, basestring):
36 name = model
37 else:
38 name = (model.__name__ if hasattr(model, '__name__')
39 else model.__class__.__name__)
40
41 key = key if not isinstance(key, dict) else make_key(**key)
42 return u':'.join([prefix, name, method, key])
43
44
45 def make_key(*args, **kwargs):
46 """Creates a cache key with key-value pairs from a dict."""
47 return ':'.join([
48 '%s=%s' % (k, v) for k, v in sorted(kwargs.iteritems())
49 ])
50
51
52 def get_cache(cache=None):
53 """Return ``cache`` or the 'default' cache if ``cache`` is not specified or
54 ``cache`` is not configured.
55
56 :param cache: The name of the requested cache.
57 """
58 try:
59 return caches[cache]
60 except InvalidCacheBackendError:
61 return default_cache
62
[end of pootle/core/cache.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pootle/core/cache.py b/pootle/core/cache.py
--- a/pootle/core/cache.py
+++ b/pootle/core/cache.py
@@ -19,8 +19,13 @@
# along with this program; if not, see <http://www.gnu.org/licenses/>.
+from django.conf import settings
from django.core.cache import caches, cache as default_cache
from django.core.cache.backends.base import InvalidCacheBackendError
+from django.core.exceptions import ImproperlyConfigured
+
+
+PERSISTENT_STORES = ('redis', 'stats')
def make_method_key(model, method, key):
@@ -56,6 +61,17 @@
:param cache: The name of the requested cache.
"""
try:
+ # Check for proper Redis persistent backends
+ # FIXME: this logic needs to be a system sanity check
+ if (cache in PERSISTENT_STORES and
+ (cache not in settings.CACHES or
+ 'RedisCache' not in settings.CACHES[cache]['BACKEND'] or
+ settings.CACHES[cache].get('TIMEOUT', '') != None)):
+ raise ImproperlyConfigured(
+ 'Pootle requires a Redis-backed caching backend for %r '
+ 'with `TIMEOUT: None`. Please review your settings.' % cache
+ )
+
return caches[cache]
except InvalidCacheBackendError:
return default_cache
diff --git a/pootle/core/models.py b/pootle/core/models.py
--- a/pootle/core/models.py
+++ b/pootle/core/models.py
@@ -24,7 +24,7 @@
from .mixins import TreeItem
-cache = get_cache()
+cache = get_cache('redis')
class Revision(object):
|
{"golden_diff": "diff --git a/pootle/core/cache.py b/pootle/core/cache.py\n--- a/pootle/core/cache.py\n+++ b/pootle/core/cache.py\n@@ -19,8 +19,13 @@\n # along with this program; if not, see <http://www.gnu.org/licenses/>.\n \n \n+from django.conf import settings\n from django.core.cache import caches, cache as default_cache\n from django.core.cache.backends.base import InvalidCacheBackendError\n+from django.core.exceptions import ImproperlyConfigured\n+\n+\n+PERSISTENT_STORES = ('redis', 'stats')\n \n \n def make_method_key(model, method, key):\n@@ -56,6 +61,17 @@\n :param cache: The name of the requested cache.\n \"\"\"\n try:\n+ # Check for proper Redis persistent backends\n+ # FIXME: this logic needs to be a system sanity check\n+ if (cache in PERSISTENT_STORES and\n+ (cache not in settings.CACHES or\n+ 'RedisCache' not in settings.CACHES[cache]['BACKEND'] or\n+ settings.CACHES[cache].get('TIMEOUT', '') != None)):\n+ raise ImproperlyConfigured(\n+ 'Pootle requires a Redis-backed caching backend for %r '\n+ 'with `TIMEOUT: None`. Please review your settings.' % cache\n+ )\n+\n return caches[cache]\n except InvalidCacheBackendError:\n return default_cache\ndiff --git a/pootle/core/models.py b/pootle/core/models.py\n--- a/pootle/core/models.py\n+++ b/pootle/core/models.py\n@@ -24,7 +24,7 @@\n from .mixins import TreeItem\n \n \n-cache = get_cache()\n+cache = get_cache('redis')\n \n \n class Revision(object):\n", "issue": "Mitigate the risk of revision counter also being in 'default' Redis cache\nThe revision counter goes into the 'default' cache. This adds the risk of people clearing the default cache and also wiping out the revision counter \u2014 even if there's a way to restore it, we might want to prevent removal in the first place. This concern was raised in https://github.com/translate/pootle/issues/3500#issuecomment-73204160\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# translate is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with translate; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n\n\nfrom .cache import get_cache\nfrom .mixins import TreeItem\n\n\ncache = get_cache()\n\n\nclass Revision(object):\n \"\"\"Wrapper around the revision counter stored in Redis.\"\"\"\n\n CACHE_KEY = 'pootle:revision'\n INITIAL = 0\n\n @classmethod\n def initialize(cls, force=False):\n \"\"\"Initializes the revision with `cls.INITIAL`.\n\n :param force: whether to overwrite the number if there's a\n revision already set or not.\n :return: `True` if the initial value was set, `False` otherwise.\n \"\"\"\n if force:\n return cls.set(cls.INITIAL)\n\n return cls.add(cls.INITIAL)\n\n @classmethod\n def get(cls):\n \"\"\"Gets the current revision number.\n\n :return: The current revision number, or the initial number if\n there's no revision stored yet.\n \"\"\"\n return cache.get(cls.CACHE_KEY, cls.INITIAL)\n\n @classmethod\n def set(cls, value):\n \"\"\"Sets the revision number to `value`, regardless of whether\n there's a value previously set or not.\n\n :return: `True` if the value was set, `False` otherwise.\n \"\"\"\n return cache.set(cls.CACHE_KEY, value, None)\n\n @classmethod\n def add(cls, value):\n \"\"\"Sets the revision number to `value`, only if there's no\n revision already set.\n\n :return: `True` if the value was set, `False` otherwise.\n \"\"\"\n return cache.add(cls.CACHE_KEY, value, None)\n\n @classmethod\n def incr(cls):\n \"\"\"Increments the revision number.\n\n :return: the new revision number after incrementing it, or the\n initial number if there's no revision stored yet.\n \"\"\"\n try:\n return cache.incr(cls.CACHE_KEY)\n except ValueError:\n return cls.INITIAL\n\n\nclass VirtualResource(TreeItem):\n \"\"\"An object representing a virtual resource.\n\n A virtual resource doesn't live in the DB and has a unique\n `pootle_path` of its own. It's a simple collection of actual\n resources.\n\n For instance, this can be used in projects to have cross-language\n references.\n\n Don't use this object as-is, rather subclass it and adapt the\n implementation details for each context.\n \"\"\"\n def __init__(self, resources, pootle_path, *args, **kwargs):\n self.resources = resources #: Collection of underlying resources\n self.pootle_path = pootle_path\n\n super(VirtualResource, self).__init__(*args, **kwargs)\n\n def __unicode__(self):\n return self.pootle_path\n\n ### TreeItem\n\n def get_children(self):\n return self.resources\n\n def get_cachekey(self):\n return self.pootle_path\n\n ### /TreeItem\n", "path": "pootle/core/models.py"}, {"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n#\n# Copyright 2013-2015 Evernote Corporation\n#\n# This file is part of Pootle.\n#\n# Pootle is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, see <http://www.gnu.org/licenses/>.\n\n\nfrom django.core.cache import caches, cache as default_cache\nfrom django.core.cache.backends.base import InvalidCacheBackendError\n\n\ndef make_method_key(model, method, key):\n \"\"\"Creates a cache key for model's `method` method.\n\n :param model: A model instance\n :param method: Method name to cache\n :param key: a unique key to identify the object to be cached\n \"\"\"\n prefix = 'method-cache'\n\n if isinstance(model, basestring):\n name = model\n else:\n name = (model.__name__ if hasattr(model, '__name__')\n else model.__class__.__name__)\n\n key = key if not isinstance(key, dict) else make_key(**key)\n return u':'.join([prefix, name, method, key])\n\n\ndef make_key(*args, **kwargs):\n \"\"\"Creates a cache key with key-value pairs from a dict.\"\"\"\n return ':'.join([\n '%s=%s' % (k, v) for k, v in sorted(kwargs.iteritems())\n ])\n\n\ndef get_cache(cache=None):\n \"\"\"Return ``cache`` or the 'default' cache if ``cache`` is not specified or\n ``cache`` is not configured.\n\n :param cache: The name of the requested cache.\n \"\"\"\n try:\n return caches[cache]\n except InvalidCacheBackendError:\n return default_cache\n", "path": "pootle/core/cache.py"}]}
| 2,355 | 396 |
gh_patches_debug_32284
|
rasdani/github-patches
|
git_diff
|
getnikola__nikola-1011
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
reST listings can’t number lines, while code-blocks do it incompatibly
1. One can’t do a `.. listing::` in Nikola with line numbers.
2. In `.. code-block::`s, one must use the reST `:number-lines:` option syntax. However, Sphinx wants `:linenos:` instead. (#770)
</issue>
<code>
[start of nikola/plugins/compile/rest/listing.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2014 Roberto Alsina and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27
28 """ Define and register a listing directive using the existing CodeBlock """
29
30
31 from __future__ import unicode_literals
32 from codecs import open as codecs_open # for patching purposes
33 import os
34 try:
35 from urlparse import urlunsplit
36 except ImportError:
37 from urllib.parse import urlunsplit # NOQA
38
39 from docutils import core
40 from docutils import nodes
41 from docutils.parsers.rst import Directive, directives
42 from docutils.parsers.rst.directives.misc import Include
43 try:
44 from docutils.parsers.rst.directives.body import CodeBlock
45 except ImportError: # docutils < 0.9 (Debian Sid For The Loss)
46 class CodeBlock(Directive):
47 required_arguments = 1
48 has_content = True
49 CODE = '<pre>{0}</pre>'
50
51 def run(self):
52 """ Required by the Directive interface. Create docutils nodes """
53 return [nodes.raw('', self.CODE.format('\n'.join(self.content)), format='html')]
54 directives.register_directive('code', CodeBlock)
55
56
57 from nikola.plugin_categories import RestExtension
58
59
60 class Plugin(RestExtension):
61
62 name = "rest_listing"
63
64 def set_site(self, site):
65 self.site = site
66 # Even though listings don't use CodeBlock anymore, I am
67 # leaving these to make the code directive work with
68 # docutils < 0.9
69 directives.register_directive('code-block', CodeBlock)
70 directives.register_directive('sourcecode', CodeBlock)
71 directives.register_directive('listing', Listing)
72 return super(Plugin, self).set_site(site)
73
74
75 class Listing(Include):
76 """ listing directive: create a highlighted block of code from a file in listings/
77
78 Usage:
79
80 .. listing:: nikola.py python
81 :number-lines:
82
83 """
84 has_content = False
85 required_arguments = 1
86 optional_arguments = 1
87
88 def run(self):
89 fname = self.arguments.pop(0)
90 lang = self.arguments.pop(0)
91 fpath = os.path.join('listings', fname)
92 self.arguments.insert(0, fpath)
93 self.options['code'] = lang
94 with codecs_open(fpath, 'rb+', 'utf8') as fileobject:
95 self.content = fileobject.read().splitlines()
96 self.state.document.settings.record_dependencies.add(fpath)
97 target = urlunsplit(("link", 'listing', fname, '', ''))
98 generated_nodes = (
99 [core.publish_doctree('`{0} <{1}>`_'.format(fname, target))[0]])
100 generated_nodes += self.get_code_from_file(fileobject)
101 return generated_nodes
102
103 def get_code_from_file(self, data):
104 """ Create CodeBlock nodes from file object content """
105 return super(Listing, self).run()
106
107 def assert_has_content(self):
108 """ Listing has no content, override check from superclass """
109 pass
110
[end of nikola/plugins/compile/rest/listing.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nikola/plugins/compile/rest/listing.py b/nikola/plugins/compile/rest/listing.py
--- a/nikola/plugins/compile/rest/listing.py
+++ b/nikola/plugins/compile/rest/listing.py
@@ -56,6 +56,18 @@
from nikola.plugin_categories import RestExtension
+# Add sphinx compatibility option
+CodeBlock.option_spec['linenos'] = directives.unchanged
+
+
+class FlexibleCodeBlock(CodeBlock):
+
+ def run(self):
+ if 'linenos' in self.options:
+ self.options['number-lines'] = self.options['linenos']
+ return super(FlexibleCodeBlock, self).run()
+CodeBlock = FlexibleCodeBlock
+
class Plugin(RestExtension):
@@ -71,6 +83,11 @@
directives.register_directive('listing', Listing)
return super(Plugin, self).set_site(site)
+# Add sphinx compatibility option
+listing_spec = Include.option_spec
+listing_spec['linenos'] = directives.unchanged
+print(listing_spec)
+
class Listing(Include):
""" listing directive: create a highlighted block of code from a file in listings/
@@ -84,6 +101,7 @@
has_content = False
required_arguments = 1
optional_arguments = 1
+ option_spec = listing_spec
def run(self):
fname = self.arguments.pop(0)
@@ -91,6 +109,8 @@
fpath = os.path.join('listings', fname)
self.arguments.insert(0, fpath)
self.options['code'] = lang
+ if 'linenos' in self.options:
+ self.options['number-lines'] = self.options['linenos']
with codecs_open(fpath, 'rb+', 'utf8') as fileobject:
self.content = fileobject.read().splitlines()
self.state.document.settings.record_dependencies.add(fpath)
|
{"golden_diff": "diff --git a/nikola/plugins/compile/rest/listing.py b/nikola/plugins/compile/rest/listing.py\n--- a/nikola/plugins/compile/rest/listing.py\n+++ b/nikola/plugins/compile/rest/listing.py\n@@ -56,6 +56,18 @@\n \n from nikola.plugin_categories import RestExtension\n \n+# Add sphinx compatibility option\n+CodeBlock.option_spec['linenos'] = directives.unchanged\n+\n+\n+class FlexibleCodeBlock(CodeBlock):\n+\n+ def run(self):\n+ if 'linenos' in self.options:\n+ self.options['number-lines'] = self.options['linenos']\n+ return super(FlexibleCodeBlock, self).run()\n+CodeBlock = FlexibleCodeBlock\n+\n \n class Plugin(RestExtension):\n \n@@ -71,6 +83,11 @@\n directives.register_directive('listing', Listing)\n return super(Plugin, self).set_site(site)\n \n+# Add sphinx compatibility option\n+listing_spec = Include.option_spec\n+listing_spec['linenos'] = directives.unchanged\n+print(listing_spec)\n+\n \n class Listing(Include):\n \"\"\" listing directive: create a highlighted block of code from a file in listings/\n@@ -84,6 +101,7 @@\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n+ option_spec = listing_spec\n \n def run(self):\n fname = self.arguments.pop(0)\n@@ -91,6 +109,8 @@\n fpath = os.path.join('listings', fname)\n self.arguments.insert(0, fpath)\n self.options['code'] = lang\n+ if 'linenos' in self.options:\n+ self.options['number-lines'] = self.options['linenos']\n with codecs_open(fpath, 'rb+', 'utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n", "issue": "reST listings can\u2019t number lines, while code-blocks do it incompatibly\n1. One can\u2019t do a `.. listing::` in Nikola with line numbers.\n2. In `.. code-block::`s, one must use the reST `:number-lines:` option syntax. However, Sphinx wants `:linenos:` instead. (#770)\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2014 Roberto Alsina and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\n\"\"\" Define and register a listing directive using the existing CodeBlock \"\"\"\n\n\nfrom __future__ import unicode_literals\nfrom codecs import open as codecs_open # for patching purposes\nimport os\ntry:\n from urlparse import urlunsplit\nexcept ImportError:\n from urllib.parse import urlunsplit # NOQA\n\nfrom docutils import core\nfrom docutils import nodes\nfrom docutils.parsers.rst import Directive, directives\nfrom docutils.parsers.rst.directives.misc import Include\ntry:\n from docutils.parsers.rst.directives.body import CodeBlock\nexcept ImportError: # docutils < 0.9 (Debian Sid For The Loss)\n class CodeBlock(Directive):\n required_arguments = 1\n has_content = True\n CODE = '<pre>{0}</pre>'\n\n def run(self):\n \"\"\" Required by the Directive interface. Create docutils nodes \"\"\"\n return [nodes.raw('', self.CODE.format('\\n'.join(self.content)), format='html')]\n directives.register_directive('code', CodeBlock)\n\n\nfrom nikola.plugin_categories import RestExtension\n\n\nclass Plugin(RestExtension):\n\n name = \"rest_listing\"\n\n def set_site(self, site):\n self.site = site\n # Even though listings don't use CodeBlock anymore, I am\n # leaving these to make the code directive work with\n # docutils < 0.9\n directives.register_directive('code-block', CodeBlock)\n directives.register_directive('sourcecode', CodeBlock)\n directives.register_directive('listing', Listing)\n return super(Plugin, self).set_site(site)\n\n\nclass Listing(Include):\n \"\"\" listing directive: create a highlighted block of code from a file in listings/\n\n Usage:\n\n .. listing:: nikola.py python\n :number-lines:\n\n \"\"\"\n has_content = False\n required_arguments = 1\n optional_arguments = 1\n\n def run(self):\n fname = self.arguments.pop(0)\n lang = self.arguments.pop(0)\n fpath = os.path.join('listings', fname)\n self.arguments.insert(0, fpath)\n self.options['code'] = lang\n with codecs_open(fpath, 'rb+', 'utf8') as fileobject:\n self.content = fileobject.read().splitlines()\n self.state.document.settings.record_dependencies.add(fpath)\n target = urlunsplit((\"link\", 'listing', fname, '', ''))\n generated_nodes = (\n [core.publish_doctree('`{0} <{1}>`_'.format(fname, target))[0]])\n generated_nodes += self.get_code_from_file(fileobject)\n return generated_nodes\n\n def get_code_from_file(self, data):\n \"\"\" Create CodeBlock nodes from file object content \"\"\"\n return super(Listing, self).run()\n\n def assert_has_content(self):\n \"\"\" Listing has no content, override check from superclass \"\"\"\n pass\n", "path": "nikola/plugins/compile/rest/listing.py"}]}
| 1,728 | 430 |
gh_patches_debug_32545
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-395
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG: Simple model comparison shows irrelevant labels
To reproduce:
https://www.kaggle.com/itay94/notebook05f499eb19

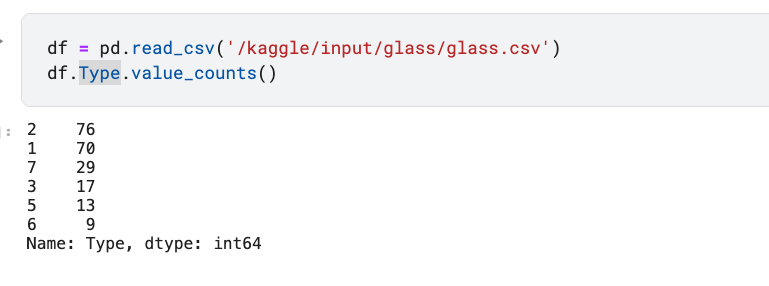
</issue>
<code>
[start of deepchecks/checks/performance/simple_model_comparison.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """Module containing simple comparison check."""
12 from typing import Callable, Dict, Hashable, List
13 import numpy as np
14 import pandas as pd
15 import plotly.express as px
16 from sklearn.dummy import DummyRegressor, DummyClassifier
17 from sklearn.pipeline import Pipeline
18 from sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor
19 from deepchecks.checks.distribution.preprocessing import ScaledNumerics
20 from deepchecks.utils.strings import format_number
21
22 from deepchecks import CheckResult, Dataset
23 from deepchecks.base.check import ConditionResult, TrainTestBaseCheck
24 from deepchecks.utils.metrics import task_type_check, ModelType, initialize_multi_scorers, \
25 get_scorers_list, get_scores_ratio, get_scorer_single
26 from deepchecks.utils.validation import validate_model
27 from deepchecks.errors import DeepchecksValueError
28
29
30 __all__ = ['SimpleModelComparison']
31
32
33 class SimpleModelComparison(TrainTestBaseCheck):
34 """Compare given model score to simple model score (according to given model type).
35
36 Args:
37 simple_model_type (str):
38 Type of the simple model ['random', 'constant', 'tree'].
39 + random - select one of the labels by random.
40 + constant - in regression is mean value, in classification the most common value.
41 + tree - runs a simple decision tree.
42 alternative_scorers (Dict[str, Callable], default None):
43 An optional dictionary of scorer name to scorer functions.
44 If none given, using default scorers
45 maximum_ratio (int):
46 the ratio can be up to infinity so choose maximum value to limit to.
47 max_depth (int):
48 the max depth of the tree (used only if simple model type is tree).
49 random_state (int):
50 the random state (used only if simple model type is tree or random).
51 """
52
53 def __init__(self, simple_model_type: str = 'constant', alternative_scorers: Dict[str, Callable] = None,
54 maximum_ratio: int = 50, max_depth: int = 3, random_state: int = 42):
55 super().__init__()
56 self.simple_model_type = simple_model_type
57 self.alternative_scorers = initialize_multi_scorers(alternative_scorers)
58 self.maximum_ratio = maximum_ratio
59 self.max_depth = max_depth
60 self.random_state = random_state
61
62 def run(self, train_dataset, test_dataset, model) -> CheckResult:
63 """Run check.
64
65 Args:
66 train_dataset (Dataset): The training dataset object. Must contain a label.
67 test_dataset (Dataset): The test dataset object. Must contain a label.
68 model (BaseEstimator): A scikit-learn-compatible fitted estimator instance.
69
70 Returns:
71 CheckResult: value is a Dict of: given_model_score, simple_model_score, ratio
72 ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)
73 if ratio is infinite max_ratio is returned
74
75 Raises:
76 DeepchecksValueError: If the object is not a Dataset instance.
77 """
78 Dataset.validate_dataset(train_dataset)
79 Dataset.validate_dataset(test_dataset)
80 train_dataset.validate_label()
81 test_dataset.validate_label()
82 validate_model(test_dataset, model)
83
84 # If user defined scorers used them, else use a single scorer
85 if self.alternative_scorers:
86 scorers = get_scorers_list(model, train_dataset, self.alternative_scorers, multiclass_avg=False)
87 else:
88 scorers = [get_scorer_single(model, train_dataset, multiclass_avg=False)]
89
90 task_type = task_type_check(model, train_dataset)
91 simple_model = self._create_simple_model(train_dataset, task_type)
92
93 models = [
94 (f'{type(model).__name__} model', 'Origin', model),
95 (f'Simple model - {self.simple_model_type}', 'Simple', simple_model)
96 ]
97
98 # Multiclass have different return type from the scorer, list of score per class instead of single score
99 if task_type == ModelType.MULTICLASS:
100 results = []
101 for model_name, model_type, model_instance in models:
102 for scorer in scorers:
103 score_result: np.ndarray = scorer(model_instance, test_dataset)
104 # Multiclass scorers return numpy array of result per class
105 for class_i, class_score in enumerate(score_result):
106 # The proba returns in order of the sorted classes.
107 class_value = train_dataset.classes[class_i]
108 results.append([model_name, model_type, class_score, scorer.name, class_value])
109
110 results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])
111
112 # Plot the metrics in a graph, grouping by the model and class
113 fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',
114 facet_col='Metric', facet_col_spacing=0.05)
115 fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)
116 fig.update_yaxes(title=None, matches=None)
117 fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))
118 fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))
119 # Model is binary or regression
120 else:
121 results = []
122 for model_name, model_type, model_instance in models:
123 for scorer in scorers:
124 score_result: float = scorer(model_instance, test_dataset)
125 results.append([model_name, model_type, score_result, scorer.name])
126
127 results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric'])
128
129 # Plot the metrics in a graph, grouping by the model
130 fig = px.bar(results_df, x='Model', y='Value', color='Model', barmode='group',
131 facet_col='Metric', facet_col_spacing=0.05)
132 fig.update_xaxes(title=None)
133 fig.update_yaxes(title=None, matches=None)
134 fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))
135 fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))
136
137 return CheckResult({'scores': results_df, 'type': task_type}, display=fig)
138
139 def _create_simple_model(self, train_ds: Dataset, task_type: ModelType):
140 """Create a simple model of given type (random/constant/tree) to the given dataset.
141
142 Args:
143 train_ds (Dataset): The training dataset object.
144 task_type (ModelType): the model type.
145 Returns:
146 Classifier object.
147
148 Raises:
149 NotImplementedError: If the simple_model_type is not supported
150 """
151 np.random.seed(self.random_state)
152
153 if self.simple_model_type == 'random':
154 simple_model = RandomModel()
155
156 elif self.simple_model_type == 'constant':
157 if task_type == ModelType.REGRESSION:
158 simple_model = DummyRegressor(strategy='mean')
159 elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:
160 simple_model = DummyClassifier(strategy='most_frequent')
161 else:
162 raise DeepchecksValueError(f'Unknown task type - {task_type}')
163 elif self.simple_model_type == 'tree':
164 if task_type == ModelType.REGRESSION:
165 clf = DecisionTreeRegressor(
166 max_depth=self.max_depth,
167 random_state=self.random_state
168 )
169 elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:
170 clf = DecisionTreeClassifier(
171 max_depth=self.max_depth,
172 random_state=self.random_state,
173 class_weight='balanced'
174 )
175 else:
176 raise DeepchecksValueError(f'Unknown task type - {task_type}')
177
178 simple_model = Pipeline([('scaler', ScaledNumerics(train_ds.cat_features, max_num_categories=10)),
179 ('tree-model', clf)])
180 else:
181 raise DeepchecksValueError(
182 f'Unknown model type - {self.simple_model_type}, expected to be one of '
183 f"['random', 'constant', 'tree'] "
184 f"but instead got {self.simple_model_type}" # pylint: disable=inconsistent-quotes
185 )
186
187 simple_model.fit(train_ds.features_columns, train_ds.label_col)
188 return simple_model
189
190 def add_condition_ratio_not_less_than(self, min_allowed_ratio: float = 1.1, classes: List[Hashable] = None):
191 """Add condition - require min allowed ratio between the given and the simple model.
192
193 Args:
194 min_allowed_ratio (float): Min allowed ratio between the given and the simple model -
195 ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)
196 classes (List[Hashable]): Used in multiclass models to limit condition only to given classes.
197 """
198 def condition(result: Dict, max_ratio=self.maximum_ratio, class_list=classes) -> ConditionResult:
199 scores_df = result['scores']
200 task_type = result['type']
201 metrics = scores_df['Metric'].unique()
202
203 def get_ratio(df):
204 simple_score = df[df['Type'] == 'Simple']['Value'].iloc[0]
205 origin_score = df[df['Type'] == 'Origin']['Value'].iloc[0]
206 return get_scores_ratio(simple_score, origin_score, max_ratio)
207
208 fails = []
209 if task_type == ModelType.MULTICLASS:
210 if class_list is None:
211 class_list = scores_df['Class'].unique()
212 for metric in metrics:
213 failed_classes = []
214 for clas in class_list:
215 score_rows = scores_df[(scores_df['Metric'] == metric) & (scores_df['Class'] == clas)]
216 ratio = get_ratio(score_rows)
217 if ratio < min_allowed_ratio:
218 failed_classes.append(str(clas))
219 if failed_classes:
220 fails.append(f'"{metric}" - Classes: {", ".join(failed_classes)}')
221 else:
222 for metric in metrics:
223 score_rows = scores_df[(scores_df['Metric'] == metric)]
224 ratio = get_ratio(score_rows)
225 if ratio < min_allowed_ratio:
226 fails.append(f'"{metric}"')
227
228 if fails:
229 msg = f'Metrics failed: {", ".join(sorted(fails))}'
230 return ConditionResult(False, msg)
231 else:
232 return ConditionResult(True)
233
234 return self.add_condition('$$\\frac{\\text{model score}}{\\text{simple model score}} >= '
235 f'{format_number(min_allowed_ratio)}$$', condition)
236
237
238 class RandomModel:
239 """Model used to randomly predict from given series of labels."""
240
241 def __init__(self):
242 self.labels = None
243
244 def fit(self, X, y): # pylint: disable=unused-argument,invalid-name
245 # The X is not used, but it is needed to be matching to sklearn `fit` signature
246 self.labels = y
247
248 def predict(self, X): # pylint: disable=invalid-name
249 return np.random.choice(self.labels, X.shape[0])
250
251 def predict_proba(self, X): # pylint: disable=invalid-name
252 classes = sorted(self.labels.unique().tolist())
253 predictions = self.predict(X)
254
255 def prediction_to_proba(y_pred):
256 proba = np.zeros(len(classes))
257 proba[classes.index(y_pred)] = 1
258 return proba
259 return np.apply_along_axis(prediction_to_proba, axis=1, arr=predictions)
260
[end of deepchecks/checks/performance/simple_model_comparison.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/checks/performance/simple_model_comparison.py b/deepchecks/checks/performance/simple_model_comparison.py
--- a/deepchecks/checks/performance/simple_model_comparison.py
+++ b/deepchecks/checks/performance/simple_model_comparison.py
@@ -101,10 +101,8 @@
for model_name, model_type, model_instance in models:
for scorer in scorers:
score_result: np.ndarray = scorer(model_instance, test_dataset)
- # Multiclass scorers return numpy array of result per class
- for class_i, class_score in enumerate(score_result):
- # The proba returns in order of the sorted classes.
- class_value = train_dataset.classes[class_i]
+ # Multiclass scorers return numpy array of result per class in order of sorted classes
+ for class_score, class_value in zip(score_result, test_dataset.classes):
results.append([model_name, model_type, class_score, scorer.name, class_value])
results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])
@@ -112,7 +110,7 @@
# Plot the metrics in a graph, grouping by the model and class
fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',
facet_col='Metric', facet_col_spacing=0.05)
- fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)
+ fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60, type='category')
fig.update_yaxes(title=None, matches=None)
fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))
fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))
|
{"golden_diff": "diff --git a/deepchecks/checks/performance/simple_model_comparison.py b/deepchecks/checks/performance/simple_model_comparison.py\n--- a/deepchecks/checks/performance/simple_model_comparison.py\n+++ b/deepchecks/checks/performance/simple_model_comparison.py\n@@ -101,10 +101,8 @@\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: np.ndarray = scorer(model_instance, test_dataset)\n- # Multiclass scorers return numpy array of result per class\n- for class_i, class_score in enumerate(score_result):\n- # The proba returns in order of the sorted classes.\n- class_value = train_dataset.classes[class_i]\n+ # Multiclass scorers return numpy array of result per class in order of sorted classes\n+ for class_score, class_value in zip(score_result, test_dataset.classes):\n results.append([model_name, model_type, class_score, scorer.name, class_value])\n \n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])\n@@ -112,7 +110,7 @@\n # Plot the metrics in a graph, grouping by the model and class\n fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n- fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)\n+ fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60, type='category')\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n", "issue": "BUG: Simple model comparison shows irrelevant labels\nTo reproduce:\r\nhttps://www.kaggle.com/itay94/notebook05f499eb19\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"Module containing simple comparison check.\"\"\"\nfrom typing import Callable, Dict, Hashable, List\nimport numpy as np\nimport pandas as pd\nimport plotly.express as px\nfrom sklearn.dummy import DummyRegressor, DummyClassifier\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.tree import DecisionTreeClassifier, DecisionTreeRegressor\nfrom deepchecks.checks.distribution.preprocessing import ScaledNumerics\nfrom deepchecks.utils.strings import format_number\n\nfrom deepchecks import CheckResult, Dataset\nfrom deepchecks.base.check import ConditionResult, TrainTestBaseCheck\nfrom deepchecks.utils.metrics import task_type_check, ModelType, initialize_multi_scorers, \\\n get_scorers_list, get_scores_ratio, get_scorer_single\nfrom deepchecks.utils.validation import validate_model\nfrom deepchecks.errors import DeepchecksValueError\n\n\n__all__ = ['SimpleModelComparison']\n\n\nclass SimpleModelComparison(TrainTestBaseCheck):\n \"\"\"Compare given model score to simple model score (according to given model type).\n\n Args:\n simple_model_type (str):\n Type of the simple model ['random', 'constant', 'tree'].\n + random - select one of the labels by random.\n + constant - in regression is mean value, in classification the most common value.\n + tree - runs a simple decision tree.\n alternative_scorers (Dict[str, Callable], default None):\n An optional dictionary of scorer name to scorer functions.\n If none given, using default scorers\n maximum_ratio (int):\n the ratio can be up to infinity so choose maximum value to limit to.\n max_depth (int):\n the max depth of the tree (used only if simple model type is tree).\n random_state (int):\n the random state (used only if simple model type is tree or random).\n \"\"\"\n\n def __init__(self, simple_model_type: str = 'constant', alternative_scorers: Dict[str, Callable] = None,\n maximum_ratio: int = 50, max_depth: int = 3, random_state: int = 42):\n super().__init__()\n self.simple_model_type = simple_model_type\n self.alternative_scorers = initialize_multi_scorers(alternative_scorers)\n self.maximum_ratio = maximum_ratio\n self.max_depth = max_depth\n self.random_state = random_state\n\n def run(self, train_dataset, test_dataset, model) -> CheckResult:\n \"\"\"Run check.\n\n Args:\n train_dataset (Dataset): The training dataset object. Must contain a label.\n test_dataset (Dataset): The test dataset object. Must contain a label.\n model (BaseEstimator): A scikit-learn-compatible fitted estimator instance.\n\n Returns:\n CheckResult: value is a Dict of: given_model_score, simple_model_score, ratio\n ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)\n if ratio is infinite max_ratio is returned\n\n Raises:\n DeepchecksValueError: If the object is not a Dataset instance.\n \"\"\"\n Dataset.validate_dataset(train_dataset)\n Dataset.validate_dataset(test_dataset)\n train_dataset.validate_label()\n test_dataset.validate_label()\n validate_model(test_dataset, model)\n\n # If user defined scorers used them, else use a single scorer\n if self.alternative_scorers:\n scorers = get_scorers_list(model, train_dataset, self.alternative_scorers, multiclass_avg=False)\n else:\n scorers = [get_scorer_single(model, train_dataset, multiclass_avg=False)]\n\n task_type = task_type_check(model, train_dataset)\n simple_model = self._create_simple_model(train_dataset, task_type)\n\n models = [\n (f'{type(model).__name__} model', 'Origin', model),\n (f'Simple model - {self.simple_model_type}', 'Simple', simple_model)\n ]\n\n # Multiclass have different return type from the scorer, list of score per class instead of single score\n if task_type == ModelType.MULTICLASS:\n results = []\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: np.ndarray = scorer(model_instance, test_dataset)\n # Multiclass scorers return numpy array of result per class\n for class_i, class_score in enumerate(score_result):\n # The proba returns in order of the sorted classes.\n class_value = train_dataset.classes[class_i]\n results.append([model_name, model_type, class_score, scorer.name, class_value])\n\n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric', 'Class'])\n\n # Plot the metrics in a graph, grouping by the model and class\n fig = px.bar(results_df, x=['Class', 'Model'], y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n fig.update_xaxes(title=None, tickprefix='Class ', tickangle=60)\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n # Model is binary or regression\n else:\n results = []\n for model_name, model_type, model_instance in models:\n for scorer in scorers:\n score_result: float = scorer(model_instance, test_dataset)\n results.append([model_name, model_type, score_result, scorer.name])\n\n results_df = pd.DataFrame(results, columns=['Model', 'Type', 'Value', 'Metric'])\n\n # Plot the metrics in a graph, grouping by the model\n fig = px.bar(results_df, x='Model', y='Value', color='Model', barmode='group',\n facet_col='Metric', facet_col_spacing=0.05)\n fig.update_xaxes(title=None)\n fig.update_yaxes(title=None, matches=None)\n fig.for_each_annotation(lambda a: a.update(text=a.text.split('=')[-1]))\n fig.for_each_yaxis(lambda yaxis: yaxis.update(showticklabels=True))\n\n return CheckResult({'scores': results_df, 'type': task_type}, display=fig)\n\n def _create_simple_model(self, train_ds: Dataset, task_type: ModelType):\n \"\"\"Create a simple model of given type (random/constant/tree) to the given dataset.\n\n Args:\n train_ds (Dataset): The training dataset object.\n task_type (ModelType): the model type.\n Returns:\n Classifier object.\n\n Raises:\n NotImplementedError: If the simple_model_type is not supported\n \"\"\"\n np.random.seed(self.random_state)\n\n if self.simple_model_type == 'random':\n simple_model = RandomModel()\n\n elif self.simple_model_type == 'constant':\n if task_type == ModelType.REGRESSION:\n simple_model = DummyRegressor(strategy='mean')\n elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:\n simple_model = DummyClassifier(strategy='most_frequent')\n else:\n raise DeepchecksValueError(f'Unknown task type - {task_type}')\n elif self.simple_model_type == 'tree':\n if task_type == ModelType.REGRESSION:\n clf = DecisionTreeRegressor(\n max_depth=self.max_depth,\n random_state=self.random_state\n )\n elif task_type in {ModelType.BINARY, ModelType.MULTICLASS}:\n clf = DecisionTreeClassifier(\n max_depth=self.max_depth,\n random_state=self.random_state,\n class_weight='balanced'\n )\n else:\n raise DeepchecksValueError(f'Unknown task type - {task_type}')\n\n simple_model = Pipeline([('scaler', ScaledNumerics(train_ds.cat_features, max_num_categories=10)),\n ('tree-model', clf)])\n else:\n raise DeepchecksValueError(\n f'Unknown model type - {self.simple_model_type}, expected to be one of '\n f\"['random', 'constant', 'tree'] \"\n f\"but instead got {self.simple_model_type}\" # pylint: disable=inconsistent-quotes\n )\n\n simple_model.fit(train_ds.features_columns, train_ds.label_col)\n return simple_model\n\n def add_condition_ratio_not_less_than(self, min_allowed_ratio: float = 1.1, classes: List[Hashable] = None):\n \"\"\"Add condition - require min allowed ratio between the given and the simple model.\n\n Args:\n min_allowed_ratio (float): Min allowed ratio between the given and the simple model -\n ratio is given model / simple model (if the scorer returns negative values we divide 1 by it)\n classes (List[Hashable]): Used in multiclass models to limit condition only to given classes.\n \"\"\"\n def condition(result: Dict, max_ratio=self.maximum_ratio, class_list=classes) -> ConditionResult:\n scores_df = result['scores']\n task_type = result['type']\n metrics = scores_df['Metric'].unique()\n\n def get_ratio(df):\n simple_score = df[df['Type'] == 'Simple']['Value'].iloc[0]\n origin_score = df[df['Type'] == 'Origin']['Value'].iloc[0]\n return get_scores_ratio(simple_score, origin_score, max_ratio)\n\n fails = []\n if task_type == ModelType.MULTICLASS:\n if class_list is None:\n class_list = scores_df['Class'].unique()\n for metric in metrics:\n failed_classes = []\n for clas in class_list:\n score_rows = scores_df[(scores_df['Metric'] == metric) & (scores_df['Class'] == clas)]\n ratio = get_ratio(score_rows)\n if ratio < min_allowed_ratio:\n failed_classes.append(str(clas))\n if failed_classes:\n fails.append(f'\"{metric}\" - Classes: {\", \".join(failed_classes)}')\n else:\n for metric in metrics:\n score_rows = scores_df[(scores_df['Metric'] == metric)]\n ratio = get_ratio(score_rows)\n if ratio < min_allowed_ratio:\n fails.append(f'\"{metric}\"')\n\n if fails:\n msg = f'Metrics failed: {\", \".join(sorted(fails))}'\n return ConditionResult(False, msg)\n else:\n return ConditionResult(True)\n\n return self.add_condition('$$\\\\frac{\\\\text{model score}}{\\\\text{simple model score}} >= '\n f'{format_number(min_allowed_ratio)}$$', condition)\n\n\nclass RandomModel:\n \"\"\"Model used to randomly predict from given series of labels.\"\"\"\n\n def __init__(self):\n self.labels = None\n\n def fit(self, X, y): # pylint: disable=unused-argument,invalid-name\n # The X is not used, but it is needed to be matching to sklearn `fit` signature\n self.labels = y\n\n def predict(self, X): # pylint: disable=invalid-name\n return np.random.choice(self.labels, X.shape[0])\n\n def predict_proba(self, X): # pylint: disable=invalid-name\n classes = sorted(self.labels.unique().tolist())\n predictions = self.predict(X)\n\n def prediction_to_proba(y_pred):\n proba = np.zeros(len(classes))\n proba[classes.index(y_pred)] = 1\n return proba\n return np.apply_along_axis(prediction_to_proba, axis=1, arr=predictions)\n", "path": "deepchecks/checks/performance/simple_model_comparison.py"}]}
| 3,928 | 405 |
gh_patches_debug_26336
|
rasdani/github-patches
|
git_diff
|
ipython__ipython-13744
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Suggestion: 'undeprecate' extensions
I can't think of a single reason why it is deprecated. Python package management is really bad to rely on pip, packing small personal customization extensions is a massive overkill and can lead to potential pip conflicts in the future and publishing it is a horrendous waste of time (and might not even be possible in some cases). Extensions folder was perfect for very simple personal extensions and now using it constantly shows warnings that can't be disabled. Startup scripts aren't a good alternative because they clutter globals space and trying to do something without putting anything into globals leads to extremely ugly code in startup scripts.
</issue>
<code>
[start of IPython/core/extensions.py]
1 # encoding: utf-8
2 """A class for managing IPython extensions."""
3
4 # Copyright (c) IPython Development Team.
5 # Distributed under the terms of the Modified BSD License.
6
7 import os
8 import os.path
9 import sys
10 from importlib import import_module, reload
11
12 from traitlets.config.configurable import Configurable
13 from IPython.utils.path import ensure_dir_exists, compress_user
14 from IPython.utils.decorators import undoc
15 from traitlets import Instance
16
17
18 #-----------------------------------------------------------------------------
19 # Main class
20 #-----------------------------------------------------------------------------
21
22 BUILTINS_EXTS = {"storemagic": False, "autoreload": False}
23
24
25 class ExtensionManager(Configurable):
26 """A class to manage IPython extensions.
27
28 An IPython extension is an importable Python module that has
29 a function with the signature::
30
31 def load_ipython_extension(ipython):
32 # Do things with ipython
33
34 This function is called after your extension is imported and the
35 currently active :class:`InteractiveShell` instance is passed as
36 the only argument. You can do anything you want with IPython at
37 that point, including defining new magic and aliases, adding new
38 components, etc.
39
40 You can also optionally define an :func:`unload_ipython_extension(ipython)`
41 function, which will be called if the user unloads or reloads the extension.
42 The extension manager will only call :func:`load_ipython_extension` again
43 if the extension is reloaded.
44
45 You can put your extension modules anywhere you want, as long as
46 they can be imported by Python's standard import mechanism. However,
47 to make it easy to write extensions, you can also put your extensions
48 in ``os.path.join(self.ipython_dir, 'extensions')``. This directory
49 is added to ``sys.path`` automatically.
50 """
51
52 shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)
53
54 def __init__(self, shell=None, **kwargs):
55 super(ExtensionManager, self).__init__(shell=shell, **kwargs)
56 self.shell.observe(
57 self._on_ipython_dir_changed, names=('ipython_dir',)
58 )
59 self.loaded = set()
60
61 @property
62 def ipython_extension_dir(self):
63 return os.path.join(self.shell.ipython_dir, u'extensions')
64
65 def _on_ipython_dir_changed(self, change):
66 ensure_dir_exists(self.ipython_extension_dir)
67
68 def load_extension(self, module_str: str):
69 """Load an IPython extension by its module name.
70
71 Returns the string "already loaded" if the extension is already loaded,
72 "no load function" if the module doesn't have a load_ipython_extension
73 function, or None if it succeeded.
74 """
75 try:
76 return self._load_extension(module_str)
77 except ModuleNotFoundError:
78 if module_str in BUILTINS_EXTS:
79 BUILTINS_EXTS[module_str] = True
80 return self._load_extension("IPython.extensions." + module_str)
81 raise
82
83 def _load_extension(self, module_str: str):
84 if module_str in self.loaded:
85 return "already loaded"
86
87 from IPython.utils.syspathcontext import prepended_to_syspath
88
89 with self.shell.builtin_trap:
90 if module_str not in sys.modules:
91 with prepended_to_syspath(self.ipython_extension_dir):
92 mod = import_module(module_str)
93 if mod.__file__.startswith(self.ipython_extension_dir):
94 print(("Loading extensions from {dir} is deprecated. "
95 "We recommend managing extensions like any "
96 "other Python packages, in site-packages.").format(
97 dir=compress_user(self.ipython_extension_dir)))
98 mod = sys.modules[module_str]
99 if self._call_load_ipython_extension(mod):
100 self.loaded.add(module_str)
101 else:
102 return "no load function"
103
104 def unload_extension(self, module_str: str):
105 """Unload an IPython extension by its module name.
106
107 This function looks up the extension's name in ``sys.modules`` and
108 simply calls ``mod.unload_ipython_extension(self)``.
109
110 Returns the string "no unload function" if the extension doesn't define
111 a function to unload itself, "not loaded" if the extension isn't loaded,
112 otherwise None.
113 """
114 if BUILTINS_EXTS.get(module_str, False) is True:
115 module_str = "IPython.extensions." + module_str
116 if module_str not in self.loaded:
117 return "not loaded"
118
119 if module_str in sys.modules:
120 mod = sys.modules[module_str]
121 if self._call_unload_ipython_extension(mod):
122 self.loaded.discard(module_str)
123 else:
124 return "no unload function"
125
126 def reload_extension(self, module_str: str):
127 """Reload an IPython extension by calling reload.
128
129 If the module has not been loaded before,
130 :meth:`InteractiveShell.load_extension` is called. Otherwise
131 :func:`reload` is called and then the :func:`load_ipython_extension`
132 function of the module, if it exists is called.
133 """
134 from IPython.utils.syspathcontext import prepended_to_syspath
135
136 if BUILTINS_EXTS.get(module_str, False) is True:
137 module_str = "IPython.extensions." + module_str
138
139 if (module_str in self.loaded) and (module_str in sys.modules):
140 self.unload_extension(module_str)
141 mod = sys.modules[module_str]
142 with prepended_to_syspath(self.ipython_extension_dir):
143 reload(mod)
144 if self._call_load_ipython_extension(mod):
145 self.loaded.add(module_str)
146 else:
147 self.load_extension(module_str)
148
149 def _call_load_ipython_extension(self, mod):
150 if hasattr(mod, 'load_ipython_extension'):
151 mod.load_ipython_extension(self.shell)
152 return True
153
154 def _call_unload_ipython_extension(self, mod):
155 if hasattr(mod, 'unload_ipython_extension'):
156 mod.unload_ipython_extension(self.shell)
157 return True
158
159 @undoc
160 def install_extension(self, url, filename=None):
161 """
162 Deprecated.
163 """
164 # Ensure the extension directory exists
165 raise DeprecationWarning(
166 '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'
167 'Use pip or other package managers to manage ipython extensions.')
168
[end of IPython/core/extensions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/IPython/core/extensions.py b/IPython/core/extensions.py
--- a/IPython/core/extensions.py
+++ b/IPython/core/extensions.py
@@ -88,13 +88,7 @@
with self.shell.builtin_trap:
if module_str not in sys.modules:
- with prepended_to_syspath(self.ipython_extension_dir):
- mod = import_module(module_str)
- if mod.__file__.startswith(self.ipython_extension_dir):
- print(("Loading extensions from {dir} is deprecated. "
- "We recommend managing extensions like any "
- "other Python packages, in site-packages.").format(
- dir=compress_user(self.ipython_extension_dir)))
+ mod = import_module(module_str)
mod = sys.modules[module_str]
if self._call_load_ipython_extension(mod):
self.loaded.add(module_str)
@@ -155,13 +149,3 @@
if hasattr(mod, 'unload_ipython_extension'):
mod.unload_ipython_extension(self.shell)
return True
-
- @undoc
- def install_extension(self, url, filename=None):
- """
- Deprecated.
- """
- # Ensure the extension directory exists
- raise DeprecationWarning(
- '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'
- 'Use pip or other package managers to manage ipython extensions.')
|
{"golden_diff": "diff --git a/IPython/core/extensions.py b/IPython/core/extensions.py\n--- a/IPython/core/extensions.py\n+++ b/IPython/core/extensions.py\n@@ -88,13 +88,7 @@\n \n with self.shell.builtin_trap:\n if module_str not in sys.modules:\n- with prepended_to_syspath(self.ipython_extension_dir):\n- mod = import_module(module_str)\n- if mod.__file__.startswith(self.ipython_extension_dir):\n- print((\"Loading extensions from {dir} is deprecated. \"\n- \"We recommend managing extensions like any \"\n- \"other Python packages, in site-packages.\").format(\n- dir=compress_user(self.ipython_extension_dir)))\n+ mod = import_module(module_str)\n mod = sys.modules[module_str]\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n@@ -155,13 +149,3 @@\n if hasattr(mod, 'unload_ipython_extension'):\n mod.unload_ipython_extension(self.shell)\n return True\n-\n- @undoc\n- def install_extension(self, url, filename=None):\n- \"\"\"\n- Deprecated.\n- \"\"\"\n- # Ensure the extension directory exists\n- raise DeprecationWarning(\n- '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'\n- 'Use pip or other package managers to manage ipython extensions.')\n", "issue": "Suggestion: 'undeprecate' extensions\nI can't think of a single reason why it is deprecated. Python package management is really bad to rely on pip, packing small personal customization extensions is a massive overkill and can lead to potential pip conflicts in the future and publishing it is a horrendous waste of time (and might not even be possible in some cases). Extensions folder was perfect for very simple personal extensions and now using it constantly shows warnings that can't be disabled. Startup scripts aren't a good alternative because they clutter globals space and trying to do something without putting anything into globals leads to extremely ugly code in startup scripts.\n", "before_files": [{"content": "# encoding: utf-8\n\"\"\"A class for managing IPython extensions.\"\"\"\n\n# Copyright (c) IPython Development Team.\n# Distributed under the terms of the Modified BSD License.\n\nimport os\nimport os.path\nimport sys\nfrom importlib import import_module, reload\n\nfrom traitlets.config.configurable import Configurable\nfrom IPython.utils.path import ensure_dir_exists, compress_user\nfrom IPython.utils.decorators import undoc\nfrom traitlets import Instance\n\n\n#-----------------------------------------------------------------------------\n# Main class\n#-----------------------------------------------------------------------------\n\nBUILTINS_EXTS = {\"storemagic\": False, \"autoreload\": False}\n\n\nclass ExtensionManager(Configurable):\n \"\"\"A class to manage IPython extensions.\n\n An IPython extension is an importable Python module that has\n a function with the signature::\n\n def load_ipython_extension(ipython):\n # Do things with ipython\n\n This function is called after your extension is imported and the\n currently active :class:`InteractiveShell` instance is passed as\n the only argument. You can do anything you want with IPython at\n that point, including defining new magic and aliases, adding new\n components, etc.\n \n You can also optionally define an :func:`unload_ipython_extension(ipython)`\n function, which will be called if the user unloads or reloads the extension.\n The extension manager will only call :func:`load_ipython_extension` again\n if the extension is reloaded.\n\n You can put your extension modules anywhere you want, as long as\n they can be imported by Python's standard import mechanism. However,\n to make it easy to write extensions, you can also put your extensions\n in ``os.path.join(self.ipython_dir, 'extensions')``. This directory\n is added to ``sys.path`` automatically.\n \"\"\"\n\n shell = Instance('IPython.core.interactiveshell.InteractiveShellABC', allow_none=True)\n\n def __init__(self, shell=None, **kwargs):\n super(ExtensionManager, self).__init__(shell=shell, **kwargs)\n self.shell.observe(\n self._on_ipython_dir_changed, names=('ipython_dir',)\n )\n self.loaded = set()\n\n @property\n def ipython_extension_dir(self):\n return os.path.join(self.shell.ipython_dir, u'extensions')\n\n def _on_ipython_dir_changed(self, change):\n ensure_dir_exists(self.ipython_extension_dir)\n\n def load_extension(self, module_str: str):\n \"\"\"Load an IPython extension by its module name.\n\n Returns the string \"already loaded\" if the extension is already loaded,\n \"no load function\" if the module doesn't have a load_ipython_extension\n function, or None if it succeeded.\n \"\"\"\n try:\n return self._load_extension(module_str)\n except ModuleNotFoundError:\n if module_str in BUILTINS_EXTS:\n BUILTINS_EXTS[module_str] = True\n return self._load_extension(\"IPython.extensions.\" + module_str)\n raise\n\n def _load_extension(self, module_str: str):\n if module_str in self.loaded:\n return \"already loaded\"\n\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n with self.shell.builtin_trap:\n if module_str not in sys.modules:\n with prepended_to_syspath(self.ipython_extension_dir):\n mod = import_module(module_str)\n if mod.__file__.startswith(self.ipython_extension_dir):\n print((\"Loading extensions from {dir} is deprecated. \"\n \"We recommend managing extensions like any \"\n \"other Python packages, in site-packages.\").format(\n dir=compress_user(self.ipython_extension_dir)))\n mod = sys.modules[module_str]\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n return \"no load function\"\n\n def unload_extension(self, module_str: str):\n \"\"\"Unload an IPython extension by its module name.\n\n This function looks up the extension's name in ``sys.modules`` and\n simply calls ``mod.unload_ipython_extension(self)``.\n\n Returns the string \"no unload function\" if the extension doesn't define\n a function to unload itself, \"not loaded\" if the extension isn't loaded,\n otherwise None.\n \"\"\"\n if BUILTINS_EXTS.get(module_str, False) is True:\n module_str = \"IPython.extensions.\" + module_str\n if module_str not in self.loaded:\n return \"not loaded\"\n\n if module_str in sys.modules:\n mod = sys.modules[module_str]\n if self._call_unload_ipython_extension(mod):\n self.loaded.discard(module_str)\n else:\n return \"no unload function\"\n\n def reload_extension(self, module_str: str):\n \"\"\"Reload an IPython extension by calling reload.\n\n If the module has not been loaded before,\n :meth:`InteractiveShell.load_extension` is called. Otherwise\n :func:`reload` is called and then the :func:`load_ipython_extension`\n function of the module, if it exists is called.\n \"\"\"\n from IPython.utils.syspathcontext import prepended_to_syspath\n\n if BUILTINS_EXTS.get(module_str, False) is True:\n module_str = \"IPython.extensions.\" + module_str\n\n if (module_str in self.loaded) and (module_str in sys.modules):\n self.unload_extension(module_str)\n mod = sys.modules[module_str]\n with prepended_to_syspath(self.ipython_extension_dir):\n reload(mod)\n if self._call_load_ipython_extension(mod):\n self.loaded.add(module_str)\n else:\n self.load_extension(module_str)\n\n def _call_load_ipython_extension(self, mod):\n if hasattr(mod, 'load_ipython_extension'):\n mod.load_ipython_extension(self.shell)\n return True\n\n def _call_unload_ipython_extension(self, mod):\n if hasattr(mod, 'unload_ipython_extension'):\n mod.unload_ipython_extension(self.shell)\n return True\n\n @undoc\n def install_extension(self, url, filename=None):\n \"\"\"\n Deprecated.\n \"\"\"\n # Ensure the extension directory exists\n raise DeprecationWarning(\n '`install_extension` and the `install_ext` magic have been deprecated since IPython 4.0'\n 'Use pip or other package managers to manage ipython extensions.')\n", "path": "IPython/core/extensions.py"}]}
| 2,445 | 313 |
gh_patches_debug_33107
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-6317
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] authentication error is handled incorrectly in client.rest.uploader_downloader.FileDownloader
When installing a Conan package I've got this error message:
```
tools.get(**self.conan_data["sources"][self.version])
AttributeError: 'NoneType' object has no attribute 'token'
```
Obviously, the message isn't very helpful as it implies that there's a problem with the package recipe (there wasn't).
After some investigation I found out that the error ultimately happens in `client.rest.uploader_downloader.FileDownloader` when the download fails with a 403.
The method does the following check: `auth.token is None`. The issue is, `auth` is an optional parameter. Also it is effectively allowed to be a tuple according to documentation for `tools.get`. So, I assume the check should have been `not auth or not hasattr(auth, "token") or auth.token is None`.
Conan version: 1.21.0
</issue>
<code>
[start of conans/client/rest/uploader_downloader.py]
1 import os
2 import traceback
3 import time
4 from copy import copy
5
6 import six
7
8 from conans.util import progress_bar
9 from conans.client.rest import response_to_str
10 from conans.errors import AuthenticationException, ConanConnectionError, ConanException, \
11 NotFoundException, ForbiddenException, RequestErrorException
12 from conans.util.files import mkdir, sha1sum
13 from conans.util.log import logger
14 from conans.util.tracer import log_download
15
16
17 class FileUploader(object):
18
19 def __init__(self, requester, output, verify, chunk_size=1000):
20 self.chunk_size = chunk_size
21 self.output = output
22 self.requester = requester
23 self.verify = verify
24
25 def upload(self, url, abs_path, auth=None, dedup=False, retry=None, retry_wait=None,
26 headers=None):
27 retry = retry if retry is not None else self.requester.retry
28 retry = retry if retry is not None else 1
29 retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait
30 retry_wait = retry_wait if retry_wait is not None else 5
31
32 # Send always the header with the Sha1
33 headers = copy(headers) or {}
34 headers["X-Checksum-Sha1"] = sha1sum(abs_path)
35 if dedup:
36 dedup_headers = {"X-Checksum-Deploy": "true"}
37 if headers:
38 dedup_headers.update(headers)
39 response = self.requester.put(url, data="", verify=self.verify, headers=dedup_headers,
40 auth=auth)
41 if response.status_code == 400:
42 raise RequestErrorException(response_to_str(response))
43
44 if response.status_code == 401:
45 raise AuthenticationException(response_to_str(response))
46
47 if response.status_code == 403:
48 if auth.token is None:
49 raise AuthenticationException(response_to_str(response))
50 raise ForbiddenException(response_to_str(response))
51 if response.status_code == 201: # Artifactory returns 201 if the file is there
52 return response
53
54 ret = call_with_retry(self.output, retry, retry_wait, self._upload_file, url,
55 abs_path=abs_path, headers=headers, auth=auth)
56 return ret
57
58 def _upload_file(self, url, abs_path, headers, auth):
59
60 file_size = os.stat(abs_path).st_size
61 file_name = os.path.basename(abs_path)
62 description = "Uploading {}".format(file_name)
63
64 def load_in_chunks(_file, size):
65 """Lazy function (generator) to read a file piece by piece.
66 Default chunk size: 1k."""
67 while True:
68 chunk = _file.read(size)
69 if not chunk:
70 break
71 yield chunk
72
73 with open(abs_path, mode='rb') as file_handler:
74 progress = progress_bar.Progress(file_size, self.output, description, print_dot=True)
75 chunk_size = 1024
76 data = progress.update(load_in_chunks(file_handler, chunk_size), chunk_size)
77 iterable_to_file = IterableToFileAdapter(data, file_size)
78 try:
79 response = self.requester.put(url, data=iterable_to_file, verify=self.verify,
80 headers=headers, auth=auth)
81
82 if response.status_code == 400:
83 raise RequestErrorException(response_to_str(response))
84
85 if response.status_code == 401:
86 raise AuthenticationException(response_to_str(response))
87
88 if response.status_code == 403:
89 if auth.token is None:
90 raise AuthenticationException(response_to_str(response))
91 raise ForbiddenException(response_to_str(response))
92
93 response.raise_for_status() # Raise HTTPError for bad http response status
94
95 except ConanException:
96 raise
97 except Exception as exc:
98 raise ConanException(exc)
99
100 return response
101
102
103 class IterableToFileAdapter(object):
104 def __init__(self, iterable, total_size):
105 self.iterator = iter(iterable)
106 self.total_size = total_size
107
108 def read(self, size=-1): # @UnusedVariable
109 return next(self.iterator, b'')
110
111 def __len__(self):
112 return self.total_size
113
114 def __iter__(self):
115 return self.iterator.__iter__()
116
117
118 class FileDownloader(object):
119
120 def __init__(self, requester, output, verify, chunk_size=1000):
121 self.chunk_size = chunk_size
122 self.output = output
123 self.requester = requester
124 self.verify = verify
125
126 def download(self, url, file_path=None, auth=None, retry=None, retry_wait=None, overwrite=False,
127 headers=None):
128 retry = retry if retry is not None else self.requester.retry
129 retry = retry if retry is not None else 2
130 retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait
131 retry_wait = retry_wait if retry_wait is not None else 0
132
133 if file_path and not os.path.isabs(file_path):
134 file_path = os.path.abspath(file_path)
135
136 if file_path and os.path.exists(file_path):
137 if overwrite:
138 if self.output:
139 self.output.warn("file '%s' already exists, overwriting" % file_path)
140 else:
141 # Should not happen, better to raise, probably we had to remove
142 # the dest folder before
143 raise ConanException("Error, the file to download already exists: '%s'" % file_path)
144
145 return call_with_retry(self.output, retry, retry_wait, self._download_file, url, auth,
146 headers, file_path)
147
148 def _download_file(self, url, auth, headers, file_path):
149 t1 = time.time()
150 try:
151 response = self.requester.get(url, stream=True, verify=self.verify, auth=auth,
152 headers=headers)
153 except Exception as exc:
154 raise ConanException("Error downloading file %s: '%s'" % (url, exc))
155
156 if not response.ok:
157 if response.status_code == 404:
158 raise NotFoundException("Not found: %s" % url)
159 elif response.status_code == 403:
160 if auth.token is None:
161 raise AuthenticationException(response_to_str(response))
162 raise ForbiddenException(response_to_str(response))
163 elif response.status_code == 401:
164 raise AuthenticationException()
165 raise ConanException("Error %d downloading file %s" % (response.status_code, url))
166
167 def read_response(size):
168 for chunk in response.iter_content(size):
169 yield chunk
170
171 def write_chunks(chunks, path):
172 ret = None
173 downloaded_size = 0
174 if path:
175 mkdir(os.path.dirname(path))
176 with open(path, 'wb') as file_handler:
177 for chunk in chunks:
178 assert ((six.PY3 and isinstance(chunk, bytes)) or
179 (six.PY2 and isinstance(chunk, str)))
180 file_handler.write(chunk)
181 downloaded_size += len(chunk)
182 else:
183 ret_data = bytearray()
184 for chunk in chunks:
185 ret_data.extend(chunk)
186 downloaded_size += len(chunk)
187 ret = bytes(ret_data)
188 return ret, downloaded_size
189
190 try:
191 logger.debug("DOWNLOAD: %s" % url)
192 total_length = response.headers.get('content-length') or len(response.content)
193 total_length = int(total_length)
194 description = "Downloading {}".format(os.path.basename(file_path)) if file_path else None
195 progress = progress_bar.Progress(total_length, self.output, description, print_dot=False)
196
197 chunk_size = 1024 if not file_path else 1024 * 100
198 encoding = response.headers.get('content-encoding')
199 gzip = (encoding == "gzip")
200
201 written_chunks, total_downloaded_size = write_chunks(
202 progress.update(read_response(chunk_size), chunk_size),
203 file_path
204 )
205
206 response.close()
207 if total_downloaded_size != total_length and not gzip:
208 raise ConanException("Transfer interrupted before "
209 "complete: %s < %s" % (total_downloaded_size, total_length))
210
211 duration = time.time() - t1
212 log_download(url, duration)
213 return written_chunks
214
215 except Exception as e:
216 logger.debug(e.__class__)
217 logger.debug(traceback.format_exc())
218 # If this part failed, it means problems with the connection to server
219 raise ConanConnectionError("Download failed, check server, possibly try again\n%s"
220 % str(e))
221
222
223 def print_progress(output, units, progress=""):
224 if output.is_terminal:
225 output.rewrite_line("[%s%s] %s" % ('=' * units, ' ' * (50 - units), progress))
226
227
228 def call_with_retry(out, retry, retry_wait, method, *args, **kwargs):
229 for counter in range(retry + 1):
230 try:
231 return method(*args, **kwargs)
232 except (NotFoundException, ForbiddenException, AuthenticationException,
233 RequestErrorException):
234 raise
235 except ConanException as exc:
236 if counter == retry:
237 raise
238 else:
239 if out:
240 out.error(exc)
241 out.info("Waiting %d seconds to retry..." % retry_wait)
242 time.sleep(retry_wait)
243
[end of conans/client/rest/uploader_downloader.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/rest/uploader_downloader.py b/conans/client/rest/uploader_downloader.py
--- a/conans/client/rest/uploader_downloader.py
+++ b/conans/client/rest/uploader_downloader.py
@@ -45,7 +45,7 @@
raise AuthenticationException(response_to_str(response))
if response.status_code == 403:
- if auth.token is None:
+ if auth is None or auth.token is None:
raise AuthenticationException(response_to_str(response))
raise ForbiddenException(response_to_str(response))
if response.status_code == 201: # Artifactory returns 201 if the file is there
@@ -86,7 +86,7 @@
raise AuthenticationException(response_to_str(response))
if response.status_code == 403:
- if auth.token is None:
+ if auth is None or auth.token is None:
raise AuthenticationException(response_to_str(response))
raise ForbiddenException(response_to_str(response))
@@ -157,7 +157,8 @@
if response.status_code == 404:
raise NotFoundException("Not found: %s" % url)
elif response.status_code == 403:
- if auth.token is None:
+ if auth is None or (hasattr(auth, "token") and auth.token is None):
+ # TODO: This is a bit weird, why this conversion? Need to investigate
raise AuthenticationException(response_to_str(response))
raise ForbiddenException(response_to_str(response))
elif response.status_code == 401:
|
{"golden_diff": "diff --git a/conans/client/rest/uploader_downloader.py b/conans/client/rest/uploader_downloader.py\n--- a/conans/client/rest/uploader_downloader.py\n+++ b/conans/client/rest/uploader_downloader.py\n@@ -45,7 +45,7 @@\n raise AuthenticationException(response_to_str(response))\n \n if response.status_code == 403:\n- if auth.token is None:\n+ if auth is None or auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n if response.status_code == 201: # Artifactory returns 201 if the file is there\n@@ -86,7 +86,7 @@\n raise AuthenticationException(response_to_str(response))\n \n if response.status_code == 403:\n- if auth.token is None:\n+ if auth is None or auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n \n@@ -157,7 +157,8 @@\n if response.status_code == 404:\n raise NotFoundException(\"Not found: %s\" % url)\n elif response.status_code == 403:\n- if auth.token is None:\n+ if auth is None or (hasattr(auth, \"token\") and auth.token is None):\n+ # TODO: This is a bit weird, why this conversion? Need to investigate\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n elif response.status_code == 401:\n", "issue": "[bug] authentication error is handled incorrectly in client.rest.uploader_downloader.FileDownloader\nWhen installing a Conan package I've got this error message:\r\n```\r\ntools.get(**self.conan_data[\"sources\"][self.version])\r\nAttributeError: 'NoneType' object has no attribute 'token'\r\n```\r\nObviously, the message isn't very helpful as it implies that there's a problem with the package recipe (there wasn't).\r\n\r\nAfter some investigation I found out that the error ultimately happens in `client.rest.uploader_downloader.FileDownloader` when the download fails with a 403.\r\nThe method does the following check: `auth.token is None`. The issue is, `auth` is an optional parameter. Also it is effectively allowed to be a tuple according to documentation for `tools.get`. So, I assume the check should have been `not auth or not hasattr(auth, \"token\") or auth.token is None`.\r\n\r\nConan version: 1.21.0\r\n\n", "before_files": [{"content": "import os\nimport traceback\nimport time\nfrom copy import copy\n\nimport six\n\nfrom conans.util import progress_bar\nfrom conans.client.rest import response_to_str\nfrom conans.errors import AuthenticationException, ConanConnectionError, ConanException, \\\n NotFoundException, ForbiddenException, RequestErrorException\nfrom conans.util.files import mkdir, sha1sum\nfrom conans.util.log import logger\nfrom conans.util.tracer import log_download\n\n\nclass FileUploader(object):\n\n def __init__(self, requester, output, verify, chunk_size=1000):\n self.chunk_size = chunk_size\n self.output = output\n self.requester = requester\n self.verify = verify\n\n def upload(self, url, abs_path, auth=None, dedup=False, retry=None, retry_wait=None,\n headers=None):\n retry = retry if retry is not None else self.requester.retry\n retry = retry if retry is not None else 1\n retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait\n retry_wait = retry_wait if retry_wait is not None else 5\n\n # Send always the header with the Sha1\n headers = copy(headers) or {}\n headers[\"X-Checksum-Sha1\"] = sha1sum(abs_path)\n if dedup:\n dedup_headers = {\"X-Checksum-Deploy\": \"true\"}\n if headers:\n dedup_headers.update(headers)\n response = self.requester.put(url, data=\"\", verify=self.verify, headers=dedup_headers,\n auth=auth)\n if response.status_code == 400:\n raise RequestErrorException(response_to_str(response))\n\n if response.status_code == 401:\n raise AuthenticationException(response_to_str(response))\n\n if response.status_code == 403:\n if auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n if response.status_code == 201: # Artifactory returns 201 if the file is there\n return response\n\n ret = call_with_retry(self.output, retry, retry_wait, self._upload_file, url,\n abs_path=abs_path, headers=headers, auth=auth)\n return ret\n\n def _upload_file(self, url, abs_path, headers, auth):\n\n file_size = os.stat(abs_path).st_size\n file_name = os.path.basename(abs_path)\n description = \"Uploading {}\".format(file_name)\n\n def load_in_chunks(_file, size):\n \"\"\"Lazy function (generator) to read a file piece by piece.\n Default chunk size: 1k.\"\"\"\n while True:\n chunk = _file.read(size)\n if not chunk:\n break\n yield chunk\n\n with open(abs_path, mode='rb') as file_handler:\n progress = progress_bar.Progress(file_size, self.output, description, print_dot=True)\n chunk_size = 1024\n data = progress.update(load_in_chunks(file_handler, chunk_size), chunk_size)\n iterable_to_file = IterableToFileAdapter(data, file_size)\n try:\n response = self.requester.put(url, data=iterable_to_file, verify=self.verify,\n headers=headers, auth=auth)\n\n if response.status_code == 400:\n raise RequestErrorException(response_to_str(response))\n\n if response.status_code == 401:\n raise AuthenticationException(response_to_str(response))\n\n if response.status_code == 403:\n if auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n\n response.raise_for_status() # Raise HTTPError for bad http response status\n\n except ConanException:\n raise\n except Exception as exc:\n raise ConanException(exc)\n\n return response\n\n\nclass IterableToFileAdapter(object):\n def __init__(self, iterable, total_size):\n self.iterator = iter(iterable)\n self.total_size = total_size\n\n def read(self, size=-1): # @UnusedVariable\n return next(self.iterator, b'')\n\n def __len__(self):\n return self.total_size\n\n def __iter__(self):\n return self.iterator.__iter__()\n\n\nclass FileDownloader(object):\n\n def __init__(self, requester, output, verify, chunk_size=1000):\n self.chunk_size = chunk_size\n self.output = output\n self.requester = requester\n self.verify = verify\n\n def download(self, url, file_path=None, auth=None, retry=None, retry_wait=None, overwrite=False,\n headers=None):\n retry = retry if retry is not None else self.requester.retry\n retry = retry if retry is not None else 2\n retry_wait = retry_wait if retry_wait is not None else self.requester.retry_wait\n retry_wait = retry_wait if retry_wait is not None else 0\n\n if file_path and not os.path.isabs(file_path):\n file_path = os.path.abspath(file_path)\n\n if file_path and os.path.exists(file_path):\n if overwrite:\n if self.output:\n self.output.warn(\"file '%s' already exists, overwriting\" % file_path)\n else:\n # Should not happen, better to raise, probably we had to remove\n # the dest folder before\n raise ConanException(\"Error, the file to download already exists: '%s'\" % file_path)\n\n return call_with_retry(self.output, retry, retry_wait, self._download_file, url, auth,\n headers, file_path)\n\n def _download_file(self, url, auth, headers, file_path):\n t1 = time.time()\n try:\n response = self.requester.get(url, stream=True, verify=self.verify, auth=auth,\n headers=headers)\n except Exception as exc:\n raise ConanException(\"Error downloading file %s: '%s'\" % (url, exc))\n\n if not response.ok:\n if response.status_code == 404:\n raise NotFoundException(\"Not found: %s\" % url)\n elif response.status_code == 403:\n if auth.token is None:\n raise AuthenticationException(response_to_str(response))\n raise ForbiddenException(response_to_str(response))\n elif response.status_code == 401:\n raise AuthenticationException()\n raise ConanException(\"Error %d downloading file %s\" % (response.status_code, url))\n\n def read_response(size):\n for chunk in response.iter_content(size):\n yield chunk\n\n def write_chunks(chunks, path):\n ret = None\n downloaded_size = 0\n if path:\n mkdir(os.path.dirname(path))\n with open(path, 'wb') as file_handler:\n for chunk in chunks:\n assert ((six.PY3 and isinstance(chunk, bytes)) or\n (six.PY2 and isinstance(chunk, str)))\n file_handler.write(chunk)\n downloaded_size += len(chunk)\n else:\n ret_data = bytearray()\n for chunk in chunks:\n ret_data.extend(chunk)\n downloaded_size += len(chunk)\n ret = bytes(ret_data)\n return ret, downloaded_size\n\n try:\n logger.debug(\"DOWNLOAD: %s\" % url)\n total_length = response.headers.get('content-length') or len(response.content)\n total_length = int(total_length)\n description = \"Downloading {}\".format(os.path.basename(file_path)) if file_path else None\n progress = progress_bar.Progress(total_length, self.output, description, print_dot=False)\n\n chunk_size = 1024 if not file_path else 1024 * 100\n encoding = response.headers.get('content-encoding')\n gzip = (encoding == \"gzip\")\n\n written_chunks, total_downloaded_size = write_chunks(\n progress.update(read_response(chunk_size), chunk_size),\n file_path\n )\n\n response.close()\n if total_downloaded_size != total_length and not gzip:\n raise ConanException(\"Transfer interrupted before \"\n \"complete: %s < %s\" % (total_downloaded_size, total_length))\n\n duration = time.time() - t1\n log_download(url, duration)\n return written_chunks\n\n except Exception as e:\n logger.debug(e.__class__)\n logger.debug(traceback.format_exc())\n # If this part failed, it means problems with the connection to server\n raise ConanConnectionError(\"Download failed, check server, possibly try again\\n%s\"\n % str(e))\n\n\ndef print_progress(output, units, progress=\"\"):\n if output.is_terminal:\n output.rewrite_line(\"[%s%s] %s\" % ('=' * units, ' ' * (50 - units), progress))\n\n\ndef call_with_retry(out, retry, retry_wait, method, *args, **kwargs):\n for counter in range(retry + 1):\n try:\n return method(*args, **kwargs)\n except (NotFoundException, ForbiddenException, AuthenticationException,\n RequestErrorException):\n raise\n except ConanException as exc:\n if counter == retry:\n raise\n else:\n if out:\n out.error(exc)\n out.info(\"Waiting %d seconds to retry...\" % retry_wait)\n time.sleep(retry_wait)\n", "path": "conans/client/rest/uploader_downloader.py"}]}
| 3,342 | 344 |
gh_patches_debug_31330
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-2324
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Upgrade websockets to 10.1 ?
* Version: 5.25.0
* Python: 3.8
* OS: osx
* `pip freeze` output
```
solana==0.19.0 (problem)
```
### What was wrong?
Currently in dependency hell trying to use solana-py and web3 in same service. solana-py requires websockets 10.1, web3 seems to not support that. Below is the changelog for 10.1 release of websockets, there are no incompatible changes. Any chance I could bother the team to consider upgrading support to 10.1?
Also, from my logs it seems web3 needs "websockets<10" but i think changes were made to support 10.0 (#2175) . May need to update requirements:
remote: The conflict is caused by:
remote: solana 0.19.0 depends on websockets<11.0 and >=10.1
remote: web3 5.25.0 depends on websockets<10 and >=9.1
https://websockets.readthedocs.io/en/latest/project/changelog.html#id3
Thanks!
### How can it be fixed?
Upgrade websockets support to 10.1
---
**Note:** We prefer to use issues to track our work. If you think you've encountered a bug in web3py or
have a feature request, you're in the right place. If you have implementation or usage questions,
please refer to our [documentation](https://web3py.readthedocs.io/en/latest/) and/or join the conversation
on [discord](https://discord.gg/GHryRvPB84).
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 from setuptools import (
4 find_packages,
5 setup,
6 )
7
8 extras_require = {
9 'tester': [
10 "eth-tester[py-evm]==v0.6.0-beta.6",
11 "py-geth>=3.7.0,<4",
12 ],
13 'linter': [
14 "flake8==3.8.3",
15 "isort>=4.2.15,<4.3.5",
16 "mypy==0.910",
17 "types-setuptools>=57.4.4,<58",
18 "types-requests>=2.26.1,<3",
19 "types-protobuf>=3.18.2,<4",
20 ],
21 'docs': [
22 "mock",
23 "sphinx-better-theme>=0.1.4",
24 "click>=5.1",
25 "configparser==3.5.0",
26 "contextlib2>=0.5.4",
27 "py-geth>=3.6.0,<4",
28 "py-solc>=0.4.0",
29 "pytest>=4.4.0,<5.0.0",
30 "sphinx>=3.0,<4",
31 "sphinx_rtd_theme>=0.1.9",
32 "toposort>=1.4",
33 "towncrier==18.5.0",
34 "urllib3",
35 "wheel"
36 ],
37 'dev': [
38 "bumpversion",
39 "flaky>=3.7.0,<4",
40 "hypothesis>=3.31.2,<6",
41 "pytest>=4.4.0,<5.0.0",
42 "pytest-asyncio>=0.10.0,<0.11",
43 "pytest-mock>=1.10,<2",
44 "pytest-pythonpath>=0.3",
45 "pytest-watch>=4.2,<5",
46 "pytest-xdist>=1.29,<2",
47 "setuptools>=38.6.0",
48 "tox>=1.8.0",
49 "tqdm>4.32,<5",
50 "twine>=1.13,<2",
51 "pluggy==0.13.1",
52 "when-changed>=0.3.0,<0.4"
53 ]
54 }
55
56 extras_require['dev'] = (
57 extras_require['tester']
58 + extras_require['linter']
59 + extras_require['docs']
60 + extras_require['dev']
61 )
62
63 with open('./README.md') as readme:
64 long_description = readme.read()
65
66 setup(
67 name='web3',
68 # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.
69 version='5.28.0',
70 description="""Web3.py""",
71 long_description_content_type='text/markdown',
72 long_description=long_description,
73 author='Piper Merriam',
74 author_email='[email protected]',
75 url='https://github.com/ethereum/web3.py',
76 include_package_data=True,
77 install_requires=[
78 "aiohttp>=3.7.4.post0,<4",
79 "eth-abi>=2.0.0b6,<3.0.0",
80 "eth-account>=0.5.7,<0.6.0",
81 "eth-hash[pycryptodome]>=0.2.0,<1.0.0",
82 "eth-typing>=2.0.0,<3.0.0",
83 "eth-utils>=1.9.5,<2.0.0",
84 "hexbytes>=0.1.0,<1.0.0",
85 "ipfshttpclient==0.8.0a2",
86 "jsonschema>=3.2.0,<4.0.0",
87 "lru-dict>=1.1.6,<2.0.0",
88 "protobuf>=3.10.0,<4",
89 "pywin32>=223;platform_system=='Windows'",
90 "requests>=2.16.0,<3.0.0",
91 # remove typing_extensions after python_requires>=3.8, see web3._utils.compat
92 "typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
93 "websockets>=9.1,<10",
94 ],
95 python_requires='>=3.7,<3.10',
96 extras_require=extras_require,
97 py_modules=['web3', 'ens', 'ethpm'],
98 entry_points={"pytest11": ["pytest_ethereum = web3.tools.pytest_ethereum.plugins"]},
99 license="MIT",
100 zip_safe=False,
101 keywords='ethereum',
102 packages=find_packages(exclude=["tests", "tests.*"]),
103 package_data={"web3": ["py.typed"]},
104 classifiers=[
105 'Development Status :: 5 - Production/Stable',
106 'Intended Audience :: Developers',
107 'License :: OSI Approved :: MIT License',
108 'Natural Language :: English',
109 'Programming Language :: Python :: 3',
110 'Programming Language :: Python :: 3.7',
111 'Programming Language :: Python :: 3.8',
112 'Programming Language :: Python :: 3.9',
113 ],
114 )
115
[end of setup.py]
[start of web3/providers/websocket.py]
1 import asyncio
2 import json
3 import logging
4 import os
5 from threading import (
6 Thread,
7 )
8 from types import (
9 TracebackType,
10 )
11 from typing import (
12 Any,
13 Optional,
14 Type,
15 Union,
16 )
17
18 from eth_typing import (
19 URI,
20 )
21 from websockets.client import (
22 connect,
23 )
24 from websockets.legacy.client import (
25 WebSocketClientProtocol,
26 )
27
28 from web3.exceptions import (
29 ValidationError,
30 )
31 from web3.providers.base import (
32 JSONBaseProvider,
33 )
34 from web3.types import (
35 RPCEndpoint,
36 RPCResponse,
37 )
38
39 RESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}
40 DEFAULT_WEBSOCKET_TIMEOUT = 10
41
42
43 def _start_event_loop(loop: asyncio.AbstractEventLoop) -> None:
44 asyncio.set_event_loop(loop)
45 loop.run_forever()
46 loop.close()
47
48
49 def _get_threaded_loop() -> asyncio.AbstractEventLoop:
50 new_loop = asyncio.new_event_loop()
51 thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)
52 thread_loop.start()
53 return new_loop
54
55
56 def get_default_endpoint() -> URI:
57 return URI(os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546'))
58
59
60 class PersistentWebSocket:
61
62 def __init__(
63 self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any
64 ) -> None:
65 self.ws: WebSocketClientProtocol = None
66 self.endpoint_uri = endpoint_uri
67 self.loop = loop
68 self.websocket_kwargs = websocket_kwargs
69
70 async def __aenter__(self) -> WebSocketClientProtocol:
71 if self.ws is None:
72 self.ws = await connect(
73 uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs
74 )
75 return self.ws
76
77 async def __aexit__(
78 self, exc_type: Type[BaseException], exc_val: BaseException, exc_tb: TracebackType
79 ) -> None:
80 if exc_val is not None:
81 try:
82 await self.ws.close()
83 except Exception:
84 pass
85 self.ws = None
86
87
88 class WebsocketProvider(JSONBaseProvider):
89 logger = logging.getLogger("web3.providers.WebsocketProvider")
90 _loop = None
91
92 def __init__(
93 self,
94 endpoint_uri: Optional[Union[URI, str]] = None,
95 websocket_kwargs: Optional[Any] = None,
96 websocket_timeout: int = DEFAULT_WEBSOCKET_TIMEOUT,
97 ) -> None:
98 self.endpoint_uri = URI(endpoint_uri)
99 self.websocket_timeout = websocket_timeout
100 if self.endpoint_uri is None:
101 self.endpoint_uri = get_default_endpoint()
102 if WebsocketProvider._loop is None:
103 WebsocketProvider._loop = _get_threaded_loop()
104 if websocket_kwargs is None:
105 websocket_kwargs = {}
106 else:
107 found_restricted_keys = set(websocket_kwargs.keys()).intersection(
108 RESTRICTED_WEBSOCKET_KWARGS
109 )
110 if found_restricted_keys:
111 raise ValidationError(
112 '{0} are not allowed in websocket_kwargs, '
113 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)
114 )
115 self.conn = PersistentWebSocket(
116 self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs
117 )
118 super().__init__()
119
120 def __str__(self) -> str:
121 return "WS connection {0}".format(self.endpoint_uri)
122
123 async def coro_make_request(self, request_data: bytes) -> RPCResponse:
124 async with self.conn as conn:
125 await asyncio.wait_for(
126 conn.send(request_data),
127 timeout=self.websocket_timeout
128 )
129 return json.loads(
130 await asyncio.wait_for(
131 conn.recv(),
132 timeout=self.websocket_timeout
133 )
134 )
135
136 def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:
137 self.logger.debug("Making request WebSocket. URI: %s, "
138 "Method: %s", self.endpoint_uri, method)
139 request_data = self.encode_rpc_request(method, params)
140 future = asyncio.run_coroutine_threadsafe(
141 self.coro_make_request(request_data),
142 WebsocketProvider._loop
143 )
144 return future.result()
145
[end of web3/providers/websocket.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -90,7 +90,7 @@
"requests>=2.16.0,<3.0.0",
# remove typing_extensions after python_requires>=3.8, see web3._utils.compat
"typing-extensions>=3.7.4.1,<5;python_version<'3.8'",
- "websockets>=9.1,<10",
+ "websockets>=10.0.0,<11",
],
python_requires='>=3.7,<3.10',
extras_require=extras_require,
diff --git a/web3/providers/websocket.py b/web3/providers/websocket.py
--- a/web3/providers/websocket.py
+++ b/web3/providers/websocket.py
@@ -60,17 +60,16 @@
class PersistentWebSocket:
def __init__(
- self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any
+ self, endpoint_uri: URI, websocket_kwargs: Any
) -> None:
self.ws: WebSocketClientProtocol = None
self.endpoint_uri = endpoint_uri
- self.loop = loop
self.websocket_kwargs = websocket_kwargs
async def __aenter__(self) -> WebSocketClientProtocol:
if self.ws is None:
self.ws = await connect(
- uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs
+ uri=self.endpoint_uri, **self.websocket_kwargs
)
return self.ws
@@ -113,7 +112,7 @@
'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)
)
self.conn = PersistentWebSocket(
- self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs
+ self.endpoint_uri, websocket_kwargs
)
super().__init__()
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -90,7 +90,7 @@\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n- \"websockets>=9.1,<10\",\n+ \"websockets>=10.0.0,<11\",\n ],\n python_requires='>=3.7,<3.10',\n extras_require=extras_require,\ndiff --git a/web3/providers/websocket.py b/web3/providers/websocket.py\n--- a/web3/providers/websocket.py\n+++ b/web3/providers/websocket.py\n@@ -60,17 +60,16 @@\n class PersistentWebSocket:\n \n def __init__(\n- self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any\n+ self, endpoint_uri: URI, websocket_kwargs: Any\n ) -> None:\n self.ws: WebSocketClientProtocol = None\n self.endpoint_uri = endpoint_uri\n- self.loop = loop\n self.websocket_kwargs = websocket_kwargs\n \n async def __aenter__(self) -> WebSocketClientProtocol:\n if self.ws is None:\n self.ws = await connect(\n- uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs\n+ uri=self.endpoint_uri, **self.websocket_kwargs\n )\n return self.ws\n \n@@ -113,7 +112,7 @@\n 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n )\n self.conn = PersistentWebSocket(\n- self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs\n+ self.endpoint_uri, websocket_kwargs\n )\n super().__init__()\n", "issue": "Upgrade websockets to 10.1 ?\n* Version: 5.25.0\r\n* Python: 3.8\r\n* OS: osx\r\n* `pip freeze` output\r\n\r\n```\r\nsolana==0.19.0 (problem)\r\n```\r\n\r\n\r\n### What was wrong?\r\n\r\nCurrently in dependency hell trying to use solana-py and web3 in same service. solana-py requires websockets 10.1, web3 seems to not support that. Below is the changelog for 10.1 release of websockets, there are no incompatible changes. Any chance I could bother the team to consider upgrading support to 10.1?\r\n\r\nAlso, from my logs it seems web3 needs \"websockets<10\" but i think changes were made to support 10.0 (#2175) . May need to update requirements:\r\n\r\nremote: The conflict is caused by:\r\nremote: solana 0.19.0 depends on websockets<11.0 and >=10.1\r\nremote: web3 5.25.0 depends on websockets<10 and >=9.1\r\n\r\nhttps://websockets.readthedocs.io/en/latest/project/changelog.html#id3\r\n\r\nThanks!\r\n\r\n\r\n### How can it be fixed?\r\n\r\nUpgrade websockets support to 10.1\r\n\r\n---\r\n**Note:** We prefer to use issues to track our work. If you think you've encountered a bug in web3py or \r\nhave a feature request, you're in the right place. If you have implementation or usage questions, \r\nplease refer to our [documentation](https://web3py.readthedocs.io/en/latest/) and/or join the conversation \r\non [discord](https://discord.gg/GHryRvPB84).\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom setuptools import (\n find_packages,\n setup,\n)\n\nextras_require = {\n 'tester': [\n \"eth-tester[py-evm]==v0.6.0-beta.6\",\n \"py-geth>=3.7.0,<4\",\n ],\n 'linter': [\n \"flake8==3.8.3\",\n \"isort>=4.2.15,<4.3.5\",\n \"mypy==0.910\",\n \"types-setuptools>=57.4.4,<58\",\n \"types-requests>=2.26.1,<3\",\n \"types-protobuf>=3.18.2,<4\",\n ],\n 'docs': [\n \"mock\",\n \"sphinx-better-theme>=0.1.4\",\n \"click>=5.1\",\n \"configparser==3.5.0\",\n \"contextlib2>=0.5.4\",\n \"py-geth>=3.6.0,<4\",\n \"py-solc>=0.4.0\",\n \"pytest>=4.4.0,<5.0.0\",\n \"sphinx>=3.0,<4\",\n \"sphinx_rtd_theme>=0.1.9\",\n \"toposort>=1.4\",\n \"towncrier==18.5.0\",\n \"urllib3\",\n \"wheel\"\n ],\n 'dev': [\n \"bumpversion\",\n \"flaky>=3.7.0,<4\",\n \"hypothesis>=3.31.2,<6\",\n \"pytest>=4.4.0,<5.0.0\",\n \"pytest-asyncio>=0.10.0,<0.11\",\n \"pytest-mock>=1.10,<2\",\n \"pytest-pythonpath>=0.3\",\n \"pytest-watch>=4.2,<5\",\n \"pytest-xdist>=1.29,<2\",\n \"setuptools>=38.6.0\",\n \"tox>=1.8.0\",\n \"tqdm>4.32,<5\",\n \"twine>=1.13,<2\",\n \"pluggy==0.13.1\",\n \"when-changed>=0.3.0,<0.4\"\n ]\n}\n\nextras_require['dev'] = (\n extras_require['tester']\n + extras_require['linter']\n + extras_require['docs']\n + extras_require['dev']\n)\n\nwith open('./README.md') as readme:\n long_description = readme.read()\n\nsetup(\n name='web3',\n # *IMPORTANT*: Don't manually change the version here. Use the 'bumpversion' utility.\n version='5.28.0',\n description=\"\"\"Web3.py\"\"\",\n long_description_content_type='text/markdown',\n long_description=long_description,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/ethereum/web3.py',\n include_package_data=True,\n install_requires=[\n \"aiohttp>=3.7.4.post0,<4\",\n \"eth-abi>=2.0.0b6,<3.0.0\",\n \"eth-account>=0.5.7,<0.6.0\",\n \"eth-hash[pycryptodome]>=0.2.0,<1.0.0\",\n \"eth-typing>=2.0.0,<3.0.0\",\n \"eth-utils>=1.9.5,<2.0.0\",\n \"hexbytes>=0.1.0,<1.0.0\",\n \"ipfshttpclient==0.8.0a2\",\n \"jsonschema>=3.2.0,<4.0.0\",\n \"lru-dict>=1.1.6,<2.0.0\",\n \"protobuf>=3.10.0,<4\",\n \"pywin32>=223;platform_system=='Windows'\",\n \"requests>=2.16.0,<3.0.0\",\n # remove typing_extensions after python_requires>=3.8, see web3._utils.compat\n \"typing-extensions>=3.7.4.1,<5;python_version<'3.8'\",\n \"websockets>=9.1,<10\",\n ],\n python_requires='>=3.7,<3.10',\n extras_require=extras_require,\n py_modules=['web3', 'ens', 'ethpm'],\n entry_points={\"pytest11\": [\"pytest_ethereum = web3.tools.pytest_ethereum.plugins\"]},\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n package_data={\"web3\": [\"py.typed\"]},\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n ],\n)\n", "path": "setup.py"}, {"content": "import asyncio\nimport json\nimport logging\nimport os\nfrom threading import (\n Thread,\n)\nfrom types import (\n TracebackType,\n)\nfrom typing import (\n Any,\n Optional,\n Type,\n Union,\n)\n\nfrom eth_typing import (\n URI,\n)\nfrom websockets.client import (\n connect,\n)\nfrom websockets.legacy.client import (\n WebSocketClientProtocol,\n)\n\nfrom web3.exceptions import (\n ValidationError,\n)\nfrom web3.providers.base import (\n JSONBaseProvider,\n)\nfrom web3.types import (\n RPCEndpoint,\n RPCResponse,\n)\n\nRESTRICTED_WEBSOCKET_KWARGS = {'uri', 'loop'}\nDEFAULT_WEBSOCKET_TIMEOUT = 10\n\n\ndef _start_event_loop(loop: asyncio.AbstractEventLoop) -> None:\n asyncio.set_event_loop(loop)\n loop.run_forever()\n loop.close()\n\n\ndef _get_threaded_loop() -> asyncio.AbstractEventLoop:\n new_loop = asyncio.new_event_loop()\n thread_loop = Thread(target=_start_event_loop, args=(new_loop,), daemon=True)\n thread_loop.start()\n return new_loop\n\n\ndef get_default_endpoint() -> URI:\n return URI(os.environ.get('WEB3_WS_PROVIDER_URI', 'ws://127.0.0.1:8546'))\n\n\nclass PersistentWebSocket:\n\n def __init__(\n self, endpoint_uri: URI, loop: asyncio.AbstractEventLoop, websocket_kwargs: Any\n ) -> None:\n self.ws: WebSocketClientProtocol = None\n self.endpoint_uri = endpoint_uri\n self.loop = loop\n self.websocket_kwargs = websocket_kwargs\n\n async def __aenter__(self) -> WebSocketClientProtocol:\n if self.ws is None:\n self.ws = await connect(\n uri=self.endpoint_uri, loop=self.loop, **self.websocket_kwargs\n )\n return self.ws\n\n async def __aexit__(\n self, exc_type: Type[BaseException], exc_val: BaseException, exc_tb: TracebackType\n ) -> None:\n if exc_val is not None:\n try:\n await self.ws.close()\n except Exception:\n pass\n self.ws = None\n\n\nclass WebsocketProvider(JSONBaseProvider):\n logger = logging.getLogger(\"web3.providers.WebsocketProvider\")\n _loop = None\n\n def __init__(\n self,\n endpoint_uri: Optional[Union[URI, str]] = None,\n websocket_kwargs: Optional[Any] = None,\n websocket_timeout: int = DEFAULT_WEBSOCKET_TIMEOUT,\n ) -> None:\n self.endpoint_uri = URI(endpoint_uri)\n self.websocket_timeout = websocket_timeout\n if self.endpoint_uri is None:\n self.endpoint_uri = get_default_endpoint()\n if WebsocketProvider._loop is None:\n WebsocketProvider._loop = _get_threaded_loop()\n if websocket_kwargs is None:\n websocket_kwargs = {}\n else:\n found_restricted_keys = set(websocket_kwargs.keys()).intersection(\n RESTRICTED_WEBSOCKET_KWARGS\n )\n if found_restricted_keys:\n raise ValidationError(\n '{0} are not allowed in websocket_kwargs, '\n 'found: {1}'.format(RESTRICTED_WEBSOCKET_KWARGS, found_restricted_keys)\n )\n self.conn = PersistentWebSocket(\n self.endpoint_uri, WebsocketProvider._loop, websocket_kwargs\n )\n super().__init__()\n\n def __str__(self) -> str:\n return \"WS connection {0}\".format(self.endpoint_uri)\n\n async def coro_make_request(self, request_data: bytes) -> RPCResponse:\n async with self.conn as conn:\n await asyncio.wait_for(\n conn.send(request_data),\n timeout=self.websocket_timeout\n )\n return json.loads(\n await asyncio.wait_for(\n conn.recv(),\n timeout=self.websocket_timeout\n )\n )\n\n def make_request(self, method: RPCEndpoint, params: Any) -> RPCResponse:\n self.logger.debug(\"Making request WebSocket. URI: %s, \"\n \"Method: %s\", self.endpoint_uri, method)\n request_data = self.encode_rpc_request(method, params)\n future = asyncio.run_coroutine_threadsafe(\n self.coro_make_request(request_data),\n WebsocketProvider._loop\n )\n return future.result()\n", "path": "web3/providers/websocket.py"}]}
| 3,563 | 418 |
gh_patches_debug_22585
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-2656
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ENH: Add support for RFC 87: Signed int8 data type for raster
Cf https://github.com/OSGeo/gdal/pull/6634 "RFC 87: Signed int8 data type for raster" that will likely be implemented in GDAL 3.7
_Originally posted by @rouault in https://github.com/rasterio/rasterio/issues/1595#issuecomment-1307086052_
</issue>
<code>
[start of rasterio/dtypes.py]
1 """Mapping of GDAL to Numpy data types.
2
3 Since 0.13 we are not importing numpy here and data types are strings.
4 Happily strings can be used throughout Numpy and so existing code will
5 not break.
6
7 """
8 import numpy
9
10 from rasterio.env import GDALVersion
11
12 _GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least("3.5")
13
14 bool_ = 'bool'
15 ubyte = uint8 = 'uint8'
16 sbyte = int8 = 'int8'
17 uint16 = 'uint16'
18 int16 = 'int16'
19 uint32 = 'uint32'
20 int32 = 'int32'
21 uint64 = 'uint64'
22 int64 = 'int64'
23 float32 = 'float32'
24 float64 = 'float64'
25 complex_ = 'complex'
26 complex64 = 'complex64'
27 complex128 = 'complex128'
28
29 complex_int16 = "complex_int16"
30
31 dtype_fwd = {
32 0: None, # GDT_Unknown
33 1: ubyte, # GDT_Byte
34 2: uint16, # GDT_UInt16
35 3: int16, # GDT_Int16
36 4: uint32, # GDT_UInt32
37 5: int32, # GDT_Int32
38 6: float32, # GDT_Float32
39 7: float64, # GDT_Float64
40 8: complex_int16, # GDT_CInt16
41 9: complex64, # GDT_CInt32
42 10: complex64, # GDT_CFloat32
43 11: complex128, # GDT_CFloat64
44 }
45
46 if _GDAL_AT_LEAST_35:
47 dtype_fwd[12] = int64 # GDT_Int64
48 dtype_fwd[13] = uint64 # GDT_UInt64
49
50 dtype_rev = dict((v, k) for k, v in dtype_fwd.items())
51
52 dtype_rev["uint8"] = 1
53 dtype_rev["int8"] = 1
54 dtype_rev["complex"] = 11
55 dtype_rev["complex_int16"] = 8
56
57
58 def _get_gdal_dtype(type_name):
59 try:
60 return dtype_rev[type_name]
61 except KeyError:
62 raise TypeError(
63 f"Unsupported data type {type_name}. "
64 f"Allowed data types: {list(dtype_rev)}."
65 )
66
67 typename_fwd = {
68 0: 'Unknown',
69 1: 'Byte',
70 2: 'UInt16',
71 3: 'Int16',
72 4: 'UInt32',
73 5: 'Int32',
74 6: 'Float32',
75 7: 'Float64',
76 8: 'CInt16',
77 9: 'CInt32',
78 10: 'CFloat32',
79 11: 'CFloat64'}
80
81 if _GDAL_AT_LEAST_35:
82 typename_fwd[12] = 'Int64'
83 typename_fwd[13] = 'UInt64'
84
85 typename_rev = dict((v, k) for k, v in typename_fwd.items())
86
87 dtype_ranges = {
88 'int8': (-128, 127),
89 'uint8': (0, 255),
90 'uint16': (0, 65535),
91 'int16': (-32768, 32767),
92 'uint32': (0, 4294967295),
93 'int32': (-2147483648, 2147483647),
94 'float32': (-3.4028235e+38, 3.4028235e+38),
95 'float64': (-1.7976931348623157e+308, 1.7976931348623157e+308)}
96
97 if _GDAL_AT_LEAST_35:
98 dtype_ranges['int64'] = (-9223372036854775808, 9223372036854775807)
99 dtype_ranges['uint64'] = (0, 18446744073709551615)
100
101
102 def in_dtype_range(value, dtype):
103 """
104 Check if the value is within the dtype range
105 """
106 if numpy.dtype(dtype).kind == "f" and (numpy.isinf(value) or numpy.isnan(value)):
107 return True
108 range_min, range_max = dtype_ranges[dtype]
109 return range_min <= value <= range_max
110
111
112 def _gdal_typename(dt):
113 try:
114 return typename_fwd[dtype_rev[dt]]
115 except KeyError:
116 return typename_fwd[dtype_rev[dt().dtype.name]]
117
118
119 def check_dtype(dt):
120 """Check if dtype is a known dtype."""
121 if str(dt) in dtype_rev:
122 return True
123 elif callable(dt) and str(dt().dtype) in dtype_rev:
124 return True
125 return False
126
127
128 def get_minimum_dtype(values):
129 """Determine minimum type to represent values.
130
131 Uses range checking to determine the minimum integer or floating point
132 data type required to represent values.
133
134 Parameters
135 ----------
136 values: list-like
137
138
139 Returns
140 -------
141 rasterio dtype string
142 """
143 import numpy as np
144
145 if not is_ndarray(values):
146 values = np.array(values)
147
148 min_value = values.min()
149 max_value = values.max()
150
151 if values.dtype.kind in ('i', 'u'):
152 if min_value >= 0:
153 if max_value <= 255:
154 return uint8
155 elif max_value <= 65535:
156 return uint16
157 elif max_value <= 4294967295:
158 return uint32
159 if not _GDAL_AT_LEAST_35:
160 raise ValueError("Values out of range for supported dtypes")
161 return uint64
162 elif min_value >= -32768 and max_value <= 32767:
163 return int16
164 elif min_value >= -2147483648 and max_value <= 2147483647:
165 return int32
166 if not _GDAL_AT_LEAST_35:
167 raise ValueError("Values out of range for supported dtypes")
168 return int64
169
170 else:
171 if min_value >= -3.4028235e+38 and max_value <= 3.4028235e+38:
172 return float32
173 return float64
174
175
176 def is_ndarray(array):
177 """Check if array is a ndarray."""
178 import numpy as np
179
180 return isinstance(array, np.ndarray) or hasattr(array, '__array__')
181
182
183 def can_cast_dtype(values, dtype):
184 """Test if values can be cast to dtype without loss of information.
185
186 Parameters
187 ----------
188 values: list-like
189 dtype: numpy.dtype or string
190
191 Returns
192 -------
193 boolean
194 True if values can be cast to data type.
195 """
196 import numpy as np
197
198 if not is_ndarray(values):
199 values = np.array(values)
200
201 if values.dtype.name == _getnpdtype(dtype).name:
202 return True
203
204 elif values.dtype.kind == 'f':
205 return np.allclose(values, values.astype(dtype), equal_nan=True)
206
207 else:
208 return np.array_equal(values, values.astype(dtype))
209
210
211 def validate_dtype(values, valid_dtypes):
212 """Test if dtype of values is one of valid_dtypes.
213
214 Parameters
215 ----------
216 values: list-like
217 valid_dtypes: list-like
218 list of valid dtype strings, e.g., ('int16', 'int32')
219
220 Returns
221 -------
222 boolean:
223 True if dtype of values is one of valid_dtypes
224 """
225 import numpy as np
226
227 if not is_ndarray(values):
228 values = np.array(values)
229
230 return (values.dtype.name in valid_dtypes or
231 get_minimum_dtype(values) in valid_dtypes)
232
233
234 def _is_complex_int(dtype):
235 return isinstance(dtype, str) and dtype.startswith("complex_int")
236
237
238 def _getnpdtype(dtype):
239 import numpy as np
240 if _is_complex_int(dtype):
241 return np.dtype("complex64")
242 else:
243 return np.dtype(dtype)
244
[end of rasterio/dtypes.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/dtypes.py b/rasterio/dtypes.py
--- a/rasterio/dtypes.py
+++ b/rasterio/dtypes.py
@@ -10,6 +10,7 @@
from rasterio.env import GDALVersion
_GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least("3.5")
+_GDAL_AT_LEAST_37 = GDALVersion.runtime().at_least("3.7")
bool_ = 'bool'
ubyte = uint8 = 'uint8'
@@ -47,10 +48,15 @@
dtype_fwd[12] = int64 # GDT_Int64
dtype_fwd[13] = uint64 # GDT_UInt64
+if _GDAL_AT_LEAST_37:
+ dtype_fwd[14] = sbyte # GDT_Int8
+
dtype_rev = dict((v, k) for k, v in dtype_fwd.items())
dtype_rev["uint8"] = 1
-dtype_rev["int8"] = 1
+if not _GDAL_AT_LEAST_37:
+ dtype_rev["int8"] = 1
+
dtype_rev["complex"] = 11
dtype_rev["complex_int16"] = 8
@@ -82,6 +88,9 @@
typename_fwd[12] = 'Int64'
typename_fwd[13] = 'UInt64'
+if _GDAL_AT_LEAST_37:
+ typename_fwd[14] = 'Int8'
+
typename_rev = dict((v, k) for k, v in typename_fwd.items())
dtype_ranges = {
|
{"golden_diff": "diff --git a/rasterio/dtypes.py b/rasterio/dtypes.py\n--- a/rasterio/dtypes.py\n+++ b/rasterio/dtypes.py\n@@ -10,6 +10,7 @@\n from rasterio.env import GDALVersion\n \n _GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least(\"3.5\")\n+_GDAL_AT_LEAST_37 = GDALVersion.runtime().at_least(\"3.7\")\n \n bool_ = 'bool'\n ubyte = uint8 = 'uint8'\n@@ -47,10 +48,15 @@\n dtype_fwd[12] = int64 # GDT_Int64\n dtype_fwd[13] = uint64 # GDT_UInt64\n \n+if _GDAL_AT_LEAST_37:\n+ dtype_fwd[14] = sbyte # GDT_Int8\n+\n dtype_rev = dict((v, k) for k, v in dtype_fwd.items())\n \n dtype_rev[\"uint8\"] = 1\n-dtype_rev[\"int8\"] = 1\n+if not _GDAL_AT_LEAST_37:\n+ dtype_rev[\"int8\"] = 1\n+\n dtype_rev[\"complex\"] = 11\n dtype_rev[\"complex_int16\"] = 8\n \n@@ -82,6 +88,9 @@\n typename_fwd[12] = 'Int64'\n typename_fwd[13] = 'UInt64'\n \n+if _GDAL_AT_LEAST_37:\n+ typename_fwd[14] = 'Int8'\n+\n typename_rev = dict((v, k) for k, v in typename_fwd.items())\n \n dtype_ranges = {\n", "issue": "ENH: Add support for RFC 87: Signed int8 data type for raster\n Cf https://github.com/OSGeo/gdal/pull/6634 \"RFC 87: Signed int8 data type for raster\" that will likely be implemented in GDAL 3.7\r\n\r\n_Originally posted by @rouault in https://github.com/rasterio/rasterio/issues/1595#issuecomment-1307086052_\r\n \n", "before_files": [{"content": "\"\"\"Mapping of GDAL to Numpy data types.\n\nSince 0.13 we are not importing numpy here and data types are strings.\nHappily strings can be used throughout Numpy and so existing code will\nnot break.\n\n\"\"\"\nimport numpy\n\nfrom rasterio.env import GDALVersion\n\n_GDAL_AT_LEAST_35 = GDALVersion.runtime().at_least(\"3.5\")\n\nbool_ = 'bool'\nubyte = uint8 = 'uint8'\nsbyte = int8 = 'int8'\nuint16 = 'uint16'\nint16 = 'int16'\nuint32 = 'uint32'\nint32 = 'int32'\nuint64 = 'uint64'\nint64 = 'int64'\nfloat32 = 'float32'\nfloat64 = 'float64'\ncomplex_ = 'complex'\ncomplex64 = 'complex64'\ncomplex128 = 'complex128'\n\ncomplex_int16 = \"complex_int16\"\n\ndtype_fwd = {\n 0: None, # GDT_Unknown\n 1: ubyte, # GDT_Byte\n 2: uint16, # GDT_UInt16\n 3: int16, # GDT_Int16\n 4: uint32, # GDT_UInt32\n 5: int32, # GDT_Int32\n 6: float32, # GDT_Float32\n 7: float64, # GDT_Float64\n 8: complex_int16, # GDT_CInt16\n 9: complex64, # GDT_CInt32\n 10: complex64, # GDT_CFloat32\n 11: complex128, # GDT_CFloat64\n}\n\nif _GDAL_AT_LEAST_35:\n dtype_fwd[12] = int64 # GDT_Int64\n dtype_fwd[13] = uint64 # GDT_UInt64\n\ndtype_rev = dict((v, k) for k, v in dtype_fwd.items())\n\ndtype_rev[\"uint8\"] = 1\ndtype_rev[\"int8\"] = 1\ndtype_rev[\"complex\"] = 11\ndtype_rev[\"complex_int16\"] = 8\n\n\ndef _get_gdal_dtype(type_name):\n try:\n return dtype_rev[type_name]\n except KeyError:\n raise TypeError(\n f\"Unsupported data type {type_name}. \"\n f\"Allowed data types: {list(dtype_rev)}.\"\n )\n\ntypename_fwd = {\n 0: 'Unknown',\n 1: 'Byte',\n 2: 'UInt16',\n 3: 'Int16',\n 4: 'UInt32',\n 5: 'Int32',\n 6: 'Float32',\n 7: 'Float64',\n 8: 'CInt16',\n 9: 'CInt32',\n 10: 'CFloat32',\n 11: 'CFloat64'}\n\nif _GDAL_AT_LEAST_35:\n typename_fwd[12] = 'Int64'\n typename_fwd[13] = 'UInt64'\n\ntypename_rev = dict((v, k) for k, v in typename_fwd.items())\n\ndtype_ranges = {\n 'int8': (-128, 127),\n 'uint8': (0, 255),\n 'uint16': (0, 65535),\n 'int16': (-32768, 32767),\n 'uint32': (0, 4294967295),\n 'int32': (-2147483648, 2147483647),\n 'float32': (-3.4028235e+38, 3.4028235e+38),\n 'float64': (-1.7976931348623157e+308, 1.7976931348623157e+308)}\n\nif _GDAL_AT_LEAST_35:\n dtype_ranges['int64'] = (-9223372036854775808, 9223372036854775807)\n dtype_ranges['uint64'] = (0, 18446744073709551615)\n\n\ndef in_dtype_range(value, dtype):\n \"\"\"\n Check if the value is within the dtype range\n \"\"\"\n if numpy.dtype(dtype).kind == \"f\" and (numpy.isinf(value) or numpy.isnan(value)):\n return True\n range_min, range_max = dtype_ranges[dtype]\n return range_min <= value <= range_max\n\n\ndef _gdal_typename(dt):\n try:\n return typename_fwd[dtype_rev[dt]]\n except KeyError:\n return typename_fwd[dtype_rev[dt().dtype.name]]\n\n\ndef check_dtype(dt):\n \"\"\"Check if dtype is a known dtype.\"\"\"\n if str(dt) in dtype_rev:\n return True\n elif callable(dt) and str(dt().dtype) in dtype_rev:\n return True\n return False\n\n\ndef get_minimum_dtype(values):\n \"\"\"Determine minimum type to represent values.\n\n Uses range checking to determine the minimum integer or floating point\n data type required to represent values.\n\n Parameters\n ----------\n values: list-like\n\n\n Returns\n -------\n rasterio dtype string\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n min_value = values.min()\n max_value = values.max()\n\n if values.dtype.kind in ('i', 'u'):\n if min_value >= 0:\n if max_value <= 255:\n return uint8\n elif max_value <= 65535:\n return uint16\n elif max_value <= 4294967295:\n return uint32\n if not _GDAL_AT_LEAST_35:\n raise ValueError(\"Values out of range for supported dtypes\")\n return uint64\n elif min_value >= -32768 and max_value <= 32767:\n return int16\n elif min_value >= -2147483648 and max_value <= 2147483647:\n return int32\n if not _GDAL_AT_LEAST_35:\n raise ValueError(\"Values out of range for supported dtypes\")\n return int64\n\n else:\n if min_value >= -3.4028235e+38 and max_value <= 3.4028235e+38:\n return float32\n return float64\n\n\ndef is_ndarray(array):\n \"\"\"Check if array is a ndarray.\"\"\"\n import numpy as np\n\n return isinstance(array, np.ndarray) or hasattr(array, '__array__')\n\n\ndef can_cast_dtype(values, dtype):\n \"\"\"Test if values can be cast to dtype without loss of information.\n\n Parameters\n ----------\n values: list-like\n dtype: numpy.dtype or string\n\n Returns\n -------\n boolean\n True if values can be cast to data type.\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n if values.dtype.name == _getnpdtype(dtype).name:\n return True\n\n elif values.dtype.kind == 'f':\n return np.allclose(values, values.astype(dtype), equal_nan=True)\n\n else:\n return np.array_equal(values, values.astype(dtype))\n\n\ndef validate_dtype(values, valid_dtypes):\n \"\"\"Test if dtype of values is one of valid_dtypes.\n\n Parameters\n ----------\n values: list-like\n valid_dtypes: list-like\n list of valid dtype strings, e.g., ('int16', 'int32')\n\n Returns\n -------\n boolean:\n True if dtype of values is one of valid_dtypes\n \"\"\"\n import numpy as np\n\n if not is_ndarray(values):\n values = np.array(values)\n\n return (values.dtype.name in valid_dtypes or\n get_minimum_dtype(values) in valid_dtypes)\n\n\ndef _is_complex_int(dtype):\n return isinstance(dtype, str) and dtype.startswith(\"complex_int\")\n\n\ndef _getnpdtype(dtype):\n import numpy as np\n if _is_complex_int(dtype):\n return np.dtype(\"complex64\")\n else:\n return np.dtype(dtype)\n", "path": "rasterio/dtypes.py"}]}
| 3,255 | 375 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.