
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_21667
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-2005
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bodhi-dequqe-stable dies if any update in the queue is no longer eligible to go stable
QuLogic from Freenode reported today that batched updates didn't go stable at 03:00 UTC like they should have. I confirmed that the cron job ran, but I didn't see any notes about its output. I then ran the command by hand and received this output:
```
[bowlofeggs@bodhi-backend01 ~][PROD]$ sudo -u apache /usr/bin/bodhi-dequeue-stable
No handlers could be found for logger "bodhi.server"
This update has not yet met the minimum testing requirements defined in the <a href="https://fedoraproject.org/wiki/Package_update_acceptance_criteria">Package Update Acceptance Criteria</a>
```
The [```dequeue_stable()```](https://github.com/fedora-infra/bodhi/blob/3.0.0/bodhi/server/scripts/dequeue_stable.py#L28-L46) function runs a large transaction with only a single try/except. It seems that some update in the queue no longer meets testing requirements (probably due to receiving a -1 karma after going to batched) and is raising an Exception when the tool attempts to mark it for stable. Since there is only one try/except handler, this causes the whole transaction to be rolled back.
It should be easy to fix this - we just need a try/except around each update.
Thanks to QuLogic from Freenode for reporting this issue to me.
</issue>
<code>
[start of bodhi/server/scripts/dequeue_stable.py]
1 # -*- coding: utf-8 -*-
2 # Copyright © 2017 Caleigh Runge-Hottman
3 #
4 # This file is part of Bodhi.
5 #
6 # This program is free software; you can redistribute it and/or
7 # modify it under the terms of the GNU General Public License
8 # as published by the Free Software Foundation; either version 2
9 # of the License, or (at your option) any later version.
10 #
11 # This program is distributed in the hope that it will be useful,
12 # but WITHOUT ANY WARRANTY; without even the implied warranty of
13 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
14 # GNU General Public License for more details.
15 #
16 # You should have received a copy of the GNU General Public License
17 # along with this program; if not, write to the Free Software
18 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
19 """This script is responsible for moving all updates with a batched request to a stable request."""
20
21 import sys
22
23 import click
24
25 from bodhi.server import buildsys, config, models, Session, initialize_db
26
27
28 @click.command()
29 @click.version_option(message='%(version)s')
30 def dequeue_stable():
31 """Convert all batched requests to stable requests."""
32 initialize_db(config.config)
33 buildsys.setup_buildsystem(config.config)
34 db = Session()
35
36 try:
37 batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()
38 for update in batched:
39 update.set_request(db, models.UpdateRequest.stable, u'bodhi')
40 db.commit()
41
42 except Exception as e:
43 print(str(e))
44 db.rollback()
45 Session.remove()
46 sys.exit(1)
47
[end of bodhi/server/scripts/dequeue_stable.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bodhi/server/scripts/dequeue_stable.py b/bodhi/server/scripts/dequeue_stable.py
--- a/bodhi/server/scripts/dequeue_stable.py
+++ b/bodhi/server/scripts/dequeue_stable.py
@@ -1,5 +1,5 @@
# -*- coding: utf-8 -*-
-# Copyright © 2017 Caleigh Runge-Hottman
+# Copyright © 2017 Caleigh Runge-Hottman and Red Hat, Inc.
#
# This file is part of Bodhi.
#
@@ -36,11 +36,17 @@
try:
batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()
for update in batched:
- update.set_request(db, models.UpdateRequest.stable, u'bodhi')
- db.commit()
-
+ try:
+ update.set_request(db, models.UpdateRequest.stable, u'bodhi')
+ db.commit()
+ except Exception as e:
+ print('Unable to stabilize {}: {}'.format(update.alias, str(e)))
+ db.rollback()
+ msg = u"Bodhi is unable to request this update for stabilization: {}"
+ update.comment(db, msg.format(str(e)), author=u'bodhi')
+ db.commit()
except Exception as e:
print(str(e))
- db.rollback()
- Session.remove()
sys.exit(1)
+ finally:
+ Session.remove()
|
{"golden_diff": "diff --git a/bodhi/server/scripts/dequeue_stable.py b/bodhi/server/scripts/dequeue_stable.py\n--- a/bodhi/server/scripts/dequeue_stable.py\n+++ b/bodhi/server/scripts/dequeue_stable.py\n@@ -1,5 +1,5 @@\n # -*- coding: utf-8 -*-\n-# Copyright \u00a9 2017 Caleigh Runge-Hottman\n+# Copyright \u00a9 2017 Caleigh Runge-Hottman and Red Hat, Inc.\n #\n # This file is part of Bodhi.\n #\n@@ -36,11 +36,17 @@\n try:\n batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()\n for update in batched:\n- update.set_request(db, models.UpdateRequest.stable, u'bodhi')\n- db.commit()\n-\n+ try:\n+ update.set_request(db, models.UpdateRequest.stable, u'bodhi')\n+ db.commit()\n+ except Exception as e:\n+ print('Unable to stabilize {}: {}'.format(update.alias, str(e)))\n+ db.rollback()\n+ msg = u\"Bodhi is unable to request this update for stabilization: {}\"\n+ update.comment(db, msg.format(str(e)), author=u'bodhi')\n+ db.commit()\n except Exception as e:\n print(str(e))\n- db.rollback()\n- Session.remove()\n sys.exit(1)\n+ finally:\n+ Session.remove()\n", "issue": "bodhi-dequqe-stable dies if any update in the queue is no longer eligible to go stable\nQuLogic from Freenode reported today that batched updates didn't go stable at 03:00 UTC like they should have. I confirmed that the cron job ran, but I didn't see any notes about its output. I then ran the command by hand and received this output:\r\n\r\n```\r\n[bowlofeggs@bodhi-backend01 ~][PROD]$ sudo -u apache /usr/bin/bodhi-dequeue-stable\r\nNo handlers could be found for logger \"bodhi.server\"\r\nThis update has not yet met the minimum testing requirements defined in the <a href=\"https://fedoraproject.org/wiki/Package_update_acceptance_criteria\">Package Update Acceptance Criteria</a>\r\n```\r\n\r\nThe [```dequeue_stable()```](https://github.com/fedora-infra/bodhi/blob/3.0.0/bodhi/server/scripts/dequeue_stable.py#L28-L46) function runs a large transaction with only a single try/except. It seems that some update in the queue no longer meets testing requirements (probably due to receiving a -1 karma after going to batched) and is raising an Exception when the tool attempts to mark it for stable. Since there is only one try/except handler, this causes the whole transaction to be rolled back.\r\n\r\nIt should be easy to fix this - we just need a try/except around each update.\r\n\r\nThanks to QuLogic from Freenode for reporting this issue to me.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n# Copyright \u00a9 2017 Caleigh Runge-Hottman\n#\n# This file is part of Bodhi.\n#\n# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\"\"\"This script is responsible for moving all updates with a batched request to a stable request.\"\"\"\n\nimport sys\n\nimport click\n\nfrom bodhi.server import buildsys, config, models, Session, initialize_db\n\n\[email protected]()\[email protected]_option(message='%(version)s')\ndef dequeue_stable():\n \"\"\"Convert all batched requests to stable requests.\"\"\"\n initialize_db(config.config)\n buildsys.setup_buildsystem(config.config)\n db = Session()\n\n try:\n batched = db.query(models.Update).filter_by(request=models.UpdateRequest.batched).all()\n for update in batched:\n update.set_request(db, models.UpdateRequest.stable, u'bodhi')\n db.commit()\n\n except Exception as e:\n print(str(e))\n db.rollback()\n Session.remove()\n sys.exit(1)\n", "path": "bodhi/server/scripts/dequeue_stable.py"}]}
| 1,336 | 319 |
gh_patches_debug_38003
|
rasdani/github-patches
|
git_diff
|
napari__napari-2436
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
mac thinks that napari is named "__main__.py" in bundled app
## 🐛 Bug
My mac seems to think that napari is named "__main__.py" in bundled app
## To Reproduce
Steps to reproduce the behavior:
1. Launch napari bundled app on mac
2. Click "napari" on menu bar
3. See the menu items "Hide __main__.py" and "Close __main__.py"
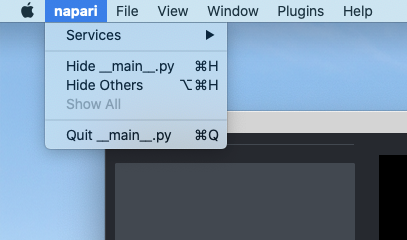
## Expected behavior
menu items include "Hide napari" and "Close napari", similar to Chrome...
<!-- A clear and concise description of what you expected to happen. -->
## Environment
napari: 0.4.6
Platform: macOS-10.15.7-x86_64-i386-64bit
System: MacOS 10.15.7
Python: 3.8.7 (default, Jan 2 2021, 04:16:43) [Clang 11.0.0 (clang-1100.0.33.17)]
Qt: 5.15.2
PySide2: 5.15.2
NumPy: 1.19.3
SciPy: 1.6.1
Dask: 2021.03.0
VisPy: 0.6.6
OpenGL:
- GL version: 2.1 ATI-3.10.19
- MAX_TEXTURE_SIZE: 16384
Screens:
- screen 1: resolution 1792x1120, scale 2.0
- screen 2: resolution 2560x1440, scale 1.0
Plugins:
- affinder: 0.1.0
- aicsimageio: 0.2.0
- aicsimageio_delayed: 0.2.0
- brainreg: 0.2.3
- brainreg_standard: 0.2.3
- cellfinder: 0.2.1
- console: 0.0.3
- napari-hdf5-labels-io: 0.2.dev1
- ndtiffs: 0.1.1
- svg: 0.1.4
</issue>
<code>
[start of bundle.py]
1 import configparser
2 import os
3 import re
4 import shutil
5 import subprocess
6 import sys
7 import time
8 from contextlib import contextmanager
9
10 import tomlkit
11
12 APP = 'napari'
13
14 # EXTRA_REQS will be added to the bundle, in addition to those specified in
15 # setup.cfg. To add additional packages to the bundle, or to override any of
16 # the packages listed here or in `setup.cfg, use the `--add` command line
17 # argument with a series of "pip install" style strings when running this file.
18 # For example, the following will ADD ome-zarr, and CHANGE the version of
19 # PySide2:
20 # python bundle.py --add 'PySide2==5.15.0' 'ome-zarr'
21
22 EXTRA_REQS = [
23 "pip",
24 "PySide2==5.15.2",
25 "scikit-image",
26 "zarr",
27 "pims",
28 "numpy==1.19.3",
29 ]
30
31 WINDOWS = os.name == 'nt'
32 MACOS = sys.platform == 'darwin'
33 LINUX = sys.platform.startswith("linux")
34 HERE = os.path.abspath(os.path.dirname(__file__))
35 PYPROJECT_TOML = os.path.join(HERE, 'pyproject.toml')
36 SETUP_CFG = os.path.join(HERE, 'setup.cfg')
37
38 if WINDOWS:
39 BUILD_DIR = os.path.join(HERE, 'windows')
40 elif LINUX:
41 BUILD_DIR = os.path.join(HERE, 'linux')
42 elif MACOS:
43 BUILD_DIR = os.path.join(HERE, 'macOS')
44 APP_DIR = os.path.join(BUILD_DIR, APP, f'{APP}.app')
45
46
47 with open(os.path.join(HERE, "napari", "_version.py")) as f:
48 match = re.search(r'version\s?=\s?\'([^\']+)', f.read())
49 if match:
50 VERSION = match.groups()[0].split('+')[0]
51
52
53 @contextmanager
54 def patched_toml():
55 parser = configparser.ConfigParser()
56 parser.read(SETUP_CFG)
57 requirements = parser.get("options", "install_requires").splitlines()
58 requirements = [r.split('#')[0].strip() for r in requirements if r]
59
60 with open(PYPROJECT_TOML) as f:
61 original_toml = f.read()
62
63 toml = tomlkit.parse(original_toml)
64
65 # parse command line arguments
66 if '--add' in sys.argv:
67 for item in sys.argv[sys.argv.index('--add') + 1 :]:
68 if item.startswith('-'):
69 break
70 EXTRA_REQS.append(item)
71
72 for item in EXTRA_REQS:
73 _base = re.split('<|>|=', item, maxsplit=1)[0]
74 for r in requirements:
75 if r.startswith(_base):
76 requirements.remove(r)
77 break
78 if _base.lower().startswith('pyqt5'):
79 try:
80 i = next(x for x in requirements if x.startswith('PySide'))
81 requirements.remove(i)
82 except StopIteration:
83 pass
84
85 requirements += EXTRA_REQS
86
87 toml['tool']['briefcase']['app'][APP]['requires'] = requirements
88 toml['tool']['briefcase']['version'] = VERSION
89
90 print("patching pyroject.toml to version: ", VERSION)
91 print(
92 "patching pyroject.toml requirements to : \n",
93 "\n".join(toml['tool']['briefcase']['app'][APP]['requires']),
94 )
95 with open(PYPROJECT_TOML, 'w') as f:
96 f.write(tomlkit.dumps(toml))
97
98 try:
99 yield
100 finally:
101 with open(PYPROJECT_TOML, 'w') as f:
102 f.write(original_toml)
103
104
105 def patch_dmgbuild():
106 if not MACOS:
107 return
108 from dmgbuild import core
109
110 # will not be required after dmgbuild > v1.3.3
111 # see https://github.com/al45tair/dmgbuild/pull/18
112 with open(core.__file__) as f:
113 src = f.read()
114 with open(core.__file__, 'w') as f:
115 f.write(
116 src.replace(
117 "shutil.rmtree(os.path.join(mount_point, '.Trashes'), True)",
118 "shutil.rmtree(os.path.join(mount_point, '.Trashes'), True);time.sleep(30)",
119 )
120 )
121 print("patched dmgbuild.core")
122
123
124 def add_site_packages_to_path():
125 # on mac, make sure the site-packages folder exists even before the user
126 # has pip installed, so it is in sys.path on the first run
127 # (otherwise, newly installed plugins will not be detected until restart)
128 if MACOS:
129 pkgs_dir = os.path.join(
130 APP_DIR,
131 'Contents',
132 'Resources',
133 'Support',
134 'lib',
135 f'python{sys.version_info.major}.{sys.version_info.minor}',
136 'site-packages',
137 )
138 os.makedirs(pkgs_dir)
139 print("created site-packages at", pkgs_dir)
140
141 # on windows, briefcase uses a _pth file to determine the sys.path at
142 # runtime. https://docs.python.org/3/using/windows.html#finding-modules
143 # We update that file with the eventual location of pip site-packages
144 elif WINDOWS:
145 py = "".join(map(str, sys.version_info[:2]))
146 python_dir = os.path.join(BUILD_DIR, APP, 'src', 'python')
147 pth = os.path.join(python_dir, f'python{py}._pth')
148 with open(pth, "a") as f:
149 # Append 'hello' at the end of file
150 f.write(".\\\\Lib\\\\site-packages\n")
151 print("added bundled site-packages to", pth)
152
153 pkgs_dir = os.path.join(python_dir, 'Lib', 'site-packages')
154 os.makedirs(pkgs_dir)
155 print("created site-packages at", pkgs_dir)
156 with open(os.path.join(pkgs_dir, 'readme.txt'), 'w') as f:
157 f.write("this is where plugin packages will go")
158
159
160 def patch_wxs():
161 # must run after briefcase create
162 fname = os.path.join(BUILD_DIR, APP, f'{APP}.wxs')
163
164 if os.path.exists(fname):
165 with open(fname) as f:
166 source = f.read()
167 with open(fname, 'w') as f:
168 f.write(source.replace('pythonw.exe', 'python.exe'))
169 print("patched pythonw.exe -> python.exe")
170
171
172 def make_zip():
173 import glob
174 import zipfile
175
176 if WINDOWS:
177 ext, OS = '*.msi', 'Windows'
178 elif LINUX:
179 ext, OS = '*.AppImage', 'Linux'
180 elif MACOS:
181 ext, OS = '*.dmg', 'macOS'
182 artifact = glob.glob(os.path.join(BUILD_DIR, ext))[0]
183 dest = f'napari-{VERSION}-{OS}.zip'
184
185 with zipfile.ZipFile(dest, 'w', zipfile.ZIP_DEFLATED) as zf:
186 zf.write(artifact, arcname=os.path.basename(artifact))
187 print("created zipfile: ", dest)
188 return dest
189
190
191 def clean():
192 shutil.rmtree(BUILD_DIR, ignore_errors=True)
193
194
195 def bundle():
196 clean()
197
198 if MACOS:
199 patch_dmgbuild()
200
201 # smoke test, and build resources
202 subprocess.check_call([sys.executable, '-m', APP, '--info'])
203
204 with patched_toml():
205 # create
206 cmd = ['briefcase', 'create'] + (['--no-docker'] if LINUX else [])
207 subprocess.check_call(cmd)
208
209 time.sleep(0.5)
210
211 add_site_packages_to_path()
212
213 if WINDOWS:
214 patch_wxs()
215
216 # build
217 cmd = ['briefcase', 'build'] + (['--no-docker'] if LINUX else [])
218 subprocess.check_call(cmd)
219
220 # package
221 cmd = ['briefcase', 'package']
222 cmd += ['--no-sign'] if MACOS else (['--no-docker'] if LINUX else [])
223 subprocess.check_call(cmd)
224
225 # compress
226 dest = make_zip()
227 clean()
228
229 return dest
230
231
232 if __name__ == "__main__":
233 if '--clean' in sys.argv:
234 clean()
235 sys.exit()
236 if '--version' in sys.argv:
237 print(VERSION)
238 sys.exit()
239 print('created', bundle())
240
[end of bundle.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bundle.py b/bundle.py
--- a/bundle.py
+++ b/bundle.py
@@ -87,9 +87,9 @@
toml['tool']['briefcase']['app'][APP]['requires'] = requirements
toml['tool']['briefcase']['version'] = VERSION
- print("patching pyroject.toml to version: ", VERSION)
+ print("patching pyproject.toml to version: ", VERSION)
print(
- "patching pyroject.toml requirements to : \n",
+ "patching pyproject.toml requirements to : \n",
"\n".join(toml['tool']['briefcase']['app'][APP]['requires']),
)
with open(PYPROJECT_TOML, 'w') as f:
@@ -107,15 +107,14 @@
return
from dmgbuild import core
- # will not be required after dmgbuild > v1.3.3
- # see https://github.com/al45tair/dmgbuild/pull/18
with open(core.__file__) as f:
src = f.read()
with open(core.__file__, 'w') as f:
f.write(
src.replace(
"shutil.rmtree(os.path.join(mount_point, '.Trashes'), True)",
- "shutil.rmtree(os.path.join(mount_point, '.Trashes'), True);time.sleep(30)",
+ "shutil.rmtree(os.path.join(mount_point, '.Trashes'), True)"
+ ";time.sleep(30)",
)
)
print("patched dmgbuild.core")
@@ -201,6 +200,7 @@
# smoke test, and build resources
subprocess.check_call([sys.executable, '-m', APP, '--info'])
+ # the briefcase calls need to happen while the pyproject toml is patched
with patched_toml():
# create
cmd = ['briefcase', 'create'] + (['--no-docker'] if LINUX else [])
@@ -213,20 +213,20 @@
if WINDOWS:
patch_wxs()
- # build
- cmd = ['briefcase', 'build'] + (['--no-docker'] if LINUX else [])
- subprocess.check_call(cmd)
+ # build
+ cmd = ['briefcase', 'build'] + (['--no-docker'] if LINUX else [])
+ subprocess.check_call(cmd)
- # package
- cmd = ['briefcase', 'package']
- cmd += ['--no-sign'] if MACOS else (['--no-docker'] if LINUX else [])
- subprocess.check_call(cmd)
+ # package
+ cmd = ['briefcase', 'package']
+ cmd += ['--no-sign'] if MACOS else (['--no-docker'] if LINUX else [])
+ subprocess.check_call(cmd)
- # compress
- dest = make_zip()
- clean()
+ # compress
+ dest = make_zip()
+ clean()
- return dest
+ return dest
if __name__ == "__main__":
|
{"golden_diff": "diff --git a/bundle.py b/bundle.py\n--- a/bundle.py\n+++ b/bundle.py\n@@ -87,9 +87,9 @@\n toml['tool']['briefcase']['app'][APP]['requires'] = requirements\n toml['tool']['briefcase']['version'] = VERSION\n \n- print(\"patching pyroject.toml to version: \", VERSION)\n+ print(\"patching pyproject.toml to version: \", VERSION)\n print(\n- \"patching pyroject.toml requirements to : \\n\",\n+ \"patching pyproject.toml requirements to : \\n\",\n \"\\n\".join(toml['tool']['briefcase']['app'][APP]['requires']),\n )\n with open(PYPROJECT_TOML, 'w') as f:\n@@ -107,15 +107,14 @@\n return\n from dmgbuild import core\n \n- # will not be required after dmgbuild > v1.3.3\n- # see https://github.com/al45tair/dmgbuild/pull/18\n with open(core.__file__) as f:\n src = f.read()\n with open(core.__file__, 'w') as f:\n f.write(\n src.replace(\n \"shutil.rmtree(os.path.join(mount_point, '.Trashes'), True)\",\n- \"shutil.rmtree(os.path.join(mount_point, '.Trashes'), True);time.sleep(30)\",\n+ \"shutil.rmtree(os.path.join(mount_point, '.Trashes'), True)\"\n+ \";time.sleep(30)\",\n )\n )\n print(\"patched dmgbuild.core\")\n@@ -201,6 +200,7 @@\n # smoke test, and build resources\n subprocess.check_call([sys.executable, '-m', APP, '--info'])\n \n+ # the briefcase calls need to happen while the pyproject toml is patched\n with patched_toml():\n # create\n cmd = ['briefcase', 'create'] + (['--no-docker'] if LINUX else [])\n@@ -213,20 +213,20 @@\n if WINDOWS:\n patch_wxs()\n \n- # build\n- cmd = ['briefcase', 'build'] + (['--no-docker'] if LINUX else [])\n- subprocess.check_call(cmd)\n+ # build\n+ cmd = ['briefcase', 'build'] + (['--no-docker'] if LINUX else [])\n+ subprocess.check_call(cmd)\n \n- # package\n- cmd = ['briefcase', 'package']\n- cmd += ['--no-sign'] if MACOS else (['--no-docker'] if LINUX else [])\n- subprocess.check_call(cmd)\n+ # package\n+ cmd = ['briefcase', 'package']\n+ cmd += ['--no-sign'] if MACOS else (['--no-docker'] if LINUX else [])\n+ subprocess.check_call(cmd)\n \n- # compress\n- dest = make_zip()\n- clean()\n+ # compress\n+ dest = make_zip()\n+ clean()\n \n- return dest\n+ return dest\n \n \n if __name__ == \"__main__\":\n", "issue": "mac thinks that napari is named \"__main__.py\" in bundled app\n## \ud83d\udc1b Bug\r\n\r\nMy mac seems to think that napari is named \"__main__.py\" in bundled app\r\n\r\n## To Reproduce\r\n\r\nSteps to reproduce the behavior:\r\n\r\n1. Launch napari bundled app on mac\r\n2. Click \"napari\" on menu bar\r\n3. See the menu items \"Hide __main__.py\" and \"Close __main__.py\"\r\n\r\n\r\n\r\n## Expected behavior\r\n\r\nmenu items include \"Hide napari\" and \"Close napari\", similar to Chrome...\r\n\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\n\r\n## Environment\r\n\r\nnapari: 0.4.6\r\nPlatform: macOS-10.15.7-x86_64-i386-64bit\r\nSystem: MacOS 10.15.7\r\nPython: 3.8.7 (default, Jan 2 2021, 04:16:43) [Clang 11.0.0 (clang-1100.0.33.17)]\r\nQt: 5.15.2\r\nPySide2: 5.15.2\r\nNumPy: 1.19.3\r\nSciPy: 1.6.1\r\nDask: 2021.03.0\r\nVisPy: 0.6.6\r\n\r\nOpenGL:\r\n- GL version: 2.1 ATI-3.10.19\r\n- MAX_TEXTURE_SIZE: 16384\r\n\r\nScreens:\r\n- screen 1: resolution 1792x1120, scale 2.0\r\n- screen 2: resolution 2560x1440, scale 1.0\r\n\r\nPlugins:\r\n- affinder: 0.1.0\r\n- aicsimageio: 0.2.0\r\n- aicsimageio_delayed: 0.2.0\r\n- brainreg: 0.2.3\r\n- brainreg_standard: 0.2.3\r\n- cellfinder: 0.2.1\r\n- console: 0.0.3\r\n- napari-hdf5-labels-io: 0.2.dev1\r\n- ndtiffs: 0.1.1\r\n- svg: 0.1.4\r\n\n", "before_files": [{"content": "import configparser\nimport os\nimport re\nimport shutil\nimport subprocess\nimport sys\nimport time\nfrom contextlib import contextmanager\n\nimport tomlkit\n\nAPP = 'napari'\n\n# EXTRA_REQS will be added to the bundle, in addition to those specified in\n# setup.cfg. To add additional packages to the bundle, or to override any of\n# the packages listed here or in `setup.cfg, use the `--add` command line\n# argument with a series of \"pip install\" style strings when running this file.\n# For example, the following will ADD ome-zarr, and CHANGE the version of\n# PySide2:\n# python bundle.py --add 'PySide2==5.15.0' 'ome-zarr'\n\nEXTRA_REQS = [\n \"pip\",\n \"PySide2==5.15.2\",\n \"scikit-image\",\n \"zarr\",\n \"pims\",\n \"numpy==1.19.3\",\n]\n\nWINDOWS = os.name == 'nt'\nMACOS = sys.platform == 'darwin'\nLINUX = sys.platform.startswith(\"linux\")\nHERE = os.path.abspath(os.path.dirname(__file__))\nPYPROJECT_TOML = os.path.join(HERE, 'pyproject.toml')\nSETUP_CFG = os.path.join(HERE, 'setup.cfg')\n\nif WINDOWS:\n BUILD_DIR = os.path.join(HERE, 'windows')\nelif LINUX:\n BUILD_DIR = os.path.join(HERE, 'linux')\nelif MACOS:\n BUILD_DIR = os.path.join(HERE, 'macOS')\n APP_DIR = os.path.join(BUILD_DIR, APP, f'{APP}.app')\n\n\nwith open(os.path.join(HERE, \"napari\", \"_version.py\")) as f:\n match = re.search(r'version\\s?=\\s?\\'([^\\']+)', f.read())\n if match:\n VERSION = match.groups()[0].split('+')[0]\n\n\n@contextmanager\ndef patched_toml():\n parser = configparser.ConfigParser()\n parser.read(SETUP_CFG)\n requirements = parser.get(\"options\", \"install_requires\").splitlines()\n requirements = [r.split('#')[0].strip() for r in requirements if r]\n\n with open(PYPROJECT_TOML) as f:\n original_toml = f.read()\n\n toml = tomlkit.parse(original_toml)\n\n # parse command line arguments\n if '--add' in sys.argv:\n for item in sys.argv[sys.argv.index('--add') + 1 :]:\n if item.startswith('-'):\n break\n EXTRA_REQS.append(item)\n\n for item in EXTRA_REQS:\n _base = re.split('<|>|=', item, maxsplit=1)[0]\n for r in requirements:\n if r.startswith(_base):\n requirements.remove(r)\n break\n if _base.lower().startswith('pyqt5'):\n try:\n i = next(x for x in requirements if x.startswith('PySide'))\n requirements.remove(i)\n except StopIteration:\n pass\n\n requirements += EXTRA_REQS\n\n toml['tool']['briefcase']['app'][APP]['requires'] = requirements\n toml['tool']['briefcase']['version'] = VERSION\n\n print(\"patching pyroject.toml to version: \", VERSION)\n print(\n \"patching pyroject.toml requirements to : \\n\",\n \"\\n\".join(toml['tool']['briefcase']['app'][APP]['requires']),\n )\n with open(PYPROJECT_TOML, 'w') as f:\n f.write(tomlkit.dumps(toml))\n\n try:\n yield\n finally:\n with open(PYPROJECT_TOML, 'w') as f:\n f.write(original_toml)\n\n\ndef patch_dmgbuild():\n if not MACOS:\n return\n from dmgbuild import core\n\n # will not be required after dmgbuild > v1.3.3\n # see https://github.com/al45tair/dmgbuild/pull/18\n with open(core.__file__) as f:\n src = f.read()\n with open(core.__file__, 'w') as f:\n f.write(\n src.replace(\n \"shutil.rmtree(os.path.join(mount_point, '.Trashes'), True)\",\n \"shutil.rmtree(os.path.join(mount_point, '.Trashes'), True);time.sleep(30)\",\n )\n )\n print(\"patched dmgbuild.core\")\n\n\ndef add_site_packages_to_path():\n # on mac, make sure the site-packages folder exists even before the user\n # has pip installed, so it is in sys.path on the first run\n # (otherwise, newly installed plugins will not be detected until restart)\n if MACOS:\n pkgs_dir = os.path.join(\n APP_DIR,\n 'Contents',\n 'Resources',\n 'Support',\n 'lib',\n f'python{sys.version_info.major}.{sys.version_info.minor}',\n 'site-packages',\n )\n os.makedirs(pkgs_dir)\n print(\"created site-packages at\", pkgs_dir)\n\n # on windows, briefcase uses a _pth file to determine the sys.path at\n # runtime. https://docs.python.org/3/using/windows.html#finding-modules\n # We update that file with the eventual location of pip site-packages\n elif WINDOWS:\n py = \"\".join(map(str, sys.version_info[:2]))\n python_dir = os.path.join(BUILD_DIR, APP, 'src', 'python')\n pth = os.path.join(python_dir, f'python{py}._pth')\n with open(pth, \"a\") as f:\n # Append 'hello' at the end of file\n f.write(\".\\\\\\\\Lib\\\\\\\\site-packages\\n\")\n print(\"added bundled site-packages to\", pth)\n\n pkgs_dir = os.path.join(python_dir, 'Lib', 'site-packages')\n os.makedirs(pkgs_dir)\n print(\"created site-packages at\", pkgs_dir)\n with open(os.path.join(pkgs_dir, 'readme.txt'), 'w') as f:\n f.write(\"this is where plugin packages will go\")\n\n\ndef patch_wxs():\n # must run after briefcase create\n fname = os.path.join(BUILD_DIR, APP, f'{APP}.wxs')\n\n if os.path.exists(fname):\n with open(fname) as f:\n source = f.read()\n with open(fname, 'w') as f:\n f.write(source.replace('pythonw.exe', 'python.exe'))\n print(\"patched pythonw.exe -> python.exe\")\n\n\ndef make_zip():\n import glob\n import zipfile\n\n if WINDOWS:\n ext, OS = '*.msi', 'Windows'\n elif LINUX:\n ext, OS = '*.AppImage', 'Linux'\n elif MACOS:\n ext, OS = '*.dmg', 'macOS'\n artifact = glob.glob(os.path.join(BUILD_DIR, ext))[0]\n dest = f'napari-{VERSION}-{OS}.zip'\n\n with zipfile.ZipFile(dest, 'w', zipfile.ZIP_DEFLATED) as zf:\n zf.write(artifact, arcname=os.path.basename(artifact))\n print(\"created zipfile: \", dest)\n return dest\n\n\ndef clean():\n shutil.rmtree(BUILD_DIR, ignore_errors=True)\n\n\ndef bundle():\n clean()\n\n if MACOS:\n patch_dmgbuild()\n\n # smoke test, and build resources\n subprocess.check_call([sys.executable, '-m', APP, '--info'])\n\n with patched_toml():\n # create\n cmd = ['briefcase', 'create'] + (['--no-docker'] if LINUX else [])\n subprocess.check_call(cmd)\n\n time.sleep(0.5)\n\n add_site_packages_to_path()\n\n if WINDOWS:\n patch_wxs()\n\n # build\n cmd = ['briefcase', 'build'] + (['--no-docker'] if LINUX else [])\n subprocess.check_call(cmd)\n\n # package\n cmd = ['briefcase', 'package']\n cmd += ['--no-sign'] if MACOS else (['--no-docker'] if LINUX else [])\n subprocess.check_call(cmd)\n\n # compress\n dest = make_zip()\n clean()\n\n return dest\n\n\nif __name__ == \"__main__\":\n if '--clean' in sys.argv:\n clean()\n sys.exit()\n if '--version' in sys.argv:\n print(VERSION)\n sys.exit()\n print('created', bundle())\n", "path": "bundle.py"}]}
| 3,625 | 697 |
gh_patches_debug_34895
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-509
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add test coverage for Cython modules
Right now, we are not getting coverage of Cython modules from our test suite. This would be good to do, especially if it is [pretty straightforward](http://blog.behnel.de/posts/coverage-analysis-for-cython-modules.html).
I'll look into this for #496
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2
3 # Two environmental variables influence this script.
4 #
5 # GDAL_CONFIG: the path to a gdal-config program that points to GDAL headers,
6 # libraries, and data files.
7 #
8 # PACKAGE_DATA: if defined, GDAL and PROJ4 data files will be copied into the
9 # source or binary distribution. This is essential when creating self-contained
10 # binary wheels.
11
12 import logging
13 import os
14 import pprint
15 import shutil
16 import subprocess
17 import sys
18
19 from setuptools import setup
20 from setuptools.extension import Extension
21
22 logging.basicConfig()
23 log = logging.getLogger()
24
25 # python -W all setup.py ...
26 if 'all' in sys.warnoptions:
27 log.level = logging.DEBUG
28
29 def check_output(cmd):
30 # since subprocess.check_output doesn't exist in 2.6
31 # we wrap it here.
32 try:
33 out = subprocess.check_output(cmd)
34 return out.decode('utf')
35 except AttributeError:
36 # For some reasone check_output doesn't exist
37 # So fall back on Popen
38 p = subprocess.Popen(cmd, stdout=subprocess.PIPE)
39 out, err = p.communicate()
40 return out
41
42 def copy_data_tree(datadir, destdir):
43 try:
44 shutil.rmtree(destdir)
45 except OSError:
46 pass
47 shutil.copytree(datadir, destdir)
48
49 # Parse the version from the rasterio module.
50 with open('rasterio/__init__.py') as f:
51 for line in f:
52 if line.find("__version__") >= 0:
53 version = line.split("=")[1].strip()
54 version = version.strip('"')
55 version = version.strip("'")
56 continue
57
58 with open('VERSION.txt', 'w') as f:
59 f.write(version)
60
61 # Use Cython if available.
62 try:
63 from Cython.Build import cythonize
64 except ImportError:
65 cythonize = None
66
67 # By default we'll try to get options via gdal-config. On systems without,
68 # options will need to be set in setup.cfg or on the setup command line.
69 include_dirs = []
70 library_dirs = []
71 libraries = []
72 extra_link_args = []
73 gdal_output = [None]*3
74
75 try:
76 import numpy
77 include_dirs.append(numpy.get_include())
78 except ImportError:
79 log.critical("Numpy and its headers are required to run setup(). Exiting.")
80 sys.exit(1)
81
82 try:
83 gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')
84 for i, flag in enumerate(("--cflags", "--libs", "--datadir")):
85 gdal_output[i] = check_output([gdal_config, flag]).strip()
86
87 for item in gdal_output[0].split():
88 if item.startswith("-I"):
89 include_dirs.extend(item[2:].split(":"))
90 for item in gdal_output[1].split():
91 if item.startswith("-L"):
92 library_dirs.extend(item[2:].split(":"))
93 elif item.startswith("-l"):
94 libraries.append(item[2:])
95 else:
96 # e.g. -framework GDAL
97 extra_link_args.append(item)
98
99 except Exception as e:
100 if os.name == "nt":
101 log.info(("Building on Windows requires extra options to setup.py to locate needed GDAL files.\n"
102 "More information is available in the README."))
103 else:
104 log.warning("Failed to get options via gdal-config: %s", str(e))
105
106
107 # Conditionally copy the GDAL data. To be used in conjunction with
108 # the bdist_wheel command to make self-contained binary wheels.
109 if os.environ.get('PACKAGE_DATA'):
110 destdir = 'rasterio/gdal_data'
111 if gdal_output[2]:
112 log.info("Copying gdal data from %s" % gdal_output[2])
113 copy_data_tree(gdal_output[2], destdir)
114 else:
115 # check to see if GDAL_DATA is defined
116 gdal_data = os.environ.get('GDAL_DATA', None)
117 if gdal_data:
118 log.info("Copying gdal_data from %s" % gdal_data)
119 copy_data_tree(gdal_data, destdir)
120
121 # Conditionally copy PROJ.4 data.
122 projdatadir = os.environ.get('PROJ_LIB', '/usr/local/share/proj')
123 if os.path.exists(projdatadir):
124 log.info("Copying proj_data from %s" % projdatadir)
125 copy_data_tree(projdatadir, 'rasterio/proj_data')
126
127 ext_options = dict(
128 include_dirs=include_dirs,
129 library_dirs=library_dirs,
130 libraries=libraries,
131 extra_link_args=extra_link_args)
132
133 if not os.name == "nt":
134 # These options fail on Windows if using Visual Studio
135 ext_options['extra_compile_args'] = ['-Wno-unused-parameter',
136 '-Wno-unused-function']
137
138 log.debug('ext_options:\n%s', pprint.pformat(ext_options))
139
140 # When building from a repo, Cython is required.
141 if os.path.exists("MANIFEST.in") and "clean" not in sys.argv:
142 log.info("MANIFEST.in found, presume a repo, cythonizing...")
143 if not cythonize:
144 log.critical(
145 "Cython.Build.cythonize not found. "
146 "Cython is required to build from a repo.")
147 sys.exit(1)
148 ext_modules = cythonize([
149 Extension(
150 'rasterio._base', ['rasterio/_base.pyx'], **ext_options),
151 Extension(
152 'rasterio._io', ['rasterio/_io.pyx'], **ext_options),
153 Extension(
154 'rasterio._copy', ['rasterio/_copy.pyx'], **ext_options),
155 Extension(
156 'rasterio._features', ['rasterio/_features.pyx'], **ext_options),
157 Extension(
158 'rasterio._drivers', ['rasterio/_drivers.pyx'], **ext_options),
159 Extension(
160 'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),
161 Extension(
162 'rasterio._fill', ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp'], **ext_options),
163 Extension(
164 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),
165 Extension(
166 'rasterio._example', ['rasterio/_example.pyx'], **ext_options),
167 ], quiet=True)
168
169 # If there's no manifest template, as in an sdist, we just specify .c files.
170 else:
171 ext_modules = [
172 Extension(
173 'rasterio._base', ['rasterio/_base.c'], **ext_options),
174 Extension(
175 'rasterio._io', ['rasterio/_io.c'], **ext_options),
176 Extension(
177 'rasterio._copy', ['rasterio/_copy.c'], **ext_options),
178 Extension(
179 'rasterio._features', ['rasterio/_features.c'], **ext_options),
180 Extension(
181 'rasterio._drivers', ['rasterio/_drivers.c'], **ext_options),
182 Extension(
183 'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),
184 Extension(
185 'rasterio._fill', ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp'], **ext_options),
186 Extension(
187 'rasterio._err', ['rasterio/_err.c'], **ext_options),
188 Extension(
189 'rasterio._example', ['rasterio/_example.c'], **ext_options),
190 ]
191
192 with open('README.rst') as f:
193 readme = f.read()
194
195 # Runtime requirements.
196 inst_reqs = ['affine', 'cligj', 'numpy', 'snuggs', 'click-plugins']
197
198 if sys.version_info < (3, 4):
199 inst_reqs.append('enum34')
200
201 setup_args = dict(
202 name='rasterio',
203 version=version,
204 description="Fast and direct raster I/O for use with Numpy and SciPy",
205 long_description=readme,
206 classifiers=[
207 'Development Status :: 4 - Beta',
208 'Intended Audience :: Developers',
209 'Intended Audience :: Information Technology',
210 'Intended Audience :: Science/Research',
211 'License :: OSI Approved :: BSD License',
212 'Programming Language :: C',
213 'Programming Language :: Python :: 2.6',
214 'Programming Language :: Python :: 2.7',
215 'Programming Language :: Python :: 3.3',
216 'Programming Language :: Python :: 3.4',
217 'Topic :: Multimedia :: Graphics :: Graphics Conversion',
218 'Topic :: Scientific/Engineering :: GIS'],
219 keywords='raster gdal',
220 author='Sean Gillies',
221 author_email='[email protected]',
222 url='https://github.com/mapbox/rasterio',
223 license='BSD',
224 package_dir={'': '.'},
225 packages=['rasterio', 'rasterio.rio', 'rasterio.tools'],
226 entry_points='''
227 [console_scripts]
228 rio=rasterio.rio.main:main_group
229
230 [rasterio.rio_commands]
231 bounds=rasterio.rio.features:bounds
232 calc=rasterio.rio.calc:calc
233 clip=rasterio.rio.convert:clip
234 convert=rasterio.rio.convert:convert
235 edit-info=rasterio.rio.info:edit
236 env=rasterio.rio.info:env
237 info=rasterio.rio.info:info
238 insp=rasterio.rio.info:insp
239 mask=rasterio.rio.features:mask
240 merge=rasterio.rio.merge:merge
241 overview=rasterio.rio.overview:overview
242 rasterize=rasterio.rio.features:rasterize
243 sample=rasterio.rio.sample:sample
244 shapes=rasterio.rio.features:shapes
245 stack=rasterio.rio.bands:stack
246 warp=rasterio.rio.warp:warp
247 transform=rasterio.rio.info:transform
248 ''',
249 include_package_data=True,
250 ext_modules=ext_modules,
251 zip_safe=False,
252 install_requires=inst_reqs,
253 extras_require={
254 'ipython': ['ipython>=2.0']})
255
256 if os.environ.get('PACKAGE_DATA'):
257 setup_args['package_data'] = {'rasterio': ['gdal_data/*', 'proj_data/*']}
258
259 setup(**setup_args)
260
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -19,12 +19,10 @@
from setuptools import setup
from setuptools.extension import Extension
+
logging.basicConfig()
log = logging.getLogger()
-# python -W all setup.py ...
-if 'all' in sys.warnoptions:
- log.level = logging.DEBUG
def check_output(cmd):
# since subprocess.check_output doesn't exist in 2.6
@@ -39,6 +37,7 @@
out, err = p.communicate()
return out
+
def copy_data_tree(datadir, destdir):
try:
shutil.rmtree(destdir)
@@ -46,6 +45,11 @@
pass
shutil.copytree(datadir, destdir)
+
+# python -W all setup.py ...
+if 'all' in sys.warnoptions:
+ log.level = logging.DEBUG
+
# Parse the version from the rasterio module.
with open('rasterio/__init__.py') as f:
for line in f:
@@ -135,6 +139,13 @@
ext_options['extra_compile_args'] = ['-Wno-unused-parameter',
'-Wno-unused-function']
+cythonize_options = {}
+if os.environ.get('CYTHON_COVERAGE'):
+ cythonize_options['compiler_directives'] = {'linetrace': True}
+ cythonize_options['annotate'] = True
+ ext_options['define_macros'] = [('CYTHON_TRACE', '1'),
+ ('CYTHON_TRACE_NOGIL', '1')]
+
log.debug('ext_options:\n%s', pprint.pformat(ext_options))
# When building from a repo, Cython is required.
@@ -164,7 +175,7 @@
'rasterio._err', ['rasterio/_err.pyx'], **ext_options),
Extension(
'rasterio._example', ['rasterio/_example.pyx'], **ext_options),
- ], quiet=True)
+ ], quiet=True, **cythonize_options)
# If there's no manifest template, as in an sdist, we just specify .c files.
else:
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -19,12 +19,10 @@\n from setuptools import setup\n from setuptools.extension import Extension\n \n+\n logging.basicConfig()\n log = logging.getLogger()\n \n-# python -W all setup.py ...\n-if 'all' in sys.warnoptions:\n- log.level = logging.DEBUG\n \n def check_output(cmd):\n # since subprocess.check_output doesn't exist in 2.6\n@@ -39,6 +37,7 @@\n out, err = p.communicate()\n return out\n \n+\n def copy_data_tree(datadir, destdir):\n try:\n shutil.rmtree(destdir)\n@@ -46,6 +45,11 @@\n pass\n shutil.copytree(datadir, destdir)\n \n+\n+# python -W all setup.py ...\n+if 'all' in sys.warnoptions:\n+ log.level = logging.DEBUG\n+\n # Parse the version from the rasterio module.\n with open('rasterio/__init__.py') as f:\n for line in f:\n@@ -135,6 +139,13 @@\n ext_options['extra_compile_args'] = ['-Wno-unused-parameter',\n '-Wno-unused-function']\n \n+cythonize_options = {}\n+if os.environ.get('CYTHON_COVERAGE'):\n+ cythonize_options['compiler_directives'] = {'linetrace': True}\n+ cythonize_options['annotate'] = True\n+ ext_options['define_macros'] = [('CYTHON_TRACE', '1'),\n+ ('CYTHON_TRACE_NOGIL', '1')]\n+\n log.debug('ext_options:\\n%s', pprint.pformat(ext_options))\n \n # When building from a repo, Cython is required.\n@@ -164,7 +175,7 @@\n 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.pyx'], **ext_options),\n- ], quiet=True)\n+ ], quiet=True, **cythonize_options)\n \n # If there's no manifest template, as in an sdist, we just specify .c files.\n else:\n", "issue": "Add test coverage for Cython modules\nRight now, we are not getting coverage of Cython modules from our test suite. This would be good to do, especially if it is [pretty straightforward](http://blog.behnel.de/posts/coverage-analysis-for-cython-modules.html).\n\nI'll look into this for #496\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\n# Two environmental variables influence this script.\n#\n# GDAL_CONFIG: the path to a gdal-config program that points to GDAL headers,\n# libraries, and data files.\n#\n# PACKAGE_DATA: if defined, GDAL and PROJ4 data files will be copied into the\n# source or binary distribution. This is essential when creating self-contained\n# binary wheels.\n\nimport logging\nimport os\nimport pprint\nimport shutil\nimport subprocess\nimport sys\n\nfrom setuptools import setup\nfrom setuptools.extension import Extension\n\nlogging.basicConfig()\nlog = logging.getLogger()\n\n# python -W all setup.py ...\nif 'all' in sys.warnoptions:\n log.level = logging.DEBUG\n\ndef check_output(cmd):\n # since subprocess.check_output doesn't exist in 2.6\n # we wrap it here.\n try:\n out = subprocess.check_output(cmd)\n return out.decode('utf')\n except AttributeError:\n # For some reasone check_output doesn't exist\n # So fall back on Popen\n p = subprocess.Popen(cmd, stdout=subprocess.PIPE)\n out, err = p.communicate()\n return out\n\ndef copy_data_tree(datadir, destdir):\n try:\n shutil.rmtree(destdir)\n except OSError:\n pass\n shutil.copytree(datadir, destdir)\n\n# Parse the version from the rasterio module.\nwith open('rasterio/__init__.py') as f:\n for line in f:\n if line.find(\"__version__\") >= 0:\n version = line.split(\"=\")[1].strip()\n version = version.strip('\"')\n version = version.strip(\"'\")\n continue\n\nwith open('VERSION.txt', 'w') as f:\n f.write(version)\n\n# Use Cython if available.\ntry:\n from Cython.Build import cythonize\nexcept ImportError:\n cythonize = None\n\n# By default we'll try to get options via gdal-config. On systems without,\n# options will need to be set in setup.cfg or on the setup command line.\ninclude_dirs = []\nlibrary_dirs = []\nlibraries = []\nextra_link_args = []\ngdal_output = [None]*3\n\ntry:\n import numpy\n include_dirs.append(numpy.get_include())\nexcept ImportError:\n log.critical(\"Numpy and its headers are required to run setup(). Exiting.\")\n sys.exit(1)\n\ntry:\n gdal_config = os.environ.get('GDAL_CONFIG', 'gdal-config')\n for i, flag in enumerate((\"--cflags\", \"--libs\", \"--datadir\")):\n gdal_output[i] = check_output([gdal_config, flag]).strip()\n\n for item in gdal_output[0].split():\n if item.startswith(\"-I\"):\n include_dirs.extend(item[2:].split(\":\"))\n for item in gdal_output[1].split():\n if item.startswith(\"-L\"):\n library_dirs.extend(item[2:].split(\":\"))\n elif item.startswith(\"-l\"):\n libraries.append(item[2:])\n else:\n # e.g. -framework GDAL\n extra_link_args.append(item)\n\nexcept Exception as e:\n if os.name == \"nt\":\n log.info((\"Building on Windows requires extra options to setup.py to locate needed GDAL files.\\n\"\n \"More information is available in the README.\"))\n else:\n log.warning(\"Failed to get options via gdal-config: %s\", str(e))\n\n\n# Conditionally copy the GDAL data. To be used in conjunction with\n# the bdist_wheel command to make self-contained binary wheels.\nif os.environ.get('PACKAGE_DATA'):\n destdir = 'rasterio/gdal_data'\n if gdal_output[2]:\n log.info(\"Copying gdal data from %s\" % gdal_output[2])\n copy_data_tree(gdal_output[2], destdir)\n else:\n # check to see if GDAL_DATA is defined\n gdal_data = os.environ.get('GDAL_DATA', None)\n if gdal_data:\n log.info(\"Copying gdal_data from %s\" % gdal_data)\n copy_data_tree(gdal_data, destdir)\n\n # Conditionally copy PROJ.4 data.\n projdatadir = os.environ.get('PROJ_LIB', '/usr/local/share/proj')\n if os.path.exists(projdatadir):\n log.info(\"Copying proj_data from %s\" % projdatadir)\n copy_data_tree(projdatadir, 'rasterio/proj_data')\n\next_options = dict(\n include_dirs=include_dirs,\n library_dirs=library_dirs,\n libraries=libraries,\n extra_link_args=extra_link_args)\n\nif not os.name == \"nt\":\n # These options fail on Windows if using Visual Studio\n ext_options['extra_compile_args'] = ['-Wno-unused-parameter',\n '-Wno-unused-function']\n\nlog.debug('ext_options:\\n%s', pprint.pformat(ext_options))\n\n# When building from a repo, Cython is required.\nif os.path.exists(\"MANIFEST.in\") and \"clean\" not in sys.argv:\n log.info(\"MANIFEST.in found, presume a repo, cythonizing...\")\n if not cythonize:\n log.critical(\n \"Cython.Build.cythonize not found. \"\n \"Cython is required to build from a repo.\")\n sys.exit(1)\n ext_modules = cythonize([\n Extension(\n 'rasterio._base', ['rasterio/_base.pyx'], **ext_options),\n Extension(\n 'rasterio._io', ['rasterio/_io.pyx'], **ext_options),\n Extension(\n 'rasterio._copy', ['rasterio/_copy.pyx'], **ext_options),\n Extension(\n 'rasterio._features', ['rasterio/_features.pyx'], **ext_options),\n Extension(\n 'rasterio._drivers', ['rasterio/_drivers.pyx'], **ext_options),\n Extension(\n 'rasterio._warp', ['rasterio/_warp.pyx'], **ext_options),\n Extension(\n 'rasterio._fill', ['rasterio/_fill.pyx', 'rasterio/rasterfill.cpp'], **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.pyx'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.pyx'], **ext_options),\n ], quiet=True)\n\n# If there's no manifest template, as in an sdist, we just specify .c files.\nelse:\n ext_modules = [\n Extension(\n 'rasterio._base', ['rasterio/_base.c'], **ext_options),\n Extension(\n 'rasterio._io', ['rasterio/_io.c'], **ext_options),\n Extension(\n 'rasterio._copy', ['rasterio/_copy.c'], **ext_options),\n Extension(\n 'rasterio._features', ['rasterio/_features.c'], **ext_options),\n Extension(\n 'rasterio._drivers', ['rasterio/_drivers.c'], **ext_options),\n Extension(\n 'rasterio._warp', ['rasterio/_warp.cpp'], **ext_options),\n Extension(\n 'rasterio._fill', ['rasterio/_fill.cpp', 'rasterio/rasterfill.cpp'], **ext_options),\n Extension(\n 'rasterio._err', ['rasterio/_err.c'], **ext_options),\n Extension(\n 'rasterio._example', ['rasterio/_example.c'], **ext_options),\n ]\n\nwith open('README.rst') as f:\n readme = f.read()\n\n# Runtime requirements.\ninst_reqs = ['affine', 'cligj', 'numpy', 'snuggs', 'click-plugins']\n\nif sys.version_info < (3, 4):\n inst_reqs.append('enum34')\n\nsetup_args = dict(\n name='rasterio',\n version=version,\n description=\"Fast and direct raster I/O for use with Numpy and SciPy\",\n long_description=readme,\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Information Technology',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Programming Language :: C',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Topic :: Multimedia :: Graphics :: Graphics Conversion',\n 'Topic :: Scientific/Engineering :: GIS'],\n keywords='raster gdal',\n author='Sean Gillies',\n author_email='[email protected]',\n url='https://github.com/mapbox/rasterio',\n license='BSD',\n package_dir={'': '.'},\n packages=['rasterio', 'rasterio.rio', 'rasterio.tools'],\n entry_points='''\n [console_scripts]\n rio=rasterio.rio.main:main_group\n\n [rasterio.rio_commands]\n bounds=rasterio.rio.features:bounds\n calc=rasterio.rio.calc:calc\n clip=rasterio.rio.convert:clip\n convert=rasterio.rio.convert:convert\n edit-info=rasterio.rio.info:edit\n env=rasterio.rio.info:env\n info=rasterio.rio.info:info\n insp=rasterio.rio.info:insp\n mask=rasterio.rio.features:mask\n merge=rasterio.rio.merge:merge\n overview=rasterio.rio.overview:overview\n rasterize=rasterio.rio.features:rasterize\n sample=rasterio.rio.sample:sample\n shapes=rasterio.rio.features:shapes\n stack=rasterio.rio.bands:stack\n warp=rasterio.rio.warp:warp\n transform=rasterio.rio.info:transform\n ''',\n include_package_data=True,\n ext_modules=ext_modules,\n zip_safe=False,\n install_requires=inst_reqs,\n extras_require={\n 'ipython': ['ipython>=2.0']})\n\nif os.environ.get('PACKAGE_DATA'):\n setup_args['package_data'] = {'rasterio': ['gdal_data/*', 'proj_data/*']}\n\nsetup(**setup_args)\n", "path": "setup.py"}]}
| 3,522 | 481 |
gh_patches_debug_33793
|
rasdani/github-patches
|
git_diff
|
Project-MONAI__MONAI-7664
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SABlock parameters when using more heads
**Describe the bug**
The number of parameters in the SABlock should be increased when increasing the number of heads (_num_heads_). However, this is not the case and limits comparability to famous scaling like ViT-S or ViT-B.
**To Reproduce**
Steps to reproduce the behavior:
```
from monai.networks.nets import ViT
def count_trainable_parameters(model: nn.Module) -> int:
return sum(p.numel() for p in model.parameters() if p.requires_grad)
# Create ViT models with different numbers of heads
vit_b = ViT(1, 224, 16, num_heads=12)
vit_s = ViT(1, 224, 16, num_heads=6)
print("ViT with 12 heads parameters:", count_trainable_parameters(vit_b))
print("ViT with 6 heads parameters:", count_trainable_parameters(vit_s))
>>> ViT with 12 heads parameters: 90282240
>>> ViT with 6 heads parameters: 90282240
```
**Expected behavior**
The number of trainable parameters should be increased with increasing number of heads.
**Environment**
```
================================
Printing MONAI config...
================================
MONAI version: 0.8.1rc4+1384.g139182ea
Numpy version: 1.26.4
Pytorch version: 2.2.2+cpu
MONAI flags: HAS_EXT = False, USE_COMPILED = False, USE_META_DICT = False
MONAI rev id: 139182ea52725aa3c9214dc18082b9837e32f9a2
MONAI __file__: C:\Users\<username>\MONAI\monai\__init__.py
Optional dependencies:
Pytorch Ignite version: 0.4.11
ITK version: 5.3.0
Nibabel version: 5.2.1
scikit-image version: 0.23.1
scipy version: 1.13.0
Pillow version: 10.3.0
Tensorboard version: 2.16.2
gdown version: 4.7.3
TorchVision version: 0.17.2+cpu
tqdm version: 4.66.2
lmdb version: 1.4.1
psutil version: 5.9.8
pandas version: 2.2.2
einops version: 0.7.0
transformers version: 4.39.3
mlflow version: 2.12.1
pynrrd version: 1.0.0
clearml version: 1.15.1
For details about installing the optional dependencies, please visit:
https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies
================================
Printing system config...
================================
System: Windows
Win32 version: ('10', '10.0.22621', 'SP0', 'Multiprocessor Free')
Win32 edition: Professional
Platform: Windows-10-10.0.22621-SP0
Processor: Intel64 Family 6 Model 142 Stepping 12, GenuineIntel
Machine: AMD64
Python version: 3.11.8
Process name: python.exe
Command: ['python', '-c', 'import monai; monai.config.print_debug_info()']
Open files: [popenfile(path='C:\\Windows\\System32\\de-DE\\KernelBase.dll.mui', fd=-1), popenfile(path='C:\\Windows\\System32\\de-DE\\kernel32.dll.mui', fd=-1), popenfile(path='C:\\Windows\\System32\\de-DE\\tzres.dll.mui', fd=-1)]
Num physical CPUs: 4
Num logical CPUs: 8
Num usable CPUs: 8
CPU usage (%): [3.9, 0.2, 3.7, 0.9, 3.9, 3.9, 2.8, 32.2]
CPU freq. (MHz): 1803
Load avg. in last 1, 5, 15 mins (%): [0.0, 0.0, 0.0]
Disk usage (%): 83.1
Avg. sensor temp. (Celsius): UNKNOWN for given OS
Total physical memory (GB): 15.8
Available memory (GB): 5.5
Used memory (GB): 10.2
================================
Printing GPU config...
================================
Num GPUs: 0
Has CUDA: False
cuDNN enabled: False
NVIDIA_TF32_OVERRIDE: None
TORCH_ALLOW_TF32_CUBLAS_OVERRIDE: None
```
</issue>
<code>
[start of monai/networks/blocks/selfattention.py]
1 # Copyright (c) MONAI Consortium
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 # http://www.apache.org/licenses/LICENSE-2.0
6 # Unless required by applicable law or agreed to in writing, software
7 # distributed under the License is distributed on an "AS IS" BASIS,
8 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
9 # See the License for the specific language governing permissions and
10 # limitations under the License.
11
12 from __future__ import annotations
13
14 import torch
15 import torch.nn as nn
16
17 from monai.utils import optional_import
18
19 Rearrange, _ = optional_import("einops.layers.torch", name="Rearrange")
20
21
22 class SABlock(nn.Module):
23 """
24 A self-attention block, based on: "Dosovitskiy et al.,
25 An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>"
26 """
27
28 def __init__(
29 self,
30 hidden_size: int,
31 num_heads: int,
32 dropout_rate: float = 0.0,
33 qkv_bias: bool = False,
34 save_attn: bool = False,
35 ) -> None:
36 """
37 Args:
38 hidden_size (int): dimension of hidden layer.
39 num_heads (int): number of attention heads.
40 dropout_rate (float, optional): fraction of the input units to drop. Defaults to 0.0.
41 qkv_bias (bool, optional): bias term for the qkv linear layer. Defaults to False.
42 save_attn (bool, optional): to make accessible the attention matrix. Defaults to False.
43
44 """
45
46 super().__init__()
47
48 if not (0 <= dropout_rate <= 1):
49 raise ValueError("dropout_rate should be between 0 and 1.")
50
51 if hidden_size % num_heads != 0:
52 raise ValueError("hidden size should be divisible by num_heads.")
53
54 self.num_heads = num_heads
55 self.out_proj = nn.Linear(hidden_size, hidden_size)
56 self.qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)
57 self.input_rearrange = Rearrange("b h (qkv l d) -> qkv b l h d", qkv=3, l=num_heads)
58 self.out_rearrange = Rearrange("b h l d -> b l (h d)")
59 self.drop_output = nn.Dropout(dropout_rate)
60 self.drop_weights = nn.Dropout(dropout_rate)
61 self.head_dim = hidden_size // num_heads
62 self.scale = self.head_dim**-0.5
63 self.save_attn = save_attn
64 self.att_mat = torch.Tensor()
65
66 def forward(self, x):
67 output = self.input_rearrange(self.qkv(x))
68 q, k, v = output[0], output[1], output[2]
69 att_mat = (torch.einsum("blxd,blyd->blxy", q, k) * self.scale).softmax(dim=-1)
70 if self.save_attn:
71 # no gradients and new tensor;
72 # https://pytorch.org/docs/stable/generated/torch.Tensor.detach.html
73 self.att_mat = att_mat.detach()
74
75 att_mat = self.drop_weights(att_mat)
76 x = torch.einsum("bhxy,bhyd->bhxd", att_mat, v)
77 x = self.out_rearrange(x)
78 x = self.out_proj(x)
79 x = self.drop_output(x)
80 return x
81
[end of monai/networks/blocks/selfattention.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/monai/networks/blocks/selfattention.py b/monai/networks/blocks/selfattention.py
--- a/monai/networks/blocks/selfattention.py
+++ b/monai/networks/blocks/selfattention.py
@@ -32,6 +32,7 @@
dropout_rate: float = 0.0,
qkv_bias: bool = False,
save_attn: bool = False,
+ dim_head: int | None = None,
) -> None:
"""
Args:
@@ -40,6 +41,7 @@
dropout_rate (float, optional): fraction of the input units to drop. Defaults to 0.0.
qkv_bias (bool, optional): bias term for the qkv linear layer. Defaults to False.
save_attn (bool, optional): to make accessible the attention matrix. Defaults to False.
+ dim_head (int, optional): dimension of each head. Defaults to hidden_size // num_heads.
"""
@@ -52,14 +54,16 @@
raise ValueError("hidden size should be divisible by num_heads.")
self.num_heads = num_heads
- self.out_proj = nn.Linear(hidden_size, hidden_size)
- self.qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)
+ self.dim_head = hidden_size // num_heads if dim_head is None else dim_head
+ self.inner_dim = self.dim_head * num_heads
+
+ self.out_proj = nn.Linear(self.inner_dim, hidden_size)
+ self.qkv = nn.Linear(hidden_size, self.inner_dim * 3, bias=qkv_bias)
self.input_rearrange = Rearrange("b h (qkv l d) -> qkv b l h d", qkv=3, l=num_heads)
self.out_rearrange = Rearrange("b h l d -> b l (h d)")
self.drop_output = nn.Dropout(dropout_rate)
self.drop_weights = nn.Dropout(dropout_rate)
- self.head_dim = hidden_size // num_heads
- self.scale = self.head_dim**-0.5
+ self.scale = self.dim_head**-0.5
self.save_attn = save_attn
self.att_mat = torch.Tensor()
|
{"golden_diff": "diff --git a/monai/networks/blocks/selfattention.py b/monai/networks/blocks/selfattention.py\n--- a/monai/networks/blocks/selfattention.py\n+++ b/monai/networks/blocks/selfattention.py\n@@ -32,6 +32,7 @@\n dropout_rate: float = 0.0,\n qkv_bias: bool = False,\n save_attn: bool = False,\n+ dim_head: int | None = None,\n ) -> None:\n \"\"\"\n Args:\n@@ -40,6 +41,7 @@\n dropout_rate (float, optional): fraction of the input units to drop. Defaults to 0.0.\n qkv_bias (bool, optional): bias term for the qkv linear layer. Defaults to False.\n save_attn (bool, optional): to make accessible the attention matrix. Defaults to False.\n+ dim_head (int, optional): dimension of each head. Defaults to hidden_size // num_heads.\n \n \"\"\"\n \n@@ -52,14 +54,16 @@\n raise ValueError(\"hidden size should be divisible by num_heads.\")\n \n self.num_heads = num_heads\n- self.out_proj = nn.Linear(hidden_size, hidden_size)\n- self.qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)\n+ self.dim_head = hidden_size // num_heads if dim_head is None else dim_head\n+ self.inner_dim = self.dim_head * num_heads\n+\n+ self.out_proj = nn.Linear(self.inner_dim, hidden_size)\n+ self.qkv = nn.Linear(hidden_size, self.inner_dim * 3, bias=qkv_bias)\n self.input_rearrange = Rearrange(\"b h (qkv l d) -> qkv b l h d\", qkv=3, l=num_heads)\n self.out_rearrange = Rearrange(\"b h l d -> b l (h d)\")\n self.drop_output = nn.Dropout(dropout_rate)\n self.drop_weights = nn.Dropout(dropout_rate)\n- self.head_dim = hidden_size // num_heads\n- self.scale = self.head_dim**-0.5\n+ self.scale = self.dim_head**-0.5\n self.save_attn = save_attn\n self.att_mat = torch.Tensor()\n", "issue": "SABlock parameters when using more heads\n**Describe the bug**\r\nThe number of parameters in the SABlock should be increased when increasing the number of heads (_num_heads_). However, this is not the case and limits comparability to famous scaling like ViT-S or ViT-B.\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n```\r\nfrom monai.networks.nets import ViT\r\n\r\ndef count_trainable_parameters(model: nn.Module) -> int:\r\n return sum(p.numel() for p in model.parameters() if p.requires_grad)\r\n\r\n# Create ViT models with different numbers of heads\r\nvit_b = ViT(1, 224, 16, num_heads=12)\r\nvit_s = ViT(1, 224, 16, num_heads=6)\r\n\r\nprint(\"ViT with 12 heads parameters:\", count_trainable_parameters(vit_b))\r\nprint(\"ViT with 6 heads parameters:\", count_trainable_parameters(vit_s))\r\n\r\n>>> ViT with 12 heads parameters: 90282240\r\n>>> ViT with 6 heads parameters: 90282240\r\n```\r\n\r\n**Expected behavior**\r\nThe number of trainable parameters should be increased with increasing number of heads.\r\n\r\n**Environment**\r\n```\r\n================================\r\nPrinting MONAI config...\r\n================================\r\nMONAI version: 0.8.1rc4+1384.g139182ea\r\nNumpy version: 1.26.4\r\nPytorch version: 2.2.2+cpu\r\nMONAI flags: HAS_EXT = False, USE_COMPILED = False, USE_META_DICT = False\r\nMONAI rev id: 139182ea52725aa3c9214dc18082b9837e32f9a2\r\nMONAI __file__: C:\\Users\\<username>\\MONAI\\monai\\__init__.py\r\n\r\nOptional dependencies:\r\nPytorch Ignite version: 0.4.11\r\nITK version: 5.3.0\r\nNibabel version: 5.2.1\r\nscikit-image version: 0.23.1\r\nscipy version: 1.13.0\r\nPillow version: 10.3.0\r\nTensorboard version: 2.16.2\r\ngdown version: 4.7.3\r\nTorchVision version: 0.17.2+cpu\r\ntqdm version: 4.66.2\r\nlmdb version: 1.4.1\r\npsutil version: 5.9.8\r\npandas version: 2.2.2\r\neinops version: 0.7.0\r\ntransformers version: 4.39.3\r\nmlflow version: 2.12.1\r\npynrrd version: 1.0.0\r\nclearml version: 1.15.1\r\n\r\nFor details about installing the optional dependencies, please visit:\r\n https://docs.monai.io/en/latest/installation.html#installing-the-recommended-dependencies\r\n\r\n\r\n================================\r\nPrinting system config...\r\n================================\r\nSystem: Windows\r\nWin32 version: ('10', '10.0.22621', 'SP0', 'Multiprocessor Free')\r\nWin32 edition: Professional\r\nPlatform: Windows-10-10.0.22621-SP0\r\nProcessor: Intel64 Family 6 Model 142 Stepping 12, GenuineIntel\r\nMachine: AMD64\r\nPython version: 3.11.8\r\nProcess name: python.exe\r\nCommand: ['python', '-c', 'import monai; monai.config.print_debug_info()']\r\nOpen files: [popenfile(path='C:\\\\Windows\\\\System32\\\\de-DE\\\\KernelBase.dll.mui', fd=-1), popenfile(path='C:\\\\Windows\\\\System32\\\\de-DE\\\\kernel32.dll.mui', fd=-1), popenfile(path='C:\\\\Windows\\\\System32\\\\de-DE\\\\tzres.dll.mui', fd=-1)]\r\nNum physical CPUs: 4\r\nNum logical CPUs: 8\r\nNum usable CPUs: 8\r\nCPU usage (%): [3.9, 0.2, 3.7, 0.9, 3.9, 3.9, 2.8, 32.2]\r\nCPU freq. (MHz): 1803\r\nLoad avg. in last 1, 5, 15 mins (%): [0.0, 0.0, 0.0]\r\nDisk usage (%): 83.1\r\nAvg. sensor temp. (Celsius): UNKNOWN for given OS\r\nTotal physical memory (GB): 15.8\r\nAvailable memory (GB): 5.5\r\nUsed memory (GB): 10.2\r\n\r\n================================\r\nPrinting GPU config...\r\n================================\r\nNum GPUs: 0\r\nHas CUDA: False\r\ncuDNN enabled: False\r\nNVIDIA_TF32_OVERRIDE: None\r\nTORCH_ALLOW_TF32_CUBLAS_OVERRIDE: None\r\n```\n", "before_files": [{"content": "# Copyright (c) MONAI Consortium\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n# http://www.apache.org/licenses/LICENSE-2.0\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import annotations\n\nimport torch\nimport torch.nn as nn\n\nfrom monai.utils import optional_import\n\nRearrange, _ = optional_import(\"einops.layers.torch\", name=\"Rearrange\")\n\n\nclass SABlock(nn.Module):\n \"\"\"\n A self-attention block, based on: \"Dosovitskiy et al.,\n An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale <https://arxiv.org/abs/2010.11929>\"\n \"\"\"\n\n def __init__(\n self,\n hidden_size: int,\n num_heads: int,\n dropout_rate: float = 0.0,\n qkv_bias: bool = False,\n save_attn: bool = False,\n ) -> None:\n \"\"\"\n Args:\n hidden_size (int): dimension of hidden layer.\n num_heads (int): number of attention heads.\n dropout_rate (float, optional): fraction of the input units to drop. Defaults to 0.0.\n qkv_bias (bool, optional): bias term for the qkv linear layer. Defaults to False.\n save_attn (bool, optional): to make accessible the attention matrix. Defaults to False.\n\n \"\"\"\n\n super().__init__()\n\n if not (0 <= dropout_rate <= 1):\n raise ValueError(\"dropout_rate should be between 0 and 1.\")\n\n if hidden_size % num_heads != 0:\n raise ValueError(\"hidden size should be divisible by num_heads.\")\n\n self.num_heads = num_heads\n self.out_proj = nn.Linear(hidden_size, hidden_size)\n self.qkv = nn.Linear(hidden_size, hidden_size * 3, bias=qkv_bias)\n self.input_rearrange = Rearrange(\"b h (qkv l d) -> qkv b l h d\", qkv=3, l=num_heads)\n self.out_rearrange = Rearrange(\"b h l d -> b l (h d)\")\n self.drop_output = nn.Dropout(dropout_rate)\n self.drop_weights = nn.Dropout(dropout_rate)\n self.head_dim = hidden_size // num_heads\n self.scale = self.head_dim**-0.5\n self.save_attn = save_attn\n self.att_mat = torch.Tensor()\n\n def forward(self, x):\n output = self.input_rearrange(self.qkv(x))\n q, k, v = output[0], output[1], output[2]\n att_mat = (torch.einsum(\"blxd,blyd->blxy\", q, k) * self.scale).softmax(dim=-1)\n if self.save_attn:\n # no gradients and new tensor;\n # https://pytorch.org/docs/stable/generated/torch.Tensor.detach.html\n self.att_mat = att_mat.detach()\n\n att_mat = self.drop_weights(att_mat)\n x = torch.einsum(\"bhxy,bhyd->bhxd\", att_mat, v)\n x = self.out_rearrange(x)\n x = self.out_proj(x)\n x = self.drop_output(x)\n return x\n", "path": "monai/networks/blocks/selfattention.py"}]}
| 2,603 | 497 |
gh_patches_debug_4008
|
rasdani/github-patches
|
git_diff
|
zestedesavoir__zds-site-2705
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Derniers sujets sur la Home : la date sur mobile n'est pas optimisée
Sur mobile on à en général pas beaucoup de place. Et il faudrait éviter d'afficher la date literralle pour optimiser la place. Cf screen (paysage).

</issue>
<code>
[start of zds/featured/forms.py]
1 # coding: utf-8
2 from crispy_forms.bootstrap import StrictButton
3 from crispy_forms.helper import FormHelper
4 from crispy_forms.layout import Layout, Field, ButtonHolder
5 from django import forms
6 from django.core.urlresolvers import reverse
7 from django.utils.translation import ugettext_lazy as _
8
9 from zds.featured.models import FeaturedResource, FeaturedMessage
10
11
12 class FeaturedResourceForm(forms.ModelForm):
13 class Meta:
14 model = FeaturedResource
15
16 fields = ['title', 'type', 'authors', 'image_url', 'url']
17
18 title = forms.CharField(
19 label=_(u'Titre'),
20 max_length=FeaturedResource._meta.get_field('title').max_length,
21 widget=forms.TextInput(
22 attrs={
23 'required': 'required',
24 }
25 )
26 )
27
28 type = forms.CharField(
29 label=_(u'Type'),
30 max_length=FeaturedResource._meta.get_field('type').max_length,
31 widget=forms.TextInput(
32 attrs={
33 'placeholder': _(u'ex: Un projet, un article, un tutoriel...'),
34 'required': 'required',
35 }
36 )
37 )
38
39 authors = forms.CharField(
40 label=_('Auteurs'),
41 widget=forms.TextInput(
42 attrs={
43 'placeholder': _(u'Les auteurs doivent être séparés par une virgule.'),
44 'required': 'required',
45 'data-autocomplete': '{ "type": "multiple" }'
46 }
47 )
48 )
49
50 image_url = forms.CharField(
51 label='Image URL',
52 max_length=FeaturedResource._meta.get_field('image_url').max_length,
53 widget=forms.TextInput(
54 attrs={
55 'placeholder': _(u'Lien vers l\'url de l\'image de la une.')
56 }
57 )
58 )
59
60 url = forms.CharField(
61 label='URL',
62 max_length=FeaturedResource._meta.get_field('url').max_length,
63 widget=forms.TextInput(
64 attrs={
65 'placeholder': _(u'Lien vers l\'url de la ressource.')
66 }
67 )
68 )
69
70 def __init__(self, *args, **kwargs):
71 super(FeaturedResourceForm, self).__init__(*args, **kwargs)
72 self.helper = FormHelper()
73 self.helper.form_class = 'content-wrapper'
74 self.helper.form_method = 'post'
75 self.helper.form_action = reverse('featured-resource-create')
76
77 self.helper.layout = Layout(
78 Field('title'),
79 Field('type'),
80 Field('authors'),
81 Field('image_url'),
82 Field('url'),
83 ButtonHolder(
84 StrictButton(_(u'Enregistrer'), type='submit'),
85 ),
86 )
87
88
89 class FeaturedMessageForm(forms.ModelForm):
90 class Meta:
91 model = FeaturedMessage
92
93 fields = ['message', 'url']
94
95 message = forms.CharField(
96 label=_(u'Message'),
97 max_length=FeaturedMessage._meta.get_field('message').max_length,
98 widget=forms.TextInput(
99 attrs={
100 'required': 'required',
101 }
102 )
103 )
104
105 url = forms.CharField(
106 label=_(u'URL'),
107 max_length=FeaturedMessage._meta.get_field('url').max_length,
108 widget=forms.TextInput(
109 attrs={
110 'placeholder': _(u'Lien vers l\'url du message.'),
111 'required': 'required',
112 }
113 )
114 )
115
116 def __init__(self, *args, **kwargs):
117 super(FeaturedMessageForm, self).__init__(*args, **kwargs)
118 self.helper = FormHelper()
119 self.helper.form_class = 'content-wrapper'
120 self.helper.form_method = 'post'
121 self.helper.form_action = reverse('featured-message-create')
122
123 self.helper.layout = Layout(
124 Field('message'),
125 Field('url'),
126 ButtonHolder(
127 StrictButton(_(u'Enregistrer'), type='submit'),
128 ),
129 )
130
[end of zds/featured/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/zds/featured/forms.py b/zds/featured/forms.py
--- a/zds/featured/forms.py
+++ b/zds/featured/forms.py
@@ -52,7 +52,7 @@
max_length=FeaturedResource._meta.get_field('image_url').max_length,
widget=forms.TextInput(
attrs={
- 'placeholder': _(u'Lien vers l\'url de l\'image de la une.')
+ 'placeholder': _(u'Lien vers l\'url de l\'image de la une (dimensions: 228x228).')
}
)
)
|
{"golden_diff": "diff --git a/zds/featured/forms.py b/zds/featured/forms.py\n--- a/zds/featured/forms.py\n+++ b/zds/featured/forms.py\n@@ -52,7 +52,7 @@\n max_length=FeaturedResource._meta.get_field('image_url').max_length,\n widget=forms.TextInput(\n attrs={\n- 'placeholder': _(u'Lien vers l\\'url de l\\'image de la une.')\n+ 'placeholder': _(u'Lien vers l\\'url de l\\'image de la une (dimensions: 228x228).')\n }\n )\n )\n", "issue": "Derniers sujets sur la Home : la date sur mobile n'est pas optimis\u00e9e \nSur mobile on \u00e0 en g\u00e9n\u00e9ral pas beaucoup de place. Et il faudrait \u00e9viter d'afficher la date literralle pour optimiser la place. Cf screen (paysage).\n\n\n\n", "before_files": [{"content": "# coding: utf-8\nfrom crispy_forms.bootstrap import StrictButton\nfrom crispy_forms.helper import FormHelper\nfrom crispy_forms.layout import Layout, Field, ButtonHolder\nfrom django import forms\nfrom django.core.urlresolvers import reverse\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom zds.featured.models import FeaturedResource, FeaturedMessage\n\n\nclass FeaturedResourceForm(forms.ModelForm):\n class Meta:\n model = FeaturedResource\n\n fields = ['title', 'type', 'authors', 'image_url', 'url']\n\n title = forms.CharField(\n label=_(u'Titre'),\n max_length=FeaturedResource._meta.get_field('title').max_length,\n widget=forms.TextInput(\n attrs={\n 'required': 'required',\n }\n )\n )\n\n type = forms.CharField(\n label=_(u'Type'),\n max_length=FeaturedResource._meta.get_field('type').max_length,\n widget=forms.TextInput(\n attrs={\n 'placeholder': _(u'ex: Un projet, un article, un tutoriel...'),\n 'required': 'required',\n }\n )\n )\n\n authors = forms.CharField(\n label=_('Auteurs'),\n widget=forms.TextInput(\n attrs={\n 'placeholder': _(u'Les auteurs doivent \u00eatre s\u00e9par\u00e9s par une virgule.'),\n 'required': 'required',\n 'data-autocomplete': '{ \"type\": \"multiple\" }'\n }\n )\n )\n\n image_url = forms.CharField(\n label='Image URL',\n max_length=FeaturedResource._meta.get_field('image_url').max_length,\n widget=forms.TextInput(\n attrs={\n 'placeholder': _(u'Lien vers l\\'url de l\\'image de la une.')\n }\n )\n )\n\n url = forms.CharField(\n label='URL',\n max_length=FeaturedResource._meta.get_field('url').max_length,\n widget=forms.TextInput(\n attrs={\n 'placeholder': _(u'Lien vers l\\'url de la ressource.')\n }\n )\n )\n\n def __init__(self, *args, **kwargs):\n super(FeaturedResourceForm, self).__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.form_class = 'content-wrapper'\n self.helper.form_method = 'post'\n self.helper.form_action = reverse('featured-resource-create')\n\n self.helper.layout = Layout(\n Field('title'),\n Field('type'),\n Field('authors'),\n Field('image_url'),\n Field('url'),\n ButtonHolder(\n StrictButton(_(u'Enregistrer'), type='submit'),\n ),\n )\n\n\nclass FeaturedMessageForm(forms.ModelForm):\n class Meta:\n model = FeaturedMessage\n\n fields = ['message', 'url']\n\n message = forms.CharField(\n label=_(u'Message'),\n max_length=FeaturedMessage._meta.get_field('message').max_length,\n widget=forms.TextInput(\n attrs={\n 'required': 'required',\n }\n )\n )\n\n url = forms.CharField(\n label=_(u'URL'),\n max_length=FeaturedMessage._meta.get_field('url').max_length,\n widget=forms.TextInput(\n attrs={\n 'placeholder': _(u'Lien vers l\\'url du message.'),\n 'required': 'required',\n }\n )\n )\n\n def __init__(self, *args, **kwargs):\n super(FeaturedMessageForm, self).__init__(*args, **kwargs)\n self.helper = FormHelper()\n self.helper.form_class = 'content-wrapper'\n self.helper.form_method = 'post'\n self.helper.form_action = reverse('featured-message-create')\n\n self.helper.layout = Layout(\n Field('message'),\n Field('url'),\n ButtonHolder(\n StrictButton(_(u'Enregistrer'), type='submit'),\n ),\n )\n", "path": "zds/featured/forms.py"}]}
| 1,772 | 133 |
gh_patches_debug_7194
|
rasdani/github-patches
|
git_diff
|
instadeepai__Mava-1041
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG]: Flasbax bug on LBF (type issue)
### Describe the bug
In the AgentID wrapper, the new_agents_view type is not enforced to be consistent, so for LBF with flashbax a dtype error emerges.
### To Reproduce
Steps to reproduce the behavior:
1. Run LBF with flashbax.
### Expected behavior
Expected the observation to be added easily to the buffer.
### Context (Environment)
- Updated jumanji
### Additional context
This is somewhat an exercise in opening an issue!
### Possible Solution
Will make a PR soon! Basically a cast to the agents_view type.
</issue>
<code>
[start of mava/wrappers/observation.py]
1 # Copyright 2022 InstaDeep Ltd. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from typing import Tuple, Union
16
17 import chex
18 import jax.numpy as jnp
19 from jumanji import specs
20 from jumanji.env import Environment
21 from jumanji.types import TimeStep
22 from jumanji.wrappers import Wrapper
23
24 from mava.types import Observation, ObservationGlobalState, State
25
26
27 class AgentIDWrapper(Wrapper):
28 """A wrapper to add a one-hot vector as agent IDs to the original observation.
29 It can be useful in multi-agent environments where agents require unique identification.
30 """
31
32 def __init__(self, env: Environment):
33 super().__init__(env)
34
35 def _add_agent_ids(
36 self, timestep: TimeStep, num_agents: int
37 ) -> Union[Observation, ObservationGlobalState]:
38 """Adds agent IDs to the observation."""
39 obs = timestep.observation
40 agent_ids = jnp.eye(num_agents)
41 agents_view = jnp.concatenate([agent_ids, obs.agents_view], axis=-1)
42
43 return obs._replace(agents_view=agents_view) # type: ignore
44
45 def reset(self, key: chex.PRNGKey) -> Tuple[State, TimeStep]:
46 """Reset the environment."""
47 state, timestep = self._env.reset(key)
48 timestep.observation = self._add_agent_ids(timestep, self._env.num_agents)
49
50 return state, timestep
51
52 def step(
53 self,
54 state: State,
55 action: chex.Array,
56 ) -> Tuple[State, TimeStep]:
57 """Step the environment."""
58 state, timestep = self._env.step(state, action)
59 timestep.observation = self._add_agent_ids(timestep, self._env.num_agents)
60
61 return state, timestep
62
63 def observation_spec(
64 self,
65 ) -> Union[specs.Spec[Observation], specs.Spec[ObservationGlobalState]]:
66 """Specification of the observation of the selected environment."""
67 obs_spec = self._env.observation_spec()
68 num_obs_features = obs_spec.agents_view.shape[-1] + self._env.num_agents
69 dtype = obs_spec.agents_view.dtype
70 agents_view = specs.Array((self._env.num_agents, num_obs_features), dtype, "agents_view")
71
72 return obs_spec.replace(agents_view=agents_view)
73
74
75 class GlobalStateWrapper(Wrapper):
76 """Wrapper for adding global state to an environment that follows the mava API.
77
78 The wrapper includes a global environment state to be used by the centralised critic.
79 Note here that since most environments do not have a global state, we create one
80 by concatenating the observations of all agents.
81 """
82
83 def modify_timestep(self, timestep: TimeStep) -> TimeStep[ObservationGlobalState]:
84 global_state = jnp.concatenate(timestep.observation.agents_view, axis=0)
85 global_state = jnp.tile(global_state, (self._env.num_agents, 1))
86
87 observation = ObservationGlobalState(
88 global_state=global_state,
89 agents_view=timestep.observation.agents_view,
90 action_mask=timestep.observation.action_mask,
91 step_count=timestep.observation.step_count,
92 )
93
94 return timestep.replace(observation=observation)
95
96 def reset(self, key: chex.PRNGKey) -> Tuple[State, TimeStep]:
97 """Reset the environment. Updates the step count."""
98 state, timestep = self._env.reset(key)
99 return state, self.modify_timestep(timestep)
100
101 def step(self, state: State, action: chex.Array) -> Tuple[State, TimeStep]:
102 """Step the environment. Updates the step count."""
103 state, timestep = self._env.step(state, action)
104 return state, self.modify_timestep(timestep)
105
106 def observation_spec(self) -> specs.Spec[ObservationGlobalState]:
107 """Specification of the observation of the selected environment."""
108
109 obs_spec = self._env.observation_spec()
110 num_obs_features = obs_spec.agents_view.shape[-1]
111 global_state = specs.Array(
112 (self._env.num_agents, self._env.num_agents * num_obs_features),
113 obs_spec.agents_view.dtype,
114 "global_state",
115 )
116
117 return specs.Spec(
118 ObservationGlobalState,
119 "ObservationSpec",
120 agents_view=obs_spec.agents_view,
121 action_mask=obs_spec.action_mask,
122 global_state=global_state,
123 step_count=obs_spec.step_count,
124 )
125
[end of mava/wrappers/observation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mava/wrappers/observation.py b/mava/wrappers/observation.py
--- a/mava/wrappers/observation.py
+++ b/mava/wrappers/observation.py
@@ -38,7 +38,11 @@
"""Adds agent IDs to the observation."""
obs = timestep.observation
agent_ids = jnp.eye(num_agents)
- agents_view = jnp.concatenate([agent_ids, obs.agents_view], axis=-1)
+ agents_view = jnp.concatenate(
+ [agent_ids, obs.agents_view],
+ axis=-1,
+ dtype=obs.agents_view.dtype,
+ )
return obs._replace(agents_view=agents_view) # type: ignore
|
{"golden_diff": "diff --git a/mava/wrappers/observation.py b/mava/wrappers/observation.py\n--- a/mava/wrappers/observation.py\n+++ b/mava/wrappers/observation.py\n@@ -38,7 +38,11 @@\n \"\"\"Adds agent IDs to the observation.\"\"\"\n obs = timestep.observation\n agent_ids = jnp.eye(num_agents)\n- agents_view = jnp.concatenate([agent_ids, obs.agents_view], axis=-1)\n+ agents_view = jnp.concatenate(\n+ [agent_ids, obs.agents_view],\n+ axis=-1,\n+ dtype=obs.agents_view.dtype,\n+ )\n \n return obs._replace(agents_view=agents_view) # type: ignore\n", "issue": "[BUG]: Flasbax bug on LBF (type issue)\n### Describe the bug\r\nIn the AgentID wrapper, the new_agents_view type is not enforced to be consistent, so for LBF with flashbax a dtype error emerges.\r\n\r\n### To Reproduce\r\nSteps to reproduce the behavior:\r\n1. Run LBF with flashbax.\r\n\r\n### Expected behavior\r\nExpected the observation to be added easily to the buffer.\r\n\r\n### Context (Environment)\r\n - Updated jumanji\r\n\r\n### Additional context\r\nThis is somewhat an exercise in opening an issue!\r\n\r\n### Possible Solution\r\nWill make a PR soon! Basically a cast to the agents_view type.\r\n\n", "before_files": [{"content": "# Copyright 2022 InstaDeep Ltd. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom typing import Tuple, Union\n\nimport chex\nimport jax.numpy as jnp\nfrom jumanji import specs\nfrom jumanji.env import Environment\nfrom jumanji.types import TimeStep\nfrom jumanji.wrappers import Wrapper\n\nfrom mava.types import Observation, ObservationGlobalState, State\n\n\nclass AgentIDWrapper(Wrapper):\n \"\"\"A wrapper to add a one-hot vector as agent IDs to the original observation.\n It can be useful in multi-agent environments where agents require unique identification.\n \"\"\"\n\n def __init__(self, env: Environment):\n super().__init__(env)\n\n def _add_agent_ids(\n self, timestep: TimeStep, num_agents: int\n ) -> Union[Observation, ObservationGlobalState]:\n \"\"\"Adds agent IDs to the observation.\"\"\"\n obs = timestep.observation\n agent_ids = jnp.eye(num_agents)\n agents_view = jnp.concatenate([agent_ids, obs.agents_view], axis=-1)\n\n return obs._replace(agents_view=agents_view) # type: ignore\n\n def reset(self, key: chex.PRNGKey) -> Tuple[State, TimeStep]:\n \"\"\"Reset the environment.\"\"\"\n state, timestep = self._env.reset(key)\n timestep.observation = self._add_agent_ids(timestep, self._env.num_agents)\n\n return state, timestep\n\n def step(\n self,\n state: State,\n action: chex.Array,\n ) -> Tuple[State, TimeStep]:\n \"\"\"Step the environment.\"\"\"\n state, timestep = self._env.step(state, action)\n timestep.observation = self._add_agent_ids(timestep, self._env.num_agents)\n\n return state, timestep\n\n def observation_spec(\n self,\n ) -> Union[specs.Spec[Observation], specs.Spec[ObservationGlobalState]]:\n \"\"\"Specification of the observation of the selected environment.\"\"\"\n obs_spec = self._env.observation_spec()\n num_obs_features = obs_spec.agents_view.shape[-1] + self._env.num_agents\n dtype = obs_spec.agents_view.dtype\n agents_view = specs.Array((self._env.num_agents, num_obs_features), dtype, \"agents_view\")\n\n return obs_spec.replace(agents_view=agents_view)\n\n\nclass GlobalStateWrapper(Wrapper):\n \"\"\"Wrapper for adding global state to an environment that follows the mava API.\n\n The wrapper includes a global environment state to be used by the centralised critic.\n Note here that since most environments do not have a global state, we create one\n by concatenating the observations of all agents.\n \"\"\"\n\n def modify_timestep(self, timestep: TimeStep) -> TimeStep[ObservationGlobalState]:\n global_state = jnp.concatenate(timestep.observation.agents_view, axis=0)\n global_state = jnp.tile(global_state, (self._env.num_agents, 1))\n\n observation = ObservationGlobalState(\n global_state=global_state,\n agents_view=timestep.observation.agents_view,\n action_mask=timestep.observation.action_mask,\n step_count=timestep.observation.step_count,\n )\n\n return timestep.replace(observation=observation)\n\n def reset(self, key: chex.PRNGKey) -> Tuple[State, TimeStep]:\n \"\"\"Reset the environment. Updates the step count.\"\"\"\n state, timestep = self._env.reset(key)\n return state, self.modify_timestep(timestep)\n\n def step(self, state: State, action: chex.Array) -> Tuple[State, TimeStep]:\n \"\"\"Step the environment. Updates the step count.\"\"\"\n state, timestep = self._env.step(state, action)\n return state, self.modify_timestep(timestep)\n\n def observation_spec(self) -> specs.Spec[ObservationGlobalState]:\n \"\"\"Specification of the observation of the selected environment.\"\"\"\n\n obs_spec = self._env.observation_spec()\n num_obs_features = obs_spec.agents_view.shape[-1]\n global_state = specs.Array(\n (self._env.num_agents, self._env.num_agents * num_obs_features),\n obs_spec.agents_view.dtype,\n \"global_state\",\n )\n\n return specs.Spec(\n ObservationGlobalState,\n \"ObservationSpec\",\n agents_view=obs_spec.agents_view,\n action_mask=obs_spec.action_mask,\n global_state=global_state,\n step_count=obs_spec.step_count,\n )\n", "path": "mava/wrappers/observation.py"}]}
| 2,018 | 162 |
gh_patches_debug_33669
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-441
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement a !role command
Currently, we have a `!roles` command, which lists out all the roles. However, it would also be useful to have a `!role <role>` command, to get more info on a certain role.
**Implementation details**
- Ability to get info on multiple roles? `!role <role_1> <role_2>`
- Info that would be helpful:
- Role ID
- Role Name
- Role Color as hex/hsv
- Is role mentionable
- Number of members with the role? (Blacklist certain high volume, easily checked ones like `@Developers`)
- Restrict to core developers and moderator+
</issue>
<code>
[start of bot/cogs/information.py]
1 import logging
2 import textwrap
3
4 from discord import CategoryChannel, Colour, Embed, Member, TextChannel, VoiceChannel
5 from discord.ext.commands import Bot, Cog, Context, command
6
7 from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES
8 from bot.decorators import InChannelCheckFailure, with_role
9 from bot.utils.checks import with_role_check
10 from bot.utils.time import time_since
11
12 log = logging.getLogger(__name__)
13
14
15 class Information(Cog):
16 """A cog with commands for generating embeds with server info, such as server stats and user info."""
17
18 def __init__(self, bot: Bot):
19 self.bot = bot
20
21 @with_role(*MODERATION_ROLES)
22 @command(name="roles")
23 async def roles_info(self, ctx: Context) -> None:
24 """Returns a list of all roles and their corresponding IDs."""
25 # Sort the roles alphabetically and remove the @everyone role
26 roles = sorted(ctx.guild.roles, key=lambda role: role.name)
27 roles = [role for role in roles if role.name != "@everyone"]
28
29 # Build a string
30 role_string = ""
31 for role in roles:
32 role_string += f"`{role.id}` - {role.mention}\n"
33
34 # Build an embed
35 embed = Embed(
36 title="Role information",
37 colour=Colour.blurple(),
38 description=role_string
39 )
40
41 embed.set_footer(text=f"Total roles: {len(roles)}")
42
43 await ctx.send(embed=embed)
44
45 @command(name="server", aliases=["server_info", "guild", "guild_info"])
46 async def server_info(self, ctx: Context) -> None:
47 """Returns an embed full of server information."""
48 created = time_since(ctx.guild.created_at, precision="days")
49 features = ", ".join(ctx.guild.features)
50 region = ctx.guild.region
51
52 # How many of each type of channel?
53 roles = len(ctx.guild.roles)
54 channels = ctx.guild.channels
55 text_channels = 0
56 category_channels = 0
57 voice_channels = 0
58 for channel in channels:
59 if type(channel) == TextChannel:
60 text_channels += 1
61 elif type(channel) == CategoryChannel:
62 category_channels += 1
63 elif type(channel) == VoiceChannel:
64 voice_channels += 1
65
66 # How many of each user status?
67 member_count = ctx.guild.member_count
68 members = ctx.guild.members
69 online = 0
70 dnd = 0
71 idle = 0
72 offline = 0
73 for member in members:
74 if str(member.status) == "online":
75 online += 1
76 elif str(member.status) == "offline":
77 offline += 1
78 elif str(member.status) == "idle":
79 idle += 1
80 elif str(member.status) == "dnd":
81 dnd += 1
82
83 embed = Embed(
84 colour=Colour.blurple(),
85 description=textwrap.dedent(f"""
86 **Server information**
87 Created: {created}
88 Voice region: {region}
89 Features: {features}
90
91 **Counts**
92 Members: {member_count:,}
93 Roles: {roles}
94 Text: {text_channels}
95 Voice: {voice_channels}
96 Channel categories: {category_channels}
97
98 **Members**
99 {Emojis.status_online} {online}
100 {Emojis.status_idle} {idle}
101 {Emojis.status_dnd} {dnd}
102 {Emojis.status_offline} {offline}
103 """)
104 )
105
106 embed.set_thumbnail(url=ctx.guild.icon_url)
107
108 await ctx.send(embed=embed)
109
110 @command(name="user", aliases=["user_info", "member", "member_info"])
111 async def user_info(self, ctx: Context, user: Member = None, hidden: bool = False) -> None:
112 """Returns info about a user."""
113 if user is None:
114 user = ctx.author
115
116 # Do a role check if this is being executed on someone other than the caller
117 if user != ctx.author and not with_role_check(ctx, *MODERATION_ROLES):
118 await ctx.send("You may not use this command on users other than yourself.")
119 return
120
121 # Non-moderators may only do this in #bot-commands and can't see hidden infractions.
122 if not with_role_check(ctx, *STAFF_ROLES):
123 if not ctx.channel.id == Channels.bot:
124 raise InChannelCheckFailure(Channels.bot)
125 # Hide hidden infractions for users without a moderation role
126 hidden = False
127
128 # User information
129 created = time_since(user.created_at, max_units=3)
130
131 name = str(user)
132 if user.nick:
133 name = f"{user.nick} ({name})"
134
135 # Member information
136 joined = time_since(user.joined_at, precision="days")
137
138 # You're welcome, Volcyyyyyyyyyyyyyyyy
139 roles = ", ".join(role.mention for role in user.roles if role.name != "@everyone")
140
141 # Infractions
142 infractions = await self.bot.api_client.get(
143 'bot/infractions',
144 params={
145 'hidden': str(hidden),
146 'user__id': str(user.id)
147 }
148 )
149
150 infr_total = 0
151 infr_active = 0
152
153 # At least it's readable.
154 for infr in infractions:
155 if infr["active"]:
156 infr_active += 1
157
158 infr_total += 1
159
160 # Let's build the embed now
161 embed = Embed(
162 title=name,
163 description=textwrap.dedent(f"""
164 **User Information**
165 Created: {created}
166 Profile: {user.mention}
167 ID: {user.id}
168
169 **Member Information**
170 Joined: {joined}
171 Roles: {roles or None}
172
173 **Infractions**
174 Total: {infr_total}
175 Active: {infr_active}
176 """)
177 )
178
179 embed.set_thumbnail(url=user.avatar_url_as(format="png"))
180 embed.colour = user.top_role.colour if roles else Colour.blurple()
181
182 await ctx.send(embed=embed)
183
184
185 def setup(bot: Bot) -> None:
186 """Information cog load."""
187 bot.add_cog(Information(bot))
188 log.info("Cog loaded: Information")
189
[end of bot/cogs/information.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/information.py b/bot/cogs/information.py
--- a/bot/cogs/information.py
+++ b/bot/cogs/information.py
@@ -1,7 +1,9 @@
+import colorsys
import logging
import textwrap
+import typing
-from discord import CategoryChannel, Colour, Embed, Member, TextChannel, VoiceChannel
+from discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils
from discord.ext.commands import Bot, Cog, Context, command
from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES
@@ -42,6 +44,52 @@
await ctx.send(embed=embed)
+ @with_role(*MODERATION_ROLES)
+ @command(name="role")
+ async def role_info(self, ctx: Context, *roles: typing.Union[Role, str]) -> None:
+ """
+ Return information on a role or list of roles.
+
+ To specify multiple roles just add to the arguments, delimit roles with spaces in them using quotation marks.
+ """
+ parsed_roles = []
+
+ for role_name in roles:
+ if isinstance(role_name, Role):
+ # Role conversion has already succeeded
+ parsed_roles.append(role_name)
+ continue
+
+ role = utils.find(lambda r: r.name.lower() == role_name.lower(), ctx.guild.roles)
+
+ if not role:
+ await ctx.send(f":x: Could not convert `{role_name}` to a role")
+ continue
+
+ parsed_roles.append(role)
+
+ for role in parsed_roles:
+ embed = Embed(
+ title=f"{role.name} info",
+ colour=role.colour,
+ )
+
+ embed.add_field(name="ID", value=role.id, inline=True)
+
+ embed.add_field(name="Colour (RGB)", value=f"#{role.colour.value:0>6x}", inline=True)
+
+ h, s, v = colorsys.rgb_to_hsv(*role.colour.to_rgb())
+
+ embed.add_field(name="Colour (HSV)", value=f"{h:.2f} {s:.2f} {v}", inline=True)
+
+ embed.add_field(name="Member count", value=len(role.members), inline=True)
+
+ embed.add_field(name="Position", value=role.position)
+
+ embed.add_field(name="Permission code", value=role.permissions.value, inline=True)
+
+ await ctx.send(embed=embed)
+
@command(name="server", aliases=["server_info", "guild", "guild_info"])
async def server_info(self, ctx: Context) -> None:
"""Returns an embed full of server information."""
|
{"golden_diff": "diff --git a/bot/cogs/information.py b/bot/cogs/information.py\n--- a/bot/cogs/information.py\n+++ b/bot/cogs/information.py\n@@ -1,7 +1,9 @@\n+import colorsys\n import logging\n import textwrap\n+import typing\n \n-from discord import CategoryChannel, Colour, Embed, Member, TextChannel, VoiceChannel\n+from discord import CategoryChannel, Colour, Embed, Member, Role, TextChannel, VoiceChannel, utils\n from discord.ext.commands import Bot, Cog, Context, command\n \n from bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES\n@@ -42,6 +44,52 @@\n \n await ctx.send(embed=embed)\n \n+ @with_role(*MODERATION_ROLES)\n+ @command(name=\"role\")\n+ async def role_info(self, ctx: Context, *roles: typing.Union[Role, str]) -> None:\n+ \"\"\"\n+ Return information on a role or list of roles.\n+\n+ To specify multiple roles just add to the arguments, delimit roles with spaces in them using quotation marks.\n+ \"\"\"\n+ parsed_roles = []\n+\n+ for role_name in roles:\n+ if isinstance(role_name, Role):\n+ # Role conversion has already succeeded\n+ parsed_roles.append(role_name)\n+ continue\n+\n+ role = utils.find(lambda r: r.name.lower() == role_name.lower(), ctx.guild.roles)\n+\n+ if not role:\n+ await ctx.send(f\":x: Could not convert `{role_name}` to a role\")\n+ continue\n+\n+ parsed_roles.append(role)\n+\n+ for role in parsed_roles:\n+ embed = Embed(\n+ title=f\"{role.name} info\",\n+ colour=role.colour,\n+ )\n+\n+ embed.add_field(name=\"ID\", value=role.id, inline=True)\n+\n+ embed.add_field(name=\"Colour (RGB)\", value=f\"#{role.colour.value:0>6x}\", inline=True)\n+\n+ h, s, v = colorsys.rgb_to_hsv(*role.colour.to_rgb())\n+\n+ embed.add_field(name=\"Colour (HSV)\", value=f\"{h:.2f} {s:.2f} {v}\", inline=True)\n+\n+ embed.add_field(name=\"Member count\", value=len(role.members), inline=True)\n+\n+ embed.add_field(name=\"Position\", value=role.position)\n+\n+ embed.add_field(name=\"Permission code\", value=role.permissions.value, inline=True)\n+\n+ await ctx.send(embed=embed)\n+\n @command(name=\"server\", aliases=[\"server_info\", \"guild\", \"guild_info\"])\n async def server_info(self, ctx: Context) -> None:\n \"\"\"Returns an embed full of server information.\"\"\"\n", "issue": "Implement a !role command\nCurrently, we have a `!roles` command, which lists out all the roles. However, it would also be useful to have a `!role <role>` command, to get more info on a certain role.\r\n\r\n**Implementation details**\r\n- Ability to get info on multiple roles? `!role <role_1> <role_2>`\r\n- Info that would be helpful:\r\n - Role ID\r\n - Role Name\r\n - Role Color as hex/hsv\r\n - Is role mentionable\r\n - Number of members with the role? (Blacklist certain high volume, easily checked ones like `@Developers`)\r\n- Restrict to core developers and moderator+\r\n\n", "before_files": [{"content": "import logging\nimport textwrap\n\nfrom discord import CategoryChannel, Colour, Embed, Member, TextChannel, VoiceChannel\nfrom discord.ext.commands import Bot, Cog, Context, command\n\nfrom bot.constants import Channels, Emojis, MODERATION_ROLES, STAFF_ROLES\nfrom bot.decorators import InChannelCheckFailure, with_role\nfrom bot.utils.checks import with_role_check\nfrom bot.utils.time import time_since\n\nlog = logging.getLogger(__name__)\n\n\nclass Information(Cog):\n \"\"\"A cog with commands for generating embeds with server info, such as server stats and user info.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n @with_role(*MODERATION_ROLES)\n @command(name=\"roles\")\n async def roles_info(self, ctx: Context) -> None:\n \"\"\"Returns a list of all roles and their corresponding IDs.\"\"\"\n # Sort the roles alphabetically and remove the @everyone role\n roles = sorted(ctx.guild.roles, key=lambda role: role.name)\n roles = [role for role in roles if role.name != \"@everyone\"]\n\n # Build a string\n role_string = \"\"\n for role in roles:\n role_string += f\"`{role.id}` - {role.mention}\\n\"\n\n # Build an embed\n embed = Embed(\n title=\"Role information\",\n colour=Colour.blurple(),\n description=role_string\n )\n\n embed.set_footer(text=f\"Total roles: {len(roles)}\")\n\n await ctx.send(embed=embed)\n\n @command(name=\"server\", aliases=[\"server_info\", \"guild\", \"guild_info\"])\n async def server_info(self, ctx: Context) -> None:\n \"\"\"Returns an embed full of server information.\"\"\"\n created = time_since(ctx.guild.created_at, precision=\"days\")\n features = \", \".join(ctx.guild.features)\n region = ctx.guild.region\n\n # How many of each type of channel?\n roles = len(ctx.guild.roles)\n channels = ctx.guild.channels\n text_channels = 0\n category_channels = 0\n voice_channels = 0\n for channel in channels:\n if type(channel) == TextChannel:\n text_channels += 1\n elif type(channel) == CategoryChannel:\n category_channels += 1\n elif type(channel) == VoiceChannel:\n voice_channels += 1\n\n # How many of each user status?\n member_count = ctx.guild.member_count\n members = ctx.guild.members\n online = 0\n dnd = 0\n idle = 0\n offline = 0\n for member in members:\n if str(member.status) == \"online\":\n online += 1\n elif str(member.status) == \"offline\":\n offline += 1\n elif str(member.status) == \"idle\":\n idle += 1\n elif str(member.status) == \"dnd\":\n dnd += 1\n\n embed = Embed(\n colour=Colour.blurple(),\n description=textwrap.dedent(f\"\"\"\n **Server information**\n Created: {created}\n Voice region: {region}\n Features: {features}\n\n **Counts**\n Members: {member_count:,}\n Roles: {roles}\n Text: {text_channels}\n Voice: {voice_channels}\n Channel categories: {category_channels}\n\n **Members**\n {Emojis.status_online} {online}\n {Emojis.status_idle} {idle}\n {Emojis.status_dnd} {dnd}\n {Emojis.status_offline} {offline}\n \"\"\")\n )\n\n embed.set_thumbnail(url=ctx.guild.icon_url)\n\n await ctx.send(embed=embed)\n\n @command(name=\"user\", aliases=[\"user_info\", \"member\", \"member_info\"])\n async def user_info(self, ctx: Context, user: Member = None, hidden: bool = False) -> None:\n \"\"\"Returns info about a user.\"\"\"\n if user is None:\n user = ctx.author\n\n # Do a role check if this is being executed on someone other than the caller\n if user != ctx.author and not with_role_check(ctx, *MODERATION_ROLES):\n await ctx.send(\"You may not use this command on users other than yourself.\")\n return\n\n # Non-moderators may only do this in #bot-commands and can't see hidden infractions.\n if not with_role_check(ctx, *STAFF_ROLES):\n if not ctx.channel.id == Channels.bot:\n raise InChannelCheckFailure(Channels.bot)\n # Hide hidden infractions for users without a moderation role\n hidden = False\n\n # User information\n created = time_since(user.created_at, max_units=3)\n\n name = str(user)\n if user.nick:\n name = f\"{user.nick} ({name})\"\n\n # Member information\n joined = time_since(user.joined_at, precision=\"days\")\n\n # You're welcome, Volcyyyyyyyyyyyyyyyy\n roles = \", \".join(role.mention for role in user.roles if role.name != \"@everyone\")\n\n # Infractions\n infractions = await self.bot.api_client.get(\n 'bot/infractions',\n params={\n 'hidden': str(hidden),\n 'user__id': str(user.id)\n }\n )\n\n infr_total = 0\n infr_active = 0\n\n # At least it's readable.\n for infr in infractions:\n if infr[\"active\"]:\n infr_active += 1\n\n infr_total += 1\n\n # Let's build the embed now\n embed = Embed(\n title=name,\n description=textwrap.dedent(f\"\"\"\n **User Information**\n Created: {created}\n Profile: {user.mention}\n ID: {user.id}\n\n **Member Information**\n Joined: {joined}\n Roles: {roles or None}\n\n **Infractions**\n Total: {infr_total}\n Active: {infr_active}\n \"\"\")\n )\n\n embed.set_thumbnail(url=user.avatar_url_as(format=\"png\"))\n embed.colour = user.top_role.colour if roles else Colour.blurple()\n\n await ctx.send(embed=embed)\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Information cog load.\"\"\"\n bot.add_cog(Information(bot))\n log.info(\"Cog loaded: Information\")\n", "path": "bot/cogs/information.py"}]}
| 2,513 | 604 |
gh_patches_debug_183
|
rasdani/github-patches
|
git_diff
|
wemake-services__wemake-python-styleguide-776
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add `reveal_type` to forbidden functions
Now it is not recognised as invalid.
However, there's no reason to use it in production.
</issue>
<code>
[start of wemake_python_styleguide/constants.py]
1 # -*- coding: utf-8 -*-
2
3 """
4 This module contains list of white- and black-listed ``python`` members.
5
6 It contains lists of keywords and built-in functions we discourage to use.
7 It also contains some exceptions that we allow to use in our codebase.
8 """
9
10 import re
11
12 from typing_extensions import Final
13
14 #: List of functions we forbid to use.
15 FUNCTIONS_BLACKLIST: Final = frozenset((
16 # Code generation:
17 'eval',
18 'exec',
19 'compile',
20
21 # Termination:
22 'exit',
23 'quit',
24
25 # Magic:
26 'globals',
27 'locals',
28 'vars',
29 'dir',
30
31 # IO:
32 'input', # print is handled via `flake8-print`
33 'breakpoint',
34
35 # Attribute access:
36 'hasattr',
37 'delattr',
38
39 # Gratis:
40 'copyright',
41 'help',
42 'credits',
43
44 # Dynamic imports:
45 '__import__',
46
47 # OOP:
48 'staticmethod',
49 ))
50
51 #: List of module metadata we forbid to use.
52 MODULE_METADATA_VARIABLES_BLACKLIST: Final = frozenset((
53 '__author__',
54 '__all__',
55 '__version__',
56 '__about__',
57 ))
58
59 #: List of variable names we forbid to use.
60 VARIABLE_NAMES_BLACKLIST: Final = frozenset((
61 # Meaningless words:
62 'data',
63 'result',
64 'results',
65 'item',
66 'items',
67 'value',
68 'values',
69 'val',
70 'vals',
71 'var',
72 'vars',
73 'variable',
74 'content',
75 'contents',
76 'info',
77 'handle',
78 'handler',
79 'file',
80 'obj',
81 'objects',
82 'objs',
83 'some',
84 'do',
85 'param',
86 'params',
87 'parameters',
88
89 # Confuseables:
90 'no',
91 'true',
92 'false',
93
94 # Names from examples:
95 'foo',
96 'bar',
97 'baz',
98 ))
99
100 #: List of special names that are used only as first argument in methods.
101 SPECIAL_ARGUMENT_NAMES_WHITELIST: Final = frozenset((
102 'self',
103 'cls',
104 'mcs',
105 ))
106
107 #: List of all magic methods from the python docs.
108 ALL_MAGIC_METHODS: Final = frozenset((
109 '__new__',
110 '__init__',
111 '__del__',
112
113 '__repr__',
114 '__str__',
115 '__bytes__',
116 '__format__',
117
118 '__lt__',
119 '__le__',
120 '__eq__',
121 '__ne__',
122 '__gt__',
123 '__ge__',
124
125 '__hash__',
126 '__bool__',
127
128 '__getattr__',
129 '__getattribute__',
130 '__setattr__',
131 '__delattr__',
132 '__dir__',
133
134 '__get__',
135 '__set__',
136 '__delete__',
137 '__set_name__',
138
139 '__init_subclass__',
140 '__instancecheck__',
141 '__subclasscheck__',
142 '__class_getitem__',
143
144 '__call__',
145 '__len__',
146 '__length_hint__',
147 '__getitem__',
148 '__setitem__',
149 '__delitem__',
150 '__missing__',
151 '__iter__',
152 '__reversed__',
153 '__contains__',
154
155 '__add__',
156 '__sub__',
157 '__mul__',
158 '__matmul__',
159 '__truediv__',
160 '__floordiv__',
161 '__mod__',
162 '__divmod__',
163 '__pow__',
164 '__lshift__',
165 '__rshift__',
166 '__and__',
167 '__xor__',
168 '__or__',
169 '__radd__',
170 '__rsub__',
171 '__rmul__',
172 '__rmatmul__',
173 '__rtruediv__',
174 '__rfloordiv__',
175 '__rmod__',
176 '__rdivmod__',
177 '__rpow__',
178 '__rlshift__',
179 '__rrshift__',
180 '__rand__',
181 '__rxor__',
182 '__ror__',
183 '__iadd__',
184 '__isub__',
185 '__imul__',
186 '__imatmul__',
187 '__itruediv__',
188 '__ifloordiv__',
189 '__imod__',
190 '__ipow__',
191 '__ilshift__',
192 '__irshift__',
193 '__iand__',
194 '__ixor__',
195 '__ior__',
196 '__neg__',
197 '__pos__',
198 '__abs__',
199 '__invert__',
200 '__complex__',
201 '__int__',
202 '__float__',
203 '__index__',
204 '__round__',
205 '__trunc__',
206 '__floor__',
207 '__ceil__',
208
209 '__enter__',
210 '__exit__',
211
212 '__await__',
213 '__aiter__',
214 '__anext__',
215 '__aenter__',
216 '__aexit__',
217 ))
218
219 #: List of magic methods that are forbidden to use.
220 MAGIC_METHODS_BLACKLIST: Final = frozenset((
221 # Since we don't use `del`:
222 '__del__',
223 '__delitem__',
224 '__delete__',
225
226 '__dir__', # since we don't use `dir()`
227 '__delattr__', # since we don't use `delattr()`
228 ))
229
230 #: List of magic methods that are not allowed to be generators.
231 YIELD_MAGIC_METHODS_BLACKLIST: Final = ALL_MAGIC_METHODS.difference({
232 # Allowed to be used with ``yield`` keyowrd:
233 '__iter__',
234 })
235
236 #: List of magic methods that are not allowed to be async.
237 ASYNC_MAGIC_METHODS_BLACKLIST: Final = ALL_MAGIC_METHODS.difference({
238 # In order of appearance on
239 # https://docs.python.org/3/reference/datamodel.html#basic-customization
240 # Allowed magic methods are:
241 '__anext__',
242 '__aenter__',
243 '__aexit__',
244 })
245
246 #: List of nested classes' names we allow to use.
247 NESTED_CLASSES_WHITELIST: Final = frozenset((
248 'Meta', # django forms, models, drf, etc
249 'Params', # factoryboy specific
250 ))
251
252 #: List of builtin classes that are allowed to subclass.
253 ALLOWED_BUILTIN_CLASSES: Final = frozenset((
254 'type',
255 'object',
256 ))
257
258 #: List of nested functions' names we allow to use.
259 NESTED_FUNCTIONS_WHITELIST: Final = frozenset((
260 'decorator',
261 'factory',
262 ))
263
264 #: List of allowed ``__future__`` imports.
265 FUTURE_IMPORTS_WHITELIST: Final = frozenset((
266 'annotations',
267 'generator_stop',
268 ))
269
270 #: List of blacklisted module names.
271 MODULE_NAMES_BLACKLIST: Final = frozenset((
272 'util',
273 'utils',
274 'utilities',
275 'helpers',
276 ))
277
278 #: List of allowed module magic names.
279 MAGIC_MODULE_NAMES_WHITELIST: Final = frozenset((
280 '__init__',
281 '__main__',
282 ))
283
284 #: List of bad magic module functions.
285 MAGIC_MODULE_NAMES_BLACKLIST: Final = frozenset((
286 '__getattr__',
287 '__dir__',
288 ))
289
290 #: Regex pattern to name modules.
291 MODULE_NAME_PATTERN: Final = re.compile(r'^_?_?[a-z][a-z\d_]*[a-z\d](__)?$')
292
293 #: Common numbers that are allowed to be used without being called "magic".
294 MAGIC_NUMBERS_WHITELIST: Final = frozenset((
295 0, # both int and float
296 0.5,
297 100,
298 1000,
299 1024, # bytes
300 24, # hours
301 60, # seconds, minutes
302
303 1j, # imaginary part of a complex number
304 ))
305
306 #: Maximum amount of ``noqa`` comments per module.
307 MAX_NOQA_COMMENTS: Final = 10
308
309 #: Maximum amount of ``pragma`` no-cover comments per module.
310 MAX_NO_COVER_COMMENTS: Final = 5
311
312 #: Maximum length of ``yield`` ``tuple`` expressions.
313 MAX_LEN_YIELD_TUPLE: Final = 5
314
315
316 # Internal variables
317 # They are not publicly documented since they are not used by the end user.
318
319 # Used as a default filename, when it is not passed by flake8:
320 STDIN: Final = 'stdin'
321
322 # Used as a special name patterns for unused variables, like _, __:
323 UNUSED_VARIABLE_REGEX: Final = re.compile(r'^_+$')
324
325 # Used to specify as a placeholder for `__init__`:
326 INIT: Final = '__init__'
327
328 # Allowed magic number modulo:
329 NON_MAGIC_MODULO: Final = 10
330
331 # Used to specify a pattern which checks variables and modules for underscored
332 # numbers in their names:
333 UNDERSCORED_NUMBER_PATTERN: Final = re.compile(r'.+\D\_\d+(\D|$)')
334
[end of wemake_python_styleguide/constants.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wemake_python_styleguide/constants.py b/wemake_python_styleguide/constants.py
--- a/wemake_python_styleguide/constants.py
+++ b/wemake_python_styleguide/constants.py
@@ -46,6 +46,9 @@
# OOP:
'staticmethod',
+
+ # Mypy:
+ 'reveal_type',
))
#: List of module metadata we forbid to use.
|
{"golden_diff": "diff --git a/wemake_python_styleguide/constants.py b/wemake_python_styleguide/constants.py\n--- a/wemake_python_styleguide/constants.py\n+++ b/wemake_python_styleguide/constants.py\n@@ -46,6 +46,9 @@\n \n # OOP:\n 'staticmethod',\n+\n+ # Mypy:\n+ 'reveal_type',\n ))\n \n #: List of module metadata we forbid to use.\n", "issue": "Add `reveal_type` to forbidden functions\nNow it is not recognised as invalid.\r\nHowever, there's no reason to use it in production.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n\"\"\"\nThis module contains list of white- and black-listed ``python`` members.\n\nIt contains lists of keywords and built-in functions we discourage to use.\nIt also contains some exceptions that we allow to use in our codebase.\n\"\"\"\n\nimport re\n\nfrom typing_extensions import Final\n\n#: List of functions we forbid to use.\nFUNCTIONS_BLACKLIST: Final = frozenset((\n # Code generation:\n 'eval',\n 'exec',\n 'compile',\n\n # Termination:\n 'exit',\n 'quit',\n\n # Magic:\n 'globals',\n 'locals',\n 'vars',\n 'dir',\n\n # IO:\n 'input', # print is handled via `flake8-print`\n 'breakpoint',\n\n # Attribute access:\n 'hasattr',\n 'delattr',\n\n # Gratis:\n 'copyright',\n 'help',\n 'credits',\n\n # Dynamic imports:\n '__import__',\n\n # OOP:\n 'staticmethod',\n))\n\n#: List of module metadata we forbid to use.\nMODULE_METADATA_VARIABLES_BLACKLIST: Final = frozenset((\n '__author__',\n '__all__',\n '__version__',\n '__about__',\n))\n\n#: List of variable names we forbid to use.\nVARIABLE_NAMES_BLACKLIST: Final = frozenset((\n # Meaningless words:\n 'data',\n 'result',\n 'results',\n 'item',\n 'items',\n 'value',\n 'values',\n 'val',\n 'vals',\n 'var',\n 'vars',\n 'variable',\n 'content',\n 'contents',\n 'info',\n 'handle',\n 'handler',\n 'file',\n 'obj',\n 'objects',\n 'objs',\n 'some',\n 'do',\n 'param',\n 'params',\n 'parameters',\n\n # Confuseables:\n 'no',\n 'true',\n 'false',\n\n # Names from examples:\n 'foo',\n 'bar',\n 'baz',\n))\n\n#: List of special names that are used only as first argument in methods.\nSPECIAL_ARGUMENT_NAMES_WHITELIST: Final = frozenset((\n 'self',\n 'cls',\n 'mcs',\n))\n\n#: List of all magic methods from the python docs.\nALL_MAGIC_METHODS: Final = frozenset((\n '__new__',\n '__init__',\n '__del__',\n\n '__repr__',\n '__str__',\n '__bytes__',\n '__format__',\n\n '__lt__',\n '__le__',\n '__eq__',\n '__ne__',\n '__gt__',\n '__ge__',\n\n '__hash__',\n '__bool__',\n\n '__getattr__',\n '__getattribute__',\n '__setattr__',\n '__delattr__',\n '__dir__',\n\n '__get__',\n '__set__',\n '__delete__',\n '__set_name__',\n\n '__init_subclass__',\n '__instancecheck__',\n '__subclasscheck__',\n '__class_getitem__',\n\n '__call__',\n '__len__',\n '__length_hint__',\n '__getitem__',\n '__setitem__',\n '__delitem__',\n '__missing__',\n '__iter__',\n '__reversed__',\n '__contains__',\n\n '__add__',\n '__sub__',\n '__mul__',\n '__matmul__',\n '__truediv__',\n '__floordiv__',\n '__mod__',\n '__divmod__',\n '__pow__',\n '__lshift__',\n '__rshift__',\n '__and__',\n '__xor__',\n '__or__',\n '__radd__',\n '__rsub__',\n '__rmul__',\n '__rmatmul__',\n '__rtruediv__',\n '__rfloordiv__',\n '__rmod__',\n '__rdivmod__',\n '__rpow__',\n '__rlshift__',\n '__rrshift__',\n '__rand__',\n '__rxor__',\n '__ror__',\n '__iadd__',\n '__isub__',\n '__imul__',\n '__imatmul__',\n '__itruediv__',\n '__ifloordiv__',\n '__imod__',\n '__ipow__',\n '__ilshift__',\n '__irshift__',\n '__iand__',\n '__ixor__',\n '__ior__',\n '__neg__',\n '__pos__',\n '__abs__',\n '__invert__',\n '__complex__',\n '__int__',\n '__float__',\n '__index__',\n '__round__',\n '__trunc__',\n '__floor__',\n '__ceil__',\n\n '__enter__',\n '__exit__',\n\n '__await__',\n '__aiter__',\n '__anext__',\n '__aenter__',\n '__aexit__',\n))\n\n#: List of magic methods that are forbidden to use.\nMAGIC_METHODS_BLACKLIST: Final = frozenset((\n # Since we don't use `del`:\n '__del__',\n '__delitem__',\n '__delete__',\n\n '__dir__', # since we don't use `dir()`\n '__delattr__', # since we don't use `delattr()`\n))\n\n#: List of magic methods that are not allowed to be generators.\nYIELD_MAGIC_METHODS_BLACKLIST: Final = ALL_MAGIC_METHODS.difference({\n # Allowed to be used with ``yield`` keyowrd:\n '__iter__',\n})\n\n#: List of magic methods that are not allowed to be async.\nASYNC_MAGIC_METHODS_BLACKLIST: Final = ALL_MAGIC_METHODS.difference({\n # In order of appearance on\n # https://docs.python.org/3/reference/datamodel.html#basic-customization\n # Allowed magic methods are:\n '__anext__',\n '__aenter__',\n '__aexit__',\n})\n\n#: List of nested classes' names we allow to use.\nNESTED_CLASSES_WHITELIST: Final = frozenset((\n 'Meta', # django forms, models, drf, etc\n 'Params', # factoryboy specific\n))\n\n#: List of builtin classes that are allowed to subclass.\nALLOWED_BUILTIN_CLASSES: Final = frozenset((\n 'type',\n 'object',\n))\n\n#: List of nested functions' names we allow to use.\nNESTED_FUNCTIONS_WHITELIST: Final = frozenset((\n 'decorator',\n 'factory',\n))\n\n#: List of allowed ``__future__`` imports.\nFUTURE_IMPORTS_WHITELIST: Final = frozenset((\n 'annotations',\n 'generator_stop',\n))\n\n#: List of blacklisted module names.\nMODULE_NAMES_BLACKLIST: Final = frozenset((\n 'util',\n 'utils',\n 'utilities',\n 'helpers',\n))\n\n#: List of allowed module magic names.\nMAGIC_MODULE_NAMES_WHITELIST: Final = frozenset((\n '__init__',\n '__main__',\n))\n\n#: List of bad magic module functions.\nMAGIC_MODULE_NAMES_BLACKLIST: Final = frozenset((\n '__getattr__',\n '__dir__',\n))\n\n#: Regex pattern to name modules.\nMODULE_NAME_PATTERN: Final = re.compile(r'^_?_?[a-z][a-z\\d_]*[a-z\\d](__)?$')\n\n#: Common numbers that are allowed to be used without being called \"magic\".\nMAGIC_NUMBERS_WHITELIST: Final = frozenset((\n 0, # both int and float\n 0.5,\n 100,\n 1000,\n 1024, # bytes\n 24, # hours\n 60, # seconds, minutes\n\n 1j, # imaginary part of a complex number\n))\n\n#: Maximum amount of ``noqa`` comments per module.\nMAX_NOQA_COMMENTS: Final = 10\n\n#: Maximum amount of ``pragma`` no-cover comments per module.\nMAX_NO_COVER_COMMENTS: Final = 5\n\n#: Maximum length of ``yield`` ``tuple`` expressions.\nMAX_LEN_YIELD_TUPLE: Final = 5\n\n\n# Internal variables\n# They are not publicly documented since they are not used by the end user.\n\n# Used as a default filename, when it is not passed by flake8:\nSTDIN: Final = 'stdin'\n\n# Used as a special name patterns for unused variables, like _, __:\nUNUSED_VARIABLE_REGEX: Final = re.compile(r'^_+$')\n\n# Used to specify as a placeholder for `__init__`:\nINIT: Final = '__init__'\n\n# Allowed magic number modulo:\nNON_MAGIC_MODULO: Final = 10\n\n# Used to specify a pattern which checks variables and modules for underscored\n# numbers in their names:\nUNDERSCORED_NUMBER_PATTERN: Final = re.compile(r'.+\\D\\_\\d+(\\D|$)')\n", "path": "wemake_python_styleguide/constants.py"}]}
| 3,395 | 91 |
gh_patches_debug_3263
|
rasdani/github-patches
|
git_diff
|
aws-cloudformation__cfn-lint-2208
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Custom Rule not working for boolean values
*cfn-lint version: (`cfn-lint --version`)* 0.54.4
*Description of issue.* Attempting to create a custom rule to detect KMS keys that do not have auto rotate enabled. I discovered https://github.com/aws-cloudformation/cfn-lint/issues/2185 which covers the inability to react to absence of a value, but I'm just having issues with booleans. I'm able to trip the rules, so I know custom rules are registering, but I'm unable to get it to trip only against KMS Key resources who's EnableKeyRotation is false
Please provide as much information as possible:
* Template linting issues:
* Please provide a CloudFormation sample that generated the issue.
* If present, please add links to the (official) documentation for clarification.
* Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files
* Feature request:
* Please provide argumentation about the missing feature. Context is key!
Example cfn
```
---
AWSTemplateFormatVersion: '2010-09-09'
Resources:
TestKey:
Properties:
EnableKeyRotation: false
KeyPolicy:
Statement:
- Action: kms:*
Effect: Allow
Principal:
AWS:
Fn::Sub: arn:${AWS::Partition}:iam::${AWS::AccountId}:root
Resource: "*"
Sid: Enable key management, including IAM user permissions
Version: '2012-10-17'
Type: AWS::KMS::Key
```
rules file (showing different casings/quotings in case it's relevant)-
```
AWS::KMS::Key EnableKeyRotation == True ERROR "KMS keys should be configured to auto rotate"
AWS::KMS::Key EnableKeyRotation == true ERROR "KMS keys should be configured to auto rotate"
AWS::KMS::Key EnableKeyRotation == TRUE ERROR "KMS keys should be configured to auto rotate"
AWS::KMS::Key EnableKeyRotation == "True" ERROR "KMS keys should be configured to auto rotate"
AWS::KMS::Key EnableKeyRotation == "true" ERROR "KMS keys should be configured to auto rotate"
AWS::KMS::Key EnableKeyRotation == "TRUE" ERROR "KMS keys should be configured to auto rotate"
```
if I flip the rules to
```
AWS::KMS::Key EnableKeyRotation == false ERROR "KMS keys should be configured to auto rotate"
```
No change. But if I then flip the cfn template's EnableKeyRotation to `true` it is then flagged in violation
Cfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)
</issue>
<code>
[start of src/cfnlint/rules/custom/Operators.py]
1 """
2 Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
3 SPDX-License-Identifier: MIT-0
4 """
5 #pylint: disable=cyclic-import
6 import cfnlint.rules
7
8 OPERATOR = [
9 'EQUALS',
10 'NOT_EQUALS',
11 '==',
12 '!=',
13 'IN',
14 'NOT_IN',
15 '>=',
16 '<=']
17
18
19 def CreateCustomRule(rule_id, resourceType, prop, value, error_message, description, shortdesc, rule_func):
20
21 class CustomRule(cfnlint.rules.CloudFormationLintRule):
22
23 def __init__(self, rule_id, resourceType, prop, value, error_message, description, shortdesc, rule_func):
24 super(CustomRule, self).__init__()
25 self.resource_property_types.append(resourceType)
26 self.id = rule_id
27 self.property_chain = prop.split('.')
28 self.property_value = value
29 self.error_message = error_message
30 self.description = description
31 self.shortdesc = shortdesc
32 self.rule_func = rule_func
33
34 def _remaining_inset_properties(self, property_chain):
35 if len(property_chain) > 1:
36 return property_chain[1:]
37
38 return []
39
40 def _check_value(self, value, path, property_chain, cfn):
41 matches = []
42 if property_chain:
43 new_property_chain = self._remaining_inset_properties(property_chain)
44 matches.extend(
45 cfn.check_value(
46 value, property_chain[0], path,
47 check_value=self._check_value,
48 property_chain=new_property_chain,
49 cfn=cfn,
50 ))
51 return matches
52 if value:
53 matches.extend(self.rule_func(value, self.property_value, path))
54 return matches
55
56 def match_resource_properties(self, properties, _, path, cfn):
57 new_property_chain = self._remaining_inset_properties(self.property_chain)
58 return cfn.check_value(
59 properties, self.property_chain[0], path,
60 check_value=self._check_value,
61 property_chain=new_property_chain,
62 cfn=cfn,
63 )
64
65 return CustomRule(rule_id, resourceType, prop, value, error_message, description, shortdesc, rule_func)
66
67
68 def CreateEqualsRule(rule_id, resourceType, prop, value, error_message):
69 def rule_func(value, expected_value, path):
70 matches = []
71 if str(value).strip().lower() != str(expected_value).strip().lower():
72 matches.append(cfnlint.rules.RuleMatch(
73 path, error_message or 'Must equal check failed'))
74
75 return matches
76
77 return CreateCustomRule(
78 rule_id, resourceType, prop, value, error_message,
79 shortdesc='Custom rule to check for equal values',
80 description='Created from the custom rules parameter. This rule will check if a property value is equal to the specified value.',
81 rule_func=rule_func,
82 )
83
84
85 def CreateNotEqualsRule(rule_id, resourceType, prop, value, error_message):
86 def rule_func(value, expected_values, path):
87 matches = []
88 if str(value).strip().lower() == str(expected_values).strip().lower():
89 matches.append(cfnlint.rules.RuleMatch(
90 path, error_message or 'Must not equal check failed'))
91
92 return matches
93
94 return CreateCustomRule(
95 rule_id, resourceType, prop, value, error_message,
96 shortdesc='Custom rule to check for not equal values',
97 description='Created from the custom rules parameter. This rule will check if a property value is NOT equal to the specified value.',
98 rule_func=rule_func,
99 )
100
101
102 def CreateGreaterRule(rule_id, resourceType, prop, value, error_message):
103 def rule_func(value, expected_value, path):
104 matches = []
105 if checkInt(value.strip()) and checkInt(str(expected_value).strip()):
106 if value.strip().lower() < str(expected_value).strip().lower():
107 matches.append(cfnlint.rules.RuleMatch(
108 path, error_message or 'Greater than check failed'))
109 else:
110 matches.append(cfnlint.rules.RuleMatch(
111 path, error_message or 'Given values are not numeric'))
112
113 return matches
114
115 return CreateCustomRule(
116 rule_id, resourceType, prop, value, error_message,
117 shortdesc='Custom rule to check for if a value is greater than the specified value',
118 description='Created from the custom rules parameter. This rule will check if a property value is greater than the specified value.',
119 rule_func=rule_func,
120 )
121
122
123 def CreateLesserRule(rule_id, resourceType, prop, value, error_message):
124 def rule_func(value, expected_value, path):
125 matches = []
126 if checkInt(value.strip()) and checkInt(str(expected_value).strip()):
127 if value.strip().lower() > str(expected_value).strip().lower():
128 matches.append(cfnlint.rules.RuleMatch(
129 path, error_message or 'Lesser than check failed'))
130 else:
131 matches.append(cfnlint.rules.RuleMatch(
132 path, error_message or 'Given values are not numeric'))
133
134 return matches
135
136 return CreateCustomRule(
137 rule_id, resourceType, prop, value, error_message,
138 shortdesc='Custom rule to check for if a value is lesser than the specified value',
139 description='Created from the custom rules parameter. This rule will check if a property value is lesser than the specified value.',
140 rule_func=rule_func,
141 )
142
143
144 def CreateInSetRule(rule_id, resourceType, prop, value, error_message):
145 def rule_func(value, expected_values, path):
146 matches = []
147 if value not in expected_values:
148 matches.append(cfnlint.rules.RuleMatch(path, error_message or 'In set check failed'))
149
150 return matches
151
152 return CreateCustomRule(
153 rule_id, resourceType, prop, value, error_message,
154 shortdesc='Custom rule to check for if a value exists in a list of specified values',
155 description='Created from the custom rules parameter. This rule will check if a property value exists inside a list of specified values.',
156 rule_func=rule_func,
157 )
158
159
160 def CreateNotInSetRule(rule_id, resourceType, prop, value, error_message):
161 def rule_func(value, expected_values, path):
162 matches = []
163 if value in expected_values:
164 matches.append(cfnlint.rules.RuleMatch(
165 path, error_message or 'Not in set check failed'))
166
167 return matches
168
169 return CreateCustomRule(
170 rule_id, resourceType, prop, value, error_message,
171 shortdesc='Custom rule to check for if a value does not exist in a list of specified values',
172 description='Created from the custom rules parameter. This rule will check if a property value does not exist inside a list of specified values.',
173 rule_func=rule_func,
174 )
175
176
177 def CreateInvalidRule(rule_id, operator):
178 class InvalidRule(cfnlint.rules.CloudFormationLintRule):
179
180 def __init__(self, rule_id, operator):
181 super(InvalidRule, self).__init__()
182 self.id = rule_id
183 self.operator = operator
184 self.description = 'Created from the custom rule parameter. This rule is the result of an invalid configuration of a custom rule.'
185 self.shortdesc = 'Invalid custom rule configuration'
186
187 def match(self, _):
188 message = '"{0}" not in supported operators: [{1}]'
189 return [
190 cfnlint.rules.RuleMatch(
191 [], message.format(str(self.operator), ', '.join(OPERATOR)))
192 ]
193
194 return InvalidRule(rule_id, operator)
195
196
197 def checkInt(i):
198 """ Python 2.7 Compatibility - There is no isnumeric() method """
199 try:
200 int(i)
201 return True
202 except ValueError:
203 return False
204
[end of src/cfnlint/rules/custom/Operators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cfnlint/rules/custom/Operators.py b/src/cfnlint/rules/custom/Operators.py
--- a/src/cfnlint/rules/custom/Operators.py
+++ b/src/cfnlint/rules/custom/Operators.py
@@ -49,7 +49,7 @@
cfn=cfn,
))
return matches
- if value:
+ if value is not None:
matches.extend(self.rule_func(value, self.property_value, path))
return matches
|
{"golden_diff": "diff --git a/src/cfnlint/rules/custom/Operators.py b/src/cfnlint/rules/custom/Operators.py\n--- a/src/cfnlint/rules/custom/Operators.py\n+++ b/src/cfnlint/rules/custom/Operators.py\n@@ -49,7 +49,7 @@\n cfn=cfn,\n ))\n return matches\n- if value:\n+ if value is not None:\n matches.extend(self.rule_func(value, self.property_value, path))\n return matches\n", "issue": "Custom Rule not working for boolean values\n*cfn-lint version: (`cfn-lint --version`)* 0.54.4\r\n\r\n*Description of issue.* Attempting to create a custom rule to detect KMS keys that do not have auto rotate enabled. I discovered https://github.com/aws-cloudformation/cfn-lint/issues/2185 which covers the inability to react to absence of a value, but I'm just having issues with booleans. I'm able to trip the rules, so I know custom rules are registering, but I'm unable to get it to trip only against KMS Key resources who's EnableKeyRotation is false\r\n\r\nPlease provide as much information as possible:\r\n* Template linting issues:\r\n * Please provide a CloudFormation sample that generated the issue.\r\n * If present, please add links to the (official) documentation for clarification.\r\n * Validate if the issue still exists with the latest version of `cfn-lint` and/or the latest Spec files\r\n* Feature request:\r\n * Please provide argumentation about the missing feature. Context is key!\r\nExample cfn\r\n```\r\n---\r\nAWSTemplateFormatVersion: '2010-09-09'\r\nResources:\r\n TestKey:\r\n Properties:\r\n EnableKeyRotation: false\r\n KeyPolicy:\r\n Statement:\r\n - Action: kms:*\r\n Effect: Allow\r\n Principal:\r\n AWS:\r\n Fn::Sub: arn:${AWS::Partition}:iam::${AWS::AccountId}:root\r\n Resource: \"*\"\r\n Sid: Enable key management, including IAM user permissions\r\n Version: '2012-10-17'\r\n Type: AWS::KMS::Key\r\n```\r\n\r\nrules file (showing different casings/quotings in case it's relevant)-\r\n```\r\nAWS::KMS::Key EnableKeyRotation == True ERROR \"KMS keys should be configured to auto rotate\"\r\nAWS::KMS::Key EnableKeyRotation == true ERROR \"KMS keys should be configured to auto rotate\"\r\nAWS::KMS::Key EnableKeyRotation == TRUE ERROR \"KMS keys should be configured to auto rotate\"\r\nAWS::KMS::Key EnableKeyRotation == \"True\" ERROR \"KMS keys should be configured to auto rotate\"\r\nAWS::KMS::Key EnableKeyRotation == \"true\" ERROR \"KMS keys should be configured to auto rotate\"\r\nAWS::KMS::Key EnableKeyRotation == \"TRUE\" ERROR \"KMS keys should be configured to auto rotate\"\r\n```\r\n\r\nif I flip the rules to\r\n```\r\nAWS::KMS::Key EnableKeyRotation == false ERROR \"KMS keys should be configured to auto rotate\"\r\n```\r\nNo change. But if I then flip the cfn template's EnableKeyRotation to `true` it is then flagged in violation\r\n\r\nCfn-lint uses the [CloudFormation Resource Specifications](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/cfn-resource-specification.html) as the base to do validation. These files are included as part of the application version. Please update to the latest version of `cfn-lint` or update the spec files manually (`cfn-lint -u`)\r\n\n", "before_files": [{"content": "\"\"\"\nCopyright Amazon.com, Inc. or its affiliates. All Rights Reserved.\nSPDX-License-Identifier: MIT-0\n\"\"\"\n#pylint: disable=cyclic-import\nimport cfnlint.rules\n\nOPERATOR = [\n 'EQUALS',\n 'NOT_EQUALS',\n '==',\n '!=',\n 'IN',\n 'NOT_IN',\n '>=',\n '<=']\n\n\ndef CreateCustomRule(rule_id, resourceType, prop, value, error_message, description, shortdesc, rule_func):\n\n class CustomRule(cfnlint.rules.CloudFormationLintRule):\n\n def __init__(self, rule_id, resourceType, prop, value, error_message, description, shortdesc, rule_func):\n super(CustomRule, self).__init__()\n self.resource_property_types.append(resourceType)\n self.id = rule_id\n self.property_chain = prop.split('.')\n self.property_value = value\n self.error_message = error_message\n self.description = description\n self.shortdesc = shortdesc\n self.rule_func = rule_func\n\n def _remaining_inset_properties(self, property_chain):\n if len(property_chain) > 1:\n return property_chain[1:]\n\n return []\n\n def _check_value(self, value, path, property_chain, cfn):\n matches = []\n if property_chain:\n new_property_chain = self._remaining_inset_properties(property_chain)\n matches.extend(\n cfn.check_value(\n value, property_chain[0], path,\n check_value=self._check_value,\n property_chain=new_property_chain,\n cfn=cfn,\n ))\n return matches\n if value:\n matches.extend(self.rule_func(value, self.property_value, path))\n return matches\n\n def match_resource_properties(self, properties, _, path, cfn):\n new_property_chain = self._remaining_inset_properties(self.property_chain)\n return cfn.check_value(\n properties, self.property_chain[0], path,\n check_value=self._check_value,\n property_chain=new_property_chain,\n cfn=cfn,\n )\n\n return CustomRule(rule_id, resourceType, prop, value, error_message, description, shortdesc, rule_func)\n\n\ndef CreateEqualsRule(rule_id, resourceType, prop, value, error_message):\n def rule_func(value, expected_value, path):\n matches = []\n if str(value).strip().lower() != str(expected_value).strip().lower():\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Must equal check failed'))\n\n return matches\n\n return CreateCustomRule(\n rule_id, resourceType, prop, value, error_message,\n shortdesc='Custom rule to check for equal values',\n description='Created from the custom rules parameter. This rule will check if a property value is equal to the specified value.',\n rule_func=rule_func,\n )\n\n\ndef CreateNotEqualsRule(rule_id, resourceType, prop, value, error_message):\n def rule_func(value, expected_values, path):\n matches = []\n if str(value).strip().lower() == str(expected_values).strip().lower():\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Must not equal check failed'))\n\n return matches\n\n return CreateCustomRule(\n rule_id, resourceType, prop, value, error_message,\n shortdesc='Custom rule to check for not equal values',\n description='Created from the custom rules parameter. This rule will check if a property value is NOT equal to the specified value.',\n rule_func=rule_func,\n )\n\n\ndef CreateGreaterRule(rule_id, resourceType, prop, value, error_message):\n def rule_func(value, expected_value, path):\n matches = []\n if checkInt(value.strip()) and checkInt(str(expected_value).strip()):\n if value.strip().lower() < str(expected_value).strip().lower():\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Greater than check failed'))\n else:\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Given values are not numeric'))\n\n return matches\n\n return CreateCustomRule(\n rule_id, resourceType, prop, value, error_message,\n shortdesc='Custom rule to check for if a value is greater than the specified value',\n description='Created from the custom rules parameter. This rule will check if a property value is greater than the specified value.',\n rule_func=rule_func,\n )\n\n\ndef CreateLesserRule(rule_id, resourceType, prop, value, error_message):\n def rule_func(value, expected_value, path):\n matches = []\n if checkInt(value.strip()) and checkInt(str(expected_value).strip()):\n if value.strip().lower() > str(expected_value).strip().lower():\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Lesser than check failed'))\n else:\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Given values are not numeric'))\n\n return matches\n\n return CreateCustomRule(\n rule_id, resourceType, prop, value, error_message,\n shortdesc='Custom rule to check for if a value is lesser than the specified value',\n description='Created from the custom rules parameter. This rule will check if a property value is lesser than the specified value.',\n rule_func=rule_func,\n )\n\n\ndef CreateInSetRule(rule_id, resourceType, prop, value, error_message):\n def rule_func(value, expected_values, path):\n matches = []\n if value not in expected_values:\n matches.append(cfnlint.rules.RuleMatch(path, error_message or 'In set check failed'))\n\n return matches\n\n return CreateCustomRule(\n rule_id, resourceType, prop, value, error_message,\n shortdesc='Custom rule to check for if a value exists in a list of specified values',\n description='Created from the custom rules parameter. This rule will check if a property value exists inside a list of specified values.',\n rule_func=rule_func,\n )\n\n\ndef CreateNotInSetRule(rule_id, resourceType, prop, value, error_message):\n def rule_func(value, expected_values, path):\n matches = []\n if value in expected_values:\n matches.append(cfnlint.rules.RuleMatch(\n path, error_message or 'Not in set check failed'))\n\n return matches\n\n return CreateCustomRule(\n rule_id, resourceType, prop, value, error_message,\n shortdesc='Custom rule to check for if a value does not exist in a list of specified values',\n description='Created from the custom rules parameter. This rule will check if a property value does not exist inside a list of specified values.',\n rule_func=rule_func,\n )\n\n\ndef CreateInvalidRule(rule_id, operator):\n class InvalidRule(cfnlint.rules.CloudFormationLintRule):\n\n def __init__(self, rule_id, operator):\n super(InvalidRule, self).__init__()\n self.id = rule_id\n self.operator = operator\n self.description = 'Created from the custom rule parameter. This rule is the result of an invalid configuration of a custom rule.'\n self.shortdesc = 'Invalid custom rule configuration'\n\n def match(self, _):\n message = '\"{0}\" not in supported operators: [{1}]'\n return [\n cfnlint.rules.RuleMatch(\n [], message.format(str(self.operator), ', '.join(OPERATOR)))\n ]\n\n return InvalidRule(rule_id, operator)\n\n\ndef checkInt(i):\n \"\"\" Python 2.7 Compatibility - There is no isnumeric() method \"\"\"\n try:\n int(i)\n return True\n except ValueError:\n return False\n", "path": "src/cfnlint/rules/custom/Operators.py"}]}
| 3,352 | 103 |
gh_patches_debug_4076
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-1893
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Concurrent imports cause error in force_pydevd
Happened in Flask multiproc test on macOS, but I think it can potentially occur in any scenario where a module is imported concurrently from another thread:
```
I+05.947: Debuggee-86 stderr:
b'Error on request:\n'
b'Traceback (most recent call last):\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/werkzeug/serving.py", line 304, in run_wsgi\n'
b' execute(self.server.app)\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/werkzeug/serving.py", line 292, in execute\n'
b' application_iter = app(environ, start_response)\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/flask/_compat.py", line 36, in reraise\n'
b' raise value\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/tests/test_data/flask1/__init__.py", line 1, in <module>\n'
b' import debug_me # noqa\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/tests/DEBUGGEE_PYTHONPATH/debug_me/__init__.py", line 49, in <module>\n'
b' import ptvsd.server\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/ptvsd/server/__init__.py", line 9, in <module>\n'
b' import ptvsd._vendored.force_pydevd # noqa\n'
b' File "/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/ptvsd/_vendored/force_pydevd.py", line 14, in <module>\n'
b" prefix_matcher('pydev', '_pydev'))\n"
b' File "/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/ptvsd/_vendored/__init__.py", line 101, in check_modules\n'
b' for modname, mod in sys.modules.items():\n'
b'RuntimeError: dictionary changed size during iteration\n'
```
It needs to take a snapshot of the module list before iterating.
</issue>
<code>
[start of src/ptvsd/_vendored/__init__.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License. See LICENSE in the project root
3 # for license information.
4
5 from __future__ import absolute_import, division, print_function, unicode_literals
6
7 import contextlib
8 from importlib import import_module
9 import os
10 import sys
11
12 from . import _util
13
14
15 VENDORED_ROOT = os.path.dirname(os.path.abspath(__file__))
16 # TODO: Move the "pydevd" git submodule to the ptvsd/_vendored directory
17 # and then drop the following fallback.
18 if 'pydevd' not in os.listdir(VENDORED_ROOT):
19 VENDORED_ROOT = os.path.dirname(VENDORED_ROOT)
20
21
22 def list_all(resolve=False):
23 """Return the list of vendored projects."""
24 # TODO: Derive from os.listdir(VENDORED_ROOT)?
25 projects = [
26 'pydevd',
27 ]
28 if not resolve:
29 return projects
30 return [project_root(name) for name in projects]
31
32
33 def project_root(project):
34 """Return the path the root dir of the vendored project.
35
36 If "project" is an empty string then the path prefix for vendored
37 projects (e.g. "ptvsd/_vendored/") will be returned.
38 """
39 if not project:
40 project = ''
41 return os.path.join(VENDORED_ROOT, project)
42
43
44 def iter_project_files(project, relative=False, **kwargs):
45 """Yield (dirname, basename, filename) for all files in the project."""
46 if relative:
47 with _util.cwd(VENDORED_ROOT):
48 for result in _util.iter_all_files(project, **kwargs):
49 yield result
50 else:
51 root = project_root(project)
52 for result in _util.iter_all_files(root, **kwargs):
53 yield result
54
55
56 def iter_packaging_files(project):
57 """Yield the filenames for all files in the project.
58
59 The filenames are relative to "ptvsd/_vendored". This is most
60 useful for the "package data" in a setup.py.
61 """
62 # TODO: Use default filters? __pycache__ and .pyc?
63 prune_dir = None
64 exclude_file = None
65 try:
66 mod = import_module('._{}_packaging'.format(project), __name__)
67 except ImportError:
68 pass
69 else:
70 prune_dir = getattr(mod, 'prune_dir', prune_dir)
71 exclude_file = getattr(mod, 'exclude_file', exclude_file)
72 results = iter_project_files(
73 project,
74 relative=True,
75 prune_dir=prune_dir,
76 exclude_file=exclude_file,
77 )
78 for _, _, filename in results:
79 yield filename
80
81
82 def prefix_matcher(*prefixes):
83 """Return a module match func that matches any of the given prefixes."""
84 assert prefixes
85
86 def match(name, module):
87 for prefix in prefixes:
88 if name.startswith(prefix):
89 return True
90 else:
91 return False
92 return match
93
94
95 def check_modules(project, match, root=None):
96 """Verify that only vendored modules have been imported."""
97 if root is None:
98 root = project_root(project)
99 extensions = []
100 unvendored = {}
101 for modname, mod in sys.modules.items():
102 if not match(modname, mod):
103 continue
104 if not hasattr(mod, '__file__'): # extension module
105 extensions.append(modname)
106 elif not mod.__file__.startswith(root):
107 unvendored[modname] = mod.__file__
108 return unvendored, extensions
109
110
111 @contextlib.contextmanager
112 def vendored(project, root=None):
113 """A context manager under which the vendored project will be imported."""
114 if root is None:
115 root = project_root(project)
116 # Add the vendored project directory, so that it gets tried first.
117 sys.path.insert(0, root)
118 try:
119 yield root
120 finally:
121 sys.path.remove(root)
122
123
124 def preimport(project, modules, **kwargs):
125 """Import each of the named modules out of the vendored project."""
126 with vendored(project, **kwargs):
127 for name in modules:
128 import_module(name)
129
[end of src/ptvsd/_vendored/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/ptvsd/_vendored/__init__.py b/src/ptvsd/_vendored/__init__.py
--- a/src/ptvsd/_vendored/__init__.py
+++ b/src/ptvsd/_vendored/__init__.py
@@ -98,7 +98,7 @@
root = project_root(project)
extensions = []
unvendored = {}
- for modname, mod in sys.modules.items():
+ for modname, mod in list(sys.modules.items()):
if not match(modname, mod):
continue
if not hasattr(mod, '__file__'): # extension module
|
{"golden_diff": "diff --git a/src/ptvsd/_vendored/__init__.py b/src/ptvsd/_vendored/__init__.py\n--- a/src/ptvsd/_vendored/__init__.py\n+++ b/src/ptvsd/_vendored/__init__.py\n@@ -98,7 +98,7 @@\n root = project_root(project)\n extensions = []\n unvendored = {}\n- for modname, mod in sys.modules.items():\n+ for modname, mod in list(sys.modules.items()):\n if not match(modname, mod):\n continue\n if not hasattr(mod, '__file__'): # extension module\n", "issue": "Concurrent imports cause error in force_pydevd \nHappened in Flask multiproc test on macOS, but I think it can potentially occur in any scenario where a module is imported concurrently from another thread:\r\n```\r\nI+05.947: Debuggee-86 stderr:\r\n b'Error on request:\\n'\r\n b'Traceback (most recent call last):\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/werkzeug/serving.py\", line 304, in run_wsgi\\n'\r\n b' execute(self.server.app)\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/werkzeug/serving.py\", line 292, in execute\\n'\r\n b' application_iter = app(environ, start_response)\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/flask/_compat.py\", line 36, in reraise\\n'\r\n b' raise value\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/tests/test_data/flask1/__init__.py\", line 1, in <module>\\n'\r\n b' import debug_me # noqa\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/tests/DEBUGGEE_PYTHONPATH/debug_me/__init__.py\", line 49, in <module>\\n'\r\n b' import ptvsd.server\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/ptvsd/server/__init__.py\", line 9, in <module>\\n'\r\n b' import ptvsd._vendored.force_pydevd # noqa\\n'\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/ptvsd/_vendored/force_pydevd.py\", line 14, in <module>\\n'\r\n b\" prefix_matcher('pydev', '_pydev'))\\n\"\r\n b' File \"/Users/runner/runners/2.159.2/work/1/s/.tox/py37/lib/python3.7/site-packages/ptvsd/_vendored/__init__.py\", line 101, in check_modules\\n'\r\n b' for modname, mod in sys.modules.items():\\n'\r\n b'RuntimeError: dictionary changed size during iteration\\n'\r\n```\r\nIt needs to take a snapshot of the module list before iterating.\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nimport contextlib\nfrom importlib import import_module\nimport os\nimport sys\n\nfrom . import _util\n\n\nVENDORED_ROOT = os.path.dirname(os.path.abspath(__file__))\n# TODO: Move the \"pydevd\" git submodule to the ptvsd/_vendored directory\n# and then drop the following fallback.\nif 'pydevd' not in os.listdir(VENDORED_ROOT):\n VENDORED_ROOT = os.path.dirname(VENDORED_ROOT)\n\n\ndef list_all(resolve=False):\n \"\"\"Return the list of vendored projects.\"\"\"\n # TODO: Derive from os.listdir(VENDORED_ROOT)?\n projects = [\n 'pydevd',\n ]\n if not resolve:\n return projects\n return [project_root(name) for name in projects]\n\n\ndef project_root(project):\n \"\"\"Return the path the root dir of the vendored project.\n\n If \"project\" is an empty string then the path prefix for vendored\n projects (e.g. \"ptvsd/_vendored/\") will be returned.\n \"\"\"\n if not project:\n project = ''\n return os.path.join(VENDORED_ROOT, project)\n\n\ndef iter_project_files(project, relative=False, **kwargs):\n \"\"\"Yield (dirname, basename, filename) for all files in the project.\"\"\"\n if relative:\n with _util.cwd(VENDORED_ROOT):\n for result in _util.iter_all_files(project, **kwargs):\n yield result\n else:\n root = project_root(project)\n for result in _util.iter_all_files(root, **kwargs):\n yield result\n\n\ndef iter_packaging_files(project):\n \"\"\"Yield the filenames for all files in the project.\n\n The filenames are relative to \"ptvsd/_vendored\". This is most\n useful for the \"package data\" in a setup.py.\n \"\"\"\n # TODO: Use default filters? __pycache__ and .pyc?\n prune_dir = None\n exclude_file = None\n try:\n mod = import_module('._{}_packaging'.format(project), __name__)\n except ImportError:\n pass\n else:\n prune_dir = getattr(mod, 'prune_dir', prune_dir)\n exclude_file = getattr(mod, 'exclude_file', exclude_file)\n results = iter_project_files(\n project,\n relative=True,\n prune_dir=prune_dir,\n exclude_file=exclude_file,\n )\n for _, _, filename in results:\n yield filename\n\n\ndef prefix_matcher(*prefixes):\n \"\"\"Return a module match func that matches any of the given prefixes.\"\"\"\n assert prefixes\n\n def match(name, module):\n for prefix in prefixes:\n if name.startswith(prefix):\n return True\n else:\n return False\n return match\n\n\ndef check_modules(project, match, root=None):\n \"\"\"Verify that only vendored modules have been imported.\"\"\"\n if root is None:\n root = project_root(project)\n extensions = []\n unvendored = {}\n for modname, mod in sys.modules.items():\n if not match(modname, mod):\n continue\n if not hasattr(mod, '__file__'): # extension module\n extensions.append(modname)\n elif not mod.__file__.startswith(root):\n unvendored[modname] = mod.__file__\n return unvendored, extensions\n\n\[email protected]\ndef vendored(project, root=None):\n \"\"\"A context manager under which the vendored project will be imported.\"\"\"\n if root is None:\n root = project_root(project)\n # Add the vendored project directory, so that it gets tried first.\n sys.path.insert(0, root)\n try:\n yield root\n finally:\n sys.path.remove(root)\n\n\ndef preimport(project, modules, **kwargs):\n \"\"\"Import each of the named modules out of the vendored project.\"\"\"\n with vendored(project, **kwargs):\n for name in modules:\n import_module(name)\n", "path": "src/ptvsd/_vendored/__init__.py"}]}
| 2,384 | 146 |
gh_patches_debug_62030
|
rasdani/github-patches
|
git_diff
|
fonttools__fonttools-2472
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[feaLib] "fonttools feaLib" should error out, not continue
If there's a parse/build error when using the feaLib command line tool, we currently do this:
https://github.com/fonttools/fonttools/blob/445108f735b22a5ca37f669808d47906d024fe24/Lib/fontTools/feaLib/__main__.py#L69-L73
i.e. we save the font anyway and exit with status code 0.
My Makefiles and I think this is a terrible idea, and I would like to change it. Any objections / thoughts?
</issue>
<code>
[start of Lib/fontTools/feaLib/__main__.py]
1 from fontTools.ttLib import TTFont
2 from fontTools.feaLib.builder import addOpenTypeFeatures, Builder
3 from fontTools.feaLib.error import FeatureLibError
4 from fontTools import configLogger
5 from fontTools.misc.cliTools import makeOutputFileName
6 import sys
7 import argparse
8 import logging
9
10
11 log = logging.getLogger("fontTools.feaLib")
12
13
14 def main(args=None):
15 """Add features from a feature file (.fea) into a OTF font"""
16 parser = argparse.ArgumentParser(
17 description="Use fontTools to compile OpenType feature files (*.fea)."
18 )
19 parser.add_argument(
20 "input_fea", metavar="FEATURES", help="Path to the feature file"
21 )
22 parser.add_argument(
23 "input_font", metavar="INPUT_FONT", help="Path to the input font"
24 )
25 parser.add_argument(
26 "-o",
27 "--output",
28 dest="output_font",
29 metavar="OUTPUT_FONT",
30 help="Path to the output font.",
31 )
32 parser.add_argument(
33 "-t",
34 "--tables",
35 metavar="TABLE_TAG",
36 choices=Builder.supportedTables,
37 nargs="+",
38 help="Specify the table(s) to be built.",
39 )
40 parser.add_argument(
41 "-d",
42 "--debug",
43 action="store_true",
44 help="Add source-level debugging information to font.",
45 )
46 parser.add_argument(
47 "-v",
48 "--verbose",
49 help="increase the logger verbosity. Multiple -v " "options are allowed.",
50 action="count",
51 default=0,
52 )
53 parser.add_argument(
54 "--traceback", help="show traceback for exceptions.", action="store_true"
55 )
56 options = parser.parse_args(args)
57
58 levels = ["WARNING", "INFO", "DEBUG"]
59 configLogger(level=levels[min(len(levels) - 1, options.verbose)])
60
61 output_font = options.output_font or makeOutputFileName(options.input_font)
62 log.info("Compiling features to '%s'" % (output_font))
63
64 font = TTFont(options.input_font)
65 try:
66 addOpenTypeFeatures(
67 font, options.input_fea, tables=options.tables, debug=options.debug
68 )
69 except FeatureLibError as e:
70 if options.traceback:
71 raise
72 log.error(e)
73 font.save(output_font)
74
75
76 if __name__ == "__main__":
77 sys.exit(main())
78
[end of Lib/fontTools/feaLib/__main__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/Lib/fontTools/feaLib/__main__.py b/Lib/fontTools/feaLib/__main__.py
--- a/Lib/fontTools/feaLib/__main__.py
+++ b/Lib/fontTools/feaLib/__main__.py
@@ -70,6 +70,7 @@
if options.traceback:
raise
log.error(e)
+ sys.exit(1)
font.save(output_font)
|
{"golden_diff": "diff --git a/Lib/fontTools/feaLib/__main__.py b/Lib/fontTools/feaLib/__main__.py\n--- a/Lib/fontTools/feaLib/__main__.py\n+++ b/Lib/fontTools/feaLib/__main__.py\n@@ -70,6 +70,7 @@\n if options.traceback:\n raise\n log.error(e)\n+ sys.exit(1)\n font.save(output_font)\n", "issue": "[feaLib] \"fonttools feaLib\" should error out, not continue\nIf there's a parse/build error when using the feaLib command line tool, we currently do this:\r\n\r\nhttps://github.com/fonttools/fonttools/blob/445108f735b22a5ca37f669808d47906d024fe24/Lib/fontTools/feaLib/__main__.py#L69-L73\r\n\r\ni.e. we save the font anyway and exit with status code 0.\r\n\r\nMy Makefiles and I think this is a terrible idea, and I would like to change it. Any objections / thoughts?\r\n\r\n\n", "before_files": [{"content": "from fontTools.ttLib import TTFont\nfrom fontTools.feaLib.builder import addOpenTypeFeatures, Builder\nfrom fontTools.feaLib.error import FeatureLibError\nfrom fontTools import configLogger\nfrom fontTools.misc.cliTools import makeOutputFileName\nimport sys\nimport argparse\nimport logging\n\n\nlog = logging.getLogger(\"fontTools.feaLib\")\n\n\ndef main(args=None):\n \"\"\"Add features from a feature file (.fea) into a OTF font\"\"\"\n parser = argparse.ArgumentParser(\n description=\"Use fontTools to compile OpenType feature files (*.fea).\"\n )\n parser.add_argument(\n \"input_fea\", metavar=\"FEATURES\", help=\"Path to the feature file\"\n )\n parser.add_argument(\n \"input_font\", metavar=\"INPUT_FONT\", help=\"Path to the input font\"\n )\n parser.add_argument(\n \"-o\",\n \"--output\",\n dest=\"output_font\",\n metavar=\"OUTPUT_FONT\",\n help=\"Path to the output font.\",\n )\n parser.add_argument(\n \"-t\",\n \"--tables\",\n metavar=\"TABLE_TAG\",\n choices=Builder.supportedTables,\n nargs=\"+\",\n help=\"Specify the table(s) to be built.\",\n )\n parser.add_argument(\n \"-d\",\n \"--debug\",\n action=\"store_true\",\n help=\"Add source-level debugging information to font.\",\n )\n parser.add_argument(\n \"-v\",\n \"--verbose\",\n help=\"increase the logger verbosity. Multiple -v \" \"options are allowed.\",\n action=\"count\",\n default=0,\n )\n parser.add_argument(\n \"--traceback\", help=\"show traceback for exceptions.\", action=\"store_true\"\n )\n options = parser.parse_args(args)\n\n levels = [\"WARNING\", \"INFO\", \"DEBUG\"]\n configLogger(level=levels[min(len(levels) - 1, options.verbose)])\n\n output_font = options.output_font or makeOutputFileName(options.input_font)\n log.info(\"Compiling features to '%s'\" % (output_font))\n\n font = TTFont(options.input_font)\n try:\n addOpenTypeFeatures(\n font, options.input_fea, tables=options.tables, debug=options.debug\n )\n except FeatureLibError as e:\n if options.traceback:\n raise\n log.error(e)\n font.save(output_font)\n\n\nif __name__ == \"__main__\":\n sys.exit(main())\n", "path": "Lib/fontTools/feaLib/__main__.py"}]}
| 1,346 | 95 |
gh_patches_debug_6903
|
rasdani/github-patches
|
git_diff
|
spyder-ide__spyder-9831
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fail to Launch Spyder Tutorial
## Description
### What steps will reproduce the problem?
<!--- You can use Markdown here --->
After updating to spyder 4, when I click Help and than click to start spyder tutorial, it does not start the tutorial and will lead me to issue reporter.
### Traceback
```python-traceback
File "C:\Users\fengyy\AppData\Local\Continuum\anaconda3\lib\site-packages\spyder\plugins\help\plugin.py", line 453, in show_tutorial
text = open(tutorial).read()
FileNotFoundError: [Errno 2] No such file or directory: 'C:\\Users\\fengyy\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\spyder\\plugins\\help\\utils\\tutorial.rst'
```
## Versions
* Spyder version: 4.0.0b3
* Python version: 3.6.8
* Qt version: 5.9.6
* PyQt5 version: 5.9.2
* Operating System: Windows 7
### Dependencies
```
pygments >=2.0 : 2.4.2 (OK)
qdarkstyle >=2.6.4: 2.7 (OK)
sphinx >=0.6.6 : 2.1.2 (OK)
pyls >=0.27.0 : 0.27.0 (OK)
nbconvert >=4.0 : 5.5.0 (OK)
pandas >=0.13.1 : 0.23.4 (OK)
numpy >=1.7 : 1.16.4 (OK)
sympy >=0.7.3 : 1.4 (OK)
cython >=0.21 : 0.29.11 (OK)
qtconsole >=4.5.0 : 4.5.1 (OK)
IPython >=4.0 : 7.6.0 (OK)
matplotlib >=2.0.0: 3.1.0 (OK)
pylint >=0.25 : 2.3.1 (OK)
```
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright © Spyder Project Contributors
4 # Licensed under the terms of the MIT License
5 # (see spyder/__init__.py for details)
6
7 """
8 Spyder
9 ======
10
11 The Scientific Python Development Environment
12
13 Spyder is a powerful scientific environment written in Python, for Python,
14 and designed by and for scientists, engineers and data analysts.
15
16 It features a unique combination of the advanced editing, analysis, debugging
17 and profiling functionality of a comprehensive development tool with the data
18 exploration, interactive execution, deep inspection and beautiful visualization
19 capabilities of a scientific package.
20 """
21
22 from __future__ import print_function
23
24 import io
25 import os
26 import os.path as osp
27 import subprocess
28 import sys
29 import shutil
30
31 from distutils.core import setup
32 from distutils.command.install_data import install_data
33
34
35 #==============================================================================
36 # Check for Python 3
37 #==============================================================================
38 PY3 = sys.version_info[0] == 3
39
40
41 #==============================================================================
42 # Minimal Python version sanity check
43 # Taken from the notebook setup.py -- Modified BSD License
44 #==============================================================================
45 v = sys.version_info
46 if v[:2] < (2, 7) or (v[0] >= 3 and v[:2] < (3, 4)):
47 error = "ERROR: Spyder requires Python version 2.7 or 3.4 and above."
48 print(error, file=sys.stderr)
49 sys.exit(1)
50
51
52 #==============================================================================
53 # Constants
54 #==============================================================================
55 NAME = 'spyder'
56 LIBNAME = 'spyder'
57 from spyder import __version__, __website_url__ #analysis:ignore
58
59
60 #==============================================================================
61 # Auxiliary functions
62 #==============================================================================
63 def get_package_data(name, extlist):
64 """Return data files for package *name* with extensions in *extlist*"""
65 flist = []
66 # Workaround to replace os.path.relpath (not available until Python 2.6):
67 offset = len(name)+len(os.pathsep)
68 for dirpath, _dirnames, filenames in os.walk(name):
69 if 'tests' not in dirpath:
70 for fname in filenames:
71 if (not fname.startswith('.') and
72 osp.splitext(fname)[1] in extlist):
73 flist.append(osp.join(dirpath, fname)[offset:])
74 return flist
75
76
77 def get_subpackages(name):
78 """Return subpackages of package *name*"""
79 splist = []
80 for dirpath, _dirnames, _filenames in os.walk(name):
81 if 'tests' not in dirpath:
82 if osp.isfile(osp.join(dirpath, '__init__.py')):
83 splist.append(".".join(dirpath.split(os.sep)))
84 return splist
85
86
87 def get_data_files():
88 """Return data_files in a platform dependent manner"""
89 if sys.platform.startswith('linux'):
90 if PY3:
91 data_files = [('share/applications', ['scripts/spyder3.desktop']),
92 ('share/icons', ['img_src/spyder3.png']),
93 ('share/metainfo', ['scripts/spyder3.appdata.xml'])]
94 else:
95 data_files = [('share/applications', ['scripts/spyder.desktop']),
96 ('share/icons', ['img_src/spyder.png'])]
97 elif os.name == 'nt':
98 data_files = [('scripts', ['img_src/spyder.ico',
99 'img_src/spyder_reset.ico'])]
100 else:
101 data_files = []
102 return data_files
103
104
105 def get_packages():
106 """Return package list"""
107 packages = get_subpackages(LIBNAME)
108 return packages
109
110
111 #==============================================================================
112 # Make Linux detect Spyder desktop file
113 #==============================================================================
114 class MyInstallData(install_data):
115 def run(self):
116 install_data.run(self)
117 if sys.platform.startswith('linux'):
118 try:
119 subprocess.call(['update-desktop-database'])
120 except:
121 print("ERROR: unable to update desktop database",
122 file=sys.stderr)
123 CMDCLASS = {'install_data': MyInstallData}
124
125
126 #==============================================================================
127 # Main scripts
128 #==============================================================================
129 # NOTE: the '[...]_win_post_install.py' script is installed even on non-Windows
130 # platforms due to a bug in pip installation process
131 # See spyder-ide/spyder#1158.
132 SCRIPTS = ['%s_win_post_install.py' % NAME]
133 if PY3 and sys.platform.startswith('linux'):
134 SCRIPTS.append('spyder3')
135 else:
136 SCRIPTS.append('spyder')
137
138
139 #==============================================================================
140 # Files added to the package
141 #==============================================================================
142 EXTLIST = ['.pot', '.po', '.mo', '.svg', '.png', '.css', '.html', '.js',
143 '.ini', '.txt', '.qss', '.ttf', '.json']
144 if os.name == 'nt':
145 SCRIPTS += ['spyder.bat']
146 EXTLIST += ['.ico']
147
148
149 #==============================================================================
150 # Use Readme for long description
151 #==============================================================================
152 with io.open('README.md', encoding='utf-8') as f:
153 LONG_DESCRIPTION = f.read()
154
155
156 #==============================================================================
157 # Setup arguments
158 #==============================================================================
159 setup_args = dict(
160 name=NAME,
161 version=__version__,
162 description='The Scientific Python Development Environment',
163 long_description=LONG_DESCRIPTION,
164 long_description_content_type='text/markdown',
165 download_url=__website_url__ + "#fh5co-download",
166 author="The Spyder Project Contributors",
167 author_email="[email protected]",
168 url=__website_url__,
169 license='MIT',
170 keywords='PyQt5 editor console widgets IDE science data analysis IPython',
171 platforms=["Windows", "Linux", "Mac OS-X"],
172 packages=get_packages(),
173 package_data={LIBNAME: get_package_data(LIBNAME, EXTLIST)},
174 scripts=[osp.join('scripts', fname) for fname in SCRIPTS],
175 data_files=get_data_files(),
176 classifiers=['License :: OSI Approved :: MIT License',
177 'Operating System :: MacOS',
178 'Operating System :: Microsoft :: Windows',
179 'Operating System :: POSIX :: Linux',
180 'Programming Language :: Python :: 2',
181 'Programming Language :: Python :: 2.7',
182 'Programming Language :: Python :: 3',
183 'Programming Language :: Python :: 3.4',
184 'Programming Language :: Python :: 3.5',
185 'Programming Language :: Python :: 3.6',
186 'Programming Language :: Python :: 3.7',
187 'Development Status :: 5 - Production/Stable',
188 'Intended Audience :: Education',
189 'Intended Audience :: Science/Research',
190 'Intended Audience :: Developers',
191 'Topic :: Scientific/Engineering',
192 'Topic :: Software Development :: Widget Sets'],
193 cmdclass=CMDCLASS)
194
195
196 #==============================================================================
197 # Setuptools deps
198 #==============================================================================
199 if any(arg == 'bdist_wheel' for arg in sys.argv):
200 import setuptools # analysis:ignore
201
202 install_requires = [
203 'cloudpickle',
204 'pygments>=2.0',
205 'qtconsole>=4.5.0',
206 'nbconvert',
207 'sphinx',
208 'pylint',
209 'psutil',
210 'qtawesome>=0.5.7',
211 'qtpy>=1.5.0',
212 'pickleshare',
213 'pyzmq',
214 'chardet>=2.0.0',
215 'numpydoc',
216 'spyder-kernels>=1.4.0,<1.5.0',
217 'qdarkstyle>=2.7',
218 'atomicwrites',
219 'diff-match-patch',
220 'watchdog',
221 # Don't require keyring for Python 2 and Linux
222 # because it depends on system packages
223 'keyring;sys_platform!="linux2"',
224 # Packages for pyqt5 are only available in
225 # Python 3
226 'pyqt5<5.13;python_version>="3"',
227 # pyqt5 5.12 split WebEngine into the
228 # pyqtwebengine module
229 'pyqtwebengine<5.13;python_version>="3"',
230 # Pyls with all its dependencies
231 'python-language-server[all]>=0.27.0',
232 # Required to get SSH connections to remote kernels
233 'pexpect',
234 'paramiko;platform_system=="Windows"',
235 # Required for accesing xdg spec on Linux
236 'pyxdg;platform_system=="Linux"',
237 ]
238
239 extras_require = {
240 'test:python_version == "2.7"': ['mock'],
241 'test:platform_system == "Windows"': ['pywin32'],
242 'test': ['pytest<5.0',
243 'pytest-qt',
244 'pytest-mock',
245 'pytest-cov',
246 'pytest-xvfb;platform_system=="Linux"',
247 'pytest-ordering',
248 'pytest-lazy-fixture',
249 'mock',
250 'flaky',
251 'pandas',
252 'scipy',
253 'sympy',
254 'pillow',
255 'matplotlib',
256 'cython'],
257 }
258
259 if 'setuptools' in sys.modules:
260 setup_args['install_requires'] = install_requires
261 setup_args['extras_require'] = extras_require
262
263 setup_args['entry_points'] = {
264 'gui_scripts': [
265 '{} = spyder.app.start:main'.format(
266 'spyder3' if PY3 else 'spyder')
267 ]
268 }
269
270 setup_args.pop('scripts', None)
271
272
273 #==============================================================================
274 # Main setup
275 #==============================================================================
276 setup(**setup_args)
277
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -140,7 +140,7 @@
# Files added to the package
#==============================================================================
EXTLIST = ['.pot', '.po', '.mo', '.svg', '.png', '.css', '.html', '.js',
- '.ini', '.txt', '.qss', '.ttf', '.json']
+ '.ini', '.txt', '.qss', '.ttf', '.json', '.rst']
if os.name == 'nt':
SCRIPTS += ['spyder.bat']
EXTLIST += ['.ico']
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -140,7 +140,7 @@\n # Files added to the package\n #==============================================================================\n EXTLIST = ['.pot', '.po', '.mo', '.svg', '.png', '.css', '.html', '.js',\n- '.ini', '.txt', '.qss', '.ttf', '.json']\n+ '.ini', '.txt', '.qss', '.ttf', '.json', '.rst']\n if os.name == 'nt':\n SCRIPTS += ['spyder.bat']\n EXTLIST += ['.ico']\n", "issue": "Fail to Launch Spyder Tutorial\n## Description\n\n### What steps will reproduce the problem?\n\n<!--- You can use Markdown here --->\n\nAfter updating to spyder 4, when I click Help and than click to start spyder tutorial, it does not start the tutorial and will lead me to issue reporter.\n\n### Traceback\n```python-traceback\n File \"C:\\Users\\fengyy\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\spyder\\plugins\\help\\plugin.py\", line 453, in show_tutorial\n text = open(tutorial).read()\nFileNotFoundError: [Errno 2] No such file or directory: 'C:\\\\Users\\\\fengyy\\\\AppData\\\\Local\\\\Continuum\\\\anaconda3\\\\lib\\\\site-packages\\\\spyder\\\\plugins\\\\help\\\\utils\\\\tutorial.rst'\n```\n\n## Versions\n\n* Spyder version: 4.0.0b3 \n* Python version: 3.6.8\n* Qt version: 5.9.6\n* PyQt5 version: 5.9.2\n* Operating System: Windows 7\n\n### Dependencies\n\n```\npygments >=2.0 : 2.4.2 (OK)\r\nqdarkstyle >=2.6.4: 2.7 (OK)\r\nsphinx >=0.6.6 : 2.1.2 (OK)\r\npyls >=0.27.0 : 0.27.0 (OK)\r\nnbconvert >=4.0 : 5.5.0 (OK)\r\npandas >=0.13.1 : 0.23.4 (OK)\r\nnumpy >=1.7 : 1.16.4 (OK)\r\nsympy >=0.7.3 : 1.4 (OK)\r\ncython >=0.21 : 0.29.11 (OK)\r\nqtconsole >=4.5.0 : 4.5.1 (OK)\r\nIPython >=4.0 : 7.6.0 (OK)\r\nmatplotlib >=2.0.0: 3.1.0 (OK)\r\npylint >=0.25 : 2.3.1 (OK)\r\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright \u00a9 Spyder Project Contributors\n# Licensed under the terms of the MIT License\n# (see spyder/__init__.py for details)\n\n\"\"\"\nSpyder\n======\n\nThe Scientific Python Development Environment\n\nSpyder is a powerful scientific environment written in Python, for Python,\nand designed by and for scientists, engineers and data analysts.\n\nIt features a unique combination of the advanced editing, analysis, debugging\nand profiling functionality of a comprehensive development tool with the data\nexploration, interactive execution, deep inspection and beautiful visualization\ncapabilities of a scientific package.\n\"\"\"\n\nfrom __future__ import print_function\n\nimport io\nimport os\nimport os.path as osp\nimport subprocess\nimport sys\nimport shutil\n\nfrom distutils.core import setup\nfrom distutils.command.install_data import install_data\n\n\n#==============================================================================\n# Check for Python 3\n#==============================================================================\nPY3 = sys.version_info[0] == 3\n\n\n#==============================================================================\n# Minimal Python version sanity check\n# Taken from the notebook setup.py -- Modified BSD License\n#==============================================================================\nv = sys.version_info\nif v[:2] < (2, 7) or (v[0] >= 3 and v[:2] < (3, 4)):\n error = \"ERROR: Spyder requires Python version 2.7 or 3.4 and above.\"\n print(error, file=sys.stderr)\n sys.exit(1)\n\n\n#==============================================================================\n# Constants\n#==============================================================================\nNAME = 'spyder'\nLIBNAME = 'spyder'\nfrom spyder import __version__, __website_url__ #analysis:ignore\n\n\n#==============================================================================\n# Auxiliary functions\n#==============================================================================\ndef get_package_data(name, extlist):\n \"\"\"Return data files for package *name* with extensions in *extlist*\"\"\"\n flist = []\n # Workaround to replace os.path.relpath (not available until Python 2.6):\n offset = len(name)+len(os.pathsep)\n for dirpath, _dirnames, filenames in os.walk(name):\n if 'tests' not in dirpath:\n for fname in filenames:\n if (not fname.startswith('.') and\n osp.splitext(fname)[1] in extlist):\n flist.append(osp.join(dirpath, fname)[offset:])\n return flist\n\n\ndef get_subpackages(name):\n \"\"\"Return subpackages of package *name*\"\"\"\n splist = []\n for dirpath, _dirnames, _filenames in os.walk(name):\n if 'tests' not in dirpath:\n if osp.isfile(osp.join(dirpath, '__init__.py')):\n splist.append(\".\".join(dirpath.split(os.sep)))\n return splist\n\n\ndef get_data_files():\n \"\"\"Return data_files in a platform dependent manner\"\"\"\n if sys.platform.startswith('linux'):\n if PY3:\n data_files = [('share/applications', ['scripts/spyder3.desktop']),\n ('share/icons', ['img_src/spyder3.png']),\n ('share/metainfo', ['scripts/spyder3.appdata.xml'])]\n else:\n data_files = [('share/applications', ['scripts/spyder.desktop']),\n ('share/icons', ['img_src/spyder.png'])]\n elif os.name == 'nt':\n data_files = [('scripts', ['img_src/spyder.ico',\n 'img_src/spyder_reset.ico'])]\n else:\n data_files = []\n return data_files\n\n\ndef get_packages():\n \"\"\"Return package list\"\"\"\n packages = get_subpackages(LIBNAME)\n return packages\n\n\n#==============================================================================\n# Make Linux detect Spyder desktop file\n#==============================================================================\nclass MyInstallData(install_data):\n def run(self):\n install_data.run(self)\n if sys.platform.startswith('linux'):\n try:\n subprocess.call(['update-desktop-database'])\n except:\n print(\"ERROR: unable to update desktop database\",\n file=sys.stderr)\nCMDCLASS = {'install_data': MyInstallData}\n\n\n#==============================================================================\n# Main scripts\n#==============================================================================\n# NOTE: the '[...]_win_post_install.py' script is installed even on non-Windows\n# platforms due to a bug in pip installation process\n# See spyder-ide/spyder#1158.\nSCRIPTS = ['%s_win_post_install.py' % NAME]\nif PY3 and sys.platform.startswith('linux'):\n SCRIPTS.append('spyder3')\nelse:\n SCRIPTS.append('spyder')\n\n\n#==============================================================================\n# Files added to the package\n#==============================================================================\nEXTLIST = ['.pot', '.po', '.mo', '.svg', '.png', '.css', '.html', '.js',\n '.ini', '.txt', '.qss', '.ttf', '.json']\nif os.name == 'nt':\n SCRIPTS += ['spyder.bat']\n EXTLIST += ['.ico']\n\n\n#==============================================================================\n# Use Readme for long description\n#==============================================================================\nwith io.open('README.md', encoding='utf-8') as f:\n LONG_DESCRIPTION = f.read()\n\n\n#==============================================================================\n# Setup arguments\n#==============================================================================\nsetup_args = dict(\n name=NAME,\n version=__version__,\n description='The Scientific Python Development Environment',\n long_description=LONG_DESCRIPTION,\n long_description_content_type='text/markdown',\n download_url=__website_url__ + \"#fh5co-download\",\n author=\"The Spyder Project Contributors\",\n author_email=\"[email protected]\",\n url=__website_url__,\n license='MIT',\n keywords='PyQt5 editor console widgets IDE science data analysis IPython',\n platforms=[\"Windows\", \"Linux\", \"Mac OS-X\"],\n packages=get_packages(),\n package_data={LIBNAME: get_package_data(LIBNAME, EXTLIST)},\n scripts=[osp.join('scripts', fname) for fname in SCRIPTS],\n data_files=get_data_files(),\n classifiers=['License :: OSI Approved :: MIT License',\n 'Operating System :: MacOS',\n 'Operating System :: Microsoft :: Windows',\n 'Operating System :: POSIX :: Linux',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Developers',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Software Development :: Widget Sets'],\n cmdclass=CMDCLASS)\n\n\n#==============================================================================\n# Setuptools deps\n#==============================================================================\nif any(arg == 'bdist_wheel' for arg in sys.argv):\n import setuptools # analysis:ignore\n\ninstall_requires = [\n 'cloudpickle',\n 'pygments>=2.0',\n 'qtconsole>=4.5.0',\n 'nbconvert',\n 'sphinx',\n 'pylint',\n 'psutil',\n 'qtawesome>=0.5.7',\n 'qtpy>=1.5.0',\n 'pickleshare',\n 'pyzmq',\n 'chardet>=2.0.0',\n 'numpydoc',\n 'spyder-kernels>=1.4.0,<1.5.0',\n 'qdarkstyle>=2.7',\n 'atomicwrites',\n 'diff-match-patch',\n 'watchdog',\n # Don't require keyring for Python 2 and Linux\n # because it depends on system packages\n 'keyring;sys_platform!=\"linux2\"',\n # Packages for pyqt5 are only available in\n # Python 3\n 'pyqt5<5.13;python_version>=\"3\"',\n # pyqt5 5.12 split WebEngine into the\n # pyqtwebengine module\n 'pyqtwebengine<5.13;python_version>=\"3\"',\n # Pyls with all its dependencies\n 'python-language-server[all]>=0.27.0',\n # Required to get SSH connections to remote kernels\n 'pexpect',\n 'paramiko;platform_system==\"Windows\"',\n # Required for accesing xdg spec on Linux\n 'pyxdg;platform_system==\"Linux\"',\n]\n\nextras_require = {\n 'test:python_version == \"2.7\"': ['mock'],\n 'test:platform_system == \"Windows\"': ['pywin32'],\n 'test': ['pytest<5.0',\n 'pytest-qt',\n 'pytest-mock',\n 'pytest-cov',\n 'pytest-xvfb;platform_system==\"Linux\"',\n 'pytest-ordering',\n 'pytest-lazy-fixture',\n 'mock',\n 'flaky',\n 'pandas',\n 'scipy',\n 'sympy',\n 'pillow',\n 'matplotlib',\n 'cython'],\n}\n\nif 'setuptools' in sys.modules:\n setup_args['install_requires'] = install_requires\n setup_args['extras_require'] = extras_require\n\n setup_args['entry_points'] = {\n 'gui_scripts': [\n '{} = spyder.app.start:main'.format(\n 'spyder3' if PY3 else 'spyder')\n ]\n }\n\n setup_args.pop('scripts', None)\n\n\n#==============================================================================\n# Main setup\n#==============================================================================\nsetup(**setup_args)\n", "path": "setup.py"}]}
| 3,787 | 137 |
gh_patches_debug_12613
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-2138
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
RSR API - allow more than 1 parameter
## Test plan
The example queries in the doc string of filters.py are good examples of queries that should work and return objects (the domain part needs changing of course). I can help construct other more complex examples if needed. One possibility is to construct queries that return the same result as long as the objects in the result set aren't changed that could then be used in the integration/web tests (I'm not sure about the current status of our testing suite). This could be existing project updates for instance, they are pretty stable I'd say.
To test the select_related and prefetch_related functionality is harder. For that you really need to analyze the queries executed with and without them included on sufficiently complex queries, and I don't know if we have that functionality in place right now. Django-debug-toolbar can tell you how many queries a view generates, and I think you can get it to work with DRF.
## Issue description
Akvo Sites partners are currently in need of the more flexibility when it comes to pulling information to their sites from RSR.
Currently you cannot filter project updates to be read by 'project_partnerships_organisation' AND 'keywords' (for example).
Use case:
Akvo Site, drydev.org
Akvo Data Feed plugin currently uses the RSR API to read, then display in widgets, all project updates for 'project_partnerships_organisation=415'
Unfortunately, not all of the projects for 'project_partnerships_organisation=415' have anything to do with the 'DryDev' project they have the site for.
They would like to filter that data by the keyword used on the projects ie. 'drydev'.
This can currently not be done, the ability to add additional parameters for reading data via the API is required.
</issue>
<code>
[start of akvo/rest/viewsets.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from django.db.models.fields.related import ForeignKey, ForeignObject
8
9 from akvo.rest.models import TastyTokenAuthentication
10
11 from rest_framework import authentication, filters, permissions, viewsets
12
13 from .filters import RSRGenericFilterBackend
14
15
16 class SafeMethodsPermissions(permissions.DjangoObjectPermissions):
17 """
18 Base class to allow any safe methods ('GET', 'OPTIONS' and 'HEAD') without needing to
19 authenticate.
20 """
21
22 def has_permission(self, request, view):
23 if request.method in permissions.SAFE_METHODS:
24 return True
25 return super(SafeMethodsPermissions, self).has_permission(request, view)
26
27
28 class BaseRSRViewSet(viewsets.ModelViewSet):
29 """
30 Base class used for the view sets for RSR models. Provides unified auth and perms settings.
31 """
32 authentication_classes = (authentication.SessionAuthentication, TastyTokenAuthentication, )
33 permission_classes = (SafeMethodsPermissions, )
34 filter_backends = (filters.OrderingFilter, RSRGenericFilterBackend,)
35 ordering_fields = '__all__'
36
37 def get_queryset(self):
38
39 def django_filter_filters(request):
40 """
41 Support emulating the DjangoFilterBackend-based filtering that some views used to have
42 """
43 # query string keys reserved by the RSRGenericFilterBackend
44 qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related', ]
45 # query string keys used by core DRF and OrderingFilter
46 exclude_params = ['limit', 'format', 'page', 'order_by', ]
47 filters = {}
48 for key in request.QUERY_PARAMS.keys():
49 if key not in qs_params + exclude_params:
50 filters.update({key: request.QUERY_PARAMS.get(key)})
51 return filters
52
53 def get_lookups_from_filters(legacy_filters):
54 """
55 Cast the values in DjangoFilterBackend-styled query string filters to correct types to
56 be able to use them in regular queryset-filter() calls
57 """
58 # types of lookups supported by the views using DjangoFilterBackend
59 LEGACY_FIELD_LOOKUPS = ['exact', 'contains', 'icontains', 'gt', 'gte', 'lt',
60 'lte', ]
61 query_set_lookups = []
62 for key, value in legacy_filters.items():
63 parts = key.split('__')
64 if parts[-1] in LEGACY_FIELD_LOOKUPS:
65 parts = parts[:-1]
66 model = queryset.model
67 for part in parts:
68 field_object, related_model, direct, m2m = model._meta.get_field_by_name(
69 part)
70 if direct:
71 if issubclass(field_object.__class__, ForeignObject):
72 model = field_object.related.parent_model
73 else:
74 value = field_object.to_python(value)
75 break
76 else:
77 model = related_model
78 query_set_lookups += [{key: value}]
79 return query_set_lookups
80
81 queryset = super(BaseRSRViewSet, self).get_queryset()
82
83 # support for old DjangoFilterBackend-based filtering
84 # find all "old styled" filters
85 legacy_filters = django_filter_filters(self.request)
86 # create lookup dicts from the filters found
87 lookups = get_lookups_from_filters(legacy_filters)
88 for lookup in lookups:
89 queryset = queryset.filter(**lookup)
90
91 return queryset
92
93
94 class PublicProjectViewSet(BaseRSRViewSet):
95 """
96 Only public projects or objects related to public projects will be shown.
97 """
98 # project_relation is the default string for constructing a field lookup to the is_public field
99 # on the related Project. Override this in when the viewset is for a model that doesn't have a
100 # direct FK to Project or the FK field isn't named project. E.g. IndicatorViewSet:
101 # project_relation = 'result__project__'
102 # The lookup is used to filter out objects associated with private projects, see below.
103 project_relation = 'project__'
104
105 def get_queryset(self):
106
107 request = self.request
108 user = request.user
109
110 queryset = super(PublicProjectViewSet, self).get_queryset()
111
112 def projects_filter_for_non_privileged_users(user, queryset):
113 # Construct the public projects filter field lookup.
114 project_filter = self.project_relation + 'is_public'
115
116 # Filter the object list into two querysets;
117 # One where the related Projects are public and one where they are private
118 public_objects = queryset.filter(**{project_filter: True}).distinct()
119 private_objects = queryset.filter(**{project_filter: False}).distinct()
120
121 # In case of an anonymous user, only return the public objects
122 if user.is_anonymous():
123 queryset = public_objects
124
125 # Otherwise, check to which objects the user has (change) permission
126 elif private_objects:
127 permission = type(private_objects[0])._meta.db_table.replace('_', '.change_')
128 permitted_obj_pks = []
129
130 # Loop through all 'private' objects to see if the user has permission to change
131 # it. If so add its PK to the list of permitted objects.
132 for obj in private_objects:
133 if user.has_perm(permission, obj):
134 permitted_obj_pks.append(obj.pk)
135
136 queryset = public_objects | queryset.filter(pk__in=permitted_obj_pks).distinct()
137
138 return queryset
139
140 # filter projects if user is "non-privileged"
141 if user.is_anonymous() or not (user.is_superuser or user.is_admin):
142 queryset = projects_filter_for_non_privileged_users(user, queryset)
143
144 return queryset
145
[end of akvo/rest/viewsets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/viewsets.py b/akvo/rest/viewsets.py
--- a/akvo/rest/viewsets.py
+++ b/akvo/rest/viewsets.py
@@ -43,7 +43,7 @@
# query string keys reserved by the RSRGenericFilterBackend
qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related', ]
# query string keys used by core DRF and OrderingFilter
- exclude_params = ['limit', 'format', 'page', 'order_by', ]
+ exclude_params = ['limit', 'format', 'page', 'ordering', ]
filters = {}
for key in request.QUERY_PARAMS.keys():
if key not in qs_params + exclude_params:
|
{"golden_diff": "diff --git a/akvo/rest/viewsets.py b/akvo/rest/viewsets.py\n--- a/akvo/rest/viewsets.py\n+++ b/akvo/rest/viewsets.py\n@@ -43,7 +43,7 @@\n # query string keys reserved by the RSRGenericFilterBackend\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related', ]\n # query string keys used by core DRF and OrderingFilter\n- exclude_params = ['limit', 'format', 'page', 'order_by', ]\n+ exclude_params = ['limit', 'format', 'page', 'ordering', ]\n filters = {}\n for key in request.QUERY_PARAMS.keys():\n if key not in qs_params + exclude_params:\n", "issue": "RSR API - allow more than 1 parameter\n## Test plan\n\nThe example queries in the doc string of filters.py are good examples of queries that should work and return objects (the domain part needs changing of course). I can help construct other more complex examples if needed. One possibility is to construct queries that return the same result as long as the objects in the result set aren't changed that could then be used in the integration/web tests (I'm not sure about the current status of our testing suite). This could be existing project updates for instance, they are pretty stable I'd say.\n\nTo test the select_related and prefetch_related functionality is harder. For that you really need to analyze the queries executed with and without them included on sufficiently complex queries, and I don't know if we have that functionality in place right now. Django-debug-toolbar can tell you how many queries a view generates, and I think you can get it to work with DRF.\n## Issue description\n\nAkvo Sites partners are currently in need of the more flexibility when it comes to pulling information to their sites from RSR. \n\nCurrently you cannot filter project updates to be read by 'project_partnerships_organisation' AND 'keywords' (for example).\n\nUse case:\nAkvo Site, drydev.org\nAkvo Data Feed plugin currently uses the RSR API to read, then display in widgets, all project updates for 'project_partnerships_organisation=415' \nUnfortunately, not all of the projects for 'project_partnerships_organisation=415' have anything to do with the 'DryDev' project they have the site for.\nThey would like to filter that data by the keyword used on the projects ie. 'drydev'.\n\nThis can currently not be done, the ability to add additional parameters for reading data via the API is required.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom django.db.models.fields.related import ForeignKey, ForeignObject\n\nfrom akvo.rest.models import TastyTokenAuthentication\n\nfrom rest_framework import authentication, filters, permissions, viewsets\n\nfrom .filters import RSRGenericFilterBackend\n\n\nclass SafeMethodsPermissions(permissions.DjangoObjectPermissions):\n \"\"\"\n Base class to allow any safe methods ('GET', 'OPTIONS' and 'HEAD') without needing to\n authenticate.\n \"\"\"\n\n def has_permission(self, request, view):\n if request.method in permissions.SAFE_METHODS:\n return True\n return super(SafeMethodsPermissions, self).has_permission(request, view)\n\n\nclass BaseRSRViewSet(viewsets.ModelViewSet):\n \"\"\"\n Base class used for the view sets for RSR models. Provides unified auth and perms settings.\n \"\"\"\n authentication_classes = (authentication.SessionAuthentication, TastyTokenAuthentication, )\n permission_classes = (SafeMethodsPermissions, )\n filter_backends = (filters.OrderingFilter, RSRGenericFilterBackend,)\n ordering_fields = '__all__'\n\n def get_queryset(self):\n\n def django_filter_filters(request):\n \"\"\"\n Support emulating the DjangoFilterBackend-based filtering that some views used to have\n \"\"\"\n # query string keys reserved by the RSRGenericFilterBackend\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related', ]\n # query string keys used by core DRF and OrderingFilter\n exclude_params = ['limit', 'format', 'page', 'order_by', ]\n filters = {}\n for key in request.QUERY_PARAMS.keys():\n if key not in qs_params + exclude_params:\n filters.update({key: request.QUERY_PARAMS.get(key)})\n return filters\n\n def get_lookups_from_filters(legacy_filters):\n \"\"\"\n Cast the values in DjangoFilterBackend-styled query string filters to correct types to\n be able to use them in regular queryset-filter() calls\n \"\"\"\n # types of lookups supported by the views using DjangoFilterBackend\n LEGACY_FIELD_LOOKUPS = ['exact', 'contains', 'icontains', 'gt', 'gte', 'lt',\n 'lte', ]\n query_set_lookups = []\n for key, value in legacy_filters.items():\n parts = key.split('__')\n if parts[-1] in LEGACY_FIELD_LOOKUPS:\n parts = parts[:-1]\n model = queryset.model\n for part in parts:\n field_object, related_model, direct, m2m = model._meta.get_field_by_name(\n part)\n if direct:\n if issubclass(field_object.__class__, ForeignObject):\n model = field_object.related.parent_model\n else:\n value = field_object.to_python(value)\n break\n else:\n model = related_model\n query_set_lookups += [{key: value}]\n return query_set_lookups\n\n queryset = super(BaseRSRViewSet, self).get_queryset()\n\n # support for old DjangoFilterBackend-based filtering\n # find all \"old styled\" filters\n legacy_filters = django_filter_filters(self.request)\n # create lookup dicts from the filters found\n lookups = get_lookups_from_filters(legacy_filters)\n for lookup in lookups:\n queryset = queryset.filter(**lookup)\n\n return queryset\n\n\nclass PublicProjectViewSet(BaseRSRViewSet):\n \"\"\"\n Only public projects or objects related to public projects will be shown.\n \"\"\"\n # project_relation is the default string for constructing a field lookup to the is_public field\n # on the related Project. Override this in when the viewset is for a model that doesn't have a\n # direct FK to Project or the FK field isn't named project. E.g. IndicatorViewSet:\n # project_relation = 'result__project__'\n # The lookup is used to filter out objects associated with private projects, see below.\n project_relation = 'project__'\n\n def get_queryset(self):\n\n request = self.request\n user = request.user\n\n queryset = super(PublicProjectViewSet, self).get_queryset()\n\n def projects_filter_for_non_privileged_users(user, queryset):\n # Construct the public projects filter field lookup.\n project_filter = self.project_relation + 'is_public'\n\n # Filter the object list into two querysets;\n # One where the related Projects are public and one where they are private\n public_objects = queryset.filter(**{project_filter: True}).distinct()\n private_objects = queryset.filter(**{project_filter: False}).distinct()\n\n # In case of an anonymous user, only return the public objects\n if user.is_anonymous():\n queryset = public_objects\n\n # Otherwise, check to which objects the user has (change) permission\n elif private_objects:\n permission = type(private_objects[0])._meta.db_table.replace('_', '.change_')\n permitted_obj_pks = []\n\n # Loop through all 'private' objects to see if the user has permission to change\n # it. If so add its PK to the list of permitted objects.\n for obj in private_objects:\n if user.has_perm(permission, obj):\n permitted_obj_pks.append(obj.pk)\n\n queryset = public_objects | queryset.filter(pk__in=permitted_obj_pks).distinct()\n\n return queryset\n\n # filter projects if user is \"non-privileged\"\n if user.is_anonymous() or not (user.is_superuser or user.is_admin):\n queryset = projects_filter_for_non_privileged_users(user, queryset)\n\n return queryset\n", "path": "akvo/rest/viewsets.py"}]}
| 2,476 | 162 |
gh_patches_debug_25478
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-14279
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Beeg json not found
Hello, been updating ytdl but the issue remains:
root@server:~/Downloads# youtube-dl -vv https://beeg.com/6484762
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: [u'-vv', u'https://beeg.com/6484762']
[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2017.09.15
[debug] Python version 2.7.6 - Linux-3.13.0-129-generic-x86_64-with-Ubuntu-14.04-trusty
[debug] exe versions: ffmpeg N-75403-g3a8e447, ffprobe N-75403-g3a8e447, rtmpdump 2.4
[debug] Proxy map: {}
[Beeg] 6484762: Downloading webpage
[Beeg] 6484762: Downloading JSON metadata
ERROR: Unable to download JSON metadata: HTTP Error 404: Not Found (caused by HTTPError()); please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
File "/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py", line 503, in _request_webpage
return self._downloader.urlopen(url_or_request)
File "/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py", line 2177, in urlopen
return self._opener.open(req, timeout=self._socket_timeout)
File "/usr/lib/python2.7/urllib2.py", line 410, in open
response = meth(req, response)
File "/usr/lib/python2.7/urllib2.py", line 523, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python2.7/urllib2.py", line 448, in error
return self._call_chain(*args)
File "/usr/lib/python2.7/urllib2.py", line 382, in _call_chain
result = func(*args)
File "/usr/lib/python2.7/urllib2.py", line 531, in http_error_default
raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)
</issue>
<code>
[start of youtube_dl/extractor/beeg.py]
1 from __future__ import unicode_literals
2
3 from .common import InfoExtractor
4 from ..compat import (
5 compat_chr,
6 compat_ord,
7 compat_urllib_parse_unquote,
8 )
9 from ..utils import (
10 int_or_none,
11 parse_iso8601,
12 )
13
14
15 class BeegIE(InfoExtractor):
16 _VALID_URL = r'https?://(?:www\.)?beeg\.com/(?P<id>\d+)'
17 _TEST = {
18 'url': 'http://beeg.com/5416503',
19 'md5': 'a1a1b1a8bc70a89e49ccfd113aed0820',
20 'info_dict': {
21 'id': '5416503',
22 'ext': 'mp4',
23 'title': 'Sultry Striptease',
24 'description': 'md5:d22219c09da287c14bed3d6c37ce4bc2',
25 'timestamp': 1391813355,
26 'upload_date': '20140207',
27 'duration': 383,
28 'tags': list,
29 'age_limit': 18,
30 }
31 }
32
33 def _real_extract(self, url):
34 video_id = self._match_id(url)
35
36 webpage = self._download_webpage(url, video_id)
37
38 cpl_url = self._search_regex(
39 r'<script[^>]+src=(["\'])(?P<url>(?:https?:)?//static\.beeg\.com/cpl/\d+\.js.*?)\1',
40 webpage, 'cpl', default=None, group='url')
41
42 beeg_version, beeg_salt = [None] * 2
43
44 if cpl_url:
45 cpl = self._download_webpage(
46 self._proto_relative_url(cpl_url), video_id,
47 'Downloading cpl JS', fatal=False)
48 if cpl:
49 beeg_version = int_or_none(self._search_regex(
50 r'beeg_version\s*=\s*([^\b]+)', cpl,
51 'beeg version', default=None)) or self._search_regex(
52 r'/(\d+)\.js', cpl_url, 'beeg version', default=None)
53 beeg_salt = self._search_regex(
54 r'beeg_salt\s*=\s*(["\'])(?P<beeg_salt>.+?)\1', cpl, 'beeg salt',
55 default=None, group='beeg_salt')
56
57 beeg_version = beeg_version or '2000'
58 beeg_salt = beeg_salt or 'pmweAkq8lAYKdfWcFCUj0yoVgoPlinamH5UE1CB3H'
59
60 video = self._download_json(
61 'https://api.beeg.com/api/v6/%s/video/%s' % (beeg_version, video_id),
62 video_id)
63
64 def split(o, e):
65 def cut(s, x):
66 n.append(s[:x])
67 return s[x:]
68 n = []
69 r = len(o) % e
70 if r > 0:
71 o = cut(o, r)
72 while len(o) > e:
73 o = cut(o, e)
74 n.append(o)
75 return n
76
77 def decrypt_key(key):
78 # Reverse engineered from http://static.beeg.com/cpl/1738.js
79 a = beeg_salt
80 e = compat_urllib_parse_unquote(key)
81 o = ''.join([
82 compat_chr(compat_ord(e[n]) - compat_ord(a[n % len(a)]) % 21)
83 for n in range(len(e))])
84 return ''.join(split(o, 3)[::-1])
85
86 def decrypt_url(encrypted_url):
87 encrypted_url = self._proto_relative_url(
88 encrypted_url.replace('{DATA_MARKERS}', ''), 'https:')
89 key = self._search_regex(
90 r'/key=(.*?)%2Cend=', encrypted_url, 'key', default=None)
91 if not key:
92 return encrypted_url
93 return encrypted_url.replace(key, decrypt_key(key))
94
95 formats = []
96 for format_id, video_url in video.items():
97 if not video_url:
98 continue
99 height = self._search_regex(
100 r'^(\d+)[pP]$', format_id, 'height', default=None)
101 if not height:
102 continue
103 formats.append({
104 'url': decrypt_url(video_url),
105 'format_id': format_id,
106 'height': int(height),
107 })
108 self._sort_formats(formats)
109
110 title = video['title']
111 video_id = video.get('id') or video_id
112 display_id = video.get('code')
113 description = video.get('desc')
114
115 timestamp = parse_iso8601(video.get('date'), ' ')
116 duration = int_or_none(video.get('duration'))
117
118 tags = [tag.strip() for tag in video['tags'].split(',')] if video.get('tags') else None
119
120 return {
121 'id': video_id,
122 'display_id': display_id,
123 'title': title,
124 'description': description,
125 'timestamp': timestamp,
126 'duration': duration,
127 'tags': tags,
128 'formats': formats,
129 'age_limit': self._rta_search(webpage),
130 }
131
[end of youtube_dl/extractor/beeg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/youtube_dl/extractor/beeg.py b/youtube_dl/extractor/beeg.py
--- a/youtube_dl/extractor/beeg.py
+++ b/youtube_dl/extractor/beeg.py
@@ -9,6 +9,7 @@
from ..utils import (
int_or_none,
parse_iso8601,
+ urljoin,
)
@@ -36,9 +37,11 @@
webpage = self._download_webpage(url, video_id)
cpl_url = self._search_regex(
- r'<script[^>]+src=(["\'])(?P<url>(?:https?:)?//static\.beeg\.com/cpl/\d+\.js.*?)\1',
+ r'<script[^>]+src=(["\'])(?P<url>(?:/static|(?:https?:)?//static\.beeg\.com)/cpl/\d+\.js.*?)\1',
webpage, 'cpl', default=None, group='url')
+ cpl_url = urljoin(url, cpl_url)
+
beeg_version, beeg_salt = [None] * 2
if cpl_url:
@@ -54,7 +57,7 @@
r'beeg_salt\s*=\s*(["\'])(?P<beeg_salt>.+?)\1', cpl, 'beeg salt',
default=None, group='beeg_salt')
- beeg_version = beeg_version or '2000'
+ beeg_version = beeg_version or '2185'
beeg_salt = beeg_salt or 'pmweAkq8lAYKdfWcFCUj0yoVgoPlinamH5UE1CB3H'
video = self._download_json(
|
{"golden_diff": "diff --git a/youtube_dl/extractor/beeg.py b/youtube_dl/extractor/beeg.py\n--- a/youtube_dl/extractor/beeg.py\n+++ b/youtube_dl/extractor/beeg.py\n@@ -9,6 +9,7 @@\n from ..utils import (\n int_or_none,\n parse_iso8601,\n+ urljoin,\n )\n \n \n@@ -36,9 +37,11 @@\n webpage = self._download_webpage(url, video_id)\n \n cpl_url = self._search_regex(\n- r'<script[^>]+src=([\"\\'])(?P<url>(?:https?:)?//static\\.beeg\\.com/cpl/\\d+\\.js.*?)\\1',\n+ r'<script[^>]+src=([\"\\'])(?P<url>(?:/static|(?:https?:)?//static\\.beeg\\.com)/cpl/\\d+\\.js.*?)\\1',\n webpage, 'cpl', default=None, group='url')\n \n+ cpl_url = urljoin(url, cpl_url)\n+\n beeg_version, beeg_salt = [None] * 2\n \n if cpl_url:\n@@ -54,7 +57,7 @@\n r'beeg_salt\\s*=\\s*([\"\\'])(?P<beeg_salt>.+?)\\1', cpl, 'beeg salt',\n default=None, group='beeg_salt')\n \n- beeg_version = beeg_version or '2000'\n+ beeg_version = beeg_version or '2185'\n beeg_salt = beeg_salt or 'pmweAkq8lAYKdfWcFCUj0yoVgoPlinamH5UE1CB3H'\n \n video = self._download_json(\n", "issue": "Beeg json not found\nHello, been updating ytdl but the issue remains:\r\n\r\nroot@server:~/Downloads# youtube-dl -vv https://beeg.com/6484762\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: [u'-vv', u'https://beeg.com/6484762']\r\n[debug] Encodings: locale UTF-8, fs UTF-8, out UTF-8, pref UTF-8\r\n[debug] youtube-dl version 2017.09.15\r\n[debug] Python version 2.7.6 - Linux-3.13.0-129-generic-x86_64-with-Ubuntu-14.04-trusty\r\n[debug] exe versions: ffmpeg N-75403-g3a8e447, ffprobe N-75403-g3a8e447, rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[Beeg] 6484762: Downloading webpage\r\n[Beeg] 6484762: Downloading JSON metadata\r\nERROR: Unable to download JSON metadata: HTTP Error 404: Not Found (caused by HTTPError()); please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/extractor/common.py\", line 503, in _request_webpage\r\n return self._downloader.urlopen(url_or_request)\r\n File \"/usr/local/bin/youtube-dl/youtube_dl/YoutubeDL.py\", line 2177, in urlopen\r\n return self._opener.open(req, timeout=self._socket_timeout)\r\n File \"/usr/lib/python2.7/urllib2.py\", line 410, in open\r\n response = meth(req, response)\r\n File \"/usr/lib/python2.7/urllib2.py\", line 523, in http_response\r\n 'http', request, response, code, msg, hdrs)\r\n File \"/usr/lib/python2.7/urllib2.py\", line 448, in error\r\n return self._call_chain(*args)\r\n File \"/usr/lib/python2.7/urllib2.py\", line 382, in _call_chain\r\n result = func(*args)\r\n File \"/usr/lib/python2.7/urllib2.py\", line 531, in http_error_default\r\n raise HTTPError(req.get_full_url(), code, msg, hdrs, fp)\r\n\n", "before_files": [{"content": "from __future__ import unicode_literals\n\nfrom .common import InfoExtractor\nfrom ..compat import (\n compat_chr,\n compat_ord,\n compat_urllib_parse_unquote,\n)\nfrom ..utils import (\n int_or_none,\n parse_iso8601,\n)\n\n\nclass BeegIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?beeg\\.com/(?P<id>\\d+)'\n _TEST = {\n 'url': 'http://beeg.com/5416503',\n 'md5': 'a1a1b1a8bc70a89e49ccfd113aed0820',\n 'info_dict': {\n 'id': '5416503',\n 'ext': 'mp4',\n 'title': 'Sultry Striptease',\n 'description': 'md5:d22219c09da287c14bed3d6c37ce4bc2',\n 'timestamp': 1391813355,\n 'upload_date': '20140207',\n 'duration': 383,\n 'tags': list,\n 'age_limit': 18,\n }\n }\n\n def _real_extract(self, url):\n video_id = self._match_id(url)\n\n webpage = self._download_webpage(url, video_id)\n\n cpl_url = self._search_regex(\n r'<script[^>]+src=([\"\\'])(?P<url>(?:https?:)?//static\\.beeg\\.com/cpl/\\d+\\.js.*?)\\1',\n webpage, 'cpl', default=None, group='url')\n\n beeg_version, beeg_salt = [None] * 2\n\n if cpl_url:\n cpl = self._download_webpage(\n self._proto_relative_url(cpl_url), video_id,\n 'Downloading cpl JS', fatal=False)\n if cpl:\n beeg_version = int_or_none(self._search_regex(\n r'beeg_version\\s*=\\s*([^\\b]+)', cpl,\n 'beeg version', default=None)) or self._search_regex(\n r'/(\\d+)\\.js', cpl_url, 'beeg version', default=None)\n beeg_salt = self._search_regex(\n r'beeg_salt\\s*=\\s*([\"\\'])(?P<beeg_salt>.+?)\\1', cpl, 'beeg salt',\n default=None, group='beeg_salt')\n\n beeg_version = beeg_version or '2000'\n beeg_salt = beeg_salt or 'pmweAkq8lAYKdfWcFCUj0yoVgoPlinamH5UE1CB3H'\n\n video = self._download_json(\n 'https://api.beeg.com/api/v6/%s/video/%s' % (beeg_version, video_id),\n video_id)\n\n def split(o, e):\n def cut(s, x):\n n.append(s[:x])\n return s[x:]\n n = []\n r = len(o) % e\n if r > 0:\n o = cut(o, r)\n while len(o) > e:\n o = cut(o, e)\n n.append(o)\n return n\n\n def decrypt_key(key):\n # Reverse engineered from http://static.beeg.com/cpl/1738.js\n a = beeg_salt\n e = compat_urllib_parse_unquote(key)\n o = ''.join([\n compat_chr(compat_ord(e[n]) - compat_ord(a[n % len(a)]) % 21)\n for n in range(len(e))])\n return ''.join(split(o, 3)[::-1])\n\n def decrypt_url(encrypted_url):\n encrypted_url = self._proto_relative_url(\n encrypted_url.replace('{DATA_MARKERS}', ''), 'https:')\n key = self._search_regex(\n r'/key=(.*?)%2Cend=', encrypted_url, 'key', default=None)\n if not key:\n return encrypted_url\n return encrypted_url.replace(key, decrypt_key(key))\n\n formats = []\n for format_id, video_url in video.items():\n if not video_url:\n continue\n height = self._search_regex(\n r'^(\\d+)[pP]$', format_id, 'height', default=None)\n if not height:\n continue\n formats.append({\n 'url': decrypt_url(video_url),\n 'format_id': format_id,\n 'height': int(height),\n })\n self._sort_formats(formats)\n\n title = video['title']\n video_id = video.get('id') or video_id\n display_id = video.get('code')\n description = video.get('desc')\n\n timestamp = parse_iso8601(video.get('date'), ' ')\n duration = int_or_none(video.get('duration'))\n\n tags = [tag.strip() for tag in video['tags'].split(',')] if video.get('tags') else None\n\n return {\n 'id': video_id,\n 'display_id': display_id,\n 'title': title,\n 'description': description,\n 'timestamp': timestamp,\n 'duration': duration,\n 'tags': tags,\n 'formats': formats,\n 'age_limit': self._rta_search(webpage),\n }\n", "path": "youtube_dl/extractor/beeg.py"}]}
| 2,625 | 397 |
gh_patches_debug_18045
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-244
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Don't use objects.get in best_language_title()
Reproduce bug:
There must be at least one page without english translation. Then edit a page in the english backend. => Error
Reason:
To show the page in the page mirroring drop down menu, the root language of the region is used. A language node of the region is chosen by `LanguageTreeNode.objects.get(region__id=self.region.id)`.
But get() apparently only works if there is excactly one matching object. So it would only work if the region had only one language at all.
</issue>
<code>
[start of backend/cms/models/page.py]
1 """Models representing a page and page translation with content
2 """
3
4 import logging
5
6 from django.db import models
7 from django.conf import settings
8 from django.urls import reverse
9 from django.utils import timezone
10 from django.utils.translation import get_language
11
12 from mptt.models import MPTTModel, TreeForeignKey
13
14 from .language import Language, LanguageTreeNode
15 from .region import Region
16 from ..constants import status
17
18
19 logger = logging.getLogger(__name__)
20
21
22 class Page(MPTTModel):
23 """Class that represents an Page database object
24
25 Args:
26 MPTTModel : Library for hierachical data structures
27 """
28
29 parent = TreeForeignKey(
30 'self',
31 blank=True,
32 null=True,
33 related_name='children',
34 on_delete=models.PROTECT
35 )
36 icon = models.ImageField(
37 blank=True,
38 null=True,
39 upload_to='pages/%Y/%m/%d'
40 )
41 region = models.ForeignKey(Region, related_name='pages', on_delete=models.CASCADE)
42 archived = models.BooleanField(default=False)
43 mirrored_page = models.ForeignKey('self', null=True, blank=True, on_delete=models.PROTECT)
44 mirrored_page_first = models.BooleanField(default=True)
45 editors = models.ManyToManyField(settings.AUTH_USER_MODEL, related_name='editors', blank=True)
46 publishers = models.ManyToManyField(settings.AUTH_USER_MODEL, related_name='publishers', blank=True)
47 created_date = models.DateTimeField(default=timezone.now)
48 last_updated = models.DateTimeField(auto_now=True)
49
50 @property
51 def depth(self):
52 """Provide level of inheritance
53
54 Returns:
55 Int : Number of ancestors
56 """
57
58 return len(self.get_ancestors())
59
60 @property
61 def languages(self):
62 page_translations = self.page_translations.prefetch_related('language').all()
63 languages = []
64 for page_translation in page_translations:
65 if page_translation.language not in languages:
66 languages.append(page_translation.language)
67 return languages
68
69 def get_translation(self, language_code):
70 return self.page_translations.filter(
71 language__code=language_code
72 ).first()
73
74 # Helper function for page labels, second level paths etc. where the ancestor translation might not exist
75 def get_first_translation(self, priority_language_codes=None):
76 # Taking [] directly as default parameter would be dangerous because it is mutable
77 if not priority_language_codes:
78 priority_language_codes = []
79 for language_code in priority_language_codes + ['en-us', 'de-de']:
80 if self.page_translations.filter(language__code=language_code).exists():
81 return self.page_translations.filter(language__code=language_code).first()
82 return self.page_translations.first()
83
84 def get_public_translation(self, language_code):
85 return self.page_translations.filter(
86 language__code=language_code,
87 status=status.PUBLIC,
88 ).first()
89
90 def get_mirrored_text(self, language_code):
91 """
92 This content needs to be added when delivering content to end users
93 """
94 return self.mirrored_page.get_translation(language_code).text
95
96 def get_absolute_url(self):
97 return reverse('edit_page', kwargs={
98 'page_id': self.id,
99 'region_slug': self.region.slug,
100 'language_code': self.region.default_language.code,
101 })
102
103 @staticmethod
104 def get_archived(region_slug):
105 return Page.objects.filter(archived=True, region__slug=region_slug)
106
107 @staticmethod
108 def archived_count(region_slug):
109 return Page.objects.filter(archived=True, region__slug=region_slug).count()
110
111 def __str__(self):
112 first_translation = self.get_first_translation()
113 return '(id: {}, slug: {} ({}))'.format(self.id, first_translation.slug, first_translation.language.code)
114
115 @classmethod
116 def get_tree(cls, region_slug, archived=False):
117 """Function for building up a Treeview of all pages
118
119 Args:
120 region_slug: slug of the region the page belongs to
121 archived: if true archived pages will be included
122
123 Returns:
124 [pages]: Array of pages connected with their relations
125 """
126
127 if archived:
128 pages = cls.objects.all().prefetch_related(
129 'page_translations'
130 ).filter(
131 region__slug=region_slug
132 )
133 else:
134 pages = cls.objects.all().prefetch_related(
135 'page_translations'
136 ).filter(
137 region__slug=region_slug,
138 archived=False
139 )
140
141 return pages
142
143 def best_language_title(self):
144 page_translation = self.page_translations.filter(language__code=get_language())
145 if not page_translation:
146 alt_code = LanguageTreeNode.objects.get(region__id=self.region.id).get_root().language.code
147 page_translation = self.page_translations.filter(language__code=alt_code)
148 return page_translation.first().title
149
150 class Meta:
151 default_permissions = ()
152 permissions = (
153 ('view_pages', 'Can view pages'),
154 ('edit_pages', 'Can edit pages'),
155 ('publish_pages', 'Can publish pages'),
156 ('grant_page_permissions', 'Can grant page permissions'),
157 )
158
159
160 class PageTranslation(models.Model):
161 """Class defining a Translation of a Page
162
163 Args:
164 models : Class inherit of django-Models
165 """
166
167 page = models.ForeignKey(Page, related_name='page_translations', on_delete=models.CASCADE)
168 language = models.ForeignKey(
169 Language,
170 related_name='page_translations',
171 on_delete=models.CASCADE
172 )
173 slug = models.SlugField(max_length=200, blank=True, allow_unicode=True)
174 title = models.CharField(max_length=250)
175 text = models.TextField()
176 status = models.CharField(max_length=6, choices=status.CHOICES, default=status.DRAFT)
177 currently_in_translation = models.BooleanField(default=False)
178 version = models.PositiveIntegerField(default=0)
179 minor_edit = models.BooleanField(default=False)
180 creator = models.ForeignKey(settings.AUTH_USER_MODEL, null=True, on_delete=models.SET_NULL)
181 created_date = models.DateTimeField(default=timezone.now)
182 last_updated = models.DateTimeField(auto_now=True)
183
184 @property
185 def ancestor_path(self):
186 return '/'.join([
187 ancestor.get_first_translation([self.language.code]).slug
188 for ancestor in self.page.get_ancestors()
189 ])
190
191 @property
192 def permalink(self):
193 return '{}/{}/{}/{}'.format(
194 self.page.region.slug, self.language.code, self.ancestor_path, self.slug
195 )
196
197 @property
198 def available_languages(self):
199 languages = self.page.languages
200 languages.remove(self.language)
201 available_languages = {}
202 for language in languages:
203 other_translation = self.page.get_public_translation(language.code)
204 if other_translation:
205 available_languages[language.code] = {
206 'id': other_translation.id,
207 'url': other_translation.permalink
208 }
209 return available_languages
210
211 @property
212 def source_translation(self):
213 source_language_tree_node = self.page.region.language_tree_nodes.get(language=self.language).parent
214 if source_language_tree_node:
215 return self.page.get_translation(source_language_tree_node.code)
216 return None
217
218 @property
219 def latest_public_revision(self):
220 return self.page.page_translations.filter(
221 language=self.language,
222 status=status.PUBLIC,
223 ).first()
224
225 @property
226 def latest_major_revision(self):
227 return self.page.page_translations.filter(
228 language=self.language,
229 minor_edit=False,
230 ).first()
231
232 @property
233 def latest_major_public_revision(self):
234 return self.page.page_translations.filter(
235 language=self.language,
236 status=status.PUBLIC,
237 minor_edit=False,
238 ).first()
239
240 @property
241 def previous_revision(self):
242 version = self.version - 1
243 return self.page.page_translations.filter(
244 language=self.language,
245 version=version,
246 ).first()
247
248 @property
249 def is_outdated(self):
250 source_translation = self.source_translation
251 # If self.language is the root language, this translation can never be outdated
252 if not source_translation:
253 return False
254 # If the source translation is outdated, this translation can not be up to date
255 if source_translation.is_outdated:
256 return True
257 self_revision = self.latest_major_public_revision
258 source_revision = source_translation.latest_major_public_revision
259 # If on of the translations has no major public revision, it cannot be outdated
260 if not self_revision or not source_revision:
261 return False
262 return self_revision.last_updated < source_revision.last_updated
263
264 @property
265 def combined_text(self):
266 """
267 Combines the text from the PageTranslation with the text from the mirrored page.
268 """
269 if self.page.mirrored_page_first:
270 return self.page.get_mirrored_text(self.language.code) + self.text
271 return self.text + self.page.get_mirrored_text(self.language.code)
272
273 def __str__(self):
274 return '(id: {}, lang: {}, slug: {})'.format(self.id, self.language.code, self.slug)
275
276 class Meta:
277 ordering = ['page', '-version']
278 default_permissions = ()
279
[end of backend/cms/models/page.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/backend/cms/models/page.py b/backend/cms/models/page.py
--- a/backend/cms/models/page.py
+++ b/backend/cms/models/page.py
@@ -11,7 +11,7 @@
from mptt.models import MPTTModel, TreeForeignKey
-from .language import Language, LanguageTreeNode
+from .language import Language
from .region import Region
from ..constants import status
@@ -143,7 +143,7 @@
def best_language_title(self):
page_translation = self.page_translations.filter(language__code=get_language())
if not page_translation:
- alt_code = LanguageTreeNode.objects.get(region__id=self.region.id).get_root().language.code
+ alt_code = self.region.default_language.code
page_translation = self.page_translations.filter(language__code=alt_code)
return page_translation.first().title
|
{"golden_diff": "diff --git a/backend/cms/models/page.py b/backend/cms/models/page.py\n--- a/backend/cms/models/page.py\n+++ b/backend/cms/models/page.py\n@@ -11,7 +11,7 @@\n \n from mptt.models import MPTTModel, TreeForeignKey\n \n-from .language import Language, LanguageTreeNode\n+from .language import Language\n from .region import Region\n from ..constants import status\n \n@@ -143,7 +143,7 @@\n def best_language_title(self):\n page_translation = self.page_translations.filter(language__code=get_language())\n if not page_translation:\n- alt_code = LanguageTreeNode.objects.get(region__id=self.region.id).get_root().language.code\n+ alt_code = self.region.default_language.code\n page_translation = self.page_translations.filter(language__code=alt_code)\n return page_translation.first().title\n", "issue": "Don't use objects.get in best_language_title()\nReproduce bug:\r\nThere must be at least one page without english translation. Then edit a page in the english backend. => Error\r\n\r\nReason:\r\nTo show the page in the page mirroring drop down menu, the root language of the region is used. A language node of the region is chosen by `LanguageTreeNode.objects.get(region__id=self.region.id)`.\r\nBut get() apparently only works if there is excactly one matching object. So it would only work if the region had only one language at all.\n", "before_files": [{"content": "\"\"\"Models representing a page and page translation with content\n\"\"\"\n\nimport logging\n\nfrom django.db import models\nfrom django.conf import settings\nfrom django.urls import reverse\nfrom django.utils import timezone\nfrom django.utils.translation import get_language\n\nfrom mptt.models import MPTTModel, TreeForeignKey\n\nfrom .language import Language, LanguageTreeNode\nfrom .region import Region\nfrom ..constants import status\n\n\nlogger = logging.getLogger(__name__)\n\n\nclass Page(MPTTModel):\n \"\"\"Class that represents an Page database object\n\n Args:\n MPTTModel : Library for hierachical data structures\n \"\"\"\n\n parent = TreeForeignKey(\n 'self',\n blank=True,\n null=True,\n related_name='children',\n on_delete=models.PROTECT\n )\n icon = models.ImageField(\n blank=True,\n null=True,\n upload_to='pages/%Y/%m/%d'\n )\n region = models.ForeignKey(Region, related_name='pages', on_delete=models.CASCADE)\n archived = models.BooleanField(default=False)\n mirrored_page = models.ForeignKey('self', null=True, blank=True, on_delete=models.PROTECT)\n mirrored_page_first = models.BooleanField(default=True)\n editors = models.ManyToManyField(settings.AUTH_USER_MODEL, related_name='editors', blank=True)\n publishers = models.ManyToManyField(settings.AUTH_USER_MODEL, related_name='publishers', blank=True)\n created_date = models.DateTimeField(default=timezone.now)\n last_updated = models.DateTimeField(auto_now=True)\n\n @property\n def depth(self):\n \"\"\"Provide level of inheritance\n\n Returns:\n Int : Number of ancestors\n \"\"\"\n\n return len(self.get_ancestors())\n\n @property\n def languages(self):\n page_translations = self.page_translations.prefetch_related('language').all()\n languages = []\n for page_translation in page_translations:\n if page_translation.language not in languages:\n languages.append(page_translation.language)\n return languages\n\n def get_translation(self, language_code):\n return self.page_translations.filter(\n language__code=language_code\n ).first()\n\n # Helper function for page labels, second level paths etc. where the ancestor translation might not exist\n def get_first_translation(self, priority_language_codes=None):\n # Taking [] directly as default parameter would be dangerous because it is mutable\n if not priority_language_codes:\n priority_language_codes = []\n for language_code in priority_language_codes + ['en-us', 'de-de']:\n if self.page_translations.filter(language__code=language_code).exists():\n return self.page_translations.filter(language__code=language_code).first()\n return self.page_translations.first()\n\n def get_public_translation(self, language_code):\n return self.page_translations.filter(\n language__code=language_code,\n status=status.PUBLIC,\n ).first()\n\n def get_mirrored_text(self, language_code):\n \"\"\"\n This content needs to be added when delivering content to end users\n \"\"\"\n return self.mirrored_page.get_translation(language_code).text\n\n def get_absolute_url(self):\n return reverse('edit_page', kwargs={\n 'page_id': self.id,\n 'region_slug': self.region.slug,\n 'language_code': self.region.default_language.code,\n })\n\n @staticmethod\n def get_archived(region_slug):\n return Page.objects.filter(archived=True, region__slug=region_slug)\n\n @staticmethod\n def archived_count(region_slug):\n return Page.objects.filter(archived=True, region__slug=region_slug).count()\n\n def __str__(self):\n first_translation = self.get_first_translation()\n return '(id: {}, slug: {} ({}))'.format(self.id, first_translation.slug, first_translation.language.code)\n\n @classmethod\n def get_tree(cls, region_slug, archived=False):\n \"\"\"Function for building up a Treeview of all pages\n\n Args:\n region_slug: slug of the region the page belongs to\n archived: if true archived pages will be included\n\n Returns:\n [pages]: Array of pages connected with their relations\n \"\"\"\n\n if archived:\n pages = cls.objects.all().prefetch_related(\n 'page_translations'\n ).filter(\n region__slug=region_slug\n )\n else:\n pages = cls.objects.all().prefetch_related(\n 'page_translations'\n ).filter(\n region__slug=region_slug,\n archived=False\n )\n\n return pages\n\n def best_language_title(self):\n page_translation = self.page_translations.filter(language__code=get_language())\n if not page_translation:\n alt_code = LanguageTreeNode.objects.get(region__id=self.region.id).get_root().language.code\n page_translation = self.page_translations.filter(language__code=alt_code)\n return page_translation.first().title\n\n class Meta:\n default_permissions = ()\n permissions = (\n ('view_pages', 'Can view pages'),\n ('edit_pages', 'Can edit pages'),\n ('publish_pages', 'Can publish pages'),\n ('grant_page_permissions', 'Can grant page permissions'),\n )\n\n\nclass PageTranslation(models.Model):\n \"\"\"Class defining a Translation of a Page\n\n Args:\n models : Class inherit of django-Models\n \"\"\"\n\n page = models.ForeignKey(Page, related_name='page_translations', on_delete=models.CASCADE)\n language = models.ForeignKey(\n Language,\n related_name='page_translations',\n on_delete=models.CASCADE\n )\n slug = models.SlugField(max_length=200, blank=True, allow_unicode=True)\n title = models.CharField(max_length=250)\n text = models.TextField()\n status = models.CharField(max_length=6, choices=status.CHOICES, default=status.DRAFT)\n currently_in_translation = models.BooleanField(default=False)\n version = models.PositiveIntegerField(default=0)\n minor_edit = models.BooleanField(default=False)\n creator = models.ForeignKey(settings.AUTH_USER_MODEL, null=True, on_delete=models.SET_NULL)\n created_date = models.DateTimeField(default=timezone.now)\n last_updated = models.DateTimeField(auto_now=True)\n\n @property\n def ancestor_path(self):\n return '/'.join([\n ancestor.get_first_translation([self.language.code]).slug\n for ancestor in self.page.get_ancestors()\n ])\n\n @property\n def permalink(self):\n return '{}/{}/{}/{}'.format(\n self.page.region.slug, self.language.code, self.ancestor_path, self.slug\n )\n\n @property\n def available_languages(self):\n languages = self.page.languages\n languages.remove(self.language)\n available_languages = {}\n for language in languages:\n other_translation = self.page.get_public_translation(language.code)\n if other_translation:\n available_languages[language.code] = {\n 'id': other_translation.id,\n 'url': other_translation.permalink\n }\n return available_languages\n\n @property\n def source_translation(self):\n source_language_tree_node = self.page.region.language_tree_nodes.get(language=self.language).parent\n if source_language_tree_node:\n return self.page.get_translation(source_language_tree_node.code)\n return None\n\n @property\n def latest_public_revision(self):\n return self.page.page_translations.filter(\n language=self.language,\n status=status.PUBLIC,\n ).first()\n\n @property\n def latest_major_revision(self):\n return self.page.page_translations.filter(\n language=self.language,\n minor_edit=False,\n ).first()\n\n @property\n def latest_major_public_revision(self):\n return self.page.page_translations.filter(\n language=self.language,\n status=status.PUBLIC,\n minor_edit=False,\n ).first()\n\n @property\n def previous_revision(self):\n version = self.version - 1\n return self.page.page_translations.filter(\n language=self.language,\n version=version,\n ).first()\n\n @property\n def is_outdated(self):\n source_translation = self.source_translation\n # If self.language is the root language, this translation can never be outdated\n if not source_translation:\n return False\n # If the source translation is outdated, this translation can not be up to date\n if source_translation.is_outdated:\n return True\n self_revision = self.latest_major_public_revision\n source_revision = source_translation.latest_major_public_revision\n # If on of the translations has no major public revision, it cannot be outdated\n if not self_revision or not source_revision:\n return False\n return self_revision.last_updated < source_revision.last_updated\n\n @property\n def combined_text(self):\n \"\"\"\n Combines the text from the PageTranslation with the text from the mirrored page.\n \"\"\"\n if self.page.mirrored_page_first:\n return self.page.get_mirrored_text(self.language.code) + self.text\n return self.text + self.page.get_mirrored_text(self.language.code)\n\n def __str__(self):\n return '(id: {}, lang: {}, slug: {})'.format(self.id, self.language.code, self.slug)\n\n class Meta:\n ordering = ['page', '-version']\n default_permissions = ()\n", "path": "backend/cms/models/page.py"}]}
| 3,313 | 186 |
gh_patches_debug_9816
|
rasdani/github-patches
|
git_diff
|
ivy-llc__ivy-17588
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
remainder
</issue>
<code>
[start of ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py]
1 # global
2 import ivy
3
4 from ivy.functional.frontends.numpy import promote_types_of_numpy_inputs
5
6 from ivy.functional.frontends.numpy.func_wrapper import (
7 to_ivy_arrays_and_back,
8 handle_numpy_casting,
9 handle_numpy_dtype,
10 from_zero_dim_arrays_to_scalar,
11 handle_numpy_out,
12 )
13
14
15 @handle_numpy_out
16 @handle_numpy_dtype
17 @to_ivy_arrays_and_back
18 @handle_numpy_casting
19 @from_zero_dim_arrays_to_scalar
20 def _add(
21 x1,
22 x2,
23 /,
24 out=None,
25 *,
26 where=True,
27 casting="same_kind",
28 order="k",
29 dtype=None,
30 subok=True,
31 ):
32 x1, x2 = promote_types_of_numpy_inputs(x1, x2)
33 ret = ivy.add(x1, x2, out=out)
34 if ivy.is_array(where):
35 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
36 return ret
37
38
39 @handle_numpy_out
40 @handle_numpy_dtype
41 @to_ivy_arrays_and_back
42 @handle_numpy_casting
43 @from_zero_dim_arrays_to_scalar
44 def _subtract(
45 x1,
46 x2,
47 /,
48 out=None,
49 *,
50 where=True,
51 casting="same_kind",
52 order="k",
53 dtype=None,
54 subok=True,
55 ):
56 x1, x2 = promote_types_of_numpy_inputs(x1, x2)
57 ret = ivy.subtract(x1, x2, out=out)
58 if ivy.is_array(where):
59 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
60 return ret
61
62
63 @handle_numpy_out
64 @handle_numpy_dtype
65 @to_ivy_arrays_and_back
66 @handle_numpy_casting
67 @from_zero_dim_arrays_to_scalar
68 def _divide(
69 x1,
70 x2,
71 /,
72 out=None,
73 *,
74 where=True,
75 casting="same_kind",
76 order="k",
77 dtype=None,
78 subok=True,
79 ):
80 x1, x2 = promote_types_of_numpy_inputs(x1, x2)
81 ret = ivy.divide(x1, x2, out=out)
82 if ivy.is_array(where):
83 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
84 return ret
85
86
87 @handle_numpy_out
88 @handle_numpy_dtype
89 @to_ivy_arrays_and_back
90 @handle_numpy_casting
91 @from_zero_dim_arrays_to_scalar
92 def _multiply(
93 x1,
94 x2,
95 /,
96 out=None,
97 *,
98 where=True,
99 casting="same_kind",
100 order="k",
101 dtype=None,
102 subok=True,
103 ):
104 x1, x2 = promote_types_of_numpy_inputs(x1, x2)
105 ret = ivy.multiply(x1, x2, out=out)
106 if ivy.is_array(where):
107 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
108 return ret
109
110
111 @handle_numpy_out
112 @handle_numpy_dtype
113 @to_ivy_arrays_and_back
114 @handle_numpy_casting
115 @from_zero_dim_arrays_to_scalar
116 def _power(
117 x1,
118 x2,
119 /,
120 out=None,
121 *,
122 where=True,
123 casting="same_kind",
124 order="k",
125 dtype=None,
126 subok=True,
127 ):
128 x1, x2 = promote_types_of_numpy_inputs(x1, x2)
129 ret = ivy.pow(x1, x2, out=out)
130 if ivy.is_array(where):
131 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
132 return ret
133
134
135 @handle_numpy_out
136 @handle_numpy_dtype
137 @to_ivy_arrays_and_back
138 @handle_numpy_casting
139 @from_zero_dim_arrays_to_scalar
140 def _float_power(
141 x1,
142 x2,
143 /,
144 out=None,
145 *,
146 where=True,
147 casting="same_kind",
148 order="k",
149 dtype=None,
150 subok=True,
151 ):
152 x1, x2 = promote_types_of_numpy_inputs(x1, x2)
153 ret = ivy.float_power(x1, x2, out=out)
154 if ivy.is_array(where):
155 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
156 return ret
157
158
159 @to_ivy_arrays_and_back
160 @from_zero_dim_arrays_to_scalar
161 def vdot(
162 a,
163 b,
164 /,
165 ):
166 a, b = promote_types_of_numpy_inputs(a, b)
167 return ivy.multiply(a, b).sum()
168
169
170 @handle_numpy_out
171 @handle_numpy_dtype
172 @to_ivy_arrays_and_back
173 @handle_numpy_casting
174 @from_zero_dim_arrays_to_scalar
175 def _positive(
176 x,
177 /,
178 out=None,
179 *,
180 where=True,
181 casting="same_kind",
182 order="K",
183 dtype=None,
184 subok=True,
185 ):
186 ret = ivy.positive(x, out=out)
187 if ivy.is_array(where):
188 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
189 return ret
190
191
192 @handle_numpy_out
193 @handle_numpy_dtype
194 @to_ivy_arrays_and_back
195 @handle_numpy_casting
196 @from_zero_dim_arrays_to_scalar
197 def _negative(
198 x,
199 /,
200 out=None,
201 *,
202 where=True,
203 casting="same_kind",
204 order="K",
205 dtype=None,
206 subok=True,
207 ):
208 ret = ivy.negative(x, out=out)
209 if ivy.is_array(where):
210 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
211 return ret
212
213
214 @handle_numpy_out
215 @handle_numpy_dtype
216 @to_ivy_arrays_and_back
217 @handle_numpy_casting
218 @from_zero_dim_arrays_to_scalar
219 def _floor_divide(
220 x1,
221 x2,
222 /,
223 out=None,
224 *,
225 where=True,
226 casting="same_kind",
227 order="k",
228 dtype=None,
229 subok=True,
230 ):
231 if dtype:
232 x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))
233 x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))
234 ret = ivy.floor_divide(x1, x2, out=out)
235 if ivy.is_array(where):
236 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
237 return ret
238
239
240 @handle_numpy_out
241 @handle_numpy_dtype
242 @to_ivy_arrays_and_back
243 @handle_numpy_casting
244 @from_zero_dim_arrays_to_scalar
245 def _reciprocal(
246 x,
247 /,
248 out=None,
249 *,
250 where=True,
251 casting="same_kind",
252 order="K",
253 dtype=None,
254 subok=True,
255 ):
256 if dtype is None:
257 dtype = ivy.as_ivy_dtype(x.dtype)
258 ret = ivy.reciprocal(x, out=out)
259 if ivy.is_array(where):
260 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
261 return ret.astype(dtype)
262
263
264 @handle_numpy_out
265 @handle_numpy_dtype
266 @to_ivy_arrays_and_back
267 @handle_numpy_casting
268 @from_zero_dim_arrays_to_scalar
269 def _mod(
270 x1,
271 x2,
272 /,
273 out=None,
274 *,
275 where=True,
276 casting="same_kind",
277 order="K",
278 dtype=None,
279 subok=True,
280 ):
281 if dtype:
282 x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))
283 x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))
284 ret = ivy.remainder(x1, x2, out=out)
285 if ivy.is_array(where):
286 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
287 return ret
288
289
290 @handle_numpy_out
291 @handle_numpy_dtype
292 @to_ivy_arrays_and_back
293 @handle_numpy_casting
294 @from_zero_dim_arrays_to_scalar
295 def _modf(
296 x,
297 /,
298 out1_2=(None, None),
299 out=None,
300 *,
301 where=True,
302 casting="same_kind",
303 order="K",
304 dtype=None,
305 subok=True,
306 ):
307 if dtype:
308 x = ivy.astype(ivy.array(x), ivy.as_ivy_dtype(dtype))
309
310 integral_part = ivy.floor(x)
311 fractional_part = x - integral_part
312
313 if ivy.is_array(where):
314 integral_part = ivy.where(
315 where,
316 integral_part,
317 ivy.default(out, ivy.zeros_like(integral_part)),
318 out=out,
319 )
320 fractional_part = ivy.where(
321 where,
322 fractional_part,
323 ivy.default(out, ivy.zeros_like(fractional_part)),
324 out=out,
325 )
326
327 return fractional_part, integral_part
328
329
330 @handle_numpy_out
331 @handle_numpy_dtype
332 @to_ivy_arrays_and_back
333 @handle_numpy_casting
334 @from_zero_dim_arrays_to_scalar
335 def _fmod(
336 x1,
337 x2,
338 /,
339 out=None,
340 *,
341 where=True,
342 casting="same_kind",
343 order="K",
344 dtype=None,
345 subok=True,
346 ):
347 if dtype:
348 x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))
349 x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))
350 ret = ivy.fmod(x1, x2, out=out)
351 if ivy.is_array(where):
352 ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
353 return ret
354
355
356 @handle_numpy_out
357 @handle_numpy_dtype
358 @to_ivy_arrays_and_back
359 @handle_numpy_casting
360 @from_zero_dim_arrays_to_scalar
361 def _divmod(
362 x1,
363 x2,
364 /,
365 out1_2=(None, None),
366 out=None,
367 *,
368 where=True,
369 casting="same_kind",
370 order="K",
371 dtype=None,
372 subok=True,
373 ):
374 if dtype:
375 x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))
376 x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))
377
378 ret = [ivy.floor_divide(x1, x2, out=out), ivy.remainder(x1, x2, out=out)]
379 if ivy.is_array(where):
380 ret = ivy.where(
381 where,
382 ret,
383 (
384 [
385 ivy.default(out, ivy.zeros_like(ret[0])),
386 ivy.default(out, ivy.zeros_like(ret[1])),
387 ]
388 ),
389 out=out,
390 )
391 return ret
392
[end of ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py b/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py
--- a/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py
+++ b/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py
@@ -389,3 +389,29 @@
out=out,
)
return ret
+
+
+@handle_numpy_out
+@handle_numpy_dtype
+@to_ivy_arrays_and_back
+@handle_numpy_casting
+@from_zero_dim_arrays_to_scalar
+def remainder(
+ x1,
+ x2,
+ /,
+ out=None,
+ *,
+ where=True,
+ casting="same_kind",
+ order="K",
+ dtype=None,
+ subok=True,
+):
+ if dtype:
+ x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))
+ x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))
+ ret = ivy.remainder(x1, x2, out=out)
+ if ivy.is_array(where):
+ ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)
+ return ret
|
{"golden_diff": "diff --git a/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py b/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py\n--- a/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py\n+++ b/ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py\n@@ -389,3 +389,29 @@\n out=out,\n )\n return ret\n+\n+\n+@handle_numpy_out\n+@handle_numpy_dtype\n+@to_ivy_arrays_and_back\n+@handle_numpy_casting\n+@from_zero_dim_arrays_to_scalar\n+def remainder(\n+ x1,\n+ x2,\n+ /,\n+ out=None,\n+ *,\n+ where=True,\n+ casting=\"same_kind\",\n+ order=\"K\",\n+ dtype=None,\n+ subok=True,\n+):\n+ if dtype:\n+ x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))\n+ x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))\n+ ret = ivy.remainder(x1, x2, out=out)\n+ if ivy.is_array(where):\n+ ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n+ return ret\n", "issue": "remainder\n\n", "before_files": [{"content": "# global\nimport ivy\n\nfrom ivy.functional.frontends.numpy import promote_types_of_numpy_inputs\n\nfrom ivy.functional.frontends.numpy.func_wrapper import (\n to_ivy_arrays_and_back,\n handle_numpy_casting,\n handle_numpy_dtype,\n from_zero_dim_arrays_to_scalar,\n handle_numpy_out,\n)\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _add(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n x1, x2 = promote_types_of_numpy_inputs(x1, x2)\n ret = ivy.add(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _subtract(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n x1, x2 = promote_types_of_numpy_inputs(x1, x2)\n ret = ivy.subtract(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _divide(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n x1, x2 = promote_types_of_numpy_inputs(x1, x2)\n ret = ivy.divide(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _multiply(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n x1, x2 = promote_types_of_numpy_inputs(x1, x2)\n ret = ivy.multiply(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _power(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n x1, x2 = promote_types_of_numpy_inputs(x1, x2)\n ret = ivy.pow(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _float_power(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n x1, x2 = promote_types_of_numpy_inputs(x1, x2)\n ret = ivy.float_power(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@to_ivy_arrays_and_back\n@from_zero_dim_arrays_to_scalar\ndef vdot(\n a,\n b,\n /,\n):\n a, b = promote_types_of_numpy_inputs(a, b)\n return ivy.multiply(a, b).sum()\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _positive(\n x,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n ret = ivy.positive(x, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _negative(\n x,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n ret = ivy.negative(x, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _floor_divide(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"k\",\n dtype=None,\n subok=True,\n):\n if dtype:\n x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))\n x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))\n ret = ivy.floor_divide(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _reciprocal(\n x,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n if dtype is None:\n dtype = ivy.as_ivy_dtype(x.dtype)\n ret = ivy.reciprocal(x, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret.astype(dtype)\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _mod(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n if dtype:\n x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))\n x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))\n ret = ivy.remainder(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _modf(\n x,\n /,\n out1_2=(None, None),\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n if dtype:\n x = ivy.astype(ivy.array(x), ivy.as_ivy_dtype(dtype))\n\n integral_part = ivy.floor(x)\n fractional_part = x - integral_part\n\n if ivy.is_array(where):\n integral_part = ivy.where(\n where,\n integral_part,\n ivy.default(out, ivy.zeros_like(integral_part)),\n out=out,\n )\n fractional_part = ivy.where(\n where,\n fractional_part,\n ivy.default(out, ivy.zeros_like(fractional_part)),\n out=out,\n )\n\n return fractional_part, integral_part\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _fmod(\n x1,\n x2,\n /,\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n if dtype:\n x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))\n x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))\n ret = ivy.fmod(x1, x2, out=out)\n if ivy.is_array(where):\n ret = ivy.where(where, ret, ivy.default(out, ivy.zeros_like(ret)), out=out)\n return ret\n\n\n@handle_numpy_out\n@handle_numpy_dtype\n@to_ivy_arrays_and_back\n@handle_numpy_casting\n@from_zero_dim_arrays_to_scalar\ndef _divmod(\n x1,\n x2,\n /,\n out1_2=(None, None),\n out=None,\n *,\n where=True,\n casting=\"same_kind\",\n order=\"K\",\n dtype=None,\n subok=True,\n):\n if dtype:\n x1 = ivy.astype(ivy.array(x1), ivy.as_ivy_dtype(dtype))\n x2 = ivy.astype(ivy.array(x2), ivy.as_ivy_dtype(dtype))\n\n ret = [ivy.floor_divide(x1, x2, out=out), ivy.remainder(x1, x2, out=out)]\n if ivy.is_array(where):\n ret = ivy.where(\n where,\n ret,\n (\n [\n ivy.default(out, ivy.zeros_like(ret[0])),\n ivy.default(out, ivy.zeros_like(ret[1])),\n ]\n ),\n out=out,\n )\n return ret\n", "path": "ivy/functional/frontends/numpy/mathematical_functions/arithmetic_operations.py"}]}
| 4,031 | 303 |
gh_patches_debug_3887
|
rasdani/github-patches
|
git_diff
|
nvaccess__nvda-10304
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When BRLTTY for Windows is installed scons fails to bundle BrlAPI
Discovered while debugging #10228
### Steps to reproduce:
1. Install BRLTTY for Windows you do not need to have any actual braille display connected.
2. Execute scons launcher from the root of the NVDA repo.
3. Start newly created launcher.
### Actual behavior:
BrlAPI dll is missing. It is therefore not possible to switch to BRLTTY.
### Expected behavior:
BrlAPI should be working regardless of what is installed on the system.
### System configuration
#### NVDA installed/portable/running from source:
Source
#### NVDA version:
Any after migration to BrlAPI 07 and Python 3.
#### Windows version:
Windows 7 x64
#### Name and version of other software in use when reproducing the issue:
Python, BRLTTY for Windows
#### Other information about your system:
### Other questions
#### Does the issue still occur after restarting your PC?
Yes
#### Have you tried any other versions of NVDA? If so, please report their behaviors.
This is new after Python 3 migration.
#### Additional info:
WHen BRLTTY is installed it places brlapi-0.7.dll in the syswow64 directory. When this dll is removed either manually or by uninstall of BRLTTY BrlAPI is bundled correctly.
</issue>
<code>
[start of source/setup.py]
1 # -*- coding: UTF-8 -*-
2 #setup.py
3 #A part of NonVisual Desktop Access (NVDA)
4 #Copyright (C) 2006-2018 NV Access Limited, Peter Vágner, Joseph Lee
5 #This file is covered by the GNU General Public License.
6 #See the file COPYING for more details.
7
8 import os
9 import copy
10 import gettext
11 gettext.install("nvda")
12 from setuptools import setup
13 import py2exe as py2exeModule
14 from glob import glob
15 import fnmatch
16 from versionInfo import *
17 from py2exe import distutils_buildexe
18 from py2exe.dllfinder import DllFinder
19 import wx
20 import importlib.machinery
21
22 RT_MANIFEST = 24
23 manifest_template = """\
24 <?xml version="1.0" encoding="UTF-8" standalone="yes"?>
25 <assembly xmlns="urn:schemas-microsoft-com:asm.v1" manifestVersion="1.0">
26 <trustInfo xmlns="urn:schemas-microsoft-com:asm.v3">
27 <security>
28 <requestedPrivileges>
29 <requestedExecutionLevel
30 level="asInvoker"
31 uiAccess="%(uiAccess)s"
32 />
33 </requestedPrivileges>
34 </security>
35 </trustInfo>
36 <compatibility xmlns="urn:schemas-microsoft-com:compatibility.v1">
37 <application>
38 <!-- Windows 7 -->
39 <supportedOS
40 Id="{35138b9a-5d96-4fbd-8e2d-a2440225f93a}"
41 />
42 <!-- Windows 8 -->
43 <supportedOS
44 Id="{4a2f28e3-53b9-4441-ba9c-d69d4a4a6e38}"
45 />
46 <!-- Windows 8.1 -->
47 <supportedOS
48 Id="{1f676c76-80e1-4239-95bb-83d0f6d0da78}"
49 />
50 <!-- Windows 10 -->
51 <supportedOS
52 Id="{8e0f7a12-bfb3-4fe8-b9a5-48fd50a15a9a}"
53 />
54 </application>
55 </compatibility>
56 </assembly>
57 """
58
59 # py2exe's idea of whether a dll is a system dll appears to be wrong sometimes, so monkey patch it.
60 orig_determine_dll_type = DllFinder.determine_dll_type
61 def determine_dll_type(self, imagename):
62 dll = os.path.basename(imagename).lower()
63 if dll.startswith("api-ms-win-") or dll in ("powrprof.dll", "mpr.dll", "crypt32.dll"):
64 # These are definitely system dlls available on all systems and must be excluded.
65 # Including them can cause serious problems when a binary build is run on a different version of Windows.
66 return None
67 return orig_determine_dll_type(self, imagename)
68 DllFinder.determine_dll_type = determine_dll_type
69
70 class py2exe(distutils_buildexe.py2exe):
71 """Overridden py2exe command to:
72 * Add a command line option --enable-uiAccess to enable uiAccess for the main executable and EOA proxy
73 * Add a manifest to the executables
74 """
75
76 user_options = distutils_buildexe.py2exe.user_options + [
77 ("enable-uiAccess", "u", "enable uiAccess for the main executable"),
78 ]
79
80 def initialize_options(self):
81 super(py2exe, self).initialize_options()
82 self.enable_uiAccess = False
83
84 def run(self):
85 dist = self.distribution
86 if self.enable_uiAccess:
87 # Add a target for nvda_uiAccess, using nvda_noUIAccess as a base.
88 target = copy.deepcopy(dist.windows[0])
89 target["dest_base"] = "nvda_uiAccess"
90 target['uiAccess'] = True
91 dist.windows.insert(1, target)
92 # nvda_eoaProxy should have uiAccess.
93 target = dist.windows[3]
94 target['uiAccess'] = True
95 # Add a manifest resource to every target at runtime.
96 for target in dist.windows:
97 target["other_resources"] = [
98 (
99 RT_MANIFEST,
100 1,
101 (manifest_template % dict(uiAccess=target['uiAccess'])).encode("utf-8")
102 ),
103 ]
104 super(py2exe, self).run()
105
106 def getLocaleDataFiles():
107 wxDir=wx.__path__[0]
108 localeMoFiles=set()
109 for f in glob("locale/*/LC_MESSAGES"):
110 localeMoFiles.add((f, (os.path.join(f,"nvda.mo"),)))
111 wxMoFile=os.path.join(wxDir,f,"wxstd.mo")
112 if os.path.isfile(wxMoFile):
113 localeMoFiles.add((f,(wxMoFile,)))
114 lang=os.path.split(os.path.split(f)[0])[1]
115 if '_' in lang:
116 lang=lang.split('_')[0]
117 f=os.path.join('locale',lang,'lc_messages')
118 wxMoFile=os.path.join(wxDir,f,"wxstd.mo")
119 if os.path.isfile(wxMoFile):
120 localeMoFiles.add((f,(wxMoFile,)))
121 localeDicFiles=[(os.path.dirname(f), (f,)) for f in glob("locale/*/*.dic")]
122 NVDALocaleGestureMaps=[(os.path.dirname(f), (f,)) for f in glob("locale/*/gestures.ini")]
123 return list(localeMoFiles)+localeDicFiles+NVDALocaleGestureMaps
124
125 def getRecursiveDataFiles(dest,source,excludes=()):
126 rulesList=[]
127 rulesList.append((dest,
128 [f for f in glob("%s/*"%source) if not any(fnmatch.fnmatch(f,exclude) for exclude in excludes) and os.path.isfile(f)]))
129 [rulesList.extend(getRecursiveDataFiles(os.path.join(dest,dirName),os.path.join(source,dirName),excludes=excludes)) for dirName in os.listdir(source) if os.path.isdir(os.path.join(source,dirName)) and not dirName.startswith('.')]
130 return rulesList
131
132 setup(
133 name = name,
134 version=version,
135 description=description,
136 url=url,
137 classifiers=[
138 'Development Status :: 3 - Alpha',
139 'Environment :: Win32 (MS Windows)',
140 'Topic :: Adaptive Technologies'
141 'Intended Audience :: Developers',
142 'Intended Audience :: End Users/Desktop',
143 'License :: OSI Approved :: GNU General Public License (GPL)',
144 'Natural Language :: English',
145 'Programming Language :: Python',
146 'Operating System :: Microsoft :: Windows',
147 ],
148 cmdclass={"py2exe": py2exe},
149 windows=[
150 {
151 "script":"nvda.pyw",
152 "dest_base":"nvda_noUIAccess",
153 "uiAccess": False,
154 "icon_resources":[(1,"images/nvda.ico")],
155 "other_resources": [], # Populated at run time
156 "version":formatBuildVersionString(),
157 "description":"NVDA application",
158 "product_name":name,
159 "product_version":version,
160 "copyright":copyright,
161 "company_name":publisher,
162 },
163 # The nvda_uiAccess target will be added at runtime if required.
164 {
165 "script": "nvda_slave.pyw",
166 "uiAccess": False,
167 "icon_resources": [(1,"images/nvda.ico")],
168 "other_resources": [], # Populated at run time
169 "version":formatBuildVersionString(),
170 "description": name,
171 "product_name":name,
172 "product_version": version,
173 "copyright": copyright,
174 "company_name": publisher,
175 },
176 {
177 "script": "nvda_eoaProxy.pyw",
178 # uiAccess will be enabled at runtime if appropriate.
179 "uiAccess": False,
180 "icon_resources": [(1,"images/nvda.ico")],
181 "other_resources": [], # Populated at run time
182 "version":formatBuildVersionString(),
183 "description": "NVDA Ease of Access proxy",
184 "product_name":name,
185 "product_version": version,
186 "copyright": copyright,
187 "company_name": publisher,
188 },
189 ],
190 options = {"py2exe": {
191 "bundle_files": 3,
192 "excludes": ["tkinter",
193 "serial.loopback_connection",
194 "serial.rfc2217",
195 "serial.serialcli",
196 "serial.serialjava",
197 "serial.serialposix",
198 "serial.socket_connection",
199 # netbios (from pywin32) is optionally used by Python3's uuid module.
200 # This is not needed.
201 # We also need to exclude win32wnet explicitly.
202 "netbios",
203 "win32wnet",
204 # winxptheme is optionally used by wx.lib.agw.aui.
205 # We don't need this.
206 "winxptheme",
207 ],
208 "packages": [
209 "NVDAObjects",
210 "virtualBuffers",
211 "appModules",
212 "comInterfaces",
213 "brailleDisplayDrivers",
214 "synthDrivers",
215 "visionEnhancementProviders",
216 ],
217 "includes": [
218 "nvdaBuiltin",
219 # #3368: bisect was implicitly included with Python 2.7.3, but isn't with 2.7.5.
220 "bisect",
221 ],
222 }},
223 data_files=[
224 (".",glob("*.dll")+glob("*.manifest")+["builtin.dic"]),
225 ("documentation", ['../copying.txt', '../contributors.txt']),
226 ("lib/%s"%version, glob("lib/*.dll")),
227 ("lib64/%s"%version, glob("lib64/*.dll") + glob("lib64/*.exe")),
228 ("libArm64/%s"%version, glob("libArm64/*.dll") + glob("libArm64/*.exe")),
229 ("waves", glob("waves/*.wav")),
230 ("images", glob("images/*.ico")),
231 ("louis/tables",glob("louis/tables/*")),
232 ("COMRegistrationFixes", glob("COMRegistrationFixes/*.reg")),
233 (".", ['message.html' ])
234 ] + (
235 getLocaleDataFiles()
236 + getRecursiveDataFiles("synthDrivers", "synthDrivers",
237 excludes=tuple(
238 "*%s" % ext
239 for ext in importlib.machinery.SOURCE_SUFFIXES + importlib.machinery.BYTECODE_SUFFIXES
240 ) + (
241 "*.exp",
242 "*.lib",
243 "*.pdb",
244 "__pycache__"
245 ))
246 + getRecursiveDataFiles("brailleDisplayDrivers", "brailleDisplayDrivers",
247 excludes=tuple(
248 "*%s" % ext
249 for ext in importlib.machinery.SOURCE_SUFFIXES + importlib.machinery.BYTECODE_SUFFIXES
250 ) + (
251 "__pycache__",
252 ))
253 + getRecursiveDataFiles('documentation', '../user_docs', excludes=('*.t2t', '*.t2tconf', '*/developerGuide.*'))
254 ),
255 )
256
[end of source/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/source/setup.py b/source/setup.py
--- a/source/setup.py
+++ b/source/setup.py
@@ -230,6 +230,7 @@
("images", glob("images/*.ico")),
("louis/tables",glob("louis/tables/*")),
("COMRegistrationFixes", glob("COMRegistrationFixes/*.reg")),
+ (".", glob("../miscDeps/python/*.dll")),
(".", ['message.html' ])
] + (
getLocaleDataFiles()
|
{"golden_diff": "diff --git a/source/setup.py b/source/setup.py\n--- a/source/setup.py\n+++ b/source/setup.py\n@@ -230,6 +230,7 @@\n \t\t(\"images\", glob(\"images/*.ico\")),\r\n \t\t(\"louis/tables\",glob(\"louis/tables/*\")),\r\n \t\t(\"COMRegistrationFixes\", glob(\"COMRegistrationFixes/*.reg\")),\r\n+\t\t(\".\", glob(\"../miscDeps/python/*.dll\")),\r\n \t\t(\".\", ['message.html' ])\r\n \t] + (\r\n \t\tgetLocaleDataFiles()\n", "issue": "When BRLTTY for Windows is installed scons fails to bundle BrlAPI\nDiscovered while debugging #10228\r\n### Steps to reproduce:\r\n1. Install BRLTTY for Windows you do not need to have any actual braille display connected.\r\n2. Execute scons launcher from the root of the NVDA repo.\r\n3. Start newly created launcher.\r\n### Actual behavior:\r\nBrlAPI dll is missing. It is therefore not possible to switch to BRLTTY.\r\n### Expected behavior:\r\nBrlAPI should be working regardless of what is installed on the system.\r\n### System configuration\r\n#### NVDA installed/portable/running from source:\r\nSource\r\n#### NVDA version:\r\nAny after migration to BrlAPI 07 and Python 3.\r\n#### Windows version:\r\nWindows 7 x64\r\n#### Name and version of other software in use when reproducing the issue:\r\nPython, BRLTTY for Windows\r\n#### Other information about your system:\r\n\r\n### Other questions\r\n#### Does the issue still occur after restarting your PC?\r\nYes\r\n#### Have you tried any other versions of NVDA? If so, please report their behaviors.\r\nThis is new after Python 3 migration.\r\n#### Additional info:\r\nWHen BRLTTY is installed it places brlapi-0.7.dll in the syswow64 directory. When this dll is removed either manually or by uninstall of BRLTTY BrlAPI is bundled correctly.\n", "before_files": [{"content": "# -*- coding: UTF-8 -*-\r\n#setup.py\r\n#A part of NonVisual Desktop Access (NVDA)\r\n#Copyright (C) 2006-2018 NV Access Limited, Peter V\u00e1gner, Joseph Lee\r\n#This file is covered by the GNU General Public License.\r\n#See the file COPYING for more details.\r\n\r\nimport os\r\nimport copy\r\nimport gettext\r\ngettext.install(\"nvda\")\r\nfrom setuptools import setup\r\nimport py2exe as py2exeModule\r\nfrom glob import glob\r\nimport fnmatch\r\nfrom versionInfo import *\r\nfrom py2exe import distutils_buildexe\r\nfrom py2exe.dllfinder import DllFinder\r\nimport wx\r\nimport importlib.machinery\r\n\r\nRT_MANIFEST = 24\r\nmanifest_template = \"\"\"\\\r\n<?xml version=\"1.0\" encoding=\"UTF-8\" standalone=\"yes\"?>\r\n<assembly xmlns=\"urn:schemas-microsoft-com:asm.v1\" manifestVersion=\"1.0\">\r\n\t<trustInfo xmlns=\"urn:schemas-microsoft-com:asm.v3\">\r\n\t\t<security>\r\n\t\t\t<requestedPrivileges>\r\n\t\t\t\t<requestedExecutionLevel\r\n\t\t\t\t\tlevel=\"asInvoker\"\r\n\t\t\t\t\tuiAccess=\"%(uiAccess)s\"\r\n\t\t\t\t/>\r\n\t\t\t</requestedPrivileges>\r\n\t\t</security>\r\n\t</trustInfo>\r\n\t<compatibility xmlns=\"urn:schemas-microsoft-com:compatibility.v1\">\r\n\t\t<application>\r\n\t\t\t<!-- Windows 7 -->\r\n\t\t\t<supportedOS\r\n\t\t\t\tId=\"{35138b9a-5d96-4fbd-8e2d-a2440225f93a}\"\r\n\t\t\t/>\r\n\t\t\t<!-- Windows 8 -->\r\n\t\t\t<supportedOS\r\n\t\t\t\tId=\"{4a2f28e3-53b9-4441-ba9c-d69d4a4a6e38}\"\r\n\t\t\t/>\r\n\t\t\t<!-- Windows 8.1 -->\r\n\t\t\t<supportedOS\r\n\t\t\t\tId=\"{1f676c76-80e1-4239-95bb-83d0f6d0da78}\"\r\n\t\t\t/>\r\n\t\t\t<!-- Windows 10 -->\r\n\t\t\t<supportedOS\r\n\t\t\t\tId=\"{8e0f7a12-bfb3-4fe8-b9a5-48fd50a15a9a}\"\r\n\t\t\t/>\r\n\t\t</application> \r\n\t</compatibility>\r\n</assembly>\r\n\"\"\"\r\n\r\n# py2exe's idea of whether a dll is a system dll appears to be wrong sometimes, so monkey patch it.\r\norig_determine_dll_type = DllFinder.determine_dll_type\r\ndef determine_dll_type(self, imagename):\r\n\tdll = os.path.basename(imagename).lower()\r\n\tif dll.startswith(\"api-ms-win-\") or dll in (\"powrprof.dll\", \"mpr.dll\", \"crypt32.dll\"):\r\n\t\t# These are definitely system dlls available on all systems and must be excluded.\r\n\t\t# Including them can cause serious problems when a binary build is run on a different version of Windows.\r\n\t\treturn None\r\n\treturn orig_determine_dll_type(self, imagename)\r\nDllFinder.determine_dll_type = determine_dll_type\r\n\r\nclass py2exe(distutils_buildexe.py2exe):\r\n\t\"\"\"Overridden py2exe command to:\r\n\t\t* Add a command line option --enable-uiAccess to enable uiAccess for the main executable and EOA proxy\r\n\t\t* Add a manifest to the executables\r\n\t\"\"\"\r\n\r\n\tuser_options = distutils_buildexe.py2exe.user_options + [\r\n\t\t(\"enable-uiAccess\", \"u\", \"enable uiAccess for the main executable\"),\r\n\t]\r\n\r\n\tdef initialize_options(self):\r\n\t\tsuper(py2exe, self).initialize_options()\r\n\t\tself.enable_uiAccess = False\r\n\r\n\tdef run(self):\r\n\t\tdist = self.distribution\r\n\t\tif self.enable_uiAccess:\r\n\t\t\t# Add a target for nvda_uiAccess, using nvda_noUIAccess as a base.\r\n\t\t\ttarget = copy.deepcopy(dist.windows[0])\r\n\t\t\ttarget[\"dest_base\"] = \"nvda_uiAccess\"\r\n\t\t\ttarget['uiAccess'] = True\r\n\t\t\tdist.windows.insert(1, target)\r\n\t\t\t# nvda_eoaProxy should have uiAccess.\r\n\t\t\ttarget = dist.windows[3]\r\n\t\t\ttarget['uiAccess'] = True\r\n\t\t# Add a manifest resource to every target at runtime.\r\n\t\tfor target in dist.windows:\r\n\t\t\ttarget[\"other_resources\"] = [\r\n\t\t\t\t(\r\n\t\t\t\t\tRT_MANIFEST,\r\n\t\t\t\t\t1,\r\n\t\t\t\t\t(manifest_template % dict(uiAccess=target['uiAccess'])).encode(\"utf-8\")\r\n\t\t\t\t),\r\n\t\t\t]\r\n\t\tsuper(py2exe, self).run()\r\n\r\ndef getLocaleDataFiles():\r\n\twxDir=wx.__path__[0]\r\n\tlocaleMoFiles=set()\r\n\tfor f in glob(\"locale/*/LC_MESSAGES\"):\r\n\t\tlocaleMoFiles.add((f, (os.path.join(f,\"nvda.mo\"),)))\r\n\t\twxMoFile=os.path.join(wxDir,f,\"wxstd.mo\")\r\n\t\tif os.path.isfile(wxMoFile):\r\n\t\t\tlocaleMoFiles.add((f,(wxMoFile,))) \r\n\t\tlang=os.path.split(os.path.split(f)[0])[1]\r\n\t\tif '_' in lang:\r\n\t\t\t\tlang=lang.split('_')[0]\r\n\t\t\t\tf=os.path.join('locale',lang,'lc_messages')\r\n\t\t\t\twxMoFile=os.path.join(wxDir,f,\"wxstd.mo\")\r\n\t\t\t\tif os.path.isfile(wxMoFile):\r\n\t\t\t\t\tlocaleMoFiles.add((f,(wxMoFile,))) \r\n\tlocaleDicFiles=[(os.path.dirname(f), (f,)) for f in glob(\"locale/*/*.dic\")]\r\n\tNVDALocaleGestureMaps=[(os.path.dirname(f), (f,)) for f in glob(\"locale/*/gestures.ini\")]\r\n\treturn list(localeMoFiles)+localeDicFiles+NVDALocaleGestureMaps\r\n\r\ndef getRecursiveDataFiles(dest,source,excludes=()):\r\n\trulesList=[]\r\n\trulesList.append((dest,\r\n\t\t[f for f in glob(\"%s/*\"%source) if not any(fnmatch.fnmatch(f,exclude) for exclude in excludes) and os.path.isfile(f)]))\r\n\t[rulesList.extend(getRecursiveDataFiles(os.path.join(dest,dirName),os.path.join(source,dirName),excludes=excludes)) for dirName in os.listdir(source) if os.path.isdir(os.path.join(source,dirName)) and not dirName.startswith('.')]\r\n\treturn rulesList\r\n\r\nsetup(\r\n\tname = name,\r\n\tversion=version,\r\n\tdescription=description,\r\n\turl=url,\r\n\tclassifiers=[\r\n'Development Status :: 3 - Alpha',\r\n'Environment :: Win32 (MS Windows)',\r\n'Topic :: Adaptive Technologies'\r\n'Intended Audience :: Developers',\r\n'Intended Audience :: End Users/Desktop',\r\n'License :: OSI Approved :: GNU General Public License (GPL)',\r\n'Natural Language :: English',\r\n'Programming Language :: Python',\r\n'Operating System :: Microsoft :: Windows',\r\n],\r\n\tcmdclass={\"py2exe\": py2exe},\r\n\twindows=[\r\n\t\t{\r\n\t\t\t\"script\":\"nvda.pyw\",\r\n\t\t\t\"dest_base\":\"nvda_noUIAccess\",\r\n\t\t\t\"uiAccess\": False,\r\n\t\t\t\"icon_resources\":[(1,\"images/nvda.ico\")],\r\n\t\t\t\"other_resources\": [], # Populated at run time\r\n\t\t\t\"version\":formatBuildVersionString(),\r\n\t\t\t\"description\":\"NVDA application\",\r\n\t\t\t\"product_name\":name,\r\n\t\t\t\"product_version\":version,\r\n\t\t\t\"copyright\":copyright,\r\n\t\t\t\"company_name\":publisher,\r\n\t\t},\r\n\t\t# The nvda_uiAccess target will be added at runtime if required.\r\n\t\t{\r\n\t\t\t\"script\": \"nvda_slave.pyw\",\r\n\t\t\t\"uiAccess\": False,\r\n\t\t\t\"icon_resources\": [(1,\"images/nvda.ico\")],\r\n\t\t\t\"other_resources\": [], # Populated at run time\r\n\t\t\t\"version\":formatBuildVersionString(),\r\n\t\t\t\"description\": name,\r\n\t\t\t\"product_name\":name,\r\n\t\t\t\"product_version\": version,\r\n\t\t\t\"copyright\": copyright,\r\n\t\t\t\"company_name\": publisher,\r\n\t\t},\r\n\t\t{\r\n\t\t\t\"script\": \"nvda_eoaProxy.pyw\",\r\n\t\t\t# uiAccess will be enabled at runtime if appropriate.\r\n\t\t\t\"uiAccess\": False,\r\n\t\t\t\"icon_resources\": [(1,\"images/nvda.ico\")],\r\n\t\t\t\"other_resources\": [], # Populated at run time\r\n\t\t\t\"version\":formatBuildVersionString(),\r\n\t\t\t\"description\": \"NVDA Ease of Access proxy\",\r\n\t\t\t\"product_name\":name,\r\n\t\t\t\"product_version\": version,\r\n\t\t\t\"copyright\": copyright,\r\n\t\t\t\"company_name\": publisher,\r\n\t\t},\r\n\t],\r\n\toptions = {\"py2exe\": {\r\n\t\t\"bundle_files\": 3,\r\n\t\t\"excludes\": [\"tkinter\",\r\n\t\t\t\"serial.loopback_connection\", \r\n\t\t\t\"serial.rfc2217\", \r\n\t\t\t\"serial.serialcli\", \r\n\t\t\t\"serial.serialjava\", \r\n\t\t\t\"serial.serialposix\", \r\n\t\t\t\"serial.socket_connection\",\r\n\t\t\t# netbios (from pywin32) is optionally used by Python3's uuid module.\r\n\t\t\t# This is not needed.\r\n\t\t\t# We also need to exclude win32wnet explicitly.\r\n\t\t\t\"netbios\",\r\n\t\t\t\"win32wnet\",\r\n\t\t\t# winxptheme is optionally used by wx.lib.agw.aui.\r\n\t\t\t# We don't need this.\r\n\t\t\t\"winxptheme\",\r\n\t\t],\r\n\t\t\"packages\": [\r\n\t\t\t\"NVDAObjects\",\r\n\t\t\t\"virtualBuffers\",\r\n\t\t\t\"appModules\",\r\n\t\t\t\"comInterfaces\",\r\n\t\t\t\"brailleDisplayDrivers\",\r\n\t\t\t\"synthDrivers\",\r\n\t\t\t\"visionEnhancementProviders\",\r\n\t\t],\r\n\t\t\"includes\": [\r\n\t\t\t\"nvdaBuiltin\",\r\n\t\t\t# #3368: bisect was implicitly included with Python 2.7.3, but isn't with 2.7.5.\r\n\t\t\t\"bisect\",\r\n\t\t],\r\n\t}},\r\n\tdata_files=[\r\n\t\t(\".\",glob(\"*.dll\")+glob(\"*.manifest\")+[\"builtin.dic\"]),\r\n\t\t(\"documentation\", ['../copying.txt', '../contributors.txt']),\r\n\t\t(\"lib/%s\"%version, glob(\"lib/*.dll\")),\r\n\t\t(\"lib64/%s\"%version, glob(\"lib64/*.dll\") + glob(\"lib64/*.exe\")),\r\n\t\t(\"libArm64/%s\"%version, glob(\"libArm64/*.dll\") + glob(\"libArm64/*.exe\")),\r\n\t\t(\"waves\", glob(\"waves/*.wav\")),\r\n\t\t(\"images\", glob(\"images/*.ico\")),\r\n\t\t(\"louis/tables\",glob(\"louis/tables/*\")),\r\n\t\t(\"COMRegistrationFixes\", glob(\"COMRegistrationFixes/*.reg\")),\r\n\t\t(\".\", ['message.html' ])\r\n\t] + (\r\n\t\tgetLocaleDataFiles()\r\n\t\t+ getRecursiveDataFiles(\"synthDrivers\", \"synthDrivers\",\r\n\t\t\texcludes=tuple(\r\n\t\t\t\t\"*%s\" % ext\r\n\t\t\t\tfor ext in importlib.machinery.SOURCE_SUFFIXES + importlib.machinery.BYTECODE_SUFFIXES\r\n\t\t\t) + (\r\n\t\t\t\t\"*.exp\",\r\n\t\t\t\t\"*.lib\",\r\n\t\t\t\t\"*.pdb\",\r\n\t\t\t\t\"__pycache__\"\r\n\t\t))\r\n\t\t+ getRecursiveDataFiles(\"brailleDisplayDrivers\", \"brailleDisplayDrivers\",\r\n\t\t\texcludes=tuple(\r\n\t\t\t\t\"*%s\" % ext\r\n\t\t\t\tfor ext in importlib.machinery.SOURCE_SUFFIXES + importlib.machinery.BYTECODE_SUFFIXES\r\n\t\t\t) + (\r\n\t\t\t\t\"__pycache__\",\r\n\t\t))\r\n\t\t+ getRecursiveDataFiles('documentation', '../user_docs', excludes=('*.t2t', '*.t2tconf', '*/developerGuide.*'))\r\n\t),\r\n)\r\n", "path": "source/setup.py"}]}
| 4,042 | 119 |
gh_patches_debug_43633
|
rasdani/github-patches
|
git_diff
|
bids-standard__pybids-17
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add get_fieldmap() method
Option 1 (simple):
```
>> layout = BIDSLayout("/data/ds")
>> layout.get_fieldmap("sub-01/func/sub-01_task-rest_bold.nii.gz")
[
"/data/ds/sub-01/fmap/sub-01_magnitude1.nii.gz",
"/data/ds/sub-01/fmap/sub-01_magnitude2.nii.gz",
"/data/ds/sub-01/fmap/sub-01_phasediff.nii.gz"
]
```
Option 2 (extensive):
```
>> layout = BIDSLayout("/data/ds")
>> layout.get_fieldmap("sub-01/func/sub-01_task-rest_bold.nii.gz")
{
'type': 'phasediff',
'metadata': {
"EchoTime1" : 0.00600,
"EchoTime2" : 0.00746,
"IntendedFor" : "func/sub01_taskmotor_bold.nii.gz"
},
'data' : [
"/data/ds/sub-01/fmap/sub-01_magnitude1.nii.gz",
"/data/ds/sub-01/fmap/sub-01_magnitude2.nii.gz",
"/data/ds/sub-01/fmap/sub-01_phasediff.nii.gz"
]
}
```
WDYT @rwblair @oesteban @yarikoptic @tyarkoni @satra?
</issue>
<code>
[start of bids/grabbids/bids_layout.py]
1 import os
2 import re
3 import json
4
5 from itertools import combinations
6 from os.path import dirname
7 from os.path import realpath
8 from os.path import join as pathjoin
9 from os.path import split as pathsplit
10
11 from grabbit import Layout
12
13 __all__ = ['BIDSLayout']
14
15
16 class BIDSLayout(Layout):
17 def __init__(self, path, config=None):
18 if config is None:
19 root = dirname(realpath(__file__))
20 config = pathjoin(root, 'config', 'bids.json')
21 super(BIDSLayout, self).__init__(path, config)
22
23 def get_metadata(self, path):
24 sidecarJSON = path.replace(".nii.gz", ".json").replace(".nii", ".json")
25 path_components = pathsplit(sidecarJSON)
26 filename_components = path_components[-1].split("_")
27 ses = None
28 suffix = filename_components[-1]
29
30 sub = filename_components[0]
31 keyword_components = filename_components[1:-1]
32 if filename_components[1][:3] == "ses":
33 ses = filename_components[1]
34 keyword_components = filename_components[2:-1]
35
36 potentialJSONs = []
37 for prefixes, conditional in ( # Levels
38 (tuple(), True), # top
39 ((sub,), True), # subject
40 ((sub, ses), ses) # session
41 ):
42 if not conditional:
43 continue
44 for k in range(len(keyword_components) + 1):
45 # print(k)
46 for components in combinations(keyword_components, k):
47 # print(components)
48 potentialJSONs.append(
49 pathjoin(
50 self.root,
51 *(prefixes +
52 ("_".join(prefixes + components + (suffix,)),))))
53
54 merged_param_dict = {}
55 for json_file_path in potentialJSONs:
56 if os.path.exists(json_file_path):
57 param_dict = json.load(open(json_file_path, "r"))
58 merged_param_dict.update(param_dict)
59
60 return merged_param_dict
61
62 def find_match(self, target, source=None):
63
64 # Try to take the easy way out
65 if source is not None:
66 _target = source.split('.')[0] + '.' + target
67 if os.path.exists(_target):
68 return target
69
70 if target in list(self.entities.keys()):
71 candidates = list(self.entities[target].files.keys())
72 else:
73 candidates = []
74
75 for root, directories, filenames in os.walk(self.root):
76 for f in filenames:
77 if re.search(target + '$', f):
78 if os.path.sep == "\\":
79 f = f.replace("\\", "\\\\")
80 candidates.append(f)
81
82 if source is None:
83 return candidates
84
85 # Walk up the file hierarchy from source, find first match
86 if not os.path.exists(source):
87 raise OSError("The file '%s' doesn't exist." % source)
88 elif not source.startswith(self.root):
89 raise ValueError("The file '%s' is not contained "
90 "within the current project "
91 "directory (%s)." % (source, self.root))
92 rel = os.path.relpath(dirname(source), self.root)
93 sep = os.path.sep
94 chunks = rel.split(sep)
95 n_chunks = len(chunks)
96 for i in range(n_chunks, -1, -1):
97 path = pathjoin(self.root, *chunks[:i])
98 patt = path + '\%s[^\%s]+$' % (sep, sep)
99 if sep == "\\":
100 patt = path + '\\[^\\]+$'
101 patt = patt.replace("\\", "\\\\")
102 matches = [x for x in candidates if re.search(patt, x)]
103 if matches:
104 if len(matches) == 1:
105 return matches[0]
106 else:
107 raise ValueError("Ambiguous target: more than one "
108 "candidate file found in "
109 "directory '%s'." % path)
110 return None
111
[end of bids/grabbids/bids_layout.py]
[start of setup.py]
1 #!/usr/bin/env python
2
3 import os
4 from setuptools import setup, find_packages
5 PACKAGES = find_packages()
6
7 # Get version and release info, which is all stored in bids/version.py
8 ver_file = os.path.join('bids', 'version.py')
9 with open(ver_file) as f:
10 exec(f.read())
11
12 opts = dict(name=NAME,
13 maintainer=MAINTAINER,
14 maintainer_email=MAINTAINER_EMAIL,
15 description=DESCRIPTION,
16 long_description=LONG_DESCRIPTION,
17 url=URL,
18 download_url=DOWNLOAD_URL,
19 license=LICENSE,
20 classifiers=CLASSIFIERS,
21 author=AUTHOR,
22 author_email=AUTHOR_EMAIL,
23 platforms=PLATFORMS,
24 version=VERSION,
25 packages=PACKAGES,
26 requires=REQUIRES,
27 install_requires=REQUIRES)
28
29
30 if __name__ == '__main__':
31 setup(**opts)
32
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bids/grabbids/bids_layout.py b/bids/grabbids/bids_layout.py
--- a/bids/grabbids/bids_layout.py
+++ b/bids/grabbids/bids_layout.py
@@ -18,7 +18,7 @@
if config is None:
root = dirname(realpath(__file__))
config = pathjoin(root, 'config', 'bids.json')
- super(BIDSLayout, self).__init__(path, config)
+ super(BIDSLayout, self).__init__(path, config, dynamic_getters=True)
def get_metadata(self, path):
sidecarJSON = path.replace(".nii.gz", ".json").replace(".nii", ".json")
@@ -34,21 +34,21 @@
keyword_components = filename_components[2:-1]
potentialJSONs = []
- for prefixes, conditional in ( # Levels
- (tuple(), True), # top
- ((sub,), True), # subject
- ((sub, ses), ses) # session
+ for prefixes, midlayer, conditional in ( # Levels
+ (tuple(), tuple(), True), # top
+ ((sub,), tuple(), True), # subject
+ ((sub, ), (pathsplit(path_components[-2])[-1],), True),
+ ((sub, ses), tuple(), ses), # session
+ ((sub, ses), (pathsplit(path_components[-2])[-1],), ses)
):
if not conditional:
continue
for k in range(len(keyword_components) + 1):
- # print(k)
for components in combinations(keyword_components, k):
- # print(components)
potentialJSONs.append(
pathjoin(
self.root,
- *(prefixes +
+ *(prefixes + midlayer +
("_".join(prefixes + components + (suffix,)),))))
merged_param_dict = {}
@@ -59,6 +59,45 @@
return merged_param_dict
+ def get_fieldmap(self, path):
+ sub = os.path.split(path)[1].split("_")[0].split("sub-")[1]
+ fieldmap_set = {}
+ for file in self.get(subject=sub,
+ type='(phase1|phase2|phasediff|epi|fieldmap)',
+ extensions=['nii.gz', 'nii']):
+ metadata = self.get_metadata(file.filename)
+ if metadata and "IntendedFor" in metadata.keys():
+ if path.endswith(metadata["IntendedFor"]):
+ if file.type == "phasediff":
+ fieldmap_set = {"phasediff": file.filename,
+ "magnitude1": file.filename.replace(
+ "phasediff", "magnitude1"),
+ "magnitude2": file.filename.replace(
+ "phasediff", "magnitude2"),
+ "type": "phasediff"}
+ break
+ elif file.type == "phase1":
+ fieldmap_set["phase1"] = file.filename
+ fieldmap_set["magnitude1"] = \
+ file.filename.replace("phase1", "magnitude1")
+ fieldmap_set["type"] = "phase"
+ elif file.type == "phase2":
+ fieldmap_set["phase2"] = file.filename
+ fieldmap_set["magnitude2"] = \
+ file.filename.replace("phase2", "magnitude2")
+ fieldmap_set["type"] = "phase"
+ elif file.type == "epi":
+ if "epi" not in fieldmap_set.keys():
+ fieldmap_set["epi"] = []
+ fieldmap_set["epi"].append(file.filename)
+ fieldmap_set["type"] = "epi"
+ elif file.type == "fieldmap":
+ fieldmap_set["fieldmap"] = file.filename
+ fieldmap_set["magnitude"] = \
+ file.filename.replace("fieldmap", "magnitude")
+ fieldmap_set["type"] = "fieldmap"
+ return fieldmap_set
+
def find_match(self, target, source=None):
# Try to take the easy way out
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -23,6 +23,7 @@
platforms=PLATFORMS,
version=VERSION,
packages=PACKAGES,
+ package_data={'bids': ['grabbids/config/bids.json']},
requires=REQUIRES,
install_requires=REQUIRES)
|
{"golden_diff": "diff --git a/bids/grabbids/bids_layout.py b/bids/grabbids/bids_layout.py\n--- a/bids/grabbids/bids_layout.py\n+++ b/bids/grabbids/bids_layout.py\n@@ -18,7 +18,7 @@\n if config is None:\n root = dirname(realpath(__file__))\n config = pathjoin(root, 'config', 'bids.json')\n- super(BIDSLayout, self).__init__(path, config)\n+ super(BIDSLayout, self).__init__(path, config, dynamic_getters=True)\n \n def get_metadata(self, path):\n sidecarJSON = path.replace(\".nii.gz\", \".json\").replace(\".nii\", \".json\")\n@@ -34,21 +34,21 @@\n keyword_components = filename_components[2:-1]\n \n potentialJSONs = []\n- for prefixes, conditional in ( # Levels\n- (tuple(), True), # top\n- ((sub,), True), # subject\n- ((sub, ses), ses) # session\n+ for prefixes, midlayer, conditional in ( # Levels\n+ (tuple(), tuple(), True), # top\n+ ((sub,), tuple(), True), # subject\n+ ((sub, ), (pathsplit(path_components[-2])[-1],), True),\n+ ((sub, ses), tuple(), ses), # session\n+ ((sub, ses), (pathsplit(path_components[-2])[-1],), ses)\n ):\n if not conditional:\n continue\n for k in range(len(keyword_components) + 1):\n- # print(k)\n for components in combinations(keyword_components, k):\n- # print(components)\n potentialJSONs.append(\n pathjoin(\n self.root,\n- *(prefixes +\n+ *(prefixes + midlayer +\n (\"_\".join(prefixes + components + (suffix,)),))))\n \n merged_param_dict = {}\n@@ -59,6 +59,45 @@\n \n return merged_param_dict\n \n+ def get_fieldmap(self, path):\n+ sub = os.path.split(path)[1].split(\"_\")[0].split(\"sub-\")[1]\n+ fieldmap_set = {}\n+ for file in self.get(subject=sub,\n+ type='(phase1|phase2|phasediff|epi|fieldmap)',\n+ extensions=['nii.gz', 'nii']):\n+ metadata = self.get_metadata(file.filename)\n+ if metadata and \"IntendedFor\" in metadata.keys():\n+ if path.endswith(metadata[\"IntendedFor\"]):\n+ if file.type == \"phasediff\":\n+ fieldmap_set = {\"phasediff\": file.filename,\n+ \"magnitude1\": file.filename.replace(\n+ \"phasediff\", \"magnitude1\"),\n+ \"magnitude2\": file.filename.replace(\n+ \"phasediff\", \"magnitude2\"),\n+ \"type\": \"phasediff\"}\n+ break\n+ elif file.type == \"phase1\":\n+ fieldmap_set[\"phase1\"] = file.filename\n+ fieldmap_set[\"magnitude1\"] = \\\n+ file.filename.replace(\"phase1\", \"magnitude1\")\n+ fieldmap_set[\"type\"] = \"phase\"\n+ elif file.type == \"phase2\":\n+ fieldmap_set[\"phase2\"] = file.filename\n+ fieldmap_set[\"magnitude2\"] = \\\n+ file.filename.replace(\"phase2\", \"magnitude2\")\n+ fieldmap_set[\"type\"] = \"phase\"\n+ elif file.type == \"epi\":\n+ if \"epi\" not in fieldmap_set.keys():\n+ fieldmap_set[\"epi\"] = []\n+ fieldmap_set[\"epi\"].append(file.filename)\n+ fieldmap_set[\"type\"] = \"epi\"\n+ elif file.type == \"fieldmap\":\n+ fieldmap_set[\"fieldmap\"] = file.filename\n+ fieldmap_set[\"magnitude\"] = \\\n+ file.filename.replace(\"fieldmap\", \"magnitude\")\n+ fieldmap_set[\"type\"] = \"fieldmap\"\n+ return fieldmap_set\n+\n def find_match(self, target, source=None):\n \n # Try to take the easy way out\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -23,6 +23,7 @@\n platforms=PLATFORMS,\n version=VERSION,\n packages=PACKAGES,\n+ package_data={'bids': ['grabbids/config/bids.json']},\n requires=REQUIRES,\n install_requires=REQUIRES)\n", "issue": "Add get_fieldmap() method\nOption 1 (simple):\n\n```\n>> layout = BIDSLayout(\"/data/ds\")\n>> layout.get_fieldmap(\"sub-01/func/sub-01_task-rest_bold.nii.gz\")\n[\n \"/data/ds/sub-01/fmap/sub-01_magnitude1.nii.gz\", \n \"/data/ds/sub-01/fmap/sub-01_magnitude2.nii.gz\", \n \"/data/ds/sub-01/fmap/sub-01_phasediff.nii.gz\"\n]\n```\n\nOption 2 (extensive):\n\n```\n>> layout = BIDSLayout(\"/data/ds\")\n>> layout.get_fieldmap(\"sub-01/func/sub-01_task-rest_bold.nii.gz\")\n{\n'type': 'phasediff',\n'metadata': {\n \"EchoTime1\" : 0.00600,\n \"EchoTime2\" : 0.00746,\n \"IntendedFor\" : \"func/sub\u00ad01_task\u00admotor_bold.nii.gz\" \n },\n'data' : [\n \"/data/ds/sub-01/fmap/sub-01_magnitude1.nii.gz\", \n \"/data/ds/sub-01/fmap/sub-01_magnitude2.nii.gz\", \n \"/data/ds/sub-01/fmap/sub-01_phasediff.nii.gz\"\n ]\n}\n```\n\nWDYT @rwblair @oesteban @yarikoptic @tyarkoni @satra?\n\n", "before_files": [{"content": "import os\nimport re\nimport json\n\nfrom itertools import combinations\nfrom os.path import dirname\nfrom os.path import realpath\nfrom os.path import join as pathjoin\nfrom os.path import split as pathsplit\n\nfrom grabbit import Layout\n\n__all__ = ['BIDSLayout']\n\n\nclass BIDSLayout(Layout):\n def __init__(self, path, config=None):\n if config is None:\n root = dirname(realpath(__file__))\n config = pathjoin(root, 'config', 'bids.json')\n super(BIDSLayout, self).__init__(path, config)\n\n def get_metadata(self, path):\n sidecarJSON = path.replace(\".nii.gz\", \".json\").replace(\".nii\", \".json\")\n path_components = pathsplit(sidecarJSON)\n filename_components = path_components[-1].split(\"_\")\n ses = None\n suffix = filename_components[-1]\n\n sub = filename_components[0]\n keyword_components = filename_components[1:-1]\n if filename_components[1][:3] == \"ses\":\n ses = filename_components[1]\n keyword_components = filename_components[2:-1]\n\n potentialJSONs = []\n for prefixes, conditional in ( # Levels\n (tuple(), True), # top\n ((sub,), True), # subject\n ((sub, ses), ses) # session\n ):\n if not conditional:\n continue\n for k in range(len(keyword_components) + 1):\n # print(k)\n for components in combinations(keyword_components, k):\n # print(components)\n potentialJSONs.append(\n pathjoin(\n self.root,\n *(prefixes +\n (\"_\".join(prefixes + components + (suffix,)),))))\n\n merged_param_dict = {}\n for json_file_path in potentialJSONs:\n if os.path.exists(json_file_path):\n param_dict = json.load(open(json_file_path, \"r\"))\n merged_param_dict.update(param_dict)\n\n return merged_param_dict\n\n def find_match(self, target, source=None):\n\n # Try to take the easy way out\n if source is not None:\n _target = source.split('.')[0] + '.' + target\n if os.path.exists(_target):\n return target\n\n if target in list(self.entities.keys()):\n candidates = list(self.entities[target].files.keys())\n else:\n candidates = []\n\n for root, directories, filenames in os.walk(self.root):\n for f in filenames:\n if re.search(target + '$', f):\n if os.path.sep == \"\\\\\":\n f = f.replace(\"\\\\\", \"\\\\\\\\\")\n candidates.append(f)\n\n if source is None:\n return candidates\n\n # Walk up the file hierarchy from source, find first match\n if not os.path.exists(source):\n raise OSError(\"The file '%s' doesn't exist.\" % source)\n elif not source.startswith(self.root):\n raise ValueError(\"The file '%s' is not contained \"\n \"within the current project \"\n \"directory (%s).\" % (source, self.root))\n rel = os.path.relpath(dirname(source), self.root)\n sep = os.path.sep\n chunks = rel.split(sep)\n n_chunks = len(chunks)\n for i in range(n_chunks, -1, -1):\n path = pathjoin(self.root, *chunks[:i])\n patt = path + '\\%s[^\\%s]+$' % (sep, sep)\n if sep == \"\\\\\":\n patt = path + '\\\\[^\\\\]+$'\n patt = patt.replace(\"\\\\\", \"\\\\\\\\\")\n matches = [x for x in candidates if re.search(patt, x)]\n if matches:\n if len(matches) == 1:\n return matches[0]\n else:\n raise ValueError(\"Ambiguous target: more than one \"\n \"candidate file found in \"\n \"directory '%s'.\" % path)\n return None\n", "path": "bids/grabbids/bids_layout.py"}, {"content": "#!/usr/bin/env python\n\nimport os\nfrom setuptools import setup, find_packages\nPACKAGES = find_packages()\n\n# Get version and release info, which is all stored in bids/version.py\nver_file = os.path.join('bids', 'version.py')\nwith open(ver_file) as f:\n exec(f.read())\n\nopts = dict(name=NAME,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n url=URL,\n download_url=DOWNLOAD_URL,\n license=LICENSE,\n classifiers=CLASSIFIERS,\n author=AUTHOR,\n author_email=AUTHOR_EMAIL,\n platforms=PLATFORMS,\n version=VERSION,\n packages=PACKAGES,\n requires=REQUIRES,\n install_requires=REQUIRES)\n\n\nif __name__ == '__main__':\n setup(**opts)\n", "path": "setup.py"}]}
| 2,180 | 995 |
gh_patches_debug_51
|
rasdani/github-patches
|
git_diff
|
magenta__magenta-1254
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pip installation fails due to librosa dependency
Hi,
I'm trying to install the magenta-gpu but when I did a pip install magenta-gpu:
**librosa 0.6.2 has requirement joblib>=0.12, but you'll have joblib 0.11 which is incompatible.**
</issue>
<code>
[start of magenta/version.py]
1 # Copyright 2016 Google Inc. All Rights Reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 r"""Separate file for storing the current version of Magenta.
15
16 Stored in a separate file so that setup.py can reference the version without
17 pulling in all the dependencies in __init__.py.
18 """
19
20 __version__ = '0.3.10'
21
[end of magenta/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/magenta/version.py b/magenta/version.py
--- a/magenta/version.py
+++ b/magenta/version.py
@@ -17,4 +17,4 @@
pulling in all the dependencies in __init__.py.
"""
-__version__ = '0.3.10'
+__version__ = '0.3.11'
|
{"golden_diff": "diff --git a/magenta/version.py b/magenta/version.py\n--- a/magenta/version.py\n+++ b/magenta/version.py\n@@ -17,4 +17,4 @@\n pulling in all the dependencies in __init__.py.\n \"\"\"\n \n-__version__ = '0.3.10'\n+__version__ = '0.3.11'\n", "issue": "Pip installation fails due to librosa dependency\nHi,\r\n\r\nI'm trying to install the magenta-gpu but when I did a pip install magenta-gpu:\r\n\r\n**librosa 0.6.2 has requirement joblib>=0.12, but you'll have joblib 0.11 which is incompatible.**\r\n\n", "before_files": [{"content": "# Copyright 2016 Google Inc. All Rights Reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nr\"\"\"Separate file for storing the current version of Magenta.\n\nStored in a separate file so that setup.py can reference the version without\npulling in all the dependencies in __init__.py.\n\"\"\"\n\n__version__ = '0.3.10'\n", "path": "magenta/version.py"}]}
| 827 | 79 |
gh_patches_debug_6648
|
rasdani/github-patches
|
git_diff
|
apache__airflow-34568
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
DryRun is not optional for patch task instance
## Summary
According to the [REST api docs](https://airflow.apache.org/docs/apache-airflow/stable/stable-rest-api-ref.html#operation/patch_mapped_task_instance).
you can patch a task instance state. When you hit the api without sending a
"dry_run" variable, you get a KeyError (This is from a server running version 2.5.3):
```
Traceback (most recent call last):
File "/home/airflow/.local/lib/python3.10/site-packages/flask/app.py", line 2528, in wsgi_app
response = self.full_dispatch_request()
File "/home/airflow/.local/lib/python3.10/site-packages/flask/app.py", line 1825, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/airflow/.local/lib/python3.10/site-packages/flask/app.py", line 1823, in full_dispatch_request
rv = self.dispatch_request()
File "/home/airflow/.local/lib/python3.10/site-packages/flask/app.py", line 1799, in dispatch_request
return self.ensure_sync(self.view_functions[rule.endpoint])(**view_args)
File "/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/decorator.py", line 68, in wrapper
response = function(request)
File "/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/uri_parsing.py", line 149, in wrapper
response = function(request)
File "/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/validation.py", line 196, in wrapper
response = function(request)
File "/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/validation.py", line 399, in wrapper
return function(request)
File "/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/response.py", line 112, in wrapper
response = function(request)
File "/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/parameter.py", line 120, in wrapper
return function(**kwargs)
File "/home/airflow/.local/lib/python3.10/site-packages/airflow/api_connexion/security.py", line 51, in decorated
return func(*args, **kwargs)
File "/home/airflow/.local/lib/python3.10/site-packages/airflow/utils/session.py", line 75, in wrapper
return func(*args, session=session, **kwargs)
File "/home/airflow/.local/lib/python3.10/site-packages/airflow/api_connexion/endpoints/task_instance_endpoint.py", line 594, in patch_task_instance
if not data["dry_run"]:
KeyError: 'dry_run'
```
The API docs state that dry_run is not required and that it is defaulted to false.
This can be reproduced in `main` with the tests by commenting out line 1699 in
[test_task_instance_endpoint.py](https://github.com/apache/airflow/blob/5b0ce3db4d36e2a7f20a78903daf538bbde5e38a/tests/api_connexion/endpoints/test_task_instance_endpoint.py#L1695-L1709)
</issue>
<code>
[start of airflow/api_connexion/schemas/task_instance_schema.py]
1 # Licensed to the Apache Software Foundation (ASF) under one
2 # or more contributor license agreements. See the NOTICE file
3 # distributed with this work for additional information
4 # regarding copyright ownership. The ASF licenses this file
5 # to you under the Apache License, Version 2.0 (the
6 # "License"); you may not use this file except in compliance
7 # with the License. You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing,
12 # software distributed under the License is distributed on an
13 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
14 # KIND, either express or implied. See the License for the
15 # specific language governing permissions and limitations
16 # under the License.
17 from __future__ import annotations
18
19 from typing import TYPE_CHECKING, NamedTuple
20
21 from marshmallow import Schema, ValidationError, fields, validate, validates_schema
22 from marshmallow.utils import get_value
23 from marshmallow_sqlalchemy import SQLAlchemySchema, auto_field
24
25 from airflow.api_connexion.parameters import validate_istimezone
26 from airflow.api_connexion.schemas.common_schema import JsonObjectField
27 from airflow.api_connexion.schemas.enum_schemas import TaskInstanceStateField
28 from airflow.api_connexion.schemas.job_schema import JobSchema
29 from airflow.api_connexion.schemas.sla_miss_schema import SlaMissSchema
30 from airflow.api_connexion.schemas.trigger_schema import TriggerSchema
31 from airflow.models import TaskInstance
32 from airflow.utils.helpers import exactly_one
33 from airflow.utils.state import TaskInstanceState
34
35 if TYPE_CHECKING:
36 from airflow.models import SlaMiss
37
38
39 class TaskInstanceSchema(SQLAlchemySchema):
40 """Task instance schema."""
41
42 class Meta:
43 """Meta."""
44
45 model = TaskInstance
46
47 task_id = auto_field()
48 dag_id = auto_field()
49 run_id = auto_field(data_key="dag_run_id")
50 map_index = auto_field()
51 execution_date = auto_field()
52 start_date = auto_field()
53 end_date = auto_field()
54 duration = auto_field()
55 state = TaskInstanceStateField()
56 _try_number = auto_field(data_key="try_number")
57 max_tries = auto_field()
58 hostname = auto_field()
59 unixname = auto_field()
60 pool = auto_field()
61 pool_slots = auto_field()
62 queue = auto_field()
63 priority_weight = auto_field()
64 operator = auto_field()
65 queued_dttm = auto_field(data_key="queued_when")
66 pid = auto_field()
67 executor_config = auto_field()
68 note = auto_field()
69 sla_miss = fields.Nested(SlaMissSchema, dump_default=None)
70 rendered_fields = JsonObjectField(dump_default={})
71 trigger = fields.Nested(TriggerSchema)
72 triggerer_job = fields.Nested(JobSchema)
73
74 def get_attribute(self, obj, attr, default):
75 if attr == "sla_miss":
76 # Object is a tuple of task_instance and slamiss
77 # and the get_value expects a dict with key, value
78 # corresponding to the attr.
79 slamiss_instance = {"sla_miss": obj[1]}
80 return get_value(slamiss_instance, attr, default)
81 elif attr == "rendered_fields":
82 return get_value(obj[0], "rendered_task_instance_fields.rendered_fields", default)
83 return get_value(obj[0], attr, default)
84
85
86 class TaskInstanceCollection(NamedTuple):
87 """List of task instances with metadata."""
88
89 task_instances: list[tuple[TaskInstance, SlaMiss | None]]
90 total_entries: int
91
92
93 class TaskInstanceCollectionSchema(Schema):
94 """Task instance collection schema."""
95
96 task_instances = fields.List(fields.Nested(TaskInstanceSchema))
97 total_entries = fields.Int()
98
99
100 class TaskInstanceBatchFormSchema(Schema):
101 """Schema for the request form passed to Task Instance Batch endpoint."""
102
103 page_offset = fields.Int(load_default=0, validate=validate.Range(min=0))
104 page_limit = fields.Int(load_default=100, validate=validate.Range(min=1))
105 dag_ids = fields.List(fields.Str(), load_default=None)
106 dag_run_ids = fields.List(fields.Str(), load_default=None)
107 task_ids = fields.List(fields.Str(), load_default=None)
108 execution_date_gte = fields.DateTime(load_default=None, validate=validate_istimezone)
109 execution_date_lte = fields.DateTime(load_default=None, validate=validate_istimezone)
110 start_date_gte = fields.DateTime(load_default=None, validate=validate_istimezone)
111 start_date_lte = fields.DateTime(load_default=None, validate=validate_istimezone)
112 end_date_gte = fields.DateTime(load_default=None, validate=validate_istimezone)
113 end_date_lte = fields.DateTime(load_default=None, validate=validate_istimezone)
114 duration_gte = fields.Int(load_default=None)
115 duration_lte = fields.Int(load_default=None)
116 state = fields.List(fields.Str(allow_none=True), load_default=None)
117 pool = fields.List(fields.Str(), load_default=None)
118 queue = fields.List(fields.Str(), load_default=None)
119
120
121 class ClearTaskInstanceFormSchema(Schema):
122 """Schema for handling the request of clearing task instance of a Dag."""
123
124 dry_run = fields.Boolean(load_default=True)
125 start_date = fields.DateTime(load_default=None, validate=validate_istimezone)
126 end_date = fields.DateTime(load_default=None, validate=validate_istimezone)
127 only_failed = fields.Boolean(load_default=True)
128 only_running = fields.Boolean(load_default=False)
129 include_subdags = fields.Boolean(load_default=False)
130 include_parentdag = fields.Boolean(load_default=False)
131 reset_dag_runs = fields.Boolean(load_default=False)
132 task_ids = fields.List(fields.String(), validate=validate.Length(min=1))
133 dag_run_id = fields.Str(load_default=None)
134 include_upstream = fields.Boolean(load_default=False)
135 include_downstream = fields.Boolean(load_default=False)
136 include_future = fields.Boolean(load_default=False)
137 include_past = fields.Boolean(load_default=False)
138
139 @validates_schema
140 def validate_form(self, data, **kwargs):
141 """Validate clear task instance form."""
142 if data["only_failed"] and data["only_running"]:
143 raise ValidationError("only_failed and only_running both are set to True")
144 if data["start_date"] and data["end_date"]:
145 if data["start_date"] > data["end_date"]:
146 raise ValidationError("end_date is sooner than start_date")
147 if data["start_date"] and data["end_date"] and data["dag_run_id"]:
148 raise ValidationError("Exactly one of dag_run_id or (start_date and end_date) must be provided")
149 if data["start_date"] and data["dag_run_id"]:
150 raise ValidationError("Exactly one of dag_run_id or start_date must be provided")
151 if data["end_date"] and data["dag_run_id"]:
152 raise ValidationError("Exactly one of dag_run_id or end_date must be provided")
153
154
155 class SetTaskInstanceStateFormSchema(Schema):
156 """Schema for handling the request of setting state of task instance of a DAG."""
157
158 dry_run = fields.Boolean(dump_default=True)
159 task_id = fields.Str(required=True)
160 execution_date = fields.DateTime(validate=validate_istimezone)
161 dag_run_id = fields.Str()
162 include_upstream = fields.Boolean(required=True)
163 include_downstream = fields.Boolean(required=True)
164 include_future = fields.Boolean(required=True)
165 include_past = fields.Boolean(required=True)
166 new_state = TaskInstanceStateField(
167 required=True,
168 validate=validate.OneOf(
169 [TaskInstanceState.SUCCESS, TaskInstanceState.FAILED, TaskInstanceState.SKIPPED]
170 ),
171 )
172
173 @validates_schema
174 def validate_form(self, data, **kwargs):
175 """Validate set task instance state form."""
176 if not exactly_one(data.get("execution_date"), data.get("dag_run_id")):
177 raise ValidationError("Exactly one of execution_date or dag_run_id must be provided")
178
179
180 class SetSingleTaskInstanceStateFormSchema(Schema):
181 """Schema for handling the request of updating state of a single task instance."""
182
183 dry_run = fields.Boolean(dump_default=True)
184 new_state = TaskInstanceStateField(
185 required=True,
186 validate=validate.OneOf(
187 [TaskInstanceState.SUCCESS, TaskInstanceState.FAILED, TaskInstanceState.SKIPPED]
188 ),
189 )
190
191
192 class TaskInstanceReferenceSchema(Schema):
193 """Schema for the task instance reference schema."""
194
195 task_id = fields.Str()
196 run_id = fields.Str(data_key="dag_run_id")
197 dag_id = fields.Str()
198 execution_date = fields.DateTime()
199
200
201 class TaskInstanceReferenceCollection(NamedTuple):
202 """List of objects with metadata about taskinstance and dag_run_id."""
203
204 task_instances: list[tuple[TaskInstance, str]]
205
206
207 class TaskInstanceReferenceCollectionSchema(Schema):
208 """Collection schema for task reference."""
209
210 task_instances = fields.List(fields.Nested(TaskInstanceReferenceSchema))
211
212
213 class SetTaskInstanceNoteFormSchema(Schema):
214 """Schema for settings a note for a TaskInstance."""
215
216 # Note: We can't add map_index to the url as subpaths can't start with dashes.
217 map_index = fields.Int(allow_none=False)
218 note = fields.String(allow_none=True, validate=validate.Length(max=1000))
219
220
221 task_instance_schema = TaskInstanceSchema()
222 task_instance_collection_schema = TaskInstanceCollectionSchema()
223 task_instance_batch_form = TaskInstanceBatchFormSchema()
224 clear_task_instance_form = ClearTaskInstanceFormSchema()
225 set_task_instance_state_form = SetTaskInstanceStateFormSchema()
226 set_single_task_instance_state_form = SetSingleTaskInstanceStateFormSchema()
227 task_instance_reference_schema = TaskInstanceReferenceSchema()
228 task_instance_reference_collection_schema = TaskInstanceReferenceCollectionSchema()
229 set_task_instance_note_form_schema = SetTaskInstanceNoteFormSchema()
230
[end of airflow/api_connexion/schemas/task_instance_schema.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/airflow/api_connexion/schemas/task_instance_schema.py b/airflow/api_connexion/schemas/task_instance_schema.py
--- a/airflow/api_connexion/schemas/task_instance_schema.py
+++ b/airflow/api_connexion/schemas/task_instance_schema.py
@@ -180,7 +180,7 @@
class SetSingleTaskInstanceStateFormSchema(Schema):
"""Schema for handling the request of updating state of a single task instance."""
- dry_run = fields.Boolean(dump_default=True)
+ dry_run = fields.Boolean(load_default=True)
new_state = TaskInstanceStateField(
required=True,
validate=validate.OneOf(
|
{"golden_diff": "diff --git a/airflow/api_connexion/schemas/task_instance_schema.py b/airflow/api_connexion/schemas/task_instance_schema.py\n--- a/airflow/api_connexion/schemas/task_instance_schema.py\n+++ b/airflow/api_connexion/schemas/task_instance_schema.py\n@@ -180,7 +180,7 @@\n class SetSingleTaskInstanceStateFormSchema(Schema):\n \"\"\"Schema for handling the request of updating state of a single task instance.\"\"\"\n \n- dry_run = fields.Boolean(dump_default=True)\n+ dry_run = fields.Boolean(load_default=True)\n new_state = TaskInstanceStateField(\n required=True,\n validate=validate.OneOf(\n", "issue": "DryRun is not optional for patch task instance\n## Summary\n\nAccording to the [REST api docs](https://airflow.apache.org/docs/apache-airflow/stable/stable-rest-api-ref.html#operation/patch_mapped_task_instance).\nyou can patch a task instance state. When you hit the api without sending a\n\"dry_run\" variable, you get a KeyError (This is from a server running version 2.5.3):\n\n```\nTraceback (most recent call last):\n File \"/home/airflow/.local/lib/python3.10/site-packages/flask/app.py\", line 2528, in wsgi_app\n response = self.full_dispatch_request()\n File \"/home/airflow/.local/lib/python3.10/site-packages/flask/app.py\", line 1825, in full_dispatch_request\n rv = self.handle_user_exception(e)\n File \"/home/airflow/.local/lib/python3.10/site-packages/flask/app.py\", line 1823, in full_dispatch_request\n rv = self.dispatch_request()\n File \"/home/airflow/.local/lib/python3.10/site-packages/flask/app.py\", line 1799, in dispatch_request\n return self.ensure_sync(self.view_functions[rule.endpoint])(**view_args)\n File \"/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/decorator.py\", line 68, in wrapper\n response = function(request)\n File \"/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/uri_parsing.py\", line 149, in wrapper\n response = function(request)\n File \"/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/validation.py\", line 196, in wrapper\n response = function(request)\n File \"/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/validation.py\", line 399, in wrapper\n return function(request)\n File \"/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/response.py\", line 112, in wrapper\n response = function(request)\n File \"/home/airflow/.local/lib/python3.10/site-packages/connexion/decorators/parameter.py\", line 120, in wrapper\n return function(**kwargs)\n File \"/home/airflow/.local/lib/python3.10/site-packages/airflow/api_connexion/security.py\", line 51, in decorated\n return func(*args, **kwargs)\n File \"/home/airflow/.local/lib/python3.10/site-packages/airflow/utils/session.py\", line 75, in wrapper\n return func(*args, session=session, **kwargs)\n File \"/home/airflow/.local/lib/python3.10/site-packages/airflow/api_connexion/endpoints/task_instance_endpoint.py\", line 594, in patch_task_instance\n if not data[\"dry_run\"]:\nKeyError: 'dry_run'\n```\n\nThe API docs state that dry_run is not required and that it is defaulted to false.\n\nThis can be reproduced in `main` with the tests by commenting out line 1699 in\n[test_task_instance_endpoint.py](https://github.com/apache/airflow/blob/5b0ce3db4d36e2a7f20a78903daf538bbde5e38a/tests/api_connexion/endpoints/test_task_instance_endpoint.py#L1695-L1709)\n\n\n\n\n", "before_files": [{"content": "# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\nfrom __future__ import annotations\n\nfrom typing import TYPE_CHECKING, NamedTuple\n\nfrom marshmallow import Schema, ValidationError, fields, validate, validates_schema\nfrom marshmallow.utils import get_value\nfrom marshmallow_sqlalchemy import SQLAlchemySchema, auto_field\n\nfrom airflow.api_connexion.parameters import validate_istimezone\nfrom airflow.api_connexion.schemas.common_schema import JsonObjectField\nfrom airflow.api_connexion.schemas.enum_schemas import TaskInstanceStateField\nfrom airflow.api_connexion.schemas.job_schema import JobSchema\nfrom airflow.api_connexion.schemas.sla_miss_schema import SlaMissSchema\nfrom airflow.api_connexion.schemas.trigger_schema import TriggerSchema\nfrom airflow.models import TaskInstance\nfrom airflow.utils.helpers import exactly_one\nfrom airflow.utils.state import TaskInstanceState\n\nif TYPE_CHECKING:\n from airflow.models import SlaMiss\n\n\nclass TaskInstanceSchema(SQLAlchemySchema):\n \"\"\"Task instance schema.\"\"\"\n\n class Meta:\n \"\"\"Meta.\"\"\"\n\n model = TaskInstance\n\n task_id = auto_field()\n dag_id = auto_field()\n run_id = auto_field(data_key=\"dag_run_id\")\n map_index = auto_field()\n execution_date = auto_field()\n start_date = auto_field()\n end_date = auto_field()\n duration = auto_field()\n state = TaskInstanceStateField()\n _try_number = auto_field(data_key=\"try_number\")\n max_tries = auto_field()\n hostname = auto_field()\n unixname = auto_field()\n pool = auto_field()\n pool_slots = auto_field()\n queue = auto_field()\n priority_weight = auto_field()\n operator = auto_field()\n queued_dttm = auto_field(data_key=\"queued_when\")\n pid = auto_field()\n executor_config = auto_field()\n note = auto_field()\n sla_miss = fields.Nested(SlaMissSchema, dump_default=None)\n rendered_fields = JsonObjectField(dump_default={})\n trigger = fields.Nested(TriggerSchema)\n triggerer_job = fields.Nested(JobSchema)\n\n def get_attribute(self, obj, attr, default):\n if attr == \"sla_miss\":\n # Object is a tuple of task_instance and slamiss\n # and the get_value expects a dict with key, value\n # corresponding to the attr.\n slamiss_instance = {\"sla_miss\": obj[1]}\n return get_value(slamiss_instance, attr, default)\n elif attr == \"rendered_fields\":\n return get_value(obj[0], \"rendered_task_instance_fields.rendered_fields\", default)\n return get_value(obj[0], attr, default)\n\n\nclass TaskInstanceCollection(NamedTuple):\n \"\"\"List of task instances with metadata.\"\"\"\n\n task_instances: list[tuple[TaskInstance, SlaMiss | None]]\n total_entries: int\n\n\nclass TaskInstanceCollectionSchema(Schema):\n \"\"\"Task instance collection schema.\"\"\"\n\n task_instances = fields.List(fields.Nested(TaskInstanceSchema))\n total_entries = fields.Int()\n\n\nclass TaskInstanceBatchFormSchema(Schema):\n \"\"\"Schema for the request form passed to Task Instance Batch endpoint.\"\"\"\n\n page_offset = fields.Int(load_default=0, validate=validate.Range(min=0))\n page_limit = fields.Int(load_default=100, validate=validate.Range(min=1))\n dag_ids = fields.List(fields.Str(), load_default=None)\n dag_run_ids = fields.List(fields.Str(), load_default=None)\n task_ids = fields.List(fields.Str(), load_default=None)\n execution_date_gte = fields.DateTime(load_default=None, validate=validate_istimezone)\n execution_date_lte = fields.DateTime(load_default=None, validate=validate_istimezone)\n start_date_gte = fields.DateTime(load_default=None, validate=validate_istimezone)\n start_date_lte = fields.DateTime(load_default=None, validate=validate_istimezone)\n end_date_gte = fields.DateTime(load_default=None, validate=validate_istimezone)\n end_date_lte = fields.DateTime(load_default=None, validate=validate_istimezone)\n duration_gte = fields.Int(load_default=None)\n duration_lte = fields.Int(load_default=None)\n state = fields.List(fields.Str(allow_none=True), load_default=None)\n pool = fields.List(fields.Str(), load_default=None)\n queue = fields.List(fields.Str(), load_default=None)\n\n\nclass ClearTaskInstanceFormSchema(Schema):\n \"\"\"Schema for handling the request of clearing task instance of a Dag.\"\"\"\n\n dry_run = fields.Boolean(load_default=True)\n start_date = fields.DateTime(load_default=None, validate=validate_istimezone)\n end_date = fields.DateTime(load_default=None, validate=validate_istimezone)\n only_failed = fields.Boolean(load_default=True)\n only_running = fields.Boolean(load_default=False)\n include_subdags = fields.Boolean(load_default=False)\n include_parentdag = fields.Boolean(load_default=False)\n reset_dag_runs = fields.Boolean(load_default=False)\n task_ids = fields.List(fields.String(), validate=validate.Length(min=1))\n dag_run_id = fields.Str(load_default=None)\n include_upstream = fields.Boolean(load_default=False)\n include_downstream = fields.Boolean(load_default=False)\n include_future = fields.Boolean(load_default=False)\n include_past = fields.Boolean(load_default=False)\n\n @validates_schema\n def validate_form(self, data, **kwargs):\n \"\"\"Validate clear task instance form.\"\"\"\n if data[\"only_failed\"] and data[\"only_running\"]:\n raise ValidationError(\"only_failed and only_running both are set to True\")\n if data[\"start_date\"] and data[\"end_date\"]:\n if data[\"start_date\"] > data[\"end_date\"]:\n raise ValidationError(\"end_date is sooner than start_date\")\n if data[\"start_date\"] and data[\"end_date\"] and data[\"dag_run_id\"]:\n raise ValidationError(\"Exactly one of dag_run_id or (start_date and end_date) must be provided\")\n if data[\"start_date\"] and data[\"dag_run_id\"]:\n raise ValidationError(\"Exactly one of dag_run_id or start_date must be provided\")\n if data[\"end_date\"] and data[\"dag_run_id\"]:\n raise ValidationError(\"Exactly one of dag_run_id or end_date must be provided\")\n\n\nclass SetTaskInstanceStateFormSchema(Schema):\n \"\"\"Schema for handling the request of setting state of task instance of a DAG.\"\"\"\n\n dry_run = fields.Boolean(dump_default=True)\n task_id = fields.Str(required=True)\n execution_date = fields.DateTime(validate=validate_istimezone)\n dag_run_id = fields.Str()\n include_upstream = fields.Boolean(required=True)\n include_downstream = fields.Boolean(required=True)\n include_future = fields.Boolean(required=True)\n include_past = fields.Boolean(required=True)\n new_state = TaskInstanceStateField(\n required=True,\n validate=validate.OneOf(\n [TaskInstanceState.SUCCESS, TaskInstanceState.FAILED, TaskInstanceState.SKIPPED]\n ),\n )\n\n @validates_schema\n def validate_form(self, data, **kwargs):\n \"\"\"Validate set task instance state form.\"\"\"\n if not exactly_one(data.get(\"execution_date\"), data.get(\"dag_run_id\")):\n raise ValidationError(\"Exactly one of execution_date or dag_run_id must be provided\")\n\n\nclass SetSingleTaskInstanceStateFormSchema(Schema):\n \"\"\"Schema for handling the request of updating state of a single task instance.\"\"\"\n\n dry_run = fields.Boolean(dump_default=True)\n new_state = TaskInstanceStateField(\n required=True,\n validate=validate.OneOf(\n [TaskInstanceState.SUCCESS, TaskInstanceState.FAILED, TaskInstanceState.SKIPPED]\n ),\n )\n\n\nclass TaskInstanceReferenceSchema(Schema):\n \"\"\"Schema for the task instance reference schema.\"\"\"\n\n task_id = fields.Str()\n run_id = fields.Str(data_key=\"dag_run_id\")\n dag_id = fields.Str()\n execution_date = fields.DateTime()\n\n\nclass TaskInstanceReferenceCollection(NamedTuple):\n \"\"\"List of objects with metadata about taskinstance and dag_run_id.\"\"\"\n\n task_instances: list[tuple[TaskInstance, str]]\n\n\nclass TaskInstanceReferenceCollectionSchema(Schema):\n \"\"\"Collection schema for task reference.\"\"\"\n\n task_instances = fields.List(fields.Nested(TaskInstanceReferenceSchema))\n\n\nclass SetTaskInstanceNoteFormSchema(Schema):\n \"\"\"Schema for settings a note for a TaskInstance.\"\"\"\n\n # Note: We can't add map_index to the url as subpaths can't start with dashes.\n map_index = fields.Int(allow_none=False)\n note = fields.String(allow_none=True, validate=validate.Length(max=1000))\n\n\ntask_instance_schema = TaskInstanceSchema()\ntask_instance_collection_schema = TaskInstanceCollectionSchema()\ntask_instance_batch_form = TaskInstanceBatchFormSchema()\nclear_task_instance_form = ClearTaskInstanceFormSchema()\nset_task_instance_state_form = SetTaskInstanceStateFormSchema()\nset_single_task_instance_state_form = SetSingleTaskInstanceStateFormSchema()\ntask_instance_reference_schema = TaskInstanceReferenceSchema()\ntask_instance_reference_collection_schema = TaskInstanceReferenceCollectionSchema()\nset_task_instance_note_form_schema = SetTaskInstanceNoteFormSchema()\n", "path": "airflow/api_connexion/schemas/task_instance_schema.py"}]}
| 3,993 | 143 |
gh_patches_debug_2350
|
rasdani/github-patches
|
git_diff
|
mirumee__ariadne-184
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update setup.py to include html and py.typed files in published package
Ariadne now includes `graphql_playground.html` django template and `py.typed` file for enabling typing. We should make sure those two get published together with rest of the project.
</issue>
<code>
[start of setup.py]
1 #! /usr/bin/env python
2 import os
3 from setuptools import setup
4
5 CLASSIFIERS = [
6 "Development Status :: 4 - Beta",
7 "Intended Audience :: Developers",
8 "License :: OSI Approved :: BSD License",
9 "Operating System :: OS Independent",
10 "Programming Language :: Python",
11 "Programming Language :: Python :: 3.6",
12 "Programming Language :: Python :: 3.7",
13 "Topic :: Software Development :: Libraries :: Python Modules",
14 ]
15
16 README_PATH = os.path.join(os.path.dirname(os.path.abspath(__file__)), "README.md")
17 with open(README_PATH, "r") as f:
18 README = f.read()
19
20 setup(
21 name="ariadne",
22 author="Mirumee Software",
23 author_email="[email protected]",
24 description="Ariadne is a Python library for implementing GraphQL servers.",
25 long_description=README,
26 long_description_content_type="text/markdown",
27 license="BSD",
28 version="0.4.0",
29 url="https://github.com/mirumee/ariadne",
30 packages=["ariadne"],
31 package_data={"ariadne": ["py.typed"]},
32 install_requires=[
33 "graphql-core-next>=1.0.4",
34 "starlette<0.13",
35 "typing_extensions>=3.6.0",
36 ],
37 classifiers=CLASSIFIERS,
38 platforms=["any"],
39 zip_safe=False,
40 )
41
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
old mode 100644
new mode 100755
--- a/setup.py
+++ b/setup.py
@@ -28,7 +28,7 @@
version="0.4.0",
url="https://github.com/mirumee/ariadne",
packages=["ariadne"],
- package_data={"ariadne": ["py.typed"]},
+ include_package_data=True,
install_requires=[
"graphql-core-next>=1.0.4",
"starlette<0.13",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\nold mode 100644\nnew mode 100755\n--- a/setup.py\n+++ b/setup.py\n@@ -28,7 +28,7 @@\n version=\"0.4.0\",\n url=\"https://github.com/mirumee/ariadne\",\n packages=[\"ariadne\"],\n- package_data={\"ariadne\": [\"py.typed\"]},\n+ include_package_data=True,\n install_requires=[\n \"graphql-core-next>=1.0.4\",\n \"starlette<0.13\",\n", "issue": "Update setup.py to include html and py.typed files in published package\nAriadne now includes `graphql_playground.html` django template and `py.typed` file for enabling typing. We should make sure those two get published together with rest of the project.\n", "before_files": [{"content": "#! /usr/bin/env python\nimport os\nfrom setuptools import setup\n\nCLASSIFIERS = [\n \"Development Status :: 4 - Beta\",\n \"Intended Audience :: Developers\",\n \"License :: OSI Approved :: BSD License\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Topic :: Software Development :: Libraries :: Python Modules\",\n]\n\nREADME_PATH = os.path.join(os.path.dirname(os.path.abspath(__file__)), \"README.md\")\nwith open(README_PATH, \"r\") as f:\n README = f.read()\n\nsetup(\n name=\"ariadne\",\n author=\"Mirumee Software\",\n author_email=\"[email protected]\",\n description=\"Ariadne is a Python library for implementing GraphQL servers.\",\n long_description=README,\n long_description_content_type=\"text/markdown\",\n license=\"BSD\",\n version=\"0.4.0\",\n url=\"https://github.com/mirumee/ariadne\",\n packages=[\"ariadne\"],\n package_data={\"ariadne\": [\"py.typed\"]},\n install_requires=[\n \"graphql-core-next>=1.0.4\",\n \"starlette<0.13\",\n \"typing_extensions>=3.6.0\",\n ],\n classifiers=CLASSIFIERS,\n platforms=[\"any\"],\n zip_safe=False,\n)\n", "path": "setup.py"}]}
| 965 | 132 |
gh_patches_debug_10933
|
rasdani/github-patches
|
git_diff
|
hydroshare__hydroshare-4917
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
prevent timezone warnings during session logging
**Describe the feature you'd like and what it will do**
Most actions within HS result in at least 4 RuntimeWarnings to be logged
Example creating a resource:
This makes it difficult to sift through the logs and find what we need.
Get rid of these unnecessary warnings
**Why is this feature important?**
Make debugging and audit trail easier
</issue>
<code>
[start of hs_tracking/models.py]
1 from datetime import datetime, timedelta
2
3 from django.db import models
4 from django.db.models import F
5 from django.core import signing
6 from django.conf import settings
7 from django.core.exceptions import ImproperlyConfigured
8 from django.contrib.auth.models import User
9
10 from theme.models import UserProfile
11 from .utils import get_std_log_fields
12 from hs_core.models import BaseResource
13 from hs_core.hydroshare import get_resource_by_shortkey
14
15 SESSION_TIMEOUT = settings.TRACKING_SESSION_TIMEOUT
16 PROFILE_FIELDS = settings.TRACKING_PROFILE_FIELDS
17 USER_FIELDS = settings.TRACKING_USER_FIELDS
18 VISITOR_FIELDS = ["id"] + USER_FIELDS + PROFILE_FIELDS
19 if set(PROFILE_FIELDS) & set(USER_FIELDS):
20 raise ImproperlyConfigured("hs_tracking PROFILE_FIELDS and USER_FIELDS must not contain"
21 " overlapping field names")
22
23
24 class SessionManager(models.Manager):
25 def for_request(self, request, user=None):
26 if hasattr(request, 'user'):
27 user = request.user
28
29 signed_id = request.session.get('hs_tracking_id')
30 if signed_id:
31 tracking_id = signing.loads(signed_id)
32 cut_off = datetime.now() - timedelta(seconds=SESSION_TIMEOUT)
33 session = None
34
35 try:
36 session = Session.objects.filter(
37 variable__timestamp__gte=cut_off).filter(id=tracking_id['id']).first()
38 except Session.DoesNotExist:
39 pass
40
41 if session is not None and user is not None:
42 if session.visitor.user is None and user.is_authenticated:
43 try:
44 session.visitor = Visitor.objects.get(user=user)
45 session.save()
46 except Visitor.DoesNotExist:
47 session.visitor.user = user
48 session.visitor.save()
49 return session
50
51 # No session found, create one
52 if user.is_authenticated:
53 visitor, _ = Visitor.objects.get_or_create(user=user)
54 else:
55 visitor = Visitor.objects.create()
56
57 session = Session.objects.create(visitor=visitor)
58
59 # get standard fields and format
60 fields = get_std_log_fields(request, session)
61 msg = Variable.format_kwargs(**fields)
62
63 session.record('begin_session', msg)
64 request.session['hs_tracking_id'] = signing.dumps({'id': session.id})
65 return session
66
67
68 class Visitor(models.Model):
69 first_seen = models.DateTimeField(auto_now_add=True)
70 user = models.OneToOneField(settings.AUTH_USER_MODEL, null=True,
71 on_delete=models.SET_NULL,
72 related_name='visitor')
73
74 def export_visitor_information(self):
75 """Exports visitor profile information."""
76 info = {
77 "id": self.id,
78 }
79 if self.user:
80 profile = UserProfile.objects.get(user=self.user)
81 for field in PROFILE_FIELDS:
82 info[field] = getattr(profile, field)
83 for field in USER_FIELDS:
84 info[field] = getattr(self.user, field)
85 else:
86 profile = None
87 for field in PROFILE_FIELDS:
88 info[field] = None
89 for field in USER_FIELDS:
90 info[field] = None
91 return info
92
93
94 class Session(models.Model):
95 begin = models.DateTimeField(auto_now_add=True)
96 visitor = models.ForeignKey(Visitor, on_delete=models.CASCADE, related_name='session')
97 # TODO: hostname = models.CharField(null=True, default=None, max_length=256)
98
99 objects = SessionManager()
100
101 def get(self, name):
102 return Variable.objects.filter(session=self, name=name).first().get_value()
103
104 def getlist(self, name):
105 return [v.get_value() for v in Variable.objects.filter(session=self, name=name)]
106
107 def record(self, *args, **kwargs):
108 args = (self,) + args
109 return Variable.record(*args, **kwargs)
110
111
112 class Variable(models.Model):
113 TYPES = (
114 ('Integer', int),
115 ('Floating Point', float),
116 ('Text', str),
117 ('Flag', bool),
118 ('None', lambda o: None)
119 )
120 TYPE_CHOICES = [
121 (i, label)
122 for (i, label) in
123 enumerate(label for (label, coercer) in TYPES)
124 ]
125
126 from hs_core.models import BaseResource
127
128 session = models.ForeignKey(Session, on_delete=models.CASCADE, related_name='variable')
129 timestamp = models.DateTimeField(auto_now_add=True)
130 name = models.CharField(max_length=32)
131 type = models.IntegerField(choices=TYPE_CHOICES)
132 # change value to TextField to be less restrictive as max_length of CharField has been
133 # exceeded a couple of times
134 value = models.TextField()
135
136 # If a resource no longer exists, last_resource_id remains valid but resource is NULL
137 resource = models.ForeignKey(BaseResource, null=True,
138 related_name='variable',
139 on_delete=models.SET_NULL)
140 last_resource_id = models.CharField(null=True, max_length=32)
141
142 # flags describe kind of visit. False for non-visits
143 landing = models.BooleanField(null=False, default=False)
144 rest = models.BooleanField(null=False, default=False)
145 # REDUNDANT: internal = models.BooleanField(null=False, default=False)
146
147 def get_value(self):
148 v = self.value
149 if self.type == 3: # boolean types don't coerce reflexively
150 if v == 'true':
151 return True
152 else:
153 return False
154 else:
155 t = self.TYPES[self.type][1]
156 return t(v)
157
158 @classmethod
159 def format_kwargs(cls, **kwargs):
160 msg_items = []
161 for k, v in list(kwargs.items()):
162 msg_items.append('%s=%s' % (str(k), str(v)))
163 return '|'.join(msg_items)
164
165 @classmethod
166 def record(cls, session, name, value=None, resource=None, resource_id=None,
167 rest=False, landing=False):
168 if resource is None and resource_id is not None:
169 try:
170 resource = get_resource_by_shortkey(resource_id, or_404=False)
171 except BaseResource.DoesNotExist:
172 resource = None
173 return Variable.objects.create(session=session, name=name,
174 type=cls.encode_type(value),
175 value=cls.encode(value),
176 last_resource_id=resource_id,
177 resource=resource,
178 rest=rest,
179 landing=landing)
180
181 @classmethod
182 def encode(cls, value):
183 if value is None:
184 return ''
185 elif isinstance(value, bool):
186 return 'true' if value else 'false' # only empty strings are False
187 elif isinstance(value, (int, float, str)):
188 return str(value)
189 else:
190 raise ValueError("Unknown type (%s) for tracking variable: %r",
191 type(value).__name__, value)
192
193 @classmethod
194 def encode_type(cls, value):
195 if value is None:
196 return 4
197 elif isinstance(value, bool):
198 return 3
199 elif isinstance(value, str):
200 return 2
201 elif isinstance(value, float):
202 return 1
203 elif isinstance(value, int):
204 return 0
205 else:
206 raise TypeError("Unable to record variable of unrecognized type %s",
207 type(value).__name__)
208
209 @classmethod
210 def recent_resources(cls, user, n_resources=5, days=60):
211 """
212 fetch the most recent n resources with which a specific user has interacted
213
214 :param user: The user to document.
215 :param n_resources: the number of resources to return.
216 :param days: the number of days to scan.
217
218 The reason for the parameter `days` is that the runtime of this method
219 is very dependent upon the days that one scans. Thus, there is a tradeoff
220 between reporting history and timely responsiveness of the dashboard.
221 """
222 # TODO: document actions like labeling and commenting (currently these are 'visit's)
223 return BaseResource.objects.filter(
224 variable__session__visitor__user=user,
225 variable__timestamp__gte=(datetime.now()-timedelta(days)),
226 variable__resource__isnull=False,
227 variable__name='visit')\
228 .only('short_id', 'created')\
229 .distinct()\
230 .annotate(public=F('raccess__public'),
231 discoverable=F('raccess__discoverable'),
232 published=F('raccess__published'),
233 last_accessed=models.Max('variable__timestamp'))\
234 .filter(variable__timestamp=F('last_accessed'))\
235 .order_by('-last_accessed')[:n_resources]
236
237 @classmethod
238 def popular_resources(cls, n_resources=5, days=60, today=None):
239 """
240 fetch the most recent n resources with which a specific user has interacted
241
242 :param n_resources: the number of resources to return.
243 :param days: the number of days to scan.
244
245 The reason for the parameter `days` is that the runtime of this method
246 is very dependent upon the days that one scans. Thus, there is a tradeoff
247 between reporting history and timely responsiveness of the dashboard.
248 """
249 # TODO: document actions like labeling and commenting (currently these are 'visit's)
250 if today is None:
251 today = datetime.now()
252 return BaseResource.objects.filter(
253 variable__timestamp__gte=(today-timedelta(days)),
254 variable__timestamp__lt=(today),
255 variable__resource__isnull=False,
256 variable__name='visit')\
257 .distinct()\
258 .annotate(users=models.Count('variable__session__visitor__user'))\
259 .annotate(public=F('raccess__public'),
260 discoverable=F('raccess__discoverable'),
261 published=F('raccess__published'),
262 last_accessed=models.Max('variable__timestamp'))\
263 .order_by('-users')[:n_resources]
264
265 @classmethod
266 def recent_users(cls, resource, n_users=5, days=60):
267 """
268 fetch the identities of the most recent users who have accessed a resource
269
270 :param resource: The resource to document.
271 :param n_users: the number of users to return.
272 :param days: the number of days to scan.
273
274 The reason for the parameter `days` is that the runtime of this method
275 is very dependent upon the number of days that one scans. Thus, there is a
276 tradeoff between reporting history and timely responsiveness of the dashboard.
277 """
278 return User.objects\
279 .filter(visitor__session__variable__resource=resource,
280 visitor__session__variable__name='visit',
281 visitor__session__variable__timestamp__gte=(datetime.now() -
282 timedelta(days)))\
283 .distinct()\
284 .annotate(last_accessed=models.Max('visitor__session__variable__timestamp'))\
285 .filter(visitor__session__variable__timestamp=F('last_accessed'))\
286 .order_by('-last_accessed')[:n_users]
287
[end of hs_tracking/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hs_tracking/models.py b/hs_tracking/models.py
--- a/hs_tracking/models.py
+++ b/hs_tracking/models.py
@@ -1,4 +1,5 @@
from datetime import datetime, timedelta
+from django.utils import timezone
from django.db import models
from django.db.models import F
@@ -30,6 +31,7 @@
if signed_id:
tracking_id = signing.loads(signed_id)
cut_off = datetime.now() - timedelta(seconds=SESSION_TIMEOUT)
+ cut_off = timezone.make_aware(cut_off)
session = None
try:
|
{"golden_diff": "diff --git a/hs_tracking/models.py b/hs_tracking/models.py\n--- a/hs_tracking/models.py\n+++ b/hs_tracking/models.py\n@@ -1,4 +1,5 @@\n from datetime import datetime, timedelta\n+from django.utils import timezone\n \n from django.db import models\n from django.db.models import F\n@@ -30,6 +31,7 @@\n if signed_id:\n tracking_id = signing.loads(signed_id)\n cut_off = datetime.now() - timedelta(seconds=SESSION_TIMEOUT)\n+ cut_off = timezone.make_aware(cut_off)\n session = None\n \n try:\n", "issue": "prevent timezone warnings during session logging\n**Describe the feature you'd like and what it will do**\r\nMost actions within HS result in at least 4 RuntimeWarnings to be logged\r\nExample creating a resource:\r\n\r\nThis makes it difficult to sift through the logs and find what we need.\r\nGet rid of these unnecessary warnings\r\n\r\n**Why is this feature important?**\r\nMake debugging and audit trail easier\r\n\n", "before_files": [{"content": "from datetime import datetime, timedelta\n\nfrom django.db import models\nfrom django.db.models import F\nfrom django.core import signing\nfrom django.conf import settings\nfrom django.core.exceptions import ImproperlyConfigured\nfrom django.contrib.auth.models import User\n\nfrom theme.models import UserProfile\nfrom .utils import get_std_log_fields\nfrom hs_core.models import BaseResource\nfrom hs_core.hydroshare import get_resource_by_shortkey\n\nSESSION_TIMEOUT = settings.TRACKING_SESSION_TIMEOUT\nPROFILE_FIELDS = settings.TRACKING_PROFILE_FIELDS\nUSER_FIELDS = settings.TRACKING_USER_FIELDS\nVISITOR_FIELDS = [\"id\"] + USER_FIELDS + PROFILE_FIELDS\nif set(PROFILE_FIELDS) & set(USER_FIELDS):\n raise ImproperlyConfigured(\"hs_tracking PROFILE_FIELDS and USER_FIELDS must not contain\"\n \" overlapping field names\")\n\n\nclass SessionManager(models.Manager):\n def for_request(self, request, user=None):\n if hasattr(request, 'user'):\n user = request.user\n\n signed_id = request.session.get('hs_tracking_id')\n if signed_id:\n tracking_id = signing.loads(signed_id)\n cut_off = datetime.now() - timedelta(seconds=SESSION_TIMEOUT)\n session = None\n\n try:\n session = Session.objects.filter(\n variable__timestamp__gte=cut_off).filter(id=tracking_id['id']).first()\n except Session.DoesNotExist:\n pass\n\n if session is not None and user is not None:\n if session.visitor.user is None and user.is_authenticated:\n try:\n session.visitor = Visitor.objects.get(user=user)\n session.save()\n except Visitor.DoesNotExist:\n session.visitor.user = user\n session.visitor.save()\n return session\n\n # No session found, create one\n if user.is_authenticated:\n visitor, _ = Visitor.objects.get_or_create(user=user)\n else:\n visitor = Visitor.objects.create()\n\n session = Session.objects.create(visitor=visitor)\n\n # get standard fields and format\n fields = get_std_log_fields(request, session)\n msg = Variable.format_kwargs(**fields)\n\n session.record('begin_session', msg)\n request.session['hs_tracking_id'] = signing.dumps({'id': session.id})\n return session\n\n\nclass Visitor(models.Model):\n first_seen = models.DateTimeField(auto_now_add=True)\n user = models.OneToOneField(settings.AUTH_USER_MODEL, null=True,\n on_delete=models.SET_NULL,\n related_name='visitor')\n\n def export_visitor_information(self):\n \"\"\"Exports visitor profile information.\"\"\"\n info = {\n \"id\": self.id,\n }\n if self.user:\n profile = UserProfile.objects.get(user=self.user)\n for field in PROFILE_FIELDS:\n info[field] = getattr(profile, field)\n for field in USER_FIELDS:\n info[field] = getattr(self.user, field)\n else:\n profile = None\n for field in PROFILE_FIELDS:\n info[field] = None\n for field in USER_FIELDS:\n info[field] = None\n return info\n\n\nclass Session(models.Model):\n begin = models.DateTimeField(auto_now_add=True)\n visitor = models.ForeignKey(Visitor, on_delete=models.CASCADE, related_name='session')\n # TODO: hostname = models.CharField(null=True, default=None, max_length=256)\n\n objects = SessionManager()\n\n def get(self, name):\n return Variable.objects.filter(session=self, name=name).first().get_value()\n\n def getlist(self, name):\n return [v.get_value() for v in Variable.objects.filter(session=self, name=name)]\n\n def record(self, *args, **kwargs):\n args = (self,) + args\n return Variable.record(*args, **kwargs)\n\n\nclass Variable(models.Model):\n TYPES = (\n ('Integer', int),\n ('Floating Point', float),\n ('Text', str),\n ('Flag', bool),\n ('None', lambda o: None)\n )\n TYPE_CHOICES = [\n (i, label)\n for (i, label) in\n enumerate(label for (label, coercer) in TYPES)\n ]\n\n from hs_core.models import BaseResource\n\n session = models.ForeignKey(Session, on_delete=models.CASCADE, related_name='variable')\n timestamp = models.DateTimeField(auto_now_add=True)\n name = models.CharField(max_length=32)\n type = models.IntegerField(choices=TYPE_CHOICES)\n # change value to TextField to be less restrictive as max_length of CharField has been\n # exceeded a couple of times\n value = models.TextField()\n\n # If a resource no longer exists, last_resource_id remains valid but resource is NULL\n resource = models.ForeignKey(BaseResource, null=True,\n related_name='variable',\n on_delete=models.SET_NULL)\n last_resource_id = models.CharField(null=True, max_length=32)\n\n # flags describe kind of visit. False for non-visits\n landing = models.BooleanField(null=False, default=False)\n rest = models.BooleanField(null=False, default=False)\n # REDUNDANT: internal = models.BooleanField(null=False, default=False)\n\n def get_value(self):\n v = self.value\n if self.type == 3: # boolean types don't coerce reflexively\n if v == 'true':\n return True\n else:\n return False\n else:\n t = self.TYPES[self.type][1]\n return t(v)\n\n @classmethod\n def format_kwargs(cls, **kwargs):\n msg_items = []\n for k, v in list(kwargs.items()):\n msg_items.append('%s=%s' % (str(k), str(v)))\n return '|'.join(msg_items)\n\n @classmethod\n def record(cls, session, name, value=None, resource=None, resource_id=None,\n rest=False, landing=False):\n if resource is None and resource_id is not None:\n try:\n resource = get_resource_by_shortkey(resource_id, or_404=False)\n except BaseResource.DoesNotExist:\n resource = None\n return Variable.objects.create(session=session, name=name,\n type=cls.encode_type(value),\n value=cls.encode(value),\n last_resource_id=resource_id,\n resource=resource,\n rest=rest,\n landing=landing)\n\n @classmethod\n def encode(cls, value):\n if value is None:\n return ''\n elif isinstance(value, bool):\n return 'true' if value else 'false' # only empty strings are False\n elif isinstance(value, (int, float, str)):\n return str(value)\n else:\n raise ValueError(\"Unknown type (%s) for tracking variable: %r\",\n type(value).__name__, value)\n\n @classmethod\n def encode_type(cls, value):\n if value is None:\n return 4\n elif isinstance(value, bool):\n return 3\n elif isinstance(value, str):\n return 2\n elif isinstance(value, float):\n return 1\n elif isinstance(value, int):\n return 0\n else:\n raise TypeError(\"Unable to record variable of unrecognized type %s\",\n type(value).__name__)\n\n @classmethod\n def recent_resources(cls, user, n_resources=5, days=60):\n \"\"\"\n fetch the most recent n resources with which a specific user has interacted\n\n :param user: The user to document.\n :param n_resources: the number of resources to return.\n :param days: the number of days to scan.\n\n The reason for the parameter `days` is that the runtime of this method\n is very dependent upon the days that one scans. Thus, there is a tradeoff\n between reporting history and timely responsiveness of the dashboard.\n \"\"\"\n # TODO: document actions like labeling and commenting (currently these are 'visit's)\n return BaseResource.objects.filter(\n variable__session__visitor__user=user,\n variable__timestamp__gte=(datetime.now()-timedelta(days)),\n variable__resource__isnull=False,\n variable__name='visit')\\\n .only('short_id', 'created')\\\n .distinct()\\\n .annotate(public=F('raccess__public'),\n discoverable=F('raccess__discoverable'),\n published=F('raccess__published'),\n last_accessed=models.Max('variable__timestamp'))\\\n .filter(variable__timestamp=F('last_accessed'))\\\n .order_by('-last_accessed')[:n_resources]\n\n @classmethod\n def popular_resources(cls, n_resources=5, days=60, today=None):\n \"\"\"\n fetch the most recent n resources with which a specific user has interacted\n\n :param n_resources: the number of resources to return.\n :param days: the number of days to scan.\n\n The reason for the parameter `days` is that the runtime of this method\n is very dependent upon the days that one scans. Thus, there is a tradeoff\n between reporting history and timely responsiveness of the dashboard.\n \"\"\"\n # TODO: document actions like labeling and commenting (currently these are 'visit's)\n if today is None:\n today = datetime.now()\n return BaseResource.objects.filter(\n variable__timestamp__gte=(today-timedelta(days)),\n variable__timestamp__lt=(today),\n variable__resource__isnull=False,\n variable__name='visit')\\\n .distinct()\\\n .annotate(users=models.Count('variable__session__visitor__user'))\\\n .annotate(public=F('raccess__public'),\n discoverable=F('raccess__discoverable'),\n published=F('raccess__published'),\n last_accessed=models.Max('variable__timestamp'))\\\n .order_by('-users')[:n_resources]\n\n @classmethod\n def recent_users(cls, resource, n_users=5, days=60):\n \"\"\"\n fetch the identities of the most recent users who have accessed a resource\n\n :param resource: The resource to document.\n :param n_users: the number of users to return.\n :param days: the number of days to scan.\n\n The reason for the parameter `days` is that the runtime of this method\n is very dependent upon the number of days that one scans. Thus, there is a\n tradeoff between reporting history and timely responsiveness of the dashboard.\n \"\"\"\n return User.objects\\\n .filter(visitor__session__variable__resource=resource,\n visitor__session__variable__name='visit',\n visitor__session__variable__timestamp__gte=(datetime.now() -\n timedelta(days)))\\\n .distinct()\\\n .annotate(last_accessed=models.Max('visitor__session__variable__timestamp'))\\\n .filter(visitor__session__variable__timestamp=F('last_accessed'))\\\n .order_by('-last_accessed')[:n_users]\n", "path": "hs_tracking/models.py"}]}
| 3,699 | 131 |
gh_patches_debug_36798
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-3025
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[SUGG] Little verification in Mailu setup
Hi thanks for Mailu it is a good project.
I submit this suggestion because i made the error and take many time to find it.
In step 4 of Mailu Setup for Docker compose :
**Subnet of the docker network** it could be nice to verify if the last octet of the IP4 address is equal to 0 because if it is not the SMTP wont work.

Regards
</issue>
<code>
[start of setup/server.py]
1 import flask
2 import flask_bootstrap
3 import redis
4 import json
5 import os
6 import jinja2
7 import uuid
8 import string
9 import random
10 import ipaddress
11 import hashlib
12 import time
13
14
15 version = os.getenv("this_version", "master")
16 static_url_path = "/" + version + "/static"
17 app = flask.Flask(__name__, static_url_path=static_url_path)
18 flask_bootstrap.Bootstrap(app)
19 db = redis.StrictRedis(host='redis', port=6379, db=0)
20
21
22 def render_flavor(flavor, template, data):
23 return flask.render_template(
24 os.path.join(flavor, template),
25 **data
26 )
27
28
29 @app.add_template_global
30 def secret(length=16):
31 charset = string.ascii_uppercase + string.digits
32 return ''.join(
33 random.SystemRandom().choice(charset)
34 for _ in range(length)
35 )
36
37 #Original copied from https://github.com/andrewlkho/ulagen
38 def random_ipv6_subnet():
39 eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff
40 eui64_canon = "-".join([format(eui64, "02X")[i:i+2] for i in range(0, 18, 2)])
41
42 h = hashlib.sha1()
43 h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))
44 globalid = h.hexdigest()[0:10]
45
46 prefix = ":".join(("fd" + globalid[0:2], globalid[2:6], globalid[6:10]))
47 return prefix
48
49 def build_app(path):
50
51 app.jinja_env.trim_blocks = True
52 app.jinja_env.lstrip_blocks = True
53
54 @app.context_processor
55 def app_context():
56 return dict(
57 versions=os.getenv("VERSIONS","master").split(','),
58 stable_version = os.getenv("stable_version", "master")
59 )
60
61 prefix_bp = flask.Blueprint(version.replace(".", "_"), __name__)
62 prefix_bp.jinja_loader = jinja2.ChoiceLoader([
63 jinja2.FileSystemLoader(os.path.join(path, "templates")),
64 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
65 ])
66
67 root_bp = flask.Blueprint("root", __name__)
68 root_bp.jinja_loader = jinja2.ChoiceLoader([
69 jinja2.FileSystemLoader(os.path.join(path, "templates")),
70 jinja2.FileSystemLoader(os.path.join(path, "flavors"))
71 ])
72
73 @prefix_bp.context_processor
74 @root_bp.context_processor
75 def bp_context(version=version):
76 return dict(version=version)
77
78 @prefix_bp.route("/")
79 @root_bp.route("/")
80 def wizard():
81 return flask.render_template(
82 'wizard.html',
83 flavor="compose",
84 steps=sorted(os.listdir(os.path.join(path, "templates", "steps", "compose"))),
85 subnet6=random_ipv6_subnet()
86 )
87
88 @prefix_bp.route("/submit", methods=["POST"])
89 @root_bp.route("/submit", methods=["POST"])
90 def submit():
91 data = flask.request.form.copy()
92 data['uid'] = str(uuid.uuid4())
93 try:
94 data['dns'] = str(ipaddress.IPv4Network(data['subnet'], strict=False)[-2])
95 except ValueError as err:
96 return "Error while generating files: " + str(err)
97 db.set(data['uid'], json.dumps(data))
98 return flask.redirect(flask.url_for('.setup', uid=data['uid']))
99
100 @prefix_bp.route("/setup/<uid>", methods=["GET"])
101 @root_bp.route("/setup/<uid>", methods=["GET"])
102 def setup(uid):
103 data = json.loads(db.get(uid))
104 flavor = data.get("flavor", "compose")
105 rendered = render_flavor(flavor, "setup.html", data)
106 return flask.render_template("setup.html", contents=rendered)
107
108 @prefix_bp.route("/file/<uid>/<filepath>", methods=["GET"])
109 @root_bp.route("/file/<uid>/<filepath>", methods=["GET"])
110 def file(uid, filepath):
111 data = json.loads(db.get(uid))
112 flavor = data.get("flavor", "compose")
113 return flask.Response(
114 render_flavor(flavor, filepath, data),
115 mimetype="application/text"
116 )
117
118 app.register_blueprint(prefix_bp, url_prefix="/{}".format(version))
119 app.register_blueprint(root_bp)
120
121
122 if __name__ == "__main__":
123 build_app("/tmp/mailutest")
124 app.run(debug=True)
125
[end of setup/server.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup/server.py b/setup/server.py
--- a/setup/server.py
+++ b/setup/server.py
@@ -10,12 +10,16 @@
import ipaddress
import hashlib
import time
-
+import secrets
+from flask_bootstrap import StaticCDN
version = os.getenv("this_version", "master")
static_url_path = "/" + version + "/static"
app = flask.Flask(__name__, static_url_path=static_url_path)
+app.secret_key = secrets.token_hex(16)
flask_bootstrap.Bootstrap(app)
+# Load our jQuery. Do not use jQuery 1.
+app.extensions['bootstrap']['cdns']['jquery'] = StaticCDN()
db = redis.StrictRedis(host='redis', port=6379, db=0)
@@ -90,12 +94,47 @@
def submit():
data = flask.request.form.copy()
data['uid'] = str(uuid.uuid4())
+ valid = True
+ try:
+ ipaddress.IPv4Address(data['bind4'])
+ except:
+ flask.flash('Configured IPv4 address is invalid', 'error')
+ valid = False
+ try:
+ ipaddress.IPv6Address(data['bind6'])
+ except:
+ flask.flash('Configured IPv6 address is invalid', 'error')
+ valid = False
+ try:
+ ipaddress.IPv4Network(data['subnet'])
+ except:
+ flask.flash('Configured subnet(IPv4) is invalid', 'error')
+ valid = False
+ try:
+ ipaddress.IPv6Network(data['subnet6'])
+ except:
+ flask.flash('Configured subnet(IPv6) is invalid', 'error')
+ valid = False
try:
data['dns'] = str(ipaddress.IPv4Network(data['subnet'], strict=False)[-2])
except ValueError as err:
- return "Error while generating files: " + str(err)
- db.set(data['uid'], json.dumps(data))
- return flask.redirect(flask.url_for('.setup', uid=data['uid']))
+ flask.flash('Invalid configuration: ' + str(err))
+ valid = False
+ if 'api_enabled' in data:
+ if (data['api_enabled'] == 'true'):
+ if data['api_token'] == '':
+ flask.flash('API token cannot be empty when API is enabled', 'error')
+ valid = False
+ if valid:
+ db.set(data['uid'], json.dumps(data))
+ return flask.redirect(flask.url_for('.setup', uid=data['uid']))
+ else:
+ return flask.render_template(
+ 'wizard.html',
+ flavor="compose",
+ steps=sorted(os.listdir(os.path.join(path, "templates", "steps", "compose"))),
+ subnet6=random_ipv6_subnet()
+ )
@prefix_bp.route("/setup/<uid>", methods=["GET"])
@root_bp.route("/setup/<uid>", methods=["GET"])
|
{"golden_diff": "diff --git a/setup/server.py b/setup/server.py\n--- a/setup/server.py\n+++ b/setup/server.py\n@@ -10,12 +10,16 @@\n import ipaddress\n import hashlib\n import time\n-\n+import secrets\n+from flask_bootstrap import StaticCDN\n \n version = os.getenv(\"this_version\", \"master\")\n static_url_path = \"/\" + version + \"/static\"\n app = flask.Flask(__name__, static_url_path=static_url_path)\n+app.secret_key = secrets.token_hex(16)\n flask_bootstrap.Bootstrap(app)\n+# Load our jQuery. Do not use jQuery 1.\n+app.extensions['bootstrap']['cdns']['jquery'] = StaticCDN()\n db = redis.StrictRedis(host='redis', port=6379, db=0)\n \n \n@@ -90,12 +94,47 @@\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n+ valid = True\n+ try:\n+ ipaddress.IPv4Address(data['bind4'])\n+ except:\n+ flask.flash('Configured IPv4 address is invalid', 'error')\n+ valid = False\n+ try:\n+ ipaddress.IPv6Address(data['bind6'])\n+ except:\n+ flask.flash('Configured IPv6 address is invalid', 'error')\n+ valid = False\n+ try:\n+ ipaddress.IPv4Network(data['subnet'])\n+ except:\n+ flask.flash('Configured subnet(IPv4) is invalid', 'error')\n+ valid = False\n+ try:\n+ ipaddress.IPv6Network(data['subnet6'])\n+ except:\n+ flask.flash('Configured subnet(IPv6) is invalid', 'error')\n+ valid = False\n try:\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'], strict=False)[-2])\n except ValueError as err:\n- return \"Error while generating files: \" + str(err)\n- db.set(data['uid'], json.dumps(data))\n- return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n+ flask.flash('Invalid configuration: ' + str(err))\n+ valid = False\n+ if 'api_enabled' in data:\n+ if (data['api_enabled'] == 'true'):\n+ if data['api_token'] == '':\n+ flask.flash('API token cannot be empty when API is enabled', 'error')\n+ valid = False\n+ if valid:\n+ db.set(data['uid'], json.dumps(data))\n+ return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n+ else:\n+ return flask.render_template(\n+ 'wizard.html',\n+ flavor=\"compose\",\n+ steps=sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", \"compose\"))),\n+ subnet6=random_ipv6_subnet()\n+ )\n \n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n", "issue": "[SUGG] Little verification in Mailu setup\nHi thanks for Mailu it is a good project.\r\nI submit this suggestion because i made the error and take many time to find it.\r\nIn step 4 of Mailu Setup for Docker compose : \r\n**Subnet of the docker network** it could be nice to verify if the last octet of the IP4 address is equal to 0 because if it is not the SMTP wont work.\r\n\r\n\r\n\r\nRegards \r\n\n", "before_files": [{"content": "import flask\nimport flask_bootstrap\nimport redis\nimport json\nimport os\nimport jinja2\nimport uuid\nimport string\nimport random\nimport ipaddress\nimport hashlib\nimport time\n\n\nversion = os.getenv(\"this_version\", \"master\")\nstatic_url_path = \"/\" + version + \"/static\"\napp = flask.Flask(__name__, static_url_path=static_url_path)\nflask_bootstrap.Bootstrap(app)\ndb = redis.StrictRedis(host='redis', port=6379, db=0)\n\n\ndef render_flavor(flavor, template, data):\n return flask.render_template(\n os.path.join(flavor, template),\n **data\n )\n\n\[email protected]_template_global\ndef secret(length=16):\n charset = string.ascii_uppercase + string.digits\n return ''.join(\n random.SystemRandom().choice(charset)\n for _ in range(length)\n )\n\n#Original copied from https://github.com/andrewlkho/ulagen\ndef random_ipv6_subnet():\n eui64 = uuid.getnode() >> 24 << 48 | 0xfffe000000 | uuid.getnode() & 0xffffff\n eui64_canon = \"-\".join([format(eui64, \"02X\")[i:i+2] for i in range(0, 18, 2)])\n\n h = hashlib.sha1()\n h.update((eui64_canon + str(time.time() - time.mktime((1900, 1, 1, 0, 0, 0, 0, 1, -1)))).encode('utf-8'))\n globalid = h.hexdigest()[0:10]\n\n prefix = \":\".join((\"fd\" + globalid[0:2], globalid[2:6], globalid[6:10]))\n return prefix\n\ndef build_app(path):\n\n app.jinja_env.trim_blocks = True\n app.jinja_env.lstrip_blocks = True\n\n @app.context_processor\n def app_context():\n return dict(\n versions=os.getenv(\"VERSIONS\",\"master\").split(','),\n stable_version = os.getenv(\"stable_version\", \"master\")\n )\n\n prefix_bp = flask.Blueprint(version.replace(\".\", \"_\"), __name__)\n prefix_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n root_bp = flask.Blueprint(\"root\", __name__)\n root_bp.jinja_loader = jinja2.ChoiceLoader([\n jinja2.FileSystemLoader(os.path.join(path, \"templates\")),\n jinja2.FileSystemLoader(os.path.join(path, \"flavors\"))\n ])\n\n @prefix_bp.context_processor\n @root_bp.context_processor\n def bp_context(version=version):\n return dict(version=version)\n\n @prefix_bp.route(\"/\")\n @root_bp.route(\"/\")\n def wizard():\n return flask.render_template(\n 'wizard.html',\n flavor=\"compose\",\n steps=sorted(os.listdir(os.path.join(path, \"templates\", \"steps\", \"compose\"))),\n subnet6=random_ipv6_subnet()\n )\n\n @prefix_bp.route(\"/submit\", methods=[\"POST\"])\n @root_bp.route(\"/submit\", methods=[\"POST\"])\n def submit():\n data = flask.request.form.copy()\n data['uid'] = str(uuid.uuid4())\n try:\n data['dns'] = str(ipaddress.IPv4Network(data['subnet'], strict=False)[-2])\n except ValueError as err:\n return \"Error while generating files: \" + str(err)\n db.set(data['uid'], json.dumps(data))\n return flask.redirect(flask.url_for('.setup', uid=data['uid']))\n\n @prefix_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n @root_bp.route(\"/setup/<uid>\", methods=[\"GET\"])\n def setup(uid):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n rendered = render_flavor(flavor, \"setup.html\", data)\n return flask.render_template(\"setup.html\", contents=rendered)\n\n @prefix_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n @root_bp.route(\"/file/<uid>/<filepath>\", methods=[\"GET\"])\n def file(uid, filepath):\n data = json.loads(db.get(uid))\n flavor = data.get(\"flavor\", \"compose\")\n return flask.Response(\n render_flavor(flavor, filepath, data),\n mimetype=\"application/text\"\n )\n\n app.register_blueprint(prefix_bp, url_prefix=\"/{}\".format(version))\n app.register_blueprint(root_bp)\n\n\nif __name__ == \"__main__\":\n build_app(\"/tmp/mailutest\")\n app.run(debug=True)\n", "path": "setup/server.py"}]}
| 1,986 | 656 |
gh_patches_debug_27635
|
rasdani/github-patches
|
git_diff
|
open-telemetry__opentelemetry-python-1095
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
OTLP Exporter should report instrumentation info
Currently the Python OTLP exporter does not export instrumentation information, other implementations do.
</issue>
<code>
[start of exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py]
1 # Copyright The OpenTelemetry Authors
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 #
6 # http://www.apache.org/licenses/LICENSE-2.0
7 #
8 # Unless required by applicable law or agreed to in writing, software
9 # distributed under the License is distributed on an "AS IS" BASIS,
10 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 """OTLP Span Exporter"""
15
16 import logging
17 from typing import Sequence
18
19 from opentelemetry.exporter.otlp.exporter import (
20 OTLPExporterMixin,
21 _get_resource_data,
22 _translate_key_values,
23 )
24 from opentelemetry.proto.collector.trace.v1.trace_service_pb2 import (
25 ExportTraceServiceRequest,
26 )
27 from opentelemetry.proto.collector.trace.v1.trace_service_pb2_grpc import (
28 TraceServiceStub,
29 )
30 from opentelemetry.proto.trace.v1.trace_pb2 import (
31 InstrumentationLibrarySpans,
32 ResourceSpans,
33 )
34 from opentelemetry.proto.trace.v1.trace_pb2 import Span as CollectorSpan
35 from opentelemetry.proto.trace.v1.trace_pb2 import Status
36 from opentelemetry.sdk.trace import Span as SDKSpan
37 from opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult
38
39 logger = logging.getLogger(__name__)
40
41
42 # pylint: disable=no-member
43 class OTLPSpanExporter(SpanExporter, OTLPExporterMixin):
44 """OTLP span exporter
45
46 Args:
47 endpoint: OpenTelemetry Collector receiver endpoint
48 credentials: Credentials object for server authentication
49 metadata: Metadata to send when exporting
50 """
51
52 _result = SpanExportResult
53 _stub = TraceServiceStub
54
55 def _translate_name(self, sdk_span):
56 self._collector_span_kwargs["name"] = sdk_span.name
57
58 def _translate_start_time(self, sdk_span):
59 self._collector_span_kwargs[
60 "start_time_unix_nano"
61 ] = sdk_span.start_time
62
63 def _translate_end_time(self, sdk_span):
64 self._collector_span_kwargs["end_time_unix_nano"] = sdk_span.end_time
65
66 def _translate_span_id(self, sdk_span):
67 self._collector_span_kwargs[
68 "span_id"
69 ] = sdk_span.context.span_id.to_bytes(8, "big")
70
71 def _translate_trace_id(self, sdk_span):
72 self._collector_span_kwargs[
73 "trace_id"
74 ] = sdk_span.context.trace_id.to_bytes(16, "big")
75
76 def _translate_parent(self, sdk_span):
77 if sdk_span.parent is not None:
78 self._collector_span_kwargs[
79 "parent_span_id"
80 ] = sdk_span.parent.span_id.to_bytes(8, "big")
81
82 def _translate_context_trace_state(self, sdk_span):
83 if sdk_span.context.trace_state is not None:
84 self._collector_span_kwargs["trace_state"] = ",".join(
85 [
86 "{}={}".format(key, value)
87 for key, value in (sdk_span.context.trace_state.items())
88 ]
89 )
90
91 def _translate_attributes(self, sdk_span):
92 if sdk_span.attributes:
93
94 self._collector_span_kwargs["attributes"] = []
95
96 for key, value in sdk_span.attributes.items():
97
98 try:
99 self._collector_span_kwargs["attributes"].append(
100 _translate_key_values(key, value)
101 )
102 except Exception as error: # pylint: disable=broad-except
103 logger.exception(error)
104
105 def _translate_events(self, sdk_span):
106 if sdk_span.events:
107 self._collector_span_kwargs["events"] = []
108
109 for sdk_span_event in sdk_span.events:
110
111 collector_span_event = CollectorSpan.Event(
112 name=sdk_span_event.name,
113 time_unix_nano=sdk_span_event.timestamp,
114 )
115
116 for key, value in sdk_span_event.attributes.items():
117 try:
118 collector_span_event.attributes.append(
119 _translate_key_values(key, value)
120 )
121 # pylint: disable=broad-except
122 except Exception as error:
123 logger.exception(error)
124
125 self._collector_span_kwargs["events"].append(
126 collector_span_event
127 )
128
129 def _translate_links(self, sdk_span):
130 if sdk_span.links:
131 self._collector_span_kwargs["links"] = []
132
133 for sdk_span_link in sdk_span.links:
134
135 collector_span_link = CollectorSpan.Link(
136 trace_id=(
137 sdk_span_link.context.trace_id.to_bytes(16, "big")
138 ),
139 span_id=(sdk_span_link.context.span_id.to_bytes(8, "big")),
140 )
141
142 for key, value in sdk_span_link.attributes.items():
143 try:
144 collector_span_link.attributes.append(
145 _translate_key_values(key, value)
146 )
147 # pylint: disable=broad-except
148 except Exception as error:
149 logger.exception(error)
150
151 self._collector_span_kwargs["links"].append(
152 collector_span_link
153 )
154
155 def _translate_status(self, sdk_span):
156 if sdk_span.status is not None:
157 self._collector_span_kwargs["status"] = Status(
158 code=sdk_span.status.canonical_code.value,
159 message=sdk_span.status.description,
160 )
161
162 def _translate_data(self, data) -> ExportTraceServiceRequest:
163
164 sdk_resource_instrumentation_library_spans = {}
165
166 for sdk_span in data:
167
168 if sdk_span.resource not in (
169 sdk_resource_instrumentation_library_spans.keys()
170 ):
171 sdk_resource_instrumentation_library_spans[
172 sdk_span.resource
173 ] = InstrumentationLibrarySpans()
174
175 self._collector_span_kwargs = {}
176
177 self._translate_name(sdk_span)
178 self._translate_start_time(sdk_span)
179 self._translate_end_time(sdk_span)
180 self._translate_span_id(sdk_span)
181 self._translate_trace_id(sdk_span)
182 self._translate_parent(sdk_span)
183 self._translate_context_trace_state(sdk_span)
184 self._translate_attributes(sdk_span)
185 self._translate_events(sdk_span)
186 self._translate_links(sdk_span)
187 self._translate_status(sdk_span)
188
189 self._collector_span_kwargs["kind"] = getattr(
190 CollectorSpan.SpanKind, sdk_span.kind.name
191 )
192
193 sdk_resource_instrumentation_library_spans[
194 sdk_span.resource
195 ].spans.append(CollectorSpan(**self._collector_span_kwargs))
196
197 return ExportTraceServiceRequest(
198 resource_spans=_get_resource_data(
199 sdk_resource_instrumentation_library_spans,
200 ResourceSpans,
201 "spans",
202 )
203 )
204
205 def export(self, spans: Sequence[SDKSpan]) -> SpanExportResult:
206 return self._export(spans)
207
[end of exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py b/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py
--- a/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py
+++ b/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py
@@ -27,6 +27,7 @@
from opentelemetry.proto.collector.trace.v1.trace_service_pb2_grpc import (
TraceServiceStub,
)
+from opentelemetry.proto.common.v1.common_pb2 import InstrumentationLibrary
from opentelemetry.proto.trace.v1.trace_pb2 import (
InstrumentationLibrarySpans,
ResourceSpans,
@@ -168,9 +169,22 @@
if sdk_span.resource not in (
sdk_resource_instrumentation_library_spans.keys()
):
+ if sdk_span.instrumentation_info is not None:
+ instrumentation_library_spans = InstrumentationLibrarySpans(
+ instrumentation_library=InstrumentationLibrary(
+ name=sdk_span.instrumentation_info.name,
+ version=sdk_span.instrumentation_info.version,
+ )
+ )
+
+ else:
+ instrumentation_library_spans = (
+ InstrumentationLibrarySpans()
+ )
+
sdk_resource_instrumentation_library_spans[
sdk_span.resource
- ] = InstrumentationLibrarySpans()
+ ] = instrumentation_library_spans
self._collector_span_kwargs = {}
|
{"golden_diff": "diff --git a/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py b/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py\n--- a/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py\n+++ b/exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py\n@@ -27,6 +27,7 @@\n from opentelemetry.proto.collector.trace.v1.trace_service_pb2_grpc import (\n TraceServiceStub,\n )\n+from opentelemetry.proto.common.v1.common_pb2 import InstrumentationLibrary\n from opentelemetry.proto.trace.v1.trace_pb2 import (\n InstrumentationLibrarySpans,\n ResourceSpans,\n@@ -168,9 +169,22 @@\n if sdk_span.resource not in (\n sdk_resource_instrumentation_library_spans.keys()\n ):\n+ if sdk_span.instrumentation_info is not None:\n+ instrumentation_library_spans = InstrumentationLibrarySpans(\n+ instrumentation_library=InstrumentationLibrary(\n+ name=sdk_span.instrumentation_info.name,\n+ version=sdk_span.instrumentation_info.version,\n+ )\n+ )\n+\n+ else:\n+ instrumentation_library_spans = (\n+ InstrumentationLibrarySpans()\n+ )\n+\n sdk_resource_instrumentation_library_spans[\n sdk_span.resource\n- ] = InstrumentationLibrarySpans()\n+ ] = instrumentation_library_spans\n \n self._collector_span_kwargs = {}\n", "issue": "OTLP Exporter should report instrumentation info\nCurrently the Python OTLP exporter does not export instrumentation information, other implementations do.\n", "before_files": [{"content": "# Copyright The OpenTelemetry Authors\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"OTLP Span Exporter\"\"\"\n\nimport logging\nfrom typing import Sequence\n\nfrom opentelemetry.exporter.otlp.exporter import (\n OTLPExporterMixin,\n _get_resource_data,\n _translate_key_values,\n)\nfrom opentelemetry.proto.collector.trace.v1.trace_service_pb2 import (\n ExportTraceServiceRequest,\n)\nfrom opentelemetry.proto.collector.trace.v1.trace_service_pb2_grpc import (\n TraceServiceStub,\n)\nfrom opentelemetry.proto.trace.v1.trace_pb2 import (\n InstrumentationLibrarySpans,\n ResourceSpans,\n)\nfrom opentelemetry.proto.trace.v1.trace_pb2 import Span as CollectorSpan\nfrom opentelemetry.proto.trace.v1.trace_pb2 import Status\nfrom opentelemetry.sdk.trace import Span as SDKSpan\nfrom opentelemetry.sdk.trace.export import SpanExporter, SpanExportResult\n\nlogger = logging.getLogger(__name__)\n\n\n# pylint: disable=no-member\nclass OTLPSpanExporter(SpanExporter, OTLPExporterMixin):\n \"\"\"OTLP span exporter\n\n Args:\n endpoint: OpenTelemetry Collector receiver endpoint\n credentials: Credentials object for server authentication\n metadata: Metadata to send when exporting\n \"\"\"\n\n _result = SpanExportResult\n _stub = TraceServiceStub\n\n def _translate_name(self, sdk_span):\n self._collector_span_kwargs[\"name\"] = sdk_span.name\n\n def _translate_start_time(self, sdk_span):\n self._collector_span_kwargs[\n \"start_time_unix_nano\"\n ] = sdk_span.start_time\n\n def _translate_end_time(self, sdk_span):\n self._collector_span_kwargs[\"end_time_unix_nano\"] = sdk_span.end_time\n\n def _translate_span_id(self, sdk_span):\n self._collector_span_kwargs[\n \"span_id\"\n ] = sdk_span.context.span_id.to_bytes(8, \"big\")\n\n def _translate_trace_id(self, sdk_span):\n self._collector_span_kwargs[\n \"trace_id\"\n ] = sdk_span.context.trace_id.to_bytes(16, \"big\")\n\n def _translate_parent(self, sdk_span):\n if sdk_span.parent is not None:\n self._collector_span_kwargs[\n \"parent_span_id\"\n ] = sdk_span.parent.span_id.to_bytes(8, \"big\")\n\n def _translate_context_trace_state(self, sdk_span):\n if sdk_span.context.trace_state is not None:\n self._collector_span_kwargs[\"trace_state\"] = \",\".join(\n [\n \"{}={}\".format(key, value)\n for key, value in (sdk_span.context.trace_state.items())\n ]\n )\n\n def _translate_attributes(self, sdk_span):\n if sdk_span.attributes:\n\n self._collector_span_kwargs[\"attributes\"] = []\n\n for key, value in sdk_span.attributes.items():\n\n try:\n self._collector_span_kwargs[\"attributes\"].append(\n _translate_key_values(key, value)\n )\n except Exception as error: # pylint: disable=broad-except\n logger.exception(error)\n\n def _translate_events(self, sdk_span):\n if sdk_span.events:\n self._collector_span_kwargs[\"events\"] = []\n\n for sdk_span_event in sdk_span.events:\n\n collector_span_event = CollectorSpan.Event(\n name=sdk_span_event.name,\n time_unix_nano=sdk_span_event.timestamp,\n )\n\n for key, value in sdk_span_event.attributes.items():\n try:\n collector_span_event.attributes.append(\n _translate_key_values(key, value)\n )\n # pylint: disable=broad-except\n except Exception as error:\n logger.exception(error)\n\n self._collector_span_kwargs[\"events\"].append(\n collector_span_event\n )\n\n def _translate_links(self, sdk_span):\n if sdk_span.links:\n self._collector_span_kwargs[\"links\"] = []\n\n for sdk_span_link in sdk_span.links:\n\n collector_span_link = CollectorSpan.Link(\n trace_id=(\n sdk_span_link.context.trace_id.to_bytes(16, \"big\")\n ),\n span_id=(sdk_span_link.context.span_id.to_bytes(8, \"big\")),\n )\n\n for key, value in sdk_span_link.attributes.items():\n try:\n collector_span_link.attributes.append(\n _translate_key_values(key, value)\n )\n # pylint: disable=broad-except\n except Exception as error:\n logger.exception(error)\n\n self._collector_span_kwargs[\"links\"].append(\n collector_span_link\n )\n\n def _translate_status(self, sdk_span):\n if sdk_span.status is not None:\n self._collector_span_kwargs[\"status\"] = Status(\n code=sdk_span.status.canonical_code.value,\n message=sdk_span.status.description,\n )\n\n def _translate_data(self, data) -> ExportTraceServiceRequest:\n\n sdk_resource_instrumentation_library_spans = {}\n\n for sdk_span in data:\n\n if sdk_span.resource not in (\n sdk_resource_instrumentation_library_spans.keys()\n ):\n sdk_resource_instrumentation_library_spans[\n sdk_span.resource\n ] = InstrumentationLibrarySpans()\n\n self._collector_span_kwargs = {}\n\n self._translate_name(sdk_span)\n self._translate_start_time(sdk_span)\n self._translate_end_time(sdk_span)\n self._translate_span_id(sdk_span)\n self._translate_trace_id(sdk_span)\n self._translate_parent(sdk_span)\n self._translate_context_trace_state(sdk_span)\n self._translate_attributes(sdk_span)\n self._translate_events(sdk_span)\n self._translate_links(sdk_span)\n self._translate_status(sdk_span)\n\n self._collector_span_kwargs[\"kind\"] = getattr(\n CollectorSpan.SpanKind, sdk_span.kind.name\n )\n\n sdk_resource_instrumentation_library_spans[\n sdk_span.resource\n ].spans.append(CollectorSpan(**self._collector_span_kwargs))\n\n return ExportTraceServiceRequest(\n resource_spans=_get_resource_data(\n sdk_resource_instrumentation_library_spans,\n ResourceSpans,\n \"spans\",\n )\n )\n\n def export(self, spans: Sequence[SDKSpan]) -> SpanExportResult:\n return self._export(spans)\n", "path": "exporter/opentelemetry-exporter-otlp/src/opentelemetry/exporter/otlp/trace_exporter/__init__.py"}]}
| 2,573 | 363 |
gh_patches_debug_12803
|
rasdani/github-patches
|
git_diff
|
cocotb__cocotb-2382
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
cocotb colorizer does not support custom logging levels
The attached file demonstrates that cocotb does not support custom logging levels. This may be the intention as there is an assertion in the code regarding acceptable logging levels, it is limiting.
I don't think cocotb should throw an exception on an unexpected level. Instead I think it should have a default behavior. It appears the log colorization system doesn't know what to do with `5`. It likely needs a `try`/`except`.
```
Traceback (most recent call last):
File "/Users/raysalemi/opt/anaconda3/lib/python3.8/logging/__init__.py", line 1081, in emit
msg = self.format(record)
File "/Users/raysalemi/opt/anaconda3/lib/python3.8/logging/__init__.py", line 925, in format
return fmt.format(record)
File "/Users/raysalemi/opt/anaconda3/lib/python3.8/site-packages/cocotb/log.py", line 251, in format
msg = '\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\n')])
File "/Users/raysalemi/opt/anaconda3/lib/python3.8/site-packages/cocotb/log.py", line 251, in <listcomp>
msg = '\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\n')])
KeyError: 5
Call stack:
```
[bug_example.zip](https://github.com/cocotb/cocotb/files/5842227/bug_example.zip)
</issue>
<code>
[start of cocotb/log.py]
1 # Copyright (c) 2013, 2018 Potential Ventures Ltd
2 # Copyright (c) 2013 SolarFlare Communications Inc
3 # All rights reserved.
4 #
5 # Redistribution and use in source and binary forms, with or without
6 # modification, are permitted provided that the following conditions are met:
7 # * Redistributions of source code must retain the above copyright
8 # notice, this list of conditions and the following disclaimer.
9 # * Redistributions in binary form must reproduce the above copyright
10 # notice, this list of conditions and the following disclaimer in the
11 # documentation and/or other materials provided with the distribution.
12 # * Neither the name of Potential Ventures Ltd,
13 # SolarFlare Communications Inc nor the
14 # names of its contributors may be used to endorse or promote products
15 # derived from this software without specific prior written permission.
16 #
17 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND
18 # ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
19 # WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
20 # DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY
21 # DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
22 # (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
23 # LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
24 # ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
25 # (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
26 # SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
27
28 """
29 Everything related to logging
30 """
31
32 import os
33 import sys
34 import logging
35 import warnings
36
37 from cocotb.utils import (
38 get_sim_time, get_time_from_sim_steps, want_color_output
39 )
40
41 import cocotb.ANSI as ANSI
42
43 if "COCOTB_REDUCED_LOG_FMT" in os.environ:
44 _suppress = True
45 else:
46 _suppress = False
47
48 # Column alignment
49 _LEVEL_CHARS = len("CRITICAL") # noqa
50 _RECORD_CHARS = 35 # noqa
51 _FILENAME_CHARS = 20 # noqa
52 _LINENO_CHARS = 4 # noqa
53 _FUNCNAME_CHARS = 31 # noqa
54
55 # Default log level if not overwritten by the user.
56 _COCOTB_LOG_LEVEL_DEFAULT = "INFO"
57
58
59 def default_config():
60 """ Apply the default cocotb log formatting to the root logger.
61
62 This hooks up the logger to write to stdout, using either
63 :class:`SimColourLogFormatter` or :class:`SimLogFormatter` depending
64 on whether colored output is requested. It also adds a
65 :class:`SimTimeContextFilter` filter so that
66 :attr:`~logging.LogRecord.created_sim_time` is available to the formatter.
67
68 The logging level for cocotb logs is set based on the
69 :envvar:`COCOTB_LOG_LEVEL` environment variable, which defaults to ``INFO``.
70
71 If desired, this logging configuration can be overwritten by calling
72 ``logging.basicConfig(..., force=True)`` (in Python 3.8 onwards), or by
73 manually resetting the root logger instance.
74 An example of this can be found in the section on :ref:`rotating-logger`.
75
76 .. versionadded:: 1.4
77 """
78 # construct an appropriate handler
79 hdlr = logging.StreamHandler(sys.stdout)
80 hdlr.addFilter(SimTimeContextFilter())
81 if want_color_output():
82 hdlr.setFormatter(SimColourLogFormatter())
83 else:
84 hdlr.setFormatter(SimLogFormatter())
85
86 logging.setLoggerClass(SimBaseLog) # For backwards compatibility
87 logging.basicConfig()
88 logging.getLogger().handlers = [hdlr] # overwrite default handlers
89
90 # apply level settings for cocotb
91 log = logging.getLogger('cocotb')
92
93 try:
94 # All log levels are upper case, convert the user input for convenience.
95 level = os.environ["COCOTB_LOG_LEVEL"].upper()
96 except KeyError:
97 level = _COCOTB_LOG_LEVEL_DEFAULT
98
99 try:
100 log.setLevel(level)
101 except ValueError:
102 valid_levels = ('CRITICAL', 'ERROR', 'WARNING', 'INFO', 'DEBUG')
103 raise ValueError("Invalid log level %r passed through the "
104 "COCOTB_LOG_LEVEL environment variable. Valid log "
105 "levels: %s" % (level, ', '.join(valid_levels)))
106
107 # Notify GPI of log level, which it uses as an optimization to avoid
108 # calling into Python.
109 from cocotb import simulator
110 simulator.log_level(log.getEffectiveLevel())
111
112
113 class SimBaseLog(logging.getLoggerClass()):
114 """ This class only exists for backwards compatibility """
115
116 @property
117 def logger(self):
118 warnings.warn(
119 "the .logger attribute should not be used now that `SimLog` "
120 "returns a native logger instance directly.",
121 DeprecationWarning, stacklevel=2)
122 return self
123
124 @property
125 def colour(self):
126 warnings.warn(
127 "the .colour attribute may be removed in future, use the "
128 "equivalent `cocotb.utils.want_color_output()` instead",
129 DeprecationWarning, stacklevel=2)
130 return want_color_output()
131
132
133 # this used to be a class, hence the unusual capitalization
134 def SimLog(name, ident=None):
135 """ Like logging.getLogger, but append a numeric identifier to the name """
136 if ident is not None:
137 name = "%s.0x%x" % (name, ident)
138 return logging.getLogger(name)
139
140
141 class SimTimeContextFilter(logging.Filter):
142 """
143 A filter to inject simulator times into the log records.
144
145 This uses the approach described in the :ref:`Python logging cookbook <python:filters-contextual>`.
146
147 This adds the :attr:`~logging.LogRecord.created_sim_time` attribute.
148
149 .. versionadded:: 1.4
150 """
151
152 # needed to make our docs render well
153 def __init__(self):
154 """"""
155 super().__init__()
156
157 def filter(self, record):
158 try:
159 record.created_sim_time = get_sim_time()
160 except RecursionError:
161 # get_sim_time may try to log - if that happens, we can't
162 # attach a simulator time to this message.
163 record.created_sim_time = None
164 return True
165
166
167 class SimLogFormatter(logging.Formatter):
168 """Log formatter to provide consistent log message handling.
169
170 This will only add simulator timestamps if the handler object this
171 formatter is attached to has a :class:`SimTimeContextFilter` filter
172 attached, which cocotb ensures by default.
173 """
174
175 # Removes the arguments from the base class. Docstring needed to make
176 # sphinx happy.
177 def __init__(self):
178 """ Takes no arguments. """
179 super().__init__()
180
181 # Justify and truncate
182 @staticmethod
183 def ljust(string, chars):
184 if len(string) > chars:
185 return ".." + string[(chars - 2) * -1:]
186 return string.ljust(chars)
187
188 @staticmethod
189 def rjust(string, chars):
190 if len(string) > chars:
191 return ".." + string[(chars - 2) * -1:]
192 return string.rjust(chars)
193
194 def _format(self, level, record, msg, coloured=False):
195 sim_time = getattr(record, 'created_sim_time', None)
196 if sim_time is None:
197 sim_time_str = " -.--ns"
198 else:
199 time_ns = get_time_from_sim_steps(sim_time, 'ns')
200 sim_time_str = "{:6.2f}ns".format(time_ns)
201 prefix = sim_time_str.rjust(11) + ' ' + level + ' '
202 if not _suppress:
203 prefix += self.ljust(record.name, _RECORD_CHARS) + \
204 self.rjust(os.path.split(record.filename)[1], _FILENAME_CHARS) + \
205 ':' + self.ljust(str(record.lineno), _LINENO_CHARS) + \
206 ' in ' + self.ljust(str(record.funcName), _FUNCNAME_CHARS) + ' '
207
208 # these lines are copied from the builtin logger
209 if record.exc_info:
210 # Cache the traceback text to avoid converting it multiple times
211 # (it's constant anyway)
212 if not record.exc_text:
213 record.exc_text = self.formatException(record.exc_info)
214 if record.exc_text:
215 if msg[-1:] != "\n":
216 msg = msg + "\n"
217 msg = msg + record.exc_text
218
219 prefix_len = len(prefix)
220 if coloured:
221 prefix_len -= (len(level) - _LEVEL_CHARS)
222 pad = "\n" + " " * (prefix_len)
223 return prefix + pad.join(msg.split('\n'))
224
225 def format(self, record):
226 """Prettify the log output, annotate with simulation time"""
227
228 msg = record.getMessage()
229 level = record.levelname.ljust(_LEVEL_CHARS)
230
231 return self._format(level, record, msg)
232
233
234 class SimColourLogFormatter(SimLogFormatter):
235 """Log formatter to provide consistent log message handling."""
236
237 loglevel2colour = {
238 logging.DEBUG : "%s",
239 logging.INFO : ANSI.COLOR_INFO + "%s" + ANSI.COLOR_DEFAULT,
240 logging.WARNING : ANSI.COLOR_WARNING + "%s" + ANSI.COLOR_DEFAULT,
241 logging.ERROR : ANSI.COLOR_ERROR + "%s" + ANSI.COLOR_DEFAULT,
242 logging.CRITICAL: ANSI.COLOR_CRITICAL + "%s" + ANSI.COLOR_DEFAULT,
243 }
244
245 def format(self, record):
246 """Prettify the log output, annotate with simulation time"""
247
248 msg = record.getMessage()
249
250 # Need to colour each line in case coloring is applied in the message
251 msg = '\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\n')])
252 level = (SimColourLogFormatter.loglevel2colour[record.levelno] %
253 record.levelname.ljust(_LEVEL_CHARS))
254
255 return self._format(level, record, msg, coloured=True)
256
257
258 def _filter_from_c(logger_name, level):
259 return logging.getLogger(logger_name).isEnabledFor(level)
260
261
262 def _log_from_c(logger_name, level, filename, lineno, msg, function_name):
263 """
264 This is for use from the C world, and allows us to insert C stack
265 information.
266 """
267 logger = logging.getLogger(logger_name)
268 if logger.isEnabledFor(level):
269 record = logger.makeRecord(
270 logger.name,
271 level,
272 filename,
273 lineno,
274 msg,
275 None,
276 None,
277 function_name
278 )
279 logger.handle(record)
280
[end of cocotb/log.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cocotb/log.py b/cocotb/log.py
--- a/cocotb/log.py
+++ b/cocotb/log.py
@@ -248,8 +248,8 @@
msg = record.getMessage()
# Need to colour each line in case coloring is applied in the message
- msg = '\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\n')])
- level = (SimColourLogFormatter.loglevel2colour[record.levelno] %
+ msg = '\n'.join([SimColourLogFormatter.loglevel2colour.get(record.levelno,"%s") % line for line in msg.split('\n')])
+ level = (SimColourLogFormatter.loglevel2colour.get(record.levelno, "%s") %
record.levelname.ljust(_LEVEL_CHARS))
return self._format(level, record, msg, coloured=True)
|
{"golden_diff": "diff --git a/cocotb/log.py b/cocotb/log.py\n--- a/cocotb/log.py\n+++ b/cocotb/log.py\n@@ -248,8 +248,8 @@\n msg = record.getMessage()\n \n # Need to colour each line in case coloring is applied in the message\n- msg = '\\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\\n')])\n- level = (SimColourLogFormatter.loglevel2colour[record.levelno] %\n+ msg = '\\n'.join([SimColourLogFormatter.loglevel2colour.get(record.levelno,\"%s\") % line for line in msg.split('\\n')])\n+ level = (SimColourLogFormatter.loglevel2colour.get(record.levelno, \"%s\") %\n record.levelname.ljust(_LEVEL_CHARS))\n \n return self._format(level, record, msg, coloured=True)\n", "issue": "cocotb colorizer does not support custom logging levels\nThe attached file demonstrates that cocotb does not support custom logging levels. This may be the intention as there is an assertion in the code regarding acceptable logging levels, it is limiting. \r\n\r\nI don't think cocotb should throw an exception on an unexpected level. Instead I think it should have a default behavior. It appears the log colorization system doesn't know what to do with `5`. It likely needs a `try`/`except`.\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/raysalemi/opt/anaconda3/lib/python3.8/logging/__init__.py\", line 1081, in emit\r\n msg = self.format(record)\r\n File \"/Users/raysalemi/opt/anaconda3/lib/python3.8/logging/__init__.py\", line 925, in format\r\n return fmt.format(record)\r\n File \"/Users/raysalemi/opt/anaconda3/lib/python3.8/site-packages/cocotb/log.py\", line 251, in format\r\n msg = '\\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\\n')])\r\n File \"/Users/raysalemi/opt/anaconda3/lib/python3.8/site-packages/cocotb/log.py\", line 251, in <listcomp>\r\n msg = '\\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\\n')])\r\nKeyError: 5\r\nCall stack:\r\n```\r\n[bug_example.zip](https://github.com/cocotb/cocotb/files/5842227/bug_example.zip)\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) 2013, 2018 Potential Ventures Ltd\n# Copyright (c) 2013 SolarFlare Communications Inc\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n# * Redistributions of source code must retain the above copyright\n# notice, this list of conditions and the following disclaimer.\n# * Redistributions in binary form must reproduce the above copyright\n# notice, this list of conditions and the following disclaimer in the\n# documentation and/or other materials provided with the distribution.\n# * Neither the name of Potential Ventures Ltd,\n# SolarFlare Communications Inc nor the\n# names of its contributors may be used to endorse or promote products\n# derived from this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL POTENTIAL VENTURES LTD BE LIABLE FOR ANY\n# DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\n\"\"\"\nEverything related to logging\n\"\"\"\n\nimport os\nimport sys\nimport logging\nimport warnings\n\nfrom cocotb.utils import (\n get_sim_time, get_time_from_sim_steps, want_color_output\n)\n\nimport cocotb.ANSI as ANSI\n\nif \"COCOTB_REDUCED_LOG_FMT\" in os.environ:\n _suppress = True\nelse:\n _suppress = False\n\n# Column alignment\n_LEVEL_CHARS = len(\"CRITICAL\") # noqa\n_RECORD_CHARS = 35 # noqa\n_FILENAME_CHARS = 20 # noqa\n_LINENO_CHARS = 4 # noqa\n_FUNCNAME_CHARS = 31 # noqa\n\n# Default log level if not overwritten by the user.\n_COCOTB_LOG_LEVEL_DEFAULT = \"INFO\"\n\n\ndef default_config():\n \"\"\" Apply the default cocotb log formatting to the root logger.\n\n This hooks up the logger to write to stdout, using either\n :class:`SimColourLogFormatter` or :class:`SimLogFormatter` depending\n on whether colored output is requested. It also adds a\n :class:`SimTimeContextFilter` filter so that\n :attr:`~logging.LogRecord.created_sim_time` is available to the formatter.\n\n The logging level for cocotb logs is set based on the\n :envvar:`COCOTB_LOG_LEVEL` environment variable, which defaults to ``INFO``.\n\n If desired, this logging configuration can be overwritten by calling\n ``logging.basicConfig(..., force=True)`` (in Python 3.8 onwards), or by\n manually resetting the root logger instance.\n An example of this can be found in the section on :ref:`rotating-logger`.\n\n .. versionadded:: 1.4\n \"\"\"\n # construct an appropriate handler\n hdlr = logging.StreamHandler(sys.stdout)\n hdlr.addFilter(SimTimeContextFilter())\n if want_color_output():\n hdlr.setFormatter(SimColourLogFormatter())\n else:\n hdlr.setFormatter(SimLogFormatter())\n\n logging.setLoggerClass(SimBaseLog) # For backwards compatibility\n logging.basicConfig()\n logging.getLogger().handlers = [hdlr] # overwrite default handlers\n\n # apply level settings for cocotb\n log = logging.getLogger('cocotb')\n\n try:\n # All log levels are upper case, convert the user input for convenience.\n level = os.environ[\"COCOTB_LOG_LEVEL\"].upper()\n except KeyError:\n level = _COCOTB_LOG_LEVEL_DEFAULT\n\n try:\n log.setLevel(level)\n except ValueError:\n valid_levels = ('CRITICAL', 'ERROR', 'WARNING', 'INFO', 'DEBUG')\n raise ValueError(\"Invalid log level %r passed through the \"\n \"COCOTB_LOG_LEVEL environment variable. Valid log \"\n \"levels: %s\" % (level, ', '.join(valid_levels)))\n\n # Notify GPI of log level, which it uses as an optimization to avoid\n # calling into Python.\n from cocotb import simulator\n simulator.log_level(log.getEffectiveLevel())\n\n\nclass SimBaseLog(logging.getLoggerClass()):\n \"\"\" This class only exists for backwards compatibility \"\"\"\n\n @property\n def logger(self):\n warnings.warn(\n \"the .logger attribute should not be used now that `SimLog` \"\n \"returns a native logger instance directly.\",\n DeprecationWarning, stacklevel=2)\n return self\n\n @property\n def colour(self):\n warnings.warn(\n \"the .colour attribute may be removed in future, use the \"\n \"equivalent `cocotb.utils.want_color_output()` instead\",\n DeprecationWarning, stacklevel=2)\n return want_color_output()\n\n\n# this used to be a class, hence the unusual capitalization\ndef SimLog(name, ident=None):\n \"\"\" Like logging.getLogger, but append a numeric identifier to the name \"\"\"\n if ident is not None:\n name = \"%s.0x%x\" % (name, ident)\n return logging.getLogger(name)\n\n\nclass SimTimeContextFilter(logging.Filter):\n \"\"\"\n A filter to inject simulator times into the log records.\n\n This uses the approach described in the :ref:`Python logging cookbook <python:filters-contextual>`.\n\n This adds the :attr:`~logging.LogRecord.created_sim_time` attribute.\n\n .. versionadded:: 1.4\n \"\"\"\n\n # needed to make our docs render well\n def __init__(self):\n \"\"\"\"\"\"\n super().__init__()\n\n def filter(self, record):\n try:\n record.created_sim_time = get_sim_time()\n except RecursionError:\n # get_sim_time may try to log - if that happens, we can't\n # attach a simulator time to this message.\n record.created_sim_time = None\n return True\n\n\nclass SimLogFormatter(logging.Formatter):\n \"\"\"Log formatter to provide consistent log message handling.\n\n This will only add simulator timestamps if the handler object this\n formatter is attached to has a :class:`SimTimeContextFilter` filter\n attached, which cocotb ensures by default.\n \"\"\"\n\n # Removes the arguments from the base class. Docstring needed to make\n # sphinx happy.\n def __init__(self):\n \"\"\" Takes no arguments. \"\"\"\n super().__init__()\n\n # Justify and truncate\n @staticmethod\n def ljust(string, chars):\n if len(string) > chars:\n return \"..\" + string[(chars - 2) * -1:]\n return string.ljust(chars)\n\n @staticmethod\n def rjust(string, chars):\n if len(string) > chars:\n return \"..\" + string[(chars - 2) * -1:]\n return string.rjust(chars)\n\n def _format(self, level, record, msg, coloured=False):\n sim_time = getattr(record, 'created_sim_time', None)\n if sim_time is None:\n sim_time_str = \" -.--ns\"\n else:\n time_ns = get_time_from_sim_steps(sim_time, 'ns')\n sim_time_str = \"{:6.2f}ns\".format(time_ns)\n prefix = sim_time_str.rjust(11) + ' ' + level + ' '\n if not _suppress:\n prefix += self.ljust(record.name, _RECORD_CHARS) + \\\n self.rjust(os.path.split(record.filename)[1], _FILENAME_CHARS) + \\\n ':' + self.ljust(str(record.lineno), _LINENO_CHARS) + \\\n ' in ' + self.ljust(str(record.funcName), _FUNCNAME_CHARS) + ' '\n\n # these lines are copied from the builtin logger\n if record.exc_info:\n # Cache the traceback text to avoid converting it multiple times\n # (it's constant anyway)\n if not record.exc_text:\n record.exc_text = self.formatException(record.exc_info)\n if record.exc_text:\n if msg[-1:] != \"\\n\":\n msg = msg + \"\\n\"\n msg = msg + record.exc_text\n\n prefix_len = len(prefix)\n if coloured:\n prefix_len -= (len(level) - _LEVEL_CHARS)\n pad = \"\\n\" + \" \" * (prefix_len)\n return prefix + pad.join(msg.split('\\n'))\n\n def format(self, record):\n \"\"\"Prettify the log output, annotate with simulation time\"\"\"\n\n msg = record.getMessage()\n level = record.levelname.ljust(_LEVEL_CHARS)\n\n return self._format(level, record, msg)\n\n\nclass SimColourLogFormatter(SimLogFormatter):\n \"\"\"Log formatter to provide consistent log message handling.\"\"\"\n\n loglevel2colour = {\n logging.DEBUG : \"%s\",\n logging.INFO : ANSI.COLOR_INFO + \"%s\" + ANSI.COLOR_DEFAULT,\n logging.WARNING : ANSI.COLOR_WARNING + \"%s\" + ANSI.COLOR_DEFAULT,\n logging.ERROR : ANSI.COLOR_ERROR + \"%s\" + ANSI.COLOR_DEFAULT,\n logging.CRITICAL: ANSI.COLOR_CRITICAL + \"%s\" + ANSI.COLOR_DEFAULT,\n }\n\n def format(self, record):\n \"\"\"Prettify the log output, annotate with simulation time\"\"\"\n\n msg = record.getMessage()\n\n # Need to colour each line in case coloring is applied in the message\n msg = '\\n'.join([SimColourLogFormatter.loglevel2colour[record.levelno] % line for line in msg.split('\\n')])\n level = (SimColourLogFormatter.loglevel2colour[record.levelno] %\n record.levelname.ljust(_LEVEL_CHARS))\n\n return self._format(level, record, msg, coloured=True)\n\n\ndef _filter_from_c(logger_name, level):\n return logging.getLogger(logger_name).isEnabledFor(level)\n\n\ndef _log_from_c(logger_name, level, filename, lineno, msg, function_name):\n \"\"\"\n This is for use from the C world, and allows us to insert C stack\n information.\n \"\"\"\n logger = logging.getLogger(logger_name)\n if logger.isEnabledFor(level):\n record = logger.makeRecord(\n logger.name,\n level,\n filename,\n lineno,\n msg,\n None,\n None,\n function_name\n )\n logger.handle(record)\n", "path": "cocotb/log.py"}]}
| 3,979 | 205 |
gh_patches_debug_10910
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-4096
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
The new learners and coachs account, can't view the kolibri 0.11.0a3 at first login
<!--
Instructions:
* Fill out the sections below, replace …'s with information about your issue
* Use the 'preview' function above this text box to verify formatting before submitting
-->
### Observed behavior
When I create a learners account and test to login, the page show like this "The requested URL / was not found on this server."
<!--
Description of the behavior that was observed, including screenshots or other references when applicable
-->
### Expected behavior
Must login to kolibri page.
<!--
Description of what behavior was expected but did not occur
-->
### Errors and logs
```
The character encoding of the HTML document was not declared. The document will render with garbled text in some browser configurations if the document contains characters from outside the US-ASCII range. The character encoding of the page must be declared in the document or in the transfer protocol. 127.0.0.1:8080
```
<!--
Relevant logs from:
* the command line
* ~/.kolibri/kolibri.log
* the browser console
Please wrap errors in triple backticks for clean formatting like this:
```
01:10 info: something happened
01:12 error: something bad happened
```
-->
…
### Steps to reproduce
1. login with admin account
2. go to facility and user tab
3. create new learner account
4. try to login the new learner account and see the error page.
<!--
Precise steps that someone else can follow in order to see this behavior
-->
…
### Context
Windows 7 and 10
kolibri 0.11.0a3
firefox 61.0.1(64-bit)
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
### Screenshot

</issue>
<code>
[start of kolibri/core/views.py]
1 from django import http
2 from django.conf import settings
3 from django.contrib.auth import logout
4 from django.core.urlresolvers import translate_url
5 from django.http import Http404
6 from django.http import HttpResponseRedirect
7 from django.utils.http import is_safe_url
8 from django.utils.translation import check_for_language
9 from django.utils.translation import LANGUAGE_SESSION_KEY
10 from django.utils.translation import ugettext_lazy as _
11 from django.views.generic.base import View
12 from django.views.i18n import LANGUAGE_QUERY_PARAMETER
13
14 from kolibri.core.auth.constants import user_kinds
15 from kolibri.core.auth.models import Role
16 from kolibri.core.decorators import signin_redirect_exempt
17 from kolibri.core.hooks import RoleBasedRedirectHook
18
19
20 # Modified from django.views.i18n
21 @signin_redirect_exempt
22 def set_language(request):
23 """
24 Redirect to a given url while setting the chosen language in the
25 session or cookie. The url and the language code need to be
26 specified in the request parameters.
27 Since this view changes how the user will see the rest of the site, it must
28 only be accessed as a POST request. If called as a GET request, it will
29 redirect to the page in the request (the 'next' parameter) without changing
30 any state.
31 """
32 next = request.POST.get('next', request.GET.get('next'))
33 if not is_safe_url(url=next, host=request.get_host()):
34 next = request.META.get('HTTP_REFERER')
35 if not is_safe_url(url=next, host=request.get_host()):
36 next = '/'
37 response = http.HttpResponseRedirect(next)
38 if request.method == 'POST':
39 lang_code = request.POST.get(LANGUAGE_QUERY_PARAMETER)
40 if lang_code and check_for_language(lang_code):
41 next_trans = translate_url(next, lang_code)
42 if next_trans != next:
43 response = http.HttpResponseRedirect(next_trans)
44 if hasattr(request, 'session'):
45 request.session[LANGUAGE_SESSION_KEY] = lang_code
46 # Always set cookie
47 response.set_cookie(settings.LANGUAGE_COOKIE_NAME, lang_code,
48 max_age=settings.LANGUAGE_COOKIE_AGE,
49 path=settings.LANGUAGE_COOKIE_PATH,
50 domain=settings.LANGUAGE_COOKIE_DOMAIN)
51 return response
52
53
54 def logout_view(request):
55 logout(request)
56 return http.HttpResponseRedirect('/')
57
58
59 def get_url_by_role(role, first_login):
60 obj = next((hook for hook in RoleBasedRedirectHook().registered_hooks
61 if hook.role == role and hook.first_login == first_login), None)
62 if obj:
63 return obj.url
64
65
66 class GuestRedirectView(View):
67 def get(self, request):
68 """
69 Redirects a guest user to a learner accessible page.
70 """
71 return HttpResponseRedirect(get_url_by_role(user_kinds.LEARNER, False))
72
73
74 class RootURLRedirectView(View):
75
76 def get(self, request):
77 """
78 Redirects user based on the highest role they have for which a redirect is defined.
79 """
80 first_login = request.session.get("first_login", False)
81 if request.user.is_authenticated():
82 url = None
83 if request.user.is_superuser:
84 url = url or get_url_by_role(user_kinds.SUPERUSER, first_login)
85 roles = set(Role.objects.filter(user_id=request.user.id).values_list('kind', flat=True).distinct())
86 if user_kinds.ADMIN in roles:
87 url = url or get_url_by_role(user_kinds.ADMIN, first_login)
88 if user_kinds.COACH in roles:
89 url = url or get_url_by_role(user_kinds.COACH, first_login)
90 url = url or get_url_by_role(user_kinds.LEARNER, first_login)
91 else:
92 url = get_url_by_role(user_kinds.ANONYMOUS, first_login)
93 if url:
94 return HttpResponseRedirect(url)
95 raise Http404(_("No appropriate redirect pages found, it is likely that Kolibri is badly configured"))
96
[end of kolibri/core/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/views.py b/kolibri/core/views.py
--- a/kolibri/core/views.py
+++ b/kolibri/core/views.py
@@ -59,6 +59,13 @@
def get_url_by_role(role, first_login):
obj = next((hook for hook in RoleBasedRedirectHook().registered_hooks
if hook.role == role and hook.first_login == first_login), None)
+
+ if obj is None and first_login:
+ # If it is the first_login, do a fallback to find the non-first login behaviour when it is
+ # not available
+ obj = next((hook for hook in RoleBasedRedirectHook().registered_hooks
+ if hook.role == role and hook.first_login is False), None)
+
if obj:
return obj.url
|
{"golden_diff": "diff --git a/kolibri/core/views.py b/kolibri/core/views.py\n--- a/kolibri/core/views.py\n+++ b/kolibri/core/views.py\n@@ -59,6 +59,13 @@\n def get_url_by_role(role, first_login):\n obj = next((hook for hook in RoleBasedRedirectHook().registered_hooks\n if hook.role == role and hook.first_login == first_login), None)\n+\n+ if obj is None and first_login:\n+ # If it is the first_login, do a fallback to find the non-first login behaviour when it is\n+ # not available\n+ obj = next((hook for hook in RoleBasedRedirectHook().registered_hooks\n+ if hook.role == role and hook.first_login is False), None)\n+\n if obj:\n return obj.url\n", "issue": "The new learners and coachs account, can't view the kolibri 0.11.0a3 at first login\n<!--\r\nInstructions:\r\n * Fill out the sections below, replace \u2026's with information about your issue\r\n * Use the 'preview' function above this text box to verify formatting before submitting\r\n-->\r\n\r\n### Observed behavior\r\nWhen I create a learners account and test to login, the page show like this \"The requested URL / was not found on this server.\"\r\n\r\n<!--\r\nDescription of the behavior that was observed, including screenshots or other references when applicable\r\n-->\r\n\r\n\r\n\r\n### Expected behavior\r\nMust login to kolibri page.\r\n<!--\r\nDescription of what behavior was expected but did not occur\r\n-->\r\n\r\n\r\n### Errors and logs\r\n```\r\nThe character encoding of the HTML document was not declared. The document will render with garbled text in some browser configurations if the document contains characters from outside the US-ASCII range. The character encoding of the page must be declared in the document or in the transfer protocol. 127.0.0.1:8080 \r\n```\r\n<!--\r\nRelevant logs from:\r\n * the command line\r\n * ~/.kolibri/kolibri.log\r\n * the browser console\r\n\r\nPlease wrap errors in triple backticks for clean formatting like this:\r\n```\r\n01:10 info: something happened\r\n01:12 error: something bad happened\r\n```\r\n-->\r\n\r\n\u2026\r\n\r\n### Steps to reproduce\r\n1. login with admin account\r\n2. go to facility and user tab\r\n3. create new learner account\r\n4. try to login the new learner account and see the error page.\r\n<!--\r\nPrecise steps that someone else can follow in order to see this behavior\r\n-->\r\n\r\n\u2026\r\n\r\n### Context\r\nWindows 7 and 10\r\nkolibri 0.11.0a3\r\nfirefox 61.0.1(64-bit)\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\n### Screenshot\r\n\r\n\n", "before_files": [{"content": "from django import http\nfrom django.conf import settings\nfrom django.contrib.auth import logout\nfrom django.core.urlresolvers import translate_url\nfrom django.http import Http404\nfrom django.http import HttpResponseRedirect\nfrom django.utils.http import is_safe_url\nfrom django.utils.translation import check_for_language\nfrom django.utils.translation import LANGUAGE_SESSION_KEY\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.generic.base import View\nfrom django.views.i18n import LANGUAGE_QUERY_PARAMETER\n\nfrom kolibri.core.auth.constants import user_kinds\nfrom kolibri.core.auth.models import Role\nfrom kolibri.core.decorators import signin_redirect_exempt\nfrom kolibri.core.hooks import RoleBasedRedirectHook\n\n\n# Modified from django.views.i18n\n@signin_redirect_exempt\ndef set_language(request):\n \"\"\"\n Redirect to a given url while setting the chosen language in the\n session or cookie. The url and the language code need to be\n specified in the request parameters.\n Since this view changes how the user will see the rest of the site, it must\n only be accessed as a POST request. If called as a GET request, it will\n redirect to the page in the request (the 'next' parameter) without changing\n any state.\n \"\"\"\n next = request.POST.get('next', request.GET.get('next'))\n if not is_safe_url(url=next, host=request.get_host()):\n next = request.META.get('HTTP_REFERER')\n if not is_safe_url(url=next, host=request.get_host()):\n next = '/'\n response = http.HttpResponseRedirect(next)\n if request.method == 'POST':\n lang_code = request.POST.get(LANGUAGE_QUERY_PARAMETER)\n if lang_code and check_for_language(lang_code):\n next_trans = translate_url(next, lang_code)\n if next_trans != next:\n response = http.HttpResponseRedirect(next_trans)\n if hasattr(request, 'session'):\n request.session[LANGUAGE_SESSION_KEY] = lang_code\n # Always set cookie\n response.set_cookie(settings.LANGUAGE_COOKIE_NAME, lang_code,\n max_age=settings.LANGUAGE_COOKIE_AGE,\n path=settings.LANGUAGE_COOKIE_PATH,\n domain=settings.LANGUAGE_COOKIE_DOMAIN)\n return response\n\n\ndef logout_view(request):\n logout(request)\n return http.HttpResponseRedirect('/')\n\n\ndef get_url_by_role(role, first_login):\n obj = next((hook for hook in RoleBasedRedirectHook().registered_hooks\n if hook.role == role and hook.first_login == first_login), None)\n if obj:\n return obj.url\n\n\nclass GuestRedirectView(View):\n def get(self, request):\n \"\"\"\n Redirects a guest user to a learner accessible page.\n \"\"\"\n return HttpResponseRedirect(get_url_by_role(user_kinds.LEARNER, False))\n\n\nclass RootURLRedirectView(View):\n\n def get(self, request):\n \"\"\"\n Redirects user based on the highest role they have for which a redirect is defined.\n \"\"\"\n first_login = request.session.get(\"first_login\", False)\n if request.user.is_authenticated():\n url = None\n if request.user.is_superuser:\n url = url or get_url_by_role(user_kinds.SUPERUSER, first_login)\n roles = set(Role.objects.filter(user_id=request.user.id).values_list('kind', flat=True).distinct())\n if user_kinds.ADMIN in roles:\n url = url or get_url_by_role(user_kinds.ADMIN, first_login)\n if user_kinds.COACH in roles:\n url = url or get_url_by_role(user_kinds.COACH, first_login)\n url = url or get_url_by_role(user_kinds.LEARNER, first_login)\n else:\n url = get_url_by_role(user_kinds.ANONYMOUS, first_login)\n if url:\n return HttpResponseRedirect(url)\n raise Http404(_(\"No appropriate redirect pages found, it is likely that Kolibri is badly configured\"))\n", "path": "kolibri/core/views.py"}]}
| 2,029 | 177 |
gh_patches_debug_30172
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-12864
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: Draft order uses incorrect tax rate for lines on changing order's country
### What are you trying to achieve?
Create a draft order with taxes for one country, and changing the country to another one, and have the taxes correctly recalculated with a new rate.
### Steps to reproduce the problem
The easiest way to recreate the issue is be using Saleor Dashboard:
1. Create channel A with the default country e.g. Germany.
2. Enable flat rates in channel A; create a tax class; configure tax rates for Germany by setting some value for the tax class, and leaving the "Country default rate" empty.
3. Add tax configuration for some other country, e.g. Poland, and provide tax rates for both the tax class as well as the "Country default rate".
4. Create a draft order without an address in channel A.
5. Add an order line with a product without a tax class (also product type cannot have a tax class). Taxes should be 0, since there is no default country rate or tax class.
6. Set order addresses to some valid addresses from Poland. Default rate for Poland is set and Saleor should recalculate taxes with the Polish rate. Currently, it doesn't happen and taxes stay 0.
### What did you expect to happen?
Taxes should be correctly recalculated when changing addresses in draft order.
### Logs
_No response_
### Environment
Saleor version: 3.12.22
</issue>
<code>
[start of saleor/tax/calculations/order.py]
1 from decimal import Decimal
2 from typing import TYPE_CHECKING, Iterable, Tuple
3
4 from prices import Money, TaxedMoney
5
6 from ...core.prices import quantize_price
7 from ...core.taxes import zero_money, zero_taxed_money
8 from ...discount import OrderDiscountType
9 from ...order import base_calculations
10 from ...order.utils import (
11 get_order_country,
12 get_total_order_discount_excluding_shipping,
13 )
14 from ..models import TaxClassCountryRate
15 from ..utils import (
16 denormalize_tax_rate_from_db,
17 get_tax_rate_for_tax_class,
18 normalize_tax_rate_for_db,
19 )
20 from . import calculate_flat_rate_tax
21
22 if TYPE_CHECKING:
23 from ...order.models import Order, OrderLine
24
25
26 def update_order_prices_with_flat_rates(
27 order: "Order",
28 lines: Iterable["OrderLine"],
29 prices_entered_with_tax: bool,
30 ):
31 country_code = get_order_country(order)
32 default_country_rate_obj = TaxClassCountryRate.objects.filter(
33 country=country_code, tax_class=None
34 ).first()
35 default_tax_rate = (
36 default_country_rate_obj.rate if default_country_rate_obj else Decimal(0)
37 )
38
39 # Calculate order line totals.
40 _, undiscounted_subtotal = update_taxes_for_order_lines(
41 order, lines, country_code, default_tax_rate, prices_entered_with_tax
42 )
43
44 # Calculate order shipping.
45 shipping_method = order.shipping_method
46 shipping_tax_class = getattr(shipping_method, "tax_class", None)
47 if shipping_tax_class:
48 shipping_tax_rate = get_tax_rate_for_tax_class(
49 shipping_tax_class,
50 shipping_tax_class.country_rates.all(),
51 default_tax_rate,
52 country_code,
53 )
54 elif order.shipping_tax_rate is not None:
55 # Use order.shipping_tax_rate if it was ever set before (it's non-null now).
56 # This is a valid case when recalculating shipping price and the tax class is
57 # null, because it was removed from the system.
58 shipping_tax_rate = denormalize_tax_rate_from_db(order.shipping_tax_rate)
59 else:
60 shipping_tax_rate = default_tax_rate
61
62 order.shipping_price = _calculate_order_shipping(
63 order, shipping_tax_rate, prices_entered_with_tax
64 )
65 order.shipping_tax_rate = normalize_tax_rate_for_db(shipping_tax_rate)
66
67 # Calculate order total.
68 order.undiscounted_total = undiscounted_subtotal + order.base_shipping_price
69 order.total = _calculate_order_total(order, lines)
70
71
72 def _calculate_order_total(
73 order: "Order",
74 lines: Iterable["OrderLine"],
75 ) -> TaxedMoney:
76 currency = order.currency
77
78 default_value = base_calculations.base_order_total(order, lines)
79 default_value = TaxedMoney(default_value, default_value)
80 if default_value <= zero_taxed_money(currency):
81 return quantize_price(default_value, currency)
82
83 total = zero_taxed_money(currency)
84 undiscounted_subtotal = zero_taxed_money(currency)
85 for line in lines:
86 total += line.total_price
87 undiscounted_subtotal += line.undiscounted_total_price
88 total += order.shipping_price
89
90 order_discount = order.discounts.filter(type=OrderDiscountType.MANUAL).first()
91 if order_discount and order_discount.amount > undiscounted_subtotal.gross:
92 remaining_amount = order_discount.amount - undiscounted_subtotal.gross
93 total -= remaining_amount
94 return quantize_price(max(total, zero_taxed_money(currency)), currency)
95
96
97 def _calculate_order_shipping(
98 order: "Order", tax_rate: Decimal, prices_entered_with_tax: bool
99 ) -> TaxedMoney:
100 shipping_price = order.base_shipping_price
101 taxed_shipping_price = calculate_flat_rate_tax(
102 shipping_price, tax_rate, prices_entered_with_tax
103 )
104 return quantize_price(taxed_shipping_price, taxed_shipping_price.currency)
105
106
107 def update_taxes_for_order_lines(
108 order: "Order",
109 lines: Iterable["OrderLine"],
110 country_code: str,
111 default_tax_rate: Decimal,
112 prices_entered_with_tax: bool,
113 ) -> Tuple[Iterable["OrderLine"], TaxedMoney]:
114 currency = order.currency
115 lines = list(lines)
116
117 total_discount_amount = get_total_order_discount_excluding_shipping(order).amount
118 order_total_price = sum(
119 [line.base_unit_price.amount * line.quantity for line in lines]
120 )
121 total_line_discounts = 0
122
123 undiscounted_subtotal = zero_taxed_money(order.currency)
124
125 for line in lines:
126 variant = line.variant
127 if not variant:
128 continue
129
130 tax_class = line.tax_class
131 if tax_class:
132 tax_rate = get_tax_rate_for_tax_class(
133 tax_class,
134 tax_class.country_rates.all() if tax_class else [],
135 default_tax_rate,
136 country_code,
137 )
138 elif line.tax_rate is not None:
139 # line.tax_class can be None when the tax class was removed from DB. In
140 # this case try to use line.tax_rate which stores the denormalized tax rate
141 # value that was originally used.
142 tax_rate = denormalize_tax_rate_from_db(line.tax_rate)
143 else:
144 tax_rate = default_tax_rate
145
146 line_total_price = line.base_unit_price * line.quantity
147 undiscounted_subtotal += line_total_price
148
149 price_with_discounts = line.base_unit_price
150 if total_discount_amount:
151 if line is lines[-1]:
152 # for the last line applied remaining discount
153 discount_amount = total_discount_amount - total_line_discounts
154 else:
155 # calculate discount proportionally to the rate of total line price
156 # to order total price.
157 discount_amount = quantize_price(
158 line_total_price.amount / order_total_price * total_discount_amount,
159 currency,
160 )
161 price_with_discounts = max(
162 quantize_price(
163 (line_total_price - Money(discount_amount, currency))
164 / line.quantity,
165 currency,
166 ),
167 zero_money(currency),
168 )
169 # sum already applied discounts
170 total_line_discounts += discount_amount
171
172 unit_price = calculate_flat_rate_tax(
173 price_with_discounts, tax_rate, prices_entered_with_tax
174 )
175 undiscounted_unit_price = calculate_flat_rate_tax(
176 line.undiscounted_base_unit_price, tax_rate, prices_entered_with_tax
177 )
178
179 line.unit_price = quantize_price(unit_price, currency)
180 line.undiscounted_unit_price = quantize_price(undiscounted_unit_price, currency)
181
182 line.total_price = quantize_price(unit_price * line.quantity, currency)
183 line.undiscounted_total_price = quantize_price(
184 undiscounted_unit_price * line.quantity, currency
185 )
186 line.tax_rate = normalize_tax_rate_for_db(tax_rate)
187
188 return lines, undiscounted_subtotal
189
[end of saleor/tax/calculations/order.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/tax/calculations/order.py b/saleor/tax/calculations/order.py
--- a/saleor/tax/calculations/order.py
+++ b/saleor/tax/calculations/order.py
@@ -51,10 +51,13 @@
default_tax_rate,
country_code,
)
- elif order.shipping_tax_rate is not None:
- # Use order.shipping_tax_rate if it was ever set before (it's non-null now).
- # This is a valid case when recalculating shipping price and the tax class is
- # null, because it was removed from the system.
+ elif (
+ order.shipping_tax_class_name is not None
+ and order.shipping_tax_rate is not None
+ ):
+ # Use order.shipping_tax_rate if it was ever set before (it's non-null now and
+ # the name is non-null). This is a valid case when recalculating shipping price
+ # and the tax class is null, because it was removed from the system.
shipping_tax_rate = denormalize_tax_rate_from_db(order.shipping_tax_rate)
else:
shipping_tax_rate = default_tax_rate
@@ -135,10 +138,11 @@
default_tax_rate,
country_code,
)
- elif line.tax_rate is not None:
- # line.tax_class can be None when the tax class was removed from DB. In
- # this case try to use line.tax_rate which stores the denormalized tax rate
- # value that was originally used.
+ elif line.tax_class_name is not None and line.tax_rate is not None:
+ # If tax_class is None but tax_class_name is set, the tax class was set
+ # for this line before, but is now removed from the system. In this case
+ # try to use line.tax_rate which stores the denormalized tax rate value
+ # that was originally provided by the tax class.
tax_rate = denormalize_tax_rate_from_db(line.tax_rate)
else:
tax_rate = default_tax_rate
|
{"golden_diff": "diff --git a/saleor/tax/calculations/order.py b/saleor/tax/calculations/order.py\n--- a/saleor/tax/calculations/order.py\n+++ b/saleor/tax/calculations/order.py\n@@ -51,10 +51,13 @@\n default_tax_rate,\n country_code,\n )\n- elif order.shipping_tax_rate is not None:\n- # Use order.shipping_tax_rate if it was ever set before (it's non-null now).\n- # This is a valid case when recalculating shipping price and the tax class is\n- # null, because it was removed from the system.\n+ elif (\n+ order.shipping_tax_class_name is not None\n+ and order.shipping_tax_rate is not None\n+ ):\n+ # Use order.shipping_tax_rate if it was ever set before (it's non-null now and\n+ # the name is non-null). This is a valid case when recalculating shipping price\n+ # and the tax class is null, because it was removed from the system.\n shipping_tax_rate = denormalize_tax_rate_from_db(order.shipping_tax_rate)\n else:\n shipping_tax_rate = default_tax_rate\n@@ -135,10 +138,11 @@\n default_tax_rate,\n country_code,\n )\n- elif line.tax_rate is not None:\n- # line.tax_class can be None when the tax class was removed from DB. In\n- # this case try to use line.tax_rate which stores the denormalized tax rate\n- # value that was originally used.\n+ elif line.tax_class_name is not None and line.tax_rate is not None:\n+ # If tax_class is None but tax_class_name is set, the tax class was set\n+ # for this line before, but is now removed from the system. In this case\n+ # try to use line.tax_rate which stores the denormalized tax rate value\n+ # that was originally provided by the tax class.\n tax_rate = denormalize_tax_rate_from_db(line.tax_rate)\n else:\n tax_rate = default_tax_rate\n", "issue": "Bug: Draft order uses incorrect tax rate for lines on changing order's country\n### What are you trying to achieve?\n\nCreate a draft order with taxes for one country, and changing the country to another one, and have the taxes correctly recalculated with a new rate.\n\n### Steps to reproduce the problem\n\nThe easiest way to recreate the issue is be using Saleor Dashboard:\r\n1. Create channel A with the default country e.g. Germany.\r\n2. Enable flat rates in channel A; create a tax class; configure tax rates for Germany by setting some value for the tax class, and leaving the \"Country default rate\" empty.\r\n3. Add tax configuration for some other country, e.g. Poland, and provide tax rates for both the tax class as well as the \"Country default rate\".\r\n4. Create a draft order without an address in channel A.\r\n5. Add an order line with a product without a tax class (also product type cannot have a tax class). Taxes should be 0, since there is no default country rate or tax class.\r\n6. Set order addresses to some valid addresses from Poland. Default rate for Poland is set and Saleor should recalculate taxes with the Polish rate. Currently, it doesn't happen and taxes stay 0.\n\n### What did you expect to happen?\n\nTaxes should be correctly recalculated when changing addresses in draft order.\n\n### Logs\n\n_No response_\n\n### Environment\n\nSaleor version: 3.12.22\r\n\n", "before_files": [{"content": "from decimal import Decimal\nfrom typing import TYPE_CHECKING, Iterable, Tuple\n\nfrom prices import Money, TaxedMoney\n\nfrom ...core.prices import quantize_price\nfrom ...core.taxes import zero_money, zero_taxed_money\nfrom ...discount import OrderDiscountType\nfrom ...order import base_calculations\nfrom ...order.utils import (\n get_order_country,\n get_total_order_discount_excluding_shipping,\n)\nfrom ..models import TaxClassCountryRate\nfrom ..utils import (\n denormalize_tax_rate_from_db,\n get_tax_rate_for_tax_class,\n normalize_tax_rate_for_db,\n)\nfrom . import calculate_flat_rate_tax\n\nif TYPE_CHECKING:\n from ...order.models import Order, OrderLine\n\n\ndef update_order_prices_with_flat_rates(\n order: \"Order\",\n lines: Iterable[\"OrderLine\"],\n prices_entered_with_tax: bool,\n):\n country_code = get_order_country(order)\n default_country_rate_obj = TaxClassCountryRate.objects.filter(\n country=country_code, tax_class=None\n ).first()\n default_tax_rate = (\n default_country_rate_obj.rate if default_country_rate_obj else Decimal(0)\n )\n\n # Calculate order line totals.\n _, undiscounted_subtotal = update_taxes_for_order_lines(\n order, lines, country_code, default_tax_rate, prices_entered_with_tax\n )\n\n # Calculate order shipping.\n shipping_method = order.shipping_method\n shipping_tax_class = getattr(shipping_method, \"tax_class\", None)\n if shipping_tax_class:\n shipping_tax_rate = get_tax_rate_for_tax_class(\n shipping_tax_class,\n shipping_tax_class.country_rates.all(),\n default_tax_rate,\n country_code,\n )\n elif order.shipping_tax_rate is not None:\n # Use order.shipping_tax_rate if it was ever set before (it's non-null now).\n # This is a valid case when recalculating shipping price and the tax class is\n # null, because it was removed from the system.\n shipping_tax_rate = denormalize_tax_rate_from_db(order.shipping_tax_rate)\n else:\n shipping_tax_rate = default_tax_rate\n\n order.shipping_price = _calculate_order_shipping(\n order, shipping_tax_rate, prices_entered_with_tax\n )\n order.shipping_tax_rate = normalize_tax_rate_for_db(shipping_tax_rate)\n\n # Calculate order total.\n order.undiscounted_total = undiscounted_subtotal + order.base_shipping_price\n order.total = _calculate_order_total(order, lines)\n\n\ndef _calculate_order_total(\n order: \"Order\",\n lines: Iterable[\"OrderLine\"],\n) -> TaxedMoney:\n currency = order.currency\n\n default_value = base_calculations.base_order_total(order, lines)\n default_value = TaxedMoney(default_value, default_value)\n if default_value <= zero_taxed_money(currency):\n return quantize_price(default_value, currency)\n\n total = zero_taxed_money(currency)\n undiscounted_subtotal = zero_taxed_money(currency)\n for line in lines:\n total += line.total_price\n undiscounted_subtotal += line.undiscounted_total_price\n total += order.shipping_price\n\n order_discount = order.discounts.filter(type=OrderDiscountType.MANUAL).first()\n if order_discount and order_discount.amount > undiscounted_subtotal.gross:\n remaining_amount = order_discount.amount - undiscounted_subtotal.gross\n total -= remaining_amount\n return quantize_price(max(total, zero_taxed_money(currency)), currency)\n\n\ndef _calculate_order_shipping(\n order: \"Order\", tax_rate: Decimal, prices_entered_with_tax: bool\n) -> TaxedMoney:\n shipping_price = order.base_shipping_price\n taxed_shipping_price = calculate_flat_rate_tax(\n shipping_price, tax_rate, prices_entered_with_tax\n )\n return quantize_price(taxed_shipping_price, taxed_shipping_price.currency)\n\n\ndef update_taxes_for_order_lines(\n order: \"Order\",\n lines: Iterable[\"OrderLine\"],\n country_code: str,\n default_tax_rate: Decimal,\n prices_entered_with_tax: bool,\n) -> Tuple[Iterable[\"OrderLine\"], TaxedMoney]:\n currency = order.currency\n lines = list(lines)\n\n total_discount_amount = get_total_order_discount_excluding_shipping(order).amount\n order_total_price = sum(\n [line.base_unit_price.amount * line.quantity for line in lines]\n )\n total_line_discounts = 0\n\n undiscounted_subtotal = zero_taxed_money(order.currency)\n\n for line in lines:\n variant = line.variant\n if not variant:\n continue\n\n tax_class = line.tax_class\n if tax_class:\n tax_rate = get_tax_rate_for_tax_class(\n tax_class,\n tax_class.country_rates.all() if tax_class else [],\n default_tax_rate,\n country_code,\n )\n elif line.tax_rate is not None:\n # line.tax_class can be None when the tax class was removed from DB. In\n # this case try to use line.tax_rate which stores the denormalized tax rate\n # value that was originally used.\n tax_rate = denormalize_tax_rate_from_db(line.tax_rate)\n else:\n tax_rate = default_tax_rate\n\n line_total_price = line.base_unit_price * line.quantity\n undiscounted_subtotal += line_total_price\n\n price_with_discounts = line.base_unit_price\n if total_discount_amount:\n if line is lines[-1]:\n # for the last line applied remaining discount\n discount_amount = total_discount_amount - total_line_discounts\n else:\n # calculate discount proportionally to the rate of total line price\n # to order total price.\n discount_amount = quantize_price(\n line_total_price.amount / order_total_price * total_discount_amount,\n currency,\n )\n price_with_discounts = max(\n quantize_price(\n (line_total_price - Money(discount_amount, currency))\n / line.quantity,\n currency,\n ),\n zero_money(currency),\n )\n # sum already applied discounts\n total_line_discounts += discount_amount\n\n unit_price = calculate_flat_rate_tax(\n price_with_discounts, tax_rate, prices_entered_with_tax\n )\n undiscounted_unit_price = calculate_flat_rate_tax(\n line.undiscounted_base_unit_price, tax_rate, prices_entered_with_tax\n )\n\n line.unit_price = quantize_price(unit_price, currency)\n line.undiscounted_unit_price = quantize_price(undiscounted_unit_price, currency)\n\n line.total_price = quantize_price(unit_price * line.quantity, currency)\n line.undiscounted_total_price = quantize_price(\n undiscounted_unit_price * line.quantity, currency\n )\n line.tax_rate = normalize_tax_rate_for_db(tax_rate)\n\n return lines, undiscounted_subtotal\n", "path": "saleor/tax/calculations/order.py"}]}
| 2,786 | 469 |
gh_patches_debug_31795
|
rasdani/github-patches
|
git_diff
|
facebookresearch__ParlAI-3718
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Using world-logs while evaluating a model with more than one task, only keeps the world log for the last task.
Trying to evaluate one mode with two tasks, while keeping the model outputs in world logs, I noticed that there was no result from one of the tasks in the world log. To reproduce this one may try running
```
parlai eval_model -t wizard_of_wikipedia,babi \
--world-logs /some/path/world-log \
--num-examples 1 --model repeat_label
```
Running this, there is only a single line in the `world-log.json` file. Checking the file you can see `"id": "babi:Task1k:1"` which may mean that parlai is generating separate world log files for each task, but assumes same name for all of them and writes over the previous ones.
</issue>
<code>
[start of parlai/scripts/eval_model.py]
1 #!/usr/bin/env python3
2
3 # Copyright (c) Facebook, Inc. and its affiliates.
4 # This source code is licensed under the MIT license found in the
5 # LICENSE file in the root directory of this source tree.
6
7 """
8 Basic example which iterates through the tasks specified and evaluates the given model
9 on them.
10
11 ## Examples
12
13 ```shell
14 parlai eval_model --task "babi:Task1k:2" -m "repeat_label"
15 parlai eval_model --task convai2 --model-file "/path/to/model_file"
16 ```
17 """
18
19 from parlai.core.params import ParlaiParser, print_announcements
20 from parlai.core.agents import create_agent
21 from parlai.core.logs import TensorboardLogger
22 from parlai.core.metrics import (
23 aggregate_named_reports,
24 aggregate_unnamed_reports,
25 Metric,
26 )
27 from parlai.core.worlds import create_task
28 from parlai.utils.misc import TimeLogger, nice_report
29 from parlai.utils.world_logging import WorldLogger
30 from parlai.core.script import ParlaiScript, register_script
31 from parlai.utils.io import PathManager
32 import parlai.utils.logging as logging
33
34 import json
35 import os
36 import random
37
38 from parlai.utils.distributed import (
39 is_primary_worker,
40 all_gather_list,
41 is_distributed,
42 get_rank,
43 )
44
45
46 def setup_args(parser=None):
47 if parser is None:
48 parser = ParlaiParser(True, True, 'Evaluate a model')
49 # Get command line arguments
50 parser.add_argument(
51 '-rf',
52 '--report-filename',
53 type=str,
54 default='',
55 help='Saves a json file of the evaluation report either as an '
56 'extension to the model-file (if begins with a ".") or a whole '
57 'file path. Set to the empty string to not save at all.',
58 )
59 parser.add_argument(
60 '--world-logs',
61 type=str,
62 default='',
63 help='Saves a jsonl file of the world logs.'
64 'Set to the empty string to not save at all.',
65 )
66 parser.add_argument(
67 '--save-format',
68 type=str,
69 default='conversations',
70 choices=['conversations', 'parlai'],
71 )
72 parser.add_argument('-ne', '--num-examples', type=int, default=-1)
73 parser.add_argument('-d', '--display-examples', type='bool', default=False)
74 parser.add_argument('-ltim', '--log-every-n-secs', type=float, default=10)
75 parser.add_argument(
76 '-mcs',
77 '--metrics',
78 type=str,
79 default='default',
80 help='list of metrics to show/compute, e.g. all, default,'
81 'or give a list split by , like '
82 'ppl,f1,accuracy,hits@1,rouge,bleu'
83 'the rouge metrics will be computed as rouge-1, rouge-2 and rouge-l',
84 )
85 parser.add_argument(
86 '-micro',
87 '--aggregate-micro',
88 type='bool',
89 default=False,
90 help='Report micro-averaged metrics instead of macro averaged metrics.',
91 recommended=False,
92 )
93 WorldLogger.add_cmdline_args(parser, partial_opt=None)
94 TensorboardLogger.add_cmdline_args(parser, partial_opt=None)
95 parser.set_params(datatype='valid')
96 return parser
97
98
99 def _save_eval_stats(opt, report):
100 if not is_primary_worker:
101 return
102 report_fname = opt['report_filename']
103 if report_fname == '':
104 return
105 if report_fname.startswith('.'):
106 report_fname = opt['model_file'] + report_fname
107
108 json_serializable_report = report
109 for k, v in report.items():
110 if isinstance(v, Metric):
111 v = v.value()
112 json_serializable_report[k] = v
113
114 # Save report
115 with PathManager.open(report_fname, 'w') as f:
116 logging.info(f'Saving model report to {report_fname}')
117 json.dump({'opt': opt, 'report': json_serializable_report}, f, indent=4)
118 f.write("\n") # for jq
119
120
121 def _eval_single_world(opt, agent, task):
122 logging.info(f'Evaluating task {task} using datatype {opt.get("datatype")}.')
123 # set up world logger
124 world_logger = WorldLogger(opt) if opt['world_logs'] else None
125
126 task_opt = opt.copy() # copy opt since we're editing the task
127 task_opt['task'] = task
128 world = create_task(task_opt, agent) # create worlds for tasks
129
130 # set up logging
131 log_every_n_secs = opt.get('log_every_n_secs', -1)
132 if log_every_n_secs <= 0:
133 log_every_n_secs = float('inf')
134 log_time = TimeLogger()
135
136 # max number of examples to evaluate
137 max_cnt = opt['num_examples'] if opt['num_examples'] > 0 else float('inf')
138 cnt = 0
139 total_cnt = world.num_examples()
140
141 if is_distributed():
142 logging.warning('Progress bar is approximate in distributed mode.')
143
144 while not world.epoch_done() and cnt < max_cnt:
145 cnt += opt.get('batchsize', 1)
146 world.parley()
147 if world_logger is not None:
148 world_logger.log(world)
149 if opt['display_examples']:
150 # display examples
151 print(world.display() + '\n~~')
152 if log_time.time() > log_every_n_secs:
153 report = world.report()
154 text, report = log_time.log(
155 report.get('exs', 0), min(max_cnt, total_cnt), report
156 )
157 logging.info(text)
158
159 if world_logger is not None:
160 # dump world acts to file
161 world_logger.reset() # add final acts to logs
162 if is_distributed():
163 rank = get_rank()
164 base_outfile, extension = os.path.splitext(opt['world_logs'])
165 outfile = base_outfile + f'_{rank}' + extension
166 else:
167 outfile = opt['world_logs']
168 world_logger.write(outfile, world, file_format=opt['save_format'])
169
170 report = aggregate_unnamed_reports(all_gather_list(world.report()))
171 world.reset()
172
173 return report
174
175
176 def eval_model(opt):
177 """
178 Evaluates a model.
179
180 :param opt: tells the evaluation function how to run
181 :return: the final result of calling report()
182 """
183 random.seed(42)
184 if 'train' in opt['datatype'] and 'evalmode' not in opt['datatype']:
185 raise ValueError(
186 'You should use --datatype train:evalmode if you want to evaluate on '
187 'the training set.'
188 )
189
190 # load model and possibly print opt
191 agent = create_agent(opt, requireModelExists=True)
192 agent.opt.log()
193
194 tasks = opt['task'].split(',')
195 reports = []
196 for task in tasks:
197 task_report = _eval_single_world(opt, agent, task)
198 reports.append(task_report)
199
200 report = aggregate_named_reports(
201 dict(zip(tasks, reports)), micro_average=opt.get('aggregate_micro', False)
202 )
203
204 # print announcments and report
205 print_announcements(opt)
206 logging.info(
207 f'Finished evaluating tasks {tasks} using datatype {opt.get("datatype")}'
208 )
209
210 print(nice_report(report))
211 _save_eval_stats(opt, report)
212 return report
213
214
215 @register_script('eval_model', aliases=['em', 'eval'])
216 class EvalModel(ParlaiScript):
217 @classmethod
218 def setup_args(cls):
219 return setup_args()
220
221 def run(self):
222 return eval_model(self.opt)
223
224
225 if __name__ == '__main__':
226 EvalModel.main()
227
[end of parlai/scripts/eval_model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parlai/scripts/eval_model.py b/parlai/scripts/eval_model.py
--- a/parlai/scripts/eval_model.py
+++ b/parlai/scripts/eval_model.py
@@ -118,13 +118,27 @@
f.write("\n") # for jq
+def get_task_world_logs(task, world_logs, is_multitask=False):
+ if not is_multitask:
+ return world_logs
+ else:
+ base_outfile, extension = os.path.splitext(world_logs)
+ return f'{base_outfile}_{task}{extension}'
+
+
def _eval_single_world(opt, agent, task):
logging.info(f'Evaluating task {task} using datatype {opt.get("datatype")}.')
# set up world logger
- world_logger = WorldLogger(opt) if opt['world_logs'] else None
-
task_opt = opt.copy() # copy opt since we're editing the task
task_opt['task'] = task
+ # add task suffix in case of multi-tasking
+ if opt['world_logs']:
+ task_opt['world_logs'] = get_task_world_logs(
+ task, task_opt['world_logs'], is_multitask=len(opt['task'].split(',')) > 1
+ )
+
+ world_logger = WorldLogger(task_opt) if task_opt['world_logs'] else None
+
world = create_task(task_opt, agent) # create worlds for tasks
# set up logging
@@ -161,10 +175,10 @@
world_logger.reset() # add final acts to logs
if is_distributed():
rank = get_rank()
- base_outfile, extension = os.path.splitext(opt['world_logs'])
+ base_outfile, extension = os.path.splitext(task_opt['world_logs'])
outfile = base_outfile + f'_{rank}' + extension
else:
- outfile = opt['world_logs']
+ outfile = task_opt['world_logs']
world_logger.write(outfile, world, file_format=opt['save_format'])
report = aggregate_unnamed_reports(all_gather_list(world.report()))
|
{"golden_diff": "diff --git a/parlai/scripts/eval_model.py b/parlai/scripts/eval_model.py\n--- a/parlai/scripts/eval_model.py\n+++ b/parlai/scripts/eval_model.py\n@@ -118,13 +118,27 @@\n f.write(\"\\n\") # for jq\n \n \n+def get_task_world_logs(task, world_logs, is_multitask=False):\n+ if not is_multitask:\n+ return world_logs\n+ else:\n+ base_outfile, extension = os.path.splitext(world_logs)\n+ return f'{base_outfile}_{task}{extension}'\n+\n+\n def _eval_single_world(opt, agent, task):\n logging.info(f'Evaluating task {task} using datatype {opt.get(\"datatype\")}.')\n # set up world logger\n- world_logger = WorldLogger(opt) if opt['world_logs'] else None\n-\n task_opt = opt.copy() # copy opt since we're editing the task\n task_opt['task'] = task\n+ # add task suffix in case of multi-tasking\n+ if opt['world_logs']:\n+ task_opt['world_logs'] = get_task_world_logs(\n+ task, task_opt['world_logs'], is_multitask=len(opt['task'].split(',')) > 1\n+ )\n+\n+ world_logger = WorldLogger(task_opt) if task_opt['world_logs'] else None\n+\n world = create_task(task_opt, agent) # create worlds for tasks\n \n # set up logging\n@@ -161,10 +175,10 @@\n world_logger.reset() # add final acts to logs\n if is_distributed():\n rank = get_rank()\n- base_outfile, extension = os.path.splitext(opt['world_logs'])\n+ base_outfile, extension = os.path.splitext(task_opt['world_logs'])\n outfile = base_outfile + f'_{rank}' + extension\n else:\n- outfile = opt['world_logs']\n+ outfile = task_opt['world_logs']\n world_logger.write(outfile, world, file_format=opt['save_format'])\n \n report = aggregate_unnamed_reports(all_gather_list(world.report()))\n", "issue": "Using world-logs while evaluating a model with more than one task, only keeps the world log for the last task.\nTrying to evaluate one mode with two tasks, while keeping the model outputs in world logs, I noticed that there was no result from one of the tasks in the world log. To reproduce this one may try running\r\n```\r\n parlai eval_model -t wizard_of_wikipedia,babi \\\r\n--world-logs /some/path/world-log \\\r\n--num-examples 1 --model repeat_label\r\n```\r\nRunning this, there is only a single line in the `world-log.json` file. Checking the file you can see `\"id\": \"babi:Task1k:1\"` which may mean that parlai is generating separate world log files for each task, but assumes same name for all of them and writes over the previous ones.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\n# Copyright (c) Facebook, Inc. and its affiliates.\n# This source code is licensed under the MIT license found in the\n# LICENSE file in the root directory of this source tree.\n\n\"\"\"\nBasic example which iterates through the tasks specified and evaluates the given model\non them.\n\n## Examples\n\n```shell\nparlai eval_model --task \"babi:Task1k:2\" -m \"repeat_label\"\nparlai eval_model --task convai2 --model-file \"/path/to/model_file\"\n```\n\"\"\"\n\nfrom parlai.core.params import ParlaiParser, print_announcements\nfrom parlai.core.agents import create_agent\nfrom parlai.core.logs import TensorboardLogger\nfrom parlai.core.metrics import (\n aggregate_named_reports,\n aggregate_unnamed_reports,\n Metric,\n)\nfrom parlai.core.worlds import create_task\nfrom parlai.utils.misc import TimeLogger, nice_report\nfrom parlai.utils.world_logging import WorldLogger\nfrom parlai.core.script import ParlaiScript, register_script\nfrom parlai.utils.io import PathManager\nimport parlai.utils.logging as logging\n\nimport json\nimport os\nimport random\n\nfrom parlai.utils.distributed import (\n is_primary_worker,\n all_gather_list,\n is_distributed,\n get_rank,\n)\n\n\ndef setup_args(parser=None):\n if parser is None:\n parser = ParlaiParser(True, True, 'Evaluate a model')\n # Get command line arguments\n parser.add_argument(\n '-rf',\n '--report-filename',\n type=str,\n default='',\n help='Saves a json file of the evaluation report either as an '\n 'extension to the model-file (if begins with a \".\") or a whole '\n 'file path. Set to the empty string to not save at all.',\n )\n parser.add_argument(\n '--world-logs',\n type=str,\n default='',\n help='Saves a jsonl file of the world logs.'\n 'Set to the empty string to not save at all.',\n )\n parser.add_argument(\n '--save-format',\n type=str,\n default='conversations',\n choices=['conversations', 'parlai'],\n )\n parser.add_argument('-ne', '--num-examples', type=int, default=-1)\n parser.add_argument('-d', '--display-examples', type='bool', default=False)\n parser.add_argument('-ltim', '--log-every-n-secs', type=float, default=10)\n parser.add_argument(\n '-mcs',\n '--metrics',\n type=str,\n default='default',\n help='list of metrics to show/compute, e.g. all, default,'\n 'or give a list split by , like '\n 'ppl,f1,accuracy,hits@1,rouge,bleu'\n 'the rouge metrics will be computed as rouge-1, rouge-2 and rouge-l',\n )\n parser.add_argument(\n '-micro',\n '--aggregate-micro',\n type='bool',\n default=False,\n help='Report micro-averaged metrics instead of macro averaged metrics.',\n recommended=False,\n )\n WorldLogger.add_cmdline_args(parser, partial_opt=None)\n TensorboardLogger.add_cmdline_args(parser, partial_opt=None)\n parser.set_params(datatype='valid')\n return parser\n\n\ndef _save_eval_stats(opt, report):\n if not is_primary_worker:\n return\n report_fname = opt['report_filename']\n if report_fname == '':\n return\n if report_fname.startswith('.'):\n report_fname = opt['model_file'] + report_fname\n\n json_serializable_report = report\n for k, v in report.items():\n if isinstance(v, Metric):\n v = v.value()\n json_serializable_report[k] = v\n\n # Save report\n with PathManager.open(report_fname, 'w') as f:\n logging.info(f'Saving model report to {report_fname}')\n json.dump({'opt': opt, 'report': json_serializable_report}, f, indent=4)\n f.write(\"\\n\") # for jq\n\n\ndef _eval_single_world(opt, agent, task):\n logging.info(f'Evaluating task {task} using datatype {opt.get(\"datatype\")}.')\n # set up world logger\n world_logger = WorldLogger(opt) if opt['world_logs'] else None\n\n task_opt = opt.copy() # copy opt since we're editing the task\n task_opt['task'] = task\n world = create_task(task_opt, agent) # create worlds for tasks\n\n # set up logging\n log_every_n_secs = opt.get('log_every_n_secs', -1)\n if log_every_n_secs <= 0:\n log_every_n_secs = float('inf')\n log_time = TimeLogger()\n\n # max number of examples to evaluate\n max_cnt = opt['num_examples'] if opt['num_examples'] > 0 else float('inf')\n cnt = 0\n total_cnt = world.num_examples()\n\n if is_distributed():\n logging.warning('Progress bar is approximate in distributed mode.')\n\n while not world.epoch_done() and cnt < max_cnt:\n cnt += opt.get('batchsize', 1)\n world.parley()\n if world_logger is not None:\n world_logger.log(world)\n if opt['display_examples']:\n # display examples\n print(world.display() + '\\n~~')\n if log_time.time() > log_every_n_secs:\n report = world.report()\n text, report = log_time.log(\n report.get('exs', 0), min(max_cnt, total_cnt), report\n )\n logging.info(text)\n\n if world_logger is not None:\n # dump world acts to file\n world_logger.reset() # add final acts to logs\n if is_distributed():\n rank = get_rank()\n base_outfile, extension = os.path.splitext(opt['world_logs'])\n outfile = base_outfile + f'_{rank}' + extension\n else:\n outfile = opt['world_logs']\n world_logger.write(outfile, world, file_format=opt['save_format'])\n\n report = aggregate_unnamed_reports(all_gather_list(world.report()))\n world.reset()\n\n return report\n\n\ndef eval_model(opt):\n \"\"\"\n Evaluates a model.\n\n :param opt: tells the evaluation function how to run\n :return: the final result of calling report()\n \"\"\"\n random.seed(42)\n if 'train' in opt['datatype'] and 'evalmode' not in opt['datatype']:\n raise ValueError(\n 'You should use --datatype train:evalmode if you want to evaluate on '\n 'the training set.'\n )\n\n # load model and possibly print opt\n agent = create_agent(opt, requireModelExists=True)\n agent.opt.log()\n\n tasks = opt['task'].split(',')\n reports = []\n for task in tasks:\n task_report = _eval_single_world(opt, agent, task)\n reports.append(task_report)\n\n report = aggregate_named_reports(\n dict(zip(tasks, reports)), micro_average=opt.get('aggregate_micro', False)\n )\n\n # print announcments and report\n print_announcements(opt)\n logging.info(\n f'Finished evaluating tasks {tasks} using datatype {opt.get(\"datatype\")}'\n )\n\n print(nice_report(report))\n _save_eval_stats(opt, report)\n return report\n\n\n@register_script('eval_model', aliases=['em', 'eval'])\nclass EvalModel(ParlaiScript):\n @classmethod\n def setup_args(cls):\n return setup_args()\n\n def run(self):\n return eval_model(self.opt)\n\n\nif __name__ == '__main__':\n EvalModel.main()\n", "path": "parlai/scripts/eval_model.py"}]}
| 2,945 | 477 |
gh_patches_debug_38217
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-1026
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Path scrubbing not working for python 3.8 package installed with homebrew
Hi there, I got an issue with a pex file embedding a dependency (protobuf) under OSX. I guess it could be related to the protobuf package and how the package is installed with brew but maybe also in the way the scrubbing is done by PEX.
If I install `protobuf` through `pip3.8 install protobuf` the scrubbing works fine because `protobuf` is inside the path `/usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages//google/protobuf/`.
But if you install the `protobuf` brew package through `brew install protobuf`, it is installed under `/usr/local/Cellar/protobuf/` and the python package is registered inside `/usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages//homebrew-protobuf.pth` with the following line:
```
import site; site.addsitedir('/usr/local/Cellar/protobuf/3.12.4/libexec/lib/python3.8/site-packages')
```
I put some logs to print `module.__path__` and `site_libs` before `cls._tainted_path(...)` is [called](https://github.com/pantsbuild/pex/blob/master/pex/pex.py#L209). Here is the difference between python3.7 and 3.8.
Python 3.7:
```
Module path: ['/Users/XXX/repack.pex/google', '/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/google']
Site_libs : {'/usr/local/lib/python3.7/site-packages', '/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages'}
pex: Scrubbing google.__path__: /usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/google
```
Python 3.8:
```
Module path: ['/Users/XXX/repack.pex/google', '/usr/local/Cellar/protobuf/3.12.4/libexec/lib/python3.8/site-packages/google']
Site_libs : {'/usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages', '/usr/local/lib/python3.8/site-packages'}
```
Notice there is no "Scrubbing" for python 3.8. It is due to the change in where python package is located. Instead of being inside the python 3.8 directory, it is put as a standard `brew` package. The import is indirectly managed inside the `homebrew-protofbu.pth` file (see above for the path and content)
The `cls._tainted_path(...)` is then not able to to identify that the path matches in python 3.8 since they are completely different.
python 3.7 match
Module path : **/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages**/google
Site_libs : **/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages**
python 3.8 no match
Module path : /usr/local/Cellar/protobuf/3.12.4/libexec/lib/python3.8/site-packages/google
Site_libs : /usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages
Any solution ?
</issue>
<code>
[start of pex/util.py]
1 # Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 from __future__ import absolute_import
5
6 import contextlib
7 import os
8 import tempfile
9 from hashlib import sha1
10 from site import makepath
11
12 from pex.common import atomic_directory, safe_mkdir, safe_mkdtemp
13 from pex.compatibility import PY2, exec_function
14 from pex.third_party.pkg_resources import (
15 find_distributions,
16 resource_isdir,
17 resource_listdir,
18 resource_string,
19 )
20 from pex.tracer import TRACER
21
22
23 class DistributionHelper(object):
24 @classmethod
25 def access_zipped_assets(cls, static_module_name, static_path, dir_location=None):
26 """Create a copy of static resource files as we can't serve them from within the pex file.
27
28 :param static_module_name: Module name containing module to cache in a tempdir
29 :type static_module_name: string, for example 'twitter.common.zookeeper' or similar
30 :param static_path: Module name, for example 'serverset'
31 :param dir_location: create a new temporary directory inside, or None to have one created
32 :returns temp_dir: Temporary directory with the zipped assets inside
33 :rtype: str
34 """
35 # asset_path is initially a module name that's the same as the static_path, but will be
36 # changed to walk the directory tree
37 # TODO(John Sirois): Unify with `pex.third_party.isolated(recursive_copy)`.
38 def walk_zipped_assets(static_module_name, static_path, asset_path, temp_dir):
39 for asset in resource_listdir(static_module_name, asset_path):
40 if not asset:
41 # The `resource_listdir` function returns a '' asset for the directory entry
42 # itself if it is either present on the filesystem or present as an explicit
43 # zip entry. Since we only care about files and subdirectories at this point,
44 # skip these assets.
45 continue
46 asset_target = os.path.normpath(
47 os.path.join(os.path.relpath(asset_path, static_path), asset)
48 )
49 if resource_isdir(static_module_name, os.path.join(asset_path, asset)):
50 safe_mkdir(os.path.join(temp_dir, asset_target))
51 walk_zipped_assets(
52 static_module_name, static_path, os.path.join(asset_path, asset), temp_dir
53 )
54 else:
55 with open(os.path.join(temp_dir, asset_target), "wb") as fp:
56 path = os.path.join(static_path, asset_target)
57 file_data = resource_string(static_module_name, path)
58 fp.write(file_data)
59
60 if dir_location is None:
61 temp_dir = safe_mkdtemp()
62 else:
63 temp_dir = dir_location
64
65 walk_zipped_assets(static_module_name, static_path, static_path, temp_dir)
66
67 return temp_dir
68
69 @classmethod
70 def distribution_from_path(cls, path, name=None):
71 """Return a distribution from a path.
72
73 If name is provided, find the distribution. If none is found matching the name, return
74 None. If name is not provided and there is unambiguously a single distribution, return that
75 distribution otherwise None.
76 """
77 if name is None:
78 distributions = set(find_distributions(path))
79 if len(distributions) == 1:
80 return distributions.pop()
81 else:
82 for dist in find_distributions(path):
83 if dist.project_name == name:
84 return dist
85
86
87 class CacheHelper(object):
88 @classmethod
89 def update_hash(cls, filelike, digest):
90 """Update the digest of a single file in a memory-efficient manner."""
91 block_size = digest.block_size * 1024
92 for chunk in iter(lambda: filelike.read(block_size), b""):
93 digest.update(chunk)
94
95 @classmethod
96 def hash(cls, path, digest=None, hasher=sha1):
97 """Return the digest of a single file in a memory-efficient manner."""
98 if digest is None:
99 digest = hasher()
100 with open(path, "rb") as fh:
101 cls.update_hash(fh, digest)
102 return digest.hexdigest()
103
104 @classmethod
105 def _compute_hash(cls, names, stream_factory):
106 digest = sha1()
107 # Always use / as the path separator, since that's what zip uses.
108 hashed_names = [n.replace(os.sep, "/") for n in names]
109 digest.update("".join(hashed_names).encode("utf-8"))
110 for name in names:
111 with contextlib.closing(stream_factory(name)) as fp:
112 cls.update_hash(fp, digest)
113 return digest.hexdigest()
114
115 @classmethod
116 def _iter_files(cls, directory):
117 normpath = os.path.realpath(os.path.normpath(directory))
118 for root, _, files in os.walk(normpath):
119 for f in files:
120 yield os.path.relpath(os.path.join(root, f), normpath)
121
122 @classmethod
123 def pex_hash(cls, d):
124 """Return a reproducible hash of the contents of a directory."""
125 names = sorted(
126 f for f in cls._iter_files(d) if not (f.endswith(".pyc") or f.startswith("."))
127 )
128
129 def stream_factory(name):
130 return open(os.path.join(d, name), "rb") # noqa: T802
131
132 return cls._compute_hash(names, stream_factory)
133
134 @classmethod
135 def dir_hash(cls, d):
136 """Return a reproducible hash of the contents of a directory."""
137 names = sorted(f for f in cls._iter_files(d) if not f.endswith(".pyc"))
138
139 def stream_factory(name):
140 return open(os.path.join(d, name), "rb") # noqa: T802
141
142 return cls._compute_hash(names, stream_factory)
143
144 @classmethod
145 def cache_distribution(cls, zf, source, target_dir):
146 """Possibly cache a wheel from within a zipfile into `target_dir`.
147
148 Given a zipfile handle and a source path prefix corresponding to a wheel install embedded within
149 that zip, maybe extract the wheel install into the target cache and then return a distribution
150 from the cache.
151
152 :param zf: An open zip file (a zipped pex).
153 :type zf: :class:`zipfile.ZipFile`
154 :param str source: The path prefix of a wheel install embedded in the zip file.
155 :param str target_dir: The directory to cache the distribution in if not already cached.
156 :returns: The cached distribution.
157 :rtype: :class:`pex.third_party.pkg_resources.Distribution`
158 """
159 with atomic_directory(target_dir, source=source) as target_dir_tmp:
160 if target_dir_tmp is None:
161 TRACER.log("Using cached {}".format(target_dir))
162 else:
163 with TRACER.timed("Caching {}:{} in {}".format(zf.filename, source, target_dir)):
164 for name in zf.namelist():
165 if name.startswith(source) and not name.endswith("/"):
166 zf.extract(name, target_dir_tmp)
167
168 dist = DistributionHelper.distribution_from_path(target_dir)
169 assert dist is not None, "Failed to cache distribution ".format(source)
170 return dist
171
172
173 @contextlib.contextmanager
174 def named_temporary_file(*args, **kwargs):
175 """Due to a bug in python (https://bugs.python.org/issue14243), we need this to be able to use
176 the temporary file without deleting it."""
177 assert "delete" not in kwargs
178 kwargs["delete"] = False
179 fp = tempfile.NamedTemporaryFile(*args, **kwargs)
180 try:
181 with fp:
182 yield fp
183 finally:
184 os.remove(fp.name)
185
186
187 def iter_pth_paths(filename):
188 """Given a .pth file, extract and yield all inner paths without honoring imports.
189
190 This shadows Python's site.py behavior, which is invoked at interpreter startup.
191 """
192 try:
193 f = open(filename, "rU" if PY2 else "r") # noqa
194 except IOError:
195 return
196
197 dirname = os.path.dirname(filename)
198 known_paths = set()
199
200 with f:
201 for line in f:
202 line = line.rstrip()
203 if not line or line.startswith("#"):
204 continue
205 elif line.startswith(("import ", "import\t")):
206 try:
207 exec_function(line, globals_map={})
208 continue
209 except Exception:
210 # NB: import lines are routinely abused with extra code appended using `;` so the class of
211 # exceptions that might be raised in broader than ImportError. As such we cacth broadly
212 # here.
213
214 # Defer error handling to the higher level site.py logic invoked at startup.
215 return
216 else:
217 extras_dir, extras_dir_case_insensitive = makepath(dirname, line)
218 if extras_dir_case_insensitive not in known_paths and os.path.exists(extras_dir):
219 yield extras_dir
220 known_paths.add(extras_dir_case_insensitive)
221
[end of pex/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/util.py b/pex/util.py
--- a/pex/util.py
+++ b/pex/util.py
@@ -5,6 +5,7 @@
import contextlib
import os
+import sys
import tempfile
from hashlib import sha1
from site import makepath
@@ -198,21 +199,42 @@
known_paths = set()
with f:
- for line in f:
+ for i, line in enumerate(f, start=1):
line = line.rstrip()
if not line or line.startswith("#"):
continue
elif line.startswith(("import ", "import\t")):
+ # One important side effect of executing import lines can be alteration of the
+ # sys.path directly or indirectly as a programmatic way to add sys.path entries
+ # in contrast to the standard .pth mechanism of including fixed paths as
+ # individual lines in the file. Here we capture all such programmatic attempts
+ # to expand the sys.path and report the additions.
+ original_sys_path = sys.path[:]
try:
+ # N.B.: Setting sys.path to empty is ok since all the .pth files we find and
+ # execute have already been found and executed by our ambient sys.executable
+ # when it started up before running this PEX file. As such, all symbols imported
+ # by the .pth files then will still be available now as cached in sys.modules.
+ sys.path = []
exec_function(line, globals_map={})
- continue
- except Exception:
- # NB: import lines are routinely abused with extra code appended using `;` so the class of
- # exceptions that might be raised in broader than ImportError. As such we cacth broadly
- # here.
+ for path in sys.path:
+ yield path
+ except Exception as e:
+ # NB: import lines are routinely abused with extra code appended using `;` so
+ # the class of exceptions that might be raised in broader than ImportError. As
+ # such we catch broadly here.
+ TRACER.log(
+ "Error executing line {linenumber} of {pth_file} with content:\n"
+ "{content}\n"
+ "Error was:\n"
+ "{error}".format(linenumber=i, pth_file=filename, content=line, error=e),
+ V=9,
+ )
# Defer error handling to the higher level site.py logic invoked at startup.
return
+ finally:
+ sys.path = original_sys_path
else:
extras_dir, extras_dir_case_insensitive = makepath(dirname, line)
if extras_dir_case_insensitive not in known_paths and os.path.exists(extras_dir):
|
{"golden_diff": "diff --git a/pex/util.py b/pex/util.py\n--- a/pex/util.py\n+++ b/pex/util.py\n@@ -5,6 +5,7 @@\n \n import contextlib\n import os\n+import sys\n import tempfile\n from hashlib import sha1\n from site import makepath\n@@ -198,21 +199,42 @@\n known_paths = set()\n \n with f:\n- for line in f:\n+ for i, line in enumerate(f, start=1):\n line = line.rstrip()\n if not line or line.startswith(\"#\"):\n continue\n elif line.startswith((\"import \", \"import\\t\")):\n+ # One important side effect of executing import lines can be alteration of the\n+ # sys.path directly or indirectly as a programmatic way to add sys.path entries\n+ # in contrast to the standard .pth mechanism of including fixed paths as\n+ # individual lines in the file. Here we capture all such programmatic attempts\n+ # to expand the sys.path and report the additions.\n+ original_sys_path = sys.path[:]\n try:\n+ # N.B.: Setting sys.path to empty is ok since all the .pth files we find and\n+ # execute have already been found and executed by our ambient sys.executable\n+ # when it started up before running this PEX file. As such, all symbols imported\n+ # by the .pth files then will still be available now as cached in sys.modules.\n+ sys.path = []\n exec_function(line, globals_map={})\n- continue\n- except Exception:\n- # NB: import lines are routinely abused with extra code appended using `;` so the class of\n- # exceptions that might be raised in broader than ImportError. As such we cacth broadly\n- # here.\n+ for path in sys.path:\n+ yield path\n+ except Exception as e:\n+ # NB: import lines are routinely abused with extra code appended using `;` so\n+ # the class of exceptions that might be raised in broader than ImportError. As\n+ # such we catch broadly here.\n+ TRACER.log(\n+ \"Error executing line {linenumber} of {pth_file} with content:\\n\"\n+ \"{content}\\n\"\n+ \"Error was:\\n\"\n+ \"{error}\".format(linenumber=i, pth_file=filename, content=line, error=e),\n+ V=9,\n+ )\n \n # Defer error handling to the higher level site.py logic invoked at startup.\n return\n+ finally:\n+ sys.path = original_sys_path\n else:\n extras_dir, extras_dir_case_insensitive = makepath(dirname, line)\n if extras_dir_case_insensitive not in known_paths and os.path.exists(extras_dir):\n", "issue": "Path scrubbing not working for python 3.8 package installed with homebrew\nHi there, I got an issue with a pex file embedding a dependency (protobuf) under OSX. I guess it could be related to the protobuf package and how the package is installed with brew but maybe also in the way the scrubbing is done by PEX.\r\n\r\nIf I install `protobuf` through `pip3.8 install protobuf` the scrubbing works fine because `protobuf` is inside the path `/usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages//google/protobuf/`.\r\n\r\nBut if you install the `protobuf` brew package through `brew install protobuf`, it is installed under `/usr/local/Cellar/protobuf/` and the python package is registered inside `/usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages//homebrew-protobuf.pth` with the following line:\r\n```\r\nimport site; site.addsitedir('/usr/local/Cellar/protobuf/3.12.4/libexec/lib/python3.8/site-packages')\r\n```\r\n\r\nI put some logs to print `module.__path__` and `site_libs` before `cls._tainted_path(...)` is [called](https://github.com/pantsbuild/pex/blob/master/pex/pex.py#L209). Here is the difference between python3.7 and 3.8.\r\n\r\nPython 3.7:\r\n```\r\nModule path: ['/Users/XXX/repack.pex/google', '/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/google']\r\nSite_libs : {'/usr/local/lib/python3.7/site-packages', '/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages'}\r\npex: Scrubbing google.__path__: /usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/google\r\n```\r\n\r\nPython 3.8:\r\n```\r\nModule path: ['/Users/XXX/repack.pex/google', '/usr/local/Cellar/protobuf/3.12.4/libexec/lib/python3.8/site-packages/google']\r\nSite_libs : {'/usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages', '/usr/local/lib/python3.8/site-packages'}\r\n\r\n```\r\n\r\nNotice there is no \"Scrubbing\" for python 3.8. It is due to the change in where python package is located. Instead of being inside the python 3.8 directory, it is put as a standard `brew` package. The import is indirectly managed inside the `homebrew-protofbu.pth` file (see above for the path and content)\r\n\r\nThe `cls._tainted_path(...)` is then not able to to identify that the path matches in python 3.8 since they are completely different.\r\n\r\npython 3.7 match\r\nModule path : **/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages**/google\r\nSite_libs : **/usr/local/Cellar/[email protected]/3.7.8_1/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages**\r\n\r\npython 3.8 no match\r\nModule path : /usr/local/Cellar/protobuf/3.12.4/libexec/lib/python3.8/site-packages/google\r\nSite_libs : /usr/local/Cellar/[email protected]/3.8.5/Frameworks/Python.framework/Versions/3.8/lib/python3.8/site-packages\r\n\r\n\r\nAny solution ?\n", "before_files": [{"content": "# Copyright 2014 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\nfrom __future__ import absolute_import\n\nimport contextlib\nimport os\nimport tempfile\nfrom hashlib import sha1\nfrom site import makepath\n\nfrom pex.common import atomic_directory, safe_mkdir, safe_mkdtemp\nfrom pex.compatibility import PY2, exec_function\nfrom pex.third_party.pkg_resources import (\n find_distributions,\n resource_isdir,\n resource_listdir,\n resource_string,\n)\nfrom pex.tracer import TRACER\n\n\nclass DistributionHelper(object):\n @classmethod\n def access_zipped_assets(cls, static_module_name, static_path, dir_location=None):\n \"\"\"Create a copy of static resource files as we can't serve them from within the pex file.\n\n :param static_module_name: Module name containing module to cache in a tempdir\n :type static_module_name: string, for example 'twitter.common.zookeeper' or similar\n :param static_path: Module name, for example 'serverset'\n :param dir_location: create a new temporary directory inside, or None to have one created\n :returns temp_dir: Temporary directory with the zipped assets inside\n :rtype: str\n \"\"\"\n # asset_path is initially a module name that's the same as the static_path, but will be\n # changed to walk the directory tree\n # TODO(John Sirois): Unify with `pex.third_party.isolated(recursive_copy)`.\n def walk_zipped_assets(static_module_name, static_path, asset_path, temp_dir):\n for asset in resource_listdir(static_module_name, asset_path):\n if not asset:\n # The `resource_listdir` function returns a '' asset for the directory entry\n # itself if it is either present on the filesystem or present as an explicit\n # zip entry. Since we only care about files and subdirectories at this point,\n # skip these assets.\n continue\n asset_target = os.path.normpath(\n os.path.join(os.path.relpath(asset_path, static_path), asset)\n )\n if resource_isdir(static_module_name, os.path.join(asset_path, asset)):\n safe_mkdir(os.path.join(temp_dir, asset_target))\n walk_zipped_assets(\n static_module_name, static_path, os.path.join(asset_path, asset), temp_dir\n )\n else:\n with open(os.path.join(temp_dir, asset_target), \"wb\") as fp:\n path = os.path.join(static_path, asset_target)\n file_data = resource_string(static_module_name, path)\n fp.write(file_data)\n\n if dir_location is None:\n temp_dir = safe_mkdtemp()\n else:\n temp_dir = dir_location\n\n walk_zipped_assets(static_module_name, static_path, static_path, temp_dir)\n\n return temp_dir\n\n @classmethod\n def distribution_from_path(cls, path, name=None):\n \"\"\"Return a distribution from a path.\n\n If name is provided, find the distribution. If none is found matching the name, return\n None. If name is not provided and there is unambiguously a single distribution, return that\n distribution otherwise None.\n \"\"\"\n if name is None:\n distributions = set(find_distributions(path))\n if len(distributions) == 1:\n return distributions.pop()\n else:\n for dist in find_distributions(path):\n if dist.project_name == name:\n return dist\n\n\nclass CacheHelper(object):\n @classmethod\n def update_hash(cls, filelike, digest):\n \"\"\"Update the digest of a single file in a memory-efficient manner.\"\"\"\n block_size = digest.block_size * 1024\n for chunk in iter(lambda: filelike.read(block_size), b\"\"):\n digest.update(chunk)\n\n @classmethod\n def hash(cls, path, digest=None, hasher=sha1):\n \"\"\"Return the digest of a single file in a memory-efficient manner.\"\"\"\n if digest is None:\n digest = hasher()\n with open(path, \"rb\") as fh:\n cls.update_hash(fh, digest)\n return digest.hexdigest()\n\n @classmethod\n def _compute_hash(cls, names, stream_factory):\n digest = sha1()\n # Always use / as the path separator, since that's what zip uses.\n hashed_names = [n.replace(os.sep, \"/\") for n in names]\n digest.update(\"\".join(hashed_names).encode(\"utf-8\"))\n for name in names:\n with contextlib.closing(stream_factory(name)) as fp:\n cls.update_hash(fp, digest)\n return digest.hexdigest()\n\n @classmethod\n def _iter_files(cls, directory):\n normpath = os.path.realpath(os.path.normpath(directory))\n for root, _, files in os.walk(normpath):\n for f in files:\n yield os.path.relpath(os.path.join(root, f), normpath)\n\n @classmethod\n def pex_hash(cls, d):\n \"\"\"Return a reproducible hash of the contents of a directory.\"\"\"\n names = sorted(\n f for f in cls._iter_files(d) if not (f.endswith(\".pyc\") or f.startswith(\".\"))\n )\n\n def stream_factory(name):\n return open(os.path.join(d, name), \"rb\") # noqa: T802\n\n return cls._compute_hash(names, stream_factory)\n\n @classmethod\n def dir_hash(cls, d):\n \"\"\"Return a reproducible hash of the contents of a directory.\"\"\"\n names = sorted(f for f in cls._iter_files(d) if not f.endswith(\".pyc\"))\n\n def stream_factory(name):\n return open(os.path.join(d, name), \"rb\") # noqa: T802\n\n return cls._compute_hash(names, stream_factory)\n\n @classmethod\n def cache_distribution(cls, zf, source, target_dir):\n \"\"\"Possibly cache a wheel from within a zipfile into `target_dir`.\n\n Given a zipfile handle and a source path prefix corresponding to a wheel install embedded within\n that zip, maybe extract the wheel install into the target cache and then return a distribution\n from the cache.\n\n :param zf: An open zip file (a zipped pex).\n :type zf: :class:`zipfile.ZipFile`\n :param str source: The path prefix of a wheel install embedded in the zip file.\n :param str target_dir: The directory to cache the distribution in if not already cached.\n :returns: The cached distribution.\n :rtype: :class:`pex.third_party.pkg_resources.Distribution`\n \"\"\"\n with atomic_directory(target_dir, source=source) as target_dir_tmp:\n if target_dir_tmp is None:\n TRACER.log(\"Using cached {}\".format(target_dir))\n else:\n with TRACER.timed(\"Caching {}:{} in {}\".format(zf.filename, source, target_dir)):\n for name in zf.namelist():\n if name.startswith(source) and not name.endswith(\"/\"):\n zf.extract(name, target_dir_tmp)\n\n dist = DistributionHelper.distribution_from_path(target_dir)\n assert dist is not None, \"Failed to cache distribution \".format(source)\n return dist\n\n\[email protected]\ndef named_temporary_file(*args, **kwargs):\n \"\"\"Due to a bug in python (https://bugs.python.org/issue14243), we need this to be able to use\n the temporary file without deleting it.\"\"\"\n assert \"delete\" not in kwargs\n kwargs[\"delete\"] = False\n fp = tempfile.NamedTemporaryFile(*args, **kwargs)\n try:\n with fp:\n yield fp\n finally:\n os.remove(fp.name)\n\n\ndef iter_pth_paths(filename):\n \"\"\"Given a .pth file, extract and yield all inner paths without honoring imports.\n\n This shadows Python's site.py behavior, which is invoked at interpreter startup.\n \"\"\"\n try:\n f = open(filename, \"rU\" if PY2 else \"r\") # noqa\n except IOError:\n return\n\n dirname = os.path.dirname(filename)\n known_paths = set()\n\n with f:\n for line in f:\n line = line.rstrip()\n if not line or line.startswith(\"#\"):\n continue\n elif line.startswith((\"import \", \"import\\t\")):\n try:\n exec_function(line, globals_map={})\n continue\n except Exception:\n # NB: import lines are routinely abused with extra code appended using `;` so the class of\n # exceptions that might be raised in broader than ImportError. As such we cacth broadly\n # here.\n\n # Defer error handling to the higher level site.py logic invoked at startup.\n return\n else:\n extras_dir, extras_dir_case_insensitive = makepath(dirname, line)\n if extras_dir_case_insensitive not in known_paths and os.path.exists(extras_dir):\n yield extras_dir\n known_paths.add(extras_dir_case_insensitive)\n", "path": "pex/util.py"}]}
| 3,911 | 607 |
gh_patches_debug_34390
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-1276
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Replace_more() AssertionError After Refreshing Comment
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
Using the replace_more() function on a comment's replies after the comment has been refreshed raises an AssertionError. This only happens on certain submissions and I'm not sure why (the code below is an example of a submission that fails). Also, the AssertionError is not raised if the refresh() function is not called on the comment.
**To Reproduce**
Run this code after replacing your client_id, client_secret, and user_agent.
```
import praw
reddit = praw.Reddit(
client_id="YOUR-CLIENT-ID",
client_secret="YOUR-CLIENT-SECRET",
user_agent="YOUR-USER-AGENT",
)
submission = reddit.submission(id="6aeian")
submission.comment_sort = "confidence"
submission.comments.replace_more()
comments = submission.comments.list()
for comment in comments:
comment.reply_sort = "confidence"
comment.refresh()
# Errors on line below
comment.replies.replace_more()
```
**Expected behavior**
<!-- A clear and concise description of what you expected to happen. -->
I expected this to run without raising any exceptions.
**Code/Logs**
<!-- include your code, without the Reddit() initialization, so as to not leak private credentials. -->
```
Traceback (most recent call last):
File "/mnt/c/Users/<NAME>/Documents/GitHub/Reddit-Bot/test_praw.py", line 19, in <module>
comment.replies.replace_more()
File "/mnt/c/Users/<NAME>/Documents/GitHub/Reddit-Bot/Reddit-Bot/lib/python3.6/site-packages/praw/models/comment_forest.py", line 177, in replace_more
self._insert_comment(comment)
File "/mnt/c/Users/<NAME>/Documents/GitHub/Reddit-Bot/Reddit-Bot/lib/python3.6/site-packages/praw/models/comment_forest.py", line 69, in _insert_comment
assert comment.name not in self._submission._comments_by_id
AssertionError
```
**System Info**
- OS: WSL running Ubuntu 18.04.3 LTS
- Python: 3.6.9
- PRAW Version: 6.4.0
</issue>
<code>
[start of praw/models/comment_forest.py]
1 """Provide CommentForest for Submission comments."""
2 from heapq import heappop, heappush
3 from typing import List, Optional, TypeVar, Union
4
5 from .reddit.more import MoreComments
6
7 Comment = TypeVar("Comment")
8 Submission = TypeVar("Submission")
9
10
11 class CommentForest:
12 """A forest of comments starts with multiple top-level comments.
13
14 Each of these comments can be a tree of replies.
15
16 """
17
18 @staticmethod
19 def _gather_more_comments(tree, parent_tree=None):
20 """Return a list of MoreComments objects obtained from tree."""
21 more_comments = []
22 queue = [(None, x) for x in tree]
23 while queue:
24 parent, comment = queue.pop(0)
25 if isinstance(comment, MoreComments):
26 heappush(more_comments, comment)
27 if parent:
28 comment._remove_from = parent.replies._comments
29 else:
30 comment._remove_from = parent_tree or tree
31 else:
32 for item in comment.replies:
33 queue.append((comment, item))
34 return more_comments
35
36 def __getitem__(self, index: int):
37 """Return the comment at position ``index`` in the list.
38
39 This method is to be used like an array access, such as:
40
41 .. code-block:: python
42
43 first_comment = submission.comments[0]
44
45 Alternatively, the presence of this method enables one to iterate over
46 all top_level comments, like so:
47
48 .. code-block:: python
49
50 for comment in submission.comments:
51 print(comment.body)
52
53 """
54 return self._comments[index]
55
56 def __init__(
57 self, submission: Submission, comments: Optional[List[Comment]] = None
58 ):
59 """Initialize a CommentForest instance.
60
61 :param submission: An instance of :class:`~.Subreddit` that is the
62 parent of the comments.
63 :param comments: Initialize the Forest with a list of comments
64 (default: None).
65
66 """
67 self._comments = comments
68 self._submission = submission
69
70 def __len__(self) -> int:
71 """Return the number of top-level comments in the forest."""
72 return len(self._comments)
73
74 def _insert_comment(self, comment):
75 assert comment.name not in self._submission._comments_by_id
76 comment.submission = self._submission
77 if isinstance(comment, MoreComments) or comment.is_root:
78 self._comments.append(comment)
79 else:
80 assert comment.parent_id in self._submission._comments_by_id
81 parent = self._submission._comments_by_id[comment.parent_id]
82 parent.replies._comments.append(comment)
83
84 def _update(self, comments):
85 self._comments = comments
86 for comment in comments:
87 comment.submission = self._submission
88
89 def list(self) -> Union[Comment, MoreComments]:
90 """Return a flattened list of all Comments.
91
92 This list may contain :class:`.MoreComments` instances if
93 :meth:`.replace_more` was not called first.
94
95 """
96 comments = []
97 queue = list(self)
98 while queue:
99 comment = queue.pop(0)
100 comments.append(comment)
101 if not isinstance(comment, MoreComments):
102 queue.extend(comment.replies)
103 return comments
104
105 def replace_more(
106 self, limit: int = 32, threshold: int = 0
107 ) -> List[MoreComments]:
108 """Update the comment forest by resolving instances of MoreComments.
109
110 :param limit: The maximum number of :class:`.MoreComments` instances to
111 replace. Each replacement requires 1 API request. Set to ``None``
112 to have no limit, or to ``0`` to remove all :class:`.MoreComments`
113 instances without additional requests (default: 32).
114 :param threshold: The minimum number of children comments a
115 :class:`.MoreComments` instance must have in order to be
116 replaced. :class:`.MoreComments` instances that represent "continue
117 this thread" links unfortunately appear to have 0
118 children. (default: 0).
119
120 :returns: A list of :class:`.MoreComments` instances that were not
121 replaced.
122
123 For example, to replace up to 32 :class:`.MoreComments` instances of a
124 submission try:
125
126 .. code-block:: python
127
128 submission = reddit.submission('3hahrw')
129 submission.comments.replace_more()
130
131 Alternatively, to replace :class:`.MoreComments` instances within the
132 replies of a single comment try:
133
134 .. code-block:: python
135
136 comment = reddit.comment('d8r4im1')
137 comment.refresh()
138 comment.replies.replace_more()
139
140 .. note:: This method can take a long time as each replacement will
141 discover at most 20 new :class:`.Comment` or
142 :class:`.MoreComments` instances. As a result, consider
143 looping and handling exceptions until the method returns
144 successfully. For example:
145
146 .. code-block:: python
147
148 while True:
149 try:
150 submission.comments.replace_more()
151 break
152 except PossibleExceptions:
153 print('Handling replace_more exception')
154 sleep(1)
155
156 """
157 remaining = limit
158 more_comments = self._gather_more_comments(self._comments)
159 skipped = []
160
161 # Fetch largest more_comments until reaching the limit or the threshold
162 while more_comments:
163 item = heappop(more_comments)
164 if (
165 remaining is not None
166 and remaining <= 0
167 or item.count < threshold
168 ):
169 skipped.append(item)
170 item._remove_from.remove(item)
171 continue
172
173 new_comments = item.comments(update=False)
174 if remaining is not None:
175 remaining -= 1
176
177 # Add new MoreComment objects to the heap of more_comments
178 for more in self._gather_more_comments(
179 new_comments, self._comments
180 ):
181 more.submission = self._submission
182 heappush(more_comments, more)
183 # Insert all items into the tree
184 for comment in new_comments:
185 self._insert_comment(comment)
186
187 # Remove from forest
188 item._remove_from.remove(item)
189
190 return more_comments + skipped
191
[end of praw/models/comment_forest.py]
[start of praw/exceptions.py]
1 """PRAW exception classes.
2
3 Includes two main exceptions: :class:`.APIException` for when something goes
4 wrong on the server side, and :class:`.ClientException` when something goes
5 wrong on the client side. Both of these classes extend :class:`.PRAWException`.
6
7 """
8 from typing import Optional
9
10
11 class PRAWException(Exception):
12 """The base PRAW Exception that all other exception classes extend."""
13
14
15 class APIException(PRAWException):
16 """Indicate exception that involve responses from Reddit's API."""
17
18 def __init__(self, error_type: str, message: str, field: Optional[str]):
19 """Initialize an instance of APIException.
20
21 :param error_type: The error type set on Reddit's end.
22 :param message: The associated message for the error.
23 :param field: The input field associated with the error if available.
24 """
25 error_str = "{}: '{}'".format(error_type, message)
26 if field:
27 error_str += " on field '{}'".format(field)
28
29 super().__init__(error_str)
30 self.error_type = error_type
31 self.message = message
32 self.field = field
33
34
35 class ClientException(PRAWException):
36 """Indicate exceptions that don't involve interaction with Reddit's API."""
37
38
39 class WebSocketException(ClientException):
40 """Indicate exceptions caused by use of WebSockets."""
41
42 def __init__(self, message: str, exception: Exception):
43 """Initialize a WebSocketException.
44
45 :param message: The exception message.
46 :param exception: The exception thrown by the websocket library.
47 """
48 super().__init__(message)
49 self.original_exception = exception
50
[end of praw/exceptions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/praw/exceptions.py b/praw/exceptions.py
--- a/praw/exceptions.py
+++ b/praw/exceptions.py
@@ -36,10 +36,21 @@
"""Indicate exceptions that don't involve interaction with Reddit's API."""
+class DuplicateReplaceException(ClientException):
+ """Indicate exceptions that involve the replacement of MoreComments."""
+
+ def __init__(self):
+ """Instantize the class."""
+ super().__init__(
+ "A duplicate comment has been detected. Are you attempting to call"
+ " ``replace_more_comments`` more than once?"
+ )
+
+
class WebSocketException(ClientException):
"""Indicate exceptions caused by use of WebSockets."""
- def __init__(self, message, exception):
+ def __init__(self, message: str, exception: Exception):
"""Initialize a WebSocketException.
:param message: The exception message.
diff --git a/praw/models/comment_forest.py b/praw/models/comment_forest.py
--- a/praw/models/comment_forest.py
+++ b/praw/models/comment_forest.py
@@ -3,6 +3,7 @@
from typing import List, Optional, TypeVar, Union
from .reddit.more import MoreComments
+from ..exceptions import DuplicateReplaceException
Comment = TypeVar("Comment")
Submission = TypeVar("Submission")
@@ -72,12 +73,16 @@
return len(self._comments)
def _insert_comment(self, comment):
- assert comment.name not in self._submission._comments_by_id
+ if comment.name in self._submission._comments_by_id:
+ raise DuplicateReplaceException
comment.submission = self._submission
if isinstance(comment, MoreComments) or comment.is_root:
self._comments.append(comment)
else:
- assert comment.parent_id in self._submission._comments_by_id
+ assert comment.parent_id in self._submission._comments_by_id, (
+ "PRAW Error occured. Please file a bug report and include "
+ "the code that caused the error."
+ )
parent = self._submission._comments_by_id[comment.parent_id]
parent.replies._comments.append(comment)
|
{"golden_diff": "diff --git a/praw/exceptions.py b/praw/exceptions.py\n--- a/praw/exceptions.py\n+++ b/praw/exceptions.py\n@@ -36,10 +36,21 @@\n \"\"\"Indicate exceptions that don't involve interaction with Reddit's API.\"\"\"\n \n \n+class DuplicateReplaceException(ClientException):\n+ \"\"\"Indicate exceptions that involve the replacement of MoreComments.\"\"\"\n+\n+ def __init__(self):\n+ \"\"\"Instantize the class.\"\"\"\n+ super().__init__(\n+ \"A duplicate comment has been detected. Are you attempting to call\"\n+ \" ``replace_more_comments`` more than once?\"\n+ )\n+\n+\n class WebSocketException(ClientException):\n \"\"\"Indicate exceptions caused by use of WebSockets.\"\"\"\n \n- def __init__(self, message, exception):\n+ def __init__(self, message: str, exception: Exception):\n \"\"\"Initialize a WebSocketException.\n \n :param message: The exception message.\ndiff --git a/praw/models/comment_forest.py b/praw/models/comment_forest.py\n--- a/praw/models/comment_forest.py\n+++ b/praw/models/comment_forest.py\n@@ -3,6 +3,7 @@\n from typing import List, Optional, TypeVar, Union\n \n from .reddit.more import MoreComments\n+from ..exceptions import DuplicateReplaceException\n \n Comment = TypeVar(\"Comment\")\n Submission = TypeVar(\"Submission\")\n@@ -72,12 +73,16 @@\n return len(self._comments)\n \n def _insert_comment(self, comment):\n- assert comment.name not in self._submission._comments_by_id\n+ if comment.name in self._submission._comments_by_id:\n+ raise DuplicateReplaceException\n comment.submission = self._submission\n if isinstance(comment, MoreComments) or comment.is_root:\n self._comments.append(comment)\n else:\n- assert comment.parent_id in self._submission._comments_by_id\n+ assert comment.parent_id in self._submission._comments_by_id, (\n+ \"PRAW Error occured. Please file a bug report and include \"\n+ \"the code that caused the error.\"\n+ )\n parent = self._submission._comments_by_id[comment.parent_id]\n parent.replies._comments.append(comment)\n", "issue": "Replace_more() AssertionError After Refreshing Comment\n**Describe the bug**\r\n<!-- A clear and concise description of what the bug is. -->\r\nUsing the replace_more() function on a comment's replies after the comment has been refreshed raises an AssertionError. This only happens on certain submissions and I'm not sure why (the code below is an example of a submission that fails). Also, the AssertionError is not raised if the refresh() function is not called on the comment.\r\n\r\n**To Reproduce**\r\nRun this code after replacing your client_id, client_secret, and user_agent.\r\n\r\n```\r\nimport praw\r\n\r\nreddit = praw.Reddit(\r\n client_id=\"YOUR-CLIENT-ID\",\r\n client_secret=\"YOUR-CLIENT-SECRET\",\r\n user_agent=\"YOUR-USER-AGENT\",\r\n)\r\n\r\nsubmission = reddit.submission(id=\"6aeian\")\r\n\r\nsubmission.comment_sort = \"confidence\"\r\nsubmission.comments.replace_more()\r\ncomments = submission.comments.list()\r\n\r\nfor comment in comments:\r\n comment.reply_sort = \"confidence\"\r\n comment.refresh()\r\n\r\n # Errors on line below\r\n comment.replies.replace_more()\r\n```\r\n\r\n**Expected behavior**\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nI expected this to run without raising any exceptions.\r\n\r\n**Code/Logs**\r\n<!-- include your code, without the Reddit() initialization, so as to not leak private credentials. -->\r\n```\r\nTraceback (most recent call last):\r\n File \"/mnt/c/Users/<NAME>/Documents/GitHub/Reddit-Bot/test_praw.py\", line 19, in <module>\r\n comment.replies.replace_more()\r\n File \"/mnt/c/Users/<NAME>/Documents/GitHub/Reddit-Bot/Reddit-Bot/lib/python3.6/site-packages/praw/models/comment_forest.py\", line 177, in replace_more\r\n self._insert_comment(comment)\r\n File \"/mnt/c/Users/<NAME>/Documents/GitHub/Reddit-Bot/Reddit-Bot/lib/python3.6/site-packages/praw/models/comment_forest.py\", line 69, in _insert_comment\r\n assert comment.name not in self._submission._comments_by_id\r\nAssertionError\r\n```\r\n**System Info**\r\n - OS: WSL running Ubuntu 18.04.3 LTS\r\n - Python: 3.6.9\r\n - PRAW Version: 6.4.0\r\n\n", "before_files": [{"content": "\"\"\"Provide CommentForest for Submission comments.\"\"\"\nfrom heapq import heappop, heappush\nfrom typing import List, Optional, TypeVar, Union\n\nfrom .reddit.more import MoreComments\n\nComment = TypeVar(\"Comment\")\nSubmission = TypeVar(\"Submission\")\n\n\nclass CommentForest:\n \"\"\"A forest of comments starts with multiple top-level comments.\n\n Each of these comments can be a tree of replies.\n\n \"\"\"\n\n @staticmethod\n def _gather_more_comments(tree, parent_tree=None):\n \"\"\"Return a list of MoreComments objects obtained from tree.\"\"\"\n more_comments = []\n queue = [(None, x) for x in tree]\n while queue:\n parent, comment = queue.pop(0)\n if isinstance(comment, MoreComments):\n heappush(more_comments, comment)\n if parent:\n comment._remove_from = parent.replies._comments\n else:\n comment._remove_from = parent_tree or tree\n else:\n for item in comment.replies:\n queue.append((comment, item))\n return more_comments\n\n def __getitem__(self, index: int):\n \"\"\"Return the comment at position ``index`` in the list.\n\n This method is to be used like an array access, such as:\n\n .. code-block:: python\n\n first_comment = submission.comments[0]\n\n Alternatively, the presence of this method enables one to iterate over\n all top_level comments, like so:\n\n .. code-block:: python\n\n for comment in submission.comments:\n print(comment.body)\n\n \"\"\"\n return self._comments[index]\n\n def __init__(\n self, submission: Submission, comments: Optional[List[Comment]] = None\n ):\n \"\"\"Initialize a CommentForest instance.\n\n :param submission: An instance of :class:`~.Subreddit` that is the\n parent of the comments.\n :param comments: Initialize the Forest with a list of comments\n (default: None).\n\n \"\"\"\n self._comments = comments\n self._submission = submission\n\n def __len__(self) -> int:\n \"\"\"Return the number of top-level comments in the forest.\"\"\"\n return len(self._comments)\n\n def _insert_comment(self, comment):\n assert comment.name not in self._submission._comments_by_id\n comment.submission = self._submission\n if isinstance(comment, MoreComments) or comment.is_root:\n self._comments.append(comment)\n else:\n assert comment.parent_id in self._submission._comments_by_id\n parent = self._submission._comments_by_id[comment.parent_id]\n parent.replies._comments.append(comment)\n\n def _update(self, comments):\n self._comments = comments\n for comment in comments:\n comment.submission = self._submission\n\n def list(self) -> Union[Comment, MoreComments]:\n \"\"\"Return a flattened list of all Comments.\n\n This list may contain :class:`.MoreComments` instances if\n :meth:`.replace_more` was not called first.\n\n \"\"\"\n comments = []\n queue = list(self)\n while queue:\n comment = queue.pop(0)\n comments.append(comment)\n if not isinstance(comment, MoreComments):\n queue.extend(comment.replies)\n return comments\n\n def replace_more(\n self, limit: int = 32, threshold: int = 0\n ) -> List[MoreComments]:\n \"\"\"Update the comment forest by resolving instances of MoreComments.\n\n :param limit: The maximum number of :class:`.MoreComments` instances to\n replace. Each replacement requires 1 API request. Set to ``None``\n to have no limit, or to ``0`` to remove all :class:`.MoreComments`\n instances without additional requests (default: 32).\n :param threshold: The minimum number of children comments a\n :class:`.MoreComments` instance must have in order to be\n replaced. :class:`.MoreComments` instances that represent \"continue\n this thread\" links unfortunately appear to have 0\n children. (default: 0).\n\n :returns: A list of :class:`.MoreComments` instances that were not\n replaced.\n\n For example, to replace up to 32 :class:`.MoreComments` instances of a\n submission try:\n\n .. code-block:: python\n\n submission = reddit.submission('3hahrw')\n submission.comments.replace_more()\n\n Alternatively, to replace :class:`.MoreComments` instances within the\n replies of a single comment try:\n\n .. code-block:: python\n\n comment = reddit.comment('d8r4im1')\n comment.refresh()\n comment.replies.replace_more()\n\n .. note:: This method can take a long time as each replacement will\n discover at most 20 new :class:`.Comment` or\n :class:`.MoreComments` instances. As a result, consider\n looping and handling exceptions until the method returns\n successfully. For example:\n\n .. code-block:: python\n\n while True:\n try:\n submission.comments.replace_more()\n break\n except PossibleExceptions:\n print('Handling replace_more exception')\n sleep(1)\n\n \"\"\"\n remaining = limit\n more_comments = self._gather_more_comments(self._comments)\n skipped = []\n\n # Fetch largest more_comments until reaching the limit or the threshold\n while more_comments:\n item = heappop(more_comments)\n if (\n remaining is not None\n and remaining <= 0\n or item.count < threshold\n ):\n skipped.append(item)\n item._remove_from.remove(item)\n continue\n\n new_comments = item.comments(update=False)\n if remaining is not None:\n remaining -= 1\n\n # Add new MoreComment objects to the heap of more_comments\n for more in self._gather_more_comments(\n new_comments, self._comments\n ):\n more.submission = self._submission\n heappush(more_comments, more)\n # Insert all items into the tree\n for comment in new_comments:\n self._insert_comment(comment)\n\n # Remove from forest\n item._remove_from.remove(item)\n\n return more_comments + skipped\n", "path": "praw/models/comment_forest.py"}, {"content": "\"\"\"PRAW exception classes.\n\nIncludes two main exceptions: :class:`.APIException` for when something goes\nwrong on the server side, and :class:`.ClientException` when something goes\nwrong on the client side. Both of these classes extend :class:`.PRAWException`.\n\n\"\"\"\nfrom typing import Optional\n\n\nclass PRAWException(Exception):\n \"\"\"The base PRAW Exception that all other exception classes extend.\"\"\"\n\n\nclass APIException(PRAWException):\n \"\"\"Indicate exception that involve responses from Reddit's API.\"\"\"\n\n def __init__(self, error_type: str, message: str, field: Optional[str]):\n \"\"\"Initialize an instance of APIException.\n\n :param error_type: The error type set on Reddit's end.\n :param message: The associated message for the error.\n :param field: The input field associated with the error if available.\n \"\"\"\n error_str = \"{}: '{}'\".format(error_type, message)\n if field:\n error_str += \" on field '{}'\".format(field)\n\n super().__init__(error_str)\n self.error_type = error_type\n self.message = message\n self.field = field\n\n\nclass ClientException(PRAWException):\n \"\"\"Indicate exceptions that don't involve interaction with Reddit's API.\"\"\"\n\n\nclass WebSocketException(ClientException):\n \"\"\"Indicate exceptions caused by use of WebSockets.\"\"\"\n\n def __init__(self, message: str, exception: Exception):\n \"\"\"Initialize a WebSocketException.\n\n :param message: The exception message.\n :param exception: The exception thrown by the websocket library.\n \"\"\"\n super().__init__(message)\n self.original_exception = exception\n", "path": "praw/exceptions.py"}]}
| 3,277 | 481 |
gh_patches_debug_11282
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-1002
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bash_apps fail due to missing dir paths
I'm running into bash_app errors when I'm using `stdout=parsl.AUTO_LOGNAME`.
Here's the traceback:
```
2019-05-31 11:22:06 parsl.dataflow.dflow:251 [ERROR] Task 0 failed
Traceback (most recent call last):
File "/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/dataflow/dflow.py", line 248, in handle_exec_update
res.reraise()
File "/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/errors.py", line 163, in reraise
reraise(t, v, tb)
File "/home/yadu/.local/lib/python3.6/site-packages/six.py", line 692, in reraise
raise value.with_traceback(tb)
File "/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/errors.py", line 172, in wrapper
return func(*args, **kwargs)
File "/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/bash.py", line 79, in remote_side_bash_executor
std_out = open_std_fd('stdout')
File "/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/bash.py", line 76, in open_std_fd
raise pe.BadStdStreamFile(fname, e)
parsl.app.errors.BadStdStreamFile: FilePath: [/home/yadu/src/parsl/parsl/tests/manual_tests/runinfo/050/task_logs/0000/task_0000_sleeper_bash.stdout] Exception: [Errno 2] No such file or directory: '/home/yadu/src/parsl/parsl/tests/manual_tests/runinfo/050/task_logs/0000/task_0000_sleeper_bash.stdout'
```
I suspect this is coming from the our remote side bash wrapper, trying to open the stdout/stderr stream before we do makedirs on the dirname here
: https://github.com/Parsl/parsl/blob/master/parsl/app/bash.py#L72
</issue>
<code>
[start of parsl/app/bash.py]
1 import logging
2 from functools import update_wrapper
3 from inspect import signature, Parameter
4
5 from parsl.app.errors import wrap_error
6 from parsl.app.futures import DataFuture
7 from parsl.app.app import AppBase
8 from parsl.dataflow.dflow import DataFlowKernelLoader
9
10 logger = logging.getLogger(__name__)
11
12
13 def remote_side_bash_executor(func, *args, **kwargs):
14 """Execute the bash app type function and return the command line string.
15
16 This string is reformatted with the *args, and **kwargs
17 from call time.
18 """
19 import os
20 import time
21 import subprocess
22 import logging
23 import parsl.app.errors as pe
24
25 logging.basicConfig(filename='/tmp/bashexec.{0}.log'.format(time.time()), level=logging.DEBUG)
26
27 # start_t = time.time()
28
29 func_name = func.__name__
30
31 partial_cmdline = None
32
33 # Try to run the func to compose the commandline
34 try:
35 # Execute the func to get the commandline
36 partial_cmdline = func(*args, **kwargs)
37 # Reformat the commandline with current args and kwargs
38 executable = partial_cmdline.format(*args, **kwargs)
39
40 except AttributeError as e:
41 if partial_cmdline is not None:
42 raise pe.AppBadFormatting("App formatting failed for app '{}' with AttributeError: {}".format(func_name, e))
43 else:
44 raise pe.BashAppNoReturn("Bash app '{}' did not return a value, or returned none - with this exception: {}".format(func_name, e), None)
45
46 except IndexError as e:
47 raise pe.AppBadFormatting("App formatting failed for app '{}' with IndexError: {}".format(func_name, e))
48 except Exception as e:
49 logging.error("Caught exception during formatting of app '{}': {}".format(func_name, e))
50 raise e
51
52 logging.debug("Executable: %s", executable)
53
54 # Updating stdout, stderr if values passed at call time.
55
56 def open_std_fd(fdname):
57 # fdname is 'stdout' or 'stderr'
58 stdfspec = kwargs.get(fdname) # spec is str name or tuple (name, mode)
59 if stdfspec is None:
60 return None
61 elif isinstance(stdfspec, str):
62 fname = stdfspec
63 mode = 'a+'
64 elif isinstance(stdfspec, tuple):
65 if len(stdfspec) != 2:
66 raise pe.BadStdStreamFile("std descriptor %s has incorrect tuple length %s" % (fdname, len(stdfspec)), TypeError('Bad Tuple Length'))
67 fname, mode = stdfspec
68 else:
69 raise pe.BadStdStreamFile("std descriptor %s has unexpected type %s" % (fdname, str(type(stdfspec))), TypeError('Bad Tuple Type'))
70
71 try:
72 fd = open(fname, mode)
73 if os.path.dirname(fname):
74 os.makedirs(os.path.dirname(fname), exist_ok=True)
75 except Exception as e:
76 raise pe.BadStdStreamFile(fname, e)
77 return fd
78
79 std_out = open_std_fd('stdout')
80 std_err = open_std_fd('stderr')
81 timeout = kwargs.get('walltime')
82
83 if std_err is not None:
84 print('--> executable follows <--\n{}\n--> end executable <--'.format(executable), file=std_err)
85
86 returncode = None
87 try:
88 proc = subprocess.Popen(executable, stdout=std_out, stderr=std_err, shell=True, executable='/bin/bash')
89 proc.wait(timeout=timeout)
90 returncode = proc.returncode
91
92 except subprocess.TimeoutExpired:
93 # print("Timeout")
94 raise pe.AppTimeout("[{}] App exceeded walltime: {}".format(func_name, timeout))
95
96 except Exception as e:
97 # print("Caught exception: ", e)
98 raise pe.AppException("[{}] App caught exception: {}".format(func_name, proc.returncode), e)
99
100 if returncode != 0:
101 raise pe.AppFailure("[{}] App failed with exit code: {}".format(func_name, proc.returncode), proc.returncode)
102
103 # TODO : Add support for globs here
104
105 missing = []
106 for outputfile in kwargs.get('outputs', []):
107 fpath = outputfile
108 if type(outputfile) != str:
109 fpath = outputfile.filepath
110
111 if not os.path.exists(fpath):
112 missing.extend([outputfile])
113
114 if missing:
115 raise pe.MissingOutputs("[{}] Missing outputs".format(func_name), missing)
116
117 # exec_duration = time.time() - start_t
118 return returncode
119
120
121 class BashApp(AppBase):
122
123 def __init__(self, func, data_flow_kernel=None, walltime=60, cache=False, executors='all'):
124 super().__init__(func, data_flow_kernel=data_flow_kernel, walltime=60, executors=executors, cache=cache)
125 self.kwargs = {}
126
127 # We duplicate the extraction of parameter defaults
128 # to self.kwargs to ensure availability at point of
129 # command string format. Refer: #349
130 sig = signature(func)
131
132 for s in sig.parameters:
133 if sig.parameters[s].default != Parameter.empty:
134 self.kwargs[s] = sig.parameters[s].default
135
136 def __call__(self, *args, **kwargs):
137 """Handle the call to a Bash app.
138
139 Args:
140 - Arbitrary
141
142 Kwargs:
143 - Arbitrary
144
145 Returns:
146 If outputs=[...] was a kwarg then:
147 App_fut, [Data_Futures...]
148 else:
149 App_fut
150
151 """
152 # Update kwargs in the app definition with ones passed in at calltime
153 self.kwargs.update(kwargs)
154
155 if self.data_flow_kernel is None:
156 dfk = DataFlowKernelLoader.dfk()
157 else:
158 dfk = self.data_flow_kernel
159
160 app_fut = dfk.submit(wrap_error(update_wrapper(remote_side_bash_executor, self.func)),
161 self.func, *args,
162 executors=self.executors,
163 fn_hash=self.func_hash,
164 cache=self.cache,
165 **self.kwargs)
166
167 out_futs = [DataFuture(app_fut, o, tid=app_fut.tid)
168 for o in kwargs.get('outputs', [])]
169 app_fut._outputs = out_futs
170
171 return app_fut
172
[end of parsl/app/bash.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/app/bash.py b/parsl/app/bash.py
--- a/parsl/app/bash.py
+++ b/parsl/app/bash.py
@@ -69,9 +69,9 @@
raise pe.BadStdStreamFile("std descriptor %s has unexpected type %s" % (fdname, str(type(stdfspec))), TypeError('Bad Tuple Type'))
try:
- fd = open(fname, mode)
if os.path.dirname(fname):
os.makedirs(os.path.dirname(fname), exist_ok=True)
+ fd = open(fname, mode)
except Exception as e:
raise pe.BadStdStreamFile(fname, e)
return fd
|
{"golden_diff": "diff --git a/parsl/app/bash.py b/parsl/app/bash.py\n--- a/parsl/app/bash.py\n+++ b/parsl/app/bash.py\n@@ -69,9 +69,9 @@\n raise pe.BadStdStreamFile(\"std descriptor %s has unexpected type %s\" % (fdname, str(type(stdfspec))), TypeError('Bad Tuple Type'))\n \n try:\n- fd = open(fname, mode)\n if os.path.dirname(fname):\n os.makedirs(os.path.dirname(fname), exist_ok=True)\n+ fd = open(fname, mode)\n except Exception as e:\n raise pe.BadStdStreamFile(fname, e)\n return fd\n", "issue": "bash_apps fail due to missing dir paths\nI'm running into bash_app errors when I'm using `stdout=parsl.AUTO_LOGNAME`.\r\nHere's the traceback:\r\n```\r\n2019-05-31 11:22:06 parsl.dataflow.dflow:251 [ERROR] Task 0 failed\r\nTraceback (most recent call last):\r\n File \"/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/dataflow/dflow.py\", line 248, in handle_exec_update\r\n res.reraise()\r\n File \"/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/errors.py\", line 163, in reraise\r\n reraise(t, v, tb)\r\n File \"/home/yadu/.local/lib/python3.6/site-packages/six.py\", line 692, in reraise\r\n raise value.with_traceback(tb)\r\n File \"/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/errors.py\", line 172, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/bash.py\", line 79, in remote_side_bash_executor\r\n std_out = open_std_fd('stdout')\r\n File \"/home/yadu/miniconda3/envs/mpi_executor/lib/python3.6/site-packages/parsl/app/bash.py\", line 76, in open_std_fd\r\n raise pe.BadStdStreamFile(fname, e)\r\nparsl.app.errors.BadStdStreamFile: FilePath: [/home/yadu/src/parsl/parsl/tests/manual_tests/runinfo/050/task_logs/0000/task_0000_sleeper_bash.stdout] Exception: [Errno 2] No such file or directory: '/home/yadu/src/parsl/parsl/tests/manual_tests/runinfo/050/task_logs/0000/task_0000_sleeper_bash.stdout'\r\n```\r\n\r\nI suspect this is coming from the our remote side bash wrapper, trying to open the stdout/stderr stream before we do makedirs on the dirname here \r\n : https://github.com/Parsl/parsl/blob/master/parsl/app/bash.py#L72\n", "before_files": [{"content": "import logging\nfrom functools import update_wrapper\nfrom inspect import signature, Parameter\n\nfrom parsl.app.errors import wrap_error\nfrom parsl.app.futures import DataFuture\nfrom parsl.app.app import AppBase\nfrom parsl.dataflow.dflow import DataFlowKernelLoader\n\nlogger = logging.getLogger(__name__)\n\n\ndef remote_side_bash_executor(func, *args, **kwargs):\n \"\"\"Execute the bash app type function and return the command line string.\n\n This string is reformatted with the *args, and **kwargs\n from call time.\n \"\"\"\n import os\n import time\n import subprocess\n import logging\n import parsl.app.errors as pe\n\n logging.basicConfig(filename='/tmp/bashexec.{0}.log'.format(time.time()), level=logging.DEBUG)\n\n # start_t = time.time()\n\n func_name = func.__name__\n\n partial_cmdline = None\n\n # Try to run the func to compose the commandline\n try:\n # Execute the func to get the commandline\n partial_cmdline = func(*args, **kwargs)\n # Reformat the commandline with current args and kwargs\n executable = partial_cmdline.format(*args, **kwargs)\n\n except AttributeError as e:\n if partial_cmdline is not None:\n raise pe.AppBadFormatting(\"App formatting failed for app '{}' with AttributeError: {}\".format(func_name, e))\n else:\n raise pe.BashAppNoReturn(\"Bash app '{}' did not return a value, or returned none - with this exception: {}\".format(func_name, e), None)\n\n except IndexError as e:\n raise pe.AppBadFormatting(\"App formatting failed for app '{}' with IndexError: {}\".format(func_name, e))\n except Exception as e:\n logging.error(\"Caught exception during formatting of app '{}': {}\".format(func_name, e))\n raise e\n\n logging.debug(\"Executable: %s\", executable)\n\n # Updating stdout, stderr if values passed at call time.\n\n def open_std_fd(fdname):\n # fdname is 'stdout' or 'stderr'\n stdfspec = kwargs.get(fdname) # spec is str name or tuple (name, mode)\n if stdfspec is None:\n return None\n elif isinstance(stdfspec, str):\n fname = stdfspec\n mode = 'a+'\n elif isinstance(stdfspec, tuple):\n if len(stdfspec) != 2:\n raise pe.BadStdStreamFile(\"std descriptor %s has incorrect tuple length %s\" % (fdname, len(stdfspec)), TypeError('Bad Tuple Length'))\n fname, mode = stdfspec\n else:\n raise pe.BadStdStreamFile(\"std descriptor %s has unexpected type %s\" % (fdname, str(type(stdfspec))), TypeError('Bad Tuple Type'))\n\n try:\n fd = open(fname, mode)\n if os.path.dirname(fname):\n os.makedirs(os.path.dirname(fname), exist_ok=True)\n except Exception as e:\n raise pe.BadStdStreamFile(fname, e)\n return fd\n\n std_out = open_std_fd('stdout')\n std_err = open_std_fd('stderr')\n timeout = kwargs.get('walltime')\n\n if std_err is not None:\n print('--> executable follows <--\\n{}\\n--> end executable <--'.format(executable), file=std_err)\n\n returncode = None\n try:\n proc = subprocess.Popen(executable, stdout=std_out, stderr=std_err, shell=True, executable='/bin/bash')\n proc.wait(timeout=timeout)\n returncode = proc.returncode\n\n except subprocess.TimeoutExpired:\n # print(\"Timeout\")\n raise pe.AppTimeout(\"[{}] App exceeded walltime: {}\".format(func_name, timeout))\n\n except Exception as e:\n # print(\"Caught exception: \", e)\n raise pe.AppException(\"[{}] App caught exception: {}\".format(func_name, proc.returncode), e)\n\n if returncode != 0:\n raise pe.AppFailure(\"[{}] App failed with exit code: {}\".format(func_name, proc.returncode), proc.returncode)\n\n # TODO : Add support for globs here\n\n missing = []\n for outputfile in kwargs.get('outputs', []):\n fpath = outputfile\n if type(outputfile) != str:\n fpath = outputfile.filepath\n\n if not os.path.exists(fpath):\n missing.extend([outputfile])\n\n if missing:\n raise pe.MissingOutputs(\"[{}] Missing outputs\".format(func_name), missing)\n\n # exec_duration = time.time() - start_t\n return returncode\n\n\nclass BashApp(AppBase):\n\n def __init__(self, func, data_flow_kernel=None, walltime=60, cache=False, executors='all'):\n super().__init__(func, data_flow_kernel=data_flow_kernel, walltime=60, executors=executors, cache=cache)\n self.kwargs = {}\n\n # We duplicate the extraction of parameter defaults\n # to self.kwargs to ensure availability at point of\n # command string format. Refer: #349\n sig = signature(func)\n\n for s in sig.parameters:\n if sig.parameters[s].default != Parameter.empty:\n self.kwargs[s] = sig.parameters[s].default\n\n def __call__(self, *args, **kwargs):\n \"\"\"Handle the call to a Bash app.\n\n Args:\n - Arbitrary\n\n Kwargs:\n - Arbitrary\n\n Returns:\n If outputs=[...] was a kwarg then:\n App_fut, [Data_Futures...]\n else:\n App_fut\n\n \"\"\"\n # Update kwargs in the app definition with ones passed in at calltime\n self.kwargs.update(kwargs)\n\n if self.data_flow_kernel is None:\n dfk = DataFlowKernelLoader.dfk()\n else:\n dfk = self.data_flow_kernel\n\n app_fut = dfk.submit(wrap_error(update_wrapper(remote_side_bash_executor, self.func)),\n self.func, *args,\n executors=self.executors,\n fn_hash=self.func_hash,\n cache=self.cache,\n **self.kwargs)\n\n out_futs = [DataFuture(app_fut, o, tid=app_fut.tid)\n for o in kwargs.get('outputs', [])]\n app_fut._outputs = out_futs\n\n return app_fut\n", "path": "parsl/app/bash.py"}]}
| 2,851 | 145 |
gh_patches_debug_35237
|
rasdani/github-patches
|
git_diff
|
scikit-hep__pyhf-1435
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Correlated background simplemodel
something like
```python
def simplemodel2(s,b_up,b_nom,b_dn):
spec = {
'channels': [
{
'name': 'singlechannel',
'samples': [
{
'name': 'signal',
'data': s,
'modifiers': [{'name': 'mu', 'type': 'normfactor', 'data': None}]
},
{'name': 'background',
'data': b_nom,
'modifiers': [
{
'name': 'uncorr_bkguncrt',
'type': 'histosys',
'data': {
'hi_data': b_up,
'lo_data': b_dn
}
}
]
}
]
}
]
}
return pyhf.Model(spec)
```
with an API like `pyhf.simplemodels.correlated_bkg`
</issue>
<code>
[start of src/pyhf/simplemodels.py]
1 from . import Model
2
3 __all__ = ["hepdata_like"]
4
5
6 def __dir__():
7 return __all__
8
9
10 def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):
11 """
12 Construct a simple single channel :class:`~pyhf.pdf.Model` with a
13 :class:`~pyhf.modifiers.shapesys` modifier representing an uncorrelated
14 background uncertainty.
15
16 Example:
17 >>> import pyhf
18 >>> pyhf.set_backend("numpy")
19 >>> model = pyhf.simplemodels.hepdata_like(
20 ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]
21 ... )
22 >>> model.schema
23 'model.json'
24 >>> model.config.channels
25 ['singlechannel']
26 >>> model.config.samples
27 ['background', 'signal']
28 >>> model.config.parameters
29 ['mu', 'uncorr_bkguncrt']
30 >>> model.expected_data(model.config.suggested_init())
31 array([ 62. , 63. , 277.77777778, 55.18367347])
32
33 Args:
34 signal_data (:obj:`list`): The data in the signal sample
35 bkg_data (:obj:`list`): The data in the background sample
36 bkg_uncerts (:obj:`list`): The statistical uncertainty on the background sample counts
37 batch_size (:obj:`None` or :obj:`int`): Number of simultaneous (batched) Models to compute
38
39 Returns:
40 ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema
41
42 """
43 spec = {
44 'channels': [
45 {
46 'name': 'singlechannel',
47 'samples': [
48 {
49 'name': 'signal',
50 'data': signal_data,
51 'modifiers': [
52 {'name': 'mu', 'type': 'normfactor', 'data': None}
53 ],
54 },
55 {
56 'name': 'background',
57 'data': bkg_data,
58 'modifiers': [
59 {
60 'name': 'uncorr_bkguncrt',
61 'type': 'shapesys',
62 'data': bkg_uncerts,
63 }
64 ],
65 },
66 ],
67 }
68 ]
69 }
70 return Model(spec, batch_size=batch_size)
71
[end of src/pyhf/simplemodels.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pyhf/simplemodels.py b/src/pyhf/simplemodels.py
--- a/src/pyhf/simplemodels.py
+++ b/src/pyhf/simplemodels.py
@@ -1,12 +1,81 @@
from . import Model
-__all__ = ["hepdata_like"]
+__all__ = ["correlated_background", "hepdata_like"]
def __dir__():
return __all__
+def correlated_background(signal, bkg, bkg_up, bkg_down, batch_size=None):
+ r"""
+ Construct a simple single channel :class:`~pyhf.pdf.Model` with a
+ :class:`~pyhf.modifiers.histosys` modifier representing a background
+ with a fully correlated bin-by-bin uncertainty.
+
+ Args:
+ signal (:obj:`list`): The data in the signal sample.
+ bkg (:obj:`list`): The data in the background sample.
+ bkg_up (:obj:`list`): The background sample under an upward variation
+ corresponding to :math:`\alpha=+1`.
+ bkg_down (:obj:`list`): The background sample under a downward variation
+ corresponding to :math:`\alpha=-1`.
+ batch_size (:obj:`None` or :obj:`int`): Number of simultaneous (batched) Models to compute.
+
+ Returns:
+ ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema.
+
+ Example:
+ >>> import pyhf
+ >>> pyhf.set_backend("numpy")
+ >>> model = pyhf.simplemodels.correlated_background(
+ ... signal=[12.0, 11.0],
+ ... bkg=[50.0, 52.0],
+ ... bkg_up=[45.0, 57.0],
+ ... bkg_down=[55.0, 47.0],
+ ... )
+ >>> model.schema
+ 'model.json'
+ >>> model.config.channels
+ ['single_channel']
+ >>> model.config.samples
+ ['background', 'signal']
+ >>> model.config.parameters
+ ['correlated_bkg_uncertainty', 'mu']
+ >>> model.expected_data(model.config.suggested_init())
+ array([62., 63., 0.])
+
+ """
+ spec = {
+ "channels": [
+ {
+ "name": "single_channel",
+ "samples": [
+ {
+ "name": "signal",
+ "data": signal,
+ "modifiers": [
+ {"name": "mu", "type": "normfactor", "data": None}
+ ],
+ },
+ {
+ "name": "background",
+ "data": bkg,
+ "modifiers": [
+ {
+ "name": "correlated_bkg_uncertainty",
+ "type": "histosys",
+ "data": {"hi_data": bkg_up, "lo_data": bkg_down},
+ }
+ ],
+ },
+ ],
+ }
+ ]
+ }
+ return Model(spec, batch_size=batch_size)
+
+
def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):
"""
Construct a simple single channel :class:`~pyhf.pdf.Model` with a
|
{"golden_diff": "diff --git a/src/pyhf/simplemodels.py b/src/pyhf/simplemodels.py\n--- a/src/pyhf/simplemodels.py\n+++ b/src/pyhf/simplemodels.py\n@@ -1,12 +1,81 @@\n from . import Model\n \n-__all__ = [\"hepdata_like\"]\n+__all__ = [\"correlated_background\", \"hepdata_like\"]\n \n \n def __dir__():\n return __all__\n \n \n+def correlated_background(signal, bkg, bkg_up, bkg_down, batch_size=None):\n+ r\"\"\"\n+ Construct a simple single channel :class:`~pyhf.pdf.Model` with a\n+ :class:`~pyhf.modifiers.histosys` modifier representing a background\n+ with a fully correlated bin-by-bin uncertainty.\n+\n+ Args:\n+ signal (:obj:`list`): The data in the signal sample.\n+ bkg (:obj:`list`): The data in the background sample.\n+ bkg_up (:obj:`list`): The background sample under an upward variation\n+ corresponding to :math:`\\alpha=+1`.\n+ bkg_down (:obj:`list`): The background sample under a downward variation\n+ corresponding to :math:`\\alpha=-1`.\n+ batch_size (:obj:`None` or :obj:`int`): Number of simultaneous (batched) Models to compute.\n+\n+ Returns:\n+ ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema.\n+\n+ Example:\n+ >>> import pyhf\n+ >>> pyhf.set_backend(\"numpy\")\n+ >>> model = pyhf.simplemodels.correlated_background(\n+ ... signal=[12.0, 11.0],\n+ ... bkg=[50.0, 52.0],\n+ ... bkg_up=[45.0, 57.0],\n+ ... bkg_down=[55.0, 47.0],\n+ ... )\n+ >>> model.schema\n+ 'model.json'\n+ >>> model.config.channels\n+ ['single_channel']\n+ >>> model.config.samples\n+ ['background', 'signal']\n+ >>> model.config.parameters\n+ ['correlated_bkg_uncertainty', 'mu']\n+ >>> model.expected_data(model.config.suggested_init())\n+ array([62., 63., 0.])\n+\n+ \"\"\"\n+ spec = {\n+ \"channels\": [\n+ {\n+ \"name\": \"single_channel\",\n+ \"samples\": [\n+ {\n+ \"name\": \"signal\",\n+ \"data\": signal,\n+ \"modifiers\": [\n+ {\"name\": \"mu\", \"type\": \"normfactor\", \"data\": None}\n+ ],\n+ },\n+ {\n+ \"name\": \"background\",\n+ \"data\": bkg,\n+ \"modifiers\": [\n+ {\n+ \"name\": \"correlated_bkg_uncertainty\",\n+ \"type\": \"histosys\",\n+ \"data\": {\"hi_data\": bkg_up, \"lo_data\": bkg_down},\n+ }\n+ ],\n+ },\n+ ],\n+ }\n+ ]\n+ }\n+ return Model(spec, batch_size=batch_size)\n+\n+\n def hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):\n \"\"\"\n Construct a simple single channel :class:`~pyhf.pdf.Model` with a\n", "issue": "Correlated background simplemodel\nsomething like\r\n\r\n```python\r\ndef simplemodel2(s,b_up,b_nom,b_dn):\r\n spec = {\r\n 'channels': [\r\n {\r\n 'name': 'singlechannel',\r\n 'samples': [\r\n {\r\n 'name': 'signal',\r\n 'data': s,\r\n 'modifiers': [{'name': 'mu', 'type': 'normfactor', 'data': None}]\r\n },\r\n {'name': 'background',\r\n 'data': b_nom,\r\n 'modifiers': [\r\n {\r\n 'name': 'uncorr_bkguncrt',\r\n 'type': 'histosys',\r\n 'data': {\r\n 'hi_data': b_up,\r\n 'lo_data': b_dn\r\n }\r\n }\r\n ]\r\n }\r\n ]\r\n }\r\n ]\r\n }\r\n return pyhf.Model(spec)\r\n\r\n```\r\n\r\nwith an API like `pyhf.simplemodels.correlated_bkg`\n", "before_files": [{"content": "from . import Model\n\n__all__ = [\"hepdata_like\"]\n\n\ndef __dir__():\n return __all__\n\n\ndef hepdata_like(signal_data, bkg_data, bkg_uncerts, batch_size=None):\n \"\"\"\n Construct a simple single channel :class:`~pyhf.pdf.Model` with a\n :class:`~pyhf.modifiers.shapesys` modifier representing an uncorrelated\n background uncertainty.\n\n Example:\n >>> import pyhf\n >>> pyhf.set_backend(\"numpy\")\n >>> model = pyhf.simplemodels.hepdata_like(\n ... signal_data=[12.0, 11.0], bkg_data=[50.0, 52.0], bkg_uncerts=[3.0, 7.0]\n ... )\n >>> model.schema\n 'model.json'\n >>> model.config.channels\n ['singlechannel']\n >>> model.config.samples\n ['background', 'signal']\n >>> model.config.parameters\n ['mu', 'uncorr_bkguncrt']\n >>> model.expected_data(model.config.suggested_init())\n array([ 62. , 63. , 277.77777778, 55.18367347])\n\n Args:\n signal_data (:obj:`list`): The data in the signal sample\n bkg_data (:obj:`list`): The data in the background sample\n bkg_uncerts (:obj:`list`): The statistical uncertainty on the background sample counts\n batch_size (:obj:`None` or :obj:`int`): Number of simultaneous (batched) Models to compute\n\n Returns:\n ~pyhf.pdf.Model: The statistical model adhering to the :obj:`model.json` schema\n\n \"\"\"\n spec = {\n 'channels': [\n {\n 'name': 'singlechannel',\n 'samples': [\n {\n 'name': 'signal',\n 'data': signal_data,\n 'modifiers': [\n {'name': 'mu', 'type': 'normfactor', 'data': None}\n ],\n },\n {\n 'name': 'background',\n 'data': bkg_data,\n 'modifiers': [\n {\n 'name': 'uncorr_bkguncrt',\n 'type': 'shapesys',\n 'data': bkg_uncerts,\n }\n ],\n },\n ],\n }\n ]\n }\n return Model(spec, batch_size=batch_size)\n", "path": "src/pyhf/simplemodels.py"}]}
| 1,394 | 746 |
gh_patches_debug_25165
|
rasdani/github-patches
|
git_diff
|
weecology__retriever-1349
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Repair biotimesql
define NULL
</issue>
<code>
[start of scripts/biotimesql.py]
1 # -*- coding: utf-8 -*-
2 #retriever
3
4 import csv
5 from pkg_resources import parse_version
6
7 from retriever.lib.models import Table
8 from retriever.lib.templates import Script
9
10 try:
11 from retriever.lib.defaults import VERSION
12
13 try:
14 from retriever.lib.tools import open_fr, open_fw, open_csvw
15 except ImportError:
16 from retriever.lib.scripts import open_fr, open_fw
17 except ImportError:
18 from retriever import open_fr, open_fw, VERSION
19
20
21 class main(Script):
22 def __init__(self, **kwargs):
23 Script.__init__(self, **kwargs)
24 self.title = "Commercial Fisheries Monthly Trade Data by Product, Country/Association"
25 self.name = "biotimesql"
26 self.retriever_minimum_version = "2.2.0"
27 self.urls = {
28 "sql_file": "https://zenodo.org/record/2602708/files/BioTIMESQL02_04_2018.sql?download=1",
29 }
30 self.version = "1.0.0"
31 self.ref = "https://zenodo.org/record/1095628#.WskN7dPwYyn"
32 self.citation = "Dornelas M, Antão LH, Moyes F, et al. BioTIME: A database of biodiversity time series for the Anthropocene. Global Ecology & Biogeography. 2018; 00:1 - 26. https://doi.org/10.1111/geb.12729."
33 self.description = "The BioTIME database has species identities and abundances in ecological assemblages through time."
34 self.keywords = ["Time series", "Anthropocene", "Global"]
35 self.licenses = [{"name": "CC BY 4.0"}]
36 self.encoding = "latin1"
37
38 if parse_version(VERSION) <= parse_version("2.0.0"):
39 self.shortname = self.name
40 self.name = self.title
41 self.tags = self.keywords
42
43 def download(self, engine=None, debug=False):
44 Script.download(self, engine, debug)
45 engine = self.engine
46 original_sql_file = "BioTIMESQL02_04_2018.sql"
47 engine.download_file(self.urls["sql_file"], original_sql_file)
48 sql_data = open_fr(self.engine.format_filename(original_sql_file))
49
50 set_open = False
51 csv_writer = None
52 csv_file = None
53 table_name = None
54 for line in sql_data:
55 table_indicator = "-- Table structure for table "
56 if line.startswith(table_indicator):
57 st = line[len(table_indicator):].replace("`", "")
58 table_name = st.strip()
59 current_file_process = table_name
60 current_file_open = current_file_process
61 if set_open and not current_file_process == current_file_open:
62 csv_file.close()
63 set_open = False
64 else:
65 out_file = "{name}.csv".format(name=table_name)
66 csv_file = open_fw(engine.format_filename(out_file))
67 csv_writer = csv.writer(csv_file, quoting=csv.QUOTE_ALL)
68 set_open = True
69
70 if line.startswith("INSERT INTO `{table_name}`".format(table_name=table_name)):
71 row_val = line[line.index("VALUES (") + 8:-3]
72 table_rows = row_val.replace("\r\n","").split("),(")
73 for i_row in table_rows:
74 v = eval('[' + str(i_row) + ']')
75 csv_writer.writerows([v])
76 if csv_file:
77 csv_file.close()
78
79 # Create abundance table
80 table = Table("ID_ABUNDANCE", delimiter=",", header_rows=0, contains_pk=False)
81 table.columns = [
82 ("ID_ABUNDANCE", ("int",)),
83 ("ABUNDANCE_TYPE", ("char", "100")),
84 ]
85 engine.table = table
86 engine.create_table()
87 engine.insert_data_from_file(engine.format_filename("abundance.csv"))
88
89 # Create allrawdata table
90 table = Table("allrawdata", delimiter=",", header_rows=0, contains_pk=False)
91 table.columns = [
92 ("ID_ALL_RAW_DATA", ("int",)),
93 ("ABUNDANCE", ("double",)),
94 ("BIOMASS", ("double",)),
95 ("ID_SPECIES", ("int",)),
96 ("SAMPLE_DESC", ("char", 200)),
97 ("PLOT", ("char", 150)),
98 ("LATITUDE", ("double",)),
99 ("LONGITUDE", ("double",)),
100 ("DEPTH", ("double",)),
101 ("DAY", ("int",)),
102 ("MONTH", ("int",)),
103 ("YEAR", ("int",)),
104 ("STUDY_ID", ("int",)),
105 ]
106 engine.table = table
107 engine.create_table()
108 engine.insert_data_from_file(engine.format_filename("allrawdata.csv"))
109
110 # Create biomass table
111 table = Table("biomass", delimiter=",", header_rows=0, contains_pk=False)
112 table.columns = [("ID_BIOMASS", ("int",)), ("BIOMASS_TYPE", ("char", "100"))]
113 engine.table = table
114 engine.create_table()
115 engine.insert_data_from_file(engine.format_filename("biomass.csv"))
116
117 # Create citation1 table
118 table = Table("citation1", delimiter=",", header_rows=0, contains_pk=False)
119 table.columns = [
120 ("ID_CITATION1", ("int",)),
121 ("STUDY_ID", ("int",)),
122 ("CITATION_LINE", ("char",)),
123 ]
124 engine.table = table
125 engine.create_table()
126 engine.insert_data_from_file(engine.format_filename("citation1.csv"))
127
128 # Create contacts table
129 table = Table("contacts", delimiter=",", header_rows=0, contains_pk=False)
130 table.columns = [
131 ("ID_CONTACTS", ("int",)),
132 ("STUDY_ID", ("int",)),
133 ("CONTACT_1", ("char", 500)),
134 ("CONTACT_2", ("char", 500)),
135 ("CONT_1_MAIL", ("char", 60)),
136 ("CONT_2_MAIL", ("char", 60)),
137 ("LICENSE", ("char", 200)),
138 ("WEB_LINK", ("char", 200)),
139 ("DATA_SOURCE", ("char", 250)),
140 ]
141 engine.table = table
142 engine.create_table()
143 engine.insert_data_from_file(engine.format_filename("contacts.csv"))
144
145 # Create countries table
146 table = Table("countries", delimiter=",", header_rows=0, contains_pk=False)
147 table.columns = [("COUNT_ID", ("int",)), ("COUNTRY_NAME", ("char", 200))]
148 engine.table = table
149 engine.create_table()
150 engine.insert_data_from_file(engine.format_filename("countries.csv"))
151
152 # Create curation table
153 table = Table("curation", delimiter=",", header_rows=0, contains_pk=False)
154 table.columns = [
155 ("ID_CURATION", ("int",)),
156 ("STUDY_ID", ("int",)),
157 ("LINK_ID", ("int",)),
158 ("COMMENTS", ("char",)),
159 ("DATE_STUDY_ADDED", ("char", 50)),
160 ]
161 engine.table = table
162 engine.create_table()
163 engine.insert_data_from_file(engine.format_filename("curation.csv"))
164
165 # Create datasets table
166 table = Table("datasets", delimiter=",", header_rows=0, contains_pk=False)
167 table.columns = [
168 ("ID_DATASETS", ("int",)),
169 ("STUDY_ID", ("int",)),
170 ("TAXA", ("char", 50)),
171 ("ORGANISMS", ("char", 200)),
172 ("TITLE", ("char",800)),
173 ("AB_BIO", ("char", 2)),
174 ("HAS_PLOT", ("char", 10)),
175 ("DATA_POINTS", ("char",)),
176 ("START_YEAR", ("char",)),
177 ("END_YEAR", ("char",)),
178 ("CENT_LAT", ("double",)),
179 ("CENT_LONG", ("double",)),
180 ("NUMBER_OF_SPECIES", ("char",)),
181 ("NUMBER_OF_SAMPLES", ("char",)),
182 ("NUMBER_LAT_LONG", ("char",)),
183 ("TOTAL", ("char",)),
184 ("GRAIN_SIZE_TEXT", ("char",)),
185 ("GRAIN_SQ_KM", ("double",)),
186 ("AREA_SQ_KM", ("double",)),
187 ("AB_TYPE", ("char", )),
188 ("BIO_TYPE", ("char",)),
189 ("SAMPLE_TYPE", ("char",)),
190 ]
191 engine.table = table
192 engine.create_table()
193 engine.insert_data_from_file(engine.format_filename("datasets.csv"))
194
195 # Create downloads table
196 table = Table("downloads", delimiter=",", header_rows=0, contains_pk=False)
197 table.columns = [
198 ("D_ID", ("int",)),
199 ("STUDY", ("char", 25)),
200 ("NAME", ("char", 150)),
201 ("EMAIL", ("char", 150)),
202 ("COUNTRY", ("char", 200)),
203 ("ROLE", ("char", 150)),
204 ("PURPOSE", ("char", 500)),
205 ("LOCATION", ("char", 250)),
206 ("DATE_STAMP", ("char",)),
207 ]
208 engine.table = table
209 engine.create_table()
210 engine.insert_data_from_file(engine.format_filename("downloads.csv"))
211
212 # Create methods table
213 table = Table("methods", delimiter=",", header_rows=0, contains_pk=False)
214 table.columns = [
215 ("ID_METHODS", ("int",)),
216 ("STUDY_ID", ("int",)),
217 ("METHODS", ("char",)),
218 ("SUMMARY_METHODS", ("char", 500)),
219 ]
220 engine.table = table
221 engine.create_table()
222 engine.insert_data_from_file(engine.format_filename("methods.csv"))
223
224 # Create sample table
225 table = Table("sample", delimiter=",", header_rows=0, contains_pk=False)
226 table.columns = [
227 ("ID_SAMPLE", ("int",)),
228 ("ID_TREAT", ("int",)),
229 ("SAMPLE_DESC_NAME", ("char", 200)),
230 ]
231 engine.table = table
232 engine.create_table()
233 engine.insert_data_from_file(engine.format_filename("sample.csv"))
234
235 # Create site table
236 table = Table("site", delimiter=",", header_rows=0, contains_pk=False)
237 table.columns = [
238 ("ID_SITE", ("int",)),
239 ("STUDY_ID", ("int",)),
240 ("REALM", ("char", 11)),
241 ("CLIMATE", ("char", 20)),
242 ("GENERAL_TREAT", ("char", 200)),
243 ("TREATMENT", ("char", 200)),
244 ("TREAT_COMMENTS", ("char", 250)),
245 ("TREAT_DATE", ("char", 100)),
246 ("CEN_LATITUDE", ("double",)),
247 ("CEN_LONGITUDE", ("double",)),
248 ("HABITAT", ("char", 100)),
249 ("PROTECTED_AREA", ("char", 50)),
250 ("AREA", ("double",)),
251 ("BIOME_MAP", ("char", 500))
252 ]
253 engine.table = table
254 engine.create_table()
255 engine.insert_data_from_file(engine.format_filename("site.csv"))
256
257 # Create species table
258 table = Table("species", delimiter=",", header_rows=0, contains_pk=False)
259 table.columns = [
260 ("ID_SPECIES", ("int",)),
261 ("GENUS", ("char", 100)),
262 ("SPECIES", ("char", 100)),
263 ("GENUS_SPECIES", ("char", 100))
264 ]
265 engine.table = table
266 engine.create_table()
267 engine.insert_data_from_file(engine.format_filename("species.csv"))
268
269
270 SCRIPT = main()
271
[end of scripts/biotimesql.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/biotimesql.py b/scripts/biotimesql.py
--- a/scripts/biotimesql.py
+++ b/scripts/biotimesql.py
@@ -27,7 +27,7 @@
self.urls = {
"sql_file": "https://zenodo.org/record/2602708/files/BioTIMESQL02_04_2018.sql?download=1",
}
- self.version = "1.0.0"
+ self.version = "1.0.1"
self.ref = "https://zenodo.org/record/1095628#.WskN7dPwYyn"
self.citation = "Dornelas M, Antão LH, Moyes F, et al. BioTIME: A database of biodiversity time series for the Anthropocene. Global Ecology & Biogeography. 2018; 00:1 - 26. https://doi.org/10.1111/geb.12729."
self.description = "The BioTIME database has species identities and abundances in ecological assemblages through time."
@@ -51,6 +51,7 @@
csv_writer = None
csv_file = None
table_name = None
+ NULL = None
for line in sql_data:
table_indicator = "-- Table structure for table "
if line.startswith(table_indicator):
|
{"golden_diff": "diff --git a/scripts/biotimesql.py b/scripts/biotimesql.py\n--- a/scripts/biotimesql.py\n+++ b/scripts/biotimesql.py\n@@ -27,7 +27,7 @@\n self.urls = {\n \"sql_file\": \"https://zenodo.org/record/2602708/files/BioTIMESQL02_04_2018.sql?download=1\",\n }\n- self.version = \"1.0.0\"\n+ self.version = \"1.0.1\"\n self.ref = \"https://zenodo.org/record/1095628#.WskN7dPwYyn\"\n self.citation = \"Dornelas M, Ant\u00e3o LH, Moyes F, et al. BioTIME: A database of biodiversity time series for the Anthropocene. Global Ecology & Biogeography. 2018; 00:1 - 26. https://doi.org/10.1111/geb.12729.\"\n self.description = \"The BioTIME database has species identities and abundances in ecological assemblages through time.\"\n@@ -51,6 +51,7 @@\n csv_writer = None\n csv_file = None\n table_name = None\n+ NULL = None\n for line in sql_data:\n table_indicator = \"-- Table structure for table \"\n if line.startswith(table_indicator):\n", "issue": "Repair biotimesql\ndefine NULL\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#retriever\n\nimport csv\nfrom pkg_resources import parse_version\n\nfrom retriever.lib.models import Table\nfrom retriever.lib.templates import Script\n\ntry:\n from retriever.lib.defaults import VERSION\n\n try:\n from retriever.lib.tools import open_fr, open_fw, open_csvw\n except ImportError:\n from retriever.lib.scripts import open_fr, open_fw\nexcept ImportError:\n from retriever import open_fr, open_fw, VERSION\n\n\nclass main(Script):\n def __init__(self, **kwargs):\n Script.__init__(self, **kwargs)\n self.title = \"Commercial Fisheries Monthly Trade Data by Product, Country/Association\"\n self.name = \"biotimesql\"\n self.retriever_minimum_version = \"2.2.0\"\n self.urls = {\n \"sql_file\": \"https://zenodo.org/record/2602708/files/BioTIMESQL02_04_2018.sql?download=1\",\n }\n self.version = \"1.0.0\"\n self.ref = \"https://zenodo.org/record/1095628#.WskN7dPwYyn\"\n self.citation = \"Dornelas M, Ant\u00e3o LH, Moyes F, et al. BioTIME: A database of biodiversity time series for the Anthropocene. Global Ecology & Biogeography. 2018; 00:1 - 26. https://doi.org/10.1111/geb.12729.\"\n self.description = \"The BioTIME database has species identities and abundances in ecological assemblages through time.\"\n self.keywords = [\"Time series\", \"Anthropocene\", \"Global\"]\n self.licenses = [{\"name\": \"CC BY 4.0\"}]\n self.encoding = \"latin1\"\n\n if parse_version(VERSION) <= parse_version(\"2.0.0\"):\n self.shortname = self.name\n self.name = self.title\n self.tags = self.keywords\n\n def download(self, engine=None, debug=False):\n Script.download(self, engine, debug)\n engine = self.engine\n original_sql_file = \"BioTIMESQL02_04_2018.sql\"\n engine.download_file(self.urls[\"sql_file\"], original_sql_file)\n sql_data = open_fr(self.engine.format_filename(original_sql_file))\n\n set_open = False\n csv_writer = None\n csv_file = None\n table_name = None\n for line in sql_data:\n table_indicator = \"-- Table structure for table \"\n if line.startswith(table_indicator):\n st = line[len(table_indicator):].replace(\"`\", \"\")\n table_name = st.strip()\n current_file_process = table_name\n current_file_open = current_file_process\n if set_open and not current_file_process == current_file_open:\n csv_file.close()\n set_open = False\n else:\n out_file = \"{name}.csv\".format(name=table_name)\n csv_file = open_fw(engine.format_filename(out_file))\n csv_writer = csv.writer(csv_file, quoting=csv.QUOTE_ALL)\n set_open = True\n\n if line.startswith(\"INSERT INTO `{table_name}`\".format(table_name=table_name)):\n row_val = line[line.index(\"VALUES (\") + 8:-3]\n table_rows = row_val.replace(\"\\r\\n\",\"\").split(\"),(\")\n for i_row in table_rows:\n v = eval('[' + str(i_row) + ']')\n csv_writer.writerows([v])\n if csv_file:\n csv_file.close()\n\n # Create abundance table\n table = Table(\"ID_ABUNDANCE\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_ABUNDANCE\", (\"int\",)),\n (\"ABUNDANCE_TYPE\", (\"char\", \"100\")),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"abundance.csv\"))\n\n # Create allrawdata table\n table = Table(\"allrawdata\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_ALL_RAW_DATA\", (\"int\",)),\n (\"ABUNDANCE\", (\"double\",)),\n (\"BIOMASS\", (\"double\",)),\n (\"ID_SPECIES\", (\"int\",)),\n (\"SAMPLE_DESC\", (\"char\", 200)),\n (\"PLOT\", (\"char\", 150)),\n (\"LATITUDE\", (\"double\",)),\n (\"LONGITUDE\", (\"double\",)),\n (\"DEPTH\", (\"double\",)),\n (\"DAY\", (\"int\",)),\n (\"MONTH\", (\"int\",)),\n (\"YEAR\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"allrawdata.csv\"))\n\n # Create biomass table\n table = Table(\"biomass\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [(\"ID_BIOMASS\", (\"int\",)), (\"BIOMASS_TYPE\", (\"char\", \"100\"))]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"biomass.csv\"))\n\n # Create citation1 table\n table = Table(\"citation1\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_CITATION1\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n (\"CITATION_LINE\", (\"char\",)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"citation1.csv\"))\n\n # Create contacts table\n table = Table(\"contacts\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_CONTACTS\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n (\"CONTACT_1\", (\"char\", 500)),\n (\"CONTACT_2\", (\"char\", 500)),\n (\"CONT_1_MAIL\", (\"char\", 60)),\n (\"CONT_2_MAIL\", (\"char\", 60)),\n (\"LICENSE\", (\"char\", 200)),\n (\"WEB_LINK\", (\"char\", 200)),\n (\"DATA_SOURCE\", (\"char\", 250)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"contacts.csv\"))\n\n # Create countries table\n table = Table(\"countries\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [(\"COUNT_ID\", (\"int\",)), (\"COUNTRY_NAME\", (\"char\", 200))]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"countries.csv\"))\n\n # Create curation table\n table = Table(\"curation\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_CURATION\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n (\"LINK_ID\", (\"int\",)),\n (\"COMMENTS\", (\"char\",)),\n (\"DATE_STUDY_ADDED\", (\"char\", 50)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"curation.csv\"))\n\n # Create datasets table\n table = Table(\"datasets\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_DATASETS\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n (\"TAXA\", (\"char\", 50)),\n (\"ORGANISMS\", (\"char\", 200)),\n (\"TITLE\", (\"char\",800)),\n (\"AB_BIO\", (\"char\", 2)),\n (\"HAS_PLOT\", (\"char\", 10)),\n (\"DATA_POINTS\", (\"char\",)),\n (\"START_YEAR\", (\"char\",)),\n (\"END_YEAR\", (\"char\",)),\n (\"CENT_LAT\", (\"double\",)),\n (\"CENT_LONG\", (\"double\",)),\n (\"NUMBER_OF_SPECIES\", (\"char\",)),\n (\"NUMBER_OF_SAMPLES\", (\"char\",)),\n (\"NUMBER_LAT_LONG\", (\"char\",)),\n (\"TOTAL\", (\"char\",)),\n (\"GRAIN_SIZE_TEXT\", (\"char\",)),\n (\"GRAIN_SQ_KM\", (\"double\",)),\n (\"AREA_SQ_KM\", (\"double\",)),\n (\"AB_TYPE\", (\"char\", )),\n (\"BIO_TYPE\", (\"char\",)),\n (\"SAMPLE_TYPE\", (\"char\",)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"datasets.csv\"))\n\n # Create downloads table\n table = Table(\"downloads\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"D_ID\", (\"int\",)),\n (\"STUDY\", (\"char\", 25)),\n (\"NAME\", (\"char\", 150)),\n (\"EMAIL\", (\"char\", 150)),\n (\"COUNTRY\", (\"char\", 200)),\n (\"ROLE\", (\"char\", 150)),\n (\"PURPOSE\", (\"char\", 500)),\n (\"LOCATION\", (\"char\", 250)),\n (\"DATE_STAMP\", (\"char\",)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"downloads.csv\"))\n\n # Create methods table\n table = Table(\"methods\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_METHODS\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n (\"METHODS\", (\"char\",)),\n (\"SUMMARY_METHODS\", (\"char\", 500)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"methods.csv\"))\n\n # Create sample table\n table = Table(\"sample\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_SAMPLE\", (\"int\",)),\n (\"ID_TREAT\", (\"int\",)),\n (\"SAMPLE_DESC_NAME\", (\"char\", 200)),\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"sample.csv\"))\n\n # Create site table\n table = Table(\"site\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_SITE\", (\"int\",)),\n (\"STUDY_ID\", (\"int\",)),\n (\"REALM\", (\"char\", 11)),\n (\"CLIMATE\", (\"char\", 20)),\n (\"GENERAL_TREAT\", (\"char\", 200)),\n (\"TREATMENT\", (\"char\", 200)),\n (\"TREAT_COMMENTS\", (\"char\", 250)),\n (\"TREAT_DATE\", (\"char\", 100)),\n (\"CEN_LATITUDE\", (\"double\",)),\n (\"CEN_LONGITUDE\", (\"double\",)),\n (\"HABITAT\", (\"char\", 100)),\n (\"PROTECTED_AREA\", (\"char\", 50)),\n (\"AREA\", (\"double\",)),\n (\"BIOME_MAP\", (\"char\", 500))\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"site.csv\"))\n\n # Create species table\n table = Table(\"species\", delimiter=\",\", header_rows=0, contains_pk=False)\n table.columns = [\n (\"ID_SPECIES\", (\"int\",)),\n (\"GENUS\", (\"char\", 100)),\n (\"SPECIES\", (\"char\", 100)),\n (\"GENUS_SPECIES\", (\"char\", 100))\n ]\n engine.table = table\n engine.create_table()\n engine.insert_data_from_file(engine.format_filename(\"species.csv\"))\n\n\nSCRIPT = main()\n", "path": "scripts/biotimesql.py"}]}
| 3,846 | 316 |
gh_patches_debug_18569
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-809
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
find_packages() include does not allow inclusion of subpackages without super packages
Hello! I'm trying to solve [an issue](https://github.com/fedora-infra/bodhi/issues/994) I've got in my project with [the change in setuptools 28.0 that made exclude also exclude all subpackages](https://github.com/pypa/setuptools/pull/733). I had been relying on that behavior to exclude my package's top level package so that I could distribute one of the subpackages as its own add-on package.
I decided to try to include just the subpackage and its subpackages instead, but this also does not seem to work on 28.0 unless I include the top level package (which I am trying to avoid).
To be a little more concrete, here are examples of different behavior. With setuptools-18.0.1, I get this with my project:
```
$ python -c "from setuptools import find_packages; print find_packages(include=['bodhi.server', 'bodhi.server.*'])"
['bodhi.server', 'bodhi.server.static', 'bodhi.server.services', 'bodhi.server.models', 'bodhi.server.views', 'bodhi.server.consumers', 'bodhi.server.scripts']
```
That's the results I want (note that 'bodhi' is not included). With setuptools-28.2.0, I get this with my project:
```
$ python -c "from setuptools import find_packages; print find_packages(include=['bodhi.server', 'bodhi.server.*'])"
[]
```
If I add `'bodhi'` (which I do not want), the `bodhi.server` packages get included.
</issue>
<code>
[start of setuptools/__init__.py]
1 """Extensions to the 'distutils' for large or complex distributions"""
2
3 import os
4 import functools
5 import distutils.core
6 import distutils.filelist
7 from distutils.util import convert_path
8 from fnmatch import fnmatchcase
9
10 from setuptools.extern.six.moves import filter, filterfalse, map
11
12 import setuptools.version
13 from setuptools.extension import Extension
14 from setuptools.dist import Distribution, Feature
15 from setuptools.depends import Require
16 from . import monkey
17
18 __all__ = [
19 'setup', 'Distribution', 'Feature', 'Command', 'Extension', 'Require',
20 'find_packages',
21 ]
22
23 __version__ = setuptools.version.__version__
24
25 bootstrap_install_from = None
26
27 # If we run 2to3 on .py files, should we also convert docstrings?
28 # Default: yes; assume that we can detect doctests reliably
29 run_2to3_on_doctests = True
30 # Standard package names for fixer packages
31 lib2to3_fixer_packages = ['lib2to3.fixes']
32
33
34 class PackageFinder(object):
35 """
36 Generate a list of all Python packages found within a directory
37 """
38
39 @classmethod
40 def find(cls, where='.', exclude=(), include=('*',)):
41 """Return a list all Python packages found within directory 'where'
42
43 'where' is the root directory which will be searched for packages. It
44 should be supplied as a "cross-platform" (i.e. URL-style) path; it will
45 be converted to the appropriate local path syntax.
46
47 'exclude' is a sequence of package names to exclude; '*' can be used
48 as a wildcard in the names, such that 'foo.*' will exclude all
49 subpackages of 'foo' (but not 'foo' itself).
50
51 'include' is a sequence of package names to include. If it's
52 specified, only the named packages will be included. If it's not
53 specified, all found packages will be included. 'include' can contain
54 shell style wildcard patterns just like 'exclude'.
55 """
56
57 return list(cls._find_packages_iter(
58 convert_path(where),
59 cls._build_filter('ez_setup', '*__pycache__', *exclude),
60 cls._build_filter(*include)))
61
62 @classmethod
63 def _find_packages_iter(cls, where, exclude, include):
64 """
65 All the packages found in 'where' that pass the 'include' filter, but
66 not the 'exclude' filter.
67 """
68 for root, dirs, files in os.walk(where, followlinks=True):
69 # Copy dirs to iterate over it, then empty dirs.
70 all_dirs = dirs[:]
71 dirs[:] = []
72
73 for dir in all_dirs:
74 full_path = os.path.join(root, dir)
75 rel_path = os.path.relpath(full_path, where)
76 package = rel_path.replace(os.path.sep, '.')
77
78 # Check if the directory is a package and passes the filters
79 if ('.' not in dir
80 and include(package)
81 and not exclude(package)
82 and cls._looks_like_package(full_path)):
83 yield package
84 dirs.append(dir)
85
86 @staticmethod
87 def _looks_like_package(path):
88 """Does a directory look like a package?"""
89 return os.path.isfile(os.path.join(path, '__init__.py'))
90
91 @staticmethod
92 def _build_filter(*patterns):
93 """
94 Given a list of patterns, return a callable that will be true only if
95 the input matches at least one of the patterns.
96 """
97 return lambda name: any(fnmatchcase(name, pat=pat) for pat in patterns)
98
99
100 class PEP420PackageFinder(PackageFinder):
101
102 @staticmethod
103 def _looks_like_package(path):
104 return True
105
106
107 find_packages = PackageFinder.find
108
109 setup = distutils.core.setup
110
111 _Command = monkey.get_unpatched(distutils.core.Command)
112
113
114 class Command(_Command):
115 __doc__ = _Command.__doc__
116
117 command_consumes_arguments = False
118
119 def __init__(self, dist, **kw):
120 """
121 Construct the command for dist, updating
122 vars(self) with any keyword parameters.
123 """
124 _Command.__init__(self, dist)
125 vars(self).update(kw)
126
127 def reinitialize_command(self, command, reinit_subcommands=0, **kw):
128 cmd = _Command.reinitialize_command(self, command, reinit_subcommands)
129 vars(cmd).update(kw)
130 return cmd
131
132
133 def _find_all_simple(path):
134 """
135 Find all files under 'path'
136 """
137 results = (
138 os.path.join(base, file)
139 for base, dirs, files in os.walk(path, followlinks=True)
140 for file in files
141 )
142 return filter(os.path.isfile, results)
143
144
145 def findall(dir=os.curdir):
146 """
147 Find all files under 'dir' and return the list of full filenames.
148 Unless dir is '.', return full filenames with dir prepended.
149 """
150 files = _find_all_simple(dir)
151 if dir == os.curdir:
152 make_rel = functools.partial(os.path.relpath, start=dir)
153 files = map(make_rel, files)
154 return list(files)
155
156
157 monkey.patch_all()
158
[end of setuptools/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setuptools/__init__.py b/setuptools/__init__.py
--- a/setuptools/__init__.py
+++ b/setuptools/__init__.py
@@ -75,13 +75,17 @@
rel_path = os.path.relpath(full_path, where)
package = rel_path.replace(os.path.sep, '.')
- # Check if the directory is a package and passes the filters
- if ('.' not in dir
- and include(package)
- and not exclude(package)
- and cls._looks_like_package(full_path)):
+ # Skip directory trees that are not valid packages
+ if ('.' in dir or not cls._looks_like_package(full_path)):
+ continue
+
+ # Should this package be included?
+ if include(package) and not exclude(package):
yield package
- dirs.append(dir)
+
+ # Keep searching subdirectories, as there may be more packages
+ # down there, even if the parent was excluded.
+ dirs.append(dir)
@staticmethod
def _looks_like_package(path):
|
{"golden_diff": "diff --git a/setuptools/__init__.py b/setuptools/__init__.py\n--- a/setuptools/__init__.py\n+++ b/setuptools/__init__.py\n@@ -75,13 +75,17 @@\n rel_path = os.path.relpath(full_path, where)\n package = rel_path.replace(os.path.sep, '.')\n \n- # Check if the directory is a package and passes the filters\n- if ('.' not in dir\n- and include(package)\n- and not exclude(package)\n- and cls._looks_like_package(full_path)):\n+ # Skip directory trees that are not valid packages\n+ if ('.' in dir or not cls._looks_like_package(full_path)):\n+ continue\n+\n+ # Should this package be included?\n+ if include(package) and not exclude(package):\n yield package\n- dirs.append(dir)\n+\n+ # Keep searching subdirectories, as there may be more packages\n+ # down there, even if the parent was excluded.\n+ dirs.append(dir)\n \n @staticmethod\n def _looks_like_package(path):\n", "issue": "find_packages() include does not allow inclusion of subpackages without super packages\nHello! I'm trying to solve [an issue](https://github.com/fedora-infra/bodhi/issues/994) I've got in my project with [the change in setuptools 28.0 that made exclude also exclude all subpackages](https://github.com/pypa/setuptools/pull/733). I had been relying on that behavior to exclude my package's top level package so that I could distribute one of the subpackages as its own add-on package.\n\nI decided to try to include just the subpackage and its subpackages instead, but this also does not seem to work on 28.0 unless I include the top level package (which I am trying to avoid).\n\nTo be a little more concrete, here are examples of different behavior. With setuptools-18.0.1, I get this with my project:\n\n```\n$ python -c \"from setuptools import find_packages; print find_packages(include=['bodhi.server', 'bodhi.server.*'])\"\n['bodhi.server', 'bodhi.server.static', 'bodhi.server.services', 'bodhi.server.models', 'bodhi.server.views', 'bodhi.server.consumers', 'bodhi.server.scripts']\n```\n\nThat's the results I want (note that 'bodhi' is not included). With setuptools-28.2.0, I get this with my project:\n\n```\n$ python -c \"from setuptools import find_packages; print find_packages(include=['bodhi.server', 'bodhi.server.*'])\"\n[]\n```\n\nIf I add `'bodhi'` (which I do not want), the `bodhi.server` packages get included.\n\n", "before_files": [{"content": "\"\"\"Extensions to the 'distutils' for large or complex distributions\"\"\"\n\nimport os\nimport functools\nimport distutils.core\nimport distutils.filelist\nfrom distutils.util import convert_path\nfrom fnmatch import fnmatchcase\n\nfrom setuptools.extern.six.moves import filter, filterfalse, map\n\nimport setuptools.version\nfrom setuptools.extension import Extension\nfrom setuptools.dist import Distribution, Feature\nfrom setuptools.depends import Require\nfrom . import monkey\n\n__all__ = [\n 'setup', 'Distribution', 'Feature', 'Command', 'Extension', 'Require',\n 'find_packages',\n]\n\n__version__ = setuptools.version.__version__\n\nbootstrap_install_from = None\n\n# If we run 2to3 on .py files, should we also convert docstrings?\n# Default: yes; assume that we can detect doctests reliably\nrun_2to3_on_doctests = True\n# Standard package names for fixer packages\nlib2to3_fixer_packages = ['lib2to3.fixes']\n\n\nclass PackageFinder(object):\n \"\"\"\n Generate a list of all Python packages found within a directory\n \"\"\"\n\n @classmethod\n def find(cls, where='.', exclude=(), include=('*',)):\n \"\"\"Return a list all Python packages found within directory 'where'\n\n 'where' is the root directory which will be searched for packages. It\n should be supplied as a \"cross-platform\" (i.e. URL-style) path; it will\n be converted to the appropriate local path syntax.\n\n 'exclude' is a sequence of package names to exclude; '*' can be used\n as a wildcard in the names, such that 'foo.*' will exclude all\n subpackages of 'foo' (but not 'foo' itself).\n\n 'include' is a sequence of package names to include. If it's\n specified, only the named packages will be included. If it's not\n specified, all found packages will be included. 'include' can contain\n shell style wildcard patterns just like 'exclude'.\n \"\"\"\n\n return list(cls._find_packages_iter(\n convert_path(where),\n cls._build_filter('ez_setup', '*__pycache__', *exclude),\n cls._build_filter(*include)))\n\n @classmethod\n def _find_packages_iter(cls, where, exclude, include):\n \"\"\"\n All the packages found in 'where' that pass the 'include' filter, but\n not the 'exclude' filter.\n \"\"\"\n for root, dirs, files in os.walk(where, followlinks=True):\n # Copy dirs to iterate over it, then empty dirs.\n all_dirs = dirs[:]\n dirs[:] = []\n\n for dir in all_dirs:\n full_path = os.path.join(root, dir)\n rel_path = os.path.relpath(full_path, where)\n package = rel_path.replace(os.path.sep, '.')\n\n # Check if the directory is a package and passes the filters\n if ('.' not in dir\n and include(package)\n and not exclude(package)\n and cls._looks_like_package(full_path)):\n yield package\n dirs.append(dir)\n\n @staticmethod\n def _looks_like_package(path):\n \"\"\"Does a directory look like a package?\"\"\"\n return os.path.isfile(os.path.join(path, '__init__.py'))\n\n @staticmethod\n def _build_filter(*patterns):\n \"\"\"\n Given a list of patterns, return a callable that will be true only if\n the input matches at least one of the patterns.\n \"\"\"\n return lambda name: any(fnmatchcase(name, pat=pat) for pat in patterns)\n\n\nclass PEP420PackageFinder(PackageFinder):\n\n @staticmethod\n def _looks_like_package(path):\n return True\n\n\nfind_packages = PackageFinder.find\n\nsetup = distutils.core.setup\n\n_Command = monkey.get_unpatched(distutils.core.Command)\n\n\nclass Command(_Command):\n __doc__ = _Command.__doc__\n\n command_consumes_arguments = False\n\n def __init__(self, dist, **kw):\n \"\"\"\n Construct the command for dist, updating\n vars(self) with any keyword parameters.\n \"\"\"\n _Command.__init__(self, dist)\n vars(self).update(kw)\n\n def reinitialize_command(self, command, reinit_subcommands=0, **kw):\n cmd = _Command.reinitialize_command(self, command, reinit_subcommands)\n vars(cmd).update(kw)\n return cmd\n\n\ndef _find_all_simple(path):\n \"\"\"\n Find all files under 'path'\n \"\"\"\n results = (\n os.path.join(base, file)\n for base, dirs, files in os.walk(path, followlinks=True)\n for file in files\n )\n return filter(os.path.isfile, results)\n\n\ndef findall(dir=os.curdir):\n \"\"\"\n Find all files under 'dir' and return the list of full filenames.\n Unless dir is '.', return full filenames with dir prepended.\n \"\"\"\n files = _find_all_simple(dir)\n if dir == os.curdir:\n make_rel = functools.partial(os.path.relpath, start=dir)\n files = map(make_rel, files)\n return list(files)\n\n\nmonkey.patch_all()\n", "path": "setuptools/__init__.py"}]}
| 2,398 | 236 |
gh_patches_debug_432
|
rasdani/github-patches
|
git_diff
|
HybirdCorp__creme_crm-431
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[WIP] fix python3.9.12 3.9.13 ci issue
</issue>
<code>
[start of creme/__init__.py]
1 __version__ = '2.4-alpha1'
2
3 # App registry hooking ---------------------------------------------------------
4
5 try:
6 from django.apps.config import AppConfig
7 from django.apps.registry import Apps
8 except ImportError:
9 # This error may appear with old versions of setuptools during installation
10 import sys
11
12 sys.stderr.write(
13 'Django is not installed ; '
14 'ignore this message if you are installing Creme.'
15 )
16 else:
17 AppConfig.all_apps_ready = lambda self: None
18
19 _original_populate = Apps.populate
20
21 def _hooked_populate(self, installed_apps=None):
22 if self.ready:
23 return
24
25 if getattr(self, '_all_apps_ready', False):
26 return
27
28 _original_populate(self, installed_apps)
29
30 with self._lock:
31 if getattr(self, '_all_apps_ready', False):
32 return
33
34 for app_config in self.get_app_configs():
35 app_config.all_apps_ready()
36
37 self._all_apps_ready = True
38
39 Apps.populate = _hooked_populate
40
[end of creme/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/creme/__init__.py b/creme/__init__.py
--- a/creme/__init__.py
+++ b/creme/__init__.py
@@ -1,5 +1,10 @@
__version__ = '2.4-alpha1'
+
+def get_version():
+ return __version__
+
+
# App registry hooking ---------------------------------------------------------
try:
|
{"golden_diff": "diff --git a/creme/__init__.py b/creme/__init__.py\n--- a/creme/__init__.py\n+++ b/creme/__init__.py\n@@ -1,5 +1,10 @@\n __version__ = '2.4-alpha1'\n \n+\n+def get_version():\n+ return __version__\n+\n+\n # App registry hooking ---------------------------------------------------------\n \n try:\n", "issue": "[WIP] fix python3.9.12 3.9.13 ci issue\n\n", "before_files": [{"content": "__version__ = '2.4-alpha1'\n\n# App registry hooking ---------------------------------------------------------\n\ntry:\n from django.apps.config import AppConfig\n from django.apps.registry import Apps\nexcept ImportError:\n # This error may appear with old versions of setuptools during installation\n import sys\n\n sys.stderr.write(\n 'Django is not installed ; '\n 'ignore this message if you are installing Creme.'\n )\nelse:\n AppConfig.all_apps_ready = lambda self: None\n\n _original_populate = Apps.populate\n\n def _hooked_populate(self, installed_apps=None):\n if self.ready:\n return\n\n if getattr(self, '_all_apps_ready', False):\n return\n\n _original_populate(self, installed_apps)\n\n with self._lock:\n if getattr(self, '_all_apps_ready', False):\n return\n\n for app_config in self.get_app_configs():\n app_config.all_apps_ready()\n\n self._all_apps_ready = True\n\n Apps.populate = _hooked_populate\n", "path": "creme/__init__.py"}]}
| 850 | 87 |
gh_patches_debug_4679
|
rasdani/github-patches
|
git_diff
|
pyg-team__pytorch_geometric-8343
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Problem with torch_geometric.transforms
### 🐛 Describe the bug
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
[<ipython-input-20-2b41d296395c>](https://localhost:8080/#) in <cell line: 7>()
5 import torch.nn as nn
6 import torch.nn.functional as F
----> 7 import torch_geometric.transforms as T
8 from tqdm.auto import tqdm
9
3 frames
[/usr/local/lib/python3.10/dist-packages/torch_geometric/__init__.py](https://localhost:8080/#) in <module>
----> 1 import torch_geometric.utils
2 import torch_geometric.data
3 import torch_geometric.sampler
4 import torch_geometric.loader
5 import torch_geometric.transforms
[/usr/local/lib/python3.10/dist-packages/torch_geometric/utils/__init__.py](https://localhost:8080/#) in <module>
1 import copy
2
----> 3 from .scatter import scatter, group_argsort
4 from .segment import segment
5 from .sort import index_sort
[/usr/local/lib/python3.10/dist-packages/torch_geometric/utils/scatter.py](https://localhost:8080/#) in <module>
5
6 import torch_geometric.typing
----> 7 from torch_geometric import warnings
8 from torch_geometric.typing import torch_scatter
9 from torch_geometric.utils.functions import cumsum
[/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py](https://localhost:8080/#) in <module>
3 import torch_geometric
4
----> 5 if torch_geometric.typing.WITH_PT20: # pragma: no cover
6 from torch._dynamo import is_compiling as _is_compiling
7 else:
AttributeError: partially initialized module 'torch_geometric' has no attribute 'typing' (most likely due to a circular import)
### Environment
* PyG version: 2.4.0
* PyTorch version: 2.1.0+cu118
* OS: Windows
* Python version: 3.10.12
* CUDA/cuDNN version:
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
cuDNN version: 8900
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
</issue>
<code>
[start of torch_geometric/warnings.py]
1 import warnings
2
3 import torch_geometric
4
5 if torch_geometric.typing.WITH_PT20: # pragma: no cover
6 from torch._dynamo import is_compiling as _is_compiling
7 else:
8
9 def _is_compiling() -> bool: # pragma: no cover
10 return False
11
12
13 def warn(message: str):
14 if _is_compiling():
15 return
16
17 warnings.warn(message)
18
19
20 def filterwarnings(action: str, message: str):
21 if _is_compiling():
22 return
23
24 warnings.filterwarnings(action, message)
25
[end of torch_geometric/warnings.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/torch_geometric/warnings.py b/torch_geometric/warnings.py
--- a/torch_geometric/warnings.py
+++ b/torch_geometric/warnings.py
@@ -1,13 +1,14 @@
import warnings
+import torch
+
import torch_geometric
-if torch_geometric.typing.WITH_PT20: # pragma: no cover
- from torch._dynamo import is_compiling as _is_compiling
-else:
- def _is_compiling() -> bool: # pragma: no cover
- return False
+def _is_compiling() -> bool: # pragma: no cover
+ if torch_geometric.typing.WITH_PT21:
+ return torch._dynamo.is_compiling()
+ return False
def warn(message: str):
|
{"golden_diff": "diff --git a/torch_geometric/warnings.py b/torch_geometric/warnings.py\n--- a/torch_geometric/warnings.py\n+++ b/torch_geometric/warnings.py\n@@ -1,13 +1,14 @@\n import warnings\n \n+import torch\n+\n import torch_geometric\n \n-if torch_geometric.typing.WITH_PT20: # pragma: no cover\n- from torch._dynamo import is_compiling as _is_compiling\n-else:\n \n- def _is_compiling() -> bool: # pragma: no cover\n- return False\n+def _is_compiling() -> bool: # pragma: no cover\n+ if torch_geometric.typing.WITH_PT21:\n+ return torch._dynamo.is_compiling()\n+ return False\n \n \n def warn(message: str):\n", "issue": "Problem with torch_geometric.transforms\n### \ud83d\udc1b Describe the bug\n\n---------------------------------------------------------------------------\r\nAttributeError Traceback (most recent call last)\r\n[<ipython-input-20-2b41d296395c>](https://localhost:8080/#) in <cell line: 7>()\r\n 5 import torch.nn as nn\r\n 6 import torch.nn.functional as F\r\n----> 7 import torch_geometric.transforms as T\r\n 8 from tqdm.auto import tqdm\r\n 9 \r\n\r\n3 frames\r\n[/usr/local/lib/python3.10/dist-packages/torch_geometric/__init__.py](https://localhost:8080/#) in <module>\r\n----> 1 import torch_geometric.utils\r\n 2 import torch_geometric.data\r\n 3 import torch_geometric.sampler\r\n 4 import torch_geometric.loader\r\n 5 import torch_geometric.transforms\r\n\r\n[/usr/local/lib/python3.10/dist-packages/torch_geometric/utils/__init__.py](https://localhost:8080/#) in <module>\r\n 1 import copy\r\n 2 \r\n----> 3 from .scatter import scatter, group_argsort\r\n 4 from .segment import segment\r\n 5 from .sort import index_sort\r\n\r\n[/usr/local/lib/python3.10/dist-packages/torch_geometric/utils/scatter.py](https://localhost:8080/#) in <module>\r\n 5 \r\n 6 import torch_geometric.typing\r\n----> 7 from torch_geometric import warnings\r\n 8 from torch_geometric.typing import torch_scatter\r\n 9 from torch_geometric.utils.functions import cumsum\r\n\r\n[/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py](https://localhost:8080/#) in <module>\r\n 3 import torch_geometric\r\n 4 \r\n----> 5 if torch_geometric.typing.WITH_PT20: # pragma: no cover\r\n 6 from torch._dynamo import is_compiling as _is_compiling\r\n 7 else:\r\n\r\nAttributeError: partially initialized module 'torch_geometric' has no attribute 'typing' (most likely due to a circular import)\n\n### Environment\n\n* PyG version: 2.4.0\r\n* PyTorch version: 2.1.0+cu118\r\n* OS: Windows\r\n* Python version: 3.10.12\r\n* CUDA/cuDNN version:\r\nCuda compilation tools, release 11.8, V11.8.89\r\nBuild cuda_11.8.r11.8/compiler.31833905_0\r\ncuDNN version: 8900\r\n* How you installed PyTorch and PyG (`conda`, `pip`, source): pip\r\n* Any other relevant information (*e.g.*, version of `torch-scatter`):\r\n\n", "before_files": [{"content": "import warnings\n\nimport torch_geometric\n\nif torch_geometric.typing.WITH_PT20: # pragma: no cover\n from torch._dynamo import is_compiling as _is_compiling\nelse:\n\n def _is_compiling() -> bool: # pragma: no cover\n return False\n\n\ndef warn(message: str):\n if _is_compiling():\n return\n\n warnings.warn(message)\n\n\ndef filterwarnings(action: str, message: str):\n if _is_compiling():\n return\n\n warnings.filterwarnings(action, message)\n", "path": "torch_geometric/warnings.py"}]}
| 1,338 | 182 |
gh_patches_debug_18838
|
rasdani/github-patches
|
git_diff
|
ytdl-org__youtube-dl-13606
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
SITE REQUEST: www.5-tv.ru
Dear coders, I just visited this 5-tv.ru site, and I wanted to get news video from it, got no success.
Please, add this 5-tv.ru into YDL supported sources list. Thanks in advance!
The log is:
C:\>youtube-dl -v -F http://www.5-tv.ru/programs/broadcast/509514/
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['-v', '-F', 'http://www.5-tv.ru/programs/broadcast/509514/']
[debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251
[debug] youtube-dl version 2017.06.12
[debug] Python version 3.4.4 - Windows-7-6.1.7601-SP1
[debug] exe versions: ffmpeg 3.3.1, ffprobe 3.3.1, rtmpdump 2.4
[debug] Proxy map: {}
[FiveTV] 509514: Downloading webpage
ERROR: Unable to extract video url; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its completeoutput.
Traceback (most recent call last):
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpkyaecyzu\build\youtube_dl\YoutubeDL.py", line 762,in extract_info
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpkyaecyzu\build\youtube_dl\extractor\common.py", line 433, in extract
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpkyaecyzu\build\youtube_dl\extractor\fivetv.py", line 74, in _real_extract
File "C:\Users\dst\AppData\Roaming\Build archive\youtube-dl\rg3\tmpkyaecyzu\build\youtube_dl\extractor\common.py", line 782, in _search_regex
youtube_dl.utils.RegexNotFoundError: Unable to extract video url; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.
</issue>
<code>
[start of youtube_dl/extractor/fivetv.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4 import re
5
6 from .common import InfoExtractor
7 from ..utils import int_or_none
8
9
10 class FiveTVIE(InfoExtractor):
11 _VALID_URL = r'''(?x)
12 http://
13 (?:www\.)?5-tv\.ru/
14 (?:
15 (?:[^/]+/)+(?P<id>\d+)|
16 (?P<path>[^/?#]+)(?:[/?#])?
17 )
18 '''
19
20 _TESTS = [{
21 'url': 'http://5-tv.ru/news/96814/',
22 'md5': 'bbff554ad415ecf5416a2f48c22d9283',
23 'info_dict': {
24 'id': '96814',
25 'ext': 'mp4',
26 'title': 'Россияне выбрали имя для общенациональной платежной системы',
27 'description': 'md5:a8aa13e2b7ad36789e9f77a74b6de660',
28 'thumbnail': r're:^https?://.*\.jpg$',
29 'duration': 180,
30 },
31 }, {
32 'url': 'http://5-tv.ru/video/1021729/',
33 'info_dict': {
34 'id': '1021729',
35 'ext': 'mp4',
36 'title': '3D принтер',
37 'description': 'md5:d76c736d29ef7ec5c0cf7d7c65ffcb41',
38 'thumbnail': r're:^https?://.*\.jpg$',
39 'duration': 180,
40 },
41 }, {
42 'url': 'http://www.5-tv.ru/glavnoe/#itemDetails',
43 'info_dict': {
44 'id': 'glavnoe',
45 'ext': 'mp4',
46 'title': 'Итоги недели с 8 по 14 июня 2015 года',
47 'thumbnail': r're:^https?://.*\.jpg$',
48 },
49 }, {
50 'url': 'http://www.5-tv.ru/glavnoe/broadcasts/508645/',
51 'only_matching': True,
52 }, {
53 'url': 'http://5-tv.ru/films/1507502/',
54 'only_matching': True,
55 }, {
56 'url': 'http://5-tv.ru/programs/broadcast/508713/',
57 'only_matching': True,
58 }, {
59 'url': 'http://5-tv.ru/angel/',
60 'only_matching': True,
61 }, {
62 'url': 'http://www.5-tv.ru/schedule/?iframe=true&width=900&height=450',
63 'only_matching': True,
64 }]
65
66 def _real_extract(self, url):
67 mobj = re.match(self._VALID_URL, url)
68 video_id = mobj.group('id') or mobj.group('path')
69
70 webpage = self._download_webpage(url, video_id)
71
72 video_url = self._search_regex(
73 r'<a[^>]+?href="([^"]+)"[^>]+?class="videoplayer"',
74 webpage, 'video url')
75
76 title = self._og_search_title(webpage, default=None) or self._search_regex(
77 r'<title>([^<]+)</title>', webpage, 'title')
78 duration = int_or_none(self._og_search_property(
79 'video:duration', webpage, 'duration', default=None))
80
81 return {
82 'id': video_id,
83 'url': video_url,
84 'title': title,
85 'description': self._og_search_description(webpage, default=None),
86 'thumbnail': self._og_search_thumbnail(webpage, default=None),
87 'duration': duration,
88 }
89
[end of youtube_dl/extractor/fivetv.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/youtube_dl/extractor/fivetv.py b/youtube_dl/extractor/fivetv.py
--- a/youtube_dl/extractor/fivetv.py
+++ b/youtube_dl/extractor/fivetv.py
@@ -43,7 +43,7 @@
'info_dict': {
'id': 'glavnoe',
'ext': 'mp4',
- 'title': 'Итоги недели с 8 по 14 июня 2015 года',
+ 'title': r're:^Итоги недели с \d+ по \d+ \w+ \d{4} года$',
'thumbnail': r're:^https?://.*\.jpg$',
},
}, {
@@ -70,7 +70,8 @@
webpage = self._download_webpage(url, video_id)
video_url = self._search_regex(
- r'<a[^>]+?href="([^"]+)"[^>]+?class="videoplayer"',
+ [r'<div[^>]+?class="flowplayer[^>]+?data-href="([^"]+)"',
+ r'<a[^>]+?href="([^"]+)"[^>]+?class="videoplayer"'],
webpage, 'video url')
title = self._og_search_title(webpage, default=None) or self._search_regex(
|
{"golden_diff": "diff --git a/youtube_dl/extractor/fivetv.py b/youtube_dl/extractor/fivetv.py\n--- a/youtube_dl/extractor/fivetv.py\n+++ b/youtube_dl/extractor/fivetv.py\n@@ -43,7 +43,7 @@\n 'info_dict': {\n 'id': 'glavnoe',\n 'ext': 'mp4',\n- 'title': '\u0418\u0442\u043e\u0433\u0438 \u043d\u0435\u0434\u0435\u043b\u0438 \u0441 8 \u043f\u043e 14 \u0438\u044e\u043d\u044f 2015 \u0433\u043e\u0434\u0430',\n+ 'title': r're:^\u0418\u0442\u043e\u0433\u0438 \u043d\u0435\u0434\u0435\u043b\u0438 \u0441\u00a0\\d+ \u043f\u043e\u00a0\\d+\u00a0\\w+\u00a0\\d{4}\u00a0\u0433\u043e\u0434\u0430$',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n }, {\n@@ -70,7 +70,8 @@\n webpage = self._download_webpage(url, video_id)\n \n video_url = self._search_regex(\n- r'<a[^>]+?href=\"([^\"]+)\"[^>]+?class=\"videoplayer\"',\n+ [r'<div[^>]+?class=\"flowplayer[^>]+?data-href=\"([^\"]+)\"',\n+ r'<a[^>]+?href=\"([^\"]+)\"[^>]+?class=\"videoplayer\"'],\n webpage, 'video url')\n \n title = self._og_search_title(webpage, default=None) or self._search_regex(\n", "issue": "SITE REQUEST: www.5-tv.ru\nDear coders, I just visited this 5-tv.ru site, and I wanted to get news video from it, got no success.\r\nPlease, add this 5-tv.ru into YDL supported sources list. Thanks in advance!\r\nThe log is:\r\nC:\\>youtube-dl -v -F http://www.5-tv.ru/programs/broadcast/509514/\r\n[debug] System config: []\r\n[debug] User config: []\r\n[debug] Custom config: []\r\n[debug] Command-line args: ['-v', '-F', 'http://www.5-tv.ru/programs/broadcast/509514/']\r\n[debug] Encodings: locale cp1251, fs mbcs, out cp866, pref cp1251\r\n[debug] youtube-dl version 2017.06.12\r\n[debug] Python version 3.4.4 - Windows-7-6.1.7601-SP1\r\n[debug] exe versions: ffmpeg 3.3.1, ffprobe 3.3.1, rtmpdump 2.4\r\n[debug] Proxy map: {}\r\n[FiveTV] 509514: Downloading webpage\r\nERROR: Unable to extract video url; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its completeoutput.\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\rg3\\tmpkyaecyzu\\build\\youtube_dl\\YoutubeDL.py\", line 762,in extract_info\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\rg3\\tmpkyaecyzu\\build\\youtube_dl\\extractor\\common.py\", line 433, in extract\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\rg3\\tmpkyaecyzu\\build\\youtube_dl\\extractor\\fivetv.py\", line 74, in _real_extract\r\n File \"C:\\Users\\dst\\AppData\\Roaming\\Build archive\\youtube-dl\\rg3\\tmpkyaecyzu\\build\\youtube_dl\\extractor\\common.py\", line 782, in _search_regex\r\nyoutube_dl.utils.RegexNotFoundError: Unable to extract video url; please report this issue on https://yt-dl.org/bug . Make sure you are using the latest version; type youtube-dl -U to update. Be sure to call youtube-dl with the --verbose flag and include its complete output.\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\nimport re\n\nfrom .common import InfoExtractor\nfrom ..utils import int_or_none\n\n\nclass FiveTVIE(InfoExtractor):\n _VALID_URL = r'''(?x)\n http://\n (?:www\\.)?5-tv\\.ru/\n (?:\n (?:[^/]+/)+(?P<id>\\d+)|\n (?P<path>[^/?#]+)(?:[/?#])?\n )\n '''\n\n _TESTS = [{\n 'url': 'http://5-tv.ru/news/96814/',\n 'md5': 'bbff554ad415ecf5416a2f48c22d9283',\n 'info_dict': {\n 'id': '96814',\n 'ext': 'mp4',\n 'title': '\u0420\u043e\u0441\u0441\u0438\u044f\u043d\u0435 \u0432\u044b\u0431\u0440\u0430\u043b\u0438 \u0438\u043c\u044f \u0434\u043b\u044f \u043e\u0431\u0449\u0435\u043d\u0430\u0446\u0438\u043e\u043d\u0430\u043b\u044c\u043d\u043e\u0439 \u043f\u043b\u0430\u0442\u0435\u0436\u043d\u043e\u0439 \u0441\u0438\u0441\u0442\u0435\u043c\u044b',\n 'description': 'md5:a8aa13e2b7ad36789e9f77a74b6de660',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n 'duration': 180,\n },\n }, {\n 'url': 'http://5-tv.ru/video/1021729/',\n 'info_dict': {\n 'id': '1021729',\n 'ext': 'mp4',\n 'title': '3D \u043f\u0440\u0438\u043d\u0442\u0435\u0440',\n 'description': 'md5:d76c736d29ef7ec5c0cf7d7c65ffcb41',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n 'duration': 180,\n },\n }, {\n 'url': 'http://www.5-tv.ru/glavnoe/#itemDetails',\n 'info_dict': {\n 'id': 'glavnoe',\n 'ext': 'mp4',\n 'title': '\u0418\u0442\u043e\u0433\u0438 \u043d\u0435\u0434\u0435\u043b\u0438 \u0441 8 \u043f\u043e 14 \u0438\u044e\u043d\u044f 2015 \u0433\u043e\u0434\u0430',\n 'thumbnail': r're:^https?://.*\\.jpg$',\n },\n }, {\n 'url': 'http://www.5-tv.ru/glavnoe/broadcasts/508645/',\n 'only_matching': True,\n }, {\n 'url': 'http://5-tv.ru/films/1507502/',\n 'only_matching': True,\n }, {\n 'url': 'http://5-tv.ru/programs/broadcast/508713/',\n 'only_matching': True,\n }, {\n 'url': 'http://5-tv.ru/angel/',\n 'only_matching': True,\n }, {\n 'url': 'http://www.5-tv.ru/schedule/?iframe=true&width=900&height=450',\n 'only_matching': True,\n }]\n\n def _real_extract(self, url):\n mobj = re.match(self._VALID_URL, url)\n video_id = mobj.group('id') or mobj.group('path')\n\n webpage = self._download_webpage(url, video_id)\n\n video_url = self._search_regex(\n r'<a[^>]+?href=\"([^\"]+)\"[^>]+?class=\"videoplayer\"',\n webpage, 'video url')\n\n title = self._og_search_title(webpage, default=None) or self._search_regex(\n r'<title>([^<]+)</title>', webpage, 'title')\n duration = int_or_none(self._og_search_property(\n 'video:duration', webpage, 'duration', default=None))\n\n return {\n 'id': video_id,\n 'url': video_url,\n 'title': title,\n 'description': self._og_search_description(webpage, default=None),\n 'thumbnail': self._og_search_thumbnail(webpage, default=None),\n 'duration': duration,\n }\n", "path": "youtube_dl/extractor/fivetv.py"}]}
| 2,213 | 310 |
gh_patches_debug_47839
|
rasdani/github-patches
|
git_diff
|
holoviz__panel-3157
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add files to `__init__` for autocomplete in VS Code
When writing in vs code the autocomplete only works for modules imported in an `__init__.py` file, e.g. `pn.widgets.IntSlider` work but `pn.viewable.Viewer` does not. See here:
https://user-images.githubusercontent.com/19758978/150685703-a235b219-6052-4e6e-b1f5-b121dc1f1558.mp4
The solution is pretty easy as `.viewable` only needs to be added to the `__init__`.
https://user-images.githubusercontent.com/19758978/150685758-3b1e5468-bcbe-4337-a62a-f3a4da8d9caf.mp4
I don't know if #3132 will fix this. When you have time @MarcSkovMadsen can you check this?
</issue>
<code>
[start of panel/__init__.py]
1 from . import layout # noqa
2 from . import links # noqa
3 from . import pane # noqa
4 from . import param # noqa
5 from . import pipeline # noqa
6 from . import widgets # noqa
7
8 from .config import config, panel_extension as extension, __version__ # noqa
9 from .depends import bind, depends # noqa
10 from .interact import interact # noqa
11 from .io import _jupyter_server_extension_paths, ipywidget, serve, state # noqa
12 from .layout import ( # noqa
13 Accordion, Card, Column, GridSpec, GridBox, FlexBox, Tabs, Row,
14 Spacer, WidgetBox
15 )
16 from .pane import panel, Pane # noqa
17 from .param import Param # noqa
18 from .template import Template # noqa
19 from .widgets import indicators # noqa
20
[end of panel/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/panel/__init__.py b/panel/__init__.py
--- a/panel/__init__.py
+++ b/panel/__init__.py
@@ -3,6 +3,8 @@
from . import pane # noqa
from . import param # noqa
from . import pipeline # noqa
+from . import reactive # noqa
+from . import viewable # noqa
from . import widgets # noqa
from .config import config, panel_extension as extension, __version__ # noqa
|
{"golden_diff": "diff --git a/panel/__init__.py b/panel/__init__.py\n--- a/panel/__init__.py\n+++ b/panel/__init__.py\n@@ -3,6 +3,8 @@\n from . import pane # noqa\n from . import param # noqa\n from . import pipeline # noqa\n+from . import reactive # noqa\n+from . import viewable # noqa\n from . import widgets # noqa\n \n from .config import config, panel_extension as extension, __version__ # noqa\n", "issue": "Add files to `__init__` for autocomplete in VS Code\nWhen writing in vs code the autocomplete only works for modules imported in an `__init__.py` file, e.g. `pn.widgets.IntSlider` work but `pn.viewable.Viewer` does not. See here:\r\n\r\nhttps://user-images.githubusercontent.com/19758978/150685703-a235b219-6052-4e6e-b1f5-b121dc1f1558.mp4\r\n\r\nThe solution is pretty easy as `.viewable` only needs to be added to the `__init__`.\r\n\r\nhttps://user-images.githubusercontent.com/19758978/150685758-3b1e5468-bcbe-4337-a62a-f3a4da8d9caf.mp4\r\n\r\nI don't know if #3132 will fix this. When you have time @MarcSkovMadsen can you check this? \n", "before_files": [{"content": "from . import layout # noqa\nfrom . import links # noqa\nfrom . import pane # noqa\nfrom . import param # noqa\nfrom . import pipeline # noqa\nfrom . import widgets # noqa\n\nfrom .config import config, panel_extension as extension, __version__ # noqa\nfrom .depends import bind, depends # noqa\nfrom .interact import interact # noqa\nfrom .io import _jupyter_server_extension_paths, ipywidget, serve, state # noqa\nfrom .layout import ( # noqa\n Accordion, Card, Column, GridSpec, GridBox, FlexBox, Tabs, Row,\n Spacer, WidgetBox\n)\nfrom .pane import panel, Pane # noqa\nfrom .param import Param # noqa\nfrom .template import Template # noqa\nfrom .widgets import indicators # noqa\n", "path": "panel/__init__.py"}]}
| 970 | 108 |
gh_patches_debug_13416
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-1178
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Batched Multi-Output GP preconditioner doesn't compute noise model properly[Bug]
# 🐛 Bug
The noise checking to see if the diagonal is constant in the `init_cache` method for the preconditioner is incorrect for batched GPs. Specifically, [here](https://github.com/cornellius-gp/gpytorch/blob/1e19a641d301218936008f828bfb6e8da081ad3d/gpytorch/lazy/added_diag_lazy_tensor.py#L96) indexes the noise improperly when the noise could be batched.
## To reproduce
** Code snippet to reproduce **
```python
import torch
import gpytorch
class ExactGPModel(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood, batch_shape=torch.Size([])):
super(ExactGPModel, self).__init__(train_x, train_y, likelihood)
self.mean_module = gpytorch.means.ConstantMean(batch_shape=batch_shape)
self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel(batch_shape=batch_shape),
batch_shape=batch_shape)
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)
## base case that works
train_x = torch.randn(301, 1)
train_y = torch.sin(3.1 * train_x) + 0.1 * torch.randn_like(train_x)
likelihood = gpytorch.likelihoods.GaussianLikelihood()
model = ExactGPModel(train_x, train_y, likelihood)
with gpytorch.settings.max_cholesky_size(100), gpytorch.settings.min_preconditioning_size(100):
print(likelihood(model(train_x)).log_prob(train_y).sum())
### This doesn't work
### I'm playing with the settings here to force it to crash but it's a shaping error.
train_x = torch.randn(301, 1)
train_y = torch.cat((torch.sin(3.1 * train_x) + 0.1 * torch.randn_like(train_x),
torch.sin(train_x) + 0.1 * torch.randn_like(train_x)),dim=1)
likelihood = gpytorch.likelihoods.GaussianLikelihood(batch_shape=torch.Size([2]))
model = ExactGPModel(train_x, train_y, likelihood, batch_shape=torch.Size([2]))
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
for i in range(3):
optimizer.zero_grad()
with gpytorch.settings.max_cholesky_size(100), gpytorch.settings.min_preconditioning_size(100):
loss = -likelihood(model(train_x)).log_prob(train_y.t()).sum()
loss.backward()
optimizer.step()
```
** Stack trace/error message **
The noise checking is actually incorrect so you see this error message --- note that we got pushed into the `_init_cache_for_non_constant_diag` method for a homoscedastic noise model.
```
~/Documents/GitHub/gpytorch/gpytorch/lazy/added_diag_lazy_tensor.py in _init_cache(self)
100 self._init_cache_for_constant_diag(eye, batch_shape, n, k)
101 else:
--> 102 self._init_cache_for_non_constant_diag(eye, batch_shape, n)
103
104 self._precond_lt = PsdSumLazyTensor(RootLazyTensor(self._piv_chol_self), self._diag_tensor)
~/Documents/GitHub/gpytorch/gpytorch/lazy/added_diag_lazy_tensor.py in _init_cache_for_non_constant_diag(self, eye, batch_shape, n)
117 def _init_cache_for_non_constant_diag(self, eye, batch_shape, n):
118 # With non-constant diagonals, we cant factor out the noise as easily
--> 119 self._q_cache, self._r_cache = torch.qr(torch.cat((self._piv_chol_self / self._noise.sqrt(), eye)))
120 self._q_cache = self._q_cache[..., :n, :] / self._noise.sqrt()
121
RuntimeError: Tensors must have same number of dimensions: got 3 and 2
```
## Expected Behavior
The noise shaping should be done properly so that `_init_cache_for_constant_diag` gets called instead. It runs properly.
## System information
**Please complete the following information:**
gpytorch 1.1.1
pytorch 1.5.0
## Additional context
I'll toss up a PR in a minute. It's not that hard to fix.
</issue>
<code>
[start of gpytorch/lazy/added_diag_lazy_tensor.py]
1 #!/usr/bin/env python3
2
3 import warnings
4
5 import torch
6
7 from .. import settings
8 from ..utils import broadcasting, pivoted_cholesky
9 from ..utils.warnings import NumericalWarning
10 from .diag_lazy_tensor import DiagLazyTensor
11 from .psd_sum_lazy_tensor import PsdSumLazyTensor
12 from .root_lazy_tensor import RootLazyTensor
13 from .sum_lazy_tensor import SumLazyTensor
14
15
16 class AddedDiagLazyTensor(SumLazyTensor):
17 """
18 A SumLazyTensor, but of only two lazy tensors, the second of which must be
19 a DiagLazyTensor.
20 """
21
22 def __init__(self, *lazy_tensors, preconditioner_override=None):
23 lazy_tensors = list(lazy_tensors)
24 super(AddedDiagLazyTensor, self).__init__(*lazy_tensors, preconditioner_override=preconditioner_override)
25 if len(lazy_tensors) > 2:
26 raise RuntimeError("An AddedDiagLazyTensor can only have two components")
27
28 broadcasting._mul_broadcast_shape(lazy_tensors[0].shape, lazy_tensors[1].shape)
29
30 if isinstance(lazy_tensors[0], DiagLazyTensor) and isinstance(lazy_tensors[1], DiagLazyTensor):
31 raise RuntimeError("Trying to lazily add two DiagLazyTensors. Create a single DiagLazyTensor instead.")
32 elif isinstance(lazy_tensors[0], DiagLazyTensor):
33 self._diag_tensor = lazy_tensors[0]
34 self._lazy_tensor = lazy_tensors[1]
35 elif isinstance(lazy_tensors[1], DiagLazyTensor):
36 self._diag_tensor = lazy_tensors[1]
37 self._lazy_tensor = lazy_tensors[0]
38 else:
39 raise RuntimeError("One of the LazyTensors input to AddedDiagLazyTensor must be a DiagLazyTensor!")
40
41 self.preconditioner_override = preconditioner_override
42
43 # Placeholders
44 self._constant_diag = None
45 self._noise = None
46 self._piv_chol_self = None # <- Doesn't need to be an attribute, but used for testing purposes
47 self._precond_lt = None
48 self._precond_logdet_cache = None
49 self._q_cache = None
50 self._r_cache = None
51
52 def _matmul(self, rhs):
53 return torch.addcmul(self._lazy_tensor._matmul(rhs), self._diag_tensor._diag.unsqueeze(-1), rhs)
54
55 def add_diag(self, added_diag):
56 return AddedDiagLazyTensor(self._lazy_tensor, self._diag_tensor.add_diag(added_diag))
57
58 def __add__(self, other):
59 from .diag_lazy_tensor import DiagLazyTensor
60
61 if isinstance(other, DiagLazyTensor):
62 return AddedDiagLazyTensor(self._lazy_tensor, self._diag_tensor + other)
63 else:
64 return AddedDiagLazyTensor(self._lazy_tensor + other, self._diag_tensor)
65
66 def _preconditioner(self):
67 if self.preconditioner_override is not None:
68 return self.preconditioner_override(self)
69
70 if settings.max_preconditioner_size.value() == 0 or self.size(-1) < settings.min_preconditioning_size.value():
71 return None, None, None
72
73 if self._q_cache is None:
74 max_iter = settings.max_preconditioner_size.value()
75 self._piv_chol_self = pivoted_cholesky.pivoted_cholesky(self._lazy_tensor, max_iter)
76 if torch.any(torch.isnan(self._piv_chol_self)).item():
77 warnings.warn(
78 "NaNs encountered in preconditioner computation. Attempting to continue without preconditioning.",
79 NumericalWarning,
80 )
81 return None, None, None
82 self._init_cache()
83
84 # NOTE: We cannot memoize this precondition closure as it causes a memory leak
85 def precondition_closure(tensor):
86 qqt = self._q_cache.matmul(self._q_cache.transpose(-2, -1).matmul(tensor))
87 if self._constant_diag:
88 return (1 / self._noise) * (tensor - qqt)
89 return (tensor / self._noise) - qqt
90
91 return (precondition_closure, self._precond_lt, self._precond_logdet_cache)
92
93 def _init_cache(self):
94 *batch_shape, n, k = self._piv_chol_self.shape
95 self._noise = self._diag_tensor.diag().unsqueeze(-1)
96 self._constant_diag = torch.equal(self._noise, self._noise[0] * torch.ones_like(self._noise))
97 eye = torch.eye(k, dtype=self._piv_chol_self.dtype, device=self._piv_chol_self.device)
98
99 if self._constant_diag:
100 self._init_cache_for_constant_diag(eye, batch_shape, n, k)
101 else:
102 self._init_cache_for_non_constant_diag(eye, batch_shape, n)
103
104 self._precond_lt = PsdSumLazyTensor(RootLazyTensor(self._piv_chol_self), self._diag_tensor)
105
106 def _init_cache_for_constant_diag(self, eye, batch_shape, n, k):
107 # We can factor out the noise for for both QR and solves.
108 self._noise = self._noise.narrow(-2, 0, 1)
109 self._q_cache, self._r_cache = torch.qr(torch.cat((self._piv_chol_self, self._noise.sqrt() * eye), dim=-2))
110 self._q_cache = self._q_cache[..., :n, :]
111
112 # Use the matrix determinant lemma for the logdet, using the fact that R'R = L_k'L_k + s*I
113 logdet = self._r_cache.diagonal(dim1=-1, dim2=-2).abs().log().sum(-1).mul(2)
114 logdet = logdet + (n - k) * self._noise.squeeze(-2).squeeze(-1).log()
115 self._precond_logdet_cache = logdet.view(*batch_shape) if len(batch_shape) else logdet.squeeze()
116
117 def _init_cache_for_non_constant_diag(self, eye, batch_shape, n):
118 # With non-constant diagonals, we cant factor out the noise as easily
119 self._q_cache, self._r_cache = torch.qr(torch.cat((self._piv_chol_self / self._noise.sqrt(), eye)))
120 self._q_cache = self._q_cache[..., :n, :] / self._noise.sqrt()
121
122 logdet = self._r_cache.diagonal(dim1=-1, dim2=-2).abs().log().sum(-1).mul(2)
123 logdet -= (1.0 / self._noise).log().sum([-1, -2])
124 self._precond_logdet_cache = logdet.view(*batch_shape) if len(batch_shape) else logdet.squeeze()
125
[end of gpytorch/lazy/added_diag_lazy_tensor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpytorch/lazy/added_diag_lazy_tensor.py b/gpytorch/lazy/added_diag_lazy_tensor.py
--- a/gpytorch/lazy/added_diag_lazy_tensor.py
+++ b/gpytorch/lazy/added_diag_lazy_tensor.py
@@ -93,7 +93,10 @@
def _init_cache(self):
*batch_shape, n, k = self._piv_chol_self.shape
self._noise = self._diag_tensor.diag().unsqueeze(-1)
- self._constant_diag = torch.equal(self._noise, self._noise[0] * torch.ones_like(self._noise))
+
+ # the check for constant diag needs to be done carefully for batches.
+ noise_first_element = self._noise[..., :1, :]
+ self._constant_diag = torch.equal(self._noise, noise_first_element * torch.ones_like(self._noise))
eye = torch.eye(k, dtype=self._piv_chol_self.dtype, device=self._piv_chol_self.device)
if self._constant_diag:
|
{"golden_diff": "diff --git a/gpytorch/lazy/added_diag_lazy_tensor.py b/gpytorch/lazy/added_diag_lazy_tensor.py\n--- a/gpytorch/lazy/added_diag_lazy_tensor.py\n+++ b/gpytorch/lazy/added_diag_lazy_tensor.py\n@@ -93,7 +93,10 @@\n def _init_cache(self):\n *batch_shape, n, k = self._piv_chol_self.shape\n self._noise = self._diag_tensor.diag().unsqueeze(-1)\n- self._constant_diag = torch.equal(self._noise, self._noise[0] * torch.ones_like(self._noise))\n+\n+ # the check for constant diag needs to be done carefully for batches.\n+ noise_first_element = self._noise[..., :1, :]\n+ self._constant_diag = torch.equal(self._noise, noise_first_element * torch.ones_like(self._noise))\n eye = torch.eye(k, dtype=self._piv_chol_self.dtype, device=self._piv_chol_self.device)\n \n if self._constant_diag:\n", "issue": "Batched Multi-Output GP preconditioner doesn't compute noise model properly[Bug]\n# \ud83d\udc1b Bug\r\n\r\nThe noise checking to see if the diagonal is constant in the `init_cache` method for the preconditioner is incorrect for batched GPs. Specifically, [here](https://github.com/cornellius-gp/gpytorch/blob/1e19a641d301218936008f828bfb6e8da081ad3d/gpytorch/lazy/added_diag_lazy_tensor.py#L96) indexes the noise improperly when the noise could be batched.\r\n\r\n## To reproduce\r\n\r\n** Code snippet to reproduce **\r\n```python\r\nimport torch\r\nimport gpytorch\r\n\r\nclass ExactGPModel(gpytorch.models.ExactGP):\r\n def __init__(self, train_x, train_y, likelihood, batch_shape=torch.Size([])):\r\n super(ExactGPModel, self).__init__(train_x, train_y, likelihood)\r\n self.mean_module = gpytorch.means.ConstantMean(batch_shape=batch_shape)\r\n self.covar_module = gpytorch.kernels.ScaleKernel(gpytorch.kernels.RBFKernel(batch_shape=batch_shape),\r\n batch_shape=batch_shape)\r\n \r\n def forward(self, x):\r\n mean_x = self.mean_module(x)\r\n covar_x = self.covar_module(x)\r\n return gpytorch.distributions.MultivariateNormal(mean_x, covar_x)\r\n\r\n## base case that works\r\ntrain_x = torch.randn(301, 1)\r\ntrain_y = torch.sin(3.1 * train_x) + 0.1 * torch.randn_like(train_x)\r\n\r\nlikelihood = gpytorch.likelihoods.GaussianLikelihood()\r\nmodel = ExactGPModel(train_x, train_y, likelihood) \r\n\r\nwith gpytorch.settings.max_cholesky_size(100), gpytorch.settings.min_preconditioning_size(100):\r\n\r\n print(likelihood(model(train_x)).log_prob(train_y).sum())\r\n\r\n### This doesn't work\r\n### I'm playing with the settings here to force it to crash but it's a shaping error.\r\ntrain_x = torch.randn(301, 1)\r\ntrain_y = torch.cat((torch.sin(3.1 * train_x) + 0.1 * torch.randn_like(train_x),\r\n torch.sin(train_x) + 0.1 * torch.randn_like(train_x)),dim=1)\r\n\r\nlikelihood = gpytorch.likelihoods.GaussianLikelihood(batch_shape=torch.Size([2]))\r\nmodel = ExactGPModel(train_x, train_y, likelihood, batch_shape=torch.Size([2])) \r\n\r\noptimizer = torch.optim.Adam(model.parameters(), lr=0.1)\r\n\r\nfor i in range(3):\r\n optimizer.zero_grad()\r\n\r\n with gpytorch.settings.max_cholesky_size(100), gpytorch.settings.min_preconditioning_size(100):\r\n\r\n loss = -likelihood(model(train_x)).log_prob(train_y.t()).sum()\r\n loss.backward()\r\n optimizer.step()\r\n```\r\n\r\n** Stack trace/error message **\r\nThe noise checking is actually incorrect so you see this error message --- note that we got pushed into the `_init_cache_for_non_constant_diag` method for a homoscedastic noise model.\r\n```\r\n~/Documents/GitHub/gpytorch/gpytorch/lazy/added_diag_lazy_tensor.py in _init_cache(self)\r\n 100 self._init_cache_for_constant_diag(eye, batch_shape, n, k)\r\n 101 else:\r\n--> 102 self._init_cache_for_non_constant_diag(eye, batch_shape, n)\r\n 103 \r\n 104 self._precond_lt = PsdSumLazyTensor(RootLazyTensor(self._piv_chol_self), self._diag_tensor)\r\n\r\n~/Documents/GitHub/gpytorch/gpytorch/lazy/added_diag_lazy_tensor.py in _init_cache_for_non_constant_diag(self, eye, batch_shape, n)\r\n 117 def _init_cache_for_non_constant_diag(self, eye, batch_shape, n):\r\n 118 # With non-constant diagonals, we cant factor out the noise as easily\r\n--> 119 self._q_cache, self._r_cache = torch.qr(torch.cat((self._piv_chol_self / self._noise.sqrt(), eye)))\r\n 120 self._q_cache = self._q_cache[..., :n, :] / self._noise.sqrt()\r\n 121 \r\n\r\nRuntimeError: Tensors must have same number of dimensions: got 3 and 2\r\n```\r\n\r\n## Expected Behavior\r\n\r\nThe noise shaping should be done properly so that `_init_cache_for_constant_diag` gets called instead. It runs properly.\r\n\r\n## System information\r\n\r\n**Please complete the following information:**\r\ngpytorch 1.1.1\r\npytorch 1.5.0\r\n\r\n## Additional context\r\nI'll toss up a PR in a minute. It's not that hard to fix.\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport warnings\n\nimport torch\n\nfrom .. import settings\nfrom ..utils import broadcasting, pivoted_cholesky\nfrom ..utils.warnings import NumericalWarning\nfrom .diag_lazy_tensor import DiagLazyTensor\nfrom .psd_sum_lazy_tensor import PsdSumLazyTensor\nfrom .root_lazy_tensor import RootLazyTensor\nfrom .sum_lazy_tensor import SumLazyTensor\n\n\nclass AddedDiagLazyTensor(SumLazyTensor):\n \"\"\"\n A SumLazyTensor, but of only two lazy tensors, the second of which must be\n a DiagLazyTensor.\n \"\"\"\n\n def __init__(self, *lazy_tensors, preconditioner_override=None):\n lazy_tensors = list(lazy_tensors)\n super(AddedDiagLazyTensor, self).__init__(*lazy_tensors, preconditioner_override=preconditioner_override)\n if len(lazy_tensors) > 2:\n raise RuntimeError(\"An AddedDiagLazyTensor can only have two components\")\n\n broadcasting._mul_broadcast_shape(lazy_tensors[0].shape, lazy_tensors[1].shape)\n\n if isinstance(lazy_tensors[0], DiagLazyTensor) and isinstance(lazy_tensors[1], DiagLazyTensor):\n raise RuntimeError(\"Trying to lazily add two DiagLazyTensors. Create a single DiagLazyTensor instead.\")\n elif isinstance(lazy_tensors[0], DiagLazyTensor):\n self._diag_tensor = lazy_tensors[0]\n self._lazy_tensor = lazy_tensors[1]\n elif isinstance(lazy_tensors[1], DiagLazyTensor):\n self._diag_tensor = lazy_tensors[1]\n self._lazy_tensor = lazy_tensors[0]\n else:\n raise RuntimeError(\"One of the LazyTensors input to AddedDiagLazyTensor must be a DiagLazyTensor!\")\n\n self.preconditioner_override = preconditioner_override\n\n # Placeholders\n self._constant_diag = None\n self._noise = None\n self._piv_chol_self = None # <- Doesn't need to be an attribute, but used for testing purposes\n self._precond_lt = None\n self._precond_logdet_cache = None\n self._q_cache = None\n self._r_cache = None\n\n def _matmul(self, rhs):\n return torch.addcmul(self._lazy_tensor._matmul(rhs), self._diag_tensor._diag.unsqueeze(-1), rhs)\n\n def add_diag(self, added_diag):\n return AddedDiagLazyTensor(self._lazy_tensor, self._diag_tensor.add_diag(added_diag))\n\n def __add__(self, other):\n from .diag_lazy_tensor import DiagLazyTensor\n\n if isinstance(other, DiagLazyTensor):\n return AddedDiagLazyTensor(self._lazy_tensor, self._diag_tensor + other)\n else:\n return AddedDiagLazyTensor(self._lazy_tensor + other, self._diag_tensor)\n\n def _preconditioner(self):\n if self.preconditioner_override is not None:\n return self.preconditioner_override(self)\n\n if settings.max_preconditioner_size.value() == 0 or self.size(-1) < settings.min_preconditioning_size.value():\n return None, None, None\n\n if self._q_cache is None:\n max_iter = settings.max_preconditioner_size.value()\n self._piv_chol_self = pivoted_cholesky.pivoted_cholesky(self._lazy_tensor, max_iter)\n if torch.any(torch.isnan(self._piv_chol_self)).item():\n warnings.warn(\n \"NaNs encountered in preconditioner computation. Attempting to continue without preconditioning.\",\n NumericalWarning,\n )\n return None, None, None\n self._init_cache()\n\n # NOTE: We cannot memoize this precondition closure as it causes a memory leak\n def precondition_closure(tensor):\n qqt = self._q_cache.matmul(self._q_cache.transpose(-2, -1).matmul(tensor))\n if self._constant_diag:\n return (1 / self._noise) * (tensor - qqt)\n return (tensor / self._noise) - qqt\n\n return (precondition_closure, self._precond_lt, self._precond_logdet_cache)\n\n def _init_cache(self):\n *batch_shape, n, k = self._piv_chol_self.shape\n self._noise = self._diag_tensor.diag().unsqueeze(-1)\n self._constant_diag = torch.equal(self._noise, self._noise[0] * torch.ones_like(self._noise))\n eye = torch.eye(k, dtype=self._piv_chol_self.dtype, device=self._piv_chol_self.device)\n\n if self._constant_diag:\n self._init_cache_for_constant_diag(eye, batch_shape, n, k)\n else:\n self._init_cache_for_non_constant_diag(eye, batch_shape, n)\n\n self._precond_lt = PsdSumLazyTensor(RootLazyTensor(self._piv_chol_self), self._diag_tensor)\n\n def _init_cache_for_constant_diag(self, eye, batch_shape, n, k):\n # We can factor out the noise for for both QR and solves.\n self._noise = self._noise.narrow(-2, 0, 1)\n self._q_cache, self._r_cache = torch.qr(torch.cat((self._piv_chol_self, self._noise.sqrt() * eye), dim=-2))\n self._q_cache = self._q_cache[..., :n, :]\n\n # Use the matrix determinant lemma for the logdet, using the fact that R'R = L_k'L_k + s*I\n logdet = self._r_cache.diagonal(dim1=-1, dim2=-2).abs().log().sum(-1).mul(2)\n logdet = logdet + (n - k) * self._noise.squeeze(-2).squeeze(-1).log()\n self._precond_logdet_cache = logdet.view(*batch_shape) if len(batch_shape) else logdet.squeeze()\n\n def _init_cache_for_non_constant_diag(self, eye, batch_shape, n):\n # With non-constant diagonals, we cant factor out the noise as easily\n self._q_cache, self._r_cache = torch.qr(torch.cat((self._piv_chol_self / self._noise.sqrt(), eye)))\n self._q_cache = self._q_cache[..., :n, :] / self._noise.sqrt()\n\n logdet = self._r_cache.diagonal(dim1=-1, dim2=-2).abs().log().sum(-1).mul(2)\n logdet -= (1.0 / self._noise).log().sum([-1, -2])\n self._precond_logdet_cache = logdet.view(*batch_shape) if len(batch_shape) else logdet.squeeze()\n", "path": "gpytorch/lazy/added_diag_lazy_tensor.py"}]}
| 3,339 | 226 |
gh_patches_debug_15842
|
rasdani/github-patches
|
git_diff
|
falconry__falcon-174
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update to_query_str to intelligently handle lists
</issue>
<code>
[start of falcon/util.py]
1 """Defines Falcon utility functions
2
3 Copyright 2013 by Rackspace Hosting, Inc.
4
5 Licensed under the Apache License, Version 2.0 (the "License");
6 you may not use this file except in compliance with the License.
7 You may obtain a copy of the License at
8
9 http://www.apache.org/licenses/LICENSE-2.0
10
11 Unless required by applicable law or agreed to in writing, software
12 distributed under the License is distributed on an "AS IS" BASIS,
13 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 See the License for the specific language governing permissions and
15 limitations under the License.
16
17 """
18
19 import datetime
20 import six
21
22 if six.PY3: # pragma nocover
23 from urllib.parse import quote as url_quote
24 else: # pragma nocover
25 from urllib import quote as url_quote
26
27
28 __all__ = ('dt_to_http', 'http_date_to_dt', 'to_query_str', 'percent_escape')
29
30
31 def dt_to_http(dt):
32 """Converts a datetime instance to an HTTP date string.
33
34 Args:
35 dt: A datetime object, assumed to be UTC
36
37 Returns:
38 An HTTP date string, e.g., "Tue, 15 Nov 1994 12:45:26 GMT". See
39 also: http://goo.gl/R7So4
40 """
41
42 # Tue, 15 Nov 1994 12:45:26 GMT
43 return dt.strftime('%a, %d %b %Y %H:%M:%S GMT')
44
45
46 def http_date_to_dt(http_date):
47 """Converts an HTTP date string to a datetime instance.
48
49 Args:
50 http_date: An HTTP date string, e.g., "Tue, 15 Nov 1994 12:45:26 GMT".
51
52 Returns:
53 A UTC datetime instance corresponding to the given HTTP date.
54 """
55
56 return datetime.datetime.strptime(
57 http_date, '%a, %d %b %Y %H:%M:%S %Z')
58
59
60 def to_query_str(params):
61 """Converts a dict of params to afaln actual query string.
62
63 Args:
64 params: dict of simple key-value types, where key is a string and
65 value is a string or something that can be converted into a
66 string.
67
68 Returns:
69 A URI query string starting with '?', or and empty string if there
70 are no params (the dict is empty).
71 """
72
73 if not params:
74 return ''
75
76 # PERF: This is faster than a list comprehension and join, mainly
77 # because it allows us to inline the value transform.
78 query_str = '?'
79 for k, v in params.items():
80 if v is True:
81 v = 'true'
82 elif v is False:
83 v = 'false'
84 else:
85 v = str(v)
86
87 query_str += k + '=' + v + '&'
88
89 return query_str[:-1]
90
91
92 def percent_escape(url):
93 """Percent-escape reserved characters in the given url.
94
95 Args:
96 url: A full or relative URL.
97
98 Returns:
99 An escaped version of the URL, excluding '/', ',' and ':'
100 characters. In Python 2, unicode URL strings will be first
101 encoded to a UTF-8 byte string to work around a urllib
102 bug.
103 """
104
105 # Convert the string so that urllib.quote does not complain
106 # if it actually has Unicode chars in it.
107 if not six.PY3 and isinstance(url, six.text_type): # pragma nocover
108 url = url.encode('utf-8')
109
110 return url_quote(url, safe='/:,=?&-_')
111
[end of falcon/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/falcon/util.py b/falcon/util.py
--- a/falcon/util.py
+++ b/falcon/util.py
@@ -63,7 +63,8 @@
Args:
params: dict of simple key-value types, where key is a string and
value is a string or something that can be converted into a
- string.
+ string. If value is a list, it will be converted to a comma-
+ delimited string (e.g., thing=1,2,3)
Returns:
A URI query string starting with '?', or and empty string if there
@@ -81,6 +82,8 @@
v = 'true'
elif v is False:
v = 'false'
+ elif isinstance(v, list):
+ v = ','.join([str(i) for i in v])
else:
v = str(v)
|
{"golden_diff": "diff --git a/falcon/util.py b/falcon/util.py\n--- a/falcon/util.py\n+++ b/falcon/util.py\n@@ -63,7 +63,8 @@\n Args:\n params: dict of simple key-value types, where key is a string and\n value is a string or something that can be converted into a\n- string.\n+ string. If value is a list, it will be converted to a comma-\n+ delimited string (e.g., thing=1,2,3)\n \n Returns:\n A URI query string starting with '?', or and empty string if there\n@@ -81,6 +82,8 @@\n v = 'true'\n elif v is False:\n v = 'false'\n+ elif isinstance(v, list):\n+ v = ','.join([str(i) for i in v])\n else:\n v = str(v)\n", "issue": "Update to_query_str to intelligently handle lists\n\n", "before_files": [{"content": "\"\"\"Defines Falcon utility functions\n\nCopyright 2013 by Rackspace Hosting, Inc.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\n\"\"\"\n\nimport datetime\nimport six\n\nif six.PY3: # pragma nocover\n from urllib.parse import quote as url_quote\nelse: # pragma nocover\n from urllib import quote as url_quote\n\n\n__all__ = ('dt_to_http', 'http_date_to_dt', 'to_query_str', 'percent_escape')\n\n\ndef dt_to_http(dt):\n \"\"\"Converts a datetime instance to an HTTP date string.\n\n Args:\n dt: A datetime object, assumed to be UTC\n\n Returns:\n An HTTP date string, e.g., \"Tue, 15 Nov 1994 12:45:26 GMT\". See\n also: http://goo.gl/R7So4\n \"\"\"\n\n # Tue, 15 Nov 1994 12:45:26 GMT\n return dt.strftime('%a, %d %b %Y %H:%M:%S GMT')\n\n\ndef http_date_to_dt(http_date):\n \"\"\"Converts an HTTP date string to a datetime instance.\n\n Args:\n http_date: An HTTP date string, e.g., \"Tue, 15 Nov 1994 12:45:26 GMT\".\n\n Returns:\n A UTC datetime instance corresponding to the given HTTP date.\n \"\"\"\n\n return datetime.datetime.strptime(\n http_date, '%a, %d %b %Y %H:%M:%S %Z')\n\n\ndef to_query_str(params):\n \"\"\"Converts a dict of params to afaln actual query string.\n\n Args:\n params: dict of simple key-value types, where key is a string and\n value is a string or something that can be converted into a\n string.\n\n Returns:\n A URI query string starting with '?', or and empty string if there\n are no params (the dict is empty).\n \"\"\"\n\n if not params:\n return ''\n\n # PERF: This is faster than a list comprehension and join, mainly\n # because it allows us to inline the value transform.\n query_str = '?'\n for k, v in params.items():\n if v is True:\n v = 'true'\n elif v is False:\n v = 'false'\n else:\n v = str(v)\n\n query_str += k + '=' + v + '&'\n\n return query_str[:-1]\n\n\ndef percent_escape(url):\n \"\"\"Percent-escape reserved characters in the given url.\n\n Args:\n url: A full or relative URL.\n\n Returns:\n An escaped version of the URL, excluding '/', ',' and ':'\n characters. In Python 2, unicode URL strings will be first\n encoded to a UTF-8 byte string to work around a urllib\n bug.\n \"\"\"\n\n # Convert the string so that urllib.quote does not complain\n # if it actually has Unicode chars in it.\n if not six.PY3 and isinstance(url, six.text_type): # pragma nocover\n url = url.encode('utf-8')\n\n return url_quote(url, safe='/:,=?&-_')\n", "path": "falcon/util.py"}]}
| 1,576 | 194 |
gh_patches_debug_8308
|
rasdani/github-patches
|
git_diff
|
ktbyers__netmiko-2935
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Huawei special_login_handler is not logging in successfully
The system information is as follows:
1. netmiko version: 4.0
2. python 3.10
3. window 11
error_print:
```shell
Traceback (most recent call last):
File "E:\web_API\test.py", line 11, in <module>
app.net_ssh_proxy(switch_json = switch_json, commands=commands)
File "E:\web_API\app.py", line 25, in net_ssh_proxy
with ConnectHandler(**device_info, sock=sock) as net_connect:
File "E:\venv_02\lib\site-packages\netmiko\ssh_dispatcher.py", line 344, in ConnectHandler
return ConnectionClass(*args, **kwargs)
File "E:\venv_02\lib\site-packages\netmiko\base_connection.py", line 434, in __init__
self._open()
File "E:\venv_02\lib\site-packages\netmiko\base_connection.py", line 439, in _open
self.establish_connection()
File "E:\venv_02\lib\site-packages\netmiko\base_connection.py", line 1092, in establish_connection
self.special_login_handler()
File "E:\venv_02\lib\site-packages\netmiko\huawei\huawei.py", line 105, in special_login_handler
output = self.read_until_pattern(password_change_prompt)
File "E:\venv_02\lib\site-packages\netmiko\base_connection.py", line 631, in read_until_pattern
raise ReadException(msg)
netmiko.exceptions.ReadException: Unable to successfully split output based on pattern:
pattern=((Change now|Please choose))|([\]>]\s*$)
output='\nInfo: The max number of VTY users is 21, the number of current VTY users online is 2, and total number of terminal users online is 2.\n The current login time is 2022-03-28 15:55:30+08:00.\n<xxxx_hostname>'
results=['\nInfo: The max number of VTY users is 21, the number of current VTY users online is 2, and total number of terminal users online is 2.\n The current login time is 2022-03-28 15:55:30+08:00.\n<xxxx_hostname', None, None, '>', '']
```
test instanse
2. python 3.10
3. window 11
[Netmiko 3.4.0 Release](https://github.com/ktbyers/netmiko/releases/tag/v3.4.0)
out_print
no problem
</issue>
<code>
[start of netmiko/huawei/huawei.py]
1 from typing import Optional, Any, Union, Sequence, Iterator, TextIO
2 import time
3 import re
4 import warnings
5
6 from netmiko.no_enable import NoEnable
7 from netmiko.base_connection import DELAY_FACTOR_DEPR_SIMPLE_MSG
8 from netmiko.cisco_base_connection import CiscoBaseConnection
9 from netmiko.exceptions import NetmikoAuthenticationException
10 from netmiko import log
11
12
13 class HuaweiBase(NoEnable, CiscoBaseConnection):
14 def session_preparation(self) -> None:
15 """Prepare the session after the connection has been established."""
16 self.ansi_escape_codes = True
17 # The _test_channel_read happens in special_login_handler()
18 self.set_base_prompt()
19 self.disable_paging(command="screen-length 0 temporary")
20
21 def strip_ansi_escape_codes(self, string_buffer: str) -> str:
22 """
23 Huawei does a strange thing where they add a space and then add ESC[1D
24 to move the cursor to the left one.
25
26 The extra space is problematic.
27 """
28 code_cursor_left = chr(27) + r"\[\d+D"
29 output = string_buffer
30 pattern = rf" {code_cursor_left}"
31 output = re.sub(pattern, "", output)
32
33 return super().strip_ansi_escape_codes(output)
34
35 def config_mode(
36 self,
37 config_command: str = "system-view",
38 pattern: str = "",
39 re_flags: int = 0,
40 ) -> str:
41 return super().config_mode(
42 config_command=config_command, pattern=pattern, re_flags=re_flags
43 )
44
45 def exit_config_mode(self, exit_config: str = "return", pattern: str = r">") -> str:
46 """Exit configuration mode."""
47 return super().exit_config_mode(exit_config=exit_config, pattern=pattern)
48
49 def check_config_mode(
50 self, check_string: str = "]", pattern: str = "", force_regex: bool = False
51 ) -> bool:
52 """Checks whether in configuration mode. Returns a boolean."""
53 return super().check_config_mode(check_string=check_string)
54
55 def set_base_prompt(
56 self,
57 pri_prompt_terminator: str = ">",
58 alt_prompt_terminator: str = "]",
59 delay_factor: float = 1.0,
60 pattern: Optional[str] = None,
61 ) -> str:
62 """
63 Sets self.base_prompt
64
65 Used as delimiter for stripping of trailing prompt in output.
66
67 Should be set to something that is general and applies in multiple contexts.
68 For Huawei this will be the router prompt with < > or [ ] stripped off.
69
70 This will be set on logging in, but not when entering system-view
71 """
72
73 prompt = super().set_base_prompt(
74 pri_prompt_terminator=pri_prompt_terminator,
75 alt_prompt_terminator=alt_prompt_terminator,
76 delay_factor=delay_factor,
77 pattern=pattern,
78 )
79
80 # Strip off any leading HRP_. characters for USGv5 HA
81 prompt = re.sub(r"^HRP_.", "", prompt, flags=re.M)
82
83 # Strip off leading terminator
84 prompt = prompt[1:]
85 prompt = prompt.strip()
86 self.base_prompt = prompt
87 log.debug(f"prompt: {self.base_prompt}")
88 return self.base_prompt
89
90 def save_config(
91 self, cmd: str = "save", confirm: bool = True, confirm_response: str = "y"
92 ) -> str:
93 """Save Config for HuaweiSSH"""
94 return super().save_config(
95 cmd=cmd, confirm=confirm, confirm_response=confirm_response
96 )
97
98 def cleanup(self, command: str = "quit") -> None:
99 return super().cleanup(command=command)
100
101
102 class HuaweiSSH(HuaweiBase):
103 """Huawei SSH driver."""
104
105 def special_login_handler(self, delay_factor: float = 1.0) -> None:
106 # Huawei prompts for password change before displaying the initial base prompt.
107 # Search for that password change prompt or for base prompt.
108 password_change_prompt = r"(Change now|Please choose)"
109 prompt_or_password_change = r"(?:Change now|Please choose|[>\]])"
110 data = self.read_until_pattern(pattern=prompt_or_password_change)
111 if re.search(password_change_prompt, data):
112 self.write_channel("N" + self.RETURN)
113 self.read_until_pattern(pattern=r"[>\]]")
114
115
116 class HuaweiTelnet(HuaweiBase):
117 """Huawei Telnet driver."""
118
119 def telnet_login(
120 self,
121 pri_prompt_terminator: str = r"]\s*$",
122 alt_prompt_terminator: str = r">\s*$",
123 username_pattern: str = r"(?:user:|username|login|user name)",
124 pwd_pattern: str = r"assword",
125 delay_factor: float = 1.0,
126 max_loops: int = 20,
127 ) -> str:
128 """Telnet login for Huawei Devices"""
129
130 delay_factor = self.select_delay_factor(delay_factor)
131 password_change_prompt = r"(Change now|Please choose 'YES' or 'NO').+"
132 combined_pattern = r"({}|{}|{})".format(
133 pri_prompt_terminator, alt_prompt_terminator, password_change_prompt
134 )
135
136 output = ""
137 return_msg = ""
138 i = 1
139 while i <= max_loops:
140 try:
141 # Search for username pattern / send username
142 output = self.read_until_pattern(
143 pattern=username_pattern, re_flags=re.I
144 )
145 return_msg += output
146 self.write_channel(self.username + self.TELNET_RETURN)
147
148 # Search for password pattern / send password
149 output = self.read_until_pattern(pattern=pwd_pattern, re_flags=re.I)
150 return_msg += output
151 assert self.password is not None
152 self.write_channel(self.password + self.TELNET_RETURN)
153
154 # Waiting for combined output
155 output = self.read_until_pattern(pattern=combined_pattern)
156 return_msg += output
157
158 # Search for password change prompt, send "N"
159 if re.search(password_change_prompt, output):
160 self.write_channel("N" + self.TELNET_RETURN)
161 output = self.read_until_pattern(pattern=combined_pattern)
162 return_msg += output
163
164 # Check if proper data received
165 if re.search(pri_prompt_terminator, output, flags=re.M) or re.search(
166 alt_prompt_terminator, output, flags=re.M
167 ):
168 return return_msg
169
170 self.write_channel(self.TELNET_RETURN)
171 time.sleep(0.5 * delay_factor)
172 i += 1
173
174 except EOFError:
175 assert self.remote_conn is not None
176 self.remote_conn.close()
177 msg = f"Login failed: {self.host}"
178 raise NetmikoAuthenticationException(msg)
179
180 # Last try to see if we already logged in
181 self.write_channel(self.TELNET_RETURN)
182 time.sleep(0.5 * delay_factor)
183 output = self.read_channel()
184 return_msg += output
185 if re.search(pri_prompt_terminator, output, flags=re.M) or re.search(
186 alt_prompt_terminator, output, flags=re.M
187 ):
188 return return_msg
189
190 assert self.remote_conn is not None
191 self.remote_conn.close()
192 msg = f"Login failed: {self.host}"
193 raise NetmikoAuthenticationException(msg)
194
195
196 class HuaweiVrpv8SSH(HuaweiSSH):
197 def send_config_set(
198 self,
199 config_commands: Union[str, Sequence[str], Iterator[str], TextIO, None] = None,
200 exit_config_mode: bool = False,
201 **kwargs: Any,
202 ) -> str:
203 """Huawei VRPv8 requires you not exit from configuration mode."""
204 return super().send_config_set(
205 config_commands=config_commands, exit_config_mode=exit_config_mode, **kwargs
206 )
207
208 def commit(
209 self,
210 comment: str = "",
211 read_timeout: float = 120.0,
212 delay_factor: Optional[float] = None,
213 ) -> str:
214 """
215 Commit the candidate configuration.
216
217 Commit the entered configuration. Raise an error and return the failure
218 if the commit fails.
219
220 default:
221 command_string = commit
222 comment:
223 command_string = commit comment <comment>
224
225 delay_factor: Deprecated in Netmiko 4.x. Will be eliminated in Netmiko 5.
226 """
227
228 if delay_factor is not None:
229 warnings.warn(DELAY_FACTOR_DEPR_SIMPLE_MSG, DeprecationWarning)
230
231 error_marker = "Failed to generate committed config"
232 command_string = "commit"
233
234 if comment:
235 command_string += f' comment "{comment}"'
236
237 output = self.config_mode()
238 output += self._send_command_str(
239 command_string,
240 strip_prompt=False,
241 strip_command=False,
242 read_timeout=read_timeout,
243 expect_string=r"]",
244 )
245 output += self.exit_config_mode()
246
247 if error_marker in output:
248 raise ValueError(f"Commit failed with following errors:\n\n{output}")
249 return output
250
251 def save_config(self, *args: Any, **kwargs: Any) -> str:
252 """Not Implemented"""
253 raise NotImplementedError
254
[end of netmiko/huawei/huawei.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netmiko/huawei/huawei.py b/netmiko/huawei/huawei.py
--- a/netmiko/huawei/huawei.py
+++ b/netmiko/huawei/huawei.py
@@ -128,7 +128,7 @@
"""Telnet login for Huawei Devices"""
delay_factor = self.select_delay_factor(delay_factor)
- password_change_prompt = r"(Change now|Please choose 'YES' or 'NO').+"
+ password_change_prompt = r"(?:Change now|Please choose 'YES' or 'NO').+"
combined_pattern = r"({}|{}|{})".format(
pri_prompt_terminator, alt_prompt_terminator, password_change_prompt
)
|
{"golden_diff": "diff --git a/netmiko/huawei/huawei.py b/netmiko/huawei/huawei.py\n--- a/netmiko/huawei/huawei.py\n+++ b/netmiko/huawei/huawei.py\n@@ -128,7 +128,7 @@\n \"\"\"Telnet login for Huawei Devices\"\"\"\n \n delay_factor = self.select_delay_factor(delay_factor)\n- password_change_prompt = r\"(Change now|Please choose 'YES' or 'NO').+\"\n+ password_change_prompt = r\"(?:Change now|Please choose 'YES' or 'NO').+\"\n combined_pattern = r\"({}|{}|{})\".format(\n pri_prompt_terminator, alt_prompt_terminator, password_change_prompt\n )\n", "issue": "Huawei special_login_handler is not logging in successfully\nThe system information is as follows:\r\n1. netmiko version: 4.0\r\n2. python 3.10\r\n3. window 11\r\n\r\nerror_print:\r\n```shell\r\nTraceback (most recent call last):\r\n File \"E:\\web_API\\test.py\", line 11, in <module>\r\n app.net_ssh_proxy(switch_json = switch_json, commands=commands)\r\n File \"E:\\web_API\\app.py\", line 25, in net_ssh_proxy\r\n with ConnectHandler(**device_info, sock=sock) as net_connect:\r\n File \"E:\\venv_02\\lib\\site-packages\\netmiko\\ssh_dispatcher.py\", line 344, in ConnectHandler\r\n return ConnectionClass(*args, **kwargs)\r\n File \"E:\\venv_02\\lib\\site-packages\\netmiko\\base_connection.py\", line 434, in __init__\r\n self._open()\r\n File \"E:\\venv_02\\lib\\site-packages\\netmiko\\base_connection.py\", line 439, in _open\r\n self.establish_connection()\r\n File \"E:\\venv_02\\lib\\site-packages\\netmiko\\base_connection.py\", line 1092, in establish_connection\r\n self.special_login_handler()\r\n File \"E:\\venv_02\\lib\\site-packages\\netmiko\\huawei\\huawei.py\", line 105, in special_login_handler\r\n output = self.read_until_pattern(password_change_prompt)\r\n File \"E:\\venv_02\\lib\\site-packages\\netmiko\\base_connection.py\", line 631, in read_until_pattern\r\n raise ReadException(msg)\r\nnetmiko.exceptions.ReadException: Unable to successfully split output based on pattern:\r\npattern=((Change now|Please choose))|([\\]>]\\s*$)\r\noutput='\\nInfo: The max number of VTY users is 21, the number of current VTY users online is 2, and total number of terminal users online is 2.\\n The current login time is 2022-03-28 15:55:30+08:00.\\n<xxxx_hostname>'\r\nresults=['\\nInfo: The max number of VTY users is 21, the number of current VTY users online is 2, and total number of terminal users online is 2.\\n The current login time is 2022-03-28 15:55:30+08:00.\\n<xxxx_hostname', None, None, '>', '']\r\n\r\n```\r\n\r\n\r\ntest instanse\r\n2. python 3.10\r\n3. window 11\r\n[Netmiko 3.4.0 Release](https://github.com/ktbyers/netmiko/releases/tag/v3.4.0)\r\n\r\nout_print\r\n\r\nno problem\r\n\n", "before_files": [{"content": "from typing import Optional, Any, Union, Sequence, Iterator, TextIO\nimport time\nimport re\nimport warnings\n\nfrom netmiko.no_enable import NoEnable\nfrom netmiko.base_connection import DELAY_FACTOR_DEPR_SIMPLE_MSG\nfrom netmiko.cisco_base_connection import CiscoBaseConnection\nfrom netmiko.exceptions import NetmikoAuthenticationException\nfrom netmiko import log\n\n\nclass HuaweiBase(NoEnable, CiscoBaseConnection):\n def session_preparation(self) -> None:\n \"\"\"Prepare the session after the connection has been established.\"\"\"\n self.ansi_escape_codes = True\n # The _test_channel_read happens in special_login_handler()\n self.set_base_prompt()\n self.disable_paging(command=\"screen-length 0 temporary\")\n\n def strip_ansi_escape_codes(self, string_buffer: str) -> str:\n \"\"\"\n Huawei does a strange thing where they add a space and then add ESC[1D\n to move the cursor to the left one.\n\n The extra space is problematic.\n \"\"\"\n code_cursor_left = chr(27) + r\"\\[\\d+D\"\n output = string_buffer\n pattern = rf\" {code_cursor_left}\"\n output = re.sub(pattern, \"\", output)\n\n return super().strip_ansi_escape_codes(output)\n\n def config_mode(\n self,\n config_command: str = \"system-view\",\n pattern: str = \"\",\n re_flags: int = 0,\n ) -> str:\n return super().config_mode(\n config_command=config_command, pattern=pattern, re_flags=re_flags\n )\n\n def exit_config_mode(self, exit_config: str = \"return\", pattern: str = r\">\") -> str:\n \"\"\"Exit configuration mode.\"\"\"\n return super().exit_config_mode(exit_config=exit_config, pattern=pattern)\n\n def check_config_mode(\n self, check_string: str = \"]\", pattern: str = \"\", force_regex: bool = False\n ) -> bool:\n \"\"\"Checks whether in configuration mode. Returns a boolean.\"\"\"\n return super().check_config_mode(check_string=check_string)\n\n def set_base_prompt(\n self,\n pri_prompt_terminator: str = \">\",\n alt_prompt_terminator: str = \"]\",\n delay_factor: float = 1.0,\n pattern: Optional[str] = None,\n ) -> str:\n \"\"\"\n Sets self.base_prompt\n\n Used as delimiter for stripping of trailing prompt in output.\n\n Should be set to something that is general and applies in multiple contexts.\n For Huawei this will be the router prompt with < > or [ ] stripped off.\n\n This will be set on logging in, but not when entering system-view\n \"\"\"\n\n prompt = super().set_base_prompt(\n pri_prompt_terminator=pri_prompt_terminator,\n alt_prompt_terminator=alt_prompt_terminator,\n delay_factor=delay_factor,\n pattern=pattern,\n )\n\n # Strip off any leading HRP_. characters for USGv5 HA\n prompt = re.sub(r\"^HRP_.\", \"\", prompt, flags=re.M)\n\n # Strip off leading terminator\n prompt = prompt[1:]\n prompt = prompt.strip()\n self.base_prompt = prompt\n log.debug(f\"prompt: {self.base_prompt}\")\n return self.base_prompt\n\n def save_config(\n self, cmd: str = \"save\", confirm: bool = True, confirm_response: str = \"y\"\n ) -> str:\n \"\"\"Save Config for HuaweiSSH\"\"\"\n return super().save_config(\n cmd=cmd, confirm=confirm, confirm_response=confirm_response\n )\n\n def cleanup(self, command: str = \"quit\") -> None:\n return super().cleanup(command=command)\n\n\nclass HuaweiSSH(HuaweiBase):\n \"\"\"Huawei SSH driver.\"\"\"\n\n def special_login_handler(self, delay_factor: float = 1.0) -> None:\n # Huawei prompts for password change before displaying the initial base prompt.\n # Search for that password change prompt or for base prompt.\n password_change_prompt = r\"(Change now|Please choose)\"\n prompt_or_password_change = r\"(?:Change now|Please choose|[>\\]])\"\n data = self.read_until_pattern(pattern=prompt_or_password_change)\n if re.search(password_change_prompt, data):\n self.write_channel(\"N\" + self.RETURN)\n self.read_until_pattern(pattern=r\"[>\\]]\")\n\n\nclass HuaweiTelnet(HuaweiBase):\n \"\"\"Huawei Telnet driver.\"\"\"\n\n def telnet_login(\n self,\n pri_prompt_terminator: str = r\"]\\s*$\",\n alt_prompt_terminator: str = r\">\\s*$\",\n username_pattern: str = r\"(?:user:|username|login|user name)\",\n pwd_pattern: str = r\"assword\",\n delay_factor: float = 1.0,\n max_loops: int = 20,\n ) -> str:\n \"\"\"Telnet login for Huawei Devices\"\"\"\n\n delay_factor = self.select_delay_factor(delay_factor)\n password_change_prompt = r\"(Change now|Please choose 'YES' or 'NO').+\"\n combined_pattern = r\"({}|{}|{})\".format(\n pri_prompt_terminator, alt_prompt_terminator, password_change_prompt\n )\n\n output = \"\"\n return_msg = \"\"\n i = 1\n while i <= max_loops:\n try:\n # Search for username pattern / send username\n output = self.read_until_pattern(\n pattern=username_pattern, re_flags=re.I\n )\n return_msg += output\n self.write_channel(self.username + self.TELNET_RETURN)\n\n # Search for password pattern / send password\n output = self.read_until_pattern(pattern=pwd_pattern, re_flags=re.I)\n return_msg += output\n assert self.password is not None\n self.write_channel(self.password + self.TELNET_RETURN)\n\n # Waiting for combined output\n output = self.read_until_pattern(pattern=combined_pattern)\n return_msg += output\n\n # Search for password change prompt, send \"N\"\n if re.search(password_change_prompt, output):\n self.write_channel(\"N\" + self.TELNET_RETURN)\n output = self.read_until_pattern(pattern=combined_pattern)\n return_msg += output\n\n # Check if proper data received\n if re.search(pri_prompt_terminator, output, flags=re.M) or re.search(\n alt_prompt_terminator, output, flags=re.M\n ):\n return return_msg\n\n self.write_channel(self.TELNET_RETURN)\n time.sleep(0.5 * delay_factor)\n i += 1\n\n except EOFError:\n assert self.remote_conn is not None\n self.remote_conn.close()\n msg = f\"Login failed: {self.host}\"\n raise NetmikoAuthenticationException(msg)\n\n # Last try to see if we already logged in\n self.write_channel(self.TELNET_RETURN)\n time.sleep(0.5 * delay_factor)\n output = self.read_channel()\n return_msg += output\n if re.search(pri_prompt_terminator, output, flags=re.M) or re.search(\n alt_prompt_terminator, output, flags=re.M\n ):\n return return_msg\n\n assert self.remote_conn is not None\n self.remote_conn.close()\n msg = f\"Login failed: {self.host}\"\n raise NetmikoAuthenticationException(msg)\n\n\nclass HuaweiVrpv8SSH(HuaweiSSH):\n def send_config_set(\n self,\n config_commands: Union[str, Sequence[str], Iterator[str], TextIO, None] = None,\n exit_config_mode: bool = False,\n **kwargs: Any,\n ) -> str:\n \"\"\"Huawei VRPv8 requires you not exit from configuration mode.\"\"\"\n return super().send_config_set(\n config_commands=config_commands, exit_config_mode=exit_config_mode, **kwargs\n )\n\n def commit(\n self,\n comment: str = \"\",\n read_timeout: float = 120.0,\n delay_factor: Optional[float] = None,\n ) -> str:\n \"\"\"\n Commit the candidate configuration.\n\n Commit the entered configuration. Raise an error and return the failure\n if the commit fails.\n\n default:\n command_string = commit\n comment:\n command_string = commit comment <comment>\n\n delay_factor: Deprecated in Netmiko 4.x. Will be eliminated in Netmiko 5.\n \"\"\"\n\n if delay_factor is not None:\n warnings.warn(DELAY_FACTOR_DEPR_SIMPLE_MSG, DeprecationWarning)\n\n error_marker = \"Failed to generate committed config\"\n command_string = \"commit\"\n\n if comment:\n command_string += f' comment \"{comment}\"'\n\n output = self.config_mode()\n output += self._send_command_str(\n command_string,\n strip_prompt=False,\n strip_command=False,\n read_timeout=read_timeout,\n expect_string=r\"]\",\n )\n output += self.exit_config_mode()\n\n if error_marker in output:\n raise ValueError(f\"Commit failed with following errors:\\n\\n{output}\")\n return output\n\n def save_config(self, *args: Any, **kwargs: Any) -> str:\n \"\"\"Not Implemented\"\"\"\n raise NotImplementedError\n", "path": "netmiko/huawei/huawei.py"}]}
| 3,826 | 165 |
gh_patches_debug_48576
|
rasdani/github-patches
|
git_diff
|
openai__gym-1456
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BUG - KellyCoinflip episode should end when the agent reaches the maximum wealth.
# Bug description
The episode does not end when agent reaches the maximum wealth. This is not consistent with the information from the docstring.
A Monte Carlo approach can also be used to illustrate the problem. The distribution of realized rewards obtained by an agent betting according to the Kelly criterion is incorrect. E.g. the docstring indicates such agent should earn $240 on average, and the bug leads to a much lower mean.
# To reproduce the bug
## Code
```
import gym
env = gym.make('KellyCoinflip-v0')
env.seed(1)
env.reset()
done=False
while not done:
action = int(env.wealth * 20) # bet 20% of the wealth
observation, reward, done, info = env.step(action)
env.render()
```
## Output
```
Current wealth: 20.0 ; Rounds left: 299
[...]
Current wealth: 238.47 ; Rounds left: 192
Current wealth: 250.0 ; Rounds left: 191
Current wealth: 200.0 ; Rounds left: 190
[...]
```
## Expected output
```
Current wealth: 20.0 ; Rounds left: 299
[...]
Current wealth: 238.47 ; Rounds left: 192
Current wealth: 250.0 ; Rounds left: 191
```
# Proposed modifications
I would like to work on a PR with the following modifications:
* fix the bug described above,
* refactor to reduce code duplication,
* rename some variables to follow PEP-8 guidelines.
</issue>
<code>
[start of gym/envs/toy_text/kellycoinflip.py]
1 from scipy.stats import genpareto
2 import numpy as np
3
4 import gym
5 from gym import spaces
6 from gym.utils import seeding
7
8
9 def flip(edge, np_random):
10 return 1 if np_random.uniform() < edge else -1
11
12
13 class KellyCoinflipEnv(gym.Env):
14 """The Kelly coinflip game is a simple gambling introduced by Haghani & Dewey 2016's
15 'Rational Decision-Making Under Uncertainty: Observed Betting Patterns on a Biased
16 Coin' (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2856963), to test human
17 decision-making in a setting like that of the stock market: positive expected value
18 but highly stochastic; they found many subjects performed badly, often going broke,
19 even though optimal play would reach the maximum with ~95% probability. In the
20 coinflip game, the player starts with $25.00 to gamble over 300 rounds; each round,
21 they can bet anywhere up to their net worth (in penny increments), and then a coin is
22 flipped; with P=0.6, the player wins twice what they bet, otherwise, they lose it.
23 $250 is the maximum players are allowed to have. At the end of the 300 rounds, they
24 keep whatever they have. The human subjects earned an average of $91; a simple use of
25 the Kelly criterion (https://en.wikipedia.org/wiki/Kelly_criterion), giving a
26 strategy of betting 20% until the cap is hit, would earn $240; a decision tree
27 analysis shows that optimal play earns $246 (https://www.gwern.net/Coin-flip).
28
29 The game short-circuits when either wealth = $0 (since one can never recover) or
30 wealth = cap (trivial optimal play: one simply bets nothing thereafter).
31
32 In this implementation, we default to the paper settings of $25, 60% odds, wealth cap
33 of $250, and 300 rounds. To specify the action space in advance, we multiply the
34 wealth cap (in dollars) by 100 (to allow for all penny bets); should one attempt to
35 bet more money than one has, it is rounded down to one's net worth. (Alternately, a
36 mistaken bet could end the episode immediately; it's not clear to me which version
37 would be better.) For a harder version which randomizes the 3 key parameters, see the
38 Generalized Kelly coinflip game."""
39 metadata = {'render.modes': ['human']}
40
41 def __init__(self, initial_wealth=25.0, edge=0.6, max_wealth=250.0, max_rounds=300):
42
43 self.action_space = spaces.Discrete(int(max_wealth * 100)) # betting in penny
44 # increments
45 self.observation_space = spaces.Tuple((
46 spaces.Box(0, max_wealth, [1], dtype=np.float32), # (w,b)
47 spaces.Discrete(max_rounds + 1)))
48 self.reward_range = (0, max_wealth)
49 self.edge = edge
50 self.wealth = initial_wealth
51 self.initial_wealth = initial_wealth
52 self.max_rounds = max_rounds
53 self.max_wealth = max_wealth
54 self.np_random = None
55 self.rounds = None
56 self.seed()
57 self.reset()
58
59 def seed(self, seed=None):
60 self.np_random, seed = seeding.np_random(seed)
61 return [seed]
62
63 def step(self, action):
64 bet_in_dollars = min(action/100.0, self.wealth) # action = desired bet in pennies
65 self.rounds -= 1
66
67 coinflip = flip(self.edge, self.np_random)
68 self.wealth = min(self.max_wealth, self.wealth + coinflip * bet_in_dollars)
69
70 done = self.wealth < 0.01 or self.wealth == self.max_wealth or not self.rounds
71 reward = self.wealth if done else 0.0
72
73 return self._get_obs(), reward, done, {}
74
75 def _get_obs(self):
76 return np.array([self.wealth]), self.rounds
77
78 def reset(self):
79 self.rounds = self.max_rounds
80 self.wealth = self.initial_wealth
81 return self._get_obs()
82
83 def render(self, mode='human'):
84 print("Current wealth: ", self.wealth, "; Rounds left: ", self.rounds)
85
86
87 class KellyCoinflipGeneralizedEnv(gym.Env):
88 """The Generalized Kelly coinflip game is an extension by ArthurB & Gwern Branwen
89 which expands the Kelly coinflip game MDP into a POMDP, where the 3 key parameters
90 (edge, maximum wealth, and number of rounds) are unknown random variables drawn
91 from 3 distributions: a Beta(7,3) for the coinflip edge 0-1, a N(300,25) the total
92 number of rounds, and a Pareto(5,200) for the wealth cap. These distributions are
93 chosen to be conjugate & easily updatable, to allow for inference (other choices
94 like the geometric for number of rounds wouldn't make observations informative),
95 and to loosely reflect what a human might expect in the original Kelly coinflip
96 game given that the number of rounds wasn't strictly fixed and they weren't told
97 the wealth cap until they neared it. With these particular distributions, the
98 entire history of the game can be summarized into a few sufficient statistics of
99 rounds-elapsed/wins/losses/max-wealth-ever-reached, from which the Bayes-optimal
100 decision can (in theory) be made; to avoid all agents having to tediously track
101 those sufficient statistics manually in the same way, the observation space is
102 augmented from wealth/rounds-left (rounds-left is deleted because it is a hidden
103 variable) to current-wealth/rounds-elapsed/wins/losses/maximum-observed-wealth.
104 The simple Kelly coinflip game can easily be solved by calculating decision trees,
105 but the Generalized Kelly coinflip game may be intractable (although the analysis
106 for the edge case alone suggests that the Bayes-optimal value may be very close to
107 what one would calculate using a decision tree for any specific case), and
108 represents a good challenge for RL agents."""
109 metadata = {'render.modes': ['human']}
110
111 def __init__(self, initial_wealth=25.0, edge_prior_alpha=7, edge_prior_beta=3,
112 max_wealth_alpha=5.0, max_wealth_m=200.0, max_rounds_mean=300.0,
113 max_rounds_sd=25.0, reseed=True):
114 # store the hyper-parameters for passing back into __init__() during resets so
115 # the same hyper-parameters govern the next game's parameters, as the user
116 # expects:
117 # TODO: this is boilerplate, is there any more elegant way to do this?
118 self.initial_wealth = float(initial_wealth)
119 self.edge_prior_alpha = edge_prior_alpha
120 self.edge_prior_beta = edge_prior_beta
121 self.max_wealth_alpha = max_wealth_alpha
122 self.max_wealth_m = max_wealth_m
123 self.max_rounds_mean = max_rounds_mean
124 self.max_rounds_sd = max_rounds_sd
125
126 if reseed or not hasattr(self, 'np_random'):
127 self.seed()
128
129 # draw this game's set of parameters:
130 edge = self.np_random.beta(edge_prior_alpha, edge_prior_beta)
131 max_wealth = round(genpareto.rvs(max_wealth_alpha, max_wealth_m,
132 random_state=self.np_random))
133 max_rounds = int(round(self.np_random.normal(max_rounds_mean, max_rounds_sd)))
134
135 # add an additional global variable which is the sufficient statistic for the
136 # Pareto distribution on wealth cap; alpha doesn't update, but x_m does, and
137 # simply is the highest wealth count we've seen to date:
138 self.max_ever_wealth = float(self.initial_wealth)
139 # for the coinflip edge, it is total wins/losses:
140 self.wins = 0
141 self.losses = 0
142 # for the number of rounds, we need to remember how many rounds we've played:
143 self.rounds_elapsed = 0
144
145 # the rest proceeds as before:
146 self.action_space = spaces.Discrete(int(max_wealth*100))
147 self.observation_space = spaces.Tuple((
148 spaces.Box(0, max_wealth, shape=[1], dtype=np.float32), # current wealth
149 spaces.Discrete(max_rounds+1), # rounds elapsed
150 spaces.Discrete(max_rounds+1), # wins
151 spaces.Discrete(max_rounds+1), # losses
152 spaces.Box(0, max_wealth, [1], dtype=np.float32))) # maximum observed wealth
153 self.reward_range = (0, max_wealth)
154 self.edge = edge
155 self.wealth = self.initial_wealth
156 self.max_rounds = max_rounds
157 self.rounds = self.max_rounds
158 self.max_wealth = max_wealth
159
160 def seed(self, seed=None):
161 self.np_random, seed = seeding.np_random(seed)
162 return [seed]
163
164 def step(self, action):
165 bet_in_dollars = min(action/100.0, self.wealth)
166
167 self.rounds -= 1
168
169 coinflip = flip(self.edge, self.np_random)
170 self.wealth = min(self.max_wealth, self.wealth + coinflip * bet_in_dollars)
171 self.rounds_elapsed += 1
172
173 if coinflip:
174 self.max_ever_wealth = max(self.wealth, self.max_ever_wealth)
175 self.wins += 1
176 else:
177 self.losses += 1
178
179 done = self.wealth < 0.01 or self.wealth == self.max_wealth or not self.rounds
180 reward = self.max_wealth if done else 0.0
181
182 return self._get_obs(), reward, done, {}
183
184 def _get_obs(self):
185 return (np.array([float(self.wealth)]), self.rounds_elapsed, self.wins,
186 self.losses, np.array([float(self.max_ever_wealth)]))
187
188 def reset(self):
189 # re-init everything to draw new parameters etc, but preserve the RNG for
190 # reproducibility and pass in the same hyper-parameters as originally specified:
191 self.__init__(initial_wealth=self.initial_wealth,
192 edge_prior_alpha=self.edge_prior_alpha,
193 edge_prior_beta=self.edge_prior_beta,
194 max_wealth_alpha=self.max_wealth_alpha,
195 max_wealth_m=self.max_wealth_m,
196 max_rounds_mean=self.max_rounds_mean,
197 max_rounds_sd=self.max_rounds_sd,
198 reseed=False)
199 return self._get_obs()
200
201 def render(self, mode='human'):
202 print("Current wealth: ", self.wealth, "; Rounds left: ", self.rounds,
203 "; True edge: ", self.edge, "; True max wealth: ", self.max_wealth,
204 "; True stopping time: ", self.max_rounds, "; Rounds left: ",
205 self.max_rounds - self.rounds_elapsed)
206
[end of gym/envs/toy_text/kellycoinflip.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gym/envs/toy_text/kellycoinflip.py b/gym/envs/toy_text/kellycoinflip.py
--- a/gym/envs/toy_text/kellycoinflip.py
+++ b/gym/envs/toy_text/kellycoinflip.py
@@ -177,7 +177,7 @@
self.losses += 1
done = self.wealth < 0.01 or self.wealth == self.max_wealth or not self.rounds
- reward = self.max_wealth if done else 0.0
+ reward = self.wealth if done else 0.0
return self._get_obs(), reward, done, {}
|
{"golden_diff": "diff --git a/gym/envs/toy_text/kellycoinflip.py b/gym/envs/toy_text/kellycoinflip.py\n--- a/gym/envs/toy_text/kellycoinflip.py\n+++ b/gym/envs/toy_text/kellycoinflip.py\n@@ -177,7 +177,7 @@\n self.losses += 1\n \n done = self.wealth < 0.01 or self.wealth == self.max_wealth or not self.rounds\n- reward = self.max_wealth if done else 0.0\n+ reward = self.wealth if done else 0.0\n \n return self._get_obs(), reward, done, {}\n", "issue": "BUG - KellyCoinflip episode should end when the agent reaches the maximum wealth.\n# Bug description\r\nThe episode does not end when agent reaches the maximum wealth. This is not consistent with the information from the docstring. \r\n\r\nA Monte Carlo approach can also be used to illustrate the problem. The distribution of realized rewards obtained by an agent betting according to the Kelly criterion is incorrect. E.g. the docstring indicates such agent should earn $240 on average, and the bug leads to a much lower mean.\r\n\r\n# To reproduce the bug\r\n## Code\r\n```\r\nimport gym \r\n\r\nenv = gym.make('KellyCoinflip-v0')\r\nenv.seed(1)\r\nenv.reset()\r\ndone=False\r\n\r\nwhile not done:\r\n action = int(env.wealth * 20) # bet 20% of the wealth\r\n observation, reward, done, info = env.step(action)\r\n env.render()\r\n```\r\n\r\n## Output\r\n```\r\nCurrent wealth: 20.0 ; Rounds left: 299\r\n[...]\r\nCurrent wealth: 238.47 ; Rounds left: 192\r\nCurrent wealth: 250.0 ; Rounds left: 191\r\nCurrent wealth: 200.0 ; Rounds left: 190\r\n[...]\r\n```\r\n\r\n## Expected output \r\n```\r\nCurrent wealth: 20.0 ; Rounds left: 299\r\n[...]\r\nCurrent wealth: 238.47 ; Rounds left: 192\r\nCurrent wealth: 250.0 ; Rounds left: 191\r\n```\r\n\r\n# Proposed modifications\r\nI would like to work on a PR with the following modifications:\r\n* fix the bug described above,\r\n* refactor to reduce code duplication,\r\n* rename some variables to follow PEP-8 guidelines. \n", "before_files": [{"content": "from scipy.stats import genpareto\nimport numpy as np\n\nimport gym\nfrom gym import spaces\nfrom gym.utils import seeding\n\n\ndef flip(edge, np_random):\n return 1 if np_random.uniform() < edge else -1\n\n\nclass KellyCoinflipEnv(gym.Env):\n \"\"\"The Kelly coinflip game is a simple gambling introduced by Haghani & Dewey 2016's\n 'Rational Decision-Making Under Uncertainty: Observed Betting Patterns on a Biased\n Coin' (https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2856963), to test human\n decision-making in a setting like that of the stock market: positive expected value\n but highly stochastic; they found many subjects performed badly, often going broke,\n even though optimal play would reach the maximum with ~95% probability. In the\n coinflip game, the player starts with $25.00 to gamble over 300 rounds; each round,\n they can bet anywhere up to their net worth (in penny increments), and then a coin is\n flipped; with P=0.6, the player wins twice what they bet, otherwise, they lose it.\n $250 is the maximum players are allowed to have. At the end of the 300 rounds, they\n keep whatever they have. The human subjects earned an average of $91; a simple use of\n the Kelly criterion (https://en.wikipedia.org/wiki/Kelly_criterion), giving a\n strategy of betting 20% until the cap is hit, would earn $240; a decision tree\n analysis shows that optimal play earns $246 (https://www.gwern.net/Coin-flip).\n\n The game short-circuits when either wealth = $0 (since one can never recover) or\n wealth = cap (trivial optimal play: one simply bets nothing thereafter).\n\n In this implementation, we default to the paper settings of $25, 60% odds, wealth cap\n of $250, and 300 rounds. To specify the action space in advance, we multiply the\n wealth cap (in dollars) by 100 (to allow for all penny bets); should one attempt to\n bet more money than one has, it is rounded down to one's net worth. (Alternately, a\n mistaken bet could end the episode immediately; it's not clear to me which version\n would be better.) For a harder version which randomizes the 3 key parameters, see the\n Generalized Kelly coinflip game.\"\"\"\n metadata = {'render.modes': ['human']}\n\n def __init__(self, initial_wealth=25.0, edge=0.6, max_wealth=250.0, max_rounds=300):\n\n self.action_space = spaces.Discrete(int(max_wealth * 100)) # betting in penny\n # increments\n self.observation_space = spaces.Tuple((\n spaces.Box(0, max_wealth, [1], dtype=np.float32), # (w,b)\n spaces.Discrete(max_rounds + 1)))\n self.reward_range = (0, max_wealth)\n self.edge = edge\n self.wealth = initial_wealth\n self.initial_wealth = initial_wealth\n self.max_rounds = max_rounds\n self.max_wealth = max_wealth\n self.np_random = None\n self.rounds = None\n self.seed()\n self.reset()\n\n def seed(self, seed=None):\n self.np_random, seed = seeding.np_random(seed)\n return [seed]\n\n def step(self, action):\n bet_in_dollars = min(action/100.0, self.wealth) # action = desired bet in pennies\n self.rounds -= 1\n\n coinflip = flip(self.edge, self.np_random)\n self.wealth = min(self.max_wealth, self.wealth + coinflip * bet_in_dollars)\n\n done = self.wealth < 0.01 or self.wealth == self.max_wealth or not self.rounds\n reward = self.wealth if done else 0.0\n\n return self._get_obs(), reward, done, {}\n\n def _get_obs(self):\n return np.array([self.wealth]), self.rounds\n\n def reset(self):\n self.rounds = self.max_rounds\n self.wealth = self.initial_wealth\n return self._get_obs()\n\n def render(self, mode='human'):\n print(\"Current wealth: \", self.wealth, \"; Rounds left: \", self.rounds)\n\n\nclass KellyCoinflipGeneralizedEnv(gym.Env):\n \"\"\"The Generalized Kelly coinflip game is an extension by ArthurB & Gwern Branwen\n which expands the Kelly coinflip game MDP into a POMDP, where the 3 key parameters\n (edge, maximum wealth, and number of rounds) are unknown random variables drawn\n from 3 distributions: a Beta(7,3) for the coinflip edge 0-1, a N(300,25) the total\n number of rounds, and a Pareto(5,200) for the wealth cap. These distributions are\n chosen to be conjugate & easily updatable, to allow for inference (other choices\n like the geometric for number of rounds wouldn't make observations informative),\n and to loosely reflect what a human might expect in the original Kelly coinflip\n game given that the number of rounds wasn't strictly fixed and they weren't told\n the wealth cap until they neared it. With these particular distributions, the\n entire history of the game can be summarized into a few sufficient statistics of\n rounds-elapsed/wins/losses/max-wealth-ever-reached, from which the Bayes-optimal\n decision can (in theory) be made; to avoid all agents having to tediously track\n those sufficient statistics manually in the same way, the observation space is\n augmented from wealth/rounds-left (rounds-left is deleted because it is a hidden\n variable) to current-wealth/rounds-elapsed/wins/losses/maximum-observed-wealth.\n The simple Kelly coinflip game can easily be solved by calculating decision trees,\n but the Generalized Kelly coinflip game may be intractable (although the analysis\n for the edge case alone suggests that the Bayes-optimal value may be very close to\n what one would calculate using a decision tree for any specific case), and\n represents a good challenge for RL agents.\"\"\"\n metadata = {'render.modes': ['human']}\n\n def __init__(self, initial_wealth=25.0, edge_prior_alpha=7, edge_prior_beta=3,\n max_wealth_alpha=5.0, max_wealth_m=200.0, max_rounds_mean=300.0,\n max_rounds_sd=25.0, reseed=True):\n # store the hyper-parameters for passing back into __init__() during resets so\n # the same hyper-parameters govern the next game's parameters, as the user\n # expects:\n # TODO: this is boilerplate, is there any more elegant way to do this?\n self.initial_wealth = float(initial_wealth)\n self.edge_prior_alpha = edge_prior_alpha\n self.edge_prior_beta = edge_prior_beta\n self.max_wealth_alpha = max_wealth_alpha\n self.max_wealth_m = max_wealth_m\n self.max_rounds_mean = max_rounds_mean\n self.max_rounds_sd = max_rounds_sd\n\n if reseed or not hasattr(self, 'np_random'):\n self.seed()\n\n # draw this game's set of parameters:\n edge = self.np_random.beta(edge_prior_alpha, edge_prior_beta)\n max_wealth = round(genpareto.rvs(max_wealth_alpha, max_wealth_m,\n random_state=self.np_random))\n max_rounds = int(round(self.np_random.normal(max_rounds_mean, max_rounds_sd)))\n\n # add an additional global variable which is the sufficient statistic for the\n # Pareto distribution on wealth cap; alpha doesn't update, but x_m does, and\n # simply is the highest wealth count we've seen to date:\n self.max_ever_wealth = float(self.initial_wealth)\n # for the coinflip edge, it is total wins/losses:\n self.wins = 0\n self.losses = 0\n # for the number of rounds, we need to remember how many rounds we've played:\n self.rounds_elapsed = 0\n\n # the rest proceeds as before:\n self.action_space = spaces.Discrete(int(max_wealth*100))\n self.observation_space = spaces.Tuple((\n spaces.Box(0, max_wealth, shape=[1], dtype=np.float32), # current wealth\n spaces.Discrete(max_rounds+1), # rounds elapsed\n spaces.Discrete(max_rounds+1), # wins\n spaces.Discrete(max_rounds+1), # losses\n spaces.Box(0, max_wealth, [1], dtype=np.float32))) # maximum observed wealth\n self.reward_range = (0, max_wealth)\n self.edge = edge\n self.wealth = self.initial_wealth\n self.max_rounds = max_rounds\n self.rounds = self.max_rounds\n self.max_wealth = max_wealth\n\n def seed(self, seed=None):\n self.np_random, seed = seeding.np_random(seed)\n return [seed]\n\n def step(self, action):\n bet_in_dollars = min(action/100.0, self.wealth)\n\n self.rounds -= 1\n\n coinflip = flip(self.edge, self.np_random)\n self.wealth = min(self.max_wealth, self.wealth + coinflip * bet_in_dollars)\n self.rounds_elapsed += 1\n\n if coinflip:\n self.max_ever_wealth = max(self.wealth, self.max_ever_wealth)\n self.wins += 1\n else:\n self.losses += 1\n\n done = self.wealth < 0.01 or self.wealth == self.max_wealth or not self.rounds\n reward = self.max_wealth if done else 0.0\n\n return self._get_obs(), reward, done, {}\n\n def _get_obs(self):\n return (np.array([float(self.wealth)]), self.rounds_elapsed, self.wins,\n self.losses, np.array([float(self.max_ever_wealth)]))\n\n def reset(self):\n # re-init everything to draw new parameters etc, but preserve the RNG for\n # reproducibility and pass in the same hyper-parameters as originally specified:\n self.__init__(initial_wealth=self.initial_wealth,\n edge_prior_alpha=self.edge_prior_alpha,\n edge_prior_beta=self.edge_prior_beta,\n max_wealth_alpha=self.max_wealth_alpha,\n max_wealth_m=self.max_wealth_m,\n max_rounds_mean=self.max_rounds_mean,\n max_rounds_sd=self.max_rounds_sd,\n reseed=False)\n return self._get_obs()\n\n def render(self, mode='human'):\n print(\"Current wealth: \", self.wealth, \"; Rounds left: \", self.rounds,\n \"; True edge: \", self.edge, \"; True max wealth: \", self.max_wealth,\n \"; True stopping time: \", self.max_rounds, \"; Rounds left: \",\n self.max_rounds - self.rounds_elapsed)\n", "path": "gym/envs/toy_text/kellycoinflip.py"}]}
| 3,999 | 152 |
gh_patches_debug_33002
|
rasdani/github-patches
|
git_diff
|
hylang__hy-1294
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Any capitalization of "nan" or "inf" is interpreted as a float, not a symbol
For example:
=> (setv Nan 5)
File "<input>", line 1, column 7
(setv Nan 5)
^--^
HyTypeError: b"Can't assign or delete a HyFloat"
The fact that Hy accepts literals for floating-point infinity and NaN, albeit unintentional, is a nice feature that we might as well keep. But, Hy ought to recognize only one capitalization.
</issue>
<code>
[start of hy/models.py]
1 # Copyright 2017 the authors.
2 # This file is part of Hy, which is free software licensed under the Expat
3 # license. See the LICENSE.
4
5 from __future__ import unicode_literals
6 from hy._compat import PY3, str_type, bytes_type, long_type, string_types
7 from fractions import Fraction
8
9
10 class HyObject(object):
11 """
12 Generic Hy Object model. This is helpful to inject things into all the
13 Hy lexing Objects at once.
14 """
15
16 def replace(self, other):
17 if isinstance(other, HyObject):
18 for attr in ["start_line", "end_line",
19 "start_column", "end_column"]:
20 if not hasattr(self, attr) and hasattr(other, attr):
21 setattr(self, attr, getattr(other, attr))
22 else:
23 raise TypeError("Can't replace a non Hy object with a Hy object")
24
25 return self
26
27
28 _wrappers = {}
29
30
31 def wrap_value(x):
32 """Wrap `x` into the corresponding Hy type.
33
34 This allows replace_hy_obj to convert a non Hy object to a Hy object.
35
36 This also allows a macro to return an unquoted expression transparently.
37
38 """
39
40 wrapper = _wrappers.get(type(x))
41 if wrapper is None:
42 return x
43 else:
44 return wrapper(x)
45
46
47 def replace_hy_obj(obj, other):
48
49 if isinstance(obj, HyObject):
50 return obj.replace(other)
51
52 wrapped_obj = wrap_value(obj)
53
54 if isinstance(wrapped_obj, HyObject):
55 return wrapped_obj.replace(other)
56 else:
57 raise TypeError("Don't know how to wrap a %s object to a HyObject"
58 % type(obj))
59
60
61 class HyString(HyObject, str_type):
62 """
63 Generic Hy String object. Helpful to store string literals from Hy
64 scripts. It's either a ``str`` or a ``unicode``, depending on the
65 Python version.
66 """
67 pass
68
69 _wrappers[str_type] = HyString
70
71
72 class HyBytes(HyObject, bytes_type):
73 """
74 Generic Hy Bytes object. It's either a ``bytes`` or a ``str``, depending
75 on the Python version.
76 """
77 pass
78
79 _wrappers[bytes_type] = HyBytes
80
81
82 class HySymbol(HyString):
83 """
84 Hy Symbol. Basically a String.
85 """
86
87 def __init__(self, string):
88 self += string
89
90 _wrappers[bool] = lambda x: HySymbol("True") if x else HySymbol("False")
91 _wrappers[type(None)] = lambda foo: HySymbol("None")
92
93
94 class HyKeyword(HyObject, str_type):
95 """Generic Hy Keyword object. It's either a ``str`` or a ``unicode``,
96 depending on the Python version.
97 """
98
99 PREFIX = "\uFDD0"
100
101 def __new__(cls, value):
102 if not value.startswith(cls.PREFIX):
103 value = cls.PREFIX + value
104
105 obj = str_type.__new__(cls, value)
106 return obj
107
108
109 def strip_digit_separators(number):
110 return (number.replace("_", "").replace(",", "")
111 if isinstance(number, string_types)
112 else number)
113
114
115 class HyInteger(HyObject, long_type):
116 """
117 Internal representation of a Hy Integer. May raise a ValueError as if
118 int(foo) was called, given HyInteger(foo). On python 2.x long will
119 be used instead
120 """
121
122 def __new__(cls, number, *args, **kwargs):
123 if isinstance(number, string_types):
124 number = strip_digit_separators(number)
125 bases = {"0x": 16, "0o": 8, "0b": 2}
126 for leader, base in bases.items():
127 if number.startswith(leader):
128 # We've got a string, known leader, set base.
129 number = long_type(number, base=base)
130 break
131 else:
132 # We've got a string, no known leader; base 10.
133 number = long_type(number, base=10)
134 else:
135 # We've got a non-string; convert straight.
136 number = long_type(number)
137 return super(HyInteger, cls).__new__(cls, number)
138
139
140 _wrappers[int] = HyInteger
141 if not PY3: # do not add long on python3
142 _wrappers[long_type] = HyInteger
143
144
145 class HyFloat(HyObject, float):
146 """
147 Internal representation of a Hy Float. May raise a ValueError as if
148 float(foo) was called, given HyFloat(foo).
149 """
150
151 def __new__(cls, number, *args, **kwargs):
152 number = float(strip_digit_separators(number))
153 return super(HyFloat, cls).__new__(cls, number)
154
155 _wrappers[float] = HyFloat
156
157
158 class HyComplex(HyObject, complex):
159 """
160 Internal representation of a Hy Complex. May raise a ValueError as if
161 complex(foo) was called, given HyComplex(foo).
162 """
163
164 def __new__(cls, number, *args, **kwargs):
165 number = complex(strip_digit_separators(number))
166 return super(HyComplex, cls).__new__(cls, number)
167
168 _wrappers[complex] = HyComplex
169
170
171 class HyList(HyObject, list):
172 """
173 Hy List. Basically just a list.
174 """
175
176 def replace(self, other):
177 for x in self:
178 replace_hy_obj(x, other)
179
180 HyObject.replace(self, other)
181 return self
182
183 def __add__(self, other):
184 return self.__class__(super(HyList, self).__add__(other))
185
186 def __getslice__(self, start, end):
187 return self.__class__(super(HyList, self).__getslice__(start, end))
188
189 def __getitem__(self, item):
190 ret = super(HyList, self).__getitem__(item)
191
192 if isinstance(item, slice):
193 return self.__class__(ret)
194
195 return ret
196
197 def __repr__(self):
198 return "[%s]" % (" ".join([repr(x) for x in self]))
199
200 _wrappers[list] = lambda l: HyList(wrap_value(x) for x in l)
201 _wrappers[tuple] = lambda t: HyList(wrap_value(x) for x in t)
202
203
204 class HyDict(HyList):
205 """
206 HyDict (just a representation of a dict)
207 """
208
209 def __repr__(self):
210 return "{%s}" % (" ".join([repr(x) for x in self]))
211
212 def keys(self):
213 return self[0::2]
214
215 def values(self):
216 return self[1::2]
217
218 def items(self):
219 return list(zip(self.keys(), self.values()))
220
221 _wrappers[dict] = lambda d: HyDict(wrap_value(x) for x in sum(d.items(), ()))
222
223
224 class HyExpression(HyList):
225 """
226 Hy S-Expression. Basically just a list.
227 """
228
229 def __repr__(self):
230 return "(%s)" % (" ".join([repr(x) for x in self]))
231
232 _wrappers[HyExpression] = lambda e: HyExpression(wrap_value(x) for x in e)
233 _wrappers[Fraction] = lambda e: HyExpression(
234 [HySymbol("fraction"), wrap_value(e.numerator), wrap_value(e.denominator)])
235
236
237 class HySet(HyList):
238 """
239 Hy set (just a representation of a set)
240 """
241
242 def __repr__(self):
243 return "#{%s}" % (" ".join([repr(x) for x in self]))
244
245 _wrappers[set] = lambda s: HySet(wrap_value(x) for x in s)
246
247
248 class HyCons(HyObject):
249 """
250 HyCons: a cons object.
251
252 Building a HyCons of something and a HyList really builds a HyList
253 """
254
255 __slots__ = ["car", "cdr"]
256
257 def __new__(cls, car, cdr):
258 if isinstance(cdr, list):
259
260 # Keep unquotes in the cdr of conses
261 if type(cdr) == HyExpression:
262 if len(cdr) > 0 and type(cdr[0]) == HySymbol:
263 if cdr[0] in ("unquote", "unquote_splice"):
264 return super(HyCons, cls).__new__(cls)
265
266 return cdr.__class__([wrap_value(car)] + cdr)
267
268 elif cdr is None:
269 return HyExpression([wrap_value(car)])
270
271 else:
272 return super(HyCons, cls).__new__(cls)
273
274 def __init__(self, car, cdr):
275 self.car = wrap_value(car)
276 self.cdr = wrap_value(cdr)
277
278 def __getitem__(self, n):
279 if n == 0:
280 return self.car
281 if n == slice(1, None):
282 return self.cdr
283
284 raise IndexError(
285 "Can only get the car ([0]) or the cdr ([1:]) of a HyCons")
286
287 def __setitem__(self, n, new):
288 if n == 0:
289 self.car = new
290 return
291 if n == slice(1, None):
292 self.cdr = new
293 return
294
295 raise IndexError(
296 "Can only set the car ([0]) or the cdr ([1:]) of a HyCons")
297
298 def __iter__(self):
299 yield self.car
300 try:
301 iterator = (i for i in self.cdr)
302 except TypeError:
303 if self.cdr is not None:
304 yield self.cdr
305 raise TypeError("Iteration on malformed cons")
306 else:
307 for i in iterator:
308 yield i
309
310 def replace(self, other):
311 if self.car is not None:
312 replace_hy_obj(self.car, other)
313 if self.cdr is not None:
314 replace_hy_obj(self.cdr, other)
315
316 HyObject.replace(self, other)
317
318 def __repr__(self):
319 if isinstance(self.cdr, self.__class__):
320 return "(%s %s)" % (repr(self.car), repr(self.cdr)[1:-1])
321 else:
322 return "(%s . %s)" % (repr(self.car), repr(self.cdr))
323
324 def __eq__(self, other):
325 return (
326 isinstance(other, self.__class__) and
327 self.car == other.car and
328 self.cdr == other.cdr
329 )
330
[end of hy/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hy/models.py b/hy/models.py
--- a/hy/models.py
+++ b/hy/models.py
@@ -3,6 +3,7 @@
# license. See the LICENSE.
from __future__ import unicode_literals
+from math import isnan, isinf
from hy._compat import PY3, str_type, bytes_type, long_type, string_types
from fractions import Fraction
@@ -142,15 +143,24 @@
_wrappers[long_type] = HyInteger
+def check_inf_nan_cap(arg, value):
+ if isinstance(arg, string_types):
+ if isinf(value) and "Inf" not in arg:
+ raise ValueError('Inf must be capitalized as "Inf"')
+ if isnan(value) and "NaN" not in arg:
+ raise ValueError('NaN must be capitalized as "NaN"')
+
+
class HyFloat(HyObject, float):
"""
Internal representation of a Hy Float. May raise a ValueError as if
float(foo) was called, given HyFloat(foo).
"""
- def __new__(cls, number, *args, **kwargs):
- number = float(strip_digit_separators(number))
- return super(HyFloat, cls).__new__(cls, number)
+ def __new__(cls, num, *args, **kwargs):
+ value = super(HyFloat, cls).__new__(cls, strip_digit_separators(num))
+ check_inf_nan_cap(num, value)
+ return value
_wrappers[float] = HyFloat
@@ -161,9 +171,18 @@
complex(foo) was called, given HyComplex(foo).
"""
- def __new__(cls, number, *args, **kwargs):
- number = complex(strip_digit_separators(number))
- return super(HyComplex, cls).__new__(cls, number)
+ def __new__(cls, num, *args, **kwargs):
+ value = super(HyComplex, cls).__new__(cls, strip_digit_separators(num))
+ if isinstance(num, string_types):
+ p1, _, p2 = num.lstrip("+-").replace("-", "+").partition("+")
+ if p2:
+ check_inf_nan_cap(p1, value.real)
+ check_inf_nan_cap(p2, value.imag)
+ elif "j" in p1:
+ check_inf_nan_cap(p1, value.imag)
+ else:
+ check_inf_nan_cap(p1, value.real)
+ return value
_wrappers[complex] = HyComplex
|
{"golden_diff": "diff --git a/hy/models.py b/hy/models.py\n--- a/hy/models.py\n+++ b/hy/models.py\n@@ -3,6 +3,7 @@\n # license. See the LICENSE.\n \n from __future__ import unicode_literals\n+from math import isnan, isinf\n from hy._compat import PY3, str_type, bytes_type, long_type, string_types\n from fractions import Fraction\n \n@@ -142,15 +143,24 @@\n _wrappers[long_type] = HyInteger\n \n \n+def check_inf_nan_cap(arg, value):\n+ if isinstance(arg, string_types):\n+ if isinf(value) and \"Inf\" not in arg:\n+ raise ValueError('Inf must be capitalized as \"Inf\"')\n+ if isnan(value) and \"NaN\" not in arg:\n+ raise ValueError('NaN must be capitalized as \"NaN\"')\n+\n+\n class HyFloat(HyObject, float):\n \"\"\"\n Internal representation of a Hy Float. May raise a ValueError as if\n float(foo) was called, given HyFloat(foo).\n \"\"\"\n \n- def __new__(cls, number, *args, **kwargs):\n- number = float(strip_digit_separators(number))\n- return super(HyFloat, cls).__new__(cls, number)\n+ def __new__(cls, num, *args, **kwargs):\n+ value = super(HyFloat, cls).__new__(cls, strip_digit_separators(num))\n+ check_inf_nan_cap(num, value)\n+ return value\n \n _wrappers[float] = HyFloat\n \n@@ -161,9 +171,18 @@\n complex(foo) was called, given HyComplex(foo).\n \"\"\"\n \n- def __new__(cls, number, *args, **kwargs):\n- number = complex(strip_digit_separators(number))\n- return super(HyComplex, cls).__new__(cls, number)\n+ def __new__(cls, num, *args, **kwargs):\n+ value = super(HyComplex, cls).__new__(cls, strip_digit_separators(num))\n+ if isinstance(num, string_types):\n+ p1, _, p2 = num.lstrip(\"+-\").replace(\"-\", \"+\").partition(\"+\")\n+ if p2:\n+ check_inf_nan_cap(p1, value.real)\n+ check_inf_nan_cap(p2, value.imag)\n+ elif \"j\" in p1:\n+ check_inf_nan_cap(p1, value.imag)\n+ else:\n+ check_inf_nan_cap(p1, value.real)\n+ return value\n \n _wrappers[complex] = HyComplex\n", "issue": "Any capitalization of \"nan\" or \"inf\" is interpreted as a float, not a symbol\nFor example:\r\n\r\n => (setv Nan 5)\r\n File \"<input>\", line 1, column 7\r\n\r\n (setv Nan 5)\r\n ^--^\r\n HyTypeError: b\"Can't assign or delete a HyFloat\"\r\n\r\nThe fact that Hy accepts literals for floating-point infinity and NaN, albeit unintentional, is a nice feature that we might as well keep. But, Hy ought to recognize only one capitalization.\n", "before_files": [{"content": "# Copyright 2017 the authors.\n# This file is part of Hy, which is free software licensed under the Expat\n# license. See the LICENSE.\n\nfrom __future__ import unicode_literals\nfrom hy._compat import PY3, str_type, bytes_type, long_type, string_types\nfrom fractions import Fraction\n\n\nclass HyObject(object):\n \"\"\"\n Generic Hy Object model. This is helpful to inject things into all the\n Hy lexing Objects at once.\n \"\"\"\n\n def replace(self, other):\n if isinstance(other, HyObject):\n for attr in [\"start_line\", \"end_line\",\n \"start_column\", \"end_column\"]:\n if not hasattr(self, attr) and hasattr(other, attr):\n setattr(self, attr, getattr(other, attr))\n else:\n raise TypeError(\"Can't replace a non Hy object with a Hy object\")\n\n return self\n\n\n_wrappers = {}\n\n\ndef wrap_value(x):\n \"\"\"Wrap `x` into the corresponding Hy type.\n\n This allows replace_hy_obj to convert a non Hy object to a Hy object.\n\n This also allows a macro to return an unquoted expression transparently.\n\n \"\"\"\n\n wrapper = _wrappers.get(type(x))\n if wrapper is None:\n return x\n else:\n return wrapper(x)\n\n\ndef replace_hy_obj(obj, other):\n\n if isinstance(obj, HyObject):\n return obj.replace(other)\n\n wrapped_obj = wrap_value(obj)\n\n if isinstance(wrapped_obj, HyObject):\n return wrapped_obj.replace(other)\n else:\n raise TypeError(\"Don't know how to wrap a %s object to a HyObject\"\n % type(obj))\n\n\nclass HyString(HyObject, str_type):\n \"\"\"\n Generic Hy String object. Helpful to store string literals from Hy\n scripts. It's either a ``str`` or a ``unicode``, depending on the\n Python version.\n \"\"\"\n pass\n\n_wrappers[str_type] = HyString\n\n\nclass HyBytes(HyObject, bytes_type):\n \"\"\"\n Generic Hy Bytes object. It's either a ``bytes`` or a ``str``, depending\n on the Python version.\n \"\"\"\n pass\n\n_wrappers[bytes_type] = HyBytes\n\n\nclass HySymbol(HyString):\n \"\"\"\n Hy Symbol. Basically a String.\n \"\"\"\n\n def __init__(self, string):\n self += string\n\n_wrappers[bool] = lambda x: HySymbol(\"True\") if x else HySymbol(\"False\")\n_wrappers[type(None)] = lambda foo: HySymbol(\"None\")\n\n\nclass HyKeyword(HyObject, str_type):\n \"\"\"Generic Hy Keyword object. It's either a ``str`` or a ``unicode``,\n depending on the Python version.\n \"\"\"\n\n PREFIX = \"\\uFDD0\"\n\n def __new__(cls, value):\n if not value.startswith(cls.PREFIX):\n value = cls.PREFIX + value\n\n obj = str_type.__new__(cls, value)\n return obj\n\n\ndef strip_digit_separators(number):\n return (number.replace(\"_\", \"\").replace(\",\", \"\")\n if isinstance(number, string_types)\n else number)\n\n\nclass HyInteger(HyObject, long_type):\n \"\"\"\n Internal representation of a Hy Integer. May raise a ValueError as if\n int(foo) was called, given HyInteger(foo). On python 2.x long will\n be used instead\n \"\"\"\n\n def __new__(cls, number, *args, **kwargs):\n if isinstance(number, string_types):\n number = strip_digit_separators(number)\n bases = {\"0x\": 16, \"0o\": 8, \"0b\": 2}\n for leader, base in bases.items():\n if number.startswith(leader):\n # We've got a string, known leader, set base.\n number = long_type(number, base=base)\n break\n else:\n # We've got a string, no known leader; base 10.\n number = long_type(number, base=10)\n else:\n # We've got a non-string; convert straight.\n number = long_type(number)\n return super(HyInteger, cls).__new__(cls, number)\n\n\n_wrappers[int] = HyInteger\nif not PY3: # do not add long on python3\n _wrappers[long_type] = HyInteger\n\n\nclass HyFloat(HyObject, float):\n \"\"\"\n Internal representation of a Hy Float. May raise a ValueError as if\n float(foo) was called, given HyFloat(foo).\n \"\"\"\n\n def __new__(cls, number, *args, **kwargs):\n number = float(strip_digit_separators(number))\n return super(HyFloat, cls).__new__(cls, number)\n\n_wrappers[float] = HyFloat\n\n\nclass HyComplex(HyObject, complex):\n \"\"\"\n Internal representation of a Hy Complex. May raise a ValueError as if\n complex(foo) was called, given HyComplex(foo).\n \"\"\"\n\n def __new__(cls, number, *args, **kwargs):\n number = complex(strip_digit_separators(number))\n return super(HyComplex, cls).__new__(cls, number)\n\n_wrappers[complex] = HyComplex\n\n\nclass HyList(HyObject, list):\n \"\"\"\n Hy List. Basically just a list.\n \"\"\"\n\n def replace(self, other):\n for x in self:\n replace_hy_obj(x, other)\n\n HyObject.replace(self, other)\n return self\n\n def __add__(self, other):\n return self.__class__(super(HyList, self).__add__(other))\n\n def __getslice__(self, start, end):\n return self.__class__(super(HyList, self).__getslice__(start, end))\n\n def __getitem__(self, item):\n ret = super(HyList, self).__getitem__(item)\n\n if isinstance(item, slice):\n return self.__class__(ret)\n\n return ret\n\n def __repr__(self):\n return \"[%s]\" % (\" \".join([repr(x) for x in self]))\n\n_wrappers[list] = lambda l: HyList(wrap_value(x) for x in l)\n_wrappers[tuple] = lambda t: HyList(wrap_value(x) for x in t)\n\n\nclass HyDict(HyList):\n \"\"\"\n HyDict (just a representation of a dict)\n \"\"\"\n\n def __repr__(self):\n return \"{%s}\" % (\" \".join([repr(x) for x in self]))\n\n def keys(self):\n return self[0::2]\n\n def values(self):\n return self[1::2]\n\n def items(self):\n return list(zip(self.keys(), self.values()))\n\n_wrappers[dict] = lambda d: HyDict(wrap_value(x) for x in sum(d.items(), ()))\n\n\nclass HyExpression(HyList):\n \"\"\"\n Hy S-Expression. Basically just a list.\n \"\"\"\n\n def __repr__(self):\n return \"(%s)\" % (\" \".join([repr(x) for x in self]))\n\n_wrappers[HyExpression] = lambda e: HyExpression(wrap_value(x) for x in e)\n_wrappers[Fraction] = lambda e: HyExpression(\n [HySymbol(\"fraction\"), wrap_value(e.numerator), wrap_value(e.denominator)])\n\n\nclass HySet(HyList):\n \"\"\"\n Hy set (just a representation of a set)\n \"\"\"\n\n def __repr__(self):\n return \"#{%s}\" % (\" \".join([repr(x) for x in self]))\n\n_wrappers[set] = lambda s: HySet(wrap_value(x) for x in s)\n\n\nclass HyCons(HyObject):\n \"\"\"\n HyCons: a cons object.\n\n Building a HyCons of something and a HyList really builds a HyList\n \"\"\"\n\n __slots__ = [\"car\", \"cdr\"]\n\n def __new__(cls, car, cdr):\n if isinstance(cdr, list):\n\n # Keep unquotes in the cdr of conses\n if type(cdr) == HyExpression:\n if len(cdr) > 0 and type(cdr[0]) == HySymbol:\n if cdr[0] in (\"unquote\", \"unquote_splice\"):\n return super(HyCons, cls).__new__(cls)\n\n return cdr.__class__([wrap_value(car)] + cdr)\n\n elif cdr is None:\n return HyExpression([wrap_value(car)])\n\n else:\n return super(HyCons, cls).__new__(cls)\n\n def __init__(self, car, cdr):\n self.car = wrap_value(car)\n self.cdr = wrap_value(cdr)\n\n def __getitem__(self, n):\n if n == 0:\n return self.car\n if n == slice(1, None):\n return self.cdr\n\n raise IndexError(\n \"Can only get the car ([0]) or the cdr ([1:]) of a HyCons\")\n\n def __setitem__(self, n, new):\n if n == 0:\n self.car = new\n return\n if n == slice(1, None):\n self.cdr = new\n return\n\n raise IndexError(\n \"Can only set the car ([0]) or the cdr ([1:]) of a HyCons\")\n\n def __iter__(self):\n yield self.car\n try:\n iterator = (i for i in self.cdr)\n except TypeError:\n if self.cdr is not None:\n yield self.cdr\n raise TypeError(\"Iteration on malformed cons\")\n else:\n for i in iterator:\n yield i\n\n def replace(self, other):\n if self.car is not None:\n replace_hy_obj(self.car, other)\n if self.cdr is not None:\n replace_hy_obj(self.cdr, other)\n\n HyObject.replace(self, other)\n\n def __repr__(self):\n if isinstance(self.cdr, self.__class__):\n return \"(%s %s)\" % (repr(self.car), repr(self.cdr)[1:-1])\n else:\n return \"(%s . %s)\" % (repr(self.car), repr(self.cdr))\n\n def __eq__(self, other):\n return (\n isinstance(other, self.__class__) and\n self.car == other.car and\n self.cdr == other.cdr\n )\n", "path": "hy/models.py"}]}
| 3,803 | 570 |
gh_patches_debug_6563
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-1195
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Cannot serialize/deserialize SmoothedBoxPrior when some args are broadcast
# 🐛 Bug
It seems like `SmoothedBoxPrior` for >1d doesn't work with serialization/deserialization when only some args are broadcast.
## To reproduce
```python
import torch
import gpytorch
pr = gpytorch.priors.SmoothedBoxPrior(torch.zeros(2), torch.ones(2))
pr.load_state_dict(pr.state_dict())
```
** Stack trace/error message **
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-5-6b4b2e881beb> in <module>
2 import gpytorch
3 pr = gpytorch.priors.SmoothedBoxPrior(torch.zeros(2), torch.ones(2))
----> 4 pr.load_state_dict(pr.state_dict())
<...PATH..>/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
877 if len(error_msgs) > 0:
878 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
--> 879 self.__class__.__name__, "\n\t".join(error_msgs)))
880 return _IncompatibleKeys(missing_keys, unexpected_keys)
881
RuntimeError: Error(s) in loading state_dict for SmoothedBoxPrior:
While copying the parameter named "sigma", whose dimensions in the model are torch.Size([2]) and whose dimensions in the checkpoint are torch.Size([2]), an exception occured : ('unsupported operation: more than one element of the written-to tensor refers to a single memory location. Please clone() the tensor before performing the operation.',).
```
Note that `SmoothedBoxPrior(a=torch.zeros(2), b=torch.ones(2), sigma=torch.ones(2)*0.01)` succeeds, as does `gpytorch.priors.GammaPrior(torch.ones(2),1)`.
## Expected Behavior
Successful load.
## System information
**Please complete the following information:**
- gpytorch version: 1.1.1
- pytorch version: 1.5.0
- OS: tested on Centos and Mac OSX.
</issue>
<code>
[start of gpytorch/priors/smoothed_box_prior.py]
1 #!/usr/bin/env python3
2
3 import math
4 from numbers import Number
5
6 import torch
7 from torch.distributions import constraints
8 from torch.distributions.utils import broadcast_all
9 from torch.nn import Module as TModule
10
11 from .prior import Prior
12 from .torch_priors import NormalPrior
13
14
15 class SmoothedBoxPrior(Prior):
16 r"""A smoothed approximation of a uniform prior.
17
18 Has full support on the reals and is differentiable everywhere.
19
20 .. math::
21
22 \begin{equation*}
23 B = {x: a_i <= x_i <= b_i}
24 d(x, B) = min_{x' in B} |x - x'|
25 pdf(x) ~ exp(- d(x, B)**2 / sqrt(2 * sigma^2))
26 \end{equation*}
27
28 """
29
30 arg_constraints = {"sigma": constraints.positive, "a": constraints.real, "b": constraints.real}
31 support = constraints.real
32 _validate_args = True
33
34 def __init__(self, a, b, sigma=0.01, validate_args=False, transform=None):
35 TModule.__init__(self)
36 _a = torch.tensor(float(a)) if isinstance(a, Number) else a
37 _a = _a.view(-1) if _a.dim() < 1 else _a
38 _a, _b, _sigma = broadcast_all(_a, b, sigma)
39 if not torch.all(constraints.less_than(_b).check(_a)):
40 raise ValueError("must have that a < b (element-wise)")
41 # TODO: Proper argument validation including broadcasting
42 batch_shape, event_shape = _a.shape[:-1], _a.shape[-1:]
43 # need to assign values before registering as buffers to make argument validation work
44 self.a, self.b, self.sigma = _a, _b, _sigma
45 super(SmoothedBoxPrior, self).__init__(batch_shape, event_shape, validate_args=validate_args)
46 # now need to delete to be able to register buffer
47 del self.a, self.b, self.sigma
48 self.register_buffer("a", _a)
49 self.register_buffer("b", _b)
50 self.register_buffer("sigma", _sigma)
51 self.tails = NormalPrior(torch.zeros_like(_a), _sigma, validate_args=validate_args)
52 self._transform = transform
53
54 @property
55 def _c(self):
56 return (self.a + self.b) / 2
57
58 @property
59 def _r(self):
60 return (self.b - self.a) / 2
61
62 @property
63 def _M(self):
64 # normalization factor to make this a probability distribution
65 return torch.log(1 + (self.b - self.a) / (math.sqrt(2 * math.pi) * self.sigma))
66
67 def log_prob(self, x):
68 return self._log_prob(self.transform(x))
69
70 def _log_prob(self, x):
71 # x = "distances from box`"
72 X = ((x - self._c).abs_() - self._r).clamp(min=0)
73 return (self.tails.log_prob(X) - self._M).sum(-1)
74
[end of gpytorch/priors/smoothed_box_prior.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpytorch/priors/smoothed_box_prior.py b/gpytorch/priors/smoothed_box_prior.py
--- a/gpytorch/priors/smoothed_box_prior.py
+++ b/gpytorch/priors/smoothed_box_prior.py
@@ -47,7 +47,7 @@
del self.a, self.b, self.sigma
self.register_buffer("a", _a)
self.register_buffer("b", _b)
- self.register_buffer("sigma", _sigma)
+ self.register_buffer("sigma", _sigma.clone())
self.tails = NormalPrior(torch.zeros_like(_a), _sigma, validate_args=validate_args)
self._transform = transform
|
{"golden_diff": "diff --git a/gpytorch/priors/smoothed_box_prior.py b/gpytorch/priors/smoothed_box_prior.py\n--- a/gpytorch/priors/smoothed_box_prior.py\n+++ b/gpytorch/priors/smoothed_box_prior.py\n@@ -47,7 +47,7 @@\n del self.a, self.b, self.sigma\n self.register_buffer(\"a\", _a)\n self.register_buffer(\"b\", _b)\n- self.register_buffer(\"sigma\", _sigma)\n+ self.register_buffer(\"sigma\", _sigma.clone())\n self.tails = NormalPrior(torch.zeros_like(_a), _sigma, validate_args=validate_args)\n self._transform = transform\n", "issue": "[Bug] Cannot serialize/deserialize SmoothedBoxPrior when some args are broadcast\n# \ud83d\udc1b Bug\r\n\r\nIt seems like `SmoothedBoxPrior` for >1d doesn't work with serialization/deserialization when only some args are broadcast. \r\n\r\n## To reproduce\r\n\r\n```python\r\nimport torch\r\nimport gpytorch\r\npr = gpytorch.priors.SmoothedBoxPrior(torch.zeros(2), torch.ones(2))\r\npr.load_state_dict(pr.state_dict())\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n---------------------------------------------------------------------------\r\nRuntimeError Traceback (most recent call last)\r\n<ipython-input-5-6b4b2e881beb> in <module>\r\n 2 import gpytorch\r\n 3 pr = gpytorch.priors.SmoothedBoxPrior(torch.zeros(2), torch.ones(2))\r\n----> 4 pr.load_state_dict(pr.state_dict())\r\n\r\n<...PATH..>/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)\r\n 877 if len(error_msgs) > 0:\r\n 878 raise RuntimeError('Error(s) in loading state_dict for {}:\\n\\t{}'.format(\r\n--> 879 self.__class__.__name__, \"\\n\\t\".join(error_msgs)))\r\n 880 return _IncompatibleKeys(missing_keys, unexpected_keys)\r\n 881 \r\n\r\nRuntimeError: Error(s) in loading state_dict for SmoothedBoxPrior:\r\n\tWhile copying the parameter named \"sigma\", whose dimensions in the model are torch.Size([2]) and whose dimensions in the checkpoint are torch.Size([2]), an exception occured : ('unsupported operation: more than one element of the written-to tensor refers to a single memory location. Please clone() the tensor before performing the operation.',).\r\n\r\n```\r\n\r\nNote that `SmoothedBoxPrior(a=torch.zeros(2), b=torch.ones(2), sigma=torch.ones(2)*0.01)` succeeds, as does `gpytorch.priors.GammaPrior(torch.ones(2),1)`.\r\n\r\n## Expected Behavior\r\n\r\nSuccessful load. \r\n\r\n## System information\r\n\r\n**Please complete the following information:**\r\n- gpytorch version: 1.1.1\r\n- pytorch version: 1.5.0\r\n- OS: tested on Centos and Mac OSX. \r\n\r\n\r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport math\nfrom numbers import Number\n\nimport torch\nfrom torch.distributions import constraints\nfrom torch.distributions.utils import broadcast_all\nfrom torch.nn import Module as TModule\n\nfrom .prior import Prior\nfrom .torch_priors import NormalPrior\n\n\nclass SmoothedBoxPrior(Prior):\n r\"\"\"A smoothed approximation of a uniform prior.\n\n Has full support on the reals and is differentiable everywhere.\n\n .. math::\n\n \\begin{equation*}\n B = {x: a_i <= x_i <= b_i}\n d(x, B) = min_{x' in B} |x - x'|\n pdf(x) ~ exp(- d(x, B)**2 / sqrt(2 * sigma^2))\n \\end{equation*}\n\n \"\"\"\n\n arg_constraints = {\"sigma\": constraints.positive, \"a\": constraints.real, \"b\": constraints.real}\n support = constraints.real\n _validate_args = True\n\n def __init__(self, a, b, sigma=0.01, validate_args=False, transform=None):\n TModule.__init__(self)\n _a = torch.tensor(float(a)) if isinstance(a, Number) else a\n _a = _a.view(-1) if _a.dim() < 1 else _a\n _a, _b, _sigma = broadcast_all(_a, b, sigma)\n if not torch.all(constraints.less_than(_b).check(_a)):\n raise ValueError(\"must have that a < b (element-wise)\")\n # TODO: Proper argument validation including broadcasting\n batch_shape, event_shape = _a.shape[:-1], _a.shape[-1:]\n # need to assign values before registering as buffers to make argument validation work\n self.a, self.b, self.sigma = _a, _b, _sigma\n super(SmoothedBoxPrior, self).__init__(batch_shape, event_shape, validate_args=validate_args)\n # now need to delete to be able to register buffer\n del self.a, self.b, self.sigma\n self.register_buffer(\"a\", _a)\n self.register_buffer(\"b\", _b)\n self.register_buffer(\"sigma\", _sigma)\n self.tails = NormalPrior(torch.zeros_like(_a), _sigma, validate_args=validate_args)\n self._transform = transform\n\n @property\n def _c(self):\n return (self.a + self.b) / 2\n\n @property\n def _r(self):\n return (self.b - self.a) / 2\n\n @property\n def _M(self):\n # normalization factor to make this a probability distribution\n return torch.log(1 + (self.b - self.a) / (math.sqrt(2 * math.pi) * self.sigma))\n\n def log_prob(self, x):\n return self._log_prob(self.transform(x))\n\n def _log_prob(self, x):\n # x = \"distances from box`\"\n X = ((x - self._c).abs_() - self._r).clamp(min=0)\n return (self.tails.log_prob(X) - self._M).sum(-1)\n", "path": "gpytorch/priors/smoothed_box_prior.py"}]}
| 1,868 | 151 |
gh_patches_debug_4473
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1685
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CI fails with UserWarning raised from importing nevergrad
example failure here https://app.circleci.com/pipelines/github/facebookresearch/hydra/10584/workflows/d4c57363-bb31-42f4-a7ee-29c28a577f67/jobs/95695
this can be reproduced by simply importing nevergrad
```
>>> import nevergrad as ng
/Users/jieru/opt/anaconda3/envs/testnv/lib/python3.8/site-packages/cma/s.py:13: UserWarning: Could not import matplotlib.pyplot, therefore ``cma.plot()`` etc. is not available
_warnings.warn('Could not import matplotlib.pyplot, therefore'
```
the warnings comes from one of nevergrad's dependency `cma` which just had a new release https://github.com/CMA-ES/pycma/releases
</issue>
<code>
[start of plugins/hydra_nevergrad_sweeper/setup.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 # type: ignore
3 from pathlib import Path
4
5 from read_version import read_version
6 from setuptools import find_namespace_packages, setup
7
8 setup(
9 name="hydra-nevergrad-sweeper",
10 version=read_version("hydra_plugins/hydra_nevergrad_sweeper", "__init__.py"),
11 author="Jeremy Rapin, Omry Yadan, Jieru Hu",
12 author_email="[email protected], [email protected], [email protected]",
13 description="Hydra Nevergrad Sweeper plugin",
14 long_description=(Path(__file__).parent / "README.md").read_text(),
15 long_description_content_type="text/markdown",
16 url="https://github.com/facebookresearch/hydra/",
17 packages=find_namespace_packages(include=["hydra_plugins.*"]),
18 classifiers=[
19 "License :: OSI Approved :: MIT License",
20 "Programming Language :: Python :: 3.6",
21 "Programming Language :: Python :: 3.7",
22 "Programming Language :: Python :: 3.8",
23 "Programming Language :: Python :: 3.9",
24 "Operating System :: OS Independent",
25 "Development Status :: 4 - Beta",
26 ],
27 install_requires=[
28 "hydra-core>=1.1.0.dev7",
29 "nevergrad>=0.4.3.post2",
30 "numpy<1.20.0", # remove once nevergrad is upgraded to support numpy 1.20
31 ],
32 include_package_data=True,
33 )
34
[end of plugins/hydra_nevergrad_sweeper/setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/hydra_nevergrad_sweeper/setup.py b/plugins/hydra_nevergrad_sweeper/setup.py
--- a/plugins/hydra_nevergrad_sweeper/setup.py
+++ b/plugins/hydra_nevergrad_sweeper/setup.py
@@ -27,6 +27,7 @@
install_requires=[
"hydra-core>=1.1.0.dev7",
"nevergrad>=0.4.3.post2",
+ "cma==3.0.3", # https://github.com/facebookresearch/hydra/issues/1684
"numpy<1.20.0", # remove once nevergrad is upgraded to support numpy 1.20
],
include_package_data=True,
|
{"golden_diff": "diff --git a/plugins/hydra_nevergrad_sweeper/setup.py b/plugins/hydra_nevergrad_sweeper/setup.py\n--- a/plugins/hydra_nevergrad_sweeper/setup.py\n+++ b/plugins/hydra_nevergrad_sweeper/setup.py\n@@ -27,6 +27,7 @@\n install_requires=[\n \"hydra-core>=1.1.0.dev7\",\n \"nevergrad>=0.4.3.post2\",\n+ \"cma==3.0.3\", # https://github.com/facebookresearch/hydra/issues/1684\n \"numpy<1.20.0\", # remove once nevergrad is upgraded to support numpy 1.20\n ],\n include_package_data=True,\n", "issue": "CI fails with UserWarning raised from importing nevergrad\nexample failure here https://app.circleci.com/pipelines/github/facebookresearch/hydra/10584/workflows/d4c57363-bb31-42f4-a7ee-29c28a577f67/jobs/95695\r\n\r\nthis can be reproduced by simply importing nevergrad\r\n```\r\n>>> import nevergrad as ng\r\n/Users/jieru/opt/anaconda3/envs/testnv/lib/python3.8/site-packages/cma/s.py:13: UserWarning: Could not import matplotlib.pyplot, therefore ``cma.plot()`` etc. is not available\r\n _warnings.warn('Could not import matplotlib.pyplot, therefore'\r\n```\r\n\r\nthe warnings comes from one of nevergrad's dependency `cma` which just had a new release https://github.com/CMA-ES/pycma/releases\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n# type: ignore\nfrom pathlib import Path\n\nfrom read_version import read_version\nfrom setuptools import find_namespace_packages, setup\n\nsetup(\n name=\"hydra-nevergrad-sweeper\",\n version=read_version(\"hydra_plugins/hydra_nevergrad_sweeper\", \"__init__.py\"),\n author=\"Jeremy Rapin, Omry Yadan, Jieru Hu\",\n author_email=\"[email protected], [email protected], [email protected]\",\n description=\"Hydra Nevergrad Sweeper plugin\",\n long_description=(Path(__file__).parent / \"README.md\").read_text(),\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/facebookresearch/hydra/\",\n packages=find_namespace_packages(include=[\"hydra_plugins.*\"]),\n classifiers=[\n \"License :: OSI Approved :: MIT License\",\n \"Programming Language :: Python :: 3.6\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n \"Programming Language :: Python :: 3.9\",\n \"Operating System :: OS Independent\",\n \"Development Status :: 4 - Beta\",\n ],\n install_requires=[\n \"hydra-core>=1.1.0.dev7\",\n \"nevergrad>=0.4.3.post2\",\n \"numpy<1.20.0\", # remove once nevergrad is upgraded to support numpy 1.20\n ],\n include_package_data=True,\n)\n", "path": "plugins/hydra_nevergrad_sweeper/setup.py"}]}
| 1,138 | 169 |
gh_patches_debug_27211
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-687
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Opentracing contrib: `DroppedSpan has no attribute transaction`
**Describe the bug**: ...
When using Elastic APM with Opentracing, the program crashes on `AttributeError: DroppedSpan object has no attribute transaction` exception if `span.finish()` is called.
It turns out to be this line:
https://github.com/elastic/apm-agent-python/blob/74cd1fa56f15a3149b367bd65ea4721a6fd95615/elasticapm/contrib/opentracing/span.py#L129
It will access `transaction` attribute which does NOT exist for `DroppedSpan`.
**Expected behavior**: ...
It should be expected to behave normally even if it's `DroppedSpan`.
**Environment (please complete the following information)**
- OS: [e.g. Linux] Linux
- Python version: 2.7
- Framework and version [e.g. Django 2.1]: N/A
- APM Server version: 7.4.0
- Agent version: 5.3.2
</issue>
<code>
[start of elasticapm/contrib/opentracing/span.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 from opentracing.span import Span as OTSpanBase
32 from opentracing.span import SpanContext as OTSpanContextBase
33
34 from elasticapm import traces
35 from elasticapm.utils import compat, get_url_dict
36 from elasticapm.utils.logging import get_logger
37
38 try:
39 # opentracing-python 2.1+
40 from opentracing import tags
41 from opentracing import logs as ot_logs
42 except ImportError:
43 # opentracing-python <2.1
44 from opentracing.ext import tags
45
46 ot_logs = None
47
48
49 logger = get_logger("elasticapm.contrib.opentracing")
50
51
52 class OTSpan(OTSpanBase):
53 def __init__(self, tracer, context, elastic_apm_ref):
54 super(OTSpan, self).__init__(tracer, context)
55 self.elastic_apm_ref = elastic_apm_ref
56 self.is_transaction = isinstance(elastic_apm_ref, traces.Transaction)
57 if not context.span:
58 context.span = self
59
60 def log_kv(self, key_values, timestamp=None):
61 exc_type, exc_val, exc_tb = None, None, None
62 if "python.exception.type" in key_values:
63 exc_type = key_values["python.exception.type"]
64 exc_val = key_values.get("python.exception.val")
65 exc_tb = key_values.get("python.exception.tb")
66 elif ot_logs and key_values.get(ot_logs.EVENT) == tags.ERROR:
67 exc_type = key_values[ot_logs.ERROR_KIND]
68 exc_val = key_values.get(ot_logs.ERROR_OBJECT)
69 exc_tb = key_values.get(ot_logs.STACK)
70 else:
71 logger.debug("Can't handle non-exception type opentracing logs")
72 if exc_type:
73 agent = self.tracer._agent
74 agent.capture_exception(exc_info=(exc_type, exc_val, exc_tb))
75 return self
76
77 def set_operation_name(self, operation_name):
78 self.elastic_apm_ref.name = operation_name
79 return self
80
81 def set_tag(self, key, value):
82 if self.is_transaction:
83 if key == "type":
84 self.elastic_apm_ref.transaction_type = value
85 elif key == "result":
86 self.elastic_apm_ref.result = value
87 elif key == tags.HTTP_STATUS_CODE:
88 self.elastic_apm_ref.result = "HTTP {}xx".format(compat.text_type(value)[0])
89 traces.set_context({"status_code": value}, "response")
90 elif key == "user.id":
91 traces.set_user_context(user_id=value)
92 elif key == "user.username":
93 traces.set_user_context(username=value)
94 elif key == "user.email":
95 traces.set_user_context(email=value)
96 elif key == tags.HTTP_URL:
97 traces.set_context({"url": get_url_dict(value)}, "request")
98 elif key == tags.HTTP_METHOD:
99 traces.set_context({"method": value}, "request")
100 elif key == tags.COMPONENT:
101 traces.set_context({"framework": {"name": value}}, "service")
102 else:
103 self.elastic_apm_ref.label(**{key: value})
104 else:
105 if key.startswith("db."):
106 span_context = self.elastic_apm_ref.context or {}
107 if "db" not in span_context:
108 span_context["db"] = {}
109 if key == tags.DATABASE_STATEMENT:
110 span_context["db"]["statement"] = value
111 elif key == tags.DATABASE_USER:
112 span_context["db"]["user"] = value
113 elif key == tags.DATABASE_TYPE:
114 span_context["db"]["type"] = value
115 self.elastic_apm_ref.type = "db." + value
116 else:
117 self.elastic_apm_ref.label(**{key: value})
118 self.elastic_apm_ref.context = span_context
119 elif key == tags.SPAN_KIND:
120 self.elastic_apm_ref.type = value
121 else:
122 self.elastic_apm_ref.label(**{key: value})
123 return self
124
125 def finish(self, finish_time=None):
126 if self.is_transaction:
127 self.tracer._agent.end_transaction()
128 else:
129 self.elastic_apm_ref.transaction.end_span()
130
131
132 class OTSpanContext(OTSpanContextBase):
133 def __init__(self, trace_parent, span=None):
134 self.trace_parent = trace_parent
135 self.span = span
136
[end of elasticapm/contrib/opentracing/span.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/contrib/opentracing/span.py b/elasticapm/contrib/opentracing/span.py
--- a/elasticapm/contrib/opentracing/span.py
+++ b/elasticapm/contrib/opentracing/span.py
@@ -54,6 +54,7 @@
super(OTSpan, self).__init__(tracer, context)
self.elastic_apm_ref = elastic_apm_ref
self.is_transaction = isinstance(elastic_apm_ref, traces.Transaction)
+ self.is_dropped = isinstance(elastic_apm_ref, traces.DroppedSpan)
if not context.span:
context.span = self
@@ -101,7 +102,7 @@
traces.set_context({"framework": {"name": value}}, "service")
else:
self.elastic_apm_ref.label(**{key: value})
- else:
+ elif not self.is_dropped:
if key.startswith("db."):
span_context = self.elastic_apm_ref.context or {}
if "db" not in span_context:
@@ -125,7 +126,7 @@
def finish(self, finish_time=None):
if self.is_transaction:
self.tracer._agent.end_transaction()
- else:
+ elif not self.is_dropped:
self.elastic_apm_ref.transaction.end_span()
|
{"golden_diff": "diff --git a/elasticapm/contrib/opentracing/span.py b/elasticapm/contrib/opentracing/span.py\n--- a/elasticapm/contrib/opentracing/span.py\n+++ b/elasticapm/contrib/opentracing/span.py\n@@ -54,6 +54,7 @@\n super(OTSpan, self).__init__(tracer, context)\n self.elastic_apm_ref = elastic_apm_ref\n self.is_transaction = isinstance(elastic_apm_ref, traces.Transaction)\n+ self.is_dropped = isinstance(elastic_apm_ref, traces.DroppedSpan)\n if not context.span:\n context.span = self\n \n@@ -101,7 +102,7 @@\n traces.set_context({\"framework\": {\"name\": value}}, \"service\")\n else:\n self.elastic_apm_ref.label(**{key: value})\n- else:\n+ elif not self.is_dropped:\n if key.startswith(\"db.\"):\n span_context = self.elastic_apm_ref.context or {}\n if \"db\" not in span_context:\n@@ -125,7 +126,7 @@\n def finish(self, finish_time=None):\n if self.is_transaction:\n self.tracer._agent.end_transaction()\n- else:\n+ elif not self.is_dropped:\n self.elastic_apm_ref.transaction.end_span()\n", "issue": "Opentracing contrib: `DroppedSpan has no attribute transaction`\n**Describe the bug**: ...\r\nWhen using Elastic APM with Opentracing, the program crashes on `AttributeError: DroppedSpan object has no attribute transaction` exception if `span.finish()` is called. \r\n It turns out to be this line:\r\nhttps://github.com/elastic/apm-agent-python/blob/74cd1fa56f15a3149b367bd65ea4721a6fd95615/elasticapm/contrib/opentracing/span.py#L129\r\nIt will access `transaction` attribute which does NOT exist for `DroppedSpan`.\r\n\r\n**Expected behavior**: ...\r\nIt should be expected to behave normally even if it's `DroppedSpan`.\r\n\r\n**Environment (please complete the following information)**\r\n- OS: [e.g. Linux] Linux\r\n- Python version: 2.7\r\n- Framework and version [e.g. Django 2.1]: N/A\r\n- APM Server version: 7.4.0\r\n- Agent version: 5.3.2\r\n\r\n\r\n\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nfrom opentracing.span import Span as OTSpanBase\nfrom opentracing.span import SpanContext as OTSpanContextBase\n\nfrom elasticapm import traces\nfrom elasticapm.utils import compat, get_url_dict\nfrom elasticapm.utils.logging import get_logger\n\ntry:\n # opentracing-python 2.1+\n from opentracing import tags\n from opentracing import logs as ot_logs\nexcept ImportError:\n # opentracing-python <2.1\n from opentracing.ext import tags\n\n ot_logs = None\n\n\nlogger = get_logger(\"elasticapm.contrib.opentracing\")\n\n\nclass OTSpan(OTSpanBase):\n def __init__(self, tracer, context, elastic_apm_ref):\n super(OTSpan, self).__init__(tracer, context)\n self.elastic_apm_ref = elastic_apm_ref\n self.is_transaction = isinstance(elastic_apm_ref, traces.Transaction)\n if not context.span:\n context.span = self\n\n def log_kv(self, key_values, timestamp=None):\n exc_type, exc_val, exc_tb = None, None, None\n if \"python.exception.type\" in key_values:\n exc_type = key_values[\"python.exception.type\"]\n exc_val = key_values.get(\"python.exception.val\")\n exc_tb = key_values.get(\"python.exception.tb\")\n elif ot_logs and key_values.get(ot_logs.EVENT) == tags.ERROR:\n exc_type = key_values[ot_logs.ERROR_KIND]\n exc_val = key_values.get(ot_logs.ERROR_OBJECT)\n exc_tb = key_values.get(ot_logs.STACK)\n else:\n logger.debug(\"Can't handle non-exception type opentracing logs\")\n if exc_type:\n agent = self.tracer._agent\n agent.capture_exception(exc_info=(exc_type, exc_val, exc_tb))\n return self\n\n def set_operation_name(self, operation_name):\n self.elastic_apm_ref.name = operation_name\n return self\n\n def set_tag(self, key, value):\n if self.is_transaction:\n if key == \"type\":\n self.elastic_apm_ref.transaction_type = value\n elif key == \"result\":\n self.elastic_apm_ref.result = value\n elif key == tags.HTTP_STATUS_CODE:\n self.elastic_apm_ref.result = \"HTTP {}xx\".format(compat.text_type(value)[0])\n traces.set_context({\"status_code\": value}, \"response\")\n elif key == \"user.id\":\n traces.set_user_context(user_id=value)\n elif key == \"user.username\":\n traces.set_user_context(username=value)\n elif key == \"user.email\":\n traces.set_user_context(email=value)\n elif key == tags.HTTP_URL:\n traces.set_context({\"url\": get_url_dict(value)}, \"request\")\n elif key == tags.HTTP_METHOD:\n traces.set_context({\"method\": value}, \"request\")\n elif key == tags.COMPONENT:\n traces.set_context({\"framework\": {\"name\": value}}, \"service\")\n else:\n self.elastic_apm_ref.label(**{key: value})\n else:\n if key.startswith(\"db.\"):\n span_context = self.elastic_apm_ref.context or {}\n if \"db\" not in span_context:\n span_context[\"db\"] = {}\n if key == tags.DATABASE_STATEMENT:\n span_context[\"db\"][\"statement\"] = value\n elif key == tags.DATABASE_USER:\n span_context[\"db\"][\"user\"] = value\n elif key == tags.DATABASE_TYPE:\n span_context[\"db\"][\"type\"] = value\n self.elastic_apm_ref.type = \"db.\" + value\n else:\n self.elastic_apm_ref.label(**{key: value})\n self.elastic_apm_ref.context = span_context\n elif key == tags.SPAN_KIND:\n self.elastic_apm_ref.type = value\n else:\n self.elastic_apm_ref.label(**{key: value})\n return self\n\n def finish(self, finish_time=None):\n if self.is_transaction:\n self.tracer._agent.end_transaction()\n else:\n self.elastic_apm_ref.transaction.end_span()\n\n\nclass OTSpanContext(OTSpanContextBase):\n def __init__(self, trace_parent, span=None):\n self.trace_parent = trace_parent\n self.span = span\n", "path": "elasticapm/contrib/opentracing/span.py"}]}
| 2,347 | 293 |
gh_patches_debug_19464
|
rasdani/github-patches
|
git_diff
|
aio-libs__aiohttp-1157
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Recent change to GunicornWebWorker breaks code
## Long story short
For development, I like using the autoreload feature you can get with gunicorn; so I've been using the following python script to start up a development server:
``` python
import os
if __name__ == '__main__':
command = (
'gunicorn server:app ' +
'--bind 0.0.0.0:5000 ' +
'--workers 1 ' +
'--worker-class aiohttp.worker.GunicornUVLoopWebWorker ' +
'--reload')
os.system(command)
```
This works on the 0.22 branch, but fails when I move to the master branch (1.0.0a0). I get the following traceback using the master branch when I try to launch the server:
```
Traceback (most recent call last):
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/gunicorn/arbiter.py", line 557, in spawn_worker
worker.init_process()
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py", line 196, in init_process
super().init_process()
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py", line 36, in init_process
super().init_process()
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/gunicorn/workers/base.py", line 132, in init_process
self.run()
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py", line 43, in run
self.loop.run_until_complete(self._runner)
File "uvloop/loop.pyx", line 1133, in uvloop.loop.Loop.run_until_complete (uvloop/loop.c:19943)
File "uvloop/future.pyx", line 123, in uvloop.loop.BaseFuture.result (uvloop/loop.c:94147)
File "uvloop/future.pyx", line 78, in uvloop.loop.BaseFuture._result_impl (uvloop/loop.c:93686)
File "uvloop/task.pyx", line 126, in uvloop.loop.BaseTask._fast_step (uvloop/loop.c:99430)
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py", line 91, in _run
handler = self.make_handler(self.wsgi)
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py", line 52, in make_handler
debug=self.cfg.debug,
File "/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/gunicorn/config.py", line 58, in __getattr__
raise AttributeError("No configuration setting for: %s" % name)
AttributeError: No configuration setting for: debug
```
I think the reason is that the `make_handler` method on the `GunicornWebWorker` class has changed from this:
``` python
def make_handler(self, app):
if hasattr(self.cfg, 'debug'):
is_debug = self.cfg.debug
else:
is_debug = self.log.loglevel == logging.DEBUG
return app.make_handler(
logger=self.log,
debug=is_debug,
timeout=self.cfg.timeout,
keep_alive=self.cfg.keepalive,
access_log=self.log.access_log,
access_log_format=self.cfg.access_log_format)
```
to this:
``` python
def make_handler(self, app):
return app.make_handler(
logger=self.log,
debug=self.cfg.debug,
timeout=self.cfg.timeout,
keep_alive=self.cfg.keepalive,
access_log=self.log.access_log,
access_log_format=self._get_valid_log_format(
self.cfg.access_log_format))
```
It appears my `cfg` object has no `debug` attribute, which was fine on branch 0.22 but leads to my script failing on the master branch. Is this a bug? If not, it would be great if someone could let me know how to fix my code.
Thanks!
## My environment
```
aiohttp==1.0.0a0
gunicorn==19.6.0
uvloop==0.5.3
```
</issue>
<code>
[start of aiohttp/worker.py]
1 """Async gunicorn worker for aiohttp.web"""
2
3 import asyncio
4 import os
5 import re
6 import signal
7 import ssl
8 import sys
9
10 import gunicorn.workers.base as base
11 from gunicorn.config import AccessLogFormat as GunicornAccessLogFormat
12
13 from aiohttp.helpers import AccessLogger, ensure_future
14
15 __all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')
16
17
18 class GunicornWebWorker(base.Worker):
19
20 DEFAULT_AIOHTTP_LOG_FORMAT = AccessLogger.LOG_FORMAT
21 DEFAULT_GUNICORN_LOG_FORMAT = GunicornAccessLogFormat.default
22
23 def __init__(self, *args, **kw): # pragma: no cover
24 super().__init__(*args, **kw)
25
26 self.servers = {}
27 self.exit_code = 0
28
29 def init_process(self):
30 # create new event_loop after fork
31 asyncio.get_event_loop().close()
32
33 self.loop = asyncio.new_event_loop()
34 asyncio.set_event_loop(self.loop)
35
36 super().init_process()
37
38 def run(self):
39 self.loop.run_until_complete(self.wsgi.startup())
40 self._runner = ensure_future(self._run(), loop=self.loop)
41
42 try:
43 self.loop.run_until_complete(self._runner)
44 finally:
45 self.loop.close()
46
47 sys.exit(self.exit_code)
48
49 def make_handler(self, app):
50 return app.make_handler(
51 logger=self.log,
52 debug=self.cfg.debug,
53 timeout=self.cfg.timeout,
54 keep_alive=self.cfg.keepalive,
55 access_log=self.log.access_log,
56 access_log_format=self._get_valid_log_format(
57 self.cfg.access_log_format))
58
59 @asyncio.coroutine
60 def close(self):
61 if self.servers:
62 servers = self.servers
63 self.servers = None
64
65 # stop accepting connections
66 for server, handler in servers.items():
67 self.log.info("Stopping server: %s, connections: %s",
68 self.pid, len(handler.connections))
69 server.close()
70 yield from server.wait_closed()
71
72 # send on_shutdown event
73 yield from self.wsgi.shutdown()
74
75 # stop alive connections
76 tasks = [
77 handler.finish_connections(
78 timeout=self.cfg.graceful_timeout / 100 * 95)
79 for handler in servers.values()]
80 yield from asyncio.gather(*tasks, loop=self.loop)
81
82 # cleanup application
83 yield from self.wsgi.cleanup()
84
85 @asyncio.coroutine
86 def _run(self):
87
88 ctx = self._create_ssl_context(self.cfg) if self.cfg.is_ssl else None
89
90 for sock in self.sockets:
91 handler = self.make_handler(self.wsgi)
92 srv = yield from self.loop.create_server(handler, sock=sock.sock,
93 ssl=ctx)
94 self.servers[srv] = handler
95
96 # If our parent changed then we shut down.
97 pid = os.getpid()
98 try:
99 while self.alive:
100 self.notify()
101
102 cnt = sum(handler.requests_count
103 for handler in self.servers.values())
104 if self.cfg.max_requests and cnt > self.cfg.max_requests:
105 self.alive = False
106 self.log.info("Max requests, shutting down: %s", self)
107
108 elif pid == os.getpid() and self.ppid != os.getppid():
109 self.alive = False
110 self.log.info("Parent changed, shutting down: %s", self)
111 else:
112 yield from asyncio.sleep(1.0, loop=self.loop)
113
114 except BaseException:
115 pass
116
117 yield from self.close()
118
119 def init_signals(self):
120 # Set up signals through the event loop API.
121
122 self.loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,
123 signal.SIGQUIT, None)
124
125 self.loop.add_signal_handler(signal.SIGTERM, self.handle_exit,
126 signal.SIGTERM, None)
127
128 self.loop.add_signal_handler(signal.SIGINT, self.handle_quit,
129 signal.SIGINT, None)
130
131 self.loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,
132 signal.SIGWINCH, None)
133
134 self.loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,
135 signal.SIGUSR1, None)
136
137 self.loop.add_signal_handler(signal.SIGABRT, self.handle_abort,
138 signal.SIGABRT, None)
139
140 # Don't let SIGTERM and SIGUSR1 disturb active requests
141 # by interrupting system calls
142 signal.siginterrupt(signal.SIGTERM, False)
143 signal.siginterrupt(signal.SIGUSR1, False)
144
145 def handle_quit(self, sig, frame):
146 self.alive = False
147
148 def handle_abort(self, sig, frame):
149 self.alive = False
150 self.exit_code = 1
151
152 @staticmethod
153 def _create_ssl_context(cfg):
154 """ Creates SSLContext instance for usage in asyncio.create_server.
155
156 See ssl.SSLSocket.__init__ for more details.
157 """
158 ctx = ssl.SSLContext(cfg.ssl_version)
159 ctx.load_cert_chain(cfg.certfile, cfg.keyfile)
160 ctx.verify_mode = cfg.cert_reqs
161 if cfg.ca_certs:
162 ctx.load_verify_locations(cfg.ca_certs)
163 if cfg.ciphers:
164 ctx.set_ciphers(cfg.ciphers)
165 return ctx
166
167 def _get_valid_log_format(self, source_format):
168 if source_format == self.DEFAULT_GUNICORN_LOG_FORMAT:
169 return self.DEFAULT_AIOHTTP_LOG_FORMAT
170 elif re.search(r'%\([^\)]+\)', source_format):
171 raise ValueError(
172 "Gunicorn's style options in form of `%(name)s` are not "
173 "supported for the log formatting. Please use aiohttp's "
174 "format specification to configure access log formatting: "
175 "http://aiohttp.readthedocs.io/en/stable/logging.html"
176 "#format-specification"
177 )
178 else:
179 return source_format
180
181
182 class GunicornUVLoopWebWorker(GunicornWebWorker):
183
184 def init_process(self):
185 import uvloop
186
187 # Close any existing event loop before setting a
188 # new policy.
189 asyncio.get_event_loop().close()
190
191 # Setup uvloop policy, so that every
192 # asyncio.get_event_loop() will create an instance
193 # of uvloop event loop.
194 asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())
195
196 super().init_process()
197
[end of aiohttp/worker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/aiohttp/worker.py b/aiohttp/worker.py
--- a/aiohttp/worker.py
+++ b/aiohttp/worker.py
@@ -1,6 +1,7 @@
"""Async gunicorn worker for aiohttp.web"""
import asyncio
+import logging
import os
import re
import signal
@@ -47,11 +48,16 @@
sys.exit(self.exit_code)
def make_handler(self, app):
+ if hasattr(self.cfg, 'debug'):
+ is_debug = self.cfg.debug
+ else:
+ is_debug = self.log.loglevel == logging.DEBUG
+
return app.make_handler(
logger=self.log,
- debug=self.cfg.debug,
- timeout=self.cfg.timeout,
- keep_alive=self.cfg.keepalive,
+ debug=is_debug,
+ slow_request_timeout=self.cfg.timeout,
+ keepalive_timeout=self.cfg.keepalive,
access_log=self.log.access_log,
access_log_format=self._get_valid_log_format(
self.cfg.access_log_format))
|
{"golden_diff": "diff --git a/aiohttp/worker.py b/aiohttp/worker.py\n--- a/aiohttp/worker.py\n+++ b/aiohttp/worker.py\n@@ -1,6 +1,7 @@\n \"\"\"Async gunicorn worker for aiohttp.web\"\"\"\n \n import asyncio\n+import logging\n import os\n import re\n import signal\n@@ -47,11 +48,16 @@\n sys.exit(self.exit_code)\n \n def make_handler(self, app):\n+ if hasattr(self.cfg, 'debug'):\n+ is_debug = self.cfg.debug\n+ else:\n+ is_debug = self.log.loglevel == logging.DEBUG\n+\n return app.make_handler(\n logger=self.log,\n- debug=self.cfg.debug,\n- timeout=self.cfg.timeout,\n- keep_alive=self.cfg.keepalive,\n+ debug=is_debug,\n+ slow_request_timeout=self.cfg.timeout,\n+ keepalive_timeout=self.cfg.keepalive,\n access_log=self.log.access_log,\n access_log_format=self._get_valid_log_format(\n self.cfg.access_log_format))\n", "issue": "Recent change to GunicornWebWorker breaks code\n## Long story short\n\nFor development, I like using the autoreload feature you can get with gunicorn; so I've been using the following python script to start up a development server:\n\n``` python\nimport os\n\nif __name__ == '__main__':\n command = (\n 'gunicorn server:app ' +\n '--bind 0.0.0.0:5000 ' +\n '--workers 1 ' +\n '--worker-class aiohttp.worker.GunicornUVLoopWebWorker ' +\n '--reload')\n os.system(command)\n```\n\nThis works on the 0.22 branch, but fails when I move to the master branch (1.0.0a0). I get the following traceback using the master branch when I try to launch the server:\n\n```\nTraceback (most recent call last):\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/gunicorn/arbiter.py\", line 557, in spawn_worker\n worker.init_process()\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py\", line 196, in init_process\n super().init_process()\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py\", line 36, in init_process\n super().init_process()\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/gunicorn/workers/base.py\", line 132, in init_process\n self.run()\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py\", line 43, in run\n self.loop.run_until_complete(self._runner)\n File \"uvloop/loop.pyx\", line 1133, in uvloop.loop.Loop.run_until_complete (uvloop/loop.c:19943)\n File \"uvloop/future.pyx\", line 123, in uvloop.loop.BaseFuture.result (uvloop/loop.c:94147)\n File \"uvloop/future.pyx\", line 78, in uvloop.loop.BaseFuture._result_impl (uvloop/loop.c:93686)\n File \"uvloop/task.pyx\", line 126, in uvloop.loop.BaseTask._fast_step (uvloop/loop.c:99430)\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py\", line 91, in _run\n handler = self.make_handler(self.wsgi)\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/aiohttp/worker.py\", line 52, in make_handler\n debug=self.cfg.debug,\n File \"/Users/bcmyers/Dropbox/Programming/python/website/venv/lib/python3.5/site-packages/gunicorn/config.py\", line 58, in __getattr__\n raise AttributeError(\"No configuration setting for: %s\" % name)\nAttributeError: No configuration setting for: debug\n```\n\nI think the reason is that the `make_handler` method on the `GunicornWebWorker` class has changed from this:\n\n``` python\ndef make_handler(self, app):\n if hasattr(self.cfg, 'debug'):\n is_debug = self.cfg.debug\n else:\n is_debug = self.log.loglevel == logging.DEBUG\n\n return app.make_handler(\n logger=self.log,\n debug=is_debug,\n timeout=self.cfg.timeout,\n keep_alive=self.cfg.keepalive,\n access_log=self.log.access_log,\n access_log_format=self.cfg.access_log_format)\n```\n\nto this:\n\n``` python\ndef make_handler(self, app):\n return app.make_handler(\n logger=self.log,\n debug=self.cfg.debug,\n timeout=self.cfg.timeout,\n keep_alive=self.cfg.keepalive,\n access_log=self.log.access_log,\n access_log_format=self._get_valid_log_format(\n self.cfg.access_log_format))\n```\n\nIt appears my `cfg` object has no `debug` attribute, which was fine on branch 0.22 but leads to my script failing on the master branch. Is this a bug? If not, it would be great if someone could let me know how to fix my code.\n\nThanks!\n## My environment\n\n```\naiohttp==1.0.0a0\ngunicorn==19.6.0\nuvloop==0.5.3\n```\n\n", "before_files": [{"content": "\"\"\"Async gunicorn worker for aiohttp.web\"\"\"\n\nimport asyncio\nimport os\nimport re\nimport signal\nimport ssl\nimport sys\n\nimport gunicorn.workers.base as base\nfrom gunicorn.config import AccessLogFormat as GunicornAccessLogFormat\n\nfrom aiohttp.helpers import AccessLogger, ensure_future\n\n__all__ = ('GunicornWebWorker', 'GunicornUVLoopWebWorker')\n\n\nclass GunicornWebWorker(base.Worker):\n\n DEFAULT_AIOHTTP_LOG_FORMAT = AccessLogger.LOG_FORMAT\n DEFAULT_GUNICORN_LOG_FORMAT = GunicornAccessLogFormat.default\n\n def __init__(self, *args, **kw): # pragma: no cover\n super().__init__(*args, **kw)\n\n self.servers = {}\n self.exit_code = 0\n\n def init_process(self):\n # create new event_loop after fork\n asyncio.get_event_loop().close()\n\n self.loop = asyncio.new_event_loop()\n asyncio.set_event_loop(self.loop)\n\n super().init_process()\n\n def run(self):\n self.loop.run_until_complete(self.wsgi.startup())\n self._runner = ensure_future(self._run(), loop=self.loop)\n\n try:\n self.loop.run_until_complete(self._runner)\n finally:\n self.loop.close()\n\n sys.exit(self.exit_code)\n\n def make_handler(self, app):\n return app.make_handler(\n logger=self.log,\n debug=self.cfg.debug,\n timeout=self.cfg.timeout,\n keep_alive=self.cfg.keepalive,\n access_log=self.log.access_log,\n access_log_format=self._get_valid_log_format(\n self.cfg.access_log_format))\n\n @asyncio.coroutine\n def close(self):\n if self.servers:\n servers = self.servers\n self.servers = None\n\n # stop accepting connections\n for server, handler in servers.items():\n self.log.info(\"Stopping server: %s, connections: %s\",\n self.pid, len(handler.connections))\n server.close()\n yield from server.wait_closed()\n\n # send on_shutdown event\n yield from self.wsgi.shutdown()\n\n # stop alive connections\n tasks = [\n handler.finish_connections(\n timeout=self.cfg.graceful_timeout / 100 * 95)\n for handler in servers.values()]\n yield from asyncio.gather(*tasks, loop=self.loop)\n\n # cleanup application\n yield from self.wsgi.cleanup()\n\n @asyncio.coroutine\n def _run(self):\n\n ctx = self._create_ssl_context(self.cfg) if self.cfg.is_ssl else None\n\n for sock in self.sockets:\n handler = self.make_handler(self.wsgi)\n srv = yield from self.loop.create_server(handler, sock=sock.sock,\n ssl=ctx)\n self.servers[srv] = handler\n\n # If our parent changed then we shut down.\n pid = os.getpid()\n try:\n while self.alive:\n self.notify()\n\n cnt = sum(handler.requests_count\n for handler in self.servers.values())\n if self.cfg.max_requests and cnt > self.cfg.max_requests:\n self.alive = False\n self.log.info(\"Max requests, shutting down: %s\", self)\n\n elif pid == os.getpid() and self.ppid != os.getppid():\n self.alive = False\n self.log.info(\"Parent changed, shutting down: %s\", self)\n else:\n yield from asyncio.sleep(1.0, loop=self.loop)\n\n except BaseException:\n pass\n\n yield from self.close()\n\n def init_signals(self):\n # Set up signals through the event loop API.\n\n self.loop.add_signal_handler(signal.SIGQUIT, self.handle_quit,\n signal.SIGQUIT, None)\n\n self.loop.add_signal_handler(signal.SIGTERM, self.handle_exit,\n signal.SIGTERM, None)\n\n self.loop.add_signal_handler(signal.SIGINT, self.handle_quit,\n signal.SIGINT, None)\n\n self.loop.add_signal_handler(signal.SIGWINCH, self.handle_winch,\n signal.SIGWINCH, None)\n\n self.loop.add_signal_handler(signal.SIGUSR1, self.handle_usr1,\n signal.SIGUSR1, None)\n\n self.loop.add_signal_handler(signal.SIGABRT, self.handle_abort,\n signal.SIGABRT, None)\n\n # Don't let SIGTERM and SIGUSR1 disturb active requests\n # by interrupting system calls\n signal.siginterrupt(signal.SIGTERM, False)\n signal.siginterrupt(signal.SIGUSR1, False)\n\n def handle_quit(self, sig, frame):\n self.alive = False\n\n def handle_abort(self, sig, frame):\n self.alive = False\n self.exit_code = 1\n\n @staticmethod\n def _create_ssl_context(cfg):\n \"\"\" Creates SSLContext instance for usage in asyncio.create_server.\n\n See ssl.SSLSocket.__init__ for more details.\n \"\"\"\n ctx = ssl.SSLContext(cfg.ssl_version)\n ctx.load_cert_chain(cfg.certfile, cfg.keyfile)\n ctx.verify_mode = cfg.cert_reqs\n if cfg.ca_certs:\n ctx.load_verify_locations(cfg.ca_certs)\n if cfg.ciphers:\n ctx.set_ciphers(cfg.ciphers)\n return ctx\n\n def _get_valid_log_format(self, source_format):\n if source_format == self.DEFAULT_GUNICORN_LOG_FORMAT:\n return self.DEFAULT_AIOHTTP_LOG_FORMAT\n elif re.search(r'%\\([^\\)]+\\)', source_format):\n raise ValueError(\n \"Gunicorn's style options in form of `%(name)s` are not \"\n \"supported for the log formatting. Please use aiohttp's \"\n \"format specification to configure access log formatting: \"\n \"http://aiohttp.readthedocs.io/en/stable/logging.html\"\n \"#format-specification\"\n )\n else:\n return source_format\n\n\nclass GunicornUVLoopWebWorker(GunicornWebWorker):\n\n def init_process(self):\n import uvloop\n\n # Close any existing event loop before setting a\n # new policy.\n asyncio.get_event_loop().close()\n\n # Setup uvloop policy, so that every\n # asyncio.get_event_loop() will create an instance\n # of uvloop event loop.\n asyncio.set_event_loop_policy(uvloop.EventLoopPolicy())\n\n super().init_process()\n", "path": "aiohttp/worker.py"}]}
| 3,406 | 225 |
gh_patches_debug_6991
|
rasdani/github-patches
|
git_diff
|
optuna__optuna-1884
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Complete list of logging level for `optuna.logging.set_verbosity`
<!-- Please write a clear and concise description of what content in https://optuna.readthedocs.io/ is an issue. -->
When I read the page of [`optuna.logging.set_verbosity`](https://optuna.readthedocs.io/en/latest/reference/generated/optuna.logging.set_verbosity.html), I suppose that it is nicer to show the complete list of logging levels of optuna on the same page like [`optuna.logging.get_verbosity`](https://optuna.readthedocs.io/en/latest/reference/generated/optuna.logging.get_verbosity.html).
</issue>
<code>
[start of optuna/logging.py]
1 import logging
2 from logging import CRITICAL # NOQA
3 from logging import DEBUG # NOQA
4 from logging import ERROR # NOQA
5 from logging import FATAL # NOQA
6 from logging import INFO # NOQA
7 from logging import WARN # NOQA
8 from logging import WARNING # NOQA
9 import threading
10
11 import colorlog
12
13 from optuna import type_checking
14
15
16 if type_checking.TYPE_CHECKING:
17 from typing import Optional # NOQA
18
19 _lock = threading.Lock()
20 _default_handler = None # type: Optional[logging.Handler]
21
22
23 def create_default_formatter() -> colorlog.ColoredFormatter:
24 """Create a default formatter of log messages.
25
26 This function is not supposed to be directly accessed by library users.
27 """
28
29 return colorlog.ColoredFormatter(
30 "%(log_color)s[%(levelname)1.1s %(asctime)s]%(reset)s %(message)s"
31 )
32
33
34 def _get_library_name() -> str:
35
36 return __name__.split(".")[0]
37
38
39 def _get_library_root_logger() -> logging.Logger:
40
41 return logging.getLogger(_get_library_name())
42
43
44 def _configure_library_root_logger() -> None:
45
46 global _default_handler
47
48 with _lock:
49 if _default_handler:
50 # This library has already configured the library root logger.
51 return
52 _default_handler = logging.StreamHandler() # Set sys.stderr as stream.
53 _default_handler.setFormatter(create_default_formatter())
54
55 # Apply our default configuration to the library root logger.
56 library_root_logger = _get_library_root_logger()
57 library_root_logger.addHandler(_default_handler)
58 library_root_logger.setLevel(logging.INFO)
59 library_root_logger.propagate = False
60
61
62 def _reset_library_root_logger() -> None:
63
64 global _default_handler
65
66 with _lock:
67 if not _default_handler:
68 return
69
70 library_root_logger = _get_library_root_logger()
71 library_root_logger.removeHandler(_default_handler)
72 library_root_logger.setLevel(logging.NOTSET)
73 _default_handler = None
74
75
76 def get_logger(name: str) -> logging.Logger:
77 """Return a logger with the specified name.
78
79 This function is not supposed to be directly accessed by library users.
80 """
81
82 _configure_library_root_logger()
83 return logging.getLogger(name)
84
85
86 def get_verbosity() -> int:
87 """Return the current level for the Optuna's root logger.
88
89 Returns:
90 Logging level, e.g., ``optuna.logging.DEBUG`` and ``optuna.logging.INFO``.
91
92 .. note::
93 Optuna has following logging levels:
94
95 - ``optuna.logging.CRITICAL``, ``optuna.logging.FATAL``
96 - ``optuna.logging.ERROR``
97 - ``optuna.logging.WARNING``, ``optuna.logging.WARN``
98 - ``optuna.logging.INFO``
99 - ``optuna.logging.DEBUG``
100 """
101
102 _configure_library_root_logger()
103 return _get_library_root_logger().getEffectiveLevel()
104
105
106 def set_verbosity(verbosity: int) -> None:
107 """Set the level for the Optuna's root logger.
108
109 Args:
110 verbosity:
111 Logging level, e.g., ``optuna.logging.DEBUG`` and ``optuna.logging.INFO``.
112 """
113
114 _configure_library_root_logger()
115 _get_library_root_logger().setLevel(verbosity)
116
117
118 def disable_default_handler() -> None:
119 """Disable the default handler of the Optuna's root logger.
120
121 Example:
122
123 Stop and then resume logging to :obj:`sys.stderr`.
124
125 .. testsetup::
126
127 def objective(trial):
128 x = trial.suggest_uniform("x", -100, 100)
129 y = trial.suggest_categorical("y", [-1, 0, 1])
130 return x ** 2 + y
131
132 .. testcode::
133
134 import optuna
135
136 study = optuna.create_study()
137
138 # There are no logs in sys.stderr.
139 optuna.logging.disable_default_handler()
140 study.optimize(objective, n_trials=10)
141
142 # There are logs in sys.stderr.
143 optuna.logging.enable_default_handler()
144 study.optimize(objective, n_trials=10)
145 # [I 2020-02-23 17:00:54,314] Trial 10 finished with value: ...
146 # [I 2020-02-23 17:00:54,356] Trial 11 finished with value: ...
147 # ...
148
149 """
150
151 _configure_library_root_logger()
152
153 assert _default_handler is not None
154 _get_library_root_logger().removeHandler(_default_handler)
155
156
157 def enable_default_handler() -> None:
158 """Enable the default handler of the Optuna's root logger.
159
160 Please refer to the example shown in :func:`~optuna.logging.disable_default_handler()`.
161 """
162
163 _configure_library_root_logger()
164
165 assert _default_handler is not None
166 _get_library_root_logger().addHandler(_default_handler)
167
168
169 def disable_propagation() -> None:
170 """Disable propagation of the library log outputs.
171
172 Note that log propagation is disabled by default.
173 """
174
175 _configure_library_root_logger()
176 _get_library_root_logger().propagate = False
177
178
179 def enable_propagation() -> None:
180 """Enable propagation of the library log outputs.
181
182 Please disable the Optuna's default handler to prevent double logging if the root logger has
183 been configured.
184
185 Example:
186
187 Propagate all log output to the root logger in order to save them to the file.
188
189 .. testsetup::
190
191 def objective(trial):
192 x = trial.suggest_uniform("x", -100, 100)
193 y = trial.suggest_categorical("y", [-1, 0, 1])
194 return x ** 2 + y
195
196 .. testcode::
197
198 import optuna
199 import logging
200
201 logger = logging.getLogger()
202
203 logger.setLevel(logging.INFO) # Setup the root logger.
204 logger.addHandler(logging.FileHandler("foo.log", mode="w"))
205
206 optuna.logging.enable_propagation() # Propagate logs to the root logger.
207 optuna.logging.disable_default_handler() # Stop showing logs in sys.stderr.
208
209 study = optuna.create_study()
210
211 logger.info("Start optimization.")
212 study.optimize(objective, n_trials=10)
213
214 with open("foo.log") as f:
215 assert f.readline().startswith("A new study created")
216 assert f.readline() == "Start optimization.\\n"
217
218 """
219
220 _configure_library_root_logger()
221 _get_library_root_logger().propagate = True
222
[end of optuna/logging.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/optuna/logging.py b/optuna/logging.py
--- a/optuna/logging.py
+++ b/optuna/logging.py
@@ -109,6 +109,15 @@
Args:
verbosity:
Logging level, e.g., ``optuna.logging.DEBUG`` and ``optuna.logging.INFO``.
+
+ .. note::
+ Optuna has following logging levels:
+
+ - ``optuna.logging.CRITICAL``, ``optuna.logging.FATAL``
+ - ``optuna.logging.ERROR``
+ - ``optuna.logging.WARNING``, ``optuna.logging.WARN``
+ - ``optuna.logging.INFO``
+ - ``optuna.logging.DEBUG``
"""
_configure_library_root_logger()
|
{"golden_diff": "diff --git a/optuna/logging.py b/optuna/logging.py\n--- a/optuna/logging.py\n+++ b/optuna/logging.py\n@@ -109,6 +109,15 @@\n Args:\n verbosity:\n Logging level, e.g., ``optuna.logging.DEBUG`` and ``optuna.logging.INFO``.\n+\n+ .. note::\n+ Optuna has following logging levels:\n+\n+ - ``optuna.logging.CRITICAL``, ``optuna.logging.FATAL``\n+ - ``optuna.logging.ERROR``\n+ - ``optuna.logging.WARNING``, ``optuna.logging.WARN``\n+ - ``optuna.logging.INFO``\n+ - ``optuna.logging.DEBUG``\n \"\"\"\n \n _configure_library_root_logger()\n", "issue": "Complete list of logging level for `optuna.logging.set_verbosity`\n<!-- Please write a clear and concise description of what content in https://optuna.readthedocs.io/ is an issue. -->\r\nWhen I read the page of [`optuna.logging.set_verbosity`](https://optuna.readthedocs.io/en/latest/reference/generated/optuna.logging.set_verbosity.html), I suppose that it is nicer to show the complete list of logging levels of optuna on the same page like [`optuna.logging.get_verbosity`](https://optuna.readthedocs.io/en/latest/reference/generated/optuna.logging.get_verbosity.html).\n", "before_files": [{"content": "import logging\nfrom logging import CRITICAL # NOQA\nfrom logging import DEBUG # NOQA\nfrom logging import ERROR # NOQA\nfrom logging import FATAL # NOQA\nfrom logging import INFO # NOQA\nfrom logging import WARN # NOQA\nfrom logging import WARNING # NOQA\nimport threading\n\nimport colorlog\n\nfrom optuna import type_checking\n\n\nif type_checking.TYPE_CHECKING:\n from typing import Optional # NOQA\n\n_lock = threading.Lock()\n_default_handler = None # type: Optional[logging.Handler]\n\n\ndef create_default_formatter() -> colorlog.ColoredFormatter:\n \"\"\"Create a default formatter of log messages.\n\n This function is not supposed to be directly accessed by library users.\n \"\"\"\n\n return colorlog.ColoredFormatter(\n \"%(log_color)s[%(levelname)1.1s %(asctime)s]%(reset)s %(message)s\"\n )\n\n\ndef _get_library_name() -> str:\n\n return __name__.split(\".\")[0]\n\n\ndef _get_library_root_logger() -> logging.Logger:\n\n return logging.getLogger(_get_library_name())\n\n\ndef _configure_library_root_logger() -> None:\n\n global _default_handler\n\n with _lock:\n if _default_handler:\n # This library has already configured the library root logger.\n return\n _default_handler = logging.StreamHandler() # Set sys.stderr as stream.\n _default_handler.setFormatter(create_default_formatter())\n\n # Apply our default configuration to the library root logger.\n library_root_logger = _get_library_root_logger()\n library_root_logger.addHandler(_default_handler)\n library_root_logger.setLevel(logging.INFO)\n library_root_logger.propagate = False\n\n\ndef _reset_library_root_logger() -> None:\n\n global _default_handler\n\n with _lock:\n if not _default_handler:\n return\n\n library_root_logger = _get_library_root_logger()\n library_root_logger.removeHandler(_default_handler)\n library_root_logger.setLevel(logging.NOTSET)\n _default_handler = None\n\n\ndef get_logger(name: str) -> logging.Logger:\n \"\"\"Return a logger with the specified name.\n\n This function is not supposed to be directly accessed by library users.\n \"\"\"\n\n _configure_library_root_logger()\n return logging.getLogger(name)\n\n\ndef get_verbosity() -> int:\n \"\"\"Return the current level for the Optuna's root logger.\n\n Returns:\n Logging level, e.g., ``optuna.logging.DEBUG`` and ``optuna.logging.INFO``.\n\n .. note::\n Optuna has following logging levels:\n\n - ``optuna.logging.CRITICAL``, ``optuna.logging.FATAL``\n - ``optuna.logging.ERROR``\n - ``optuna.logging.WARNING``, ``optuna.logging.WARN``\n - ``optuna.logging.INFO``\n - ``optuna.logging.DEBUG``\n \"\"\"\n\n _configure_library_root_logger()\n return _get_library_root_logger().getEffectiveLevel()\n\n\ndef set_verbosity(verbosity: int) -> None:\n \"\"\"Set the level for the Optuna's root logger.\n\n Args:\n verbosity:\n Logging level, e.g., ``optuna.logging.DEBUG`` and ``optuna.logging.INFO``.\n \"\"\"\n\n _configure_library_root_logger()\n _get_library_root_logger().setLevel(verbosity)\n\n\ndef disable_default_handler() -> None:\n \"\"\"Disable the default handler of the Optuna's root logger.\n\n Example:\n\n Stop and then resume logging to :obj:`sys.stderr`.\n\n .. testsetup::\n\n def objective(trial):\n x = trial.suggest_uniform(\"x\", -100, 100)\n y = trial.suggest_categorical(\"y\", [-1, 0, 1])\n return x ** 2 + y\n\n .. testcode::\n\n import optuna\n\n study = optuna.create_study()\n\n # There are no logs in sys.stderr.\n optuna.logging.disable_default_handler()\n study.optimize(objective, n_trials=10)\n\n # There are logs in sys.stderr.\n optuna.logging.enable_default_handler()\n study.optimize(objective, n_trials=10)\n # [I 2020-02-23 17:00:54,314] Trial 10 finished with value: ...\n # [I 2020-02-23 17:00:54,356] Trial 11 finished with value: ...\n # ...\n\n \"\"\"\n\n _configure_library_root_logger()\n\n assert _default_handler is not None\n _get_library_root_logger().removeHandler(_default_handler)\n\n\ndef enable_default_handler() -> None:\n \"\"\"Enable the default handler of the Optuna's root logger.\n\n Please refer to the example shown in :func:`~optuna.logging.disable_default_handler()`.\n \"\"\"\n\n _configure_library_root_logger()\n\n assert _default_handler is not None\n _get_library_root_logger().addHandler(_default_handler)\n\n\ndef disable_propagation() -> None:\n \"\"\"Disable propagation of the library log outputs.\n\n Note that log propagation is disabled by default.\n \"\"\"\n\n _configure_library_root_logger()\n _get_library_root_logger().propagate = False\n\n\ndef enable_propagation() -> None:\n \"\"\"Enable propagation of the library log outputs.\n\n Please disable the Optuna's default handler to prevent double logging if the root logger has\n been configured.\n\n Example:\n\n Propagate all log output to the root logger in order to save them to the file.\n\n .. testsetup::\n\n def objective(trial):\n x = trial.suggest_uniform(\"x\", -100, 100)\n y = trial.suggest_categorical(\"y\", [-1, 0, 1])\n return x ** 2 + y\n\n .. testcode::\n\n import optuna\n import logging\n\n logger = logging.getLogger()\n\n logger.setLevel(logging.INFO) # Setup the root logger.\n logger.addHandler(logging.FileHandler(\"foo.log\", mode=\"w\"))\n\n optuna.logging.enable_propagation() # Propagate logs to the root logger.\n optuna.logging.disable_default_handler() # Stop showing logs in sys.stderr.\n\n study = optuna.create_study()\n\n logger.info(\"Start optimization.\")\n study.optimize(objective, n_trials=10)\n\n with open(\"foo.log\") as f:\n assert f.readline().startswith(\"A new study created\")\n assert f.readline() == \"Start optimization.\\\\n\"\n\n \"\"\"\n\n _configure_library_root_logger()\n _get_library_root_logger().propagate = True\n", "path": "optuna/logging.py"}]}
| 2,662 | 156 |
gh_patches_debug_6608
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__pyro-2243
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug AffineCoupling
Hello,
There seems to be a bug in [here](https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/transforms/affine_coupling.py#L106).
`mean, log_scale = self.arn(x1)`
should probably be
`mean, log_scale = self.hypernet(x1)`
instead, right?
Thanks in advance
</issue>
<code>
[start of pyro/distributions/transforms/affine_coupling.py]
1 import torch
2 from torch.distributions import constraints
3
4 from pyro.distributions.torch_transform import TransformModule
5 from pyro.distributions.util import copy_docs_from
6 from pyro.distributions.transforms.utils import clamp_preserve_gradients
7 from pyro.nn import DenseNN
8
9
10 @copy_docs_from(TransformModule)
11 class AffineCoupling(TransformModule):
12 """
13 An implementation of the affine coupling layer of RealNVP (Dinh et al., 2017) that uses the bijective transform,
14
15 :math:`\\mathbf{y}_{1:d} = \\mathbf{x}_{1:d}`
16 :math:`\\mathbf{y}_{(d+1):D} = \\mu + \\sigma\\odot\\mathbf{x}_{(d+1):D}`
17
18 where :math:`\\mathbf{x}` are the inputs, :math:`\\mathbf{y}` are the outputs, e.g. :math:`\\mathbf{x}_{1:d}`
19 represents the first :math:`d` elements of the inputs, and :math:`\\mu,\\sigma` are shift and translation
20 parameters calculated as the output of a function inputting only :math:`\\mathbf{x}_{1:d}`.
21
22 That is, the first :math:`d` components remain unchanged, and the subsequent :math:`D-d` are shifted and
23 translated by a function of the previous components.
24
25 Together with :class:`~pyro.distributions.TransformedDistribution` this provides a way to create richer
26 variational approximations.
27
28 Example usage:
29
30 >>> from pyro.nn import DenseNN
31 >>> input_dim = 10
32 >>> split_dim = 6
33 >>> base_dist = dist.Normal(torch.zeros(input_dim), torch.ones(input_dim))
34 >>> hypernet = DenseNN(split_dim, [10*input_dim], [input_dim-split_dim, input_dim-split_dim])
35 >>> transform = AffineCoupling(split_dim, hypernet)
36 >>> pyro.module("my_transform", transform) # doctest: +SKIP
37 >>> flow_dist = dist.TransformedDistribution(base_dist, [transform])
38 >>> flow_dist.sample() # doctest: +SKIP
39 tensor([-0.4071, -0.5030, 0.7924, -0.2366, -0.2387, -0.1417, 0.0868,
40 0.1389, -0.4629, 0.0986])
41
42 The inverse of the Bijector is required when, e.g., scoring the log density of a sample with
43 :class:`~pyro.distributions.TransformedDistribution`. This implementation caches the inverse of the Bijector when
44 its forward operation is called, e.g., when sampling from :class:`~pyro.distributions.TransformedDistribution`.
45 However, if the cached value isn't available, either because it was overwritten during sampling a new value or an
46 arbitary value is being scored, it will calculate it manually.
47
48 This is an operation that scales as O(1), i.e. constant in the input dimension. So in general, it is cheap
49 to sample *and* score (an arbitrary value) from :class:`~pyro.distributions.transforms.AffineCoupling`.
50
51 :param split_dim: Zero-indexed dimension :math:`d` upon which to perform input/output split for transformation.
52 :type split_dim: int
53 :param hypernet: an autoregressive neural network whose forward call returns a real-valued
54 mean and logit-scale as a tuple. The input should have final dimension split_dim and the output final
55 dimension input_dim-split_dim for each member of the tuple.
56 :type hypernet: callable
57 :param log_scale_min_clip: The minimum value for clipping the log(scale) from the autoregressive NN
58 :type log_scale_min_clip: float
59 :param log_scale_max_clip: The maximum value for clipping the log(scale) from the autoregressive NN
60 :type log_scale_max_clip: float
61
62 References:
63
64 Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using Real NVP. ICLR 2017.
65
66 """
67
68 domain = constraints.real
69 codomain = constraints.real
70 bijective = True
71 event_dim = 1
72
73 def __init__(self, split_dim, hypernet, log_scale_min_clip=-5., log_scale_max_clip=3.):
74 super(AffineCoupling, self).__init__(cache_size=1)
75 self.split_dim = split_dim
76 self.hypernet = hypernet
77 self._cached_log_scale = None
78 self.log_scale_min_clip = log_scale_min_clip
79 self.log_scale_max_clip = log_scale_max_clip
80
81 def _call(self, x):
82 """
83 :param x: the input into the bijection
84 :type x: torch.Tensor
85
86 Invokes the bijection x=>y; in the prototypical context of a
87 :class:`~pyro.distributions.TransformedDistribution` `x` is a sample from the base distribution (or the output
88 of a previous transform)
89 """
90 x1, x2 = x[..., :self.split_dim], x[..., self.split_dim:]
91
92 mean, log_scale = self.hypernet(x1)
93 log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)
94 self._cached_log_scale = log_scale
95
96 y1 = x1
97 y2 = torch.exp(log_scale) * x2 + mean
98 return torch.cat([y1, y2], dim=-1)
99
100 def _inverse(self, y):
101 """
102 :param y: the output of the bijection
103 :type y: torch.Tensor
104
105 Inverts y => x. Uses a previously cached inverse if available, otherwise performs the inversion afresh.
106 """
107 y1, y2 = y[..., :self.split_dim], y[..., self.split_dim:]
108 x1 = y1
109 mean, log_scale = self.arn(x1)
110 log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)
111 self._cached_log_scale = log_scale
112
113 x2 = (y2 - mean) * torch.exp(-log_scale)
114 return torch.cat([x1, x2], dim=-1)
115
116 def log_abs_det_jacobian(self, x, y):
117 """
118 Calculates the elementwise determinant of the log jacobian
119 """
120 x_old, y_old = self._cached_x_y
121 if self._cached_log_scale is not None and x is x_old and y is y_old:
122 log_scale = self._cached_log_scale
123 else:
124 x1 = x[..., :self.split_dim]
125 _, log_scale = self.hypernet(x1)
126 log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)
127 return log_scale.sum(-1)
128
129
130 def affine_coupling(input_dim, hidden_dims=None, split_dim=None, **kwargs):
131 """
132 A helper function to create an :class:`~pyro.distributions.transforms.AffineCoupling` object that takes care of
133 constructing a dense network with the correct input/output dimensions.
134
135 :param input_dim: Dimension of input variable
136 :type input_dim: int
137 :param hidden_dims: The desired hidden dimensions of the dense network. Defaults
138 to using [10*input_dim]
139 :type hidden_dims: list[int]
140 :param split_dim: The dimension to split the input on for the coupling transform. Defaults
141 to using input_dim // 2
142 :type split_dim: int
143 :param log_scale_min_clip: The minimum value for clipping the log(scale) from the autoregressive NN
144 :type log_scale_min_clip: float
145 :param log_scale_max_clip: The maximum value for clipping the log(scale) from the autoregressive NN
146 :type log_scale_max_clip: float
147
148 """
149 if split_dim is None:
150 split_dim = input_dim // 2
151 if hidden_dims is None:
152 hidden_dims = [10 * input_dim]
153 hypernet = DenseNN(split_dim, hidden_dims, [input_dim - split_dim, input_dim - split_dim])
154 return AffineCoupling(split_dim, hypernet, **kwargs)
155
[end of pyro/distributions/transforms/affine_coupling.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyro/distributions/transforms/affine_coupling.py b/pyro/distributions/transforms/affine_coupling.py
--- a/pyro/distributions/transforms/affine_coupling.py
+++ b/pyro/distributions/transforms/affine_coupling.py
@@ -106,7 +106,7 @@
"""
y1, y2 = y[..., :self.split_dim], y[..., self.split_dim:]
x1 = y1
- mean, log_scale = self.arn(x1)
+ mean, log_scale = self.hypernet(x1)
log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)
self._cached_log_scale = log_scale
|
{"golden_diff": "diff --git a/pyro/distributions/transforms/affine_coupling.py b/pyro/distributions/transforms/affine_coupling.py\n--- a/pyro/distributions/transforms/affine_coupling.py\n+++ b/pyro/distributions/transforms/affine_coupling.py\n@@ -106,7 +106,7 @@\n \"\"\"\n y1, y2 = y[..., :self.split_dim], y[..., self.split_dim:]\n x1 = y1\n- mean, log_scale = self.arn(x1)\n+ mean, log_scale = self.hypernet(x1)\n log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)\n self._cached_log_scale = log_scale\n", "issue": "Bug AffineCoupling\nHello,\r\n\r\nThere seems to be a bug in [here](https://github.com/pyro-ppl/pyro/blob/dev/pyro/distributions/transforms/affine_coupling.py#L106).\r\n\r\n`mean, log_scale = self.arn(x1)`\r\n\r\nshould probably be\r\n\r\n`mean, log_scale = self.hypernet(x1)`\r\n\r\ninstead, right?\r\n\r\nThanks in advance\r\n\n", "before_files": [{"content": "import torch\nfrom torch.distributions import constraints\n\nfrom pyro.distributions.torch_transform import TransformModule\nfrom pyro.distributions.util import copy_docs_from\nfrom pyro.distributions.transforms.utils import clamp_preserve_gradients\nfrom pyro.nn import DenseNN\n\n\n@copy_docs_from(TransformModule)\nclass AffineCoupling(TransformModule):\n \"\"\"\n An implementation of the affine coupling layer of RealNVP (Dinh et al., 2017) that uses the bijective transform,\n\n :math:`\\\\mathbf{y}_{1:d} = \\\\mathbf{x}_{1:d}`\n :math:`\\\\mathbf{y}_{(d+1):D} = \\\\mu + \\\\sigma\\\\odot\\\\mathbf{x}_{(d+1):D}`\n\n where :math:`\\\\mathbf{x}` are the inputs, :math:`\\\\mathbf{y}` are the outputs, e.g. :math:`\\\\mathbf{x}_{1:d}`\n represents the first :math:`d` elements of the inputs, and :math:`\\\\mu,\\\\sigma` are shift and translation\n parameters calculated as the output of a function inputting only :math:`\\\\mathbf{x}_{1:d}`.\n\n That is, the first :math:`d` components remain unchanged, and the subsequent :math:`D-d` are shifted and\n translated by a function of the previous components.\n\n Together with :class:`~pyro.distributions.TransformedDistribution` this provides a way to create richer\n variational approximations.\n\n Example usage:\n\n >>> from pyro.nn import DenseNN\n >>> input_dim = 10\n >>> split_dim = 6\n >>> base_dist = dist.Normal(torch.zeros(input_dim), torch.ones(input_dim))\n >>> hypernet = DenseNN(split_dim, [10*input_dim], [input_dim-split_dim, input_dim-split_dim])\n >>> transform = AffineCoupling(split_dim, hypernet)\n >>> pyro.module(\"my_transform\", transform) # doctest: +SKIP\n >>> flow_dist = dist.TransformedDistribution(base_dist, [transform])\n >>> flow_dist.sample() # doctest: +SKIP\n tensor([-0.4071, -0.5030, 0.7924, -0.2366, -0.2387, -0.1417, 0.0868,\n 0.1389, -0.4629, 0.0986])\n\n The inverse of the Bijector is required when, e.g., scoring the log density of a sample with\n :class:`~pyro.distributions.TransformedDistribution`. This implementation caches the inverse of the Bijector when\n its forward operation is called, e.g., when sampling from :class:`~pyro.distributions.TransformedDistribution`.\n However, if the cached value isn't available, either because it was overwritten during sampling a new value or an\n arbitary value is being scored, it will calculate it manually.\n\n This is an operation that scales as O(1), i.e. constant in the input dimension. So in general, it is cheap\n to sample *and* score (an arbitrary value) from :class:`~pyro.distributions.transforms.AffineCoupling`.\n\n :param split_dim: Zero-indexed dimension :math:`d` upon which to perform input/output split for transformation.\n :type split_dim: int\n :param hypernet: an autoregressive neural network whose forward call returns a real-valued\n mean and logit-scale as a tuple. The input should have final dimension split_dim and the output final\n dimension input_dim-split_dim for each member of the tuple.\n :type hypernet: callable\n :param log_scale_min_clip: The minimum value for clipping the log(scale) from the autoregressive NN\n :type log_scale_min_clip: float\n :param log_scale_max_clip: The maximum value for clipping the log(scale) from the autoregressive NN\n :type log_scale_max_clip: float\n\n References:\n\n Laurent Dinh, Jascha Sohl-Dickstein, and Samy Bengio. Density estimation using Real NVP. ICLR 2017.\n\n \"\"\"\n\n domain = constraints.real\n codomain = constraints.real\n bijective = True\n event_dim = 1\n\n def __init__(self, split_dim, hypernet, log_scale_min_clip=-5., log_scale_max_clip=3.):\n super(AffineCoupling, self).__init__(cache_size=1)\n self.split_dim = split_dim\n self.hypernet = hypernet\n self._cached_log_scale = None\n self.log_scale_min_clip = log_scale_min_clip\n self.log_scale_max_clip = log_scale_max_clip\n\n def _call(self, x):\n \"\"\"\n :param x: the input into the bijection\n :type x: torch.Tensor\n\n Invokes the bijection x=>y; in the prototypical context of a\n :class:`~pyro.distributions.TransformedDistribution` `x` is a sample from the base distribution (or the output\n of a previous transform)\n \"\"\"\n x1, x2 = x[..., :self.split_dim], x[..., self.split_dim:]\n\n mean, log_scale = self.hypernet(x1)\n log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)\n self._cached_log_scale = log_scale\n\n y1 = x1\n y2 = torch.exp(log_scale) * x2 + mean\n return torch.cat([y1, y2], dim=-1)\n\n def _inverse(self, y):\n \"\"\"\n :param y: the output of the bijection\n :type y: torch.Tensor\n\n Inverts y => x. Uses a previously cached inverse if available, otherwise performs the inversion afresh.\n \"\"\"\n y1, y2 = y[..., :self.split_dim], y[..., self.split_dim:]\n x1 = y1\n mean, log_scale = self.arn(x1)\n log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)\n self._cached_log_scale = log_scale\n\n x2 = (y2 - mean) * torch.exp(-log_scale)\n return torch.cat([x1, x2], dim=-1)\n\n def log_abs_det_jacobian(self, x, y):\n \"\"\"\n Calculates the elementwise determinant of the log jacobian\n \"\"\"\n x_old, y_old = self._cached_x_y\n if self._cached_log_scale is not None and x is x_old and y is y_old:\n log_scale = self._cached_log_scale\n else:\n x1 = x[..., :self.split_dim]\n _, log_scale = self.hypernet(x1)\n log_scale = clamp_preserve_gradients(log_scale, self.log_scale_min_clip, self.log_scale_max_clip)\n return log_scale.sum(-1)\n\n\ndef affine_coupling(input_dim, hidden_dims=None, split_dim=None, **kwargs):\n \"\"\"\n A helper function to create an :class:`~pyro.distributions.transforms.AffineCoupling` object that takes care of\n constructing a dense network with the correct input/output dimensions.\n\n :param input_dim: Dimension of input variable\n :type input_dim: int\n :param hidden_dims: The desired hidden dimensions of the dense network. Defaults\n to using [10*input_dim]\n :type hidden_dims: list[int]\n :param split_dim: The dimension to split the input on for the coupling transform. Defaults\n to using input_dim // 2\n :type split_dim: int\n :param log_scale_min_clip: The minimum value for clipping the log(scale) from the autoregressive NN\n :type log_scale_min_clip: float\n :param log_scale_max_clip: The maximum value for clipping the log(scale) from the autoregressive NN\n :type log_scale_max_clip: float\n\n \"\"\"\n if split_dim is None:\n split_dim = input_dim // 2\n if hidden_dims is None:\n hidden_dims = [10 * input_dim]\n hypernet = DenseNN(split_dim, hidden_dims, [input_dim - split_dim, input_dim - split_dim])\n return AffineCoupling(split_dim, hypernet, **kwargs)\n", "path": "pyro/distributions/transforms/affine_coupling.py"}]}
| 2,833 | 163 |
gh_patches_debug_40328
|
rasdani/github-patches
|
git_diff
|
cal-itp__benefits-508
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Learn more about Login.gov" link should go to `/help#login-gov`
### Steps to reproduce
On the `eligibility:start` page, click the "Learn more about Login.gov" link.
### Expected result
The link goes to the "What is Login.gov?" section on the Help page.
### Actual result
The link goes to `https://login.gov`.
</issue>
<code>
[start of benefits/eligibility/views.py]
1 """
2 The eligibility application: view definitions for the eligibility verification flow.
3 """
4 from django.conf import settings
5 from django.contrib import messages
6 from django.shortcuts import redirect
7 from django.template.response import TemplateResponse
8 from django.urls import reverse
9 from django.utils.decorators import decorator_from_middleware
10 from django.utils.translation import pgettext, gettext as _
11
12 from benefits.core import recaptcha, session, viewmodels
13 from benefits.core.middleware import AgencySessionRequired, LoginRequired, RateLimit, VerifierSessionRequired
14 from benefits.core.models import EligibilityVerifier
15 from benefits.core.views import PageTemplateResponse
16 from . import analytics, api, forms
17
18
19 @decorator_from_middleware(AgencySessionRequired)
20 def index(request):
21 """View handler for the eligibility verifier selection form."""
22
23 session.update(request, eligibility_types=[], origin=reverse("eligibility:index"))
24 agency = session.agency(request)
25
26 eligibility_start = reverse("eligibility:start")
27
28 page = viewmodels.Page(
29 title=_("eligibility.pages.index.title"),
30 content_title=_("eligibility.pages.index.content_title"),
31 forms=forms.EligibilityVerifierSelectionForm(agency=agency),
32 )
33
34 if request.method == "POST":
35 form = forms.EligibilityVerifierSelectionForm(data=request.POST, agency=agency)
36
37 if form.is_valid():
38 verifier_id = form.cleaned_data.get("verifier")
39 verifier = EligibilityVerifier.objects.get(id=verifier_id)
40 session.update(request, verifier=verifier)
41
42 response = redirect(eligibility_start)
43 else:
44 # form was not valid, allow for correction/resubmission
45 page.forms = [form]
46 response = PageTemplateResponse(request, page)
47 else:
48 if agency.eligibility_verifiers.count() == 1:
49 verifier = agency.eligibility_verifiers.first()
50 session.update(request, verifier=verifier)
51 response = redirect(eligibility_start)
52 else:
53 response = PageTemplateResponse(request, page)
54
55 return response
56
57
58 @decorator_from_middleware(AgencySessionRequired)
59 @decorator_from_middleware(VerifierSessionRequired)
60 def start(request):
61 """View handler for the eligibility verification getting started screen."""
62
63 session.update(request, eligibility_types=[], origin=reverse("eligibility:start"))
64 verifier = session.verifier(request)
65
66 button = viewmodels.Button.primary(text=_("eligibility.buttons.continue"), url=reverse("eligibility:confirm"))
67 media = [
68 dict(
69 icon=viewmodels.Icon("idcardcheck", pgettext("image alt text", "core.icons.idcardcheck")),
70 heading=_(verifier.start_item_name),
71 details=_(verifier.start_item_description),
72 ),
73 dict(
74 icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
75 heading=_("eligibility.pages.start.items[1].title"),
76 details=_("eligibility.pages.start.items[1].text"),
77 links=[
78 viewmodels.Button.link(
79 classes="btn-text btn-link",
80 text=_("eligibility.pages.start.items[1].button[0].link"),
81 url=_("eligibility.pages.start.items[1].button[0].url"),
82 ),
83 viewmodels.Button.link(
84 classes="btn-text btn-link",
85 text=_("eligibility.pages.start.items[1].button[1].link"),
86 url=_("eligibility.pages.start.items[1].button[1].url"),
87 ),
88 ],
89 ),
90 ]
91
92 if verifier.requires_authentication:
93 if settings.OAUTH_CLIENT_NAME is None:
94 raise Exception("EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None")
95
96 media.insert(
97 0,
98 dict(
99 icon=viewmodels.Icon("idscreencheck", pgettext("image alt text", "core.icons.idscreencheck")),
100 heading=_("eligibility.media.heading"),
101 details=_("eligibility.media.details"),
102 links=[
103 viewmodels.Button.link(
104 classes="btn-text btn-link",
105 text=_("eligibility.media.link_text"),
106 url=_("eligibility.media.link_url"),
107 target="_blank",
108 rel="noopener noreferrer",
109 )
110 ],
111 ),
112 )
113
114 if not session.logged_in(request):
115 button = viewmodels.Button.login(
116 label=_(verifier.auth_provider.sign_in_button_label),
117 text="",
118 url=reverse("oauth:login"),
119 )
120
121 page = viewmodels.Page(
122 title=_("eligibility.pages.start.title"),
123 noimage=True,
124 paragraphs=[_(verifier.start_blurb)],
125 button=button,
126 )
127
128 ctx = page.context_dict()
129 ctx["title"] = _(verifier.start_content_title)
130 ctx["media"] = media
131
132 return TemplateResponse(request, "eligibility/start.html", ctx)
133
134
135 @decorator_from_middleware(AgencySessionRequired)
136 @decorator_from_middleware(LoginRequired)
137 @decorator_from_middleware(RateLimit)
138 @decorator_from_middleware(VerifierSessionRequired)
139 def confirm(request):
140 """View handler for the eligibility verification form."""
141
142 verifier = session.verifier(request)
143
144 page = viewmodels.Page(
145 title=_(verifier.form_title),
146 content_title=_(verifier.form_content_title),
147 paragraphs=[_(verifier.form_blurb)],
148 form=forms.EligibilityVerificationForm(auto_id=True, label_suffix="", verifier=verifier),
149 classes="text-lg-center",
150 )
151
152 if request.method == "POST":
153 analytics.started_eligibility(request)
154
155 form = forms.EligibilityVerificationForm(data=request.POST, verifier=verifier)
156 response = _verify(request, form)
157
158 if response is None:
159 # form was not valid, allow for correction/resubmission
160 analytics.returned_error(request, form.errors)
161 page.forms = [form]
162 response = PageTemplateResponse(request, page)
163 elif session.eligible(request):
164 eligibility = session.eligibility(request)
165 response = verified(request, [eligibility.name])
166 else:
167 response = PageTemplateResponse(request, page)
168
169 return response
170
171
172 def _verify(request, form):
173 """Helper calls the eligibility verification API with user input."""
174
175 if not form.is_valid():
176 if recaptcha.has_error(form):
177 messages.error(request, "Recaptcha failed. Please try again.")
178 return None
179
180 sub, name = form.cleaned_data.get("sub"), form.cleaned_data.get("name")
181
182 agency = session.agency(request)
183 verifier = session.verifier(request)
184 client = api.Client(agency, verifier)
185
186 response = client.verify(sub, name)
187
188 if response.error and any(response.error):
189 form.add_api_errors(response.error)
190 return None
191 elif any(response.eligibility):
192 return verified(request, response.eligibility)
193 else:
194 return unverified(request)
195
196
197 @decorator_from_middleware(AgencySessionRequired)
198 @decorator_from_middleware(LoginRequired)
199 def verified(request, verified_types):
200 """View handler for the verified eligibility page."""
201
202 analytics.returned_success(request)
203
204 session.update(request, eligibility_types=verified_types)
205
206 return redirect("enrollment:index")
207
208
209 @decorator_from_middleware(AgencySessionRequired)
210 @decorator_from_middleware(LoginRequired)
211 @decorator_from_middleware(VerifierSessionRequired)
212 def unverified(request):
213 """View handler for the unverified eligibility page."""
214
215 analytics.returned_fail(request)
216
217 # tel: link to agency phone number
218 agency = session.agency(request)
219 buttons = viewmodels.Button.agency_contact_links(agency)
220
221 verifier = session.verifier(request)
222
223 page = viewmodels.Page(
224 title=_(verifier.unverified_title),
225 content_title=_(verifier.unverified_content_title),
226 icon=viewmodels.Icon("idcardquestion", pgettext("image alt text", "core.icons.idcardquestion")),
227 paragraphs=[_(verifier.unverified_blurb), _("eligibility.pages.unverified.p[1]")],
228 buttons=buttons,
229 classes="text-lg-center",
230 )
231
232 return PageTemplateResponse(request, page)
233
[end of benefits/eligibility/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/benefits/eligibility/views.py b/benefits/eligibility/views.py
--- a/benefits/eligibility/views.py
+++ b/benefits/eligibility/views.py
@@ -64,6 +64,8 @@
verifier = session.verifier(request)
button = viewmodels.Button.primary(text=_("eligibility.buttons.continue"), url=reverse("eligibility:confirm"))
+
+ payment_options_link = f"{reverse('core:help')}#payment-options"
media = [
dict(
icon=viewmodels.Icon("idcardcheck", pgettext("image alt text", "core.icons.idcardcheck")),
@@ -72,18 +74,18 @@
),
dict(
icon=viewmodels.Icon("bankcardcheck", pgettext("image alt text", "core.icons.bankcardcheck")),
- heading=_("eligibility.pages.start.items[1].title"),
- details=_("eligibility.pages.start.items[1].text"),
+ heading=_("eligibility.pages.start.bankcard.title"),
+ details=_("eligibility.pages.start.bankcard.text"),
links=[
viewmodels.Button.link(
classes="btn-text btn-link",
- text=_("eligibility.pages.start.items[1].button[0].link"),
- url=_("eligibility.pages.start.items[1].button[0].url"),
+ text=_("eligibility.pages.start.bankcard.button[0].link"),
+ url=payment_options_link,
),
viewmodels.Button.link(
classes="btn-text btn-link",
- text=_("eligibility.pages.start.items[1].button[1].link"),
- url=_("eligibility.pages.start.items[1].button[1].url"),
+ text=_("eligibility.pages.start.bankcard.button[1].link"),
+ url=payment_options_link,
),
],
),
@@ -93,18 +95,19 @@
if settings.OAUTH_CLIENT_NAME is None:
raise Exception("EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None")
+ oauth_help_link = f"{reverse('core:help')}#login-gov"
+
media.insert(
0,
dict(
icon=viewmodels.Icon("idscreencheck", pgettext("image alt text", "core.icons.idscreencheck")),
- heading=_("eligibility.media.heading"),
- details=_("eligibility.media.details"),
+ heading=_("eligibility.pages.start.oauth.heading"),
+ details=_("eligibility.pages.start.oauth.details"),
links=[
viewmodels.Button.link(
classes="btn-text btn-link",
- text=_("eligibility.media.link_text"),
- url=_("eligibility.media.link_url"),
- target="_blank",
+ text=_("eligibility.pages.start.oauth.link_text"),
+ url=oauth_help_link,
rel="noopener noreferrer",
)
],
|
{"golden_diff": "diff --git a/benefits/eligibility/views.py b/benefits/eligibility/views.py\n--- a/benefits/eligibility/views.py\n+++ b/benefits/eligibility/views.py\n@@ -64,6 +64,8 @@\n verifier = session.verifier(request)\n \n button = viewmodels.Button.primary(text=_(\"eligibility.buttons.continue\"), url=reverse(\"eligibility:confirm\"))\n+\n+ payment_options_link = f\"{reverse('core:help')}#payment-options\"\n media = [\n dict(\n icon=viewmodels.Icon(\"idcardcheck\", pgettext(\"image alt text\", \"core.icons.idcardcheck\")),\n@@ -72,18 +74,18 @@\n ),\n dict(\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n- heading=_(\"eligibility.pages.start.items[1].title\"),\n- details=_(\"eligibility.pages.start.items[1].text\"),\n+ heading=_(\"eligibility.pages.start.bankcard.title\"),\n+ details=_(\"eligibility.pages.start.bankcard.text\"),\n links=[\n viewmodels.Button.link(\n classes=\"btn-text btn-link\",\n- text=_(\"eligibility.pages.start.items[1].button[0].link\"),\n- url=_(\"eligibility.pages.start.items[1].button[0].url\"),\n+ text=_(\"eligibility.pages.start.bankcard.button[0].link\"),\n+ url=payment_options_link,\n ),\n viewmodels.Button.link(\n classes=\"btn-text btn-link\",\n- text=_(\"eligibility.pages.start.items[1].button[1].link\"),\n- url=_(\"eligibility.pages.start.items[1].button[1].url\"),\n+ text=_(\"eligibility.pages.start.bankcard.button[1].link\"),\n+ url=payment_options_link,\n ),\n ],\n ),\n@@ -93,18 +95,19 @@\n if settings.OAUTH_CLIENT_NAME is None:\n raise Exception(\"EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None\")\n \n+ oauth_help_link = f\"{reverse('core:help')}#login-gov\"\n+\n media.insert(\n 0,\n dict(\n icon=viewmodels.Icon(\"idscreencheck\", pgettext(\"image alt text\", \"core.icons.idscreencheck\")),\n- heading=_(\"eligibility.media.heading\"),\n- details=_(\"eligibility.media.details\"),\n+ heading=_(\"eligibility.pages.start.oauth.heading\"),\n+ details=_(\"eligibility.pages.start.oauth.details\"),\n links=[\n viewmodels.Button.link(\n classes=\"btn-text btn-link\",\n- text=_(\"eligibility.media.link_text\"),\n- url=_(\"eligibility.media.link_url\"),\n- target=\"_blank\",\n+ text=_(\"eligibility.pages.start.oauth.link_text\"),\n+ url=oauth_help_link,\n rel=\"noopener noreferrer\",\n )\n ],\n", "issue": "\"Learn more about Login.gov\" link should go to `/help#login-gov`\n### Steps to reproduce\r\nOn the `eligibility:start` page, click the \"Learn more about Login.gov\" link.\r\n\r\n### Expected result\r\nThe link goes to the \"What is Login.gov?\" section on the Help page.\r\n\r\n### Actual result\r\nThe link goes to `https://login.gov`.\r\n\n", "before_files": [{"content": "\"\"\"\nThe eligibility application: view definitions for the eligibility verification flow.\n\"\"\"\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.shortcuts import redirect\nfrom django.template.response import TemplateResponse\nfrom django.urls import reverse\nfrom django.utils.decorators import decorator_from_middleware\nfrom django.utils.translation import pgettext, gettext as _\n\nfrom benefits.core import recaptcha, session, viewmodels\nfrom benefits.core.middleware import AgencySessionRequired, LoginRequired, RateLimit, VerifierSessionRequired\nfrom benefits.core.models import EligibilityVerifier\nfrom benefits.core.views import PageTemplateResponse\nfrom . import analytics, api, forms\n\n\n@decorator_from_middleware(AgencySessionRequired)\ndef index(request):\n \"\"\"View handler for the eligibility verifier selection form.\"\"\"\n\n session.update(request, eligibility_types=[], origin=reverse(\"eligibility:index\"))\n agency = session.agency(request)\n\n eligibility_start = reverse(\"eligibility:start\")\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.index.title\"),\n content_title=_(\"eligibility.pages.index.content_title\"),\n forms=forms.EligibilityVerifierSelectionForm(agency=agency),\n )\n\n if request.method == \"POST\":\n form = forms.EligibilityVerifierSelectionForm(data=request.POST, agency=agency)\n\n if form.is_valid():\n verifier_id = form.cleaned_data.get(\"verifier\")\n verifier = EligibilityVerifier.objects.get(id=verifier_id)\n session.update(request, verifier=verifier)\n\n response = redirect(eligibility_start)\n else:\n # form was not valid, allow for correction/resubmission\n page.forms = [form]\n response = PageTemplateResponse(request, page)\n else:\n if agency.eligibility_verifiers.count() == 1:\n verifier = agency.eligibility_verifiers.first()\n session.update(request, verifier=verifier)\n response = redirect(eligibility_start)\n else:\n response = PageTemplateResponse(request, page)\n\n return response\n\n\n@decorator_from_middleware(AgencySessionRequired)\n@decorator_from_middleware(VerifierSessionRequired)\ndef start(request):\n \"\"\"View handler for the eligibility verification getting started screen.\"\"\"\n\n session.update(request, eligibility_types=[], origin=reverse(\"eligibility:start\"))\n verifier = session.verifier(request)\n\n button = viewmodels.Button.primary(text=_(\"eligibility.buttons.continue\"), url=reverse(\"eligibility:confirm\"))\n media = [\n dict(\n icon=viewmodels.Icon(\"idcardcheck\", pgettext(\"image alt text\", \"core.icons.idcardcheck\")),\n heading=_(verifier.start_item_name),\n details=_(verifier.start_item_description),\n ),\n dict(\n icon=viewmodels.Icon(\"bankcardcheck\", pgettext(\"image alt text\", \"core.icons.bankcardcheck\")),\n heading=_(\"eligibility.pages.start.items[1].title\"),\n details=_(\"eligibility.pages.start.items[1].text\"),\n links=[\n viewmodels.Button.link(\n classes=\"btn-text btn-link\",\n text=_(\"eligibility.pages.start.items[1].button[0].link\"),\n url=_(\"eligibility.pages.start.items[1].button[0].url\"),\n ),\n viewmodels.Button.link(\n classes=\"btn-text btn-link\",\n text=_(\"eligibility.pages.start.items[1].button[1].link\"),\n url=_(\"eligibility.pages.start.items[1].button[1].url\"),\n ),\n ],\n ),\n ]\n\n if verifier.requires_authentication:\n if settings.OAUTH_CLIENT_NAME is None:\n raise Exception(\"EligibilityVerifier requires authentication, but OAUTH_CLIENT_NAME is None\")\n\n media.insert(\n 0,\n dict(\n icon=viewmodels.Icon(\"idscreencheck\", pgettext(\"image alt text\", \"core.icons.idscreencheck\")),\n heading=_(\"eligibility.media.heading\"),\n details=_(\"eligibility.media.details\"),\n links=[\n viewmodels.Button.link(\n classes=\"btn-text btn-link\",\n text=_(\"eligibility.media.link_text\"),\n url=_(\"eligibility.media.link_url\"),\n target=\"_blank\",\n rel=\"noopener noreferrer\",\n )\n ],\n ),\n )\n\n if not session.logged_in(request):\n button = viewmodels.Button.login(\n label=_(verifier.auth_provider.sign_in_button_label),\n text=\"\",\n url=reverse(\"oauth:login\"),\n )\n\n page = viewmodels.Page(\n title=_(\"eligibility.pages.start.title\"),\n noimage=True,\n paragraphs=[_(verifier.start_blurb)],\n button=button,\n )\n\n ctx = page.context_dict()\n ctx[\"title\"] = _(verifier.start_content_title)\n ctx[\"media\"] = media\n\n return TemplateResponse(request, \"eligibility/start.html\", ctx)\n\n\n@decorator_from_middleware(AgencySessionRequired)\n@decorator_from_middleware(LoginRequired)\n@decorator_from_middleware(RateLimit)\n@decorator_from_middleware(VerifierSessionRequired)\ndef confirm(request):\n \"\"\"View handler for the eligibility verification form.\"\"\"\n\n verifier = session.verifier(request)\n\n page = viewmodels.Page(\n title=_(verifier.form_title),\n content_title=_(verifier.form_content_title),\n paragraphs=[_(verifier.form_blurb)],\n form=forms.EligibilityVerificationForm(auto_id=True, label_suffix=\"\", verifier=verifier),\n classes=\"text-lg-center\",\n )\n\n if request.method == \"POST\":\n analytics.started_eligibility(request)\n\n form = forms.EligibilityVerificationForm(data=request.POST, verifier=verifier)\n response = _verify(request, form)\n\n if response is None:\n # form was not valid, allow for correction/resubmission\n analytics.returned_error(request, form.errors)\n page.forms = [form]\n response = PageTemplateResponse(request, page)\n elif session.eligible(request):\n eligibility = session.eligibility(request)\n response = verified(request, [eligibility.name])\n else:\n response = PageTemplateResponse(request, page)\n\n return response\n\n\ndef _verify(request, form):\n \"\"\"Helper calls the eligibility verification API with user input.\"\"\"\n\n if not form.is_valid():\n if recaptcha.has_error(form):\n messages.error(request, \"Recaptcha failed. Please try again.\")\n return None\n\n sub, name = form.cleaned_data.get(\"sub\"), form.cleaned_data.get(\"name\")\n\n agency = session.agency(request)\n verifier = session.verifier(request)\n client = api.Client(agency, verifier)\n\n response = client.verify(sub, name)\n\n if response.error and any(response.error):\n form.add_api_errors(response.error)\n return None\n elif any(response.eligibility):\n return verified(request, response.eligibility)\n else:\n return unverified(request)\n\n\n@decorator_from_middleware(AgencySessionRequired)\n@decorator_from_middleware(LoginRequired)\ndef verified(request, verified_types):\n \"\"\"View handler for the verified eligibility page.\"\"\"\n\n analytics.returned_success(request)\n\n session.update(request, eligibility_types=verified_types)\n\n return redirect(\"enrollment:index\")\n\n\n@decorator_from_middleware(AgencySessionRequired)\n@decorator_from_middleware(LoginRequired)\n@decorator_from_middleware(VerifierSessionRequired)\ndef unverified(request):\n \"\"\"View handler for the unverified eligibility page.\"\"\"\n\n analytics.returned_fail(request)\n\n # tel: link to agency phone number\n agency = session.agency(request)\n buttons = viewmodels.Button.agency_contact_links(agency)\n\n verifier = session.verifier(request)\n\n page = viewmodels.Page(\n title=_(verifier.unverified_title),\n content_title=_(verifier.unverified_content_title),\n icon=viewmodels.Icon(\"idcardquestion\", pgettext(\"image alt text\", \"core.icons.idcardquestion\")),\n paragraphs=[_(verifier.unverified_blurb), _(\"eligibility.pages.unverified.p[1]\")],\n buttons=buttons,\n classes=\"text-lg-center\",\n )\n\n return PageTemplateResponse(request, page)\n", "path": "benefits/eligibility/views.py"}]}
| 2,896 | 605 |
gh_patches_debug_2196
|
rasdani/github-patches
|
git_diff
|
getredash__redash-1119
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
User should be able to delete an Alert
Can't remove Alert with UI.
Directly run sql as below.
``` sql
delete from alerts where id = 〜
```
</issue>
<code>
[start of redash/handlers/alerts.py]
1 import time
2
3 from flask import request
4 from funcy import project
5
6 from redash import models
7 from redash.permissions import require_access, require_admin_or_owner, view_only, require_permission
8 from redash.handlers.base import BaseResource, require_fields, get_object_or_404
9
10
11 class AlertResource(BaseResource):
12 def get(self, alert_id):
13 alert = get_object_or_404(models.Alert.get_by_id_and_org, alert_id, self.current_org)
14 require_access(alert.groups, self.current_user, view_only)
15 return alert.to_dict()
16
17 def post(self, alert_id):
18 req = request.get_json(True)
19 params = project(req, ('options', 'name', 'query_id', 'rearm'))
20 alert = get_object_or_404(models.Alert.get_by_id_and_org, alert_id, self.current_org)
21 require_admin_or_owner(alert.user.id)
22
23 if 'query_id' in params:
24 params['query'] = params.pop('query_id')
25
26 alert.update_instance(**params)
27
28 self.record_event({
29 'action': 'edit',
30 'timestamp': int(time.time()),
31 'object_id': alert.id,
32 'object_type': 'alert'
33 })
34
35 return alert.to_dict()
36
37
38 class AlertListResource(BaseResource):
39 def post(self):
40 req = request.get_json(True)
41 require_fields(req, ('options', 'name', 'query_id'))
42
43 query = models.Query.get_by_id_and_org(req['query_id'], self.current_org)
44 require_access(query.groups, self.current_user, view_only)
45
46 alert = models.Alert.create(
47 name=req['name'],
48 query=query,
49 user=self.current_user,
50 options=req['options']
51 )
52
53 self.record_event({
54 'action': 'create',
55 'timestamp': int(time.time()),
56 'object_id': alert.id,
57 'object_type': 'alert'
58 })
59
60 return alert.to_dict()
61
62 @require_permission('list_alerts')
63 def get(self):
64 return [alert.to_dict() for alert in models.Alert.all(groups=self.current_user.groups)]
65
66
67 class AlertSubscriptionListResource(BaseResource):
68 def post(self, alert_id):
69 req = request.get_json(True)
70
71 alert = models.Alert.get_by_id_and_org(alert_id, self.current_org)
72 require_access(alert.groups, self.current_user, view_only)
73 kwargs = {'alert': alert, 'user': self.current_user}
74
75 if 'destination_id' in req:
76 destination = models.NotificationDestination.get_by_id_and_org(req['destination_id'], self.current_org)
77 kwargs['destination'] = destination
78
79 subscription = models.AlertSubscription.create(**kwargs)
80
81 self.record_event({
82 'action': 'subscribe',
83 'timestamp': int(time.time()),
84 'object_id': alert_id,
85 'object_type': 'alert',
86 'destination': req.get('destination_id')
87 })
88
89 return subscription.to_dict()
90
91 def get(self, alert_id):
92 alert = models.Alert.get_by_id_and_org(alert_id, self.current_org)
93 require_access(alert.groups, self.current_user, view_only)
94
95 subscriptions = models.AlertSubscription.all(alert_id)
96 return [s.to_dict() for s in subscriptions]
97
98
99 class AlertSubscriptionResource(BaseResource):
100 def delete(self, alert_id, subscriber_id):
101
102 subscription = get_object_or_404(models.AlertSubscription.get_by_id, subscriber_id)
103 require_admin_or_owner(subscription.user.id)
104 subscription.delete_instance()
105
106 self.record_event({
107 'action': 'unsubscribe',
108 'timestamp': int(time.time()),
109 'object_id': alert_id,
110 'object_type': 'alert'
111 })
112
113
[end of redash/handlers/alerts.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/redash/handlers/alerts.py b/redash/handlers/alerts.py
--- a/redash/handlers/alerts.py
+++ b/redash/handlers/alerts.py
@@ -34,6 +34,11 @@
return alert.to_dict()
+ def delete(self, alert_id):
+ alert = get_object_or_404(models.Alert.get_by_id_and_org, alert_id, self.current_org)
+ require_admin_or_owner(alert.user.id)
+ alert.delete_instance(recursive=True)
+
class AlertListResource(BaseResource):
def post(self):
|
{"golden_diff": "diff --git a/redash/handlers/alerts.py b/redash/handlers/alerts.py\n--- a/redash/handlers/alerts.py\n+++ b/redash/handlers/alerts.py\n@@ -34,6 +34,11 @@\n \n return alert.to_dict()\n \n+ def delete(self, alert_id):\n+ alert = get_object_or_404(models.Alert.get_by_id_and_org, alert_id, self.current_org)\n+ require_admin_or_owner(alert.user.id)\n+ alert.delete_instance(recursive=True)\n+\n \n class AlertListResource(BaseResource):\n def post(self):\n", "issue": "User should be able to delete an Alert\nCan't remove Alert with UI.\n\nDirectly run sql as below.\n\n``` sql\ndelete from alerts where id = \u301c\n```\n\n", "before_files": [{"content": "import time\n\nfrom flask import request\nfrom funcy import project\n\nfrom redash import models\nfrom redash.permissions import require_access, require_admin_or_owner, view_only, require_permission\nfrom redash.handlers.base import BaseResource, require_fields, get_object_or_404\n\n\nclass AlertResource(BaseResource):\n def get(self, alert_id):\n alert = get_object_or_404(models.Alert.get_by_id_and_org, alert_id, self.current_org)\n require_access(alert.groups, self.current_user, view_only)\n return alert.to_dict()\n\n def post(self, alert_id):\n req = request.get_json(True)\n params = project(req, ('options', 'name', 'query_id', 'rearm'))\n alert = get_object_or_404(models.Alert.get_by_id_and_org, alert_id, self.current_org)\n require_admin_or_owner(alert.user.id)\n\n if 'query_id' in params:\n params['query'] = params.pop('query_id')\n\n alert.update_instance(**params)\n\n self.record_event({\n 'action': 'edit',\n 'timestamp': int(time.time()),\n 'object_id': alert.id,\n 'object_type': 'alert'\n })\n\n return alert.to_dict()\n\n\nclass AlertListResource(BaseResource):\n def post(self):\n req = request.get_json(True)\n require_fields(req, ('options', 'name', 'query_id'))\n\n query = models.Query.get_by_id_and_org(req['query_id'], self.current_org)\n require_access(query.groups, self.current_user, view_only)\n\n alert = models.Alert.create(\n name=req['name'],\n query=query,\n user=self.current_user,\n options=req['options']\n )\n\n self.record_event({\n 'action': 'create',\n 'timestamp': int(time.time()),\n 'object_id': alert.id,\n 'object_type': 'alert'\n })\n\n return alert.to_dict()\n\n @require_permission('list_alerts')\n def get(self):\n return [alert.to_dict() for alert in models.Alert.all(groups=self.current_user.groups)]\n\n\nclass AlertSubscriptionListResource(BaseResource):\n def post(self, alert_id):\n req = request.get_json(True)\n\n alert = models.Alert.get_by_id_and_org(alert_id, self.current_org)\n require_access(alert.groups, self.current_user, view_only)\n kwargs = {'alert': alert, 'user': self.current_user}\n\n if 'destination_id' in req:\n destination = models.NotificationDestination.get_by_id_and_org(req['destination_id'], self.current_org)\n kwargs['destination'] = destination\n\n subscription = models.AlertSubscription.create(**kwargs)\n\n self.record_event({\n 'action': 'subscribe',\n 'timestamp': int(time.time()),\n 'object_id': alert_id,\n 'object_type': 'alert',\n 'destination': req.get('destination_id')\n })\n\n return subscription.to_dict()\n\n def get(self, alert_id):\n alert = models.Alert.get_by_id_and_org(alert_id, self.current_org)\n require_access(alert.groups, self.current_user, view_only)\n\n subscriptions = models.AlertSubscription.all(alert_id)\n return [s.to_dict() for s in subscriptions]\n\n\nclass AlertSubscriptionResource(BaseResource):\n def delete(self, alert_id, subscriber_id):\n \n subscription = get_object_or_404(models.AlertSubscription.get_by_id, subscriber_id)\n require_admin_or_owner(subscription.user.id)\n subscription.delete_instance()\n\n self.record_event({\n 'action': 'unsubscribe',\n 'timestamp': int(time.time()),\n 'object_id': alert_id,\n 'object_type': 'alert'\n })\n\n", "path": "redash/handlers/alerts.py"}]}
| 1,594 | 133 |
gh_patches_debug_16403
|
rasdani/github-patches
|
git_diff
|
keras-team__autokeras-407
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
PortableImageSupervised.predict is slow with many images
# Bug Description (maybe feature enhancement.)
PortableImageSupervised.predict method on the cifar10 test dataset is a bit slower when test dataset size is bigger. The number of images in the dataset is 10000.
Maybe predict should be run on gpu like the code in the url above?
https://github.com/jhfjhfj1/autokeras/compare/master...sammy-yusuke:0e71db8dab4841a577c7943daf4bfdb19acbfc0c
### Reproducing Steps
1. Place all files in the URL below into some dir
https://gist.github.com/sammy-yusuke/bc8aa440d2fdbe3908198fdcf82442e2
2. Train model
```
python train_cifar10.py --timelimit-h 0.5 --dataset cifar10
```
3. Test model
```
python test_cifar10.py --training-output-path ~/nas_try/${trained_date}
```
### Expected Behavior
Step 3 should finish in at least 30 min.
### Setup Details
Include the details about the versions of:
- OS type and version: Description: Ubuntu 16.04.5 LTS
- Python: 3.6.6
- autokeras: master
- scikit-learn:0.19.1
- numpy:1.14.5
- keras:2.2.2
- scipy:1.1.0
- tensorflow:1.10.0
- pytorch:0.4.1
### Additional context
I was just trying to see all the results of all searched models by autokeras.
</issue>
<code>
[start of autokeras/image/image_supervised.py]
1 import os
2 from abc import ABC
3 from functools import reduce
4
5 import numpy as np
6 import torch
7
8 from autokeras.constant import Constant
9 from autokeras.nn.loss_function import classification_loss, regression_loss
10 from autokeras.nn.metric import Accuracy, MSE
11 from autokeras.preprocessor import OneHotEncoder, ImageDataTransformer
12 from autokeras.supervised import PortableClass, DeepSupervised
13 from autokeras.utils import pickle_to_file, \
14 read_csv_file, read_image, compute_image_resize_params, resize_image_data
15
16
17 def read_images(img_file_names, images_dir_path):
18 """Read the images from the path and return their numpy.ndarray instance.
19 Return a numpy.ndarray instance containing the training data.
20
21 Args:
22 img_file_names: List containing images names.
23 images_dir_path: Path to the directory containing images.
24 """
25 x_train = []
26 if os.path.isdir(images_dir_path):
27 for img_file in img_file_names:
28 img_path = os.path.join(images_dir_path, img_file)
29 if os.path.exists(img_path):
30 img = read_image(img_path)
31 if len(img.shape) < 3:
32 img = img[..., np.newaxis]
33 x_train.append(img)
34 else:
35 raise ValueError("%s image does not exist" % img_file)
36 else:
37 raise ValueError("Directory containing images does not exist")
38 return np.asanyarray(x_train)
39
40
41 def load_image_dataset(csv_file_path, images_path):
42 """Load images from the files and labels from a csv file.
43
44 Second, the dataset is a set of images and the labels are in a CSV file.
45 The CSV file should contain two columns whose names are 'File Name' and 'Label'.
46 The file names in the first column should match the file names of the images with extensions,
47 e.g., .jpg, .png.
48 The path to the CSV file should be passed through the `csv_file_path`.
49 The path to the directory containing all the images should be passed through `image_path`.
50
51 Args:
52 csv_file_path: CSV file path.
53 images_path: Path where images exist.
54
55 Returns:
56 x: Four dimensional numpy.ndarray. The channel dimension is the last dimension.
57 y: The labels.
58 """
59 img_file_name, y = read_csv_file(csv_file_path)
60 x = read_images(img_file_name, images_path)
61 return np.array(x), np.array(y)
62
63
64 class ImageSupervised(DeepSupervised, ABC):
65 """Abstract image supervised class.
66
67 Attributes:
68 path: A path to the directory to save the classifier as well as intermediate results.
69 cnn: CNN module from net_module.py.
70 y_encoder: Label encoder, used in transform_y or inverse_transform_y for encode the label. For example,
71 if one hot encoder needed, y_encoder can be OneHotEncoder.
72 data_transformer: A transformer class to process the data. See example as ImageDataTransformer.
73 verbose: A boolean value indicating the verbosity mode which determines whether the search process
74 will be printed to stdout.
75 augment: A boolean value indicating whether the data needs augmentation. If not define, then it
76 will use the value of Constant.DATA_AUGMENTATION which is True by default.
77 searcher_args: A dictionary containing the parameters for the searcher's __init__ function.
78 resize_height: resize image height.
79 resize_width: resize image width.
80 """
81
82 def __init__(self, augment=None, **kwargs):
83 """Initialize the instance.
84 The classifier will be loaded from the files in 'path' if parameter 'resume' is True.
85 Otherwise it would create a new one.
86 Args:
87 verbose: A boolean of whether the search process will be printed to stdout.
88 path: A string. The path to a directory, where the intermediate results are saved.
89 resume: A boolean. If True, the classifier will continue to previous work saved in path.
90 Otherwise, the classifier will start a new search.
91 searcher_args: A dictionary containing the parameters for the searcher's __init__ function.
92 augment: A boolean value indicating whether the data needs augmentation. If not define, then it
93 will use the value of Constant.DATA_AUGMENTATION which is True by default.
94 """
95 self.augment = augment if augment is not None else Constant.DATA_AUGMENTATION
96 self.resize_shape = []
97
98 super().__init__(**kwargs)
99
100 def fit(self, x, y, time_limit=None):
101 x = np.array(x)
102 y = np.array(y)
103
104 if self.verbose:
105 print("Preprocessing the images.")
106
107 self.resize_shape = compute_image_resize_params(x)
108
109 x = resize_image_data(x, self.resize_shape)
110
111 if self.verbose:
112 print("Preprocessing finished.")
113
114 super().fit(x, y, time_limit)
115
116 def init_transformer(self, x):
117 if self.data_transformer is None:
118 self.data_transformer = ImageDataTransformer(x, augment=self.augment)
119
120 def export_autokeras_model(self, model_file_name):
121 """ Creates and Exports the AutoKeras model to the given filename. """
122 portable_model = PortableImageSupervised(graph=self.cnn.best_model,
123 y_encoder=self.y_encoder,
124 data_transformer=self.data_transformer,
125 metric=self.metric,
126 inverse_transform_y_method=self.inverse_transform_y,
127 resize_params=self.resize_shape)
128 pickle_to_file(portable_model, model_file_name)
129
130 def preprocess(self, x):
131 return resize_image_data(x, self.resize_shape)
132
133
134 class ImageClassifier(ImageSupervised):
135 """ImageClassifier class.
136
137 It is used for image classification. It searches convolutional neural network architectures
138 for the best configuration for the image dataset.
139 """
140
141 @property
142 def loss(self):
143 return classification_loss
144
145 def transform_y(self, y_train):
146 # Transform y_train.
147 if self.y_encoder is None:
148 self.y_encoder = OneHotEncoder()
149 self.y_encoder.fit(y_train)
150 y_train = self.y_encoder.transform(y_train)
151 return y_train
152
153 def inverse_transform_y(self, output):
154 return self.y_encoder.inverse_transform(output)
155
156 def get_n_output_node(self):
157 return self.y_encoder.n_classes
158
159 @property
160 def metric(self):
161 return Accuracy
162
163
164 class ImageClassifier1D(ImageClassifier):
165 """ ImageClassifier1D class.
166
167 It is used for 1D image classification. It searches convolutional neural network architectures
168 for the best configuration for the 1D image dataset.
169 """
170
171 def __init__(self, **kwargs):
172 kwargs['augment'] = False
173 super().__init__(**kwargs)
174
175
176 class ImageClassifier3D(ImageClassifier):
177 """ ImageClassifier3D class.
178
179 It is used for 3D image classification. It searches convolutional neural network architectures
180 for the best configuration for the 1D image dataset.
181 """
182
183 def __init__(self, **kwargs):
184 kwargs['augment'] = False
185 super().__init__(**kwargs)
186
187
188 class ImageRegressor(ImageSupervised):
189 """ImageRegressor class.
190
191 It is used for image regression. It searches convolutional neural network architectures
192 for the best configuration for the image dataset.
193 """
194
195 @property
196 def loss(self):
197 return regression_loss
198
199 @property
200 def metric(self):
201 return MSE
202
203 def get_n_output_node(self):
204 return 1
205
206 def transform_y(self, y_train):
207 return y_train.flatten().reshape(len(y_train), 1)
208
209 def inverse_transform_y(self, output):
210 return output.flatten()
211
212
213 class ImageRegressor1D(ImageRegressor):
214 """ ImageRegressor1D class.
215
216 It is used for 1D image regression. It searches convolutional neural network architectures
217 for the best configuration for the 1D image dataset.
218 """
219
220 def __init__(self, **kwargs):
221 kwargs['augment'] = False
222 super().__init__(**kwargs)
223
224
225 class ImageRegressor3D(ImageRegressor):
226 """ ImageRegressor3D class.
227
228 It is used for 3D image regression. It searches convolutional neural network architectures
229 for the best configuration for the 1D image dataset.
230 """
231
232 def __init__(self, **kwargs):
233 kwargs['augment'] = False
234 super().__init__(**kwargs)
235
236
237 class PortableImageSupervised(PortableClass):
238 def __init__(self, graph, data_transformer, y_encoder, metric, inverse_transform_y_method, resize_params):
239 """Initialize the instance.
240 Args:
241 graph: The graph form of the learned model
242 """
243 super().__init__(graph)
244 self.data_transformer = data_transformer
245 self.y_encoder = y_encoder
246 self.metric = metric
247 self.inverse_transform_y_method = inverse_transform_y_method
248 self.resize_shape = resize_params
249
250 def predict(self, x_test):
251 """Return predict results for the testing data.
252
253 Args:
254 x_test: An instance of numpy.ndarray containing the testing data.
255
256 Returns:
257 A numpy.ndarray containing the results.
258 """
259 if Constant.LIMIT_MEMORY:
260 pass
261
262 test_loader = self.data_transformer.transform_test(x_test)
263 model = self.graph.produce_model()
264 model.eval()
265
266 outputs = []
267 with torch.no_grad():
268 for index, inputs in enumerate(test_loader):
269 outputs.append(model(inputs).numpy())
270 output = reduce(lambda x, y: np.concatenate((x, y)), outputs)
271 return self.inverse_transform_y(output)
272
273 def inverse_transform_y(self, output):
274 return self.inverse_transform_y_method(output)
275
276 def evaluate(self, x_test, y_test):
277 """Return the accuracy score between predict value and `y_test`."""
278 x_test = resize_image_data(x_test, self.resize_shape)
279 y_predict = self.predict(x_test)
280 return self.metric().evaluate(y_test, y_predict)
281
[end of autokeras/image/image_supervised.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/autokeras/image/image_supervised.py b/autokeras/image/image_supervised.py
--- a/autokeras/image/image_supervised.py
+++ b/autokeras/image/image_supervised.py
@@ -259,6 +259,7 @@
if Constant.LIMIT_MEMORY:
pass
+ x_test = resize_image_data(x_test, self.resize_shape)
test_loader = self.data_transformer.transform_test(x_test)
model = self.graph.produce_model()
model.eval()
@@ -275,6 +276,5 @@
def evaluate(self, x_test, y_test):
"""Return the accuracy score between predict value and `y_test`."""
- x_test = resize_image_data(x_test, self.resize_shape)
y_predict = self.predict(x_test)
return self.metric().evaluate(y_test, y_predict)
|
{"golden_diff": "diff --git a/autokeras/image/image_supervised.py b/autokeras/image/image_supervised.py\n--- a/autokeras/image/image_supervised.py\n+++ b/autokeras/image/image_supervised.py\n@@ -259,6 +259,7 @@\n if Constant.LIMIT_MEMORY:\n pass\n \n+ x_test = resize_image_data(x_test, self.resize_shape)\n test_loader = self.data_transformer.transform_test(x_test)\n model = self.graph.produce_model()\n model.eval()\n@@ -275,6 +276,5 @@\n \n def evaluate(self, x_test, y_test):\n \"\"\"Return the accuracy score between predict value and `y_test`.\"\"\"\n- x_test = resize_image_data(x_test, self.resize_shape)\n y_predict = self.predict(x_test)\n return self.metric().evaluate(y_test, y_predict)\n", "issue": "PortableImageSupervised.predict is slow with many images\n# Bug Description (maybe feature enhancement.)\r\nPortableImageSupervised.predict method on the cifar10 test dataset is a bit slower when test dataset size is bigger. The number of images in the dataset is 10000.\r\nMaybe predict should be run on gpu like the code in the url above?\r\nhttps://github.com/jhfjhfj1/autokeras/compare/master...sammy-yusuke:0e71db8dab4841a577c7943daf4bfdb19acbfc0c\r\n\r\n### Reproducing Steps\r\n1. Place all files in the URL below into some dir\r\nhttps://gist.github.com/sammy-yusuke/bc8aa440d2fdbe3908198fdcf82442e2\r\n2. Train model\r\n```\r\npython train_cifar10.py --timelimit-h 0.5 --dataset cifar10\r\n```\r\n3. Test model\r\n```\r\npython test_cifar10.py --training-output-path ~/nas_try/${trained_date}\r\n```\r\n### Expected Behavior\r\nStep 3 should finish in at least 30 min.\r\n\r\n### Setup Details\r\nInclude the details about the versions of:\r\n - OS type and version: Description: Ubuntu 16.04.5 LTS\r\n - Python: 3.6.6\r\n - autokeras: master\r\n - scikit-learn:0.19.1\r\n - numpy:1.14.5\r\n - keras:2.2.2\r\n - scipy:1.1.0\r\n - tensorflow:1.10.0\r\n - pytorch:0.4.1\r\n\r\n### Additional context\r\nI was just trying to see all the results of all searched models by autokeras.\n", "before_files": [{"content": "import os\nfrom abc import ABC\nfrom functools import reduce\n\nimport numpy as np\nimport torch\n\nfrom autokeras.constant import Constant\nfrom autokeras.nn.loss_function import classification_loss, regression_loss\nfrom autokeras.nn.metric import Accuracy, MSE\nfrom autokeras.preprocessor import OneHotEncoder, ImageDataTransformer\nfrom autokeras.supervised import PortableClass, DeepSupervised\nfrom autokeras.utils import pickle_to_file, \\\n read_csv_file, read_image, compute_image_resize_params, resize_image_data\n\n\ndef read_images(img_file_names, images_dir_path):\n \"\"\"Read the images from the path and return their numpy.ndarray instance.\n Return a numpy.ndarray instance containing the training data.\n\n Args:\n img_file_names: List containing images names.\n images_dir_path: Path to the directory containing images.\n \"\"\"\n x_train = []\n if os.path.isdir(images_dir_path):\n for img_file in img_file_names:\n img_path = os.path.join(images_dir_path, img_file)\n if os.path.exists(img_path):\n img = read_image(img_path)\n if len(img.shape) < 3:\n img = img[..., np.newaxis]\n x_train.append(img)\n else:\n raise ValueError(\"%s image does not exist\" % img_file)\n else:\n raise ValueError(\"Directory containing images does not exist\")\n return np.asanyarray(x_train)\n\n\ndef load_image_dataset(csv_file_path, images_path):\n \"\"\"Load images from the files and labels from a csv file.\n\n Second, the dataset is a set of images and the labels are in a CSV file.\n The CSV file should contain two columns whose names are 'File Name' and 'Label'.\n The file names in the first column should match the file names of the images with extensions,\n e.g., .jpg, .png.\n The path to the CSV file should be passed through the `csv_file_path`.\n The path to the directory containing all the images should be passed through `image_path`.\n\n Args:\n csv_file_path: CSV file path.\n images_path: Path where images exist.\n\n Returns:\n x: Four dimensional numpy.ndarray. The channel dimension is the last dimension.\n y: The labels.\n \"\"\"\n img_file_name, y = read_csv_file(csv_file_path)\n x = read_images(img_file_name, images_path)\n return np.array(x), np.array(y)\n\n\nclass ImageSupervised(DeepSupervised, ABC):\n \"\"\"Abstract image supervised class.\n\n Attributes:\n path: A path to the directory to save the classifier as well as intermediate results.\n cnn: CNN module from net_module.py.\n y_encoder: Label encoder, used in transform_y or inverse_transform_y for encode the label. For example,\n if one hot encoder needed, y_encoder can be OneHotEncoder.\n data_transformer: A transformer class to process the data. See example as ImageDataTransformer.\n verbose: A boolean value indicating the verbosity mode which determines whether the search process\n will be printed to stdout.\n augment: A boolean value indicating whether the data needs augmentation. If not define, then it\n will use the value of Constant.DATA_AUGMENTATION which is True by default.\n searcher_args: A dictionary containing the parameters for the searcher's __init__ function.\n resize_height: resize image height.\n resize_width: resize image width.\n \"\"\"\n\n def __init__(self, augment=None, **kwargs):\n \"\"\"Initialize the instance.\n The classifier will be loaded from the files in 'path' if parameter 'resume' is True.\n Otherwise it would create a new one.\n Args:\n verbose: A boolean of whether the search process will be printed to stdout.\n path: A string. The path to a directory, where the intermediate results are saved.\n resume: A boolean. If True, the classifier will continue to previous work saved in path.\n Otherwise, the classifier will start a new search.\n searcher_args: A dictionary containing the parameters for the searcher's __init__ function.\n augment: A boolean value indicating whether the data needs augmentation. If not define, then it\n will use the value of Constant.DATA_AUGMENTATION which is True by default.\n \"\"\"\n self.augment = augment if augment is not None else Constant.DATA_AUGMENTATION\n self.resize_shape = []\n\n super().__init__(**kwargs)\n\n def fit(self, x, y, time_limit=None):\n x = np.array(x)\n y = np.array(y)\n\n if self.verbose:\n print(\"Preprocessing the images.\")\n\n self.resize_shape = compute_image_resize_params(x)\n\n x = resize_image_data(x, self.resize_shape)\n\n if self.verbose:\n print(\"Preprocessing finished.\")\n\n super().fit(x, y, time_limit)\n\n def init_transformer(self, x):\n if self.data_transformer is None:\n self.data_transformer = ImageDataTransformer(x, augment=self.augment)\n\n def export_autokeras_model(self, model_file_name):\n \"\"\" Creates and Exports the AutoKeras model to the given filename. \"\"\"\n portable_model = PortableImageSupervised(graph=self.cnn.best_model,\n y_encoder=self.y_encoder,\n data_transformer=self.data_transformer,\n metric=self.metric,\n inverse_transform_y_method=self.inverse_transform_y,\n resize_params=self.resize_shape)\n pickle_to_file(portable_model, model_file_name)\n\n def preprocess(self, x):\n return resize_image_data(x, self.resize_shape)\n\n\nclass ImageClassifier(ImageSupervised):\n \"\"\"ImageClassifier class.\n\n It is used for image classification. It searches convolutional neural network architectures\n for the best configuration for the image dataset.\n \"\"\"\n\n @property\n def loss(self):\n return classification_loss\n\n def transform_y(self, y_train):\n # Transform y_train.\n if self.y_encoder is None:\n self.y_encoder = OneHotEncoder()\n self.y_encoder.fit(y_train)\n y_train = self.y_encoder.transform(y_train)\n return y_train\n\n def inverse_transform_y(self, output):\n return self.y_encoder.inverse_transform(output)\n\n def get_n_output_node(self):\n return self.y_encoder.n_classes\n\n @property\n def metric(self):\n return Accuracy\n\n\nclass ImageClassifier1D(ImageClassifier):\n \"\"\" ImageClassifier1D class.\n\n It is used for 1D image classification. It searches convolutional neural network architectures\n for the best configuration for the 1D image dataset.\n \"\"\"\n\n def __init__(self, **kwargs):\n kwargs['augment'] = False\n super().__init__(**kwargs)\n\n\nclass ImageClassifier3D(ImageClassifier):\n \"\"\" ImageClassifier3D class.\n\n It is used for 3D image classification. It searches convolutional neural network architectures\n for the best configuration for the 1D image dataset.\n \"\"\"\n\n def __init__(self, **kwargs):\n kwargs['augment'] = False\n super().__init__(**kwargs)\n\n\nclass ImageRegressor(ImageSupervised):\n \"\"\"ImageRegressor class.\n\n It is used for image regression. It searches convolutional neural network architectures\n for the best configuration for the image dataset.\n \"\"\"\n\n @property\n def loss(self):\n return regression_loss\n\n @property\n def metric(self):\n return MSE\n\n def get_n_output_node(self):\n return 1\n\n def transform_y(self, y_train):\n return y_train.flatten().reshape(len(y_train), 1)\n\n def inverse_transform_y(self, output):\n return output.flatten()\n\n\nclass ImageRegressor1D(ImageRegressor):\n \"\"\" ImageRegressor1D class.\n\n It is used for 1D image regression. It searches convolutional neural network architectures\n for the best configuration for the 1D image dataset.\n \"\"\"\n\n def __init__(self, **kwargs):\n kwargs['augment'] = False\n super().__init__(**kwargs)\n\n\nclass ImageRegressor3D(ImageRegressor):\n \"\"\" ImageRegressor3D class.\n\n It is used for 3D image regression. It searches convolutional neural network architectures\n for the best configuration for the 1D image dataset.\n \"\"\"\n\n def __init__(self, **kwargs):\n kwargs['augment'] = False\n super().__init__(**kwargs)\n\n\nclass PortableImageSupervised(PortableClass):\n def __init__(self, graph, data_transformer, y_encoder, metric, inverse_transform_y_method, resize_params):\n \"\"\"Initialize the instance.\n Args:\n graph: The graph form of the learned model\n \"\"\"\n super().__init__(graph)\n self.data_transformer = data_transformer\n self.y_encoder = y_encoder\n self.metric = metric\n self.inverse_transform_y_method = inverse_transform_y_method\n self.resize_shape = resize_params\n\n def predict(self, x_test):\n \"\"\"Return predict results for the testing data.\n\n Args:\n x_test: An instance of numpy.ndarray containing the testing data.\n\n Returns:\n A numpy.ndarray containing the results.\n \"\"\"\n if Constant.LIMIT_MEMORY:\n pass\n\n test_loader = self.data_transformer.transform_test(x_test)\n model = self.graph.produce_model()\n model.eval()\n\n outputs = []\n with torch.no_grad():\n for index, inputs in enumerate(test_loader):\n outputs.append(model(inputs).numpy())\n output = reduce(lambda x, y: np.concatenate((x, y)), outputs)\n return self.inverse_transform_y(output)\n\n def inverse_transform_y(self, output):\n return self.inverse_transform_y_method(output)\n\n def evaluate(self, x_test, y_test):\n \"\"\"Return the accuracy score between predict value and `y_test`.\"\"\"\n x_test = resize_image_data(x_test, self.resize_shape)\n y_predict = self.predict(x_test)\n return self.metric().evaluate(y_test, y_predict)\n", "path": "autokeras/image/image_supervised.py"}]}
| 3,800 | 190 |
gh_patches_debug_4407
|
rasdani/github-patches
|
git_diff
|
pwndbg__pwndbg-1222
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ipi doesn't work with multiline inputs
TL;DR:
<img width="550" alt="image" src="https://user-images.githubusercontent.com/10009354/193942063-af410d4d-3cdd-4bcb-a102-9bb87d101656.png">
```
pwndbg> ipi
In [1]: from ctypes import *
In [2]: class A(LittleEndianStructure):
...: a = LittleEndianStructure
...:
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-2-814bd2a1d7ec> in <module>
----> 1 class A(LittleEndianStructure):
2 a = LittleEndianStructure
3
<ipython-input-2-814bd2a1d7ec> in A()
1 class A(LittleEndianStructure):
----> 2 a = LittleEndianStructure
3
NameError: name 'LittleEndianStructure' is not defined
In [3]: ctypes
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-3-8c9cdb26e3f3> in <module>
----> 1 ctypes
NameError: name 'ctypes' is not defined
In [4]: LittleEndianStructure
Out[4]: _ctypes.Structure
In [5]: def foo():
...: return LittleEndianStructure
...:
In [6]: foo()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-6-c19b6d9633cf> in <module>
----> 1 foo()
<ipython-input-5-0b19aa36e370> in foo()
1 def foo():
----> 2 return LittleEndianStructure
3
NameError: name 'LittleEndianStructure' is not defined
In [7]:
```
</issue>
<code>
[start of pwndbg/commands/ipython_interactive.py]
1 """
2 Command to start an interactive IPython prompt.
3 """
4 import sys
5 from contextlib import contextmanager
6
7 import gdb
8
9 import pwndbg.color.message as M
10 import pwndbg.commands
11 import pwndbg.lib.stdio
12
13
14 @contextmanager
15 def switch_to_ipython_env():
16 """We need to change stdout/stderr to the default ones, otherwise we can't use tab or autocomplete"""
17 # Save GDB's excepthook
18 saved_excepthook = sys.excepthook
19 # Switch to default stdout/stderr
20 with pwndbg.lib.stdio.stdio:
21 yield
22 # Restore Python's default ps1, ps2, and excepthook for GDB's `pi` command
23 sys.ps1 = ">>> "
24 sys.ps2 = "... "
25 sys.excepthook = saved_excepthook
26
27
28 @pwndbg.commands.ArgparsedCommand("Start an interactive IPython prompt.")
29 def ipi():
30 with switch_to_ipython_env():
31 # Use `gdb.execute` to embed IPython into GDB's variable scope
32 try:
33 gdb.execute("pi import IPython")
34 except gdb.error:
35 print(
36 M.warn(
37 "Cannot import IPython.\n"
38 "You need to install IPython if you want to use this command.\n"
39 "Maybe you can try `pip install ipython` first."
40 )
41 )
42 return
43 code4ipython = """import jedi
44 import pwn
45 jedi.Interpreter._allow_descriptor_getattr_default = False
46 IPython.embed(colors='neutral',banner1='',confirm_exit=False,simple_prompt=False)
47 """
48 gdb.execute(f"py\n{code4ipython}")
49
[end of pwndbg/commands/ipython_interactive.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pwndbg/commands/ipython_interactive.py b/pwndbg/commands/ipython_interactive.py
--- a/pwndbg/commands/ipython_interactive.py
+++ b/pwndbg/commands/ipython_interactive.py
@@ -43,6 +43,6 @@
code4ipython = """import jedi
import pwn
jedi.Interpreter._allow_descriptor_getattr_default = False
-IPython.embed(colors='neutral',banner1='',confirm_exit=False,simple_prompt=False)
+IPython.embed(colors='neutral',banner1='',confirm_exit=False,simple_prompt=False, user_ns=globals())
"""
gdb.execute(f"py\n{code4ipython}")
|
{"golden_diff": "diff --git a/pwndbg/commands/ipython_interactive.py b/pwndbg/commands/ipython_interactive.py\n--- a/pwndbg/commands/ipython_interactive.py\n+++ b/pwndbg/commands/ipython_interactive.py\n@@ -43,6 +43,6 @@\n code4ipython = \"\"\"import jedi\n import pwn\n jedi.Interpreter._allow_descriptor_getattr_default = False\n-IPython.embed(colors='neutral',banner1='',confirm_exit=False,simple_prompt=False)\n+IPython.embed(colors='neutral',banner1='',confirm_exit=False,simple_prompt=False, user_ns=globals())\n \"\"\"\n gdb.execute(f\"py\\n{code4ipython}\")\n", "issue": "ipi doesn't work with multiline inputs\nTL;DR:\r\n<img width=\"550\" alt=\"image\" src=\"https://user-images.githubusercontent.com/10009354/193942063-af410d4d-3cdd-4bcb-a102-9bb87d101656.png\">\r\n\r\n```\r\npwndbg> ipi\r\n\r\nIn [1]: from ctypes import *\r\n\r\nIn [2]: class A(LittleEndianStructure):\r\n ...: a = LittleEndianStructure\r\n ...:\r\n---------------------------------------------------------------------------\r\nNameError Traceback (most recent call last)\r\n<ipython-input-2-814bd2a1d7ec> in <module>\r\n----> 1 class A(LittleEndianStructure):\r\n 2 a = LittleEndianStructure\r\n 3\r\n\r\n<ipython-input-2-814bd2a1d7ec> in A()\r\n 1 class A(LittleEndianStructure):\r\n----> 2 a = LittleEndianStructure\r\n 3\r\n\r\nNameError: name 'LittleEndianStructure' is not defined\r\n\r\nIn [3]: ctypes\r\n---------------------------------------------------------------------------\r\nNameError Traceback (most recent call last)\r\n<ipython-input-3-8c9cdb26e3f3> in <module>\r\n----> 1 ctypes\r\n\r\nNameError: name 'ctypes' is not defined\r\n\r\nIn [4]: LittleEndianStructure\r\nOut[4]: _ctypes.Structure\r\n\r\nIn [5]: def foo():\r\n ...: return LittleEndianStructure\r\n ...:\r\n\r\nIn [6]: foo()\r\n---------------------------------------------------------------------------\r\nNameError Traceback (most recent call last)\r\n<ipython-input-6-c19b6d9633cf> in <module>\r\n----> 1 foo()\r\n\r\n<ipython-input-5-0b19aa36e370> in foo()\r\n 1 def foo():\r\n----> 2 return LittleEndianStructure\r\n 3\r\n\r\nNameError: name 'LittleEndianStructure' is not defined\r\n\r\nIn [7]:\r\n```\n", "before_files": [{"content": "\"\"\"\nCommand to start an interactive IPython prompt.\n\"\"\"\nimport sys\nfrom contextlib import contextmanager\n\nimport gdb\n\nimport pwndbg.color.message as M\nimport pwndbg.commands\nimport pwndbg.lib.stdio\n\n\n@contextmanager\ndef switch_to_ipython_env():\n \"\"\"We need to change stdout/stderr to the default ones, otherwise we can't use tab or autocomplete\"\"\"\n # Save GDB's excepthook\n saved_excepthook = sys.excepthook\n # Switch to default stdout/stderr\n with pwndbg.lib.stdio.stdio:\n yield\n # Restore Python's default ps1, ps2, and excepthook for GDB's `pi` command\n sys.ps1 = \">>> \"\n sys.ps2 = \"... \"\n sys.excepthook = saved_excepthook\n\n\[email protected](\"Start an interactive IPython prompt.\")\ndef ipi():\n with switch_to_ipython_env():\n # Use `gdb.execute` to embed IPython into GDB's variable scope\n try:\n gdb.execute(\"pi import IPython\")\n except gdb.error:\n print(\n M.warn(\n \"Cannot import IPython.\\n\"\n \"You need to install IPython if you want to use this command.\\n\"\n \"Maybe you can try `pip install ipython` first.\"\n )\n )\n return\n code4ipython = \"\"\"import jedi\nimport pwn\njedi.Interpreter._allow_descriptor_getattr_default = False\nIPython.embed(colors='neutral',banner1='',confirm_exit=False,simple_prompt=False)\n\"\"\"\n gdb.execute(f\"py\\n{code4ipython}\")\n", "path": "pwndbg/commands/ipython_interactive.py"}]}
| 1,450 | 153 |
gh_patches_debug_42224
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-567
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Code actions of CodeActionLiteral type are not supported (used by eslint-server)
While experimenting with [eslint-server](https://github.com/Microsoft/vscode-eslint/tree/master/server), I've noticed that its code actions for fixing lint issues are not handled properly.
I found two issues:
- handling CodeActions action list as an array of `Command` while protocol also allows array of `CodeAction`.
- Passing `args` param to `workspace/executeCommand` instead of expected `arguments` param.
</issue>
<code>
[start of plugin/core/sessions.py]
1 from .types import ClientConfig, ClientStates, Settings
2 from .protocol import Request
3 from .transports import start_tcp_transport
4 from .rpc import Client, attach_stdio_client
5 from .process import start_server
6 from .url import filename_to_uri
7 from .logging import debug
8 import os
9 from .protocol import CompletionItemKind, SymbolKind
10 try:
11 from typing import Callable, Dict, Any, Optional
12 assert Callable and Dict and Any and Optional
13 except ImportError:
14 pass
15
16
17 def create_session(config: ClientConfig, project_path: str, env: dict, settings: Settings,
18 on_created=None, on_ended: 'Optional[Callable[[str], None]]' = None,
19 bootstrap_client=None) -> 'Optional[Session]':
20 session = None
21 if config.binary_args:
22
23 process = start_server(config.binary_args, project_path, env, settings.log_stderr)
24 if process:
25 if config.tcp_port:
26 transport = start_tcp_transport(config.tcp_port, config.tcp_host)
27 if transport:
28 session = Session(config, project_path, Client(transport, settings), on_created, on_ended)
29 else:
30 # try to terminate the process
31 try:
32 process.terminate()
33 except Exception:
34 pass
35 else:
36 client = attach_stdio_client(process, settings)
37 session = Session(config, project_path, client, on_created, on_ended)
38 else:
39 if config.tcp_port:
40 transport = start_tcp_transport(config.tcp_port)
41
42 session = Session(config, project_path, Client(transport, settings),
43 on_created, on_ended)
44 elif bootstrap_client:
45 session = Session(config, project_path, bootstrap_client,
46 on_created, on_ended)
47 else:
48 debug("No way to start session")
49
50 return session
51
52
53 def get_initialize_params(project_path: str, config: ClientConfig):
54 initializeParams = {
55 "processId": os.getpid(),
56 "rootUri": filename_to_uri(project_path),
57 "rootPath": project_path,
58 "capabilities": {
59 "textDocument": {
60 "synchronization": {
61 "didSave": True
62 },
63 "hover": {
64 "contentFormat": ["markdown", "plaintext"]
65 },
66 "completion": {
67 "completionItem": {
68 "snippetSupport": True
69 },
70 "completionItemKind": {
71 "valueSet": [
72 CompletionItemKind.Text,
73 CompletionItemKind.Method,
74 CompletionItemKind.Function,
75 CompletionItemKind.Constructor,
76 CompletionItemKind.Field,
77 CompletionItemKind.Variable,
78 CompletionItemKind.Class,
79 CompletionItemKind.Interface,
80 CompletionItemKind.Module,
81 CompletionItemKind.Property,
82 CompletionItemKind.Unit,
83 CompletionItemKind.Value,
84 CompletionItemKind.Enum,
85 CompletionItemKind.Keyword,
86 CompletionItemKind.Snippet,
87 CompletionItemKind.Color,
88 CompletionItemKind.File,
89 CompletionItemKind.Reference
90 ]
91 }
92 },
93 "signatureHelp": {
94 "signatureInformation": {
95 "documentationFormat": ["markdown", "plaintext"],
96 "parameterInformation": {
97 "labelOffsetSupport": True
98 }
99 }
100 },
101 "references": {},
102 "documentHighlight": {},
103 "documentSymbol": {
104 "symbolKind": {
105 "valueSet": [
106 SymbolKind.File,
107 SymbolKind.Module,
108 SymbolKind.Namespace,
109 SymbolKind.Package,
110 SymbolKind.Class,
111 SymbolKind.Method,
112 SymbolKind.Property,
113 SymbolKind.Field,
114 SymbolKind.Constructor,
115 SymbolKind.Enum,
116 SymbolKind.Interface,
117 SymbolKind.Function,
118 SymbolKind.Variable,
119 SymbolKind.Constant,
120 SymbolKind.String,
121 SymbolKind.Number,
122 SymbolKind.Boolean,
123 SymbolKind.Array,
124 SymbolKind.Object,
125 SymbolKind.Key,
126 SymbolKind.Null,
127 SymbolKind.EnumMember,
128 SymbolKind.Struct,
129 SymbolKind.Event,
130 SymbolKind.Operator,
131 SymbolKind.TypeParameter
132 ]
133 }
134 },
135 "formatting": {},
136 "rangeFormatting": {},
137 "definition": {},
138 "codeAction": {},
139 "rename": {}
140 },
141 "workspace": {
142 "applyEdit": True,
143 "didChangeConfiguration": {}
144 }
145 }
146 }
147 if config.init_options:
148 initializeParams['initializationOptions'] = config.init_options
149
150 return initializeParams
151
152
153 class Session(object):
154 def __init__(self, config: ClientConfig, project_path, client: Client,
155 on_created=None, on_ended: 'Optional[Callable[[str], None]]' = None) -> None:
156 self.config = config
157 self.project_path = project_path
158 self.state = ClientStates.STARTING
159 self._on_created = on_created
160 self._on_ended = on_ended
161 self.capabilities = dict() # type: Dict[str, Any]
162 self.client = client
163 self.initialize()
164
165 def has_capability(self, capability):
166 return capability in self.capabilities and self.capabilities[capability] is not False
167
168 def get_capability(self, capability):
169 return self.capabilities.get(capability)
170
171 def initialize(self):
172 params = get_initialize_params(self.project_path, self.config)
173 self.client.send_request(
174 Request.initialize(params),
175 lambda result: self._handle_initialize_result(result))
176
177 def _handle_initialize_result(self, result):
178 self.state = ClientStates.READY
179 self.capabilities = result.get('capabilities', dict())
180 if self._on_created:
181 self._on_created(self)
182
183 def end(self):
184 self.state = ClientStates.STOPPING
185 self.client.send_request(
186 Request.shutdown(),
187 lambda result: self._handle_shutdown_result(),
188 lambda: self._handle_shutdown_result())
189
190 def _handle_shutdown_result(self):
191 self.client.exit()
192 self.client = None
193 self.capabilities = dict()
194 if self._on_ended:
195 self._on_ended(self.config.name)
196
[end of plugin/core/sessions.py]
[start of plugin/code_actions.py]
1 import sublime_plugin
2 import sublime
3
4 try:
5 from typing import Any, List, Dict, Callable, Optional
6 assert Any and List and Dict and Callable and Optional
7 except ImportError:
8 pass
9
10 from .core.registry import client_for_view, LspTextCommand
11 from .core.protocol import Request
12 from .diagnostics import get_point_diagnostics
13 from .core.url import filename_to_uri
14 from .core.views import region_to_range
15 from .core.registry import session_for_view
16 from .core.settings import settings
17
18
19 def send_code_action_request(view, on_response_recieved: 'Callable'):
20 session = session_for_view(view)
21 if not session or not session.has_capability('codeActionProvider'):
22 # the server doesn't support code actions, just return
23 return
24
25 region = view.sel()[0]
26 pos = region.begin()
27 point_diagnostics = get_point_diagnostics(view, pos)
28 params = {
29 "textDocument": {
30 "uri": filename_to_uri(view.file_name())
31 },
32 "range": region_to_range(view, region).to_lsp(),
33 "context": {
34 "diagnostics": list(diagnostic.to_lsp() for diagnostic in point_diagnostics)
35 }
36 }
37 session.client.send_request(
38 Request.codeAction(params),
39 lambda response: on_response_recieved(response))
40
41
42 class LspCodeActionBulbListener(sublime_plugin.ViewEventListener):
43 def __init__(self, view: sublime.View) -> None:
44 super().__init__(view)
45 self._stored_point = -1
46
47 @classmethod
48 def is_applicable(cls, _settings):
49 if settings.show_code_actions_bulb:
50 return True
51 return False
52
53 def on_selection_modified_async(self):
54 self.hide_bulb()
55 self.schedule_request()
56
57 def schedule_request(self):
58 current_point = self.view.sel()[0].begin()
59 if self._stored_point != current_point:
60 self._stored_point = current_point
61 sublime.set_timeout_async(lambda: self.fire_request(current_point), 800)
62
63 def fire_request(self, current_point: int) -> None:
64 if current_point == self._stored_point:
65 send_code_action_request(self.view, self.handle_response)
66
67 def handle_response(self, response) -> None:
68 if settings.show_code_actions_bulb:
69 if len(response) > 0:
70 self.show_bulb()
71 else:
72 self.hide_bulb()
73
74 def show_bulb(self) -> None:
75 region = self.view.sel()[0]
76 flags = sublime.DRAW_NO_FILL | sublime.DRAW_NO_OUTLINE
77 self.view.add_regions('lsp_bulb', [region], 'markup.changed', 'Packages/LSP/icons/lightbulb.png', flags)
78
79 def hide_bulb(self) -> None:
80 self.view.erase_regions('lsp_bulb')
81
82
83 class LspCodeActionsCommand(LspTextCommand):
84 def is_enabled(self):
85 return self.has_client_with_capability('codeActionProvider')
86
87 def run(self, edit):
88 self.commands = [] # type: List[Dict]
89
90 send_code_action_request(self.view, self.handle_response)
91
92 def get_titles(self):
93 ''' Return a list of all command titles. '''
94 titles = []
95 for command in self.commands:
96 titles.append(command.get('title')) # TODO parse command and arguments
97 return titles
98
99 def handle_response(self, response: 'Optional[List[Dict]]') -> None:
100 self.commands = response or []
101 self.show_popup_menu()
102
103 def show_popup_menu(self) -> None:
104 if len(self.commands) > 0:
105 self.view.show_popup_menu(self.get_titles(), self.handle_select)
106 else:
107 self.view.show_popup('No actions available', sublime.HIDE_ON_MOUSE_MOVE_AWAY)
108
109 def handle_select(self, index: int) -> None:
110 if index > -1:
111 client = client_for_view(self.view)
112 if client:
113 client.send_request(
114 Request.executeCommand(self.commands[index]),
115 self.handle_command_response)
116
117 def handle_command_response(self, response):
118 pass
119
[end of plugin/code_actions.py]
[start of plugin/execute_command.py]
1 import sublime
2 from .core.registry import client_for_view, LspTextCommand
3 from .core.protocol import Request
4 from .core.rpc import Client
5
6 try:
7 from typing import List, Optional, Dict, Any, Tuple
8 assert List and Optional and Dict and Any, Tuple
9 except ImportError:
10 pass
11
12
13 class LspExecuteCommand(LspTextCommand):
14 def __init__(self, view):
15 super().__init__(view)
16
17 def run(self, edit, command_name=None, command_args=None) -> None:
18 client = client_for_view(self.view)
19 if client and command_name:
20 self.view.window().status_message("Running command {}".format(command_name))
21 self._send_command(client, command_name, command_args)
22
23 def _handle_response(self, command: str, response: 'Optional[Any]') -> None:
24 msg = "command {} completed".format(command)
25 if response:
26 msg += "with response: {}".format(response)
27 sublime.message_dialog(msg)
28
29 def _handle_error(self, command: str, error: 'Dict[str, Any]') -> None:
30 msg = "command {} failed. Reason: {}".format(command, error.get("message", "none provided by server :("))
31 sublime.message_dialog(msg)
32
33 def _send_command(self, client: Client, command_name: str, command_args: 'Dict[str, Any]') -> None:
34 request = {
35 "command": command_name,
36 "arguments": command_args
37 }
38 client.send_request(Request.executeCommand(request),
39 lambda reponse: self._handle_response(command_name, reponse),
40 lambda error: self._handle_error(command_name, error))
41
[end of plugin/execute_command.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/code_actions.py b/plugin/code_actions.py
--- a/plugin/code_actions.py
+++ b/plugin/code_actions.py
@@ -10,6 +10,7 @@
from .core.registry import client_for_view, LspTextCommand
from .core.protocol import Request
from .diagnostics import get_point_diagnostics
+from .core.edit import parse_workspace_edit
from .core.url import filename_to_uri
from .core.views import region_to_range
from .core.registry import session_for_view
@@ -80,6 +81,11 @@
self.view.erase_regions('lsp_bulb')
+def is_command(command_or_code_action: dict) -> bool:
+ command_field = command_or_code_action.get('command')
+ return isinstance(command_field, str)
+
+
class LspCodeActionsCommand(LspTextCommand):
def is_enabled(self):
return self.has_client_with_capability('codeActionProvider')
@@ -108,11 +114,26 @@
def handle_select(self, index: int) -> None:
if index > -1:
- client = client_for_view(self.view)
- if client:
- client.send_request(
- Request.executeCommand(self.commands[index]),
- self.handle_command_response)
+
+ selected = self.commands[index]
+ if is_command(selected):
+ self.run_command(selected)
+ else:
+ # CodeAction can have an edit and/or command.
+ maybe_edit = selected.get('edit')
+ if maybe_edit:
+ changes = parse_workspace_edit(maybe_edit)
+ self.view.window().run_command("lsp_apply_workspace_edit", {'changes': changes})
+ maybe_command = selected.get('command')
+ if maybe_command:
+ self.run_command(maybe_command)
+
+ def run_command(self, command) -> None:
+ client = client_for_view(self.view)
+ if client:
+ client.send_request(
+ Request.executeCommand(command),
+ self.handle_command_response)
def handle_command_response(self, response):
pass
diff --git a/plugin/core/sessions.py b/plugin/core/sessions.py
--- a/plugin/core/sessions.py
+++ b/plugin/core/sessions.py
@@ -135,12 +135,15 @@
"formatting": {},
"rangeFormatting": {},
"definition": {},
- "codeAction": {},
+ "codeAction": {
+ "codeActionLiteralSupport": {}
+ },
"rename": {}
},
"workspace": {
"applyEdit": True,
- "didChangeConfiguration": {}
+ "didChangeConfiguration": {},
+ "executeCommand": {},
}
}
}
diff --git a/plugin/execute_command.py b/plugin/execute_command.py
--- a/plugin/execute_command.py
+++ b/plugin/execute_command.py
@@ -24,13 +24,14 @@
msg = "command {} completed".format(command)
if response:
msg += "with response: {}".format(response)
+
sublime.message_dialog(msg)
def _handle_error(self, command: str, error: 'Dict[str, Any]') -> None:
msg = "command {} failed. Reason: {}".format(command, error.get("message", "none provided by server :("))
sublime.message_dialog(msg)
- def _send_command(self, client: Client, command_name: str, command_args: 'Dict[str, Any]') -> None:
+ def _send_command(self, client: Client, command_name: str, command_args: 'Optional[List[Any]]') -> None:
request = {
"command": command_name,
"arguments": command_args
|
{"golden_diff": "diff --git a/plugin/code_actions.py b/plugin/code_actions.py\n--- a/plugin/code_actions.py\n+++ b/plugin/code_actions.py\n@@ -10,6 +10,7 @@\n from .core.registry import client_for_view, LspTextCommand\n from .core.protocol import Request\n from .diagnostics import get_point_diagnostics\n+from .core.edit import parse_workspace_edit\n from .core.url import filename_to_uri\n from .core.views import region_to_range\n from .core.registry import session_for_view\n@@ -80,6 +81,11 @@\n self.view.erase_regions('lsp_bulb')\n \n \n+def is_command(command_or_code_action: dict) -> bool:\n+ command_field = command_or_code_action.get('command')\n+ return isinstance(command_field, str)\n+\n+\n class LspCodeActionsCommand(LspTextCommand):\n def is_enabled(self):\n return self.has_client_with_capability('codeActionProvider')\n@@ -108,11 +114,26 @@\n \n def handle_select(self, index: int) -> None:\n if index > -1:\n- client = client_for_view(self.view)\n- if client:\n- client.send_request(\n- Request.executeCommand(self.commands[index]),\n- self.handle_command_response)\n+\n+ selected = self.commands[index]\n+ if is_command(selected):\n+ self.run_command(selected)\n+ else:\n+ # CodeAction can have an edit and/or command.\n+ maybe_edit = selected.get('edit')\n+ if maybe_edit:\n+ changes = parse_workspace_edit(maybe_edit)\n+ self.view.window().run_command(\"lsp_apply_workspace_edit\", {'changes': changes})\n+ maybe_command = selected.get('command')\n+ if maybe_command:\n+ self.run_command(maybe_command)\n+\n+ def run_command(self, command) -> None:\n+ client = client_for_view(self.view)\n+ if client:\n+ client.send_request(\n+ Request.executeCommand(command),\n+ self.handle_command_response)\n \n def handle_command_response(self, response):\n pass\ndiff --git a/plugin/core/sessions.py b/plugin/core/sessions.py\n--- a/plugin/core/sessions.py\n+++ b/plugin/core/sessions.py\n@@ -135,12 +135,15 @@\n \"formatting\": {},\n \"rangeFormatting\": {},\n \"definition\": {},\n- \"codeAction\": {},\n+ \"codeAction\": {\n+ \"codeActionLiteralSupport\": {}\n+ },\n \"rename\": {}\n },\n \"workspace\": {\n \"applyEdit\": True,\n- \"didChangeConfiguration\": {}\n+ \"didChangeConfiguration\": {},\n+ \"executeCommand\": {},\n }\n }\n }\ndiff --git a/plugin/execute_command.py b/plugin/execute_command.py\n--- a/plugin/execute_command.py\n+++ b/plugin/execute_command.py\n@@ -24,13 +24,14 @@\n msg = \"command {} completed\".format(command)\n if response:\n msg += \"with response: {}\".format(response)\n+\n sublime.message_dialog(msg)\n \n def _handle_error(self, command: str, error: 'Dict[str, Any]') -> None:\n msg = \"command {} failed. Reason: {}\".format(command, error.get(\"message\", \"none provided by server :(\"))\n sublime.message_dialog(msg)\n \n- def _send_command(self, client: Client, command_name: str, command_args: 'Dict[str, Any]') -> None:\n+ def _send_command(self, client: Client, command_name: str, command_args: 'Optional[List[Any]]') -> None:\n request = {\n \"command\": command_name,\n \"arguments\": command_args\n", "issue": "Code actions of CodeActionLiteral type are not supported (used by eslint-server)\nWhile experimenting with [eslint-server](https://github.com/Microsoft/vscode-eslint/tree/master/server), I've noticed that its code actions for fixing lint issues are not handled properly.\r\n\r\nI found two issues:\r\n - handling CodeActions action list as an array of `Command` while protocol also allows array of `CodeAction`.\r\n - Passing `args` param to `workspace/executeCommand` instead of expected `arguments` param.\n", "before_files": [{"content": "from .types import ClientConfig, ClientStates, Settings\nfrom .protocol import Request\nfrom .transports import start_tcp_transport\nfrom .rpc import Client, attach_stdio_client\nfrom .process import start_server\nfrom .url import filename_to_uri\nfrom .logging import debug\nimport os\nfrom .protocol import CompletionItemKind, SymbolKind\ntry:\n from typing import Callable, Dict, Any, Optional\n assert Callable and Dict and Any and Optional\nexcept ImportError:\n pass\n\n\ndef create_session(config: ClientConfig, project_path: str, env: dict, settings: Settings,\n on_created=None, on_ended: 'Optional[Callable[[str], None]]' = None,\n bootstrap_client=None) -> 'Optional[Session]':\n session = None\n if config.binary_args:\n\n process = start_server(config.binary_args, project_path, env, settings.log_stderr)\n if process:\n if config.tcp_port:\n transport = start_tcp_transport(config.tcp_port, config.tcp_host)\n if transport:\n session = Session(config, project_path, Client(transport, settings), on_created, on_ended)\n else:\n # try to terminate the process\n try:\n process.terminate()\n except Exception:\n pass\n else:\n client = attach_stdio_client(process, settings)\n session = Session(config, project_path, client, on_created, on_ended)\n else:\n if config.tcp_port:\n transport = start_tcp_transport(config.tcp_port)\n\n session = Session(config, project_path, Client(transport, settings),\n on_created, on_ended)\n elif bootstrap_client:\n session = Session(config, project_path, bootstrap_client,\n on_created, on_ended)\n else:\n debug(\"No way to start session\")\n\n return session\n\n\ndef get_initialize_params(project_path: str, config: ClientConfig):\n initializeParams = {\n \"processId\": os.getpid(),\n \"rootUri\": filename_to_uri(project_path),\n \"rootPath\": project_path,\n \"capabilities\": {\n \"textDocument\": {\n \"synchronization\": {\n \"didSave\": True\n },\n \"hover\": {\n \"contentFormat\": [\"markdown\", \"plaintext\"]\n },\n \"completion\": {\n \"completionItem\": {\n \"snippetSupport\": True\n },\n \"completionItemKind\": {\n \"valueSet\": [\n CompletionItemKind.Text,\n CompletionItemKind.Method,\n CompletionItemKind.Function,\n CompletionItemKind.Constructor,\n CompletionItemKind.Field,\n CompletionItemKind.Variable,\n CompletionItemKind.Class,\n CompletionItemKind.Interface,\n CompletionItemKind.Module,\n CompletionItemKind.Property,\n CompletionItemKind.Unit,\n CompletionItemKind.Value,\n CompletionItemKind.Enum,\n CompletionItemKind.Keyword,\n CompletionItemKind.Snippet,\n CompletionItemKind.Color,\n CompletionItemKind.File,\n CompletionItemKind.Reference\n ]\n }\n },\n \"signatureHelp\": {\n \"signatureInformation\": {\n \"documentationFormat\": [\"markdown\", \"plaintext\"],\n \"parameterInformation\": {\n \"labelOffsetSupport\": True\n }\n }\n },\n \"references\": {},\n \"documentHighlight\": {},\n \"documentSymbol\": {\n \"symbolKind\": {\n \"valueSet\": [\n SymbolKind.File,\n SymbolKind.Module,\n SymbolKind.Namespace,\n SymbolKind.Package,\n SymbolKind.Class,\n SymbolKind.Method,\n SymbolKind.Property,\n SymbolKind.Field,\n SymbolKind.Constructor,\n SymbolKind.Enum,\n SymbolKind.Interface,\n SymbolKind.Function,\n SymbolKind.Variable,\n SymbolKind.Constant,\n SymbolKind.String,\n SymbolKind.Number,\n SymbolKind.Boolean,\n SymbolKind.Array,\n SymbolKind.Object,\n SymbolKind.Key,\n SymbolKind.Null,\n SymbolKind.EnumMember,\n SymbolKind.Struct,\n SymbolKind.Event,\n SymbolKind.Operator,\n SymbolKind.TypeParameter\n ]\n }\n },\n \"formatting\": {},\n \"rangeFormatting\": {},\n \"definition\": {},\n \"codeAction\": {},\n \"rename\": {}\n },\n \"workspace\": {\n \"applyEdit\": True,\n \"didChangeConfiguration\": {}\n }\n }\n }\n if config.init_options:\n initializeParams['initializationOptions'] = config.init_options\n\n return initializeParams\n\n\nclass Session(object):\n def __init__(self, config: ClientConfig, project_path, client: Client,\n on_created=None, on_ended: 'Optional[Callable[[str], None]]' = None) -> None:\n self.config = config\n self.project_path = project_path\n self.state = ClientStates.STARTING\n self._on_created = on_created\n self._on_ended = on_ended\n self.capabilities = dict() # type: Dict[str, Any]\n self.client = client\n self.initialize()\n\n def has_capability(self, capability):\n return capability in self.capabilities and self.capabilities[capability] is not False\n\n def get_capability(self, capability):\n return self.capabilities.get(capability)\n\n def initialize(self):\n params = get_initialize_params(self.project_path, self.config)\n self.client.send_request(\n Request.initialize(params),\n lambda result: self._handle_initialize_result(result))\n\n def _handle_initialize_result(self, result):\n self.state = ClientStates.READY\n self.capabilities = result.get('capabilities', dict())\n if self._on_created:\n self._on_created(self)\n\n def end(self):\n self.state = ClientStates.STOPPING\n self.client.send_request(\n Request.shutdown(),\n lambda result: self._handle_shutdown_result(),\n lambda: self._handle_shutdown_result())\n\n def _handle_shutdown_result(self):\n self.client.exit()\n self.client = None\n self.capabilities = dict()\n if self._on_ended:\n self._on_ended(self.config.name)\n", "path": "plugin/core/sessions.py"}, {"content": "import sublime_plugin\nimport sublime\n\ntry:\n from typing import Any, List, Dict, Callable, Optional\n assert Any and List and Dict and Callable and Optional\nexcept ImportError:\n pass\n\nfrom .core.registry import client_for_view, LspTextCommand\nfrom .core.protocol import Request\nfrom .diagnostics import get_point_diagnostics\nfrom .core.url import filename_to_uri\nfrom .core.views import region_to_range\nfrom .core.registry import session_for_view\nfrom .core.settings import settings\n\n\ndef send_code_action_request(view, on_response_recieved: 'Callable'):\n session = session_for_view(view)\n if not session or not session.has_capability('codeActionProvider'):\n # the server doesn't support code actions, just return\n return\n\n region = view.sel()[0]\n pos = region.begin()\n point_diagnostics = get_point_diagnostics(view, pos)\n params = {\n \"textDocument\": {\n \"uri\": filename_to_uri(view.file_name())\n },\n \"range\": region_to_range(view, region).to_lsp(),\n \"context\": {\n \"diagnostics\": list(diagnostic.to_lsp() for diagnostic in point_diagnostics)\n }\n }\n session.client.send_request(\n Request.codeAction(params),\n lambda response: on_response_recieved(response))\n\n\nclass LspCodeActionBulbListener(sublime_plugin.ViewEventListener):\n def __init__(self, view: sublime.View) -> None:\n super().__init__(view)\n self._stored_point = -1\n\n @classmethod\n def is_applicable(cls, _settings):\n if settings.show_code_actions_bulb:\n return True\n return False\n\n def on_selection_modified_async(self):\n self.hide_bulb()\n self.schedule_request()\n\n def schedule_request(self):\n current_point = self.view.sel()[0].begin()\n if self._stored_point != current_point:\n self._stored_point = current_point\n sublime.set_timeout_async(lambda: self.fire_request(current_point), 800)\n\n def fire_request(self, current_point: int) -> None:\n if current_point == self._stored_point:\n send_code_action_request(self.view, self.handle_response)\n\n def handle_response(self, response) -> None:\n if settings.show_code_actions_bulb:\n if len(response) > 0:\n self.show_bulb()\n else:\n self.hide_bulb()\n\n def show_bulb(self) -> None:\n region = self.view.sel()[0]\n flags = sublime.DRAW_NO_FILL | sublime.DRAW_NO_OUTLINE\n self.view.add_regions('lsp_bulb', [region], 'markup.changed', 'Packages/LSP/icons/lightbulb.png', flags)\n\n def hide_bulb(self) -> None:\n self.view.erase_regions('lsp_bulb')\n\n\nclass LspCodeActionsCommand(LspTextCommand):\n def is_enabled(self):\n return self.has_client_with_capability('codeActionProvider')\n\n def run(self, edit):\n self.commands = [] # type: List[Dict]\n\n send_code_action_request(self.view, self.handle_response)\n\n def get_titles(self):\n ''' Return a list of all command titles. '''\n titles = []\n for command in self.commands:\n titles.append(command.get('title')) # TODO parse command and arguments\n return titles\n\n def handle_response(self, response: 'Optional[List[Dict]]') -> None:\n self.commands = response or []\n self.show_popup_menu()\n\n def show_popup_menu(self) -> None:\n if len(self.commands) > 0:\n self.view.show_popup_menu(self.get_titles(), self.handle_select)\n else:\n self.view.show_popup('No actions available', sublime.HIDE_ON_MOUSE_MOVE_AWAY)\n\n def handle_select(self, index: int) -> None:\n if index > -1:\n client = client_for_view(self.view)\n if client:\n client.send_request(\n Request.executeCommand(self.commands[index]),\n self.handle_command_response)\n\n def handle_command_response(self, response):\n pass\n", "path": "plugin/code_actions.py"}, {"content": "import sublime\nfrom .core.registry import client_for_view, LspTextCommand\nfrom .core.protocol import Request\nfrom .core.rpc import Client\n\ntry:\n from typing import List, Optional, Dict, Any, Tuple\n assert List and Optional and Dict and Any, Tuple\nexcept ImportError:\n pass\n\n\nclass LspExecuteCommand(LspTextCommand):\n def __init__(self, view):\n super().__init__(view)\n\n def run(self, edit, command_name=None, command_args=None) -> None:\n client = client_for_view(self.view)\n if client and command_name:\n self.view.window().status_message(\"Running command {}\".format(command_name))\n self._send_command(client, command_name, command_args)\n\n def _handle_response(self, command: str, response: 'Optional[Any]') -> None:\n msg = \"command {} completed\".format(command)\n if response:\n msg += \"with response: {}\".format(response)\n sublime.message_dialog(msg)\n\n def _handle_error(self, command: str, error: 'Dict[str, Any]') -> None:\n msg = \"command {} failed. Reason: {}\".format(command, error.get(\"message\", \"none provided by server :(\"))\n sublime.message_dialog(msg)\n\n def _send_command(self, client: Client, command_name: str, command_args: 'Dict[str, Any]') -> None:\n request = {\n \"command\": command_name,\n \"arguments\": command_args\n }\n client.send_request(Request.executeCommand(request),\n lambda reponse: self._handle_response(command_name, reponse),\n lambda error: self._handle_error(command_name, error))\n", "path": "plugin/execute_command.py"}]}
| 3,964 | 801 |
gh_patches_debug_8385
|
rasdani/github-patches
|
git_diff
|
explosion__spaCy-2274
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Typo in docs? multi-label text classification
The docs give an example of text classification on IMDB [here](https://spacy.io/usage/training#example-textcat). It says it's "multi-label", but this dataset is binary. So I'm not sure what you mean here.
</issue>
<code>
[start of examples/training/train_textcat.py]
1 #!/usr/bin/env python
2 # coding: utf8
3 """Train a multi-label convolutional neural network text classifier on the
4 IMDB dataset, using the TextCategorizer component. The dataset will be loaded
5 automatically via Thinc's built-in dataset loader. The model is added to
6 spacy.pipeline, and predictions are available via `doc.cats`. For more details,
7 see the documentation:
8 * Training: https://spacy.io/usage/training
9
10 Compatible with: spaCy v2.0.0+
11 """
12 from __future__ import unicode_literals, print_function
13 import plac
14 import random
15 from pathlib import Path
16 import thinc.extra.datasets
17
18 import spacy
19 from spacy.util import minibatch, compounding
20
21
22 @plac.annotations(
23 model=("Model name. Defaults to blank 'en' model.", "option", "m", str),
24 output_dir=("Optional output directory", "option", "o", Path),
25 n_texts=("Number of texts to train from", "option", "t", int),
26 n_iter=("Number of training iterations", "option", "n", int))
27 def main(model=None, output_dir=None, n_iter=20, n_texts=2000):
28 if model is not None:
29 nlp = spacy.load(model) # load existing spaCy model
30 print("Loaded model '%s'" % model)
31 else:
32 nlp = spacy.blank('en') # create blank Language class
33 print("Created blank 'en' model")
34
35 # add the text classifier to the pipeline if it doesn't exist
36 # nlp.create_pipe works for built-ins that are registered with spaCy
37 if 'textcat' not in nlp.pipe_names:
38 textcat = nlp.create_pipe('textcat')
39 nlp.add_pipe(textcat, last=True)
40 # otherwise, get it, so we can add labels to it
41 else:
42 textcat = nlp.get_pipe('textcat')
43
44 # add label to text classifier
45 textcat.add_label('POSITIVE')
46
47 # load the IMDB dataset
48 print("Loading IMDB data...")
49 (train_texts, train_cats), (dev_texts, dev_cats) = load_data(limit=n_texts)
50 print("Using {} examples ({} training, {} evaluation)"
51 .format(n_texts, len(train_texts), len(dev_texts)))
52 train_data = list(zip(train_texts,
53 [{'cats': cats} for cats in train_cats]))
54
55 # get names of other pipes to disable them during training
56 other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'textcat']
57 with nlp.disable_pipes(*other_pipes): # only train textcat
58 optimizer = nlp.begin_training()
59 print("Training the model...")
60 print('{:^5}\t{:^5}\t{:^5}\t{:^5}'.format('LOSS', 'P', 'R', 'F'))
61 for i in range(n_iter):
62 losses = {}
63 # batch up the examples using spaCy's minibatch
64 batches = minibatch(train_data, size=compounding(4., 32., 1.001))
65 for batch in batches:
66 texts, annotations = zip(*batch)
67 nlp.update(texts, annotations, sgd=optimizer, drop=0.2,
68 losses=losses)
69 with textcat.model.use_params(optimizer.averages):
70 # evaluate on the dev data split off in load_data()
71 scores = evaluate(nlp.tokenizer, textcat, dev_texts, dev_cats)
72 print('{0:.3f}\t{1:.3f}\t{2:.3f}\t{3:.3f}' # print a simple table
73 .format(losses['textcat'], scores['textcat_p'],
74 scores['textcat_r'], scores['textcat_f']))
75
76 # test the trained model
77 test_text = "This movie sucked"
78 doc = nlp(test_text)
79 print(test_text, doc.cats)
80
81 if output_dir is not None:
82 output_dir = Path(output_dir)
83 if not output_dir.exists():
84 output_dir.mkdir()
85 nlp.to_disk(output_dir)
86 print("Saved model to", output_dir)
87
88 # test the saved model
89 print("Loading from", output_dir)
90 nlp2 = spacy.load(output_dir)
91 doc2 = nlp2(test_text)
92 print(test_text, doc2.cats)
93
94
95 def load_data(limit=0, split=0.8):
96 """Load data from the IMDB dataset."""
97 # Partition off part of the train data for evaluation
98 train_data, _ = thinc.extra.datasets.imdb()
99 random.shuffle(train_data)
100 train_data = train_data[-limit:]
101 texts, labels = zip(*train_data)
102 cats = [{'POSITIVE': bool(y)} for y in labels]
103 split = int(len(train_data) * split)
104 return (texts[:split], cats[:split]), (texts[split:], cats[split:])
105
106
107 def evaluate(tokenizer, textcat, texts, cats):
108 docs = (tokenizer(text) for text in texts)
109 tp = 1e-8 # True positives
110 fp = 1e-8 # False positives
111 fn = 1e-8 # False negatives
112 tn = 1e-8 # True negatives
113 for i, doc in enumerate(textcat.pipe(docs)):
114 gold = cats[i]
115 for label, score in doc.cats.items():
116 if label not in gold:
117 continue
118 if score >= 0.5 and gold[label] >= 0.5:
119 tp += 1.
120 elif score >= 0.5 and gold[label] < 0.5:
121 fp += 1.
122 elif score < 0.5 and gold[label] < 0.5:
123 tn += 1
124 elif score < 0.5 and gold[label] >= 0.5:
125 fn += 1
126 precision = tp / (tp + fp)
127 recall = tp / (tp + fn)
128 f_score = 2 * (precision * recall) / (precision + recall)
129 return {'textcat_p': precision, 'textcat_r': recall, 'textcat_f': f_score}
130
131
132 if __name__ == '__main__':
133 plac.call(main)
134
[end of examples/training/train_textcat.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/training/train_textcat.py b/examples/training/train_textcat.py
--- a/examples/training/train_textcat.py
+++ b/examples/training/train_textcat.py
@@ -1,6 +1,6 @@
#!/usr/bin/env python
# coding: utf8
-"""Train a multi-label convolutional neural network text classifier on the
+"""Train a convolutional neural network text classifier on the
IMDB dataset, using the TextCategorizer component. The dataset will be loaded
automatically via Thinc's built-in dataset loader. The model is added to
spacy.pipeline, and predictions are available via `doc.cats`. For more details,
|
{"golden_diff": "diff --git a/examples/training/train_textcat.py b/examples/training/train_textcat.py\n--- a/examples/training/train_textcat.py\n+++ b/examples/training/train_textcat.py\n@@ -1,6 +1,6 @@\n #!/usr/bin/env python\n # coding: utf8\n-\"\"\"Train a multi-label convolutional neural network text classifier on the\n+\"\"\"Train a convolutional neural network text classifier on the\n IMDB dataset, using the TextCategorizer component. The dataset will be loaded\n automatically via Thinc's built-in dataset loader. The model is added to\n spacy.pipeline, and predictions are available via `doc.cats`. For more details,\n", "issue": "Typo in docs? multi-label text classification\nThe docs give an example of text classification on IMDB [here](https://spacy.io/usage/training#example-textcat). It says it's \"multi-label\", but this dataset is binary. So I'm not sure what you mean here.\n", "before_files": [{"content": "#!/usr/bin/env python\n# coding: utf8\n\"\"\"Train a multi-label convolutional neural network text classifier on the\nIMDB dataset, using the TextCategorizer component. The dataset will be loaded\nautomatically via Thinc's built-in dataset loader. The model is added to\nspacy.pipeline, and predictions are available via `doc.cats`. For more details,\nsee the documentation:\n* Training: https://spacy.io/usage/training\n\nCompatible with: spaCy v2.0.0+\n\"\"\"\nfrom __future__ import unicode_literals, print_function\nimport plac\nimport random\nfrom pathlib import Path\nimport thinc.extra.datasets\n\nimport spacy\nfrom spacy.util import minibatch, compounding\n\n\[email protected](\n model=(\"Model name. Defaults to blank 'en' model.\", \"option\", \"m\", str),\n output_dir=(\"Optional output directory\", \"option\", \"o\", Path),\n n_texts=(\"Number of texts to train from\", \"option\", \"t\", int),\n n_iter=(\"Number of training iterations\", \"option\", \"n\", int))\ndef main(model=None, output_dir=None, n_iter=20, n_texts=2000):\n if model is not None:\n nlp = spacy.load(model) # load existing spaCy model\n print(\"Loaded model '%s'\" % model)\n else:\n nlp = spacy.blank('en') # create blank Language class\n print(\"Created blank 'en' model\")\n\n # add the text classifier to the pipeline if it doesn't exist\n # nlp.create_pipe works for built-ins that are registered with spaCy\n if 'textcat' not in nlp.pipe_names:\n textcat = nlp.create_pipe('textcat')\n nlp.add_pipe(textcat, last=True)\n # otherwise, get it, so we can add labels to it\n else:\n textcat = nlp.get_pipe('textcat')\n\n # add label to text classifier\n textcat.add_label('POSITIVE')\n\n # load the IMDB dataset\n print(\"Loading IMDB data...\")\n (train_texts, train_cats), (dev_texts, dev_cats) = load_data(limit=n_texts)\n print(\"Using {} examples ({} training, {} evaluation)\"\n .format(n_texts, len(train_texts), len(dev_texts)))\n train_data = list(zip(train_texts,\n [{'cats': cats} for cats in train_cats]))\n\n # get names of other pipes to disable them during training\n other_pipes = [pipe for pipe in nlp.pipe_names if pipe != 'textcat']\n with nlp.disable_pipes(*other_pipes): # only train textcat\n optimizer = nlp.begin_training()\n print(\"Training the model...\")\n print('{:^5}\\t{:^5}\\t{:^5}\\t{:^5}'.format('LOSS', 'P', 'R', 'F'))\n for i in range(n_iter):\n losses = {}\n # batch up the examples using spaCy's minibatch\n batches = minibatch(train_data, size=compounding(4., 32., 1.001))\n for batch in batches:\n texts, annotations = zip(*batch)\n nlp.update(texts, annotations, sgd=optimizer, drop=0.2,\n losses=losses)\n with textcat.model.use_params(optimizer.averages):\n # evaluate on the dev data split off in load_data()\n scores = evaluate(nlp.tokenizer, textcat, dev_texts, dev_cats)\n print('{0:.3f}\\t{1:.3f}\\t{2:.3f}\\t{3:.3f}' # print a simple table\n .format(losses['textcat'], scores['textcat_p'],\n scores['textcat_r'], scores['textcat_f']))\n\n # test the trained model\n test_text = \"This movie sucked\"\n doc = nlp(test_text)\n print(test_text, doc.cats)\n\n if output_dir is not None:\n output_dir = Path(output_dir)\n if not output_dir.exists():\n output_dir.mkdir()\n nlp.to_disk(output_dir)\n print(\"Saved model to\", output_dir)\n\n # test the saved model\n print(\"Loading from\", output_dir)\n nlp2 = spacy.load(output_dir)\n doc2 = nlp2(test_text)\n print(test_text, doc2.cats)\n\n\ndef load_data(limit=0, split=0.8):\n \"\"\"Load data from the IMDB dataset.\"\"\"\n # Partition off part of the train data for evaluation\n train_data, _ = thinc.extra.datasets.imdb()\n random.shuffle(train_data)\n train_data = train_data[-limit:]\n texts, labels = zip(*train_data)\n cats = [{'POSITIVE': bool(y)} for y in labels]\n split = int(len(train_data) * split)\n return (texts[:split], cats[:split]), (texts[split:], cats[split:])\n\n\ndef evaluate(tokenizer, textcat, texts, cats):\n docs = (tokenizer(text) for text in texts)\n tp = 1e-8 # True positives\n fp = 1e-8 # False positives\n fn = 1e-8 # False negatives\n tn = 1e-8 # True negatives\n for i, doc in enumerate(textcat.pipe(docs)):\n gold = cats[i]\n for label, score in doc.cats.items():\n if label not in gold:\n continue\n if score >= 0.5 and gold[label] >= 0.5:\n tp += 1.\n elif score >= 0.5 and gold[label] < 0.5:\n fp += 1.\n elif score < 0.5 and gold[label] < 0.5:\n tn += 1\n elif score < 0.5 and gold[label] >= 0.5:\n fn += 1\n precision = tp / (tp + fp)\n recall = tp / (tp + fn)\n f_score = 2 * (precision * recall) / (precision + recall)\n return {'textcat_p': precision, 'textcat_r': recall, 'textcat_f': f_score}\n\n\nif __name__ == '__main__':\n plac.call(main)\n", "path": "examples/training/train_textcat.py"}]}
| 2,264 | 143 |
gh_patches_debug_11995
|
rasdani/github-patches
|
git_diff
|
encode__starlette-1574
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Denying WebSocket connection in WebSocketEndpoint.on_connect leads to Exception
### Discussed in https://github.com/encode/starlette/discussions/1555
<div type='discussions-op-text'>
<sup>Originally posted by **dingensundso** March 27, 2022</sup>
I created a WebSocketEndpoint class in which I want to deny the connection in certain conditions.
When the WebSocket is closed in on_connect I receive the following exception:
```
File "starlette/endpoints.py", line 83, in dispatch
close_code = int(message.get("code", status.WS_1000_NORMAL_CLOSURE))
TypeError: int() argument must be a string, a bytes-like object or a real number, not 'NoneType'
```
So code is None when the server denies the connection instead of non-existant.
https://github.com/encode/starlette/blob/e086fc2da361767b532cf690e5203619bbae98aa/starlette/endpoints.py#L72-L87
Changing line 83 to the following should fix the issue:
```python
close_code = int(message.get("code") or status.WS_1000_NORMAL_CLOSURE)
````
</div>
</issue>
<code>
[start of starlette/endpoints.py]
1 import asyncio
2 import json
3 import typing
4
5 from starlette import status
6 from starlette.concurrency import run_in_threadpool
7 from starlette.exceptions import HTTPException
8 from starlette.requests import Request
9 from starlette.responses import PlainTextResponse, Response
10 from starlette.types import Message, Receive, Scope, Send
11 from starlette.websockets import WebSocket
12
13
14 class HTTPEndpoint:
15 def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:
16 assert scope["type"] == "http"
17 self.scope = scope
18 self.receive = receive
19 self.send = send
20 self._allowed_methods = [
21 method
22 for method in ("GET", "HEAD", "POST", "PUT", "PATCH", "DELETE", "OPTIONS")
23 if getattr(self, method.lower(), None) is not None
24 ]
25
26 def __await__(self) -> typing.Generator:
27 return self.dispatch().__await__()
28
29 async def dispatch(self) -> None:
30 request = Request(self.scope, receive=self.receive)
31 handler_name = (
32 "get"
33 if request.method == "HEAD" and not hasattr(self, "head")
34 else request.method.lower()
35 )
36
37 handler: typing.Callable[[Request], typing.Any] = getattr(
38 self, handler_name, self.method_not_allowed
39 )
40 is_async = asyncio.iscoroutinefunction(handler)
41 if is_async:
42 response = await handler(request)
43 else:
44 response = await run_in_threadpool(handler, request)
45 await response(self.scope, self.receive, self.send)
46
47 async def method_not_allowed(self, request: Request) -> Response:
48 # If we're running inside a starlette application then raise an
49 # exception, so that the configurable exception handler can deal with
50 # returning the response. For plain ASGI apps, just return the response.
51 headers = {"Allow": ", ".join(self._allowed_methods)}
52 if "app" in self.scope:
53 raise HTTPException(status_code=405, headers=headers)
54 return PlainTextResponse("Method Not Allowed", status_code=405, headers=headers)
55
56
57 class WebSocketEndpoint:
58
59 encoding: typing.Optional[str] = None # May be "text", "bytes", or "json".
60
61 def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:
62 assert scope["type"] == "websocket"
63 self.scope = scope
64 self.receive = receive
65 self.send = send
66
67 def __await__(self) -> typing.Generator:
68 return self.dispatch().__await__()
69
70 async def dispatch(self) -> None:
71 websocket = WebSocket(self.scope, receive=self.receive, send=self.send)
72 await self.on_connect(websocket)
73
74 close_code = status.WS_1000_NORMAL_CLOSURE
75
76 try:
77 while True:
78 message = await websocket.receive()
79 if message["type"] == "websocket.receive":
80 data = await self.decode(websocket, message)
81 await self.on_receive(websocket, data)
82 elif message["type"] == "websocket.disconnect":
83 close_code = int(message.get("code", status.WS_1000_NORMAL_CLOSURE))
84 break
85 except Exception as exc:
86 close_code = status.WS_1011_INTERNAL_ERROR
87 raise exc
88 finally:
89 await self.on_disconnect(websocket, close_code)
90
91 async def decode(self, websocket: WebSocket, message: Message) -> typing.Any:
92
93 if self.encoding == "text":
94 if "text" not in message:
95 await websocket.close(code=status.WS_1003_UNSUPPORTED_DATA)
96 raise RuntimeError("Expected text websocket messages, but got bytes")
97 return message["text"]
98
99 elif self.encoding == "bytes":
100 if "bytes" not in message:
101 await websocket.close(code=status.WS_1003_UNSUPPORTED_DATA)
102 raise RuntimeError("Expected bytes websocket messages, but got text")
103 return message["bytes"]
104
105 elif self.encoding == "json":
106 if message.get("text") is not None:
107 text = message["text"]
108 else:
109 text = message["bytes"].decode("utf-8")
110
111 try:
112 return json.loads(text)
113 except json.decoder.JSONDecodeError:
114 await websocket.close(code=status.WS_1003_UNSUPPORTED_DATA)
115 raise RuntimeError("Malformed JSON data received.")
116
117 assert (
118 self.encoding is None
119 ), f"Unsupported 'encoding' attribute {self.encoding}"
120 return message["text"] if message.get("text") else message["bytes"]
121
122 async def on_connect(self, websocket: WebSocket) -> None:
123 """Override to handle an incoming websocket connection"""
124 await websocket.accept()
125
126 async def on_receive(self, websocket: WebSocket, data: typing.Any) -> None:
127 """Override to handle an incoming websocket message"""
128
129 async def on_disconnect(self, websocket: WebSocket, close_code: int) -> None:
130 """Override to handle a disconnecting websocket"""
131
[end of starlette/endpoints.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/starlette/endpoints.py b/starlette/endpoints.py
--- a/starlette/endpoints.py
+++ b/starlette/endpoints.py
@@ -80,7 +80,9 @@
data = await self.decode(websocket, message)
await self.on_receive(websocket, data)
elif message["type"] == "websocket.disconnect":
- close_code = int(message.get("code", status.WS_1000_NORMAL_CLOSURE))
+ close_code = int(
+ message.get("code") or status.WS_1000_NORMAL_CLOSURE
+ )
break
except Exception as exc:
close_code = status.WS_1011_INTERNAL_ERROR
|
{"golden_diff": "diff --git a/starlette/endpoints.py b/starlette/endpoints.py\n--- a/starlette/endpoints.py\n+++ b/starlette/endpoints.py\n@@ -80,7 +80,9 @@\n data = await self.decode(websocket, message)\n await self.on_receive(websocket, data)\n elif message[\"type\"] == \"websocket.disconnect\":\n- close_code = int(message.get(\"code\", status.WS_1000_NORMAL_CLOSURE))\n+ close_code = int(\n+ message.get(\"code\") or status.WS_1000_NORMAL_CLOSURE\n+ )\n break\n except Exception as exc:\n close_code = status.WS_1011_INTERNAL_ERROR\n", "issue": "Denying WebSocket connection in WebSocketEndpoint.on_connect leads to Exception\n### Discussed in https://github.com/encode/starlette/discussions/1555\r\n\r\n<div type='discussions-op-text'>\r\n\r\n<sup>Originally posted by **dingensundso** March 27, 2022</sup>\r\nI created a WebSocketEndpoint class in which I want to deny the connection in certain conditions.\r\nWhen the WebSocket is closed in on_connect I receive the following exception:\r\n\r\n```\r\n File \"starlette/endpoints.py\", line 83, in dispatch\r\n close_code = int(message.get(\"code\", status.WS_1000_NORMAL_CLOSURE))\r\nTypeError: int() argument must be a string, a bytes-like object or a real number, not 'NoneType'\r\n```\r\nSo code is None when the server denies the connection instead of non-existant.\r\n\r\nhttps://github.com/encode/starlette/blob/e086fc2da361767b532cf690e5203619bbae98aa/starlette/endpoints.py#L72-L87\r\n\r\nChanging line 83 to the following should fix the issue:\r\n```python\r\nclose_code = int(message.get(\"code\") or status.WS_1000_NORMAL_CLOSURE) \r\n````\r\n</div>\n", "before_files": [{"content": "import asyncio\nimport json\nimport typing\n\nfrom starlette import status\nfrom starlette.concurrency import run_in_threadpool\nfrom starlette.exceptions import HTTPException\nfrom starlette.requests import Request\nfrom starlette.responses import PlainTextResponse, Response\nfrom starlette.types import Message, Receive, Scope, Send\nfrom starlette.websockets import WebSocket\n\n\nclass HTTPEndpoint:\n def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:\n assert scope[\"type\"] == \"http\"\n self.scope = scope\n self.receive = receive\n self.send = send\n self._allowed_methods = [\n method\n for method in (\"GET\", \"HEAD\", \"POST\", \"PUT\", \"PATCH\", \"DELETE\", \"OPTIONS\")\n if getattr(self, method.lower(), None) is not None\n ]\n\n def __await__(self) -> typing.Generator:\n return self.dispatch().__await__()\n\n async def dispatch(self) -> None:\n request = Request(self.scope, receive=self.receive)\n handler_name = (\n \"get\"\n if request.method == \"HEAD\" and not hasattr(self, \"head\")\n else request.method.lower()\n )\n\n handler: typing.Callable[[Request], typing.Any] = getattr(\n self, handler_name, self.method_not_allowed\n )\n is_async = asyncio.iscoroutinefunction(handler)\n if is_async:\n response = await handler(request)\n else:\n response = await run_in_threadpool(handler, request)\n await response(self.scope, self.receive, self.send)\n\n async def method_not_allowed(self, request: Request) -> Response:\n # If we're running inside a starlette application then raise an\n # exception, so that the configurable exception handler can deal with\n # returning the response. For plain ASGI apps, just return the response.\n headers = {\"Allow\": \", \".join(self._allowed_methods)}\n if \"app\" in self.scope:\n raise HTTPException(status_code=405, headers=headers)\n return PlainTextResponse(\"Method Not Allowed\", status_code=405, headers=headers)\n\n\nclass WebSocketEndpoint:\n\n encoding: typing.Optional[str] = None # May be \"text\", \"bytes\", or \"json\".\n\n def __init__(self, scope: Scope, receive: Receive, send: Send) -> None:\n assert scope[\"type\"] == \"websocket\"\n self.scope = scope\n self.receive = receive\n self.send = send\n\n def __await__(self) -> typing.Generator:\n return self.dispatch().__await__()\n\n async def dispatch(self) -> None:\n websocket = WebSocket(self.scope, receive=self.receive, send=self.send)\n await self.on_connect(websocket)\n\n close_code = status.WS_1000_NORMAL_CLOSURE\n\n try:\n while True:\n message = await websocket.receive()\n if message[\"type\"] == \"websocket.receive\":\n data = await self.decode(websocket, message)\n await self.on_receive(websocket, data)\n elif message[\"type\"] == \"websocket.disconnect\":\n close_code = int(message.get(\"code\", status.WS_1000_NORMAL_CLOSURE))\n break\n except Exception as exc:\n close_code = status.WS_1011_INTERNAL_ERROR\n raise exc\n finally:\n await self.on_disconnect(websocket, close_code)\n\n async def decode(self, websocket: WebSocket, message: Message) -> typing.Any:\n\n if self.encoding == \"text\":\n if \"text\" not in message:\n await websocket.close(code=status.WS_1003_UNSUPPORTED_DATA)\n raise RuntimeError(\"Expected text websocket messages, but got bytes\")\n return message[\"text\"]\n\n elif self.encoding == \"bytes\":\n if \"bytes\" not in message:\n await websocket.close(code=status.WS_1003_UNSUPPORTED_DATA)\n raise RuntimeError(\"Expected bytes websocket messages, but got text\")\n return message[\"bytes\"]\n\n elif self.encoding == \"json\":\n if message.get(\"text\") is not None:\n text = message[\"text\"]\n else:\n text = message[\"bytes\"].decode(\"utf-8\")\n\n try:\n return json.loads(text)\n except json.decoder.JSONDecodeError:\n await websocket.close(code=status.WS_1003_UNSUPPORTED_DATA)\n raise RuntimeError(\"Malformed JSON data received.\")\n\n assert (\n self.encoding is None\n ), f\"Unsupported 'encoding' attribute {self.encoding}\"\n return message[\"text\"] if message.get(\"text\") else message[\"bytes\"]\n\n async def on_connect(self, websocket: WebSocket) -> None:\n \"\"\"Override to handle an incoming websocket connection\"\"\"\n await websocket.accept()\n\n async def on_receive(self, websocket: WebSocket, data: typing.Any) -> None:\n \"\"\"Override to handle an incoming websocket message\"\"\"\n\n async def on_disconnect(self, websocket: WebSocket, close_code: int) -> None:\n \"\"\"Override to handle a disconnecting websocket\"\"\"\n", "path": "starlette/endpoints.py"}]}
| 2,178 | 155 |
gh_patches_debug_30568
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-4862
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make level parameter optional in measure.find_contours
## Description
I think that we could put a default value to level in find_contours. I would suggest (image.max() - image.min())/2. This would make this function able to be used with an image and I think this default value is meaningful.
I'm open to discussion.
</issue>
<code>
[start of skimage/measure/_find_contours.py]
1 import numpy as np
2 from skimage._shared.utils import deprecate_kwarg
3
4 from ._find_contours_cy import _get_contour_segments
5
6 from collections import deque
7
8 _param_options = ('high', 'low')
9
10
11 @deprecate_kwarg({'array': 'image'}, removed_version="0.20")
12 def find_contours(image, level,
13 fully_connected='low', positive_orientation='low',
14 *,
15 mask=None):
16 """Find iso-valued contours in a 2D array for a given level value.
17
18 Uses the "marching squares" method to compute a the iso-valued contours of
19 the input 2D array for a particular level value. Array values are linearly
20 interpolated to provide better precision for the output contours.
21
22 Parameters
23 ----------
24 image : 2D ndarray of double
25 Input image in which to find contours.
26 level : float
27 Value along which to find contours in the array.
28 fully_connected : str, {'low', 'high'}
29 Indicates whether array elements below the given level value are to be
30 considered fully-connected (and hence elements above the value will
31 only be face connected), or vice-versa. (See notes below for details.)
32 positive_orientation : str, {'low', 'high'}
33 Indicates whether the output contours will produce positively-oriented
34 polygons around islands of low- or high-valued elements. If 'low' then
35 contours will wind counter- clockwise around elements below the
36 iso-value. Alternately, this means that low-valued elements are always
37 on the left of the contour. (See below for details.)
38 mask : 2D ndarray of bool, or None
39 A boolean mask, True where we want to draw contours.
40 Note that NaN values are always excluded from the considered region
41 (``mask`` is set to ``False`` wherever ``array`` is ``NaN``).
42
43 Returns
44 -------
45 contours : list of (n,2)-ndarrays
46 Each contour is an ndarray of shape ``(n, 2)``,
47 consisting of n ``(row, column)`` coordinates along the contour.
48
49 See Also
50 --------
51 skimage.measure.marching_cubes
52
53 Notes
54 -----
55 The marching squares algorithm is a special case of the marching cubes
56 algorithm [1]_. A simple explanation is available here:
57
58 http://users.polytech.unice.fr/~lingrand/MarchingCubes/algo.html
59
60 There is a single ambiguous case in the marching squares algorithm: when
61 a given ``2 x 2``-element square has two high-valued and two low-valued
62 elements, each pair diagonally adjacent. (Where high- and low-valued is
63 with respect to the contour value sought.) In this case, either the
64 high-valued elements can be 'connected together' via a thin isthmus that
65 separates the low-valued elements, or vice-versa. When elements are
66 connected together across a diagonal, they are considered 'fully
67 connected' (also known as 'face+vertex-connected' or '8-connected'). Only
68 high-valued or low-valued elements can be fully-connected, the other set
69 will be considered as 'face-connected' or '4-connected'. By default,
70 low-valued elements are considered fully-connected; this can be altered
71 with the 'fully_connected' parameter.
72
73 Output contours are not guaranteed to be closed: contours which intersect
74 the array edge or a masked-off region (either where mask is False or where
75 array is NaN) will be left open. All other contours will be closed. (The
76 closed-ness of a contours can be tested by checking whether the beginning
77 point is the same as the end point.)
78
79 Contours are oriented. By default, array values lower than the contour
80 value are to the left of the contour and values greater than the contour
81 value are to the right. This means that contours will wind
82 counter-clockwise (i.e. in 'positive orientation') around islands of
83 low-valued pixels. This behavior can be altered with the
84 'positive_orientation' parameter.
85
86 The order of the contours in the output list is determined by the position
87 of the smallest ``x,y`` (in lexicographical order) coordinate in the
88 contour. This is a side-effect of how the input array is traversed, but
89 can be relied upon.
90
91 .. warning::
92
93 Array coordinates/values are assumed to refer to the *center* of the
94 array element. Take a simple example input: ``[0, 1]``. The interpolated
95 position of 0.5 in this array is midway between the 0-element (at
96 ``x=0``) and the 1-element (at ``x=1``), and thus would fall at
97 ``x=0.5``.
98
99 This means that to find reasonable contours, it is best to find contours
100 midway between the expected "light" and "dark" values. In particular,
101 given a binarized array, *do not* choose to find contours at the low or
102 high value of the array. This will often yield degenerate contours,
103 especially around structures that are a single array element wide. Instead
104 choose a middle value, as above.
105
106 References
107 ----------
108 .. [1] Lorensen, William and Harvey E. Cline. Marching Cubes: A High
109 Resolution 3D Surface Construction Algorithm. Computer Graphics
110 (SIGGRAPH 87 Proceedings) 21(4) July 1987, p. 163-170).
111 :DOI:`10.1145/37401.37422`
112
113 Examples
114 --------
115 >>> a = np.zeros((3, 3))
116 >>> a[0, 0] = 1
117 >>> a
118 array([[1., 0., 0.],
119 [0., 0., 0.],
120 [0., 0., 0.]])
121 >>> find_contours(a, 0.5)
122 [array([[0. , 0.5],
123 [0.5, 0. ]])]
124 """
125 if fully_connected not in _param_options:
126 raise ValueError('Parameters "fully_connected" must be either '
127 '"high" or "low".')
128 if positive_orientation not in _param_options:
129 raise ValueError('Parameters "positive_orientation" must be either '
130 '"high" or "low".')
131 if image.shape[0] < 2 or image.shape[1] < 2:
132 raise ValueError("Input array must be at least 2x2.")
133 if image.ndim != 2:
134 raise ValueError('Only 2D arrays are supported.')
135 if mask is not None:
136 if mask.shape != image.shape:
137 raise ValueError('Parameters "array" and "mask"'
138 ' must have same shape.')
139 if not np.can_cast(mask.dtype, bool, casting='safe'):
140 raise TypeError('Parameter "mask" must be a binary array.')
141 mask = mask.astype(np.uint8, copy=False)
142
143 segments = _get_contour_segments(image.astype(np.double), float(level),
144 fully_connected == 'high', mask=mask)
145 contours = _assemble_contours(segments)
146 if positive_orientation == 'high':
147 contours = [c[::-1] for c in contours]
148 return contours
149
150
151 def _assemble_contours(segments):
152 current_index = 0
153 contours = {}
154 starts = {}
155 ends = {}
156 for from_point, to_point in segments:
157 # Ignore degenerate segments.
158 # This happens when (and only when) one vertex of the square is
159 # exactly the contour level, and the rest are above or below.
160 # This degenerate vertex will be picked up later by neighboring
161 # squares.
162 if from_point == to_point:
163 continue
164
165 tail, tail_num = starts.pop(to_point, (None, None))
166 head, head_num = ends.pop(from_point, (None, None))
167
168 if tail is not None and head is not None:
169 # We need to connect these two contours.
170 if tail is head:
171 # We need to closed a contour.
172 # Add the end point
173 head.append(to_point)
174 else: # tail is not head
175 # We need to join two distinct contours.
176 # We want to keep the first contour segment created, so that
177 # the final contours are ordered left->right, top->bottom.
178 if tail_num > head_num:
179 # tail was created second. Append tail to head.
180 head.extend(tail)
181 # remove all traces of tail:
182 ends.pop(tail[-1])
183 contours.pop(tail_num, None)
184 # Update contour starts end ends
185 starts[head[0]] = (head, head_num)
186 ends[head[-1]] = (head, head_num)
187 else: # tail_num <= head_num
188 # head was created second. Prepend head to tail.
189 tail.extendleft(reversed(head))
190 # remove all traces of head:
191 starts.pop(head[0])
192 contours.pop(head_num, None)
193 # Update contour starts end ends
194 starts[tail[0]] = (tail, tail_num)
195 ends[tail[-1]] = (tail, tail_num)
196 elif tail is None and head is None:
197 # we need to add a new contour
198 new_contour = deque((from_point, to_point))
199 contours[current_index] = new_contour
200 starts[from_point] = (new_contour, current_index)
201 ends[to_point] = (new_contour, current_index)
202 current_index += 1
203 elif head is None: # tail is not None
204 # We've found a single contour to which the new segment should be
205 # prepended.
206 tail.appendleft(from_point)
207 starts[from_point] = (tail, tail_num)
208 else: # tail is None and head is not None:
209 # We've found a single contour to which the new segment should be
210 # appended
211 head.append(to_point)
212 ends[to_point] = (head, head_num)
213
214 return [np.array(contour) for _, contour in sorted(contours.items())]
215
[end of skimage/measure/_find_contours.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/measure/_find_contours.py b/skimage/measure/_find_contours.py
--- a/skimage/measure/_find_contours.py
+++ b/skimage/measure/_find_contours.py
@@ -9,7 +9,7 @@
@deprecate_kwarg({'array': 'image'}, removed_version="0.20")
-def find_contours(image, level,
+def find_contours(image, level=None,
fully_connected='low', positive_orientation='low',
*,
mask=None):
@@ -23,8 +23,9 @@
----------
image : 2D ndarray of double
Input image in which to find contours.
- level : float
- Value along which to find contours in the array.
+ level : float, optional
+ Value along which to find contours in the array. By default, the level
+ is set to (max(image) - min(image)) / 2
fully_connected : str, {'low', 'high'}
Indicates whether array elements below the given level value are to be
considered fully-connected (and hence elements above the value will
@@ -139,6 +140,8 @@
if not np.can_cast(mask.dtype, bool, casting='safe'):
raise TypeError('Parameter "mask" must be a binary array.')
mask = mask.astype(np.uint8, copy=False)
+ if level is None:
+ level = (np.nanmax(image) - np.nanmin(image)) / 2.0
segments = _get_contour_segments(image.astype(np.double), float(level),
fully_connected == 'high', mask=mask)
|
{"golden_diff": "diff --git a/skimage/measure/_find_contours.py b/skimage/measure/_find_contours.py\n--- a/skimage/measure/_find_contours.py\n+++ b/skimage/measure/_find_contours.py\n@@ -9,7 +9,7 @@\n \n \n @deprecate_kwarg({'array': 'image'}, removed_version=\"0.20\")\n-def find_contours(image, level,\n+def find_contours(image, level=None,\n fully_connected='low', positive_orientation='low',\n *,\n mask=None):\n@@ -23,8 +23,9 @@\n ----------\n image : 2D ndarray of double\n Input image in which to find contours.\n- level : float\n- Value along which to find contours in the array.\n+ level : float, optional\n+ Value along which to find contours in the array. By default, the level\n+ is set to (max(image) - min(image)) / 2\n fully_connected : str, {'low', 'high'}\n Indicates whether array elements below the given level value are to be\n considered fully-connected (and hence elements above the value will\n@@ -139,6 +140,8 @@\n if not np.can_cast(mask.dtype, bool, casting='safe'):\n raise TypeError('Parameter \"mask\" must be a binary array.')\n mask = mask.astype(np.uint8, copy=False)\n+ if level is None:\n+ level = (np.nanmax(image) - np.nanmin(image)) / 2.0\n \n segments = _get_contour_segments(image.astype(np.double), float(level),\n fully_connected == 'high', mask=mask)\n", "issue": "Make level parameter optional in measure.find_contours\n## Description\r\n\r\n\r\nI think that we could put a default value to level in find_contours. I would suggest (image.max() - image.min())/2. This would make this function able to be used with an image and I think this default value is meaningful.\r\n\r\nI'm open to discussion.\n", "before_files": [{"content": "import numpy as np\nfrom skimage._shared.utils import deprecate_kwarg\n\nfrom ._find_contours_cy import _get_contour_segments\n\nfrom collections import deque\n\n_param_options = ('high', 'low')\n\n\n@deprecate_kwarg({'array': 'image'}, removed_version=\"0.20\")\ndef find_contours(image, level,\n fully_connected='low', positive_orientation='low',\n *,\n mask=None):\n \"\"\"Find iso-valued contours in a 2D array for a given level value.\n\n Uses the \"marching squares\" method to compute a the iso-valued contours of\n the input 2D array for a particular level value. Array values are linearly\n interpolated to provide better precision for the output contours.\n\n Parameters\n ----------\n image : 2D ndarray of double\n Input image in which to find contours.\n level : float\n Value along which to find contours in the array.\n fully_connected : str, {'low', 'high'}\n Indicates whether array elements below the given level value are to be\n considered fully-connected (and hence elements above the value will\n only be face connected), or vice-versa. (See notes below for details.)\n positive_orientation : str, {'low', 'high'}\n Indicates whether the output contours will produce positively-oriented\n polygons around islands of low- or high-valued elements. If 'low' then\n contours will wind counter- clockwise around elements below the\n iso-value. Alternately, this means that low-valued elements are always\n on the left of the contour. (See below for details.)\n mask : 2D ndarray of bool, or None\n A boolean mask, True where we want to draw contours.\n Note that NaN values are always excluded from the considered region\n (``mask`` is set to ``False`` wherever ``array`` is ``NaN``).\n\n Returns\n -------\n contours : list of (n,2)-ndarrays\n Each contour is an ndarray of shape ``(n, 2)``,\n consisting of n ``(row, column)`` coordinates along the contour.\n\n See Also\n --------\n skimage.measure.marching_cubes\n\n Notes\n -----\n The marching squares algorithm is a special case of the marching cubes\n algorithm [1]_. A simple explanation is available here:\n\n http://users.polytech.unice.fr/~lingrand/MarchingCubes/algo.html\n\n There is a single ambiguous case in the marching squares algorithm: when\n a given ``2 x 2``-element square has two high-valued and two low-valued\n elements, each pair diagonally adjacent. (Where high- and low-valued is\n with respect to the contour value sought.) In this case, either the\n high-valued elements can be 'connected together' via a thin isthmus that\n separates the low-valued elements, or vice-versa. When elements are\n connected together across a diagonal, they are considered 'fully\n connected' (also known as 'face+vertex-connected' or '8-connected'). Only\n high-valued or low-valued elements can be fully-connected, the other set\n will be considered as 'face-connected' or '4-connected'. By default,\n low-valued elements are considered fully-connected; this can be altered\n with the 'fully_connected' parameter.\n\n Output contours are not guaranteed to be closed: contours which intersect\n the array edge or a masked-off region (either where mask is False or where\n array is NaN) will be left open. All other contours will be closed. (The\n closed-ness of a contours can be tested by checking whether the beginning\n point is the same as the end point.)\n\n Contours are oriented. By default, array values lower than the contour\n value are to the left of the contour and values greater than the contour\n value are to the right. This means that contours will wind\n counter-clockwise (i.e. in 'positive orientation') around islands of\n low-valued pixels. This behavior can be altered with the\n 'positive_orientation' parameter.\n\n The order of the contours in the output list is determined by the position\n of the smallest ``x,y`` (in lexicographical order) coordinate in the\n contour. This is a side-effect of how the input array is traversed, but\n can be relied upon.\n\n .. warning::\n\n Array coordinates/values are assumed to refer to the *center* of the\n array element. Take a simple example input: ``[0, 1]``. The interpolated\n position of 0.5 in this array is midway between the 0-element (at\n ``x=0``) and the 1-element (at ``x=1``), and thus would fall at\n ``x=0.5``.\n\n This means that to find reasonable contours, it is best to find contours\n midway between the expected \"light\" and \"dark\" values. In particular,\n given a binarized array, *do not* choose to find contours at the low or\n high value of the array. This will often yield degenerate contours,\n especially around structures that are a single array element wide. Instead\n choose a middle value, as above.\n\n References\n ----------\n .. [1] Lorensen, William and Harvey E. Cline. Marching Cubes: A High\n Resolution 3D Surface Construction Algorithm. Computer Graphics\n (SIGGRAPH 87 Proceedings) 21(4) July 1987, p. 163-170).\n :DOI:`10.1145/37401.37422`\n\n Examples\n --------\n >>> a = np.zeros((3, 3))\n >>> a[0, 0] = 1\n >>> a\n array([[1., 0., 0.],\n [0., 0., 0.],\n [0., 0., 0.]])\n >>> find_contours(a, 0.5)\n [array([[0. , 0.5],\n [0.5, 0. ]])]\n \"\"\"\n if fully_connected not in _param_options:\n raise ValueError('Parameters \"fully_connected\" must be either '\n '\"high\" or \"low\".')\n if positive_orientation not in _param_options:\n raise ValueError('Parameters \"positive_orientation\" must be either '\n '\"high\" or \"low\".')\n if image.shape[0] < 2 or image.shape[1] < 2:\n raise ValueError(\"Input array must be at least 2x2.\")\n if image.ndim != 2:\n raise ValueError('Only 2D arrays are supported.')\n if mask is not None:\n if mask.shape != image.shape:\n raise ValueError('Parameters \"array\" and \"mask\"'\n ' must have same shape.')\n if not np.can_cast(mask.dtype, bool, casting='safe'):\n raise TypeError('Parameter \"mask\" must be a binary array.')\n mask = mask.astype(np.uint8, copy=False)\n\n segments = _get_contour_segments(image.astype(np.double), float(level),\n fully_connected == 'high', mask=mask)\n contours = _assemble_contours(segments)\n if positive_orientation == 'high':\n contours = [c[::-1] for c in contours]\n return contours\n\n\ndef _assemble_contours(segments):\n current_index = 0\n contours = {}\n starts = {}\n ends = {}\n for from_point, to_point in segments:\n # Ignore degenerate segments.\n # This happens when (and only when) one vertex of the square is\n # exactly the contour level, and the rest are above or below.\n # This degenerate vertex will be picked up later by neighboring\n # squares.\n if from_point == to_point:\n continue\n\n tail, tail_num = starts.pop(to_point, (None, None))\n head, head_num = ends.pop(from_point, (None, None))\n\n if tail is not None and head is not None:\n # We need to connect these two contours.\n if tail is head:\n # We need to closed a contour.\n # Add the end point\n head.append(to_point)\n else: # tail is not head\n # We need to join two distinct contours.\n # We want to keep the first contour segment created, so that\n # the final contours are ordered left->right, top->bottom.\n if tail_num > head_num:\n # tail was created second. Append tail to head.\n head.extend(tail)\n # remove all traces of tail:\n ends.pop(tail[-1])\n contours.pop(tail_num, None)\n # Update contour starts end ends\n starts[head[0]] = (head, head_num)\n ends[head[-1]] = (head, head_num)\n else: # tail_num <= head_num\n # head was created second. Prepend head to tail.\n tail.extendleft(reversed(head))\n # remove all traces of head:\n starts.pop(head[0])\n contours.pop(head_num, None)\n # Update contour starts end ends\n starts[tail[0]] = (tail, tail_num)\n ends[tail[-1]] = (tail, tail_num)\n elif tail is None and head is None:\n # we need to add a new contour\n new_contour = deque((from_point, to_point))\n contours[current_index] = new_contour\n starts[from_point] = (new_contour, current_index)\n ends[to_point] = (new_contour, current_index)\n current_index += 1\n elif head is None: # tail is not None\n # We've found a single contour to which the new segment should be\n # prepended.\n tail.appendleft(from_point)\n starts[from_point] = (tail, tail_num)\n else: # tail is None and head is not None:\n # We've found a single contour to which the new segment should be\n # appended\n head.append(to_point)\n ends[to_point] = (head, head_num)\n\n return [np.array(contour) for _, contour in sorted(contours.items())]\n", "path": "skimage/measure/_find_contours.py"}]}
| 3,377 | 362 |
gh_patches_debug_38768
|
rasdani/github-patches
|
git_diff
|
sublimelsp__LSP-717
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Formatting adding trailing newline clears last line
* OS and language server
Linux + Gopls
* How you installed LSP (Package Control or from git?)
Package Control
* Minimal reproduction steps
```go
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello, world")
} // No newline!
```
Format
```go
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello, world")
```
* Log
No diagnostic output.
Initially reported to [gopls](https://github.com/golang/go/issues/33717), but they pointed out that the gopls commandline does the right thing.
Is this a LSP issue or Sublime itself?
Let me know if I can provide any other helpful information!
</issue>
<code>
[start of plugin/edit.py]
1 import sublime
2 import sublime_plugin
3 from .core.edit import sort_by_application_order
4 try:
5 from typing import List, Dict, Optional, Any, Iterable, Tuple
6 from .core.edit import TextEdit
7 assert List and Dict and Optional and Any and Iterable and Tuple and TextEdit
8 except ImportError:
9 pass
10 from .core.logging import debug
11
12
13 class LspApplyWorkspaceEditCommand(sublime_plugin.WindowCommand):
14 def run(self, changes: 'Optional[Dict[str, List[TextEdit]]]' = None):
15 documents_changed = 0
16 if changes:
17 for path, document_changes in changes.items():
18 self.open_and_apply_edits(path, document_changes)
19 documents_changed += 1
20
21 if documents_changed > 0:
22 message = 'Applied changes to {} documents'.format(documents_changed)
23 self.window.status_message(message)
24 else:
25 self.window.status_message('No changes to apply to workspace')
26
27 def open_and_apply_edits(self, path, file_changes):
28 view = self.window.open_file(path)
29 if view:
30 if view.is_loading():
31 # TODO: wait for event instead.
32 sublime.set_timeout_async(
33 lambda: view.run_command('lsp_apply_document_edit', {'changes': file_changes}),
34 500
35 )
36 else:
37 view.run_command('lsp_apply_document_edit',
38 {'changes': file_changes})
39 else:
40 debug('view not found to apply', path, file_changes)
41
42
43 class LspApplyDocumentEditCommand(sublime_plugin.TextCommand):
44 def run(self, edit, changes: 'Optional[List[TextEdit]]' = None):
45 # Apply the changes in reverse, so that we don't invalidate the range
46 # of any change that we haven't applied yet.
47 if changes:
48 for change in sort_by_application_order(changes):
49 start, end, newText = change
50 region = sublime.Region(self.view.text_point(*start), self.view.text_point(*end))
51 self.apply_change(region, newText, edit)
52
53 def apply_change(self, region: 'sublime.Region', newText: str, edit):
54 if region.empty():
55 self.view.insert(edit, region.a, newText)
56 else:
57 if len(newText) > 0:
58 self.view.replace(edit, region, newText)
59 else:
60 self.view.erase(edit, region)
61
[end of plugin/edit.py]
[start of plugin/core/edit.py]
1 from .url import uri_to_filename
2 try:
3 from typing import List, Dict, Optional, Any, Iterable, Tuple
4 TextEdit = Tuple[Tuple[int, int], Tuple[int, int], str]
5 assert List and Dict and Optional and Any and Iterable and Tuple
6 except ImportError:
7 pass
8
9
10 def parse_workspace_edit(workspace_edit: 'Dict[str, Any]') -> 'Dict[str, List[TextEdit]]':
11 changes = {} # type: Dict[str, List[TextEdit]]
12 if 'changes' in workspace_edit:
13 for uri, file_changes in workspace_edit.get('changes', {}).items():
14 changes[uri_to_filename(uri)] = list(parse_text_edit(change) for change in file_changes)
15 if 'documentChanges' in workspace_edit:
16 for document_change in workspace_edit.get('documentChanges', []):
17 uri = document_change.get('textDocument').get('uri')
18 changes[uri_to_filename(uri)] = list(parse_text_edit(change) for change in document_change.get('edits'))
19 return changes
20
21
22 def parse_range(range: 'Dict[str, int]') -> 'Tuple[int, int]':
23 return range['line'], range['character']
24
25
26 def parse_text_edit(text_edit: 'Dict[str, Any]') -> 'TextEdit':
27 return (
28 parse_range(text_edit['range']['start']),
29 parse_range(text_edit['range']['end']),
30 text_edit.get('newText', '')
31 )
32
33
34 def sort_by_application_order(changes: 'Iterable[TextEdit]') -> 'List[TextEdit]':
35
36 def get_start_position(pair: 'Tuple[int, TextEdit]'):
37 index, change = pair
38 return change[0][0], change[0][1], index
39
40 # The spec reads:
41 # > However, it is possible that multiple edits have the same start position: multiple
42 # > inserts, or any number of inserts followed by a single remove or replace edit. If
43 # > multiple inserts have the same position, the order in the array defines the order in
44 # > which the inserted strings appear in the resulting text.
45 # So we sort by start position. But if multiple text edits start at the same position,
46 # we use the index in the array as the key.
47
48 return list(map(lambda pair: pair[1], sorted(enumerate(changes), key=get_start_position, reverse=True)))
49
[end of plugin/core/edit.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugin/core/edit.py b/plugin/core/edit.py
--- a/plugin/core/edit.py
+++ b/plugin/core/edit.py
@@ -1,4 +1,5 @@
from .url import uri_to_filename
+import operator
try:
from typing import List, Dict, Optional, Any, Iterable, Tuple
TextEdit = Tuple[Tuple[int, int], Tuple[int, int], str]
@@ -32,11 +33,6 @@
def sort_by_application_order(changes: 'Iterable[TextEdit]') -> 'List[TextEdit]':
-
- def get_start_position(pair: 'Tuple[int, TextEdit]'):
- index, change = pair
- return change[0][0], change[0][1], index
-
# The spec reads:
# > However, it is possible that multiple edits have the same start position: multiple
# > inserts, or any number of inserts followed by a single remove or replace edit. If
@@ -45,4 +41,4 @@
# So we sort by start position. But if multiple text edits start at the same position,
# we use the index in the array as the key.
- return list(map(lambda pair: pair[1], sorted(enumerate(changes), key=get_start_position, reverse=True)))
+ return list(sorted(changes, key=operator.itemgetter(0)))
diff --git a/plugin/edit.py b/plugin/edit.py
--- a/plugin/edit.py
+++ b/plugin/edit.py
@@ -41,14 +41,24 @@
class LspApplyDocumentEditCommand(sublime_plugin.TextCommand):
+
def run(self, edit, changes: 'Optional[List[TextEdit]]' = None):
# Apply the changes in reverse, so that we don't invalidate the range
# of any change that we haven't applied yet.
if changes:
- for change in sort_by_application_order(changes):
+ last_row, last_col = self.view.rowcol(self.view.size())
+ for change in reversed(sort_by_application_order(changes)):
start, end, newText = change
region = sublime.Region(self.view.text_point(*start), self.view.text_point(*end))
- self.apply_change(region, newText, edit)
+
+ if start[0] > last_row and newText[0] != '\n':
+ # Handle when a language server (eg gopls) inserts at a row beyond the document
+ # some editors create the line automatically, sublime needs to have the newline prepended.
+ debug('adding new line for edit at line {}, document ended at line {}'.format(start[0], last_row))
+ self.apply_change(region, '\n' + newText, edit)
+ last_row, last_col = self.view.rowcol(self.view.size())
+ else:
+ self.apply_change(region, newText, edit)
def apply_change(self, region: 'sublime.Region', newText: str, edit):
if region.empty():
|
{"golden_diff": "diff --git a/plugin/core/edit.py b/plugin/core/edit.py\n--- a/plugin/core/edit.py\n+++ b/plugin/core/edit.py\n@@ -1,4 +1,5 @@\n from .url import uri_to_filename\n+import operator\n try:\n from typing import List, Dict, Optional, Any, Iterable, Tuple\n TextEdit = Tuple[Tuple[int, int], Tuple[int, int], str]\n@@ -32,11 +33,6 @@\n \n \n def sort_by_application_order(changes: 'Iterable[TextEdit]') -> 'List[TextEdit]':\n-\n- def get_start_position(pair: 'Tuple[int, TextEdit]'):\n- index, change = pair\n- return change[0][0], change[0][1], index\n-\n # The spec reads:\n # > However, it is possible that multiple edits have the same start position: multiple\n # > inserts, or any number of inserts followed by a single remove or replace edit. If\n@@ -45,4 +41,4 @@\n # So we sort by start position. But if multiple text edits start at the same position,\n # we use the index in the array as the key.\n \n- return list(map(lambda pair: pair[1], sorted(enumerate(changes), key=get_start_position, reverse=True)))\n+ return list(sorted(changes, key=operator.itemgetter(0)))\ndiff --git a/plugin/edit.py b/plugin/edit.py\n--- a/plugin/edit.py\n+++ b/plugin/edit.py\n@@ -41,14 +41,24 @@\n \n \n class LspApplyDocumentEditCommand(sublime_plugin.TextCommand):\n+\n def run(self, edit, changes: 'Optional[List[TextEdit]]' = None):\n # Apply the changes in reverse, so that we don't invalidate the range\n # of any change that we haven't applied yet.\n if changes:\n- for change in sort_by_application_order(changes):\n+ last_row, last_col = self.view.rowcol(self.view.size())\n+ for change in reversed(sort_by_application_order(changes)):\n start, end, newText = change\n region = sublime.Region(self.view.text_point(*start), self.view.text_point(*end))\n- self.apply_change(region, newText, edit)\n+\n+ if start[0] > last_row and newText[0] != '\\n':\n+ # Handle when a language server (eg gopls) inserts at a row beyond the document\n+ # some editors create the line automatically, sublime needs to have the newline prepended.\n+ debug('adding new line for edit at line {}, document ended at line {}'.format(start[0], last_row))\n+ self.apply_change(region, '\\n' + newText, edit)\n+ last_row, last_col = self.view.rowcol(self.view.size())\n+ else:\n+ self.apply_change(region, newText, edit)\n \n def apply_change(self, region: 'sublime.Region', newText: str, edit):\n if region.empty():\n", "issue": "Formatting adding trailing newline clears last line\n* OS and language server\r\nLinux + Gopls\r\n* How you installed LSP (Package Control or from git?)\r\nPackage Control\r\n* Minimal reproduction steps\r\n```go\r\npackage main\r\n\r\nimport (\r\n\t\"fmt\"\r\n)\r\n\r\nfunc main() {\r\n\tfmt.Println(\"Hello, world\")\r\n} // No newline!\r\n```\r\n\r\nFormat\r\n\r\n```go\r\npackage main\r\n\r\nimport (\r\n\t\"fmt\"\r\n)\r\n\r\nfunc main() {\r\n\tfmt.Println(\"Hello, world\")\r\n```\r\n* Log\r\nNo diagnostic output. \r\n\r\nInitially reported to [gopls](https://github.com/golang/go/issues/33717), but they pointed out that the gopls commandline does the right thing.\r\n\r\nIs this a LSP issue or Sublime itself?\r\nLet me know if I can provide any other helpful information!\n", "before_files": [{"content": "import sublime\nimport sublime_plugin\nfrom .core.edit import sort_by_application_order\ntry:\n from typing import List, Dict, Optional, Any, Iterable, Tuple\n from .core.edit import TextEdit\n assert List and Dict and Optional and Any and Iterable and Tuple and TextEdit\nexcept ImportError:\n pass\nfrom .core.logging import debug\n\n\nclass LspApplyWorkspaceEditCommand(sublime_plugin.WindowCommand):\n def run(self, changes: 'Optional[Dict[str, List[TextEdit]]]' = None):\n documents_changed = 0\n if changes:\n for path, document_changes in changes.items():\n self.open_and_apply_edits(path, document_changes)\n documents_changed += 1\n\n if documents_changed > 0:\n message = 'Applied changes to {} documents'.format(documents_changed)\n self.window.status_message(message)\n else:\n self.window.status_message('No changes to apply to workspace')\n\n def open_and_apply_edits(self, path, file_changes):\n view = self.window.open_file(path)\n if view:\n if view.is_loading():\n # TODO: wait for event instead.\n sublime.set_timeout_async(\n lambda: view.run_command('lsp_apply_document_edit', {'changes': file_changes}),\n 500\n )\n else:\n view.run_command('lsp_apply_document_edit',\n {'changes': file_changes})\n else:\n debug('view not found to apply', path, file_changes)\n\n\nclass LspApplyDocumentEditCommand(sublime_plugin.TextCommand):\n def run(self, edit, changes: 'Optional[List[TextEdit]]' = None):\n # Apply the changes in reverse, so that we don't invalidate the range\n # of any change that we haven't applied yet.\n if changes:\n for change in sort_by_application_order(changes):\n start, end, newText = change\n region = sublime.Region(self.view.text_point(*start), self.view.text_point(*end))\n self.apply_change(region, newText, edit)\n\n def apply_change(self, region: 'sublime.Region', newText: str, edit):\n if region.empty():\n self.view.insert(edit, region.a, newText)\n else:\n if len(newText) > 0:\n self.view.replace(edit, region, newText)\n else:\n self.view.erase(edit, region)\n", "path": "plugin/edit.py"}, {"content": "from .url import uri_to_filename\ntry:\n from typing import List, Dict, Optional, Any, Iterable, Tuple\n TextEdit = Tuple[Tuple[int, int], Tuple[int, int], str]\n assert List and Dict and Optional and Any and Iterable and Tuple\nexcept ImportError:\n pass\n\n\ndef parse_workspace_edit(workspace_edit: 'Dict[str, Any]') -> 'Dict[str, List[TextEdit]]':\n changes = {} # type: Dict[str, List[TextEdit]]\n if 'changes' in workspace_edit:\n for uri, file_changes in workspace_edit.get('changes', {}).items():\n changes[uri_to_filename(uri)] = list(parse_text_edit(change) for change in file_changes)\n if 'documentChanges' in workspace_edit:\n for document_change in workspace_edit.get('documentChanges', []):\n uri = document_change.get('textDocument').get('uri')\n changes[uri_to_filename(uri)] = list(parse_text_edit(change) for change in document_change.get('edits'))\n return changes\n\n\ndef parse_range(range: 'Dict[str, int]') -> 'Tuple[int, int]':\n return range['line'], range['character']\n\n\ndef parse_text_edit(text_edit: 'Dict[str, Any]') -> 'TextEdit':\n return (\n parse_range(text_edit['range']['start']),\n parse_range(text_edit['range']['end']),\n text_edit.get('newText', '')\n )\n\n\ndef sort_by_application_order(changes: 'Iterable[TextEdit]') -> 'List[TextEdit]':\n\n def get_start_position(pair: 'Tuple[int, TextEdit]'):\n index, change = pair\n return change[0][0], change[0][1], index\n\n # The spec reads:\n # > However, it is possible that multiple edits have the same start position: multiple\n # > inserts, or any number of inserts followed by a single remove or replace edit. If\n # > multiple inserts have the same position, the order in the array defines the order in\n # > which the inserted strings appear in the resulting text.\n # So we sort by start position. But if multiple text edits start at the same position,\n # we use the index in the array as the key.\n\n return list(map(lambda pair: pair[1], sorted(enumerate(changes), key=get_start_position, reverse=True)))\n", "path": "plugin/core/edit.py"}]}
| 1,916 | 635 |
gh_patches_debug_1674
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-4324
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
tools.environment_append raises if tries to unset variable which was never set
after #4224, I may use the following code, for instance, to ensure variable is not set:
```
with environment_append({'CONAN_BASH_PATH': None}):
pass
```
however, it raises if `CONAN_BASH_PATH` is not set (prior to the environment_append invocation):
```
Traceback (most recent call last):
File "C:\bincrafters\conan\conans\test\unittests\client\tools\os_info\osinfo_test.py", line 39, in test_windows
with environment_append(new_env):
File "c:\users\sse4\appdata\local\programs\python\python36\lib\contextlib.py", line 81, in __enter__
return next(self.gen)
File "C:\bincrafters\conan\conans\client\tools\env.py", line 57, in environment_append
os.environ.pop(var)
File "c:\users\sse4\appdata\local\programs\python\python36\lib\_collections_abc.py", line 795, in pop
value = self[key]
File "c:\users\sse4\appdata\local\programs\python\python36\lib\os.py", line 669, in __getitem__
raise KeyError(key) from None
KeyError: 'CONAN_BASH_PATH'
```
I would expect `tools.environment_append` to be no op in such case, otherwise, it requires additional logic to workaround this behavior.
To help us debug your issue please explain:
- [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).
- [ ] I've specified the Conan version, operating system version and any tool that can be relevant.
- [ ] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.
</issue>
<code>
[start of conans/client/tools/env.py]
1 import os
2 import sys
3 from contextlib import contextmanager
4
5 from conans.client.run_environment import RunEnvironment
6 from conans.client.tools.files import _path_equals, which
7 from conans.errors import ConanException
8
9
10 @contextmanager
11 def pythonpath(conanfile):
12 python_path = conanfile.env.get("PYTHONPATH", None)
13 if python_path:
14 old_path = sys.path[:]
15 if isinstance(python_path, list):
16 sys.path.extend(python_path)
17 else:
18 sys.path.append(python_path)
19
20 yield
21 sys.path = old_path
22 else:
23 yield
24
25
26 @contextmanager
27 def run_environment(conanfile):
28 with environment_append(RunEnvironment(conanfile).vars):
29 yield
30
31
32 @contextmanager
33 def environment_append(env_vars):
34 """
35 :param env_vars: List (dict) of simple environment vars. {name: value, name2: value2} => e.g.: MYVAR=1
36 The values can also be lists of appendable environment vars. {name: [value, value2]}
37 => e.g. PATH=/path/1:/path/2
38 If the value is set to None, then that environment variable is unset.
39 :return: None
40 """
41 unset_vars = []
42 for key in env_vars.keys():
43 if env_vars[key] is None:
44 unset_vars.append(key)
45 for var in unset_vars:
46 env_vars.pop(var, None)
47 for name, value in env_vars.items():
48 if isinstance(value, list):
49 env_vars[name] = os.pathsep.join(value)
50 old = os.environ.get(name)
51 if old:
52 env_vars[name] += os.pathsep + old
53 if env_vars or unset_vars:
54 old_env = dict(os.environ)
55 os.environ.update(env_vars)
56 for var in unset_vars:
57 os.environ.pop(var)
58 try:
59 yield
60 finally:
61 os.environ.clear()
62 os.environ.update(old_env)
63 else:
64 yield
65
66
67 @contextmanager
68 def no_op():
69 yield
70
71
72 @contextmanager
73 def remove_from_path(command):
74 curpath = os.getenv("PATH")
75 first_it = True
76 for _ in range(30):
77 if not first_it:
78 with environment_append({"PATH": curpath}):
79 the_command = which(command)
80 else:
81 the_command = which(command)
82 first_it = False
83
84 if not the_command:
85 break
86 new_path = []
87 for entry in curpath.split(os.pathsep):
88 if not _path_equals(entry, os.path.dirname(the_command)):
89 new_path.append(entry)
90
91 curpath = os.pathsep.join(new_path)
92 else:
93 raise ConanException("Error in tools.remove_from_path!! couldn't remove the tool '%s' "
94 "from the path after 30 attempts, still found in '%s' this is a "
95 "Conan client bug, please open an issue at: "
96 "https://github.com/conan-io/conan\n\nPATH=%s"
97 % (command, the_command, os.getenv("PATH")))
98
99 with environment_append({"PATH": curpath}):
100 yield
101
[end of conans/client/tools/env.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/tools/env.py b/conans/client/tools/env.py
--- a/conans/client/tools/env.py
+++ b/conans/client/tools/env.py
@@ -54,7 +54,7 @@
old_env = dict(os.environ)
os.environ.update(env_vars)
for var in unset_vars:
- os.environ.pop(var)
+ os.environ.pop(var, None)
try:
yield
finally:
|
{"golden_diff": "diff --git a/conans/client/tools/env.py b/conans/client/tools/env.py\n--- a/conans/client/tools/env.py\n+++ b/conans/client/tools/env.py\n@@ -54,7 +54,7 @@\n old_env = dict(os.environ)\n os.environ.update(env_vars)\n for var in unset_vars:\n- os.environ.pop(var)\n+ os.environ.pop(var, None)\n try:\n yield\n finally:\n", "issue": "tools.environment_append raises if tries to unset variable which was never set\nafter #4224, I may use the following code, for instance, to ensure variable is not set:\r\n```\r\nwith environment_append({'CONAN_BASH_PATH': None}):\r\n pass\r\n```\r\nhowever, it raises if `CONAN_BASH_PATH` is not set (prior to the environment_append invocation):\r\n```\r\nTraceback (most recent call last):\r\n File \"C:\\bincrafters\\conan\\conans\\test\\unittests\\client\\tools\\os_info\\osinfo_test.py\", line 39, in test_windows\r\n with environment_append(new_env):\r\n File \"c:\\users\\sse4\\appdata\\local\\programs\\python\\python36\\lib\\contextlib.py\", line 81, in __enter__\r\n return next(self.gen)\r\n File \"C:\\bincrafters\\conan\\conans\\client\\tools\\env.py\", line 57, in environment_append\r\n os.environ.pop(var)\r\n File \"c:\\users\\sse4\\appdata\\local\\programs\\python\\python36\\lib\\_collections_abc.py\", line 795, in pop\r\n value = self[key]\r\n File \"c:\\users\\sse4\\appdata\\local\\programs\\python\\python36\\lib\\os.py\", line 669, in __getitem__\r\n raise KeyError(key) from None\r\nKeyError: 'CONAN_BASH_PATH'\r\n```\r\nI would expect `tools.environment_append` to be no op in such case, otherwise, it requires additional logic to workaround this behavior.\r\n\r\nTo help us debug your issue please explain:\r\n\r\n- [ ] I've read the [CONTRIBUTING guide](https://github.com/conan-io/conan/blob/develop/.github/CONTRIBUTING.md).\r\n- [ ] I've specified the Conan version, operating system version and any tool that can be relevant.\r\n- [ ] I've explained the steps to reproduce the error or the motivation/use case of the question/suggestion.\r\n\r\n\n", "before_files": [{"content": "import os\nimport sys\nfrom contextlib import contextmanager\n\nfrom conans.client.run_environment import RunEnvironment\nfrom conans.client.tools.files import _path_equals, which\nfrom conans.errors import ConanException\n\n\n@contextmanager\ndef pythonpath(conanfile):\n python_path = conanfile.env.get(\"PYTHONPATH\", None)\n if python_path:\n old_path = sys.path[:]\n if isinstance(python_path, list):\n sys.path.extend(python_path)\n else:\n sys.path.append(python_path)\n\n yield\n sys.path = old_path\n else:\n yield\n\n\n@contextmanager\ndef run_environment(conanfile):\n with environment_append(RunEnvironment(conanfile).vars):\n yield\n\n\n@contextmanager\ndef environment_append(env_vars):\n \"\"\"\n :param env_vars: List (dict) of simple environment vars. {name: value, name2: value2} => e.g.: MYVAR=1\n The values can also be lists of appendable environment vars. {name: [value, value2]}\n => e.g. PATH=/path/1:/path/2\n If the value is set to None, then that environment variable is unset.\n :return: None\n \"\"\"\n unset_vars = []\n for key in env_vars.keys():\n if env_vars[key] is None:\n unset_vars.append(key)\n for var in unset_vars:\n env_vars.pop(var, None)\n for name, value in env_vars.items():\n if isinstance(value, list):\n env_vars[name] = os.pathsep.join(value)\n old = os.environ.get(name)\n if old:\n env_vars[name] += os.pathsep + old\n if env_vars or unset_vars:\n old_env = dict(os.environ)\n os.environ.update(env_vars)\n for var in unset_vars:\n os.environ.pop(var)\n try:\n yield\n finally:\n os.environ.clear()\n os.environ.update(old_env)\n else:\n yield\n\n\n@contextmanager\ndef no_op():\n yield\n\n\n@contextmanager\ndef remove_from_path(command):\n curpath = os.getenv(\"PATH\")\n first_it = True\n for _ in range(30):\n if not first_it:\n with environment_append({\"PATH\": curpath}):\n the_command = which(command)\n else:\n the_command = which(command)\n first_it = False\n\n if not the_command:\n break\n new_path = []\n for entry in curpath.split(os.pathsep):\n if not _path_equals(entry, os.path.dirname(the_command)):\n new_path.append(entry)\n\n curpath = os.pathsep.join(new_path)\n else:\n raise ConanException(\"Error in tools.remove_from_path!! couldn't remove the tool '%s' \"\n \"from the path after 30 attempts, still found in '%s' this is a \"\n \"Conan client bug, please open an issue at: \"\n \"https://github.com/conan-io/conan\\n\\nPATH=%s\"\n % (command, the_command, os.getenv(\"PATH\")))\n\n with environment_append({\"PATH\": curpath}):\n yield\n", "path": "conans/client/tools/env.py"}]}
| 1,853 | 95 |
gh_patches_debug_38875
|
rasdani/github-patches
|
git_diff
|
python-discord__bot-1062
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Truncate the charinfo embed to fit within 2048 characters
Sentry Issue: [BOT-3D](https://sentry.io/organizations/python-discord/issues/1621405078/?referrer=github_integration)
```
HTTPException: 400 Bad Request (error code: 50035): Invalid Form Body
In embed.description: Must be 2048 or fewer in length.
File "discord/ext/commands/core.py", line 83, in wrapped
ret = await coro(*args, **kwargs)
File "bot/cogs/utils.py", line 162, in charinfo
await ctx.send(embed=embed)
File "discord/abc.py", line 856, in send
data = await state.http.send_message(channel.id, content, tts=tts, embed=embed, nonce=nonce)
File "discord/http.py", line 225, in request
raise HTTPException(r, data)
Error executing command invoked by <REDACTED>: !charinfo ﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹﯹ
```
</issue>
<code>
[start of bot/cogs/utils.py]
1 import difflib
2 import logging
3 import re
4 import unicodedata
5 from email.parser import HeaderParser
6 from io import StringIO
7 from typing import Tuple, Union
8
9 from discord import Colour, Embed, utils
10 from discord.ext.commands import BadArgument, Cog, Context, command
11
12 from bot.bot import Bot
13 from bot.constants import Channels, MODERATION_ROLES, STAFF_ROLES
14 from bot.decorators import in_whitelist, with_role
15
16 log = logging.getLogger(__name__)
17
18 ZEN_OF_PYTHON = """\
19 Beautiful is better than ugly.
20 Explicit is better than implicit.
21 Simple is better than complex.
22 Complex is better than complicated.
23 Flat is better than nested.
24 Sparse is better than dense.
25 Readability counts.
26 Special cases aren't special enough to break the rules.
27 Although practicality beats purity.
28 Errors should never pass silently.
29 Unless explicitly silenced.
30 In the face of ambiguity, refuse the temptation to guess.
31 There should be one-- and preferably only one --obvious way to do it.
32 Although that way may not be obvious at first unless you're Dutch.
33 Now is better than never.
34 Although never is often better than *right* now.
35 If the implementation is hard to explain, it's a bad idea.
36 If the implementation is easy to explain, it may be a good idea.
37 Namespaces are one honking great idea -- let's do more of those!
38 """
39
40 ICON_URL = "https://www.python.org/static/opengraph-icon-200x200.png"
41
42
43 class Utils(Cog):
44 """A selection of utilities which don't have a clear category."""
45
46 def __init__(self, bot: Bot):
47 self.bot = bot
48
49 self.base_pep_url = "http://www.python.org/dev/peps/pep-"
50 self.base_github_pep_url = "https://raw.githubusercontent.com/python/peps/master/pep-"
51
52 @command(name='pep', aliases=('get_pep', 'p'))
53 async def pep_command(self, ctx: Context, pep_number: str) -> None:
54 """Fetches information about a PEP and sends it to the channel."""
55 if pep_number.isdigit():
56 pep_number = int(pep_number)
57 else:
58 await ctx.send_help(ctx.command)
59 return
60
61 # Handle PEP 0 directly because it's not in .rst or .txt so it can't be accessed like other PEPs.
62 if pep_number == 0:
63 return await self.send_pep_zero(ctx)
64
65 possible_extensions = ['.txt', '.rst']
66 found_pep = False
67 for extension in possible_extensions:
68 # Attempt to fetch the PEP
69 pep_url = f"{self.base_github_pep_url}{pep_number:04}{extension}"
70 log.trace(f"Requesting PEP {pep_number} with {pep_url}")
71 response = await self.bot.http_session.get(pep_url)
72
73 if response.status == 200:
74 log.trace("PEP found")
75 found_pep = True
76
77 pep_content = await response.text()
78
79 # Taken from https://github.com/python/peps/blob/master/pep0/pep.py#L179
80 pep_header = HeaderParser().parse(StringIO(pep_content))
81
82 # Assemble the embed
83 pep_embed = Embed(
84 title=f"**PEP {pep_number} - {pep_header['Title']}**",
85 description=f"[Link]({self.base_pep_url}{pep_number:04})",
86 )
87
88 pep_embed.set_thumbnail(url=ICON_URL)
89
90 # Add the interesting information
91 fields_to_check = ("Status", "Python-Version", "Created", "Type")
92 for field in fields_to_check:
93 # Check for a PEP metadata field that is present but has an empty value
94 # embed field values can't contain an empty string
95 if pep_header.get(field, ""):
96 pep_embed.add_field(name=field, value=pep_header[field])
97
98 elif response.status != 404:
99 # any response except 200 and 404 is expected
100 found_pep = True # actually not, but it's easier to display this way
101 log.trace(f"The user requested PEP {pep_number}, but the response had an unexpected status code: "
102 f"{response.status}.\n{response.text}")
103
104 error_message = "Unexpected HTTP error during PEP search. Please let us know."
105 pep_embed = Embed(title="Unexpected error", description=error_message)
106 pep_embed.colour = Colour.red()
107 break
108
109 if not found_pep:
110 log.trace("PEP was not found")
111 not_found = f"PEP {pep_number} does not exist."
112 pep_embed = Embed(title="PEP not found", description=not_found)
113 pep_embed.colour = Colour.red()
114
115 await ctx.message.channel.send(embed=pep_embed)
116
117 @command()
118 @in_whitelist(channels=(Channels.bot_commands,), roles=STAFF_ROLES)
119 async def charinfo(self, ctx: Context, *, characters: str) -> None:
120 """Shows you information on up to 25 unicode characters."""
121 match = re.match(r"<(a?):(\w+):(\d+)>", characters)
122 if match:
123 embed = Embed(
124 title="Non-Character Detected",
125 description=(
126 "Only unicode characters can be processed, but a custom Discord emoji "
127 "was found. Please remove it and try again."
128 )
129 )
130 embed.colour = Colour.red()
131 await ctx.send(embed=embed)
132 return
133
134 if len(characters) > 25:
135 embed = Embed(title=f"Too many characters ({len(characters)}/25)")
136 embed.colour = Colour.red()
137 await ctx.send(embed=embed)
138 return
139
140 def get_info(char: str) -> Tuple[str, str]:
141 digit = f"{ord(char):x}"
142 if len(digit) <= 4:
143 u_code = f"\\u{digit:>04}"
144 else:
145 u_code = f"\\U{digit:>08}"
146 url = f"https://www.compart.com/en/unicode/U+{digit:>04}"
147 name = f"[{unicodedata.name(char, '')}]({url})"
148 info = f"`{u_code.ljust(10)}`: {name} - {utils.escape_markdown(char)}"
149 return info, u_code
150
151 charlist, rawlist = zip(*(get_info(c) for c in characters))
152
153 embed = Embed(description="\n".join(charlist))
154 embed.set_author(name="Character Info")
155
156 if len(characters) > 1:
157 embed.add_field(name='Raw', value=f"`{''.join(rawlist)}`", inline=False)
158
159 await ctx.send(embed=embed)
160
161 @command()
162 async def zen(self, ctx: Context, *, search_value: Union[int, str, None] = None) -> None:
163 """
164 Show the Zen of Python.
165
166 Without any arguments, the full Zen will be produced.
167 If an integer is provided, the line with that index will be produced.
168 If a string is provided, the line which matches best will be produced.
169 """
170 embed = Embed(
171 colour=Colour.blurple(),
172 title="The Zen of Python",
173 description=ZEN_OF_PYTHON
174 )
175
176 if search_value is None:
177 embed.title += ", by Tim Peters"
178 await ctx.send(embed=embed)
179 return
180
181 zen_lines = ZEN_OF_PYTHON.splitlines()
182
183 # handle if it's an index int
184 if isinstance(search_value, int):
185 upper_bound = len(zen_lines) - 1
186 lower_bound = -1 * upper_bound
187 if not (lower_bound <= search_value <= upper_bound):
188 raise BadArgument(f"Please provide an index between {lower_bound} and {upper_bound}.")
189
190 embed.title += f" (line {search_value % len(zen_lines)}):"
191 embed.description = zen_lines[search_value]
192 await ctx.send(embed=embed)
193 return
194
195 # Try to handle first exact word due difflib.SequenceMatched may use some other similar word instead
196 # exact word.
197 for i, line in enumerate(zen_lines):
198 for word in line.split():
199 if word.lower() == search_value.lower():
200 embed.title += f" (line {i}):"
201 embed.description = line
202 await ctx.send(embed=embed)
203 return
204
205 # handle if it's a search string and not exact word
206 matcher = difflib.SequenceMatcher(None, search_value.lower())
207
208 best_match = ""
209 match_index = 0
210 best_ratio = 0
211
212 for index, line in enumerate(zen_lines):
213 matcher.set_seq2(line.lower())
214
215 # the match ratio needs to be adjusted because, naturally,
216 # longer lines will have worse ratios than shorter lines when
217 # fuzzy searching for keywords. this seems to work okay.
218 adjusted_ratio = (len(line) - 5) ** 0.5 * matcher.ratio()
219
220 if adjusted_ratio > best_ratio:
221 best_ratio = adjusted_ratio
222 best_match = line
223 match_index = index
224
225 if not best_match:
226 raise BadArgument("I didn't get a match! Please try again with a different search term.")
227
228 embed.title += f" (line {match_index}):"
229 embed.description = best_match
230 await ctx.send(embed=embed)
231
232 @command(aliases=("poll",))
233 @with_role(*MODERATION_ROLES)
234 async def vote(self, ctx: Context, title: str, *options: str) -> None:
235 """
236 Build a quick voting poll with matching reactions with the provided options.
237
238 A maximum of 20 options can be provided, as Discord supports a max of 20
239 reactions on a single message.
240 """
241 if len(options) < 2:
242 raise BadArgument("Please provide at least 2 options.")
243 if len(options) > 20:
244 raise BadArgument("I can only handle 20 options!")
245
246 codepoint_start = 127462 # represents "regional_indicator_a" unicode value
247 options = {chr(i): f"{chr(i)} - {v}" for i, v in enumerate(options, start=codepoint_start)}
248 embed = Embed(title=title, description="\n".join(options.values()))
249 message = await ctx.send(embed=embed)
250 for reaction in options:
251 await message.add_reaction(reaction)
252
253 async def send_pep_zero(self, ctx: Context) -> None:
254 """Send information about PEP 0."""
255 pep_embed = Embed(
256 title="**PEP 0 - Index of Python Enhancement Proposals (PEPs)**",
257 description="[Link](https://www.python.org/dev/peps/)"
258 )
259 pep_embed.set_thumbnail(url=ICON_URL)
260 pep_embed.add_field(name="Status", value="Active")
261 pep_embed.add_field(name="Created", value="13-Jul-2000")
262 pep_embed.add_field(name="Type", value="Informational")
263
264 await ctx.send(embed=pep_embed)
265
266
267 def setup(bot: Bot) -> None:
268 """Load the Utils cog."""
269 bot.add_cog(Utils(bot))
270
[end of bot/cogs/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bot/cogs/utils.py b/bot/cogs/utils.py
--- a/bot/cogs/utils.py
+++ b/bot/cogs/utils.py
@@ -12,6 +12,8 @@
from bot.bot import Bot
from bot.constants import Channels, MODERATION_ROLES, STAFF_ROLES
from bot.decorators import in_whitelist, with_role
+from bot.pagination import LinePaginator
+from bot.utils import messages
log = logging.getLogger(__name__)
@@ -117,25 +119,18 @@
@command()
@in_whitelist(channels=(Channels.bot_commands,), roles=STAFF_ROLES)
async def charinfo(self, ctx: Context, *, characters: str) -> None:
- """Shows you information on up to 25 unicode characters."""
+ """Shows you information on up to 50 unicode characters."""
match = re.match(r"<(a?):(\w+):(\d+)>", characters)
if match:
- embed = Embed(
- title="Non-Character Detected",
- description=(
- "Only unicode characters can be processed, but a custom Discord emoji "
- "was found. Please remove it and try again."
- )
+ return await messages.send_denial(
+ ctx,
+ "**Non-Character Detected**\n"
+ "Only unicode characters can be processed, but a custom Discord emoji "
+ "was found. Please remove it and try again."
)
- embed.colour = Colour.red()
- await ctx.send(embed=embed)
- return
- if len(characters) > 25:
- embed = Embed(title=f"Too many characters ({len(characters)}/25)")
- embed.colour = Colour.red()
- await ctx.send(embed=embed)
- return
+ if len(characters) > 50:
+ return await messages.send_denial(ctx, f"Too many characters ({len(characters)}/50)")
def get_info(char: str) -> Tuple[str, str]:
digit = f"{ord(char):x}"
@@ -148,15 +143,14 @@
info = f"`{u_code.ljust(10)}`: {name} - {utils.escape_markdown(char)}"
return info, u_code
- charlist, rawlist = zip(*(get_info(c) for c in characters))
-
- embed = Embed(description="\n".join(charlist))
- embed.set_author(name="Character Info")
+ char_list, raw_list = zip(*(get_info(c) for c in characters))
+ embed = Embed().set_author(name="Character Info")
if len(characters) > 1:
- embed.add_field(name='Raw', value=f"`{''.join(rawlist)}`", inline=False)
+ # Maximum length possible is 502 out of 1024, so there's no need to truncate.
+ embed.add_field(name='Full Raw Text', value=f"`{''.join(raw_list)}`", inline=False)
- await ctx.send(embed=embed)
+ await LinePaginator.paginate(char_list, ctx, embed, max_lines=10, max_size=2000, empty=False)
@command()
async def zen(self, ctx: Context, *, search_value: Union[int, str, None] = None) -> None:
|
{"golden_diff": "diff --git a/bot/cogs/utils.py b/bot/cogs/utils.py\n--- a/bot/cogs/utils.py\n+++ b/bot/cogs/utils.py\n@@ -12,6 +12,8 @@\n from bot.bot import Bot\n from bot.constants import Channels, MODERATION_ROLES, STAFF_ROLES\n from bot.decorators import in_whitelist, with_role\n+from bot.pagination import LinePaginator\n+from bot.utils import messages\n \n log = logging.getLogger(__name__)\n \n@@ -117,25 +119,18 @@\n @command()\n @in_whitelist(channels=(Channels.bot_commands,), roles=STAFF_ROLES)\n async def charinfo(self, ctx: Context, *, characters: str) -> None:\n- \"\"\"Shows you information on up to 25 unicode characters.\"\"\"\n+ \"\"\"Shows you information on up to 50 unicode characters.\"\"\"\n match = re.match(r\"<(a?):(\\w+):(\\d+)>\", characters)\n if match:\n- embed = Embed(\n- title=\"Non-Character Detected\",\n- description=(\n- \"Only unicode characters can be processed, but a custom Discord emoji \"\n- \"was found. Please remove it and try again.\"\n- )\n+ return await messages.send_denial(\n+ ctx,\n+ \"**Non-Character Detected**\\n\"\n+ \"Only unicode characters can be processed, but a custom Discord emoji \"\n+ \"was found. Please remove it and try again.\"\n )\n- embed.colour = Colour.red()\n- await ctx.send(embed=embed)\n- return\n \n- if len(characters) > 25:\n- embed = Embed(title=f\"Too many characters ({len(characters)}/25)\")\n- embed.colour = Colour.red()\n- await ctx.send(embed=embed)\n- return\n+ if len(characters) > 50:\n+ return await messages.send_denial(ctx, f\"Too many characters ({len(characters)}/50)\")\n \n def get_info(char: str) -> Tuple[str, str]:\n digit = f\"{ord(char):x}\"\n@@ -148,15 +143,14 @@\n info = f\"`{u_code.ljust(10)}`: {name} - {utils.escape_markdown(char)}\"\n return info, u_code\n \n- charlist, rawlist = zip(*(get_info(c) for c in characters))\n-\n- embed = Embed(description=\"\\n\".join(charlist))\n- embed.set_author(name=\"Character Info\")\n+ char_list, raw_list = zip(*(get_info(c) for c in characters))\n+ embed = Embed().set_author(name=\"Character Info\")\n \n if len(characters) > 1:\n- embed.add_field(name='Raw', value=f\"`{''.join(rawlist)}`\", inline=False)\n+ # Maximum length possible is 502 out of 1024, so there's no need to truncate.\n+ embed.add_field(name='Full Raw Text', value=f\"`{''.join(raw_list)}`\", inline=False)\n \n- await ctx.send(embed=embed)\n+ await LinePaginator.paginate(char_list, ctx, embed, max_lines=10, max_size=2000, empty=False)\n \n @command()\n async def zen(self, ctx: Context, *, search_value: Union[int, str, None] = None) -> None:\n", "issue": "Truncate the charinfo embed to fit within 2048 characters\nSentry Issue: [BOT-3D](https://sentry.io/organizations/python-discord/issues/1621405078/?referrer=github_integration)\n\n```\nHTTPException: 400 Bad Request (error code: 50035): Invalid Form Body\nIn embed.description: Must be 2048 or fewer in length.\n File \"discord/ext/commands/core.py\", line 83, in wrapped\n ret = await coro(*args, **kwargs)\n File \"bot/cogs/utils.py\", line 162, in charinfo\n await ctx.send(embed=embed)\n File \"discord/abc.py\", line 856, in send\n data = await state.http.send_message(channel.id, content, tts=tts, embed=embed, nonce=nonce)\n File \"discord/http.py\", line 225, in request\n raise HTTPException(r, data)\n\nError executing command invoked by <REDACTED>: !charinfo \ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\ufbf9\n```\n", "before_files": [{"content": "import difflib\nimport logging\nimport re\nimport unicodedata\nfrom email.parser import HeaderParser\nfrom io import StringIO\nfrom typing import Tuple, Union\n\nfrom discord import Colour, Embed, utils\nfrom discord.ext.commands import BadArgument, Cog, Context, command\n\nfrom bot.bot import Bot\nfrom bot.constants import Channels, MODERATION_ROLES, STAFF_ROLES\nfrom bot.decorators import in_whitelist, with_role\n\nlog = logging.getLogger(__name__)\n\nZEN_OF_PYTHON = \"\"\"\\\nBeautiful is better than ugly.\nExplicit is better than implicit.\nSimple is better than complex.\nComplex is better than complicated.\nFlat is better than nested.\nSparse is better than dense.\nReadability counts.\nSpecial cases aren't special enough to break the rules.\nAlthough practicality beats purity.\nErrors should never pass silently.\nUnless explicitly silenced.\nIn the face of ambiguity, refuse the temptation to guess.\nThere should be one-- and preferably only one --obvious way to do it.\nAlthough that way may not be obvious at first unless you're Dutch.\nNow is better than never.\nAlthough never is often better than *right* now.\nIf the implementation is hard to explain, it's a bad idea.\nIf the implementation is easy to explain, it may be a good idea.\nNamespaces are one honking great idea -- let's do more of those!\n\"\"\"\n\nICON_URL = \"https://www.python.org/static/opengraph-icon-200x200.png\"\n\n\nclass Utils(Cog):\n \"\"\"A selection of utilities which don't have a clear category.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n self.base_pep_url = \"http://www.python.org/dev/peps/pep-\"\n self.base_github_pep_url = \"https://raw.githubusercontent.com/python/peps/master/pep-\"\n\n @command(name='pep', aliases=('get_pep', 'p'))\n async def pep_command(self, ctx: Context, pep_number: str) -> None:\n \"\"\"Fetches information about a PEP and sends it to the channel.\"\"\"\n if pep_number.isdigit():\n pep_number = int(pep_number)\n else:\n await ctx.send_help(ctx.command)\n return\n\n # Handle PEP 0 directly because it's not in .rst or .txt so it can't be accessed like other PEPs.\n if pep_number == 0:\n return await self.send_pep_zero(ctx)\n\n possible_extensions = ['.txt', '.rst']\n found_pep = False\n for extension in possible_extensions:\n # Attempt to fetch the PEP\n pep_url = f\"{self.base_github_pep_url}{pep_number:04}{extension}\"\n log.trace(f\"Requesting PEP {pep_number} with {pep_url}\")\n response = await self.bot.http_session.get(pep_url)\n\n if response.status == 200:\n log.trace(\"PEP found\")\n found_pep = True\n\n pep_content = await response.text()\n\n # Taken from https://github.com/python/peps/blob/master/pep0/pep.py#L179\n pep_header = HeaderParser().parse(StringIO(pep_content))\n\n # Assemble the embed\n pep_embed = Embed(\n title=f\"**PEP {pep_number} - {pep_header['Title']}**\",\n description=f\"[Link]({self.base_pep_url}{pep_number:04})\",\n )\n\n pep_embed.set_thumbnail(url=ICON_URL)\n\n # Add the interesting information\n fields_to_check = (\"Status\", \"Python-Version\", \"Created\", \"Type\")\n for field in fields_to_check:\n # Check for a PEP metadata field that is present but has an empty value\n # embed field values can't contain an empty string\n if pep_header.get(field, \"\"):\n pep_embed.add_field(name=field, value=pep_header[field])\n\n elif response.status != 404:\n # any response except 200 and 404 is expected\n found_pep = True # actually not, but it's easier to display this way\n log.trace(f\"The user requested PEP {pep_number}, but the response had an unexpected status code: \"\n f\"{response.status}.\\n{response.text}\")\n\n error_message = \"Unexpected HTTP error during PEP search. Please let us know.\"\n pep_embed = Embed(title=\"Unexpected error\", description=error_message)\n pep_embed.colour = Colour.red()\n break\n\n if not found_pep:\n log.trace(\"PEP was not found\")\n not_found = f\"PEP {pep_number} does not exist.\"\n pep_embed = Embed(title=\"PEP not found\", description=not_found)\n pep_embed.colour = Colour.red()\n\n await ctx.message.channel.send(embed=pep_embed)\n\n @command()\n @in_whitelist(channels=(Channels.bot_commands,), roles=STAFF_ROLES)\n async def charinfo(self, ctx: Context, *, characters: str) -> None:\n \"\"\"Shows you information on up to 25 unicode characters.\"\"\"\n match = re.match(r\"<(a?):(\\w+):(\\d+)>\", characters)\n if match:\n embed = Embed(\n title=\"Non-Character Detected\",\n description=(\n \"Only unicode characters can be processed, but a custom Discord emoji \"\n \"was found. Please remove it and try again.\"\n )\n )\n embed.colour = Colour.red()\n await ctx.send(embed=embed)\n return\n\n if len(characters) > 25:\n embed = Embed(title=f\"Too many characters ({len(characters)}/25)\")\n embed.colour = Colour.red()\n await ctx.send(embed=embed)\n return\n\n def get_info(char: str) -> Tuple[str, str]:\n digit = f\"{ord(char):x}\"\n if len(digit) <= 4:\n u_code = f\"\\\\u{digit:>04}\"\n else:\n u_code = f\"\\\\U{digit:>08}\"\n url = f\"https://www.compart.com/en/unicode/U+{digit:>04}\"\n name = f\"[{unicodedata.name(char, '')}]({url})\"\n info = f\"`{u_code.ljust(10)}`: {name} - {utils.escape_markdown(char)}\"\n return info, u_code\n\n charlist, rawlist = zip(*(get_info(c) for c in characters))\n\n embed = Embed(description=\"\\n\".join(charlist))\n embed.set_author(name=\"Character Info\")\n\n if len(characters) > 1:\n embed.add_field(name='Raw', value=f\"`{''.join(rawlist)}`\", inline=False)\n\n await ctx.send(embed=embed)\n\n @command()\n async def zen(self, ctx: Context, *, search_value: Union[int, str, None] = None) -> None:\n \"\"\"\n Show the Zen of Python.\n\n Without any arguments, the full Zen will be produced.\n If an integer is provided, the line with that index will be produced.\n If a string is provided, the line which matches best will be produced.\n \"\"\"\n embed = Embed(\n colour=Colour.blurple(),\n title=\"The Zen of Python\",\n description=ZEN_OF_PYTHON\n )\n\n if search_value is None:\n embed.title += \", by Tim Peters\"\n await ctx.send(embed=embed)\n return\n\n zen_lines = ZEN_OF_PYTHON.splitlines()\n\n # handle if it's an index int\n if isinstance(search_value, int):\n upper_bound = len(zen_lines) - 1\n lower_bound = -1 * upper_bound\n if not (lower_bound <= search_value <= upper_bound):\n raise BadArgument(f\"Please provide an index between {lower_bound} and {upper_bound}.\")\n\n embed.title += f\" (line {search_value % len(zen_lines)}):\"\n embed.description = zen_lines[search_value]\n await ctx.send(embed=embed)\n return\n\n # Try to handle first exact word due difflib.SequenceMatched may use some other similar word instead\n # exact word.\n for i, line in enumerate(zen_lines):\n for word in line.split():\n if word.lower() == search_value.lower():\n embed.title += f\" (line {i}):\"\n embed.description = line\n await ctx.send(embed=embed)\n return\n\n # handle if it's a search string and not exact word\n matcher = difflib.SequenceMatcher(None, search_value.lower())\n\n best_match = \"\"\n match_index = 0\n best_ratio = 0\n\n for index, line in enumerate(zen_lines):\n matcher.set_seq2(line.lower())\n\n # the match ratio needs to be adjusted because, naturally,\n # longer lines will have worse ratios than shorter lines when\n # fuzzy searching for keywords. this seems to work okay.\n adjusted_ratio = (len(line) - 5) ** 0.5 * matcher.ratio()\n\n if adjusted_ratio > best_ratio:\n best_ratio = adjusted_ratio\n best_match = line\n match_index = index\n\n if not best_match:\n raise BadArgument(\"I didn't get a match! Please try again with a different search term.\")\n\n embed.title += f\" (line {match_index}):\"\n embed.description = best_match\n await ctx.send(embed=embed)\n\n @command(aliases=(\"poll\",))\n @with_role(*MODERATION_ROLES)\n async def vote(self, ctx: Context, title: str, *options: str) -> None:\n \"\"\"\n Build a quick voting poll with matching reactions with the provided options.\n\n A maximum of 20 options can be provided, as Discord supports a max of 20\n reactions on a single message.\n \"\"\"\n if len(options) < 2:\n raise BadArgument(\"Please provide at least 2 options.\")\n if len(options) > 20:\n raise BadArgument(\"I can only handle 20 options!\")\n\n codepoint_start = 127462 # represents \"regional_indicator_a\" unicode value\n options = {chr(i): f\"{chr(i)} - {v}\" for i, v in enumerate(options, start=codepoint_start)}\n embed = Embed(title=title, description=\"\\n\".join(options.values()))\n message = await ctx.send(embed=embed)\n for reaction in options:\n await message.add_reaction(reaction)\n\n async def send_pep_zero(self, ctx: Context) -> None:\n \"\"\"Send information about PEP 0.\"\"\"\n pep_embed = Embed(\n title=\"**PEP 0 - Index of Python Enhancement Proposals (PEPs)**\",\n description=\"[Link](https://www.python.org/dev/peps/)\"\n )\n pep_embed.set_thumbnail(url=ICON_URL)\n pep_embed.add_field(name=\"Status\", value=\"Active\")\n pep_embed.add_field(name=\"Created\", value=\"13-Jul-2000\")\n pep_embed.add_field(name=\"Type\", value=\"Informational\")\n\n await ctx.send(embed=pep_embed)\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Utils cog.\"\"\"\n bot.add_cog(Utils(bot))\n", "path": "bot/cogs/utils.py"}]}
| 3,952 | 745 |
gh_patches_debug_3685
|
rasdani/github-patches
|
git_diff
|
praw-dev__praw-888
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ListingGenerator gets stuck in loop when 'before' parameter is supplied.
## Issue Description
When retrieving submissions and supplying the 'before' parameter, the ListingGenerator gets stuck in a loop where the same 'after' parameter is submitted to reddit infinitely. I'm submitting a pull request with a fix. Additional details can be found in the pull request.
Example:
``reddit.subreddit(subreddit).new(limit=1024,params={'before': 't3_7xxxxx', 'count': 1024 })``
## System Information
PRAW Version: 5.3.0
Python Version: 3.5.3
Operating System: Debian 9.3
</issue>
<code>
[start of praw/models/listing/generator.py]
1 """Provide the ListingGenerator class."""
2 from copy import deepcopy
3
4 from .listing import FlairListing
5 from ..base import PRAWBase
6
7
8 class ListingGenerator(PRAWBase):
9 """Instances of this class generate :class:`.RedditBase` instances.
10
11 .. warning:: This class should not be directly utilized. Instead you will
12 find a number of methods that return instances of the class:
13
14 http://praw.readthedocs.io/en/latest/search.html?q=ListingGenerator
15
16 """
17
18 def __init__(self, reddit, url, limit=100, params=None):
19 """Initialize a ListingGenerator instance.
20
21 :param reddit: An instance of :class:`.Reddit`.
22 :param url: A URL returning a reddit listing.
23 :param limit: The number of content entries to fetch. If ``limit`` is
24 None, then fetch as many entries as possible. Most of reddit's
25 listings contain a maximum of 1000 items, and are returned 100 at a
26 time. This class will automatically issue all necessary
27 requests (default: 100).
28 :param params: A dictionary containing additional query string
29 parameters to send with the request.
30
31 """
32 super(ListingGenerator, self).__init__(reddit, None)
33 self._exhausted = False
34 self._listing = None
35 self._list_index = None
36 self.limit = limit
37 self.params = deepcopy(params) if params else {}
38 self.params['limit'] = limit or 1024
39 self.url = url
40 self.yielded = 0
41
42 def __iter__(self):
43 """Permit ListingGenerator to operate as an iterator."""
44 return self
45
46 def __next__(self):
47 """Permit ListingGenerator to operate as a generator in py3."""
48 if self.limit is not None and self.yielded >= self.limit:
49 raise StopIteration()
50
51 if self._listing is None or self._list_index >= len(self._listing):
52 self._next_batch()
53
54 self._list_index += 1
55 self.yielded += 1
56 return self._listing[self._list_index - 1]
57
58 def _next_batch(self):
59 if self._exhausted:
60 raise StopIteration()
61
62 self._listing = self._reddit.get(self.url, params=self.params)
63 if isinstance(self._listing, list):
64 self._listing = self._listing[1] # for submission duplicates
65 elif isinstance(self._listing, dict):
66 self._listing = FlairListing(self._reddit, self._listing)
67 self._list_index = 0
68
69 if not self._listing:
70 raise StopIteration()
71
72 if self._listing.after:
73 self.params['after'] = self._listing.after
74 else:
75 self._exhausted = True
76
77 def next(self):
78 """Permit ListingGenerator to operate as a generator in py2."""
79 return self.__next__()
80
[end of praw/models/listing/generator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/praw/models/listing/generator.py b/praw/models/listing/generator.py
--- a/praw/models/listing/generator.py
+++ b/praw/models/listing/generator.py
@@ -69,7 +69,8 @@
if not self._listing:
raise StopIteration()
- if self._listing.after:
+ if (self._listing.after and
+ self._listing.after != self.params.get('after')):
self.params['after'] = self._listing.after
else:
self._exhausted = True
|
{"golden_diff": "diff --git a/praw/models/listing/generator.py b/praw/models/listing/generator.py\n--- a/praw/models/listing/generator.py\n+++ b/praw/models/listing/generator.py\n@@ -69,7 +69,8 @@\n if not self._listing:\n raise StopIteration()\n \n- if self._listing.after:\n+ if (self._listing.after and\n+ self._listing.after != self.params.get('after')):\n self.params['after'] = self._listing.after\n else:\n self._exhausted = True\n", "issue": "ListingGenerator gets stuck in loop when 'before' parameter is supplied.\n## Issue Description\r\n\r\nWhen retrieving submissions and supplying the 'before' parameter, the ListingGenerator gets stuck in a loop where the same 'after' parameter is submitted to reddit infinitely. I'm submitting a pull request with a fix. Additional details can be found in the pull request.\r\n\r\nExample:\r\n``reddit.subreddit(subreddit).new(limit=1024,params={'before': 't3_7xxxxx', 'count': 1024 })``\r\n\r\n## System Information\r\n\r\n PRAW Version: 5.3.0\r\n Python Version: 3.5.3\r\nOperating System: Debian 9.3\r\n\n", "before_files": [{"content": "\"\"\"Provide the ListingGenerator class.\"\"\"\nfrom copy import deepcopy\n\nfrom .listing import FlairListing\nfrom ..base import PRAWBase\n\n\nclass ListingGenerator(PRAWBase):\n \"\"\"Instances of this class generate :class:`.RedditBase` instances.\n\n .. warning:: This class should not be directly utilized. Instead you will\n find a number of methods that return instances of the class:\n\n http://praw.readthedocs.io/en/latest/search.html?q=ListingGenerator\n\n \"\"\"\n\n def __init__(self, reddit, url, limit=100, params=None):\n \"\"\"Initialize a ListingGenerator instance.\n\n :param reddit: An instance of :class:`.Reddit`.\n :param url: A URL returning a reddit listing.\n :param limit: The number of content entries to fetch. If ``limit`` is\n None, then fetch as many entries as possible. Most of reddit's\n listings contain a maximum of 1000 items, and are returned 100 at a\n time. This class will automatically issue all necessary\n requests (default: 100).\n :param params: A dictionary containing additional query string\n parameters to send with the request.\n\n \"\"\"\n super(ListingGenerator, self).__init__(reddit, None)\n self._exhausted = False\n self._listing = None\n self._list_index = None\n self.limit = limit\n self.params = deepcopy(params) if params else {}\n self.params['limit'] = limit or 1024\n self.url = url\n self.yielded = 0\n\n def __iter__(self):\n \"\"\"Permit ListingGenerator to operate as an iterator.\"\"\"\n return self\n\n def __next__(self):\n \"\"\"Permit ListingGenerator to operate as a generator in py3.\"\"\"\n if self.limit is not None and self.yielded >= self.limit:\n raise StopIteration()\n\n if self._listing is None or self._list_index >= len(self._listing):\n self._next_batch()\n\n self._list_index += 1\n self.yielded += 1\n return self._listing[self._list_index - 1]\n\n def _next_batch(self):\n if self._exhausted:\n raise StopIteration()\n\n self._listing = self._reddit.get(self.url, params=self.params)\n if isinstance(self._listing, list):\n self._listing = self._listing[1] # for submission duplicates\n elif isinstance(self._listing, dict):\n self._listing = FlairListing(self._reddit, self._listing)\n self._list_index = 0\n\n if not self._listing:\n raise StopIteration()\n\n if self._listing.after:\n self.params['after'] = self._listing.after\n else:\n self._exhausted = True\n\n def next(self):\n \"\"\"Permit ListingGenerator to operate as a generator in py2.\"\"\"\n return self.__next__()\n", "path": "praw/models/listing/generator.py"}]}
| 1,482 | 124 |
gh_patches_debug_17194
|
rasdani/github-patches
|
git_diff
|
vacanza__python-holidays-1592
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Regression in holidays in the Netherlands
I noticed the change Update Netherlands holidays: add holiday categories #1552 broke my unit tests as it no longer considers Liberation day as a holiday on the 5yr interval even though it is a holiday for most people in the Netherlands every 5 years.
On Liberation day (Bevrijdingsdag) the majority of employees have a day off every 5 years (2005, 2010, 2015, etc.). This was the previous behaviour which worked as expected.
Now the 5-year rule of Liberation day is combined with Good Friday in the OPTIONAL category. This equates the status of Liberation day with Good Friday, but this is not logical. Good Fridays is more similar to Liberation Day on the non 5yr-years as those are still a bank holiday but fewer people have a guaranteed holiday than in the 5-yr years. There is no option to add the non-5yr holidays it seems.
The behaviour I would expect is:
- PUBLIC includes 5yr Liberation days
- OPTIONAL includes Good Friday and the non-5yr liberation days
</issue>
<code>
[start of holidays/countries/netherlands.py]
1 # python-holidays
2 # ---------------
3 # A fast, efficient Python library for generating country, province and state
4 # specific sets of holidays on the fly. It aims to make determining whether a
5 # specific date is a holiday as fast and flexible as possible.
6 #
7 # Authors: dr-prodigy <[email protected]> (c) 2017-2023
8 # ryanss <[email protected]> (c) 2014-2017
9 # Website: https://github.com/dr-prodigy/python-holidays
10 # License: MIT (see LICENSE file)
11
12 from datetime import date
13 from datetime import timedelta as td
14 from gettext import gettext as tr
15
16 from holidays.calendars.gregorian import APR, AUG
17 from holidays.constants import OPTIONAL, PUBLIC
18 from holidays.groups import ChristianHolidays, InternationalHolidays
19 from holidays.holiday_base import HolidayBase
20
21
22 class Netherlands(HolidayBase, ChristianHolidays, InternationalHolidays):
23 """
24 References:
25
26 - https://en.wikipedia.org/wiki/Public_holidays_in_the_Netherlands
27 - https://nl.wikipedia.org/wiki/Feestdagen_in_Nederland
28 - http://www.iamsterdam.com/en/plan-your-trip/practical-info/public-holidays
29 """
30
31 country = "NL"
32 default_language = "nl"
33 supported_categories = (OPTIONAL, PUBLIC)
34 supported_languages = ("en_US", "nl", "uk")
35
36 def __init__(self, *args, **kwargs):
37 ChristianHolidays.__init__(self)
38 InternationalHolidays.__init__(self)
39 super().__init__(*args, **kwargs)
40
41 def _populate_public_holidays(self):
42 # New Year's Day.
43 self._add_new_years_day(tr("Nieuwjaarsdag"))
44
45 # Easter Sunday.
46 self._add_easter_sunday(tr("Eerste paasdag"))
47
48 # Easter Monday.
49 self._add_easter_monday(tr("Tweede paasdag"))
50
51 # King's / Queen's day
52 if self._year >= 1891:
53 name = (
54 # King's Day.
55 tr("Koningsdag")
56 if self._year >= 2014
57 # Queen's Day.
58 else tr("Koninginnedag")
59 )
60 if self._year >= 2014:
61 dt = date(self._year, APR, 27)
62 elif self._year >= 1949:
63 dt = date(self._year, APR, 30)
64 else:
65 dt = date(self._year, AUG, 31)
66 if self._is_sunday(dt):
67 dt += td(days=-1) if self._year >= 1980 else td(days=+1)
68 self._add_holiday(name, dt)
69
70 # Ascension Day.
71 self._add_ascension_thursday(tr("Hemelvaartsdag"))
72
73 # Whit Sunday.
74 self._add_whit_sunday(tr("Eerste Pinksterdag"))
75
76 # Whit Monday.
77 self._add_whit_monday(tr("Tweede Pinksterdag"))
78
79 # Christmas Day.
80 self._add_christmas_day(tr("Eerste Kerstdag"))
81
82 # Second Day of Christmas.
83 self._add_christmas_day_two(tr("Tweede Kerstdag"))
84
85 def _populate_optional_holidays(self):
86 # Good Friday.
87 self._add_good_friday(tr("Goede Vrijdag"))
88
89 if (self._year >= 1945 and self._year % 5 == 0) or self._year >= 1990:
90 # Liberation Day.
91 self._add_holiday_may_5(tr("Bevrijdingsdag"))
92
93
94 class NL(Netherlands):
95 pass
96
97
98 class NLD(Netherlands):
99 pass
100
[end of holidays/countries/netherlands.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/holidays/countries/netherlands.py b/holidays/countries/netherlands.py
--- a/holidays/countries/netherlands.py
+++ b/holidays/countries/netherlands.py
@@ -67,6 +67,10 @@
dt += td(days=-1) if self._year >= 1980 else td(days=+1)
self._add_holiday(name, dt)
+ if self._year >= 1950 and self._year % 5 == 0:
+ # Liberation Day.
+ self._add_holiday_may_5(tr("Bevrijdingsdag"))
+
# Ascension Day.
self._add_ascension_thursday(tr("Hemelvaartsdag"))
@@ -86,7 +90,7 @@
# Good Friday.
self._add_good_friday(tr("Goede Vrijdag"))
- if (self._year >= 1945 and self._year % 5 == 0) or self._year >= 1990:
+ if self._year >= 1990:
# Liberation Day.
self._add_holiday_may_5(tr("Bevrijdingsdag"))
|
{"golden_diff": "diff --git a/holidays/countries/netherlands.py b/holidays/countries/netherlands.py\n--- a/holidays/countries/netherlands.py\n+++ b/holidays/countries/netherlands.py\n@@ -67,6 +67,10 @@\n dt += td(days=-1) if self._year >= 1980 else td(days=+1)\n self._add_holiday(name, dt)\n \n+ if self._year >= 1950 and self._year % 5 == 0:\n+ # Liberation Day.\n+ self._add_holiday_may_5(tr(\"Bevrijdingsdag\"))\n+\n # Ascension Day.\n self._add_ascension_thursday(tr(\"Hemelvaartsdag\"))\n \n@@ -86,7 +90,7 @@\n # Good Friday.\n self._add_good_friday(tr(\"Goede Vrijdag\"))\n \n- if (self._year >= 1945 and self._year % 5 == 0) or self._year >= 1990:\n+ if self._year >= 1990:\n # Liberation Day.\n self._add_holiday_may_5(tr(\"Bevrijdingsdag\"))\n", "issue": "Regression in holidays in the Netherlands\nI noticed the change Update Netherlands holidays: add holiday categories #1552 broke my unit tests as it no longer considers Liberation day as a holiday on the 5yr interval even though it is a holiday for most people in the Netherlands every 5 years.\r\n\r\nOn Liberation day (Bevrijdingsdag) the majority of employees have a day off every 5 years (2005, 2010, 2015, etc.). This was the previous behaviour which worked as expected.\r\n\r\nNow the 5-year rule of Liberation day is combined with Good Friday in the OPTIONAL category. This equates the status of Liberation day with Good Friday, but this is not logical. Good Fridays is more similar to Liberation Day on the non 5yr-years as those are still a bank holiday but fewer people have a guaranteed holiday than in the 5-yr years. There is no option to add the non-5yr holidays it seems.\r\n\r\nThe behaviour I would expect is:\r\n- PUBLIC includes 5yr Liberation days\r\n- OPTIONAL includes Good Friday and the non-5yr liberation days\n", "before_files": [{"content": "# python-holidays\n# ---------------\n# A fast, efficient Python library for generating country, province and state\n# specific sets of holidays on the fly. It aims to make determining whether a\n# specific date is a holiday as fast and flexible as possible.\n#\n# Authors: dr-prodigy <[email protected]> (c) 2017-2023\n# ryanss <[email protected]> (c) 2014-2017\n# Website: https://github.com/dr-prodigy/python-holidays\n# License: MIT (see LICENSE file)\n\nfrom datetime import date\nfrom datetime import timedelta as td\nfrom gettext import gettext as tr\n\nfrom holidays.calendars.gregorian import APR, AUG\nfrom holidays.constants import OPTIONAL, PUBLIC\nfrom holidays.groups import ChristianHolidays, InternationalHolidays\nfrom holidays.holiday_base import HolidayBase\n\n\nclass Netherlands(HolidayBase, ChristianHolidays, InternationalHolidays):\n \"\"\"\n References:\n\n - https://en.wikipedia.org/wiki/Public_holidays_in_the_Netherlands\n - https://nl.wikipedia.org/wiki/Feestdagen_in_Nederland\n - http://www.iamsterdam.com/en/plan-your-trip/practical-info/public-holidays\n \"\"\"\n\n country = \"NL\"\n default_language = \"nl\"\n supported_categories = (OPTIONAL, PUBLIC)\n supported_languages = (\"en_US\", \"nl\", \"uk\")\n\n def __init__(self, *args, **kwargs):\n ChristianHolidays.__init__(self)\n InternationalHolidays.__init__(self)\n super().__init__(*args, **kwargs)\n\n def _populate_public_holidays(self):\n # New Year's Day.\n self._add_new_years_day(tr(\"Nieuwjaarsdag\"))\n\n # Easter Sunday.\n self._add_easter_sunday(tr(\"Eerste paasdag\"))\n\n # Easter Monday.\n self._add_easter_monday(tr(\"Tweede paasdag\"))\n\n # King's / Queen's day\n if self._year >= 1891:\n name = (\n # King's Day.\n tr(\"Koningsdag\")\n if self._year >= 2014\n # Queen's Day.\n else tr(\"Koninginnedag\")\n )\n if self._year >= 2014:\n dt = date(self._year, APR, 27)\n elif self._year >= 1949:\n dt = date(self._year, APR, 30)\n else:\n dt = date(self._year, AUG, 31)\n if self._is_sunday(dt):\n dt += td(days=-1) if self._year >= 1980 else td(days=+1)\n self._add_holiday(name, dt)\n\n # Ascension Day.\n self._add_ascension_thursday(tr(\"Hemelvaartsdag\"))\n\n # Whit Sunday.\n self._add_whit_sunday(tr(\"Eerste Pinksterdag\"))\n\n # Whit Monday.\n self._add_whit_monday(tr(\"Tweede Pinksterdag\"))\n\n # Christmas Day.\n self._add_christmas_day(tr(\"Eerste Kerstdag\"))\n\n # Second Day of Christmas.\n self._add_christmas_day_two(tr(\"Tweede Kerstdag\"))\n\n def _populate_optional_holidays(self):\n # Good Friday.\n self._add_good_friday(tr(\"Goede Vrijdag\"))\n\n if (self._year >= 1945 and self._year % 5 == 0) or self._year >= 1990:\n # Liberation Day.\n self._add_holiday_may_5(tr(\"Bevrijdingsdag\"))\n\n\nclass NL(Netherlands):\n pass\n\n\nclass NLD(Netherlands):\n pass\n", "path": "holidays/countries/netherlands.py"}]}
| 1,815 | 266 |
gh_patches_debug_14234
|
rasdani/github-patches
|
git_diff
|
comic__grand-challenge.org-864
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix read the docs generation
We're using autodoc which requires an install of the dev environment. Read the docs does not support pipenv yet, so we should be able to fix when this PR is released: https://github.com/rtfd/readthedocs.org/pull/4783
For the time being, local generation works fine.
</issue>
<code>
[start of docs/conf.py]
1 #!/usr/bin/env python3
2 #
3 # grand-challenge.org documentation build configuration file, created by
4 # sphinx-quickstart on Fri Jan 5 16:19:37 2018.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 # If extensions (or modules to document with autodoc) are in another directory,
16 # add these directories to sys.path here. If the directory is relative to the
17 # documentation root, use os.path.abspath to make it absolute, like shown here.
18 #
19 import os
20 import sys
21
22 sys.path.insert(0, os.path.abspath("../app"))
23
24 os.environ["DJANGO_SETTINGS_MODULE"] = "config.settings"
25
26 import django
27
28 django.setup()
29
30 # -- General configuration ------------------------------------------------
31
32 # If your documentation needs a minimal Sphinx version, state it here.
33 #
34 # needs_sphinx = '1.0'
35
36 # Add any Sphinx extension module names here, as strings. They can be
37 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
38 # ones.
39 extensions = [
40 "sphinx.ext.autodoc",
41 "sphinx.ext.doctest",
42 "sphinx.ext.todo",
43 "sphinx.ext.coverage",
44 "sphinx.ext.mathjax",
45 "sphinx.ext.viewcode",
46 "sphinx.ext.napoleon",
47 "sphinx_autodoc_typehints",
48 ]
49
50 napoleon_google_docstring = False
51 napoleon_numpy_docstring = True
52 napoleon_use_rtype = False
53
54 # Add any paths that contain templates here, relative to this directory.
55 templates_path = ["_templates"]
56
57 # The suffix(es) of source filenames.
58 # You can specify multiple suffix as a list of string:
59 #
60 # source_suffix = ['.rst', '.md']
61 source_suffix = ".rst"
62
63 # The master toctree document.
64 master_doc = "index"
65
66 # General information about the project.
67 project = "grand-challenge.org"
68 copyright = "2018, James Meakin"
69 author = "James Meakin"
70
71 # The version info for the project you're documenting, acts as replacement for
72 # |version| and |release|, also used in various other places throughout the
73 # built documents.
74 #
75 # The short X.Y version.
76 version = ""
77 # The full version, including alpha/beta/rc tags.
78 release = ""
79
80 # The language for content autogenerated by Sphinx. Refer to documentation
81 # for a list of supported languages.
82 #
83 # This is also used if you do content translation via gettext catalogs.
84 # Usually you set "language" from the command line for these cases.
85 language = None
86
87 # List of patterns, relative to source directory, that match files and
88 # directories to ignore when looking for source files.
89 # This patterns also effect to html_static_path and html_extra_path
90 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store"]
91
92 # The name of the Pygments (syntax highlighting) style to use.
93 pygments_style = "sphinx"
94
95 # If true, `todo` and `todoList` produce output, else they produce nothing.
96 todo_include_todos = True
97
98
99 # -- Options for HTML output ----------------------------------------------
100
101 # The theme to use for HTML and HTML Help pages. See the documentation for
102 # a list of builtin themes.
103 #
104 html_theme = "alabaster"
105
106 # Theme options are theme-specific and customize the look and feel of a theme
107 # further. For a list of options available for each theme, see the
108 # documentation.
109 #
110 # html_theme_options = {}
111
112 # Add any paths that contain custom static files (such as style sheets) here,
113 # relative to this directory. They are copied after the builtin static files,
114 # so a file named "default.css" will overwrite the builtin "default.css".
115 html_static_path = ["_static"]
116
117 # Custom sidebar templates, must be a dictionary that maps document names
118 # to template names.
119 #
120 # This is required for the alabaster theme
121 # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
122 html_sidebars = {
123 "**": [
124 "relations.html", # needs 'show_related': True theme option to display
125 "searchbox.html",
126 ]
127 }
128
129
130 # -- Options for HTMLHelp output ------------------------------------------
131
132 # Output file base name for HTML help builder.
133 htmlhelp_basename = "grand-challenge.orgdoc"
134
135
136 # -- Options for LaTeX output ---------------------------------------------
137
138 latex_elements = {
139 # The paper size ('letterpaper' or 'a4paper').
140 #
141 # 'papersize': 'letterpaper',
142 # The font size ('10pt', '11pt' or '12pt').
143 #
144 # 'pointsize': '10pt',
145 # Additional stuff for the LaTeX preamble.
146 #
147 # 'preamble': '',
148 # Latex figure (float) alignment
149 #
150 # 'figure_align': 'htbp',
151 }
152
153 # Grouping the document tree into LaTeX files. List of tuples
154 # (source start file, target name, title,
155 # author, documentclass [howto, manual, or own class]).
156 latex_documents = [
157 (
158 master_doc,
159 "grand-challenge.org.tex",
160 "grand-challenge.org Documentation",
161 "James Meakin",
162 "manual",
163 )
164 ]
165
166
167 # -- Options for manual page output ---------------------------------------
168
169 # One entry per manual page. List of tuples
170 # (source start file, name, description, authors, manual section).
171 man_pages = [
172 (
173 master_doc,
174 "grand-challenge.org",
175 "grand-challenge.org Documentation",
176 [author],
177 1,
178 )
179 ]
180
181
182 # -- Options for Texinfo output -------------------------------------------
183
184 # Grouping the document tree into Texinfo files. List of tuples
185 # (source start file, target name, title, author,
186 # dir menu entry, description, category)
187 texinfo_documents = [
188 (
189 master_doc,
190 "grand-challenge.org",
191 "grand-challenge.org Documentation",
192 author,
193 "grand-challenge.org",
194 "One line description of project.",
195 "Miscellaneous",
196 )
197 ]
198
199 rst_epilog = ".. |project_name| replace:: %s" % project
200
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -45,6 +45,7 @@
"sphinx.ext.viewcode",
"sphinx.ext.napoleon",
"sphinx_autodoc_typehints",
+ "sphinx_rtd_theme",
]
napoleon_google_docstring = False
@@ -101,7 +102,7 @@
# The theme to use for HTML and HTML Help pages. See the documentation for
# a list of builtin themes.
#
-html_theme = "alabaster"
+html_theme = "sphinx_rtd_theme"
# Theme options are theme-specific and customize the look and feel of a theme
# further. For a list of options available for each theme, see the
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -45,6 +45,7 @@\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.napoleon\",\n \"sphinx_autodoc_typehints\",\n+ \"sphinx_rtd_theme\",\n ]\n \n napoleon_google_docstring = False\n@@ -101,7 +102,7 @@\n # The theme to use for HTML and HTML Help pages. See the documentation for\n # a list of builtin themes.\n #\n-html_theme = \"alabaster\"\n+html_theme = \"sphinx_rtd_theme\"\n \n # Theme options are theme-specific and customize the look and feel of a theme\n # further. For a list of options available for each theme, see the\n", "issue": "Fix read the docs generation\nWe're using autodoc which requires an install of the dev environment. Read the docs does not support pipenv yet, so we should be able to fix when this PR is released: https://github.com/rtfd/readthedocs.org/pull/4783\r\n\r\nFor the time being, local generation works fine. \n", "before_files": [{"content": "#!/usr/bin/env python3\n#\n# grand-challenge.org documentation build configuration file, created by\n# sphinx-quickstart on Fri Jan 5 16:19:37 2018.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\n\nsys.path.insert(0, os.path.abspath(\"../app\"))\n\nos.environ[\"DJANGO_SETTINGS_MODULE\"] = \"config.settings\"\n\nimport django\n\ndjango.setup()\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinx.ext.mathjax\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.napoleon\",\n \"sphinx_autodoc_typehints\",\n]\n\nnapoleon_google_docstring = False\nnapoleon_numpy_docstring = True\nnapoleon_use_rtype = False\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = \".rst\"\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# General information about the project.\nproject = \"grand-challenge.org\"\ncopyright = \"2018, James Meakin\"\nauthor = \"James Meakin\"\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = \"\"\n# The full version, including alpha/beta/rc tags.\nrelease = \"\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"alabaster\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n \"**\": [\n \"relations.html\", # needs 'show_related': True theme option to display\n \"searchbox.html\",\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"grand-challenge.orgdoc\"\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (\n master_doc,\n \"grand-challenge.org.tex\",\n \"grand-challenge.org Documentation\",\n \"James Meakin\",\n \"manual\",\n )\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (\n master_doc,\n \"grand-challenge.org\",\n \"grand-challenge.org Documentation\",\n [author],\n 1,\n )\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"grand-challenge.org\",\n \"grand-challenge.org Documentation\",\n author,\n \"grand-challenge.org\",\n \"One line description of project.\",\n \"Miscellaneous\",\n )\n]\n\nrst_epilog = \".. |project_name| replace:: %s\" % project\n", "path": "docs/conf.py"}]}
| 2,469 | 175 |
gh_patches_debug_44298
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-319
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
additonal_dependencies isn't "rollback safe"
Using old pre-commit + a hook repo with `additional_dependencies` it'll happily create the repo without installing the additional dependencies. Upon upgrading to a newer pre-commit, it doesn't know that the additional dependencies aren't installed yet and will happily attempt to run in there (usually causing an executable to not be found). We need some way to signify when these have been installed in order for this to be rollable. A workaround is to `pre-commit clean` when upgrading, but that kinda is not the best (and especially confusing).
</issue>
<code>
[start of setup.py]
1 from setuptools import find_packages
2 from setuptools import setup
3
4
5 setup(
6 name='pre_commit',
7 description=(
8 'A framework for managing and maintaining multi-language pre-commit '
9 'hooks.'
10 ),
11 url='https://github.com/pre-commit/pre-commit',
12 version='0.6.8',
13
14 author='Anthony Sottile',
15 author_email='[email protected]',
16
17 platforms='linux',
18 classifiers=[
19 'License :: OSI Approved :: MIT License',
20 'Programming Language :: Python :: 2',
21 'Programming Language :: Python :: 2.6',
22 'Programming Language :: Python :: 2.7',
23 'Programming Language :: Python :: 3',
24 'Programming Language :: Python :: 3.3',
25 'Programming Language :: Python :: 3.4',
26 'Programming Language :: Python :: 3.5',
27 'Programming Language :: Python :: Implementation :: CPython',
28 'Programming Language :: Python :: Implementation :: PyPy',
29 ],
30
31 packages=find_packages('.', exclude=('tests*', 'testing*')),
32 package_data={
33 'pre_commit': [
34 'resources/hook-tmpl',
35 'resources/pre-push-tmpl',
36 'resources/rbenv.tar.gz',
37 'resources/ruby-build.tar.gz',
38 'resources/ruby-download.tar.gz',
39 ]
40 },
41 install_requires=[
42 'argparse',
43 'aspy.yaml',
44 'cached-property',
45 'jsonschema',
46 'nodeenv>=0.11.1',
47 'ordereddict',
48 'pyyaml',
49 'simplejson',
50 'virtualenv',
51 ],
52 entry_points={
53 'console_scripts': [
54 'pre-commit = pre_commit.main:main',
55 'pre-commit-validate-config = pre_commit.clientlib.validate_config:run', # noqa
56 'pre-commit-validate-manifest = pre_commit.clientlib.validate_manifest:run', # noqa
57 ],
58 },
59 )
60
[end of setup.py]
[start of pre_commit/repository.py]
1 from __future__ import unicode_literals
2
3 import logging
4 import shutil
5 from collections import defaultdict
6
7 import pkg_resources
8 from cached_property import cached_property
9
10 from pre_commit import git
11 from pre_commit.clientlib.validate_config import is_local_hooks
12 from pre_commit.clientlib.validate_manifest import MANIFEST_JSON_SCHEMA
13 from pre_commit.jsonschema_extensions import apply_defaults
14 from pre_commit.languages.all import languages
15 from pre_commit.languages.helpers import environment_dir
16 from pre_commit.manifest import Manifest
17 from pre_commit.prefixed_command_runner import PrefixedCommandRunner
18
19
20 logger = logging.getLogger('pre_commit')
21
22 _pre_commit_version = pkg_resources.parse_version(
23 pkg_resources.get_distribution('pre-commit').version
24 )
25
26
27 class Repository(object):
28 def __init__(self, repo_config, repo_path_getter):
29 self.repo_config = repo_config
30 self.repo_path_getter = repo_path_getter
31 self.__installed = False
32
33 @classmethod
34 def create(cls, config, store):
35 if is_local_hooks(config):
36 return LocalRepository(config)
37 else:
38 repo_path_getter = store.get_repo_path_getter(
39 config['repo'], config['sha']
40 )
41 return cls(config, repo_path_getter)
42
43 @cached_property
44 def repo_url(self):
45 return self.repo_config['repo']
46
47 @cached_property
48 def sha(self):
49 return self.repo_config['sha']
50
51 @cached_property
52 def languages(self):
53 return set(
54 (hook['language'], hook['language_version'])
55 for _, hook in self.hooks
56 )
57
58 @cached_property
59 def additional_dependencies(self):
60 dep_dict = defaultdict(lambda: defaultdict(set))
61 for _, hook in self.hooks:
62 dep_dict[hook['language']][hook['language_version']].update(
63 hook.get('additional_dependencies', []),
64 )
65 return dep_dict
66
67 @cached_property
68 def hooks(self):
69 for hook in self.repo_config['hooks']:
70 if hook['id'] not in self.manifest.hooks:
71 logger.error(
72 '`{0}` is not present in repository {1}. '
73 'Typo? Perhaps it is introduced in a newer version? '
74 'Often `pre-commit autoupdate` fixes this.'.format(
75 hook['id'], self.repo_config['repo'],
76 )
77 )
78 exit(1)
79 hook_version = pkg_resources.parse_version(
80 self.manifest.hooks[hook['id']]['minimum_pre_commit_version'],
81 )
82 if hook_version > _pre_commit_version:
83 logger.error(
84 'The hook `{0}` requires pre-commit version {1} but '
85 'version {2} is installed. '
86 'Perhaps run `pip install --upgrade pre-commit`.'.format(
87 hook['id'], hook_version, _pre_commit_version,
88 )
89 )
90 exit(1)
91 return tuple(
92 (hook['id'], dict(self.manifest.hooks[hook['id']], **hook))
93 for hook in self.repo_config['hooks']
94 )
95
96 @cached_property
97 def manifest(self):
98 return Manifest(self.repo_path_getter)
99
100 @cached_property
101 def cmd_runner(self):
102 return PrefixedCommandRunner(self.repo_path_getter.repo_path)
103
104 def require_installed(self):
105 if self.__installed:
106 return
107
108 self.install()
109 self.__installed = True
110
111 def install(self):
112 """Install the hook repository."""
113 def language_is_installed(language_name, language_version):
114 language = languages[language_name]
115 directory = environment_dir(
116 language.ENVIRONMENT_DIR, language_version,
117 )
118 return (
119 directory is None or
120 self.cmd_runner.exists(directory, '.installed')
121 )
122
123 if not all(
124 language_is_installed(language_name, language_version)
125 for language_name, language_version in self.languages
126 ):
127 logger.info(
128 'Installing environment for {0}.'.format(self.repo_url)
129 )
130 logger.info('Once installed this environment will be reused.')
131 logger.info('This may take a few minutes...')
132
133 for language_name, language_version in self.languages:
134 language = languages[language_name]
135 if language_is_installed(language_name, language_version):
136 continue
137
138 directory = environment_dir(
139 language.ENVIRONMENT_DIR, language_version,
140 )
141 # There's potentially incomplete cleanup from previous runs
142 # Clean it up!
143 if self.cmd_runner.exists(directory):
144 shutil.rmtree(self.cmd_runner.path(directory))
145
146 language.install_environment(
147 self.cmd_runner, language_version,
148 self.additional_dependencies[language_name][language_version],
149 )
150 # Touch the .installed file (atomic) to indicate we've installed
151 open(self.cmd_runner.path(directory, '.installed'), 'w').close()
152
153 def run_hook(self, hook, file_args):
154 """Run a hook.
155
156 Args:
157 hook - Hook dictionary
158 file_args - List of files to run
159 """
160 self.require_installed()
161 return languages[hook['language']].run_hook(
162 self.cmd_runner, hook, file_args,
163 )
164
165
166 class LocalRepository(Repository):
167 def __init__(self, repo_config):
168 super(LocalRepository, self).__init__(repo_config, None)
169
170 @cached_property
171 def hooks(self):
172 return tuple(
173 (hook['id'], apply_defaults(hook, MANIFEST_JSON_SCHEMA['items']))
174 for hook in self.repo_config['hooks']
175 )
176
177 @cached_property
178 def cmd_runner(self):
179 return PrefixedCommandRunner(git.get_root())
180
181 @cached_property
182 def sha(self):
183 raise NotImplementedError
184
185 @cached_property
186 def manifest(self):
187 raise NotImplementedError
188
[end of pre_commit/repository.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/repository.py b/pre_commit/repository.py
--- a/pre_commit/repository.py
+++ b/pre_commit/repository.py
@@ -1,12 +1,16 @@
from __future__ import unicode_literals
+import io
+import json
import logging
+import os
import shutil
from collections import defaultdict
import pkg_resources
from cached_property import cached_property
+from pre_commit import five
from pre_commit import git
from pre_commit.clientlib.validate_config import is_local_hooks
from pre_commit.clientlib.validate_manifest import MANIFEST_JSON_SCHEMA
@@ -23,6 +27,9 @@
pkg_resources.get_distribution('pre-commit').version
)
+# Bump when installation changes in a backwards / forwards incompatible way
+INSTALLED_STATE_VERSION = '1'
+
class Repository(object):
def __init__(self, repo_config, repo_path_getter):
@@ -110,14 +117,45 @@
def install(self):
"""Install the hook repository."""
+ def state(language_name, language_version):
+ return {
+ 'additional_dependencies': sorted(
+ self.additional_dependencies[
+ language_name
+ ][language_version],
+ )
+ }
+
+ def state_filename(venv, suffix=''):
+ return self.cmd_runner.path(
+ venv, '.install_state_v' + INSTALLED_STATE_VERSION + suffix,
+ )
+
+ def read_state(venv):
+ if not os.path.exists(state_filename(venv)):
+ return None
+ else:
+ return json.loads(io.open(state_filename(venv)).read())
+
+ def write_state(venv, language_name, language_version):
+ with io.open(
+ state_filename(venv, suffix='staging'), 'w',
+ ) as state_file:
+ state_file.write(five.to_text(json.dumps(
+ state(language_name, language_version),
+ )))
+ # Move the file into place atomically to indicate we've installed
+ os.rename(
+ state_filename(venv, suffix='staging'),
+ state_filename(venv),
+ )
+
def language_is_installed(language_name, language_version):
language = languages[language_name]
- directory = environment_dir(
- language.ENVIRONMENT_DIR, language_version,
- )
+ venv = environment_dir(language.ENVIRONMENT_DIR, language_version)
return (
- directory is None or
- self.cmd_runner.exists(directory, '.installed')
+ venv is None or
+ read_state(venv) == state(language_name, language_version)
)
if not all(
@@ -131,24 +169,23 @@
logger.info('This may take a few minutes...')
for language_name, language_version in self.languages:
- language = languages[language_name]
if language_is_installed(language_name, language_version):
continue
- directory = environment_dir(
- language.ENVIRONMENT_DIR, language_version,
- )
+ language = languages[language_name]
+ venv = environment_dir(language.ENVIRONMENT_DIR, language_version)
+
# There's potentially incomplete cleanup from previous runs
# Clean it up!
- if self.cmd_runner.exists(directory):
- shutil.rmtree(self.cmd_runner.path(directory))
+ if self.cmd_runner.exists(venv):
+ shutil.rmtree(self.cmd_runner.path(venv))
language.install_environment(
self.cmd_runner, language_version,
self.additional_dependencies[language_name][language_version],
)
- # Touch the .installed file (atomic) to indicate we've installed
- open(self.cmd_runner.path(directory, '.installed'), 'w').close()
+ # Write our state to indicate we're installed
+ write_state(venv, language_name, language_version)
def run_hook(self, hook, file_args):
"""Run a hook.
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -46,7 +46,6 @@
'nodeenv>=0.11.1',
'ordereddict',
'pyyaml',
- 'simplejson',
'virtualenv',
],
entry_points={
|
{"golden_diff": "diff --git a/pre_commit/repository.py b/pre_commit/repository.py\n--- a/pre_commit/repository.py\n+++ b/pre_commit/repository.py\n@@ -1,12 +1,16 @@\n from __future__ import unicode_literals\n \n+import io\n+import json\n import logging\n+import os\n import shutil\n from collections import defaultdict\n \n import pkg_resources\n from cached_property import cached_property\n \n+from pre_commit import five\n from pre_commit import git\n from pre_commit.clientlib.validate_config import is_local_hooks\n from pre_commit.clientlib.validate_manifest import MANIFEST_JSON_SCHEMA\n@@ -23,6 +27,9 @@\n pkg_resources.get_distribution('pre-commit').version\n )\n \n+# Bump when installation changes in a backwards / forwards incompatible way\n+INSTALLED_STATE_VERSION = '1'\n+\n \n class Repository(object):\n def __init__(self, repo_config, repo_path_getter):\n@@ -110,14 +117,45 @@\n \n def install(self):\n \"\"\"Install the hook repository.\"\"\"\n+ def state(language_name, language_version):\n+ return {\n+ 'additional_dependencies': sorted(\n+ self.additional_dependencies[\n+ language_name\n+ ][language_version],\n+ )\n+ }\n+\n+ def state_filename(venv, suffix=''):\n+ return self.cmd_runner.path(\n+ venv, '.install_state_v' + INSTALLED_STATE_VERSION + suffix,\n+ )\n+\n+ def read_state(venv):\n+ if not os.path.exists(state_filename(venv)):\n+ return None\n+ else:\n+ return json.loads(io.open(state_filename(venv)).read())\n+\n+ def write_state(venv, language_name, language_version):\n+ with io.open(\n+ state_filename(venv, suffix='staging'), 'w',\n+ ) as state_file:\n+ state_file.write(five.to_text(json.dumps(\n+ state(language_name, language_version),\n+ )))\n+ # Move the file into place atomically to indicate we've installed\n+ os.rename(\n+ state_filename(venv, suffix='staging'),\n+ state_filename(venv),\n+ )\n+\n def language_is_installed(language_name, language_version):\n language = languages[language_name]\n- directory = environment_dir(\n- language.ENVIRONMENT_DIR, language_version,\n- )\n+ venv = environment_dir(language.ENVIRONMENT_DIR, language_version)\n return (\n- directory is None or\n- self.cmd_runner.exists(directory, '.installed')\n+ venv is None or\n+ read_state(venv) == state(language_name, language_version)\n )\n \n if not all(\n@@ -131,24 +169,23 @@\n logger.info('This may take a few minutes...')\n \n for language_name, language_version in self.languages:\n- language = languages[language_name]\n if language_is_installed(language_name, language_version):\n continue\n \n- directory = environment_dir(\n- language.ENVIRONMENT_DIR, language_version,\n- )\n+ language = languages[language_name]\n+ venv = environment_dir(language.ENVIRONMENT_DIR, language_version)\n+\n # There's potentially incomplete cleanup from previous runs\n # Clean it up!\n- if self.cmd_runner.exists(directory):\n- shutil.rmtree(self.cmd_runner.path(directory))\n+ if self.cmd_runner.exists(venv):\n+ shutil.rmtree(self.cmd_runner.path(venv))\n \n language.install_environment(\n self.cmd_runner, language_version,\n self.additional_dependencies[language_name][language_version],\n )\n- # Touch the .installed file (atomic) to indicate we've installed\n- open(self.cmd_runner.path(directory, '.installed'), 'w').close()\n+ # Write our state to indicate we're installed\n+ write_state(venv, language_name, language_version)\n \n def run_hook(self, hook, file_args):\n \"\"\"Run a hook.\ndiff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -46,7 +46,6 @@\n 'nodeenv>=0.11.1',\n 'ordereddict',\n 'pyyaml',\n- 'simplejson',\n 'virtualenv',\n ],\n entry_points={\n", "issue": "additonal_dependencies isn't \"rollback safe\"\nUsing old pre-commit + a hook repo with `additional_dependencies` it'll happily create the repo without installing the additional dependencies. Upon upgrading to a newer pre-commit, it doesn't know that the additional dependencies aren't installed yet and will happily attempt to run in there (usually causing an executable to not be found). We need some way to signify when these have been installed in order for this to be rollable. A workaround is to `pre-commit clean` when upgrading, but that kinda is not the best (and especially confusing).\n\n", "before_files": [{"content": "from setuptools import find_packages\nfrom setuptools import setup\n\n\nsetup(\n name='pre_commit',\n description=(\n 'A framework for managing and maintaining multi-language pre-commit '\n 'hooks.'\n ),\n url='https://github.com/pre-commit/pre-commit',\n version='0.6.8',\n\n author='Anthony Sottile',\n author_email='[email protected]',\n\n platforms='linux',\n classifiers=[\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.6',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n ],\n\n packages=find_packages('.', exclude=('tests*', 'testing*')),\n package_data={\n 'pre_commit': [\n 'resources/hook-tmpl',\n 'resources/pre-push-tmpl',\n 'resources/rbenv.tar.gz',\n 'resources/ruby-build.tar.gz',\n 'resources/ruby-download.tar.gz',\n ]\n },\n install_requires=[\n 'argparse',\n 'aspy.yaml',\n 'cached-property',\n 'jsonschema',\n 'nodeenv>=0.11.1',\n 'ordereddict',\n 'pyyaml',\n 'simplejson',\n 'virtualenv',\n ],\n entry_points={\n 'console_scripts': [\n 'pre-commit = pre_commit.main:main',\n 'pre-commit-validate-config = pre_commit.clientlib.validate_config:run', # noqa\n 'pre-commit-validate-manifest = pre_commit.clientlib.validate_manifest:run', # noqa\n ],\n },\n)\n", "path": "setup.py"}, {"content": "from __future__ import unicode_literals\n\nimport logging\nimport shutil\nfrom collections import defaultdict\n\nimport pkg_resources\nfrom cached_property import cached_property\n\nfrom pre_commit import git\nfrom pre_commit.clientlib.validate_config import is_local_hooks\nfrom pre_commit.clientlib.validate_manifest import MANIFEST_JSON_SCHEMA\nfrom pre_commit.jsonschema_extensions import apply_defaults\nfrom pre_commit.languages.all import languages\nfrom pre_commit.languages.helpers import environment_dir\nfrom pre_commit.manifest import Manifest\nfrom pre_commit.prefixed_command_runner import PrefixedCommandRunner\n\n\nlogger = logging.getLogger('pre_commit')\n\n_pre_commit_version = pkg_resources.parse_version(\n pkg_resources.get_distribution('pre-commit').version\n)\n\n\nclass Repository(object):\n def __init__(self, repo_config, repo_path_getter):\n self.repo_config = repo_config\n self.repo_path_getter = repo_path_getter\n self.__installed = False\n\n @classmethod\n def create(cls, config, store):\n if is_local_hooks(config):\n return LocalRepository(config)\n else:\n repo_path_getter = store.get_repo_path_getter(\n config['repo'], config['sha']\n )\n return cls(config, repo_path_getter)\n\n @cached_property\n def repo_url(self):\n return self.repo_config['repo']\n\n @cached_property\n def sha(self):\n return self.repo_config['sha']\n\n @cached_property\n def languages(self):\n return set(\n (hook['language'], hook['language_version'])\n for _, hook in self.hooks\n )\n\n @cached_property\n def additional_dependencies(self):\n dep_dict = defaultdict(lambda: defaultdict(set))\n for _, hook in self.hooks:\n dep_dict[hook['language']][hook['language_version']].update(\n hook.get('additional_dependencies', []),\n )\n return dep_dict\n\n @cached_property\n def hooks(self):\n for hook in self.repo_config['hooks']:\n if hook['id'] not in self.manifest.hooks:\n logger.error(\n '`{0}` is not present in repository {1}. '\n 'Typo? Perhaps it is introduced in a newer version? '\n 'Often `pre-commit autoupdate` fixes this.'.format(\n hook['id'], self.repo_config['repo'],\n )\n )\n exit(1)\n hook_version = pkg_resources.parse_version(\n self.manifest.hooks[hook['id']]['minimum_pre_commit_version'],\n )\n if hook_version > _pre_commit_version:\n logger.error(\n 'The hook `{0}` requires pre-commit version {1} but '\n 'version {2} is installed. '\n 'Perhaps run `pip install --upgrade pre-commit`.'.format(\n hook['id'], hook_version, _pre_commit_version,\n )\n )\n exit(1)\n return tuple(\n (hook['id'], dict(self.manifest.hooks[hook['id']], **hook))\n for hook in self.repo_config['hooks']\n )\n\n @cached_property\n def manifest(self):\n return Manifest(self.repo_path_getter)\n\n @cached_property\n def cmd_runner(self):\n return PrefixedCommandRunner(self.repo_path_getter.repo_path)\n\n def require_installed(self):\n if self.__installed:\n return\n\n self.install()\n self.__installed = True\n\n def install(self):\n \"\"\"Install the hook repository.\"\"\"\n def language_is_installed(language_name, language_version):\n language = languages[language_name]\n directory = environment_dir(\n language.ENVIRONMENT_DIR, language_version,\n )\n return (\n directory is None or\n self.cmd_runner.exists(directory, '.installed')\n )\n\n if not all(\n language_is_installed(language_name, language_version)\n for language_name, language_version in self.languages\n ):\n logger.info(\n 'Installing environment for {0}.'.format(self.repo_url)\n )\n logger.info('Once installed this environment will be reused.')\n logger.info('This may take a few minutes...')\n\n for language_name, language_version in self.languages:\n language = languages[language_name]\n if language_is_installed(language_name, language_version):\n continue\n\n directory = environment_dir(\n language.ENVIRONMENT_DIR, language_version,\n )\n # There's potentially incomplete cleanup from previous runs\n # Clean it up!\n if self.cmd_runner.exists(directory):\n shutil.rmtree(self.cmd_runner.path(directory))\n\n language.install_environment(\n self.cmd_runner, language_version,\n self.additional_dependencies[language_name][language_version],\n )\n # Touch the .installed file (atomic) to indicate we've installed\n open(self.cmd_runner.path(directory, '.installed'), 'w').close()\n\n def run_hook(self, hook, file_args):\n \"\"\"Run a hook.\n\n Args:\n hook - Hook dictionary\n file_args - List of files to run\n \"\"\"\n self.require_installed()\n return languages[hook['language']].run_hook(\n self.cmd_runner, hook, file_args,\n )\n\n\nclass LocalRepository(Repository):\n def __init__(self, repo_config):\n super(LocalRepository, self).__init__(repo_config, None)\n\n @cached_property\n def hooks(self):\n return tuple(\n (hook['id'], apply_defaults(hook, MANIFEST_JSON_SCHEMA['items']))\n for hook in self.repo_config['hooks']\n )\n\n @cached_property\n def cmd_runner(self):\n return PrefixedCommandRunner(git.get_root())\n\n @cached_property\n def sha(self):\n raise NotImplementedError\n\n @cached_property\n def manifest(self):\n raise NotImplementedError\n", "path": "pre_commit/repository.py"}]}
| 2,840 | 920 |
gh_patches_debug_12213
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-2288
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Incorrect timeframe plugin behaviour when loading items from an entry_list
### Expected behaviour:
The 1080p is downloaded
### Actual behaviour:
The plugin ignores 1080p and sees only 720p
### Steps to reproduce:
- Step 1: Add movies from rss http://rutor.info/rss.php?cat=7 to list movies_list
#### Config:
```
schedules:
- tasks: ["download *"]
interval:
minutes: 15
web_server: yes
tasks:
download good movies:
entry_list: movies_list
seen_movies:
scope: local
seen: local
seen_info_hash: local
timeframe:
wait: 14 day
on_reached: do_nothing
target: 1080p
priority: 5
imdb:
min_score: 6.3
min_votes: 1000
reject_genres:
- documentary
- musical
- music
- history
- biography
- war
list_remove:
- entry_list: movies_list
download: /downloads
```
#### Log:
<details>
<summary>(click to expand)</summary>
```
2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 720p от селезень | iTunes` by timeframe plugin because timeframe waiting
2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 1080p от TeamHD | iTunes` by timeframe plugin because timeframe waiting
2018-10-26 09:16 INFO timeframe download good movies `incredibles 2 2018`: timeframe waiting for 321h:59min. Currently best is `Incredibles 2 (2018) WEB-DL 720p от селезень | iTunes`.
```
<details><summary>--dump output excerpt</summary>
720p:
```
title : Incredibles 2 (2018) WEB-DL 720p от селезень | iTunes
url : http://d.rutor.is/download.php?rss=661218
original_url : http://d.rutor.is/download.php?rss=661218
accepted_by : imdb
content-length : 82000
content_files : [Incredibles.2.2018.720p.WEB-DL.selezen.mkv]
content_size : 4012.526089668274
description : Мультипликация
filename : [rutor.is]Incredibles.2.2018.720p.WEB-DL.selezen.mkv.torrent
id : incredibles 2 2018
imdb_id : tt3606756
quality : 720p webdl
reason : timeframe waiting
rejected_by : timeframe
```
1080p:
```
title : Incredibles 2 (2018) WEB-DL 1080p от TeamHD | iTunes
url : http://d.rutor.is/download.php?rss=661219
original_url : http://d.rutor.is/download.php?rss=661219
accepted_by : imdb
content-length : 90640
content_files : [Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv]
content_size : 4444.096870422363
description : Мультипликация
filename : [rutor.is]Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv.torrent
id : incredibles 2 2018
imdb_id : tt3606756
quality : 1080p webdl
raw_title : Суперсемейка 2 / Incredibles 2 (2018) WEB-DL 1080p от TeamHD | iTunes
reason : timeframe waiting
rejected_by : timeframe
```
</details>
</details>
### Additional information:
- FlexGet version: 2.17.5 (first time noticed on 2.17.0, but probably is here for long time)
- Python version: 3.5.3
- Installation method: pip3 install (+docker)
- Using daemon (yes/no): yes
- OS and version: Debian Stretch
Incorrect timeframe plugin behaviour when loading items from an entry_list
### Expected behaviour:
The 1080p is downloaded
### Actual behaviour:
The plugin ignores 1080p and sees only 720p
### Steps to reproduce:
- Step 1: Add movies from rss http://rutor.info/rss.php?cat=7 to list movies_list
#### Config:
```
schedules:
- tasks: ["download *"]
interval:
minutes: 15
web_server: yes
tasks:
download good movies:
entry_list: movies_list
seen_movies:
scope: local
seen: local
seen_info_hash: local
timeframe:
wait: 14 day
on_reached: do_nothing
target: 1080p
priority: 5
imdb:
min_score: 6.3
min_votes: 1000
reject_genres:
- documentary
- musical
- music
- history
- biography
- war
list_remove:
- entry_list: movies_list
download: /downloads
```
#### Log:
<details>
<summary>(click to expand)</summary>
```
2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 720p от селезень | iTunes` by timeframe plugin because timeframe waiting
2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 1080p от TeamHD | iTunes` by timeframe plugin because timeframe waiting
2018-10-26 09:16 INFO timeframe download good movies `incredibles 2 2018`: timeframe waiting for 321h:59min. Currently best is `Incredibles 2 (2018) WEB-DL 720p от селезень | iTunes`.
```
<details><summary>--dump output excerpt</summary>
720p:
```
title : Incredibles 2 (2018) WEB-DL 720p от селезень | iTunes
url : http://d.rutor.is/download.php?rss=661218
original_url : http://d.rutor.is/download.php?rss=661218
accepted_by : imdb
content-length : 82000
content_files : [Incredibles.2.2018.720p.WEB-DL.selezen.mkv]
content_size : 4012.526089668274
description : Мультипликация
filename : [rutor.is]Incredibles.2.2018.720p.WEB-DL.selezen.mkv.torrent
id : incredibles 2 2018
imdb_id : tt3606756
quality : 720p webdl
reason : timeframe waiting
rejected_by : timeframe
```
1080p:
```
title : Incredibles 2 (2018) WEB-DL 1080p от TeamHD | iTunes
url : http://d.rutor.is/download.php?rss=661219
original_url : http://d.rutor.is/download.php?rss=661219
accepted_by : imdb
content-length : 90640
content_files : [Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv]
content_size : 4444.096870422363
description : Мультипликация
filename : [rutor.is]Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv.torrent
id : incredibles 2 2018
imdb_id : tt3606756
quality : 1080p webdl
raw_title : Суперсемейка 2 / Incredibles 2 (2018) WEB-DL 1080p от TeamHD | iTunes
reason : timeframe waiting
rejected_by : timeframe
```
</details>
</details>
### Additional information:
- FlexGet version: 2.17.5 (first time noticed on 2.17.0, but probably is here for long time)
- Python version: 3.5.3
- Installation method: pip3 install (+docker)
- Using daemon (yes/no): yes
- OS and version: Debian Stretch
</issue>
<code>
[start of flexget/plugins/metainfo/quality.py]
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # noqa pylint: disable=unused-import, redefined-builtin
3
4 import logging
5
6 from flexget import plugin
7 from flexget.event import event
8 from flexget.utils import qualities
9
10 log = logging.getLogger('metainfo_quality')
11
12
13 class MetainfoQuality(object):
14 """
15 Utility:
16
17 Set quality attribute for entries.
18 """
19
20 schema = {'type': 'boolean'}
21
22 @plugin.priority(127) # Run after other plugins that might fill quality (series)
23 def on_task_metainfo(self, task, config):
24 # check if disabled (value set to false)
25 if config is False:
26 return
27 for entry in task.entries:
28 entry.register_lazy_func(self.get_quality, ['quality'])
29
30 def get_quality(self, entry):
31 if entry.get('quality', eval_lazy=False):
32 log.debug('Quality is already set to %s for %s, skipping quality detection.' %
33 (entry['quality'], entry['title']))
34 return
35 entry['quality'] = qualities.Quality(entry['title'])
36 if entry['quality']:
37 log.trace('Found quality %s for %s' % (entry['quality'], entry['title']))
38
39
40 @event('plugin.register')
41 def register_plugin():
42 plugin.register(MetainfoQuality, 'metainfo_quality', api_ver=2, builtin=True)
43
[end of flexget/plugins/metainfo/quality.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/plugins/metainfo/quality.py b/flexget/plugins/metainfo/quality.py
--- a/flexget/plugins/metainfo/quality.py
+++ b/flexget/plugins/metainfo/quality.py
@@ -25,7 +25,12 @@
if config is False:
return
for entry in task.entries:
- entry.register_lazy_func(self.get_quality, ['quality'])
+ if isinstance(entry.get('quality', eval_lazy=False), str):
+ log.debug('Quality is already set to %s for %s, but has not been instantiated properly.' %
+ (entry['quality'], entry['title']))
+ entry['quality'] = qualities.Quality(entry.get('quality', eval_lazy=False))
+ else:
+ entry.register_lazy_func(self.get_quality, ['quality'])
def get_quality(self, entry):
if entry.get('quality', eval_lazy=False):
|
{"golden_diff": "diff --git a/flexget/plugins/metainfo/quality.py b/flexget/plugins/metainfo/quality.py\n--- a/flexget/plugins/metainfo/quality.py\n+++ b/flexget/plugins/metainfo/quality.py\n@@ -25,7 +25,12 @@\n if config is False:\n return\n for entry in task.entries:\n- entry.register_lazy_func(self.get_quality, ['quality'])\n+ if isinstance(entry.get('quality', eval_lazy=False), str):\n+ log.debug('Quality is already set to %s for %s, but has not been instantiated properly.' %\n+ (entry['quality'], entry['title']))\n+ entry['quality'] = qualities.Quality(entry.get('quality', eval_lazy=False))\n+ else:\n+ entry.register_lazy_func(self.get_quality, ['quality'])\n \n def get_quality(self, entry):\n if entry.get('quality', eval_lazy=False):\n", "issue": "Incorrect timeframe plugin behaviour when loading items from an entry_list\n### Expected behaviour:\r\nThe 1080p is downloaded\r\n\r\n### Actual behaviour:\r\nThe plugin ignores 1080p and sees only 720p\r\n\r\n### Steps to reproduce:\r\n- Step 1: Add movies from rss http://rutor.info/rss.php?cat=7 to list movies_list\r\n\r\n#### Config:\r\n```\r\nschedules:\r\n - tasks: [\"download *\"]\r\n interval:\r\n minutes: 15\r\n\r\nweb_server: yes\r\n\r\ntasks:\r\n download good movies:\r\n entry_list: movies_list\r\n seen_movies:\r\n scope: local\r\n seen: local\r\n seen_info_hash: local\r\n timeframe:\r\n wait: 14 day\r\n on_reached: do_nothing\r\n target: 1080p\r\n priority: 5\r\n imdb:\r\n min_score: 6.3\r\n min_votes: 1000\r\n reject_genres:\r\n - documentary\r\n - musical\r\n - music\r\n - history\r\n - biography\r\n - war\r\n list_remove:\r\n - entry_list: movies_list\r\n download: /downloads\r\n```\r\n \r\n#### Log:\r\n<details>\r\n <summary>(click to expand)</summary>\r\n\r\n```\r\n2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 720p \u043e\u0442 \u0441\u0435\u043b\u0435\u0437\u0435\u043d\u044c | iTunes` by timeframe plugin because timeframe waiting\r\n2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 1080p \u043e\u0442 TeamHD | iTunes` by timeframe plugin because timeframe waiting\r\n2018-10-26 09:16 INFO timeframe download good movies `incredibles 2 2018`: timeframe waiting for 321h:59min. Currently best is `Incredibles 2 (2018) WEB-DL 720p \u043e\u0442 \u0441\u0435\u043b\u0435\u0437\u0435\u043d\u044c | iTunes`.\r\n```\r\n\r\n<details><summary>--dump output excerpt</summary>\r\n720p:\r\n\r\n```\r\ntitle : Incredibles 2 (2018) WEB-DL 720p \u043e\u0442 \u0441\u0435\u043b\u0435\u0437\u0435\u043d\u044c | iTunes\r\nurl : http://d.rutor.is/download.php?rss=661218\r\noriginal_url : http://d.rutor.is/download.php?rss=661218\r\naccepted_by : imdb\r\ncontent-length : 82000\r\ncontent_files : [Incredibles.2.2018.720p.WEB-DL.selezen.mkv]\r\ncontent_size : 4012.526089668274\r\ndescription : \u041c\u0443\u043b\u044c\u0442\u0438\u043f\u043b\u0438\u043a\u0430\u0446\u0438\u044f\r\nfilename : [rutor.is]Incredibles.2.2018.720p.WEB-DL.selezen.mkv.torrent\r\nid : incredibles 2 2018\r\nimdb_id : tt3606756\r\nquality : 720p webdl\r\nreason : timeframe waiting\r\nrejected_by : timeframe\r\n```\r\n\r\n1080p:\r\n```\r\ntitle : Incredibles 2 (2018) WEB-DL 1080p \u043e\u0442 TeamHD | iTunes\r\nurl : http://d.rutor.is/download.php?rss=661219\r\noriginal_url : http://d.rutor.is/download.php?rss=661219\r\naccepted_by : imdb\r\ncontent-length : 90640\r\ncontent_files : [Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv]\r\ncontent_size : 4444.096870422363\r\ndescription : \u041c\u0443\u043b\u044c\u0442\u0438\u043f\u043b\u0438\u043a\u0430\u0446\u0438\u044f\r\nfilename : [rutor.is]Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv.torrent\r\nid : incredibles 2 2018\r\nimdb_id : tt3606756\r\nquality : 1080p webdl\r\nraw_title : \u0421\u0443\u043f\u0435\u0440\u0441\u0435\u043c\u0435\u0439\u043a\u0430 2 / Incredibles 2 (2018) WEB-DL 1080p \u043e\u0442 TeamHD | iTunes\r\nreason : timeframe waiting\r\nrejected_by : timeframe\r\n```\r\n\r\n</details>\r\n</details>\r\n\r\n### Additional information:\r\n\r\n- FlexGet version: 2.17.5 (first time noticed on 2.17.0, but probably is here for long time)\r\n- Python version: 3.5.3\r\n- Installation method: pip3 install (+docker)\r\n- Using daemon (yes/no): yes\r\n- OS and version: Debian Stretch\nIncorrect timeframe plugin behaviour when loading items from an entry_list\n### Expected behaviour:\r\nThe 1080p is downloaded\r\n\r\n### Actual behaviour:\r\nThe plugin ignores 1080p and sees only 720p\r\n\r\n### Steps to reproduce:\r\n- Step 1: Add movies from rss http://rutor.info/rss.php?cat=7 to list movies_list\r\n\r\n#### Config:\r\n```\r\nschedules:\r\n - tasks: [\"download *\"]\r\n interval:\r\n minutes: 15\r\n\r\nweb_server: yes\r\n\r\ntasks:\r\n download good movies:\r\n entry_list: movies_list\r\n seen_movies:\r\n scope: local\r\n seen: local\r\n seen_info_hash: local\r\n timeframe:\r\n wait: 14 day\r\n on_reached: do_nothing\r\n target: 1080p\r\n priority: 5\r\n imdb:\r\n min_score: 6.3\r\n min_votes: 1000\r\n reject_genres:\r\n - documentary\r\n - musical\r\n - music\r\n - history\r\n - biography\r\n - war\r\n list_remove:\r\n - entry_list: movies_list\r\n download: /downloads\r\n```\r\n \r\n#### Log:\r\n<details>\r\n <summary>(click to expand)</summary>\r\n\r\n```\r\n2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 720p \u043e\u0442 \u0441\u0435\u043b\u0435\u0437\u0435\u043d\u044c | iTunes` by timeframe plugin because timeframe waiting\r\n2018-10-26 09:16 VERBOSE task download good movies REJECTED: `Incredibles 2 (2018) WEB-DL 1080p \u043e\u0442 TeamHD | iTunes` by timeframe plugin because timeframe waiting\r\n2018-10-26 09:16 INFO timeframe download good movies `incredibles 2 2018`: timeframe waiting for 321h:59min. Currently best is `Incredibles 2 (2018) WEB-DL 720p \u043e\u0442 \u0441\u0435\u043b\u0435\u0437\u0435\u043d\u044c | iTunes`.\r\n```\r\n\r\n<details><summary>--dump output excerpt</summary>\r\n720p:\r\n\r\n```\r\ntitle : Incredibles 2 (2018) WEB-DL 720p \u043e\u0442 \u0441\u0435\u043b\u0435\u0437\u0435\u043d\u044c | iTunes\r\nurl : http://d.rutor.is/download.php?rss=661218\r\noriginal_url : http://d.rutor.is/download.php?rss=661218\r\naccepted_by : imdb\r\ncontent-length : 82000\r\ncontent_files : [Incredibles.2.2018.720p.WEB-DL.selezen.mkv]\r\ncontent_size : 4012.526089668274\r\ndescription : \u041c\u0443\u043b\u044c\u0442\u0438\u043f\u043b\u0438\u043a\u0430\u0446\u0438\u044f\r\nfilename : [rutor.is]Incredibles.2.2018.720p.WEB-DL.selezen.mkv.torrent\r\nid : incredibles 2 2018\r\nimdb_id : tt3606756\r\nquality : 720p webdl\r\nreason : timeframe waiting\r\nrejected_by : timeframe\r\n```\r\n\r\n1080p:\r\n```\r\ntitle : Incredibles 2 (2018) WEB-DL 1080p \u043e\u0442 TeamHD | iTunes\r\nurl : http://d.rutor.is/download.php?rss=661219\r\noriginal_url : http://d.rutor.is/download.php?rss=661219\r\naccepted_by : imdb\r\ncontent-length : 90640\r\ncontent_files : [Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv]\r\ncontent_size : 4444.096870422363\r\ndescription : \u041c\u0443\u043b\u044c\u0442\u0438\u043f\u043b\u0438\u043a\u0430\u0446\u0438\u044f\r\nfilename : [rutor.is]Incredibles.2.2018.1080p.WEB-DL.TeamHD.mkv.torrent\r\nid : incredibles 2 2018\r\nimdb_id : tt3606756\r\nquality : 1080p webdl\r\nraw_title : \u0421\u0443\u043f\u0435\u0440\u0441\u0435\u043c\u0435\u0439\u043a\u0430 2 / Incredibles 2 (2018) WEB-DL 1080p \u043e\u0442 TeamHD | iTunes\r\nreason : timeframe waiting\r\nrejected_by : timeframe\r\n```\r\n\r\n</details>\r\n</details>\r\n\r\n### Additional information:\r\n\r\n- FlexGet version: 2.17.5 (first time noticed on 2.17.0, but probably is here for long time)\r\n- Python version: 3.5.3\r\n- Installation method: pip3 install (+docker)\r\n- Using daemon (yes/no): yes\r\n- OS and version: Debian Stretch\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # noqa pylint: disable=unused-import, redefined-builtin\n\nimport logging\n\nfrom flexget import plugin\nfrom flexget.event import event\nfrom flexget.utils import qualities\n\nlog = logging.getLogger('metainfo_quality')\n\n\nclass MetainfoQuality(object):\n \"\"\"\n Utility:\n\n Set quality attribute for entries.\n \"\"\"\n\n schema = {'type': 'boolean'}\n\n @plugin.priority(127) # Run after other plugins that might fill quality (series)\n def on_task_metainfo(self, task, config):\n # check if disabled (value set to false)\n if config is False:\n return\n for entry in task.entries:\n entry.register_lazy_func(self.get_quality, ['quality'])\n\n def get_quality(self, entry):\n if entry.get('quality', eval_lazy=False):\n log.debug('Quality is already set to %s for %s, skipping quality detection.' %\n (entry['quality'], entry['title']))\n return\n entry['quality'] = qualities.Quality(entry['title'])\n if entry['quality']:\n log.trace('Found quality %s for %s' % (entry['quality'], entry['title']))\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(MetainfoQuality, 'metainfo_quality', api_ver=2, builtin=True)\n", "path": "flexget/plugins/metainfo/quality.py"}]}
| 3,125 | 200 |
gh_patches_debug_6755
|
rasdani/github-patches
|
git_diff
|
wagtail__wagtail-3277
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Elasticsearch backend indexes draft updates of existing pages
### Issue Summary
When saving a draft version of an existing live page the Elasticsearch backend reindexes the page with the draft content. The reindexed content will potentially cause frontend search results to include the page if the search query matches the draft content.
I'm using the following search query in my view:
search_results = Page.objects.live().search(search_query)
New content that is saved as draft is not an issue since the live() filter excludes it.
### Steps to Reproduce
1. Edit an indexed field of an existing published page
2. Insert a unique term in the indexed field
3. Click 'Save Draft'
4. On the fontend search for the unique term.
5. The editted page will be returned in the results
I can see the value of having the draft content indexed on the Wagtail backend but since the frontend shares the same index, that can be a problem.
### Technical details
* Python version: 3.5.2.
* Django version: 1.10.4.
* Wagtail version: 1.8.
* Elasticsearch: 5
</issue>
<code>
[start of wagtail/wagtailsearch/signal_handlers.py]
1 from __future__ import absolute_import, unicode_literals
2
3 from django.db.models.signals import post_delete, post_save
4
5 from wagtail.wagtailsearch import index
6
7
8 def post_save_signal_handler(instance, **kwargs):
9 index.insert_or_update_object(instance)
10
11
12 def post_delete_signal_handler(instance, **kwargs):
13 index.remove_object(instance)
14
15
16 def register_signal_handlers():
17 # Loop through list and register signal handlers for each one
18 for model in index.get_indexed_models():
19 post_save.connect(post_save_signal_handler, sender=model)
20 post_delete.connect(post_delete_signal_handler, sender=model)
21
[end of wagtail/wagtailsearch/signal_handlers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wagtail/wagtailsearch/signal_handlers.py b/wagtail/wagtailsearch/signal_handlers.py
--- a/wagtail/wagtailsearch/signal_handlers.py
+++ b/wagtail/wagtailsearch/signal_handlers.py
@@ -5,7 +5,13 @@
from wagtail.wagtailsearch import index
-def post_save_signal_handler(instance, **kwargs):
+def post_save_signal_handler(instance, update_fields=None, **kwargs):
+ if update_fields is not None:
+ # fetch a fresh copy of instance from the database to ensure
+ # that we're not indexing any of the unsaved data contained in
+ # the fields that were not passed in update_fields
+ instance = type(instance).objects.get(pk=instance.pk)
+
index.insert_or_update_object(instance)
|
{"golden_diff": "diff --git a/wagtail/wagtailsearch/signal_handlers.py b/wagtail/wagtailsearch/signal_handlers.py\n--- a/wagtail/wagtailsearch/signal_handlers.py\n+++ b/wagtail/wagtailsearch/signal_handlers.py\n@@ -5,7 +5,13 @@\n from wagtail.wagtailsearch import index\n \n \n-def post_save_signal_handler(instance, **kwargs):\n+def post_save_signal_handler(instance, update_fields=None, **kwargs):\n+ if update_fields is not None:\n+ # fetch a fresh copy of instance from the database to ensure\n+ # that we're not indexing any of the unsaved data contained in\n+ # the fields that were not passed in update_fields\n+ instance = type(instance).objects.get(pk=instance.pk)\n+\n index.insert_or_update_object(instance)\n", "issue": "Elasticsearch backend indexes draft updates of existing pages\n### Issue Summary\r\n\r\nWhen saving a draft version of an existing live page the Elasticsearch backend reindexes the page with the draft content. The reindexed content will potentially cause frontend search results to include the page if the search query matches the draft content.\r\n\r\nI'm using the following search query in my view:\r\n\r\n search_results = Page.objects.live().search(search_query)\r\n\r\nNew content that is saved as draft is not an issue since the live() filter excludes it.\r\n\r\n\r\n### Steps to Reproduce\r\n\r\n1. Edit an indexed field of an existing published page\r\n2. Insert a unique term in the indexed field\r\n3. Click 'Save Draft'\r\n4. On the fontend search for the unique term.\r\n5. The editted page will be returned in the results\r\n\r\nI can see the value of having the draft content indexed on the Wagtail backend but since the frontend shares the same index, that can be a problem.\r\n\r\n### Technical details\r\n\r\n* Python version: 3.5.2.\r\n* Django version: 1.10.4.\r\n* Wagtail version: 1.8.\r\n* Elasticsearch: 5\r\n\n", "before_files": [{"content": "from __future__ import absolute_import, unicode_literals\n\nfrom django.db.models.signals import post_delete, post_save\n\nfrom wagtail.wagtailsearch import index\n\n\ndef post_save_signal_handler(instance, **kwargs):\n index.insert_or_update_object(instance)\n\n\ndef post_delete_signal_handler(instance, **kwargs):\n index.remove_object(instance)\n\n\ndef register_signal_handlers():\n # Loop through list and register signal handlers for each one\n for model in index.get_indexed_models():\n post_save.connect(post_save_signal_handler, sender=model)\n post_delete.connect(post_delete_signal_handler, sender=model)\n", "path": "wagtail/wagtailsearch/signal_handlers.py"}]}
| 944 | 180 |
gh_patches_debug_23357
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-1076
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Bug: dvc remote remove leads to Initialization error / config file error.
**Setup**
- dvc version 0.18.9, installed with pip, python Anaconda 3.6.4, Ubuntu 16.04
**Repro**
```bash
set -e
set -x
rm -rf foo
mkdir -p foo && cd foo
git init && dvc init
echo bar > bar.txt
dvc remote add -d dummy s3://dummy
dvc remote remove dummy
dvc add bar.txt
```
```bash
+ rm -rf foo
+ mkdir -p foo
+ cd foo
+ git init
Initialized empty Git repository in /home/tmain/foo/.git/
+ dvc init
Adding '.dvc/state' to '.dvc/.gitignore'.
Adding '.dvc/state.lock' to '.dvc/.gitignore'.
Adding '.dvc/link.state' to '.dvc/.gitignore'.
Adding '.dvc/link.state.lock' to '.dvc/.gitignore'.
Adding '.dvc/lock' to '.dvc/.gitignore'.
Adding '.dvc/config.local' to '.dvc/.gitignore'.
Adding '.dvc/updater' to '.dvc/.gitignore'.
Adding '.dvc/cache' to '.dvc/.gitignore'.
Checking for updates...
+ echo bar
+ dvc remote add -d dummy s3://dummy
Setting 'dummy' as a default remote.
+ dvc remote remove dummy
+ dvc add bar.txt
Error: Initialization error: Config file error: Can't find remote section 'remote "dummy"' in config
```
</issue>
<code>
[start of dvc/command/remote.py]
1 import re
2
3 from dvc.config import Config
4 from dvc.command.config import CmdConfig
5 from dvc.logger import Logger
6
7
8 class CmdRemoteAdd(CmdConfig):
9 def run(self):
10 section = Config.SECTION_REMOTE_FMT.format(self.args.name)
11 ret = self.set(section, Config.SECTION_REMOTE_URL, self.args.url)
12 if ret != 0:
13 return ret
14
15 if self.args.default:
16 msg = 'Setting \'{}\' as a default remote.'.format(self.args.name)
17 Logger.info(msg)
18 ret = self.set(Config.SECTION_CORE,
19 Config.SECTION_CORE_REMOTE,
20 self.args.name)
21
22 return ret
23
24
25 class CmdRemoteRemove(CmdConfig):
26 def run(self):
27 section = Config.SECTION_REMOTE_FMT.format(self.args.name)
28 return self.unset(section, Config.SECTION_REMOTE_URL)
29
30
31 class CmdRemoteModify(CmdConfig):
32 def run(self):
33 section = Config.SECTION_REMOTE_FMT.format(self.args.name)
34 self.args.name = '{}.{}'.format(section, self.args.option)
35 return super(CmdRemoteModify, self).run()
36
37
38 class CmdRemoteList(CmdConfig):
39 def run(self):
40 for section in self.configobj.keys():
41 r = re.match(Config.SECTION_REMOTE_REGEX, section)
42 if r:
43 name = r.group('name')
44 url = self.configobj[section].get(Config.SECTION_REMOTE_URL,
45 '')
46 Logger.info('{}\t{}'.format(name, url))
47 return 0
48
[end of dvc/command/remote.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/command/remote.py b/dvc/command/remote.py
--- a/dvc/command/remote.py
+++ b/dvc/command/remote.py
@@ -1,4 +1,6 @@
+import os
import re
+import configobj
from dvc.config import Config
from dvc.command.config import CmdConfig
@@ -23,9 +25,35 @@
class CmdRemoteRemove(CmdConfig):
+ def _remove_default(self, config_file, remote):
+ path = os.path.join(os.path.dirname(self.config_file),
+ config_file)
+ config = configobj.ConfigObj(path)
+
+ core = config.get(Config.SECTION_CORE, None)
+ if core is None:
+ return
+
+ default = core.get(Config.SECTION_CORE_REMOTE, None)
+ if default is None:
+ return
+
+ if default == remote:
+ del config[Config.SECTION_CORE][Config.SECTION_CORE_REMOTE]
+ if len(config[Config.SECTION_CORE]) == 0:
+ del config[Config.SECTION_CORE]
+
+ config.write()
+
def run(self):
section = Config.SECTION_REMOTE_FMT.format(self.args.name)
- return self.unset(section, Config.SECTION_REMOTE_URL)
+ ret = self.unset(section)
+ if ret != 0:
+ return ret
+
+ self._remove_default(Config.CONFIG, self.args.name)
+ self._remove_default(Config.CONFIG_LOCAL, self.args.name)
+ return 0
class CmdRemoteModify(CmdConfig):
|
{"golden_diff": "diff --git a/dvc/command/remote.py b/dvc/command/remote.py\n--- a/dvc/command/remote.py\n+++ b/dvc/command/remote.py\n@@ -1,4 +1,6 @@\n+import os\n import re\n+import configobj\n \n from dvc.config import Config\n from dvc.command.config import CmdConfig\n@@ -23,9 +25,35 @@\n \n \n class CmdRemoteRemove(CmdConfig):\n+ def _remove_default(self, config_file, remote):\n+ path = os.path.join(os.path.dirname(self.config_file),\n+ config_file)\n+ config = configobj.ConfigObj(path)\n+\n+ core = config.get(Config.SECTION_CORE, None)\n+ if core is None:\n+ return\n+\n+ default = core.get(Config.SECTION_CORE_REMOTE, None)\n+ if default is None:\n+ return\n+\n+ if default == remote:\n+ del config[Config.SECTION_CORE][Config.SECTION_CORE_REMOTE]\n+ if len(config[Config.SECTION_CORE]) == 0:\n+ del config[Config.SECTION_CORE]\n+\n+ config.write()\n+\n def run(self):\n section = Config.SECTION_REMOTE_FMT.format(self.args.name)\n- return self.unset(section, Config.SECTION_REMOTE_URL)\n+ ret = self.unset(section)\n+ if ret != 0:\n+ return ret\n+\n+ self._remove_default(Config.CONFIG, self.args.name)\n+ self._remove_default(Config.CONFIG_LOCAL, self.args.name)\n+ return 0\n \n \n class CmdRemoteModify(CmdConfig):\n", "issue": "Bug: dvc remote remove leads to Initialization error / config file error.\n**Setup**\r\n\r\n- dvc version 0.18.9, installed with pip, python Anaconda 3.6.4, Ubuntu 16.04\r\n\r\n**Repro**\r\n\r\n```bash\r\nset -e\r\nset -x\r\nrm -rf foo\r\nmkdir -p foo && cd foo\r\ngit init && dvc init\r\necho bar > bar.txt\r\ndvc remote add -d dummy s3://dummy\r\ndvc remote remove dummy\r\ndvc add bar.txt\r\n```\r\n\r\n```bash\r\n+ rm -rf foo\r\n+ mkdir -p foo\r\n+ cd foo\r\n+ git init\r\nInitialized empty Git repository in /home/tmain/foo/.git/\r\n+ dvc init\r\nAdding '.dvc/state' to '.dvc/.gitignore'.\r\nAdding '.dvc/state.lock' to '.dvc/.gitignore'.\r\nAdding '.dvc/link.state' to '.dvc/.gitignore'.\r\nAdding '.dvc/link.state.lock' to '.dvc/.gitignore'.\r\nAdding '.dvc/lock' to '.dvc/.gitignore'.\r\nAdding '.dvc/config.local' to '.dvc/.gitignore'.\r\nAdding '.dvc/updater' to '.dvc/.gitignore'.\r\nAdding '.dvc/cache' to '.dvc/.gitignore'.\r\nChecking for updates...\r\n+ echo bar\r\n+ dvc remote add -d dummy s3://dummy\r\nSetting 'dummy' as a default remote.\r\n+ dvc remote remove dummy\r\n+ dvc add bar.txt\r\nError: Initialization error: Config file error: Can't find remote section 'remote \"dummy\"' in config\r\n\r\n```\n", "before_files": [{"content": "import re\n\nfrom dvc.config import Config\nfrom dvc.command.config import CmdConfig\nfrom dvc.logger import Logger\n\n\nclass CmdRemoteAdd(CmdConfig):\n def run(self):\n section = Config.SECTION_REMOTE_FMT.format(self.args.name)\n ret = self.set(section, Config.SECTION_REMOTE_URL, self.args.url)\n if ret != 0:\n return ret\n\n if self.args.default:\n msg = 'Setting \\'{}\\' as a default remote.'.format(self.args.name)\n Logger.info(msg)\n ret = self.set(Config.SECTION_CORE,\n Config.SECTION_CORE_REMOTE,\n self.args.name)\n\n return ret\n\n\nclass CmdRemoteRemove(CmdConfig):\n def run(self):\n section = Config.SECTION_REMOTE_FMT.format(self.args.name)\n return self.unset(section, Config.SECTION_REMOTE_URL)\n\n\nclass CmdRemoteModify(CmdConfig):\n def run(self):\n section = Config.SECTION_REMOTE_FMT.format(self.args.name)\n self.args.name = '{}.{}'.format(section, self.args.option)\n return super(CmdRemoteModify, self).run()\n\n\nclass CmdRemoteList(CmdConfig):\n def run(self):\n for section in self.configobj.keys():\n r = re.match(Config.SECTION_REMOTE_REGEX, section)\n if r:\n name = r.group('name')\n url = self.configobj[section].get(Config.SECTION_REMOTE_URL,\n '')\n Logger.info('{}\\t{}'.format(name, url))\n return 0\n", "path": "dvc/command/remote.py"}]}
| 1,300 | 342 |
gh_patches_debug_11289
|
rasdani/github-patches
|
git_diff
|
Parsl__parsl-544
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Do not CD to engine_dir
Currently in the IPP submit script we CD to the `engine_dir`. This breaks staging stuff. We should just send engine-related files there rather than changing the PWD.
</issue>
<code>
[start of parsl/executors/ipp.py]
1 import logging
2 import os
3 import pathlib
4 import uuid
5
6 from ipyparallel import Client
7 from parsl.providers import LocalProvider
8 from parsl.utils import RepresentationMixin
9
10 from parsl.dataflow.error import ConfigurationError
11 from parsl.executors.base import ParslExecutor
12 from parsl.executors.errors import *
13 from parsl.executors.ipp_controller import Controller
14 from parsl.utils import wait_for_file
15
16 logger = logging.getLogger(__name__)
17
18
19 class IPyParallelExecutor(ParslExecutor, RepresentationMixin):
20 """The IPython Parallel executor.
21
22 This executor uses IPythonParallel's pilot execution system to manage multiple processes
23 running locally or remotely.
24
25 Parameters
26 ----------
27 provider : :class:`~parsl.providers.provider_base.ExecutionProvider`
28 Provider to access computation resources. Can be one of :class:`~parsl.providers.aws.aws.EC2Provider`,
29 :class:`~parsl.providers.azureProvider.azureProvider.AzureProvider`,
30 :class:`~parsl.providers.cobalt.cobalt.Cobalt`,
31 :class:`~parsl.providers.condor.condor.Condor`,
32 :class:`~parsl.providers.googlecloud.googlecloud.GoogleCloud`,
33 :class:`~parsl.providers.gridEngine.gridEngine.GridEngine`,
34 :class:`~parsl.providers.jetstream.jetstream.Jetstream`,
35 :class:`~parsl.providers.local.local.Local`,
36 :class:`~parsl.providers.sge.sge.GridEngine`,
37 :class:`~parsl.providers.slurm.slurm.Slurm`, or
38 :class:`~parsl.providers.torque.torque.Torque`.
39 label : str
40 Label for this executor instance.
41 controller : :class:`~parsl.executors.ipp_controller.Controller`
42 Which Controller instance to use. Default is `Controller()`.
43 container_image : str
44 Launch tasks in a container using this docker image. If set to None, no container is used.
45 Default is None.
46 engine_dir : str
47 Directory where engine logs and configuration files will be stored.
48 working_dir : str
49 Directory where input data should be staged to.
50 storage_access : list of :class:`~parsl.data_provider.scheme.Scheme`
51 Specifications for accessing data this executor remotely. Multiple `Scheme`s are not yet supported.
52 managed : bool
53 If True, parsl will control dynamic scaling of this executor, and be responsible. Otherwise,
54 this is managed by the user.
55 engine_debug_level : int | str
56 Sets engine logging to specified debug level. Choices: (0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL')
57
58 .. note::
59 Some deficiencies with this executor are:
60
61 1. Ipengine's execute one task at a time. This means one engine per core
62 is necessary to exploit the full parallelism of a node.
63 2. No notion of remaining walltime.
64 3. Lack of throttling means tasks could be queued up on a worker.
65 """
66
67 def __init__(self,
68 provider=LocalProvider(),
69 label='ipp',
70 working_dir=None,
71 controller=Controller(),
72 container_image=None,
73 engine_dir=None,
74 storage_access=None,
75 engine_debug_level=None,
76 managed=True):
77 self.provider = provider
78 self.label = label
79 self.working_dir = working_dir
80 self.controller = controller
81 self.engine_debug_level = engine_debug_level
82 self.container_image = container_image
83 self.engine_dir = engine_dir
84 self.storage_access = storage_access if storage_access is not None else []
85 if len(self.storage_access) > 1:
86 raise ConfigurationError('Multiple storage access schemes are not yet supported')
87 self.managed = managed
88
89 self.debug_option = ""
90 if self.engine_debug_level:
91 self.debug_option = "--log-level={}".format(self.engine_debug_level)
92
93 def start(self):
94 self.controller.profile = self.label
95 self.controller.ipython_dir = self.run_dir
96 if self.engine_dir is None:
97 parent, child = pathlib.Path(self.run_dir).parts[-2:]
98 self.engine_dir = os.path.join(parent, child)
99 self.controller.start()
100
101 self.engine_file = self.controller.engine_file
102
103 with wait_for_file(self.controller.client_file, seconds=120):
104 logger.debug("Waiting for {0}".format(self.controller.client_file))
105
106 if not os.path.exists(self.controller.client_file):
107 raise Exception("Controller client file is missing at {0}".format(self.controller.client_file))
108
109 command_composer = self.compose_launch_cmd
110
111 self.executor = Client(url_file=self.controller.client_file)
112 if self.container_image:
113 command_composer = self.compose_containerized_launch_cmd
114 logger.info("Launching IPP with Docker:{0}".format(self.container_image))
115
116 self.launch_cmd = command_composer(self.engine_file, self.engine_dir, self.container_image)
117 self.engines = []
118
119 self._scaling_enabled = self.provider.scaling_enabled
120 logger.debug("Starting IPyParallelExecutor with provider:\n%s", self.provider)
121 if hasattr(self.provider, 'init_blocks'):
122 try:
123 for i in range(self.provider.init_blocks):
124 engine = self.provider.submit(self.launch_cmd, 1)
125 logger.debug("Launched block: {0}:{1}".format(i, engine))
126 if not engine:
127 raise(ScalingFailed(self.provider.label,
128 "Attempts to provision nodes via provider has failed"))
129 self.engines.extend([engine])
130
131 except Exception as e:
132 logger.error("Scaling out failed: %s" % e)
133 raise e
134
135 self.lb_view = self.executor.load_balanced_view()
136 logger.debug("Starting executor")
137
138 def compose_launch_cmd(self, filepath, engine_dir, container_image):
139 """Reads the json contents from filepath and uses that to compose the engine launch command.
140
141 Args:
142 filepath: Path to the engine file
143 engine_dir: CWD for the engines
144
145 """
146 self.engine_file = os.path.expanduser(filepath)
147 uid = str(uuid.uuid4())
148 engine_json = None
149 try:
150 with open(self.engine_file, 'r') as f:
151 engine_json = f.read()
152
153 except OSError as e:
154 logger.error("Could not open engine_json : ", self.engine_file)
155 raise e
156
157 return """mkdir -p {0}
158 cd {0}
159 cat <<EOF > ipengine.{uid}.json
160 {1}
161 EOF
162
163 mkdir -p 'engine_logs'
164 ipengine --file=ipengine.{uid}.json {debug_option} >> engine_logs/$JOBNAME.log 2>&1
165 """.format(engine_dir, engine_json, debug_option=self.debug_option, uid=uid)
166
167 def compose_containerized_launch_cmd(self, filepath, engine_dir, container_image):
168 """Reads the json contents from filepath and uses that to compose the engine launch command.
169
170 Notes: Add this to the ipengine launch for debug logs :
171 --log-to-file --debug
172 Args:
173 filepath (str): Path to the engine file
174 engine_dir (str): CWD for the engines .
175 container_image (str): The container to be used to launch workers
176 """
177 self.engine_file = os.path.expanduser(filepath)
178 uid = str(uuid.uuid4())
179 engine_json = None
180 try:
181 with open(self.engine_file, 'r') as f:
182 engine_json = f.read()
183
184 except OSError as e:
185 logger.error("Could not open engine_json : ", self.engine_file)
186 raise e
187
188 return """mkdir -p {0}
189 cd {0}
190 cat <<EOF > ipengine.{uid}.json
191 {1}
192 EOF
193
194 DOCKER_ID=$(docker create --network host {2} ipengine --file=/tmp/ipengine.{uid}.json) {debug_option}
195 docker cp ipengine.{uid}.json $DOCKER_ID:/tmp/ipengine.{uid}.json
196
197 # Copy current dir to the working directory
198 DOCKER_CWD=$(docker image inspect --format='{{{{.Config.WorkingDir}}}}' {2})
199 docker cp -a . $DOCKER_ID:$DOCKER_CWD
200 docker start $DOCKER_ID
201
202 at_exit() {{
203 echo "Caught SIGTERM/SIGINT signal!"
204 docker stop $DOCKER_ID
205 }}
206
207 trap at_exit SIGTERM SIGINT
208 sleep infinity
209 """.format(engine_dir, engine_json, container_image, debug_option=self.debug_option, uid=uid)
210
211 @property
212 def scaling_enabled(self):
213 return self._scaling_enabled
214
215 def submit(self, *args, **kwargs):
216 """Submits work to the thread pool.
217
218 This method is simply pass through and behaves like a submit call as described
219 here `Python docs: <https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ThreadPoolExecutor>`_
220
221 Returns:
222 Future
223 """
224 return self.lb_view.apply_async(*args, **kwargs)
225
226 def scale_out(self, *args, **kwargs):
227 """Scales out the number of active workers by 1.
228
229 This method is notImplemented for threads and will raise the error if called.
230
231 """
232 if self.provider:
233 r = self.provider.submit(self.launch_cmd, *args, **kwargs)
234 self.engines.extend([r])
235 else:
236 logger.error("No execution provider available")
237 r = None
238
239 return r
240
241 def scale_in(self, blocks):
242 """Scale in the number of active blocks by the specified number.
243
244 """
245 status = dict(zip(self.engines, self.provider.status(self.engines)))
246
247 # This works for blocks=0
248 to_kill = [engine for engine in status if status[engine] == "RUNNING"][:blocks]
249
250 if self.provider:
251 r = self.provider.cancel(to_kill)
252 else:
253 logger.error("No execution provider available")
254 r = None
255
256 return r
257
258 def status(self):
259 """Returns the status of the executor via probing the execution providers."""
260 if self.provider:
261 status = self.provider.status(self.engines)
262
263 else:
264 status = []
265
266 return status
267
268 def shutdown(self, hub=True, targets='all', block=False):
269 """Shutdown the executor, including all workers and controllers.
270
271 The interface documentation for IPP is `here <http://ipyparallel.readthedocs.io/en/latest/api/ipyparallel.html#ipyparallel.Client.shutdown>`_
272
273 Kwargs:
274 - hub (Bool): Whether the hub should be shutdown, Default:True,
275 - targets (list of ints| 'all'): List of engine id's to kill, Default:'all'
276 - block (Bool): To block for confirmations or not
277
278 Raises:
279 NotImplementedError
280 """
281 if self.controller:
282 logger.debug("IPP:Shutdown sequence: Attempting controller kill")
283 self.controller.close()
284
285 # We do not actually do executor.shutdown because
286 # this blocks even when requested to not block, killing the
287 # controller is more effective although impolite.
288 # x = self.executor.shutdown(targets=targets,
289 # hub=hub,
290 # block=block)
291
292 logger.debug("Done with executor shutdown")
293 return True
294
295
296 if __name__ == "__main__":
297
298 pool1_config = {"poolname": "pool1",
299 "queue": "foo"}
300
[end of parsl/executors/ipp.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsl/executors/ipp.py b/parsl/executors/ipp.py
--- a/parsl/executors/ipp.py
+++ b/parsl/executors/ipp.py
@@ -155,13 +155,12 @@
raise e
return """mkdir -p {0}
-cd {0}
-cat <<EOF > ipengine.{uid}.json
+cat <<EOF > {0}/ipengine.{uid}.json
{1}
EOF
-mkdir -p 'engine_logs'
-ipengine --file=ipengine.{uid}.json {debug_option} >> engine_logs/$JOBNAME.log 2>&1
+mkdir -p '{0}/engine_logs'
+ipengine --file={0}/ipengine.{uid}.json {debug_option} >> {0}/engine_logs/$JOBNAME.log 2>&1
""".format(engine_dir, engine_json, debug_option=self.debug_option, uid=uid)
def compose_containerized_launch_cmd(self, filepath, engine_dir, container_image):
|
{"golden_diff": "diff --git a/parsl/executors/ipp.py b/parsl/executors/ipp.py\n--- a/parsl/executors/ipp.py\n+++ b/parsl/executors/ipp.py\n@@ -155,13 +155,12 @@\n raise e\n \n return \"\"\"mkdir -p {0}\n-cd {0}\n-cat <<EOF > ipengine.{uid}.json\n+cat <<EOF > {0}/ipengine.{uid}.json\n {1}\n EOF\n \n-mkdir -p 'engine_logs'\n-ipengine --file=ipengine.{uid}.json {debug_option} >> engine_logs/$JOBNAME.log 2>&1\n+mkdir -p '{0}/engine_logs'\n+ipengine --file={0}/ipengine.{uid}.json {debug_option} >> {0}/engine_logs/$JOBNAME.log 2>&1\n \"\"\".format(engine_dir, engine_json, debug_option=self.debug_option, uid=uid)\n \n def compose_containerized_launch_cmd(self, filepath, engine_dir, container_image):\n", "issue": "Do not CD to engine_dir\nCurrently in the IPP submit script we CD to the `engine_dir`. This breaks staging stuff. We should just send engine-related files there rather than changing the PWD.\n", "before_files": [{"content": "import logging\nimport os\nimport pathlib\nimport uuid\n\nfrom ipyparallel import Client\nfrom parsl.providers import LocalProvider\nfrom parsl.utils import RepresentationMixin\n\nfrom parsl.dataflow.error import ConfigurationError\nfrom parsl.executors.base import ParslExecutor\nfrom parsl.executors.errors import *\nfrom parsl.executors.ipp_controller import Controller\nfrom parsl.utils import wait_for_file\n\nlogger = logging.getLogger(__name__)\n\n\nclass IPyParallelExecutor(ParslExecutor, RepresentationMixin):\n \"\"\"The IPython Parallel executor.\n\n This executor uses IPythonParallel's pilot execution system to manage multiple processes\n running locally or remotely.\n\n Parameters\n ----------\n provider : :class:`~parsl.providers.provider_base.ExecutionProvider`\n Provider to access computation resources. Can be one of :class:`~parsl.providers.aws.aws.EC2Provider`,\n :class:`~parsl.providers.azureProvider.azureProvider.AzureProvider`,\n :class:`~parsl.providers.cobalt.cobalt.Cobalt`,\n :class:`~parsl.providers.condor.condor.Condor`,\n :class:`~parsl.providers.googlecloud.googlecloud.GoogleCloud`,\n :class:`~parsl.providers.gridEngine.gridEngine.GridEngine`,\n :class:`~parsl.providers.jetstream.jetstream.Jetstream`,\n :class:`~parsl.providers.local.local.Local`,\n :class:`~parsl.providers.sge.sge.GridEngine`,\n :class:`~parsl.providers.slurm.slurm.Slurm`, or\n :class:`~parsl.providers.torque.torque.Torque`.\n label : str\n Label for this executor instance.\n controller : :class:`~parsl.executors.ipp_controller.Controller`\n Which Controller instance to use. Default is `Controller()`.\n container_image : str\n Launch tasks in a container using this docker image. If set to None, no container is used.\n Default is None.\n engine_dir : str\n Directory where engine logs and configuration files will be stored.\n working_dir : str\n Directory where input data should be staged to.\n storage_access : list of :class:`~parsl.data_provider.scheme.Scheme`\n Specifications for accessing data this executor remotely. Multiple `Scheme`s are not yet supported.\n managed : bool\n If True, parsl will control dynamic scaling of this executor, and be responsible. Otherwise,\n this is managed by the user.\n engine_debug_level : int | str\n Sets engine logging to specified debug level. Choices: (0, 10, 20, 30, 40, 50, 'DEBUG', 'INFO', 'WARN', 'ERROR', 'CRITICAL')\n\n .. note::\n Some deficiencies with this executor are:\n\n 1. Ipengine's execute one task at a time. This means one engine per core\n is necessary to exploit the full parallelism of a node.\n 2. No notion of remaining walltime.\n 3. Lack of throttling means tasks could be queued up on a worker.\n \"\"\"\n\n def __init__(self,\n provider=LocalProvider(),\n label='ipp',\n working_dir=None,\n controller=Controller(),\n container_image=None,\n engine_dir=None,\n storage_access=None,\n engine_debug_level=None,\n managed=True):\n self.provider = provider\n self.label = label\n self.working_dir = working_dir\n self.controller = controller\n self.engine_debug_level = engine_debug_level\n self.container_image = container_image\n self.engine_dir = engine_dir\n self.storage_access = storage_access if storage_access is not None else []\n if len(self.storage_access) > 1:\n raise ConfigurationError('Multiple storage access schemes are not yet supported')\n self.managed = managed\n\n self.debug_option = \"\"\n if self.engine_debug_level:\n self.debug_option = \"--log-level={}\".format(self.engine_debug_level)\n\n def start(self):\n self.controller.profile = self.label\n self.controller.ipython_dir = self.run_dir\n if self.engine_dir is None:\n parent, child = pathlib.Path(self.run_dir).parts[-2:]\n self.engine_dir = os.path.join(parent, child)\n self.controller.start()\n\n self.engine_file = self.controller.engine_file\n\n with wait_for_file(self.controller.client_file, seconds=120):\n logger.debug(\"Waiting for {0}\".format(self.controller.client_file))\n\n if not os.path.exists(self.controller.client_file):\n raise Exception(\"Controller client file is missing at {0}\".format(self.controller.client_file))\n\n command_composer = self.compose_launch_cmd\n\n self.executor = Client(url_file=self.controller.client_file)\n if self.container_image:\n command_composer = self.compose_containerized_launch_cmd\n logger.info(\"Launching IPP with Docker:{0}\".format(self.container_image))\n\n self.launch_cmd = command_composer(self.engine_file, self.engine_dir, self.container_image)\n self.engines = []\n\n self._scaling_enabled = self.provider.scaling_enabled\n logger.debug(\"Starting IPyParallelExecutor with provider:\\n%s\", self.provider)\n if hasattr(self.provider, 'init_blocks'):\n try:\n for i in range(self.provider.init_blocks):\n engine = self.provider.submit(self.launch_cmd, 1)\n logger.debug(\"Launched block: {0}:{1}\".format(i, engine))\n if not engine:\n raise(ScalingFailed(self.provider.label,\n \"Attempts to provision nodes via provider has failed\"))\n self.engines.extend([engine])\n\n except Exception as e:\n logger.error(\"Scaling out failed: %s\" % e)\n raise e\n\n self.lb_view = self.executor.load_balanced_view()\n logger.debug(\"Starting executor\")\n\n def compose_launch_cmd(self, filepath, engine_dir, container_image):\n \"\"\"Reads the json contents from filepath and uses that to compose the engine launch command.\n\n Args:\n filepath: Path to the engine file\n engine_dir: CWD for the engines\n\n \"\"\"\n self.engine_file = os.path.expanduser(filepath)\n uid = str(uuid.uuid4())\n engine_json = None\n try:\n with open(self.engine_file, 'r') as f:\n engine_json = f.read()\n\n except OSError as e:\n logger.error(\"Could not open engine_json : \", self.engine_file)\n raise e\n\n return \"\"\"mkdir -p {0}\ncd {0}\ncat <<EOF > ipengine.{uid}.json\n{1}\nEOF\n\nmkdir -p 'engine_logs'\nipengine --file=ipengine.{uid}.json {debug_option} >> engine_logs/$JOBNAME.log 2>&1\n\"\"\".format(engine_dir, engine_json, debug_option=self.debug_option, uid=uid)\n\n def compose_containerized_launch_cmd(self, filepath, engine_dir, container_image):\n \"\"\"Reads the json contents from filepath and uses that to compose the engine launch command.\n\n Notes: Add this to the ipengine launch for debug logs :\n --log-to-file --debug\n Args:\n filepath (str): Path to the engine file\n engine_dir (str): CWD for the engines .\n container_image (str): The container to be used to launch workers\n \"\"\"\n self.engine_file = os.path.expanduser(filepath)\n uid = str(uuid.uuid4())\n engine_json = None\n try:\n with open(self.engine_file, 'r') as f:\n engine_json = f.read()\n\n except OSError as e:\n logger.error(\"Could not open engine_json : \", self.engine_file)\n raise e\n\n return \"\"\"mkdir -p {0}\ncd {0}\ncat <<EOF > ipengine.{uid}.json\n{1}\nEOF\n\nDOCKER_ID=$(docker create --network host {2} ipengine --file=/tmp/ipengine.{uid}.json) {debug_option}\ndocker cp ipengine.{uid}.json $DOCKER_ID:/tmp/ipengine.{uid}.json\n\n# Copy current dir to the working directory\nDOCKER_CWD=$(docker image inspect --format='{{{{.Config.WorkingDir}}}}' {2})\ndocker cp -a . $DOCKER_ID:$DOCKER_CWD\ndocker start $DOCKER_ID\n\nat_exit() {{\n echo \"Caught SIGTERM/SIGINT signal!\"\n docker stop $DOCKER_ID\n}}\n\ntrap at_exit SIGTERM SIGINT\nsleep infinity\n\"\"\".format(engine_dir, engine_json, container_image, debug_option=self.debug_option, uid=uid)\n\n @property\n def scaling_enabled(self):\n return self._scaling_enabled\n\n def submit(self, *args, **kwargs):\n \"\"\"Submits work to the thread pool.\n\n This method is simply pass through and behaves like a submit call as described\n here `Python docs: <https://docs.python.org/3/library/concurrent.futures.html#concurrent.futures.ThreadPoolExecutor>`_\n\n Returns:\n Future\n \"\"\"\n return self.lb_view.apply_async(*args, **kwargs)\n\n def scale_out(self, *args, **kwargs):\n \"\"\"Scales out the number of active workers by 1.\n\n This method is notImplemented for threads and will raise the error if called.\n\n \"\"\"\n if self.provider:\n r = self.provider.submit(self.launch_cmd, *args, **kwargs)\n self.engines.extend([r])\n else:\n logger.error(\"No execution provider available\")\n r = None\n\n return r\n\n def scale_in(self, blocks):\n \"\"\"Scale in the number of active blocks by the specified number.\n\n \"\"\"\n status = dict(zip(self.engines, self.provider.status(self.engines)))\n\n # This works for blocks=0\n to_kill = [engine for engine in status if status[engine] == \"RUNNING\"][:blocks]\n\n if self.provider:\n r = self.provider.cancel(to_kill)\n else:\n logger.error(\"No execution provider available\")\n r = None\n\n return r\n\n def status(self):\n \"\"\"Returns the status of the executor via probing the execution providers.\"\"\"\n if self.provider:\n status = self.provider.status(self.engines)\n\n else:\n status = []\n\n return status\n\n def shutdown(self, hub=True, targets='all', block=False):\n \"\"\"Shutdown the executor, including all workers and controllers.\n\n The interface documentation for IPP is `here <http://ipyparallel.readthedocs.io/en/latest/api/ipyparallel.html#ipyparallel.Client.shutdown>`_\n\n Kwargs:\n - hub (Bool): Whether the hub should be shutdown, Default:True,\n - targets (list of ints| 'all'): List of engine id's to kill, Default:'all'\n - block (Bool): To block for confirmations or not\n\n Raises:\n NotImplementedError\n \"\"\"\n if self.controller:\n logger.debug(\"IPP:Shutdown sequence: Attempting controller kill\")\n self.controller.close()\n\n # We do not actually do executor.shutdown because\n # this blocks even when requested to not block, killing the\n # controller is more effective although impolite.\n # x = self.executor.shutdown(targets=targets,\n # hub=hub,\n # block=block)\n\n logger.debug(\"Done with executor shutdown\")\n return True\n\n\nif __name__ == \"__main__\":\n\n pool1_config = {\"poolname\": \"pool1\",\n \"queue\": \"foo\"}\n", "path": "parsl/executors/ipp.py"}]}
| 3,800 | 223 |
gh_patches_debug_64107
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-2161
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug] Link to upgrade guide crashes documentation site
In `hydra-core==1.2.0dev5`, `basic_launcher` produces the following warning:
```
/home/runner/work/hydra-zen/hydra-zen/.tox/pre-release/lib/python3.8/site-packages/hydra/_internal/core_plugins
/basic_launcher.py:74:
UserWarning: Future Hydra versions will no longer change working directory at job runtime by default.
See https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir for more information.
```
But following the provided URL, https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir , leads to a crash in the docs site:

</issue>
<code>
[start of hydra/core/utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import copy
3 import logging
4 import os
5 import re
6 import sys
7 from contextlib import contextmanager
8 from dataclasses import dataclass
9 from datetime import datetime
10 from enum import Enum
11 from os.path import splitext
12 from pathlib import Path
13 from textwrap import dedent
14 from typing import Any, Dict, Optional, Sequence, Union, cast
15
16 from omegaconf import DictConfig, OmegaConf, open_dict, read_write
17
18 from hydra import version
19 from hydra._internal.deprecation_warning import deprecation_warning
20 from hydra.core.hydra_config import HydraConfig
21 from hydra.core.singleton import Singleton
22 from hydra.types import HydraContext, TaskFunction
23
24 log = logging.getLogger(__name__)
25
26
27 def simple_stdout_log_config(level: int = logging.INFO) -> None:
28 root = logging.getLogger()
29 root.setLevel(level)
30 handler = logging.StreamHandler(sys.stdout)
31 formatter = logging.Formatter("%(message)s")
32 handler.setFormatter(formatter)
33 root.addHandler(handler)
34
35
36 def configure_log(
37 log_config: DictConfig,
38 verbose_config: Union[bool, str, Sequence[str]] = False,
39 ) -> None:
40 assert isinstance(verbose_config, (bool, str)) or OmegaConf.is_list(verbose_config)
41 if log_config is not None:
42 conf: Dict[str, Any] = OmegaConf.to_container( # type: ignore
43 log_config, resolve=True
44 )
45 if conf["root"] is not None:
46 logging.config.dictConfig(conf)
47 else:
48 # default logging to stdout
49 root = logging.getLogger()
50 root.setLevel(logging.INFO)
51 handler = logging.StreamHandler(sys.stdout)
52 formatter = logging.Formatter(
53 "[%(asctime)s][%(name)s][%(levelname)s] - %(message)s"
54 )
55 handler.setFormatter(formatter)
56 root.addHandler(handler)
57 if isinstance(verbose_config, bool):
58 if verbose_config:
59 logging.getLogger().setLevel(logging.DEBUG)
60 else:
61 if isinstance(verbose_config, str):
62 verbose_list = OmegaConf.create([verbose_config])
63 elif OmegaConf.is_list(verbose_config):
64 verbose_list = verbose_config # type: ignore
65 else:
66 assert False
67
68 for logger in verbose_list:
69 logging.getLogger(logger).setLevel(logging.DEBUG)
70
71
72 def _save_config(cfg: DictConfig, filename: str, output_dir: Path) -> None:
73 output_dir.mkdir(parents=True, exist_ok=True)
74 with open(str(output_dir / filename), "w", encoding="utf-8") as file:
75 file.write(OmegaConf.to_yaml(cfg))
76
77
78 def filter_overrides(overrides: Sequence[str]) -> Sequence[str]:
79 """
80 :param overrides: overrides list
81 :return: returning a new overrides list with all the keys starting with hydra. filtered.
82 """
83 return [x for x in overrides if not x.startswith("hydra.")]
84
85
86 def _check_hydra_context(hydra_context: Optional[HydraContext]) -> None:
87 if hydra_context is None:
88 # hydra_context is required as of Hydra 1.2.
89 # We can remove this check in Hydra 1.3.
90 raise TypeError(
91 dedent(
92 """
93 run_job's signature has changed: the `hydra_context` arg is now required.
94 For more info, check https://github.com/facebookresearch/hydra/pull/1581."""
95 ),
96 )
97
98
99 def run_job(
100 task_function: TaskFunction,
101 config: DictConfig,
102 job_dir_key: str,
103 job_subdir_key: Optional[str],
104 hydra_context: HydraContext,
105 configure_logging: bool = True,
106 ) -> "JobReturn":
107 _check_hydra_context(hydra_context)
108 callbacks = hydra_context.callbacks
109
110 old_cwd = os.getcwd()
111 orig_hydra_cfg = HydraConfig.instance().cfg
112
113 # init Hydra config for config evaluation
114 HydraConfig.instance().set_config(config)
115
116 output_dir = str(OmegaConf.select(config, job_dir_key))
117 if job_subdir_key is not None:
118 # evaluate job_subdir_key lazily.
119 # this is running on the client side in sweep and contains things such as job:id which
120 # are only available there.
121 subdir = str(OmegaConf.select(config, job_subdir_key))
122 output_dir = os.path.join(output_dir, subdir)
123
124 with read_write(config.hydra.runtime):
125 with open_dict(config.hydra.runtime):
126 config.hydra.runtime.output_dir = os.path.abspath(output_dir)
127
128 # update Hydra config
129 HydraConfig.instance().set_config(config)
130 _chdir = None
131 try:
132 ret = JobReturn()
133 task_cfg = copy.deepcopy(config)
134 with read_write(task_cfg):
135 with open_dict(task_cfg):
136 del task_cfg["hydra"]
137
138 ret.cfg = task_cfg
139 hydra_cfg = copy.deepcopy(HydraConfig.instance().cfg)
140 assert isinstance(hydra_cfg, DictConfig)
141 ret.hydra_cfg = hydra_cfg
142 overrides = OmegaConf.to_container(config.hydra.overrides.task)
143 assert isinstance(overrides, list)
144 ret.overrides = overrides
145 # handle output directories here
146 Path(str(output_dir)).mkdir(parents=True, exist_ok=True)
147
148 _chdir = hydra_cfg.hydra.job.chdir
149
150 if _chdir is None:
151 if version.base_at_least("1.2"):
152 _chdir = False
153
154 if _chdir is None:
155 url = "https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir"
156 deprecation_warning(
157 message=dedent(
158 f"""\
159 Future Hydra versions will no longer change working directory at job runtime by default.
160 See {url} for more information."""
161 ),
162 stacklevel=2,
163 )
164 _chdir = True
165
166 if _chdir:
167 os.chdir(output_dir)
168 ret.working_dir = output_dir
169 else:
170 ret.working_dir = os.getcwd()
171
172 if configure_logging:
173 configure_log(config.hydra.job_logging, config.hydra.verbose)
174
175 if config.hydra.output_subdir is not None:
176 hydra_output = Path(config.hydra.runtime.output_dir) / Path(
177 config.hydra.output_subdir
178 )
179 _save_config(task_cfg, "config.yaml", hydra_output)
180 _save_config(hydra_cfg, "hydra.yaml", hydra_output)
181 _save_config(config.hydra.overrides.task, "overrides.yaml", hydra_output)
182
183 with env_override(hydra_cfg.hydra.job.env_set):
184 callbacks.on_job_start(config=config)
185 try:
186 ret.return_value = task_function(task_cfg)
187 ret.status = JobStatus.COMPLETED
188 except Exception as e:
189 ret.return_value = e
190 ret.status = JobStatus.FAILED
191
192 ret.task_name = JobRuntime.instance().get("name")
193
194 _flush_loggers()
195
196 callbacks.on_job_end(config=config, job_return=ret)
197
198 return ret
199 finally:
200 HydraConfig.instance().cfg = orig_hydra_cfg
201 if _chdir:
202 os.chdir(old_cwd)
203
204
205 def get_valid_filename(s: str) -> str:
206 s = str(s).strip().replace(" ", "_")
207 return re.sub(r"(?u)[^-\w.]", "", s)
208
209
210 def setup_globals() -> None:
211 # please add documentation when you add a new resolver
212 OmegaConf.register_new_resolver(
213 "now",
214 lambda pattern: datetime.now().strftime(pattern),
215 use_cache=True,
216 replace=True,
217 )
218 OmegaConf.register_new_resolver(
219 "hydra",
220 lambda path: OmegaConf.select(cast(DictConfig, HydraConfig.get()), path),
221 replace=True,
222 )
223
224 vi = sys.version_info
225 version_dict = {
226 "major": f"{vi[0]}",
227 "minor": f"{vi[0]}.{vi[1]}",
228 "micro": f"{vi[0]}.{vi[1]}.{vi[2]}",
229 }
230 OmegaConf.register_new_resolver(
231 "python_version", lambda level="minor": version_dict.get(level), replace=True
232 )
233
234
235 class JobStatus(Enum):
236 UNKNOWN = 0
237 COMPLETED = 1
238 FAILED = 2
239
240
241 @dataclass
242 class JobReturn:
243 overrides: Optional[Sequence[str]] = None
244 cfg: Optional[DictConfig] = None
245 hydra_cfg: Optional[DictConfig] = None
246 working_dir: Optional[str] = None
247 task_name: Optional[str] = None
248 status: JobStatus = JobStatus.UNKNOWN
249 _return_value: Any = None
250
251 @property
252 def return_value(self) -> Any:
253 assert self.status != JobStatus.UNKNOWN, "return_value not yet available"
254 if self.status == JobStatus.COMPLETED:
255 return self._return_value
256 else:
257 sys.stderr.write(
258 f"Error executing job with overrides: {self.overrides}" + os.linesep
259 )
260 raise self._return_value
261
262 @return_value.setter
263 def return_value(self, value: Any) -> None:
264 self._return_value = value
265
266
267 class JobRuntime(metaclass=Singleton):
268 def __init__(self) -> None:
269 self.conf: DictConfig = OmegaConf.create()
270 self.set("name", "UNKNOWN_NAME")
271
272 def get(self, key: str) -> Any:
273 ret = OmegaConf.select(self.conf, key)
274 if ret is None:
275 raise KeyError(f"Key not found in {type(self).__name__}: {key}")
276 return ret
277
278 def set(self, key: str, value: Any) -> None:
279 log.debug(f"Setting {type(self).__name__}:{key}={value}")
280 self.conf[key] = value
281
282
283 def validate_config_path(config_path: Optional[str]) -> None:
284 if config_path is not None:
285 split_file = splitext(config_path)
286 if split_file[1] in (".yaml", ".yml"):
287 msg = dedent(
288 """\
289 Using config_path to specify the config name is not supported, specify the config name via config_name.
290 See https://hydra.cc/docs/next/upgrades/0.11_to_1.0/config_path_changes
291 """
292 )
293 raise ValueError(msg)
294
295
296 @contextmanager
297 def env_override(env: Dict[str, str]) -> Any:
298 """Temporarily set environment variables inside the context manager and
299 fully restore previous environment afterwards
300 """
301 original_env = {key: os.getenv(key) for key in env}
302 os.environ.update(env)
303 try:
304 yield
305 finally:
306 for key, value in original_env.items():
307 if value is None:
308 del os.environ[key]
309 else:
310 os.environ[key] = value
311
312
313 def _flush_loggers() -> None:
314 # Python logging does not have an official API to flush all loggers.
315 # This will have to do.
316 for h_weak_ref in logging._handlerList: # type: ignore
317 try:
318 h_weak_ref().flush()
319 except Exception:
320 # ignore exceptions thrown during flushing
321 pass
322
[end of hydra/core/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/core/utils.py b/hydra/core/utils.py
--- a/hydra/core/utils.py
+++ b/hydra/core/utils.py
@@ -152,7 +152,7 @@
_chdir = False
if _chdir is None:
- url = "https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir"
+ url = "https://hydra.cc/docs/next/upgrades/1.1_to_1.2/changes_to_job_working_dir/"
deprecation_warning(
message=dedent(
f"""\
|
{"golden_diff": "diff --git a/hydra/core/utils.py b/hydra/core/utils.py\n--- a/hydra/core/utils.py\n+++ b/hydra/core/utils.py\n@@ -152,7 +152,7 @@\n _chdir = False\n \n if _chdir is None:\n- url = \"https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir\"\n+ url = \"https://hydra.cc/docs/next/upgrades/1.1_to_1.2/changes_to_job_working_dir/\"\n deprecation_warning(\n message=dedent(\n f\"\"\"\\\n", "issue": "[Bug] Link to upgrade guide crashes documentation site\nIn `hydra-core==1.2.0dev5`, `basic_launcher` produces the following warning:\r\n``` \r\n/home/runner/work/hydra-zen/hydra-zen/.tox/pre-release/lib/python3.8/site-packages/hydra/_internal/core_plugins\r\n/basic_launcher.py:74: \r\n\r\nUserWarning: Future Hydra versions will no longer change working directory at job runtime by default.\r\n See https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir for more information.\r\n```\r\n\r\nBut following the provided URL, https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir , leads to a crash in the docs site:\r\n\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport copy\nimport logging\nimport os\nimport re\nimport sys\nfrom contextlib import contextmanager\nfrom dataclasses import dataclass\nfrom datetime import datetime\nfrom enum import Enum\nfrom os.path import splitext\nfrom pathlib import Path\nfrom textwrap import dedent\nfrom typing import Any, Dict, Optional, Sequence, Union, cast\n\nfrom omegaconf import DictConfig, OmegaConf, open_dict, read_write\n\nfrom hydra import version\nfrom hydra._internal.deprecation_warning import deprecation_warning\nfrom hydra.core.hydra_config import HydraConfig\nfrom hydra.core.singleton import Singleton\nfrom hydra.types import HydraContext, TaskFunction\n\nlog = logging.getLogger(__name__)\n\n\ndef simple_stdout_log_config(level: int = logging.INFO) -> None:\n root = logging.getLogger()\n root.setLevel(level)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\"%(message)s\")\n handler.setFormatter(formatter)\n root.addHandler(handler)\n\n\ndef configure_log(\n log_config: DictConfig,\n verbose_config: Union[bool, str, Sequence[str]] = False,\n) -> None:\n assert isinstance(verbose_config, (bool, str)) or OmegaConf.is_list(verbose_config)\n if log_config is not None:\n conf: Dict[str, Any] = OmegaConf.to_container( # type: ignore\n log_config, resolve=True\n )\n if conf[\"root\"] is not None:\n logging.config.dictConfig(conf)\n else:\n # default logging to stdout\n root = logging.getLogger()\n root.setLevel(logging.INFO)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\n \"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s\"\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n if isinstance(verbose_config, bool):\n if verbose_config:\n logging.getLogger().setLevel(logging.DEBUG)\n else:\n if isinstance(verbose_config, str):\n verbose_list = OmegaConf.create([verbose_config])\n elif OmegaConf.is_list(verbose_config):\n verbose_list = verbose_config # type: ignore\n else:\n assert False\n\n for logger in verbose_list:\n logging.getLogger(logger).setLevel(logging.DEBUG)\n\n\ndef _save_config(cfg: DictConfig, filename: str, output_dir: Path) -> None:\n output_dir.mkdir(parents=True, exist_ok=True)\n with open(str(output_dir / filename), \"w\", encoding=\"utf-8\") as file:\n file.write(OmegaConf.to_yaml(cfg))\n\n\ndef filter_overrides(overrides: Sequence[str]) -> Sequence[str]:\n \"\"\"\n :param overrides: overrides list\n :return: returning a new overrides list with all the keys starting with hydra. filtered.\n \"\"\"\n return [x for x in overrides if not x.startswith(\"hydra.\")]\n\n\ndef _check_hydra_context(hydra_context: Optional[HydraContext]) -> None:\n if hydra_context is None:\n # hydra_context is required as of Hydra 1.2.\n # We can remove this check in Hydra 1.3.\n raise TypeError(\n dedent(\n \"\"\"\n run_job's signature has changed: the `hydra_context` arg is now required.\n For more info, check https://github.com/facebookresearch/hydra/pull/1581.\"\"\"\n ),\n )\n\n\ndef run_job(\n task_function: TaskFunction,\n config: DictConfig,\n job_dir_key: str,\n job_subdir_key: Optional[str],\n hydra_context: HydraContext,\n configure_logging: bool = True,\n) -> \"JobReturn\":\n _check_hydra_context(hydra_context)\n callbacks = hydra_context.callbacks\n\n old_cwd = os.getcwd()\n orig_hydra_cfg = HydraConfig.instance().cfg\n\n # init Hydra config for config evaluation\n HydraConfig.instance().set_config(config)\n\n output_dir = str(OmegaConf.select(config, job_dir_key))\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n # are only available there.\n subdir = str(OmegaConf.select(config, job_subdir_key))\n output_dir = os.path.join(output_dir, subdir)\n\n with read_write(config.hydra.runtime):\n with open_dict(config.hydra.runtime):\n config.hydra.runtime.output_dir = os.path.abspath(output_dir)\n\n # update Hydra config\n HydraConfig.instance().set_config(config)\n _chdir = None\n try:\n ret = JobReturn()\n task_cfg = copy.deepcopy(config)\n with read_write(task_cfg):\n with open_dict(task_cfg):\n del task_cfg[\"hydra\"]\n\n ret.cfg = task_cfg\n hydra_cfg = copy.deepcopy(HydraConfig.instance().cfg)\n assert isinstance(hydra_cfg, DictConfig)\n ret.hydra_cfg = hydra_cfg\n overrides = OmegaConf.to_container(config.hydra.overrides.task)\n assert isinstance(overrides, list)\n ret.overrides = overrides\n # handle output directories here\n Path(str(output_dir)).mkdir(parents=True, exist_ok=True)\n\n _chdir = hydra_cfg.hydra.job.chdir\n\n if _chdir is None:\n if version.base_at_least(\"1.2\"):\n _chdir = False\n\n if _chdir is None:\n url = \"https://hydra.cc/docs/upgrades/1.1_to_1.2/changes_to_job_working_dir\"\n deprecation_warning(\n message=dedent(\n f\"\"\"\\\n Future Hydra versions will no longer change working directory at job runtime by default.\n See {url} for more information.\"\"\"\n ),\n stacklevel=2,\n )\n _chdir = True\n\n if _chdir:\n os.chdir(output_dir)\n ret.working_dir = output_dir\n else:\n ret.working_dir = os.getcwd()\n\n if configure_logging:\n configure_log(config.hydra.job_logging, config.hydra.verbose)\n\n if config.hydra.output_subdir is not None:\n hydra_output = Path(config.hydra.runtime.output_dir) / Path(\n config.hydra.output_subdir\n )\n _save_config(task_cfg, \"config.yaml\", hydra_output)\n _save_config(hydra_cfg, \"hydra.yaml\", hydra_output)\n _save_config(config.hydra.overrides.task, \"overrides.yaml\", hydra_output)\n\n with env_override(hydra_cfg.hydra.job.env_set):\n callbacks.on_job_start(config=config)\n try:\n ret.return_value = task_function(task_cfg)\n ret.status = JobStatus.COMPLETED\n except Exception as e:\n ret.return_value = e\n ret.status = JobStatus.FAILED\n\n ret.task_name = JobRuntime.instance().get(\"name\")\n\n _flush_loggers()\n\n callbacks.on_job_end(config=config, job_return=ret)\n\n return ret\n finally:\n HydraConfig.instance().cfg = orig_hydra_cfg\n if _chdir:\n os.chdir(old_cwd)\n\n\ndef get_valid_filename(s: str) -> str:\n s = str(s).strip().replace(\" \", \"_\")\n return re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n\ndef setup_globals() -> None:\n # please add documentation when you add a new resolver\n OmegaConf.register_new_resolver(\n \"now\",\n lambda pattern: datetime.now().strftime(pattern),\n use_cache=True,\n replace=True,\n )\n OmegaConf.register_new_resolver(\n \"hydra\",\n lambda path: OmegaConf.select(cast(DictConfig, HydraConfig.get()), path),\n replace=True,\n )\n\n vi = sys.version_info\n version_dict = {\n \"major\": f\"{vi[0]}\",\n \"minor\": f\"{vi[0]}.{vi[1]}\",\n \"micro\": f\"{vi[0]}.{vi[1]}.{vi[2]}\",\n }\n OmegaConf.register_new_resolver(\n \"python_version\", lambda level=\"minor\": version_dict.get(level), replace=True\n )\n\n\nclass JobStatus(Enum):\n UNKNOWN = 0\n COMPLETED = 1\n FAILED = 2\n\n\n@dataclass\nclass JobReturn:\n overrides: Optional[Sequence[str]] = None\n cfg: Optional[DictConfig] = None\n hydra_cfg: Optional[DictConfig] = None\n working_dir: Optional[str] = None\n task_name: Optional[str] = None\n status: JobStatus = JobStatus.UNKNOWN\n _return_value: Any = None\n\n @property\n def return_value(self) -> Any:\n assert self.status != JobStatus.UNKNOWN, \"return_value not yet available\"\n if self.status == JobStatus.COMPLETED:\n return self._return_value\n else:\n sys.stderr.write(\n f\"Error executing job with overrides: {self.overrides}\" + os.linesep\n )\n raise self._return_value\n\n @return_value.setter\n def return_value(self, value: Any) -> None:\n self._return_value = value\n\n\nclass JobRuntime(metaclass=Singleton):\n def __init__(self) -> None:\n self.conf: DictConfig = OmegaConf.create()\n self.set(\"name\", \"UNKNOWN_NAME\")\n\n def get(self, key: str) -> Any:\n ret = OmegaConf.select(self.conf, key)\n if ret is None:\n raise KeyError(f\"Key not found in {type(self).__name__}: {key}\")\n return ret\n\n def set(self, key: str, value: Any) -> None:\n log.debug(f\"Setting {type(self).__name__}:{key}={value}\")\n self.conf[key] = value\n\n\ndef validate_config_path(config_path: Optional[str]) -> None:\n if config_path is not None:\n split_file = splitext(config_path)\n if split_file[1] in (\".yaml\", \".yml\"):\n msg = dedent(\n \"\"\"\\\n Using config_path to specify the config name is not supported, specify the config name via config_name.\n See https://hydra.cc/docs/next/upgrades/0.11_to_1.0/config_path_changes\n \"\"\"\n )\n raise ValueError(msg)\n\n\n@contextmanager\ndef env_override(env: Dict[str, str]) -> Any:\n \"\"\"Temporarily set environment variables inside the context manager and\n fully restore previous environment afterwards\n \"\"\"\n original_env = {key: os.getenv(key) for key in env}\n os.environ.update(env)\n try:\n yield\n finally:\n for key, value in original_env.items():\n if value is None:\n del os.environ[key]\n else:\n os.environ[key] = value\n\n\ndef _flush_loggers() -> None:\n # Python logging does not have an official API to flush all loggers.\n # This will have to do.\n for h_weak_ref in logging._handlerList: # type: ignore\n try:\n h_weak_ref().flush()\n except Exception:\n # ignore exceptions thrown during flushing\n pass\n", "path": "hydra/core/utils.py"}]}
| 4,047 | 140 |
gh_patches_debug_12525
|
rasdani/github-patches
|
git_diff
|
ethereum__web3.py-306
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Transform Markdown on PyPi release
### What was wrong?
README is not readable on PyPI: https://pypi.python.org/pypi/web3/1.4.0
`setuptools-markdown` allows to publish README.md on PyPi
- https://pypi.python.org/pypi/setuptools-markdown
#### Cute Animal Picture

</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 import os
4 import sys
5
6 from setuptools import (
7 setup,
8 find_packages,
9 )
10
11
12 DIR = os.path.dirname(os.path.abspath(__file__))
13
14
15 readme = open(os.path.join(DIR, 'README.md')).read()
16
17 install_requires = [
18 "cytoolz>=0.8.2",
19 "ethereum-abi-utils>=0.4.0",
20 "ethereum-utils>=0.4.0",
21 "pylru>=1.0.9",
22 "pysha3>=0.3",
23 "requests>=2.12.4",
24 "rlp>=0.4.7",
25 "toolz>=0.8.2",
26 ]
27
28 if sys.platform == 'win32':
29 install_requires.append('pypiwin32')
30
31 setup(
32 name='web3',
33 version='3.13.5',
34 description="""Web3.py""",
35 long_description=readme,
36 author='Piper Merriam',
37 author_email='[email protected]',
38 url='https://github.com/pipermerriam/web3.py',
39 include_package_data=True,
40 install_requires=install_requires,
41 extras_require={
42 'tester': ["eth-testrpc>=1.2.0"],
43 'gevent': [
44 "gevent>=1.1.1,<1.2.0",
45 "geventhttpclient>=1.3.1",
46 ],
47 },
48 py_modules=['web3'],
49 license="MIT",
50 zip_safe=False,
51 keywords='ethereum',
52 packages=find_packages(exclude=["tests", "tests.*"]),
53 classifiers=[
54 'Development Status :: 2 - Pre-Alpha',
55 'Intended Audience :: Developers',
56 'License :: OSI Approved :: MIT License',
57 'Natural Language :: English',
58 'Programming Language :: Python :: 2',
59 'Programming Language :: Python :: 2.7',
60 'Programming Language :: Python :: 3',
61 'Programming Language :: Python :: 3.4',
62 'Programming Language :: Python :: 3.5',
63 ],
64 )
65
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -32,12 +32,13 @@
name='web3',
version='3.13.5',
description="""Web3.py""",
- long_description=readme,
+ long_description_markdown_filename='README.md',
author='Piper Merriam',
author_email='[email protected]',
url='https://github.com/pipermerriam/web3.py',
include_package_data=True,
install_requires=install_requires,
+ setup_requires=['setuptools-markdown'],
extras_require={
'tester': ["eth-testrpc>=1.2.0"],
'gevent': [
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -32,12 +32,13 @@\n name='web3',\n version='3.13.5',\n description=\"\"\"Web3.py\"\"\",\n- long_description=readme,\n+ long_description_markdown_filename='README.md',\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/pipermerriam/web3.py',\n include_package_data=True,\n install_requires=install_requires,\n+ setup_requires=['setuptools-markdown'],\n extras_require={\n 'tester': [\"eth-testrpc>=1.2.0\"],\n 'gevent': [\n", "issue": "Transform Markdown on PyPi release\n### What was wrong?\n\nREADME is not readable on PyPI: https://pypi.python.org/pypi/web3/1.4.0\n\n`setuptools-markdown` allows to publish README.md on PyPi\n- https://pypi.python.org/pypi/setuptools-markdown\n#### Cute Animal Picture\n\n\n\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nimport os\nimport sys\n\nfrom setuptools import (\n setup,\n find_packages,\n)\n\n\nDIR = os.path.dirname(os.path.abspath(__file__))\n\n\nreadme = open(os.path.join(DIR, 'README.md')).read()\n\ninstall_requires = [\n \"cytoolz>=0.8.2\",\n \"ethereum-abi-utils>=0.4.0\",\n \"ethereum-utils>=0.4.0\",\n \"pylru>=1.0.9\",\n \"pysha3>=0.3\",\n \"requests>=2.12.4\",\n \"rlp>=0.4.7\",\n \"toolz>=0.8.2\",\n]\n\nif sys.platform == 'win32':\n install_requires.append('pypiwin32')\n\nsetup(\n name='web3',\n version='3.13.5',\n description=\"\"\"Web3.py\"\"\",\n long_description=readme,\n author='Piper Merriam',\n author_email='[email protected]',\n url='https://github.com/pipermerriam/web3.py',\n include_package_data=True,\n install_requires=install_requires,\n extras_require={\n 'tester': [\"eth-testrpc>=1.2.0\"],\n 'gevent': [\n \"gevent>=1.1.1,<1.2.0\",\n \"geventhttpclient>=1.3.1\",\n ],\n },\n py_modules=['web3'],\n license=\"MIT\",\n zip_safe=False,\n keywords='ethereum',\n packages=find_packages(exclude=[\"tests\", \"tests.*\"]),\n classifiers=[\n 'Development Status :: 2 - Pre-Alpha',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: MIT License',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.4',\n 'Programming Language :: Python :: 3.5',\n ],\n)\n", "path": "setup.py"}]}
| 1,193 | 160 |
gh_patches_debug_56861
|
rasdani/github-patches
|
git_diff
|
bentoml__BentoML-822
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add support for Alpine based docker image
**Is your feature request related to a problem? Please describe.**
Allow users to use `bentoml/model-server:0.7.8-alpine` as the base image, which is currently defined here: https://github.com/bentoml/BentoML/blob/master/docker/model-server/Dockerfile-alpine
**Describe the solution you'd like**
Improve the `bentoml_init.sh` script to make sure it works on both debian and alpine based docker image.
**Describe alternatives you've considered**
n/a
**Additional context**
See https://github.com/bentoml/BentoML/issues/693
</issue>
<code>
[start of bentoml/saved_bundle/bundler.py]
1 # Copyright 2019 Atalaya Tech, Inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import importlib
15 import os
16 import shutil
17 import stat
18 import logging
19
20 from setuptools import sandbox
21
22 from bentoml.configuration import _is_pypi_release
23
24 from bentoml.exceptions import BentoMLException
25 from bentoml.saved_bundle.py_module_utils import copy_used_py_modules
26 from bentoml.saved_bundle.templates import (
27 BENTO_SERVICE_BUNDLE_SETUP_PY_TEMPLATE,
28 MANIFEST_IN_TEMPLATE,
29 MODEL_SERVER_DOCKERFILE_CPU,
30 INIT_PY_TEMPLATE,
31 )
32 from bentoml.utils.usage_stats import track_save
33 from bentoml.saved_bundle.config import SavedBundleConfig
34
35
36 DEFAULT_SAVED_BUNDLE_README = """\
37 # Generated BentoService bundle - {}:{}
38
39 This is a ML Service bundle created with BentoML, it is not recommended to edit
40 code or files contained in this directory. Instead, edit the code that uses BentoML
41 to create this bundle, and save a new BentoService bundle.
42 """
43
44 logger = logging.getLogger(__name__)
45
46
47 def save_to_dir(bento_service, path, version=None, silent=False):
48 """Save given BentoService along with all its artifacts, source code and
49 dependencies to target file path, assuming path exist and empty. If target path
50 is not empty, this call may override existing files in the given path.
51
52 :param bento_service (bentoml.service.BentoService): a Bento Service instance
53 :param path (str): Destination of where the bento service will be saved
54 :param version (str): Override the service version with given version string
55 :param silent (boolean): whether to hide the log message showing target save path
56 """
57 track_save(bento_service)
58
59 from bentoml.service import BentoService
60
61 if not isinstance(bento_service, BentoService):
62 raise BentoMLException(
63 "save_to_dir only work with instance of custom BentoService class"
64 )
65
66 if version is not None:
67 # If parameter version provided, set bento_service version
68 # Otherwise it will bet set the first time the `version` property get accessed
69 bento_service.set_version(version)
70
71 if not os.path.exists(path):
72 raise BentoMLException("Directory '{}' not found".format(path))
73
74 for artifact in bento_service._artifacts:
75 if artifact.name not in bento_service._packed_artifacts:
76 logger.warning(
77 "Missing declared artifact '%s' for BentoService '%s'",
78 artifact.name,
79 bento_service.name,
80 )
81
82 module_base_path = os.path.join(path, bento_service.name)
83 try:
84 os.mkdir(module_base_path)
85 except FileExistsError:
86 raise BentoMLException(
87 f"Existing module file found for BentoService {bento_service.name}"
88 )
89
90 # write README.md with custom BentoService's docstring if presented
91 saved_bundle_readme = DEFAULT_SAVED_BUNDLE_README.format(
92 bento_service.name, bento_service.version
93 )
94 if bento_service.__class__.__doc__:
95 saved_bundle_readme += "\n"
96 saved_bundle_readme += bento_service.__class__.__doc__.strip()
97
98 with open(os.path.join(path, "README.md"), "w") as f:
99 f.write(saved_bundle_readme)
100
101 # save all model artifacts to 'base_path/name/artifacts/' directory
102 if bento_service.artifacts:
103 bento_service.artifacts.save(module_base_path)
104
105 # write conda environment, requirement.txt
106 bento_service.env.save(path, bento_service)
107
108 # TODO: add bentoml.find_packages helper for more fine grained control over this
109 # process, e.g. packages=find_packages(base, [], exclude=[], used_module_only=True)
110 # copy over all custom model code
111 module_name, module_file = copy_used_py_modules(
112 bento_service.__class__.__module__, os.path.join(path, bento_service.name)
113 )
114
115 # create __init__.py
116 with open(os.path.join(path, bento_service.name, "__init__.py"), "w") as f:
117 f.write(
118 INIT_PY_TEMPLATE.format(
119 service_name=bento_service.name,
120 module_name=module_name,
121 pypi_package_version=bento_service.version,
122 )
123 )
124
125 # write setup.py, this make saved BentoService bundle pip installable
126 setup_py_content = BENTO_SERVICE_BUNDLE_SETUP_PY_TEMPLATE.format(
127 name=bento_service.name,
128 pypi_package_version=bento_service.version,
129 long_description=saved_bundle_readme,
130 )
131 with open(os.path.join(path, "setup.py"), "w") as f:
132 f.write(setup_py_content)
133
134 with open(os.path.join(path, "MANIFEST.in"), "w") as f:
135 f.write(MANIFEST_IN_TEMPLATE.format(service_name=bento_service.name))
136
137 # write Dockerfile
138 with open(os.path.join(path, "Dockerfile"), "w") as f:
139 f.write(
140 MODEL_SERVER_DOCKERFILE_CPU.format(
141 docker_base_image=bento_service._env._docker_base_image
142 )
143 )
144
145 # Copy docker-entrypoint.sh
146 docker_entrypoint_sh_file_src = os.path.join(
147 os.path.dirname(__file__), "docker-entrypoint.sh"
148 )
149 docker_entrypoint_sh_file_dst = os.path.join(path, "docker-entrypoint.sh")
150 shutil.copyfile(docker_entrypoint_sh_file_src, docker_entrypoint_sh_file_dst)
151 # chmod +x docker-entrypoint.sh
152 st = os.stat(docker_entrypoint_sh_file_dst)
153 os.chmod(docker_entrypoint_sh_file_dst, st.st_mode | stat.S_IEXEC)
154
155 # copy bentoml-init.sh for install targz bundles
156 bentoml_init_sh_file_src = os.path.join(
157 os.path.dirname(__file__), "bentoml-init.sh"
158 )
159 bentoml_init_sh_file_dst = os.path.join(path, "bentoml-init.sh")
160 shutil.copyfile(bentoml_init_sh_file_src, bentoml_init_sh_file_dst)
161 # chmod +x bentoml_init_script file
162 st = os.stat(bentoml_init_sh_file_dst)
163 os.chmod(bentoml_init_sh_file_dst, st.st_mode | stat.S_IEXEC)
164
165 # write bentoml.yml
166 config = SavedBundleConfig(bento_service)
167 config["metadata"].update({"module_name": module_name, "module_file": module_file})
168
169 config.write_to_path(path)
170 # Also write bentoml.yml to module base path to make it accessible
171 # as package data after pip installed as a python package
172 config.write_to_path(module_base_path)
173
174 bundled_pip_dependencies_path = os.path.join(path, 'bundled_pip_dependencies')
175 _bundle_local_bentoml_if_installed_from_source(bundled_pip_dependencies_path)
176
177 if not silent:
178 logger.info(
179 "BentoService bundle '%s:%s' created at: %s",
180 bento_service.name,
181 bento_service.version,
182 path,
183 )
184
185
186 def _bundle_local_bentoml_if_installed_from_source(target_path):
187 """
188 if bentoml is installed in editor mode(pip install -e), this will build a source
189 distribution with the local bentoml fork and add it to saved BentoService bundle
190 path under bundled_pip_dependencies directory
191 """
192
193 # Find bentoml module path
194 (module_location,) = importlib.util.find_spec('bentoml').submodule_search_locations
195
196 bentoml_setup_py = os.path.abspath(os.path.join(module_location, '..', 'setup.py'))
197
198 # this is for BentoML developer to create BentoService containing custom develop
199 # branches of BentoML library, it is True only when BentoML module is installed in
200 # development mode via "pip install --editable ."
201 if not _is_pypi_release() and os.path.isfile(bentoml_setup_py):
202 logger.info(
203 "Detect BentoML installed in development model, copying local BentoML "
204 "module file to target saved bundle path"
205 )
206
207 # Create tmp directory inside bentoml module for storing the bundled
208 # targz file. Since dist-dir can only be inside of the module directory
209 bundle_dir_name = '__bentoml_tmp_sdist_build'
210 source_dir = os.path.abspath(
211 os.path.join(module_location, '..', bundle_dir_name)
212 )
213
214 if os.path.isdir(source_dir):
215 shutil.rmtree(source_dir, ignore_errors=True)
216 os.mkdir(source_dir)
217
218 sandbox.run_setup(
219 bentoml_setup_py,
220 ['sdist', '--format', 'gztar', '--dist-dir', bundle_dir_name],
221 )
222
223 # copy the generated targz to saved bundle directory and remove it from
224 # bentoml module directory
225 shutil.copytree(source_dir, target_path)
226
227 # clean up sdist build files
228 shutil.rmtree(source_dir)
229
[end of bentoml/saved_bundle/bundler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bentoml/saved_bundle/bundler.py b/bentoml/saved_bundle/bundler.py
--- a/bentoml/saved_bundle/bundler.py
+++ b/bentoml/saved_bundle/bundler.py
@@ -135,6 +135,7 @@
f.write(MANIFEST_IN_TEMPLATE.format(service_name=bento_service.name))
# write Dockerfile
+ logger.debug("Using Docker Base Image %s", bento_service._env._docker_base_image)
with open(os.path.join(path, "Dockerfile"), "w") as f:
f.write(
MODEL_SERVER_DOCKERFILE_CPU.format(
|
{"golden_diff": "diff --git a/bentoml/saved_bundle/bundler.py b/bentoml/saved_bundle/bundler.py\n--- a/bentoml/saved_bundle/bundler.py\n+++ b/bentoml/saved_bundle/bundler.py\n@@ -135,6 +135,7 @@\n f.write(MANIFEST_IN_TEMPLATE.format(service_name=bento_service.name))\n \n # write Dockerfile\n+ logger.debug(\"Using Docker Base Image %s\", bento_service._env._docker_base_image)\n with open(os.path.join(path, \"Dockerfile\"), \"w\") as f:\n f.write(\n MODEL_SERVER_DOCKERFILE_CPU.format(\n", "issue": "Add support for Alpine based docker image\n**Is your feature request related to a problem? Please describe.**\r\n\r\nAllow users to use `bentoml/model-server:0.7.8-alpine` as the base image, which is currently defined here: https://github.com/bentoml/BentoML/blob/master/docker/model-server/Dockerfile-alpine\r\n\r\n**Describe the solution you'd like**\r\n\r\nImprove the `bentoml_init.sh` script to make sure it works on both debian and alpine based docker image.\r\n\r\n**Describe alternatives you've considered**\r\nn/a\r\n\r\n**Additional context**\r\n\r\nSee https://github.com/bentoml/BentoML/issues/693\r\n\n", "before_files": [{"content": "# Copyright 2019 Atalaya Tech, Inc.\n\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n\n# http://www.apache.org/licenses/LICENSE-2.0\n\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport importlib\nimport os\nimport shutil\nimport stat\nimport logging\n\nfrom setuptools import sandbox\n\nfrom bentoml.configuration import _is_pypi_release\n\nfrom bentoml.exceptions import BentoMLException\nfrom bentoml.saved_bundle.py_module_utils import copy_used_py_modules\nfrom bentoml.saved_bundle.templates import (\n BENTO_SERVICE_BUNDLE_SETUP_PY_TEMPLATE,\n MANIFEST_IN_TEMPLATE,\n MODEL_SERVER_DOCKERFILE_CPU,\n INIT_PY_TEMPLATE,\n)\nfrom bentoml.utils.usage_stats import track_save\nfrom bentoml.saved_bundle.config import SavedBundleConfig\n\n\nDEFAULT_SAVED_BUNDLE_README = \"\"\"\\\n# Generated BentoService bundle - {}:{}\n\nThis is a ML Service bundle created with BentoML, it is not recommended to edit\ncode or files contained in this directory. Instead, edit the code that uses BentoML\nto create this bundle, and save a new BentoService bundle.\n\"\"\"\n\nlogger = logging.getLogger(__name__)\n\n\ndef save_to_dir(bento_service, path, version=None, silent=False):\n \"\"\"Save given BentoService along with all its artifacts, source code and\n dependencies to target file path, assuming path exist and empty. If target path\n is not empty, this call may override existing files in the given path.\n\n :param bento_service (bentoml.service.BentoService): a Bento Service instance\n :param path (str): Destination of where the bento service will be saved\n :param version (str): Override the service version with given version string\n :param silent (boolean): whether to hide the log message showing target save path\n \"\"\"\n track_save(bento_service)\n\n from bentoml.service import BentoService\n\n if not isinstance(bento_service, BentoService):\n raise BentoMLException(\n \"save_to_dir only work with instance of custom BentoService class\"\n )\n\n if version is not None:\n # If parameter version provided, set bento_service version\n # Otherwise it will bet set the first time the `version` property get accessed\n bento_service.set_version(version)\n\n if not os.path.exists(path):\n raise BentoMLException(\"Directory '{}' not found\".format(path))\n\n for artifact in bento_service._artifacts:\n if artifact.name not in bento_service._packed_artifacts:\n logger.warning(\n \"Missing declared artifact '%s' for BentoService '%s'\",\n artifact.name,\n bento_service.name,\n )\n\n module_base_path = os.path.join(path, bento_service.name)\n try:\n os.mkdir(module_base_path)\n except FileExistsError:\n raise BentoMLException(\n f\"Existing module file found for BentoService {bento_service.name}\"\n )\n\n # write README.md with custom BentoService's docstring if presented\n saved_bundle_readme = DEFAULT_SAVED_BUNDLE_README.format(\n bento_service.name, bento_service.version\n )\n if bento_service.__class__.__doc__:\n saved_bundle_readme += \"\\n\"\n saved_bundle_readme += bento_service.__class__.__doc__.strip()\n\n with open(os.path.join(path, \"README.md\"), \"w\") as f:\n f.write(saved_bundle_readme)\n\n # save all model artifacts to 'base_path/name/artifacts/' directory\n if bento_service.artifacts:\n bento_service.artifacts.save(module_base_path)\n\n # write conda environment, requirement.txt\n bento_service.env.save(path, bento_service)\n\n # TODO: add bentoml.find_packages helper for more fine grained control over this\n # process, e.g. packages=find_packages(base, [], exclude=[], used_module_only=True)\n # copy over all custom model code\n module_name, module_file = copy_used_py_modules(\n bento_service.__class__.__module__, os.path.join(path, bento_service.name)\n )\n\n # create __init__.py\n with open(os.path.join(path, bento_service.name, \"__init__.py\"), \"w\") as f:\n f.write(\n INIT_PY_TEMPLATE.format(\n service_name=bento_service.name,\n module_name=module_name,\n pypi_package_version=bento_service.version,\n )\n )\n\n # write setup.py, this make saved BentoService bundle pip installable\n setup_py_content = BENTO_SERVICE_BUNDLE_SETUP_PY_TEMPLATE.format(\n name=bento_service.name,\n pypi_package_version=bento_service.version,\n long_description=saved_bundle_readme,\n )\n with open(os.path.join(path, \"setup.py\"), \"w\") as f:\n f.write(setup_py_content)\n\n with open(os.path.join(path, \"MANIFEST.in\"), \"w\") as f:\n f.write(MANIFEST_IN_TEMPLATE.format(service_name=bento_service.name))\n\n # write Dockerfile\n with open(os.path.join(path, \"Dockerfile\"), \"w\") as f:\n f.write(\n MODEL_SERVER_DOCKERFILE_CPU.format(\n docker_base_image=bento_service._env._docker_base_image\n )\n )\n\n # Copy docker-entrypoint.sh\n docker_entrypoint_sh_file_src = os.path.join(\n os.path.dirname(__file__), \"docker-entrypoint.sh\"\n )\n docker_entrypoint_sh_file_dst = os.path.join(path, \"docker-entrypoint.sh\")\n shutil.copyfile(docker_entrypoint_sh_file_src, docker_entrypoint_sh_file_dst)\n # chmod +x docker-entrypoint.sh\n st = os.stat(docker_entrypoint_sh_file_dst)\n os.chmod(docker_entrypoint_sh_file_dst, st.st_mode | stat.S_IEXEC)\n\n # copy bentoml-init.sh for install targz bundles\n bentoml_init_sh_file_src = os.path.join(\n os.path.dirname(__file__), \"bentoml-init.sh\"\n )\n bentoml_init_sh_file_dst = os.path.join(path, \"bentoml-init.sh\")\n shutil.copyfile(bentoml_init_sh_file_src, bentoml_init_sh_file_dst)\n # chmod +x bentoml_init_script file\n st = os.stat(bentoml_init_sh_file_dst)\n os.chmod(bentoml_init_sh_file_dst, st.st_mode | stat.S_IEXEC)\n\n # write bentoml.yml\n config = SavedBundleConfig(bento_service)\n config[\"metadata\"].update({\"module_name\": module_name, \"module_file\": module_file})\n\n config.write_to_path(path)\n # Also write bentoml.yml to module base path to make it accessible\n # as package data after pip installed as a python package\n config.write_to_path(module_base_path)\n\n bundled_pip_dependencies_path = os.path.join(path, 'bundled_pip_dependencies')\n _bundle_local_bentoml_if_installed_from_source(bundled_pip_dependencies_path)\n\n if not silent:\n logger.info(\n \"BentoService bundle '%s:%s' created at: %s\",\n bento_service.name,\n bento_service.version,\n path,\n )\n\n\ndef _bundle_local_bentoml_if_installed_from_source(target_path):\n \"\"\"\n if bentoml is installed in editor mode(pip install -e), this will build a source\n distribution with the local bentoml fork and add it to saved BentoService bundle\n path under bundled_pip_dependencies directory\n \"\"\"\n\n # Find bentoml module path\n (module_location,) = importlib.util.find_spec('bentoml').submodule_search_locations\n\n bentoml_setup_py = os.path.abspath(os.path.join(module_location, '..', 'setup.py'))\n\n # this is for BentoML developer to create BentoService containing custom develop\n # branches of BentoML library, it is True only when BentoML module is installed in\n # development mode via \"pip install --editable .\"\n if not _is_pypi_release() and os.path.isfile(bentoml_setup_py):\n logger.info(\n \"Detect BentoML installed in development model, copying local BentoML \"\n \"module file to target saved bundle path\"\n )\n\n # Create tmp directory inside bentoml module for storing the bundled\n # targz file. Since dist-dir can only be inside of the module directory\n bundle_dir_name = '__bentoml_tmp_sdist_build'\n source_dir = os.path.abspath(\n os.path.join(module_location, '..', bundle_dir_name)\n )\n\n if os.path.isdir(source_dir):\n shutil.rmtree(source_dir, ignore_errors=True)\n os.mkdir(source_dir)\n\n sandbox.run_setup(\n bentoml_setup_py,\n ['sdist', '--format', 'gztar', '--dist-dir', bundle_dir_name],\n )\n\n # copy the generated targz to saved bundle directory and remove it from\n # bentoml module directory\n shutil.copytree(source_dir, target_path)\n\n # clean up sdist build files\n shutil.rmtree(source_dir)\n", "path": "bentoml/saved_bundle/bundler.py"}]}
| 3,343 | 144 |
gh_patches_debug_6412
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmocr-1119
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Meaning of Recognition Scores
I am using ABINet to do some text recognition on TorchServe, and my question is very similar to https://github.com/open-mmlab/mmocr/issues/1092
However, in my case I modified https://github.com/open-mmlab/mmocr/blob/main/tools/deployment/mmocr_handler.py#L46 to be `results = model_inference(self.model, data, batch_mode=True)` so the result I got has multiple scores instead of 1:
```
(open-mmlab) root@d40b21f4becb:/mmocr# curl -X POST http://localhost:8080/predictions/ABINet -T "{images435/forms_f1120_0_1628795799/0.png,images435/forms_f1120_0_1628795799/1.png}"
{
"text": "us",
"score": [
18.370647430419922,
15.632901191711426
]
}{
"text": "corporation",
"score": [
23.138269424438477,
21.309354782104492,
21.27399444580078,
25.794034957885742,
22.265600204467773,
22.63265037536621,
22.026500701904297,
20.361919403076172,
19.674522399902344,
19.15252113342285,
20.794090270996094
]
```
My questions are:
1. What exactly do the scores mean here?
2. What is the range of score?
3. Why there are multiple scores for a single image?
4. Why sometimes I have 2 scores but sometimes I have many more scores? (I noticed that the number of scores is not fixed)
I have been trying to looking at source codes but I couldn't find exactly where it's leading this to happen. Any help is appreciated.
Meaning of Recognition Scores
I am using ABINet to do some text recognition on TorchServe, and my question is very similar to https://github.com/open-mmlab/mmocr/issues/1092
However, in my case I modified https://github.com/open-mmlab/mmocr/blob/main/tools/deployment/mmocr_handler.py#L46 to be `results = model_inference(self.model, data, batch_mode=True)` so the result I got has multiple scores instead of 1:
```
(open-mmlab) root@d40b21f4becb:/mmocr# curl -X POST http://localhost:8080/predictions/ABINet -T "{images435/forms_f1120_0_1628795799/0.png,images435/forms_f1120_0_1628795799/1.png}"
{
"text": "us",
"score": [
18.370647430419922,
15.632901191711426
]
}{
"text": "corporation",
"score": [
23.138269424438477,
21.309354782104492,
21.27399444580078,
25.794034957885742,
22.265600204467773,
22.63265037536621,
22.026500701904297,
20.361919403076172,
19.674522399902344,
19.15252113342285,
20.794090270996094
]
```
My questions are:
1. What exactly do the scores mean here?
2. What is the range of score?
3. Why there are multiple scores for a single image?
4. Why sometimes I have 2 scores but sometimes I have many more scores? (I noticed that the number of scores is not fixed)
I have been trying to looking at source codes but I couldn't find exactly where it's leading this to happen. Any help is appreciated.
</issue>
<code>
[start of mmocr/models/textrecog/convertors/attn.py]
1 # Copyright (c) OpenMMLab. All rights reserved.
2 import torch
3
4 import mmocr.utils as utils
5 from mmocr.models.builder import CONVERTORS
6 from .base import BaseConvertor
7
8
9 @CONVERTORS.register_module()
10 class AttnConvertor(BaseConvertor):
11 """Convert between text, index and tensor for encoder-decoder based
12 pipeline.
13
14 Args:
15 dict_type (str): Type of dict, should be one of {'DICT36', 'DICT90'}.
16 dict_file (None|str): Character dict file path. If not none,
17 higher priority than dict_type.
18 dict_list (None|list[str]): Character list. If not none, higher
19 priority than dict_type, but lower than dict_file.
20 with_unknown (bool): If True, add `UKN` token to class.
21 max_seq_len (int): Maximum sequence length of label.
22 lower (bool): If True, convert original string to lower case.
23 start_end_same (bool): Whether use the same index for
24 start and end token or not. Default: True.
25 """
26
27 def __init__(self,
28 dict_type='DICT90',
29 dict_file=None,
30 dict_list=None,
31 with_unknown=True,
32 max_seq_len=40,
33 lower=False,
34 start_end_same=True,
35 **kwargs):
36 super().__init__(dict_type, dict_file, dict_list)
37 assert isinstance(with_unknown, bool)
38 assert isinstance(max_seq_len, int)
39 assert isinstance(lower, bool)
40
41 self.with_unknown = with_unknown
42 self.max_seq_len = max_seq_len
43 self.lower = lower
44 self.start_end_same = start_end_same
45
46 self.update_dict()
47
48 def update_dict(self):
49 start_end_token = '<BOS/EOS>'
50 unknown_token = '<UKN>'
51 padding_token = '<PAD>'
52
53 # unknown
54 self.unknown_idx = None
55 if self.with_unknown:
56 self.idx2char.append(unknown_token)
57 self.unknown_idx = len(self.idx2char) - 1
58
59 # BOS/EOS
60 self.idx2char.append(start_end_token)
61 self.start_idx = len(self.idx2char) - 1
62 if not self.start_end_same:
63 self.idx2char.append(start_end_token)
64 self.end_idx = len(self.idx2char) - 1
65
66 # padding
67 self.idx2char.append(padding_token)
68 self.padding_idx = len(self.idx2char) - 1
69
70 # update char2idx
71 self.char2idx = {}
72 for idx, char in enumerate(self.idx2char):
73 self.char2idx[char] = idx
74
75 def str2tensor(self, strings):
76 """
77 Convert text-string into tensor.
78 Args:
79 strings (list[str]): ['hello', 'world']
80 Returns:
81 dict (str: Tensor | list[tensor]):
82 tensors (list[Tensor]): [torch.Tensor([1,2,3,3,4]),
83 torch.Tensor([5,4,6,3,7])]
84 padded_targets (Tensor(bsz * max_seq_len))
85 """
86 assert utils.is_type_list(strings, str)
87
88 tensors, padded_targets = [], []
89 indexes = self.str2idx(strings)
90 for index in indexes:
91 tensor = torch.LongTensor(index)
92 tensors.append(tensor)
93 # target tensor for loss
94 src_target = torch.LongTensor(tensor.size(0) + 2).fill_(0)
95 src_target[-1] = self.end_idx
96 src_target[0] = self.start_idx
97 src_target[1:-1] = tensor
98 padded_target = (torch.ones(self.max_seq_len) *
99 self.padding_idx).long()
100 char_num = src_target.size(0)
101 if char_num > self.max_seq_len:
102 padded_target = src_target[:self.max_seq_len]
103 else:
104 padded_target[:char_num] = src_target
105 padded_targets.append(padded_target)
106 padded_targets = torch.stack(padded_targets, 0).long()
107
108 return {'targets': tensors, 'padded_targets': padded_targets}
109
110 def tensor2idx(self, outputs, img_metas=None):
111 """
112 Convert output tensor to text-index
113 Args:
114 outputs (tensor): model outputs with size: N * T * C
115 img_metas (list[dict]): Each dict contains one image info.
116 Returns:
117 indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]]
118 scores (list[list[float]]): [[0.9,0.8,0.95,0.97,0.94],
119 [0.9,0.9,0.98,0.97,0.96]]
120 """
121 batch_size = outputs.size(0)
122 ignore_indexes = [self.padding_idx]
123 indexes, scores = [], []
124 for idx in range(batch_size):
125 seq = outputs[idx, :, :]
126 max_value, max_idx = torch.max(seq, -1)
127 str_index, str_score = [], []
128 output_index = max_idx.cpu().detach().numpy().tolist()
129 output_score = max_value.cpu().detach().numpy().tolist()
130 for char_index, char_score in zip(output_index, output_score):
131 if char_index in ignore_indexes:
132 continue
133 if char_index == self.end_idx:
134 break
135 str_index.append(char_index)
136 str_score.append(char_score)
137
138 indexes.append(str_index)
139 scores.append(str_score)
140
141 return indexes, scores
142
[end of mmocr/models/textrecog/convertors/attn.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmocr/models/textrecog/convertors/attn.py b/mmocr/models/textrecog/convertors/attn.py
--- a/mmocr/models/textrecog/convertors/attn.py
+++ b/mmocr/models/textrecog/convertors/attn.py
@@ -123,6 +123,7 @@
indexes, scores = [], []
for idx in range(batch_size):
seq = outputs[idx, :, :]
+ seq = seq.softmax(dim=-1)
max_value, max_idx = torch.max(seq, -1)
str_index, str_score = [], []
output_index = max_idx.cpu().detach().numpy().tolist()
|
{"golden_diff": "diff --git a/mmocr/models/textrecog/convertors/attn.py b/mmocr/models/textrecog/convertors/attn.py\n--- a/mmocr/models/textrecog/convertors/attn.py\n+++ b/mmocr/models/textrecog/convertors/attn.py\n@@ -123,6 +123,7 @@\n indexes, scores = [], []\n for idx in range(batch_size):\n seq = outputs[idx, :, :]\n+ seq = seq.softmax(dim=-1)\n max_value, max_idx = torch.max(seq, -1)\n str_index, str_score = [], []\n output_index = max_idx.cpu().detach().numpy().tolist()\n", "issue": "Meaning of Recognition Scores\nI am using ABINet to do some text recognition on TorchServe, and my question is very similar to https://github.com/open-mmlab/mmocr/issues/1092\r\nHowever, in my case I modified https://github.com/open-mmlab/mmocr/blob/main/tools/deployment/mmocr_handler.py#L46 to be `results = model_inference(self.model, data, batch_mode=True)` so the result I got has multiple scores instead of 1:\r\n```\r\n(open-mmlab) root@d40b21f4becb:/mmocr# curl -X POST http://localhost:8080/predictions/ABINet -T \"{images435/forms_f1120_0_1628795799/0.png,images435/forms_f1120_0_1628795799/1.png}\"\r\n{\r\n \"text\": \"us\",\r\n \"score\": [\r\n 18.370647430419922,\r\n 15.632901191711426\r\n ]\r\n}{\r\n \"text\": \"corporation\",\r\n \"score\": [\r\n 23.138269424438477,\r\n 21.309354782104492,\r\n 21.27399444580078,\r\n 25.794034957885742,\r\n 22.265600204467773,\r\n 22.63265037536621,\r\n 22.026500701904297,\r\n 20.361919403076172,\r\n 19.674522399902344,\r\n 19.15252113342285,\r\n 20.794090270996094\r\n ]\r\n```\r\nMy questions are:\r\n1. What exactly do the scores mean here? \r\n2. What is the range of score? \r\n3. Why there are multiple scores for a single image?\r\n4. Why sometimes I have 2 scores but sometimes I have many more scores? (I noticed that the number of scores is not fixed)\r\n\r\nI have been trying to looking at source codes but I couldn't find exactly where it's leading this to happen. Any help is appreciated. \nMeaning of Recognition Scores\nI am using ABINet to do some text recognition on TorchServe, and my question is very similar to https://github.com/open-mmlab/mmocr/issues/1092\r\nHowever, in my case I modified https://github.com/open-mmlab/mmocr/blob/main/tools/deployment/mmocr_handler.py#L46 to be `results = model_inference(self.model, data, batch_mode=True)` so the result I got has multiple scores instead of 1:\r\n```\r\n(open-mmlab) root@d40b21f4becb:/mmocr# curl -X POST http://localhost:8080/predictions/ABINet -T \"{images435/forms_f1120_0_1628795799/0.png,images435/forms_f1120_0_1628795799/1.png}\"\r\n{\r\n \"text\": \"us\",\r\n \"score\": [\r\n 18.370647430419922,\r\n 15.632901191711426\r\n ]\r\n}{\r\n \"text\": \"corporation\",\r\n \"score\": [\r\n 23.138269424438477,\r\n 21.309354782104492,\r\n 21.27399444580078,\r\n 25.794034957885742,\r\n 22.265600204467773,\r\n 22.63265037536621,\r\n 22.026500701904297,\r\n 20.361919403076172,\r\n 19.674522399902344,\r\n 19.15252113342285,\r\n 20.794090270996094\r\n ]\r\n```\r\nMy questions are:\r\n1. What exactly do the scores mean here? \r\n2. What is the range of score? \r\n3. Why there are multiple scores for a single image?\r\n4. Why sometimes I have 2 scores but sometimes I have many more scores? (I noticed that the number of scores is not fixed)\r\n\r\nI have been trying to looking at source codes but I couldn't find exactly where it's leading this to happen. Any help is appreciated. \n", "before_files": [{"content": "# Copyright (c) OpenMMLab. All rights reserved.\nimport torch\n\nimport mmocr.utils as utils\nfrom mmocr.models.builder import CONVERTORS\nfrom .base import BaseConvertor\n\n\[email protected]_module()\nclass AttnConvertor(BaseConvertor):\n \"\"\"Convert between text, index and tensor for encoder-decoder based\n pipeline.\n\n Args:\n dict_type (str): Type of dict, should be one of {'DICT36', 'DICT90'}.\n dict_file (None|str): Character dict file path. If not none,\n higher priority than dict_type.\n dict_list (None|list[str]): Character list. If not none, higher\n priority than dict_type, but lower than dict_file.\n with_unknown (bool): If True, add `UKN` token to class.\n max_seq_len (int): Maximum sequence length of label.\n lower (bool): If True, convert original string to lower case.\n start_end_same (bool): Whether use the same index for\n start and end token or not. Default: True.\n \"\"\"\n\n def __init__(self,\n dict_type='DICT90',\n dict_file=None,\n dict_list=None,\n with_unknown=True,\n max_seq_len=40,\n lower=False,\n start_end_same=True,\n **kwargs):\n super().__init__(dict_type, dict_file, dict_list)\n assert isinstance(with_unknown, bool)\n assert isinstance(max_seq_len, int)\n assert isinstance(lower, bool)\n\n self.with_unknown = with_unknown\n self.max_seq_len = max_seq_len\n self.lower = lower\n self.start_end_same = start_end_same\n\n self.update_dict()\n\n def update_dict(self):\n start_end_token = '<BOS/EOS>'\n unknown_token = '<UKN>'\n padding_token = '<PAD>'\n\n # unknown\n self.unknown_idx = None\n if self.with_unknown:\n self.idx2char.append(unknown_token)\n self.unknown_idx = len(self.idx2char) - 1\n\n # BOS/EOS\n self.idx2char.append(start_end_token)\n self.start_idx = len(self.idx2char) - 1\n if not self.start_end_same:\n self.idx2char.append(start_end_token)\n self.end_idx = len(self.idx2char) - 1\n\n # padding\n self.idx2char.append(padding_token)\n self.padding_idx = len(self.idx2char) - 1\n\n # update char2idx\n self.char2idx = {}\n for idx, char in enumerate(self.idx2char):\n self.char2idx[char] = idx\n\n def str2tensor(self, strings):\n \"\"\"\n Convert text-string into tensor.\n Args:\n strings (list[str]): ['hello', 'world']\n Returns:\n dict (str: Tensor | list[tensor]):\n tensors (list[Tensor]): [torch.Tensor([1,2,3,3,4]),\n torch.Tensor([5,4,6,3,7])]\n padded_targets (Tensor(bsz * max_seq_len))\n \"\"\"\n assert utils.is_type_list(strings, str)\n\n tensors, padded_targets = [], []\n indexes = self.str2idx(strings)\n for index in indexes:\n tensor = torch.LongTensor(index)\n tensors.append(tensor)\n # target tensor for loss\n src_target = torch.LongTensor(tensor.size(0) + 2).fill_(0)\n src_target[-1] = self.end_idx\n src_target[0] = self.start_idx\n src_target[1:-1] = tensor\n padded_target = (torch.ones(self.max_seq_len) *\n self.padding_idx).long()\n char_num = src_target.size(0)\n if char_num > self.max_seq_len:\n padded_target = src_target[:self.max_seq_len]\n else:\n padded_target[:char_num] = src_target\n padded_targets.append(padded_target)\n padded_targets = torch.stack(padded_targets, 0).long()\n\n return {'targets': tensors, 'padded_targets': padded_targets}\n\n def tensor2idx(self, outputs, img_metas=None):\n \"\"\"\n Convert output tensor to text-index\n Args:\n outputs (tensor): model outputs with size: N * T * C\n img_metas (list[dict]): Each dict contains one image info.\n Returns:\n indexes (list[list[int]]): [[1,2,3,3,4], [5,4,6,3,7]]\n scores (list[list[float]]): [[0.9,0.8,0.95,0.97,0.94],\n [0.9,0.9,0.98,0.97,0.96]]\n \"\"\"\n batch_size = outputs.size(0)\n ignore_indexes = [self.padding_idx]\n indexes, scores = [], []\n for idx in range(batch_size):\n seq = outputs[idx, :, :]\n max_value, max_idx = torch.max(seq, -1)\n str_index, str_score = [], []\n output_index = max_idx.cpu().detach().numpy().tolist()\n output_score = max_value.cpu().detach().numpy().tolist()\n for char_index, char_score in zip(output_index, output_score):\n if char_index in ignore_indexes:\n continue\n if char_index == self.end_idx:\n break\n str_index.append(char_index)\n str_score.append(char_score)\n\n indexes.append(str_index)\n scores.append(str_score)\n\n return indexes, scores\n", "path": "mmocr/models/textrecog/convertors/attn.py"}]}
| 3,278 | 144 |
gh_patches_debug_11161
|
rasdani/github-patches
|
git_diff
|
google__timesketch-898
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IndexError: cannot do a non-empty take from an empty axes. (when domain_count_array is empty)
I don't know why domain_count_array is empty but in this case an error is raised:
```
[2019-05-15 15:57:25,067: ERROR/ForkPoolWorker-1] Task timesketch.lib.tasks.run_sketch_analyzer[87c2fee5-d10c-4a92-8d28-a6acc970a7fe] raised unexpected: IndexError('cannot do a non-empty take from an empty axes.',)
Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/celery/app/trace.py", line 385, in trace_task
R = retval = fun(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/__init__.py", line 181, in __call__
return TaskBase.__call__(self, *args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/celery/app/trace.py", line 648, in __protected_call__
return self.run(*args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/tasks.py", line 334, in run_sketch_analyzer
result = analyzer.run_wrapper()
File "/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/analyzers/interface.py", line 37, in wrapper
func_return = func(self, *args, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/analyzers/interface.py", line 403, in run_wrapper
result = self.run()
File "/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/analyzers/domain.py", line 71, in run
domain_20th_percentile = int(numpy.percentile(domain_count_array, 20))
File "/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py", line 3707, in percentile
a, q, axis, out, overwrite_input, interpolation, keepdims)
File "/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py", line 3826, in _quantile_unchecked
interpolation=interpolation)
File "/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py", line 3405, in _ureduce
r = func(a, **kwargs)
File "/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py", line 3941, in _quantile_ureduce_func
x1 = take(ap, indices_below, axis=axis) * weights_below
File "/usr/local/lib/python3.6/dist-packages/numpy/core/fromnumeric.py", line 189, in take
return _wrapfunc(a, 'take', indices, axis=axis, out=out, mode=mode)
File "/usr/local/lib/python3.6/dist-packages/numpy/core/fromnumeric.py", line 56, in _wrapfunc
return getattr(obj, method)(*args, **kwds)
IndexError: cannot do a non-empty take from an empty axes.```
Should I add something here https://github.com/google/timesketch/blob/7244f821b9c257d42402115f6a39cab266f0a84c/timesketch/lib/analyzers/domain.py#L70
in order to set at 0 for example in case domain_count_array returns empty?
</issue>
<code>
[start of timesketch/lib/analyzers/domain.py]
1 """Sketch analyzer plugin for domain."""
2 from __future__ import unicode_literals
3
4 import collections
5 import numpy
6
7 from timesketch.lib import emojis
8 from timesketch.lib.analyzers import interface
9 from timesketch.lib.analyzers import manager
10 from timesketch.lib.analyzers import utils
11
12
13 class DomainSketchPlugin(interface.BaseSketchAnalyzer):
14 """Sketch analyzer for Domain."""
15
16 NAME = 'domain'
17
18 DEPENDENCIES = frozenset()
19
20 def __init__(self, index_name, sketch_id):
21 """Initialize The Sketch Analyzer.
22
23 Args:
24 index_name: Elasticsearch index name
25 sketch_id: Sketch ID
26 """
27 self.index_name = index_name
28 super(DomainSketchPlugin, self).__init__(index_name, sketch_id)
29
30 def run(self):
31 """Entry point for the analyzer.
32
33 Returns:
34 String with summary of the analyzer result
35 """
36 query = (
37 '{"query": { "bool": { "should": [ '
38 '{ "exists" : { "field" : "url" }}, '
39 '{ "exists" : { "field" : "domain" }} ] } } }')
40
41 return_fields = ['domain', 'url']
42
43 events = self.event_stream(
44 '', query_dsl=query, return_fields=return_fields)
45
46 domains = {}
47 domain_counter = collections.Counter()
48 tld_counter = collections.Counter()
49 cdn_counter = collections.Counter()
50
51 for event in events:
52 domain = event.source.get('domain')
53
54 if not domain:
55 url = event.source.get('url')
56 if not url:
57 continue
58 domain = utils.get_domain_from_url(url)
59
60 if not domain:
61 continue
62
63 domain_counter[domain] += 1
64 domains.setdefault(domain, [])
65 domains[domain].append(event)
66
67 tld = '.'.join(domain.split('.')[-2:])
68 tld_counter[tld] += 1
69
70 domain_count_array = numpy.array(list(domain_counter.values()))
71 domain_20th_percentile = int(numpy.percentile(domain_count_array, 20))
72 domain_85th_percentile = int(numpy.percentile(domain_count_array, 85))
73
74 common_domains = [
75 x for x, y in domain_counter.most_common()
76 if y >= domain_85th_percentile]
77 rare_domains = [
78 x for x, y in domain_counter.most_common()
79 if y <= domain_20th_percentile]
80
81 satellite_emoji = emojis.get_emoji('SATELLITE')
82 for domain, count in iter(domain_counter.items()):
83 emojis_to_add = [satellite_emoji]
84 tags_to_add = []
85
86 cdn_provider = utils.get_cdn_provider(domain)
87 if cdn_provider:
88 tags_to_add.append('known-cdn')
89 cdn_counter[cdn_provider] += 1
90
91 if domain in common_domains:
92 tags_to_add.append('common_domain')
93
94 if domain in rare_domains:
95 tags_to_add.append('rare_domain')
96
97 for event in domains.get(domain, []):
98 event.add_tags(tags_to_add)
99 event.add_emojis(emojis_to_add)
100
101 new_attributes = {'domain': domain, 'domain_count': count}
102 if cdn_provider:
103 new_attributes['cdn_provider'] = cdn_provider
104 event.add_attributes(new_attributes)
105
106 # Commit the event to the datastore.
107 event.commit()
108
109 return (
110 '{0:d} domains discovered ({1:d} TLDs) and {2:d} known '
111 'CDN networks found.').format(
112 len(domains), len(tld_counter), len(cdn_counter))
113
114
115 manager.AnalysisManager.register_analyzer(DomainSketchPlugin)
116
[end of timesketch/lib/analyzers/domain.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/timesketch/lib/analyzers/domain.py b/timesketch/lib/analyzers/domain.py
--- a/timesketch/lib/analyzers/domain.py
+++ b/timesketch/lib/analyzers/domain.py
@@ -67,6 +67,10 @@
tld = '.'.join(domain.split('.')[-2:])
tld_counter[tld] += 1
+ # Exit early if there are no domains in the data set to analyze.
+ if not domain_counter:
+ return 'No domains to analyze.'
+
domain_count_array = numpy.array(list(domain_counter.values()))
domain_20th_percentile = int(numpy.percentile(domain_count_array, 20))
domain_85th_percentile = int(numpy.percentile(domain_count_array, 85))
|
{"golden_diff": "diff --git a/timesketch/lib/analyzers/domain.py b/timesketch/lib/analyzers/domain.py\n--- a/timesketch/lib/analyzers/domain.py\n+++ b/timesketch/lib/analyzers/domain.py\n@@ -67,6 +67,10 @@\n tld = '.'.join(domain.split('.')[-2:])\n tld_counter[tld] += 1\n \n+ # Exit early if there are no domains in the data set to analyze.\n+ if not domain_counter:\n+ return 'No domains to analyze.'\n+\n domain_count_array = numpy.array(list(domain_counter.values()))\n domain_20th_percentile = int(numpy.percentile(domain_count_array, 20))\n domain_85th_percentile = int(numpy.percentile(domain_count_array, 85))\n", "issue": "IndexError: cannot do a non-empty take from an empty axes. (when domain_count_array is empty)\nI don't know why domain_count_array is empty but in this case an error is raised:\r\n```\r\n[2019-05-15 15:57:25,067: ERROR/ForkPoolWorker-1] Task timesketch.lib.tasks.run_sketch_analyzer[87c2fee5-d10c-4a92-8d28-a6acc970a7fe] raised unexpected: IndexError('cannot do a non-empty take from an empty axes.',)\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.6/dist-packages/celery/app/trace.py\", line 385, in trace_task\r\n R = retval = fun(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/__init__.py\", line 181, in __call__\r\n return TaskBase.__call__(self, *args, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/celery/app/trace.py\", line 648, in __protected_call__\r\n return self.run(*args, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/tasks.py\", line 334, in run_sketch_analyzer\r\n result = analyzer.run_wrapper()\r\n File \"/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/analyzers/interface.py\", line 37, in wrapper\r\n func_return = func(self, *args, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/analyzers/interface.py\", line 403, in run_wrapper\r\n result = self.run()\r\n File \"/usr/local/lib/python3.6/dist-packages/timesketch-20190207-py3.6.egg/timesketch/lib/analyzers/domain.py\", line 71, in run\r\n domain_20th_percentile = int(numpy.percentile(domain_count_array, 20))\r\n File \"/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py\", line 3707, in percentile\r\n a, q, axis, out, overwrite_input, interpolation, keepdims)\r\n File \"/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py\", line 3826, in _quantile_unchecked\r\n interpolation=interpolation)\r\n File \"/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py\", line 3405, in _ureduce\r\n r = func(a, **kwargs)\r\n File \"/usr/local/lib/python3.6/dist-packages/numpy/lib/function_base.py\", line 3941, in _quantile_ureduce_func\r\n x1 = take(ap, indices_below, axis=axis) * weights_below\r\n File \"/usr/local/lib/python3.6/dist-packages/numpy/core/fromnumeric.py\", line 189, in take\r\n return _wrapfunc(a, 'take', indices, axis=axis, out=out, mode=mode)\r\n File \"/usr/local/lib/python3.6/dist-packages/numpy/core/fromnumeric.py\", line 56, in _wrapfunc\r\n return getattr(obj, method)(*args, **kwds)\r\nIndexError: cannot do a non-empty take from an empty axes.```\r\n\r\nShould I add something here https://github.com/google/timesketch/blob/7244f821b9c257d42402115f6a39cab266f0a84c/timesketch/lib/analyzers/domain.py#L70\r\nin order to set at 0 for example in case domain_count_array returns empty?\r\n\n", "before_files": [{"content": "\"\"\"Sketch analyzer plugin for domain.\"\"\"\nfrom __future__ import unicode_literals\n\nimport collections\nimport numpy\n\nfrom timesketch.lib import emojis\nfrom timesketch.lib.analyzers import interface\nfrom timesketch.lib.analyzers import manager\nfrom timesketch.lib.analyzers import utils\n\n\nclass DomainSketchPlugin(interface.BaseSketchAnalyzer):\n \"\"\"Sketch analyzer for Domain.\"\"\"\n\n NAME = 'domain'\n\n DEPENDENCIES = frozenset()\n\n def __init__(self, index_name, sketch_id):\n \"\"\"Initialize The Sketch Analyzer.\n\n Args:\n index_name: Elasticsearch index name\n sketch_id: Sketch ID\n \"\"\"\n self.index_name = index_name\n super(DomainSketchPlugin, self).__init__(index_name, sketch_id)\n\n def run(self):\n \"\"\"Entry point for the analyzer.\n\n Returns:\n String with summary of the analyzer result\n \"\"\"\n query = (\n '{\"query\": { \"bool\": { \"should\": [ '\n '{ \"exists\" : { \"field\" : \"url\" }}, '\n '{ \"exists\" : { \"field\" : \"domain\" }} ] } } }')\n\n return_fields = ['domain', 'url']\n\n events = self.event_stream(\n '', query_dsl=query, return_fields=return_fields)\n\n domains = {}\n domain_counter = collections.Counter()\n tld_counter = collections.Counter()\n cdn_counter = collections.Counter()\n\n for event in events:\n domain = event.source.get('domain')\n\n if not domain:\n url = event.source.get('url')\n if not url:\n continue\n domain = utils.get_domain_from_url(url)\n\n if not domain:\n continue\n\n domain_counter[domain] += 1\n domains.setdefault(domain, [])\n domains[domain].append(event)\n\n tld = '.'.join(domain.split('.')[-2:])\n tld_counter[tld] += 1\n\n domain_count_array = numpy.array(list(domain_counter.values()))\n domain_20th_percentile = int(numpy.percentile(domain_count_array, 20))\n domain_85th_percentile = int(numpy.percentile(domain_count_array, 85))\n\n common_domains = [\n x for x, y in domain_counter.most_common()\n if y >= domain_85th_percentile]\n rare_domains = [\n x for x, y in domain_counter.most_common()\n if y <= domain_20th_percentile]\n\n satellite_emoji = emojis.get_emoji('SATELLITE')\n for domain, count in iter(domain_counter.items()):\n emojis_to_add = [satellite_emoji]\n tags_to_add = []\n\n cdn_provider = utils.get_cdn_provider(domain)\n if cdn_provider:\n tags_to_add.append('known-cdn')\n cdn_counter[cdn_provider] += 1\n\n if domain in common_domains:\n tags_to_add.append('common_domain')\n\n if domain in rare_domains:\n tags_to_add.append('rare_domain')\n\n for event in domains.get(domain, []):\n event.add_tags(tags_to_add)\n event.add_emojis(emojis_to_add)\n\n new_attributes = {'domain': domain, 'domain_count': count}\n if cdn_provider:\n new_attributes['cdn_provider'] = cdn_provider\n event.add_attributes(new_attributes)\n\n # Commit the event to the datastore.\n event.commit()\n\n return (\n '{0:d} domains discovered ({1:d} TLDs) and {2:d} known '\n 'CDN networks found.').format(\n len(domains), len(tld_counter), len(cdn_counter))\n\n\nmanager.AnalysisManager.register_analyzer(DomainSketchPlugin)\n", "path": "timesketch/lib/analyzers/domain.py"}]}
| 2,510 | 177 |
gh_patches_debug_6493
|
rasdani/github-patches
|
git_diff
|
pwr-Solaar__Solaar-2305
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Extend Makefile with installation and test targets
**Information**
- Solaar version: 1.1.11rc4
**Is your feature request related to a problem? Please describe.**
The Solaar installation with all its dependencies (pip, apt, udev etc.) is cumbersome. Although some setup steps for GItHub CI exists, they are not usable for local setup of Solaar.
**Describe the solution you'd like**
Move the setup commands into a Makefile and use the targets in GitHub workflow files. Thus, the commands are in a single place and also usable for local setups.
**Additional context**
This extends #2263
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python3
2 import subprocess
3
4 from glob import glob as _glob
5
6 try:
7 from setuptools import setup
8 except ImportError:
9 from distutils.core import setup
10
11 NAME = 'Solaar'
12
13 with open('lib/solaar/version', 'r') as vfile:
14 version = vfile.read().strip()
15
16 try: # get commit from git describe
17 commit = subprocess.check_output(['git', 'describe', '--always'], stderr=subprocess.DEVNULL).strip().decode()
18 with open('lib/solaar/commit', 'w') as vfile:
19 vfile.write(f'{commit}\n')
20 except Exception: # get commit from Ubuntu dpkg-parsechangelog
21 try:
22 commit = subprocess.check_output(['dpkg-parsechangelog', '--show-field', 'Version'],
23 stderr=subprocess.DEVNULL).strip().decode()
24 commit = commit.split('~')
25 with open('lib/solaar/commit', 'w') as vfile:
26 vfile.write(f'{commit[0]}\n')
27 except Exception as e:
28 print('Exception using dpkg-parsechangelog', e)
29
30
31 def _data_files():
32 from os.path import dirname as _dirname
33
34 yield 'share/icons/hicolor/scalable/apps', _glob('share/solaar/icons/solaar*.svg')
35 yield 'share/icons/hicolor/32x32/apps', _glob('share/solaar/icons/solaar-light_*.png')
36
37 for mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):
38 yield _dirname(mo), [mo]
39
40 yield 'share/applications', ['share/applications/solaar.desktop']
41 yield 'lib/udev/rules.d', ['rules.d/42-logitech-unify-permissions.rules']
42 yield 'share/metainfo', ['share/solaar/io.github.pwr_solaar.solaar.metainfo.xml']
43
44 del _dirname
45
46
47 setup(
48 name=NAME.lower(),
49 version=version,
50 description='Linux device manager for Logitech receivers, keyboards, mice, and tablets.',
51 long_description='''
52 Solaar is a Linux device manager for many Logitech peripherals that connect through
53 Unifying and other receivers or via USB or Bluetooth.
54 Solaar is able to pair/unpair devices with receivers and show and modify some of the
55 modifiable features of devices.
56 For instructions on installing Solaar see https://pwr-solaar.github.io/Solaar/installation'''.strip(),
57 author='Daniel Pavel',
58 license='GPLv2',
59 url='http://pwr-solaar.github.io/Solaar/',
60 classifiers=[
61 'Development Status :: 4 - Beta',
62 'Environment :: X11 Applications :: GTK',
63 'Environment :: Console',
64 'Intended Audience :: End Users/Desktop',
65 'License :: DFSG approved',
66 'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',
67 'Natural Language :: English',
68 'Programming Language :: Python :: 3 :: Only',
69 'Operating System :: POSIX :: Linux',
70 'Topic :: Utilities',
71 ],
72 platforms=['linux'],
73
74 # sudo apt install python-gi python3-gi \
75 # gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1
76 # os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],
77 python_requires='>=3.7',
78 install_requires=[
79 'evdev (>= 1.1.2) ; platform_system=="Linux"',
80 'pyudev (>= 0.13)',
81 'PyYAML (>= 3.12)',
82 'python-xlib (>= 0.27)',
83 'psutil (>= 5.4.3)',
84 'dbus-python ; platform_system=="Linux"',
85 ],
86 extras_require={
87 'report-descriptor': ['hid-parser'],
88 'desktop-notifications': ['Notify (>= 0.7)'],
89 'git-commit': ['python-git-info'],
90 'test': ['pytest'],
91 },
92 package_dir={'': 'lib'},
93 packages=['keysyms', 'hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],
94 data_files=list(_data_files()),
95 include_package_data=True,
96 scripts=_glob('bin/*'),
97 )
98
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -87,7 +87,7 @@
'report-descriptor': ['hid-parser'],
'desktop-notifications': ['Notify (>= 0.7)'],
'git-commit': ['python-git-info'],
- 'test': ['pytest'],
+ 'test': ['pytest', 'pytest-cov'],
},
package_dir={'': 'lib'},
packages=['keysyms', 'hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -87,7 +87,7 @@\n 'report-descriptor': ['hid-parser'],\n 'desktop-notifications': ['Notify (>= 0.7)'],\n 'git-commit': ['python-git-info'],\n- 'test': ['pytest'],\n+ 'test': ['pytest', 'pytest-cov'],\n },\n package_dir={'': 'lib'},\n packages=['keysyms', 'hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],\n", "issue": "Extend Makefile with installation and test targets\n**Information**\r\n- Solaar version: 1.1.11rc4\r\n\r\n**Is your feature request related to a problem? Please describe.**\r\nThe Solaar installation with all its dependencies (pip, apt, udev etc.) is cumbersome. Although some setup steps for GItHub CI exists, they are not usable for local setup of Solaar. \r\n\r\n**Describe the solution you'd like**\r\nMove the setup commands into a Makefile and use the targets in GitHub workflow files. Thus, the commands are in a single place and also usable for local setups.\r\n\r\n**Additional context**\r\nThis extends #2263 \r\n\n", "before_files": [{"content": "#!/usr/bin/env python3\nimport subprocess\n\nfrom glob import glob as _glob\n\ntry:\n from setuptools import setup\nexcept ImportError:\n from distutils.core import setup\n\nNAME = 'Solaar'\n\nwith open('lib/solaar/version', 'r') as vfile:\n version = vfile.read().strip()\n\ntry: # get commit from git describe\n commit = subprocess.check_output(['git', 'describe', '--always'], stderr=subprocess.DEVNULL).strip().decode()\n with open('lib/solaar/commit', 'w') as vfile:\n vfile.write(f'{commit}\\n')\nexcept Exception: # get commit from Ubuntu dpkg-parsechangelog\n try:\n commit = subprocess.check_output(['dpkg-parsechangelog', '--show-field', 'Version'],\n stderr=subprocess.DEVNULL).strip().decode()\n commit = commit.split('~')\n with open('lib/solaar/commit', 'w') as vfile:\n vfile.write(f'{commit[0]}\\n')\n except Exception as e:\n print('Exception using dpkg-parsechangelog', e)\n\n\ndef _data_files():\n from os.path import dirname as _dirname\n\n yield 'share/icons/hicolor/scalable/apps', _glob('share/solaar/icons/solaar*.svg')\n yield 'share/icons/hicolor/32x32/apps', _glob('share/solaar/icons/solaar-light_*.png')\n\n for mo in _glob('share/locale/*/LC_MESSAGES/solaar.mo'):\n yield _dirname(mo), [mo]\n\n yield 'share/applications', ['share/applications/solaar.desktop']\n yield 'lib/udev/rules.d', ['rules.d/42-logitech-unify-permissions.rules']\n yield 'share/metainfo', ['share/solaar/io.github.pwr_solaar.solaar.metainfo.xml']\n\n del _dirname\n\n\nsetup(\n name=NAME.lower(),\n version=version,\n description='Linux device manager for Logitech receivers, keyboards, mice, and tablets.',\n long_description='''\nSolaar is a Linux device manager for many Logitech peripherals that connect through\nUnifying and other receivers or via USB or Bluetooth.\nSolaar is able to pair/unpair devices with receivers and show and modify some of the\nmodifiable features of devices.\nFor instructions on installing Solaar see https://pwr-solaar.github.io/Solaar/installation'''.strip(),\n author='Daniel Pavel',\n license='GPLv2',\n url='http://pwr-solaar.github.io/Solaar/',\n classifiers=[\n 'Development Status :: 4 - Beta',\n 'Environment :: X11 Applications :: GTK',\n 'Environment :: Console',\n 'Intended Audience :: End Users/Desktop',\n 'License :: DFSG approved',\n 'License :: OSI Approved :: GNU General Public License v2 (GPLv2)',\n 'Natural Language :: English',\n 'Programming Language :: Python :: 3 :: Only',\n 'Operating System :: POSIX :: Linux',\n 'Topic :: Utilities',\n ],\n platforms=['linux'],\n\n # sudo apt install python-gi python3-gi \\\n # gir1.2-gtk-3.0 gir1.2-notify-0.7 gir1.2-ayatanaappindicator3-0.1\n # os_requires=['gi.repository.GObject (>= 2.0)', 'gi.repository.Gtk (>= 3.0)'],\n python_requires='>=3.7',\n install_requires=[\n 'evdev (>= 1.1.2) ; platform_system==\"Linux\"',\n 'pyudev (>= 0.13)',\n 'PyYAML (>= 3.12)',\n 'python-xlib (>= 0.27)',\n 'psutil (>= 5.4.3)',\n 'dbus-python ; platform_system==\"Linux\"',\n ],\n extras_require={\n 'report-descriptor': ['hid-parser'],\n 'desktop-notifications': ['Notify (>= 0.7)'],\n 'git-commit': ['python-git-info'],\n 'test': ['pytest'],\n },\n package_dir={'': 'lib'},\n packages=['keysyms', 'hidapi', 'logitech_receiver', 'solaar', 'solaar.ui', 'solaar.cli'],\n data_files=list(_data_files()),\n include_package_data=True,\n scripts=_glob('bin/*'),\n)\n", "path": "setup.py"}]}
| 1,820 | 130 |
gh_patches_debug_28607
|
rasdani/github-patches
|
git_diff
|
CTFd__CTFd-966
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CTFd permission error by using custom Vagrant
**Environment**:
- CTFd Version/Commit:master
- Operating System: VERSION="16.04.6 LTS (Xenial Xerus)" (vagrant machine)
**What happened?**
Permission denied
**How to reproduce your issue**
Create the following Vagrantfile
```ruby
# Defines our Vagrant environment
#
# -*- mode: ruby -*-
# vi: set ft=ruby :
Vagrant.configure("2") do |config|
DOCKER_REBUILD = true
DOCKER_DESTROY = false
config.vm.define :dockermachine do |config|
config.vm.box = "ubuntu/xenial64"
config.vm.hostname = "dsp"
config.vm.provision :docker
config.vm.provision :docker_compose
# Run docker compose networks
config.vm.synced_folder ".", "/vagrant", disabled: true
config.vm.synced_folder "./provision/", "/provision", disabled: false
config.vm.network "forwarded_port", guest: 8000, host: 8000
config.ssh.keep_alive = true
config.vm.provider "virtualbox" do |vb|
vb.gui = false
vb.default_nic_type = nil
vb.memory = "2048"
end
end
```
Install docker plugin prerequisite:
```
vagrant plugin install vagrant-docker-compose
```
Start machine and manually set ctfd
```bash
vagrant up
vagrant ssh
git clone https://github.com/CTFd/CTFd.git
cd CTFd
#add secret key in docker-compose
environment:
- SECRET_KEY=password
docker-compose up
```
- Issue no.1:
The first issue is about log directory permission; the user created in Dockerfile (uid=1001) is different than the current user id(1000) .
You can solve it by changing the userid in Dockerfile and by sending docker-compose build and docker-compose up:
```
sed -i "s/1001/$UID/g" Dockerfile
sudo chown -hR vagrant:vagrant .data
docker-compose up --build
```
- Issue 2:
After these steps, the application runs, but it is not possible to go over the setup phase:
<img width="617" alt="Schermata 2019-04-20 alle 12 58 05" src="https://user-images.githubusercontent.com/18548727/56456394-f71c7a80-636b-11e9-9c82-8d8e0319fb09.png">
<img width="1008" alt="Schermata 2019-04-20 alle 12 59 00" src="https://user-images.githubusercontent.com/18548727/56456401-216e3800-636c-11e9-876e-46d05470bce2.png">
I am not able to overcome this problem. Could you give me any hint about it?
Thanks very much
**Any associated stack traces or error logs**
Permission denied (issue no.1):
```
ctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'
ctfd_ctfd_1 exited with code 1
ctfd_1 | Waiting for db: to be ready
ctfd_1 | .db is ready
ctfd_1 | Traceback (most recent call last):
ctfd_1 | File "manage.py", line 8, in <module>
ctfd_1 | app = create_app()
ctfd_1 | File "/opt/CTFd/CTFd/__init__.py", line 225, in create_app
ctfd_1 | init_logs(app)
ctfd_1 | File "/opt/CTFd/CTFd/utils/initialization/__init__.py", line 90, in init_logs
ctfd_1 | open(log, 'a').close()
ctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'
ctfd_1 | Waiting for db: to be ready
ctfd_1 | db is ready
ctfd_1 | Traceback (most recent call last):
ctfd_1 | File "manage.py", line 8, in <module>
ctfd_1 | app = create_app()
ctfd_1 | File "/opt/CTFd/CTFd/__init__.py", line 225, in create_app
ctfd_1 | init_logs(app)
ctfd_1 | File "/opt/CTFd/CTFd/utils/initialization/__init__.py", line 90, in init_logs
ctfd_1 | open(log, 'a').close()
ctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'
ctfd_1 | Waiting for db: to be ready
ctfd_1 | db is ready
ctfd_1 | Traceback (most recent call last):
ctfd_1 | File "manage.py", line 8, in <module>
ctfd_1 | app = create_app()
ctfd_1 | File "/opt/CTFd/CTFd/__init__.py", line 225, in create_app
ctfd_1 | init_logs(app)
ctfd_1 | File "/opt/CTFd/CTFd/utils/initialization/__init__.py", line 90, in init_logs
ctfd_1 | open(log, 'a').close()
ctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'
```
</issue>
<code>
[start of CTFd/utils/initialization/__init__.py]
1 from flask import request, session, redirect, url_for, abort, render_template
2 from werkzeug.wsgi import DispatcherMiddleware
3 from CTFd.models import db, Tracking
4
5 from CTFd.utils import markdown, get_config
6 from CTFd.utils.dates import unix_time_millis, unix_time, isoformat
7
8 from CTFd.utils import config
9 from CTFd.utils.config import can_send_mail, ctf_logo, ctf_name, ctf_theme
10 from CTFd.utils.config.pages import get_pages
11 from CTFd.utils.events import EventManager, RedisEventManager
12 from CTFd.utils.plugins import (
13 get_registered_stylesheets,
14 get_registered_scripts,
15 get_configurable_plugins,
16 get_registered_admin_scripts,
17 get_registered_admin_stylesheets
18 )
19
20 from CTFd.utils.countries import get_countries, lookup_country_code
21 from CTFd.utils.user import authed, get_ip, get_current_user, get_current_team
22 from CTFd.utils.modes import generate_account_url
23 from CTFd.utils.config import is_setup
24 from CTFd.utils.security.csrf import generate_nonce
25
26 from CTFd.utils.config.visibility import (
27 accounts_visible,
28 challenges_visible,
29 registration_visible,
30 scores_visible
31 )
32
33 from sqlalchemy.exc import InvalidRequestError, IntegrityError
34
35 import datetime
36 import logging
37 import os
38
39
40 def init_template_filters(app):
41 app.jinja_env.filters['markdown'] = markdown
42 app.jinja_env.filters['unix_time'] = unix_time
43 app.jinja_env.filters['unix_time_millis'] = unix_time_millis
44 app.jinja_env.filters['isoformat'] = isoformat
45
46
47 def init_template_globals(app):
48 app.jinja_env.globals.update(config=config)
49 app.jinja_env.globals.update(get_pages=get_pages)
50 app.jinja_env.globals.update(can_send_mail=can_send_mail)
51 app.jinja_env.globals.update(get_ctf_name=ctf_name)
52 app.jinja_env.globals.update(get_ctf_logo=ctf_logo)
53 app.jinja_env.globals.update(get_ctf_theme=ctf_theme)
54 app.jinja_env.globals.update(get_configurable_plugins=get_configurable_plugins)
55 app.jinja_env.globals.update(get_registered_scripts=get_registered_scripts)
56 app.jinja_env.globals.update(get_registered_stylesheets=get_registered_stylesheets)
57 app.jinja_env.globals.update(get_registered_admin_scripts=get_registered_admin_scripts)
58 app.jinja_env.globals.update(get_registered_admin_stylesheets=get_registered_admin_stylesheets)
59 app.jinja_env.globals.update(get_config=get_config)
60 app.jinja_env.globals.update(generate_account_url=generate_account_url)
61 app.jinja_env.globals.update(get_countries=get_countries)
62 app.jinja_env.globals.update(lookup_country_code=lookup_country_code)
63 app.jinja_env.globals.update(accounts_visible=accounts_visible)
64 app.jinja_env.globals.update(challenges_visible=challenges_visible)
65 app.jinja_env.globals.update(registration_visible=registration_visible)
66 app.jinja_env.globals.update(scores_visible=scores_visible)
67
68
69 def init_logs(app):
70 logger_submissions = logging.getLogger('submissions')
71 logger_logins = logging.getLogger('logins')
72 logger_registrations = logging.getLogger('registrations')
73
74 logger_submissions.setLevel(logging.INFO)
75 logger_logins.setLevel(logging.INFO)
76 logger_registrations.setLevel(logging.INFO)
77
78 log_dir = app.config['LOG_FOLDER']
79 if not os.path.exists(log_dir):
80 os.makedirs(log_dir)
81
82 logs = {
83 'submissions': os.path.join(log_dir, 'submissions.log'),
84 'logins': os.path.join(log_dir, 'logins.log'),
85 'registrations': os.path.join(log_dir, 'registrations.log')
86 }
87
88 for log in logs.values():
89 if not os.path.exists(log):
90 open(log, 'a').close()
91
92 submission_log = logging.handlers.RotatingFileHandler(logs['submissions'], maxBytes=10000)
93 login_log = logging.handlers.RotatingFileHandler(logs['logins'], maxBytes=10000)
94 registration_log = logging.handlers.RotatingFileHandler(logs['registrations'], maxBytes=10000)
95
96 logger_submissions.addHandler(
97 submission_log
98 )
99 logger_logins.addHandler(
100 login_log
101 )
102 logger_registrations.addHandler(
103 registration_log
104 )
105
106 logger_submissions.propagate = 0
107 logger_logins.propagate = 0
108 logger_registrations.propagate = 0
109
110
111 def init_events(app):
112 if app.config.get('CACHE_TYPE') == 'redis':
113 app.events_manager = RedisEventManager()
114 elif app.config.get('CACHE_TYPE') == 'filesystem':
115 app.events_manager = EventManager()
116 else:
117 app.events_manager = EventManager()
118
119
120 def init_request_processors(app):
121 @app.context_processor
122 def inject_user():
123 if session:
124 return dict(session)
125 return dict()
126
127 @app.url_defaults
128 def inject_theme(endpoint, values):
129 if 'theme' not in values and app.url_map.is_endpoint_expecting(endpoint, 'theme'):
130 values['theme'] = ctf_theme()
131
132 @app.before_request
133 def needs_setup():
134 if request.path == url_for('views.setup') or request.path.startswith('/themes'):
135 return
136 if not is_setup():
137 return redirect(url_for('views.setup'))
138
139 @app.before_request
140 def tracker():
141 # TODO: This function shouldn't cause a DB hit for lookups if possible
142 if authed():
143 track = Tracking.query.filter_by(ip=get_ip(), user_id=session['id']).first()
144 if not track:
145 visit = Tracking(ip=get_ip(), user_id=session['id'])
146 db.session.add(visit)
147 else:
148 track.date = datetime.datetime.utcnow()
149
150 try:
151 db.session.commit()
152 except (InvalidRequestError, IntegrityError) as e:
153 print(e.message)
154 db.session.rollback()
155 session.clear()
156
157 if authed():
158 user = get_current_user()
159 team = get_current_team()
160
161 if request.path.startswith('/themes') is False:
162 if user and user.banned:
163 return render_template('errors/403.html', error='You have been banned from this CTF'), 403
164
165 if team and team.banned:
166 return render_template('errors/403.html', error='Your team has been banned from this CTF'), 403
167
168 db.session.close()
169
170 @app.before_request
171 def csrf():
172 try:
173 func = app.view_functions[request.endpoint]
174 except KeyError:
175 abort(404)
176 if hasattr(func, '_bypass_csrf'):
177 return
178 if not session.get('nonce'):
179 session['nonce'] = generate_nonce()
180 if request.method not in ('GET', 'HEAD', 'OPTIONS', 'TRACE'):
181 if request.content_type == 'application/json':
182 if session['nonce'] != request.headers.get('CSRF-Token'):
183 abort(403)
184 if request.content_type != 'application/json':
185 if session['nonce'] != request.form.get('nonce'):
186 abort(403)
187
188 application_root = app.config.get('APPLICATION_ROOT')
189 if application_root != '/':
190 @app.before_request
191 def force_subdirectory_redirect():
192 if request.path.startswith(application_root) is False:
193 return redirect(application_root + request.script_root + request.full_path)
194
195 app.wsgi_app = DispatcherMiddleware(app.wsgi_app, {
196 application_root: app,
197 })
198
[end of CTFd/utils/initialization/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/CTFd/utils/initialization/__init__.py b/CTFd/utils/initialization/__init__.py
--- a/CTFd/utils/initialization/__init__.py
+++ b/CTFd/utils/initialization/__init__.py
@@ -35,6 +35,7 @@
import datetime
import logging
import os
+import sys
def init_template_filters(app):
@@ -85,22 +86,37 @@
'registrations': os.path.join(log_dir, 'registrations.log')
}
- for log in logs.values():
- if not os.path.exists(log):
- open(log, 'a').close()
-
- submission_log = logging.handlers.RotatingFileHandler(logs['submissions'], maxBytes=10000)
- login_log = logging.handlers.RotatingFileHandler(logs['logins'], maxBytes=10000)
- registration_log = logging.handlers.RotatingFileHandler(logs['registrations'], maxBytes=10000)
+ try:
+ for log in logs.values():
+ if not os.path.exists(log):
+ open(log, 'a').close()
+
+ submission_log = logging.handlers.RotatingFileHandler(logs['submissions'], maxBytes=10000)
+ login_log = logging.handlers.RotatingFileHandler(logs['logins'], maxBytes=10000)
+ registration_log = logging.handlers.RotatingFileHandler(logs['registrations'], maxBytes=10000)
+
+ logger_submissions.addHandler(
+ submission_log
+ )
+ logger_logins.addHandler(
+ login_log
+ )
+ logger_registrations.addHandler(
+ registration_log
+ )
+ except IOError:
+ pass
+
+ stdout = logging.StreamHandler(stream=sys.stdout)
logger_submissions.addHandler(
- submission_log
+ stdout
)
logger_logins.addHandler(
- login_log
+ stdout
)
logger_registrations.addHandler(
- registration_log
+ stdout
)
logger_submissions.propagate = 0
|
{"golden_diff": "diff --git a/CTFd/utils/initialization/__init__.py b/CTFd/utils/initialization/__init__.py\n--- a/CTFd/utils/initialization/__init__.py\n+++ b/CTFd/utils/initialization/__init__.py\n@@ -35,6 +35,7 @@\n import datetime\n import logging\n import os\n+import sys\n \n \n def init_template_filters(app):\n@@ -85,22 +86,37 @@\n 'registrations': os.path.join(log_dir, 'registrations.log')\n }\n \n- for log in logs.values():\n- if not os.path.exists(log):\n- open(log, 'a').close()\n-\n- submission_log = logging.handlers.RotatingFileHandler(logs['submissions'], maxBytes=10000)\n- login_log = logging.handlers.RotatingFileHandler(logs['logins'], maxBytes=10000)\n- registration_log = logging.handlers.RotatingFileHandler(logs['registrations'], maxBytes=10000)\n+ try:\n+ for log in logs.values():\n+ if not os.path.exists(log):\n+ open(log, 'a').close()\n+\n+ submission_log = logging.handlers.RotatingFileHandler(logs['submissions'], maxBytes=10000)\n+ login_log = logging.handlers.RotatingFileHandler(logs['logins'], maxBytes=10000)\n+ registration_log = logging.handlers.RotatingFileHandler(logs['registrations'], maxBytes=10000)\n+\n+ logger_submissions.addHandler(\n+ submission_log\n+ )\n+ logger_logins.addHandler(\n+ login_log\n+ )\n+ logger_registrations.addHandler(\n+ registration_log\n+ )\n+ except IOError:\n+ pass\n+\n+ stdout = logging.StreamHandler(stream=sys.stdout)\n \n logger_submissions.addHandler(\n- submission_log\n+ stdout\n )\n logger_logins.addHandler(\n- login_log\n+ stdout\n )\n logger_registrations.addHandler(\n- registration_log\n+ stdout\n )\n \n logger_submissions.propagate = 0\n", "issue": "CTFd permission error by using custom Vagrant\n**Environment**:\r\n\r\n - CTFd Version/Commit:master\r\n - Operating System: VERSION=\"16.04.6 LTS (Xenial Xerus)\" (vagrant machine)\r\n\r\n\r\n**What happened?**\r\nPermission denied \r\n**How to reproduce your issue**\r\nCreate the following Vagrantfile\r\n```ruby\r\n # Defines our Vagrant environment\r\n #\r\n # -*- mode: ruby -*-\r\n # vi: set ft=ruby :\r\n \r\n Vagrant.configure(\"2\") do |config|\r\n \r\n DOCKER_REBUILD = true\r\n DOCKER_DESTROY = false\r\n config.vm.define :dockermachine do |config|\r\n config.vm.box = \"ubuntu/xenial64\"\r\n config.vm.hostname = \"dsp\"\r\n config.vm.provision :docker\r\n config.vm.provision :docker_compose\r\n \r\n # Run docker compose networks\r\n config.vm.synced_folder \".\", \"/vagrant\", disabled: true\r\n config.vm.synced_folder \"./provision/\", \"/provision\", disabled: false\r\n config.vm.network \"forwarded_port\", guest: 8000, host: 8000\r\n config.ssh.keep_alive = true\r\n config.vm.provider \"virtualbox\" do |vb|\r\n vb.gui = false\r\n vb.default_nic_type = nil\r\n vb.memory = \"2048\"\r\n end\r\n end\r\n```\r\nInstall docker plugin prerequisite: \r\n```\r\nvagrant plugin install vagrant-docker-compose\r\n```\r\nStart machine and manually set ctfd\r\n```bash\r\nvagrant up \r\nvagrant ssh\r\ngit clone https://github.com/CTFd/CTFd.git\r\ncd CTFd\r\n#add secret key in docker-compose\r\n environment:\r\n - SECRET_KEY=password \r\ndocker-compose up\r\n```\r\n- Issue no.1: \r\nThe first issue is about log directory permission; the user created in Dockerfile (uid=1001) is different than the current user id(1000) . \r\nYou can solve it by changing the userid in Dockerfile and by sending docker-compose build and docker-compose up: \r\n```\r\nsed -i \"s/1001/$UID/g\" Dockerfile\r\nsudo chown -hR vagrant:vagrant .data\r\ndocker-compose up --build\r\n``` \r\n- Issue 2: \r\nAfter these steps, the application runs, but it is not possible to go over the setup phase: \r\n<img width=\"617\" alt=\"Schermata 2019-04-20 alle 12 58 05\" src=\"https://user-images.githubusercontent.com/18548727/56456394-f71c7a80-636b-11e9-9c82-8d8e0319fb09.png\">\r\n\r\n<img width=\"1008\" alt=\"Schermata 2019-04-20 alle 12 59 00\" src=\"https://user-images.githubusercontent.com/18548727/56456401-216e3800-636c-11e9-876e-46d05470bce2.png\">\r\n\r\n\r\nI am not able to overcome this problem. Could you give me any hint about it? \r\nThanks very much\r\n\r\n\r\n**Any associated stack traces or error logs**\r\nPermission denied (issue no.1): \r\n```\r\nctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'\r\nctfd_ctfd_1 exited with code 1\r\nctfd_1 | Waiting for db: to be ready\r\nctfd_1 | .db is ready\r\nctfd_1 | Traceback (most recent call last):\r\nctfd_1 | File \"manage.py\", line 8, in <module>\r\nctfd_1 | app = create_app()\r\nctfd_1 | File \"/opt/CTFd/CTFd/__init__.py\", line 225, in create_app\r\nctfd_1 | init_logs(app)\r\nctfd_1 | File \"/opt/CTFd/CTFd/utils/initialization/__init__.py\", line 90, in init_logs\r\nctfd_1 | open(log, 'a').close()\r\nctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'\r\nctfd_1 | Waiting for db: to be ready\r\nctfd_1 | db is ready\r\nctfd_1 | Traceback (most recent call last):\r\nctfd_1 | File \"manage.py\", line 8, in <module>\r\nctfd_1 | app = create_app()\r\nctfd_1 | File \"/opt/CTFd/CTFd/__init__.py\", line 225, in create_app\r\nctfd_1 | init_logs(app)\r\nctfd_1 | File \"/opt/CTFd/CTFd/utils/initialization/__init__.py\", line 90, in init_logs\r\nctfd_1 | open(log, 'a').close()\r\nctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'\r\nctfd_1 | Waiting for db: to be ready\r\nctfd_1 | db is ready\r\nctfd_1 | Traceback (most recent call last):\r\nctfd_1 | File \"manage.py\", line 8, in <module>\r\nctfd_1 | app = create_app()\r\nctfd_1 | File \"/opt/CTFd/CTFd/__init__.py\", line 225, in create_app\r\nctfd_1 | init_logs(app)\r\nctfd_1 | File \"/opt/CTFd/CTFd/utils/initialization/__init__.py\", line 90, in init_logs\r\nctfd_1 | open(log, 'a').close()\r\nctfd_1 | IOError: [Errno 13] Permission denied: '/var/log/CTFd/logins.log'\r\n```\n", "before_files": [{"content": "from flask import request, session, redirect, url_for, abort, render_template\nfrom werkzeug.wsgi import DispatcherMiddleware\nfrom CTFd.models import db, Tracking\n\nfrom CTFd.utils import markdown, get_config\nfrom CTFd.utils.dates import unix_time_millis, unix_time, isoformat\n\nfrom CTFd.utils import config\nfrom CTFd.utils.config import can_send_mail, ctf_logo, ctf_name, ctf_theme\nfrom CTFd.utils.config.pages import get_pages\nfrom CTFd.utils.events import EventManager, RedisEventManager\nfrom CTFd.utils.plugins import (\n get_registered_stylesheets,\n get_registered_scripts,\n get_configurable_plugins,\n get_registered_admin_scripts,\n get_registered_admin_stylesheets\n)\n\nfrom CTFd.utils.countries import get_countries, lookup_country_code\nfrom CTFd.utils.user import authed, get_ip, get_current_user, get_current_team\nfrom CTFd.utils.modes import generate_account_url\nfrom CTFd.utils.config import is_setup\nfrom CTFd.utils.security.csrf import generate_nonce\n\nfrom CTFd.utils.config.visibility import (\n accounts_visible,\n challenges_visible,\n registration_visible,\n scores_visible\n)\n\nfrom sqlalchemy.exc import InvalidRequestError, IntegrityError\n\nimport datetime\nimport logging\nimport os\n\n\ndef init_template_filters(app):\n app.jinja_env.filters['markdown'] = markdown\n app.jinja_env.filters['unix_time'] = unix_time\n app.jinja_env.filters['unix_time_millis'] = unix_time_millis\n app.jinja_env.filters['isoformat'] = isoformat\n\n\ndef init_template_globals(app):\n app.jinja_env.globals.update(config=config)\n app.jinja_env.globals.update(get_pages=get_pages)\n app.jinja_env.globals.update(can_send_mail=can_send_mail)\n app.jinja_env.globals.update(get_ctf_name=ctf_name)\n app.jinja_env.globals.update(get_ctf_logo=ctf_logo)\n app.jinja_env.globals.update(get_ctf_theme=ctf_theme)\n app.jinja_env.globals.update(get_configurable_plugins=get_configurable_plugins)\n app.jinja_env.globals.update(get_registered_scripts=get_registered_scripts)\n app.jinja_env.globals.update(get_registered_stylesheets=get_registered_stylesheets)\n app.jinja_env.globals.update(get_registered_admin_scripts=get_registered_admin_scripts)\n app.jinja_env.globals.update(get_registered_admin_stylesheets=get_registered_admin_stylesheets)\n app.jinja_env.globals.update(get_config=get_config)\n app.jinja_env.globals.update(generate_account_url=generate_account_url)\n app.jinja_env.globals.update(get_countries=get_countries)\n app.jinja_env.globals.update(lookup_country_code=lookup_country_code)\n app.jinja_env.globals.update(accounts_visible=accounts_visible)\n app.jinja_env.globals.update(challenges_visible=challenges_visible)\n app.jinja_env.globals.update(registration_visible=registration_visible)\n app.jinja_env.globals.update(scores_visible=scores_visible)\n\n\ndef init_logs(app):\n logger_submissions = logging.getLogger('submissions')\n logger_logins = logging.getLogger('logins')\n logger_registrations = logging.getLogger('registrations')\n\n logger_submissions.setLevel(logging.INFO)\n logger_logins.setLevel(logging.INFO)\n logger_registrations.setLevel(logging.INFO)\n\n log_dir = app.config['LOG_FOLDER']\n if not os.path.exists(log_dir):\n os.makedirs(log_dir)\n\n logs = {\n 'submissions': os.path.join(log_dir, 'submissions.log'),\n 'logins': os.path.join(log_dir, 'logins.log'),\n 'registrations': os.path.join(log_dir, 'registrations.log')\n }\n\n for log in logs.values():\n if not os.path.exists(log):\n open(log, 'a').close()\n\n submission_log = logging.handlers.RotatingFileHandler(logs['submissions'], maxBytes=10000)\n login_log = logging.handlers.RotatingFileHandler(logs['logins'], maxBytes=10000)\n registration_log = logging.handlers.RotatingFileHandler(logs['registrations'], maxBytes=10000)\n\n logger_submissions.addHandler(\n submission_log\n )\n logger_logins.addHandler(\n login_log\n )\n logger_registrations.addHandler(\n registration_log\n )\n\n logger_submissions.propagate = 0\n logger_logins.propagate = 0\n logger_registrations.propagate = 0\n\n\ndef init_events(app):\n if app.config.get('CACHE_TYPE') == 'redis':\n app.events_manager = RedisEventManager()\n elif app.config.get('CACHE_TYPE') == 'filesystem':\n app.events_manager = EventManager()\n else:\n app.events_manager = EventManager()\n\n\ndef init_request_processors(app):\n @app.context_processor\n def inject_user():\n if session:\n return dict(session)\n return dict()\n\n @app.url_defaults\n def inject_theme(endpoint, values):\n if 'theme' not in values and app.url_map.is_endpoint_expecting(endpoint, 'theme'):\n values['theme'] = ctf_theme()\n\n @app.before_request\n def needs_setup():\n if request.path == url_for('views.setup') or request.path.startswith('/themes'):\n return\n if not is_setup():\n return redirect(url_for('views.setup'))\n\n @app.before_request\n def tracker():\n # TODO: This function shouldn't cause a DB hit for lookups if possible\n if authed():\n track = Tracking.query.filter_by(ip=get_ip(), user_id=session['id']).first()\n if not track:\n visit = Tracking(ip=get_ip(), user_id=session['id'])\n db.session.add(visit)\n else:\n track.date = datetime.datetime.utcnow()\n\n try:\n db.session.commit()\n except (InvalidRequestError, IntegrityError) as e:\n print(e.message)\n db.session.rollback()\n session.clear()\n\n if authed():\n user = get_current_user()\n team = get_current_team()\n\n if request.path.startswith('/themes') is False:\n if user and user.banned:\n return render_template('errors/403.html', error='You have been banned from this CTF'), 403\n\n if team and team.banned:\n return render_template('errors/403.html', error='Your team has been banned from this CTF'), 403\n\n db.session.close()\n\n @app.before_request\n def csrf():\n try:\n func = app.view_functions[request.endpoint]\n except KeyError:\n abort(404)\n if hasattr(func, '_bypass_csrf'):\n return\n if not session.get('nonce'):\n session['nonce'] = generate_nonce()\n if request.method not in ('GET', 'HEAD', 'OPTIONS', 'TRACE'):\n if request.content_type == 'application/json':\n if session['nonce'] != request.headers.get('CSRF-Token'):\n abort(403)\n if request.content_type != 'application/json':\n if session['nonce'] != request.form.get('nonce'):\n abort(403)\n\n application_root = app.config.get('APPLICATION_ROOT')\n if application_root != '/':\n @app.before_request\n def force_subdirectory_redirect():\n if request.path.startswith(application_root) is False:\n return redirect(application_root + request.script_root + request.full_path)\n\n app.wsgi_app = DispatcherMiddleware(app.wsgi_app, {\n application_root: app,\n })\n", "path": "CTFd/utils/initialization/__init__.py"}]}
| 4,019 | 475 |
gh_patches_debug_21755
|
rasdani/github-patches
|
git_diff
|
deepchecks__deepchecks-613
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[DOCS] Simple Model Comparison example improvement
Currently, the Simple Model Comparison notebook lacks some explanations.
Please follow the guidelines from this issue: #543 to improve it
</issue>
<code>
[start of deepchecks/utils/validation.py]
1 # ----------------------------------------------------------------------------
2 # Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)
3 #
4 # This file is part of Deepchecks.
5 # Deepchecks is distributed under the terms of the GNU Affero General
6 # Public License (version 3 or later).
7 # You should have received a copy of the GNU Affero General Public License
8 # along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.
9 # ----------------------------------------------------------------------------
10 #
11 """objects validation utilities."""
12 import typing as t
13
14 import pandas as pd
15
16 from deepchecks import base # pylint: disable=unused-import, is used in type annotations
17 from deepchecks import errors
18 from deepchecks.utils.typing import Hashable, BasicModel
19
20 __all__ = ['model_type_validation', 'ensure_hashable_or_mutable_sequence', 'validate_model', 'ensure_dataframe_type']
21
22
23 def model_type_validation(model: t.Any):
24 """Receive any object and check if it's an instance of a model we support.
25
26 Raises:
27 DeepchecksValueError: If the object is not of a supported type
28 """
29 if not isinstance(model, BasicModel):
30 raise errors.DeepchecksValueError(
31 'Model must inherit from one of supported '
32 'models: sklearn.base.BaseEstimator or CatBoost, '
33 f'Received: {model.__class__.__name__}'
34 )
35
36
37 def validate_model(
38 data: t.Union['base.Dataset', pd.DataFrame],
39 model: t.Any
40 ):
41 """Check model is able to predict on the dataset.
42
43 Args:
44 data (Dataset, pandas.DataFrame):
45 model (BaseEstimator):
46
47 Raise:
48 DeepchecksValueError: if dataset does not match model
49 """
50 model_type_validation(model)
51
52 error_message = (
53 'In order to evaluate model correctness we need not empty dataset '
54 'with the same set of features that was used to fit the model. {0}'
55 )
56
57 if isinstance(data, base.Dataset):
58 features = data.features_columns
59 features_names = set(data.features)
60 else:
61 features = data
62 features_names = set(data.columns)
63
64 model_features = getattr(model, 'feature_names_in_', None)
65
66 if features is None:
67 raise errors.DeepchecksValueError(error_message.format(
68 'But function received dataset without feature columns.'
69 ))
70
71 if len(features) == 0:
72 raise errors.DeepchecksValueError(error_message.format(
73 'But function received empty dataset.'
74 ))
75
76 try:
77 model_features = set(model_features) # type: ignore
78 if model_features != features_names:
79 raise errors.DeepchecksValueError(error_message.format(
80 'But function received dataset with a different set of features.'
81 ))
82 except (TypeError, ValueError):
83 # in case if 'model.feature_names_in_' was None or not iterable
84 pass
85
86 try:
87 model.predict(features.head(1))
88 except Exception as exc:
89 raise errors.DeepchecksValueError(
90 f'Got error when trying to predict with model on dataset: {str(exc)}'
91 )
92
93
94 T = t.TypeVar('T', bound=Hashable)
95
96
97 def ensure_hashable_or_mutable_sequence(
98 value: t.Union[T, t.MutableSequence[T]],
99 message: str = (
100 'Provided value is neither hashable nor mutable '
101 'sequence of hashable items. Got {type}')
102 ) -> t.List[T]:
103 """Validate that provided value is either hashable or mutable sequence of hashable values."""
104 if isinstance(value, Hashable):
105 return [value]
106
107 if isinstance(value, t.MutableSequence):
108 if len(value) > 0 and not isinstance(value[0], Hashable):
109 raise errors.DeepchecksValueError(message.format(
110 type=f'MutableSequence[{type(value).__name__}]'
111 ))
112 return list(value)
113
114 raise errors.DeepchecksValueError(message.format(
115 type=type(value).__name__
116 ))
117
118
119 def ensure_dataframe_type(obj: t.Any) -> pd.DataFrame:
120 """Ensure that given object is of type DataFrame or Dataset and return it as DataFrame. else raise error.
121
122 Args:
123 obj: Object to ensure it is DataFrame or Dataset
124
125 Returns:
126 (pd.DataFrame)
127 """
128 if isinstance(obj, pd.DataFrame):
129 return obj
130 elif isinstance(obj, base.Dataset):
131 return obj.data
132 else:
133 raise errors.DeepchecksValueError(
134 f'dataset must be of type DataFrame or Dataset, but got: {type(obj).__name__}'
135 )
136
[end of deepchecks/utils/validation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/deepchecks/utils/validation.py b/deepchecks/utils/validation.py
--- a/deepchecks/utils/validation.py
+++ b/deepchecks/utils/validation.py
@@ -56,12 +56,8 @@
if isinstance(data, base.Dataset):
features = data.features_columns
- features_names = set(data.features)
else:
features = data
- features_names = set(data.columns)
-
- model_features = getattr(model, 'feature_names_in_', None)
if features is None:
raise errors.DeepchecksValueError(error_message.format(
@@ -73,16 +69,6 @@
'But function received empty dataset.'
))
- try:
- model_features = set(model_features) # type: ignore
- if model_features != features_names:
- raise errors.DeepchecksValueError(error_message.format(
- 'But function received dataset with a different set of features.'
- ))
- except (TypeError, ValueError):
- # in case if 'model.feature_names_in_' was None or not iterable
- pass
-
try:
model.predict(features.head(1))
except Exception as exc:
|
{"golden_diff": "diff --git a/deepchecks/utils/validation.py b/deepchecks/utils/validation.py\n--- a/deepchecks/utils/validation.py\n+++ b/deepchecks/utils/validation.py\n@@ -56,12 +56,8 @@\n \n if isinstance(data, base.Dataset):\n features = data.features_columns\n- features_names = set(data.features)\n else:\n features = data\n- features_names = set(data.columns)\n-\n- model_features = getattr(model, 'feature_names_in_', None)\n \n if features is None:\n raise errors.DeepchecksValueError(error_message.format(\n@@ -73,16 +69,6 @@\n 'But function received empty dataset.'\n ))\n \n- try:\n- model_features = set(model_features) # type: ignore\n- if model_features != features_names:\n- raise errors.DeepchecksValueError(error_message.format(\n- 'But function received dataset with a different set of features.'\n- ))\n- except (TypeError, ValueError):\n- # in case if 'model.feature_names_in_' was None or not iterable\n- pass\n-\n try:\n model.predict(features.head(1))\n except Exception as exc:\n", "issue": "[DOCS] Simple Model Comparison example improvement \nCurrently, the Simple Model Comparison notebook lacks some explanations.\r\nPlease follow the guidelines from this issue: #543 to improve it\n", "before_files": [{"content": "# ----------------------------------------------------------------------------\n# Copyright (C) 2021 Deepchecks (https://www.deepchecks.com)\n#\n# This file is part of Deepchecks.\n# Deepchecks is distributed under the terms of the GNU Affero General\n# Public License (version 3 or later).\n# You should have received a copy of the GNU Affero General Public License\n# along with Deepchecks. If not, see <http://www.gnu.org/licenses/>.\n# ----------------------------------------------------------------------------\n#\n\"\"\"objects validation utilities.\"\"\"\nimport typing as t\n\nimport pandas as pd\n\nfrom deepchecks import base # pylint: disable=unused-import, is used in type annotations\nfrom deepchecks import errors\nfrom deepchecks.utils.typing import Hashable, BasicModel\n\n__all__ = ['model_type_validation', 'ensure_hashable_or_mutable_sequence', 'validate_model', 'ensure_dataframe_type']\n\n\ndef model_type_validation(model: t.Any):\n \"\"\"Receive any object and check if it's an instance of a model we support.\n\n Raises:\n DeepchecksValueError: If the object is not of a supported type\n \"\"\"\n if not isinstance(model, BasicModel):\n raise errors.DeepchecksValueError(\n 'Model must inherit from one of supported '\n 'models: sklearn.base.BaseEstimator or CatBoost, '\n f'Received: {model.__class__.__name__}'\n )\n\n\ndef validate_model(\n data: t.Union['base.Dataset', pd.DataFrame],\n model: t.Any\n):\n \"\"\"Check model is able to predict on the dataset.\n\n Args:\n data (Dataset, pandas.DataFrame):\n model (BaseEstimator):\n\n Raise:\n DeepchecksValueError: if dataset does not match model\n \"\"\"\n model_type_validation(model)\n\n error_message = (\n 'In order to evaluate model correctness we need not empty dataset '\n 'with the same set of features that was used to fit the model. {0}'\n )\n\n if isinstance(data, base.Dataset):\n features = data.features_columns\n features_names = set(data.features)\n else:\n features = data\n features_names = set(data.columns)\n\n model_features = getattr(model, 'feature_names_in_', None)\n\n if features is None:\n raise errors.DeepchecksValueError(error_message.format(\n 'But function received dataset without feature columns.'\n ))\n\n if len(features) == 0:\n raise errors.DeepchecksValueError(error_message.format(\n 'But function received empty dataset.'\n ))\n\n try:\n model_features = set(model_features) # type: ignore\n if model_features != features_names:\n raise errors.DeepchecksValueError(error_message.format(\n 'But function received dataset with a different set of features.'\n ))\n except (TypeError, ValueError):\n # in case if 'model.feature_names_in_' was None or not iterable\n pass\n\n try:\n model.predict(features.head(1))\n except Exception as exc:\n raise errors.DeepchecksValueError(\n f'Got error when trying to predict with model on dataset: {str(exc)}'\n )\n\n\nT = t.TypeVar('T', bound=Hashable)\n\n\ndef ensure_hashable_or_mutable_sequence(\n value: t.Union[T, t.MutableSequence[T]],\n message: str = (\n 'Provided value is neither hashable nor mutable '\n 'sequence of hashable items. Got {type}')\n) -> t.List[T]:\n \"\"\"Validate that provided value is either hashable or mutable sequence of hashable values.\"\"\"\n if isinstance(value, Hashable):\n return [value]\n\n if isinstance(value, t.MutableSequence):\n if len(value) > 0 and not isinstance(value[0], Hashable):\n raise errors.DeepchecksValueError(message.format(\n type=f'MutableSequence[{type(value).__name__}]'\n ))\n return list(value)\n\n raise errors.DeepchecksValueError(message.format(\n type=type(value).__name__\n ))\n\n\ndef ensure_dataframe_type(obj: t.Any) -> pd.DataFrame:\n \"\"\"Ensure that given object is of type DataFrame or Dataset and return it as DataFrame. else raise error.\n\n Args:\n obj: Object to ensure it is DataFrame or Dataset\n\n Returns:\n (pd.DataFrame)\n \"\"\"\n if isinstance(obj, pd.DataFrame):\n return obj\n elif isinstance(obj, base.Dataset):\n return obj.data\n else:\n raise errors.DeepchecksValueError(\n f'dataset must be of type DataFrame or Dataset, but got: {type(obj).__name__}'\n )\n", "path": "deepchecks/utils/validation.py"}]}
| 1,831 | 254 |
gh_patches_debug_15150
|
rasdani/github-patches
|
git_diff
|
huggingface__dataset-viewer-410
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Error with RGBA images
https://huggingface.co/datasets/huggan/few-shot-skulls
```
Status code: 500
Exception: Status500Error
Message: cannot write mode RGBA as JPEG
```
reported by @NielsRogge
</issue>
<code>
[start of services/worker/src/worker/models/column/image.py]
1 from typing import Any, List
2
3 from datasets import Image
4 from PIL import Image as PILImage # type: ignore
5
6 from worker.models.asset import create_image_file
7 from worker.models.column.default import (
8 Cell,
9 CellTypeError,
10 ColumnInferenceError,
11 ColumnTypeError,
12 CommonColumn,
13 )
14
15
16 def check_value(value: Any) -> None:
17 if value is None:
18 return
19 if not isinstance(value, PILImage.Image):
20 raise CellTypeError("image cell must be a PIL image")
21
22
23 def infer_from_values(values: List[Any]) -> None:
24 for value in values:
25 check_value(value)
26 if values and all(value is None for value in values):
27 raise ColumnInferenceError("all the values are None, cannot infer column type")
28
29
30 class ImageColumn(CommonColumn):
31 def __init__(self, name: str, feature: Any, values: List[Any]):
32 if feature:
33 if not isinstance(feature, Image):
34 raise ColumnTypeError("feature type mismatch")
35 else:
36 infer_from_values(values)
37 self.name = name
38 self.type = "RELATIVE_IMAGE_URL"
39
40 def get_cell_value(self, dataset_name: str, config_name: str, split_name: str, row_idx: int, value: Any) -> Cell:
41 if value is None:
42 return None
43 check_value(value)
44 # this function can raise, we don't catch it
45 return create_image_file(dataset_name, config_name, split_name, row_idx, self.name, "image.jpg", value)
46
[end of services/worker/src/worker/models/column/image.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/services/worker/src/worker/models/column/image.py b/services/worker/src/worker/models/column/image.py
--- a/services/worker/src/worker/models/column/image.py
+++ b/services/worker/src/worker/models/column/image.py
@@ -41,5 +41,15 @@
if value is None:
return None
check_value(value)
- # this function can raise, we don't catch it
- return create_image_file(dataset_name, config_name, split_name, row_idx, self.name, "image.jpg", value)
+ # attempt to generate one of the supported formats; if unsuccessful, throw an error
+ for ext in [".jpg", ".png"]:
+ try:
+ return create_image_file(
+ dataset_name, config_name, split_name, row_idx, self.name, f"image{ext}", value
+ )
+ except OSError:
+ # if wrong format, try the next one, see https://github.com/huggingface/datasets-server/issues/191
+ # OSError: cannot write mode P as JPEG
+ # OSError: cannot write mode RGBA as JPEG
+ continue
+ raise ValueError("Image cannot be written as JPEG or PNG")
|
{"golden_diff": "diff --git a/services/worker/src/worker/models/column/image.py b/services/worker/src/worker/models/column/image.py\n--- a/services/worker/src/worker/models/column/image.py\n+++ b/services/worker/src/worker/models/column/image.py\n@@ -41,5 +41,15 @@\n if value is None:\n return None\n check_value(value)\n- # this function can raise, we don't catch it\n- return create_image_file(dataset_name, config_name, split_name, row_idx, self.name, \"image.jpg\", value)\n+ # attempt to generate one of the supported formats; if unsuccessful, throw an error\n+ for ext in [\".jpg\", \".png\"]:\n+ try:\n+ return create_image_file(\n+ dataset_name, config_name, split_name, row_idx, self.name, f\"image{ext}\", value\n+ )\n+ except OSError:\n+ # if wrong format, try the next one, see https://github.com/huggingface/datasets-server/issues/191\n+ # OSError: cannot write mode P as JPEG\n+ # OSError: cannot write mode RGBA as JPEG\n+ continue\n+ raise ValueError(\"Image cannot be written as JPEG or PNG\")\n", "issue": "Error with RGBA images\nhttps://huggingface.co/datasets/huggan/few-shot-skulls\r\n\r\n```\r\nStatus code: 500\r\nException: Status500Error\r\nMessage: cannot write mode RGBA as JPEG\r\n```\r\n\r\nreported by @NielsRogge \r\n\r\n\n", "before_files": [{"content": "from typing import Any, List\n\nfrom datasets import Image\nfrom PIL import Image as PILImage # type: ignore\n\nfrom worker.models.asset import create_image_file\nfrom worker.models.column.default import (\n Cell,\n CellTypeError,\n ColumnInferenceError,\n ColumnTypeError,\n CommonColumn,\n)\n\n\ndef check_value(value: Any) -> None:\n if value is None:\n return\n if not isinstance(value, PILImage.Image):\n raise CellTypeError(\"image cell must be a PIL image\")\n\n\ndef infer_from_values(values: List[Any]) -> None:\n for value in values:\n check_value(value)\n if values and all(value is None for value in values):\n raise ColumnInferenceError(\"all the values are None, cannot infer column type\")\n\n\nclass ImageColumn(CommonColumn):\n def __init__(self, name: str, feature: Any, values: List[Any]):\n if feature:\n if not isinstance(feature, Image):\n raise ColumnTypeError(\"feature type mismatch\")\n else:\n infer_from_values(values)\n self.name = name\n self.type = \"RELATIVE_IMAGE_URL\"\n\n def get_cell_value(self, dataset_name: str, config_name: str, split_name: str, row_idx: int, value: Any) -> Cell:\n if value is None:\n return None\n check_value(value)\n # this function can raise, we don't catch it\n return create_image_file(dataset_name, config_name, split_name, row_idx, self.name, \"image.jpg\", value)\n", "path": "services/worker/src/worker/models/column/image.py"}]}
| 1,021 | 269 |
gh_patches_debug_17642
|
rasdani/github-patches
|
git_diff
|
graspologic-org__graspologic-351
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Change default for MASE
<!--
The issue tracker is a tool to address bugs in GraSPy itself. If you'd like to report a bug in GraSPy, fill out the template below and provide any extra information that may be useful / related to your problem.
-->
Make `scaled = True` as default for MASE
</issue>
<code>
[start of graspy/embed/mase.py]
1 # Copyright 2019 NeuroData (http://neurodata.io)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import numpy as np
16 from sklearn.utils.validation import check_is_fitted
17
18 from ..utils import import_graph, is_almost_symmetric
19 from .base import BaseEmbedMulti
20 from .svd import select_dimension, selectSVD
21
22
23 class MultipleASE(BaseEmbedMulti):
24 r"""
25 Multiple Adjacency Spectral Embedding (MASE) embeds arbitrary number of input
26 graphs with matched vertex sets.
27
28 For a population of undirected graphs, MASE assumes that the population of graphs
29 is sampled from :math:`VR^{(i)}V^T` where :math:`V \in \mathbb{R}^{n\times d}` and
30 :math:`R^{(i)} \in \mathbb{R}^{d\times d}`. Score matrices, :math:`R^{(i)}`, are
31 allowed to vary for each graph, but are symmetric. All graphs share a common a
32 latent position matrix :math:`V`.
33
34 For a population of directed graphs, MASE assumes that the population is sampled
35 from :math:`UR^{(i)}V^T` where :math:`U \in \mathbb{R}^{n\times d_1}`,
36 :math:`V \in \mathbb{R}^{n\times d_2}`, and
37 :math:`R^{(i)} \in \mathbb{R}^{d_1\times d_2}`. In this case, score matrices
38 :math:`R^{(i)}` can be assymetric and non-square, but all graphs still share a
39 common latent position matrices :math:`U` and :math:`V`.
40
41 Parameters
42 ----------
43 n_components : int or None, default = None
44 Desired dimensionality of output data. If "full",
45 n_components must be <= min(X.shape). Otherwise, n_components must be
46 < min(X.shape). If None, then optimal dimensions will be chosen by
47 :func:`~graspy.embed.select_dimension` using ``n_elbows`` argument.
48
49 n_elbows : int, optional, default: 2
50 If ``n_components=None``, then compute the optimal embedding dimension using
51 :func:`~graspy.embed.select_dimension`. Otherwise, ignored.
52
53 algorithm : {'randomized' (default), 'full', 'truncated'}, optional
54 SVD solver to use:
55
56 - 'randomized'
57 Computes randomized svd using
58 :func:`sklearn.utils.extmath.randomized_svd`
59 - 'full'
60 Computes full svd using :func:`scipy.linalg.svd`
61 - 'truncated'
62 Computes truncated svd using :func:`scipy.sparse.linalg.svds`
63
64 n_iter : int, optional (default = 5)
65 Number of iterations for randomized SVD solver. Not used by 'full' or
66 'truncated'. The default is larger than the default in randomized_svd
67 to handle sparse matrices that may have large slowly decaying spectrum.
68
69 scaled : bool, optional (default=False)
70 Whether to scale individual eigenvectors with eigenvalues in first embedding
71 stage.
72
73 Attributes
74 ----------
75 n_graphs_ : int
76 Number of graphs
77
78 n_vertices_ : int
79 Number of vertices in each graph
80
81 latent_left_ : array, shape (n_samples, n_components)
82 Estimated left latent positions of the graph.
83
84 latent_right_ : array, shape (n_samples, n_components), or None
85 Estimated right latent positions of the graph. Only computed when the an input
86 graph is directed, or adjacency matrix is assymetric. Otherwise, None.
87
88 scores_ : array, shape (n_samples, n_components, n_components)
89 Estimated :math:`\hat{R}` matrices for each input graph.
90
91 Notes
92 -----
93 When an input graph is directed, `n_components` of `latent_left_` may not be equal
94 to `n_components` of `latent_right_`.
95 """
96
97 def __init__(
98 self,
99 n_components=None,
100 n_elbows=2,
101 algorithm="randomized",
102 n_iter=5,
103 scaled=False,
104 ):
105 if not isinstance(scaled, bool):
106 msg = "scaled must be a boolean, not {}".format(scaled)
107 raise TypeError(msg)
108
109 super().__init__(
110 n_components=n_components,
111 n_elbows=n_elbows,
112 algorithm=algorithm,
113 n_iter=n_iter,
114 )
115 self.scaled = scaled
116
117 def _reduce_dim(self, graphs):
118 # first embed into log2(n_vertices) for each graph
119 n_components = int(np.ceil(np.log2(np.min(self.n_vertices_))))
120
121 # embed individual graphs
122 embeddings = [
123 selectSVD(
124 graph,
125 n_components=n_components,
126 algorithm=self.algorithm,
127 n_iter=self.n_iter,
128 )
129 for graph in graphs
130 ]
131 Us, Ds, Vs = zip(*embeddings)
132
133 # Choose the best embedding dimension for each graphs
134 if self.n_components is None:
135 embedding_dimensions = []
136 for D in Ds:
137 elbows, _ = select_dimension(D, n_elbows=self.n_elbows)
138 embedding_dimensions.append(elbows[-1])
139
140 # Choose the max of all of best embedding dimension of all graphs
141 best_dimension = int(np.ceil(np.max(embedding_dimensions)))
142 else:
143 best_dimension = self.n_components
144
145 if not self.scaled:
146 Us = np.hstack([U[:, :best_dimension] for U in Us])
147 Vs = np.hstack([V.T[:, :best_dimension] for V in Vs])
148 else:
149 # Equivalent to ASE
150 Us = np.hstack(
151 [
152 U[:, :best_dimension] @ np.diag(np.sqrt(D[:best_dimension]))
153 for U, D in zip(Us, Ds)
154 ]
155 )
156 Vs = np.hstack(
157 [
158 V.T[:, :best_dimension] @ np.diag(np.sqrt(D[:best_dimension]))
159 for V, D in zip(Vs, Ds)
160 ]
161 )
162
163 # Second SVD for vertices
164 # The notation is slightly different than the paper
165 Uhat, _, _ = selectSVD(
166 Us,
167 n_components=self.n_components,
168 n_elbows=self.n_elbows,
169 algorithm=self.algorithm,
170 n_iter=self.n_iter,
171 )
172
173 Vhat, _, _ = selectSVD(
174 Vs,
175 n_components=self.n_components,
176 n_elbows=self.n_elbows,
177 algorithm=self.algorithm,
178 n_iter=self.n_iter,
179 )
180 return Uhat, Vhat
181
182 def fit(self, graphs, y=None):
183 """
184 Fit the model with graphs.
185
186 Parameters
187 ----------
188 graphs : list of nx.Graph or ndarray, or ndarray
189 If list of nx.Graph, each Graph must contain same number of nodes.
190 If list of ndarray, each array must have shape (n_vertices, n_vertices).
191 If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).
192
193 Returns
194 -------
195 self : object
196 Returns an instance of self.
197 """
198 graphs = self._check_input_graphs(graphs)
199
200 # Check if undirected
201 undirected = all(is_almost_symmetric(g) for g in graphs)
202
203 # embed
204 Uhat, Vhat = self._reduce_dim(graphs)
205 self.latent_left_ = Uhat
206 if not undirected:
207 self.latent_right_ = Vhat
208 self.scores_ = Uhat.T @ graphs @ Vhat
209 else:
210 self.latent_right_ = None
211 self.scores_ = Uhat.T @ graphs @ Uhat
212
213 return self
214
215 def fit_transform(self, graphs, y=None):
216 """
217 Fit the model with graphs and apply the embedding on graphs.
218 n_components is either automatically determined or based on user input.
219
220 Parameters
221 ----------
222 graphs : list of nx.Graph or ndarray, or ndarray
223 If list of nx.Graph, each Graph must contain same number of nodes.
224 If list of ndarray, each array must have shape (n_vertices, n_vertices).
225 If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).
226
227 Returns
228 -------
229 out : array-like, shape (n_vertices, n_components) if input
230 graphs were symmetric. If graphs were directed, returns tuple of
231 two arrays (same shape as above) where the first corresponds to the
232 left latent positions, and the right to the right latent positions
233 """
234 return self._fit_transform(graphs)
235
[end of graspy/embed/mase.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/graspy/embed/mase.py b/graspy/embed/mase.py
--- a/graspy/embed/mase.py
+++ b/graspy/embed/mase.py
@@ -66,7 +66,7 @@
'truncated'. The default is larger than the default in randomized_svd
to handle sparse matrices that may have large slowly decaying spectrum.
- scaled : bool, optional (default=False)
+ scaled : bool, optional (default=True)
Whether to scale individual eigenvectors with eigenvalues in first embedding
stage.
@@ -100,7 +100,7 @@
n_elbows=2,
algorithm="randomized",
n_iter=5,
- scaled=False,
+ scaled=True,
):
if not isinstance(scaled, bool):
msg = "scaled must be a boolean, not {}".format(scaled)
|
{"golden_diff": "diff --git a/graspy/embed/mase.py b/graspy/embed/mase.py\n--- a/graspy/embed/mase.py\n+++ b/graspy/embed/mase.py\n@@ -66,7 +66,7 @@\n 'truncated'. The default is larger than the default in randomized_svd \n to handle sparse matrices that may have large slowly decaying spectrum.\n \n- scaled : bool, optional (default=False)\n+ scaled : bool, optional (default=True)\n Whether to scale individual eigenvectors with eigenvalues in first embedding \n stage.\n \n@@ -100,7 +100,7 @@\n n_elbows=2,\n algorithm=\"randomized\",\n n_iter=5,\n- scaled=False,\n+ scaled=True,\n ):\n if not isinstance(scaled, bool):\n msg = \"scaled must be a boolean, not {}\".format(scaled)\n", "issue": "Change default for MASE\n<!--\r\nThe issue tracker is a tool to address bugs in GraSPy itself. If you'd like to report a bug in GraSPy, fill out the template below and provide any extra information that may be useful / related to your problem.\r\n-->\r\nMake `scaled = True` as default for MASE\n", "before_files": [{"content": "# Copyright 2019 NeuroData (http://neurodata.io)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport numpy as np\nfrom sklearn.utils.validation import check_is_fitted\n\nfrom ..utils import import_graph, is_almost_symmetric\nfrom .base import BaseEmbedMulti\nfrom .svd import select_dimension, selectSVD\n\n\nclass MultipleASE(BaseEmbedMulti):\n r\"\"\"\n Multiple Adjacency Spectral Embedding (MASE) embeds arbitrary number of input \n graphs with matched vertex sets.\n\n For a population of undirected graphs, MASE assumes that the population of graphs \n is sampled from :math:`VR^{(i)}V^T` where :math:`V \\in \\mathbb{R}^{n\\times d}` and \n :math:`R^{(i)} \\in \\mathbb{R}^{d\\times d}`. Score matrices, :math:`R^{(i)}`, are \n allowed to vary for each graph, but are symmetric. All graphs share a common a \n latent position matrix :math:`V`. \n \n For a population of directed graphs, MASE assumes that the population is sampled\n from :math:`UR^{(i)}V^T` where :math:`U \\in \\mathbb{R}^{n\\times d_1}`, \n :math:`V \\in \\mathbb{R}^{n\\times d_2}`, and \n :math:`R^{(i)} \\in \\mathbb{R}^{d_1\\times d_2}`. In this case, score matrices \n :math:`R^{(i)}` can be assymetric and non-square, but all graphs still share a \n common latent position matrices :math:`U` and :math:`V`.\n\n Parameters\n ----------\n n_components : int or None, default = None\n Desired dimensionality of output data. If \"full\", \n n_components must be <= min(X.shape). Otherwise, n_components must be\n < min(X.shape). If None, then optimal dimensions will be chosen by\n :func:`~graspy.embed.select_dimension` using ``n_elbows`` argument.\n\n n_elbows : int, optional, default: 2\n If ``n_components=None``, then compute the optimal embedding dimension using\n :func:`~graspy.embed.select_dimension`. Otherwise, ignored.\n\n algorithm : {'randomized' (default), 'full', 'truncated'}, optional\n SVD solver to use:\n\n - 'randomized'\n Computes randomized svd using \n :func:`sklearn.utils.extmath.randomized_svd`\n - 'full'\n Computes full svd using :func:`scipy.linalg.svd`\n - 'truncated'\n Computes truncated svd using :func:`scipy.sparse.linalg.svds`\n\n n_iter : int, optional (default = 5)\n Number of iterations for randomized SVD solver. Not used by 'full' or \n 'truncated'. The default is larger than the default in randomized_svd \n to handle sparse matrices that may have large slowly decaying spectrum.\n\n scaled : bool, optional (default=False)\n Whether to scale individual eigenvectors with eigenvalues in first embedding \n stage.\n\n Attributes\n ----------\n n_graphs_ : int\n Number of graphs\n\n n_vertices_ : int\n Number of vertices in each graph\n\n latent_left_ : array, shape (n_samples, n_components)\n Estimated left latent positions of the graph. \n\n latent_right_ : array, shape (n_samples, n_components), or None\n Estimated right latent positions of the graph. Only computed when the an input \n graph is directed, or adjacency matrix is assymetric. Otherwise, None.\n\n scores_ : array, shape (n_samples, n_components, n_components)\n Estimated :math:`\\hat{R}` matrices for each input graph.\n\n Notes\n -----\n When an input graph is directed, `n_components` of `latent_left_` may not be equal\n to `n_components` of `latent_right_`.\n \"\"\"\n\n def __init__(\n self,\n n_components=None,\n n_elbows=2,\n algorithm=\"randomized\",\n n_iter=5,\n scaled=False,\n ):\n if not isinstance(scaled, bool):\n msg = \"scaled must be a boolean, not {}\".format(scaled)\n raise TypeError(msg)\n\n super().__init__(\n n_components=n_components,\n n_elbows=n_elbows,\n algorithm=algorithm,\n n_iter=n_iter,\n )\n self.scaled = scaled\n\n def _reduce_dim(self, graphs):\n # first embed into log2(n_vertices) for each graph\n n_components = int(np.ceil(np.log2(np.min(self.n_vertices_))))\n\n # embed individual graphs\n embeddings = [\n selectSVD(\n graph,\n n_components=n_components,\n algorithm=self.algorithm,\n n_iter=self.n_iter,\n )\n for graph in graphs\n ]\n Us, Ds, Vs = zip(*embeddings)\n\n # Choose the best embedding dimension for each graphs\n if self.n_components is None:\n embedding_dimensions = []\n for D in Ds:\n elbows, _ = select_dimension(D, n_elbows=self.n_elbows)\n embedding_dimensions.append(elbows[-1])\n\n # Choose the max of all of best embedding dimension of all graphs\n best_dimension = int(np.ceil(np.max(embedding_dimensions)))\n else:\n best_dimension = self.n_components\n\n if not self.scaled:\n Us = np.hstack([U[:, :best_dimension] for U in Us])\n Vs = np.hstack([V.T[:, :best_dimension] for V in Vs])\n else:\n # Equivalent to ASE\n Us = np.hstack(\n [\n U[:, :best_dimension] @ np.diag(np.sqrt(D[:best_dimension]))\n for U, D in zip(Us, Ds)\n ]\n )\n Vs = np.hstack(\n [\n V.T[:, :best_dimension] @ np.diag(np.sqrt(D[:best_dimension]))\n for V, D in zip(Vs, Ds)\n ]\n )\n\n # Second SVD for vertices\n # The notation is slightly different than the paper\n Uhat, _, _ = selectSVD(\n Us,\n n_components=self.n_components,\n n_elbows=self.n_elbows,\n algorithm=self.algorithm,\n n_iter=self.n_iter,\n )\n\n Vhat, _, _ = selectSVD(\n Vs,\n n_components=self.n_components,\n n_elbows=self.n_elbows,\n algorithm=self.algorithm,\n n_iter=self.n_iter,\n )\n return Uhat, Vhat\n\n def fit(self, graphs, y=None):\n \"\"\"\n Fit the model with graphs.\n\n Parameters\n ----------\n graphs : list of nx.Graph or ndarray, or ndarray\n If list of nx.Graph, each Graph must contain same number of nodes.\n If list of ndarray, each array must have shape (n_vertices, n_vertices).\n If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).\n\n Returns\n -------\n self : object\n Returns an instance of self.\n \"\"\"\n graphs = self._check_input_graphs(graphs)\n\n # Check if undirected\n undirected = all(is_almost_symmetric(g) for g in graphs)\n\n # embed\n Uhat, Vhat = self._reduce_dim(graphs)\n self.latent_left_ = Uhat\n if not undirected:\n self.latent_right_ = Vhat\n self.scores_ = Uhat.T @ graphs @ Vhat\n else:\n self.latent_right_ = None\n self.scores_ = Uhat.T @ graphs @ Uhat\n\n return self\n\n def fit_transform(self, graphs, y=None):\n \"\"\"\n Fit the model with graphs and apply the embedding on graphs. \n n_components is either automatically determined or based on user input.\n\n Parameters\n ----------\n graphs : list of nx.Graph or ndarray, or ndarray\n If list of nx.Graph, each Graph must contain same number of nodes.\n If list of ndarray, each array must have shape (n_vertices, n_vertices).\n If ndarray, then array must have shape (n_graphs, n_vertices, n_vertices).\n\n Returns\n -------\n out : array-like, shape (n_vertices, n_components) if input \n graphs were symmetric. If graphs were directed, returns tuple of \n two arrays (same shape as above) where the first corresponds to the\n left latent positions, and the right to the right latent positions\n \"\"\"\n return self._fit_transform(graphs)\n", "path": "graspy/embed/mase.py"}]}
| 3,208 | 195 |
gh_patches_debug_20495
|
rasdani/github-patches
|
git_diff
|
akvo__akvo-rsr-3180
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
API should exclude unpublished projects by default?
The API currently filters out private projects for unauthenticated users, but doesn't do the same for unpublished projects.
</issue>
<code>
[start of akvo/rest/viewsets.py]
1 # -*- coding: utf-8 -*-
2
3 # Akvo RSR is covered by the GNU Affero General Public License.
4 # See more details in the license.txt file located at the root folder of the Akvo RSR module.
5 # For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.
6
7 from django.db.models.fields import FieldDoesNotExist
8 from django.db.models.fields.related import ForeignObject
9 from django.core.exceptions import FieldError
10
11 from akvo.rest.models import TastyTokenAuthentication
12
13 from rest_framework import authentication, filters, permissions, viewsets
14
15 from .filters import RSRGenericFilterBackend
16 from .pagination import TastypieOffsetPagination
17
18
19 class SafeMethodsPermissions(permissions.DjangoObjectPermissions):
20 """
21 Base class to allow any safe methods ('GET', 'OPTIONS' and 'HEAD') without needing to
22 authenticate.
23 """
24
25 def has_permission(self, request, view):
26 if request.method in permissions.SAFE_METHODS:
27 return True
28 return super(SafeMethodsPermissions, self).has_permission(request, view)
29
30
31 class BaseRSRViewSet(viewsets.ModelViewSet):
32 """
33 Base class used for the view sets for RSR models. Provides unified auth and perms settings.
34 """
35 authentication_classes = (authentication.SessionAuthentication, TastyTokenAuthentication, )
36 permission_classes = (SafeMethodsPermissions, )
37 filter_backends = (filters.OrderingFilter, RSRGenericFilterBackend,)
38 ordering_fields = '__all__'
39
40 def paginate_queryset(self, queryset):
41 """ Custom offset-based pagination for the Tastypie API emulation
42 """
43 if self.request and '/api/v1/' in self.request.path:
44 self.pagination_class = TastypieOffsetPagination
45 return super(BaseRSRViewSet, self).paginate_queryset(queryset)
46
47 def get_queryset(self):
48
49 def django_filter_filters(request):
50 """
51 Support emulating the DjangoFilterBackend-based filtering that some views used to have
52 """
53 # query string keys reserved by the RSRGenericFilterBackend
54 qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related', ]
55 # query string keys used by core DRF, OrderingFilter and Akvo custom views
56 exclude_params = ['limit', 'format', 'page', 'offset', 'ordering', 'partner_type',
57 'sync_owner', 'reporting_org', ]
58 filters = {}
59 for key in request.query_params.keys():
60 if key not in qs_params + exclude_params and not key.startswith('image_thumb_'):
61 filters.update({key: request.query_params.get(key)})
62 return filters
63
64 def get_lookups_from_filters(legacy_filters):
65 """
66 Cast the values in DjangoFilterBackend-styled query string filters to correct types to
67 be able to use them in regular queryset-filter() calls
68 """
69 # types of lookups supported by the views using DjangoFilterBackend
70 LEGACY_FIELD_LOOKUPS = ['exact', 'contains', 'icontains', 'gt', 'gte', 'lt',
71 'lte', ]
72 query_set_lookups = []
73 for key, value in legacy_filters.items():
74 parts = key.split('__')
75 if parts[-1] in LEGACY_FIELD_LOOKUPS:
76 parts = parts[:-1]
77 model = queryset.model
78 for part in parts:
79 try:
80 field_object, related_model, direct, m2m = model._meta.\
81 get_field_by_name(part)
82
83 if direct:
84 if issubclass(field_object.__class__, ForeignObject):
85 model = field_object.related.parent_model
86 else:
87 value = field_object.to_python(value)
88 break
89 else:
90 model = related_model
91 except FieldDoesNotExist:
92 pass
93 query_set_lookups += [{key: value}]
94 return query_set_lookups
95
96 queryset = super(BaseRSRViewSet, self).get_queryset()
97
98 # support for old DjangoFilterBackend-based filtering if not pk is given
99 if not self.kwargs.get(u'pk'):
100 # find all "old styled" filters
101 legacy_filters = django_filter_filters(self.request)
102 # create lookup dicts from the filters found
103 lookups = get_lookups_from_filters(legacy_filters)
104 for lookup in lookups:
105 try:
106 queryset = queryset.filter(**lookup)
107 except (FieldError, ValueError):
108 # In order to mimick 'old' behaviour of the API, we should ignore non-valid
109 # parameters or values. Returning a warning would be more preferable.
110 pass
111
112 return queryset
113
114
115 class PublicProjectViewSet(BaseRSRViewSet):
116 """
117 Only public projects or objects related to public projects will be shown.
118 """
119 # project_relation is the default string for constructing a field lookup to the is_public field
120 # on the related Project. Override this in when the viewset is for a model that doesn't have a
121 # direct FK to Project or the FK field isn't named project. E.g. IndicatorViewSet:
122 # project_relation = 'result__project__'
123 # The lookup is used to filter out objects associated with private projects, see below.
124 project_relation = 'project__'
125
126 def get_queryset(self):
127
128 request = self.request
129 user = request.user
130
131 queryset = super(PublicProjectViewSet, self).get_queryset()
132
133 # filter projects if user is "non-privileged"
134 if user.is_anonymous() or not (user.is_superuser or user.is_admin):
135 queryset = self.projects_filter_for_non_privileged_users(user, queryset, self.project_relation)
136
137 return queryset.distinct()
138
139 @staticmethod
140 def projects_filter_for_non_privileged_users(user, queryset, project_relation):
141
142 if not user.is_anonymous() and (user.is_admin or user.is_superuser):
143 return queryset.distinct()
144
145 # Construct the public projects filter field lookup.
146 project_filter = project_relation + 'is_public'
147
148 # Filter the object list into two querysets;
149 # One where the related Projects are public and one where they are private
150 public_objects = queryset.filter(**{project_filter: True}).distinct()
151 private_objects = queryset.filter(**{project_filter: False}).distinct()
152
153 # In case of an anonymous user, only return the public objects
154 if user.is_anonymous():
155 queryset = public_objects
156
157 # Otherwise, check to which objects the user has (change) permission
158 elif private_objects.exists():
159 permission = type(private_objects[0])._meta.db_table.replace('_', '.change_')
160 filter_ = user.get_permission_filter(permission, project_relation)
161 queryset = public_objects | private_objects.filter(filter_).distinct()
162
163 return queryset.distinct()
164
[end of akvo/rest/viewsets.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/akvo/rest/viewsets.py b/akvo/rest/viewsets.py
--- a/akvo/rest/viewsets.py
+++ b/akvo/rest/viewsets.py
@@ -8,6 +8,7 @@
from django.db.models.fields.related import ForeignObject
from django.core.exceptions import FieldError
+from akvo.rsr.models import PublishingStatus
from akvo.rest.models import TastyTokenAuthentication
from rest_framework import authentication, filters, permissions, viewsets
@@ -152,7 +153,10 @@
# In case of an anonymous user, only return the public objects
if user.is_anonymous():
- queryset = public_objects
+ unpublished_exclude = project_relation + 'publishingstatus__status'
+ queryset = public_objects.exclude(
+ **{unpublished_exclude: PublishingStatus.STATUS_UNPUBLISHED}
+ ).distinct()
# Otherwise, check to which objects the user has (change) permission
elif private_objects.exists():
|
{"golden_diff": "diff --git a/akvo/rest/viewsets.py b/akvo/rest/viewsets.py\n--- a/akvo/rest/viewsets.py\n+++ b/akvo/rest/viewsets.py\n@@ -8,6 +8,7 @@\n from django.db.models.fields.related import ForeignObject\n from django.core.exceptions import FieldError\n \n+from akvo.rsr.models import PublishingStatus\n from akvo.rest.models import TastyTokenAuthentication\n \n from rest_framework import authentication, filters, permissions, viewsets\n@@ -152,7 +153,10 @@\n \n # In case of an anonymous user, only return the public objects\n if user.is_anonymous():\n- queryset = public_objects\n+ unpublished_exclude = project_relation + 'publishingstatus__status'\n+ queryset = public_objects.exclude(\n+ **{unpublished_exclude: PublishingStatus.STATUS_UNPUBLISHED}\n+ ).distinct()\n \n # Otherwise, check to which objects the user has (change) permission\n elif private_objects.exists():\n", "issue": "API should exclude unpublished projects by default?\nThe API currently filters out private projects for unauthenticated users, but doesn't do the same for unpublished projects. \n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Akvo RSR is covered by the GNU Affero General Public License.\n# See more details in the license.txt file located at the root folder of the Akvo RSR module.\n# For additional details on the GNU license please see < http://www.gnu.org/licenses/agpl.html >.\n\nfrom django.db.models.fields import FieldDoesNotExist\nfrom django.db.models.fields.related import ForeignObject\nfrom django.core.exceptions import FieldError\n\nfrom akvo.rest.models import TastyTokenAuthentication\n\nfrom rest_framework import authentication, filters, permissions, viewsets\n\nfrom .filters import RSRGenericFilterBackend\nfrom .pagination import TastypieOffsetPagination\n\n\nclass SafeMethodsPermissions(permissions.DjangoObjectPermissions):\n \"\"\"\n Base class to allow any safe methods ('GET', 'OPTIONS' and 'HEAD') without needing to\n authenticate.\n \"\"\"\n\n def has_permission(self, request, view):\n if request.method in permissions.SAFE_METHODS:\n return True\n return super(SafeMethodsPermissions, self).has_permission(request, view)\n\n\nclass BaseRSRViewSet(viewsets.ModelViewSet):\n \"\"\"\n Base class used for the view sets for RSR models. Provides unified auth and perms settings.\n \"\"\"\n authentication_classes = (authentication.SessionAuthentication, TastyTokenAuthentication, )\n permission_classes = (SafeMethodsPermissions, )\n filter_backends = (filters.OrderingFilter, RSRGenericFilterBackend,)\n ordering_fields = '__all__'\n\n def paginate_queryset(self, queryset):\n \"\"\" Custom offset-based pagination for the Tastypie API emulation\n \"\"\"\n if self.request and '/api/v1/' in self.request.path:\n self.pagination_class = TastypieOffsetPagination\n return super(BaseRSRViewSet, self).paginate_queryset(queryset)\n\n def get_queryset(self):\n\n def django_filter_filters(request):\n \"\"\"\n Support emulating the DjangoFilterBackend-based filtering that some views used to have\n \"\"\"\n # query string keys reserved by the RSRGenericFilterBackend\n qs_params = ['filter', 'exclude', 'select_related', 'prefetch_related', ]\n # query string keys used by core DRF, OrderingFilter and Akvo custom views\n exclude_params = ['limit', 'format', 'page', 'offset', 'ordering', 'partner_type',\n 'sync_owner', 'reporting_org', ]\n filters = {}\n for key in request.query_params.keys():\n if key not in qs_params + exclude_params and not key.startswith('image_thumb_'):\n filters.update({key: request.query_params.get(key)})\n return filters\n\n def get_lookups_from_filters(legacy_filters):\n \"\"\"\n Cast the values in DjangoFilterBackend-styled query string filters to correct types to\n be able to use them in regular queryset-filter() calls\n \"\"\"\n # types of lookups supported by the views using DjangoFilterBackend\n LEGACY_FIELD_LOOKUPS = ['exact', 'contains', 'icontains', 'gt', 'gte', 'lt',\n 'lte', ]\n query_set_lookups = []\n for key, value in legacy_filters.items():\n parts = key.split('__')\n if parts[-1] in LEGACY_FIELD_LOOKUPS:\n parts = parts[:-1]\n model = queryset.model\n for part in parts:\n try:\n field_object, related_model, direct, m2m = model._meta.\\\n get_field_by_name(part)\n\n if direct:\n if issubclass(field_object.__class__, ForeignObject):\n model = field_object.related.parent_model\n else:\n value = field_object.to_python(value)\n break\n else:\n model = related_model\n except FieldDoesNotExist:\n pass\n query_set_lookups += [{key: value}]\n return query_set_lookups\n\n queryset = super(BaseRSRViewSet, self).get_queryset()\n\n # support for old DjangoFilterBackend-based filtering if not pk is given\n if not self.kwargs.get(u'pk'):\n # find all \"old styled\" filters\n legacy_filters = django_filter_filters(self.request)\n # create lookup dicts from the filters found\n lookups = get_lookups_from_filters(legacy_filters)\n for lookup in lookups:\n try:\n queryset = queryset.filter(**lookup)\n except (FieldError, ValueError):\n # In order to mimick 'old' behaviour of the API, we should ignore non-valid\n # parameters or values. Returning a warning would be more preferable.\n pass\n\n return queryset\n\n\nclass PublicProjectViewSet(BaseRSRViewSet):\n \"\"\"\n Only public projects or objects related to public projects will be shown.\n \"\"\"\n # project_relation is the default string for constructing a field lookup to the is_public field\n # on the related Project. Override this in when the viewset is for a model that doesn't have a\n # direct FK to Project or the FK field isn't named project. E.g. IndicatorViewSet:\n # project_relation = 'result__project__'\n # The lookup is used to filter out objects associated with private projects, see below.\n project_relation = 'project__'\n\n def get_queryset(self):\n\n request = self.request\n user = request.user\n\n queryset = super(PublicProjectViewSet, self).get_queryset()\n\n # filter projects if user is \"non-privileged\"\n if user.is_anonymous() or not (user.is_superuser or user.is_admin):\n queryset = self.projects_filter_for_non_privileged_users(user, queryset, self.project_relation)\n\n return queryset.distinct()\n\n @staticmethod\n def projects_filter_for_non_privileged_users(user, queryset, project_relation):\n\n if not user.is_anonymous() and (user.is_admin or user.is_superuser):\n return queryset.distinct()\n\n # Construct the public projects filter field lookup.\n project_filter = project_relation + 'is_public'\n\n # Filter the object list into two querysets;\n # One where the related Projects are public and one where they are private\n public_objects = queryset.filter(**{project_filter: True}).distinct()\n private_objects = queryset.filter(**{project_filter: False}).distinct()\n\n # In case of an anonymous user, only return the public objects\n if user.is_anonymous():\n queryset = public_objects\n\n # Otherwise, check to which objects the user has (change) permission\n elif private_objects.exists():\n permission = type(private_objects[0])._meta.db_table.replace('_', '.change_')\n filter_ = user.get_permission_filter(permission, project_relation)\n queryset = public_objects | private_objects.filter(filter_).distinct()\n\n return queryset.distinct()\n", "path": "akvo/rest/viewsets.py"}]}
| 2,367 | 215 |
gh_patches_debug_13319
|
rasdani/github-patches
|
git_diff
|
pypi__warehouse-578
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Support CORS on JSON API
Say I want to show project stats like monthly downloads on the project page. Fetching this from client side JavaScript allows me to retain a completely static project page (can be hosted on a CDN).
However, the JSON API does not set `Access-Control-Allow-Origin` header - no CORS support.
Test:
https://github.com/oberstet/scratchbox/blob/master/js/badges/pypi.html
For comparison, this is what GitHub does with it's API:
https://github.com/oberstet/scratchbox/blob/master/js/badges/github.html
If above would work, that makes #330 void (for me) - if the API doesn't get rate limited or such ..
</issue>
<code>
[start of warehouse/legacy/api/json.py]
1 # Licensed under the Apache License, Version 2.0 (the "License");
2 # you may not use this file except in compliance with the License.
3 # You may obtain a copy of the License at
4 #
5 # http://www.apache.org/licenses/LICENSE-2.0
6 #
7 # Unless required by applicable law or agreed to in writing, software
8 # distributed under the License is distributed on an "AS IS" BASIS,
9 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
10 # See the License for the specific language governing permissions and
11 # limitations under the License.
12
13 from pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound
14 from pyramid.view import view_config
15 from sqlalchemy import func
16 from sqlalchemy.orm.exc import NoResultFound
17
18 from warehouse.cache.http import cache_control
19 from warehouse.cache.origin import origin_cache
20 from warehouse.packaging.interfaces import IDownloadStatService
21 from warehouse.packaging.models import File, Release, JournalEntry
22
23
24 @view_config(
25 route_name="legacy.api.json.project",
26 renderer="json",
27 decorator=[
28 cache_control(
29 1 * 24 * 60 * 60, # 1 day
30 stale_while_revalidate=1 * 24 * 60 * 60, # 1 day
31 stale_if_error=1 * 24 * 60 * 60, # 1 day
32 ),
33 origin_cache(7 * 24 * 60 * 60), # 7 days
34 ],
35 )
36 def json_project(project, request):
37 if project.name != request.matchdict.get("name", project.name):
38 return HTTPMovedPermanently(
39 request.current_route_path(name=project.name),
40 )
41
42 try:
43 release = project.releases.order_by(
44 Release._pypi_ordering.desc()
45 ).limit(1).one()
46 except NoResultFound:
47 return HTTPNotFound()
48
49 return json_release(release, request)
50
51
52 @view_config(
53 route_name="legacy.api.json.release",
54 renderer="json",
55 decorator=[
56 cache_control(
57 7 * 24 * 60 * 60, # 7 days
58 stale_while_revalidate=1 * 24 * 60 * 60, # 1 day
59 stale_if_error=1 * 24 * 60 * 60, # 1 day
60 ),
61 origin_cache(30 * 24 * 60 * 60), # 30 days
62 ],
63 )
64 def json_release(release, request):
65 project = release.project
66
67 if project.name != request.matchdict.get("name", project.name):
68 return HTTPMovedPermanently(
69 request.current_route_path(name=project.name),
70 )
71
72 # We want to allow CORS here to enable anyone to fetch data from this API
73 request.response.headers["Access-Control-Allow-Origin"] = "*"
74
75 # Get the latest serial number for this project.
76 serial = (
77 request.db.query(func.max(JournalEntry.id))
78 .filter(JournalEntry.name == project.name)
79 .scalar()
80 )
81 request.response.headers["X-PyPI-Last-Serial"] = serial or 0
82
83 # Get all of the releases and files for this project.
84 release_files = (
85 request.db.query(Release, File)
86 .outerjoin(File)
87 .filter(Release.project == project)
88 .order_by(Release._pypi_ordering.desc(), File.filename)
89 .all()
90 )
91
92 # Map our releases + files into a dictionary that maps each release to a
93 # list of all its files.
94 releases = {}
95 for r, file_ in release_files:
96 files = releases.setdefault(r, [])
97 if file_ is not None:
98 files.append(file_)
99
100 # Serialize our database objects to match the way that PyPI legacy
101 # presented this data.
102 releases = {
103 r.version: [
104 {
105 "filename": f.filename,
106 "packagetype": f.packagetype,
107 "python_version": f.python_version,
108 "has_sig": f.has_signature,
109 "comment_text": f.comment_text,
110 "md5_digest": f.md5_digest,
111 "size": f.size,
112 "downloads": f.downloads,
113 "upload_time": f.upload_time.strftime("%Y-%m-%dT%H:%M:%S"),
114 "url": request.route_url("packaging.file", path=f.path),
115 }
116 for f in fs
117 ]
118 for r, fs in releases.items()
119 }
120
121 # Get our stats service
122 stats_svc = request.find_service(IDownloadStatService)
123
124 return {
125 "info": {
126 "name": project.name,
127 "version": release.version,
128 "summary": release.summary,
129 "description": release.description,
130 "keywords": release.keywords,
131 "license": release.license,
132 "classifiers": list(release.classifiers),
133 "author": release.author,
134 "author_email": release.author_email,
135 "maintainer": release.maintainer,
136 "maintainer_email": release.maintainer_email,
137 "requires_python": release.requires_python,
138 "platform": release.platform,
139 "downloads": {
140 "last_day": stats_svc.get_daily_stats(project.name),
141 "last_week": stats_svc.get_weekly_stats(project.name),
142 "last_month": stats_svc.get_monthly_stats(project.name),
143 },
144 "project_url": request.route_url(
145 "packaging.project",
146 name=project.name,
147 ),
148 "release_url": request.route_url(
149 "packaging.release",
150 name=project.name,
151 version=release.version,
152 ),
153 "docs_url": project.documentation_url,
154 "bugtrack_url": project.bugtrack_url,
155 "home_page": release.home_page,
156 "download_url": release.download_url,
157 },
158 "urls": releases[release.version],
159 "releases": releases,
160 }
161
[end of warehouse/legacy/api/json.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/warehouse/legacy/api/json.py b/warehouse/legacy/api/json.py
--- a/warehouse/legacy/api/json.py
+++ b/warehouse/legacy/api/json.py
@@ -71,6 +71,18 @@
# We want to allow CORS here to enable anyone to fetch data from this API
request.response.headers["Access-Control-Allow-Origin"] = "*"
+ request.response.headers["Access-Control-Allow-Headers"] = ", ".join([
+ "Content-Type",
+ "If-Match",
+ "If-Modified-Since",
+ "If-None-Match",
+ "If-Unmodified-Since",
+ ])
+ request.response.headers["Access-Control-Allow-Methods"] = "GET"
+ request.response.headers["Access-Control-Max-Age"] = "86400"
+ request.response.headers["Access-Control-Expose-Headers"] = ", ".join([
+ "X-PyPI-Last-Serial",
+ ])
# Get the latest serial number for this project.
serial = (
|
{"golden_diff": "diff --git a/warehouse/legacy/api/json.py b/warehouse/legacy/api/json.py\n--- a/warehouse/legacy/api/json.py\n+++ b/warehouse/legacy/api/json.py\n@@ -71,6 +71,18 @@\n \n # We want to allow CORS here to enable anyone to fetch data from this API\n request.response.headers[\"Access-Control-Allow-Origin\"] = \"*\"\n+ request.response.headers[\"Access-Control-Allow-Headers\"] = \", \".join([\n+ \"Content-Type\",\n+ \"If-Match\",\n+ \"If-Modified-Since\",\n+ \"If-None-Match\",\n+ \"If-Unmodified-Since\",\n+ ])\n+ request.response.headers[\"Access-Control-Allow-Methods\"] = \"GET\"\n+ request.response.headers[\"Access-Control-Max-Age\"] = \"86400\"\n+ request.response.headers[\"Access-Control-Expose-Headers\"] = \", \".join([\n+ \"X-PyPI-Last-Serial\",\n+ ])\n \n # Get the latest serial number for this project.\n serial = (\n", "issue": "Support CORS on JSON API\nSay I want to show project stats like monthly downloads on the project page. Fetching this from client side JavaScript allows me to retain a completely static project page (can be hosted on a CDN).\n\nHowever, the JSON API does not set `Access-Control-Allow-Origin` header - no CORS support.\n\nTest:\nhttps://github.com/oberstet/scratchbox/blob/master/js/badges/pypi.html\n\nFor comparison, this is what GitHub does with it's API:\nhttps://github.com/oberstet/scratchbox/blob/master/js/badges/github.html\n\nIf above would work, that makes #330 void (for me) - if the API doesn't get rate limited or such ..\n\n", "before_files": [{"content": "# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom pyramid.httpexceptions import HTTPMovedPermanently, HTTPNotFound\nfrom pyramid.view import view_config\nfrom sqlalchemy import func\nfrom sqlalchemy.orm.exc import NoResultFound\n\nfrom warehouse.cache.http import cache_control\nfrom warehouse.cache.origin import origin_cache\nfrom warehouse.packaging.interfaces import IDownloadStatService\nfrom warehouse.packaging.models import File, Release, JournalEntry\n\n\n@view_config(\n route_name=\"legacy.api.json.project\",\n renderer=\"json\",\n decorator=[\n cache_control(\n 1 * 24 * 60 * 60, # 1 day\n stale_while_revalidate=1 * 24 * 60 * 60, # 1 day\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n origin_cache(7 * 24 * 60 * 60), # 7 days\n ],\n)\ndef json_project(project, request):\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name),\n )\n\n try:\n release = project.releases.order_by(\n Release._pypi_ordering.desc()\n ).limit(1).one()\n except NoResultFound:\n return HTTPNotFound()\n\n return json_release(release, request)\n\n\n@view_config(\n route_name=\"legacy.api.json.release\",\n renderer=\"json\",\n decorator=[\n cache_control(\n 7 * 24 * 60 * 60, # 7 days\n stale_while_revalidate=1 * 24 * 60 * 60, # 1 day\n stale_if_error=1 * 24 * 60 * 60, # 1 day\n ),\n origin_cache(30 * 24 * 60 * 60), # 30 days\n ],\n)\ndef json_release(release, request):\n project = release.project\n\n if project.name != request.matchdict.get(\"name\", project.name):\n return HTTPMovedPermanently(\n request.current_route_path(name=project.name),\n )\n\n # We want to allow CORS here to enable anyone to fetch data from this API\n request.response.headers[\"Access-Control-Allow-Origin\"] = \"*\"\n\n # Get the latest serial number for this project.\n serial = (\n request.db.query(func.max(JournalEntry.id))\n .filter(JournalEntry.name == project.name)\n .scalar()\n )\n request.response.headers[\"X-PyPI-Last-Serial\"] = serial or 0\n\n # Get all of the releases and files for this project.\n release_files = (\n request.db.query(Release, File)\n .outerjoin(File)\n .filter(Release.project == project)\n .order_by(Release._pypi_ordering.desc(), File.filename)\n .all()\n )\n\n # Map our releases + files into a dictionary that maps each release to a\n # list of all its files.\n releases = {}\n for r, file_ in release_files:\n files = releases.setdefault(r, [])\n if file_ is not None:\n files.append(file_)\n\n # Serialize our database objects to match the way that PyPI legacy\n # presented this data.\n releases = {\n r.version: [\n {\n \"filename\": f.filename,\n \"packagetype\": f.packagetype,\n \"python_version\": f.python_version,\n \"has_sig\": f.has_signature,\n \"comment_text\": f.comment_text,\n \"md5_digest\": f.md5_digest,\n \"size\": f.size,\n \"downloads\": f.downloads,\n \"upload_time\": f.upload_time.strftime(\"%Y-%m-%dT%H:%M:%S\"),\n \"url\": request.route_url(\"packaging.file\", path=f.path),\n }\n for f in fs\n ]\n for r, fs in releases.items()\n }\n\n # Get our stats service\n stats_svc = request.find_service(IDownloadStatService)\n\n return {\n \"info\": {\n \"name\": project.name,\n \"version\": release.version,\n \"summary\": release.summary,\n \"description\": release.description,\n \"keywords\": release.keywords,\n \"license\": release.license,\n \"classifiers\": list(release.classifiers),\n \"author\": release.author,\n \"author_email\": release.author_email,\n \"maintainer\": release.maintainer,\n \"maintainer_email\": release.maintainer_email,\n \"requires_python\": release.requires_python,\n \"platform\": release.platform,\n \"downloads\": {\n \"last_day\": stats_svc.get_daily_stats(project.name),\n \"last_week\": stats_svc.get_weekly_stats(project.name),\n \"last_month\": stats_svc.get_monthly_stats(project.name),\n },\n \"project_url\": request.route_url(\n \"packaging.project\",\n name=project.name,\n ),\n \"release_url\": request.route_url(\n \"packaging.release\",\n name=project.name,\n version=release.version,\n ),\n \"docs_url\": project.documentation_url,\n \"bugtrack_url\": project.bugtrack_url,\n \"home_page\": release.home_page,\n \"download_url\": release.download_url,\n },\n \"urls\": releases[release.version],\n \"releases\": releases,\n }\n", "path": "warehouse/legacy/api/json.py"}]}
| 2,340 | 228 |
gh_patches_debug_37013
|
rasdani/github-patches
|
git_diff
|
cornellius-gp__gpytorch-186
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exact GP regression Lapack Error syev
Training a simple GP regression model produces following runtime error randomly at some seeds:
`RuntimeError: Lapack Error syev : 3 off-diagonal elements didn't converge to zero at /pytorch/aten/src/TH/generic/THTensorLapack.c:388`.
I have been able to reproduce the error with the following code:
```
import math
import torch
import gpytorch
from matplotlib import pyplot as plt
from torch import optim
from gpytorch.kernels import RBFKernel
from gpytorch.means import ConstantMean
from gpytorch.likelihoods import GaussianLikelihood
from gpytorch.random_variables import GaussianRandomVariable
torch.manual_seed(1)
train_x = torch.FloatTensor([[ 6, 6],
[ 7, 3],
[ 7, 8],
[ 8, 6],
[10, 0]])
train_y = torch.FloatTensor([2.38922077, 0.35414244, 2.24837906, 1.40895557, 0.68164634])
class ExactGPModel(gpytorch.models.ExactGP):
def __init__(self, train_x, train_y, likelihood):
super(ExactGPModel, self).__init__(train_x, train_y, likelihood)
self.mean_module = ConstantMean(constant_bounds=(-10, 10))
self.covar_module = RBFKernel(log_lengthscale_bounds=(-5, 5))
def forward(self, x):
mean_x = self.mean_module(x)
covar_x = self.covar_module(x)
return GaussianRandomVariable(mean_x, covar_x)
likelihood = GaussianLikelihood(log_noise_bounds=(-5, 5))
model = ExactGPModel(train_x.data, train_y.data, likelihood)
model.train()
likelihood.train()
optimizer = torch.optim.Adam([
{'params': model.parameters()},
], lr=0.1)
mll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)
training_iter = 50
for i in range(training_iter):
optimizer.zero_grad()
output = model(train_x)
loss = -mll(output, train_y)
loss.backward()
print('Iter %d/%d - Loss: %.3f log_lengthscale: %.3f log_noise: %.3f' % (
i + 1, training_iter, loss.data[0],
model.covar_module.log_lengthscale.data[0, 0],
model.likelihood.log_noise.data[0]
))
optimizer.step()
```
I am using the latest version of Gpytorch and Pytorch (0.4.0). The above code is identical to the simple gp regression example provided with this repo with changes in train_x and train_y only. Also, the code works fine for seed = 0.
</issue>
<code>
[start of gpytorch/utils/linear_cg.py]
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4 from __future__ import unicode_literals
5
6 import torch
7 from .. import settings
8
9
10 def _default_preconditioner(x):
11 return x.clone()
12
13
14 def linear_cg(
15 matmul_closure,
16 rhs,
17 n_tridiag=0,
18 tolerance=1e-6,
19 eps=1e-20,
20 max_iter=None,
21 max_tridiag_iter=None,
22 initial_guess=None,
23 preconditioner=None,
24 ):
25 """
26 Implements the linear conjugate gradients method for (approximately) solving systems of the form
27
28 lhs result = rhs
29
30 for positive definite and symmetric matrices.
31
32 Args:
33 - matmul_closure - a function which performs a left matrix multiplication with lhs_mat
34 - rhs - the right-hand side of the equation
35 - n_tridiag - returns a tridiagonalization of the first n_tridiag columns of rhs
36 - tolerance - stop the solve when the max residual is less than this
37 - eps - noise to add to prevent division by zero
38 - max_iter - the maximum number of CG iterations
39 - max_tridiag_iter - the maximum size of the tridiagonalization matrix
40 - initial_guess - an initial guess at the solution `result`
41 - precondition_closure - a functions which left-preconditions a supplied vector
42
43 Returns:
44 result - a solution to the system (if n_tridiag is 0)
45 result, tridiags - a solution to the system, and corresponding tridiagonal matrices (if n_tridiag > 0)
46 """
47 # Unsqueeze, if necesasry
48 is_vector = rhs.ndimension() == 1
49 if is_vector:
50 rhs = rhs.unsqueeze(-1)
51
52 # Some default arguments
53 if max_iter is None:
54 max_iter = settings.max_cg_iterations.value()
55 if max_tridiag_iter is None:
56 max_tridiag_iter = settings.max_lanczos_quadrature_iterations.value()
57 if initial_guess is None:
58 initial_guess = rhs.new(rhs.size()).zero_()
59 if preconditioner is None:
60 preconditioner = _default_preconditioner
61
62 # If we are running m CG iterations, we obviously can't get more than m Lanczos coefficients
63 if max_tridiag_iter > max_iter:
64 raise RuntimeError("Getting a tridiagonalization larger than the number of CG iterations run is not possible!")
65
66 # Check matmul_closure object
67 if torch.is_tensor(matmul_closure):
68 matmul_closure = matmul_closure.matmul
69 elif not callable(matmul_closure):
70 raise RuntimeError("matmul_closure must be a tensor, or a callable object!")
71
72 # Get some constants
73 n_rows = rhs.size(-2)
74 n_iter = min(max_iter, n_rows)
75 n_tridiag_iter = min(max_tridiag_iter, n_rows)
76
77 # result <- x_{0}
78 result = initial_guess
79
80 # residual: residual_{0} = b_vec - lhs x_{0}
81 residual = rhs - matmul_closure(result)
82
83 # Check for NaNs
84 if not torch.equal(residual, residual):
85 raise RuntimeError("NaNs encounterd when trying to perform matrix-vector multiplication")
86
87 # Sometime we're lucky and the preconditioner solves the system right away
88 residual_norm = residual.norm(2, dim=-2)
89 if (residual_norm < tolerance).all() and not n_tridiag:
90 n_iter = 0 # Skip the iteration!
91
92 # Otherwise, let's define precond_residual and curr_conjugate_vec
93 else:
94 # precon_residual{0} = M^-1 residual_{0}
95 precond_residual = preconditioner(residual)
96 curr_conjugate_vec = precond_residual
97 residual_inner_prod = precond_residual.mul(residual).sum(-2, keepdim=True)
98
99 # Define storage matrices
100 mul_storage = residual.new(residual.size())
101 alpha = residual.new(rhs.size(0), 1, rhs.size(-1)) if rhs.ndimension() == 3 else residual.new(1, rhs.size(-1))
102 beta = alpha.new(alpha.size())
103
104 # Define tridiagonal matrices, if applicable
105 if n_tridiag:
106 if rhs.ndimension() == 3:
107 t_mat = residual.new(n_tridiag_iter, n_tridiag_iter, rhs.size(0), n_tridiag).zero_()
108 alpha_reciprocal = alpha.new(rhs.size(0), n_tridiag)
109 else:
110 t_mat = residual.new(n_tridiag_iter, n_tridiag_iter, n_tridiag).zero_()
111 alpha_reciprocal = alpha.new(n_tridiag)
112
113 prev_alpha_reciprocal = alpha.new(alpha_reciprocal.size())
114 prev_beta = alpha.new(alpha_reciprocal.size())
115
116 # Start the iteration
117 for k in range(n_iter):
118 # Get next alpha
119 # alpha_{k} = (residual_{k-1}^T precon_residual{k-1}) / (p_vec_{k-1}^T mat p_vec_{k-1})
120 mvms = matmul_closure(curr_conjugate_vec)
121 torch.mul(curr_conjugate_vec, mvms, out=mul_storage)
122 torch.sum(mul_storage, -2, keepdim=True, out=alpha)
123 alpha.add_(eps)
124 torch.div(residual_inner_prod, alpha, out=alpha)
125
126 # Update result
127 # result_{k} = result_{k-1} + alpha_{k} p_vec_{k-1}
128 torch.addcmul(result, alpha, curr_conjugate_vec, out=result)
129
130 # Update residual
131 # residual_{k} = residual_{k-1} - alpha_{k} mat p_vec_{k-1}
132 torch.addcmul(residual, -1, alpha, mvms, out=residual)
133
134 # If residual are sufficiently small, then exit loop
135 # Alternatively, exit if this is our last iteration
136 torch.norm(residual, 2, dim=-2, out=residual_norm)
137 if (residual_norm < tolerance).all() and not n_tridiag:
138 break
139
140 # Update precond_residual
141 # precon_residual{k} = M^-1 residual_{k}
142 precond_residual = preconditioner(residual)
143
144 # beta_{k} = (precon_residual{k}^T r_vec_{k}) / (precon_residual{k-1}^T r_vec_{k-1})
145 residual_inner_prod.add_(eps)
146 torch.reciprocal(residual_inner_prod, out=beta)
147 torch.mul(residual, precond_residual, out=mul_storage)
148 torch.sum(mul_storage, -2, keepdim=True, out=residual_inner_prod)
149 beta.mul_(residual_inner_prod)
150
151 # Update curr_conjugate_vec
152 # curr_conjugate_vec_{k} = precon_residual{k} + beta_{k} curr_conjugate_vec_{k-1}
153 curr_conjugate_vec.mul_(beta).add_(precond_residual)
154
155 # Update tridiagonal matrices, if applicable
156 if n_tridiag and k < n_tridiag_iter:
157 alpha_tridiag = alpha.squeeze_(-2).narrow(-1, 0, n_tridiag)
158 beta_tridiag = beta.squeeze_(-2).narrow(-1, 0, n_tridiag)
159 torch.reciprocal(alpha_tridiag, out=alpha_reciprocal)
160
161 if k == 0:
162 t_mat[k, k].copy_(alpha_reciprocal)
163 else:
164 torch.addcmul(alpha_reciprocal, prev_beta, prev_alpha_reciprocal, out=t_mat[k, k])
165 torch.mul(prev_beta.sqrt_(), prev_alpha_reciprocal, out=t_mat[k, k - 1])
166 t_mat[k - 1, k].copy_(t_mat[k, k - 1])
167
168 prev_alpha_reciprocal.copy_(alpha_reciprocal)
169 prev_beta.copy_(beta_tridiag)
170
171 if is_vector:
172 result = result.squeeze(-1)
173
174 if n_tridiag:
175 if rhs.ndimension() == 3:
176 return result, t_mat.permute(3, 2, 0, 1).contiguous()
177 else:
178 return result, t_mat.permute(2, 0, 1).contiguous()
179 else:
180 return result
181
[end of gpytorch/utils/linear_cg.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/gpytorch/utils/linear_cg.py b/gpytorch/utils/linear_cg.py
--- a/gpytorch/utils/linear_cg.py
+++ b/gpytorch/utils/linear_cg.py
@@ -113,6 +113,8 @@
prev_alpha_reciprocal = alpha.new(alpha_reciprocal.size())
prev_beta = alpha.new(alpha_reciprocal.size())
+ update_tridiag = True
+ last_tridiag_iter = 0
# Start the iteration
for k in range(n_iter):
# Get next alpha
@@ -134,7 +136,7 @@
# If residual are sufficiently small, then exit loop
# Alternatively, exit if this is our last iteration
torch.norm(residual, 2, dim=-2, out=residual_norm)
- if (residual_norm < tolerance).all() and not n_tridiag:
+ if (residual_norm < tolerance).all() and not (n_tridiag and k < n_tridiag_iter):
break
# Update precond_residual
@@ -153,7 +155,7 @@
curr_conjugate_vec.mul_(beta).add_(precond_residual)
# Update tridiagonal matrices, if applicable
- if n_tridiag and k < n_tridiag_iter:
+ if n_tridiag and k < n_tridiag_iter and update_tridiag:
alpha_tridiag = alpha.squeeze_(-2).narrow(-1, 0, n_tridiag)
beta_tridiag = beta.squeeze_(-2).narrow(-1, 0, n_tridiag)
torch.reciprocal(alpha_tridiag, out=alpha_reciprocal)
@@ -165,6 +167,11 @@
torch.mul(prev_beta.sqrt_(), prev_alpha_reciprocal, out=t_mat[k, k - 1])
t_mat[k - 1, k].copy_(t_mat[k, k - 1])
+ if t_mat[k - 1, k].max() < 1e-6:
+ update_tridiag = False
+
+ last_tridiag_iter = k
+
prev_alpha_reciprocal.copy_(alpha_reciprocal)
prev_beta.copy_(beta_tridiag)
@@ -172,6 +179,7 @@
result = result.squeeze(-1)
if n_tridiag:
+ t_mat = t_mat[:last_tridiag_iter + 1, :last_tridiag_iter + 1]
if rhs.ndimension() == 3:
return result, t_mat.permute(3, 2, 0, 1).contiguous()
else:
|
{"golden_diff": "diff --git a/gpytorch/utils/linear_cg.py b/gpytorch/utils/linear_cg.py\n--- a/gpytorch/utils/linear_cg.py\n+++ b/gpytorch/utils/linear_cg.py\n@@ -113,6 +113,8 @@\n prev_alpha_reciprocal = alpha.new(alpha_reciprocal.size())\n prev_beta = alpha.new(alpha_reciprocal.size())\n \n+ update_tridiag = True\n+ last_tridiag_iter = 0\n # Start the iteration\n for k in range(n_iter):\n # Get next alpha\n@@ -134,7 +136,7 @@\n # If residual are sufficiently small, then exit loop\n # Alternatively, exit if this is our last iteration\n torch.norm(residual, 2, dim=-2, out=residual_norm)\n- if (residual_norm < tolerance).all() and not n_tridiag:\n+ if (residual_norm < tolerance).all() and not (n_tridiag and k < n_tridiag_iter):\n break\n \n # Update precond_residual\n@@ -153,7 +155,7 @@\n curr_conjugate_vec.mul_(beta).add_(precond_residual)\n \n # Update tridiagonal matrices, if applicable\n- if n_tridiag and k < n_tridiag_iter:\n+ if n_tridiag and k < n_tridiag_iter and update_tridiag:\n alpha_tridiag = alpha.squeeze_(-2).narrow(-1, 0, n_tridiag)\n beta_tridiag = beta.squeeze_(-2).narrow(-1, 0, n_tridiag)\n torch.reciprocal(alpha_tridiag, out=alpha_reciprocal)\n@@ -165,6 +167,11 @@\n torch.mul(prev_beta.sqrt_(), prev_alpha_reciprocal, out=t_mat[k, k - 1])\n t_mat[k - 1, k].copy_(t_mat[k, k - 1])\n \n+ if t_mat[k - 1, k].max() < 1e-6:\n+ update_tridiag = False\n+\n+ last_tridiag_iter = k\n+\n prev_alpha_reciprocal.copy_(alpha_reciprocal)\n prev_beta.copy_(beta_tridiag)\n \n@@ -172,6 +179,7 @@\n result = result.squeeze(-1)\n \n if n_tridiag:\n+ t_mat = t_mat[:last_tridiag_iter + 1, :last_tridiag_iter + 1]\n if rhs.ndimension() == 3:\n return result, t_mat.permute(3, 2, 0, 1).contiguous()\n else:\n", "issue": "Exact GP regression Lapack Error syev\nTraining a simple GP regression model produces following runtime error randomly at some seeds: \r\n`RuntimeError: Lapack Error syev : 3 off-diagonal elements didn't converge to zero at /pytorch/aten/src/TH/generic/THTensorLapack.c:388`.\r\nI have been able to reproduce the error with the following code:\r\n\r\n```\r\nimport math\r\nimport torch\r\nimport gpytorch\r\nfrom matplotlib import pyplot as plt\r\n\r\nfrom torch import optim\r\nfrom gpytorch.kernels import RBFKernel\r\nfrom gpytorch.means import ConstantMean\r\nfrom gpytorch.likelihoods import GaussianLikelihood\r\nfrom gpytorch.random_variables import GaussianRandomVariable\r\n\r\ntorch.manual_seed(1)\r\ntrain_x = torch.FloatTensor([[ 6, 6],\r\n [ 7, 3],\r\n [ 7, 8],\r\n [ 8, 6],\r\n [10, 0]])\r\n\r\ntrain_y = torch.FloatTensor([2.38922077, 0.35414244, 2.24837906, 1.40895557, 0.68164634])\r\n\r\nclass ExactGPModel(gpytorch.models.ExactGP):\r\n def __init__(self, train_x, train_y, likelihood):\r\n super(ExactGPModel, self).__init__(train_x, train_y, likelihood)\r\n self.mean_module = ConstantMean(constant_bounds=(-10, 10))\r\n self.covar_module = RBFKernel(log_lengthscale_bounds=(-5, 5))\r\n \r\n def forward(self, x):\r\n mean_x = self.mean_module(x)\r\n covar_x = self.covar_module(x)\r\n return GaussianRandomVariable(mean_x, covar_x)\r\n\r\nlikelihood = GaussianLikelihood(log_noise_bounds=(-5, 5))\r\nmodel = ExactGPModel(train_x.data, train_y.data, likelihood)\r\n\r\nmodel.train()\r\nlikelihood.train()\r\n\r\noptimizer = torch.optim.Adam([\r\n {'params': model.parameters()}, \r\n], lr=0.1)\r\n\r\nmll = gpytorch.mlls.ExactMarginalLogLikelihood(likelihood, model)\r\n\r\ntraining_iter = 50\r\nfor i in range(training_iter):\r\n optimizer.zero_grad()\r\n output = model(train_x)\r\n loss = -mll(output, train_y)\r\n loss.backward()\r\n print('Iter %d/%d - Loss: %.3f log_lengthscale: %.3f log_noise: %.3f' % (\r\n i + 1, training_iter, loss.data[0],\r\n model.covar_module.log_lengthscale.data[0, 0],\r\n model.likelihood.log_noise.data[0]\r\n ))\r\n optimizer.step()\r\n\r\n\r\n```\r\nI am using the latest version of Gpytorch and Pytorch (0.4.0). The above code is identical to the simple gp regression example provided with this repo with changes in train_x and train_y only. Also, the code works fine for seed = 0. \r\n\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport torch\nfrom .. import settings\n\n\ndef _default_preconditioner(x):\n return x.clone()\n\n\ndef linear_cg(\n matmul_closure,\n rhs,\n n_tridiag=0,\n tolerance=1e-6,\n eps=1e-20,\n max_iter=None,\n max_tridiag_iter=None,\n initial_guess=None,\n preconditioner=None,\n):\n \"\"\"\n Implements the linear conjugate gradients method for (approximately) solving systems of the form\n\n lhs result = rhs\n\n for positive definite and symmetric matrices.\n\n Args:\n - matmul_closure - a function which performs a left matrix multiplication with lhs_mat\n - rhs - the right-hand side of the equation\n - n_tridiag - returns a tridiagonalization of the first n_tridiag columns of rhs\n - tolerance - stop the solve when the max residual is less than this\n - eps - noise to add to prevent division by zero\n - max_iter - the maximum number of CG iterations\n - max_tridiag_iter - the maximum size of the tridiagonalization matrix\n - initial_guess - an initial guess at the solution `result`\n - precondition_closure - a functions which left-preconditions a supplied vector\n\n Returns:\n result - a solution to the system (if n_tridiag is 0)\n result, tridiags - a solution to the system, and corresponding tridiagonal matrices (if n_tridiag > 0)\n \"\"\"\n # Unsqueeze, if necesasry\n is_vector = rhs.ndimension() == 1\n if is_vector:\n rhs = rhs.unsqueeze(-1)\n\n # Some default arguments\n if max_iter is None:\n max_iter = settings.max_cg_iterations.value()\n if max_tridiag_iter is None:\n max_tridiag_iter = settings.max_lanczos_quadrature_iterations.value()\n if initial_guess is None:\n initial_guess = rhs.new(rhs.size()).zero_()\n if preconditioner is None:\n preconditioner = _default_preconditioner\n\n # If we are running m CG iterations, we obviously can't get more than m Lanczos coefficients\n if max_tridiag_iter > max_iter:\n raise RuntimeError(\"Getting a tridiagonalization larger than the number of CG iterations run is not possible!\")\n\n # Check matmul_closure object\n if torch.is_tensor(matmul_closure):\n matmul_closure = matmul_closure.matmul\n elif not callable(matmul_closure):\n raise RuntimeError(\"matmul_closure must be a tensor, or a callable object!\")\n\n # Get some constants\n n_rows = rhs.size(-2)\n n_iter = min(max_iter, n_rows)\n n_tridiag_iter = min(max_tridiag_iter, n_rows)\n\n # result <- x_{0}\n result = initial_guess\n\n # residual: residual_{0} = b_vec - lhs x_{0}\n residual = rhs - matmul_closure(result)\n\n # Check for NaNs\n if not torch.equal(residual, residual):\n raise RuntimeError(\"NaNs encounterd when trying to perform matrix-vector multiplication\")\n\n # Sometime we're lucky and the preconditioner solves the system right away\n residual_norm = residual.norm(2, dim=-2)\n if (residual_norm < tolerance).all() and not n_tridiag:\n n_iter = 0 # Skip the iteration!\n\n # Otherwise, let's define precond_residual and curr_conjugate_vec\n else:\n # precon_residual{0} = M^-1 residual_{0}\n precond_residual = preconditioner(residual)\n curr_conjugate_vec = precond_residual\n residual_inner_prod = precond_residual.mul(residual).sum(-2, keepdim=True)\n\n # Define storage matrices\n mul_storage = residual.new(residual.size())\n alpha = residual.new(rhs.size(0), 1, rhs.size(-1)) if rhs.ndimension() == 3 else residual.new(1, rhs.size(-1))\n beta = alpha.new(alpha.size())\n\n # Define tridiagonal matrices, if applicable\n if n_tridiag:\n if rhs.ndimension() == 3:\n t_mat = residual.new(n_tridiag_iter, n_tridiag_iter, rhs.size(0), n_tridiag).zero_()\n alpha_reciprocal = alpha.new(rhs.size(0), n_tridiag)\n else:\n t_mat = residual.new(n_tridiag_iter, n_tridiag_iter, n_tridiag).zero_()\n alpha_reciprocal = alpha.new(n_tridiag)\n\n prev_alpha_reciprocal = alpha.new(alpha_reciprocal.size())\n prev_beta = alpha.new(alpha_reciprocal.size())\n\n # Start the iteration\n for k in range(n_iter):\n # Get next alpha\n # alpha_{k} = (residual_{k-1}^T precon_residual{k-1}) / (p_vec_{k-1}^T mat p_vec_{k-1})\n mvms = matmul_closure(curr_conjugate_vec)\n torch.mul(curr_conjugate_vec, mvms, out=mul_storage)\n torch.sum(mul_storage, -2, keepdim=True, out=alpha)\n alpha.add_(eps)\n torch.div(residual_inner_prod, alpha, out=alpha)\n\n # Update result\n # result_{k} = result_{k-1} + alpha_{k} p_vec_{k-1}\n torch.addcmul(result, alpha, curr_conjugate_vec, out=result)\n\n # Update residual\n # residual_{k} = residual_{k-1} - alpha_{k} mat p_vec_{k-1}\n torch.addcmul(residual, -1, alpha, mvms, out=residual)\n\n # If residual are sufficiently small, then exit loop\n # Alternatively, exit if this is our last iteration\n torch.norm(residual, 2, dim=-2, out=residual_norm)\n if (residual_norm < tolerance).all() and not n_tridiag:\n break\n\n # Update precond_residual\n # precon_residual{k} = M^-1 residual_{k}\n precond_residual = preconditioner(residual)\n\n # beta_{k} = (precon_residual{k}^T r_vec_{k}) / (precon_residual{k-1}^T r_vec_{k-1})\n residual_inner_prod.add_(eps)\n torch.reciprocal(residual_inner_prod, out=beta)\n torch.mul(residual, precond_residual, out=mul_storage)\n torch.sum(mul_storage, -2, keepdim=True, out=residual_inner_prod)\n beta.mul_(residual_inner_prod)\n\n # Update curr_conjugate_vec\n # curr_conjugate_vec_{k} = precon_residual{k} + beta_{k} curr_conjugate_vec_{k-1}\n curr_conjugate_vec.mul_(beta).add_(precond_residual)\n\n # Update tridiagonal matrices, if applicable\n if n_tridiag and k < n_tridiag_iter:\n alpha_tridiag = alpha.squeeze_(-2).narrow(-1, 0, n_tridiag)\n beta_tridiag = beta.squeeze_(-2).narrow(-1, 0, n_tridiag)\n torch.reciprocal(alpha_tridiag, out=alpha_reciprocal)\n\n if k == 0:\n t_mat[k, k].copy_(alpha_reciprocal)\n else:\n torch.addcmul(alpha_reciprocal, prev_beta, prev_alpha_reciprocal, out=t_mat[k, k])\n torch.mul(prev_beta.sqrt_(), prev_alpha_reciprocal, out=t_mat[k, k - 1])\n t_mat[k - 1, k].copy_(t_mat[k, k - 1])\n\n prev_alpha_reciprocal.copy_(alpha_reciprocal)\n prev_beta.copy_(beta_tridiag)\n\n if is_vector:\n result = result.squeeze(-1)\n\n if n_tridiag:\n if rhs.ndimension() == 3:\n return result, t_mat.permute(3, 2, 0, 1).contiguous()\n else:\n return result, t_mat.permute(2, 0, 1).contiguous()\n else:\n return result\n", "path": "gpytorch/utils/linear_cg.py"}]}
| 3,477 | 605 |
gh_patches_debug_39091
|
rasdani/github-patches
|
git_diff
|
kedro-org__kedro-3222
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove deprecated `project_version`
`project_version` was deprecated in favour of `kedro_init_version` in https://github.com/kedro-org/kedro/issues/2118 and https://github.com/kedro-org/kedro/pull/2219, but hasn't been removed yet.
</issue>
<code>
[start of kedro/framework/startup.py]
1 """This module provides metadata for a Kedro project."""
2 import os
3 import sys
4 import warnings
5 from pathlib import Path
6 from typing import NamedTuple, Union
7
8 import anyconfig
9
10 from kedro import KedroDeprecationWarning
11 from kedro import __version__ as kedro_version
12 from kedro.framework.project import configure_project
13
14 _PYPROJECT = "pyproject.toml"
15
16
17 class ProjectMetadata(NamedTuple):
18 """Structure holding project metadata derived from `pyproject.toml`"""
19
20 config_file: Path
21 package_name: str
22 project_name: str
23 project_path: Path
24 project_version: str
25 source_dir: Path
26 kedro_init_version: str
27
28
29 def _version_mismatch_error(kedro_init_version) -> str:
30 return (
31 f"Your Kedro project version {kedro_init_version} does not match Kedro package "
32 f"version {kedro_version} you are running. Make sure to update your project "
33 f"template. See https://github.com/kedro-org/kedro/blob/main/RELEASE.md "
34 f"for how to migrate your Kedro project."
35 )
36
37
38 def _is_project(project_path: Union[str, Path]) -> bool:
39 metadata_file = Path(project_path).expanduser().resolve() / _PYPROJECT
40 if not metadata_file.is_file():
41 return False
42
43 try:
44 return "[tool.kedro]" in metadata_file.read_text(encoding="utf-8")
45 except Exception: # noqa: broad-except
46 return False
47
48
49 def _get_project_metadata(project_path: Union[str, Path]) -> ProjectMetadata:
50 """Read project metadata from `<project_root>/pyproject.toml` config file,
51 under the `[tool.kedro]` section.
52
53 Args:
54 project_path: Local path to project root directory to look up `pyproject.toml` in.
55
56 Raises:
57 RuntimeError: `pyproject.toml` was not found or the `[tool.kedro]` section
58 is missing, or config file cannot be parsed.
59 ValueError: If project version is different from Kedro package version.
60 Note: Project version is the Kedro version the project was generated with.
61
62 Returns:
63 A named tuple that contains project metadata.
64 """
65 project_path = Path(project_path).expanduser().resolve()
66 pyproject_toml = project_path / _PYPROJECT
67
68 if not pyproject_toml.is_file():
69 raise RuntimeError(
70 f"Could not find the project configuration file '{_PYPROJECT}' in {project_path}. "
71 f"If you have created your project with Kedro "
72 f"version <0.17.0, make sure to update your project template. "
73 f"See https://github.com/kedro-org/kedro/blob/main/RELEASE.md"
74 f"#migration-guide-from-kedro-016-to-kedro-0170 "
75 f"for how to migrate your Kedro project."
76 )
77
78 try:
79 metadata_dict = anyconfig.load(pyproject_toml)
80 except Exception as exc:
81 raise RuntimeError(f"Failed to parse '{_PYPROJECT}' file.") from exc
82
83 try:
84 metadata_dict = metadata_dict["tool"]["kedro"]
85 except KeyError as exc:
86 raise RuntimeError(
87 f"There's no '[tool.kedro]' section in the '{_PYPROJECT}'. "
88 f"Please add '[tool.kedro]' section to the file with appropriate "
89 f"configuration parameters."
90 ) from exc
91
92 mandatory_keys = ["package_name", "project_name"]
93 missing_keys = [key for key in mandatory_keys if key not in metadata_dict]
94 if missing_keys:
95 raise RuntimeError(f"Missing required keys {missing_keys} from '{_PYPROJECT}'.")
96
97 # Temporary solution to keep project_version backwards compatible to be removed in 0.19.0
98 if "project_version" in metadata_dict:
99 warnings.warn(
100 "project_version in pyproject.toml is deprecated, use kedro_init_version instead",
101 KedroDeprecationWarning,
102 )
103 metadata_dict["kedro_init_version"] = metadata_dict["project_version"]
104 elif "kedro_init_version" in metadata_dict:
105 metadata_dict["project_version"] = metadata_dict["kedro_init_version"]
106 else:
107 raise RuntimeError(
108 f"Missing required key kedro_init_version from '{_PYPROJECT}'."
109 )
110
111 mandatory_keys.append("kedro_init_version")
112 # check the match for major and minor version (skip patch version)
113 if (
114 metadata_dict["kedro_init_version"].split(".")[:2]
115 != kedro_version.split(".")[:2]
116 ):
117 raise ValueError(_version_mismatch_error(metadata_dict["kedro_init_version"]))
118
119 source_dir = Path(metadata_dict.get("source_dir", "src")).expanduser()
120 source_dir = (project_path / source_dir).resolve()
121 metadata_dict["source_dir"] = source_dir
122 metadata_dict["config_file"] = pyproject_toml
123 metadata_dict["project_path"] = project_path
124 metadata_dict.pop("micropkg", {}) # don't include micro-packaging specs
125
126 try:
127 return ProjectMetadata(**metadata_dict)
128 except TypeError as exc:
129 expected_keys = mandatory_keys + ["source_dir"]
130 raise RuntimeError(
131 f"Found unexpected keys in '{_PYPROJECT}'. Make sure "
132 f"it only contains the following keys: {expected_keys}."
133 ) from exc
134
135
136 def _validate_source_path(source_path: Path, project_path: Path) -> None:
137 """Validate the source path exists and is relative to the project path.
138
139 Args:
140 source_path: Absolute source path.
141 project_path: Path to the Kedro project.
142
143 Raises:
144 ValueError: If source_path is not relative to project_path.
145 NotADirectoryError: If source_path does not exist.
146 """
147 try:
148 source_path.relative_to(project_path)
149 except ValueError as exc:
150 raise ValueError(
151 f"Source path '{source_path}' has to be relative to "
152 f"your project root '{project_path}'."
153 ) from exc
154 if not source_path.exists():
155 raise NotADirectoryError(f"Source path '{source_path}' cannot be found.")
156
157
158 def _add_src_to_path(source_dir: Path, project_path: Path) -> None:
159 _validate_source_path(source_dir, project_path)
160
161 if str(source_dir) not in sys.path:
162 sys.path.insert(0, str(source_dir))
163
164 python_path = os.getenv("PYTHONPATH", "")
165 if str(source_dir) not in python_path:
166 sep = os.pathsep if python_path else ""
167 os.environ["PYTHONPATH"] = f"{str(source_dir)}{sep}{python_path}"
168
169
170 def bootstrap_project(project_path: Path) -> ProjectMetadata:
171 """Run setup required at the beginning of the workflow
172 when running in project mode, and return project metadata.
173 """
174 metadata = _get_project_metadata(project_path)
175 _add_src_to_path(metadata.source_dir, project_path)
176 configure_project(metadata.package_name)
177 return metadata
178
[end of kedro/framework/startup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kedro/framework/startup.py b/kedro/framework/startup.py
--- a/kedro/framework/startup.py
+++ b/kedro/framework/startup.py
@@ -1,13 +1,11 @@
"""This module provides metadata for a Kedro project."""
import os
import sys
-import warnings
from pathlib import Path
from typing import NamedTuple, Union
import anyconfig
-from kedro import KedroDeprecationWarning
from kedro import __version__ as kedro_version
from kedro.framework.project import configure_project
@@ -21,9 +19,9 @@
package_name: str
project_name: str
project_path: Path
- project_version: str
source_dir: Path
kedro_init_version: str
+ add_ons: list
def _version_mismatch_error(kedro_init_version) -> str:
@@ -89,26 +87,11 @@
f"configuration parameters."
) from exc
- mandatory_keys = ["package_name", "project_name"]
+ mandatory_keys = ["package_name", "project_name", "kedro_init_version"]
missing_keys = [key for key in mandatory_keys if key not in metadata_dict]
if missing_keys:
raise RuntimeError(f"Missing required keys {missing_keys} from '{_PYPROJECT}'.")
- # Temporary solution to keep project_version backwards compatible to be removed in 0.19.0
- if "project_version" in metadata_dict:
- warnings.warn(
- "project_version in pyproject.toml is deprecated, use kedro_init_version instead",
- KedroDeprecationWarning,
- )
- metadata_dict["kedro_init_version"] = metadata_dict["project_version"]
- elif "kedro_init_version" in metadata_dict:
- metadata_dict["project_version"] = metadata_dict["kedro_init_version"]
- else:
- raise RuntimeError(
- f"Missing required key kedro_init_version from '{_PYPROJECT}'."
- )
-
- mandatory_keys.append("kedro_init_version")
# check the match for major and minor version (skip patch version)
if (
metadata_dict["kedro_init_version"].split(".")[:2]
@@ -116,8 +99,11 @@
):
raise ValueError(_version_mismatch_error(metadata_dict["kedro_init_version"]))
+ # Default settings
source_dir = Path(metadata_dict.get("source_dir", "src")).expanduser()
source_dir = (project_path / source_dir).resolve()
+ metadata_dict["add_ons"] = metadata_dict.get("add_ons")
+
metadata_dict["source_dir"] = source_dir
metadata_dict["config_file"] = pyproject_toml
metadata_dict["project_path"] = project_path
|
{"golden_diff": "diff --git a/kedro/framework/startup.py b/kedro/framework/startup.py\n--- a/kedro/framework/startup.py\n+++ b/kedro/framework/startup.py\n@@ -1,13 +1,11 @@\n \"\"\"This module provides metadata for a Kedro project.\"\"\"\n import os\n import sys\n-import warnings\n from pathlib import Path\n from typing import NamedTuple, Union\n \n import anyconfig\n \n-from kedro import KedroDeprecationWarning\n from kedro import __version__ as kedro_version\n from kedro.framework.project import configure_project\n \n@@ -21,9 +19,9 @@\n package_name: str\n project_name: str\n project_path: Path\n- project_version: str\n source_dir: Path\n kedro_init_version: str\n+ add_ons: list\n \n \n def _version_mismatch_error(kedro_init_version) -> str:\n@@ -89,26 +87,11 @@\n f\"configuration parameters.\"\n ) from exc\n \n- mandatory_keys = [\"package_name\", \"project_name\"]\n+ mandatory_keys = [\"package_name\", \"project_name\", \"kedro_init_version\"]\n missing_keys = [key for key in mandatory_keys if key not in metadata_dict]\n if missing_keys:\n raise RuntimeError(f\"Missing required keys {missing_keys} from '{_PYPROJECT}'.\")\n \n- # Temporary solution to keep project_version backwards compatible to be removed in 0.19.0\n- if \"project_version\" in metadata_dict:\n- warnings.warn(\n- \"project_version in pyproject.toml is deprecated, use kedro_init_version instead\",\n- KedroDeprecationWarning,\n- )\n- metadata_dict[\"kedro_init_version\"] = metadata_dict[\"project_version\"]\n- elif \"kedro_init_version\" in metadata_dict:\n- metadata_dict[\"project_version\"] = metadata_dict[\"kedro_init_version\"]\n- else:\n- raise RuntimeError(\n- f\"Missing required key kedro_init_version from '{_PYPROJECT}'.\"\n- )\n-\n- mandatory_keys.append(\"kedro_init_version\")\n # check the match for major and minor version (skip patch version)\n if (\n metadata_dict[\"kedro_init_version\"].split(\".\")[:2]\n@@ -116,8 +99,11 @@\n ):\n raise ValueError(_version_mismatch_error(metadata_dict[\"kedro_init_version\"]))\n \n+ # Default settings\n source_dir = Path(metadata_dict.get(\"source_dir\", \"src\")).expanduser()\n source_dir = (project_path / source_dir).resolve()\n+ metadata_dict[\"add_ons\"] = metadata_dict.get(\"add_ons\")\n+\n metadata_dict[\"source_dir\"] = source_dir\n metadata_dict[\"config_file\"] = pyproject_toml\n metadata_dict[\"project_path\"] = project_path\n", "issue": "Remove deprecated `project_version`\n`project_version` was deprecated in favour of `kedro_init_version` in https://github.com/kedro-org/kedro/issues/2118 and https://github.com/kedro-org/kedro/pull/2219, but hasn't been removed yet. \n", "before_files": [{"content": "\"\"\"This module provides metadata for a Kedro project.\"\"\"\nimport os\nimport sys\nimport warnings\nfrom pathlib import Path\nfrom typing import NamedTuple, Union\n\nimport anyconfig\n\nfrom kedro import KedroDeprecationWarning\nfrom kedro import __version__ as kedro_version\nfrom kedro.framework.project import configure_project\n\n_PYPROJECT = \"pyproject.toml\"\n\n\nclass ProjectMetadata(NamedTuple):\n \"\"\"Structure holding project metadata derived from `pyproject.toml`\"\"\"\n\n config_file: Path\n package_name: str\n project_name: str\n project_path: Path\n project_version: str\n source_dir: Path\n kedro_init_version: str\n\n\ndef _version_mismatch_error(kedro_init_version) -> str:\n return (\n f\"Your Kedro project version {kedro_init_version} does not match Kedro package \"\n f\"version {kedro_version} you are running. Make sure to update your project \"\n f\"template. See https://github.com/kedro-org/kedro/blob/main/RELEASE.md \"\n f\"for how to migrate your Kedro project.\"\n )\n\n\ndef _is_project(project_path: Union[str, Path]) -> bool:\n metadata_file = Path(project_path).expanduser().resolve() / _PYPROJECT\n if not metadata_file.is_file():\n return False\n\n try:\n return \"[tool.kedro]\" in metadata_file.read_text(encoding=\"utf-8\")\n except Exception: # noqa: broad-except\n return False\n\n\ndef _get_project_metadata(project_path: Union[str, Path]) -> ProjectMetadata:\n \"\"\"Read project metadata from `<project_root>/pyproject.toml` config file,\n under the `[tool.kedro]` section.\n\n Args:\n project_path: Local path to project root directory to look up `pyproject.toml` in.\n\n Raises:\n RuntimeError: `pyproject.toml` was not found or the `[tool.kedro]` section\n is missing, or config file cannot be parsed.\n ValueError: If project version is different from Kedro package version.\n Note: Project version is the Kedro version the project was generated with.\n\n Returns:\n A named tuple that contains project metadata.\n \"\"\"\n project_path = Path(project_path).expanduser().resolve()\n pyproject_toml = project_path / _PYPROJECT\n\n if not pyproject_toml.is_file():\n raise RuntimeError(\n f\"Could not find the project configuration file '{_PYPROJECT}' in {project_path}. \"\n f\"If you have created your project with Kedro \"\n f\"version <0.17.0, make sure to update your project template. \"\n f\"See https://github.com/kedro-org/kedro/blob/main/RELEASE.md\"\n f\"#migration-guide-from-kedro-016-to-kedro-0170 \"\n f\"for how to migrate your Kedro project.\"\n )\n\n try:\n metadata_dict = anyconfig.load(pyproject_toml)\n except Exception as exc:\n raise RuntimeError(f\"Failed to parse '{_PYPROJECT}' file.\") from exc\n\n try:\n metadata_dict = metadata_dict[\"tool\"][\"kedro\"]\n except KeyError as exc:\n raise RuntimeError(\n f\"There's no '[tool.kedro]' section in the '{_PYPROJECT}'. \"\n f\"Please add '[tool.kedro]' section to the file with appropriate \"\n f\"configuration parameters.\"\n ) from exc\n\n mandatory_keys = [\"package_name\", \"project_name\"]\n missing_keys = [key for key in mandatory_keys if key not in metadata_dict]\n if missing_keys:\n raise RuntimeError(f\"Missing required keys {missing_keys} from '{_PYPROJECT}'.\")\n\n # Temporary solution to keep project_version backwards compatible to be removed in 0.19.0\n if \"project_version\" in metadata_dict:\n warnings.warn(\n \"project_version in pyproject.toml is deprecated, use kedro_init_version instead\",\n KedroDeprecationWarning,\n )\n metadata_dict[\"kedro_init_version\"] = metadata_dict[\"project_version\"]\n elif \"kedro_init_version\" in metadata_dict:\n metadata_dict[\"project_version\"] = metadata_dict[\"kedro_init_version\"]\n else:\n raise RuntimeError(\n f\"Missing required key kedro_init_version from '{_PYPROJECT}'.\"\n )\n\n mandatory_keys.append(\"kedro_init_version\")\n # check the match for major and minor version (skip patch version)\n if (\n metadata_dict[\"kedro_init_version\"].split(\".\")[:2]\n != kedro_version.split(\".\")[:2]\n ):\n raise ValueError(_version_mismatch_error(metadata_dict[\"kedro_init_version\"]))\n\n source_dir = Path(metadata_dict.get(\"source_dir\", \"src\")).expanduser()\n source_dir = (project_path / source_dir).resolve()\n metadata_dict[\"source_dir\"] = source_dir\n metadata_dict[\"config_file\"] = pyproject_toml\n metadata_dict[\"project_path\"] = project_path\n metadata_dict.pop(\"micropkg\", {}) # don't include micro-packaging specs\n\n try:\n return ProjectMetadata(**metadata_dict)\n except TypeError as exc:\n expected_keys = mandatory_keys + [\"source_dir\"]\n raise RuntimeError(\n f\"Found unexpected keys in '{_PYPROJECT}'. Make sure \"\n f\"it only contains the following keys: {expected_keys}.\"\n ) from exc\n\n\ndef _validate_source_path(source_path: Path, project_path: Path) -> None:\n \"\"\"Validate the source path exists and is relative to the project path.\n\n Args:\n source_path: Absolute source path.\n project_path: Path to the Kedro project.\n\n Raises:\n ValueError: If source_path is not relative to project_path.\n NotADirectoryError: If source_path does not exist.\n \"\"\"\n try:\n source_path.relative_to(project_path)\n except ValueError as exc:\n raise ValueError(\n f\"Source path '{source_path}' has to be relative to \"\n f\"your project root '{project_path}'.\"\n ) from exc\n if not source_path.exists():\n raise NotADirectoryError(f\"Source path '{source_path}' cannot be found.\")\n\n\ndef _add_src_to_path(source_dir: Path, project_path: Path) -> None:\n _validate_source_path(source_dir, project_path)\n\n if str(source_dir) not in sys.path:\n sys.path.insert(0, str(source_dir))\n\n python_path = os.getenv(\"PYTHONPATH\", \"\")\n if str(source_dir) not in python_path:\n sep = os.pathsep if python_path else \"\"\n os.environ[\"PYTHONPATH\"] = f\"{str(source_dir)}{sep}{python_path}\"\n\n\ndef bootstrap_project(project_path: Path) -> ProjectMetadata:\n \"\"\"Run setup required at the beginning of the workflow\n when running in project mode, and return project metadata.\n \"\"\"\n metadata = _get_project_metadata(project_path)\n _add_src_to_path(metadata.source_dir, project_path)\n configure_project(metadata.package_name)\n return metadata\n", "path": "kedro/framework/startup.py"}]}
| 2,572 | 616 |
gh_patches_debug_7070
|
rasdani/github-patches
|
git_diff
|
gwastro__pycbc-2623
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Remove upper requirement on the astropy version
Is there any reason for having the upper version bound on astropy (`astropy>=2.0.3,<3.0.0`) in the requirements file? Is this just that PyCBC is not yet completely Python 3 compatible yet? From looking at the locations where astropy is used in the code, and testing them with astropy v3.1.2 installed, I don't seem to see any problems.
If the issue is that not having the upper bound makes the test suite try and download a non-Python 2 compatible astropy version, you could edit the requirements file to, e.g.,
```
astropy>=2.0.3,<3.0.0; python_version <= '2.7'
astropy>=2.0.3; python_version > '3.4'
```
</issue>
<code>
[start of setup.py]
1 #!/usr/bin/env python
2 # Copyright (C) 2012 Alex Nitz, Duncan Brown, Andrew Miller, Josh Willis
3 #
4 # This program is free software; you can redistribute it and/or modify it
5 # under the terms of the GNU General Public License as published by the
6 # Free Software Foundation; either version 2 of the License, or (at your
7 # option) any later version.
8 #
9 # This program is distributed in the hope that it will be useful, but
10 # WITHOUT ANY WARRANTY; without even the implied warranty of
11 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General
12 # Public License for more details.
13 #
14 # You should have received a copy of the GNU General Public License along
15 # with this program; if not, write to the Free Software Foundation, Inc.,
16 # 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
17
18 """
19 setup.py file for PyCBC package
20 """
21
22 from __future__ import print_function
23
24 import os, sys, subprocess, shutil
25
26 from distutils.errors import DistutilsError
27 from distutils.command.clean import clean as _clean
28
29 from setuptools.command.install import install as _install
30 from setuptools import Extension, setup, Command
31 from setuptools.command.build_ext import build_ext as _build_ext
32 from setuptools import find_packages
33
34 PY3 = sys.version_info[0] == 3
35
36 requires = []
37 setup_requires = ['numpy>=1.13.0,<1.15.3',]
38 install_requires = setup_requires + ['Mako>=1.0.1',
39 'cython',
40 'decorator>=3.4.2',
41 'scipy>=0.16.0',
42 'matplotlib>=1.5.1',
43 'pillow',
44 'h5py>=2.5',
45 'jinja2',
46 'astropy>=2.0.3,<3.0.0',
47 'mpld3>=0.3',
48 'lscsoft-glue>=1.59.3',
49 'emcee==2.2.1',
50 'requests>=1.2.1',
51 'beautifulsoup4>=4.6.0',
52 'six>=1.10.0',
53 'ligo-segments',
54 ]
55
56 if not PY3:
57 install_requires += ['weave>=0.16.0']
58
59 def find_files(dirname, relpath=None):
60 def find_paths(dirname):
61 items = []
62 for fname in os.listdir(dirname):
63 path = os.path.join(dirname, fname)
64 if os.path.isdir(path):
65 items += find_paths(path)
66 elif not path.endswith(".py") and not path.endswith(".pyc"):
67 items.append(path)
68 return items
69 items = find_paths(dirname)
70 if relpath is None:
71 relpath = dirname
72 return [os.path.relpath(path, relpath) for path in items]
73
74 class cbuild_ext(_build_ext):
75 def run(self):
76 import pkg_resources
77
78 # At this point we can be sure pip has already installed numpy
79 numpy_incl = pkg_resources.resource_filename('numpy', 'core/include')
80
81 for ext in self.extensions:
82 if (hasattr(ext, 'include_dirs') and
83 numpy_incl not in ext.include_dirs):
84 ext.include_dirs.append(numpy_incl)
85
86 _build_ext.run(self)
87
88
89 # Add swig-generated files to the list of things to clean, so they
90 # get regenerated each time.
91 class clean(_clean):
92 def finalize_options (self):
93 _clean.finalize_options(self)
94 self.clean_files = []
95 self.clean_folders = ['docs/_build']
96 def run(self):
97 _clean.run(self)
98 for f in self.clean_files:
99 try:
100 os.unlink(f)
101 print('removed {0}'.format(f))
102 except:
103 pass
104
105 for fol in self.clean_folders:
106 shutil.rmtree(fol, ignore_errors=True)
107 print('removed {0}'.format(fol))
108
109 # write versioning info
110 def get_version_info():
111 """Get VCS info and write version info to version.py
112 """
113 from pycbc import _version_helper
114
115 class vdummy(object):
116 def __getattr__(self, attr):
117 return ''
118
119 # If this is a pycbc git repo always populate version information using GIT
120 try:
121 vinfo = _version_helper.generate_git_version_info()
122 except:
123 vinfo = vdummy()
124 vinfo.version = '1.13.dev6'
125 vinfo.release = 'False'
126
127 with open('pycbc/version.py', 'w') as f:
128 f.write("# coding: utf-8\n")
129 f.write("# Generated by setup.py for PyCBC on %s.\n\n"
130 % vinfo.build_date)
131
132 # print general info
133 f.write('version = \'%s\'\n' % vinfo.version)
134 f.write('date = \'%s\'\n' % vinfo.date)
135 f.write('release = %s\n' % vinfo.release)
136 f.write('last_release = \'%s\'\n' % vinfo.last_release)
137
138 # print git info
139 f.write('\ngit_hash = \'%s\'\n' % vinfo.hash)
140 f.write('git_branch = \'%s\'\n' % vinfo.branch)
141 f.write('git_tag = \'%s\'\n' % vinfo.tag)
142 f.write('git_author = \'%s\'\n' % vinfo.author)
143 f.write('git_committer = \'%s\'\n' % vinfo.committer)
144 f.write('git_status = \'%s\'\n' % vinfo.status)
145 f.write('git_builder = \'%s\'\n' % vinfo.builder)
146 f.write('git_build_date = \'%s\'\n' % vinfo.build_date)
147 f.write('git_verbose_msg = """Version: %s\n'
148 'Branch: %s\n'
149 'Tag: %s\n'
150 'Id: %s\n'
151 'Builder: %s\n'
152 'Build date: %s\n'
153 'Repository status is %s"""\n' %(
154 vinfo.version,
155 vinfo.branch,
156 vinfo.tag,
157 vinfo.hash,
158 vinfo.builder,
159 vinfo.build_date,
160 vinfo.status))
161 f.write('from pycbc._version import *\n')
162 version = vinfo.version
163
164 from pycbc import version
165 version = version.version
166 return version
167
168 class build_docs(Command):
169 user_options = []
170 description = "Build the documentation pages"
171 def initialize_options(self):
172 pass
173 def finalize_options(self):
174 pass
175 def run(self):
176 subprocess.check_call("cd docs; cp Makefile.std Makefile; cp conf_std.py conf.py; sphinx-apidoc "
177 " -o ./ -f -A 'PyCBC dev team' -V '0.1' ../pycbc && make html",
178 stderr=subprocess.STDOUT, shell=True)
179
180 class build_gh_pages(Command):
181 user_options = []
182 description = "Build the documentation pages for GitHub"
183 def initialize_options(self):
184 pass
185 def finalize_options(self):
186 pass
187 def run(self):
188 subprocess.check_call("mkdir -p _gh-pages/latest && touch _gh-pages/.nojekyll && "
189 "cd docs; cp Makefile.gh_pages Makefile; cp conf_std.py conf.py; sphinx-apidoc "
190 " -o ./ -f -A 'PyCBC dev team' -V '0.1' ../pycbc && make html",
191 stderr=subprocess.STDOUT, shell=True)
192
193 cmdclass = { 'build_docs' : build_docs,
194 'build_gh_pages' : build_gh_pages,
195 'clean' : clean,
196 'build_ext':cbuild_ext
197 }
198
199 extras_require = {'cuda': ['pycuda>=2015.1', 'scikit-cuda']}
200
201 # do the actual work of building the package
202 VERSION = get_version_info()
203
204 cythonext = ['waveform.spa_tmplt',
205 'waveform.utils',
206 'types.array',
207 'filter.matchedfilter']
208 ext = []
209 for name in cythonext:
210 e = Extension("pycbc.%s_cpu" % name,
211 ["pycbc/%s_cpu.pyx" % name.replace('.', '/')],
212 extra_compile_args=[ '-O3', '-w', '-msse4.2',
213 '-ffast-math', '-ffinite-math-only'],
214 compiler_directives={'embedsignature': True})
215 ext.append(e)
216
217 setup (
218 name = 'PyCBC',
219 version = VERSION,
220 description = 'Core library to analyze gravitational-wave data, find signals, and study their parameters.',
221 long_description = open('descr.rst').read(),
222 author = 'Ligo-Virgo Collaborations and the PyCBC team',
223 author_email = '[email protected]',
224 url = 'http://www.pycbc.org/',
225 download_url = 'https://github.com/gwastro/pycbc/tarball/v%s' % VERSION,
226 keywords = ['ligo', 'physics', 'gravity', 'signal processing', 'gravitational waves'],
227 cmdclass = cmdclass,
228 setup_requires = setup_requires,
229 extras_require = extras_require,
230 install_requires = install_requires,
231 scripts = find_files('bin', relpath='./') + ['tools/einsteinathome/pycbc_build_eah.sh'],
232 packages = find_packages(),
233 package_data = {'pycbc.workflow': find_files('pycbc/workflow'),
234 'pycbc.results': find_files('pycbc/results'),
235 'pycbc.tmpltbank': find_files('pycbc/tmpltbank')},
236 ext_modules = ext,
237 classifiers=[
238 'Programming Language :: Python',
239 'Programming Language :: Python :: 2',
240 'Programming Language :: Python :: 2.7',
241 'Intended Audience :: Science/Research',
242 'Natural Language :: English',
243 'Topic :: Scientific/Engineering',
244 'Topic :: Scientific/Engineering :: Astronomy',
245 'Topic :: Scientific/Engineering :: Physics',
246 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',
247 ],
248 )
249
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -43,7 +43,8 @@
'pillow',
'h5py>=2.5',
'jinja2',
- 'astropy>=2.0.3,<3.0.0',
+ 'astropy>=2.0.3,<3.0.0; python_version <= "2.7"',
+ 'astropy>=2.0.3; python_version > "3.4"',
'mpld3>=0.3',
'lscsoft-glue>=1.59.3',
'emcee==2.2.1',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -43,7 +43,8 @@\n 'pillow',\n 'h5py>=2.5',\n 'jinja2',\n- 'astropy>=2.0.3,<3.0.0',\n+ 'astropy>=2.0.3,<3.0.0; python_version <= \"2.7\"',\n+ 'astropy>=2.0.3; python_version > \"3.4\"',\n 'mpld3>=0.3',\n 'lscsoft-glue>=1.59.3',\n 'emcee==2.2.1',\n", "issue": "Remove upper requirement on the astropy version\nIs there any reason for having the upper version bound on astropy (`astropy>=2.0.3,<3.0.0`) in the requirements file? Is this just that PyCBC is not yet completely Python 3 compatible yet? From looking at the locations where astropy is used in the code, and testing them with astropy v3.1.2 installed, I don't seem to see any problems.\r\n\r\nIf the issue is that not having the upper bound makes the test suite try and download a non-Python 2 compatible astropy version, you could edit the requirements file to, e.g.,\r\n\r\n```\r\nastropy>=2.0.3,<3.0.0; python_version <= '2.7'\r\nastropy>=2.0.3; python_version > '3.4'\r\n```\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright (C) 2012 Alex Nitz, Duncan Brown, Andrew Miller, Josh Willis\n#\n# This program is free software; you can redistribute it and/or modify it\n# under the terms of the GNU General Public License as published by the\n# Free Software Foundation; either version 2 of the License, or (at your\n# option) any later version.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General\n# Public License for more details.\n#\n# You should have received a copy of the GNU General Public License along\n# with this program; if not, write to the Free Software Foundation, Inc.,\n# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\n\"\"\"\nsetup.py file for PyCBC package\n\"\"\"\n\nfrom __future__ import print_function\n\nimport os, sys, subprocess, shutil\n\nfrom distutils.errors import DistutilsError\nfrom distutils.command.clean import clean as _clean\n\nfrom setuptools.command.install import install as _install\nfrom setuptools import Extension, setup, Command\nfrom setuptools.command.build_ext import build_ext as _build_ext\nfrom setuptools import find_packages\n\nPY3 = sys.version_info[0] == 3\n\nrequires = []\nsetup_requires = ['numpy>=1.13.0,<1.15.3',]\ninstall_requires = setup_requires + ['Mako>=1.0.1',\n 'cython',\n 'decorator>=3.4.2',\n 'scipy>=0.16.0',\n 'matplotlib>=1.5.1',\n 'pillow',\n 'h5py>=2.5',\n 'jinja2',\n 'astropy>=2.0.3,<3.0.0',\n 'mpld3>=0.3',\n 'lscsoft-glue>=1.59.3',\n 'emcee==2.2.1',\n 'requests>=1.2.1',\n 'beautifulsoup4>=4.6.0',\n 'six>=1.10.0',\n 'ligo-segments',\n ]\n\nif not PY3:\n install_requires += ['weave>=0.16.0']\n\ndef find_files(dirname, relpath=None):\n def find_paths(dirname):\n items = []\n for fname in os.listdir(dirname):\n path = os.path.join(dirname, fname)\n if os.path.isdir(path):\n items += find_paths(path)\n elif not path.endswith(\".py\") and not path.endswith(\".pyc\"):\n items.append(path)\n return items\n items = find_paths(dirname)\n if relpath is None:\n relpath = dirname\n return [os.path.relpath(path, relpath) for path in items]\n\nclass cbuild_ext(_build_ext):\n def run(self):\n import pkg_resources\n\n # At this point we can be sure pip has already installed numpy\n numpy_incl = pkg_resources.resource_filename('numpy', 'core/include')\n\n for ext in self.extensions:\n if (hasattr(ext, 'include_dirs') and\n numpy_incl not in ext.include_dirs):\n ext.include_dirs.append(numpy_incl)\n\n _build_ext.run(self)\n\n\n# Add swig-generated files to the list of things to clean, so they\n# get regenerated each time.\nclass clean(_clean):\n def finalize_options (self):\n _clean.finalize_options(self)\n self.clean_files = []\n self.clean_folders = ['docs/_build']\n def run(self):\n _clean.run(self)\n for f in self.clean_files:\n try:\n os.unlink(f)\n print('removed {0}'.format(f))\n except:\n pass\n\n for fol in self.clean_folders:\n shutil.rmtree(fol, ignore_errors=True)\n print('removed {0}'.format(fol))\n\n# write versioning info\ndef get_version_info():\n \"\"\"Get VCS info and write version info to version.py\n \"\"\"\n from pycbc import _version_helper\n\n class vdummy(object):\n def __getattr__(self, attr):\n return ''\n\n # If this is a pycbc git repo always populate version information using GIT\n try:\n vinfo = _version_helper.generate_git_version_info()\n except:\n vinfo = vdummy()\n vinfo.version = '1.13.dev6'\n vinfo.release = 'False'\n\n with open('pycbc/version.py', 'w') as f:\n f.write(\"# coding: utf-8\\n\")\n f.write(\"# Generated by setup.py for PyCBC on %s.\\n\\n\"\n % vinfo.build_date)\n\n # print general info\n f.write('version = \\'%s\\'\\n' % vinfo.version)\n f.write('date = \\'%s\\'\\n' % vinfo.date)\n f.write('release = %s\\n' % vinfo.release)\n f.write('last_release = \\'%s\\'\\n' % vinfo.last_release)\n\n # print git info\n f.write('\\ngit_hash = \\'%s\\'\\n' % vinfo.hash)\n f.write('git_branch = \\'%s\\'\\n' % vinfo.branch)\n f.write('git_tag = \\'%s\\'\\n' % vinfo.tag)\n f.write('git_author = \\'%s\\'\\n' % vinfo.author)\n f.write('git_committer = \\'%s\\'\\n' % vinfo.committer)\n f.write('git_status = \\'%s\\'\\n' % vinfo.status)\n f.write('git_builder = \\'%s\\'\\n' % vinfo.builder)\n f.write('git_build_date = \\'%s\\'\\n' % vinfo.build_date)\n f.write('git_verbose_msg = \"\"\"Version: %s\\n'\n 'Branch: %s\\n'\n 'Tag: %s\\n'\n 'Id: %s\\n'\n 'Builder: %s\\n'\n 'Build date: %s\\n'\n 'Repository status is %s\"\"\"\\n' %(\n vinfo.version,\n vinfo.branch,\n vinfo.tag,\n vinfo.hash,\n vinfo.builder,\n vinfo.build_date,\n vinfo.status))\n f.write('from pycbc._version import *\\n')\n version = vinfo.version\n\n from pycbc import version\n version = version.version\n return version\n\nclass build_docs(Command):\n user_options = []\n description = \"Build the documentation pages\"\n def initialize_options(self):\n pass\n def finalize_options(self):\n pass\n def run(self):\n subprocess.check_call(\"cd docs; cp Makefile.std Makefile; cp conf_std.py conf.py; sphinx-apidoc \"\n \" -o ./ -f -A 'PyCBC dev team' -V '0.1' ../pycbc && make html\",\n stderr=subprocess.STDOUT, shell=True)\n\nclass build_gh_pages(Command):\n user_options = []\n description = \"Build the documentation pages for GitHub\"\n def initialize_options(self):\n pass\n def finalize_options(self):\n pass\n def run(self):\n subprocess.check_call(\"mkdir -p _gh-pages/latest && touch _gh-pages/.nojekyll && \"\n \"cd docs; cp Makefile.gh_pages Makefile; cp conf_std.py conf.py; sphinx-apidoc \"\n \" -o ./ -f -A 'PyCBC dev team' -V '0.1' ../pycbc && make html\",\n stderr=subprocess.STDOUT, shell=True)\n\ncmdclass = { 'build_docs' : build_docs,\n 'build_gh_pages' : build_gh_pages,\n 'clean' : clean,\n 'build_ext':cbuild_ext\n }\n\nextras_require = {'cuda': ['pycuda>=2015.1', 'scikit-cuda']}\n\n# do the actual work of building the package\nVERSION = get_version_info()\n\ncythonext = ['waveform.spa_tmplt',\n 'waveform.utils',\n 'types.array',\n 'filter.matchedfilter']\next = []\nfor name in cythonext:\n e = Extension(\"pycbc.%s_cpu\" % name,\n [\"pycbc/%s_cpu.pyx\" % name.replace('.', '/')],\n extra_compile_args=[ '-O3', '-w', '-msse4.2',\n '-ffast-math', '-ffinite-math-only'],\n compiler_directives={'embedsignature': True})\n ext.append(e)\n\nsetup (\n name = 'PyCBC',\n version = VERSION,\n description = 'Core library to analyze gravitational-wave data, find signals, and study their parameters.',\n long_description = open('descr.rst').read(),\n author = 'Ligo-Virgo Collaborations and the PyCBC team',\n author_email = '[email protected]',\n url = 'http://www.pycbc.org/',\n download_url = 'https://github.com/gwastro/pycbc/tarball/v%s' % VERSION,\n keywords = ['ligo', 'physics', 'gravity', 'signal processing', 'gravitational waves'],\n cmdclass = cmdclass,\n setup_requires = setup_requires,\n extras_require = extras_require,\n install_requires = install_requires,\n scripts = find_files('bin', relpath='./') + ['tools/einsteinathome/pycbc_build_eah.sh'],\n packages = find_packages(),\n package_data = {'pycbc.workflow': find_files('pycbc/workflow'),\n 'pycbc.results': find_files('pycbc/results'),\n 'pycbc.tmpltbank': find_files('pycbc/tmpltbank')},\n ext_modules = ext,\n classifiers=[\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Intended Audience :: Science/Research',\n 'Natural Language :: English',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Astronomy',\n 'Topic :: Scientific/Engineering :: Physics',\n 'License :: OSI Approved :: GNU General Public License v3 (GPLv3)',\n ],\n)\n", "path": "setup.py"}]}
| 3,572 | 153 |
gh_patches_debug_14943
|
rasdani/github-patches
|
git_diff
|
python-poetry__poetry-590
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Excluding file with unsupported VCS
<!-- Checked checkbox should look like this: [x] -->
- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.
- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.
- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).
- **OS version and name**: Fedora 28
- **Poetry version**: 0.12.5
- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: https://gist.github.com/Lothiraldan/7e4c1ffde3ed90ec183ad4eb5e72a44c
## Issue
<!-- Now feel free to write your issue, but please be descriptive! Thanks again 🙌 ❤️ -->
Hello, first thank you for your work on poetry, packaging in Python is something we should be better at and poetry looks very promising.
I'm trying to use poetry with one of my project https://github.com/lothiraldan/balto which will include a compiled react project. I develop the project using Mercurial and then export the repository to Github.
The first time I ran `poetry build`, I saw that the nodes_modules directory was included so I try explictly excluding it with:
```toml
[tool.poetry]
exclude = ["balto/web_interfaces/balto_react/node_modules/**/*"]
```
But it didn't help.
I start taking a look at the code and found that the `find_excluded_files` early abort in case it didn't find the VCS (in my case Mercurial). Apart from adding Mercurial support (which I may do in the future), I think excluding files shouldn't depend on projects using a supported VCS.
I applied the following diff locally to still reads the explicitely excluded files that did the trick:
```diff
diff --git a/poetry/masonry/builders/builder.py b/poetry/masonry/builders/builder.py
index 627e006..477ec8d 100644
--- a/poetry/masonry/builders/builder.py
+++ b/poetry/masonry/builders/builder.py
@@ -43,14 +43,16 @@ class Builder(object):
# Checking VCS
vcs = get_vcs(self._path)
if not vcs:
- return []
+ vcs_ignored_files = []
+ else:
+ vcs_ignored_files = vcs.get_ignored_files()
explicitely_excluded = []
for excluded_glob in self._package.exclude:
for excluded in self._path.glob(excluded_glob):
explicitely_excluded.append(excluded)
- ignored = vcs.get_ignored_files() + explicitely_excluded
+ ignored = vcs_ignored_files + explicitely_excluded
result = []
for file in ignored:
try:
```
I can send a PR with it if the code looks correct and the behavior change is ok.
</issue>
<code>
[start of poetry/masonry/builders/builder.py]
1 # -*- coding: utf-8 -*-
2 import os
3 import re
4 import shutil
5 import tempfile
6
7 from collections import defaultdict
8 from contextlib import contextmanager
9
10 from poetry.utils._compat import Path
11 from poetry.vcs import get_vcs
12
13 from ..metadata import Metadata
14 from ..utils.module import Module
15 from ..utils.package_include import PackageInclude
16
17
18 AUTHOR_REGEX = re.compile(r"(?u)^(?P<name>[- .,\w\d'’\"()]+) <(?P<email>.+?)>$")
19
20
21 class Builder(object):
22
23 AVAILABLE_PYTHONS = {"2", "2.7", "3", "3.4", "3.5", "3.6", "3.7"}
24
25 def __init__(self, poetry, env, io):
26 self._poetry = poetry
27 self._env = env
28 self._io = io
29 self._package = poetry.package
30 self._path = poetry.file.parent
31 self._module = Module(
32 self._package.name,
33 self._path.as_posix(),
34 packages=self._package.packages,
35 includes=self._package.include,
36 )
37 self._meta = Metadata.from_package(self._package)
38
39 def build(self):
40 raise NotImplementedError()
41
42 def find_excluded_files(self): # type: () -> list
43 # Checking VCS
44 vcs = get_vcs(self._path)
45 if not vcs:
46 return []
47
48 explicitely_excluded = []
49 for excluded_glob in self._package.exclude:
50 for excluded in self._path.glob(excluded_glob):
51 explicitely_excluded.append(excluded)
52
53 ignored = vcs.get_ignored_files() + explicitely_excluded
54 result = []
55 for file in ignored:
56 try:
57 file = Path(file).absolute().relative_to(self._path)
58 except ValueError:
59 # Should only happen in tests
60 continue
61
62 result.append(file)
63
64 return result
65
66 def find_files_to_add(self, exclude_build=True): # type: () -> list
67 """
68 Finds all files to add to the tarball
69 """
70 excluded = self.find_excluded_files()
71 to_add = []
72
73 for include in self._module.includes:
74 for file in include.elements:
75 if "__pycache__" in str(file):
76 continue
77
78 if file.is_dir():
79 continue
80
81 file = file.relative_to(self._path)
82
83 if file in excluded and isinstance(include, PackageInclude):
84 continue
85
86 if file.suffix == ".pyc":
87 continue
88
89 if file in to_add:
90 # Skip duplicates
91 continue
92
93 self._io.writeln(
94 " - Adding: <comment>{}</comment>".format(str(file)),
95 verbosity=self._io.VERBOSITY_VERY_VERBOSE,
96 )
97 to_add.append(file)
98
99 # Include project files
100 self._io.writeln(
101 " - Adding: <comment>pyproject.toml</comment>",
102 verbosity=self._io.VERBOSITY_VERY_VERBOSE,
103 )
104 to_add.append(Path("pyproject.toml"))
105
106 # If a license file exists, add it
107 for license_file in self._path.glob("LICENSE*"):
108 self._io.writeln(
109 " - Adding: <comment>{}</comment>".format(
110 license_file.relative_to(self._path)
111 ),
112 verbosity=self._io.VERBOSITY_VERY_VERBOSE,
113 )
114 to_add.append(license_file.relative_to(self._path))
115
116 # If a README is specificed we need to include it
117 # to avoid errors
118 if "readme" in self._poetry.local_config:
119 readme = self._path / self._poetry.local_config["readme"]
120 if readme.exists():
121 self._io.writeln(
122 " - Adding: <comment>{}</comment>".format(
123 readme.relative_to(self._path)
124 ),
125 verbosity=self._io.VERBOSITY_VERY_VERBOSE,
126 )
127 to_add.append(readme.relative_to(self._path))
128
129 # If a build script is specified and explicitely required
130 # we add it to the list of files
131 if self._package.build and not exclude_build:
132 to_add.append(Path(self._package.build))
133
134 return sorted(to_add)
135
136 def convert_entry_points(self): # type: () -> dict
137 result = defaultdict(list)
138
139 # Scripts -> Entry points
140 for name, ep in self._poetry.local_config.get("scripts", {}).items():
141 extras = ""
142 if isinstance(ep, dict):
143 extras = "[{}]".format(", ".join(ep["extras"]))
144 ep = ep["callable"]
145
146 result["console_scripts"].append("{} = {}{}".format(name, ep, extras))
147
148 # Plugins -> entry points
149 plugins = self._poetry.local_config.get("plugins", {})
150 for groupname, group in plugins.items():
151 for name, ep in sorted(group.items()):
152 result[groupname].append("{} = {}".format(name, ep))
153
154 for groupname in result:
155 result[groupname] = sorted(result[groupname])
156
157 return dict(result)
158
159 @classmethod
160 def convert_author(cls, author): # type: () -> dict
161 m = AUTHOR_REGEX.match(author)
162
163 name = m.group("name")
164 email = m.group("email")
165
166 return {"name": name, "email": email}
167
168 @classmethod
169 @contextmanager
170 def temporary_directory(cls, *args, **kwargs):
171 try:
172 from tempfile import TemporaryDirectory
173
174 with TemporaryDirectory(*args, **kwargs) as name:
175 yield name
176 except ImportError:
177 name = tempfile.mkdtemp(*args, **kwargs)
178
179 yield name
180
181 shutil.rmtree(name)
182
[end of poetry/masonry/builders/builder.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/poetry/masonry/builders/builder.py b/poetry/masonry/builders/builder.py
--- a/poetry/masonry/builders/builder.py
+++ b/poetry/masonry/builders/builder.py
@@ -43,14 +43,16 @@
# Checking VCS
vcs = get_vcs(self._path)
if not vcs:
- return []
+ vcs_ignored_files = []
+ else:
+ vcs_ignored_files = vcs.get_ignored_files()
explicitely_excluded = []
for excluded_glob in self._package.exclude:
for excluded in self._path.glob(excluded_glob):
explicitely_excluded.append(excluded)
- ignored = vcs.get_ignored_files() + explicitely_excluded
+ ignored = vcs_ignored_files + explicitely_excluded
result = []
for file in ignored:
try:
|
{"golden_diff": "diff --git a/poetry/masonry/builders/builder.py b/poetry/masonry/builders/builder.py\n--- a/poetry/masonry/builders/builder.py\n+++ b/poetry/masonry/builders/builder.py\n@@ -43,14 +43,16 @@\n # Checking VCS\n vcs = get_vcs(self._path)\n if not vcs:\n- return []\n+ vcs_ignored_files = []\n+ else:\n+ vcs_ignored_files = vcs.get_ignored_files()\n \n explicitely_excluded = []\n for excluded_glob in self._package.exclude:\n for excluded in self._path.glob(excluded_glob):\n explicitely_excluded.append(excluded)\n \n- ignored = vcs.get_ignored_files() + explicitely_excluded\n+ ignored = vcs_ignored_files + explicitely_excluded\n result = []\n for file in ignored:\n try:\n", "issue": "Excluding file with unsupported VCS\n<!-- Checked checkbox should look like this: [x] -->\r\n- [x] I am on the [latest](https://github.com/sdispater/poetry/releases/latest) Poetry version.\r\n- [x] I have searched the [issues](https://github.com/sdispater/poetry/issues) of this repo and believe that this is not a duplicate.\r\n- [x] If an exception occurs when executing a command, I executed it again in debug mode (`-vvv` option).\r\n\r\n- **OS version and name**: Fedora 28\r\n- **Poetry version**: 0.12.5\r\n- **Link of a [Gist](https://gist.github.com/) with the contents of your pyproject.toml file**: https://gist.github.com/Lothiraldan/7e4c1ffde3ed90ec183ad4eb5e72a44c\r\n\r\n## Issue\r\n<!-- Now feel free to write your issue, but please be descriptive! Thanks again \ud83d\ude4c \u2764\ufe0f -->\r\n\r\nHello, first thank you for your work on poetry, packaging in Python is something we should be better at and poetry looks very promising.\r\n\r\nI'm trying to use poetry with one of my project https://github.com/lothiraldan/balto which will include a compiled react project. I develop the project using Mercurial and then export the repository to Github.\r\n\r\nThe first time I ran `poetry build`, I saw that the nodes_modules directory was included so I try explictly excluding it with:\r\n\r\n```toml\r\n[tool.poetry]\r\nexclude = [\"balto/web_interfaces/balto_react/node_modules/**/*\"]\r\n```\r\n\r\nBut it didn't help.\r\n\r\nI start taking a look at the code and found that the `find_excluded_files` early abort in case it didn't find the VCS (in my case Mercurial). Apart from adding Mercurial support (which I may do in the future), I think excluding files shouldn't depend on projects using a supported VCS.\r\n\r\nI applied the following diff locally to still reads the explicitely excluded files that did the trick:\r\n\r\n```diff\r\ndiff --git a/poetry/masonry/builders/builder.py b/poetry/masonry/builders/builder.py\r\nindex 627e006..477ec8d 100644\r\n--- a/poetry/masonry/builders/builder.py\r\n+++ b/poetry/masonry/builders/builder.py\r\n@@ -43,14 +43,16 @@ class Builder(object):\r\n # Checking VCS\r\n vcs = get_vcs(self._path)\r\n if not vcs:\r\n- return []\r\n+ vcs_ignored_files = []\r\n+ else:\r\n+ vcs_ignored_files = vcs.get_ignored_files()\r\n \r\n explicitely_excluded = []\r\n for excluded_glob in self._package.exclude:\r\n for excluded in self._path.glob(excluded_glob):\r\n explicitely_excluded.append(excluded)\r\n \r\n- ignored = vcs.get_ignored_files() + explicitely_excluded\r\n+ ignored = vcs_ignored_files + explicitely_excluded\r\n result = []\r\n for file in ignored:\r\n try:\r\n```\r\n\r\nI can send a PR with it if the code looks correct and the behavior change is ok.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nimport re\nimport shutil\nimport tempfile\n\nfrom collections import defaultdict\nfrom contextlib import contextmanager\n\nfrom poetry.utils._compat import Path\nfrom poetry.vcs import get_vcs\n\nfrom ..metadata import Metadata\nfrom ..utils.module import Module\nfrom ..utils.package_include import PackageInclude\n\n\nAUTHOR_REGEX = re.compile(r\"(?u)^(?P<name>[- .,\\w\\d'\u2019\\\"()]+) <(?P<email>.+?)>$\")\n\n\nclass Builder(object):\n\n AVAILABLE_PYTHONS = {\"2\", \"2.7\", \"3\", \"3.4\", \"3.5\", \"3.6\", \"3.7\"}\n\n def __init__(self, poetry, env, io):\n self._poetry = poetry\n self._env = env\n self._io = io\n self._package = poetry.package\n self._path = poetry.file.parent\n self._module = Module(\n self._package.name,\n self._path.as_posix(),\n packages=self._package.packages,\n includes=self._package.include,\n )\n self._meta = Metadata.from_package(self._package)\n\n def build(self):\n raise NotImplementedError()\n\n def find_excluded_files(self): # type: () -> list\n # Checking VCS\n vcs = get_vcs(self._path)\n if not vcs:\n return []\n\n explicitely_excluded = []\n for excluded_glob in self._package.exclude:\n for excluded in self._path.glob(excluded_glob):\n explicitely_excluded.append(excluded)\n\n ignored = vcs.get_ignored_files() + explicitely_excluded\n result = []\n for file in ignored:\n try:\n file = Path(file).absolute().relative_to(self._path)\n except ValueError:\n # Should only happen in tests\n continue\n\n result.append(file)\n\n return result\n\n def find_files_to_add(self, exclude_build=True): # type: () -> list\n \"\"\"\n Finds all files to add to the tarball\n \"\"\"\n excluded = self.find_excluded_files()\n to_add = []\n\n for include in self._module.includes:\n for file in include.elements:\n if \"__pycache__\" in str(file):\n continue\n\n if file.is_dir():\n continue\n\n file = file.relative_to(self._path)\n\n if file in excluded and isinstance(include, PackageInclude):\n continue\n\n if file.suffix == \".pyc\":\n continue\n\n if file in to_add:\n # Skip duplicates\n continue\n\n self._io.writeln(\n \" - Adding: <comment>{}</comment>\".format(str(file)),\n verbosity=self._io.VERBOSITY_VERY_VERBOSE,\n )\n to_add.append(file)\n\n # Include project files\n self._io.writeln(\n \" - Adding: <comment>pyproject.toml</comment>\",\n verbosity=self._io.VERBOSITY_VERY_VERBOSE,\n )\n to_add.append(Path(\"pyproject.toml\"))\n\n # If a license file exists, add it\n for license_file in self._path.glob(\"LICENSE*\"):\n self._io.writeln(\n \" - Adding: <comment>{}</comment>\".format(\n license_file.relative_to(self._path)\n ),\n verbosity=self._io.VERBOSITY_VERY_VERBOSE,\n )\n to_add.append(license_file.relative_to(self._path))\n\n # If a README is specificed we need to include it\n # to avoid errors\n if \"readme\" in self._poetry.local_config:\n readme = self._path / self._poetry.local_config[\"readme\"]\n if readme.exists():\n self._io.writeln(\n \" - Adding: <comment>{}</comment>\".format(\n readme.relative_to(self._path)\n ),\n verbosity=self._io.VERBOSITY_VERY_VERBOSE,\n )\n to_add.append(readme.relative_to(self._path))\n\n # If a build script is specified and explicitely required\n # we add it to the list of files\n if self._package.build and not exclude_build:\n to_add.append(Path(self._package.build))\n\n return sorted(to_add)\n\n def convert_entry_points(self): # type: () -> dict\n result = defaultdict(list)\n\n # Scripts -> Entry points\n for name, ep in self._poetry.local_config.get(\"scripts\", {}).items():\n extras = \"\"\n if isinstance(ep, dict):\n extras = \"[{}]\".format(\", \".join(ep[\"extras\"]))\n ep = ep[\"callable\"]\n\n result[\"console_scripts\"].append(\"{} = {}{}\".format(name, ep, extras))\n\n # Plugins -> entry points\n plugins = self._poetry.local_config.get(\"plugins\", {})\n for groupname, group in plugins.items():\n for name, ep in sorted(group.items()):\n result[groupname].append(\"{} = {}\".format(name, ep))\n\n for groupname in result:\n result[groupname] = sorted(result[groupname])\n\n return dict(result)\n\n @classmethod\n def convert_author(cls, author): # type: () -> dict\n m = AUTHOR_REGEX.match(author)\n\n name = m.group(\"name\")\n email = m.group(\"email\")\n\n return {\"name\": name, \"email\": email}\n\n @classmethod\n @contextmanager\n def temporary_directory(cls, *args, **kwargs):\n try:\n from tempfile import TemporaryDirectory\n\n with TemporaryDirectory(*args, **kwargs) as name:\n yield name\n except ImportError:\n name = tempfile.mkdtemp(*args, **kwargs)\n\n yield name\n\n shutil.rmtree(name)\n", "path": "poetry/masonry/builders/builder.py"}]}
| 2,923 | 206 |
gh_patches_debug_32029
|
rasdani/github-patches
|
git_diff
|
PrefectHQ__prefect-3465
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Set flow labels through the CLI register command
## Current behavior
Right now there is no way to add a label to a **flow** when registering it using the CLI. You only can set the label from inside the flow's code.
## Proposed behavior
It would be really nice to have a `--label` parameter (just like the one we have for agents) that would allow us to add labels on the fly when registering a flow from the CLI.
## Example
Adding the parameter would look something like this:
`prefect register flow --file my_flow.py --name My-Flow --label my-label`
or this:
`prefect register flow --file my_flow.py --name My-Flow -l my-label`
This could be very useful for registering flows with continuous integration depending on the environment you want to build the flow for (for example, `dev` or `prod`).
Thanks a lot and keep it up!
</issue>
<code>
[start of src/prefect/cli/register.py]
1 import os
2
3 import click
4
5 import prefect
6 from prefect.utilities.storage import extract_flow_from_file
7
8
9 @click.group(hidden=True)
10 def register():
11 """
12 Register flows
13
14 \b
15 Usage:
16 $ prefect register [OBJECT]
17
18 \b
19 Arguments:
20 flow Register flows with a backend API
21
22 \b
23 Examples:
24 $ prefect register flow --file my_flow.py --name My-Flow
25 """
26
27
28 @register.command(
29 hidden=True,
30 context_settings=dict(ignore_unknown_options=True, allow_extra_args=True),
31 )
32 @click.option(
33 "--file",
34 "-f",
35 required=True,
36 help="A file that contains a flow",
37 hidden=True,
38 default=None,
39 type=click.Path(exists=True),
40 )
41 @click.option(
42 "--name",
43 "-n",
44 required=False,
45 help="The `flow.name` to pull out of the file provided.",
46 hidden=True,
47 default=None,
48 )
49 @click.option(
50 "--project",
51 "-p",
52 required=False,
53 help="The name of a Prefect project to register this flow.",
54 hidden=True,
55 default=None,
56 )
57 def flow(file, name, project):
58 """
59 Register a flow from a file. This call will pull a Flow object out of a `.py` file
60 and call `flow.register` on it.
61
62 \b
63 Options:
64 --file, -f TEXT The path to a local file which contains a flow [required]
65 --name, -n TEXT The `flow.name` to pull out of the file provided. If a name
66 is not provided then the first flow object found will be registered.
67 --project TEXT The name of a Prefect project to register this flow
68
69 \b
70 Examples:
71 $ prefect register flow --file my_flow.py --name My-Flow
72 """
73
74 # Don't run extra `run` and `register` functions inside file
75 with prefect.context({"loading_flow": True}):
76 file_path = os.path.abspath(file)
77 flow_obj = extract_flow_from_file(file_path=file_path, flow_name=name)
78
79 flow_obj.register(project_name=project)
80
[end of src/prefect/cli/register.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/prefect/cli/register.py b/src/prefect/cli/register.py
--- a/src/prefect/cli/register.py
+++ b/src/prefect/cli/register.py
@@ -54,7 +54,14 @@
hidden=True,
default=None,
)
-def flow(file, name, project):
[email protected](
+ "--label",
+ "-l",
+ required=False,
+ hidden=True,
+ multiple=True,
+)
+def flow(file, name, project, label):
"""
Register a flow from a file. This call will pull a Flow object out of a `.py` file
and call `flow.register` on it.
@@ -64,16 +71,23 @@
--file, -f TEXT The path to a local file which contains a flow [required]
--name, -n TEXT The `flow.name` to pull out of the file provided. If a name
is not provided then the first flow object found will be registered.
- --project TEXT The name of a Prefect project to register this flow
+ --project, -p TEXT The name of a Prefect project to register this flow
+ --label, -l TEXT A label to set on the flow, extending any existing labels.
+ Multiple labels are supported, eg. `-l label1 -l label2`.
\b
Examples:
- $ prefect register flow --file my_flow.py --name My-Flow
+ $ prefect register flow --file my_flow.py --name My-Flow -l label1 -l label2
"""
# Don't run extra `run` and `register` functions inside file
with prefect.context({"loading_flow": True}):
file_path = os.path.abspath(file)
- flow_obj = extract_flow_from_file(file_path=file_path, flow_name=name)
+ flow = extract_flow_from_file(file_path=file_path, flow_name=name)
+
+ if getattr(flow, "run_config", None) is not None:
+ flow.run_config.labels.update(label)
+ else:
+ flow.environment.labels.update(label)
- flow_obj.register(project_name=project)
+ flow.register(project_name=project)
|
{"golden_diff": "diff --git a/src/prefect/cli/register.py b/src/prefect/cli/register.py\n--- a/src/prefect/cli/register.py\n+++ b/src/prefect/cli/register.py\n@@ -54,7 +54,14 @@\n hidden=True,\n default=None,\n )\n-def flow(file, name, project):\[email protected](\n+ \"--label\",\n+ \"-l\",\n+ required=False,\n+ hidden=True,\n+ multiple=True,\n+)\n+def flow(file, name, project, label):\n \"\"\"\n Register a flow from a file. This call will pull a Flow object out of a `.py` file\n and call `flow.register` on it.\n@@ -64,16 +71,23 @@\n --file, -f TEXT The path to a local file which contains a flow [required]\n --name, -n TEXT The `flow.name` to pull out of the file provided. If a name\n is not provided then the first flow object found will be registered.\n- --project TEXT The name of a Prefect project to register this flow\n+ --project, -p TEXT The name of a Prefect project to register this flow\n+ --label, -l TEXT A label to set on the flow, extending any existing labels.\n+ Multiple labels are supported, eg. `-l label1 -l label2`.\n \n \\b\n Examples:\n- $ prefect register flow --file my_flow.py --name My-Flow\n+ $ prefect register flow --file my_flow.py --name My-Flow -l label1 -l label2\n \"\"\"\n \n # Don't run extra `run` and `register` functions inside file\n with prefect.context({\"loading_flow\": True}):\n file_path = os.path.abspath(file)\n- flow_obj = extract_flow_from_file(file_path=file_path, flow_name=name)\n+ flow = extract_flow_from_file(file_path=file_path, flow_name=name)\n+\n+ if getattr(flow, \"run_config\", None) is not None:\n+ flow.run_config.labels.update(label)\n+ else:\n+ flow.environment.labels.update(label)\n \n- flow_obj.register(project_name=project)\n+ flow.register(project_name=project)\n", "issue": "Set flow labels through the CLI register command\n## Current behavior\r\nRight now there is no way to add a label to a **flow** when registering it using the CLI. You only can set the label from inside the flow's code.\r\n\r\n## Proposed behavior\r\nIt would be really nice to have a `--label` parameter (just like the one we have for agents) that would allow us to add labels on the fly when registering a flow from the CLI.\r\n\r\n## Example\r\nAdding the parameter would look something like this:\r\n`prefect register flow --file my_flow.py --name My-Flow --label my-label`\r\nor this:\r\n`prefect register flow --file my_flow.py --name My-Flow -l my-label`\r\n\r\nThis could be very useful for registering flows with continuous integration depending on the environment you want to build the flow for (for example, `dev` or `prod`).\r\n\r\nThanks a lot and keep it up!\r\n\n", "before_files": [{"content": "import os\n\nimport click\n\nimport prefect\nfrom prefect.utilities.storage import extract_flow_from_file\n\n\[email protected](hidden=True)\ndef register():\n \"\"\"\n Register flows\n\n \\b\n Usage:\n $ prefect register [OBJECT]\n\n \\b\n Arguments:\n flow Register flows with a backend API\n\n \\b\n Examples:\n $ prefect register flow --file my_flow.py --name My-Flow\n \"\"\"\n\n\[email protected](\n hidden=True,\n context_settings=dict(ignore_unknown_options=True, allow_extra_args=True),\n)\[email protected](\n \"--file\",\n \"-f\",\n required=True,\n help=\"A file that contains a flow\",\n hidden=True,\n default=None,\n type=click.Path(exists=True),\n)\[email protected](\n \"--name\",\n \"-n\",\n required=False,\n help=\"The `flow.name` to pull out of the file provided.\",\n hidden=True,\n default=None,\n)\[email protected](\n \"--project\",\n \"-p\",\n required=False,\n help=\"The name of a Prefect project to register this flow.\",\n hidden=True,\n default=None,\n)\ndef flow(file, name, project):\n \"\"\"\n Register a flow from a file. This call will pull a Flow object out of a `.py` file\n and call `flow.register` on it.\n\n \\b\n Options:\n --file, -f TEXT The path to a local file which contains a flow [required]\n --name, -n TEXT The `flow.name` to pull out of the file provided. If a name\n is not provided then the first flow object found will be registered.\n --project TEXT The name of a Prefect project to register this flow\n\n \\b\n Examples:\n $ prefect register flow --file my_flow.py --name My-Flow\n \"\"\"\n\n # Don't run extra `run` and `register` functions inside file\n with prefect.context({\"loading_flow\": True}):\n file_path = os.path.abspath(file)\n flow_obj = extract_flow_from_file(file_path=file_path, flow_name=name)\n\n flow_obj.register(project_name=project)\n", "path": "src/prefect/cli/register.py"}]}
| 1,353 | 490 |
gh_patches_debug_17801
|
rasdani/github-patches
|
git_diff
|
apache__airflow-9759
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Replace flask_oauthlib with Authlib
**Description**
flask_oauthlib has been deprecated in favour of Authlib. It would be good if airflow starts using Authlib
**Use case / motivation**
FlaskAppBuilder is now using Authlib.
Since FlaskAppBuilder is deeply integrated into Airflow, it will be good to also have this Authlib. Flask-oauthlib documentation recommends Authlib
**Related Issues**
</issue>
<code>
[start of airflow/config_templates/default_webserver_config.py]
1 #
2 # Licensed to the Apache Software Foundation (ASF) under one
3 # or more contributor license agreements. See the NOTICE file
4 # distributed with this work for additional information
5 # regarding copyright ownership. The ASF licenses this file
6 # to you under the Apache License, Version 2.0 (the
7 # "License"); you may not use this file except in compliance
8 # with the License. You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing,
13 # software distributed under the License is distributed on an
14 # "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
15 # KIND, either express or implied. See the License for the
16 # specific language governing permissions and limitations
17 # under the License.
18 """Default configuration for the Airflow webserver"""
19 import os
20
21 from flask_appbuilder.security.manager import AUTH_DB
22
23 from airflow.configuration import conf
24
25 # from flask_appbuilder.security.manager import AUTH_LDAP
26 # from flask_appbuilder.security.manager import AUTH_OAUTH
27 # from flask_appbuilder.security.manager import AUTH_OID
28 # from flask_appbuilder.security.manager import AUTH_REMOTE_USER
29
30
31 basedir = os.path.abspath(os.path.dirname(__file__))
32
33 # The SQLAlchemy connection string.
34 SQLALCHEMY_DATABASE_URI = conf.get('core', 'SQL_ALCHEMY_CONN')
35
36 # Flask-WTF flag for CSRF
37 WTF_CSRF_ENABLED = True
38
39 # ----------------------------------------------------
40 # AUTHENTICATION CONFIG
41 # ----------------------------------------------------
42 # For details on how to set up each of the following authentication, see
43 # http://flask-appbuilder.readthedocs.io/en/latest/security.html# authentication-methods
44 # for details.
45
46 # The authentication type
47 # AUTH_OID : Is for OpenID
48 # AUTH_DB : Is for database
49 # AUTH_LDAP : Is for LDAP
50 # AUTH_REMOTE_USER : Is for using REMOTE_USER from web server
51 # AUTH_OAUTH : Is for OAuth
52 AUTH_TYPE = AUTH_DB
53
54 # Uncomment to setup Full admin role name
55 # AUTH_ROLE_ADMIN = 'Admin'
56
57 # Uncomment to setup Public role name, no authentication needed
58 # AUTH_ROLE_PUBLIC = 'Public'
59
60 # Will allow user self registration
61 # AUTH_USER_REGISTRATION = True
62
63 # The default user self registration role
64 # AUTH_USER_REGISTRATION_ROLE = "Public"
65
66 # When using OAuth Auth, uncomment to setup provider(s) info
67 # Google OAuth example:
68 # OAUTH_PROVIDERS = [{
69 # 'name':'google',
70 # 'token_key':'access_token',
71 # 'icon':'fa-google',
72 # 'remote_app': {
73 # 'base_url':'https://www.googleapis.com/oauth2/v2/',
74 # 'request_token_params':{
75 # 'scope': 'email profile'
76 # },
77 # 'access_token_url':'https://accounts.google.com/o/oauth2/token',
78 # 'authorize_url':'https://accounts.google.com/o/oauth2/auth',
79 # 'request_token_url': None,
80 # 'consumer_key': CONSUMER_KEY,
81 # 'consumer_secret': SECRET_KEY,
82 # }
83 # }]
84
85 # When using LDAP Auth, setup the ldap server
86 # AUTH_LDAP_SERVER = "ldap://ldapserver.new"
87
88 # When using OpenID Auth, uncomment to setup OpenID providers.
89 # example for OpenID authentication
90 # OPENID_PROVIDERS = [
91 # { 'name': 'Yahoo', 'url': 'https://me.yahoo.com' },
92 # { 'name': 'AOL', 'url': 'http://openid.aol.com/<username>' },
93 # { 'name': 'Flickr', 'url': 'http://www.flickr.com/<username>' },
94 # { 'name': 'MyOpenID', 'url': 'https://www.myopenid.com' }]
95
96 # ----------------------------------------------------
97 # Theme CONFIG
98 # ----------------------------------------------------
99 # Flask App Builder comes up with a number of predefined themes
100 # that you can use for Apache Airflow.
101 # http://flask-appbuilder.readthedocs.io/en/latest/customizing.html#changing-themes
102 # Please make sure to remove "navbar_color" configuration from airflow.cfg
103 # in order to fully utilize the theme. (or use that property in conjunction with theme)
104 # APP_THEME = "bootstrap-theme.css" # default bootstrap
105 # APP_THEME = "amelia.css"
106 # APP_THEME = "cerulean.css"
107 # APP_THEME = "cosmo.css"
108 # APP_THEME = "cyborg.css"
109 # APP_THEME = "darkly.css"
110 # APP_THEME = "flatly.css"
111 # APP_THEME = "journal.css"
112 # APP_THEME = "lumen.css"
113 # APP_THEME = "paper.css"
114 # APP_THEME = "readable.css"
115 # APP_THEME = "sandstone.css"
116 # APP_THEME = "simplex.css"
117 # APP_THEME = "slate.css"
118 # APP_THEME = "solar.css"
119 # APP_THEME = "spacelab.css"
120 # APP_THEME = "superhero.css"
121 # APP_THEME = "united.css"
122 # APP_THEME = "yeti.css"
123
[end of airflow/config_templates/default_webserver_config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/airflow/config_templates/default_webserver_config.py b/airflow/config_templates/default_webserver_config.py
--- a/airflow/config_templates/default_webserver_config.py
+++ b/airflow/config_templates/default_webserver_config.py
@@ -70,15 +70,15 @@
# 'token_key':'access_token',
# 'icon':'fa-google',
# 'remote_app': {
-# 'base_url':'https://www.googleapis.com/oauth2/v2/',
-# 'request_token_params':{
+# 'api_base_url':'https://www.googleapis.com/oauth2/v2/',
+# 'client_kwargs':{
# 'scope': 'email profile'
# },
# 'access_token_url':'https://accounts.google.com/o/oauth2/token',
# 'authorize_url':'https://accounts.google.com/o/oauth2/auth',
# 'request_token_url': None,
-# 'consumer_key': CONSUMER_KEY,
-# 'consumer_secret': SECRET_KEY,
+# 'client_id': GOOGLE_KEY,
+# 'client_secret': GOOGLE_SECRET_KEY,
# }
# }]
|
{"golden_diff": "diff --git a/airflow/config_templates/default_webserver_config.py b/airflow/config_templates/default_webserver_config.py\n--- a/airflow/config_templates/default_webserver_config.py\n+++ b/airflow/config_templates/default_webserver_config.py\n@@ -70,15 +70,15 @@\n # 'token_key':'access_token',\n # 'icon':'fa-google',\n # 'remote_app': {\n-# 'base_url':'https://www.googleapis.com/oauth2/v2/',\n-# 'request_token_params':{\n+# 'api_base_url':'https://www.googleapis.com/oauth2/v2/',\n+# 'client_kwargs':{\n # 'scope': 'email profile'\n # },\n # 'access_token_url':'https://accounts.google.com/o/oauth2/token',\n # 'authorize_url':'https://accounts.google.com/o/oauth2/auth',\n # 'request_token_url': None,\n-# 'consumer_key': CONSUMER_KEY,\n-# 'consumer_secret': SECRET_KEY,\n+# 'client_id': GOOGLE_KEY,\n+# 'client_secret': GOOGLE_SECRET_KEY,\n # }\n # }]\n", "issue": "Replace flask_oauthlib with Authlib\n\r\n**Description**\r\n\r\nflask_oauthlib has been deprecated in favour of Authlib. It would be good if airflow starts using Authlib\r\n\r\n**Use case / motivation**\r\n\r\nFlaskAppBuilder is now using Authlib. \r\nSince FlaskAppBuilder is deeply integrated into Airflow, it will be good to also have this Authlib. Flask-oauthlib documentation recommends Authlib\r\n\r\n**Related Issues**\r\n\n", "before_files": [{"content": "#\n# Licensed to the Apache Software Foundation (ASF) under one\n# or more contributor license agreements. See the NOTICE file\n# distributed with this work for additional information\n# regarding copyright ownership. The ASF licenses this file\n# to you under the Apache License, Version 2.0 (the\n# \"License\"); you may not use this file except in compliance\n# with the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing,\n# software distributed under the License is distributed on an\n# \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY\n# KIND, either express or implied. See the License for the\n# specific language governing permissions and limitations\n# under the License.\n\"\"\"Default configuration for the Airflow webserver\"\"\"\nimport os\n\nfrom flask_appbuilder.security.manager import AUTH_DB\n\nfrom airflow.configuration import conf\n\n# from flask_appbuilder.security.manager import AUTH_LDAP\n# from flask_appbuilder.security.manager import AUTH_OAUTH\n# from flask_appbuilder.security.manager import AUTH_OID\n# from flask_appbuilder.security.manager import AUTH_REMOTE_USER\n\n\nbasedir = os.path.abspath(os.path.dirname(__file__))\n\n# The SQLAlchemy connection string.\nSQLALCHEMY_DATABASE_URI = conf.get('core', 'SQL_ALCHEMY_CONN')\n\n# Flask-WTF flag for CSRF\nWTF_CSRF_ENABLED = True\n\n# ----------------------------------------------------\n# AUTHENTICATION CONFIG\n# ----------------------------------------------------\n# For details on how to set up each of the following authentication, see\n# http://flask-appbuilder.readthedocs.io/en/latest/security.html# authentication-methods\n# for details.\n\n# The authentication type\n# AUTH_OID : Is for OpenID\n# AUTH_DB : Is for database\n# AUTH_LDAP : Is for LDAP\n# AUTH_REMOTE_USER : Is for using REMOTE_USER from web server\n# AUTH_OAUTH : Is for OAuth\nAUTH_TYPE = AUTH_DB\n\n# Uncomment to setup Full admin role name\n# AUTH_ROLE_ADMIN = 'Admin'\n\n# Uncomment to setup Public role name, no authentication needed\n# AUTH_ROLE_PUBLIC = 'Public'\n\n# Will allow user self registration\n# AUTH_USER_REGISTRATION = True\n\n# The default user self registration role\n# AUTH_USER_REGISTRATION_ROLE = \"Public\"\n\n# When using OAuth Auth, uncomment to setup provider(s) info\n# Google OAuth example:\n# OAUTH_PROVIDERS = [{\n# 'name':'google',\n# 'token_key':'access_token',\n# 'icon':'fa-google',\n# 'remote_app': {\n# 'base_url':'https://www.googleapis.com/oauth2/v2/',\n# 'request_token_params':{\n# 'scope': 'email profile'\n# },\n# 'access_token_url':'https://accounts.google.com/o/oauth2/token',\n# 'authorize_url':'https://accounts.google.com/o/oauth2/auth',\n# 'request_token_url': None,\n# 'consumer_key': CONSUMER_KEY,\n# 'consumer_secret': SECRET_KEY,\n# }\n# }]\n\n# When using LDAP Auth, setup the ldap server\n# AUTH_LDAP_SERVER = \"ldap://ldapserver.new\"\n\n# When using OpenID Auth, uncomment to setup OpenID providers.\n# example for OpenID authentication\n# OPENID_PROVIDERS = [\n# { 'name': 'Yahoo', 'url': 'https://me.yahoo.com' },\n# { 'name': 'AOL', 'url': 'http://openid.aol.com/<username>' },\n# { 'name': 'Flickr', 'url': 'http://www.flickr.com/<username>' },\n# { 'name': 'MyOpenID', 'url': 'https://www.myopenid.com' }]\n\n# ----------------------------------------------------\n# Theme CONFIG\n# ----------------------------------------------------\n# Flask App Builder comes up with a number of predefined themes\n# that you can use for Apache Airflow.\n# http://flask-appbuilder.readthedocs.io/en/latest/customizing.html#changing-themes\n# Please make sure to remove \"navbar_color\" configuration from airflow.cfg\n# in order to fully utilize the theme. (or use that property in conjunction with theme)\n# APP_THEME = \"bootstrap-theme.css\" # default bootstrap\n# APP_THEME = \"amelia.css\"\n# APP_THEME = \"cerulean.css\"\n# APP_THEME = \"cosmo.css\"\n# APP_THEME = \"cyborg.css\"\n# APP_THEME = \"darkly.css\"\n# APP_THEME = \"flatly.css\"\n# APP_THEME = \"journal.css\"\n# APP_THEME = \"lumen.css\"\n# APP_THEME = \"paper.css\"\n# APP_THEME = \"readable.css\"\n# APP_THEME = \"sandstone.css\"\n# APP_THEME = \"simplex.css\"\n# APP_THEME = \"slate.css\"\n# APP_THEME = \"solar.css\"\n# APP_THEME = \"spacelab.css\"\n# APP_THEME = \"superhero.css\"\n# APP_THEME = \"united.css\"\n# APP_THEME = \"yeti.css\"\n", "path": "airflow/config_templates/default_webserver_config.py"}]}
| 1,960 | 239 |
gh_patches_debug_41426
|
rasdani/github-patches
|
git_diff
|
ansible-collections__community.general-7472
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
community.general.gitlab_runner SSLError cert verify failed
### Summary
I am trying to register some gitlab runners. On new openstack instances.
I get a SSL certificate verify failed error as the return.
If I curl the gitlab url from the command line of the box that I am trying to register I get a response back no TLS issues.
The gitlab servers certificate is signed by an internal CA, which is installed into the system ca-trust /etc/pki/ca-trust/source/anchors and update-ca-trust has been run.
I am unable to copy and paste the actual out from the servers. Due to interal work policy
### Issue Type
Bug Report
### Component Name
gitlab_runner
### Ansible Version
```console (paste below)
$ ansible --version
```
ansible 2.9.33
python version 3.9.5
### Configuration
```
```
### OS / Environment
CentOS 8 on Openstack train
Gitlab 14.0.1 runner same version
### Steps to Reproduce
<!--- Paste example playbooks or commands between quotes below -->
```yaml (paste below)
- name: register gitlab runner
community.general.gitlab_runner
api_url: https://gitlab.internal.addressing
api_token: abc
registration_token: def
description: "{{ anisble_hostname }}"
state: present
active: false
tag_list: shell
run_untagged: false
locked: false
```
### Expected Results
The ansible task to connect to the gitlab server and register the runner
### Actual Results
```console (paste below)
SSLError "Certificate_verify_failed"
```
### Code of Conduct
- [X] I agree to follow the Ansible Code of Conduct
</issue>
<code>
[start of plugins/module_utils/gitlab.py]
1 # -*- coding: utf-8 -*-
2
3 # Copyright (c) 2019, Guillaume Martinez ([email protected])
4 # Copyright (c) 2018, Marcus Watkins <[email protected]>
5 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
6 # SPDX-License-Identifier: GPL-3.0-or-later
7
8 from __future__ import (absolute_import, division, print_function)
9 __metaclass__ = type
10
11 from ansible.module_utils.basic import missing_required_lib
12 from ansible.module_utils.common.text.converters import to_native
13 from ansible.module_utils.six import integer_types, string_types
14
15 from ansible_collections.community.general.plugins.module_utils.version import LooseVersion
16
17 try:
18 from urlparse import urljoin
19 except ImportError:
20 from urllib.parse import urljoin # Python 3+
21
22 import traceback
23
24 GITLAB_IMP_ERR = None
25 try:
26 import gitlab
27 import requests
28 HAS_GITLAB_PACKAGE = True
29 except Exception:
30 gitlab = None
31 GITLAB_IMP_ERR = traceback.format_exc()
32 HAS_GITLAB_PACKAGE = False
33
34
35 def auth_argument_spec(spec=None):
36 arg_spec = (dict(
37 api_token=dict(type='str', no_log=True),
38 api_oauth_token=dict(type='str', no_log=True),
39 api_job_token=dict(type='str', no_log=True),
40 ))
41 if spec:
42 arg_spec.update(spec)
43 return arg_spec
44
45
46 def find_project(gitlab_instance, identifier):
47 try:
48 project = gitlab_instance.projects.get(identifier)
49 except Exception as e:
50 current_user = gitlab_instance.user
51 try:
52 project = gitlab_instance.projects.get(current_user.username + '/' + identifier)
53 except Exception as e:
54 return None
55
56 return project
57
58
59 def find_group(gitlab_instance, identifier):
60 try:
61 project = gitlab_instance.groups.get(identifier)
62 except Exception as e:
63 return None
64
65 return project
66
67
68 def ensure_gitlab_package(module):
69 if not HAS_GITLAB_PACKAGE:
70 module.fail_json(
71 msg=missing_required_lib("python-gitlab", url='https://python-gitlab.readthedocs.io/en/stable/'),
72 exception=GITLAB_IMP_ERR
73 )
74
75
76 def gitlab_authentication(module):
77 gitlab_url = module.params['api_url']
78 validate_certs = module.params['validate_certs']
79 gitlab_user = module.params['api_username']
80 gitlab_password = module.params['api_password']
81 gitlab_token = module.params['api_token']
82 gitlab_oauth_token = module.params['api_oauth_token']
83 gitlab_job_token = module.params['api_job_token']
84
85 ensure_gitlab_package(module)
86
87 try:
88 # python-gitlab library remove support for username/password authentication since 1.13.0
89 # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0
90 # This condition allow to still support older version of the python-gitlab library
91 if LooseVersion(gitlab.__version__) < LooseVersion("1.13.0"):
92 gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,
93 private_token=gitlab_token, api_version=4)
94 else:
95 # We can create an oauth_token using a username and password
96 # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow
97 if gitlab_user:
98 data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}
99 resp = requests.post(urljoin(gitlab_url, "oauth/token"), data=data, verify=validate_certs)
100 resp_data = resp.json()
101 gitlab_oauth_token = resp_data["access_token"]
102
103 gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,
104 oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)
105
106 gitlab_instance.auth()
107 except (gitlab.exceptions.GitlabAuthenticationError, gitlab.exceptions.GitlabGetError) as e:
108 module.fail_json(msg="Failed to connect to GitLab server: %s" % to_native(e))
109 except (gitlab.exceptions.GitlabHttpError) as e:
110 module.fail_json(msg="Failed to connect to GitLab server: %s. \
111 GitLab remove Session API now that private tokens are removed from user API endpoints since version 10.2." % to_native(e))
112
113 return gitlab_instance
114
115
116 def filter_returned_variables(gitlab_variables):
117 # pop properties we don't know
118 existing_variables = [dict(x.attributes) for x in gitlab_variables]
119 KNOWN = ['key', 'value', 'masked', 'protected', 'variable_type', 'environment_scope', 'raw']
120 for item in existing_variables:
121 for key in list(item.keys()):
122 if key not in KNOWN:
123 item.pop(key)
124 return existing_variables
125
126
127 def vars_to_variables(vars, module):
128 # transform old vars to new variables structure
129 variables = list()
130 for item, value in vars.items():
131 if isinstance(value, (string_types, integer_types, float)):
132 variables.append(
133 {
134 "name": item,
135 "value": str(value),
136 "masked": False,
137 "protected": False,
138 "raw": False,
139 "variable_type": "env_var",
140 }
141 )
142
143 elif isinstance(value, dict):
144 new_item = {
145 "name": item,
146 "value": value.get('value'),
147 "masked": value.get('masked'),
148 "protected": value.get('protected'),
149 "raw": value.get('raw'),
150 "variable_type": value.get('variable_type'),
151 }
152
153 if value.get('environment_scope'):
154 new_item['environment_scope'] = value.get('environment_scope')
155
156 variables.append(new_item)
157
158 else:
159 module.fail_json(msg="value must be of type string, integer, float or dict")
160
161 return variables
162
[end of plugins/module_utils/gitlab.py]
[start of plugins/doc_fragments/gitlab.py]
1 # -*- coding: utf-8 -*-
2 # Copyright (c) Ansible project
3 # GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)
4 # SPDX-License-Identifier: GPL-3.0-or-later
5
6 from __future__ import (absolute_import, division, print_function)
7 __metaclass__ = type
8
9
10 class ModuleDocFragment(object):
11
12 # Standard files documentation fragment
13 DOCUMENTATION = r'''
14 requirements:
15 - requests (Python library U(https://pypi.org/project/requests/))
16
17 options:
18 api_token:
19 description:
20 - GitLab access token with API permissions.
21 type: str
22 api_oauth_token:
23 description:
24 - GitLab OAuth token for logging in.
25 type: str
26 version_added: 4.2.0
27 api_job_token:
28 description:
29 - GitLab CI job token for logging in.
30 type: str
31 version_added: 4.2.0
32 '''
33
[end of plugins/doc_fragments/gitlab.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/doc_fragments/gitlab.py b/plugins/doc_fragments/gitlab.py
--- a/plugins/doc_fragments/gitlab.py
+++ b/plugins/doc_fragments/gitlab.py
@@ -29,4 +29,9 @@
- GitLab CI job token for logging in.
type: str
version_added: 4.2.0
+ ca_path:
+ description:
+ - The CA certificates bundle to use to verify GitLab server certificate.
+ type: str
+ version_added: 8.1.0
'''
diff --git a/plugins/module_utils/gitlab.py b/plugins/module_utils/gitlab.py
--- a/plugins/module_utils/gitlab.py
+++ b/plugins/module_utils/gitlab.py
@@ -34,6 +34,7 @@
def auth_argument_spec(spec=None):
arg_spec = (dict(
+ ca_path=dict(type='str'),
api_token=dict(type='str', no_log=True),
api_oauth_token=dict(type='str', no_log=True),
api_job_token=dict(type='str', no_log=True),
@@ -76,6 +77,7 @@
def gitlab_authentication(module):
gitlab_url = module.params['api_url']
validate_certs = module.params['validate_certs']
+ ca_path = module.params['ca_path']
gitlab_user = module.params['api_username']
gitlab_password = module.params['api_password']
gitlab_token = module.params['api_token']
@@ -84,23 +86,25 @@
ensure_gitlab_package(module)
+ verify = ca_path if validate_certs and ca_path else validate_certs
+
try:
# python-gitlab library remove support for username/password authentication since 1.13.0
# Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0
# This condition allow to still support older version of the python-gitlab library
if LooseVersion(gitlab.__version__) < LooseVersion("1.13.0"):
- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,
+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, email=gitlab_user, password=gitlab_password,
private_token=gitlab_token, api_version=4)
else:
# We can create an oauth_token using a username and password
# https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow
if gitlab_user:
data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}
- resp = requests.post(urljoin(gitlab_url, "oauth/token"), data=data, verify=validate_certs)
+ resp = requests.post(urljoin(gitlab_url, "oauth/token"), data=data, verify=verify)
resp_data = resp.json()
gitlab_oauth_token = resp_data["access_token"]
- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,
+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, private_token=gitlab_token,
oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)
gitlab_instance.auth()
|
{"golden_diff": "diff --git a/plugins/doc_fragments/gitlab.py b/plugins/doc_fragments/gitlab.py\n--- a/plugins/doc_fragments/gitlab.py\n+++ b/plugins/doc_fragments/gitlab.py\n@@ -29,4 +29,9 @@\n - GitLab CI job token for logging in.\n type: str\n version_added: 4.2.0\n+ ca_path:\n+ description:\n+ - The CA certificates bundle to use to verify GitLab server certificate.\n+ type: str\n+ version_added: 8.1.0\n '''\ndiff --git a/plugins/module_utils/gitlab.py b/plugins/module_utils/gitlab.py\n--- a/plugins/module_utils/gitlab.py\n+++ b/plugins/module_utils/gitlab.py\n@@ -34,6 +34,7 @@\n \n def auth_argument_spec(spec=None):\n arg_spec = (dict(\n+ ca_path=dict(type='str'),\n api_token=dict(type='str', no_log=True),\n api_oauth_token=dict(type='str', no_log=True),\n api_job_token=dict(type='str', no_log=True),\n@@ -76,6 +77,7 @@\n def gitlab_authentication(module):\n gitlab_url = module.params['api_url']\n validate_certs = module.params['validate_certs']\n+ ca_path = module.params['ca_path']\n gitlab_user = module.params['api_username']\n gitlab_password = module.params['api_password']\n gitlab_token = module.params['api_token']\n@@ -84,23 +86,25 @@\n \n ensure_gitlab_package(module)\n \n+ verify = ca_path if validate_certs and ca_path else validate_certs\n+\n try:\n # python-gitlab library remove support for username/password authentication since 1.13.0\n # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0\n # This condition allow to still support older version of the python-gitlab library\n if LooseVersion(gitlab.__version__) < LooseVersion(\"1.13.0\"):\n- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,\n+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, email=gitlab_user, password=gitlab_password,\n private_token=gitlab_token, api_version=4)\n else:\n # We can create an oauth_token using a username and password\n # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow\n if gitlab_user:\n data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}\n- resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=validate_certs)\n+ resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=verify)\n resp_data = resp.json()\n gitlab_oauth_token = resp_data[\"access_token\"]\n \n- gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,\n+ gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=verify, private_token=gitlab_token,\n oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)\n \n gitlab_instance.auth()\n", "issue": "community.general.gitlab_runner SSLError cert verify failed\n### Summary\n\nI am trying to register some gitlab runners. On new openstack instances.\r\nI get a SSL certificate verify failed error as the return.\r\n\r\nIf I curl the gitlab url from the command line of the box that I am trying to register I get a response back no TLS issues. \r\nThe gitlab servers certificate is signed by an internal CA, which is installed into the system ca-trust /etc/pki/ca-trust/source/anchors and update-ca-trust has been run.\r\n\r\nI am unable to copy and paste the actual out from the servers. Due to interal work policy\n\n### Issue Type\n\nBug Report\n\n### Component Name\n\ngitlab_runner\n\n### Ansible Version\n\n```console (paste below)\r\n$ ansible --version\r\n\r\n```\r\nansible 2.9.33\r\npython version 3.9.5\n\n### Configuration\n\n```\r\n\r\n```\r\n\n\n### OS / Environment\n\nCentOS 8 on Openstack train\r\nGitlab 14.0.1 runner same version\r\n\n\n### Steps to Reproduce\n\n<!--- Paste example playbooks or commands between quotes below -->\r\n```yaml (paste below)\r\n- name: register gitlab runner\r\n community.general.gitlab_runner\r\n api_url: https://gitlab.internal.addressing\r\n api_token: abc\r\n registration_token: def\r\n description: \"{{ anisble_hostname }}\"\r\n state: present\r\n active: false\r\n tag_list: shell\r\n run_untagged: false\r\n locked: false\r\n```\r\n\n\n### Expected Results\n\nThe ansible task to connect to the gitlab server and register the runner\n\n### Actual Results\n\n```console (paste below)\r\nSSLError \"Certificate_verify_failed\"\r\n```\r\n\n\n### Code of Conduct\n\n- [X] I agree to follow the Ansible Code of Conduct\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright (c) 2019, Guillaume Martinez ([email protected])\n# Copyright (c) 2018, Marcus Watkins <[email protected]>\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\nfrom ansible.module_utils.basic import missing_required_lib\nfrom ansible.module_utils.common.text.converters import to_native\nfrom ansible.module_utils.six import integer_types, string_types\n\nfrom ansible_collections.community.general.plugins.module_utils.version import LooseVersion\n\ntry:\n from urlparse import urljoin\nexcept ImportError:\n from urllib.parse import urljoin # Python 3+\n\nimport traceback\n\nGITLAB_IMP_ERR = None\ntry:\n import gitlab\n import requests\n HAS_GITLAB_PACKAGE = True\nexcept Exception:\n gitlab = None\n GITLAB_IMP_ERR = traceback.format_exc()\n HAS_GITLAB_PACKAGE = False\n\n\ndef auth_argument_spec(spec=None):\n arg_spec = (dict(\n api_token=dict(type='str', no_log=True),\n api_oauth_token=dict(type='str', no_log=True),\n api_job_token=dict(type='str', no_log=True),\n ))\n if spec:\n arg_spec.update(spec)\n return arg_spec\n\n\ndef find_project(gitlab_instance, identifier):\n try:\n project = gitlab_instance.projects.get(identifier)\n except Exception as e:\n current_user = gitlab_instance.user\n try:\n project = gitlab_instance.projects.get(current_user.username + '/' + identifier)\n except Exception as e:\n return None\n\n return project\n\n\ndef find_group(gitlab_instance, identifier):\n try:\n project = gitlab_instance.groups.get(identifier)\n except Exception as e:\n return None\n\n return project\n\n\ndef ensure_gitlab_package(module):\n if not HAS_GITLAB_PACKAGE:\n module.fail_json(\n msg=missing_required_lib(\"python-gitlab\", url='https://python-gitlab.readthedocs.io/en/stable/'),\n exception=GITLAB_IMP_ERR\n )\n\n\ndef gitlab_authentication(module):\n gitlab_url = module.params['api_url']\n validate_certs = module.params['validate_certs']\n gitlab_user = module.params['api_username']\n gitlab_password = module.params['api_password']\n gitlab_token = module.params['api_token']\n gitlab_oauth_token = module.params['api_oauth_token']\n gitlab_job_token = module.params['api_job_token']\n\n ensure_gitlab_package(module)\n\n try:\n # python-gitlab library remove support for username/password authentication since 1.13.0\n # Changelog : https://github.com/python-gitlab/python-gitlab/releases/tag/v1.13.0\n # This condition allow to still support older version of the python-gitlab library\n if LooseVersion(gitlab.__version__) < LooseVersion(\"1.13.0\"):\n gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, email=gitlab_user, password=gitlab_password,\n private_token=gitlab_token, api_version=4)\n else:\n # We can create an oauth_token using a username and password\n # https://docs.gitlab.com/ee/api/oauth2.html#authorization-code-flow\n if gitlab_user:\n data = {'grant_type': 'password', 'username': gitlab_user, 'password': gitlab_password}\n resp = requests.post(urljoin(gitlab_url, \"oauth/token\"), data=data, verify=validate_certs)\n resp_data = resp.json()\n gitlab_oauth_token = resp_data[\"access_token\"]\n\n gitlab_instance = gitlab.Gitlab(url=gitlab_url, ssl_verify=validate_certs, private_token=gitlab_token,\n oauth_token=gitlab_oauth_token, job_token=gitlab_job_token, api_version=4)\n\n gitlab_instance.auth()\n except (gitlab.exceptions.GitlabAuthenticationError, gitlab.exceptions.GitlabGetError) as e:\n module.fail_json(msg=\"Failed to connect to GitLab server: %s\" % to_native(e))\n except (gitlab.exceptions.GitlabHttpError) as e:\n module.fail_json(msg=\"Failed to connect to GitLab server: %s. \\\n GitLab remove Session API now that private tokens are removed from user API endpoints since version 10.2.\" % to_native(e))\n\n return gitlab_instance\n\n\ndef filter_returned_variables(gitlab_variables):\n # pop properties we don't know\n existing_variables = [dict(x.attributes) for x in gitlab_variables]\n KNOWN = ['key', 'value', 'masked', 'protected', 'variable_type', 'environment_scope', 'raw']\n for item in existing_variables:\n for key in list(item.keys()):\n if key not in KNOWN:\n item.pop(key)\n return existing_variables\n\n\ndef vars_to_variables(vars, module):\n # transform old vars to new variables structure\n variables = list()\n for item, value in vars.items():\n if isinstance(value, (string_types, integer_types, float)):\n variables.append(\n {\n \"name\": item,\n \"value\": str(value),\n \"masked\": False,\n \"protected\": False,\n \"raw\": False,\n \"variable_type\": \"env_var\",\n }\n )\n\n elif isinstance(value, dict):\n new_item = {\n \"name\": item,\n \"value\": value.get('value'),\n \"masked\": value.get('masked'),\n \"protected\": value.get('protected'),\n \"raw\": value.get('raw'),\n \"variable_type\": value.get('variable_type'),\n }\n\n if value.get('environment_scope'):\n new_item['environment_scope'] = value.get('environment_scope')\n\n variables.append(new_item)\n\n else:\n module.fail_json(msg=\"value must be of type string, integer, float or dict\")\n\n return variables\n", "path": "plugins/module_utils/gitlab.py"}, {"content": "# -*- coding: utf-8 -*-\n# Copyright (c) Ansible project\n# GNU General Public License v3.0+ (see LICENSES/GPL-3.0-or-later.txt or https://www.gnu.org/licenses/gpl-3.0.txt)\n# SPDX-License-Identifier: GPL-3.0-or-later\n\nfrom __future__ import (absolute_import, division, print_function)\n__metaclass__ = type\n\n\nclass ModuleDocFragment(object):\n\n # Standard files documentation fragment\n DOCUMENTATION = r'''\nrequirements:\n - requests (Python library U(https://pypi.org/project/requests/))\n\noptions:\n api_token:\n description:\n - GitLab access token with API permissions.\n type: str\n api_oauth_token:\n description:\n - GitLab OAuth token for logging in.\n type: str\n version_added: 4.2.0\n api_job_token:\n description:\n - GitLab CI job token for logging in.\n type: str\n version_added: 4.2.0\n'''\n", "path": "plugins/doc_fragments/gitlab.py"}]}
| 2,954 | 755 |
gh_patches_debug_4633
|
rasdani/github-patches
|
git_diff
|
encode__uvicorn-349
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
byes_data not working with Channels consumers
Uvicorn sends its data like this:
```
is_text = isinstance(data, str)
return {
"type": "websocket.receive",
"text": data if is_text else None,
"bytes": None if is_text else data,
}
```
Channels generic consumers work like this:
```
def websocket_receive(self, message):
"""
Called when a WebSocket frame is received. Decodes it and passes it
to receive().
"""
if "text" in message:
self.receive(text_data=message["text"])
else:
self.receive(bytes_data=message["bytes"])
```
Since `text` is present but set to none `self.receive` is called with text_data discarding the bytes_data when it is present.
I don't know if this is a bug in Uvicorn or Channels. Its a simple fix either way. Either don't set it on the dict or the channels people should check if its a truthy value and not just present.
</issue>
<code>
[start of uvicorn/protocols/websockets/websockets_impl.py]
1 import asyncio
2 import http
3 from urllib.parse import unquote
4
5 import websockets
6
7 from uvicorn.protocols.utils import get_local_addr, get_remote_addr, is_ssl
8
9
10 class Server:
11 closing = False
12
13 def register(self, ws):
14 pass
15
16 def unregister(self, ws):
17 pass
18
19
20 class WebSocketProtocol(websockets.WebSocketServerProtocol):
21 def __init__(self, config, server_state, _loop=None):
22 if not config.loaded:
23 config.load()
24
25 self.config = config
26 self.app = config.loaded_app
27 self.loop = _loop or asyncio.get_event_loop()
28 self.logger = config.logger_instance
29 self.root_path = config.root_path
30
31 # Shared server state
32 self.connections = server_state.connections
33 self.tasks = server_state.tasks
34
35 # Connection state
36 self.transport = None
37 self.server = None
38 self.client = None
39 self.scheme = None
40
41 # Connection events
42 self.scope = None
43 self.handshake_started_event = asyncio.Event()
44 self.handshake_completed_event = asyncio.Event()
45 self.closed_event = asyncio.Event()
46 self.initial_response = None
47 self.connect_sent = False
48 self.accepted_subprotocol = None
49
50 server = Server()
51
52 super().__init__(ws_handler=self.ws_handler, ws_server=server)
53
54 def connection_made(self, transport):
55 self.connections.add(self)
56 self.transport = transport
57 self.server = get_local_addr(transport)
58 self.client = get_remote_addr(transport)
59 self.scheme = "wss" if is_ssl(transport) else "ws"
60 super().connection_made(transport)
61
62 def connection_lost(self, exc):
63 self.connections.remove(self)
64 self.handshake_completed_event.set()
65 super().connection_lost(exc)
66
67 def shutdown(self):
68 self.transport.close()
69
70 def on_task_complete(self, task):
71 self.tasks.discard(task)
72
73 async def process_request(self, path, headers):
74 """
75 This hook is called to determine if the websocket should return
76 an HTTP response and close.
77
78 Our behavior here is to start the ASGI application, and then wait
79 for either `accept` or `close` in order to determine if we should
80 close the connection.
81 """
82 path_portion, _, query_string = path.partition("?")
83
84 websockets.handshake.check_request(headers)
85
86 subprotocols = []
87 for header in headers.get_all("Sec-WebSocket-Protocol"):
88 subprotocols.extend([token.strip() for token in header.split(",")])
89
90 asgi_headers = [
91 (name.encode("ascii"), value.encode("ascii"))
92 for name, value in headers.raw_items()
93 ]
94
95 self.scope = {
96 "type": "websocket",
97 "scheme": self.scheme,
98 "server": self.server,
99 "client": self.client,
100 "root_path": self.root_path,
101 "path": unquote(path_portion),
102 "query_string": query_string.encode("ascii"),
103 "headers": asgi_headers,
104 "subprotocols": subprotocols,
105 }
106 task = self.loop.create_task(self.run_asgi())
107 task.add_done_callback(self.on_task_complete)
108 self.tasks.add(task)
109 await self.handshake_started_event.wait()
110 return self.initial_response
111
112 def process_subprotocol(self, headers, available_subprotocols):
113 """
114 We override the standard 'process_subprotocol' behavior here so that
115 we return whatever subprotocol is sent in the 'accept' message.
116 """
117 return self.accepted_subprotocol
118
119 def send_500_response(self):
120 msg = b"Internal Server Error"
121 content = [
122 b"HTTP/1.1 500 Internal Server Error\r\n"
123 b"content-type: text/plain; charset=utf-8\r\n",
124 b"content-length: " + str(len(msg)).encode("ascii") + b"\r\n",
125 b"connection: close\r\n",
126 b"\r\n",
127 msg,
128 ]
129 self.transport.write(b"".join(content))
130
131 async def ws_handler(self, protocol, path):
132 """
133 This is the main handler function for the 'websockets' implementation
134 to call into. We just wait for close then return, and instead allow
135 'send' and 'receive' events to drive the flow.
136 """
137 self.handshake_completed_event.set()
138 await self.closed_event.wait()
139
140 async def run_asgi(self):
141 """
142 Wrapper around the ASGI callable, handling exceptions and unexpected
143 termination states.
144 """
145 try:
146 result = await self.app(self.scope, self.asgi_receive, self.asgi_send)
147 except BaseException as exc:
148 self.closed_event.set()
149 msg = "Exception in ASGI application\n"
150 self.logger.error(msg, exc_info=exc)
151 if not self.handshake_started_event.is_set():
152 self.send_500_response()
153 else:
154 await self.handshake_completed_event.wait()
155 self.transport.close()
156 else:
157 self.closed_event.set()
158 if not self.handshake_started_event.is_set():
159 msg = "ASGI callable returned without sending handshake."
160 self.logger.error(msg)
161 self.send_500_response()
162 self.transport.close()
163 elif result is not None:
164 msg = "ASGI callable should return None, but returned '%s'."
165 self.logger.error(msg, result)
166 await self.handshake_completed_event.wait()
167 self.transport.close()
168
169 async def asgi_send(self, message):
170 message_type = message["type"]
171
172 if not self.handshake_started_event.is_set():
173 if message_type == "websocket.accept":
174 self.logger.info(
175 '%s - "WebSocket %s" [accepted]',
176 self.scope["client"],
177 self.scope["root_path"] + self.scope["path"],
178 )
179 self.initial_response = None
180 self.accepted_subprotocol = message.get("subprotocol")
181 self.handshake_started_event.set()
182
183 elif message_type == "websocket.close":
184 self.logger.info(
185 '%s - "WebSocket %s" 403',
186 self.scope["client"],
187 self.scope["root_path"] + self.scope["path"],
188 )
189 self.initial_response = (http.HTTPStatus.FORBIDDEN, [], b"")
190 self.handshake_started_event.set()
191 self.closed_event.set()
192
193 else:
194 msg = "Expected ASGI message 'websocket.accept' or 'websocket.close', but got '%s'."
195 raise RuntimeError(msg % message_type)
196
197 elif not self.closed_event.is_set():
198 await self.handshake_completed_event.wait()
199
200 if message_type == "websocket.send":
201 bytes_data = message.get("bytes")
202 text_data = message.get("text")
203 data = text_data if bytes_data is None else bytes_data
204 await self.send(data)
205
206 elif message_type == "websocket.close":
207 code = message.get("code", 1000)
208 await self.close(code)
209 self.closed_event.set()
210
211 else:
212 msg = "Expected ASGI message 'websocket.send' or 'websocket.close', but got '%s'."
213 raise RuntimeError(msg % message_type)
214
215 else:
216 msg = "Unexpected ASGI message '%s', after sending 'websocket.close'."
217 raise RuntimeError(msg % message_type)
218
219 async def asgi_receive(self):
220 if not self.connect_sent:
221 self.connect_sent = True
222 return {"type": "websocket.connect"}
223
224 await self.handshake_completed_event.wait()
225 try:
226 data = await self.recv()
227 except websockets.ConnectionClosed as exc:
228 return {"type": "websocket.disconnect", "code": exc.code}
229
230 is_text = isinstance(data, str)
231 return {
232 "type": "websocket.receive",
233 "text": data if is_text else None,
234 "bytes": None if is_text else data,
235 }
236
[end of uvicorn/protocols/websockets/websockets_impl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/uvicorn/protocols/websockets/websockets_impl.py b/uvicorn/protocols/websockets/websockets_impl.py
--- a/uvicorn/protocols/websockets/websockets_impl.py
+++ b/uvicorn/protocols/websockets/websockets_impl.py
@@ -226,9 +226,11 @@
"code": exc.code,
}
- is_text = isinstance(data, str)
- return {
- "type": "websocket.receive",
- "text": data if is_text else None,
- "bytes": None if is_text else data,
- }
+ msg = {"type": "websocket.receive"}
+
+ if isinstance(data, str):
+ msg["text"] = data
+ else:
+ msg["bytes"] = data
+
+ return msg
|
{"golden_diff": "diff --git a/uvicorn/protocols/websockets/websockets_impl.py b/uvicorn/protocols/websockets/websockets_impl.py\n--- a/uvicorn/protocols/websockets/websockets_impl.py\n+++ b/uvicorn/protocols/websockets/websockets_impl.py\n@@ -226,9 +226,11 @@\n \"code\": exc.code,\n }\n \n- is_text = isinstance(data, str)\n- return {\n- \"type\": \"websocket.receive\",\n- \"text\": data if is_text else None,\n- \"bytes\": None if is_text else data,\n- }\n+ msg = {\"type\": \"websocket.receive\"}\n+\n+ if isinstance(data, str):\n+ msg[\"text\"] = data\n+ else:\n+ msg[\"bytes\"] = data\n+\n+ return msg\n", "issue": "byes_data not working with Channels consumers\nUvicorn sends its data like this:\r\n\r\n```\r\n is_text = isinstance(data, str)\r\n return {\r\n \"type\": \"websocket.receive\",\r\n \"text\": data if is_text else None,\r\n \"bytes\": None if is_text else data,\r\n }\r\n```\r\n\r\nChannels generic consumers work like this:\r\n```\r\n def websocket_receive(self, message):\r\n \"\"\"\r\n Called when a WebSocket frame is received. Decodes it and passes it\r\n to receive().\r\n \"\"\"\r\n if \"text\" in message:\r\n self.receive(text_data=message[\"text\"])\r\n else:\r\n self.receive(bytes_data=message[\"bytes\"])\r\n```\r\n\r\nSince `text` is present but set to none `self.receive` is called with text_data discarding the bytes_data when it is present.\r\n\r\nI don't know if this is a bug in Uvicorn or Channels. Its a simple fix either way. Either don't set it on the dict or the channels people should check if its a truthy value and not just present.\n", "before_files": [{"content": "import asyncio\nimport http\nfrom urllib.parse import unquote\n\nimport websockets\n\nfrom uvicorn.protocols.utils import get_local_addr, get_remote_addr, is_ssl\n\n\nclass Server:\n closing = False\n\n def register(self, ws):\n pass\n\n def unregister(self, ws):\n pass\n\n\nclass WebSocketProtocol(websockets.WebSocketServerProtocol):\n def __init__(self, config, server_state, _loop=None):\n if not config.loaded:\n config.load()\n\n self.config = config\n self.app = config.loaded_app\n self.loop = _loop or asyncio.get_event_loop()\n self.logger = config.logger_instance\n self.root_path = config.root_path\n\n # Shared server state\n self.connections = server_state.connections\n self.tasks = server_state.tasks\n\n # Connection state\n self.transport = None\n self.server = None\n self.client = None\n self.scheme = None\n\n # Connection events\n self.scope = None\n self.handshake_started_event = asyncio.Event()\n self.handshake_completed_event = asyncio.Event()\n self.closed_event = asyncio.Event()\n self.initial_response = None\n self.connect_sent = False\n self.accepted_subprotocol = None\n\n server = Server()\n\n super().__init__(ws_handler=self.ws_handler, ws_server=server)\n\n def connection_made(self, transport):\n self.connections.add(self)\n self.transport = transport\n self.server = get_local_addr(transport)\n self.client = get_remote_addr(transport)\n self.scheme = \"wss\" if is_ssl(transport) else \"ws\"\n super().connection_made(transport)\n\n def connection_lost(self, exc):\n self.connections.remove(self)\n self.handshake_completed_event.set()\n super().connection_lost(exc)\n\n def shutdown(self):\n self.transport.close()\n\n def on_task_complete(self, task):\n self.tasks.discard(task)\n\n async def process_request(self, path, headers):\n \"\"\"\n This hook is called to determine if the websocket should return\n an HTTP response and close.\n\n Our behavior here is to start the ASGI application, and then wait\n for either `accept` or `close` in order to determine if we should\n close the connection.\n \"\"\"\n path_portion, _, query_string = path.partition(\"?\")\n\n websockets.handshake.check_request(headers)\n\n subprotocols = []\n for header in headers.get_all(\"Sec-WebSocket-Protocol\"):\n subprotocols.extend([token.strip() for token in header.split(\",\")])\n\n asgi_headers = [\n (name.encode(\"ascii\"), value.encode(\"ascii\"))\n for name, value in headers.raw_items()\n ]\n\n self.scope = {\n \"type\": \"websocket\",\n \"scheme\": self.scheme,\n \"server\": self.server,\n \"client\": self.client,\n \"root_path\": self.root_path,\n \"path\": unquote(path_portion),\n \"query_string\": query_string.encode(\"ascii\"),\n \"headers\": asgi_headers,\n \"subprotocols\": subprotocols,\n }\n task = self.loop.create_task(self.run_asgi())\n task.add_done_callback(self.on_task_complete)\n self.tasks.add(task)\n await self.handshake_started_event.wait()\n return self.initial_response\n\n def process_subprotocol(self, headers, available_subprotocols):\n \"\"\"\n We override the standard 'process_subprotocol' behavior here so that\n we return whatever subprotocol is sent in the 'accept' message.\n \"\"\"\n return self.accepted_subprotocol\n\n def send_500_response(self):\n msg = b\"Internal Server Error\"\n content = [\n b\"HTTP/1.1 500 Internal Server Error\\r\\n\"\n b\"content-type: text/plain; charset=utf-8\\r\\n\",\n b\"content-length: \" + str(len(msg)).encode(\"ascii\") + b\"\\r\\n\",\n b\"connection: close\\r\\n\",\n b\"\\r\\n\",\n msg,\n ]\n self.transport.write(b\"\".join(content))\n\n async def ws_handler(self, protocol, path):\n \"\"\"\n This is the main handler function for the 'websockets' implementation\n to call into. We just wait for close then return, and instead allow\n 'send' and 'receive' events to drive the flow.\n \"\"\"\n self.handshake_completed_event.set()\n await self.closed_event.wait()\n\n async def run_asgi(self):\n \"\"\"\n Wrapper around the ASGI callable, handling exceptions and unexpected\n termination states.\n \"\"\"\n try:\n result = await self.app(self.scope, self.asgi_receive, self.asgi_send)\n except BaseException as exc:\n self.closed_event.set()\n msg = \"Exception in ASGI application\\n\"\n self.logger.error(msg, exc_info=exc)\n if not self.handshake_started_event.is_set():\n self.send_500_response()\n else:\n await self.handshake_completed_event.wait()\n self.transport.close()\n else:\n self.closed_event.set()\n if not self.handshake_started_event.is_set():\n msg = \"ASGI callable returned without sending handshake.\"\n self.logger.error(msg)\n self.send_500_response()\n self.transport.close()\n elif result is not None:\n msg = \"ASGI callable should return None, but returned '%s'.\"\n self.logger.error(msg, result)\n await self.handshake_completed_event.wait()\n self.transport.close()\n\n async def asgi_send(self, message):\n message_type = message[\"type\"]\n\n if not self.handshake_started_event.is_set():\n if message_type == \"websocket.accept\":\n self.logger.info(\n '%s - \"WebSocket %s\" [accepted]',\n self.scope[\"client\"],\n self.scope[\"root_path\"] + self.scope[\"path\"],\n )\n self.initial_response = None\n self.accepted_subprotocol = message.get(\"subprotocol\")\n self.handshake_started_event.set()\n\n elif message_type == \"websocket.close\":\n self.logger.info(\n '%s - \"WebSocket %s\" 403',\n self.scope[\"client\"],\n self.scope[\"root_path\"] + self.scope[\"path\"],\n )\n self.initial_response = (http.HTTPStatus.FORBIDDEN, [], b\"\")\n self.handshake_started_event.set()\n self.closed_event.set()\n\n else:\n msg = \"Expected ASGI message 'websocket.accept' or 'websocket.close', but got '%s'.\"\n raise RuntimeError(msg % message_type)\n\n elif not self.closed_event.is_set():\n await self.handshake_completed_event.wait()\n\n if message_type == \"websocket.send\":\n bytes_data = message.get(\"bytes\")\n text_data = message.get(\"text\")\n data = text_data if bytes_data is None else bytes_data\n await self.send(data)\n\n elif message_type == \"websocket.close\":\n code = message.get(\"code\", 1000)\n await self.close(code)\n self.closed_event.set()\n\n else:\n msg = \"Expected ASGI message 'websocket.send' or 'websocket.close', but got '%s'.\"\n raise RuntimeError(msg % message_type)\n\n else:\n msg = \"Unexpected ASGI message '%s', after sending 'websocket.close'.\"\n raise RuntimeError(msg % message_type)\n\n async def asgi_receive(self):\n if not self.connect_sent:\n self.connect_sent = True\n return {\"type\": \"websocket.connect\"}\n\n await self.handshake_completed_event.wait()\n try:\n data = await self.recv()\n except websockets.ConnectionClosed as exc:\n return {\"type\": \"websocket.disconnect\", \"code\": exc.code}\n\n is_text = isinstance(data, str)\n return {\n \"type\": \"websocket.receive\",\n \"text\": data if is_text else None,\n \"bytes\": None if is_text else data,\n }\n", "path": "uvicorn/protocols/websockets/websockets_impl.py"}]}
| 3,044 | 179 |
gh_patches_debug_1731
|
rasdani/github-patches
|
git_diff
|
ray-project__ray-8572
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"lr_schedule" option ignored using torch framework and PPO algorithm
<!--Please include [tune], [rllib], [autoscaler] etc. in the issue title if relevant-->
*Ray version and other system information (Python version, TensorFlow version, OS):*
- Ray: [0.9.0.dev0 (2c599dbf05e41e338920ee2fbe692658bcbec4dd)](https://s3-us-west-2.amazonaws.com/ray-wheels/releases/0.8.5/02c1ab0ec6d615ad54ebf33bd93c51c04000534e/ray-0.8.5-cp36-cp36m-manylinux1_x86_64.whl)
- CUDA: 10.1
- Pytorch: 1.4.0 with GPU support
- Ubuntu 18.04
- Python 3.6
### What is the problem?
Setting the hyperparameter "lr_schedule" as no effect when using PyTorch as backend framework and PPO learning algorithm.
### Reproduction (REQUIRED)
```
import ray
from ray.rllib.agents.ppo import PPOTrainer, DEFAULT_CONFIG
config = DEFAULT_CONFIG.copy()
for key, val in {
"env": "CartPole-v0",
"num_workers": 0,
"use_pytorch": False,
"lr": 1.0e-5,
"lr_schedule": [
[0, 1.0e-6],
[1, 1.0e-7],
]
}.items(): config[key] = val
ray.init()
for use_pytorch in [False, True]:
config["use_pytorch"] = use_pytorch
agent = PPOTrainer(config, "CartPole-v0")
for _ in range(2):
result = agent.train()
print(f"use_pytorch: {use_pytorch} - Current learning rate: "\
f"{result['info']['learner']['default_policy']['cur_lr']}")
```
- [x] I have verified my script runs in a clean environment and reproduces the issue.
- [x] I have verified the issue also occurs with the [latest wheels](https://docs.ray.io/en/latest/installation.html).
</issue>
<code>
[start of rllib/agents/ppo/ppo_torch_policy.py]
1 import logging
2
3 import ray
4 from ray.rllib.agents.a3c.a3c_torch_policy import apply_grad_clipping
5 from ray.rllib.agents.ppo.ppo_tf_policy import postprocess_ppo_gae, \
6 setup_config
7 from ray.rllib.evaluation.postprocessing import Postprocessing
8 from ray.rllib.policy.sample_batch import SampleBatch
9 from ray.rllib.policy.torch_policy import EntropyCoeffSchedule, \
10 LearningRateSchedule
11 from ray.rllib.policy.torch_policy_template import build_torch_policy
12 from ray.rllib.utils.explained_variance import explained_variance
13 from ray.rllib.utils.torch_ops import sequence_mask
14 from ray.rllib.utils import try_import_torch
15
16 torch, nn = try_import_torch()
17
18 logger = logging.getLogger(__name__)
19
20
21 class PPOLoss:
22 def __init__(self,
23 dist_class,
24 model,
25 value_targets,
26 advantages,
27 actions,
28 prev_logits,
29 prev_actions_logp,
30 vf_preds,
31 curr_action_dist,
32 value_fn,
33 cur_kl_coeff,
34 valid_mask,
35 entropy_coeff=0,
36 clip_param=0.1,
37 vf_clip_param=0.1,
38 vf_loss_coeff=1.0,
39 use_gae=True):
40 """Constructs the loss for Proximal Policy Objective.
41
42 Arguments:
43 dist_class: action distribution class for logits.
44 value_targets (Placeholder): Placeholder for target values; used
45 for GAE.
46 actions (Placeholder): Placeholder for actions taken
47 from previous model evaluation.
48 advantages (Placeholder): Placeholder for calculated advantages
49 from previous model evaluation.
50 prev_logits (Placeholder): Placeholder for logits output from
51 previous model evaluation.
52 prev_actions_logp (Placeholder): Placeholder for prob output from
53 previous model evaluation.
54 vf_preds (Placeholder): Placeholder for value function output
55 from previous model evaluation.
56 curr_action_dist (ActionDistribution): ActionDistribution
57 of the current model.
58 value_fn (Tensor): Current value function output Tensor.
59 cur_kl_coeff (Variable): Variable holding the current PPO KL
60 coefficient.
61 valid_mask (Tensor): A bool mask of valid input elements (#2992).
62 entropy_coeff (float): Coefficient of the entropy regularizer.
63 clip_param (float): Clip parameter
64 vf_clip_param (float): Clip parameter for the value function
65 vf_loss_coeff (float): Coefficient of the value function loss
66 use_gae (bool): If true, use the Generalized Advantage Estimator.
67 """
68 if valid_mask is not None:
69 num_valid = torch.sum(valid_mask)
70
71 def reduce_mean_valid(t):
72 return torch.sum(t * valid_mask) / num_valid
73
74 else:
75
76 def reduce_mean_valid(t):
77 return torch.mean(t)
78
79 prev_dist = dist_class(prev_logits, model)
80 # Make loss functions.
81 logp_ratio = torch.exp(
82 curr_action_dist.logp(actions) - prev_actions_logp)
83 action_kl = prev_dist.kl(curr_action_dist)
84 self.mean_kl = reduce_mean_valid(action_kl)
85
86 curr_entropy = curr_action_dist.entropy()
87 self.mean_entropy = reduce_mean_valid(curr_entropy)
88
89 surrogate_loss = torch.min(
90 advantages * logp_ratio,
91 advantages * torch.clamp(logp_ratio, 1 - clip_param,
92 1 + clip_param))
93 self.mean_policy_loss = reduce_mean_valid(-surrogate_loss)
94
95 if use_gae:
96 vf_loss1 = torch.pow(value_fn - value_targets, 2.0)
97 vf_clipped = vf_preds + torch.clamp(value_fn - vf_preds,
98 -vf_clip_param, vf_clip_param)
99 vf_loss2 = torch.pow(vf_clipped - value_targets, 2.0)
100 vf_loss = torch.max(vf_loss1, vf_loss2)
101 self.mean_vf_loss = reduce_mean_valid(vf_loss)
102 loss = reduce_mean_valid(
103 -surrogate_loss + cur_kl_coeff * action_kl +
104 vf_loss_coeff * vf_loss - entropy_coeff * curr_entropy)
105 else:
106 self.mean_vf_loss = 0.0
107 loss = reduce_mean_valid(-surrogate_loss +
108 cur_kl_coeff * action_kl -
109 entropy_coeff * curr_entropy)
110 self.loss = loss
111
112
113 def ppo_surrogate_loss(policy, model, dist_class, train_batch):
114 logits, state = model.from_batch(train_batch)
115 action_dist = dist_class(logits, model)
116
117 mask = None
118 if state:
119 max_seq_len = torch.max(train_batch["seq_lens"])
120 mask = sequence_mask(train_batch["seq_lens"], max_seq_len)
121 mask = torch.reshape(mask, [-1])
122
123 policy.loss_obj = PPOLoss(
124 dist_class,
125 model,
126 train_batch[Postprocessing.VALUE_TARGETS],
127 train_batch[Postprocessing.ADVANTAGES],
128 train_batch[SampleBatch.ACTIONS],
129 train_batch[SampleBatch.ACTION_DIST_INPUTS],
130 train_batch[SampleBatch.ACTION_LOGP],
131 train_batch[SampleBatch.VF_PREDS],
132 action_dist,
133 model.value_function(),
134 policy.kl_coeff,
135 mask,
136 entropy_coeff=policy.entropy_coeff,
137 clip_param=policy.config["clip_param"],
138 vf_clip_param=policy.config["vf_clip_param"],
139 vf_loss_coeff=policy.config["vf_loss_coeff"],
140 use_gae=policy.config["use_gae"],
141 )
142
143 return policy.loss_obj.loss
144
145
146 def kl_and_loss_stats(policy, train_batch):
147 return {
148 "cur_kl_coeff": policy.kl_coeff,
149 "cur_lr": policy.cur_lr,
150 "total_loss": policy.loss_obj.loss,
151 "policy_loss": policy.loss_obj.mean_policy_loss,
152 "vf_loss": policy.loss_obj.mean_vf_loss,
153 "vf_explained_var": explained_variance(
154 train_batch[Postprocessing.VALUE_TARGETS],
155 policy.model.value_function(),
156 framework="torch"),
157 "kl": policy.loss_obj.mean_kl,
158 "entropy": policy.loss_obj.mean_entropy,
159 "entropy_coeff": policy.entropy_coeff,
160 }
161
162
163 def vf_preds_fetches(policy, input_dict, state_batches, model, action_dist):
164 """Adds value function outputs to experience train_batches."""
165 return {
166 SampleBatch.VF_PREDS: policy.model.value_function(),
167 }
168
169
170 class KLCoeffMixin:
171 def __init__(self, config):
172 # KL Coefficient.
173 self.kl_coeff = config["kl_coeff"]
174 self.kl_target = config["kl_target"]
175
176 def update_kl(self, sampled_kl):
177 if sampled_kl > 2.0 * self.kl_target:
178 self.kl_coeff *= 1.5
179 elif sampled_kl < 0.5 * self.kl_target:
180 self.kl_coeff *= 0.5
181 return self.kl_coeff
182
183
184 class ValueNetworkMixin:
185 def __init__(self, obs_space, action_space, config):
186 if config["use_gae"]:
187
188 def value(ob, prev_action, prev_reward, *state):
189 model_out, _ = self.model({
190 SampleBatch.CUR_OBS: self._convert_to_tensor([ob]),
191 SampleBatch.PREV_ACTIONS: self._convert_to_tensor(
192 [prev_action]),
193 SampleBatch.PREV_REWARDS: self._convert_to_tensor(
194 [prev_reward]),
195 "is_training": False,
196 }, [self._convert_to_tensor(s) for s in state],
197 self._convert_to_tensor([1]))
198 return self.model.value_function()[0]
199
200 else:
201
202 def value(ob, prev_action, prev_reward, *state):
203 return 0.0
204
205 self._value = value
206
207
208 def setup_mixins(policy, obs_space, action_space, config):
209 ValueNetworkMixin.__init__(policy, obs_space, action_space, config)
210 KLCoeffMixin.__init__(policy, config)
211 EntropyCoeffSchedule.__init__(policy, config["entropy_coeff"],
212 config["entropy_coeff_schedule"])
213 LearningRateSchedule.__init__(policy, config["lr"], config["lr_schedule"])
214
215
216 PPOTorchPolicy = build_torch_policy(
217 name="PPOTorchPolicy",
218 get_default_config=lambda: ray.rllib.agents.ppo.ppo.DEFAULT_CONFIG,
219 loss_fn=ppo_surrogate_loss,
220 stats_fn=kl_and_loss_stats,
221 extra_action_out_fn=vf_preds_fetches,
222 postprocess_fn=postprocess_ppo_gae,
223 extra_grad_process_fn=apply_grad_clipping,
224 before_init=setup_config,
225 after_init=setup_mixins,
226 mixins=[KLCoeffMixin, ValueNetworkMixin])
227
[end of rllib/agents/ppo/ppo_torch_policy.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rllib/agents/ppo/ppo_torch_policy.py b/rllib/agents/ppo/ppo_torch_policy.py
--- a/rllib/agents/ppo/ppo_torch_policy.py
+++ b/rllib/agents/ppo/ppo_torch_policy.py
@@ -223,4 +223,7 @@
extra_grad_process_fn=apply_grad_clipping,
before_init=setup_config,
after_init=setup_mixins,
- mixins=[KLCoeffMixin, ValueNetworkMixin])
+ mixins=[
+ LearningRateSchedule, EntropyCoeffSchedule, KLCoeffMixin,
+ ValueNetworkMixin
+ ])
|
{"golden_diff": "diff --git a/rllib/agents/ppo/ppo_torch_policy.py b/rllib/agents/ppo/ppo_torch_policy.py\n--- a/rllib/agents/ppo/ppo_torch_policy.py\n+++ b/rllib/agents/ppo/ppo_torch_policy.py\n@@ -223,4 +223,7 @@\n extra_grad_process_fn=apply_grad_clipping,\n before_init=setup_config,\n after_init=setup_mixins,\n- mixins=[KLCoeffMixin, ValueNetworkMixin])\n+ mixins=[\n+ LearningRateSchedule, EntropyCoeffSchedule, KLCoeffMixin,\n+ ValueNetworkMixin\n+ ])\n", "issue": "\"lr_schedule\" option ignored using torch framework and PPO algorithm\n<!--Please include [tune], [rllib], [autoscaler] etc. in the issue title if relevant-->\r\n\r\n*Ray version and other system information (Python version, TensorFlow version, OS):*\r\n- Ray: [0.9.0.dev0 (2c599dbf05e41e338920ee2fbe692658bcbec4dd)](https://s3-us-west-2.amazonaws.com/ray-wheels/releases/0.8.5/02c1ab0ec6d615ad54ebf33bd93c51c04000534e/ray-0.8.5-cp36-cp36m-manylinux1_x86_64.whl)\r\n- CUDA: 10.1\r\n- Pytorch: 1.4.0 with GPU support\r\n- Ubuntu 18.04\r\n- Python 3.6\r\n\r\n### What is the problem?\r\n\r\nSetting the hyperparameter \"lr_schedule\" as no effect when using PyTorch as backend framework and PPO learning algorithm.\r\n\r\n### Reproduction (REQUIRED)\r\n\r\n```\r\nimport ray \r\nfrom ray.rllib.agents.ppo import PPOTrainer, DEFAULT_CONFIG \r\n \r\nconfig = DEFAULT_CONFIG.copy() \r\nfor key, val in { \r\n \"env\": \"CartPole-v0\", \r\n \"num_workers\": 0, \r\n \"use_pytorch\": False, \r\n \"lr\": 1.0e-5, \r\n \"lr_schedule\": [ \r\n [0, 1.0e-6], \r\n [1, 1.0e-7], \r\n ] \r\n}.items(): config[key] = val \r\n \r\nray.init() \r\n\r\nfor use_pytorch in [False, True]: \r\n config[\"use_pytorch\"] = use_pytorch \r\n agent = PPOTrainer(config, \"CartPole-v0\") \r\n for _ in range(2): \r\n result = agent.train() \r\n print(f\"use_pytorch: {use_pytorch} - Current learning rate: \"\\\r\n f\"{result['info']['learner']['default_policy']['cur_lr']}\")\r\n```\r\n\r\n- [x] I have verified my script runs in a clean environment and reproduces the issue.\r\n- [x] I have verified the issue also occurs with the [latest wheels](https://docs.ray.io/en/latest/installation.html).\r\n\n", "before_files": [{"content": "import logging\n\nimport ray\nfrom ray.rllib.agents.a3c.a3c_torch_policy import apply_grad_clipping\nfrom ray.rllib.agents.ppo.ppo_tf_policy import postprocess_ppo_gae, \\\n setup_config\nfrom ray.rllib.evaluation.postprocessing import Postprocessing\nfrom ray.rllib.policy.sample_batch import SampleBatch\nfrom ray.rllib.policy.torch_policy import EntropyCoeffSchedule, \\\n LearningRateSchedule\nfrom ray.rllib.policy.torch_policy_template import build_torch_policy\nfrom ray.rllib.utils.explained_variance import explained_variance\nfrom ray.rllib.utils.torch_ops import sequence_mask\nfrom ray.rllib.utils import try_import_torch\n\ntorch, nn = try_import_torch()\n\nlogger = logging.getLogger(__name__)\n\n\nclass PPOLoss:\n def __init__(self,\n dist_class,\n model,\n value_targets,\n advantages,\n actions,\n prev_logits,\n prev_actions_logp,\n vf_preds,\n curr_action_dist,\n value_fn,\n cur_kl_coeff,\n valid_mask,\n entropy_coeff=0,\n clip_param=0.1,\n vf_clip_param=0.1,\n vf_loss_coeff=1.0,\n use_gae=True):\n \"\"\"Constructs the loss for Proximal Policy Objective.\n\n Arguments:\n dist_class: action distribution class for logits.\n value_targets (Placeholder): Placeholder for target values; used\n for GAE.\n actions (Placeholder): Placeholder for actions taken\n from previous model evaluation.\n advantages (Placeholder): Placeholder for calculated advantages\n from previous model evaluation.\n prev_logits (Placeholder): Placeholder for logits output from\n previous model evaluation.\n prev_actions_logp (Placeholder): Placeholder for prob output from\n previous model evaluation.\n vf_preds (Placeholder): Placeholder for value function output\n from previous model evaluation.\n curr_action_dist (ActionDistribution): ActionDistribution\n of the current model.\n value_fn (Tensor): Current value function output Tensor.\n cur_kl_coeff (Variable): Variable holding the current PPO KL\n coefficient.\n valid_mask (Tensor): A bool mask of valid input elements (#2992).\n entropy_coeff (float): Coefficient of the entropy regularizer.\n clip_param (float): Clip parameter\n vf_clip_param (float): Clip parameter for the value function\n vf_loss_coeff (float): Coefficient of the value function loss\n use_gae (bool): If true, use the Generalized Advantage Estimator.\n \"\"\"\n if valid_mask is not None:\n num_valid = torch.sum(valid_mask)\n\n def reduce_mean_valid(t):\n return torch.sum(t * valid_mask) / num_valid\n\n else:\n\n def reduce_mean_valid(t):\n return torch.mean(t)\n\n prev_dist = dist_class(prev_logits, model)\n # Make loss functions.\n logp_ratio = torch.exp(\n curr_action_dist.logp(actions) - prev_actions_logp)\n action_kl = prev_dist.kl(curr_action_dist)\n self.mean_kl = reduce_mean_valid(action_kl)\n\n curr_entropy = curr_action_dist.entropy()\n self.mean_entropy = reduce_mean_valid(curr_entropy)\n\n surrogate_loss = torch.min(\n advantages * logp_ratio,\n advantages * torch.clamp(logp_ratio, 1 - clip_param,\n 1 + clip_param))\n self.mean_policy_loss = reduce_mean_valid(-surrogate_loss)\n\n if use_gae:\n vf_loss1 = torch.pow(value_fn - value_targets, 2.0)\n vf_clipped = vf_preds + torch.clamp(value_fn - vf_preds,\n -vf_clip_param, vf_clip_param)\n vf_loss2 = torch.pow(vf_clipped - value_targets, 2.0)\n vf_loss = torch.max(vf_loss1, vf_loss2)\n self.mean_vf_loss = reduce_mean_valid(vf_loss)\n loss = reduce_mean_valid(\n -surrogate_loss + cur_kl_coeff * action_kl +\n vf_loss_coeff * vf_loss - entropy_coeff * curr_entropy)\n else:\n self.mean_vf_loss = 0.0\n loss = reduce_mean_valid(-surrogate_loss +\n cur_kl_coeff * action_kl -\n entropy_coeff * curr_entropy)\n self.loss = loss\n\n\ndef ppo_surrogate_loss(policy, model, dist_class, train_batch):\n logits, state = model.from_batch(train_batch)\n action_dist = dist_class(logits, model)\n\n mask = None\n if state:\n max_seq_len = torch.max(train_batch[\"seq_lens\"])\n mask = sequence_mask(train_batch[\"seq_lens\"], max_seq_len)\n mask = torch.reshape(mask, [-1])\n\n policy.loss_obj = PPOLoss(\n dist_class,\n model,\n train_batch[Postprocessing.VALUE_TARGETS],\n train_batch[Postprocessing.ADVANTAGES],\n train_batch[SampleBatch.ACTIONS],\n train_batch[SampleBatch.ACTION_DIST_INPUTS],\n train_batch[SampleBatch.ACTION_LOGP],\n train_batch[SampleBatch.VF_PREDS],\n action_dist,\n model.value_function(),\n policy.kl_coeff,\n mask,\n entropy_coeff=policy.entropy_coeff,\n clip_param=policy.config[\"clip_param\"],\n vf_clip_param=policy.config[\"vf_clip_param\"],\n vf_loss_coeff=policy.config[\"vf_loss_coeff\"],\n use_gae=policy.config[\"use_gae\"],\n )\n\n return policy.loss_obj.loss\n\n\ndef kl_and_loss_stats(policy, train_batch):\n return {\n \"cur_kl_coeff\": policy.kl_coeff,\n \"cur_lr\": policy.cur_lr,\n \"total_loss\": policy.loss_obj.loss,\n \"policy_loss\": policy.loss_obj.mean_policy_loss,\n \"vf_loss\": policy.loss_obj.mean_vf_loss,\n \"vf_explained_var\": explained_variance(\n train_batch[Postprocessing.VALUE_TARGETS],\n policy.model.value_function(),\n framework=\"torch\"),\n \"kl\": policy.loss_obj.mean_kl,\n \"entropy\": policy.loss_obj.mean_entropy,\n \"entropy_coeff\": policy.entropy_coeff,\n }\n\n\ndef vf_preds_fetches(policy, input_dict, state_batches, model, action_dist):\n \"\"\"Adds value function outputs to experience train_batches.\"\"\"\n return {\n SampleBatch.VF_PREDS: policy.model.value_function(),\n }\n\n\nclass KLCoeffMixin:\n def __init__(self, config):\n # KL Coefficient.\n self.kl_coeff = config[\"kl_coeff\"]\n self.kl_target = config[\"kl_target\"]\n\n def update_kl(self, sampled_kl):\n if sampled_kl > 2.0 * self.kl_target:\n self.kl_coeff *= 1.5\n elif sampled_kl < 0.5 * self.kl_target:\n self.kl_coeff *= 0.5\n return self.kl_coeff\n\n\nclass ValueNetworkMixin:\n def __init__(self, obs_space, action_space, config):\n if config[\"use_gae\"]:\n\n def value(ob, prev_action, prev_reward, *state):\n model_out, _ = self.model({\n SampleBatch.CUR_OBS: self._convert_to_tensor([ob]),\n SampleBatch.PREV_ACTIONS: self._convert_to_tensor(\n [prev_action]),\n SampleBatch.PREV_REWARDS: self._convert_to_tensor(\n [prev_reward]),\n \"is_training\": False,\n }, [self._convert_to_tensor(s) for s in state],\n self._convert_to_tensor([1]))\n return self.model.value_function()[0]\n\n else:\n\n def value(ob, prev_action, prev_reward, *state):\n return 0.0\n\n self._value = value\n\n\ndef setup_mixins(policy, obs_space, action_space, config):\n ValueNetworkMixin.__init__(policy, obs_space, action_space, config)\n KLCoeffMixin.__init__(policy, config)\n EntropyCoeffSchedule.__init__(policy, config[\"entropy_coeff\"],\n config[\"entropy_coeff_schedule\"])\n LearningRateSchedule.__init__(policy, config[\"lr\"], config[\"lr_schedule\"])\n\n\nPPOTorchPolicy = build_torch_policy(\n name=\"PPOTorchPolicy\",\n get_default_config=lambda: ray.rllib.agents.ppo.ppo.DEFAULT_CONFIG,\n loss_fn=ppo_surrogate_loss,\n stats_fn=kl_and_loss_stats,\n extra_action_out_fn=vf_preds_fetches,\n postprocess_fn=postprocess_ppo_gae,\n extra_grad_process_fn=apply_grad_clipping,\n before_init=setup_config,\n after_init=setup_mixins,\n mixins=[KLCoeffMixin, ValueNetworkMixin])\n", "path": "rllib/agents/ppo/ppo_torch_policy.py"}]}
| 3,512 | 142 |
gh_patches_debug_4949
|
rasdani/github-patches
|
git_diff
|
mathesar-foundation__mathesar-2654
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
If PK of table is a UUID, table wont render
## Description
<!-- A clear and concise description of what the bug is. -->
If PK of table is a UUID, table wont render
## Expected behavior
<!-- A clear and concise description of what you expected to happen. -->
Table should render
## To Reproduce
<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->
Create a table where PK is a UUID in postgres
## Environment
- OS: (_eg._ macOS 10.14.6; Fedora 32)
- Browser: (_eg._ Safari; Firefox)
- Browser Version: (_eg._ 13; 73)
- Other info:
## Additional context
<!-- Add any other context about the problem or screenshots here. -->

</issue>
<code>
[start of db/columns/base.py]
1 from sqlalchemy import Column, ForeignKey, inspect
2
3 from db.columns.defaults import TYPE, PRIMARY_KEY, NULLABLE, DEFAULT_COLUMNS
4 from db.columns.operations.select import (
5 get_column_attnum_from_name, get_column_default, get_column_default_dict,
6 )
7 from db.tables.operations.select import get_oid_from_table
8 from db.types.operations.cast import get_full_cast_map
9 from db.types.operations.convert import get_db_type_enum_from_class
10
11
12 # TODO consider renaming to DbColumn or DatabaseColumn
13 # We are attempting to reserve the term Mathesar for types in the mathesar namespace.
14 class MathesarColumn(Column):
15 """
16 This class constrains the possible arguments, enabling us to include
17 a copy method (which has been deprecated in upstream SQLAlchemy since
18 1.4). The idea is that we can faithfully copy the subset of the
19 column definition that we care about, and this class defines that
20 subset.
21 """
22
23 def __init__(
24 self,
25 name,
26 sa_type,
27 foreign_keys=None,
28 primary_key=False,
29 nullable=True,
30 autoincrement=False,
31 server_default=None,
32 engine=None,
33 ):
34 """
35 Construct a new ``MathesarColumn`` object.
36
37 Required arguments:
38 name -- String giving the name of the column in the database.
39 sa_type -- the SQLAlchemy type of the column.
40
41 Optional keyword arguments:
42 primary_key -- Boolean giving whether the column is a primary key.
43 nullable -- Boolean giving whether the column is nullable.
44 server_default -- String or DefaultClause giving the default value
45 """
46 if foreign_keys is None:
47 foreign_keys = set()
48 self.engine = engine
49 super().__init__(
50 *foreign_keys,
51 name=name,
52 type_=sa_type,
53 primary_key=primary_key,
54 nullable=nullable,
55 autoincrement=autoincrement,
56 server_default=server_default
57 )
58 # NOTE: For some reason, sometimes `self._proxies` is a tuple. SA expects it to be
59 # appendable, however. Was not able to track down the source of it. As a workaround, we
60 # convert it into a list here. I (Dom) offer a bounty of bragging rights to anyone who
61 # figures out what's causing `_proxies` to be tuples.
62 if isinstance(self._proxies, tuple):
63 self._proxies = list(self._proxies)
64
65 @classmethod
66 def _constructor(cls, *args, **kwargs):
67 """
68 Needed to support Column.copy().
69
70 See https://docs.sqlalchemy.org/en/14/changelog/changelog_07.html?highlight=_constructor#change-de8c32a6729c83da17177f6a13979717
71 """
72 return MathesarColumn.from_column(
73 Column(*args, **kwargs)
74 )
75
76 @classmethod
77 def from_column(cls, column, engine=None):
78 """
79 This alternate init method creates a new column (a copy) of the
80 given column. It respects only the properties in the __init__
81 of the MathesarColumn.
82 """
83 try:
84 fkeys = {ForeignKey(fk.target_fullname) for fk in column.foreign_keys}
85 new_column = cls(
86 column.name,
87 column.type,
88 foreign_keys=fkeys,
89 primary_key=column.primary_key,
90 nullable=column.nullable,
91 autoincrement=column.autoincrement,
92 server_default=column.server_default,
93 engine=engine,
94 )
95 new_column.original_table = column.table
96 # dirty hack to handle cases where this isn't a real column
97 except AttributeError:
98 new_column = cls(
99 column.name,
100 column.type,
101 engine=engine,
102 )
103 return new_column
104
105 def to_sa_column(self):
106 """
107 MathesarColumn sometimes is not interchangeable with SQLAlchemy's Column.
108 For use in those situations, this method attempts to recreate an SA Column.
109
110 NOTE: this method is incomplete: it does not account for all properties of MathesarColumn.
111 """
112 sa_column = Column(name=self.name, type_=self.type)
113 sa_column.table = self.table_
114 return sa_column
115
116 @property
117 def table_(self):
118 """
119 Returns the current table the column is associated with if it exists, otherwise
120 returns the table the column was originally created from.
121 """
122 if hasattr(self, "table") and self.table is not None:
123 return self.table
124 elif hasattr(self, "original_table") and self.original_table is not None:
125 return self.original_table
126 return None
127
128 @property
129 def table_oid(self):
130 if self.table_ is not None:
131 oid = get_oid_from_table(
132 self.table_.name, self.table_.schema, self.engine
133 )
134 else:
135 oid = None
136 return oid
137
138 @property
139 def is_default(self):
140 default_def = DEFAULT_COLUMNS.get(self.name, False)
141 return (
142 default_def
143 and self.type.python_type == default_def[TYPE]().python_type
144 and self.primary_key == default_def.get(PRIMARY_KEY, False)
145 and self.nullable == default_def.get(NULLABLE, True)
146 )
147
148 def add_engine(self, engine):
149 self.engine = engine
150
151 @property
152 def valid_target_types(self):
153 """
154 Returns a set of valid types to which the type of the column can be
155 altered.
156 """
157 if (
158 self.engine is not None
159 and not self.is_default
160 and self.db_type is not None
161 ):
162 db_type = self.db_type
163 valid_target_types = sorted(
164 list(
165 set(
166 get_full_cast_map(self.engine).get(db_type, [])
167 )
168 ),
169 key=lambda db_type: db_type.id
170 )
171 return valid_target_types if valid_target_types else None
172
173 @property
174 def column_attnum(self):
175 """
176 Get the attnum of this column in its table, if it is
177 attached to a table that is associated with the column's engine.
178 """
179 engine_exists = self.engine is not None
180 table_exists = self.table_ is not None
181 # TODO are we checking here that the table exists on the database? explain why we have to do
182 # that.
183 engine_has_table = inspect(self.engine).has_table(
184 self.table_.name,
185 schema=self.table_.schema,
186 )
187 if engine_exists and table_exists and engine_has_table:
188 metadata = self.table_.metadata
189 return get_column_attnum_from_name(
190 self.table_oid,
191 self.name,
192 self.engine,
193 metadata=metadata,
194 )
195
196 @property
197 def column_default_dict(self):
198 if self.table_ is None:
199 return
200 metadata = self.table_.metadata
201 default_dict = get_column_default_dict(
202 self.table_oid, self.column_attnum, self.engine, metadata=metadata,
203 )
204 if default_dict:
205 return {
206 'is_dynamic': default_dict['is_dynamic'],
207 'value': default_dict['value']
208 }
209
210 @property
211 def default_value(self):
212 if self.table_ is not None:
213 metadata = self.table_.metadata
214 return get_column_default(
215 self.table_oid,
216 self.column_attnum,
217 self.engine,
218 metadata=metadata,
219 )
220
221 @property
222 def db_type(self):
223 """
224 Get this column's database type enum.
225 """
226 self._assert_that_engine_is_present()
227 return get_db_type_enum_from_class(self.type.__class__)
228
229 @property
230 def type_options(self):
231 item_type = getattr(self.type, "item_type", None)
232 if item_type is not None:
233 item_type_name = get_db_type_enum_from_class(item_type.__class__).id
234 else:
235 item_type_name = None
236 full_type_options = {
237 "length": getattr(self.type, "length", None),
238 "precision": getattr(self.type, "precision", None),
239 "scale": getattr(self.type, "scale", None),
240 "fields": getattr(self.type, "fields", None),
241 "item_type": item_type_name,
242 "dimensions": getattr(self.type, "dimensions", None)
243 }
244 _type_options = {k: v for k, v in full_type_options.items() if v is not None}
245 return _type_options if _type_options else None
246
247 def _assert_that_engine_is_present(self):
248 if self.engine is None:
249 raise Exception("Engine should not be None.")
250
[end of db/columns/base.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/db/columns/base.py b/db/columns/base.py
--- a/db/columns/base.py
+++ b/db/columns/base.py
@@ -138,6 +138,10 @@
@property
def is_default(self):
default_def = DEFAULT_COLUMNS.get(self.name, False)
+ try:
+ self.type.python_type
+ except NotImplementedError:
+ return False
return (
default_def
and self.type.python_type == default_def[TYPE]().python_type
|
{"golden_diff": "diff --git a/db/columns/base.py b/db/columns/base.py\n--- a/db/columns/base.py\n+++ b/db/columns/base.py\n@@ -138,6 +138,10 @@\n @property\n def is_default(self):\n default_def = DEFAULT_COLUMNS.get(self.name, False)\n+ try:\n+ self.type.python_type\n+ except NotImplementedError:\n+ return False\n return (\n default_def\n and self.type.python_type == default_def[TYPE]().python_type\n", "issue": "If PK of table is a UUID, table wont render\n## Description\r\n<!-- A clear and concise description of what the bug is. -->\r\nIf PK of table is a UUID, table wont render\r\n\r\n## Expected behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nTable should render\r\n\r\n## To Reproduce\r\n<!-- How can we recreate this bug? Please try to provide a Minimal, Complete, and Verifiable (http://stackoverflow.com/help/mcve) example if code-related. -->\r\nCreate a table where PK is a UUID in postgres\r\n## Environment\r\n - OS: (_eg._ macOS 10.14.6; Fedora 32)\r\n - Browser: (_eg._ Safari; Firefox)\r\n - Browser Version: (_eg._ 13; 73)\r\n - Other info:\r\n\r\n## Additional context\r\n<!-- Add any other context about the problem or screenshots here. -->\r\n\r\n\r\n\n", "before_files": [{"content": "from sqlalchemy import Column, ForeignKey, inspect\n\nfrom db.columns.defaults import TYPE, PRIMARY_KEY, NULLABLE, DEFAULT_COLUMNS\nfrom db.columns.operations.select import (\n get_column_attnum_from_name, get_column_default, get_column_default_dict,\n)\nfrom db.tables.operations.select import get_oid_from_table\nfrom db.types.operations.cast import get_full_cast_map\nfrom db.types.operations.convert import get_db_type_enum_from_class\n\n\n# TODO consider renaming to DbColumn or DatabaseColumn\n# We are attempting to reserve the term Mathesar for types in the mathesar namespace.\nclass MathesarColumn(Column):\n \"\"\"\n This class constrains the possible arguments, enabling us to include\n a copy method (which has been deprecated in upstream SQLAlchemy since\n 1.4). The idea is that we can faithfully copy the subset of the\n column definition that we care about, and this class defines that\n subset.\n \"\"\"\n\n def __init__(\n self,\n name,\n sa_type,\n foreign_keys=None,\n primary_key=False,\n nullable=True,\n autoincrement=False,\n server_default=None,\n engine=None,\n ):\n \"\"\"\n Construct a new ``MathesarColumn`` object.\n\n Required arguments:\n name -- String giving the name of the column in the database.\n sa_type -- the SQLAlchemy type of the column.\n\n Optional keyword arguments:\n primary_key -- Boolean giving whether the column is a primary key.\n nullable -- Boolean giving whether the column is nullable.\n server_default -- String or DefaultClause giving the default value\n \"\"\"\n if foreign_keys is None:\n foreign_keys = set()\n self.engine = engine\n super().__init__(\n *foreign_keys,\n name=name,\n type_=sa_type,\n primary_key=primary_key,\n nullable=nullable,\n autoincrement=autoincrement,\n server_default=server_default\n )\n # NOTE: For some reason, sometimes `self._proxies` is a tuple. SA expects it to be\n # appendable, however. Was not able to track down the source of it. As a workaround, we\n # convert it into a list here. I (Dom) offer a bounty of bragging rights to anyone who\n # figures out what's causing `_proxies` to be tuples.\n if isinstance(self._proxies, tuple):\n self._proxies = list(self._proxies)\n\n @classmethod\n def _constructor(cls, *args, **kwargs):\n \"\"\"\n Needed to support Column.copy().\n\n See https://docs.sqlalchemy.org/en/14/changelog/changelog_07.html?highlight=_constructor#change-de8c32a6729c83da17177f6a13979717\n \"\"\"\n return MathesarColumn.from_column(\n Column(*args, **kwargs)\n )\n\n @classmethod\n def from_column(cls, column, engine=None):\n \"\"\"\n This alternate init method creates a new column (a copy) of the\n given column. It respects only the properties in the __init__\n of the MathesarColumn.\n \"\"\"\n try:\n fkeys = {ForeignKey(fk.target_fullname) for fk in column.foreign_keys}\n new_column = cls(\n column.name,\n column.type,\n foreign_keys=fkeys,\n primary_key=column.primary_key,\n nullable=column.nullable,\n autoincrement=column.autoincrement,\n server_default=column.server_default,\n engine=engine,\n )\n new_column.original_table = column.table\n # dirty hack to handle cases where this isn't a real column\n except AttributeError:\n new_column = cls(\n column.name,\n column.type,\n engine=engine,\n )\n return new_column\n\n def to_sa_column(self):\n \"\"\"\n MathesarColumn sometimes is not interchangeable with SQLAlchemy's Column.\n For use in those situations, this method attempts to recreate an SA Column.\n\n NOTE: this method is incomplete: it does not account for all properties of MathesarColumn.\n \"\"\"\n sa_column = Column(name=self.name, type_=self.type)\n sa_column.table = self.table_\n return sa_column\n\n @property\n def table_(self):\n \"\"\"\n Returns the current table the column is associated with if it exists, otherwise\n returns the table the column was originally created from.\n \"\"\"\n if hasattr(self, \"table\") and self.table is not None:\n return self.table\n elif hasattr(self, \"original_table\") and self.original_table is not None:\n return self.original_table\n return None\n\n @property\n def table_oid(self):\n if self.table_ is not None:\n oid = get_oid_from_table(\n self.table_.name, self.table_.schema, self.engine\n )\n else:\n oid = None\n return oid\n\n @property\n def is_default(self):\n default_def = DEFAULT_COLUMNS.get(self.name, False)\n return (\n default_def\n and self.type.python_type == default_def[TYPE]().python_type\n and self.primary_key == default_def.get(PRIMARY_KEY, False)\n and self.nullable == default_def.get(NULLABLE, True)\n )\n\n def add_engine(self, engine):\n self.engine = engine\n\n @property\n def valid_target_types(self):\n \"\"\"\n Returns a set of valid types to which the type of the column can be\n altered.\n \"\"\"\n if (\n self.engine is not None\n and not self.is_default\n and self.db_type is not None\n ):\n db_type = self.db_type\n valid_target_types = sorted(\n list(\n set(\n get_full_cast_map(self.engine).get(db_type, [])\n )\n ),\n key=lambda db_type: db_type.id\n )\n return valid_target_types if valid_target_types else None\n\n @property\n def column_attnum(self):\n \"\"\"\n Get the attnum of this column in its table, if it is\n attached to a table that is associated with the column's engine.\n \"\"\"\n engine_exists = self.engine is not None\n table_exists = self.table_ is not None\n # TODO are we checking here that the table exists on the database? explain why we have to do\n # that.\n engine_has_table = inspect(self.engine).has_table(\n self.table_.name,\n schema=self.table_.schema,\n )\n if engine_exists and table_exists and engine_has_table:\n metadata = self.table_.metadata\n return get_column_attnum_from_name(\n self.table_oid,\n self.name,\n self.engine,\n metadata=metadata,\n )\n\n @property\n def column_default_dict(self):\n if self.table_ is None:\n return\n metadata = self.table_.metadata\n default_dict = get_column_default_dict(\n self.table_oid, self.column_attnum, self.engine, metadata=metadata,\n )\n if default_dict:\n return {\n 'is_dynamic': default_dict['is_dynamic'],\n 'value': default_dict['value']\n }\n\n @property\n def default_value(self):\n if self.table_ is not None:\n metadata = self.table_.metadata\n return get_column_default(\n self.table_oid,\n self.column_attnum,\n self.engine,\n metadata=metadata,\n )\n\n @property\n def db_type(self):\n \"\"\"\n Get this column's database type enum.\n \"\"\"\n self._assert_that_engine_is_present()\n return get_db_type_enum_from_class(self.type.__class__)\n\n @property\n def type_options(self):\n item_type = getattr(self.type, \"item_type\", None)\n if item_type is not None:\n item_type_name = get_db_type_enum_from_class(item_type.__class__).id\n else:\n item_type_name = None\n full_type_options = {\n \"length\": getattr(self.type, \"length\", None),\n \"precision\": getattr(self.type, \"precision\", None),\n \"scale\": getattr(self.type, \"scale\", None),\n \"fields\": getattr(self.type, \"fields\", None),\n \"item_type\": item_type_name,\n \"dimensions\": getattr(self.type, \"dimensions\", None)\n }\n _type_options = {k: v for k, v in full_type_options.items() if v is not None}\n return _type_options if _type_options else None\n\n def _assert_that_engine_is_present(self):\n if self.engine is None:\n raise Exception(\"Engine should not be None.\")\n", "path": "db/columns/base.py"}]}
| 3,314 | 113 |
gh_patches_debug_4985
|
rasdani/github-patches
|
git_diff
|
spack__spack-2022
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`spack checksum` finds wrong URLs
I was having some problems getting spack to find the correct URL for files.
With these settings
``` python
homepage = "http://fishshell.com/"
url = "http://fishshell.com/files/2.2.0/fish-2.2.0.tar.gz"
list_url = homepage
```
I get the following result (with wrong URLs):
``` sh
$ spack checksum fish
==> Found 5 versions of fish.
2.2.0 http://fishshell.com/fish-2.2.0.tar.gz
2.1.2 http://fishshell.com/fish-2.1.2.tar.gz
2.1.1 http://fishshell.com/fish-2.1.1.tar.gz
2.1.0 http://fishshell.com/fish-2.1.0.tar.gz
2.0.0 http://fishshell.com/fish-2.0.0.tar.gz
How many would you like to checksum? (default is 5, q to abort)
==> Downloading...
==> Trying to fetch from http://fishshell.com/fish-2.2.0.tar.gz
curl: (22) The requested URL returned error: 404 Not Found
==> Fetching from http://fishshell.com/fish-2.2.0.tar.gz failed.
==> Error: All fetchers failed for spack-stage-Slflbn
```
</issue>
<code>
[start of var/spack/repos/builtin/packages/fish/package.py]
1 ##############################################################################
2 # Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.
3 # Produced at the Lawrence Livermore National Laboratory.
4 #
5 # This file is part of Spack.
6 # Created by Todd Gamblin, [email protected], All rights reserved.
7 # LLNL-CODE-647188
8 #
9 # For details, see https://github.com/llnl/spack
10 # Please also see the LICENSE file for our notice and the LGPL.
11 #
12 # This program is free software; you can redistribute it and/or modify
13 # it under the terms of the GNU Lesser General Public License (as
14 # published by the Free Software Foundation) version 2.1, February 1999.
15 #
16 # This program is distributed in the hope that it will be useful, but
17 # WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
18 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
19 # conditions of the GNU Lesser General Public License for more details.
20 #
21 # You should have received a copy of the GNU Lesser General Public
22 # License along with this program; if not, write to the Free Software
23 # Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
24 ##############################################################################
25 from spack import *
26
27
28 class Fish(Package):
29 """fish is a smart and user-friendly command line shell for OS X, Linux, and
30 the rest of the family.
31 """
32
33 homepage = "http://fishshell.com/"
34 url = "http://fishshell.com/files/2.2.0/fish-2.2.0.tar.gz"
35 list_url = "http://fishshell.com/files/"
36 list_depth = 2
37
38 version('2.2.0', 'a76339fd14ce2ec229283c53e805faac48c3e99d9e3ede9d82c0554acfc7b77a')
39
40 def install(self, spec, prefix):
41 configure('--prefix=%s' % prefix)
42
43 make()
44 make("install")
45
[end of var/spack/repos/builtin/packages/fish/package.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/var/spack/repos/builtin/packages/fish/package.py b/var/spack/repos/builtin/packages/fish/package.py
--- a/var/spack/repos/builtin/packages/fish/package.py
+++ b/var/spack/repos/builtin/packages/fish/package.py
@@ -32,8 +32,7 @@
homepage = "http://fishshell.com/"
url = "http://fishshell.com/files/2.2.0/fish-2.2.0.tar.gz"
- list_url = "http://fishshell.com/files/"
- list_depth = 2
+ list_url = "http://fishshell.com/"
version('2.2.0', 'a76339fd14ce2ec229283c53e805faac48c3e99d9e3ede9d82c0554acfc7b77a')
|
{"golden_diff": "diff --git a/var/spack/repos/builtin/packages/fish/package.py b/var/spack/repos/builtin/packages/fish/package.py\n--- a/var/spack/repos/builtin/packages/fish/package.py\n+++ b/var/spack/repos/builtin/packages/fish/package.py\n@@ -32,8 +32,7 @@\n \n homepage = \"http://fishshell.com/\"\n url = \"http://fishshell.com/files/2.2.0/fish-2.2.0.tar.gz\"\n- list_url = \"http://fishshell.com/files/\"\n- list_depth = 2\n+ list_url = \"http://fishshell.com/\"\n \n version('2.2.0', 'a76339fd14ce2ec229283c53e805faac48c3e99d9e3ede9d82c0554acfc7b77a')\n", "issue": "`spack checksum` finds wrong URLs\nI was having some problems getting spack to find the correct URL for files.\n\nWith these settings\n\n``` python\n homepage = \"http://fishshell.com/\"\n url = \"http://fishshell.com/files/2.2.0/fish-2.2.0.tar.gz\"\n list_url = homepage\n```\n\nI get the following result (with wrong URLs):\n\n``` sh\n$ spack checksum fish\n==> Found 5 versions of fish.\n 2.2.0 http://fishshell.com/fish-2.2.0.tar.gz\n 2.1.2 http://fishshell.com/fish-2.1.2.tar.gz\n 2.1.1 http://fishshell.com/fish-2.1.1.tar.gz\n 2.1.0 http://fishshell.com/fish-2.1.0.tar.gz\n 2.0.0 http://fishshell.com/fish-2.0.0.tar.gz\n\nHow many would you like to checksum? (default is 5, q to abort)\n==> Downloading...\n==> Trying to fetch from http://fishshell.com/fish-2.2.0.tar.gz\n\ncurl: (22) The requested URL returned error: 404 Not Found\n==> Fetching from http://fishshell.com/fish-2.2.0.tar.gz failed.\n==> Error: All fetchers failed for spack-stage-Slflbn\n```\n\n", "before_files": [{"content": "##############################################################################\n# Copyright (c) 2013-2016, Lawrence Livermore National Security, LLC.\n# Produced at the Lawrence Livermore National Laboratory.\n#\n# This file is part of Spack.\n# Created by Todd Gamblin, [email protected], All rights reserved.\n# LLNL-CODE-647188\n#\n# For details, see https://github.com/llnl/spack\n# Please also see the LICENSE file for our notice and the LGPL.\n#\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU Lesser General Public License (as\n# published by the Free Software Foundation) version 2.1, February 1999.\n#\n# This program is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and\n# conditions of the GNU Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this program; if not, write to the Free Software\n# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA\n##############################################################################\nfrom spack import *\n\n\nclass Fish(Package):\n \"\"\"fish is a smart and user-friendly command line shell for OS X, Linux, and\n the rest of the family.\n \"\"\"\n\n homepage = \"http://fishshell.com/\"\n url = \"http://fishshell.com/files/2.2.0/fish-2.2.0.tar.gz\"\n list_url = \"http://fishshell.com/files/\"\n list_depth = 2\n\n version('2.2.0', 'a76339fd14ce2ec229283c53e805faac48c3e99d9e3ede9d82c0554acfc7b77a')\n\n def install(self, spec, prefix):\n configure('--prefix=%s' % prefix)\n\n make()\n make(\"install\")\n", "path": "var/spack/repos/builtin/packages/fish/package.py"}]}
| 1,433 | 207 |
gh_patches_debug_29840
|
rasdani/github-patches
|
git_diff
|
onnx__sklearn-onnx-459
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fix discrepencies introduced by sciki-learn 0.23
</issue>
<code>
[start of skl2onnx/operator_converters/gaussian_process.py]
1 # -------------------------------------------------------------------------
2 # Copyright (c) Microsoft Corporation. All rights reserved.
3 # Licensed under the MIT License. See License.txt in the project root for
4 # license information.
5 # --------------------------------------------------------------------------
6 import numpy as np
7 from sklearn.gaussian_process.kernels import ConstantKernel as C, RBF
8 from ..common._registration import register_converter
9 from ..algebra.onnx_ops import (
10 OnnxAdd, OnnxSqrt, OnnxMatMul, OnnxSub, OnnxReduceSum,
11 OnnxMul, OnnxMax
12 )
13 try:
14 from ..algebra.onnx_ops import OnnxConstantOfShape
15 except ImportError:
16 OnnxConstantOfShape = None
17
18 from ._gp_kernels import (
19 convert_kernel_diag,
20 convert_kernel,
21 _zero_vector_of_size
22 )
23
24
25 def convert_gaussian_process_regressor(scope, operator, container):
26 """
27 The method *predict* from class *GaussianProcessRegressor*
28 may cache some results if it is called with parameter
29 ``return_std=True`` or ``return_cov=True``. This converter
30 needs to be called with theses options to enable
31 the second results.
32 See example :ref:`l-gpr-example` to see how to
33 use this converter which does not behave exactly
34 as the others.
35 """
36 dtype = container.dtype
37 if dtype is None:
38 raise RuntimeError("dtype cannot be None")
39 X = operator.inputs[0]
40 out = operator.outputs
41 op = operator.raw_operator
42 opv = container.target_opset
43 if opv is None:
44 raise RuntimeError("container.target_opset must not be None")
45
46 options = container.get_options(op, dict(return_cov=False,
47 return_std=False,
48 optim=None))
49 if hasattr(op, 'kernel_') and op.kernel_ is not None:
50 kernel = op.kernel_
51 elif op.kernel is None:
52 kernel = (C(1.0, constant_value_bounds="fixed") *
53 RBF(1.0, length_scale_bounds="fixed"))
54 else:
55 kernel = op.kernel
56
57 if not hasattr(op, "X_train_") or op.X_train_ is None:
58 out0 = _zero_vector_of_size(X, keepdims=1, output_names=out[:1],
59 dtype=dtype)
60
61 outputs = [out0]
62 if options['return_cov']:
63 outputs.append(convert_kernel(kernel, X,
64 output_names=out[1:],
65 dtype=dtype,
66 op_version=opv))
67 if options['return_std']:
68 outputs.append(
69 OnnxSqrt(
70 convert_kernel_diag(
71 kernel, X, dtype=dtype, op_version=opv),
72 output_names=out[1:], op_version=opv))
73 else:
74 out0 = _zero_vector_of_size(
75 X, keepdims=1, dtype=dtype, op_version=opv)
76
77 # Code scikit-learn
78 # K_trans = self.kernel_(X, self.X_train_)
79 # y_mean = K_trans.dot(self.alpha_) # Line 4 (y_mean = f_star)
80 # y_mean = self._y_train_mean + y_mean # undo normal.
81
82 k_trans = convert_kernel(kernel, X,
83 x_train=op.X_train_.astype(dtype),
84 dtype=dtype,
85 optim=options.get('optim', None),
86 op_version=opv)
87 k_trans.set_onnx_name_prefix('kgpd')
88 y_mean_b = OnnxMatMul(k_trans, op.alpha_.astype(dtype), op_version=opv)
89
90 mean_y = op._y_train_mean.astype(dtype)
91 if len(mean_y.shape) == 1:
92 mean_y = mean_y.reshape(mean_y.shape + (1,))
93 y_mean = OnnxAdd(y_mean_b, mean_y,
94 output_names=out[:1],
95 op_version=opv)
96 y_mean.set_onnx_name_prefix('gpr')
97 outputs = [y_mean]
98
99 if options['return_cov']:
100 raise NotImplementedError()
101 if options['return_std']:
102 if op._K_inv is None:
103 raise RuntimeError(
104 "The method *predict* must be called once with parameter "
105 "return_std=True to compute internal variables. "
106 "They cannot be computed here as the same operation "
107 "(matrix inversion) produces too many discrepencies "
108 "if done with single floats than double floats.")
109 _K_inv = op._K_inv
110
111 # y_var = self.kernel_.diag(X)
112 y_var = convert_kernel_diag(kernel, X, dtype=dtype,
113 optim=options.get('optim', None),
114 op_version=opv)
115
116 # y_var -= np.einsum("ij,ij->i",
117 # np.dot(K_trans, self._K_inv), K_trans)
118 k_dot = OnnxMatMul(k_trans, _K_inv.astype(dtype), op_version=opv)
119 ys_var = OnnxSub(
120 y_var, OnnxReduceSum(
121 OnnxMul(k_dot, k_trans, op_version=opv),
122 axes=[1], keepdims=0, op_version=opv),
123 op_version=opv)
124
125 # y_var_negative = y_var < 0
126 # if np.any(y_var_negative):
127 # y_var[y_var_negative] = 0.0
128 ys0_var = OnnxMax(ys_var, np.array([0], dtype=dtype),
129 op_version=opv)
130
131 # var = np.sqrt(ys0_var)
132 var = OnnxSqrt(ys0_var, output_names=out[1:], op_version=opv)
133 var.set_onnx_name_prefix('gprv')
134 outputs.append(var)
135
136 for o in outputs:
137 o.add_to(scope, container)
138
139
140 if OnnxConstantOfShape is not None:
141 register_converter('SklearnGaussianProcessRegressor',
142 convert_gaussian_process_regressor,
143 options={'return_cov': [False, True],
144 'return_std': [False, True],
145 'optim': [None, 'cdist']})
146
[end of skl2onnx/operator_converters/gaussian_process.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skl2onnx/operator_converters/gaussian_process.py b/skl2onnx/operator_converters/gaussian_process.py
--- a/skl2onnx/operator_converters/gaussian_process.py
+++ b/skl2onnx/operator_converters/gaussian_process.py
@@ -90,9 +90,22 @@
mean_y = op._y_train_mean.astype(dtype)
if len(mean_y.shape) == 1:
mean_y = mean_y.reshape(mean_y.shape + (1,))
- y_mean = OnnxAdd(y_mean_b, mean_y,
- output_names=out[:1],
- op_version=opv)
+
+ if not hasattr(op, '_y_train_std') or op._y_train_std == 1:
+ y_mean = OnnxAdd(y_mean_b, mean_y, output_names=out[:1],
+ op_version=opv)
+ else:
+ # A bug was fixed in 0.23 and it changed
+ # the predictions when return_std is True.
+ # See https://github.com/scikit-learn/scikit-learn/pull/15782.
+ # y_mean = self._y_train_std * y_mean + self._y_train_mean
+ var_y = op._y_train_std.astype(dtype)
+ if len(var_y.shape) == 1:
+ var_y = var_y.reshape(var_y.shape + (1,))
+ y_mean = OnnxAdd(
+ OnnxMul(y_mean_b, var_y, op_version=opv),
+ mean_y, output_names=out[:1], op_version=opv)
+
y_mean.set_onnx_name_prefix('gpr')
outputs = [y_mean]
@@ -128,6 +141,10 @@
ys0_var = OnnxMax(ys_var, np.array([0], dtype=dtype),
op_version=opv)
+ if hasattr(op, '_y_train_std') and op._y_train_std != 1:
+ # y_var = y_var * self._y_train_std**2
+ ys0_var = OnnxMul(ys0_var, var_y ** 2, op_version=opv)
+
# var = np.sqrt(ys0_var)
var = OnnxSqrt(ys0_var, output_names=out[1:], op_version=opv)
var.set_onnx_name_prefix('gprv')
|
{"golden_diff": "diff --git a/skl2onnx/operator_converters/gaussian_process.py b/skl2onnx/operator_converters/gaussian_process.py\n--- a/skl2onnx/operator_converters/gaussian_process.py\n+++ b/skl2onnx/operator_converters/gaussian_process.py\n@@ -90,9 +90,22 @@\n mean_y = op._y_train_mean.astype(dtype)\n if len(mean_y.shape) == 1:\n mean_y = mean_y.reshape(mean_y.shape + (1,))\n- y_mean = OnnxAdd(y_mean_b, mean_y,\n- output_names=out[:1],\n- op_version=opv)\n+\n+ if not hasattr(op, '_y_train_std') or op._y_train_std == 1:\n+ y_mean = OnnxAdd(y_mean_b, mean_y, output_names=out[:1],\n+ op_version=opv)\n+ else:\n+ # A bug was fixed in 0.23 and it changed\n+ # the predictions when return_std is True.\n+ # See https://github.com/scikit-learn/scikit-learn/pull/15782.\n+ # y_mean = self._y_train_std * y_mean + self._y_train_mean\n+ var_y = op._y_train_std.astype(dtype)\n+ if len(var_y.shape) == 1:\n+ var_y = var_y.reshape(var_y.shape + (1,))\n+ y_mean = OnnxAdd(\n+ OnnxMul(y_mean_b, var_y, op_version=opv),\n+ mean_y, output_names=out[:1], op_version=opv)\n+\n y_mean.set_onnx_name_prefix('gpr')\n outputs = [y_mean]\n \n@@ -128,6 +141,10 @@\n ys0_var = OnnxMax(ys_var, np.array([0], dtype=dtype),\n op_version=opv)\n \n+ if hasattr(op, '_y_train_std') and op._y_train_std != 1:\n+ # y_var = y_var * self._y_train_std**2\n+ ys0_var = OnnxMul(ys0_var, var_y ** 2, op_version=opv)\n+\n # var = np.sqrt(ys0_var)\n var = OnnxSqrt(ys0_var, output_names=out[1:], op_version=opv)\n var.set_onnx_name_prefix('gprv')\n", "issue": "Fix discrepencies introduced by sciki-learn 0.23\n\n", "before_files": [{"content": "# -------------------------------------------------------------------------\n# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See License.txt in the project root for\n# license information.\n# --------------------------------------------------------------------------\nimport numpy as np\nfrom sklearn.gaussian_process.kernels import ConstantKernel as C, RBF\nfrom ..common._registration import register_converter\nfrom ..algebra.onnx_ops import (\n OnnxAdd, OnnxSqrt, OnnxMatMul, OnnxSub, OnnxReduceSum,\n OnnxMul, OnnxMax\n)\ntry:\n from ..algebra.onnx_ops import OnnxConstantOfShape\nexcept ImportError:\n OnnxConstantOfShape = None\n\nfrom ._gp_kernels import (\n convert_kernel_diag,\n convert_kernel,\n _zero_vector_of_size\n)\n\n\ndef convert_gaussian_process_regressor(scope, operator, container):\n \"\"\"\n The method *predict* from class *GaussianProcessRegressor*\n may cache some results if it is called with parameter\n ``return_std=True`` or ``return_cov=True``. This converter\n needs to be called with theses options to enable\n the second results.\n See example :ref:`l-gpr-example` to see how to\n use this converter which does not behave exactly\n as the others.\n \"\"\"\n dtype = container.dtype\n if dtype is None:\n raise RuntimeError(\"dtype cannot be None\")\n X = operator.inputs[0]\n out = operator.outputs\n op = operator.raw_operator\n opv = container.target_opset\n if opv is None:\n raise RuntimeError(\"container.target_opset must not be None\")\n\n options = container.get_options(op, dict(return_cov=False,\n return_std=False,\n optim=None))\n if hasattr(op, 'kernel_') and op.kernel_ is not None:\n kernel = op.kernel_\n elif op.kernel is None:\n kernel = (C(1.0, constant_value_bounds=\"fixed\") *\n RBF(1.0, length_scale_bounds=\"fixed\"))\n else:\n kernel = op.kernel\n\n if not hasattr(op, \"X_train_\") or op.X_train_ is None:\n out0 = _zero_vector_of_size(X, keepdims=1, output_names=out[:1],\n dtype=dtype)\n\n outputs = [out0]\n if options['return_cov']:\n outputs.append(convert_kernel(kernel, X,\n output_names=out[1:],\n dtype=dtype,\n op_version=opv))\n if options['return_std']:\n outputs.append(\n OnnxSqrt(\n convert_kernel_diag(\n kernel, X, dtype=dtype, op_version=opv),\n output_names=out[1:], op_version=opv))\n else:\n out0 = _zero_vector_of_size(\n X, keepdims=1, dtype=dtype, op_version=opv)\n\n # Code scikit-learn\n # K_trans = self.kernel_(X, self.X_train_)\n # y_mean = K_trans.dot(self.alpha_) # Line 4 (y_mean = f_star)\n # y_mean = self._y_train_mean + y_mean # undo normal.\n\n k_trans = convert_kernel(kernel, X,\n x_train=op.X_train_.astype(dtype),\n dtype=dtype,\n optim=options.get('optim', None),\n op_version=opv)\n k_trans.set_onnx_name_prefix('kgpd')\n y_mean_b = OnnxMatMul(k_trans, op.alpha_.astype(dtype), op_version=opv)\n\n mean_y = op._y_train_mean.astype(dtype)\n if len(mean_y.shape) == 1:\n mean_y = mean_y.reshape(mean_y.shape + (1,))\n y_mean = OnnxAdd(y_mean_b, mean_y,\n output_names=out[:1],\n op_version=opv)\n y_mean.set_onnx_name_prefix('gpr')\n outputs = [y_mean]\n\n if options['return_cov']:\n raise NotImplementedError()\n if options['return_std']:\n if op._K_inv is None:\n raise RuntimeError(\n \"The method *predict* must be called once with parameter \"\n \"return_std=True to compute internal variables. \"\n \"They cannot be computed here as the same operation \"\n \"(matrix inversion) produces too many discrepencies \"\n \"if done with single floats than double floats.\")\n _K_inv = op._K_inv\n\n # y_var = self.kernel_.diag(X)\n y_var = convert_kernel_diag(kernel, X, dtype=dtype,\n optim=options.get('optim', None),\n op_version=opv)\n\n # y_var -= np.einsum(\"ij,ij->i\",\n # np.dot(K_trans, self._K_inv), K_trans)\n k_dot = OnnxMatMul(k_trans, _K_inv.astype(dtype), op_version=opv)\n ys_var = OnnxSub(\n y_var, OnnxReduceSum(\n OnnxMul(k_dot, k_trans, op_version=opv),\n axes=[1], keepdims=0, op_version=opv),\n op_version=opv)\n\n # y_var_negative = y_var < 0\n # if np.any(y_var_negative):\n # y_var[y_var_negative] = 0.0\n ys0_var = OnnxMax(ys_var, np.array([0], dtype=dtype),\n op_version=opv)\n\n # var = np.sqrt(ys0_var)\n var = OnnxSqrt(ys0_var, output_names=out[1:], op_version=opv)\n var.set_onnx_name_prefix('gprv')\n outputs.append(var)\n\n for o in outputs:\n o.add_to(scope, container)\n\n\nif OnnxConstantOfShape is not None:\n register_converter('SklearnGaussianProcessRegressor',\n convert_gaussian_process_regressor,\n options={'return_cov': [False, True],\n 'return_std': [False, True],\n 'optim': [None, 'cdist']})\n", "path": "skl2onnx/operator_converters/gaussian_process.py"}]}
| 2,183 | 532 |
gh_patches_debug_28803
|
rasdani/github-patches
|
git_diff
|
pypa__virtualenv-1691
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[20.0.8] import hook assumes existence of `exec_module` but the api is optional according to PEP 302/451
A contained example is https://github.com/asottile/pymonkey
the import machinery in virtualenv 20.0.8 assumes all loaders have an `exec_module` attribute, however that's optional (and not part of PEP 302 at all)
The crash in my case looks like:
```
Traceback (most recent call last):
File "<frozen importlib._bootstrap>", line 888, in _find_spec
AttributeError: 'PymonkeyImportHook' object has no attribute 'find_spec'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/tmp/pymonkey/testing/pkg1/patchingmod_main.py", line 8, in <module>
exit(main())
File "/tmp/pymonkey/pymonkey.py", line 270, in entry
tuple(patches) + ('--', original_entry_point) + tuple(argv)
File "/tmp/pymonkey/pymonkey.py", line 258, in main
return entry.load()()
File "/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/pkg_resources/__init__.py", line 2445, in load
return self.resolve()
File "/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/pkg_resources/__init__.py", line 2451, in resolve
module = __import__(self.module_name, fromlist=['__name__'], level=0)
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 656, in _load_unlocked
File "<frozen importlib._bootstrap>", line 626, in _load_backward_compatible
File "/tmp/pymonkey/pymonkey.py", line 173, in load_module
module = importmod(fullname)
File "/tmp/pymonkey/pymonkey.py", line 94, in importmod
return __import__(mod, fromlist=[str('__name__')], level=0)
File "/tmp/pymonkey/testing/pkg2/targetmod.py", line 4, in <module>
import setuptools # Some weird import hook
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 656, in _load_unlocked
File "<frozen importlib._bootstrap>", line 626, in _load_backward_compatible
File "/tmp/pymonkey/pymonkey.py", line 173, in load_module
module = importmod(fullname)
File "/tmp/pymonkey/pymonkey.py", line 94, in importmod
return __import__(mod, fromlist=[str('__name__')], level=0)
File "/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/setuptools/__init__.py", line 5, in <module>
import distutils.core
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 955, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 656, in _load_unlocked
File "<frozen importlib._bootstrap>", line 626, in _load_backward_compatible
File "/tmp/pymonkey/pymonkey.py", line 173, in load_module
module = importmod(fullname)
File "/tmp/pymonkey/pymonkey.py", line 94, in importmod
return __import__(mod, fromlist=[str('__name__')], level=0)
File "/usr/lib/python3.6/distutils/core.py", line 16, in <module>
from distutils.dist import Distribution
File "<frozen importlib._bootstrap>", line 971, in _find_and_load
File "<frozen importlib._bootstrap>", line 951, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 890, in _find_spec
File "<frozen importlib._bootstrap>", line 864, in _find_spec_legacy
File "/tmp/pymonkey/pymonkey.py", line 162, in find_module
elif self._module_exists(fullname, path):
File "/tmp/pymonkey/pymonkey.py", line 122, in _module_exists
getattr(entry, 'find_spec', _noop)(module, path) or
File "/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/_virtualenv.py", line 58, in find_spec
old = spec.loader.exec_module
AttributeError: 'PymonkeyImportHook' object has no attribute 'exec_module'
```
</issue>
<code>
[start of src/virtualenv/create/via_global_ref/_virtualenv.py]
1 """Patches that are applied at runtime to the virtual environment"""
2 # -*- coding: utf-8 -*-
3
4 import os
5 import sys
6
7 VIRTUALENV_PATCH_FILE = os.path.join(__file__)
8
9
10 def patch_dist(dist):
11 """
12 Distutils allows user to configure some arguments via a configuration file:
13 https://docs.python.org/3/install/index.html#distutils-configuration-files
14
15 Some of this arguments though don't make sense in context of the virtual environment files, let's fix them up.
16 """
17 # we cannot allow some install config as that would get packages installed outside of the virtual environment
18 old_parse_config_files = dist.Distribution.parse_config_files
19
20 def parse_config_files(self, *args, **kwargs):
21 result = old_parse_config_files(self, *args, **kwargs)
22 install = self.get_option_dict("install")
23
24 if "prefix" in install: # the prefix governs where to install the libraries
25 install["prefix"] = VIRTUALENV_PATCH_FILE, os.path.abspath(sys.prefix)
26
27 if "install_scripts" in install: # the install_scripts governs where to generate console scripts
28 script_path = os.path.abspath(os.path.join(os.path.dirname(__file__), "__SCRIPT_DIR__"))
29 install["install_scripts"] = VIRTUALENV_PATCH_FILE, script_path
30
31 return result
32
33 dist.Distribution.parse_config_files = parse_config_files
34
35
36 # Import hook that patches some modules to ignore configuration values that break package installation in case
37 # of virtual environments.
38 _DISTUTILS_PATCH = "distutils.dist", "setuptools.dist"
39 if sys.version_info > (3, 4):
40 # https://docs.python.org/3/library/importlib.html#setting-up-an-importer
41 from importlib.abc import MetaPathFinder
42 from importlib.util import find_spec
43 from threading import Lock
44
45 class _Finder(MetaPathFinder):
46 """A meta path finder that allows patching the imported distutils modules"""
47
48 fullname = None
49 lock = Lock()
50
51 def find_spec(self, fullname, path, target=None):
52 if fullname in _DISTUTILS_PATCH and self.fullname is None:
53 with self.lock:
54 self.fullname = fullname
55 try:
56 spec = find_spec(fullname, path)
57 if spec is not None:
58 old = spec.loader.exec_module
59
60 def exec_module(module):
61 old(module)
62 patch_dist(module)
63
64 spec.loader.exec_module = exec_module
65 return spec
66 finally:
67 self.fullname = None
68
69 sys.meta_path.insert(0, _Finder())
70 else:
71 # https://www.python.org/dev/peps/pep-0302/
72 from imp import find_module
73 from pkgutil import ImpImporter, ImpLoader
74
75 class _VirtualenvImporter(object, ImpImporter):
76 def __init__(self, path=None):
77 object.__init__(self)
78 ImpImporter.__init__(self, path)
79
80 def find_module(self, fullname, path=None):
81 if fullname in _DISTUTILS_PATCH:
82 try:
83 return _VirtualenvLoader(fullname, *find_module(fullname.split(".")[-1], path))
84 except ImportError:
85 pass
86 return None
87
88 class _VirtualenvLoader(object, ImpLoader):
89 def __init__(self, fullname, file, filename, etc):
90 object.__init__(self)
91 ImpLoader.__init__(self, fullname, file, filename, etc)
92
93 def load_module(self, fullname):
94 module = super(_VirtualenvLoader, self).load_module(fullname)
95 patch_dist(module)
96 module.__loader__ = None # distlib fallback
97 return module
98
99 sys.meta_path.append(_VirtualenvImporter())
100
[end of src/virtualenv/create/via_global_ref/_virtualenv.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/virtualenv/create/via_global_ref/_virtualenv.py b/src/virtualenv/create/via_global_ref/_virtualenv.py
--- a/src/virtualenv/create/via_global_ref/_virtualenv.py
+++ b/src/virtualenv/create/via_global_ref/_virtualenv.py
@@ -3,6 +3,7 @@
import os
import sys
+from copy import deepcopy
VIRTUALENV_PATCH_FILE = os.path.join(__file__)
@@ -55,13 +56,24 @@
try:
spec = find_spec(fullname, path)
if spec is not None:
- old = spec.loader.exec_module
+ # https://www.python.org/dev/peps/pep-0451/#how-loading-will-work
+ spec.loader = deepcopy(spec.loader) # loaders may be shared, create new that also patches
+ func_name = "exec_module" if hasattr(spec.loader, "exec_module") else "load_module"
+ if func_name == "exec_module": # new API
- def exec_module(module):
- old(module)
- patch_dist(module)
+ def patch_module_load(module):
+ old(module)
+ patch_dist(module)
- spec.loader.exec_module = exec_module
+ else: # legacy API
+
+ def patch_module_load(name):
+ module = old(name)
+ patch_dist(module)
+ return module
+
+ old = getattr(spec.loader, func_name)
+ setattr(spec.loader, func_name, patch_module_load)
return spec
finally:
self.fullname = None
|
{"golden_diff": "diff --git a/src/virtualenv/create/via_global_ref/_virtualenv.py b/src/virtualenv/create/via_global_ref/_virtualenv.py\n--- a/src/virtualenv/create/via_global_ref/_virtualenv.py\n+++ b/src/virtualenv/create/via_global_ref/_virtualenv.py\n@@ -3,6 +3,7 @@\n \n import os\n import sys\n+from copy import deepcopy\n \n VIRTUALENV_PATCH_FILE = os.path.join(__file__)\n \n@@ -55,13 +56,24 @@\n try:\n spec = find_spec(fullname, path)\n if spec is not None:\n- old = spec.loader.exec_module\n+ # https://www.python.org/dev/peps/pep-0451/#how-loading-will-work\n+ spec.loader = deepcopy(spec.loader) # loaders may be shared, create new that also patches\n+ func_name = \"exec_module\" if hasattr(spec.loader, \"exec_module\") else \"load_module\"\n+ if func_name == \"exec_module\": # new API\n \n- def exec_module(module):\n- old(module)\n- patch_dist(module)\n+ def patch_module_load(module):\n+ old(module)\n+ patch_dist(module)\n \n- spec.loader.exec_module = exec_module\n+ else: # legacy API\n+\n+ def patch_module_load(name):\n+ module = old(name)\n+ patch_dist(module)\n+ return module\n+\n+ old = getattr(spec.loader, func_name)\n+ setattr(spec.loader, func_name, patch_module_load)\n return spec\n finally:\n self.fullname = None\n", "issue": "[20.0.8] import hook assumes existence of `exec_module` but the api is optional according to PEP 302/451\nA contained example is https://github.com/asottile/pymonkey\r\n\r\nthe import machinery in virtualenv 20.0.8 assumes all loaders have an `exec_module` attribute, however that's optional (and not part of PEP 302 at all)\r\n\r\nThe crash in my case looks like:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"<frozen importlib._bootstrap>\", line 888, in _find_spec\r\nAttributeError: 'PymonkeyImportHook' object has no attribute 'find_spec'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/tmp/pymonkey/testing/pkg1/patchingmod_main.py\", line 8, in <module>\r\n exit(main())\r\n File \"/tmp/pymonkey/pymonkey.py\", line 270, in entry\r\n tuple(patches) + ('--', original_entry_point) + tuple(argv)\r\n File \"/tmp/pymonkey/pymonkey.py\", line 258, in main\r\n return entry.load()()\r\n File \"/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/pkg_resources/__init__.py\", line 2445, in load\r\n return self.resolve()\r\n File \"/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/pkg_resources/__init__.py\", line 2451, in resolve\r\n module = __import__(self.module_name, fromlist=['__name__'], level=0)\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 955, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 656, in _load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 626, in _load_backward_compatible\r\n File \"/tmp/pymonkey/pymonkey.py\", line 173, in load_module\r\n module = importmod(fullname)\r\n File \"/tmp/pymonkey/pymonkey.py\", line 94, in importmod\r\n return __import__(mod, fromlist=[str('__name__')], level=0)\r\n File \"/tmp/pymonkey/testing/pkg2/targetmod.py\", line 4, in <module>\r\n import setuptools # Some weird import hook\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 955, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 656, in _load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 626, in _load_backward_compatible\r\n File \"/tmp/pymonkey/pymonkey.py\", line 173, in load_module\r\n module = importmod(fullname)\r\n File \"/tmp/pymonkey/pymonkey.py\", line 94, in importmod\r\n return __import__(mod, fromlist=[str('__name__')], level=0)\r\n File \"/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/setuptools/__init__.py\", line 5, in <module>\r\n import distutils.core\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 955, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 656, in _load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 626, in _load_backward_compatible\r\n File \"/tmp/pymonkey/pymonkey.py\", line 173, in load_module\r\n module = importmod(fullname)\r\n File \"/tmp/pymonkey/pymonkey.py\", line 94, in importmod\r\n return __import__(mod, fromlist=[str('__name__')], level=0)\r\n File \"/usr/lib/python3.6/distutils/core.py\", line 16, in <module>\r\n from distutils.dist import Distribution\r\n File \"<frozen importlib._bootstrap>\", line 971, in _find_and_load\r\n File \"<frozen importlib._bootstrap>\", line 951, in _find_and_load_unlocked\r\n File \"<frozen importlib._bootstrap>\", line 890, in _find_spec\r\n File \"<frozen importlib._bootstrap>\", line 864, in _find_spec_legacy\r\n File \"/tmp/pymonkey/pymonkey.py\", line 162, in find_module\r\n elif self._module_exists(fullname, path):\r\n File \"/tmp/pymonkey/pymonkey.py\", line 122, in _module_exists\r\n getattr(entry, 'find_spec', _noop)(module, path) or\r\n File \"/tmp/pymonkey/.tox/py36/lib/python3.6/site-packages/_virtualenv.py\", line 58, in find_spec\r\n old = spec.loader.exec_module\r\nAttributeError: 'PymonkeyImportHook' object has no attribute 'exec_module'\r\n```\n", "before_files": [{"content": "\"\"\"Patches that are applied at runtime to the virtual environment\"\"\"\n# -*- coding: utf-8 -*-\n\nimport os\nimport sys\n\nVIRTUALENV_PATCH_FILE = os.path.join(__file__)\n\n\ndef patch_dist(dist):\n \"\"\"\n Distutils allows user to configure some arguments via a configuration file:\n https://docs.python.org/3/install/index.html#distutils-configuration-files\n\n Some of this arguments though don't make sense in context of the virtual environment files, let's fix them up.\n \"\"\"\n # we cannot allow some install config as that would get packages installed outside of the virtual environment\n old_parse_config_files = dist.Distribution.parse_config_files\n\n def parse_config_files(self, *args, **kwargs):\n result = old_parse_config_files(self, *args, **kwargs)\n install = self.get_option_dict(\"install\")\n\n if \"prefix\" in install: # the prefix governs where to install the libraries\n install[\"prefix\"] = VIRTUALENV_PATCH_FILE, os.path.abspath(sys.prefix)\n\n if \"install_scripts\" in install: # the install_scripts governs where to generate console scripts\n script_path = os.path.abspath(os.path.join(os.path.dirname(__file__), \"__SCRIPT_DIR__\"))\n install[\"install_scripts\"] = VIRTUALENV_PATCH_FILE, script_path\n\n return result\n\n dist.Distribution.parse_config_files = parse_config_files\n\n\n# Import hook that patches some modules to ignore configuration values that break package installation in case\n# of virtual environments.\n_DISTUTILS_PATCH = \"distutils.dist\", \"setuptools.dist\"\nif sys.version_info > (3, 4):\n # https://docs.python.org/3/library/importlib.html#setting-up-an-importer\n from importlib.abc import MetaPathFinder\n from importlib.util import find_spec\n from threading import Lock\n\n class _Finder(MetaPathFinder):\n \"\"\"A meta path finder that allows patching the imported distutils modules\"\"\"\n\n fullname = None\n lock = Lock()\n\n def find_spec(self, fullname, path, target=None):\n if fullname in _DISTUTILS_PATCH and self.fullname is None:\n with self.lock:\n self.fullname = fullname\n try:\n spec = find_spec(fullname, path)\n if spec is not None:\n old = spec.loader.exec_module\n\n def exec_module(module):\n old(module)\n patch_dist(module)\n\n spec.loader.exec_module = exec_module\n return spec\n finally:\n self.fullname = None\n\n sys.meta_path.insert(0, _Finder())\nelse:\n # https://www.python.org/dev/peps/pep-0302/\n from imp import find_module\n from pkgutil import ImpImporter, ImpLoader\n\n class _VirtualenvImporter(object, ImpImporter):\n def __init__(self, path=None):\n object.__init__(self)\n ImpImporter.__init__(self, path)\n\n def find_module(self, fullname, path=None):\n if fullname in _DISTUTILS_PATCH:\n try:\n return _VirtualenvLoader(fullname, *find_module(fullname.split(\".\")[-1], path))\n except ImportError:\n pass\n return None\n\n class _VirtualenvLoader(object, ImpLoader):\n def __init__(self, fullname, file, filename, etc):\n object.__init__(self)\n ImpLoader.__init__(self, fullname, file, filename, etc)\n\n def load_module(self, fullname):\n module = super(_VirtualenvLoader, self).load_module(fullname)\n patch_dist(module)\n module.__loader__ = None # distlib fallback\n return module\n\n sys.meta_path.append(_VirtualenvImporter())\n", "path": "src/virtualenv/create/via_global_ref/_virtualenv.py"}]}
| 2,753 | 355 |
gh_patches_debug_19106
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-2319
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CKV_AWS_40: failure even when not setting users
**Describe the issue**
The check fails when executing checkov on Terraform plan's JSON output.
**Examples**
```
resource "aws_iam_policy_attachment" "attachment" {
...
roles = [...]
# no users
}
```
JSON:
```
{
"address": "aws_iam_policy_attachment.attachment",
...
"values": {
...
"roles": [
"data-analytics@eng-0"
],
"users": []
},
...
```
The `users` field is set to `[]` in JSON, and the [check implementation](https://github.com/bridgecrewio/checkov/blob/e2538c48df14363d6ed46e5b838e19cc71ba6cbf/checkov/terraform/checks/resource/base_resource_negative_value_check.py#L39-L53) doesn't handle this scenario correctly:
https://github.com/bridgecrewio/checkov/blob/e2538c48df14363d6ed46e5b838e19cc71ba6cbf/checkov/terraform/checks/resource/base_resource_negative_value_check.py#L39-L53
**Version (please complete the following information):**
```
> checkov --version
2.0.780
```
I saw there are tests for the check implementation, but only targeting Terraform source files. Are there tests targeting JSON output from Terraform plan?
</issue>
<code>
[start of checkov/terraform/checks/resource/base_resource_negative_value_check.py]
1 from abc import abstractmethod
2 from collections.abc import Iterable
3 from typing import List, Dict, Any, Optional
4
5 import dpath
6
7 from checkov.common.models.consts import ANY_VALUE
8 from checkov.common.models.enums import CheckResult, CheckCategories
9 from checkov.common.util.type_forcers import force_list
10 from checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck
11 from checkov.terraform.graph_builder.utils import get_referenced_vertices_in_value
12 from checkov.terraform.parser_functions import handle_dynamic_values
13
14
15 class BaseResourceNegativeValueCheck(BaseResourceCheck):
16 def __init__(
17 self,
18 name: str,
19 id: str,
20 categories: "Iterable[CheckCategories]",
21 supported_resources: "Iterable[str]",
22 missing_attribute_result: CheckResult = CheckResult.PASSED,
23 ) -> None:
24 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
25 self.missing_attribute_result = missing_attribute_result
26
27 def scan_resource_conf(self, conf: Dict[str, List[Any]]) -> CheckResult:
28 handle_dynamic_values(conf)
29
30 excluded_key = self.get_excluded_key()
31 if excluded_key is not None:
32 if dpath.search(conf, excluded_key) != {}:
33 value = dpath.get(conf, excluded_key)
34 if isinstance(value, list) and len(value) == 1:
35 value = value[0]
36 if self.check_excluded_condition(value):
37 return CheckResult.PASSED
38
39 inspected_key = self.get_inspected_key()
40 bad_values = self.get_forbidden_values()
41 if dpath.search(conf, inspected_key) != {}:
42 value = dpath.get(conf, inspected_key)
43 if isinstance(value, list) and len(value) == 1:
44 value = value[0]
45 if get_referenced_vertices_in_value(value=value, aliases={}, resources_types=[]):
46 # we don't provide resources_types as we want to stay provider agnostic
47 return CheckResult.UNKNOWN
48 if value is None:
49 return self.missing_attribute_result
50 if value in bad_values or ANY_VALUE in bad_values:
51 return CheckResult.FAILED
52 else:
53 return CheckResult.PASSED
54
55 return self.missing_attribute_result
56
57 @abstractmethod
58 def get_inspected_key(self) -> str:
59 """
60 :return: JSONPath syntax path of the checked attribute
61 """
62 raise NotImplementedError()
63
64 @abstractmethod
65 def get_forbidden_values(self) -> List[Any]:
66 """
67 Returns a list of vulnerable values for the inspected key, governed by provider best practices
68 """
69 raise NotImplementedError()
70
71 def get_excluded_key(self) -> Optional[str]:
72 """
73 :return: JSONPath syntax path of the an attribute that provides exclusion condition for the inspected key
74 """
75 return None
76
77 def check_excluded_condition(self, value: str) -> bool:
78 """
79 :param: value: value for excluded_key
80 :return: True if the value should exclude the check from failing if the inspected key has a bad value
81 """
82 return False
83
84 def get_evaluated_keys(self) -> List[str]:
85 return force_list(self.get_inspected_key())
86
[end of checkov/terraform/checks/resource/base_resource_negative_value_check.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/terraform/checks/resource/base_resource_negative_value_check.py b/checkov/terraform/checks/resource/base_resource_negative_value_check.py
--- a/checkov/terraform/checks/resource/base_resource_negative_value_check.py
+++ b/checkov/terraform/checks/resource/base_resource_negative_value_check.py
@@ -42,11 +42,11 @@
value = dpath.get(conf, inspected_key)
if isinstance(value, list) and len(value) == 1:
value = value[0]
+ if value is None or (isinstance(value, list) and not value):
+ return self.missing_attribute_result
if get_referenced_vertices_in_value(value=value, aliases={}, resources_types=[]):
# we don't provide resources_types as we want to stay provider agnostic
return CheckResult.UNKNOWN
- if value is None:
- return self.missing_attribute_result
if value in bad_values or ANY_VALUE in bad_values:
return CheckResult.FAILED
else:
|
{"golden_diff": "diff --git a/checkov/terraform/checks/resource/base_resource_negative_value_check.py b/checkov/terraform/checks/resource/base_resource_negative_value_check.py\n--- a/checkov/terraform/checks/resource/base_resource_negative_value_check.py\n+++ b/checkov/terraform/checks/resource/base_resource_negative_value_check.py\n@@ -42,11 +42,11 @@\n value = dpath.get(conf, inspected_key)\n if isinstance(value, list) and len(value) == 1:\n value = value[0]\n+ if value is None or (isinstance(value, list) and not value):\n+ return self.missing_attribute_result\n if get_referenced_vertices_in_value(value=value, aliases={}, resources_types=[]):\n # we don't provide resources_types as we want to stay provider agnostic\n return CheckResult.UNKNOWN\n- if value is None:\n- return self.missing_attribute_result\n if value in bad_values or ANY_VALUE in bad_values:\n return CheckResult.FAILED\n else:\n", "issue": "CKV_AWS_40: failure even when not setting users\n**Describe the issue**\r\nThe check fails when executing checkov on Terraform plan's JSON output.\r\n\r\n**Examples**\r\n```\r\nresource \"aws_iam_policy_attachment\" \"attachment\" {\r\n ...\r\n roles = [...]\r\n # no users\r\n}\r\n```\r\nJSON:\r\n```\r\n{\r\n \"address\": \"aws_iam_policy_attachment.attachment\",\r\n ...\r\n \"values\": {\r\n ...\r\n \"roles\": [\r\n \"data-analytics@eng-0\"\r\n ],\r\n \"users\": []\r\n },\r\n...\r\n```\r\nThe `users` field is set to `[]` in JSON, and the [check implementation](https://github.com/bridgecrewio/checkov/blob/e2538c48df14363d6ed46e5b838e19cc71ba6cbf/checkov/terraform/checks/resource/base_resource_negative_value_check.py#L39-L53) doesn't handle this scenario correctly:\r\n\r\nhttps://github.com/bridgecrewio/checkov/blob/e2538c48df14363d6ed46e5b838e19cc71ba6cbf/checkov/terraform/checks/resource/base_resource_negative_value_check.py#L39-L53\r\n\r\n**Version (please complete the following information):**\r\n```\r\n> checkov --version\r\n2.0.780\r\n```\r\n\r\nI saw there are tests for the check implementation, but only targeting Terraform source files. Are there tests targeting JSON output from Terraform plan?\n", "before_files": [{"content": "from abc import abstractmethod\nfrom collections.abc import Iterable\nfrom typing import List, Dict, Any, Optional\n\nimport dpath\n\nfrom checkov.common.models.consts import ANY_VALUE\nfrom checkov.common.models.enums import CheckResult, CheckCategories\nfrom checkov.common.util.type_forcers import force_list\nfrom checkov.terraform.checks.resource.base_resource_check import BaseResourceCheck\nfrom checkov.terraform.graph_builder.utils import get_referenced_vertices_in_value\nfrom checkov.terraform.parser_functions import handle_dynamic_values\n\n\nclass BaseResourceNegativeValueCheck(BaseResourceCheck):\n def __init__(\n self,\n name: str,\n id: str,\n categories: \"Iterable[CheckCategories]\",\n supported_resources: \"Iterable[str]\",\n missing_attribute_result: CheckResult = CheckResult.PASSED,\n ) -> None:\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n self.missing_attribute_result = missing_attribute_result\n\n def scan_resource_conf(self, conf: Dict[str, List[Any]]) -> CheckResult:\n handle_dynamic_values(conf)\n\n excluded_key = self.get_excluded_key()\n if excluded_key is not None:\n if dpath.search(conf, excluded_key) != {}:\n value = dpath.get(conf, excluded_key)\n if isinstance(value, list) and len(value) == 1:\n value = value[0]\n if self.check_excluded_condition(value):\n return CheckResult.PASSED\n\n inspected_key = self.get_inspected_key()\n bad_values = self.get_forbidden_values()\n if dpath.search(conf, inspected_key) != {}:\n value = dpath.get(conf, inspected_key)\n if isinstance(value, list) and len(value) == 1:\n value = value[0]\n if get_referenced_vertices_in_value(value=value, aliases={}, resources_types=[]):\n # we don't provide resources_types as we want to stay provider agnostic\n return CheckResult.UNKNOWN\n if value is None:\n return self.missing_attribute_result\n if value in bad_values or ANY_VALUE in bad_values:\n return CheckResult.FAILED\n else:\n return CheckResult.PASSED\n\n return self.missing_attribute_result\n\n @abstractmethod\n def get_inspected_key(self) -> str:\n \"\"\"\n :return: JSONPath syntax path of the checked attribute\n \"\"\"\n raise NotImplementedError()\n\n @abstractmethod\n def get_forbidden_values(self) -> List[Any]:\n \"\"\"\n Returns a list of vulnerable values for the inspected key, governed by provider best practices\n \"\"\"\n raise NotImplementedError()\n\n def get_excluded_key(self) -> Optional[str]:\n \"\"\"\n :return: JSONPath syntax path of the an attribute that provides exclusion condition for the inspected key\n \"\"\"\n return None\n\n def check_excluded_condition(self, value: str) -> bool:\n \"\"\"\n :param: value: value for excluded_key\n :return: True if the value should exclude the check from failing if the inspected key has a bad value\n \"\"\"\n return False\n\n def get_evaluated_keys(self) -> List[str]:\n return force_list(self.get_inspected_key())\n", "path": "checkov/terraform/checks/resource/base_resource_negative_value_check.py"}]}
| 1,734 | 218 |
gh_patches_debug_3444
|
rasdani/github-patches
|
git_diff
|
elastic__apm-agent-python-1571
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Wrong transaction name in Django 4.0+
**Describe the bug**:
When using Django versions 4.0+, the transaction names are incorrect.
Expected: `django_app.views.ListUsers`
Actual: `django_app.views.view`
**Environment (please complete the following information)**
- OS: Debian Bullseye
- Python version: 3.9.13
- Framework and version: Django 4.0.5
- APM Server version: 7.12.0
- Agent version: 6.9.1
**Additional context**
This issue seems to be introduced with the following [PR](https://github.com/django/django/pull/14124) to Django.
https://github.com/django/django/blob/e96320c91724830034033a9cb8afd9cf8c11e2fd/django/views/generic/base.py#L108-#L110
I will try to provide a fix shortly.
</issue>
<code>
[start of elasticapm/utils/__init__.py]
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31 import base64
32 import os
33 import re
34 import urllib.parse
35 from functools import partial
36 from types import FunctionType
37 from typing import Pattern
38
39 from elasticapm.conf import constants
40 from elasticapm.utils import encoding
41
42 try:
43 from functools import partialmethod
44
45 partial_types = (partial, partialmethod)
46 except ImportError:
47 # Python 2
48 partial_types = (partial,)
49
50
51 default_ports = {"https": 443, "http": 80, "postgresql": 5432, "mysql": 3306, "mssql": 1433}
52
53
54 def varmap(func, var, context=None, name=None, **kwargs):
55 """
56 Executes ``func(key_name, value)`` on all values,
57 recursively discovering dict and list scoped
58 values.
59 """
60 if context is None:
61 context = set()
62 objid = id(var)
63 if objid in context:
64 return func(name, "<...>", **kwargs)
65 context.add(objid)
66 if isinstance(var, dict):
67 # iterate over a copy of the dictionary to avoid "dictionary changed size during iteration" issues
68 ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in var.copy().items()), **kwargs)
69 elif isinstance(var, (list, tuple)):
70 ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)
71 else:
72 ret = func(name, var, **kwargs)
73 context.remove(objid)
74 return ret
75
76
77 def get_name_from_func(func: FunctionType) -> str:
78 # partials don't have `__module__` or `__name__`, so we use the values from the "inner" function
79 if isinstance(func, partial_types):
80 return "partial({})".format(get_name_from_func(func.func))
81 elif hasattr(func, "_partialmethod") and hasattr(func._partialmethod, "func"):
82 return "partial({})".format(get_name_from_func(func._partialmethod.func))
83
84 module = func.__module__
85
86 if hasattr(func, "__name__"):
87 view_name = func.__name__
88 else: # Fall back if there's no __name__
89 view_name = func.__class__.__name__
90
91 return "{0}.{1}".format(module, view_name)
92
93
94 def build_name_with_http_method_prefix(name, request):
95 return " ".join((request.method, name)) if name else name
96
97
98 def is_master_process() -> bool:
99 # currently only recognizes uwsgi master process
100 try:
101 import uwsgi
102
103 return os.getpid() == uwsgi.masterpid()
104 except ImportError:
105 return False
106
107
108 def get_url_dict(url: str) -> dict:
109 parse_result = urllib.parse.urlparse(url)
110
111 url_dict = {
112 "full": encoding.keyword_field(url),
113 "protocol": parse_result.scheme + ":",
114 "hostname": encoding.keyword_field(parse_result.hostname),
115 "pathname": encoding.keyword_field(parse_result.path),
116 }
117
118 port = None if parse_result.port is None else str(parse_result.port)
119
120 if port:
121 url_dict["port"] = port
122 if parse_result.query:
123 url_dict["search"] = encoding.keyword_field("?" + parse_result.query)
124 return url_dict
125
126
127 def sanitize_url(url: str) -> str:
128 if "@" not in url:
129 return url
130 parts = urllib.parse.urlparse(url)
131 return url.replace("%s:%s" % (parts.username, parts.password), "%s:%s" % (parts.username, constants.MASK))
132
133
134 def get_host_from_url(url: str) -> str:
135 parsed_url = urllib.parse.urlparse(url)
136 host = parsed_url.hostname or " "
137
138 if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:
139 host += ":" + str(parsed_url.port)
140
141 return host
142
143
144 def url_to_destination_resource(url: str) -> str:
145 parts = urllib.parse.urlsplit(url)
146 hostname = parts.hostname if parts.hostname else ""
147 # preserve brackets for IPv6 URLs
148 if "://[" in url:
149 hostname = "[%s]" % hostname
150 try:
151 port = parts.port
152 except ValueError:
153 # Malformed port, just use None rather than raising an exception
154 port = None
155 default_port = default_ports.get(parts.scheme, None)
156 name = "%s://%s" % (parts.scheme, hostname)
157 resource = hostname
158 if not port and parts.scheme in default_ports:
159 port = default_ports[parts.scheme]
160 if port:
161 if port != default_port:
162 name += ":%d" % port
163 resource += ":%d" % port
164 return resource
165
166
167 def read_pem_file(file_obj) -> bytes:
168 cert = b""
169 for line in file_obj:
170 if line.startswith(b"-----BEGIN CERTIFICATE-----"):
171 break
172 # scan until we find the first END CERTIFICATE marker
173 for line in file_obj:
174 if line.startswith(b"-----END CERTIFICATE-----"):
175 break
176 cert += line.strip()
177 return base64.b64decode(cert)
178
179
180 def starmatch_to_regex(pattern: str) -> Pattern:
181 options = re.DOTALL
182 # check if we are case sensitive
183 if pattern.startswith("(?-i)"):
184 pattern = pattern[5:]
185 else:
186 options |= re.IGNORECASE
187 i, n = 0, len(pattern)
188 res = []
189 while i < n:
190 c = pattern[i]
191 i = i + 1
192 if c == "*":
193 res.append(".*")
194 else:
195 res.append(re.escape(c))
196 return re.compile(r"(?:%s)\Z" % "".join(res), options)
197
198
199 def nested_key(d: dict, *args):
200 """
201 Traverses a dictionary for nested keys. Returns `None` if the at any point
202 in the traversal a key cannot be found.
203
204 Example:
205
206 >>> from elasticapm.utils import nested_key
207 >>> d = {"a": {"b": {"c": 0}}}
208 >>> nested_key(d, "a", "b", "c")
209 0
210 >>> nested_key(d, "a", "b", "d")
211 None
212 """
213 for arg in args:
214 try:
215 d = d[arg]
216 except (TypeError, KeyError):
217 d = None
218 break
219 return d
220
[end of elasticapm/utils/__init__.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py
--- a/elasticapm/utils/__init__.py
+++ b/elasticapm/utils/__init__.py
@@ -83,7 +83,9 @@
module = func.__module__
- if hasattr(func, "__name__"):
+ if hasattr(func, "view_class"):
+ view_name = func.view_class.__name__
+ elif hasattr(func, "__name__"):
view_name = func.__name__
else: # Fall back if there's no __name__
view_name = func.__class__.__name__
|
{"golden_diff": "diff --git a/elasticapm/utils/__init__.py b/elasticapm/utils/__init__.py\n--- a/elasticapm/utils/__init__.py\n+++ b/elasticapm/utils/__init__.py\n@@ -83,7 +83,9 @@\n \n module = func.__module__\n \n- if hasattr(func, \"__name__\"):\n+ if hasattr(func, \"view_class\"):\n+ view_name = func.view_class.__name__\n+ elif hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n", "issue": "Wrong transaction name in Django 4.0+\n**Describe the bug**:\r\nWhen using Django versions 4.0+, the transaction names are incorrect.\r\n\r\nExpected: `django_app.views.ListUsers`\r\nActual: `django_app.views.view`\r\n\r\n\r\n**Environment (please complete the following information)**\r\n- OS: Debian Bullseye\r\n- Python version: 3.9.13\r\n- Framework and version: Django 4.0.5\r\n- APM Server version: 7.12.0\r\n- Agent version: 6.9.1\r\n\r\n\r\n**Additional context**\r\n\r\nThis issue seems to be introduced with the following [PR](https://github.com/django/django/pull/14124) to Django.\r\nhttps://github.com/django/django/blob/e96320c91724830034033a9cb8afd9cf8c11e2fd/django/views/generic/base.py#L108-#L110\r\n\r\nI will try to provide a fix shortly.\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\nimport base64\nimport os\nimport re\nimport urllib.parse\nfrom functools import partial\nfrom types import FunctionType\nfrom typing import Pattern\n\nfrom elasticapm.conf import constants\nfrom elasticapm.utils import encoding\n\ntry:\n from functools import partialmethod\n\n partial_types = (partial, partialmethod)\nexcept ImportError:\n # Python 2\n partial_types = (partial,)\n\n\ndefault_ports = {\"https\": 443, \"http\": 80, \"postgresql\": 5432, \"mysql\": 3306, \"mssql\": 1433}\n\n\ndef varmap(func, var, context=None, name=None, **kwargs):\n \"\"\"\n Executes ``func(key_name, value)`` on all values,\n recursively discovering dict and list scoped\n values.\n \"\"\"\n if context is None:\n context = set()\n objid = id(var)\n if objid in context:\n return func(name, \"<...>\", **kwargs)\n context.add(objid)\n if isinstance(var, dict):\n # iterate over a copy of the dictionary to avoid \"dictionary changed size during iteration\" issues\n ret = func(name, dict((k, varmap(func, v, context, k, **kwargs)) for k, v in var.copy().items()), **kwargs)\n elif isinstance(var, (list, tuple)):\n ret = func(name, [varmap(func, f, context, name, **kwargs) for f in var], **kwargs)\n else:\n ret = func(name, var, **kwargs)\n context.remove(objid)\n return ret\n\n\ndef get_name_from_func(func: FunctionType) -> str:\n # partials don't have `__module__` or `__name__`, so we use the values from the \"inner\" function\n if isinstance(func, partial_types):\n return \"partial({})\".format(get_name_from_func(func.func))\n elif hasattr(func, \"_partialmethod\") and hasattr(func._partialmethod, \"func\"):\n return \"partial({})\".format(get_name_from_func(func._partialmethod.func))\n\n module = func.__module__\n\n if hasattr(func, \"__name__\"):\n view_name = func.__name__\n else: # Fall back if there's no __name__\n view_name = func.__class__.__name__\n\n return \"{0}.{1}\".format(module, view_name)\n\n\ndef build_name_with_http_method_prefix(name, request):\n return \" \".join((request.method, name)) if name else name\n\n\ndef is_master_process() -> bool:\n # currently only recognizes uwsgi master process\n try:\n import uwsgi\n\n return os.getpid() == uwsgi.masterpid()\n except ImportError:\n return False\n\n\ndef get_url_dict(url: str) -> dict:\n parse_result = urllib.parse.urlparse(url)\n\n url_dict = {\n \"full\": encoding.keyword_field(url),\n \"protocol\": parse_result.scheme + \":\",\n \"hostname\": encoding.keyword_field(parse_result.hostname),\n \"pathname\": encoding.keyword_field(parse_result.path),\n }\n\n port = None if parse_result.port is None else str(parse_result.port)\n\n if port:\n url_dict[\"port\"] = port\n if parse_result.query:\n url_dict[\"search\"] = encoding.keyword_field(\"?\" + parse_result.query)\n return url_dict\n\n\ndef sanitize_url(url: str) -> str:\n if \"@\" not in url:\n return url\n parts = urllib.parse.urlparse(url)\n return url.replace(\"%s:%s\" % (parts.username, parts.password), \"%s:%s\" % (parts.username, constants.MASK))\n\n\ndef get_host_from_url(url: str) -> str:\n parsed_url = urllib.parse.urlparse(url)\n host = parsed_url.hostname or \" \"\n\n if parsed_url.port and default_ports.get(parsed_url.scheme) != parsed_url.port:\n host += \":\" + str(parsed_url.port)\n\n return host\n\n\ndef url_to_destination_resource(url: str) -> str:\n parts = urllib.parse.urlsplit(url)\n hostname = parts.hostname if parts.hostname else \"\"\n # preserve brackets for IPv6 URLs\n if \"://[\" in url:\n hostname = \"[%s]\" % hostname\n try:\n port = parts.port\n except ValueError:\n # Malformed port, just use None rather than raising an exception\n port = None\n default_port = default_ports.get(parts.scheme, None)\n name = \"%s://%s\" % (parts.scheme, hostname)\n resource = hostname\n if not port and parts.scheme in default_ports:\n port = default_ports[parts.scheme]\n if port:\n if port != default_port:\n name += \":%d\" % port\n resource += \":%d\" % port\n return resource\n\n\ndef read_pem_file(file_obj) -> bytes:\n cert = b\"\"\n for line in file_obj:\n if line.startswith(b\"-----BEGIN CERTIFICATE-----\"):\n break\n # scan until we find the first END CERTIFICATE marker\n for line in file_obj:\n if line.startswith(b\"-----END CERTIFICATE-----\"):\n break\n cert += line.strip()\n return base64.b64decode(cert)\n\n\ndef starmatch_to_regex(pattern: str) -> Pattern:\n options = re.DOTALL\n # check if we are case sensitive\n if pattern.startswith(\"(?-i)\"):\n pattern = pattern[5:]\n else:\n options |= re.IGNORECASE\n i, n = 0, len(pattern)\n res = []\n while i < n:\n c = pattern[i]\n i = i + 1\n if c == \"*\":\n res.append(\".*\")\n else:\n res.append(re.escape(c))\n return re.compile(r\"(?:%s)\\Z\" % \"\".join(res), options)\n\n\ndef nested_key(d: dict, *args):\n \"\"\"\n Traverses a dictionary for nested keys. Returns `None` if the at any point\n in the traversal a key cannot be found.\n\n Example:\n\n >>> from elasticapm.utils import nested_key\n >>> d = {\"a\": {\"b\": {\"c\": 0}}}\n >>> nested_key(d, \"a\", \"b\", \"c\")\n 0\n >>> nested_key(d, \"a\", \"b\", \"d\")\n None\n \"\"\"\n for arg in args:\n try:\n d = d[arg]\n except (TypeError, KeyError):\n d = None\n break\n return d\n", "path": "elasticapm/utils/__init__.py"}]}
| 3,074 | 142 |
gh_patches_debug_4729
|
rasdani/github-patches
|
git_diff
|
mindsdb__lightwood-633
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Implement a `predictor_from_json_ai` high level method
## Task
Lightwood aims at offering _declarative machine learning_ capabilities by enabling users to specify _what_ they want their models to learn, without necessarily having to look at the _how_.
A key ingredient for this feature is our intermediate representation called Json AI (a.k.a. _J{ai}son_). The objective behind Json AI is to build Lightwood predictors out of a JSON-like file.
We offer a variety of methods to cover the spectrum of `ProblemDefinition` <-> `Json AI` <-> `Lightwood Predictor`. However, we are currently missing a method to go _directly_ from `Json AI` to a lightwood predictor object. The current approach is:
```python
code = code_from_json_ai(json_ai)
predictor = predictor_from_code(code)
```
In this task, we ask for an implementation of a high level function so that the user is now able to do:
```python
predictor = predictor_from_json_ai(json_ai)
```
## Steps :male_detective: :female_detective:
- Fork the Lightwood repository, checkout the `staging` branch and from it create a new one.
- Implement the function inside `lightwood/api/high_level.py`. Be sure to add type hints and a comprehensive docstring.
- Make the PR and address any comments that reviewers might make.
## Additional rewards :1st_place_medal:
Each Lightwood API PR brings 3️⃣ points for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/
</issue>
<code>
[start of lightwood/api/high_level.py]
1 import os
2 from types import ModuleType
3 from typing import Union
4 import dill
5 import pandas as pd
6 from lightwood.api.types import DataAnalysis, JsonAI, ProblemDefinition
7 import lightwood
8 from lightwood.api.predictor import PredictorInterface
9 from lightwood.api.json_ai import generate_json_ai
10 import tempfile
11 from lightwood.api.json_ai import code_from_json_ai as _code_from_json_ai
12 import importlib.util
13 import sys
14 import random
15 import string
16 import gc
17 import time
18 from lightwood.helpers.log import log
19
20
21 def predictor_from_problem(df: pd.DataFrame, problem_definition: Union[ProblemDefinition, dict]) -> PredictorInterface:
22 """
23 Creates a ready-to-train ``Predictor`` object from some raw data and a ``ProblemDefinition``. Do not use this if you want to edit the JsonAI first. Usually you'd want to next train this predictor by calling the ``learn`` method on the same dataframe used to create it.
24
25 :param df: The raw data
26 :param problem_definition: The manual specifications for your predictive problem
27
28 :returns: A lightwood ``Predictor`` object
29 """ # noqa
30 if not isinstance(problem_definition, ProblemDefinition):
31 problem_definition = ProblemDefinition.from_dict(problem_definition)
32
33 log.info(f'Dropping features: {problem_definition.ignore_features}')
34 df = df.drop(columns=problem_definition.ignore_features)
35
36 predictor_class_str = code_from_problem(df, problem_definition)
37 return predictor_from_code(predictor_class_str)
38
39
40 def json_ai_from_problem(df: pd.DataFrame, problem_definition: Union[ProblemDefinition, dict]) -> JsonAI:
41 """
42 Creates a JsonAI from your raw data and problem definition. Usually you would use this when you want to subsequently edit the JsonAI, the easiest way to do this is to unload it to a dictionary via `to_dict`, modify it, and then create a new object from it using `lightwood.JsonAI.from_dict`. It's usually better to generate the JsonAI using this function rather than writing it from scratch.
43
44 :param df: The raw data
45 :param problem_definition: The manual specifications for your predictive problem
46
47 :returns: A ``JsonAI`` object generated based on your data and problem specifications
48 """ # noqa
49 if not isinstance(problem_definition, ProblemDefinition):
50 problem_definition = ProblemDefinition.from_dict(problem_definition)
51
52 log.info(f'Dropping features: {problem_definition.ignore_features}')
53 df = df.drop(columns=problem_definition.ignore_features)
54
55 type_information = lightwood.data.infer_types(df, problem_definition.pct_invalid)
56 statistical_analysis = lightwood.data.statistical_analysis(
57 df, type_information.dtypes, type_information.identifiers, problem_definition)
58 json_ai = generate_json_ai(
59 type_information=type_information, statistical_analysis=statistical_analysis,
60 problem_definition=problem_definition)
61
62 return json_ai
63
64
65 def code_from_json_ai(json_ai: JsonAI) -> str:
66 """
67 Autogenerates custom code based on the details you specified inside your JsonAI.
68
69 :param json_ai: A ``JsonAI`` object
70
71 :returns: Code (text) generate based on the ``JsonAI`` you created
72 """
73 return _code_from_json_ai(json_ai)
74
75
76 def predictor_from_code(code: str) -> PredictorInterface:
77 """
78 :param code: The ``Predictor``'s code in text form
79
80 :returns: A lightwood ``Predictor`` object
81 """
82 module_name = ''.join(random.choices(string.ascii_uppercase + string.digits, k=12))
83 module_name += str(time.time()).replace('.', '')
84 predictor = _module_from_code(code, module_name).Predictor()
85 return predictor
86
87
88 def analyze_dataset(df: pd.DataFrame) -> DataAnalysis:
89 """
90 You can use this to understand and visualize the data, it's not a part of the pipeline one would use for creating and training predictive models.
91
92 :param df: The raw data
93
94 :returns: An object containing insights about the data (specifically the type information and statistical analysis)
95 """ # noqa
96
97 problem_definition = ProblemDefinition.from_dict({'target': str(df.columns[0])})
98
99 type_information = lightwood.data.infer_types(df, problem_definition.pct_invalid)
100 statistical_analysis = lightwood.data.statistical_analysis(
101 df, type_information.dtypes, type_information.identifiers, problem_definition)
102
103 return DataAnalysis(
104 type_information=type_information,
105 statistical_analysis=statistical_analysis
106 )
107
108
109 def code_from_problem(df: pd.DataFrame, problem_definition: Union[ProblemDefinition, dict]) -> str:
110 """
111 :param df: The raw data
112 :param problem_definition: The manual specifications for your predictive problem
113
114 :returns: The text code generated based on your data and problem specifications
115 """
116 if not isinstance(problem_definition, ProblemDefinition):
117 problem_definition = ProblemDefinition.from_dict(problem_definition)
118
119 log.info(f'Dropping features: {problem_definition.ignore_features}')
120 df = df.drop(columns=problem_definition.ignore_features)
121 json_ai = json_ai_from_problem(df, problem_definition)
122 predictor_code = code_from_json_ai(json_ai)
123 return predictor_code
124
125
126 def predictor_from_state(state_file: str, code: str = None) -> PredictorInterface:
127 """
128 :param state_file: The file containing the pickle resulting from calling ``save`` on a ``Predictor`` object
129 :param code: The ``Predictor``'s code in text form
130
131 :returns: A lightwood ``Predictor`` object
132 """
133 try:
134 module_name = None
135 with open(state_file, 'rb') as fp:
136 predictor = dill.load(fp)
137 except Exception as e:
138 module_name = str(e).lstrip("No module named '").split("'")[0]
139 if code is None:
140 raise Exception(
141 'Provide code when loading a predictor from outside the scope/script it was created in!')
142
143 if module_name is not None:
144 try:
145 del sys.modules[module_name]
146 except Exception:
147 pass
148 gc.collect()
149 _module_from_code(code, module_name)
150 with open(state_file, 'rb') as fp:
151 predictor = dill.load(fp)
152
153 return predictor
154
155
156 def _module_from_code(code: str, module_name: str) -> ModuleType:
157 """
158 Create a python module (containing the generated ``Predictor`` class) from the code. This is both a python object and an associated temporary file on your filesystem
159
160 :param code: The ``Predictor``'s code in text form
161 :param module_name: The name of the newly created module
162
163 :returns: A python module object
164 """ # noqa
165 dirname = tempfile.gettempdir()
166 filename = os.urandom(24).hex() + str(time.time()).replace('.', '') + '.py'
167 path = os.path.join(dirname, filename)
168 if 'LIGHTWOOD_DEV_SAVE_TO' in os.environ:
169 path = os.environ['LIGHTWOOD_DEV_SAVE_TO']
170
171 with open(path, 'wb') as fp:
172 fp.write(code.encode('utf-8'))
173 spec = importlib.util.spec_from_file_location(module_name, fp.name)
174 temp_module = importlib.util.module_from_spec(spec)
175 sys.modules[module_name] = temp_module
176 spec.loader.exec_module(temp_module)
177
178 return temp_module
179
[end of lightwood/api/high_level.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lightwood/api/high_level.py b/lightwood/api/high_level.py
--- a/lightwood/api/high_level.py
+++ b/lightwood/api/high_level.py
@@ -176,3 +176,16 @@
spec.loader.exec_module(temp_module)
return temp_module
+
+
+def predictor_from_json_ai(json_ai: JsonAI) -> PredictorInterface:
+ """
+ Creates a ready-to-train ``Predictor`` object based on the details you specified inside your JsonAI.
+
+ :param json_ai: A ``JsonAI`` object
+
+ :returns: A lightwood ``Predictor`` object
+ """ # noqa
+ code = code_from_json_ai(json_ai)
+ predictor = predictor_from_code(code)
+ return predictor
|
{"golden_diff": "diff --git a/lightwood/api/high_level.py b/lightwood/api/high_level.py\n--- a/lightwood/api/high_level.py\n+++ b/lightwood/api/high_level.py\n@@ -176,3 +176,16 @@\n spec.loader.exec_module(temp_module)\n \n return temp_module\n+\n+\n+def predictor_from_json_ai(json_ai: JsonAI) -> PredictorInterface:\n+ \"\"\"\n+ Creates a ready-to-train ``Predictor`` object based on the details you specified inside your JsonAI.\n+\n+ :param json_ai: A ``JsonAI`` object\n+\n+ :returns: A lightwood ``Predictor`` object\n+ \"\"\" # noqa\n+ code = code_from_json_ai(json_ai)\n+ predictor = predictor_from_code(code)\n+ return predictor\n", "issue": "Implement a `predictor_from_json_ai` high level method\n## Task\r\n\r\nLightwood aims at offering _declarative machine learning_ capabilities by enabling users to specify _what_ they want their models to learn, without necessarily having to look at the _how_.\r\n\r\nA key ingredient for this feature is our intermediate representation called Json AI (a.k.a. _J{ai}son_). The objective behind Json AI is to build Lightwood predictors out of a JSON-like file.\r\n\r\nWe offer a variety of methods to cover the spectrum of `ProblemDefinition` <-> `Json AI` <-> `Lightwood Predictor`. However, we are currently missing a method to go _directly_ from `Json AI` to a lightwood predictor object. The current approach is:\r\n\r\n```python\r\ncode = code_from_json_ai(json_ai)\r\npredictor = predictor_from_code(code)\r\n```\r\n\r\nIn this task, we ask for an implementation of a high level function so that the user is now able to do:\r\n\r\n```python\r\npredictor = predictor_from_json_ai(json_ai)\r\n```\r\n\r\n## Steps :male_detective: :female_detective: \r\n\r\n- Fork the Lightwood repository, checkout the `staging` branch and from it create a new one.\r\n- Implement the function inside `lightwood/api/high_level.py`. Be sure to add type hints and a comprehensive docstring.\r\n- Make the PR and address any comments that reviewers might make.\r\n\r\n## Additional rewards :1st_place_medal: \r\n\r\nEach Lightwood API PR brings 3\ufe0f\u20e3 points for entry into the draw for a :computer: Deep Learning Laptop powered by the NVIDIA RTX 3080 Max-Q GPU or other swag :shirt: :bear: . For more info check out https://mindsdb.com/hacktoberfest/\n", "before_files": [{"content": "import os\nfrom types import ModuleType\nfrom typing import Union\nimport dill\nimport pandas as pd\nfrom lightwood.api.types import DataAnalysis, JsonAI, ProblemDefinition\nimport lightwood\nfrom lightwood.api.predictor import PredictorInterface\nfrom lightwood.api.json_ai import generate_json_ai\nimport tempfile\nfrom lightwood.api.json_ai import code_from_json_ai as _code_from_json_ai\nimport importlib.util\nimport sys\nimport random\nimport string\nimport gc\nimport time\nfrom lightwood.helpers.log import log\n\n\ndef predictor_from_problem(df: pd.DataFrame, problem_definition: Union[ProblemDefinition, dict]) -> PredictorInterface:\n \"\"\"\n Creates a ready-to-train ``Predictor`` object from some raw data and a ``ProblemDefinition``. Do not use this if you want to edit the JsonAI first. Usually you'd want to next train this predictor by calling the ``learn`` method on the same dataframe used to create it.\n\n :param df: The raw data\n :param problem_definition: The manual specifications for your predictive problem\n\n :returns: A lightwood ``Predictor`` object\n \"\"\" # noqa\n if not isinstance(problem_definition, ProblemDefinition):\n problem_definition = ProblemDefinition.from_dict(problem_definition)\n\n log.info(f'Dropping features: {problem_definition.ignore_features}')\n df = df.drop(columns=problem_definition.ignore_features)\n\n predictor_class_str = code_from_problem(df, problem_definition)\n return predictor_from_code(predictor_class_str)\n\n\ndef json_ai_from_problem(df: pd.DataFrame, problem_definition: Union[ProblemDefinition, dict]) -> JsonAI:\n \"\"\"\n Creates a JsonAI from your raw data and problem definition. Usually you would use this when you want to subsequently edit the JsonAI, the easiest way to do this is to unload it to a dictionary via `to_dict`, modify it, and then create a new object from it using `lightwood.JsonAI.from_dict`. It's usually better to generate the JsonAI using this function rather than writing it from scratch.\n\n :param df: The raw data\n :param problem_definition: The manual specifications for your predictive problem\n\n :returns: A ``JsonAI`` object generated based on your data and problem specifications\n \"\"\" # noqa\n if not isinstance(problem_definition, ProblemDefinition):\n problem_definition = ProblemDefinition.from_dict(problem_definition)\n\n log.info(f'Dropping features: {problem_definition.ignore_features}')\n df = df.drop(columns=problem_definition.ignore_features)\n\n type_information = lightwood.data.infer_types(df, problem_definition.pct_invalid)\n statistical_analysis = lightwood.data.statistical_analysis(\n df, type_information.dtypes, type_information.identifiers, problem_definition)\n json_ai = generate_json_ai(\n type_information=type_information, statistical_analysis=statistical_analysis,\n problem_definition=problem_definition)\n\n return json_ai\n\n\ndef code_from_json_ai(json_ai: JsonAI) -> str:\n \"\"\"\n Autogenerates custom code based on the details you specified inside your JsonAI.\n\n :param json_ai: A ``JsonAI`` object\n\n :returns: Code (text) generate based on the ``JsonAI`` you created\n \"\"\"\n return _code_from_json_ai(json_ai)\n\n\ndef predictor_from_code(code: str) -> PredictorInterface:\n \"\"\"\n :param code: The ``Predictor``'s code in text form\n\n :returns: A lightwood ``Predictor`` object\n \"\"\"\n module_name = ''.join(random.choices(string.ascii_uppercase + string.digits, k=12))\n module_name += str(time.time()).replace('.', '')\n predictor = _module_from_code(code, module_name).Predictor()\n return predictor\n\n\ndef analyze_dataset(df: pd.DataFrame) -> DataAnalysis:\n \"\"\"\n You can use this to understand and visualize the data, it's not a part of the pipeline one would use for creating and training predictive models.\n\n :param df: The raw data\n\n :returns: An object containing insights about the data (specifically the type information and statistical analysis)\n \"\"\" # noqa\n\n problem_definition = ProblemDefinition.from_dict({'target': str(df.columns[0])})\n\n type_information = lightwood.data.infer_types(df, problem_definition.pct_invalid)\n statistical_analysis = lightwood.data.statistical_analysis(\n df, type_information.dtypes, type_information.identifiers, problem_definition)\n\n return DataAnalysis(\n type_information=type_information,\n statistical_analysis=statistical_analysis\n )\n\n\ndef code_from_problem(df: pd.DataFrame, problem_definition: Union[ProblemDefinition, dict]) -> str:\n \"\"\"\n :param df: The raw data\n :param problem_definition: The manual specifications for your predictive problem\n\n :returns: The text code generated based on your data and problem specifications\n \"\"\"\n if not isinstance(problem_definition, ProblemDefinition):\n problem_definition = ProblemDefinition.from_dict(problem_definition)\n\n log.info(f'Dropping features: {problem_definition.ignore_features}')\n df = df.drop(columns=problem_definition.ignore_features)\n json_ai = json_ai_from_problem(df, problem_definition)\n predictor_code = code_from_json_ai(json_ai)\n return predictor_code\n\n\ndef predictor_from_state(state_file: str, code: str = None) -> PredictorInterface:\n \"\"\"\n :param state_file: The file containing the pickle resulting from calling ``save`` on a ``Predictor`` object\n :param code: The ``Predictor``'s code in text form\n\n :returns: A lightwood ``Predictor`` object\n \"\"\"\n try:\n module_name = None\n with open(state_file, 'rb') as fp:\n predictor = dill.load(fp)\n except Exception as e:\n module_name = str(e).lstrip(\"No module named '\").split(\"'\")[0]\n if code is None:\n raise Exception(\n 'Provide code when loading a predictor from outside the scope/script it was created in!')\n\n if module_name is not None:\n try:\n del sys.modules[module_name]\n except Exception:\n pass\n gc.collect()\n _module_from_code(code, module_name)\n with open(state_file, 'rb') as fp:\n predictor = dill.load(fp)\n\n return predictor\n\n\ndef _module_from_code(code: str, module_name: str) -> ModuleType:\n \"\"\"\n Create a python module (containing the generated ``Predictor`` class) from the code. This is both a python object and an associated temporary file on your filesystem\n\n :param code: The ``Predictor``'s code in text form\n :param module_name: The name of the newly created module\n\n :returns: A python module object\n \"\"\" # noqa\n dirname = tempfile.gettempdir()\n filename = os.urandom(24).hex() + str(time.time()).replace('.', '') + '.py'\n path = os.path.join(dirname, filename)\n if 'LIGHTWOOD_DEV_SAVE_TO' in os.environ:\n path = os.environ['LIGHTWOOD_DEV_SAVE_TO']\n\n with open(path, 'wb') as fp:\n fp.write(code.encode('utf-8'))\n spec = importlib.util.spec_from_file_location(module_name, fp.name)\n temp_module = importlib.util.module_from_spec(spec)\n sys.modules[module_name] = temp_module\n spec.loader.exec_module(temp_module)\n\n return temp_module\n", "path": "lightwood/api/high_level.py"}]}
| 2,917 | 172 |
gh_patches_debug_15083
|
rasdani/github-patches
|
git_diff
|
Qiskit__qiskit-4156
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TwoQubitWeylDecomposition: failed to diagonalize M2 -- lack of normalization?
While writing [random test for 3586](https://github.com/Qiskit/qiskit-terra/pull/3586/files#diff-4dd440b6693c3194f4667ac2cdb99094), I noticed that a set this range wrongly (see https://github.com/Qiskit/qiskit-terra/pull/3586/commits/6e2b2709d8ffe702df8bce9a04089d8a9fb55245). However it seem that the previous range discover some crashes in `weyl_coordinates`.
### Steps to reproduce the problem
Currently, `two_qubit_decompose` is non-determinisic (see https://github.com/Qiskit/qiskit-terra/pull/3585), making reproduction complicated. Here are the situations I found:
```python
def test_cx_equivalence_1cx_random(rnd):
qr = QuantumRegister(2, name='q')
qc = QuantumCircuit(qr)
qc.u3(rnd[0], rnd[1], rnd[2], qr[0])
qc.u3(rnd[3], rnd[4], rnd[5], qr[1])
qc.cx(qr[1], qr[0])
qc.u3(rnd[6], rnd[7], rnd[8], qr[0])
qc.u3(rnd[9], rnd[10], rnd[11], qr[1])
sim = UnitarySimulatorPy()
U = execute(qc, sim).result().get_unitary()
two_qubit_cnot_decompose.num_basis_gates(U)
for _ in range(100):
test_cx_equivalence_1cx_random(rnd=(0.0, 0.0, 0.0, 20895.999830149118, 4097.624991416554,
0.00112247467014881, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0))
```
```python
def test_cx_equivalence_2cx_random(rnd):
qr = QuantumRegister(2, name='q')
qc = QuantumCircuit(qr)
qc.u3(rnd[0], rnd[1], rnd[2], qr[0])
qc.u3(rnd[3], rnd[4], rnd[5], qr[1])
qc.cx(qr[1], qr[0])
qc.u3(rnd[6], rnd[7], rnd[8], qr[0])
qc.u3(rnd[9], rnd[10], rnd[11], qr[1])
qc.cx(qr[0], qr[1])
qc.u3(rnd[12], rnd[13], rnd[14], qr[0])
qc.u3(rnd[15], rnd[16], rnd[17], qr[1])
sim = UnitarySimulatorPy()
U = execute(qc, sim).result().get_unitary()
two_qubit_cnot_decompose.num_basis_gates(U)
for _ in range(100):
test_cx_equivalence_2cx_random(rnd=(0.042351722707424384, 73735.43772411175,
0.01757621764727491, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.004490852354911424, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
0.0))
```
```python
def test_cx_equivalence_3cx_random(rnd):
qr = QuantumRegister(2, name='q')
qc = QuantumCircuit(qr)
qc.u3(rnd[0], rnd[1], rnd[2], qr[0])
qc.u3(rnd[3], rnd[4], rnd[5], qr[1])
qc.cx(qr[1], qr[0])
qc.u3(rnd[6], rnd[7], rnd[8], qr[0])
qc.u3(rnd[9], rnd[10], rnd[11], qr[1])
qc.cx(qr[0], qr[1])
qc.u3(rnd[12], rnd[13], rnd[14], qr[0])
qc.u3(rnd[15], rnd[16], rnd[17], qr[1])
qc.cx(qr[1], qr[0])
qc.u3(rnd[18], rnd[19], rnd[20], qr[0])
qc.u3(rnd[21], rnd[22], rnd[23], qr[1])
sim = UnitarySimulatorPy()
U = execute(qc, sim).result().get_unitary()
two_qubit_cnot_decompose.num_basis_gates(U)
for _ in range(100):
test_cx_equivalence_3cx_random(rnd=(0.17845153804438854, 8128.06054498254, 12287.99999713898,
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,
1983.8820662647765, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0))
```
All this cases trigger (eventually) `qiskit.exceptions.QiskitError: 'TwoQubitWeylDecomposition: failed to diagonalize M2'`.
Because they do not raise when the range is shorter (see https://github.com/Qiskit/qiskit-terra/pull/3586/commits/6e2b2709d8ffe702df8bce9a04089d8a9fb55245) I assume is lack of normalization.
</issue>
<code>
[start of qiskit/quantum_info/synthesis/weyl.py]
1 # -*- coding: utf-8 -*-
2
3 # This code is part of Qiskit.
4 #
5 # (C) Copyright IBM 2017, 2019.
6 #
7 # This code is licensed under the Apache License, Version 2.0. You may
8 # obtain a copy of this license in the LICENSE.txt file in the root directory
9 # of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.
10 #
11 # Any modifications or derivative works of this code must retain this
12 # copyright notice, and modified files need to carry a notice indicating
13 # that they have been altered from the originals.
14 # pylint: disable=invalid-name
15
16 """Routines that compute and use the Weyl chamber coordinates.
17 """
18
19 import numpy as np
20 import scipy.linalg as la
21 from qiskit.exceptions import QiskitError
22
23 _B = (1.0/np.sqrt(2)) * np.array([[1, 1j, 0, 0],
24 [0, 0, 1j, 1],
25 [0, 0, 1j, -1],
26 [1, -1j, 0, 0]], dtype=complex)
27 _Bd = _B.T.conj()
28
29
30 def weyl_coordinates(U):
31 """Computes the Weyl coordinates for
32 a given two-qubit unitary matrix.
33
34 Args:
35 U (ndarray): Input two-qubit unitary.
36
37 Returns:
38 ndarray: Array of Weyl coordinates.
39
40 Raises:
41 QiskitError: Computed coordinates not in Weyl chamber.
42 """
43 pi2 = np.pi/2
44 pi4 = np.pi/4
45
46 U = U / la.det(U)**(0.25)
47 Up = _Bd.dot(U).dot(_B)
48 M2 = Up.T.dot(Up)
49
50 # M2 is a symmetric complex matrix. We need to decompose it as M2 = P D P^T where
51 # P ∈ SO(4), D is diagonal with unit-magnitude elements.
52 # D, P = la.eig(M2) # this can fail for certain kinds of degeneracy
53 for _ in range(3): # FIXME: this randomized algorithm is horrendous
54 M2real = np.random.randn()*M2.real + np.random.randn()*M2.imag
55 _, P = la.eigh(M2real)
56 D = P.T.dot(M2).dot(P).diagonal()
57 if np.allclose(P.dot(np.diag(D)).dot(P.T), M2, rtol=1.0e-13, atol=1.0e-13):
58 break
59 else:
60 raise QiskitError("TwoQubitWeylDecomposition: failed to diagonalize M2")
61
62 d = -np.angle(D)/2
63 d[3] = -d[0]-d[1]-d[2]
64 cs = np.mod((d[:3]+d[3])/2, 2*np.pi)
65
66 # Reorder the eigenvalues to get in the Weyl chamber
67 cstemp = np.mod(cs, pi2)
68 np.minimum(cstemp, pi2-cstemp, cstemp)
69 order = np.argsort(cstemp)[[1, 2, 0]]
70 cs = cs[order]
71 d[:3] = d[order]
72
73 # Flip into Weyl chamber
74 if cs[0] > pi2:
75 cs[0] -= 3*pi2
76 if cs[1] > pi2:
77 cs[1] -= 3*pi2
78 conjs = 0
79 if cs[0] > pi4:
80 cs[0] = pi2-cs[0]
81 conjs += 1
82 if cs[1] > pi4:
83 cs[1] = pi2-cs[1]
84 conjs += 1
85 if cs[2] > pi2:
86 cs[2] -= 3*pi2
87 if conjs == 1:
88 cs[2] = pi2-cs[2]
89 if cs[2] > pi4:
90 cs[2] -= pi2
91
92 return cs[[1, 0, 2]]
93
[end of qiskit/quantum_info/synthesis/weyl.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qiskit/quantum_info/synthesis/weyl.py b/qiskit/quantum_info/synthesis/weyl.py
--- a/qiskit/quantum_info/synthesis/weyl.py
+++ b/qiskit/quantum_info/synthesis/weyl.py
@@ -54,10 +54,13 @@
M2real = np.random.randn()*M2.real + np.random.randn()*M2.imag
_, P = la.eigh(M2real)
D = P.T.dot(M2).dot(P).diagonal()
- if np.allclose(P.dot(np.diag(D)).dot(P.T), M2, rtol=1.0e-13, atol=1.0e-13):
+ if np.allclose(P.dot(np.diag(D)).dot(P.T), M2, rtol=1.0e-10, atol=1.0e-10):
break
else:
- raise QiskitError("TwoQubitWeylDecomposition: failed to diagonalize M2")
+ raise QiskitError("TwoQubitWeylDecomposition: failed to diagonalize M2. "
+ "Please submit this output to "
+ "https://github.com/Qiskit/qiskit-terra/issues/4159 "
+ "Input %s" % U.tolist())
d = -np.angle(D)/2
d[3] = -d[0]-d[1]-d[2]
|
{"golden_diff": "diff --git a/qiskit/quantum_info/synthesis/weyl.py b/qiskit/quantum_info/synthesis/weyl.py\n--- a/qiskit/quantum_info/synthesis/weyl.py\n+++ b/qiskit/quantum_info/synthesis/weyl.py\n@@ -54,10 +54,13 @@\n M2real = np.random.randn()*M2.real + np.random.randn()*M2.imag\n _, P = la.eigh(M2real)\n D = P.T.dot(M2).dot(P).diagonal()\n- if np.allclose(P.dot(np.diag(D)).dot(P.T), M2, rtol=1.0e-13, atol=1.0e-13):\n+ if np.allclose(P.dot(np.diag(D)).dot(P.T), M2, rtol=1.0e-10, atol=1.0e-10):\n break\n else:\n- raise QiskitError(\"TwoQubitWeylDecomposition: failed to diagonalize M2\")\n+ raise QiskitError(\"TwoQubitWeylDecomposition: failed to diagonalize M2. \"\n+ \"Please submit this output to \"\n+ \"https://github.com/Qiskit/qiskit-terra/issues/4159 \"\n+ \"Input %s\" % U.tolist())\n \n d = -np.angle(D)/2\n d[3] = -d[0]-d[1]-d[2]\n", "issue": "TwoQubitWeylDecomposition: failed to diagonalize M2 -- lack of normalization?\nWhile writing [random test for 3586](https://github.com/Qiskit/qiskit-terra/pull/3586/files#diff-4dd440b6693c3194f4667ac2cdb99094), I noticed that a set this range wrongly (see https://github.com/Qiskit/qiskit-terra/pull/3586/commits/6e2b2709d8ffe702df8bce9a04089d8a9fb55245). However it seem that the previous range discover some crashes in `weyl_coordinates`.\r\n\r\n### Steps to reproduce the problem\r\n\r\nCurrently, `two_qubit_decompose` is non-determinisic (see https://github.com/Qiskit/qiskit-terra/pull/3585), making reproduction complicated. Here are the situations I found:\r\n\r\n```python\r\ndef test_cx_equivalence_1cx_random(rnd):\r\n qr = QuantumRegister(2, name='q')\r\n qc = QuantumCircuit(qr)\r\n\r\n qc.u3(rnd[0], rnd[1], rnd[2], qr[0])\r\n qc.u3(rnd[3], rnd[4], rnd[5], qr[1])\r\n\r\n qc.cx(qr[1], qr[0])\r\n\r\n qc.u3(rnd[6], rnd[7], rnd[8], qr[0])\r\n qc.u3(rnd[9], rnd[10], rnd[11], qr[1])\r\n\r\n sim = UnitarySimulatorPy()\r\n U = execute(qc, sim).result().get_unitary()\r\n two_qubit_cnot_decompose.num_basis_gates(U)\r\n\r\n\r\nfor _ in range(100):\r\n test_cx_equivalence_1cx_random(rnd=(0.0, 0.0, 0.0, 20895.999830149118, 4097.624991416554,\r\n 0.00112247467014881, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0))\r\n```\r\n\r\n```python\r\ndef test_cx_equivalence_2cx_random(rnd):\r\n qr = QuantumRegister(2, name='q')\r\n qc = QuantumCircuit(qr)\r\n\r\n qc.u3(rnd[0], rnd[1], rnd[2], qr[0])\r\n qc.u3(rnd[3], rnd[4], rnd[5], qr[1])\r\n\r\n qc.cx(qr[1], qr[0])\r\n\r\n qc.u3(rnd[6], rnd[7], rnd[8], qr[0])\r\n qc.u3(rnd[9], rnd[10], rnd[11], qr[1])\r\n\r\n qc.cx(qr[0], qr[1])\r\n\r\n qc.u3(rnd[12], rnd[13], rnd[14], qr[0])\r\n qc.u3(rnd[15], rnd[16], rnd[17], qr[1])\r\n\r\n sim = UnitarySimulatorPy()\r\n U = execute(qc, sim).result().get_unitary()\r\n two_qubit_cnot_decompose.num_basis_gates(U)\r\n\r\n\r\nfor _ in range(100):\r\n test_cx_equivalence_2cx_random(rnd=(0.042351722707424384, 73735.43772411175,\r\n 0.01757621764727491, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,\r\n 0.004490852354911424, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,\r\n 0.0))\r\n```\r\n```python\r\ndef test_cx_equivalence_3cx_random(rnd):\r\n qr = QuantumRegister(2, name='q')\r\n qc = QuantumCircuit(qr)\r\n\r\n qc.u3(rnd[0], rnd[1], rnd[2], qr[0])\r\n qc.u3(rnd[3], rnd[4], rnd[5], qr[1])\r\n\r\n qc.cx(qr[1], qr[0])\r\n\r\n qc.u3(rnd[6], rnd[7], rnd[8], qr[0])\r\n qc.u3(rnd[9], rnd[10], rnd[11], qr[1])\r\n\r\n qc.cx(qr[0], qr[1])\r\n\r\n qc.u3(rnd[12], rnd[13], rnd[14], qr[0])\r\n qc.u3(rnd[15], rnd[16], rnd[17], qr[1])\r\n\r\n qc.cx(qr[1], qr[0])\r\n\r\n qc.u3(rnd[18], rnd[19], rnd[20], qr[0])\r\n qc.u3(rnd[21], rnd[22], rnd[23], qr[1])\r\n\r\n sim = UnitarySimulatorPy()\r\n U = execute(qc, sim).result().get_unitary()\r\n two_qubit_cnot_decompose.num_basis_gates(U)\r\n\r\nfor _ in range(100):\r\n test_cx_equivalence_3cx_random(rnd=(0.17845153804438854, 8128.06054498254, 12287.99999713898,\r\n 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0,\r\n 1983.8820662647765, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0))\r\n```\r\n\r\nAll this cases trigger (eventually) `qiskit.exceptions.QiskitError: 'TwoQubitWeylDecomposition: failed to diagonalize M2'`.\r\n\r\nBecause they do not raise when the range is shorter (see https://github.com/Qiskit/qiskit-terra/pull/3586/commits/6e2b2709d8ffe702df8bce9a04089d8a9fb55245) I assume is lack of normalization.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# This code is part of Qiskit.\n#\n# (C) Copyright IBM 2017, 2019.\n#\n# This code is licensed under the Apache License, Version 2.0. You may\n# obtain a copy of this license in the LICENSE.txt file in the root directory\n# of this source tree or at http://www.apache.org/licenses/LICENSE-2.0.\n#\n# Any modifications or derivative works of this code must retain this\n# copyright notice, and modified files need to carry a notice indicating\n# that they have been altered from the originals.\n# pylint: disable=invalid-name\n\n\"\"\"Routines that compute and use the Weyl chamber coordinates.\n\"\"\"\n\nimport numpy as np\nimport scipy.linalg as la\nfrom qiskit.exceptions import QiskitError\n\n_B = (1.0/np.sqrt(2)) * np.array([[1, 1j, 0, 0],\n [0, 0, 1j, 1],\n [0, 0, 1j, -1],\n [1, -1j, 0, 0]], dtype=complex)\n_Bd = _B.T.conj()\n\n\ndef weyl_coordinates(U):\n \"\"\"Computes the Weyl coordinates for\n a given two-qubit unitary matrix.\n\n Args:\n U (ndarray): Input two-qubit unitary.\n\n Returns:\n ndarray: Array of Weyl coordinates.\n\n Raises:\n QiskitError: Computed coordinates not in Weyl chamber.\n \"\"\"\n pi2 = np.pi/2\n pi4 = np.pi/4\n\n U = U / la.det(U)**(0.25)\n Up = _Bd.dot(U).dot(_B)\n M2 = Up.T.dot(Up)\n\n # M2 is a symmetric complex matrix. We need to decompose it as M2 = P D P^T where\n # P \u2208 SO(4), D is diagonal with unit-magnitude elements.\n # D, P = la.eig(M2) # this can fail for certain kinds of degeneracy\n for _ in range(3): # FIXME: this randomized algorithm is horrendous\n M2real = np.random.randn()*M2.real + np.random.randn()*M2.imag\n _, P = la.eigh(M2real)\n D = P.T.dot(M2).dot(P).diagonal()\n if np.allclose(P.dot(np.diag(D)).dot(P.T), M2, rtol=1.0e-13, atol=1.0e-13):\n break\n else:\n raise QiskitError(\"TwoQubitWeylDecomposition: failed to diagonalize M2\")\n\n d = -np.angle(D)/2\n d[3] = -d[0]-d[1]-d[2]\n cs = np.mod((d[:3]+d[3])/2, 2*np.pi)\n\n # Reorder the eigenvalues to get in the Weyl chamber\n cstemp = np.mod(cs, pi2)\n np.minimum(cstemp, pi2-cstemp, cstemp)\n order = np.argsort(cstemp)[[1, 2, 0]]\n cs = cs[order]\n d[:3] = d[order]\n\n # Flip into Weyl chamber\n if cs[0] > pi2:\n cs[0] -= 3*pi2\n if cs[1] > pi2:\n cs[1] -= 3*pi2\n conjs = 0\n if cs[0] > pi4:\n cs[0] = pi2-cs[0]\n conjs += 1\n if cs[1] > pi4:\n cs[1] = pi2-cs[1]\n conjs += 1\n if cs[2] > pi2:\n cs[2] -= 3*pi2\n if conjs == 1:\n cs[2] = pi2-cs[2]\n if cs[2] > pi4:\n cs[2] -= pi2\n\n return cs[[1, 0, 2]]\n", "path": "qiskit/quantum_info/synthesis/weyl.py"}]}
| 3,212 | 330 |
gh_patches_debug_30698
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-602
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Show latest feedback in dashboard
Show admins and content creators the latest feedback from app users in dashboard. This should be a list of the last ~5 messages. In some cases, the feedback only contains a thumbs up or down, in other cases it can contain a message. The title of the page or event concerned should be displayed as well and linked to the editing page.
Additional option: Add link that sends the message string to translate.google.com or deepl.com for translation. This can be useful if the feedback is given in a language the back end user does not understand. It is perfectly fine, if the link opens the translation website in a new tab. No need to fetch a translation via the API.
</issue>
<code>
[start of src/cms/views/dashboard/admin_dashboard_view.py]
1 from django.contrib.auth.decorators import login_required
2 from django.shortcuts import render
3 from django.utils.decorators import method_decorator
4 from django.views.generic import TemplateView
5
6 from ...decorators import staff_required
7
8
9 @method_decorator(login_required, name="dispatch")
10 @method_decorator(staff_required, name="dispatch")
11 class AdminDashboardView(TemplateView):
12 """
13 View for the admin dashboard
14 """
15
16 #: The template to render (see :class:`~django.views.generic.base.TemplateResponseMixin`)
17 template_name = "dashboard/admin_dashboard.html"
18 #: The context dict passed to the template (see :class:`~django.views.generic.base.ContextMixin`)
19 base_context = {"current_menu_item": "admin_dashboard"}
20
21 def get(self, request, *args, **kwargs):
22 """
23 Render admin dashboard
24
25 :param request: Object representing the user call
26 :type request: ~django.http.HttpRequest
27
28 :param args: The supplied arguments
29 :type args: list
30
31 :param kwargs: The supplied keyword arguments
32 :type kwargs: dict
33
34 :return: The rendered template response
35 :rtype: ~django.template.response.TemplateResponse
36 """
37
38 val = "To be defined"
39 return render(request, self.template_name, {"key": val, **self.base_context})
40
[end of src/cms/views/dashboard/admin_dashboard_view.py]
[start of src/cms/views/dashboard/dashboard_view.py]
1 import html
2 from urllib.parse import urlparse
3 import feedparser
4
5 from django.contrib.auth.decorators import login_required
6 from django.shortcuts import render
7 from django.utils import translation
8 from django.utils.decorators import method_decorator
9 from django.views.generic import TemplateView
10
11 from backend.settings import RSS_FEED_URLS
12 from ...decorators import region_permission_required
13
14
15 @method_decorator(login_required, name="dispatch")
16 @method_decorator(region_permission_required, name="dispatch")
17 class DashboardView(TemplateView):
18 """
19 View for the region dashboard
20 """
21
22 #: The template to render (see :class:`~django.views.generic.base.TemplateResponseMixin`)
23 template_name = "dashboard/dashboard.html"
24 #: The context dict passed to the template (see :class:`~django.views.generic.base.ContextMixin`)
25 base_context = {"current_menu_item": "region_dashboard"}
26
27 def get(self, request, *args, **kwargs):
28 """
29 Render the region dashboard
30
31 :param request: Object representing the user call
32 :type request: ~django.http.HttpRequest
33
34 :param args: The supplied arguments
35 :type args: list
36
37 :param kwargs: The supplied keyword arguments
38 :type kwargs: dict
39
40 :return: The rendered template response
41 :rtype: ~django.template.response.TemplateResponse
42 """
43
44 val = "To be defined"
45 language_code = translation.get_language()
46 feed = feedparser.parse(RSS_FEED_URLS[language_code])
47 # select five most recent feeds
48 feed["entries"] = feed["entries"][:5]
49 # decode html entities like dash and split after line break
50 for entry in feed["entries"]:
51 entry["summary"] = html.unescape(entry["summary"]).split("\n")[0]
52 domain = urlparse(RSS_FEED_URLS["home-page"]).netloc
53 return render(
54 request,
55 self.template_name,
56 {
57 "key": val,
58 **self.base_context,
59 "feed": feed,
60 "home_page": RSS_FEED_URLS["home-page"],
61 "domain": domain,
62 },
63 )
64
[end of src/cms/views/dashboard/dashboard_view.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/cms/views/dashboard/admin_dashboard_view.py b/src/cms/views/dashboard/admin_dashboard_view.py
--- a/src/cms/views/dashboard/admin_dashboard_view.py
+++ b/src/cms/views/dashboard/admin_dashboard_view.py
@@ -4,6 +4,7 @@
from django.views.generic import TemplateView
from ...decorators import staff_required
+from ...models import Feedback
@method_decorator(login_required, name="dispatch")
@@ -34,6 +35,14 @@
:return: The rendered template response
:rtype: ~django.template.response.TemplateResponse
"""
-
- val = "To be defined"
- return render(request, self.template_name, {"key": val, **self.base_context})
+ all_feedback = Feedback.objects.filter(is_technical=True)[:5]
+
+ return render(
+ request,
+ self.template_name,
+ {
+ "current_menu_item": "admin_feedback",
+ "all_feedback": all_feedback,
+ **self.base_context,
+ },
+ )
diff --git a/src/cms/views/dashboard/dashboard_view.py b/src/cms/views/dashboard/dashboard_view.py
--- a/src/cms/views/dashboard/dashboard_view.py
+++ b/src/cms/views/dashboard/dashboard_view.py
@@ -41,7 +41,6 @@
:rtype: ~django.template.response.TemplateResponse
"""
- val = "To be defined"
language_code = translation.get_language()
feed = feedparser.parse(RSS_FEED_URLS[language_code])
# select five most recent feeds
@@ -54,7 +53,6 @@
request,
self.template_name,
{
- "key": val,
**self.base_context,
"feed": feed,
"home_page": RSS_FEED_URLS["home-page"],
|
{"golden_diff": "diff --git a/src/cms/views/dashboard/admin_dashboard_view.py b/src/cms/views/dashboard/admin_dashboard_view.py\n--- a/src/cms/views/dashboard/admin_dashboard_view.py\n+++ b/src/cms/views/dashboard/admin_dashboard_view.py\n@@ -4,6 +4,7 @@\n from django.views.generic import TemplateView\n \n from ...decorators import staff_required\n+from ...models import Feedback\n \n \n @method_decorator(login_required, name=\"dispatch\")\n@@ -34,6 +35,14 @@\n :return: The rendered template response\n :rtype: ~django.template.response.TemplateResponse\n \"\"\"\n-\n- val = \"To be defined\"\n- return render(request, self.template_name, {\"key\": val, **self.base_context})\n+ all_feedback = Feedback.objects.filter(is_technical=True)[:5]\n+\n+ return render(\n+ request,\n+ self.template_name,\n+ {\n+ \"current_menu_item\": \"admin_feedback\",\n+ \"all_feedback\": all_feedback,\n+ **self.base_context,\n+ },\n+ )\ndiff --git a/src/cms/views/dashboard/dashboard_view.py b/src/cms/views/dashboard/dashboard_view.py\n--- a/src/cms/views/dashboard/dashboard_view.py\n+++ b/src/cms/views/dashboard/dashboard_view.py\n@@ -41,7 +41,6 @@\n :rtype: ~django.template.response.TemplateResponse\n \"\"\"\n \n- val = \"To be defined\"\n language_code = translation.get_language()\n feed = feedparser.parse(RSS_FEED_URLS[language_code])\n # select five most recent feeds\n@@ -54,7 +53,6 @@\n request,\n self.template_name,\n {\n- \"key\": val,\n **self.base_context,\n \"feed\": feed,\n \"home_page\": RSS_FEED_URLS[\"home-page\"],\n", "issue": "Show latest feedback in dashboard\nShow admins and content creators the latest feedback from app users in dashboard. This should be a list of the last ~5 messages. In some cases, the feedback only contains a thumbs up or down, in other cases it can contain a message. The title of the page or event concerned should be displayed as well and linked to the editing page.\r\n\r\nAdditional option: Add link that sends the message string to translate.google.com or deepl.com for translation. This can be useful if the feedback is given in a language the back end user does not understand. It is perfectly fine, if the link opens the translation website in a new tab. No need to fetch a translation via the API.\n", "before_files": [{"content": "from django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import TemplateView\n\nfrom ...decorators import staff_required\n\n\n@method_decorator(login_required, name=\"dispatch\")\n@method_decorator(staff_required, name=\"dispatch\")\nclass AdminDashboardView(TemplateView):\n \"\"\"\n View for the admin dashboard\n \"\"\"\n\n #: The template to render (see :class:`~django.views.generic.base.TemplateResponseMixin`)\n template_name = \"dashboard/admin_dashboard.html\"\n #: The context dict passed to the template (see :class:`~django.views.generic.base.ContextMixin`)\n base_context = {\"current_menu_item\": \"admin_dashboard\"}\n\n def get(self, request, *args, **kwargs):\n \"\"\"\n Render admin dashboard\n\n :param request: Object representing the user call\n :type request: ~django.http.HttpRequest\n\n :param args: The supplied arguments\n :type args: list\n\n :param kwargs: The supplied keyword arguments\n :type kwargs: dict\n\n :return: The rendered template response\n :rtype: ~django.template.response.TemplateResponse\n \"\"\"\n\n val = \"To be defined\"\n return render(request, self.template_name, {\"key\": val, **self.base_context})\n", "path": "src/cms/views/dashboard/admin_dashboard_view.py"}, {"content": "import html\nfrom urllib.parse import urlparse\nimport feedparser\n\nfrom django.contrib.auth.decorators import login_required\nfrom django.shortcuts import render\nfrom django.utils import translation\nfrom django.utils.decorators import method_decorator\nfrom django.views.generic import TemplateView\n\nfrom backend.settings import RSS_FEED_URLS\nfrom ...decorators import region_permission_required\n\n\n@method_decorator(login_required, name=\"dispatch\")\n@method_decorator(region_permission_required, name=\"dispatch\")\nclass DashboardView(TemplateView):\n \"\"\"\n View for the region dashboard\n \"\"\"\n\n #: The template to render (see :class:`~django.views.generic.base.TemplateResponseMixin`)\n template_name = \"dashboard/dashboard.html\"\n #: The context dict passed to the template (see :class:`~django.views.generic.base.ContextMixin`)\n base_context = {\"current_menu_item\": \"region_dashboard\"}\n\n def get(self, request, *args, **kwargs):\n \"\"\"\n Render the region dashboard\n\n :param request: Object representing the user call\n :type request: ~django.http.HttpRequest\n\n :param args: The supplied arguments\n :type args: list\n\n :param kwargs: The supplied keyword arguments\n :type kwargs: dict\n\n :return: The rendered template response\n :rtype: ~django.template.response.TemplateResponse\n \"\"\"\n\n val = \"To be defined\"\n language_code = translation.get_language()\n feed = feedparser.parse(RSS_FEED_URLS[language_code])\n # select five most recent feeds\n feed[\"entries\"] = feed[\"entries\"][:5]\n # decode html entities like dash and split after line break\n for entry in feed[\"entries\"]:\n entry[\"summary\"] = html.unescape(entry[\"summary\"]).split(\"\\n\")[0]\n domain = urlparse(RSS_FEED_URLS[\"home-page\"]).netloc\n return render(\n request,\n self.template_name,\n {\n \"key\": val,\n **self.base_context,\n \"feed\": feed,\n \"home_page\": RSS_FEED_URLS[\"home-page\"],\n \"domain\": domain,\n },\n )\n", "path": "src/cms/views/dashboard/dashboard_view.py"}]}
| 1,610 | 380 |
gh_patches_debug_25733
|
rasdani/github-patches
|
git_diff
|
Mailu__Mailu-731
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Increase attachment size limit
Hello,
How can web change the max file limit of attachment in Roundcube ?
Version 1.5
</issue>
<code>
[start of webmails/rainloop/start.py]
1 #!/usr/bin/python3
2
3 import jinja2
4 import os
5 import shutil
6
7 convert = lambda src, dst: open(dst, "w").write(jinja2.Template(open(src).read()).render(**os.environ))
8
9 # Actual startup script
10 os.environ["FRONT_ADDRESS"] = os.environ.get("FRONT_ADDRESS", "front")
11 os.environ["IMAP_ADDRESS"] = os.environ.get("IMAP_ADDRESS", "imap")
12
13 base = "/data/_data_/_default_/"
14 shutil.rmtree(base + "domains/", ignore_errors=True)
15 os.makedirs(base + "domains", exist_ok=True)
16 os.makedirs(base + "configs", exist_ok=True)
17
18 convert("/default.ini", "/data/_data_/_default_/domains/default.ini")
19 convert("/config.ini", "/data/_data_/_default_/configs/config.ini")
20
21 os.system("chown -R www-data:www-data /data")
22
23 os.execv("/usr/local/bin/apache2-foreground", ["apache2-foreground"])
24
25
[end of webmails/rainloop/start.py]
[start of webmails/roundcube/start.py]
1 #!/usr/bin/python3
2
3 import os
4
5 # Fix some permissions
6 os.system("mkdir -p /data/gpg")
7 os.system("chown -R www-data:www-data /data")
8
9 # Run apache
10 os.execv("/usr/local/bin/apache2-foreground", ["apache2-foreground"])
[end of webmails/roundcube/start.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/webmails/rainloop/start.py b/webmails/rainloop/start.py
--- a/webmails/rainloop/start.py
+++ b/webmails/rainloop/start.py
@@ -10,6 +10,8 @@
os.environ["FRONT_ADDRESS"] = os.environ.get("FRONT_ADDRESS", "front")
os.environ["IMAP_ADDRESS"] = os.environ.get("IMAP_ADDRESS", "imap")
+os.environ["MAX_FILESIZE"] = str(int(int(os.environ.get("MESSAGE_SIZE_LIMIT"))*0.66/1048576))
+
base = "/data/_data_/_default_/"
shutil.rmtree(base + "domains/", ignore_errors=True)
os.makedirs(base + "domains", exist_ok=True)
@@ -17,6 +19,7 @@
convert("/default.ini", "/data/_data_/_default_/domains/default.ini")
convert("/config.ini", "/data/_data_/_default_/configs/config.ini")
+convert("/php.ini", "/usr/local/etc/php/conf.d/rainloop.ini")
os.system("chown -R www-data:www-data /data")
diff --git a/webmails/roundcube/start.py b/webmails/roundcube/start.py
--- a/webmails/roundcube/start.py
+++ b/webmails/roundcube/start.py
@@ -1,6 +1,13 @@
#!/usr/bin/python3
import os
+import jinja2
+
+convert = lambda src, dst: open(dst, "w").write(jinja2.Template(open(src).read()).render(**os.environ))
+
+os.environ["MAX_FILESIZE"] = str(int(int(os.environ.get("MESSAGE_SIZE_LIMIT"))*0.66/1048576))
+
+convert("/php.ini", "/usr/local/etc/php/conf.d/roundcube.ini")
# Fix some permissions
os.system("mkdir -p /data/gpg")
|
{"golden_diff": "diff --git a/webmails/rainloop/start.py b/webmails/rainloop/start.py\n--- a/webmails/rainloop/start.py\n+++ b/webmails/rainloop/start.py\n@@ -10,6 +10,8 @@\n os.environ[\"FRONT_ADDRESS\"] = os.environ.get(\"FRONT_ADDRESS\", \"front\")\n os.environ[\"IMAP_ADDRESS\"] = os.environ.get(\"IMAP_ADDRESS\", \"imap\")\n \n+os.environ[\"MAX_FILESIZE\"] = str(int(int(os.environ.get(\"MESSAGE_SIZE_LIMIT\"))*0.66/1048576))\n+\n base = \"/data/_data_/_default_/\"\n shutil.rmtree(base + \"domains/\", ignore_errors=True)\n os.makedirs(base + \"domains\", exist_ok=True)\n@@ -17,6 +19,7 @@\n \n convert(\"/default.ini\", \"/data/_data_/_default_/domains/default.ini\")\n convert(\"/config.ini\", \"/data/_data_/_default_/configs/config.ini\")\n+convert(\"/php.ini\", \"/usr/local/etc/php/conf.d/rainloop.ini\")\n \n os.system(\"chown -R www-data:www-data /data\")\n \ndiff --git a/webmails/roundcube/start.py b/webmails/roundcube/start.py\n--- a/webmails/roundcube/start.py\n+++ b/webmails/roundcube/start.py\n@@ -1,6 +1,13 @@\n #!/usr/bin/python3\n \n import os\n+import jinja2\n+\n+convert = lambda src, dst: open(dst, \"w\").write(jinja2.Template(open(src).read()).render(**os.environ))\n+\n+os.environ[\"MAX_FILESIZE\"] = str(int(int(os.environ.get(\"MESSAGE_SIZE_LIMIT\"))*0.66/1048576))\n+\n+convert(\"/php.ini\", \"/usr/local/etc/php/conf.d/roundcube.ini\")\n \n # Fix some permissions\n os.system(\"mkdir -p /data/gpg\")\n", "issue": "Increase attachment size limit\nHello, \r\n\r\nHow can web change the max file limit of attachment in Roundcube ?\r\n\r\nVersion 1.5\n", "before_files": [{"content": "#!/usr/bin/python3\n\nimport jinja2\nimport os\nimport shutil\n\nconvert = lambda src, dst: open(dst, \"w\").write(jinja2.Template(open(src).read()).render(**os.environ))\n\n# Actual startup script\nos.environ[\"FRONT_ADDRESS\"] = os.environ.get(\"FRONT_ADDRESS\", \"front\")\nos.environ[\"IMAP_ADDRESS\"] = os.environ.get(\"IMAP_ADDRESS\", \"imap\")\n\nbase = \"/data/_data_/_default_/\"\nshutil.rmtree(base + \"domains/\", ignore_errors=True)\nos.makedirs(base + \"domains\", exist_ok=True)\nos.makedirs(base + \"configs\", exist_ok=True)\n\nconvert(\"/default.ini\", \"/data/_data_/_default_/domains/default.ini\")\nconvert(\"/config.ini\", \"/data/_data_/_default_/configs/config.ini\")\n\nos.system(\"chown -R www-data:www-data /data\")\n\nos.execv(\"/usr/local/bin/apache2-foreground\", [\"apache2-foreground\"])\n\n", "path": "webmails/rainloop/start.py"}, {"content": "#!/usr/bin/python3\n\nimport os\n\n# Fix some permissions\nos.system(\"mkdir -p /data/gpg\")\nos.system(\"chown -R www-data:www-data /data\")\n\n# Run apache\nos.execv(\"/usr/local/bin/apache2-foreground\", [\"apache2-foreground\"])", "path": "webmails/roundcube/start.py"}]}
| 918 | 417 |
gh_patches_debug_9841
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-993
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Checkov logs to stdout making the json un-parseable
**Describe the bug**
When you run checkov with the `-o json` and `LOG_LEVEL=WARNING` the logs are printed to `stdout` together with the json object. This way it's hard and error prone to parse the json output.
**Expected behavior**
At least in `-o json` (or any parseable output) mode It should use stderr to log to and use stdout only for the parseable output and log everything else to stderr.
</issue>
<code>
[start of checkov/logging_init.py]
1 import sys
2
3 import logging
4 import os
5
6
7 def init():
8 LOG_LEVEL = os.environ.get('LOG_LEVEL', 'WARNING').upper()
9 logging.basicConfig(level=LOG_LEVEL)
10 logFormatter = logging.Formatter("%(asctime)s [%(threadName)-12.12s] [%(levelname)-5.5s] %(message)s")
11 rootLogger = logging.getLogger()
12 consoleHandler = logging.StreamHandler(sys.stdout)
13 consoleHandler.setFormatter(logFormatter)
14 consoleHandler.setLevel(LOG_LEVEL)
15 rootLogger.addHandler(consoleHandler)
16 logging.getLogger("urllib3").setLevel(logging.ERROR)
17 logging.getLogger("urllib3.connectionpool").setLevel(logging.ERROR)
18 logging.getLogger("urllib3.connectionpool").propagate = False
19 logging.getLogger("urllib3").propagate = False
20
[end of checkov/logging_init.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/logging_init.py b/checkov/logging_init.py
--- a/checkov/logging_init.py
+++ b/checkov/logging_init.py
@@ -9,7 +9,7 @@
logging.basicConfig(level=LOG_LEVEL)
logFormatter = logging.Formatter("%(asctime)s [%(threadName)-12.12s] [%(levelname)-5.5s] %(message)s")
rootLogger = logging.getLogger()
- consoleHandler = logging.StreamHandler(sys.stdout)
+ consoleHandler = logging.StreamHandler(sys.stderr)
consoleHandler.setFormatter(logFormatter)
consoleHandler.setLevel(LOG_LEVEL)
rootLogger.addHandler(consoleHandler)
|
{"golden_diff": "diff --git a/checkov/logging_init.py b/checkov/logging_init.py\n--- a/checkov/logging_init.py\n+++ b/checkov/logging_init.py\n@@ -9,7 +9,7 @@\n logging.basicConfig(level=LOG_LEVEL)\n logFormatter = logging.Formatter(\"%(asctime)s [%(threadName)-12.12s] [%(levelname)-5.5s] %(message)s\")\n rootLogger = logging.getLogger()\n- consoleHandler = logging.StreamHandler(sys.stdout)\n+ consoleHandler = logging.StreamHandler(sys.stderr)\n consoleHandler.setFormatter(logFormatter)\n consoleHandler.setLevel(LOG_LEVEL)\n rootLogger.addHandler(consoleHandler)\n", "issue": "Checkov logs to stdout making the json un-parseable\n**Describe the bug**\r\nWhen you run checkov with the `-o json` and `LOG_LEVEL=WARNING` the logs are printed to `stdout` together with the json object. This way it's hard and error prone to parse the json output.\r\n\r\n**Expected behavior**\r\nAt least in `-o json` (or any parseable output) mode It should use stderr to log to and use stdout only for the parseable output and log everything else to stderr.\r\n\n", "before_files": [{"content": "import sys\n\nimport logging\nimport os\n\n\ndef init():\n LOG_LEVEL = os.environ.get('LOG_LEVEL', 'WARNING').upper()\n logging.basicConfig(level=LOG_LEVEL)\n logFormatter = logging.Formatter(\"%(asctime)s [%(threadName)-12.12s] [%(levelname)-5.5s] %(message)s\")\n rootLogger = logging.getLogger()\n consoleHandler = logging.StreamHandler(sys.stdout)\n consoleHandler.setFormatter(logFormatter)\n consoleHandler.setLevel(LOG_LEVEL)\n rootLogger.addHandler(consoleHandler)\n logging.getLogger(\"urllib3\").setLevel(logging.ERROR)\n logging.getLogger(\"urllib3.connectionpool\").setLevel(logging.ERROR)\n logging.getLogger(\"urllib3.connectionpool\").propagate = False\n logging.getLogger(\"urllib3\").propagate = False\n", "path": "checkov/logging_init.py"}]}
| 844 | 137 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.