
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.1k
25.4k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 582
39.1k
| num_tokens
int64 271
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_7890 | rasdani/github-patches | git_diff | googleapis__google-auth-library-python-846 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
JWT decoding depends upon deprecated function
#### Environment details
- OS: Debian 11 (bullseye)
- Python version: 3.9.2
- pip version: 20.3.4
- `google-auth` version: 1.30
#### Steps to reproduce
Decode a JWT token from Google Cloud Identity-Aware Proxy
#### Error
The following deprecation warnings are issues from the `cryptography` library:
```
/usr/local/lib/python3.9/dist-packages/google/auth/crypt/es256.py:56: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead
/usr/local/lib/python3.9/dist-packages/google/auth/crypt/es256.py:57: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead
```
The changes necessary seem self evident. The [function in question][frombytes] exists in Python 3.2+ and therefore falls within the currently stated supported versions (3.5+).
[frombytes]: https://docs.python.org/3/library/stdtypes.html#int.from_bytes
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/auth/crypt/es256.py`
Content:
```
1 # Copyright 2017 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """ECDSA (ES256) verifier and signer that use the ``cryptography`` library.
16 """
17
18 from cryptography import utils
19 import cryptography.exceptions
20 from cryptography.hazmat import backends
21 from cryptography.hazmat.primitives import hashes
22 from cryptography.hazmat.primitives import serialization
23 from cryptography.hazmat.primitives.asymmetric import ec
24 from cryptography.hazmat.primitives.asymmetric import padding
25 from cryptography.hazmat.primitives.asymmetric.utils import decode_dss_signature
26 from cryptography.hazmat.primitives.asymmetric.utils import encode_dss_signature
27 import cryptography.x509
28
29 from google.auth import _helpers
30 from google.auth.crypt import base
31
32
33 _CERTIFICATE_MARKER = b"-----BEGIN CERTIFICATE-----"
34 _BACKEND = backends.default_backend()
35 _PADDING = padding.PKCS1v15()
36
37
38 class ES256Verifier(base.Verifier):
39 """Verifies ECDSA cryptographic signatures using public keys.
40
41 Args:
42 public_key (
43 cryptography.hazmat.primitives.asymmetric.ec.ECDSAPublicKey):
44 The public key used to verify signatures.
45 """
46
47 def __init__(self, public_key):
48 self._pubkey = public_key
49
50 @_helpers.copy_docstring(base.Verifier)
51 def verify(self, message, signature):
52 # First convert (r||s) raw signature to ASN1 encoded signature.
53 sig_bytes = _helpers.to_bytes(signature)
54 if len(sig_bytes) != 64:
55 return False
56 r = utils.int_from_bytes(sig_bytes[:32], byteorder="big")
57 s = utils.int_from_bytes(sig_bytes[32:], byteorder="big")
58 asn1_sig = encode_dss_signature(r, s)
59
60 message = _helpers.to_bytes(message)
61 try:
62 self._pubkey.verify(asn1_sig, message, ec.ECDSA(hashes.SHA256()))
63 return True
64 except (ValueError, cryptography.exceptions.InvalidSignature):
65 return False
66
67 @classmethod
68 def from_string(cls, public_key):
69 """Construct an Verifier instance from a public key or public
70 certificate string.
71
72 Args:
73 public_key (Union[str, bytes]): The public key in PEM format or the
74 x509 public key certificate.
75
76 Returns:
77 Verifier: The constructed verifier.
78
79 Raises:
80 ValueError: If the public key can't be parsed.
81 """
82 public_key_data = _helpers.to_bytes(public_key)
83
84 if _CERTIFICATE_MARKER in public_key_data:
85 cert = cryptography.x509.load_pem_x509_certificate(
86 public_key_data, _BACKEND
87 )
88 pubkey = cert.public_key()
89
90 else:
91 pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)
92
93 return cls(pubkey)
94
95
96 class ES256Signer(base.Signer, base.FromServiceAccountMixin):
97 """Signs messages with an ECDSA private key.
98
99 Args:
100 private_key (
101 cryptography.hazmat.primitives.asymmetric.ec.ECDSAPrivateKey):
102 The private key to sign with.
103 key_id (str): Optional key ID used to identify this private key. This
104 can be useful to associate the private key with its associated
105 public key or certificate.
106 """
107
108 def __init__(self, private_key, key_id=None):
109 self._key = private_key
110 self._key_id = key_id
111
112 @property
113 @_helpers.copy_docstring(base.Signer)
114 def key_id(self):
115 return self._key_id
116
117 @_helpers.copy_docstring(base.Signer)
118 def sign(self, message):
119 message = _helpers.to_bytes(message)
120 asn1_signature = self._key.sign(message, ec.ECDSA(hashes.SHA256()))
121
122 # Convert ASN1 encoded signature to (r||s) raw signature.
123 (r, s) = decode_dss_signature(asn1_signature)
124 return utils.int_to_bytes(r, 32) + utils.int_to_bytes(s, 32)
125
126 @classmethod
127 def from_string(cls, key, key_id=None):
128 """Construct a RSASigner from a private key in PEM format.
129
130 Args:
131 key (Union[bytes, str]): Private key in PEM format.
132 key_id (str): An optional key id used to identify the private key.
133
134 Returns:
135 google.auth.crypt._cryptography_rsa.RSASigner: The
136 constructed signer.
137
138 Raises:
139 ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).
140 UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded
141 into a UTF-8 ``str``.
142 ValueError: If ``cryptography`` "Could not deserialize key data."
143 """
144 key = _helpers.to_bytes(key)
145 private_key = serialization.load_pem_private_key(
146 key, password=None, backend=_BACKEND
147 )
148 return cls(private_key, key_id=key_id)
149
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/google/auth/crypt/es256.py b/google/auth/crypt/es256.py
--- a/google/auth/crypt/es256.py
+++ b/google/auth/crypt/es256.py
@@ -53,8 +53,8 @@
sig_bytes = _helpers.to_bytes(signature)
if len(sig_bytes) != 64:
return False
- r = utils.int_from_bytes(sig_bytes[:32], byteorder="big")
- s = utils.int_from_bytes(sig_bytes[32:], byteorder="big")
+ r = int.from_bytes(sig_bytes[:32], byteorder="big")
+ s = int.from_bytes(sig_bytes[32:], byteorder="big")
asn1_sig = encode_dss_signature(r, s)
message = _helpers.to_bytes(message)
| {"golden_diff": "diff --git a/google/auth/crypt/es256.py b/google/auth/crypt/es256.py\n--- a/google/auth/crypt/es256.py\n+++ b/google/auth/crypt/es256.py\n@@ -53,8 +53,8 @@\n sig_bytes = _helpers.to_bytes(signature)\n if len(sig_bytes) != 64:\n return False\n- r = utils.int_from_bytes(sig_bytes[:32], byteorder=\"big\")\n- s = utils.int_from_bytes(sig_bytes[32:], byteorder=\"big\")\n+ r = int.from_bytes(sig_bytes[:32], byteorder=\"big\")\n+ s = int.from_bytes(sig_bytes[32:], byteorder=\"big\")\n asn1_sig = encode_dss_signature(r, s)\n \n message = _helpers.to_bytes(message)\n", "issue": "JWT decoding depends upon deprecated function\n#### Environment details\r\n\r\n - OS: Debian 11 (bullseye)\r\n - Python version: 3.9.2\r\n - pip version: 20.3.4\r\n - `google-auth` version: 1.30\r\n\r\n#### Steps to reproduce\r\n\r\nDecode a JWT token from Google Cloud Identity-Aware Proxy\r\n\r\n#### Error\r\n\r\nThe following deprecation warnings are issues from the `cryptography` library:\r\n\r\n```\r\n/usr/local/lib/python3.9/dist-packages/google/auth/crypt/es256.py:56: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n/usr/local/lib/python3.9/dist-packages/google/auth/crypt/es256.py:57: CryptographyDeprecationWarning: int_from_bytes is deprecated, use int.from_bytes instead\r\n```\r\n\r\nThe changes necessary seem self evident. The [function in question][frombytes] exists in Python 3.2+ and therefore falls within the currently stated supported versions (3.5+).\r\n\r\n[frombytes]: https://docs.python.org/3/library/stdtypes.html#int.from_bytes\n", "before_files": [{"content": "# Copyright 2017 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"ECDSA (ES256) verifier and signer that use the ``cryptography`` library.\n\"\"\"\n\nfrom cryptography import utils\nimport cryptography.exceptions\nfrom cryptography.hazmat import backends\nfrom cryptography.hazmat.primitives import hashes\nfrom cryptography.hazmat.primitives import serialization\nfrom cryptography.hazmat.primitives.asymmetric import ec\nfrom cryptography.hazmat.primitives.asymmetric import padding\nfrom cryptography.hazmat.primitives.asymmetric.utils import decode_dss_signature\nfrom cryptography.hazmat.primitives.asymmetric.utils import encode_dss_signature\nimport cryptography.x509\n\nfrom google.auth import _helpers\nfrom google.auth.crypt import base\n\n\n_CERTIFICATE_MARKER = b\"-----BEGIN CERTIFICATE-----\"\n_BACKEND = backends.default_backend()\n_PADDING = padding.PKCS1v15()\n\n\nclass ES256Verifier(base.Verifier):\n \"\"\"Verifies ECDSA cryptographic signatures using public keys.\n\n Args:\n public_key (\n cryptography.hazmat.primitives.asymmetric.ec.ECDSAPublicKey):\n The public key used to verify signatures.\n \"\"\"\n\n def __init__(self, public_key):\n self._pubkey = public_key\n\n @_helpers.copy_docstring(base.Verifier)\n def verify(self, message, signature):\n # First convert (r||s) raw signature to ASN1 encoded signature.\n sig_bytes = _helpers.to_bytes(signature)\n if len(sig_bytes) != 64:\n return False\n r = utils.int_from_bytes(sig_bytes[:32], byteorder=\"big\")\n s = utils.int_from_bytes(sig_bytes[32:], byteorder=\"big\")\n asn1_sig = encode_dss_signature(r, s)\n\n message = _helpers.to_bytes(message)\n try:\n self._pubkey.verify(asn1_sig, message, ec.ECDSA(hashes.SHA256()))\n return True\n except (ValueError, cryptography.exceptions.InvalidSignature):\n return False\n\n @classmethod\n def from_string(cls, public_key):\n \"\"\"Construct an Verifier instance from a public key or public\n certificate string.\n\n Args:\n public_key (Union[str, bytes]): The public key in PEM format or the\n x509 public key certificate.\n\n Returns:\n Verifier: The constructed verifier.\n\n Raises:\n ValueError: If the public key can't be parsed.\n \"\"\"\n public_key_data = _helpers.to_bytes(public_key)\n\n if _CERTIFICATE_MARKER in public_key_data:\n cert = cryptography.x509.load_pem_x509_certificate(\n public_key_data, _BACKEND\n )\n pubkey = cert.public_key()\n\n else:\n pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)\n\n return cls(pubkey)\n\n\nclass ES256Signer(base.Signer, base.FromServiceAccountMixin):\n \"\"\"Signs messages with an ECDSA private key.\n\n Args:\n private_key (\n cryptography.hazmat.primitives.asymmetric.ec.ECDSAPrivateKey):\n The private key to sign with.\n key_id (str): Optional key ID used to identify this private key. This\n can be useful to associate the private key with its associated\n public key or certificate.\n \"\"\"\n\n def __init__(self, private_key, key_id=None):\n self._key = private_key\n self._key_id = key_id\n\n @property\n @_helpers.copy_docstring(base.Signer)\n def key_id(self):\n return self._key_id\n\n @_helpers.copy_docstring(base.Signer)\n def sign(self, message):\n message = _helpers.to_bytes(message)\n asn1_signature = self._key.sign(message, ec.ECDSA(hashes.SHA256()))\n\n # Convert ASN1 encoded signature to (r||s) raw signature.\n (r, s) = decode_dss_signature(asn1_signature)\n return utils.int_to_bytes(r, 32) + utils.int_to_bytes(s, 32)\n\n @classmethod\n def from_string(cls, key, key_id=None):\n \"\"\"Construct a RSASigner from a private key in PEM format.\n\n Args:\n key (Union[bytes, str]): Private key in PEM format.\n key_id (str): An optional key id used to identify the private key.\n\n Returns:\n google.auth.crypt._cryptography_rsa.RSASigner: The\n constructed signer.\n\n Raises:\n ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).\n UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded\n into a UTF-8 ``str``.\n ValueError: If ``cryptography`` \"Could not deserialize key data.\"\n \"\"\"\n key = _helpers.to_bytes(key)\n private_key = serialization.load_pem_private_key(\n key, password=None, backend=_BACKEND\n )\n return cls(private_key, key_id=key_id)\n", "path": "google/auth/crypt/es256.py"}], "after_files": [{"content": "# Copyright 2017 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"ECDSA (ES256) verifier and signer that use the ``cryptography`` library.\n\"\"\"\n\nfrom cryptography import utils\nimport cryptography.exceptions\nfrom cryptography.hazmat import backends\nfrom cryptography.hazmat.primitives import hashes\nfrom cryptography.hazmat.primitives import serialization\nfrom cryptography.hazmat.primitives.asymmetric import ec\nfrom cryptography.hazmat.primitives.asymmetric import padding\nfrom cryptography.hazmat.primitives.asymmetric.utils import decode_dss_signature\nfrom cryptography.hazmat.primitives.asymmetric.utils import encode_dss_signature\nimport cryptography.x509\n\nfrom google.auth import _helpers\nfrom google.auth.crypt import base\n\n\n_CERTIFICATE_MARKER = b\"-----BEGIN CERTIFICATE-----\"\n_BACKEND = backends.default_backend()\n_PADDING = padding.PKCS1v15()\n\n\nclass ES256Verifier(base.Verifier):\n \"\"\"Verifies ECDSA cryptographic signatures using public keys.\n\n Args:\n public_key (\n cryptography.hazmat.primitives.asymmetric.ec.ECDSAPublicKey):\n The public key used to verify signatures.\n \"\"\"\n\n def __init__(self, public_key):\n self._pubkey = public_key\n\n @_helpers.copy_docstring(base.Verifier)\n def verify(self, message, signature):\n # First convert (r||s) raw signature to ASN1 encoded signature.\n sig_bytes = _helpers.to_bytes(signature)\n if len(sig_bytes) != 64:\n return False\n r = int.from_bytes(sig_bytes[:32], byteorder=\"big\")\n s = int.from_bytes(sig_bytes[32:], byteorder=\"big\")\n asn1_sig = encode_dss_signature(r, s)\n\n message = _helpers.to_bytes(message)\n try:\n self._pubkey.verify(asn1_sig, message, ec.ECDSA(hashes.SHA256()))\n return True\n except (ValueError, cryptography.exceptions.InvalidSignature):\n return False\n\n @classmethod\n def from_string(cls, public_key):\n \"\"\"Construct an Verifier instance from a public key or public\n certificate string.\n\n Args:\n public_key (Union[str, bytes]): The public key in PEM format or the\n x509 public key certificate.\n\n Returns:\n Verifier: The constructed verifier.\n\n Raises:\n ValueError: If the public key can't be parsed.\n \"\"\"\n public_key_data = _helpers.to_bytes(public_key)\n\n if _CERTIFICATE_MARKER in public_key_data:\n cert = cryptography.x509.load_pem_x509_certificate(\n public_key_data, _BACKEND\n )\n pubkey = cert.public_key()\n\n else:\n pubkey = serialization.load_pem_public_key(public_key_data, _BACKEND)\n\n return cls(pubkey)\n\n\nclass ES256Signer(base.Signer, base.FromServiceAccountMixin):\n \"\"\"Signs messages with an ECDSA private key.\n\n Args:\n private_key (\n cryptography.hazmat.primitives.asymmetric.ec.ECDSAPrivateKey):\n The private key to sign with.\n key_id (str): Optional key ID used to identify this private key. This\n can be useful to associate the private key with its associated\n public key or certificate.\n \"\"\"\n\n def __init__(self, private_key, key_id=None):\n self._key = private_key\n self._key_id = key_id\n\n @property\n @_helpers.copy_docstring(base.Signer)\n def key_id(self):\n return self._key_id\n\n @_helpers.copy_docstring(base.Signer)\n def sign(self, message):\n message = _helpers.to_bytes(message)\n asn1_signature = self._key.sign(message, ec.ECDSA(hashes.SHA256()))\n\n # Convert ASN1 encoded signature to (r||s) raw signature.\n (r, s) = decode_dss_signature(asn1_signature)\n return utils.int_to_bytes(r, 32) + utils.int_to_bytes(s, 32)\n\n @classmethod\n def from_string(cls, key, key_id=None):\n \"\"\"Construct a RSASigner from a private key in PEM format.\n\n Args:\n key (Union[bytes, str]): Private key in PEM format.\n key_id (str): An optional key id used to identify the private key.\n\n Returns:\n google.auth.crypt._cryptography_rsa.RSASigner: The\n constructed signer.\n\n Raises:\n ValueError: If ``key`` is not ``bytes`` or ``str`` (unicode).\n UnicodeDecodeError: If ``key`` is ``bytes`` but cannot be decoded\n into a UTF-8 ``str``.\n ValueError: If ``cryptography`` \"Could not deserialize key data.\"\n \"\"\"\n key = _helpers.to_bytes(key)\n private_key = serialization.load_pem_private_key(\n key, password=None, backend=_BACKEND\n )\n return cls(private_key, key_id=key_id)\n", "path": "google/auth/crypt/es256.py"}]} | 2,055 | 182 |
gh_patches_debug_12156 | rasdani/github-patches | git_diff | nltk__nltk-3022 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
nltk.chat.chatbot() endless loop
When I type `import nltk` followed by `nltk.chat.chatbots()`, it lists/asks which one I want to talk to, and then endlessly scrolls the following: ` Enter a number in the range 1-5: Error: bad chatbot number`, in both Jupyter and Spyder.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nltk/chat/__init__.py`
Content:
```
1 # Natural Language Toolkit: Chatbots
2 #
3 # Copyright (C) 2001-2022 NLTK Project
4 # Authors: Steven Bird <[email protected]>
5 # URL: <https://www.nltk.org/>
6 # For license information, see LICENSE.TXT
7
8 # Based on an Eliza implementation by Joe Strout <[email protected]>,
9 # Jeff Epler <[email protected]> and Jez Higgins <[email protected]>.
10
11 """
12 A class for simple chatbots. These perform simple pattern matching on sentences
13 typed by users, and respond with automatically generated sentences.
14
15 These chatbots may not work using the windows command line or the
16 windows IDLE GUI.
17 """
18
19 from nltk.chat.eliza import eliza_chat
20 from nltk.chat.iesha import iesha_chat
21 from nltk.chat.rude import rude_chat
22 from nltk.chat.suntsu import suntsu_chat
23 from nltk.chat.util import Chat
24 from nltk.chat.zen import zen_chat
25
26 bots = [
27 (eliza_chat, "Eliza (psycho-babble)"),
28 (iesha_chat, "Iesha (teen anime junky)"),
29 (rude_chat, "Rude (abusive bot)"),
30 (suntsu_chat, "Suntsu (Chinese sayings)"),
31 (zen_chat, "Zen (gems of wisdom)"),
32 ]
33
34
35 def chatbots():
36 import sys
37
38 print("Which chatbot would you like to talk to?")
39 botcount = len(bots)
40 for i in range(botcount):
41 print(" %d: %s" % (i + 1, bots[i][1]))
42 while True:
43 print("\nEnter a number in the range 1-%d: " % botcount, end=" ")
44 choice = sys.stdin.readline().strip()
45 if choice.isdigit() and (int(choice) - 1) in range(botcount):
46 break
47 else:
48 print(" Error: bad chatbot number")
49
50 chatbot = bots[int(choice) - 1][0]
51 chatbot()
52
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nltk/chat/__init__.py b/nltk/chat/__init__.py
--- a/nltk/chat/__init__.py
+++ b/nltk/chat/__init__.py
@@ -33,15 +33,12 @@
def chatbots():
- import sys
-
print("Which chatbot would you like to talk to?")
botcount = len(bots)
for i in range(botcount):
print(" %d: %s" % (i + 1, bots[i][1]))
while True:
- print("\nEnter a number in the range 1-%d: " % botcount, end=" ")
- choice = sys.stdin.readline().strip()
+ choice = input(f"\nEnter a number in the range 1-{botcount}: ").strip()
if choice.isdigit() and (int(choice) - 1) in range(botcount):
break
else:
| {"golden_diff": "diff --git a/nltk/chat/__init__.py b/nltk/chat/__init__.py\n--- a/nltk/chat/__init__.py\n+++ b/nltk/chat/__init__.py\n@@ -33,15 +33,12 @@\n \n \n def chatbots():\n- import sys\n-\n print(\"Which chatbot would you like to talk to?\")\n botcount = len(bots)\n for i in range(botcount):\n print(\" %d: %s\" % (i + 1, bots[i][1]))\n while True:\n- print(\"\\nEnter a number in the range 1-%d: \" % botcount, end=\" \")\n- choice = sys.stdin.readline().strip()\n+ choice = input(f\"\\nEnter a number in the range 1-{botcount}: \").strip()\n if choice.isdigit() and (int(choice) - 1) in range(botcount):\n break\n else:\n", "issue": "nltk.chat.chatbot() endless loop\nWhen I type `import nltk` followed by `nltk.chat.chatbots()`, it lists/asks which one I want to talk to, and then endlessly scrolls the following: ` Enter a number in the range 1-5: Error: bad chatbot number`, in both Jupyter and Spyder.\n", "before_files": [{"content": "# Natural Language Toolkit: Chatbots\n#\n# Copyright (C) 2001-2022 NLTK Project\n# Authors: Steven Bird <[email protected]>\n# URL: <https://www.nltk.org/>\n# For license information, see LICENSE.TXT\n\n# Based on an Eliza implementation by Joe Strout <[email protected]>,\n# Jeff Epler <[email protected]> and Jez Higgins <[email protected]>.\n\n\"\"\"\nA class for simple chatbots. These perform simple pattern matching on sentences\ntyped by users, and respond with automatically generated sentences.\n\nThese chatbots may not work using the windows command line or the\nwindows IDLE GUI.\n\"\"\"\n\nfrom nltk.chat.eliza import eliza_chat\nfrom nltk.chat.iesha import iesha_chat\nfrom nltk.chat.rude import rude_chat\nfrom nltk.chat.suntsu import suntsu_chat\nfrom nltk.chat.util import Chat\nfrom nltk.chat.zen import zen_chat\n\nbots = [\n (eliza_chat, \"Eliza (psycho-babble)\"),\n (iesha_chat, \"Iesha (teen anime junky)\"),\n (rude_chat, \"Rude (abusive bot)\"),\n (suntsu_chat, \"Suntsu (Chinese sayings)\"),\n (zen_chat, \"Zen (gems of wisdom)\"),\n]\n\n\ndef chatbots():\n import sys\n\n print(\"Which chatbot would you like to talk to?\")\n botcount = len(bots)\n for i in range(botcount):\n print(\" %d: %s\" % (i + 1, bots[i][1]))\n while True:\n print(\"\\nEnter a number in the range 1-%d: \" % botcount, end=\" \")\n choice = sys.stdin.readline().strip()\n if choice.isdigit() and (int(choice) - 1) in range(botcount):\n break\n else:\n print(\" Error: bad chatbot number\")\n\n chatbot = bots[int(choice) - 1][0]\n chatbot()\n", "path": "nltk/chat/__init__.py"}], "after_files": [{"content": "# Natural Language Toolkit: Chatbots\n#\n# Copyright (C) 2001-2022 NLTK Project\n# Authors: Steven Bird <[email protected]>\n# URL: <https://www.nltk.org/>\n# For license information, see LICENSE.TXT\n\n# Based on an Eliza implementation by Joe Strout <[email protected]>,\n# Jeff Epler <[email protected]> and Jez Higgins <[email protected]>.\n\n\"\"\"\nA class for simple chatbots. These perform simple pattern matching on sentences\ntyped by users, and respond with automatically generated sentences.\n\nThese chatbots may not work using the windows command line or the\nwindows IDLE GUI.\n\"\"\"\n\nfrom nltk.chat.eliza import eliza_chat\nfrom nltk.chat.iesha import iesha_chat\nfrom nltk.chat.rude import rude_chat\nfrom nltk.chat.suntsu import suntsu_chat\nfrom nltk.chat.util import Chat\nfrom nltk.chat.zen import zen_chat\n\nbots = [\n (eliza_chat, \"Eliza (psycho-babble)\"),\n (iesha_chat, \"Iesha (teen anime junky)\"),\n (rude_chat, \"Rude (abusive bot)\"),\n (suntsu_chat, \"Suntsu (Chinese sayings)\"),\n (zen_chat, \"Zen (gems of wisdom)\"),\n]\n\n\ndef chatbots():\n print(\"Which chatbot would you like to talk to?\")\n botcount = len(bots)\n for i in range(botcount):\n print(\" %d: %s\" % (i + 1, bots[i][1]))\n while True:\n choice = input(f\"\\nEnter a number in the range 1-{botcount}: \").strip()\n if choice.isdigit() and (int(choice) - 1) in range(botcount):\n break\n else:\n print(\" Error: bad chatbot number\")\n\n chatbot = bots[int(choice) - 1][0]\n chatbot()\n", "path": "nltk/chat/__init__.py"}]} | 882 | 200 |
gh_patches_debug_11612 | rasdani/github-patches | git_diff | DataDog__dd-trace-py-542 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Leaking sockets and connections
It looks like ddtrace writer is not closing the http connections it opens.
```
File "../lib/python3.7/threading.py", line 885, in _bootstrap
self._bootstrap_inner()
File "../lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "../lib/python3.7/threading.py", line 865, in run
self._target(*self._args, **self._kwargs)
File "../lib/python3.7/site-packages/ddtrace/writer.py", line 168, in _target
result_services = None
File "../lib/python3.7/http/client.py", line 408, in close
self._close_conn()
File "../lib/python3.7/http/client.py", line 401, in _close_conn
fp.close()
File "../lib/python3.7/socket.py", line 660, in close
self._sock = None
File "../lib/python3.7/warnings.py", line 99, in _showwarnmsg
msg.file, msg.line)
File "/app/core.py", line 30, in warn_with_traceback
traceback.print_stack(file=log)
../lib/python3.7/socket.py:660: ResourceWarning: unclosed <socket.socket fd=14, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=6, laddr=('0.0.0.0', 54954), raddr=('0.0.0.0', 8126)>
self._sock = None
```
Looking at the code, the issue is in the `_put` method of the `API` object. It creates an `HTTPConnection` but doesn't close it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `ddtrace/api.py`
Content:
```
1 # stdlib
2 import logging
3 import time
4 import ddtrace
5 from json import loads
6
7 # project
8 from .encoding import get_encoder, JSONEncoder
9 from .compat import httplib, PYTHON_VERSION, PYTHON_INTERPRETER, get_connection_response
10
11
12 log = logging.getLogger(__name__)
13
14 TRACE_COUNT_HEADER = 'X-Datadog-Trace-Count'
15
16 _VERSIONS = {'v0.4': {'traces': '/v0.4/traces',
17 'services': '/v0.4/services',
18 'compatibility_mode': False,
19 'fallback': 'v0.3'},
20 'v0.3': {'traces': '/v0.3/traces',
21 'services': '/v0.3/services',
22 'compatibility_mode': False,
23 'fallback': 'v0.2'},
24 'v0.2': {'traces': '/v0.2/traces',
25 'services': '/v0.2/services',
26 'compatibility_mode': True,
27 'fallback': None}}
28
29 def _parse_response_json(response):
30 """
31 Parse the content of a response object, and return the right type,
32 can be a string if the output was plain text, or a dictionnary if
33 the output was a JSON.
34 """
35 if hasattr(response, 'read'):
36 body = response.read()
37 try:
38 if not isinstance(body, str) and hasattr(body, 'decode'):
39 body = body.decode('utf-8')
40 if hasattr(body, 'startswith') and body.startswith('OK'):
41 # This typically happens when using a priority-sampling enabled
42 # library with an outdated agent. It still works, but priority sampling
43 # will probably send too many traces, so the next step is to upgrade agent.
44 log.debug("'OK' is not a valid JSON, please make sure trace-agent is up to date")
45 return
46 content = loads(body)
47 return content
48 except (ValueError, TypeError) as err:
49 log.debug("unable to load JSON '%s': %s" % (body, err))
50
51 class API(object):
52 """
53 Send data to the trace agent using the HTTP protocol and JSON format
54 """
55 def __init__(self, hostname, port, headers=None, encoder=None, priority_sampling=False):
56 self.hostname = hostname
57 self.port = port
58
59 self._headers = headers or {}
60 self._version = None
61
62 if priority_sampling:
63 self._set_version('v0.4', encoder=encoder)
64 else:
65 self._set_version('v0.3', encoder=encoder)
66
67 self._headers.update({
68 'Datadog-Meta-Lang': 'python',
69 'Datadog-Meta-Lang-Version': PYTHON_VERSION,
70 'Datadog-Meta-Lang-Interpreter': PYTHON_INTERPRETER,
71 'Datadog-Meta-Tracer-Version': ddtrace.__version__,
72 })
73
74 def _set_version(self, version, encoder=None):
75 if version not in _VERSIONS:
76 version = 'v0.2'
77 if version == self._version:
78 return
79 self._version = version
80 self._traces = _VERSIONS[version]['traces']
81 self._services = _VERSIONS[version]['services']
82 self._fallback = _VERSIONS[version]['fallback']
83 self._compatibility_mode = _VERSIONS[version]['compatibility_mode']
84 if self._compatibility_mode:
85 self._encoder = JSONEncoder()
86 else:
87 self._encoder = encoder or get_encoder()
88 # overwrite the Content-type with the one chosen in the Encoder
89 self._headers.update({'Content-Type': self._encoder.content_type})
90
91 def _downgrade(self):
92 """
93 Downgrades the used encoder and API level. This method must fallback to a safe
94 encoder and API, so that it will success despite users' configurations. This action
95 ensures that the compatibility mode is activated so that the downgrade will be
96 executed only once.
97 """
98 self._set_version(self._fallback)
99
100 def send_traces(self, traces):
101 if not traces:
102 return
103 start = time.time()
104 data = self._encoder.encode_traces(traces)
105 response = self._put(self._traces, data, len(traces))
106
107 # the API endpoint is not available so we should downgrade the connection and re-try the call
108 if response.status in [404, 415] and self._fallback:
109 log.debug('calling endpoint "%s" but received %s; downgrading API', self._traces, response.status)
110 self._downgrade()
111 return self.send_traces(traces)
112
113 log.debug("reported %d traces in %.5fs", len(traces), time.time() - start)
114 return response
115
116 def send_services(self, services):
117 if not services:
118 return
119 s = {}
120 for service in services:
121 s.update(service)
122 data = self._encoder.encode_services(s)
123 response = self._put(self._services, data)
124
125 # the API endpoint is not available so we should downgrade the connection and re-try the call
126 if response.status in [404, 415] and self._fallback:
127 log.debug('calling endpoint "%s" but received %s; downgrading API', self._services, response.status)
128 self._downgrade()
129 return self.send_services(services)
130
131 log.debug("reported %d services", len(services))
132 return response
133
134 def _put(self, endpoint, data, count=0):
135 conn = httplib.HTTPConnection(self.hostname, self.port)
136
137 headers = self._headers
138 if count:
139 headers = dict(self._headers)
140 headers[TRACE_COUNT_HEADER] = str(count)
141
142 conn.request("PUT", endpoint, data, headers)
143 return get_connection_response(conn)
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/ddtrace/api.py b/ddtrace/api.py
--- a/ddtrace/api.py
+++ b/ddtrace/api.py
@@ -133,11 +133,13 @@
def _put(self, endpoint, data, count=0):
conn = httplib.HTTPConnection(self.hostname, self.port)
-
- headers = self._headers
- if count:
- headers = dict(self._headers)
- headers[TRACE_COUNT_HEADER] = str(count)
-
- conn.request("PUT", endpoint, data, headers)
- return get_connection_response(conn)
+ try:
+ headers = self._headers
+ if count:
+ headers = dict(self._headers)
+ headers[TRACE_COUNT_HEADER] = str(count)
+
+ conn.request("PUT", endpoint, data, headers)
+ return get_connection_response(conn)
+ finally:
+ conn.close()
| {"golden_diff": "diff --git a/ddtrace/api.py b/ddtrace/api.py\n--- a/ddtrace/api.py\n+++ b/ddtrace/api.py\n@@ -133,11 +133,13 @@\n \n def _put(self, endpoint, data, count=0):\n conn = httplib.HTTPConnection(self.hostname, self.port)\n-\n- headers = self._headers\n- if count:\n- headers = dict(self._headers)\n- headers[TRACE_COUNT_HEADER] = str(count)\n-\n- conn.request(\"PUT\", endpoint, data, headers)\n- return get_connection_response(conn)\n+ try:\n+ headers = self._headers\n+ if count:\n+ headers = dict(self._headers)\n+ headers[TRACE_COUNT_HEADER] = str(count)\n+\n+ conn.request(\"PUT\", endpoint, data, headers)\n+ return get_connection_response(conn)\n+ finally:\n+ conn.close()\n", "issue": "Leaking sockets and connections\nIt looks like ddtrace writer is not closing the http connections it opens. \r\n\r\n```\r\n File \"../lib/python3.7/threading.py\", line 885, in _bootstrap\r\n self._bootstrap_inner()\r\n File \"../lib/python3.7/threading.py\", line 917, in _bootstrap_inner\r\n self.run()\r\n File \"../lib/python3.7/threading.py\", line 865, in run\r\n self._target(*self._args, **self._kwargs)\r\n File \"../lib/python3.7/site-packages/ddtrace/writer.py\", line 168, in _target\r\n result_services = None\r\n File \"../lib/python3.7/http/client.py\", line 408, in close\r\n self._close_conn()\r\n File \"../lib/python3.7/http/client.py\", line 401, in _close_conn\r\n fp.close()\r\n File \"../lib/python3.7/socket.py\", line 660, in close\r\n self._sock = None\r\n File \"../lib/python3.7/warnings.py\", line 99, in _showwarnmsg\r\n msg.file, msg.line)\r\n File \"/app/core.py\", line 30, in warn_with_traceback\r\n traceback.print_stack(file=log)\r\n../lib/python3.7/socket.py:660: ResourceWarning: unclosed <socket.socket fd=14, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=6, laddr=('0.0.0.0', 54954), raddr=('0.0.0.0', 8126)>\r\n self._sock = None\r\n```\r\n\r\n\r\nLooking at the code, the issue is in the `_put` method of the `API` object. It creates an `HTTPConnection` but doesn't close it. \n", "before_files": [{"content": "# stdlib\nimport logging\nimport time\nimport ddtrace\nfrom json import loads\n\n# project\nfrom .encoding import get_encoder, JSONEncoder\nfrom .compat import httplib, PYTHON_VERSION, PYTHON_INTERPRETER, get_connection_response\n\n\nlog = logging.getLogger(__name__)\n\nTRACE_COUNT_HEADER = 'X-Datadog-Trace-Count'\n\n_VERSIONS = {'v0.4': {'traces': '/v0.4/traces',\n 'services': '/v0.4/services',\n 'compatibility_mode': False,\n 'fallback': 'v0.3'},\n 'v0.3': {'traces': '/v0.3/traces',\n 'services': '/v0.3/services',\n 'compatibility_mode': False,\n 'fallback': 'v0.2'},\n 'v0.2': {'traces': '/v0.2/traces',\n 'services': '/v0.2/services',\n 'compatibility_mode': True,\n 'fallback': None}}\n\ndef _parse_response_json(response):\n \"\"\"\n Parse the content of a response object, and return the right type,\n can be a string if the output was plain text, or a dictionnary if\n the output was a JSON.\n \"\"\"\n if hasattr(response, 'read'):\n body = response.read()\n try:\n if not isinstance(body, str) and hasattr(body, 'decode'):\n body = body.decode('utf-8')\n if hasattr(body, 'startswith') and body.startswith('OK'):\n # This typically happens when using a priority-sampling enabled\n # library with an outdated agent. It still works, but priority sampling\n # will probably send too many traces, so the next step is to upgrade agent.\n log.debug(\"'OK' is not a valid JSON, please make sure trace-agent is up to date\")\n return\n content = loads(body)\n return content\n except (ValueError, TypeError) as err:\n log.debug(\"unable to load JSON '%s': %s\" % (body, err))\n\nclass API(object):\n \"\"\"\n Send data to the trace agent using the HTTP protocol and JSON format\n \"\"\"\n def __init__(self, hostname, port, headers=None, encoder=None, priority_sampling=False):\n self.hostname = hostname\n self.port = port\n\n self._headers = headers or {}\n self._version = None\n\n if priority_sampling:\n self._set_version('v0.4', encoder=encoder)\n else:\n self._set_version('v0.3', encoder=encoder)\n\n self._headers.update({\n 'Datadog-Meta-Lang': 'python',\n 'Datadog-Meta-Lang-Version': PYTHON_VERSION,\n 'Datadog-Meta-Lang-Interpreter': PYTHON_INTERPRETER,\n 'Datadog-Meta-Tracer-Version': ddtrace.__version__,\n })\n\n def _set_version(self, version, encoder=None):\n if version not in _VERSIONS:\n version = 'v0.2'\n if version == self._version:\n return\n self._version = version\n self._traces = _VERSIONS[version]['traces']\n self._services = _VERSIONS[version]['services']\n self._fallback = _VERSIONS[version]['fallback']\n self._compatibility_mode = _VERSIONS[version]['compatibility_mode']\n if self._compatibility_mode:\n self._encoder = JSONEncoder()\n else:\n self._encoder = encoder or get_encoder()\n # overwrite the Content-type with the one chosen in the Encoder\n self._headers.update({'Content-Type': self._encoder.content_type})\n\n def _downgrade(self):\n \"\"\"\n Downgrades the used encoder and API level. This method must fallback to a safe\n encoder and API, so that it will success despite users' configurations. This action\n ensures that the compatibility mode is activated so that the downgrade will be\n executed only once.\n \"\"\"\n self._set_version(self._fallback)\n\n def send_traces(self, traces):\n if not traces:\n return\n start = time.time()\n data = self._encoder.encode_traces(traces)\n response = self._put(self._traces, data, len(traces))\n\n # the API endpoint is not available so we should downgrade the connection and re-try the call\n if response.status in [404, 415] and self._fallback:\n log.debug('calling endpoint \"%s\" but received %s; downgrading API', self._traces, response.status)\n self._downgrade()\n return self.send_traces(traces)\n\n log.debug(\"reported %d traces in %.5fs\", len(traces), time.time() - start)\n return response\n\n def send_services(self, services):\n if not services:\n return\n s = {}\n for service in services:\n s.update(service)\n data = self._encoder.encode_services(s)\n response = self._put(self._services, data)\n\n # the API endpoint is not available so we should downgrade the connection and re-try the call\n if response.status in [404, 415] and self._fallback:\n log.debug('calling endpoint \"%s\" but received %s; downgrading API', self._services, response.status)\n self._downgrade()\n return self.send_services(services)\n\n log.debug(\"reported %d services\", len(services))\n return response\n\n def _put(self, endpoint, data, count=0):\n conn = httplib.HTTPConnection(self.hostname, self.port)\n\n headers = self._headers\n if count:\n headers = dict(self._headers)\n headers[TRACE_COUNT_HEADER] = str(count)\n\n conn.request(\"PUT\", endpoint, data, headers)\n return get_connection_response(conn)\n", "path": "ddtrace/api.py"}], "after_files": [{"content": "# stdlib\nimport logging\nimport time\nimport ddtrace\nfrom json import loads\n\n# project\nfrom .encoding import get_encoder, JSONEncoder\nfrom .compat import httplib, PYTHON_VERSION, PYTHON_INTERPRETER, get_connection_response\n\n\nlog = logging.getLogger(__name__)\n\nTRACE_COUNT_HEADER = 'X-Datadog-Trace-Count'\n\n_VERSIONS = {'v0.4': {'traces': '/v0.4/traces',\n 'services': '/v0.4/services',\n 'compatibility_mode': False,\n 'fallback': 'v0.3'},\n 'v0.3': {'traces': '/v0.3/traces',\n 'services': '/v0.3/services',\n 'compatibility_mode': False,\n 'fallback': 'v0.2'},\n 'v0.2': {'traces': '/v0.2/traces',\n 'services': '/v0.2/services',\n 'compatibility_mode': True,\n 'fallback': None}}\n\ndef _parse_response_json(response):\n \"\"\"\n Parse the content of a response object, and return the right type,\n can be a string if the output was plain text, or a dictionnary if\n the output was a JSON.\n \"\"\"\n if hasattr(response, 'read'):\n body = response.read()\n try:\n if not isinstance(body, str) and hasattr(body, 'decode'):\n body = body.decode('utf-8')\n if hasattr(body, 'startswith') and body.startswith('OK'):\n # This typically happens when using a priority-sampling enabled\n # library with an outdated agent. It still works, but priority sampling\n # will probably send too many traces, so the next step is to upgrade agent.\n log.debug(\"'OK' is not a valid JSON, please make sure trace-agent is up to date\")\n return\n content = loads(body)\n return content\n except (ValueError, TypeError) as err:\n log.debug(\"unable to load JSON '%s': %s\" % (body, err))\n\nclass API(object):\n \"\"\"\n Send data to the trace agent using the HTTP protocol and JSON format\n \"\"\"\n def __init__(self, hostname, port, headers=None, encoder=None, priority_sampling=False):\n self.hostname = hostname\n self.port = port\n\n self._headers = headers or {}\n self._version = None\n\n if priority_sampling:\n self._set_version('v0.4', encoder=encoder)\n else:\n self._set_version('v0.3', encoder=encoder)\n\n self._headers.update({\n 'Datadog-Meta-Lang': 'python',\n 'Datadog-Meta-Lang-Version': PYTHON_VERSION,\n 'Datadog-Meta-Lang-Interpreter': PYTHON_INTERPRETER,\n 'Datadog-Meta-Tracer-Version': ddtrace.__version__,\n })\n\n def _set_version(self, version, encoder=None):\n if version not in _VERSIONS:\n version = 'v0.2'\n if version == self._version:\n return\n self._version = version\n self._traces = _VERSIONS[version]['traces']\n self._services = _VERSIONS[version]['services']\n self._fallback = _VERSIONS[version]['fallback']\n self._compatibility_mode = _VERSIONS[version]['compatibility_mode']\n if self._compatibility_mode:\n self._encoder = JSONEncoder()\n else:\n self._encoder = encoder or get_encoder()\n # overwrite the Content-type with the one chosen in the Encoder\n self._headers.update({'Content-Type': self._encoder.content_type})\n\n def _downgrade(self):\n \"\"\"\n Downgrades the used encoder and API level. This method must fallback to a safe\n encoder and API, so that it will success despite users' configurations. This action\n ensures that the compatibility mode is activated so that the downgrade will be\n executed only once.\n \"\"\"\n self._set_version(self._fallback)\n\n def send_traces(self, traces):\n if not traces:\n return\n start = time.time()\n data = self._encoder.encode_traces(traces)\n response = self._put(self._traces, data, len(traces))\n\n # the API endpoint is not available so we should downgrade the connection and re-try the call\n if response.status in [404, 415] and self._fallback:\n log.debug('calling endpoint \"%s\" but received %s; downgrading API', self._traces, response.status)\n self._downgrade()\n return self.send_traces(traces)\n\n log.debug(\"reported %d traces in %.5fs\", len(traces), time.time() - start)\n return response\n\n def send_services(self, services):\n if not services:\n return\n s = {}\n for service in services:\n s.update(service)\n data = self._encoder.encode_services(s)\n response = self._put(self._services, data)\n\n # the API endpoint is not available so we should downgrade the connection and re-try the call\n if response.status in [404, 415] and self._fallback:\n log.debug('calling endpoint \"%s\" but received %s; downgrading API', self._services, response.status)\n self._downgrade()\n return self.send_services(services)\n\n log.debug(\"reported %d services\", len(services))\n return response\n\n def _put(self, endpoint, data, count=0):\n conn = httplib.HTTPConnection(self.hostname, self.port)\n try:\n headers = self._headers\n if count:\n headers = dict(self._headers)\n headers[TRACE_COUNT_HEADER] = str(count)\n\n conn.request(\"PUT\", endpoint, data, headers)\n return get_connection_response(conn)\n finally:\n conn.close()\n", "path": "ddtrace/api.py"}]} | 2,251 | 198 |
gh_patches_debug_2358 | rasdani/github-patches | git_diff | mars-project__mars-3146 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[BUG] There maybe duplicate `WorkerMetaAPI` creation in `TaskStageProcessor`
**Describe the bug**
We can see there is a lot of duplicate `WorkerMetaAPI` creation in the method `_update_result_meta` of `mars/services/task/execution/mars/stage.py` if there is too many chunk result and their bands are same:
```python
for tileable in tile_context.values():
chunks = [c.data for c in tileable.chunks]
for c, params_fields in zip(chunks, self._get_params_fields(tileable)):
address = chunk_to_result[c].meta["bands"][0][0]
meta_api = await WorkerMetaAPI.create(session_id, address)
call = meta_api.get_chunk_meta.delay(c.key, fields=params_fields)
worker_meta_api_to_chunk_delays[meta_api][c] = calll
```
There are 3639 chunk results and 200 workers in my job and it costs 1414s to create worker meta apis.
Maybe we can cache the worker meta apis to avoid duplicate creation.
**To Reproduce**
1. Your Python version: python-3.7.9
2. The version of Mars you use: master
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mars/services/meta/api/oscar.py`
Content:
```
1 # Copyright 1999-2021 Alibaba Group Holding Ltd.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15
16 from typing import Dict, List, Any
17
18 from .... import oscar as mo
19 from ....core import ChunkType
20 from ....core.operand import Fuse
21 from ....lib.aio import alru_cache
22 from ....typing import BandType
23 from ....utils import get_chunk_params
24 from ..core import get_meta_type
25 from ..store import AbstractMetaStore
26 from ..supervisor.core import MetaStoreManagerActor, MetaStoreActor
27 from ..worker.core import WorkerMetaStoreManagerActor
28 from .core import AbstractMetaAPI
29
30
31 class BaseMetaAPI(AbstractMetaAPI):
32 def __init__(self, session_id: str, meta_store: mo.ActorRefType[AbstractMetaStore]):
33 # make sure all meta types registered
34 from .. import metas
35
36 del metas
37
38 self._session_id = session_id
39 self._meta_store = meta_store
40
41 @mo.extensible
42 async def set_tileable_meta(
43 self, tileable, memory_size: int = None, store_size: int = None, **extra
44 ):
45 from ....dataframe.core import (
46 DATAFRAME_TYPE,
47 DATAFRAME_GROUPBY_TYPE,
48 SERIES_GROUPBY_TYPE,
49 )
50
51 params = tileable.params.copy()
52 if isinstance(
53 tileable, (DATAFRAME_TYPE, DATAFRAME_GROUPBY_TYPE, SERIES_GROUPBY_TYPE)
54 ):
55 # dataframe needs some special process for now
56 del params["columns_value"]
57 del params["dtypes"]
58 params.pop("key_dtypes", None)
59 params["dtypes_value"] = tileable.dtypes_value
60 params["nsplits"] = tileable.nsplits
61 params.update(extra)
62 meta = get_meta_type(type(tileable))(
63 object_id=tileable.key,
64 **params,
65 memory_size=memory_size,
66 store_size=store_size
67 )
68 return await self._meta_store.set_meta(tileable.key, meta)
69
70 @mo.extensible
71 async def get_tileable_meta(
72 self, object_id: str, fields: List[str] = None
73 ) -> Dict[str, Any]:
74 return await self._meta_store.get_meta(object_id, fields=fields)
75
76 @mo.extensible
77 async def del_tileable_meta(self, object_id: str):
78 return await self._meta_store.del_meta(object_id)
79
80 @classmethod
81 def _extract_chunk_meta(
82 cls,
83 chunk: ChunkType,
84 memory_size: int = None,
85 store_size: int = None,
86 bands: List[BandType] = None,
87 fields: List[str] = None,
88 exclude_fields: List[str] = None,
89 **extra
90 ):
91 if isinstance(chunk.op, Fuse):
92 # fuse op
93 chunk = chunk.chunk
94 params = get_chunk_params(chunk)
95 chunk_key = extra.pop("chunk_key", chunk.key)
96 object_ref = extra.pop("object_ref", None)
97 params.update(extra)
98
99 if object_ref:
100 object_refs = (
101 [object_ref] if not isinstance(object_ref, list) else object_ref
102 )
103 else:
104 object_refs = []
105
106 if fields is not None:
107 fields = set(fields)
108 params = {k: v for k, v in params.items() if k in fields}
109 elif exclude_fields is not None:
110 exclude_fields = set(exclude_fields)
111 params = {k: v for k, v in params.items() if k not in exclude_fields}
112
113 return get_meta_type(type(chunk))(
114 object_id=chunk_key,
115 **params,
116 bands=bands,
117 memory_size=memory_size,
118 store_size=store_size,
119 object_refs=object_refs
120 )
121
122 @mo.extensible
123 async def set_chunk_meta(
124 self,
125 chunk: ChunkType,
126 memory_size: int = None,
127 store_size: int = None,
128 bands: List[BandType] = None,
129 fields: List[str] = None,
130 exclude_fields: List[str] = None,
131 **extra
132 ):
133 """
134 Parameters
135 ----------
136 chunk: ChunkType
137 chunk to set meta
138 memory_size: int
139 memory size for chunk data
140 store_size: int
141 serialized size for chunk data
142 bands:
143 chunk data bands
144 fields: list
145 fields to include in meta
146 exclude_fields: list
147 fields to exclude in meta
148 extra
149
150 Returns
151 -------
152
153 """
154 meta = self._extract_chunk_meta(
155 chunk,
156 memory_size=memory_size,
157 store_size=store_size,
158 bands=bands,
159 fields=fields,
160 exclude_fields=exclude_fields,
161 **extra
162 )
163 return await self._meta_store.set_meta(meta.object_id, meta)
164
165 @set_chunk_meta.batch
166 async def batch_set_chunk_meta(self, args_list, kwargs_list):
167 set_chunk_metas = []
168 for args, kwargs in zip(args_list, kwargs_list):
169 meta = self._extract_chunk_meta(*args, **kwargs)
170 set_chunk_metas.append(
171 self._meta_store.set_meta.delay(meta.object_id, meta)
172 )
173 return await self._meta_store.set_meta.batch(*set_chunk_metas)
174
175 @mo.extensible
176 async def get_chunk_meta(
177 self, object_id: str, fields: List[str] = None, error="raise"
178 ):
179 return await self._meta_store.get_meta(object_id, fields=fields, error=error)
180
181 @get_chunk_meta.batch
182 async def batch_get_chunk_meta(self, args_list, kwargs_list):
183 get_chunk_metas = []
184 for args, kwargs in zip(args_list, kwargs_list):
185 get_chunk_metas.append(self._meta_store.get_meta.delay(*args, **kwargs))
186 return await self._meta_store.get_meta.batch(*get_chunk_metas)
187
188 @mo.extensible
189 async def del_chunk_meta(self, object_id: str):
190 """
191 Parameters
192 ----------
193 object_id: str
194 chunk id
195 """
196 return await self._meta_store.del_meta(object_id)
197
198 @del_chunk_meta.batch
199 async def batch_del_chunk_meta(self, args_list, kwargs_list):
200 del_chunk_metas = []
201 for args, kwargs in zip(args_list, kwargs_list):
202 del_chunk_metas.append(self._meta_store.del_meta.delay(*args, **kwargs))
203 return await self._meta_store.del_meta.batch(*del_chunk_metas)
204
205 @mo.extensible
206 async def add_chunk_bands(self, object_id: str, bands: List[BandType]):
207 return await self._meta_store.add_chunk_bands(object_id, bands)
208
209 @add_chunk_bands.batch
210 async def batch_add_chunk_bands(self, args_list, kwargs_list):
211 add_chunk_bands_tasks = []
212 for args, kwargs in zip(args_list, kwargs_list):
213 add_chunk_bands_tasks.append(
214 self._meta_store.add_chunk_bands.delay(*args, **kwargs)
215 )
216 return await self._meta_store.add_chunk_bands.batch(*add_chunk_bands_tasks)
217
218 @mo.extensible
219 async def remove_chunk_bands(self, object_id: str, bands: List[BandType]):
220 return await self._meta_store.remove_chunk_bands(object_id, bands)
221
222 @remove_chunk_bands.batch
223 async def batch_remove_chunk_bands(self, args_list, kwargs_list):
224 remove_chunk_bands_tasks = []
225 for args, kwargs in zip(args_list, kwargs_list):
226 remove_chunk_bands_tasks.append(
227 self._meta_store.remove_chunk_bands.delay(*args, **kwargs)
228 )
229 return await self._meta_store.remove_chunk_bands.batch(
230 *remove_chunk_bands_tasks
231 )
232
233 @mo.extensible
234 async def get_band_chunks(self, band: BandType) -> List[str]:
235 return await self._meta_store.get_band_chunks(band)
236
237
238 class MetaAPI(BaseMetaAPI):
239 @classmethod
240 @alru_cache(cache_exceptions=False)
241 async def create(cls, session_id: str, address: str) -> "MetaAPI":
242 """
243 Create Meta API.
244
245 Parameters
246 ----------
247 session_id : str
248 Session ID.
249 address : str
250 Supervisor address.
251
252 Returns
253 -------
254 meta_api
255 Meta api.
256 """
257 meta_store_ref = await mo.actor_ref(address, MetaStoreActor.gen_uid(session_id))
258
259 return MetaAPI(session_id, meta_store_ref)
260
261
262 class MockMetaAPI(MetaAPI):
263 @classmethod
264 async def create(cls, session_id: str, address: str) -> "MetaAPI":
265 # create an Actor for mock
266 try:
267 meta_store_manager_ref = await mo.create_actor(
268 MetaStoreManagerActor,
269 "dict",
270 dict(),
271 address=address,
272 uid=MetaStoreManagerActor.default_uid(),
273 )
274 except mo.ActorAlreadyExist:
275 # ignore if actor exists
276 meta_store_manager_ref = await mo.actor_ref(
277 MetaStoreManagerActor,
278 address=address,
279 uid=MetaStoreManagerActor.default_uid(),
280 )
281 try:
282 await meta_store_manager_ref.new_session_meta_store(session_id)
283 except mo.ActorAlreadyExist:
284 pass
285 return await super().create(session_id=session_id, address=address)
286
287
288 class WorkerMetaAPI(BaseMetaAPI):
289 @classmethod
290 @alru_cache(cache_exceptions=False)
291 async def create(cls, session_id: str, address: str) -> "WorkerMetaAPI":
292 """
293 Create worker meta API.
294
295 Parameters
296 ----------
297 session_id : str
298 Session ID.
299 address : str
300 Worker address.
301
302 Returns
303 -------
304 meta_api
305 Worker meta api.
306 """
307 worker_meta_store_manager_ref = await mo.actor_ref(
308 uid=WorkerMetaStoreManagerActor.default_uid(), address=address
309 )
310 worker_meta_store_ref = (
311 await worker_meta_store_manager_ref.new_session_meta_store(session_id)
312 )
313 return WorkerMetaAPI(session_id, worker_meta_store_ref)
314
315
316 class MockWorkerMetaAPI(WorkerMetaAPI):
317 @classmethod
318 async def create(cls, session_id: str, address: str) -> "WorkerMetaAPI":
319 # create an Actor for mock
320 try:
321 await mo.create_actor(
322 WorkerMetaStoreManagerActor,
323 "dict",
324 dict(),
325 address=address,
326 uid=WorkerMetaStoreManagerActor.default_uid(),
327 )
328 except mo.ActorAlreadyExist:
329 # ignore if actor exists
330 await mo.actor_ref(
331 WorkerMetaStoreManagerActor,
332 address=address,
333 uid=WorkerMetaStoreManagerActor.default_uid(),
334 )
335 return await super().create(session_id, address)
336
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mars/services/meta/api/oscar.py b/mars/services/meta/api/oscar.py
--- a/mars/services/meta/api/oscar.py
+++ b/mars/services/meta/api/oscar.py
@@ -237,7 +237,7 @@
class MetaAPI(BaseMetaAPI):
@classmethod
- @alru_cache(cache_exceptions=False)
+ @alru_cache(maxsize=1024, cache_exceptions=False)
async def create(cls, session_id: str, address: str) -> "MetaAPI":
"""
Create Meta API.
| {"golden_diff": "diff --git a/mars/services/meta/api/oscar.py b/mars/services/meta/api/oscar.py\n--- a/mars/services/meta/api/oscar.py\n+++ b/mars/services/meta/api/oscar.py\n@@ -237,7 +237,7 @@\n \n class MetaAPI(BaseMetaAPI):\n @classmethod\n- @alru_cache(cache_exceptions=False)\n+ @alru_cache(maxsize=1024, cache_exceptions=False)\n async def create(cls, session_id: str, address: str) -> \"MetaAPI\":\n \"\"\"\n Create Meta API.\n", "issue": "[BUG] There maybe duplicate `WorkerMetaAPI` creation in `TaskStageProcessor`\n**Describe the bug**\r\n\r\nWe can see there is a lot of duplicate `WorkerMetaAPI` creation in the method `_update_result_meta` of `mars/services/task/execution/mars/stage.py` if there is too many chunk result and their bands are same:\r\n```python\r\nfor tileable in tile_context.values():\r\n chunks = [c.data for c in tileable.chunks]\r\n for c, params_fields in zip(chunks, self._get_params_fields(tileable)):\r\n address = chunk_to_result[c].meta[\"bands\"][0][0]\r\n meta_api = await WorkerMetaAPI.create(session_id, address)\r\n call = meta_api.get_chunk_meta.delay(c.key, fields=params_fields)\r\n worker_meta_api_to_chunk_delays[meta_api][c] = calll\r\n```\r\nThere are 3639 chunk results and 200 workers in my job and it costs 1414s to create worker meta apis.\r\nMaybe we can cache the worker meta apis to avoid duplicate creation.\r\n\r\n**To Reproduce**\r\n\r\n1. Your Python version: python-3.7.9\r\n2. The version of Mars you use: master\r\n\n", "before_files": [{"content": "# Copyright 1999-2021 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom typing import Dict, List, Any\n\nfrom .... import oscar as mo\nfrom ....core import ChunkType\nfrom ....core.operand import Fuse\nfrom ....lib.aio import alru_cache\nfrom ....typing import BandType\nfrom ....utils import get_chunk_params\nfrom ..core import get_meta_type\nfrom ..store import AbstractMetaStore\nfrom ..supervisor.core import MetaStoreManagerActor, MetaStoreActor\nfrom ..worker.core import WorkerMetaStoreManagerActor\nfrom .core import AbstractMetaAPI\n\n\nclass BaseMetaAPI(AbstractMetaAPI):\n def __init__(self, session_id: str, meta_store: mo.ActorRefType[AbstractMetaStore]):\n # make sure all meta types registered\n from .. import metas\n\n del metas\n\n self._session_id = session_id\n self._meta_store = meta_store\n\n @mo.extensible\n async def set_tileable_meta(\n self, tileable, memory_size: int = None, store_size: int = None, **extra\n ):\n from ....dataframe.core import (\n DATAFRAME_TYPE,\n DATAFRAME_GROUPBY_TYPE,\n SERIES_GROUPBY_TYPE,\n )\n\n params = tileable.params.copy()\n if isinstance(\n tileable, (DATAFRAME_TYPE, DATAFRAME_GROUPBY_TYPE, SERIES_GROUPBY_TYPE)\n ):\n # dataframe needs some special process for now\n del params[\"columns_value\"]\n del params[\"dtypes\"]\n params.pop(\"key_dtypes\", None)\n params[\"dtypes_value\"] = tileable.dtypes_value\n params[\"nsplits\"] = tileable.nsplits\n params.update(extra)\n meta = get_meta_type(type(tileable))(\n object_id=tileable.key,\n **params,\n memory_size=memory_size,\n store_size=store_size\n )\n return await self._meta_store.set_meta(tileable.key, meta)\n\n @mo.extensible\n async def get_tileable_meta(\n self, object_id: str, fields: List[str] = None\n ) -> Dict[str, Any]:\n return await self._meta_store.get_meta(object_id, fields=fields)\n\n @mo.extensible\n async def del_tileable_meta(self, object_id: str):\n return await self._meta_store.del_meta(object_id)\n\n @classmethod\n def _extract_chunk_meta(\n cls,\n chunk: ChunkType,\n memory_size: int = None,\n store_size: int = None,\n bands: List[BandType] = None,\n fields: List[str] = None,\n exclude_fields: List[str] = None,\n **extra\n ):\n if isinstance(chunk.op, Fuse):\n # fuse op\n chunk = chunk.chunk\n params = get_chunk_params(chunk)\n chunk_key = extra.pop(\"chunk_key\", chunk.key)\n object_ref = extra.pop(\"object_ref\", None)\n params.update(extra)\n\n if object_ref:\n object_refs = (\n [object_ref] if not isinstance(object_ref, list) else object_ref\n )\n else:\n object_refs = []\n\n if fields is not None:\n fields = set(fields)\n params = {k: v for k, v in params.items() if k in fields}\n elif exclude_fields is not None:\n exclude_fields = set(exclude_fields)\n params = {k: v for k, v in params.items() if k not in exclude_fields}\n\n return get_meta_type(type(chunk))(\n object_id=chunk_key,\n **params,\n bands=bands,\n memory_size=memory_size,\n store_size=store_size,\n object_refs=object_refs\n )\n\n @mo.extensible\n async def set_chunk_meta(\n self,\n chunk: ChunkType,\n memory_size: int = None,\n store_size: int = None,\n bands: List[BandType] = None,\n fields: List[str] = None,\n exclude_fields: List[str] = None,\n **extra\n ):\n \"\"\"\n Parameters\n ----------\n chunk: ChunkType\n chunk to set meta\n memory_size: int\n memory size for chunk data\n store_size: int\n serialized size for chunk data\n bands:\n chunk data bands\n fields: list\n fields to include in meta\n exclude_fields: list\n fields to exclude in meta\n extra\n\n Returns\n -------\n\n \"\"\"\n meta = self._extract_chunk_meta(\n chunk,\n memory_size=memory_size,\n store_size=store_size,\n bands=bands,\n fields=fields,\n exclude_fields=exclude_fields,\n **extra\n )\n return await self._meta_store.set_meta(meta.object_id, meta)\n\n @set_chunk_meta.batch\n async def batch_set_chunk_meta(self, args_list, kwargs_list):\n set_chunk_metas = []\n for args, kwargs in zip(args_list, kwargs_list):\n meta = self._extract_chunk_meta(*args, **kwargs)\n set_chunk_metas.append(\n self._meta_store.set_meta.delay(meta.object_id, meta)\n )\n return await self._meta_store.set_meta.batch(*set_chunk_metas)\n\n @mo.extensible\n async def get_chunk_meta(\n self, object_id: str, fields: List[str] = None, error=\"raise\"\n ):\n return await self._meta_store.get_meta(object_id, fields=fields, error=error)\n\n @get_chunk_meta.batch\n async def batch_get_chunk_meta(self, args_list, kwargs_list):\n get_chunk_metas = []\n for args, kwargs in zip(args_list, kwargs_list):\n get_chunk_metas.append(self._meta_store.get_meta.delay(*args, **kwargs))\n return await self._meta_store.get_meta.batch(*get_chunk_metas)\n\n @mo.extensible\n async def del_chunk_meta(self, object_id: str):\n \"\"\"\n Parameters\n ----------\n object_id: str\n chunk id\n \"\"\"\n return await self._meta_store.del_meta(object_id)\n\n @del_chunk_meta.batch\n async def batch_del_chunk_meta(self, args_list, kwargs_list):\n del_chunk_metas = []\n for args, kwargs in zip(args_list, kwargs_list):\n del_chunk_metas.append(self._meta_store.del_meta.delay(*args, **kwargs))\n return await self._meta_store.del_meta.batch(*del_chunk_metas)\n\n @mo.extensible\n async def add_chunk_bands(self, object_id: str, bands: List[BandType]):\n return await self._meta_store.add_chunk_bands(object_id, bands)\n\n @add_chunk_bands.batch\n async def batch_add_chunk_bands(self, args_list, kwargs_list):\n add_chunk_bands_tasks = []\n for args, kwargs in zip(args_list, kwargs_list):\n add_chunk_bands_tasks.append(\n self._meta_store.add_chunk_bands.delay(*args, **kwargs)\n )\n return await self._meta_store.add_chunk_bands.batch(*add_chunk_bands_tasks)\n\n @mo.extensible\n async def remove_chunk_bands(self, object_id: str, bands: List[BandType]):\n return await self._meta_store.remove_chunk_bands(object_id, bands)\n\n @remove_chunk_bands.batch\n async def batch_remove_chunk_bands(self, args_list, kwargs_list):\n remove_chunk_bands_tasks = []\n for args, kwargs in zip(args_list, kwargs_list):\n remove_chunk_bands_tasks.append(\n self._meta_store.remove_chunk_bands.delay(*args, **kwargs)\n )\n return await self._meta_store.remove_chunk_bands.batch(\n *remove_chunk_bands_tasks\n )\n\n @mo.extensible\n async def get_band_chunks(self, band: BandType) -> List[str]:\n return await self._meta_store.get_band_chunks(band)\n\n\nclass MetaAPI(BaseMetaAPI):\n @classmethod\n @alru_cache(cache_exceptions=False)\n async def create(cls, session_id: str, address: str) -> \"MetaAPI\":\n \"\"\"\n Create Meta API.\n\n Parameters\n ----------\n session_id : str\n Session ID.\n address : str\n Supervisor address.\n\n Returns\n -------\n meta_api\n Meta api.\n \"\"\"\n meta_store_ref = await mo.actor_ref(address, MetaStoreActor.gen_uid(session_id))\n\n return MetaAPI(session_id, meta_store_ref)\n\n\nclass MockMetaAPI(MetaAPI):\n @classmethod\n async def create(cls, session_id: str, address: str) -> \"MetaAPI\":\n # create an Actor for mock\n try:\n meta_store_manager_ref = await mo.create_actor(\n MetaStoreManagerActor,\n \"dict\",\n dict(),\n address=address,\n uid=MetaStoreManagerActor.default_uid(),\n )\n except mo.ActorAlreadyExist:\n # ignore if actor exists\n meta_store_manager_ref = await mo.actor_ref(\n MetaStoreManagerActor,\n address=address,\n uid=MetaStoreManagerActor.default_uid(),\n )\n try:\n await meta_store_manager_ref.new_session_meta_store(session_id)\n except mo.ActorAlreadyExist:\n pass\n return await super().create(session_id=session_id, address=address)\n\n\nclass WorkerMetaAPI(BaseMetaAPI):\n @classmethod\n @alru_cache(cache_exceptions=False)\n async def create(cls, session_id: str, address: str) -> \"WorkerMetaAPI\":\n \"\"\"\n Create worker meta API.\n\n Parameters\n ----------\n session_id : str\n Session ID.\n address : str\n Worker address.\n\n Returns\n -------\n meta_api\n Worker meta api.\n \"\"\"\n worker_meta_store_manager_ref = await mo.actor_ref(\n uid=WorkerMetaStoreManagerActor.default_uid(), address=address\n )\n worker_meta_store_ref = (\n await worker_meta_store_manager_ref.new_session_meta_store(session_id)\n )\n return WorkerMetaAPI(session_id, worker_meta_store_ref)\n\n\nclass MockWorkerMetaAPI(WorkerMetaAPI):\n @classmethod\n async def create(cls, session_id: str, address: str) -> \"WorkerMetaAPI\":\n # create an Actor for mock\n try:\n await mo.create_actor(\n WorkerMetaStoreManagerActor,\n \"dict\",\n dict(),\n address=address,\n uid=WorkerMetaStoreManagerActor.default_uid(),\n )\n except mo.ActorAlreadyExist:\n # ignore if actor exists\n await mo.actor_ref(\n WorkerMetaStoreManagerActor,\n address=address,\n uid=WorkerMetaStoreManagerActor.default_uid(),\n )\n return await super().create(session_id, address)\n", "path": "mars/services/meta/api/oscar.py"}], "after_files": [{"content": "# Copyright 1999-2021 Alibaba Group Holding Ltd.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\nfrom typing import Dict, List, Any\n\nfrom .... import oscar as mo\nfrom ....core import ChunkType\nfrom ....core.operand import Fuse\nfrom ....lib.aio import alru_cache\nfrom ....typing import BandType\nfrom ....utils import get_chunk_params\nfrom ..core import get_meta_type\nfrom ..store import AbstractMetaStore\nfrom ..supervisor.core import MetaStoreManagerActor, MetaStoreActor\nfrom ..worker.core import WorkerMetaStoreManagerActor\nfrom .core import AbstractMetaAPI\n\n\nclass BaseMetaAPI(AbstractMetaAPI):\n def __init__(self, session_id: str, meta_store: mo.ActorRefType[AbstractMetaStore]):\n # make sure all meta types registered\n from .. import metas\n\n del metas\n\n self._session_id = session_id\n self._meta_store = meta_store\n\n @mo.extensible\n async def set_tileable_meta(\n self, tileable, memory_size: int = None, store_size: int = None, **extra\n ):\n from ....dataframe.core import (\n DATAFRAME_TYPE,\n DATAFRAME_GROUPBY_TYPE,\n SERIES_GROUPBY_TYPE,\n )\n\n params = tileable.params.copy()\n if isinstance(\n tileable, (DATAFRAME_TYPE, DATAFRAME_GROUPBY_TYPE, SERIES_GROUPBY_TYPE)\n ):\n # dataframe needs some special process for now\n del params[\"columns_value\"]\n del params[\"dtypes\"]\n params.pop(\"key_dtypes\", None)\n params[\"dtypes_value\"] = tileable.dtypes_value\n params[\"nsplits\"] = tileable.nsplits\n params.update(extra)\n meta = get_meta_type(type(tileable))(\n object_id=tileable.key,\n **params,\n memory_size=memory_size,\n store_size=store_size\n )\n return await self._meta_store.set_meta(tileable.key, meta)\n\n @mo.extensible\n async def get_tileable_meta(\n self, object_id: str, fields: List[str] = None\n ) -> Dict[str, Any]:\n return await self._meta_store.get_meta(object_id, fields=fields)\n\n @mo.extensible\n async def del_tileable_meta(self, object_id: str):\n return await self._meta_store.del_meta(object_id)\n\n @classmethod\n def _extract_chunk_meta(\n cls,\n chunk: ChunkType,\n memory_size: int = None,\n store_size: int = None,\n bands: List[BandType] = None,\n fields: List[str] = None,\n exclude_fields: List[str] = None,\n **extra\n ):\n if isinstance(chunk.op, Fuse):\n # fuse op\n chunk = chunk.chunk\n params = get_chunk_params(chunk)\n chunk_key = extra.pop(\"chunk_key\", chunk.key)\n object_ref = extra.pop(\"object_ref\", None)\n params.update(extra)\n\n if object_ref:\n object_refs = (\n [object_ref] if not isinstance(object_ref, list) else object_ref\n )\n else:\n object_refs = []\n\n if fields is not None:\n fields = set(fields)\n params = {k: v for k, v in params.items() if k in fields}\n elif exclude_fields is not None:\n exclude_fields = set(exclude_fields)\n params = {k: v for k, v in params.items() if k not in exclude_fields}\n\n return get_meta_type(type(chunk))(\n object_id=chunk_key,\n **params,\n bands=bands,\n memory_size=memory_size,\n store_size=store_size,\n object_refs=object_refs\n )\n\n @mo.extensible\n async def set_chunk_meta(\n self,\n chunk: ChunkType,\n memory_size: int = None,\n store_size: int = None,\n bands: List[BandType] = None,\n fields: List[str] = None,\n exclude_fields: List[str] = None,\n **extra\n ):\n \"\"\"\n Parameters\n ----------\n chunk: ChunkType\n chunk to set meta\n memory_size: int\n memory size for chunk data\n store_size: int\n serialized size for chunk data\n bands:\n chunk data bands\n fields: list\n fields to include in meta\n exclude_fields: list\n fields to exclude in meta\n extra\n\n Returns\n -------\n\n \"\"\"\n meta = self._extract_chunk_meta(\n chunk,\n memory_size=memory_size,\n store_size=store_size,\n bands=bands,\n fields=fields,\n exclude_fields=exclude_fields,\n **extra\n )\n return await self._meta_store.set_meta(meta.object_id, meta)\n\n @set_chunk_meta.batch\n async def batch_set_chunk_meta(self, args_list, kwargs_list):\n set_chunk_metas = []\n for args, kwargs in zip(args_list, kwargs_list):\n meta = self._extract_chunk_meta(*args, **kwargs)\n set_chunk_metas.append(\n self._meta_store.set_meta.delay(meta.object_id, meta)\n )\n return await self._meta_store.set_meta.batch(*set_chunk_metas)\n\n @mo.extensible\n async def get_chunk_meta(\n self, object_id: str, fields: List[str] = None, error=\"raise\"\n ):\n return await self._meta_store.get_meta(object_id, fields=fields, error=error)\n\n @get_chunk_meta.batch\n async def batch_get_chunk_meta(self, args_list, kwargs_list):\n get_chunk_metas = []\n for args, kwargs in zip(args_list, kwargs_list):\n get_chunk_metas.append(self._meta_store.get_meta.delay(*args, **kwargs))\n return await self._meta_store.get_meta.batch(*get_chunk_metas)\n\n @mo.extensible\n async def del_chunk_meta(self, object_id: str):\n \"\"\"\n Parameters\n ----------\n object_id: str\n chunk id\n \"\"\"\n return await self._meta_store.del_meta(object_id)\n\n @del_chunk_meta.batch\n async def batch_del_chunk_meta(self, args_list, kwargs_list):\n del_chunk_metas = []\n for args, kwargs in zip(args_list, kwargs_list):\n del_chunk_metas.append(self._meta_store.del_meta.delay(*args, **kwargs))\n return await self._meta_store.del_meta.batch(*del_chunk_metas)\n\n @mo.extensible\n async def add_chunk_bands(self, object_id: str, bands: List[BandType]):\n return await self._meta_store.add_chunk_bands(object_id, bands)\n\n @add_chunk_bands.batch\n async def batch_add_chunk_bands(self, args_list, kwargs_list):\n add_chunk_bands_tasks = []\n for args, kwargs in zip(args_list, kwargs_list):\n add_chunk_bands_tasks.append(\n self._meta_store.add_chunk_bands.delay(*args, **kwargs)\n )\n return await self._meta_store.add_chunk_bands.batch(*add_chunk_bands_tasks)\n\n @mo.extensible\n async def remove_chunk_bands(self, object_id: str, bands: List[BandType]):\n return await self._meta_store.remove_chunk_bands(object_id, bands)\n\n @remove_chunk_bands.batch\n async def batch_remove_chunk_bands(self, args_list, kwargs_list):\n remove_chunk_bands_tasks = []\n for args, kwargs in zip(args_list, kwargs_list):\n remove_chunk_bands_tasks.append(\n self._meta_store.remove_chunk_bands.delay(*args, **kwargs)\n )\n return await self._meta_store.remove_chunk_bands.batch(\n *remove_chunk_bands_tasks\n )\n\n @mo.extensible\n async def get_band_chunks(self, band: BandType) -> List[str]:\n return await self._meta_store.get_band_chunks(band)\n\n\nclass MetaAPI(BaseMetaAPI):\n @classmethod\n @alru_cache(maxsize=1024, cache_exceptions=False)\n async def create(cls, session_id: str, address: str) -> \"MetaAPI\":\n \"\"\"\n Create Meta API.\n\n Parameters\n ----------\n session_id : str\n Session ID.\n address : str\n Supervisor address.\n\n Returns\n -------\n meta_api\n Meta api.\n \"\"\"\n meta_store_ref = await mo.actor_ref(address, MetaStoreActor.gen_uid(session_id))\n\n return MetaAPI(session_id, meta_store_ref)\n\n\nclass MockMetaAPI(MetaAPI):\n @classmethod\n async def create(cls, session_id: str, address: str) -> \"MetaAPI\":\n # create an Actor for mock\n try:\n meta_store_manager_ref = await mo.create_actor(\n MetaStoreManagerActor,\n \"dict\",\n dict(),\n address=address,\n uid=MetaStoreManagerActor.default_uid(),\n )\n except mo.ActorAlreadyExist:\n # ignore if actor exists\n meta_store_manager_ref = await mo.actor_ref(\n MetaStoreManagerActor,\n address=address,\n uid=MetaStoreManagerActor.default_uid(),\n )\n try:\n await meta_store_manager_ref.new_session_meta_store(session_id)\n except mo.ActorAlreadyExist:\n pass\n return await super().create(session_id=session_id, address=address)\n\n\nclass WorkerMetaAPI(BaseMetaAPI):\n @classmethod\n @alru_cache(cache_exceptions=False)\n async def create(cls, session_id: str, address: str) -> \"WorkerMetaAPI\":\n \"\"\"\n Create worker meta API.\n\n Parameters\n ----------\n session_id : str\n Session ID.\n address : str\n Worker address.\n\n Returns\n -------\n meta_api\n Worker meta api.\n \"\"\"\n worker_meta_store_manager_ref = await mo.actor_ref(\n uid=WorkerMetaStoreManagerActor.default_uid(), address=address\n )\n worker_meta_store_ref = (\n await worker_meta_store_manager_ref.new_session_meta_store(session_id)\n )\n return WorkerMetaAPI(session_id, worker_meta_store_ref)\n\n\nclass MockWorkerMetaAPI(WorkerMetaAPI):\n @classmethod\n async def create(cls, session_id: str, address: str) -> \"WorkerMetaAPI\":\n # create an Actor for mock\n try:\n await mo.create_actor(\n WorkerMetaStoreManagerActor,\n \"dict\",\n dict(),\n address=address,\n uid=WorkerMetaStoreManagerActor.default_uid(),\n )\n except mo.ActorAlreadyExist:\n # ignore if actor exists\n await mo.actor_ref(\n WorkerMetaStoreManagerActor,\n address=address,\n uid=WorkerMetaStoreManagerActor.default_uid(),\n )\n return await super().create(session_id, address)\n", "path": "mars/services/meta/api/oscar.py"}]} | 3,840 | 125 |
gh_patches_debug_20249 | rasdani/github-patches | git_diff | holoviz__panel-5435 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Echarts not updated when removing a serie
#### Software version info
- python 3.10.12
- panel 1.2.1
- bokeh 3.2.1
- MacOS Ventura 13.5
- Chrome Version 115.0.5790.170 arm64
#### Description
I have a param `ListSelector`, used to build a panel `CheckBoxGroup`, and an `echart`
The number of series of the echart varies according to the number of values selected in the `CheckBoxGroup`.
When I click new values, a new serie is added, and the plot is properly updated.
But when I unclick an existing value, the plot isn't updated.
More details :
- in both cases, the echart series are updated. see the reproduction code below.
- having a look at the messages passing through the Websocket, I know that "ModelChanged" messages are received by the browser, *with updated series*. Check screenshots below.
- It's really only *removing* a serie that is failing. Adding series always work. This is illustrated in the video below. For instance, running my reproduction code, run the following sequence :
- check 2 (it's updated)
- check 4 (it's updated)
- uncheck 4 (it's not updated)
- check8 (it's updated as expected)
#### Complete, minimal, self-contained example code that reproduces the issue
```python
import panel as pn
import param
class DemoEchartsBug(pn.viewable.Viewer):
numbers = param.ListSelector(default=[],
objects=[2, 4, 8])
def __init__(self, **params):
super().__init__(**params)
self.cb_group = pn.widgets.CheckBoxGroup.from_param(self.param.numbers)
@param.depends("numbers")
def plot(self):
echart_index = list(range(10))
echart_series = [
{
"type": "bar",
"name": str(num),
"data": [i * num for i in range(10)],
}
for num in self.numbers
]
echart_config = {
"xAxis": [{"type": "category", "data": echart_index}],
"yAxis": [{"type": "value"}],
"series": echart_series,
}
echart_pane = pn.pane.ECharts(echart_config,
width=800,
height=400)
return pn.Column(
pn.pane.Markdown(f"# numbers : {self.numbers}"),
echart_pane
)
def __panel__(self):
return pn.Column(
pn.pane.Markdown(" # Bug with ECharts"),
self.cb_group,
pn.layout.Divider(),
self.plot
)
```
#### Stack traceback and/or browser JavaScript console output
No console output
#### Screen recording
https://github.com/holoviz/panel/assets/756464/9b4cfdf5-1414-4b1f-ad7f-c9f88981e0bd
#### Screenshots of the messages in the websocket
- Step 1 : Before removing a serie. There are two series in the echart config

- Step 2 : After removing a serie. There is one serie in the echart config, as it should be.

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `panel/pane/echarts.py`
Content:
```
1 from __future__ import annotations
2
3 import json
4 import sys
5
6 from collections import defaultdict
7 from typing import (
8 TYPE_CHECKING, Any, Callable, ClassVar, List, Mapping, Optional,
9 )
10
11 import param
12
13 from bokeh.models import CustomJS
14 from pyviz_comms import JupyterComm
15
16 from ..util import lazy_load
17 from ..viewable import Viewable
18 from .base import ModelPane
19
20 if TYPE_CHECKING:
21 from bokeh.document import Document
22 from bokeh.model import Model
23 from pyviz_comms import Comm
24
25
26 class ECharts(ModelPane):
27 """
28 ECharts panes allow rendering echarts.js dictionaries and pyecharts plots.
29
30 Reference: https://panel.holoviz.org/reference/panes/ECharts.html
31
32 :Example:
33
34 >>> pn.extension('echarts')
35 >>> ECharts(some_echart_dict_or_pyecharts_object, height=480, width=640)
36 """
37
38 object = param.Parameter(default=None, doc="""
39 The Echarts object being wrapped. Can be an Echarts dictionary or a pyecharts chart""")
40
41 renderer = param.ObjectSelector(default="canvas", objects=["canvas", "svg"], doc="""
42 Whether to render as HTML canvas or SVG""")
43
44 theme = param.ObjectSelector(default="default", objects=["default", "light", "dark"], doc="""
45 Theme to apply to plots.""")
46
47 priority: ClassVar[float | bool | None] = None
48
49 _rename: ClassVar[Mapping[str, str | None]] = {"object": "data"}
50
51 _rerender_params: ClassVar[List[str]] = []
52
53 _updates: ClassVar[bool] = True
54
55 def __init__(self, object=None, **params):
56 super().__init__(object, **params)
57 self._py_callbacks = defaultdict(lambda: defaultdict(list))
58 self._js_callbacks = defaultdict(list)
59
60 @classmethod
61 def applies(cls, obj: Any, **params) -> float | bool | None:
62 if isinstance(obj, dict):
63 return 0
64 elif cls.is_pyecharts(obj):
65 return 0.8
66 return None
67
68 @classmethod
69 def is_pyecharts(cls, obj):
70 if 'pyecharts' in sys.modules:
71 import pyecharts
72 return isinstance(obj, pyecharts.charts.chart.Chart)
73 return False
74
75 def _process_event(self, event):
76 callbacks = self._py_callbacks.get(event.type, {})
77 for cb in callbacks.get(None, []):
78 cb(event)
79 if event.query is None:
80 return
81 for cb in callbacks.get(event.query, []):
82 cb(event)
83
84 def _get_js_events(self, ref):
85 js_events = defaultdict(list)
86 for event, specs in self._js_callbacks.items():
87 for (query, code, args) in specs:
88 models = {
89 name: viewable._models[ref][0] for name, viewable in args.items()
90 if ref in viewable._models
91 }
92 js_events[event].append({'query': query, 'callback': CustomJS(code=code, args=models)})
93 return dict(js_events)
94
95 def _process_param_change(self, params):
96 props = super()._process_param_change(params)
97 if 'data' not in props:
98 return props
99 data = props['data'] or {}
100 if not isinstance(data, dict):
101 w, h = data.width, data.height
102 props['data'] = data = json.loads(data.dump_options())
103 if not self.height and h:
104 props['height'] = int(h.replace('px', ''))
105 if not self.width and w:
106 props['width'] = int(w.replace('px', ''))
107 else:
108 props['data'] = data
109 if data.get('responsive'):
110 props['sizing_mode'] = 'stretch_both'
111 return props
112
113 def _get_properties(self, document: Document):
114 props = super()._get_properties(document)
115 props['event_config'] = {
116 event: list(queries) for event, queries in self._py_callbacks.items()
117 }
118 return props
119
120 def _get_model(
121 self, doc: Document, root: Optional[Model] = None,
122 parent: Optional[Model] = None, comm: Optional[Comm] = None
123 ) -> Model:
124 self._bokeh_model = lazy_load(
125 'panel.models.echarts', 'ECharts', isinstance(comm, JupyterComm), root
126 )
127 model = super()._get_model(doc, root, parent, comm)
128 self._register_events('echarts_event', model=model, doc=doc, comm=comm)
129 return model
130
131 def on_event(self, event: str, callback: Callable, query: str | None = None):
132 """
133 Register anevent handler which triggers when the specified event is triggered.
134
135 Reference: https://apache.github.io/echarts-handbook/en/concepts/event/
136
137 Arguments
138 ---------
139 event: str
140 The name of the event to register a handler on, e.g. 'click'.
141 callback: str | CustomJS
142 The event handler to be executed when the event fires.
143 query: str | None
144 A query that determines when the event fires.
145 """
146 self._py_callbacks[event][query].append(callback)
147 event_config = {event: list(queries) for event, queries in self._py_callbacks.items()}
148 for ref, (model, _) in self._models.items():
149 self._apply_update({}, {'event_config': event_config}, model, ref)
150
151 def js_on_event(self, event: str, callback: str | CustomJS, query: str | None = None, **args):
152 """
153 Register a Javascript event handler which triggers when the
154 specified event is triggered. The callback can be a snippet
155 of Javascript code or a bokeh CustomJS object making it possible
156 to manipulate other models in response to an event.
157
158 Reference: https://apache.github.io/echarts-handbook/en/concepts/event/
159
160 Arguments
161 ---------
162 event: str
163 The name of the event to register a handler on, e.g. 'click'.
164 code: str
165 The event handler to be executed when the event fires.
166 query: str | None
167 A query that determines when the event fires.
168 args: Viewable
169 A dictionary of Viewables to make available in the namespace
170 of the object.
171 """
172 self._js_callbacks[event].append((query, callback, args))
173 for ref, (model, _) in self._models.items():
174 js_events = self._get_js_events(ref)
175 self._apply_update({}, {'js_events': js_events}, model, ref)
176
177
178 def setup_js_callbacks(root_view, root_model):
179 if 'panel.models.echarts' not in sys.modules:
180 return
181 ref = root_model.ref['id']
182 for pane in root_view.select(ECharts):
183 if ref in pane._models:
184 pane._models[ref][0].js_events = pane._get_js_events(ref)
185
186 Viewable._preprocessing_hooks.append(setup_js_callbacks)
187
```
Path: `panel/models/echarts.py`
Content:
```
1 """
2 Defines custom bokeh model to render ECharts plots.
3 """
4 from bokeh.core.properties import (
5 Any, Dict, Enum, List, Nullable, String,
6 )
7 from bokeh.events import ModelEvent
8 from bokeh.models import LayoutDOM
9
10 from ..config import config
11 from ..io.resources import bundled_files
12 from ..util import classproperty
13
14
15 class EChartsEvent(ModelEvent):
16
17 event_name = 'echarts_event'
18
19 def __init__(self, model, type=None, data=None, query=None):
20 self.type = type
21 self.data = data
22 self.query = query
23 super().__init__(model=model)
24
25
26 class ECharts(LayoutDOM):
27 """
28 A Bokeh model that wraps around an ECharts plot and renders it
29 inside a Bokeh.
30 """
31
32 __javascript_raw__ = [
33 f"{config.npm_cdn}/[email protected]/dist/echarts.min.js",
34 f"{config.npm_cdn}/[email protected]/dist/echarts-gl.min.js"
35 ]
36
37 @classproperty
38 def __javascript__(cls):
39 return bundled_files(cls)
40
41 @classproperty
42 def __js_skip__(cls):
43 return {
44 'echarts': cls.__javascript__[:1]
45 }
46
47 __js_require__ = {
48 'paths': {
49 "echarts": f"{config.npm_cdn}/[email protected]/dist/echarts.min",
50 "echarts-gl": f"{config.npm_cdn}/[email protected]/dist/echarts-gl.min"
51 },
52 'exports': {}
53 }
54
55 data = Nullable(Dict(String, Any))
56
57 event_config = Dict(String, Any)
58
59 js_events = Dict(String, List(Any))
60
61 renderer = Enum("canvas", "svg")
62
63 theme = Enum("default", "light", "dark")
64
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/panel/models/echarts.py b/panel/models/echarts.py
--- a/panel/models/echarts.py
+++ b/panel/models/echarts.py
@@ -54,6 +54,8 @@
data = Nullable(Dict(String, Any))
+ options = Nullable(Dict(String, Any))
+
event_config = Dict(String, Any)
js_events = Dict(String, List(Any))
diff --git a/panel/pane/echarts.py b/panel/pane/echarts.py
--- a/panel/pane/echarts.py
+++ b/panel/pane/echarts.py
@@ -38,6 +38,12 @@
object = param.Parameter(default=None, doc="""
The Echarts object being wrapped. Can be an Echarts dictionary or a pyecharts chart""")
+ options = param.Parameter(default=None, doc="""
+ An optional dict of options passed to Echarts.setOption. Allows to fine-tune the rendering behavior.
+ For example, you might want to use `options={ "replaceMerge": ['series'] })` when updating
+ the `objects` with a value containing a smaller number of series.
+ """)
+
renderer = param.ObjectSelector(default="canvas", objects=["canvas", "svg"], doc="""
Whether to render as HTML canvas or SVG""")
| {"golden_diff": "diff --git a/panel/models/echarts.py b/panel/models/echarts.py\n--- a/panel/models/echarts.py\n+++ b/panel/models/echarts.py\n@@ -54,6 +54,8 @@\n \n data = Nullable(Dict(String, Any))\n \n+ options = Nullable(Dict(String, Any))\n+\n event_config = Dict(String, Any)\n \n js_events = Dict(String, List(Any))\ndiff --git a/panel/pane/echarts.py b/panel/pane/echarts.py\n--- a/panel/pane/echarts.py\n+++ b/panel/pane/echarts.py\n@@ -38,6 +38,12 @@\n object = param.Parameter(default=None, doc=\"\"\"\n The Echarts object being wrapped. Can be an Echarts dictionary or a pyecharts chart\"\"\")\n \n+ options = param.Parameter(default=None, doc=\"\"\"\n+ An optional dict of options passed to Echarts.setOption. Allows to fine-tune the rendering behavior.\n+ For example, you might want to use `options={ \"replaceMerge\": ['series'] })` when updating\n+ the `objects` with a value containing a smaller number of series.\n+ \"\"\")\n+\n renderer = param.ObjectSelector(default=\"canvas\", objects=[\"canvas\", \"svg\"], doc=\"\"\"\n Whether to render as HTML canvas or SVG\"\"\")\n", "issue": "Echarts not updated when removing a serie\n#### Software version info\r\n- python 3.10.12\r\n- panel 1.2.1\r\n- bokeh 3.2.1\r\n- MacOS Ventura 13.5\r\n- Chrome Version 115.0.5790.170 arm64\r\n\r\n#### Description \r\nI have a param `ListSelector`, used to build a panel `CheckBoxGroup`, and an `echart`\r\nThe number of series of the echart varies according to the number of values selected in the `CheckBoxGroup`.\r\n\r\nWhen I click new values, a new serie is added, and the plot is properly updated.\r\nBut when I unclick an existing value, the plot isn't updated.\r\n\r\nMore details : \r\n- in both cases, the echart series are updated. see the reproduction code below.\r\n- having a look at the messages passing through the Websocket, I know that \"ModelChanged\" messages are received by the browser, *with updated series*. Check screenshots below.\r\n\r\n- It's really only *removing* a serie that is failing. Adding series always work. This is illustrated in the video below. For instance, running my reproduction code, run the following sequence : \r\n - check 2 (it's updated)\r\n - check 4 (it's updated)\r\n - uncheck 4 (it's not updated)\r\n - check8 (it's updated as expected)\r\n\r\n#### Complete, minimal, self-contained example code that reproduces the issue\r\n\r\n```python \r\nimport panel as pn\r\nimport param\r\n\r\nclass DemoEchartsBug(pn.viewable.Viewer):\r\n\r\n numbers = param.ListSelector(default=[],\r\n objects=[2, 4, 8])\r\n\r\n def __init__(self, **params):\r\n super().__init__(**params)\r\n\r\n self.cb_group = pn.widgets.CheckBoxGroup.from_param(self.param.numbers)\r\n \r\n @param.depends(\"numbers\")\r\n def plot(self):\r\n\r\n echart_index = list(range(10))\r\n \r\n echart_series = [\r\n {\r\n \"type\": \"bar\",\r\n \"name\": str(num),\r\n \"data\": [i * num for i in range(10)],\r\n }\r\n for num in self.numbers\r\n ]\r\n\r\n echart_config = {\r\n \"xAxis\": [{\"type\": \"category\", \"data\": echart_index}],\r\n \"yAxis\": [{\"type\": \"value\"}],\r\n \"series\": echart_series,\r\n }\r\n\r\n echart_pane = pn.pane.ECharts(echart_config,\r\n width=800,\r\n height=400)\r\n\r\n return pn.Column(\r\n pn.pane.Markdown(f\"# numbers : {self.numbers}\"),\r\n echart_pane\r\n )\r\n\r\n def __panel__(self):\r\n\r\n return pn.Column(\r\n pn.pane.Markdown(\" # Bug with ECharts\"),\r\n self.cb_group,\r\n pn.layout.Divider(),\r\n self.plot\r\n )\r\n```\r\n\r\n#### Stack traceback and/or browser JavaScript console output\r\nNo console output\r\n\r\n#### Screen recording \r\n\r\nhttps://github.com/holoviz/panel/assets/756464/9b4cfdf5-1414-4b1f-ad7f-c9f88981e0bd\r\n\r\n\r\n\r\n#### Screenshots of the messages in the websocket\r\n\r\n- Step 1 : Before removing a serie. There are two series in the echart config\r\n\r\n\r\n- Step 2 : After removing a serie. There is one serie in the echart config, as it should be. \r\n\r\n\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport json\nimport sys\n\nfrom collections import defaultdict\nfrom typing import (\n TYPE_CHECKING, Any, Callable, ClassVar, List, Mapping, Optional,\n)\n\nimport param\n\nfrom bokeh.models import CustomJS\nfrom pyviz_comms import JupyterComm\n\nfrom ..util import lazy_load\nfrom ..viewable import Viewable\nfrom .base import ModelPane\n\nif TYPE_CHECKING:\n from bokeh.document import Document\n from bokeh.model import Model\n from pyviz_comms import Comm\n\n\nclass ECharts(ModelPane):\n \"\"\"\n ECharts panes allow rendering echarts.js dictionaries and pyecharts plots.\n\n Reference: https://panel.holoviz.org/reference/panes/ECharts.html\n\n :Example:\n\n >>> pn.extension('echarts')\n >>> ECharts(some_echart_dict_or_pyecharts_object, height=480, width=640)\n \"\"\"\n\n object = param.Parameter(default=None, doc=\"\"\"\n The Echarts object being wrapped. Can be an Echarts dictionary or a pyecharts chart\"\"\")\n\n renderer = param.ObjectSelector(default=\"canvas\", objects=[\"canvas\", \"svg\"], doc=\"\"\"\n Whether to render as HTML canvas or SVG\"\"\")\n\n theme = param.ObjectSelector(default=\"default\", objects=[\"default\", \"light\", \"dark\"], doc=\"\"\"\n Theme to apply to plots.\"\"\")\n\n priority: ClassVar[float | bool | None] = None\n\n _rename: ClassVar[Mapping[str, str | None]] = {\"object\": \"data\"}\n\n _rerender_params: ClassVar[List[str]] = []\n\n _updates: ClassVar[bool] = True\n\n def __init__(self, object=None, **params):\n super().__init__(object, **params)\n self._py_callbacks = defaultdict(lambda: defaultdict(list))\n self._js_callbacks = defaultdict(list)\n\n @classmethod\n def applies(cls, obj: Any, **params) -> float | bool | None:\n if isinstance(obj, dict):\n return 0\n elif cls.is_pyecharts(obj):\n return 0.8\n return None\n\n @classmethod\n def is_pyecharts(cls, obj):\n if 'pyecharts' in sys.modules:\n import pyecharts\n return isinstance(obj, pyecharts.charts.chart.Chart)\n return False\n\n def _process_event(self, event):\n callbacks = self._py_callbacks.get(event.type, {})\n for cb in callbacks.get(None, []):\n cb(event)\n if event.query is None:\n return\n for cb in callbacks.get(event.query, []):\n cb(event)\n\n def _get_js_events(self, ref):\n js_events = defaultdict(list)\n for event, specs in self._js_callbacks.items():\n for (query, code, args) in specs:\n models = {\n name: viewable._models[ref][0] for name, viewable in args.items()\n if ref in viewable._models\n }\n js_events[event].append({'query': query, 'callback': CustomJS(code=code, args=models)})\n return dict(js_events)\n\n def _process_param_change(self, params):\n props = super()._process_param_change(params)\n if 'data' not in props:\n return props\n data = props['data'] or {}\n if not isinstance(data, dict):\n w, h = data.width, data.height\n props['data'] = data = json.loads(data.dump_options())\n if not self.height and h:\n props['height'] = int(h.replace('px', ''))\n if not self.width and w:\n props['width'] = int(w.replace('px', ''))\n else:\n props['data'] = data\n if data.get('responsive'):\n props['sizing_mode'] = 'stretch_both'\n return props\n\n def _get_properties(self, document: Document):\n props = super()._get_properties(document)\n props['event_config'] = {\n event: list(queries) for event, queries in self._py_callbacks.items()\n }\n return props\n\n def _get_model(\n self, doc: Document, root: Optional[Model] = None,\n parent: Optional[Model] = None, comm: Optional[Comm] = None\n ) -> Model:\n self._bokeh_model = lazy_load(\n 'panel.models.echarts', 'ECharts', isinstance(comm, JupyterComm), root\n )\n model = super()._get_model(doc, root, parent, comm)\n self._register_events('echarts_event', model=model, doc=doc, comm=comm)\n return model\n\n def on_event(self, event: str, callback: Callable, query: str | None = None):\n \"\"\"\n Register anevent handler which triggers when the specified event is triggered.\n\n Reference: https://apache.github.io/echarts-handbook/en/concepts/event/\n\n Arguments\n ---------\n event: str\n The name of the event to register a handler on, e.g. 'click'.\n callback: str | CustomJS\n The event handler to be executed when the event fires.\n query: str | None\n A query that determines when the event fires.\n \"\"\"\n self._py_callbacks[event][query].append(callback)\n event_config = {event: list(queries) for event, queries in self._py_callbacks.items()}\n for ref, (model, _) in self._models.items():\n self._apply_update({}, {'event_config': event_config}, model, ref)\n\n def js_on_event(self, event: str, callback: str | CustomJS, query: str | None = None, **args):\n \"\"\"\n Register a Javascript event handler which triggers when the\n specified event is triggered. The callback can be a snippet\n of Javascript code or a bokeh CustomJS object making it possible\n to manipulate other models in response to an event.\n\n Reference: https://apache.github.io/echarts-handbook/en/concepts/event/\n\n Arguments\n ---------\n event: str\n The name of the event to register a handler on, e.g. 'click'.\n code: str\n The event handler to be executed when the event fires.\n query: str | None\n A query that determines when the event fires.\n args: Viewable\n A dictionary of Viewables to make available in the namespace\n of the object.\n \"\"\"\n self._js_callbacks[event].append((query, callback, args))\n for ref, (model, _) in self._models.items():\n js_events = self._get_js_events(ref)\n self._apply_update({}, {'js_events': js_events}, model, ref)\n\n\ndef setup_js_callbacks(root_view, root_model):\n if 'panel.models.echarts' not in sys.modules:\n return\n ref = root_model.ref['id']\n for pane in root_view.select(ECharts):\n if ref in pane._models:\n pane._models[ref][0].js_events = pane._get_js_events(ref)\n\nViewable._preprocessing_hooks.append(setup_js_callbacks)\n", "path": "panel/pane/echarts.py"}, {"content": "\"\"\"\nDefines custom bokeh model to render ECharts plots.\n\"\"\"\nfrom bokeh.core.properties import (\n Any, Dict, Enum, List, Nullable, String,\n)\nfrom bokeh.events import ModelEvent\nfrom bokeh.models import LayoutDOM\n\nfrom ..config import config\nfrom ..io.resources import bundled_files\nfrom ..util import classproperty\n\n\nclass EChartsEvent(ModelEvent):\n\n event_name = 'echarts_event'\n\n def __init__(self, model, type=None, data=None, query=None):\n self.type = type\n self.data = data\n self.query = query\n super().__init__(model=model)\n\n\nclass ECharts(LayoutDOM):\n \"\"\"\n A Bokeh model that wraps around an ECharts plot and renders it\n inside a Bokeh.\n \"\"\"\n\n __javascript_raw__ = [\n f\"{config.npm_cdn}/[email protected]/dist/echarts.min.js\",\n f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min.js\"\n ]\n\n @classproperty\n def __javascript__(cls):\n return bundled_files(cls)\n\n @classproperty\n def __js_skip__(cls):\n return {\n 'echarts': cls.__javascript__[:1]\n }\n\n __js_require__ = {\n 'paths': {\n \"echarts\": f\"{config.npm_cdn}/[email protected]/dist/echarts.min\",\n \"echarts-gl\": f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min\"\n },\n 'exports': {}\n }\n\n data = Nullable(Dict(String, Any))\n\n event_config = Dict(String, Any)\n\n js_events = Dict(String, List(Any))\n\n renderer = Enum(\"canvas\", \"svg\")\n\n theme = Enum(\"default\", \"light\", \"dark\")\n", "path": "panel/models/echarts.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport json\nimport sys\n\nfrom collections import defaultdict\nfrom typing import (\n TYPE_CHECKING, Any, Callable, ClassVar, List, Mapping, Optional,\n)\n\nimport param\n\nfrom bokeh.models import CustomJS\nfrom pyviz_comms import JupyterComm\n\nfrom ..util import lazy_load\nfrom ..viewable import Viewable\nfrom .base import ModelPane\n\nif TYPE_CHECKING:\n from bokeh.document import Document\n from bokeh.model import Model\n from pyviz_comms import Comm\n\n\nclass ECharts(ModelPane):\n \"\"\"\n ECharts panes allow rendering echarts.js dictionaries and pyecharts plots.\n\n Reference: https://panel.holoviz.org/reference/panes/ECharts.html\n\n :Example:\n\n >>> pn.extension('echarts')\n >>> ECharts(some_echart_dict_or_pyecharts_object, height=480, width=640)\n \"\"\"\n\n object = param.Parameter(default=None, doc=\"\"\"\n The Echarts object being wrapped. Can be an Echarts dictionary or a pyecharts chart\"\"\")\n\n options = param.Parameter(default=None, doc=\"\"\"\n An optional dict of options passed to Echarts.setOption. Allows to fine-tune the rendering behavior.\n For example, you might want to use `options={ \"replaceMerge\": ['series'] })` when updating\n the `objects` with a value containing a smaller number of series.\n \"\"\")\n\n renderer = param.ObjectSelector(default=\"canvas\", objects=[\"canvas\", \"svg\"], doc=\"\"\"\n Whether to render as HTML canvas or SVG\"\"\")\n\n theme = param.ObjectSelector(default=\"default\", objects=[\"default\", \"light\", \"dark\"], doc=\"\"\"\n Theme to apply to plots.\"\"\")\n\n priority: ClassVar[float | bool | None] = None\n\n _rename: ClassVar[Mapping[str, str | None]] = {\"object\": \"data\"}\n\n _rerender_params: ClassVar[List[str]] = []\n\n _updates: ClassVar[bool] = True\n\n def __init__(self, object=None, **params):\n super().__init__(object, **params)\n self._py_callbacks = defaultdict(lambda: defaultdict(list))\n self._js_callbacks = defaultdict(list)\n\n @classmethod\n def applies(cls, obj: Any, **params) -> float | bool | None:\n if isinstance(obj, dict):\n return 0\n elif cls.is_pyecharts(obj):\n return 0.8\n return None\n\n @classmethod\n def is_pyecharts(cls, obj):\n if 'pyecharts' in sys.modules:\n import pyecharts\n return isinstance(obj, pyecharts.charts.chart.Chart)\n return False\n\n def _process_event(self, event):\n callbacks = self._py_callbacks.get(event.type, {})\n for cb in callbacks.get(None, []):\n cb(event)\n if event.query is None:\n return\n for cb in callbacks.get(event.query, []):\n cb(event)\n\n def _get_js_events(self, ref):\n js_events = defaultdict(list)\n for event, specs in self._js_callbacks.items():\n for (query, code, args) in specs:\n models = {\n name: viewable._models[ref][0] for name, viewable in args.items()\n if ref in viewable._models\n }\n js_events[event].append({'query': query, 'callback': CustomJS(code=code, args=models)})\n return dict(js_events)\n\n def _process_param_change(self, params):\n props = super()._process_param_change(params)\n if 'data' not in props:\n return props\n data = props['data'] or {}\n if not isinstance(data, dict):\n w, h = data.width, data.height\n props['data'] = data = json.loads(data.dump_options())\n if not self.height and h:\n props['height'] = int(h.replace('px', ''))\n if not self.width and w:\n props['width'] = int(w.replace('px', ''))\n else:\n props['data'] = data\n if data.get('responsive'):\n props['sizing_mode'] = 'stretch_both'\n return props\n\n def _get_properties(self, document: Document):\n props = super()._get_properties(document)\n props['event_config'] = {\n event: list(queries) for event, queries in self._py_callbacks.items()\n }\n return props\n\n def _get_model(\n self, doc: Document, root: Optional[Model] = None,\n parent: Optional[Model] = None, comm: Optional[Comm] = None\n ) -> Model:\n self._bokeh_model = lazy_load(\n 'panel.models.echarts', 'ECharts', isinstance(comm, JupyterComm), root\n )\n model = super()._get_model(doc, root, parent, comm)\n self._register_events('echarts_event', model=model, doc=doc, comm=comm)\n return model\n\n def on_event(self, event: str, callback: Callable, query: str | None = None):\n \"\"\"\n Register anevent handler which triggers when the specified event is triggered.\n\n Reference: https://apache.github.io/echarts-handbook/en/concepts/event/\n\n Arguments\n ---------\n event: str\n The name of the event to register a handler on, e.g. 'click'.\n callback: str | CustomJS\n The event handler to be executed when the event fires.\n query: str | None\n A query that determines when the event fires.\n \"\"\"\n self._py_callbacks[event][query].append(callback)\n event_config = {event: list(queries) for event, queries in self._py_callbacks.items()}\n for ref, (model, _) in self._models.items():\n self._apply_update({}, {'event_config': event_config}, model, ref)\n\n def js_on_event(self, event: str, callback: str | CustomJS, query: str | None = None, **args):\n \"\"\"\n Register a Javascript event handler which triggers when the\n specified event is triggered. The callback can be a snippet\n of Javascript code or a bokeh CustomJS object making it possible\n to manipulate other models in response to an event.\n\n Reference: https://apache.github.io/echarts-handbook/en/concepts/event/\n\n Arguments\n ---------\n event: str\n The name of the event to register a handler on, e.g. 'click'.\n code: str\n The event handler to be executed when the event fires.\n query: str | None\n A query that determines when the event fires.\n args: Viewable\n A dictionary of Viewables to make available in the namespace\n of the object.\n \"\"\"\n self._js_callbacks[event].append((query, callback, args))\n for ref, (model, _) in self._models.items():\n js_events = self._get_js_events(ref)\n self._apply_update({}, {'js_events': js_events}, model, ref)\n\n\ndef setup_js_callbacks(root_view, root_model):\n if 'panel.models.echarts' not in sys.modules:\n return\n ref = root_model.ref['id']\n for pane in root_view.select(ECharts):\n if ref in pane._models:\n pane._models[ref][0].js_events = pane._get_js_events(ref)\n\nViewable._preprocessing_hooks.append(setup_js_callbacks)\n", "path": "panel/pane/echarts.py"}, {"content": "\"\"\"\nDefines custom bokeh model to render ECharts plots.\n\"\"\"\nfrom bokeh.core.properties import (\n Any, Dict, Enum, List, Nullable, String,\n)\nfrom bokeh.events import ModelEvent\nfrom bokeh.models import LayoutDOM\n\nfrom ..config import config\nfrom ..io.resources import bundled_files\nfrom ..util import classproperty\n\n\nclass EChartsEvent(ModelEvent):\n\n event_name = 'echarts_event'\n\n def __init__(self, model, type=None, data=None, query=None):\n self.type = type\n self.data = data\n self.query = query\n super().__init__(model=model)\n\n\nclass ECharts(LayoutDOM):\n \"\"\"\n A Bokeh model that wraps around an ECharts plot and renders it\n inside a Bokeh.\n \"\"\"\n\n __javascript_raw__ = [\n f\"{config.npm_cdn}/[email protected]/dist/echarts.min.js\",\n f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min.js\"\n ]\n\n @classproperty\n def __javascript__(cls):\n return bundled_files(cls)\n\n @classproperty\n def __js_skip__(cls):\n return {\n 'echarts': cls.__javascript__[:1]\n }\n\n __js_require__ = {\n 'paths': {\n \"echarts\": f\"{config.npm_cdn}/[email protected]/dist/echarts.min\",\n \"echarts-gl\": f\"{config.npm_cdn}/[email protected]/dist/echarts-gl.min\"\n },\n 'exports': {}\n }\n\n data = Nullable(Dict(String, Any))\n\n options = Nullable(Dict(String, Any))\n\n event_config = Dict(String, Any)\n\n js_events = Dict(String, List(Any))\n\n renderer = Enum(\"canvas\", \"svg\")\n\n theme = Enum(\"default\", \"light\", \"dark\")\n", "path": "panel/models/echarts.py"}]} | 3,683 | 298 |
gh_patches_debug_3987 | rasdani/github-patches | git_diff | interlegis__sapl-2240 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Edição de norma: não recupera Esfera Federação
Ao editar dados de uma norma, o campo Esfera Federação não é recuperado. A segunda figura mostra a tela de edição. O sistema acaba reclamando tal dado depois de salvar.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sapl/norma/views.py`
Content:
```
1
2 import re
3
4 from django.contrib.auth.mixins import PermissionRequiredMixin
5 from django.core.exceptions import ObjectDoesNotExist
6 from django.core.urlresolvers import reverse
7 from django.http import HttpResponse, JsonResponse
8 from django.template import RequestContext, loader
9 from django.utils import timezone
10 from django.utils.translation import ugettext_lazy as _
11 from django.views.generic import TemplateView, UpdateView
12 from django.views.generic.base import RedirectView
13 from django.views.generic.edit import FormView
14 from django_filters.views import FilterView
15 import weasyprint
16 import sapl
17 from sapl.base.models import AppConfig
18 from sapl.compilacao.views import IntegracaoTaView
19 from sapl.crud.base import (RP_DETAIL, RP_LIST, Crud, CrudAux,
20 MasterDetailCrud, make_pagination)
21 from sapl.utils import show_results_filter_set
22
23 from .forms import (AnexoNormaJuridicaForm, NormaFilterSet, NormaJuridicaForm,
24 NormaPesquisaSimplesForm, NormaRelacionadaForm)
25 from .models import (AnexoNormaJuridica, AssuntoNorma, NormaJuridica, NormaRelacionada,
26 TipoNormaJuridica, TipoVinculoNormaJuridica)
27
28
29 # LegislacaoCitadaCrud = Crud.build(LegislacaoCitada, '')
30 AssuntoNormaCrud = CrudAux.build(AssuntoNorma, 'assunto_norma_juridica',
31 list_field_names=['assunto', 'descricao'])
32
33
34 TipoNormaCrud = CrudAux.build(
35 TipoNormaJuridica, 'tipo_norma_juridica',
36 list_field_names=['sigla', 'descricao', 'equivalente_lexml'])
37 TipoVinculoNormaJuridicaCrud = CrudAux.build(
38 TipoVinculoNormaJuridica, '',
39 list_field_names=['sigla', 'descricao_ativa', 'descricao_passiva'])
40
41
42 class NormaRelacionadaCrud(MasterDetailCrud):
43 model = NormaRelacionada
44 parent_field = 'norma_principal'
45 help_topic = 'norma_juridica'
46
47 class BaseMixin(MasterDetailCrud.BaseMixin):
48 list_field_names = ['norma_relacionada', 'tipo_vinculo']
49
50 class CreateView(MasterDetailCrud.CreateView):
51 form_class = NormaRelacionadaForm
52
53 class UpdateView(MasterDetailCrud.UpdateView):
54 form_class = NormaRelacionadaForm
55
56 def get_initial(self):
57 initial = super(UpdateView, self).get_initial()
58 initial['tipo'] = self.object.norma_relacionada.tipo.id
59 initial['numero'] = self.object.norma_relacionada.numero
60 initial['ano'] = self.object.norma_relacionada.ano
61 initial['ementa'] = self.object.norma_relacionada.ementa
62 return initial
63
64 class DetailView(MasterDetailCrud.DetailView):
65
66 layout_key = 'NormaRelacionadaDetail'
67
68
69 class NormaPesquisaView(FilterView):
70 model = NormaJuridica
71 filterset_class = NormaFilterSet
72 paginate_by = 10
73
74 def get_queryset(self):
75 qs = super().get_queryset()
76
77 qs = qs.extra({
78 'nm_i': "CAST(regexp_replace(numero,'[^0-9]','', 'g') AS INTEGER)",
79 'norma_letra': "regexp_replace(numero,'[^a-zA-Z]','', 'g')"
80 }).order_by('-data', '-nm_i', '-norma_letra')
81
82 return qs
83
84 def get_context_data(self, **kwargs):
85 context = super(NormaPesquisaView, self).get_context_data(**kwargs)
86
87 context['title'] = _('Pesquisar Norma Jurídica')
88
89 self.filterset.form.fields['o'].label = _('Ordenação')
90
91 qs = self.object_list
92 if 'o' in self.request.GET and not self.request.GET['o']:
93 qs = qs.order_by('-ano', 'tipo', '-numero')
94
95 qr = self.request.GET.copy()
96
97 if 'page' in qr:
98 del qr['page']
99
100 paginator = context['paginator']
101 page_obj = context['page_obj']
102
103 context['page_range'] = make_pagination(
104 page_obj.number, paginator.num_pages)
105
106 context['filter_url'] = ('&' + qr.urlencode()) if len(qr) > 0 else ''
107
108 context['show_results'] = show_results_filter_set(qr)
109
110 return context
111
112
113 class AnexoNormaJuridicaCrud(MasterDetailCrud):
114 model = AnexoNormaJuridica
115 parent_field = 'norma'
116 help_topic = 'anexonormajuridica'
117 public = [RP_LIST, RP_DETAIL]
118
119 class BaseMixin(MasterDetailCrud.BaseMixin):
120 list_field_names = ['id', 'anexo_arquivo', 'assunto_anexo']
121
122 class CreateView(MasterDetailCrud.CreateView):
123 form_class = AnexoNormaJuridicaForm
124 layout_key = 'AnexoNormaJuridica'
125
126 def get_initial(self):
127 initial = super(MasterDetailCrud.CreateView, self).get_initial()
128 initial['norma'] = NormaJuridica.objects.get(id=self.kwargs['pk'])
129 return initial
130
131 class UpdateView(MasterDetailCrud.UpdateView):
132 form_class = AnexoNormaJuridicaForm
133 layout_key = 'AnexoNormaJuridica'
134
135 def get_initial(self):
136 initial = super(UpdateView, self).get_initial()
137 initial['norma'] = self.object.norma
138 initial['anexo_arquivo'] = self.object.anexo_arquivo
139 initial['assunto_anexo'] = self.object.assunto_anexo
140 initial['ano'] = self.object.ano
141 return initial
142
143 class DetailView(MasterDetailCrud.DetailView):
144 form_class = AnexoNormaJuridicaForm
145 layout_key = 'AnexoNormaJuridica'
146
147
148 class NormaTaView(IntegracaoTaView):
149 model = NormaJuridica
150 model_type_foreignkey = TipoNormaJuridica
151 map_fields = {
152 'data': 'data',
153 'ementa': 'ementa',
154 'observacao': 'observacao',
155 'numero': 'numero',
156 'ano': 'ano',
157 'tipo': 'tipo',
158 }
159
160 map_funcs = {
161 'publicacao_func': True
162 }
163
164 def get(self, request, *args, **kwargs):
165 """
166 Para manter a app compilacao isolada das outras aplicações,
167 este get foi implementado para tratar uma prerrogativa externa
168 de usuário.
169 """
170 if AppConfig.attr('texto_articulado_norma'):
171 return IntegracaoTaView.get(self, request, *args, **kwargs)
172 else:
173 return self.get_redirect_deactivated()
174
175
176 class NormaCrud(Crud):
177 model = NormaJuridica
178 help_topic = 'norma_juridica'
179 public = [RP_LIST, RP_DETAIL]
180
181 class BaseMixin(Crud.BaseMixin):
182 list_field_names = ['tipo', 'numero', 'ano', 'ementa']
183
184 list_url = ''
185
186 @property
187 def search_url(self):
188 namespace = self.model._meta.app_config.name
189 return reverse('%s:%s' % (namespace, 'norma_pesquisa'))
190
191 class DetailView(Crud.DetailView):
192 pass
193
194 class DeleteView(Crud.DeleteView):
195
196 def get_success_url(self):
197 return self.search_url
198
199 class CreateView(Crud.CreateView):
200 form_class = NormaJuridicaForm
201
202 @property
203 def cancel_url(self):
204 return self.search_url
205
206 def get_initial(self):
207 try:
208 esfera = sapl.base.models.AppConfig.objects.last(
209 ).esfera_federacao
210 self.initial['esfera_federacao'] = esfera
211 except:
212 pass
213 self.initial['complemento'] = False
214 return self.initial
215
216 layout_key = 'NormaJuridicaCreate'
217
218 class ListView(Crud.ListView, RedirectView):
219
220 def get_redirect_url(self, *args, **kwargs):
221 namespace = self.model._meta.app_config.name
222 return reverse('%s:%s' % (namespace, 'norma_pesquisa'))
223
224 def get(self, request, *args, **kwargs):
225 return RedirectView.get(self, request, *args, **kwargs)
226
227 class UpdateView(Crud.UpdateView):
228 form_class = NormaJuridicaForm
229
230 layout_key = 'NormaJuridicaCreate'
231
232 def get_initial(self):
233 initial = super(UpdateView, self).get_initial()
234 norma = NormaJuridica.objects.get(id=self.kwargs['pk'])
235 if norma.materia:
236 initial['tipo_materia'] = norma.materia.tipo
237 initial['ano_materia'] = norma.materia.ano
238 initial['numero_materia'] = norma.materia.numero
239 return initial
240
241
242 def recuperar_norma(request):
243 tipo = TipoNormaJuridica.objects.get(pk=request.GET['tipo'])
244 numero = request.GET['numero']
245 ano = request.GET['ano']
246
247 try:
248 norma = NormaJuridica.objects.get(tipo=tipo,
249 ano=ano,
250 numero=numero)
251 response = JsonResponse({'ementa': norma.ementa,
252 'id': norma.id})
253 except ObjectDoesNotExist:
254 response = JsonResponse({'ementa': '', 'id': 0})
255
256 return response
257
258
259 def recuperar_numero_norma(request):
260 tipo = TipoNormaJuridica.objects.get(pk=request.GET['tipo'])
261 ano = request.GET.get('ano', '')
262 param = {'tipo': tipo}
263 param['ano'] = ano if ano else timezone.now().year
264 norma = NormaJuridica.objects.filter(**param).order_by(
265 'tipo', 'ano', 'numero').values_list('numero', 'ano').last()
266 if norma:
267 response = JsonResponse({'numero': int(re.sub("[^0-9].*", '', norma[0])) + 1,
268 'ano': norma[1]})
269 else:
270 response = JsonResponse(
271 {'numero': 1, 'ano': ano})
272
273 return response
274
275
276 class ImpressosView(PermissionRequiredMixin, TemplateView):
277 template_name = 'materia/impressos/impressos.html'
278 permission_required = ('materia.can_access_impressos', )
279
280
281 def gerar_pdf_impressos(request, context, template_name):
282 template = loader.get_template(template_name)
283 html = template.render(RequestContext(request, context))
284 pdf = weasyprint.HTML(string=html, base_url=request.build_absolute_uri()
285 ).write_pdf()
286
287 response = HttpResponse(pdf, content_type='application/pdf')
288 response['Content-Disposition'] = (
289 'inline; filename="relatorio_impressos.pdf"')
290 response['Content-Transfer-Encoding'] = 'binary'
291
292 return response
293
294
295 class NormaPesquisaSimplesView(PermissionRequiredMixin, FormView):
296 form_class = NormaPesquisaSimplesForm
297 template_name = 'materia/impressos/norma.html'
298 permission_required = ('materia.can_access_impressos', )
299
300 def form_valid(self, form):
301 normas = NormaJuridica.objects.all().order_by(
302 'numero')
303 template_norma = 'materia/impressos/normas_pdf.html'
304
305 titulo = form.cleaned_data['titulo']
306
307 if form.cleaned_data['tipo_norma']:
308 normas = normas.filter(tipo=form.cleaned_data['tipo_norma'])
309
310 if form.cleaned_data['data_inicial']:
311 normas = normas.filter(
312 data__gte=form.cleaned_data['data_inicial'],
313 data__lte=form.cleaned_data['data_final'])
314
315 qtd_resultados = len(normas)
316 if qtd_resultados > 2000:
317 normas = normas[:2000]
318
319 context = {'quantidade': qtd_resultados,
320 'titulo': titulo,
321 'normas': normas}
322
323 return gerar_pdf_impressos(self.request, context, template_norma)
324
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sapl/norma/views.py b/sapl/norma/views.py
--- a/sapl/norma/views.py
+++ b/sapl/norma/views.py
@@ -236,6 +236,7 @@
initial['tipo_materia'] = norma.materia.tipo
initial['ano_materia'] = norma.materia.ano
initial['numero_materia'] = norma.materia.numero
+ initial['esfera_federacao'] = norma.esfera_federacao
return initial
| {"golden_diff": "diff --git a/sapl/norma/views.py b/sapl/norma/views.py\n--- a/sapl/norma/views.py\n+++ b/sapl/norma/views.py\n@@ -236,6 +236,7 @@\n initial['tipo_materia'] = norma.materia.tipo\n initial['ano_materia'] = norma.materia.ano\n initial['numero_materia'] = norma.materia.numero\n+ initial['esfera_federacao'] = norma.esfera_federacao\n return initial\n", "issue": "Edi\u00e7\u00e3o de norma: n\u00e3o recupera Esfera Federa\u00e7\u00e3o\nAo editar dados de uma norma, o campo Esfera Federa\u00e7\u00e3o n\u00e3o \u00e9 recuperado. A segunda figura mostra a tela de edi\u00e7\u00e3o. O sistema acaba reclamando tal dado depois de salvar.\r\n\r\n\r\n\n", "before_files": [{"content": "\nimport re\n\nfrom django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponse, JsonResponse\nfrom django.template import RequestContext, loader\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.generic import TemplateView, UpdateView\nfrom django.views.generic.base import RedirectView\nfrom django.views.generic.edit import FormView\nfrom django_filters.views import FilterView\nimport weasyprint\nimport sapl\nfrom sapl.base.models import AppConfig\nfrom sapl.compilacao.views import IntegracaoTaView\nfrom sapl.crud.base import (RP_DETAIL, RP_LIST, Crud, CrudAux,\n MasterDetailCrud, make_pagination)\nfrom sapl.utils import show_results_filter_set\n\nfrom .forms import (AnexoNormaJuridicaForm, NormaFilterSet, NormaJuridicaForm,\n NormaPesquisaSimplesForm, NormaRelacionadaForm)\nfrom .models import (AnexoNormaJuridica, AssuntoNorma, NormaJuridica, NormaRelacionada,\n TipoNormaJuridica, TipoVinculoNormaJuridica)\n\n\n# LegislacaoCitadaCrud = Crud.build(LegislacaoCitada, '')\nAssuntoNormaCrud = CrudAux.build(AssuntoNorma, 'assunto_norma_juridica',\n list_field_names=['assunto', 'descricao'])\n\n\nTipoNormaCrud = CrudAux.build(\n TipoNormaJuridica, 'tipo_norma_juridica',\n list_field_names=['sigla', 'descricao', 'equivalente_lexml'])\nTipoVinculoNormaJuridicaCrud = CrudAux.build(\n TipoVinculoNormaJuridica, '',\n list_field_names=['sigla', 'descricao_ativa', 'descricao_passiva'])\n\n\nclass NormaRelacionadaCrud(MasterDetailCrud):\n model = NormaRelacionada\n parent_field = 'norma_principal'\n help_topic = 'norma_juridica'\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['norma_relacionada', 'tipo_vinculo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = NormaRelacionadaForm\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = NormaRelacionadaForm\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n initial['tipo'] = self.object.norma_relacionada.tipo.id\n initial['numero'] = self.object.norma_relacionada.numero\n initial['ano'] = self.object.norma_relacionada.ano\n initial['ementa'] = self.object.norma_relacionada.ementa\n return initial\n\n class DetailView(MasterDetailCrud.DetailView):\n\n layout_key = 'NormaRelacionadaDetail'\n\n\nclass NormaPesquisaView(FilterView):\n model = NormaJuridica\n filterset_class = NormaFilterSet\n paginate_by = 10\n\n def get_queryset(self):\n qs = super().get_queryset()\n\n qs = qs.extra({\n 'nm_i': \"CAST(regexp_replace(numero,'[^0-9]','', 'g') AS INTEGER)\",\n 'norma_letra': \"regexp_replace(numero,'[^a-zA-Z]','', 'g')\"\n }).order_by('-data', '-nm_i', '-norma_letra')\n\n return qs\n\n def get_context_data(self, **kwargs):\n context = super(NormaPesquisaView, self).get_context_data(**kwargs)\n\n context['title'] = _('Pesquisar Norma Jur\u00eddica')\n\n self.filterset.form.fields['o'].label = _('Ordena\u00e7\u00e3o')\n\n qs = self.object_list\n if 'o' in self.request.GET and not self.request.GET['o']:\n qs = qs.order_by('-ano', 'tipo', '-numero')\n\n qr = self.request.GET.copy()\n\n if 'page' in qr:\n del qr['page']\n\n paginator = context['paginator']\n page_obj = context['page_obj']\n\n context['page_range'] = make_pagination(\n page_obj.number, paginator.num_pages)\n\n context['filter_url'] = ('&' + qr.urlencode()) if len(qr) > 0 else ''\n\n context['show_results'] = show_results_filter_set(qr)\n\n return context\n\n\nclass AnexoNormaJuridicaCrud(MasterDetailCrud):\n model = AnexoNormaJuridica\n parent_field = 'norma'\n help_topic = 'anexonormajuridica'\n public = [RP_LIST, RP_DETAIL]\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['id', 'anexo_arquivo', 'assunto_anexo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = AnexoNormaJuridicaForm\n layout_key = 'AnexoNormaJuridica'\n\n def get_initial(self):\n initial = super(MasterDetailCrud.CreateView, self).get_initial()\n initial['norma'] = NormaJuridica.objects.get(id=self.kwargs['pk'])\n return initial\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = AnexoNormaJuridicaForm\n layout_key = 'AnexoNormaJuridica'\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n initial['norma'] = self.object.norma\n initial['anexo_arquivo'] = self.object.anexo_arquivo\n initial['assunto_anexo'] = self.object.assunto_anexo\n initial['ano'] = self.object.ano\n return initial\n\n class DetailView(MasterDetailCrud.DetailView):\n form_class = AnexoNormaJuridicaForm\n layout_key = 'AnexoNormaJuridica'\n\n\nclass NormaTaView(IntegracaoTaView):\n model = NormaJuridica\n model_type_foreignkey = TipoNormaJuridica\n map_fields = {\n 'data': 'data',\n 'ementa': 'ementa',\n 'observacao': 'observacao',\n 'numero': 'numero',\n 'ano': 'ano',\n 'tipo': 'tipo',\n }\n\n map_funcs = {\n 'publicacao_func': True\n }\n\n def get(self, request, *args, **kwargs):\n \"\"\"\n Para manter a app compilacao isolada das outras aplica\u00e7\u00f5es,\n este get foi implementado para tratar uma prerrogativa externa\n de usu\u00e1rio.\n \"\"\"\n if AppConfig.attr('texto_articulado_norma'):\n return IntegracaoTaView.get(self, request, *args, **kwargs)\n else:\n return self.get_redirect_deactivated()\n\n\nclass NormaCrud(Crud):\n model = NormaJuridica\n help_topic = 'norma_juridica'\n public = [RP_LIST, RP_DETAIL]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['tipo', 'numero', 'ano', 'ementa']\n\n list_url = ''\n\n @property\n def search_url(self):\n namespace = self.model._meta.app_config.name\n return reverse('%s:%s' % (namespace, 'norma_pesquisa'))\n\n class DetailView(Crud.DetailView):\n pass\n\n class DeleteView(Crud.DeleteView):\n\n def get_success_url(self):\n return self.search_url\n\n class CreateView(Crud.CreateView):\n form_class = NormaJuridicaForm\n\n @property\n def cancel_url(self):\n return self.search_url\n\n def get_initial(self):\n try:\n esfera = sapl.base.models.AppConfig.objects.last(\n ).esfera_federacao\n self.initial['esfera_federacao'] = esfera\n except:\n pass\n self.initial['complemento'] = False\n return self.initial\n\n layout_key = 'NormaJuridicaCreate'\n\n class ListView(Crud.ListView, RedirectView):\n\n def get_redirect_url(self, *args, **kwargs):\n namespace = self.model._meta.app_config.name\n return reverse('%s:%s' % (namespace, 'norma_pesquisa'))\n\n def get(self, request, *args, **kwargs):\n return RedirectView.get(self, request, *args, **kwargs)\n\n class UpdateView(Crud.UpdateView):\n form_class = NormaJuridicaForm\n\n layout_key = 'NormaJuridicaCreate'\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n norma = NormaJuridica.objects.get(id=self.kwargs['pk'])\n if norma.materia:\n initial['tipo_materia'] = norma.materia.tipo\n initial['ano_materia'] = norma.materia.ano\n initial['numero_materia'] = norma.materia.numero\n return initial\n\n\ndef recuperar_norma(request):\n tipo = TipoNormaJuridica.objects.get(pk=request.GET['tipo'])\n numero = request.GET['numero']\n ano = request.GET['ano']\n\n try:\n norma = NormaJuridica.objects.get(tipo=tipo,\n ano=ano,\n numero=numero)\n response = JsonResponse({'ementa': norma.ementa,\n 'id': norma.id})\n except ObjectDoesNotExist:\n response = JsonResponse({'ementa': '', 'id': 0})\n\n return response\n\n\ndef recuperar_numero_norma(request):\n tipo = TipoNormaJuridica.objects.get(pk=request.GET['tipo'])\n ano = request.GET.get('ano', '')\n param = {'tipo': tipo}\n param['ano'] = ano if ano else timezone.now().year\n norma = NormaJuridica.objects.filter(**param).order_by(\n 'tipo', 'ano', 'numero').values_list('numero', 'ano').last()\n if norma:\n response = JsonResponse({'numero': int(re.sub(\"[^0-9].*\", '', norma[0])) + 1,\n 'ano': norma[1]})\n else:\n response = JsonResponse(\n {'numero': 1, 'ano': ano})\n\n return response\n\n\nclass ImpressosView(PermissionRequiredMixin, TemplateView):\n template_name = 'materia/impressos/impressos.html'\n permission_required = ('materia.can_access_impressos', )\n\n\ndef gerar_pdf_impressos(request, context, template_name):\n template = loader.get_template(template_name)\n html = template.render(RequestContext(request, context))\n pdf = weasyprint.HTML(string=html, base_url=request.build_absolute_uri()\n ).write_pdf()\n\n response = HttpResponse(pdf, content_type='application/pdf')\n response['Content-Disposition'] = (\n 'inline; filename=\"relatorio_impressos.pdf\"')\n response['Content-Transfer-Encoding'] = 'binary'\n\n return response\n\n\nclass NormaPesquisaSimplesView(PermissionRequiredMixin, FormView):\n form_class = NormaPesquisaSimplesForm\n template_name = 'materia/impressos/norma.html'\n permission_required = ('materia.can_access_impressos', )\n\n def form_valid(self, form):\n normas = NormaJuridica.objects.all().order_by(\n 'numero')\n template_norma = 'materia/impressos/normas_pdf.html'\n\n titulo = form.cleaned_data['titulo']\n\n if form.cleaned_data['tipo_norma']:\n normas = normas.filter(tipo=form.cleaned_data['tipo_norma'])\n\n if form.cleaned_data['data_inicial']:\n normas = normas.filter(\n data__gte=form.cleaned_data['data_inicial'],\n data__lte=form.cleaned_data['data_final'])\n\n qtd_resultados = len(normas)\n if qtd_resultados > 2000:\n normas = normas[:2000]\n\n context = {'quantidade': qtd_resultados,\n 'titulo': titulo,\n 'normas': normas}\n\n return gerar_pdf_impressos(self.request, context, template_norma)\n", "path": "sapl/norma/views.py"}], "after_files": [{"content": "\nimport re\n\nfrom django.contrib.auth.mixins import PermissionRequiredMixin\nfrom django.core.exceptions import ObjectDoesNotExist\nfrom django.core.urlresolvers import reverse\nfrom django.http import HttpResponse, JsonResponse\nfrom django.template import RequestContext, loader\nfrom django.utils import timezone\nfrom django.utils.translation import ugettext_lazy as _\nfrom django.views.generic import TemplateView, UpdateView\nfrom django.views.generic.base import RedirectView\nfrom django.views.generic.edit import FormView\nfrom django_filters.views import FilterView\nimport weasyprint\nimport sapl\nfrom sapl.base.models import AppConfig\nfrom sapl.compilacao.views import IntegracaoTaView\nfrom sapl.crud.base import (RP_DETAIL, RP_LIST, Crud, CrudAux,\n MasterDetailCrud, make_pagination)\nfrom sapl.utils import show_results_filter_set\n\nfrom .forms import (AnexoNormaJuridicaForm, NormaFilterSet, NormaJuridicaForm,\n NormaPesquisaSimplesForm, NormaRelacionadaForm)\nfrom .models import (AnexoNormaJuridica, AssuntoNorma, NormaJuridica, NormaRelacionada,\n TipoNormaJuridica, TipoVinculoNormaJuridica)\n\n\n# LegislacaoCitadaCrud = Crud.build(LegislacaoCitada, '')\nAssuntoNormaCrud = CrudAux.build(AssuntoNorma, 'assunto_norma_juridica',\n list_field_names=['assunto', 'descricao'])\n\n\nTipoNormaCrud = CrudAux.build(\n TipoNormaJuridica, 'tipo_norma_juridica',\n list_field_names=['sigla', 'descricao', 'equivalente_lexml'])\nTipoVinculoNormaJuridicaCrud = CrudAux.build(\n TipoVinculoNormaJuridica, '',\n list_field_names=['sigla', 'descricao_ativa', 'descricao_passiva'])\n\n\nclass NormaRelacionadaCrud(MasterDetailCrud):\n model = NormaRelacionada\n parent_field = 'norma_principal'\n help_topic = 'norma_juridica'\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['norma_relacionada', 'tipo_vinculo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = NormaRelacionadaForm\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = NormaRelacionadaForm\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n initial['tipo'] = self.object.norma_relacionada.tipo.id\n initial['numero'] = self.object.norma_relacionada.numero\n initial['ano'] = self.object.norma_relacionada.ano\n initial['ementa'] = self.object.norma_relacionada.ementa\n return initial\n\n class DetailView(MasterDetailCrud.DetailView):\n\n layout_key = 'NormaRelacionadaDetail'\n\n\nclass NormaPesquisaView(FilterView):\n model = NormaJuridica\n filterset_class = NormaFilterSet\n paginate_by = 10\n\n def get_queryset(self):\n qs = super().get_queryset()\n\n qs = qs.extra({\n 'nm_i': \"CAST(regexp_replace(numero,'[^0-9]','', 'g') AS INTEGER)\",\n 'norma_letra': \"regexp_replace(numero,'[^a-zA-Z]','', 'g')\"\n }).order_by('-data', '-nm_i', '-norma_letra')\n\n return qs\n\n def get_context_data(self, **kwargs):\n context = super(NormaPesquisaView, self).get_context_data(**kwargs)\n\n context['title'] = _('Pesquisar Norma Jur\u00eddica')\n\n self.filterset.form.fields['o'].label = _('Ordena\u00e7\u00e3o')\n\n qs = self.object_list\n if 'o' in self.request.GET and not self.request.GET['o']:\n qs = qs.order_by('-ano', 'tipo', '-numero')\n\n qr = self.request.GET.copy()\n\n if 'page' in qr:\n del qr['page']\n\n paginator = context['paginator']\n page_obj = context['page_obj']\n\n context['page_range'] = make_pagination(\n page_obj.number, paginator.num_pages)\n\n context['filter_url'] = ('&' + qr.urlencode()) if len(qr) > 0 else ''\n\n context['show_results'] = show_results_filter_set(qr)\n\n return context\n\n\nclass AnexoNormaJuridicaCrud(MasterDetailCrud):\n model = AnexoNormaJuridica\n parent_field = 'norma'\n help_topic = 'anexonormajuridica'\n public = [RP_LIST, RP_DETAIL]\n\n class BaseMixin(MasterDetailCrud.BaseMixin):\n list_field_names = ['id', 'anexo_arquivo', 'assunto_anexo']\n\n class CreateView(MasterDetailCrud.CreateView):\n form_class = AnexoNormaJuridicaForm\n layout_key = 'AnexoNormaJuridica'\n\n def get_initial(self):\n initial = super(MasterDetailCrud.CreateView, self).get_initial()\n initial['norma'] = NormaJuridica.objects.get(id=self.kwargs['pk'])\n return initial\n\n class UpdateView(MasterDetailCrud.UpdateView):\n form_class = AnexoNormaJuridicaForm\n layout_key = 'AnexoNormaJuridica'\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n initial['norma'] = self.object.norma\n initial['anexo_arquivo'] = self.object.anexo_arquivo\n initial['assunto_anexo'] = self.object.assunto_anexo\n initial['ano'] = self.object.ano\n return initial\n\n class DetailView(MasterDetailCrud.DetailView):\n form_class = AnexoNormaJuridicaForm\n layout_key = 'AnexoNormaJuridica'\n\n\nclass NormaTaView(IntegracaoTaView):\n model = NormaJuridica\n model_type_foreignkey = TipoNormaJuridica\n map_fields = {\n 'data': 'data',\n 'ementa': 'ementa',\n 'observacao': 'observacao',\n 'numero': 'numero',\n 'ano': 'ano',\n 'tipo': 'tipo',\n }\n\n map_funcs = {\n 'publicacao_func': True\n }\n\n def get(self, request, *args, **kwargs):\n \"\"\"\n Para manter a app compilacao isolada das outras aplica\u00e7\u00f5es,\n este get foi implementado para tratar uma prerrogativa externa\n de usu\u00e1rio.\n \"\"\"\n if AppConfig.attr('texto_articulado_norma'):\n return IntegracaoTaView.get(self, request, *args, **kwargs)\n else:\n return self.get_redirect_deactivated()\n\n\nclass NormaCrud(Crud):\n model = NormaJuridica\n help_topic = 'norma_juridica'\n public = [RP_LIST, RP_DETAIL]\n\n class BaseMixin(Crud.BaseMixin):\n list_field_names = ['tipo', 'numero', 'ano', 'ementa']\n\n list_url = ''\n\n @property\n def search_url(self):\n namespace = self.model._meta.app_config.name\n return reverse('%s:%s' % (namespace, 'norma_pesquisa'))\n\n class DetailView(Crud.DetailView):\n pass\n\n class DeleteView(Crud.DeleteView):\n\n def get_success_url(self):\n return self.search_url\n\n class CreateView(Crud.CreateView):\n form_class = NormaJuridicaForm\n\n @property\n def cancel_url(self):\n return self.search_url\n\n def get_initial(self):\n try:\n esfera = sapl.base.models.AppConfig.objects.last(\n ).esfera_federacao\n self.initial['esfera_federacao'] = esfera\n except:\n pass\n self.initial['complemento'] = False\n return self.initial\n\n layout_key = 'NormaJuridicaCreate'\n\n class ListView(Crud.ListView, RedirectView):\n\n def get_redirect_url(self, *args, **kwargs):\n namespace = self.model._meta.app_config.name\n return reverse('%s:%s' % (namespace, 'norma_pesquisa'))\n\n def get(self, request, *args, **kwargs):\n return RedirectView.get(self, request, *args, **kwargs)\n\n class UpdateView(Crud.UpdateView):\n form_class = NormaJuridicaForm\n\n layout_key = 'NormaJuridicaCreate'\n\n def get_initial(self):\n initial = super(UpdateView, self).get_initial()\n norma = NormaJuridica.objects.get(id=self.kwargs['pk'])\n if norma.materia:\n initial['tipo_materia'] = norma.materia.tipo\n initial['ano_materia'] = norma.materia.ano\n initial['numero_materia'] = norma.materia.numero\n initial['esfera_federacao'] = norma.esfera_federacao\n return initial\n\n\ndef recuperar_norma(request):\n tipo = TipoNormaJuridica.objects.get(pk=request.GET['tipo'])\n numero = request.GET['numero']\n ano = request.GET['ano']\n\n try:\n norma = NormaJuridica.objects.get(tipo=tipo,\n ano=ano,\n numero=numero)\n response = JsonResponse({'ementa': norma.ementa,\n 'id': norma.id})\n except ObjectDoesNotExist:\n response = JsonResponse({'ementa': '', 'id': 0})\n\n return response\n\n\ndef recuperar_numero_norma(request):\n tipo = TipoNormaJuridica.objects.get(pk=request.GET['tipo'])\n ano = request.GET.get('ano', '')\n param = {'tipo': tipo}\n param['ano'] = ano if ano else timezone.now().year\n norma = NormaJuridica.objects.filter(**param).order_by(\n 'tipo', 'ano', 'numero').values_list('numero', 'ano').last()\n if norma:\n response = JsonResponse({'numero': int(re.sub(\"[^0-9].*\", '', norma[0])) + 1,\n 'ano': norma[1]})\n else:\n response = JsonResponse(\n {'numero': 1, 'ano': ano})\n\n return response\n\n\nclass ImpressosView(PermissionRequiredMixin, TemplateView):\n template_name = 'materia/impressos/impressos.html'\n permission_required = ('materia.can_access_impressos', )\n\n\ndef gerar_pdf_impressos(request, context, template_name):\n template = loader.get_template(template_name)\n html = template.render(RequestContext(request, context))\n pdf = weasyprint.HTML(string=html, base_url=request.build_absolute_uri()\n ).write_pdf()\n\n response = HttpResponse(pdf, content_type='application/pdf')\n response['Content-Disposition'] = (\n 'inline; filename=\"relatorio_impressos.pdf\"')\n response['Content-Transfer-Encoding'] = 'binary'\n\n return response\n\n\nclass NormaPesquisaSimplesView(PermissionRequiredMixin, FormView):\n form_class = NormaPesquisaSimplesForm\n template_name = 'materia/impressos/norma.html'\n permission_required = ('materia.can_access_impressos', )\n\n def form_valid(self, form):\n normas = NormaJuridica.objects.all().order_by(\n 'numero')\n template_norma = 'materia/impressos/normas_pdf.html'\n\n titulo = form.cleaned_data['titulo']\n\n if form.cleaned_data['tipo_norma']:\n normas = normas.filter(tipo=form.cleaned_data['tipo_norma'])\n\n if form.cleaned_data['data_inicial']:\n normas = normas.filter(\n data__gte=form.cleaned_data['data_inicial'],\n data__lte=form.cleaned_data['data_final'])\n\n qtd_resultados = len(normas)\n if qtd_resultados > 2000:\n normas = normas[:2000]\n\n context = {'quantidade': qtd_resultados,\n 'titulo': titulo,\n 'normas': normas}\n\n return gerar_pdf_impressos(self.request, context, template_norma)\n", "path": "sapl/norma/views.py"}]} | 4,045 | 122 |
gh_patches_debug_14142 | rasdani/github-patches | git_diff | encode__httpx-270 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Make ASGI dispatcher asyncio-agnostic
*Note: this issue breaks apart steps originally taken in #217.*
The ASGI dispatcher currently relies on asyncio-specific APIs to perform various operations, which is a blocker towards supporting alternative concurrency backends.
We want to make sure all of the I/O inside `ASGIDispatch` goes through the backend instead.
This will need the following, most of which can be tackled in independant PRs:
- [x] #257 Hard-code `self.backend = AsyncioBackend()` on `ASGIDispatch` to be able to iteratively defer asyncio-specific APIs to the backend.
- [x] #257 Introduce a queue-like interface:
```python
class BaseQueue:
async def get(self): ...
async def put(self, value: typing.Any): ...
```
along with a `.create_queue()` method on `ConcurrencyBackend`, to be used instead of/within the `BodyIterator`.
(For trio we'll probably need to add a `.close()` method as well, but that can be confirmed and tackled in due time.)
- [x] #260 Introduce a `BaseEvent` interface:
```python
class BaseEvent:
def set(self): ...
def is_set(self): ...
async def wait(self): ...
```
along with a `.create_event()` method on `ConcurrencyBackend` to abstract `asyncio.Event()`.
- [x] #261 Remove usage of loop.create_task() via the background manager interface.
- [x] Lastly, turn the hard-coded `backend` into a parameter. Make sure it is optional and we use `AsyncioBackend` as a default.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `httpx/dispatch/asgi.py`
Content:
```
1 import typing
2
3 from .base import AsyncDispatcher
4 from ..concurrency.base import ConcurrencyBackend
5 from ..concurrency.asyncio import AsyncioBackend
6 from ..config import CertTypes, TimeoutTypes, VerifyTypes
7 from ..models import AsyncRequest, AsyncResponse
8
9
10 class ASGIDispatch(AsyncDispatcher):
11 """
12 A custom dispatcher that handles sending requests directly to an ASGI app.
13
14 The simplest way to use this functionality is to use the `app`argument.
15 This will automatically infer if 'app' is a WSGI or an ASGI application,
16 and will setup an appropriate dispatch class:
17
18 ```
19 client = httpx.Client(app=app)
20 ```
21
22 Alternatively, you can setup the dispatch instance explicitly.
23 This allows you to include any additional configuration arguments specific
24 to the ASGIDispatch class:
25
26 ```
27 dispatch = httpx.ASGIDispatch(
28 app=app,
29 root_path="/submount",
30 client=("1.2.3.4", 123)
31 )
32 client = httpx.Client(dispatch=dispatch)
33
34 Arguments:
35
36 * `app` - The ASGI application.
37 * `raise_app_exceptions` - Boolean indicating if exceptions in the application
38 should be raised. Default to `True`. Can be set to `False` for use cases
39 such as testing the content of a client 500 response.
40 * `root_path` - The root path on which the ASGI application should be mounted.
41 * `client` - A two-tuple indicating the client IP and port of incoming requests.
42 ```
43 """
44
45 def __init__(
46 self,
47 app: typing.Callable,
48 raise_app_exceptions: bool = True,
49 root_path: str = "",
50 client: typing.Tuple[str, int] = ("127.0.0.1", 123),
51 ) -> None:
52 self.app = app
53 self.raise_app_exceptions = raise_app_exceptions
54 self.root_path = root_path
55 self.client = client
56 # This will need to be turned into a parameter on this class at some point.
57 self.backend: ConcurrencyBackend = AsyncioBackend()
58
59 async def send(
60 self,
61 request: AsyncRequest,
62 verify: VerifyTypes = None,
63 cert: CertTypes = None,
64 timeout: TimeoutTypes = None,
65 ) -> AsyncResponse:
66
67 scope = {
68 "type": "http",
69 "asgi": {"version": "3.0"},
70 "http_version": "1.1",
71 "method": request.method,
72 "headers": request.headers.raw,
73 "scheme": request.url.scheme,
74 "path": request.url.path,
75 "query_string": request.url.query.encode("ascii"),
76 "server": request.url.host,
77 "client": self.client,
78 "root_path": self.root_path,
79 }
80 app = self.app
81 app_exc = None
82 status_code = None
83 headers = None
84 response_started_or_failed = self.backend.create_event()
85 response_body = BodyIterator(self.backend)
86 request_stream = request.stream()
87
88 async def receive() -> dict:
89 nonlocal request_stream
90
91 try:
92 body = await request_stream.__anext__()
93 except StopAsyncIteration:
94 return {"type": "http.request", "body": b"", "more_body": False}
95 return {"type": "http.request", "body": body, "more_body": True}
96
97 async def send(message: dict) -> None:
98 nonlocal status_code, headers, response_started_or_failed
99 nonlocal response_body, request
100
101 if message["type"] == "http.response.start":
102 status_code = message["status"]
103 headers = message.get("headers", [])
104 response_started_or_failed.set()
105 elif message["type"] == "http.response.body":
106 body = message.get("body", b"")
107 more_body = message.get("more_body", False)
108 if body and request.method != "HEAD":
109 await response_body.put(body)
110 if not more_body:
111 await response_body.mark_as_done()
112
113 async def run_app() -> None:
114 nonlocal app, scope, receive, send, app_exc, response_body
115 try:
116 await app(scope, receive, send)
117 except Exception as exc:
118 app_exc = exc
119 finally:
120 await response_body.mark_as_done()
121 response_started_or_failed.set()
122
123 # Using the background manager here *works*, but it is weak design because
124 # the background task isn't strictly context-managed.
125 # We could consider refactoring the other uses of this abstraction
126 # (mainly sending/receiving request/response data in h11 and h2 dispatchers),
127 # and see if that allows us to come back here and refactor things out.
128 background = await self.backend.background_manager(run_app).__aenter__()
129
130 await response_started_or_failed.wait()
131
132 if app_exc is not None and self.raise_app_exceptions:
133 raise app_exc
134
135 assert status_code is not None, "application did not return a response."
136 assert headers is not None
137
138 async def on_close() -> None:
139 nonlocal response_body
140 await response_body.drain()
141 await background.__aexit__(None, None, None)
142 if app_exc is not None and self.raise_app_exceptions:
143 raise app_exc
144
145 return AsyncResponse(
146 status_code=status_code,
147 http_version="HTTP/1.1",
148 headers=headers,
149 content=response_body.iterate(),
150 on_close=on_close,
151 request=request,
152 )
153
154
155 class BodyIterator:
156 """
157 Provides a byte-iterator interface that the client can use to
158 ingest the response content from.
159 """
160
161 def __init__(self, backend: ConcurrencyBackend) -> None:
162 self._queue = backend.create_queue(max_size=1)
163 self._done = object()
164
165 async def iterate(self) -> typing.AsyncIterator[bytes]:
166 """
167 A byte-iterator, used by the client to consume the response body.
168 """
169 while True:
170 data = await self._queue.get()
171 if data is self._done:
172 break
173 assert isinstance(data, bytes)
174 yield data
175
176 async def drain(self) -> None:
177 """
178 Drain any remaining body, in order to allow any blocked `put()` calls
179 to complete.
180 """
181 async for chunk in self.iterate():
182 pass # pragma: no cover
183
184 async def put(self, data: bytes) -> None:
185 """
186 Used by the server to add data to the response body.
187 """
188 await self._queue.put(data)
189
190 async def mark_as_done(self) -> None:
191 """
192 Used by the server to signal the end of the response body.
193 """
194 await self._queue.put(self._done)
195
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/httpx/dispatch/asgi.py b/httpx/dispatch/asgi.py
--- a/httpx/dispatch/asgi.py
+++ b/httpx/dispatch/asgi.py
@@ -48,13 +48,13 @@
raise_app_exceptions: bool = True,
root_path: str = "",
client: typing.Tuple[str, int] = ("127.0.0.1", 123),
+ backend: ConcurrencyBackend = None,
) -> None:
self.app = app
self.raise_app_exceptions = raise_app_exceptions
self.root_path = root_path
self.client = client
- # This will need to be turned into a parameter on this class at some point.
- self.backend: ConcurrencyBackend = AsyncioBackend()
+ self.backend = AsyncioBackend() if backend is None else backend
async def send(
self,
| {"golden_diff": "diff --git a/httpx/dispatch/asgi.py b/httpx/dispatch/asgi.py\n--- a/httpx/dispatch/asgi.py\n+++ b/httpx/dispatch/asgi.py\n@@ -48,13 +48,13 @@\n raise_app_exceptions: bool = True,\n root_path: str = \"\",\n client: typing.Tuple[str, int] = (\"127.0.0.1\", 123),\n+ backend: ConcurrencyBackend = None,\n ) -> None:\n self.app = app\n self.raise_app_exceptions = raise_app_exceptions\n self.root_path = root_path\n self.client = client\n- # This will need to be turned into a parameter on this class at some point.\n- self.backend: ConcurrencyBackend = AsyncioBackend()\n+ self.backend = AsyncioBackend() if backend is None else backend\n \n async def send(\n self,\n", "issue": "Make ASGI dispatcher asyncio-agnostic\n*Note: this issue breaks apart steps originally taken in #217.*\r\n\r\nThe ASGI dispatcher currently relies on asyncio-specific APIs to perform various operations, which is a blocker towards supporting alternative concurrency backends.\r\n\r\nWe want to make sure all of the I/O inside `ASGIDispatch` goes through the backend instead.\r\n\r\nThis will need the following, most of which can be tackled in independant PRs:\r\n\r\n- [x] #257 Hard-code `self.backend = AsyncioBackend()` on `ASGIDispatch` to be able to iteratively defer asyncio-specific APIs to the backend.\r\n\r\n- [x] #257 Introduce a queue-like interface:\r\n\r\n```python\r\nclass BaseQueue:\r\n async def get(self): ...\r\n async def put(self, value: typing.Any): ...\r\n```\r\n\r\nalong with a `.create_queue()` method on `ConcurrencyBackend`, to be used instead of/within the `BodyIterator`.\r\n\r\n(For trio we'll probably need to add a `.close()` method as well, but that can be confirmed and tackled in due time.)\r\n\r\n- [x] #260 Introduce a `BaseEvent` interface:\r\n\r\n```python\r\nclass BaseEvent:\r\n def set(self): ...\r\n def is_set(self): ...\r\n async def wait(self): ...\r\n```\r\n\r\nalong with a `.create_event()` method on `ConcurrencyBackend` to abstract `asyncio.Event()`.\r\n\r\n- [x] #261 Remove usage of loop.create_task() via the background manager interface.\r\n\r\n- [x] Lastly, turn the hard-coded `backend` into a parameter. Make sure it is optional and we use `AsyncioBackend` as a default.\n", "before_files": [{"content": "import typing\n\nfrom .base import AsyncDispatcher\nfrom ..concurrency.base import ConcurrencyBackend\nfrom ..concurrency.asyncio import AsyncioBackend\nfrom ..config import CertTypes, TimeoutTypes, VerifyTypes\nfrom ..models import AsyncRequest, AsyncResponse\n\n\nclass ASGIDispatch(AsyncDispatcher):\n \"\"\"\n A custom dispatcher that handles sending requests directly to an ASGI app.\n\n The simplest way to use this functionality is to use the `app`argument.\n This will automatically infer if 'app' is a WSGI or an ASGI application,\n and will setup an appropriate dispatch class:\n\n ```\n client = httpx.Client(app=app)\n ```\n\n Alternatively, you can setup the dispatch instance explicitly.\n This allows you to include any additional configuration arguments specific\n to the ASGIDispatch class:\n\n ```\n dispatch = httpx.ASGIDispatch(\n app=app,\n root_path=\"/submount\",\n client=(\"1.2.3.4\", 123)\n )\n client = httpx.Client(dispatch=dispatch)\n\n Arguments:\n\n * `app` - The ASGI application.\n * `raise_app_exceptions` - Boolean indicating if exceptions in the application\n should be raised. Default to `True`. Can be set to `False` for use cases\n such as testing the content of a client 500 response.\n * `root_path` - The root path on which the ASGI application should be mounted.\n * `client` - A two-tuple indicating the client IP and port of incoming requests.\n ```\n \"\"\"\n\n def __init__(\n self,\n app: typing.Callable,\n raise_app_exceptions: bool = True,\n root_path: str = \"\",\n client: typing.Tuple[str, int] = (\"127.0.0.1\", 123),\n ) -> None:\n self.app = app\n self.raise_app_exceptions = raise_app_exceptions\n self.root_path = root_path\n self.client = client\n # This will need to be turned into a parameter on this class at some point.\n self.backend: ConcurrencyBackend = AsyncioBackend()\n\n async def send(\n self,\n request: AsyncRequest,\n verify: VerifyTypes = None,\n cert: CertTypes = None,\n timeout: TimeoutTypes = None,\n ) -> AsyncResponse:\n\n scope = {\n \"type\": \"http\",\n \"asgi\": {\"version\": \"3.0\"},\n \"http_version\": \"1.1\",\n \"method\": request.method,\n \"headers\": request.headers.raw,\n \"scheme\": request.url.scheme,\n \"path\": request.url.path,\n \"query_string\": request.url.query.encode(\"ascii\"),\n \"server\": request.url.host,\n \"client\": self.client,\n \"root_path\": self.root_path,\n }\n app = self.app\n app_exc = None\n status_code = None\n headers = None\n response_started_or_failed = self.backend.create_event()\n response_body = BodyIterator(self.backend)\n request_stream = request.stream()\n\n async def receive() -> dict:\n nonlocal request_stream\n\n try:\n body = await request_stream.__anext__()\n except StopAsyncIteration:\n return {\"type\": \"http.request\", \"body\": b\"\", \"more_body\": False}\n return {\"type\": \"http.request\", \"body\": body, \"more_body\": True}\n\n async def send(message: dict) -> None:\n nonlocal status_code, headers, response_started_or_failed\n nonlocal response_body, request\n\n if message[\"type\"] == \"http.response.start\":\n status_code = message[\"status\"]\n headers = message.get(\"headers\", [])\n response_started_or_failed.set()\n elif message[\"type\"] == \"http.response.body\":\n body = message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n if body and request.method != \"HEAD\":\n await response_body.put(body)\n if not more_body:\n await response_body.mark_as_done()\n\n async def run_app() -> None:\n nonlocal app, scope, receive, send, app_exc, response_body\n try:\n await app(scope, receive, send)\n except Exception as exc:\n app_exc = exc\n finally:\n await response_body.mark_as_done()\n response_started_or_failed.set()\n\n # Using the background manager here *works*, but it is weak design because\n # the background task isn't strictly context-managed.\n # We could consider refactoring the other uses of this abstraction\n # (mainly sending/receiving request/response data in h11 and h2 dispatchers),\n # and see if that allows us to come back here and refactor things out.\n background = await self.backend.background_manager(run_app).__aenter__()\n\n await response_started_or_failed.wait()\n\n if app_exc is not None and self.raise_app_exceptions:\n raise app_exc\n\n assert status_code is not None, \"application did not return a response.\"\n assert headers is not None\n\n async def on_close() -> None:\n nonlocal response_body\n await response_body.drain()\n await background.__aexit__(None, None, None)\n if app_exc is not None and self.raise_app_exceptions:\n raise app_exc\n\n return AsyncResponse(\n status_code=status_code,\n http_version=\"HTTP/1.1\",\n headers=headers,\n content=response_body.iterate(),\n on_close=on_close,\n request=request,\n )\n\n\nclass BodyIterator:\n \"\"\"\n Provides a byte-iterator interface that the client can use to\n ingest the response content from.\n \"\"\"\n\n def __init__(self, backend: ConcurrencyBackend) -> None:\n self._queue = backend.create_queue(max_size=1)\n self._done = object()\n\n async def iterate(self) -> typing.AsyncIterator[bytes]:\n \"\"\"\n A byte-iterator, used by the client to consume the response body.\n \"\"\"\n while True:\n data = await self._queue.get()\n if data is self._done:\n break\n assert isinstance(data, bytes)\n yield data\n\n async def drain(self) -> None:\n \"\"\"\n Drain any remaining body, in order to allow any blocked `put()` calls\n to complete.\n \"\"\"\n async for chunk in self.iterate():\n pass # pragma: no cover\n\n async def put(self, data: bytes) -> None:\n \"\"\"\n Used by the server to add data to the response body.\n \"\"\"\n await self._queue.put(data)\n\n async def mark_as_done(self) -> None:\n \"\"\"\n Used by the server to signal the end of the response body.\n \"\"\"\n await self._queue.put(self._done)\n", "path": "httpx/dispatch/asgi.py"}], "after_files": [{"content": "import typing\n\nfrom .base import AsyncDispatcher\nfrom ..concurrency.base import ConcurrencyBackend\nfrom ..concurrency.asyncio import AsyncioBackend\nfrom ..config import CertTypes, TimeoutTypes, VerifyTypes\nfrom ..models import AsyncRequest, AsyncResponse\n\n\nclass ASGIDispatch(AsyncDispatcher):\n \"\"\"\n A custom dispatcher that handles sending requests directly to an ASGI app.\n\n The simplest way to use this functionality is to use the `app`argument.\n This will automatically infer if 'app' is a WSGI or an ASGI application,\n and will setup an appropriate dispatch class:\n\n ```\n client = httpx.Client(app=app)\n ```\n\n Alternatively, you can setup the dispatch instance explicitly.\n This allows you to include any additional configuration arguments specific\n to the ASGIDispatch class:\n\n ```\n dispatch = httpx.ASGIDispatch(\n app=app,\n root_path=\"/submount\",\n client=(\"1.2.3.4\", 123)\n )\n client = httpx.Client(dispatch=dispatch)\n\n Arguments:\n\n * `app` - The ASGI application.\n * `raise_app_exceptions` - Boolean indicating if exceptions in the application\n should be raised. Default to `True`. Can be set to `False` for use cases\n such as testing the content of a client 500 response.\n * `root_path` - The root path on which the ASGI application should be mounted.\n * `client` - A two-tuple indicating the client IP and port of incoming requests.\n ```\n \"\"\"\n\n def __init__(\n self,\n app: typing.Callable,\n raise_app_exceptions: bool = True,\n root_path: str = \"\",\n client: typing.Tuple[str, int] = (\"127.0.0.1\", 123),\n backend: ConcurrencyBackend = None,\n ) -> None:\n self.app = app\n self.raise_app_exceptions = raise_app_exceptions\n self.root_path = root_path\n self.client = client\n self.backend = AsyncioBackend() if backend is None else backend\n\n async def send(\n self,\n request: AsyncRequest,\n verify: VerifyTypes = None,\n cert: CertTypes = None,\n timeout: TimeoutTypes = None,\n ) -> AsyncResponse:\n\n scope = {\n \"type\": \"http\",\n \"asgi\": {\"version\": \"3.0\"},\n \"http_version\": \"1.1\",\n \"method\": request.method,\n \"headers\": request.headers.raw,\n \"scheme\": request.url.scheme,\n \"path\": request.url.path,\n \"query_string\": request.url.query.encode(\"ascii\"),\n \"server\": request.url.host,\n \"client\": self.client,\n \"root_path\": self.root_path,\n }\n app = self.app\n app_exc = None\n status_code = None\n headers = None\n response_started_or_failed = self.backend.create_event()\n response_body = BodyIterator(self.backend)\n request_stream = request.stream()\n\n async def receive() -> dict:\n nonlocal request_stream\n\n try:\n body = await request_stream.__anext__()\n except StopAsyncIteration:\n return {\"type\": \"http.request\", \"body\": b\"\", \"more_body\": False}\n return {\"type\": \"http.request\", \"body\": body, \"more_body\": True}\n\n async def send(message: dict) -> None:\n nonlocal status_code, headers, response_started_or_failed\n nonlocal response_body, request\n\n if message[\"type\"] == \"http.response.start\":\n status_code = message[\"status\"]\n headers = message.get(\"headers\", [])\n response_started_or_failed.set()\n elif message[\"type\"] == \"http.response.body\":\n body = message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n if body and request.method != \"HEAD\":\n await response_body.put(body)\n if not more_body:\n await response_body.mark_as_done()\n\n async def run_app() -> None:\n nonlocal app, scope, receive, send, app_exc, response_body\n try:\n await app(scope, receive, send)\n except Exception as exc:\n app_exc = exc\n finally:\n await response_body.mark_as_done()\n response_started_or_failed.set()\n\n # Using the background manager here *works*, but it is weak design because\n # the background task isn't strictly context-managed.\n # We could consider refactoring the other uses of this abstraction\n # (mainly sending/receiving request/response data in h11 and h2 dispatchers),\n # and see if that allows us to come back here and refactor things out.\n background = await self.backend.background_manager(run_app).__aenter__()\n\n await response_started_or_failed.wait()\n\n if app_exc is not None and self.raise_app_exceptions:\n raise app_exc\n\n assert status_code is not None, \"application did not return a response.\"\n assert headers is not None\n\n async def on_close() -> None:\n nonlocal response_body\n await response_body.drain()\n await background.__aexit__(None, None, None)\n if app_exc is not None and self.raise_app_exceptions:\n raise app_exc\n\n return AsyncResponse(\n status_code=status_code,\n http_version=\"HTTP/1.1\",\n headers=headers,\n content=response_body.iterate(),\n on_close=on_close,\n request=request,\n )\n\n\nclass BodyIterator:\n \"\"\"\n Provides a byte-iterator interface that the client can use to\n ingest the response content from.\n \"\"\"\n\n def __init__(self, backend: ConcurrencyBackend) -> None:\n self._queue = backend.create_queue(max_size=1)\n self._done = object()\n\n async def iterate(self) -> typing.AsyncIterator[bytes]:\n \"\"\"\n A byte-iterator, used by the client to consume the response body.\n \"\"\"\n while True:\n data = await self._queue.get()\n if data is self._done:\n break\n assert isinstance(data, bytes)\n yield data\n\n async def drain(self) -> None:\n \"\"\"\n Drain any remaining body, in order to allow any blocked `put()` calls\n to complete.\n \"\"\"\n async for chunk in self.iterate():\n pass # pragma: no cover\n\n async def put(self, data: bytes) -> None:\n \"\"\"\n Used by the server to add data to the response body.\n \"\"\"\n await self._queue.put(data)\n\n async def mark_as_done(self) -> None:\n \"\"\"\n Used by the server to signal the end of the response body.\n \"\"\"\n await self._queue.put(self._done)\n", "path": "httpx/dispatch/asgi.py"}]} | 2,557 | 198 |
gh_patches_debug_27761 | rasdani/github-patches | git_diff | kserve__kserve-2216 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Incompatible versions for google protos required by kserve and dependencies
/kind bug
**What steps did you take and what happened:**
[A clear and concise description of what the bug is.]
Trying to install the kserve module, kserve requires `googleapis-common-protos==1.53.0`, but some dependencies of kserve require `googleapis-common-protos<2.0dev,>=1.56.2`, and hence kserve cannot be installed.
**What did you expect to happen:**
The version of protos required by kserve should be updated to be compatible with its dependencies
**Anything else you would like to add:**
[Miscellaneous information that will assist in solving the issue.]
**Environment:**
- Istio Version:
- Knative Version:
- KFServing Version:
- Kubeflow version:
- Kfdef:[k8s_istio/istio_dex/gcp_basic_auth/gcp_iap/aws/aws_cognito/ibm]
- Minikube version:
- Kubernetes version: (use `kubectl version`):
- OS (e.g. from `/etc/os-release`):
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/kserve/setup.py`
Content:
```
1 # Copyright 2021 The KServe Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import setuptools
16
17 TESTS_REQUIRES = [
18 'pytest',
19 'pytest-xdist',
20 'pytest-cov',
21 'pytest-asyncio',
22 'pytest-tornasync',
23 'mypy'
24 ]
25
26 with open('requirements.txt') as f:
27 REQUIRES = f.readlines()
28
29 setuptools.setup(
30 name='kserve',
31 version='0.8.0',
32 author="The KServe Authors",
33 author_email='[email protected], [email protected], [email protected]',
34 license="Apache License Version 2.0",
35 url="https://github.com/kserve/kserve/tree/master/python/kserve",
36 description="KServe Python SDK",
37 long_description="Python SDK for KServe Server and Client.",
38 python_requires='>=3.6',
39 packages=[
40 'kserve',
41 'kserve.api',
42 'kserve.constants',
43 'kserve.models',
44 'kserve.handlers',
45 'kserve.utils',
46 ],
47 package_data={'': ['requirements.txt']},
48 include_package_data=True,
49 zip_safe=False,
50 classifiers=[
51 'Intended Audience :: Developers',
52 'Intended Audience :: Education',
53 'Intended Audience :: Science/Research',
54 'Programming Language :: Python :: 3',
55 'Programming Language :: Python :: 3.6',
56 'Programming Language :: Python :: 3.7',
57 "License :: OSI Approved :: Apache Software License",
58 "Operating System :: OS Independent",
59 'Topic :: Scientific/Engineering',
60 'Topic :: Scientific/Engineering :: Artificial Intelligence',
61 'Topic :: Software Development',
62 'Topic :: Software Development :: Libraries',
63 'Topic :: Software Development :: Libraries :: Python Modules',
64 ],
65 install_requires=REQUIRES,
66 tests_require=TESTS_REQUIRES,
67 extras_require={'test': TESTS_REQUIRES}
68 )
69
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/python/kserve/setup.py b/python/kserve/setup.py
--- a/python/kserve/setup.py
+++ b/python/kserve/setup.py
@@ -28,14 +28,14 @@
setuptools.setup(
name='kserve',
- version='0.8.0',
+ version='0.9.0rc0',
author="The KServe Authors",
author_email='[email protected], [email protected], [email protected]',
license="Apache License Version 2.0",
url="https://github.com/kserve/kserve/tree/master/python/kserve",
description="KServe Python SDK",
long_description="Python SDK for KServe Server and Client.",
- python_requires='>=3.6',
+ python_requires='>=3.7',
packages=[
'kserve',
'kserve.api',
@@ -52,8 +52,9 @@
'Intended Audience :: Education',
'Intended Audience :: Science/Research',
'Programming Language :: Python :: 3',
- 'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
+ 'Programming Language :: Python :: 3.8',
+ 'Programming Language :: Python :: 3.9',
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
'Topic :: Scientific/Engineering',
| {"golden_diff": "diff --git a/python/kserve/setup.py b/python/kserve/setup.py\n--- a/python/kserve/setup.py\n+++ b/python/kserve/setup.py\n@@ -28,14 +28,14 @@\n \n setuptools.setup(\n name='kserve',\n- version='0.8.0',\n+ version='0.9.0rc0',\n author=\"The KServe Authors\",\n author_email='[email protected], [email protected], [email protected]',\n license=\"Apache License Version 2.0\",\n url=\"https://github.com/kserve/kserve/tree/master/python/kserve\",\n description=\"KServe Python SDK\",\n long_description=\"Python SDK for KServe Server and Client.\",\n- python_requires='>=3.6',\n+ python_requires='>=3.7',\n packages=[\n 'kserve',\n 'kserve.api',\n@@ -52,8 +52,9 @@\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3',\n- 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n+ 'Programming Language :: Python :: 3.8',\n+ 'Programming Language :: Python :: 3.9',\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n 'Topic :: Scientific/Engineering',\n", "issue": "Incompatible versions for google protos required by kserve and dependencies\n/kind bug\r\n\r\n**What steps did you take and what happened:**\r\n[A clear and concise description of what the bug is.]\r\nTrying to install the kserve module, kserve requires `googleapis-common-protos==1.53.0`, but some dependencies of kserve require `googleapis-common-protos<2.0dev,>=1.56.2`, and hence kserve cannot be installed.\r\n\r\n\r\n**What did you expect to happen:**\r\nThe version of protos required by kserve should be updated to be compatible with its dependencies\r\n\r\n**Anything else you would like to add:**\r\n[Miscellaneous information that will assist in solving the issue.]\r\n\r\n\r\n**Environment:**\r\n\r\n- Istio Version:\r\n- Knative Version:\r\n- KFServing Version:\r\n- Kubeflow version:\r\n- Kfdef:[k8s_istio/istio_dex/gcp_basic_auth/gcp_iap/aws/aws_cognito/ibm]\r\n- Minikube version:\r\n- Kubernetes version: (use `kubectl version`):\r\n- OS (e.g. from `/etc/os-release`):\r\n\n", "before_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport setuptools\n\nTESTS_REQUIRES = [\n 'pytest',\n 'pytest-xdist',\n 'pytest-cov',\n 'pytest-asyncio',\n 'pytest-tornasync',\n 'mypy'\n]\n\nwith open('requirements.txt') as f:\n REQUIRES = f.readlines()\n\nsetuptools.setup(\n name='kserve',\n version='0.8.0',\n author=\"The KServe Authors\",\n author_email='[email protected], [email protected], [email protected]',\n license=\"Apache License Version 2.0\",\n url=\"https://github.com/kserve/kserve/tree/master/python/kserve\",\n description=\"KServe Python SDK\",\n long_description=\"Python SDK for KServe Server and Client.\",\n python_requires='>=3.6',\n packages=[\n 'kserve',\n 'kserve.api',\n 'kserve.constants',\n 'kserve.models',\n 'kserve.handlers',\n 'kserve.utils',\n ],\n package_data={'': ['requirements.txt']},\n include_package_data=True,\n zip_safe=False,\n classifiers=[\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n install_requires=REQUIRES,\n tests_require=TESTS_REQUIRES,\n extras_require={'test': TESTS_REQUIRES}\n)\n", "path": "python/kserve/setup.py"}], "after_files": [{"content": "# Copyright 2021 The KServe Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport setuptools\n\nTESTS_REQUIRES = [\n 'pytest',\n 'pytest-xdist',\n 'pytest-cov',\n 'pytest-asyncio',\n 'pytest-tornasync',\n 'mypy'\n]\n\nwith open('requirements.txt') as f:\n REQUIRES = f.readlines()\n\nsetuptools.setup(\n name='kserve',\n version='0.9.0rc0',\n author=\"The KServe Authors\",\n author_email='[email protected], [email protected], [email protected]',\n license=\"Apache License Version 2.0\",\n url=\"https://github.com/kserve/kserve/tree/master/python/kserve\",\n description=\"KServe Python SDK\",\n long_description=\"Python SDK for KServe Server and Client.\",\n python_requires='>=3.7',\n packages=[\n 'kserve',\n 'kserve.api',\n 'kserve.constants',\n 'kserve.models',\n 'kserve.handlers',\n 'kserve.utils',\n ],\n package_data={'': ['requirements.txt']},\n include_package_data=True,\n zip_safe=False,\n classifiers=[\n 'Intended Audience :: Developers',\n 'Intended Audience :: Education',\n 'Intended Audience :: Science/Research',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: OS Independent\",\n 'Topic :: Scientific/Engineering',\n 'Topic :: Scientific/Engineering :: Artificial Intelligence',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Libraries',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n install_requires=REQUIRES,\n tests_require=TESTS_REQUIRES,\n extras_require={'test': TESTS_REQUIRES}\n)\n", "path": "python/kserve/setup.py"}]} | 1,162 | 316 |
gh_patches_debug_47853 | rasdani/github-patches | git_diff | searx__searx-3473 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
No Bing results for Searx (but for SearxNG)
The public instances Searx instances don't seem return any results for Bing but SearxNG instances do. I think the situation has been the same for days or even weeks.
I tried out several searx and searxng instances: https://searx.space/
### Searx
Example Searx instance: https://searx.roflcopter.fr/ (1.1.0-53-c647b55e)
[Bing search in roflcopter.fr](https://searx.roflcopter.fr/search?q=%21bi%20foo&categories=none&language=en-US) gave "Sorry! we didn't find any results."
### SearxNG
Example SearxNG instances: https://northboot.xyz/ (2023.2.4+7320b0c7)
[Bing search in northboot.xyz](https://northboot.xyz/search?q=%21bi+foo&category_general=1&language=en-US&time_range=&safesearch=1&theme=simple) gave a pageful of results.
### Suggestion
Might the fix be included in the [SearxNG commit list](https://github.com/searxng/searxng/commits/master/searx/engines/bing.py)? There are several references to Bing that are not included in [Searx commit list](https://github.com/searx/searx/commits/master/searx/engines/bing.py)
There is a big diff between https://raw.githubusercontent.com/searxng/searxng/master/searx/engines/bing.py and https://raw.githubusercontent.com/searx/searx/master/searx/engines/bing.py
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `searx/engines/bing.py`
Content:
```
1 # SPDX-License-Identifier: AGPL-3.0-or-later
2 """
3 Bing (Web)
4 """
5
6 import re
7 from urllib.parse import urlencode
8 from lxml import html
9 from searx import logger
10 from searx.utils import eval_xpath, extract_text, match_language
11
12 logger = logger.getChild('bing engine')
13
14 # about
15 about = {
16 "website": 'https://www.bing.com',
17 "wikidata_id": 'Q182496',
18 "official_api_documentation": 'https://www.microsoft.com/en-us/bing/apis/bing-web-search-api',
19 "use_official_api": False,
20 "require_api_key": False,
21 "results": 'HTML',
22 }
23
24 # engine dependent config
25 categories = ['general']
26 paging = True
27 supported_languages_url = 'https://www.bing.com/account/general'
28 language_aliases = {'zh-CN': 'zh-CHS', 'zh-TW': 'zh-CHT', 'zh-HK': 'zh-CHT'}
29
30 # search-url
31 base_url = 'https://www.bing.com/'
32 search_string = 'search?{query}&first={offset}'
33
34
35 def _get_offset_from_pageno(pageno):
36 return (pageno - 1) * 10 + 1
37
38
39 # do search-request
40 def request(query, params):
41 offset = _get_offset_from_pageno(params.get('pageno', 0))
42
43 if params['language'] == 'all':
44 lang = 'EN'
45 else:
46 lang = match_language(params['language'], supported_languages, language_aliases)
47
48 query = 'language:{} {}'.format(lang.split('-')[0].upper(), query)
49
50 search_path = search_string.format(
51 query=urlencode({'q': query}),
52 offset=offset)
53
54 params['url'] = base_url + search_path
55 params['headers']['User-Agent'] = ('Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '
56 '(KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36')
57
58 return params
59
60
61 # get response from search-request
62 def response(resp):
63 results = []
64 result_len = 0
65
66 dom = html.fromstring(resp.text)
67 # parse results
68 for result in eval_xpath(dom, '//div[@class="sa_cc"]'):
69 link = eval_xpath(result, './/h3/a')[0]
70 url = link.attrib.get('href')
71 pretty_url = extract_text(eval_xpath(result, './/cite'))
72 title = extract_text(link)
73 content = extract_text(eval_xpath(result, './/p'))
74
75 # append result
76 results.append({'url': url,
77 'pretty_url': pretty_url,
78 'title': title,
79 'content': content})
80
81 # parse results again if nothing is found yet
82 for result in eval_xpath(dom, '//li[@class="b_algo"]'):
83 link = eval_xpath(result, './/h2/a')[0]
84 url = link.attrib.get('href')
85 title = extract_text(link)
86 content = extract_text(eval_xpath(result, './/p'))
87
88 # append result
89 results.append({'url': url,
90 'title': title,
91 'content': content})
92
93 try:
94 result_len_container = "".join(eval_xpath(dom, '//span[@class="sb_count"]//text()'))
95 if "-" in result_len_container:
96 # Remove the part "from-to" for paginated request ...
97 result_len_container = result_len_container[result_len_container.find("-") * 2 + 2:]
98
99 result_len_container = re.sub('[^0-9]', '', result_len_container)
100 if len(result_len_container) > 0:
101 result_len = int(result_len_container)
102 except Exception as e:
103 logger.debug('result error :\n%s', e)
104
105 if result_len and _get_offset_from_pageno(resp.search_params.get("pageno", 0)) > result_len:
106 return []
107
108 results.append({'number_of_results': result_len})
109 return results
110
111
112 # get supported languages from their site
113 def _fetch_supported_languages(resp):
114 lang_tags = set()
115
116 setmkt = re.compile('setmkt=([^&]*)')
117 dom = html.fromstring(resp.text)
118 lang_links = eval_xpath(dom, "//li/a[contains(@href, 'setmkt')]")
119
120 for a in lang_links:
121 href = eval_xpath(a, './@href')[0]
122 match = setmkt.search(href)
123 l_tag = match.groups()[0]
124 _lang, _nation = l_tag.split('-', 1)
125 l_tag = _lang.lower() + '-' + _nation.upper()
126 lang_tags.add(l_tag)
127
128 return list(lang_tags)
129
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/searx/engines/bing.py b/searx/engines/bing.py
--- a/searx/engines/bing.py
+++ b/searx/engines/bing.py
@@ -52,8 +52,7 @@
offset=offset)
params['url'] = base_url + search_path
- params['headers']['User-Agent'] = ('Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36')
+ params['headers']['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
return params
| {"golden_diff": "diff --git a/searx/engines/bing.py b/searx/engines/bing.py\n--- a/searx/engines/bing.py\n+++ b/searx/engines/bing.py\n@@ -52,8 +52,7 @@\n offset=offset)\n \n params['url'] = base_url + search_path\n- params['headers']['User-Agent'] = ('Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '\n- '(KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36')\n+ params['headers']['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'\n \n return params\n", "issue": "No Bing results for Searx (but for SearxNG)\nThe public instances Searx instances don't seem return any results for Bing but SearxNG instances do. I think the situation has been the same for days or even weeks.\r\n\r\nI tried out several searx and searxng instances: https://searx.space/\r\n\r\n### Searx\r\n\r\nExample Searx instance: https://searx.roflcopter.fr/ (1.1.0-53-c647b55e)\r\n[Bing search in roflcopter.fr](https://searx.roflcopter.fr/search?q=%21bi%20foo&categories=none&language=en-US) gave \"Sorry! we didn't find any results.\"\r\n\r\n### SearxNG\r\n\r\nExample SearxNG instances: https://northboot.xyz/ (2023.2.4+7320b0c7)\r\n[Bing search in northboot.xyz](https://northboot.xyz/search?q=%21bi+foo&category_general=1&language=en-US&time_range=&safesearch=1&theme=simple) gave a pageful of results.\r\n\r\n### Suggestion\r\n\r\nMight the fix be included in the [SearxNG commit list](https://github.com/searxng/searxng/commits/master/searx/engines/bing.py)? There are several references to Bing that are not included in [Searx commit list](https://github.com/searx/searx/commits/master/searx/engines/bing.py)\r\nThere is a big diff between https://raw.githubusercontent.com/searxng/searxng/master/searx/engines/bing.py and https://raw.githubusercontent.com/searx/searx/master/searx/engines/bing.py\n", "before_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n\"\"\"\n Bing (Web)\n\"\"\"\n\nimport re\nfrom urllib.parse import urlencode\nfrom lxml import html\nfrom searx import logger\nfrom searx.utils import eval_xpath, extract_text, match_language\n\nlogger = logger.getChild('bing engine')\n\n# about\nabout = {\n \"website\": 'https://www.bing.com',\n \"wikidata_id\": 'Q182496',\n \"official_api_documentation\": 'https://www.microsoft.com/en-us/bing/apis/bing-web-search-api',\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": 'HTML',\n}\n\n# engine dependent config\ncategories = ['general']\npaging = True\nsupported_languages_url = 'https://www.bing.com/account/general'\nlanguage_aliases = {'zh-CN': 'zh-CHS', 'zh-TW': 'zh-CHT', 'zh-HK': 'zh-CHT'}\n\n# search-url\nbase_url = 'https://www.bing.com/'\nsearch_string = 'search?{query}&first={offset}'\n\n\ndef _get_offset_from_pageno(pageno):\n return (pageno - 1) * 10 + 1\n\n\n# do search-request\ndef request(query, params):\n offset = _get_offset_from_pageno(params.get('pageno', 0))\n\n if params['language'] == 'all':\n lang = 'EN'\n else:\n lang = match_language(params['language'], supported_languages, language_aliases)\n\n query = 'language:{} {}'.format(lang.split('-')[0].upper(), query)\n\n search_path = search_string.format(\n query=urlencode({'q': query}),\n offset=offset)\n\n params['url'] = base_url + search_path\n params['headers']['User-Agent'] = ('Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 '\n '(KHTML, like Gecko) Chrome/97.0.4692.71 Safari/537.36')\n\n return params\n\n\n# get response from search-request\ndef response(resp):\n results = []\n result_len = 0\n\n dom = html.fromstring(resp.text)\n # parse results\n for result in eval_xpath(dom, '//div[@class=\"sa_cc\"]'):\n link = eval_xpath(result, './/h3/a')[0]\n url = link.attrib.get('href')\n pretty_url = extract_text(eval_xpath(result, './/cite'))\n title = extract_text(link)\n content = extract_text(eval_xpath(result, './/p'))\n\n # append result\n results.append({'url': url,\n 'pretty_url': pretty_url,\n 'title': title,\n 'content': content})\n\n # parse results again if nothing is found yet\n for result in eval_xpath(dom, '//li[@class=\"b_algo\"]'):\n link = eval_xpath(result, './/h2/a')[0]\n url = link.attrib.get('href')\n title = extract_text(link)\n content = extract_text(eval_xpath(result, './/p'))\n\n # append result\n results.append({'url': url,\n 'title': title,\n 'content': content})\n\n try:\n result_len_container = \"\".join(eval_xpath(dom, '//span[@class=\"sb_count\"]//text()'))\n if \"-\" in result_len_container:\n # Remove the part \"from-to\" for paginated request ...\n result_len_container = result_len_container[result_len_container.find(\"-\") * 2 + 2:]\n\n result_len_container = re.sub('[^0-9]', '', result_len_container)\n if len(result_len_container) > 0:\n result_len = int(result_len_container)\n except Exception as e:\n logger.debug('result error :\\n%s', e)\n\n if result_len and _get_offset_from_pageno(resp.search_params.get(\"pageno\", 0)) > result_len:\n return []\n\n results.append({'number_of_results': result_len})\n return results\n\n\n# get supported languages from their site\ndef _fetch_supported_languages(resp):\n lang_tags = set()\n\n setmkt = re.compile('setmkt=([^&]*)')\n dom = html.fromstring(resp.text)\n lang_links = eval_xpath(dom, \"//li/a[contains(@href, 'setmkt')]\")\n\n for a in lang_links:\n href = eval_xpath(a, './@href')[0]\n match = setmkt.search(href)\n l_tag = match.groups()[0]\n _lang, _nation = l_tag.split('-', 1)\n l_tag = _lang.lower() + '-' + _nation.upper()\n lang_tags.add(l_tag)\n\n return list(lang_tags)\n", "path": "searx/engines/bing.py"}], "after_files": [{"content": "# SPDX-License-Identifier: AGPL-3.0-or-later\n\"\"\"\n Bing (Web)\n\"\"\"\n\nimport re\nfrom urllib.parse import urlencode\nfrom lxml import html\nfrom searx import logger\nfrom searx.utils import eval_xpath, extract_text, match_language\n\nlogger = logger.getChild('bing engine')\n\n# about\nabout = {\n \"website\": 'https://www.bing.com',\n \"wikidata_id\": 'Q182496',\n \"official_api_documentation\": 'https://www.microsoft.com/en-us/bing/apis/bing-web-search-api',\n \"use_official_api\": False,\n \"require_api_key\": False,\n \"results\": 'HTML',\n}\n\n# engine dependent config\ncategories = ['general']\npaging = True\nsupported_languages_url = 'https://www.bing.com/account/general'\nlanguage_aliases = {'zh-CN': 'zh-CHS', 'zh-TW': 'zh-CHT', 'zh-HK': 'zh-CHT'}\n\n# search-url\nbase_url = 'https://www.bing.com/'\nsearch_string = 'search?{query}&first={offset}'\n\n\ndef _get_offset_from_pageno(pageno):\n return (pageno - 1) * 10 + 1\n\n\n# do search-request\ndef request(query, params):\n offset = _get_offset_from_pageno(params.get('pageno', 0))\n\n if params['language'] == 'all':\n lang = 'EN'\n else:\n lang = match_language(params['language'], supported_languages, language_aliases)\n\n query = 'language:{} {}'.format(lang.split('-')[0].upper(), query)\n\n search_path = search_string.format(\n query=urlencode({'q': query}),\n offset=offset)\n\n params['url'] = base_url + search_path\n params['headers']['Accept'] = 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'\n\n return params\n\n\n# get response from search-request\ndef response(resp):\n results = []\n result_len = 0\n\n dom = html.fromstring(resp.text)\n # parse results\n for result in eval_xpath(dom, '//div[@class=\"sa_cc\"]'):\n link = eval_xpath(result, './/h3/a')[0]\n url = link.attrib.get('href')\n pretty_url = extract_text(eval_xpath(result, './/cite'))\n title = extract_text(link)\n content = extract_text(eval_xpath(result, './/p'))\n\n # append result\n results.append({'url': url,\n 'pretty_url': pretty_url,\n 'title': title,\n 'content': content})\n\n # parse results again if nothing is found yet\n for result in eval_xpath(dom, '//li[@class=\"b_algo\"]'):\n link = eval_xpath(result, './/h2/a')[0]\n url = link.attrib.get('href')\n title = extract_text(link)\n content = extract_text(eval_xpath(result, './/p'))\n\n # append result\n results.append({'url': url,\n 'title': title,\n 'content': content})\n\n try:\n result_len_container = \"\".join(eval_xpath(dom, '//span[@class=\"sb_count\"]//text()'))\n if \"-\" in result_len_container:\n # Remove the part \"from-to\" for paginated request ...\n result_len_container = result_len_container[result_len_container.find(\"-\") * 2 + 2:]\n\n result_len_container = re.sub('[^0-9]', '', result_len_container)\n if len(result_len_container) > 0:\n result_len = int(result_len_container)\n except Exception as e:\n logger.debug('result error :\\n%s', e)\n\n if result_len and _get_offset_from_pageno(resp.search_params.get(\"pageno\", 0)) > result_len:\n return []\n\n results.append({'number_of_results': result_len})\n return results\n\n\n# get supported languages from their site\ndef _fetch_supported_languages(resp):\n lang_tags = set()\n\n setmkt = re.compile('setmkt=([^&]*)')\n dom = html.fromstring(resp.text)\n lang_links = eval_xpath(dom, \"//li/a[contains(@href, 'setmkt')]\")\n\n for a in lang_links:\n href = eval_xpath(a, './@href')[0]\n match = setmkt.search(href)\n l_tag = match.groups()[0]\n _lang, _nation = l_tag.split('-', 1)\n l_tag = _lang.lower() + '-' + _nation.upper()\n lang_tags.add(l_tag)\n\n return list(lang_tags)\n", "path": "searx/engines/bing.py"}]} | 1,978 | 186 |
gh_patches_debug_18367 | rasdani/github-patches | git_diff | hpcaitech__ColossalAI-2683 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tensor] fix some unittests
[tensor] fix some unittests
[tensor] fix some unittests
[BUG]: Gemini is not compatible with LoRA
### 🐛 Describe the bug
`loralib` provides LoRALinear layer:
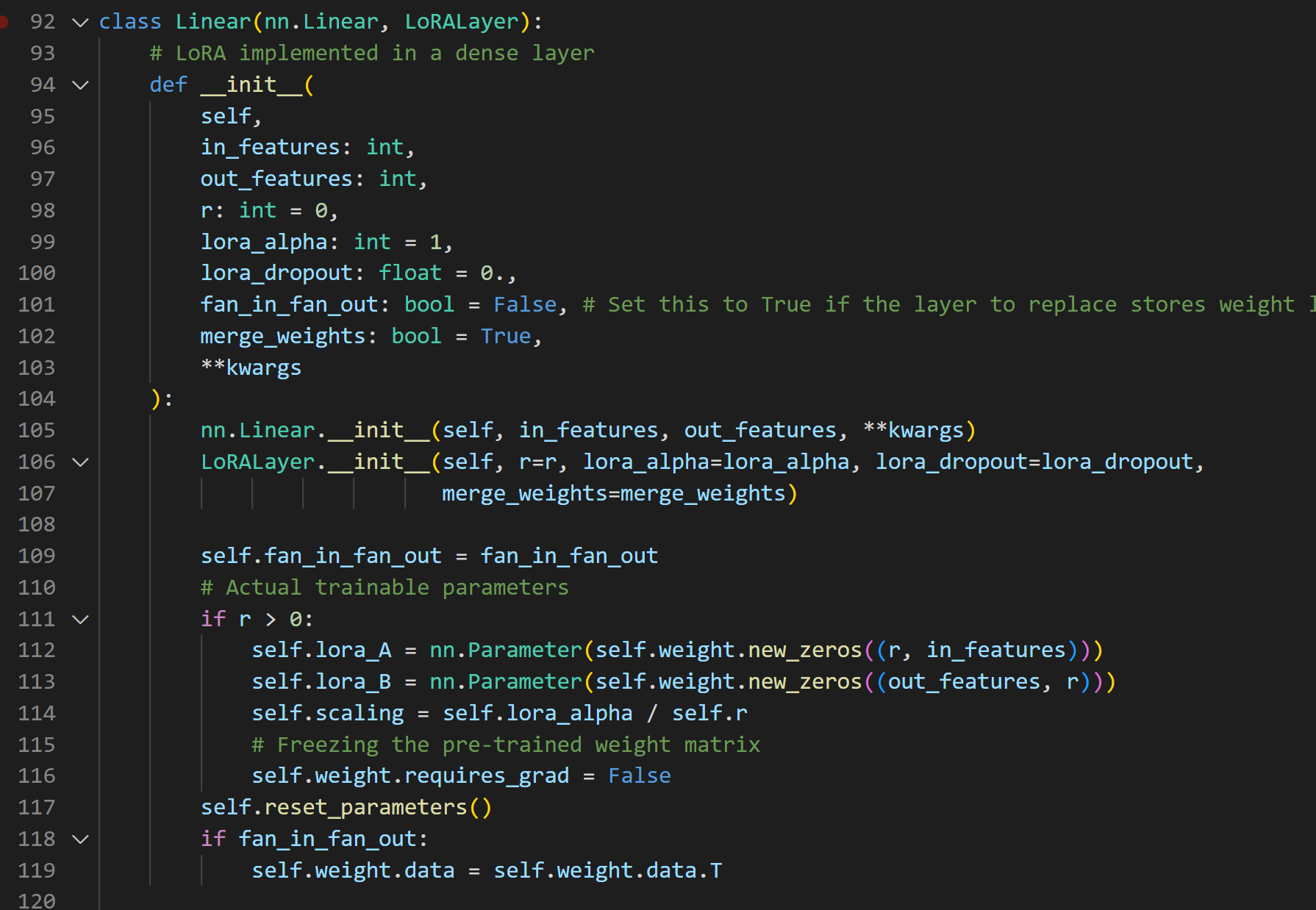
When using `ColoInitContext`, it first convert `self.weigh` to `ColoParameter` after line 105. In line 112, `self.weight.new_zeros()` will return a `ColoTensor`. Then it will be wrapped by `Parameter`. In this case, `isinstance(self.lora_A, ColoParameter)` is `True`, but it does not run `ColoParameter.__init__()`.
`ColoInitContext` should ensure `type(p) is ColoParameter`.
### Environment
torch 1.12.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `colossalai/utils/model/colo_init_context.py`
Content:
```
1 from typing import Any, Dict, Iterator, Optional, Tuple, Union
2
3 import torch
4 from torch import nn
5
6 from colossalai.nn.parallel.layers import ColoEmbedding, ColoLinear, register_colo_module
7 from colossalai.tensor import ColoParameter, ColoTensor, ProcessGroup
8
9 from .utils import InsertPostInitMethodToModuleSubClasses
10
11 # find named_params includes replica
12
13
14 def _named_params_with_replica(
15 module: nn.Module,
16 prefix: str = '',
17 recurse: bool = True,
18 ) -> Iterator[Tuple[str, Union[nn.Parameter, ColoTensor]]]:
19 modules = module.named_modules(prefix=prefix) if recurse else [(prefix, module)]
20
21 for mod_prefix, mod in modules:
22 for name, val in mod._parameters.items():
23 if val is None:
24 continue
25 name = mod_prefix + ('.' if mod_prefix else '') + name
26 yield name, val
27
28
29 def _convert_to_coloparam(param: torch.nn.Parameter,
30 device: torch.device,
31 dtype=torch.float,
32 default_pg: Optional[ProcessGroup] = None,
33 default_dist_spec: Optional[Any] = None) -> ColoParameter:
34
35 if isinstance(param, ColoParameter):
36 return param
37 # detaching tensor is necessary for optimizers.
38 requires_grad = param.requires_grad
39 # param is the global tensor.
40
41 if param.device.type == "meta":
42 colo_param = ColoParameter(param, requires_grad=requires_grad)
43 else:
44 colo_param = ColoParameter(param.to(device=device, dtype=dtype), requires_grad=requires_grad)
45
46 # if default_shard_plan exists, shard the param during initialization.
47 # This can reduce the model size after initialization.
48 # NOTE() embedding usually can not be correctly sharded. So I use except to handle
49 # the param that can not be sharded by the default plan
50 if default_pg is not None:
51 colo_param.set_process_group(default_pg)
52
53 if default_dist_spec is not None:
54 try:
55 colo_param.set_dist_spec(default_dist_spec)
56 except:
57 pass
58 return colo_param
59
60
61 def ColoModulize(module):
62 """
63 Replacing the parameters() and named_parameters() with our customized ones
64 """
65
66 module._colo_visited = True
67
68
69 class ColoInitContext(InsertPostInitMethodToModuleSubClasses):
70
71 def __init__(self,
72 device: torch.device = torch.device('cpu'),
73 dtype: torch.dtype = torch.float,
74 default_pg: Optional[ProcessGroup] = None,
75 default_dist_spec=None):
76 """
77 Args:
78 device (torch.device): the device where parameters initialized are resident. Defaults to torch.device('cpu').
79 dtype (torch.dtype): the dtype of parameters initialized. Defults to torch.float.
80 default_pg (ProcessGroup): the default process group for all initialized parameters.
81 default_dist_spec: the default distributed specifications.
82 """
83 super().__init__()
84 self._device = device
85 self._dtype = dtype
86
87 self._register_colo_modules()
88 self._default_pg = default_pg
89 self._default_dist_spec = default_dist_spec
90
91 def _register_colo_modules(self):
92 register_colo_module(torch.nn.Linear, ColoLinear())
93 register_colo_module(torch.nn.Embedding, ColoEmbedding())
94
95 def _pre_context_exec(self):
96 pass
97
98 def _post_init_method(self, module: torch.nn.Module, *args, **kwargs):
99 """
100 The function to call at the end of the constructor of each module.
101 FIXME(fjr) The module may be passed to this function multiple times?
102 """
103 name_list = []
104 for name, param in _named_params_with_replica(module):
105 if isinstance(param, ColoTensor):
106 continue
107
108 split = name.rfind('.')
109 if split >= 0: # param in submodule
110 module_name = name[:split]
111 param_name = name[split + 1:]
112 else:
113 module_name = '' # param in current module
114 param_name = name
115 name_list.append((module_name, param_name))
116
117 replaced_tensors = dict(
118 ) # record mapping between (torch.Tensor, ColoTensor) to distinguish the same reference
119 for module_name, param_name in name_list:
120 submodule = module.get_submodule(module_name)
121 param = submodule.get_parameter(param_name)
122 if param in replaced_tensors:
123 colo_param = replaced_tensors[param]
124 else:
125 colo_param = _convert_to_coloparam(param, self._device, self._dtype, self._default_pg,
126 self._default_dist_spec)
127 replaced_tensors[param] = colo_param
128 delattr(submodule, param_name)
129 setattr(submodule, param_name, colo_param)
130 colo_param.shared_param_modules.append(submodule)
131
132 param_number = 0
133 meta_param_number = 0
134 buffer_number = 0
135 meta_buffer_number = 0
136
137 for param in module.parameters():
138 param_number += 1
139 meta_param_number += (param.device.type == 'meta')
140
141 for buffer in module.buffers():
142 buffer_number += 1
143 meta_buffer_number += (buffer.device.type == 'meta')
144
145 if meta_param_number > 0 and meta_param_number != param_number:
146 raise ValueError("Meta parameters and valued parameters can not be in the same model")
147 if meta_buffer_number > 0 and meta_buffer_number != buffer_number:
148 raise ValueError("Meta buffers and valued buffers can not be in the same model")
149
150 if meta_buffer_number == 0:
151 for buffer in module.buffers():
152 buffer.data = buffer.data.to(device=self._device)
153
154
155 def post_process_colo_init_ctx(model: torch.nn.Module,
156 device: torch.device = torch.device('cpu'),
157 dtype: torch.dtype = torch.float,
158 default_pg: Optional[ProcessGroup] = None,
159 default_dist_spec=None):
160 """post_process_colo_init_ctx
161
162 This function is called after `ColoInitContext`.
163
164 Args:
165 model (torch.nn.module): the model
166 device (torch.device, optional): device type of the model params. Defaults to torch.device('cpu').
167 dtype (torch.dtype, optional): dtype of the model params. Defaults to torch.float.
168 default_pg (Optional[ProcessGroup], optional): default process group. Defaults to None. Inidicates a DP-only process group.
169 default_dist_spec (Any, optional): default dist spec of params. Defaults to None.
170
171 Raises:
172 RuntimeError: raise error if
173 """
174
175 torch_params = []
176 for n, p in model.named_parameters():
177 if not isinstance(p, ColoParameter):
178 # print(f"{n} is not a ColoParameter. We are going to converting it to ColoParameter")
179 torch_params.append((n, p))
180
181 for (n, param) in torch_params:
182 name_list = n.split('.')
183 module = model
184 for i in range(len(name_list) - 1):
185 module = module._modules[name_list[i]]
186 delattr(module, name_list[-1])
187 setattr(module, name_list[-1], _convert_to_coloparam(param, device, dtype, default_pg, default_dist_spec))
188
189 del torch_params
190 for n, p in model.named_parameters():
191 if not isinstance(p, ColoTensor):
192 raise RuntimeError
193
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/colossalai/utils/model/colo_init_context.py b/colossalai/utils/model/colo_init_context.py
--- a/colossalai/utils/model/colo_init_context.py
+++ b/colossalai/utils/model/colo_init_context.py
@@ -32,7 +32,7 @@
default_pg: Optional[ProcessGroup] = None,
default_dist_spec: Optional[Any] = None) -> ColoParameter:
- if isinstance(param, ColoParameter):
+ if type(param) is ColoParameter:
return param
# detaching tensor is necessary for optimizers.
requires_grad = param.requires_grad
@@ -102,7 +102,7 @@
"""
name_list = []
for name, param in _named_params_with_replica(module):
- if isinstance(param, ColoTensor):
+ if type(param) is ColoParameter:
continue
split = name.rfind('.')
| {"golden_diff": "diff --git a/colossalai/utils/model/colo_init_context.py b/colossalai/utils/model/colo_init_context.py\n--- a/colossalai/utils/model/colo_init_context.py\n+++ b/colossalai/utils/model/colo_init_context.py\n@@ -32,7 +32,7 @@\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec: Optional[Any] = None) -> ColoParameter:\n \n- if isinstance(param, ColoParameter):\n+ if type(param) is ColoParameter:\n return param\n # detaching tensor is necessary for optimizers.\n requires_grad = param.requires_grad\n@@ -102,7 +102,7 @@\n \"\"\"\n name_list = []\n for name, param in _named_params_with_replica(module):\n- if isinstance(param, ColoTensor):\n+ if type(param) is ColoParameter:\n continue\n \n split = name.rfind('.')\n", "issue": "[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[tensor] fix some unittests\n\n[BUG]: Gemini is not compatible with LoRA\n### \ud83d\udc1b Describe the bug\n\n`loralib` provides LoRALinear layer:\r\n\r\n\r\n\r\n\r\nWhen using `ColoInitContext`, it first convert `self.weigh` to `ColoParameter` after line 105. In line 112, `self.weight.new_zeros()` will return a `ColoTensor`. Then it will be wrapped by `Parameter`. In this case, `isinstance(self.lora_A, ColoParameter)` is `True`, but it does not run `ColoParameter.__init__()`.\r\n\r\n`ColoInitContext` should ensure `type(p) is ColoParameter`.\n\n### Environment\n\ntorch 1.12.0\n", "before_files": [{"content": "from typing import Any, Dict, Iterator, Optional, Tuple, Union\n\nimport torch\nfrom torch import nn\n\nfrom colossalai.nn.parallel.layers import ColoEmbedding, ColoLinear, register_colo_module\nfrom colossalai.tensor import ColoParameter, ColoTensor, ProcessGroup\n\nfrom .utils import InsertPostInitMethodToModuleSubClasses\n\n# find named_params includes replica\n\n\ndef _named_params_with_replica(\n module: nn.Module,\n prefix: str = '',\n recurse: bool = True,\n) -> Iterator[Tuple[str, Union[nn.Parameter, ColoTensor]]]:\n modules = module.named_modules(prefix=prefix) if recurse else [(prefix, module)]\n\n for mod_prefix, mod in modules:\n for name, val in mod._parameters.items():\n if val is None:\n continue\n name = mod_prefix + ('.' if mod_prefix else '') + name\n yield name, val\n\n\ndef _convert_to_coloparam(param: torch.nn.Parameter,\n device: torch.device,\n dtype=torch.float,\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec: Optional[Any] = None) -> ColoParameter:\n\n if isinstance(param, ColoParameter):\n return param\n # detaching tensor is necessary for optimizers.\n requires_grad = param.requires_grad\n # param is the global tensor.\n\n if param.device.type == \"meta\":\n colo_param = ColoParameter(param, requires_grad=requires_grad)\n else:\n colo_param = ColoParameter(param.to(device=device, dtype=dtype), requires_grad=requires_grad)\n\n # if default_shard_plan exists, shard the param during initialization.\n # This can reduce the model size after initialization.\n # NOTE() embedding usually can not be correctly sharded. So I use except to handle\n # the param that can not be sharded by the default plan\n if default_pg is not None:\n colo_param.set_process_group(default_pg)\n\n if default_dist_spec is not None:\n try:\n colo_param.set_dist_spec(default_dist_spec)\n except:\n pass\n return colo_param\n\n\ndef ColoModulize(module):\n \"\"\"\n Replacing the parameters() and named_parameters() with our customized ones\n \"\"\"\n\n module._colo_visited = True\n\n\nclass ColoInitContext(InsertPostInitMethodToModuleSubClasses):\n\n def __init__(self,\n device: torch.device = torch.device('cpu'),\n dtype: torch.dtype = torch.float,\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec=None):\n \"\"\"\n Args:\n device (torch.device): the device where parameters initialized are resident. Defaults to torch.device('cpu').\n dtype (torch.dtype): the dtype of parameters initialized. Defults to torch.float.\n default_pg (ProcessGroup): the default process group for all initialized parameters.\n default_dist_spec: the default distributed specifications.\n \"\"\"\n super().__init__()\n self._device = device\n self._dtype = dtype\n\n self._register_colo_modules()\n self._default_pg = default_pg\n self._default_dist_spec = default_dist_spec\n\n def _register_colo_modules(self):\n register_colo_module(torch.nn.Linear, ColoLinear())\n register_colo_module(torch.nn.Embedding, ColoEmbedding())\n\n def _pre_context_exec(self):\n pass\n\n def _post_init_method(self, module: torch.nn.Module, *args, **kwargs):\n \"\"\"\n The function to call at the end of the constructor of each module.\n FIXME(fjr) The module may be passed to this function multiple times?\n \"\"\"\n name_list = []\n for name, param in _named_params_with_replica(module):\n if isinstance(param, ColoTensor):\n continue\n\n split = name.rfind('.')\n if split >= 0: # param in submodule\n module_name = name[:split]\n param_name = name[split + 1:]\n else:\n module_name = '' # param in current module\n param_name = name\n name_list.append((module_name, param_name))\n\n replaced_tensors = dict(\n ) # record mapping between (torch.Tensor, ColoTensor) to distinguish the same reference\n for module_name, param_name in name_list:\n submodule = module.get_submodule(module_name)\n param = submodule.get_parameter(param_name)\n if param in replaced_tensors:\n colo_param = replaced_tensors[param]\n else:\n colo_param = _convert_to_coloparam(param, self._device, self._dtype, self._default_pg,\n self._default_dist_spec)\n replaced_tensors[param] = colo_param\n delattr(submodule, param_name)\n setattr(submodule, param_name, colo_param)\n colo_param.shared_param_modules.append(submodule)\n\n param_number = 0\n meta_param_number = 0\n buffer_number = 0\n meta_buffer_number = 0\n\n for param in module.parameters():\n param_number += 1\n meta_param_number += (param.device.type == 'meta')\n\n for buffer in module.buffers():\n buffer_number += 1\n meta_buffer_number += (buffer.device.type == 'meta')\n\n if meta_param_number > 0 and meta_param_number != param_number:\n raise ValueError(\"Meta parameters and valued parameters can not be in the same model\")\n if meta_buffer_number > 0 and meta_buffer_number != buffer_number:\n raise ValueError(\"Meta buffers and valued buffers can not be in the same model\")\n\n if meta_buffer_number == 0:\n for buffer in module.buffers():\n buffer.data = buffer.data.to(device=self._device)\n\n\ndef post_process_colo_init_ctx(model: torch.nn.Module,\n device: torch.device = torch.device('cpu'),\n dtype: torch.dtype = torch.float,\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec=None):\n \"\"\"post_process_colo_init_ctx\n\n This function is called after `ColoInitContext`.\n\n Args:\n model (torch.nn.module): the model\n device (torch.device, optional): device type of the model params. Defaults to torch.device('cpu').\n dtype (torch.dtype, optional): dtype of the model params. Defaults to torch.float.\n default_pg (Optional[ProcessGroup], optional): default process group. Defaults to None. Inidicates a DP-only process group.\n default_dist_spec (Any, optional): default dist spec of params. Defaults to None.\n\n Raises:\n RuntimeError: raise error if\n \"\"\"\n\n torch_params = []\n for n, p in model.named_parameters():\n if not isinstance(p, ColoParameter):\n # print(f\"{n} is not a ColoParameter. We are going to converting it to ColoParameter\")\n torch_params.append((n, p))\n\n for (n, param) in torch_params:\n name_list = n.split('.')\n module = model\n for i in range(len(name_list) - 1):\n module = module._modules[name_list[i]]\n delattr(module, name_list[-1])\n setattr(module, name_list[-1], _convert_to_coloparam(param, device, dtype, default_pg, default_dist_spec))\n\n del torch_params\n for n, p in model.named_parameters():\n if not isinstance(p, ColoTensor):\n raise RuntimeError\n", "path": "colossalai/utils/model/colo_init_context.py"}], "after_files": [{"content": "from typing import Any, Dict, Iterator, Optional, Tuple, Union\n\nimport torch\nfrom torch import nn\n\nfrom colossalai.nn.parallel.layers import ColoEmbedding, ColoLinear, register_colo_module\nfrom colossalai.tensor import ColoParameter, ColoTensor, ProcessGroup\n\nfrom .utils import InsertPostInitMethodToModuleSubClasses\n\n# find named_params includes replica\n\n\ndef _named_params_with_replica(\n module: nn.Module,\n prefix: str = '',\n recurse: bool = True,\n) -> Iterator[Tuple[str, Union[nn.Parameter, ColoTensor]]]:\n modules = module.named_modules(prefix=prefix) if recurse else [(prefix, module)]\n\n for mod_prefix, mod in modules:\n for name, val in mod._parameters.items():\n if val is None:\n continue\n name = mod_prefix + ('.' if mod_prefix else '') + name\n yield name, val\n\n\ndef _convert_to_coloparam(param: torch.nn.Parameter,\n device: torch.device,\n dtype=torch.float,\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec: Optional[Any] = None) -> ColoParameter:\n\n if type(param) is ColoParameter:\n return param\n # detaching tensor is necessary for optimizers.\n requires_grad = param.requires_grad\n # param is the global tensor.\n\n if param.device.type == \"meta\":\n colo_param = ColoParameter(param, requires_grad=requires_grad)\n else:\n colo_param = ColoParameter(param.to(device=device, dtype=dtype), requires_grad=requires_grad)\n\n # if default_shard_plan exists, shard the param during initialization.\n # This can reduce the model size after initialization.\n # NOTE() embedding usually can not be correctly sharded. So I use except to handle\n # the param that can not be sharded by the default plan\n if default_pg is not None:\n colo_param.set_process_group(default_pg)\n\n if default_dist_spec is not None:\n try:\n colo_param.set_dist_spec(default_dist_spec)\n except:\n pass\n return colo_param\n\n\ndef ColoModulize(module):\n \"\"\"\n Replacing the parameters() and named_parameters() with our customized ones\n \"\"\"\n\n module._colo_visited = True\n\n\nclass ColoInitContext(InsertPostInitMethodToModuleSubClasses):\n\n def __init__(self,\n device: torch.device = torch.device('cpu'),\n dtype: torch.dtype = torch.float,\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec=None):\n \"\"\"\n Args:\n device (torch.device): the device where parameters initialized are resident. Defaults to torch.device('cpu').\n dtype (torch.dtype): the dtype of parameters initialized. Defults to torch.float.\n default_pg (ProcessGroup): the default process group for all initialized parameters.\n default_dist_spec: the default distributed specifications.\n \"\"\"\n super().__init__()\n self._device = device\n self._dtype = dtype\n\n self._register_colo_modules()\n self._default_pg = default_pg\n self._default_dist_spec = default_dist_spec\n\n def _register_colo_modules(self):\n register_colo_module(torch.nn.Linear, ColoLinear())\n register_colo_module(torch.nn.Embedding, ColoEmbedding())\n\n def _pre_context_exec(self):\n pass\n\n def _post_init_method(self, module: torch.nn.Module, *args, **kwargs):\n \"\"\"\n The function to call at the end of the constructor of each module.\n FIXME(fjr) The module may be passed to this function multiple times?\n \"\"\"\n name_list = []\n for name, param in _named_params_with_replica(module):\n if type(param) is ColoParameter:\n continue\n\n split = name.rfind('.')\n if split >= 0: # param in submodule\n module_name = name[:split]\n param_name = name[split + 1:]\n else:\n module_name = '' # param in current module\n param_name = name\n name_list.append((module_name, param_name))\n\n replaced_tensors = dict(\n ) # record mapping between (torch.Tensor, ColoTensor) to distinguish the same reference\n for module_name, param_name in name_list:\n submodule = module.get_submodule(module_name)\n param = submodule.get_parameter(param_name)\n if param in replaced_tensors:\n colo_param = replaced_tensors[param]\n else:\n colo_param = _convert_to_coloparam(param, self._device, self._dtype, self._default_pg,\n self._default_dist_spec)\n replaced_tensors[param] = colo_param\n delattr(submodule, param_name)\n setattr(submodule, param_name, colo_param)\n colo_param.shared_param_modules.append(submodule)\n\n param_number = 0\n meta_param_number = 0\n buffer_number = 0\n meta_buffer_number = 0\n\n for param in module.parameters():\n param_number += 1\n meta_param_number += (param.device.type == 'meta')\n\n for buffer in module.buffers():\n buffer_number += 1\n meta_buffer_number += (buffer.device.type == 'meta')\n\n if meta_param_number > 0 and meta_param_number != param_number:\n raise ValueError(\"Meta parameters and valued parameters can not be in the same model\")\n if meta_buffer_number > 0 and meta_buffer_number != buffer_number:\n raise ValueError(\"Meta buffers and valued buffers can not be in the same model\")\n\n if meta_buffer_number == 0:\n for buffer in module.buffers():\n buffer.data = buffer.data.to(device=self._device)\n\n\ndef post_process_colo_init_ctx(model: torch.nn.Module,\n device: torch.device = torch.device('cpu'),\n dtype: torch.dtype = torch.float,\n default_pg: Optional[ProcessGroup] = None,\n default_dist_spec=None):\n \"\"\"post_process_colo_init_ctx\n\n This function is called after `ColoInitContext`.\n\n Args:\n model (torch.nn.module): the model\n device (torch.device, optional): device type of the model params. Defaults to torch.device('cpu').\n dtype (torch.dtype, optional): dtype of the model params. Defaults to torch.float.\n default_pg (Optional[ProcessGroup], optional): default process group. Defaults to None. Inidicates a DP-only process group.\n default_dist_spec (Any, optional): default dist spec of params. Defaults to None.\n\n Raises:\n RuntimeError: raise error if\n \"\"\"\n\n torch_params = []\n for n, p in model.named_parameters():\n if not isinstance(p, ColoParameter):\n # print(f\"{n} is not a ColoParameter. We are going to converting it to ColoParameter\")\n torch_params.append((n, p))\n\n for (n, param) in torch_params:\n name_list = n.split('.')\n module = model\n for i in range(len(name_list) - 1):\n module = module._modules[name_list[i]]\n delattr(module, name_list[-1])\n setattr(module, name_list[-1], _convert_to_coloparam(param, device, dtype, default_pg, default_dist_spec))\n\n del torch_params\n for n, p in model.named_parameters():\n if not isinstance(p, ColoTensor):\n raise RuntimeError\n", "path": "colossalai/utils/model/colo_init_context.py"}]} | 2,548 | 202 |
gh_patches_debug_27240 | rasdani/github-patches | git_diff | nerfstudio-project__nerfstudio-953 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Render fails silently traj="interp" mode (with custom data)
**Describe the bug**
When using ns-render (in google colab) and with custom images, the render "finishes" (cell executes successfully without any error), however, there's no output. The same command works well with traj="spiral"
**To Reproduce**
Executing the following command fails to output any video/rendering:
`!ns-render --load-config $config_filename --traj=interp --output-path renders/output.mp4`
However, changing the trajectory mode to spiral produces a correct video:
`!ns-render --load-config $config_filename --traj=spiral --output-path outputs/renders/output.mp4`
**Additional context**
I've checked the documentation for some pre-requisites to run the interpolation mode, but I didn't find anything.
Thanks!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/render.py`
Content:
```
1 #!/usr/bin/env python
2 """
3 render.py
4 """
5 from __future__ import annotations
6
7 import dataclasses
8 import json
9 import sys
10 from pathlib import Path
11 from typing import Optional
12
13 import mediapy as media
14 import torch
15 import tyro
16 from rich.console import Console
17 from rich.progress import (
18 BarColumn,
19 Progress,
20 TaskProgressColumn,
21 TextColumn,
22 TimeRemainingColumn,
23 )
24 from typing_extensions import Literal, assert_never
25
26 from nerfstudio.cameras.camera_paths import get_path_from_json, get_spiral_path
27 from nerfstudio.cameras.cameras import Cameras
28 from nerfstudio.configs.base_config import Config # pylint: disable=unused-import
29 from nerfstudio.pipelines.base_pipeline import Pipeline
30 from nerfstudio.utils import install_checks
31 from nerfstudio.utils.eval_utils import eval_setup
32 from nerfstudio.utils.rich_utils import ItersPerSecColumn
33
34 CONSOLE = Console(width=120)
35
36
37 def _render_trajectory_video(
38 pipeline: Pipeline,
39 cameras: Cameras,
40 output_filename: Path,
41 rendered_output_name: str,
42 rendered_resolution_scaling_factor: float = 1.0,
43 seconds: float = 5.0,
44 output_format: Literal["images", "video"] = "video",
45 ) -> None:
46 """Helper function to create a video of the spiral trajectory.
47
48 Args:
49 pipeline: Pipeline to evaluate with.
50 cameras: Cameras to render.
51 output_filename: Name of the output file.
52 rendered_output_name: Name of the renderer output to use.
53 rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.
54 seconds: Length of output video.
55 output_format: How to save output data.
56 """
57 CONSOLE.print("[bold green]Creating trajectory video")
58 images = []
59 cameras.rescale_output_resolution(rendered_resolution_scaling_factor)
60
61 progress = Progress(
62 TextColumn(":movie_camera: Rendering :movie_camera:"),
63 BarColumn(),
64 TaskProgressColumn(show_speed=True),
65 ItersPerSecColumn(suffix="fps"),
66 TimeRemainingColumn(elapsed_when_finished=True, compact=True),
67 )
68 output_image_dir = output_filename.parent / output_filename.stem
69 if output_format == "images":
70 output_image_dir.mkdir(parents=True, exist_ok=True)
71 with progress:
72 for camera_idx in progress.track(range(cameras.size), description=""):
73 camera_ray_bundle = cameras.generate_rays(camera_indices=camera_idx).to(pipeline.device)
74 with torch.no_grad():
75 outputs = pipeline.model.get_outputs_for_camera_ray_bundle(camera_ray_bundle)
76 if rendered_output_name not in outputs:
77 CONSOLE.rule("Error", style="red")
78 CONSOLE.print(f"Could not find {rendered_output_name} in the model outputs", justify="center")
79 CONSOLE.print(f"Please set --rendered_output_name to one of: {outputs.keys()}", justify="center")
80 sys.exit(1)
81 image = outputs[rendered_output_name].cpu().numpy()
82 if output_format == "images":
83 media.write_image(output_image_dir / f"{camera_idx:05d}.png", image)
84 else:
85 images.append(image)
86
87 if output_format == "video":
88 fps = len(images) / seconds
89 # make the folder if it doesn't exist
90 output_filename.parent.mkdir(parents=True, exist_ok=True)
91 with CONSOLE.status("[yellow]Saving video", spinner="bouncingBall"):
92 media.write_video(output_filename, images, fps=fps)
93 CONSOLE.rule("[green] :tada: :tada: :tada: Success :tada: :tada: :tada:")
94 CONSOLE.print(f"[green]Saved video to {output_filename}", justify="center")
95
96
97 @dataclasses.dataclass
98 class RenderTrajectory:
99 """Load a checkpoint, render a trajectory, and save to a video file."""
100
101 # Path to config YAML file.
102 load_config: Path
103 # Name of the renderer output to use. rgb, depth, etc.
104 rendered_output_name: str = "rgb"
105 # Trajectory to render.
106 traj: Literal["spiral", "interp", "filename"] = "spiral"
107 # Scaling factor to apply to the camera image resolution.
108 downscale_factor: int = 1
109 # Filename of the camera path to render.
110 camera_path_filename: Path = Path("camera_path.json")
111 # Name of the output file.
112 output_path: Path = Path("renders/output.mp4")
113 # How long the video should be.
114 seconds: float = 5.0
115 # How to save output data.
116 output_format: Literal["images", "video"] = "video"
117 # Specifies number of rays per chunk during eval.
118 eval_num_rays_per_chunk: Optional[int] = None
119
120 def main(self) -> None:
121 """Main function."""
122 _, pipeline, _ = eval_setup(
123 self.load_config,
124 eval_num_rays_per_chunk=self.eval_num_rays_per_chunk,
125 )
126
127 install_checks.check_ffmpeg_installed()
128
129 seconds = self.seconds
130
131 # TODO(ethan): use camera information from parsing args
132 if self.traj == "spiral":
133 camera_start = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)
134 # TODO(ethan): pass in the up direction of the camera
135 camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)
136 elif self.traj == "interp":
137 # cameras_a = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)
138 # cameras_b = pipeline.datamanager.eval_dataloader.get_camera(image_idx=10)
139 # camera_path = get_interpolated_camera_path(cameras, steps=30)
140 raise NotImplementedError("Interpolated camera path not implemented.")
141 elif self.traj == "filename":
142 with open(self.camera_path_filename, "r", encoding="utf-8") as f:
143 camera_path = json.load(f)
144 seconds = camera_path["seconds"]
145 camera_path = get_path_from_json(camera_path)
146 else:
147 assert_never(self.traj)
148
149 _render_trajectory_video(
150 pipeline,
151 camera_path,
152 output_filename=self.output_path,
153 rendered_output_name=self.rendered_output_name,
154 rendered_resolution_scaling_factor=1.0 / self.downscale_factor,
155 seconds=seconds,
156 output_format=self.output_format,
157 )
158
159
160 def entrypoint():
161 """Entrypoint for use with pyproject scripts."""
162 tyro.extras.set_accent_color("bright_yellow")
163 tyro.cli(RenderTrajectory).main()
164
165
166 if __name__ == "__main__":
167 entrypoint()
168
169 # For sphinx docs
170 get_parser_fn = lambda: tyro.extras.get_parser(RenderTrajectory) # noqa
171
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/scripts/render.py b/scripts/render.py
--- a/scripts/render.py
+++ b/scripts/render.py
@@ -103,7 +103,7 @@
# Name of the renderer output to use. rgb, depth, etc.
rendered_output_name: str = "rgb"
# Trajectory to render.
- traj: Literal["spiral", "interp", "filename"] = "spiral"
+ traj: Literal["spiral", "filename"] = "spiral"
# Scaling factor to apply to the camera image resolution.
downscale_factor: int = 1
# Filename of the camera path to render.
@@ -133,11 +133,6 @@
camera_start = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)
# TODO(ethan): pass in the up direction of the camera
camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)
- elif self.traj == "interp":
- # cameras_a = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)
- # cameras_b = pipeline.datamanager.eval_dataloader.get_camera(image_idx=10)
- # camera_path = get_interpolated_camera_path(cameras, steps=30)
- raise NotImplementedError("Interpolated camera path not implemented.")
elif self.traj == "filename":
with open(self.camera_path_filename, "r", encoding="utf-8") as f:
camera_path = json.load(f)
| {"golden_diff": "diff --git a/scripts/render.py b/scripts/render.py\n--- a/scripts/render.py\n+++ b/scripts/render.py\n@@ -103,7 +103,7 @@\n # Name of the renderer output to use. rgb, depth, etc.\n rendered_output_name: str = \"rgb\"\n # Trajectory to render.\n- traj: Literal[\"spiral\", \"interp\", \"filename\"] = \"spiral\"\n+ traj: Literal[\"spiral\", \"filename\"] = \"spiral\"\n # Scaling factor to apply to the camera image resolution.\n downscale_factor: int = 1\n # Filename of the camera path to render.\n@@ -133,11 +133,6 @@\n camera_start = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)\n # TODO(ethan): pass in the up direction of the camera\n camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)\n- elif self.traj == \"interp\":\n- # cameras_a = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)\n- # cameras_b = pipeline.datamanager.eval_dataloader.get_camera(image_idx=10)\n- # camera_path = get_interpolated_camera_path(cameras, steps=30)\n- raise NotImplementedError(\"Interpolated camera path not implemented.\")\n elif self.traj == \"filename\":\n with open(self.camera_path_filename, \"r\", encoding=\"utf-8\") as f:\n camera_path = json.load(f)\n", "issue": "Render fails silently traj=\"interp\" mode (with custom data)\n**Describe the bug**\r\nWhen using ns-render (in google colab) and with custom images, the render \"finishes\" (cell executes successfully without any error), however, there's no output. The same command works well with traj=\"spiral\"\r\n\r\n**To Reproduce**\r\nExecuting the following command fails to output any video/rendering:\r\n`!ns-render --load-config $config_filename --traj=interp --output-path renders/output.mp4`\r\n\r\nHowever, changing the trajectory mode to spiral produces a correct video:\r\n`!ns-render --load-config $config_filename --traj=spiral --output-path outputs/renders/output.mp4`\r\n\r\n**Additional context**\r\nI've checked the documentation for some pre-requisites to run the interpolation mode, but I didn't find anything.\r\n\r\nThanks!\r\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nrender.py\n\"\"\"\nfrom __future__ import annotations\n\nimport dataclasses\nimport json\nimport sys\nfrom pathlib import Path\nfrom typing import Optional\n\nimport mediapy as media\nimport torch\nimport tyro\nfrom rich.console import Console\nfrom rich.progress import (\n BarColumn,\n Progress,\n TaskProgressColumn,\n TextColumn,\n TimeRemainingColumn,\n)\nfrom typing_extensions import Literal, assert_never\n\nfrom nerfstudio.cameras.camera_paths import get_path_from_json, get_spiral_path\nfrom nerfstudio.cameras.cameras import Cameras\nfrom nerfstudio.configs.base_config import Config # pylint: disable=unused-import\nfrom nerfstudio.pipelines.base_pipeline import Pipeline\nfrom nerfstudio.utils import install_checks\nfrom nerfstudio.utils.eval_utils import eval_setup\nfrom nerfstudio.utils.rich_utils import ItersPerSecColumn\n\nCONSOLE = Console(width=120)\n\n\ndef _render_trajectory_video(\n pipeline: Pipeline,\n cameras: Cameras,\n output_filename: Path,\n rendered_output_name: str,\n rendered_resolution_scaling_factor: float = 1.0,\n seconds: float = 5.0,\n output_format: Literal[\"images\", \"video\"] = \"video\",\n) -> None:\n \"\"\"Helper function to create a video of the spiral trajectory.\n\n Args:\n pipeline: Pipeline to evaluate with.\n cameras: Cameras to render.\n output_filename: Name of the output file.\n rendered_output_name: Name of the renderer output to use.\n rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.\n seconds: Length of output video.\n output_format: How to save output data.\n \"\"\"\n CONSOLE.print(\"[bold green]Creating trajectory video\")\n images = []\n cameras.rescale_output_resolution(rendered_resolution_scaling_factor)\n\n progress = Progress(\n TextColumn(\":movie_camera: Rendering :movie_camera:\"),\n BarColumn(),\n TaskProgressColumn(show_speed=True),\n ItersPerSecColumn(suffix=\"fps\"),\n TimeRemainingColumn(elapsed_when_finished=True, compact=True),\n )\n output_image_dir = output_filename.parent / output_filename.stem\n if output_format == \"images\":\n output_image_dir.mkdir(parents=True, exist_ok=True)\n with progress:\n for camera_idx in progress.track(range(cameras.size), description=\"\"):\n camera_ray_bundle = cameras.generate_rays(camera_indices=camera_idx).to(pipeline.device)\n with torch.no_grad():\n outputs = pipeline.model.get_outputs_for_camera_ray_bundle(camera_ray_bundle)\n if rendered_output_name not in outputs:\n CONSOLE.rule(\"Error\", style=\"red\")\n CONSOLE.print(f\"Could not find {rendered_output_name} in the model outputs\", justify=\"center\")\n CONSOLE.print(f\"Please set --rendered_output_name to one of: {outputs.keys()}\", justify=\"center\")\n sys.exit(1)\n image = outputs[rendered_output_name].cpu().numpy()\n if output_format == \"images\":\n media.write_image(output_image_dir / f\"{camera_idx:05d}.png\", image)\n else:\n images.append(image)\n\n if output_format == \"video\":\n fps = len(images) / seconds\n # make the folder if it doesn't exist\n output_filename.parent.mkdir(parents=True, exist_ok=True)\n with CONSOLE.status(\"[yellow]Saving video\", spinner=\"bouncingBall\"):\n media.write_video(output_filename, images, fps=fps)\n CONSOLE.rule(\"[green] :tada: :tada: :tada: Success :tada: :tada: :tada:\")\n CONSOLE.print(f\"[green]Saved video to {output_filename}\", justify=\"center\")\n\n\[email protected]\nclass RenderTrajectory:\n \"\"\"Load a checkpoint, render a trajectory, and save to a video file.\"\"\"\n\n # Path to config YAML file.\n load_config: Path\n # Name of the renderer output to use. rgb, depth, etc.\n rendered_output_name: str = \"rgb\"\n # Trajectory to render.\n traj: Literal[\"spiral\", \"interp\", \"filename\"] = \"spiral\"\n # Scaling factor to apply to the camera image resolution.\n downscale_factor: int = 1\n # Filename of the camera path to render.\n camera_path_filename: Path = Path(\"camera_path.json\")\n # Name of the output file.\n output_path: Path = Path(\"renders/output.mp4\")\n # How long the video should be.\n seconds: float = 5.0\n # How to save output data.\n output_format: Literal[\"images\", \"video\"] = \"video\"\n # Specifies number of rays per chunk during eval.\n eval_num_rays_per_chunk: Optional[int] = None\n\n def main(self) -> None:\n \"\"\"Main function.\"\"\"\n _, pipeline, _ = eval_setup(\n self.load_config,\n eval_num_rays_per_chunk=self.eval_num_rays_per_chunk,\n )\n\n install_checks.check_ffmpeg_installed()\n\n seconds = self.seconds\n\n # TODO(ethan): use camera information from parsing args\n if self.traj == \"spiral\":\n camera_start = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)\n # TODO(ethan): pass in the up direction of the camera\n camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)\n elif self.traj == \"interp\":\n # cameras_a = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)\n # cameras_b = pipeline.datamanager.eval_dataloader.get_camera(image_idx=10)\n # camera_path = get_interpolated_camera_path(cameras, steps=30)\n raise NotImplementedError(\"Interpolated camera path not implemented.\")\n elif self.traj == \"filename\":\n with open(self.camera_path_filename, \"r\", encoding=\"utf-8\") as f:\n camera_path = json.load(f)\n seconds = camera_path[\"seconds\"]\n camera_path = get_path_from_json(camera_path)\n else:\n assert_never(self.traj)\n\n _render_trajectory_video(\n pipeline,\n camera_path,\n output_filename=self.output_path,\n rendered_output_name=self.rendered_output_name,\n rendered_resolution_scaling_factor=1.0 / self.downscale_factor,\n seconds=seconds,\n output_format=self.output_format,\n )\n\n\ndef entrypoint():\n \"\"\"Entrypoint for use with pyproject scripts.\"\"\"\n tyro.extras.set_accent_color(\"bright_yellow\")\n tyro.cli(RenderTrajectory).main()\n\n\nif __name__ == \"__main__\":\n entrypoint()\n\n# For sphinx docs\nget_parser_fn = lambda: tyro.extras.get_parser(RenderTrajectory) # noqa\n", "path": "scripts/render.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\"\"\"\nrender.py\n\"\"\"\nfrom __future__ import annotations\n\nimport dataclasses\nimport json\nimport sys\nfrom pathlib import Path\nfrom typing import Optional\n\nimport mediapy as media\nimport torch\nimport tyro\nfrom rich.console import Console\nfrom rich.progress import (\n BarColumn,\n Progress,\n TaskProgressColumn,\n TextColumn,\n TimeRemainingColumn,\n)\nfrom typing_extensions import Literal, assert_never\n\nfrom nerfstudio.cameras.camera_paths import get_path_from_json, get_spiral_path\nfrom nerfstudio.cameras.cameras import Cameras\nfrom nerfstudio.configs.base_config import Config # pylint: disable=unused-import\nfrom nerfstudio.pipelines.base_pipeline import Pipeline\nfrom nerfstudio.utils import install_checks\nfrom nerfstudio.utils.eval_utils import eval_setup\nfrom nerfstudio.utils.rich_utils import ItersPerSecColumn\n\nCONSOLE = Console(width=120)\n\n\ndef _render_trajectory_video(\n pipeline: Pipeline,\n cameras: Cameras,\n output_filename: Path,\n rendered_output_name: str,\n rendered_resolution_scaling_factor: float = 1.0,\n seconds: float = 5.0,\n output_format: Literal[\"images\", \"video\"] = \"video\",\n) -> None:\n \"\"\"Helper function to create a video of the spiral trajectory.\n\n Args:\n pipeline: Pipeline to evaluate with.\n cameras: Cameras to render.\n output_filename: Name of the output file.\n rendered_output_name: Name of the renderer output to use.\n rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.\n seconds: Length of output video.\n output_format: How to save output data.\n \"\"\"\n CONSOLE.print(\"[bold green]Creating trajectory video\")\n images = []\n cameras.rescale_output_resolution(rendered_resolution_scaling_factor)\n\n progress = Progress(\n TextColumn(\":movie_camera: Rendering :movie_camera:\"),\n BarColumn(),\n TaskProgressColumn(show_speed=True),\n ItersPerSecColumn(suffix=\"fps\"),\n TimeRemainingColumn(elapsed_when_finished=True, compact=True),\n )\n output_image_dir = output_filename.parent / output_filename.stem\n if output_format == \"images\":\n output_image_dir.mkdir(parents=True, exist_ok=True)\n with progress:\n for camera_idx in progress.track(range(cameras.size), description=\"\"):\n camera_ray_bundle = cameras.generate_rays(camera_indices=camera_idx).to(pipeline.device)\n with torch.no_grad():\n outputs = pipeline.model.get_outputs_for_camera_ray_bundle(camera_ray_bundle)\n if rendered_output_name not in outputs:\n CONSOLE.rule(\"Error\", style=\"red\")\n CONSOLE.print(f\"Could not find {rendered_output_name} in the model outputs\", justify=\"center\")\n CONSOLE.print(f\"Please set --rendered_output_name to one of: {outputs.keys()}\", justify=\"center\")\n sys.exit(1)\n image = outputs[rendered_output_name].cpu().numpy()\n if output_format == \"images\":\n media.write_image(output_image_dir / f\"{camera_idx:05d}.png\", image)\n else:\n images.append(image)\n\n if output_format == \"video\":\n fps = len(images) / seconds\n # make the folder if it doesn't exist\n output_filename.parent.mkdir(parents=True, exist_ok=True)\n with CONSOLE.status(\"[yellow]Saving video\", spinner=\"bouncingBall\"):\n media.write_video(output_filename, images, fps=fps)\n CONSOLE.rule(\"[green] :tada: :tada: :tada: Success :tada: :tada: :tada:\")\n CONSOLE.print(f\"[green]Saved video to {output_filename}\", justify=\"center\")\n\n\[email protected]\nclass RenderTrajectory:\n \"\"\"Load a checkpoint, render a trajectory, and save to a video file.\"\"\"\n\n # Path to config YAML file.\n load_config: Path\n # Name of the renderer output to use. rgb, depth, etc.\n rendered_output_name: str = \"rgb\"\n # Trajectory to render.\n traj: Literal[\"spiral\", \"filename\"] = \"spiral\"\n # Scaling factor to apply to the camera image resolution.\n downscale_factor: int = 1\n # Filename of the camera path to render.\n camera_path_filename: Path = Path(\"camera_path.json\")\n # Name of the output file.\n output_path: Path = Path(\"renders/output.mp4\")\n # How long the video should be.\n seconds: float = 5.0\n # How to save output data.\n output_format: Literal[\"images\", \"video\"] = \"video\"\n # Specifies number of rays per chunk during eval.\n eval_num_rays_per_chunk: Optional[int] = None\n\n def main(self) -> None:\n \"\"\"Main function.\"\"\"\n _, pipeline, _ = eval_setup(\n self.load_config,\n eval_num_rays_per_chunk=self.eval_num_rays_per_chunk,\n )\n\n install_checks.check_ffmpeg_installed()\n\n seconds = self.seconds\n\n # TODO(ethan): use camera information from parsing args\n if self.traj == \"spiral\":\n camera_start = pipeline.datamanager.eval_dataloader.get_camera(image_idx=0)\n # TODO(ethan): pass in the up direction of the camera\n camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)\n elif self.traj == \"filename\":\n with open(self.camera_path_filename, \"r\", encoding=\"utf-8\") as f:\n camera_path = json.load(f)\n seconds = camera_path[\"seconds\"]\n camera_path = get_path_from_json(camera_path)\n else:\n assert_never(self.traj)\n\n _render_trajectory_video(\n pipeline,\n camera_path,\n output_filename=self.output_path,\n rendered_output_name=self.rendered_output_name,\n rendered_resolution_scaling_factor=1.0 / self.downscale_factor,\n seconds=seconds,\n output_format=self.output_format,\n )\n\n\ndef entrypoint():\n \"\"\"Entrypoint for use with pyproject scripts.\"\"\"\n tyro.extras.set_accent_color(\"bright_yellow\")\n tyro.cli(RenderTrajectory).main()\n\n\nif __name__ == \"__main__\":\n entrypoint()\n\n# For sphinx docs\nget_parser_fn = lambda: tyro.extras.get_parser(RenderTrajectory) # noqa\n", "path": "scripts/render.py"}]} | 2,298 | 334 |
gh_patches_debug_23345 | rasdani/github-patches | git_diff | elastic__apm-agent-python-958 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Expand k8s pod ID discovery regex
Implementing elastic/apm#344
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/utils/cgroup.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2019, Elasticsearch BV
4 # All rights reserved.
5 #
6 # Redistribution and use in source and binary forms, with or without
7 # modification, are permitted provided that the following conditions are met:
8 #
9 # * Redistributions of source code must retain the above copyright notice, this
10 # list of conditions and the following disclaimer.
11 #
12 # * Redistributions in binary form must reproduce the above copyright notice,
13 # this list of conditions and the following disclaimer in the documentation
14 # and/or other materials provided with the distribution.
15 #
16 # * Neither the name of the copyright holder nor the names of its
17 # contributors may be used to endorse or promote products derived from
18 # this software without specific prior written permission.
19 #
20 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
21 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
22 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
23 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
24 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
25 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
26 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
27 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
28 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
29 # OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
30
31 import os
32 import re
33
34 CGROUP_PATH = "/proc/self/cgroup"
35
36 SYSTEMD_SCOPE_SUFFIX = ".scope"
37
38 kubepods_regexp = re.compile(
39 r"(?:^/kubepods[\S]*/pod([^/]+)$)|(?:^/kubepods\.slice/kubepods-[^/]+\.slice/kubepods-[^/]+-pod([^/]+)\.slice$)"
40 )
41
42 container_id_regexp = re.compile(
43 "^(?:[0-9a-f]{64}|[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4,})$", re.IGNORECASE
44 )
45
46
47 def get_cgroup_container_metadata():
48 """
49 Reads docker/kubernetes metadata (container id, pod id) from /proc/self/cgroup
50
51 The result is a nested dictionary with the detected IDs, e.g.
52
53 {
54 "container": {"id": "2227daf62df6694645fee5df53c1f91271546a9560e8600a525690ae252b7f63"},
55 "pod": {"uid": "90d81341_92de_11e7_8cf2_507b9d4141fa"}
56 }
57
58 :return: a dictionary with the detected ids or {}
59 """
60 if not os.path.exists(CGROUP_PATH):
61 return {}
62 with open(CGROUP_PATH) as f:
63 return parse_cgroups(f) or {}
64
65
66 def parse_cgroups(filehandle):
67 """
68 Reads lines from a file handle and tries to parse docker container IDs and kubernetes Pod IDs.
69
70 See tests.utils.docker_tests.test_cgroup_parsing for a set of test cases
71
72 :param filehandle:
73 :return: nested dictionary or None
74 """
75 for line in filehandle:
76 parts = line.strip().split(":")
77 if len(parts) != 3:
78 continue
79 cgroup_path = parts[2]
80
81 # Depending on the filesystem driver used for cgroup
82 # management, the paths in /proc/pid/cgroup will have
83 # one of the following formats in a Docker container:
84 #
85 # systemd: /system.slice/docker-<container-ID>.scope
86 # cgroupfs: /docker/<container-ID>
87 #
88 # In a Kubernetes pod, the cgroup path will look like:
89 #
90 # systemd:/kubepods.slice/kubepods-<QoS-class>.slice/kubepods-<QoS-class>-pod<pod-UID>.slice/<container-iD>.scope
91 # cgroupfs:/kubepods/<QoS-class>/pod<pod-UID>/<container-iD>
92
93 directory, container_id = os.path.split(cgroup_path)
94 if container_id.endswith(SYSTEMD_SCOPE_SUFFIX):
95 container_id = container_id[: -len(SYSTEMD_SCOPE_SUFFIX)]
96 if "-" in container_id:
97 container_id = container_id.split("-", 1)[1]
98 kubepods_match = kubepods_regexp.match(directory)
99 if kubepods_match:
100 pod_id = kubepods_match.group(1)
101 if not pod_id:
102 pod_id = kubepods_match.group(2)
103 if pod_id:
104 pod_id = pod_id.replace("_", "-")
105 return {"container": {"id": container_id}, "kubernetes": {"pod": {"uid": pod_id}}}
106 elif container_id_regexp.match(container_id):
107 return {"container": {"id": container_id}}
108
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/elasticapm/utils/cgroup.py b/elasticapm/utils/cgroup.py
--- a/elasticapm/utils/cgroup.py
+++ b/elasticapm/utils/cgroup.py
@@ -36,7 +36,7 @@
SYSTEMD_SCOPE_SUFFIX = ".scope"
kubepods_regexp = re.compile(
- r"(?:^/kubepods[\S]*/pod([^/]+)$)|(?:^/kubepods\.slice/kubepods-[^/]+\.slice/kubepods-[^/]+-pod([^/]+)\.slice$)"
+ r"(?:^/kubepods[\S]*/pod([^/]+)$)|(?:^/kubepods\.slice/(kubepods-[^/]+\.slice/)?kubepods[^/]*-pod([^/]+)\.slice$)"
)
container_id_regexp = re.compile(
@@ -97,9 +97,9 @@
container_id = container_id.split("-", 1)[1]
kubepods_match = kubepods_regexp.match(directory)
if kubepods_match:
- pod_id = kubepods_match.group(1)
+ pod_id = kubepods_match.group(1) # if first part of kubepods_regexp matched
if not pod_id:
- pod_id = kubepods_match.group(2)
+ pod_id = kubepods_match.group(3) # if second part of kubepods_regexp matched
if pod_id:
pod_id = pod_id.replace("_", "-")
return {"container": {"id": container_id}, "kubernetes": {"pod": {"uid": pod_id}}}
| {"golden_diff": "diff --git a/elasticapm/utils/cgroup.py b/elasticapm/utils/cgroup.py\n--- a/elasticapm/utils/cgroup.py\n+++ b/elasticapm/utils/cgroup.py\n@@ -36,7 +36,7 @@\n SYSTEMD_SCOPE_SUFFIX = \".scope\"\n \n kubepods_regexp = re.compile(\n- r\"(?:^/kubepods[\\S]*/pod([^/]+)$)|(?:^/kubepods\\.slice/kubepods-[^/]+\\.slice/kubepods-[^/]+-pod([^/]+)\\.slice$)\"\n+ r\"(?:^/kubepods[\\S]*/pod([^/]+)$)|(?:^/kubepods\\.slice/(kubepods-[^/]+\\.slice/)?kubepods[^/]*-pod([^/]+)\\.slice$)\"\n )\n \n container_id_regexp = re.compile(\n@@ -97,9 +97,9 @@\n container_id = container_id.split(\"-\", 1)[1]\n kubepods_match = kubepods_regexp.match(directory)\n if kubepods_match:\n- pod_id = kubepods_match.group(1)\n+ pod_id = kubepods_match.group(1) # if first part of kubepods_regexp matched\n if not pod_id:\n- pod_id = kubepods_match.group(2)\n+ pod_id = kubepods_match.group(3) # if second part of kubepods_regexp matched\n if pod_id:\n pod_id = pod_id.replace(\"_\", \"-\")\n return {\"container\": {\"id\": container_id}, \"kubernetes\": {\"pod\": {\"uid\": pod_id}}}\n", "issue": "Expand k8s pod ID discovery regex\nImplementing elastic/apm#344\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport os\nimport re\n\nCGROUP_PATH = \"/proc/self/cgroup\"\n\nSYSTEMD_SCOPE_SUFFIX = \".scope\"\n\nkubepods_regexp = re.compile(\n r\"(?:^/kubepods[\\S]*/pod([^/]+)$)|(?:^/kubepods\\.slice/kubepods-[^/]+\\.slice/kubepods-[^/]+-pod([^/]+)\\.slice$)\"\n)\n\ncontainer_id_regexp = re.compile(\n \"^(?:[0-9a-f]{64}|[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4,})$\", re.IGNORECASE\n)\n\n\ndef get_cgroup_container_metadata():\n \"\"\"\n Reads docker/kubernetes metadata (container id, pod id) from /proc/self/cgroup\n\n The result is a nested dictionary with the detected IDs, e.g.\n\n {\n \"container\": {\"id\": \"2227daf62df6694645fee5df53c1f91271546a9560e8600a525690ae252b7f63\"},\n \"pod\": {\"uid\": \"90d81341_92de_11e7_8cf2_507b9d4141fa\"}\n }\n\n :return: a dictionary with the detected ids or {}\n \"\"\"\n if not os.path.exists(CGROUP_PATH):\n return {}\n with open(CGROUP_PATH) as f:\n return parse_cgroups(f) or {}\n\n\ndef parse_cgroups(filehandle):\n \"\"\"\n Reads lines from a file handle and tries to parse docker container IDs and kubernetes Pod IDs.\n\n See tests.utils.docker_tests.test_cgroup_parsing for a set of test cases\n\n :param filehandle:\n :return: nested dictionary or None\n \"\"\"\n for line in filehandle:\n parts = line.strip().split(\":\")\n if len(parts) != 3:\n continue\n cgroup_path = parts[2]\n\n # Depending on the filesystem driver used for cgroup\n # management, the paths in /proc/pid/cgroup will have\n # one of the following formats in a Docker container:\n #\n # systemd: /system.slice/docker-<container-ID>.scope\n # cgroupfs: /docker/<container-ID>\n #\n # In a Kubernetes pod, the cgroup path will look like:\n #\n # systemd:/kubepods.slice/kubepods-<QoS-class>.slice/kubepods-<QoS-class>-pod<pod-UID>.slice/<container-iD>.scope\n # cgroupfs:/kubepods/<QoS-class>/pod<pod-UID>/<container-iD>\n\n directory, container_id = os.path.split(cgroup_path)\n if container_id.endswith(SYSTEMD_SCOPE_SUFFIX):\n container_id = container_id[: -len(SYSTEMD_SCOPE_SUFFIX)]\n if \"-\" in container_id:\n container_id = container_id.split(\"-\", 1)[1]\n kubepods_match = kubepods_regexp.match(directory)\n if kubepods_match:\n pod_id = kubepods_match.group(1)\n if not pod_id:\n pod_id = kubepods_match.group(2)\n if pod_id:\n pod_id = pod_id.replace(\"_\", \"-\")\n return {\"container\": {\"id\": container_id}, \"kubernetes\": {\"pod\": {\"uid\": pod_id}}}\n elif container_id_regexp.match(container_id):\n return {\"container\": {\"id\": container_id}}\n", "path": "elasticapm/utils/cgroup.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\nimport os\nimport re\n\nCGROUP_PATH = \"/proc/self/cgroup\"\n\nSYSTEMD_SCOPE_SUFFIX = \".scope\"\n\nkubepods_regexp = re.compile(\n r\"(?:^/kubepods[\\S]*/pod([^/]+)$)|(?:^/kubepods\\.slice/(kubepods-[^/]+\\.slice/)?kubepods[^/]*-pod([^/]+)\\.slice$)\"\n)\n\ncontainer_id_regexp = re.compile(\n \"^(?:[0-9a-f]{64}|[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4,})$\", re.IGNORECASE\n)\n\n\ndef get_cgroup_container_metadata():\n \"\"\"\n Reads docker/kubernetes metadata (container id, pod id) from /proc/self/cgroup\n\n The result is a nested dictionary with the detected IDs, e.g.\n\n {\n \"container\": {\"id\": \"2227daf62df6694645fee5df53c1f91271546a9560e8600a525690ae252b7f63\"},\n \"pod\": {\"uid\": \"90d81341_92de_11e7_8cf2_507b9d4141fa\"}\n }\n\n :return: a dictionary with the detected ids or {}\n \"\"\"\n if not os.path.exists(CGROUP_PATH):\n return {}\n with open(CGROUP_PATH) as f:\n return parse_cgroups(f) or {}\n\n\ndef parse_cgroups(filehandle):\n \"\"\"\n Reads lines from a file handle and tries to parse docker container IDs and kubernetes Pod IDs.\n\n See tests.utils.docker_tests.test_cgroup_parsing for a set of test cases\n\n :param filehandle:\n :return: nested dictionary or None\n \"\"\"\n for line in filehandle:\n parts = line.strip().split(\":\")\n if len(parts) != 3:\n continue\n cgroup_path = parts[2]\n\n # Depending on the filesystem driver used for cgroup\n # management, the paths in /proc/pid/cgroup will have\n # one of the following formats in a Docker container:\n #\n # systemd: /system.slice/docker-<container-ID>.scope\n # cgroupfs: /docker/<container-ID>\n #\n # In a Kubernetes pod, the cgroup path will look like:\n #\n # systemd:/kubepods.slice/kubepods-<QoS-class>.slice/kubepods-<QoS-class>-pod<pod-UID>.slice/<container-iD>.scope\n # cgroupfs:/kubepods/<QoS-class>/pod<pod-UID>/<container-iD>\n\n directory, container_id = os.path.split(cgroup_path)\n if container_id.endswith(SYSTEMD_SCOPE_SUFFIX):\n container_id = container_id[: -len(SYSTEMD_SCOPE_SUFFIX)]\n if \"-\" in container_id:\n container_id = container_id.split(\"-\", 1)[1]\n kubepods_match = kubepods_regexp.match(directory)\n if kubepods_match:\n pod_id = kubepods_match.group(1) # if first part of kubepods_regexp matched\n if not pod_id:\n pod_id = kubepods_match.group(3) # if second part of kubepods_regexp matched\n if pod_id:\n pod_id = pod_id.replace(\"_\", \"-\")\n return {\"container\": {\"id\": container_id}, \"kubernetes\": {\"pod\": {\"uid\": pod_id}}}\n elif container_id_regexp.match(container_id):\n return {\"container\": {\"id\": container_id}}\n", "path": "elasticapm/utils/cgroup.py"}]} | 1,656 | 383 |
gh_patches_debug_14302 | rasdani/github-patches | git_diff | learningequality__kolibri-8886 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Errors while interacting with resources in a lesson on Learn-only device
## Observed behavior
Replicable on 0.15.0b3 installed on both Windows 7 & 10 with learn-only device on Android 9.0 phone. Errors appear in seemingly random fashion on different resources at different moments. Learner device appears to be syncing correctly with the server, and progress (when achieved) is registered on Coach page.
1 | 2 | 3
--- | --- | ---
 |  | 
## Errors and logs
```
{
"data": "<h1>Server Error (500)</h1>",
"status": 500,
"statusText": "Internal Server Error",
"headers": {
"content-length": "27",
"content-type": "text/html",
"date": "Wed, 08 Dec 2021 01:20:57 GMT",
"server": "Cheroot/unknown",
"vary": "Cookie",
"x-frame-options": "SAMEORIGIN"
},
"config": {
"url": "/api/logger/trackprogress/c05a4300939687321e2195d8972941f7/",
"method": "put",
"data": "{\"time_spent_delta\":123.604}",
"headers": {
"Accept": "application/json, text/plain, */*",
"Content-Type": "application/json;charset=utf-8",
"X-Requested-With": "XMLHttpRequest",
"X-CSRFToken": "WKza1d9ZwO52LYZNL8Ve0aBq1GsoKKio2ISgQZA2cHI4mNhLu0Ux5LlCG3ZfpCpd"
},
"transformRequest": [
null
],
"transformResponse": [
null
],
"timeout": 0,
"xsrfCookieName": "kolibri_csrftoken",
"xsrfHeaderName": "X-CSRFToken",
"maxContentLength": -1
},
"request": {}
}
```
[db-and-logs.zip](https://github.com/learningequality/kolibri/files/7673793/db-and-logs.zip)
[full home folder](https://drive.google.com/file/d/1qgC6Ovfm91RzdgoFA4TEJNuWeZi-NS5L/view?usp=sharing) (Windows 7, 370MB)
## Expected behavior
...
## User-facing consequences
...
## Steps to reproduce
…
## Context
* Kolibri version: 0.15.0b3
* Operating system: Windows 7 & 10 with learn-only device on Android 9.0 phone
* Browser: Firefox
cc @marcellamaki @rtibbles
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kolibri/core/device/middleware.py`
Content:
```
1 from django.conf import settings
2 from django.db import OperationalError
3 from django.http import HttpResponse
4 from django.http import HttpResponseRedirect
5 from django.shortcuts import redirect
6 from django.urls import is_valid_path
7 from django.utils import translation
8
9 from .translation import get_language_from_request_and_is_from_path
10 from kolibri.core.device.hooks import SetupHook
11 from kolibri.core.device.utils import DeviceNotProvisioned
12 from kolibri.utils.conf import OPTIONS
13
14
15 class KolibriLocaleMiddleware(object):
16 """
17 Copied and then modified into a new style middleware from:
18 https://github.com/django/django/blob/stable/1.11.x/django/middleware/locale.py
19 Also has several other changes to suit our purposes.
20 The principal concern of this middleware is to activate translation for the current
21 language, so that throughout the lifecycle of this request, any translation or language
22 related functionality is set to the appropriate locale.
23 Unlike the Django middleware, this middleware only runs on requests to URLs that are
24 prefixed by a language code. Other URLs, such as for untranslated API endpoints do not
25 have a language code set on them.
26 """
27
28 def __init__(self, get_response):
29 # Standard boilerplate for a new style Django middleware.
30 self.get_response = get_response
31
32 def __call__(self, request):
33 # First get the language code, and whether this was calculated from the path
34 # i.e. was this a language-prefixed URL.
35 language, language_from_path = get_language_from_request_and_is_from_path(
36 request
37 )
38 # If this URL has been resolved to a view, and the view is not on a language prefixed
39 # URL, then the function above will return None for the language code to indicate that
40 # no translation is necessary.
41 if language is not None:
42 # Only activate translation if there is a language code returned.
43 translation.activate(language)
44 request.LANGUAGE_CODE = translation.get_language()
45
46 response = self.get_response(request)
47
48 if language is not None:
49
50 language = translation.get_language()
51
52 if response.status_code == 404 and not language_from_path:
53 # Maybe the language code is missing in the URL? Try adding the
54 # language prefix and redirecting to that URL.
55 # First get any global prefix that is being used.
56 script_prefix = OPTIONS["Deployment"]["URL_PATH_PREFIX"]
57 # Replace the global prefix with the global prefix and the language prefix.
58 language_path = request.path_info.replace(
59 script_prefix, "%s%s/" % (script_prefix, language), 1
60 )
61
62 # Get the urlconf from the request, default to the global settings ROOT_URLCONF
63 urlconf = getattr(request, "urlconf", settings.ROOT_URLCONF)
64 # Check if this is a valid path
65 path_valid = is_valid_path(language_path, urlconf)
66 # Check if the path is only invalid because it is missing a trailing slash
67 path_needs_slash = not path_valid and (
68 settings.APPEND_SLASH
69 and not language_path.endswith("/")
70 and is_valid_path("%s/" % language_path, urlconf)
71 )
72 # If the constructed path is valid, or it would be valid with a trailing slash
73 # then redirect to the prefixed path, with a trailing slash added if needed.
74 if path_valid or path_needs_slash:
75 # Insert language after the script prefix and before the
76 # rest of the URL
77 language_url = request.get_full_path(
78 force_append_slash=path_needs_slash
79 ).replace(script_prefix, "%s%s/" % (script_prefix, language), 1)
80 return HttpResponseRedirect(language_url)
81
82 # Add a content language header to the response if not already present.
83 if "Content-Language" not in response:
84 response["Content-Language"] = language
85
86 return response
87
88
89 class ProvisioningErrorHandler(object):
90 def __init__(self, get_response):
91 self.get_response = get_response
92
93 def process_exception(self, request, exception):
94 if (
95 isinstance(exception, DeviceNotProvisioned)
96 and SetupHook.provision_url()
97 and not request.path.startswith(SetupHook.provision_url())
98 ):
99 return redirect(SetupHook.provision_url())
100 return None
101
102 def __call__(self, request):
103 return self.get_response(request)
104
105
106 class DatabaseBusyErrorHandler(object):
107 """
108 A middleware class to raise a 503 when the database is under heavy load
109 For SQLite this will trigger for database locked errors.
110 For Postgres this will trigger for deadlocks.
111 """
112
113 def __init__(self, get_response):
114 self.get_response = get_response
115
116 def process_exception(self, request, exception):
117 if not isinstance(exception, OperationalError):
118 return None
119 if (
120 OPTIONS["Database"]["DATABASE_ENGINE"] == "sqlite"
121 and "database is locked" not in exception.args[0]
122 ):
123 return None
124 if (
125 OPTIONS["Database"]["DATABASE_ENGINE"] == "postgres"
126 and "deadlock detected" not in exception.args[0]
127 ):
128 return None
129 # Return a 503 response with a Retry-After of 10 seconds. In future we may be able to customize this value
130 # based on what is currently happening on the server.
131 return HttpResponse(
132 "Database is not available for write operations",
133 status=503,
134 headers={"Retry-After": 10},
135 )
136
137 def __call__(self, request):
138 return self.get_response(request)
139
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kolibri/core/device/middleware.py b/kolibri/core/device/middleware.py
--- a/kolibri/core/device/middleware.py
+++ b/kolibri/core/device/middleware.py
@@ -128,11 +128,12 @@
return None
# Return a 503 response with a Retry-After of 10 seconds. In future we may be able to customize this value
# based on what is currently happening on the server.
- return HttpResponse(
+ response = HttpResponse(
"Database is not available for write operations",
status=503,
- headers={"Retry-After": 10},
)
+ response["Retry-After"] = 10
+ return response
def __call__(self, request):
return self.get_response(request)
| {"golden_diff": "diff --git a/kolibri/core/device/middleware.py b/kolibri/core/device/middleware.py\n--- a/kolibri/core/device/middleware.py\n+++ b/kolibri/core/device/middleware.py\n@@ -128,11 +128,12 @@\n return None\n # Return a 503 response with a Retry-After of 10 seconds. In future we may be able to customize this value\n # based on what is currently happening on the server.\n- return HttpResponse(\n+ response = HttpResponse(\n \"Database is not available for write operations\",\n status=503,\n- headers={\"Retry-After\": 10},\n )\n+ response[\"Retry-After\"] = 10\n+ return response\n \n def __call__(self, request):\n return self.get_response(request)\n", "issue": "Errors while interacting with resources in a lesson on Learn-only device\n\r\n## Observed behavior\r\nReplicable on 0.15.0b3 installed on both Windows 7 & 10 with learn-only device on Android 9.0 phone. Errors appear in seemingly random fashion on different resources at different moments. Learner device appears to be syncing correctly with the server, and progress (when achieved) is registered on Coach page.\r\n\r\n1 | 2 | 3\r\n--- | --- | ---\r\n |  | \r\n\r\n\r\n## Errors and logs\r\n\r\n```\r\n{\r\n \"data\": \"<h1>Server Error (500)</h1>\",\r\n \"status\": 500,\r\n \"statusText\": \"Internal Server Error\",\r\n \"headers\": {\r\n \"content-length\": \"27\",\r\n \"content-type\": \"text/html\",\r\n \"date\": \"Wed, 08 Dec 2021 01:20:57 GMT\",\r\n \"server\": \"Cheroot/unknown\",\r\n \"vary\": \"Cookie\",\r\n \"x-frame-options\": \"SAMEORIGIN\"\r\n },\r\n \"config\": {\r\n \"url\": \"/api/logger/trackprogress/c05a4300939687321e2195d8972941f7/\",\r\n \"method\": \"put\",\r\n \"data\": \"{\\\"time_spent_delta\\\":123.604}\",\r\n \"headers\": {\r\n \"Accept\": \"application/json, text/plain, */*\",\r\n \"Content-Type\": \"application/json;charset=utf-8\",\r\n \"X-Requested-With\": \"XMLHttpRequest\",\r\n \"X-CSRFToken\": \"WKza1d9ZwO52LYZNL8Ve0aBq1GsoKKio2ISgQZA2cHI4mNhLu0Ux5LlCG3ZfpCpd\"\r\n },\r\n \"transformRequest\": [\r\n null\r\n ],\r\n \"transformResponse\": [\r\n null\r\n ],\r\n \"timeout\": 0,\r\n \"xsrfCookieName\": \"kolibri_csrftoken\",\r\n \"xsrfHeaderName\": \"X-CSRFToken\",\r\n \"maxContentLength\": -1\r\n },\r\n \"request\": {}\r\n}\r\n```\r\n\r\n[db-and-logs.zip](https://github.com/learningequality/kolibri/files/7673793/db-and-logs.zip)\r\n\r\n[full home folder](https://drive.google.com/file/d/1qgC6Ovfm91RzdgoFA4TEJNuWeZi-NS5L/view?usp=sharing) (Windows 7, 370MB)\r\n\r\n## Expected behavior\r\n...\r\n\r\n## User-facing consequences\r\n...\r\n\r\n## Steps to reproduce\r\n\u2026\r\n\r\n## Context\r\n * Kolibri version: 0.15.0b3\r\n * Operating system: Windows 7 & 10 with learn-only device on Android 9.0 phone\r\n * Browser: Firefox\r\n\r\ncc @marcellamaki @rtibbles \n", "before_files": [{"content": "from django.conf import settings\nfrom django.db import OperationalError\nfrom django.http import HttpResponse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import redirect\nfrom django.urls import is_valid_path\nfrom django.utils import translation\n\nfrom .translation import get_language_from_request_and_is_from_path\nfrom kolibri.core.device.hooks import SetupHook\nfrom kolibri.core.device.utils import DeviceNotProvisioned\nfrom kolibri.utils.conf import OPTIONS\n\n\nclass KolibriLocaleMiddleware(object):\n \"\"\"\n Copied and then modified into a new style middleware from:\n https://github.com/django/django/blob/stable/1.11.x/django/middleware/locale.py\n Also has several other changes to suit our purposes.\n The principal concern of this middleware is to activate translation for the current\n language, so that throughout the lifecycle of this request, any translation or language\n related functionality is set to the appropriate locale.\n Unlike the Django middleware, this middleware only runs on requests to URLs that are\n prefixed by a language code. Other URLs, such as for untranslated API endpoints do not\n have a language code set on them.\n \"\"\"\n\n def __init__(self, get_response):\n # Standard boilerplate for a new style Django middleware.\n self.get_response = get_response\n\n def __call__(self, request):\n # First get the language code, and whether this was calculated from the path\n # i.e. was this a language-prefixed URL.\n language, language_from_path = get_language_from_request_and_is_from_path(\n request\n )\n # If this URL has been resolved to a view, and the view is not on a language prefixed\n # URL, then the function above will return None for the language code to indicate that\n # no translation is necessary.\n if language is not None:\n # Only activate translation if there is a language code returned.\n translation.activate(language)\n request.LANGUAGE_CODE = translation.get_language()\n\n response = self.get_response(request)\n\n if language is not None:\n\n language = translation.get_language()\n\n if response.status_code == 404 and not language_from_path:\n # Maybe the language code is missing in the URL? Try adding the\n # language prefix and redirecting to that URL.\n # First get any global prefix that is being used.\n script_prefix = OPTIONS[\"Deployment\"][\"URL_PATH_PREFIX\"]\n # Replace the global prefix with the global prefix and the language prefix.\n language_path = request.path_info.replace(\n script_prefix, \"%s%s/\" % (script_prefix, language), 1\n )\n\n # Get the urlconf from the request, default to the global settings ROOT_URLCONF\n urlconf = getattr(request, \"urlconf\", settings.ROOT_URLCONF)\n # Check if this is a valid path\n path_valid = is_valid_path(language_path, urlconf)\n # Check if the path is only invalid because it is missing a trailing slash\n path_needs_slash = not path_valid and (\n settings.APPEND_SLASH\n and not language_path.endswith(\"/\")\n and is_valid_path(\"%s/\" % language_path, urlconf)\n )\n # If the constructed path is valid, or it would be valid with a trailing slash\n # then redirect to the prefixed path, with a trailing slash added if needed.\n if path_valid or path_needs_slash:\n # Insert language after the script prefix and before the\n # rest of the URL\n language_url = request.get_full_path(\n force_append_slash=path_needs_slash\n ).replace(script_prefix, \"%s%s/\" % (script_prefix, language), 1)\n return HttpResponseRedirect(language_url)\n\n # Add a content language header to the response if not already present.\n if \"Content-Language\" not in response:\n response[\"Content-Language\"] = language\n\n return response\n\n\nclass ProvisioningErrorHandler(object):\n def __init__(self, get_response):\n self.get_response = get_response\n\n def process_exception(self, request, exception):\n if (\n isinstance(exception, DeviceNotProvisioned)\n and SetupHook.provision_url()\n and not request.path.startswith(SetupHook.provision_url())\n ):\n return redirect(SetupHook.provision_url())\n return None\n\n def __call__(self, request):\n return self.get_response(request)\n\n\nclass DatabaseBusyErrorHandler(object):\n \"\"\"\n A middleware class to raise a 503 when the database is under heavy load\n For SQLite this will trigger for database locked errors.\n For Postgres this will trigger for deadlocks.\n \"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def process_exception(self, request, exception):\n if not isinstance(exception, OperationalError):\n return None\n if (\n OPTIONS[\"Database\"][\"DATABASE_ENGINE\"] == \"sqlite\"\n and \"database is locked\" not in exception.args[0]\n ):\n return None\n if (\n OPTIONS[\"Database\"][\"DATABASE_ENGINE\"] == \"postgres\"\n and \"deadlock detected\" not in exception.args[0]\n ):\n return None\n # Return a 503 response with a Retry-After of 10 seconds. In future we may be able to customize this value\n # based on what is currently happening on the server.\n return HttpResponse(\n \"Database is not available for write operations\",\n status=503,\n headers={\"Retry-After\": 10},\n )\n\n def __call__(self, request):\n return self.get_response(request)\n", "path": "kolibri/core/device/middleware.py"}], "after_files": [{"content": "from django.conf import settings\nfrom django.db import OperationalError\nfrom django.http import HttpResponse\nfrom django.http import HttpResponseRedirect\nfrom django.shortcuts import redirect\nfrom django.urls import is_valid_path\nfrom django.utils import translation\n\nfrom .translation import get_language_from_request_and_is_from_path\nfrom kolibri.core.device.hooks import SetupHook\nfrom kolibri.core.device.utils import DeviceNotProvisioned\nfrom kolibri.utils.conf import OPTIONS\n\n\nclass KolibriLocaleMiddleware(object):\n \"\"\"\n Copied and then modified into a new style middleware from:\n https://github.com/django/django/blob/stable/1.11.x/django/middleware/locale.py\n Also has several other changes to suit our purposes.\n The principal concern of this middleware is to activate translation for the current\n language, so that throughout the lifecycle of this request, any translation or language\n related functionality is set to the appropriate locale.\n Unlike the Django middleware, this middleware only runs on requests to URLs that are\n prefixed by a language code. Other URLs, such as for untranslated API endpoints do not\n have a language code set on them.\n \"\"\"\n\n def __init__(self, get_response):\n # Standard boilerplate for a new style Django middleware.\n self.get_response = get_response\n\n def __call__(self, request):\n # First get the language code, and whether this was calculated from the path\n # i.e. was this a language-prefixed URL.\n language, language_from_path = get_language_from_request_and_is_from_path(\n request\n )\n # If this URL has been resolved to a view, and the view is not on a language prefixed\n # URL, then the function above will return None for the language code to indicate that\n # no translation is necessary.\n if language is not None:\n # Only activate translation if there is a language code returned.\n translation.activate(language)\n request.LANGUAGE_CODE = translation.get_language()\n\n response = self.get_response(request)\n\n if language is not None:\n\n language = translation.get_language()\n\n if response.status_code == 404 and not language_from_path:\n # Maybe the language code is missing in the URL? Try adding the\n # language prefix and redirecting to that URL.\n # First get any global prefix that is being used.\n script_prefix = OPTIONS[\"Deployment\"][\"URL_PATH_PREFIX\"]\n # Replace the global prefix with the global prefix and the language prefix.\n language_path = request.path_info.replace(\n script_prefix, \"%s%s/\" % (script_prefix, language), 1\n )\n\n # Get the urlconf from the request, default to the global settings ROOT_URLCONF\n urlconf = getattr(request, \"urlconf\", settings.ROOT_URLCONF)\n # Check if this is a valid path\n path_valid = is_valid_path(language_path, urlconf)\n # Check if the path is only invalid because it is missing a trailing slash\n path_needs_slash = not path_valid and (\n settings.APPEND_SLASH\n and not language_path.endswith(\"/\")\n and is_valid_path(\"%s/\" % language_path, urlconf)\n )\n # If the constructed path is valid, or it would be valid with a trailing slash\n # then redirect to the prefixed path, with a trailing slash added if needed.\n if path_valid or path_needs_slash:\n # Insert language after the script prefix and before the\n # rest of the URL\n language_url = request.get_full_path(\n force_append_slash=path_needs_slash\n ).replace(script_prefix, \"%s%s/\" % (script_prefix, language), 1)\n return HttpResponseRedirect(language_url)\n\n # Add a content language header to the response if not already present.\n if \"Content-Language\" not in response:\n response[\"Content-Language\"] = language\n\n return response\n\n\nclass ProvisioningErrorHandler(object):\n def __init__(self, get_response):\n self.get_response = get_response\n\n def process_exception(self, request, exception):\n if (\n isinstance(exception, DeviceNotProvisioned)\n and SetupHook.provision_url()\n and not request.path.startswith(SetupHook.provision_url())\n ):\n return redirect(SetupHook.provision_url())\n return None\n\n def __call__(self, request):\n return self.get_response(request)\n\n\nclass DatabaseBusyErrorHandler(object):\n \"\"\"\n A middleware class to raise a 503 when the database is under heavy load\n For SQLite this will trigger for database locked errors.\n For Postgres this will trigger for deadlocks.\n \"\"\"\n\n def __init__(self, get_response):\n self.get_response = get_response\n\n def process_exception(self, request, exception):\n if not isinstance(exception, OperationalError):\n return None\n if (\n OPTIONS[\"Database\"][\"DATABASE_ENGINE\"] == \"sqlite\"\n and \"database is locked\" not in exception.args[0]\n ):\n return None\n if (\n OPTIONS[\"Database\"][\"DATABASE_ENGINE\"] == \"postgres\"\n and \"deadlock detected\" not in exception.args[0]\n ):\n return None\n # Return a 503 response with a Retry-After of 10 seconds. In future we may be able to customize this value\n # based on what is currently happening on the server.\n response = HttpResponse(\n \"Database is not available for write operations\",\n status=503,\n )\n response[\"Retry-After\"] = 10\n return response\n\n def __call__(self, request):\n return self.get_response(request)\n", "path": "kolibri/core/device/middleware.py"}]} | 2,750 | 183 |
gh_patches_debug_13515 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-3267 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add openAPI Specification for UI related databases endpoint
Generate openAPI spec for `databases` endpoint corresponding to UI
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `config/settings/openapi.py`
Content:
```
1 def custom_preprocessing_hook(endpoints):
2 filtered = []
3 for (path, path_regex, method, callback) in endpoints:
4 # Remove all but DRF API endpoints
5 if path.startswith("/api/db/v0/databases/") or path.startswith("/api/db/v0/data_files/") or path.startswith("/api/db/v0/schemas/") or path.startswith("/api/db/v0/tables/"):
6 filtered.append((path, path_regex, method, callback))
7 return filtered
8
9
10 def remove_url_prefix_hook(result, **kwargs):
11 # Remove namespace and version URL prefix from the operation Id of the generated API schema
12 for path, path_info in result['paths'].items():
13 for method, operation in path_info.items():
14 operation_id = operation.get('operationId')
15 if operation_id:
16 if path.startswith('/api/db/v0/'):
17 operation['operationId'] = operation_id.replace('db_v0_', '')
18 elif path.startswith('/api/ui/v0/'):
19 operation['operationId'] = operation_id.replace('ui_v0_', '')
20
21 return result
22
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/config/settings/openapi.py b/config/settings/openapi.py
--- a/config/settings/openapi.py
+++ b/config/settings/openapi.py
@@ -1,9 +1,14 @@
def custom_preprocessing_hook(endpoints):
- filtered = []
- for (path, path_regex, method, callback) in endpoints:
- # Remove all but DRF API endpoints
- if path.startswith("/api/db/v0/databases/") or path.startswith("/api/db/v0/data_files/") or path.startswith("/api/db/v0/schemas/") or path.startswith("/api/db/v0/tables/"):
- filtered.append((path, path_regex, method, callback))
+ prefixes = [
+ "/api/db/v0/databases/",
+ "/api/db/v0/data_files/",
+ "/api/db/v0/schemas/",
+ "/api/db/v0/tables/",
+ "/api/db/v0/links/",
+ "/api/db/v0/queries/",
+ "/api/ui/v0/databases/"
+ ]
+ filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]
return filtered
| {"golden_diff": "diff --git a/config/settings/openapi.py b/config/settings/openapi.py\n--- a/config/settings/openapi.py\n+++ b/config/settings/openapi.py\n@@ -1,9 +1,14 @@\n def custom_preprocessing_hook(endpoints):\n- filtered = []\n- for (path, path_regex, method, callback) in endpoints:\n- # Remove all but DRF API endpoints\n- if path.startswith(\"/api/db/v0/databases/\") or path.startswith(\"/api/db/v0/data_files/\") or path.startswith(\"/api/db/v0/schemas/\") or path.startswith(\"/api/db/v0/tables/\"):\n- filtered.append((path, path_regex, method, callback))\n+ prefixes = [\n+ \"/api/db/v0/databases/\",\n+ \"/api/db/v0/data_files/\",\n+ \"/api/db/v0/schemas/\",\n+ \"/api/db/v0/tables/\",\n+ \"/api/db/v0/links/\",\n+ \"/api/db/v0/queries/\",\n+ \"/api/ui/v0/databases/\"\n+ ]\n+ filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]\n return filtered\n", "issue": "Add openAPI Specification for UI related databases endpoint\nGenerate openAPI spec for `databases` endpoint corresponding to UI\n", "before_files": [{"content": "def custom_preprocessing_hook(endpoints):\n filtered = []\n for (path, path_regex, method, callback) in endpoints:\n # Remove all but DRF API endpoints\n if path.startswith(\"/api/db/v0/databases/\") or path.startswith(\"/api/db/v0/data_files/\") or path.startswith(\"/api/db/v0/schemas/\") or path.startswith(\"/api/db/v0/tables/\"):\n filtered.append((path, path_regex, method, callback))\n return filtered\n\n\ndef remove_url_prefix_hook(result, **kwargs):\n # Remove namespace and version URL prefix from the operation Id of the generated API schema\n for path, path_info in result['paths'].items():\n for method, operation in path_info.items():\n operation_id = operation.get('operationId')\n if operation_id:\n if path.startswith('/api/db/v0/'):\n operation['operationId'] = operation_id.replace('db_v0_', '')\n elif path.startswith('/api/ui/v0/'):\n operation['operationId'] = operation_id.replace('ui_v0_', '')\n\n return result\n", "path": "config/settings/openapi.py"}], "after_files": [{"content": "def custom_preprocessing_hook(endpoints):\n prefixes = [\n \"/api/db/v0/databases/\",\n \"/api/db/v0/data_files/\",\n \"/api/db/v0/schemas/\",\n \"/api/db/v0/tables/\",\n \"/api/db/v0/links/\",\n \"/api/db/v0/queries/\",\n \"/api/ui/v0/databases/\"\n ]\n filtered = [(path, path_regex, method, callback) for path, path_regex, method, callback in endpoints if any(path.startswith(prefix) for prefix in prefixes)]\n return filtered\n\n\ndef remove_url_prefix_hook(result, **kwargs):\n # Remove namespace and version URL prefix from the operation Id of the generated API schema\n for path, path_info in result['paths'].items():\n for method, operation in path_info.items():\n operation_id = operation.get('operationId')\n if operation_id:\n if path.startswith('/api/db/v0/'):\n operation['operationId'] = operation_id.replace('db_v0_', '')\n elif path.startswith('/api/ui/v0/'):\n operation['operationId'] = operation_id.replace('ui_v0_', '')\n\n return result\n", "path": "config/settings/openapi.py"}]} | 545 | 262 |
gh_patches_debug_14900 | rasdani/github-patches | git_diff | conan-io__conan-center-index-3850 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[swig] swig/4.0.1/2 Recipe contains code to strip executables, why?
Building swig/4.0.2 on AIX with gcc I ran into a problem with strip. Generally speaking, not all platforms will leave you with a functional binary when you run `strip <executable file>` as some platforms' strip commands will remove relocation information. It is trivial to work around by setting:
```
swig:STRIP=:
```
in a profile, but when I found that the stripping was added to the build by the recipe, I wondered why this was done.
It seems unnecessary, adds complexity, and potentially prevents producing a debug package that has debug symbols in it.
I think there should be a policy that addresses this for all of conan-center-index.
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **swig/4.0.2**
* Operating System+version: **AIX 7.1 PowerPC**
* Compiler+version: **GCC 8.4**
* Conan version: **conan 1.31.4**
* Python version: **Python 3.8.6**
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
settings]
os=AIX
os_build=AIX
os.version=7.1
compiler=gcc
compiler.version=8.4
compiler.libcxx=libstdc++
build_type=Release
arch=ppc64
arch_build=ppc64
[options]
b2:toolset=gcc
b2:use_cxx_env=True
icu:with_extras=False
[build_requires]
[env]
OBJECT_MODE=64
CFLAGS=-fexceptions -pthread -mcpu=power8 -maix64 -mvsx
CXXFLAGS=-fexceptions -pthread -mcpu=power8 -maix64 -mvsx
CONAN_CPU_COUNT=4
PATH=['/opt/cmake-3.18/bin']
CC=/opt/freeware/bin/gcc
CXX=/opt/freeware/bin/g++
icu:PATH=['/opt/freeware/bin']
jpeg-dl:PATH=['/opt/freeware/bin']
b2:NO_CXX11_CHECK=true
b2:PATH=['/opt/freeware/bin']
swig:PATH=['/opt/freeware/bin']
swig:CPPFLAGS=-D_POSIX_SOURCE=1 -D_XOPEN_SOURCE_EXTENDED=1
swig:STRIP=:
```
### Logs (Include/Attach if Applicable)
<details><summary>Click to expand log</summary>
```
Installing /home/robb/.conan/data/swig/4.0.2/_/_/package/b18a78d720bc5d9668ba289815d9ed083b41dfa9/bin/swiglib/std/std_wstring.i
Installing /home/robb/.conan/data/swig/4.0.2/_/_/package/b18a78d720bc5d9668ba289815d9ed083b41dfa9/bin/swiglib/std/std_carray.swg
Installation complete
strip: swig -- 0654-420 The file was already stripped as specified.
ERROR: swig/4.0.2: Error in package() method, line 121
self.run("{} swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
ConanException: Error 255 while executing /usr/bin/strip swig
```
</details>
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `recipes/swig/all/conanfile.py`
Content:
```
1 from conans import ConanFile, tools, AutoToolsBuildEnvironment
2 from contextlib import contextmanager
3 import os
4
5
6 class SwigConan(ConanFile):
7 name = "swig"
8 description = "SWIG is a software development tool that connects programs written in C and C++ with a variety of high-level programming languages."
9 url = "https://github.com/conan-io/conan-center-index"
10 homepage = "http://www.swig.org"
11 license = "GPL-3.0-or-later"
12 topics = ("conan", "swig", "python", "java", "wrapper")
13 exports_sources = "patches/**"
14 settings = "os", "arch", "compiler", "build_type"
15
16 _autotools = None
17
18 @property
19 def _source_subfolder(self):
20 return "source_subfolder"
21
22 def configure(self):
23 del self.settings.compiler.libcxx
24 del self.settings.compiler.cppstd
25
26 def build_requirements(self):
27 if tools.os_info.is_windows and not tools.get_env("CONAN_BASH_PATH") \
28 and tools.os_info.detect_windows_subsystem() != "msys2":
29 self.build_requires("msys2/20190524")
30 if self.settings.compiler == "Visual Studio":
31 self.build_requires("winflexbison/2.5.22")
32 else:
33 self.build_requires("bison/3.7.1")
34 self.build_requires("automake/1.16.2")
35
36 def requirements(self):
37 self.requires("pcre/8.41")
38
39 def source(self):
40 tools.get(**self.conan_data["sources"][self.version])
41 os.rename("swig-rel-{}".format(self.version), self._source_subfolder)
42
43 @contextmanager
44 def _build_context(self):
45 env = {}
46 if self.settings.compiler != "Visual Studio":
47 env["YACC"] = self.deps_user_info["bison"].YACC
48 if self.settings.compiler == "Visual Studio":
49 with tools.vcvars(self.settings):
50 env.update({
51 "CC": "{} cl -nologo".format(tools.unix_path(self.deps_user_info["automake"].compile)),
52 "CXX": "{} cl -nologo".format(tools.unix_path(self.deps_user_info["automake"].compile)),
53 "AR": "{} link".format(self.deps_user_info["automake"].ar_lib),
54 "LD": "link",
55 })
56 with tools.environment_append(env):
57 yield
58 else:
59 with tools.environment_append(env):
60 yield
61
62 def _configure_autotools(self):
63 if self._autotools:
64 return self._autotools
65
66 self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)
67 deps_libpaths = self._autotools.library_paths
68 deps_libs = self._autotools.libs
69 deps_defines = self._autotools.defines
70 if self.settings.os == "Windows" and self.settings.compiler != "Visual Studio":
71 self._autotools.link_flags.append("-static")
72
73 libargs = list("-L\"{}\"".format(p) for p in deps_libpaths) + list("-l\"{}\"".format(l) for l in deps_libs)
74 args = [
75 "PCRE_LIBS={}".format(" ".join(libargs)),
76 "PCRE_CPPFLAGS={}".format(" ".join("-D{}".format(define) for define in deps_defines)),
77 "--host={}".format(self.settings.arch),
78 "--with-swiglibdir={}".format(self._swiglibdir),
79 ]
80
81 host, build = None, None
82
83 if self.settings.compiler == "Visual Studio":
84 self.output.warn("Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.")
85 args.append("--disable-ccache")
86 self._autotools.flags.append("-FS")
87 # MSVC canonical names aren't understood
88 host, build = False, False
89
90 self._autotools.libs = []
91 self._autotools.library_paths = []
92
93 self._autotools.configure(args=args, configure_dir=self._source_subfolder,
94 host=host, build=build)
95 return self._autotools
96
97 def _patch_sources(self):
98 for patch in self.conan_data["patches"][self.version]:
99 tools.patch(**patch)
100
101 def build(self):
102 self._patch_sources()
103 with tools.chdir(os.path.join(self._source_subfolder)):
104 self.run("./autogen.sh", win_bash=tools.os_info.is_windows)
105 with self._build_context():
106 autotools = self._configure_autotools()
107 autotools.make()
108
109 def package(self):
110 self.copy(pattern="LICENSE*", dst="licenses", src=self._source_subfolder)
111 self.copy(pattern="COPYRIGHT", dst="licenses", src=self._source_subfolder)
112 with self._build_context():
113 autotools = self._configure_autotools()
114 autotools.install()
115
116 if self.settings.compiler != "Visual Studio":
117 with tools.chdir(os.path.join(self.package_folder, "bin")):
118 strip = (tools.get_env("STRIP") or tools.which("strip")).replace("\\", "/")
119 ext = ".exe" if tools.os_info.is_windows else ""
120 if strip:
121 self.run("{} swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
122 self.run("{} ccache-swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
123
124 @property
125 def _swiglibdir(self):
126 return os.path.join(self.package_folder, "bin", "swiglib").replace("\\", "/")
127
128 def package_info(self):
129 # FIXME: Don't set cmake_find_package name because conan cmake generators do not define SWIG_EXECUTABLE
130 # self.cpp_info.names["cmake_find_package"] = "SWIG"
131 # self.cpp_info.names["cmake_find_package_multi"] = "SWIG"
132
133 bindir = os.path.join(self.package_folder, "bin")
134 self.output.info("Appending PATH environment variable: {}".format(bindir))
135 self.env_info.PATH.append(bindir)
136
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/recipes/swig/all/conanfile.py b/recipes/swig/all/conanfile.py
--- a/recipes/swig/all/conanfile.py
+++ b/recipes/swig/all/conanfile.py
@@ -113,14 +113,6 @@
autotools = self._configure_autotools()
autotools.install()
- if self.settings.compiler != "Visual Studio":
- with tools.chdir(os.path.join(self.package_folder, "bin")):
- strip = (tools.get_env("STRIP") or tools.which("strip")).replace("\\", "/")
- ext = ".exe" if tools.os_info.is_windows else ""
- if strip:
- self.run("{} swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
- self.run("{} ccache-swig{}".format(strip, ext), win_bash=tools.os_info.is_windows)
-
@property
def _swiglibdir(self):
return os.path.join(self.package_folder, "bin", "swiglib").replace("\\", "/")
| {"golden_diff": "diff --git a/recipes/swig/all/conanfile.py b/recipes/swig/all/conanfile.py\n--- a/recipes/swig/all/conanfile.py\n+++ b/recipes/swig/all/conanfile.py\n@@ -113,14 +113,6 @@\n autotools = self._configure_autotools()\n autotools.install()\n \n- if self.settings.compiler != \"Visual Studio\":\n- with tools.chdir(os.path.join(self.package_folder, \"bin\")):\n- strip = (tools.get_env(\"STRIP\") or tools.which(\"strip\")).replace(\"\\\\\", \"/\")\n- ext = \".exe\" if tools.os_info.is_windows else \"\"\n- if strip:\n- self.run(\"{} swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n- self.run(\"{} ccache-swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n-\n @property\n def _swiglibdir(self):\n return os.path.join(self.package_folder, \"bin\", \"swiglib\").replace(\"\\\\\", \"/\")\n", "issue": "[swig] swig/4.0.1/2 Recipe contains code to strip executables, why?\nBuilding swig/4.0.2 on AIX with gcc I ran into a problem with strip. Generally speaking, not all platforms will leave you with a functional binary when you run `strip <executable file>` as some platforms' strip commands will remove relocation information. It is trivial to work around by setting:\r\n```\r\nswig:STRIP=:\r\n```\r\nin a profile, but when I found that the stripping was added to the build by the recipe, I wondered why this was done.\r\nIt seems unnecessary, adds complexity, and potentially prevents producing a debug package that has debug symbols in it.\r\nI think there should be a policy that addresses this for all of conan-center-index.\r\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **swig/4.0.2**\r\n * Operating System+version: **AIX 7.1 PowerPC**\r\n * Compiler+version: **GCC 8.4**\r\n * Conan version: **conan 1.31.4**\r\n * Python version: **Python 3.8.6**\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n```\r\nsettings]\r\nos=AIX\r\nos_build=AIX\r\nos.version=7.1\r\ncompiler=gcc\r\ncompiler.version=8.4\r\ncompiler.libcxx=libstdc++\r\nbuild_type=Release\r\narch=ppc64\r\narch_build=ppc64\r\n[options]\r\nb2:toolset=gcc\r\nb2:use_cxx_env=True\r\nicu:with_extras=False\r\n[build_requires]\r\n[env]\r\nOBJECT_MODE=64\r\nCFLAGS=-fexceptions -pthread -mcpu=power8 -maix64 -mvsx\r\nCXXFLAGS=-fexceptions -pthread -mcpu=power8 -maix64 -mvsx\r\nCONAN_CPU_COUNT=4\r\nPATH=['/opt/cmake-3.18/bin']\r\nCC=/opt/freeware/bin/gcc\r\nCXX=/opt/freeware/bin/g++\r\nicu:PATH=['/opt/freeware/bin']\r\njpeg-dl:PATH=['/opt/freeware/bin']\r\nb2:NO_CXX11_CHECK=true\r\nb2:PATH=['/opt/freeware/bin']\r\nswig:PATH=['/opt/freeware/bin']\r\nswig:CPPFLAGS=-D_POSIX_SOURCE=1 -D_XOPEN_SOURCE_EXTENDED=1\r\nswig:STRIP=:\r\n```\r\n\r\n### Logs (Include/Attach if Applicable)\r\n<details><summary>Click to expand log</summary>\r\n\r\n```\r\nInstalling /home/robb/.conan/data/swig/4.0.2/_/_/package/b18a78d720bc5d9668ba289815d9ed083b41dfa9/bin/swiglib/std/std_wstring.i\r\nInstalling /home/robb/.conan/data/swig/4.0.2/_/_/package/b18a78d720bc5d9668ba289815d9ed083b41dfa9/bin/swiglib/std/std_carray.swg\r\nInstallation complete\r\nstrip: swig -- 0654-420 The file was already stripped as specified.\r\nERROR: swig/4.0.2: Error in package() method, line 121\r\n self.run(\"{} swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\r\n ConanException: Error 255 while executing /usr/bin/strip swig\r\n\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom contextlib import contextmanager\nimport os\n\n\nclass SwigConan(ConanFile):\n name = \"swig\"\n description = \"SWIG is a software development tool that connects programs written in C and C++ with a variety of high-level programming languages.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"http://www.swig.org\"\n license = \"GPL-3.0-or-later\"\n topics = (\"conan\", \"swig\", \"python\", \"java\", \"wrapper\")\n exports_sources = \"patches/**\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def build_requirements(self):\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\") \\\n and tools.os_info.detect_windows_subsystem() != \"msys2\":\n self.build_requires(\"msys2/20190524\")\n if self.settings.compiler == \"Visual Studio\":\n self.build_requires(\"winflexbison/2.5.22\")\n else:\n self.build_requires(\"bison/3.7.1\")\n self.build_requires(\"automake/1.16.2\")\n\n def requirements(self):\n self.requires(\"pcre/8.41\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"swig-rel-{}\".format(self.version), self._source_subfolder)\n\n @contextmanager\n def _build_context(self):\n env = {}\n if self.settings.compiler != \"Visual Studio\":\n env[\"YACC\"] = self.deps_user_info[\"bison\"].YACC\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings):\n env.update({\n \"CC\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"CXX\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"AR\": \"{} link\".format(self.deps_user_info[\"automake\"].ar_lib),\n \"LD\": \"link\",\n })\n with tools.environment_append(env):\n yield\n else:\n with tools.environment_append(env):\n yield\n\n def _configure_autotools(self):\n if self._autotools:\n return self._autotools\n\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n deps_libpaths = self._autotools.library_paths\n deps_libs = self._autotools.libs\n deps_defines = self._autotools.defines\n if self.settings.os == \"Windows\" and self.settings.compiler != \"Visual Studio\":\n self._autotools.link_flags.append(\"-static\")\n\n libargs = list(\"-L\\\"{}\\\"\".format(p) for p in deps_libpaths) + list(\"-l\\\"{}\\\"\".format(l) for l in deps_libs)\n args = [\n \"PCRE_LIBS={}\".format(\" \".join(libargs)),\n \"PCRE_CPPFLAGS={}\".format(\" \".join(\"-D{}\".format(define) for define in deps_defines)),\n \"--host={}\".format(self.settings.arch),\n \"--with-swiglibdir={}\".format(self._swiglibdir),\n ]\n\n host, build = None, None\n\n if self.settings.compiler == \"Visual Studio\":\n self.output.warn(\"Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.\")\n args.append(\"--disable-ccache\")\n self._autotools.flags.append(\"-FS\")\n # MSVC canonical names aren't understood\n host, build = False, False\n\n self._autotools.libs = []\n self._autotools.library_paths = []\n\n self._autotools.configure(args=args, configure_dir=self._source_subfolder,\n host=host, build=build)\n return self._autotools\n\n def _patch_sources(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n with tools.chdir(os.path.join(self._source_subfolder)):\n self.run(\"./autogen.sh\", win_bash=tools.os_info.is_windows)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"LICENSE*\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(pattern=\"COPYRIGHT\", dst=\"licenses\", src=self._source_subfolder)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.install()\n\n if self.settings.compiler != \"Visual Studio\":\n with tools.chdir(os.path.join(self.package_folder, \"bin\")):\n strip = (tools.get_env(\"STRIP\") or tools.which(\"strip\")).replace(\"\\\\\", \"/\")\n ext = \".exe\" if tools.os_info.is_windows else \"\"\n if strip:\n self.run(\"{} swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n self.run(\"{} ccache-swig{}\".format(strip, ext), win_bash=tools.os_info.is_windows)\n\n @property\n def _swiglibdir(self):\n return os.path.join(self.package_folder, \"bin\", \"swiglib\").replace(\"\\\\\", \"/\")\n\n def package_info(self):\n # FIXME: Don't set cmake_find_package name because conan cmake generators do not define SWIG_EXECUTABLE\n # self.cpp_info.names[\"cmake_find_package\"] = \"SWIG\"\n # self.cpp_info.names[\"cmake_find_package_multi\"] = \"SWIG\"\n\n bindir = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bindir))\n self.env_info.PATH.append(bindir)\n", "path": "recipes/swig/all/conanfile.py"}], "after_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom contextlib import contextmanager\nimport os\n\n\nclass SwigConan(ConanFile):\n name = \"swig\"\n description = \"SWIG is a software development tool that connects programs written in C and C++ with a variety of high-level programming languages.\"\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"http://www.swig.org\"\n license = \"GPL-3.0-or-later\"\n topics = (\"conan\", \"swig\", \"python\", \"java\", \"wrapper\")\n exports_sources = \"patches/**\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n\n def build_requirements(self):\n if tools.os_info.is_windows and not tools.get_env(\"CONAN_BASH_PATH\") \\\n and tools.os_info.detect_windows_subsystem() != \"msys2\":\n self.build_requires(\"msys2/20190524\")\n if self.settings.compiler == \"Visual Studio\":\n self.build_requires(\"winflexbison/2.5.22\")\n else:\n self.build_requires(\"bison/3.7.1\")\n self.build_requires(\"automake/1.16.2\")\n\n def requirements(self):\n self.requires(\"pcre/8.41\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"swig-rel-{}\".format(self.version), self._source_subfolder)\n\n @contextmanager\n def _build_context(self):\n env = {}\n if self.settings.compiler != \"Visual Studio\":\n env[\"YACC\"] = self.deps_user_info[\"bison\"].YACC\n if self.settings.compiler == \"Visual Studio\":\n with tools.vcvars(self.settings):\n env.update({\n \"CC\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"CXX\": \"{} cl -nologo\".format(tools.unix_path(self.deps_user_info[\"automake\"].compile)),\n \"AR\": \"{} link\".format(self.deps_user_info[\"automake\"].ar_lib),\n \"LD\": \"link\",\n })\n with tools.environment_append(env):\n yield\n else:\n with tools.environment_append(env):\n yield\n\n def _configure_autotools(self):\n if self._autotools:\n return self._autotools\n\n self._autotools = AutoToolsBuildEnvironment(self, win_bash=tools.os_info.is_windows)\n deps_libpaths = self._autotools.library_paths\n deps_libs = self._autotools.libs\n deps_defines = self._autotools.defines\n if self.settings.os == \"Windows\" and self.settings.compiler != \"Visual Studio\":\n self._autotools.link_flags.append(\"-static\")\n\n libargs = list(\"-L\\\"{}\\\"\".format(p) for p in deps_libpaths) + list(\"-l\\\"{}\\\"\".format(l) for l in deps_libs)\n args = [\n \"PCRE_LIBS={}\".format(\" \".join(libargs)),\n \"PCRE_CPPFLAGS={}\".format(\" \".join(\"-D{}\".format(define) for define in deps_defines)),\n \"--host={}\".format(self.settings.arch),\n \"--with-swiglibdir={}\".format(self._swiglibdir),\n ]\n\n host, build = None, None\n\n if self.settings.compiler == \"Visual Studio\":\n self.output.warn(\"Visual Studio compiler cannot create ccache-swig. Disabling ccache-swig.\")\n args.append(\"--disable-ccache\")\n self._autotools.flags.append(\"-FS\")\n # MSVC canonical names aren't understood\n host, build = False, False\n\n self._autotools.libs = []\n self._autotools.library_paths = []\n\n self._autotools.configure(args=args, configure_dir=self._source_subfolder,\n host=host, build=build)\n return self._autotools\n\n def _patch_sources(self):\n for patch in self.conan_data[\"patches\"][self.version]:\n tools.patch(**patch)\n\n def build(self):\n self._patch_sources()\n with tools.chdir(os.path.join(self._source_subfolder)):\n self.run(\"./autogen.sh\", win_bash=tools.os_info.is_windows)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(pattern=\"LICENSE*\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(pattern=\"COPYRIGHT\", dst=\"licenses\", src=self._source_subfolder)\n with self._build_context():\n autotools = self._configure_autotools()\n autotools.install()\n\n @property\n def _swiglibdir(self):\n return os.path.join(self.package_folder, \"bin\", \"swiglib\").replace(\"\\\\\", \"/\")\n\n def package_info(self):\n # FIXME: Don't set cmake_find_package name because conan cmake generators do not define SWIG_EXECUTABLE\n # self.cpp_info.names[\"cmake_find_package\"] = \"SWIG\"\n # self.cpp_info.names[\"cmake_find_package_multi\"] = \"SWIG\"\n\n bindir = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bindir))\n self.env_info.PATH.append(bindir)\n", "path": "recipes/swig/all/conanfile.py"}]} | 2,731 | 236 |
gh_patches_debug_26362 | rasdani/github-patches | git_diff | watchdogpolska__feder-329 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Autocomplete dla JST w MonitoringFilter
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `feder/monitorings/models.py`
Content:
```
1 from itertools import groupby
2
3 import reversion
4 from autoslug.fields import AutoSlugField
5 from django.conf import settings
6 from django.contrib.auth import get_user_model
7 from django.core.urlresolvers import reverse
8 from django.db import models
9 from django.utils.translation import ugettext_lazy as _
10 from guardian.models import GroupObjectPermissionBase, UserObjectPermissionBase
11 from model_utils.models import TimeStampedModel
12
13 from .validators import validate_template_syntax
14
15 _('Monitorings index')
16 _('Can add Monitoring')
17 _('Can change Monitoring')
18 _('Can delete Monitoring')
19
20 NOTIFY_HELP = _("Notify about new alerts person who can view alerts")
21
22
23 class MonitoringQuerySet(models.QuerySet):
24 def with_case_count(self):
25 return self.annotate(case_count=models.Count('case'))
26
27
28 @reversion.register()
29 class Monitoring(TimeStampedModel):
30 perm_model = 'monitoringuserobjectpermission'
31 name = models.CharField(verbose_name=_("Name"), max_length=50)
32 slug = AutoSlugField(populate_from='name', verbose_name=_("Slug"), unique=True)
33 user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_("User"))
34 description = models.TextField(verbose_name=_("Description"), blank=True)
35 subject = models.CharField(verbose_name=_("Subject"), max_length=80)
36 template = models.TextField(verbose_name=_("Template"),
37 help_text=_("Use {{EMAIL}} for insert reply address"),
38 validators=[validate_template_syntax])
39 email_footer = models.TextField(default='',
40 verbose_name=_("Email footer"),
41 help_text=_("Footer for sent mail and replies"))
42 notify_alert = models.BooleanField(default=True,
43 verbose_name=_("Notify about alerts"),
44 help_text=NOTIFY_HELP)
45 objects = MonitoringQuerySet.as_manager()
46
47 class Meta:
48 verbose_name = _("Monitoring")
49 verbose_name_plural = _("Monitoring")
50 ordering = ['created', ]
51 permissions = (
52 ('add_questionary', _('Can add questionary')),
53 ('change_questionary', _('Can change questionary')),
54 ('delete_questionary', _('Can delete questionary')),
55 ('add_case', _('Can add case')),
56 ('change_case', _('Can change case')),
57 ('delete_case', _('Can delete case')),
58 ('add_task', _('Can add task')),
59 ('change_task', _('Can change task')),
60 ('delete_task', _('Can delete task')),
61 ('add_letter', _('Can add letter')),
62 ('reply', _('Can reply')),
63 ('add_draft', _('Add reply draft')),
64 ('change_letter', _('Can change task')),
65 ('delete_letter', _('Can delete letter')),
66 ('view_alert', _('Can view alert')),
67 ('change_alert', _('Can change alert')),
68 ('delete_alert', _('Can delete alert')),
69 ('manage_perm', _('Can manage perms')),
70 ('select_survey', _('Can select answer')),
71 ('view_log', _('Can view logs')),
72 )
73
74 def __unicode__(self):
75 return self.name
76
77 def get_users_with_perm(self, perm=None):
78 qs = get_user_model().objects.filter(**{self.perm_model + '__content_object': self})
79 if perm:
80 qs = qs.filter(**{self.perm_model + '__permission__codename': perm})
81 return qs.distinct().all()
82
83 def get_absolute_url(self):
84 return reverse('monitorings:details', kwargs={'slug': self.slug})
85
86 def permission_map(self):
87 dataset = (self.monitoringuserobjectpermission_set.select_related('permission', 'user').
88 order_by('permission').all())
89 user_list = {x.user for x in dataset}
90
91 def index_generate():
92 grouped = groupby(dataset, lambda x: x.permission)
93 for perm, users in grouped:
94 user_perm_list = [x.user for x in users]
95 yield perm, [(perm, (user in user_perm_list)) for user in user_list]
96
97 return user_list, index_generate()
98
99
100 class MonitoringUserObjectPermission(UserObjectPermissionBase):
101 content_object = models.ForeignKey(Monitoring)
102
103
104 class MonitoringGroupObjectPermission(GroupObjectPermissionBase):
105 content_object = models.ForeignKey(Monitoring)
106
```
Path: `feder/monitorings/filters.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 import django_filters
3 from dal import autocomplete
4 from django.contrib.auth import get_user_model
5 from django.db.models import Count
6 from django.utils.translation import ugettext_lazy as _
7
8 from .models import Monitoring
9
10
11 class MonitoringFilter(django_filters.FilterSet):
12 created = django_filters.DateRangeFilter(label=_("Creation date"))
13
14 def __init__(self, *args, **kwargs):
15 super(MonitoringFilter, self).__init__(*args, **kwargs)
16 self.filters['name'].lookup_expr = 'icontains'
17 self.filters['name'].label = _("Name")
18 # Limit users select to which have any cases
19 qs = (get_user_model().objects.
20 annotate(case_count=Count('case')).
21 filter(case_count__gt=0).all())
22 self.filters['user'].extra['queryset'] = qs
23 self.filters['user'].widget = autocomplete.ModelSelect2(url='users:autocomplete')
24
25 class Meta:
26 model = Monitoring
27 fields = ['name', 'user', 'created']
28 order_by = ['created', '-created', '-case_count']
29 order_by = [
30 ('created', _('Creation date (ascending)')),
31 ('-created', _('Creation date (descending)')),
32 ('case_count', _('Cases count (ascending)')),
33 ('-case_count', _('Cases count (descending)')),
34 ]
35
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/feder/monitorings/filters.py b/feder/monitorings/filters.py
--- a/feder/monitorings/filters.py
+++ b/feder/monitorings/filters.py
@@ -6,10 +6,22 @@
from django.utils.translation import ugettext_lazy as _
from .models import Monitoring
+from teryt_tree.dal_ext.filters import VoivodeshipFilter, CountyFilter, CommunityFilter
class MonitoringFilter(django_filters.FilterSet):
created = django_filters.DateRangeFilter(label=_("Creation date"))
+ voivodeship = VoivodeshipFilter(
+ widget=autocomplete.ModelSelect2(url='teryt:voivodeship-autocomplete')
+ )
+ county = CountyFilter(
+ widget=autocomplete.ModelSelect2(url='teryt:county-autocomplete',
+ forward=['voivodeship'])
+ )
+ community = CommunityFilter(
+ widget=autocomplete.ModelSelect2(url='teryt:community-autocomplete',
+ forward=['county'])
+ )
def __init__(self, *args, **kwargs):
super(MonitoringFilter, self).__init__(*args, **kwargs)
diff --git a/feder/monitorings/models.py b/feder/monitorings/models.py
--- a/feder/monitorings/models.py
+++ b/feder/monitorings/models.py
@@ -24,6 +24,9 @@
def with_case_count(self):
return self.annotate(case_count=models.Count('case'))
+ def area(self, jst):
+ return self.filter(case__institution__jst__tree_id=jst.tree_id,
+ case__institution__jst__lft__range=(jst.lft, jst.rght))
@reversion.register()
class Monitoring(TimeStampedModel):
| {"golden_diff": "diff --git a/feder/monitorings/filters.py b/feder/monitorings/filters.py\n--- a/feder/monitorings/filters.py\n+++ b/feder/monitorings/filters.py\n@@ -6,10 +6,22 @@\n from django.utils.translation import ugettext_lazy as _\n \n from .models import Monitoring\n+from teryt_tree.dal_ext.filters import VoivodeshipFilter, CountyFilter, CommunityFilter\n \n \n class MonitoringFilter(django_filters.FilterSet):\n created = django_filters.DateRangeFilter(label=_(\"Creation date\"))\n+ voivodeship = VoivodeshipFilter(\n+ widget=autocomplete.ModelSelect2(url='teryt:voivodeship-autocomplete')\n+ )\n+ county = CountyFilter(\n+ widget=autocomplete.ModelSelect2(url='teryt:county-autocomplete',\n+ forward=['voivodeship'])\n+ )\n+ community = CommunityFilter(\n+ widget=autocomplete.ModelSelect2(url='teryt:community-autocomplete',\n+ forward=['county'])\n+ )\n \n def __init__(self, *args, **kwargs):\n super(MonitoringFilter, self).__init__(*args, **kwargs)\ndiff --git a/feder/monitorings/models.py b/feder/monitorings/models.py\n--- a/feder/monitorings/models.py\n+++ b/feder/monitorings/models.py\n@@ -24,6 +24,9 @@\n def with_case_count(self):\n return self.annotate(case_count=models.Count('case'))\n \n+ def area(self, jst):\n+ return self.filter(case__institution__jst__tree_id=jst.tree_id,\n+ case__institution__jst__lft__range=(jst.lft, jst.rght))\n \n @reversion.register()\n class Monitoring(TimeStampedModel):\n", "issue": "Autocomplete dla JST w MonitoringFilter\n\n", "before_files": [{"content": "from itertools import groupby\n\nimport reversion\nfrom autoslug.fields import AutoSlugField\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom guardian.models import GroupObjectPermissionBase, UserObjectPermissionBase\nfrom model_utils.models import TimeStampedModel\n\nfrom .validators import validate_template_syntax\n\n_('Monitorings index')\n_('Can add Monitoring')\n_('Can change Monitoring')\n_('Can delete Monitoring')\n\nNOTIFY_HELP = _(\"Notify about new alerts person who can view alerts\")\n\n\nclass MonitoringQuerySet(models.QuerySet):\n def with_case_count(self):\n return self.annotate(case_count=models.Count('case'))\n\n\[email protected]()\nclass Monitoring(TimeStampedModel):\n perm_model = 'monitoringuserobjectpermission'\n name = models.CharField(verbose_name=_(\"Name\"), max_length=50)\n slug = AutoSlugField(populate_from='name', verbose_name=_(\"Slug\"), unique=True)\n user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(\"User\"))\n description = models.TextField(verbose_name=_(\"Description\"), blank=True)\n subject = models.CharField(verbose_name=_(\"Subject\"), max_length=80)\n template = models.TextField(verbose_name=_(\"Template\"),\n help_text=_(\"Use {{EMAIL}} for insert reply address\"),\n validators=[validate_template_syntax])\n email_footer = models.TextField(default='',\n verbose_name=_(\"Email footer\"),\n help_text=_(\"Footer for sent mail and replies\"))\n notify_alert = models.BooleanField(default=True,\n verbose_name=_(\"Notify about alerts\"),\n help_text=NOTIFY_HELP)\n objects = MonitoringQuerySet.as_manager()\n\n class Meta:\n verbose_name = _(\"Monitoring\")\n verbose_name_plural = _(\"Monitoring\")\n ordering = ['created', ]\n permissions = (\n ('add_questionary', _('Can add questionary')),\n ('change_questionary', _('Can change questionary')),\n ('delete_questionary', _('Can delete questionary')),\n ('add_case', _('Can add case')),\n ('change_case', _('Can change case')),\n ('delete_case', _('Can delete case')),\n ('add_task', _('Can add task')),\n ('change_task', _('Can change task')),\n ('delete_task', _('Can delete task')),\n ('add_letter', _('Can add letter')),\n ('reply', _('Can reply')),\n ('add_draft', _('Add reply draft')),\n ('change_letter', _('Can change task')),\n ('delete_letter', _('Can delete letter')),\n ('view_alert', _('Can view alert')),\n ('change_alert', _('Can change alert')),\n ('delete_alert', _('Can delete alert')),\n ('manage_perm', _('Can manage perms')),\n ('select_survey', _('Can select answer')),\n ('view_log', _('Can view logs')),\n )\n\n def __unicode__(self):\n return self.name\n\n def get_users_with_perm(self, perm=None):\n qs = get_user_model().objects.filter(**{self.perm_model + '__content_object': self})\n if perm:\n qs = qs.filter(**{self.perm_model + '__permission__codename': perm})\n return qs.distinct().all()\n\n def get_absolute_url(self):\n return reverse('monitorings:details', kwargs={'slug': self.slug})\n\n def permission_map(self):\n dataset = (self.monitoringuserobjectpermission_set.select_related('permission', 'user').\n order_by('permission').all())\n user_list = {x.user for x in dataset}\n\n def index_generate():\n grouped = groupby(dataset, lambda x: x.permission)\n for perm, users in grouped:\n user_perm_list = [x.user for x in users]\n yield perm, [(perm, (user in user_perm_list)) for user in user_list]\n\n return user_list, index_generate()\n\n\nclass MonitoringUserObjectPermission(UserObjectPermissionBase):\n content_object = models.ForeignKey(Monitoring)\n\n\nclass MonitoringGroupObjectPermission(GroupObjectPermissionBase):\n content_object = models.ForeignKey(Monitoring)\n", "path": "feder/monitorings/models.py"}, {"content": "# -*- coding: utf-8 -*-\nimport django_filters\nfrom dal import autocomplete\nfrom django.contrib.auth import get_user_model\nfrom django.db.models import Count\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom .models import Monitoring\n\n\nclass MonitoringFilter(django_filters.FilterSet):\n created = django_filters.DateRangeFilter(label=_(\"Creation date\"))\n\n def __init__(self, *args, **kwargs):\n super(MonitoringFilter, self).__init__(*args, **kwargs)\n self.filters['name'].lookup_expr = 'icontains'\n self.filters['name'].label = _(\"Name\")\n # Limit users select to which have any cases\n qs = (get_user_model().objects.\n annotate(case_count=Count('case')).\n filter(case_count__gt=0).all())\n self.filters['user'].extra['queryset'] = qs\n self.filters['user'].widget = autocomplete.ModelSelect2(url='users:autocomplete')\n\n class Meta:\n model = Monitoring\n fields = ['name', 'user', 'created']\n order_by = ['created', '-created', '-case_count']\n order_by = [\n ('created', _('Creation date (ascending)')),\n ('-created', _('Creation date (descending)')),\n ('case_count', _('Cases count (ascending)')),\n ('-case_count', _('Cases count (descending)')),\n ]\n", "path": "feder/monitorings/filters.py"}], "after_files": [{"content": "from itertools import groupby\n\nimport reversion\nfrom autoslug.fields import AutoSlugField\nfrom django.conf import settings\nfrom django.contrib.auth import get_user_model\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom django.utils.translation import ugettext_lazy as _\nfrom guardian.models import GroupObjectPermissionBase, UserObjectPermissionBase\nfrom model_utils.models import TimeStampedModel\n\nfrom .validators import validate_template_syntax\n\n_('Monitorings index')\n_('Can add Monitoring')\n_('Can change Monitoring')\n_('Can delete Monitoring')\n\nNOTIFY_HELP = _(\"Notify about new alerts person who can view alerts\")\n\n\nclass MonitoringQuerySet(models.QuerySet):\n def with_case_count(self):\n return self.annotate(case_count=models.Count('case'))\n\n def area(self, jst):\n return self.filter(case__institution__jst__tree_id=jst.tree_id,\n case__institution__jst__lft__range=(jst.lft, jst.rght))\n\[email protected]()\nclass Monitoring(TimeStampedModel):\n perm_model = 'monitoringuserobjectpermission'\n name = models.CharField(verbose_name=_(\"Name\"), max_length=50)\n slug = AutoSlugField(populate_from='name', verbose_name=_(\"Slug\"), unique=True)\n user = models.ForeignKey(settings.AUTH_USER_MODEL, verbose_name=_(\"User\"))\n description = models.TextField(verbose_name=_(\"Description\"), blank=True)\n subject = models.CharField(verbose_name=_(\"Subject\"), max_length=80)\n template = models.TextField(verbose_name=_(\"Template\"),\n help_text=_(\"Use {{EMAIL}} for insert reply address\"),\n validators=[validate_template_syntax])\n email_footer = models.TextField(default='',\n verbose_name=_(\"Email footer\"),\n help_text=_(\"Footer for sent mail and replies\"))\n notify_alert = models.BooleanField(default=True,\n verbose_name=_(\"Notify about alerts\"),\n help_text=NOTIFY_HELP)\n objects = MonitoringQuerySet.as_manager()\n\n class Meta:\n verbose_name = _(\"Monitoring\")\n verbose_name_plural = _(\"Monitoring\")\n ordering = ['created', ]\n permissions = (\n ('add_questionary', _('Can add questionary')),\n ('change_questionary', _('Can change questionary')),\n ('delete_questionary', _('Can delete questionary')),\n ('add_case', _('Can add case')),\n ('change_case', _('Can change case')),\n ('delete_case', _('Can delete case')),\n ('add_task', _('Can add task')),\n ('change_task', _('Can change task')),\n ('delete_task', _('Can delete task')),\n ('add_letter', _('Can add letter')),\n ('reply', _('Can reply')),\n ('add_draft', _('Add reply draft')),\n ('change_letter', _('Can change task')),\n ('delete_letter', _('Can delete letter')),\n ('view_alert', _('Can view alert')),\n ('change_alert', _('Can change alert')),\n ('delete_alert', _('Can delete alert')),\n ('manage_perm', _('Can manage perms')),\n ('select_survey', _('Can select answer')),\n ('view_log', _('Can view logs')),\n )\n\n def __unicode__(self):\n return self.name\n\n def get_users_with_perm(self, perm=None):\n qs = get_user_model().objects.filter(**{self.perm_model + '__content_object': self})\n if perm:\n qs = qs.filter(**{self.perm_model + '__permission__codename': perm})\n return qs.distinct().all()\n\n def get_absolute_url(self):\n return reverse('monitorings:details', kwargs={'slug': self.slug})\n\n def permission_map(self):\n dataset = (self.monitoringuserobjectpermission_set.select_related('permission', 'user').\n order_by('permission').all())\n user_list = {x.user for x in dataset}\n\n def index_generate():\n grouped = groupby(dataset, lambda x: x.permission)\n for perm, users in grouped:\n user_perm_list = [x.user for x in users]\n yield perm, [(perm, (user in user_perm_list)) for user in user_list]\n\n return user_list, index_generate()\n\n\nclass MonitoringUserObjectPermission(UserObjectPermissionBase):\n content_object = models.ForeignKey(Monitoring)\n\n\nclass MonitoringGroupObjectPermission(GroupObjectPermissionBase):\n content_object = models.ForeignKey(Monitoring)\n", "path": "feder/monitorings/models.py"}, {"content": "# -*- coding: utf-8 -*-\nimport django_filters\nfrom dal import autocomplete\nfrom django.contrib.auth import get_user_model\nfrom django.db.models import Count\nfrom django.utils.translation import ugettext_lazy as _\n\nfrom .models import Monitoring\nfrom teryt_tree.dal_ext.filters import VoivodeshipFilter, CountyFilter, CommunityFilter\n\n\nclass MonitoringFilter(django_filters.FilterSet):\n created = django_filters.DateRangeFilter(label=_(\"Creation date\"))\n voivodeship = VoivodeshipFilter(\n widget=autocomplete.ModelSelect2(url='teryt:voivodeship-autocomplete')\n )\n county = CountyFilter(\n widget=autocomplete.ModelSelect2(url='teryt:county-autocomplete',\n forward=['voivodeship'])\n )\n community = CommunityFilter(\n widget=autocomplete.ModelSelect2(url='teryt:community-autocomplete',\n forward=['county'])\n )\n\n def __init__(self, *args, **kwargs):\n super(MonitoringFilter, self).__init__(*args, **kwargs)\n self.filters['name'].lookup_expr = 'icontains'\n self.filters['name'].label = _(\"Name\")\n # Limit users select to which have any cases\n qs = (get_user_model().objects.\n annotate(case_count=Count('case')).\n filter(case_count__gt=0).all())\n self.filters['user'].extra['queryset'] = qs\n self.filters['user'].widget = autocomplete.ModelSelect2(url='users:autocomplete')\n\n class Meta:\n model = Monitoring\n fields = ['name', 'user', 'created']\n order_by = ['created', '-created', '-case_count']\n order_by = [\n ('created', _('Creation date (ascending)')),\n ('-created', _('Creation date (descending)')),\n ('case_count', _('Cases count (ascending)')),\n ('-case_count', _('Cases count (descending)')),\n ]\n", "path": "feder/monitorings/filters.py"}]} | 1,699 | 389 |
gh_patches_debug_3454 | rasdani/github-patches | git_diff | obspy__obspy-2504 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
FutureWarning for signal.headers
This happens with current master and NumPy 1.17.3:
```python
>>> from obspy import signal
```
```
[...]/obspy/signal/headers.py:93: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
], align=True)
```
FutureWarning for signal.headers
This happens with current master and NumPy 1.17.3:
```python
>>> from obspy import signal
```
```
[...]/obspy/signal/headers.py:93: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
], align=True)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `obspy/signal/headers.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 Defines the libsignal and evalresp structures and blockettes.
4 """
5 from __future__ import (absolute_import, division, print_function,
6 unicode_literals)
7 from future.builtins import * # NOQA
8 from future.utils import native_str
9
10 import ctypes as C # NOQA
11
12 import numpy as np
13
14 from obspy.core.util.libnames import _load_cdll
15
16
17 # Import shared libsignal
18 clibsignal = _load_cdll("signal")
19 # Import shared libevresp
20 clibevresp = _load_cdll("evresp")
21
22 clibsignal.calcSteer.argtypes = [
23 C.c_int, C.c_int, C.c_int, C.c_int, C.c_int, C.c_float,
24 np.ctypeslib.ndpointer(dtype=np.float32, ndim=3,
25 flags=native_str('C_CONTIGUOUS')),
26 np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,
27 flags=native_str('C_CONTIGUOUS')),
28 ]
29 clibsignal.calcSteer.restype = C.c_void_p
30
31 clibsignal.generalizedBeamformer.argtypes = [
32 np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,
33 flags=native_str('C_CONTIGUOUS')),
34 np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,
35 flags=native_str('C_CONTIGUOUS')),
36 np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,
37 flags=native_str('C_CONTIGUOUS')),
38 np.ctypeslib.ndpointer(dtype=np.complex128, ndim=3,
39 flags=native_str('C_CONTIGUOUS')),
40 C.c_int, C.c_int, C.c_int, C.c_int, C.c_int,
41 C.c_double,
42 C.c_int,
43 ]
44 clibsignal.generalizedBeamformer.restype = C.c_int
45
46 clibsignal.X_corr.argtypes = [
47 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
48 flags=native_str('C_CONTIGUOUS')),
49 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
50 flags=native_str('C_CONTIGUOUS')),
51 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
52 flags=native_str('C_CONTIGUOUS')),
53 C.c_int, C.c_int, C.c_int,
54 C.POINTER(C.c_int), C.POINTER(C.c_double)]
55 clibsignal.X_corr.restype = C.c_int
56
57 clibsignal.recstalta.argtypes = [
58 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
59 flags=native_str('C_CONTIGUOUS')),
60 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
61 flags=native_str('C_CONTIGUOUS')),
62 C.c_int, C.c_int, C.c_int]
63 clibsignal.recstalta.restype = C.c_void_p
64
65 clibsignal.ppick.argtypes = [
66 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
67 flags=native_str('C_CONTIGUOUS')),
68 C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,
69 C.c_float, C.c_float, C.c_int, C.c_int]
70 clibsignal.ppick.restype = C.c_int
71
72 clibsignal.ar_picker.argtypes = [
73 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
74 flags=native_str('C_CONTIGUOUS')),
75 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
76 flags=native_str('C_CONTIGUOUS')),
77 np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,
78 flags=native_str('C_CONTIGUOUS')),
79 C.c_int, C.c_float, C.c_float, C.c_float, C.c_float, C.c_float,
80 C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float),
81 C.POINTER(C.c_float), C.c_double, C.c_double, C.c_int]
82 clibsignal.ar_picker.restypes = C.c_int
83
84 clibsignal.utl_geo_km.argtypes = [C.c_double, C.c_double, C.c_double,
85 C.POINTER(C.c_double),
86 C.POINTER(C.c_double)]
87 clibsignal.utl_geo_km.restype = C.c_void_p
88
89 head_stalta_t = np.dtype([
90 (native_str('N'), np.uint32, 1),
91 (native_str('nsta'), np.uint32, 1),
92 (native_str('nlta'), np.uint32, 1),
93 ], align=True)
94
95 clibsignal.stalta.argtypes = [
96 np.ctypeslib.ndpointer(dtype=head_stalta_t, ndim=1,
97 flags=native_str('C_CONTIGUOUS')),
98 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
99 flags=native_str('C_CONTIGUOUS')),
100 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
101 flags=native_str('C_CONTIGUOUS')),
102 ]
103 clibsignal.stalta.restype = C.c_int
104
105 clibsignal.hermite_interpolation.argtypes = [
106 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
107 flags=native_str('C_CONTIGUOUS')),
108 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
109 flags=native_str('C_CONTIGUOUS')),
110 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
111 flags=native_str('C_CONTIGUOUS')),
112 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
113 flags=native_str('C_CONTIGUOUS')),
114 C.c_int, C.c_int, C.c_double, C.c_double]
115 clibsignal.hermite_interpolation.restype = C.c_void_p
116
117 clibsignal.lanczos_resample.argtypes = [
118 # y_in
119 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
120 flags=native_str('C_CONTIGUOUS')),
121 # y_out
122 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
123 flags=native_str('C_CONTIGUOUS')),
124 # dt
125 C.c_double,
126 # offset
127 C.c_double,
128 # len_in
129 C.c_int,
130 # len_out,
131 C.c_int,
132 # a,
133 C.c_int,
134 # window
135 C.c_int]
136 clibsignal.lanczos_resample.restype = None
137
138 clibsignal.calculate_kernel.argtypes = [
139 # double *x
140 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
141 flags=native_str('C_CONTIGUOUS')),
142 # double *y
143 np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,
144 flags=native_str('C_CONTIGUOUS')),
145 # int len
146 C.c_int,
147 # int a,
148 C.c_int,
149 # int return_type,
150 C.c_int,
151 # enum lanczos_window_type window
152 C.c_int]
153 clibsignal.calculate_kernel.restype = None
154
155 STALEN = 64
156 NETLEN = 64
157 CHALEN = 64
158 LOCIDLEN = 64
159
160
161 class C_COMPLEX(C.Structure): # noqa
162 _fields_ = [("real", C.c_double),
163 ("imag", C.c_double)]
164
165
166 class RESPONSE(C.Structure):
167 pass
168
169
170 RESPONSE._fields_ = [("station", C.c_char * STALEN),
171 ("network", C.c_char * NETLEN),
172 ("locid", C.c_char * LOCIDLEN),
173 ("channel", C.c_char * CHALEN),
174 ("rvec", C.POINTER(C_COMPLEX)),
175 ("nfreqs", C.c_int),
176 ("freqs", C.POINTER(C.c_double)),
177 ("next", C.POINTER(RESPONSE))]
178
179 clibevresp.evresp.argtypes = [
180 C.c_char_p,
181 C.c_char_p,
182 C.c_char_p,
183 C.c_char_p,
184 C.c_char_p,
185 C.c_char_p,
186 C.c_char_p,
187 np.ctypeslib.ndpointer(dtype=np.float64,
188 ndim=1,
189 flags=native_str('C_CONTIGUOUS')),
190 C.c_int,
191 C.c_char_p,
192 C.c_char_p,
193 C.c_int,
194 C.c_int,
195 C.c_int,
196 C.c_int]
197 clibevresp.evresp.restype = C.POINTER(RESPONSE)
198
199 clibevresp.free_response.argtypes = [C.POINTER(RESPONSE)]
200 clibevresp.free_response.restype = C.c_void_p
201
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/obspy/signal/headers.py b/obspy/signal/headers.py
--- a/obspy/signal/headers.py
+++ b/obspy/signal/headers.py
@@ -87,9 +87,9 @@
clibsignal.utl_geo_km.restype = C.c_void_p
head_stalta_t = np.dtype([
- (native_str('N'), np.uint32, 1),
- (native_str('nsta'), np.uint32, 1),
- (native_str('nlta'), np.uint32, 1),
+ (native_str('N'), np.uint32),
+ (native_str('nsta'), np.uint32),
+ (native_str('nlta'), np.uint32),
], align=True)
clibsignal.stalta.argtypes = [
| {"golden_diff": "diff --git a/obspy/signal/headers.py b/obspy/signal/headers.py\n--- a/obspy/signal/headers.py\n+++ b/obspy/signal/headers.py\n@@ -87,9 +87,9 @@\n clibsignal.utl_geo_km.restype = C.c_void_p\n \n head_stalta_t = np.dtype([\n- (native_str('N'), np.uint32, 1),\n- (native_str('nsta'), np.uint32, 1),\n- (native_str('nlta'), np.uint32, 1),\n+ (native_str('N'), np.uint32),\n+ (native_str('nsta'), np.uint32),\n+ (native_str('nlta'), np.uint32),\n ], align=True)\n \n clibsignal.stalta.argtypes = [\n", "issue": "FutureWarning for signal.headers\nThis happens with current master and NumPy 1.17.3:\r\n```python\r\n>>> from obspy import signal\r\n```\r\n```\r\n[...]/obspy/signal/headers.py:93: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n ], align=True)\r\n```\nFutureWarning for signal.headers\nThis happens with current master and NumPy 1.17.3:\r\n```python\r\n>>> from obspy import signal\r\n```\r\n```\r\n[...]/obspy/signal/headers.py:93: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\r\n ], align=True)\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nDefines the libsignal and evalresp structures and blockettes.\n\"\"\"\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\nfrom future.builtins import * # NOQA\nfrom future.utils import native_str\n\nimport ctypes as C # NOQA\n\nimport numpy as np\n\nfrom obspy.core.util.libnames import _load_cdll\n\n\n# Import shared libsignal\nclibsignal = _load_cdll(\"signal\")\n# Import shared libevresp\nclibevresp = _load_cdll(\"evresp\")\n\nclibsignal.calcSteer.argtypes = [\n C.c_int, C.c_int, C.c_int, C.c_int, C.c_int, C.c_float,\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=3,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,\n flags=native_str('C_CONTIGUOUS')),\n]\nclibsignal.calcSteer.restype = C.c_void_p\n\nclibsignal.generalizedBeamformer.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=3,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_int, C.c_int, C.c_int,\n C.c_double,\n C.c_int,\n]\nclibsignal.generalizedBeamformer.restype = C.c_int\n\nclibsignal.X_corr.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_int,\n C.POINTER(C.c_int), C.POINTER(C.c_double)]\nclibsignal.X_corr.restype = C.c_int\n\nclibsignal.recstalta.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_int]\nclibsignal.recstalta.restype = C.c_void_p\n\nclibsignal.ppick.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,\n C.c_float, C.c_float, C.c_int, C.c_int]\nclibsignal.ppick.restype = C.c_int\n\nclibsignal.ar_picker.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_float, C.c_float, C.c_float, C.c_float, C.c_float,\n C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float),\n C.POINTER(C.c_float), C.c_double, C.c_double, C.c_int]\nclibsignal.ar_picker.restypes = C.c_int\n\nclibsignal.utl_geo_km.argtypes = [C.c_double, C.c_double, C.c_double,\n C.POINTER(C.c_double),\n C.POINTER(C.c_double)]\nclibsignal.utl_geo_km.restype = C.c_void_p\n\nhead_stalta_t = np.dtype([\n (native_str('N'), np.uint32, 1),\n (native_str('nsta'), np.uint32, 1),\n (native_str('nlta'), np.uint32, 1),\n], align=True)\n\nclibsignal.stalta.argtypes = [\n np.ctypeslib.ndpointer(dtype=head_stalta_t, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n]\nclibsignal.stalta.restype = C.c_int\n\nclibsignal.hermite_interpolation.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_double, C.c_double]\nclibsignal.hermite_interpolation.restype = C.c_void_p\n\nclibsignal.lanczos_resample.argtypes = [\n # y_in\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # y_out\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # dt\n C.c_double,\n # offset\n C.c_double,\n # len_in\n C.c_int,\n # len_out,\n C.c_int,\n # a,\n C.c_int,\n # window\n C.c_int]\nclibsignal.lanczos_resample.restype = None\n\nclibsignal.calculate_kernel.argtypes = [\n # double *x\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # double *y\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # int len\n C.c_int,\n # int a,\n C.c_int,\n # int return_type,\n C.c_int,\n # enum lanczos_window_type window\n C.c_int]\nclibsignal.calculate_kernel.restype = None\n\nSTALEN = 64\nNETLEN = 64\nCHALEN = 64\nLOCIDLEN = 64\n\n\nclass C_COMPLEX(C.Structure): # noqa\n _fields_ = [(\"real\", C.c_double),\n (\"imag\", C.c_double)]\n\n\nclass RESPONSE(C.Structure):\n pass\n\n\nRESPONSE._fields_ = [(\"station\", C.c_char * STALEN),\n (\"network\", C.c_char * NETLEN),\n (\"locid\", C.c_char * LOCIDLEN),\n (\"channel\", C.c_char * CHALEN),\n (\"rvec\", C.POINTER(C_COMPLEX)),\n (\"nfreqs\", C.c_int),\n (\"freqs\", C.POINTER(C.c_double)),\n (\"next\", C.POINTER(RESPONSE))]\n\nclibevresp.evresp.argtypes = [\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n np.ctypeslib.ndpointer(dtype=np.float64,\n ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int,\n C.c_char_p,\n C.c_char_p,\n C.c_int,\n C.c_int,\n C.c_int,\n C.c_int]\nclibevresp.evresp.restype = C.POINTER(RESPONSE)\n\nclibevresp.free_response.argtypes = [C.POINTER(RESPONSE)]\nclibevresp.free_response.restype = C.c_void_p\n", "path": "obspy/signal/headers.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\nDefines the libsignal and evalresp structures and blockettes.\n\"\"\"\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\nfrom future.builtins import * # NOQA\nfrom future.utils import native_str\n\nimport ctypes as C # NOQA\n\nimport numpy as np\n\nfrom obspy.core.util.libnames import _load_cdll\n\n\n# Import shared libsignal\nclibsignal = _load_cdll(\"signal\")\n# Import shared libevresp\nclibevresp = _load_cdll(\"evresp\")\n\nclibsignal.calcSteer.argtypes = [\n C.c_int, C.c_int, C.c_int, C.c_int, C.c_int, C.c_float,\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=3,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,\n flags=native_str('C_CONTIGUOUS')),\n]\nclibsignal.calcSteer.restype = C.c_void_p\n\nclibsignal.generalizedBeamformer.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=2,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=4,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.complex128, ndim=3,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_int, C.c_int, C.c_int,\n C.c_double,\n C.c_int,\n]\nclibsignal.generalizedBeamformer.restype = C.c_int\n\nclibsignal.X_corr.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_int,\n C.POINTER(C.c_int), C.POINTER(C.c_double)]\nclibsignal.X_corr.restype = C.c_int\n\nclibsignal.recstalta.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_int]\nclibsignal.recstalta.restype = C.c_void_p\n\nclibsignal.ppick.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.POINTER(C.c_int), C.c_char_p, C.c_float, C.c_int, C.c_int,\n C.c_float, C.c_float, C.c_int, C.c_int]\nclibsignal.ppick.restype = C.c_int\n\nclibsignal.ar_picker.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float32, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_float, C.c_float, C.c_float, C.c_float, C.c_float,\n C.c_float, C.c_float, C.c_int, C.c_int, C.POINTER(C.c_float),\n C.POINTER(C.c_float), C.c_double, C.c_double, C.c_int]\nclibsignal.ar_picker.restypes = C.c_int\n\nclibsignal.utl_geo_km.argtypes = [C.c_double, C.c_double, C.c_double,\n C.POINTER(C.c_double),\n C.POINTER(C.c_double)]\nclibsignal.utl_geo_km.restype = C.c_void_p\n\nhead_stalta_t = np.dtype([\n (native_str('N'), np.uint32),\n (native_str('nsta'), np.uint32),\n (native_str('nlta'), np.uint32),\n], align=True)\n\nclibsignal.stalta.argtypes = [\n np.ctypeslib.ndpointer(dtype=head_stalta_t, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n]\nclibsignal.stalta.restype = C.c_int\n\nclibsignal.hermite_interpolation.argtypes = [\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int, C.c_int, C.c_double, C.c_double]\nclibsignal.hermite_interpolation.restype = C.c_void_p\n\nclibsignal.lanczos_resample.argtypes = [\n # y_in\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # y_out\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # dt\n C.c_double,\n # offset\n C.c_double,\n # len_in\n C.c_int,\n # len_out,\n C.c_int,\n # a,\n C.c_int,\n # window\n C.c_int]\nclibsignal.lanczos_resample.restype = None\n\nclibsignal.calculate_kernel.argtypes = [\n # double *x\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # double *y\n np.ctypeslib.ndpointer(dtype=np.float64, ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n # int len\n C.c_int,\n # int a,\n C.c_int,\n # int return_type,\n C.c_int,\n # enum lanczos_window_type window\n C.c_int]\nclibsignal.calculate_kernel.restype = None\n\nSTALEN = 64\nNETLEN = 64\nCHALEN = 64\nLOCIDLEN = 64\n\n\nclass C_COMPLEX(C.Structure): # noqa\n _fields_ = [(\"real\", C.c_double),\n (\"imag\", C.c_double)]\n\n\nclass RESPONSE(C.Structure):\n pass\n\n\nRESPONSE._fields_ = [(\"station\", C.c_char * STALEN),\n (\"network\", C.c_char * NETLEN),\n (\"locid\", C.c_char * LOCIDLEN),\n (\"channel\", C.c_char * CHALEN),\n (\"rvec\", C.POINTER(C_COMPLEX)),\n (\"nfreqs\", C.c_int),\n (\"freqs\", C.POINTER(C.c_double)),\n (\"next\", C.POINTER(RESPONSE))]\n\nclibevresp.evresp.argtypes = [\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n C.c_char_p,\n np.ctypeslib.ndpointer(dtype=np.float64,\n ndim=1,\n flags=native_str('C_CONTIGUOUS')),\n C.c_int,\n C.c_char_p,\n C.c_char_p,\n C.c_int,\n C.c_int,\n C.c_int,\n C.c_int]\nclibevresp.evresp.restype = C.POINTER(RESPONSE)\n\nclibevresp.free_response.argtypes = [C.POINTER(RESPONSE)]\nclibevresp.free_response.restype = C.c_void_p\n", "path": "obspy/signal/headers.py"}]} | 2,934 | 184 |
gh_patches_debug_29511 | rasdani/github-patches | git_diff | OpenCTI-Platform__connectors-448 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
VirusTotal Connector error
Please replace every line in curly brackets { like this } with an appropriate answer, and remove this line.
## Description
When trying to enrich a artefact, VirusTotal report the following error every time
<img width="1022" alt="Screenshot 2021-07-05 at 6 55 12 PM" src="https://user-images.githubusercontent.com/79446411/124463810-fc880300-ddc5-11eb-9564-2a8bded488cc.png">
When I access to the log, it shows the following error
`ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pycti/connector/opencti_connector_helper.py", line 152, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-virustotal/virustotal.py", line 116, in _process_message
return self._process_file(observable)
File "/opt/opencti-connector-virustotal/virustotal.py", line 71, in _process_file
if observable["name"] is None and len(attributes["names"]) > 0:
KeyError: 'name'
INFO:root:Reporting work update_received opencti-work--c2b1ef93-8b44-4915-b418-f759ee262f53
INFO:root:Message (delivery_tag=1) processed, thread terminated`
## Environment
1. AWS ubuntu-bionic-18.04-amd64-server
2. OpenCTI Version 4.5.5
3. OpenCTI client: frontend
4. Other environment details: VirusTotal connector version : opencti/connector-virustotal:latest
## Reproducible Steps
Steps to create the smallest reproducible scenario:
## Expected Output
Successfully extract information from VirusTotal
## Actual Output
Error occurred as mentioned above.
## Additional information
{ Any additional information, including logs or screenshots if you have any. }
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `virustotal/src/virustotal.py`
Content:
```
1 from time import sleep
2 import yaml
3 import os
4 import requests
5 import json
6
7 from pycti import OpenCTIConnectorHelper, get_config_variable
8
9
10 class VirusTotalConnector:
11 def __init__(self):
12 # Instantiate the connector helper from config
13 config_file_path = os.path.dirname(os.path.abspath(__file__)) + "/config.yml"
14 config = (
15 yaml.load(open(config_file_path), Loader=yaml.FullLoader)
16 if os.path.isfile(config_file_path)
17 else {}
18 )
19 self.helper = OpenCTIConnectorHelper(config)
20 self.token = get_config_variable(
21 "VIRUSTOTAL_TOKEN", ["virustotal", "token"], config
22 )
23 self.max_tlp = get_config_variable(
24 "VIRUSTOTAL_MAX_TLP", ["virustotal", "max_tlp"], config
25 )
26 self.api_url = "https://www.virustotal.com/api/v3"
27 self.headers = {
28 "x-apikey": self.token,
29 "accept": "application/json",
30 "content-type": "application/json",
31 }
32 self._CONNECTOR_RUN_INTERVAL_SEC = 60 * 60
33
34 def _process_file(self, observable):
35 response = requests.request(
36 "GET",
37 self.api_url + "/files/" + observable["observable_value"],
38 headers=self.headers,
39 )
40 json_data = json.loads(response.text)
41 if "error" in json_data:
42 if json_data["error"]["message"] == "Quota exceeded":
43 self.helper.log_info("Quota reached, waiting 1 hour.")
44 sleep(self._CONNECTOR_RUN_INTERVAL_SEC)
45 elif "not found" in json_data["error"]["message"]:
46 self.helper.log_info("File not found on VirusTotal.")
47 return "File not found on VirusTotal."
48 else:
49 raise ValueError(json_data["error"]["message"])
50 if "data" in json_data:
51 data = json_data["data"]
52 attributes = data["attributes"]
53 # Update the current observable
54 final_observable = self.helper.api.stix_cyber_observable.update_field(
55 id=observable["id"], key="hashes.MD5", value=attributes["md5"]
56 )
57 final_observable = self.helper.api.stix_cyber_observable.update_field(
58 id=final_observable["id"], key="hashes.SHA-1", value=attributes["sha1"]
59 )
60 final_observable = self.helper.api.stix_cyber_observable.update_field(
61 id=final_observable["id"],
62 key="hashes.SHA-256",
63 value=attributes["sha256"],
64 )
65 if observable["entity_type"] == "StixFile":
66 self.helper.api.stix_cyber_observable.update_field(
67 id=final_observable["id"],
68 key="size",
69 value=str(attributes["size"]),
70 )
71 if observable["name"] is None and len(attributes["names"]) > 0:
72 self.helper.api.stix_cyber_observable.update_field(
73 id=final_observable["id"], key="name", value=attributes["names"][0]
74 )
75 del attributes["names"][0]
76 if len(attributes["names"]) > 0:
77 self.helper.api.stix_cyber_observable.update_field(
78 id=final_observable["id"],
79 key="x_opencti_additional_names",
80 value=attributes["names"],
81 )
82
83 # Create external reference
84 external_reference = self.helper.api.external_reference.create(
85 source_name="VirusTotal",
86 url="https://www.virustotal.com/gui/file/" + attributes["sha256"],
87 description=attributes["magic"],
88 )
89
90 # Create tags
91 for tag in attributes["tags"]:
92 tag_vt = self.helper.api.label.create(value=tag, color="#0059f7")
93 self.helper.api.stix_cyber_observable.add_label(
94 id=final_observable["id"], label_id=tag_vt["id"]
95 )
96
97 self.helper.api.stix_cyber_observable.add_external_reference(
98 id=final_observable["id"],
99 external_reference_id=external_reference["id"],
100 )
101
102 return "File found on VirusTotal, knowledge attached."
103
104 def _process_message(self, data):
105 entity_id = data["entity_id"]
106 observable = self.helper.api.stix_cyber_observable.read(id=entity_id)
107 # Extract TLP
108 tlp = "TLP:WHITE"
109 for marking_definition in observable["objectMarking"]:
110 if marking_definition["definition_type"] == "TLP":
111 tlp = marking_definition["definition"]
112 if not OpenCTIConnectorHelper.check_max_tlp(tlp, self.max_tlp):
113 raise ValueError(
114 "Do not send any data, TLP of the observable is greater than MAX TLP"
115 )
116 return self._process_file(observable)
117
118 # Start the main loop
119 def start(self):
120 self.helper.listen(self._process_message)
121
122
123 if __name__ == "__main__":
124 virusTotalInstance = VirusTotalConnector()
125 virusTotalInstance.start()
126
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/virustotal/src/virustotal.py b/virustotal/src/virustotal.py
--- a/virustotal/src/virustotal.py
+++ b/virustotal/src/virustotal.py
@@ -1,10 +1,9 @@
-from time import sleep
-import yaml
+import json
import os
import requests
-import json
-
+import yaml
from pycti import OpenCTIConnectorHelper, get_config_variable
+from time import sleep
class VirusTotalConnector:
@@ -68,17 +67,20 @@
key="size",
value=str(attributes["size"]),
)
- if observable["name"] is None and len(attributes["names"]) > 0:
- self.helper.api.stix_cyber_observable.update_field(
- id=final_observable["id"], key="name", value=attributes["names"][0]
- )
- del attributes["names"][0]
- if len(attributes["names"]) > 0:
+ if observable["name"] is None and len(attributes["names"]) > 0:
self.helper.api.stix_cyber_observable.update_field(
id=final_observable["id"],
- key="x_opencti_additional_names",
- value=attributes["names"],
+ key="name",
+ value=attributes["names"][0],
)
+ del attributes["names"][0]
+
+ if len(attributes["names"]) > 0:
+ self.helper.api.stix_cyber_observable.update_field(
+ id=final_observable["id"],
+ key="x_opencti_additional_names",
+ value=attributes["names"],
+ )
# Create external reference
external_reference = self.helper.api.external_reference.create(
| {"golden_diff": "diff --git a/virustotal/src/virustotal.py b/virustotal/src/virustotal.py\n--- a/virustotal/src/virustotal.py\n+++ b/virustotal/src/virustotal.py\n@@ -1,10 +1,9 @@\n-from time import sleep\n-import yaml\n+import json\n import os\n import requests\n-import json\n-\n+import yaml\n from pycti import OpenCTIConnectorHelper, get_config_variable\n+from time import sleep\n \n \n class VirusTotalConnector:\n@@ -68,17 +67,20 @@\n key=\"size\",\n value=str(attributes[\"size\"]),\n )\n- if observable[\"name\"] is None and len(attributes[\"names\"]) > 0:\n- self.helper.api.stix_cyber_observable.update_field(\n- id=final_observable[\"id\"], key=\"name\", value=attributes[\"names\"][0]\n- )\n- del attributes[\"names\"][0]\n- if len(attributes[\"names\"]) > 0:\n+ if observable[\"name\"] is None and len(attributes[\"names\"]) > 0:\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n- key=\"x_opencti_additional_names\",\n- value=attributes[\"names\"],\n+ key=\"name\",\n+ value=attributes[\"names\"][0],\n )\n+ del attributes[\"names\"][0]\n+\n+ if len(attributes[\"names\"]) > 0:\n+ self.helper.api.stix_cyber_observable.update_field(\n+ id=final_observable[\"id\"],\n+ key=\"x_opencti_additional_names\",\n+ value=attributes[\"names\"],\n+ )\n \n # Create external reference\n external_reference = self.helper.api.external_reference.create(\n", "issue": "VirusTotal Connector error\nPlease replace every line in curly brackets { like this } with an appropriate answer, and remove this line.\r\n\r\n## Description\r\n\r\nWhen trying to enrich a artefact, VirusTotal report the following error every time \r\n<img width=\"1022\" alt=\"Screenshot 2021-07-05 at 6 55 12 PM\" src=\"https://user-images.githubusercontent.com/79446411/124463810-fc880300-ddc5-11eb-9564-2a8bded488cc.png\">\r\n\r\n\r\nWhen I access to the log, it shows the following error\r\n`ERROR:root:Error in message processing, reporting error to API\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/site-packages/pycti/connector/opencti_connector_helper.py\", line 152, in _data_handler\r\n message = self.callback(json_data[\"event\"])\r\n File \"/opt/opencti-connector-virustotal/virustotal.py\", line 116, in _process_message\r\n return self._process_file(observable)\r\n File \"/opt/opencti-connector-virustotal/virustotal.py\", line 71, in _process_file\r\n if observable[\"name\"] is None and len(attributes[\"names\"]) > 0:\r\nKeyError: 'name'\r\nINFO:root:Reporting work update_received opencti-work--c2b1ef93-8b44-4915-b418-f759ee262f53\r\nINFO:root:Message (delivery_tag=1) processed, thread terminated`\r\n\r\n## Environment\r\n\r\n1. AWS ubuntu-bionic-18.04-amd64-server\r\n2. OpenCTI Version 4.5.5\r\n3. OpenCTI client: frontend\r\n4. Other environment details: VirusTotal connector version : opencti/connector-virustotal:latest\r\n\r\n## Reproducible Steps\r\n\r\nSteps to create the smallest reproducible scenario:\r\n\r\n## Expected Output\r\n\r\nSuccessfully extract information from VirusTotal \r\n\r\n## Actual Output\r\n\r\nError occurred as mentioned above.\r\n \r\n## Additional information\r\n\r\n{ Any additional information, including logs or screenshots if you have any. }\r\n\n", "before_files": [{"content": "from time import sleep\nimport yaml\nimport os\nimport requests\nimport json\n\nfrom pycti import OpenCTIConnectorHelper, get_config_variable\n\n\nclass VirusTotalConnector:\n def __init__(self):\n # Instantiate the connector helper from config\n config_file_path = os.path.dirname(os.path.abspath(__file__)) + \"/config.yml\"\n config = (\n yaml.load(open(config_file_path), Loader=yaml.FullLoader)\n if os.path.isfile(config_file_path)\n else {}\n )\n self.helper = OpenCTIConnectorHelper(config)\n self.token = get_config_variable(\n \"VIRUSTOTAL_TOKEN\", [\"virustotal\", \"token\"], config\n )\n self.max_tlp = get_config_variable(\n \"VIRUSTOTAL_MAX_TLP\", [\"virustotal\", \"max_tlp\"], config\n )\n self.api_url = \"https://www.virustotal.com/api/v3\"\n self.headers = {\n \"x-apikey\": self.token,\n \"accept\": \"application/json\",\n \"content-type\": \"application/json\",\n }\n self._CONNECTOR_RUN_INTERVAL_SEC = 60 * 60\n\n def _process_file(self, observable):\n response = requests.request(\n \"GET\",\n self.api_url + \"/files/\" + observable[\"observable_value\"],\n headers=self.headers,\n )\n json_data = json.loads(response.text)\n if \"error\" in json_data:\n if json_data[\"error\"][\"message\"] == \"Quota exceeded\":\n self.helper.log_info(\"Quota reached, waiting 1 hour.\")\n sleep(self._CONNECTOR_RUN_INTERVAL_SEC)\n elif \"not found\" in json_data[\"error\"][\"message\"]:\n self.helper.log_info(\"File not found on VirusTotal.\")\n return \"File not found on VirusTotal.\"\n else:\n raise ValueError(json_data[\"error\"][\"message\"])\n if \"data\" in json_data:\n data = json_data[\"data\"]\n attributes = data[\"attributes\"]\n # Update the current observable\n final_observable = self.helper.api.stix_cyber_observable.update_field(\n id=observable[\"id\"], key=\"hashes.MD5\", value=attributes[\"md5\"]\n )\n final_observable = self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"], key=\"hashes.SHA-1\", value=attributes[\"sha1\"]\n )\n final_observable = self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"hashes.SHA-256\",\n value=attributes[\"sha256\"],\n )\n if observable[\"entity_type\"] == \"StixFile\":\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"size\",\n value=str(attributes[\"size\"]),\n )\n if observable[\"name\"] is None and len(attributes[\"names\"]) > 0:\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"], key=\"name\", value=attributes[\"names\"][0]\n )\n del attributes[\"names\"][0]\n if len(attributes[\"names\"]) > 0:\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"x_opencti_additional_names\",\n value=attributes[\"names\"],\n )\n\n # Create external reference\n external_reference = self.helper.api.external_reference.create(\n source_name=\"VirusTotal\",\n url=\"https://www.virustotal.com/gui/file/\" + attributes[\"sha256\"],\n description=attributes[\"magic\"],\n )\n\n # Create tags\n for tag in attributes[\"tags\"]:\n tag_vt = self.helper.api.label.create(value=tag, color=\"#0059f7\")\n self.helper.api.stix_cyber_observable.add_label(\n id=final_observable[\"id\"], label_id=tag_vt[\"id\"]\n )\n\n self.helper.api.stix_cyber_observable.add_external_reference(\n id=final_observable[\"id\"],\n external_reference_id=external_reference[\"id\"],\n )\n\n return \"File found on VirusTotal, knowledge attached.\"\n\n def _process_message(self, data):\n entity_id = data[\"entity_id\"]\n observable = self.helper.api.stix_cyber_observable.read(id=entity_id)\n # Extract TLP\n tlp = \"TLP:WHITE\"\n for marking_definition in observable[\"objectMarking\"]:\n if marking_definition[\"definition_type\"] == \"TLP\":\n tlp = marking_definition[\"definition\"]\n if not OpenCTIConnectorHelper.check_max_tlp(tlp, self.max_tlp):\n raise ValueError(\n \"Do not send any data, TLP of the observable is greater than MAX TLP\"\n )\n return self._process_file(observable)\n\n # Start the main loop\n def start(self):\n self.helper.listen(self._process_message)\n\n\nif __name__ == \"__main__\":\n virusTotalInstance = VirusTotalConnector()\n virusTotalInstance.start()\n", "path": "virustotal/src/virustotal.py"}], "after_files": [{"content": "import json\nimport os\nimport requests\nimport yaml\nfrom pycti import OpenCTIConnectorHelper, get_config_variable\nfrom time import sleep\n\n\nclass VirusTotalConnector:\n def __init__(self):\n # Instantiate the connector helper from config\n config_file_path = os.path.dirname(os.path.abspath(__file__)) + \"/config.yml\"\n config = (\n yaml.load(open(config_file_path), Loader=yaml.FullLoader)\n if os.path.isfile(config_file_path)\n else {}\n )\n self.helper = OpenCTIConnectorHelper(config)\n self.token = get_config_variable(\n \"VIRUSTOTAL_TOKEN\", [\"virustotal\", \"token\"], config\n )\n self.max_tlp = get_config_variable(\n \"VIRUSTOTAL_MAX_TLP\", [\"virustotal\", \"max_tlp\"], config\n )\n self.api_url = \"https://www.virustotal.com/api/v3\"\n self.headers = {\n \"x-apikey\": self.token,\n \"accept\": \"application/json\",\n \"content-type\": \"application/json\",\n }\n self._CONNECTOR_RUN_INTERVAL_SEC = 60 * 60\n\n def _process_file(self, observable):\n response = requests.request(\n \"GET\",\n self.api_url + \"/files/\" + observable[\"observable_value\"],\n headers=self.headers,\n )\n json_data = json.loads(response.text)\n if \"error\" in json_data:\n if json_data[\"error\"][\"message\"] == \"Quota exceeded\":\n self.helper.log_info(\"Quota reached, waiting 1 hour.\")\n sleep(self._CONNECTOR_RUN_INTERVAL_SEC)\n elif \"not found\" in json_data[\"error\"][\"message\"]:\n self.helper.log_info(\"File not found on VirusTotal.\")\n return \"File not found on VirusTotal.\"\n else:\n raise ValueError(json_data[\"error\"][\"message\"])\n if \"data\" in json_data:\n data = json_data[\"data\"]\n attributes = data[\"attributes\"]\n # Update the current observable\n final_observable = self.helper.api.stix_cyber_observable.update_field(\n id=observable[\"id\"], key=\"hashes.MD5\", value=attributes[\"md5\"]\n )\n final_observable = self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"], key=\"hashes.SHA-1\", value=attributes[\"sha1\"]\n )\n final_observable = self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"hashes.SHA-256\",\n value=attributes[\"sha256\"],\n )\n if observable[\"entity_type\"] == \"StixFile\":\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"size\",\n value=str(attributes[\"size\"]),\n )\n if observable[\"name\"] is None and len(attributes[\"names\"]) > 0:\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"name\",\n value=attributes[\"names\"][0],\n )\n del attributes[\"names\"][0]\n\n if len(attributes[\"names\"]) > 0:\n self.helper.api.stix_cyber_observable.update_field(\n id=final_observable[\"id\"],\n key=\"x_opencti_additional_names\",\n value=attributes[\"names\"],\n )\n\n # Create external reference\n external_reference = self.helper.api.external_reference.create(\n source_name=\"VirusTotal\",\n url=\"https://www.virustotal.com/gui/file/\" + attributes[\"sha256\"],\n description=attributes[\"magic\"],\n )\n\n # Create tags\n for tag in attributes[\"tags\"]:\n tag_vt = self.helper.api.label.create(value=tag, color=\"#0059f7\")\n self.helper.api.stix_cyber_observable.add_label(\n id=final_observable[\"id\"], label_id=tag_vt[\"id\"]\n )\n\n self.helper.api.stix_cyber_observable.add_external_reference(\n id=final_observable[\"id\"],\n external_reference_id=external_reference[\"id\"],\n )\n\n return \"File found on VirusTotal, knowledge attached.\"\n\n def _process_message(self, data):\n entity_id = data[\"entity_id\"]\n observable = self.helper.api.stix_cyber_observable.read(id=entity_id)\n # Extract TLP\n tlp = \"TLP:WHITE\"\n for marking_definition in observable[\"objectMarking\"]:\n if marking_definition[\"definition_type\"] == \"TLP\":\n tlp = marking_definition[\"definition\"]\n if not OpenCTIConnectorHelper.check_max_tlp(tlp, self.max_tlp):\n raise ValueError(\n \"Do not send any data, TLP of the observable is greater than MAX TLP\"\n )\n return self._process_file(observable)\n\n # Start the main loop\n def start(self):\n self.helper.listen(self._process_message)\n\n\nif __name__ == \"__main__\":\n virusTotalInstance = VirusTotalConnector()\n virusTotalInstance.start()\n", "path": "virustotal/src/virustotal.py"}]} | 2,134 | 390 |
gh_patches_debug_29515 | rasdani/github-patches | git_diff | plone__Products.CMFPlone-1512 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Resources from third party add-ons are not being included in compiled plone-legacy bundle
Seems JS resources registered in Plone 5 using old approach (`jsregistry.xml`) are not included in the final compilation: I installed an add-on and, even as I can see the JS resources listed in `default.js`, the source code is not present.
If I enable development mode, then I can see the source code included in `plone-legacy-compiled.js` and it's executed normally.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `Products/CMFPlone/resources/browser/combine.py`
Content:
```
1 import re
2 from zExceptions import NotFound
3 from Acquisition import aq_base
4 from datetime import datetime
5 from plone.registry.interfaces import IRegistry
6 from plone.resource.file import FilesystemFile
7 from plone.resource.interfaces import IResourceDirectory
8 from Products.CMFPlone.interfaces import IBundleRegistry
9 from Products.CMFPlone.interfaces.resources import (
10 OVERRIDE_RESOURCE_DIRECTORY_NAME,
11 )
12 from StringIO import StringIO
13 from zope.component import getUtility
14 from zope.component import queryUtility
15
16 PRODUCTION_RESOURCE_DIRECTORY = "production"
17
18
19 def get_production_resource_directory():
20 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
21 if persistent_directory is None:
22 return ''
23 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
24 try:
25 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
26 except NotFound:
27 return "%s/++unique++1" % PRODUCTION_RESOURCE_DIRECTORY
28 timestamp = production_folder.readFile('timestamp.txt')
29 return "%s/++unique++%s" % (
30 PRODUCTION_RESOURCE_DIRECTORY, timestamp)
31
32
33 def get_resource(context, path):
34 resource = context.unrestrictedTraverse(path)
35 if isinstance(resource, FilesystemFile):
36 (directory, sep, filename) = path.rpartition('/')
37 return context.unrestrictedTraverse(directory).readFile(filename)
38 else:
39 if hasattr(aq_base(resource), 'GET'):
40 # for FileResource
41 return resource.GET()
42 else:
43 # any BrowserView
44 return resource()
45
46
47 def write_js(context, folder, meta_bundle):
48 registry = getUtility(IRegistry)
49 resources = []
50
51 # default resources
52 if meta_bundle == 'default' and registry.records.get(
53 'plone.resources/jquery.js'
54 ):
55 resources.append(get_resource(context,
56 registry.records['plone.resources/jquery.js'].value))
57 resources.append(get_resource(context,
58 registry.records['plone.resources.requirejs'].value))
59 resources.append(get_resource(context,
60 registry.records['plone.resources.configjs'].value))
61
62 # bundles
63 bundles = registry.collectionOfInterface(
64 IBundleRegistry, prefix="plone.bundles", check=False)
65 for bundle in bundles.values():
66 if bundle.merge_with == meta_bundle:
67 resources.append(get_resource(context, bundle.jscompilation))
68
69 fi = StringIO()
70 for script in resources:
71 fi.write(script + '\n')
72 folder.writeFile(meta_bundle + ".js", fi)
73
74
75 def write_css(context, folder, meta_bundle):
76 registry = getUtility(IRegistry)
77 resources = []
78
79 bundles = registry.collectionOfInterface(
80 IBundleRegistry, prefix="plone.bundles", check=False)
81 for bundle in bundles.values():
82 if bundle.merge_with == meta_bundle:
83 css = get_resource(context, bundle.csscompilation)
84 # Preserve relative urls:
85 # we prefix with '../'' any url not starting with '/'
86 # or http: or data:
87 css = re.sub(
88 r"""(url\(['"]?(?!['"]?([a-z]+:|\/)))""",
89 r'\1../',
90 css)
91 resources.append(css)
92
93 fi = StringIO()
94 for script in resources:
95 fi.write(script + '\n')
96 folder.writeFile(meta_bundle + ".css", fi)
97
98
99 def combine_bundles(context):
100 persistent_directory = queryUtility(IResourceDirectory, name="persistent")
101 if persistent_directory is None:
102 return
103 if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
104 persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
105 container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
106 if PRODUCTION_RESOURCE_DIRECTORY not in container:
107 container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)
108 production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
109
110 # store timestamp
111 fi = StringIO()
112 fi.write(datetime.now().isoformat())
113 production_folder.writeFile("timestamp.txt", fi)
114
115 # generate new combined bundles
116 write_js(context, production_folder, 'default')
117 write_js(context, production_folder, 'logged-in')
118 write_css(context, production_folder, 'default')
119 write_css(context, production_folder, 'logged-in')
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py
--- a/Products/CMFPlone/resources/browser/combine.py
+++ b/Products/CMFPlone/resources/browser/combine.py
@@ -31,6 +31,14 @@
def get_resource(context, path):
+ if path.startswith('++plone++'):
+ # ++plone++ resources can be customized, we return their override
+ # value if any
+ overrides = get_override_directory(context)
+ filepath = path[9:]
+ if overrides.isFile(filepath):
+ return overrides.readFile(filepath)
+
resource = context.unrestrictedTraverse(path)
if isinstance(resource, FilesystemFile):
(directory, sep, filename) = path.rpartition('/')
@@ -96,13 +104,17 @@
folder.writeFile(meta_bundle + ".css", fi)
-def combine_bundles(context):
+def get_override_directory(context):
persistent_directory = queryUtility(IResourceDirectory, name="persistent")
if persistent_directory is None:
return
if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:
persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)
- container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
+ return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]
+
+
+def combine_bundles(context):
+ container = get_override_directory(context)
if PRODUCTION_RESOURCE_DIRECTORY not in container:
container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)
production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]
| {"golden_diff": "diff --git a/Products/CMFPlone/resources/browser/combine.py b/Products/CMFPlone/resources/browser/combine.py\n--- a/Products/CMFPlone/resources/browser/combine.py\n+++ b/Products/CMFPlone/resources/browser/combine.py\n@@ -31,6 +31,14 @@\n \n \n def get_resource(context, path):\n+ if path.startswith('++plone++'):\n+ # ++plone++ resources can be customized, we return their override\n+ # value if any\n+ overrides = get_override_directory(context)\n+ filepath = path[9:]\n+ if overrides.isFile(filepath):\n+ return overrides.readFile(filepath)\n+\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n@@ -96,13 +104,17 @@\n folder.writeFile(meta_bundle + \".css\", fi)\n \n \n-def combine_bundles(context):\n+def get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n- container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n+ return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n+\n+\n+def combine_bundles(context):\n+ container = get_override_directory(context)\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n", "issue": "Resources from third party add-ons are not being included in compiled plone-legacy bundle\nSeems JS resources registered in Plone 5 using old approach (`jsregistry.xml`) are not included in the final compilation: I installed an add-on and, even as I can see the JS resources listed in `default.js`, the source code is not present.\n\nIf I enable development mode, then I can see the source code included in `plone-legacy-compiled.js` and it's executed normally.\n\n", "before_files": [{"content": "import re\nfrom zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n css = get_resource(context, bundle.csscompilation)\n # Preserve relative urls:\n # we prefix with '../'' any url not starting with '/'\n # or http: or data:\n css = re.sub(\n r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n r'\\1../',\n css)\n resources.append(css)\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef combine_bundles(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}], "after_files": [{"content": "import re\nfrom zExceptions import NotFound\nfrom Acquisition import aq_base\nfrom datetime import datetime\nfrom plone.registry.interfaces import IRegistry\nfrom plone.resource.file import FilesystemFile\nfrom plone.resource.interfaces import IResourceDirectory\nfrom Products.CMFPlone.interfaces import IBundleRegistry\nfrom Products.CMFPlone.interfaces.resources import (\n OVERRIDE_RESOURCE_DIRECTORY_NAME,\n)\nfrom StringIO import StringIO\nfrom zope.component import getUtility\nfrom zope.component import queryUtility\n\nPRODUCTION_RESOURCE_DIRECTORY = \"production\"\n\n\ndef get_production_resource_directory():\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return ''\n container = persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n try:\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n except NotFound:\n return \"%s/++unique++1\" % PRODUCTION_RESOURCE_DIRECTORY\n timestamp = production_folder.readFile('timestamp.txt')\n return \"%s/++unique++%s\" % (\n PRODUCTION_RESOURCE_DIRECTORY, timestamp)\n\n\ndef get_resource(context, path):\n if path.startswith('++plone++'):\n # ++plone++ resources can be customized, we return their override\n # value if any\n overrides = get_override_directory(context)\n filepath = path[9:]\n if overrides.isFile(filepath):\n return overrides.readFile(filepath)\n\n resource = context.unrestrictedTraverse(path)\n if isinstance(resource, FilesystemFile):\n (directory, sep, filename) = path.rpartition('/')\n return context.unrestrictedTraverse(directory).readFile(filename)\n else:\n if hasattr(aq_base(resource), 'GET'):\n # for FileResource\n return resource.GET()\n else:\n # any BrowserView\n return resource()\n\n\ndef write_js(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n # default resources\n if meta_bundle == 'default' and registry.records.get(\n 'plone.resources/jquery.js'\n ):\n resources.append(get_resource(context,\n registry.records['plone.resources/jquery.js'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.requirejs'].value))\n resources.append(get_resource(context,\n registry.records['plone.resources.configjs'].value))\n\n # bundles\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n resources.append(get_resource(context, bundle.jscompilation))\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".js\", fi)\n\n\ndef write_css(context, folder, meta_bundle):\n registry = getUtility(IRegistry)\n resources = []\n\n bundles = registry.collectionOfInterface(\n IBundleRegistry, prefix=\"plone.bundles\", check=False)\n for bundle in bundles.values():\n if bundle.merge_with == meta_bundle:\n css = get_resource(context, bundle.csscompilation)\n # Preserve relative urls:\n # we prefix with '../'' any url not starting with '/'\n # or http: or data:\n css = re.sub(\n r\"\"\"(url\\(['\"]?(?!['\"]?([a-z]+:|\\/)))\"\"\",\n r'\\1../',\n css)\n resources.append(css)\n\n fi = StringIO()\n for script in resources:\n fi.write(script + '\\n')\n folder.writeFile(meta_bundle + \".css\", fi)\n\n\ndef get_override_directory(context):\n persistent_directory = queryUtility(IResourceDirectory, name=\"persistent\")\n if persistent_directory is None:\n return\n if OVERRIDE_RESOURCE_DIRECTORY_NAME not in persistent_directory:\n persistent_directory.makeDirectory(OVERRIDE_RESOURCE_DIRECTORY_NAME)\n return persistent_directory[OVERRIDE_RESOURCE_DIRECTORY_NAME]\n\n\ndef combine_bundles(context):\n container = get_override_directory(context)\n if PRODUCTION_RESOURCE_DIRECTORY not in container:\n container.makeDirectory(PRODUCTION_RESOURCE_DIRECTORY)\n production_folder = container[PRODUCTION_RESOURCE_DIRECTORY]\n\n # store timestamp\n fi = StringIO()\n fi.write(datetime.now().isoformat())\n production_folder.writeFile(\"timestamp.txt\", fi)\n\n # generate new combined bundles\n write_js(context, production_folder, 'default')\n write_js(context, production_folder, 'logged-in')\n write_css(context, production_folder, 'default')\n write_css(context, production_folder, 'logged-in')\n", "path": "Products/CMFPlone/resources/browser/combine.py"}]} | 1,482 | 339 |
gh_patches_debug_24757 | rasdani/github-patches | git_diff | dbt-labs__dbt-core-7635 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[CT-2479] replace all instances of set-output and node16
Details in https://github.com/dbt-labs/actions/issues/39.
### Acceptance Criteria
- [ ] Verified there are no workflows to update
_or_
- [ ] removed all uses of `set-output` - either directly or up updating any marketplace actions we reference
- [ ] removed all references to node16 - either directly or up updating any marketplace actions we reference
- [ ] backport changes
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `.github/actions/latest-wrangler/main.py`
Content:
```
1 import os
2 import sys
3 import requests
4 from distutils.util import strtobool
5 from typing import Union
6 from packaging.version import parse, Version
7
8 if __name__ == "__main__":
9
10 # get inputs
11 package = os.environ["INPUT_PACKAGE"]
12 new_version = parse(os.environ["INPUT_NEW_VERSION"])
13 gh_token = os.environ["INPUT_GH_TOKEN"]
14 halt_on_missing = strtobool(os.environ.get("INPUT_HALT_ON_MISSING", "False"))
15
16 # get package metadata from github
17 package_request = requests.get(
18 f"https://api.github.com/orgs/dbt-labs/packages/container/{package}/versions",
19 auth=("", gh_token),
20 )
21 package_meta = package_request.json()
22
23 # Log info if we don't get a 200
24 if package_request.status_code != 200:
25 print(f"Call to GH API failed: {package_request.status_code} {package_meta['message']}")
26
27 # Make an early exit if there is no matching package in github
28 if package_request.status_code == 404:
29 if halt_on_missing:
30 sys.exit(1)
31 else:
32 # everything is the latest if the package doesn't exist
33 print(f"::set-output name=latest::{True}")
34 print(f"::set-output name=minor_latest::{True}")
35 sys.exit(0)
36
37 # TODO: verify package meta is "correct"
38 # https://github.com/dbt-labs/dbt-core/issues/4640
39
40 # map versions and tags
41 version_tag_map = {
42 version["id"]: version["metadata"]["container"]["tags"] for version in package_meta
43 }
44
45 # is pre-release
46 pre_rel = True if any(x in str(new_version) for x in ["a", "b", "rc"]) else False
47
48 # semver of current latest
49 for version, tags in version_tag_map.items():
50 if "latest" in tags:
51 # N.B. This seems counterintuitive, but we expect any version tagged
52 # 'latest' to have exactly three associated tags:
53 # latest, major.minor.latest, and major.minor.patch.
54 # Subtracting everything that contains the string 'latest' gets us
55 # the major.minor.patch which is what's needed for comparison.
56 current_latest = parse([tag for tag in tags if "latest" not in tag][0])
57 else:
58 current_latest = False
59
60 # semver of current_minor_latest
61 for version, tags in version_tag_map.items():
62 if f"{new_version.major}.{new_version.minor}.latest" in tags:
63 # Similar to above, only now we expect exactly two tags:
64 # major.minor.patch and major.minor.latest
65 current_minor_latest = parse([tag for tag in tags if "latest" not in tag][0])
66 else:
67 current_minor_latest = False
68
69 def is_latest(
70 pre_rel: bool, new_version: Version, remote_latest: Union[bool, Version]
71 ) -> bool:
72 """Determine if a given contaier should be tagged 'latest' based on:
73 - it's pre-release status
74 - it's version
75 - the version of a previously identified container tagged 'latest'
76
77 :param pre_rel: Wether or not the version of the new container is a pre-release
78 :param new_version: The version of the new container
79 :param remote_latest: The version of the previously identified container that's
80 already tagged latest or False
81 """
82 # is a pre-release = not latest
83 if pre_rel:
84 return False
85 # + no latest tag found = is latest
86 if not remote_latest:
87 return True
88 # + if remote version is lower than current = is latest, else not latest
89 return True if remote_latest <= new_version else False
90
91 latest = is_latest(pre_rel, new_version, current_latest)
92 minor_latest = is_latest(pre_rel, new_version, current_minor_latest)
93
94 print(f"::set-output name=latest::{latest}")
95 print(f"::set-output name=minor_latest::{minor_latest}")
96
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/.github/actions/latest-wrangler/main.py b/.github/actions/latest-wrangler/main.py
--- a/.github/actions/latest-wrangler/main.py
+++ b/.github/actions/latest-wrangler/main.py
@@ -28,11 +28,12 @@
if package_request.status_code == 404:
if halt_on_missing:
sys.exit(1)
- else:
- # everything is the latest if the package doesn't exist
- print(f"::set-output name=latest::{True}")
- print(f"::set-output name=minor_latest::{True}")
- sys.exit(0)
+ # everything is the latest if the package doesn't exist
+ github_output = os.environ.get("GITHUB_OUTPUT")
+ with open(github_output, "at", encoding="utf-8") as gh_output:
+ gh_output.write("latest=True")
+ gh_output.write("minor_latest=True")
+ sys.exit(0)
# TODO: verify package meta is "correct"
# https://github.com/dbt-labs/dbt-core/issues/4640
@@ -91,5 +92,7 @@
latest = is_latest(pre_rel, new_version, current_latest)
minor_latest = is_latest(pre_rel, new_version, current_minor_latest)
- print(f"::set-output name=latest::{latest}")
- print(f"::set-output name=minor_latest::{minor_latest}")
+ github_output = os.environ.get("GITHUB_OUTPUT")
+ with open(github_output, "at", encoding="utf-8") as gh_output:
+ gh_output.write(f"latest={latest}")
+ gh_output.write(f"minor_latest={minor_latest}")
| {"golden_diff": "diff --git a/.github/actions/latest-wrangler/main.py b/.github/actions/latest-wrangler/main.py\n--- a/.github/actions/latest-wrangler/main.py\n+++ b/.github/actions/latest-wrangler/main.py\n@@ -28,11 +28,12 @@\n if package_request.status_code == 404:\n if halt_on_missing:\n sys.exit(1)\n- else:\n- # everything is the latest if the package doesn't exist\n- print(f\"::set-output name=latest::{True}\")\n- print(f\"::set-output name=minor_latest::{True}\")\n- sys.exit(0)\n+ # everything is the latest if the package doesn't exist\n+ github_output = os.environ.get(\"GITHUB_OUTPUT\")\n+ with open(github_output, \"at\", encoding=\"utf-8\") as gh_output:\n+ gh_output.write(\"latest=True\")\n+ gh_output.write(\"minor_latest=True\")\n+ sys.exit(0)\n \n # TODO: verify package meta is \"correct\"\n # https://github.com/dbt-labs/dbt-core/issues/4640\n@@ -91,5 +92,7 @@\n latest = is_latest(pre_rel, new_version, current_latest)\n minor_latest = is_latest(pre_rel, new_version, current_minor_latest)\n \n- print(f\"::set-output name=latest::{latest}\")\n- print(f\"::set-output name=minor_latest::{minor_latest}\")\n+ github_output = os.environ.get(\"GITHUB_OUTPUT\")\n+ with open(github_output, \"at\", encoding=\"utf-8\") as gh_output:\n+ gh_output.write(f\"latest={latest}\")\n+ gh_output.write(f\"minor_latest={minor_latest}\")\n", "issue": "[CT-2479] replace all instances of set-output and node16\nDetails in https://github.com/dbt-labs/actions/issues/39.\r\n\r\n### Acceptance Criteria\r\n- [ ] Verified there are no workflows to update\r\n_or_\r\n- [ ] removed all uses of `set-output` - either directly or up updating any marketplace actions we reference\r\n- [ ] removed all references to node16 - either directly or up updating any marketplace actions we reference\r\n- [ ] backport changes\n", "before_files": [{"content": "import os\nimport sys\nimport requests\nfrom distutils.util import strtobool\nfrom typing import Union\nfrom packaging.version import parse, Version\n\nif __name__ == \"__main__\":\n\n # get inputs\n package = os.environ[\"INPUT_PACKAGE\"]\n new_version = parse(os.environ[\"INPUT_NEW_VERSION\"])\n gh_token = os.environ[\"INPUT_GH_TOKEN\"]\n halt_on_missing = strtobool(os.environ.get(\"INPUT_HALT_ON_MISSING\", \"False\"))\n\n # get package metadata from github\n package_request = requests.get(\n f\"https://api.github.com/orgs/dbt-labs/packages/container/{package}/versions\",\n auth=(\"\", gh_token),\n )\n package_meta = package_request.json()\n\n # Log info if we don't get a 200\n if package_request.status_code != 200:\n print(f\"Call to GH API failed: {package_request.status_code} {package_meta['message']}\")\n\n # Make an early exit if there is no matching package in github\n if package_request.status_code == 404:\n if halt_on_missing:\n sys.exit(1)\n else:\n # everything is the latest if the package doesn't exist\n print(f\"::set-output name=latest::{True}\")\n print(f\"::set-output name=minor_latest::{True}\")\n sys.exit(0)\n\n # TODO: verify package meta is \"correct\"\n # https://github.com/dbt-labs/dbt-core/issues/4640\n\n # map versions and tags\n version_tag_map = {\n version[\"id\"]: version[\"metadata\"][\"container\"][\"tags\"] for version in package_meta\n }\n\n # is pre-release\n pre_rel = True if any(x in str(new_version) for x in [\"a\", \"b\", \"rc\"]) else False\n\n # semver of current latest\n for version, tags in version_tag_map.items():\n if \"latest\" in tags:\n # N.B. This seems counterintuitive, but we expect any version tagged\n # 'latest' to have exactly three associated tags:\n # latest, major.minor.latest, and major.minor.patch.\n # Subtracting everything that contains the string 'latest' gets us\n # the major.minor.patch which is what's needed for comparison.\n current_latest = parse([tag for tag in tags if \"latest\" not in tag][0])\n else:\n current_latest = False\n\n # semver of current_minor_latest\n for version, tags in version_tag_map.items():\n if f\"{new_version.major}.{new_version.minor}.latest\" in tags:\n # Similar to above, only now we expect exactly two tags:\n # major.minor.patch and major.minor.latest\n current_minor_latest = parse([tag for tag in tags if \"latest\" not in tag][0])\n else:\n current_minor_latest = False\n\n def is_latest(\n pre_rel: bool, new_version: Version, remote_latest: Union[bool, Version]\n ) -> bool:\n \"\"\"Determine if a given contaier should be tagged 'latest' based on:\n - it's pre-release status\n - it's version\n - the version of a previously identified container tagged 'latest'\n\n :param pre_rel: Wether or not the version of the new container is a pre-release\n :param new_version: The version of the new container\n :param remote_latest: The version of the previously identified container that's\n already tagged latest or False\n \"\"\"\n # is a pre-release = not latest\n if pre_rel:\n return False\n # + no latest tag found = is latest\n if not remote_latest:\n return True\n # + if remote version is lower than current = is latest, else not latest\n return True if remote_latest <= new_version else False\n\n latest = is_latest(pre_rel, new_version, current_latest)\n minor_latest = is_latest(pre_rel, new_version, current_minor_latest)\n\n print(f\"::set-output name=latest::{latest}\")\n print(f\"::set-output name=minor_latest::{minor_latest}\")\n", "path": ".github/actions/latest-wrangler/main.py"}], "after_files": [{"content": "import os\nimport sys\nimport requests\nfrom distutils.util import strtobool\nfrom typing import Union\nfrom packaging.version import parse, Version\n\nif __name__ == \"__main__\":\n\n # get inputs\n package = os.environ[\"INPUT_PACKAGE\"]\n new_version = parse(os.environ[\"INPUT_NEW_VERSION\"])\n gh_token = os.environ[\"INPUT_GH_TOKEN\"]\n halt_on_missing = strtobool(os.environ.get(\"INPUT_HALT_ON_MISSING\", \"False\"))\n\n # get package metadata from github\n package_request = requests.get(\n f\"https://api.github.com/orgs/dbt-labs/packages/container/{package}/versions\",\n auth=(\"\", gh_token),\n )\n package_meta = package_request.json()\n\n # Log info if we don't get a 200\n if package_request.status_code != 200:\n print(f\"Call to GH API failed: {package_request.status_code} {package_meta['message']}\")\n\n # Make an early exit if there is no matching package in github\n if package_request.status_code == 404:\n if halt_on_missing:\n sys.exit(1)\n # everything is the latest if the package doesn't exist\n github_output = os.environ.get(\"GITHUB_OUTPUT\")\n with open(github_output, \"at\", encoding=\"utf-8\") as gh_output:\n gh_output.write(\"latest=True\")\n gh_output.write(\"minor_latest=True\")\n sys.exit(0)\n\n # TODO: verify package meta is \"correct\"\n # https://github.com/dbt-labs/dbt-core/issues/4640\n\n # map versions and tags\n version_tag_map = {\n version[\"id\"]: version[\"metadata\"][\"container\"][\"tags\"] for version in package_meta\n }\n\n # is pre-release\n pre_rel = True if any(x in str(new_version) for x in [\"a\", \"b\", \"rc\"]) else False\n\n # semver of current latest\n for version, tags in version_tag_map.items():\n if \"latest\" in tags:\n # N.B. This seems counterintuitive, but we expect any version tagged\n # 'latest' to have exactly three associated tags:\n # latest, major.minor.latest, and major.minor.patch.\n # Subtracting everything that contains the string 'latest' gets us\n # the major.minor.patch which is what's needed for comparison.\n current_latest = parse([tag for tag in tags if \"latest\" not in tag][0])\n else:\n current_latest = False\n\n # semver of current_minor_latest\n for version, tags in version_tag_map.items():\n if f\"{new_version.major}.{new_version.minor}.latest\" in tags:\n # Similar to above, only now we expect exactly two tags:\n # major.minor.patch and major.minor.latest\n current_minor_latest = parse([tag for tag in tags if \"latest\" not in tag][0])\n else:\n current_minor_latest = False\n\n def is_latest(\n pre_rel: bool, new_version: Version, remote_latest: Union[bool, Version]\n ) -> bool:\n \"\"\"Determine if a given contaier should be tagged 'latest' based on:\n - it's pre-release status\n - it's version\n - the version of a previously identified container tagged 'latest'\n\n :param pre_rel: Wether or not the version of the new container is a pre-release\n :param new_version: The version of the new container\n :param remote_latest: The version of the previously identified container that's\n already tagged latest or False\n \"\"\"\n # is a pre-release = not latest\n if pre_rel:\n return False\n # + no latest tag found = is latest\n if not remote_latest:\n return True\n # + if remote version is lower than current = is latest, else not latest\n return True if remote_latest <= new_version else False\n\n latest = is_latest(pre_rel, new_version, current_latest)\n minor_latest = is_latest(pre_rel, new_version, current_minor_latest)\n\n github_output = os.environ.get(\"GITHUB_OUTPUT\")\n with open(github_output, \"at\", encoding=\"utf-8\") as gh_output:\n gh_output.write(f\"latest={latest}\")\n gh_output.write(f\"minor_latest={minor_latest}\")\n", "path": ".github/actions/latest-wrangler/main.py"}]} | 1,441 | 377 |
gh_patches_debug_58009 | rasdani/github-patches | git_diff | sopel-irc__sopel-611 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[search].duck is horribly broken.
It appears we're scraping the page wrong, since ".duck wikipedia" returns an ad page.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `willie/modules/search.py`
Content:
```
1 # coding=utf8
2 """
3 search.py - Willie Web Search Module
4 Copyright 2008-9, Sean B. Palmer, inamidst.com
5 Copyright 2012, Edward Powell, embolalia.net
6 Licensed under the Eiffel Forum License 2.
7
8 http://willie.dftba.net
9 """
10 from __future__ import unicode_literals
11
12 import re
13 from willie import web
14 from willie.module import commands, example
15 import json
16 import sys
17 import time
18
19
20 def google_ajax(query):
21 """Search using AjaxSearch, and return its JSON."""
22 uri = 'http://ajax.googleapis.com/ajax/services/search/web'
23 args = '?v=1.0&safe=off&q=' + query
24 bytes = web.get(uri + args)
25 return json.loads(bytes)
26
27
28 def google_search(query):
29 results = google_ajax(query)
30 try:
31 return results['responseData']['results'][0]['unescapedUrl']
32 except IndexError:
33 return None
34 except TypeError:
35 return False
36
37
38 def google_count(query):
39 results = google_ajax(query)
40 if not 'responseData' in results:
41 return '0'
42 if not 'cursor' in results['responseData']:
43 return '0'
44 if not 'estimatedResultCount' in results['responseData']['cursor']:
45 return '0'
46 return results['responseData']['cursor']['estimatedResultCount']
47
48
49 def formatnumber(n):
50 """Format a number with beautiful commas."""
51 parts = list(str(n))
52 for i in range((len(parts) - 3), 0, -3):
53 parts.insert(i, ',')
54 return ''.join(parts)
55
56
57 @commands('g', 'google')
58 @example('.g swhack')
59 def g(bot, trigger):
60 """Queries Google for the specified input."""
61 query = trigger.group(2)
62 if not query:
63 return bot.reply('.g what?')
64 uri = google_search(query)
65 if uri:
66 bot.reply(uri)
67 bot.memory['last_seen_url'][trigger.sender] = uri
68 elif uri is False:
69 bot.reply("Problem getting data from Google.")
70 else:
71 bot.reply("No results found for '%s'." % query)
72
73
74 @commands('gc')
75 @example('.gc extrapolate')
76 def gc(bot, trigger):
77 """Returns the number of Google results for the specified input."""
78 query = trigger.group(2)
79 if not query:
80 return bot.reply('.gc what?')
81 num = formatnumber(google_count(query))
82 bot.say(query + ': ' + num)
83
84 r_query = re.compile(
85 r'\+?"[^"\\]*(?:\\.[^"\\]*)*"|\[[^]\\]*(?:\\.[^]\\]*)*\]|\S+'
86 )
87
88
89 @commands('gcs', 'comp')
90 @example('.gcs foo bar')
91 def gcs(bot, trigger):
92 """Compare the number of Google search results"""
93 if not trigger.group(2):
94 return bot.reply("Nothing to compare.")
95 queries = r_query.findall(trigger.group(2))
96 if len(queries) > 6:
97 return bot.reply('Sorry, can only compare up to six things.')
98
99 results = []
100 for i, query in enumerate(queries):
101 query = query.strip('[]')
102 n = int((formatnumber(google_count(query)) or '0').replace(',', ''))
103 results.append((n, query))
104 if i >= 2:
105 time.sleep(0.25)
106 if i >= 4:
107 time.sleep(0.25)
108
109 results = [(term, n) for (n, term) in reversed(sorted(results))]
110 reply = ', '.join('%s (%s)' % (t, formatnumber(n)) for (t, n) in results)
111 bot.say(reply)
112
113 r_bing = re.compile(r'<h3><a href="([^"]+)"')
114
115
116 def bing_search(query, lang='en-GB'):
117 base = 'http://www.bing.com/search?mkt=%s&q=' % lang
118 bytes = web.get(base + query)
119 m = r_bing.search(bytes)
120 if m:
121 return m.group(1)
122
123 r_duck = re.compile(r'nofollow" class="[^"]+" href="(.*?)">')
124
125
126 def duck_search(query):
127 query = query.replace('!', '')
128 uri = 'http://duckduckgo.com/html/?q=%s&kl=uk-en' % query
129 bytes = web.get(uri)
130 m = r_duck.search(bytes)
131 if m:
132 return web.decode(m.group(1))
133
134
135 def duck_api(query):
136 if '!bang' in query.lower():
137 return 'https://duckduckgo.com/bang.html'
138
139 uri = 'http://api.duckduckgo.com/?q=%s&format=json&no_html=1&no_redirect=1' % query
140 results = json.loads(web.get(uri))
141 if results['Redirect']:
142 return results['Redirect']
143 else:
144 return None
145
146
147 @commands('duck', 'ddg')
148 @example('.duck privacy or .duck !mcwiki obsidian')
149 def duck(bot, trigger):
150 """Queries Duck Duck Go for the specified input."""
151 query = trigger.group(2)
152 if not query:
153 return bot.reply('.ddg what?')
154
155 #If the API gives us something, say it and stop
156 result = duck_api(query)
157 if result:
158 bot.reply(result)
159 return
160
161 #Otherwise, look it up on the HTMl version
162 uri = duck_search(query)
163
164 if uri:
165 bot.reply(uri)
166 bot.memory['last_seen_url'][trigger.sender] = uri
167 else:
168 bot.reply("No results found for '%s'." % query)
169
170
171 @commands('search')
172 @example('.search nerdfighter')
173 def search(bot, trigger):
174 """Searches Google, Bing, and Duck Duck Go."""
175 if not trigger.group(2):
176 return bot.reply('.search for what?')
177 query = trigger.group(2)
178 gu = google_search(query) or '-'
179 bu = bing_search(query) or '-'
180 du = duck_search(query) or '-'
181
182 if (gu == bu) and (bu == du):
183 result = '%s (g, b, d)' % gu
184 elif (gu == bu):
185 result = '%s (g, b), %s (d)' % (gu, du)
186 elif (bu == du):
187 result = '%s (b, d), %s (g)' % (bu, gu)
188 elif (gu == du):
189 result = '%s (g, d), %s (b)' % (gu, bu)
190 else:
191 if len(gu) > 250:
192 gu = '(extremely long link)'
193 if len(bu) > 150:
194 bu = '(extremely long link)'
195 if len(du) > 150:
196 du = '(extremely long link)'
197 result = '%s (g), %s (b), %s (d)' % (gu, bu, du)
198
199 bot.reply(result)
200
201
202 @commands('suggest')
203 def suggest(bot, trigger):
204 """Suggest terms starting with given input"""
205 if not trigger.group(2):
206 return bot.reply("No query term.")
207 query = trigger.group(2)
208 uri = 'http://websitedev.de/temp-bin/suggest.pl?q='
209 answer = web.get(uri+query.replace('+', '%2B'))
210 if answer:
211 bot.say(answer)
212 else:
213 bot.reply('Sorry, no result.')
214
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/willie/modules/search.py b/willie/modules/search.py
--- a/willie/modules/search.py
+++ b/willie/modules/search.py
@@ -127,6 +127,8 @@
query = query.replace('!', '')
uri = 'http://duckduckgo.com/html/?q=%s&kl=uk-en' % query
bytes = web.get(uri)
+ if 'web-result"' in bytes: #filter out the adds on top of the page
+ bytes = bytes.split('web-result"')[1]
m = r_duck.search(bytes)
if m:
return web.decode(m.group(1))
| {"golden_diff": "diff --git a/willie/modules/search.py b/willie/modules/search.py\n--- a/willie/modules/search.py\n+++ b/willie/modules/search.py\n@@ -127,6 +127,8 @@\n query = query.replace('!', '')\n uri = 'http://duckduckgo.com/html/?q=%s&kl=uk-en' % query\n bytes = web.get(uri)\n+ if 'web-result\"' in bytes: #filter out the adds on top of the page\n+ bytes = bytes.split('web-result\"')[1]\n m = r_duck.search(bytes)\n if m:\n return web.decode(m.group(1))\n", "issue": "[search].duck is horribly broken.\nIt appears we're scraping the page wrong, since \".duck wikipedia\" returns an ad page.\n\n", "before_files": [{"content": "# coding=utf8\n\"\"\"\nsearch.py - Willie Web Search Module\nCopyright 2008-9, Sean B. Palmer, inamidst.com\nCopyright 2012, Edward Powell, embolalia.net\nLicensed under the Eiffel Forum License 2.\n\nhttp://willie.dftba.net\n\"\"\"\nfrom __future__ import unicode_literals\n\nimport re\nfrom willie import web\nfrom willie.module import commands, example\nimport json\nimport sys\nimport time\n\n\ndef google_ajax(query):\n \"\"\"Search using AjaxSearch, and return its JSON.\"\"\"\n uri = 'http://ajax.googleapis.com/ajax/services/search/web'\n args = '?v=1.0&safe=off&q=' + query\n bytes = web.get(uri + args)\n return json.loads(bytes)\n\n\ndef google_search(query):\n results = google_ajax(query)\n try:\n return results['responseData']['results'][0]['unescapedUrl']\n except IndexError:\n return None\n except TypeError:\n return False\n\n\ndef google_count(query):\n results = google_ajax(query)\n if not 'responseData' in results:\n return '0'\n if not 'cursor' in results['responseData']:\n return '0'\n if not 'estimatedResultCount' in results['responseData']['cursor']:\n return '0'\n return results['responseData']['cursor']['estimatedResultCount']\n\n\ndef formatnumber(n):\n \"\"\"Format a number with beautiful commas.\"\"\"\n parts = list(str(n))\n for i in range((len(parts) - 3), 0, -3):\n parts.insert(i, ',')\n return ''.join(parts)\n\n\n@commands('g', 'google')\n@example('.g swhack')\ndef g(bot, trigger):\n \"\"\"Queries Google for the specified input.\"\"\"\n query = trigger.group(2)\n if not query:\n return bot.reply('.g what?')\n uri = google_search(query)\n if uri:\n bot.reply(uri)\n bot.memory['last_seen_url'][trigger.sender] = uri\n elif uri is False:\n bot.reply(\"Problem getting data from Google.\")\n else:\n bot.reply(\"No results found for '%s'.\" % query)\n\n\n@commands('gc')\n@example('.gc extrapolate')\ndef gc(bot, trigger):\n \"\"\"Returns the number of Google results for the specified input.\"\"\"\n query = trigger.group(2)\n if not query:\n return bot.reply('.gc what?')\n num = formatnumber(google_count(query))\n bot.say(query + ': ' + num)\n\nr_query = re.compile(\n r'\\+?\"[^\"\\\\]*(?:\\\\.[^\"\\\\]*)*\"|\\[[^]\\\\]*(?:\\\\.[^]\\\\]*)*\\]|\\S+'\n)\n\n\n@commands('gcs', 'comp')\n@example('.gcs foo bar')\ndef gcs(bot, trigger):\n \"\"\"Compare the number of Google search results\"\"\"\n if not trigger.group(2):\n return bot.reply(\"Nothing to compare.\")\n queries = r_query.findall(trigger.group(2))\n if len(queries) > 6:\n return bot.reply('Sorry, can only compare up to six things.')\n\n results = []\n for i, query in enumerate(queries):\n query = query.strip('[]')\n n = int((formatnumber(google_count(query)) or '0').replace(',', ''))\n results.append((n, query))\n if i >= 2:\n time.sleep(0.25)\n if i >= 4:\n time.sleep(0.25)\n\n results = [(term, n) for (n, term) in reversed(sorted(results))]\n reply = ', '.join('%s (%s)' % (t, formatnumber(n)) for (t, n) in results)\n bot.say(reply)\n\nr_bing = re.compile(r'<h3><a href=\"([^\"]+)\"')\n\n\ndef bing_search(query, lang='en-GB'):\n base = 'http://www.bing.com/search?mkt=%s&q=' % lang\n bytes = web.get(base + query)\n m = r_bing.search(bytes)\n if m:\n return m.group(1)\n\nr_duck = re.compile(r'nofollow\" class=\"[^\"]+\" href=\"(.*?)\">')\n\n\ndef duck_search(query):\n query = query.replace('!', '')\n uri = 'http://duckduckgo.com/html/?q=%s&kl=uk-en' % query\n bytes = web.get(uri)\n m = r_duck.search(bytes)\n if m:\n return web.decode(m.group(1))\n\n\ndef duck_api(query):\n if '!bang' in query.lower():\n return 'https://duckduckgo.com/bang.html'\n\n uri = 'http://api.duckduckgo.com/?q=%s&format=json&no_html=1&no_redirect=1' % query\n results = json.loads(web.get(uri))\n if results['Redirect']:\n return results['Redirect']\n else:\n return None\n\n\n@commands('duck', 'ddg')\n@example('.duck privacy or .duck !mcwiki obsidian')\ndef duck(bot, trigger):\n \"\"\"Queries Duck Duck Go for the specified input.\"\"\"\n query = trigger.group(2)\n if not query:\n return bot.reply('.ddg what?')\n\n #If the API gives us something, say it and stop\n result = duck_api(query)\n if result:\n bot.reply(result)\n return\n\n #Otherwise, look it up on the HTMl version\n uri = duck_search(query)\n\n if uri:\n bot.reply(uri)\n bot.memory['last_seen_url'][trigger.sender] = uri\n else:\n bot.reply(\"No results found for '%s'.\" % query)\n\n\n@commands('search')\n@example('.search nerdfighter')\ndef search(bot, trigger):\n \"\"\"Searches Google, Bing, and Duck Duck Go.\"\"\"\n if not trigger.group(2):\n return bot.reply('.search for what?')\n query = trigger.group(2)\n gu = google_search(query) or '-'\n bu = bing_search(query) or '-'\n du = duck_search(query) or '-'\n\n if (gu == bu) and (bu == du):\n result = '%s (g, b, d)' % gu\n elif (gu == bu):\n result = '%s (g, b), %s (d)' % (gu, du)\n elif (bu == du):\n result = '%s (b, d), %s (g)' % (bu, gu)\n elif (gu == du):\n result = '%s (g, d), %s (b)' % (gu, bu)\n else:\n if len(gu) > 250:\n gu = '(extremely long link)'\n if len(bu) > 150:\n bu = '(extremely long link)'\n if len(du) > 150:\n du = '(extremely long link)'\n result = '%s (g), %s (b), %s (d)' % (gu, bu, du)\n\n bot.reply(result)\n\n\n@commands('suggest')\ndef suggest(bot, trigger):\n \"\"\"Suggest terms starting with given input\"\"\"\n if not trigger.group(2):\n return bot.reply(\"No query term.\")\n query = trigger.group(2)\n uri = 'http://websitedev.de/temp-bin/suggest.pl?q='\n answer = web.get(uri+query.replace('+', '%2B'))\n if answer:\n bot.say(answer)\n else:\n bot.reply('Sorry, no result.')\n", "path": "willie/modules/search.py"}], "after_files": [{"content": "# coding=utf8\n\"\"\"\nsearch.py - Willie Web Search Module\nCopyright 2008-9, Sean B. Palmer, inamidst.com\nCopyright 2012, Edward Powell, embolalia.net\nLicensed under the Eiffel Forum License 2.\n\nhttp://willie.dftba.net\n\"\"\"\nfrom __future__ import unicode_literals\n\nimport re\nfrom willie import web\nfrom willie.module import commands, example\nimport json\nimport sys\nimport time\n\n\ndef google_ajax(query):\n \"\"\"Search using AjaxSearch, and return its JSON.\"\"\"\n uri = 'http://ajax.googleapis.com/ajax/services/search/web'\n args = '?v=1.0&safe=off&q=' + query\n bytes = web.get(uri + args)\n return json.loads(bytes)\n\n\ndef google_search(query):\n results = google_ajax(query)\n try:\n return results['responseData']['results'][0]['unescapedUrl']\n except IndexError:\n return None\n except TypeError:\n return False\n\n\ndef google_count(query):\n results = google_ajax(query)\n if not 'responseData' in results:\n return '0'\n if not 'cursor' in results['responseData']:\n return '0'\n if not 'estimatedResultCount' in results['responseData']['cursor']:\n return '0'\n return results['responseData']['cursor']['estimatedResultCount']\n\n\ndef formatnumber(n):\n \"\"\"Format a number with beautiful commas.\"\"\"\n parts = list(str(n))\n for i in range((len(parts) - 3), 0, -3):\n parts.insert(i, ',')\n return ''.join(parts)\n\n\n@commands('g', 'google')\n@example('.g swhack')\ndef g(bot, trigger):\n \"\"\"Queries Google for the specified input.\"\"\"\n query = trigger.group(2)\n if not query:\n return bot.reply('.g what?')\n uri = google_search(query)\n if uri:\n bot.reply(uri)\n bot.memory['last_seen_url'][trigger.sender] = uri\n elif uri is False:\n bot.reply(\"Problem getting data from Google.\")\n else:\n bot.reply(\"No results found for '%s'.\" % query)\n\n\n@commands('gc')\n@example('.gc extrapolate')\ndef gc(bot, trigger):\n \"\"\"Returns the number of Google results for the specified input.\"\"\"\n query = trigger.group(2)\n if not query:\n return bot.reply('.gc what?')\n num = formatnumber(google_count(query))\n bot.say(query + ': ' + num)\n\nr_query = re.compile(\n r'\\+?\"[^\"\\\\]*(?:\\\\.[^\"\\\\]*)*\"|\\[[^]\\\\]*(?:\\\\.[^]\\\\]*)*\\]|\\S+'\n)\n\n\n@commands('gcs', 'comp')\n@example('.gcs foo bar')\ndef gcs(bot, trigger):\n \"\"\"Compare the number of Google search results\"\"\"\n if not trigger.group(2):\n return bot.reply(\"Nothing to compare.\")\n queries = r_query.findall(trigger.group(2))\n if len(queries) > 6:\n return bot.reply('Sorry, can only compare up to six things.')\n\n results = []\n for i, query in enumerate(queries):\n query = query.strip('[]')\n n = int((formatnumber(google_count(query)) or '0').replace(',', ''))\n results.append((n, query))\n if i >= 2:\n time.sleep(0.25)\n if i >= 4:\n time.sleep(0.25)\n\n results = [(term, n) for (n, term) in reversed(sorted(results))]\n reply = ', '.join('%s (%s)' % (t, formatnumber(n)) for (t, n) in results)\n bot.say(reply)\n\nr_bing = re.compile(r'<h3><a href=\"([^\"]+)\"')\n\n\ndef bing_search(query, lang='en-GB'):\n base = 'http://www.bing.com/search?mkt=%s&q=' % lang\n bytes = web.get(base + query)\n m = r_bing.search(bytes)\n if m:\n return m.group(1)\n\nr_duck = re.compile(r'nofollow\" class=\"[^\"]+\" href=\"(.*?)\">')\n\n\ndef duck_search(query):\n query = query.replace('!', '')\n uri = 'http://duckduckgo.com/html/?q=%s&kl=uk-en' % query\n bytes = web.get(uri)\n if 'web-result\"' in bytes: #filter out the adds on top of the page\n bytes = bytes.split('web-result\"')[1]\n m = r_duck.search(bytes)\n if m:\n return web.decode(m.group(1))\n\n\ndef duck_api(query):\n if '!bang' in query.lower():\n return 'https://duckduckgo.com/bang.html'\n\n uri = 'http://api.duckduckgo.com/?q=%s&format=json&no_html=1&no_redirect=1' % query\n results = json.loads(web.get(uri))\n if results['Redirect']:\n return results['Redirect']\n else:\n return None\n\n\n@commands('duck', 'ddg')\n@example('.duck privacy or .duck !mcwiki obsidian')\ndef duck(bot, trigger):\n \"\"\"Queries Duck Duck Go for the specified input.\"\"\"\n query = trigger.group(2)\n if not query:\n return bot.reply('.ddg what?')\n\n #If the API gives us something, say it and stop\n result = duck_api(query)\n if result:\n bot.reply(result)\n return\n\n #Otherwise, look it up on the HTMl version\n uri = duck_search(query)\n\n if uri:\n bot.reply(uri)\n bot.memory['last_seen_url'][trigger.sender] = uri\n else:\n bot.reply(\"No results found for '%s'.\" % query)\n\n\n@commands('search')\n@example('.search nerdfighter')\ndef search(bot, trigger):\n \"\"\"Searches Google, Bing, and Duck Duck Go.\"\"\"\n if not trigger.group(2):\n return bot.reply('.search for what?')\n query = trigger.group(2)\n gu = google_search(query) or '-'\n bu = bing_search(query) or '-'\n du = duck_search(query) or '-'\n\n if (gu == bu) and (bu == du):\n result = '%s (g, b, d)' % gu\n elif (gu == bu):\n result = '%s (g, b), %s (d)' % (gu, du)\n elif (bu == du):\n result = '%s (b, d), %s (g)' % (bu, gu)\n elif (gu == du):\n result = '%s (g, d), %s (b)' % (gu, bu)\n else:\n if len(gu) > 250:\n gu = '(extremely long link)'\n if len(bu) > 150:\n bu = '(extremely long link)'\n if len(du) > 150:\n du = '(extremely long link)'\n result = '%s (g), %s (b), %s (d)' % (gu, bu, du)\n\n bot.reply(result)\n\n\n@commands('suggest')\ndef suggest(bot, trigger):\n \"\"\"Suggest terms starting with given input\"\"\"\n if not trigger.group(2):\n return bot.reply(\"No query term.\")\n query = trigger.group(2)\n uri = 'http://websitedev.de/temp-bin/suggest.pl?q='\n answer = web.get(uri+query.replace('+', '%2B'))\n if answer:\n bot.say(answer)\n else:\n bot.reply('Sorry, no result.')\n", "path": "willie/modules/search.py"}]} | 2,463 | 145 |
gh_patches_debug_16178 | rasdani/github-patches | git_diff | safe-global__safe-config-service-58 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change default renderer to JSONRenderer
- The renderer in production should show the json payload without a browsable API
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/config/settings.py`
Content:
```
1 """
2 Django settings for safe_client_config_service project.
3
4 Generated by 'django-admin startproject' using Django 3.2.
5
6 For more information on this file, see
7 https://docs.djangoproject.com/en/3.2/topics/settings/
8
9 For the full list of settings and their values, see
10 https://docs.djangoproject.com/en/3.2/ref/settings/
11 """
12 import os
13 from distutils.util import strtobool
14 from pathlib import Path
15
16 # Build paths inside the project like this: BASE_DIR / 'subdir'.
17 BASE_DIR = Path(__file__).resolve().parent.parent
18
19 # Quick-start development settings - unsuitable for production
20 # See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/
21
22 # SECURITY WARNING: keep the secret key used in production secret!
23 SECRET_KEY = os.getenv("SECRET_KEY", None)
24
25 # SECURITY WARNING: don't run with debug turned on in production!
26 DEBUG = bool(strtobool(os.getenv("DEBUG", "false")))
27
28 # https://docs.djangoproject.com/en/3.2/ref/settings/#std:setting-ALLOWED_HOSTS
29 allowed_hosts = os.getenv("DJANGO_ALLOWED_HOSTS", ".localhost,127.0.0.1,[::1]")
30 ALLOWED_HOSTS = list(map(str.strip, allowed_hosts.split(",")))
31
32 # Application definition
33
34 INSTALLED_APPS = [
35 "safe_apps.apps.AppsConfig",
36 "django.contrib.admin",
37 "django.contrib.auth",
38 "django.contrib.contenttypes",
39 "django.contrib.sessions",
40 "django.contrib.messages",
41 "django.contrib.staticfiles",
42 "rest_framework",
43 ]
44
45 MIDDLEWARE = [
46 "config.middleware.LoggingMiddleware",
47 "django.middleware.security.SecurityMiddleware",
48 "django.contrib.sessions.middleware.SessionMiddleware",
49 "django.middleware.common.CommonMiddleware",
50 "django.middleware.csrf.CsrfViewMiddleware",
51 "django.contrib.auth.middleware.AuthenticationMiddleware",
52 "django.contrib.messages.middleware.MessageMiddleware",
53 "django.middleware.clickjacking.XFrameOptionsMiddleware",
54 ]
55
56 CACHES = {
57 "default": {
58 "BACKEND": "django.core.cache.backends.locmem.LocMemCache",
59 },
60 "safe-apps": {
61 "BACKEND": "django.core.cache.backends.locmem.LocMemCache",
62 },
63 }
64
65 LOGGING = {
66 "version": 1,
67 "disable_existing_loggers": False,
68 "formatters": {
69 "short": {"format": "%(asctime)s %(message)s"},
70 "verbose": {
71 "format": "%(asctime)s [%(levelname)s] [%(processName)s] %(message)s"
72 },
73 },
74 "handlers": {
75 "console": {
76 "class": "logging.StreamHandler",
77 "formatter": "verbose",
78 },
79 "console_short": {
80 "class": "logging.StreamHandler",
81 "formatter": "short",
82 },
83 },
84 "root": {
85 "handlers": ["console"],
86 "level": os.getenv("ROOT_LOG_LEVEL", "INFO"),
87 },
88 "loggers": {
89 "LoggingMiddleware": {
90 "handlers": ["console_short"],
91 "level": "INFO",
92 "propagate": False,
93 },
94 },
95 }
96
97 ROOT_URLCONF = "config.urls"
98
99 TEMPLATES = [
100 {
101 "BACKEND": "django.template.backends.django.DjangoTemplates",
102 "DIRS": [],
103 "APP_DIRS": True,
104 "OPTIONS": {
105 "context_processors": [
106 "django.template.context_processors.debug",
107 "django.template.context_processors.request",
108 "django.contrib.auth.context_processors.auth",
109 "django.contrib.messages.context_processors.messages",
110 ],
111 },
112 },
113 ]
114
115 WSGI_APPLICATION = "config.wsgi.application"
116
117 # Database
118 # https://docs.djangoproject.com/en/3.2/ref/settings/#databases
119
120 DATABASES = {
121 "default": {
122 "ENGINE": "django.db.backends.postgresql",
123 "NAME": os.getenv("POSTGRES_NAME", "postgres"),
124 "USER": os.getenv("POSTGRES_USER", "postgres"),
125 "PASSWORD": os.getenv("POSTGRES_PASSWORD", "postgres"),
126 "HOST": os.getenv("POSTGRES_HOST", "db"),
127 "PORT": os.getenv("POSTGRES_PORT", "5432"),
128 }
129 }
130
131 # Password validation
132 # https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators
133
134 AUTH_PASSWORD_VALIDATORS = [
135 {
136 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
137 },
138 {
139 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
140 },
141 {
142 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
143 },
144 {
145 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
146 },
147 ]
148
149 # Internationalization
150 # https://docs.djangoproject.com/en/3.2/topics/i18n/
151
152 LANGUAGE_CODE = "en-us"
153
154 TIME_ZONE = "UTC"
155
156 USE_I18N = True
157
158 USE_L10N = True
159
160 USE_TZ = True
161
162 # Static files (CSS, JavaScript, Images)
163 # https://docs.djangoproject.com/en/3.2/howto/static-files/
164
165 STATIC_URL = "/static/"
166
167 # Default primary key field type
168 # https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field
169
170 DEFAULT_AUTO_FIELD = "django.db.models.BigAutoField"
171
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/config/settings.py b/src/config/settings.py
--- a/src/config/settings.py
+++ b/src/config/settings.py
@@ -27,10 +27,21 @@
# https://docs.djangoproject.com/en/3.2/ref/settings/#std:setting-ALLOWED_HOSTS
allowed_hosts = os.getenv("DJANGO_ALLOWED_HOSTS", ".localhost,127.0.0.1,[::1]")
-ALLOWED_HOSTS = list(map(str.strip, allowed_hosts.split(",")))
+ALLOWED_HOSTS = [allowed_host.strip() for allowed_host in allowed_hosts.split(",")]
# Application definition
+default_renderer_classes = os.getenv(
+ "REST_DEFAULT_RENDERER_CLASSES", "rest_framework.renderers.JSONRenderer"
+)
+REST_FRAMEWORK = {
+ # https://www.django-rest-framework.org/api-guide/renderers/
+ "DEFAULT_RENDERER_CLASSES": [
+ default_renderer_class.strip()
+ for default_renderer_class in default_renderer_classes.split(",")
+ ]
+}
+
INSTALLED_APPS = [
"safe_apps.apps.AppsConfig",
"django.contrib.admin",
| {"golden_diff": "diff --git a/src/config/settings.py b/src/config/settings.py\n--- a/src/config/settings.py\n+++ b/src/config/settings.py\n@@ -27,10 +27,21 @@\n \n # https://docs.djangoproject.com/en/3.2/ref/settings/#std:setting-ALLOWED_HOSTS\n allowed_hosts = os.getenv(\"DJANGO_ALLOWED_HOSTS\", \".localhost,127.0.0.1,[::1]\")\n-ALLOWED_HOSTS = list(map(str.strip, allowed_hosts.split(\",\")))\n+ALLOWED_HOSTS = [allowed_host.strip() for allowed_host in allowed_hosts.split(\",\")]\n \n # Application definition\n \n+default_renderer_classes = os.getenv(\n+ \"REST_DEFAULT_RENDERER_CLASSES\", \"rest_framework.renderers.JSONRenderer\"\n+)\n+REST_FRAMEWORK = {\n+ # https://www.django-rest-framework.org/api-guide/renderers/\n+ \"DEFAULT_RENDERER_CLASSES\": [\n+ default_renderer_class.strip()\n+ for default_renderer_class in default_renderer_classes.split(\",\")\n+ ]\n+}\n+\n INSTALLED_APPS = [\n \"safe_apps.apps.AppsConfig\",\n \"django.contrib.admin\",\n", "issue": "Change default renderer to JSONRenderer\n- The renderer in production should show the json payload without a browsable API\n", "before_files": [{"content": "\"\"\"\nDjango settings for safe_client_config_service project.\n\nGenerated by 'django-admin startproject' using Django 3.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.2/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.2/ref/settings/\n\"\"\"\nimport os\nfrom distutils.util import strtobool\nfrom pathlib import Path\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.getenv(\"SECRET_KEY\", None)\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = bool(strtobool(os.getenv(\"DEBUG\", \"false\")))\n\n# https://docs.djangoproject.com/en/3.2/ref/settings/#std:setting-ALLOWED_HOSTS\nallowed_hosts = os.getenv(\"DJANGO_ALLOWED_HOSTS\", \".localhost,127.0.0.1,[::1]\")\nALLOWED_HOSTS = list(map(str.strip, allowed_hosts.split(\",\")))\n\n# Application definition\n\nINSTALLED_APPS = [\n \"safe_apps.apps.AppsConfig\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n]\n\nMIDDLEWARE = [\n \"config.middleware.LoggingMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nCACHES = {\n \"default\": {\n \"BACKEND\": \"django.core.cache.backends.locmem.LocMemCache\",\n },\n \"safe-apps\": {\n \"BACKEND\": \"django.core.cache.backends.locmem.LocMemCache\",\n },\n}\n\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"formatters\": {\n \"short\": {\"format\": \"%(asctime)s %(message)s\"},\n \"verbose\": {\n \"format\": \"%(asctime)s [%(levelname)s] [%(processName)s] %(message)s\"\n },\n },\n \"handlers\": {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"verbose\",\n },\n \"console_short\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"short\",\n },\n },\n \"root\": {\n \"handlers\": [\"console\"],\n \"level\": os.getenv(\"ROOT_LOG_LEVEL\", \"INFO\"),\n },\n \"loggers\": {\n \"LoggingMiddleware\": {\n \"handlers\": [\"console_short\"],\n \"level\": \"INFO\",\n \"propagate\": False,\n },\n },\n}\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.2/ref/settings/#databases\n\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.postgresql\",\n \"NAME\": os.getenv(\"POSTGRES_NAME\", \"postgres\"),\n \"USER\": os.getenv(\"POSTGRES_USER\", \"postgres\"),\n \"PASSWORD\": os.getenv(\"POSTGRES_PASSWORD\", \"postgres\"),\n \"HOST\": os.getenv(\"POSTGRES_HOST\", \"db\"),\n \"PORT\": os.getenv(\"POSTGRES_PORT\", \"5432\"),\n }\n}\n\n# Password validation\n# https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.2/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.2/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\n# Default primary key field type\n# https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field\n\nDEFAULT_AUTO_FIELD = \"django.db.models.BigAutoField\"\n", "path": "src/config/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for safe_client_config_service project.\n\nGenerated by 'django-admin startproject' using Django 3.2.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/3.2/topics/settings/\n\nFor the full list of settings and their values, see\nhttps://docs.djangoproject.com/en/3.2/ref/settings/\n\"\"\"\nimport os\nfrom distutils.util import strtobool\nfrom pathlib import Path\n\n# Build paths inside the project like this: BASE_DIR / 'subdir'.\nBASE_DIR = Path(__file__).resolve().parent.parent\n\n# Quick-start development settings - unsuitable for production\n# See https://docs.djangoproject.com/en/3.2/howto/deployment/checklist/\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.getenv(\"SECRET_KEY\", None)\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = bool(strtobool(os.getenv(\"DEBUG\", \"false\")))\n\n# https://docs.djangoproject.com/en/3.2/ref/settings/#std:setting-ALLOWED_HOSTS\nallowed_hosts = os.getenv(\"DJANGO_ALLOWED_HOSTS\", \".localhost,127.0.0.1,[::1]\")\nALLOWED_HOSTS = [allowed_host.strip() for allowed_host in allowed_hosts.split(\",\")]\n\n# Application definition\n\ndefault_renderer_classes = os.getenv(\n \"REST_DEFAULT_RENDERER_CLASSES\", \"rest_framework.renderers.JSONRenderer\"\n)\nREST_FRAMEWORK = {\n # https://www.django-rest-framework.org/api-guide/renderers/\n \"DEFAULT_RENDERER_CLASSES\": [\n default_renderer_class.strip()\n for default_renderer_class in default_renderer_classes.split(\",\")\n ]\n}\n\nINSTALLED_APPS = [\n \"safe_apps.apps.AppsConfig\",\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.sessions\",\n \"django.contrib.messages\",\n \"django.contrib.staticfiles\",\n \"rest_framework\",\n]\n\nMIDDLEWARE = [\n \"config.middleware.LoggingMiddleware\",\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n]\n\nCACHES = {\n \"default\": {\n \"BACKEND\": \"django.core.cache.backends.locmem.LocMemCache\",\n },\n \"safe-apps\": {\n \"BACKEND\": \"django.core.cache.backends.locmem.LocMemCache\",\n },\n}\n\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"formatters\": {\n \"short\": {\"format\": \"%(asctime)s %(message)s\"},\n \"verbose\": {\n \"format\": \"%(asctime)s [%(levelname)s] [%(processName)s] %(message)s\"\n },\n },\n \"handlers\": {\n \"console\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"verbose\",\n },\n \"console_short\": {\n \"class\": \"logging.StreamHandler\",\n \"formatter\": \"short\",\n },\n },\n \"root\": {\n \"handlers\": [\"console\"],\n \"level\": os.getenv(\"ROOT_LOG_LEVEL\", \"INFO\"),\n },\n \"loggers\": {\n \"LoggingMiddleware\": {\n \"handlers\": [\"console_short\"],\n \"level\": \"INFO\",\n \"propagate\": False,\n },\n },\n}\n\nROOT_URLCONF = \"config.urls\"\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": [\n \"django.template.context_processors.debug\",\n \"django.template.context_processors.request\",\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ],\n },\n },\n]\n\nWSGI_APPLICATION = \"config.wsgi.application\"\n\n# Database\n# https://docs.djangoproject.com/en/3.2/ref/settings/#databases\n\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.postgresql\",\n \"NAME\": os.getenv(\"POSTGRES_NAME\", \"postgres\"),\n \"USER\": os.getenv(\"POSTGRES_USER\", \"postgres\"),\n \"PASSWORD\": os.getenv(\"POSTGRES_PASSWORD\", \"postgres\"),\n \"HOST\": os.getenv(\"POSTGRES_HOST\", \"db\"),\n \"PORT\": os.getenv(\"POSTGRES_PORT\", \"5432\"),\n }\n}\n\n# Password validation\n# https://docs.djangoproject.com/en/3.2/ref/settings/#auth-password-validators\n\nAUTH_PASSWORD_VALIDATORS = [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n]\n\n# Internationalization\n# https://docs.djangoproject.com/en/3.2/topics/i18n/\n\nLANGUAGE_CODE = \"en-us\"\n\nTIME_ZONE = \"UTC\"\n\nUSE_I18N = True\n\nUSE_L10N = True\n\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n# https://docs.djangoproject.com/en/3.2/howto/static-files/\n\nSTATIC_URL = \"/static/\"\n\n# Default primary key field type\n# https://docs.djangoproject.com/en/3.2/ref/settings/#default-auto-field\n\nDEFAULT_AUTO_FIELD = \"django.db.models.BigAutoField\"\n", "path": "src/config/settings.py"}]} | 1,826 | 236 |
gh_patches_debug_32258 | rasdani/github-patches | git_diff | fidals__shopelectro-222 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Gen categories tags to sitemap
Сейчас в sitemap выгружаются, помимо прочего, страницы категорий.
Выгружай не только страницы, но и все варианты их тегов.
Однако, не должно быть страниц, удовлетворяющих паттерну `*-or-*`
Пример страницы, которую нужно выгрузить в sitemap:
https://www.shopelectro.ru/catalog/categories/universalnye-ot-seti-12-v/tags/vanson/
Строчку `Disallow: /*-or-*` из `robots.txt` не выпиливай ни в коем случае
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `shopelectro/sitemaps.py`
Content:
```
1 from django.contrib.sitemaps import Sitemap
2 from django.urls import reverse
3
4 from pages.models import Page
5
6 from shopelectro.models import Product, Category
7
8
9 class AbstractSitemap(Sitemap):
10 protocol = 'https'
11 changefreq = 'weekly'
12 priority = 0.9
13
14
15 class IndexSitemap(Sitemap):
16 protocol = 'https'
17 changefreq = 'monthly'
18 priority = 1
19
20 # items()
21 # Required. A method that returns a list of objects.
22 # https://docs.djangoproject.com/ja/1.9/ref/contrib/sitemaps/#django.contrib.sitemaps.Sitemap.items
23 def items(self):
24 return ['']
25
26 # location()
27 # Optional. If location isn’t provided, the framework will call the get_absolute_url()
28 # method on each object as returned by items().
29 # https://docs.djangoproject.com/ja/1.9/ref/contrib/sitemaps/#django.contrib.sitemaps.Sitemap.location
30 def location(self, model):
31 return reverse(Page.CUSTOM_PAGES_URL_NAME, args=(model, ))
32
33
34 class CategorySitemap(AbstractSitemap):
35
36 def items(self):
37 return Category.objects.filter(page__is_active=True)
38
39
40 class ProductSitemap(AbstractSitemap):
41
42 def items(self):
43 return Product.objects.filter(page__is_active=True)
44
45
46 class PagesSitemap(AbstractSitemap):
47
48 def items(self):
49 return Page.objects.filter(is_active=True)
50
```
Path: `shopelectro/urls.py`
Content:
```
1 from collections import OrderedDict
2
3 from django.conf import settings
4 from django.conf.urls import url, include
5 from django.conf.urls.static import static
6 from django.contrib.sitemaps.views import sitemap
7 from django.views.decorators.cache import cache_page
8
9 from pages.models import Page
10 from pages.views import robots, SitemapPage
11
12 from shopelectro import sitemaps, config, views
13 from shopelectro.admin import se_admin
14
15 # Orders sitemaps instances
16 sitemaps = OrderedDict([
17 ('index', sitemaps.IndexSitemap),
18 ('category', sitemaps.CategorySitemap),
19 ('products', sitemaps.ProductSitemap),
20 ('site', sitemaps.PagesSitemap)
21 ])
22
23 # disable cache
24 if settings.DEBUG:
25 def cache_page(arg): # Ignore PyFlakesBear
26 if callable(arg):
27 return arg
28 return cache_page
29
30 cached_60d = cache_page(config.cached_time(days=60))
31 cached_2h = cache_page(config.cached_time(hours=2))
32
33 admin_urls = [
34 url(r'^', se_admin.urls),
35 url(r'^autocomplete/$', views.AdminAutocomplete.as_view(), name='admin_autocomplete'),
36 url(r'^get-tree-items/$', views.Tree.as_view()),
37 url(r'^redirect-to-product/$', views.RedirectToProduct.as_view()),
38 url(r'^table-editor-api/$', views.TableEditorAPI.as_view()),
39 url(r'^select2/', include('django_select2.urls')),
40 ]
41
42 catalog_urls = [
43 url(r'^categories/(?P<slug>[\w-]+)/$',
44 cached_2h(views.CategoryPage.as_view()), name='category'),
45 url(r'^categories/(?P<slug>[\w-]+)/tags/(?P<tags>[\w-]+)/$',
46 cached_2h(views.CategoryPage.as_view()), name='category'),
47 url(r'^categories/(?P<slug>[\w-]+)/(?P<sorting>[0-9]*)/$',
48 views.CategoryPage.as_view(), name='category'),
49 url(r'^categories/(?P<slug>[\w-]+)/(?P<sorting>[0-9]*)/tags/(?P<tags>[\w-]+)/$',
50 views.CategoryPage.as_view(), name='category'),
51 url(r'categories/(?P<category_slug>[\w-]+)/load-more/'
52 r'(?P<offset>[0-9]+)/(?P<sorting>[0-9]*)/$',
53 views.load_more, name='load_more'),
54 url(r'categories/(?P<category_slug>[\w-]+)/load-more/'
55 r'(?P<offset>[0-9]+)/(?P<sorting>[0-9]*)/tags/(?P<tags>[\w-]+)/$',
56 views.load_more, name='load_more'),
57 url(r'^no-images/$', views.ProductsWithoutImages.as_view(),
58 name='products_without_images'),
59 url(r'^no-text/$', views.ProductsWithoutText.as_view(),
60 name='products_without_text'),
61 url(r'^products/(?P<product_vendor_code>[0-9]+)/$',
62 views.ProductPage.as_view(), name='product'),
63 ]
64
65 service_urls = [
66 url(r'^ya-kassa/aviso/$', views.yandex_aviso, name='yandex_aviso'),
67 url(r'^ya-kassa/check/$', views.yandex_check, name='yandex_check'),
68 url(r'^ya-feedback/redirect/$',
69 views.ya_feedback_with_redirect, name='ya_feedback_with_redirect'),
70 url(r'^ya-feedback/request/$',
71 views.ya_feedback_request, name='ya_feedback_request'),
72 ]
73
74 search_urls = [
75 url(r'^autocomplete/$', views.Autocomplete.as_view(), name='autocomplete'),
76 ]
77
78 ecommerce_urls = [
79 url(r'^cart-add/$', views.AddToCart.as_view(), name='cart_add'),
80 url(r'^cart-change/$', views.ChangeCount.as_view(), name='cart_set_count'),
81 url(r'^cart-flush/$', views.FlushCart.as_view(), name='cart_flush'),
82 url(r'^cart-remove/$', views.RemoveFromCart.as_view(), name='cart_remove'),
83 url(r'^order-call/$', views.order_call),
84 url(r'^one-click-buy/$', views.one_click_buy),
85 url(r'^yandex-order/$', views.YandexOrder.as_view()),
86 url(r'', include('ecommerce.urls')),
87 ]
88
89 url_name = Page.CUSTOM_PAGES_URL_NAME
90 custom_pages = [
91 url(r'^(?P<page>)$', cached_2h(views.IndexPage.as_view()), name=url_name),
92 url(r'^(?P<page>search)/$', views.Search.as_view(), name=url_name),
93 url(r'^(?P<page>catalog)/$', cached_2h(views.CategoryTree.as_view()), name=url_name),
94 url(r'^shop/(?P<page>order)/$', views.OrderPage.as_view(), name=url_name),
95 url(r'^shop/(?P<page>order-success)/$', views.OrderSuccess.as_view(), name=url_name),
96 url(r'^(?P<page>sitemap)/$', SitemapPage.as_view(), name=url_name),
97 ]
98
99 urlpatterns = [
100 url('', include(custom_pages)),
101 url(r'^admin/', include(admin_urls)),
102 url(r'^catalog/', include(catalog_urls)),
103 url(r'^pages/', include('pages.urls')),
104 url(r'^robots\.txt$', robots),
105 url(r'^save-feedback/$', views.save_feedback),
106 url(r'^delete-feedback/$', views.delete_feedback),
107 url(r'^set-view-type/$', views.set_view_type, name='set_view_type'),
108 url(r'^shop/', include(ecommerce_urls)),
109 url(r'^search/', include(search_urls)),
110 url(r'^service/', include(service_urls)),
111 url(r'^sitemap\.xml$', cached_60d(sitemap), {'sitemaps': sitemaps}, name='sitemap'),
112 ]
113
114 if settings.DEBUG:
115 import debug_toolbar
116
117 urlpatterns += [
118 url(r'^__debug__/', include(debug_toolbar.urls)),
119 *static(settings.STATIC_URL, document_root=settings.STATIC_ROOT),
120 *static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT),
121 ]
122
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/shopelectro/sitemaps.py b/shopelectro/sitemaps.py
--- a/shopelectro/sitemaps.py
+++ b/shopelectro/sitemaps.py
@@ -1,9 +1,11 @@
+from typing import Generator, Tuple
+
from django.contrib.sitemaps import Sitemap
from django.urls import reverse
from pages.models import Page
-from shopelectro.models import Product, Category
+from shopelectro.models import Category, Product, TagGroup, Tag
class AbstractSitemap(Sitemap):
@@ -37,6 +39,39 @@
return Category.objects.filter(page__is_active=True)
+def get_categories_with_tags() -> Generator[
+ Tuple[Category, Tuple[TagGroup, Tag]], None, None
+]:
+ """
+ Return all unique Category+TagGroup pairs.
+
+ Currently, tags per category is limited to 1 tag (by SEO requirements).
+ So, for each tags group in each category we'll get 1 tag.
+ """
+ for category in Category.objects.filter(page__is_active=True):
+ products = Product.objects.get_by_category(category)
+ tags = Tag.objects.filter(products__in=products).distinct()
+ for group_name, group_tags in tags.get_group_tags_pairs():
+ for group_tag in group_tags:
+ yield category, (group_name, [group_tag])
+
+
+class CategoryWithTagsSitemap(AbstractSitemap):
+
+ def items(self):
+ # `items` method can't return generator (by django design)
+ # so we moved items collection code to dedicated function
+ return list(get_categories_with_tags())
+
+ def location(self, item):
+ category, tags = item
+ tags_slug = Tag.serialize_url_tags([tags])
+ return reverse('category', kwargs={
+ 'slug': category.page.slug,
+ 'tags': tags_slug,
+ })
+
+
class ProductSitemap(AbstractSitemap):
def items(self):
diff --git a/shopelectro/urls.py b/shopelectro/urls.py
--- a/shopelectro/urls.py
+++ b/shopelectro/urls.py
@@ -16,6 +16,7 @@
sitemaps = OrderedDict([
('index', sitemaps.IndexSitemap),
('category', sitemaps.CategorySitemap),
+ ('category-with-tags', sitemaps.CategoryWithTagsSitemap),
('products', sitemaps.ProductSitemap),
('site', sitemaps.PagesSitemap)
])
| {"golden_diff": "diff --git a/shopelectro/sitemaps.py b/shopelectro/sitemaps.py\n--- a/shopelectro/sitemaps.py\n+++ b/shopelectro/sitemaps.py\n@@ -1,9 +1,11 @@\n+from typing import Generator, Tuple\n+\n from django.contrib.sitemaps import Sitemap\n from django.urls import reverse\n \n from pages.models import Page\n \n-from shopelectro.models import Product, Category\n+from shopelectro.models import Category, Product, TagGroup, Tag\n \n \n class AbstractSitemap(Sitemap):\n@@ -37,6 +39,39 @@\n return Category.objects.filter(page__is_active=True)\n \n \n+def get_categories_with_tags() -> Generator[\n+ Tuple[Category, Tuple[TagGroup, Tag]], None, None\n+]:\n+ \"\"\"\n+ Return all unique Category+TagGroup pairs.\n+\n+ Currently, tags per category is limited to 1 tag (by SEO requirements).\n+ So, for each tags group in each category we'll get 1 tag.\n+ \"\"\"\n+ for category in Category.objects.filter(page__is_active=True):\n+ products = Product.objects.get_by_category(category)\n+ tags = Tag.objects.filter(products__in=products).distinct()\n+ for group_name, group_tags in tags.get_group_tags_pairs():\n+ for group_tag in group_tags:\n+ yield category, (group_name, [group_tag])\n+\n+\n+class CategoryWithTagsSitemap(AbstractSitemap):\n+\n+ def items(self):\n+ # `items` method can't return generator (by django design)\n+ # so we moved items collection code to dedicated function\n+ return list(get_categories_with_tags())\n+\n+ def location(self, item):\n+ category, tags = item\n+ tags_slug = Tag.serialize_url_tags([tags])\n+ return reverse('category', kwargs={\n+ 'slug': category.page.slug,\n+ 'tags': tags_slug,\n+ })\n+\n+\n class ProductSitemap(AbstractSitemap):\n \n def items(self):\ndiff --git a/shopelectro/urls.py b/shopelectro/urls.py\n--- a/shopelectro/urls.py\n+++ b/shopelectro/urls.py\n@@ -16,6 +16,7 @@\n sitemaps = OrderedDict([\n ('index', sitemaps.IndexSitemap),\n ('category', sitemaps.CategorySitemap),\n+ ('category-with-tags', sitemaps.CategoryWithTagsSitemap),\n ('products', sitemaps.ProductSitemap),\n ('site', sitemaps.PagesSitemap)\n ])\n", "issue": "Gen categories tags to sitemap\n\u0421\u0435\u0439\u0447\u0430\u0441 \u0432 sitemap \u0432\u044b\u0433\u0440\u0443\u0436\u0430\u044e\u0442\u0441\u044f, \u043f\u043e\u043c\u0438\u043c\u043e \u043f\u0440\u043e\u0447\u0435\u0433\u043e, \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u044b \u043a\u0430\u0442\u0435\u0433\u043e\u0440\u0438\u0439.\r\n\u0412\u044b\u0433\u0440\u0443\u0436\u0430\u0439 \u043d\u0435 \u0442\u043e\u043b\u044c\u043a\u043e \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u044b, \u043d\u043e \u0438 \u0432\u0441\u0435 \u0432\u0430\u0440\u0438\u0430\u043d\u0442\u044b \u0438\u0445 \u0442\u0435\u0433\u043e\u0432.\r\n\u041e\u0434\u043d\u0430\u043a\u043e, \u043d\u0435 \u0434\u043e\u043b\u0436\u043d\u043e \u0431\u044b\u0442\u044c \u0441\u0442\u0440\u0430\u043d\u0438\u0446, \u0443\u0434\u043e\u0432\u043b\u0435\u0442\u0432\u043e\u0440\u044f\u044e\u0449\u0438\u0445 \u043f\u0430\u0442\u0442\u0435\u0440\u043d\u0443 `*-or-*`\r\n\r\n\u041f\u0440\u0438\u043c\u0435\u0440 \u0441\u0442\u0440\u0430\u043d\u0438\u0446\u044b, \u043a\u043e\u0442\u043e\u0440\u0443\u044e \u043d\u0443\u0436\u043d\u043e \u0432\u044b\u0433\u0440\u0443\u0437\u0438\u0442\u044c \u0432 sitemap:\r\nhttps://www.shopelectro.ru/catalog/categories/universalnye-ot-seti-12-v/tags/vanson/\r\n\r\n\u0421\u0442\u0440\u043e\u0447\u043a\u0443 `Disallow: /*-or-*` \u0438\u0437 `robots.txt` \u043d\u0435 \u0432\u044b\u043f\u0438\u043b\u0438\u0432\u0430\u0439 \u043d\u0438 \u0432 \u043a\u043e\u0435\u043c \u0441\u043b\u0443\u0447\u0430\u0435\r\n\n", "before_files": [{"content": "from django.contrib.sitemaps import Sitemap\nfrom django.urls import reverse\n\nfrom pages.models import Page\n\nfrom shopelectro.models import Product, Category\n\n\nclass AbstractSitemap(Sitemap):\n protocol = 'https'\n changefreq = 'weekly'\n priority = 0.9\n\n\nclass IndexSitemap(Sitemap):\n protocol = 'https'\n changefreq = 'monthly'\n priority = 1\n\n # items()\n # Required. A method that returns a list of objects.\n # https://docs.djangoproject.com/ja/1.9/ref/contrib/sitemaps/#django.contrib.sitemaps.Sitemap.items\n def items(self):\n return ['']\n\n # location()\n # Optional. If location isn\u2019t provided, the framework will call the get_absolute_url()\n # method on each object as returned by items().\n # https://docs.djangoproject.com/ja/1.9/ref/contrib/sitemaps/#django.contrib.sitemaps.Sitemap.location\n def location(self, model):\n return reverse(Page.CUSTOM_PAGES_URL_NAME, args=(model, ))\n\n\nclass CategorySitemap(AbstractSitemap):\n\n def items(self):\n return Category.objects.filter(page__is_active=True)\n\n\nclass ProductSitemap(AbstractSitemap):\n\n def items(self):\n return Product.objects.filter(page__is_active=True)\n\n\nclass PagesSitemap(AbstractSitemap):\n\n def items(self):\n return Page.objects.filter(is_active=True)\n", "path": "shopelectro/sitemaps.py"}, {"content": "from collections import OrderedDict\n\nfrom django.conf import settings\nfrom django.conf.urls import url, include\nfrom django.conf.urls.static import static\nfrom django.contrib.sitemaps.views import sitemap\nfrom django.views.decorators.cache import cache_page\n\nfrom pages.models import Page\nfrom pages.views import robots, SitemapPage\n\nfrom shopelectro import sitemaps, config, views\nfrom shopelectro.admin import se_admin\n\n# Orders sitemaps instances\nsitemaps = OrderedDict([\n ('index', sitemaps.IndexSitemap),\n ('category', sitemaps.CategorySitemap),\n ('products', sitemaps.ProductSitemap),\n ('site', sitemaps.PagesSitemap)\n])\n\n# disable cache\nif settings.DEBUG:\n def cache_page(arg): # Ignore PyFlakesBear\n if callable(arg):\n return arg\n return cache_page\n\ncached_60d = cache_page(config.cached_time(days=60))\ncached_2h = cache_page(config.cached_time(hours=2))\n\nadmin_urls = [\n url(r'^', se_admin.urls),\n url(r'^autocomplete/$', views.AdminAutocomplete.as_view(), name='admin_autocomplete'),\n url(r'^get-tree-items/$', views.Tree.as_view()),\n url(r'^redirect-to-product/$', views.RedirectToProduct.as_view()),\n url(r'^table-editor-api/$', views.TableEditorAPI.as_view()),\n url(r'^select2/', include('django_select2.urls')),\n]\n\ncatalog_urls = [\n url(r'^categories/(?P<slug>[\\w-]+)/$',\n cached_2h(views.CategoryPage.as_view()), name='category'),\n url(r'^categories/(?P<slug>[\\w-]+)/tags/(?P<tags>[\\w-]+)/$',\n cached_2h(views.CategoryPage.as_view()), name='category'),\n url(r'^categories/(?P<slug>[\\w-]+)/(?P<sorting>[0-9]*)/$',\n views.CategoryPage.as_view(), name='category'),\n url(r'^categories/(?P<slug>[\\w-]+)/(?P<sorting>[0-9]*)/tags/(?P<tags>[\\w-]+)/$',\n views.CategoryPage.as_view(), name='category'),\n url(r'categories/(?P<category_slug>[\\w-]+)/load-more/'\n r'(?P<offset>[0-9]+)/(?P<sorting>[0-9]*)/$',\n views.load_more, name='load_more'),\n url(r'categories/(?P<category_slug>[\\w-]+)/load-more/'\n r'(?P<offset>[0-9]+)/(?P<sorting>[0-9]*)/tags/(?P<tags>[\\w-]+)/$',\n views.load_more, name='load_more'),\n url(r'^no-images/$', views.ProductsWithoutImages.as_view(),\n name='products_without_images'),\n url(r'^no-text/$', views.ProductsWithoutText.as_view(),\n name='products_without_text'),\n url(r'^products/(?P<product_vendor_code>[0-9]+)/$',\n views.ProductPage.as_view(), name='product'),\n]\n\nservice_urls = [\n url(r'^ya-kassa/aviso/$', views.yandex_aviso, name='yandex_aviso'),\n url(r'^ya-kassa/check/$', views.yandex_check, name='yandex_check'),\n url(r'^ya-feedback/redirect/$',\n views.ya_feedback_with_redirect, name='ya_feedback_with_redirect'),\n url(r'^ya-feedback/request/$',\n views.ya_feedback_request, name='ya_feedback_request'),\n]\n\nsearch_urls = [\n url(r'^autocomplete/$', views.Autocomplete.as_view(), name='autocomplete'),\n]\n\necommerce_urls = [\n url(r'^cart-add/$', views.AddToCart.as_view(), name='cart_add'),\n url(r'^cart-change/$', views.ChangeCount.as_view(), name='cart_set_count'),\n url(r'^cart-flush/$', views.FlushCart.as_view(), name='cart_flush'),\n url(r'^cart-remove/$', views.RemoveFromCart.as_view(), name='cart_remove'),\n url(r'^order-call/$', views.order_call),\n url(r'^one-click-buy/$', views.one_click_buy),\n url(r'^yandex-order/$', views.YandexOrder.as_view()),\n url(r'', include('ecommerce.urls')),\n]\n\nurl_name = Page.CUSTOM_PAGES_URL_NAME\ncustom_pages = [\n url(r'^(?P<page>)$', cached_2h(views.IndexPage.as_view()), name=url_name),\n url(r'^(?P<page>search)/$', views.Search.as_view(), name=url_name),\n url(r'^(?P<page>catalog)/$', cached_2h(views.CategoryTree.as_view()), name=url_name),\n url(r'^shop/(?P<page>order)/$', views.OrderPage.as_view(), name=url_name),\n url(r'^shop/(?P<page>order-success)/$', views.OrderSuccess.as_view(), name=url_name),\n url(r'^(?P<page>sitemap)/$', SitemapPage.as_view(), name=url_name),\n]\n\nurlpatterns = [\n url('', include(custom_pages)),\n url(r'^admin/', include(admin_urls)),\n url(r'^catalog/', include(catalog_urls)),\n url(r'^pages/', include('pages.urls')),\n url(r'^robots\\.txt$', robots),\n url(r'^save-feedback/$', views.save_feedback),\n url(r'^delete-feedback/$', views.delete_feedback),\n url(r'^set-view-type/$', views.set_view_type, name='set_view_type'),\n url(r'^shop/', include(ecommerce_urls)),\n url(r'^search/', include(search_urls)),\n url(r'^service/', include(service_urls)),\n url(r'^sitemap\\.xml$', cached_60d(sitemap), {'sitemaps': sitemaps}, name='sitemap'),\n]\n\nif settings.DEBUG:\n import debug_toolbar\n\n urlpatterns += [\n url(r'^__debug__/', include(debug_toolbar.urls)),\n *static(settings.STATIC_URL, document_root=settings.STATIC_ROOT),\n *static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT),\n ]\n", "path": "shopelectro/urls.py"}], "after_files": [{"content": "from typing import Generator, Tuple\n\nfrom django.contrib.sitemaps import Sitemap\nfrom django.urls import reverse\n\nfrom pages.models import Page\n\nfrom shopelectro.models import Category, Product, TagGroup, Tag\n\n\nclass AbstractSitemap(Sitemap):\n protocol = 'https'\n changefreq = 'weekly'\n priority = 0.9\n\n\nclass IndexSitemap(Sitemap):\n protocol = 'https'\n changefreq = 'monthly'\n priority = 1\n\n # items()\n # Required. A method that returns a list of objects.\n # https://docs.djangoproject.com/ja/1.9/ref/contrib/sitemaps/#django.contrib.sitemaps.Sitemap.items\n def items(self):\n return ['']\n\n # location()\n # Optional. If location isn\u2019t provided, the framework will call the get_absolute_url()\n # method on each object as returned by items().\n # https://docs.djangoproject.com/ja/1.9/ref/contrib/sitemaps/#django.contrib.sitemaps.Sitemap.location\n def location(self, model):\n return reverse(Page.CUSTOM_PAGES_URL_NAME, args=(model, ))\n\n\nclass CategorySitemap(AbstractSitemap):\n\n def items(self):\n return Category.objects.filter(page__is_active=True)\n\n\ndef get_categories_with_tags() -> Generator[\n Tuple[Category, Tuple[TagGroup, Tag]], None, None\n]:\n \"\"\"\n Return all unique Category+TagGroup pairs.\n\n Currently, tags per category is limited to 1 tag (by SEO requirements).\n So, for each tags group in each category we'll get 1 tag.\n \"\"\"\n for category in Category.objects.filter(page__is_active=True):\n products = Product.objects.get_by_category(category)\n tags = Tag.objects.filter(products__in=products).distinct()\n for group_name, group_tags in tags.get_group_tags_pairs():\n for group_tag in group_tags:\n yield category, (group_name, [group_tag])\n\n\nclass CategoryWithTagsSitemap(AbstractSitemap):\n\n def items(self):\n # `items` method can't return generator (by django design)\n # so we moved items collection code to dedicated function\n return list(get_categories_with_tags())\n\n def location(self, item):\n category, tags = item\n tags_slug = Tag.serialize_url_tags([tags])\n return reverse('category', kwargs={\n 'slug': category.page.slug,\n 'tags': tags_slug,\n })\n\n\nclass ProductSitemap(AbstractSitemap):\n\n def items(self):\n return Product.objects.filter(page__is_active=True)\n\n\nclass PagesSitemap(AbstractSitemap):\n\n def items(self):\n return Page.objects.filter(is_active=True)\n", "path": "shopelectro/sitemaps.py"}, {"content": "from collections import OrderedDict\n\nfrom django.conf import settings\nfrom django.conf.urls import url, include\nfrom django.conf.urls.static import static\nfrom django.contrib.sitemaps.views import sitemap\nfrom django.views.decorators.cache import cache_page\n\nfrom pages.models import Page\nfrom pages.views import robots, SitemapPage\n\nfrom shopelectro import sitemaps, config, views\nfrom shopelectro.admin import se_admin\n\n# Orders sitemaps instances\nsitemaps = OrderedDict([\n ('index', sitemaps.IndexSitemap),\n ('category', sitemaps.CategorySitemap),\n ('category-with-tags', sitemaps.CategoryWithTagsSitemap),\n ('products', sitemaps.ProductSitemap),\n ('site', sitemaps.PagesSitemap)\n])\n\n# disable cache\nif settings.DEBUG:\n def cache_page(arg): # Ignore PyFlakesBear\n if callable(arg):\n return arg\n return cache_page\n\ncached_60d = cache_page(config.cached_time(days=60))\ncached_2h = cache_page(config.cached_time(hours=2))\n\nadmin_urls = [\n url(r'^', se_admin.urls),\n url(r'^autocomplete/$', views.AdminAutocomplete.as_view(), name='admin_autocomplete'),\n url(r'^get-tree-items/$', views.Tree.as_view()),\n url(r'^redirect-to-product/$', views.RedirectToProduct.as_view()),\n url(r'^table-editor-api/$', views.TableEditorAPI.as_view()),\n url(r'^select2/', include('django_select2.urls')),\n]\n\ncatalog_urls = [\n url(r'^categories/(?P<slug>[\\w-]+)/$',\n cached_2h(views.CategoryPage.as_view()), name='category'),\n url(r'^categories/(?P<slug>[\\w-]+)/tags/(?P<tags>[\\w-]+)/$',\n cached_2h(views.CategoryPage.as_view()), name='category'),\n url(r'^categories/(?P<slug>[\\w-]+)/(?P<sorting>[0-9]*)/$',\n views.CategoryPage.as_view(), name='category'),\n url(r'^categories/(?P<slug>[\\w-]+)/(?P<sorting>[0-9]*)/tags/(?P<tags>[\\w-]+)/$',\n views.CategoryPage.as_view(), name='category'),\n url(r'categories/(?P<category_slug>[\\w-]+)/load-more/'\n r'(?P<offset>[0-9]+)/(?P<sorting>[0-9]*)/$',\n views.load_more, name='load_more'),\n url(r'categories/(?P<category_slug>[\\w-]+)/load-more/'\n r'(?P<offset>[0-9]+)/(?P<sorting>[0-9]*)/tags/(?P<tags>[\\w-]+)/$',\n views.load_more, name='load_more'),\n url(r'^no-images/$', views.ProductsWithoutImages.as_view(),\n name='products_without_images'),\n url(r'^no-text/$', views.ProductsWithoutText.as_view(),\n name='products_without_text'),\n url(r'^products/(?P<product_vendor_code>[0-9]+)/$',\n views.ProductPage.as_view(), name='product'),\n]\n\nservice_urls = [\n url(r'^ya-kassa/aviso/$', views.yandex_aviso, name='yandex_aviso'),\n url(r'^ya-kassa/check/$', views.yandex_check, name='yandex_check'),\n url(r'^ya-feedback/redirect/$',\n views.ya_feedback_with_redirect, name='ya_feedback_with_redirect'),\n url(r'^ya-feedback/request/$',\n views.ya_feedback_request, name='ya_feedback_request'),\n]\n\nsearch_urls = [\n url(r'^autocomplete/$', views.Autocomplete.as_view(), name='autocomplete'),\n]\n\necommerce_urls = [\n url(r'^cart-add/$', views.AddToCart.as_view(), name='cart_add'),\n url(r'^cart-change/$', views.ChangeCount.as_view(), name='cart_set_count'),\n url(r'^cart-flush/$', views.FlushCart.as_view(), name='cart_flush'),\n url(r'^cart-remove/$', views.RemoveFromCart.as_view(), name='cart_remove'),\n url(r'^order-call/$', views.order_call),\n url(r'^one-click-buy/$', views.one_click_buy),\n url(r'^yandex-order/$', views.YandexOrder.as_view()),\n url(r'', include('ecommerce.urls')),\n]\n\nurl_name = Page.CUSTOM_PAGES_URL_NAME\ncustom_pages = [\n url(r'^(?P<page>)$', cached_2h(views.IndexPage.as_view()), name=url_name),\n url(r'^(?P<page>search)/$', views.Search.as_view(), name=url_name),\n url(r'^(?P<page>catalog)/$', cached_2h(views.CategoryTree.as_view()), name=url_name),\n url(r'^shop/(?P<page>order)/$', views.OrderPage.as_view(), name=url_name),\n url(r'^shop/(?P<page>order-success)/$', views.OrderSuccess.as_view(), name=url_name),\n url(r'^(?P<page>sitemap)/$', SitemapPage.as_view(), name=url_name),\n]\n\nurlpatterns = [\n url('', include(custom_pages)),\n url(r'^admin/', include(admin_urls)),\n url(r'^catalog/', include(catalog_urls)),\n url(r'^pages/', include('pages.urls')),\n url(r'^robots\\.txt$', robots),\n url(r'^save-feedback/$', views.save_feedback),\n url(r'^delete-feedback/$', views.delete_feedback),\n url(r'^set-view-type/$', views.set_view_type, name='set_view_type'),\n url(r'^shop/', include(ecommerce_urls)),\n url(r'^search/', include(search_urls)),\n url(r'^service/', include(service_urls)),\n url(r'^sitemap\\.xml$', cached_60d(sitemap), {'sitemaps': sitemaps}, name='sitemap'),\n]\n\nif settings.DEBUG:\n import debug_toolbar\n\n urlpatterns += [\n url(r'^__debug__/', include(debug_toolbar.urls)),\n *static(settings.STATIC_URL, document_root=settings.STATIC_ROOT),\n *static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT),\n ]\n", "path": "shopelectro/urls.py"}]} | 2,379 | 558 |
gh_patches_debug_53536 | rasdani/github-patches | git_diff | quantumlib__Cirq-2374 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cirq should ship a py.typed file
[PEP 561](https://www.python.org/dev/peps/pep-0561/) says that any packages that ship with type information should have a py.typed file in their package. Otherwise, type checkers like mypy can't find Cirq. (FWIW I just did `touch ~/.virtualenvs/.../cirq/py.typed`, and then mypy type-checks the file correctly.)
Other than that, Cirq seems pretty awesome so far :ok_hand:.
Cirq should ship a py.typed file
[PEP 561](https://www.python.org/dev/peps/pep-0561/) says that any packages that ship with type information should have a py.typed file in their package. Otherwise, type checkers like mypy can't find Cirq. (FWIW I just did `touch ~/.virtualenvs/.../cirq/py.typed`, and then mypy type-checks the file correctly.)
Other than that, Cirq seems pretty awesome so far :ok_hand:.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import io
16 import os
17 from setuptools import find_packages, setup
18
19 # This reads the __version__ variable from cirq/_version.py
20 __version__ = ''
21 exec(open('cirq/_version.py').read())
22
23 name = 'cirq'
24
25 description = ('A framework for creating, editing, and invoking '
26 'Noisy Intermediate Scale Quantum (NISQ) circuits.')
27
28 # README file as long_description.
29 long_description = io.open('README.rst', encoding='utf-8').read()
30
31 # If CIRQ_DEV_VERSION is set then we use cirq-dev as the name of the package
32 # and update the version to this value.
33 if 'CIRQ_DEV_VERSION' in os.environ:
34 name = 'cirq-dev'
35 __version__ = os.environ['CIRQ_DEV_VERSION']
36 long_description = (
37 "**This is a development version of Cirq and may be "
38 "unstable.**\n\n**For the latest stable release of Cirq "
39 "see**\n`here <https://pypi.org/project/cirq>`__.\n\n" +
40 long_description)
41
42 # Read in requirements
43 requirements = open('requirements.txt').readlines()
44 requirements = [r.strip() for r in requirements]
45 contrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()
46 contrib_requirements = [r.strip() for r in contrib_requirements]
47 dev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()
48 dev_requirements = [r.strip() for r in dev_requirements]
49
50 cirq_packages = ['cirq'] + [
51 'cirq.' + package for package in find_packages(where='cirq')
52 ]
53
54 # Sanity check
55 assert __version__, 'Version string cannot be empty'
56
57 setup(name=name,
58 version=__version__,
59 url='http://github.com/quantumlib/cirq',
60 author='The Cirq Developers',
61 author_email='[email protected]',
62 python_requires=('>=3.6.0'),
63 install_requires=requirements,
64 extras_require={
65 'contrib': contrib_requirements,
66 'dev_env': dev_requirements + contrib_requirements,
67 },
68 license='Apache 2',
69 description=description,
70 long_description=long_description,
71 packages=cirq_packages,
72 package_data={
73 'cirq.api.google.v1': ['*.proto'],
74 'cirq.api.google.v2': ['*.proto'],
75 'cirq.google.api.v1': ['*.proto'],
76 'cirq.google.api.v2': ['*.proto'],
77 })
78
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -70,6 +70,7 @@
long_description=long_description,
packages=cirq_packages,
package_data={
+ 'cirq': ['py.typed'],
'cirq.api.google.v1': ['*.proto'],
'cirq.api.google.v2': ['*.proto'],
'cirq.google.api.v1': ['*.proto'],
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -70,6 +70,7 @@\n long_description=long_description,\n packages=cirq_packages,\n package_data={\n+ 'cirq': ['py.typed'],\n 'cirq.api.google.v1': ['*.proto'],\n 'cirq.api.google.v2': ['*.proto'],\n 'cirq.google.api.v1': ['*.proto'],\n", "issue": "Cirq should ship a py.typed file\n[PEP 561](https://www.python.org/dev/peps/pep-0561/) says that any packages that ship with type information should have a py.typed file in their package. Otherwise, type checkers like mypy can't find Cirq. (FWIW I just did `touch ~/.virtualenvs/.../cirq/py.typed`, and then mypy type-checks the file correctly.)\r\n\r\nOther than that, Cirq seems pretty awesome so far :ok_hand:.\nCirq should ship a py.typed file\n[PEP 561](https://www.python.org/dev/peps/pep-0561/) says that any packages that ship with type information should have a py.typed file in their package. Otherwise, type checkers like mypy can't find Cirq. (FWIW I just did `touch ~/.virtualenvs/.../cirq/py.typed`, and then mypy type-checks the file correctly.)\r\n\r\nOther than that, Cirq seems pretty awesome so far :ok_hand:.\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\nexec(open('cirq/_version.py').read())\n\nname = 'cirq'\n\ndescription = ('A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.')\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# If CIRQ_DEV_VERSION is set then we use cirq-dev as the name of the package\n# and update the version to this value.\nif 'CIRQ_DEV_VERSION' in os.environ:\n name = 'cirq-dev'\n __version__ = os.environ['CIRQ_DEV_VERSION']\n long_description = (\n \"**This is a development version of Cirq and may be \"\n \"unstable.**\\n\\n**For the latest stable release of Cirq \"\n \"see**\\n`here <https://pypi.org/project/cirq>`__.\\n\\n\" +\n long_description)\n\n# Read in requirements\nrequirements = open('requirements.txt').readlines()\nrequirements = [r.strip() for r in requirements]\ncontrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()\ncontrib_requirements = [r.strip() for r in contrib_requirements]\ndev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()\ndev_requirements = [r.strip() for r in dev_requirements]\n\ncirq_packages = ['cirq'] + [\n 'cirq.' + package for package in find_packages(where='cirq')\n]\n\n# Sanity check\nassert __version__, 'Version string cannot be empty'\n\nsetup(name=name,\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n extras_require={\n 'contrib': contrib_requirements,\n 'dev_env': dev_requirements + contrib_requirements,\n },\n license='Apache 2',\n description=description,\n long_description=long_description,\n packages=cirq_packages,\n package_data={\n 'cirq.api.google.v1': ['*.proto'],\n 'cirq.api.google.v2': ['*.proto'],\n 'cirq.google.api.v1': ['*.proto'],\n 'cirq.google.api.v2': ['*.proto'],\n })\n", "path": "setup.py"}], "after_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport io\nimport os\nfrom setuptools import find_packages, setup\n\n# This reads the __version__ variable from cirq/_version.py\n__version__ = ''\nexec(open('cirq/_version.py').read())\n\nname = 'cirq'\n\ndescription = ('A framework for creating, editing, and invoking '\n 'Noisy Intermediate Scale Quantum (NISQ) circuits.')\n\n# README file as long_description.\nlong_description = io.open('README.rst', encoding='utf-8').read()\n\n# If CIRQ_DEV_VERSION is set then we use cirq-dev as the name of the package\n# and update the version to this value.\nif 'CIRQ_DEV_VERSION' in os.environ:\n name = 'cirq-dev'\n __version__ = os.environ['CIRQ_DEV_VERSION']\n long_description = (\n \"**This is a development version of Cirq and may be \"\n \"unstable.**\\n\\n**For the latest stable release of Cirq \"\n \"see**\\n`here <https://pypi.org/project/cirq>`__.\\n\\n\" +\n long_description)\n\n# Read in requirements\nrequirements = open('requirements.txt').readlines()\nrequirements = [r.strip() for r in requirements]\ncontrib_requirements = open('cirq/contrib/contrib-requirements.txt').readlines()\ncontrib_requirements = [r.strip() for r in contrib_requirements]\ndev_requirements = open('dev_tools/conf/pip-list-dev-tools.txt').readlines()\ndev_requirements = [r.strip() for r in dev_requirements]\n\ncirq_packages = ['cirq'] + [\n 'cirq.' + package for package in find_packages(where='cirq')\n]\n\n# Sanity check\nassert __version__, 'Version string cannot be empty'\n\nsetup(name=name,\n version=__version__,\n url='http://github.com/quantumlib/cirq',\n author='The Cirq Developers',\n author_email='[email protected]',\n python_requires=('>=3.6.0'),\n install_requires=requirements,\n extras_require={\n 'contrib': contrib_requirements,\n 'dev_env': dev_requirements + contrib_requirements,\n },\n license='Apache 2',\n description=description,\n long_description=long_description,\n packages=cirq_packages,\n package_data={\n 'cirq': ['py.typed'],\n 'cirq.api.google.v1': ['*.proto'],\n 'cirq.api.google.v2': ['*.proto'],\n 'cirq.google.api.v1': ['*.proto'],\n 'cirq.google.api.v2': ['*.proto'],\n })\n", "path": "setup.py"}]} | 1,312 | 99 |
gh_patches_debug_42327 | rasdani/github-patches | git_diff | cupy__cupy-3655 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cupy.full does not have order parameter
Hello,
I noticed that Cupy.full does not have an order parameter, this both exists in Numpy.full and all the other Cupy.full like functions like full_like, ones_like and zeros_like. Is there any reason for that? I'm trying to use CuPy in a project as a drop in replacement and this errors out.
Thank you!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/creation/basic.py`
Content:
```
1 import cupy
2 import numpy
3
4 from cupy.core.core import _update_order_char, _get_strides_for_order_K
5
6
7 def empty(shape, dtype=float, order='C'):
8 """Returns an array without initializing the elements.
9
10 Args:
11 shape (int or tuple of ints): Dimensionalities of the array.
12 dtype: Data type specifier.
13 order ({'C', 'F'}): Row-major (C-style) or column-major
14 (Fortran-style) order.
15
16 Returns:
17 cupy.ndarray: A new array with elements not initialized.
18
19 .. seealso:: :func:`numpy.empty`
20
21 """
22 return cupy.ndarray(shape, dtype, order=order)
23
24
25 def _new_like_order_and_strides(a, dtype, order, shape=None):
26 """
27 Determine order and strides as in NumPy's PyArray_NewLikeArray.
28
29 (see: numpy/core/src/multiarray/ctors.c)
30 """
31 order = order.upper()
32 if order not in ['C', 'F', 'K', 'A']:
33 raise ValueError('order not understood: {}'.format(order))
34
35 if numpy.isscalar(shape):
36 shape = (shape,)
37
38 # Fallback to c_contiguous if keep order and number of dimensions
39 # of new shape mismatch
40 if order == 'K' and shape is not None and len(shape) != a.ndim:
41 return 'C', None, None
42
43 order = chr(_update_order_char(a, ord(order)))
44
45 if order == 'K':
46 strides = _get_strides_for_order_K(a, numpy.dtype(dtype), shape)
47 order = 'C'
48 memptr = cupy.empty(a.size, dtype=dtype).data
49 return order, strides, memptr
50 else:
51 return order, None, None
52
53
54 def empty_like(a, dtype=None, order='K', subok=None, shape=None):
55 """Returns a new array with same shape and dtype of a given array.
56
57 This function currently does not support ``subok`` option.
58
59 Args:
60 a (cupy.ndarray): Base array.
61 dtype: Data type specifier. The data type of ``a`` is used by default.
62 order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the
63 result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if
64 ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the
65 layout of ``a`` as closely as possible.
66 subok: Not supported yet, must be None.
67 shape (int or tuple of ints): Overrides the shape of the result. If
68 order='K' and the number of dimensions is unchanged, will try to
69 keep order, otherwise, order='C' is implied.
70
71
72 Returns:
73 cupy.ndarray: A new array with same shape and dtype of ``a`` with
74 elements not initialized.
75
76 .. seealso:: :func:`numpy.empty_like`
77
78 """
79 if subok is not None:
80 raise TypeError('subok is not supported yet')
81 if dtype is None:
82 dtype = a.dtype
83
84 order, strides, memptr = _new_like_order_and_strides(a, dtype, order,
85 shape)
86 shape = shape if shape else a.shape
87 return cupy.ndarray(shape, dtype, memptr, strides, order)
88
89
90 def eye(N, M=None, k=0, dtype=float):
91 """Returns a 2-D array with ones on the diagonals and zeros elsewhere.
92
93 Args:
94 N (int): Number of rows.
95 M (int): Number of columns. M == N by default.
96 k (int): Index of the diagonal. Zero indicates the main diagonal,
97 a positive index an upper diagonal, and a negative index a lower
98 diagonal.
99 dtype: Data type specifier.
100
101 Returns:
102 cupy.ndarray: A 2-D array with given diagonals filled with ones and
103 zeros elsewhere.
104
105 .. seealso:: :func:`numpy.eye`
106
107 """
108 if M is None:
109 M = N
110 ret = zeros((N, M), dtype)
111 ret.diagonal(k)[:] = 1
112 return ret
113
114
115 def identity(n, dtype=float):
116 """Returns a 2-D identity array.
117
118 It is equivalent to ``eye(n, n, dtype)``.
119
120 Args:
121 n (int): Number of rows and columns.
122 dtype: Data type specifier.
123
124 Returns:
125 cupy.ndarray: A 2-D identity array.
126
127 .. seealso:: :func:`numpy.identity`
128
129 """
130 return eye(n, dtype=dtype)
131
132
133 def ones(shape, dtype=float):
134 """Returns a new array of given shape and dtype, filled with ones.
135
136 This function currently does not support ``order`` option.
137
138 Args:
139 shape (int or tuple of ints): Dimensionalities of the array.
140 dtype: Data type specifier.
141
142 Returns:
143 cupy.ndarray: An array filled with ones.
144
145 .. seealso:: :func:`numpy.ones`
146
147 """
148 # TODO(beam2d): Support ordering option
149 a = cupy.ndarray(shape, dtype)
150 a.fill(1)
151 return a
152
153
154 def ones_like(a, dtype=None, order='K', subok=None, shape=None):
155 """Returns an array of ones with same shape and dtype as a given array.
156
157 This function currently does not support ``subok`` option.
158
159 Args:
160 a (cupy.ndarray): Base array.
161 dtype: Data type specifier. The dtype of ``a`` is used by default.
162 order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the
163 result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if
164 ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the
165 layout of ``a`` as closely as possible.
166 subok: Not supported yet, must be None.
167 shape (int or tuple of ints): Overrides the shape of the result. If
168 order='K' and the number of dimensions is unchanged, will try to
169 keep order, otherwise, order='C' is implied.
170
171 Returns:
172 cupy.ndarray: An array filled with ones.
173
174 .. seealso:: :func:`numpy.ones_like`
175
176 """
177 if subok is not None:
178 raise TypeError('subok is not supported yet')
179 if dtype is None:
180 dtype = a.dtype
181
182 order, strides, memptr = _new_like_order_and_strides(a, dtype, order,
183 shape)
184 shape = shape if shape else a.shape
185 a = cupy.ndarray(shape, dtype, memptr, strides, order)
186 a.fill(1)
187 return a
188
189
190 def zeros(shape, dtype=float, order='C'):
191 """Returns a new array of given shape and dtype, filled with zeros.
192
193 Args:
194 shape (int or tuple of ints): Dimensionalities of the array.
195 dtype: Data type specifier.
196 order ({'C', 'F'}): Row-major (C-style) or column-major
197 (Fortran-style) order.
198
199 Returns:
200 cupy.ndarray: An array filled with zeros.
201
202 .. seealso:: :func:`numpy.zeros`
203
204 """
205 a = cupy.ndarray(shape, dtype, order=order)
206 a.data.memset_async(0, a.nbytes)
207 return a
208
209
210 def zeros_like(a, dtype=None, order='K', subok=None, shape=None):
211 """Returns an array of zeros with same shape and dtype as a given array.
212
213 This function currently does not support ``subok`` option.
214
215 Args:
216 a (cupy.ndarray): Base array.
217 dtype: Data type specifier. The dtype of ``a`` is used by default.
218 order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the
219 result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if
220 ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the
221 layout of ``a`` as closely as possible.
222 subok: Not supported yet, must be None.
223 shape (int or tuple of ints): Overrides the shape of the result. If
224 order='K' and the number of dimensions is unchanged, will try to
225 keep order, otherwise, order='C' is implied.
226
227 Returns:
228 cupy.ndarray: An array filled with zeros.
229
230 .. seealso:: :func:`numpy.zeros_like`
231
232 """
233 if subok is not None:
234 raise TypeError('subok is not supported yet')
235 if dtype is None:
236 dtype = a.dtype
237
238 order, strides, memptr = _new_like_order_and_strides(a, dtype, order,
239 shape)
240 shape = shape if shape else a.shape
241 a = cupy.ndarray(shape, dtype, memptr, strides, order)
242 a.data.memset_async(0, a.nbytes)
243 return a
244
245
246 def full(shape, fill_value, dtype=None):
247 """Returns a new array of given shape and dtype, filled with a given value.
248
249 This function currently does not support ``order`` option.
250
251 Args:
252 shape (int or tuple of ints): Dimensionalities of the array.
253 fill_value: A scalar value to fill a new array.
254 dtype: Data type specifier.
255
256 Returns:
257 cupy.ndarray: An array filled with ``fill_value``.
258
259 .. seealso:: :func:`numpy.full`
260
261 """
262 # TODO(beam2d): Support ordering option
263 if dtype is None:
264 if isinstance(fill_value, cupy.ndarray):
265 dtype = fill_value.dtype
266 else:
267 dtype = numpy.array(fill_value).dtype
268 a = cupy.ndarray(shape, dtype)
269 a.fill(fill_value)
270 return a
271
272
273 def full_like(a, fill_value, dtype=None, order='K', subok=None, shape=None):
274 """Returns a full array with same shape and dtype as a given array.
275
276 This function currently does not support ``subok`` option.
277
278 Args:
279 a (cupy.ndarray): Base array.
280 fill_value: A scalar value to fill a new array.
281 dtype: Data type specifier. The dtype of ``a`` is used by default.
282 order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the
283 result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if
284 ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the
285 layout of ``a`` as closely as possible.
286 subok: Not supported yet, must be None.
287 shape (int or tuple of ints): Overrides the shape of the result. If
288 order='K' and the number of dimensions is unchanged, will try to
289 keep order, otherwise, order='C' is implied.
290
291 Returns:
292 cupy.ndarray: An array filled with ``fill_value``.
293
294 .. seealso:: :func:`numpy.full_like`
295
296 """
297 if subok is not None:
298 raise TypeError('subok is not supported yet')
299 if dtype is None:
300 dtype = a.dtype
301
302 order, strides, memptr = _new_like_order_and_strides(a, dtype, order,
303 shape)
304 shape = shape if shape else a.shape
305 a = cupy.ndarray(shape, dtype, memptr, strides, order)
306 a.fill(fill_value)
307 return a
308
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cupy/creation/basic.py b/cupy/creation/basic.py
--- a/cupy/creation/basic.py
+++ b/cupy/creation/basic.py
@@ -87,7 +87,7 @@
return cupy.ndarray(shape, dtype, memptr, strides, order)
-def eye(N, M=None, k=0, dtype=float):
+def eye(N, M=None, k=0, dtype=float, order='C'):
"""Returns a 2-D array with ones on the diagonals and zeros elsewhere.
Args:
@@ -97,6 +97,8 @@
a positive index an upper diagonal, and a negative index a lower
diagonal.
dtype: Data type specifier.
+ order ({'C', 'F'}): Row-major (C-style) or column-major
+ (Fortran-style) order.
Returns:
cupy.ndarray: A 2-D array with given diagonals filled with ones and
@@ -107,7 +109,7 @@
"""
if M is None:
M = N
- ret = zeros((N, M), dtype)
+ ret = zeros((N, M), dtype, order=order)
ret.diagonal(k)[:] = 1
return ret
@@ -130,7 +132,7 @@
return eye(n, dtype=dtype)
-def ones(shape, dtype=float):
+def ones(shape, dtype=float, order='C'):
"""Returns a new array of given shape and dtype, filled with ones.
This function currently does not support ``order`` option.
@@ -138,6 +140,8 @@
Args:
shape (int or tuple of ints): Dimensionalities of the array.
dtype: Data type specifier.
+ order ({'C', 'F'}): Row-major (C-style) or column-major
+ (Fortran-style) order.
Returns:
cupy.ndarray: An array filled with ones.
@@ -145,8 +149,7 @@
.. seealso:: :func:`numpy.ones`
"""
- # TODO(beam2d): Support ordering option
- a = cupy.ndarray(shape, dtype)
+ a = cupy.ndarray(shape, dtype, order=order)
a.fill(1)
return a
@@ -243,7 +246,7 @@
return a
-def full(shape, fill_value, dtype=None):
+def full(shape, fill_value, dtype=None, order='C'):
"""Returns a new array of given shape and dtype, filled with a given value.
This function currently does not support ``order`` option.
@@ -252,6 +255,8 @@
shape (int or tuple of ints): Dimensionalities of the array.
fill_value: A scalar value to fill a new array.
dtype: Data type specifier.
+ order ({'C', 'F'}): Row-major (C-style) or column-major
+ (Fortran-style) order.
Returns:
cupy.ndarray: An array filled with ``fill_value``.
@@ -259,13 +264,12 @@
.. seealso:: :func:`numpy.full`
"""
- # TODO(beam2d): Support ordering option
if dtype is None:
if isinstance(fill_value, cupy.ndarray):
dtype = fill_value.dtype
else:
dtype = numpy.array(fill_value).dtype
- a = cupy.ndarray(shape, dtype)
+ a = cupy.ndarray(shape, dtype, order=order)
a.fill(fill_value)
return a
| {"golden_diff": "diff --git a/cupy/creation/basic.py b/cupy/creation/basic.py\n--- a/cupy/creation/basic.py\n+++ b/cupy/creation/basic.py\n@@ -87,7 +87,7 @@\n return cupy.ndarray(shape, dtype, memptr, strides, order)\n \n \n-def eye(N, M=None, k=0, dtype=float):\n+def eye(N, M=None, k=0, dtype=float, order='C'):\n \"\"\"Returns a 2-D array with ones on the diagonals and zeros elsewhere.\n \n Args:\n@@ -97,6 +97,8 @@\n a positive index an upper diagonal, and a negative index a lower\n diagonal.\n dtype: Data type specifier.\n+ order ({'C', 'F'}): Row-major (C-style) or column-major\n+ (Fortran-style) order.\n \n Returns:\n cupy.ndarray: A 2-D array with given diagonals filled with ones and\n@@ -107,7 +109,7 @@\n \"\"\"\n if M is None:\n M = N\n- ret = zeros((N, M), dtype)\n+ ret = zeros((N, M), dtype, order=order)\n ret.diagonal(k)[:] = 1\n return ret\n \n@@ -130,7 +132,7 @@\n return eye(n, dtype=dtype)\n \n \n-def ones(shape, dtype=float):\n+def ones(shape, dtype=float, order='C'):\n \"\"\"Returns a new array of given shape and dtype, filled with ones.\n \n This function currently does not support ``order`` option.\n@@ -138,6 +140,8 @@\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n+ order ({'C', 'F'}): Row-major (C-style) or column-major\n+ (Fortran-style) order.\n \n Returns:\n cupy.ndarray: An array filled with ones.\n@@ -145,8 +149,7 @@\n .. seealso:: :func:`numpy.ones`\n \n \"\"\"\n- # TODO(beam2d): Support ordering option\n- a = cupy.ndarray(shape, dtype)\n+ a = cupy.ndarray(shape, dtype, order=order)\n a.fill(1)\n return a\n \n@@ -243,7 +246,7 @@\n return a\n \n \n-def full(shape, fill_value, dtype=None):\n+def full(shape, fill_value, dtype=None, order='C'):\n \"\"\"Returns a new array of given shape and dtype, filled with a given value.\n \n This function currently does not support ``order`` option.\n@@ -252,6 +255,8 @@\n shape (int or tuple of ints): Dimensionalities of the array.\n fill_value: A scalar value to fill a new array.\n dtype: Data type specifier.\n+ order ({'C', 'F'}): Row-major (C-style) or column-major\n+ (Fortran-style) order.\n \n Returns:\n cupy.ndarray: An array filled with ``fill_value``.\n@@ -259,13 +264,12 @@\n .. seealso:: :func:`numpy.full`\n \n \"\"\"\n- # TODO(beam2d): Support ordering option\n if dtype is None:\n if isinstance(fill_value, cupy.ndarray):\n dtype = fill_value.dtype\n else:\n dtype = numpy.array(fill_value).dtype\n- a = cupy.ndarray(shape, dtype)\n+ a = cupy.ndarray(shape, dtype, order=order)\n a.fill(fill_value)\n return a\n", "issue": "Cupy.full does not have order parameter\nHello, \r\n\r\nI noticed that Cupy.full does not have an order parameter, this both exists in Numpy.full and all the other Cupy.full like functions like full_like, ones_like and zeros_like. Is there any reason for that? I'm trying to use CuPy in a project as a drop in replacement and this errors out. \r\n\r\nThank you!\n", "before_files": [{"content": "import cupy\nimport numpy\n\nfrom cupy.core.core import _update_order_char, _get_strides_for_order_K\n\n\ndef empty(shape, dtype=float, order='C'):\n \"\"\"Returns an array without initializing the elements.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: A new array with elements not initialized.\n\n .. seealso:: :func:`numpy.empty`\n\n \"\"\"\n return cupy.ndarray(shape, dtype, order=order)\n\n\ndef _new_like_order_and_strides(a, dtype, order, shape=None):\n \"\"\"\n Determine order and strides as in NumPy's PyArray_NewLikeArray.\n\n (see: numpy/core/src/multiarray/ctors.c)\n \"\"\"\n order = order.upper()\n if order not in ['C', 'F', 'K', 'A']:\n raise ValueError('order not understood: {}'.format(order))\n\n if numpy.isscalar(shape):\n shape = (shape,)\n\n # Fallback to c_contiguous if keep order and number of dimensions\n # of new shape mismatch\n if order == 'K' and shape is not None and len(shape) != a.ndim:\n return 'C', None, None\n\n order = chr(_update_order_char(a, ord(order)))\n\n if order == 'K':\n strides = _get_strides_for_order_K(a, numpy.dtype(dtype), shape)\n order = 'C'\n memptr = cupy.empty(a.size, dtype=dtype).data\n return order, strides, memptr\n else:\n return order, None, None\n\n\ndef empty_like(a, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns a new array with same shape and dtype of a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n dtype: Data type specifier. The data type of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n\n Returns:\n cupy.ndarray: A new array with same shape and dtype of ``a`` with\n elements not initialized.\n\n .. seealso:: :func:`numpy.empty_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n return cupy.ndarray(shape, dtype, memptr, strides, order)\n\n\ndef eye(N, M=None, k=0, dtype=float):\n \"\"\"Returns a 2-D array with ones on the diagonals and zeros elsewhere.\n\n Args:\n N (int): Number of rows.\n M (int): Number of columns. M == N by default.\n k (int): Index of the diagonal. Zero indicates the main diagonal,\n a positive index an upper diagonal, and a negative index a lower\n diagonal.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: A 2-D array with given diagonals filled with ones and\n zeros elsewhere.\n\n .. seealso:: :func:`numpy.eye`\n\n \"\"\"\n if M is None:\n M = N\n ret = zeros((N, M), dtype)\n ret.diagonal(k)[:] = 1\n return ret\n\n\ndef identity(n, dtype=float):\n \"\"\"Returns a 2-D identity array.\n\n It is equivalent to ``eye(n, n, dtype)``.\n\n Args:\n n (int): Number of rows and columns.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: A 2-D identity array.\n\n .. seealso:: :func:`numpy.identity`\n\n \"\"\"\n return eye(n, dtype=dtype)\n\n\ndef ones(shape, dtype=float):\n \"\"\"Returns a new array of given shape and dtype, filled with ones.\n\n This function currently does not support ``order`` option.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: An array filled with ones.\n\n .. seealso:: :func:`numpy.ones`\n\n \"\"\"\n # TODO(beam2d): Support ordering option\n a = cupy.ndarray(shape, dtype)\n a.fill(1)\n return a\n\n\ndef ones_like(a, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns an array of ones with same shape and dtype as a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n dtype: Data type specifier. The dtype of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n Returns:\n cupy.ndarray: An array filled with ones.\n\n .. seealso:: :func:`numpy.ones_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n a = cupy.ndarray(shape, dtype, memptr, strides, order)\n a.fill(1)\n return a\n\n\ndef zeros(shape, dtype=float, order='C'):\n \"\"\"Returns a new array of given shape and dtype, filled with zeros.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: An array filled with zeros.\n\n .. seealso:: :func:`numpy.zeros`\n\n \"\"\"\n a = cupy.ndarray(shape, dtype, order=order)\n a.data.memset_async(0, a.nbytes)\n return a\n\n\ndef zeros_like(a, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns an array of zeros with same shape and dtype as a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n dtype: Data type specifier. The dtype of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n Returns:\n cupy.ndarray: An array filled with zeros.\n\n .. seealso:: :func:`numpy.zeros_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n a = cupy.ndarray(shape, dtype, memptr, strides, order)\n a.data.memset_async(0, a.nbytes)\n return a\n\n\ndef full(shape, fill_value, dtype=None):\n \"\"\"Returns a new array of given shape and dtype, filled with a given value.\n\n This function currently does not support ``order`` option.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n fill_value: A scalar value to fill a new array.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: An array filled with ``fill_value``.\n\n .. seealso:: :func:`numpy.full`\n\n \"\"\"\n # TODO(beam2d): Support ordering option\n if dtype is None:\n if isinstance(fill_value, cupy.ndarray):\n dtype = fill_value.dtype\n else:\n dtype = numpy.array(fill_value).dtype\n a = cupy.ndarray(shape, dtype)\n a.fill(fill_value)\n return a\n\n\ndef full_like(a, fill_value, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns a full array with same shape and dtype as a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n fill_value: A scalar value to fill a new array.\n dtype: Data type specifier. The dtype of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n Returns:\n cupy.ndarray: An array filled with ``fill_value``.\n\n .. seealso:: :func:`numpy.full_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n a = cupy.ndarray(shape, dtype, memptr, strides, order)\n a.fill(fill_value)\n return a\n", "path": "cupy/creation/basic.py"}], "after_files": [{"content": "import cupy\nimport numpy\n\nfrom cupy.core.core import _update_order_char, _get_strides_for_order_K\n\n\ndef empty(shape, dtype=float, order='C'):\n \"\"\"Returns an array without initializing the elements.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: A new array with elements not initialized.\n\n .. seealso:: :func:`numpy.empty`\n\n \"\"\"\n return cupy.ndarray(shape, dtype, order=order)\n\n\ndef _new_like_order_and_strides(a, dtype, order, shape=None):\n \"\"\"\n Determine order and strides as in NumPy's PyArray_NewLikeArray.\n\n (see: numpy/core/src/multiarray/ctors.c)\n \"\"\"\n order = order.upper()\n if order not in ['C', 'F', 'K', 'A']:\n raise ValueError('order not understood: {}'.format(order))\n\n if numpy.isscalar(shape):\n shape = (shape,)\n\n # Fallback to c_contiguous if keep order and number of dimensions\n # of new shape mismatch\n if order == 'K' and shape is not None and len(shape) != a.ndim:\n return 'C', None, None\n\n order = chr(_update_order_char(a, ord(order)))\n\n if order == 'K':\n strides = _get_strides_for_order_K(a, numpy.dtype(dtype), shape)\n order = 'C'\n memptr = cupy.empty(a.size, dtype=dtype).data\n return order, strides, memptr\n else:\n return order, None, None\n\n\ndef empty_like(a, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns a new array with same shape and dtype of a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n dtype: Data type specifier. The data type of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n\n Returns:\n cupy.ndarray: A new array with same shape and dtype of ``a`` with\n elements not initialized.\n\n .. seealso:: :func:`numpy.empty_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n return cupy.ndarray(shape, dtype, memptr, strides, order)\n\n\ndef eye(N, M=None, k=0, dtype=float, order='C'):\n \"\"\"Returns a 2-D array with ones on the diagonals and zeros elsewhere.\n\n Args:\n N (int): Number of rows.\n M (int): Number of columns. M == N by default.\n k (int): Index of the diagonal. Zero indicates the main diagonal,\n a positive index an upper diagonal, and a negative index a lower\n diagonal.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: A 2-D array with given diagonals filled with ones and\n zeros elsewhere.\n\n .. seealso:: :func:`numpy.eye`\n\n \"\"\"\n if M is None:\n M = N\n ret = zeros((N, M), dtype, order=order)\n ret.diagonal(k)[:] = 1\n return ret\n\n\ndef identity(n, dtype=float):\n \"\"\"Returns a 2-D identity array.\n\n It is equivalent to ``eye(n, n, dtype)``.\n\n Args:\n n (int): Number of rows and columns.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: A 2-D identity array.\n\n .. seealso:: :func:`numpy.identity`\n\n \"\"\"\n return eye(n, dtype=dtype)\n\n\ndef ones(shape, dtype=float, order='C'):\n \"\"\"Returns a new array of given shape and dtype, filled with ones.\n\n This function currently does not support ``order`` option.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: An array filled with ones.\n\n .. seealso:: :func:`numpy.ones`\n\n \"\"\"\n a = cupy.ndarray(shape, dtype, order=order)\n a.fill(1)\n return a\n\n\ndef ones_like(a, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns an array of ones with same shape and dtype as a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n dtype: Data type specifier. The dtype of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n Returns:\n cupy.ndarray: An array filled with ones.\n\n .. seealso:: :func:`numpy.ones_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n a = cupy.ndarray(shape, dtype, memptr, strides, order)\n a.fill(1)\n return a\n\n\ndef zeros(shape, dtype=float, order='C'):\n \"\"\"Returns a new array of given shape and dtype, filled with zeros.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: An array filled with zeros.\n\n .. seealso:: :func:`numpy.zeros`\n\n \"\"\"\n a = cupy.ndarray(shape, dtype, order=order)\n a.data.memset_async(0, a.nbytes)\n return a\n\n\ndef zeros_like(a, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns an array of zeros with same shape and dtype as a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n dtype: Data type specifier. The dtype of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n Returns:\n cupy.ndarray: An array filled with zeros.\n\n .. seealso:: :func:`numpy.zeros_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n a = cupy.ndarray(shape, dtype, memptr, strides, order)\n a.data.memset_async(0, a.nbytes)\n return a\n\n\ndef full(shape, fill_value, dtype=None, order='C'):\n \"\"\"Returns a new array of given shape and dtype, filled with a given value.\n\n This function currently does not support ``order`` option.\n\n Args:\n shape (int or tuple of ints): Dimensionalities of the array.\n fill_value: A scalar value to fill a new array.\n dtype: Data type specifier.\n order ({'C', 'F'}): Row-major (C-style) or column-major\n (Fortran-style) order.\n\n Returns:\n cupy.ndarray: An array filled with ``fill_value``.\n\n .. seealso:: :func:`numpy.full`\n\n \"\"\"\n if dtype is None:\n if isinstance(fill_value, cupy.ndarray):\n dtype = fill_value.dtype\n else:\n dtype = numpy.array(fill_value).dtype\n a = cupy.ndarray(shape, dtype, order=order)\n a.fill(fill_value)\n return a\n\n\ndef full_like(a, fill_value, dtype=None, order='K', subok=None, shape=None):\n \"\"\"Returns a full array with same shape and dtype as a given array.\n\n This function currently does not support ``subok`` option.\n\n Args:\n a (cupy.ndarray): Base array.\n fill_value: A scalar value to fill a new array.\n dtype: Data type specifier. The dtype of ``a`` is used by default.\n order ({'C', 'F', 'A', or 'K'}): Overrides the memory layout of the\n result. 'C' means C-order, 'F' means F-order, 'A' means 'F' if\n ``a`` is Fortran contiguous, 'C' otherwise. 'K' means match the\n layout of ``a`` as closely as possible.\n subok: Not supported yet, must be None.\n shape (int or tuple of ints): Overrides the shape of the result. If\n order='K' and the number of dimensions is unchanged, will try to\n keep order, otherwise, order='C' is implied.\n\n Returns:\n cupy.ndarray: An array filled with ``fill_value``.\n\n .. seealso:: :func:`numpy.full_like`\n\n \"\"\"\n if subok is not None:\n raise TypeError('subok is not supported yet')\n if dtype is None:\n dtype = a.dtype\n\n order, strides, memptr = _new_like_order_and_strides(a, dtype, order,\n shape)\n shape = shape if shape else a.shape\n a = cupy.ndarray(shape, dtype, memptr, strides, order)\n a.fill(fill_value)\n return a\n", "path": "cupy/creation/basic.py"}]} | 3,710 | 802 |
gh_patches_debug_28688 | rasdani/github-patches | git_diff | getredash__redash-617 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add time zone support
Right now re:dash assumes that all timestamps are in the local time zone. However, Redshift (and many other databases, depending on the configuration) default to UTC, and thus re:dash parses the data incorrectly. What's confusing is that in Highcharts also formats the data in local time, leading to this awkward display:

Notice how the data is highlighted at the beginning of April 23 (which hasn't happened yet in GMT), but the date is showing April 22 4:00 pm (which hasn't happened yet in Pacific Standard Time).
I temporarily worked around this by patching ng_highchart.js:
``` diff
if (moment.isMoment(this.x)) {
- var s = '<b>' + this.x.toDate().toLocaleString() + '</b>',
+ var s = '<b>' + this.x.toDate().toISOString() + '</b>',
pointsCount = this.points.length;
```
resources.js:
``` diff
if (angular.isNumber(v)) {
columnTypes[k] = 'float';
} else if (_.isString(v) && v.match(/^\d{4}-\d{2}-\d{2}T/)) {
- row[k] = moment(v);
+ row[k] = moment.utc(v);
columnTypes[k] = 'datetime';
} else if (_.isString(v) && v.match(/^\d{4}-\d{2}-\d{2}/)) {
- row[k] = moment(v);
+ row[k] = moment.utc(v);
columnTypes[k] = 'date';
} else if (typeof(v) == 'object' && v !== null) {
row[k] = JSON.stringify(v);
```
I'd imagine there will be cases where some users have their database configured to output a specific standard time and others will use UTC. What's the best way to support this feature? Options:
1. Store the UTC offset in the `query_result` (so moment will parse the right value)
2. Allow configuration option in re:dash for time zone (e.g. UTC, America/Los_Angeles)
What do you think, @arikfr?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `redash/handlers/static.py`
Content:
```
1 import hashlib
2 import json
3
4 from flask import render_template, send_from_directory, current_app
5 from flask_login import current_user, login_required
6
7 from redash import settings
8 from redash.wsgi import app
9
10
11 @app.route('/admin/<anything>/<whatever>')
12 @app.route('/admin/<anything>')
13 @app.route('/dashboard/<anything>')
14 @app.route('/alerts')
15 @app.route('/alerts/<pk>')
16 @app.route('/queries')
17 @app.route('/data_sources')
18 @app.route('/data_sources/<pk>')
19 @app.route('/users')
20 @app.route('/users/<pk>')
21 @app.route('/queries/<query_id>')
22 @app.route('/queries/<query_id>/<anything>')
23 @app.route('/personal')
24 @app.route('/')
25 @login_required
26 def index(**kwargs):
27 email_md5 = hashlib.md5(current_user.email.lower()).hexdigest()
28 gravatar_url = "https://www.gravatar.com/avatar/%s?s=40" % email_md5
29
30 user = {
31 'gravatar_url': gravatar_url,
32 'id': current_user.id,
33 'name': current_user.name,
34 'email': current_user.email,
35 'groups': current_user.groups,
36 'permissions': current_user.permissions
37 }
38
39 features = {
40 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,
41 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,
42 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD
43 }
44
45 return render_template("index.html", user=json.dumps(user), name=settings.NAME,
46 features=json.dumps(features),
47 analytics=settings.ANALYTICS)
48
49
50 @app.route('/<path:filename>')
51 def send_static(filename):
52 if current_app.debug:
53 cache_timeout = 0
54 else:
55 cache_timeout = None
56
57 return send_from_directory(settings.STATIC_ASSETS_PATH, filename, cache_timeout=cache_timeout)
58
```
Path: `redash/settings.py`
Content:
```
1 import json
2 import os
3 import urlparse
4 from funcy import distinct
5
6
7 def parse_db_url(url):
8 url_parts = urlparse.urlparse(url)
9 connection = {'threadlocals': True}
10
11 if url_parts.hostname and not url_parts.path:
12 connection['name'] = url_parts.hostname
13 else:
14 connection['name'] = url_parts.path[1:]
15 connection['host'] = url_parts.hostname
16 connection['port'] = url_parts.port
17 connection['user'] = url_parts.username
18 connection['password'] = url_parts.password
19
20 return connection
21
22
23 def fix_assets_path(path):
24 fullpath = os.path.join(os.path.dirname(__file__), path)
25 return fullpath
26
27
28 def array_from_string(str):
29 array = str.split(',')
30 if "" in array:
31 array.remove("")
32
33 return array
34
35
36 def set_from_string(str):
37 return set(array_from_string(str))
38
39
40 def parse_boolean(str):
41 return json.loads(str.lower())
42
43
44 def all_settings():
45 from types import ModuleType
46
47 settings = {}
48 for name, item in globals().iteritems():
49 if not callable(item) and not name.startswith("__") and not isinstance(item, ModuleType):
50 settings[name] = item
51
52 return settings
53
54
55 NAME = os.environ.get('REDASH_NAME', 're:dash')
56
57 REDIS_URL = os.environ.get('REDASH_REDIS_URL', "redis://localhost:6379/0")
58
59 STATSD_HOST = os.environ.get('REDASH_STATSD_HOST', "127.0.0.1")
60 STATSD_PORT = int(os.environ.get('REDASH_STATSD_PORT', "8125"))
61 STATSD_PREFIX = os.environ.get('REDASH_STATSD_PREFIX', "redash")
62
63 # Connection settings for re:dash's own database (where we store the queries, results, etc)
64 DATABASE_CONFIG = parse_db_url(os.environ.get("REDASH_DATABASE_URL", "postgresql://postgres"))
65
66 # Celery related settings
67 CELERY_BROKER = os.environ.get("REDASH_CELERY_BROKER", REDIS_URL)
68 CELERY_BACKEND = os.environ.get("REDASH_CELERY_BACKEND", CELERY_BROKER)
69
70 # The following enables periodic job (every 5 minutes) of removing unused query results.
71 QUERY_RESULTS_CLEANUP_ENABLED = parse_boolean(os.environ.get("REDASH_QUERY_RESULTS_CLEANUP_ENABLED", "true"))
72
73 AUTH_TYPE = os.environ.get("REDASH_AUTH_TYPE", "api_key")
74 PASSWORD_LOGIN_ENABLED = parse_boolean(os.environ.get("REDASH_PASSWORD_LOGIN_ENABLED", "true"))
75
76 # Google Apps domain to allow access from; any user with email in this Google Apps will be allowed
77 # access
78 GOOGLE_APPS_DOMAIN = set_from_string(os.environ.get("REDASH_GOOGLE_APPS_DOMAIN", ""))
79
80 GOOGLE_CLIENT_ID = os.environ.get("REDASH_GOOGLE_CLIENT_ID", "")
81 GOOGLE_CLIENT_SECRET = os.environ.get("REDASH_GOOGLE_CLIENT_SECRET", "")
82 GOOGLE_OAUTH_ENABLED = GOOGLE_CLIENT_ID and GOOGLE_CLIENT_SECRET
83
84 SAML_METADATA_URL = os.environ.get("REDASH_SAML_METADATA_URL", "")
85 SAML_LOGIN_ENABLED = SAML_METADATA_URL != ""
86 SAML_CALLBACK_SERVER_NAME = os.environ.get("REDASH_SAML_CALLBACK_SERVER_NAME", "")
87
88 STATIC_ASSETS_PATH = fix_assets_path(os.environ.get("REDASH_STATIC_ASSETS_PATH", "../rd_ui/app/"))
89 JOB_EXPIRY_TIME = int(os.environ.get("REDASH_JOB_EXPIRY_TIME", 3600 * 6))
90 COOKIE_SECRET = os.environ.get("REDASH_COOKIE_SECRET", "c292a0a3aa32397cdb050e233733900f")
91 LOG_LEVEL = os.environ.get("REDASH_LOG_LEVEL", "INFO")
92 ANALYTICS = os.environ.get("REDASH_ANALYTICS", "")
93
94 # Mail settings:
95 MAIL_SERVER = os.environ.get('REDASH_MAIL_SERVER', 'localhost')
96 MAIL_PORT = int(os.environ.get('REDASH_MAIL_PORT', 25))
97 MAIL_USE_TLS = parse_boolean(os.environ.get('REDASH_MAIL_USE_TLS', 'false'))
98 MAIL_USE_SSL = parse_boolean(os.environ.get('REDASH_MAIL_USE_SSL', 'false'))
99 MAIL_USERNAME = os.environ.get('REDASH_MAIL_USERNAME', None)
100 MAIL_PASSWORD = os.environ.get('REDASH_MAIL_PASSWORD', None)
101 MAIL_DEFAULT_SENDER = os.environ.get('REDASH_MAIL_DEFAULT_SENDER', None)
102 MAIL_MAX_EMAILS = os.environ.get('REDASH_MAIL_MAX_EMAILS', None)
103 MAIL_ASCII_ATTACHMENTS = parse_boolean(os.environ.get('REDASH_MAIL_ASCII_ATTACHMENTS', 'false'))
104
105 HOST = os.environ.get('REDASH_HOST', '')
106
107 # CORS settings for the Query Result API (and possbily future external APIs).
108 # In most cases all you need to do is set REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN
109 # to the calling domain (or domains in a comma separated list).
110 ACCESS_CONTROL_ALLOW_ORIGIN = set_from_string(os.environ.get("REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN", ""))
111 ACCESS_CONTROL_ALLOW_CREDENTIALS = parse_boolean(os.environ.get("REDASH_CORS_ACCESS_CONTROL_ALLOW_CREDENTIALS", "false"))
112 ACCESS_CONTROL_REQUEST_METHOD = os.environ.get("REDASH_CORS_ACCESS_CONTROL_REQUEST_METHOD", "GET, POST, PUT")
113 ACCESS_CONTROL_ALLOW_HEADERS = os.environ.get("REDASH_CORS_ACCESS_CONTROL_ALLOW_HEADERS", "Content-Type")
114
115 # Query Runners
116 default_query_runners = [
117 'redash.query_runner.big_query',
118 'redash.query_runner.google_spreadsheets',
119 'redash.query_runner.graphite',
120 'redash.query_runner.mongodb',
121 'redash.query_runner.mysql',
122 'redash.query_runner.pg',
123 'redash.query_runner.url',
124 'redash.query_runner.influx_db',
125 'redash.query_runner.elasticsearch',
126 'redash.query_runner.presto',
127 'redash.query_runner.hive_ds',
128 'redash.query_runner.impala_ds',
129 'redash.query_runner.vertica',
130 'redash.query_runner.treasuredata'
131 ]
132
133 enabled_query_runners = array_from_string(os.environ.get("REDASH_ENABLED_QUERY_RUNNERS", ",".join(default_query_runners)))
134 additional_query_runners = array_from_string(os.environ.get("REDASH_ADDITIONAL_QUERY_RUNNERS", ""))
135
136 QUERY_RUNNERS = distinct(enabled_query_runners + additional_query_runners)
137
138 # Support for Sentry (http://getsentry.com/). Just set your Sentry DSN to enable it:
139 SENTRY_DSN = os.environ.get("REDASH_SENTRY_DSN", "")
140
141 # Client side toggles:
142 ALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get("REDASH_ALLOW_SCRIPTS_IN_USER_INPUT", "false"))
143 CLIENT_SIDE_METRICS = parse_boolean(os.environ.get("REDASH_CLIENT_SIDE_METRICS", "false"))
144 # http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold
145 HIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get("REDASH_HIGHCHARTS_TURBO_THRESHOLD", "1000"))
146
147 # Features:
148 FEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get("REDASH_FEATURE_ALLOW_ALL_TO_EDIT", "true"))
149 FEATURE_TABLES_PERMISSIONS = parse_boolean(os.environ.get("REDASH_FEATURE_TABLES_PERMISSIONS", "false"))
150
151 # BigQuery
152 BIGQUERY_HTTP_TIMEOUT = int(os.environ.get("REDASH_BIGQUERY_HTTP_TIMEOUT", "600"))
153
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/redash/handlers/static.py b/redash/handlers/static.py
--- a/redash/handlers/static.py
+++ b/redash/handlers/static.py
@@ -36,14 +36,16 @@
'permissions': current_user.permissions
}
- features = {
+ client_config = {
'clientSideMetrics': settings.CLIENT_SIDE_METRICS,
'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,
- 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD
+ 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD,
+ 'dateFormat': settings.DATE_FORMAT,
+ 'dateTimeFormat': "{0} HH:mm".format(settings.DATE_FORMAT)
}
return render_template("index.html", user=json.dumps(user), name=settings.NAME,
- features=json.dumps(features),
+ client_config=json.dumps(client_config),
analytics=settings.ANALYTICS)
diff --git a/redash/settings.py b/redash/settings.py
--- a/redash/settings.py
+++ b/redash/settings.py
@@ -143,6 +143,7 @@
CLIENT_SIDE_METRICS = parse_boolean(os.environ.get("REDASH_CLIENT_SIDE_METRICS", "false"))
# http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold
HIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get("REDASH_HIGHCHARTS_TURBO_THRESHOLD", "1000"))
+DATE_FORMAT = os.environ.get("REDASH_DATE_FORMAT", "DD/MM/YY")
# Features:
FEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get("REDASH_FEATURE_ALLOW_ALL_TO_EDIT", "true"))
| {"golden_diff": "diff --git a/redash/handlers/static.py b/redash/handlers/static.py\n--- a/redash/handlers/static.py\n+++ b/redash/handlers/static.py\n@@ -36,14 +36,16 @@\n 'permissions': current_user.permissions\n }\n \n- features = {\n+ client_config = {\n 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,\n 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,\n- 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD\n+ 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD,\n+ 'dateFormat': settings.DATE_FORMAT,\n+ 'dateTimeFormat': \"{0} HH:mm\".format(settings.DATE_FORMAT)\n }\n \n return render_template(\"index.html\", user=json.dumps(user), name=settings.NAME,\n- features=json.dumps(features),\n+ client_config=json.dumps(client_config),\n analytics=settings.ANALYTICS)\n \n \ndiff --git a/redash/settings.py b/redash/settings.py\n--- a/redash/settings.py\n+++ b/redash/settings.py\n@@ -143,6 +143,7 @@\n CLIENT_SIDE_METRICS = parse_boolean(os.environ.get(\"REDASH_CLIENT_SIDE_METRICS\", \"false\"))\n # http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold\n HIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get(\"REDASH_HIGHCHARTS_TURBO_THRESHOLD\", \"1000\"))\n+DATE_FORMAT = os.environ.get(\"REDASH_DATE_FORMAT\", \"DD/MM/YY\")\n \n # Features:\n FEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get(\"REDASH_FEATURE_ALLOW_ALL_TO_EDIT\", \"true\"))\n", "issue": "Add time zone support\nRight now re:dash assumes that all timestamps are in the local time zone. However, Redshift (and many other databases, depending on the configuration) default to UTC, and thus re:dash parses the data incorrectly. What's confusing is that in Highcharts also formats the data in local time, leading to this awkward display:\n\n\n\nNotice how the data is highlighted at the beginning of April 23 (which hasn't happened yet in GMT), but the date is showing April 22 4:00 pm (which hasn't happened yet in Pacific Standard Time).\n\nI temporarily worked around this by patching ng_highchart.js:\n\n``` diff\n if (moment.isMoment(this.x)) {\n- var s = '<b>' + this.x.toDate().toLocaleString() + '</b>',\n+ var s = '<b>' + this.x.toDate().toISOString() + '</b>',\n pointsCount = this.points.length;\n```\n\nresources.js:\n\n``` diff\n if (angular.isNumber(v)) {\n columnTypes[k] = 'float';\n } else if (_.isString(v) && v.match(/^\\d{4}-\\d{2}-\\d{2}T/)) {\n- row[k] = moment(v);\n+ row[k] = moment.utc(v);\n columnTypes[k] = 'datetime';\n } else if (_.isString(v) && v.match(/^\\d{4}-\\d{2}-\\d{2}/)) {\n- row[k] = moment(v);\n+ row[k] = moment.utc(v);\n columnTypes[k] = 'date';\n } else if (typeof(v) == 'object' && v !== null) {\n row[k] = JSON.stringify(v);\n```\n\nI'd imagine there will be cases where some users have their database configured to output a specific standard time and others will use UTC. What's the best way to support this feature? Options:\n1. Store the UTC offset in the `query_result` (so moment will parse the right value)\n2. Allow configuration option in re:dash for time zone (e.g. UTC, America/Los_Angeles) \n\nWhat do you think, @arikfr?\n\n", "before_files": [{"content": "import hashlib\nimport json\n\nfrom flask import render_template, send_from_directory, current_app\nfrom flask_login import current_user, login_required\n\nfrom redash import settings\nfrom redash.wsgi import app\n\n\[email protected]('/admin/<anything>/<whatever>')\[email protected]('/admin/<anything>')\[email protected]('/dashboard/<anything>')\[email protected]('/alerts')\[email protected]('/alerts/<pk>')\[email protected]('/queries')\[email protected]('/data_sources')\[email protected]('/data_sources/<pk>')\[email protected]('/users')\[email protected]('/users/<pk>')\[email protected]('/queries/<query_id>')\[email protected]('/queries/<query_id>/<anything>')\[email protected]('/personal')\[email protected]('/')\n@login_required\ndef index(**kwargs):\n email_md5 = hashlib.md5(current_user.email.lower()).hexdigest()\n gravatar_url = \"https://www.gravatar.com/avatar/%s?s=40\" % email_md5\n\n user = {\n 'gravatar_url': gravatar_url,\n 'id': current_user.id,\n 'name': current_user.name,\n 'email': current_user.email,\n 'groups': current_user.groups,\n 'permissions': current_user.permissions\n }\n\n features = {\n 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,\n 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,\n 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD\n }\n\n return render_template(\"index.html\", user=json.dumps(user), name=settings.NAME,\n features=json.dumps(features),\n analytics=settings.ANALYTICS)\n\n\[email protected]('/<path:filename>')\ndef send_static(filename):\n if current_app.debug:\n cache_timeout = 0\n else:\n cache_timeout = None\n\n return send_from_directory(settings.STATIC_ASSETS_PATH, filename, cache_timeout=cache_timeout)\n", "path": "redash/handlers/static.py"}, {"content": "import json\nimport os\nimport urlparse\nfrom funcy import distinct\n\n\ndef parse_db_url(url):\n url_parts = urlparse.urlparse(url)\n connection = {'threadlocals': True}\n\n if url_parts.hostname and not url_parts.path:\n connection['name'] = url_parts.hostname\n else:\n connection['name'] = url_parts.path[1:]\n connection['host'] = url_parts.hostname\n connection['port'] = url_parts.port\n connection['user'] = url_parts.username\n connection['password'] = url_parts.password\n\n return connection\n\n\ndef fix_assets_path(path):\n fullpath = os.path.join(os.path.dirname(__file__), path)\n return fullpath\n\n\ndef array_from_string(str):\n array = str.split(',')\n if \"\" in array:\n array.remove(\"\")\n\n return array\n\n\ndef set_from_string(str):\n return set(array_from_string(str))\n\n\ndef parse_boolean(str):\n return json.loads(str.lower())\n\n\ndef all_settings():\n from types import ModuleType\n\n settings = {}\n for name, item in globals().iteritems():\n if not callable(item) and not name.startswith(\"__\") and not isinstance(item, ModuleType):\n settings[name] = item\n\n return settings\n\n\nNAME = os.environ.get('REDASH_NAME', 're:dash')\n\nREDIS_URL = os.environ.get('REDASH_REDIS_URL', \"redis://localhost:6379/0\")\n\nSTATSD_HOST = os.environ.get('REDASH_STATSD_HOST', \"127.0.0.1\")\nSTATSD_PORT = int(os.environ.get('REDASH_STATSD_PORT', \"8125\"))\nSTATSD_PREFIX = os.environ.get('REDASH_STATSD_PREFIX', \"redash\")\n\n# Connection settings for re:dash's own database (where we store the queries, results, etc)\nDATABASE_CONFIG = parse_db_url(os.environ.get(\"REDASH_DATABASE_URL\", \"postgresql://postgres\"))\n\n# Celery related settings\nCELERY_BROKER = os.environ.get(\"REDASH_CELERY_BROKER\", REDIS_URL)\nCELERY_BACKEND = os.environ.get(\"REDASH_CELERY_BACKEND\", CELERY_BROKER)\n\n# The following enables periodic job (every 5 minutes) of removing unused query results.\nQUERY_RESULTS_CLEANUP_ENABLED = parse_boolean(os.environ.get(\"REDASH_QUERY_RESULTS_CLEANUP_ENABLED\", \"true\"))\n\nAUTH_TYPE = os.environ.get(\"REDASH_AUTH_TYPE\", \"api_key\")\nPASSWORD_LOGIN_ENABLED = parse_boolean(os.environ.get(\"REDASH_PASSWORD_LOGIN_ENABLED\", \"true\"))\n\n# Google Apps domain to allow access from; any user with email in this Google Apps will be allowed\n# access\nGOOGLE_APPS_DOMAIN = set_from_string(os.environ.get(\"REDASH_GOOGLE_APPS_DOMAIN\", \"\"))\n\nGOOGLE_CLIENT_ID = os.environ.get(\"REDASH_GOOGLE_CLIENT_ID\", \"\")\nGOOGLE_CLIENT_SECRET = os.environ.get(\"REDASH_GOOGLE_CLIENT_SECRET\", \"\")\nGOOGLE_OAUTH_ENABLED = GOOGLE_CLIENT_ID and GOOGLE_CLIENT_SECRET\n\nSAML_METADATA_URL = os.environ.get(\"REDASH_SAML_METADATA_URL\", \"\")\nSAML_LOGIN_ENABLED = SAML_METADATA_URL != \"\"\nSAML_CALLBACK_SERVER_NAME = os.environ.get(\"REDASH_SAML_CALLBACK_SERVER_NAME\", \"\")\n\nSTATIC_ASSETS_PATH = fix_assets_path(os.environ.get(\"REDASH_STATIC_ASSETS_PATH\", \"../rd_ui/app/\"))\nJOB_EXPIRY_TIME = int(os.environ.get(\"REDASH_JOB_EXPIRY_TIME\", 3600 * 6))\nCOOKIE_SECRET = os.environ.get(\"REDASH_COOKIE_SECRET\", \"c292a0a3aa32397cdb050e233733900f\")\nLOG_LEVEL = os.environ.get(\"REDASH_LOG_LEVEL\", \"INFO\")\nANALYTICS = os.environ.get(\"REDASH_ANALYTICS\", \"\")\n\n# Mail settings:\nMAIL_SERVER = os.environ.get('REDASH_MAIL_SERVER', 'localhost')\nMAIL_PORT = int(os.environ.get('REDASH_MAIL_PORT', 25))\nMAIL_USE_TLS = parse_boolean(os.environ.get('REDASH_MAIL_USE_TLS', 'false'))\nMAIL_USE_SSL = parse_boolean(os.environ.get('REDASH_MAIL_USE_SSL', 'false'))\nMAIL_USERNAME = os.environ.get('REDASH_MAIL_USERNAME', None)\nMAIL_PASSWORD = os.environ.get('REDASH_MAIL_PASSWORD', None)\nMAIL_DEFAULT_SENDER = os.environ.get('REDASH_MAIL_DEFAULT_SENDER', None)\nMAIL_MAX_EMAILS = os.environ.get('REDASH_MAIL_MAX_EMAILS', None)\nMAIL_ASCII_ATTACHMENTS = parse_boolean(os.environ.get('REDASH_MAIL_ASCII_ATTACHMENTS', 'false'))\n\nHOST = os.environ.get('REDASH_HOST', '')\n\n# CORS settings for the Query Result API (and possbily future external APIs).\n# In most cases all you need to do is set REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN\n# to the calling domain (or domains in a comma separated list).\nACCESS_CONTROL_ALLOW_ORIGIN = set_from_string(os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN\", \"\"))\nACCESS_CONTROL_ALLOW_CREDENTIALS = parse_boolean(os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_CREDENTIALS\", \"false\"))\nACCESS_CONTROL_REQUEST_METHOD = os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_REQUEST_METHOD\", \"GET, POST, PUT\")\nACCESS_CONTROL_ALLOW_HEADERS = os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_HEADERS\", \"Content-Type\")\n\n# Query Runners\ndefault_query_runners = [\n 'redash.query_runner.big_query',\n 'redash.query_runner.google_spreadsheets',\n 'redash.query_runner.graphite',\n 'redash.query_runner.mongodb',\n 'redash.query_runner.mysql',\n 'redash.query_runner.pg',\n 'redash.query_runner.url',\n 'redash.query_runner.influx_db',\n 'redash.query_runner.elasticsearch',\n 'redash.query_runner.presto',\n 'redash.query_runner.hive_ds',\n 'redash.query_runner.impala_ds',\n 'redash.query_runner.vertica',\n 'redash.query_runner.treasuredata'\n]\n\nenabled_query_runners = array_from_string(os.environ.get(\"REDASH_ENABLED_QUERY_RUNNERS\", \",\".join(default_query_runners)))\nadditional_query_runners = array_from_string(os.environ.get(\"REDASH_ADDITIONAL_QUERY_RUNNERS\", \"\"))\n\nQUERY_RUNNERS = distinct(enabled_query_runners + additional_query_runners)\n\n# Support for Sentry (http://getsentry.com/). Just set your Sentry DSN to enable it:\nSENTRY_DSN = os.environ.get(\"REDASH_SENTRY_DSN\", \"\")\n\n# Client side toggles:\nALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get(\"REDASH_ALLOW_SCRIPTS_IN_USER_INPUT\", \"false\"))\nCLIENT_SIDE_METRICS = parse_boolean(os.environ.get(\"REDASH_CLIENT_SIDE_METRICS\", \"false\"))\n# http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold\nHIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get(\"REDASH_HIGHCHARTS_TURBO_THRESHOLD\", \"1000\"))\n\n# Features:\nFEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get(\"REDASH_FEATURE_ALLOW_ALL_TO_EDIT\", \"true\"))\nFEATURE_TABLES_PERMISSIONS = parse_boolean(os.environ.get(\"REDASH_FEATURE_TABLES_PERMISSIONS\", \"false\"))\n\n# BigQuery\nBIGQUERY_HTTP_TIMEOUT = int(os.environ.get(\"REDASH_BIGQUERY_HTTP_TIMEOUT\", \"600\"))\n", "path": "redash/settings.py"}], "after_files": [{"content": "import hashlib\nimport json\n\nfrom flask import render_template, send_from_directory, current_app\nfrom flask_login import current_user, login_required\n\nfrom redash import settings\nfrom redash.wsgi import app\n\n\[email protected]('/admin/<anything>/<whatever>')\[email protected]('/admin/<anything>')\[email protected]('/dashboard/<anything>')\[email protected]('/alerts')\[email protected]('/alerts/<pk>')\[email protected]('/queries')\[email protected]('/data_sources')\[email protected]('/data_sources/<pk>')\[email protected]('/users')\[email protected]('/users/<pk>')\[email protected]('/queries/<query_id>')\[email protected]('/queries/<query_id>/<anything>')\[email protected]('/personal')\[email protected]('/')\n@login_required\ndef index(**kwargs):\n email_md5 = hashlib.md5(current_user.email.lower()).hexdigest()\n gravatar_url = \"https://www.gravatar.com/avatar/%s?s=40\" % email_md5\n\n user = {\n 'gravatar_url': gravatar_url,\n 'id': current_user.id,\n 'name': current_user.name,\n 'email': current_user.email,\n 'groups': current_user.groups,\n 'permissions': current_user.permissions\n }\n\n client_config = {\n 'clientSideMetrics': settings.CLIENT_SIDE_METRICS,\n 'allowScriptsInUserInput': settings.ALLOW_SCRIPTS_IN_USER_INPUT,\n 'highChartsTurboThreshold': settings.HIGHCHARTS_TURBO_THRESHOLD,\n 'dateFormat': settings.DATE_FORMAT,\n 'dateTimeFormat': \"{0} HH:mm\".format(settings.DATE_FORMAT)\n }\n\n return render_template(\"index.html\", user=json.dumps(user), name=settings.NAME,\n client_config=json.dumps(client_config),\n analytics=settings.ANALYTICS)\n\n\[email protected]('/<path:filename>')\ndef send_static(filename):\n if current_app.debug:\n cache_timeout = 0\n else:\n cache_timeout = None\n\n return send_from_directory(settings.STATIC_ASSETS_PATH, filename, cache_timeout=cache_timeout)\n", "path": "redash/handlers/static.py"}, {"content": "import json\nimport os\nimport urlparse\nfrom funcy import distinct\n\n\ndef parse_db_url(url):\n url_parts = urlparse.urlparse(url)\n connection = {'threadlocals': True}\n\n if url_parts.hostname and not url_parts.path:\n connection['name'] = url_parts.hostname\n else:\n connection['name'] = url_parts.path[1:]\n connection['host'] = url_parts.hostname\n connection['port'] = url_parts.port\n connection['user'] = url_parts.username\n connection['password'] = url_parts.password\n\n return connection\n\n\ndef fix_assets_path(path):\n fullpath = os.path.join(os.path.dirname(__file__), path)\n return fullpath\n\n\ndef array_from_string(str):\n array = str.split(',')\n if \"\" in array:\n array.remove(\"\")\n\n return array\n\n\ndef set_from_string(str):\n return set(array_from_string(str))\n\n\ndef parse_boolean(str):\n return json.loads(str.lower())\n\n\ndef all_settings():\n from types import ModuleType\n\n settings = {}\n for name, item in globals().iteritems():\n if not callable(item) and not name.startswith(\"__\") and not isinstance(item, ModuleType):\n settings[name] = item\n\n return settings\n\n\nNAME = os.environ.get('REDASH_NAME', 're:dash')\n\nREDIS_URL = os.environ.get('REDASH_REDIS_URL', \"redis://localhost:6379/0\")\n\nSTATSD_HOST = os.environ.get('REDASH_STATSD_HOST', \"127.0.0.1\")\nSTATSD_PORT = int(os.environ.get('REDASH_STATSD_PORT', \"8125\"))\nSTATSD_PREFIX = os.environ.get('REDASH_STATSD_PREFIX', \"redash\")\n\n# Connection settings for re:dash's own database (where we store the queries, results, etc)\nDATABASE_CONFIG = parse_db_url(os.environ.get(\"REDASH_DATABASE_URL\", \"postgresql://postgres\"))\n\n# Celery related settings\nCELERY_BROKER = os.environ.get(\"REDASH_CELERY_BROKER\", REDIS_URL)\nCELERY_BACKEND = os.environ.get(\"REDASH_CELERY_BACKEND\", CELERY_BROKER)\n\n# The following enables periodic job (every 5 minutes) of removing unused query results.\nQUERY_RESULTS_CLEANUP_ENABLED = parse_boolean(os.environ.get(\"REDASH_QUERY_RESULTS_CLEANUP_ENABLED\", \"true\"))\n\nAUTH_TYPE = os.environ.get(\"REDASH_AUTH_TYPE\", \"api_key\")\nPASSWORD_LOGIN_ENABLED = parse_boolean(os.environ.get(\"REDASH_PASSWORD_LOGIN_ENABLED\", \"true\"))\n\n# Google Apps domain to allow access from; any user with email in this Google Apps will be allowed\n# access\nGOOGLE_APPS_DOMAIN = set_from_string(os.environ.get(\"REDASH_GOOGLE_APPS_DOMAIN\", \"\"))\n\nGOOGLE_CLIENT_ID = os.environ.get(\"REDASH_GOOGLE_CLIENT_ID\", \"\")\nGOOGLE_CLIENT_SECRET = os.environ.get(\"REDASH_GOOGLE_CLIENT_SECRET\", \"\")\nGOOGLE_OAUTH_ENABLED = GOOGLE_CLIENT_ID and GOOGLE_CLIENT_SECRET\n\nSAML_METADATA_URL = os.environ.get(\"REDASH_SAML_METADATA_URL\", \"\")\nSAML_LOGIN_ENABLED = SAML_METADATA_URL != \"\"\nSAML_CALLBACK_SERVER_NAME = os.environ.get(\"REDASH_SAML_CALLBACK_SERVER_NAME\", \"\")\n\nSTATIC_ASSETS_PATH = fix_assets_path(os.environ.get(\"REDASH_STATIC_ASSETS_PATH\", \"../rd_ui/app/\"))\nJOB_EXPIRY_TIME = int(os.environ.get(\"REDASH_JOB_EXPIRY_TIME\", 3600 * 6))\nCOOKIE_SECRET = os.environ.get(\"REDASH_COOKIE_SECRET\", \"c292a0a3aa32397cdb050e233733900f\")\nLOG_LEVEL = os.environ.get(\"REDASH_LOG_LEVEL\", \"INFO\")\nANALYTICS = os.environ.get(\"REDASH_ANALYTICS\", \"\")\n\n# Mail settings:\nMAIL_SERVER = os.environ.get('REDASH_MAIL_SERVER', 'localhost')\nMAIL_PORT = int(os.environ.get('REDASH_MAIL_PORT', 25))\nMAIL_USE_TLS = parse_boolean(os.environ.get('REDASH_MAIL_USE_TLS', 'false'))\nMAIL_USE_SSL = parse_boolean(os.environ.get('REDASH_MAIL_USE_SSL', 'false'))\nMAIL_USERNAME = os.environ.get('REDASH_MAIL_USERNAME', None)\nMAIL_PASSWORD = os.environ.get('REDASH_MAIL_PASSWORD', None)\nMAIL_DEFAULT_SENDER = os.environ.get('REDASH_MAIL_DEFAULT_SENDER', None)\nMAIL_MAX_EMAILS = os.environ.get('REDASH_MAIL_MAX_EMAILS', None)\nMAIL_ASCII_ATTACHMENTS = parse_boolean(os.environ.get('REDASH_MAIL_ASCII_ATTACHMENTS', 'false'))\n\nHOST = os.environ.get('REDASH_HOST', '')\n\n# CORS settings for the Query Result API (and possbily future external APIs).\n# In most cases all you need to do is set REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN\n# to the calling domain (or domains in a comma separated list).\nACCESS_CONTROL_ALLOW_ORIGIN = set_from_string(os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_ORIGIN\", \"\"))\nACCESS_CONTROL_ALLOW_CREDENTIALS = parse_boolean(os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_CREDENTIALS\", \"false\"))\nACCESS_CONTROL_REQUEST_METHOD = os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_REQUEST_METHOD\", \"GET, POST, PUT\")\nACCESS_CONTROL_ALLOW_HEADERS = os.environ.get(\"REDASH_CORS_ACCESS_CONTROL_ALLOW_HEADERS\", \"Content-Type\")\n\n# Query Runners\ndefault_query_runners = [\n 'redash.query_runner.big_query',\n 'redash.query_runner.google_spreadsheets',\n 'redash.query_runner.graphite',\n 'redash.query_runner.mongodb',\n 'redash.query_runner.mysql',\n 'redash.query_runner.pg',\n 'redash.query_runner.url',\n 'redash.query_runner.influx_db',\n 'redash.query_runner.elasticsearch',\n 'redash.query_runner.presto',\n 'redash.query_runner.hive_ds',\n 'redash.query_runner.impala_ds',\n 'redash.query_runner.vertica',\n 'redash.query_runner.treasuredata'\n]\n\nenabled_query_runners = array_from_string(os.environ.get(\"REDASH_ENABLED_QUERY_RUNNERS\", \",\".join(default_query_runners)))\nadditional_query_runners = array_from_string(os.environ.get(\"REDASH_ADDITIONAL_QUERY_RUNNERS\", \"\"))\n\nQUERY_RUNNERS = distinct(enabled_query_runners + additional_query_runners)\n\n# Support for Sentry (http://getsentry.com/). Just set your Sentry DSN to enable it:\nSENTRY_DSN = os.environ.get(\"REDASH_SENTRY_DSN\", \"\")\n\n# Client side toggles:\nALLOW_SCRIPTS_IN_USER_INPUT = parse_boolean(os.environ.get(\"REDASH_ALLOW_SCRIPTS_IN_USER_INPUT\", \"false\"))\nCLIENT_SIDE_METRICS = parse_boolean(os.environ.get(\"REDASH_CLIENT_SIDE_METRICS\", \"false\"))\n# http://api.highcharts.com/highcharts#plotOptions.series.turboThreshold\nHIGHCHARTS_TURBO_THRESHOLD = int(os.environ.get(\"REDASH_HIGHCHARTS_TURBO_THRESHOLD\", \"1000\"))\nDATE_FORMAT = os.environ.get(\"REDASH_DATE_FORMAT\", \"DD/MM/YY\")\n\n# Features:\nFEATURE_ALLOW_ALL_TO_EDIT_QUERIES = parse_boolean(os.environ.get(\"REDASH_FEATURE_ALLOW_ALL_TO_EDIT\", \"true\"))\nFEATURE_TABLES_PERMISSIONS = parse_boolean(os.environ.get(\"REDASH_FEATURE_TABLES_PERMISSIONS\", \"false\"))\n\n# BigQuery\nBIGQUERY_HTTP_TIMEOUT = int(os.environ.get(\"REDASH_BIGQUERY_HTTP_TIMEOUT\", \"600\"))\n", "path": "redash/settings.py"}]} | 3,227 | 377 |
gh_patches_debug_8566 | rasdani/github-patches | git_diff | great-expectations__great_expectations-1229 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Great Expectations is still marked as Python 2 compatible
It looks like running `pip install great_expectations==0.9.7` in a Python 2 environment starts working, before failing when pulling `marshmallow`. This is expected since this PR: https://github.com/great-expectations/great_expectations/pull/1187 but on PyPI, GE is still marked as Python 2 compatible because of the `setup.py` file.
I'm opening a PR that fixes this in a sec, but feel free to close if I'm missing something! :)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `setup.py`
Content:
```
1 from setuptools import setup, find_packages
2 import versioneer
3
4 # Parse requirements.txt
5 with open('requirements.txt') as f:
6 required = f.read().splitlines()
7
8 #try:
9 # import pypandoc
10 # long_description = pypandoc.convert_file('README.md', 'rst')
11 #except (IOError, ImportError):
12 long_description = 'Always know what to expect from your data. (See https://github.com/great-expectations/great_expectations for full description).'
13
14 config = {
15 'description': 'Always know what to expect from your data.',
16 'author': 'The Great Expectations Team',
17 'url': 'https://github.com/great-expectations/great_expectations',
18 'author_email': '[email protected]',
19 'version': versioneer.get_version(),
20 'cmdclass': versioneer.get_cmdclass(),
21 'install_requires': required,
22 'extras_require': {
23 'spark': ['pyspark>=2.3.2'],
24 'sqlalchemy': ['sqlalchemy>=1.2'],
25 'airflow': ['apache-airflow[s3]>=1.9.0', 'boto3>=1.7.3']
26 },
27 'packages': find_packages(exclude=['docs', 'tests', 'examples']),
28 'entry_points': {
29 'console_scripts': ['great_expectations=great_expectations.cli:main']
30 },
31 'name': 'great_expectations',
32 'long_description': long_description,
33 'license': 'Apache-2.0',
34 'keywords': 'data science testing pipeline data quality dataquality validation datavalidation',
35 'include_package_data': True,
36 'classifiers': [
37 'Development Status :: 4 - Beta',
38 'Intended Audience :: Developers',
39 'Intended Audience :: Science/Research',
40 'Intended Audience :: Other Audience',
41 'Topic :: Scientific/Engineering',
42 'Topic :: Software Development',
43 'Topic :: Software Development :: Testing',
44 'License :: OSI Approved :: Apache Software License',
45 'Programming Language :: Python :: 2',
46 'Programming Language :: Python :: 2.7',
47 'Programming Language :: Python :: 3',
48 'Programming Language :: Python :: 3.6',
49 'Programming Language :: Python :: 3.7',
50 ]
51 }
52
53 setup(**config)
54
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -42,8 +42,6 @@
'Topic :: Software Development',
'Topic :: Software Development :: Testing',
'License :: OSI Approved :: Apache Software License',
- 'Programming Language :: Python :: 2',
- 'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
| {"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -42,8 +42,6 @@\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Testing',\n 'License :: OSI Approved :: Apache Software License',\n- 'Programming Language :: Python :: 2',\n- 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n", "issue": "Great Expectations is still marked as Python 2 compatible\nIt looks like running `pip install great_expectations==0.9.7` in a Python 2 environment starts working, before failing when pulling `marshmallow`. This is expected since this PR: https://github.com/great-expectations/great_expectations/pull/1187 but on PyPI, GE is still marked as Python 2 compatible because of the `setup.py` file.\r\n\r\nI'm opening a PR that fixes this in a sec, but feel free to close if I'm missing something! :)\n", "before_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\n\n# Parse requirements.txt\nwith open('requirements.txt') as f:\n required = f.read().splitlines()\n\n#try:\n# import pypandoc\n# long_description = pypandoc.convert_file('README.md', 'rst')\n#except (IOError, ImportError):\nlong_description = 'Always know what to expect from your data. (See https://github.com/great-expectations/great_expectations for full description).'\n\nconfig = {\n 'description': 'Always know what to expect from your data.',\n 'author': 'The Great Expectations Team',\n 'url': 'https://github.com/great-expectations/great_expectations',\n 'author_email': '[email protected]',\n 'version': versioneer.get_version(),\n 'cmdclass': versioneer.get_cmdclass(),\n 'install_requires': required,\n 'extras_require': {\n 'spark': ['pyspark>=2.3.2'],\n 'sqlalchemy': ['sqlalchemy>=1.2'],\n 'airflow': ['apache-airflow[s3]>=1.9.0', 'boto3>=1.7.3']\n },\n 'packages': find_packages(exclude=['docs', 'tests', 'examples']),\n 'entry_points': {\n 'console_scripts': ['great_expectations=great_expectations.cli:main']\n },\n 'name': 'great_expectations',\n 'long_description': long_description,\n 'license': 'Apache-2.0',\n 'keywords': 'data science testing pipeline data quality dataquality validation datavalidation',\n 'include_package_data': True,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Other Audience',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Testing',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 2',\n 'Programming Language :: Python :: 2.7',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ]\n}\n\nsetup(**config)\n", "path": "setup.py"}], "after_files": [{"content": "from setuptools import setup, find_packages\nimport versioneer\n\n# Parse requirements.txt\nwith open('requirements.txt') as f:\n required = f.read().splitlines()\n\n#try:\n# import pypandoc\n# long_description = pypandoc.convert_file('README.md', 'rst')\n#except (IOError, ImportError):\nlong_description = 'Always know what to expect from your data. (See https://github.com/great-expectations/great_expectations for full description).'\n\nconfig = {\n 'description': 'Always know what to expect from your data.',\n 'author': 'The Great Expectations Team',\n 'url': 'https://github.com/great-expectations/great_expectations',\n 'author_email': '[email protected]',\n 'version': versioneer.get_version(),\n 'cmdclass': versioneer.get_cmdclass(),\n 'install_requires': required,\n 'extras_require': {\n 'spark': ['pyspark>=2.3.2'],\n 'sqlalchemy': ['sqlalchemy>=1.2'],\n 'airflow': ['apache-airflow[s3]>=1.9.0', 'boto3>=1.7.3']\n },\n 'packages': find_packages(exclude=['docs', 'tests', 'examples']),\n 'entry_points': {\n 'console_scripts': ['great_expectations=great_expectations.cli:main']\n },\n 'name': 'great_expectations',\n 'long_description': long_description,\n 'license': 'Apache-2.0',\n 'keywords': 'data science testing pipeline data quality dataquality validation datavalidation',\n 'include_package_data': True,\n 'classifiers': [\n 'Development Status :: 4 - Beta',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'Intended Audience :: Other Audience',\n 'Topic :: Scientific/Engineering',\n 'Topic :: Software Development',\n 'Topic :: Software Development :: Testing',\n 'License :: OSI Approved :: Apache Software License',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 3.7',\n ]\n}\n\nsetup(**config)\n", "path": "setup.py"}]} | 975 | 117 |
gh_patches_debug_22225 | rasdani/github-patches | git_diff | getnikola__nikola-3742 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
New plugin manager does not support symlinks
### Environment
**Python Version:** 3.11
**Nikola Version:** 8.3.0
**Operating System:** openSUSE Tumbleweed
### Description:
The new plugin manager does not detect plugins if the plugin folder is a symlink (e.g. `ln -s ../nikola-plugins/v8/projectpages plugins/projectpages`).
Apparently, `pathlib.Path.rglob` ignores symlinks. We’ll need a custom thing to scan directories that does not ignore symlinks.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nikola/plugin_manager.py`
Content:
```
1 # -*- coding: utf-8 -*-
2
3 # Copyright © 2012-2024 Chris Warrick and others.
4
5 # Permission is hereby granted, free of charge, to any
6 # person obtaining a copy of this software and associated
7 # documentation files (the "Software"), to deal in the
8 # Software without restriction, including without limitation
9 # the rights to use, copy, modify, merge, publish,
10 # distribute, sublicense, and/or sell copies of the
11 # Software, and to permit persons to whom the Software is
12 # furnished to do so, subject to the following conditions:
13 #
14 # The above copyright notice and this permission notice
15 # shall be included in all copies or substantial portions of
16 # the Software.
17 #
18 # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY
19 # KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE
20 # WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
21 # PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS
22 # OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR
23 # OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
24 # OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
25 # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
26
27 """The Nikola plugin manager. Inspired by yapsy."""
28
29 import configparser
30 import importlib
31 import importlib.util
32 import time
33 import sys
34 from dataclasses import dataclass
35 from pathlib import Path
36 from typing import Dict, List, Optional, Type, TYPE_CHECKING, Set
37
38 from .plugin_categories import BasePlugin, CATEGORIES
39 from .utils import get_logger
40
41 if TYPE_CHECKING:
42 import logging
43
44 LEGACY_PLUGIN_NAMES: Dict[str, str] = {
45 "Compiler": "PageCompiler",
46 "Shortcode": "ShortcodePlugin",
47 "Template": "TemplateSystem",
48 }
49
50 CATEGORY_NAMES: Set[str] = set(CATEGORIES.keys())
51 CATEGORY_TYPES: Set[Type[BasePlugin]] = set(CATEGORIES.values())
52
53
54 @dataclass(frozen=True)
55 class PluginCandidate:
56 """A candidate plugin that was located but not yet loaded (imported)."""
57
58 name: str
59 description: Optional[str]
60 plugin_id: str
61 category: str
62 compiler: Optional[str]
63 source_dir: Path
64 module_name: str
65
66
67 @dataclass(frozen=True)
68 class PluginInfo:
69 """A plugin that was loaded (imported)."""
70
71 name: str
72 description: Optional[str]
73 plugin_id: str
74 category: str
75 compiler: Optional[str]
76 source_dir: Path
77 module_name: str
78 module_object: object
79 plugin_object: BasePlugin
80
81
82 class PluginManager:
83 """The Nikola plugin manager."""
84
85 categories_filter: Dict[str, Type[BasePlugin]]
86 plugin_places: List[Path]
87 logger: "logging.Logger"
88 candidates: List[PluginCandidate]
89 plugins: List[PluginInfo]
90 _plugins_by_category: Dict[str, List[PluginInfo]]
91 has_warnings: bool = False
92
93 def __init__(self, plugin_places: List[Path]):
94 """Initialize the plugin manager."""
95 self.plugin_places = plugin_places
96 self.candidates = []
97 self.plugins = []
98 self._plugins_by_category = {}
99 self.logger = get_logger("PluginManager")
100
101 def locate_plugins(self) -> List[PluginCandidate]:
102 """Locate plugins in plugin_places."""
103 self.candidates = []
104
105 plugin_files: List[Path] = []
106 for place in self.plugin_places:
107 plugin_files += place.rglob("*.plugin")
108
109 for plugin_file in plugin_files:
110 source_dir = plugin_file.parent
111 config = configparser.ConfigParser()
112 config.read(plugin_file)
113 name = config["Core"]["name"]
114 module_name = config["Core"]["module"]
115 plugin_id = f"Plugin {name} from {plugin_file}"
116 description = None
117 if "Documentation" in config:
118 description = config["Documentation"].get("Description")
119 if "Nikola" not in config:
120 self.logger.warning(f"{plugin_id} does not specify Nikola configuration - plugin will not be loaded")
121 self.logger.warning("Please add a [Nikola] section to the {plugin_file} file with a PluginCategory entry")
122 self.has_warnings = True
123 continue
124 category = config["Nikola"].get("PluginCategory")
125 compiler = config["Nikola"].get("Compiler")
126 if not category:
127 self.logger.warning(f"{plugin_id} does not specify any category (Nikola.PluginCategory is missing in .plugin file) - plugin will not be loaded")
128 self.has_warnings = True
129 continue
130 if category in LEGACY_PLUGIN_NAMES:
131 category = LEGACY_PLUGIN_NAMES[category]
132 if category not in CATEGORY_NAMES:
133 self.logger.warning(f"{plugin_id} specifies invalid category '{category}' in the .plugin file - plugin will not be loaded")
134 self.has_warnings = True
135 continue
136 self.logger.debug(f"Discovered {plugin_id}")
137 self.candidates.append(
138 PluginCandidate(
139 name=name,
140 description=description,
141 plugin_id=plugin_id,
142 category=category,
143 compiler=compiler,
144 source_dir=source_dir,
145 module_name=module_name,
146 )
147 )
148 return self.candidates
149
150 def load_plugins(self, candidates: List[PluginCandidate]) -> None:
151 """Load selected candidate plugins."""
152 plugins_root = Path(__file__).parent.parent
153
154 for candidate in candidates:
155 name = candidate.name
156 module_name = candidate.module_name
157 source_dir = candidate.source_dir
158 py_file_location = source_dir / f"{module_name}.py"
159 plugin_id = candidate.plugin_id
160 if not py_file_location.exists():
161 py_file_location = source_dir / module_name / "__init__.py"
162 if not py_file_location.exists():
163 self.logger.warning(f"{plugin_id} could not be loaded (no valid module detected)")
164 self.has_warnings = True
165 continue
166
167 plugin_id += f" ({py_file_location})"
168 full_module_name = module_name
169
170 try:
171 name_parts = list(py_file_location.relative_to(plugins_root).parts)
172 if name_parts[-1] == "__init__.py":
173 name_parts.pop(-1)
174 elif name_parts[-1].endswith(".py"):
175 name_parts[-1] = name_parts[-1][:-3]
176 full_module_name = ".".join(name_parts)
177 except ValueError:
178 pass
179
180 try:
181 spec = importlib.util.spec_from_file_location(full_module_name, py_file_location)
182 module_object = importlib.util.module_from_spec(spec)
183 if full_module_name not in sys.modules:
184 sys.modules[full_module_name] = module_object
185 spec.loader.exec_module(module_object)
186 except Exception:
187 self.logger.exception(f"{plugin_id} threw an exception while loading")
188 self.has_warnings = True
189 continue
190
191 plugin_classes = [
192 c
193 for c in vars(module_object).values()
194 if isinstance(c, type) and issubclass(c, BasePlugin) and c not in CATEGORY_TYPES
195 ]
196 if len(plugin_classes) == 0:
197 self.logger.warning(f"{plugin_id} does not have any plugin classes - plugin will not be loaded")
198 self.has_warnings = True
199 continue
200 elif len(plugin_classes) > 1:
201 self.logger.warning(f"{plugin_id} has multiple plugin classes; this is not supported - plugin will not be loaded")
202 self.has_warnings = True
203 continue
204
205 plugin_class = plugin_classes[0]
206
207 if not issubclass(plugin_class, CATEGORIES[candidate.category]):
208 self.logger.warning(f"{plugin_id} has category '{candidate.category}' in the .plugin file, but the implementation class {plugin_class} does not inherit from this category - plugin will not be loaded")
209 self.has_warnings = True
210 continue
211
212 try:
213 plugin_object = plugin_class()
214 except Exception:
215 self.logger.exception(f"{plugin_id} threw an exception while creating the instance")
216 self.has_warnings = True
217 continue
218 self.logger.debug(f"Loaded {plugin_id}")
219 info = PluginInfo(
220 name=name,
221 description=candidate.description,
222 plugin_id=candidate.plugin_id,
223 category=candidate.category,
224 compiler=candidate.compiler,
225 source_dir=source_dir,
226 module_name=module_name,
227 module_object=module_object,
228 plugin_object=plugin_object,
229 )
230 self.plugins.append(info)
231
232 self._plugins_by_category = {category: [] for category in CATEGORY_NAMES}
233 for plugin_info in self.plugins:
234 self._plugins_by_category[plugin_info.category].append(plugin_info)
235
236 if self.has_warnings:
237 self.logger.warning("Some plugins failed to load. Please review the above warning messages.")
238 # TODO remove following messages and delay in v8.3.1
239 self.logger.warning("You may need to update some plugins (from plugins.getnikola.com) or to fix their .plugin files.")
240 self.logger.warning("Waiting 2 seconds before continuing.")
241 time.sleep(2)
242
243 def get_plugins_of_category(self, category: str) -> List[PluginInfo]:
244 """Get loaded plugins of a given category."""
245 return self._plugins_by_category.get(category, [])
246
247 def get_plugin_by_name(self, name: str, category: Optional[str] = None) -> Optional[PluginInfo]:
248 """Get a loaded plugin by name and optionally by category. Returns None if no such plugin is loaded."""
249 for p in self.plugins:
250 if p.name == name and (category is None or p.category == category):
251 return p
252
253 # Aliases for Yapsy compatibility
254 # TODO: remove in v9
255 def getPluginsOfCategory(self, category: str) -> List[PluginInfo]:
256 """Get loaded plugins of a given category."""
257 self.logger.warning("Legacy getPluginsOfCategory method was used, it may be removed in the future. Please change it to get_plugins_of_category.")
258 return self._plugins_by_category.get(category, [])
259
260 # TODO: remove in v9
261 def getPluginByName(self, name: str, category: Optional[str] = None) -> Optional[PluginInfo]:
262 """Get a loaded plugin by name and optionally by category. Returns None if no such plugin is loaded."""
263 self.logger.warning("Legacy getPluginByName method was used, it may be removed in the future. Please change it to get_plugin_by_name.")
264 return self.get_plugin_by_name(name, category)
265
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nikola/plugin_manager.py b/nikola/plugin_manager.py
--- a/nikola/plugin_manager.py
+++ b/nikola/plugin_manager.py
@@ -31,6 +31,8 @@
import importlib.util
import time
import sys
+
+from collections import deque
from dataclasses import dataclass
from pathlib import Path
from typing import Dict, List, Optional, Type, TYPE_CHECKING, Set
@@ -102,9 +104,13 @@
"""Locate plugins in plugin_places."""
self.candidates = []
+ plugin_folders: deque = deque([place for place in self.plugin_places if place.exists() and place.is_dir()])
plugin_files: List[Path] = []
- for place in self.plugin_places:
- plugin_files += place.rglob("*.plugin")
+ while plugin_folders:
+ base_folder = plugin_folders.popleft()
+ items = list(base_folder.iterdir())
+ plugin_folders.extend([item for item in items if item.is_dir() and item.name != "__pycache__"])
+ plugin_files.extend([item for item in items if item.suffix == ".plugin" and not item.is_dir()])
for plugin_file in plugin_files:
source_dir = plugin_file.parent
| {"golden_diff": "diff --git a/nikola/plugin_manager.py b/nikola/plugin_manager.py\n--- a/nikola/plugin_manager.py\n+++ b/nikola/plugin_manager.py\n@@ -31,6 +31,8 @@\n import importlib.util\n import time\n import sys\n+\n+from collections import deque\n from dataclasses import dataclass\n from pathlib import Path\n from typing import Dict, List, Optional, Type, TYPE_CHECKING, Set\n@@ -102,9 +104,13 @@\n \"\"\"Locate plugins in plugin_places.\"\"\"\n self.candidates = []\n \n+ plugin_folders: deque = deque([place for place in self.plugin_places if place.exists() and place.is_dir()])\n plugin_files: List[Path] = []\n- for place in self.plugin_places:\n- plugin_files += place.rglob(\"*.plugin\")\n+ while plugin_folders:\n+ base_folder = plugin_folders.popleft()\n+ items = list(base_folder.iterdir())\n+ plugin_folders.extend([item for item in items if item.is_dir() and item.name != \"__pycache__\"])\n+ plugin_files.extend([item for item in items if item.suffix == \".plugin\" and not item.is_dir()])\n \n for plugin_file in plugin_files:\n source_dir = plugin_file.parent\n", "issue": "New plugin manager does not support symlinks\n### Environment\r\n\r\n**Python Version:** 3.11\r\n\r\n**Nikola Version:** 8.3.0\r\n\r\n**Operating System:** openSUSE Tumbleweed\r\n\r\n### Description:\r\n\r\nThe new plugin manager does not detect plugins if the plugin folder is a symlink (e.g. `ln -s ../nikola-plugins/v8/projectpages plugins/projectpages`).\r\n\r\nApparently, `pathlib.Path.rglob` ignores symlinks. We\u2019ll need a custom thing to scan directories that does not ignore symlinks.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2024 Chris Warrick and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"The Nikola plugin manager. Inspired by yapsy.\"\"\"\n\nimport configparser\nimport importlib\nimport importlib.util\nimport time\nimport sys\nfrom dataclasses import dataclass\nfrom pathlib import Path\nfrom typing import Dict, List, Optional, Type, TYPE_CHECKING, Set\n\nfrom .plugin_categories import BasePlugin, CATEGORIES\nfrom .utils import get_logger\n\nif TYPE_CHECKING:\n import logging\n\nLEGACY_PLUGIN_NAMES: Dict[str, str] = {\n \"Compiler\": \"PageCompiler\",\n \"Shortcode\": \"ShortcodePlugin\",\n \"Template\": \"TemplateSystem\",\n}\n\nCATEGORY_NAMES: Set[str] = set(CATEGORIES.keys())\nCATEGORY_TYPES: Set[Type[BasePlugin]] = set(CATEGORIES.values())\n\n\n@dataclass(frozen=True)\nclass PluginCandidate:\n \"\"\"A candidate plugin that was located but not yet loaded (imported).\"\"\"\n\n name: str\n description: Optional[str]\n plugin_id: str\n category: str\n compiler: Optional[str]\n source_dir: Path\n module_name: str\n\n\n@dataclass(frozen=True)\nclass PluginInfo:\n \"\"\"A plugin that was loaded (imported).\"\"\"\n\n name: str\n description: Optional[str]\n plugin_id: str\n category: str\n compiler: Optional[str]\n source_dir: Path\n module_name: str\n module_object: object\n plugin_object: BasePlugin\n\n\nclass PluginManager:\n \"\"\"The Nikola plugin manager.\"\"\"\n\n categories_filter: Dict[str, Type[BasePlugin]]\n plugin_places: List[Path]\n logger: \"logging.Logger\"\n candidates: List[PluginCandidate]\n plugins: List[PluginInfo]\n _plugins_by_category: Dict[str, List[PluginInfo]]\n has_warnings: bool = False\n\n def __init__(self, plugin_places: List[Path]):\n \"\"\"Initialize the plugin manager.\"\"\"\n self.plugin_places = plugin_places\n self.candidates = []\n self.plugins = []\n self._plugins_by_category = {}\n self.logger = get_logger(\"PluginManager\")\n\n def locate_plugins(self) -> List[PluginCandidate]:\n \"\"\"Locate plugins in plugin_places.\"\"\"\n self.candidates = []\n\n plugin_files: List[Path] = []\n for place in self.plugin_places:\n plugin_files += place.rglob(\"*.plugin\")\n\n for plugin_file in plugin_files:\n source_dir = plugin_file.parent\n config = configparser.ConfigParser()\n config.read(plugin_file)\n name = config[\"Core\"][\"name\"]\n module_name = config[\"Core\"][\"module\"]\n plugin_id = f\"Plugin {name} from {plugin_file}\"\n description = None\n if \"Documentation\" in config:\n description = config[\"Documentation\"].get(\"Description\")\n if \"Nikola\" not in config:\n self.logger.warning(f\"{plugin_id} does not specify Nikola configuration - plugin will not be loaded\")\n self.logger.warning(\"Please add a [Nikola] section to the {plugin_file} file with a PluginCategory entry\")\n self.has_warnings = True\n continue\n category = config[\"Nikola\"].get(\"PluginCategory\")\n compiler = config[\"Nikola\"].get(\"Compiler\")\n if not category:\n self.logger.warning(f\"{plugin_id} does not specify any category (Nikola.PluginCategory is missing in .plugin file) - plugin will not be loaded\")\n self.has_warnings = True\n continue\n if category in LEGACY_PLUGIN_NAMES:\n category = LEGACY_PLUGIN_NAMES[category]\n if category not in CATEGORY_NAMES:\n self.logger.warning(f\"{plugin_id} specifies invalid category '{category}' in the .plugin file - plugin will not be loaded\")\n self.has_warnings = True\n continue\n self.logger.debug(f\"Discovered {plugin_id}\")\n self.candidates.append(\n PluginCandidate(\n name=name,\n description=description,\n plugin_id=plugin_id,\n category=category,\n compiler=compiler,\n source_dir=source_dir,\n module_name=module_name,\n )\n )\n return self.candidates\n\n def load_plugins(self, candidates: List[PluginCandidate]) -> None:\n \"\"\"Load selected candidate plugins.\"\"\"\n plugins_root = Path(__file__).parent.parent\n\n for candidate in candidates:\n name = candidate.name\n module_name = candidate.module_name\n source_dir = candidate.source_dir\n py_file_location = source_dir / f\"{module_name}.py\"\n plugin_id = candidate.plugin_id\n if not py_file_location.exists():\n py_file_location = source_dir / module_name / \"__init__.py\"\n if not py_file_location.exists():\n self.logger.warning(f\"{plugin_id} could not be loaded (no valid module detected)\")\n self.has_warnings = True\n continue\n\n plugin_id += f\" ({py_file_location})\"\n full_module_name = module_name\n\n try:\n name_parts = list(py_file_location.relative_to(plugins_root).parts)\n if name_parts[-1] == \"__init__.py\":\n name_parts.pop(-1)\n elif name_parts[-1].endswith(\".py\"):\n name_parts[-1] = name_parts[-1][:-3]\n full_module_name = \".\".join(name_parts)\n except ValueError:\n pass\n\n try:\n spec = importlib.util.spec_from_file_location(full_module_name, py_file_location)\n module_object = importlib.util.module_from_spec(spec)\n if full_module_name not in sys.modules:\n sys.modules[full_module_name] = module_object\n spec.loader.exec_module(module_object)\n except Exception:\n self.logger.exception(f\"{plugin_id} threw an exception while loading\")\n self.has_warnings = True\n continue\n\n plugin_classes = [\n c\n for c in vars(module_object).values()\n if isinstance(c, type) and issubclass(c, BasePlugin) and c not in CATEGORY_TYPES\n ]\n if len(plugin_classes) == 0:\n self.logger.warning(f\"{plugin_id} does not have any plugin classes - plugin will not be loaded\")\n self.has_warnings = True\n continue\n elif len(plugin_classes) > 1:\n self.logger.warning(f\"{plugin_id} has multiple plugin classes; this is not supported - plugin will not be loaded\")\n self.has_warnings = True\n continue\n\n plugin_class = plugin_classes[0]\n\n if not issubclass(plugin_class, CATEGORIES[candidate.category]):\n self.logger.warning(f\"{plugin_id} has category '{candidate.category}' in the .plugin file, but the implementation class {plugin_class} does not inherit from this category - plugin will not be loaded\")\n self.has_warnings = True\n continue\n\n try:\n plugin_object = plugin_class()\n except Exception:\n self.logger.exception(f\"{plugin_id} threw an exception while creating the instance\")\n self.has_warnings = True\n continue\n self.logger.debug(f\"Loaded {plugin_id}\")\n info = PluginInfo(\n name=name,\n description=candidate.description,\n plugin_id=candidate.plugin_id,\n category=candidate.category,\n compiler=candidate.compiler,\n source_dir=source_dir,\n module_name=module_name,\n module_object=module_object,\n plugin_object=plugin_object,\n )\n self.plugins.append(info)\n\n self._plugins_by_category = {category: [] for category in CATEGORY_NAMES}\n for plugin_info in self.plugins:\n self._plugins_by_category[plugin_info.category].append(plugin_info)\n\n if self.has_warnings:\n self.logger.warning(\"Some plugins failed to load. Please review the above warning messages.\")\n # TODO remove following messages and delay in v8.3.1\n self.logger.warning(\"You may need to update some plugins (from plugins.getnikola.com) or to fix their .plugin files.\")\n self.logger.warning(\"Waiting 2 seconds before continuing.\")\n time.sleep(2)\n\n def get_plugins_of_category(self, category: str) -> List[PluginInfo]:\n \"\"\"Get loaded plugins of a given category.\"\"\"\n return self._plugins_by_category.get(category, [])\n\n def get_plugin_by_name(self, name: str, category: Optional[str] = None) -> Optional[PluginInfo]:\n \"\"\"Get a loaded plugin by name and optionally by category. Returns None if no such plugin is loaded.\"\"\"\n for p in self.plugins:\n if p.name == name and (category is None or p.category == category):\n return p\n\n # Aliases for Yapsy compatibility\n # TODO: remove in v9\n def getPluginsOfCategory(self, category: str) -> List[PluginInfo]:\n \"\"\"Get loaded plugins of a given category.\"\"\"\n self.logger.warning(\"Legacy getPluginsOfCategory method was used, it may be removed in the future. Please change it to get_plugins_of_category.\")\n return self._plugins_by_category.get(category, [])\n\n # TODO: remove in v9\n def getPluginByName(self, name: str, category: Optional[str] = None) -> Optional[PluginInfo]:\n \"\"\"Get a loaded plugin by name and optionally by category. Returns None if no such plugin is loaded.\"\"\"\n self.logger.warning(\"Legacy getPluginByName method was used, it may be removed in the future. Please change it to get_plugin_by_name.\")\n return self.get_plugin_by_name(name, category)\n", "path": "nikola/plugin_manager.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\n# Copyright \u00a9 2012-2024 Chris Warrick and others.\n\n# Permission is hereby granted, free of charge, to any\n# person obtaining a copy of this software and associated\n# documentation files (the \"Software\"), to deal in the\n# Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish,\n# distribute, sublicense, and/or sell copies of the\n# Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice\n# shall be included in all copies or substantial portions of\n# the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY\n# KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE\n# WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR\n# PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS\n# OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR\n# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR\n# OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE\n# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n\"\"\"The Nikola plugin manager. Inspired by yapsy.\"\"\"\n\nimport configparser\nimport importlib\nimport importlib.util\nimport time\nimport sys\n\nfrom collections import deque\nfrom dataclasses import dataclass\nfrom pathlib import Path\nfrom typing import Dict, List, Optional, Type, TYPE_CHECKING, Set\n\nfrom .plugin_categories import BasePlugin, CATEGORIES\nfrom .utils import get_logger\n\nif TYPE_CHECKING:\n import logging\n\nLEGACY_PLUGIN_NAMES: Dict[str, str] = {\n \"Compiler\": \"PageCompiler\",\n \"Shortcode\": \"ShortcodePlugin\",\n \"Template\": \"TemplateSystem\",\n}\n\nCATEGORY_NAMES: Set[str] = set(CATEGORIES.keys())\nCATEGORY_TYPES: Set[Type[BasePlugin]] = set(CATEGORIES.values())\n\n\n@dataclass(frozen=True)\nclass PluginCandidate:\n \"\"\"A candidate plugin that was located but not yet loaded (imported).\"\"\"\n\n name: str\n description: Optional[str]\n plugin_id: str\n category: str\n compiler: Optional[str]\n source_dir: Path\n module_name: str\n\n\n@dataclass(frozen=True)\nclass PluginInfo:\n \"\"\"A plugin that was loaded (imported).\"\"\"\n\n name: str\n description: Optional[str]\n plugin_id: str\n category: str\n compiler: Optional[str]\n source_dir: Path\n module_name: str\n module_object: object\n plugin_object: BasePlugin\n\n\nclass PluginManager:\n \"\"\"The Nikola plugin manager.\"\"\"\n\n categories_filter: Dict[str, Type[BasePlugin]]\n plugin_places: List[Path]\n logger: \"logging.Logger\"\n candidates: List[PluginCandidate]\n plugins: List[PluginInfo]\n _plugins_by_category: Dict[str, List[PluginInfo]]\n has_warnings: bool = False\n\n def __init__(self, plugin_places: List[Path]):\n \"\"\"Initialize the plugin manager.\"\"\"\n self.plugin_places = plugin_places\n self.candidates = []\n self.plugins = []\n self._plugins_by_category = {}\n self.logger = get_logger(\"PluginManager\")\n\n def locate_plugins(self) -> List[PluginCandidate]:\n \"\"\"Locate plugins in plugin_places.\"\"\"\n self.candidates = []\n\n plugin_folders: deque = deque([place for place in self.plugin_places if place.exists() and place.is_dir()])\n plugin_files: List[Path] = []\n while plugin_folders:\n base_folder = plugin_folders.popleft()\n items = list(base_folder.iterdir())\n plugin_folders.extend([item for item in items if item.is_dir() and item.name != \"__pycache__\"])\n plugin_files.extend([item for item in items if item.suffix == \".plugin\" and not item.is_dir()])\n\n for plugin_file in plugin_files:\n source_dir = plugin_file.parent\n config = configparser.ConfigParser()\n config.read(plugin_file)\n name = config[\"Core\"][\"name\"]\n module_name = config[\"Core\"][\"module\"]\n plugin_id = f\"Plugin {name} from {plugin_file}\"\n description = None\n if \"Documentation\" in config:\n description = config[\"Documentation\"].get(\"Description\")\n if \"Nikola\" not in config:\n self.logger.warning(f\"{plugin_id} does not specify Nikola configuration - plugin will not be loaded\")\n self.logger.warning(\"Please add a [Nikola] section to the {plugin_file} file with a PluginCategory entry\")\n self.has_warnings = True\n continue\n category = config[\"Nikola\"].get(\"PluginCategory\")\n compiler = config[\"Nikola\"].get(\"Compiler\")\n if not category:\n self.logger.warning(f\"{plugin_id} does not specify any category (Nikola.PluginCategory is missing in .plugin file) - plugin will not be loaded\")\n self.has_warnings = True\n continue\n if category in LEGACY_PLUGIN_NAMES:\n category = LEGACY_PLUGIN_NAMES[category]\n if category not in CATEGORY_NAMES:\n self.logger.warning(f\"{plugin_id} specifies invalid category '{category}' in the .plugin file - plugin will not be loaded\")\n self.has_warnings = True\n continue\n self.logger.debug(f\"Discovered {plugin_id}\")\n self.candidates.append(\n PluginCandidate(\n name=name,\n description=description,\n plugin_id=plugin_id,\n category=category,\n compiler=compiler,\n source_dir=source_dir,\n module_name=module_name,\n )\n )\n return self.candidates\n\n def load_plugins(self, candidates: List[PluginCandidate]) -> None:\n \"\"\"Load selected candidate plugins.\"\"\"\n plugins_root = Path(__file__).parent.parent\n\n for candidate in candidates:\n name = candidate.name\n module_name = candidate.module_name\n source_dir = candidate.source_dir\n py_file_location = source_dir / f\"{module_name}.py\"\n plugin_id = candidate.plugin_id\n if not py_file_location.exists():\n py_file_location = source_dir / module_name / \"__init__.py\"\n if not py_file_location.exists():\n self.logger.warning(f\"{plugin_id} could not be loaded (no valid module detected)\")\n self.has_warnings = True\n continue\n\n plugin_id += f\" ({py_file_location})\"\n full_module_name = module_name\n\n try:\n name_parts = list(py_file_location.relative_to(plugins_root).parts)\n if name_parts[-1] == \"__init__.py\":\n name_parts.pop(-1)\n elif name_parts[-1].endswith(\".py\"):\n name_parts[-1] = name_parts[-1][:-3]\n full_module_name = \".\".join(name_parts)\n except ValueError:\n pass\n\n try:\n spec = importlib.util.spec_from_file_location(full_module_name, py_file_location)\n module_object = importlib.util.module_from_spec(spec)\n if full_module_name not in sys.modules:\n sys.modules[full_module_name] = module_object\n spec.loader.exec_module(module_object)\n except Exception:\n self.logger.exception(f\"{plugin_id} threw an exception while loading\")\n self.has_warnings = True\n continue\n\n plugin_classes = [\n c\n for c in vars(module_object).values()\n if isinstance(c, type) and issubclass(c, BasePlugin) and c not in CATEGORY_TYPES\n ]\n if len(plugin_classes) == 0:\n self.logger.warning(f\"{plugin_id} does not have any plugin classes - plugin will not be loaded\")\n self.has_warnings = True\n continue\n elif len(plugin_classes) > 1:\n self.logger.warning(f\"{plugin_id} has multiple plugin classes; this is not supported - plugin will not be loaded\")\n self.has_warnings = True\n continue\n\n plugin_class = plugin_classes[0]\n\n if not issubclass(plugin_class, CATEGORIES[candidate.category]):\n self.logger.warning(f\"{plugin_id} has category '{candidate.category}' in the .plugin file, but the implementation class {plugin_class} does not inherit from this category - plugin will not be loaded\")\n self.has_warnings = True\n continue\n\n try:\n plugin_object = plugin_class()\n except Exception:\n self.logger.exception(f\"{plugin_id} threw an exception while creating the instance\")\n self.has_warnings = True\n continue\n self.logger.debug(f\"Loaded {plugin_id}\")\n info = PluginInfo(\n name=name,\n description=candidate.description,\n plugin_id=candidate.plugin_id,\n category=candidate.category,\n compiler=candidate.compiler,\n source_dir=source_dir,\n module_name=module_name,\n module_object=module_object,\n plugin_object=plugin_object,\n )\n self.plugins.append(info)\n\n self._plugins_by_category = {category: [] for category in CATEGORY_NAMES}\n for plugin_info in self.plugins:\n self._plugins_by_category[plugin_info.category].append(plugin_info)\n\n if self.has_warnings:\n self.logger.warning(\"Some plugins failed to load. Please review the above warning messages.\")\n # TODO remove following messages and delay in v8.3.1\n self.logger.warning(\"You may need to update some plugins (from plugins.getnikola.com) or to fix their .plugin files.\")\n self.logger.warning(\"Waiting 2 seconds before continuing.\")\n time.sleep(2)\n\n def get_plugins_of_category(self, category: str) -> List[PluginInfo]:\n \"\"\"Get loaded plugins of a given category.\"\"\"\n return self._plugins_by_category.get(category, [])\n\n def get_plugin_by_name(self, name: str, category: Optional[str] = None) -> Optional[PluginInfo]:\n \"\"\"Get a loaded plugin by name and optionally by category. Returns None if no such plugin is loaded.\"\"\"\n for p in self.plugins:\n if p.name == name and (category is None or p.category == category):\n return p\n\n # Aliases for Yapsy compatibility\n # TODO: remove in v9\n def getPluginsOfCategory(self, category: str) -> List[PluginInfo]:\n \"\"\"Get loaded plugins of a given category.\"\"\"\n self.logger.warning(\"Legacy getPluginsOfCategory method was used, it may be removed in the future. Please change it to get_plugins_of_category.\")\n return self._plugins_by_category.get(category, [])\n\n # TODO: remove in v9\n def getPluginByName(self, name: str, category: Optional[str] = None) -> Optional[PluginInfo]:\n \"\"\"Get a loaded plugin by name and optionally by category. Returns None if no such plugin is loaded.\"\"\"\n self.logger.warning(\"Legacy getPluginByName method was used, it may be removed in the future. Please change it to get_plugin_by_name.\")\n return self.get_plugin_by_name(name, category)\n", "path": "nikola/plugin_manager.py"}]} | 3,306 | 275 |
gh_patches_debug_6345 | rasdani/github-patches | git_diff | carpentries__amy-743 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Escaped tags in every revision page

Escaped tags in every revision page

--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `workshops/templatetags/diff.py`
Content:
```
1 from django import template
2
3 from reversion.helpers import generate_patch_html
4
5 register = template.Library()
6
7
8 @register.simple_tag
9 def semantic_diff(left, right, field):
10 return generate_patch_html(left, right, field, cleanup='semantic')
11
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/workshops/templatetags/diff.py b/workshops/templatetags/diff.py
--- a/workshops/templatetags/diff.py
+++ b/workshops/templatetags/diff.py
@@ -1,4 +1,5 @@
from django import template
+from django.utils.safestring import mark_safe
from reversion.helpers import generate_patch_html
@@ -7,4 +8,4 @@
@register.simple_tag
def semantic_diff(left, right, field):
- return generate_patch_html(left, right, field, cleanup='semantic')
+ return mark_safe(generate_patch_html(left, right, field, cleanup='semantic'))
| {"golden_diff": "diff --git a/workshops/templatetags/diff.py b/workshops/templatetags/diff.py\n--- a/workshops/templatetags/diff.py\n+++ b/workshops/templatetags/diff.py\n@@ -1,4 +1,5 @@\n from django import template\n+from django.utils.safestring import mark_safe\n \n from reversion.helpers import generate_patch_html\n \n@@ -7,4 +8,4 @@\n \n @register.simple_tag\n def semantic_diff(left, right, field):\n- return generate_patch_html(left, right, field, cleanup='semantic')\n+ return mark_safe(generate_patch_html(left, right, field, cleanup='semantic'))\n", "issue": "Escaped tags in every revision page\n\n\nEscaped tags in every revision page\n\n\n", "before_files": [{"content": "from django import template\n\nfrom reversion.helpers import generate_patch_html\n\nregister = template.Library()\n\n\[email protected]_tag\ndef semantic_diff(left, right, field):\n return generate_patch_html(left, right, field, cleanup='semantic')\n", "path": "workshops/templatetags/diff.py"}], "after_files": [{"content": "from django import template\nfrom django.utils.safestring import mark_safe\n\nfrom reversion.helpers import generate_patch_html\n\nregister = template.Library()\n\n\[email protected]_tag\ndef semantic_diff(left, right, field):\n return mark_safe(generate_patch_html(left, right, field, cleanup='semantic'))\n", "path": "workshops/templatetags/diff.py"}]} | 507 | 147 |
gh_patches_debug_5199 | rasdani/github-patches | git_diff | PrefectHQ__prefect-1165 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Cannot raise a skip signal with a result
I am filing an issue by suggestion of @cicdw after a conversation on gitter.
I came up with the following use case: a task that raises a skip signal with a result because its logic has detected that there is no work to do and the result is already calculated somewhere. I could just return it, but it would be useful for me to know that the _heavy_ part of the task did not actually execute.
An example of the use case would be:
```python
from prefect import task, Flow
from prefect.engine import signals
@task
def test_skipped():
raise signals.SKIP('skipping', result=5)
f = Flow("test", tasks=[test_skipped])
flow_state = f.run()
```
which fails because of how the `PrefectStateSignal` constructor handles its initialization:
```
Traceback (most recent call last):
File ".../prefect/engine/signals.py", line 27, in __init__
result=self, message=message, *args, **kwargs
TypeError: type object got multiple values for keyword argument 'result'
```
Chris suggested the following workaround, which works correctly, but still pointed out that the case above should work.
```python
from prefect import task, Flow
from prefect.engine.runner import ENDRUN
from prefect.engine.state import Skipped
@task
def test_skipped():
skip = Skipped("skipping", result=5)
raise ENDRUN(state=skip)
f = Flow("test", tasks=[test_skipped])
flow_state = f.run()
flow_state.result[test_skipped].result # 5
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/prefect/engine/signals.py`
Content:
```
1 """
2 These Exceptions, when raised, are used to signal state changes when tasks or flows are running. Signals
3 are used in TaskRunners and FlowRunners as a way of communicating the changes in states.
4 """
5
6 from prefect.engine import state
7 from prefect.utilities.exceptions import PrefectError
8
9
10 class PrefectStateSignal(PrefectError):
11 """
12 Create a new PrefectStateSignal object.
13
14 Args:
15 - message (Any, optional): Defaults to `None`. A message about the signal.
16 - *args (Any, optional): additional arguments to pass to this Signal's
17 associated state constructor
18 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
19 associated state constructor
20 """
21
22 _state_cls = state.State
23
24 def __init__(self, message: str = None, *args, **kwargs): # type: ignore
25 super().__init__(message) # type: ignore
26 self.state = self._state_cls( # type: ignore
27 result=self, message=message, *args, **kwargs
28 )
29
30
31 class FAIL(PrefectStateSignal):
32 """
33 Indicates that a task failed.
34
35 Args:
36 - message (Any, optional): Defaults to `None`. A message about the signal.
37 - *args (Any, optional): additional arguments to pass to this Signal's
38 associated state constructor
39 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
40 associated state constructor
41 """
42
43 _state_cls = state.Failed
44
45
46 class TRIGGERFAIL(FAIL):
47 """
48 Indicates that a task trigger failed.
49
50 Args:
51 - message (Any, optional): Defaults to `None`. A message about the signal.
52 - *args (Any, optional): additional arguments to pass to this Signal's
53 associated state constructor
54 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
55 associated state constructor
56 """
57
58 _state_cls = state.TriggerFailed
59
60
61 class SUCCESS(PrefectStateSignal):
62 """
63 Indicates that a task succeeded.
64
65 Args:
66 - message (Any, optional): Defaults to `None`. A message about the signal.
67 - *args (Any, optional): additional arguments to pass to this Signal's
68 associated state constructor
69 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
70 associated state constructor
71 """
72
73 _state_cls = state.Success
74
75
76 class RETRY(PrefectStateSignal):
77 """
78 Used to indicate that a task should be retried.
79
80 Args:
81 - message (Any, optional): Defaults to `None`. A message about the signal.
82 - *args (Any, optional): additional arguments to pass to this Signal's
83 associated state constructor
84 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
85 associated state constructor
86 """
87
88 _state_cls = state.Retrying
89
90
91 class SKIP(PrefectStateSignal):
92 """
93 Indicates that a task was skipped. By default, downstream tasks will
94 act as if skipped tasks succeeded.
95
96 Args:
97 - message (Any, optional): Defaults to `None`. A message about the signal.
98 - *args (Any, optional): additional arguments to pass to this Signal's
99 associated state constructor
100 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
101 associated state constructor
102 """
103
104 _state_cls = state.Skipped
105
106
107 class PAUSE(PrefectStateSignal):
108 """
109 Indicates that a task should not run and wait for manual execution.
110
111 Args:
112 - message (Any, optional): Defaults to `None`. A message about the signal.
113 - *args (Any, optional): additional arguments to pass to this Signal's
114 associated state constructor
115 - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's
116 associated state constructor
117 """
118
119 _state_cls = state.Paused
120
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/prefect/engine/signals.py b/src/prefect/engine/signals.py
--- a/src/prefect/engine/signals.py
+++ b/src/prefect/engine/signals.py
@@ -23,8 +23,9 @@
def __init__(self, message: str = None, *args, **kwargs): # type: ignore
super().__init__(message) # type: ignore
+ kwargs.setdefault("result", self)
self.state = self._state_cls( # type: ignore
- result=self, message=message, *args, **kwargs
+ message=message, *args, **kwargs
)
| {"golden_diff": "diff --git a/src/prefect/engine/signals.py b/src/prefect/engine/signals.py\n--- a/src/prefect/engine/signals.py\n+++ b/src/prefect/engine/signals.py\n@@ -23,8 +23,9 @@\n \n def __init__(self, message: str = None, *args, **kwargs): # type: ignore\n super().__init__(message) # type: ignore\n+ kwargs.setdefault(\"result\", self)\n self.state = self._state_cls( # type: ignore\n- result=self, message=message, *args, **kwargs\n+ message=message, *args, **kwargs\n )\n", "issue": "Cannot raise a skip signal with a result\nI am filing an issue by suggestion of @cicdw after a conversation on gitter.\r\nI came up with the following use case: a task that raises a skip signal with a result because its logic has detected that there is no work to do and the result is already calculated somewhere. I could just return it, but it would be useful for me to know that the _heavy_ part of the task did not actually execute.\r\n\r\nAn example of the use case would be:\r\n\r\n```python\r\nfrom prefect import task, Flow\r\nfrom prefect.engine import signals\r\n\r\n@task\r\ndef test_skipped():\r\n raise signals.SKIP('skipping', result=5)\r\n\r\nf = Flow(\"test\", tasks=[test_skipped])\r\nflow_state = f.run()\r\n```\r\n\r\nwhich fails because of how the `PrefectStateSignal` constructor handles its initialization:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \".../prefect/engine/signals.py\", line 27, in __init__\r\n result=self, message=message, *args, **kwargs\r\nTypeError: type object got multiple values for keyword argument 'result'\r\n```\r\n\r\nChris suggested the following workaround, which works correctly, but still pointed out that the case above should work.\r\n\r\n```python\r\nfrom prefect import task, Flow\r\nfrom prefect.engine.runner import ENDRUN\r\nfrom prefect.engine.state import Skipped\r\n\r\n@task\r\ndef test_skipped():\r\n skip = Skipped(\"skipping\", result=5)\r\n raise ENDRUN(state=skip)\r\n\r\nf = Flow(\"test\", tasks=[test_skipped])\r\nflow_state = f.run()\r\n\r\nflow_state.result[test_skipped].result # 5\r\n```\n", "before_files": [{"content": "\"\"\"\nThese Exceptions, when raised, are used to signal state changes when tasks or flows are running. Signals\nare used in TaskRunners and FlowRunners as a way of communicating the changes in states.\n\"\"\"\n\nfrom prefect.engine import state\nfrom prefect.utilities.exceptions import PrefectError\n\n\nclass PrefectStateSignal(PrefectError):\n \"\"\"\n Create a new PrefectStateSignal object.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.State\n\n def __init__(self, message: str = None, *args, **kwargs): # type: ignore\n super().__init__(message) # type: ignore\n self.state = self._state_cls( # type: ignore\n result=self, message=message, *args, **kwargs\n )\n\n\nclass FAIL(PrefectStateSignal):\n \"\"\"\n Indicates that a task failed.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Failed\n\n\nclass TRIGGERFAIL(FAIL):\n \"\"\"\n Indicates that a task trigger failed.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.TriggerFailed\n\n\nclass SUCCESS(PrefectStateSignal):\n \"\"\"\n Indicates that a task succeeded.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Success\n\n\nclass RETRY(PrefectStateSignal):\n \"\"\"\n Used to indicate that a task should be retried.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Retrying\n\n\nclass SKIP(PrefectStateSignal):\n \"\"\"\n Indicates that a task was skipped. By default, downstream tasks will\n act as if skipped tasks succeeded.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Skipped\n\n\nclass PAUSE(PrefectStateSignal):\n \"\"\"\n Indicates that a task should not run and wait for manual execution.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Paused\n", "path": "src/prefect/engine/signals.py"}], "after_files": [{"content": "\"\"\"\nThese Exceptions, when raised, are used to signal state changes when tasks or flows are running. Signals\nare used in TaskRunners and FlowRunners as a way of communicating the changes in states.\n\"\"\"\n\nfrom prefect.engine import state\nfrom prefect.utilities.exceptions import PrefectError\n\n\nclass PrefectStateSignal(PrefectError):\n \"\"\"\n Create a new PrefectStateSignal object.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.State\n\n def __init__(self, message: str = None, *args, **kwargs): # type: ignore\n super().__init__(message) # type: ignore\n kwargs.setdefault(\"result\", self)\n self.state = self._state_cls( # type: ignore\n message=message, *args, **kwargs\n )\n\n\nclass FAIL(PrefectStateSignal):\n \"\"\"\n Indicates that a task failed.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Failed\n\n\nclass TRIGGERFAIL(FAIL):\n \"\"\"\n Indicates that a task trigger failed.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.TriggerFailed\n\n\nclass SUCCESS(PrefectStateSignal):\n \"\"\"\n Indicates that a task succeeded.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Success\n\n\nclass RETRY(PrefectStateSignal):\n \"\"\"\n Used to indicate that a task should be retried.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Retrying\n\n\nclass SKIP(PrefectStateSignal):\n \"\"\"\n Indicates that a task was skipped. By default, downstream tasks will\n act as if skipped tasks succeeded.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Skipped\n\n\nclass PAUSE(PrefectStateSignal):\n \"\"\"\n Indicates that a task should not run and wait for manual execution.\n\n Args:\n - message (Any, optional): Defaults to `None`. A message about the signal.\n - *args (Any, optional): additional arguments to pass to this Signal's\n associated state constructor\n - **kwargs (Any, optional): additional keyword arguments to pass to this Signal's\n associated state constructor\n \"\"\"\n\n _state_cls = state.Paused\n", "path": "src/prefect/engine/signals.py"}]} | 1,733 | 146 |
gh_patches_debug_30961 | rasdani/github-patches | git_diff | nerfstudio-project__nerfstudio-190 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Report "Rays Per Sec" in easier to read format.
It would be great to report the "Rays Per Sec" to fewer sig figs. Ie "1343535.4324" -> "1.34 mil" or "1.34 M". It is becoming trickier to quickly read these numbers now that the model is getting quicker.
Also maybe "Rays Per Sec" -> "Rays / Sec"
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/run_eval.py`
Content:
```
1 """
2 run_eval.py
3 """
4 import enum
5 import os
6 from typing import Dict, List, Optional
7
8 import dcargs
9 import mediapy as media
10 import torch
11 from hydra import compose, initialize
12 from omegaconf import DictConfig
13 from tqdm import tqdm
14
15 from pyrad.cameras.camera_paths import CameraPath, get_interpolated_camera_path, get_spiral_path
16 from pyrad.data.dataloader import EvalDataloader, setup_dataset_eval, setup_dataset_train
17 from pyrad.graphs.base import Graph, setup_graph
18 from pyrad.utils.writer import TimeWriter
19
20
21 def _update_avg(prev_avg: float, new_val: float, step: int) -> float:
22 """helper to calculate the running average
23
24 Args:
25 prev_avg (float): previous average value
26 new_val (float): new value to update the average with
27 step (int): current step number
28
29 Returns:
30 float: new updated average
31 """
32 return (step * prev_avg + new_val) / (step + 1)
33
34
35 def _load_checkpoint(config: DictConfig, graph: Graph) -> None:
36 """Helper function to load checkpointed graph
37
38 Args:
39 config (DictConfig): Configuration of graph to load
40 graph (Graph): Graph instance of which to load weights
41 """
42 assert config.load_dir is not None
43 if config.load_step is None:
44 print("Loading latest checkpoint from load_dir")
45 # NOTE: this is specific to the checkpoint name format
46 load_step = sorted([int(x[x.find("-") + 1 : x.find(".")]) for x in os.listdir(config.load_dir)])[-1]
47 else:
48 load_step = config.load_step
49 load_path = os.path.join(config.load_dir, f"step-{load_step:09d}.ckpt")
50 assert os.path.exists(load_path), f"Checkpoint {load_path} does not exist"
51 loaded_state = torch.load(load_path, map_location="cpu")
52 graph.load_graph(loaded_state)
53 print(f"done loading checkpoint from {load_path}")
54
55
56 def run_inference_from_config(config: DictConfig) -> Dict[str, float]:
57 """helper function to run inference given config specifications (also used in benchmarking)
58
59 Args:
60 config (DictConfig): Configuration for loading the evaluation.
61
62 Returns:
63 Tuple[float, float]: returns both the avg psnr and avg rays per second
64 """
65 print("Running inference.")
66 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
67 # setup graph and dataset
68 dataset_inputs_train, _ = setup_dataset_train(config.data, device=device)
69 _, dataloader_eval = setup_dataset_eval(config.data, test_mode=True, device=device)
70 graph = setup_graph(config.graph, dataset_inputs_train, device=device)
71 graph.eval()
72
73 # load checkpointed information
74 _load_checkpoint(config.trainer.resume_train, graph)
75
76 # calculate average psnr across test dataset
77 return render_stats_dict(graph, dataloader_eval)
78
79
80 def render_stats_dict(graph: Graph, dataloader_eval: EvalDataloader) -> Dict[str, float]:
81 """Helper function to evaluate the graph on a dataloader.
82
83 Args:
84 graph (Graph): Graph to evaluate
85 dataloader_eval (EvalDataloader): Dataloader to evaluate on
86
87 Returns:
88 dict: returns the average psnr and average rays per second
89 """
90 avg_psnr = 0
91 avg_rays_per_sec = 0
92 avg_fps = 0
93 for step, (camera_ray_bundle, batch) in tqdm(enumerate(dataloader_eval)):
94 with TimeWriter(writer=None, name=None, write=False) as t:
95 with torch.no_grad():
96 image_idx = int(camera_ray_bundle.camera_indices[0, 0])
97 outputs = graph.get_outputs_for_camera_ray_bundle(camera_ray_bundle)
98 psnr = graph.log_test_image_outputs(image_idx, step, batch, outputs)
99 avg_rays_per_sec = _update_avg(avg_rays_per_sec, camera_ray_bundle.origins.shape[0] / t.duration, step)
100 avg_psnr = _update_avg(avg_psnr, psnr, step)
101 avg_fps = _update_avg(avg_fps, 1 / t.duration, step)
102 return {"avg psnr": avg_psnr, "avg rays per sec": avg_rays_per_sec, "avg fps": avg_fps}
103
104
105 def render_trajectory_video(
106 graph: Graph,
107 camera_path: CameraPath,
108 output_filename: Optional[str] = None,
109 rendered_output_name: Optional[str] = None,
110 rendered_resolution_scaling_factor: float = 1.0,
111 num_rays_per_chunk: int = 4096,
112 ) -> None:
113 """Helper function to create a video of the spiral trajectory.
114
115 Args:
116 graph: Graph to evaluate with.
117 camera_path: Index of the image to render.
118 output_filename: Name of the output file.
119 rendered_output_name: Name of the renderer output to use.
120 rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.
121 Defaults to 1.0.
122 num_rays_per_chunk: Number of rays to use per chunk. Defaults to 4096.
123 """
124 print("Creating trajectory video.")
125 images = []
126 for camera in tqdm(camera_path.cameras):
127 camera.rescale_output_resolution(rendered_resolution_scaling_factor)
128 camera_ray_bundle = camera.get_camera_ray_bundle().to(graph.device)
129 camera_ray_bundle.num_rays_per_chunk = num_rays_per_chunk
130 with torch.no_grad():
131 outputs = graph.get_outputs_for_camera_ray_bundle(camera_ray_bundle)
132 # TODO: don't hardcode the key! this will break for some nerf Graphs
133 image = outputs[rendered_output_name].cpu().numpy()
134 images.append(image)
135
136 seconds = 5.0
137 fps = len(images) / seconds
138 media.write_video(output_filename, images, fps=fps)
139
140
141 class MethodType(enum.Enum):
142 """Enum for the method type."""
143
144 PSNR = enum.auto()
145 TRAJ = enum.auto()
146
147
148 class TrajectoryType(enum.Enum):
149 """Enum for the trajectory type."""
150
151 SPIRAL = enum.auto()
152 INTERP = enum.auto()
153
154
155 def main(
156 config_name: str,
157 checkpoint_dir: str,
158 rendered_output_name: str,
159 method: MethodType = MethodType.PSNR,
160 traj: TrajectoryType = TrajectoryType.SPIRAL,
161 output_filename: str = "output.mp4",
162 rendered_resolution_scaling_factor: float = 1.0,
163 config_overrides: Optional[List[str]] = None,
164 ):
165 """Evaluate trained model. This evaluation can either render a trajectory or compute the eval psnr.
166
167 Args:
168 config_name: Name of the config file to use.
169 checkpoint_dir: Directory to load the checkpoint from.
170 rendered_output_name: Name of the renderer output to use.
171 method: Method to use for evaluation. PSNR computes metrics, TRAJ renders a trajectory.
172 traj: Trajectory to render.
173 output_filename: Name of the output file.
174 rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.
175 Defaults to 1.0.
176 config_overrides: List of strings to override config values.
177 """
178 # parser = my_func_that_returns_a_parser()
179 # args = parser.parse_args()
180
181 config_path = "../configs"
182 initialize(version_base="1.2", config_path=config_path)
183 config_overrides = config_overrides or []
184 config = compose(config_name, overrides=config_overrides)
185
186 config.trainer.resume_train.load_dir = checkpoint_dir
187
188 device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
189 # setup graph and dataset
190 dataset_inputs_train, _ = setup_dataset_train(config.data, device=device)
191 _, dataloader_eval = setup_dataset_eval(config.data, test_mode=True, device=device)
192 graph = setup_graph(config.graph, dataset_inputs_train, device=device)
193 graph.eval()
194 # load checkpointed information
195 _load_checkpoint(config.trainer.resume_train, graph)
196
197 if method == MethodType.PSNR:
198 stats_dict = render_stats_dict(graph, dataloader_eval)
199 avg_psnr = stats_dict["avg psnr"]
200 avg_rays_per_sec = stats_dict["avg rays per sec"]
201 avg_fps = stats_dict["avg fps"]
202 print(f"Avg. PSNR: {avg_psnr:0.4f}")
203 print(f"Avg. Rays per sec: {avg_rays_per_sec:0.4f}")
204 print(f"Avg. FPS: {avg_fps:0.4f}")
205 elif method == MethodType.TRAJ:
206 # TODO(ethan): pass in camera information into argparse parser
207 if traj == TrajectoryType.SPIRAL:
208 camera_start = dataloader_eval.get_camera(image_idx=0)
209 # TODO(ethan): pass in the up direction of the camera
210 camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)
211 elif traj == TrajectoryType.INTERP:
212 camera_start = dataloader_eval.get_camera(image_idx=0)
213 camera_end = dataloader_eval.get_camera(image_idx=10)
214 camera_path = get_interpolated_camera_path(camera_start, camera_end, steps=30)
215 render_trajectory_video(
216 graph,
217 camera_path,
218 output_filename=output_filename,
219 rendered_output_name=rendered_output_name,
220 rendered_resolution_scaling_factor=rendered_resolution_scaling_factor,
221 num_rays_per_chunk=config.data.dataloader_eval.num_rays_per_chunk,
222 )
223
224
225 if __name__ == "__main__":
226 dcargs.cli(main)
227
```
Path: `pyrad/utils/misc.py`
Content:
```
1 # Copyright 2022 The Plenoptix Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """
16 Miscellaneous helper code.
17 """
18
19 import hashlib
20 import json
21 from pydoc import locate
22 from typing import Any, Dict
23
24 import torch
25 from omegaconf import DictConfig
26
27
28 class DotDict(dict):
29 """
30 dot.notation access to dictionary attributes
31 """
32
33 def __getattr__(self, attr):
34 return self[attr]
35
36 __setattr__ = dict.__setitem__
37 __delattr__ = dict.__delitem__
38
39
40 def get_dict_to_torch(stuff, device="cpu"):
41 """Set everything in the dict to the specified torch device."""
42 if isinstance(stuff, dict):
43 for k, v in stuff.items():
44 stuff[k] = get_dict_to_torch(v, device)
45 return stuff
46 if isinstance(stuff, torch.Tensor):
47 return stuff.to(device)
48 return stuff
49
50
51 def get_dict_to_cpu(stuff):
52 """Set everything in the dict to CPU."""
53 if isinstance(stuff, dict):
54 for k, v in stuff.items():
55 stuff[k] = get_dict_to_cpu(v)
56 return stuff
57 if isinstance(stuff, torch.Tensor):
58 return stuff.detach().cpu()
59 return stuff
60
61
62 def is_not_none(var):
63 """Return True if the variable var is None."""
64 return not isinstance(var, type(None))
65
66
67 def get_masked_dict(d, mask):
68 """Return a masked dictionary.
69 TODO(ethan): add more asserts/checks so this doesn't have unpredictable behavior."""
70 masked_dict = {}
71 for key, value in d.items():
72 masked_dict[key] = value[mask]
73 return masked_dict
74
75
76 def instantiate_from_dict_config(dict_config: DictConfig, **kwargs):
77 """Our version of hydra's instantiate function."""
78 dict_config_kwargs = {k: v for k, v in dict_config.items() if k != "_target_"}
79 uninstantiated_class = locate(dict_config._target_) # pylint: disable=protected-access
80 all_kwargs = dict_config_kwargs
81 all_kwargs.update(kwargs)
82 instantiated_class = uninstantiated_class(**all_kwargs)
83 return instantiated_class
84
85
86 def get_hash_str_from_dict(dictionary: Dict[str, Any]) -> str:
87 """MD5 hash of a dictionary. Based on
88 https://www.doc.ic.ac.uk/~nuric/coding/how-to-hash-a-dictionary-in-python.html"""
89 dhash = hashlib.md5()
90 encoded = json.dumps(dictionary, sort_keys=True).encode()
91 dhash.update(encoded)
92 return dhash.hexdigest()
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyrad/utils/misc.py b/pyrad/utils/misc.py
--- a/pyrad/utils/misc.py
+++ b/pyrad/utils/misc.py
@@ -21,6 +21,7 @@
from pydoc import locate
from typing import Any, Dict
+from math import floor, log
import torch
from omegaconf import DictConfig
@@ -90,3 +91,11 @@
encoded = json.dumps(dictionary, sort_keys=True).encode()
dhash.update(encoded)
return dhash.hexdigest()
+
+
+def human_format(num):
+ """Format a number in a more human readable way"""
+ units = ["", "K", "M", "B", "T", "P"]
+ k = 1000.0
+ magnitude = int(floor(log(num, k)))
+ return f"{(num / k**magnitude):.2f} {units[magnitude]}"
diff --git a/scripts/run_eval.py b/scripts/run_eval.py
--- a/scripts/run_eval.py
+++ b/scripts/run_eval.py
@@ -15,6 +15,7 @@
from pyrad.cameras.camera_paths import CameraPath, get_interpolated_camera_path, get_spiral_path
from pyrad.data.dataloader import EvalDataloader, setup_dataset_eval, setup_dataset_train
from pyrad.graphs.base import Graph, setup_graph
+from pyrad.utils.misc import human_format
from pyrad.utils.writer import TimeWriter
@@ -200,7 +201,7 @@
avg_rays_per_sec = stats_dict["avg rays per sec"]
avg_fps = stats_dict["avg fps"]
print(f"Avg. PSNR: {avg_psnr:0.4f}")
- print(f"Avg. Rays per sec: {avg_rays_per_sec:0.4f}")
+ print(f"Avg. Rays / Sec: {human_format(avg_rays_per_sec)}")
print(f"Avg. FPS: {avg_fps:0.4f}")
elif method == MethodType.TRAJ:
# TODO(ethan): pass in camera information into argparse parser
| {"golden_diff": "diff --git a/pyrad/utils/misc.py b/pyrad/utils/misc.py\n--- a/pyrad/utils/misc.py\n+++ b/pyrad/utils/misc.py\n@@ -21,6 +21,7 @@\n from pydoc import locate\n from typing import Any, Dict\n \n+from math import floor, log\n import torch\n from omegaconf import DictConfig\n \n@@ -90,3 +91,11 @@\n encoded = json.dumps(dictionary, sort_keys=True).encode()\n dhash.update(encoded)\n return dhash.hexdigest()\n+\n+\n+def human_format(num):\n+ \"\"\"Format a number in a more human readable way\"\"\"\n+ units = [\"\", \"K\", \"M\", \"B\", \"T\", \"P\"]\n+ k = 1000.0\n+ magnitude = int(floor(log(num, k)))\n+ return f\"{(num / k**magnitude):.2f} {units[magnitude]}\"\ndiff --git a/scripts/run_eval.py b/scripts/run_eval.py\n--- a/scripts/run_eval.py\n+++ b/scripts/run_eval.py\n@@ -15,6 +15,7 @@\n from pyrad.cameras.camera_paths import CameraPath, get_interpolated_camera_path, get_spiral_path\n from pyrad.data.dataloader import EvalDataloader, setup_dataset_eval, setup_dataset_train\n from pyrad.graphs.base import Graph, setup_graph\n+from pyrad.utils.misc import human_format\n from pyrad.utils.writer import TimeWriter\n \n \n@@ -200,7 +201,7 @@\n avg_rays_per_sec = stats_dict[\"avg rays per sec\"]\n avg_fps = stats_dict[\"avg fps\"]\n print(f\"Avg. PSNR: {avg_psnr:0.4f}\")\n- print(f\"Avg. Rays per sec: {avg_rays_per_sec:0.4f}\")\n+ print(f\"Avg. Rays / Sec: {human_format(avg_rays_per_sec)}\")\n print(f\"Avg. FPS: {avg_fps:0.4f}\")\n elif method == MethodType.TRAJ:\n # TODO(ethan): pass in camera information into argparse parser\n", "issue": "Report \"Rays Per Sec\" in easier to read format.\nIt would be great to report the \"Rays Per Sec\" to fewer sig figs. Ie \"1343535.4324\" -> \"1.34 mil\" or \"1.34 M\". It is becoming trickier to quickly read these numbers now that the model is getting quicker.\r\n\r\nAlso maybe \"Rays Per Sec\" -> \"Rays / Sec\"\n", "before_files": [{"content": "\"\"\"\nrun_eval.py\n\"\"\"\nimport enum\nimport os\nfrom typing import Dict, List, Optional\n\nimport dcargs\nimport mediapy as media\nimport torch\nfrom hydra import compose, initialize\nfrom omegaconf import DictConfig\nfrom tqdm import tqdm\n\nfrom pyrad.cameras.camera_paths import CameraPath, get_interpolated_camera_path, get_spiral_path\nfrom pyrad.data.dataloader import EvalDataloader, setup_dataset_eval, setup_dataset_train\nfrom pyrad.graphs.base import Graph, setup_graph\nfrom pyrad.utils.writer import TimeWriter\n\n\ndef _update_avg(prev_avg: float, new_val: float, step: int) -> float:\n \"\"\"helper to calculate the running average\n\n Args:\n prev_avg (float): previous average value\n new_val (float): new value to update the average with\n step (int): current step number\n\n Returns:\n float: new updated average\n \"\"\"\n return (step * prev_avg + new_val) / (step + 1)\n\n\ndef _load_checkpoint(config: DictConfig, graph: Graph) -> None:\n \"\"\"Helper function to load checkpointed graph\n\n Args:\n config (DictConfig): Configuration of graph to load\n graph (Graph): Graph instance of which to load weights\n \"\"\"\n assert config.load_dir is not None\n if config.load_step is None:\n print(\"Loading latest checkpoint from load_dir\")\n # NOTE: this is specific to the checkpoint name format\n load_step = sorted([int(x[x.find(\"-\") + 1 : x.find(\".\")]) for x in os.listdir(config.load_dir)])[-1]\n else:\n load_step = config.load_step\n load_path = os.path.join(config.load_dir, f\"step-{load_step:09d}.ckpt\")\n assert os.path.exists(load_path), f\"Checkpoint {load_path} does not exist\"\n loaded_state = torch.load(load_path, map_location=\"cpu\")\n graph.load_graph(loaded_state)\n print(f\"done loading checkpoint from {load_path}\")\n\n\ndef run_inference_from_config(config: DictConfig) -> Dict[str, float]:\n \"\"\"helper function to run inference given config specifications (also used in benchmarking)\n\n Args:\n config (DictConfig): Configuration for loading the evaluation.\n\n Returns:\n Tuple[float, float]: returns both the avg psnr and avg rays per second\n \"\"\"\n print(\"Running inference.\")\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n # setup graph and dataset\n dataset_inputs_train, _ = setup_dataset_train(config.data, device=device)\n _, dataloader_eval = setup_dataset_eval(config.data, test_mode=True, device=device)\n graph = setup_graph(config.graph, dataset_inputs_train, device=device)\n graph.eval()\n\n # load checkpointed information\n _load_checkpoint(config.trainer.resume_train, graph)\n\n # calculate average psnr across test dataset\n return render_stats_dict(graph, dataloader_eval)\n\n\ndef render_stats_dict(graph: Graph, dataloader_eval: EvalDataloader) -> Dict[str, float]:\n \"\"\"Helper function to evaluate the graph on a dataloader.\n\n Args:\n graph (Graph): Graph to evaluate\n dataloader_eval (EvalDataloader): Dataloader to evaluate on\n\n Returns:\n dict: returns the average psnr and average rays per second\n \"\"\"\n avg_psnr = 0\n avg_rays_per_sec = 0\n avg_fps = 0\n for step, (camera_ray_bundle, batch) in tqdm(enumerate(dataloader_eval)):\n with TimeWriter(writer=None, name=None, write=False) as t:\n with torch.no_grad():\n image_idx = int(camera_ray_bundle.camera_indices[0, 0])\n outputs = graph.get_outputs_for_camera_ray_bundle(camera_ray_bundle)\n psnr = graph.log_test_image_outputs(image_idx, step, batch, outputs)\n avg_rays_per_sec = _update_avg(avg_rays_per_sec, camera_ray_bundle.origins.shape[0] / t.duration, step)\n avg_psnr = _update_avg(avg_psnr, psnr, step)\n avg_fps = _update_avg(avg_fps, 1 / t.duration, step)\n return {\"avg psnr\": avg_psnr, \"avg rays per sec\": avg_rays_per_sec, \"avg fps\": avg_fps}\n\n\ndef render_trajectory_video(\n graph: Graph,\n camera_path: CameraPath,\n output_filename: Optional[str] = None,\n rendered_output_name: Optional[str] = None,\n rendered_resolution_scaling_factor: float = 1.0,\n num_rays_per_chunk: int = 4096,\n) -> None:\n \"\"\"Helper function to create a video of the spiral trajectory.\n\n Args:\n graph: Graph to evaluate with.\n camera_path: Index of the image to render.\n output_filename: Name of the output file.\n rendered_output_name: Name of the renderer output to use.\n rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.\n Defaults to 1.0.\n num_rays_per_chunk: Number of rays to use per chunk. Defaults to 4096.\n \"\"\"\n print(\"Creating trajectory video.\")\n images = []\n for camera in tqdm(camera_path.cameras):\n camera.rescale_output_resolution(rendered_resolution_scaling_factor)\n camera_ray_bundle = camera.get_camera_ray_bundle().to(graph.device)\n camera_ray_bundle.num_rays_per_chunk = num_rays_per_chunk\n with torch.no_grad():\n outputs = graph.get_outputs_for_camera_ray_bundle(camera_ray_bundle)\n # TODO: don't hardcode the key! this will break for some nerf Graphs\n image = outputs[rendered_output_name].cpu().numpy()\n images.append(image)\n\n seconds = 5.0\n fps = len(images) / seconds\n media.write_video(output_filename, images, fps=fps)\n\n\nclass MethodType(enum.Enum):\n \"\"\"Enum for the method type.\"\"\"\n\n PSNR = enum.auto()\n TRAJ = enum.auto()\n\n\nclass TrajectoryType(enum.Enum):\n \"\"\"Enum for the trajectory type.\"\"\"\n\n SPIRAL = enum.auto()\n INTERP = enum.auto()\n\n\ndef main(\n config_name: str,\n checkpoint_dir: str,\n rendered_output_name: str,\n method: MethodType = MethodType.PSNR,\n traj: TrajectoryType = TrajectoryType.SPIRAL,\n output_filename: str = \"output.mp4\",\n rendered_resolution_scaling_factor: float = 1.0,\n config_overrides: Optional[List[str]] = None,\n):\n \"\"\"Evaluate trained model. This evaluation can either render a trajectory or compute the eval psnr.\n\n Args:\n config_name: Name of the config file to use.\n checkpoint_dir: Directory to load the checkpoint from.\n rendered_output_name: Name of the renderer output to use.\n method: Method to use for evaluation. PSNR computes metrics, TRAJ renders a trajectory.\n traj: Trajectory to render.\n output_filename: Name of the output file.\n rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.\n Defaults to 1.0.\n config_overrides: List of strings to override config values.\n \"\"\"\n # parser = my_func_that_returns_a_parser()\n # args = parser.parse_args()\n\n config_path = \"../configs\"\n initialize(version_base=\"1.2\", config_path=config_path)\n config_overrides = config_overrides or []\n config = compose(config_name, overrides=config_overrides)\n\n config.trainer.resume_train.load_dir = checkpoint_dir\n\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n # setup graph and dataset\n dataset_inputs_train, _ = setup_dataset_train(config.data, device=device)\n _, dataloader_eval = setup_dataset_eval(config.data, test_mode=True, device=device)\n graph = setup_graph(config.graph, dataset_inputs_train, device=device)\n graph.eval()\n # load checkpointed information\n _load_checkpoint(config.trainer.resume_train, graph)\n\n if method == MethodType.PSNR:\n stats_dict = render_stats_dict(graph, dataloader_eval)\n avg_psnr = stats_dict[\"avg psnr\"]\n avg_rays_per_sec = stats_dict[\"avg rays per sec\"]\n avg_fps = stats_dict[\"avg fps\"]\n print(f\"Avg. PSNR: {avg_psnr:0.4f}\")\n print(f\"Avg. Rays per sec: {avg_rays_per_sec:0.4f}\")\n print(f\"Avg. FPS: {avg_fps:0.4f}\")\n elif method == MethodType.TRAJ:\n # TODO(ethan): pass in camera information into argparse parser\n if traj == TrajectoryType.SPIRAL:\n camera_start = dataloader_eval.get_camera(image_idx=0)\n # TODO(ethan): pass in the up direction of the camera\n camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)\n elif traj == TrajectoryType.INTERP:\n camera_start = dataloader_eval.get_camera(image_idx=0)\n camera_end = dataloader_eval.get_camera(image_idx=10)\n camera_path = get_interpolated_camera_path(camera_start, camera_end, steps=30)\n render_trajectory_video(\n graph,\n camera_path,\n output_filename=output_filename,\n rendered_output_name=rendered_output_name,\n rendered_resolution_scaling_factor=rendered_resolution_scaling_factor,\n num_rays_per_chunk=config.data.dataloader_eval.num_rays_per_chunk,\n )\n\n\nif __name__ == \"__main__\":\n dcargs.cli(main)\n", "path": "scripts/run_eval.py"}, {"content": "# Copyright 2022 The Plenoptix Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nMiscellaneous helper code.\n\"\"\"\n\nimport hashlib\nimport json\nfrom pydoc import locate\nfrom typing import Any, Dict\n\nimport torch\nfrom omegaconf import DictConfig\n\n\nclass DotDict(dict):\n \"\"\"\n dot.notation access to dictionary attributes\n \"\"\"\n\n def __getattr__(self, attr):\n return self[attr]\n\n __setattr__ = dict.__setitem__\n __delattr__ = dict.__delitem__\n\n\ndef get_dict_to_torch(stuff, device=\"cpu\"):\n \"\"\"Set everything in the dict to the specified torch device.\"\"\"\n if isinstance(stuff, dict):\n for k, v in stuff.items():\n stuff[k] = get_dict_to_torch(v, device)\n return stuff\n if isinstance(stuff, torch.Tensor):\n return stuff.to(device)\n return stuff\n\n\ndef get_dict_to_cpu(stuff):\n \"\"\"Set everything in the dict to CPU.\"\"\"\n if isinstance(stuff, dict):\n for k, v in stuff.items():\n stuff[k] = get_dict_to_cpu(v)\n return stuff\n if isinstance(stuff, torch.Tensor):\n return stuff.detach().cpu()\n return stuff\n\n\ndef is_not_none(var):\n \"\"\"Return True if the variable var is None.\"\"\"\n return not isinstance(var, type(None))\n\n\ndef get_masked_dict(d, mask):\n \"\"\"Return a masked dictionary.\n TODO(ethan): add more asserts/checks so this doesn't have unpredictable behavior.\"\"\"\n masked_dict = {}\n for key, value in d.items():\n masked_dict[key] = value[mask]\n return masked_dict\n\n\ndef instantiate_from_dict_config(dict_config: DictConfig, **kwargs):\n \"\"\"Our version of hydra's instantiate function.\"\"\"\n dict_config_kwargs = {k: v for k, v in dict_config.items() if k != \"_target_\"}\n uninstantiated_class = locate(dict_config._target_) # pylint: disable=protected-access\n all_kwargs = dict_config_kwargs\n all_kwargs.update(kwargs)\n instantiated_class = uninstantiated_class(**all_kwargs)\n return instantiated_class\n\n\ndef get_hash_str_from_dict(dictionary: Dict[str, Any]) -> str:\n \"\"\"MD5 hash of a dictionary. Based on\n https://www.doc.ic.ac.uk/~nuric/coding/how-to-hash-a-dictionary-in-python.html\"\"\"\n dhash = hashlib.md5()\n encoded = json.dumps(dictionary, sort_keys=True).encode()\n dhash.update(encoded)\n return dhash.hexdigest()\n", "path": "pyrad/utils/misc.py"}], "after_files": [{"content": "\"\"\"\nrun_eval.py\n\"\"\"\nimport enum\nimport os\nfrom typing import Dict, List, Optional\n\nimport dcargs\nimport mediapy as media\nimport torch\nfrom hydra import compose, initialize\nfrom omegaconf import DictConfig\nfrom tqdm import tqdm\n\nfrom pyrad.cameras.camera_paths import CameraPath, get_interpolated_camera_path, get_spiral_path\nfrom pyrad.data.dataloader import EvalDataloader, setup_dataset_eval, setup_dataset_train\nfrom pyrad.graphs.base import Graph, setup_graph\nfrom pyrad.utils.misc import human_format\nfrom pyrad.utils.writer import TimeWriter\n\n\ndef _update_avg(prev_avg: float, new_val: float, step: int) -> float:\n \"\"\"helper to calculate the running average\n\n Args:\n prev_avg (float): previous average value\n new_val (float): new value to update the average with\n step (int): current step number\n\n Returns:\n float: new updated average\n \"\"\"\n return (step * prev_avg + new_val) / (step + 1)\n\n\ndef _load_checkpoint(config: DictConfig, graph: Graph) -> None:\n \"\"\"Helper function to load checkpointed graph\n\n Args:\n config (DictConfig): Configuration of graph to load\n graph (Graph): Graph instance of which to load weights\n \"\"\"\n assert config.load_dir is not None\n if config.load_step is None:\n print(\"Loading latest checkpoint from load_dir\")\n # NOTE: this is specific to the checkpoint name format\n load_step = sorted([int(x[x.find(\"-\") + 1 : x.find(\".\")]) for x in os.listdir(config.load_dir)])[-1]\n else:\n load_step = config.load_step\n load_path = os.path.join(config.load_dir, f\"step-{load_step:09d}.ckpt\")\n assert os.path.exists(load_path), f\"Checkpoint {load_path} does not exist\"\n loaded_state = torch.load(load_path, map_location=\"cpu\")\n graph.load_graph(loaded_state)\n print(f\"done loading checkpoint from {load_path}\")\n\n\ndef run_inference_from_config(config: DictConfig) -> Dict[str, float]:\n \"\"\"helper function to run inference given config specifications (also used in benchmarking)\n\n Args:\n config (DictConfig): Configuration for loading the evaluation.\n\n Returns:\n Tuple[float, float]: returns both the avg psnr and avg rays per second\n \"\"\"\n print(\"Running inference.\")\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n # setup graph and dataset\n dataset_inputs_train, _ = setup_dataset_train(config.data, device=device)\n _, dataloader_eval = setup_dataset_eval(config.data, test_mode=True, device=device)\n graph = setup_graph(config.graph, dataset_inputs_train, device=device)\n graph.eval()\n\n # load checkpointed information\n _load_checkpoint(config.trainer.resume_train, graph)\n\n # calculate average psnr across test dataset\n return render_stats_dict(graph, dataloader_eval)\n\n\ndef render_stats_dict(graph: Graph, dataloader_eval: EvalDataloader) -> Dict[str, float]:\n \"\"\"Helper function to evaluate the graph on a dataloader.\n\n Args:\n graph (Graph): Graph to evaluate\n dataloader_eval (EvalDataloader): Dataloader to evaluate on\n\n Returns:\n dict: returns the average psnr and average rays per second\n \"\"\"\n avg_psnr = 0\n avg_rays_per_sec = 0\n avg_fps = 0\n for step, (camera_ray_bundle, batch) in tqdm(enumerate(dataloader_eval)):\n with TimeWriter(writer=None, name=None, write=False) as t:\n with torch.no_grad():\n image_idx = int(camera_ray_bundle.camera_indices[0, 0])\n outputs = graph.get_outputs_for_camera_ray_bundle(camera_ray_bundle)\n psnr = graph.log_test_image_outputs(image_idx, step, batch, outputs)\n avg_rays_per_sec = _update_avg(avg_rays_per_sec, camera_ray_bundle.origins.shape[0] / t.duration, step)\n avg_psnr = _update_avg(avg_psnr, psnr, step)\n avg_fps = _update_avg(avg_fps, 1 / t.duration, step)\n return {\"avg psnr\": avg_psnr, \"avg rays per sec\": avg_rays_per_sec, \"avg fps\": avg_fps}\n\n\ndef render_trajectory_video(\n graph: Graph,\n camera_path: CameraPath,\n output_filename: Optional[str] = None,\n rendered_output_name: Optional[str] = None,\n rendered_resolution_scaling_factor: float = 1.0,\n num_rays_per_chunk: int = 4096,\n) -> None:\n \"\"\"Helper function to create a video of the spiral trajectory.\n\n Args:\n graph: Graph to evaluate with.\n camera_path: Index of the image to render.\n output_filename: Name of the output file.\n rendered_output_name: Name of the renderer output to use.\n rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.\n Defaults to 1.0.\n num_rays_per_chunk: Number of rays to use per chunk. Defaults to 4096.\n \"\"\"\n print(\"Creating trajectory video.\")\n images = []\n for camera in tqdm(camera_path.cameras):\n camera.rescale_output_resolution(rendered_resolution_scaling_factor)\n camera_ray_bundle = camera.get_camera_ray_bundle().to(graph.device)\n camera_ray_bundle.num_rays_per_chunk = num_rays_per_chunk\n with torch.no_grad():\n outputs = graph.get_outputs_for_camera_ray_bundle(camera_ray_bundle)\n # TODO: don't hardcode the key! this will break for some nerf Graphs\n image = outputs[rendered_output_name].cpu().numpy()\n images.append(image)\n\n seconds = 5.0\n fps = len(images) / seconds\n media.write_video(output_filename, images, fps=fps)\n\n\nclass MethodType(enum.Enum):\n \"\"\"Enum for the method type.\"\"\"\n\n PSNR = enum.auto()\n TRAJ = enum.auto()\n\n\nclass TrajectoryType(enum.Enum):\n \"\"\"Enum for the trajectory type.\"\"\"\n\n SPIRAL = enum.auto()\n INTERP = enum.auto()\n\n\ndef main(\n config_name: str,\n checkpoint_dir: str,\n rendered_output_name: str,\n method: MethodType = MethodType.PSNR,\n traj: TrajectoryType = TrajectoryType.SPIRAL,\n output_filename: str = \"output.mp4\",\n rendered_resolution_scaling_factor: float = 1.0,\n config_overrides: Optional[List[str]] = None,\n):\n \"\"\"Evaluate trained model. This evaluation can either render a trajectory or compute the eval psnr.\n\n Args:\n config_name: Name of the config file to use.\n checkpoint_dir: Directory to load the checkpoint from.\n rendered_output_name: Name of the renderer output to use.\n method: Method to use for evaluation. PSNR computes metrics, TRAJ renders a trajectory.\n traj: Trajectory to render.\n output_filename: Name of the output file.\n rendered_resolution_scaling_factor: Scaling factor to apply to the camera image resolution.\n Defaults to 1.0.\n config_overrides: List of strings to override config values.\n \"\"\"\n # parser = my_func_that_returns_a_parser()\n # args = parser.parse_args()\n\n config_path = \"../configs\"\n initialize(version_base=\"1.2\", config_path=config_path)\n config_overrides = config_overrides or []\n config = compose(config_name, overrides=config_overrides)\n\n config.trainer.resume_train.load_dir = checkpoint_dir\n\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n # setup graph and dataset\n dataset_inputs_train, _ = setup_dataset_train(config.data, device=device)\n _, dataloader_eval = setup_dataset_eval(config.data, test_mode=True, device=device)\n graph = setup_graph(config.graph, dataset_inputs_train, device=device)\n graph.eval()\n # load checkpointed information\n _load_checkpoint(config.trainer.resume_train, graph)\n\n if method == MethodType.PSNR:\n stats_dict = render_stats_dict(graph, dataloader_eval)\n avg_psnr = stats_dict[\"avg psnr\"]\n avg_rays_per_sec = stats_dict[\"avg rays per sec\"]\n avg_fps = stats_dict[\"avg fps\"]\n print(f\"Avg. PSNR: {avg_psnr:0.4f}\")\n print(f\"Avg. Rays / Sec: {human_format(avg_rays_per_sec)}\")\n print(f\"Avg. FPS: {avg_fps:0.4f}\")\n elif method == MethodType.TRAJ:\n # TODO(ethan): pass in camera information into argparse parser\n if traj == TrajectoryType.SPIRAL:\n camera_start = dataloader_eval.get_camera(image_idx=0)\n # TODO(ethan): pass in the up direction of the camera\n camera_path = get_spiral_path(camera_start, steps=30, radius=0.1)\n elif traj == TrajectoryType.INTERP:\n camera_start = dataloader_eval.get_camera(image_idx=0)\n camera_end = dataloader_eval.get_camera(image_idx=10)\n camera_path = get_interpolated_camera_path(camera_start, camera_end, steps=30)\n render_trajectory_video(\n graph,\n camera_path,\n output_filename=output_filename,\n rendered_output_name=rendered_output_name,\n rendered_resolution_scaling_factor=rendered_resolution_scaling_factor,\n num_rays_per_chunk=config.data.dataloader_eval.num_rays_per_chunk,\n )\n\n\nif __name__ == \"__main__\":\n dcargs.cli(main)\n", "path": "scripts/run_eval.py"}, {"content": "# Copyright 2022 The Plenoptix Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nMiscellaneous helper code.\n\"\"\"\n\nimport hashlib\nimport json\nfrom pydoc import locate\nfrom typing import Any, Dict\n\nfrom math import floor, log\nimport torch\nfrom omegaconf import DictConfig\n\n\nclass DotDict(dict):\n \"\"\"\n dot.notation access to dictionary attributes\n \"\"\"\n\n def __getattr__(self, attr):\n return self[attr]\n\n __setattr__ = dict.__setitem__\n __delattr__ = dict.__delitem__\n\n\ndef get_dict_to_torch(stuff, device=\"cpu\"):\n \"\"\"Set everything in the dict to the specified torch device.\"\"\"\n if isinstance(stuff, dict):\n for k, v in stuff.items():\n stuff[k] = get_dict_to_torch(v, device)\n return stuff\n if isinstance(stuff, torch.Tensor):\n return stuff.to(device)\n return stuff\n\n\ndef get_dict_to_cpu(stuff):\n \"\"\"Set everything in the dict to CPU.\"\"\"\n if isinstance(stuff, dict):\n for k, v in stuff.items():\n stuff[k] = get_dict_to_cpu(v)\n return stuff\n if isinstance(stuff, torch.Tensor):\n return stuff.detach().cpu()\n return stuff\n\n\ndef is_not_none(var):\n \"\"\"Return True if the variable var is None.\"\"\"\n return not isinstance(var, type(None))\n\n\ndef get_masked_dict(d, mask):\n \"\"\"Return a masked dictionary.\n TODO(ethan): add more asserts/checks so this doesn't have unpredictable behavior.\"\"\"\n masked_dict = {}\n for key, value in d.items():\n masked_dict[key] = value[mask]\n return masked_dict\n\n\ndef instantiate_from_dict_config(dict_config: DictConfig, **kwargs):\n \"\"\"Our version of hydra's instantiate function.\"\"\"\n dict_config_kwargs = {k: v for k, v in dict_config.items() if k != \"_target_\"}\n uninstantiated_class = locate(dict_config._target_) # pylint: disable=protected-access\n all_kwargs = dict_config_kwargs\n all_kwargs.update(kwargs)\n instantiated_class = uninstantiated_class(**all_kwargs)\n return instantiated_class\n\n\ndef get_hash_str_from_dict(dictionary: Dict[str, Any]) -> str:\n \"\"\"MD5 hash of a dictionary. Based on\n https://www.doc.ic.ac.uk/~nuric/coding/how-to-hash-a-dictionary-in-python.html\"\"\"\n dhash = hashlib.md5()\n encoded = json.dumps(dictionary, sort_keys=True).encode()\n dhash.update(encoded)\n return dhash.hexdigest()\n\n\ndef human_format(num):\n \"\"\"Format a number in a more human readable way\"\"\"\n units = [\"\", \"K\", \"M\", \"B\", \"T\", \"P\"]\n k = 1000.0\n magnitude = int(floor(log(num, k)))\n return f\"{(num / k**magnitude):.2f} {units[magnitude]}\"\n", "path": "pyrad/utils/misc.py"}]} | 3,885 | 459 |
gh_patches_debug_17105 | rasdani/github-patches | git_diff | dask__distributed-592 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Failure on a 3-core VM in distributed\deploy\tests\test_local.py
```
________________________________ test_defaults ________________________________
distributed\deploy\tests\test_local.py:93: in test_defaults
assert sum(w.ncores for w in c.workers) == max(2, _ncores)
E assert 2 == 3
E + where 2 = sum(<generator object test_defaults.<locals>.<genexpr> at 0x00
000000084A6048>)
E + and 3 = max(2, 3)
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `distributed/deploy/local.py`
Content:
```
1 from __future__ import print_function, division, absolute_import
2
3 import logging
4 from threading import Thread
5 from time import sleep
6
7 from tornado.ioloop import IOLoop
8 from tornado.iostream import StreamClosedError
9 from tornado import gen
10
11 from ..http.scheduler import HTTPScheduler
12 from ..utils import sync, ignoring, All
13 from ..client import Client
14 from ..nanny import Nanny
15 from ..scheduler import Scheduler
16 from ..worker import Worker, _ncores
17
18 logger = logging.getLogger(__file__)
19
20
21 class LocalCluster(object):
22 """ Create local Scheduler and Workers
23
24 This creates a "cluster" of a scheduler and workers running on the local
25 machine.
26
27 Parameters
28 ----------
29 n_workers: int
30 Number of workers to start
31 threads_per_worker: int
32 Number of threads per each worker
33 nanny: boolean
34 If true start the workers in separate processes managed by a nanny.
35 If False keep the workers in the main calling process
36 scheduler_port: int
37 Port of the scheduler. 8786 by default, use 0 to choose a random port
38
39 Examples
40 --------
41 >>> c = LocalCluster() # Create a local cluster with as many workers as cores # doctest: +SKIP
42 >>> c # doctest: +SKIP
43 LocalCluster("127.0.0.1:8786", workers=8, ncores=8)
44
45 >>> c = Client(c) # connect to local cluster # doctest: +SKIP
46
47 Add a new worker to the cluster
48 >>> w = c.start_worker(ncores=2) # doctest: +SKIP
49
50 Shut down the extra worker
51 >>> c.remove_worker(w) # doctest: +SKIP
52
53 Start a diagnostic web server and open a new browser tab
54 >>> c.start_diagnostics_server(show=True) # doctest: +SKIP
55 """
56 def __init__(self, n_workers=None, threads_per_worker=None, nanny=True,
57 loop=None, start=True, scheduler_port=8786,
58 silence_logs=logging.CRITICAL, diagnostics_port=8787,
59 services={'http': HTTPScheduler}, **kwargs):
60 self.status = None
61 self.nanny = nanny
62 if silence_logs:
63 for l in ['distributed.scheduler',
64 'distributed.worker',
65 'distributed.core',
66 'distributed.nanny']:
67 logging.getLogger(l).setLevel(silence_logs)
68 if n_workers is None and threads_per_worker is None:
69 if nanny:
70 n_workers = _ncores
71 threads_per_worker = 1
72 else:
73 n_workers = 1
74 threads_per_worker = _ncores
75 if n_workers is None and threads_per_worker is not None:
76 n_workers = max(1, _ncores // threads_per_worker)
77 if n_workers and threads_per_worker is None:
78 threads_per_worker = max(1, _ncores // n_workers)
79
80 self.loop = loop or IOLoop()
81 if not self.loop._running:
82 self._thread = Thread(target=self.loop.start)
83 self._thread.daemon = True
84 self._thread.start()
85 while not self.loop._running:
86 sleep(0.001)
87
88 self.scheduler = Scheduler(loop=self.loop, ip='127.0.0.1',
89 services=services)
90 self.scheduler.start(scheduler_port)
91 self.workers = []
92
93 if start:
94 _start_worker = self.start_worker
95 else:
96 _start_worker = lambda *args, **kwargs: self.loop.add_callback(self._start_worker, *args, **kwargs)
97 for i in range(n_workers):
98 _start_worker(ncores=threads_per_worker, nanny=nanny)
99 self.status = 'running'
100
101 self.diagnostics = None
102 if diagnostics_port is not None:
103 self.start_diagnostics_server(diagnostics_port,
104 silence=silence_logs)
105
106 def __str__(self):
107 return 'LocalCluster("%s", workers=%d, ncores=%d)' % (
108 self.scheduler_address,
109 len(self.workers),
110 sum(w.ncores for w in self.workers))
111
112 __repr__ = __str__
113
114 @gen.coroutine
115 def _start_worker(self, port=0, nanny=None, **kwargs):
116 if nanny is None:
117 nanny = self.nanny
118 if nanny:
119 W = Nanny
120 kwargs['quiet'] = True
121 else:
122 W = Worker
123 w = W(self.scheduler.ip, self.scheduler.port, loop=self.loop, **kwargs)
124 yield w._start(port)
125
126 self.workers.append(w)
127
128 while w.worker_address not in self.scheduler.worker_info:
129 yield gen.sleep(0.01)
130
131 raise gen.Return(w)
132
133 def start_worker(self, port=0, ncores=0, **kwargs):
134 """ Add a new worker to the running cluster
135
136 Parameters
137 ----------
138 port: int (optional)
139 Port on which to serve the worker, defaults to 0 or random
140 ncores: int (optional)
141 Number of threads to use. Defaults to number of logical cores
142 nanny: boolean
143 If true start worker in separate process managed by a nanny
144
145 Examples
146 --------
147 >>> c = LocalCluster() # doctest: +SKIP
148 >>> c.start_worker(ncores=2) # doctest: +SKIP
149
150 Returns
151 -------
152 The created Worker or Nanny object. Can be discarded.
153 """
154 return sync(self.loop, self._start_worker, port, ncores=ncores, **kwargs)
155
156 @gen.coroutine
157 def _stop_worker(self, w):
158 yield w._close()
159 self.workers.remove(w)
160
161 def stop_worker(self, w):
162 """ Stop a running worker
163
164 Examples
165 --------
166 >>> c = LocalCluster() # doctest: +SKIP
167 >>> w = c.start_worker(ncores=2) # doctest: +SKIP
168 >>> c.stop_worker(w) # doctest: +SKIP
169 """
170 sync(self.loop, self._stop_worker, w)
171
172 def start_diagnostics_server(self, port=8787, show=False,
173 silence=logging.CRITICAL):
174 """ Start Diagnostics Web Server
175
176 This starts a web application to show diagnostics of what is happening
177 on the cluster. This application runs in a separate process and is
178 generally available at the following location:
179
180 http://localhost:8787/status/
181 """
182 try:
183 from distributed.bokeh.application import BokehWebInterface
184 except ImportError:
185 logger.info("To start diagnostics web server please install Bokeh")
186 return
187
188 assert self.diagnostics is None
189 if 'http' not in self.scheduler.services:
190 self.scheduler.services['http'] = HTTPScheduler(self.scheduler,
191 io_loop=self.scheduler.loop)
192 self.scheduler.services['http'].listen(0)
193 self.diagnostics = BokehWebInterface(
194 tcp_port=self.scheduler.port,
195 http_port=self.scheduler.services['http'].port,
196 bokeh_port=port, show=show,
197 log_level=logging.getLevelName(silence).lower())
198
199 @gen.coroutine
200 def _close(self):
201 with ignoring(gen.TimeoutError, StreamClosedError, OSError):
202 yield All([w._close() for w in self.workers])
203 with ignoring(gen.TimeoutError, StreamClosedError, OSError):
204 yield self.scheduler.close(fast=True)
205 del self.workers[:]
206 if self.diagnostics:
207 self.diagnostics.close()
208
209 def close(self):
210 """ Close the cluster """
211 if self.status == 'running':
212 self.status = 'closed'
213 if self.loop._running:
214 sync(self.loop, self._close)
215 if hasattr(self, '_thread'):
216 sync(self.loop, self.loop.stop)
217 self._thread.join(timeout=1)
218 self.loop.close()
219 del self._thread
220
221 @gen.coroutine
222 def scale_up(self, n, **kwargs):
223 """ Bring the total count of workers up to ``n``
224
225 This function/coroutine should bring the total number of workers up to
226 the number ``n``.
227
228 This can be implemented either as a function or as a Tornado coroutine.
229 """
230 yield [self._start_worker(**kwargs)
231 for i in range(n - len(self.workers))]
232
233 @gen.coroutine
234 def scale_down(self, workers):
235 """ Remove ``workers`` from the cluster
236
237 Given a list of worker addresses this function should remove those
238 workers from the cluster. This may require tracking which jobs are
239 associated to which worker address.
240
241 This can be implemented either as a function or as a Tornado coroutine.
242 """
243 workers = set(workers)
244 yield [self._stop_worker(w)
245 for w in self.workers
246 if w.worker_address in workers]
247 while workers & set(self.workers):
248 yield gen.sleep(0.01)
249
250 def __del__(self):
251 self.close()
252
253 def __enter__(self):
254 return self
255
256 def __exit__(self, *args):
257 self.close()
258
259 @property
260 def scheduler_address(self):
261 return self.scheduler.address
262
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/distributed/deploy/local.py b/distributed/deploy/local.py
--- a/distributed/deploy/local.py
+++ b/distributed/deploy/local.py
@@ -1,6 +1,7 @@
from __future__ import print_function, division, absolute_import
import logging
+import math
from threading import Thread
from time import sleep
@@ -75,7 +76,8 @@
if n_workers is None and threads_per_worker is not None:
n_workers = max(1, _ncores // threads_per_worker)
if n_workers and threads_per_worker is None:
- threads_per_worker = max(1, _ncores // n_workers)
+ # Overcommit threads per worker, rather than undercommit
+ threads_per_worker = max(1, int(math.ceil(_ncores / n_workers)))
self.loop = loop or IOLoop()
if not self.loop._running:
| {"golden_diff": "diff --git a/distributed/deploy/local.py b/distributed/deploy/local.py\n--- a/distributed/deploy/local.py\n+++ b/distributed/deploy/local.py\n@@ -1,6 +1,7 @@\n from __future__ import print_function, division, absolute_import\n \n import logging\n+import math\n from threading import Thread\n from time import sleep\n \n@@ -75,7 +76,8 @@\n if n_workers is None and threads_per_worker is not None:\n n_workers = max(1, _ncores // threads_per_worker)\n if n_workers and threads_per_worker is None:\n- threads_per_worker = max(1, _ncores // n_workers)\n+ # Overcommit threads per worker, rather than undercommit\n+ threads_per_worker = max(1, int(math.ceil(_ncores / n_workers)))\n \n self.loop = loop or IOLoop()\n if not self.loop._running:\n", "issue": "Failure on a 3-core VM in distributed\\deploy\\tests\\test_local.py\n```\n________________________________ test_defaults ________________________________\ndistributed\\deploy\\tests\\test_local.py:93: in test_defaults\n assert sum(w.ncores for w in c.workers) == max(2, _ncores)\nE assert 2 == 3\nE + where 2 = sum(<generator object test_defaults.<locals>.<genexpr> at 0x00\n000000084A6048>)\nE + and 3 = max(2, 3)\n```\n\n", "before_files": [{"content": "from __future__ import print_function, division, absolute_import\n\nimport logging\nfrom threading import Thread\nfrom time import sleep\n\nfrom tornado.ioloop import IOLoop\nfrom tornado.iostream import StreamClosedError\nfrom tornado import gen\n\nfrom ..http.scheduler import HTTPScheduler\nfrom ..utils import sync, ignoring, All\nfrom ..client import Client\nfrom ..nanny import Nanny\nfrom ..scheduler import Scheduler\nfrom ..worker import Worker, _ncores\n\nlogger = logging.getLogger(__file__)\n\n\nclass LocalCluster(object):\n \"\"\" Create local Scheduler and Workers\n\n This creates a \"cluster\" of a scheduler and workers running on the local\n machine.\n\n Parameters\n ----------\n n_workers: int\n Number of workers to start\n threads_per_worker: int\n Number of threads per each worker\n nanny: boolean\n If true start the workers in separate processes managed by a nanny.\n If False keep the workers in the main calling process\n scheduler_port: int\n Port of the scheduler. 8786 by default, use 0 to choose a random port\n\n Examples\n --------\n >>> c = LocalCluster() # Create a local cluster with as many workers as cores # doctest: +SKIP\n >>> c # doctest: +SKIP\n LocalCluster(\"127.0.0.1:8786\", workers=8, ncores=8)\n\n >>> c = Client(c) # connect to local cluster # doctest: +SKIP\n\n Add a new worker to the cluster\n >>> w = c.start_worker(ncores=2) # doctest: +SKIP\n\n Shut down the extra worker\n >>> c.remove_worker(w) # doctest: +SKIP\n\n Start a diagnostic web server and open a new browser tab\n >>> c.start_diagnostics_server(show=True) # doctest: +SKIP\n \"\"\"\n def __init__(self, n_workers=None, threads_per_worker=None, nanny=True,\n loop=None, start=True, scheduler_port=8786,\n silence_logs=logging.CRITICAL, diagnostics_port=8787,\n services={'http': HTTPScheduler}, **kwargs):\n self.status = None\n self.nanny = nanny\n if silence_logs:\n for l in ['distributed.scheduler',\n 'distributed.worker',\n 'distributed.core',\n 'distributed.nanny']:\n logging.getLogger(l).setLevel(silence_logs)\n if n_workers is None and threads_per_worker is None:\n if nanny:\n n_workers = _ncores\n threads_per_worker = 1\n else:\n n_workers = 1\n threads_per_worker = _ncores\n if n_workers is None and threads_per_worker is not None:\n n_workers = max(1, _ncores // threads_per_worker)\n if n_workers and threads_per_worker is None:\n threads_per_worker = max(1, _ncores // n_workers)\n\n self.loop = loop or IOLoop()\n if not self.loop._running:\n self._thread = Thread(target=self.loop.start)\n self._thread.daemon = True\n self._thread.start()\n while not self.loop._running:\n sleep(0.001)\n\n self.scheduler = Scheduler(loop=self.loop, ip='127.0.0.1',\n services=services)\n self.scheduler.start(scheduler_port)\n self.workers = []\n\n if start:\n _start_worker = self.start_worker\n else:\n _start_worker = lambda *args, **kwargs: self.loop.add_callback(self._start_worker, *args, **kwargs)\n for i in range(n_workers):\n _start_worker(ncores=threads_per_worker, nanny=nanny)\n self.status = 'running'\n\n self.diagnostics = None\n if diagnostics_port is not None:\n self.start_diagnostics_server(diagnostics_port,\n silence=silence_logs)\n\n def __str__(self):\n return 'LocalCluster(\"%s\", workers=%d, ncores=%d)' % (\n self.scheduler_address,\n len(self.workers),\n sum(w.ncores for w in self.workers))\n\n __repr__ = __str__\n\n @gen.coroutine\n def _start_worker(self, port=0, nanny=None, **kwargs):\n if nanny is None:\n nanny = self.nanny\n if nanny:\n W = Nanny\n kwargs['quiet'] = True\n else:\n W = Worker\n w = W(self.scheduler.ip, self.scheduler.port, loop=self.loop, **kwargs)\n yield w._start(port)\n\n self.workers.append(w)\n\n while w.worker_address not in self.scheduler.worker_info:\n yield gen.sleep(0.01)\n\n raise gen.Return(w)\n\n def start_worker(self, port=0, ncores=0, **kwargs):\n \"\"\" Add a new worker to the running cluster\n\n Parameters\n ----------\n port: int (optional)\n Port on which to serve the worker, defaults to 0 or random\n ncores: int (optional)\n Number of threads to use. Defaults to number of logical cores\n nanny: boolean\n If true start worker in separate process managed by a nanny\n\n Examples\n --------\n >>> c = LocalCluster() # doctest: +SKIP\n >>> c.start_worker(ncores=2) # doctest: +SKIP\n\n Returns\n -------\n The created Worker or Nanny object. Can be discarded.\n \"\"\"\n return sync(self.loop, self._start_worker, port, ncores=ncores, **kwargs)\n\n @gen.coroutine\n def _stop_worker(self, w):\n yield w._close()\n self.workers.remove(w)\n\n def stop_worker(self, w):\n \"\"\" Stop a running worker\n\n Examples\n --------\n >>> c = LocalCluster() # doctest: +SKIP\n >>> w = c.start_worker(ncores=2) # doctest: +SKIP\n >>> c.stop_worker(w) # doctest: +SKIP\n \"\"\"\n sync(self.loop, self._stop_worker, w)\n\n def start_diagnostics_server(self, port=8787, show=False,\n silence=logging.CRITICAL):\n \"\"\" Start Diagnostics Web Server\n\n This starts a web application to show diagnostics of what is happening\n on the cluster. This application runs in a separate process and is\n generally available at the following location:\n\n http://localhost:8787/status/\n \"\"\"\n try:\n from distributed.bokeh.application import BokehWebInterface\n except ImportError:\n logger.info(\"To start diagnostics web server please install Bokeh\")\n return\n\n assert self.diagnostics is None\n if 'http' not in self.scheduler.services:\n self.scheduler.services['http'] = HTTPScheduler(self.scheduler,\n io_loop=self.scheduler.loop)\n self.scheduler.services['http'].listen(0)\n self.diagnostics = BokehWebInterface(\n tcp_port=self.scheduler.port,\n http_port=self.scheduler.services['http'].port,\n bokeh_port=port, show=show,\n log_level=logging.getLevelName(silence).lower())\n\n @gen.coroutine\n def _close(self):\n with ignoring(gen.TimeoutError, StreamClosedError, OSError):\n yield All([w._close() for w in self.workers])\n with ignoring(gen.TimeoutError, StreamClosedError, OSError):\n yield self.scheduler.close(fast=True)\n del self.workers[:]\n if self.diagnostics:\n self.diagnostics.close()\n\n def close(self):\n \"\"\" Close the cluster \"\"\"\n if self.status == 'running':\n self.status = 'closed'\n if self.loop._running:\n sync(self.loop, self._close)\n if hasattr(self, '_thread'):\n sync(self.loop, self.loop.stop)\n self._thread.join(timeout=1)\n self.loop.close()\n del self._thread\n\n @gen.coroutine\n def scale_up(self, n, **kwargs):\n \"\"\" Bring the total count of workers up to ``n``\n\n This function/coroutine should bring the total number of workers up to\n the number ``n``.\n\n This can be implemented either as a function or as a Tornado coroutine.\n \"\"\"\n yield [self._start_worker(**kwargs)\n for i in range(n - len(self.workers))]\n\n @gen.coroutine\n def scale_down(self, workers):\n \"\"\" Remove ``workers`` from the cluster\n\n Given a list of worker addresses this function should remove those\n workers from the cluster. This may require tracking which jobs are\n associated to which worker address.\n\n This can be implemented either as a function or as a Tornado coroutine.\n \"\"\"\n workers = set(workers)\n yield [self._stop_worker(w)\n for w in self.workers\n if w.worker_address in workers]\n while workers & set(self.workers):\n yield gen.sleep(0.01)\n\n def __del__(self):\n self.close()\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n @property\n def scheduler_address(self):\n return self.scheduler.address\n", "path": "distributed/deploy/local.py"}], "after_files": [{"content": "from __future__ import print_function, division, absolute_import\n\nimport logging\nimport math\nfrom threading import Thread\nfrom time import sleep\n\nfrom tornado.ioloop import IOLoop\nfrom tornado.iostream import StreamClosedError\nfrom tornado import gen\n\nfrom ..http.scheduler import HTTPScheduler\nfrom ..utils import sync, ignoring, All\nfrom ..client import Client\nfrom ..nanny import Nanny\nfrom ..scheduler import Scheduler\nfrom ..worker import Worker, _ncores\n\nlogger = logging.getLogger(__file__)\n\n\nclass LocalCluster(object):\n \"\"\" Create local Scheduler and Workers\n\n This creates a \"cluster\" of a scheduler and workers running on the local\n machine.\n\n Parameters\n ----------\n n_workers: int\n Number of workers to start\n threads_per_worker: int\n Number of threads per each worker\n nanny: boolean\n If true start the workers in separate processes managed by a nanny.\n If False keep the workers in the main calling process\n scheduler_port: int\n Port of the scheduler. 8786 by default, use 0 to choose a random port\n\n Examples\n --------\n >>> c = LocalCluster() # Create a local cluster with as many workers as cores # doctest: +SKIP\n >>> c # doctest: +SKIP\n LocalCluster(\"127.0.0.1:8786\", workers=8, ncores=8)\n\n >>> c = Client(c) # connect to local cluster # doctest: +SKIP\n\n Add a new worker to the cluster\n >>> w = c.start_worker(ncores=2) # doctest: +SKIP\n\n Shut down the extra worker\n >>> c.remove_worker(w) # doctest: +SKIP\n\n Start a diagnostic web server and open a new browser tab\n >>> c.start_diagnostics_server(show=True) # doctest: +SKIP\n \"\"\"\n def __init__(self, n_workers=None, threads_per_worker=None, nanny=True,\n loop=None, start=True, scheduler_port=8786,\n silence_logs=logging.CRITICAL, diagnostics_port=8787,\n services={'http': HTTPScheduler}, **kwargs):\n self.status = None\n self.nanny = nanny\n if silence_logs:\n for l in ['distributed.scheduler',\n 'distributed.worker',\n 'distributed.core',\n 'distributed.nanny']:\n logging.getLogger(l).setLevel(silence_logs)\n if n_workers is None and threads_per_worker is None:\n if nanny:\n n_workers = _ncores\n threads_per_worker = 1\n else:\n n_workers = 1\n threads_per_worker = _ncores\n if n_workers is None and threads_per_worker is not None:\n n_workers = max(1, _ncores // threads_per_worker)\n if n_workers and threads_per_worker is None:\n # Overcommit threads per worker, rather than undercommit\n threads_per_worker = max(1, int(math.ceil(_ncores / n_workers)))\n\n self.loop = loop or IOLoop()\n if not self.loop._running:\n self._thread = Thread(target=self.loop.start)\n self._thread.daemon = True\n self._thread.start()\n while not self.loop._running:\n sleep(0.001)\n\n self.scheduler = Scheduler(loop=self.loop, ip='127.0.0.1',\n services=services)\n self.scheduler.start(scheduler_port)\n self.workers = []\n\n if start:\n _start_worker = self.start_worker\n else:\n _start_worker = lambda *args, **kwargs: self.loop.add_callback(self._start_worker, *args, **kwargs)\n for i in range(n_workers):\n _start_worker(ncores=threads_per_worker, nanny=nanny)\n self.status = 'running'\n\n self.diagnostics = None\n if diagnostics_port is not None:\n self.start_diagnostics_server(diagnostics_port,\n silence=silence_logs)\n\n def __str__(self):\n return 'LocalCluster(\"%s\", workers=%d, ncores=%d)' % (\n self.scheduler_address,\n len(self.workers),\n sum(w.ncores for w in self.workers))\n\n __repr__ = __str__\n\n @gen.coroutine\n def _start_worker(self, port=0, nanny=None, **kwargs):\n if nanny is None:\n nanny = self.nanny\n if nanny:\n W = Nanny\n kwargs['quiet'] = True\n else:\n W = Worker\n w = W(self.scheduler.ip, self.scheduler.port, loop=self.loop, **kwargs)\n yield w._start(port)\n\n self.workers.append(w)\n\n while w.worker_address not in self.scheduler.worker_info:\n yield gen.sleep(0.01)\n\n raise gen.Return(w)\n\n def start_worker(self, port=0, ncores=0, **kwargs):\n \"\"\" Add a new worker to the running cluster\n\n Parameters\n ----------\n port: int (optional)\n Port on which to serve the worker, defaults to 0 or random\n ncores: int (optional)\n Number of threads to use. Defaults to number of logical cores\n nanny: boolean\n If true start worker in separate process managed by a nanny\n\n Examples\n --------\n >>> c = LocalCluster() # doctest: +SKIP\n >>> c.start_worker(ncores=2) # doctest: +SKIP\n\n Returns\n -------\n The created Worker or Nanny object. Can be discarded.\n \"\"\"\n return sync(self.loop, self._start_worker, port, ncores=ncores, **kwargs)\n\n @gen.coroutine\n def _stop_worker(self, w):\n yield w._close()\n self.workers.remove(w)\n\n def stop_worker(self, w):\n \"\"\" Stop a running worker\n\n Examples\n --------\n >>> c = LocalCluster() # doctest: +SKIP\n >>> w = c.start_worker(ncores=2) # doctest: +SKIP\n >>> c.stop_worker(w) # doctest: +SKIP\n \"\"\"\n sync(self.loop, self._stop_worker, w)\n\n def start_diagnostics_server(self, port=8787, show=False,\n silence=logging.CRITICAL):\n \"\"\" Start Diagnostics Web Server\n\n This starts a web application to show diagnostics of what is happening\n on the cluster. This application runs in a separate process and is\n generally available at the following location:\n\n http://localhost:8787/status/\n \"\"\"\n try:\n from distributed.bokeh.application import BokehWebInterface\n except ImportError:\n logger.info(\"To start diagnostics web server please install Bokeh\")\n return\n\n assert self.diagnostics is None\n if 'http' not in self.scheduler.services:\n self.scheduler.services['http'] = HTTPScheduler(self.scheduler,\n io_loop=self.scheduler.loop)\n self.scheduler.services['http'].listen(0)\n self.diagnostics = BokehWebInterface(\n tcp_port=self.scheduler.port,\n http_port=self.scheduler.services['http'].port,\n bokeh_port=port, show=show,\n log_level=logging.getLevelName(silence).lower())\n\n @gen.coroutine\n def _close(self):\n with ignoring(gen.TimeoutError, StreamClosedError, OSError):\n yield All([w._close() for w in self.workers])\n with ignoring(gen.TimeoutError, StreamClosedError, OSError):\n yield self.scheduler.close(fast=True)\n del self.workers[:]\n if self.diagnostics:\n self.diagnostics.close()\n\n def close(self):\n \"\"\" Close the cluster \"\"\"\n if self.status == 'running':\n self.status = 'closed'\n if self.loop._running:\n sync(self.loop, self._close)\n if hasattr(self, '_thread'):\n sync(self.loop, self.loop.stop)\n self._thread.join(timeout=1)\n self.loop.close()\n del self._thread\n\n @gen.coroutine\n def scale_up(self, n, **kwargs):\n \"\"\" Bring the total count of workers up to ``n``\n\n This function/coroutine should bring the total number of workers up to\n the number ``n``.\n\n This can be implemented either as a function or as a Tornado coroutine.\n \"\"\"\n yield [self._start_worker(**kwargs)\n for i in range(n - len(self.workers))]\n\n @gen.coroutine\n def scale_down(self, workers):\n \"\"\" Remove ``workers`` from the cluster\n\n Given a list of worker addresses this function should remove those\n workers from the cluster. This may require tracking which jobs are\n associated to which worker address.\n\n This can be implemented either as a function or as a Tornado coroutine.\n \"\"\"\n workers = set(workers)\n yield [self._stop_worker(w)\n for w in self.workers\n if w.worker_address in workers]\n while workers & set(self.workers):\n yield gen.sleep(0.01)\n\n def __del__(self):\n self.close()\n\n def __enter__(self):\n return self\n\n def __exit__(self, *args):\n self.close()\n\n @property\n def scheduler_address(self):\n return self.scheduler.address\n", "path": "distributed/deploy/local.py"}]} | 3,078 | 199 |
gh_patches_debug_37735 | rasdani/github-patches | git_diff | cupy__cupy-2875 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove dtype argument from min/max?
It looks to me there's no point for these functions to have `dtype` argument.
They should be keyword-only at the very least, for numpy compatibility.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/statistics/order.py`
Content:
```
1 import warnings
2
3 import cupy
4 from cupy import core
5 from cupy.core import _routines_statistics as _statistics
6 from cupy.core import fusion
7 from cupy.logic import content
8
9
10 def amin(a, axis=None, out=None, keepdims=False, dtype=None):
11 """Returns the minimum of an array or the minimum along an axis.
12
13 .. note::
14
15 When at least one element is NaN, the corresponding min value will be
16 NaN.
17
18 Args:
19 a (cupy.ndarray): Array to take the minimum.
20 axis (int): Along which axis to take the minimum. The flattened array
21 is used by default.
22 out (cupy.ndarray): Output array.
23 keepdims (bool): If ``True``, the axis is remained as an axis of
24 size one.
25 dtype: Data type specifier.
26
27 Returns:
28 cupy.ndarray: The minimum of ``a``, along the axis if specified.
29
30 .. seealso:: :func:`numpy.amin`
31
32 """
33 if fusion._is_fusing():
34 if keepdims:
35 raise NotImplementedError(
36 'cupy.amin does not support `keepdims` in fusion yet.')
37 return fusion._call_reduction(_statistics.amin,
38 a, axis=axis, dtype=dtype, out=out)
39
40 # TODO(okuta): check type
41 return a.min(axis=axis, dtype=dtype, out=out, keepdims=keepdims)
42
43
44 def amax(a, axis=None, out=None, keepdims=False, dtype=None):
45 """Returns the maximum of an array or the maximum along an axis.
46
47 .. note::
48
49 When at least one element is NaN, the corresponding min value will be
50 NaN.
51
52 Args:
53 a (cupy.ndarray): Array to take the maximum.
54 axis (int): Along which axis to take the maximum. The flattened array
55 is used by default.
56 out (cupy.ndarray): Output array.
57 keepdims (bool): If ``True``, the axis is remained as an axis of
58 size one.
59 dtype: Data type specifier.
60
61 Returns:
62 cupy.ndarray: The maximum of ``a``, along the axis if specified.
63
64 .. seealso:: :func:`numpy.amax`
65
66 """
67 if fusion._is_fusing():
68 if keepdims:
69 raise NotImplementedError(
70 'cupy.amax does not support `keepdims` in fusion yet.')
71 return fusion._call_reduction(_statistics.amax,
72 a, axis=axis, dtype=dtype, out=out)
73
74 # TODO(okuta): check type
75 return a.max(axis=axis, dtype=dtype, out=out, keepdims=keepdims)
76
77
78 def nanmin(a, axis=None, out=None, keepdims=False):
79 """Returns the minimum of an array along an axis ignoring NaN.
80
81 When there is a slice whose elements are all NaN, a :class:`RuntimeWarning`
82 is raised and NaN is returned.
83
84 Args:
85 a (cupy.ndarray): Array to take the minimum.
86 axis (int): Along which axis to take the minimum. The flattened array
87 is used by default.
88 out (cupy.ndarray): Output array.
89 keepdims (bool): If ``True``, the axis is remained as an axis of
90 size one.
91
92 Returns:
93 cupy.ndarray: The minimum of ``a``, along the axis if specified.
94
95 .. warning::
96
97 This function may synchronize the device.
98
99 .. seealso:: :func:`numpy.nanmin`
100
101 """
102 # TODO(niboshi): Avoid synchronization.
103 res = core.nanmin(a, axis=axis, out=out, keepdims=keepdims)
104 if content.isnan(res).any(): # synchronize!
105 warnings.warn('All-NaN slice encountered', RuntimeWarning)
106 return res
107
108
109 def nanmax(a, axis=None, out=None, keepdims=False):
110 """Returns the maximum of an array along an axis ignoring NaN.
111
112 When there is a slice whose elements are all NaN, a :class:`RuntimeWarning`
113 is raised and NaN is returned.
114
115 Args:
116 a (cupy.ndarray): Array to take the maximum.
117 axis (int): Along which axis to take the maximum. The flattened array
118 is used by default.
119 out (cupy.ndarray): Output array.
120 keepdims (bool): If ``True``, the axis is remained as an axis of
121 size one.
122
123 Returns:
124 cupy.ndarray: The maximum of ``a``, along the axis if specified.
125
126 .. warning::
127
128 This function may synchronize the device.
129
130 .. seealso:: :func:`numpy.nanmax`
131
132 """
133 # TODO(niboshi): Avoid synchronization.
134 res = core.nanmax(a, axis=axis, out=out, keepdims=keepdims)
135 if content.isnan(res).any(): # synchronize!
136 warnings.warn('All-NaN slice encountered', RuntimeWarning)
137 return res
138
139
140 # TODO(okuta): Implement ptp
141
142
143 def percentile(a, q, axis=None, out=None, interpolation='linear',
144 keepdims=False):
145 """Computes the q-th percentile of the data along the specified axis.
146
147 Args:
148 a (cupy.ndarray): Array for which to compute percentiles.
149 q (float, tuple of floats or cupy.ndarray): Percentiles to compute
150 in the range between 0 and 100 inclusive.
151 axis (int or tuple of ints): Along which axis or axes to compute the
152 percentiles. The flattened array is used by default.
153 out (cupy.ndarray): Output array.
154 interpolation (str): Interpolation method when a quantile lies between
155 two data points. ``linear`` interpolation is used by default.
156 Supported interpolations are``lower``, ``higher``, ``midpoint``,
157 ``nearest`` and ``linear``.
158 keepdims (bool): If ``True``, the axis is remained as an axis of
159 size one.
160
161 Returns:
162 cupy.ndarray: The percentiles of ``a``, along the axis if specified.
163
164 .. seealso:: :func:`numpy.percentile`
165
166 """
167 q = cupy.asarray(q, dtype=a.dtype)
168 if q.ndim == 0:
169 q = q[None]
170 zerod = True
171 else:
172 zerod = False
173 if q.ndim > 1:
174 raise ValueError('Expected q to have a dimension of 1.\n'
175 'Actual: {0} != 1'.format(q.ndim))
176
177 if keepdims:
178 if axis is None:
179 keepdim = (1,) * a.ndim
180 else:
181 keepdim = list(a.shape)
182 for ax in axis:
183 keepdim[ax % a.ndim] = 1
184 keepdim = tuple(keepdim)
185
186 # Copy a since we need it sorted but without modifying the original array
187 if isinstance(axis, int):
188 axis = axis,
189 if axis is None:
190 ap = a.flatten()
191 nkeep = 0
192 else:
193 # Reduce axes from a and put them last
194 axis = tuple(ax % a.ndim for ax in axis)
195 keep = set(range(a.ndim)) - set(axis)
196 nkeep = len(keep)
197 for i, s in enumerate(sorted(keep)):
198 a = a.swapaxes(i, s)
199 ap = a.reshape(a.shape[:nkeep] + (-1,)).copy()
200
201 axis = -1
202 ap.sort(axis=axis)
203 Nx = ap.shape[axis]
204 indices = q * 0.01 * (Nx - 1.) # percents to decimals
205
206 if interpolation == 'lower':
207 indices = cupy.floor(indices).astype(cupy.int32)
208 elif interpolation == 'higher':
209 indices = cupy.ceil(indices).astype(cupy.int32)
210 elif interpolation == 'midpoint':
211 indices = 0.5 * (cupy.floor(indices) + cupy.ceil(indices))
212 elif interpolation == 'nearest':
213 # TODO(hvy): Implement nearest using around
214 raise ValueError('\'nearest\' interpolation is not yet supported. '
215 'Please use any other interpolation method.')
216 elif interpolation == 'linear':
217 pass
218 else:
219 raise ValueError('Unexpected interpolation method.\n'
220 'Actual: \'{0}\' not in (\'linear\', \'lower\', '
221 '\'higher\', \'midpoint\')'.format(interpolation))
222
223 if indices.dtype == cupy.int32:
224 ret = cupy.rollaxis(ap, axis)
225 ret = ret.take(indices, axis=0, out=out)
226 else:
227 if out is None:
228 ret = cupy.empty(ap.shape[:-1] + q.shape, dtype=cupy.float64)
229 else:
230 ret = cupy.rollaxis(out, 0, out.ndim)
231
232 cupy.ElementwiseKernel(
233 'S idx, raw T a, raw int32 offset', 'U ret',
234 '''
235 ptrdiff_t idx_below = floor(idx);
236 U weight_above = idx - idx_below;
237
238 ptrdiff_t offset_i = _ind.get()[0] * offset;
239 ret = a[offset_i + idx_below] * (1.0 - weight_above)
240 + a[offset_i + idx_below + 1] * weight_above;
241 ''',
242 'percentile_weightnening'
243 )(indices, ap, ap.shape[-1] if ap.ndim > 1 else 0, ret)
244 ret = cupy.rollaxis(ret, -1) # Roll q dimension back to first axis
245
246 if zerod:
247 ret = ret.squeeze(0)
248 if keepdims:
249 if q.size > 1:
250 keepdim = (-1,) + keepdim
251 ret = ret.reshape(keepdim)
252
253 return core._internal_ascontiguousarray(ret)
254
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cupy/statistics/order.py b/cupy/statistics/order.py
--- a/cupy/statistics/order.py
+++ b/cupy/statistics/order.py
@@ -7,7 +7,7 @@
from cupy.logic import content
-def amin(a, axis=None, out=None, keepdims=False, dtype=None):
+def amin(a, axis=None, out=None, keepdims=False):
"""Returns the minimum of an array or the minimum along an axis.
.. note::
@@ -22,7 +22,6 @@
out (cupy.ndarray): Output array.
keepdims (bool): If ``True``, the axis is remained as an axis of
size one.
- dtype: Data type specifier.
Returns:
cupy.ndarray: The minimum of ``a``, along the axis if specified.
@@ -35,13 +34,13 @@
raise NotImplementedError(
'cupy.amin does not support `keepdims` in fusion yet.')
return fusion._call_reduction(_statistics.amin,
- a, axis=axis, dtype=dtype, out=out)
+ a, axis=axis, out=out)
# TODO(okuta): check type
- return a.min(axis=axis, dtype=dtype, out=out, keepdims=keepdims)
+ return a.min(axis=axis, out=out, keepdims=keepdims)
-def amax(a, axis=None, out=None, keepdims=False, dtype=None):
+def amax(a, axis=None, out=None, keepdims=False):
"""Returns the maximum of an array or the maximum along an axis.
.. note::
@@ -56,7 +55,6 @@
out (cupy.ndarray): Output array.
keepdims (bool): If ``True``, the axis is remained as an axis of
size one.
- dtype: Data type specifier.
Returns:
cupy.ndarray: The maximum of ``a``, along the axis if specified.
@@ -69,10 +67,10 @@
raise NotImplementedError(
'cupy.amax does not support `keepdims` in fusion yet.')
return fusion._call_reduction(_statistics.amax,
- a, axis=axis, dtype=dtype, out=out)
+ a, axis=axis, out=out)
# TODO(okuta): check type
- return a.max(axis=axis, dtype=dtype, out=out, keepdims=keepdims)
+ return a.max(axis=axis, out=out, keepdims=keepdims)
def nanmin(a, axis=None, out=None, keepdims=False):
| {"golden_diff": "diff --git a/cupy/statistics/order.py b/cupy/statistics/order.py\n--- a/cupy/statistics/order.py\n+++ b/cupy/statistics/order.py\n@@ -7,7 +7,7 @@\n from cupy.logic import content\n \n \n-def amin(a, axis=None, out=None, keepdims=False, dtype=None):\n+def amin(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the minimum of an array or the minimum along an axis.\n \n .. note::\n@@ -22,7 +22,6 @@\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n- dtype: Data type specifier.\n \n Returns:\n cupy.ndarray: The minimum of ``a``, along the axis if specified.\n@@ -35,13 +34,13 @@\n raise NotImplementedError(\n 'cupy.amin does not support `keepdims` in fusion yet.')\n return fusion._call_reduction(_statistics.amin,\n- a, axis=axis, dtype=dtype, out=out)\n+ a, axis=axis, out=out)\n \n # TODO(okuta): check type\n- return a.min(axis=axis, dtype=dtype, out=out, keepdims=keepdims)\n+ return a.min(axis=axis, out=out, keepdims=keepdims)\n \n \n-def amax(a, axis=None, out=None, keepdims=False, dtype=None):\n+def amax(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the maximum of an array or the maximum along an axis.\n \n .. note::\n@@ -56,7 +55,6 @@\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n- dtype: Data type specifier.\n \n Returns:\n cupy.ndarray: The maximum of ``a``, along the axis if specified.\n@@ -69,10 +67,10 @@\n raise NotImplementedError(\n 'cupy.amax does not support `keepdims` in fusion yet.')\n return fusion._call_reduction(_statistics.amax,\n- a, axis=axis, dtype=dtype, out=out)\n+ a, axis=axis, out=out)\n \n # TODO(okuta): check type\n- return a.max(axis=axis, dtype=dtype, out=out, keepdims=keepdims)\n+ return a.max(axis=axis, out=out, keepdims=keepdims)\n \n \n def nanmin(a, axis=None, out=None, keepdims=False):\n", "issue": "Remove dtype argument from min/max?\nIt looks to me there's no point for these functions to have `dtype` argument.\r\nThey should be keyword-only at the very least, for numpy compatibility.\n", "before_files": [{"content": "import warnings\n\nimport cupy\nfrom cupy import core\nfrom cupy.core import _routines_statistics as _statistics\nfrom cupy.core import fusion\nfrom cupy.logic import content\n\n\ndef amin(a, axis=None, out=None, keepdims=False, dtype=None):\n \"\"\"Returns the minimum of an array or the minimum along an axis.\n\n .. note::\n\n When at least one element is NaN, the corresponding min value will be\n NaN.\n\n Args:\n a (cupy.ndarray): Array to take the minimum.\n axis (int): Along which axis to take the minimum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: The minimum of ``a``, along the axis if specified.\n\n .. seealso:: :func:`numpy.amin`\n\n \"\"\"\n if fusion._is_fusing():\n if keepdims:\n raise NotImplementedError(\n 'cupy.amin does not support `keepdims` in fusion yet.')\n return fusion._call_reduction(_statistics.amin,\n a, axis=axis, dtype=dtype, out=out)\n\n # TODO(okuta): check type\n return a.min(axis=axis, dtype=dtype, out=out, keepdims=keepdims)\n\n\ndef amax(a, axis=None, out=None, keepdims=False, dtype=None):\n \"\"\"Returns the maximum of an array or the maximum along an axis.\n\n .. note::\n\n When at least one element is NaN, the corresponding min value will be\n NaN.\n\n Args:\n a (cupy.ndarray): Array to take the maximum.\n axis (int): Along which axis to take the maximum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n dtype: Data type specifier.\n\n Returns:\n cupy.ndarray: The maximum of ``a``, along the axis if specified.\n\n .. seealso:: :func:`numpy.amax`\n\n \"\"\"\n if fusion._is_fusing():\n if keepdims:\n raise NotImplementedError(\n 'cupy.amax does not support `keepdims` in fusion yet.')\n return fusion._call_reduction(_statistics.amax,\n a, axis=axis, dtype=dtype, out=out)\n\n # TODO(okuta): check type\n return a.max(axis=axis, dtype=dtype, out=out, keepdims=keepdims)\n\n\ndef nanmin(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the minimum of an array along an axis ignoring NaN.\n\n When there is a slice whose elements are all NaN, a :class:`RuntimeWarning`\n is raised and NaN is returned.\n\n Args:\n a (cupy.ndarray): Array to take the minimum.\n axis (int): Along which axis to take the minimum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The minimum of ``a``, along the axis if specified.\n\n .. warning::\n\n This function may synchronize the device.\n\n .. seealso:: :func:`numpy.nanmin`\n\n \"\"\"\n # TODO(niboshi): Avoid synchronization.\n res = core.nanmin(a, axis=axis, out=out, keepdims=keepdims)\n if content.isnan(res).any(): # synchronize!\n warnings.warn('All-NaN slice encountered', RuntimeWarning)\n return res\n\n\ndef nanmax(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the maximum of an array along an axis ignoring NaN.\n\n When there is a slice whose elements are all NaN, a :class:`RuntimeWarning`\n is raised and NaN is returned.\n\n Args:\n a (cupy.ndarray): Array to take the maximum.\n axis (int): Along which axis to take the maximum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The maximum of ``a``, along the axis if specified.\n\n .. warning::\n\n This function may synchronize the device.\n\n .. seealso:: :func:`numpy.nanmax`\n\n \"\"\"\n # TODO(niboshi): Avoid synchronization.\n res = core.nanmax(a, axis=axis, out=out, keepdims=keepdims)\n if content.isnan(res).any(): # synchronize!\n warnings.warn('All-NaN slice encountered', RuntimeWarning)\n return res\n\n\n# TODO(okuta): Implement ptp\n\n\ndef percentile(a, q, axis=None, out=None, interpolation='linear',\n keepdims=False):\n \"\"\"Computes the q-th percentile of the data along the specified axis.\n\n Args:\n a (cupy.ndarray): Array for which to compute percentiles.\n q (float, tuple of floats or cupy.ndarray): Percentiles to compute\n in the range between 0 and 100 inclusive.\n axis (int or tuple of ints): Along which axis or axes to compute the\n percentiles. The flattened array is used by default.\n out (cupy.ndarray): Output array.\n interpolation (str): Interpolation method when a quantile lies between\n two data points. ``linear`` interpolation is used by default.\n Supported interpolations are``lower``, ``higher``, ``midpoint``,\n ``nearest`` and ``linear``.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The percentiles of ``a``, along the axis if specified.\n\n .. seealso:: :func:`numpy.percentile`\n\n \"\"\"\n q = cupy.asarray(q, dtype=a.dtype)\n if q.ndim == 0:\n q = q[None]\n zerod = True\n else:\n zerod = False\n if q.ndim > 1:\n raise ValueError('Expected q to have a dimension of 1.\\n'\n 'Actual: {0} != 1'.format(q.ndim))\n\n if keepdims:\n if axis is None:\n keepdim = (1,) * a.ndim\n else:\n keepdim = list(a.shape)\n for ax in axis:\n keepdim[ax % a.ndim] = 1\n keepdim = tuple(keepdim)\n\n # Copy a since we need it sorted but without modifying the original array\n if isinstance(axis, int):\n axis = axis,\n if axis is None:\n ap = a.flatten()\n nkeep = 0\n else:\n # Reduce axes from a and put them last\n axis = tuple(ax % a.ndim for ax in axis)\n keep = set(range(a.ndim)) - set(axis)\n nkeep = len(keep)\n for i, s in enumerate(sorted(keep)):\n a = a.swapaxes(i, s)\n ap = a.reshape(a.shape[:nkeep] + (-1,)).copy()\n\n axis = -1\n ap.sort(axis=axis)\n Nx = ap.shape[axis]\n indices = q * 0.01 * (Nx - 1.) # percents to decimals\n\n if interpolation == 'lower':\n indices = cupy.floor(indices).astype(cupy.int32)\n elif interpolation == 'higher':\n indices = cupy.ceil(indices).astype(cupy.int32)\n elif interpolation == 'midpoint':\n indices = 0.5 * (cupy.floor(indices) + cupy.ceil(indices))\n elif interpolation == 'nearest':\n # TODO(hvy): Implement nearest using around\n raise ValueError('\\'nearest\\' interpolation is not yet supported. '\n 'Please use any other interpolation method.')\n elif interpolation == 'linear':\n pass\n else:\n raise ValueError('Unexpected interpolation method.\\n'\n 'Actual: \\'{0}\\' not in (\\'linear\\', \\'lower\\', '\n '\\'higher\\', \\'midpoint\\')'.format(interpolation))\n\n if indices.dtype == cupy.int32:\n ret = cupy.rollaxis(ap, axis)\n ret = ret.take(indices, axis=0, out=out)\n else:\n if out is None:\n ret = cupy.empty(ap.shape[:-1] + q.shape, dtype=cupy.float64)\n else:\n ret = cupy.rollaxis(out, 0, out.ndim)\n\n cupy.ElementwiseKernel(\n 'S idx, raw T a, raw int32 offset', 'U ret',\n '''\n ptrdiff_t idx_below = floor(idx);\n U weight_above = idx - idx_below;\n\n ptrdiff_t offset_i = _ind.get()[0] * offset;\n ret = a[offset_i + idx_below] * (1.0 - weight_above)\n + a[offset_i + idx_below + 1] * weight_above;\n ''',\n 'percentile_weightnening'\n )(indices, ap, ap.shape[-1] if ap.ndim > 1 else 0, ret)\n ret = cupy.rollaxis(ret, -1) # Roll q dimension back to first axis\n\n if zerod:\n ret = ret.squeeze(0)\n if keepdims:\n if q.size > 1:\n keepdim = (-1,) + keepdim\n ret = ret.reshape(keepdim)\n\n return core._internal_ascontiguousarray(ret)\n", "path": "cupy/statistics/order.py"}], "after_files": [{"content": "import warnings\n\nimport cupy\nfrom cupy import core\nfrom cupy.core import _routines_statistics as _statistics\nfrom cupy.core import fusion\nfrom cupy.logic import content\n\n\ndef amin(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the minimum of an array or the minimum along an axis.\n\n .. note::\n\n When at least one element is NaN, the corresponding min value will be\n NaN.\n\n Args:\n a (cupy.ndarray): Array to take the minimum.\n axis (int): Along which axis to take the minimum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The minimum of ``a``, along the axis if specified.\n\n .. seealso:: :func:`numpy.amin`\n\n \"\"\"\n if fusion._is_fusing():\n if keepdims:\n raise NotImplementedError(\n 'cupy.amin does not support `keepdims` in fusion yet.')\n return fusion._call_reduction(_statistics.amin,\n a, axis=axis, out=out)\n\n # TODO(okuta): check type\n return a.min(axis=axis, out=out, keepdims=keepdims)\n\n\ndef amax(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the maximum of an array or the maximum along an axis.\n\n .. note::\n\n When at least one element is NaN, the corresponding min value will be\n NaN.\n\n Args:\n a (cupy.ndarray): Array to take the maximum.\n axis (int): Along which axis to take the maximum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The maximum of ``a``, along the axis if specified.\n\n .. seealso:: :func:`numpy.amax`\n\n \"\"\"\n if fusion._is_fusing():\n if keepdims:\n raise NotImplementedError(\n 'cupy.amax does not support `keepdims` in fusion yet.')\n return fusion._call_reduction(_statistics.amax,\n a, axis=axis, out=out)\n\n # TODO(okuta): check type\n return a.max(axis=axis, out=out, keepdims=keepdims)\n\n\ndef nanmin(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the minimum of an array along an axis ignoring NaN.\n\n When there is a slice whose elements are all NaN, a :class:`RuntimeWarning`\n is raised and NaN is returned.\n\n Args:\n a (cupy.ndarray): Array to take the minimum.\n axis (int): Along which axis to take the minimum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The minimum of ``a``, along the axis if specified.\n\n .. warning::\n\n This function may synchronize the device.\n\n .. seealso:: :func:`numpy.nanmin`\n\n \"\"\"\n # TODO(niboshi): Avoid synchronization.\n res = core.nanmin(a, axis=axis, out=out, keepdims=keepdims)\n if content.isnan(res).any(): # synchronize!\n warnings.warn('All-NaN slice encountered', RuntimeWarning)\n return res\n\n\ndef nanmax(a, axis=None, out=None, keepdims=False):\n \"\"\"Returns the maximum of an array along an axis ignoring NaN.\n\n When there is a slice whose elements are all NaN, a :class:`RuntimeWarning`\n is raised and NaN is returned.\n\n Args:\n a (cupy.ndarray): Array to take the maximum.\n axis (int): Along which axis to take the maximum. The flattened array\n is used by default.\n out (cupy.ndarray): Output array.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The maximum of ``a``, along the axis if specified.\n\n .. warning::\n\n This function may synchronize the device.\n\n .. seealso:: :func:`numpy.nanmax`\n\n \"\"\"\n # TODO(niboshi): Avoid synchronization.\n res = core.nanmax(a, axis=axis, out=out, keepdims=keepdims)\n if content.isnan(res).any(): # synchronize!\n warnings.warn('All-NaN slice encountered', RuntimeWarning)\n return res\n\n\n# TODO(okuta): Implement ptp\n\n\ndef percentile(a, q, axis=None, out=None, interpolation='linear',\n keepdims=False):\n \"\"\"Computes the q-th percentile of the data along the specified axis.\n\n Args:\n a (cupy.ndarray): Array for which to compute percentiles.\n q (float, tuple of floats or cupy.ndarray): Percentiles to compute\n in the range between 0 and 100 inclusive.\n axis (int or tuple of ints): Along which axis or axes to compute the\n percentiles. The flattened array is used by default.\n out (cupy.ndarray): Output array.\n interpolation (str): Interpolation method when a quantile lies between\n two data points. ``linear`` interpolation is used by default.\n Supported interpolations are``lower``, ``higher``, ``midpoint``,\n ``nearest`` and ``linear``.\n keepdims (bool): If ``True``, the axis is remained as an axis of\n size one.\n\n Returns:\n cupy.ndarray: The percentiles of ``a``, along the axis if specified.\n\n .. seealso:: :func:`numpy.percentile`\n\n \"\"\"\n q = cupy.asarray(q, dtype=a.dtype)\n if q.ndim == 0:\n q = q[None]\n zerod = True\n else:\n zerod = False\n if q.ndim > 1:\n raise ValueError('Expected q to have a dimension of 1.\\n'\n 'Actual: {0} != 1'.format(q.ndim))\n\n if keepdims:\n if axis is None:\n keepdim = (1,) * a.ndim\n else:\n keepdim = list(a.shape)\n for ax in axis:\n keepdim[ax % a.ndim] = 1\n keepdim = tuple(keepdim)\n\n # Copy a since we need it sorted but without modifying the original array\n if isinstance(axis, int):\n axis = axis,\n if axis is None:\n ap = a.flatten()\n nkeep = 0\n else:\n # Reduce axes from a and put them last\n axis = tuple(ax % a.ndim for ax in axis)\n keep = set(range(a.ndim)) - set(axis)\n nkeep = len(keep)\n for i, s in enumerate(sorted(keep)):\n a = a.swapaxes(i, s)\n ap = a.reshape(a.shape[:nkeep] + (-1,)).copy()\n\n axis = -1\n ap.sort(axis=axis)\n Nx = ap.shape[axis]\n indices = q * 0.01 * (Nx - 1.) # percents to decimals\n\n if interpolation == 'lower':\n indices = cupy.floor(indices).astype(cupy.int32)\n elif interpolation == 'higher':\n indices = cupy.ceil(indices).astype(cupy.int32)\n elif interpolation == 'midpoint':\n indices = 0.5 * (cupy.floor(indices) + cupy.ceil(indices))\n elif interpolation == 'nearest':\n # TODO(hvy): Implement nearest using around\n raise ValueError('\\'nearest\\' interpolation is not yet supported. '\n 'Please use any other interpolation method.')\n elif interpolation == 'linear':\n pass\n else:\n raise ValueError('Unexpected interpolation method.\\n'\n 'Actual: \\'{0}\\' not in (\\'linear\\', \\'lower\\', '\n '\\'higher\\', \\'midpoint\\')'.format(interpolation))\n\n if indices.dtype == cupy.int32:\n ret = cupy.rollaxis(ap, axis)\n ret = ret.take(indices, axis=0, out=out)\n else:\n if out is None:\n ret = cupy.empty(ap.shape[:-1] + q.shape, dtype=cupy.float64)\n else:\n ret = cupy.rollaxis(out, 0, out.ndim)\n\n cupy.ElementwiseKernel(\n 'S idx, raw T a, raw int32 offset', 'U ret',\n '''\n ptrdiff_t idx_below = floor(idx);\n U weight_above = idx - idx_below;\n\n ptrdiff_t offset_i = _ind.get()[0] * offset;\n ret = a[offset_i + idx_below] * (1.0 - weight_above)\n + a[offset_i + idx_below + 1] * weight_above;\n ''',\n 'percentile_weightnening'\n )(indices, ap, ap.shape[-1] if ap.ndim > 1 else 0, ret)\n ret = cupy.rollaxis(ret, -1) # Roll q dimension back to first axis\n\n if zerod:\n ret = ret.squeeze(0)\n if keepdims:\n if q.size > 1:\n keepdim = (-1,) + keepdim\n ret = ret.reshape(keepdim)\n\n return core._internal_ascontiguousarray(ret)\n", "path": "cupy/statistics/order.py"}]} | 3,064 | 571 |
gh_patches_debug_61243 | rasdani/github-patches | git_diff | sanic-org__sanic-1654 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
The response.content_type is not add to headers in ASGI
Perhaps the response.content_type is add to headers here.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sanic/asgi.py`
Content:
```
1 import asyncio
2 import warnings
3
4 from inspect import isawaitable
5 from typing import Any, Awaitable, Callable, MutableMapping, Union
6 from urllib.parse import quote
7
8 from multidict import CIMultiDict
9
10 from sanic.exceptions import InvalidUsage, ServerError
11 from sanic.log import logger
12 from sanic.request import Request
13 from sanic.response import HTTPResponse, StreamingHTTPResponse
14 from sanic.server import StreamBuffer
15 from sanic.websocket import WebSocketConnection
16
17
18 ASGIScope = MutableMapping[str, Any]
19 ASGIMessage = MutableMapping[str, Any]
20 ASGISend = Callable[[ASGIMessage], Awaitable[None]]
21 ASGIReceive = Callable[[], Awaitable[ASGIMessage]]
22
23
24 class MockProtocol:
25 def __init__(self, transport: "MockTransport", loop):
26 self.transport = transport
27 self._not_paused = asyncio.Event(loop=loop)
28 self._not_paused.set()
29 self._complete = asyncio.Event(loop=loop)
30
31 def pause_writing(self) -> None:
32 self._not_paused.clear()
33
34 def resume_writing(self) -> None:
35 self._not_paused.set()
36
37 async def complete(self) -> None:
38 self._not_paused.set()
39 await self.transport.send(
40 {"type": "http.response.body", "body": b"", "more_body": False}
41 )
42
43 @property
44 def is_complete(self) -> bool:
45 return self._complete.is_set()
46
47 async def push_data(self, data: bytes) -> None:
48 if not self.is_complete:
49 await self.transport.send(
50 {"type": "http.response.body", "body": data, "more_body": True}
51 )
52
53 async def drain(self) -> None:
54 await self._not_paused.wait()
55
56
57 class MockTransport:
58 def __init__(
59 self, scope: ASGIScope, receive: ASGIReceive, send: ASGISend
60 ) -> None:
61 self.scope = scope
62 self._receive = receive
63 self._send = send
64 self._protocol = None
65 self.loop = None
66
67 def get_protocol(self) -> MockProtocol:
68 if not self._protocol:
69 self._protocol = MockProtocol(self, self.loop)
70 return self._protocol
71
72 def get_extra_info(self, info: str) -> Union[str, bool]:
73 if info == "peername":
74 return self.scope.get("server")
75 elif info == "sslcontext":
76 return self.scope.get("scheme") in ["https", "wss"]
77
78 def get_websocket_connection(self) -> WebSocketConnection:
79 try:
80 return self._websocket_connection
81 except AttributeError:
82 raise InvalidUsage("Improper websocket connection.")
83
84 def create_websocket_connection(
85 self, send: ASGISend, receive: ASGIReceive
86 ) -> WebSocketConnection:
87 self._websocket_connection = WebSocketConnection(send, receive)
88 return self._websocket_connection
89
90 def add_task(self) -> None:
91 raise NotImplementedError
92
93 async def send(self, data) -> None:
94 # TODO:
95 # - Validation on data and that it is formatted properly and is valid
96 await self._send(data)
97
98 async def receive(self) -> ASGIMessage:
99 return await self._receive()
100
101
102 class Lifespan:
103 def __init__(self, asgi_app: "ASGIApp") -> None:
104 self.asgi_app = asgi_app
105
106 if "before_server_start" in self.asgi_app.sanic_app.listeners:
107 warnings.warn(
108 'You have set a listener for "before_server_start" '
109 "in ASGI mode. "
110 "It will be executed as early as possible, but not before "
111 "the ASGI server is started."
112 )
113 if "after_server_stop" in self.asgi_app.sanic_app.listeners:
114 warnings.warn(
115 'You have set a listener for "after_server_stop" '
116 "in ASGI mode. "
117 "It will be executed as late as possible, but not after "
118 "the ASGI server is stopped."
119 )
120
121 async def startup(self) -> None:
122 """
123 Gather the listeners to fire on server start.
124 Because we are using a third-party server and not Sanic server, we do
125 not have access to fire anything BEFORE the server starts.
126 Therefore, we fire before_server_start and after_server_start
127 in sequence since the ASGI lifespan protocol only supports a single
128 startup event.
129 """
130 listeners = self.asgi_app.sanic_app.listeners.get(
131 "before_server_start", []
132 ) + self.asgi_app.sanic_app.listeners.get("after_server_start", [])
133
134 for handler in listeners:
135 response = handler(
136 self.asgi_app.sanic_app, self.asgi_app.sanic_app.loop
137 )
138 if isawaitable(response):
139 await response
140
141 async def shutdown(self) -> None:
142 """
143 Gather the listeners to fire on server stop.
144 Because we are using a third-party server and not Sanic server, we do
145 not have access to fire anything AFTER the server stops.
146 Therefore, we fire before_server_stop and after_server_stop
147 in sequence since the ASGI lifespan protocol only supports a single
148 shutdown event.
149 """
150 listeners = self.asgi_app.sanic_app.listeners.get(
151 "before_server_stop", []
152 ) + self.asgi_app.sanic_app.listeners.get("after_server_stop", [])
153
154 for handler in listeners:
155 response = handler(
156 self.asgi_app.sanic_app, self.asgi_app.sanic_app.loop
157 )
158 if isawaitable(response):
159 await response
160
161 async def __call__(
162 self, scope: ASGIScope, receive: ASGIReceive, send: ASGISend
163 ) -> None:
164 message = await receive()
165 if message["type"] == "lifespan.startup":
166 await self.startup()
167 await send({"type": "lifespan.startup.complete"})
168
169 message = await receive()
170 if message["type"] == "lifespan.shutdown":
171 await self.shutdown()
172 await send({"type": "lifespan.shutdown.complete"})
173
174
175 class ASGIApp:
176 def __init__(self) -> None:
177 self.ws = None
178
179 @classmethod
180 async def create(
181 cls, sanic_app, scope: ASGIScope, receive: ASGIReceive, send: ASGISend
182 ) -> "ASGIApp":
183 instance = cls()
184 instance.sanic_app = sanic_app
185 instance.transport = MockTransport(scope, receive, send)
186 instance.transport.add_task = sanic_app.loop.create_task
187 instance.transport.loop = sanic_app.loop
188
189 headers = CIMultiDict(
190 [
191 (key.decode("latin-1"), value.decode("latin-1"))
192 for key, value in scope.get("headers", [])
193 ]
194 )
195 instance.do_stream = (
196 True if headers.get("expect") == "100-continue" else False
197 )
198 instance.lifespan = Lifespan(instance)
199
200 if scope["type"] == "lifespan":
201 await instance.lifespan(scope, receive, send)
202 else:
203 url_bytes = scope.get("root_path", "") + quote(scope["path"])
204 url_bytes = url_bytes.encode("latin-1")
205 url_bytes += b"?" + scope["query_string"]
206
207 if scope["type"] == "http":
208 version = scope["http_version"]
209 method = scope["method"]
210 elif scope["type"] == "websocket":
211 version = "1.1"
212 method = "GET"
213
214 instance.ws = instance.transport.create_websocket_connection(
215 send, receive
216 )
217 await instance.ws.accept()
218 else:
219 pass
220 # TODO:
221 # - close connection
222
223 request_class = sanic_app.request_class or Request
224 instance.request = request_class(
225 url_bytes,
226 headers,
227 version,
228 method,
229 instance.transport,
230 sanic_app,
231 )
232
233 if sanic_app.is_request_stream:
234 is_stream_handler = sanic_app.router.is_stream_handler(
235 instance.request
236 )
237 if is_stream_handler:
238 instance.request.stream = StreamBuffer(
239 sanic_app.config.REQUEST_BUFFER_QUEUE_SIZE
240 )
241 instance.do_stream = True
242
243 return instance
244
245 async def read_body(self) -> bytes:
246 """
247 Read and return the entire body from an incoming ASGI message.
248 """
249 body = b""
250 more_body = True
251 while more_body:
252 message = await self.transport.receive()
253 body += message.get("body", b"")
254 more_body = message.get("more_body", False)
255
256 return body
257
258 async def stream_body(self) -> None:
259 """
260 Read and stream the body in chunks from an incoming ASGI message.
261 """
262 more_body = True
263
264 while more_body:
265 message = await self.transport.receive()
266 chunk = message.get("body", b"")
267 await self.request.stream.put(chunk)
268
269 more_body = message.get("more_body", False)
270
271 await self.request.stream.put(None)
272
273 async def __call__(self) -> None:
274 """
275 Handle the incoming request.
276 """
277 if not self.do_stream:
278 self.request.body = await self.read_body()
279 else:
280 self.sanic_app.loop.create_task(self.stream_body())
281
282 handler = self.sanic_app.handle_request
283 callback = None if self.ws else self.stream_callback
284 await handler(self.request, None, callback)
285
286 async def stream_callback(self, response: HTTPResponse) -> None:
287 """
288 Write the response.
289 """
290 headers = []
291 cookies = {}
292 try:
293 cookies = {
294 v.key: v
295 for _, v in list(
296 filter(
297 lambda item: item[0].lower() == "set-cookie",
298 response.headers.items(),
299 )
300 )
301 }
302 headers += [
303 (str(name).encode("latin-1"), str(value).encode("latin-1"))
304 for name, value in response.headers.items()
305 if name.lower() not in ["set-cookie"]
306 ]
307 except AttributeError:
308 logger.error(
309 "Invalid response object for url %s, "
310 "Expected Type: HTTPResponse, Actual Type: %s",
311 self.request.url,
312 type(response),
313 )
314 exception = ServerError("Invalid response type")
315 response = self.sanic_app.error_handler.response(
316 self.request, exception
317 )
318 headers = [
319 (str(name).encode("latin-1"), str(value).encode("latin-1"))
320 for name, value in response.headers.items()
321 if name not in (b"Set-Cookie",)
322 ]
323
324 if "content-length" not in response.headers and not isinstance(
325 response, StreamingHTTPResponse
326 ):
327 headers += [
328 (b"content-length", str(len(response.body)).encode("latin-1"))
329 ]
330
331 if response.cookies:
332 cookies.update(
333 {
334 v.key: v
335 for _, v in response.cookies.items()
336 if v.key not in cookies.keys()
337 }
338 )
339
340 headers += [
341 (b"set-cookie", cookie.encode("utf-8"))
342 for k, cookie in cookies.items()
343 ]
344
345 await self.transport.send(
346 {
347 "type": "http.response.start",
348 "status": response.status,
349 "headers": headers,
350 }
351 )
352
353 if isinstance(response, StreamingHTTPResponse):
354 response.protocol = self.transport.get_protocol()
355 await response.stream()
356 await response.protocol.complete()
357
358 else:
359 await self.transport.send(
360 {
361 "type": "http.response.body",
362 "body": response.body,
363 "more_body": False,
364 }
365 )
366
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sanic/asgi.py b/sanic/asgi.py
--- a/sanic/asgi.py
+++ b/sanic/asgi.py
@@ -328,6 +328,11 @@
(b"content-length", str(len(response.body)).encode("latin-1"))
]
+ if "content-type" not in response.headers:
+ headers += [
+ (b"content-type", str(response.content_type).encode("latin-1"))
+ ]
+
if response.cookies:
cookies.update(
{
| {"golden_diff": "diff --git a/sanic/asgi.py b/sanic/asgi.py\n--- a/sanic/asgi.py\n+++ b/sanic/asgi.py\n@@ -328,6 +328,11 @@\n (b\"content-length\", str(len(response.body)).encode(\"latin-1\"))\n ]\n \n+ if \"content-type\" not in response.headers:\n+ headers += [\n+ (b\"content-type\", str(response.content_type).encode(\"latin-1\"))\n+ ]\n+\n if response.cookies:\n cookies.update(\n {\n", "issue": "The response.content_type is not add to headers in ASGI\nPerhaps the response.content_type is add to headers here.\n", "before_files": [{"content": "import asyncio\nimport warnings\n\nfrom inspect import isawaitable\nfrom typing import Any, Awaitable, Callable, MutableMapping, Union\nfrom urllib.parse import quote\n\nfrom multidict import CIMultiDict\n\nfrom sanic.exceptions import InvalidUsage, ServerError\nfrom sanic.log import logger\nfrom sanic.request import Request\nfrom sanic.response import HTTPResponse, StreamingHTTPResponse\nfrom sanic.server import StreamBuffer\nfrom sanic.websocket import WebSocketConnection\n\n\nASGIScope = MutableMapping[str, Any]\nASGIMessage = MutableMapping[str, Any]\nASGISend = Callable[[ASGIMessage], Awaitable[None]]\nASGIReceive = Callable[[], Awaitable[ASGIMessage]]\n\n\nclass MockProtocol:\n def __init__(self, transport: \"MockTransport\", loop):\n self.transport = transport\n self._not_paused = asyncio.Event(loop=loop)\n self._not_paused.set()\n self._complete = asyncio.Event(loop=loop)\n\n def pause_writing(self) -> None:\n self._not_paused.clear()\n\n def resume_writing(self) -> None:\n self._not_paused.set()\n\n async def complete(self) -> None:\n self._not_paused.set()\n await self.transport.send(\n {\"type\": \"http.response.body\", \"body\": b\"\", \"more_body\": False}\n )\n\n @property\n def is_complete(self) -> bool:\n return self._complete.is_set()\n\n async def push_data(self, data: bytes) -> None:\n if not self.is_complete:\n await self.transport.send(\n {\"type\": \"http.response.body\", \"body\": data, \"more_body\": True}\n )\n\n async def drain(self) -> None:\n await self._not_paused.wait()\n\n\nclass MockTransport:\n def __init__(\n self, scope: ASGIScope, receive: ASGIReceive, send: ASGISend\n ) -> None:\n self.scope = scope\n self._receive = receive\n self._send = send\n self._protocol = None\n self.loop = None\n\n def get_protocol(self) -> MockProtocol:\n if not self._protocol:\n self._protocol = MockProtocol(self, self.loop)\n return self._protocol\n\n def get_extra_info(self, info: str) -> Union[str, bool]:\n if info == \"peername\":\n return self.scope.get(\"server\")\n elif info == \"sslcontext\":\n return self.scope.get(\"scheme\") in [\"https\", \"wss\"]\n\n def get_websocket_connection(self) -> WebSocketConnection:\n try:\n return self._websocket_connection\n except AttributeError:\n raise InvalidUsage(\"Improper websocket connection.\")\n\n def create_websocket_connection(\n self, send: ASGISend, receive: ASGIReceive\n ) -> WebSocketConnection:\n self._websocket_connection = WebSocketConnection(send, receive)\n return self._websocket_connection\n\n def add_task(self) -> None:\n raise NotImplementedError\n\n async def send(self, data) -> None:\n # TODO:\n # - Validation on data and that it is formatted properly and is valid\n await self._send(data)\n\n async def receive(self) -> ASGIMessage:\n return await self._receive()\n\n\nclass Lifespan:\n def __init__(self, asgi_app: \"ASGIApp\") -> None:\n self.asgi_app = asgi_app\n\n if \"before_server_start\" in self.asgi_app.sanic_app.listeners:\n warnings.warn(\n 'You have set a listener for \"before_server_start\" '\n \"in ASGI mode. \"\n \"It will be executed as early as possible, but not before \"\n \"the ASGI server is started.\"\n )\n if \"after_server_stop\" in self.asgi_app.sanic_app.listeners:\n warnings.warn(\n 'You have set a listener for \"after_server_stop\" '\n \"in ASGI mode. \"\n \"It will be executed as late as possible, but not after \"\n \"the ASGI server is stopped.\"\n )\n\n async def startup(self) -> None:\n \"\"\"\n Gather the listeners to fire on server start.\n Because we are using a third-party server and not Sanic server, we do\n not have access to fire anything BEFORE the server starts.\n Therefore, we fire before_server_start and after_server_start\n in sequence since the ASGI lifespan protocol only supports a single\n startup event.\n \"\"\"\n listeners = self.asgi_app.sanic_app.listeners.get(\n \"before_server_start\", []\n ) + self.asgi_app.sanic_app.listeners.get(\"after_server_start\", [])\n\n for handler in listeners:\n response = handler(\n self.asgi_app.sanic_app, self.asgi_app.sanic_app.loop\n )\n if isawaitable(response):\n await response\n\n async def shutdown(self) -> None:\n \"\"\"\n Gather the listeners to fire on server stop.\n Because we are using a third-party server and not Sanic server, we do\n not have access to fire anything AFTER the server stops.\n Therefore, we fire before_server_stop and after_server_stop\n in sequence since the ASGI lifespan protocol only supports a single\n shutdown event.\n \"\"\"\n listeners = self.asgi_app.sanic_app.listeners.get(\n \"before_server_stop\", []\n ) + self.asgi_app.sanic_app.listeners.get(\"after_server_stop\", [])\n\n for handler in listeners:\n response = handler(\n self.asgi_app.sanic_app, self.asgi_app.sanic_app.loop\n )\n if isawaitable(response):\n await response\n\n async def __call__(\n self, scope: ASGIScope, receive: ASGIReceive, send: ASGISend\n ) -> None:\n message = await receive()\n if message[\"type\"] == \"lifespan.startup\":\n await self.startup()\n await send({\"type\": \"lifespan.startup.complete\"})\n\n message = await receive()\n if message[\"type\"] == \"lifespan.shutdown\":\n await self.shutdown()\n await send({\"type\": \"lifespan.shutdown.complete\"})\n\n\nclass ASGIApp:\n def __init__(self) -> None:\n self.ws = None\n\n @classmethod\n async def create(\n cls, sanic_app, scope: ASGIScope, receive: ASGIReceive, send: ASGISend\n ) -> \"ASGIApp\":\n instance = cls()\n instance.sanic_app = sanic_app\n instance.transport = MockTransport(scope, receive, send)\n instance.transport.add_task = sanic_app.loop.create_task\n instance.transport.loop = sanic_app.loop\n\n headers = CIMultiDict(\n [\n (key.decode(\"latin-1\"), value.decode(\"latin-1\"))\n for key, value in scope.get(\"headers\", [])\n ]\n )\n instance.do_stream = (\n True if headers.get(\"expect\") == \"100-continue\" else False\n )\n instance.lifespan = Lifespan(instance)\n\n if scope[\"type\"] == \"lifespan\":\n await instance.lifespan(scope, receive, send)\n else:\n url_bytes = scope.get(\"root_path\", \"\") + quote(scope[\"path\"])\n url_bytes = url_bytes.encode(\"latin-1\")\n url_bytes += b\"?\" + scope[\"query_string\"]\n\n if scope[\"type\"] == \"http\":\n version = scope[\"http_version\"]\n method = scope[\"method\"]\n elif scope[\"type\"] == \"websocket\":\n version = \"1.1\"\n method = \"GET\"\n\n instance.ws = instance.transport.create_websocket_connection(\n send, receive\n )\n await instance.ws.accept()\n else:\n pass\n # TODO:\n # - close connection\n\n request_class = sanic_app.request_class or Request\n instance.request = request_class(\n url_bytes,\n headers,\n version,\n method,\n instance.transport,\n sanic_app,\n )\n\n if sanic_app.is_request_stream:\n is_stream_handler = sanic_app.router.is_stream_handler(\n instance.request\n )\n if is_stream_handler:\n instance.request.stream = StreamBuffer(\n sanic_app.config.REQUEST_BUFFER_QUEUE_SIZE\n )\n instance.do_stream = True\n\n return instance\n\n async def read_body(self) -> bytes:\n \"\"\"\n Read and return the entire body from an incoming ASGI message.\n \"\"\"\n body = b\"\"\n more_body = True\n while more_body:\n message = await self.transport.receive()\n body += message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n\n return body\n\n async def stream_body(self) -> None:\n \"\"\"\n Read and stream the body in chunks from an incoming ASGI message.\n \"\"\"\n more_body = True\n\n while more_body:\n message = await self.transport.receive()\n chunk = message.get(\"body\", b\"\")\n await self.request.stream.put(chunk)\n\n more_body = message.get(\"more_body\", False)\n\n await self.request.stream.put(None)\n\n async def __call__(self) -> None:\n \"\"\"\n Handle the incoming request.\n \"\"\"\n if not self.do_stream:\n self.request.body = await self.read_body()\n else:\n self.sanic_app.loop.create_task(self.stream_body())\n\n handler = self.sanic_app.handle_request\n callback = None if self.ws else self.stream_callback\n await handler(self.request, None, callback)\n\n async def stream_callback(self, response: HTTPResponse) -> None:\n \"\"\"\n Write the response.\n \"\"\"\n headers = []\n cookies = {}\n try:\n cookies = {\n v.key: v\n for _, v in list(\n filter(\n lambda item: item[0].lower() == \"set-cookie\",\n response.headers.items(),\n )\n )\n }\n headers += [\n (str(name).encode(\"latin-1\"), str(value).encode(\"latin-1\"))\n for name, value in response.headers.items()\n if name.lower() not in [\"set-cookie\"]\n ]\n except AttributeError:\n logger.error(\n \"Invalid response object for url %s, \"\n \"Expected Type: HTTPResponse, Actual Type: %s\",\n self.request.url,\n type(response),\n )\n exception = ServerError(\"Invalid response type\")\n response = self.sanic_app.error_handler.response(\n self.request, exception\n )\n headers = [\n (str(name).encode(\"latin-1\"), str(value).encode(\"latin-1\"))\n for name, value in response.headers.items()\n if name not in (b\"Set-Cookie\",)\n ]\n\n if \"content-length\" not in response.headers and not isinstance(\n response, StreamingHTTPResponse\n ):\n headers += [\n (b\"content-length\", str(len(response.body)).encode(\"latin-1\"))\n ]\n\n if response.cookies:\n cookies.update(\n {\n v.key: v\n for _, v in response.cookies.items()\n if v.key not in cookies.keys()\n }\n )\n\n headers += [\n (b\"set-cookie\", cookie.encode(\"utf-8\"))\n for k, cookie in cookies.items()\n ]\n\n await self.transport.send(\n {\n \"type\": \"http.response.start\",\n \"status\": response.status,\n \"headers\": headers,\n }\n )\n\n if isinstance(response, StreamingHTTPResponse):\n response.protocol = self.transport.get_protocol()\n await response.stream()\n await response.protocol.complete()\n\n else:\n await self.transport.send(\n {\n \"type\": \"http.response.body\",\n \"body\": response.body,\n \"more_body\": False,\n }\n )\n", "path": "sanic/asgi.py"}], "after_files": [{"content": "import asyncio\nimport warnings\n\nfrom inspect import isawaitable\nfrom typing import Any, Awaitable, Callable, MutableMapping, Union\nfrom urllib.parse import quote\n\nfrom multidict import CIMultiDict\n\nfrom sanic.exceptions import InvalidUsage, ServerError\nfrom sanic.log import logger\nfrom sanic.request import Request\nfrom sanic.response import HTTPResponse, StreamingHTTPResponse\nfrom sanic.server import StreamBuffer\nfrom sanic.websocket import WebSocketConnection\n\n\nASGIScope = MutableMapping[str, Any]\nASGIMessage = MutableMapping[str, Any]\nASGISend = Callable[[ASGIMessage], Awaitable[None]]\nASGIReceive = Callable[[], Awaitable[ASGIMessage]]\n\n\nclass MockProtocol:\n def __init__(self, transport: \"MockTransport\", loop):\n self.transport = transport\n self._not_paused = asyncio.Event(loop=loop)\n self._not_paused.set()\n self._complete = asyncio.Event(loop=loop)\n\n def pause_writing(self) -> None:\n self._not_paused.clear()\n\n def resume_writing(self) -> None:\n self._not_paused.set()\n\n async def complete(self) -> None:\n self._not_paused.set()\n await self.transport.send(\n {\"type\": \"http.response.body\", \"body\": b\"\", \"more_body\": False}\n )\n\n @property\n def is_complete(self) -> bool:\n return self._complete.is_set()\n\n async def push_data(self, data: bytes) -> None:\n if not self.is_complete:\n await self.transport.send(\n {\"type\": \"http.response.body\", \"body\": data, \"more_body\": True}\n )\n\n async def drain(self) -> None:\n await self._not_paused.wait()\n\n\nclass MockTransport:\n def __init__(\n self, scope: ASGIScope, receive: ASGIReceive, send: ASGISend\n ) -> None:\n self.scope = scope\n self._receive = receive\n self._send = send\n self._protocol = None\n self.loop = None\n\n def get_protocol(self) -> MockProtocol:\n if not self._protocol:\n self._protocol = MockProtocol(self, self.loop)\n return self._protocol\n\n def get_extra_info(self, info: str) -> Union[str, bool]:\n if info == \"peername\":\n return self.scope.get(\"server\")\n elif info == \"sslcontext\":\n return self.scope.get(\"scheme\") in [\"https\", \"wss\"]\n\n def get_websocket_connection(self) -> WebSocketConnection:\n try:\n return self._websocket_connection\n except AttributeError:\n raise InvalidUsage(\"Improper websocket connection.\")\n\n def create_websocket_connection(\n self, send: ASGISend, receive: ASGIReceive\n ) -> WebSocketConnection:\n self._websocket_connection = WebSocketConnection(send, receive)\n return self._websocket_connection\n\n def add_task(self) -> None:\n raise NotImplementedError\n\n async def send(self, data) -> None:\n # TODO:\n # - Validation on data and that it is formatted properly and is valid\n await self._send(data)\n\n async def receive(self) -> ASGIMessage:\n return await self._receive()\n\n\nclass Lifespan:\n def __init__(self, asgi_app: \"ASGIApp\") -> None:\n self.asgi_app = asgi_app\n\n if \"before_server_start\" in self.asgi_app.sanic_app.listeners:\n warnings.warn(\n 'You have set a listener for \"before_server_start\" '\n \"in ASGI mode. \"\n \"It will be executed as early as possible, but not before \"\n \"the ASGI server is started.\"\n )\n if \"after_server_stop\" in self.asgi_app.sanic_app.listeners:\n warnings.warn(\n 'You have set a listener for \"after_server_stop\" '\n \"in ASGI mode. \"\n \"It will be executed as late as possible, but not after \"\n \"the ASGI server is stopped.\"\n )\n\n async def startup(self) -> None:\n \"\"\"\n Gather the listeners to fire on server start.\n Because we are using a third-party server and not Sanic server, we do\n not have access to fire anything BEFORE the server starts.\n Therefore, we fire before_server_start and after_server_start\n in sequence since the ASGI lifespan protocol only supports a single\n startup event.\n \"\"\"\n listeners = self.asgi_app.sanic_app.listeners.get(\n \"before_server_start\", []\n ) + self.asgi_app.sanic_app.listeners.get(\"after_server_start\", [])\n\n for handler in listeners:\n response = handler(\n self.asgi_app.sanic_app, self.asgi_app.sanic_app.loop\n )\n if isawaitable(response):\n await response\n\n async def shutdown(self) -> None:\n \"\"\"\n Gather the listeners to fire on server stop.\n Because we are using a third-party server and not Sanic server, we do\n not have access to fire anything AFTER the server stops.\n Therefore, we fire before_server_stop and after_server_stop\n in sequence since the ASGI lifespan protocol only supports a single\n shutdown event.\n \"\"\"\n listeners = self.asgi_app.sanic_app.listeners.get(\n \"before_server_stop\", []\n ) + self.asgi_app.sanic_app.listeners.get(\"after_server_stop\", [])\n\n for handler in listeners:\n response = handler(\n self.asgi_app.sanic_app, self.asgi_app.sanic_app.loop\n )\n if isawaitable(response):\n await response\n\n async def __call__(\n self, scope: ASGIScope, receive: ASGIReceive, send: ASGISend\n ) -> None:\n message = await receive()\n if message[\"type\"] == \"lifespan.startup\":\n await self.startup()\n await send({\"type\": \"lifespan.startup.complete\"})\n\n message = await receive()\n if message[\"type\"] == \"lifespan.shutdown\":\n await self.shutdown()\n await send({\"type\": \"lifespan.shutdown.complete\"})\n\n\nclass ASGIApp:\n def __init__(self) -> None:\n self.ws = None\n\n @classmethod\n async def create(\n cls, sanic_app, scope: ASGIScope, receive: ASGIReceive, send: ASGISend\n ) -> \"ASGIApp\":\n instance = cls()\n instance.sanic_app = sanic_app\n instance.transport = MockTransport(scope, receive, send)\n instance.transport.add_task = sanic_app.loop.create_task\n instance.transport.loop = sanic_app.loop\n\n headers = CIMultiDict(\n [\n (key.decode(\"latin-1\"), value.decode(\"latin-1\"))\n for key, value in scope.get(\"headers\", [])\n ]\n )\n instance.do_stream = (\n True if headers.get(\"expect\") == \"100-continue\" else False\n )\n instance.lifespan = Lifespan(instance)\n\n if scope[\"type\"] == \"lifespan\":\n await instance.lifespan(scope, receive, send)\n else:\n url_bytes = scope.get(\"root_path\", \"\") + quote(scope[\"path\"])\n url_bytes = url_bytes.encode(\"latin-1\")\n url_bytes += b\"?\" + scope[\"query_string\"]\n\n if scope[\"type\"] == \"http\":\n version = scope[\"http_version\"]\n method = scope[\"method\"]\n elif scope[\"type\"] == \"websocket\":\n version = \"1.1\"\n method = \"GET\"\n\n instance.ws = instance.transport.create_websocket_connection(\n send, receive\n )\n await instance.ws.accept()\n else:\n pass\n # TODO:\n # - close connection\n\n request_class = sanic_app.request_class or Request\n instance.request = request_class(\n url_bytes,\n headers,\n version,\n method,\n instance.transport,\n sanic_app,\n )\n\n if sanic_app.is_request_stream:\n is_stream_handler = sanic_app.router.is_stream_handler(\n instance.request\n )\n if is_stream_handler:\n instance.request.stream = StreamBuffer(\n sanic_app.config.REQUEST_BUFFER_QUEUE_SIZE\n )\n instance.do_stream = True\n\n return instance\n\n async def read_body(self) -> bytes:\n \"\"\"\n Read and return the entire body from an incoming ASGI message.\n \"\"\"\n body = b\"\"\n more_body = True\n while more_body:\n message = await self.transport.receive()\n body += message.get(\"body\", b\"\")\n more_body = message.get(\"more_body\", False)\n\n return body\n\n async def stream_body(self) -> None:\n \"\"\"\n Read and stream the body in chunks from an incoming ASGI message.\n \"\"\"\n more_body = True\n\n while more_body:\n message = await self.transport.receive()\n chunk = message.get(\"body\", b\"\")\n await self.request.stream.put(chunk)\n\n more_body = message.get(\"more_body\", False)\n\n await self.request.stream.put(None)\n\n async def __call__(self) -> None:\n \"\"\"\n Handle the incoming request.\n \"\"\"\n if not self.do_stream:\n self.request.body = await self.read_body()\n else:\n self.sanic_app.loop.create_task(self.stream_body())\n\n handler = self.sanic_app.handle_request\n callback = None if self.ws else self.stream_callback\n await handler(self.request, None, callback)\n\n async def stream_callback(self, response: HTTPResponse) -> None:\n \"\"\"\n Write the response.\n \"\"\"\n headers = []\n cookies = {}\n try:\n cookies = {\n v.key: v\n for _, v in list(\n filter(\n lambda item: item[0].lower() == \"set-cookie\",\n response.headers.items(),\n )\n )\n }\n headers += [\n (str(name).encode(\"latin-1\"), str(value).encode(\"latin-1\"))\n for name, value in response.headers.items()\n if name.lower() not in [\"set-cookie\"]\n ]\n except AttributeError:\n logger.error(\n \"Invalid response object for url %s, \"\n \"Expected Type: HTTPResponse, Actual Type: %s\",\n self.request.url,\n type(response),\n )\n exception = ServerError(\"Invalid response type\")\n response = self.sanic_app.error_handler.response(\n self.request, exception\n )\n headers = [\n (str(name).encode(\"latin-1\"), str(value).encode(\"latin-1\"))\n for name, value in response.headers.items()\n if name not in (b\"Set-Cookie\",)\n ]\n\n if \"content-length\" not in response.headers and not isinstance(\n response, StreamingHTTPResponse\n ):\n headers += [\n (b\"content-length\", str(len(response.body)).encode(\"latin-1\"))\n ]\n\n if \"content-type\" not in response.headers:\n headers += [\n (b\"content-type\", str(response.content_type).encode(\"latin-1\"))\n ]\n\n if response.cookies:\n cookies.update(\n {\n v.key: v\n for _, v in response.cookies.items()\n if v.key not in cookies.keys()\n }\n )\n\n headers += [\n (b\"set-cookie\", cookie.encode(\"utf-8\"))\n for k, cookie in cookies.items()\n ]\n\n await self.transport.send(\n {\n \"type\": \"http.response.start\",\n \"status\": response.status,\n \"headers\": headers,\n }\n )\n\n if isinstance(response, StreamingHTTPResponse):\n response.protocol = self.transport.get_protocol()\n await response.stream()\n await response.protocol.complete()\n\n else:\n await self.transport.send(\n {\n \"type\": \"http.response.body\",\n \"body\": response.body,\n \"more_body\": False,\n }\n )\n", "path": "sanic/asgi.py"}]} | 3,799 | 119 |
gh_patches_debug_15255 | rasdani/github-patches | git_diff | chainer__chainer-1421 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SerialIterator's shuffle does not work under certain batch sizes
When we give `shuffle=True` to `SerialIterator`, re-shuffling after an epoch is skipped if `len(dataset)` is divisible by `batch_size`.

https://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L65
Variable `_order` is never re-shuffled if `rest` > 0 (i.e., `len(dataset)` is divisible by `batch_size`).
(If it is okay, I'm interested in working on this issue at the development meeting tomorrow.)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `chainer/iterators/serial_iterator.py`
Content:
```
1 from __future__ import division
2
3 import numpy
4
5 from chainer.dataset import iterator
6
7
8 class SerialIterator(iterator.Iterator):
9
10 """Dataset iterator that serially reads the examples.
11
12 This is a simple implementation of :class:`~chainer.dataset.Iterator`
13 that just visits each example in either the order of indexes or a shuffled
14 order.
15
16 To avoid unintentional performance degradation, the ``shuffle`` option is
17 set to ``True`` by default. For validation, it is better to set it to
18 ``False`` when the underlying dataset supports fast slicing. If the
19 order of examples has an important meaning and the updater depends on the
20 original order, this option should be set to ``False``.
21
22 Args:
23 dataset: Dataset to iterate.
24 batch_size (int): Number of examples within each batch.
25 repeat (bool): If ``True``, it infinitely loops over the dataset.
26 Otherwise, it stops iteration at the end of the first epoch.
27 shuffle (bool): If ``True``, the order of examples is shuffled at the
28 beginning of each epoch. Otherwise, examples are extracted in the
29 order of indexes.
30
31 """
32 def __init__(self, dataset, batch_size, repeat=True, shuffle=True):
33 self.dataset = dataset
34 self.batch_size = batch_size
35 self._repeat = repeat
36 if shuffle:
37 self._order = numpy.random.permutation(len(dataset))
38 else:
39 self._order = None
40
41 self.current_position = 0
42 self.epoch = 0
43 self.is_new_epoch = False
44
45 def __next__(self):
46 if not self._repeat and self.epoch > 0:
47 raise StopIteration
48
49 i = self.current_position
50 i_end = i + self.batch_size
51 N = len(self.dataset)
52
53 if self._order is None:
54 batch = self.dataset[i:i_end]
55 else:
56 batch = [self.dataset[index] for index in self._order[i:i_end]]
57
58 if i_end >= N:
59 if self._repeat:
60 rest = i_end - N
61 if rest > 0:
62 if self._order is None:
63 batch += list(self.dataset[:rest])
64 else:
65 numpy.random.shuffle(self._order)
66 batch += [self.dataset[index]
67 for index in self._order[:rest]]
68 self.current_position = rest
69 else:
70 self.current_position = N
71
72 self.epoch += 1
73 self.is_new_epoch = True
74 else:
75 self.is_new_epoch = False
76 self.current_position = i_end
77
78 return batch
79
80 next = __next__
81
82 @property
83 def epoch_detail(self):
84 return self.epoch + self.current_position / len(self.dataset)
85
86 def serialize(self, serializer):
87 self.current_position = serializer('current_position',
88 self.current_position)
89 self.epoch = serializer('epoch', self.epoch)
90 self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)
91 if self._order is not None:
92 serializer('_order', self._order)
93
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/chainer/iterators/serial_iterator.py b/chainer/iterators/serial_iterator.py
--- a/chainer/iterators/serial_iterator.py
+++ b/chainer/iterators/serial_iterator.py
@@ -58,11 +58,12 @@
if i_end >= N:
if self._repeat:
rest = i_end - N
+ if self._order is not None:
+ numpy.random.shuffle(self._order)
if rest > 0:
if self._order is None:
batch += list(self.dataset[:rest])
else:
- numpy.random.shuffle(self._order)
batch += [self.dataset[index]
for index in self._order[:rest]]
self.current_position = rest
| {"golden_diff": "diff --git a/chainer/iterators/serial_iterator.py b/chainer/iterators/serial_iterator.py\n--- a/chainer/iterators/serial_iterator.py\n+++ b/chainer/iterators/serial_iterator.py\n@@ -58,11 +58,12 @@\n if i_end >= N:\n if self._repeat:\n rest = i_end - N\n+ if self._order is not None:\n+ numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n batch += list(self.dataset[:rest])\n else:\n- numpy.random.shuffle(self._order)\n batch += [self.dataset[index]\n for index in self._order[:rest]]\n self.current_position = rest\n", "issue": "SerialIterator's shuffle does not work under certain batch sizes\nWhen we give `shuffle=True` to `SerialIterator`, re-shuffling after an epoch is skipped if `len(dataset)` is divisible by `batch_size`.\n\n\n\nhttps://github.com/pfnet/chainer/blob/master/chainer/iterators/serial_iterator.py#L65\n\nVariable `_order` is never re-shuffled if `rest` > 0 (i.e., `len(dataset)` is divisible by `batch_size`).\n\n(If it is okay, I'm interested in working on this issue at the development meeting tomorrow.)\n\n", "before_files": [{"content": "from __future__ import division\n\nimport numpy\n\nfrom chainer.dataset import iterator\n\n\nclass SerialIterator(iterator.Iterator):\n\n \"\"\"Dataset iterator that serially reads the examples.\n\n This is a simple implementation of :class:`~chainer.dataset.Iterator`\n that just visits each example in either the order of indexes or a shuffled\n order.\n\n To avoid unintentional performance degradation, the ``shuffle`` option is\n set to ``True`` by default. For validation, it is better to set it to\n ``False`` when the underlying dataset supports fast slicing. If the\n order of examples has an important meaning and the updater depends on the\n original order, this option should be set to ``False``.\n\n Args:\n dataset: Dataset to iterate.\n batch_size (int): Number of examples within each batch.\n repeat (bool): If ``True``, it infinitely loops over the dataset.\n Otherwise, it stops iteration at the end of the first epoch.\n shuffle (bool): If ``True``, the order of examples is shuffled at the\n beginning of each epoch. Otherwise, examples are extracted in the\n order of indexes.\n\n \"\"\"\n def __init__(self, dataset, batch_size, repeat=True, shuffle=True):\n self.dataset = dataset\n self.batch_size = batch_size\n self._repeat = repeat\n if shuffle:\n self._order = numpy.random.permutation(len(dataset))\n else:\n self._order = None\n\n self.current_position = 0\n self.epoch = 0\n self.is_new_epoch = False\n\n def __next__(self):\n if not self._repeat and self.epoch > 0:\n raise StopIteration\n\n i = self.current_position\n i_end = i + self.batch_size\n N = len(self.dataset)\n\n if self._order is None:\n batch = self.dataset[i:i_end]\n else:\n batch = [self.dataset[index] for index in self._order[i:i_end]]\n\n if i_end >= N:\n if self._repeat:\n rest = i_end - N\n if rest > 0:\n if self._order is None:\n batch += list(self.dataset[:rest])\n else:\n numpy.random.shuffle(self._order)\n batch += [self.dataset[index]\n for index in self._order[:rest]]\n self.current_position = rest\n else:\n self.current_position = N\n\n self.epoch += 1\n self.is_new_epoch = True\n else:\n self.is_new_epoch = False\n self.current_position = i_end\n\n return batch\n\n next = __next__\n\n @property\n def epoch_detail(self):\n return self.epoch + self.current_position / len(self.dataset)\n\n def serialize(self, serializer):\n self.current_position = serializer('current_position',\n self.current_position)\n self.epoch = serializer('epoch', self.epoch)\n self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)\n if self._order is not None:\n serializer('_order', self._order)\n", "path": "chainer/iterators/serial_iterator.py"}], "after_files": [{"content": "from __future__ import division\n\nimport numpy\n\nfrom chainer.dataset import iterator\n\n\nclass SerialIterator(iterator.Iterator):\n\n \"\"\"Dataset iterator that serially reads the examples.\n\n This is a simple implementation of :class:`~chainer.dataset.Iterator`\n that just visits each example in either the order of indexes or a shuffled\n order.\n\n To avoid unintentional performance degradation, the ``shuffle`` option is\n set to ``True`` by default. For validation, it is better to set it to\n ``False`` when the underlying dataset supports fast slicing. If the\n order of examples has an important meaning and the updater depends on the\n original order, this option should be set to ``False``.\n\n Args:\n dataset: Dataset to iterate.\n batch_size (int): Number of examples within each batch.\n repeat (bool): If ``True``, it infinitely loops over the dataset.\n Otherwise, it stops iteration at the end of the first epoch.\n shuffle (bool): If ``True``, the order of examples is shuffled at the\n beginning of each epoch. Otherwise, examples are extracted in the\n order of indexes.\n\n \"\"\"\n def __init__(self, dataset, batch_size, repeat=True, shuffle=True):\n self.dataset = dataset\n self.batch_size = batch_size\n self._repeat = repeat\n if shuffle:\n self._order = numpy.random.permutation(len(dataset))\n else:\n self._order = None\n\n self.current_position = 0\n self.epoch = 0\n self.is_new_epoch = False\n\n def __next__(self):\n if not self._repeat and self.epoch > 0:\n raise StopIteration\n\n i = self.current_position\n i_end = i + self.batch_size\n N = len(self.dataset)\n\n if self._order is None:\n batch = self.dataset[i:i_end]\n else:\n batch = [self.dataset[index] for index in self._order[i:i_end]]\n\n if i_end >= N:\n if self._repeat:\n rest = i_end - N\n if self._order is not None:\n numpy.random.shuffle(self._order)\n if rest > 0:\n if self._order is None:\n batch += list(self.dataset[:rest])\n else:\n batch += [self.dataset[index]\n for index in self._order[:rest]]\n self.current_position = rest\n else:\n self.current_position = N\n\n self.epoch += 1\n self.is_new_epoch = True\n else:\n self.is_new_epoch = False\n self.current_position = i_end\n\n return batch\n\n next = __next__\n\n @property\n def epoch_detail(self):\n return self.epoch + self.current_position / len(self.dataset)\n\n def serialize(self, serializer):\n self.current_position = serializer('current_position',\n self.current_position)\n self.epoch = serializer('epoch', self.epoch)\n self.is_new_epoch = serializer('is_new_epoch', self.is_new_epoch)\n if self._order is not None:\n serializer('_order', self._order)\n", "path": "chainer/iterators/serial_iterator.py"}]} | 1,281 | 163 |
gh_patches_debug_12636 | rasdani/github-patches | git_diff | Mailu__Mailu-2630 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Docker container crashes if IPv6 is disabled at the system level.
If listen [::] is found somewhere in the configs, but IPv6 is disabled at the host system level and in the docker, then the process crashes, and, accordingly, the docker container also crashes.
This can be manually climbed into each container, corrected, but it is not very convenient.
docker exec mailu_front_1 sed -i '/listen \[/d' /conf/nginx.conf
docker exec mailu_front_1 sed -i '/listen \[/d' /etc/nginx/nginx.conf
docker exec mailu_front_1 sed -i '/listen \[/d' /etc/nginx/http.d/default.conf
docker restart mailu_front_1
docker restart mailu_webdav_1 && docker exec -it mailu_webdav_1 sed -i 's/hosts =.*\[::\].*/hosts = 0.0.0.0:5232/g' /radicale.conf && docker restart mailu_webdav_1
Can you add a container launch option to remove listen [::] from configs?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `core/admin/start.py`
Content:
```
1 #!/usr/bin/env python3
2
3 import os
4 import logging as log
5 import sys
6 from socrate import system
7
8 os.system("chown mailu:mailu -R /dkim")
9 os.system("find /data | grep -v /fetchmail | xargs -n1 chown mailu:mailu")
10 system.drop_privs_to('mailu')
11
12 log.basicConfig(stream=sys.stderr, level=os.environ.get("LOG_LEVEL", "INFO"))
13 system.set_env(['SECRET'])
14
15 os.system("flask mailu advertise")
16 os.system("flask db upgrade")
17
18 account = os.environ.get("INITIAL_ADMIN_ACCOUNT")
19 domain = os.environ.get("INITIAL_ADMIN_DOMAIN")
20 password = os.environ.get("INITIAL_ADMIN_PW")
21
22 if account is not None and domain is not None and password is not None:
23 mode = os.environ.get("INITIAL_ADMIN_MODE", default="ifmissing")
24 log.info("Creating initial admin account %s@%s with mode %s", account, domain, mode)
25 os.system("flask mailu admin %s %s '%s' --mode %s" % (account, domain, password, mode))
26
27 def test_DNS():
28 import dns.resolver
29 import dns.exception
30 import dns.flags
31 import dns.rdtypes
32 import dns.rdatatype
33 import dns.rdataclass
34 import time
35 # DNS stub configured to do DNSSEC enabled queries
36 resolver = dns.resolver.Resolver()
37 resolver.use_edns(0, dns.flags.DO, 1232)
38 resolver.flags = dns.flags.AD | dns.flags.RD
39 nameservers = resolver.nameservers
40 for ns in nameservers:
41 resolver.nameservers=[ns]
42 while True:
43 try:
44 result = resolver.resolve('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)
45 except Exception as e:
46 log.critical("Your DNS resolver at %s is not working (%s). Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation", ns, e)
47 else:
48 if result.response.flags & dns.flags.AD:
49 break
50 log.critical("Your DNS resolver at %s isn't doing DNSSEC validation; Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation.", ns)
51 time.sleep(5)
52
53 test_DNS()
54
55 start_command=" ".join([
56 "gunicorn",
57 f"--threads {str(os.cpu_count())}",
58 "-b :80",
59 "--logger-class mailu.Logger",
60 "--worker-tmp-dir /dev/shm",
61 "--access-logfile -" if (log.root.level<=log.INFO) else "",
62 "--error-logfile -",
63 "--preload",
64 "'mailu:create_app()'"])
65
66 os.system(start_command)
67
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/core/admin/start.py b/core/admin/start.py
--- a/core/admin/start.py
+++ b/core/admin/start.py
@@ -52,15 +52,21 @@
test_DNS()
-start_command=" ".join([
- "gunicorn",
- f"--threads {str(os.cpu_count())}",
- "-b :80",
+cmdline = [
+ "gunicorn",
+ "--threads", f"{os.cpu_count()}",
+ # If SUBNET6 is defined, gunicorn must listen on IPv6 as well as IPv4
+ "-b", f"{'[::]' if os.environ.get('SUBNET6') else ''}:80",
"--logger-class mailu.Logger",
"--worker-tmp-dir /dev/shm",
- "--access-logfile -" if (log.root.level<=log.INFO) else "",
- "--error-logfile -",
- "--preload",
- "'mailu:create_app()'"])
+ "--error-logfile", "-",
+ "--preload"
+]
-os.system(start_command)
+# logging
+if log.root.level <= log.INFO:
+ cmdline.extend(["--access-logfile", "-"])
+
+cmdline.append("'mailu:create_app()'")
+
+os.system(" ".join(cmdline))
| {"golden_diff": "diff --git a/core/admin/start.py b/core/admin/start.py\n--- a/core/admin/start.py\n+++ b/core/admin/start.py\n@@ -52,15 +52,21 @@\n \n test_DNS()\n \n-start_command=\" \".join([\n- \"gunicorn\",\n- f\"--threads {str(os.cpu_count())}\",\n- \"-b :80\",\n+cmdline = [\n+\t\"gunicorn\",\n+\t\"--threads\", f\"{os.cpu_count()}\",\n+\t# If SUBNET6 is defined, gunicorn must listen on IPv6 as well as IPv4\n+\t\"-b\", f\"{'[::]' if os.environ.get('SUBNET6') else ''}:80\",\n \"--logger-class mailu.Logger\",\n \"--worker-tmp-dir /dev/shm\",\n- \"--access-logfile -\" if (log.root.level<=log.INFO) else \"\",\n- \"--error-logfile -\",\n- \"--preload\",\n- \"'mailu:create_app()'\"])\n+\t\"--error-logfile\", \"-\",\n+\t\"--preload\"\n+]\n \n-os.system(start_command)\n+# logging\n+if log.root.level <= log.INFO:\n+\tcmdline.extend([\"--access-logfile\", \"-\"])\n+\n+cmdline.append(\"'mailu:create_app()'\")\n+\n+os.system(\" \".join(cmdline))\n", "issue": "Docker container crashes if IPv6 is disabled at the system level.\nIf listen [::] is found somewhere in the configs, but IPv6 is disabled at the host system level and in the docker, then the process crashes, and, accordingly, the docker container also crashes.\r\n\r\nThis can be manually climbed into each container, corrected, but it is not very convenient.\r\n\r\ndocker exec mailu_front_1 sed -i '/listen \\[/d' /conf/nginx.conf\r\ndocker exec mailu_front_1 sed -i '/listen \\[/d' /etc/nginx/nginx.conf\r\ndocker exec mailu_front_1 sed -i '/listen \\[/d' /etc/nginx/http.d/default.conf\r\ndocker restart mailu_front_1\r\n\r\ndocker restart mailu_webdav_1 && docker exec -it mailu_webdav_1 sed -i 's/hosts =.*\\[::\\].*/hosts = 0.0.0.0:5232/g' /radicale.conf && docker restart mailu_webdav_1\r\n\r\n\r\nCan you add a container launch option to remove listen [::] from configs?\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport logging as log\nimport sys\nfrom socrate import system\n\nos.system(\"chown mailu:mailu -R /dkim\")\nos.system(\"find /data | grep -v /fetchmail | xargs -n1 chown mailu:mailu\")\nsystem.drop_privs_to('mailu')\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"INFO\"))\nsystem.set_env(['SECRET'])\n\nos.system(\"flask mailu advertise\")\nos.system(\"flask db upgrade\")\n\naccount = os.environ.get(\"INITIAL_ADMIN_ACCOUNT\")\ndomain = os.environ.get(\"INITIAL_ADMIN_DOMAIN\")\npassword = os.environ.get(\"INITIAL_ADMIN_PW\")\n\nif account is not None and domain is not None and password is not None:\n mode = os.environ.get(\"INITIAL_ADMIN_MODE\", default=\"ifmissing\")\n log.info(\"Creating initial admin account %s@%s with mode %s\", account, domain, mode)\n os.system(\"flask mailu admin %s %s '%s' --mode %s\" % (account, domain, password, mode))\n\ndef test_DNS():\n import dns.resolver\n import dns.exception\n import dns.flags\n import dns.rdtypes\n import dns.rdatatype\n import dns.rdataclass\n import time\n # DNS stub configured to do DNSSEC enabled queries\n resolver = dns.resolver.Resolver()\n resolver.use_edns(0, dns.flags.DO, 1232)\n resolver.flags = dns.flags.AD | dns.flags.RD\n nameservers = resolver.nameservers\n for ns in nameservers:\n resolver.nameservers=[ns]\n while True:\n try:\n result = resolver.resolve('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)\n except Exception as e:\n log.critical(\"Your DNS resolver at %s is not working (%s). Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation\", ns, e)\n else:\n if result.response.flags & dns.flags.AD:\n break\n log.critical(\"Your DNS resolver at %s isn't doing DNSSEC validation; Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation.\", ns)\n time.sleep(5)\n\ntest_DNS()\n\nstart_command=\" \".join([\n \"gunicorn\",\n f\"--threads {str(os.cpu_count())}\",\n \"-b :80\",\n \"--logger-class mailu.Logger\",\n \"--worker-tmp-dir /dev/shm\",\n \"--access-logfile -\" if (log.root.level<=log.INFO) else \"\",\n \"--error-logfile -\",\n \"--preload\",\n \"'mailu:create_app()'\"])\n\nos.system(start_command)\n", "path": "core/admin/start.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n\nimport os\nimport logging as log\nimport sys\nfrom socrate import system\n\nos.system(\"chown mailu:mailu -R /dkim\")\nos.system(\"find /data | grep -v /fetchmail | xargs -n1 chown mailu:mailu\")\nsystem.drop_privs_to('mailu')\n\nlog.basicConfig(stream=sys.stderr, level=os.environ.get(\"LOG_LEVEL\", \"INFO\"))\nsystem.set_env(['SECRET'])\n\nos.system(\"flask mailu advertise\")\nos.system(\"flask db upgrade\")\n\naccount = os.environ.get(\"INITIAL_ADMIN_ACCOUNT\")\ndomain = os.environ.get(\"INITIAL_ADMIN_DOMAIN\")\npassword = os.environ.get(\"INITIAL_ADMIN_PW\")\n\nif account is not None and domain is not None and password is not None:\n mode = os.environ.get(\"INITIAL_ADMIN_MODE\", default=\"ifmissing\")\n log.info(\"Creating initial admin account %s@%s with mode %s\", account, domain, mode)\n os.system(\"flask mailu admin %s %s '%s' --mode %s\" % (account, domain, password, mode))\n\ndef test_DNS():\n import dns.resolver\n import dns.exception\n import dns.flags\n import dns.rdtypes\n import dns.rdatatype\n import dns.rdataclass\n import time\n # DNS stub configured to do DNSSEC enabled queries\n resolver = dns.resolver.Resolver()\n resolver.use_edns(0, dns.flags.DO, 1232)\n resolver.flags = dns.flags.AD | dns.flags.RD\n nameservers = resolver.nameservers\n for ns in nameservers:\n resolver.nameservers=[ns]\n while True:\n try:\n result = resolver.resolve('example.org', dns.rdatatype.A, dns.rdataclass.IN, lifetime=10)\n except Exception as e:\n log.critical(\"Your DNS resolver at %s is not working (%s). Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation\", ns, e)\n else:\n if result.response.flags & dns.flags.AD:\n break\n log.critical(\"Your DNS resolver at %s isn't doing DNSSEC validation; Please see https://mailu.io/master/faq.html#the-admin-container-won-t-start-and-its-log-says-critical-your-dns-resolver-isn-t-doing-dnssec-validation.\", ns)\n time.sleep(5)\n\ntest_DNS()\n\ncmdline = [\n\t\"gunicorn\",\n\t\"--threads\", f\"{os.cpu_count()}\",\n\t# If SUBNET6 is defined, gunicorn must listen on IPv6 as well as IPv4\n\t\"-b\", f\"{'[::]' if os.environ.get('SUBNET6') else ''}:80\",\n \"--logger-class mailu.Logger\",\n \"--worker-tmp-dir /dev/shm\",\n\t\"--error-logfile\", \"-\",\n\t\"--preload\"\n]\n\n# logging\nif log.root.level <= log.INFO:\n\tcmdline.extend([\"--access-logfile\", \"-\"])\n\ncmdline.append(\"'mailu:create_app()'\")\n\nos.system(\" \".join(cmdline))\n", "path": "core/admin/start.py"}]} | 1,263 | 279 |
gh_patches_debug_3119 | rasdani/github-patches | git_diff | Kinto__kinto-186 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Allow POST on buckets using the id_generator or the id provided in the data.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `kinto/views/buckets.py`
Content:
```
1 from six import text_type
2 from uuid import UUID
3
4 from pyramid.httpexceptions import (HTTPForbidden, HTTPPreconditionFailed,
5 HTTPException)
6 from pyramid.security import NO_PERMISSION_REQUIRED
7 from pyramid.view import view_config
8
9 from cliquet import resource
10 from cliquet.utils import hmac_digest, build_request, reapply_cors
11
12 from kinto.views import NameGenerator
13
14
15 def create_bucket(request, bucket_id):
16 """Create a bucket if it doesn't exists."""
17 bucket_put = (request.method.lower() == 'put' and
18 request.path.endswith('buckets/default'))
19
20 if not bucket_put:
21 subrequest = build_request(request, {
22 'method': 'PUT',
23 'path': '/buckets/%s' % bucket_id,
24 'body': {"data": {}},
25 'headers': {'If-None-Match': '*'.encode('utf-8')}
26 })
27
28 try:
29 request.invoke_subrequest(subrequest)
30 except HTTPPreconditionFailed:
31 # The bucket already exists
32 pass
33
34
35 def create_collection(request, bucket_id):
36 subpath = request.matchdict.get('subpath')
37 if subpath and subpath.startswith('collections/'):
38 collection_id = subpath.split('/')[1]
39 collection_put = (request.method.lower() == 'put' and
40 request.path.endswith(collection_id))
41 if not collection_put:
42 subrequest = build_request(request, {
43 'method': 'PUT',
44 'path': '/buckets/%s/collections/%s' % (
45 bucket_id, collection_id),
46 'body': {"data": {}},
47 'headers': {'If-None-Match': '*'.encode('utf-8')}
48 })
49 try:
50 request.invoke_subrequest(subrequest)
51 except HTTPPreconditionFailed:
52 # The collection already exists
53 pass
54
55
56 @view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)
57 @view_config(route_name='default_bucket_collection',
58 permission=NO_PERMISSION_REQUIRED)
59 def default_bucket(request):
60 if request.method.lower() == 'options':
61 path = request.path.replace('default', 'unknown')
62 subrequest = build_request(request, {
63 'method': 'OPTIONS',
64 'path': path
65 })
66 return request.invoke_subrequest(subrequest)
67
68 if getattr(request, 'prefixed_userid', None) is None:
69 raise HTTPForbidden # Pass through the forbidden_view_config
70
71 settings = request.registry.settings
72 hmac_secret = settings['cliquet.userid_hmac_secret']
73 # Build the user unguessable bucket_id UUID from its user_id
74 digest = hmac_digest(hmac_secret, request.prefixed_userid)
75 bucket_id = text_type(UUID(digest[:32]))
76 path = request.path.replace('/buckets/default', '/buckets/%s' % bucket_id)
77 querystring = request.url[(request.url.index(request.path) +
78 len(request.path)):]
79
80 # Make sure bucket exists
81 create_bucket(request, bucket_id)
82
83 # Make sure the collection exists
84 create_collection(request, bucket_id)
85
86 subrequest = build_request(request, {
87 'method': request.method,
88 'path': path + querystring,
89 'body': request.body
90 })
91
92 try:
93 response = request.invoke_subrequest(subrequest)
94 except HTTPException as error:
95 response = reapply_cors(subrequest, error)
96 return response
97
98
99 @resource.register(name='bucket',
100 collection_methods=('GET',),
101 collection_path='/buckets',
102 record_path='/buckets/{{id}}')
103 class Bucket(resource.ProtectedResource):
104 permissions = ('read', 'write', 'collection:create', 'group:create')
105
106 def __init__(self, *args, **kwargs):
107 super(Bucket, self).__init__(*args, **kwargs)
108 self.collection.id_generator = NameGenerator()
109
110 def get_parent_id(self, request):
111 # Buckets are not isolated by user, unlike Cliquet resources.
112 return ''
113
114 def delete(self):
115 result = super(Bucket, self).delete()
116
117 # Delete groups.
118 storage = self.collection.storage
119 parent_id = '/buckets/%s' % self.record_id
120 storage.delete_all(collection_id='group',
121 parent_id=parent_id,
122 with_deleted=False)
123 storage.purge_deleted(collection_id='group',
124 parent_id=parent_id)
125
126 # Delete collections.
127 deleted = storage.delete_all(collection_id='collection',
128 parent_id=parent_id,
129 with_deleted=False)
130 storage.purge_deleted(collection_id='collection',
131 parent_id=parent_id)
132
133 # Delete records.
134 id_field = self.collection.id_field
135 for collection in deleted:
136 parent_id = '/buckets/%s/collections/%s' % (self.record_id,
137 collection[id_field])
138 storage.delete_all(collection_id='record',
139 parent_id=parent_id,
140 with_deleted=False)
141 storage.purge_deleted(collection_id='record', parent_id=parent_id)
142
143 return result
144
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/kinto/views/buckets.py b/kinto/views/buckets.py
--- a/kinto/views/buckets.py
+++ b/kinto/views/buckets.py
@@ -97,7 +97,7 @@
@resource.register(name='bucket',
- collection_methods=('GET',),
+ collection_methods=('GET', 'POST'),
collection_path='/buckets',
record_path='/buckets/{{id}}')
class Bucket(resource.ProtectedResource):
| {"golden_diff": "diff --git a/kinto/views/buckets.py b/kinto/views/buckets.py\n--- a/kinto/views/buckets.py\n+++ b/kinto/views/buckets.py\n@@ -97,7 +97,7 @@\n \n \n @resource.register(name='bucket',\n- collection_methods=('GET',),\n+ collection_methods=('GET', 'POST'),\n collection_path='/buckets',\n record_path='/buckets/{{id}}')\n class Bucket(resource.ProtectedResource):\n", "issue": "Allow POST on buckets using the id_generator or the id provided in the data.\n\n", "before_files": [{"content": "from six import text_type\nfrom uuid import UUID\n\nfrom pyramid.httpexceptions import (HTTPForbidden, HTTPPreconditionFailed,\n HTTPException)\nfrom pyramid.security import NO_PERMISSION_REQUIRED\nfrom pyramid.view import view_config\n\nfrom cliquet import resource\nfrom cliquet.utils import hmac_digest, build_request, reapply_cors\n\nfrom kinto.views import NameGenerator\n\n\ndef create_bucket(request, bucket_id):\n \"\"\"Create a bucket if it doesn't exists.\"\"\"\n bucket_put = (request.method.lower() == 'put' and\n request.path.endswith('buckets/default'))\n\n if not bucket_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s' % bucket_id,\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The bucket already exists\n pass\n\n\ndef create_collection(request, bucket_id):\n subpath = request.matchdict.get('subpath')\n if subpath and subpath.startswith('collections/'):\n collection_id = subpath.split('/')[1]\n collection_put = (request.method.lower() == 'put' and\n request.path.endswith(collection_id))\n if not collection_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s/collections/%s' % (\n bucket_id, collection_id),\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The collection already exists\n pass\n\n\n@view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)\n@view_config(route_name='default_bucket_collection',\n permission=NO_PERMISSION_REQUIRED)\ndef default_bucket(request):\n if request.method.lower() == 'options':\n path = request.path.replace('default', 'unknown')\n subrequest = build_request(request, {\n 'method': 'OPTIONS',\n 'path': path\n })\n return request.invoke_subrequest(subrequest)\n\n if getattr(request, 'prefixed_userid', None) is None:\n raise HTTPForbidden # Pass through the forbidden_view_config\n\n settings = request.registry.settings\n hmac_secret = settings['cliquet.userid_hmac_secret']\n # Build the user unguessable bucket_id UUID from its user_id\n digest = hmac_digest(hmac_secret, request.prefixed_userid)\n bucket_id = text_type(UUID(digest[:32]))\n path = request.path.replace('/buckets/default', '/buckets/%s' % bucket_id)\n querystring = request.url[(request.url.index(request.path) +\n len(request.path)):]\n\n # Make sure bucket exists\n create_bucket(request, bucket_id)\n\n # Make sure the collection exists\n create_collection(request, bucket_id)\n\n subrequest = build_request(request, {\n 'method': request.method,\n 'path': path + querystring,\n 'body': request.body\n })\n\n try:\n response = request.invoke_subrequest(subrequest)\n except HTTPException as error:\n response = reapply_cors(subrequest, error)\n return response\n\n\[email protected](name='bucket',\n collection_methods=('GET',),\n collection_path='/buckets',\n record_path='/buckets/{{id}}')\nclass Bucket(resource.ProtectedResource):\n permissions = ('read', 'write', 'collection:create', 'group:create')\n\n def __init__(self, *args, **kwargs):\n super(Bucket, self).__init__(*args, **kwargs)\n self.collection.id_generator = NameGenerator()\n\n def get_parent_id(self, request):\n # Buckets are not isolated by user, unlike Cliquet resources.\n return ''\n\n def delete(self):\n result = super(Bucket, self).delete()\n\n # Delete groups.\n storage = self.collection.storage\n parent_id = '/buckets/%s' % self.record_id\n storage.delete_all(collection_id='group',\n parent_id=parent_id,\n with_deleted=False)\n storage.purge_deleted(collection_id='group',\n parent_id=parent_id)\n\n # Delete collections.\n deleted = storage.delete_all(collection_id='collection',\n parent_id=parent_id,\n with_deleted=False)\n storage.purge_deleted(collection_id='collection',\n parent_id=parent_id)\n\n # Delete records.\n id_field = self.collection.id_field\n for collection in deleted:\n parent_id = '/buckets/%s/collections/%s' % (self.record_id,\n collection[id_field])\n storage.delete_all(collection_id='record',\n parent_id=parent_id,\n with_deleted=False)\n storage.purge_deleted(collection_id='record', parent_id=parent_id)\n\n return result\n", "path": "kinto/views/buckets.py"}], "after_files": [{"content": "from six import text_type\nfrom uuid import UUID\n\nfrom pyramid.httpexceptions import (HTTPForbidden, HTTPPreconditionFailed,\n HTTPException)\nfrom pyramid.security import NO_PERMISSION_REQUIRED\nfrom pyramid.view import view_config\n\nfrom cliquet import resource\nfrom cliquet.utils import hmac_digest, build_request, reapply_cors\n\nfrom kinto.views import NameGenerator\n\n\ndef create_bucket(request, bucket_id):\n \"\"\"Create a bucket if it doesn't exists.\"\"\"\n bucket_put = (request.method.lower() == 'put' and\n request.path.endswith('buckets/default'))\n\n if not bucket_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s' % bucket_id,\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The bucket already exists\n pass\n\n\ndef create_collection(request, bucket_id):\n subpath = request.matchdict.get('subpath')\n if subpath and subpath.startswith('collections/'):\n collection_id = subpath.split('/')[1]\n collection_put = (request.method.lower() == 'put' and\n request.path.endswith(collection_id))\n if not collection_put:\n subrequest = build_request(request, {\n 'method': 'PUT',\n 'path': '/buckets/%s/collections/%s' % (\n bucket_id, collection_id),\n 'body': {\"data\": {}},\n 'headers': {'If-None-Match': '*'.encode('utf-8')}\n })\n try:\n request.invoke_subrequest(subrequest)\n except HTTPPreconditionFailed:\n # The collection already exists\n pass\n\n\n@view_config(route_name='default_bucket', permission=NO_PERMISSION_REQUIRED)\n@view_config(route_name='default_bucket_collection',\n permission=NO_PERMISSION_REQUIRED)\ndef default_bucket(request):\n if request.method.lower() == 'options':\n path = request.path.replace('default', 'unknown')\n subrequest = build_request(request, {\n 'method': 'OPTIONS',\n 'path': path\n })\n return request.invoke_subrequest(subrequest)\n\n if getattr(request, 'prefixed_userid', None) is None:\n raise HTTPForbidden # Pass through the forbidden_view_config\n\n settings = request.registry.settings\n hmac_secret = settings['cliquet.userid_hmac_secret']\n # Build the user unguessable bucket_id UUID from its user_id\n digest = hmac_digest(hmac_secret, request.prefixed_userid)\n bucket_id = text_type(UUID(digest[:32]))\n path = request.path.replace('/buckets/default', '/buckets/%s' % bucket_id)\n querystring = request.url[(request.url.index(request.path) +\n len(request.path)):]\n\n # Make sure bucket exists\n create_bucket(request, bucket_id)\n\n # Make sure the collection exists\n create_collection(request, bucket_id)\n\n subrequest = build_request(request, {\n 'method': request.method,\n 'path': path + querystring,\n 'body': request.body\n })\n\n try:\n response = request.invoke_subrequest(subrequest)\n except HTTPException as error:\n response = reapply_cors(subrequest, error)\n return response\n\n\[email protected](name='bucket',\n collection_methods=('GET', 'POST'),\n collection_path='/buckets',\n record_path='/buckets/{{id}}')\nclass Bucket(resource.ProtectedResource):\n permissions = ('read', 'write', 'collection:create', 'group:create')\n\n def __init__(self, *args, **kwargs):\n super(Bucket, self).__init__(*args, **kwargs)\n self.collection.id_generator = NameGenerator()\n\n def get_parent_id(self, request):\n # Buckets are not isolated by user, unlike Cliquet resources.\n return ''\n\n def delete(self):\n result = super(Bucket, self).delete()\n\n # Delete groups.\n storage = self.collection.storage\n parent_id = '/buckets/%s' % self.record_id\n storage.delete_all(collection_id='group',\n parent_id=parent_id,\n with_deleted=False)\n storage.purge_deleted(collection_id='group',\n parent_id=parent_id)\n\n # Delete collections.\n deleted = storage.delete_all(collection_id='collection',\n parent_id=parent_id,\n with_deleted=False)\n storage.purge_deleted(collection_id='collection',\n parent_id=parent_id)\n\n # Delete records.\n id_field = self.collection.id_field\n for collection in deleted:\n parent_id = '/buckets/%s/collections/%s' % (self.record_id,\n collection[id_field])\n storage.delete_all(collection_id='record',\n parent_id=parent_id,\n with_deleted=False)\n storage.purge_deleted(collection_id='record', parent_id=parent_id)\n\n return result\n", "path": "kinto/views/buckets.py"}]} | 1,651 | 96 |
gh_patches_debug_42915 | rasdani/github-patches | git_diff | TheAlgorithms__Python-1403 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`Head` and `temp` names should change
Hi,
In your [Linked List implementation](https://github.com/TheAlgorithms/Python/blob/master/data_structures/linked_list/singly_linked_list.py), I think `temp` is wrongly spelled as `tamp`. The code works but for readability purpose all `tamp` should be replaced by `temp`.
Also, I find it strange to name the `head` with a capital `Head`. Generally, capitalization in Python is saved for Class names, not class attributes or methods. If you think the code should be more *Pythonic*, please consider changing all `Head` to `head` in the class attributes for Linked List.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `data_structures/linked_list/singly_linked_list.py`
Content:
```
1 class Node: # create a Node
2 def __init__(self, data):
3 self.data = data # given data
4 self.next = None # given next to None
5
6
7 class Linked_List:
8 def __init__(self):
9 self.Head = None # Initialize Head to None
10
11 def insert_tail(self, data):
12 if self.Head is None:
13 self.insert_head(data) # If this is first node, call insert_head
14 else:
15 temp = self.Head
16 while temp.next != None: # traverse to last node
17 temp = temp.next
18 temp.next = Node(data) # create node & link to tail
19
20 def insert_head(self, data):
21 newNod = Node(data) # create a new node
22 if self.Head != None:
23 newNod.next = self.Head # link newNode to head
24 self.Head = newNod # make NewNode as Head
25
26 def printList(self): # print every node data
27 tamp = self.Head
28 while tamp is not None:
29 print(tamp.data)
30 tamp = tamp.next
31
32 def delete_head(self): # delete from head
33 temp = self.Head
34 if self.Head != None:
35 self.Head = self.Head.next
36 temp.next = None
37 return temp
38
39 def delete_tail(self): # delete from tail
40 tamp = self.Head
41 if self.Head != None:
42 if self.Head.next is None: # if Head is the only Node in the Linked List
43 self.Head = None
44 else:
45 while tamp.next.next is not None: # find the 2nd last element
46 tamp = tamp.next
47 tamp.next, tamp = (
48 None,
49 tamp.next,
50 ) # (2nd last element).next = None and tamp = last element
51 return tamp
52
53 def isEmpty(self):
54 return self.Head is None # Return if Head is none
55
56 def reverse(self):
57 prev = None
58 current = self.Head
59
60 while current:
61 # Store the current node's next node.
62 next_node = current.next
63 # Make the current node's next point backwards
64 current.next = prev
65 # Make the previous node be the current node
66 prev = current
67 # Make the current node the next node (to progress iteration)
68 current = next_node
69 # Return prev in order to put the head at the end
70 self.Head = prev
71
72
73 def main():
74 A = Linked_List()
75 print("Inserting 1st at Head")
76 a1 = input()
77 A.insert_head(a1)
78 print("Inserting 2nd at Head")
79 a2 = input()
80 A.insert_head(a2)
81 print("\nPrint List : ")
82 A.printList()
83 print("\nInserting 1st at Tail")
84 a3 = input()
85 A.insert_tail(a3)
86 print("Inserting 2nd at Tail")
87 a4 = input()
88 A.insert_tail(a4)
89 print("\nPrint List : ")
90 A.printList()
91 print("\nDelete Head")
92 A.delete_head()
93 print("Delete Tail")
94 A.delete_tail()
95 print("\nPrint List : ")
96 A.printList()
97 print("\nReverse Linked List")
98 A.reverse()
99 print("\nPrint List : ")
100 A.printList()
101
102
103 if __name__ == "__main__":
104 main()
105
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/data_structures/linked_list/singly_linked_list.py b/data_structures/linked_list/singly_linked_list.py
--- a/data_structures/linked_list/singly_linked_list.py
+++ b/data_structures/linked_list/singly_linked_list.py
@@ -6,56 +6,56 @@
class Linked_List:
def __init__(self):
- self.Head = None # Initialize Head to None
+ self.head = None # Initialize head to None
def insert_tail(self, data):
- if self.Head is None:
+ if self.head is None:
self.insert_head(data) # If this is first node, call insert_head
else:
- temp = self.Head
+ temp = self.head
while temp.next != None: # traverse to last node
temp = temp.next
temp.next = Node(data) # create node & link to tail
def insert_head(self, data):
newNod = Node(data) # create a new node
- if self.Head != None:
- newNod.next = self.Head # link newNode to head
- self.Head = newNod # make NewNode as Head
+ if self.head != None:
+ newNod.next = self.head # link newNode to head
+ self.head = newNod # make NewNode as head
def printList(self): # print every node data
- tamp = self.Head
- while tamp is not None:
- print(tamp.data)
- tamp = tamp.next
+ temp = self.head
+ while temp is not None:
+ print(temp.data)
+ temp = temp.next
def delete_head(self): # delete from head
- temp = self.Head
- if self.Head != None:
- self.Head = self.Head.next
+ temp = self.head
+ if self.head != None:
+ self.head = self.head.next
temp.next = None
return temp
def delete_tail(self): # delete from tail
- tamp = self.Head
- if self.Head != None:
- if self.Head.next is None: # if Head is the only Node in the Linked List
- self.Head = None
+ temp = self.head
+ if self.head != None:
+ if self.head.next is None: # if head is the only Node in the Linked List
+ self.head = None
else:
- while tamp.next.next is not None: # find the 2nd last element
- tamp = tamp.next
- tamp.next, tamp = (
+ while temp.next.next is not None: # find the 2nd last element
+ temp = temp.next
+ temp.next, temp = (
None,
- tamp.next,
- ) # (2nd last element).next = None and tamp = last element
- return tamp
+ temp.next,
+ ) # (2nd last element).next = None and temp = last element
+ return temp
def isEmpty(self):
- return self.Head is None # Return if Head is none
+ return self.head is None # Return if head is none
def reverse(self):
prev = None
- current = self.Head
+ current = self.head
while current:
# Store the current node's next node.
@@ -67,15 +67,15 @@
# Make the current node the next node (to progress iteration)
current = next_node
# Return prev in order to put the head at the end
- self.Head = prev
+ self.head = prev
def main():
A = Linked_List()
- print("Inserting 1st at Head")
+ print("Inserting 1st at head")
a1 = input()
A.insert_head(a1)
- print("Inserting 2nd at Head")
+ print("Inserting 2nd at head")
a2 = input()
A.insert_head(a2)
print("\nPrint List : ")
@@ -88,7 +88,7 @@
A.insert_tail(a4)
print("\nPrint List : ")
A.printList()
- print("\nDelete Head")
+ print("\nDelete head")
A.delete_head()
print("Delete Tail")
A.delete_tail()
| {"golden_diff": "diff --git a/data_structures/linked_list/singly_linked_list.py b/data_structures/linked_list/singly_linked_list.py\n--- a/data_structures/linked_list/singly_linked_list.py\n+++ b/data_structures/linked_list/singly_linked_list.py\n@@ -6,56 +6,56 @@\n \n class Linked_List:\n def __init__(self):\n- self.Head = None # Initialize Head to None\n+ self.head = None # Initialize head to None\n \n def insert_tail(self, data):\n- if self.Head is None:\n+ if self.head is None:\n self.insert_head(data) # If this is first node, call insert_head\n else:\n- temp = self.Head\n+ temp = self.head\n while temp.next != None: # traverse to last node\n temp = temp.next\n temp.next = Node(data) # create node & link to tail\n \n def insert_head(self, data):\n newNod = Node(data) # create a new node\n- if self.Head != None:\n- newNod.next = self.Head # link newNode to head\n- self.Head = newNod # make NewNode as Head\n+ if self.head != None:\n+ newNod.next = self.head # link newNode to head\n+ self.head = newNod # make NewNode as head\n \n def printList(self): # print every node data\n- tamp = self.Head\n- while tamp is not None:\n- print(tamp.data)\n- tamp = tamp.next\n+ temp = self.head\n+ while temp is not None:\n+ print(temp.data)\n+ temp = temp.next\n \n def delete_head(self): # delete from head\n- temp = self.Head\n- if self.Head != None:\n- self.Head = self.Head.next\n+ temp = self.head\n+ if self.head != None:\n+ self.head = self.head.next\n temp.next = None\n return temp\n \n def delete_tail(self): # delete from tail\n- tamp = self.Head\n- if self.Head != None:\n- if self.Head.next is None: # if Head is the only Node in the Linked List\n- self.Head = None\n+ temp = self.head\n+ if self.head != None:\n+ if self.head.next is None: # if head is the only Node in the Linked List\n+ self.head = None\n else:\n- while tamp.next.next is not None: # find the 2nd last element\n- tamp = tamp.next\n- tamp.next, tamp = (\n+ while temp.next.next is not None: # find the 2nd last element\n+ temp = temp.next\n+ temp.next, temp = (\n None,\n- tamp.next,\n- ) # (2nd last element).next = None and tamp = last element\n- return tamp\n+ temp.next,\n+ ) # (2nd last element).next = None and temp = last element\n+ return temp\n \n def isEmpty(self):\n- return self.Head is None # Return if Head is none\n+ return self.head is None # Return if head is none\n \n def reverse(self):\n prev = None\n- current = self.Head\n+ current = self.head\n \n while current:\n # Store the current node's next node.\n@@ -67,15 +67,15 @@\n # Make the current node the next node (to progress iteration)\n current = next_node\n # Return prev in order to put the head at the end\n- self.Head = prev\n+ self.head = prev\n \n \n def main():\n A = Linked_List()\n- print(\"Inserting 1st at Head\")\n+ print(\"Inserting 1st at head\")\n a1 = input()\n A.insert_head(a1)\n- print(\"Inserting 2nd at Head\")\n+ print(\"Inserting 2nd at head\")\n a2 = input()\n A.insert_head(a2)\n print(\"\\nPrint List : \")\n@@ -88,7 +88,7 @@\n A.insert_tail(a4)\n print(\"\\nPrint List : \")\n A.printList()\n- print(\"\\nDelete Head\")\n+ print(\"\\nDelete head\")\n A.delete_head()\n print(\"Delete Tail\")\n A.delete_tail()\n", "issue": "`Head` and `temp` names should change\nHi,\r\n\r\nIn your [Linked List implementation](https://github.com/TheAlgorithms/Python/blob/master/data_structures/linked_list/singly_linked_list.py), I think `temp` is wrongly spelled as `tamp`. The code works but for readability purpose all `tamp` should be replaced by `temp`.\r\n\r\nAlso, I find it strange to name the `head` with a capital `Head`. Generally, capitalization in Python is saved for Class names, not class attributes or methods. If you think the code should be more *Pythonic*, please consider changing all `Head` to `head` in the class attributes for Linked List.\r\n\r\n\n", "before_files": [{"content": "class Node: # create a Node\n def __init__(self, data):\n self.data = data # given data\n self.next = None # given next to None\n\n\nclass Linked_List:\n def __init__(self):\n self.Head = None # Initialize Head to None\n\n def insert_tail(self, data):\n if self.Head is None:\n self.insert_head(data) # If this is first node, call insert_head\n else:\n temp = self.Head\n while temp.next != None: # traverse to last node\n temp = temp.next\n temp.next = Node(data) # create node & link to tail\n\n def insert_head(self, data):\n newNod = Node(data) # create a new node\n if self.Head != None:\n newNod.next = self.Head # link newNode to head\n self.Head = newNod # make NewNode as Head\n\n def printList(self): # print every node data\n tamp = self.Head\n while tamp is not None:\n print(tamp.data)\n tamp = tamp.next\n\n def delete_head(self): # delete from head\n temp = self.Head\n if self.Head != None:\n self.Head = self.Head.next\n temp.next = None\n return temp\n\n def delete_tail(self): # delete from tail\n tamp = self.Head\n if self.Head != None:\n if self.Head.next is None: # if Head is the only Node in the Linked List\n self.Head = None\n else:\n while tamp.next.next is not None: # find the 2nd last element\n tamp = tamp.next\n tamp.next, tamp = (\n None,\n tamp.next,\n ) # (2nd last element).next = None and tamp = last element\n return tamp\n\n def isEmpty(self):\n return self.Head is None # Return if Head is none\n\n def reverse(self):\n prev = None\n current = self.Head\n\n while current:\n # Store the current node's next node.\n next_node = current.next\n # Make the current node's next point backwards\n current.next = prev\n # Make the previous node be the current node\n prev = current\n # Make the current node the next node (to progress iteration)\n current = next_node\n # Return prev in order to put the head at the end\n self.Head = prev\n\n\ndef main():\n A = Linked_List()\n print(\"Inserting 1st at Head\")\n a1 = input()\n A.insert_head(a1)\n print(\"Inserting 2nd at Head\")\n a2 = input()\n A.insert_head(a2)\n print(\"\\nPrint List : \")\n A.printList()\n print(\"\\nInserting 1st at Tail\")\n a3 = input()\n A.insert_tail(a3)\n print(\"Inserting 2nd at Tail\")\n a4 = input()\n A.insert_tail(a4)\n print(\"\\nPrint List : \")\n A.printList()\n print(\"\\nDelete Head\")\n A.delete_head()\n print(\"Delete Tail\")\n A.delete_tail()\n print(\"\\nPrint List : \")\n A.printList()\n print(\"\\nReverse Linked List\")\n A.reverse()\n print(\"\\nPrint List : \")\n A.printList()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "data_structures/linked_list/singly_linked_list.py"}], "after_files": [{"content": "class Node: # create a Node\n def __init__(self, data):\n self.data = data # given data\n self.next = None # given next to None\n\n\nclass Linked_List:\n def __init__(self):\n self.head = None # Initialize head to None\n\n def insert_tail(self, data):\n if self.head is None:\n self.insert_head(data) # If this is first node, call insert_head\n else:\n temp = self.head\n while temp.next != None: # traverse to last node\n temp = temp.next\n temp.next = Node(data) # create node & link to tail\n\n def insert_head(self, data):\n newNod = Node(data) # create a new node\n if self.head != None:\n newNod.next = self.head # link newNode to head\n self.head = newNod # make NewNode as head\n\n def printList(self): # print every node data\n temp = self.head\n while temp is not None:\n print(temp.data)\n temp = temp.next\n\n def delete_head(self): # delete from head\n temp = self.head\n if self.head != None:\n self.head = self.head.next\n temp.next = None\n return temp\n\n def delete_tail(self): # delete from tail\n temp = self.head\n if self.head != None:\n if self.head.next is None: # if head is the only Node in the Linked List\n self.head = None\n else:\n while temp.next.next is not None: # find the 2nd last element\n temp = temp.next\n temp.next, temp = (\n None,\n temp.next,\n ) # (2nd last element).next = None and temp = last element\n return temp\n\n def isEmpty(self):\n return self.head is None # Return if head is none\n\n def reverse(self):\n prev = None\n current = self.head\n\n while current:\n # Store the current node's next node.\n next_node = current.next\n # Make the current node's next point backwards\n current.next = prev\n # Make the previous node be the current node\n prev = current\n # Make the current node the next node (to progress iteration)\n current = next_node\n # Return prev in order to put the head at the end\n self.head = prev\n\n\ndef main():\n A = Linked_List()\n print(\"Inserting 1st at head\")\n a1 = input()\n A.insert_head(a1)\n print(\"Inserting 2nd at head\")\n a2 = input()\n A.insert_head(a2)\n print(\"\\nPrint List : \")\n A.printList()\n print(\"\\nInserting 1st at Tail\")\n a3 = input()\n A.insert_tail(a3)\n print(\"Inserting 2nd at Tail\")\n a4 = input()\n A.insert_tail(a4)\n print(\"\\nPrint List : \")\n A.printList()\n print(\"\\nDelete head\")\n A.delete_head()\n print(\"Delete Tail\")\n A.delete_tail()\n print(\"\\nPrint List : \")\n A.printList()\n print(\"\\nReverse Linked List\")\n A.reverse()\n print(\"\\nPrint List : \")\n A.printList()\n\n\nif __name__ == \"__main__\":\n main()\n", "path": "data_structures/linked_list/singly_linked_list.py"}]} | 1,363 | 971 |
gh_patches_debug_38558 | rasdani/github-patches | git_diff | hylang__hy-1431 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
repl shouldn't crash
```Hy
=> (defmacro bad [] `(macro-error 'x ""))
<function <lambda> at 0x000001D01D0ED7B8>
=> (bad)
Traceback (most recent call last):
File "c:\users\me\documents\github\hy\hy\cmdline.py", line 99, in runsource
ast_callback)
File "c:\users\me\documents\github\hy\hy\importer.py", line 198, in hy_eval
eval(ast_compile(_ast, "<eval_body>", "exec"), namespace)
File "<eval_body>", line 1, in <module>
hy.errors.HyMacroExpansionError: <exception str() failed>
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\ME\workspace\hy36-gilch\Scripts\hy-script.py", line 11, in <module>
load_entry_point('hy', 'console_scripts', 'hy')()
File "c:\users\me\documents\github\hy\hy\cmdline.py", line 346, in hy_main
sys.exit(cmdline_handler("hy", sys.argv))
File "c:\users\me\documents\github\hy\hy\cmdline.py", line 341, in cmdline_handler
return run_repl(spy=options.spy, output_fn=options.repl_output_fn)
File "c:\users\me\documents\github\hy\hy\cmdline.py", line 236, in run_repl
os=platform.system()
File "C:\Users\ME\AppData\Local\Programs\Python\Python36\lib\code.py", line 233, in interact
more = self.push(line)
File "C:\Users\ME\AppData\Local\Programs\Python\Python36\lib\code.py", line 259, in push
more = self.runsource(source, self.filename)
File "c:\users\me\documents\github\hy\hy\cmdline.py", line 105, in runsource
print(e, file=sys.stderr)
File "c:\users\me\documents\github\hy\hy\errors.py", line 46, in __str__
line = self.expression.start_line
AttributeError: 'HySymbol' object has no attribute 'start_line'
```
The repl should report errors, but not exit.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `hy/errors.py`
Content:
```
1 # -*- encoding: utf-8 -*-
2 # Copyright 2017 the authors.
3 # This file is part of Hy, which is free software licensed under the Expat
4 # license. See the LICENSE.
5
6 import traceback
7
8 from clint.textui import colored
9
10
11 class HyError(Exception):
12 """
13 Generic Hy error. All internal Exceptions will be subclassed from this
14 Exception.
15 """
16 pass
17
18
19 class HyCompileError(HyError):
20 def __init__(self, exception, traceback=None):
21 self.exception = exception
22 self.traceback = traceback
23
24 def __str__(self):
25 if isinstance(self.exception, HyTypeError):
26 return str(self.exception)
27 if self.traceback:
28 tb = "".join(traceback.format_tb(self.traceback)).strip()
29 else:
30 tb = "No traceback available. 😟"
31 return("Internal Compiler Bug 😱\n⤷ %s: %s\nCompilation traceback:\n%s"
32 % (self.exception.__class__.__name__,
33 self.exception, tb))
34
35
36 class HyTypeError(TypeError):
37 def __init__(self, expression, message):
38 super(HyTypeError, self).__init__(message)
39 self.expression = expression
40 self.message = message
41 self.source = None
42 self.filename = None
43
44 def __str__(self):
45
46 line = self.expression.start_line
47 start = self.expression.start_column
48 end = self.expression.end_column
49
50 source = []
51 if self.source is not None:
52 source = self.source.split("\n")[line-1:self.expression.end_line]
53
54 if line == self.expression.end_line:
55 length = end - start
56 else:
57 length = len(source[0]) - start
58
59 result = ""
60
61 result += ' File "%s", line %d, column %d\n\n' % (self.filename,
62 line,
63 start)
64
65 if len(source) == 1:
66 result += ' %s\n' % colored.red(source[0])
67 result += ' %s%s\n' % (' '*(start-1),
68 colored.green('^' + '-'*(length-1) + '^'))
69 if len(source) > 1:
70 result += ' %s\n' % colored.red(source[0])
71 result += ' %s%s\n' % (' '*(start-1),
72 colored.green('^' + '-'*length))
73 if len(source) > 2: # write the middle lines
74 for line in source[1:-1]:
75 result += ' %s\n' % colored.red("".join(line))
76 result += ' %s\n' % colored.green("-"*len(line))
77
78 # write the last line
79 result += ' %s\n' % colored.red("".join(source[-1]))
80 result += ' %s\n' % colored.green('-'*(end-1) + '^')
81
82 result += colored.yellow("%s: %s\n\n" %
83 (self.__class__.__name__,
84 self.message.encode('utf-8')))
85
86 return result
87
88
89 class HyMacroExpansionError(HyTypeError):
90 pass
91
92
93 class HyIOError(HyError, IOError):
94 """
95 Trivial subclass of IOError and HyError, to distinguish between
96 IOErrors raised by Hy itself as opposed to Hy programs.
97 """
98 pass
99
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/hy/errors.py b/hy/errors.py
--- a/hy/errors.py
+++ b/hy/errors.py
@@ -43,41 +43,47 @@
def __str__(self):
- line = self.expression.start_line
- start = self.expression.start_column
- end = self.expression.end_column
-
- source = []
- if self.source is not None:
- source = self.source.split("\n")[line-1:self.expression.end_line]
-
- if line == self.expression.end_line:
- length = end - start
- else:
- length = len(source[0]) - start
-
result = ""
- result += ' File "%s", line %d, column %d\n\n' % (self.filename,
- line,
- start)
-
- if len(source) == 1:
- result += ' %s\n' % colored.red(source[0])
- result += ' %s%s\n' % (' '*(start-1),
- colored.green('^' + '-'*(length-1) + '^'))
- if len(source) > 1:
- result += ' %s\n' % colored.red(source[0])
- result += ' %s%s\n' % (' '*(start-1),
- colored.green('^' + '-'*length))
- if len(source) > 2: # write the middle lines
- for line in source[1:-1]:
- result += ' %s\n' % colored.red("".join(line))
- result += ' %s\n' % colored.green("-"*len(line))
-
- # write the last line
- result += ' %s\n' % colored.red("".join(source[-1]))
- result += ' %s\n' % colored.green('-'*(end-1) + '^')
+ if all(getattr(self.expression, x, None) is not None
+ for x in ("start_line", "start_column", "end_column")):
+
+ line = self.expression.start_line
+ start = self.expression.start_column
+ end = self.expression.end_column
+
+ source = []
+ if self.source is not None:
+ source = self.source.split("\n")[line-1:self.expression.end_line]
+
+ if line == self.expression.end_line:
+ length = end - start
+ else:
+ length = len(source[0]) - start
+
+ result += ' File "%s", line %d, column %d\n\n' % (self.filename,
+ line,
+ start)
+
+ if len(source) == 1:
+ result += ' %s\n' % colored.red(source[0])
+ result += ' %s%s\n' % (' '*(start-1),
+ colored.green('^' + '-'*(length-1) + '^'))
+ if len(source) > 1:
+ result += ' %s\n' % colored.red(source[0])
+ result += ' %s%s\n' % (' '*(start-1),
+ colored.green('^' + '-'*length))
+ if len(source) > 2: # write the middle lines
+ for line in source[1:-1]:
+ result += ' %s\n' % colored.red("".join(line))
+ result += ' %s\n' % colored.green("-"*len(line))
+
+ # write the last line
+ result += ' %s\n' % colored.red("".join(source[-1]))
+ result += ' %s\n' % colored.green('-'*(end-1) + '^')
+
+ else:
+ result += ' File "%s", unknown location\n' % self.filename
result += colored.yellow("%s: %s\n\n" %
(self.__class__.__name__,
| {"golden_diff": "diff --git a/hy/errors.py b/hy/errors.py\n--- a/hy/errors.py\n+++ b/hy/errors.py\n@@ -43,41 +43,47 @@\n \n def __str__(self):\n \n- line = self.expression.start_line\n- start = self.expression.start_column\n- end = self.expression.end_column\n-\n- source = []\n- if self.source is not None:\n- source = self.source.split(\"\\n\")[line-1:self.expression.end_line]\n-\n- if line == self.expression.end_line:\n- length = end - start\n- else:\n- length = len(source[0]) - start\n-\n result = \"\"\n \n- result += ' File \"%s\", line %d, column %d\\n\\n' % (self.filename,\n- line,\n- start)\n-\n- if len(source) == 1:\n- result += ' %s\\n' % colored.red(source[0])\n- result += ' %s%s\\n' % (' '*(start-1),\n- colored.green('^' + '-'*(length-1) + '^'))\n- if len(source) > 1:\n- result += ' %s\\n' % colored.red(source[0])\n- result += ' %s%s\\n' % (' '*(start-1),\n- colored.green('^' + '-'*length))\n- if len(source) > 2: # write the middle lines\n- for line in source[1:-1]:\n- result += ' %s\\n' % colored.red(\"\".join(line))\n- result += ' %s\\n' % colored.green(\"-\"*len(line))\n-\n- # write the last line\n- result += ' %s\\n' % colored.red(\"\".join(source[-1]))\n- result += ' %s\\n' % colored.green('-'*(end-1) + '^')\n+ if all(getattr(self.expression, x, None) is not None\n+ for x in (\"start_line\", \"start_column\", \"end_column\")):\n+\n+ line = self.expression.start_line\n+ start = self.expression.start_column\n+ end = self.expression.end_column\n+\n+ source = []\n+ if self.source is not None:\n+ source = self.source.split(\"\\n\")[line-1:self.expression.end_line]\n+\n+ if line == self.expression.end_line:\n+ length = end - start\n+ else:\n+ length = len(source[0]) - start\n+\n+ result += ' File \"%s\", line %d, column %d\\n\\n' % (self.filename,\n+ line,\n+ start)\n+\n+ if len(source) == 1:\n+ result += ' %s\\n' % colored.red(source[0])\n+ result += ' %s%s\\n' % (' '*(start-1),\n+ colored.green('^' + '-'*(length-1) + '^'))\n+ if len(source) > 1:\n+ result += ' %s\\n' % colored.red(source[0])\n+ result += ' %s%s\\n' % (' '*(start-1),\n+ colored.green('^' + '-'*length))\n+ if len(source) > 2: # write the middle lines\n+ for line in source[1:-1]:\n+ result += ' %s\\n' % colored.red(\"\".join(line))\n+ result += ' %s\\n' % colored.green(\"-\"*len(line))\n+\n+ # write the last line\n+ result += ' %s\\n' % colored.red(\"\".join(source[-1]))\n+ result += ' %s\\n' % colored.green('-'*(end-1) + '^')\n+\n+ else:\n+ result += ' File \"%s\", unknown location\\n' % self.filename\n \n result += colored.yellow(\"%s: %s\\n\\n\" %\n (self.__class__.__name__,\n", "issue": "repl shouldn't crash\n```Hy\r\n=> (defmacro bad [] `(macro-error 'x \"\"))\r\n<function <lambda> at 0x000001D01D0ED7B8>\r\n=> (bad)\r\nTraceback (most recent call last):\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\cmdline.py\", line 99, in runsource\r\n ast_callback)\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\importer.py\", line 198, in hy_eval\r\n eval(ast_compile(_ast, \"<eval_body>\", \"exec\"), namespace)\r\n File \"<eval_body>\", line 1, in <module>\r\nhy.errors.HyMacroExpansionError: <exception str() failed>\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\ME\\workspace\\hy36-gilch\\Scripts\\hy-script.py\", line 11, in <module>\r\n load_entry_point('hy', 'console_scripts', 'hy')()\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\cmdline.py\", line 346, in hy_main\r\n sys.exit(cmdline_handler(\"hy\", sys.argv))\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\cmdline.py\", line 341, in cmdline_handler\r\n return run_repl(spy=options.spy, output_fn=options.repl_output_fn)\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\cmdline.py\", line 236, in run_repl\r\n os=platform.system()\r\n File \"C:\\Users\\ME\\AppData\\Local\\Programs\\Python\\Python36\\lib\\code.py\", line 233, in interact\r\n more = self.push(line)\r\n File \"C:\\Users\\ME\\AppData\\Local\\Programs\\Python\\Python36\\lib\\code.py\", line 259, in push\r\n more = self.runsource(source, self.filename)\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\cmdline.py\", line 105, in runsource\r\n print(e, file=sys.stderr)\r\n File \"c:\\users\\me\\documents\\github\\hy\\hy\\errors.py\", line 46, in __str__\r\n line = self.expression.start_line\r\nAttributeError: 'HySymbol' object has no attribute 'start_line'\r\n```\r\nThe repl should report errors, but not exit.\n", "before_files": [{"content": "# -*- encoding: utf-8 -*-\n# Copyright 2017 the authors.\n# This file is part of Hy, which is free software licensed under the Expat\n# license. See the LICENSE.\n\nimport traceback\n\nfrom clint.textui import colored\n\n\nclass HyError(Exception):\n \"\"\"\n Generic Hy error. All internal Exceptions will be subclassed from this\n Exception.\n \"\"\"\n pass\n\n\nclass HyCompileError(HyError):\n def __init__(self, exception, traceback=None):\n self.exception = exception\n self.traceback = traceback\n\n def __str__(self):\n if isinstance(self.exception, HyTypeError):\n return str(self.exception)\n if self.traceback:\n tb = \"\".join(traceback.format_tb(self.traceback)).strip()\n else:\n tb = \"No traceback available. \ud83d\ude1f\"\n return(\"Internal Compiler Bug \ud83d\ude31\\n\u2937 %s: %s\\nCompilation traceback:\\n%s\"\n % (self.exception.__class__.__name__,\n self.exception, tb))\n\n\nclass HyTypeError(TypeError):\n def __init__(self, expression, message):\n super(HyTypeError, self).__init__(message)\n self.expression = expression\n self.message = message\n self.source = None\n self.filename = None\n\n def __str__(self):\n\n line = self.expression.start_line\n start = self.expression.start_column\n end = self.expression.end_column\n\n source = []\n if self.source is not None:\n source = self.source.split(\"\\n\")[line-1:self.expression.end_line]\n\n if line == self.expression.end_line:\n length = end - start\n else:\n length = len(source[0]) - start\n\n result = \"\"\n\n result += ' File \"%s\", line %d, column %d\\n\\n' % (self.filename,\n line,\n start)\n\n if len(source) == 1:\n result += ' %s\\n' % colored.red(source[0])\n result += ' %s%s\\n' % (' '*(start-1),\n colored.green('^' + '-'*(length-1) + '^'))\n if len(source) > 1:\n result += ' %s\\n' % colored.red(source[0])\n result += ' %s%s\\n' % (' '*(start-1),\n colored.green('^' + '-'*length))\n if len(source) > 2: # write the middle lines\n for line in source[1:-1]:\n result += ' %s\\n' % colored.red(\"\".join(line))\n result += ' %s\\n' % colored.green(\"-\"*len(line))\n\n # write the last line\n result += ' %s\\n' % colored.red(\"\".join(source[-1]))\n result += ' %s\\n' % colored.green('-'*(end-1) + '^')\n\n result += colored.yellow(\"%s: %s\\n\\n\" %\n (self.__class__.__name__,\n self.message.encode('utf-8')))\n\n return result\n\n\nclass HyMacroExpansionError(HyTypeError):\n pass\n\n\nclass HyIOError(HyError, IOError):\n \"\"\"\n Trivial subclass of IOError and HyError, to distinguish between\n IOErrors raised by Hy itself as opposed to Hy programs.\n \"\"\"\n pass\n", "path": "hy/errors.py"}], "after_files": [{"content": "# -*- encoding: utf-8 -*-\n# Copyright 2017 the authors.\n# This file is part of Hy, which is free software licensed under the Expat\n# license. See the LICENSE.\n\nimport traceback\n\nfrom clint.textui import colored\n\n\nclass HyError(Exception):\n \"\"\"\n Generic Hy error. All internal Exceptions will be subclassed from this\n Exception.\n \"\"\"\n pass\n\n\nclass HyCompileError(HyError):\n def __init__(self, exception, traceback=None):\n self.exception = exception\n self.traceback = traceback\n\n def __str__(self):\n if isinstance(self.exception, HyTypeError):\n return str(self.exception)\n if self.traceback:\n tb = \"\".join(traceback.format_tb(self.traceback)).strip()\n else:\n tb = \"No traceback available. \ud83d\ude1f\"\n return(\"Internal Compiler Bug \ud83d\ude31\\n\u2937 %s: %s\\nCompilation traceback:\\n%s\"\n % (self.exception.__class__.__name__,\n self.exception, tb))\n\n\nclass HyTypeError(TypeError):\n def __init__(self, expression, message):\n super(HyTypeError, self).__init__(message)\n self.expression = expression\n self.message = message\n self.source = None\n self.filename = None\n\n def __str__(self):\n\n result = \"\"\n\n if all(getattr(self.expression, x, None) is not None\n for x in (\"start_line\", \"start_column\", \"end_column\")):\n\n line = self.expression.start_line\n start = self.expression.start_column\n end = self.expression.end_column\n\n source = []\n if self.source is not None:\n source = self.source.split(\"\\n\")[line-1:self.expression.end_line]\n\n if line == self.expression.end_line:\n length = end - start\n else:\n length = len(source[0]) - start\n\n result += ' File \"%s\", line %d, column %d\\n\\n' % (self.filename,\n line,\n start)\n\n if len(source) == 1:\n result += ' %s\\n' % colored.red(source[0])\n result += ' %s%s\\n' % (' '*(start-1),\n colored.green('^' + '-'*(length-1) + '^'))\n if len(source) > 1:\n result += ' %s\\n' % colored.red(source[0])\n result += ' %s%s\\n' % (' '*(start-1),\n colored.green('^' + '-'*length))\n if len(source) > 2: # write the middle lines\n for line in source[1:-1]:\n result += ' %s\\n' % colored.red(\"\".join(line))\n result += ' %s\\n' % colored.green(\"-\"*len(line))\n\n # write the last line\n result += ' %s\\n' % colored.red(\"\".join(source[-1]))\n result += ' %s\\n' % colored.green('-'*(end-1) + '^')\n\n else:\n result += ' File \"%s\", unknown location\\n' % self.filename\n\n result += colored.yellow(\"%s: %s\\n\\n\" %\n (self.__class__.__name__,\n self.message.encode('utf-8')))\n\n return result\n\n\nclass HyMacroExpansionError(HyTypeError):\n pass\n\n\nclass HyIOError(HyError, IOError):\n \"\"\"\n Trivial subclass of IOError and HyError, to distinguish between\n IOErrors raised by Hy itself as opposed to Hy programs.\n \"\"\"\n pass\n", "path": "hy/errors.py"}]} | 1,724 | 867 |
gh_patches_debug_36003 | rasdani/github-patches | git_diff | Parsl__parsl-1501 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
slurm mandatory `partition` and non-mandatory `qos` are not always mandatory and non-mandatory.
See Parsl/libsubmit#66
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `parsl/providers/slurm/slurm.py`
Content:
```
1 import os
2 import math
3 import time
4 import logging
5 import typeguard
6
7 from typing import Optional
8
9 from parsl.channels import LocalChannel
10 from parsl.channels.base import Channel
11 from parsl.launchers import SingleNodeLauncher
12 from parsl.launchers.launchers import Launcher
13 from parsl.providers.cluster_provider import ClusterProvider
14 from parsl.providers.provider_base import JobState, JobStatus
15 from parsl.providers.slurm.template import template_string
16 from parsl.utils import RepresentationMixin, wtime_to_minutes
17
18 logger = logging.getLogger(__name__)
19
20 translate_table = {
21 'PD': JobState.PENDING,
22 'R': JobState.RUNNING,
23 'CA': JobState.CANCELLED,
24 'CF': JobState.PENDING, # (configuring),
25 'CG': JobState.RUNNING, # (completing),
26 'CD': JobState.COMPLETED,
27 'F': JobState.FAILED, # (failed),
28 'TO': JobState.TIMEOUT, # (timeout),
29 'NF': JobState.FAILED, # (node failure),
30 'RV': JobState.FAILED, # (revoked) and
31 'SE': JobState.FAILED
32 } # (special exit state
33
34
35 class SlurmProvider(ClusterProvider, RepresentationMixin):
36 """Slurm Execution Provider
37
38 This provider uses sbatch to submit, squeue for status and scancel to cancel
39 jobs. The sbatch script to be used is created from a template file in this
40 same module.
41
42 Parameters
43 ----------
44 partition : str
45 Slurm partition to request blocks from.
46 channel : Channel
47 Channel for accessing this provider. Possible channels include
48 :class:`~parsl.channels.LocalChannel` (the default),
49 :class:`~parsl.channels.SSHChannel`, or
50 :class:`~parsl.channels.SSHInteractiveLoginChannel`.
51 nodes_per_block : int
52 Nodes to provision per block.
53 cores_per_node : int
54 Specify the number of cores to provision per node. If set to None, executors
55 will assume all cores on the node are available for computation. Default is None.
56 mem_per_node : int
57 Specify the real memory to provision per node in GB. If set to None, no
58 explicit request to the scheduler will be made. Default is None.
59 min_blocks : int
60 Minimum number of blocks to maintain.
61 max_blocks : int
62 Maximum number of blocks to maintain.
63 parallelism : float
64 Ratio of provisioned task slots to active tasks. A parallelism value of 1 represents aggressive
65 scaling where as many resources as possible are used; parallelism close to 0 represents
66 the opposite situation in which as few resources as possible (i.e., min_blocks) are used.
67 walltime : str
68 Walltime requested per block in HH:MM:SS.
69 scheduler_options : str
70 String to prepend to the #SBATCH blocks in the submit script to the scheduler.
71 worker_init : str
72 Command to be run before starting a worker, such as 'module load Anaconda; source activate env'.
73 exclusive : bool (Default = True)
74 Requests nodes which are not shared with other running jobs.
75 launcher : Launcher
76 Launcher for this provider. Possible launchers include
77 :class:`~parsl.launchers.SingleNodeLauncher` (the default),
78 :class:`~parsl.launchers.SrunLauncher`, or
79 :class:`~parsl.launchers.AprunLauncher`
80 move_files : Optional[Bool]: should files be moved? by default, Parsl will try to move files.
81 """
82
83 @typeguard.typechecked
84 def __init__(self,
85 partition: str,
86 channel: Channel = LocalChannel(),
87 nodes_per_block: int = 1,
88 cores_per_node: Optional[int] = None,
89 mem_per_node: Optional[int] = None,
90 init_blocks: int = 1,
91 min_blocks: int = 0,
92 max_blocks: int = 10,
93 parallelism: float = 1,
94 walltime: str = "00:10:00",
95 scheduler_options: str = '',
96 worker_init: str = '',
97 cmd_timeout: int = 10,
98 exclusive: bool = True,
99 move_files: bool = True,
100 launcher: Launcher = SingleNodeLauncher()):
101 label = 'slurm'
102 super().__init__(label,
103 channel,
104 nodes_per_block,
105 init_blocks,
106 min_blocks,
107 max_blocks,
108 parallelism,
109 walltime,
110 cmd_timeout=cmd_timeout,
111 launcher=launcher)
112
113 self.partition = partition
114 self.cores_per_node = cores_per_node
115 self.mem_per_node = mem_per_node
116 self.exclusive = exclusive
117 self.move_files = move_files
118 self.scheduler_options = scheduler_options + '\n'
119 if exclusive:
120 self.scheduler_options += "#SBATCH --exclusive\n"
121 self.worker_init = worker_init + '\n'
122
123 def _status(self):
124 ''' Internal: Do not call. Returns the status list for a list of job_ids
125
126 Args:
127 self
128
129 Returns:
130 [status...] : Status list of all jobs
131 '''
132 job_id_list = ','.join(self.resources.keys())
133 cmd = "squeue --job {0}".format(job_id_list)
134
135 retcode, stdout, stderr = self.execute_wait(cmd)
136
137 # Execute_wait failed. Do no update
138 if retcode != 0:
139 return
140
141 jobs_missing = list(self.resources.keys())
142 for line in stdout.split('\n'):
143 parts = line.split()
144 if parts and parts[0] != 'JOBID':
145 job_id = parts[0]
146 status = translate_table.get(parts[4], JobState.UNKNOWN)
147 self.resources[job_id]['status'] = JobStatus(status)
148 jobs_missing.remove(job_id)
149
150 # squeue does not report on jobs that are not running. So we are filling in the
151 # blanks for missing jobs, we might lose some information about why the jobs failed.
152 for missing_job in jobs_missing:
153 self.resources[missing_job]['status'] = JobStatus(JobState.COMPLETED)
154
155 def submit(self, command, tasks_per_node, job_name="parsl.slurm"):
156 """Submit the command as a slurm job.
157
158 Parameters
159 ----------
160 command : str
161 Command to be made on the remote side.
162 tasks_per_node : int
163 Command invocations to be launched per node
164 job_name : str
165 Name for the job (must be unique).
166 Returns
167 -------
168 None or str
169 If at capacity, returns None; otherwise, a string identifier for the job
170 """
171
172 if self.provisioned_blocks >= self.max_blocks:
173 logger.warning("Slurm provider '{}' is at capacity (no more blocks will be added)".format(self.label))
174 return None
175
176 scheduler_options = self.scheduler_options
177 worker_init = self.worker_init
178 if self.mem_per_node is not None:
179 scheduler_options += '#SBATCH --mem={}g\n'.format(self.mem_per_node)
180 worker_init += 'export PARSL_MEMORY_GB={}\n'.format(self.mem_per_node)
181 if self.cores_per_node is not None:
182 cpus_per_task = math.floor(self.cores_per_node / tasks_per_node)
183 scheduler_options += '#SBATCH --cpus-per-task={}'.format(cpus_per_task)
184 worker_init += 'export PARSL_CORES={}\n'.format(cpus_per_task)
185
186 job_name = "{0}.{1}".format(job_name, time.time())
187
188 script_path = "{0}/{1}.submit".format(self.script_dir, job_name)
189 script_path = os.path.abspath(script_path)
190
191 logger.debug("Requesting one block with {} nodes".format(self.nodes_per_block))
192
193 job_config = {}
194 job_config["submit_script_dir"] = self.channel.script_dir
195 job_config["nodes"] = self.nodes_per_block
196 job_config["tasks_per_node"] = tasks_per_node
197 job_config["walltime"] = wtime_to_minutes(self.walltime)
198 job_config["scheduler_options"] = scheduler_options
199 job_config["worker_init"] = worker_init
200 job_config["partition"] = self.partition
201 job_config["user_script"] = command
202
203 # Wrap the command
204 job_config["user_script"] = self.launcher(command,
205 tasks_per_node,
206 self.nodes_per_block)
207
208 logger.debug("Writing submit script")
209 self._write_submit_script(template_string, script_path, job_name, job_config)
210
211 if self.move_files:
212 logger.debug("moving files")
213 channel_script_path = self.channel.push_file(script_path, self.channel.script_dir)
214 else:
215 logger.debug("not moving files")
216 channel_script_path = script_path
217
218 retcode, stdout, stderr = self.execute_wait("sbatch {0}".format(channel_script_path))
219
220 job_id = None
221 if retcode == 0:
222 for line in stdout.split('\n'):
223 if line.startswith("Submitted batch job"):
224 job_id = line.split("Submitted batch job")[1].strip()
225 self.resources[job_id] = {'job_id': job_id, 'status': JobStatus(JobState.PENDING)}
226 else:
227 print("Submission of command to scale_out failed")
228 logger.error("Retcode:%s STDOUT:%s STDERR:%s", retcode, stdout.strip(), stderr.strip())
229 return job_id
230
231 def cancel(self, job_ids):
232 ''' Cancels the jobs specified by a list of job ids
233
234 Args:
235 job_ids : [<job_id> ...]
236
237 Returns :
238 [True/False...] : If the cancel operation fails the entire list will be False.
239 '''
240
241 job_id_list = ' '.join(job_ids)
242 retcode, stdout, stderr = self.execute_wait("scancel {0}".format(job_id_list))
243 rets = None
244 if retcode == 0:
245 for jid in job_ids:
246 self.resources[jid]['status'] = JobStatus(JobState.CANCELLED) # Setting state to cancelled
247 rets = [True for i in job_ids]
248 else:
249 rets = [False for i in job_ids]
250
251 return rets
252
253 def _test_add_resource(self, job_id):
254 self.resources.extend([{'job_id': job_id, 'status': JobStatus(JobState.PENDING), 'size': 1}])
255 return True
256
257
258 if __name__ == "__main__":
259
260 print("None")
261
```
Path: `parsl/providers/slurm/template.py`
Content:
```
1 template_string = '''#!/bin/bash
2
3 #SBATCH --job-name=${jobname}
4 #SBATCH --output=${submit_script_dir}/${jobname}.submit.stdout
5 #SBATCH --error=${submit_script_dir}/${jobname}.submit.stderr
6 #SBATCH --nodes=${nodes}
7 #SBATCH --partition=${partition}
8 #SBATCH --time=${walltime}
9 #SBATCH --ntasks-per-node=${tasks_per_node}
10 ${scheduler_options}
11
12 ${worker_init}
13
14 export JOBNAME="${jobname}"
15
16 $user_script
17 '''
18
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/parsl/providers/slurm/slurm.py b/parsl/providers/slurm/slurm.py
--- a/parsl/providers/slurm/slurm.py
+++ b/parsl/providers/slurm/slurm.py
@@ -42,7 +42,7 @@
Parameters
----------
partition : str
- Slurm partition to request blocks from.
+ Slurm partition to request blocks from. If none, no partition slurm directive will be specified.
channel : Channel
Channel for accessing this provider. Possible channels include
:class:`~parsl.channels.LocalChannel` (the default),
@@ -82,7 +82,7 @@
@typeguard.typechecked
def __init__(self,
- partition: str,
+ partition: Optional[str],
channel: Channel = LocalChannel(),
nodes_per_block: int = 1,
cores_per_node: Optional[int] = None,
@@ -118,6 +118,8 @@
self.scheduler_options = scheduler_options + '\n'
if exclusive:
self.scheduler_options += "#SBATCH --exclusive\n"
+ if partition:
+ self.scheduler_options += "#SBATCH --partition={}\n".format(partition)
self.worker_init = worker_init + '\n'
def _status(self):
@@ -197,7 +199,6 @@
job_config["walltime"] = wtime_to_minutes(self.walltime)
job_config["scheduler_options"] = scheduler_options
job_config["worker_init"] = worker_init
- job_config["partition"] = self.partition
job_config["user_script"] = command
# Wrap the command
diff --git a/parsl/providers/slurm/template.py b/parsl/providers/slurm/template.py
--- a/parsl/providers/slurm/template.py
+++ b/parsl/providers/slurm/template.py
@@ -4,7 +4,6 @@
#SBATCH --output=${submit_script_dir}/${jobname}.submit.stdout
#SBATCH --error=${submit_script_dir}/${jobname}.submit.stderr
#SBATCH --nodes=${nodes}
-#SBATCH --partition=${partition}
#SBATCH --time=${walltime}
#SBATCH --ntasks-per-node=${tasks_per_node}
${scheduler_options}
| {"golden_diff": "diff --git a/parsl/providers/slurm/slurm.py b/parsl/providers/slurm/slurm.py\n--- a/parsl/providers/slurm/slurm.py\n+++ b/parsl/providers/slurm/slurm.py\n@@ -42,7 +42,7 @@\n Parameters\n ----------\n partition : str\n- Slurm partition to request blocks from.\n+ Slurm partition to request blocks from. If none, no partition slurm directive will be specified.\n channel : Channel\n Channel for accessing this provider. Possible channels include\n :class:`~parsl.channels.LocalChannel` (the default),\n@@ -82,7 +82,7 @@\n \n @typeguard.typechecked\n def __init__(self,\n- partition: str,\n+ partition: Optional[str],\n channel: Channel = LocalChannel(),\n nodes_per_block: int = 1,\n cores_per_node: Optional[int] = None,\n@@ -118,6 +118,8 @@\n self.scheduler_options = scheduler_options + '\\n'\n if exclusive:\n self.scheduler_options += \"#SBATCH --exclusive\\n\"\n+ if partition:\n+ self.scheduler_options += \"#SBATCH --partition={}\\n\".format(partition)\n self.worker_init = worker_init + '\\n'\n \n def _status(self):\n@@ -197,7 +199,6 @@\n job_config[\"walltime\"] = wtime_to_minutes(self.walltime)\n job_config[\"scheduler_options\"] = scheduler_options\n job_config[\"worker_init\"] = worker_init\n- job_config[\"partition\"] = self.partition\n job_config[\"user_script\"] = command\n \n # Wrap the command\ndiff --git a/parsl/providers/slurm/template.py b/parsl/providers/slurm/template.py\n--- a/parsl/providers/slurm/template.py\n+++ b/parsl/providers/slurm/template.py\n@@ -4,7 +4,6 @@\n #SBATCH --output=${submit_script_dir}/${jobname}.submit.stdout\n #SBATCH --error=${submit_script_dir}/${jobname}.submit.stderr\n #SBATCH --nodes=${nodes}\n-#SBATCH --partition=${partition}\n #SBATCH --time=${walltime}\n #SBATCH --ntasks-per-node=${tasks_per_node}\n ${scheduler_options}\n", "issue": "slurm mandatory `partition` and non-mandatory `qos` are not always mandatory and non-mandatory. \nSee Parsl/libsubmit#66\n", "before_files": [{"content": "import os\nimport math\nimport time\nimport logging\nimport typeguard\n\nfrom typing import Optional\n\nfrom parsl.channels import LocalChannel\nfrom parsl.channels.base import Channel\nfrom parsl.launchers import SingleNodeLauncher\nfrom parsl.launchers.launchers import Launcher\nfrom parsl.providers.cluster_provider import ClusterProvider\nfrom parsl.providers.provider_base import JobState, JobStatus\nfrom parsl.providers.slurm.template import template_string\nfrom parsl.utils import RepresentationMixin, wtime_to_minutes\n\nlogger = logging.getLogger(__name__)\n\ntranslate_table = {\n 'PD': JobState.PENDING,\n 'R': JobState.RUNNING,\n 'CA': JobState.CANCELLED,\n 'CF': JobState.PENDING, # (configuring),\n 'CG': JobState.RUNNING, # (completing),\n 'CD': JobState.COMPLETED,\n 'F': JobState.FAILED, # (failed),\n 'TO': JobState.TIMEOUT, # (timeout),\n 'NF': JobState.FAILED, # (node failure),\n 'RV': JobState.FAILED, # (revoked) and\n 'SE': JobState.FAILED\n} # (special exit state\n\n\nclass SlurmProvider(ClusterProvider, RepresentationMixin):\n \"\"\"Slurm Execution Provider\n\n This provider uses sbatch to submit, squeue for status and scancel to cancel\n jobs. The sbatch script to be used is created from a template file in this\n same module.\n\n Parameters\n ----------\n partition : str\n Slurm partition to request blocks from.\n channel : Channel\n Channel for accessing this provider. Possible channels include\n :class:`~parsl.channels.LocalChannel` (the default),\n :class:`~parsl.channels.SSHChannel`, or\n :class:`~parsl.channels.SSHInteractiveLoginChannel`.\n nodes_per_block : int\n Nodes to provision per block.\n cores_per_node : int\n Specify the number of cores to provision per node. If set to None, executors\n will assume all cores on the node are available for computation. Default is None.\n mem_per_node : int\n Specify the real memory to provision per node in GB. If set to None, no\n explicit request to the scheduler will be made. Default is None.\n min_blocks : int\n Minimum number of blocks to maintain.\n max_blocks : int\n Maximum number of blocks to maintain.\n parallelism : float\n Ratio of provisioned task slots to active tasks. A parallelism value of 1 represents aggressive\n scaling where as many resources as possible are used; parallelism close to 0 represents\n the opposite situation in which as few resources as possible (i.e., min_blocks) are used.\n walltime : str\n Walltime requested per block in HH:MM:SS.\n scheduler_options : str\n String to prepend to the #SBATCH blocks in the submit script to the scheduler.\n worker_init : str\n Command to be run before starting a worker, such as 'module load Anaconda; source activate env'.\n exclusive : bool (Default = True)\n Requests nodes which are not shared with other running jobs.\n launcher : Launcher\n Launcher for this provider. Possible launchers include\n :class:`~parsl.launchers.SingleNodeLauncher` (the default),\n :class:`~parsl.launchers.SrunLauncher`, or\n :class:`~parsl.launchers.AprunLauncher`\n move_files : Optional[Bool]: should files be moved? by default, Parsl will try to move files.\n \"\"\"\n\n @typeguard.typechecked\n def __init__(self,\n partition: str,\n channel: Channel = LocalChannel(),\n nodes_per_block: int = 1,\n cores_per_node: Optional[int] = None,\n mem_per_node: Optional[int] = None,\n init_blocks: int = 1,\n min_blocks: int = 0,\n max_blocks: int = 10,\n parallelism: float = 1,\n walltime: str = \"00:10:00\",\n scheduler_options: str = '',\n worker_init: str = '',\n cmd_timeout: int = 10,\n exclusive: bool = True,\n move_files: bool = True,\n launcher: Launcher = SingleNodeLauncher()):\n label = 'slurm'\n super().__init__(label,\n channel,\n nodes_per_block,\n init_blocks,\n min_blocks,\n max_blocks,\n parallelism,\n walltime,\n cmd_timeout=cmd_timeout,\n launcher=launcher)\n\n self.partition = partition\n self.cores_per_node = cores_per_node\n self.mem_per_node = mem_per_node\n self.exclusive = exclusive\n self.move_files = move_files\n self.scheduler_options = scheduler_options + '\\n'\n if exclusive:\n self.scheduler_options += \"#SBATCH --exclusive\\n\"\n self.worker_init = worker_init + '\\n'\n\n def _status(self):\n ''' Internal: Do not call. Returns the status list for a list of job_ids\n\n Args:\n self\n\n Returns:\n [status...] : Status list of all jobs\n '''\n job_id_list = ','.join(self.resources.keys())\n cmd = \"squeue --job {0}\".format(job_id_list)\n\n retcode, stdout, stderr = self.execute_wait(cmd)\n\n # Execute_wait failed. Do no update\n if retcode != 0:\n return\n\n jobs_missing = list(self.resources.keys())\n for line in stdout.split('\\n'):\n parts = line.split()\n if parts and parts[0] != 'JOBID':\n job_id = parts[0]\n status = translate_table.get(parts[4], JobState.UNKNOWN)\n self.resources[job_id]['status'] = JobStatus(status)\n jobs_missing.remove(job_id)\n\n # squeue does not report on jobs that are not running. So we are filling in the\n # blanks for missing jobs, we might lose some information about why the jobs failed.\n for missing_job in jobs_missing:\n self.resources[missing_job]['status'] = JobStatus(JobState.COMPLETED)\n\n def submit(self, command, tasks_per_node, job_name=\"parsl.slurm\"):\n \"\"\"Submit the command as a slurm job.\n\n Parameters\n ----------\n command : str\n Command to be made on the remote side.\n tasks_per_node : int\n Command invocations to be launched per node\n job_name : str\n Name for the job (must be unique).\n Returns\n -------\n None or str\n If at capacity, returns None; otherwise, a string identifier for the job\n \"\"\"\n\n if self.provisioned_blocks >= self.max_blocks:\n logger.warning(\"Slurm provider '{}' is at capacity (no more blocks will be added)\".format(self.label))\n return None\n\n scheduler_options = self.scheduler_options\n worker_init = self.worker_init\n if self.mem_per_node is not None:\n scheduler_options += '#SBATCH --mem={}g\\n'.format(self.mem_per_node)\n worker_init += 'export PARSL_MEMORY_GB={}\\n'.format(self.mem_per_node)\n if self.cores_per_node is not None:\n cpus_per_task = math.floor(self.cores_per_node / tasks_per_node)\n scheduler_options += '#SBATCH --cpus-per-task={}'.format(cpus_per_task)\n worker_init += 'export PARSL_CORES={}\\n'.format(cpus_per_task)\n\n job_name = \"{0}.{1}\".format(job_name, time.time())\n\n script_path = \"{0}/{1}.submit\".format(self.script_dir, job_name)\n script_path = os.path.abspath(script_path)\n\n logger.debug(\"Requesting one block with {} nodes\".format(self.nodes_per_block))\n\n job_config = {}\n job_config[\"submit_script_dir\"] = self.channel.script_dir\n job_config[\"nodes\"] = self.nodes_per_block\n job_config[\"tasks_per_node\"] = tasks_per_node\n job_config[\"walltime\"] = wtime_to_minutes(self.walltime)\n job_config[\"scheduler_options\"] = scheduler_options\n job_config[\"worker_init\"] = worker_init\n job_config[\"partition\"] = self.partition\n job_config[\"user_script\"] = command\n\n # Wrap the command\n job_config[\"user_script\"] = self.launcher(command,\n tasks_per_node,\n self.nodes_per_block)\n\n logger.debug(\"Writing submit script\")\n self._write_submit_script(template_string, script_path, job_name, job_config)\n\n if self.move_files:\n logger.debug(\"moving files\")\n channel_script_path = self.channel.push_file(script_path, self.channel.script_dir)\n else:\n logger.debug(\"not moving files\")\n channel_script_path = script_path\n\n retcode, stdout, stderr = self.execute_wait(\"sbatch {0}\".format(channel_script_path))\n\n job_id = None\n if retcode == 0:\n for line in stdout.split('\\n'):\n if line.startswith(\"Submitted batch job\"):\n job_id = line.split(\"Submitted batch job\")[1].strip()\n self.resources[job_id] = {'job_id': job_id, 'status': JobStatus(JobState.PENDING)}\n else:\n print(\"Submission of command to scale_out failed\")\n logger.error(\"Retcode:%s STDOUT:%s STDERR:%s\", retcode, stdout.strip(), stderr.strip())\n return job_id\n\n def cancel(self, job_ids):\n ''' Cancels the jobs specified by a list of job ids\n\n Args:\n job_ids : [<job_id> ...]\n\n Returns :\n [True/False...] : If the cancel operation fails the entire list will be False.\n '''\n\n job_id_list = ' '.join(job_ids)\n retcode, stdout, stderr = self.execute_wait(\"scancel {0}\".format(job_id_list))\n rets = None\n if retcode == 0:\n for jid in job_ids:\n self.resources[jid]['status'] = JobStatus(JobState.CANCELLED) # Setting state to cancelled\n rets = [True for i in job_ids]\n else:\n rets = [False for i in job_ids]\n\n return rets\n\n def _test_add_resource(self, job_id):\n self.resources.extend([{'job_id': job_id, 'status': JobStatus(JobState.PENDING), 'size': 1}])\n return True\n\n\nif __name__ == \"__main__\":\n\n print(\"None\")\n", "path": "parsl/providers/slurm/slurm.py"}, {"content": "template_string = '''#!/bin/bash\n\n#SBATCH --job-name=${jobname}\n#SBATCH --output=${submit_script_dir}/${jobname}.submit.stdout\n#SBATCH --error=${submit_script_dir}/${jobname}.submit.stderr\n#SBATCH --nodes=${nodes}\n#SBATCH --partition=${partition}\n#SBATCH --time=${walltime}\n#SBATCH --ntasks-per-node=${tasks_per_node}\n${scheduler_options}\n\n${worker_init}\n\nexport JOBNAME=\"${jobname}\"\n\n$user_script\n'''\n", "path": "parsl/providers/slurm/template.py"}], "after_files": [{"content": "import os\nimport math\nimport time\nimport logging\nimport typeguard\n\nfrom typing import Optional\n\nfrom parsl.channels import LocalChannel\nfrom parsl.channels.base import Channel\nfrom parsl.launchers import SingleNodeLauncher\nfrom parsl.launchers.launchers import Launcher\nfrom parsl.providers.cluster_provider import ClusterProvider\nfrom parsl.providers.provider_base import JobState, JobStatus\nfrom parsl.providers.slurm.template import template_string\nfrom parsl.utils import RepresentationMixin, wtime_to_minutes\n\nlogger = logging.getLogger(__name__)\n\ntranslate_table = {\n 'PD': JobState.PENDING,\n 'R': JobState.RUNNING,\n 'CA': JobState.CANCELLED,\n 'CF': JobState.PENDING, # (configuring),\n 'CG': JobState.RUNNING, # (completing),\n 'CD': JobState.COMPLETED,\n 'F': JobState.FAILED, # (failed),\n 'TO': JobState.TIMEOUT, # (timeout),\n 'NF': JobState.FAILED, # (node failure),\n 'RV': JobState.FAILED, # (revoked) and\n 'SE': JobState.FAILED\n} # (special exit state\n\n\nclass SlurmProvider(ClusterProvider, RepresentationMixin):\n \"\"\"Slurm Execution Provider\n\n This provider uses sbatch to submit, squeue for status and scancel to cancel\n jobs. The sbatch script to be used is created from a template file in this\n same module.\n\n Parameters\n ----------\n partition : str\n Slurm partition to request blocks from. If none, no partition slurm directive will be specified.\n channel : Channel\n Channel for accessing this provider. Possible channels include\n :class:`~parsl.channels.LocalChannel` (the default),\n :class:`~parsl.channels.SSHChannel`, or\n :class:`~parsl.channels.SSHInteractiveLoginChannel`.\n nodes_per_block : int\n Nodes to provision per block.\n cores_per_node : int\n Specify the number of cores to provision per node. If set to None, executors\n will assume all cores on the node are available for computation. Default is None.\n mem_per_node : int\n Specify the real memory to provision per node in GB. If set to None, no\n explicit request to the scheduler will be made. Default is None.\n min_blocks : int\n Minimum number of blocks to maintain.\n max_blocks : int\n Maximum number of blocks to maintain.\n parallelism : float\n Ratio of provisioned task slots to active tasks. A parallelism value of 1 represents aggressive\n scaling where as many resources as possible are used; parallelism close to 0 represents\n the opposite situation in which as few resources as possible (i.e., min_blocks) are used.\n walltime : str\n Walltime requested per block in HH:MM:SS.\n scheduler_options : str\n String to prepend to the #SBATCH blocks in the submit script to the scheduler.\n worker_init : str\n Command to be run before starting a worker, such as 'module load Anaconda; source activate env'.\n exclusive : bool (Default = True)\n Requests nodes which are not shared with other running jobs.\n launcher : Launcher\n Launcher for this provider. Possible launchers include\n :class:`~parsl.launchers.SingleNodeLauncher` (the default),\n :class:`~parsl.launchers.SrunLauncher`, or\n :class:`~parsl.launchers.AprunLauncher`\n move_files : Optional[Bool]: should files be moved? by default, Parsl will try to move files.\n \"\"\"\n\n @typeguard.typechecked\n def __init__(self,\n partition: Optional[str],\n channel: Channel = LocalChannel(),\n nodes_per_block: int = 1,\n cores_per_node: Optional[int] = None,\n mem_per_node: Optional[int] = None,\n init_blocks: int = 1,\n min_blocks: int = 0,\n max_blocks: int = 10,\n parallelism: float = 1,\n walltime: str = \"00:10:00\",\n scheduler_options: str = '',\n worker_init: str = '',\n cmd_timeout: int = 10,\n exclusive: bool = True,\n move_files: bool = True,\n launcher: Launcher = SingleNodeLauncher()):\n label = 'slurm'\n super().__init__(label,\n channel,\n nodes_per_block,\n init_blocks,\n min_blocks,\n max_blocks,\n parallelism,\n walltime,\n cmd_timeout=cmd_timeout,\n launcher=launcher)\n\n self.partition = partition\n self.cores_per_node = cores_per_node\n self.mem_per_node = mem_per_node\n self.exclusive = exclusive\n self.move_files = move_files\n self.scheduler_options = scheduler_options + '\\n'\n if exclusive:\n self.scheduler_options += \"#SBATCH --exclusive\\n\"\n if partition:\n self.scheduler_options += \"#SBATCH --partition={}\\n\".format(partition)\n self.worker_init = worker_init + '\\n'\n\n def _status(self):\n ''' Internal: Do not call. Returns the status list for a list of job_ids\n\n Args:\n self\n\n Returns:\n [status...] : Status list of all jobs\n '''\n job_id_list = ','.join(self.resources.keys())\n cmd = \"squeue --job {0}\".format(job_id_list)\n\n retcode, stdout, stderr = self.execute_wait(cmd)\n\n # Execute_wait failed. Do no update\n if retcode != 0:\n return\n\n jobs_missing = list(self.resources.keys())\n for line in stdout.split('\\n'):\n parts = line.split()\n if parts and parts[0] != 'JOBID':\n job_id = parts[0]\n status = translate_table.get(parts[4], JobState.UNKNOWN)\n self.resources[job_id]['status'] = JobStatus(status)\n jobs_missing.remove(job_id)\n\n # squeue does not report on jobs that are not running. So we are filling in the\n # blanks for missing jobs, we might lose some information about why the jobs failed.\n for missing_job in jobs_missing:\n self.resources[missing_job]['status'] = JobStatus(JobState.COMPLETED)\n\n def submit(self, command, tasks_per_node, job_name=\"parsl.slurm\"):\n \"\"\"Submit the command as a slurm job.\n\n Parameters\n ----------\n command : str\n Command to be made on the remote side.\n tasks_per_node : int\n Command invocations to be launched per node\n job_name : str\n Name for the job (must be unique).\n Returns\n -------\n None or str\n If at capacity, returns None; otherwise, a string identifier for the job\n \"\"\"\n\n if self.provisioned_blocks >= self.max_blocks:\n logger.warning(\"Slurm provider '{}' is at capacity (no more blocks will be added)\".format(self.label))\n return None\n\n scheduler_options = self.scheduler_options\n worker_init = self.worker_init\n if self.mem_per_node is not None:\n scheduler_options += '#SBATCH --mem={}g\\n'.format(self.mem_per_node)\n worker_init += 'export PARSL_MEMORY_GB={}\\n'.format(self.mem_per_node)\n if self.cores_per_node is not None:\n cpus_per_task = math.floor(self.cores_per_node / tasks_per_node)\n scheduler_options += '#SBATCH --cpus-per-task={}'.format(cpus_per_task)\n worker_init += 'export PARSL_CORES={}\\n'.format(cpus_per_task)\n\n job_name = \"{0}.{1}\".format(job_name, time.time())\n\n script_path = \"{0}/{1}.submit\".format(self.script_dir, job_name)\n script_path = os.path.abspath(script_path)\n\n logger.debug(\"Requesting one block with {} nodes\".format(self.nodes_per_block))\n\n job_config = {}\n job_config[\"submit_script_dir\"] = self.channel.script_dir\n job_config[\"nodes\"] = self.nodes_per_block\n job_config[\"tasks_per_node\"] = tasks_per_node\n job_config[\"walltime\"] = wtime_to_minutes(self.walltime)\n job_config[\"scheduler_options\"] = scheduler_options\n job_config[\"worker_init\"] = worker_init\n job_config[\"user_script\"] = command\n\n # Wrap the command\n job_config[\"user_script\"] = self.launcher(command,\n tasks_per_node,\n self.nodes_per_block)\n\n logger.debug(\"Writing submit script\")\n self._write_submit_script(template_string, script_path, job_name, job_config)\n\n if self.move_files:\n logger.debug(\"moving files\")\n channel_script_path = self.channel.push_file(script_path, self.channel.script_dir)\n else:\n logger.debug(\"not moving files\")\n channel_script_path = script_path\n\n retcode, stdout, stderr = self.execute_wait(\"sbatch {0}\".format(channel_script_path))\n\n job_id = None\n if retcode == 0:\n for line in stdout.split('\\n'):\n if line.startswith(\"Submitted batch job\"):\n job_id = line.split(\"Submitted batch job\")[1].strip()\n self.resources[job_id] = {'job_id': job_id, 'status': JobStatus(JobState.PENDING)}\n else:\n print(\"Submission of command to scale_out failed\")\n logger.error(\"Retcode:%s STDOUT:%s STDERR:%s\", retcode, stdout.strip(), stderr.strip())\n return job_id\n\n def cancel(self, job_ids):\n ''' Cancels the jobs specified by a list of job ids\n\n Args:\n job_ids : [<job_id> ...]\n\n Returns :\n [True/False...] : If the cancel operation fails the entire list will be False.\n '''\n\n job_id_list = ' '.join(job_ids)\n retcode, stdout, stderr = self.execute_wait(\"scancel {0}\".format(job_id_list))\n rets = None\n if retcode == 0:\n for jid in job_ids:\n self.resources[jid]['status'] = JobStatus(JobState.CANCELLED) # Setting state to cancelled\n rets = [True for i in job_ids]\n else:\n rets = [False for i in job_ids]\n\n return rets\n\n def _test_add_resource(self, job_id):\n self.resources.extend([{'job_id': job_id, 'status': JobStatus(JobState.PENDING), 'size': 1}])\n return True\n\n\nif __name__ == \"__main__\":\n\n print(\"None\")\n", "path": "parsl/providers/slurm/slurm.py"}, {"content": "template_string = '''#!/bin/bash\n\n#SBATCH --job-name=${jobname}\n#SBATCH --output=${submit_script_dir}/${jobname}.submit.stdout\n#SBATCH --error=${submit_script_dir}/${jobname}.submit.stderr\n#SBATCH --nodes=${nodes}\n#SBATCH --time=${walltime}\n#SBATCH --ntasks-per-node=${tasks_per_node}\n${scheduler_options}\n\n${worker_init}\n\nexport JOBNAME=\"${jobname}\"\n\n$user_script\n'''\n", "path": "parsl/providers/slurm/template.py"}]} | 3,388 | 484 |
gh_patches_debug_7062 | rasdani/github-patches | git_diff | pyqtgraph__pyqtgraph-108 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Memory Leak when adding GLScatterPlotItem
I have found that adding and removing the same `GLScatterPlotItem` in a `GLViewWidget` causes a memory leak. Here is a script to demonstrate the behavior:
``` python
import numpy as np
from PySide import QtCore, QtGui
import sys
import pyqtgraph.opengl as gl
num_points = 10
refresh_interval = 1 # ms
class PlotWidget(QtGui.QWidget):
def __init__(self, parent=None):
super().__init__(parent)
# Basic layout setup
self.viewWidget = gl.GLViewWidget()
layout = QtGui.QVBoxLayout()
layout.addWidget(self.viewWidget)
self.setLayout(layout)
# Create out scatter plot item. Note that this leak only happens with
# scatter items, not with line or mesh items.
pos = np.random.rand(num_points, 3)
self.scatter = gl.GLScatterPlotItem(pos=pos)
self.viewWidget.addItem(self.scatter)
# Create and run timer to repeatedly add and remove scatter item.
self.timer = QtCore.QTimer()
self.timer.timeout.connect(self._add_remove)
self.timer.start(refresh_interval)
def _add_remove(self):
self.viewWidget.addItem(self.scatter)
self.viewWidget.removeItem(self.scatter)
def sizeHint(self):
return QtCore.QSize(800, 800)
if __name__ == "__main__":
app = QtGui.QApplication(sys.argv)
widget = PlotWidget()
widget.show()
sys.exit(app.exec_())
```
I have tried using other plot items (like `GLLinePlotItem` and `GLAxisItem`), and I do not see the memory leak, so it seems only GLScatterPlotItem creates the leak. I have also tried using PyQt4 and the script still generates a memory leak.
Could this be a problem with binding data to the OpenGL context, but then that data does not get released when the plot item is removed? This is my current theory, because I used the `objgraph` package to find new Python objects every few seconds, and it couldn't find any. Furthermore, `GLScatterPlotItem` is the only item I tested that has a non-trivial `initializeGL` method.
I will do more investigation. If there is a workaround, I would appreciate that too :)
Thanks in advance for any help!
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyqtgraph/opengl/items/GLScatterPlotItem.py`
Content:
```
1 from OpenGL.GL import *
2 from OpenGL.arrays import vbo
3 from .. GLGraphicsItem import GLGraphicsItem
4 from .. import shaders
5 from ... import QtGui
6 import numpy as np
7
8 __all__ = ['GLScatterPlotItem']
9
10 class GLScatterPlotItem(GLGraphicsItem):
11 """Draws points at a list of 3D positions."""
12
13 def __init__(self, **kwds):
14 GLGraphicsItem.__init__(self)
15 glopts = kwds.pop('glOptions', 'additive')
16 self.setGLOptions(glopts)
17 self.pos = []
18 self.size = 10
19 self.color = [1.0,1.0,1.0,0.5]
20 self.pxMode = True
21 #self.vbo = {} ## VBO does not appear to improve performance very much.
22 self.setData(**kwds)
23
24 def setData(self, **kwds):
25 """
26 Update the data displayed by this item. All arguments are optional;
27 for example it is allowed to update spot positions while leaving
28 colors unchanged, etc.
29
30 ==================== ==================================================
31 **Arguments:**
32 pos (N,3) array of floats specifying point locations.
33 color (N,4) array of floats (0.0-1.0) specifying
34 spot colors OR a tuple of floats specifying
35 a single color for all spots.
36 size (N,) array of floats specifying spot sizes or
37 a single value to apply to all spots.
38 pxMode If True, spot sizes are expressed in pixels.
39 Otherwise, they are expressed in item coordinates.
40 ==================== ==================================================
41 """
42 args = ['pos', 'color', 'size', 'pxMode']
43 for k in kwds.keys():
44 if k not in args:
45 raise Exception('Invalid keyword argument: %s (allowed arguments are %s)' % (k, str(args)))
46
47 args.remove('pxMode')
48 for arg in args:
49 if arg in kwds:
50 setattr(self, arg, kwds[arg])
51 #self.vbo.pop(arg, None)
52
53 self.pxMode = kwds.get('pxMode', self.pxMode)
54 self.update()
55
56 def initializeGL(self):
57
58 ## Generate texture for rendering points
59 w = 64
60 def fn(x,y):
61 r = ((x-w/2.)**2 + (y-w/2.)**2) ** 0.5
62 return 255 * (w/2. - np.clip(r, w/2.-1.0, w/2.))
63 pData = np.empty((w, w, 4))
64 pData[:] = 255
65 pData[:,:,3] = np.fromfunction(fn, pData.shape[:2])
66 #print pData.shape, pData.min(), pData.max()
67 pData = pData.astype(np.ubyte)
68
69 self.pointTexture = glGenTextures(1)
70 glActiveTexture(GL_TEXTURE0)
71 glEnable(GL_TEXTURE_2D)
72 glBindTexture(GL_TEXTURE_2D, self.pointTexture)
73 glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, pData.shape[0], pData.shape[1], 0, GL_RGBA, GL_UNSIGNED_BYTE, pData)
74
75 self.shader = shaders.getShaderProgram('pointSprite')
76
77 #def getVBO(self, name):
78 #if name not in self.vbo:
79 #self.vbo[name] = vbo.VBO(getattr(self, name).astype('f'))
80 #return self.vbo[name]
81
82 #def setupGLState(self):
83 #"""Prepare OpenGL state for drawing. This function is called immediately before painting."""
84 ##glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA) ## requires z-sorting to render properly.
85 #glBlendFunc(GL_SRC_ALPHA, GL_ONE)
86 #glEnable( GL_BLEND )
87 #glEnable( GL_ALPHA_TEST )
88 #glDisable( GL_DEPTH_TEST )
89
90 ##glEnable( GL_POINT_SMOOTH )
91
92 ##glHint(GL_POINT_SMOOTH_HINT, GL_NICEST)
93 ##glPointParameterfv(GL_POINT_DISTANCE_ATTENUATION, (0, 0, -1e-3))
94 ##glPointParameterfv(GL_POINT_SIZE_MAX, (65500,))
95 ##glPointParameterfv(GL_POINT_SIZE_MIN, (0,))
96
97 def paint(self):
98 self.setupGLState()
99
100 glEnable(GL_POINT_SPRITE)
101
102 glActiveTexture(GL_TEXTURE0)
103 glEnable( GL_TEXTURE_2D )
104 glBindTexture(GL_TEXTURE_2D, self.pointTexture)
105
106 glTexEnvi(GL_POINT_SPRITE, GL_COORD_REPLACE, GL_TRUE)
107 #glTexEnvi(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE) ## use texture color exactly
108 #glTexEnvf( GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_MODULATE ) ## texture modulates current color
109 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)
110 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)
111 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE)
112 glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE)
113 glEnable(GL_PROGRAM_POINT_SIZE)
114
115
116 with self.shader:
117 #glUniform1i(self.shader.uniform('texture'), 0) ## inform the shader which texture to use
118 glEnableClientState(GL_VERTEX_ARRAY)
119 try:
120 pos = self.pos
121 #if pos.ndim > 2:
122 #pos = pos.reshape((reduce(lambda a,b: a*b, pos.shape[:-1]), pos.shape[-1]))
123 glVertexPointerf(pos)
124
125 if isinstance(self.color, np.ndarray):
126 glEnableClientState(GL_COLOR_ARRAY)
127 glColorPointerf(self.color)
128 else:
129 if isinstance(self.color, QtGui.QColor):
130 glColor4f(*fn.glColor(self.color))
131 else:
132 glColor4f(*self.color)
133
134 if not self.pxMode or isinstance(self.size, np.ndarray):
135 glEnableClientState(GL_NORMAL_ARRAY)
136 norm = np.empty(pos.shape)
137 if self.pxMode:
138 norm[...,0] = self.size
139 else:
140 gpos = self.mapToView(pos.transpose()).transpose()
141 pxSize = self.view().pixelSize(gpos)
142 norm[...,0] = self.size / pxSize
143
144 glNormalPointerf(norm)
145 else:
146 glNormal3f(self.size, 0, 0) ## vertex shader uses norm.x to determine point size
147 #glPointSize(self.size)
148 glDrawArrays(GL_POINTS, 0, int(pos.size / pos.shape[-1]))
149 finally:
150 glDisableClientState(GL_NORMAL_ARRAY)
151 glDisableClientState(GL_VERTEX_ARRAY)
152 glDisableClientState(GL_COLOR_ARRAY)
153 #posVBO.unbind()
154
155 #for i in range(len(self.pos)):
156 #pos = self.pos[i]
157
158 #if isinstance(self.color, np.ndarray):
159 #color = self.color[i]
160 #else:
161 #color = self.color
162 #if isinstance(self.color, QtGui.QColor):
163 #color = fn.glColor(self.color)
164
165 #if isinstance(self.size, np.ndarray):
166 #size = self.size[i]
167 #else:
168 #size = self.size
169
170 #pxSize = self.view().pixelSize(QtGui.QVector3D(*pos))
171
172 #glPointSize(size / pxSize)
173 #glBegin( GL_POINTS )
174 #glColor4f(*color) # x is blue
175 ##glNormal3f(size, 0, 0)
176 #glVertex3f(*pos)
177 #glEnd()
178
179
180
181
182
183
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyqtgraph/opengl/items/GLScatterPlotItem.py b/pyqtgraph/opengl/items/GLScatterPlotItem.py
--- a/pyqtgraph/opengl/items/GLScatterPlotItem.py
+++ b/pyqtgraph/opengl/items/GLScatterPlotItem.py
@@ -66,7 +66,8 @@
#print pData.shape, pData.min(), pData.max()
pData = pData.astype(np.ubyte)
- self.pointTexture = glGenTextures(1)
+ if getattr(self, "pointTexture", None) is None:
+ self.pointTexture = glGenTextures(1)
glActiveTexture(GL_TEXTURE0)
glEnable(GL_TEXTURE_2D)
glBindTexture(GL_TEXTURE_2D, self.pointTexture)
| {"golden_diff": "diff --git a/pyqtgraph/opengl/items/GLScatterPlotItem.py b/pyqtgraph/opengl/items/GLScatterPlotItem.py\n--- a/pyqtgraph/opengl/items/GLScatterPlotItem.py\n+++ b/pyqtgraph/opengl/items/GLScatterPlotItem.py\n@@ -66,7 +66,8 @@\n #print pData.shape, pData.min(), pData.max()\n pData = pData.astype(np.ubyte)\n \n- self.pointTexture = glGenTextures(1)\n+ if getattr(self, \"pointTexture\", None) is None:\n+ self.pointTexture = glGenTextures(1)\n glActiveTexture(GL_TEXTURE0)\n glEnable(GL_TEXTURE_2D)\n glBindTexture(GL_TEXTURE_2D, self.pointTexture)\n", "issue": "Memory Leak when adding GLScatterPlotItem\nI have found that adding and removing the same `GLScatterPlotItem` in a `GLViewWidget` causes a memory leak. Here is a script to demonstrate the behavior:\n\n``` python\nimport numpy as np\nfrom PySide import QtCore, QtGui\nimport sys\n\nimport pyqtgraph.opengl as gl\n\nnum_points = 10\nrefresh_interval = 1 # ms\n\n\nclass PlotWidget(QtGui.QWidget):\n\n def __init__(self, parent=None):\n super().__init__(parent)\n\n # Basic layout setup\n self.viewWidget = gl.GLViewWidget()\n layout = QtGui.QVBoxLayout()\n layout.addWidget(self.viewWidget)\n self.setLayout(layout)\n\n # Create out scatter plot item. Note that this leak only happens with\n # scatter items, not with line or mesh items.\n pos = np.random.rand(num_points, 3)\n self.scatter = gl.GLScatterPlotItem(pos=pos)\n self.viewWidget.addItem(self.scatter)\n\n # Create and run timer to repeatedly add and remove scatter item.\n self.timer = QtCore.QTimer()\n self.timer.timeout.connect(self._add_remove)\n self.timer.start(refresh_interval)\n\n def _add_remove(self):\n self.viewWidget.addItem(self.scatter)\n self.viewWidget.removeItem(self.scatter)\n\n def sizeHint(self):\n return QtCore.QSize(800, 800)\n\n\nif __name__ == \"__main__\":\n app = QtGui.QApplication(sys.argv)\n\n widget = PlotWidget()\n widget.show()\n\n sys.exit(app.exec_())\n```\n\nI have tried using other plot items (like `GLLinePlotItem` and `GLAxisItem`), and I do not see the memory leak, so it seems only GLScatterPlotItem creates the leak. I have also tried using PyQt4 and the script still generates a memory leak.\n\nCould this be a problem with binding data to the OpenGL context, but then that data does not get released when the plot item is removed? This is my current theory, because I used the `objgraph` package to find new Python objects every few seconds, and it couldn't find any. Furthermore, `GLScatterPlotItem` is the only item I tested that has a non-trivial `initializeGL` method.\n\nI will do more investigation. If there is a workaround, I would appreciate that too :)\n\nThanks in advance for any help!\n\n", "before_files": [{"content": "from OpenGL.GL import *\nfrom OpenGL.arrays import vbo\nfrom .. GLGraphicsItem import GLGraphicsItem\nfrom .. import shaders\nfrom ... import QtGui\nimport numpy as np\n\n__all__ = ['GLScatterPlotItem']\n\nclass GLScatterPlotItem(GLGraphicsItem):\n \"\"\"Draws points at a list of 3D positions.\"\"\"\n \n def __init__(self, **kwds):\n GLGraphicsItem.__init__(self)\n glopts = kwds.pop('glOptions', 'additive')\n self.setGLOptions(glopts)\n self.pos = []\n self.size = 10\n self.color = [1.0,1.0,1.0,0.5]\n self.pxMode = True\n #self.vbo = {} ## VBO does not appear to improve performance very much.\n self.setData(**kwds)\n \n def setData(self, **kwds):\n \"\"\"\n Update the data displayed by this item. All arguments are optional; \n for example it is allowed to update spot positions while leaving \n colors unchanged, etc.\n \n ==================== ==================================================\n **Arguments:**\n pos (N,3) array of floats specifying point locations.\n color (N,4) array of floats (0.0-1.0) specifying\n spot colors OR a tuple of floats specifying\n a single color for all spots.\n size (N,) array of floats specifying spot sizes or \n a single value to apply to all spots.\n pxMode If True, spot sizes are expressed in pixels. \n Otherwise, they are expressed in item coordinates.\n ==================== ==================================================\n \"\"\"\n args = ['pos', 'color', 'size', 'pxMode']\n for k in kwds.keys():\n if k not in args:\n raise Exception('Invalid keyword argument: %s (allowed arguments are %s)' % (k, str(args)))\n \n args.remove('pxMode')\n for arg in args:\n if arg in kwds:\n setattr(self, arg, kwds[arg])\n #self.vbo.pop(arg, None)\n \n self.pxMode = kwds.get('pxMode', self.pxMode)\n self.update()\n\n def initializeGL(self):\n \n ## Generate texture for rendering points\n w = 64\n def fn(x,y):\n r = ((x-w/2.)**2 + (y-w/2.)**2) ** 0.5\n return 255 * (w/2. - np.clip(r, w/2.-1.0, w/2.))\n pData = np.empty((w, w, 4))\n pData[:] = 255\n pData[:,:,3] = np.fromfunction(fn, pData.shape[:2])\n #print pData.shape, pData.min(), pData.max()\n pData = pData.astype(np.ubyte)\n \n self.pointTexture = glGenTextures(1)\n glActiveTexture(GL_TEXTURE0)\n glEnable(GL_TEXTURE_2D)\n glBindTexture(GL_TEXTURE_2D, self.pointTexture)\n glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, pData.shape[0], pData.shape[1], 0, GL_RGBA, GL_UNSIGNED_BYTE, pData)\n \n self.shader = shaders.getShaderProgram('pointSprite')\n \n #def getVBO(self, name):\n #if name not in self.vbo:\n #self.vbo[name] = vbo.VBO(getattr(self, name).astype('f'))\n #return self.vbo[name]\n \n #def setupGLState(self):\n #\"\"\"Prepare OpenGL state for drawing. This function is called immediately before painting.\"\"\"\n ##glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA) ## requires z-sorting to render properly.\n #glBlendFunc(GL_SRC_ALPHA, GL_ONE)\n #glEnable( GL_BLEND )\n #glEnable( GL_ALPHA_TEST )\n #glDisable( GL_DEPTH_TEST )\n \n ##glEnable( GL_POINT_SMOOTH )\n\n ##glHint(GL_POINT_SMOOTH_HINT, GL_NICEST)\n ##glPointParameterfv(GL_POINT_DISTANCE_ATTENUATION, (0, 0, -1e-3))\n ##glPointParameterfv(GL_POINT_SIZE_MAX, (65500,))\n ##glPointParameterfv(GL_POINT_SIZE_MIN, (0,))\n \n def paint(self):\n self.setupGLState()\n \n glEnable(GL_POINT_SPRITE)\n \n glActiveTexture(GL_TEXTURE0)\n glEnable( GL_TEXTURE_2D )\n glBindTexture(GL_TEXTURE_2D, self.pointTexture)\n \n glTexEnvi(GL_POINT_SPRITE, GL_COORD_REPLACE, GL_TRUE)\n #glTexEnvi(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE) ## use texture color exactly\n #glTexEnvf( GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_MODULATE ) ## texture modulates current color\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE)\n glEnable(GL_PROGRAM_POINT_SIZE)\n \n \n with self.shader:\n #glUniform1i(self.shader.uniform('texture'), 0) ## inform the shader which texture to use\n glEnableClientState(GL_VERTEX_ARRAY)\n try:\n pos = self.pos\n #if pos.ndim > 2:\n #pos = pos.reshape((reduce(lambda a,b: a*b, pos.shape[:-1]), pos.shape[-1]))\n glVertexPointerf(pos)\n \n if isinstance(self.color, np.ndarray):\n glEnableClientState(GL_COLOR_ARRAY)\n glColorPointerf(self.color)\n else:\n if isinstance(self.color, QtGui.QColor):\n glColor4f(*fn.glColor(self.color))\n else:\n glColor4f(*self.color)\n \n if not self.pxMode or isinstance(self.size, np.ndarray):\n glEnableClientState(GL_NORMAL_ARRAY)\n norm = np.empty(pos.shape)\n if self.pxMode:\n norm[...,0] = self.size\n else:\n gpos = self.mapToView(pos.transpose()).transpose()\n pxSize = self.view().pixelSize(gpos)\n norm[...,0] = self.size / pxSize\n \n glNormalPointerf(norm)\n else:\n glNormal3f(self.size, 0, 0) ## vertex shader uses norm.x to determine point size\n #glPointSize(self.size)\n glDrawArrays(GL_POINTS, 0, int(pos.size / pos.shape[-1]))\n finally:\n glDisableClientState(GL_NORMAL_ARRAY)\n glDisableClientState(GL_VERTEX_ARRAY)\n glDisableClientState(GL_COLOR_ARRAY)\n #posVBO.unbind()\n \n #for i in range(len(self.pos)):\n #pos = self.pos[i]\n \n #if isinstance(self.color, np.ndarray):\n #color = self.color[i]\n #else:\n #color = self.color\n #if isinstance(self.color, QtGui.QColor):\n #color = fn.glColor(self.color)\n \n #if isinstance(self.size, np.ndarray):\n #size = self.size[i]\n #else:\n #size = self.size\n \n #pxSize = self.view().pixelSize(QtGui.QVector3D(*pos))\n \n #glPointSize(size / pxSize)\n #glBegin( GL_POINTS )\n #glColor4f(*color) # x is blue\n ##glNormal3f(size, 0, 0)\n #glVertex3f(*pos)\n #glEnd()\n\n \n \n \n \n", "path": "pyqtgraph/opengl/items/GLScatterPlotItem.py"}], "after_files": [{"content": "from OpenGL.GL import *\nfrom OpenGL.arrays import vbo\nfrom .. GLGraphicsItem import GLGraphicsItem\nfrom .. import shaders\nfrom ... import QtGui\nimport numpy as np\n\n__all__ = ['GLScatterPlotItem']\n\nclass GLScatterPlotItem(GLGraphicsItem):\n \"\"\"Draws points at a list of 3D positions.\"\"\"\n \n def __init__(self, **kwds):\n GLGraphicsItem.__init__(self)\n glopts = kwds.pop('glOptions', 'additive')\n self.setGLOptions(glopts)\n self.pos = []\n self.size = 10\n self.color = [1.0,1.0,1.0,0.5]\n self.pxMode = True\n #self.vbo = {} ## VBO does not appear to improve performance very much.\n self.setData(**kwds)\n \n def setData(self, **kwds):\n \"\"\"\n Update the data displayed by this item. All arguments are optional; \n for example it is allowed to update spot positions while leaving \n colors unchanged, etc.\n \n ==================== ==================================================\n **Arguments:**\n pos (N,3) array of floats specifying point locations.\n color (N,4) array of floats (0.0-1.0) specifying\n spot colors OR a tuple of floats specifying\n a single color for all spots.\n size (N,) array of floats specifying spot sizes or \n a single value to apply to all spots.\n pxMode If True, spot sizes are expressed in pixels. \n Otherwise, they are expressed in item coordinates.\n ==================== ==================================================\n \"\"\"\n args = ['pos', 'color', 'size', 'pxMode']\n for k in kwds.keys():\n if k not in args:\n raise Exception('Invalid keyword argument: %s (allowed arguments are %s)' % (k, str(args)))\n \n args.remove('pxMode')\n for arg in args:\n if arg in kwds:\n setattr(self, arg, kwds[arg])\n #self.vbo.pop(arg, None)\n \n self.pxMode = kwds.get('pxMode', self.pxMode)\n self.update()\n\n def initializeGL(self):\n \n ## Generate texture for rendering points\n w = 64\n def fn(x,y):\n r = ((x-w/2.)**2 + (y-w/2.)**2) ** 0.5\n return 255 * (w/2. - np.clip(r, w/2.-1.0, w/2.))\n pData = np.empty((w, w, 4))\n pData[:] = 255\n pData[:,:,3] = np.fromfunction(fn, pData.shape[:2])\n #print pData.shape, pData.min(), pData.max()\n pData = pData.astype(np.ubyte)\n \n if getattr(self, \"pointTexture\", None) is None:\n self.pointTexture = glGenTextures(1)\n glActiveTexture(GL_TEXTURE0)\n glEnable(GL_TEXTURE_2D)\n glBindTexture(GL_TEXTURE_2D, self.pointTexture)\n glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, pData.shape[0], pData.shape[1], 0, GL_RGBA, GL_UNSIGNED_BYTE, pData)\n \n self.shader = shaders.getShaderProgram('pointSprite')\n \n #def getVBO(self, name):\n #if name not in self.vbo:\n #self.vbo[name] = vbo.VBO(getattr(self, name).astype('f'))\n #return self.vbo[name]\n \n #def setupGLState(self):\n #\"\"\"Prepare OpenGL state for drawing. This function is called immediately before painting.\"\"\"\n ##glBlendFunc(GL_SRC_ALPHA, GL_ONE_MINUS_SRC_ALPHA) ## requires z-sorting to render properly.\n #glBlendFunc(GL_SRC_ALPHA, GL_ONE)\n #glEnable( GL_BLEND )\n #glEnable( GL_ALPHA_TEST )\n #glDisable( GL_DEPTH_TEST )\n \n ##glEnable( GL_POINT_SMOOTH )\n\n ##glHint(GL_POINT_SMOOTH_HINT, GL_NICEST)\n ##glPointParameterfv(GL_POINT_DISTANCE_ATTENUATION, (0, 0, -1e-3))\n ##glPointParameterfv(GL_POINT_SIZE_MAX, (65500,))\n ##glPointParameterfv(GL_POINT_SIZE_MIN, (0,))\n \n def paint(self):\n self.setupGLState()\n \n glEnable(GL_POINT_SPRITE)\n \n glActiveTexture(GL_TEXTURE0)\n glEnable( GL_TEXTURE_2D )\n glBindTexture(GL_TEXTURE_2D, self.pointTexture)\n \n glTexEnvi(GL_POINT_SPRITE, GL_COORD_REPLACE, GL_TRUE)\n #glTexEnvi(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE) ## use texture color exactly\n #glTexEnvf( GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_MODULATE ) ## texture modulates current color\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_CLAMP_TO_EDGE)\n glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_CLAMP_TO_EDGE)\n glEnable(GL_PROGRAM_POINT_SIZE)\n \n \n with self.shader:\n #glUniform1i(self.shader.uniform('texture'), 0) ## inform the shader which texture to use\n glEnableClientState(GL_VERTEX_ARRAY)\n try:\n pos = self.pos\n #if pos.ndim > 2:\n #pos = pos.reshape((reduce(lambda a,b: a*b, pos.shape[:-1]), pos.shape[-1]))\n glVertexPointerf(pos)\n \n if isinstance(self.color, np.ndarray):\n glEnableClientState(GL_COLOR_ARRAY)\n glColorPointerf(self.color)\n else:\n if isinstance(self.color, QtGui.QColor):\n glColor4f(*fn.glColor(self.color))\n else:\n glColor4f(*self.color)\n \n if not self.pxMode or isinstance(self.size, np.ndarray):\n glEnableClientState(GL_NORMAL_ARRAY)\n norm = np.empty(pos.shape)\n if self.pxMode:\n norm[...,0] = self.size\n else:\n gpos = self.mapToView(pos.transpose()).transpose()\n pxSize = self.view().pixelSize(gpos)\n norm[...,0] = self.size / pxSize\n \n glNormalPointerf(norm)\n else:\n glNormal3f(self.size, 0, 0) ## vertex shader uses norm.x to determine point size\n #glPointSize(self.size)\n glDrawArrays(GL_POINTS, 0, int(pos.size / pos.shape[-1]))\n finally:\n glDisableClientState(GL_NORMAL_ARRAY)\n glDisableClientState(GL_VERTEX_ARRAY)\n glDisableClientState(GL_COLOR_ARRAY)\n #posVBO.unbind()\n \n #for i in range(len(self.pos)):\n #pos = self.pos[i]\n \n #if isinstance(self.color, np.ndarray):\n #color = self.color[i]\n #else:\n #color = self.color\n #if isinstance(self.color, QtGui.QColor):\n #color = fn.glColor(self.color)\n \n #if isinstance(self.size, np.ndarray):\n #size = self.size[i]\n #else:\n #size = self.size\n \n #pxSize = self.view().pixelSize(QtGui.QVector3D(*pos))\n \n #glPointSize(size / pxSize)\n #glBegin( GL_POINTS )\n #glColor4f(*color) # x is blue\n ##glNormal3f(size, 0, 0)\n #glVertex3f(*pos)\n #glEnd()\n\n \n \n \n \n", "path": "pyqtgraph/opengl/items/GLScatterPlotItem.py"}]} | 2,866 | 160 |
gh_patches_debug_1599 | rasdani/github-patches | git_diff | bridgecrewio__checkov-2214 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
CKV_AZURE_80 - dotnet_framework_version with v6.0 fails
**Describe the issue**
Currently .NET 6.0 is the latest LTS version. However, CKV_AZURE_80 expects that latest version is v5.0.
**Examples**
```
resource "azurerm_app_service" "searchApi" {
...
site_config {
dotnet_framework_version = "v6.0"
}
}
```
There should be no warning for CKV_AZURE_80 with the above configuration.
**Version (please complete the following information):**
- Checkov Version 2.0.717
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py`
Content:
```
1 from checkov.common.models.enums import CheckCategories
2 from checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck
3
4
5 class AppServiceDotnetFrameworkVersion(BaseResourceValueCheck):
6 def __init__(self):
7 name = "Ensure that 'Net Framework' version is the latest, if used as a part of the web app"
8 id = "CKV_AZURE_80"
9 supported_resources = ['azurerm_app_service']
10 categories = [CheckCategories.GENERAL_SECURITY]
11 super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)
12
13 def get_inspected_key(self):
14 return "site_config/0/dotnet_framework_version"
15
16 def get_expected_value(self):
17 return "v5.0"
18
19
20 check = AppServiceDotnetFrameworkVersion()
21
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py b/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py
--- a/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py
+++ b/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py
@@ -14,7 +14,7 @@
return "site_config/0/dotnet_framework_version"
def get_expected_value(self):
- return "v5.0"
+ return "v6.0"
check = AppServiceDotnetFrameworkVersion()
| {"golden_diff": "diff --git a/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py b/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py\n--- a/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py\n+++ b/checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py\n@@ -14,7 +14,7 @@\n return \"site_config/0/dotnet_framework_version\"\n \n def get_expected_value(self):\n- return \"v5.0\"\n+ return \"v6.0\"\n \n \n check = AppServiceDotnetFrameworkVersion()\n", "issue": "CKV_AZURE_80 - dotnet_framework_version with v6.0 fails\n**Describe the issue**\r\nCurrently .NET 6.0 is the latest LTS version. However, CKV_AZURE_80 expects that latest version is v5.0.\r\n\r\n**Examples**\r\n```\r\nresource \"azurerm_app_service\" \"searchApi\" {\r\n ...\r\n site_config {\r\n dotnet_framework_version = \"v6.0\"\r\n }\r\n}\r\n```\r\nThere should be no warning for CKV_AZURE_80 with the above configuration.\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version 2.0.717\r\n\n", "before_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AppServiceDotnetFrameworkVersion(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure that 'Net Framework' version is the latest, if used as a part of the web app\"\n id = \"CKV_AZURE_80\"\n supported_resources = ['azurerm_app_service']\n categories = [CheckCategories.GENERAL_SECURITY]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"site_config/0/dotnet_framework_version\"\n\n def get_expected_value(self):\n return \"v5.0\"\n\n\ncheck = AppServiceDotnetFrameworkVersion()\n", "path": "checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py"}], "after_files": [{"content": "from checkov.common.models.enums import CheckCategories\nfrom checkov.terraform.checks.resource.base_resource_value_check import BaseResourceValueCheck\n\n\nclass AppServiceDotnetFrameworkVersion(BaseResourceValueCheck):\n def __init__(self):\n name = \"Ensure that 'Net Framework' version is the latest, if used as a part of the web app\"\n id = \"CKV_AZURE_80\"\n supported_resources = ['azurerm_app_service']\n categories = [CheckCategories.GENERAL_SECURITY]\n super().__init__(name=name, id=id, categories=categories, supported_resources=supported_resources)\n\n def get_inspected_key(self):\n return \"site_config/0/dotnet_framework_version\"\n\n def get_expected_value(self):\n return \"v6.0\"\n\n\ncheck = AppServiceDotnetFrameworkVersion()\n", "path": "checkov/terraform/checks/resource/azure/AppServiceDotnetFrameworkVersion.py"}]} | 624 | 137 |
gh_patches_debug_32202 | rasdani/github-patches | git_diff | PennyLaneAI__pennylane-889 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Arithmetic operations between pennylane.numpy arrays have inconsistent `requires_grad` output
**Issue**
The PennyLane wrapper if the numpy library, which is used to optimise circuits with the standard autograd interface, has an inconsistent behaviour when using arithmetic functions such as +, -, * (here using the sum to demonstrate).
Summing two `pennylane.numpy.array` objects, one having gradients enabled and the other not, returns a differentiable array or not, depending on the order.
``` python
import pennylane as qml
from pennylane import numpy as np
a = np.array(1., requires_grad=True)
b = np.array(0., requires_grad=False)
c = a+b
print(c.requires_grad) # True
d = b+a
print(d.requires_grad) # False
```
**Expected behaviour**
The `requires_grad = True` flag should always be overwriting, and the output of the two print statements should be true in both cases. This is important for example in loss function where target outputs (which do not require gradients) and predictions (which depend on the parameters and require gradients) are compared, i.e. via `np.sum(np.abs((target - prediction))**2)`.
**System information**
Reproducible with PennyLane v0.12 stable release, and with the current master, in tape mode or not in tape mode.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pennylane/numpy/tensor.py`
Content:
```
1 # Copyright 2018-2020 Xanadu Quantum Technologies Inc.
2
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6
7 # http://www.apache.org/licenses/LICENSE-2.0
8
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """
15 This module provides the PennyLane :class:`~.tensor` class.
16 """
17 import numpy as onp
18
19 from autograd import numpy as _np
20
21 from autograd.tracer import Box
22 from autograd.numpy.numpy_boxes import ArrayBox
23 from autograd.numpy.numpy_vspaces import ComplexArrayVSpace, ArrayVSpace
24 from autograd.core import VSpace
25
26
27 __doc__ = "NumPy with automatic differentiation support, provided by Autograd and PennyLane."
28
29
30 class tensor(_np.ndarray):
31 """Constructs a PennyLane tensor for use with Autograd QNodes.
32
33 The ``tensor`` class is a subclass of ``numpy.ndarray``,
34 providing the same multidimensional, homogeneous data-structure
35 of fixed-size items, with an additional flag to indicate to PennyLane
36 whether the contained data is differentiable or not.
37
38 .. warning::
39
40 PennyLane ``tensor`` objects are only used as part of the Autograd QNode
41 interface. If using another machine learning library such as PyTorch or
42 TensorFlow, use their built-in ``tf.Variable`` and ``torch.tensor`` classes
43 instead.
44
45 .. warning::
46
47 Tensors should be constructed using standard array construction functions
48 provided as part of PennyLane's NumPy implementation, including
49 ``np.array``, ``np.zeros`` or ``np.empty``.
50
51 The parameters given here refer to a low-level class
52 for instantiating tensors.
53
54
55 Args:
56 input_array (array_like): Any data structure in any form that can be converted to
57 an array. This includes lists, lists of tuples, tuples, tuples of tuples,
58 tuples of lists and ndarrays.
59 requires_grad (bool): whether the tensor supports differentiation
60
61 **Example**
62
63 The trainability of a tensor can be set on construction via the
64 ``requires_grad`` keyword argument,
65
66 >>> from pennylane import numpy as np
67 >>> x = np.array([0, 1, 2], requires_grad=True)
68 >>> x
69 tensor([0, 1, 2], requires_grad=True)
70
71 or in-place by modifying the ``requires_grad`` attribute:
72
73 >>> x.requires_grad = False
74 tensor([0, 1, 2], requires_grad=False)
75
76 Since tensors are subclasses of ``np.ndarray``, they can be provided as arguments
77 to any PennyLane-wrapped NumPy function:
78
79 >>> np.sin(x)
80 tensor([0. , 0.84147098, 0.90929743], requires_grad=True)
81
82 When composing functions of multiple tensors, if at least one input tensor is differentiable,
83 then the output will also be differentiable:
84
85 >>> x = np.array([0, 1, 2], requires_grad=False)
86 >>> y = np.zeros([3], requires_grad=True)
87 >>> np.vstack([x, y])
88 tensor([[0., 1., 2.],
89 [0., 0., 0.]], requires_grad=True)
90 """
91
92 def __new__(cls, input_array, *args, requires_grad=True, **kwargs):
93 obj = _np.array(input_array, *args, **kwargs)
94
95 if isinstance(obj, _np.ndarray):
96 obj = obj.view(cls)
97 obj.requires_grad = requires_grad
98
99 return obj
100
101 def __array_finalize__(self, obj):
102 # pylint: disable=attribute-defined-outside-init
103 if obj is None: # pragma: no cover
104 return
105
106 self.requires_grad = getattr(obj, "requires_grad", None)
107
108 def __repr__(self):
109 string = super().__repr__()
110 return string[:-1] + ", requires_grad={})".format(self.requires_grad)
111
112 def __array_wrap__(self, obj):
113 out_arr = tensor(obj, requires_grad=self.requires_grad)
114 return super().__array_wrap__(out_arr)
115
116 def __getitem__(self, *args, **kwargs):
117 item = super().__getitem__(*args, **kwargs)
118
119 if not isinstance(item, tensor):
120 item = tensor(item, requires_grad=self.requires_grad)
121
122 return item
123
124 def __hash__(self):
125 if self.ndim == 0:
126 # Allowing hashing if the tensor is a scalar.
127 # We hash both the scalar value *and* the differentiability information,
128 # to match the behaviour of PyTorch.
129 return hash((self.item(), self.requires_grad))
130
131 raise TypeError("unhashable type: 'numpy.tensor'")
132
133 def unwrap(self):
134 """Converts the tensor to a standard, non-differentiable NumPy ndarray or Python scalar if
135 the tensor is 0-dimensional.
136
137 All information regarding differentiability of the tensor will be lost.
138
139 .. warning::
140
141 The returned array is a new view onto the **same data**. That is,
142 the tensor and the returned ``ndarray`` share the same underlying storage.
143 Changes to the tensor object will be reflected within the returned array,
144 and vice versa.
145
146 **Example**
147
148 >>> from pennylane import numpy as np
149 >>> x = np.array([1, 2], requires_grad=True)
150 >>> x
151 tensor([1, 2], requires_grad=True)
152 >>> x.unwrap()
153 array([1, 2])
154
155 Zero dimensional array are converted to Python scalars:
156
157 >>> x = np.array(1.543, requires_grad=False)
158 >>> x.unwrap()
159 1.543
160 >>> type(x.unwrap())
161 float
162
163 The underlying data is **not** copied:
164
165 >>> x = np.array([1, 2], requires_grad=True)
166 >>> y = x.unwrap()
167 >>> x[0] = 5
168 >>> y
169 array([5, 2])
170 >>> y[1] = 7
171 >>> x
172 tensor([5, 7], requires_grad=True)
173
174
175 To create a copy, the ``copy()`` method can be used:
176
177 >>> x = np.array([1, 2], requires_grad=True)
178 >>> y = x.unwrap().copy()
179 >>> x[0] = 5
180 >>> y
181 array([1, 2])
182 """
183 if self.ndim == 0:
184 return self.view(onp.ndarray).item()
185
186 return self.view(onp.ndarray)
187
188 def numpy(self):
189 """Converts the tensor to a standard, non-differentiable NumPy ndarray or Python scalar if
190 the tensor is 0-dimensional.
191
192 This method is an alias for :meth:`~.unwrap`. See :meth:`~.unwrap` for more details.
193 """
194 return self.unwrap()
195
196
197 class NonDifferentiableError(Exception):
198 """Exception raised if attempting to differentiate non-trainable
199 :class:`~.tensor` using Autograd."""
200
201
202 def tensor_to_arraybox(x, *args):
203 """Convert a :class:`~.tensor` to an Autograd ``ArrayBox``.
204
205 Args:
206 x (array_like): Any data structure in any form that can be converted to
207 an array. This includes lists, lists of tuples, tuples, tuples of tuples,
208 tuples of lists and ndarrays.
209
210 Returns:
211 autograd.numpy.numpy_boxes.ArrayBox: Autograd ArrayBox instance of the array
212
213 Raises:
214 NonDifferentiableError: if the provided tensor is non-differentiable
215 """
216 if isinstance(x, tensor):
217 if x.requires_grad:
218 return ArrayBox(x, *args)
219
220 raise NonDifferentiableError(
221 "{} is non-differentiable. Set the requires_grad attribute to True.".format(x)
222 )
223
224 return ArrayBox(x, *args)
225
226
227 Box.type_mappings[tensor] = tensor_to_arraybox
228 VSpace.mappings[tensor] = lambda x: ComplexArrayVSpace(x) if onp.iscomplexobj(x) else ArrayVSpace(x)
229
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pennylane/numpy/tensor.py b/pennylane/numpy/tensor.py
--- a/pennylane/numpy/tensor.py
+++ b/pennylane/numpy/tensor.py
@@ -113,6 +113,55 @@
out_arr = tensor(obj, requires_grad=self.requires_grad)
return super().__array_wrap__(out_arr)
+ def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):
+ # pylint: disable=no-member,attribute-defined-outside-init
+
+ # unwrap any outputs the ufunc might have
+ outputs = [i.view(onp.ndarray) for i in kwargs.get("out", ())]
+
+ if outputs:
+ # Insert the unwrapped outputs into the keyword
+ # args dictionary, to be passed to ndarray.__array_ufunc__
+ outputs = tuple(outputs)
+ kwargs["out"] = outputs
+ else:
+ # If the ufunc has no ouputs, we simply
+ # create a tuple containing None for all potential outputs.
+ outputs = (None,) * ufunc.nout
+
+ # unwrap the input arguments to the ufunc
+ args = [i.unwrap() if hasattr(i, "unwrap") else i for i in inputs]
+
+ # call the ndarray.__array_ufunc__ method to compute the result
+ # of the vectorized ufunc
+ res = super().__array_ufunc__(ufunc, method, *args, **kwargs)
+
+ if ufunc.nout == 1:
+ res = (res,)
+
+ # construct a list of ufunc outputs to return
+ ufunc_output = [
+ (onp.asarray(result) if output is None else output)
+ for result, output in zip(res, outputs)
+ ]
+
+ # if any of the inputs were trainable, the output is also trainable
+ requires_grad = any(
+ isinstance(x, onp.ndarray) and getattr(x, "requires_grad", True) for x in inputs
+ )
+
+ # Iterate through the ufunc outputs and convert each to a PennyLane tensor.
+ # We also correctly set the requires_grad attribute.
+ for i in range(len(ufunc_output)): # pylint: disable=consider-using-enumerate
+ ufunc_output[i] = tensor(ufunc_output[i], requires_grad=requires_grad)
+
+ if len(ufunc_output) == 1:
+ # the ufunc has a single output so return a single tensor
+ return ufunc_output[0]
+
+ # otherwise we must return a tuple of tensors
+ return tuple(ufunc_output)
+
def __getitem__(self, *args, **kwargs):
item = super().__getitem__(*args, **kwargs)
| {"golden_diff": "diff --git a/pennylane/numpy/tensor.py b/pennylane/numpy/tensor.py\n--- a/pennylane/numpy/tensor.py\n+++ b/pennylane/numpy/tensor.py\n@@ -113,6 +113,55 @@\n out_arr = tensor(obj, requires_grad=self.requires_grad)\r\n return super().__array_wrap__(out_arr)\r\n \r\n+ def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):\r\n+ # pylint: disable=no-member,attribute-defined-outside-init\r\n+\r\n+ # unwrap any outputs the ufunc might have\r\n+ outputs = [i.view(onp.ndarray) for i in kwargs.get(\"out\", ())]\r\n+\r\n+ if outputs:\r\n+ # Insert the unwrapped outputs into the keyword\r\n+ # args dictionary, to be passed to ndarray.__array_ufunc__\r\n+ outputs = tuple(outputs)\r\n+ kwargs[\"out\"] = outputs\r\n+ else:\r\n+ # If the ufunc has no ouputs, we simply\r\n+ # create a tuple containing None for all potential outputs.\r\n+ outputs = (None,) * ufunc.nout\r\n+\r\n+ # unwrap the input arguments to the ufunc\r\n+ args = [i.unwrap() if hasattr(i, \"unwrap\") else i for i in inputs]\r\n+\r\n+ # call the ndarray.__array_ufunc__ method to compute the result\r\n+ # of the vectorized ufunc\r\n+ res = super().__array_ufunc__(ufunc, method, *args, **kwargs)\r\n+\r\n+ if ufunc.nout == 1:\r\n+ res = (res,)\r\n+\r\n+ # construct a list of ufunc outputs to return\r\n+ ufunc_output = [\r\n+ (onp.asarray(result) if output is None else output)\r\n+ for result, output in zip(res, outputs)\r\n+ ]\r\n+\r\n+ # if any of the inputs were trainable, the output is also trainable\r\n+ requires_grad = any(\r\n+ isinstance(x, onp.ndarray) and getattr(x, \"requires_grad\", True) for x in inputs\r\n+ )\r\n+\r\n+ # Iterate through the ufunc outputs and convert each to a PennyLane tensor.\r\n+ # We also correctly set the requires_grad attribute.\r\n+ for i in range(len(ufunc_output)): # pylint: disable=consider-using-enumerate\r\n+ ufunc_output[i] = tensor(ufunc_output[i], requires_grad=requires_grad)\r\n+\r\n+ if len(ufunc_output) == 1:\r\n+ # the ufunc has a single output so return a single tensor\r\n+ return ufunc_output[0]\r\n+\r\n+ # otherwise we must return a tuple of tensors\r\n+ return tuple(ufunc_output)\r\n+\r\n def __getitem__(self, *args, **kwargs):\r\n item = super().__getitem__(*args, **kwargs)\n", "issue": "Arithmetic operations between pennylane.numpy arrays have inconsistent `requires_grad` output \n**Issue**\r\n\r\nThe PennyLane wrapper if the numpy library, which is used to optimise circuits with the standard autograd interface, has an inconsistent behaviour when using arithmetic functions such as +, -, * (here using the sum to demonstrate). \r\n\r\nSumming two `pennylane.numpy.array` objects, one having gradients enabled and the other not, returns a differentiable array or not, depending on the order.\r\n\r\n``` python\r\nimport pennylane as qml\r\nfrom pennylane import numpy as np\r\n\r\na = np.array(1., requires_grad=True)\r\nb = np.array(0., requires_grad=False)\r\n\r\nc = a+b\r\nprint(c.requires_grad) # True\r\n\r\nd = b+a\r\nprint(d.requires_grad) # False\r\n```\r\n**Expected behaviour**\r\nThe `requires_grad = True` flag should always be overwriting, and the output of the two print statements should be true in both cases. This is important for example in loss function where target outputs (which do not require gradients) and predictions (which depend on the parameters and require gradients) are compared, i.e. via `np.sum(np.abs((target - prediction))**2)`.\r\n\r\n**System information**\r\nReproducible with PennyLane v0.12 stable release, and with the current master, in tape mode or not in tape mode.\r\n\n", "before_files": [{"content": "# Copyright 2018-2020 Xanadu Quantum Technologies Inc.\r\n\r\n# Licensed under the Apache License, Version 2.0 (the \"License\");\r\n# you may not use this file except in compliance with the License.\r\n# You may obtain a copy of the License at\r\n\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\n\"\"\"\r\nThis module provides the PennyLane :class:`~.tensor` class.\r\n\"\"\"\r\nimport numpy as onp\r\n\r\nfrom autograd import numpy as _np\r\n\r\nfrom autograd.tracer import Box\r\nfrom autograd.numpy.numpy_boxes import ArrayBox\r\nfrom autograd.numpy.numpy_vspaces import ComplexArrayVSpace, ArrayVSpace\r\nfrom autograd.core import VSpace\r\n\r\n\r\n__doc__ = \"NumPy with automatic differentiation support, provided by Autograd and PennyLane.\"\r\n\r\n\r\nclass tensor(_np.ndarray):\r\n \"\"\"Constructs a PennyLane tensor for use with Autograd QNodes.\r\n\r\n The ``tensor`` class is a subclass of ``numpy.ndarray``,\r\n providing the same multidimensional, homogeneous data-structure\r\n of fixed-size items, with an additional flag to indicate to PennyLane\r\n whether the contained data is differentiable or not.\r\n\r\n .. warning::\r\n\r\n PennyLane ``tensor`` objects are only used as part of the Autograd QNode\r\n interface. If using another machine learning library such as PyTorch or\r\n TensorFlow, use their built-in ``tf.Variable`` and ``torch.tensor`` classes\r\n instead.\r\n\r\n .. warning::\r\n\r\n Tensors should be constructed using standard array construction functions\r\n provided as part of PennyLane's NumPy implementation, including\r\n ``np.array``, ``np.zeros`` or ``np.empty``.\r\n\r\n The parameters given here refer to a low-level class\r\n for instantiating tensors.\r\n\r\n\r\n Args:\r\n input_array (array_like): Any data structure in any form that can be converted to\r\n an array. This includes lists, lists of tuples, tuples, tuples of tuples,\r\n tuples of lists and ndarrays.\r\n requires_grad (bool): whether the tensor supports differentiation\r\n\r\n **Example**\r\n\r\n The trainability of a tensor can be set on construction via the\r\n ``requires_grad`` keyword argument,\r\n\r\n >>> from pennylane import numpy as np\r\n >>> x = np.array([0, 1, 2], requires_grad=True)\r\n >>> x\r\n tensor([0, 1, 2], requires_grad=True)\r\n\r\n or in-place by modifying the ``requires_grad`` attribute:\r\n\r\n >>> x.requires_grad = False\r\n tensor([0, 1, 2], requires_grad=False)\r\n\r\n Since tensors are subclasses of ``np.ndarray``, they can be provided as arguments\r\n to any PennyLane-wrapped NumPy function:\r\n\r\n >>> np.sin(x)\r\n tensor([0. , 0.84147098, 0.90929743], requires_grad=True)\r\n\r\n When composing functions of multiple tensors, if at least one input tensor is differentiable,\r\n then the output will also be differentiable:\r\n\r\n >>> x = np.array([0, 1, 2], requires_grad=False)\r\n >>> y = np.zeros([3], requires_grad=True)\r\n >>> np.vstack([x, y])\r\n tensor([[0., 1., 2.],\r\n [0., 0., 0.]], requires_grad=True)\r\n \"\"\"\r\n\r\n def __new__(cls, input_array, *args, requires_grad=True, **kwargs):\r\n obj = _np.array(input_array, *args, **kwargs)\r\n\r\n if isinstance(obj, _np.ndarray):\r\n obj = obj.view(cls)\r\n obj.requires_grad = requires_grad\r\n\r\n return obj\r\n\r\n def __array_finalize__(self, obj):\r\n # pylint: disable=attribute-defined-outside-init\r\n if obj is None: # pragma: no cover\r\n return\r\n\r\n self.requires_grad = getattr(obj, \"requires_grad\", None)\r\n\r\n def __repr__(self):\r\n string = super().__repr__()\r\n return string[:-1] + \", requires_grad={})\".format(self.requires_grad)\r\n\r\n def __array_wrap__(self, obj):\r\n out_arr = tensor(obj, requires_grad=self.requires_grad)\r\n return super().__array_wrap__(out_arr)\r\n\r\n def __getitem__(self, *args, **kwargs):\r\n item = super().__getitem__(*args, **kwargs)\r\n\r\n if not isinstance(item, tensor):\r\n item = tensor(item, requires_grad=self.requires_grad)\r\n\r\n return item\r\n\r\n def __hash__(self):\r\n if self.ndim == 0:\r\n # Allowing hashing if the tensor is a scalar.\r\n # We hash both the scalar value *and* the differentiability information,\r\n # to match the behaviour of PyTorch.\r\n return hash((self.item(), self.requires_grad))\r\n\r\n raise TypeError(\"unhashable type: 'numpy.tensor'\")\r\n\r\n def unwrap(self):\r\n \"\"\"Converts the tensor to a standard, non-differentiable NumPy ndarray or Python scalar if\r\n the tensor is 0-dimensional.\r\n\r\n All information regarding differentiability of the tensor will be lost.\r\n\r\n .. warning::\r\n\r\n The returned array is a new view onto the **same data**. That is,\r\n the tensor and the returned ``ndarray`` share the same underlying storage.\r\n Changes to the tensor object will be reflected within the returned array,\r\n and vice versa.\r\n\r\n **Example**\r\n\r\n >>> from pennylane import numpy as np\r\n >>> x = np.array([1, 2], requires_grad=True)\r\n >>> x\r\n tensor([1, 2], requires_grad=True)\r\n >>> x.unwrap()\r\n array([1, 2])\r\n\r\n Zero dimensional array are converted to Python scalars:\r\n\r\n >>> x = np.array(1.543, requires_grad=False)\r\n >>> x.unwrap()\r\n 1.543\r\n >>> type(x.unwrap())\r\n float\r\n\r\n The underlying data is **not** copied:\r\n\r\n >>> x = np.array([1, 2], requires_grad=True)\r\n >>> y = x.unwrap()\r\n >>> x[0] = 5\r\n >>> y\r\n array([5, 2])\r\n >>> y[1] = 7\r\n >>> x\r\n tensor([5, 7], requires_grad=True)\r\n\r\n\r\n To create a copy, the ``copy()`` method can be used:\r\n\r\n >>> x = np.array([1, 2], requires_grad=True)\r\n >>> y = x.unwrap().copy()\r\n >>> x[0] = 5\r\n >>> y\r\n array([1, 2])\r\n \"\"\"\r\n if self.ndim == 0:\r\n return self.view(onp.ndarray).item()\r\n\r\n return self.view(onp.ndarray)\r\n\r\n def numpy(self):\r\n \"\"\"Converts the tensor to a standard, non-differentiable NumPy ndarray or Python scalar if\r\n the tensor is 0-dimensional.\r\n\r\n This method is an alias for :meth:`~.unwrap`. See :meth:`~.unwrap` for more details.\r\n \"\"\"\r\n return self.unwrap()\r\n\r\n\r\nclass NonDifferentiableError(Exception):\r\n \"\"\"Exception raised if attempting to differentiate non-trainable\r\n :class:`~.tensor` using Autograd.\"\"\"\r\n\r\n\r\ndef tensor_to_arraybox(x, *args):\r\n \"\"\"Convert a :class:`~.tensor` to an Autograd ``ArrayBox``.\r\n\r\n Args:\r\n x (array_like): Any data structure in any form that can be converted to\r\n an array. This includes lists, lists of tuples, tuples, tuples of tuples,\r\n tuples of lists and ndarrays.\r\n\r\n Returns:\r\n autograd.numpy.numpy_boxes.ArrayBox: Autograd ArrayBox instance of the array\r\n\r\n Raises:\r\n NonDifferentiableError: if the provided tensor is non-differentiable\r\n \"\"\"\r\n if isinstance(x, tensor):\r\n if x.requires_grad:\r\n return ArrayBox(x, *args)\r\n\r\n raise NonDifferentiableError(\r\n \"{} is non-differentiable. Set the requires_grad attribute to True.\".format(x)\r\n )\r\n\r\n return ArrayBox(x, *args)\r\n\r\n\r\nBox.type_mappings[tensor] = tensor_to_arraybox\r\nVSpace.mappings[tensor] = lambda x: ComplexArrayVSpace(x) if onp.iscomplexobj(x) else ArrayVSpace(x)\r\n", "path": "pennylane/numpy/tensor.py"}], "after_files": [{"content": "# Copyright 2018-2020 Xanadu Quantum Technologies Inc.\r\n\r\n# Licensed under the Apache License, Version 2.0 (the \"License\");\r\n# you may not use this file except in compliance with the License.\r\n# You may obtain a copy of the License at\r\n\r\n# http://www.apache.org/licenses/LICENSE-2.0\r\n\r\n# Unless required by applicable law or agreed to in writing, software\r\n# distributed under the License is distributed on an \"AS IS\" BASIS,\r\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\r\n# See the License for the specific language governing permissions and\r\n# limitations under the License.\r\n\"\"\"\r\nThis module provides the PennyLane :class:`~.tensor` class.\r\n\"\"\"\r\nimport numpy as onp\r\n\r\nfrom autograd import numpy as _np\r\n\r\nfrom autograd.tracer import Box\r\nfrom autograd.numpy.numpy_boxes import ArrayBox\r\nfrom autograd.numpy.numpy_vspaces import ComplexArrayVSpace, ArrayVSpace\r\nfrom autograd.core import VSpace\r\n\r\n\r\n__doc__ = \"NumPy with automatic differentiation support, provided by Autograd and PennyLane.\"\r\n\r\n\r\nclass tensor(_np.ndarray):\r\n \"\"\"Constructs a PennyLane tensor for use with Autograd QNodes.\r\n\r\n The ``tensor`` class is a subclass of ``numpy.ndarray``,\r\n providing the same multidimensional, homogeneous data-structure\r\n of fixed-size items, with an additional flag to indicate to PennyLane\r\n whether the contained data is differentiable or not.\r\n\r\n .. warning::\r\n\r\n PennyLane ``tensor`` objects are only used as part of the Autograd QNode\r\n interface. If using another machine learning library such as PyTorch or\r\n TensorFlow, use their built-in ``tf.Variable`` and ``torch.tensor`` classes\r\n instead.\r\n\r\n .. warning::\r\n\r\n Tensors should be constructed using standard array construction functions\r\n provided as part of PennyLane's NumPy implementation, including\r\n ``np.array``, ``np.zeros`` or ``np.empty``.\r\n\r\n The parameters given here refer to a low-level class\r\n for instantiating tensors.\r\n\r\n\r\n Args:\r\n input_array (array_like): Any data structure in any form that can be converted to\r\n an array. This includes lists, lists of tuples, tuples, tuples of tuples,\r\n tuples of lists and ndarrays.\r\n requires_grad (bool): whether the tensor supports differentiation\r\n\r\n **Example**\r\n\r\n The trainability of a tensor can be set on construction via the\r\n ``requires_grad`` keyword argument,\r\n\r\n >>> from pennylane import numpy as np\r\n >>> x = np.array([0, 1, 2], requires_grad=True)\r\n >>> x\r\n tensor([0, 1, 2], requires_grad=True)\r\n\r\n or in-place by modifying the ``requires_grad`` attribute:\r\n\r\n >>> x.requires_grad = False\r\n tensor([0, 1, 2], requires_grad=False)\r\n\r\n Since tensors are subclasses of ``np.ndarray``, they can be provided as arguments\r\n to any PennyLane-wrapped NumPy function:\r\n\r\n >>> np.sin(x)\r\n tensor([0. , 0.84147098, 0.90929743], requires_grad=True)\r\n\r\n When composing functions of multiple tensors, if at least one input tensor is differentiable,\r\n then the output will also be differentiable:\r\n\r\n >>> x = np.array([0, 1, 2], requires_grad=False)\r\n >>> y = np.zeros([3], requires_grad=True)\r\n >>> np.vstack([x, y])\r\n tensor([[0., 1., 2.],\r\n [0., 0., 0.]], requires_grad=True)\r\n \"\"\"\r\n\r\n def __new__(cls, input_array, *args, requires_grad=True, **kwargs):\r\n obj = _np.array(input_array, *args, **kwargs)\r\n\r\n if isinstance(obj, _np.ndarray):\r\n obj = obj.view(cls)\r\n obj.requires_grad = requires_grad\r\n\r\n return obj\r\n\r\n def __array_finalize__(self, obj):\r\n # pylint: disable=attribute-defined-outside-init\r\n if obj is None: # pragma: no cover\r\n return\r\n\r\n self.requires_grad = getattr(obj, \"requires_grad\", None)\r\n\r\n def __repr__(self):\r\n string = super().__repr__()\r\n return string[:-1] + \", requires_grad={})\".format(self.requires_grad)\r\n\r\n def __array_wrap__(self, obj):\r\n out_arr = tensor(obj, requires_grad=self.requires_grad)\r\n return super().__array_wrap__(out_arr)\r\n\r\n def __array_ufunc__(self, ufunc, method, *inputs, **kwargs):\r\n # pylint: disable=no-member,attribute-defined-outside-init\r\n\r\n # unwrap any outputs the ufunc might have\r\n outputs = [i.view(onp.ndarray) for i in kwargs.get(\"out\", ())]\r\n\r\n if outputs:\r\n # Insert the unwrapped outputs into the keyword\r\n # args dictionary, to be passed to ndarray.__array_ufunc__\r\n outputs = tuple(outputs)\r\n kwargs[\"out\"] = outputs\r\n else:\r\n # If the ufunc has no ouputs, we simply\r\n # create a tuple containing None for all potential outputs.\r\n outputs = (None,) * ufunc.nout\r\n\r\n # unwrap the input arguments to the ufunc\r\n args = [i.unwrap() if hasattr(i, \"unwrap\") else i for i in inputs]\r\n\r\n # call the ndarray.__array_ufunc__ method to compute the result\r\n # of the vectorized ufunc\r\n res = super().__array_ufunc__(ufunc, method, *args, **kwargs)\r\n\r\n if ufunc.nout == 1:\r\n res = (res,)\r\n\r\n # construct a list of ufunc outputs to return\r\n ufunc_output = [\r\n (onp.asarray(result) if output is None else output)\r\n for result, output in zip(res, outputs)\r\n ]\r\n\r\n # if any of the inputs were trainable, the output is also trainable\r\n requires_grad = any(\r\n isinstance(x, onp.ndarray) and getattr(x, \"requires_grad\", True) for x in inputs\r\n )\r\n\r\n # Iterate through the ufunc outputs and convert each to a PennyLane tensor.\r\n # We also correctly set the requires_grad attribute.\r\n for i in range(len(ufunc_output)): # pylint: disable=consider-using-enumerate\r\n ufunc_output[i] = tensor(ufunc_output[i], requires_grad=requires_grad)\r\n\r\n if len(ufunc_output) == 1:\r\n # the ufunc has a single output so return a single tensor\r\n return ufunc_output[0]\r\n\r\n # otherwise we must return a tuple of tensors\r\n return tuple(ufunc_output)\r\n\r\n def __getitem__(self, *args, **kwargs):\r\n item = super().__getitem__(*args, **kwargs)\r\n\r\n if not isinstance(item, tensor):\r\n item = tensor(item, requires_grad=self.requires_grad)\r\n\r\n return item\r\n\r\n def __hash__(self):\r\n if self.ndim == 0:\r\n # Allowing hashing if the tensor is a scalar.\r\n # We hash both the scalar value *and* the differentiability information,\r\n # to match the behaviour of PyTorch.\r\n return hash((self.item(), self.requires_grad))\r\n\r\n raise TypeError(\"unhashable type: 'numpy.tensor'\")\r\n\r\n def unwrap(self):\r\n \"\"\"Converts the tensor to a standard, non-differentiable NumPy ndarray or Python scalar if\r\n the tensor is 0-dimensional.\r\n\r\n All information regarding differentiability of the tensor will be lost.\r\n\r\n .. warning::\r\n\r\n The returned array is a new view onto the **same data**. That is,\r\n the tensor and the returned ``ndarray`` share the same underlying storage.\r\n Changes to the tensor object will be reflected within the returned array,\r\n and vice versa.\r\n\r\n **Example**\r\n\r\n >>> from pennylane import numpy as np\r\n >>> x = np.array([1, 2], requires_grad=True)\r\n >>> x\r\n tensor([1, 2], requires_grad=True)\r\n >>> x.unwrap()\r\n array([1, 2])\r\n\r\n Zero dimensional array are converted to Python scalars:\r\n\r\n >>> x = np.array(1.543, requires_grad=False)\r\n >>> x.unwrap()\r\n 1.543\r\n >>> type(x.unwrap())\r\n float\r\n\r\n The underlying data is **not** copied:\r\n\r\n >>> x = np.array([1, 2], requires_grad=True)\r\n >>> y = x.unwrap()\r\n >>> x[0] = 5\r\n >>> y\r\n array([5, 2])\r\n >>> y[1] = 7\r\n >>> x\r\n tensor([5, 7], requires_grad=True)\r\n\r\n\r\n To create a copy, the ``copy()`` method can be used:\r\n\r\n >>> x = np.array([1, 2], requires_grad=True)\r\n >>> y = x.unwrap().copy()\r\n >>> x[0] = 5\r\n >>> y\r\n array([1, 2])\r\n \"\"\"\r\n if self.ndim == 0:\r\n return self.view(onp.ndarray).item()\r\n\r\n return self.view(onp.ndarray)\r\n\r\n def numpy(self):\r\n \"\"\"Converts the tensor to a standard, non-differentiable NumPy ndarray or Python scalar if\r\n the tensor is 0-dimensional.\r\n\r\n This method is an alias for :meth:`~.unwrap`. See :meth:`~.unwrap` for more details.\r\n \"\"\"\r\n return self.unwrap()\r\n\r\n\r\nclass NonDifferentiableError(Exception):\r\n \"\"\"Exception raised if attempting to differentiate non-trainable\r\n :class:`~.tensor` using Autograd.\"\"\"\r\n\r\n\r\ndef tensor_to_arraybox(x, *args):\r\n \"\"\"Convert a :class:`~.tensor` to an Autograd ``ArrayBox``.\r\n\r\n Args:\r\n x (array_like): Any data structure in any form that can be converted to\r\n an array. This includes lists, lists of tuples, tuples, tuples of tuples,\r\n tuples of lists and ndarrays.\r\n\r\n Returns:\r\n autograd.numpy.numpy_boxes.ArrayBox: Autograd ArrayBox instance of the array\r\n\r\n Raises:\r\n NonDifferentiableError: if the provided tensor is non-differentiable\r\n \"\"\"\r\n if isinstance(x, tensor):\r\n if x.requires_grad:\r\n return ArrayBox(x, *args)\r\n\r\n raise NonDifferentiableError(\r\n \"{} is non-differentiable. Set the requires_grad attribute to True.\".format(x)\r\n )\r\n\r\n return ArrayBox(x, *args)\r\n\r\n\r\nBox.type_mappings[tensor] = tensor_to_arraybox\r\nVSpace.mappings[tensor] = lambda x: ComplexArrayVSpace(x) if onp.iscomplexobj(x) else ArrayVSpace(x)\r\n", "path": "pennylane/numpy/tensor.py"}]} | 2,984 | 637 |
gh_patches_debug_1157 | rasdani/github-patches | git_diff | cal-itp__benefits-213 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Send X-XSS-Protection header
The X-XSS-Protection header can be used to manage certain browser's protection against reflected cross-site scripting (XSS), stopping a page from being loaded if an attack is detected. In modern browsers, the Content-Security-Policy header can provide better protection against XSS and setting X-XSS-Protection might be redundant (#203 tracks CSP implementation).
See more at https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-XSS-Protection
We'll want the following header/value:
```
X-XSS-Protection: 1; mode=block
```
This can be done in a new Middleware and configured in [`settings.py`](https://github.com/cal-itp/benefits/blob/dev/benefits/settings.py#L45) for all requests/responses.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `benefits/settings.py`
Content:
```
1 """
2 Django settings for benefits project.
3 """
4 import os
5
6 # Build paths inside the project like this: os.path.join(BASE_DIR, ...)
7 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
8
9 # SECURITY WARNING: keep the secret key used in production secret!
10 SECRET_KEY = os.environ["DJANGO_SECRET_KEY"]
11
12 # SECURITY WARNING: don't run with debug turned on in production!
13 DEBUG = os.environ.get("DJANGO_DEBUG", "False").lower() == "true"
14
15 ADMIN = os.environ.get("DJANGO_ADMIN", "False").lower() == "true"
16
17 ALLOWED_HOSTS = []
18
19 if DEBUG:
20 ALLOWED_HOSTS.extend(["*"])
21 else:
22 hosts = os.environ["DJANGO_ALLOWED_HOSTS"].split(",")
23 ALLOWED_HOSTS.extend(hosts)
24
25 # Application definition
26
27 INSTALLED_APPS = [
28 "django.contrib.sessions",
29 "django.contrib.staticfiles",
30 "benefits.core",
31 "benefits.enrollment",
32 "benefits.eligibility",
33 ]
34
35 if ADMIN:
36 INSTALLED_APPS.extend(
37 [
38 "django.contrib.admin",
39 "django.contrib.auth",
40 "django.contrib.contenttypes",
41 "django.contrib.messages",
42 ]
43 )
44
45 MIDDLEWARE = [
46 "django.middleware.security.SecurityMiddleware",
47 "django.contrib.sessions.middleware.SessionMiddleware",
48 "django.middleware.locale.LocaleMiddleware",
49 "benefits.core.middleware.Healthcheck",
50 "django.middleware.common.CommonMiddleware",
51 "django.middleware.csrf.CsrfViewMiddleware",
52 "django.middleware.clickjacking.XFrameOptionsMiddleware",
53 "benefits.core.middleware.DebugSession",
54 "benefits.core.middleware.ChangedLanguageEvent",
55 ]
56
57 if ADMIN:
58 MIDDLEWARE.extend(
59 [
60 "django.contrib.auth.middleware.AuthenticationMiddleware",
61 "django.contrib.messages.middleware.MessageMiddleware",
62 ]
63 )
64
65 CSRF_COOKIE_AGE = None
66 CSRF_COOKIE_SAMESITE = "Strict"
67 CSRF_COOKIE_HTTPONLY = True
68
69 SESSION_COOKIE_SAMESITE = "Strict"
70 SESSION_ENGINE = "django.contrib.sessions.backends.signed_cookies"
71 SESSION_EXPIRE_AT_BROWSER_CLOSE = True
72
73 if not DEBUG:
74 CSRF_COOKIE_SECURE = True
75 CSRF_FAILURE_VIEW = "benefits.core.views.csrf_failure"
76 SESSION_COOKIE_SECURE = True
77
78 ROOT_URLCONF = "benefits.urls"
79
80 template_ctx_processors = [
81 "django.template.context_processors.request",
82 "benefits.core.context_processors.analytics",
83 ]
84
85 if DEBUG:
86 template_ctx_processors.extend(
87 [
88 "django.template.context_processors.debug",
89 "benefits.core.context_processors.debug",
90 ]
91 )
92
93 if ADMIN:
94 template_ctx_processors.extend(
95 [
96 "django.contrib.auth.context_processors.auth",
97 "django.contrib.messages.context_processors.messages",
98 ]
99 )
100
101 TEMPLATES = [
102 {
103 "BACKEND": "django.template.backends.django.DjangoTemplates",
104 "DIRS": [os.path.join(BASE_DIR, "benefits", "templates")],
105 "APP_DIRS": True,
106 "OPTIONS": {
107 "context_processors": template_ctx_processors,
108 },
109 },
110 ]
111
112 WSGI_APPLICATION = "benefits.wsgi.application"
113
114 DATABASES = {
115 "default": {
116 "ENGINE": "django.db.backends.sqlite3",
117 "NAME": os.environ.get("DJANGO_DB", "django") + ".db",
118 }
119 }
120
121 # Password validation
122
123 AUTH_PASSWORD_VALIDATORS = []
124
125 if ADMIN:
126 AUTH_PASSWORD_VALIDATORS.extend(
127 [
128 {
129 "NAME": "django.contrib.auth.password_validation.UserAttributeSimilarityValidator",
130 },
131 {
132 "NAME": "django.contrib.auth.password_validation.MinimumLengthValidator",
133 },
134 {
135 "NAME": "django.contrib.auth.password_validation.CommonPasswordValidator",
136 },
137 {
138 "NAME": "django.contrib.auth.password_validation.NumericPasswordValidator",
139 },
140 ]
141 )
142
143 # Internationalization
144
145 LANGUAGE_CODE = "en"
146
147 LANGUAGE_COOKIE_HTTPONLY = True
148 LANGUAGE_COOKIE_SAMESITE = "Strict"
149 LANGUAGE_COOKIE_SECURE = True
150
151 LANGUAGES = [("en", "English"), ("es", "Español")]
152
153 LOCALE_PATHS = [os.path.join(BASE_DIR, "benefits", "locale")]
154
155 USE_I18N = True
156 USE_L10N = True
157
158 TIME_ZONE = "UTC"
159 USE_TZ = True
160
161 # Static files (CSS, JavaScript, Images)
162
163 STATIC_URL = "/static/"
164 STATICFILES_DIRS = [os.path.join(BASE_DIR, "benefits", "static")]
165 STATIC_ROOT = os.path.join(BASE_DIR, "static")
166
167 # Logging configuration
168
169 LOG_LEVEL = os.environ.get("DJANGO_LOG_LEVEL", "DEBUG" if DEBUG else "WARNING")
170 LOGGING = {
171 "version": 1,
172 "disable_existing_loggers": False,
173 "formatters": {
174 "default": {
175 "format": "[{asctime}] {levelname} {name}:{lineno} {message}",
176 "datefmt": "%d/%b/%Y %H:%M:%S",
177 "style": "{",
178 },
179 },
180 "handlers": {
181 "default": {"class": "logging.StreamHandler", "formatter": "default"},
182 },
183 "root": {
184 "handlers": ["default"],
185 "level": LOG_LEVEL,
186 },
187 "loggers": {"django": {"handlers": ["default"], "propagate": False}},
188 }
189
190 # Analytics configuration
191
192 ANALYTICS_KEY = os.environ.get("ANALYTICS_KEY")
193
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/benefits/settings.py b/benefits/settings.py
--- a/benefits/settings.py
+++ b/benefits/settings.py
@@ -75,6 +75,8 @@
CSRF_FAILURE_VIEW = "benefits.core.views.csrf_failure"
SESSION_COOKIE_SECURE = True
+SECURE_BROWSER_XSS_FILTER = True
+
ROOT_URLCONF = "benefits.urls"
template_ctx_processors = [
| {"golden_diff": "diff --git a/benefits/settings.py b/benefits/settings.py\n--- a/benefits/settings.py\n+++ b/benefits/settings.py\n@@ -75,6 +75,8 @@\n CSRF_FAILURE_VIEW = \"benefits.core.views.csrf_failure\"\n SESSION_COOKIE_SECURE = True\n \n+SECURE_BROWSER_XSS_FILTER = True\n+\n ROOT_URLCONF = \"benefits.urls\"\n \n template_ctx_processors = [\n", "issue": "Send X-XSS-Protection header\nThe X-XSS-Protection header can be used to manage certain browser's protection against reflected cross-site scripting (XSS), stopping a page from being loaded if an attack is detected. In modern browsers, the Content-Security-Policy header can provide better protection against XSS and setting X-XSS-Protection might be redundant (#203 tracks CSP implementation).\r\n\r\nSee more at https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/X-XSS-Protection\r\n\r\n\r\nWe'll want the following header/value:\r\n\r\n```\r\nX-XSS-Protection: 1; mode=block\r\n```\r\n\r\nThis can be done in a new Middleware and configured in [`settings.py`](https://github.com/cal-itp/benefits/blob/dev/benefits/settings.py#L45) for all requests/responses.\n", "before_files": [{"content": "\"\"\"\nDjango settings for benefits project.\n\"\"\"\nimport os\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ[\"DJANGO_SECRET_KEY\"]\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = os.environ.get(\"DJANGO_DEBUG\", \"False\").lower() == \"true\"\n\nADMIN = os.environ.get(\"DJANGO_ADMIN\", \"False\").lower() == \"true\"\n\nALLOWED_HOSTS = []\n\nif DEBUG:\n ALLOWED_HOSTS.extend([\"*\"])\nelse:\n hosts = os.environ[\"DJANGO_ALLOWED_HOSTS\"].split(\",\")\n ALLOWED_HOSTS.extend(hosts)\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.sessions\",\n \"django.contrib.staticfiles\",\n \"benefits.core\",\n \"benefits.enrollment\",\n \"benefits.eligibility\",\n]\n\nif ADMIN:\n INSTALLED_APPS.extend(\n [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.messages\",\n ]\n )\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.locale.LocaleMiddleware\",\n \"benefits.core.middleware.Healthcheck\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"benefits.core.middleware.DebugSession\",\n \"benefits.core.middleware.ChangedLanguageEvent\",\n]\n\nif ADMIN:\n MIDDLEWARE.extend(\n [\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n ]\n )\n\nCSRF_COOKIE_AGE = None\nCSRF_COOKIE_SAMESITE = \"Strict\"\nCSRF_COOKIE_HTTPONLY = True\n\nSESSION_COOKIE_SAMESITE = \"Strict\"\nSESSION_ENGINE = \"django.contrib.sessions.backends.signed_cookies\"\nSESSION_EXPIRE_AT_BROWSER_CLOSE = True\n\nif not DEBUG:\n CSRF_COOKIE_SECURE = True\n CSRF_FAILURE_VIEW = \"benefits.core.views.csrf_failure\"\n SESSION_COOKIE_SECURE = True\n\nROOT_URLCONF = \"benefits.urls\"\n\ntemplate_ctx_processors = [\n \"django.template.context_processors.request\",\n \"benefits.core.context_processors.analytics\",\n]\n\nif DEBUG:\n template_ctx_processors.extend(\n [\n \"django.template.context_processors.debug\",\n \"benefits.core.context_processors.debug\",\n ]\n )\n\nif ADMIN:\n template_ctx_processors.extend(\n [\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ]\n )\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [os.path.join(BASE_DIR, \"benefits\", \"templates\")],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": template_ctx_processors,\n },\n },\n]\n\nWSGI_APPLICATION = \"benefits.wsgi.application\"\n\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": os.environ.get(\"DJANGO_DB\", \"django\") + \".db\",\n }\n}\n\n# Password validation\n\nAUTH_PASSWORD_VALIDATORS = []\n\nif ADMIN:\n AUTH_PASSWORD_VALIDATORS.extend(\n [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n ]\n )\n\n# Internationalization\n\nLANGUAGE_CODE = \"en\"\n\nLANGUAGE_COOKIE_HTTPONLY = True\nLANGUAGE_COOKIE_SAMESITE = \"Strict\"\nLANGUAGE_COOKIE_SECURE = True\n\nLANGUAGES = [(\"en\", \"English\"), (\"es\", \"Espa\u00f1ol\")]\n\nLOCALE_PATHS = [os.path.join(BASE_DIR, \"benefits\", \"locale\")]\n\nUSE_I18N = True\nUSE_L10N = True\n\nTIME_ZONE = \"UTC\"\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = [os.path.join(BASE_DIR, \"benefits\", \"static\")]\nSTATIC_ROOT = os.path.join(BASE_DIR, \"static\")\n\n# Logging configuration\n\nLOG_LEVEL = os.environ.get(\"DJANGO_LOG_LEVEL\", \"DEBUG\" if DEBUG else \"WARNING\")\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"formatters\": {\n \"default\": {\n \"format\": \"[{asctime}] {levelname} {name}:{lineno} {message}\",\n \"datefmt\": \"%d/%b/%Y %H:%M:%S\",\n \"style\": \"{\",\n },\n },\n \"handlers\": {\n \"default\": {\"class\": \"logging.StreamHandler\", \"formatter\": \"default\"},\n },\n \"root\": {\n \"handlers\": [\"default\"],\n \"level\": LOG_LEVEL,\n },\n \"loggers\": {\"django\": {\"handlers\": [\"default\"], \"propagate\": False}},\n}\n\n# Analytics configuration\n\nANALYTICS_KEY = os.environ.get(\"ANALYTICS_KEY\")\n", "path": "benefits/settings.py"}], "after_files": [{"content": "\"\"\"\nDjango settings for benefits project.\n\"\"\"\nimport os\n\n# Build paths inside the project like this: os.path.join(BASE_DIR, ...)\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\n\n# SECURITY WARNING: keep the secret key used in production secret!\nSECRET_KEY = os.environ[\"DJANGO_SECRET_KEY\"]\n\n# SECURITY WARNING: don't run with debug turned on in production!\nDEBUG = os.environ.get(\"DJANGO_DEBUG\", \"False\").lower() == \"true\"\n\nADMIN = os.environ.get(\"DJANGO_ADMIN\", \"False\").lower() == \"true\"\n\nALLOWED_HOSTS = []\n\nif DEBUG:\n ALLOWED_HOSTS.extend([\"*\"])\nelse:\n hosts = os.environ[\"DJANGO_ALLOWED_HOSTS\"].split(\",\")\n ALLOWED_HOSTS.extend(hosts)\n\n# Application definition\n\nINSTALLED_APPS = [\n \"django.contrib.sessions\",\n \"django.contrib.staticfiles\",\n \"benefits.core\",\n \"benefits.enrollment\",\n \"benefits.eligibility\",\n]\n\nif ADMIN:\n INSTALLED_APPS.extend(\n [\n \"django.contrib.admin\",\n \"django.contrib.auth\",\n \"django.contrib.contenttypes\",\n \"django.contrib.messages\",\n ]\n )\n\nMIDDLEWARE = [\n \"django.middleware.security.SecurityMiddleware\",\n \"django.contrib.sessions.middleware.SessionMiddleware\",\n \"django.middleware.locale.LocaleMiddleware\",\n \"benefits.core.middleware.Healthcheck\",\n \"django.middleware.common.CommonMiddleware\",\n \"django.middleware.csrf.CsrfViewMiddleware\",\n \"django.middleware.clickjacking.XFrameOptionsMiddleware\",\n \"benefits.core.middleware.DebugSession\",\n \"benefits.core.middleware.ChangedLanguageEvent\",\n]\n\nif ADMIN:\n MIDDLEWARE.extend(\n [\n \"django.contrib.auth.middleware.AuthenticationMiddleware\",\n \"django.contrib.messages.middleware.MessageMiddleware\",\n ]\n )\n\nCSRF_COOKIE_AGE = None\nCSRF_COOKIE_SAMESITE = \"Strict\"\nCSRF_COOKIE_HTTPONLY = True\n\nSESSION_COOKIE_SAMESITE = \"Strict\"\nSESSION_ENGINE = \"django.contrib.sessions.backends.signed_cookies\"\nSESSION_EXPIRE_AT_BROWSER_CLOSE = True\n\nif not DEBUG:\n CSRF_COOKIE_SECURE = True\n CSRF_FAILURE_VIEW = \"benefits.core.views.csrf_failure\"\n SESSION_COOKIE_SECURE = True\n\nSECURE_BROWSER_XSS_FILTER = True\n\nROOT_URLCONF = \"benefits.urls\"\n\ntemplate_ctx_processors = [\n \"django.template.context_processors.request\",\n \"benefits.core.context_processors.analytics\",\n]\n\nif DEBUG:\n template_ctx_processors.extend(\n [\n \"django.template.context_processors.debug\",\n \"benefits.core.context_processors.debug\",\n ]\n )\n\nif ADMIN:\n template_ctx_processors.extend(\n [\n \"django.contrib.auth.context_processors.auth\",\n \"django.contrib.messages.context_processors.messages\",\n ]\n )\n\nTEMPLATES = [\n {\n \"BACKEND\": \"django.template.backends.django.DjangoTemplates\",\n \"DIRS\": [os.path.join(BASE_DIR, \"benefits\", \"templates\")],\n \"APP_DIRS\": True,\n \"OPTIONS\": {\n \"context_processors\": template_ctx_processors,\n },\n },\n]\n\nWSGI_APPLICATION = \"benefits.wsgi.application\"\n\nDATABASES = {\n \"default\": {\n \"ENGINE\": \"django.db.backends.sqlite3\",\n \"NAME\": os.environ.get(\"DJANGO_DB\", \"django\") + \".db\",\n }\n}\n\n# Password validation\n\nAUTH_PASSWORD_VALIDATORS = []\n\nif ADMIN:\n AUTH_PASSWORD_VALIDATORS.extend(\n [\n {\n \"NAME\": \"django.contrib.auth.password_validation.UserAttributeSimilarityValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.MinimumLengthValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.CommonPasswordValidator\",\n },\n {\n \"NAME\": \"django.contrib.auth.password_validation.NumericPasswordValidator\",\n },\n ]\n )\n\n# Internationalization\n\nLANGUAGE_CODE = \"en\"\n\nLANGUAGE_COOKIE_HTTPONLY = True\nLANGUAGE_COOKIE_SAMESITE = \"Strict\"\nLANGUAGE_COOKIE_SECURE = True\n\nLANGUAGES = [(\"en\", \"English\"), (\"es\", \"Espa\u00f1ol\")]\n\nLOCALE_PATHS = [os.path.join(BASE_DIR, \"benefits\", \"locale\")]\n\nUSE_I18N = True\nUSE_L10N = True\n\nTIME_ZONE = \"UTC\"\nUSE_TZ = True\n\n# Static files (CSS, JavaScript, Images)\n\nSTATIC_URL = \"/static/\"\nSTATICFILES_DIRS = [os.path.join(BASE_DIR, \"benefits\", \"static\")]\nSTATIC_ROOT = os.path.join(BASE_DIR, \"static\")\n\n# Logging configuration\n\nLOG_LEVEL = os.environ.get(\"DJANGO_LOG_LEVEL\", \"DEBUG\" if DEBUG else \"WARNING\")\nLOGGING = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"formatters\": {\n \"default\": {\n \"format\": \"[{asctime}] {levelname} {name}:{lineno} {message}\",\n \"datefmt\": \"%d/%b/%Y %H:%M:%S\",\n \"style\": \"{\",\n },\n },\n \"handlers\": {\n \"default\": {\"class\": \"logging.StreamHandler\", \"formatter\": \"default\"},\n },\n \"root\": {\n \"handlers\": [\"default\"],\n \"level\": LOG_LEVEL,\n },\n \"loggers\": {\"django\": {\"handlers\": [\"default\"], \"propagate\": False}},\n}\n\n# Analytics configuration\n\nANALYTICS_KEY = os.environ.get(\"ANALYTICS_KEY\")\n", "path": "benefits/settings.py"}]} | 2,043 | 90 |
gh_patches_debug_36974 | rasdani/github-patches | git_diff | pulp__pulpcore-2315 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Clean up TaskReservedResources/task-table at migration to new-tasking-system
See https://bugzilla.redhat.com/show_bug.cgi?id=2031154 for details.
Migration that needs to be updated to purge taskreservedresource entries: 0064_add_new_style_task_columns.py
This wants to be cherrypicked into 3.14/15/16 (after which the offending table no longer exists)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/migrations/0064_add_new_style_task_columns.py`
Content:
```
1 # Generated by Django 2.2.20 on 2021-04-27 07:51
2
3 import django.contrib.postgres.fields
4 import django.contrib.postgres.fields.jsonb
5 from django.db import migrations, models
6
7
8 def copy_reserved_resources_record(apps, schema_editor):
9 Task = apps.get_model('core', 'Task')
10 for task in Task.objects.iterator():
11 task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))
12 task.save()
13
14
15 def noop(apps, schema_editor):
16 pass
17
18
19 class Migration(migrations.Migration):
20
21 dependencies = [
22 ('core', '0063_repository_retained_versions'),
23 ]
24
25 operations = [
26 migrations.AddField(
27 model_name='task',
28 name='args',
29 field=django.contrib.postgres.fields.jsonb.JSONField(null=True),
30 ),
31 migrations.AddField(
32 model_name='task',
33 name='kwargs',
34 field=django.contrib.postgres.fields.jsonb.JSONField(null=True),
35 ),
36 migrations.AddField(
37 model_name='task',
38 name='_reserved_resources_record',
39 field=django.contrib.postgres.fields.ArrayField(base_field=models.CharField(max_length=256), null=True, size=None),
40 ),
41 migrations.AlterField(
42 model_name='task',
43 name='_resource_job_id',
44 field=models.UUIDField(null=True),
45 ),
46 migrations.AlterField(
47 model_name='progressreport',
48 name='state',
49 field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')], default='waiting'),
50 ),
51 migrations.AlterField(
52 model_name='task',
53 name='state',
54 field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')]),
55 ),
56 migrations.AddIndex(
57 model_name='task',
58 index=models.Index(fields=['pulp_created'], name='core_task_pulp_cr_10223f_idx'),
59 ),
60 migrations.RunPython(
61 code=copy_reserved_resources_record,
62 reverse_code=noop,
63 ),
64 migrations.RemoveField(
65 model_name='taskreservedresourcerecord',
66 name='resource',
67 ),
68 migrations.RemoveField(
69 model_name='taskreservedresourcerecord',
70 name='task',
71 ),
72 migrations.DeleteModel(
73 name='ReservedResourceRecord',
74 ),
75 migrations.DeleteModel(
76 name='TaskReservedResourceRecord',
77 ),
78 migrations.RenameField(
79 model_name='task',
80 old_name='_reserved_resources_record',
81 new_name='reserved_resources_record',
82 ),
83 ]
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pulpcore/app/migrations/0064_add_new_style_task_columns.py b/pulpcore/app/migrations/0064_add_new_style_task_columns.py
--- a/pulpcore/app/migrations/0064_add_new_style_task_columns.py
+++ b/pulpcore/app/migrations/0064_add_new_style_task_columns.py
@@ -4,16 +4,34 @@
import django.contrib.postgres.fields.jsonb
from django.db import migrations, models
+TASK_BATCH_SIZE = 1000
+
def copy_reserved_resources_record(apps, schema_editor):
Task = apps.get_model('core', 'Task')
- for task in Task.objects.iterator():
+
+ # Update _reserved_resource_record for all tasks, 1000 tasks at a time.
+ # When we hit 1K tasks, go to the db for the batch.
+ # Make sure to update the final batch!
+ tasks = []
+ for task in Task.objects.iterator(chunk_size=TASK_BATCH_SIZE):
task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))
- task.save()
+ tasks.append(task)
+ if len(tasks) == TASK_BATCH_SIZE:
+ Task.objects.bulk_update(tasks, ["_reserved_resources_record"])
+ tasks.clear()
+
+ # Update last set of tasks
+ if len(tasks) > 0:
+ Task.objects.bulk_update(tasks, ["_reserved_resources_record"])
+
+def purge_reservedresources(apps, schema_editor):
+ TaskReservedResource = apps.get_model('core', 'TaskReservedResource')
+ TaskReservedResource.objects.all().delete()
-def noop(apps, schema_editor):
- pass
+ ReservedResource = apps.get_model('core', 'ReservedResource')
+ ReservedResource.objects.all().delete()
class Migration(migrations.Migration):
@@ -23,6 +41,12 @@
]
operations = [
+ # Purge any ReservedResource entries - if there are any, they're orphans
+ migrations.RunPython(
+ code=purge_reservedresources,
+ reverse_code=migrations.RunPython.noop,
+ ),
+ # Update entities for the new task-system
migrations.AddField(
model_name='task',
name='args',
@@ -59,7 +83,7 @@
),
migrations.RunPython(
code=copy_reserved_resources_record,
- reverse_code=noop,
+ reverse_code=migrations.RunPython.noop,
),
migrations.RemoveField(
model_name='taskreservedresourcerecord',
@@ -80,4 +104,5 @@
old_name='_reserved_resources_record',
new_name='reserved_resources_record',
),
+
]
| {"golden_diff": "diff --git a/pulpcore/app/migrations/0064_add_new_style_task_columns.py b/pulpcore/app/migrations/0064_add_new_style_task_columns.py\n--- a/pulpcore/app/migrations/0064_add_new_style_task_columns.py\n+++ b/pulpcore/app/migrations/0064_add_new_style_task_columns.py\n@@ -4,16 +4,34 @@\n import django.contrib.postgres.fields.jsonb\n from django.db import migrations, models\n \n+TASK_BATCH_SIZE = 1000\n+\n \n def copy_reserved_resources_record(apps, schema_editor):\n Task = apps.get_model('core', 'Task')\n- for task in Task.objects.iterator():\n+\n+ # Update _reserved_resource_record for all tasks, 1000 tasks at a time.\n+ # When we hit 1K tasks, go to the db for the batch.\n+ # Make sure to update the final batch!\n+ tasks = []\n+ for task in Task.objects.iterator(chunk_size=TASK_BATCH_SIZE):\n task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))\n- task.save()\n+ tasks.append(task)\n+ if len(tasks) == TASK_BATCH_SIZE:\n+ Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n+ tasks.clear()\n+\n+ # Update last set of tasks\n+ if len(tasks) > 0:\n+ Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n+\n \n+def purge_reservedresources(apps, schema_editor):\n+ TaskReservedResource = apps.get_model('core', 'TaskReservedResource')\n+ TaskReservedResource.objects.all().delete()\n \n-def noop(apps, schema_editor):\n- pass\n+ ReservedResource = apps.get_model('core', 'ReservedResource')\n+ ReservedResource.objects.all().delete()\n \n \n class Migration(migrations.Migration):\n@@ -23,6 +41,12 @@\n ]\n \n operations = [\n+ # Purge any ReservedResource entries - if there are any, they're orphans\n+ migrations.RunPython(\n+ code=purge_reservedresources,\n+ reverse_code=migrations.RunPython.noop,\n+ ),\n+ # Update entities for the new task-system\n migrations.AddField(\n model_name='task',\n name='args',\n@@ -59,7 +83,7 @@\n ),\n migrations.RunPython(\n code=copy_reserved_resources_record,\n- reverse_code=noop,\n+ reverse_code=migrations.RunPython.noop,\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n@@ -80,4 +104,5 @@\n old_name='_reserved_resources_record',\n new_name='reserved_resources_record',\n ),\n+\n ]\n", "issue": "Clean up TaskReservedResources/task-table at migration to new-tasking-system\nSee https://bugzilla.redhat.com/show_bug.cgi?id=2031154 for details.\r\n\r\nMigration that needs to be updated to purge taskreservedresource entries: 0064_add_new_style_task_columns.py\r\n\r\nThis wants to be cherrypicked into 3.14/15/16 (after which the offending table no longer exists)\n", "before_files": [{"content": "# Generated by Django 2.2.20 on 2021-04-27 07:51\n\nimport django.contrib.postgres.fields\nimport django.contrib.postgres.fields.jsonb\nfrom django.db import migrations, models\n\n\ndef copy_reserved_resources_record(apps, schema_editor):\n Task = apps.get_model('core', 'Task')\n for task in Task.objects.iterator():\n task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))\n task.save()\n\n\ndef noop(apps, schema_editor):\n pass\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0063_repository_retained_versions'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='task',\n name='args',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='kwargs',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='_reserved_resources_record',\n field=django.contrib.postgres.fields.ArrayField(base_field=models.CharField(max_length=256), null=True, size=None),\n ),\n migrations.AlterField(\n model_name='task',\n name='_resource_job_id',\n field=models.UUIDField(null=True),\n ),\n migrations.AlterField(\n model_name='progressreport',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')], default='waiting'),\n ),\n migrations.AlterField(\n model_name='task',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')]),\n ),\n migrations.AddIndex(\n model_name='task',\n index=models.Index(fields=['pulp_created'], name='core_task_pulp_cr_10223f_idx'),\n ),\n migrations.RunPython(\n code=copy_reserved_resources_record,\n reverse_code=noop,\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='resource',\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='task',\n ),\n migrations.DeleteModel(\n name='ReservedResourceRecord',\n ),\n migrations.DeleteModel(\n name='TaskReservedResourceRecord',\n ),\n migrations.RenameField(\n model_name='task',\n old_name='_reserved_resources_record',\n new_name='reserved_resources_record',\n ),\n ]\n", "path": "pulpcore/app/migrations/0064_add_new_style_task_columns.py"}], "after_files": [{"content": "# Generated by Django 2.2.20 on 2021-04-27 07:51\n\nimport django.contrib.postgres.fields\nimport django.contrib.postgres.fields.jsonb\nfrom django.db import migrations, models\n\nTASK_BATCH_SIZE = 1000\n\n\ndef copy_reserved_resources_record(apps, schema_editor):\n Task = apps.get_model('core', 'Task')\n\n # Update _reserved_resource_record for all tasks, 1000 tasks at a time.\n # When we hit 1K tasks, go to the db for the batch.\n # Make sure to update the final batch!\n tasks = []\n for task in Task.objects.iterator(chunk_size=TASK_BATCH_SIZE):\n task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))\n tasks.append(task)\n if len(tasks) == TASK_BATCH_SIZE:\n Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n tasks.clear()\n\n # Update last set of tasks\n if len(tasks) > 0:\n Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n\n\ndef purge_reservedresources(apps, schema_editor):\n TaskReservedResource = apps.get_model('core', 'TaskReservedResource')\n TaskReservedResource.objects.all().delete()\n\n ReservedResource = apps.get_model('core', 'ReservedResource')\n ReservedResource.objects.all().delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0063_repository_retained_versions'),\n ]\n\n operations = [\n # Purge any ReservedResource entries - if there are any, they're orphans\n migrations.RunPython(\n code=purge_reservedresources,\n reverse_code=migrations.RunPython.noop,\n ),\n # Update entities for the new task-system\n migrations.AddField(\n model_name='task',\n name='args',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='kwargs',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='_reserved_resources_record',\n field=django.contrib.postgres.fields.ArrayField(base_field=models.CharField(max_length=256), null=True, size=None),\n ),\n migrations.AlterField(\n model_name='task',\n name='_resource_job_id',\n field=models.UUIDField(null=True),\n ),\n migrations.AlterField(\n model_name='progressreport',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')], default='waiting'),\n ),\n migrations.AlterField(\n model_name='task',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')]),\n ),\n migrations.AddIndex(\n model_name='task',\n index=models.Index(fields=['pulp_created'], name='core_task_pulp_cr_10223f_idx'),\n ),\n migrations.RunPython(\n code=copy_reserved_resources_record,\n reverse_code=migrations.RunPython.noop,\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='resource',\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='task',\n ),\n migrations.DeleteModel(\n name='ReservedResourceRecord',\n ),\n migrations.DeleteModel(\n name='TaskReservedResourceRecord',\n ),\n migrations.RenameField(\n model_name='task',\n old_name='_reserved_resources_record',\n new_name='reserved_resources_record',\n ),\n\n ]\n", "path": "pulpcore/app/migrations/0064_add_new_style_task_columns.py"}]} | 1,140 | 600 |
gh_patches_debug_20603 | rasdani/github-patches | git_diff | DataBiosphere__toil-1324 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
setuptools 8.0.0 or later is now required for PEP 440 version support
python 2.7.9
setuptools 5.5.1
```
Traceback (most recent call last):
File "version_template.py", line 137, in <module>
_main()
File "version_template.py", line 133, in _main
sys.stdout.write(expand_(*sys.argv[1:]))
File "version_template.py", line 128, in expand_
return resolve(name)
File "version_template.py", line 122, in resolve
v = v()
File "version_template.py", line 61, in distVersion
if build_number is not None and parse_version(baseVersion).is_prerelease:
AttributeError: 'tuple' object has no attribute 'is_prerelease'
```
setuptools 8.0.0 or later is now required for PEP 440 version support
python 2.7.9
setuptools 5.5.1
```
Traceback (most recent call last):
File "version_template.py", line 137, in <module>
_main()
File "version_template.py", line 133, in _main
sys.stdout.write(expand_(*sys.argv[1:]))
File "version_template.py", line 128, in expand_
return resolve(name)
File "version_template.py", line 122, in resolve
v = v()
File "version_template.py", line 61, in distVersion
if build_number is not None and parse_version(baseVersion).is_prerelease:
AttributeError: 'tuple' object has no attribute 'is_prerelease'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `version_template.py`
Content:
```
1 # Copyright (C) 2015-2016 Regents of the University of California
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """This script is a template for src/toil/version.py. Running it without arguments echoes all
16 globals, i.e. module attributes. Constant assignments will be echoed verbatim while callables
17 will be invoked and their result echoed as an assignment using the function name as the left-hand
18 side and the return value of the function as right-hand side. To prevent a module attribute from
19 being echoed, start or end the attribute name with an underscore. To print the value of a single
20 symbol, pass the name of that attribute to the script as a command line argument. You can also
21 import the expand_ function and invoke it directly with either no or exactly one argument."""
22
23 # Note to maintainers:
24 #
25 # - don't import at module level unless you intend for the import to be included in the output
26 # - only import from the Python standard run-time library (you can't have any dependencies)
27
28 baseVersion = '3.5.0a1'
29
30 cgcloudVersion = '1.6.0a1.dev378'
31
32
33 def version():
34 """
35 A version identifier that includes the full-legth commit SHA1 and an optional suffix to
36 indicate that the working copy is dirty.
37 """
38 return _version()
39
40
41 def shortVersion():
42 """
43 A version identifier that includes the abbreviated commit SHA1 and an optional suffix to
44 indicate that the working copy is dirty.
45 """
46 return _version(shorten=True)
47
48
49 def _version(shorten=False):
50 return '-'.join(filter(None, [distVersion(),
51 currentCommit()[:7 if shorten else None],
52 ('dirty' if dirty() else None)]))
53
54
55 def distVersion():
56 """
57 The distribution version identifying a published release on PyPI.
58 """
59 from pkg_resources import parse_version
60 build_number = buildNumber()
61 if build_number is not None and parse_version(baseVersion).is_prerelease:
62 return baseVersion + '.dev' + build_number
63 else:
64 return baseVersion
65
66
67 def dockerTag():
68 """
69 The primary tag of the Docker image for the appliance. This uniquely identifies the appliance
70 image.
71 """
72 return version()
73
74
75 def dockerShortTag():
76 """
77 A secondary, shortened form of :func:`dockerTag` with which to tag the appliance image for
78 convenience.
79 """
80 return shortVersion()
81
82
83 def dockerMinimalTag():
84 """
85 A minimal tag with which to tag the appliance image for convenience. Does not include
86 information about the git commit or working copy dirtyness.
87 """
88 return distVersion()
89
90
91 dockerRegistry = 'quay.io/ucsc_cgl'
92
93 dockerName = 'toil'
94
95
96 def buildNumber():
97 """
98 The Jenkins build number, if defined, else None.
99 """
100 import os
101 return os.getenv('BUILD_NUMBER')
102
103
104 def currentCommit():
105 from subprocess import check_output
106 return check_output('git log --pretty=oneline -n 1 -- $(pwd)', shell=True).split()[0]
107
108
109 def dirty():
110 from subprocess import call
111 return 0 != call('(git diff --exit-code '
112 '&& git diff --cached --exit-code) > /dev/null', shell=True)
113
114
115 def expand_(name=None):
116 variables = {k: v for k, v in globals().iteritems()
117 if not k.startswith('_') and not k.endswith('_')}
118
119 def resolve(k):
120 v = variables[k]
121 if callable(v):
122 v = v()
123 return v
124
125 if name is None:
126 return ''.join("%s = %s\n" % (k, repr(resolve(k))) for k, v in variables.iteritems())
127 else:
128 return resolve(name)
129
130
131 def _main():
132 import sys
133 sys.stdout.write(expand_(*sys.argv[1:]))
134
135
136 if __name__ == '__main__':
137 _main()
138
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/version_template.py b/version_template.py
--- a/version_template.py
+++ b/version_template.py
@@ -22,7 +22,7 @@
# Note to maintainers:
#
-# - don't import at module level unless you intend for the import to be included in the output
+# - don't import at module level unless you want the imported value to be included in the output
# - only import from the Python standard run-time library (you can't have any dependencies)
baseVersion = '3.5.0a1'
@@ -58,7 +58,12 @@
"""
from pkg_resources import parse_version
build_number = buildNumber()
- if build_number is not None and parse_version(baseVersion).is_prerelease:
+ parsedBaseVersion = parse_version(baseVersion)
+ if isinstance(parsedBaseVersion, tuple):
+ raise RuntimeError("Setuptools version 8.0 or newer required. Update by running "
+ "'pip install setuptools --upgrade'")
+
+ if build_number is not None and parsedBaseVersion.is_prerelease:
return baseVersion + '.dev' + build_number
else:
return baseVersion
| {"golden_diff": "diff --git a/version_template.py b/version_template.py\n--- a/version_template.py\n+++ b/version_template.py\n@@ -22,7 +22,7 @@\n \n # Note to maintainers:\n #\n-# - don't import at module level unless you intend for the import to be included in the output\n+# - don't import at module level unless you want the imported value to be included in the output\n # - only import from the Python standard run-time library (you can't have any dependencies)\n \n baseVersion = '3.5.0a1'\n@@ -58,7 +58,12 @@\n \"\"\"\n from pkg_resources import parse_version\n build_number = buildNumber()\n- if build_number is not None and parse_version(baseVersion).is_prerelease:\n+ parsedBaseVersion = parse_version(baseVersion)\n+ if isinstance(parsedBaseVersion, tuple):\n+ raise RuntimeError(\"Setuptools version 8.0 or newer required. Update by running \"\n+ \"'pip install setuptools --upgrade'\")\n+\n+ if build_number is not None and parsedBaseVersion.is_prerelease:\n return baseVersion + '.dev' + build_number\n else:\n return baseVersion\n", "issue": "setuptools 8.0.0 or later is now required for PEP 440 version support\npython 2.7.9\r\nsetuptools 5.5.1\r\n```\r\nTraceback (most recent call last):\r\n File \"version_template.py\", line 137, in <module>\r\n _main()\r\n File \"version_template.py\", line 133, in _main\r\n sys.stdout.write(expand_(*sys.argv[1:]))\r\n File \"version_template.py\", line 128, in expand_\r\n return resolve(name)\r\n File \"version_template.py\", line 122, in resolve\r\n v = v()\r\n File \"version_template.py\", line 61, in distVersion\r\n if build_number is not None and parse_version(baseVersion).is_prerelease:\r\nAttributeError: 'tuple' object has no attribute 'is_prerelease'\r\n```\r\n\nsetuptools 8.0.0 or later is now required for PEP 440 version support\npython 2.7.9\r\nsetuptools 5.5.1\r\n```\r\nTraceback (most recent call last):\r\n File \"version_template.py\", line 137, in <module>\r\n _main()\r\n File \"version_template.py\", line 133, in _main\r\n sys.stdout.write(expand_(*sys.argv[1:]))\r\n File \"version_template.py\", line 128, in expand_\r\n return resolve(name)\r\n File \"version_template.py\", line 122, in resolve\r\n v = v()\r\n File \"version_template.py\", line 61, in distVersion\r\n if build_number is not None and parse_version(baseVersion).is_prerelease:\r\nAttributeError: 'tuple' object has no attribute 'is_prerelease'\r\n```\r\n\n", "before_files": [{"content": "# Copyright (C) 2015-2016 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This script is a template for src/toil/version.py. Running it without arguments echoes all\nglobals, i.e. module attributes. Constant assignments will be echoed verbatim while callables\nwill be invoked and their result echoed as an assignment using the function name as the left-hand\nside and the return value of the function as right-hand side. To prevent a module attribute from\nbeing echoed, start or end the attribute name with an underscore. To print the value of a single\nsymbol, pass the name of that attribute to the script as a command line argument. You can also\nimport the expand_ function and invoke it directly with either no or exactly one argument.\"\"\"\n\n# Note to maintainers:\n#\n# - don't import at module level unless you intend for the import to be included in the output\n# - only import from the Python standard run-time library (you can't have any dependencies)\n\nbaseVersion = '3.5.0a1'\n\ncgcloudVersion = '1.6.0a1.dev378'\n\n\ndef version():\n \"\"\"\n A version identifier that includes the full-legth commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version()\n\n\ndef shortVersion():\n \"\"\"\n A version identifier that includes the abbreviated commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version(shorten=True)\n\n\ndef _version(shorten=False):\n return '-'.join(filter(None, [distVersion(),\n currentCommit()[:7 if shorten else None],\n ('dirty' if dirty() else None)]))\n\n\ndef distVersion():\n \"\"\"\n The distribution version identifying a published release on PyPI.\n \"\"\"\n from pkg_resources import parse_version\n build_number = buildNumber()\n if build_number is not None and parse_version(baseVersion).is_prerelease:\n return baseVersion + '.dev' + build_number\n else:\n return baseVersion\n\n\ndef dockerTag():\n \"\"\"\n The primary tag of the Docker image for the appliance. This uniquely identifies the appliance\n image.\n \"\"\"\n return version()\n\n\ndef dockerShortTag():\n \"\"\"\n A secondary, shortened form of :func:`dockerTag` with which to tag the appliance image for\n convenience.\n \"\"\"\n return shortVersion()\n\n\ndef dockerMinimalTag():\n \"\"\"\n A minimal tag with which to tag the appliance image for convenience. Does not include\n information about the git commit or working copy dirtyness.\n \"\"\"\n return distVersion()\n\n\ndockerRegistry = 'quay.io/ucsc_cgl'\n\ndockerName = 'toil'\n\n\ndef buildNumber():\n \"\"\"\n The Jenkins build number, if defined, else None.\n \"\"\"\n import os\n return os.getenv('BUILD_NUMBER')\n\n\ndef currentCommit():\n from subprocess import check_output\n return check_output('git log --pretty=oneline -n 1 -- $(pwd)', shell=True).split()[0]\n\n\ndef dirty():\n from subprocess import call\n return 0 != call('(git diff --exit-code '\n '&& git diff --cached --exit-code) > /dev/null', shell=True)\n\n\ndef expand_(name=None):\n variables = {k: v for k, v in globals().iteritems()\n if not k.startswith('_') and not k.endswith('_')}\n\n def resolve(k):\n v = variables[k]\n if callable(v):\n v = v()\n return v\n\n if name is None:\n return ''.join(\"%s = %s\\n\" % (k, repr(resolve(k))) for k, v in variables.iteritems())\n else:\n return resolve(name)\n\n\ndef _main():\n import sys\n sys.stdout.write(expand_(*sys.argv[1:]))\n\n\nif __name__ == '__main__':\n _main()\n", "path": "version_template.py"}], "after_files": [{"content": "# Copyright (C) 2015-2016 Regents of the University of California\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"This script is a template for src/toil/version.py. Running it without arguments echoes all\nglobals, i.e. module attributes. Constant assignments will be echoed verbatim while callables\nwill be invoked and their result echoed as an assignment using the function name as the left-hand\nside and the return value of the function as right-hand side. To prevent a module attribute from\nbeing echoed, start or end the attribute name with an underscore. To print the value of a single\nsymbol, pass the name of that attribute to the script as a command line argument. You can also\nimport the expand_ function and invoke it directly with either no or exactly one argument.\"\"\"\n\n# Note to maintainers:\n#\n# - don't import at module level unless you want the imported value to be included in the output\n# - only import from the Python standard run-time library (you can't have any dependencies)\n\nbaseVersion = '3.5.0a1'\n\ncgcloudVersion = '1.6.0a1.dev378'\n\n\ndef version():\n \"\"\"\n A version identifier that includes the full-legth commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version()\n\n\ndef shortVersion():\n \"\"\"\n A version identifier that includes the abbreviated commit SHA1 and an optional suffix to\n indicate that the working copy is dirty.\n \"\"\"\n return _version(shorten=True)\n\n\ndef _version(shorten=False):\n return '-'.join(filter(None, [distVersion(),\n currentCommit()[:7 if shorten else None],\n ('dirty' if dirty() else None)]))\n\n\ndef distVersion():\n \"\"\"\n The distribution version identifying a published release on PyPI.\n \"\"\"\n from pkg_resources import parse_version\n build_number = buildNumber()\n parsedBaseVersion = parse_version(baseVersion)\n if isinstance(parsedBaseVersion, tuple):\n raise RuntimeError(\"Setuptools version 8.0 or newer required. Update by running \"\n \"'pip install setuptools --upgrade'\")\n\n if build_number is not None and parsedBaseVersion.is_prerelease:\n return baseVersion + '.dev' + build_number\n else:\n return baseVersion\n\n\ndef dockerTag():\n \"\"\"\n The primary tag of the Docker image for the appliance. This uniquely identifies the appliance\n image.\n \"\"\"\n return version()\n\n\ndef dockerShortTag():\n \"\"\"\n A secondary, shortened form of :func:`dockerTag` with which to tag the appliance image for\n convenience.\n \"\"\"\n return shortVersion()\n\n\ndef dockerMinimalTag():\n \"\"\"\n A minimal tag with which to tag the appliance image for convenience. Does not include\n information about the git commit or working copy dirtyness.\n \"\"\"\n return distVersion()\n\n\ndockerRegistry = 'quay.io/ucsc_cgl'\n\ndockerName = 'toil'\n\n\ndef buildNumber():\n \"\"\"\n The Jenkins build number, if defined, else None.\n \"\"\"\n import os\n return os.getenv('BUILD_NUMBER')\n\n\ndef currentCommit():\n from subprocess import check_output\n return check_output('git log --pretty=oneline -n 1 -- $(pwd)', shell=True).split()[0]\n\n\ndef dirty():\n from subprocess import call\n return 0 != call('(git diff --exit-code '\n '&& git diff --cached --exit-code) > /dev/null', shell=True)\n\n\ndef expand_(name=None):\n variables = {k: v for k, v in globals().iteritems()\n if not k.startswith('_') and not k.endswith('_')}\n\n def resolve(k):\n v = variables[k]\n if callable(v):\n v = v()\n return v\n\n if name is None:\n return ''.join(\"%s = %s\\n\" % (k, repr(resolve(k))) for k, v in variables.iteritems())\n else:\n return resolve(name)\n\n\ndef _main():\n import sys\n sys.stdout.write(expand_(*sys.argv[1:]))\n\n\nif __name__ == '__main__':\n _main()\n", "path": "version_template.py"}]} | 1,928 | 259 |
gh_patches_debug_7193 | rasdani/github-patches | git_diff | translate__pootle-5924 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Setting FORCE_SCRIPT_NAME breaks views
Seems like a number of views are not parsing path correctly when FORCE_SCRIPT_NAME is set.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pootle/apps/pootle_translationproject/views.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright (C) Pootle contributors.
4 #
5 # This file is a part of the Pootle project. It is distributed under the GPL3
6 # or later license. See the LICENSE file for a copy of the license and the
7 # AUTHORS file for copyright and authorship information.
8
9 import functools
10
11 from django.conf import settings
12 from django.http import Http404
13 from django.shortcuts import get_object_or_404, redirect
14 from django.urls import resolve, reverse
15 from django.utils.functional import cached_property
16 from django.utils.lru_cache import lru_cache
17
18 from pootle.core.browser import (
19 get_parent, make_directory_item, make_store_item)
20 from pootle.core.decorators import get_path_obj, permission_required
21 from pootle.core.helpers import get_sidebar_announcements_context
22 from pootle.core.views import PootleBrowseView, PootleTranslateView
23 from pootle.core.views.display import StatsDisplay
24 from pootle_app.models import Directory
25 from pootle_app.models.permissions import get_matching_permissions
26 from pootle_app.views.admin.permissions import admin_permissions as admin_perms
27 from pootle_language.models import Language
28 from pootle_store.models import Store
29
30 from .apps import PootleTPConfig
31 from .models import TranslationProject
32
33
34 @get_path_obj
35 @permission_required('administrate')
36 def admin_permissions(request, translation_project):
37 ctx = {
38 'page': 'admin-permissions',
39
40 'browse_url': reverse('pootle-tp-browse', kwargs={
41 'language_code': translation_project.language.code,
42 'project_code': translation_project.project.code,
43 }),
44 'translate_url': reverse('pootle-tp-translate', kwargs={
45 'language_code': translation_project.language.code,
46 'project_code': translation_project.project.code,
47 }),
48
49 'translation_project': translation_project,
50 'project': translation_project.project,
51 'language': translation_project.language,
52 'directory': translation_project.directory,
53 }
54 return admin_perms(request, translation_project.directory,
55 'translation_projects/admin/permissions.html', ctx)
56
57
58 def redirect_to_tp_on_404(f):
59
60 @functools.wraps(f)
61 def method_wrapper(self, request, *args, **kwargs):
62 try:
63 request.permissions = get_matching_permissions(
64 request.user,
65 self.permission_context) or []
66 except Http404 as e:
67 # Test if lang code is not canonical but valid
68 lang = Language.get_canonical(kwargs['language_code'])
69 if lang is not None and lang.code != kwargs['language_code']:
70 kwargs["language_code"] = lang.code
71 return redirect(
72 resolve(request.path).view_name,
73 permanent=True,
74 **kwargs)
75
76 elif kwargs["dir_path"] or kwargs.get("filename", None):
77 try:
78 TranslationProject.objects.get(
79 project__code=kwargs["project_code"],
80 language__code=kwargs["language_code"])
81 # the TP exists so redirect to it
82 return redirect(
83 reverse(
84 'pootle-tp-browse',
85 kwargs={
86 k: v
87 for k, v
88 in kwargs.items()
89 if k in [
90 "language_code",
91 "project_code"]}))
92 except TranslationProject.DoesNotExist:
93 pass
94
95 # if we get here - the TP does not exist
96 user_choice = self.request.COOKIES.get(
97 'user-choice', None)
98 if user_choice:
99 url = None
100 if user_choice == 'language':
101 url = reverse(
102 'pootle-language-browse',
103 args=[kwargs["language_code"]])
104 elif user_choice == "project":
105 url = reverse(
106 'pootle-project-browse',
107 args=[kwargs["project_code"], '', ''])
108 if url:
109 response = redirect(url)
110 response.delete_cookie('user-choice')
111 return response
112 raise e
113 return f(self, request, *args, **kwargs)
114 return method_wrapper
115
116
117 class TPMixin(object):
118 """This Mixin is used by all TP views.
119
120 The context object may be a resource with the TP, ie a Directory or Store.
121 """
122
123 ns = "pootle.tp"
124 sw_version = PootleTPConfig.version
125
126 @redirect_to_tp_on_404
127 def dispatch(self, request, *args, **kwargs):
128 return super(TPMixin, self).dispatch(request, *args, **kwargs)
129
130 @property
131 def ctx_path(self):
132 return self.tp.pootle_path
133
134 @property
135 def resource_path(self):
136 return self.object.pootle_path.replace(self.ctx_path, "")
137
138 @property
139 def dir_path(self):
140 return self.resource_path
141
142 @cached_property
143 def tp(self):
144 if not self.object.tp:
145 return self.object.translation_project
146 return self.object.tp
147
148 @cached_property
149 def project(self):
150 if self.tp.project.disabled and not self.request.user.is_superuser:
151 raise Http404
152 return self.tp.project
153
154 @cached_property
155 def language(self):
156 return self.tp.language
157
158 @cached_property
159 def sidebar_announcements(self):
160 return get_sidebar_announcements_context(
161 self.request,
162 (self.project, self.language, self.tp))
163
164
165 class TPDirectoryMixin(TPMixin):
166 model = Directory
167 browse_url_path = "pootle-tp-browse"
168 translate_url_path = "pootle-tp-translate"
169
170 @property
171 def object_related(self):
172 return [
173 "parent",
174 "tp",
175 "tp__language",
176 "tp__language__directory",
177 "tp__project"]
178
179 @lru_cache()
180 def get_object(self):
181 return get_object_or_404(
182 Directory.objects.select_related(*self.object_related),
183 pootle_path=self.path)
184
185 @property
186 def url_kwargs(self):
187 return {
188 "language_code": self.language.code,
189 "project_code": self.project.code,
190 "dir_path": self.dir_path}
191
192 @cached_property
193 def vfolders_data_view(self):
194 if 'virtualfolder' not in settings.INSTALLED_APPS:
195 return
196 from virtualfolder.delegate import vfolders_data_view
197
198 return vfolders_data_view.get(self.object.__class__)(
199 self.object, self.request.user, self.has_admin_access)
200
201
202 class TPStoreMixin(TPMixin):
203 model = Store
204 browse_url_path = "pootle-tp-store-browse"
205 translate_url_path = "pootle-tp-store-translate"
206 is_store = True
207 panels = ()
208
209 @property
210 def permission_context(self):
211 return self.get_object().parent
212
213 @cached_property
214 def tp(self):
215 return self.object.translation_project
216
217 @property
218 def dir_path(self):
219 return self.resource_path.replace(self.object.name, "")
220
221 @property
222 def url_kwargs(self):
223 return {
224 "language_code": self.language.code,
225 "project_code": self.project.code,
226 "dir_path": self.dir_path,
227 "filename": self.object.name}
228
229 @lru_cache()
230 def get_object(self):
231 path = (
232 "/%(language_code)s/%(project_code)s/%(dir_path)s%(filename)s"
233 % self.kwargs)
234 return get_object_or_404(
235 Store.objects.select_related(
236 "parent",
237 "translation_project__language",
238 "translation_project__project"),
239 pootle_path=path)
240
241
242 class TPBrowseBaseView(PootleBrowseView):
243 template_extends = 'translation_projects/base.html'
244
245 def get_context_data(self, *args, **kwargs):
246 upload_widget = self.get_upload_widget()
247 ctx = super(TPBrowseBaseView, self).get_context_data(*args, **kwargs)
248 ctx.update(upload_widget)
249 ctx.update(
250 {'parent': get_parent(self.object)})
251 return ctx
252
253 @property
254 def can_upload(self):
255 return (
256 "import_export" in settings.INSTALLED_APPS
257 and self.request.user.is_authenticated
258 and (self.request.user.is_superuser
259 or "translate" in self.request.permissions
260 or "administrate" in self.request.permissions))
261
262 def get_upload_widget(self):
263 ctx = {}
264 if self.can_upload:
265 from import_export.views import handle_upload_form
266
267 ctx.update(handle_upload_form(self.request, self.tp))
268 ctx.update(
269 {'display_download': True,
270 'has_sidebar': True})
271 return ctx
272
273 def post(self, *args, **kwargs):
274 return self.get(*args, **kwargs)
275
276 @property
277 def score_context(self):
278 return self.tp
279
280
281 class TPBrowseStoreView(TPStoreMixin, TPBrowseBaseView):
282
283 disabled_items = False
284
285 @property
286 def cache_key(self):
287 return ""
288
289
290 class TPBrowseView(TPDirectoryMixin, TPBrowseBaseView):
291 view_name = "tp"
292 panel_names = ('vfolders', 'children')
293
294 @cached_property
295 def object_children(self):
296 dirs_with_vfolders = []
297 if 'virtualfolder' in settings.INSTALLED_APPS:
298 stores = self.tp.stores
299 if self.object.tp_path != "/":
300 stores = stores.filter(
301 tp_path__startswith=self.object.tp_path)
302 vf_stores = stores.filter(
303 vfolders__isnull=False).exclude(parent=self.object)
304 dirs_with_vfolders = set(
305 [path.replace(self.object.pootle_path, "").split("/")[0]
306 for path
307 in vf_stores.values_list(
308 "pootle_path", flat=True)])
309 directories = [
310 make_directory_item(
311 child,
312 **(dict(sort="priority")
313 if child.name in dirs_with_vfolders
314 else {}))
315 for child in self.object.children
316 if isinstance(child, Directory)]
317 stores = [
318 make_store_item(child)
319 for child in self.object.children
320 if isinstance(child, Store)]
321 return self.add_child_stats(directories + stores)
322
323 @cached_property
324 def has_vfolders(self):
325 vfdata = self.vfolders_data_view
326 return bool(
327 vfdata
328 and vfdata.table_data
329 and vfdata.table_data.get("children"))
330
331 @cached_property
332 def stats(self):
333 stats_ob = (
334 self.object.tp
335 if self.object.tp_path == "/"
336 else self.object)
337 return StatsDisplay(
338 stats_ob,
339 stats=stats_ob.data_tool.get_stats(
340 user=self.request.user)).stats
341
342
343 class TPTranslateBaseView(PootleTranslateView):
344 translate_url_path = "pootle-tp-translate"
345 browse_url_path = "pootle-tp-browse"
346 template_extends = 'translation_projects/base.html'
347
348 @property
349 def pootle_path(self):
350 return "%s%s" % (self.ctx_path, self.resource_path)
351
352
353 class TPTranslateView(TPDirectoryMixin, TPTranslateBaseView):
354
355 @property
356 def request_path(self):
357 return "/%(language_code)s/%(project_code)s/%(dir_path)s" % self.kwargs
358
359 @cached_property
360 def display_vfolder_priority(self):
361 return self.vfolders_data_view.has_data
362
363 @property
364 def path(self):
365 return self.request_path
366
367
368 class TPTranslateStoreView(TPStoreMixin, TPTranslateBaseView):
369 pass
370
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pootle/apps/pootle_translationproject/views.py b/pootle/apps/pootle_translationproject/views.py
--- a/pootle/apps/pootle_translationproject/views.py
+++ b/pootle/apps/pootle_translationproject/views.py
@@ -291,6 +291,15 @@
view_name = "tp"
panel_names = ('vfolders', 'children')
+ @property
+ def path(self):
+ kwargs = self.kwargs
+ kwargs["dir_path"] = kwargs.get("dir_path", "")
+ kwargs["filename"] = kwargs.get("filename", "")
+ return (
+ "/%(language_code)s/%(project_code)s/%(dir_path)s%(filename)s"
+ % kwargs)
+
@cached_property
def object_children(self):
dirs_with_vfolders = []
| {"golden_diff": "diff --git a/pootle/apps/pootle_translationproject/views.py b/pootle/apps/pootle_translationproject/views.py\n--- a/pootle/apps/pootle_translationproject/views.py\n+++ b/pootle/apps/pootle_translationproject/views.py\n@@ -291,6 +291,15 @@\n view_name = \"tp\"\n panel_names = ('vfolders', 'children')\n \n+ @property\n+ def path(self):\n+ kwargs = self.kwargs\n+ kwargs[\"dir_path\"] = kwargs.get(\"dir_path\", \"\")\n+ kwargs[\"filename\"] = kwargs.get(\"filename\", \"\")\n+ return (\n+ \"/%(language_code)s/%(project_code)s/%(dir_path)s%(filename)s\"\n+ % kwargs)\n+\n @cached_property\n def object_children(self):\n dirs_with_vfolders = []\n", "issue": "Setting FORCE_SCRIPT_NAME breaks views\nSeems like a number of views are not parsing path correctly when FORCE_SCRIPT_NAME is set.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport functools\n\nfrom django.conf import settings\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.urls import resolve, reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.lru_cache import lru_cache\n\nfrom pootle.core.browser import (\n get_parent, make_directory_item, make_store_item)\nfrom pootle.core.decorators import get_path_obj, permission_required\nfrom pootle.core.helpers import get_sidebar_announcements_context\nfrom pootle.core.views import PootleBrowseView, PootleTranslateView\nfrom pootle.core.views.display import StatsDisplay\nfrom pootle_app.models import Directory\nfrom pootle_app.models.permissions import get_matching_permissions\nfrom pootle_app.views.admin.permissions import admin_permissions as admin_perms\nfrom pootle_language.models import Language\nfrom pootle_store.models import Store\n\nfrom .apps import PootleTPConfig\nfrom .models import TranslationProject\n\n\n@get_path_obj\n@permission_required('administrate')\ndef admin_permissions(request, translation_project):\n ctx = {\n 'page': 'admin-permissions',\n\n 'browse_url': reverse('pootle-tp-browse', kwargs={\n 'language_code': translation_project.language.code,\n 'project_code': translation_project.project.code,\n }),\n 'translate_url': reverse('pootle-tp-translate', kwargs={\n 'language_code': translation_project.language.code,\n 'project_code': translation_project.project.code,\n }),\n\n 'translation_project': translation_project,\n 'project': translation_project.project,\n 'language': translation_project.language,\n 'directory': translation_project.directory,\n }\n return admin_perms(request, translation_project.directory,\n 'translation_projects/admin/permissions.html', ctx)\n\n\ndef redirect_to_tp_on_404(f):\n\n @functools.wraps(f)\n def method_wrapper(self, request, *args, **kwargs):\n try:\n request.permissions = get_matching_permissions(\n request.user,\n self.permission_context) or []\n except Http404 as e:\n # Test if lang code is not canonical but valid\n lang = Language.get_canonical(kwargs['language_code'])\n if lang is not None and lang.code != kwargs['language_code']:\n kwargs[\"language_code\"] = lang.code\n return redirect(\n resolve(request.path).view_name,\n permanent=True,\n **kwargs)\n\n elif kwargs[\"dir_path\"] or kwargs.get(\"filename\", None):\n try:\n TranslationProject.objects.get(\n project__code=kwargs[\"project_code\"],\n language__code=kwargs[\"language_code\"])\n # the TP exists so redirect to it\n return redirect(\n reverse(\n 'pootle-tp-browse',\n kwargs={\n k: v\n for k, v\n in kwargs.items()\n if k in [\n \"language_code\",\n \"project_code\"]}))\n except TranslationProject.DoesNotExist:\n pass\n\n # if we get here - the TP does not exist\n user_choice = self.request.COOKIES.get(\n 'user-choice', None)\n if user_choice:\n url = None\n if user_choice == 'language':\n url = reverse(\n 'pootle-language-browse',\n args=[kwargs[\"language_code\"]])\n elif user_choice == \"project\":\n url = reverse(\n 'pootle-project-browse',\n args=[kwargs[\"project_code\"], '', ''])\n if url:\n response = redirect(url)\n response.delete_cookie('user-choice')\n return response\n raise e\n return f(self, request, *args, **kwargs)\n return method_wrapper\n\n\nclass TPMixin(object):\n \"\"\"This Mixin is used by all TP views.\n\n The context object may be a resource with the TP, ie a Directory or Store.\n \"\"\"\n\n ns = \"pootle.tp\"\n sw_version = PootleTPConfig.version\n\n @redirect_to_tp_on_404\n def dispatch(self, request, *args, **kwargs):\n return super(TPMixin, self).dispatch(request, *args, **kwargs)\n\n @property\n def ctx_path(self):\n return self.tp.pootle_path\n\n @property\n def resource_path(self):\n return self.object.pootle_path.replace(self.ctx_path, \"\")\n\n @property\n def dir_path(self):\n return self.resource_path\n\n @cached_property\n def tp(self):\n if not self.object.tp:\n return self.object.translation_project\n return self.object.tp\n\n @cached_property\n def project(self):\n if self.tp.project.disabled and not self.request.user.is_superuser:\n raise Http404\n return self.tp.project\n\n @cached_property\n def language(self):\n return self.tp.language\n\n @cached_property\n def sidebar_announcements(self):\n return get_sidebar_announcements_context(\n self.request,\n (self.project, self.language, self.tp))\n\n\nclass TPDirectoryMixin(TPMixin):\n model = Directory\n browse_url_path = \"pootle-tp-browse\"\n translate_url_path = \"pootle-tp-translate\"\n\n @property\n def object_related(self):\n return [\n \"parent\",\n \"tp\",\n \"tp__language\",\n \"tp__language__directory\",\n \"tp__project\"]\n\n @lru_cache()\n def get_object(self):\n return get_object_or_404(\n Directory.objects.select_related(*self.object_related),\n pootle_path=self.path)\n\n @property\n def url_kwargs(self):\n return {\n \"language_code\": self.language.code,\n \"project_code\": self.project.code,\n \"dir_path\": self.dir_path}\n\n @cached_property\n def vfolders_data_view(self):\n if 'virtualfolder' not in settings.INSTALLED_APPS:\n return\n from virtualfolder.delegate import vfolders_data_view\n\n return vfolders_data_view.get(self.object.__class__)(\n self.object, self.request.user, self.has_admin_access)\n\n\nclass TPStoreMixin(TPMixin):\n model = Store\n browse_url_path = \"pootle-tp-store-browse\"\n translate_url_path = \"pootle-tp-store-translate\"\n is_store = True\n panels = ()\n\n @property\n def permission_context(self):\n return self.get_object().parent\n\n @cached_property\n def tp(self):\n return self.object.translation_project\n\n @property\n def dir_path(self):\n return self.resource_path.replace(self.object.name, \"\")\n\n @property\n def url_kwargs(self):\n return {\n \"language_code\": self.language.code,\n \"project_code\": self.project.code,\n \"dir_path\": self.dir_path,\n \"filename\": self.object.name}\n\n @lru_cache()\n def get_object(self):\n path = (\n \"/%(language_code)s/%(project_code)s/%(dir_path)s%(filename)s\"\n % self.kwargs)\n return get_object_or_404(\n Store.objects.select_related(\n \"parent\",\n \"translation_project__language\",\n \"translation_project__project\"),\n pootle_path=path)\n\n\nclass TPBrowseBaseView(PootleBrowseView):\n template_extends = 'translation_projects/base.html'\n\n def get_context_data(self, *args, **kwargs):\n upload_widget = self.get_upload_widget()\n ctx = super(TPBrowseBaseView, self).get_context_data(*args, **kwargs)\n ctx.update(upload_widget)\n ctx.update(\n {'parent': get_parent(self.object)})\n return ctx\n\n @property\n def can_upload(self):\n return (\n \"import_export\" in settings.INSTALLED_APPS\n and self.request.user.is_authenticated\n and (self.request.user.is_superuser\n or \"translate\" in self.request.permissions\n or \"administrate\" in self.request.permissions))\n\n def get_upload_widget(self):\n ctx = {}\n if self.can_upload:\n from import_export.views import handle_upload_form\n\n ctx.update(handle_upload_form(self.request, self.tp))\n ctx.update(\n {'display_download': True,\n 'has_sidebar': True})\n return ctx\n\n def post(self, *args, **kwargs):\n return self.get(*args, **kwargs)\n\n @property\n def score_context(self):\n return self.tp\n\n\nclass TPBrowseStoreView(TPStoreMixin, TPBrowseBaseView):\n\n disabled_items = False\n\n @property\n def cache_key(self):\n return \"\"\n\n\nclass TPBrowseView(TPDirectoryMixin, TPBrowseBaseView):\n view_name = \"tp\"\n panel_names = ('vfolders', 'children')\n\n @cached_property\n def object_children(self):\n dirs_with_vfolders = []\n if 'virtualfolder' in settings.INSTALLED_APPS:\n stores = self.tp.stores\n if self.object.tp_path != \"/\":\n stores = stores.filter(\n tp_path__startswith=self.object.tp_path)\n vf_stores = stores.filter(\n vfolders__isnull=False).exclude(parent=self.object)\n dirs_with_vfolders = set(\n [path.replace(self.object.pootle_path, \"\").split(\"/\")[0]\n for path\n in vf_stores.values_list(\n \"pootle_path\", flat=True)])\n directories = [\n make_directory_item(\n child,\n **(dict(sort=\"priority\")\n if child.name in dirs_with_vfolders\n else {}))\n for child in self.object.children\n if isinstance(child, Directory)]\n stores = [\n make_store_item(child)\n for child in self.object.children\n if isinstance(child, Store)]\n return self.add_child_stats(directories + stores)\n\n @cached_property\n def has_vfolders(self):\n vfdata = self.vfolders_data_view\n return bool(\n vfdata\n and vfdata.table_data\n and vfdata.table_data.get(\"children\"))\n\n @cached_property\n def stats(self):\n stats_ob = (\n self.object.tp\n if self.object.tp_path == \"/\"\n else self.object)\n return StatsDisplay(\n stats_ob,\n stats=stats_ob.data_tool.get_stats(\n user=self.request.user)).stats\n\n\nclass TPTranslateBaseView(PootleTranslateView):\n translate_url_path = \"pootle-tp-translate\"\n browse_url_path = \"pootle-tp-browse\"\n template_extends = 'translation_projects/base.html'\n\n @property\n def pootle_path(self):\n return \"%s%s\" % (self.ctx_path, self.resource_path)\n\n\nclass TPTranslateView(TPDirectoryMixin, TPTranslateBaseView):\n\n @property\n def request_path(self):\n return \"/%(language_code)s/%(project_code)s/%(dir_path)s\" % self.kwargs\n\n @cached_property\n def display_vfolder_priority(self):\n return self.vfolders_data_view.has_data\n\n @property\n def path(self):\n return self.request_path\n\n\nclass TPTranslateStoreView(TPStoreMixin, TPTranslateBaseView):\n pass\n", "path": "pootle/apps/pootle_translationproject/views.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright (C) Pootle contributors.\n#\n# This file is a part of the Pootle project. It is distributed under the GPL3\n# or later license. See the LICENSE file for a copy of the license and the\n# AUTHORS file for copyright and authorship information.\n\nimport functools\n\nfrom django.conf import settings\nfrom django.http import Http404\nfrom django.shortcuts import get_object_or_404, redirect\nfrom django.urls import resolve, reverse\nfrom django.utils.functional import cached_property\nfrom django.utils.lru_cache import lru_cache\n\nfrom pootle.core.browser import (\n get_parent, make_directory_item, make_store_item)\nfrom pootle.core.decorators import get_path_obj, permission_required\nfrom pootle.core.helpers import get_sidebar_announcements_context\nfrom pootle.core.views import PootleBrowseView, PootleTranslateView\nfrom pootle.core.views.display import StatsDisplay\nfrom pootle_app.models import Directory\nfrom pootle_app.models.permissions import get_matching_permissions\nfrom pootle_app.views.admin.permissions import admin_permissions as admin_perms\nfrom pootle_language.models import Language\nfrom pootle_store.models import Store\n\nfrom .apps import PootleTPConfig\nfrom .models import TranslationProject\n\n\n@get_path_obj\n@permission_required('administrate')\ndef admin_permissions(request, translation_project):\n ctx = {\n 'page': 'admin-permissions',\n\n 'browse_url': reverse('pootle-tp-browse', kwargs={\n 'language_code': translation_project.language.code,\n 'project_code': translation_project.project.code,\n }),\n 'translate_url': reverse('pootle-tp-translate', kwargs={\n 'language_code': translation_project.language.code,\n 'project_code': translation_project.project.code,\n }),\n\n 'translation_project': translation_project,\n 'project': translation_project.project,\n 'language': translation_project.language,\n 'directory': translation_project.directory,\n }\n return admin_perms(request, translation_project.directory,\n 'translation_projects/admin/permissions.html', ctx)\n\n\ndef redirect_to_tp_on_404(f):\n\n @functools.wraps(f)\n def method_wrapper(self, request, *args, **kwargs):\n try:\n request.permissions = get_matching_permissions(\n request.user,\n self.permission_context) or []\n except Http404 as e:\n # Test if lang code is not canonical but valid\n lang = Language.get_canonical(kwargs['language_code'])\n if lang is not None and lang.code != kwargs['language_code']:\n kwargs[\"language_code\"] = lang.code\n return redirect(\n resolve(request.path).view_name,\n permanent=True,\n **kwargs)\n\n elif kwargs[\"dir_path\"] or kwargs.get(\"filename\", None):\n try:\n TranslationProject.objects.get(\n project__code=kwargs[\"project_code\"],\n language__code=kwargs[\"language_code\"])\n # the TP exists so redirect to it\n return redirect(\n reverse(\n 'pootle-tp-browse',\n kwargs={\n k: v\n for k, v\n in kwargs.items()\n if k in [\n \"language_code\",\n \"project_code\"]}))\n except TranslationProject.DoesNotExist:\n pass\n\n # if we get here - the TP does not exist\n user_choice = self.request.COOKIES.get(\n 'user-choice', None)\n if user_choice:\n url = None\n if user_choice == 'language':\n url = reverse(\n 'pootle-language-browse',\n args=[kwargs[\"language_code\"]])\n elif user_choice == \"project\":\n url = reverse(\n 'pootle-project-browse',\n args=[kwargs[\"project_code\"], '', ''])\n if url:\n response = redirect(url)\n response.delete_cookie('user-choice')\n return response\n raise e\n return f(self, request, *args, **kwargs)\n return method_wrapper\n\n\nclass TPMixin(object):\n \"\"\"This Mixin is used by all TP views.\n\n The context object may be a resource with the TP, ie a Directory or Store.\n \"\"\"\n\n ns = \"pootle.tp\"\n sw_version = PootleTPConfig.version\n\n @redirect_to_tp_on_404\n def dispatch(self, request, *args, **kwargs):\n return super(TPMixin, self).dispatch(request, *args, **kwargs)\n\n @property\n def ctx_path(self):\n return self.tp.pootle_path\n\n @property\n def resource_path(self):\n return self.object.pootle_path.replace(self.ctx_path, \"\")\n\n @property\n def dir_path(self):\n return self.resource_path\n\n @cached_property\n def tp(self):\n if not self.object.tp:\n return self.object.translation_project\n return self.object.tp\n\n @cached_property\n def project(self):\n if self.tp.project.disabled and not self.request.user.is_superuser:\n raise Http404\n return self.tp.project\n\n @cached_property\n def language(self):\n return self.tp.language\n\n @cached_property\n def sidebar_announcements(self):\n return get_sidebar_announcements_context(\n self.request,\n (self.project, self.language, self.tp))\n\n\nclass TPDirectoryMixin(TPMixin):\n model = Directory\n browse_url_path = \"pootle-tp-browse\"\n translate_url_path = \"pootle-tp-translate\"\n\n @property\n def object_related(self):\n return [\n \"parent\",\n \"tp\",\n \"tp__language\",\n \"tp__language__directory\",\n \"tp__project\"]\n\n @lru_cache()\n def get_object(self):\n return get_object_or_404(\n Directory.objects.select_related(*self.object_related),\n pootle_path=self.path)\n\n @property\n def url_kwargs(self):\n return {\n \"language_code\": self.language.code,\n \"project_code\": self.project.code,\n \"dir_path\": self.dir_path}\n\n @cached_property\n def vfolders_data_view(self):\n if 'virtualfolder' not in settings.INSTALLED_APPS:\n return\n from virtualfolder.delegate import vfolders_data_view\n\n return vfolders_data_view.get(self.object.__class__)(\n self.object, self.request.user, self.has_admin_access)\n\n\nclass TPStoreMixin(TPMixin):\n model = Store\n browse_url_path = \"pootle-tp-store-browse\"\n translate_url_path = \"pootle-tp-store-translate\"\n is_store = True\n panels = ()\n\n @property\n def permission_context(self):\n return self.get_object().parent\n\n @cached_property\n def tp(self):\n return self.object.translation_project\n\n @property\n def dir_path(self):\n return self.resource_path.replace(self.object.name, \"\")\n\n @property\n def url_kwargs(self):\n return {\n \"language_code\": self.language.code,\n \"project_code\": self.project.code,\n \"dir_path\": self.dir_path,\n \"filename\": self.object.name}\n\n @lru_cache()\n def get_object(self):\n path = (\n \"/%(language_code)s/%(project_code)s/%(dir_path)s%(filename)s\"\n % self.kwargs)\n return get_object_or_404(\n Store.objects.select_related(\n \"parent\",\n \"translation_project__language\",\n \"translation_project__project\"),\n pootle_path=path)\n\n\nclass TPBrowseBaseView(PootleBrowseView):\n template_extends = 'translation_projects/base.html'\n\n def get_context_data(self, *args, **kwargs):\n upload_widget = self.get_upload_widget()\n ctx = super(TPBrowseBaseView, self).get_context_data(*args, **kwargs)\n ctx.update(upload_widget)\n ctx.update(\n {'parent': get_parent(self.object)})\n return ctx\n\n @property\n def can_upload(self):\n return (\n \"import_export\" in settings.INSTALLED_APPS\n and self.request.user.is_authenticated\n and (self.request.user.is_superuser\n or \"translate\" in self.request.permissions\n or \"administrate\" in self.request.permissions))\n\n def get_upload_widget(self):\n ctx = {}\n if self.can_upload:\n from import_export.views import handle_upload_form\n\n ctx.update(handle_upload_form(self.request, self.tp))\n ctx.update(\n {'display_download': True,\n 'has_sidebar': True})\n return ctx\n\n def post(self, *args, **kwargs):\n return self.get(*args, **kwargs)\n\n @property\n def score_context(self):\n return self.tp\n\n\nclass TPBrowseStoreView(TPStoreMixin, TPBrowseBaseView):\n\n disabled_items = False\n\n @property\n def cache_key(self):\n return \"\"\n\n\nclass TPBrowseView(TPDirectoryMixin, TPBrowseBaseView):\n view_name = \"tp\"\n panel_names = ('vfolders', 'children')\n\n @property\n def path(self):\n kwargs = self.kwargs\n kwargs[\"dir_path\"] = kwargs.get(\"dir_path\", \"\")\n kwargs[\"filename\"] = kwargs.get(\"filename\", \"\")\n return (\n \"/%(language_code)s/%(project_code)s/%(dir_path)s%(filename)s\"\n % kwargs)\n\n @cached_property\n def object_children(self):\n dirs_with_vfolders = []\n if 'virtualfolder' in settings.INSTALLED_APPS:\n stores = self.tp.stores\n if self.object.tp_path != \"/\":\n stores = stores.filter(\n tp_path__startswith=self.object.tp_path)\n vf_stores = stores.filter(\n vfolders__isnull=False).exclude(parent=self.object)\n dirs_with_vfolders = set(\n [path.replace(self.object.pootle_path, \"\").split(\"/\")[0]\n for path\n in vf_stores.values_list(\n \"pootle_path\", flat=True)])\n directories = [\n make_directory_item(\n child,\n **(dict(sort=\"priority\")\n if child.name in dirs_with_vfolders\n else {}))\n for child in self.object.children\n if isinstance(child, Directory)]\n stores = [\n make_store_item(child)\n for child in self.object.children\n if isinstance(child, Store)]\n return self.add_child_stats(directories + stores)\n\n @cached_property\n def has_vfolders(self):\n vfdata = self.vfolders_data_view\n return bool(\n vfdata\n and vfdata.table_data\n and vfdata.table_data.get(\"children\"))\n\n @cached_property\n def stats(self):\n stats_ob = (\n self.object.tp\n if self.object.tp_path == \"/\"\n else self.object)\n return StatsDisplay(\n stats_ob,\n stats=stats_ob.data_tool.get_stats(\n user=self.request.user)).stats\n\n\nclass TPTranslateBaseView(PootleTranslateView):\n translate_url_path = \"pootle-tp-translate\"\n browse_url_path = \"pootle-tp-browse\"\n template_extends = 'translation_projects/base.html'\n\n @property\n def pootle_path(self):\n return \"%s%s\" % (self.ctx_path, self.resource_path)\n\n\nclass TPTranslateView(TPDirectoryMixin, TPTranslateBaseView):\n\n @property\n def request_path(self):\n return \"/%(language_code)s/%(project_code)s/%(dir_path)s\" % self.kwargs\n\n @cached_property\n def display_vfolder_priority(self):\n return self.vfolders_data_view.has_data\n\n @property\n def path(self):\n return self.request_path\n\n\nclass TPTranslateStoreView(TPStoreMixin, TPTranslateBaseView):\n pass\n", "path": "pootle/apps/pootle_translationproject/views.py"}]} | 3,760 | 185 |
gh_patches_debug_19503 | rasdani/github-patches | git_diff | cupy__cupy-4108 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ROCm: `cupy.show_config()` not working
```
$ python -c "import cupy; cupy.show_config()"
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "/home/leofang/dev/cupy_rocm3.5.0/cupy/__init__.py", line 874, in show_config
_sys.stdout.write(str(_cupyx.get_runtime_info()))
File "/home/leofang/dev/cupy_rocm3.5.0/cupyx/_runtime.py", line 215, in __str__
props['name'].decode('utf-8')),
AttributeError: 'str' object has no attribute 'decode'
```
Following #3858, I will add another branching to `getDeviceProperties` to support HIP.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupyx/_runtime.py`
Content:
```
1 import inspect
2 import io
3 import os
4 import platform
5
6 import numpy
7
8 import cupy
9
10 try:
11 import cupy.cuda.thrust as thrust
12 except ImportError:
13 thrust = None
14
15 try:
16 import cupy_backends.cuda.libs.cudnn as cudnn
17 except ImportError:
18 cudnn = None
19
20 try:
21 import cupy.cuda.nccl as nccl
22 except ImportError:
23 nccl = None
24
25 try:
26 import cupy.cuda.cub as cub
27 except ImportError:
28 cub = None
29
30 try:
31 import cupy_backends.cuda.libs.cutensor as cutensor
32 except ImportError:
33 cutensor = None
34
35 try:
36 import scipy
37 except ImportError:
38 scipy = None
39
40
41 def _eval_or_error(func, errors):
42 # Evaluates `func` and return the result.
43 # If an error specified by `errors` occured, it returns a string
44 # representing the error.
45 try:
46 return func()
47 except errors as e:
48 return repr(e)
49
50
51 class _InstallInfo(object):
52
53 # TODO(niboshi): Add is_binary_distribution
54
55 def __init__(self):
56 cupy_package_root = self._get_cupy_package_root()
57 if cupy_package_root is not None:
58 data_root = os.path.join(cupy_package_root, '.data')
59 data_paths = {
60 'lib': _dir_or_none(os.path.join(data_root, 'lib')),
61 'include': _dir_or_none(os.path.join(data_root, 'include')),
62 }
63 else:
64 data_paths = {
65 'lib': None,
66 'include': None,
67 }
68
69 self.cupy_package_root = cupy_package_root
70 self.data_paths = data_paths
71
72 def get_data_path(self, data_type):
73 if data_type not in self.data_paths:
74 raise ValueError('Invalid data type: {}'.format(data_type))
75 return self.data_paths[data_type]
76
77 def _get_cupy_package_root(self):
78 try:
79 cupy_path = inspect.getfile(cupy)
80 except TypeError:
81 return None
82 return os.path.dirname(cupy_path)
83
84
85 class _RuntimeInfo(object):
86
87 cupy_version = None
88 cuda_path = None
89
90 # CUDA Driver
91 cuda_build_version = None
92 cuda_driver_version = None
93
94 # CUDA Runtime
95 cuda_runtime_version = None
96
97 # CUDA Toolkit
98 cublas_version = None
99 cufft_version = None
100 curand_version = None
101 cusolver_version = None
102 cusparse_version = None
103 nvrtc_version = None
104 thrust_version = None
105
106 # Optional Libraries
107 cudnn_build_version = None
108 cudnn_version = None
109 nccl_build_version = None
110 nccl_runtime_version = None
111 cub_build_version = None
112 cutensor_version = None
113
114 numpy_version = None
115 scipy_version = None
116
117 def __init__(self):
118 self.cupy_version = cupy.__version__
119
120 self.cuda_path = cupy.cuda.get_cuda_path()
121
122 self.cuda_build_version = cupy.cuda.driver.get_build_version()
123 self.cuda_driver_version = _eval_or_error(
124 cupy.cuda.runtime.driverGetVersion,
125 cupy.cuda.runtime.CUDARuntimeError)
126
127 self.cuda_runtime_version = _eval_or_error(
128 cupy.cuda.runtime.runtimeGetVersion,
129 cupy.cuda.runtime.CUDARuntimeError)
130
131 self.cublas_version = _eval_or_error(
132 lambda: cupy.cuda.cublas.getVersion(
133 cupy.cuda.device.get_cublas_handle()),
134 cupy.cuda.cublas.CUBLASError)
135 self.cufft_version = _eval_or_error(
136 cupy.cuda.cufft.getVersion,
137 cupy.cuda.cufft.CuFFTError)
138 self.curand_version = _eval_or_error(
139 cupy.cuda.curand.getVersion,
140 cupy.cuda.curand.CURANDError)
141 self.cusolver_version = _eval_or_error(
142 cupy.cuda.cusolver._getVersion,
143 cupy.cuda.cusolver.CUSOLVERError)
144 self.cusparse_version = _eval_or_error(
145 lambda: cupy.cuda.cusparse.getVersion(
146 cupy.cuda.device.get_cusparse_handle()),
147 cupy.cuda.cusparse.CuSparseError)
148 self.nvrtc_version = _eval_or_error(
149 cupy.cuda.nvrtc.getVersion,
150 cupy.cuda.nvrtc.NVRTCError)
151
152 if thrust is not None:
153 self.thrust_version = thrust.get_build_version()
154
155 if cudnn is not None:
156 self.cudnn_build_version = cudnn.get_build_version()
157 self.cudnn_version = _eval_or_error(
158 cudnn.getVersion, cudnn.CuDNNError)
159
160 if nccl is not None:
161 self.nccl_build_version = nccl.get_build_version()
162 nccl_runtime_version = nccl.get_version()
163 if nccl_runtime_version == 0:
164 nccl_runtime_version = '(unknown)'
165 self.nccl_runtime_version = nccl_runtime_version
166
167 if cub is not None:
168 self.cub_build_version = cub.get_build_version()
169
170 if cutensor is not None:
171 self.cutensor_version = cutensor.get_version()
172
173 self.numpy_version = numpy.version.full_version
174 if scipy is not None:
175 self.scipy_version = scipy.version.full_version
176
177 def __str__(self):
178 records = [
179 ('OS', platform.platform()),
180 ('CuPy Version', self.cupy_version),
181 ('NumPy Version', self.numpy_version),
182 ('SciPy Version', self.scipy_version),
183 ('CUDA Root', self.cuda_path),
184
185 ('CUDA Build Version', self.cuda_build_version),
186 ('CUDA Driver Version', self.cuda_driver_version),
187
188 ('CUDA Runtime Version', self.cuda_runtime_version),
189 ]
190
191 records += [
192 ('cuBLAS Version', self.cublas_version),
193 ('cuFFT Version', self.cufft_version),
194 ('cuRAND Version', self.curand_version),
195 ('cuSOLVER Version', self.cusolver_version),
196 ('cuSPARSE Version', self.cusparse_version),
197 ('NVRTC Version', self.nvrtc_version),
198 ('Thrust Version', self.thrust_version),
199 ('CUB Build Version', self.cub_build_version),
200 ]
201
202 records += [
203 ('cuDNN Build Version', self.cudnn_build_version),
204 ('cuDNN Version', self.cudnn_version),
205 ('NCCL Build Version', self.nccl_build_version),
206 ('NCCL Runtime Version', self.nccl_runtime_version),
207 ('cuTENSOR Version', self.cutensor_version),
208 ]
209
210 for device_id in range(cupy.cuda.runtime.getDeviceCount()):
211 with cupy.cuda.Device(device_id) as device:
212 props = cupy.cuda.runtime.getDeviceProperties(device_id)
213 records += [
214 ('Device {} Name'.format(device_id),
215 props['name'].decode('utf-8')),
216 ('Device {} Compute Capability'.format(device_id),
217 device.compute_capability),
218 ]
219
220 width = max([len(r[0]) for r in records]) + 2
221 fmt = '{:' + str(width) + '}: {}\n'
222 s = io.StringIO()
223 for k, v in records:
224 s.write(fmt.format(k, v))
225
226 return s.getvalue()
227
228
229 def get_runtime_info():
230 return _RuntimeInfo()
231
232
233 def get_install_info():
234 return _InstallInfo()
235
236
237 def _dir_or_none(path):
238 """Returns None if path does not exist."""
239 if os.path.isdir(path):
240 return path
241 return None
242
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cupyx/_runtime.py b/cupyx/_runtime.py
--- a/cupyx/_runtime.py
+++ b/cupyx/_runtime.py
@@ -6,6 +6,7 @@
import numpy
import cupy
+import cupy_backends
try:
import cupy.cuda.thrust as thrust
@@ -37,6 +38,8 @@
except ImportError:
scipy = None
+is_hip = cupy_backends.cuda.api.runtime.is_hip
+
def _eval_or_error(func, errors):
# Evaluates `func` and return the result.
@@ -117,7 +120,10 @@
def __init__(self):
self.cupy_version = cupy.__version__
- self.cuda_path = cupy.cuda.get_cuda_path()
+ if not is_hip:
+ self.cuda_path = cupy.cuda.get_cuda_path()
+ else:
+ self.cuda_path = cupy._environment.get_rocm_path()
self.cuda_build_version = cupy.cuda.driver.get_build_version()
self.cuda_driver_version = _eval_or_error(
| {"golden_diff": "diff --git a/cupyx/_runtime.py b/cupyx/_runtime.py\n--- a/cupyx/_runtime.py\n+++ b/cupyx/_runtime.py\n@@ -6,6 +6,7 @@\n import numpy\n \n import cupy\n+import cupy_backends\n \n try:\n import cupy.cuda.thrust as thrust\n@@ -37,6 +38,8 @@\n except ImportError:\n scipy = None\n \n+is_hip = cupy_backends.cuda.api.runtime.is_hip\n+\n \n def _eval_or_error(func, errors):\n # Evaluates `func` and return the result.\n@@ -117,7 +120,10 @@\n def __init__(self):\n self.cupy_version = cupy.__version__\n \n- self.cuda_path = cupy.cuda.get_cuda_path()\n+ if not is_hip:\n+ self.cuda_path = cupy.cuda.get_cuda_path()\n+ else:\n+ self.cuda_path = cupy._environment.get_rocm_path()\n \n self.cuda_build_version = cupy.cuda.driver.get_build_version()\n self.cuda_driver_version = _eval_or_error(\n", "issue": "ROCm: `cupy.show_config()` not working\n```\r\n$ python -c \"import cupy; cupy.show_config()\"\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"/home/leofang/dev/cupy_rocm3.5.0/cupy/__init__.py\", line 874, in show_config\r\n _sys.stdout.write(str(_cupyx.get_runtime_info()))\r\n File \"/home/leofang/dev/cupy_rocm3.5.0/cupyx/_runtime.py\", line 215, in __str__\r\n props['name'].decode('utf-8')),\r\nAttributeError: 'str' object has no attribute 'decode'\r\n```\r\nFollowing #3858, I will add another branching to `getDeviceProperties` to support HIP.\n", "before_files": [{"content": "import inspect\nimport io\nimport os\nimport platform\n\nimport numpy\n\nimport cupy\n\ntry:\n import cupy.cuda.thrust as thrust\nexcept ImportError:\n thrust = None\n\ntry:\n import cupy_backends.cuda.libs.cudnn as cudnn\nexcept ImportError:\n cudnn = None\n\ntry:\n import cupy.cuda.nccl as nccl\nexcept ImportError:\n nccl = None\n\ntry:\n import cupy.cuda.cub as cub\nexcept ImportError:\n cub = None\n\ntry:\n import cupy_backends.cuda.libs.cutensor as cutensor\nexcept ImportError:\n cutensor = None\n\ntry:\n import scipy\nexcept ImportError:\n scipy = None\n\n\ndef _eval_or_error(func, errors):\n # Evaluates `func` and return the result.\n # If an error specified by `errors` occured, it returns a string\n # representing the error.\n try:\n return func()\n except errors as e:\n return repr(e)\n\n\nclass _InstallInfo(object):\n\n # TODO(niboshi): Add is_binary_distribution\n\n def __init__(self):\n cupy_package_root = self._get_cupy_package_root()\n if cupy_package_root is not None:\n data_root = os.path.join(cupy_package_root, '.data')\n data_paths = {\n 'lib': _dir_or_none(os.path.join(data_root, 'lib')),\n 'include': _dir_or_none(os.path.join(data_root, 'include')),\n }\n else:\n data_paths = {\n 'lib': None,\n 'include': None,\n }\n\n self.cupy_package_root = cupy_package_root\n self.data_paths = data_paths\n\n def get_data_path(self, data_type):\n if data_type not in self.data_paths:\n raise ValueError('Invalid data type: {}'.format(data_type))\n return self.data_paths[data_type]\n\n def _get_cupy_package_root(self):\n try:\n cupy_path = inspect.getfile(cupy)\n except TypeError:\n return None\n return os.path.dirname(cupy_path)\n\n\nclass _RuntimeInfo(object):\n\n cupy_version = None\n cuda_path = None\n\n # CUDA Driver\n cuda_build_version = None\n cuda_driver_version = None\n\n # CUDA Runtime\n cuda_runtime_version = None\n\n # CUDA Toolkit\n cublas_version = None\n cufft_version = None\n curand_version = None\n cusolver_version = None\n cusparse_version = None\n nvrtc_version = None\n thrust_version = None\n\n # Optional Libraries\n cudnn_build_version = None\n cudnn_version = None\n nccl_build_version = None\n nccl_runtime_version = None\n cub_build_version = None\n cutensor_version = None\n\n numpy_version = None\n scipy_version = None\n\n def __init__(self):\n self.cupy_version = cupy.__version__\n\n self.cuda_path = cupy.cuda.get_cuda_path()\n\n self.cuda_build_version = cupy.cuda.driver.get_build_version()\n self.cuda_driver_version = _eval_or_error(\n cupy.cuda.runtime.driverGetVersion,\n cupy.cuda.runtime.CUDARuntimeError)\n\n self.cuda_runtime_version = _eval_or_error(\n cupy.cuda.runtime.runtimeGetVersion,\n cupy.cuda.runtime.CUDARuntimeError)\n\n self.cublas_version = _eval_or_error(\n lambda: cupy.cuda.cublas.getVersion(\n cupy.cuda.device.get_cublas_handle()),\n cupy.cuda.cublas.CUBLASError)\n self.cufft_version = _eval_or_error(\n cupy.cuda.cufft.getVersion,\n cupy.cuda.cufft.CuFFTError)\n self.curand_version = _eval_or_error(\n cupy.cuda.curand.getVersion,\n cupy.cuda.curand.CURANDError)\n self.cusolver_version = _eval_or_error(\n cupy.cuda.cusolver._getVersion,\n cupy.cuda.cusolver.CUSOLVERError)\n self.cusparse_version = _eval_or_error(\n lambda: cupy.cuda.cusparse.getVersion(\n cupy.cuda.device.get_cusparse_handle()),\n cupy.cuda.cusparse.CuSparseError)\n self.nvrtc_version = _eval_or_error(\n cupy.cuda.nvrtc.getVersion,\n cupy.cuda.nvrtc.NVRTCError)\n\n if thrust is not None:\n self.thrust_version = thrust.get_build_version()\n\n if cudnn is not None:\n self.cudnn_build_version = cudnn.get_build_version()\n self.cudnn_version = _eval_or_error(\n cudnn.getVersion, cudnn.CuDNNError)\n\n if nccl is not None:\n self.nccl_build_version = nccl.get_build_version()\n nccl_runtime_version = nccl.get_version()\n if nccl_runtime_version == 0:\n nccl_runtime_version = '(unknown)'\n self.nccl_runtime_version = nccl_runtime_version\n\n if cub is not None:\n self.cub_build_version = cub.get_build_version()\n\n if cutensor is not None:\n self.cutensor_version = cutensor.get_version()\n\n self.numpy_version = numpy.version.full_version\n if scipy is not None:\n self.scipy_version = scipy.version.full_version\n\n def __str__(self):\n records = [\n ('OS', platform.platform()),\n ('CuPy Version', self.cupy_version),\n ('NumPy Version', self.numpy_version),\n ('SciPy Version', self.scipy_version),\n ('CUDA Root', self.cuda_path),\n\n ('CUDA Build Version', self.cuda_build_version),\n ('CUDA Driver Version', self.cuda_driver_version),\n\n ('CUDA Runtime Version', self.cuda_runtime_version),\n ]\n\n records += [\n ('cuBLAS Version', self.cublas_version),\n ('cuFFT Version', self.cufft_version),\n ('cuRAND Version', self.curand_version),\n ('cuSOLVER Version', self.cusolver_version),\n ('cuSPARSE Version', self.cusparse_version),\n ('NVRTC Version', self.nvrtc_version),\n ('Thrust Version', self.thrust_version),\n ('CUB Build Version', self.cub_build_version),\n ]\n\n records += [\n ('cuDNN Build Version', self.cudnn_build_version),\n ('cuDNN Version', self.cudnn_version),\n ('NCCL Build Version', self.nccl_build_version),\n ('NCCL Runtime Version', self.nccl_runtime_version),\n ('cuTENSOR Version', self.cutensor_version),\n ]\n\n for device_id in range(cupy.cuda.runtime.getDeviceCount()):\n with cupy.cuda.Device(device_id) as device:\n props = cupy.cuda.runtime.getDeviceProperties(device_id)\n records += [\n ('Device {} Name'.format(device_id),\n props['name'].decode('utf-8')),\n ('Device {} Compute Capability'.format(device_id),\n device.compute_capability),\n ]\n\n width = max([len(r[0]) for r in records]) + 2\n fmt = '{:' + str(width) + '}: {}\\n'\n s = io.StringIO()\n for k, v in records:\n s.write(fmt.format(k, v))\n\n return s.getvalue()\n\n\ndef get_runtime_info():\n return _RuntimeInfo()\n\n\ndef get_install_info():\n return _InstallInfo()\n\n\ndef _dir_or_none(path):\n \"\"\"Returns None if path does not exist.\"\"\"\n if os.path.isdir(path):\n return path\n return None\n", "path": "cupyx/_runtime.py"}], "after_files": [{"content": "import inspect\nimport io\nimport os\nimport platform\n\nimport numpy\n\nimport cupy\nimport cupy_backends\n\ntry:\n import cupy.cuda.thrust as thrust\nexcept ImportError:\n thrust = None\n\ntry:\n import cupy_backends.cuda.libs.cudnn as cudnn\nexcept ImportError:\n cudnn = None\n\ntry:\n import cupy.cuda.nccl as nccl\nexcept ImportError:\n nccl = None\n\ntry:\n import cupy.cuda.cub as cub\nexcept ImportError:\n cub = None\n\ntry:\n import cupy_backends.cuda.libs.cutensor as cutensor\nexcept ImportError:\n cutensor = None\n\ntry:\n import scipy\nexcept ImportError:\n scipy = None\n\nis_hip = cupy_backends.cuda.api.runtime.is_hip\n\n\ndef _eval_or_error(func, errors):\n # Evaluates `func` and return the result.\n # If an error specified by `errors` occured, it returns a string\n # representing the error.\n try:\n return func()\n except errors as e:\n return repr(e)\n\n\nclass _InstallInfo(object):\n\n # TODO(niboshi): Add is_binary_distribution\n\n def __init__(self):\n cupy_package_root = self._get_cupy_package_root()\n if cupy_package_root is not None:\n data_root = os.path.join(cupy_package_root, '.data')\n data_paths = {\n 'lib': _dir_or_none(os.path.join(data_root, 'lib')),\n 'include': _dir_or_none(os.path.join(data_root, 'include')),\n }\n else:\n data_paths = {\n 'lib': None,\n 'include': None,\n }\n\n self.cupy_package_root = cupy_package_root\n self.data_paths = data_paths\n\n def get_data_path(self, data_type):\n if data_type not in self.data_paths:\n raise ValueError('Invalid data type: {}'.format(data_type))\n return self.data_paths[data_type]\n\n def _get_cupy_package_root(self):\n try:\n cupy_path = inspect.getfile(cupy)\n except TypeError:\n return None\n return os.path.dirname(cupy_path)\n\n\nclass _RuntimeInfo(object):\n\n cupy_version = None\n cuda_path = None\n\n # CUDA Driver\n cuda_build_version = None\n cuda_driver_version = None\n\n # CUDA Runtime\n cuda_runtime_version = None\n\n # CUDA Toolkit\n cublas_version = None\n cufft_version = None\n curand_version = None\n cusolver_version = None\n cusparse_version = None\n nvrtc_version = None\n thrust_version = None\n\n # Optional Libraries\n cudnn_build_version = None\n cudnn_version = None\n nccl_build_version = None\n nccl_runtime_version = None\n cub_build_version = None\n cutensor_version = None\n\n numpy_version = None\n scipy_version = None\n\n def __init__(self):\n self.cupy_version = cupy.__version__\n\n if not is_hip:\n self.cuda_path = cupy.cuda.get_cuda_path()\n else:\n self.cuda_path = cupy._environment.get_rocm_path()\n\n self.cuda_build_version = cupy.cuda.driver.get_build_version()\n self.cuda_driver_version = _eval_or_error(\n cupy.cuda.runtime.driverGetVersion,\n cupy.cuda.runtime.CUDARuntimeError)\n\n self.cuda_runtime_version = _eval_or_error(\n cupy.cuda.runtime.runtimeGetVersion,\n cupy.cuda.runtime.CUDARuntimeError)\n\n self.cublas_version = _eval_or_error(\n lambda: cupy.cuda.cublas.getVersion(\n cupy.cuda.device.get_cublas_handle()),\n cupy.cuda.cublas.CUBLASError)\n self.cufft_version = _eval_or_error(\n cupy.cuda.cufft.getVersion,\n cupy.cuda.cufft.CuFFTError)\n self.curand_version = _eval_or_error(\n cupy.cuda.curand.getVersion,\n cupy.cuda.curand.CURANDError)\n self.cusolver_version = _eval_or_error(\n cupy.cuda.cusolver._getVersion,\n cupy.cuda.cusolver.CUSOLVERError)\n self.cusparse_version = _eval_or_error(\n lambda: cupy.cuda.cusparse.getVersion(\n cupy.cuda.device.get_cusparse_handle()),\n cupy.cuda.cusparse.CuSparseError)\n self.nvrtc_version = _eval_or_error(\n cupy.cuda.nvrtc.getVersion,\n cupy.cuda.nvrtc.NVRTCError)\n\n if thrust is not None:\n self.thrust_version = thrust.get_build_version()\n\n if cudnn is not None:\n self.cudnn_build_version = cudnn.get_build_version()\n self.cudnn_version = _eval_or_error(\n cudnn.getVersion, cudnn.CuDNNError)\n\n if nccl is not None:\n self.nccl_build_version = nccl.get_build_version()\n nccl_runtime_version = nccl.get_version()\n if nccl_runtime_version == 0:\n nccl_runtime_version = '(unknown)'\n self.nccl_runtime_version = nccl_runtime_version\n\n if cub is not None:\n self.cub_build_version = cub.get_build_version()\n\n if cutensor is not None:\n self.cutensor_version = cutensor.get_version()\n\n self.numpy_version = numpy.version.full_version\n if scipy is not None:\n self.scipy_version = scipy.version.full_version\n\n def __str__(self):\n records = [\n ('OS', platform.platform()),\n ('CuPy Version', self.cupy_version),\n ('NumPy Version', self.numpy_version),\n ('SciPy Version', self.scipy_version),\n ('CUDA Root', self.cuda_path),\n\n ('CUDA Build Version', self.cuda_build_version),\n ('CUDA Driver Version', self.cuda_driver_version),\n\n ('CUDA Runtime Version', self.cuda_runtime_version),\n ]\n\n records += [\n ('cuBLAS Version', self.cublas_version),\n ('cuFFT Version', self.cufft_version),\n ('cuRAND Version', self.curand_version),\n ('cuSOLVER Version', self.cusolver_version),\n ('cuSPARSE Version', self.cusparse_version),\n ('NVRTC Version', self.nvrtc_version),\n ('Thrust Version', self.thrust_version),\n ('CUB Build Version', self.cub_build_version),\n ]\n\n records += [\n ('cuDNN Build Version', self.cudnn_build_version),\n ('cuDNN Version', self.cudnn_version),\n ('NCCL Build Version', self.nccl_build_version),\n ('NCCL Runtime Version', self.nccl_runtime_version),\n ('cuTENSOR Version', self.cutensor_version),\n ]\n\n for device_id in range(cupy.cuda.runtime.getDeviceCount()):\n with cupy.cuda.Device(device_id) as device:\n props = cupy.cuda.runtime.getDeviceProperties(device_id)\n records += [\n ('Device {} Name'.format(device_id),\n props['name'].decode('utf-8')),\n ('Device {} Compute Capability'.format(device_id),\n device.compute_capability),\n ]\n\n width = max([len(r[0]) for r in records]) + 2\n fmt = '{:' + str(width) + '}: {}\\n'\n s = io.StringIO()\n for k, v in records:\n s.write(fmt.format(k, v))\n\n return s.getvalue()\n\n\ndef get_runtime_info():\n return _RuntimeInfo()\n\n\ndef get_install_info():\n return _InstallInfo()\n\n\ndef _dir_or_none(path):\n \"\"\"Returns None if path does not exist.\"\"\"\n if os.path.isdir(path):\n return path\n return None\n", "path": "cupyx/_runtime.py"}]} | 2,707 | 244 |
gh_patches_debug_26608 | rasdani/github-patches | git_diff | cowrie__cowrie-1482 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Mysql error? [twisted.internet.defer#critical] Unhandled error in Deferred
```
2021-01-11T16:54:56.352309Z [CowrieTelnetTransport,2,41.13.224.97] login attempt [b'root'/b'5up'] succeeded
2021-01-11T16:54:56.353787Z [CowrieTelnetTransport,2,41.13.224.97] Initialized emulated server as architecture: linux-x64-lsb
2021-01-11T16:54:56.354732Z [twisted.internet.defer#critical] Unhandled error in Deferred:
2021-01-11T16:54:56.354941Z [twisted.internet.defer#critical]
Traceback (most recent call last):
File "/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/logger/_legacy.py", line 93, in __call__
self.legacyObserver(event)
File "/home/cowrie/cowrie/src/cowrie/core/output.py", line 218, in emit
self.write(ev)
File "/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/internet/defer.py", line 1613, in unwindGenerator
return _cancellableInlineCallbacks(gen)
File "/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/internet/defer.py", line 1529, in _cancellableInlineCallbacks
_inlineCallbacks(None, g, status)
--- <exception caught here> ---
File "/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/internet/defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "/home/cowrie/cowrie/src/cowrie/output/mysql.py", line 147, in write
(entry["session"], entry["time"], entry['url'], entry['outfile'], entry['shasum']))
builtins.KeyError: 'url'
2021-01-11T16:54:56.413032Z [CowrieTelnetTransport,2,41.13.224.97] Warning: state changed and new state returned
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/cowrie/output/mysql.py`
Content:
```
1 """
2 MySQL output connector. Writes audit logs to MySQL database
3 """
4
5 from __future__ import absolute_import, division
6
7 import MySQLdb
8
9 from twisted.enterprise import adbapi
10 from twisted.internet import defer
11 from twisted.python import log
12
13 import cowrie.core.output
14 from cowrie.core.config import CowrieConfig
15
16
17 class ReconnectingConnectionPool(adbapi.ConnectionPool):
18 """
19 Reconnecting adbapi connection pool for MySQL.
20
21 This class improves on the solution posted at
22 http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/
23 by checking exceptions by error code and only disconnecting the current
24 connection instead of all of them.
25
26 Also see:
27 http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html
28 """
29
30 def _runInteraction(self, interaction, *args, **kw):
31 try:
32 return adbapi.ConnectionPool._runInteraction(
33 self, interaction, *args, **kw)
34 except (MySQLdb.OperationalError, MySQLdb._exceptions.OperationalError) as e:
35 if e.args[0] not in (2003, 2006, 2013):
36 raise e
37 log.msg("RCP: got error {0}, retrying operation".format(e))
38 conn = self.connections.get(self.threadID())
39 self.disconnect(conn)
40 # Try the interaction again
41 return adbapi.ConnectionPool._runInteraction(
42 self, interaction, *args, **kw)
43
44
45 class Output(cowrie.core.output.Output):
46 """
47 mysql output
48 """
49 db = None
50
51 def start(self):
52 self.debug = CowrieConfig().getboolean('output_mysql', 'debug', fallback=False)
53 port = CowrieConfig().getint('output_mysql', 'port', fallback=3306)
54 try:
55 self.db = ReconnectingConnectionPool(
56 'MySQLdb',
57 host=CowrieConfig().get('output_mysql', 'host'),
58 db=CowrieConfig().get('output_mysql', 'database'),
59 user=CowrieConfig().get('output_mysql', 'username'),
60 passwd=CowrieConfig().get('output_mysql', 'password', raw=True),
61 port=port,
62 cp_min=1,
63 cp_max=1,
64 charset='utf8mb4',
65 cp_reconnect=True,
66 use_unicode=True
67 )
68 except (MySQLdb.Error, MySQLdb._exceptons.Error) as e:
69 log.msg("output_mysql: Error %d: %s" % (e.args[0], e.args[1]))
70
71 def stop(self):
72 self.db.commit()
73 self.db.close()
74
75 def sqlerror(self, error):
76 """
77 1146, "Table '...' doesn't exist"
78 1406, "Data too long for column '...' at row ..."
79 """
80 if error.value[0] in (1146, 1406):
81 log.msg("output_mysql: MySQL Error: {}".format(error.value))
82 log.msg("MySQL schema maybe misconfigured, doublecheck database!")
83 else:
84 log.err("output_mysql: MySQL Error: {}".format(error.value))
85
86 def simpleQuery(self, sql, args):
87 """
88 Just run a deferred sql query, only care about errors
89 """
90 if self.debug:
91 log.msg("output_mysql: MySQL query: {} {}".format(sql, repr(args)))
92 d = self.db.runQuery(sql, args)
93 d.addErrback(self.sqlerror)
94
95 @defer.inlineCallbacks
96 def write(self, entry):
97 if entry["eventid"] == 'cowrie.session.connect':
98 r = yield self.db.runQuery(
99 "SELECT `id`"
100 "FROM `sensors`"
101 "WHERE `ip` = %s",
102 (self.sensor,))
103
104 if r:
105 sensorid = r[0][0]
106 else:
107 yield self.db.runQuery(
108 'INSERT INTO `sensors` (`ip`) '
109 'VALUES (%s)',
110 (self.sensor,))
111
112 r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')
113 sensorid = int(r[0][0])
114 self.simpleQuery(
115 "INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) "
116 "VALUES (%s, FROM_UNIXTIME(%s), %s, %s)",
117 (entry["session"], entry["time"], sensorid, entry["src_ip"]))
118
119 elif entry["eventid"] == 'cowrie.login.success':
120 self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '
121 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',
122 (entry["session"], 1, entry['username'], entry['password'], entry["time"]))
123
124 elif entry["eventid"] == 'cowrie.login.failed':
125 self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '
126 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',
127 (entry["session"], 0, entry['username'], entry['password'], entry["time"]))
128
129 elif entry["eventid"] == 'cowrie.session.params':
130 self.simpleQuery('INSERT INTO `params` (`session`, `arch`) '
131 'VALUES (%s, %s)',
132 (entry["session"], entry["arch"]))
133
134 elif entry["eventid"] == 'cowrie.command.input':
135 self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '
136 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',
137 (entry["session"], entry["time"], 1, entry["input"]))
138
139 elif entry["eventid"] == 'cowrie.command.failed':
140 self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '
141 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',
142 (entry["session"], entry["time"], 0, entry["input"]))
143
144 elif entry["eventid"] == 'cowrie.session.file_download':
145 self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
146 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
147 (entry["session"], entry["time"], entry['url'], entry['outfile'], entry['shasum']))
148
149 elif entry["eventid"] == 'cowrie.session.file_download.failed':
150 self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
151 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
152 (entry["session"], entry["time"], entry['url'], 'NULL', 'NULL'))
153
154 elif entry["eventid"] == 'cowrie.session.file_upload':
155 self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
156 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
157 (entry["session"], entry["time"], '', entry['outfile'], entry['shasum']))
158
159 elif entry["eventid"] == 'cowrie.session.input':
160 self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) '
161 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',
162 (entry["session"], entry["time"], entry["realm"], entry["input"]))
163
164 elif entry["eventid"] == 'cowrie.client.version':
165 r = yield self.db.runQuery(
166 'SELECT `id` FROM `clients` '
167 'WHERE `version` = %s',
168 (entry['version'],))
169
170 if r:
171 id = int(r[0][0])
172 else:
173 yield self.db.runQuery(
174 'INSERT INTO `clients` (`version`) '
175 'VALUES (%s)',
176 (entry['version'],))
177
178 r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')
179 id = int(r[0][0])
180 self.simpleQuery(
181 'UPDATE `sessions` '
182 'SET `client` = %s '
183 'WHERE `id` = %s',
184 (id, entry["session"]))
185
186 elif entry["eventid"] == 'cowrie.client.size':
187 self.simpleQuery(
188 'UPDATE `sessions` '
189 'SET `termsize` = %s '
190 'WHERE `id` = %s',
191 ('%sx%s' % (entry['width'], entry['height']), entry["session"]))
192
193 elif entry["eventid"] == 'cowrie.session.closed':
194 self.simpleQuery(
195 'UPDATE `sessions` '
196 'SET `endtime` = FROM_UNIXTIME(%s) '
197 'WHERE `id` = %s',
198 (entry["time"], entry["session"]))
199
200 elif entry["eventid"] == 'cowrie.log.closed':
201 self.simpleQuery(
202 'INSERT INTO `ttylog` (`session`, `ttylog`, `size`) '
203 'VALUES (%s, %s, %s)',
204 (entry["session"], entry["ttylog"], entry["size"]))
205
206 elif entry["eventid"] == 'cowrie.client.fingerprint':
207 self.simpleQuery(
208 'INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) '
209 'VALUES (%s, %s, %s)',
210 (entry["session"], entry["username"], entry["fingerprint"]))
211
212 elif entry["eventid"] == 'cowrie.direct-tcpip.request':
213 self.simpleQuery(
214 'INSERT INTO `ipforwards` (`session`, `timestamp`, `dst_ip`, `dst_port`) '
215 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s)',
216 (entry["session"], entry["time"], entry["dst_ip"], entry["dst_port"]))
217
218 elif entry["eventid"] == 'cowrie.direct-tcpip.data':
219 self.simpleQuery(
220 'INSERT INTO `ipforwardsdata` (`session`, `timestamp`, `dst_ip`, `dst_port`, `data`) '
221 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
222 (entry["session"], entry["time"], entry["dst_ip"], entry["dst_port"], entry["data"]))
223
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/cowrie/output/mysql.py b/src/cowrie/output/mysql.py
--- a/src/cowrie/output/mysql.py
+++ b/src/cowrie/output/mysql.py
@@ -144,12 +144,12 @@
elif entry["eventid"] == 'cowrie.session.file_download':
self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
- (entry["session"], entry["time"], entry['url'], entry['outfile'], entry['shasum']))
+ (entry["session"], entry["time"], entry.get("url", ""), entry['outfile'], entry['shasum']))
elif entry["eventid"] == 'cowrie.session.file_download.failed':
self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',
- (entry["session"], entry["time"], entry['url'], 'NULL', 'NULL'))
+ (entry["session"], entry["time"], entry.get("url", ""), 'NULL', 'NULL'))
elif entry["eventid"] == 'cowrie.session.file_upload':
self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '
| {"golden_diff": "diff --git a/src/cowrie/output/mysql.py b/src/cowrie/output/mysql.py\n--- a/src/cowrie/output/mysql.py\n+++ b/src/cowrie/output/mysql.py\n@@ -144,12 +144,12 @@\n elif entry[\"eventid\"] == 'cowrie.session.file_download':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n- (entry[\"session\"], entry[\"time\"], entry['url'], entry['outfile'], entry['shasum']))\n+ (entry[\"session\"], entry[\"time\"], entry.get(\"url\", \"\"), entry['outfile'], entry['shasum']))\n \n elif entry[\"eventid\"] == 'cowrie.session.file_download.failed':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n- (entry[\"session\"], entry[\"time\"], entry['url'], 'NULL', 'NULL'))\n+ (entry[\"session\"], entry[\"time\"], entry.get(\"url\", \"\"), 'NULL', 'NULL'))\n \n elif entry[\"eventid\"] == 'cowrie.session.file_upload':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n", "issue": "Mysql error? [twisted.internet.defer#critical] Unhandled error in Deferred\n```\r\n2021-01-11T16:54:56.352309Z [CowrieTelnetTransport,2,41.13.224.97] login attempt [b'root'/b'5up'] succeeded\r\n2021-01-11T16:54:56.353787Z [CowrieTelnetTransport,2,41.13.224.97] Initialized emulated server as architecture: linux-x64-lsb\r\n2021-01-11T16:54:56.354732Z [twisted.internet.defer#critical] Unhandled error in Deferred:\r\n2021-01-11T16:54:56.354941Z [twisted.internet.defer#critical]\r\n Traceback (most recent call last):\r\n File \"/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/logger/_legacy.py\", line 93, in __call__\r\n self.legacyObserver(event)\r\n File \"/home/cowrie/cowrie/src/cowrie/core/output.py\", line 218, in emit\r\n self.write(ev)\r\n File \"/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1613, in unwindGenerator\r\n return _cancellableInlineCallbacks(gen)\r\n File \"/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1529, in _cancellableInlineCallbacks\r\n _inlineCallbacks(None, g, status)\r\n --- <exception caught here> ---\r\n File \"/home/cowrie/cowrie/cowrie-env/lib/python3.8/site-packages/twisted/internet/defer.py\", line 1418, in _inlineCallbacks\r\n result = g.send(result)\r\n File \"/home/cowrie/cowrie/src/cowrie/output/mysql.py\", line 147, in write\r\n (entry[\"session\"], entry[\"time\"], entry['url'], entry['outfile'], entry['shasum']))\r\n builtins.KeyError: 'url'\r\n\r\n2021-01-11T16:54:56.413032Z [CowrieTelnetTransport,2,41.13.224.97] Warning: state changed and new state returned\r\n```\n", "before_files": [{"content": "\"\"\"\nMySQL output connector. Writes audit logs to MySQL database\n\"\"\"\n\nfrom __future__ import absolute_import, division\n\nimport MySQLdb\n\nfrom twisted.enterprise import adbapi\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nimport cowrie.core.output\nfrom cowrie.core.config import CowrieConfig\n\n\nclass ReconnectingConnectionPool(adbapi.ConnectionPool):\n \"\"\"\n Reconnecting adbapi connection pool for MySQL.\n\n This class improves on the solution posted at\n http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/\n by checking exceptions by error code and only disconnecting the current\n connection instead of all of them.\n\n Also see:\n http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html\n \"\"\"\n\n def _runInteraction(self, interaction, *args, **kw):\n try:\n return adbapi.ConnectionPool._runInteraction(\n self, interaction, *args, **kw)\n except (MySQLdb.OperationalError, MySQLdb._exceptions.OperationalError) as e:\n if e.args[0] not in (2003, 2006, 2013):\n raise e\n log.msg(\"RCP: got error {0}, retrying operation\".format(e))\n conn = self.connections.get(self.threadID())\n self.disconnect(conn)\n # Try the interaction again\n return adbapi.ConnectionPool._runInteraction(\n self, interaction, *args, **kw)\n\n\nclass Output(cowrie.core.output.Output):\n \"\"\"\n mysql output\n \"\"\"\n db = None\n\n def start(self):\n self.debug = CowrieConfig().getboolean('output_mysql', 'debug', fallback=False)\n port = CowrieConfig().getint('output_mysql', 'port', fallback=3306)\n try:\n self.db = ReconnectingConnectionPool(\n 'MySQLdb',\n host=CowrieConfig().get('output_mysql', 'host'),\n db=CowrieConfig().get('output_mysql', 'database'),\n user=CowrieConfig().get('output_mysql', 'username'),\n passwd=CowrieConfig().get('output_mysql', 'password', raw=True),\n port=port,\n cp_min=1,\n cp_max=1,\n charset='utf8mb4',\n cp_reconnect=True,\n use_unicode=True\n )\n except (MySQLdb.Error, MySQLdb._exceptons.Error) as e:\n log.msg(\"output_mysql: Error %d: %s\" % (e.args[0], e.args[1]))\n\n def stop(self):\n self.db.commit()\n self.db.close()\n\n def sqlerror(self, error):\n \"\"\"\n 1146, \"Table '...' doesn't exist\"\n 1406, \"Data too long for column '...' at row ...\"\n \"\"\"\n if error.value[0] in (1146, 1406):\n log.msg(\"output_mysql: MySQL Error: {}\".format(error.value))\n log.msg(\"MySQL schema maybe misconfigured, doublecheck database!\")\n else:\n log.err(\"output_mysql: MySQL Error: {}\".format(error.value))\n\n def simpleQuery(self, sql, args):\n \"\"\"\n Just run a deferred sql query, only care about errors\n \"\"\"\n if self.debug:\n log.msg(\"output_mysql: MySQL query: {} {}\".format(sql, repr(args)))\n d = self.db.runQuery(sql, args)\n d.addErrback(self.sqlerror)\n\n @defer.inlineCallbacks\n def write(self, entry):\n if entry[\"eventid\"] == 'cowrie.session.connect':\n r = yield self.db.runQuery(\n \"SELECT `id`\"\n \"FROM `sensors`\"\n \"WHERE `ip` = %s\",\n (self.sensor,))\n\n if r:\n sensorid = r[0][0]\n else:\n yield self.db.runQuery(\n 'INSERT INTO `sensors` (`ip`) '\n 'VALUES (%s)',\n (self.sensor,))\n\n r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')\n sensorid = int(r[0][0])\n self.simpleQuery(\n \"INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], sensorid, entry[\"src_ip\"]))\n\n elif entry[\"eventid\"] == 'cowrie.login.success':\n self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 1, entry['username'], entry['password'], entry[\"time\"]))\n\n elif entry[\"eventid\"] == 'cowrie.login.failed':\n self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 0, entry['username'], entry['password'], entry[\"time\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.params':\n self.simpleQuery('INSERT INTO `params` (`session`, `arch`) '\n 'VALUES (%s, %s)',\n (entry[\"session\"], entry[\"arch\"]))\n\n elif entry[\"eventid\"] == 'cowrie.command.input':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], 1, entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.command.failed':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], 0, entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_download':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry['url'], entry['outfile'], entry['shasum']))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_download.failed':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry['url'], 'NULL', 'NULL'))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_upload':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], '', entry['outfile'], entry['shasum']))\n\n elif entry[\"eventid\"] == 'cowrie.session.input':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"realm\"], entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.version':\n r = yield self.db.runQuery(\n 'SELECT `id` FROM `clients` '\n 'WHERE `version` = %s',\n (entry['version'],))\n\n if r:\n id = int(r[0][0])\n else:\n yield self.db.runQuery(\n 'INSERT INTO `clients` (`version`) '\n 'VALUES (%s)',\n (entry['version'],))\n\n r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')\n id = int(r[0][0])\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `client` = %s '\n 'WHERE `id` = %s',\n (id, entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.size':\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `termsize` = %s '\n 'WHERE `id` = %s',\n ('%sx%s' % (entry['width'], entry['height']), entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.closed':\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `endtime` = FROM_UNIXTIME(%s) '\n 'WHERE `id` = %s',\n (entry[\"time\"], entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.log.closed':\n self.simpleQuery(\n 'INSERT INTO `ttylog` (`session`, `ttylog`, `size`) '\n 'VALUES (%s, %s, %s)',\n (entry[\"session\"], entry[\"ttylog\"], entry[\"size\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.fingerprint':\n self.simpleQuery(\n 'INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) '\n 'VALUES (%s, %s, %s)',\n (entry[\"session\"], entry[\"username\"], entry[\"fingerprint\"]))\n\n elif entry[\"eventid\"] == 'cowrie.direct-tcpip.request':\n self.simpleQuery(\n 'INSERT INTO `ipforwards` (`session`, `timestamp`, `dst_ip`, `dst_port`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"dst_ip\"], entry[\"dst_port\"]))\n\n elif entry[\"eventid\"] == 'cowrie.direct-tcpip.data':\n self.simpleQuery(\n 'INSERT INTO `ipforwardsdata` (`session`, `timestamp`, `dst_ip`, `dst_port`, `data`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"dst_ip\"], entry[\"dst_port\"], entry[\"data\"]))\n", "path": "src/cowrie/output/mysql.py"}], "after_files": [{"content": "\"\"\"\nMySQL output connector. Writes audit logs to MySQL database\n\"\"\"\n\nfrom __future__ import absolute_import, division\n\nimport MySQLdb\n\nfrom twisted.enterprise import adbapi\nfrom twisted.internet import defer\nfrom twisted.python import log\n\nimport cowrie.core.output\nfrom cowrie.core.config import CowrieConfig\n\n\nclass ReconnectingConnectionPool(adbapi.ConnectionPool):\n \"\"\"\n Reconnecting adbapi connection pool for MySQL.\n\n This class improves on the solution posted at\n http://www.gelens.org/2008/09/12/reinitializing-twisted-connectionpool/\n by checking exceptions by error code and only disconnecting the current\n connection instead of all of them.\n\n Also see:\n http://twistedmatrix.com/pipermail/twisted-python/2009-July/020007.html\n \"\"\"\n\n def _runInteraction(self, interaction, *args, **kw):\n try:\n return adbapi.ConnectionPool._runInteraction(\n self, interaction, *args, **kw)\n except (MySQLdb.OperationalError, MySQLdb._exceptions.OperationalError) as e:\n if e.args[0] not in (2003, 2006, 2013):\n raise e\n log.msg(\"RCP: got error {0}, retrying operation\".format(e))\n conn = self.connections.get(self.threadID())\n self.disconnect(conn)\n # Try the interaction again\n return adbapi.ConnectionPool._runInteraction(\n self, interaction, *args, **kw)\n\n\nclass Output(cowrie.core.output.Output):\n \"\"\"\n mysql output\n \"\"\"\n db = None\n\n def start(self):\n self.debug = CowrieConfig().getboolean('output_mysql', 'debug', fallback=False)\n port = CowrieConfig().getint('output_mysql', 'port', fallback=3306)\n try:\n self.db = ReconnectingConnectionPool(\n 'MySQLdb',\n host=CowrieConfig().get('output_mysql', 'host'),\n db=CowrieConfig().get('output_mysql', 'database'),\n user=CowrieConfig().get('output_mysql', 'username'),\n passwd=CowrieConfig().get('output_mysql', 'password', raw=True),\n port=port,\n cp_min=1,\n cp_max=1,\n charset='utf8mb4',\n cp_reconnect=True,\n use_unicode=True\n )\n except (MySQLdb.Error, MySQLdb._exceptons.Error) as e:\n log.msg(\"output_mysql: Error %d: %s\" % (e.args[0], e.args[1]))\n\n def stop(self):\n self.db.commit()\n self.db.close()\n\n def sqlerror(self, error):\n \"\"\"\n 1146, \"Table '...' doesn't exist\"\n 1406, \"Data too long for column '...' at row ...\"\n \"\"\"\n if error.value[0] in (1146, 1406):\n log.msg(\"output_mysql: MySQL Error: {}\".format(error.value))\n log.msg(\"MySQL schema maybe misconfigured, doublecheck database!\")\n else:\n log.err(\"output_mysql: MySQL Error: {}\".format(error.value))\n\n def simpleQuery(self, sql, args):\n \"\"\"\n Just run a deferred sql query, only care about errors\n \"\"\"\n if self.debug:\n log.msg(\"output_mysql: MySQL query: {} {}\".format(sql, repr(args)))\n d = self.db.runQuery(sql, args)\n d.addErrback(self.sqlerror)\n\n @defer.inlineCallbacks\n def write(self, entry):\n if entry[\"eventid\"] == 'cowrie.session.connect':\n r = yield self.db.runQuery(\n \"SELECT `id`\"\n \"FROM `sensors`\"\n \"WHERE `ip` = %s\",\n (self.sensor,))\n\n if r:\n sensorid = r[0][0]\n else:\n yield self.db.runQuery(\n 'INSERT INTO `sensors` (`ip`) '\n 'VALUES (%s)',\n (self.sensor,))\n\n r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')\n sensorid = int(r[0][0])\n self.simpleQuery(\n \"INSERT INTO `sessions` (`id`, `starttime`, `sensor`, `ip`) \"\n \"VALUES (%s, FROM_UNIXTIME(%s), %s, %s)\",\n (entry[\"session\"], entry[\"time\"], sensorid, entry[\"src_ip\"]))\n\n elif entry[\"eventid\"] == 'cowrie.login.success':\n self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 1, entry['username'], entry['password'], entry[\"time\"]))\n\n elif entry[\"eventid\"] == 'cowrie.login.failed':\n self.simpleQuery('INSERT INTO `auth` (`session`, `success`, `username`, `password`, `timestamp`) '\n 'VALUES (%s, %s, %s, %s, FROM_UNIXTIME(%s))',\n (entry[\"session\"], 0, entry['username'], entry['password'], entry[\"time\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.params':\n self.simpleQuery('INSERT INTO `params` (`session`, `arch`) '\n 'VALUES (%s, %s)',\n (entry[\"session\"], entry[\"arch\"]))\n\n elif entry[\"eventid\"] == 'cowrie.command.input':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], 1, entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.command.failed':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `success`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], 0, entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_download':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry.get(\"url\", \"\"), entry['outfile'], entry['shasum']))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_download.failed':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry.get(\"url\", \"\"), 'NULL', 'NULL'))\n\n elif entry[\"eventid\"] == 'cowrie.session.file_upload':\n self.simpleQuery('INSERT INTO `downloads` (`session`, `timestamp`, `url`, `outfile`, `shasum`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], '', entry['outfile'], entry['shasum']))\n\n elif entry[\"eventid\"] == 'cowrie.session.input':\n self.simpleQuery('INSERT INTO `input` (`session`, `timestamp`, `realm`, `input`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s , %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"realm\"], entry[\"input\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.version':\n r = yield self.db.runQuery(\n 'SELECT `id` FROM `clients` '\n 'WHERE `version` = %s',\n (entry['version'],))\n\n if r:\n id = int(r[0][0])\n else:\n yield self.db.runQuery(\n 'INSERT INTO `clients` (`version`) '\n 'VALUES (%s)',\n (entry['version'],))\n\n r = yield self.db.runQuery('SELECT LAST_INSERT_ID()')\n id = int(r[0][0])\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `client` = %s '\n 'WHERE `id` = %s',\n (id, entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.size':\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `termsize` = %s '\n 'WHERE `id` = %s',\n ('%sx%s' % (entry['width'], entry['height']), entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.session.closed':\n self.simpleQuery(\n 'UPDATE `sessions` '\n 'SET `endtime` = FROM_UNIXTIME(%s) '\n 'WHERE `id` = %s',\n (entry[\"time\"], entry[\"session\"]))\n\n elif entry[\"eventid\"] == 'cowrie.log.closed':\n self.simpleQuery(\n 'INSERT INTO `ttylog` (`session`, `ttylog`, `size`) '\n 'VALUES (%s, %s, %s)',\n (entry[\"session\"], entry[\"ttylog\"], entry[\"size\"]))\n\n elif entry[\"eventid\"] == 'cowrie.client.fingerprint':\n self.simpleQuery(\n 'INSERT INTO `keyfingerprints` (`session`, `username`, `fingerprint`) '\n 'VALUES (%s, %s, %s)',\n (entry[\"session\"], entry[\"username\"], entry[\"fingerprint\"]))\n\n elif entry[\"eventid\"] == 'cowrie.direct-tcpip.request':\n self.simpleQuery(\n 'INSERT INTO `ipforwards` (`session`, `timestamp`, `dst_ip`, `dst_port`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"dst_ip\"], entry[\"dst_port\"]))\n\n elif entry[\"eventid\"] == 'cowrie.direct-tcpip.data':\n self.simpleQuery(\n 'INSERT INTO `ipforwardsdata` (`session`, `timestamp`, `dst_ip`, `dst_port`, `data`) '\n 'VALUES (%s, FROM_UNIXTIME(%s), %s, %s, %s)',\n (entry[\"session\"], entry[\"time\"], entry[\"dst_ip\"], entry[\"dst_port\"], entry[\"data\"]))\n", "path": "src/cowrie/output/mysql.py"}]} | 3,704 | 326 |
gh_patches_debug_7135 | rasdani/github-patches | git_diff | mitmproxy__mitmproxy-6088 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Toggling follow new option fails in single flow view.
#### Problem Description
Toggling follow new flow option via <kbd>F</kbd> does not work while in the view of a single flow.
#### Steps to reproduce the behavior:
1. launch mitmproxy
2. continually generate new requests
3. activate `Follow new` option
4. enter a flow
5. try to deactivate `Follow new` option
6. error: the view still follows the new flows
#### System Information
mitmproxy version 9.0.1
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `mitmproxy/tools/console/defaultkeys.py`
Content:
```
1 from mitmproxy.tools.console.keymap import Keymap
2
3
4 def map(km: Keymap) -> None:
5 km.add(":", "console.command ", ["commonkey", "global"], "Command prompt")
6 km.add(
7 ";",
8 "console.command flow.comment @focus ''",
9 ["flowlist", "flowview"],
10 "Add comment to flow",
11 )
12 km.add("?", "console.view.help", ["global"], "View help")
13 km.add("B", "browser.start", ["global"], "Start an attached browser")
14 km.add("C", "console.view.commands", ["global"], "View commands")
15 km.add("K", "console.view.keybindings", ["global"], "View key bindings")
16 km.add("O", "console.view.options", ["commonkey", "global"], "View options")
17 km.add("E", "console.view.eventlog", ["commonkey", "global"], "View event log")
18 km.add("Q", "console.exit", ["global"], "Exit immediately")
19 km.add("q", "console.view.pop", ["commonkey", "global"], "Exit the current view")
20 km.add("-", "console.layout.cycle", ["global"], "Cycle to next layout")
21 km.add("ctrl right", "console.panes.next", ["global"], "Focus next layout pane")
22 km.add("ctrl left", "console.panes.prev", ["global"], "Focus previous layout pane")
23 km.add("shift tab", "console.panes.next", ["global"], "Focus next layout pane")
24 km.add("P", "console.view.flow @focus", ["global"], "View flow details")
25
26 km.add("?", "console.view.pop", ["help"], "Exit help")
27
28 km.add("g", "console.nav.start", ["global"], "Go to start")
29 km.add("G", "console.nav.end", ["global"], "Go to end")
30 km.add("k", "console.nav.up", ["global"], "Up")
31 km.add("j", "console.nav.down", ["global"], "Down")
32 km.add("l", "console.nav.right", ["global"], "Right")
33 km.add("h", "console.nav.left", ["global"], "Left")
34 km.add("tab", "console.nav.next", ["commonkey", "global"], "Next")
35 km.add("enter", "console.nav.select", ["commonkey", "global"], "Select")
36 km.add("space", "console.nav.pagedown", ["global"], "Page down")
37 km.add("ctrl f", "console.nav.pagedown", ["global"], "Page down")
38 km.add("ctrl b", "console.nav.pageup", ["global"], "Page up")
39
40 km.add(
41 "I",
42 "set intercept_active toggle",
43 ["global"],
44 "Toggle whether the filtering via the intercept option is enabled",
45 )
46 km.add("i", "console.command.set intercept", ["global"], "Set intercept")
47 km.add("W", "console.command.set save_stream_file", ["global"], "Stream to file")
48 km.add(
49 "A",
50 "flow.resume @all",
51 ["flowlist", "flowview"],
52 "Resume all intercepted flows",
53 )
54 km.add(
55 "a",
56 "flow.resume @focus",
57 ["flowlist", "flowview"],
58 "Resume this intercepted flow",
59 )
60 km.add(
61 "b",
62 "console.command cut.save @focus response.content ",
63 ["flowlist", "flowview"],
64 "Save response body to file",
65 )
66 km.add(
67 "d",
68 "view.flows.remove @focus",
69 ["flowlist", "flowview"],
70 "Delete flow from view",
71 )
72 km.add(
73 "D", "view.flows.duplicate @focus", ["flowlist", "flowview"], "Duplicate flow"
74 )
75 km.add(
76 "e",
77 """
78 console.choose.cmd Format export.formats
79 console.command export.file {choice} @focus
80 """,
81 ["flowlist", "flowview"],
82 "Export this flow to file",
83 )
84 km.add("f", "console.command.set view_filter", ["flowlist"], "Set view filter")
85 km.add("F", "set console_focus_follow toggle", ["flowlist"], "Set focus follow")
86 km.add(
87 "ctrl l",
88 "console.command cut.clip ",
89 ["flowlist", "flowview"],
90 "Send cuts to clipboard",
91 )
92 km.add(
93 "L", "console.command view.flows.load ", ["flowlist"], "Load flows from file"
94 )
95 km.add("m", "flow.mark.toggle @focus", ["flowlist"], "Toggle mark on this flow")
96 km.add(
97 "M",
98 "view.properties.marked.toggle",
99 ["flowlist"],
100 "Toggle viewing marked flows",
101 )
102 km.add(
103 "n",
104 "console.command view.flows.create get https://example.com/",
105 ["flowlist"],
106 "Create a new flow",
107 )
108 km.add(
109 "o",
110 """
111 console.choose.cmd Order view.order.options
112 set view_order {choice}
113 """,
114 ["flowlist"],
115 "Set flow list order",
116 )
117 km.add("r", "replay.client @focus", ["flowlist", "flowview"], "Replay this flow")
118 km.add("S", "console.command replay.server ", ["flowlist"], "Start server replay")
119 km.add(
120 "v", "set view_order_reversed toggle", ["flowlist"], "Reverse flow list order"
121 )
122 km.add("U", "flow.mark @all false", ["flowlist"], "Un-set all marks")
123 km.add(
124 "w",
125 "console.command save.file @shown ",
126 ["flowlist"],
127 "Save listed flows to file",
128 )
129 km.add(
130 "V",
131 "flow.revert @focus",
132 ["flowlist", "flowview"],
133 "Revert changes to this flow",
134 )
135 km.add("X", "flow.kill @focus", ["flowlist"], "Kill this flow")
136 km.add("z", "view.flows.remove @all", ["flowlist"], "Clear flow list")
137 km.add(
138 "Z", "view.flows.remove @hidden", ["flowlist"], "Purge all flows not showing"
139 )
140 km.add(
141 "|",
142 "console.command script.run @focus ",
143 ["flowlist", "flowview"],
144 "Run a script on this flow",
145 )
146
147 km.add(
148 "e",
149 """
150 console.choose.cmd Part console.edit.focus.options
151 console.edit.focus {choice}
152 """,
153 ["flowview"],
154 "Edit a flow component",
155 )
156 km.add(
157 "f",
158 "view.settings.setval.toggle @focus fullcontents",
159 ["flowview"],
160 "Toggle viewing full contents on this flow",
161 )
162 km.add("w", "console.command save.file @focus ", ["flowview"], "Save flow to file")
163 km.add("space", "view.focus.next", ["flowview"], "Go to next flow")
164
165 km.add(
166 "v",
167 """
168 console.choose "View Part" request,response
169 console.bodyview @focus {choice}
170 """,
171 ["flowview"],
172 "View flow body in an external viewer",
173 )
174 km.add("p", "view.focus.prev", ["flowview"], "Go to previous flow")
175 km.add(
176 "m",
177 """
178 console.choose.cmd Mode console.flowview.mode.options
179 console.flowview.mode.set {choice}
180 """,
181 ["flowview"],
182 "Set flow view mode",
183 )
184 km.add(
185 "z",
186 """
187 console.choose "Part" request,response
188 flow.encode.toggle @focus {choice}
189 """,
190 ["flowview"],
191 "Encode/decode flow body",
192 )
193
194 km.add("L", "console.command options.load ", ["options"], "Load from file")
195 km.add("S", "console.command options.save ", ["options"], "Save to file")
196 km.add("D", "options.reset", ["options"], "Reset all options")
197 km.add("d", "console.options.reset.focus", ["options"], "Reset this option")
198
199 km.add("a", "console.grideditor.add", ["grideditor"], "Add a row after cursor")
200 km.add(
201 "A", "console.grideditor.insert", ["grideditor"], "Insert a row before cursor"
202 )
203 km.add("d", "console.grideditor.delete", ["grideditor"], "Delete this row")
204 km.add(
205 "r",
206 "console.command console.grideditor.load",
207 ["grideditor"],
208 "Read unescaped data into the current cell from file",
209 )
210 km.add(
211 "R",
212 "console.command console.grideditor.load_escaped",
213 ["grideditor"],
214 "Load a Python-style escaped string into the current cell from file",
215 )
216 km.add("e", "console.grideditor.editor", ["grideditor"], "Edit in external editor")
217 km.add(
218 "w",
219 "console.command console.grideditor.save ",
220 ["grideditor"],
221 "Save data to file as CSV",
222 )
223
224 km.add("z", "eventstore.clear", ["eventlog"], "Clear")
225
226 km.add(
227 "a",
228 """
229 console.choose.cmd "Context" console.key.contexts
230 console.command console.key.bind {choice}
231 """,
232 ["keybindings"],
233 "Add a key binding",
234 )
235 km.add(
236 "d",
237 "console.key.unbind.focus",
238 ["keybindings"],
239 "Unbind the currently focused key binding",
240 )
241 km.add(
242 "x",
243 "console.key.execute.focus",
244 ["keybindings"],
245 "Execute the currently focused key binding",
246 )
247 km.add(
248 "enter",
249 "console.key.edit.focus",
250 ["keybindings"],
251 "Edit the currently focused key binding",
252 )
253
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/mitmproxy/tools/console/defaultkeys.py b/mitmproxy/tools/console/defaultkeys.py
--- a/mitmproxy/tools/console/defaultkeys.py
+++ b/mitmproxy/tools/console/defaultkeys.py
@@ -82,7 +82,12 @@
"Export this flow to file",
)
km.add("f", "console.command.set view_filter", ["flowlist"], "Set view filter")
- km.add("F", "set console_focus_follow toggle", ["flowlist"], "Set focus follow")
+ km.add(
+ "F",
+ "set console_focus_follow toggle",
+ ["flowlist", "flowview"],
+ "Set focus follow",
+ )
km.add(
"ctrl l",
"console.command cut.clip ",
| {"golden_diff": "diff --git a/mitmproxy/tools/console/defaultkeys.py b/mitmproxy/tools/console/defaultkeys.py\n--- a/mitmproxy/tools/console/defaultkeys.py\n+++ b/mitmproxy/tools/console/defaultkeys.py\n@@ -82,7 +82,12 @@\n \"Export this flow to file\",\n )\n km.add(\"f\", \"console.command.set view_filter\", [\"flowlist\"], \"Set view filter\")\n- km.add(\"F\", \"set console_focus_follow toggle\", [\"flowlist\"], \"Set focus follow\")\n+ km.add(\n+ \"F\",\n+ \"set console_focus_follow toggle\",\n+ [\"flowlist\", \"flowview\"],\n+ \"Set focus follow\",\n+ )\n km.add(\n \"ctrl l\",\n \"console.command cut.clip \",\n", "issue": "Toggling follow new option fails in single flow view.\n#### Problem Description\r\nToggling follow new flow option via <kbd>F</kbd> does not work while in the view of a single flow.\r\n\r\n#### Steps to reproduce the behavior:\r\n1. launch mitmproxy\r\n2. continually generate new requests\r\n3. activate `Follow new` option\r\n4. enter a flow\r\n5. try to deactivate `Follow new` option\r\n6. error: the view still follows the new flows\r\n\r\n#### System Information\r\nmitmproxy version 9.0.1\r\n\n", "before_files": [{"content": "from mitmproxy.tools.console.keymap import Keymap\n\n\ndef map(km: Keymap) -> None:\n km.add(\":\", \"console.command \", [\"commonkey\", \"global\"], \"Command prompt\")\n km.add(\n \";\",\n \"console.command flow.comment @focus ''\",\n [\"flowlist\", \"flowview\"],\n \"Add comment to flow\",\n )\n km.add(\"?\", \"console.view.help\", [\"global\"], \"View help\")\n km.add(\"B\", \"browser.start\", [\"global\"], \"Start an attached browser\")\n km.add(\"C\", \"console.view.commands\", [\"global\"], \"View commands\")\n km.add(\"K\", \"console.view.keybindings\", [\"global\"], \"View key bindings\")\n km.add(\"O\", \"console.view.options\", [\"commonkey\", \"global\"], \"View options\")\n km.add(\"E\", \"console.view.eventlog\", [\"commonkey\", \"global\"], \"View event log\")\n km.add(\"Q\", \"console.exit\", [\"global\"], \"Exit immediately\")\n km.add(\"q\", \"console.view.pop\", [\"commonkey\", \"global\"], \"Exit the current view\")\n km.add(\"-\", \"console.layout.cycle\", [\"global\"], \"Cycle to next layout\")\n km.add(\"ctrl right\", \"console.panes.next\", [\"global\"], \"Focus next layout pane\")\n km.add(\"ctrl left\", \"console.panes.prev\", [\"global\"], \"Focus previous layout pane\")\n km.add(\"shift tab\", \"console.panes.next\", [\"global\"], \"Focus next layout pane\")\n km.add(\"P\", \"console.view.flow @focus\", [\"global\"], \"View flow details\")\n\n km.add(\"?\", \"console.view.pop\", [\"help\"], \"Exit help\")\n\n km.add(\"g\", \"console.nav.start\", [\"global\"], \"Go to start\")\n km.add(\"G\", \"console.nav.end\", [\"global\"], \"Go to end\")\n km.add(\"k\", \"console.nav.up\", [\"global\"], \"Up\")\n km.add(\"j\", \"console.nav.down\", [\"global\"], \"Down\")\n km.add(\"l\", \"console.nav.right\", [\"global\"], \"Right\")\n km.add(\"h\", \"console.nav.left\", [\"global\"], \"Left\")\n km.add(\"tab\", \"console.nav.next\", [\"commonkey\", \"global\"], \"Next\")\n km.add(\"enter\", \"console.nav.select\", [\"commonkey\", \"global\"], \"Select\")\n km.add(\"space\", \"console.nav.pagedown\", [\"global\"], \"Page down\")\n km.add(\"ctrl f\", \"console.nav.pagedown\", [\"global\"], \"Page down\")\n km.add(\"ctrl b\", \"console.nav.pageup\", [\"global\"], \"Page up\")\n\n km.add(\n \"I\",\n \"set intercept_active toggle\",\n [\"global\"],\n \"Toggle whether the filtering via the intercept option is enabled\",\n )\n km.add(\"i\", \"console.command.set intercept\", [\"global\"], \"Set intercept\")\n km.add(\"W\", \"console.command.set save_stream_file\", [\"global\"], \"Stream to file\")\n km.add(\n \"A\",\n \"flow.resume @all\",\n [\"flowlist\", \"flowview\"],\n \"Resume all intercepted flows\",\n )\n km.add(\n \"a\",\n \"flow.resume @focus\",\n [\"flowlist\", \"flowview\"],\n \"Resume this intercepted flow\",\n )\n km.add(\n \"b\",\n \"console.command cut.save @focus response.content \",\n [\"flowlist\", \"flowview\"],\n \"Save response body to file\",\n )\n km.add(\n \"d\",\n \"view.flows.remove @focus\",\n [\"flowlist\", \"flowview\"],\n \"Delete flow from view\",\n )\n km.add(\n \"D\", \"view.flows.duplicate @focus\", [\"flowlist\", \"flowview\"], \"Duplicate flow\"\n )\n km.add(\n \"e\",\n \"\"\"\n console.choose.cmd Format export.formats\n console.command export.file {choice} @focus\n \"\"\",\n [\"flowlist\", \"flowview\"],\n \"Export this flow to file\",\n )\n km.add(\"f\", \"console.command.set view_filter\", [\"flowlist\"], \"Set view filter\")\n km.add(\"F\", \"set console_focus_follow toggle\", [\"flowlist\"], \"Set focus follow\")\n km.add(\n \"ctrl l\",\n \"console.command cut.clip \",\n [\"flowlist\", \"flowview\"],\n \"Send cuts to clipboard\",\n )\n km.add(\n \"L\", \"console.command view.flows.load \", [\"flowlist\"], \"Load flows from file\"\n )\n km.add(\"m\", \"flow.mark.toggle @focus\", [\"flowlist\"], \"Toggle mark on this flow\")\n km.add(\n \"M\",\n \"view.properties.marked.toggle\",\n [\"flowlist\"],\n \"Toggle viewing marked flows\",\n )\n km.add(\n \"n\",\n \"console.command view.flows.create get https://example.com/\",\n [\"flowlist\"],\n \"Create a new flow\",\n )\n km.add(\n \"o\",\n \"\"\"\n console.choose.cmd Order view.order.options\n set view_order {choice}\n \"\"\",\n [\"flowlist\"],\n \"Set flow list order\",\n )\n km.add(\"r\", \"replay.client @focus\", [\"flowlist\", \"flowview\"], \"Replay this flow\")\n km.add(\"S\", \"console.command replay.server \", [\"flowlist\"], \"Start server replay\")\n km.add(\n \"v\", \"set view_order_reversed toggle\", [\"flowlist\"], \"Reverse flow list order\"\n )\n km.add(\"U\", \"flow.mark @all false\", [\"flowlist\"], \"Un-set all marks\")\n km.add(\n \"w\",\n \"console.command save.file @shown \",\n [\"flowlist\"],\n \"Save listed flows to file\",\n )\n km.add(\n \"V\",\n \"flow.revert @focus\",\n [\"flowlist\", \"flowview\"],\n \"Revert changes to this flow\",\n )\n km.add(\"X\", \"flow.kill @focus\", [\"flowlist\"], \"Kill this flow\")\n km.add(\"z\", \"view.flows.remove @all\", [\"flowlist\"], \"Clear flow list\")\n km.add(\n \"Z\", \"view.flows.remove @hidden\", [\"flowlist\"], \"Purge all flows not showing\"\n )\n km.add(\n \"|\",\n \"console.command script.run @focus \",\n [\"flowlist\", \"flowview\"],\n \"Run a script on this flow\",\n )\n\n km.add(\n \"e\",\n \"\"\"\n console.choose.cmd Part console.edit.focus.options\n console.edit.focus {choice}\n \"\"\",\n [\"flowview\"],\n \"Edit a flow component\",\n )\n km.add(\n \"f\",\n \"view.settings.setval.toggle @focus fullcontents\",\n [\"flowview\"],\n \"Toggle viewing full contents on this flow\",\n )\n km.add(\"w\", \"console.command save.file @focus \", [\"flowview\"], \"Save flow to file\")\n km.add(\"space\", \"view.focus.next\", [\"flowview\"], \"Go to next flow\")\n\n km.add(\n \"v\",\n \"\"\"\n console.choose \"View Part\" request,response\n console.bodyview @focus {choice}\n \"\"\",\n [\"flowview\"],\n \"View flow body in an external viewer\",\n )\n km.add(\"p\", \"view.focus.prev\", [\"flowview\"], \"Go to previous flow\")\n km.add(\n \"m\",\n \"\"\"\n console.choose.cmd Mode console.flowview.mode.options\n console.flowview.mode.set {choice}\n \"\"\",\n [\"flowview\"],\n \"Set flow view mode\",\n )\n km.add(\n \"z\",\n \"\"\"\n console.choose \"Part\" request,response\n flow.encode.toggle @focus {choice}\n \"\"\",\n [\"flowview\"],\n \"Encode/decode flow body\",\n )\n\n km.add(\"L\", \"console.command options.load \", [\"options\"], \"Load from file\")\n km.add(\"S\", \"console.command options.save \", [\"options\"], \"Save to file\")\n km.add(\"D\", \"options.reset\", [\"options\"], \"Reset all options\")\n km.add(\"d\", \"console.options.reset.focus\", [\"options\"], \"Reset this option\")\n\n km.add(\"a\", \"console.grideditor.add\", [\"grideditor\"], \"Add a row after cursor\")\n km.add(\n \"A\", \"console.grideditor.insert\", [\"grideditor\"], \"Insert a row before cursor\"\n )\n km.add(\"d\", \"console.grideditor.delete\", [\"grideditor\"], \"Delete this row\")\n km.add(\n \"r\",\n \"console.command console.grideditor.load\",\n [\"grideditor\"],\n \"Read unescaped data into the current cell from file\",\n )\n km.add(\n \"R\",\n \"console.command console.grideditor.load_escaped\",\n [\"grideditor\"],\n \"Load a Python-style escaped string into the current cell from file\",\n )\n km.add(\"e\", \"console.grideditor.editor\", [\"grideditor\"], \"Edit in external editor\")\n km.add(\n \"w\",\n \"console.command console.grideditor.save \",\n [\"grideditor\"],\n \"Save data to file as CSV\",\n )\n\n km.add(\"z\", \"eventstore.clear\", [\"eventlog\"], \"Clear\")\n\n km.add(\n \"a\",\n \"\"\"\n console.choose.cmd \"Context\" console.key.contexts\n console.command console.key.bind {choice}\n \"\"\",\n [\"keybindings\"],\n \"Add a key binding\",\n )\n km.add(\n \"d\",\n \"console.key.unbind.focus\",\n [\"keybindings\"],\n \"Unbind the currently focused key binding\",\n )\n km.add(\n \"x\",\n \"console.key.execute.focus\",\n [\"keybindings\"],\n \"Execute the currently focused key binding\",\n )\n km.add(\n \"enter\",\n \"console.key.edit.focus\",\n [\"keybindings\"],\n \"Edit the currently focused key binding\",\n )\n", "path": "mitmproxy/tools/console/defaultkeys.py"}], "after_files": [{"content": "from mitmproxy.tools.console.keymap import Keymap\n\n\ndef map(km: Keymap) -> None:\n km.add(\":\", \"console.command \", [\"commonkey\", \"global\"], \"Command prompt\")\n km.add(\n \";\",\n \"console.command flow.comment @focus ''\",\n [\"flowlist\", \"flowview\"],\n \"Add comment to flow\",\n )\n km.add(\"?\", \"console.view.help\", [\"global\"], \"View help\")\n km.add(\"B\", \"browser.start\", [\"global\"], \"Start an attached browser\")\n km.add(\"C\", \"console.view.commands\", [\"global\"], \"View commands\")\n km.add(\"K\", \"console.view.keybindings\", [\"global\"], \"View key bindings\")\n km.add(\"O\", \"console.view.options\", [\"commonkey\", \"global\"], \"View options\")\n km.add(\"E\", \"console.view.eventlog\", [\"commonkey\", \"global\"], \"View event log\")\n km.add(\"Q\", \"console.exit\", [\"global\"], \"Exit immediately\")\n km.add(\"q\", \"console.view.pop\", [\"commonkey\", \"global\"], \"Exit the current view\")\n km.add(\"-\", \"console.layout.cycle\", [\"global\"], \"Cycle to next layout\")\n km.add(\"ctrl right\", \"console.panes.next\", [\"global\"], \"Focus next layout pane\")\n km.add(\"ctrl left\", \"console.panes.prev\", [\"global\"], \"Focus previous layout pane\")\n km.add(\"shift tab\", \"console.panes.next\", [\"global\"], \"Focus next layout pane\")\n km.add(\"P\", \"console.view.flow @focus\", [\"global\"], \"View flow details\")\n\n km.add(\"?\", \"console.view.pop\", [\"help\"], \"Exit help\")\n\n km.add(\"g\", \"console.nav.start\", [\"global\"], \"Go to start\")\n km.add(\"G\", \"console.nav.end\", [\"global\"], \"Go to end\")\n km.add(\"k\", \"console.nav.up\", [\"global\"], \"Up\")\n km.add(\"j\", \"console.nav.down\", [\"global\"], \"Down\")\n km.add(\"l\", \"console.nav.right\", [\"global\"], \"Right\")\n km.add(\"h\", \"console.nav.left\", [\"global\"], \"Left\")\n km.add(\"tab\", \"console.nav.next\", [\"commonkey\", \"global\"], \"Next\")\n km.add(\"enter\", \"console.nav.select\", [\"commonkey\", \"global\"], \"Select\")\n km.add(\"space\", \"console.nav.pagedown\", [\"global\"], \"Page down\")\n km.add(\"ctrl f\", \"console.nav.pagedown\", [\"global\"], \"Page down\")\n km.add(\"ctrl b\", \"console.nav.pageup\", [\"global\"], \"Page up\")\n\n km.add(\n \"I\",\n \"set intercept_active toggle\",\n [\"global\"],\n \"Toggle whether the filtering via the intercept option is enabled\",\n )\n km.add(\"i\", \"console.command.set intercept\", [\"global\"], \"Set intercept\")\n km.add(\"W\", \"console.command.set save_stream_file\", [\"global\"], \"Stream to file\")\n km.add(\n \"A\",\n \"flow.resume @all\",\n [\"flowlist\", \"flowview\"],\n \"Resume all intercepted flows\",\n )\n km.add(\n \"a\",\n \"flow.resume @focus\",\n [\"flowlist\", \"flowview\"],\n \"Resume this intercepted flow\",\n )\n km.add(\n \"b\",\n \"console.command cut.save @focus response.content \",\n [\"flowlist\", \"flowview\"],\n \"Save response body to file\",\n )\n km.add(\n \"d\",\n \"view.flows.remove @focus\",\n [\"flowlist\", \"flowview\"],\n \"Delete flow from view\",\n )\n km.add(\n \"D\", \"view.flows.duplicate @focus\", [\"flowlist\", \"flowview\"], \"Duplicate flow\"\n )\n km.add(\n \"e\",\n \"\"\"\n console.choose.cmd Format export.formats\n console.command export.file {choice} @focus\n \"\"\",\n [\"flowlist\", \"flowview\"],\n \"Export this flow to file\",\n )\n km.add(\"f\", \"console.command.set view_filter\", [\"flowlist\"], \"Set view filter\")\n km.add(\n \"F\",\n \"set console_focus_follow toggle\",\n [\"flowlist\", \"flowview\"],\n \"Set focus follow\",\n )\n km.add(\n \"ctrl l\",\n \"console.command cut.clip \",\n [\"flowlist\", \"flowview\"],\n \"Send cuts to clipboard\",\n )\n km.add(\n \"L\", \"console.command view.flows.load \", [\"flowlist\"], \"Load flows from file\"\n )\n km.add(\"m\", \"flow.mark.toggle @focus\", [\"flowlist\"], \"Toggle mark on this flow\")\n km.add(\n \"M\",\n \"view.properties.marked.toggle\",\n [\"flowlist\"],\n \"Toggle viewing marked flows\",\n )\n km.add(\n \"n\",\n \"console.command view.flows.create get https://example.com/\",\n [\"flowlist\"],\n \"Create a new flow\",\n )\n km.add(\n \"o\",\n \"\"\"\n console.choose.cmd Order view.order.options\n set view_order {choice}\n \"\"\",\n [\"flowlist\"],\n \"Set flow list order\",\n )\n km.add(\"r\", \"replay.client @focus\", [\"flowlist\", \"flowview\"], \"Replay this flow\")\n km.add(\"S\", \"console.command replay.server \", [\"flowlist\"], \"Start server replay\")\n km.add(\n \"v\", \"set view_order_reversed toggle\", [\"flowlist\"], \"Reverse flow list order\"\n )\n km.add(\"U\", \"flow.mark @all false\", [\"flowlist\"], \"Un-set all marks\")\n km.add(\n \"w\",\n \"console.command save.file @shown \",\n [\"flowlist\"],\n \"Save listed flows to file\",\n )\n km.add(\n \"V\",\n \"flow.revert @focus\",\n [\"flowlist\", \"flowview\"],\n \"Revert changes to this flow\",\n )\n km.add(\"X\", \"flow.kill @focus\", [\"flowlist\"], \"Kill this flow\")\n km.add(\"z\", \"view.flows.remove @all\", [\"flowlist\"], \"Clear flow list\")\n km.add(\n \"Z\", \"view.flows.remove @hidden\", [\"flowlist\"], \"Purge all flows not showing\"\n )\n km.add(\n \"|\",\n \"console.command script.run @focus \",\n [\"flowlist\", \"flowview\"],\n \"Run a script on this flow\",\n )\n\n km.add(\n \"e\",\n \"\"\"\n console.choose.cmd Part console.edit.focus.options\n console.edit.focus {choice}\n \"\"\",\n [\"flowview\"],\n \"Edit a flow component\",\n )\n km.add(\n \"f\",\n \"view.settings.setval.toggle @focus fullcontents\",\n [\"flowview\"],\n \"Toggle viewing full contents on this flow\",\n )\n km.add(\"w\", \"console.command save.file @focus \", [\"flowview\"], \"Save flow to file\")\n km.add(\"space\", \"view.focus.next\", [\"flowview\"], \"Go to next flow\")\n\n km.add(\n \"v\",\n \"\"\"\n console.choose \"View Part\" request,response\n console.bodyview @focus {choice}\n \"\"\",\n [\"flowview\"],\n \"View flow body in an external viewer\",\n )\n km.add(\"p\", \"view.focus.prev\", [\"flowview\"], \"Go to previous flow\")\n km.add(\n \"m\",\n \"\"\"\n console.choose.cmd Mode console.flowview.mode.options\n console.flowview.mode.set {choice}\n \"\"\",\n [\"flowview\"],\n \"Set flow view mode\",\n )\n km.add(\n \"z\",\n \"\"\"\n console.choose \"Part\" request,response\n flow.encode.toggle @focus {choice}\n \"\"\",\n [\"flowview\"],\n \"Encode/decode flow body\",\n )\n\n km.add(\"L\", \"console.command options.load \", [\"options\"], \"Load from file\")\n km.add(\"S\", \"console.command options.save \", [\"options\"], \"Save to file\")\n km.add(\"D\", \"options.reset\", [\"options\"], \"Reset all options\")\n km.add(\"d\", \"console.options.reset.focus\", [\"options\"], \"Reset this option\")\n\n km.add(\"a\", \"console.grideditor.add\", [\"grideditor\"], \"Add a row after cursor\")\n km.add(\n \"A\", \"console.grideditor.insert\", [\"grideditor\"], \"Insert a row before cursor\"\n )\n km.add(\"d\", \"console.grideditor.delete\", [\"grideditor\"], \"Delete this row\")\n km.add(\n \"r\",\n \"console.command console.grideditor.load\",\n [\"grideditor\"],\n \"Read unescaped data into the current cell from file\",\n )\n km.add(\n \"R\",\n \"console.command console.grideditor.load_escaped\",\n [\"grideditor\"],\n \"Load a Python-style escaped string into the current cell from file\",\n )\n km.add(\"e\", \"console.grideditor.editor\", [\"grideditor\"], \"Edit in external editor\")\n km.add(\n \"w\",\n \"console.command console.grideditor.save \",\n [\"grideditor\"],\n \"Save data to file as CSV\",\n )\n\n km.add(\"z\", \"eventstore.clear\", [\"eventlog\"], \"Clear\")\n\n km.add(\n \"a\",\n \"\"\"\n console.choose.cmd \"Context\" console.key.contexts\n console.command console.key.bind {choice}\n \"\"\",\n [\"keybindings\"],\n \"Add a key binding\",\n )\n km.add(\n \"d\",\n \"console.key.unbind.focus\",\n [\"keybindings\"],\n \"Unbind the currently focused key binding\",\n )\n km.add(\n \"x\",\n \"console.key.execute.focus\",\n [\"keybindings\"],\n \"Execute the currently focused key binding\",\n )\n km.add(\n \"enter\",\n \"console.key.edit.focus\",\n [\"keybindings\"],\n \"Edit the currently focused key binding\",\n )\n", "path": "mitmproxy/tools/console/defaultkeys.py"}]} | 3,155 | 167 |
gh_patches_debug_12741 | rasdani/github-patches | git_diff | googleapis__google-cloud-python-259 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
datastore: default to empty dataset
When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending "s~" to dataset ids as that is not always a valid operation.
datastore: default to empty dataset
When working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending "s~" to dataset ids as that is not always a valid operation.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gcloud/datastore/key.py`
Content:
```
1 """Create / interact with gcloud datastore keys."""
2
3 import copy
4 from itertools import izip
5
6 from gcloud.datastore import datastore_v1_pb2 as datastore_pb
7 from gcloud.datastore.dataset import Dataset
8
9
10 class Key(object):
11 """An immutable representation of a datastore Key.
12
13 .. automethod:: __init__
14 """
15
16 def __init__(self, dataset=None, namespace=None, path=None):
17 """Constructor / initializer for a key.
18
19 :type dataset: :class:`gcloud.datastore.dataset.Dataset`
20 :param dataset: A dataset instance for the key.
21
22 :type namespace: :class:`str`
23 :param namespace: A namespace identifier for the key.
24
25 :type path: sequence of dicts
26 :param path: Each dict must have keys 'kind' (a string) and optionally
27 'name' (a string) or 'id' (an integer).
28 """
29 self._dataset = dataset
30 self._namespace = namespace
31 self._path = path or [{'kind': ''}]
32
33 def _clone(self):
34 """Duplicates the Key.
35
36 We make a shallow copy of the :class:`gcloud.datastore.dataset.Dataset`
37 because it holds a reference an authenticated connection,
38 which we don't want to lose.
39
40 :rtype: :class:`gcloud.datastore.key.Key`
41 :returns: a new `Key` instance
42 """
43 clone = copy.deepcopy(self)
44 clone._dataset = self._dataset # Make a shallow copy of the Dataset.
45 return clone
46
47 @classmethod
48 def from_protobuf(cls, pb, dataset=None):
49 """Factory method for creating a key based on a protobuf.
50
51 The protobuf should be one returned from the Cloud Datastore
52 Protobuf API.
53
54 :type pb: :class:`gcloud.datastore.datastore_v1_pb2.Key`
55 :param pb: The Protobuf representing the key.
56
57 :type dataset: :class:`gcloud.datastore.dataset.Dataset`
58 :param dataset: A dataset instance. If not passed, defaults to an
59 instance whose ID is derived from pb.
60
61 :rtype: :class:`gcloud.datastore.key.Key`
62 :returns: a new `Key` instance
63 """
64 path = []
65 for element in pb.path_element:
66 element_dict = {'kind': element.kind}
67
68 if element.HasField('id'):
69 element_dict['id'] = element.id
70
71 # This is safe: we expect proto objects returned will only have
72 # one of `name` or `id` set.
73 if element.HasField('name'):
74 element_dict['name'] = element.name
75
76 path.append(element_dict)
77
78 if not dataset:
79 dataset = Dataset(id=pb.partition_id.dataset_id)
80 namespace = pb.partition_id.namespace
81 else:
82 namespace = None
83
84 return cls(dataset, namespace, path)
85
86 def to_protobuf(self):
87 """Return a protobuf corresponding to the key.
88
89 :rtype: :class:`gcloud.datastore.datastore_v1_pb2.Key`
90 :returns: The Protobuf representing the key.
91 """
92 key = datastore_pb.Key()
93
94 # Technically a dataset is required to do anything with the key,
95 # but we shouldn't throw a cryptic error if one isn't provided
96 # in the initializer.
97 if self.dataset():
98 # Apparently 's~' is a prefix for High-Replication and is necessary
99 # here. Another valid preflix is 'e~' indicating EU datacenters.
100 dataset_id = self.dataset().id()
101 if dataset_id:
102 if dataset_id[:2] not in ['s~', 'e~']:
103 dataset_id = 's~' + dataset_id
104
105 key.partition_id.dataset_id = dataset_id
106
107 if self._namespace:
108 key.partition_id.namespace = self._namespace
109
110 for item in self.path():
111 element = key.path_element.add()
112 if 'kind' in item:
113 element.kind = item['kind']
114 if 'id' in item:
115 element.id = item['id']
116 if 'name' in item:
117 element.name = item['name']
118
119 return key
120
121 @classmethod
122 def from_path(cls, *args, **kwargs):
123 """Factory method for creating a key based on a path.
124
125 :type args: :class:`tuple`
126 :param args: sequence of even length, where the first of each pair is a
127 string representing the 'kind' of the path element, and
128 the second of the pair is either a string (for the path
129 element's name) or an integer (for its id).
130
131 :type kwargs: :class:`dict`
132 :param kwargs: Other named parameters which can be passed to
133 :func:`Key.__init__`.
134
135 :rtype: :class:`gcloud.datastore.key.Key`
136 :returns: a new :class:`Key` instance
137 """
138 if len(args) % 2:
139 raise ValueError('Must pass an even number of args.')
140
141 path = []
142 items = iter(args)
143
144 for kind, id_or_name in izip(items, items):
145 entry = {'kind': kind}
146 if isinstance(id_or_name, basestring):
147 entry['name'] = id_or_name
148 else:
149 entry['id'] = id_or_name
150 path.append(entry)
151
152 kwargs['path'] = path
153 return cls(**kwargs)
154
155 def is_partial(self):
156 """Boolean test: is the key fully mapped onto a backend entity?
157
158 :rtype: :class:`bool`
159 :returns: True if the last element of the key's path does not have
160 an 'id' or a 'name'.
161 """
162 return self.id_or_name() is None
163
164 def dataset(self, dataset=None):
165 """Dataset setter / getter.
166
167 :type dataset: :class:`gcloud.datastore.dataset.Dataset`
168 :param dataset: A dataset instance for the key.
169
170 :rtype: :class:`Key` (for setter); or
171 :class:`gcloud.datastore.dataset.Dataset` (for getter)
172 :returns: a new key, cloned from self., with the given dataset
173 (setter); or self's dataset (getter).
174 """
175 if dataset:
176 clone = self._clone()
177 clone._dataset = dataset
178 return clone
179 else:
180 return self._dataset
181
182 def namespace(self, namespace=None):
183 """Namespace setter / getter.
184
185 :type namespace: :class:`str`
186 :param namespace: A namespace identifier for the key.
187
188 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
189 :returns: a new key, cloned from self., with the given namespace
190 (setter); or self's namespace (getter).
191 """
192 if namespace:
193 clone = self._clone()
194 clone._namespace = namespace
195 return clone
196 else:
197 return self._namespace
198
199 def path(self, path=None):
200 """Path setter / getter.
201
202 :type path: sequence of dicts
203 :param path: Each dict must have keys 'kind' (a string) and optionally
204 'name' (a string) or 'id' (an integer).
205
206 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
207 :returns: a new key, cloned from self., with the given path (setter);
208 or self's path (getter).
209 """
210 if path:
211 clone = self._clone()
212 clone._path = path
213 return clone
214 else:
215 return self._path
216
217 def kind(self, kind=None):
218 """Kind setter / getter. Based on the last element of path.
219
220 :type kind: :class:`str`
221 :param kind: The new kind for the key.
222
223 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
224 :returns: a new key, cloned from self., with the given kind (setter);
225 or self's kind (getter).
226 """
227 if kind:
228 clone = self._clone()
229 clone._path[-1]['kind'] = kind
230 return clone
231 elif self.path():
232 return self._path[-1]['kind']
233
234 def id(self, id_to_set=None):
235 """ID setter / getter. Based on the last element of path.
236
237 :type id_to_set: :class:`int`
238 :param id_to_set: The new ID for the key.
239
240 :rtype: :class:`Key` (for setter); or :class:`int` (for getter)
241 :returns: a new key, cloned from self., with the given id (setter);
242 or self's id (getter).
243 """
244 if id_to_set:
245 clone = self._clone()
246 clone._path[-1]['id'] = id_to_set
247 return clone
248 elif self.path():
249 return self._path[-1].get('id')
250
251 def name(self, name=None):
252 """Name setter / getter. Based on the last element of path.
253
254 :type kind: :class:`str`
255 :param kind: The new name for the key.
256
257 :rtype: :class:`Key` (for setter); or :class:`str` (for getter)
258 :returns: a new key, cloned from self., with the given name (setter);
259 or self's name (getter).
260 """
261 if name:
262 clone = self._clone()
263 clone._path[-1]['name'] = name
264 return clone
265 elif self.path():
266 return self._path[-1].get('name')
267
268 def id_or_name(self):
269 """Getter. Based on the last element of path.
270
271 :rtype: :class:`int` (if 'id' is set); or :class:`str` (the 'name')
272 :returns: True if the last element of the key's path has either an 'id'
273 or a 'name'.
274 """
275 return self.id() or self.name()
276
277 def parent(self):
278 """Getter: return a new key for the next highest element in path.
279
280 :rtype: :class:`gcloud.datastore.key.Key`
281 :returns: a new `Key` instance, whose path consists of all but the last
282 element of self's path. If self has only one path element,
283 return None.
284 """
285 if len(self._path) <= 1:
286 return None
287 return self.path(self.path()[:-1])
288
289 def __repr__(self):
290 return '<Key%s>' % self.path()
291
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gcloud/datastore/key.py b/gcloud/datastore/key.py
--- a/gcloud/datastore/key.py
+++ b/gcloud/datastore/key.py
@@ -95,13 +95,8 @@
# but we shouldn't throw a cryptic error if one isn't provided
# in the initializer.
if self.dataset():
- # Apparently 's~' is a prefix for High-Replication and is necessary
- # here. Another valid preflix is 'e~' indicating EU datacenters.
dataset_id = self.dataset().id()
if dataset_id:
- if dataset_id[:2] not in ['s~', 'e~']:
- dataset_id = 's~' + dataset_id
-
key.partition_id.dataset_id = dataset_id
if self._namespace:
| {"golden_diff": "diff --git a/gcloud/datastore/key.py b/gcloud/datastore/key.py\n--- a/gcloud/datastore/key.py\n+++ b/gcloud/datastore/key.py\n@@ -95,13 +95,8 @@\n # but we shouldn't throw a cryptic error if one isn't provided\n # in the initializer.\n if self.dataset():\n- # Apparently 's~' is a prefix for High-Replication and is necessary\n- # here. Another valid preflix is 'e~' indicating EU datacenters.\n dataset_id = self.dataset().id()\n if dataset_id:\n- if dataset_id[:2] not in ['s~', 'e~']:\n- dataset_id = 's~' + dataset_id\n-\n key.partition_id.dataset_id = dataset_id\n \n if self._namespace:\n", "issue": "datastore: default to empty dataset\nWhen working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation.\n\ndatastore: default to empty dataset\nWhen working with datasets, the Datastore backend will normalize any empty datasets to the dataset of the calling application. This should be preferred to prepending \"s~\" to dataset ids as that is not always a valid operation.\n\n", "before_files": [{"content": "\"\"\"Create / interact with gcloud datastore keys.\"\"\"\n\nimport copy\nfrom itertools import izip\n\nfrom gcloud.datastore import datastore_v1_pb2 as datastore_pb\nfrom gcloud.datastore.dataset import Dataset\n\n\nclass Key(object):\n \"\"\"An immutable representation of a datastore Key.\n\n .. automethod:: __init__\n \"\"\"\n\n def __init__(self, dataset=None, namespace=None, path=None):\n \"\"\"Constructor / initializer for a key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n \"\"\"\n self._dataset = dataset\n self._namespace = namespace\n self._path = path or [{'kind': ''}]\n\n def _clone(self):\n \"\"\"Duplicates the Key.\n\n We make a shallow copy of the :class:`gcloud.datastore.dataset.Dataset`\n because it holds a reference an authenticated connection,\n which we don't want to lose.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n clone = copy.deepcopy(self)\n clone._dataset = self._dataset # Make a shallow copy of the Dataset.\n return clone\n\n @classmethod\n def from_protobuf(cls, pb, dataset=None):\n \"\"\"Factory method for creating a key based on a protobuf.\n\n The protobuf should be one returned from the Cloud Datastore\n Protobuf API.\n\n :type pb: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :param pb: The Protobuf representing the key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance. If not passed, defaults to an\n instance whose ID is derived from pb.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n path = []\n for element in pb.path_element:\n element_dict = {'kind': element.kind}\n\n if element.HasField('id'):\n element_dict['id'] = element.id\n\n # This is safe: we expect proto objects returned will only have\n # one of `name` or `id` set.\n if element.HasField('name'):\n element_dict['name'] = element.name\n\n path.append(element_dict)\n\n if not dataset:\n dataset = Dataset(id=pb.partition_id.dataset_id)\n namespace = pb.partition_id.namespace\n else:\n namespace = None\n\n return cls(dataset, namespace, path)\n\n def to_protobuf(self):\n \"\"\"Return a protobuf corresponding to the key.\n\n :rtype: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :returns: The Protobuf representing the key.\n \"\"\"\n key = datastore_pb.Key()\n\n # Technically a dataset is required to do anything with the key,\n # but we shouldn't throw a cryptic error if one isn't provided\n # in the initializer.\n if self.dataset():\n # Apparently 's~' is a prefix for High-Replication and is necessary\n # here. Another valid preflix is 'e~' indicating EU datacenters.\n dataset_id = self.dataset().id()\n if dataset_id:\n if dataset_id[:2] not in ['s~', 'e~']:\n dataset_id = 's~' + dataset_id\n\n key.partition_id.dataset_id = dataset_id\n\n if self._namespace:\n key.partition_id.namespace = self._namespace\n\n for item in self.path():\n element = key.path_element.add()\n if 'kind' in item:\n element.kind = item['kind']\n if 'id' in item:\n element.id = item['id']\n if 'name' in item:\n element.name = item['name']\n\n return key\n\n @classmethod\n def from_path(cls, *args, **kwargs):\n \"\"\"Factory method for creating a key based on a path.\n\n :type args: :class:`tuple`\n :param args: sequence of even length, where the first of each pair is a\n string representing the 'kind' of the path element, and\n the second of the pair is either a string (for the path\n element's name) or an integer (for its id).\n\n :type kwargs: :class:`dict`\n :param kwargs: Other named parameters which can be passed to\n :func:`Key.__init__`.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new :class:`Key` instance\n \"\"\"\n if len(args) % 2:\n raise ValueError('Must pass an even number of args.')\n\n path = []\n items = iter(args)\n\n for kind, id_or_name in izip(items, items):\n entry = {'kind': kind}\n if isinstance(id_or_name, basestring):\n entry['name'] = id_or_name\n else:\n entry['id'] = id_or_name\n path.append(entry)\n\n kwargs['path'] = path\n return cls(**kwargs)\n\n def is_partial(self):\n \"\"\"Boolean test: is the key fully mapped onto a backend entity?\n\n :rtype: :class:`bool`\n :returns: True if the last element of the key's path does not have\n an 'id' or a 'name'.\n \"\"\"\n return self.id_or_name() is None\n\n def dataset(self, dataset=None):\n \"\"\"Dataset setter / getter.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :rtype: :class:`Key` (for setter); or\n :class:`gcloud.datastore.dataset.Dataset` (for getter)\n :returns: a new key, cloned from self., with the given dataset\n (setter); or self's dataset (getter).\n \"\"\"\n if dataset:\n clone = self._clone()\n clone._dataset = dataset\n return clone\n else:\n return self._dataset\n\n def namespace(self, namespace=None):\n \"\"\"Namespace setter / getter.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given namespace\n (setter); or self's namespace (getter).\n \"\"\"\n if namespace:\n clone = self._clone()\n clone._namespace = namespace\n return clone\n else:\n return self._namespace\n\n def path(self, path=None):\n \"\"\"Path setter / getter.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given path (setter);\n or self's path (getter).\n \"\"\"\n if path:\n clone = self._clone()\n clone._path = path\n return clone\n else:\n return self._path\n\n def kind(self, kind=None):\n \"\"\"Kind setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new kind for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given kind (setter);\n or self's kind (getter).\n \"\"\"\n if kind:\n clone = self._clone()\n clone._path[-1]['kind'] = kind\n return clone\n elif self.path():\n return self._path[-1]['kind']\n\n def id(self, id_to_set=None):\n \"\"\"ID setter / getter. Based on the last element of path.\n\n :type id_to_set: :class:`int`\n :param id_to_set: The new ID for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`int` (for getter)\n :returns: a new key, cloned from self., with the given id (setter);\n or self's id (getter).\n \"\"\"\n if id_to_set:\n clone = self._clone()\n clone._path[-1]['id'] = id_to_set\n return clone\n elif self.path():\n return self._path[-1].get('id')\n\n def name(self, name=None):\n \"\"\"Name setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new name for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given name (setter);\n or self's name (getter).\n \"\"\"\n if name:\n clone = self._clone()\n clone._path[-1]['name'] = name\n return clone\n elif self.path():\n return self._path[-1].get('name')\n\n def id_or_name(self):\n \"\"\"Getter. Based on the last element of path.\n\n :rtype: :class:`int` (if 'id' is set); or :class:`str` (the 'name')\n :returns: True if the last element of the key's path has either an 'id'\n or a 'name'.\n \"\"\"\n return self.id() or self.name()\n\n def parent(self):\n \"\"\"Getter: return a new key for the next highest element in path.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance, whose path consists of all but the last\n element of self's path. If self has only one path element,\n return None.\n \"\"\"\n if len(self._path) <= 1:\n return None\n return self.path(self.path()[:-1])\n\n def __repr__(self):\n return '<Key%s>' % self.path()\n", "path": "gcloud/datastore/key.py"}], "after_files": [{"content": "\"\"\"Create / interact with gcloud datastore keys.\"\"\"\n\nimport copy\nfrom itertools import izip\n\nfrom gcloud.datastore import datastore_v1_pb2 as datastore_pb\nfrom gcloud.datastore.dataset import Dataset\n\n\nclass Key(object):\n \"\"\"An immutable representation of a datastore Key.\n\n .. automethod:: __init__\n \"\"\"\n\n def __init__(self, dataset=None, namespace=None, path=None):\n \"\"\"Constructor / initializer for a key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n \"\"\"\n self._dataset = dataset\n self._namespace = namespace\n self._path = path or [{'kind': ''}]\n\n def _clone(self):\n \"\"\"Duplicates the Key.\n\n We make a shallow copy of the :class:`gcloud.datastore.dataset.Dataset`\n because it holds a reference an authenticated connection,\n which we don't want to lose.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n clone = copy.deepcopy(self)\n clone._dataset = self._dataset # Make a shallow copy of the Dataset.\n return clone\n\n @classmethod\n def from_protobuf(cls, pb, dataset=None):\n \"\"\"Factory method for creating a key based on a protobuf.\n\n The protobuf should be one returned from the Cloud Datastore\n Protobuf API.\n\n :type pb: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :param pb: The Protobuf representing the key.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance. If not passed, defaults to an\n instance whose ID is derived from pb.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance\n \"\"\"\n path = []\n for element in pb.path_element:\n element_dict = {'kind': element.kind}\n\n if element.HasField('id'):\n element_dict['id'] = element.id\n\n # This is safe: we expect proto objects returned will only have\n # one of `name` or `id` set.\n if element.HasField('name'):\n element_dict['name'] = element.name\n\n path.append(element_dict)\n\n if not dataset:\n dataset = Dataset(id=pb.partition_id.dataset_id)\n namespace = pb.partition_id.namespace\n else:\n namespace = None\n\n return cls(dataset, namespace, path)\n\n def to_protobuf(self):\n \"\"\"Return a protobuf corresponding to the key.\n\n :rtype: :class:`gcloud.datastore.datastore_v1_pb2.Key`\n :returns: The Protobuf representing the key.\n \"\"\"\n key = datastore_pb.Key()\n\n # Technically a dataset is required to do anything with the key,\n # but we shouldn't throw a cryptic error if one isn't provided\n # in the initializer.\n if self.dataset():\n dataset_id = self.dataset().id()\n if dataset_id:\n key.partition_id.dataset_id = dataset_id\n\n if self._namespace:\n key.partition_id.namespace = self._namespace\n\n for item in self.path():\n element = key.path_element.add()\n if 'kind' in item:\n element.kind = item['kind']\n if 'id' in item:\n element.id = item['id']\n if 'name' in item:\n element.name = item['name']\n\n return key\n\n @classmethod\n def from_path(cls, *args, **kwargs):\n \"\"\"Factory method for creating a key based on a path.\n\n :type args: :class:`tuple`\n :param args: sequence of even length, where the first of each pair is a\n string representing the 'kind' of the path element, and\n the second of the pair is either a string (for the path\n element's name) or an integer (for its id).\n\n :type kwargs: :class:`dict`\n :param kwargs: Other named parameters which can be passed to\n :func:`Key.__init__`.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new :class:`Key` instance\n \"\"\"\n if len(args) % 2:\n raise ValueError('Must pass an even number of args.')\n\n path = []\n items = iter(args)\n\n for kind, id_or_name in izip(items, items):\n entry = {'kind': kind}\n if isinstance(id_or_name, basestring):\n entry['name'] = id_or_name\n else:\n entry['id'] = id_or_name\n path.append(entry)\n\n kwargs['path'] = path\n return cls(**kwargs)\n\n def is_partial(self):\n \"\"\"Boolean test: is the key fully mapped onto a backend entity?\n\n :rtype: :class:`bool`\n :returns: True if the last element of the key's path does not have\n an 'id' or a 'name'.\n \"\"\"\n return self.id_or_name() is None\n\n def dataset(self, dataset=None):\n \"\"\"Dataset setter / getter.\n\n :type dataset: :class:`gcloud.datastore.dataset.Dataset`\n :param dataset: A dataset instance for the key.\n\n :rtype: :class:`Key` (for setter); or\n :class:`gcloud.datastore.dataset.Dataset` (for getter)\n :returns: a new key, cloned from self., with the given dataset\n (setter); or self's dataset (getter).\n \"\"\"\n if dataset:\n clone = self._clone()\n clone._dataset = dataset\n return clone\n else:\n return self._dataset\n\n def namespace(self, namespace=None):\n \"\"\"Namespace setter / getter.\n\n :type namespace: :class:`str`\n :param namespace: A namespace identifier for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given namespace\n (setter); or self's namespace (getter).\n \"\"\"\n if namespace:\n clone = self._clone()\n clone._namespace = namespace\n return clone\n else:\n return self._namespace\n\n def path(self, path=None):\n \"\"\"Path setter / getter.\n\n :type path: sequence of dicts\n :param path: Each dict must have keys 'kind' (a string) and optionally\n 'name' (a string) or 'id' (an integer).\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given path (setter);\n or self's path (getter).\n \"\"\"\n if path:\n clone = self._clone()\n clone._path = path\n return clone\n else:\n return self._path\n\n def kind(self, kind=None):\n \"\"\"Kind setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new kind for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given kind (setter);\n or self's kind (getter).\n \"\"\"\n if kind:\n clone = self._clone()\n clone._path[-1]['kind'] = kind\n return clone\n elif self.path():\n return self._path[-1]['kind']\n\n def id(self, id_to_set=None):\n \"\"\"ID setter / getter. Based on the last element of path.\n\n :type id_to_set: :class:`int`\n :param id_to_set: The new ID for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`int` (for getter)\n :returns: a new key, cloned from self., with the given id (setter);\n or self's id (getter).\n \"\"\"\n if id_to_set:\n clone = self._clone()\n clone._path[-1]['id'] = id_to_set\n return clone\n elif self.path():\n return self._path[-1].get('id')\n\n def name(self, name=None):\n \"\"\"Name setter / getter. Based on the last element of path.\n\n :type kind: :class:`str`\n :param kind: The new name for the key.\n\n :rtype: :class:`Key` (for setter); or :class:`str` (for getter)\n :returns: a new key, cloned from self., with the given name (setter);\n or self's name (getter).\n \"\"\"\n if name:\n clone = self._clone()\n clone._path[-1]['name'] = name\n return clone\n elif self.path():\n return self._path[-1].get('name')\n\n def id_or_name(self):\n \"\"\"Getter. Based on the last element of path.\n\n :rtype: :class:`int` (if 'id' is set); or :class:`str` (the 'name')\n :returns: True if the last element of the key's path has either an 'id'\n or a 'name'.\n \"\"\"\n return self.id() or self.name()\n\n def parent(self):\n \"\"\"Getter: return a new key for the next highest element in path.\n\n :rtype: :class:`gcloud.datastore.key.Key`\n :returns: a new `Key` instance, whose path consists of all but the last\n element of self's path. If self has only one path element,\n return None.\n \"\"\"\n if len(self._path) <= 1:\n return None\n return self.path(self.path()[:-1])\n\n def __repr__(self):\n return '<Key%s>' % self.path()\n", "path": "gcloud/datastore/key.py"}]} | 3,438 | 178 |
gh_patches_debug_6644 | rasdani/github-patches | git_diff | GPflow__GPflow-1727 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Small issue in the text of kernel in the heteroskedastic example
*Are there any mistakes in the docs?*
Hi,
In
https://gpflow.readthedocs.io/en/develop/notebooks/advanced/heteroskedastic.html
the explanation of the kernel has an issue when rendering. In my Chrome, it looks like
"withbothkernelsbeingmodeledasseparateandindependent:math:‘SquaredExponential‘kernels."
It does look ok here:
https://github.com/GPflow/docs/blob/develop/doc/source/notebooks/advanced/heteroskedastic.ipynb
Kind regards,
Ivan
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `doc/source/notebooks/advanced/heteroskedastic.pct.py`
Content:
```
1 # ---
2 # jupyter:
3 # jupytext:
4 # formats: ipynb,.pct.py:percent
5 # text_representation:
6 # extension: .py
7 # format_name: percent
8 # format_version: '1.3'
9 # jupytext_version: 1.6.0
10 # kernelspec:
11 # display_name: Python 3
12 # language: python
13 # name: python3
14 # ---
15
16 # %% [markdown]
17 # # Heteroskedastic Likelihood and Multi-Latent GP
18
19 # %% [markdown]
20 # ## Standard (Homoskedastic) Regression
21 # In standard GP regression, the GP latent function is used to learn the location parameter of a likelihood distribution (usually a Gaussian) as a function of the input $x$, whereas the scale parameter is considered constant. This is a homoskedastic model, which is unable to capture variations of the noise distribution with the input $x$.
22 #
23 #
24 # ## Heteroskedastic Regression
25 # This notebooks shows how to construct a model which uses multiple (here two) GP latent functions to learn both the location and the scale of the Gaussian likelihood distribution. It does so by connecting a **Multi-Output Kernel**, which generates multiple GP latent functions, to a **Heteroskedastic Likelihood**, which maps the latent GPs into a single likelihood.
26 #
27 # The generative model is described as:
28 #
29 # $$ f_1(x) \sim \mathcal{GP}(0, k_1(\cdot, \cdot)) $$
30 # $$ f_2(x) \sim \mathcal{GP}(0, k_2(\cdot, \cdot)) $$
31 # $$ \text{loc}(x) = f_1(x) $$
32 # $$ \text{scale}(x) = \text{transform}(f_2(x)) $$
33 # $$ y_i|f_1, f_2, x_i \sim \mathcal{N}(\text{loc}(x_i),\;\text{scale}(x_i)^2)$$
34 #
35 # The function $\text{transform}$ is used to map from the unconstrained GP $f_2$ to **positive-only values**, which is required as it represents the $\text{scale}$ of a Gaussian likelihood. In this notebook, the $\exp$ function will be used as the $\text{transform}$. Other positive transforms such as the $\text{softplus}$ function can also be used.
36
37 # %%
38 import matplotlib.pyplot as plt
39 import numpy as np
40 import tensorflow as tf
41 import tensorflow_probability as tfp
42 import gpflow as gpf
43
44
45 # %% [markdown]
46 # ## Data Generation
47 # We generate heteroskedastic data by substituting the random latent functions $f_1$ and $f_2$ of the generative model by deterministic $\sin$ and $\cos$ functions. The input $X$ is built with $N=1001$ uniformly spaced values in the interval $[0, 4\pi]$. The outputs $Y$ are still sampled from a Gaussian likelihood.
48 #
49 # $$ x_i \in [0, 4\pi], \quad i = 1,\dots,N $$
50 # $$ f_1(x) = \sin(x) $$
51 # $$ f_2(x) = \cos(x) $$
52 # $$ \text{loc}(x) = f_1(x) $$
53 # $$ \text{scale}(x) = \exp(f_2(x)) $$
54 # $$ y_i|x_i \sim \mathcal{N}(\text{loc}(x_i),\;\text{scale}(x_i)^2)$$
55
56 # %%
57 N = 1001
58
59 np.random.seed(0)
60 tf.random.set_seed(0)
61
62 # Build inputs X
63 X = np.linspace(0, 4 * np.pi, N)[:, None] # X must be of shape [N, 1]
64
65 # Deterministic functions in place of latent ones
66 f1 = np.sin
67 f2 = np.cos
68
69 # Use transform = exp to ensure positive-only scale values
70 transform = np.exp
71
72 # Compute loc and scale as functions of input X
73 loc = f1(X)
74 scale = transform(f2(X))
75
76 # Sample outputs Y from Gaussian Likelihood
77 Y = np.random.normal(loc, scale)
78
79 # %% [markdown]
80 # ### Plot Data
81 # Note how the distribution density (shaded area) and the outputs $Y$ both change depending on the input $X$.
82
83 # %%
84 def plot_distribution(X, Y, loc, scale):
85 plt.figure(figsize=(15, 5))
86 x = X.squeeze()
87 for k in (1, 2):
88 lb = (loc - k * scale).squeeze()
89 ub = (loc + k * scale).squeeze()
90 plt.fill_between(x, lb, ub, color="silver", alpha=1 - 0.05 * k ** 3)
91 plt.plot(x, lb, color="silver")
92 plt.plot(x, ub, color="silver")
93 plt.plot(X, loc, color="black")
94 plt.scatter(X, Y, color="gray", alpha=0.8)
95 plt.show()
96 plt.close()
97
98
99 plot_distribution(X, Y, loc, scale)
100
101
102 # %% [markdown]
103 # ## Build Model
104
105 # %% [markdown]
106 # ### Likelihood
107 # This implements the following part of the generative model:
108 # $$ \text{loc}(x) = f_1(x) $$
109 # $$ \text{scale}(x) = \text{transform}(f_2(x)) $$
110 # $$ y_i|f_1, f_2, x_i \sim \mathcal{N}(\text{loc}(x_i),\;\text{scale}(x_i)^2)$$
111
112 # %%
113 likelihood = gpf.likelihoods.HeteroskedasticTFPConditional(
114 distribution_class=tfp.distributions.Normal, # Gaussian Likelihood
115 scale_transform=tfp.bijectors.Exp(), # Exponential Transform
116 )
117
118 print(f"Likelihood's expected latent_dim: {likelihood.latent_dim}")
119
120 # %% [markdown]
121 # ### Kernel
122 # This implements the following part of the generative model:
123 # $$ f_1(x) \sim \mathcal{GP}(0, k_1(\cdot, \cdot)) $$
124 # $$ f_2(x) \sim \mathcal{GP}(0, k_2(\cdot, \cdot)) $$
125 # with both kernels being modeled as separate and independent $\text{SquaredExponential}$ kernels.
126
127 # %%
128 kernel = gpf.kernels.SeparateIndependent(
129 [
130 gpf.kernels.SquaredExponential(), # This is k1, the kernel of f1
131 gpf.kernels.SquaredExponential(), # this is k2, the kernel of f2
132 ]
133 )
134 # The number of kernels contained in gpf.kernels.SeparateIndependent must be the same as likelihood.latent_dim
135
136 # %% [markdown]
137 # ### Inducing Points
138 # Since we will use the **SVGP** model to perform inference, we need to implement the inducing variables $U_1$ and $U_2$, both with size $M=20$, which are used to approximate $f_1$ and $f_2$ respectively, and initialize the inducing points positions $Z_1$ and $Z_2$. This gives a total of $2M=40$ inducing variables and inducing points.
139 #
140 # The inducing variables and their corresponding inputs will be Separate and Independent, but both $Z_1$ and $Z_2$ will be initialized as $Z$, which are placed as $M=20$ equally spaced points in $[\min(X), \max(X)]$.
141 #
142
143 # %%
144 M = 20 # Number of inducing variables for each f_i
145
146 # Initial inducing points position Z
147 Z = np.linspace(X.min(), X.max(), M)[:, None] # Z must be of shape [M, 1]
148
149 inducing_variable = gpf.inducing_variables.SeparateIndependentInducingVariables(
150 [
151 gpf.inducing_variables.InducingPoints(Z), # This is U1 = f1(Z1)
152 gpf.inducing_variables.InducingPoints(Z), # This is U2 = f2(Z2)
153 ]
154 )
155
156 # %% [markdown]
157 # ### SVGP Model
158 # Build the **SVGP** model by composing the **Kernel**, the **Likelihood** and the **Inducing Variables**.
159 #
160 # Note that the model needs to be instructed about the number of latent GPs by passing `num_latent_gps=likelihood.latent_dim`.
161
162 # %%
163 model = gpf.models.SVGP(
164 kernel=kernel,
165 likelihood=likelihood,
166 inducing_variable=inducing_variable,
167 num_latent_gps=likelihood.latent_dim,
168 )
169
170 model
171
172 # %% [markdown]
173 # ## Model Optimization
174 #
175 # ### Build Optimizers (NatGrad + Adam)
176
177 # %%
178 data = (X, Y)
179 loss_fn = model.training_loss_closure(data)
180
181 gpf.utilities.set_trainable(model.q_mu, False)
182 gpf.utilities.set_trainable(model.q_sqrt, False)
183
184 variational_vars = [(model.q_mu, model.q_sqrt)]
185 natgrad_opt = gpf.optimizers.NaturalGradient(gamma=0.1)
186
187 adam_vars = model.trainable_variables
188 adam_opt = tf.optimizers.Adam(0.01)
189
190
191 @tf.function
192 def optimisation_step():
193 natgrad_opt.minimize(loss_fn, variational_vars)
194 adam_opt.minimize(loss_fn, adam_vars)
195
196
197 # %% [markdown]
198 # ### Run Optimization Loop
199
200 # %%
201 epochs = 100
202 log_freq = 20
203
204 for epoch in range(1, epochs + 1):
205 optimisation_step()
206
207 # For every 'log_freq' epochs, print the epoch and plot the predictions against the data
208 if epoch % log_freq == 0 and epoch > 0:
209 print(f"Epoch {epoch} - Loss: {loss_fn().numpy() : .4f}")
210 Ymean, Yvar = model.predict_y(X)
211 Ymean = Ymean.numpy().squeeze()
212 Ystd = tf.sqrt(Yvar).numpy().squeeze()
213 plot_distribution(X, Y, Ymean, Ystd)
214
215 model
216
217 # %% [markdown]
218 # ## Further reading
219 #
220 # See [Chained Gaussian Processes](http://proceedings.mlr.press/v51/saul16.html) by Saul et al. (AISTATS 2016).
221
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/doc/source/notebooks/advanced/heteroskedastic.pct.py b/doc/source/notebooks/advanced/heteroskedastic.pct.py
--- a/doc/source/notebooks/advanced/heteroskedastic.pct.py
+++ b/doc/source/notebooks/advanced/heteroskedastic.pct.py
@@ -122,6 +122,7 @@
# This implements the following part of the generative model:
# $$ f_1(x) \sim \mathcal{GP}(0, k_1(\cdot, \cdot)) $$
# $$ f_2(x) \sim \mathcal{GP}(0, k_2(\cdot, \cdot)) $$
+#
# with both kernels being modeled as separate and independent $\text{SquaredExponential}$ kernels.
# %%
| {"golden_diff": "diff --git a/doc/source/notebooks/advanced/heteroskedastic.pct.py b/doc/source/notebooks/advanced/heteroskedastic.pct.py\n--- a/doc/source/notebooks/advanced/heteroskedastic.pct.py\n+++ b/doc/source/notebooks/advanced/heteroskedastic.pct.py\n@@ -122,6 +122,7 @@\n # This implements the following part of the generative model:\n # $$ f_1(x) \\sim \\mathcal{GP}(0, k_1(\\cdot, \\cdot)) $$\n # $$ f_2(x) \\sim \\mathcal{GP}(0, k_2(\\cdot, \\cdot)) $$\n+#\n # with both kernels being modeled as separate and independent $\\text{SquaredExponential}$ kernels.\n \n # %%\n", "issue": "Small issue in the text of kernel in the heteroskedastic example\n*Are there any mistakes in the docs?*\r\nHi,\r\n\r\nIn\r\nhttps://gpflow.readthedocs.io/en/develop/notebooks/advanced/heteroskedastic.html\r\nthe explanation of the kernel has an issue when rendering. In my Chrome, it looks like\r\n\"withbothkernelsbeingmodeledasseparateandindependent:math:\u2018SquaredExponential\u2018kernels.\"\r\n\r\nIt does look ok here:\r\nhttps://github.com/GPflow/docs/blob/develop/doc/source/notebooks/advanced/heteroskedastic.ipynb\r\n\r\nKind regards, \r\n\r\nIvan\r\n\n", "before_files": [{"content": "# ---\n# jupyter:\n# jupytext:\n# formats: ipynb,.pct.py:percent\n# text_representation:\n# extension: .py\n# format_name: percent\n# format_version: '1.3'\n# jupytext_version: 1.6.0\n# kernelspec:\n# display_name: Python 3\n# language: python\n# name: python3\n# ---\n\n# %% [markdown]\n# # Heteroskedastic Likelihood and Multi-Latent GP\n\n# %% [markdown]\n# ## Standard (Homoskedastic) Regression\n# In standard GP regression, the GP latent function is used to learn the location parameter of a likelihood distribution (usually a Gaussian) as a function of the input $x$, whereas the scale parameter is considered constant. This is a homoskedastic model, which is unable to capture variations of the noise distribution with the input $x$.\n#\n#\n# ## Heteroskedastic Regression\n# This notebooks shows how to construct a model which uses multiple (here two) GP latent functions to learn both the location and the scale of the Gaussian likelihood distribution. It does so by connecting a **Multi-Output Kernel**, which generates multiple GP latent functions, to a **Heteroskedastic Likelihood**, which maps the latent GPs into a single likelihood.\n#\n# The generative model is described as:\n#\n# $$ f_1(x) \\sim \\mathcal{GP}(0, k_1(\\cdot, \\cdot)) $$\n# $$ f_2(x) \\sim \\mathcal{GP}(0, k_2(\\cdot, \\cdot)) $$\n# $$ \\text{loc}(x) = f_1(x) $$\n# $$ \\text{scale}(x) = \\text{transform}(f_2(x)) $$\n# $$ y_i|f_1, f_2, x_i \\sim \\mathcal{N}(\\text{loc}(x_i),\\;\\text{scale}(x_i)^2)$$\n#\n# The function $\\text{transform}$ is used to map from the unconstrained GP $f_2$ to **positive-only values**, which is required as it represents the $\\text{scale}$ of a Gaussian likelihood. In this notebook, the $\\exp$ function will be used as the $\\text{transform}$. Other positive transforms such as the $\\text{softplus}$ function can also be used.\n\n# %%\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport tensorflow as tf\nimport tensorflow_probability as tfp\nimport gpflow as gpf\n\n\n# %% [markdown]\n# ## Data Generation\n# We generate heteroskedastic data by substituting the random latent functions $f_1$ and $f_2$ of the generative model by deterministic $\\sin$ and $\\cos$ functions. The input $X$ is built with $N=1001$ uniformly spaced values in the interval $[0, 4\\pi]$. The outputs $Y$ are still sampled from a Gaussian likelihood.\n#\n# $$ x_i \\in [0, 4\\pi], \\quad i = 1,\\dots,N $$\n# $$ f_1(x) = \\sin(x) $$\n# $$ f_2(x) = \\cos(x) $$\n# $$ \\text{loc}(x) = f_1(x) $$\n# $$ \\text{scale}(x) = \\exp(f_2(x)) $$\n# $$ y_i|x_i \\sim \\mathcal{N}(\\text{loc}(x_i),\\;\\text{scale}(x_i)^2)$$\n\n# %%\nN = 1001\n\nnp.random.seed(0)\ntf.random.set_seed(0)\n\n# Build inputs X\nX = np.linspace(0, 4 * np.pi, N)[:, None] # X must be of shape [N, 1]\n\n# Deterministic functions in place of latent ones\nf1 = np.sin\nf2 = np.cos\n\n# Use transform = exp to ensure positive-only scale values\ntransform = np.exp\n\n# Compute loc and scale as functions of input X\nloc = f1(X)\nscale = transform(f2(X))\n\n# Sample outputs Y from Gaussian Likelihood\nY = np.random.normal(loc, scale)\n\n# %% [markdown]\n# ### Plot Data\n# Note how the distribution density (shaded area) and the outputs $Y$ both change depending on the input $X$.\n\n# %%\ndef plot_distribution(X, Y, loc, scale):\n plt.figure(figsize=(15, 5))\n x = X.squeeze()\n for k in (1, 2):\n lb = (loc - k * scale).squeeze()\n ub = (loc + k * scale).squeeze()\n plt.fill_between(x, lb, ub, color=\"silver\", alpha=1 - 0.05 * k ** 3)\n plt.plot(x, lb, color=\"silver\")\n plt.plot(x, ub, color=\"silver\")\n plt.plot(X, loc, color=\"black\")\n plt.scatter(X, Y, color=\"gray\", alpha=0.8)\n plt.show()\n plt.close()\n\n\nplot_distribution(X, Y, loc, scale)\n\n\n# %% [markdown]\n# ## Build Model\n\n# %% [markdown]\n# ### Likelihood\n# This implements the following part of the generative model:\n# $$ \\text{loc}(x) = f_1(x) $$\n# $$ \\text{scale}(x) = \\text{transform}(f_2(x)) $$\n# $$ y_i|f_1, f_2, x_i \\sim \\mathcal{N}(\\text{loc}(x_i),\\;\\text{scale}(x_i)^2)$$\n\n# %%\nlikelihood = gpf.likelihoods.HeteroskedasticTFPConditional(\n distribution_class=tfp.distributions.Normal, # Gaussian Likelihood\n scale_transform=tfp.bijectors.Exp(), # Exponential Transform\n)\n\nprint(f\"Likelihood's expected latent_dim: {likelihood.latent_dim}\")\n\n# %% [markdown]\n# ### Kernel\n# This implements the following part of the generative model:\n# $$ f_1(x) \\sim \\mathcal{GP}(0, k_1(\\cdot, \\cdot)) $$\n# $$ f_2(x) \\sim \\mathcal{GP}(0, k_2(\\cdot, \\cdot)) $$\n# with both kernels being modeled as separate and independent $\\text{SquaredExponential}$ kernels.\n\n# %%\nkernel = gpf.kernels.SeparateIndependent(\n [\n gpf.kernels.SquaredExponential(), # This is k1, the kernel of f1\n gpf.kernels.SquaredExponential(), # this is k2, the kernel of f2\n ]\n)\n# The number of kernels contained in gpf.kernels.SeparateIndependent must be the same as likelihood.latent_dim\n\n# %% [markdown]\n# ### Inducing Points\n# Since we will use the **SVGP** model to perform inference, we need to implement the inducing variables $U_1$ and $U_2$, both with size $M=20$, which are used to approximate $f_1$ and $f_2$ respectively, and initialize the inducing points positions $Z_1$ and $Z_2$. This gives a total of $2M=40$ inducing variables and inducing points.\n#\n# The inducing variables and their corresponding inputs will be Separate and Independent, but both $Z_1$ and $Z_2$ will be initialized as $Z$, which are placed as $M=20$ equally spaced points in $[\\min(X), \\max(X)]$.\n#\n\n# %%\nM = 20 # Number of inducing variables for each f_i\n\n# Initial inducing points position Z\nZ = np.linspace(X.min(), X.max(), M)[:, None] # Z must be of shape [M, 1]\n\ninducing_variable = gpf.inducing_variables.SeparateIndependentInducingVariables(\n [\n gpf.inducing_variables.InducingPoints(Z), # This is U1 = f1(Z1)\n gpf.inducing_variables.InducingPoints(Z), # This is U2 = f2(Z2)\n ]\n)\n\n# %% [markdown]\n# ### SVGP Model\n# Build the **SVGP** model by composing the **Kernel**, the **Likelihood** and the **Inducing Variables**.\n#\n# Note that the model needs to be instructed about the number of latent GPs by passing `num_latent_gps=likelihood.latent_dim`.\n\n# %%\nmodel = gpf.models.SVGP(\n kernel=kernel,\n likelihood=likelihood,\n inducing_variable=inducing_variable,\n num_latent_gps=likelihood.latent_dim,\n)\n\nmodel\n\n# %% [markdown]\n# ## Model Optimization\n#\n# ### Build Optimizers (NatGrad + Adam)\n\n# %%\ndata = (X, Y)\nloss_fn = model.training_loss_closure(data)\n\ngpf.utilities.set_trainable(model.q_mu, False)\ngpf.utilities.set_trainable(model.q_sqrt, False)\n\nvariational_vars = [(model.q_mu, model.q_sqrt)]\nnatgrad_opt = gpf.optimizers.NaturalGradient(gamma=0.1)\n\nadam_vars = model.trainable_variables\nadam_opt = tf.optimizers.Adam(0.01)\n\n\[email protected]\ndef optimisation_step():\n natgrad_opt.minimize(loss_fn, variational_vars)\n adam_opt.minimize(loss_fn, adam_vars)\n\n\n# %% [markdown]\n# ### Run Optimization Loop\n\n# %%\nepochs = 100\nlog_freq = 20\n\nfor epoch in range(1, epochs + 1):\n optimisation_step()\n\n # For every 'log_freq' epochs, print the epoch and plot the predictions against the data\n if epoch % log_freq == 0 and epoch > 0:\n print(f\"Epoch {epoch} - Loss: {loss_fn().numpy() : .4f}\")\n Ymean, Yvar = model.predict_y(X)\n Ymean = Ymean.numpy().squeeze()\n Ystd = tf.sqrt(Yvar).numpy().squeeze()\n plot_distribution(X, Y, Ymean, Ystd)\n\nmodel\n\n# %% [markdown]\n# ## Further reading\n#\n# See [Chained Gaussian Processes](http://proceedings.mlr.press/v51/saul16.html) by Saul et al. (AISTATS 2016).\n", "path": "doc/source/notebooks/advanced/heteroskedastic.pct.py"}], "after_files": [{"content": "# ---\n# jupyter:\n# jupytext:\n# formats: ipynb,.pct.py:percent\n# text_representation:\n# extension: .py\n# format_name: percent\n# format_version: '1.3'\n# jupytext_version: 1.6.0\n# kernelspec:\n# display_name: Python 3\n# language: python\n# name: python3\n# ---\n\n# %% [markdown]\n# # Heteroskedastic Likelihood and Multi-Latent GP\n\n# %% [markdown]\n# ## Standard (Homoskedastic) Regression\n# In standard GP regression, the GP latent function is used to learn the location parameter of a likelihood distribution (usually a Gaussian) as a function of the input $x$, whereas the scale parameter is considered constant. This is a homoskedastic model, which is unable to capture variations of the noise distribution with the input $x$.\n#\n#\n# ## Heteroskedastic Regression\n# This notebooks shows how to construct a model which uses multiple (here two) GP latent functions to learn both the location and the scale of the Gaussian likelihood distribution. It does so by connecting a **Multi-Output Kernel**, which generates multiple GP latent functions, to a **Heteroskedastic Likelihood**, which maps the latent GPs into a single likelihood.\n#\n# The generative model is described as:\n#\n# $$ f_1(x) \\sim \\mathcal{GP}(0, k_1(\\cdot, \\cdot)) $$\n# $$ f_2(x) \\sim \\mathcal{GP}(0, k_2(\\cdot, \\cdot)) $$\n# $$ \\text{loc}(x) = f_1(x) $$\n# $$ \\text{scale}(x) = \\text{transform}(f_2(x)) $$\n# $$ y_i|f_1, f_2, x_i \\sim \\mathcal{N}(\\text{loc}(x_i),\\;\\text{scale}(x_i)^2)$$\n#\n# The function $\\text{transform}$ is used to map from the unconstrained GP $f_2$ to **positive-only values**, which is required as it represents the $\\text{scale}$ of a Gaussian likelihood. In this notebook, the $\\exp$ function will be used as the $\\text{transform}$. Other positive transforms such as the $\\text{softplus}$ function can also be used.\n\n# %%\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport tensorflow as tf\nimport tensorflow_probability as tfp\nimport gpflow as gpf\n\n\n# %% [markdown]\n# ## Data Generation\n# We generate heteroskedastic data by substituting the random latent functions $f_1$ and $f_2$ of the generative model by deterministic $\\sin$ and $\\cos$ functions. The input $X$ is built with $N=1001$ uniformly spaced values in the interval $[0, 4\\pi]$. The outputs $Y$ are still sampled from a Gaussian likelihood.\n#\n# $$ x_i \\in [0, 4\\pi], \\quad i = 1,\\dots,N $$\n# $$ f_1(x) = \\sin(x) $$\n# $$ f_2(x) = \\cos(x) $$\n# $$ \\text{loc}(x) = f_1(x) $$\n# $$ \\text{scale}(x) = \\exp(f_2(x)) $$\n# $$ y_i|x_i \\sim \\mathcal{N}(\\text{loc}(x_i),\\;\\text{scale}(x_i)^2)$$\n\n# %%\nN = 1001\n\nnp.random.seed(0)\ntf.random.set_seed(0)\n\n# Build inputs X\nX = np.linspace(0, 4 * np.pi, N)[:, None] # X must be of shape [N, 1]\n\n# Deterministic functions in place of latent ones\nf1 = np.sin\nf2 = np.cos\n\n# Use transform = exp to ensure positive-only scale values\ntransform = np.exp\n\n# Compute loc and scale as functions of input X\nloc = f1(X)\nscale = transform(f2(X))\n\n# Sample outputs Y from Gaussian Likelihood\nY = np.random.normal(loc, scale)\n\n# %% [markdown]\n# ### Plot Data\n# Note how the distribution density (shaded area) and the outputs $Y$ both change depending on the input $X$.\n\n# %%\ndef plot_distribution(X, Y, loc, scale):\n plt.figure(figsize=(15, 5))\n x = X.squeeze()\n for k in (1, 2):\n lb = (loc - k * scale).squeeze()\n ub = (loc + k * scale).squeeze()\n plt.fill_between(x, lb, ub, color=\"silver\", alpha=1 - 0.05 * k ** 3)\n plt.plot(x, lb, color=\"silver\")\n plt.plot(x, ub, color=\"silver\")\n plt.plot(X, loc, color=\"black\")\n plt.scatter(X, Y, color=\"gray\", alpha=0.8)\n plt.show()\n plt.close()\n\n\nplot_distribution(X, Y, loc, scale)\n\n\n# %% [markdown]\n# ## Build Model\n\n# %% [markdown]\n# ### Likelihood\n# This implements the following part of the generative model:\n# $$ \\text{loc}(x) = f_1(x) $$\n# $$ \\text{scale}(x) = \\text{transform}(f_2(x)) $$\n# $$ y_i|f_1, f_2, x_i \\sim \\mathcal{N}(\\text{loc}(x_i),\\;\\text{scale}(x_i)^2)$$\n\n# %%\nlikelihood = gpf.likelihoods.HeteroskedasticTFPConditional(\n distribution_class=tfp.distributions.Normal, # Gaussian Likelihood\n scale_transform=tfp.bijectors.Exp(), # Exponential Transform\n)\n\nprint(f\"Likelihood's expected latent_dim: {likelihood.latent_dim}\")\n\n# %% [markdown]\n# ### Kernel\n# This implements the following part of the generative model:\n# $$ f_1(x) \\sim \\mathcal{GP}(0, k_1(\\cdot, \\cdot)) $$\n# $$ f_2(x) \\sim \\mathcal{GP}(0, k_2(\\cdot, \\cdot)) $$\n#\n# with both kernels being modeled as separate and independent $\\text{SquaredExponential}$ kernels.\n\n# %%\nkernel = gpf.kernels.SeparateIndependent(\n [\n gpf.kernels.SquaredExponential(), # This is k1, the kernel of f1\n gpf.kernels.SquaredExponential(), # this is k2, the kernel of f2\n ]\n)\n# The number of kernels contained in gpf.kernels.SeparateIndependent must be the same as likelihood.latent_dim\n\n# %% [markdown]\n# ### Inducing Points\n# Since we will use the **SVGP** model to perform inference, we need to implement the inducing variables $U_1$ and $U_2$, both with size $M=20$, which are used to approximate $f_1$ and $f_2$ respectively, and initialize the inducing points positions $Z_1$ and $Z_2$. This gives a total of $2M=40$ inducing variables and inducing points.\n#\n# The inducing variables and their corresponding inputs will be Separate and Independent, but both $Z_1$ and $Z_2$ will be initialized as $Z$, which are placed as $M=20$ equally spaced points in $[\\min(X), \\max(X)]$.\n#\n\n# %%\nM = 20 # Number of inducing variables for each f_i\n\n# Initial inducing points position Z\nZ = np.linspace(X.min(), X.max(), M)[:, None] # Z must be of shape [M, 1]\n\ninducing_variable = gpf.inducing_variables.SeparateIndependentInducingVariables(\n [\n gpf.inducing_variables.InducingPoints(Z), # This is U1 = f1(Z1)\n gpf.inducing_variables.InducingPoints(Z), # This is U2 = f2(Z2)\n ]\n)\n\n# %% [markdown]\n# ### SVGP Model\n# Build the **SVGP** model by composing the **Kernel**, the **Likelihood** and the **Inducing Variables**.\n#\n# Note that the model needs to be instructed about the number of latent GPs by passing `num_latent_gps=likelihood.latent_dim`.\n\n# %%\nmodel = gpf.models.SVGP(\n kernel=kernel,\n likelihood=likelihood,\n inducing_variable=inducing_variable,\n num_latent_gps=likelihood.latent_dim,\n)\n\nmodel\n\n# %% [markdown]\n# ## Model Optimization\n#\n# ### Build Optimizers (NatGrad + Adam)\n\n# %%\ndata = (X, Y)\nloss_fn = model.training_loss_closure(data)\n\ngpf.utilities.set_trainable(model.q_mu, False)\ngpf.utilities.set_trainable(model.q_sqrt, False)\n\nvariational_vars = [(model.q_mu, model.q_sqrt)]\nnatgrad_opt = gpf.optimizers.NaturalGradient(gamma=0.1)\n\nadam_vars = model.trainable_variables\nadam_opt = tf.optimizers.Adam(0.01)\n\n\[email protected]\ndef optimisation_step():\n natgrad_opt.minimize(loss_fn, variational_vars)\n adam_opt.minimize(loss_fn, adam_vars)\n\n\n# %% [markdown]\n# ### Run Optimization Loop\n\n# %%\nepochs = 100\nlog_freq = 20\n\nfor epoch in range(1, epochs + 1):\n optimisation_step()\n\n # For every 'log_freq' epochs, print the epoch and plot the predictions against the data\n if epoch % log_freq == 0 and epoch > 0:\n print(f\"Epoch {epoch} - Loss: {loss_fn().numpy() : .4f}\")\n Ymean, Yvar = model.predict_y(X)\n Ymean = Ymean.numpy().squeeze()\n Ystd = tf.sqrt(Yvar).numpy().squeeze()\n plot_distribution(X, Y, Ymean, Ystd)\n\nmodel\n\n# %% [markdown]\n# ## Further reading\n#\n# See [Chained Gaussian Processes](http://proceedings.mlr.press/v51/saul16.html) by Saul et al. (AISTATS 2016).\n", "path": "doc/source/notebooks/advanced/heteroskedastic.pct.py"}]} | 3,237 | 178 |
gh_patches_debug_35139 | rasdani/github-patches | git_diff | spotify__luigi-1744 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
HdfsTarget commands fail when many targets are instantiated
I've recently added an existence check to a large mapreduce task for which some input files may be missing. With a large enough set of inputs, it will fail every time. I've simplified it to the following code:
``` python
from luigi.contrib.hdfs import HdfsTarget
many_targets = [HdfsTarget('/') for _ in range(2000)]
all(target.exists() for target in many_targets)
```
This will break if I use any past 1000 or so. Here the client uses snakebite. For a more direct triggering, we can also do
``` python
from snakebite.client import AutoConfigClient
clients = [AutoConfigClient() for _ in range(10000)]
all(client.test('/', exists=True) for client in clients)
```
In either case, the bug goes away if I use a generator expression rather than a list comprehension. The problem is that when I'm dealing with objects coming out of luigi calls like input_hadoop, it's too late for me to decide between lists and iterators. I can code around this by instantiating all of my HdfsTargets with the same client, but I'm not sure this is safe. It could also be fixed in luigi if we had get_autoconfig_client return the same object each time. Is there any reason this wouldn't work?
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `luigi/contrib/hdfs/clients.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 #
3 # Copyright 2012-2015 Spotify AB
4 #
5 # Licensed under the Apache License, Version 2.0 (the "License");
6 # you may not use this file except in compliance with the License.
7 # You may obtain a copy of the License at
8 #
9 # http://www.apache.org/licenses/LICENSE-2.0
10 #
11 # Unless required by applicable law or agreed to in writing, software
12 # distributed under the License is distributed on an "AS IS" BASIS,
13 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
14 # See the License for the specific language governing permissions and
15 # limitations under the License.
16 #
17
18 """
19 The implementations of the hdfs clients. The hadoop cli client and the
20 snakebite client.
21 """
22
23
24 from luigi.contrib.hdfs import config as hdfs_config
25 from luigi.contrib.hdfs import snakebite_client as hdfs_snakebite_client
26 from luigi.contrib.hdfs import webhdfs_client as hdfs_webhdfs_client
27 from luigi.contrib.hdfs import hadoopcli_clients as hdfs_hadoopcli_clients
28 import luigi.contrib.target
29 import logging
30
31 logger = logging.getLogger('luigi-interface')
32
33
34 def get_autoconfig_client():
35 """
36 Creates the client as specified in the `luigi.cfg` configuration.
37 """
38 configured_client = hdfs_config.get_configured_hdfs_client()
39 if configured_client == "webhdfs":
40 return hdfs_webhdfs_client.WebHdfsClient()
41 if configured_client == "snakebite":
42 return hdfs_snakebite_client.SnakebiteHdfsClient()
43 if configured_client == "snakebite_with_hadoopcli_fallback":
44 return luigi.contrib.target.CascadingClient([hdfs_snakebite_client.SnakebiteHdfsClient(),
45 hdfs_hadoopcli_clients.create_hadoopcli_client()])
46 if configured_client == "hadoopcli":
47 return hdfs_hadoopcli_clients.create_hadoopcli_client()
48 raise Exception("Unknown hdfs client " + configured_client)
49
50
51 def _with_ac(method_name):
52 def result(*args, **kwargs):
53 return getattr(get_autoconfig_client(), method_name)(*args, **kwargs)
54 return result
55
56 exists = _with_ac('exists')
57 rename = _with_ac('rename')
58 remove = _with_ac('remove')
59 mkdir = _with_ac('mkdir')
60 listdir = _with_ac('listdir')
61
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/luigi/contrib/hdfs/clients.py b/luigi/contrib/hdfs/clients.py
--- a/luigi/contrib/hdfs/clients.py
+++ b/luigi/contrib/hdfs/clients.py
@@ -19,33 +19,42 @@
The implementations of the hdfs clients. The hadoop cli client and the
snakebite client.
"""
-
+import logging
+import threading
from luigi.contrib.hdfs import config as hdfs_config
from luigi.contrib.hdfs import snakebite_client as hdfs_snakebite_client
from luigi.contrib.hdfs import webhdfs_client as hdfs_webhdfs_client
from luigi.contrib.hdfs import hadoopcli_clients as hdfs_hadoopcli_clients
import luigi.contrib.target
-import logging
logger = logging.getLogger('luigi-interface')
+_AUTOCONFIG_CLIENT = threading.local()
+
-def get_autoconfig_client():
+def get_autoconfig_client(client_cache=_AUTOCONFIG_CLIENT):
"""
Creates the client as specified in the `luigi.cfg` configuration.
"""
- configured_client = hdfs_config.get_configured_hdfs_client()
- if configured_client == "webhdfs":
- return hdfs_webhdfs_client.WebHdfsClient()
- if configured_client == "snakebite":
- return hdfs_snakebite_client.SnakebiteHdfsClient()
- if configured_client == "snakebite_with_hadoopcli_fallback":
- return luigi.contrib.target.CascadingClient([hdfs_snakebite_client.SnakebiteHdfsClient(),
- hdfs_hadoopcli_clients.create_hadoopcli_client()])
- if configured_client == "hadoopcli":
- return hdfs_hadoopcli_clients.create_hadoopcli_client()
- raise Exception("Unknown hdfs client " + configured_client)
+ try:
+ return client_cache.client
+ except AttributeError:
+ configured_client = hdfs_config.get_configured_hdfs_client()
+ if configured_client == "webhdfs":
+ client_cache.client = hdfs_webhdfs_client.WebHdfsClient()
+ elif configured_client == "snakebite":
+ client_cache.client = hdfs_snakebite_client.SnakebiteHdfsClient()
+ elif configured_client == "snakebite_with_hadoopcli_fallback":
+ client_cache.client = luigi.contrib.target.CascadingClient([
+ hdfs_snakebite_client.SnakebiteHdfsClient(),
+ hdfs_hadoopcli_clients.create_hadoopcli_client(),
+ ])
+ elif configured_client == "hadoopcli":
+ client_cache.client = hdfs_hadoopcli_clients.create_hadoopcli_client()
+ else:
+ raise Exception("Unknown hdfs client " + configured_client)
+ return client_cache.client
def _with_ac(method_name):
| {"golden_diff": "diff --git a/luigi/contrib/hdfs/clients.py b/luigi/contrib/hdfs/clients.py\n--- a/luigi/contrib/hdfs/clients.py\n+++ b/luigi/contrib/hdfs/clients.py\n@@ -19,33 +19,42 @@\n The implementations of the hdfs clients. The hadoop cli client and the\n snakebite client.\n \"\"\"\n-\n+import logging\n+import threading\n \n from luigi.contrib.hdfs import config as hdfs_config\n from luigi.contrib.hdfs import snakebite_client as hdfs_snakebite_client\n from luigi.contrib.hdfs import webhdfs_client as hdfs_webhdfs_client\n from luigi.contrib.hdfs import hadoopcli_clients as hdfs_hadoopcli_clients\n import luigi.contrib.target\n-import logging\n \n logger = logging.getLogger('luigi-interface')\n \n+_AUTOCONFIG_CLIENT = threading.local()\n+\n \n-def get_autoconfig_client():\n+def get_autoconfig_client(client_cache=_AUTOCONFIG_CLIENT):\n \"\"\"\n Creates the client as specified in the `luigi.cfg` configuration.\n \"\"\"\n- configured_client = hdfs_config.get_configured_hdfs_client()\n- if configured_client == \"webhdfs\":\n- return hdfs_webhdfs_client.WebHdfsClient()\n- if configured_client == \"snakebite\":\n- return hdfs_snakebite_client.SnakebiteHdfsClient()\n- if configured_client == \"snakebite_with_hadoopcli_fallback\":\n- return luigi.contrib.target.CascadingClient([hdfs_snakebite_client.SnakebiteHdfsClient(),\n- hdfs_hadoopcli_clients.create_hadoopcli_client()])\n- if configured_client == \"hadoopcli\":\n- return hdfs_hadoopcli_clients.create_hadoopcli_client()\n- raise Exception(\"Unknown hdfs client \" + configured_client)\n+ try:\n+ return client_cache.client\n+ except AttributeError:\n+ configured_client = hdfs_config.get_configured_hdfs_client()\n+ if configured_client == \"webhdfs\":\n+ client_cache.client = hdfs_webhdfs_client.WebHdfsClient()\n+ elif configured_client == \"snakebite\":\n+ client_cache.client = hdfs_snakebite_client.SnakebiteHdfsClient()\n+ elif configured_client == \"snakebite_with_hadoopcli_fallback\":\n+ client_cache.client = luigi.contrib.target.CascadingClient([\n+ hdfs_snakebite_client.SnakebiteHdfsClient(),\n+ hdfs_hadoopcli_clients.create_hadoopcli_client(),\n+ ])\n+ elif configured_client == \"hadoopcli\":\n+ client_cache.client = hdfs_hadoopcli_clients.create_hadoopcli_client()\n+ else:\n+ raise Exception(\"Unknown hdfs client \" + configured_client)\n+ return client_cache.client\n \n \n def _with_ac(method_name):\n", "issue": "HdfsTarget commands fail when many targets are instantiated\nI've recently added an existence check to a large mapreduce task for which some input files may be missing. With a large enough set of inputs, it will fail every time. I've simplified it to the following code:\n\n``` python\nfrom luigi.contrib.hdfs import HdfsTarget\n\nmany_targets = [HdfsTarget('/') for _ in range(2000)]\nall(target.exists() for target in many_targets)\n```\n\nThis will break if I use any past 1000 or so. Here the client uses snakebite. For a more direct triggering, we can also do\n\n``` python\nfrom snakebite.client import AutoConfigClient\n\nclients = [AutoConfigClient() for _ in range(10000)]\nall(client.test('/', exists=True) for client in clients)\n```\n\nIn either case, the bug goes away if I use a generator expression rather than a list comprehension. The problem is that when I'm dealing with objects coming out of luigi calls like input_hadoop, it's too late for me to decide between lists and iterators. I can code around this by instantiating all of my HdfsTargets with the same client, but I'm not sure this is safe. It could also be fixed in luigi if we had get_autoconfig_client return the same object each time. Is there any reason this wouldn't work?\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2012-2015 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nThe implementations of the hdfs clients. The hadoop cli client and the\nsnakebite client.\n\"\"\"\n\n\nfrom luigi.contrib.hdfs import config as hdfs_config\nfrom luigi.contrib.hdfs import snakebite_client as hdfs_snakebite_client\nfrom luigi.contrib.hdfs import webhdfs_client as hdfs_webhdfs_client\nfrom luigi.contrib.hdfs import hadoopcli_clients as hdfs_hadoopcli_clients\nimport luigi.contrib.target\nimport logging\n\nlogger = logging.getLogger('luigi-interface')\n\n\ndef get_autoconfig_client():\n \"\"\"\n Creates the client as specified in the `luigi.cfg` configuration.\n \"\"\"\n configured_client = hdfs_config.get_configured_hdfs_client()\n if configured_client == \"webhdfs\":\n return hdfs_webhdfs_client.WebHdfsClient()\n if configured_client == \"snakebite\":\n return hdfs_snakebite_client.SnakebiteHdfsClient()\n if configured_client == \"snakebite_with_hadoopcli_fallback\":\n return luigi.contrib.target.CascadingClient([hdfs_snakebite_client.SnakebiteHdfsClient(),\n hdfs_hadoopcli_clients.create_hadoopcli_client()])\n if configured_client == \"hadoopcli\":\n return hdfs_hadoopcli_clients.create_hadoopcli_client()\n raise Exception(\"Unknown hdfs client \" + configured_client)\n\n\ndef _with_ac(method_name):\n def result(*args, **kwargs):\n return getattr(get_autoconfig_client(), method_name)(*args, **kwargs)\n return result\n\nexists = _with_ac('exists')\nrename = _with_ac('rename')\nremove = _with_ac('remove')\nmkdir = _with_ac('mkdir')\nlistdir = _with_ac('listdir')\n", "path": "luigi/contrib/hdfs/clients.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# Copyright 2012-2015 Spotify AB\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\"\"\"\nThe implementations of the hdfs clients. The hadoop cli client and the\nsnakebite client.\n\"\"\"\nimport logging\nimport threading\n\nfrom luigi.contrib.hdfs import config as hdfs_config\nfrom luigi.contrib.hdfs import snakebite_client as hdfs_snakebite_client\nfrom luigi.contrib.hdfs import webhdfs_client as hdfs_webhdfs_client\nfrom luigi.contrib.hdfs import hadoopcli_clients as hdfs_hadoopcli_clients\nimport luigi.contrib.target\n\nlogger = logging.getLogger('luigi-interface')\n\n_AUTOCONFIG_CLIENT = threading.local()\n\n\ndef get_autoconfig_client(client_cache=_AUTOCONFIG_CLIENT):\n \"\"\"\n Creates the client as specified in the `luigi.cfg` configuration.\n \"\"\"\n try:\n return client_cache.client\n except AttributeError:\n configured_client = hdfs_config.get_configured_hdfs_client()\n if configured_client == \"webhdfs\":\n client_cache.client = hdfs_webhdfs_client.WebHdfsClient()\n elif configured_client == \"snakebite\":\n client_cache.client = hdfs_snakebite_client.SnakebiteHdfsClient()\n elif configured_client == \"snakebite_with_hadoopcli_fallback\":\n client_cache.client = luigi.contrib.target.CascadingClient([\n hdfs_snakebite_client.SnakebiteHdfsClient(),\n hdfs_hadoopcli_clients.create_hadoopcli_client(),\n ])\n elif configured_client == \"hadoopcli\":\n client_cache.client = hdfs_hadoopcli_clients.create_hadoopcli_client()\n else:\n raise Exception(\"Unknown hdfs client \" + configured_client)\n return client_cache.client\n\n\ndef _with_ac(method_name):\n def result(*args, **kwargs):\n return getattr(get_autoconfig_client(), method_name)(*args, **kwargs)\n return result\n\nexists = _with_ac('exists')\nrename = _with_ac('rename')\nremove = _with_ac('remove')\nmkdir = _with_ac('mkdir')\nlistdir = _with_ac('listdir')\n", "path": "luigi/contrib/hdfs/clients.py"}]} | 1,182 | 606 |
gh_patches_debug_20778 | rasdani/github-patches | git_diff | saleor__saleor-113 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Improve payments templates
Use Bootstrap 3 classes.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `saleor/core/templatetags/bootstrap.py`
Content:
```
1 from django import forms
2 from django.forms.forms import BoundField, BaseForm
3 from django.forms.util import ErrorList
4 from django.template import Library, Context, TemplateSyntaxError
5 from django.template.loader import render_to_string
6 from django.utils.safestring import mark_safe
7
8 register = Library()
9
10 TEMPLATE_ERRORS = 'bootstrap/_non_field_errors.html'
11 TEMPLATE_HORIZONTAL = 'bootstrap/_field_horizontal.html'
12 TEMPLATE_VERTICAL = 'bootstrap/_field_vertical.html'
13
14
15 def render_non_field_errors(errors):
16 if not errors:
17 return ''
18 context = Context({'errors': errors})
19 return render_to_string(TEMPLATE_ERRORS, context_instance=context)
20
21
22 def render_field(bound_field, show_label, template):
23 widget = bound_field.field.widget
24
25 if isinstance(widget, forms.RadioSelect):
26 input_type = 'radio'
27 elif isinstance(widget, forms.Select):
28 input_type = 'select'
29 elif isinstance(widget, forms.Textarea):
30 input_type = 'textarea'
31 elif isinstance(widget, forms.CheckboxInput):
32 input_type = 'checkbox'
33 else:
34 input_type = 'input'
35
36 context = Context({'bound_field': bound_field,
37 'input_type': input_type,
38 'show_label': show_label})
39 return render_to_string(template, context_instance=context)
40
41
42 def as_bootstrap(obj, show_label, template):
43 if isinstance(obj, BoundField):
44 return render_field(obj, show_label, template)
45 elif isinstance(obj, ErrorList):
46 return render_non_field_errors(obj)
47 elif isinstance(obj, BaseForm):
48 non_field_errors = render_non_field_errors(obj.non_field_errors())
49 fields = (render_field(field, show_label, template) for field in obj)
50 form = ''.join(fields)
51 return mark_safe(non_field_errors + form)
52 else:
53 raise TemplateSyntaxError('Filter accepts form, field and non fields '
54 'errors.')
55
56
57 @register.filter
58 def as_horizontal_form(obj, show_label=True):
59 return as_bootstrap(obj=obj, show_label=show_label,
60 template=TEMPLATE_HORIZONTAL)
61
62
63 @register.filter
64 def as_vertical_form(obj, show_label=True):
65 return as_bootstrap(obj=obj, show_label=show_label,
66 template=TEMPLATE_VERTICAL)
67
68
69 @register.simple_tag
70 def render_widget(obj, **attrs):
71 return obj.as_widget(attrs=attrs)
72
```
Path: `saleor/settings.py`
Content:
```
1 import os.path
2
3 DEBUG = True
4 TEMPLATE_DEBUG = DEBUG
5
6 SITE_ID = 1
7
8 PROJECT_ROOT = os.path.normpath(os.path.join(os.path.dirname(__file__), '..'))
9
10 ROOT_URLCONF = 'saleor.urls'
11
12 WSGI_APPLICATION = 'saleor.wsgi.application'
13
14 ADMINS = (
15 # ('Your Name', '[email protected]'),
16 )
17 MANAGERS = ADMINS
18 INTERNAL_IPS = ['127.0.0.1']
19
20 DATABASES = {
21 'default': {
22 'ENGINE': 'django.db.backends.sqlite3',
23 'NAME': 'dev.sqlite'
24 }
25 }
26
27 TIME_ZONE = 'America/Chicago'
28 LANGUAGE_CODE = 'en-us'
29 USE_I18N = True
30 USE_L10N = True
31 USE_TZ = True
32
33 MEDIA_ROOT = os.path.join(PROJECT_ROOT, 'media')
34 MEDIA_URL = '/media/'
35
36 STATIC_ROOT = os.path.join(PROJECT_ROOT, 'static')
37 STATIC_URL = '/static/'
38 STATICFILES_DIRS = [
39 os.path.join(PROJECT_ROOT, 'saleor', 'static')
40 ]
41 STATICFILES_FINDERS = [
42 'django.contrib.staticfiles.finders.FileSystemFinder',
43 'django.contrib.staticfiles.finders.AppDirectoriesFinder'
44 ]
45
46 TEMPLATE_DIRS = [
47 os.path.join(PROJECT_ROOT, 'templates')
48 ]
49 TEMPLATE_LOADERS = [
50 'django.template.loaders.filesystem.Loader',
51 'django.template.loaders.app_directories.Loader',
52 # TODO: this one is slow, but for now need for mptt?
53 'django.template.loaders.eggs.Loader'
54 ]
55
56 # Make this unique, and don't share it with anybody.
57 SECRET_KEY = '{{ secret_key }}'
58
59 MIDDLEWARE_CLASSES = [
60 'django.contrib.sessions.middleware.SessionMiddleware',
61 'django.middleware.common.CommonMiddleware',
62 'django.middleware.csrf.CsrfViewMiddleware',
63 'django.contrib.auth.middleware.AuthenticationMiddleware',
64 'django.contrib.messages.middleware.MessageMiddleware',
65 'saleor.cart.middleware.CartMiddleware',
66 'saleor.core.middleware.GoogleAnalytics',
67 'saleor.core.middleware.CheckHTML'
68 ]
69
70 TEMPLATE_CONTEXT_PROCESSORS = [
71 'django.contrib.auth.context_processors.auth',
72 'django.core.context_processors.debug',
73 'django.core.context_processors.i18n',
74 'django.core.context_processors.media',
75 'django.core.context_processors.static',
76 'django.core.context_processors.tz',
77 'django.contrib.messages.context_processors.messages',
78 'django.core.context_processors.request',
79 'saleor.core.context_processors.canonical_hostname',
80 'saleor.core.context_processors.default_currency'
81 ]
82
83 INSTALLED_APPS = [
84 # External apps that need to go before django's
85
86 # Django modules
87 'django.contrib.contenttypes',
88 'django.contrib.sessions',
89 'django.contrib.messages',
90 'django.contrib.staticfiles',
91 'django.contrib.admin',
92 'django.contrib.webdesign',
93
94 # External apps
95 'django_images',
96 'django_prices',
97 'mptt',
98 'payments',
99 'south',
100
101 # Local apps
102 'saleor.cart',
103 'saleor.checkout',
104 'saleor.core',
105 'saleor.order',
106 'saleor.payment',
107 'saleor.product',
108 'saleor.registration',
109 'saleor.userprofile'
110 ]
111
112 LOGGING = {
113 'version': 1,
114 'disable_existing_loggers': False,
115 'formatters': {
116 'verbose': {
117 'format': '%(levelname)s %(asctime)s %(module)s '
118 '%(process)d %(thread)d %(message)s'
119 },
120 'simple': {
121 'format': '%(levelname)s %(message)s'
122 },
123 },
124 'filters': {
125 'require_debug_false': {
126 '()': 'django.utils.log.RequireDebugFalse'
127 },
128 'require_debug_true': {
129 '()': 'django.utils.log.RequireDebugTrue'
130 }
131 },
132 'handlers': {
133 'mail_admins': {
134 'level': 'ERROR',
135 'filters': ['require_debug_false'],
136 'class': 'django.utils.log.AdminEmailHandler'
137 },
138 'console': {
139 'level': 'DEBUG',
140 'class': 'logging.StreamHandler',
141 'filters': ['require_debug_true'],
142 'formatter': 'simple'
143 },
144 },
145 'loggers': {
146 'django.request': {
147 'handlers': ['mail_admins'],
148 'level': 'ERROR',
149 'propagate': True
150 },
151 'saleor': {
152 'handlers': ['console'],
153 'level': 'DEBUG',
154 'propagate': True
155 }
156 }
157 }
158
159 AUTHENTICATION_BACKENDS = (
160 'saleor.registration.backends.EmailPasswordBackend',
161 'saleor.registration.backends.ExternalLoginBackend',
162 'saleor.registration.backends.TrivialBackend'
163 )
164
165 AUTH_USER_MODEL = 'userprofile.User'
166
167 CANONICAL_HOSTNAME = 'localhost:8000'
168
169 IMAGE_SIZES = {
170 'normal': {
171 'size': (750, 0)
172 },
173 'admin': {
174 'size': (50, 50),
175 'crop': True
176 }
177 }
178
179 EMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'
180
181 LOGIN_URL = '/account/login'
182
183 WARN_ABOUT_INVALID_HTML5_OUTPUT = False
184
185 SATCHLESS_DEFAULT_CURRENCY = 'USD'
186
187 ACCOUNT_ACTIVATION_DAYS = 3
188
189 LOGIN_REDIRECT_URL = 'home'
190
191 FACEBOOK_APP_ID = None
192 FACEBOOK_SECRET = None
193
194 GOOGLE_ANALYTICS_TRACKING_ID = None
195 GOOGLE_CLIENT_ID = None
196 GOOGLE_CLIENT_SECRET = None
197
198 PAYMENT_BASE_URL = 'http://%s/' % CANONICAL_HOSTNAME
199
200 PAYMENT_MODEL = 'payment.Payment'
201
202 PAYMENT_VARIANTS = {
203 'default': ('payments.dummy.DummyProvider', {'url': 'http://google.pl/'})
204 }
205
206 SESSION_SERIALIZER = 'django.contrib.sessions.serializers.PickleSerializer'
207
208 CHECKOUT_PAYMENT_CHOICES = [
209 ('default', 'Dummy provider')
210 ]
211
212 TEMPLATE_STRING_IF_INVALID = '<< MISSING VARIABLE >>'
213
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/saleor/core/templatetags/bootstrap.py b/saleor/core/templatetags/bootstrap.py
--- a/saleor/core/templatetags/bootstrap.py
+++ b/saleor/core/templatetags/bootstrap.py
@@ -30,6 +30,8 @@
input_type = 'textarea'
elif isinstance(widget, forms.CheckboxInput):
input_type = 'checkbox'
+ elif issubclass(type(widget), forms.MultiWidget):
+ input_type = 'multi_widget'
else:
input_type = 'input'
diff --git a/saleor/settings.py b/saleor/settings.py
--- a/saleor/settings.py
+++ b/saleor/settings.py
@@ -91,13 +91,6 @@
'django.contrib.admin',
'django.contrib.webdesign',
- # External apps
- 'django_images',
- 'django_prices',
- 'mptt',
- 'payments',
- 'south',
-
# Local apps
'saleor.cart',
'saleor.checkout',
@@ -106,7 +99,14 @@
'saleor.payment',
'saleor.product',
'saleor.registration',
- 'saleor.userprofile'
+ 'saleor.userprofile',
+
+ # External apps
+ 'django_images',
+ 'django_prices',
+ 'mptt',
+ 'payments',
+ 'south'
]
LOGGING = {
| {"golden_diff": "diff --git a/saleor/core/templatetags/bootstrap.py b/saleor/core/templatetags/bootstrap.py\n--- a/saleor/core/templatetags/bootstrap.py\n+++ b/saleor/core/templatetags/bootstrap.py\n@@ -30,6 +30,8 @@\n input_type = 'textarea'\n elif isinstance(widget, forms.CheckboxInput):\n input_type = 'checkbox'\n+ elif issubclass(type(widget), forms.MultiWidget):\n+ input_type = 'multi_widget'\n else:\n input_type = 'input'\n \ndiff --git a/saleor/settings.py b/saleor/settings.py\n--- a/saleor/settings.py\n+++ b/saleor/settings.py\n@@ -91,13 +91,6 @@\n 'django.contrib.admin',\n 'django.contrib.webdesign',\n \n- # External apps\n- 'django_images',\n- 'django_prices',\n- 'mptt',\n- 'payments',\n- 'south',\n-\n # Local apps\n 'saleor.cart',\n 'saleor.checkout',\n@@ -106,7 +99,14 @@\n 'saleor.payment',\n 'saleor.product',\n 'saleor.registration',\n- 'saleor.userprofile'\n+ 'saleor.userprofile',\n+\n+ # External apps\n+ 'django_images',\n+ 'django_prices',\n+ 'mptt',\n+ 'payments',\n+ 'south'\n ]\n \n LOGGING = {\n", "issue": "Improve payments templates\nUse Bootstrap 3 classes.\n\n", "before_files": [{"content": "from django import forms\nfrom django.forms.forms import BoundField, BaseForm\nfrom django.forms.util import ErrorList\nfrom django.template import Library, Context, TemplateSyntaxError\nfrom django.template.loader import render_to_string\nfrom django.utils.safestring import mark_safe\n\nregister = Library()\n\nTEMPLATE_ERRORS = 'bootstrap/_non_field_errors.html'\nTEMPLATE_HORIZONTAL = 'bootstrap/_field_horizontal.html'\nTEMPLATE_VERTICAL = 'bootstrap/_field_vertical.html'\n\n\ndef render_non_field_errors(errors):\n if not errors:\n return ''\n context = Context({'errors': errors})\n return render_to_string(TEMPLATE_ERRORS, context_instance=context)\n\n\ndef render_field(bound_field, show_label, template):\n widget = bound_field.field.widget\n\n if isinstance(widget, forms.RadioSelect):\n input_type = 'radio'\n elif isinstance(widget, forms.Select):\n input_type = 'select'\n elif isinstance(widget, forms.Textarea):\n input_type = 'textarea'\n elif isinstance(widget, forms.CheckboxInput):\n input_type = 'checkbox'\n else:\n input_type = 'input'\n\n context = Context({'bound_field': bound_field,\n 'input_type': input_type,\n 'show_label': show_label})\n return render_to_string(template, context_instance=context)\n\n\ndef as_bootstrap(obj, show_label, template):\n if isinstance(obj, BoundField):\n return render_field(obj, show_label, template)\n elif isinstance(obj, ErrorList):\n return render_non_field_errors(obj)\n elif isinstance(obj, BaseForm):\n non_field_errors = render_non_field_errors(obj.non_field_errors())\n fields = (render_field(field, show_label, template) for field in obj)\n form = ''.join(fields)\n return mark_safe(non_field_errors + form)\n else:\n raise TemplateSyntaxError('Filter accepts form, field and non fields '\n 'errors.')\n\n\[email protected]\ndef as_horizontal_form(obj, show_label=True):\n return as_bootstrap(obj=obj, show_label=show_label,\n template=TEMPLATE_HORIZONTAL)\n\n\[email protected]\ndef as_vertical_form(obj, show_label=True):\n return as_bootstrap(obj=obj, show_label=show_label,\n template=TEMPLATE_VERTICAL)\n\n\[email protected]_tag\ndef render_widget(obj, **attrs):\n return obj.as_widget(attrs=attrs)\n", "path": "saleor/core/templatetags/bootstrap.py"}, {"content": "import os.path\n\nDEBUG = True\nTEMPLATE_DEBUG = DEBUG\n\nSITE_ID = 1\n\nPROJECT_ROOT = os.path.normpath(os.path.join(os.path.dirname(__file__), '..'))\n\nROOT_URLCONF = 'saleor.urls'\n\nWSGI_APPLICATION = 'saleor.wsgi.application'\n\nADMINS = (\n # ('Your Name', '[email protected]'),\n)\nMANAGERS = ADMINS\nINTERNAL_IPS = ['127.0.0.1']\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': 'dev.sqlite'\n }\n}\n\nTIME_ZONE = 'America/Chicago'\nLANGUAGE_CODE = 'en-us'\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nMEDIA_ROOT = os.path.join(PROJECT_ROOT, 'media')\nMEDIA_URL = '/media/'\n\nSTATIC_ROOT = os.path.join(PROJECT_ROOT, 'static')\nSTATIC_URL = '/static/'\nSTATICFILES_DIRS = [\n os.path.join(PROJECT_ROOT, 'saleor', 'static')\n]\nSTATICFILES_FINDERS = [\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder'\n]\n\nTEMPLATE_DIRS = [\n os.path.join(PROJECT_ROOT, 'templates')\n]\nTEMPLATE_LOADERS = [\n 'django.template.loaders.filesystem.Loader',\n 'django.template.loaders.app_directories.Loader',\n # TODO: this one is slow, but for now need for mptt?\n 'django.template.loaders.eggs.Loader'\n]\n\n# Make this unique, and don't share it with anybody.\nSECRET_KEY = '{{ secret_key }}'\n\nMIDDLEWARE_CLASSES = [\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'saleor.cart.middleware.CartMiddleware',\n 'saleor.core.middleware.GoogleAnalytics',\n 'saleor.core.middleware.CheckHTML'\n]\n\nTEMPLATE_CONTEXT_PROCESSORS = [\n 'django.contrib.auth.context_processors.auth',\n 'django.core.context_processors.debug',\n 'django.core.context_processors.i18n',\n 'django.core.context_processors.media',\n 'django.core.context_processors.static',\n 'django.core.context_processors.tz',\n 'django.contrib.messages.context_processors.messages',\n 'django.core.context_processors.request',\n 'saleor.core.context_processors.canonical_hostname',\n 'saleor.core.context_processors.default_currency'\n]\n\nINSTALLED_APPS = [\n # External apps that need to go before django's\n\n # Django modules\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.admin',\n 'django.contrib.webdesign',\n\n # External apps\n 'django_images',\n 'django_prices',\n 'mptt',\n 'payments',\n 'south',\n\n # Local apps\n 'saleor.cart',\n 'saleor.checkout',\n 'saleor.core',\n 'saleor.order',\n 'saleor.payment',\n 'saleor.product',\n 'saleor.registration',\n 'saleor.userprofile'\n]\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(module)s '\n '%(process)d %(thread)d %(message)s'\n },\n 'simple': {\n 'format': '%(levelname)s %(message)s'\n },\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse'\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue'\n }\n },\n 'handlers': {\n 'mail_admins': {\n 'level': 'ERROR',\n 'filters': ['require_debug_false'],\n 'class': 'django.utils.log.AdminEmailHandler'\n },\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n 'filters': ['require_debug_true'],\n 'formatter': 'simple'\n },\n },\n 'loggers': {\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': True\n },\n 'saleor': {\n 'handlers': ['console'],\n 'level': 'DEBUG',\n 'propagate': True\n }\n }\n}\n\nAUTHENTICATION_BACKENDS = (\n 'saleor.registration.backends.EmailPasswordBackend',\n 'saleor.registration.backends.ExternalLoginBackend',\n 'saleor.registration.backends.TrivialBackend'\n)\n\nAUTH_USER_MODEL = 'userprofile.User'\n\nCANONICAL_HOSTNAME = 'localhost:8000'\n\nIMAGE_SIZES = {\n 'normal': {\n 'size': (750, 0)\n },\n 'admin': {\n 'size': (50, 50),\n 'crop': True\n }\n}\n\nEMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\nLOGIN_URL = '/account/login'\n\nWARN_ABOUT_INVALID_HTML5_OUTPUT = False\n\nSATCHLESS_DEFAULT_CURRENCY = 'USD'\n\nACCOUNT_ACTIVATION_DAYS = 3\n\nLOGIN_REDIRECT_URL = 'home'\n\nFACEBOOK_APP_ID = None\nFACEBOOK_SECRET = None\n\nGOOGLE_ANALYTICS_TRACKING_ID = None\nGOOGLE_CLIENT_ID = None\nGOOGLE_CLIENT_SECRET = None\n\nPAYMENT_BASE_URL = 'http://%s/' % CANONICAL_HOSTNAME\n\nPAYMENT_MODEL = 'payment.Payment'\n\nPAYMENT_VARIANTS = {\n 'default': ('payments.dummy.DummyProvider', {'url': 'http://google.pl/'})\n}\n\nSESSION_SERIALIZER = 'django.contrib.sessions.serializers.PickleSerializer'\n\nCHECKOUT_PAYMENT_CHOICES = [\n ('default', 'Dummy provider')\n]\n\nTEMPLATE_STRING_IF_INVALID = '<< MISSING VARIABLE >>'\n", "path": "saleor/settings.py"}], "after_files": [{"content": "from django import forms\nfrom django.forms.forms import BoundField, BaseForm\nfrom django.forms.util import ErrorList\nfrom django.template import Library, Context, TemplateSyntaxError\nfrom django.template.loader import render_to_string\nfrom django.utils.safestring import mark_safe\n\nregister = Library()\n\nTEMPLATE_ERRORS = 'bootstrap/_non_field_errors.html'\nTEMPLATE_HORIZONTAL = 'bootstrap/_field_horizontal.html'\nTEMPLATE_VERTICAL = 'bootstrap/_field_vertical.html'\n\n\ndef render_non_field_errors(errors):\n if not errors:\n return ''\n context = Context({'errors': errors})\n return render_to_string(TEMPLATE_ERRORS, context_instance=context)\n\n\ndef render_field(bound_field, show_label, template):\n widget = bound_field.field.widget\n\n if isinstance(widget, forms.RadioSelect):\n input_type = 'radio'\n elif isinstance(widget, forms.Select):\n input_type = 'select'\n elif isinstance(widget, forms.Textarea):\n input_type = 'textarea'\n elif isinstance(widget, forms.CheckboxInput):\n input_type = 'checkbox'\n elif issubclass(type(widget), forms.MultiWidget):\n input_type = 'multi_widget'\n else:\n input_type = 'input'\n\n context = Context({'bound_field': bound_field,\n 'input_type': input_type,\n 'show_label': show_label})\n return render_to_string(template, context_instance=context)\n\n\ndef as_bootstrap(obj, show_label, template):\n if isinstance(obj, BoundField):\n return render_field(obj, show_label, template)\n elif isinstance(obj, ErrorList):\n return render_non_field_errors(obj)\n elif isinstance(obj, BaseForm):\n non_field_errors = render_non_field_errors(obj.non_field_errors())\n fields = (render_field(field, show_label, template) for field in obj)\n form = ''.join(fields)\n return mark_safe(non_field_errors + form)\n else:\n raise TemplateSyntaxError('Filter accepts form, field and non fields '\n 'errors.')\n\n\[email protected]\ndef as_horizontal_form(obj, show_label=True):\n return as_bootstrap(obj=obj, show_label=show_label,\n template=TEMPLATE_HORIZONTAL)\n\n\[email protected]\ndef as_vertical_form(obj, show_label=True):\n return as_bootstrap(obj=obj, show_label=show_label,\n template=TEMPLATE_VERTICAL)\n\n\[email protected]_tag\ndef render_widget(obj, **attrs):\n return obj.as_widget(attrs=attrs)\n", "path": "saleor/core/templatetags/bootstrap.py"}, {"content": "import os.path\n\nDEBUG = True\nTEMPLATE_DEBUG = DEBUG\n\nSITE_ID = 1\n\nPROJECT_ROOT = os.path.normpath(os.path.join(os.path.dirname(__file__), '..'))\n\nROOT_URLCONF = 'saleor.urls'\n\nWSGI_APPLICATION = 'saleor.wsgi.application'\n\nADMINS = (\n # ('Your Name', '[email protected]'),\n)\nMANAGERS = ADMINS\nINTERNAL_IPS = ['127.0.0.1']\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': 'dev.sqlite'\n }\n}\n\nTIME_ZONE = 'America/Chicago'\nLANGUAGE_CODE = 'en-us'\nUSE_I18N = True\nUSE_L10N = True\nUSE_TZ = True\n\nMEDIA_ROOT = os.path.join(PROJECT_ROOT, 'media')\nMEDIA_URL = '/media/'\n\nSTATIC_ROOT = os.path.join(PROJECT_ROOT, 'static')\nSTATIC_URL = '/static/'\nSTATICFILES_DIRS = [\n os.path.join(PROJECT_ROOT, 'saleor', 'static')\n]\nSTATICFILES_FINDERS = [\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder'\n]\n\nTEMPLATE_DIRS = [\n os.path.join(PROJECT_ROOT, 'templates')\n]\nTEMPLATE_LOADERS = [\n 'django.template.loaders.filesystem.Loader',\n 'django.template.loaders.app_directories.Loader',\n # TODO: this one is slow, but for now need for mptt?\n 'django.template.loaders.eggs.Loader'\n]\n\n# Make this unique, and don't share it with anybody.\nSECRET_KEY = '{{ secret_key }}'\n\nMIDDLEWARE_CLASSES = [\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.common.CommonMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'saleor.cart.middleware.CartMiddleware',\n 'saleor.core.middleware.GoogleAnalytics',\n 'saleor.core.middleware.CheckHTML'\n]\n\nTEMPLATE_CONTEXT_PROCESSORS = [\n 'django.contrib.auth.context_processors.auth',\n 'django.core.context_processors.debug',\n 'django.core.context_processors.i18n',\n 'django.core.context_processors.media',\n 'django.core.context_processors.static',\n 'django.core.context_processors.tz',\n 'django.contrib.messages.context_processors.messages',\n 'django.core.context_processors.request',\n 'saleor.core.context_processors.canonical_hostname',\n 'saleor.core.context_processors.default_currency'\n]\n\nINSTALLED_APPS = [\n # External apps that need to go before django's\n\n # Django modules\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.admin',\n 'django.contrib.webdesign',\n\n # Local apps\n 'saleor.cart',\n 'saleor.checkout',\n 'saleor.core',\n 'saleor.order',\n 'saleor.payment',\n 'saleor.product',\n 'saleor.registration',\n 'saleor.userprofile',\n\n # External apps\n 'django_images',\n 'django_prices',\n 'mptt',\n 'payments',\n 'south'\n]\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(module)s '\n '%(process)d %(thread)d %(message)s'\n },\n 'simple': {\n 'format': '%(levelname)s %(message)s'\n },\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse'\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue'\n }\n },\n 'handlers': {\n 'mail_admins': {\n 'level': 'ERROR',\n 'filters': ['require_debug_false'],\n 'class': 'django.utils.log.AdminEmailHandler'\n },\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n 'filters': ['require_debug_true'],\n 'formatter': 'simple'\n },\n },\n 'loggers': {\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': True\n },\n 'saleor': {\n 'handlers': ['console'],\n 'level': 'DEBUG',\n 'propagate': True\n }\n }\n}\n\nAUTHENTICATION_BACKENDS = (\n 'saleor.registration.backends.EmailPasswordBackend',\n 'saleor.registration.backends.ExternalLoginBackend',\n 'saleor.registration.backends.TrivialBackend'\n)\n\nAUTH_USER_MODEL = 'userprofile.User'\n\nCANONICAL_HOSTNAME = 'localhost:8000'\n\nIMAGE_SIZES = {\n 'normal': {\n 'size': (750, 0)\n },\n 'admin': {\n 'size': (50, 50),\n 'crop': True\n }\n}\n\nEMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\nLOGIN_URL = '/account/login'\n\nWARN_ABOUT_INVALID_HTML5_OUTPUT = False\n\nSATCHLESS_DEFAULT_CURRENCY = 'USD'\n\nACCOUNT_ACTIVATION_DAYS = 3\n\nLOGIN_REDIRECT_URL = 'home'\n\nFACEBOOK_APP_ID = None\nFACEBOOK_SECRET = None\n\nGOOGLE_ANALYTICS_TRACKING_ID = None\nGOOGLE_CLIENT_ID = None\nGOOGLE_CLIENT_SECRET = None\n\nPAYMENT_BASE_URL = 'http://%s/' % CANONICAL_HOSTNAME\n\nPAYMENT_MODEL = 'payment.Payment'\n\nPAYMENT_VARIANTS = {\n 'default': ('payments.dummy.DummyProvider', {'url': 'http://google.pl/'})\n}\n\nSESSION_SERIALIZER = 'django.contrib.sessions.serializers.PickleSerializer'\n\nCHECKOUT_PAYMENT_CHOICES = [\n ('default', 'Dummy provider')\n]\n\nTEMPLATE_STRING_IF_INVALID = '<< MISSING VARIABLE >>'\n", "path": "saleor/settings.py"}]} | 2,730 | 327 |
gh_patches_debug_2493 | rasdani/github-patches | git_diff | freedomofpress__securedrop-359 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
securedrop_init script in Tails doesn't work right if you run it twice
It appends torrc-additions to torrc multiple times, and it should just append it once.
securedrop_init script in Tails doesn't work right if you run it twice
It appends torrc-additions to torrc multiple times, and it should just append it once.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `tails_files/securedrop_init.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os, sys, subprocess
4
5 if __name__ == '__main__':
6 # check for root
7 if not os.geteuid()==0:
8 sys.exit('You need to run this as root')
9
10 # paths
11 path_torrc_additions = '/home/amnesia/Persistent/.securedrop/torrc_additions'
12 path_torrc_backup = '/etc/tor/torrc.bak'
13 path_torrc = '/etc/tor/torrc'
14
15 # load torrc_additions
16 if os.path.isfile(path_torrc_additions):
17 torrc_additions = open(path_torrc_additions).read()
18 else:
19 sys.exit('Error opening {0} for reading'.format(path_torrc_additions));
20
21 # load torrc
22 if os.path.isfile(path_torrc_backup):
23 torrc = open(path_torrc_backup).read()
24 else:
25 if os.path.isfile(path_torrc):
26 torrc = open(path_torrc).read()
27 else:
28 sys.exit('Error opening {0} for reading'.format(path_torrc));
29
30 # save a backup
31 open(path_torrc_backup, 'w').write(torrc)
32
33 # append the additions
34 open(path_torrc, 'a').write(torrc_additions)
35
36 # reload tor
37 subprocess.call(['/usr/sbin/service', 'tor', 'reload'])
38
39 # success
40 subprocess.call(['/usr/bin/sudo', '-u', 'amnesia', '/usr/bin/notify-send', 'Updated torrc', 'You can now connect to your SecureDrop document interface']);
41
42
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/tails_files/securedrop_init.py b/tails_files/securedrop_init.py
--- a/tails_files/securedrop_init.py
+++ b/tails_files/securedrop_init.py
@@ -31,7 +31,7 @@
open(path_torrc_backup, 'w').write(torrc)
# append the additions
- open(path_torrc, 'a').write(torrc_additions)
+ open(path_torrc, 'w').write(torrc+torrc_additions)
# reload tor
subprocess.call(['/usr/sbin/service', 'tor', 'reload'])
| {"golden_diff": "diff --git a/tails_files/securedrop_init.py b/tails_files/securedrop_init.py\n--- a/tails_files/securedrop_init.py\n+++ b/tails_files/securedrop_init.py\n@@ -31,7 +31,7 @@\n open(path_torrc_backup, 'w').write(torrc)\n \n # append the additions\n- open(path_torrc, 'a').write(torrc_additions)\n+ open(path_torrc, 'w').write(torrc+torrc_additions)\n \n # reload tor\n subprocess.call(['/usr/sbin/service', 'tor', 'reload'])\n", "issue": "securedrop_init script in Tails doesn't work right if you run it twice\nIt appends torrc-additions to torrc multiple times, and it should just append it once.\n\nsecuredrop_init script in Tails doesn't work right if you run it twice\nIt appends torrc-additions to torrc multiple times, and it should just append it once.\n\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os, sys, subprocess\n\nif __name__ == '__main__':\n # check for root\n if not os.geteuid()==0:\n sys.exit('You need to run this as root')\n\n # paths\n path_torrc_additions = '/home/amnesia/Persistent/.securedrop/torrc_additions'\n path_torrc_backup = '/etc/tor/torrc.bak'\n path_torrc = '/etc/tor/torrc'\n\n # load torrc_additions\n if os.path.isfile(path_torrc_additions):\n torrc_additions = open(path_torrc_additions).read()\n else:\n sys.exit('Error opening {0} for reading'.format(path_torrc_additions));\n\n # load torrc\n if os.path.isfile(path_torrc_backup):\n torrc = open(path_torrc_backup).read()\n else:\n if os.path.isfile(path_torrc):\n torrc = open(path_torrc).read()\n else:\n sys.exit('Error opening {0} for reading'.format(path_torrc));\n\n # save a backup\n open(path_torrc_backup, 'w').write(torrc)\n\n # append the additions\n open(path_torrc, 'a').write(torrc_additions)\n\n # reload tor\n subprocess.call(['/usr/sbin/service', 'tor', 'reload'])\n\n # success\n subprocess.call(['/usr/bin/sudo', '-u', 'amnesia', '/usr/bin/notify-send', 'Updated torrc', 'You can now connect to your SecureDrop document interface']);\n\n", "path": "tails_files/securedrop_init.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport os, sys, subprocess\n\nif __name__ == '__main__':\n # check for root\n if not os.geteuid()==0:\n sys.exit('You need to run this as root')\n\n # paths\n path_torrc_additions = '/home/amnesia/Persistent/.securedrop/torrc_additions'\n path_torrc_backup = '/etc/tor/torrc.bak'\n path_torrc = '/etc/tor/torrc'\n\n # load torrc_additions\n if os.path.isfile(path_torrc_additions):\n torrc_additions = open(path_torrc_additions).read()\n else:\n sys.exit('Error opening {0} for reading'.format(path_torrc_additions));\n\n # load torrc\n if os.path.isfile(path_torrc_backup):\n torrc = open(path_torrc_backup).read()\n else:\n if os.path.isfile(path_torrc):\n torrc = open(path_torrc).read()\n else:\n sys.exit('Error opening {0} for reading'.format(path_torrc));\n\n # save a backup\n open(path_torrc_backup, 'w').write(torrc)\n\n # append the additions\n open(path_torrc, 'w').write(torrc+torrc_additions)\n\n # reload tor\n subprocess.call(['/usr/sbin/service', 'tor', 'reload'])\n\n # success\n subprocess.call(['/usr/bin/sudo', '-u', 'amnesia', '/usr/bin/notify-send', 'Updated torrc', 'You can now connect to your SecureDrop document interface']);\n\n", "path": "tails_files/securedrop_init.py"}]} | 773 | 138 |
gh_patches_debug_21415 | rasdani/github-patches | git_diff | fossasia__open-event-server-5056 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
key error in POST ticket
**Describe the bug**
<!-- A clear and concise description of what the bug is. -->
The server returns HTTP 500 when posting Tickets.
Request:
```
{
"data": {
"relationships": {
"event": {
"data": {
"type": "event",
"id": "{{event}}"
}
}
},
"attributes": {
"name": "test ticket for demo",
"description": "some description",
"type": "VIP-ticket",
"price": "1.00",
"quantity": "15",
"is-description-visible": "false",
"position": "1",
"is-fee-absorbed": "false",
"sales-starts-at": "2018-06-01T01:24:47.500127+00:00",
"sales-ends-at": "2018-06-30T00:24:47.500127+00:00",
"is-hidden": "true",
"min-order": "1",
"max-order": "1"
},
"type": "ticket"
}
}
```
**Stacktrace**
```
Traceback (most recent call last):
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2309, in __call__
return self.wsgi_app(environ, start_response)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/__init__.py", line 66, in __call__
return self.app(environ, start_response)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2295, in wsgi_app
response = self.handle_exception(e)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1741, in handle_exception
reraise(exc_type, exc_value, tb)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1815, in full_dispatch_request
rv = self.handle_user_exception(e)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py", line 161, in wrapped_function
return cors_after_request(app.make_response(f(*args, **kwargs)))
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1718, in handle_user_exception
reraise(exc_type, exc_value, tb)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py", line 35, in reraise
raise value
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1813, in full_dispatch_request
rv = self.dispatch_request()
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py", line 1799, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py", line 32, in wrapper
return func(*args, **kwargs)
File "/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/views.py", line 88, in view
return self.dispatch_request(*args, **kwargs)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py", line 68, in dispatch_request
response = method(*args, **kwargs)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py", line 56, in wrapper
return func(*args, **kwargs)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py", line 202, in post
self.before_post(args, kwargs, data=data)
File "/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/api/tickets.py", line 37, in before_post
"Event: {} not found".format(data['event_id']))
KeyError: 'event_id'
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `app/api/tickets.py`
Content:
```
1 from flask import request, current_app
2 from flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship
3 from flask_rest_jsonapi.exceptions import ObjectNotFound
4 from flask_jwt import current_identity as current_user, _jwt_required
5
6 from app.api.bootstrap import api
7 from app.api.helpers.db import safe_query
8 from app.api.helpers.permission_manager import has_access
9 from app.api.helpers.query import event_query
10 from app.api.helpers.utilities import require_relationship
11 from app.api.schema.tickets import TicketSchema, TicketSchemaPublic
12 from app.models import db
13 from app.models.access_code import AccessCode
14 from app.models.order import Order
15 from app.models.ticket import Ticket, TicketTag, ticket_tags_table
16 from app.models.event import Event
17 from app.models.ticket_holder import TicketHolder
18 from app.api.helpers.exceptions import ConflictException, MethodNotAllowed
19 from app.api.helpers.db import get_count
20
21
22 class TicketListPost(ResourceList):
23 """
24 Create and List Tickets
25 """
26 def before_post(self, args, kwargs, data):
27 """
28 before post method to check for required relationship and proper permission
29 :param args:
30 :param kwargs:
31 :param data:
32 :return:
33 """
34 require_relationship(['event'], data)
35 if not has_access('is_coorganizer', event_id=data['event']):
36 raise ObjectNotFound({'parameter': 'event_id'},
37 "Event: {} not found".format(data['event_id']))
38
39 if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']),
40 deleted_at=None)) > 0:
41 raise ConflictException({'pointer': '/data/attributes/name'}, "Ticket already exists")
42
43 if get_count(db.session.query(Event).filter_by(id=int(data['event']), is_ticketing_enabled=False)) > 0:
44 raise MethodNotAllowed({'parameter': 'event_id'}, "Ticketing is disabled for this Event")
45
46 schema = TicketSchema
47 methods = ['POST', ]
48 data_layer = {'session': db.session,
49 'model': Ticket}
50
51
52 class TicketList(ResourceList):
53 """
54 List Tickets based on different params
55 """
56 def before_get(self, args, view_kwargs):
57 """
58 before get method to get the resource id for assigning schema
59 :param args:
60 :param view_kwargs:
61 :return:
62 """
63 if view_kwargs.get('ticket_tag_id') or view_kwargs.get('access_code_id') or view_kwargs.get('order_identifier'):
64 self.schema = TicketSchemaPublic
65
66 def query(self, view_kwargs):
67 """
68 query method for resource list
69 :param view_kwargs:
70 :return:
71 """
72
73 if 'Authorization' in request.headers:
74 _jwt_required(current_app.config['JWT_DEFAULT_REALM'])
75 if current_user.is_super_admin or current_user.is_admin:
76 query_ = self.session.query(Ticket)
77 elif view_kwargs.get('event_id') and has_access('is_organizer', event_id=view_kwargs['event_id']):
78 query_ = self.session.query(Ticket)
79 else:
80 query_ = self.session.query(Ticket).filter_by(is_hidden=False)
81 else:
82 query_ = self.session.query(Ticket).filter_by(is_hidden=False)
83
84 if view_kwargs.get('ticket_tag_id'):
85 ticket_tag = safe_query(self, TicketTag, 'id', view_kwargs['ticket_tag_id'], 'ticket_tag_id')
86 query_ = query_.join(ticket_tags_table).filter_by(ticket_tag_id=ticket_tag.id)
87 query_ = event_query(self, query_, view_kwargs)
88 if view_kwargs.get('access_code_id'):
89 access_code = safe_query(self, AccessCode, 'id', view_kwargs['access_code_id'], 'access_code_id')
90 # access_code - ticket :: many-to-many relationship
91 query_ = Ticket.query.filter(Ticket.access_codes.any(id=access_code.id))
92
93 if view_kwargs.get('order_identifier'):
94 order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')
95 ticket_ids = []
96 for ticket in order.tickets:
97 ticket_ids.append(ticket.id)
98 query_ = query_.filter(Ticket.id.in_(tuple(ticket_ids)))
99
100 return query_
101
102 view_kwargs = True
103 methods = ['GET', ]
104 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
105 fetch_as="event_id", model=Ticket, methods="POST",
106 check=lambda a: a.get('event_id') or a.get('event_identifier')),)
107 schema = TicketSchema
108 data_layer = {'session': db.session,
109 'model': Ticket,
110 'methods': {
111 'query': query,
112 }}
113
114
115 class TicketDetail(ResourceDetail):
116 """
117 Ticket Resource
118 """
119 def before_get(self, args, view_kwargs):
120 """
121 before get method to get the resource id for assigning schema
122 :param args:
123 :param view_kwargs:
124 :return:
125 """
126 if view_kwargs.get('attendee_id'):
127 self.schema = TicketSchemaPublic
128
129 def before_get_object(self, view_kwargs):
130 """
131 before get object method to get the resource id for fetching details
132 :param view_kwargs:
133 :return:
134 """
135 if view_kwargs.get('attendee_id') is not None:
136 attendee = safe_query(self, TicketHolder, 'id', view_kwargs['attendee_id'], 'attendee_id')
137 if attendee.ticket_id is not None:
138 view_kwargs['id'] = attendee.ticket_id
139 else:
140 view_kwargs['id'] = None
141
142 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
143 fetch_as="event_id", model=Ticket, methods="PATCH,DELETE"),)
144 schema = TicketSchema
145 data_layer = {'session': db.session,
146 'model': Ticket,
147 'methods': {
148 'before_get_object': before_get_object
149 }}
150
151
152 class TicketRelationshipRequired(ResourceRelationship):
153 """
154 Tickets Relationship (Required)
155 """
156 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
157 fetch_as="event_id", model=Ticket, methods="PATCH"),)
158 methods = ['GET', 'PATCH']
159 schema = TicketSchema
160 data_layer = {'session': db.session,
161 'model': Ticket}
162
163
164 class TicketRelationshipOptional(ResourceRelationship):
165 """
166 Tickets Relationship (Optional)
167 """
168 decorators = (api.has_permission('is_coorganizer', fetch='event_id',
169 fetch_as="event_id", model=Ticket, methods="PATCH,DELETE"),)
170 schema = TicketSchema
171 data_layer = {'session': db.session,
172 'model': Ticket}
173
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/app/api/tickets.py b/app/api/tickets.py
--- a/app/api/tickets.py
+++ b/app/api/tickets.py
@@ -18,7 +18,6 @@
from app.api.helpers.exceptions import ConflictException, MethodNotAllowed
from app.api.helpers.db import get_count
-
class TicketListPost(ResourceList):
"""
Create and List Tickets
@@ -34,7 +33,7 @@
require_relationship(['event'], data)
if not has_access('is_coorganizer', event_id=data['event']):
raise ObjectNotFound({'parameter': 'event_id'},
- "Event: {} not found".format(data['event_id']))
+ "Event: {} not found".format(data['event']))
if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']),
deleted_at=None)) > 0:
| {"golden_diff": "diff --git a/app/api/tickets.py b/app/api/tickets.py\n--- a/app/api/tickets.py\n+++ b/app/api/tickets.py\n@@ -18,7 +18,6 @@\n from app.api.helpers.exceptions import ConflictException, MethodNotAllowed\n from app.api.helpers.db import get_count\n \n-\n class TicketListPost(ResourceList):\n \"\"\"\n Create and List Tickets\n@@ -34,7 +33,7 @@\n require_relationship(['event'], data)\n if not has_access('is_coorganizer', event_id=data['event']):\n raise ObjectNotFound({'parameter': 'event_id'},\n- \"Event: {} not found\".format(data['event_id']))\n+ \"Event: {} not found\".format(data['event']))\n \n if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']),\n deleted_at=None)) > 0:\n", "issue": "key error in POST ticket\n**Describe the bug**\r\n<!-- A clear and concise description of what the bug is. -->\r\nThe server returns HTTP 500 when posting Tickets. \r\n\r\nRequest:\r\n```\r\n{\r\n \"data\": {\r\n \"relationships\": {\r\n \"event\": {\r\n \"data\": {\r\n \"type\": \"event\",\r\n \"id\": \"{{event}}\"\r\n }\r\n }\r\n },\r\n \"attributes\": {\r\n \"name\": \"test ticket for demo\",\r\n \"description\": \"some description\",\r\n \"type\": \"VIP-ticket\",\r\n \"price\": \"1.00\",\r\n \"quantity\": \"15\",\r\n \"is-description-visible\": \"false\",\r\n \"position\": \"1\",\r\n \"is-fee-absorbed\": \"false\",\r\n \"sales-starts-at\": \"2018-06-01T01:24:47.500127+00:00\",\r\n \"sales-ends-at\": \"2018-06-30T00:24:47.500127+00:00\",\r\n \"is-hidden\": \"true\",\r\n \"min-order\": \"1\",\r\n \"max-order\": \"1\"\r\n },\r\n \"type\": \"ticket\"\r\n }\r\n}\r\n```\r\n\r\n\r\n**Stacktrace**\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2309, in __call__\r\n return self.wsgi_app(environ, start_response)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/__init__.py\", line 66, in __call__\r\n return self.app(environ, start_response)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2295, in wsgi_app\r\n response = self.handle_exception(e)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1741, in handle_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 2292, in wsgi_app\r\n response = self.full_dispatch_request()\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1815, in full_dispatch_request\r\n rv = self.handle_user_exception(e)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask_cors/extension.py\", line 161, in wrapped_function\r\n return cors_after_request(app.make_response(f(*args, **kwargs)))\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1718, in handle_user_exception\r\n reraise(exc_type, exc_value, tb)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/_compat.py\", line 35, in reraise\r\n raise value\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1813, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/app.py\", line 1799, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py\", line 32, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/home/srv_twry/anaconda3/envs/open-event-server/lib/python3.6/site-packages/flask/views.py\", line 88, in view\r\n return self.dispatch_request(*args, **kwargs)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py\", line 68, in dispatch_request\r\n response = method(*args, **kwargs)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/decorators.py\", line 56, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/src/flask-rest-jsonapi/flask_rest_jsonapi/resource.py\", line 202, in post\r\n self.before_post(args, kwargs, data=data)\r\n File \"/media/srv_twry/work/Projects/Community-Projects/Fossasia/open-event-server/app/api/tickets.py\", line 37, in before_post\r\n \"Event: {} not found\".format(data['event_id']))\r\nKeyError: 'event_id'\r\n```\n", "before_files": [{"content": "from flask import request, current_app\nfrom flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship\nfrom flask_rest_jsonapi.exceptions import ObjectNotFound\nfrom flask_jwt import current_identity as current_user, _jwt_required\n\nfrom app.api.bootstrap import api\nfrom app.api.helpers.db import safe_query\nfrom app.api.helpers.permission_manager import has_access\nfrom app.api.helpers.query import event_query\nfrom app.api.helpers.utilities import require_relationship\nfrom app.api.schema.tickets import TicketSchema, TicketSchemaPublic\nfrom app.models import db\nfrom app.models.access_code import AccessCode\nfrom app.models.order import Order\nfrom app.models.ticket import Ticket, TicketTag, ticket_tags_table\nfrom app.models.event import Event\nfrom app.models.ticket_holder import TicketHolder\nfrom app.api.helpers.exceptions import ConflictException, MethodNotAllowed\nfrom app.api.helpers.db import get_count\n\n\nclass TicketListPost(ResourceList):\n \"\"\"\n Create and List Tickets\n \"\"\"\n def before_post(self, args, kwargs, data):\n \"\"\"\n before post method to check for required relationship and proper permission\n :param args:\n :param kwargs:\n :param data:\n :return:\n \"\"\"\n require_relationship(['event'], data)\n if not has_access('is_coorganizer', event_id=data['event']):\n raise ObjectNotFound({'parameter': 'event_id'},\n \"Event: {} not found\".format(data['event_id']))\n\n if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']),\n deleted_at=None)) > 0:\n raise ConflictException({'pointer': '/data/attributes/name'}, \"Ticket already exists\")\n\n if get_count(db.session.query(Event).filter_by(id=int(data['event']), is_ticketing_enabled=False)) > 0:\n raise MethodNotAllowed({'parameter': 'event_id'}, \"Ticketing is disabled for this Event\")\n\n schema = TicketSchema\n methods = ['POST', ]\n data_layer = {'session': db.session,\n 'model': Ticket}\n\n\nclass TicketList(ResourceList):\n \"\"\"\n List Tickets based on different params\n \"\"\"\n def before_get(self, args, view_kwargs):\n \"\"\"\n before get method to get the resource id for assigning schema\n :param args:\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('ticket_tag_id') or view_kwargs.get('access_code_id') or view_kwargs.get('order_identifier'):\n self.schema = TicketSchemaPublic\n\n def query(self, view_kwargs):\n \"\"\"\n query method for resource list\n :param view_kwargs:\n :return:\n \"\"\"\n\n if 'Authorization' in request.headers:\n _jwt_required(current_app.config['JWT_DEFAULT_REALM'])\n if current_user.is_super_admin or current_user.is_admin:\n query_ = self.session.query(Ticket)\n elif view_kwargs.get('event_id') and has_access('is_organizer', event_id=view_kwargs['event_id']):\n query_ = self.session.query(Ticket)\n else:\n query_ = self.session.query(Ticket).filter_by(is_hidden=False)\n else:\n query_ = self.session.query(Ticket).filter_by(is_hidden=False)\n\n if view_kwargs.get('ticket_tag_id'):\n ticket_tag = safe_query(self, TicketTag, 'id', view_kwargs['ticket_tag_id'], 'ticket_tag_id')\n query_ = query_.join(ticket_tags_table).filter_by(ticket_tag_id=ticket_tag.id)\n query_ = event_query(self, query_, view_kwargs)\n if view_kwargs.get('access_code_id'):\n access_code = safe_query(self, AccessCode, 'id', view_kwargs['access_code_id'], 'access_code_id')\n # access_code - ticket :: many-to-many relationship\n query_ = Ticket.query.filter(Ticket.access_codes.any(id=access_code.id))\n\n if view_kwargs.get('order_identifier'):\n order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')\n ticket_ids = []\n for ticket in order.tickets:\n ticket_ids.append(ticket.id)\n query_ = query_.filter(Ticket.id.in_(tuple(ticket_ids)))\n\n return query_\n\n view_kwargs = True\n methods = ['GET', ]\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"POST\",\n check=lambda a: a.get('event_id') or a.get('event_identifier')),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket,\n 'methods': {\n 'query': query,\n }}\n\n\nclass TicketDetail(ResourceDetail):\n \"\"\"\n Ticket Resource\n \"\"\"\n def before_get(self, args, view_kwargs):\n \"\"\"\n before get method to get the resource id for assigning schema\n :param args:\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('attendee_id'):\n self.schema = TicketSchemaPublic\n\n def before_get_object(self, view_kwargs):\n \"\"\"\n before get object method to get the resource id for fetching details\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('attendee_id') is not None:\n attendee = safe_query(self, TicketHolder, 'id', view_kwargs['attendee_id'], 'attendee_id')\n if attendee.ticket_id is not None:\n view_kwargs['id'] = attendee.ticket_id\n else:\n view_kwargs['id'] = None\n\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH,DELETE\"),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket,\n 'methods': {\n 'before_get_object': before_get_object\n }}\n\n\nclass TicketRelationshipRequired(ResourceRelationship):\n \"\"\"\n Tickets Relationship (Required)\n \"\"\"\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH\"),)\n methods = ['GET', 'PATCH']\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n\n\nclass TicketRelationshipOptional(ResourceRelationship):\n \"\"\"\n Tickets Relationship (Optional)\n \"\"\"\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH,DELETE\"),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n", "path": "app/api/tickets.py"}], "after_files": [{"content": "from flask import request, current_app\nfrom flask_rest_jsonapi import ResourceDetail, ResourceList, ResourceRelationship\nfrom flask_rest_jsonapi.exceptions import ObjectNotFound\nfrom flask_jwt import current_identity as current_user, _jwt_required\n\nfrom app.api.bootstrap import api\nfrom app.api.helpers.db import safe_query\nfrom app.api.helpers.permission_manager import has_access\nfrom app.api.helpers.query import event_query\nfrom app.api.helpers.utilities import require_relationship\nfrom app.api.schema.tickets import TicketSchema, TicketSchemaPublic\nfrom app.models import db\nfrom app.models.access_code import AccessCode\nfrom app.models.order import Order\nfrom app.models.ticket import Ticket, TicketTag, ticket_tags_table\nfrom app.models.event import Event\nfrom app.models.ticket_holder import TicketHolder\nfrom app.api.helpers.exceptions import ConflictException, MethodNotAllowed\nfrom app.api.helpers.db import get_count\n\nclass TicketListPost(ResourceList):\n \"\"\"\n Create and List Tickets\n \"\"\"\n def before_post(self, args, kwargs, data):\n \"\"\"\n before post method to check for required relationship and proper permission\n :param args:\n :param kwargs:\n :param data:\n :return:\n \"\"\"\n require_relationship(['event'], data)\n if not has_access('is_coorganizer', event_id=data['event']):\n raise ObjectNotFound({'parameter': 'event_id'},\n \"Event: {} not found\".format(data['event']))\n\n if get_count(db.session.query(Ticket.id).filter_by(name=data['name'], event_id=int(data['event']),\n deleted_at=None)) > 0:\n raise ConflictException({'pointer': '/data/attributes/name'}, \"Ticket already exists\")\n\n if get_count(db.session.query(Event).filter_by(id=int(data['event']), is_ticketing_enabled=False)) > 0:\n raise MethodNotAllowed({'parameter': 'event_id'}, \"Ticketing is disabled for this Event\")\n\n schema = TicketSchema\n methods = ['POST', ]\n data_layer = {'session': db.session,\n 'model': Ticket}\n\n\nclass TicketList(ResourceList):\n \"\"\"\n List Tickets based on different params\n \"\"\"\n def before_get(self, args, view_kwargs):\n \"\"\"\n before get method to get the resource id for assigning schema\n :param args:\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('ticket_tag_id') or view_kwargs.get('access_code_id') or view_kwargs.get('order_identifier'):\n self.schema = TicketSchemaPublic\n\n def query(self, view_kwargs):\n \"\"\"\n query method for resource list\n :param view_kwargs:\n :return:\n \"\"\"\n\n if 'Authorization' in request.headers:\n _jwt_required(current_app.config['JWT_DEFAULT_REALM'])\n if current_user.is_super_admin or current_user.is_admin:\n query_ = self.session.query(Ticket)\n elif view_kwargs.get('event_id') and has_access('is_organizer', event_id=view_kwargs['event_id']):\n query_ = self.session.query(Ticket)\n else:\n query_ = self.session.query(Ticket).filter_by(is_hidden=False)\n else:\n query_ = self.session.query(Ticket).filter_by(is_hidden=False)\n\n if view_kwargs.get('ticket_tag_id'):\n ticket_tag = safe_query(self, TicketTag, 'id', view_kwargs['ticket_tag_id'], 'ticket_tag_id')\n query_ = query_.join(ticket_tags_table).filter_by(ticket_tag_id=ticket_tag.id)\n query_ = event_query(self, query_, view_kwargs)\n if view_kwargs.get('access_code_id'):\n access_code = safe_query(self, AccessCode, 'id', view_kwargs['access_code_id'], 'access_code_id')\n # access_code - ticket :: many-to-many relationship\n query_ = Ticket.query.filter(Ticket.access_codes.any(id=access_code.id))\n\n if view_kwargs.get('order_identifier'):\n order = safe_query(self, Order, 'identifier', view_kwargs['order_identifier'], 'order_identifier')\n ticket_ids = []\n for ticket in order.tickets:\n ticket_ids.append(ticket.id)\n query_ = query_.filter(Ticket.id.in_(tuple(ticket_ids)))\n\n return query_\n\n view_kwargs = True\n methods = ['GET', ]\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"POST\",\n check=lambda a: a.get('event_id') or a.get('event_identifier')),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket,\n 'methods': {\n 'query': query,\n }}\n\n\nclass TicketDetail(ResourceDetail):\n \"\"\"\n Ticket Resource\n \"\"\"\n def before_get(self, args, view_kwargs):\n \"\"\"\n before get method to get the resource id for assigning schema\n :param args:\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('attendee_id'):\n self.schema = TicketSchemaPublic\n\n def before_get_object(self, view_kwargs):\n \"\"\"\n before get object method to get the resource id for fetching details\n :param view_kwargs:\n :return:\n \"\"\"\n if view_kwargs.get('attendee_id') is not None:\n attendee = safe_query(self, TicketHolder, 'id', view_kwargs['attendee_id'], 'attendee_id')\n if attendee.ticket_id is not None:\n view_kwargs['id'] = attendee.ticket_id\n else:\n view_kwargs['id'] = None\n\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH,DELETE\"),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket,\n 'methods': {\n 'before_get_object': before_get_object\n }}\n\n\nclass TicketRelationshipRequired(ResourceRelationship):\n \"\"\"\n Tickets Relationship (Required)\n \"\"\"\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH\"),)\n methods = ['GET', 'PATCH']\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n\n\nclass TicketRelationshipOptional(ResourceRelationship):\n \"\"\"\n Tickets Relationship (Optional)\n \"\"\"\n decorators = (api.has_permission('is_coorganizer', fetch='event_id',\n fetch_as=\"event_id\", model=Ticket, methods=\"PATCH,DELETE\"),)\n schema = TicketSchema\n data_layer = {'session': db.session,\n 'model': Ticket}\n", "path": "app/api/tickets.py"}]} | 3,467 | 193 |
gh_patches_debug_20269 | rasdani/github-patches | git_diff | Pylons__pyramid-1519 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
prequest doesn't setup logging
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pyramid/scripts/prequest.py`
Content:
```
1 import base64
2 import optparse
3 import sys
4 import textwrap
5
6 from pyramid.compat import url_unquote
7 from pyramid.request import Request
8 from pyramid.paster import get_app
9 from pyramid.scripts.common import parse_vars
10
11 def main(argv=sys.argv, quiet=False):
12 command = PRequestCommand(argv, quiet)
13 return command.run()
14
15 class PRequestCommand(object):
16 description = """\
17 Run a request for the described application.
18
19 This command makes an artifical request to a web application that uses a
20 PasteDeploy (.ini) configuration file for the server and application.
21
22 Use "prequest config.ini /path" to request "/path".
23
24 Use "prequest --method=POST config.ini /path < data" to do a POST with
25 the given request body.
26
27 Use "prequest --method=PUT config.ini /path < data" to do a
28 PUT with the given request body.
29
30 Use "prequest --method=PATCH config.ini /path < data" to do a
31 PATCH with the given request body.
32
33 Use "prequest --method=OPTIONS config.ini /path" to do an
34 OPTIONS request.
35
36 Use "prequest --method=PROPFIND config.ini /path" to do a
37 PROPFIND request.
38
39 If the path is relative (doesn't begin with "/") it is interpreted as
40 relative to "/". The path passed to this script should be URL-quoted.
41 The path can be succeeded with a query string (e.g. `/path?a=1&=b2').
42
43 The variable "environ['paste.command_request']" will be set to "True" in
44 the request's WSGI environment, so your application can distinguish these
45 calls from normal requests.
46 """
47 usage = "usage: %prog config_uri path_info [args/options]"
48 parser = optparse.OptionParser(
49 usage=usage,
50 description=textwrap.dedent(description)
51 )
52 parser.add_option(
53 '-n', '--app-name',
54 dest='app_name',
55 metavar= 'NAME',
56 help="Load the named application from the config file (default 'main')",
57 type="string",
58 )
59 parser.add_option(
60 '--header',
61 dest='headers',
62 metavar='NAME:VALUE',
63 type='string',
64 action='append',
65 help="Header to add to request (you can use this option multiple times)"
66 )
67 parser.add_option(
68 '-d', '--display-headers',
69 dest='display_headers',
70 action='store_true',
71 help='Display status and headers before the response body'
72 )
73 parser.add_option(
74 '-m', '--method',
75 dest='method',
76 choices=['GET', 'HEAD', 'POST', 'PUT', 'PATCH','DELETE',
77 'PROPFIND', 'OPTIONS'],
78 type='choice',
79 help='Request method type (GET, POST, PUT, PATCH, DELETE, '
80 'PROPFIND, OPTIONS)',
81 )
82 parser.add_option(
83 '-l', '--login',
84 dest='login',
85 type='string',
86 help='HTTP basic auth username:password pair',
87 )
88
89 get_app = staticmethod(get_app)
90 stdin = sys.stdin
91
92 def __init__(self, argv, quiet=False):
93 self.quiet = quiet
94 self.options, self.args = self.parser.parse_args(argv[1:])
95
96 def out(self, msg): # pragma: no cover
97 if not self.quiet:
98 print(msg)
99
100 def run(self):
101 if not len(self.args) >= 2:
102 self.out('You must provide at least two arguments')
103 return 2
104 app_spec = self.args[0]
105 path = self.args[1]
106 if not path.startswith('/'):
107 path = '/' + path
108
109 try:
110 path, qs = path.split('?', 1)
111 except ValueError:
112 qs = ''
113
114 path = url_unquote(path)
115
116 headers = {}
117 if self.options.login:
118 enc = base64.b64encode(self.options.login.encode('ascii'))
119 headers['Authorization'] = 'Basic ' + enc.decode('ascii')
120
121 if self.options.headers:
122 for item in self.options.headers:
123 if ':' not in item:
124 self.out(
125 "Bad --header=%s option, value must be in the form "
126 "'name:value'" % item)
127 return 2
128 name, value = item.split(':', 1)
129 headers[name] = value.strip()
130
131 app = self.get_app(app_spec, self.options.app_name,
132 options=parse_vars(self.args[2:]))
133
134 request_method = (self.options.method or 'GET').upper()
135
136 environ = {
137 'REQUEST_METHOD': request_method,
138 'SCRIPT_NAME': '', # may be empty if app is at the root
139 'PATH_INFO': path,
140 'SERVER_NAME': 'localhost', # always mandatory
141 'SERVER_PORT': '80', # always mandatory
142 'SERVER_PROTOCOL': 'HTTP/1.0',
143 'CONTENT_TYPE': 'text/plain',
144 'REMOTE_ADDR':'127.0.0.1',
145 'wsgi.run_once': True,
146 'wsgi.multithread': False,
147 'wsgi.multiprocess': False,
148 'wsgi.errors': sys.stderr,
149 'wsgi.url_scheme': 'http',
150 'wsgi.version': (1, 0),
151 'QUERY_STRING': qs,
152 'HTTP_ACCEPT': 'text/plain;q=1.0, */*;q=0.1',
153 'paste.command_request': True,
154 }
155
156 if request_method in ('POST', 'PUT', 'PATCH'):
157 environ['wsgi.input'] = self.stdin
158 environ['CONTENT_LENGTH'] = '-1'
159
160 for name, value in headers.items():
161 if name.lower() == 'content-type':
162 name = 'CONTENT_TYPE'
163 else:
164 name = 'HTTP_'+name.upper().replace('-', '_')
165 environ[name] = value
166
167 request = Request.blank(path, environ=environ)
168 response = request.get_response(app)
169 if self.options.display_headers:
170 self.out(response.status)
171 for name, value in response.headerlist:
172 self.out('%s: %s' % (name, value))
173 if response.charset:
174 self.out(response.ubody)
175 else:
176 self.out(response.body)
177 return 0
178
179 if __name__ == '__main__': # pragma: no cover
180 sys.exit(main() or 0)
181
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pyramid/scripts/prequest.py b/pyramid/scripts/prequest.py
--- a/pyramid/scripts/prequest.py
+++ b/pyramid/scripts/prequest.py
@@ -5,7 +5,7 @@
from pyramid.compat import url_unquote
from pyramid.request import Request
-from pyramid.paster import get_app
+from pyramid.paster import get_app, setup_logging
from pyramid.scripts.common import parse_vars
def main(argv=sys.argv, quiet=False):
@@ -97,12 +97,18 @@
if not self.quiet:
print(msg)
+ def configure_logging(self, app_spec):
+ setup_logging(app_spec)
+
def run(self):
if not len(self.args) >= 2:
self.out('You must provide at least two arguments')
return 2
app_spec = self.args[0]
path = self.args[1]
+
+ self.configure_logging(app_spec)
+
if not path.startswith('/'):
path = '/' + path
| {"golden_diff": "diff --git a/pyramid/scripts/prequest.py b/pyramid/scripts/prequest.py\n--- a/pyramid/scripts/prequest.py\n+++ b/pyramid/scripts/prequest.py\n@@ -5,7 +5,7 @@\n \n from pyramid.compat import url_unquote\n from pyramid.request import Request\n-from pyramid.paster import get_app\n+from pyramid.paster import get_app, setup_logging\n from pyramid.scripts.common import parse_vars\n \n def main(argv=sys.argv, quiet=False):\n@@ -97,12 +97,18 @@\n if not self.quiet:\n print(msg)\n \n+ def configure_logging(self, app_spec):\n+ setup_logging(app_spec)\n+\n def run(self):\n if not len(self.args) >= 2:\n self.out('You must provide at least two arguments')\n return 2\n app_spec = self.args[0]\n path = self.args[1]\n+\n+ self.configure_logging(app_spec)\n+\n if not path.startswith('/'):\n path = '/' + path\n", "issue": "prequest doesn't setup logging\n\n", "before_files": [{"content": "import base64\nimport optparse\nimport sys\nimport textwrap\n\nfrom pyramid.compat import url_unquote\nfrom pyramid.request import Request\nfrom pyramid.paster import get_app\nfrom pyramid.scripts.common import parse_vars\n\ndef main(argv=sys.argv, quiet=False):\n command = PRequestCommand(argv, quiet)\n return command.run()\n\nclass PRequestCommand(object):\n description = \"\"\"\\\n Run a request for the described application.\n\n This command makes an artifical request to a web application that uses a\n PasteDeploy (.ini) configuration file for the server and application.\n\n Use \"prequest config.ini /path\" to request \"/path\".\n\n Use \"prequest --method=POST config.ini /path < data\" to do a POST with\n the given request body.\n\n Use \"prequest --method=PUT config.ini /path < data\" to do a\n PUT with the given request body.\n\n Use \"prequest --method=PATCH config.ini /path < data\" to do a\n PATCH with the given request body.\n\n Use \"prequest --method=OPTIONS config.ini /path\" to do an\n OPTIONS request.\n\n Use \"prequest --method=PROPFIND config.ini /path\" to do a\n PROPFIND request.\n\n If the path is relative (doesn't begin with \"/\") it is interpreted as\n relative to \"/\". The path passed to this script should be URL-quoted.\n The path can be succeeded with a query string (e.g. `/path?a=1&=b2').\n\n The variable \"environ['paste.command_request']\" will be set to \"True\" in\n the request's WSGI environment, so your application can distinguish these\n calls from normal requests.\n \"\"\"\n usage = \"usage: %prog config_uri path_info [args/options]\"\n parser = optparse.OptionParser(\n usage=usage,\n description=textwrap.dedent(description)\n )\n parser.add_option(\n '-n', '--app-name',\n dest='app_name',\n metavar= 'NAME',\n help=\"Load the named application from the config file (default 'main')\",\n type=\"string\",\n )\n parser.add_option(\n '--header',\n dest='headers',\n metavar='NAME:VALUE',\n type='string',\n action='append',\n help=\"Header to add to request (you can use this option multiple times)\"\n )\n parser.add_option(\n '-d', '--display-headers',\n dest='display_headers',\n action='store_true',\n help='Display status and headers before the response body'\n )\n parser.add_option(\n '-m', '--method',\n dest='method',\n choices=['GET', 'HEAD', 'POST', 'PUT', 'PATCH','DELETE',\n 'PROPFIND', 'OPTIONS'],\n type='choice',\n help='Request method type (GET, POST, PUT, PATCH, DELETE, '\n 'PROPFIND, OPTIONS)',\n )\n parser.add_option(\n '-l', '--login',\n dest='login',\n type='string',\n help='HTTP basic auth username:password pair',\n )\n\n get_app = staticmethod(get_app)\n stdin = sys.stdin\n\n def __init__(self, argv, quiet=False):\n self.quiet = quiet\n self.options, self.args = self.parser.parse_args(argv[1:])\n\n def out(self, msg): # pragma: no cover\n if not self.quiet:\n print(msg)\n\n def run(self):\n if not len(self.args) >= 2:\n self.out('You must provide at least two arguments')\n return 2\n app_spec = self.args[0]\n path = self.args[1]\n if not path.startswith('/'):\n path = '/' + path\n\n try:\n path, qs = path.split('?', 1)\n except ValueError:\n qs = ''\n\n path = url_unquote(path)\n\n headers = {}\n if self.options.login:\n enc = base64.b64encode(self.options.login.encode('ascii'))\n headers['Authorization'] = 'Basic ' + enc.decode('ascii')\n\n if self.options.headers:\n for item in self.options.headers:\n if ':' not in item:\n self.out(\n \"Bad --header=%s option, value must be in the form \"\n \"'name:value'\" % item)\n return 2\n name, value = item.split(':', 1)\n headers[name] = value.strip()\n\n app = self.get_app(app_spec, self.options.app_name,\n options=parse_vars(self.args[2:]))\n\n request_method = (self.options.method or 'GET').upper()\n\n environ = {\n 'REQUEST_METHOD': request_method,\n 'SCRIPT_NAME': '', # may be empty if app is at the root\n 'PATH_INFO': path,\n 'SERVER_NAME': 'localhost', # always mandatory\n 'SERVER_PORT': '80', # always mandatory\n 'SERVER_PROTOCOL': 'HTTP/1.0',\n 'CONTENT_TYPE': 'text/plain',\n 'REMOTE_ADDR':'127.0.0.1',\n 'wsgi.run_once': True,\n 'wsgi.multithread': False,\n 'wsgi.multiprocess': False,\n 'wsgi.errors': sys.stderr,\n 'wsgi.url_scheme': 'http',\n 'wsgi.version': (1, 0),\n 'QUERY_STRING': qs,\n 'HTTP_ACCEPT': 'text/plain;q=1.0, */*;q=0.1',\n 'paste.command_request': True,\n }\n\n if request_method in ('POST', 'PUT', 'PATCH'):\n environ['wsgi.input'] = self.stdin\n environ['CONTENT_LENGTH'] = '-1'\n\n for name, value in headers.items():\n if name.lower() == 'content-type':\n name = 'CONTENT_TYPE'\n else:\n name = 'HTTP_'+name.upper().replace('-', '_')\n environ[name] = value\n\n request = Request.blank(path, environ=environ)\n response = request.get_response(app)\n if self.options.display_headers:\n self.out(response.status)\n for name, value in response.headerlist:\n self.out('%s: %s' % (name, value))\n if response.charset:\n self.out(response.ubody)\n else:\n self.out(response.body)\n return 0\n\nif __name__ == '__main__': # pragma: no cover\n sys.exit(main() or 0)\n", "path": "pyramid/scripts/prequest.py"}], "after_files": [{"content": "import base64\nimport optparse\nimport sys\nimport textwrap\n\nfrom pyramid.compat import url_unquote\nfrom pyramid.request import Request\nfrom pyramid.paster import get_app, setup_logging\nfrom pyramid.scripts.common import parse_vars\n\ndef main(argv=sys.argv, quiet=False):\n command = PRequestCommand(argv, quiet)\n return command.run()\n\nclass PRequestCommand(object):\n description = \"\"\"\\\n Run a request for the described application.\n\n This command makes an artifical request to a web application that uses a\n PasteDeploy (.ini) configuration file for the server and application.\n\n Use \"prequest config.ini /path\" to request \"/path\".\n\n Use \"prequest --method=POST config.ini /path < data\" to do a POST with\n the given request body.\n\n Use \"prequest --method=PUT config.ini /path < data\" to do a\n PUT with the given request body.\n\n Use \"prequest --method=PATCH config.ini /path < data\" to do a\n PATCH with the given request body.\n\n Use \"prequest --method=OPTIONS config.ini /path\" to do an\n OPTIONS request.\n\n Use \"prequest --method=PROPFIND config.ini /path\" to do a\n PROPFIND request.\n\n If the path is relative (doesn't begin with \"/\") it is interpreted as\n relative to \"/\". The path passed to this script should be URL-quoted.\n The path can be succeeded with a query string (e.g. `/path?a=1&=b2').\n\n The variable \"environ['paste.command_request']\" will be set to \"True\" in\n the request's WSGI environment, so your application can distinguish these\n calls from normal requests.\n \"\"\"\n usage = \"usage: %prog config_uri path_info [args/options]\"\n parser = optparse.OptionParser(\n usage=usage,\n description=textwrap.dedent(description)\n )\n parser.add_option(\n '-n', '--app-name',\n dest='app_name',\n metavar= 'NAME',\n help=\"Load the named application from the config file (default 'main')\",\n type=\"string\",\n )\n parser.add_option(\n '--header',\n dest='headers',\n metavar='NAME:VALUE',\n type='string',\n action='append',\n help=\"Header to add to request (you can use this option multiple times)\"\n )\n parser.add_option(\n '-d', '--display-headers',\n dest='display_headers',\n action='store_true',\n help='Display status and headers before the response body'\n )\n parser.add_option(\n '-m', '--method',\n dest='method',\n choices=['GET', 'HEAD', 'POST', 'PUT', 'PATCH','DELETE',\n 'PROPFIND', 'OPTIONS'],\n type='choice',\n help='Request method type (GET, POST, PUT, PATCH, DELETE, '\n 'PROPFIND, OPTIONS)',\n )\n parser.add_option(\n '-l', '--login',\n dest='login',\n type='string',\n help='HTTP basic auth username:password pair',\n )\n\n get_app = staticmethod(get_app)\n stdin = sys.stdin\n\n def __init__(self, argv, quiet=False):\n self.quiet = quiet\n self.options, self.args = self.parser.parse_args(argv[1:])\n\n def out(self, msg): # pragma: no cover\n if not self.quiet:\n print(msg)\n\n def configure_logging(self, app_spec):\n setup_logging(app_spec)\n\n def run(self):\n if not len(self.args) >= 2:\n self.out('You must provide at least two arguments')\n return 2\n app_spec = self.args[0]\n path = self.args[1]\n\n self.configure_logging(app_spec)\n\n if not path.startswith('/'):\n path = '/' + path\n\n try:\n path, qs = path.split('?', 1)\n except ValueError:\n qs = ''\n\n path = url_unquote(path)\n\n headers = {}\n if self.options.login:\n enc = base64.b64encode(self.options.login.encode('ascii'))\n headers['Authorization'] = 'Basic ' + enc.decode('ascii')\n\n if self.options.headers:\n for item in self.options.headers:\n if ':' not in item:\n self.out(\n \"Bad --header=%s option, value must be in the form \"\n \"'name:value'\" % item)\n return 2\n name, value = item.split(':', 1)\n headers[name] = value.strip()\n\n app = self.get_app(app_spec, self.options.app_name,\n options=parse_vars(self.args[2:]))\n\n request_method = (self.options.method or 'GET').upper()\n\n environ = {\n 'REQUEST_METHOD': request_method,\n 'SCRIPT_NAME': '', # may be empty if app is at the root\n 'PATH_INFO': path,\n 'SERVER_NAME': 'localhost', # always mandatory\n 'SERVER_PORT': '80', # always mandatory\n 'SERVER_PROTOCOL': 'HTTP/1.0',\n 'CONTENT_TYPE': 'text/plain',\n 'REMOTE_ADDR':'127.0.0.1',\n 'wsgi.run_once': True,\n 'wsgi.multithread': False,\n 'wsgi.multiprocess': False,\n 'wsgi.errors': sys.stderr,\n 'wsgi.url_scheme': 'http',\n 'wsgi.version': (1, 0),\n 'QUERY_STRING': qs,\n 'HTTP_ACCEPT': 'text/plain;q=1.0, */*;q=0.1',\n 'paste.command_request': True,\n }\n\n if request_method in ('POST', 'PUT', 'PATCH'):\n environ['wsgi.input'] = self.stdin\n environ['CONTENT_LENGTH'] = '-1'\n\n for name, value in headers.items():\n if name.lower() == 'content-type':\n name = 'CONTENT_TYPE'\n else:\n name = 'HTTP_'+name.upper().replace('-', '_')\n environ[name] = value\n\n request = Request.blank(path, environ=environ)\n response = request.get_response(app)\n if self.options.display_headers:\n self.out(response.status)\n for name, value in response.headerlist:\n self.out('%s: %s' % (name, value))\n if response.charset:\n self.out(response.ubody)\n else:\n self.out(response.body)\n return 0\n\nif __name__ == '__main__': # pragma: no cover\n sys.exit(main() or 0)\n", "path": "pyramid/scripts/prequest.py"}]} | 2,109 | 217 |
gh_patches_debug_16054 | rasdani/github-patches | git_diff | geopandas__geopandas-1124 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Writing to file doesn't respect fiona vsi schemes
Fiona supports writing to different OGR virtual filesystem schemes via the file path, e.g., `zip://`, `s3://`, etc. However, these schemes get overwritten in `gpd.to_file()`, which attempts to take the path and construct an absolute path:
https://github.com/geopandas/geopandas/blob/29add0a735b00dc20c79e0fccc8e6a775c4997b0/geopandas/io/file.py#L127
so you get bad paths like `/home/username/s3:/bucket/object`.
Is this absolute file path important? Is there a reason to not allow VSI-based paths in `gpd.to_file()`? Can we check for a url-like scheme before trying to abs-path it? If so, I'd be happy to submit a PR.
(N.b., the corresponding `gpd.read_file()` handles these URLs correctly).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `geopandas/io/file.py`
Content:
```
1 from distutils.version import LooseVersion
2 import os
3
4 import numpy as np
5 import six
6
7 import fiona
8
9 from geopandas import GeoDataFrame, GeoSeries
10
11 try:
12 from fiona import Env as fiona_env
13 except ImportError:
14 from fiona import drivers as fiona_env
15
16
17 _FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion("1.8")
18
19
20 # Adapted from pandas.io.common
21 if six.PY3:
22 from urllib.request import urlopen as _urlopen
23 from urllib.parse import urlparse as parse_url
24 from urllib.parse import uses_relative, uses_netloc, uses_params
25 else:
26 from urllib2 import urlopen as _urlopen
27 from urlparse import urlparse as parse_url
28 from urlparse import uses_relative, uses_netloc, uses_params
29
30 _VALID_URLS = set(uses_relative + uses_netloc + uses_params)
31 _VALID_URLS.discard("")
32
33
34 def _is_url(url):
35 """Check to see if *url* has a valid protocol."""
36 try:
37 return parse_url(url).scheme in _VALID_URLS
38 except Exception:
39 return False
40
41
42 def read_file(filename, bbox=None, **kwargs):
43 """
44 Returns a GeoDataFrame from a file or URL.
45
46 Parameters
47 ----------
48 filename: str
49 Either the absolute or relative path to the file or URL to
50 be opened.
51 bbox : tuple | GeoDataFrame or GeoSeries, default None
52 Filter features by given bounding box, GeoSeries, or GeoDataFrame.
53 CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.
54 **kwargs:
55 Keyword args to be passed to the `open` or `BytesCollection` method
56 in the fiona library when opening the file. For more information on
57 possible keywords, type:
58 ``import fiona; help(fiona.open)``
59
60 Examples
61 --------
62 >>> df = geopandas.read_file("nybb.shp")
63
64 Returns
65 -------
66 geodataframe : GeoDataFrame
67 """
68 if _is_url(filename):
69 req = _urlopen(filename)
70 path_or_bytes = req.read()
71 reader = fiona.BytesCollection
72 else:
73 path_or_bytes = filename
74 reader = fiona.open
75
76 with fiona_env():
77 with reader(path_or_bytes, **kwargs) as features:
78
79 # In a future Fiona release the crs attribute of features will
80 # no longer be a dict. The following code will be both forward
81 # and backward compatible.
82 if hasattr(features.crs, "to_dict"):
83 crs = features.crs.to_dict()
84 else:
85 crs = features.crs
86
87 if bbox is not None:
88 if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):
89 bbox = tuple(bbox.to_crs(crs).total_bounds)
90 assert len(bbox) == 4
91 f_filt = features.filter(bbox=bbox)
92 else:
93 f_filt = features
94
95 columns = list(features.meta["schema"]["properties"]) + ["geometry"]
96 gdf = GeoDataFrame.from_features(f_filt, crs=crs, columns=columns)
97
98 return gdf
99
100
101 def to_file(df, filename, driver="ESRI Shapefile", schema=None, **kwargs):
102 """
103 Write this GeoDataFrame to an OGR data source
104
105 A dictionary of supported OGR providers is available via:
106 >>> import fiona
107 >>> fiona.supported_drivers
108
109 Parameters
110 ----------
111 df : GeoDataFrame to be written
112 filename : string
113 File path or file handle to write to.
114 driver : string, default 'ESRI Shapefile'
115 The OGR format driver used to write the vector file.
116 schema : dict, default None
117 If specified, the schema dictionary is passed to Fiona to
118 better control how the file is written. If None, GeoPandas
119 will determine the schema based on each column's dtype
120
121 The *kwargs* are passed to fiona.open and can be used to write
122 to multi-layer data, store data within archives (zip files), etc.
123 """
124 if schema is None:
125 schema = infer_schema(df)
126 filename = os.path.abspath(os.path.expanduser(filename))
127 with fiona_env():
128 with fiona.open(
129 filename, "w", driver=driver, crs=df.crs, schema=schema, **kwargs
130 ) as colxn:
131 colxn.writerecords(df.iterfeatures())
132
133
134 def infer_schema(df):
135 try:
136 from collections import OrderedDict
137 except ImportError:
138 from ordereddict import OrderedDict
139
140 def convert_type(column, in_type):
141 if in_type == object:
142 return "str"
143 if in_type.name.startswith("datetime64"):
144 # numpy datetime type regardless of frequency
145 return "datetime"
146 out_type = type(np.zeros(1, in_type).item()).__name__
147 if out_type == "long":
148 out_type = "int"
149 if not _FIONA18 and out_type == "bool":
150 raise ValueError(
151 'column "{}" is boolean type, '.format(column)
152 + "which is unsupported in file writing with fiona "
153 "< 1.8. Consider casting the column to int type."
154 )
155 return out_type
156
157 properties = OrderedDict(
158 [
159 (col, convert_type(col, _type))
160 for col, _type in zip(df.columns, df.dtypes)
161 if col != df._geometry_column_name
162 ]
163 )
164
165 if df.empty:
166 raise ValueError("Cannot write empty DataFrame to file.")
167
168 # Since https://github.com/Toblerity/Fiona/issues/446 resolution,
169 # Fiona allows a list of geometry types
170 geom_types = _geometry_types(df)
171
172 schema = {"geometry": geom_types, "properties": properties}
173
174 return schema
175
176
177 def _geometry_types(df):
178 """
179 Determine the geometry types in the GeoDataFrame for the schema.
180 """
181 if _FIONA18:
182 # Starting from Fiona 1.8, schema submitted to fiona to write a gdf
183 # can have mixed geometries:
184 # - 3D and 2D shapes can coexist in inferred schema
185 # - Shape and MultiShape types can (and must) coexist in inferred
186 # schema
187 geom_types_2D = df[~df.geometry.has_z].geometry.geom_type.unique()
188 geom_types_2D = [gtype for gtype in geom_types_2D if gtype is not None]
189 geom_types_3D = df[df.geometry.has_z].geometry.geom_type.unique()
190 geom_types_3D = ["3D " + gtype for gtype in geom_types_3D if gtype is not None]
191 geom_types = geom_types_3D + geom_types_2D
192
193 else:
194 # Before Fiona 1.8, schema submitted to write a gdf should have
195 # one single geometry type whenever possible:
196 # - 3D and 2D shapes cannot coexist in inferred schema
197 # - Shape and MultiShape can not coexist in inferred schema
198 geom_types = _geometry_types_back_compat(df)
199
200 if len(geom_types) == 0:
201 # Default geometry type supported by Fiona
202 # (Since https://github.com/Toblerity/Fiona/issues/446 resolution)
203 return "Unknown"
204
205 if len(geom_types) == 1:
206 geom_types = geom_types[0]
207
208 return geom_types
209
210
211 def _geometry_types_back_compat(df):
212 """
213 for backward compatibility with Fiona<1.8 only
214 """
215 unique_geom_types = df.geometry.geom_type.unique()
216 unique_geom_types = [gtype for gtype in unique_geom_types if gtype is not None]
217
218 # merge single and Multi types (eg Polygon and MultiPolygon)
219 unique_geom_types = [
220 gtype
221 for gtype in unique_geom_types
222 if not gtype.startswith("Multi") or gtype[5:] not in unique_geom_types
223 ]
224
225 if df.geometry.has_z.any():
226 # declare all geometries as 3D geometries
227 unique_geom_types = ["3D " + type for type in unique_geom_types]
228 # by default, all geometries are 2D geometries
229
230 return unique_geom_types
231
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/geopandas/io/file.py b/geopandas/io/file.py
--- a/geopandas/io/file.py
+++ b/geopandas/io/file.py
@@ -1,5 +1,4 @@
from distutils.version import LooseVersion
-import os
import numpy as np
import six
@@ -120,10 +119,10 @@
The *kwargs* are passed to fiona.open and can be used to write
to multi-layer data, store data within archives (zip files), etc.
+ The path may specify a fiona VSI scheme.
"""
if schema is None:
schema = infer_schema(df)
- filename = os.path.abspath(os.path.expanduser(filename))
with fiona_env():
with fiona.open(
filename, "w", driver=driver, crs=df.crs, schema=schema, **kwargs
| {"golden_diff": "diff --git a/geopandas/io/file.py b/geopandas/io/file.py\n--- a/geopandas/io/file.py\n+++ b/geopandas/io/file.py\n@@ -1,5 +1,4 @@\n from distutils.version import LooseVersion\n-import os\n \n import numpy as np\n import six\n@@ -120,10 +119,10 @@\n \n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n+ The path may specify a fiona VSI scheme.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n- filename = os.path.abspath(os.path.expanduser(filename))\n with fiona_env():\n with fiona.open(\n filename, \"w\", driver=driver, crs=df.crs, schema=schema, **kwargs\n", "issue": "Writing to file doesn't respect fiona vsi schemes\nFiona supports writing to different OGR virtual filesystem schemes via the file path, e.g., `zip://`, `s3://`, etc. However, these schemes get overwritten in `gpd.to_file()`, which attempts to take the path and construct an absolute path:\r\nhttps://github.com/geopandas/geopandas/blob/29add0a735b00dc20c79e0fccc8e6a775c4997b0/geopandas/io/file.py#L127\r\nso you get bad paths like `/home/username/s3:/bucket/object`.\r\n\r\nIs this absolute file path important? Is there a reason to not allow VSI-based paths in `gpd.to_file()`? Can we check for a url-like scheme before trying to abs-path it? If so, I'd be happy to submit a PR.\r\n\r\n(N.b., the corresponding `gpd.read_file()` handles these URLs correctly).\n", "before_files": [{"content": "from distutils.version import LooseVersion\nimport os\n\nimport numpy as np\nimport six\n\nimport fiona\n\nfrom geopandas import GeoDataFrame, GeoSeries\n\ntry:\n from fiona import Env as fiona_env\nexcept ImportError:\n from fiona import drivers as fiona_env\n\n\n_FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion(\"1.8\")\n\n\n# Adapted from pandas.io.common\nif six.PY3:\n from urllib.request import urlopen as _urlopen\n from urllib.parse import urlparse as parse_url\n from urllib.parse import uses_relative, uses_netloc, uses_params\nelse:\n from urllib2 import urlopen as _urlopen\n from urlparse import urlparse as parse_url\n from urlparse import uses_relative, uses_netloc, uses_params\n\n_VALID_URLS = set(uses_relative + uses_netloc + uses_params)\n_VALID_URLS.discard(\"\")\n\n\ndef _is_url(url):\n \"\"\"Check to see if *url* has a valid protocol.\"\"\"\n try:\n return parse_url(url).scheme in _VALID_URLS\n except Exception:\n return False\n\n\ndef read_file(filename, bbox=None, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file or URL.\n\n Parameters\n ----------\n filename: str\n Either the absolute or relative path to the file or URL to\n be opened.\n bbox : tuple | GeoDataFrame or GeoSeries, default None\n Filter features by given bounding box, GeoSeries, or GeoDataFrame.\n CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.\n **kwargs:\n Keyword args to be passed to the `open` or `BytesCollection` method\n in the fiona library when opening the file. For more information on\n possible keywords, type:\n ``import fiona; help(fiona.open)``\n\n Examples\n --------\n >>> df = geopandas.read_file(\"nybb.shp\")\n\n Returns\n -------\n geodataframe : GeoDataFrame\n \"\"\"\n if _is_url(filename):\n req = _urlopen(filename)\n path_or_bytes = req.read()\n reader = fiona.BytesCollection\n else:\n path_or_bytes = filename\n reader = fiona.open\n\n with fiona_env():\n with reader(path_or_bytes, **kwargs) as features:\n\n # In a future Fiona release the crs attribute of features will\n # no longer be a dict. The following code will be both forward\n # and backward compatible.\n if hasattr(features.crs, \"to_dict\"):\n crs = features.crs.to_dict()\n else:\n crs = features.crs\n\n if bbox is not None:\n if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):\n bbox = tuple(bbox.to_crs(crs).total_bounds)\n assert len(bbox) == 4\n f_filt = features.filter(bbox=bbox)\n else:\n f_filt = features\n\n columns = list(features.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n gdf = GeoDataFrame.from_features(f_filt, crs=crs, columns=columns)\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None, **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n filename = os.path.abspath(os.path.expanduser(filename))\n with fiona_env():\n with fiona.open(\n filename, \"w\", driver=driver, crs=df.crs, schema=schema, **kwargs\n ) as colxn:\n colxn.writerecords(df.iterfeatures())\n\n\ndef infer_schema(df):\n try:\n from collections import OrderedDict\n except ImportError:\n from ordereddict import OrderedDict\n\n def convert_type(column, in_type):\n if in_type == object:\n return \"str\"\n if in_type.name.startswith(\"datetime64\"):\n # numpy datetime type regardless of frequency\n return \"datetime\"\n out_type = type(np.zeros(1, in_type).item()).__name__\n if out_type == \"long\":\n out_type = \"int\"\n if not _FIONA18 and out_type == \"bool\":\n raise ValueError(\n 'column \"{}\" is boolean type, '.format(column)\n + \"which is unsupported in file writing with fiona \"\n \"< 1.8. Consider casting the column to int type.\"\n )\n return out_type\n\n properties = OrderedDict(\n [\n (col, convert_type(col, _type))\n for col, _type in zip(df.columns, df.dtypes)\n if col != df._geometry_column_name\n ]\n )\n\n if df.empty:\n raise ValueError(\"Cannot write empty DataFrame to file.\")\n\n # Since https://github.com/Toblerity/Fiona/issues/446 resolution,\n # Fiona allows a list of geometry types\n geom_types = _geometry_types(df)\n\n schema = {\"geometry\": geom_types, \"properties\": properties}\n\n return schema\n\n\ndef _geometry_types(df):\n \"\"\"\n Determine the geometry types in the GeoDataFrame for the schema.\n \"\"\"\n if _FIONA18:\n # Starting from Fiona 1.8, schema submitted to fiona to write a gdf\n # can have mixed geometries:\n # - 3D and 2D shapes can coexist in inferred schema\n # - Shape and MultiShape types can (and must) coexist in inferred\n # schema\n geom_types_2D = df[~df.geometry.has_z].geometry.geom_type.unique()\n geom_types_2D = [gtype for gtype in geom_types_2D if gtype is not None]\n geom_types_3D = df[df.geometry.has_z].geometry.geom_type.unique()\n geom_types_3D = [\"3D \" + gtype for gtype in geom_types_3D if gtype is not None]\n geom_types = geom_types_3D + geom_types_2D\n\n else:\n # Before Fiona 1.8, schema submitted to write a gdf should have\n # one single geometry type whenever possible:\n # - 3D and 2D shapes cannot coexist in inferred schema\n # - Shape and MultiShape can not coexist in inferred schema\n geom_types = _geometry_types_back_compat(df)\n\n if len(geom_types) == 0:\n # Default geometry type supported by Fiona\n # (Since https://github.com/Toblerity/Fiona/issues/446 resolution)\n return \"Unknown\"\n\n if len(geom_types) == 1:\n geom_types = geom_types[0]\n\n return geom_types\n\n\ndef _geometry_types_back_compat(df):\n \"\"\"\n for backward compatibility with Fiona<1.8 only\n \"\"\"\n unique_geom_types = df.geometry.geom_type.unique()\n unique_geom_types = [gtype for gtype in unique_geom_types if gtype is not None]\n\n # merge single and Multi types (eg Polygon and MultiPolygon)\n unique_geom_types = [\n gtype\n for gtype in unique_geom_types\n if not gtype.startswith(\"Multi\") or gtype[5:] not in unique_geom_types\n ]\n\n if df.geometry.has_z.any():\n # declare all geometries as 3D geometries\n unique_geom_types = [\"3D \" + type for type in unique_geom_types]\n # by default, all geometries are 2D geometries\n\n return unique_geom_types\n", "path": "geopandas/io/file.py"}], "after_files": [{"content": "from distutils.version import LooseVersion\n\nimport numpy as np\nimport six\n\nimport fiona\n\nfrom geopandas import GeoDataFrame, GeoSeries\n\ntry:\n from fiona import Env as fiona_env\nexcept ImportError:\n from fiona import drivers as fiona_env\n\n\n_FIONA18 = LooseVersion(fiona.__version__) >= LooseVersion(\"1.8\")\n\n\n# Adapted from pandas.io.common\nif six.PY3:\n from urllib.request import urlopen as _urlopen\n from urllib.parse import urlparse as parse_url\n from urllib.parse import uses_relative, uses_netloc, uses_params\nelse:\n from urllib2 import urlopen as _urlopen\n from urlparse import urlparse as parse_url\n from urlparse import uses_relative, uses_netloc, uses_params\n\n_VALID_URLS = set(uses_relative + uses_netloc + uses_params)\n_VALID_URLS.discard(\"\")\n\n\ndef _is_url(url):\n \"\"\"Check to see if *url* has a valid protocol.\"\"\"\n try:\n return parse_url(url).scheme in _VALID_URLS\n except Exception:\n return False\n\n\ndef read_file(filename, bbox=None, **kwargs):\n \"\"\"\n Returns a GeoDataFrame from a file or URL.\n\n Parameters\n ----------\n filename: str\n Either the absolute or relative path to the file or URL to\n be opened.\n bbox : tuple | GeoDataFrame or GeoSeries, default None\n Filter features by given bounding box, GeoSeries, or GeoDataFrame.\n CRS mis-matches are resolved if given a GeoSeries or GeoDataFrame.\n **kwargs:\n Keyword args to be passed to the `open` or `BytesCollection` method\n in the fiona library when opening the file. For more information on\n possible keywords, type:\n ``import fiona; help(fiona.open)``\n\n Examples\n --------\n >>> df = geopandas.read_file(\"nybb.shp\")\n\n Returns\n -------\n geodataframe : GeoDataFrame\n \"\"\"\n if _is_url(filename):\n req = _urlopen(filename)\n path_or_bytes = req.read()\n reader = fiona.BytesCollection\n else:\n path_or_bytes = filename\n reader = fiona.open\n\n with fiona_env():\n with reader(path_or_bytes, **kwargs) as features:\n\n # In a future Fiona release the crs attribute of features will\n # no longer be a dict. The following code will be both forward\n # and backward compatible.\n if hasattr(features.crs, \"to_dict\"):\n crs = features.crs.to_dict()\n else:\n crs = features.crs\n\n if bbox is not None:\n if isinstance(bbox, GeoDataFrame) or isinstance(bbox, GeoSeries):\n bbox = tuple(bbox.to_crs(crs).total_bounds)\n assert len(bbox) == 4\n f_filt = features.filter(bbox=bbox)\n else:\n f_filt = features\n\n columns = list(features.meta[\"schema\"][\"properties\"]) + [\"geometry\"]\n gdf = GeoDataFrame.from_features(f_filt, crs=crs, columns=columns)\n\n return gdf\n\n\ndef to_file(df, filename, driver=\"ESRI Shapefile\", schema=None, **kwargs):\n \"\"\"\n Write this GeoDataFrame to an OGR data source\n\n A dictionary of supported OGR providers is available via:\n >>> import fiona\n >>> fiona.supported_drivers\n\n Parameters\n ----------\n df : GeoDataFrame to be written\n filename : string\n File path or file handle to write to.\n driver : string, default 'ESRI Shapefile'\n The OGR format driver used to write the vector file.\n schema : dict, default None\n If specified, the schema dictionary is passed to Fiona to\n better control how the file is written. If None, GeoPandas\n will determine the schema based on each column's dtype\n\n The *kwargs* are passed to fiona.open and can be used to write\n to multi-layer data, store data within archives (zip files), etc.\n The path may specify a fiona VSI scheme.\n \"\"\"\n if schema is None:\n schema = infer_schema(df)\n with fiona_env():\n with fiona.open(\n filename, \"w\", driver=driver, crs=df.crs, schema=schema, **kwargs\n ) as colxn:\n colxn.writerecords(df.iterfeatures())\n\n\ndef infer_schema(df):\n try:\n from collections import OrderedDict\n except ImportError:\n from ordereddict import OrderedDict\n\n def convert_type(column, in_type):\n if in_type == object:\n return \"str\"\n if in_type.name.startswith(\"datetime64\"):\n # numpy datetime type regardless of frequency\n return \"datetime\"\n out_type = type(np.zeros(1, in_type).item()).__name__\n if out_type == \"long\":\n out_type = \"int\"\n if not _FIONA18 and out_type == \"bool\":\n raise ValueError(\n 'column \"{}\" is boolean type, '.format(column)\n + \"which is unsupported in file writing with fiona \"\n \"< 1.8. Consider casting the column to int type.\"\n )\n return out_type\n\n properties = OrderedDict(\n [\n (col, convert_type(col, _type))\n for col, _type in zip(df.columns, df.dtypes)\n if col != df._geometry_column_name\n ]\n )\n\n if df.empty:\n raise ValueError(\"Cannot write empty DataFrame to file.\")\n\n # Since https://github.com/Toblerity/Fiona/issues/446 resolution,\n # Fiona allows a list of geometry types\n geom_types = _geometry_types(df)\n\n schema = {\"geometry\": geom_types, \"properties\": properties}\n\n return schema\n\n\ndef _geometry_types(df):\n \"\"\"\n Determine the geometry types in the GeoDataFrame for the schema.\n \"\"\"\n if _FIONA18:\n # Starting from Fiona 1.8, schema submitted to fiona to write a gdf\n # can have mixed geometries:\n # - 3D and 2D shapes can coexist in inferred schema\n # - Shape and MultiShape types can (and must) coexist in inferred\n # schema\n geom_types_2D = df[~df.geometry.has_z].geometry.geom_type.unique()\n geom_types_2D = [gtype for gtype in geom_types_2D if gtype is not None]\n geom_types_3D = df[df.geometry.has_z].geometry.geom_type.unique()\n geom_types_3D = [\"3D \" + gtype for gtype in geom_types_3D if gtype is not None]\n geom_types = geom_types_3D + geom_types_2D\n\n else:\n # Before Fiona 1.8, schema submitted to write a gdf should have\n # one single geometry type whenever possible:\n # - 3D and 2D shapes cannot coexist in inferred schema\n # - Shape and MultiShape can not coexist in inferred schema\n geom_types = _geometry_types_back_compat(df)\n\n if len(geom_types) == 0:\n # Default geometry type supported by Fiona\n # (Since https://github.com/Toblerity/Fiona/issues/446 resolution)\n return \"Unknown\"\n\n if len(geom_types) == 1:\n geom_types = geom_types[0]\n\n return geom_types\n\n\ndef _geometry_types_back_compat(df):\n \"\"\"\n for backward compatibility with Fiona<1.8 only\n \"\"\"\n unique_geom_types = df.geometry.geom_type.unique()\n unique_geom_types = [gtype for gtype in unique_geom_types if gtype is not None]\n\n # merge single and Multi types (eg Polygon and MultiPolygon)\n unique_geom_types = [\n gtype\n for gtype in unique_geom_types\n if not gtype.startswith(\"Multi\") or gtype[5:] not in unique_geom_types\n ]\n\n if df.geometry.has_z.any():\n # declare all geometries as 3D geometries\n unique_geom_types = [\"3D \" + type for type in unique_geom_types]\n # by default, all geometries are 2D geometries\n\n return unique_geom_types\n", "path": "geopandas/io/file.py"}]} | 2,871 | 192 |
gh_patches_debug_25602 | rasdani/github-patches | git_diff | elastic__apm-agent-python-1099 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AttributeError: 'NoneType' object has no attribute 'config' in Flask Agent
**Describe the bug**: By using the flask agent and opting to [build the application on the fly](https://www.elastic.co/guide/en/apm/agent/python/current/flask-support.html#flask-building-applications-on-the-fly) an error occurs **AttributeError: 'NoneType' object has no attribute 'config'**.
**To Reproduce**
1. run the following
```python
from elasticapm.contrib.flask import ElasticAPM
from flask import Flask
apm = ElasticAPM()
app = Flask(__name__)
apm.init_app(app)
```
**Environment (please complete the following information)**
- OS: Linux
- Python version: 3.8.5
- Framework and version: Flask 1.1.2
- APM Server version: NA
- Agent version: NA
**Additional context**
This error does not happen with version 6.0.0. This bug seems to be incorporated into the project in the [PR-1043](https://github.com/elastic/apm-agent-python/pull/1043) with the removal from the [if statement L128 - L129](https://github.com/elastic/apm-agent-python/pull/1043/files#diff-f7d7281cc8ddf8897f2fe37e9ad1facc0aefb57bdda156a5de603db46d1d9b1eL128-L129) in the `init_app()` method that would initiate a possible NoneType client. Based on the efforts of the [PR-1043](https://github.com/elastic/apm-agent-python/pull/1043) to make the client global, it would ideally be initiated in the constructor from the class ElasticAPM. That would only apply [if there's an existent app](https://github.com/elastic/apm-agent-python/pull/1043/files#diff-f7d7281cc8ddf8897f2fe37e9ad1facc0aefb57bdda156a5de603db46d1d9b1eL103) which does not happen if the user opted to [build the application on the fly](https://www.elastic.co/guide/en/apm/agent/python/current/flask-support.html#flask-building-applications-on-the-fly).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `elasticapm/contrib/flask/__init__.py`
Content:
```
1 # BSD 3-Clause License
2 #
3 # Copyright (c) 2012, the Sentry Team, see AUTHORS for more details
4 # Copyright (c) 2019, Elasticsearch BV
5 # All rights reserved.
6 #
7 # Redistribution and use in source and binary forms, with or without
8 # modification, are permitted provided that the following conditions are met:
9 #
10 # * Redistributions of source code must retain the above copyright notice, this
11 # list of conditions and the following disclaimer.
12 #
13 # * Redistributions in binary form must reproduce the above copyright notice,
14 # this list of conditions and the following disclaimer in the documentation
15 # and/or other materials provided with the distribution.
16 #
17 # * Neither the name of the copyright holder nor the names of its
18 # contributors may be used to endorse or promote products derived from
19 # this software without specific prior written permission.
20 #
21 # THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
22 # AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
23 # IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
24 # DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
25 # FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
26 # DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
27 # SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
28 # CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
29 # OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
30
31
32 from __future__ import absolute_import
33
34 import logging
35
36 import flask
37 from flask import request, signals
38
39 import elasticapm
40 import elasticapm.instrumentation.control
41 from elasticapm import get_client
42 from elasticapm.base import Client
43 from elasticapm.conf import constants, setup_logging
44 from elasticapm.contrib.flask.utils import get_data_from_request, get_data_from_response
45 from elasticapm.handlers.logging import LoggingHandler
46 from elasticapm.traces import execution_context
47 from elasticapm.utils import build_name_with_http_method_prefix
48 from elasticapm.utils.disttracing import TraceParent
49 from elasticapm.utils.logging import get_logger
50
51 logger = get_logger("elasticapm.errors.client")
52
53
54 class ElasticAPM(object):
55 """
56 Flask application for Elastic APM.
57
58 Look up configuration from ``os.environ.get('ELASTIC_APM_APP_NAME')`` and
59 ``os.environ.get('ELASTIC_APM_SECRET_TOKEN')``::
60
61 >>> elasticapm = ElasticAPM(app)
62
63 Pass an arbitrary APP_NAME and SECRET_TOKEN::
64
65 >>> elasticapm = ElasticAPM(app, service_name='myapp', secret_token='asdasdasd')
66
67 Pass an explicit client::
68
69 >>> elasticapm = ElasticAPM(app, client=client)
70
71 Automatically configure logging::
72
73 >>> elasticapm = ElasticAPM(app, logging=True)
74
75 Capture an exception::
76
77 >>> try:
78 >>> 1 / 0
79 >>> except ZeroDivisionError:
80 >>> elasticapm.capture_exception()
81
82 Capture a message::
83
84 >>> elasticapm.capture_message('hello, world!')
85 """
86
87 def __init__(self, app=None, client=None, client_cls=Client, logging=False, **defaults):
88 self.app = app
89 self.logging = logging
90 self.client = client or get_client()
91
92 if app:
93 if not self.client:
94 config = app.config.get("ELASTIC_APM", {})
95
96 if "framework_name" not in defaults:
97 defaults["framework_name"] = "flask"
98 defaults["framework_version"] = getattr(flask, "__version__", "<0.7")
99
100 self.client = client_cls(config, **defaults)
101
102 self.init_app(app, **defaults)
103
104 def handle_exception(self, *args, **kwargs):
105 if not self.client:
106 return
107
108 if self.app.debug and not self.client.config.debug:
109 return
110
111 self.client.capture_exception(
112 exc_info=kwargs.get("exc_info"),
113 context={"request": get_data_from_request(request, self.client.config, constants.ERROR)},
114 custom={"app": self.app},
115 handled=False,
116 )
117 # End the transaction here, as `request_finished` won't be called when an
118 # unhandled exception occurs.
119 #
120 # Unfortunately, that also means that we can't capture any response data,
121 # as the response isn't ready at this point in time.
122 self.client.end_transaction(result="HTTP 5xx")
123
124 def init_app(self, app, **defaults):
125 self.app = app
126
127 # 0 is a valid log level (NOTSET), so we need to check explicitly for it
128 if self.logging or self.logging is logging.NOTSET:
129 if self.logging is not True:
130 kwargs = {"level": self.logging}
131 else:
132 kwargs = {}
133 setup_logging(LoggingHandler(self.client, **kwargs))
134
135 signals.got_request_exception.connect(self.handle_exception, sender=app, weak=False)
136
137 try:
138 from elasticapm.contrib.celery import register_exception_tracking
139
140 register_exception_tracking(self.client)
141 except ImportError:
142 pass
143
144 # Instrument to get spans
145 if self.client.config.instrument and self.client.config.enabled:
146 elasticapm.instrumentation.control.instrument()
147
148 signals.request_started.connect(self.request_started, sender=app)
149 signals.request_finished.connect(self.request_finished, sender=app)
150 try:
151 from elasticapm.contrib.celery import register_instrumentation
152
153 register_instrumentation(self.client)
154 except ImportError:
155 pass
156 else:
157 logger.debug("Skipping instrumentation. INSTRUMENT is set to False.")
158
159 @app.context_processor
160 def rum_tracing():
161 """
162 Adds APM related IDs to the context used for correlating the backend transaction with the RUM transaction
163 """
164 transaction = execution_context.get_transaction()
165 if transaction and transaction.trace_parent:
166 return {
167 "apm": {
168 "trace_id": transaction.trace_parent.trace_id,
169 "span_id": lambda: transaction.ensure_parent_id(),
170 "is_sampled": transaction.is_sampled,
171 "is_sampled_js": "true" if transaction.is_sampled else "false",
172 }
173 }
174 return {}
175
176 def request_started(self, app):
177 if (not self.app.debug or self.client.config.debug) and not self.client.should_ignore_url(request.path):
178 trace_parent = TraceParent.from_headers(request.headers)
179 self.client.begin_transaction("request", trace_parent=trace_parent)
180 elasticapm.set_context(
181 lambda: get_data_from_request(request, self.client.config, constants.TRANSACTION), "request"
182 )
183 rule = request.url_rule.rule if request.url_rule is not None else ""
184 rule = build_name_with_http_method_prefix(rule, request)
185 elasticapm.set_transaction_name(rule, override=False)
186
187 def request_finished(self, app, response):
188 if not self.app.debug or self.client.config.debug:
189 elasticapm.set_context(
190 lambda: get_data_from_response(response, self.client.config, constants.TRANSACTION), "response"
191 )
192 if response.status_code:
193 result = "HTTP {}xx".format(response.status_code // 100)
194 elasticapm.set_transaction_outcome(http_status_code=response.status_code, override=False)
195 else:
196 result = response.status
197 elasticapm.set_transaction_outcome(http_status_code=response.status, override=False)
198 elasticapm.set_transaction_result(result, override=False)
199 # Instead of calling end_transaction here, we defer the call until the response is closed.
200 # This ensures that we capture things that happen until the WSGI server closes the response.
201 response.call_on_close(self.client.end_transaction)
202
203 def capture_exception(self, *args, **kwargs):
204 assert self.client, "capture_exception called before application configured"
205 return self.client.capture_exception(*args, **kwargs)
206
207 def capture_message(self, *args, **kwargs):
208 assert self.client, "capture_message called before application configured"
209 return self.client.capture_message(*args, **kwargs)
210
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/elasticapm/contrib/flask/__init__.py b/elasticapm/contrib/flask/__init__.py
--- a/elasticapm/contrib/flask/__init__.py
+++ b/elasticapm/contrib/flask/__init__.py
@@ -88,17 +88,9 @@
self.app = app
self.logging = logging
self.client = client or get_client()
+ self.client_cls = client_cls
if app:
- if not self.client:
- config = app.config.get("ELASTIC_APM", {})
-
- if "framework_name" not in defaults:
- defaults["framework_name"] = "flask"
- defaults["framework_version"] = getattr(flask, "__version__", "<0.7")
-
- self.client = client_cls(config, **defaults)
-
self.init_app(app, **defaults)
def handle_exception(self, *args, **kwargs):
@@ -123,6 +115,14 @@
def init_app(self, app, **defaults):
self.app = app
+ if not self.client:
+ config = self.app.config.get("ELASTIC_APM", {})
+
+ if "framework_name" not in defaults:
+ defaults["framework_name"] = "flask"
+ defaults["framework_version"] = getattr(flask, "__version__", "<0.7")
+
+ self.client = self.client_cls(config, **defaults)
# 0 is a valid log level (NOTSET), so we need to check explicitly for it
if self.logging or self.logging is logging.NOTSET:
| {"golden_diff": "diff --git a/elasticapm/contrib/flask/__init__.py b/elasticapm/contrib/flask/__init__.py\n--- a/elasticapm/contrib/flask/__init__.py\n+++ b/elasticapm/contrib/flask/__init__.py\n@@ -88,17 +88,9 @@\n self.app = app\n self.logging = logging\n self.client = client or get_client()\n+ self.client_cls = client_cls\n \n if app:\n- if not self.client:\n- config = app.config.get(\"ELASTIC_APM\", {})\n-\n- if \"framework_name\" not in defaults:\n- defaults[\"framework_name\"] = \"flask\"\n- defaults[\"framework_version\"] = getattr(flask, \"__version__\", \"<0.7\")\n-\n- self.client = client_cls(config, **defaults)\n-\n self.init_app(app, **defaults)\n \n def handle_exception(self, *args, **kwargs):\n@@ -123,6 +115,14 @@\n \n def init_app(self, app, **defaults):\n self.app = app\n+ if not self.client:\n+ config = self.app.config.get(\"ELASTIC_APM\", {})\n+\n+ if \"framework_name\" not in defaults:\n+ defaults[\"framework_name\"] = \"flask\"\n+ defaults[\"framework_version\"] = getattr(flask, \"__version__\", \"<0.7\")\n+\n+ self.client = self.client_cls(config, **defaults)\n \n # 0 is a valid log level (NOTSET), so we need to check explicitly for it\n if self.logging or self.logging is logging.NOTSET:\n", "issue": "AttributeError: 'NoneType' object has no attribute 'config' in Flask Agent\n**Describe the bug**: By using the flask agent and opting to [build the application on the fly](https://www.elastic.co/guide/en/apm/agent/python/current/flask-support.html#flask-building-applications-on-the-fly) an error occurs **AttributeError: 'NoneType' object has no attribute 'config'**.\r\n\r\n**To Reproduce**\r\n\r\n1. run the following\r\n```python\r\nfrom elasticapm.contrib.flask import ElasticAPM\r\nfrom flask import Flask\r\napm = ElasticAPM()\r\n\r\napp = Flask(__name__)\r\napm.init_app(app)\r\n```\r\n\r\n**Environment (please complete the following information)**\r\n- OS: Linux\r\n- Python version: 3.8.5\r\n- Framework and version: Flask 1.1.2 \r\n- APM Server version: NA\r\n- Agent version: NA\r\n\r\n\r\n**Additional context**\r\n\r\nThis error does not happen with version 6.0.0. This bug seems to be incorporated into the project in the [PR-1043](https://github.com/elastic/apm-agent-python/pull/1043) with the removal from the [if statement L128 - L129](https://github.com/elastic/apm-agent-python/pull/1043/files#diff-f7d7281cc8ddf8897f2fe37e9ad1facc0aefb57bdda156a5de603db46d1d9b1eL128-L129) in the `init_app()` method that would initiate a possible NoneType client. Based on the efforts of the [PR-1043](https://github.com/elastic/apm-agent-python/pull/1043) to make the client global, it would ideally be initiated in the constructor from the class ElasticAPM. That would only apply [if there's an existent app](https://github.com/elastic/apm-agent-python/pull/1043/files#diff-f7d7281cc8ddf8897f2fe37e9ad1facc0aefb57bdda156a5de603db46d1d9b1eL103) which does not happen if the user opted to [build the application on the fly](https://www.elastic.co/guide/en/apm/agent/python/current/flask-support.html#flask-building-applications-on-the-fly).\n", "before_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom __future__ import absolute_import\n\nimport logging\n\nimport flask\nfrom flask import request, signals\n\nimport elasticapm\nimport elasticapm.instrumentation.control\nfrom elasticapm import get_client\nfrom elasticapm.base import Client\nfrom elasticapm.conf import constants, setup_logging\nfrom elasticapm.contrib.flask.utils import get_data_from_request, get_data_from_response\nfrom elasticapm.handlers.logging import LoggingHandler\nfrom elasticapm.traces import execution_context\nfrom elasticapm.utils import build_name_with_http_method_prefix\nfrom elasticapm.utils.disttracing import TraceParent\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.errors.client\")\n\n\nclass ElasticAPM(object):\n \"\"\"\n Flask application for Elastic APM.\n\n Look up configuration from ``os.environ.get('ELASTIC_APM_APP_NAME')`` and\n ``os.environ.get('ELASTIC_APM_SECRET_TOKEN')``::\n\n >>> elasticapm = ElasticAPM(app)\n\n Pass an arbitrary APP_NAME and SECRET_TOKEN::\n\n >>> elasticapm = ElasticAPM(app, service_name='myapp', secret_token='asdasdasd')\n\n Pass an explicit client::\n\n >>> elasticapm = ElasticAPM(app, client=client)\n\n Automatically configure logging::\n\n >>> elasticapm = ElasticAPM(app, logging=True)\n\n Capture an exception::\n\n >>> try:\n >>> 1 / 0\n >>> except ZeroDivisionError:\n >>> elasticapm.capture_exception()\n\n Capture a message::\n\n >>> elasticapm.capture_message('hello, world!')\n \"\"\"\n\n def __init__(self, app=None, client=None, client_cls=Client, logging=False, **defaults):\n self.app = app\n self.logging = logging\n self.client = client or get_client()\n\n if app:\n if not self.client:\n config = app.config.get(\"ELASTIC_APM\", {})\n\n if \"framework_name\" not in defaults:\n defaults[\"framework_name\"] = \"flask\"\n defaults[\"framework_version\"] = getattr(flask, \"__version__\", \"<0.7\")\n\n self.client = client_cls(config, **defaults)\n\n self.init_app(app, **defaults)\n\n def handle_exception(self, *args, **kwargs):\n if not self.client:\n return\n\n if self.app.debug and not self.client.config.debug:\n return\n\n self.client.capture_exception(\n exc_info=kwargs.get(\"exc_info\"),\n context={\"request\": get_data_from_request(request, self.client.config, constants.ERROR)},\n custom={\"app\": self.app},\n handled=False,\n )\n # End the transaction here, as `request_finished` won't be called when an\n # unhandled exception occurs.\n #\n # Unfortunately, that also means that we can't capture any response data,\n # as the response isn't ready at this point in time.\n self.client.end_transaction(result=\"HTTP 5xx\")\n\n def init_app(self, app, **defaults):\n self.app = app\n\n # 0 is a valid log level (NOTSET), so we need to check explicitly for it\n if self.logging or self.logging is logging.NOTSET:\n if self.logging is not True:\n kwargs = {\"level\": self.logging}\n else:\n kwargs = {}\n setup_logging(LoggingHandler(self.client, **kwargs))\n\n signals.got_request_exception.connect(self.handle_exception, sender=app, weak=False)\n\n try:\n from elasticapm.contrib.celery import register_exception_tracking\n\n register_exception_tracking(self.client)\n except ImportError:\n pass\n\n # Instrument to get spans\n if self.client.config.instrument and self.client.config.enabled:\n elasticapm.instrumentation.control.instrument()\n\n signals.request_started.connect(self.request_started, sender=app)\n signals.request_finished.connect(self.request_finished, sender=app)\n try:\n from elasticapm.contrib.celery import register_instrumentation\n\n register_instrumentation(self.client)\n except ImportError:\n pass\n else:\n logger.debug(\"Skipping instrumentation. INSTRUMENT is set to False.\")\n\n @app.context_processor\n def rum_tracing():\n \"\"\"\n Adds APM related IDs to the context used for correlating the backend transaction with the RUM transaction\n \"\"\"\n transaction = execution_context.get_transaction()\n if transaction and transaction.trace_parent:\n return {\n \"apm\": {\n \"trace_id\": transaction.trace_parent.trace_id,\n \"span_id\": lambda: transaction.ensure_parent_id(),\n \"is_sampled\": transaction.is_sampled,\n \"is_sampled_js\": \"true\" if transaction.is_sampled else \"false\",\n }\n }\n return {}\n\n def request_started(self, app):\n if (not self.app.debug or self.client.config.debug) and not self.client.should_ignore_url(request.path):\n trace_parent = TraceParent.from_headers(request.headers)\n self.client.begin_transaction(\"request\", trace_parent=trace_parent)\n elasticapm.set_context(\n lambda: get_data_from_request(request, self.client.config, constants.TRANSACTION), \"request\"\n )\n rule = request.url_rule.rule if request.url_rule is not None else \"\"\n rule = build_name_with_http_method_prefix(rule, request)\n elasticapm.set_transaction_name(rule, override=False)\n\n def request_finished(self, app, response):\n if not self.app.debug or self.client.config.debug:\n elasticapm.set_context(\n lambda: get_data_from_response(response, self.client.config, constants.TRANSACTION), \"response\"\n )\n if response.status_code:\n result = \"HTTP {}xx\".format(response.status_code // 100)\n elasticapm.set_transaction_outcome(http_status_code=response.status_code, override=False)\n else:\n result = response.status\n elasticapm.set_transaction_outcome(http_status_code=response.status, override=False)\n elasticapm.set_transaction_result(result, override=False)\n # Instead of calling end_transaction here, we defer the call until the response is closed.\n # This ensures that we capture things that happen until the WSGI server closes the response.\n response.call_on_close(self.client.end_transaction)\n\n def capture_exception(self, *args, **kwargs):\n assert self.client, \"capture_exception called before application configured\"\n return self.client.capture_exception(*args, **kwargs)\n\n def capture_message(self, *args, **kwargs):\n assert self.client, \"capture_message called before application configured\"\n return self.client.capture_message(*args, **kwargs)\n", "path": "elasticapm/contrib/flask/__init__.py"}], "after_files": [{"content": "# BSD 3-Clause License\n#\n# Copyright (c) 2012, the Sentry Team, see AUTHORS for more details\n# Copyright (c) 2019, Elasticsearch BV\n# All rights reserved.\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# * Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n#\n# * Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# * Neither the name of the copyright holder nor the names of its\n# contributors may be used to endorse or promote products derived from\n# this software without specific prior written permission.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\"\n# AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE\n# IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE\n# FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL\n# DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n# SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n# CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n\n\nfrom __future__ import absolute_import\n\nimport logging\n\nimport flask\nfrom flask import request, signals\n\nimport elasticapm\nimport elasticapm.instrumentation.control\nfrom elasticapm import get_client\nfrom elasticapm.base import Client\nfrom elasticapm.conf import constants, setup_logging\nfrom elasticapm.contrib.flask.utils import get_data_from_request, get_data_from_response\nfrom elasticapm.handlers.logging import LoggingHandler\nfrom elasticapm.traces import execution_context\nfrom elasticapm.utils import build_name_with_http_method_prefix\nfrom elasticapm.utils.disttracing import TraceParent\nfrom elasticapm.utils.logging import get_logger\n\nlogger = get_logger(\"elasticapm.errors.client\")\n\n\nclass ElasticAPM(object):\n \"\"\"\n Flask application for Elastic APM.\n\n Look up configuration from ``os.environ.get('ELASTIC_APM_APP_NAME')`` and\n ``os.environ.get('ELASTIC_APM_SECRET_TOKEN')``::\n\n >>> elasticapm = ElasticAPM(app)\n\n Pass an arbitrary APP_NAME and SECRET_TOKEN::\n\n >>> elasticapm = ElasticAPM(app, service_name='myapp', secret_token='asdasdasd')\n\n Pass an explicit client::\n\n >>> elasticapm = ElasticAPM(app, client=client)\n\n Automatically configure logging::\n\n >>> elasticapm = ElasticAPM(app, logging=True)\n\n Capture an exception::\n\n >>> try:\n >>> 1 / 0\n >>> except ZeroDivisionError:\n >>> elasticapm.capture_exception()\n\n Capture a message::\n\n >>> elasticapm.capture_message('hello, world!')\n \"\"\"\n\n def __init__(self, app=None, client=None, client_cls=Client, logging=False, **defaults):\n self.app = app\n self.logging = logging\n self.client = client or get_client()\n self.client_cls = client_cls\n\n if app:\n self.init_app(app, **defaults)\n\n def handle_exception(self, *args, **kwargs):\n if not self.client:\n return\n\n if self.app.debug and not self.client.config.debug:\n return\n\n self.client.capture_exception(\n exc_info=kwargs.get(\"exc_info\"),\n context={\"request\": get_data_from_request(request, self.client.config, constants.ERROR)},\n custom={\"app\": self.app},\n handled=False,\n )\n # End the transaction here, as `request_finished` won't be called when an\n # unhandled exception occurs.\n #\n # Unfortunately, that also means that we can't capture any response data,\n # as the response isn't ready at this point in time.\n self.client.end_transaction(result=\"HTTP 5xx\")\n\n def init_app(self, app, **defaults):\n self.app = app\n if not self.client:\n config = self.app.config.get(\"ELASTIC_APM\", {})\n\n if \"framework_name\" not in defaults:\n defaults[\"framework_name\"] = \"flask\"\n defaults[\"framework_version\"] = getattr(flask, \"__version__\", \"<0.7\")\n\n self.client = self.client_cls(config, **defaults)\n\n # 0 is a valid log level (NOTSET), so we need to check explicitly for it\n if self.logging or self.logging is logging.NOTSET:\n if self.logging is not True:\n kwargs = {\"level\": self.logging}\n else:\n kwargs = {}\n setup_logging(LoggingHandler(self.client, **kwargs))\n\n signals.got_request_exception.connect(self.handle_exception, sender=app, weak=False)\n\n try:\n from elasticapm.contrib.celery import register_exception_tracking\n\n register_exception_tracking(self.client)\n except ImportError:\n pass\n\n # Instrument to get spans\n if self.client.config.instrument and self.client.config.enabled:\n elasticapm.instrumentation.control.instrument()\n\n signals.request_started.connect(self.request_started, sender=app)\n signals.request_finished.connect(self.request_finished, sender=app)\n try:\n from elasticapm.contrib.celery import register_instrumentation\n\n register_instrumentation(self.client)\n except ImportError:\n pass\n else:\n logger.debug(\"Skipping instrumentation. INSTRUMENT is set to False.\")\n\n @app.context_processor\n def rum_tracing():\n \"\"\"\n Adds APM related IDs to the context used for correlating the backend transaction with the RUM transaction\n \"\"\"\n transaction = execution_context.get_transaction()\n if transaction and transaction.trace_parent:\n return {\n \"apm\": {\n \"trace_id\": transaction.trace_parent.trace_id,\n \"span_id\": lambda: transaction.ensure_parent_id(),\n \"is_sampled\": transaction.is_sampled,\n \"is_sampled_js\": \"true\" if transaction.is_sampled else \"false\",\n }\n }\n return {}\n\n def request_started(self, app):\n if (not self.app.debug or self.client.config.debug) and not self.client.should_ignore_url(request.path):\n trace_parent = TraceParent.from_headers(request.headers)\n self.client.begin_transaction(\"request\", trace_parent=trace_parent)\n elasticapm.set_context(\n lambda: get_data_from_request(request, self.client.config, constants.TRANSACTION), \"request\"\n )\n rule = request.url_rule.rule if request.url_rule is not None else \"\"\n rule = build_name_with_http_method_prefix(rule, request)\n elasticapm.set_transaction_name(rule, override=False)\n\n def request_finished(self, app, response):\n if not self.app.debug or self.client.config.debug:\n elasticapm.set_context(\n lambda: get_data_from_response(response, self.client.config, constants.TRANSACTION), \"response\"\n )\n if response.status_code:\n result = \"HTTP {}xx\".format(response.status_code // 100)\n elasticapm.set_transaction_outcome(http_status_code=response.status_code, override=False)\n else:\n result = response.status\n elasticapm.set_transaction_outcome(http_status_code=response.status, override=False)\n elasticapm.set_transaction_result(result, override=False)\n # Instead of calling end_transaction here, we defer the call until the response is closed.\n # This ensures that we capture things that happen until the WSGI server closes the response.\n response.call_on_close(self.client.end_transaction)\n\n def capture_exception(self, *args, **kwargs):\n assert self.client, \"capture_exception called before application configured\"\n return self.client.capture_exception(*args, **kwargs)\n\n def capture_message(self, *args, **kwargs):\n assert self.client, \"capture_message called before application configured\"\n return self.client.capture_message(*args, **kwargs)\n", "path": "elasticapm/contrib/flask/__init__.py"}]} | 3,094 | 360 |
gh_patches_debug_44029 | rasdani/github-patches | git_diff | Lightning-AI__pytorch-lightning-1913 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use .comet.config file for CometLogger
## 🚀 Feature
When creating a CometML experiment normally, the API key will be read from the file `~/.comet.config` or from an environment variable if it isn't passed in directly. It would be nice if the `CometLogger` supported these uses as well.
### Motivation
Putting the API key in code is certainly a bad practice, and it's a pain to have to export it as an environment variable and then get its value in Python or else read it from the file manually. Adding this feature makes things more seamless compared to how people use CometML when not using PyTorch Lightning.
### Additional context
I have a [patch] written for this already; it only changes a few lines of code. From the template message when I went to create a PR, though, it seemed I should create an issue first. Let me know if you have thoughts about this.
(somewhat related - the REST API key is also [deprecated]; the normal API key should be used instead now. I didn't change that code, though, because I'm not sure if older versions of Comet would have any issues with that change.)
[patch]: https://github.com/PyTorchLightning/pytorch-lightning/compare/master...neighthan:master
[deprecated]: https://www.comet.ml/docs/python-sdk/advanced/#python-configuration
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pytorch_lightning/loggers/comet.py`
Content:
```
1 """
2 Comet
3 -----
4 """
5
6 from argparse import Namespace
7 from typing import Optional, Dict, Union, Any
8
9 try:
10 from comet_ml import Experiment as CometExperiment
11 from comet_ml import ExistingExperiment as CometExistingExperiment
12 from comet_ml import OfflineExperiment as CometOfflineExperiment
13 from comet_ml import BaseExperiment as CometBaseExperiment
14 try:
15 from comet_ml.api import API
16 except ImportError: # pragma: no-cover
17 # For more information, see: https://www.comet.ml/docs/python-sdk/releases/#release-300
18 from comet_ml.papi import API # pragma: no-cover
19
20 _COMET_AVAILABLE = True
21 except ImportError: # pragma: no-cover
22 CometExperiment = None
23 CometExistingExperiment = None
24 CometOfflineExperiment = None
25 CometBaseExperiment = None
26 API = None
27 _COMET_AVAILABLE = False
28
29
30 import torch
31 from torch import is_tensor
32
33 from pytorch_lightning import _logger as log
34 from pytorch_lightning.loggers.base import LightningLoggerBase, rank_zero_experiment
35 from pytorch_lightning.utilities.exceptions import MisconfigurationException
36 from pytorch_lightning.utilities import rank_zero_only
37
38
39 class CometLogger(LightningLoggerBase):
40 r"""
41 Log using `Comet.ml <https://www.comet.ml>`_. Install it with pip:
42
43 .. code-block:: bash
44
45 pip install comet-ml
46
47 Comet requires either an API Key (online mode) or a local directory path (offline mode).
48
49 **ONLINE MODE**
50
51 Example:
52 >>> import os
53 >>> from pytorch_lightning import Trainer
54 >>> from pytorch_lightning.loggers import CometLogger
55 >>> # arguments made to CometLogger are passed on to the comet_ml.Experiment class
56 >>> comet_logger = CometLogger(
57 ... api_key=os.environ.get('COMET_API_KEY'),
58 ... workspace=os.environ.get('COMET_WORKSPACE'), # Optional
59 ... save_dir='.', # Optional
60 ... project_name='default_project', # Optional
61 ... rest_api_key=os.environ.get('COMET_REST_API_KEY'), # Optional
62 ... experiment_name='default' # Optional
63 ... )
64 >>> trainer = Trainer(logger=comet_logger)
65
66 **OFFLINE MODE**
67
68 Example:
69 >>> from pytorch_lightning.loggers import CometLogger
70 >>> # arguments made to CometLogger are passed on to the comet_ml.Experiment class
71 >>> comet_logger = CometLogger(
72 ... save_dir='.',
73 ... workspace=os.environ.get('COMET_WORKSPACE'), # Optional
74 ... project_name='default_project', # Optional
75 ... rest_api_key=os.environ.get('COMET_REST_API_KEY'), # Optional
76 ... experiment_name='default' # Optional
77 ... )
78 >>> trainer = Trainer(logger=comet_logger)
79
80 Args:
81 api_key: Required in online mode. API key, found on Comet.ml
82 save_dir: Required in offline mode. The path for the directory to save local comet logs
83 workspace: Optional. Name of workspace for this user
84 project_name: Optional. Send your experiment to a specific project.
85 Otherwise will be sent to Uncategorized Experiments.
86 If the project name does not already exist, Comet.ml will create a new project.
87 rest_api_key: Optional. Rest API key found in Comet.ml settings.
88 This is used to determine version number
89 experiment_name: Optional. String representing the name for this particular experiment on Comet.ml.
90 experiment_key: Optional. If set, restores from existing experiment.
91 """
92
93 def __init__(self,
94 api_key: Optional[str] = None,
95 save_dir: Optional[str] = None,
96 workspace: Optional[str] = None,
97 project_name: Optional[str] = None,
98 rest_api_key: Optional[str] = None,
99 experiment_name: Optional[str] = None,
100 experiment_key: Optional[str] = None,
101 **kwargs):
102
103 if not _COMET_AVAILABLE:
104 raise ImportError('You want to use `comet_ml` logger which is not installed yet,'
105 ' install it with `pip install comet-ml`.')
106 super().__init__()
107 self._experiment = None
108 self._save_dir = save_dir
109
110 # Determine online or offline mode based on which arguments were passed to CometLogger
111 if api_key is not None:
112 self.mode = "online"
113 self.api_key = api_key
114 elif save_dir is not None:
115 self.mode = "offline"
116 self._save_dir = save_dir
117 else:
118 # If neither api_key nor save_dir are passed as arguments, raise an exception
119 raise MisconfigurationException("CometLogger requires either api_key or save_dir during initialization.")
120
121 log.info(f"CometLogger will be initialized in {self.mode} mode")
122
123 self.workspace = workspace
124 self.project_name = project_name
125 self.experiment_key = experiment_key
126 self._kwargs = kwargs
127
128 if rest_api_key is not None:
129 # Comet.ml rest API, used to determine version number
130 self.rest_api_key = rest_api_key
131 self.comet_api = API(self.rest_api_key)
132 else:
133 self.rest_api_key = None
134 self.comet_api = None
135
136 if experiment_name:
137 self.experiment.set_name(experiment_name)
138 self._kwargs = kwargs
139
140 @property
141 @rank_zero_experiment
142 def experiment(self) -> CometBaseExperiment:
143 r"""
144 Actual Comet object. To use Comet features in your
145 :class:`~pytorch_lightning.core.lightning.LightningModule` do the following.
146
147 Example::
148
149 self.logger.experiment.some_comet_function()
150
151 """
152 if self._experiment is not None:
153 return self._experiment
154
155 if self.mode == "online":
156 if self.experiment_key is None:
157 self._experiment = CometExperiment(
158 api_key=self.api_key,
159 workspace=self.workspace,
160 project_name=self.project_name,
161 **self._kwargs
162 )
163 self.experiment_key = self._experiment.get_key()
164 else:
165 self._experiment = CometExistingExperiment(
166 api_key=self.api_key,
167 workspace=self.workspace,
168 project_name=self.project_name,
169 previous_experiment=self.experiment_key,
170 **self._kwargs
171 )
172 else:
173 self._experiment = CometOfflineExperiment(
174 offline_directory=self.save_dir,
175 workspace=self.workspace,
176 project_name=self.project_name,
177 **self._kwargs
178 )
179
180 return self._experiment
181
182 @rank_zero_only
183 def log_hyperparams(self, params: Union[Dict[str, Any], Namespace]) -> None:
184 params = self._convert_params(params)
185 params = self._flatten_dict(params)
186 self.experiment.log_parameters(params)
187
188 @rank_zero_only
189 def log_metrics(
190 self,
191 metrics: Dict[str, Union[torch.Tensor, float]],
192 step: Optional[int] = None
193 ) -> None:
194 assert rank_zero_only.rank == 0, 'experiment tried to log from global_rank != 0'
195
196 # Comet.ml expects metrics to be a dictionary of detached tensors on CPU
197 for key, val in metrics.items():
198 if is_tensor(val):
199 metrics[key] = val.cpu().detach()
200
201 self.experiment.log_metrics(metrics, step=step)
202
203 def reset_experiment(self):
204 self._experiment = None
205
206 @rank_zero_only
207 def finalize(self, status: str) -> None:
208 r"""
209 When calling ``self.experiment.end()``, that experiment won't log any more data to Comet.
210 That's why, if you need to log any more data, you need to create an ExistingCometExperiment.
211 For example, to log data when testing your model after training, because when training is
212 finalized :meth:`CometLogger.finalize` is called.
213
214 This happens automatically in the :meth:`~CometLogger.experiment` property, when
215 ``self._experiment`` is set to ``None``, i.e. ``self.reset_experiment()``.
216 """
217 self.experiment.end()
218 self.reset_experiment()
219
220 @property
221 def save_dir(self) -> Optional[str]:
222 return self._save_dir
223
224 @property
225 def name(self) -> str:
226 return str(self.experiment.project_name)
227
228 @property
229 def version(self) -> str:
230 return self.experiment.id
231
232 def __getstate__(self):
233 state = self.__dict__.copy()
234 state["_experiment"] = None
235 return state
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pytorch_lightning/loggers/comet.py b/pytorch_lightning/loggers/comet.py
--- a/pytorch_lightning/loggers/comet.py
+++ b/pytorch_lightning/loggers/comet.py
@@ -16,8 +16,7 @@
except ImportError: # pragma: no-cover
# For more information, see: https://www.comet.ml/docs/python-sdk/releases/#release-300
from comet_ml.papi import API # pragma: no-cover
-
- _COMET_AVAILABLE = True
+ from comet_ml.config import get_config, get_api_key
except ImportError: # pragma: no-cover
CometExperiment = None
CometExistingExperiment = None
@@ -25,6 +24,8 @@
CometBaseExperiment = None
API = None
_COMET_AVAILABLE = False
+else:
+ _COMET_AVAILABLE = True
import torch
@@ -78,8 +79,11 @@
>>> trainer = Trainer(logger=comet_logger)
Args:
- api_key: Required in online mode. API key, found on Comet.ml
- save_dir: Required in offline mode. The path for the directory to save local comet logs
+ api_key: Required in online mode. API key, found on Comet.ml. If not given, this
+ will be loaded from the environment variable COMET_API_KEY or ~/.comet.config
+ if either exists.
+ save_dir: Required in offline mode. The path for the directory to save local
+ comet logs. If given, this also sets the directory for saving checkpoints.
workspace: Optional. Name of workspace for this user
project_name: Optional. Send your experiment to a specific project.
Otherwise will be sent to Uncategorized Experiments.
@@ -88,6 +92,10 @@
This is used to determine version number
experiment_name: Optional. String representing the name for this particular experiment on Comet.ml.
experiment_key: Optional. If set, restores from existing experiment.
+ offline: If api_key and save_dir are both given, this determines whether
+ the experiment will be in online or offline mode. This is useful if you use
+ save_dir to control the checkpoints directory and have a ~/.comet.config
+ file but still want to run offline experiments.
"""
def __init__(self,
@@ -98,6 +106,7 @@
rest_api_key: Optional[str] = None,
experiment_name: Optional[str] = None,
experiment_key: Optional[str] = None,
+ offline: bool = False,
**kwargs):
if not _COMET_AVAILABLE:
@@ -105,10 +114,15 @@
' install it with `pip install comet-ml`.')
super().__init__()
self._experiment = None
- self._save_dir = save_dir
# Determine online or offline mode based on which arguments were passed to CometLogger
- if api_key is not None:
+ api_key = api_key or get_api_key(None, get_config())
+
+ if api_key is not None and save_dir is not None:
+ self.mode = "offline" if offline else "online"
+ self.api_key = api_key
+ self._save_dir = save_dir
+ elif api_key is not None:
self.mode = "online"
self.api_key = api_key
elif save_dir is not None:
@@ -116,7 +130,9 @@
self._save_dir = save_dir
else:
# If neither api_key nor save_dir are passed as arguments, raise an exception
- raise MisconfigurationException("CometLogger requires either api_key or save_dir during initialization.")
+ raise MisconfigurationException(
+ "CometLogger requires either api_key or save_dir during initialization."
+ )
log.info(f"CometLogger will be initialized in {self.mode} mode")
| {"golden_diff": "diff --git a/pytorch_lightning/loggers/comet.py b/pytorch_lightning/loggers/comet.py\n--- a/pytorch_lightning/loggers/comet.py\n+++ b/pytorch_lightning/loggers/comet.py\n@@ -16,8 +16,7 @@\n except ImportError: # pragma: no-cover\n # For more information, see: https://www.comet.ml/docs/python-sdk/releases/#release-300\n from comet_ml.papi import API # pragma: no-cover\n-\n- _COMET_AVAILABLE = True\n+ from comet_ml.config import get_config, get_api_key\n except ImportError: # pragma: no-cover\n CometExperiment = None\n CometExistingExperiment = None\n@@ -25,6 +24,8 @@\n CometBaseExperiment = None\n API = None\n _COMET_AVAILABLE = False\n+else:\n+ _COMET_AVAILABLE = True\n \n \n import torch\n@@ -78,8 +79,11 @@\n >>> trainer = Trainer(logger=comet_logger)\n \n Args:\n- api_key: Required in online mode. API key, found on Comet.ml\n- save_dir: Required in offline mode. The path for the directory to save local comet logs\n+ api_key: Required in online mode. API key, found on Comet.ml. If not given, this\n+ will be loaded from the environment variable COMET_API_KEY or ~/.comet.config\n+ if either exists.\n+ save_dir: Required in offline mode. The path for the directory to save local\n+ comet logs. If given, this also sets the directory for saving checkpoints.\n workspace: Optional. Name of workspace for this user\n project_name: Optional. Send your experiment to a specific project.\n Otherwise will be sent to Uncategorized Experiments.\n@@ -88,6 +92,10 @@\n This is used to determine version number\n experiment_name: Optional. String representing the name for this particular experiment on Comet.ml.\n experiment_key: Optional. If set, restores from existing experiment.\n+ offline: If api_key and save_dir are both given, this determines whether\n+ the experiment will be in online or offline mode. This is useful if you use\n+ save_dir to control the checkpoints directory and have a ~/.comet.config\n+ file but still want to run offline experiments.\n \"\"\"\n \n def __init__(self,\n@@ -98,6 +106,7 @@\n rest_api_key: Optional[str] = None,\n experiment_name: Optional[str] = None,\n experiment_key: Optional[str] = None,\n+ offline: bool = False,\n **kwargs):\n \n if not _COMET_AVAILABLE:\n@@ -105,10 +114,15 @@\n ' install it with `pip install comet-ml`.')\n super().__init__()\n self._experiment = None\n- self._save_dir = save_dir\n \n # Determine online or offline mode based on which arguments were passed to CometLogger\n- if api_key is not None:\n+ api_key = api_key or get_api_key(None, get_config())\n+\n+ if api_key is not None and save_dir is not None:\n+ self.mode = \"offline\" if offline else \"online\"\n+ self.api_key = api_key\n+ self._save_dir = save_dir\n+ elif api_key is not None:\n self.mode = \"online\"\n self.api_key = api_key\n elif save_dir is not None:\n@@ -116,7 +130,9 @@\n self._save_dir = save_dir\n else:\n # If neither api_key nor save_dir are passed as arguments, raise an exception\n- raise MisconfigurationException(\"CometLogger requires either api_key or save_dir during initialization.\")\n+ raise MisconfigurationException(\n+ \"CometLogger requires either api_key or save_dir during initialization.\"\n+ )\n \n log.info(f\"CometLogger will be initialized in {self.mode} mode\")\n", "issue": "Use .comet.config file for CometLogger\n## \ud83d\ude80 Feature\r\n\r\nWhen creating a CometML experiment normally, the API key will be read from the file `~/.comet.config` or from an environment variable if it isn't passed in directly. It would be nice if the `CometLogger` supported these uses as well.\r\n\r\n### Motivation\r\n\r\nPutting the API key in code is certainly a bad practice, and it's a pain to have to export it as an environment variable and then get its value in Python or else read it from the file manually. Adding this feature makes things more seamless compared to how people use CometML when not using PyTorch Lightning.\r\n\r\n### Additional context\r\n\r\nI have a [patch] written for this already; it only changes a few lines of code. From the template message when I went to create a PR, though, it seemed I should create an issue first. Let me know if you have thoughts about this.\r\n\r\n(somewhat related - the REST API key is also [deprecated]; the normal API key should be used instead now. I didn't change that code, though, because I'm not sure if older versions of Comet would have any issues with that change.)\r\n\r\n[patch]: https://github.com/PyTorchLightning/pytorch-lightning/compare/master...neighthan:master\r\n[deprecated]: https://www.comet.ml/docs/python-sdk/advanced/#python-configuration\n", "before_files": [{"content": "\"\"\"\nComet\n-----\n\"\"\"\n\nfrom argparse import Namespace\nfrom typing import Optional, Dict, Union, Any\n\ntry:\n from comet_ml import Experiment as CometExperiment\n from comet_ml import ExistingExperiment as CometExistingExperiment\n from comet_ml import OfflineExperiment as CometOfflineExperiment\n from comet_ml import BaseExperiment as CometBaseExperiment\n try:\n from comet_ml.api import API\n except ImportError: # pragma: no-cover\n # For more information, see: https://www.comet.ml/docs/python-sdk/releases/#release-300\n from comet_ml.papi import API # pragma: no-cover\n\n _COMET_AVAILABLE = True\nexcept ImportError: # pragma: no-cover\n CometExperiment = None\n CometExistingExperiment = None\n CometOfflineExperiment = None\n CometBaseExperiment = None\n API = None\n _COMET_AVAILABLE = False\n\n\nimport torch\nfrom torch import is_tensor\n\nfrom pytorch_lightning import _logger as log\nfrom pytorch_lightning.loggers.base import LightningLoggerBase, rank_zero_experiment\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom pytorch_lightning.utilities import rank_zero_only\n\n\nclass CometLogger(LightningLoggerBase):\n r\"\"\"\n Log using `Comet.ml <https://www.comet.ml>`_. Install it with pip:\n\n .. code-block:: bash\n\n pip install comet-ml\n\n Comet requires either an API Key (online mode) or a local directory path (offline mode).\n\n **ONLINE MODE**\n\n Example:\n >>> import os\n >>> from pytorch_lightning import Trainer\n >>> from pytorch_lightning.loggers import CometLogger\n >>> # arguments made to CometLogger are passed on to the comet_ml.Experiment class\n >>> comet_logger = CometLogger(\n ... api_key=os.environ.get('COMET_API_KEY'),\n ... workspace=os.environ.get('COMET_WORKSPACE'), # Optional\n ... save_dir='.', # Optional\n ... project_name='default_project', # Optional\n ... rest_api_key=os.environ.get('COMET_REST_API_KEY'), # Optional\n ... experiment_name='default' # Optional\n ... )\n >>> trainer = Trainer(logger=comet_logger)\n\n **OFFLINE MODE**\n\n Example:\n >>> from pytorch_lightning.loggers import CometLogger\n >>> # arguments made to CometLogger are passed on to the comet_ml.Experiment class\n >>> comet_logger = CometLogger(\n ... save_dir='.',\n ... workspace=os.environ.get('COMET_WORKSPACE'), # Optional\n ... project_name='default_project', # Optional\n ... rest_api_key=os.environ.get('COMET_REST_API_KEY'), # Optional\n ... experiment_name='default' # Optional\n ... )\n >>> trainer = Trainer(logger=comet_logger)\n\n Args:\n api_key: Required in online mode. API key, found on Comet.ml\n save_dir: Required in offline mode. The path for the directory to save local comet logs\n workspace: Optional. Name of workspace for this user\n project_name: Optional. Send your experiment to a specific project.\n Otherwise will be sent to Uncategorized Experiments.\n If the project name does not already exist, Comet.ml will create a new project.\n rest_api_key: Optional. Rest API key found in Comet.ml settings.\n This is used to determine version number\n experiment_name: Optional. String representing the name for this particular experiment on Comet.ml.\n experiment_key: Optional. If set, restores from existing experiment.\n \"\"\"\n\n def __init__(self,\n api_key: Optional[str] = None,\n save_dir: Optional[str] = None,\n workspace: Optional[str] = None,\n project_name: Optional[str] = None,\n rest_api_key: Optional[str] = None,\n experiment_name: Optional[str] = None,\n experiment_key: Optional[str] = None,\n **kwargs):\n\n if not _COMET_AVAILABLE:\n raise ImportError('You want to use `comet_ml` logger which is not installed yet,'\n ' install it with `pip install comet-ml`.')\n super().__init__()\n self._experiment = None\n self._save_dir = save_dir\n\n # Determine online or offline mode based on which arguments were passed to CometLogger\n if api_key is not None:\n self.mode = \"online\"\n self.api_key = api_key\n elif save_dir is not None:\n self.mode = \"offline\"\n self._save_dir = save_dir\n else:\n # If neither api_key nor save_dir are passed as arguments, raise an exception\n raise MisconfigurationException(\"CometLogger requires either api_key or save_dir during initialization.\")\n\n log.info(f\"CometLogger will be initialized in {self.mode} mode\")\n\n self.workspace = workspace\n self.project_name = project_name\n self.experiment_key = experiment_key\n self._kwargs = kwargs\n\n if rest_api_key is not None:\n # Comet.ml rest API, used to determine version number\n self.rest_api_key = rest_api_key\n self.comet_api = API(self.rest_api_key)\n else:\n self.rest_api_key = None\n self.comet_api = None\n\n if experiment_name:\n self.experiment.set_name(experiment_name)\n self._kwargs = kwargs\n\n @property\n @rank_zero_experiment\n def experiment(self) -> CometBaseExperiment:\n r\"\"\"\n Actual Comet object. To use Comet features in your\n :class:`~pytorch_lightning.core.lightning.LightningModule` do the following.\n\n Example::\n\n self.logger.experiment.some_comet_function()\n\n \"\"\"\n if self._experiment is not None:\n return self._experiment\n\n if self.mode == \"online\":\n if self.experiment_key is None:\n self._experiment = CometExperiment(\n api_key=self.api_key,\n workspace=self.workspace,\n project_name=self.project_name,\n **self._kwargs\n )\n self.experiment_key = self._experiment.get_key()\n else:\n self._experiment = CometExistingExperiment(\n api_key=self.api_key,\n workspace=self.workspace,\n project_name=self.project_name,\n previous_experiment=self.experiment_key,\n **self._kwargs\n )\n else:\n self._experiment = CometOfflineExperiment(\n offline_directory=self.save_dir,\n workspace=self.workspace,\n project_name=self.project_name,\n **self._kwargs\n )\n\n return self._experiment\n\n @rank_zero_only\n def log_hyperparams(self, params: Union[Dict[str, Any], Namespace]) -> None:\n params = self._convert_params(params)\n params = self._flatten_dict(params)\n self.experiment.log_parameters(params)\n\n @rank_zero_only\n def log_metrics(\n self,\n metrics: Dict[str, Union[torch.Tensor, float]],\n step: Optional[int] = None\n ) -> None:\n assert rank_zero_only.rank == 0, 'experiment tried to log from global_rank != 0'\n\n # Comet.ml expects metrics to be a dictionary of detached tensors on CPU\n for key, val in metrics.items():\n if is_tensor(val):\n metrics[key] = val.cpu().detach()\n\n self.experiment.log_metrics(metrics, step=step)\n\n def reset_experiment(self):\n self._experiment = None\n\n @rank_zero_only\n def finalize(self, status: str) -> None:\n r\"\"\"\n When calling ``self.experiment.end()``, that experiment won't log any more data to Comet.\n That's why, if you need to log any more data, you need to create an ExistingCometExperiment.\n For example, to log data when testing your model after training, because when training is\n finalized :meth:`CometLogger.finalize` is called.\n\n This happens automatically in the :meth:`~CometLogger.experiment` property, when\n ``self._experiment`` is set to ``None``, i.e. ``self.reset_experiment()``.\n \"\"\"\n self.experiment.end()\n self.reset_experiment()\n\n @property\n def save_dir(self) -> Optional[str]:\n return self._save_dir\n\n @property\n def name(self) -> str:\n return str(self.experiment.project_name)\n\n @property\n def version(self) -> str:\n return self.experiment.id\n\n def __getstate__(self):\n state = self.__dict__.copy()\n state[\"_experiment\"] = None\n return state\n", "path": "pytorch_lightning/loggers/comet.py"}], "after_files": [{"content": "\"\"\"\nComet\n-----\n\"\"\"\n\nfrom argparse import Namespace\nfrom typing import Optional, Dict, Union, Any\n\ntry:\n from comet_ml import Experiment as CometExperiment\n from comet_ml import ExistingExperiment as CometExistingExperiment\n from comet_ml import OfflineExperiment as CometOfflineExperiment\n from comet_ml import BaseExperiment as CometBaseExperiment\n try:\n from comet_ml.api import API\n except ImportError: # pragma: no-cover\n # For more information, see: https://www.comet.ml/docs/python-sdk/releases/#release-300\n from comet_ml.papi import API # pragma: no-cover\n from comet_ml.config import get_config, get_api_key\nexcept ImportError: # pragma: no-cover\n CometExperiment = None\n CometExistingExperiment = None\n CometOfflineExperiment = None\n CometBaseExperiment = None\n API = None\n _COMET_AVAILABLE = False\nelse:\n _COMET_AVAILABLE = True\n\n\nimport torch\nfrom torch import is_tensor\n\nfrom pytorch_lightning import _logger as log\nfrom pytorch_lightning.loggers.base import LightningLoggerBase, rank_zero_experiment\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom pytorch_lightning.utilities import rank_zero_only\n\n\nclass CometLogger(LightningLoggerBase):\n r\"\"\"\n Log using `Comet.ml <https://www.comet.ml>`_. Install it with pip:\n\n .. code-block:: bash\n\n pip install comet-ml\n\n Comet requires either an API Key (online mode) or a local directory path (offline mode).\n\n **ONLINE MODE**\n\n Example:\n >>> import os\n >>> from pytorch_lightning import Trainer\n >>> from pytorch_lightning.loggers import CometLogger\n >>> # arguments made to CometLogger are passed on to the comet_ml.Experiment class\n >>> comet_logger = CometLogger(\n ... api_key=os.environ.get('COMET_API_KEY'),\n ... workspace=os.environ.get('COMET_WORKSPACE'), # Optional\n ... save_dir='.', # Optional\n ... project_name='default_project', # Optional\n ... rest_api_key=os.environ.get('COMET_REST_API_KEY'), # Optional\n ... experiment_name='default' # Optional\n ... )\n >>> trainer = Trainer(logger=comet_logger)\n\n **OFFLINE MODE**\n\n Example:\n >>> from pytorch_lightning.loggers import CometLogger\n >>> # arguments made to CometLogger are passed on to the comet_ml.Experiment class\n >>> comet_logger = CometLogger(\n ... save_dir='.',\n ... workspace=os.environ.get('COMET_WORKSPACE'), # Optional\n ... project_name='default_project', # Optional\n ... rest_api_key=os.environ.get('COMET_REST_API_KEY'), # Optional\n ... experiment_name='default' # Optional\n ... )\n >>> trainer = Trainer(logger=comet_logger)\n\n Args:\n api_key: Required in online mode. API key, found on Comet.ml. If not given, this\n will be loaded from the environment variable COMET_API_KEY or ~/.comet.config\n if either exists.\n save_dir: Required in offline mode. The path for the directory to save local\n comet logs. If given, this also sets the directory for saving checkpoints.\n workspace: Optional. Name of workspace for this user\n project_name: Optional. Send your experiment to a specific project.\n Otherwise will be sent to Uncategorized Experiments.\n If the project name does not already exist, Comet.ml will create a new project.\n rest_api_key: Optional. Rest API key found in Comet.ml settings.\n This is used to determine version number\n experiment_name: Optional. String representing the name for this particular experiment on Comet.ml.\n experiment_key: Optional. If set, restores from existing experiment.\n offline: If api_key and save_dir are both given, this determines whether\n the experiment will be in online or offline mode. This is useful if you use\n save_dir to control the checkpoints directory and have a ~/.comet.config\n file but still want to run offline experiments.\n \"\"\"\n\n def __init__(self,\n api_key: Optional[str] = None,\n save_dir: Optional[str] = None,\n workspace: Optional[str] = None,\n project_name: Optional[str] = None,\n rest_api_key: Optional[str] = None,\n experiment_name: Optional[str] = None,\n experiment_key: Optional[str] = None,\n offline: bool = False,\n **kwargs):\n\n if not _COMET_AVAILABLE:\n raise ImportError('You want to use `comet_ml` logger which is not installed yet,'\n ' install it with `pip install comet-ml`.')\n super().__init__()\n self._experiment = None\n\n # Determine online or offline mode based on which arguments were passed to CometLogger\n api_key = api_key or get_api_key(None, get_config())\n\n if api_key is not None and save_dir is not None:\n self.mode = \"offline\" if offline else \"online\"\n self.api_key = api_key\n self._save_dir = save_dir\n elif api_key is not None:\n self.mode = \"online\"\n self.api_key = api_key\n elif save_dir is not None:\n self.mode = \"offline\"\n self._save_dir = save_dir\n else:\n # If neither api_key nor save_dir are passed as arguments, raise an exception\n raise MisconfigurationException(\n \"CometLogger requires either api_key or save_dir during initialization.\"\n )\n\n log.info(f\"CometLogger will be initialized in {self.mode} mode\")\n\n self.workspace = workspace\n self.project_name = project_name\n self.experiment_key = experiment_key\n self._kwargs = kwargs\n\n if rest_api_key is not None:\n # Comet.ml rest API, used to determine version number\n self.rest_api_key = rest_api_key\n self.comet_api = API(self.rest_api_key)\n else:\n self.rest_api_key = None\n self.comet_api = None\n\n if experiment_name:\n self.experiment.set_name(experiment_name)\n self._kwargs = kwargs\n\n @property\n @rank_zero_experiment\n def experiment(self) -> CometBaseExperiment:\n r\"\"\"\n Actual Comet object. To use Comet features in your\n :class:`~pytorch_lightning.core.lightning.LightningModule` do the following.\n\n Example::\n\n self.logger.experiment.some_comet_function()\n\n \"\"\"\n if self._experiment is not None:\n return self._experiment\n\n if self.mode == \"online\":\n if self.experiment_key is None:\n self._experiment = CometExperiment(\n api_key=self.api_key,\n workspace=self.workspace,\n project_name=self.project_name,\n **self._kwargs\n )\n self.experiment_key = self._experiment.get_key()\n else:\n self._experiment = CometExistingExperiment(\n api_key=self.api_key,\n workspace=self.workspace,\n project_name=self.project_name,\n previous_experiment=self.experiment_key,\n **self._kwargs\n )\n else:\n self._experiment = CometOfflineExperiment(\n offline_directory=self.save_dir,\n workspace=self.workspace,\n project_name=self.project_name,\n **self._kwargs\n )\n\n return self._experiment\n\n @rank_zero_only\n def log_hyperparams(self, params: Union[Dict[str, Any], Namespace]) -> None:\n params = self._convert_params(params)\n params = self._flatten_dict(params)\n self.experiment.log_parameters(params)\n\n @rank_zero_only\n def log_metrics(\n self,\n metrics: Dict[str, Union[torch.Tensor, float]],\n step: Optional[int] = None\n ) -> None:\n assert rank_zero_only.rank == 0, 'experiment tried to log from global_rank != 0'\n\n # Comet.ml expects metrics to be a dictionary of detached tensors on CPU\n for key, val in metrics.items():\n if is_tensor(val):\n metrics[key] = val.cpu().detach()\n\n self.experiment.log_metrics(metrics, step=step)\n\n def reset_experiment(self):\n self._experiment = None\n\n @rank_zero_only\n def finalize(self, status: str) -> None:\n r\"\"\"\n When calling ``self.experiment.end()``, that experiment won't log any more data to Comet.\n That's why, if you need to log any more data, you need to create an ExistingCometExperiment.\n For example, to log data when testing your model after training, because when training is\n finalized :meth:`CometLogger.finalize` is called.\n\n This happens automatically in the :meth:`~CometLogger.experiment` property, when\n ``self._experiment`` is set to ``None``, i.e. ``self.reset_experiment()``.\n \"\"\"\n self.experiment.end()\n self.reset_experiment()\n\n @property\n def save_dir(self) -> Optional[str]:\n return self._save_dir\n\n @property\n def name(self) -> str:\n return str(self.experiment.project_name)\n\n @property\n def version(self) -> str:\n return self.experiment.id\n\n def __getstate__(self):\n state = self.__dict__.copy()\n state[\"_experiment\"] = None\n return state\n", "path": "pytorch_lightning/loggers/comet.py"}]} | 3,006 | 870 |
gh_patches_debug_2438 | rasdani/github-patches | git_diff | mne-tools__mne-bids-pipeline-289 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`ValueError: n_jobs must be an integer` when calling freesurfer
Hi,
When I run `python run.py freesurfer --config=~/hMT+/config.py`, I get the following error traceback:
```
Traceback (most recent call last):
File "/home/merlin/PhD/mne-bids-pipeline/run.py", line 194, in <module>
fire.Fire(process)
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py", line 141, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py", line 466, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py", line 681, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "/home/merlin/PhD/mne-bids-pipeline/run.py", line 189, in process
_run_script(script_path, config, root_dir, subject, session, task, run)
File "/home/merlin/PhD/mne-bids-pipeline/run.py", line 98, in _run_script
runpy.run_path(script_path, run_name='__main__')
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/runpy.py", line 268, in run_path
return _run_module_code(code, init_globals, run_name,
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/runpy.py", line 97, in _run_module_code
_run_code(code, mod_globals, init_globals,
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/merlin/PhD/mne-bids-pipeline/scripts/freesurfer/recon_all.py", line 112, in <module>
fire.Fire(main)
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py", line 141, in Fire
component_trace = _Fire(component, args, parsed_flag_args, context, name)
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py", line 466, in _Fire
component, remaining_args = _CallAndUpdateTrace(
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py", line 681, in _CallAndUpdateTrace
component = fn(*varargs, **kwargs)
File "/home/merlin/PhD/mne-bids-pipeline/scripts/freesurfer/recon_all.py", line 94, in main
parallel, run_func, _ = parallel_func(run_recon, n_jobs=n_jobs)
File "<decorator-gen-42>", line 24, in parallel_func
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/mne/parallel.py", line 112, in parallel_func
n_jobs = check_n_jobs(n_jobs)
File "/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/mne/parallel.py", line 159, in check_n_jobs
raise ValueError('n_jobs must be an integer')
ValueError: n_jobs must be an integer
```
Checking with pdb, it seems that `recon_all` is called with `n_jobs = "freesurfer"`. I'm not sure why that is.
```
19:36:39 Using custom configuration: /home/merlin/hMT+/config.py
19:36:39 [Step-01] Running: Initializing output directories.
19:36:39 [Step-01] Initializing output directories.
19:36:39 [Step-01] Completed: Initializing output directories.
2021-04-14 19:36:39 INFO Successfully finished running: init_derivatives_dir
2021-04-14 19:36:39 INFO Now running: on_all
> /home/merlin/PhD/mne-bids-pipeline/scripts/freesurfer/recon_all.py(88)main()
87
---> 88 logger.info('Running FreeSurfer')
89
ipdb> n_jobs
'freesurfer'
ipdb>
```
It might be the config needs to be changed, but I can't figure out how.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `scripts/freesurfer/recon_all.py`
Content:
```
1 #!/usr/bin/env python
2
3 import os
4 import shutil
5 import sys
6 from pathlib import Path
7 import logging
8 from typing import Union
9
10 import fire
11
12 from mne.utils import run_subprocess
13 from mne.parallel import parallel_func
14
15 import config
16
17 PathLike = Union[str, Path]
18 logger = logging.getLogger('mne-bids-pipeline')
19 fs_bids_app = Path(__file__).parent / 'contrib' / 'run.py'
20
21
22 def _get_subjects_dir(root_dir) -> Path:
23 subjects_dir = \
24 Path(root_dir) / "derivatives" / "freesurfer" / "subjects"
25 return subjects_dir
26
27
28 def run_recon(root_dir, subject, fs_bids_app) -> None:
29 logger.info(f"Running recon-all on subject {subject}. This will take "
30 f"a LONG time – it's a good idea to let it run over night.")
31
32 subjects_dir = _get_subjects_dir(root_dir)
33 subj_dir = subjects_dir / f"sub-{subject}"
34
35 if subj_dir.exists():
36 logger.info(f"Subject {subject} is already present. Please delete the "
37 f"directory if you want to recompute.")
38 return
39
40 env = os.environ
41 if 'FREESURFER_HOME' not in env:
42 raise RuntimeError("FreeSurfer is not available.")
43
44 license_file = Path(f"{env['FREESURFER_HOME']}/license.txt")
45 if not license_file.exists():
46 license_file = Path(f"{env['FREESURFER_HOME']}/.license")
47 if not license_file.exists():
48 raise RuntimeError("FreeSurfer license file not found.")
49
50 cmd = [
51 f"{sys.executable}",
52 f"{fs_bids_app}",
53 f"{root_dir}",
54 f"{subjects_dir}", "participant",
55 "--n_cpus=2", "--stages=all", "--skip_bids_validator",
56 f"--license_file={license_file}",
57 f"--participant_label={subject}"
58 ]
59 logger.debug("Running: " + " ".join(cmd))
60 run_subprocess(cmd, env=env, verbose=logger.level)
61
62
63 def main(n_jobs: int = 1) -> None:
64 """Run freesurfer recon-all command on BIDS dataset.
65
66 The command allows to run the freesurfer recon-all
67 command on all subjects of your BIDS dataset. It can
68 run in parallel with the --n_jobs parameter.
69
70 It is built on top of the FreeSurfer BIDS app:
71
72 https://github.com/BIDS-Apps/freesurfer
73
74 You must have freesurfer available on your system.
75
76 Examples
77 --------
78 run_freesurfer.py /path/to/bids/dataset/study-template-config.py /path/to/freesurfer_bids_app/
79
80 or to run in parallel (3 subjects at a time):
81
82 run_freesurfer.py /path/to/bids/dataset/study-template-config.py /path/to/freesurfer_bids_app/ --n_jobs=3
83
84 """ # noqa
85
86 logger.info('Running FreeSurfer')
87
88 subjects = config.get_subjects()
89
90 root_dir = config.bids_root
91 subjects_dir = _get_subjects_dir(root_dir)
92 subjects_dir.mkdir(parents=True, exist_ok=True)
93
94 parallel, run_func, _ = parallel_func(run_recon, n_jobs=n_jobs)
95 parallel(run_func(root_dir, subject, fs_bids_app)
96 for subject in subjects)
97
98 # Handle fsaverage
99 fsaverage_dir = subjects_dir / 'fsaverage'
100 if fsaverage_dir.exists():
101 if fsaverage_dir.is_symlink():
102 fsaverage_dir.unlink()
103 else:
104 shutil.rmtree(fsaverage_dir)
105
106 env = os.environ
107 shutil.copytree(f"{env['FREESURFER_HOME']}/subjects/fsaverage",
108 subjects_dir / 'fsaverage')
109
110
111 if __name__ == '__main__':
112 fire.Fire(main)
113
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/scripts/freesurfer/recon_all.py b/scripts/freesurfer/recon_all.py
--- a/scripts/freesurfer/recon_all.py
+++ b/scripts/freesurfer/recon_all.py
@@ -60,7 +60,7 @@
run_subprocess(cmd, env=env, verbose=logger.level)
-def main(n_jobs: int = 1) -> None:
+def main(*, n_jobs: int = 1) -> None:
"""Run freesurfer recon-all command on BIDS dataset.
The command allows to run the freesurfer recon-all
| {"golden_diff": "diff --git a/scripts/freesurfer/recon_all.py b/scripts/freesurfer/recon_all.py\n--- a/scripts/freesurfer/recon_all.py\n+++ b/scripts/freesurfer/recon_all.py\n@@ -60,7 +60,7 @@\n run_subprocess(cmd, env=env, verbose=logger.level)\n \n \n-def main(n_jobs: int = 1) -> None:\n+def main(*, n_jobs: int = 1) -> None:\n \"\"\"Run freesurfer recon-all command on BIDS dataset.\n \n The command allows to run the freesurfer recon-all\n", "issue": "`ValueError: n_jobs must be an integer` when calling freesurfer\nHi,\r\n\r\nWhen I run `python run.py freesurfer --config=~/hMT+/config.py`, I get the following error traceback:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/merlin/PhD/mne-bids-pipeline/run.py\", line 194, in <module>\r\n fire.Fire(process)\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py\", line 141, in Fire\r\n component_trace = _Fire(component, args, parsed_flag_args, context, name)\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py\", line 466, in _Fire\r\n component, remaining_args = _CallAndUpdateTrace(\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py\", line 681, in _CallAndUpdateTrace\r\n component = fn(*varargs, **kwargs)\r\n File \"/home/merlin/PhD/mne-bids-pipeline/run.py\", line 189, in process\r\n _run_script(script_path, config, root_dir, subject, session, task, run)\r\n File \"/home/merlin/PhD/mne-bids-pipeline/run.py\", line 98, in _run_script\r\n runpy.run_path(script_path, run_name='__main__')\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/runpy.py\", line 268, in run_path\r\n return _run_module_code(code, init_globals, run_name,\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/runpy.py\", line 97, in _run_module_code\r\n _run_code(code, mod_globals, init_globals,\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/home/merlin/PhD/mne-bids-pipeline/scripts/freesurfer/recon_all.py\", line 112, in <module>\r\n fire.Fire(main)\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py\", line 141, in Fire\r\n component_trace = _Fire(component, args, parsed_flag_args, context, name)\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py\", line 466, in _Fire\r\n component, remaining_args = _CallAndUpdateTrace(\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/fire/core.py\", line 681, in _CallAndUpdateTrace\r\n component = fn(*varargs, **kwargs)\r\n File \"/home/merlin/PhD/mne-bids-pipeline/scripts/freesurfer/recon_all.py\", line 94, in main\r\n parallel, run_func, _ = parallel_func(run_recon, n_jobs=n_jobs)\r\n File \"<decorator-gen-42>\", line 24, in parallel_func\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/mne/parallel.py\", line 112, in parallel_func\r\n n_jobs = check_n_jobs(n_jobs)\r\n File \"/home/merlin/miniconda3/envs/mne-bids/lib/python3.9/site-packages/mne/parallel.py\", line 159, in check_n_jobs\r\n raise ValueError('n_jobs must be an integer')\r\nValueError: n_jobs must be an integer\r\n```\r\n\r\nChecking with pdb, it seems that `recon_all` is called with `n_jobs = \"freesurfer\"`. I'm not sure why that is.\r\n\r\n```\r\n19:36:39 Using custom configuration: /home/merlin/hMT+/config.py\r\n19:36:39 [Step-01] Running: Initializing output directories.\r\n19:36:39 [Step-01] Initializing output directories.\r\n19:36:39 [Step-01] Completed: Initializing output directories.\r\n2021-04-14 19:36:39 INFO Successfully finished running: init_derivatives_dir\r\n2021-04-14 19:36:39 INFO Now running: on_all\r\n> /home/merlin/PhD/mne-bids-pipeline/scripts/freesurfer/recon_all.py(88)main()\r\n 87 \r\n---> 88 logger.info('Running FreeSurfer')\r\n 89 \r\n\r\nipdb> n_jobs\r\n'freesurfer'\r\nipdb> \r\n```\r\n\r\nIt might be the config needs to be changed, but I can't figure out how.\n", "before_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport shutil\nimport sys\nfrom pathlib import Path\nimport logging\nfrom typing import Union\n\nimport fire\n\nfrom mne.utils import run_subprocess\nfrom mne.parallel import parallel_func\n\nimport config\n\nPathLike = Union[str, Path]\nlogger = logging.getLogger('mne-bids-pipeline')\nfs_bids_app = Path(__file__).parent / 'contrib' / 'run.py'\n\n\ndef _get_subjects_dir(root_dir) -> Path:\n subjects_dir = \\\n Path(root_dir) / \"derivatives\" / \"freesurfer\" / \"subjects\"\n return subjects_dir\n\n\ndef run_recon(root_dir, subject, fs_bids_app) -> None:\n logger.info(f\"Running recon-all on subject {subject}. This will take \"\n f\"a LONG time \u2013 it's a good idea to let it run over night.\")\n\n subjects_dir = _get_subjects_dir(root_dir)\n subj_dir = subjects_dir / f\"sub-{subject}\"\n\n if subj_dir.exists():\n logger.info(f\"Subject {subject} is already present. Please delete the \"\n f\"directory if you want to recompute.\")\n return\n\n env = os.environ\n if 'FREESURFER_HOME' not in env:\n raise RuntimeError(\"FreeSurfer is not available.\")\n\n license_file = Path(f\"{env['FREESURFER_HOME']}/license.txt\")\n if not license_file.exists():\n license_file = Path(f\"{env['FREESURFER_HOME']}/.license\")\n if not license_file.exists():\n raise RuntimeError(\"FreeSurfer license file not found.\")\n\n cmd = [\n f\"{sys.executable}\",\n f\"{fs_bids_app}\",\n f\"{root_dir}\",\n f\"{subjects_dir}\", \"participant\",\n \"--n_cpus=2\", \"--stages=all\", \"--skip_bids_validator\",\n f\"--license_file={license_file}\",\n f\"--participant_label={subject}\"\n ]\n logger.debug(\"Running: \" + \" \".join(cmd))\n run_subprocess(cmd, env=env, verbose=logger.level)\n\n\ndef main(n_jobs: int = 1) -> None:\n \"\"\"Run freesurfer recon-all command on BIDS dataset.\n\n The command allows to run the freesurfer recon-all\n command on all subjects of your BIDS dataset. It can\n run in parallel with the --n_jobs parameter.\n\n It is built on top of the FreeSurfer BIDS app:\n\n https://github.com/BIDS-Apps/freesurfer\n\n You must have freesurfer available on your system.\n\n Examples\n --------\n run_freesurfer.py /path/to/bids/dataset/study-template-config.py /path/to/freesurfer_bids_app/\n\n or to run in parallel (3 subjects at a time):\n\n run_freesurfer.py /path/to/bids/dataset/study-template-config.py /path/to/freesurfer_bids_app/ --n_jobs=3\n\n \"\"\" # noqa\n\n logger.info('Running FreeSurfer')\n\n subjects = config.get_subjects()\n\n root_dir = config.bids_root\n subjects_dir = _get_subjects_dir(root_dir)\n subjects_dir.mkdir(parents=True, exist_ok=True)\n\n parallel, run_func, _ = parallel_func(run_recon, n_jobs=n_jobs)\n parallel(run_func(root_dir, subject, fs_bids_app)\n for subject in subjects)\n\n # Handle fsaverage\n fsaverage_dir = subjects_dir / 'fsaverage'\n if fsaverage_dir.exists():\n if fsaverage_dir.is_symlink():\n fsaverage_dir.unlink()\n else:\n shutil.rmtree(fsaverage_dir)\n\n env = os.environ\n shutil.copytree(f\"{env['FREESURFER_HOME']}/subjects/fsaverage\",\n subjects_dir / 'fsaverage')\n\n\nif __name__ == '__main__':\n fire.Fire(main)\n", "path": "scripts/freesurfer/recon_all.py"}], "after_files": [{"content": "#!/usr/bin/env python\n\nimport os\nimport shutil\nimport sys\nfrom pathlib import Path\nimport logging\nfrom typing import Union\n\nimport fire\n\nfrom mne.utils import run_subprocess\nfrom mne.parallel import parallel_func\n\nimport config\n\nPathLike = Union[str, Path]\nlogger = logging.getLogger('mne-bids-pipeline')\nfs_bids_app = Path(__file__).parent / 'contrib' / 'run.py'\n\n\ndef _get_subjects_dir(root_dir) -> Path:\n subjects_dir = \\\n Path(root_dir) / \"derivatives\" / \"freesurfer\" / \"subjects\"\n return subjects_dir\n\n\ndef run_recon(root_dir, subject, fs_bids_app) -> None:\n logger.info(f\"Running recon-all on subject {subject}. This will take \"\n f\"a LONG time \u2013 it's a good idea to let it run over night.\")\n\n subjects_dir = _get_subjects_dir(root_dir)\n subj_dir = subjects_dir / f\"sub-{subject}\"\n\n if subj_dir.exists():\n logger.info(f\"Subject {subject} is already present. Please delete the \"\n f\"directory if you want to recompute.\")\n return\n\n env = os.environ\n if 'FREESURFER_HOME' not in env:\n raise RuntimeError(\"FreeSurfer is not available.\")\n\n license_file = Path(f\"{env['FREESURFER_HOME']}/license.txt\")\n if not license_file.exists():\n license_file = Path(f\"{env['FREESURFER_HOME']}/.license\")\n if not license_file.exists():\n raise RuntimeError(\"FreeSurfer license file not found.\")\n\n cmd = [\n f\"{sys.executable}\",\n f\"{fs_bids_app}\",\n f\"{root_dir}\",\n f\"{subjects_dir}\", \"participant\",\n \"--n_cpus=2\", \"--stages=all\", \"--skip_bids_validator\",\n f\"--license_file={license_file}\",\n f\"--participant_label={subject}\"\n ]\n logger.debug(\"Running: \" + \" \".join(cmd))\n run_subprocess(cmd, env=env, verbose=logger.level)\n\n\ndef main(*, n_jobs: int = 1) -> None:\n \"\"\"Run freesurfer recon-all command on BIDS dataset.\n\n The command allows to run the freesurfer recon-all\n command on all subjects of your BIDS dataset. It can\n run in parallel with the --n_jobs parameter.\n\n It is built on top of the FreeSurfer BIDS app:\n\n https://github.com/BIDS-Apps/freesurfer\n\n You must have freesurfer available on your system.\n\n Examples\n --------\n run_freesurfer.py /path/to/bids/dataset/study-template-config.py /path/to/freesurfer_bids_app/\n\n or to run in parallel (3 subjects at a time):\n\n run_freesurfer.py /path/to/bids/dataset/study-template-config.py /path/to/freesurfer_bids_app/ --n_jobs=3\n\n \"\"\" # noqa\n\n logger.info('Running FreeSurfer')\n\n subjects = config.get_subjects()\n\n root_dir = config.bids_root\n subjects_dir = _get_subjects_dir(root_dir)\n subjects_dir.mkdir(parents=True, exist_ok=True)\n\n parallel, run_func, _ = parallel_func(run_recon, n_jobs=n_jobs)\n parallel(run_func(root_dir, subject, fs_bids_app)\n for subject in subjects)\n\n # Handle fsaverage\n fsaverage_dir = subjects_dir / 'fsaverage'\n if fsaverage_dir.exists():\n if fsaverage_dir.is_symlink():\n fsaverage_dir.unlink()\n else:\n shutil.rmtree(fsaverage_dir)\n\n env = os.environ\n shutil.copytree(f\"{env['FREESURFER_HOME']}/subjects/fsaverage\",\n subjects_dir / 'fsaverage')\n\n\nif __name__ == '__main__':\n fire.Fire(main)\n", "path": "scripts/freesurfer/recon_all.py"}]} | 2,477 | 133 |
gh_patches_debug_10284 | rasdani/github-patches | git_diff | e-valuation__EvaP-1395 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add confirmation for login with login key
External users can login by clicking on the login URL sent to them via email. Before users are actually authenticated on the platform after clicking on this link, they should have to confirm the login by, e.g., clicking a confirmation button in a modal or on a designated page.
This prevents cases in which the URL is already requested for, e.g., a preview of the page and thus invalidates the login key which results in a new link being sent when users actively click on the link (which is then already the second GET request).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `evap/evaluation/views.py`
Content:
```
1 import logging
2 from datetime import date, timedelta
3
4 from django.conf import settings
5 from django.contrib import messages, auth
6 from django.contrib.auth.decorators import login_required
7 from django.core.mail import EmailMessage
8 from django.http import HttpResponse, HttpResponseBadRequest
9 from django.shortcuts import redirect, render
10 from django.utils.translation import ugettext as _
11 from django.views.decorators.http import require_POST
12 from django.views.decorators.debug import sensitive_post_parameters
13 from django.views.i18n import set_language
14
15 from evap.evaluation.forms import NewKeyForm, LoginUsernameForm
16 from evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester
17
18 logger = logging.getLogger(__name__)
19
20
21 @sensitive_post_parameters("password")
22 def index(request):
23 """Main entry page into EvaP providing all the login options available. The username/password
24 login is thought to be used for internal users, e.g. by connecting to a LDAP directory.
25 The login key mechanism is meant to be used to include external participants, e.g. visiting
26 students or visiting contributors.
27 """
28
29 # parse the form data into the respective form
30 submit_type = request.POST.get("submit_type", "no_submit")
31 new_key_form = NewKeyForm(request.POST if submit_type == "new_key" else None)
32 login_username_form = LoginUsernameForm(request, request.POST if submit_type == "login_username" else None)
33
34 # process form data
35 if request.method == 'POST':
36 if new_key_form.is_valid():
37 # user wants a new login key
38 profile = new_key_form.get_user()
39 profile.ensure_valid_login_key()
40 profile.save()
41
42 EmailTemplate.send_login_url_to_user(new_key_form.get_user())
43
44 messages.success(request, _("We sent you an email with a one-time login URL. Please check your inbox."))
45 return redirect('evaluation:index')
46 elif login_username_form.is_valid():
47 # user would like to login with username and password and passed password test
48 auth.login(request, login_username_form.get_user())
49
50 # clean up our test cookie
51 if request.session.test_cookie_worked():
52 request.session.delete_test_cookie()
53
54 # if not logged in by now, render form
55 if not request.user.is_authenticated:
56 # set test cookie to verify whether they work in the next step
57 request.session.set_test_cookie()
58
59 template_data = dict(
60 new_key_form=new_key_form,
61 login_username_form=login_username_form,
62 openid_active=settings.ACTIVATE_OPEN_ID_LOGIN,
63 )
64 return render(request, "index.html", template_data)
65 else:
66 user, __ = UserProfile.objects.get_or_create(username=request.user.username)
67
68 # check for redirect variable
69 redirect_to = request.GET.get("next", None)
70 if redirect_to is not None:
71 return redirect(redirect_to)
72
73 # redirect user to appropriate start page
74 if request.user.is_reviewer:
75 return redirect('staff:semester_view', Semester.active_semester().id)
76 if request.user.is_manager:
77 return redirect('staff:index')
78 elif request.user.is_grade_publisher:
79 return redirect('grades:semester_view', Semester.active_semester().id)
80 elif user.is_student:
81 return redirect('student:index')
82 elif user.is_responsible_or_contributor_or_delegate:
83 return redirect('contributor:index')
84 else:
85 return redirect('results:index')
86
87
88 def login_key_authentication(request, key):
89 user = auth.authenticate(request, key=key)
90
91 if user and not user.is_active:
92 messages.error(request, _("Inactive users are not allowed to login."))
93 return redirect('evaluation:index')
94
95 # If we already have an authenticated user don't try to login a new user. Show an error message if another user
96 # tries to login with a URL in this situation.
97 if request.user.is_authenticated:
98 if user != request.user:
99 messages.error(request, _("Another user is currently logged in. Please logout first and then use the login URL again."))
100 return redirect('evaluation:index')
101
102 if user and user.login_key_valid_until >= date.today():
103 # User is valid. Set request.user and persist user in the session by logging the user in.
104 request.user = user
105 auth.login(request, user)
106 messages.success(request, _("Logged in as %s.") % user.full_name)
107 # Invalidate the login key, but keep it stored so we can later identify the user that is trying to login and send a new link
108 user.login_key_valid_until = date.today() - timedelta(1)
109 user.save()
110 elif user:
111 # A user exists, but the login key is not valid anymore. Send the user a new one.
112 user.ensure_valid_login_key()
113 EmailTemplate.send_login_url_to_user(user)
114 messages.warning(request, _("The login URL is not valid anymore. We sent you a new one to your email address."))
115 else:
116 messages.warning(request, _("Invalid login URL. Please request a new one below."))
117
118 return redirect('evaluation:index')
119
120
121 def faq(request):
122 return render(request, "faq.html", dict(sections=FaqSection.objects.all()))
123
124
125 def legal_notice(request):
126 return render(request, "legal_notice.html", dict())
127
128
129 @require_POST
130 @login_required
131 def contact(request):
132 message = request.POST.get("message")
133 title = request.POST.get("title")
134 subject = "[EvaP] Message from {}".format(request.user.username)
135
136 if message:
137 mail = EmailMessage(
138 subject=subject,
139 body="{}\n{} ({})\n\n{}".format(title, request.user.username, request.user.email, message),
140 to=[settings.CONTACT_EMAIL])
141 try:
142 mail.send()
143 logger.info('Sent contact email: \n{}\n'.format(mail.message()))
144 return HttpResponse()
145 except Exception:
146 logger.exception('An exception occurred when sending the following contact email:\n{}\n'.format(mail.message()))
147 raise
148
149 return HttpResponseBadRequest()
150
151
152 @require_POST
153 def set_lang(request):
154 if request.user.is_authenticated:
155 user = request.user
156 user.language = request.POST['language']
157 user.save()
158
159 return set_language(request)
160
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py
--- a/evap/evaluation/views.py
+++ b/evap/evaluation/views.py
@@ -100,6 +100,12 @@
return redirect('evaluation:index')
if user and user.login_key_valid_until >= date.today():
+ if request.method != "POST":
+ template_data = {
+ 'username': user.full_name
+ }
+ return render(request, "external_user_confirm_login.html", template_data)
+
# User is valid. Set request.user and persist user in the session by logging the user in.
request.user = user
auth.login(request, user)
| {"golden_diff": "diff --git a/evap/evaluation/views.py b/evap/evaluation/views.py\n--- a/evap/evaluation/views.py\n+++ b/evap/evaluation/views.py\n@@ -100,6 +100,12 @@\n return redirect('evaluation:index')\n \n if user and user.login_key_valid_until >= date.today():\n+ if request.method != \"POST\":\n+ template_data = {\n+ 'username': user.full_name\n+ }\n+ return render(request, \"external_user_confirm_login.html\", template_data)\n+\n # User is valid. Set request.user and persist user in the session by logging the user in.\n request.user = user\n auth.login(request, user)\n", "issue": "Add confirmation for login with login key\nExternal users can login by clicking on the login URL sent to them via email. Before users are actually authenticated on the platform after clicking on this link, they should have to confirm the login by, e.g., clicking a confirmation button in a modal or on a designated page.\r\n\r\nThis prevents cases in which the URL is already requested for, e.g., a preview of the page and thus invalidates the login key which results in a new link being sent when users actively click on the link (which is then already the second GET request).\n", "before_files": [{"content": "import logging\nfrom datetime import date, timedelta\n\nfrom django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.mail import EmailMessage\nfrom django.http import HttpResponse, HttpResponseBadRequest\nfrom django.shortcuts import redirect, render\nfrom django.utils.translation import ugettext as _\nfrom django.views.decorators.http import require_POST\nfrom django.views.decorators.debug import sensitive_post_parameters\nfrom django.views.i18n import set_language\n\nfrom evap.evaluation.forms import NewKeyForm, LoginUsernameForm\nfrom evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n\nlogger = logging.getLogger(__name__)\n\n\n@sensitive_post_parameters(\"password\")\ndef index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n The login key mechanism is meant to be used to include external participants, e.g. visiting\n students or visiting contributors.\n \"\"\"\n\n # parse the form data into the respective form\n submit_type = request.POST.get(\"submit_type\", \"no_submit\")\n new_key_form = NewKeyForm(request.POST if submit_type == \"new_key\" else None)\n login_username_form = LoginUsernameForm(request, request.POST if submit_type == \"login_username\" else None)\n\n # process form data\n if request.method == 'POST':\n if new_key_form.is_valid():\n # user wants a new login key\n profile = new_key_form.get_user()\n profile.ensure_valid_login_key()\n profile.save()\n\n EmailTemplate.send_login_url_to_user(new_key_form.get_user())\n\n messages.success(request, _(\"We sent you an email with a one-time login URL. Please check your inbox.\"))\n return redirect('evaluation:index')\n elif login_username_form.is_valid():\n # user would like to login with username and password and passed password test\n auth.login(request, login_username_form.get_user())\n\n # clean up our test cookie\n if request.session.test_cookie_worked():\n request.session.delete_test_cookie()\n\n # if not logged in by now, render form\n if not request.user.is_authenticated:\n # set test cookie to verify whether they work in the next step\n request.session.set_test_cookie()\n\n template_data = dict(\n new_key_form=new_key_form,\n login_username_form=login_username_form,\n openid_active=settings.ACTIVATE_OPEN_ID_LOGIN,\n )\n return render(request, \"index.html\", template_data)\n else:\n user, __ = UserProfile.objects.get_or_create(username=request.user.username)\n\n # check for redirect variable\n redirect_to = request.GET.get(\"next\", None)\n if redirect_to is not None:\n return redirect(redirect_to)\n\n # redirect user to appropriate start page\n if request.user.is_reviewer:\n return redirect('staff:semester_view', Semester.active_semester().id)\n if request.user.is_manager:\n return redirect('staff:index')\n elif request.user.is_grade_publisher:\n return redirect('grades:semester_view', Semester.active_semester().id)\n elif user.is_student:\n return redirect('student:index')\n elif user.is_responsible_or_contributor_or_delegate:\n return redirect('contributor:index')\n else:\n return redirect('results:index')\n\n\ndef login_key_authentication(request, key):\n user = auth.authenticate(request, key=key)\n\n if user and not user.is_active:\n messages.error(request, _(\"Inactive users are not allowed to login.\"))\n return redirect('evaluation:index')\n\n # If we already have an authenticated user don't try to login a new user. Show an error message if another user\n # tries to login with a URL in this situation.\n if request.user.is_authenticated:\n if user != request.user:\n messages.error(request, _(\"Another user is currently logged in. Please logout first and then use the login URL again.\"))\n return redirect('evaluation:index')\n\n if user and user.login_key_valid_until >= date.today():\n # User is valid. Set request.user and persist user in the session by logging the user in.\n request.user = user\n auth.login(request, user)\n messages.success(request, _(\"Logged in as %s.\") % user.full_name)\n # Invalidate the login key, but keep it stored so we can later identify the user that is trying to login and send a new link\n user.login_key_valid_until = date.today() - timedelta(1)\n user.save()\n elif user:\n # A user exists, but the login key is not valid anymore. Send the user a new one.\n user.ensure_valid_login_key()\n EmailTemplate.send_login_url_to_user(user)\n messages.warning(request, _(\"The login URL is not valid anymore. We sent you a new one to your email address.\"))\n else:\n messages.warning(request, _(\"Invalid login URL. Please request a new one below.\"))\n\n return redirect('evaluation:index')\n\n\ndef faq(request):\n return render(request, \"faq.html\", dict(sections=FaqSection.objects.all()))\n\n\ndef legal_notice(request):\n return render(request, \"legal_notice.html\", dict())\n\n\n@require_POST\n@login_required\ndef contact(request):\n message = request.POST.get(\"message\")\n title = request.POST.get(\"title\")\n subject = \"[EvaP] Message from {}\".format(request.user.username)\n\n if message:\n mail = EmailMessage(\n subject=subject,\n body=\"{}\\n{} ({})\\n\\n{}\".format(title, request.user.username, request.user.email, message),\n to=[settings.CONTACT_EMAIL])\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n return HttpResponse()\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n\n return HttpResponseBadRequest()\n\n\n@require_POST\ndef set_lang(request):\n if request.user.is_authenticated:\n user = request.user\n user.language = request.POST['language']\n user.save()\n\n return set_language(request)\n", "path": "evap/evaluation/views.py"}], "after_files": [{"content": "import logging\nfrom datetime import date, timedelta\n\nfrom django.conf import settings\nfrom django.contrib import messages, auth\nfrom django.contrib.auth.decorators import login_required\nfrom django.core.mail import EmailMessage\nfrom django.http import HttpResponse, HttpResponseBadRequest\nfrom django.shortcuts import redirect, render\nfrom django.utils.translation import ugettext as _\nfrom django.views.decorators.http import require_POST\nfrom django.views.decorators.debug import sensitive_post_parameters\nfrom django.views.i18n import set_language\n\nfrom evap.evaluation.forms import NewKeyForm, LoginUsernameForm\nfrom evap.evaluation.models import UserProfile, FaqSection, EmailTemplate, Semester\n\nlogger = logging.getLogger(__name__)\n\n\n@sensitive_post_parameters(\"password\")\ndef index(request):\n \"\"\"Main entry page into EvaP providing all the login options available. The username/password\n login is thought to be used for internal users, e.g. by connecting to a LDAP directory.\n The login key mechanism is meant to be used to include external participants, e.g. visiting\n students or visiting contributors.\n \"\"\"\n\n # parse the form data into the respective form\n submit_type = request.POST.get(\"submit_type\", \"no_submit\")\n new_key_form = NewKeyForm(request.POST if submit_type == \"new_key\" else None)\n login_username_form = LoginUsernameForm(request, request.POST if submit_type == \"login_username\" else None)\n\n # process form data\n if request.method == 'POST':\n if new_key_form.is_valid():\n # user wants a new login key\n profile = new_key_form.get_user()\n profile.ensure_valid_login_key()\n profile.save()\n\n EmailTemplate.send_login_url_to_user(new_key_form.get_user())\n\n messages.success(request, _(\"We sent you an email with a one-time login URL. Please check your inbox.\"))\n return redirect('evaluation:index')\n elif login_username_form.is_valid():\n # user would like to login with username and password and passed password test\n auth.login(request, login_username_form.get_user())\n\n # clean up our test cookie\n if request.session.test_cookie_worked():\n request.session.delete_test_cookie()\n\n # if not logged in by now, render form\n if not request.user.is_authenticated:\n # set test cookie to verify whether they work in the next step\n request.session.set_test_cookie()\n\n template_data = dict(\n new_key_form=new_key_form,\n login_username_form=login_username_form,\n openid_active=settings.ACTIVATE_OPEN_ID_LOGIN,\n )\n return render(request, \"index.html\", template_data)\n else:\n user, __ = UserProfile.objects.get_or_create(username=request.user.username)\n\n # check for redirect variable\n redirect_to = request.GET.get(\"next\", None)\n if redirect_to is not None:\n return redirect(redirect_to)\n\n # redirect user to appropriate start page\n if request.user.is_reviewer:\n return redirect('staff:semester_view', Semester.active_semester().id)\n if request.user.is_manager:\n return redirect('staff:index')\n elif request.user.is_grade_publisher:\n return redirect('grades:semester_view', Semester.active_semester().id)\n elif user.is_student:\n return redirect('student:index')\n elif user.is_responsible_or_contributor_or_delegate:\n return redirect('contributor:index')\n else:\n return redirect('results:index')\n\n\ndef login_key_authentication(request, key):\n user = auth.authenticate(request, key=key)\n\n if user and not user.is_active:\n messages.error(request, _(\"Inactive users are not allowed to login.\"))\n return redirect('evaluation:index')\n\n # If we already have an authenticated user don't try to login a new user. Show an error message if another user\n # tries to login with a URL in this situation.\n if request.user.is_authenticated:\n if user != request.user:\n messages.error(request, _(\"Another user is currently logged in. Please logout first and then use the login URL again.\"))\n return redirect('evaluation:index')\n\n if user and user.login_key_valid_until >= date.today():\n if request.method != \"POST\":\n template_data = {\n 'username': user.full_name\n }\n return render(request, \"external_user_confirm_login.html\", template_data)\n\n # User is valid. Set request.user and persist user in the session by logging the user in.\n request.user = user\n auth.login(request, user)\n messages.success(request, _(\"Logged in as %s.\") % user.full_name)\n # Invalidate the login key, but keep it stored so we can later identify the user that is trying to login and send a new link\n user.login_key_valid_until = date.today() - timedelta(1)\n user.save()\n elif user:\n # A user exists, but the login key is not valid anymore. Send the user a new one.\n user.ensure_valid_login_key()\n EmailTemplate.send_login_url_to_user(user)\n messages.warning(request, _(\"The login URL is not valid anymore. We sent you a new one to your email address.\"))\n else:\n messages.warning(request, _(\"Invalid login URL. Please request a new one below.\"))\n\n return redirect('evaluation:index')\n\n\ndef faq(request):\n return render(request, \"faq.html\", dict(sections=FaqSection.objects.all()))\n\n\ndef legal_notice(request):\n return render(request, \"legal_notice.html\", dict())\n\n\n@require_POST\n@login_required\ndef contact(request):\n message = request.POST.get(\"message\")\n title = request.POST.get(\"title\")\n subject = \"[EvaP] Message from {}\".format(request.user.username)\n\n if message:\n mail = EmailMessage(\n subject=subject,\n body=\"{}\\n{} ({})\\n\\n{}\".format(title, request.user.username, request.user.email, message),\n to=[settings.CONTACT_EMAIL])\n try:\n mail.send()\n logger.info('Sent contact email: \\n{}\\n'.format(mail.message()))\n return HttpResponse()\n except Exception:\n logger.exception('An exception occurred when sending the following contact email:\\n{}\\n'.format(mail.message()))\n raise\n\n return HttpResponseBadRequest()\n\n\n@require_POST\ndef set_lang(request):\n if request.user.is_authenticated:\n user = request.user\n user.language = request.POST['language']\n user.save()\n\n return set_language(request)\n", "path": "evap/evaluation/views.py"}]} | 2,054 | 154 |
gh_patches_debug_26302 | rasdani/github-patches | git_diff | svthalia__concrexit-2918 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Add organisers back to event admin list
### Is your feature request related to a problem? Please describe.
The organiser column was removed #2459.
### Describe the solution you'd like
A comma-separated list of organisers, optionally as links to the organiser's admin pages.
### Motivation
Then you get a nice overview of who does which events.
### Describe alternatives you've considered
Leave it.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `website/events/admin/event.py`
Content:
```
1 """Registers admin interfaces for the event model."""
2
3 from django.contrib import admin, messages
4 from django.template.defaultfilters import date as _date
5 from django.urls import path, reverse
6 from django.utils import timezone
7 from django.utils.html import format_html
8 from django.utils.translation import gettext_lazy as _
9
10 from events import emails, models, services
11 from events.admin.filters import LectureYearFilter
12 from events.admin.forms import EventAdminForm, RegistrationInformationFieldForm
13 from events.admin.inlines import (
14 PizzaEventInline,
15 PromotionRequestInline,
16 RegistrationInformationFieldInline,
17 )
18 from events.admin.views import (
19 EventAdminDetails,
20 EventMarkPresentQR,
21 EventRegistrationsExport,
22 )
23 from utils.admin import DoNextModelAdmin
24
25
26 @admin.register(models.Event)
27 class EventAdmin(DoNextModelAdmin):
28 """Manage the events."""
29
30 form = EventAdminForm
31
32 inlines = (
33 RegistrationInformationFieldInline,
34 PizzaEventInline,
35 PromotionRequestInline,
36 )
37
38 list_display = (
39 "overview_link",
40 "event_date",
41 "registration_date",
42 "num_participants",
43 "category",
44 "published",
45 "edit_link",
46 )
47 list_display_links = ("edit_link",)
48 list_filter = (LectureYearFilter, "start", "published", "category")
49 actions = ("make_published", "make_unpublished")
50 date_hierarchy = "start"
51 search_fields = ("title", "description")
52 prepopulated_fields = {
53 "map_location": ("location",),
54 }
55
56 filter_horizontal = ("documents", "organisers")
57
58 fieldsets = (
59 (
60 _("General"),
61 {
62 "fields": (
63 "title",
64 "slug",
65 "published",
66 "organisers",
67 )
68 },
69 ),
70 (
71 _("Detail"),
72 {
73 "fields": (
74 "category",
75 "start",
76 "end",
77 "description",
78 "caption",
79 "location",
80 "map_location",
81 ),
82 "classes": ("collapse", "start-open"),
83 },
84 ),
85 (
86 _("Registrations"),
87 {
88 "fields": (
89 "price",
90 "fine",
91 "tpay_allowed",
92 "max_participants",
93 "registration_without_membership",
94 "registration_start",
95 "registration_end",
96 "cancel_deadline",
97 "send_cancel_email",
98 "optional_registrations",
99 "no_registration_message",
100 ),
101 "classes": ("collapse",),
102 },
103 ),
104 (
105 _("Extra"),
106 {"fields": ("documents", "shift"), "classes": ("collapse",)},
107 ),
108 )
109
110 def get_queryset(self, request):
111 return super().get_queryset(request).select_properties("participant_count")
112
113 def get_form(self, request, obj=None, change=False, **kwargs):
114 form = super().get_form(request, obj, change, **kwargs)
115 form.clean = lambda form: form.instance.clean_changes(form.changed_data)
116 form.request = request
117 return form
118
119 def overview_link(self, obj):
120 return format_html(
121 '<a href="{link}">{title}</a>',
122 link=reverse("admin:events_event_details", kwargs={"pk": obj.pk}),
123 title=obj.title,
124 )
125
126 def has_change_permission(self, request, obj=None):
127 """Only allow access to the change form if the user is an organiser."""
128 if obj is not None and not services.is_organiser(request.member, obj):
129 return False
130 return super().has_change_permission(request, obj)
131
132 def event_date(self, obj):
133 event_date = timezone.make_naive(obj.start)
134 return _date(event_date, "l d b Y, G:i")
135
136 event_date.short_description = _("Event Date")
137 event_date.admin_order_field = "start"
138
139 def registration_date(self, obj):
140 if obj.registration_start is not None:
141 start_date = timezone.make_naive(obj.registration_start)
142 else:
143 start_date = obj.registration_start
144
145 return _date(start_date, "l d b Y, G:i")
146
147 registration_date.short_description = _("Registration Start")
148 registration_date.admin_order_field = "registration_start"
149
150 def edit_link(self, obj):
151 return _("Edit")
152
153 edit_link.short_description = ""
154
155 def num_participants(self, obj):
156 """Pretty-print the number of participants."""
157 num = obj.participant_count # prefetched aggregateproperty
158 if not obj.max_participants:
159 return f"{num}/∞"
160 return f"{num}/{obj.max_participants}"
161
162 num_participants.short_description = _("Number of participants")
163
164 def make_published(self, request, queryset):
165 """Change the status of the event to published."""
166 self._change_published(request, queryset, True)
167
168 make_published.short_description = _("Publish selected events")
169
170 def make_unpublished(self, request, queryset):
171 """Change the status of the event to unpublished."""
172 self._change_published(request, queryset, False)
173
174 make_unpublished.short_description = _("Unpublish selected events")
175
176 @staticmethod
177 def _change_published(request, queryset, published):
178 if not request.user.is_superuser:
179 queryset = queryset.filter(
180 organisers__in=request.member.get_member_groups()
181 )
182 queryset.update(published=published)
183
184 def save_formset(self, request, form, formset, change):
185 """Save formsets with their order."""
186 formset.save()
187
188 informationfield_forms = (
189 x
190 for x in formset.forms
191 if isinstance(x, RegistrationInformationFieldForm)
192 and "DELETE" not in x.changed_data
193 )
194 form.instance.set_registrationinformationfield_order(
195 [
196 f.instance.pk
197 for f in sorted(
198 informationfield_forms,
199 key=lambda x: (x.cleaned_data["order"], x.instance.pk),
200 )
201 ]
202 )
203 form.instance.save()
204
205 def save_model(self, request, obj, form, change):
206 if change and "max_participants" in form.changed_data:
207 prev = self.model.objects.get(id=obj.id)
208 prev_limit = prev.max_participants
209 self_limit = obj.max_participants
210 if prev_limit is None:
211 prev_limit = prev.participant_count
212 if self_limit is None:
213 self_limit = obj.participant_count
214
215 if prev_limit < self_limit and prev_limit < obj.participant_count:
216 diff = self_limit - prev_limit
217 joiners = prev.queue[:diff]
218 for registration in joiners:
219 emails.notify_waiting(obj, registration)
220 messages.info(
221 request,
222 "The maximum number of participants was increased. Any members that moved from the waiting list to the participants list have been notified.",
223 )
224 elif self_limit < prev_limit and self_limit < obj.participant_count:
225 diff = self_limit - prev_limit
226 leavers = prev.registrations[self_limit:]
227 address = map(lambda r: r.email, leavers)
228 link = "mailto:?bcc=" + ",".join(address)
229 messages.warning(
230 request,
231 format_html(
232 "The maximum number of participants was decreased and some members moved to the waiting list. <a href='{}' style='text-decoration: underline;'>Use this link to send them an email.</a>",
233 link,
234 ),
235 )
236 super().save_model(request, obj, form, change)
237
238 def get_actions(self, request):
239 actions = super().get_actions(request)
240 if "delete_selected" in actions:
241 del actions["delete_selected"]
242 return actions
243
244 def get_formsets_with_inlines(self, request, obj=None):
245 for inline in self.get_inline_instances(request, obj):
246 if self.has_change_permission(request, obj) or obj is None:
247 yield inline.get_formset(request, obj), inline
248
249 def get_urls(self):
250 urls = super().get_urls()
251 custom_urls = [
252 path(
253 "<int:pk>/details/",
254 self.admin_site.admin_view(EventAdminDetails.as_view()),
255 name="events_event_details",
256 ),
257 path(
258 "<int:pk>/export/",
259 self.admin_site.admin_view(EventRegistrationsExport.as_view()),
260 name="events_event_export",
261 ),
262 path(
263 "<int:pk>/mark-present-qr/",
264 self.admin_site.admin_view(EventMarkPresentQR.as_view()),
265 name="events_event_mark_present_qr",
266 ),
267 ]
268 return custom_urls + urls
269
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/website/events/admin/event.py b/website/events/admin/event.py
--- a/website/events/admin/event.py
+++ b/website/events/admin/event.py
@@ -40,6 +40,7 @@
"event_date",
"registration_date",
"num_participants",
+ "get_organisers",
"category",
"published",
"edit_link",
@@ -108,7 +109,12 @@
)
def get_queryset(self, request):
- return super().get_queryset(request).select_properties("participant_count")
+ return (
+ super()
+ .get_queryset(request)
+ .select_properties("participant_count")
+ .prefetch_related("organisers")
+ )
def get_form(self, request, obj=None, change=False, **kwargs):
form = super().get_form(request, obj, change, **kwargs)
@@ -161,6 +167,11 @@
num_participants.short_description = _("Number of participants")
+ def get_organisers(self, obj):
+ return ", ".join(str(o) for o in obj.organisers.all())
+
+ get_organisers.short_description = _("Organisers")
+
def make_published(self, request, queryset):
"""Change the status of the event to published."""
self._change_published(request, queryset, True)
| {"golden_diff": "diff --git a/website/events/admin/event.py b/website/events/admin/event.py\n--- a/website/events/admin/event.py\n+++ b/website/events/admin/event.py\n@@ -40,6 +40,7 @@\n \"event_date\",\n \"registration_date\",\n \"num_participants\",\n+ \"get_organisers\",\n \"category\",\n \"published\",\n \"edit_link\",\n@@ -108,7 +109,12 @@\n )\n \n def get_queryset(self, request):\n- return super().get_queryset(request).select_properties(\"participant_count\")\n+ return (\n+ super()\n+ .get_queryset(request)\n+ .select_properties(\"participant_count\")\n+ .prefetch_related(\"organisers\")\n+ )\n \n def get_form(self, request, obj=None, change=False, **kwargs):\n form = super().get_form(request, obj, change, **kwargs)\n@@ -161,6 +167,11 @@\n \n num_participants.short_description = _(\"Number of participants\")\n \n+ def get_organisers(self, obj):\n+ return \", \".join(str(o) for o in obj.organisers.all())\n+\n+ get_organisers.short_description = _(\"Organisers\")\n+\n def make_published(self, request, queryset):\n \"\"\"Change the status of the event to published.\"\"\"\n self._change_published(request, queryset, True)\n", "issue": "Add organisers back to event admin list\n### Is your feature request related to a problem? Please describe.\r\nThe organiser column was removed #2459. \r\n\r\n### Describe the solution you'd like\r\nA comma-separated list of organisers, optionally as links to the organiser's admin pages.\r\n\r\n### Motivation\r\nThen you get a nice overview of who does which events.\r\n\r\n### Describe alternatives you've considered\r\nLeave it.\r\n\n", "before_files": [{"content": "\"\"\"Registers admin interfaces for the event model.\"\"\"\n\nfrom django.contrib import admin, messages\nfrom django.template.defaultfilters import date as _date\nfrom django.urls import path, reverse\nfrom django.utils import timezone\nfrom django.utils.html import format_html\nfrom django.utils.translation import gettext_lazy as _\n\nfrom events import emails, models, services\nfrom events.admin.filters import LectureYearFilter\nfrom events.admin.forms import EventAdminForm, RegistrationInformationFieldForm\nfrom events.admin.inlines import (\n PizzaEventInline,\n PromotionRequestInline,\n RegistrationInformationFieldInline,\n)\nfrom events.admin.views import (\n EventAdminDetails,\n EventMarkPresentQR,\n EventRegistrationsExport,\n)\nfrom utils.admin import DoNextModelAdmin\n\n\[email protected](models.Event)\nclass EventAdmin(DoNextModelAdmin):\n \"\"\"Manage the events.\"\"\"\n\n form = EventAdminForm\n\n inlines = (\n RegistrationInformationFieldInline,\n PizzaEventInline,\n PromotionRequestInline,\n )\n\n list_display = (\n \"overview_link\",\n \"event_date\",\n \"registration_date\",\n \"num_participants\",\n \"category\",\n \"published\",\n \"edit_link\",\n )\n list_display_links = (\"edit_link\",)\n list_filter = (LectureYearFilter, \"start\", \"published\", \"category\")\n actions = (\"make_published\", \"make_unpublished\")\n date_hierarchy = \"start\"\n search_fields = (\"title\", \"description\")\n prepopulated_fields = {\n \"map_location\": (\"location\",),\n }\n\n filter_horizontal = (\"documents\", \"organisers\")\n\n fieldsets = (\n (\n _(\"General\"),\n {\n \"fields\": (\n \"title\",\n \"slug\",\n \"published\",\n \"organisers\",\n )\n },\n ),\n (\n _(\"Detail\"),\n {\n \"fields\": (\n \"category\",\n \"start\",\n \"end\",\n \"description\",\n \"caption\",\n \"location\",\n \"map_location\",\n ),\n \"classes\": (\"collapse\", \"start-open\"),\n },\n ),\n (\n _(\"Registrations\"),\n {\n \"fields\": (\n \"price\",\n \"fine\",\n \"tpay_allowed\",\n \"max_participants\",\n \"registration_without_membership\",\n \"registration_start\",\n \"registration_end\",\n \"cancel_deadline\",\n \"send_cancel_email\",\n \"optional_registrations\",\n \"no_registration_message\",\n ),\n \"classes\": (\"collapse\",),\n },\n ),\n (\n _(\"Extra\"),\n {\"fields\": (\"documents\", \"shift\"), \"classes\": (\"collapse\",)},\n ),\n )\n\n def get_queryset(self, request):\n return super().get_queryset(request).select_properties(\"participant_count\")\n\n def get_form(self, request, obj=None, change=False, **kwargs):\n form = super().get_form(request, obj, change, **kwargs)\n form.clean = lambda form: form.instance.clean_changes(form.changed_data)\n form.request = request\n return form\n\n def overview_link(self, obj):\n return format_html(\n '<a href=\"{link}\">{title}</a>',\n link=reverse(\"admin:events_event_details\", kwargs={\"pk\": obj.pk}),\n title=obj.title,\n )\n\n def has_change_permission(self, request, obj=None):\n \"\"\"Only allow access to the change form if the user is an organiser.\"\"\"\n if obj is not None and not services.is_organiser(request.member, obj):\n return False\n return super().has_change_permission(request, obj)\n\n def event_date(self, obj):\n event_date = timezone.make_naive(obj.start)\n return _date(event_date, \"l d b Y, G:i\")\n\n event_date.short_description = _(\"Event Date\")\n event_date.admin_order_field = \"start\"\n\n def registration_date(self, obj):\n if obj.registration_start is not None:\n start_date = timezone.make_naive(obj.registration_start)\n else:\n start_date = obj.registration_start\n\n return _date(start_date, \"l d b Y, G:i\")\n\n registration_date.short_description = _(\"Registration Start\")\n registration_date.admin_order_field = \"registration_start\"\n\n def edit_link(self, obj):\n return _(\"Edit\")\n\n edit_link.short_description = \"\"\n\n def num_participants(self, obj):\n \"\"\"Pretty-print the number of participants.\"\"\"\n num = obj.participant_count # prefetched aggregateproperty\n if not obj.max_participants:\n return f\"{num}/\u221e\"\n return f\"{num}/{obj.max_participants}\"\n\n num_participants.short_description = _(\"Number of participants\")\n\n def make_published(self, request, queryset):\n \"\"\"Change the status of the event to published.\"\"\"\n self._change_published(request, queryset, True)\n\n make_published.short_description = _(\"Publish selected events\")\n\n def make_unpublished(self, request, queryset):\n \"\"\"Change the status of the event to unpublished.\"\"\"\n self._change_published(request, queryset, False)\n\n make_unpublished.short_description = _(\"Unpublish selected events\")\n\n @staticmethod\n def _change_published(request, queryset, published):\n if not request.user.is_superuser:\n queryset = queryset.filter(\n organisers__in=request.member.get_member_groups()\n )\n queryset.update(published=published)\n\n def save_formset(self, request, form, formset, change):\n \"\"\"Save formsets with their order.\"\"\"\n formset.save()\n\n informationfield_forms = (\n x\n for x in formset.forms\n if isinstance(x, RegistrationInformationFieldForm)\n and \"DELETE\" not in x.changed_data\n )\n form.instance.set_registrationinformationfield_order(\n [\n f.instance.pk\n for f in sorted(\n informationfield_forms,\n key=lambda x: (x.cleaned_data[\"order\"], x.instance.pk),\n )\n ]\n )\n form.instance.save()\n\n def save_model(self, request, obj, form, change):\n if change and \"max_participants\" in form.changed_data:\n prev = self.model.objects.get(id=obj.id)\n prev_limit = prev.max_participants\n self_limit = obj.max_participants\n if prev_limit is None:\n prev_limit = prev.participant_count\n if self_limit is None:\n self_limit = obj.participant_count\n\n if prev_limit < self_limit and prev_limit < obj.participant_count:\n diff = self_limit - prev_limit\n joiners = prev.queue[:diff]\n for registration in joiners:\n emails.notify_waiting(obj, registration)\n messages.info(\n request,\n \"The maximum number of participants was increased. Any members that moved from the waiting list to the participants list have been notified.\",\n )\n elif self_limit < prev_limit and self_limit < obj.participant_count:\n diff = self_limit - prev_limit\n leavers = prev.registrations[self_limit:]\n address = map(lambda r: r.email, leavers)\n link = \"mailto:?bcc=\" + \",\".join(address)\n messages.warning(\n request,\n format_html(\n \"The maximum number of participants was decreased and some members moved to the waiting list. <a href='{}' style='text-decoration: underline;'>Use this link to send them an email.</a>\",\n link,\n ),\n )\n super().save_model(request, obj, form, change)\n\n def get_actions(self, request):\n actions = super().get_actions(request)\n if \"delete_selected\" in actions:\n del actions[\"delete_selected\"]\n return actions\n\n def get_formsets_with_inlines(self, request, obj=None):\n for inline in self.get_inline_instances(request, obj):\n if self.has_change_permission(request, obj) or obj is None:\n yield inline.get_formset(request, obj), inline\n\n def get_urls(self):\n urls = super().get_urls()\n custom_urls = [\n path(\n \"<int:pk>/details/\",\n self.admin_site.admin_view(EventAdminDetails.as_view()),\n name=\"events_event_details\",\n ),\n path(\n \"<int:pk>/export/\",\n self.admin_site.admin_view(EventRegistrationsExport.as_view()),\n name=\"events_event_export\",\n ),\n path(\n \"<int:pk>/mark-present-qr/\",\n self.admin_site.admin_view(EventMarkPresentQR.as_view()),\n name=\"events_event_mark_present_qr\",\n ),\n ]\n return custom_urls + urls\n", "path": "website/events/admin/event.py"}], "after_files": [{"content": "\"\"\"Registers admin interfaces for the event model.\"\"\"\n\nfrom django.contrib import admin, messages\nfrom django.template.defaultfilters import date as _date\nfrom django.urls import path, reverse\nfrom django.utils import timezone\nfrom django.utils.html import format_html\nfrom django.utils.translation import gettext_lazy as _\n\nfrom events import emails, models, services\nfrom events.admin.filters import LectureYearFilter\nfrom events.admin.forms import EventAdminForm, RegistrationInformationFieldForm\nfrom events.admin.inlines import (\n PizzaEventInline,\n PromotionRequestInline,\n RegistrationInformationFieldInline,\n)\nfrom events.admin.views import (\n EventAdminDetails,\n EventMarkPresentQR,\n EventRegistrationsExport,\n)\nfrom utils.admin import DoNextModelAdmin\n\n\[email protected](models.Event)\nclass EventAdmin(DoNextModelAdmin):\n \"\"\"Manage the events.\"\"\"\n\n form = EventAdminForm\n\n inlines = (\n RegistrationInformationFieldInline,\n PizzaEventInline,\n PromotionRequestInline,\n )\n\n list_display = (\n \"overview_link\",\n \"event_date\",\n \"registration_date\",\n \"num_participants\",\n \"get_organisers\",\n \"category\",\n \"published\",\n \"edit_link\",\n )\n list_display_links = (\"edit_link\",)\n list_filter = (LectureYearFilter, \"start\", \"published\", \"category\")\n actions = (\"make_published\", \"make_unpublished\")\n date_hierarchy = \"start\"\n search_fields = (\"title\", \"description\")\n prepopulated_fields = {\n \"map_location\": (\"location\",),\n }\n\n filter_horizontal = (\"documents\", \"organisers\")\n\n fieldsets = (\n (\n _(\"General\"),\n {\n \"fields\": (\n \"title\",\n \"slug\",\n \"published\",\n \"organisers\",\n )\n },\n ),\n (\n _(\"Detail\"),\n {\n \"fields\": (\n \"category\",\n \"start\",\n \"end\",\n \"description\",\n \"caption\",\n \"location\",\n \"map_location\",\n ),\n \"classes\": (\"collapse\", \"start-open\"),\n },\n ),\n (\n _(\"Registrations\"),\n {\n \"fields\": (\n \"price\",\n \"fine\",\n \"tpay_allowed\",\n \"max_participants\",\n \"registration_without_membership\",\n \"registration_start\",\n \"registration_end\",\n \"cancel_deadline\",\n \"send_cancel_email\",\n \"optional_registrations\",\n \"no_registration_message\",\n ),\n \"classes\": (\"collapse\",),\n },\n ),\n (\n _(\"Extra\"),\n {\"fields\": (\"documents\", \"shift\"), \"classes\": (\"collapse\",)},\n ),\n )\n\n def get_queryset(self, request):\n return (\n super()\n .get_queryset(request)\n .select_properties(\"participant_count\")\n .prefetch_related(\"organisers\")\n )\n\n def get_form(self, request, obj=None, change=False, **kwargs):\n form = super().get_form(request, obj, change, **kwargs)\n form.clean = lambda form: form.instance.clean_changes(form.changed_data)\n form.request = request\n return form\n\n def overview_link(self, obj):\n return format_html(\n '<a href=\"{link}\">{title}</a>',\n link=reverse(\"admin:events_event_details\", kwargs={\"pk\": obj.pk}),\n title=obj.title,\n )\n\n def has_change_permission(self, request, obj=None):\n \"\"\"Only allow access to the change form if the user is an organiser.\"\"\"\n if obj is not None and not services.is_organiser(request.member, obj):\n return False\n return super().has_change_permission(request, obj)\n\n def event_date(self, obj):\n event_date = timezone.make_naive(obj.start)\n return _date(event_date, \"l d b Y, G:i\")\n\n event_date.short_description = _(\"Event Date\")\n event_date.admin_order_field = \"start\"\n\n def registration_date(self, obj):\n if obj.registration_start is not None:\n start_date = timezone.make_naive(obj.registration_start)\n else:\n start_date = obj.registration_start\n\n return _date(start_date, \"l d b Y, G:i\")\n\n registration_date.short_description = _(\"Registration Start\")\n registration_date.admin_order_field = \"registration_start\"\n\n def edit_link(self, obj):\n return _(\"Edit\")\n\n edit_link.short_description = \"\"\n\n def num_participants(self, obj):\n \"\"\"Pretty-print the number of participants.\"\"\"\n num = obj.participant_count # prefetched aggregateproperty\n if not obj.max_participants:\n return f\"{num}/\u221e\"\n return f\"{num}/{obj.max_participants}\"\n\n num_participants.short_description = _(\"Number of participants\")\n\n def get_organisers(self, obj):\n return \", \".join(str(o) for o in obj.organisers.all())\n\n get_organisers.short_description = _(\"Organisers\")\n\n def make_published(self, request, queryset):\n \"\"\"Change the status of the event to published.\"\"\"\n self._change_published(request, queryset, True)\n\n make_published.short_description = _(\"Publish selected events\")\n\n def make_unpublished(self, request, queryset):\n \"\"\"Change the status of the event to unpublished.\"\"\"\n self._change_published(request, queryset, False)\n\n make_unpublished.short_description = _(\"Unpublish selected events\")\n\n @staticmethod\n def _change_published(request, queryset, published):\n if not request.user.is_superuser:\n queryset = queryset.filter(\n organisers__in=request.member.get_member_groups()\n )\n queryset.update(published=published)\n\n def save_formset(self, request, form, formset, change):\n \"\"\"Save formsets with their order.\"\"\"\n formset.save()\n\n informationfield_forms = (\n x\n for x in formset.forms\n if isinstance(x, RegistrationInformationFieldForm)\n and \"DELETE\" not in x.changed_data\n )\n form.instance.set_registrationinformationfield_order(\n [\n f.instance.pk\n for f in sorted(\n informationfield_forms,\n key=lambda x: (x.cleaned_data[\"order\"], x.instance.pk),\n )\n ]\n )\n form.instance.save()\n\n def save_model(self, request, obj, form, change):\n if change and \"max_participants\" in form.changed_data:\n prev = self.model.objects.get(id=obj.id)\n prev_limit = prev.max_participants\n self_limit = obj.max_participants\n if prev_limit is None:\n prev_limit = prev.participant_count\n if self_limit is None:\n self_limit = obj.participant_count\n\n if prev_limit < self_limit and prev_limit < obj.participant_count:\n diff = self_limit - prev_limit\n joiners = prev.queue[:diff]\n for registration in joiners:\n emails.notify_waiting(obj, registration)\n messages.info(\n request,\n \"The maximum number of participants was increased. Any members that moved from the waiting list to the participants list have been notified.\",\n )\n elif self_limit < prev_limit and self_limit < obj.participant_count:\n diff = self_limit - prev_limit\n leavers = prev.registrations[self_limit:]\n address = map(lambda r: r.email, leavers)\n link = \"mailto:?bcc=\" + \",\".join(address)\n messages.warning(\n request,\n format_html(\n \"The maximum number of participants was decreased and some members moved to the waiting list. <a href='{}' style='text-decoration: underline;'>Use this link to send them an email.</a>\",\n link,\n ),\n )\n super().save_model(request, obj, form, change)\n\n def get_actions(self, request):\n actions = super().get_actions(request)\n if \"delete_selected\" in actions:\n del actions[\"delete_selected\"]\n return actions\n\n def get_formsets_with_inlines(self, request, obj=None):\n for inline in self.get_inline_instances(request, obj):\n if self.has_change_permission(request, obj) or obj is None:\n yield inline.get_formset(request, obj), inline\n\n def get_urls(self):\n urls = super().get_urls()\n custom_urls = [\n path(\n \"<int:pk>/details/\",\n self.admin_site.admin_view(EventAdminDetails.as_view()),\n name=\"events_event_details\",\n ),\n path(\n \"<int:pk>/export/\",\n self.admin_site.admin_view(EventRegistrationsExport.as_view()),\n name=\"events_event_export\",\n ),\n path(\n \"<int:pk>/mark-present-qr/\",\n self.admin_site.admin_view(EventMarkPresentQR.as_view()),\n name=\"events_event_mark_present_qr\",\n ),\n ]\n return custom_urls + urls\n", "path": "website/events/admin/event.py"}]} | 2,829 | 301 |
gh_patches_debug_9703 | rasdani/github-patches | git_diff | searx__searx-487 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
AttributeError: 'module' object has no attribute 'old_where'
I updated my searx instance today, and got the following error:
```
Traceback (most recent call last):
File "/usr/local/searx/searx/__init__.py", line 55, in <module>
environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()
AttributeError: 'module' object has no attribute 'old_where'
```
I updated the dependencies with `pip install --upgrade -r requirements.txt` before running searx.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `searx/__init__.py`
Content:
```
1 '''
2 searx is free software: you can redistribute it and/or modify
3 it under the terms of the GNU Affero General Public License as published by
4 the Free Software Foundation, either version 3 of the License, or
5 (at your option) any later version.
6
7 searx is distributed in the hope that it will be useful,
8 but WITHOUT ANY WARRANTY; without even the implied warranty of
9 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
10 GNU Affero General Public License for more details.
11
12 You should have received a copy of the GNU Affero General Public License
13 along with searx. If not, see < http://www.gnu.org/licenses/ >.
14
15 (C) 2013- by Adam Tauber, <[email protected]>
16 '''
17
18 import certifi
19 import logging
20 from os import environ
21 from os.path import realpath, dirname, join, abspath
22 from ssl import OPENSSL_VERSION_INFO, OPENSSL_VERSION
23 try:
24 from yaml import load
25 except:
26 from sys import exit, stderr
27 stderr.write('[E] install pyyaml\n')
28 exit(2)
29
30 searx_dir = abspath(dirname(__file__))
31 engine_dir = dirname(realpath(__file__))
32
33 # if possible set path to settings using the
34 # enviroment variable SEARX_SETTINGS_PATH
35 if 'SEARX_SETTINGS_PATH' in environ:
36 settings_path = environ['SEARX_SETTINGS_PATH']
37 # otherwise using default path
38 else:
39 settings_path = join(searx_dir, 'settings.yml')
40
41 # load settings
42 with open(settings_path) as settings_yaml:
43 settings = load(settings_yaml)
44
45 if settings.get('general', {}).get('debug'):
46 logging.basicConfig(level=logging.DEBUG)
47 else:
48 logging.basicConfig(level=logging.WARNING)
49
50 logger = logging.getLogger('searx')
51
52 # Workaround for openssl versions <1.0.2
53 # https://github.com/certifi/python-certifi/issues/26
54 if OPENSSL_VERSION_INFO[0:3] < (1, 0, 2):
55 environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()
56 logger.warning('You are using an old openssl version({0}), please upgrade above 1.0.2!'.format(OPENSSL_VERSION))
57
58 logger.info('Initialisation done')
59
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/searx/__init__.py b/searx/__init__.py
--- a/searx/__init__.py
+++ b/searx/__init__.py
@@ -52,7 +52,8 @@
# Workaround for openssl versions <1.0.2
# https://github.com/certifi/python-certifi/issues/26
if OPENSSL_VERSION_INFO[0:3] < (1, 0, 2):
- environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()
+ if hasattr(certifi, 'old_where'):
+ environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()
logger.warning('You are using an old openssl version({0}), please upgrade above 1.0.2!'.format(OPENSSL_VERSION))
logger.info('Initialisation done')
| {"golden_diff": "diff --git a/searx/__init__.py b/searx/__init__.py\n--- a/searx/__init__.py\n+++ b/searx/__init__.py\n@@ -52,7 +52,8 @@\n # Workaround for openssl versions <1.0.2\n # https://github.com/certifi/python-certifi/issues/26\n if OPENSSL_VERSION_INFO[0:3] < (1, 0, 2):\n- environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()\n+ if hasattr(certifi, 'old_where'):\n+ environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()\n logger.warning('You are using an old openssl version({0}), please upgrade above 1.0.2!'.format(OPENSSL_VERSION))\n \n logger.info('Initialisation done')\n", "issue": "AttributeError: 'module' object has no attribute 'old_where'\nI updated my searx instance today, and got the following error:\n\n```\nTraceback (most recent call last):\n File \"/usr/local/searx/searx/__init__.py\", line 55, in <module>\n environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()\nAttributeError: 'module' object has no attribute 'old_where'\n```\n\nI updated the dependencies with `pip install --upgrade -r requirements.txt` before running searx.\n\n", "before_files": [{"content": "'''\nsearx is free software: you can redistribute it and/or modify\nit under the terms of the GNU Affero General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nsearx is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU Affero General Public License for more details.\n\nYou should have received a copy of the GNU Affero General Public License\nalong with searx. If not, see < http://www.gnu.org/licenses/ >.\n\n(C) 2013- by Adam Tauber, <[email protected]>\n'''\n\nimport certifi\nimport logging\nfrom os import environ\nfrom os.path import realpath, dirname, join, abspath\nfrom ssl import OPENSSL_VERSION_INFO, OPENSSL_VERSION\ntry:\n from yaml import load\nexcept:\n from sys import exit, stderr\n stderr.write('[E] install pyyaml\\n')\n exit(2)\n\nsearx_dir = abspath(dirname(__file__))\nengine_dir = dirname(realpath(__file__))\n\n# if possible set path to settings using the\n# enviroment variable SEARX_SETTINGS_PATH\nif 'SEARX_SETTINGS_PATH' in environ:\n settings_path = environ['SEARX_SETTINGS_PATH']\n# otherwise using default path\nelse:\n settings_path = join(searx_dir, 'settings.yml')\n\n# load settings\nwith open(settings_path) as settings_yaml:\n settings = load(settings_yaml)\n\nif settings.get('general', {}).get('debug'):\n logging.basicConfig(level=logging.DEBUG)\nelse:\n logging.basicConfig(level=logging.WARNING)\n\nlogger = logging.getLogger('searx')\n\n# Workaround for openssl versions <1.0.2\n# https://github.com/certifi/python-certifi/issues/26\nif OPENSSL_VERSION_INFO[0:3] < (1, 0, 2):\n environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()\n logger.warning('You are using an old openssl version({0}), please upgrade above 1.0.2!'.format(OPENSSL_VERSION))\n\nlogger.info('Initialisation done')\n", "path": "searx/__init__.py"}], "after_files": [{"content": "'''\nsearx is free software: you can redistribute it and/or modify\nit under the terms of the GNU Affero General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nsearx is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU Affero General Public License for more details.\n\nYou should have received a copy of the GNU Affero General Public License\nalong with searx. If not, see < http://www.gnu.org/licenses/ >.\n\n(C) 2013- by Adam Tauber, <[email protected]>\n'''\n\nimport certifi\nimport logging\nfrom os import environ\nfrom os.path import realpath, dirname, join, abspath\nfrom ssl import OPENSSL_VERSION_INFO, OPENSSL_VERSION\ntry:\n from yaml import load\nexcept:\n from sys import exit, stderr\n stderr.write('[E] install pyyaml\\n')\n exit(2)\n\nsearx_dir = abspath(dirname(__file__))\nengine_dir = dirname(realpath(__file__))\n\n# if possible set path to settings using the\n# enviroment variable SEARX_SETTINGS_PATH\nif 'SEARX_SETTINGS_PATH' in environ:\n settings_path = environ['SEARX_SETTINGS_PATH']\n# otherwise using default path\nelse:\n settings_path = join(searx_dir, 'settings.yml')\n\n# load settings\nwith open(settings_path) as settings_yaml:\n settings = load(settings_yaml)\n\nif settings.get('general', {}).get('debug'):\n logging.basicConfig(level=logging.DEBUG)\nelse:\n logging.basicConfig(level=logging.WARNING)\n\nlogger = logging.getLogger('searx')\n\n# Workaround for openssl versions <1.0.2\n# https://github.com/certifi/python-certifi/issues/26\nif OPENSSL_VERSION_INFO[0:3] < (1, 0, 2):\n if hasattr(certifi, 'old_where'):\n environ['REQUESTS_CA_BUNDLE'] = certifi.old_where()\n logger.warning('You are using an old openssl version({0}), please upgrade above 1.0.2!'.format(OPENSSL_VERSION))\n\nlogger.info('Initialisation done')\n", "path": "searx/__init__.py"}]} | 971 | 183 |
gh_patches_debug_42563 | rasdani/github-patches | git_diff | litestar-org__litestar-1474 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
StaticFilesConfig and virtual directories
I'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem.
This is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.
https://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `litestar/constants.py`
Content:
```
1 from inspect import Signature
2
3 from pydantic.fields import Undefined
4
5 from litestar.types import Empty
6
7 DEFAULT_ALLOWED_CORS_HEADERS = {"Accept", "Accept-Language", "Content-Language", "Content-Type"}
8 DEFAULT_CHUNK_SIZE = 1024 * 128 # 128KB
9 HTTP_DISCONNECT = "http.disconnect"
10 HTTP_RESPONSE_BODY = "http.response.body"
11 HTTP_RESPONSE_START = "http.response.start"
12 ONE_MEGABYTE = 1024 * 1024
13 OPENAPI_NOT_INITIALIZED = "Litestar has not been instantiated with OpenAPIConfig"
14 REDIRECT_STATUS_CODES = {301, 302, 303, 307, 308}
15 RESERVED_KWARGS = {"state", "headers", "cookies", "request", "socket", "data", "query", "scope", "body"}
16 SCOPE_STATE_DEPENDENCY_CACHE = "dependency_cache"
17 SCOPE_STATE_NAMESPACE = "__litestar__"
18 SCOPE_STATE_RESPONSE_COMPRESSED = "response_compressed"
19 SKIP_VALIDATION_NAMES = {"request", "socket", "scope", "receive", "send"}
20 UNDEFINED_SENTINELS = {Undefined, Signature.empty, Empty, Ellipsis}
21 WEBSOCKET_CLOSE = "websocket.close"
22 WEBSOCKET_DISCONNECT = "websocket.disconnect"
23
```
Path: `litestar/response/redirect.py`
Content:
```
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Any, Literal
4 from urllib.parse import quote
5
6 from litestar.constants import REDIRECT_STATUS_CODES
7 from litestar.enums import MediaType
8 from litestar.exceptions import ImproperlyConfiguredException
9 from litestar.response.base import Response
10 from litestar.status_codes import HTTP_307_TEMPORARY_REDIRECT
11
12 __all__ = ("RedirectResponse",)
13
14
15 if TYPE_CHECKING:
16 from litestar.background_tasks import BackgroundTask, BackgroundTasks
17 from litestar.types import ResponseCookies
18
19
20 class RedirectResponse(Response[Any]):
21 """A redirect response."""
22
23 def __init__(
24 self,
25 url: str,
26 *,
27 status_code: Literal[301, 302, 303, 307, 308] = HTTP_307_TEMPORARY_REDIRECT,
28 background: BackgroundTask | BackgroundTasks | None = None,
29 headers: dict[str, Any] | None = None,
30 cookies: ResponseCookies | None = None,
31 encoding: str = "utf-8",
32 ) -> None:
33 """Initialize the response.
34
35 Args:
36 url: A url to redirect to.
37 status_code: An HTTP status code. The status code should be one of 301, 302, 303, 307 or 308,
38 otherwise an exception will be raised.
39 background: A background task or tasks to be run after the response is sent.
40 headers: A string keyed dictionary of response headers. Header keys are insensitive.
41 cookies: A list of :class:`Cookie <.datastructures.Cookie>` instances to be set under the response
42 ``Set-Cookie`` header.
43 encoding: The encoding to be used for the response headers.
44
45 Raises:
46 ImproperlyConfiguredException: If status code is not a redirect status code.
47 """
48 if status_code not in REDIRECT_STATUS_CODES:
49 raise ImproperlyConfiguredException(
50 f"{status_code} is not a valid for this response. "
51 f"Redirect responses should have one of "
52 f"the following status codes: {', '.join([str(s) for s in REDIRECT_STATUS_CODES])}"
53 )
54 super().__init__(
55 background=background,
56 content=b"",
57 cookies=cookies,
58 headers={**(headers or {}), "location": quote(url, safe="/#%[]=:;$&()+,!?*@'~")},
59 media_type=MediaType.TEXT,
60 status_code=status_code,
61 encoding=encoding,
62 )
63
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/litestar/constants.py b/litestar/constants.py
--- a/litestar/constants.py
+++ b/litestar/constants.py
@@ -2,6 +2,7 @@
from pydantic.fields import Undefined
+from litestar.enums import MediaType
from litestar.types import Empty
DEFAULT_ALLOWED_CORS_HEADERS = {"Accept", "Accept-Language", "Content-Language", "Content-Type"}
@@ -12,6 +13,7 @@
ONE_MEGABYTE = 1024 * 1024
OPENAPI_NOT_INITIALIZED = "Litestar has not been instantiated with OpenAPIConfig"
REDIRECT_STATUS_CODES = {301, 302, 303, 307, 308}
+REDIRECT_ALLOWED_MEDIA_TYPES = {MediaType.TEXT, MediaType.HTML}
RESERVED_KWARGS = {"state", "headers", "cookies", "request", "socket", "data", "query", "scope", "body"}
SCOPE_STATE_DEPENDENCY_CACHE = "dependency_cache"
SCOPE_STATE_NAMESPACE = "__litestar__"
diff --git a/litestar/response/redirect.py b/litestar/response/redirect.py
--- a/litestar/response/redirect.py
+++ b/litestar/response/redirect.py
@@ -3,7 +3,7 @@
from typing import TYPE_CHECKING, Any, Literal
from urllib.parse import quote
-from litestar.constants import REDIRECT_STATUS_CODES
+from litestar.constants import REDIRECT_ALLOWED_MEDIA_TYPES, REDIRECT_STATUS_CODES
from litestar.enums import MediaType
from litestar.exceptions import ImproperlyConfiguredException
from litestar.response.base import Response
@@ -29,6 +29,7 @@
headers: dict[str, Any] | None = None,
cookies: ResponseCookies | None = None,
encoding: str = "utf-8",
+ media_type: str | MediaType = MediaType.TEXT,
) -> None:
"""Initialize the response.
@@ -41,9 +42,11 @@
cookies: A list of :class:`Cookie <.datastructures.Cookie>` instances to be set under the response
``Set-Cookie`` header.
encoding: The encoding to be used for the response headers.
+ media_type: A value for the response ``Content-Type`` header.
+
Raises:
- ImproperlyConfiguredException: If status code is not a redirect status code.
+ ImproperlyConfiguredException: Either if status code is not a redirect status code or media type is not supported.
"""
if status_code not in REDIRECT_STATUS_CODES:
raise ImproperlyConfiguredException(
@@ -51,12 +54,18 @@
f"Redirect responses should have one of "
f"the following status codes: {', '.join([str(s) for s in REDIRECT_STATUS_CODES])}"
)
+ if media_type not in REDIRECT_ALLOWED_MEDIA_TYPES:
+ raise ImproperlyConfiguredException(
+ f"{media_type} media type is not supported yet. "
+ f"Media type should be one of "
+ f"the following values: {', '.join([str(s) for s in REDIRECT_ALLOWED_MEDIA_TYPES])}"
+ )
super().__init__(
background=background,
content=b"",
cookies=cookies,
headers={**(headers or {}), "location": quote(url, safe="/#%[]=:;$&()+,!?*@'~")},
- media_type=MediaType.TEXT,
+ media_type=media_type,
status_code=status_code,
encoding=encoding,
)
| {"golden_diff": "diff --git a/litestar/constants.py b/litestar/constants.py\n--- a/litestar/constants.py\n+++ b/litestar/constants.py\n@@ -2,6 +2,7 @@\n \n from pydantic.fields import Undefined\n \n+from litestar.enums import MediaType\n from litestar.types import Empty\n \n DEFAULT_ALLOWED_CORS_HEADERS = {\"Accept\", \"Accept-Language\", \"Content-Language\", \"Content-Type\"}\n@@ -12,6 +13,7 @@\n ONE_MEGABYTE = 1024 * 1024\n OPENAPI_NOT_INITIALIZED = \"Litestar has not been instantiated with OpenAPIConfig\"\n REDIRECT_STATUS_CODES = {301, 302, 303, 307, 308}\n+REDIRECT_ALLOWED_MEDIA_TYPES = {MediaType.TEXT, MediaType.HTML}\n RESERVED_KWARGS = {\"state\", \"headers\", \"cookies\", \"request\", \"socket\", \"data\", \"query\", \"scope\", \"body\"}\n SCOPE_STATE_DEPENDENCY_CACHE = \"dependency_cache\"\n SCOPE_STATE_NAMESPACE = \"__litestar__\"\ndiff --git a/litestar/response/redirect.py b/litestar/response/redirect.py\n--- a/litestar/response/redirect.py\n+++ b/litestar/response/redirect.py\n@@ -3,7 +3,7 @@\n from typing import TYPE_CHECKING, Any, Literal\n from urllib.parse import quote\n \n-from litestar.constants import REDIRECT_STATUS_CODES\n+from litestar.constants import REDIRECT_ALLOWED_MEDIA_TYPES, REDIRECT_STATUS_CODES\n from litestar.enums import MediaType\n from litestar.exceptions import ImproperlyConfiguredException\n from litestar.response.base import Response\n@@ -29,6 +29,7 @@\n headers: dict[str, Any] | None = None,\n cookies: ResponseCookies | None = None,\n encoding: str = \"utf-8\",\n+ media_type: str | MediaType = MediaType.TEXT,\n ) -> None:\n \"\"\"Initialize the response.\n \n@@ -41,9 +42,11 @@\n cookies: A list of :class:`Cookie <.datastructures.Cookie>` instances to be set under the response\n ``Set-Cookie`` header.\n encoding: The encoding to be used for the response headers.\n+ media_type: A value for the response ``Content-Type`` header.\n+\n \n Raises:\n- ImproperlyConfiguredException: If status code is not a redirect status code.\n+ ImproperlyConfiguredException: Either if status code is not a redirect status code or media type is not supported.\n \"\"\"\n if status_code not in REDIRECT_STATUS_CODES:\n raise ImproperlyConfiguredException(\n@@ -51,12 +54,18 @@\n f\"Redirect responses should have one of \"\n f\"the following status codes: {', '.join([str(s) for s in REDIRECT_STATUS_CODES])}\"\n )\n+ if media_type not in REDIRECT_ALLOWED_MEDIA_TYPES:\n+ raise ImproperlyConfiguredException(\n+ f\"{media_type} media type is not supported yet. \"\n+ f\"Media type should be one of \"\n+ f\"the following values: {', '.join([str(s) for s in REDIRECT_ALLOWED_MEDIA_TYPES])}\"\n+ )\n super().__init__(\n background=background,\n content=b\"\",\n cookies=cookies,\n headers={**(headers or {}), \"location\": quote(url, safe=\"/#%[]=:;$&()+,!?*@'~\")},\n- media_type=MediaType.TEXT,\n+ media_type=media_type,\n status_code=status_code,\n encoding=encoding,\n )\n", "issue": "StaticFilesConfig and virtual directories\nI'm trying to write a ``FileSystemProtocol`` to load files from the package data using [importlib_resources](https://importlib-resources.readthedocs.io/en/latest/using.html#). But because ``directories`` is defined as ``DirectoryPath``, pydantic checks if the given directories exist in the local filesystem. \r\n\r\nThis is not generally true, especially in any kind of virtual filesystem (e.g. a zipped package). I think this condition should be relaxed to support virtual filesystems.\r\n\r\nhttps://github.com/starlite-api/starlite/blob/9bb6dcd57c10a591377cf8e3a537e9292566d5b9/starlite/config/static_files.py#L32\n", "before_files": [{"content": "from inspect import Signature\n\nfrom pydantic.fields import Undefined\n\nfrom litestar.types import Empty\n\nDEFAULT_ALLOWED_CORS_HEADERS = {\"Accept\", \"Accept-Language\", \"Content-Language\", \"Content-Type\"}\nDEFAULT_CHUNK_SIZE = 1024 * 128 # 128KB\nHTTP_DISCONNECT = \"http.disconnect\"\nHTTP_RESPONSE_BODY = \"http.response.body\"\nHTTP_RESPONSE_START = \"http.response.start\"\nONE_MEGABYTE = 1024 * 1024\nOPENAPI_NOT_INITIALIZED = \"Litestar has not been instantiated with OpenAPIConfig\"\nREDIRECT_STATUS_CODES = {301, 302, 303, 307, 308}\nRESERVED_KWARGS = {\"state\", \"headers\", \"cookies\", \"request\", \"socket\", \"data\", \"query\", \"scope\", \"body\"}\nSCOPE_STATE_DEPENDENCY_CACHE = \"dependency_cache\"\nSCOPE_STATE_NAMESPACE = \"__litestar__\"\nSCOPE_STATE_RESPONSE_COMPRESSED = \"response_compressed\"\nSKIP_VALIDATION_NAMES = {\"request\", \"socket\", \"scope\", \"receive\", \"send\"}\nUNDEFINED_SENTINELS = {Undefined, Signature.empty, Empty, Ellipsis}\nWEBSOCKET_CLOSE = \"websocket.close\"\nWEBSOCKET_DISCONNECT = \"websocket.disconnect\"\n", "path": "litestar/constants.py"}, {"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, Literal\nfrom urllib.parse import quote\n\nfrom litestar.constants import REDIRECT_STATUS_CODES\nfrom litestar.enums import MediaType\nfrom litestar.exceptions import ImproperlyConfiguredException\nfrom litestar.response.base import Response\nfrom litestar.status_codes import HTTP_307_TEMPORARY_REDIRECT\n\n__all__ = (\"RedirectResponse\",)\n\n\nif TYPE_CHECKING:\n from litestar.background_tasks import BackgroundTask, BackgroundTasks\n from litestar.types import ResponseCookies\n\n\nclass RedirectResponse(Response[Any]):\n \"\"\"A redirect response.\"\"\"\n\n def __init__(\n self,\n url: str,\n *,\n status_code: Literal[301, 302, 303, 307, 308] = HTTP_307_TEMPORARY_REDIRECT,\n background: BackgroundTask | BackgroundTasks | None = None,\n headers: dict[str, Any] | None = None,\n cookies: ResponseCookies | None = None,\n encoding: str = \"utf-8\",\n ) -> None:\n \"\"\"Initialize the response.\n\n Args:\n url: A url to redirect to.\n status_code: An HTTP status code. The status code should be one of 301, 302, 303, 307 or 308,\n otherwise an exception will be raised.\n background: A background task or tasks to be run after the response is sent.\n headers: A string keyed dictionary of response headers. Header keys are insensitive.\n cookies: A list of :class:`Cookie <.datastructures.Cookie>` instances to be set under the response\n ``Set-Cookie`` header.\n encoding: The encoding to be used for the response headers.\n\n Raises:\n ImproperlyConfiguredException: If status code is not a redirect status code.\n \"\"\"\n if status_code not in REDIRECT_STATUS_CODES:\n raise ImproperlyConfiguredException(\n f\"{status_code} is not a valid for this response. \"\n f\"Redirect responses should have one of \"\n f\"the following status codes: {', '.join([str(s) for s in REDIRECT_STATUS_CODES])}\"\n )\n super().__init__(\n background=background,\n content=b\"\",\n cookies=cookies,\n headers={**(headers or {}), \"location\": quote(url, safe=\"/#%[]=:;$&()+,!?*@'~\")},\n media_type=MediaType.TEXT,\n status_code=status_code,\n encoding=encoding,\n )\n", "path": "litestar/response/redirect.py"}], "after_files": [{"content": "from inspect import Signature\n\nfrom pydantic.fields import Undefined\n\nfrom litestar.enums import MediaType\nfrom litestar.types import Empty\n\nDEFAULT_ALLOWED_CORS_HEADERS = {\"Accept\", \"Accept-Language\", \"Content-Language\", \"Content-Type\"}\nDEFAULT_CHUNK_SIZE = 1024 * 128 # 128KB\nHTTP_DISCONNECT = \"http.disconnect\"\nHTTP_RESPONSE_BODY = \"http.response.body\"\nHTTP_RESPONSE_START = \"http.response.start\"\nONE_MEGABYTE = 1024 * 1024\nOPENAPI_NOT_INITIALIZED = \"Litestar has not been instantiated with OpenAPIConfig\"\nREDIRECT_STATUS_CODES = {301, 302, 303, 307, 308}\nREDIRECT_ALLOWED_MEDIA_TYPES = {MediaType.TEXT, MediaType.HTML}\nRESERVED_KWARGS = {\"state\", \"headers\", \"cookies\", \"request\", \"socket\", \"data\", \"query\", \"scope\", \"body\"}\nSCOPE_STATE_DEPENDENCY_CACHE = \"dependency_cache\"\nSCOPE_STATE_NAMESPACE = \"__litestar__\"\nSCOPE_STATE_RESPONSE_COMPRESSED = \"response_compressed\"\nSKIP_VALIDATION_NAMES = {\"request\", \"socket\", \"scope\", \"receive\", \"send\"}\nUNDEFINED_SENTINELS = {Undefined, Signature.empty, Empty, Ellipsis}\nWEBSOCKET_CLOSE = \"websocket.close\"\nWEBSOCKET_DISCONNECT = \"websocket.disconnect\"\n", "path": "litestar/constants.py"}, {"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, Literal\nfrom urllib.parse import quote\n\nfrom litestar.constants import REDIRECT_ALLOWED_MEDIA_TYPES, REDIRECT_STATUS_CODES\nfrom litestar.enums import MediaType\nfrom litestar.exceptions import ImproperlyConfiguredException\nfrom litestar.response.base import Response\nfrom litestar.status_codes import HTTP_307_TEMPORARY_REDIRECT\n\n__all__ = (\"RedirectResponse\",)\n\n\nif TYPE_CHECKING:\n from litestar.background_tasks import BackgroundTask, BackgroundTasks\n from litestar.types import ResponseCookies\n\n\nclass RedirectResponse(Response[Any]):\n \"\"\"A redirect response.\"\"\"\n\n def __init__(\n self,\n url: str,\n *,\n status_code: Literal[301, 302, 303, 307, 308] = HTTP_307_TEMPORARY_REDIRECT,\n background: BackgroundTask | BackgroundTasks | None = None,\n headers: dict[str, Any] | None = None,\n cookies: ResponseCookies | None = None,\n encoding: str = \"utf-8\",\n media_type: str | MediaType = MediaType.TEXT,\n ) -> None:\n \"\"\"Initialize the response.\n\n Args:\n url: A url to redirect to.\n status_code: An HTTP status code. The status code should be one of 301, 302, 303, 307 or 308,\n otherwise an exception will be raised.\n background: A background task or tasks to be run after the response is sent.\n headers: A string keyed dictionary of response headers. Header keys are insensitive.\n cookies: A list of :class:`Cookie <.datastructures.Cookie>` instances to be set under the response\n ``Set-Cookie`` header.\n encoding: The encoding to be used for the response headers.\n media_type: A value for the response ``Content-Type`` header.\n\n\n Raises:\n ImproperlyConfiguredException: Either if status code is not a redirect status code or media type is not supported.\n \"\"\"\n if status_code not in REDIRECT_STATUS_CODES:\n raise ImproperlyConfiguredException(\n f\"{status_code} is not a valid for this response. \"\n f\"Redirect responses should have one of \"\n f\"the following status codes: {', '.join([str(s) for s in REDIRECT_STATUS_CODES])}\"\n )\n if media_type not in REDIRECT_ALLOWED_MEDIA_TYPES:\n raise ImproperlyConfiguredException(\n f\"{media_type} media type is not supported yet. \"\n f\"Media type should be one of \"\n f\"the following values: {', '.join([str(s) for s in REDIRECT_ALLOWED_MEDIA_TYPES])}\"\n )\n super().__init__(\n background=background,\n content=b\"\",\n cookies=cookies,\n headers={**(headers or {}), \"location\": quote(url, safe=\"/#%[]=:;$&()+,!?*@'~\")},\n media_type=media_type,\n status_code=status_code,\n encoding=encoding,\n )\n", "path": "litestar/response/redirect.py"}]} | 1,423 | 774 |
gh_patches_debug_34305 | rasdani/github-patches | git_diff | opensearch-project__opensearch-build-549 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Use DependencyInstaller to sync maven and build dependencies in Integtests
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bundle-workflow/src/manifests/build_manifest.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import os
8
9 from aws.s3_bucket import S3Bucket
10 from manifests.manifest import Manifest
11
12 """
13 A BuildManifest is an immutable view of the outputs from a build step
14 The manifest contains information about the product that was built (in the `build` section),
15 and the components that made up the build in the `components` section.
16
17 The format for schema version 1.0 is:
18 schema-version: "1.0"
19 build:
20 name: string
21 version: string
22 architecture: x64 or arm64
23 components:
24 - name: string
25 repository: URL of git repository
26 ref: git ref that was built (sha, branch, or tag)
27 commit_id: The actual git commit ID that was built (i.e. the resolved "ref")
28 artifacts:
29 maven:
30 - maven/relative/path/to/artifact
31 - ...
32 plugins:
33 - plugins/relative/path/to/artifact
34 - ...
35 libs:
36 - libs/relative/path/to/artifact
37 - ...
38 - ...
39 """
40
41
42 class BuildManifest(Manifest):
43 components: list
44
45 SCHEMA = {
46 "build": {
47 "required": True,
48 "type": "dict",
49 "schema": {
50 "architecture": {"required": True, "type": "string"},
51 "id": {"required": True, "type": "string"},
52 "name": {"required": True, "type": "string"},
53 "version": {"required": True, "type": "string"},
54 },
55 },
56 "schema-version": {"required": True, "type": "string", "allowed": ["1.0"]},
57 "components": {
58 "type": "list",
59 "schema": {
60 "type": "dict",
61 "schema": {
62 "artifacts": {
63 "type": "dict",
64 "schema": {
65 "maven": {"type": "list"},
66 "plugins": {"type": "list"},
67 "bundle": {"type": "list"},
68 "core-plugins": {"type": "list"},
69 "libs": {"type": "list"},
70 },
71 },
72 "commit_id": {"required": True, "type": "string"},
73 "name": {"required": True, "type": "string"},
74 "ref": {"required": True, "type": "string"},
75 "repository": {"required": True, "type": "string"},
76 "version": {"required": True, "type": "string"},
77 },
78 },
79 },
80 }
81
82 def __init__(self, data):
83 super().__init__(data)
84
85 self.build = self.Build(data["build"])
86 self.components = list(
87 map(lambda entry: self.Component(entry), data.get("components", []))
88 )
89
90 def __to_dict__(self):
91 return {
92 "schema-version": "1.0",
93 "build": self.build.__to_dict__(),
94 "components": list(
95 map(lambda component: component.__to_dict__(), self.components)
96 ),
97 }
98
99 @staticmethod
100 def get_build_manifest_relative_location(
101 build_id, opensearch_version, architecture
102 ):
103 return f"builds/{opensearch_version}/{build_id}/{architecture}/manifest.yml"
104
105 @staticmethod
106 def from_s3(bucket_name, build_id, opensearch_version, architecture, work_dir=None):
107 work_dir = work_dir if not None else str(os.getcwd())
108 manifest_s3_path = BuildManifest.get_build_manifest_relative_location(
109 build_id, opensearch_version, architecture
110 )
111 S3Bucket(bucket_name).download_file(manifest_s3_path, work_dir)
112 with open("manifest.yml", "r") as file:
113 build_manifest = BuildManifest.from_file(file)
114 os.remove(os.path.realpath(os.path.join(work_dir, "manifest.yml")))
115 return build_manifest
116
117 class Build:
118 def __init__(self, data):
119 self.name = data["name"]
120 self.version = data["version"]
121 self.architecture = data["architecture"]
122 self.id = data["id"]
123
124 def __to_dict__(self):
125 return {
126 "name": self.name,
127 "version": self.version,
128 "architecture": self.architecture,
129 "id": self.id,
130 }
131
132 class Component:
133 def __init__(self, data):
134 self.name = data["name"]
135 self.repository = data["repository"]
136 self.ref = data["ref"]
137 self.commit_id = data["commit_id"]
138 self.artifacts = data.get("artifacts", [])
139 self.version = data["version"]
140
141 def __to_dict__(self):
142 return {
143 "name": self.name,
144 "repository": self.repository,
145 "ref": self.ref,
146 "commit_id": self.commit_id,
147 "artifacts": self.artifacts,
148 "version": self.version,
149 }
150
```
Path: `bundle-workflow/src/aws/s3_bucket.py`
Content:
```
1 # SPDX-License-Identifier: Apache-2.0
2 #
3 # The OpenSearch Contributors require contributions made to
4 # this file be licensed under the Apache-2.0 license or a
5 # compatible open source license.
6
7 import os
8 from pathlib import Path
9 from urllib.parse import urlparse
10
11 import boto3
12 from botocore.exceptions import ClientError
13
14
15 class S3Bucket:
16 AWS_ROLE_ARN = "AWS_ROLE_ARN"
17 AWS_ROLE_SESSION_NAME = "AWS_ROLE_SESSION_NAME"
18
19 def __init__(self, bucket_name, role_arn=None, role_session_name=None):
20 """
21 Provides methods to download/upload files and folders to S3 bucket
22
23 :param bucket_name: The s3 bucket name
24 :param role_arn: the arn of the role that has permissions to access S3
25 :param role_session_name: the aws role session name
26 """
27 self.bucket_name = bucket_name
28 self.role_arn = (
29 role_arn if role_arn is not None else os.environ.get(S3Bucket.AWS_ROLE_ARN)
30 )
31 self.role_session_name = (
32 role_session_name
33 if role_session_name is not None
34 else os.environ.get(S3Bucket.AWS_ROLE_SESSION_NAME)
35 )
36 # TODO: later use for credential refereshing
37 assumed_role_creds = self.__sts_assume_role()
38 self.__s3_client, self.__s3_resource = self.__create_s3_clients(
39 assumed_role_creds
40 )
41
42 def __sts_assume_role(self):
43 try:
44 sts_connection = boto3.client("sts")
45 response = sts_connection.assume_role(
46 RoleArn=self.role_arn,
47 RoleSessionName=self.role_session_name,
48 DurationSeconds=3600,
49 )
50 return response["Credentials"]
51 except Exception as e:
52 raise STSError(e)
53
54 def __create_s3_clients(self, assumed_role_cred):
55 s3_client = boto3.client(
56 "s3",
57 aws_access_key_id=assumed_role_cred["AccessKeyId"],
58 aws_secret_access_key=assumed_role_cred["SecretAccessKey"],
59 aws_session_token=assumed_role_cred["SessionToken"],
60 )
61 s3_resource = boto3.resource(
62 "s3",
63 aws_access_key_id=assumed_role_cred["AccessKeyId"],
64 aws_secret_access_key=assumed_role_cred["SecretAccessKey"],
65 aws_session_token=assumed_role_cred["SessionToken"],
66 )
67 return s3_client, s3_resource
68
69 def download_folder(self, prefix, dest):
70 """
71 Download the contents of a folder directory
72
73 :param prefix: The folder path inside the bucket
74 :param dest: local destination to download the folder at
75 """
76 bucket = self.__s3_resource.Bucket(self.bucket_name)
77 s3_path = urlparse(prefix).path.lstrip("/")
78 local_dir = Path(dest)
79 s3_response = bucket.objects.filter(Prefix=s3_path)
80 for obj in s3_response:
81 target = (
82 obj.key
83 if local_dir is None
84 else local_dir / Path(obj.key).relative_to(s3_path)
85 )
86 target.parent.mkdir(parents=True, exist_ok=True)
87 if obj.key[-1] == "/":
88 continue
89 self.__download(bucket, obj.key, str(target))
90
91 def download_file(self, key, dest):
92 """
93 Download a single object from s3.
94
95 :param key: The s3 key for the object to download
96 :param dest: local destination
97 """
98 bucket = self.__s3_resource.Bucket(self.bucket_name)
99 local_dir = Path(dest)
100 file_name = key.split("/")[-1]
101 target = Path(local_dir) / Path(file_name)
102 return self.__download(bucket, key, str(target))
103
104 @staticmethod
105 def __download(bucket, key, path):
106 try:
107 bucket.download_file(key, path)
108 except ClientError as e:
109 raise S3DownloadError(e)
110
111 def upload_file(self, key, source):
112 """
113 Upload a file to s3.
114
115 :param key: The s3 key for the uploaded object
116 :param source: local path of the file
117 """
118 try:
119 self.__s3_client.upload_file(source, self.bucket_name, key)
120 except ClientError as e:
121 raise S3UploadError(e)
122
123
124 class S3Error(Exception):
125 """Base class for S3 Errors"""
126
127 pass
128
129
130 class STSError(Exception):
131 """Base class for STS Error"""
132
133 pass
134
135
136 class S3DownloadError(S3Error):
137 """Raised when there is a download object failure"""
138
139 pass
140
141
142 class S3UploadError(S3Error):
143 """Raised when there is an upload object failure"""
144
145 pass
146
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bundle-workflow/src/aws/s3_bucket.py b/bundle-workflow/src/aws/s3_bucket.py
--- a/bundle-workflow/src/aws/s3_bucket.py
+++ b/bundle-workflow/src/aws/s3_bucket.py
@@ -4,6 +4,7 @@
# this file be licensed under the Apache-2.0 license or a
# compatible open source license.
+import logging
import os
from pathlib import Path
from urllib.parse import urlparse
@@ -106,6 +107,7 @@
try:
bucket.download_file(key, path)
except ClientError as e:
+ logging.error(f"Failed to download s3 key: {key} from path: {path}")
raise S3DownloadError(e)
def upload_file(self, key, source):
@@ -118,6 +120,7 @@
try:
self.__s3_client.upload_file(source, self.bucket_name, key)
except ClientError as e:
+ logging.error(f"Failed to upload s3 key: {key} from local source: {source}")
raise S3UploadError(e)
diff --git a/bundle-workflow/src/manifests/build_manifest.py b/bundle-workflow/src/manifests/build_manifest.py
--- a/bundle-workflow/src/manifests/build_manifest.py
+++ b/bundle-workflow/src/manifests/build_manifest.py
@@ -96,6 +96,17 @@
),
}
+ def get_component(self, component_name):
+ component = next(
+ iter(filter(lambda comp: comp.name == component_name, self.components)),
+ None,
+ )
+ if component is None:
+ raise BuildManifest.ComponentNotFoundError(
+ f"{component_name} not found in build manifest.yml"
+ )
+ return component
+
@staticmethod
def get_build_manifest_relative_location(
build_id, opensearch_version, architecture
@@ -114,6 +125,9 @@
os.remove(os.path.realpath(os.path.join(work_dir, "manifest.yml")))
return build_manifest
+ class ComponentNotFoundError(Exception):
+ pass
+
class Build:
def __init__(self, data):
self.name = data["name"]
| {"golden_diff": "diff --git a/bundle-workflow/src/aws/s3_bucket.py b/bundle-workflow/src/aws/s3_bucket.py\n--- a/bundle-workflow/src/aws/s3_bucket.py\n+++ b/bundle-workflow/src/aws/s3_bucket.py\n@@ -4,6 +4,7 @@\n # this file be licensed under the Apache-2.0 license or a\n # compatible open source license.\n \n+import logging\n import os\n from pathlib import Path\n from urllib.parse import urlparse\n@@ -106,6 +107,7 @@\n try:\n bucket.download_file(key, path)\n except ClientError as e:\n+ logging.error(f\"Failed to download s3 key: {key} from path: {path}\")\n raise S3DownloadError(e)\n \n def upload_file(self, key, source):\n@@ -118,6 +120,7 @@\n try:\n self.__s3_client.upload_file(source, self.bucket_name, key)\n except ClientError as e:\n+ logging.error(f\"Failed to upload s3 key: {key} from local source: {source}\")\n raise S3UploadError(e)\n \n \ndiff --git a/bundle-workflow/src/manifests/build_manifest.py b/bundle-workflow/src/manifests/build_manifest.py\n--- a/bundle-workflow/src/manifests/build_manifest.py\n+++ b/bundle-workflow/src/manifests/build_manifest.py\n@@ -96,6 +96,17 @@\n ),\n }\n \n+ def get_component(self, component_name):\n+ component = next(\n+ iter(filter(lambda comp: comp.name == component_name, self.components)),\n+ None,\n+ )\n+ if component is None:\n+ raise BuildManifest.ComponentNotFoundError(\n+ f\"{component_name} not found in build manifest.yml\"\n+ )\n+ return component\n+\n @staticmethod\n def get_build_manifest_relative_location(\n build_id, opensearch_version, architecture\n@@ -114,6 +125,9 @@\n os.remove(os.path.realpath(os.path.join(work_dir, \"manifest.yml\")))\n return build_manifest\n \n+ class ComponentNotFoundError(Exception):\n+ pass\n+\n class Build:\n def __init__(self, data):\n self.name = data[\"name\"]\n", "issue": "Use DependencyInstaller to sync maven and build dependencies in Integtests\n\n", "before_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\n\nfrom aws.s3_bucket import S3Bucket\nfrom manifests.manifest import Manifest\n\n\"\"\"\nA BuildManifest is an immutable view of the outputs from a build step\nThe manifest contains information about the product that was built (in the `build` section),\nand the components that made up the build in the `components` section.\n\nThe format for schema version 1.0 is:\nschema-version: \"1.0\"\nbuild:\n name: string\n version: string\n architecture: x64 or arm64\ncomponents:\n - name: string\n repository: URL of git repository\n ref: git ref that was built (sha, branch, or tag)\n commit_id: The actual git commit ID that was built (i.e. the resolved \"ref\")\n artifacts:\n maven:\n - maven/relative/path/to/artifact\n - ...\n plugins:\n - plugins/relative/path/to/artifact\n - ...\n libs:\n - libs/relative/path/to/artifact\n - ...\n - ...\n\"\"\"\n\n\nclass BuildManifest(Manifest):\n components: list\n\n SCHEMA = {\n \"build\": {\n \"required\": True,\n \"type\": \"dict\",\n \"schema\": {\n \"architecture\": {\"required\": True, \"type\": \"string\"},\n \"id\": {\"required\": True, \"type\": \"string\"},\n \"name\": {\"required\": True, \"type\": \"string\"},\n \"version\": {\"required\": True, \"type\": \"string\"},\n },\n },\n \"schema-version\": {\"required\": True, \"type\": \"string\", \"allowed\": [\"1.0\"]},\n \"components\": {\n \"type\": \"list\",\n \"schema\": {\n \"type\": \"dict\",\n \"schema\": {\n \"artifacts\": {\n \"type\": \"dict\",\n \"schema\": {\n \"maven\": {\"type\": \"list\"},\n \"plugins\": {\"type\": \"list\"},\n \"bundle\": {\"type\": \"list\"},\n \"core-plugins\": {\"type\": \"list\"},\n \"libs\": {\"type\": \"list\"},\n },\n },\n \"commit_id\": {\"required\": True, \"type\": \"string\"},\n \"name\": {\"required\": True, \"type\": \"string\"},\n \"ref\": {\"required\": True, \"type\": \"string\"},\n \"repository\": {\"required\": True, \"type\": \"string\"},\n \"version\": {\"required\": True, \"type\": \"string\"},\n },\n },\n },\n }\n\n def __init__(self, data):\n super().__init__(data)\n\n self.build = self.Build(data[\"build\"])\n self.components = list(\n map(lambda entry: self.Component(entry), data.get(\"components\", []))\n )\n\n def __to_dict__(self):\n return {\n \"schema-version\": \"1.0\",\n \"build\": self.build.__to_dict__(),\n \"components\": list(\n map(lambda component: component.__to_dict__(), self.components)\n ),\n }\n\n @staticmethod\n def get_build_manifest_relative_location(\n build_id, opensearch_version, architecture\n ):\n return f\"builds/{opensearch_version}/{build_id}/{architecture}/manifest.yml\"\n\n @staticmethod\n def from_s3(bucket_name, build_id, opensearch_version, architecture, work_dir=None):\n work_dir = work_dir if not None else str(os.getcwd())\n manifest_s3_path = BuildManifest.get_build_manifest_relative_location(\n build_id, opensearch_version, architecture\n )\n S3Bucket(bucket_name).download_file(manifest_s3_path, work_dir)\n with open(\"manifest.yml\", \"r\") as file:\n build_manifest = BuildManifest.from_file(file)\n os.remove(os.path.realpath(os.path.join(work_dir, \"manifest.yml\")))\n return build_manifest\n\n class Build:\n def __init__(self, data):\n self.name = data[\"name\"]\n self.version = data[\"version\"]\n self.architecture = data[\"architecture\"]\n self.id = data[\"id\"]\n\n def __to_dict__(self):\n return {\n \"name\": self.name,\n \"version\": self.version,\n \"architecture\": self.architecture,\n \"id\": self.id,\n }\n\n class Component:\n def __init__(self, data):\n self.name = data[\"name\"]\n self.repository = data[\"repository\"]\n self.ref = data[\"ref\"]\n self.commit_id = data[\"commit_id\"]\n self.artifacts = data.get(\"artifacts\", [])\n self.version = data[\"version\"]\n\n def __to_dict__(self):\n return {\n \"name\": self.name,\n \"repository\": self.repository,\n \"ref\": self.ref,\n \"commit_id\": self.commit_id,\n \"artifacts\": self.artifacts,\n \"version\": self.version,\n }\n", "path": "bundle-workflow/src/manifests/build_manifest.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\nfrom pathlib import Path\nfrom urllib.parse import urlparse\n\nimport boto3\nfrom botocore.exceptions import ClientError\n\n\nclass S3Bucket:\n AWS_ROLE_ARN = \"AWS_ROLE_ARN\"\n AWS_ROLE_SESSION_NAME = \"AWS_ROLE_SESSION_NAME\"\n\n def __init__(self, bucket_name, role_arn=None, role_session_name=None):\n \"\"\"\n Provides methods to download/upload files and folders to S3 bucket\n\n :param bucket_name: The s3 bucket name\n :param role_arn: the arn of the role that has permissions to access S3\n :param role_session_name: the aws role session name\n \"\"\"\n self.bucket_name = bucket_name\n self.role_arn = (\n role_arn if role_arn is not None else os.environ.get(S3Bucket.AWS_ROLE_ARN)\n )\n self.role_session_name = (\n role_session_name\n if role_session_name is not None\n else os.environ.get(S3Bucket.AWS_ROLE_SESSION_NAME)\n )\n # TODO: later use for credential refereshing\n assumed_role_creds = self.__sts_assume_role()\n self.__s3_client, self.__s3_resource = self.__create_s3_clients(\n assumed_role_creds\n )\n\n def __sts_assume_role(self):\n try:\n sts_connection = boto3.client(\"sts\")\n response = sts_connection.assume_role(\n RoleArn=self.role_arn,\n RoleSessionName=self.role_session_name,\n DurationSeconds=3600,\n )\n return response[\"Credentials\"]\n except Exception as e:\n raise STSError(e)\n\n def __create_s3_clients(self, assumed_role_cred):\n s3_client = boto3.client(\n \"s3\",\n aws_access_key_id=assumed_role_cred[\"AccessKeyId\"],\n aws_secret_access_key=assumed_role_cred[\"SecretAccessKey\"],\n aws_session_token=assumed_role_cred[\"SessionToken\"],\n )\n s3_resource = boto3.resource(\n \"s3\",\n aws_access_key_id=assumed_role_cred[\"AccessKeyId\"],\n aws_secret_access_key=assumed_role_cred[\"SecretAccessKey\"],\n aws_session_token=assumed_role_cred[\"SessionToken\"],\n )\n return s3_client, s3_resource\n\n def download_folder(self, prefix, dest):\n \"\"\"\n Download the contents of a folder directory\n\n :param prefix: The folder path inside the bucket\n :param dest: local destination to download the folder at\n \"\"\"\n bucket = self.__s3_resource.Bucket(self.bucket_name)\n s3_path = urlparse(prefix).path.lstrip(\"/\")\n local_dir = Path(dest)\n s3_response = bucket.objects.filter(Prefix=s3_path)\n for obj in s3_response:\n target = (\n obj.key\n if local_dir is None\n else local_dir / Path(obj.key).relative_to(s3_path)\n )\n target.parent.mkdir(parents=True, exist_ok=True)\n if obj.key[-1] == \"/\":\n continue\n self.__download(bucket, obj.key, str(target))\n\n def download_file(self, key, dest):\n \"\"\"\n Download a single object from s3.\n\n :param key: The s3 key for the object to download\n :param dest: local destination\n \"\"\"\n bucket = self.__s3_resource.Bucket(self.bucket_name)\n local_dir = Path(dest)\n file_name = key.split(\"/\")[-1]\n target = Path(local_dir) / Path(file_name)\n return self.__download(bucket, key, str(target))\n\n @staticmethod\n def __download(bucket, key, path):\n try:\n bucket.download_file(key, path)\n except ClientError as e:\n raise S3DownloadError(e)\n\n def upload_file(self, key, source):\n \"\"\"\n Upload a file to s3.\n\n :param key: The s3 key for the uploaded object\n :param source: local path of the file\n \"\"\"\n try:\n self.__s3_client.upload_file(source, self.bucket_name, key)\n except ClientError as e:\n raise S3UploadError(e)\n\n\nclass S3Error(Exception):\n \"\"\"Base class for S3 Errors\"\"\"\n\n pass\n\n\nclass STSError(Exception):\n \"\"\"Base class for STS Error\"\"\"\n\n pass\n\n\nclass S3DownloadError(S3Error):\n \"\"\"Raised when there is a download object failure\"\"\"\n\n pass\n\n\nclass S3UploadError(S3Error):\n \"\"\"Raised when there is an upload object failure\"\"\"\n\n pass\n", "path": "bundle-workflow/src/aws/s3_bucket.py"}], "after_files": [{"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport os\n\nfrom aws.s3_bucket import S3Bucket\nfrom manifests.manifest import Manifest\n\n\"\"\"\nA BuildManifest is an immutable view of the outputs from a build step\nThe manifest contains information about the product that was built (in the `build` section),\nand the components that made up the build in the `components` section.\n\nThe format for schema version 1.0 is:\nschema-version: \"1.0\"\nbuild:\n name: string\n version: string\n architecture: x64 or arm64\ncomponents:\n - name: string\n repository: URL of git repository\n ref: git ref that was built (sha, branch, or tag)\n commit_id: The actual git commit ID that was built (i.e. the resolved \"ref\")\n artifacts:\n maven:\n - maven/relative/path/to/artifact\n - ...\n plugins:\n - plugins/relative/path/to/artifact\n - ...\n libs:\n - libs/relative/path/to/artifact\n - ...\n - ...\n\"\"\"\n\n\nclass BuildManifest(Manifest):\n components: list\n\n SCHEMA = {\n \"build\": {\n \"required\": True,\n \"type\": \"dict\",\n \"schema\": {\n \"architecture\": {\"required\": True, \"type\": \"string\"},\n \"id\": {\"required\": True, \"type\": \"string\"},\n \"name\": {\"required\": True, \"type\": \"string\"},\n \"version\": {\"required\": True, \"type\": \"string\"},\n },\n },\n \"schema-version\": {\"required\": True, \"type\": \"string\", \"allowed\": [\"1.0\"]},\n \"components\": {\n \"type\": \"list\",\n \"schema\": {\n \"type\": \"dict\",\n \"schema\": {\n \"artifacts\": {\n \"type\": \"dict\",\n \"schema\": {\n \"maven\": {\"type\": \"list\"},\n \"plugins\": {\"type\": \"list\"},\n \"bundle\": {\"type\": \"list\"},\n \"core-plugins\": {\"type\": \"list\"},\n \"libs\": {\"type\": \"list\"},\n },\n },\n \"commit_id\": {\"required\": True, \"type\": \"string\"},\n \"name\": {\"required\": True, \"type\": \"string\"},\n \"ref\": {\"required\": True, \"type\": \"string\"},\n \"repository\": {\"required\": True, \"type\": \"string\"},\n \"version\": {\"required\": True, \"type\": \"string\"},\n },\n },\n },\n }\n\n def __init__(self, data):\n super().__init__(data)\n\n self.build = self.Build(data[\"build\"])\n self.components = list(\n map(lambda entry: self.Component(entry), data.get(\"components\", []))\n )\n\n def __to_dict__(self):\n return {\n \"schema-version\": \"1.0\",\n \"build\": self.build.__to_dict__(),\n \"components\": list(\n map(lambda component: component.__to_dict__(), self.components)\n ),\n }\n\n def get_component(self, component_name):\n component = next(\n iter(filter(lambda comp: comp.name == component_name, self.components)),\n None,\n )\n if component is None:\n raise BuildManifest.ComponentNotFoundError(\n f\"{component_name} not found in build manifest.yml\"\n )\n return component\n\n @staticmethod\n def get_build_manifest_relative_location(\n build_id, opensearch_version, architecture\n ):\n return f\"builds/{opensearch_version}/{build_id}/{architecture}/manifest.yml\"\n\n @staticmethod\n def from_s3(bucket_name, build_id, opensearch_version, architecture, work_dir=None):\n work_dir = work_dir if not None else str(os.getcwd())\n manifest_s3_path = BuildManifest.get_build_manifest_relative_location(\n build_id, opensearch_version, architecture\n )\n S3Bucket(bucket_name).download_file(manifest_s3_path, work_dir)\n with open(\"manifest.yml\", \"r\") as file:\n build_manifest = BuildManifest.from_file(file)\n os.remove(os.path.realpath(os.path.join(work_dir, \"manifest.yml\")))\n return build_manifest\n\n class ComponentNotFoundError(Exception):\n pass\n\n class Build:\n def __init__(self, data):\n self.name = data[\"name\"]\n self.version = data[\"version\"]\n self.architecture = data[\"architecture\"]\n self.id = data[\"id\"]\n\n def __to_dict__(self):\n return {\n \"name\": self.name,\n \"version\": self.version,\n \"architecture\": self.architecture,\n \"id\": self.id,\n }\n\n class Component:\n def __init__(self, data):\n self.name = data[\"name\"]\n self.repository = data[\"repository\"]\n self.ref = data[\"ref\"]\n self.commit_id = data[\"commit_id\"]\n self.artifacts = data.get(\"artifacts\", [])\n self.version = data[\"version\"]\n\n def __to_dict__(self):\n return {\n \"name\": self.name,\n \"repository\": self.repository,\n \"ref\": self.ref,\n \"commit_id\": self.commit_id,\n \"artifacts\": self.artifacts,\n \"version\": self.version,\n }\n", "path": "bundle-workflow/src/manifests/build_manifest.py"}, {"content": "# SPDX-License-Identifier: Apache-2.0\n#\n# The OpenSearch Contributors require contributions made to\n# this file be licensed under the Apache-2.0 license or a\n# compatible open source license.\n\nimport logging\nimport os\nfrom pathlib import Path\nfrom urllib.parse import urlparse\n\nimport boto3\nfrom botocore.exceptions import ClientError\n\n\nclass S3Bucket:\n AWS_ROLE_ARN = \"AWS_ROLE_ARN\"\n AWS_ROLE_SESSION_NAME = \"AWS_ROLE_SESSION_NAME\"\n\n def __init__(self, bucket_name, role_arn=None, role_session_name=None):\n \"\"\"\n Provides methods to download/upload files and folders to S3 bucket\n\n :param bucket_name: The s3 bucket name\n :param role_arn: the arn of the role that has permissions to access S3\n :param role_session_name: the aws role session name\n \"\"\"\n self.bucket_name = bucket_name\n self.role_arn = (\n role_arn if role_arn is not None else os.environ.get(S3Bucket.AWS_ROLE_ARN)\n )\n self.role_session_name = (\n role_session_name\n if role_session_name is not None\n else os.environ.get(S3Bucket.AWS_ROLE_SESSION_NAME)\n )\n # TODO: later use for credential refereshing\n assumed_role_creds = self.__sts_assume_role()\n self.__s3_client, self.__s3_resource = self.__create_s3_clients(\n assumed_role_creds\n )\n\n def __sts_assume_role(self):\n try:\n sts_connection = boto3.client(\"sts\")\n response = sts_connection.assume_role(\n RoleArn=self.role_arn,\n RoleSessionName=self.role_session_name,\n DurationSeconds=3600,\n )\n return response[\"Credentials\"]\n except Exception as e:\n raise STSError(e)\n\n def __create_s3_clients(self, assumed_role_cred):\n s3_client = boto3.client(\n \"s3\",\n aws_access_key_id=assumed_role_cred[\"AccessKeyId\"],\n aws_secret_access_key=assumed_role_cred[\"SecretAccessKey\"],\n aws_session_token=assumed_role_cred[\"SessionToken\"],\n )\n s3_resource = boto3.resource(\n \"s3\",\n aws_access_key_id=assumed_role_cred[\"AccessKeyId\"],\n aws_secret_access_key=assumed_role_cred[\"SecretAccessKey\"],\n aws_session_token=assumed_role_cred[\"SessionToken\"],\n )\n return s3_client, s3_resource\n\n def download_folder(self, prefix, dest):\n \"\"\"\n Download the contents of a folder directory\n\n :param prefix: The folder path inside the bucket\n :param dest: local destination to download the folder at\n \"\"\"\n bucket = self.__s3_resource.Bucket(self.bucket_name)\n s3_path = urlparse(prefix).path.lstrip(\"/\")\n local_dir = Path(dest)\n s3_response = bucket.objects.filter(Prefix=s3_path)\n for obj in s3_response:\n target = (\n obj.key\n if local_dir is None\n else local_dir / Path(obj.key).relative_to(s3_path)\n )\n target.parent.mkdir(parents=True, exist_ok=True)\n if obj.key[-1] == \"/\":\n continue\n self.__download(bucket, obj.key, str(target))\n\n def download_file(self, key, dest):\n \"\"\"\n Download a single object from s3.\n\n :param key: The s3 key for the object to download\n :param dest: local destination\n \"\"\"\n bucket = self.__s3_resource.Bucket(self.bucket_name)\n local_dir = Path(dest)\n file_name = key.split(\"/\")[-1]\n target = Path(local_dir) / Path(file_name)\n return self.__download(bucket, key, str(target))\n\n @staticmethod\n def __download(bucket, key, path):\n try:\n bucket.download_file(key, path)\n except ClientError as e:\n logging.error(f\"Failed to download s3 key: {key} from path: {path}\")\n raise S3DownloadError(e)\n\n def upload_file(self, key, source):\n \"\"\"\n Upload a file to s3.\n\n :param key: The s3 key for the uploaded object\n :param source: local path of the file\n \"\"\"\n try:\n self.__s3_client.upload_file(source, self.bucket_name, key)\n except ClientError as e:\n logging.error(f\"Failed to upload s3 key: {key} from local source: {source}\")\n raise S3UploadError(e)\n\n\nclass S3Error(Exception):\n \"\"\"Base class for S3 Errors\"\"\"\n\n pass\n\n\nclass STSError(Exception):\n \"\"\"Base class for STS Error\"\"\"\n\n pass\n\n\nclass S3DownloadError(S3Error):\n \"\"\"Raised when there is a download object failure\"\"\"\n\n pass\n\n\nclass S3UploadError(S3Error):\n \"\"\"Raised when there is an upload object failure\"\"\"\n\n pass\n", "path": "bundle-workflow/src/aws/s3_bucket.py"}]} | 3,092 | 490 |
gh_patches_debug_9207 | rasdani/github-patches | git_diff | ray-project__ray-3431 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Remove duplicate feed dict constructing
in `python/ray/experimental/sgd/sgd_worker.py`
```python
def compute_gradients(self):
start = time.time()
feed_dict = self._grad_feed_dict()
# Aggregate feed dicts for each model on this worker.
for model in self.models:
feed_dict.update(model.get_feed_dict())
```
with `_grad_feed_dict` definitions:
```python
def _grad_feed_dict(self):
# Aggregate feed dicts for each model on this worker.
feed_dict = {}
for model in self.models:
feed_dict.update(model.get_feed_dict())
return feed_dict
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/ray/experimental/sgd/sgd_worker.py`
Content:
```
1 from __future__ import absolute_import
2 from __future__ import division
3 from __future__ import print_function
4
5 import logging
6 import time
7
8 import pyarrow.plasma as plasma
9 import tensorflow as tf
10
11 import ray
12 from ray.experimental.sgd.util import fetch, run_timeline, warmup
13 from ray.experimental.sgd.modified_allreduce import sum_gradients_all_reduce, \
14 unpack_small_tensors
15
16 logger = logging.getLogger(__name__)
17
18
19 class SGDWorker(object):
20 """Helper class for ray.experimental.sgd.DistributedSGD."""
21
22 def __init__(self,
23 worker_index,
24 model_creator,
25 all_reduce_alg="simple",
26 num_devices=1,
27 gpu=False,
28 max_bytes=10000000,
29 plasma_op=False):
30 self.worker_index = worker_index
31 assert num_devices > 0
32
33 # TODO(ekl) support custom session
34 tf_session_args = {
35 "device_count": {
36 "CPU": num_devices
37 },
38 "log_device_placement": False,
39 "gpu_options": tf.GPUOptions(force_gpu_compatible=True),
40 "inter_op_parallelism_threads": 128,
41 }
42 config_proto = tf.ConfigProto(**tf_session_args)
43 self.sess = tf.Session(config=config_proto)
44 self.models = []
45 grad_ops = []
46
47 if gpu:
48 device_tmpl = "/gpu:%d"
49 else:
50 device_tmpl = "/cpu:%d"
51 with self.sess.as_default():
52 for device_idx in range(num_devices):
53 device = device_tmpl % device_idx
54 with tf.device(device):
55 with tf.variable_scope("device_%d" % device_idx):
56 model = model_creator(worker_index, device_idx)
57 self.models.append(model)
58 grads = [
59 t for t in model.optimizer.compute_gradients(
60 model.loss) if t[0] is not None
61 ]
62 grad_ops.append(grads)
63
64 if num_devices == 1:
65 if max_bytes:
66 raise ValueError(
67 "Implementation limitation: grad_shard_bytes > 0 "
68 "({}) currently requires > 1 device".format(max_bytes))
69 self.packed_grads_and_vars = grad_ops
70 else:
71 if max_bytes:
72 self.packed_grads_and_vars, packing_vals = (
73 sum_gradients_all_reduce(
74 "",
75 grad_ops,
76 1,
77 all_reduce_alg,
78 1,
79 list(range(num_devices)),
80 agg_small_grads_max_bytes=max_bytes))
81 else:
82 self.packed_grads_and_vars, _ = (sum_gradients_all_reduce(
83 "",
84 grad_ops,
85 1,
86 all_reduce_alg,
87 1,
88 list(range(num_devices)),
89 agg_small_grads_max_bytes=0))
90 self.per_device_grads = [
91 list(zip(*dev_gv))[0] for dev_gv in self.packed_grads_and_vars
92 ]
93 assert (len(self.per_device_grads) == num_devices)
94 self.num_grads = num_grads = len(self.packed_grads_and_vars[0])
95 if max_bytes:
96 logger.info("Packed grads => {} tensors".format(num_grads))
97
98 # Ops for reading grads with the right control deps
99 nccl_noops = []
100 for j in range(num_grads)[::-1]:
101 deps = nccl_noops + [
102 dev_grad[j] for dev_grad in self.per_device_grads
103 ]
104 with tf.control_dependencies(deps):
105 nccl_noops = [tf.no_op()]
106
107 # You must fetch this otherwise the NCCL allreduce will hang
108 self.nccl_control_out = tf.group(*nccl_noops)
109
110 if plasma_op:
111 store_socket = (
112 ray.worker.global_worker.plasma_client.store_socket_name)
113 manager_socket = (
114 ray.worker.global_worker.plasma_client.manager_socket_name)
115 if not plasma.tf_plasma_op:
116 plasma.build_plasma_tensorflow_op()
117
118 # For fetching grads -> plasma
119 self.plasma_in_grads = []
120 self.plasma_in_grads_oids = [
121 tf.placeholder(shape=[], dtype=tf.string, name="in_grad_oids")
122 for _ in range(num_grads)
123 ]
124 for j in range(num_grads):
125 grad = self.per_device_grads[0][j]
126 with tf.device(self.models[0].loss.device):
127 plasma_grad = plasma.tf_plasma_op.tensor_to_plasma(
128 [grad],
129 self.plasma_in_grads_oids[j],
130 plasma_store_socket_name=store_socket,
131 plasma_manager_socket_name=manager_socket)
132 self.plasma_in_grads.append(plasma_grad)
133
134 # For applying grads <- plasma
135 unpacked_gv = []
136 self.plasma_out_grads_oids = [
137 tf.placeholder(
138 shape=[], dtype=tf.string, name="grad_out_oids")
139 for _ in range(num_grads)
140 ]
141 packed_plasma_grads = []
142 for j in range(num_grads):
143 with tf.device(self.plasma_in_grads[j].device):
144 with tf.control_dependencies([self.plasma_in_grads[j]]):
145 grad_ph = plasma.tf_plasma_op.plasma_to_tensor(
146 self.plasma_out_grads_oids[j],
147 dtype=tf.float32,
148 plasma_store_socket_name=store_socket,
149 plasma_manager_socket_name=manager_socket)
150 grad_ph = tf.reshape(grad_ph,
151 self.packed_grads_and_vars[0][j][0].shape)
152 logger.debug("Packed tensor {}".format(grad_ph))
153 packed_plasma_grads.append(grad_ph)
154 for i in range(num_devices):
155 per_device = []
156 for j, (g, v) in enumerate(self.packed_grads_and_vars[i]):
157 grad_ph = packed_plasma_grads[j]
158 per_device.append((grad_ph, v))
159 unpacked_gv.append(per_device)
160
161 if max_bytes:
162 unpacked_gv = unpack_small_tensors(unpacked_gv, packing_vals)
163
164 elif max_bytes:
165 unpacked_gv = unpack_small_tensors(self.packed_grads_and_vars,
166 packing_vals)
167 else:
168 unpacked_gv = self.packed_grads_and_vars
169
170 # Same shape as packed_grads_and_vars
171 assert len(unpacked_gv) == num_devices
172 assert len(unpacked_gv[0][0]) == 2
173
174 apply_ops = []
175 to_apply = unpacked_gv[0]
176 for ix, m in enumerate(self.models):
177 apply_ops.append(
178 m.optimizer.apply_gradients(
179 [(g, v)
180 for ((g, _), (_, v)) in zip(to_apply, unpacked_gv[ix])]))
181 self.apply_op = tf.group(*apply_ops)
182 init_op = tf.group(tf.global_variables_initializer(),
183 tf.local_variables_initializer())
184 self.sess.run(init_op)
185
186 def _grad_feed_dict(self):
187 # Aggregate feed dicts for each model on this worker.
188 feed_dict = {}
189 for model in self.models:
190 feed_dict.update(model.get_feed_dict())
191 return feed_dict
192
193 def foreach_model(self, fn):
194 with self.sess.as_default():
195 return [fn(m) for m in self.models]
196
197 def foreach_worker(self, fn):
198 with self.sess.as_default():
199 return fn(self)
200
201 def for_model(self, fn):
202 with self.sess.as_default():
203 return fn(self.models[0])
204
205 def compute_gradients(self):
206 start = time.time()
207 feed_dict = self._grad_feed_dict()
208 # Aggregate feed dicts for each model on this worker.
209 for model in self.models:
210 feed_dict.update(model.get_feed_dict())
211 # We only need to fetch the first per_device_grad, since they are
212 # averaged across all devices by allreduce.
213 fetches = self.sess.run(
214 [
215 self.models[0].loss, self.per_device_grads[0],
216 self.nccl_control_out
217 ],
218 feed_dict=feed_dict)
219 logger.debug(
220 "Compute grad interior time {}".format(time.time() - start))
221 return fetches
222
223 def apply_gradients(self, avg_grads):
224 start = time.time()
225 result = {
226 g: avg_grads[i]
227 for (i, g) in enumerate(self.per_device_grads[0])
228 }
229 self.sess.run(self.apply_op, feed_dict=result)
230 logger.debug("Apply grad interior time {}".format(time.time() - start))
231
232 def compute_apply(self):
233 fetches = run_timeline(
234 self.sess,
235 [self.models[0].loss, self.apply_op, self.nccl_control_out],
236 feed_dict=self._grad_feed_dict(),
237 name="compute_apply")
238 return fetches[0]
239
240 def ps_compute_apply(self,
241 out_grad_shard_oids,
242 agg_grad_shard_oids,
243 tl_name="ps_compute_apply",
244 write_timeline=False):
245 feed_dict = self._grad_feed_dict()
246 feed_dict.update(
247 dict(zip(self.plasma_in_grads_oids, out_grad_shard_oids)))
248 feed_dict.update(
249 dict(zip(self.plasma_out_grads_oids, agg_grad_shard_oids)))
250 fetch(agg_grad_shard_oids)
251 fetches = run_timeline(
252 self.sess, [
253 self.models[0].loss, self.plasma_in_grads, self.apply_op,
254 self.nccl_control_out
255 ],
256 feed_dict=feed_dict,
257 write_timeline=write_timeline)
258 return fetches[0]
259
260 def num_grad_shards(self):
261 return self.num_grads
262
263 def shard_shapes(self):
264 main_gv = self.packed_grads_and_vars[0]
265 return [g.shape for g, _ in main_gv]
266
267 def ip(self):
268 return ray.services.get_node_ip_address()
269
270 def warmup(self):
271 warmup()
272
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/python/ray/experimental/sgd/sgd_worker.py b/python/ray/experimental/sgd/sgd_worker.py
--- a/python/ray/experimental/sgd/sgd_worker.py
+++ b/python/ray/experimental/sgd/sgd_worker.py
@@ -205,9 +205,6 @@
def compute_gradients(self):
start = time.time()
feed_dict = self._grad_feed_dict()
- # Aggregate feed dicts for each model on this worker.
- for model in self.models:
- feed_dict.update(model.get_feed_dict())
# We only need to fetch the first per_device_grad, since they are
# averaged across all devices by allreduce.
fetches = self.sess.run(
| {"golden_diff": "diff --git a/python/ray/experimental/sgd/sgd_worker.py b/python/ray/experimental/sgd/sgd_worker.py\n--- a/python/ray/experimental/sgd/sgd_worker.py\n+++ b/python/ray/experimental/sgd/sgd_worker.py\n@@ -205,9 +205,6 @@\n def compute_gradients(self):\n start = time.time()\n feed_dict = self._grad_feed_dict()\n- # Aggregate feed dicts for each model on this worker.\n- for model in self.models:\n- feed_dict.update(model.get_feed_dict())\n # We only need to fetch the first per_device_grad, since they are\n # averaged across all devices by allreduce.\n fetches = self.sess.run(\n", "issue": "Remove duplicate feed dict constructing\nin `python/ray/experimental/sgd/sgd_worker.py` \r\n\r\n```python\r\n def compute_gradients(self):\r\n start = time.time()\r\n feed_dict = self._grad_feed_dict()\r\n # Aggregate feed dicts for each model on this worker.\r\n for model in self.models:\r\n feed_dict.update(model.get_feed_dict())\r\n```\r\n\r\nwith `_grad_feed_dict` definitions:\r\n\r\n```python\r\n def _grad_feed_dict(self):\r\n # Aggregate feed dicts for each model on this worker.\r\n feed_dict = {}\r\n for model in self.models:\r\n feed_dict.update(model.get_feed_dict())\r\n return feed_dict\r\n```\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport logging\nimport time\n\nimport pyarrow.plasma as plasma\nimport tensorflow as tf\n\nimport ray\nfrom ray.experimental.sgd.util import fetch, run_timeline, warmup\nfrom ray.experimental.sgd.modified_allreduce import sum_gradients_all_reduce, \\\n unpack_small_tensors\n\nlogger = logging.getLogger(__name__)\n\n\nclass SGDWorker(object):\n \"\"\"Helper class for ray.experimental.sgd.DistributedSGD.\"\"\"\n\n def __init__(self,\n worker_index,\n model_creator,\n all_reduce_alg=\"simple\",\n num_devices=1,\n gpu=False,\n max_bytes=10000000,\n plasma_op=False):\n self.worker_index = worker_index\n assert num_devices > 0\n\n # TODO(ekl) support custom session\n tf_session_args = {\n \"device_count\": {\n \"CPU\": num_devices\n },\n \"log_device_placement\": False,\n \"gpu_options\": tf.GPUOptions(force_gpu_compatible=True),\n \"inter_op_parallelism_threads\": 128,\n }\n config_proto = tf.ConfigProto(**tf_session_args)\n self.sess = tf.Session(config=config_proto)\n self.models = []\n grad_ops = []\n\n if gpu:\n device_tmpl = \"/gpu:%d\"\n else:\n device_tmpl = \"/cpu:%d\"\n with self.sess.as_default():\n for device_idx in range(num_devices):\n device = device_tmpl % device_idx\n with tf.device(device):\n with tf.variable_scope(\"device_%d\" % device_idx):\n model = model_creator(worker_index, device_idx)\n self.models.append(model)\n grads = [\n t for t in model.optimizer.compute_gradients(\n model.loss) if t[0] is not None\n ]\n grad_ops.append(grads)\n\n if num_devices == 1:\n if max_bytes:\n raise ValueError(\n \"Implementation limitation: grad_shard_bytes > 0 \"\n \"({}) currently requires > 1 device\".format(max_bytes))\n self.packed_grads_and_vars = grad_ops\n else:\n if max_bytes:\n self.packed_grads_and_vars, packing_vals = (\n sum_gradients_all_reduce(\n \"\",\n grad_ops,\n 1,\n all_reduce_alg,\n 1,\n list(range(num_devices)),\n agg_small_grads_max_bytes=max_bytes))\n else:\n self.packed_grads_and_vars, _ = (sum_gradients_all_reduce(\n \"\",\n grad_ops,\n 1,\n all_reduce_alg,\n 1,\n list(range(num_devices)),\n agg_small_grads_max_bytes=0))\n self.per_device_grads = [\n list(zip(*dev_gv))[0] for dev_gv in self.packed_grads_and_vars\n ]\n assert (len(self.per_device_grads) == num_devices)\n self.num_grads = num_grads = len(self.packed_grads_and_vars[0])\n if max_bytes:\n logger.info(\"Packed grads => {} tensors\".format(num_grads))\n\n # Ops for reading grads with the right control deps\n nccl_noops = []\n for j in range(num_grads)[::-1]:\n deps = nccl_noops + [\n dev_grad[j] for dev_grad in self.per_device_grads\n ]\n with tf.control_dependencies(deps):\n nccl_noops = [tf.no_op()]\n\n # You must fetch this otherwise the NCCL allreduce will hang\n self.nccl_control_out = tf.group(*nccl_noops)\n\n if plasma_op:\n store_socket = (\n ray.worker.global_worker.plasma_client.store_socket_name)\n manager_socket = (\n ray.worker.global_worker.plasma_client.manager_socket_name)\n if not plasma.tf_plasma_op:\n plasma.build_plasma_tensorflow_op()\n\n # For fetching grads -> plasma\n self.plasma_in_grads = []\n self.plasma_in_grads_oids = [\n tf.placeholder(shape=[], dtype=tf.string, name=\"in_grad_oids\")\n for _ in range(num_grads)\n ]\n for j in range(num_grads):\n grad = self.per_device_grads[0][j]\n with tf.device(self.models[0].loss.device):\n plasma_grad = plasma.tf_plasma_op.tensor_to_plasma(\n [grad],\n self.plasma_in_grads_oids[j],\n plasma_store_socket_name=store_socket,\n plasma_manager_socket_name=manager_socket)\n self.plasma_in_grads.append(plasma_grad)\n\n # For applying grads <- plasma\n unpacked_gv = []\n self.plasma_out_grads_oids = [\n tf.placeholder(\n shape=[], dtype=tf.string, name=\"grad_out_oids\")\n for _ in range(num_grads)\n ]\n packed_plasma_grads = []\n for j in range(num_grads):\n with tf.device(self.plasma_in_grads[j].device):\n with tf.control_dependencies([self.plasma_in_grads[j]]):\n grad_ph = plasma.tf_plasma_op.plasma_to_tensor(\n self.plasma_out_grads_oids[j],\n dtype=tf.float32,\n plasma_store_socket_name=store_socket,\n plasma_manager_socket_name=manager_socket)\n grad_ph = tf.reshape(grad_ph,\n self.packed_grads_and_vars[0][j][0].shape)\n logger.debug(\"Packed tensor {}\".format(grad_ph))\n packed_plasma_grads.append(grad_ph)\n for i in range(num_devices):\n per_device = []\n for j, (g, v) in enumerate(self.packed_grads_and_vars[i]):\n grad_ph = packed_plasma_grads[j]\n per_device.append((grad_ph, v))\n unpacked_gv.append(per_device)\n\n if max_bytes:\n unpacked_gv = unpack_small_tensors(unpacked_gv, packing_vals)\n\n elif max_bytes:\n unpacked_gv = unpack_small_tensors(self.packed_grads_and_vars,\n packing_vals)\n else:\n unpacked_gv = self.packed_grads_and_vars\n\n # Same shape as packed_grads_and_vars\n assert len(unpacked_gv) == num_devices\n assert len(unpacked_gv[0][0]) == 2\n\n apply_ops = []\n to_apply = unpacked_gv[0]\n for ix, m in enumerate(self.models):\n apply_ops.append(\n m.optimizer.apply_gradients(\n [(g, v)\n for ((g, _), (_, v)) in zip(to_apply, unpacked_gv[ix])]))\n self.apply_op = tf.group(*apply_ops)\n init_op = tf.group(tf.global_variables_initializer(),\n tf.local_variables_initializer())\n self.sess.run(init_op)\n\n def _grad_feed_dict(self):\n # Aggregate feed dicts for each model on this worker.\n feed_dict = {}\n for model in self.models:\n feed_dict.update(model.get_feed_dict())\n return feed_dict\n\n def foreach_model(self, fn):\n with self.sess.as_default():\n return [fn(m) for m in self.models]\n\n def foreach_worker(self, fn):\n with self.sess.as_default():\n return fn(self)\n\n def for_model(self, fn):\n with self.sess.as_default():\n return fn(self.models[0])\n\n def compute_gradients(self):\n start = time.time()\n feed_dict = self._grad_feed_dict()\n # Aggregate feed dicts for each model on this worker.\n for model in self.models:\n feed_dict.update(model.get_feed_dict())\n # We only need to fetch the first per_device_grad, since they are\n # averaged across all devices by allreduce.\n fetches = self.sess.run(\n [\n self.models[0].loss, self.per_device_grads[0],\n self.nccl_control_out\n ],\n feed_dict=feed_dict)\n logger.debug(\n \"Compute grad interior time {}\".format(time.time() - start))\n return fetches\n\n def apply_gradients(self, avg_grads):\n start = time.time()\n result = {\n g: avg_grads[i]\n for (i, g) in enumerate(self.per_device_grads[0])\n }\n self.sess.run(self.apply_op, feed_dict=result)\n logger.debug(\"Apply grad interior time {}\".format(time.time() - start))\n\n def compute_apply(self):\n fetches = run_timeline(\n self.sess,\n [self.models[0].loss, self.apply_op, self.nccl_control_out],\n feed_dict=self._grad_feed_dict(),\n name=\"compute_apply\")\n return fetches[0]\n\n def ps_compute_apply(self,\n out_grad_shard_oids,\n agg_grad_shard_oids,\n tl_name=\"ps_compute_apply\",\n write_timeline=False):\n feed_dict = self._grad_feed_dict()\n feed_dict.update(\n dict(zip(self.plasma_in_grads_oids, out_grad_shard_oids)))\n feed_dict.update(\n dict(zip(self.plasma_out_grads_oids, agg_grad_shard_oids)))\n fetch(agg_grad_shard_oids)\n fetches = run_timeline(\n self.sess, [\n self.models[0].loss, self.plasma_in_grads, self.apply_op,\n self.nccl_control_out\n ],\n feed_dict=feed_dict,\n write_timeline=write_timeline)\n return fetches[0]\n\n def num_grad_shards(self):\n return self.num_grads\n\n def shard_shapes(self):\n main_gv = self.packed_grads_and_vars[0]\n return [g.shape for g, _ in main_gv]\n\n def ip(self):\n return ray.services.get_node_ip_address()\n\n def warmup(self):\n warmup()\n", "path": "python/ray/experimental/sgd/sgd_worker.py"}], "after_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport logging\nimport time\n\nimport pyarrow.plasma as plasma\nimport tensorflow as tf\n\nimport ray\nfrom ray.experimental.sgd.util import fetch, run_timeline, warmup\nfrom ray.experimental.sgd.modified_allreduce import sum_gradients_all_reduce, \\\n unpack_small_tensors\n\nlogger = logging.getLogger(__name__)\n\n\nclass SGDWorker(object):\n \"\"\"Helper class for ray.experimental.sgd.DistributedSGD.\"\"\"\n\n def __init__(self,\n worker_index,\n model_creator,\n all_reduce_alg=\"simple\",\n num_devices=1,\n gpu=False,\n max_bytes=10000000,\n plasma_op=False):\n self.worker_index = worker_index\n assert num_devices > 0\n\n # TODO(ekl) support custom session\n tf_session_args = {\n \"device_count\": {\n \"CPU\": num_devices\n },\n \"log_device_placement\": False,\n \"gpu_options\": tf.GPUOptions(force_gpu_compatible=True),\n \"inter_op_parallelism_threads\": 128,\n }\n config_proto = tf.ConfigProto(**tf_session_args)\n self.sess = tf.Session(config=config_proto)\n self.models = []\n grad_ops = []\n\n if gpu:\n device_tmpl = \"/gpu:%d\"\n else:\n device_tmpl = \"/cpu:%d\"\n with self.sess.as_default():\n for device_idx in range(num_devices):\n device = device_tmpl % device_idx\n with tf.device(device):\n with tf.variable_scope(\"device_%d\" % device_idx):\n model = model_creator(worker_index, device_idx)\n self.models.append(model)\n grads = [\n t for t in model.optimizer.compute_gradients(\n model.loss) if t[0] is not None\n ]\n grad_ops.append(grads)\n\n if num_devices == 1:\n if max_bytes:\n raise ValueError(\n \"Implementation limitation: grad_shard_bytes > 0 \"\n \"({}) currently requires > 1 device\".format(max_bytes))\n self.packed_grads_and_vars = grad_ops\n else:\n if max_bytes:\n self.packed_grads_and_vars, packing_vals = (\n sum_gradients_all_reduce(\n \"\",\n grad_ops,\n 1,\n all_reduce_alg,\n 1,\n list(range(num_devices)),\n agg_small_grads_max_bytes=max_bytes))\n else:\n self.packed_grads_and_vars, _ = (sum_gradients_all_reduce(\n \"\",\n grad_ops,\n 1,\n all_reduce_alg,\n 1,\n list(range(num_devices)),\n agg_small_grads_max_bytes=0))\n self.per_device_grads = [\n list(zip(*dev_gv))[0] for dev_gv in self.packed_grads_and_vars\n ]\n assert (len(self.per_device_grads) == num_devices)\n self.num_grads = num_grads = len(self.packed_grads_and_vars[0])\n if max_bytes:\n logger.info(\"Packed grads => {} tensors\".format(num_grads))\n\n # Ops for reading grads with the right control deps\n nccl_noops = []\n for j in range(num_grads)[::-1]:\n deps = nccl_noops + [\n dev_grad[j] for dev_grad in self.per_device_grads\n ]\n with tf.control_dependencies(deps):\n nccl_noops = [tf.no_op()]\n\n # You must fetch this otherwise the NCCL allreduce will hang\n self.nccl_control_out = tf.group(*nccl_noops)\n\n if plasma_op:\n store_socket = (\n ray.worker.global_worker.plasma_client.store_socket_name)\n manager_socket = (\n ray.worker.global_worker.plasma_client.manager_socket_name)\n if not plasma.tf_plasma_op:\n plasma.build_plasma_tensorflow_op()\n\n # For fetching grads -> plasma\n self.plasma_in_grads = []\n self.plasma_in_grads_oids = [\n tf.placeholder(shape=[], dtype=tf.string, name=\"in_grad_oids\")\n for _ in range(num_grads)\n ]\n for j in range(num_grads):\n grad = self.per_device_grads[0][j]\n with tf.device(self.models[0].loss.device):\n plasma_grad = plasma.tf_plasma_op.tensor_to_plasma(\n [grad],\n self.plasma_in_grads_oids[j],\n plasma_store_socket_name=store_socket,\n plasma_manager_socket_name=manager_socket)\n self.plasma_in_grads.append(plasma_grad)\n\n # For applying grads <- plasma\n unpacked_gv = []\n self.plasma_out_grads_oids = [\n tf.placeholder(\n shape=[], dtype=tf.string, name=\"grad_out_oids\")\n for _ in range(num_grads)\n ]\n packed_plasma_grads = []\n for j in range(num_grads):\n with tf.device(self.plasma_in_grads[j].device):\n with tf.control_dependencies([self.plasma_in_grads[j]]):\n grad_ph = plasma.tf_plasma_op.plasma_to_tensor(\n self.plasma_out_grads_oids[j],\n dtype=tf.float32,\n plasma_store_socket_name=store_socket,\n plasma_manager_socket_name=manager_socket)\n grad_ph = tf.reshape(grad_ph,\n self.packed_grads_and_vars[0][j][0].shape)\n logger.debug(\"Packed tensor {}\".format(grad_ph))\n packed_plasma_grads.append(grad_ph)\n for i in range(num_devices):\n per_device = []\n for j, (g, v) in enumerate(self.packed_grads_and_vars[i]):\n grad_ph = packed_plasma_grads[j]\n per_device.append((grad_ph, v))\n unpacked_gv.append(per_device)\n\n if max_bytes:\n unpacked_gv = unpack_small_tensors(unpacked_gv, packing_vals)\n\n elif max_bytes:\n unpacked_gv = unpack_small_tensors(self.packed_grads_and_vars,\n packing_vals)\n else:\n unpacked_gv = self.packed_grads_and_vars\n\n # Same shape as packed_grads_and_vars\n assert len(unpacked_gv) == num_devices\n assert len(unpacked_gv[0][0]) == 2\n\n apply_ops = []\n to_apply = unpacked_gv[0]\n for ix, m in enumerate(self.models):\n apply_ops.append(\n m.optimizer.apply_gradients(\n [(g, v)\n for ((g, _), (_, v)) in zip(to_apply, unpacked_gv[ix])]))\n self.apply_op = tf.group(*apply_ops)\n init_op = tf.group(tf.global_variables_initializer(),\n tf.local_variables_initializer())\n self.sess.run(init_op)\n\n def _grad_feed_dict(self):\n # Aggregate feed dicts for each model on this worker.\n feed_dict = {}\n for model in self.models:\n feed_dict.update(model.get_feed_dict())\n return feed_dict\n\n def foreach_model(self, fn):\n with self.sess.as_default():\n return [fn(m) for m in self.models]\n\n def foreach_worker(self, fn):\n with self.sess.as_default():\n return fn(self)\n\n def for_model(self, fn):\n with self.sess.as_default():\n return fn(self.models[0])\n\n def compute_gradients(self):\n start = time.time()\n feed_dict = self._grad_feed_dict()\n # We only need to fetch the first per_device_grad, since they are\n # averaged across all devices by allreduce.\n fetches = self.sess.run(\n [\n self.models[0].loss, self.per_device_grads[0],\n self.nccl_control_out\n ],\n feed_dict=feed_dict)\n logger.debug(\n \"Compute grad interior time {}\".format(time.time() - start))\n return fetches\n\n def apply_gradients(self, avg_grads):\n start = time.time()\n result = {\n g: avg_grads[i]\n for (i, g) in enumerate(self.per_device_grads[0])\n }\n self.sess.run(self.apply_op, feed_dict=result)\n logger.debug(\"Apply grad interior time {}\".format(time.time() - start))\n\n def compute_apply(self):\n fetches = run_timeline(\n self.sess,\n [self.models[0].loss, self.apply_op, self.nccl_control_out],\n feed_dict=self._grad_feed_dict(),\n name=\"compute_apply\")\n return fetches[0]\n\n def ps_compute_apply(self,\n out_grad_shard_oids,\n agg_grad_shard_oids,\n tl_name=\"ps_compute_apply\",\n write_timeline=False):\n feed_dict = self._grad_feed_dict()\n feed_dict.update(\n dict(zip(self.plasma_in_grads_oids, out_grad_shard_oids)))\n feed_dict.update(\n dict(zip(self.plasma_out_grads_oids, agg_grad_shard_oids)))\n fetch(agg_grad_shard_oids)\n fetches = run_timeline(\n self.sess, [\n self.models[0].loss, self.plasma_in_grads, self.apply_op,\n self.nccl_control_out\n ],\n feed_dict=feed_dict,\n write_timeline=write_timeline)\n return fetches[0]\n\n def num_grad_shards(self):\n return self.num_grads\n\n def shard_shapes(self):\n main_gv = self.packed_grads_and_vars[0]\n return [g.shape for g, _ in main_gv]\n\n def ip(self):\n return ray.services.get_node_ip_address()\n\n def warmup(self):\n warmup()\n", "path": "python/ray/experimental/sgd/sgd_worker.py"}]} | 3,213 | 166 |
gh_patches_debug_7722 | rasdani/github-patches | git_diff | googleapis__python-bigquery-624 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
google.auth.exceptions.TransportError is not being retried
Hi,
Recently i faced an error can you please consider using this exception as a retry one also. Since i have faced this error in one of our production system
https://github.com/googleapis/python-storage/issues/414
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `google/cloud/bigquery/retry.py`
Content:
```
1 # Copyright 2018 Google LLC
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from google.api_core import exceptions
16 from google.api_core import retry
17 import requests.exceptions
18
19
20 _RETRYABLE_REASONS = frozenset(
21 ["rateLimitExceeded", "backendError", "internalError", "badGateway"]
22 )
23
24 _UNSTRUCTURED_RETRYABLE_TYPES = (
25 ConnectionError,
26 exceptions.TooManyRequests,
27 exceptions.InternalServerError,
28 exceptions.BadGateway,
29 requests.exceptions.ConnectionError,
30 )
31
32
33 def _should_retry(exc):
34 """Predicate for determining when to retry.
35
36 We retry if and only if the 'reason' is 'backendError'
37 or 'rateLimitExceeded'.
38 """
39 if not hasattr(exc, "errors") or len(exc.errors) == 0:
40 # Check for unstructured error returns, e.g. from GFE
41 return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)
42
43 reason = exc.errors[0]["reason"]
44 return reason in _RETRYABLE_REASONS
45
46
47 DEFAULT_RETRY = retry.Retry(predicate=_should_retry)
48 """The default retry object.
49
50 Any method with a ``retry`` parameter will be retried automatically,
51 with reasonable defaults. To disable retry, pass ``retry=None``.
52 To modify the default retry behavior, call a ``with_XXX`` method
53 on ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,
54 pass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.
55 """
56
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py
--- a/google/cloud/bigquery/retry.py
+++ b/google/cloud/bigquery/retry.py
@@ -14,6 +14,7 @@
from google.api_core import exceptions
from google.api_core import retry
+from google.auth import exceptions as auth_exceptions
import requests.exceptions
@@ -27,6 +28,7 @@
exceptions.InternalServerError,
exceptions.BadGateway,
requests.exceptions.ConnectionError,
+ auth_exceptions.TransportError,
)
| {"golden_diff": "diff --git a/google/cloud/bigquery/retry.py b/google/cloud/bigquery/retry.py\n--- a/google/cloud/bigquery/retry.py\n+++ b/google/cloud/bigquery/retry.py\n@@ -14,6 +14,7 @@\n \n from google.api_core import exceptions\n from google.api_core import retry\n+from google.auth import exceptions as auth_exceptions\n import requests.exceptions\n \n \n@@ -27,6 +28,7 @@\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ConnectionError,\n+ auth_exceptions.TransportError,\n )\n", "issue": "google.auth.exceptions.TransportError is not being retried\nHi, \r\n\r\nRecently i faced an error can you please consider using this exception as a retry one also. Since i have faced this error in one of our production system\r\n\r\nhttps://github.com/googleapis/python-storage/issues/414\r\n\r\n\n", "before_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ConnectionError,\n)\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}], "after_files": [{"content": "# Copyright 2018 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom google.api_core import exceptions\nfrom google.api_core import retry\nfrom google.auth import exceptions as auth_exceptions\nimport requests.exceptions\n\n\n_RETRYABLE_REASONS = frozenset(\n [\"rateLimitExceeded\", \"backendError\", \"internalError\", \"badGateway\"]\n)\n\n_UNSTRUCTURED_RETRYABLE_TYPES = (\n ConnectionError,\n exceptions.TooManyRequests,\n exceptions.InternalServerError,\n exceptions.BadGateway,\n requests.exceptions.ConnectionError,\n auth_exceptions.TransportError,\n)\n\n\ndef _should_retry(exc):\n \"\"\"Predicate for determining when to retry.\n\n We retry if and only if the 'reason' is 'backendError'\n or 'rateLimitExceeded'.\n \"\"\"\n if not hasattr(exc, \"errors\") or len(exc.errors) == 0:\n # Check for unstructured error returns, e.g. from GFE\n return isinstance(exc, _UNSTRUCTURED_RETRYABLE_TYPES)\n\n reason = exc.errors[0][\"reason\"]\n return reason in _RETRYABLE_REASONS\n\n\nDEFAULT_RETRY = retry.Retry(predicate=_should_retry)\n\"\"\"The default retry object.\n\nAny method with a ``retry`` parameter will be retried automatically,\nwith reasonable defaults. To disable retry, pass ``retry=None``.\nTo modify the default retry behavior, call a ``with_XXX`` method\non ``DEFAULT_RETRY``. For example, to change the deadline to 30 seconds,\npass ``retry=bigquery.DEFAULT_RETRY.with_deadline(30)``.\n\"\"\"\n", "path": "google/cloud/bigquery/retry.py"}]} | 861 | 118 |
gh_patches_debug_22346 | rasdani/github-patches | git_diff | python-discord__bot-721 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
PEP Command Fails on Empty Metadata
Currently, the PEP command assumes that if a metadata field is present in the PEP's summary table that the value is populated:
https://github.com/python-discord/bot/blob/74d990540a1072c1782fa7593d7d1abe3c165f49/bot/cogs/utils.py#L64-L72
However, this is not always the case, e.g. [PEP 249](https://www.python.org/dev/peps/pep-0249/):

Because of this, the embed field's `value` can be provided an empty string, causing an exception to be raised:
```
HTTPException: 400 BAD REQUEST (error code: 50035): Invalid Form Body
In embed.fields.1.value: This field is required
```
To fix this, there should be a catch for empty values to prevent a field being added if there's no value to populate.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bot/cogs/utils.py`
Content:
```
1 import logging
2 import re
3 import unicodedata
4 from asyncio import TimeoutError, sleep
5 from email.parser import HeaderParser
6 from io import StringIO
7 from typing import Tuple
8
9 from dateutil import relativedelta
10 from discord import Colour, Embed, Message, Role
11 from discord.ext.commands import Cog, Context, command
12
13 from bot.bot import Bot
14 from bot.constants import Channels, MODERATION_ROLES, Mention, STAFF_ROLES
15 from bot.decorators import in_channel, with_role
16 from bot.utils.time import humanize_delta
17
18 log = logging.getLogger(__name__)
19
20
21 class Utils(Cog):
22 """A selection of utilities which don't have a clear category."""
23
24 def __init__(self, bot: Bot):
25 self.bot = bot
26
27 self.base_pep_url = "http://www.python.org/dev/peps/pep-"
28 self.base_github_pep_url = "https://raw.githubusercontent.com/python/peps/master/pep-"
29
30 @command(name='pep', aliases=('get_pep', 'p'))
31 async def pep_command(self, ctx: Context, pep_number: str) -> None:
32 """Fetches information about a PEP and sends it to the channel."""
33 if pep_number.isdigit():
34 pep_number = int(pep_number)
35 else:
36 await ctx.invoke(self.bot.get_command("help"), "pep")
37 return
38
39 possible_extensions = ['.txt', '.rst']
40 found_pep = False
41 for extension in possible_extensions:
42 # Attempt to fetch the PEP
43 pep_url = f"{self.base_github_pep_url}{pep_number:04}{extension}"
44 log.trace(f"Requesting PEP {pep_number} with {pep_url}")
45 response = await self.bot.http_session.get(pep_url)
46
47 if response.status == 200:
48 log.trace("PEP found")
49 found_pep = True
50
51 pep_content = await response.text()
52
53 # Taken from https://github.com/python/peps/blob/master/pep0/pep.py#L179
54 pep_header = HeaderParser().parse(StringIO(pep_content))
55
56 # Assemble the embed
57 pep_embed = Embed(
58 title=f"**PEP {pep_number} - {pep_header['Title']}**",
59 description=f"[Link]({self.base_pep_url}{pep_number:04})",
60 )
61
62 pep_embed.set_thumbnail(url="https://www.python.org/static/opengraph-icon-200x200.png")
63
64 # Add the interesting information
65 if "Status" in pep_header:
66 pep_embed.add_field(name="Status", value=pep_header["Status"])
67 if "Python-Version" in pep_header:
68 pep_embed.add_field(name="Python-Version", value=pep_header["Python-Version"])
69 if "Created" in pep_header:
70 pep_embed.add_field(name="Created", value=pep_header["Created"])
71 if "Type" in pep_header:
72 pep_embed.add_field(name="Type", value=pep_header["Type"])
73
74 elif response.status != 404:
75 # any response except 200 and 404 is expected
76 found_pep = True # actually not, but it's easier to display this way
77 log.trace(f"The user requested PEP {pep_number}, but the response had an unexpected status code: "
78 f"{response.status}.\n{response.text}")
79
80 error_message = "Unexpected HTTP error during PEP search. Please let us know."
81 pep_embed = Embed(title="Unexpected error", description=error_message)
82 pep_embed.colour = Colour.red()
83 break
84
85 if not found_pep:
86 log.trace("PEP was not found")
87 not_found = f"PEP {pep_number} does not exist."
88 pep_embed = Embed(title="PEP not found", description=not_found)
89 pep_embed.colour = Colour.red()
90
91 await ctx.message.channel.send(embed=pep_embed)
92
93 @command()
94 @in_channel(Channels.bot, bypass_roles=STAFF_ROLES)
95 async def charinfo(self, ctx: Context, *, characters: str) -> None:
96 """Shows you information on up to 25 unicode characters."""
97 match = re.match(r"<(a?):(\w+):(\d+)>", characters)
98 if match:
99 embed = Embed(
100 title="Non-Character Detected",
101 description=(
102 "Only unicode characters can be processed, but a custom Discord emoji "
103 "was found. Please remove it and try again."
104 )
105 )
106 embed.colour = Colour.red()
107 await ctx.send(embed=embed)
108 return
109
110 if len(characters) > 25:
111 embed = Embed(title=f"Too many characters ({len(characters)}/25)")
112 embed.colour = Colour.red()
113 await ctx.send(embed=embed)
114 return
115
116 def get_info(char: str) -> Tuple[str, str]:
117 digit = f"{ord(char):x}"
118 if len(digit) <= 4:
119 u_code = f"\\u{digit:>04}"
120 else:
121 u_code = f"\\U{digit:>08}"
122 url = f"https://www.compart.com/en/unicode/U+{digit:>04}"
123 name = f"[{unicodedata.name(char, '')}]({url})"
124 info = f"`{u_code.ljust(10)}`: {name} - {char}"
125 return info, u_code
126
127 charlist, rawlist = zip(*(get_info(c) for c in characters))
128
129 embed = Embed(description="\n".join(charlist))
130 embed.set_author(name="Character Info")
131
132 if len(characters) > 1:
133 embed.add_field(name='Raw', value=f"`{''.join(rawlist)}`", inline=False)
134
135 await ctx.send(embed=embed)
136
137 @command()
138 @with_role(*MODERATION_ROLES)
139 async def mention(self, ctx: Context, *, role: Role) -> None:
140 """Set a role to be mentionable for a limited time."""
141 if role.mentionable:
142 await ctx.send(f"{role} is already mentionable!")
143 return
144
145 await role.edit(reason=f"Role unlocked by {ctx.author}", mentionable=True)
146
147 human_time = humanize_delta(relativedelta.relativedelta(seconds=Mention.message_timeout))
148 await ctx.send(
149 f"{role} has been made mentionable. I will reset it in {human_time}, or when someone mentions this role."
150 )
151
152 def check(m: Message) -> bool:
153 """Checks that the message contains the role mention."""
154 return role in m.role_mentions
155
156 try:
157 msg = await self.bot.wait_for("message", check=check, timeout=Mention.message_timeout)
158 except TimeoutError:
159 await role.edit(mentionable=False, reason="Automatic role lock - timeout.")
160 await ctx.send(f"{ctx.author.mention}, you took too long. I have reset {role} to be unmentionable.")
161 return
162
163 if any(r.id in MODERATION_ROLES for r in msg.author.roles):
164 await sleep(Mention.reset_delay)
165 await role.edit(mentionable=False, reason=f"Automatic role lock by {msg.author}")
166 await ctx.send(
167 f"{ctx.author.mention}, I have reset {role} to be unmentionable as "
168 f"{msg.author if msg.author != ctx.author else 'you'} sent a message mentioning it."
169 )
170 return
171
172 await role.edit(mentionable=False, reason=f"Automatic role lock - unauthorised use by {msg.author}")
173 await ctx.send(
174 f"{ctx.author.mention}, I have reset {role} to be unmentionable "
175 f"as I detected unauthorised use by {msg.author} (ID: {msg.author.id})."
176 )
177
178
179 def setup(bot: Bot) -> None:
180 """Load the Utils cog."""
181 bot.add_cog(Utils(bot))
182
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bot/cogs/utils.py b/bot/cogs/utils.py
--- a/bot/cogs/utils.py
+++ b/bot/cogs/utils.py
@@ -62,14 +62,12 @@
pep_embed.set_thumbnail(url="https://www.python.org/static/opengraph-icon-200x200.png")
# Add the interesting information
- if "Status" in pep_header:
- pep_embed.add_field(name="Status", value=pep_header["Status"])
- if "Python-Version" in pep_header:
- pep_embed.add_field(name="Python-Version", value=pep_header["Python-Version"])
- if "Created" in pep_header:
- pep_embed.add_field(name="Created", value=pep_header["Created"])
- if "Type" in pep_header:
- pep_embed.add_field(name="Type", value=pep_header["Type"])
+ fields_to_check = ("Status", "Python-Version", "Created", "Type")
+ for field in fields_to_check:
+ # Check for a PEP metadata field that is present but has an empty value
+ # embed field values can't contain an empty string
+ if pep_header.get(field, ""):
+ pep_embed.add_field(name=field, value=pep_header[field])
elif response.status != 404:
# any response except 200 and 404 is expected
| {"golden_diff": "diff --git a/bot/cogs/utils.py b/bot/cogs/utils.py\n--- a/bot/cogs/utils.py\n+++ b/bot/cogs/utils.py\n@@ -62,14 +62,12 @@\n pep_embed.set_thumbnail(url=\"https://www.python.org/static/opengraph-icon-200x200.png\")\n \n # Add the interesting information\n- if \"Status\" in pep_header:\n- pep_embed.add_field(name=\"Status\", value=pep_header[\"Status\"])\n- if \"Python-Version\" in pep_header:\n- pep_embed.add_field(name=\"Python-Version\", value=pep_header[\"Python-Version\"])\n- if \"Created\" in pep_header:\n- pep_embed.add_field(name=\"Created\", value=pep_header[\"Created\"])\n- if \"Type\" in pep_header:\n- pep_embed.add_field(name=\"Type\", value=pep_header[\"Type\"])\n+ fields_to_check = (\"Status\", \"Python-Version\", \"Created\", \"Type\")\n+ for field in fields_to_check:\n+ # Check for a PEP metadata field that is present but has an empty value\n+ # embed field values can't contain an empty string\n+ if pep_header.get(field, \"\"):\n+ pep_embed.add_field(name=field, value=pep_header[field])\n \n elif response.status != 404:\n # any response except 200 and 404 is expected\n", "issue": "PEP Command Fails on Empty Metadata\nCurrently, the PEP command assumes that if a metadata field is present in the PEP's summary table that the value is populated:\r\n\r\nhttps://github.com/python-discord/bot/blob/74d990540a1072c1782fa7593d7d1abe3c165f49/bot/cogs/utils.py#L64-L72\r\n\r\nHowever, this is not always the case, e.g. [PEP 249](https://www.python.org/dev/peps/pep-0249/):\r\n\r\n\r\n\r\nBecause of this, the embed field's `value` can be provided an empty string, causing an exception to be raised:\r\n\r\n```\r\nHTTPException: 400 BAD REQUEST (error code: 50035): Invalid Form Body\r\nIn embed.fields.1.value: This field is required\r\n```\r\n\r\nTo fix this, there should be a catch for empty values to prevent a field being added if there's no value to populate.\n", "before_files": [{"content": "import logging\nimport re\nimport unicodedata\nfrom asyncio import TimeoutError, sleep\nfrom email.parser import HeaderParser\nfrom io import StringIO\nfrom typing import Tuple\n\nfrom dateutil import relativedelta\nfrom discord import Colour, Embed, Message, Role\nfrom discord.ext.commands import Cog, Context, command\n\nfrom bot.bot import Bot\nfrom bot.constants import Channels, MODERATION_ROLES, Mention, STAFF_ROLES\nfrom bot.decorators import in_channel, with_role\nfrom bot.utils.time import humanize_delta\n\nlog = logging.getLogger(__name__)\n\n\nclass Utils(Cog):\n \"\"\"A selection of utilities which don't have a clear category.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n self.base_pep_url = \"http://www.python.org/dev/peps/pep-\"\n self.base_github_pep_url = \"https://raw.githubusercontent.com/python/peps/master/pep-\"\n\n @command(name='pep', aliases=('get_pep', 'p'))\n async def pep_command(self, ctx: Context, pep_number: str) -> None:\n \"\"\"Fetches information about a PEP and sends it to the channel.\"\"\"\n if pep_number.isdigit():\n pep_number = int(pep_number)\n else:\n await ctx.invoke(self.bot.get_command(\"help\"), \"pep\")\n return\n\n possible_extensions = ['.txt', '.rst']\n found_pep = False\n for extension in possible_extensions:\n # Attempt to fetch the PEP\n pep_url = f\"{self.base_github_pep_url}{pep_number:04}{extension}\"\n log.trace(f\"Requesting PEP {pep_number} with {pep_url}\")\n response = await self.bot.http_session.get(pep_url)\n\n if response.status == 200:\n log.trace(\"PEP found\")\n found_pep = True\n\n pep_content = await response.text()\n\n # Taken from https://github.com/python/peps/blob/master/pep0/pep.py#L179\n pep_header = HeaderParser().parse(StringIO(pep_content))\n\n # Assemble the embed\n pep_embed = Embed(\n title=f\"**PEP {pep_number} - {pep_header['Title']}**\",\n description=f\"[Link]({self.base_pep_url}{pep_number:04})\",\n )\n\n pep_embed.set_thumbnail(url=\"https://www.python.org/static/opengraph-icon-200x200.png\")\n\n # Add the interesting information\n if \"Status\" in pep_header:\n pep_embed.add_field(name=\"Status\", value=pep_header[\"Status\"])\n if \"Python-Version\" in pep_header:\n pep_embed.add_field(name=\"Python-Version\", value=pep_header[\"Python-Version\"])\n if \"Created\" in pep_header:\n pep_embed.add_field(name=\"Created\", value=pep_header[\"Created\"])\n if \"Type\" in pep_header:\n pep_embed.add_field(name=\"Type\", value=pep_header[\"Type\"])\n\n elif response.status != 404:\n # any response except 200 and 404 is expected\n found_pep = True # actually not, but it's easier to display this way\n log.trace(f\"The user requested PEP {pep_number}, but the response had an unexpected status code: \"\n f\"{response.status}.\\n{response.text}\")\n\n error_message = \"Unexpected HTTP error during PEP search. Please let us know.\"\n pep_embed = Embed(title=\"Unexpected error\", description=error_message)\n pep_embed.colour = Colour.red()\n break\n\n if not found_pep:\n log.trace(\"PEP was not found\")\n not_found = f\"PEP {pep_number} does not exist.\"\n pep_embed = Embed(title=\"PEP not found\", description=not_found)\n pep_embed.colour = Colour.red()\n\n await ctx.message.channel.send(embed=pep_embed)\n\n @command()\n @in_channel(Channels.bot, bypass_roles=STAFF_ROLES)\n async def charinfo(self, ctx: Context, *, characters: str) -> None:\n \"\"\"Shows you information on up to 25 unicode characters.\"\"\"\n match = re.match(r\"<(a?):(\\w+):(\\d+)>\", characters)\n if match:\n embed = Embed(\n title=\"Non-Character Detected\",\n description=(\n \"Only unicode characters can be processed, but a custom Discord emoji \"\n \"was found. Please remove it and try again.\"\n )\n )\n embed.colour = Colour.red()\n await ctx.send(embed=embed)\n return\n\n if len(characters) > 25:\n embed = Embed(title=f\"Too many characters ({len(characters)}/25)\")\n embed.colour = Colour.red()\n await ctx.send(embed=embed)\n return\n\n def get_info(char: str) -> Tuple[str, str]:\n digit = f\"{ord(char):x}\"\n if len(digit) <= 4:\n u_code = f\"\\\\u{digit:>04}\"\n else:\n u_code = f\"\\\\U{digit:>08}\"\n url = f\"https://www.compart.com/en/unicode/U+{digit:>04}\"\n name = f\"[{unicodedata.name(char, '')}]({url})\"\n info = f\"`{u_code.ljust(10)}`: {name} - {char}\"\n return info, u_code\n\n charlist, rawlist = zip(*(get_info(c) for c in characters))\n\n embed = Embed(description=\"\\n\".join(charlist))\n embed.set_author(name=\"Character Info\")\n\n if len(characters) > 1:\n embed.add_field(name='Raw', value=f\"`{''.join(rawlist)}`\", inline=False)\n\n await ctx.send(embed=embed)\n\n @command()\n @with_role(*MODERATION_ROLES)\n async def mention(self, ctx: Context, *, role: Role) -> None:\n \"\"\"Set a role to be mentionable for a limited time.\"\"\"\n if role.mentionable:\n await ctx.send(f\"{role} is already mentionable!\")\n return\n\n await role.edit(reason=f\"Role unlocked by {ctx.author}\", mentionable=True)\n\n human_time = humanize_delta(relativedelta.relativedelta(seconds=Mention.message_timeout))\n await ctx.send(\n f\"{role} has been made mentionable. I will reset it in {human_time}, or when someone mentions this role.\"\n )\n\n def check(m: Message) -> bool:\n \"\"\"Checks that the message contains the role mention.\"\"\"\n return role in m.role_mentions\n\n try:\n msg = await self.bot.wait_for(\"message\", check=check, timeout=Mention.message_timeout)\n except TimeoutError:\n await role.edit(mentionable=False, reason=\"Automatic role lock - timeout.\")\n await ctx.send(f\"{ctx.author.mention}, you took too long. I have reset {role} to be unmentionable.\")\n return\n\n if any(r.id in MODERATION_ROLES for r in msg.author.roles):\n await sleep(Mention.reset_delay)\n await role.edit(mentionable=False, reason=f\"Automatic role lock by {msg.author}\")\n await ctx.send(\n f\"{ctx.author.mention}, I have reset {role} to be unmentionable as \"\n f\"{msg.author if msg.author != ctx.author else 'you'} sent a message mentioning it.\"\n )\n return\n\n await role.edit(mentionable=False, reason=f\"Automatic role lock - unauthorised use by {msg.author}\")\n await ctx.send(\n f\"{ctx.author.mention}, I have reset {role} to be unmentionable \"\n f\"as I detected unauthorised use by {msg.author} (ID: {msg.author.id}).\"\n )\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Utils cog.\"\"\"\n bot.add_cog(Utils(bot))\n", "path": "bot/cogs/utils.py"}], "after_files": [{"content": "import logging\nimport re\nimport unicodedata\nfrom asyncio import TimeoutError, sleep\nfrom email.parser import HeaderParser\nfrom io import StringIO\nfrom typing import Tuple\n\nfrom dateutil import relativedelta\nfrom discord import Colour, Embed, Message, Role\nfrom discord.ext.commands import Cog, Context, command\n\nfrom bot.bot import Bot\nfrom bot.constants import Channels, MODERATION_ROLES, Mention, STAFF_ROLES\nfrom bot.decorators import in_channel, with_role\nfrom bot.utils.time import humanize_delta\n\nlog = logging.getLogger(__name__)\n\n\nclass Utils(Cog):\n \"\"\"A selection of utilities which don't have a clear category.\"\"\"\n\n def __init__(self, bot: Bot):\n self.bot = bot\n\n self.base_pep_url = \"http://www.python.org/dev/peps/pep-\"\n self.base_github_pep_url = \"https://raw.githubusercontent.com/python/peps/master/pep-\"\n\n @command(name='pep', aliases=('get_pep', 'p'))\n async def pep_command(self, ctx: Context, pep_number: str) -> None:\n \"\"\"Fetches information about a PEP and sends it to the channel.\"\"\"\n if pep_number.isdigit():\n pep_number = int(pep_number)\n else:\n await ctx.invoke(self.bot.get_command(\"help\"), \"pep\")\n return\n\n possible_extensions = ['.txt', '.rst']\n found_pep = False\n for extension in possible_extensions:\n # Attempt to fetch the PEP\n pep_url = f\"{self.base_github_pep_url}{pep_number:04}{extension}\"\n log.trace(f\"Requesting PEP {pep_number} with {pep_url}\")\n response = await self.bot.http_session.get(pep_url)\n\n if response.status == 200:\n log.trace(\"PEP found\")\n found_pep = True\n\n pep_content = await response.text()\n\n # Taken from https://github.com/python/peps/blob/master/pep0/pep.py#L179\n pep_header = HeaderParser().parse(StringIO(pep_content))\n\n # Assemble the embed\n pep_embed = Embed(\n title=f\"**PEP {pep_number} - {pep_header['Title']}**\",\n description=f\"[Link]({self.base_pep_url}{pep_number:04})\",\n )\n\n pep_embed.set_thumbnail(url=\"https://www.python.org/static/opengraph-icon-200x200.png\")\n\n # Add the interesting information\n fields_to_check = (\"Status\", \"Python-Version\", \"Created\", \"Type\")\n for field in fields_to_check:\n # Check for a PEP metadata field that is present but has an empty value\n # embed field values can't contain an empty string\n if pep_header.get(field, \"\"):\n pep_embed.add_field(name=field, value=pep_header[field])\n\n elif response.status != 404:\n # any response except 200 and 404 is expected\n found_pep = True # actually not, but it's easier to display this way\n log.trace(f\"The user requested PEP {pep_number}, but the response had an unexpected status code: \"\n f\"{response.status}.\\n{response.text}\")\n\n error_message = \"Unexpected HTTP error during PEP search. Please let us know.\"\n pep_embed = Embed(title=\"Unexpected error\", description=error_message)\n pep_embed.colour = Colour.red()\n break\n\n if not found_pep:\n log.trace(\"PEP was not found\")\n not_found = f\"PEP {pep_number} does not exist.\"\n pep_embed = Embed(title=\"PEP not found\", description=not_found)\n pep_embed.colour = Colour.red()\n\n await ctx.message.channel.send(embed=pep_embed)\n\n @command()\n @in_channel(Channels.bot, bypass_roles=STAFF_ROLES)\n async def charinfo(self, ctx: Context, *, characters: str) -> None:\n \"\"\"Shows you information on up to 25 unicode characters.\"\"\"\n match = re.match(r\"<(a?):(\\w+):(\\d+)>\", characters)\n if match:\n embed = Embed(\n title=\"Non-Character Detected\",\n description=(\n \"Only unicode characters can be processed, but a custom Discord emoji \"\n \"was found. Please remove it and try again.\"\n )\n )\n embed.colour = Colour.red()\n await ctx.send(embed=embed)\n return\n\n if len(characters) > 25:\n embed = Embed(title=f\"Too many characters ({len(characters)}/25)\")\n embed.colour = Colour.red()\n await ctx.send(embed=embed)\n return\n\n def get_info(char: str) -> Tuple[str, str]:\n digit = f\"{ord(char):x}\"\n if len(digit) <= 4:\n u_code = f\"\\\\u{digit:>04}\"\n else:\n u_code = f\"\\\\U{digit:>08}\"\n url = f\"https://www.compart.com/en/unicode/U+{digit:>04}\"\n name = f\"[{unicodedata.name(char, '')}]({url})\"\n info = f\"`{u_code.ljust(10)}`: {name} - {char}\"\n return info, u_code\n\n charlist, rawlist = zip(*(get_info(c) for c in characters))\n\n embed = Embed(description=\"\\n\".join(charlist))\n embed.set_author(name=\"Character Info\")\n\n if len(characters) > 1:\n embed.add_field(name='Raw', value=f\"`{''.join(rawlist)}`\", inline=False)\n\n await ctx.send(embed=embed)\n\n @command()\n @with_role(*MODERATION_ROLES)\n async def mention(self, ctx: Context, *, role: Role) -> None:\n \"\"\"Set a role to be mentionable for a limited time.\"\"\"\n if role.mentionable:\n await ctx.send(f\"{role} is already mentionable!\")\n return\n\n await role.edit(reason=f\"Role unlocked by {ctx.author}\", mentionable=True)\n\n human_time = humanize_delta(relativedelta.relativedelta(seconds=Mention.message_timeout))\n await ctx.send(\n f\"{role} has been made mentionable. I will reset it in {human_time}, or when someone mentions this role.\"\n )\n\n def check(m: Message) -> bool:\n \"\"\"Checks that the message contains the role mention.\"\"\"\n return role in m.role_mentions\n\n try:\n msg = await self.bot.wait_for(\"message\", check=check, timeout=Mention.message_timeout)\n except TimeoutError:\n await role.edit(mentionable=False, reason=\"Automatic role lock - timeout.\")\n await ctx.send(f\"{ctx.author.mention}, you took too long. I have reset {role} to be unmentionable.\")\n return\n\n if any(r.id in MODERATION_ROLES for r in msg.author.roles):\n await sleep(Mention.reset_delay)\n await role.edit(mentionable=False, reason=f\"Automatic role lock by {msg.author}\")\n await ctx.send(\n f\"{ctx.author.mention}, I have reset {role} to be unmentionable as \"\n f\"{msg.author if msg.author != ctx.author else 'you'} sent a message mentioning it.\"\n )\n return\n\n await role.edit(mentionable=False, reason=f\"Automatic role lock - unauthorised use by {msg.author}\")\n await ctx.send(\n f\"{ctx.author.mention}, I have reset {role} to be unmentionable \"\n f\"as I detected unauthorised use by {msg.author} (ID: {msg.author.id}).\"\n )\n\n\ndef setup(bot: Bot) -> None:\n \"\"\"Load the Utils cog.\"\"\"\n bot.add_cog(Utils(bot))\n", "path": "bot/cogs/utils.py"}]} | 2,728 | 315 |
gh_patches_debug_12735 | rasdani/github-patches | git_diff | wright-group__WrightTools-82 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
link to github on sphinx docs
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `docs/conf.py`
Content:
```
1 #!/usr/bin/env python3
2 # -*- coding: utf-8 -*-
3 #
4 # WrightTools documentation build configuration file, created by
5 # sphinx-quickstart on Tue Jul 18 13:01:20 2017.
6 #
7 # This file is execfile()d with the current directory set to its
8 # containing dir.
9 #
10 # Note that not all possible configuration values are present in this
11 # autogenerated file.
12 #
13 # All configuration values have a default; values that are commented out
14 # serve to show the default.
15
16 # If extensions (or modules to document with autodoc) are in another directory,
17 # add these directories to sys.path here. If the directory is relative to the
18 # documentation root, use os.path.abspath to make it absolute, like shown here.
19 #
20 import os
21 import sys
22 sys.path.insert(0, os.path.abspath('.'))
23 sys.path.insert(0, os.path.abspath('../WrightTools'))
24
25
26 # -- General configuration ------------------------------------------------
27
28 # If your documentation needs a minimal Sphinx version, state it here.
29 #
30 # needs_sphinx = '1.0'
31
32 # Add any Sphinx extension module names here, as strings. They can be
33 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
34 # ones.
35 extensions = ['sphinx.ext.autodoc',
36 'sphinx.ext.doctest',
37 'sphinx.ext.intersphinx',
38 'sphinx.ext.todo',
39 'sphinx.ext.coverage',
40 'sphinx.ext.mathjax',
41 'sphinx.ext.ifconfig',
42 'sphinx.ext.viewcode',
43 'numpydoc']
44
45 # Add any paths that contain templates here, relative to this directory.
46 templates_path = ['_templates']
47
48 # The suffix(es) of source filenames.
49 # You can specify multiple suffix as a list of string:
50 #
51 # source_suffix = ['.rst', '.md']
52 source_suffix = '.rst'
53
54 # The master toctree document.
55 master_doc = 'index'
56
57 # General information about the project.
58 project = 'WrightTools'
59 copyright = '2016-2017, WrightTools Developers'
60 author = 'WrightTools Developers'
61
62 # The version info for the project you're documenting, acts as replacement for
63 # |version| and |release|, also used in various other places throughout the
64 # built documents.
65 #
66 # The short X.Y version.
67 version = '2.13.1'
68 # The full version, including alpha/beta/rc tags.
69 release = '2.13.1'
70
71 # The language for content autogenerated by Sphinx. Refer to documentation
72 # for a list of supported languages.
73 #
74 # This is also used if you do content translation via gettext catalogs.
75 # Usually you set "language" from the command line for these cases.
76 language = None
77
78 # List of patterns, relative to source directory, that match files and
79 # directories to ignore when looking for source files.
80 # This patterns also effect to html_static_path and html_extra_path
81 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
82
83 # The name of the Pygments (syntax highlighting) style to use.
84 pygments_style = 'sphinx'
85
86 # If true, `todo` and `todoList` produce output, else they produce nothing.
87 todo_include_todos = True
88
89
90 # -- Options for HTML output ----------------------------------------------
91
92 # The theme to use for HTML and HTML Help pages. See the documentation for
93 # a list of builtin themes.
94 #
95 html_theme = 'sphinx_rtd_theme'
96
97 # Theme options are theme-specific and customize the look and feel of a theme
98 # further. For a list of options available for each theme, see the
99 # documentation.
100 #
101 # html_theme_options = {}
102
103 # Add any paths that contain custom static files (such as style sheets) here,
104 # relative to this directory. They are copied after the builtin static files,
105 # so a file named "default.css" will overwrite the builtin "default.css".
106 html_static_path = ['_static']
107
108 # Custom sidebar templates, must be a dictionary that maps document names
109 # to template names.
110 #
111 # This is required for the alabaster theme
112 # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
113 html_sidebars = {
114 '**': [
115 'about.html',
116 'navigation.html',
117 'relations.html', # needs 'show_related': True theme option to display
118 'searchbox.html',
119 'donate.html',
120 ]
121 }
122
123
124 # -- Options for HTMLHelp output ------------------------------------------
125
126 # Output file base name for HTML help builder.
127 htmlhelp_basename = 'WrightToolsdoc'
128
129
130 # -- Options for LaTeX output ---------------------------------------------
131
132 latex_elements = {
133 # The paper size ('letterpaper' or 'a4paper').
134 #
135 # 'papersize': 'letterpaper',
136
137 # The font size ('10pt', '11pt' or '12pt').
138 #
139 # 'pointsize': '10pt',
140
141 # Additional stuff for the LaTeX preamble.
142 #
143 # 'preamble': '',
144
145 # Latex figure (float) alignment
146 #
147 # 'figure_align': 'htbp',
148 }
149
150 # Grouping the document tree into LaTeX files. List of tuples
151 # (source start file, target name, title,
152 # author, documentclass [howto, manual, or own class]).
153 latex_documents = [
154 (master_doc, 'WrightTools.tex', 'WrightTools Documentation',
155 'WrightTools Developers', 'manual'),
156 ]
157
158
159 # -- Options for manual page output ---------------------------------------
160
161 # One entry per manual page. List of tuples
162 # (source start file, name, description, authors, manual section).
163 man_pages = [
164 (master_doc, 'wrighttools', 'WrightTools Documentation',
165 [author], 1)
166 ]
167
168
169 # -- Options for Texinfo output -------------------------------------------
170
171 # Grouping the document tree into Texinfo files. List of tuples
172 # (source start file, target name, title, author,
173 # dir menu entry, description, category)
174 texinfo_documents = [
175 (master_doc, 'WrightTools', 'WrightTools Documentation',
176 author, 'WrightTools', 'One line description of project.',
177 'Miscellaneous'),
178 ]
179
180
181
182
183 # Example configuration for intersphinx: refer to the Python standard library.
184 intersphinx_mapping = {'https://docs.python.org/': None}
185
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -100,6 +100,15 @@
#
# html_theme_options = {}
+# HTML context adapted from http://docs.readthedocs.io/en/latest/vcs.html
+html_context = {
+ "display_github": True, # Integrate GitHub
+ "github_user": "wright-group", # Username
+ "github_repo": "WrightTools", # Repo name
+ "github_version": "documentation", # Version
+ "conf_py_path": "/docs/", # Path in the checkout to the docs root
+}
+
# Add any paths that contain custom static files (such as style sheets) here,
# relative to this directory. They are copied after the builtin static files,
# so a file named "default.css" will overwrite the builtin "default.css".
| {"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -100,6 +100,15 @@\n #\n # html_theme_options = {}\n \n+# HTML context adapted from http://docs.readthedocs.io/en/latest/vcs.html\n+html_context = {\n+ \"display_github\": True, # Integrate GitHub\n+ \"github_user\": \"wright-group\", # Username\n+ \"github_repo\": \"WrightTools\", # Repo name\n+ \"github_version\": \"documentation\", # Version\n+ \"conf_py_path\": \"/docs/\", # Path in the checkout to the docs root\n+}\n+\n # Add any paths that contain custom static files (such as style sheets) here,\n # relative to this directory. They are copied after the builtin static files,\n # so a file named \"default.css\" will overwrite the builtin \"default.css\".\n", "issue": "link to github on sphinx docs\n\n", "before_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# WrightTools documentation build configuration file, created by\n# sphinx-quickstart on Tue Jul 18 13:01:20 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('../WrightTools'))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.todo',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.ifconfig',\n 'sphinx.ext.viewcode',\n 'numpydoc']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'WrightTools'\ncopyright = '2016-2017, WrightTools Developers'\nauthor = 'WrightTools Developers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '2.13.1'\n# The full version, including alpha/beta/rc tags.\nrelease = '2.13.1'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n '**': [\n 'about.html',\n 'navigation.html',\n 'relations.html', # needs 'show_related': True theme option to display\n 'searchbox.html',\n 'donate.html',\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'WrightToolsdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'WrightTools.tex', 'WrightTools Documentation',\n 'WrightTools Developers', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'wrighttools', 'WrightTools Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'WrightTools', 'WrightTools Documentation',\n author, 'WrightTools', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {'https://docs.python.org/': None}\n", "path": "docs/conf.py"}], "after_files": [{"content": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n#\n# WrightTools documentation build configuration file, created by\n# sphinx-quickstart on Tue Jul 18 13:01:20 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nsys.path.insert(0, os.path.abspath('.'))\nsys.path.insert(0, os.path.abspath('../WrightTools'))\n\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.autodoc',\n 'sphinx.ext.doctest',\n 'sphinx.ext.intersphinx',\n 'sphinx.ext.todo',\n 'sphinx.ext.coverage',\n 'sphinx.ext.mathjax',\n 'sphinx.ext.ifconfig',\n 'sphinx.ext.viewcode',\n 'numpydoc']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = 'WrightTools'\ncopyright = '2016-2017, WrightTools Developers'\nauthor = 'WrightTools Developers'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '2.13.1'\n# The full version, including alpha/beta/rc tags.\nrelease = '2.13.1'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# HTML context adapted from http://docs.readthedocs.io/en/latest/vcs.html\nhtml_context = {\n \"display_github\": True, # Integrate GitHub\n \"github_user\": \"wright-group\", # Username\n \"github_repo\": \"WrightTools\", # Repo name\n \"github_version\": \"documentation\", # Version\n \"conf_py_path\": \"/docs/\", # Path in the checkout to the docs root\n}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n '**': [\n 'about.html',\n 'navigation.html',\n 'relations.html', # needs 'show_related': True theme option to display\n 'searchbox.html',\n 'donate.html',\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'WrightToolsdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'WrightTools.tex', 'WrightTools Documentation',\n 'WrightTools Developers', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'wrighttools', 'WrightTools Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'WrightTools', 'WrightTools Documentation',\n author, 'WrightTools', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\n\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {'https://docs.python.org/': None}\n", "path": "docs/conf.py"}]} | 2,083 | 196 |
gh_patches_debug_5757 | rasdani/github-patches | git_diff | edgedb__edgedb-7149 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
ALTER MODULE foo RENAME TO bar gives ISE
We should produce a parse error or an unimplemented message.
We could actually support it, but it might actually be kind of hairy to do, since in the data model modules really don't *do* anything, they *just* lay claim to a name. (And DDL isn't *that* important anyway; renaming a module might actually work in SDL...)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `edb/schema/modules.py`
Content:
```
1 #
2 # This source file is part of the EdgeDB open source project.
3 #
4 # Copyright 2008-present MagicStack Inc. and the EdgeDB authors.
5 #
6 # Licensed under the Apache License, Version 2.0 (the "License");
7 # you may not use this file except in compliance with the License.
8 # You may obtain a copy of the License at
9 #
10 # http://www.apache.org/licenses/LICENSE-2.0
11 #
12 # Unless required by applicable law or agreed to in writing, software
13 # distributed under the License is distributed on an "AS IS" BASIS,
14 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
15 # See the License for the specific language governing permissions and
16 # limitations under the License.
17 #
18
19
20 from __future__ import annotations
21
22
23 from edb import errors
24
25 from edb.edgeql import ast as qlast
26 from edb.edgeql import qltypes
27
28 from . import annos as s_anno
29 from . import delta as sd
30 from . import name as sn
31 from . import objects as so
32 from . import schema as s_schema
33
34 RESERVED_MODULE_NAMES = {
35 'super',
36 }
37
38
39 class Module(
40 s_anno.AnnotationSubject,
41 so.Object, # Help reflection figure out the right db MRO
42 qlkind=qltypes.SchemaObjectClass.MODULE,
43 data_safe=False,
44 ):
45 # N.B: Modules are not "qualified" objects, even though they can
46 # be nested (because they might *not* be nested) and we arrange
47 # for their names to always be represented with an UnqualName.
48 pass
49
50
51 class ModuleCommandContext(sd.ObjectCommandContext[Module]):
52 pass
53
54
55 class ModuleCommand(
56 sd.ObjectCommand[Module],
57 context_class=ModuleCommandContext,
58 ):
59
60 def _validate_legal_command(
61 self,
62 schema: s_schema.Schema,
63 context: sd.CommandContext,
64 ) -> None:
65 super()._validate_legal_command(schema, context)
66
67 last = str(self.classname)
68 first = last
69 enclosing = None
70 if '::' in str(self.classname):
71 first, _, _ = str(self.classname).partition('::')
72 enclosing, _, last = str(self.classname).rpartition('::')
73 if not schema.has_module(enclosing):
74 raise errors.UnknownModuleError(
75 f'module {enclosing!r} is not in this schema')
76
77 if last in RESERVED_MODULE_NAMES:
78 raise errors.SchemaDefinitionError(
79 f"module {last!r} is a reserved module name")
80
81 if (
82 not context.stdmode and not context.testmode
83 and sn.UnqualName(first) in s_schema.STD_MODULES
84 ):
85 raise errors.SchemaDefinitionError(
86 f'cannot {self._delta_action} {self.get_verbosename()}: '
87 f'module {first} is read-only',
88 span=self.span)
89
90
91 class CreateModule(ModuleCommand, sd.CreateObject[Module]):
92 astnode = qlast.CreateModule
93
94
95 class AlterModule(ModuleCommand, sd.AlterObject[Module]):
96 astnode = qlast.AlterModule
97
98
99 class DeleteModule(ModuleCommand, sd.DeleteObject[Module]):
100 astnode = qlast.DropModule
101
102 def _validate_legal_command(
103 self,
104 schema: s_schema.Schema,
105 context: sd.CommandContext,
106 ) -> None:
107 super()._validate_legal_command(schema, context)
108
109 # For now, we disallow deleting non-empty modules.
110
111 # Modules aren't actually stored with any direct linkage
112 # to the objects in them, so explicitly search for objects
113 # in the module (excluding the module itself).
114 has_objects = bool(any(schema.get_objects(
115 included_modules=[self.classname],
116 excluded_items=[self.classname],
117 )))
118
119 if has_objects:
120 vn = self.scls.get_verbosename(schema)
121 raise errors.SchemaError(
122 f'cannot drop {vn} because it is not empty'
123 )
124
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/edb/schema/modules.py b/edb/schema/modules.py
--- a/edb/schema/modules.py
+++ b/edb/schema/modules.py
@@ -96,6 +96,19 @@
astnode = qlast.AlterModule
+class RenameModule(ModuleCommand, sd.RenameObject[Module]):
+
+ def apply(
+ self,
+ schema: s_schema.Schema,
+ context: sd.CommandContext,
+ ) -> s_schema.Schema:
+ raise errors.SchemaError(
+ f'renaming modules is not supported',
+ span=self.span,
+ )
+
+
class DeleteModule(ModuleCommand, sd.DeleteObject[Module]):
astnode = qlast.DropModule
| {"golden_diff": "diff --git a/edb/schema/modules.py b/edb/schema/modules.py\n--- a/edb/schema/modules.py\n+++ b/edb/schema/modules.py\n@@ -96,6 +96,19 @@\n astnode = qlast.AlterModule\n \n \n+class RenameModule(ModuleCommand, sd.RenameObject[Module]):\n+\n+ def apply(\n+ self,\n+ schema: s_schema.Schema,\n+ context: sd.CommandContext,\n+ ) -> s_schema.Schema:\n+ raise errors.SchemaError(\n+ f'renaming modules is not supported',\n+ span=self.span,\n+ )\n+\n+\n class DeleteModule(ModuleCommand, sd.DeleteObject[Module]):\n astnode = qlast.DropModule\n", "issue": "ALTER MODULE foo RENAME TO bar gives ISE\nWe should produce a parse error or an unimplemented message.\r\n\r\nWe could actually support it, but it might actually be kind of hairy to do, since in the data model modules really don't *do* anything, they *just* lay claim to a name. (And DDL isn't *that* important anyway; renaming a module might actually work in SDL...)\n", "before_files": [{"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2008-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\nfrom __future__ import annotations\n\n\nfrom edb import errors\n\nfrom edb.edgeql import ast as qlast\nfrom edb.edgeql import qltypes\n\nfrom . import annos as s_anno\nfrom . import delta as sd\nfrom . import name as sn\nfrom . import objects as so\nfrom . import schema as s_schema\n\nRESERVED_MODULE_NAMES = {\n 'super',\n}\n\n\nclass Module(\n s_anno.AnnotationSubject,\n so.Object, # Help reflection figure out the right db MRO\n qlkind=qltypes.SchemaObjectClass.MODULE,\n data_safe=False,\n):\n # N.B: Modules are not \"qualified\" objects, even though they can\n # be nested (because they might *not* be nested) and we arrange\n # for their names to always be represented with an UnqualName.\n pass\n\n\nclass ModuleCommandContext(sd.ObjectCommandContext[Module]):\n pass\n\n\nclass ModuleCommand(\n sd.ObjectCommand[Module],\n context_class=ModuleCommandContext,\n):\n\n def _validate_legal_command(\n self,\n schema: s_schema.Schema,\n context: sd.CommandContext,\n ) -> None:\n super()._validate_legal_command(schema, context)\n\n last = str(self.classname)\n first = last\n enclosing = None\n if '::' in str(self.classname):\n first, _, _ = str(self.classname).partition('::')\n enclosing, _, last = str(self.classname).rpartition('::')\n if not schema.has_module(enclosing):\n raise errors.UnknownModuleError(\n f'module {enclosing!r} is not in this schema')\n\n if last in RESERVED_MODULE_NAMES:\n raise errors.SchemaDefinitionError(\n f\"module {last!r} is a reserved module name\")\n\n if (\n not context.stdmode and not context.testmode\n and sn.UnqualName(first) in s_schema.STD_MODULES\n ):\n raise errors.SchemaDefinitionError(\n f'cannot {self._delta_action} {self.get_verbosename()}: '\n f'module {first} is read-only',\n span=self.span)\n\n\nclass CreateModule(ModuleCommand, sd.CreateObject[Module]):\n astnode = qlast.CreateModule\n\n\nclass AlterModule(ModuleCommand, sd.AlterObject[Module]):\n astnode = qlast.AlterModule\n\n\nclass DeleteModule(ModuleCommand, sd.DeleteObject[Module]):\n astnode = qlast.DropModule\n\n def _validate_legal_command(\n self,\n schema: s_schema.Schema,\n context: sd.CommandContext,\n ) -> None:\n super()._validate_legal_command(schema, context)\n\n # For now, we disallow deleting non-empty modules.\n\n # Modules aren't actually stored with any direct linkage\n # to the objects in them, so explicitly search for objects\n # in the module (excluding the module itself).\n has_objects = bool(any(schema.get_objects(\n included_modules=[self.classname],\n excluded_items=[self.classname],\n )))\n\n if has_objects:\n vn = self.scls.get_verbosename(schema)\n raise errors.SchemaError(\n f'cannot drop {vn} because it is not empty'\n )\n", "path": "edb/schema/modules.py"}], "after_files": [{"content": "#\n# This source file is part of the EdgeDB open source project.\n#\n# Copyright 2008-present MagicStack Inc. and the EdgeDB authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\n\nfrom __future__ import annotations\n\n\nfrom edb import errors\n\nfrom edb.edgeql import ast as qlast\nfrom edb.edgeql import qltypes\n\nfrom . import annos as s_anno\nfrom . import delta as sd\nfrom . import name as sn\nfrom . import objects as so\nfrom . import schema as s_schema\n\nRESERVED_MODULE_NAMES = {\n 'super',\n}\n\n\nclass Module(\n s_anno.AnnotationSubject,\n so.Object, # Help reflection figure out the right db MRO\n qlkind=qltypes.SchemaObjectClass.MODULE,\n data_safe=False,\n):\n # N.B: Modules are not \"qualified\" objects, even though they can\n # be nested (because they might *not* be nested) and we arrange\n # for their names to always be represented with an UnqualName.\n pass\n\n\nclass ModuleCommandContext(sd.ObjectCommandContext[Module]):\n pass\n\n\nclass ModuleCommand(\n sd.ObjectCommand[Module],\n context_class=ModuleCommandContext,\n):\n\n def _validate_legal_command(\n self,\n schema: s_schema.Schema,\n context: sd.CommandContext,\n ) -> None:\n super()._validate_legal_command(schema, context)\n\n last = str(self.classname)\n first = last\n enclosing = None\n if '::' in str(self.classname):\n first, _, _ = str(self.classname).partition('::')\n enclosing, _, last = str(self.classname).rpartition('::')\n if not schema.has_module(enclosing):\n raise errors.UnknownModuleError(\n f'module {enclosing!r} is not in this schema')\n\n if last in RESERVED_MODULE_NAMES:\n raise errors.SchemaDefinitionError(\n f\"module {last!r} is a reserved module name\")\n\n if (\n not context.stdmode and not context.testmode\n and sn.UnqualName(first) in s_schema.STD_MODULES\n ):\n raise errors.SchemaDefinitionError(\n f'cannot {self._delta_action} {self.get_verbosename()}: '\n f'module {first} is read-only',\n span=self.span)\n\n\nclass CreateModule(ModuleCommand, sd.CreateObject[Module]):\n astnode = qlast.CreateModule\n\n\nclass AlterModule(ModuleCommand, sd.AlterObject[Module]):\n astnode = qlast.AlterModule\n\n\nclass RenameModule(ModuleCommand, sd.RenameObject[Module]):\n\n def apply(\n self,\n schema: s_schema.Schema,\n context: sd.CommandContext,\n ) -> s_schema.Schema:\n raise errors.SchemaError(\n f'renaming modules is not supported',\n span=self.span,\n )\n\n\nclass DeleteModule(ModuleCommand, sd.DeleteObject[Module]):\n astnode = qlast.DropModule\n\n def _validate_legal_command(\n self,\n schema: s_schema.Schema,\n context: sd.CommandContext,\n ) -> None:\n super()._validate_legal_command(schema, context)\n\n # For now, we disallow deleting non-empty modules.\n\n # Modules aren't actually stored with any direct linkage\n # to the objects in them, so explicitly search for objects\n # in the module (excluding the module itself).\n has_objects = bool(any(schema.get_objects(\n included_modules=[self.classname],\n excluded_items=[self.classname],\n )))\n\n if has_objects:\n vn = self.scls.get_verbosename(schema)\n raise errors.SchemaError(\n f'cannot drop {vn} because it is not empty'\n )\n", "path": "edb/schema/modules.py"}]} | 1,458 | 153 |
gh_patches_debug_14587 | rasdani/github-patches | git_diff | tobymao__sqlglot-2956 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Table incorrectly parsed as column
# Description
Table of format `<schema>.<table>` in a join gets mis-parsed as a column. In the attached example, the table `"usage"."company_names"` gets misparsed as a column.
### Version details
- Dialect is 'redshift'
- The issue exists on the latest pip version of sqlglot (21.0.2)
- The issue doesn't exist on the latest pip version of sqlglot (20.4.0)
### Correct output with sqlglot==20.4.0
```
Python 3.11.7 (main, Dec 4 2023, 18:10:11) [Clang 15.0.0 (clang-1500.1.0.2.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sqlglot
from sqlglot import parse_one
sqlglot.__version__>>> from sqlglot import parse_one
>>> sqlglot.__version__
'20.4.0'
>>> dialect = 'redshift'
>>> query = 'SELECT * FROM "usage"."usage" JOIN "usage"."company_names" ON "company_names"."id" = "usage"."customerid"'
>>> parse_one(query, dialect=dialect)
(SELECT expressions:
(STAR ), from:
(FROM this:
(TABLE this:
(IDENTIFIER this: usage, quoted: True), db:
(IDENTIFIER this: usage, quoted: True))), joins:
(JOIN this:
(TABLE this:
(IDENTIFIER this: company_names, quoted: True), db:
(IDENTIFIER this: usage, quoted: True)), on:
(EQ this:
(COLUMN this:
(IDENTIFIER this: id, quoted: True), table:
(IDENTIFIER this: company_names, quoted: True)), expression:
(COLUMN this:
(IDENTIFIER this: customerid, quoted: True), table:
(IDENTIFIER this: usage, quoted: True)))))
```
### Incorrect output with sqlglot==21.0.2
```
Python 3.11.7 (main, Dec 4 2023, 18:10:11) [Clang 15.0.0 (clang-1500.1.0.2.5)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import sqlglot
from sqlglot import parse_one
sqlglot.__version__>>> from sqlglot import parse_one
>>> sqlglot.__version__
'21.0.2'
>>> dialect = 'redshift'
>>> query = 'SELECT * FROM "usage"."usage" JOIN "usage"."company_names" ON "company_names"."id" = "usage"."customerid"'
>>> parse_one(query, dialect=dialect)
Select(
expressions=[
Star()],
from=From(
this=Table(
this=Identifier(this=usage, quoted=True),
db=Identifier(this=usage, quoted=True))),
joins=[
Join(
this=Column(
this=Identifier(this=company_names, quoted=True),
table=Identifier(this=usage, quoted=True)),
on=EQ(
this=Column(
this=Identifier(this=id, quoted=True),
table=Identifier(this=company_names, quoted=True)),
expression=Column(
this=Identifier(this=customerid, quoted=True),
table=Identifier(this=usage, quoted=True))))])
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `sqlglot/dialects/redshift.py`
Content:
```
1 from __future__ import annotations
2
3 import typing as t
4
5 from sqlglot import exp, transforms
6 from sqlglot.dialects.dialect import (
7 NormalizationStrategy,
8 concat_to_dpipe_sql,
9 concat_ws_to_dpipe_sql,
10 date_delta_sql,
11 generatedasidentitycolumnconstraint_sql,
12 json_extract_segments,
13 no_tablesample_sql,
14 rename_func,
15 )
16 from sqlglot.dialects.postgres import Postgres
17 from sqlglot.helper import seq_get
18 from sqlglot.tokens import TokenType
19
20 if t.TYPE_CHECKING:
21 from sqlglot._typing import E
22
23
24 def _parse_date_delta(expr_type: t.Type[E]) -> t.Callable[[t.List], E]:
25 def _parse_delta(args: t.List) -> E:
26 expr = expr_type(this=seq_get(args, 2), expression=seq_get(args, 1), unit=seq_get(args, 0))
27 if expr_type is exp.TsOrDsAdd:
28 expr.set("return_type", exp.DataType.build("TIMESTAMP"))
29
30 return expr
31
32 return _parse_delta
33
34
35 class Redshift(Postgres):
36 # https://docs.aws.amazon.com/redshift/latest/dg/r_names.html
37 NORMALIZATION_STRATEGY = NormalizationStrategy.CASE_INSENSITIVE
38
39 SUPPORTS_USER_DEFINED_TYPES = False
40 INDEX_OFFSET = 0
41
42 TIME_FORMAT = "'YYYY-MM-DD HH:MI:SS'"
43 TIME_MAPPING = {
44 **Postgres.TIME_MAPPING,
45 "MON": "%b",
46 "HH": "%H",
47 }
48
49 class Parser(Postgres.Parser):
50 FUNCTIONS = {
51 **Postgres.Parser.FUNCTIONS,
52 "ADD_MONTHS": lambda args: exp.TsOrDsAdd(
53 this=seq_get(args, 0),
54 expression=seq_get(args, 1),
55 unit=exp.var("month"),
56 return_type=exp.DataType.build("TIMESTAMP"),
57 ),
58 "DATEADD": _parse_date_delta(exp.TsOrDsAdd),
59 "DATE_ADD": _parse_date_delta(exp.TsOrDsAdd),
60 "DATEDIFF": _parse_date_delta(exp.TsOrDsDiff),
61 "DATE_DIFF": _parse_date_delta(exp.TsOrDsDiff),
62 "GETDATE": exp.CurrentTimestamp.from_arg_list,
63 "LISTAGG": exp.GroupConcat.from_arg_list,
64 "STRTOL": exp.FromBase.from_arg_list,
65 }
66
67 NO_PAREN_FUNCTION_PARSERS = {
68 **Postgres.Parser.NO_PAREN_FUNCTION_PARSERS,
69 "APPROXIMATE": lambda self: self._parse_approximate_count(),
70 "SYSDATE": lambda self: self.expression(exp.CurrentTimestamp, transaction=True),
71 }
72
73 def _parse_table(
74 self,
75 schema: bool = False,
76 joins: bool = False,
77 alias_tokens: t.Optional[t.Collection[TokenType]] = None,
78 parse_bracket: bool = False,
79 is_db_reference: bool = False,
80 ) -> t.Optional[exp.Expression]:
81 # Redshift supports UNPIVOTing SUPER objects, e.g. `UNPIVOT foo.obj[0] AS val AT attr`
82 unpivot = self._match(TokenType.UNPIVOT)
83 table = super()._parse_table(
84 schema=schema,
85 joins=joins,
86 alias_tokens=alias_tokens,
87 parse_bracket=parse_bracket,
88 is_db_reference=is_db_reference,
89 )
90
91 return self.expression(exp.Pivot, this=table, unpivot=True) if unpivot else table
92
93 def _parse_types(
94 self, check_func: bool = False, schema: bool = False, allow_identifiers: bool = True
95 ) -> t.Optional[exp.Expression]:
96 this = super()._parse_types(
97 check_func=check_func, schema=schema, allow_identifiers=allow_identifiers
98 )
99
100 if (
101 isinstance(this, exp.DataType)
102 and this.is_type("varchar")
103 and this.expressions
104 and this.expressions[0].this == exp.column("MAX")
105 ):
106 this.set("expressions", [exp.var("MAX")])
107
108 return this
109
110 def _parse_convert(
111 self, strict: bool, safe: t.Optional[bool] = None
112 ) -> t.Optional[exp.Expression]:
113 to = self._parse_types()
114 self._match(TokenType.COMMA)
115 this = self._parse_bitwise()
116 return self.expression(exp.TryCast, this=this, to=to, safe=safe)
117
118 def _parse_approximate_count(self) -> t.Optional[exp.ApproxDistinct]:
119 index = self._index - 1
120 func = self._parse_function()
121
122 if isinstance(func, exp.Count) and isinstance(func.this, exp.Distinct):
123 return self.expression(exp.ApproxDistinct, this=seq_get(func.this.expressions, 0))
124 self._retreat(index)
125 return None
126
127 def _parse_query_modifiers(
128 self, this: t.Optional[exp.Expression]
129 ) -> t.Optional[exp.Expression]:
130 this = super()._parse_query_modifiers(this)
131
132 if this:
133 refs = set()
134
135 for i, join in enumerate(this.args.get("joins", [])):
136 refs.add(
137 (
138 this.args["from"] if i == 0 else this.args["joins"][i - 1]
139 ).alias_or_name.lower()
140 )
141 table = join.this
142
143 if isinstance(table, exp.Table):
144 if table.parts[0].name.lower() in refs:
145 table.replace(table.to_column())
146 return this
147
148 class Tokenizer(Postgres.Tokenizer):
149 BIT_STRINGS = []
150 HEX_STRINGS = []
151 STRING_ESCAPES = ["\\", "'"]
152
153 KEYWORDS = {
154 **Postgres.Tokenizer.KEYWORDS,
155 "HLLSKETCH": TokenType.HLLSKETCH,
156 "SUPER": TokenType.SUPER,
157 "TOP": TokenType.TOP,
158 "UNLOAD": TokenType.COMMAND,
159 "VARBYTE": TokenType.VARBINARY,
160 }
161
162 # Redshift allows # to appear as a table identifier prefix
163 SINGLE_TOKENS = Postgres.Tokenizer.SINGLE_TOKENS.copy()
164 SINGLE_TOKENS.pop("#")
165
166 class Generator(Postgres.Generator):
167 LOCKING_READS_SUPPORTED = False
168 QUERY_HINTS = False
169 VALUES_AS_TABLE = False
170 TZ_TO_WITH_TIME_ZONE = True
171 NVL2_SUPPORTED = True
172 LAST_DAY_SUPPORTS_DATE_PART = False
173
174 TYPE_MAPPING = {
175 **Postgres.Generator.TYPE_MAPPING,
176 exp.DataType.Type.BINARY: "VARBYTE",
177 exp.DataType.Type.INT: "INTEGER",
178 exp.DataType.Type.TIMETZ: "TIME",
179 exp.DataType.Type.TIMESTAMPTZ: "TIMESTAMP",
180 exp.DataType.Type.VARBINARY: "VARBYTE",
181 }
182
183 TRANSFORMS = {
184 **Postgres.Generator.TRANSFORMS,
185 exp.Concat: concat_to_dpipe_sql,
186 exp.ConcatWs: concat_ws_to_dpipe_sql,
187 exp.ApproxDistinct: lambda self,
188 e: f"APPROXIMATE COUNT(DISTINCT {self.sql(e, 'this')})",
189 exp.CurrentTimestamp: lambda self, e: (
190 "SYSDATE" if e.args.get("transaction") else "GETDATE()"
191 ),
192 exp.DateAdd: date_delta_sql("DATEADD"),
193 exp.DateDiff: date_delta_sql("DATEDIFF"),
194 exp.DistKeyProperty: lambda self, e: f"DISTKEY({e.name})",
195 exp.DistStyleProperty: lambda self, e: self.naked_property(e),
196 exp.FromBase: rename_func("STRTOL"),
197 exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,
198 exp.JSONExtract: json_extract_segments("JSON_EXTRACT_PATH_TEXT"),
199 exp.GroupConcat: rename_func("LISTAGG"),
200 exp.ParseJSON: rename_func("JSON_PARSE"),
201 exp.Select: transforms.preprocess(
202 [transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]
203 ),
204 exp.SortKeyProperty: lambda self,
205 e: f"{'COMPOUND ' if e.args['compound'] else ''}SORTKEY({self.format_args(*e.this)})",
206 exp.TableSample: no_tablesample_sql,
207 exp.TsOrDsAdd: date_delta_sql("DATEADD"),
208 exp.TsOrDsDiff: date_delta_sql("DATEDIFF"),
209 }
210
211 # Postgres maps exp.Pivot to no_pivot_sql, but Redshift support pivots
212 TRANSFORMS.pop(exp.Pivot)
213
214 # Redshift uses the POW | POWER (expr1, expr2) syntax instead of expr1 ^ expr2 (postgres)
215 TRANSFORMS.pop(exp.Pow)
216
217 # Redshift supports ANY_VALUE(..)
218 TRANSFORMS.pop(exp.AnyValue)
219
220 # Redshift supports LAST_DAY(..)
221 TRANSFORMS.pop(exp.LastDay)
222
223 RESERVED_KEYWORDS = {*Postgres.Generator.RESERVED_KEYWORDS, "snapshot", "type"}
224
225 def with_properties(self, properties: exp.Properties) -> str:
226 """Redshift doesn't have `WITH` as part of their with_properties so we remove it"""
227 return self.properties(properties, prefix=" ", suffix="")
228
229 def cast_sql(self, expression: exp.Cast, safe_prefix: t.Optional[str] = None) -> str:
230 if expression.is_type(exp.DataType.Type.JSON):
231 # Redshift doesn't support a JSON type, so casting to it is treated as a noop
232 return self.sql(expression, "this")
233
234 return super().cast_sql(expression, safe_prefix=safe_prefix)
235
236 def datatype_sql(self, expression: exp.DataType) -> str:
237 """
238 Redshift converts the `TEXT` data type to `VARCHAR(255)` by default when people more generally mean
239 VARCHAR of max length which is `VARCHAR(max)` in Redshift. Therefore if we get a `TEXT` data type
240 without precision we convert it to `VARCHAR(max)` and if it does have precision then we just convert
241 `TEXT` to `VARCHAR`.
242 """
243 if expression.is_type("text"):
244 expression.set("this", exp.DataType.Type.VARCHAR)
245 precision = expression.args.get("expressions")
246
247 if not precision:
248 expression.append("expressions", exp.var("MAX"))
249
250 return super().datatype_sql(expression)
251
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/sqlglot/dialects/redshift.py b/sqlglot/dialects/redshift.py
--- a/sqlglot/dialects/redshift.py
+++ b/sqlglot/dialects/redshift.py
@@ -136,11 +136,11 @@
refs.add(
(
this.args["from"] if i == 0 else this.args["joins"][i - 1]
- ).alias_or_name.lower()
+ ).this.alias.lower()
)
- table = join.this
- if isinstance(table, exp.Table):
+ table = join.this
+ if isinstance(table, exp.Table) and not join.args.get("on"):
if table.parts[0].name.lower() in refs:
table.replace(table.to_column())
return this
| {"golden_diff": "diff --git a/sqlglot/dialects/redshift.py b/sqlglot/dialects/redshift.py\n--- a/sqlglot/dialects/redshift.py\n+++ b/sqlglot/dialects/redshift.py\n@@ -136,11 +136,11 @@\n refs.add(\n (\n this.args[\"from\"] if i == 0 else this.args[\"joins\"][i - 1]\n- ).alias_or_name.lower()\n+ ).this.alias.lower()\n )\n- table = join.this\n \n- if isinstance(table, exp.Table):\n+ table = join.this\n+ if isinstance(table, exp.Table) and not join.args.get(\"on\"):\n if table.parts[0].name.lower() in refs:\n table.replace(table.to_column())\n return this\n", "issue": "Table incorrectly parsed as column\n# Description\r\nTable of format `<schema>.<table>` in a join gets mis-parsed as a column. In the attached example, the table `\"usage\".\"company_names\"` gets misparsed as a column. \r\n\r\n### Version details\r\n- Dialect is 'redshift'\r\n- The issue exists on the latest pip version of sqlglot (21.0.2)\r\n- The issue doesn't exist on the latest pip version of sqlglot (20.4.0)\r\n\r\n### Correct output with sqlglot==20.4.0\r\n```\r\nPython 3.11.7 (main, Dec 4 2023, 18:10:11) [Clang 15.0.0 (clang-1500.1.0.2.5)] on darwin\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import sqlglot\r\nfrom sqlglot import parse_one\r\nsqlglot.__version__>>> from sqlglot import parse_one\r\n>>> sqlglot.__version__\r\n'20.4.0'\r\n>>> dialect = 'redshift'\r\n>>> query = 'SELECT * FROM \"usage\".\"usage\" JOIN \"usage\".\"company_names\" ON \"company_names\".\"id\" = \"usage\".\"customerid\"'\r\n>>> parse_one(query, dialect=dialect)\r\n(SELECT expressions: \r\n (STAR ), from: \r\n (FROM this: \r\n (TABLE this: \r\n (IDENTIFIER this: usage, quoted: True), db: \r\n (IDENTIFIER this: usage, quoted: True))), joins: \r\n (JOIN this: \r\n (TABLE this: \r\n (IDENTIFIER this: company_names, quoted: True), db: \r\n (IDENTIFIER this: usage, quoted: True)), on: \r\n (EQ this: \r\n (COLUMN this: \r\n (IDENTIFIER this: id, quoted: True), table: \r\n (IDENTIFIER this: company_names, quoted: True)), expression: \r\n (COLUMN this: \r\n (IDENTIFIER this: customerid, quoted: True), table: \r\n (IDENTIFIER this: usage, quoted: True)))))\r\n``` \r\n\r\n### Incorrect output with sqlglot==21.0.2\r\n```\r\nPython 3.11.7 (main, Dec 4 2023, 18:10:11) [Clang 15.0.0 (clang-1500.1.0.2.5)] on darwin\r\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\r\n>>> import sqlglot\r\nfrom sqlglot import parse_one\r\nsqlglot.__version__>>> from sqlglot import parse_one\r\n>>> sqlglot.__version__\r\n'21.0.2'\r\n>>> dialect = 'redshift'\r\n>>> query = 'SELECT * FROM \"usage\".\"usage\" JOIN \"usage\".\"company_names\" ON \"company_names\".\"id\" = \"usage\".\"customerid\"'\r\n>>> parse_one(query, dialect=dialect)\r\nSelect(\r\n expressions=[\r\n Star()],\r\n from=From(\r\n this=Table(\r\n this=Identifier(this=usage, quoted=True),\r\n db=Identifier(this=usage, quoted=True))),\r\n joins=[\r\n Join(\r\n this=Column(\r\n this=Identifier(this=company_names, quoted=True),\r\n table=Identifier(this=usage, quoted=True)),\r\n on=EQ(\r\n this=Column(\r\n this=Identifier(this=id, quoted=True),\r\n table=Identifier(this=company_names, quoted=True)),\r\n expression=Column(\r\n this=Identifier(this=customerid, quoted=True),\r\n table=Identifier(this=usage, quoted=True))))])\r\n```\r\n \r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, transforms\nfrom sqlglot.dialects.dialect import (\n NormalizationStrategy,\n concat_to_dpipe_sql,\n concat_ws_to_dpipe_sql,\n date_delta_sql,\n generatedasidentitycolumnconstraint_sql,\n json_extract_segments,\n no_tablesample_sql,\n rename_func,\n)\nfrom sqlglot.dialects.postgres import Postgres\nfrom sqlglot.helper import seq_get\nfrom sqlglot.tokens import TokenType\n\nif t.TYPE_CHECKING:\n from sqlglot._typing import E\n\n\ndef _parse_date_delta(expr_type: t.Type[E]) -> t.Callable[[t.List], E]:\n def _parse_delta(args: t.List) -> E:\n expr = expr_type(this=seq_get(args, 2), expression=seq_get(args, 1), unit=seq_get(args, 0))\n if expr_type is exp.TsOrDsAdd:\n expr.set(\"return_type\", exp.DataType.build(\"TIMESTAMP\"))\n\n return expr\n\n return _parse_delta\n\n\nclass Redshift(Postgres):\n # https://docs.aws.amazon.com/redshift/latest/dg/r_names.html\n NORMALIZATION_STRATEGY = NormalizationStrategy.CASE_INSENSITIVE\n\n SUPPORTS_USER_DEFINED_TYPES = False\n INDEX_OFFSET = 0\n\n TIME_FORMAT = \"'YYYY-MM-DD HH:MI:SS'\"\n TIME_MAPPING = {\n **Postgres.TIME_MAPPING,\n \"MON\": \"%b\",\n \"HH\": \"%H\",\n }\n\n class Parser(Postgres.Parser):\n FUNCTIONS = {\n **Postgres.Parser.FUNCTIONS,\n \"ADD_MONTHS\": lambda args: exp.TsOrDsAdd(\n this=seq_get(args, 0),\n expression=seq_get(args, 1),\n unit=exp.var(\"month\"),\n return_type=exp.DataType.build(\"TIMESTAMP\"),\n ),\n \"DATEADD\": _parse_date_delta(exp.TsOrDsAdd),\n \"DATE_ADD\": _parse_date_delta(exp.TsOrDsAdd),\n \"DATEDIFF\": _parse_date_delta(exp.TsOrDsDiff),\n \"DATE_DIFF\": _parse_date_delta(exp.TsOrDsDiff),\n \"GETDATE\": exp.CurrentTimestamp.from_arg_list,\n \"LISTAGG\": exp.GroupConcat.from_arg_list,\n \"STRTOL\": exp.FromBase.from_arg_list,\n }\n\n NO_PAREN_FUNCTION_PARSERS = {\n **Postgres.Parser.NO_PAREN_FUNCTION_PARSERS,\n \"APPROXIMATE\": lambda self: self._parse_approximate_count(),\n \"SYSDATE\": lambda self: self.expression(exp.CurrentTimestamp, transaction=True),\n }\n\n def _parse_table(\n self,\n schema: bool = False,\n joins: bool = False,\n alias_tokens: t.Optional[t.Collection[TokenType]] = None,\n parse_bracket: bool = False,\n is_db_reference: bool = False,\n ) -> t.Optional[exp.Expression]:\n # Redshift supports UNPIVOTing SUPER objects, e.g. `UNPIVOT foo.obj[0] AS val AT attr`\n unpivot = self._match(TokenType.UNPIVOT)\n table = super()._parse_table(\n schema=schema,\n joins=joins,\n alias_tokens=alias_tokens,\n parse_bracket=parse_bracket,\n is_db_reference=is_db_reference,\n )\n\n return self.expression(exp.Pivot, this=table, unpivot=True) if unpivot else table\n\n def _parse_types(\n self, check_func: bool = False, schema: bool = False, allow_identifiers: bool = True\n ) -> t.Optional[exp.Expression]:\n this = super()._parse_types(\n check_func=check_func, schema=schema, allow_identifiers=allow_identifiers\n )\n\n if (\n isinstance(this, exp.DataType)\n and this.is_type(\"varchar\")\n and this.expressions\n and this.expressions[0].this == exp.column(\"MAX\")\n ):\n this.set(\"expressions\", [exp.var(\"MAX\")])\n\n return this\n\n def _parse_convert(\n self, strict: bool, safe: t.Optional[bool] = None\n ) -> t.Optional[exp.Expression]:\n to = self._parse_types()\n self._match(TokenType.COMMA)\n this = self._parse_bitwise()\n return self.expression(exp.TryCast, this=this, to=to, safe=safe)\n\n def _parse_approximate_count(self) -> t.Optional[exp.ApproxDistinct]:\n index = self._index - 1\n func = self._parse_function()\n\n if isinstance(func, exp.Count) and isinstance(func.this, exp.Distinct):\n return self.expression(exp.ApproxDistinct, this=seq_get(func.this.expressions, 0))\n self._retreat(index)\n return None\n\n def _parse_query_modifiers(\n self, this: t.Optional[exp.Expression]\n ) -> t.Optional[exp.Expression]:\n this = super()._parse_query_modifiers(this)\n\n if this:\n refs = set()\n\n for i, join in enumerate(this.args.get(\"joins\", [])):\n refs.add(\n (\n this.args[\"from\"] if i == 0 else this.args[\"joins\"][i - 1]\n ).alias_or_name.lower()\n )\n table = join.this\n\n if isinstance(table, exp.Table):\n if table.parts[0].name.lower() in refs:\n table.replace(table.to_column())\n return this\n\n class Tokenizer(Postgres.Tokenizer):\n BIT_STRINGS = []\n HEX_STRINGS = []\n STRING_ESCAPES = [\"\\\\\", \"'\"]\n\n KEYWORDS = {\n **Postgres.Tokenizer.KEYWORDS,\n \"HLLSKETCH\": TokenType.HLLSKETCH,\n \"SUPER\": TokenType.SUPER,\n \"TOP\": TokenType.TOP,\n \"UNLOAD\": TokenType.COMMAND,\n \"VARBYTE\": TokenType.VARBINARY,\n }\n\n # Redshift allows # to appear as a table identifier prefix\n SINGLE_TOKENS = Postgres.Tokenizer.SINGLE_TOKENS.copy()\n SINGLE_TOKENS.pop(\"#\")\n\n class Generator(Postgres.Generator):\n LOCKING_READS_SUPPORTED = False\n QUERY_HINTS = False\n VALUES_AS_TABLE = False\n TZ_TO_WITH_TIME_ZONE = True\n NVL2_SUPPORTED = True\n LAST_DAY_SUPPORTS_DATE_PART = False\n\n TYPE_MAPPING = {\n **Postgres.Generator.TYPE_MAPPING,\n exp.DataType.Type.BINARY: \"VARBYTE\",\n exp.DataType.Type.INT: \"INTEGER\",\n exp.DataType.Type.TIMETZ: \"TIME\",\n exp.DataType.Type.TIMESTAMPTZ: \"TIMESTAMP\",\n exp.DataType.Type.VARBINARY: \"VARBYTE\",\n }\n\n TRANSFORMS = {\n **Postgres.Generator.TRANSFORMS,\n exp.Concat: concat_to_dpipe_sql,\n exp.ConcatWs: concat_ws_to_dpipe_sql,\n exp.ApproxDistinct: lambda self,\n e: f\"APPROXIMATE COUNT(DISTINCT {self.sql(e, 'this')})\",\n exp.CurrentTimestamp: lambda self, e: (\n \"SYSDATE\" if e.args.get(\"transaction\") else \"GETDATE()\"\n ),\n exp.DateAdd: date_delta_sql(\"DATEADD\"),\n exp.DateDiff: date_delta_sql(\"DATEDIFF\"),\n exp.DistKeyProperty: lambda self, e: f\"DISTKEY({e.name})\",\n exp.DistStyleProperty: lambda self, e: self.naked_property(e),\n exp.FromBase: rename_func(\"STRTOL\"),\n exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,\n exp.JSONExtract: json_extract_segments(\"JSON_EXTRACT_PATH_TEXT\"),\n exp.GroupConcat: rename_func(\"LISTAGG\"),\n exp.ParseJSON: rename_func(\"JSON_PARSE\"),\n exp.Select: transforms.preprocess(\n [transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]\n ),\n exp.SortKeyProperty: lambda self,\n e: f\"{'COMPOUND ' if e.args['compound'] else ''}SORTKEY({self.format_args(*e.this)})\",\n exp.TableSample: no_tablesample_sql,\n exp.TsOrDsAdd: date_delta_sql(\"DATEADD\"),\n exp.TsOrDsDiff: date_delta_sql(\"DATEDIFF\"),\n }\n\n # Postgres maps exp.Pivot to no_pivot_sql, but Redshift support pivots\n TRANSFORMS.pop(exp.Pivot)\n\n # Redshift uses the POW | POWER (expr1, expr2) syntax instead of expr1 ^ expr2 (postgres)\n TRANSFORMS.pop(exp.Pow)\n\n # Redshift supports ANY_VALUE(..)\n TRANSFORMS.pop(exp.AnyValue)\n\n # Redshift supports LAST_DAY(..)\n TRANSFORMS.pop(exp.LastDay)\n\n RESERVED_KEYWORDS = {*Postgres.Generator.RESERVED_KEYWORDS, \"snapshot\", \"type\"}\n\n def with_properties(self, properties: exp.Properties) -> str:\n \"\"\"Redshift doesn't have `WITH` as part of their with_properties so we remove it\"\"\"\n return self.properties(properties, prefix=\" \", suffix=\"\")\n\n def cast_sql(self, expression: exp.Cast, safe_prefix: t.Optional[str] = None) -> str:\n if expression.is_type(exp.DataType.Type.JSON):\n # Redshift doesn't support a JSON type, so casting to it is treated as a noop\n return self.sql(expression, \"this\")\n\n return super().cast_sql(expression, safe_prefix=safe_prefix)\n\n def datatype_sql(self, expression: exp.DataType) -> str:\n \"\"\"\n Redshift converts the `TEXT` data type to `VARCHAR(255)` by default when people more generally mean\n VARCHAR of max length which is `VARCHAR(max)` in Redshift. Therefore if we get a `TEXT` data type\n without precision we convert it to `VARCHAR(max)` and if it does have precision then we just convert\n `TEXT` to `VARCHAR`.\n \"\"\"\n if expression.is_type(\"text\"):\n expression.set(\"this\", exp.DataType.Type.VARCHAR)\n precision = expression.args.get(\"expressions\")\n\n if not precision:\n expression.append(\"expressions\", exp.var(\"MAX\"))\n\n return super().datatype_sql(expression)\n", "path": "sqlglot/dialects/redshift.py"}], "after_files": [{"content": "from __future__ import annotations\n\nimport typing as t\n\nfrom sqlglot import exp, transforms\nfrom sqlglot.dialects.dialect import (\n NormalizationStrategy,\n concat_to_dpipe_sql,\n concat_ws_to_dpipe_sql,\n date_delta_sql,\n generatedasidentitycolumnconstraint_sql,\n json_extract_segments,\n no_tablesample_sql,\n rename_func,\n)\nfrom sqlglot.dialects.postgres import Postgres\nfrom sqlglot.helper import seq_get\nfrom sqlglot.tokens import TokenType\n\nif t.TYPE_CHECKING:\n from sqlglot._typing import E\n\n\ndef _parse_date_delta(expr_type: t.Type[E]) -> t.Callable[[t.List], E]:\n def _parse_delta(args: t.List) -> E:\n expr = expr_type(this=seq_get(args, 2), expression=seq_get(args, 1), unit=seq_get(args, 0))\n if expr_type is exp.TsOrDsAdd:\n expr.set(\"return_type\", exp.DataType.build(\"TIMESTAMP\"))\n\n return expr\n\n return _parse_delta\n\n\nclass Redshift(Postgres):\n # https://docs.aws.amazon.com/redshift/latest/dg/r_names.html\n NORMALIZATION_STRATEGY = NormalizationStrategy.CASE_INSENSITIVE\n\n SUPPORTS_USER_DEFINED_TYPES = False\n INDEX_OFFSET = 0\n\n TIME_FORMAT = \"'YYYY-MM-DD HH:MI:SS'\"\n TIME_MAPPING = {\n **Postgres.TIME_MAPPING,\n \"MON\": \"%b\",\n \"HH\": \"%H\",\n }\n\n class Parser(Postgres.Parser):\n FUNCTIONS = {\n **Postgres.Parser.FUNCTIONS,\n \"ADD_MONTHS\": lambda args: exp.TsOrDsAdd(\n this=seq_get(args, 0),\n expression=seq_get(args, 1),\n unit=exp.var(\"month\"),\n return_type=exp.DataType.build(\"TIMESTAMP\"),\n ),\n \"DATEADD\": _parse_date_delta(exp.TsOrDsAdd),\n \"DATE_ADD\": _parse_date_delta(exp.TsOrDsAdd),\n \"DATEDIFF\": _parse_date_delta(exp.TsOrDsDiff),\n \"DATE_DIFF\": _parse_date_delta(exp.TsOrDsDiff),\n \"GETDATE\": exp.CurrentTimestamp.from_arg_list,\n \"LISTAGG\": exp.GroupConcat.from_arg_list,\n \"STRTOL\": exp.FromBase.from_arg_list,\n }\n\n NO_PAREN_FUNCTION_PARSERS = {\n **Postgres.Parser.NO_PAREN_FUNCTION_PARSERS,\n \"APPROXIMATE\": lambda self: self._parse_approximate_count(),\n \"SYSDATE\": lambda self: self.expression(exp.CurrentTimestamp, transaction=True),\n }\n\n def _parse_table(\n self,\n schema: bool = False,\n joins: bool = False,\n alias_tokens: t.Optional[t.Collection[TokenType]] = None,\n parse_bracket: bool = False,\n is_db_reference: bool = False,\n ) -> t.Optional[exp.Expression]:\n # Redshift supports UNPIVOTing SUPER objects, e.g. `UNPIVOT foo.obj[0] AS val AT attr`\n unpivot = self._match(TokenType.UNPIVOT)\n table = super()._parse_table(\n schema=schema,\n joins=joins,\n alias_tokens=alias_tokens,\n parse_bracket=parse_bracket,\n is_db_reference=is_db_reference,\n )\n\n return self.expression(exp.Pivot, this=table, unpivot=True) if unpivot else table\n\n def _parse_types(\n self, check_func: bool = False, schema: bool = False, allow_identifiers: bool = True\n ) -> t.Optional[exp.Expression]:\n this = super()._parse_types(\n check_func=check_func, schema=schema, allow_identifiers=allow_identifiers\n )\n\n if (\n isinstance(this, exp.DataType)\n and this.is_type(\"varchar\")\n and this.expressions\n and this.expressions[0].this == exp.column(\"MAX\")\n ):\n this.set(\"expressions\", [exp.var(\"MAX\")])\n\n return this\n\n def _parse_convert(\n self, strict: bool, safe: t.Optional[bool] = None\n ) -> t.Optional[exp.Expression]:\n to = self._parse_types()\n self._match(TokenType.COMMA)\n this = self._parse_bitwise()\n return self.expression(exp.TryCast, this=this, to=to, safe=safe)\n\n def _parse_approximate_count(self) -> t.Optional[exp.ApproxDistinct]:\n index = self._index - 1\n func = self._parse_function()\n\n if isinstance(func, exp.Count) and isinstance(func.this, exp.Distinct):\n return self.expression(exp.ApproxDistinct, this=seq_get(func.this.expressions, 0))\n self._retreat(index)\n return None\n\n def _parse_query_modifiers(\n self, this: t.Optional[exp.Expression]\n ) -> t.Optional[exp.Expression]:\n this = super()._parse_query_modifiers(this)\n\n if this:\n refs = set()\n\n for i, join in enumerate(this.args.get(\"joins\", [])):\n refs.add(\n (\n this.args[\"from\"] if i == 0 else this.args[\"joins\"][i - 1]\n ).this.alias.lower()\n )\n\n table = join.this\n if isinstance(table, exp.Table) and not join.args.get(\"on\"):\n if table.parts[0].name.lower() in refs:\n table.replace(table.to_column())\n return this\n\n class Tokenizer(Postgres.Tokenizer):\n BIT_STRINGS = []\n HEX_STRINGS = []\n STRING_ESCAPES = [\"\\\\\", \"'\"]\n\n KEYWORDS = {\n **Postgres.Tokenizer.KEYWORDS,\n \"HLLSKETCH\": TokenType.HLLSKETCH,\n \"SUPER\": TokenType.SUPER,\n \"TOP\": TokenType.TOP,\n \"UNLOAD\": TokenType.COMMAND,\n \"VARBYTE\": TokenType.VARBINARY,\n }\n\n # Redshift allows # to appear as a table identifier prefix\n SINGLE_TOKENS = Postgres.Tokenizer.SINGLE_TOKENS.copy()\n SINGLE_TOKENS.pop(\"#\")\n\n class Generator(Postgres.Generator):\n LOCKING_READS_SUPPORTED = False\n QUERY_HINTS = False\n VALUES_AS_TABLE = False\n TZ_TO_WITH_TIME_ZONE = True\n NVL2_SUPPORTED = True\n LAST_DAY_SUPPORTS_DATE_PART = False\n\n TYPE_MAPPING = {\n **Postgres.Generator.TYPE_MAPPING,\n exp.DataType.Type.BINARY: \"VARBYTE\",\n exp.DataType.Type.INT: \"INTEGER\",\n exp.DataType.Type.TIMETZ: \"TIME\",\n exp.DataType.Type.TIMESTAMPTZ: \"TIMESTAMP\",\n exp.DataType.Type.VARBINARY: \"VARBYTE\",\n }\n\n TRANSFORMS = {\n **Postgres.Generator.TRANSFORMS,\n exp.Concat: concat_to_dpipe_sql,\n exp.ConcatWs: concat_ws_to_dpipe_sql,\n exp.ApproxDistinct: lambda self,\n e: f\"APPROXIMATE COUNT(DISTINCT {self.sql(e, 'this')})\",\n exp.CurrentTimestamp: lambda self, e: (\n \"SYSDATE\" if e.args.get(\"transaction\") else \"GETDATE()\"\n ),\n exp.DateAdd: date_delta_sql(\"DATEADD\"),\n exp.DateDiff: date_delta_sql(\"DATEDIFF\"),\n exp.DistKeyProperty: lambda self, e: f\"DISTKEY({e.name})\",\n exp.DistStyleProperty: lambda self, e: self.naked_property(e),\n exp.FromBase: rename_func(\"STRTOL\"),\n exp.GeneratedAsIdentityColumnConstraint: generatedasidentitycolumnconstraint_sql,\n exp.JSONExtract: json_extract_segments(\"JSON_EXTRACT_PATH_TEXT\"),\n exp.GroupConcat: rename_func(\"LISTAGG\"),\n exp.ParseJSON: rename_func(\"JSON_PARSE\"),\n exp.Select: transforms.preprocess(\n [transforms.eliminate_distinct_on, transforms.eliminate_semi_and_anti_joins]\n ),\n exp.SortKeyProperty: lambda self,\n e: f\"{'COMPOUND ' if e.args['compound'] else ''}SORTKEY({self.format_args(*e.this)})\",\n exp.TableSample: no_tablesample_sql,\n exp.TsOrDsAdd: date_delta_sql(\"DATEADD\"),\n exp.TsOrDsDiff: date_delta_sql(\"DATEDIFF\"),\n }\n\n # Postgres maps exp.Pivot to no_pivot_sql, but Redshift support pivots\n TRANSFORMS.pop(exp.Pivot)\n\n # Redshift uses the POW | POWER (expr1, expr2) syntax instead of expr1 ^ expr2 (postgres)\n TRANSFORMS.pop(exp.Pow)\n\n # Redshift supports ANY_VALUE(..)\n TRANSFORMS.pop(exp.AnyValue)\n\n # Redshift supports LAST_DAY(..)\n TRANSFORMS.pop(exp.LastDay)\n\n RESERVED_KEYWORDS = {*Postgres.Generator.RESERVED_KEYWORDS, \"snapshot\", \"type\"}\n\n def with_properties(self, properties: exp.Properties) -> str:\n \"\"\"Redshift doesn't have `WITH` as part of their with_properties so we remove it\"\"\"\n return self.properties(properties, prefix=\" \", suffix=\"\")\n\n def cast_sql(self, expression: exp.Cast, safe_prefix: t.Optional[str] = None) -> str:\n if expression.is_type(exp.DataType.Type.JSON):\n # Redshift doesn't support a JSON type, so casting to it is treated as a noop\n return self.sql(expression, \"this\")\n\n return super().cast_sql(expression, safe_prefix=safe_prefix)\n\n def datatype_sql(self, expression: exp.DataType) -> str:\n \"\"\"\n Redshift converts the `TEXT` data type to `VARCHAR(255)` by default when people more generally mean\n VARCHAR of max length which is `VARCHAR(max)` in Redshift. Therefore if we get a `TEXT` data type\n without precision we convert it to `VARCHAR(max)` and if it does have precision then we just convert\n `TEXT` to `VARCHAR`.\n \"\"\"\n if expression.is_type(\"text\"):\n expression.set(\"this\", exp.DataType.Type.VARCHAR)\n precision = expression.args.get(\"expressions\")\n\n if not precision:\n expression.append(\"expressions\", exp.var(\"MAX\"))\n\n return super().datatype_sql(expression)\n", "path": "sqlglot/dialects/redshift.py"}]} | 3,939 | 174 |
gh_patches_debug_21809 | rasdani/github-patches | git_diff | prowler-cloud__prowler-2639 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[Bug]: The check 'Potential secret found in EC2 instance * User Data.' does not include the line numbers where the secrets were found
### Steps to Reproduce
The check 'Potential secret found in EC2 instance * User Data.' does not show the line numbers, whereas 'Potential secret found in variables of ECS task definition' does. Why is it so?
The results of check without precise pointing at the line are frustrating: you do not know where exactly the scanner found the secret and how many secrets were found.
Same issue will rise if you need to troubleshoot the scanner.
### Expected behavior
Numbers of lines with secrets are included in issue description.
### Actual Result with Screenshots or Logs
-
### How did you install Prowler?
Docker (docker pull toniblyx/prowler)
### Environment Resource
Fargate
### OS used
--
### Prowler version
3
### Pip version
--
### Context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py`
Content:
```
1 import os
2 import tempfile
3 import zlib
4 from base64 import b64decode
5
6 from detect_secrets import SecretsCollection
7 from detect_secrets.settings import default_settings
8
9 from prowler.lib.check.models import Check, Check_Report_AWS
10 from prowler.providers.aws.services.ec2.ec2_client import ec2_client
11
12
13 class ec2_instance_secrets_user_data(Check):
14 def execute(self):
15 findings = []
16 for instance in ec2_client.instances:
17 if instance.state != "terminated":
18 report = Check_Report_AWS(self.metadata())
19 report.region = instance.region
20 report.resource_id = instance.id
21 report.resource_arn = instance.arn
22 report.resource_tags = instance.tags
23 if instance.user_data:
24 temp_user_data_file = tempfile.NamedTemporaryFile(delete=False)
25 user_data = b64decode(instance.user_data)
26 if user_data[0:2] == b"\x1f\x8b": # GZIP magic number
27 user_data = zlib.decompress(
28 user_data, zlib.MAX_WBITS | 32
29 ).decode("utf-8")
30 else:
31 user_data = user_data.decode("utf-8")
32
33 temp_user_data_file.write(
34 bytes(user_data, encoding="raw_unicode_escape")
35 )
36 temp_user_data_file.close()
37 secrets = SecretsCollection()
38 with default_settings():
39 secrets.scan_file(temp_user_data_file.name)
40
41 if secrets.json():
42 report.status = "FAIL"
43 report.status_extended = f"Potential secret found in EC2 instance {instance.id} User Data."
44 else:
45 report.status = "PASS"
46 report.status_extended = (
47 f"No secrets found in EC2 instance {instance.id} User Data."
48 )
49
50 os.remove(temp_user_data_file.name)
51 else:
52 report.status = "PASS"
53 report.status_extended = f"No secrets found in EC2 instance {instance.id} since User Data is empty."
54
55 findings.append(report)
56
57 return findings
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py b/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py
--- a/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py
+++ b/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py
@@ -38,9 +38,19 @@
with default_settings():
secrets.scan_file(temp_user_data_file.name)
- if secrets.json():
+ detect_secrets_output = secrets.json()
+ if detect_secrets_output:
+ secrets_string = ", ".join(
+ [
+ f"{secret['type']} on line {secret['line_number']}"
+ for secret in detect_secrets_output[
+ temp_user_data_file.name
+ ]
+ ]
+ )
report.status = "FAIL"
- report.status_extended = f"Potential secret found in EC2 instance {instance.id} User Data."
+ report.status_extended = f"Potential secret found in EC2 instance {instance.id} User Data -> {secrets_string}."
+
else:
report.status = "PASS"
report.status_extended = (
| {"golden_diff": "diff --git a/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py b/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py\n--- a/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py\n+++ b/prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py\n@@ -38,9 +38,19 @@\n with default_settings():\n secrets.scan_file(temp_user_data_file.name)\n \n- if secrets.json():\n+ detect_secrets_output = secrets.json()\n+ if detect_secrets_output:\n+ secrets_string = \", \".join(\n+ [\n+ f\"{secret['type']} on line {secret['line_number']}\"\n+ for secret in detect_secrets_output[\n+ temp_user_data_file.name\n+ ]\n+ ]\n+ )\n report.status = \"FAIL\"\n- report.status_extended = f\"Potential secret found in EC2 instance {instance.id} User Data.\"\n+ report.status_extended = f\"Potential secret found in EC2 instance {instance.id} User Data -> {secrets_string}.\"\n+\n else:\n report.status = \"PASS\"\n report.status_extended = (\n", "issue": "[Bug]: The check 'Potential secret found in EC2 instance * User Data.' does not include the line numbers where the secrets were found\n### Steps to Reproduce\n\nThe check 'Potential secret found in EC2 instance * User Data.' does not show the line numbers, whereas 'Potential secret found in variables of ECS task definition' does. Why is it so?\r\n\r\nThe results of check without precise pointing at the line are frustrating: you do not know where exactly the scanner found the secret and how many secrets were found.\r\n\r\nSame issue will rise if you need to troubleshoot the scanner.\n\n### Expected behavior\n\nNumbers of lines with secrets are included in issue description.\n\n### Actual Result with Screenshots or Logs\n\n-\n\n### How did you install Prowler?\n\nDocker (docker pull toniblyx/prowler)\n\n### Environment Resource\n\nFargate\n\n### OS used\n\n--\n\n### Prowler version\n\n3\n\n### Pip version\n\n--\n\n### Context\n\n_No response_\n", "before_files": [{"content": "import os\nimport tempfile\nimport zlib\nfrom base64 import b64decode\n\nfrom detect_secrets import SecretsCollection\nfrom detect_secrets.settings import default_settings\n\nfrom prowler.lib.check.models import Check, Check_Report_AWS\nfrom prowler.providers.aws.services.ec2.ec2_client import ec2_client\n\n\nclass ec2_instance_secrets_user_data(Check):\n def execute(self):\n findings = []\n for instance in ec2_client.instances:\n if instance.state != \"terminated\":\n report = Check_Report_AWS(self.metadata())\n report.region = instance.region\n report.resource_id = instance.id\n report.resource_arn = instance.arn\n report.resource_tags = instance.tags\n if instance.user_data:\n temp_user_data_file = tempfile.NamedTemporaryFile(delete=False)\n user_data = b64decode(instance.user_data)\n if user_data[0:2] == b\"\\x1f\\x8b\": # GZIP magic number\n user_data = zlib.decompress(\n user_data, zlib.MAX_WBITS | 32\n ).decode(\"utf-8\")\n else:\n user_data = user_data.decode(\"utf-8\")\n\n temp_user_data_file.write(\n bytes(user_data, encoding=\"raw_unicode_escape\")\n )\n temp_user_data_file.close()\n secrets = SecretsCollection()\n with default_settings():\n secrets.scan_file(temp_user_data_file.name)\n\n if secrets.json():\n report.status = \"FAIL\"\n report.status_extended = f\"Potential secret found in EC2 instance {instance.id} User Data.\"\n else:\n report.status = \"PASS\"\n report.status_extended = (\n f\"No secrets found in EC2 instance {instance.id} User Data.\"\n )\n\n os.remove(temp_user_data_file.name)\n else:\n report.status = \"PASS\"\n report.status_extended = f\"No secrets found in EC2 instance {instance.id} since User Data is empty.\"\n\n findings.append(report)\n\n return findings\n", "path": "prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py"}], "after_files": [{"content": "import os\nimport tempfile\nimport zlib\nfrom base64 import b64decode\n\nfrom detect_secrets import SecretsCollection\nfrom detect_secrets.settings import default_settings\n\nfrom prowler.lib.check.models import Check, Check_Report_AWS\nfrom prowler.providers.aws.services.ec2.ec2_client import ec2_client\n\n\nclass ec2_instance_secrets_user_data(Check):\n def execute(self):\n findings = []\n for instance in ec2_client.instances:\n if instance.state != \"terminated\":\n report = Check_Report_AWS(self.metadata())\n report.region = instance.region\n report.resource_id = instance.id\n report.resource_arn = instance.arn\n report.resource_tags = instance.tags\n if instance.user_data:\n temp_user_data_file = tempfile.NamedTemporaryFile(delete=False)\n user_data = b64decode(instance.user_data)\n if user_data[0:2] == b\"\\x1f\\x8b\": # GZIP magic number\n user_data = zlib.decompress(\n user_data, zlib.MAX_WBITS | 32\n ).decode(\"utf-8\")\n else:\n user_data = user_data.decode(\"utf-8\")\n\n temp_user_data_file.write(\n bytes(user_data, encoding=\"raw_unicode_escape\")\n )\n temp_user_data_file.close()\n secrets = SecretsCollection()\n with default_settings():\n secrets.scan_file(temp_user_data_file.name)\n\n detect_secrets_output = secrets.json()\n if detect_secrets_output:\n secrets_string = \", \".join(\n [\n f\"{secret['type']} on line {secret['line_number']}\"\n for secret in detect_secrets_output[\n temp_user_data_file.name\n ]\n ]\n )\n report.status = \"FAIL\"\n report.status_extended = f\"Potential secret found in EC2 instance {instance.id} User Data -> {secrets_string}.\"\n\n else:\n report.status = \"PASS\"\n report.status_extended = (\n f\"No secrets found in EC2 instance {instance.id} User Data.\"\n )\n\n os.remove(temp_user_data_file.name)\n else:\n report.status = \"PASS\"\n report.status_extended = f\"No secrets found in EC2 instance {instance.id} since User Data is empty.\"\n\n findings.append(report)\n\n return findings\n", "path": "prowler/providers/aws/services/ec2/ec2_instance_secrets_user_data/ec2_instance_secrets_user_data.py"}]} | 1,004 | 287 |
gh_patches_debug_24676 | rasdani/github-patches | git_diff | encode__starlette-208 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Response's content default to b''
close https://github.com/encode/starlette/issues/201
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlette/responses.py`
Content:
```
1 import hashlib
2 import http.cookies
3 import json
4 import os
5 import stat
6 import typing
7 from email.utils import formatdate
8 from mimetypes import guess_type
9 from urllib.parse import quote_plus
10
11 from starlette.background import BackgroundTask
12 from starlette.datastructures import URL, MutableHeaders
13 from starlette.types import Receive, Send
14
15 try:
16 import aiofiles
17 from aiofiles.os import stat as aio_stat
18 except ImportError: # pragma: nocover
19 aiofiles = None # type: ignore
20 aio_stat = None # type: ignore
21
22 try:
23 import ujson
24 except ImportError: # pragma: nocover
25 ujson = None # type: ignore
26
27
28 class Response:
29 media_type = None
30 charset = "utf-8"
31
32 def __init__(
33 self,
34 content: typing.Any,
35 status_code: int = 200,
36 headers: dict = None,
37 media_type: str = None,
38 background: BackgroundTask = None,
39 ) -> None:
40 self.body = self.render(content)
41 self.status_code = status_code
42 if media_type is not None:
43 self.media_type = media_type
44 self.background = background
45 self.init_headers(headers)
46
47 def render(self, content: typing.Any) -> bytes:
48 if isinstance(content, bytes):
49 return content
50 return content.encode(self.charset)
51
52 def init_headers(self, headers: typing.Mapping[str, str] = None) -> None:
53 if headers is None:
54 raw_headers = [] # type: typing.List[typing.Tuple[bytes, bytes]]
55 populate_content_length = True
56 populate_content_type = True
57 else:
58 raw_headers = [
59 (k.lower().encode("latin-1"), v.encode("latin-1"))
60 for k, v in headers.items()
61 ]
62 keys = [h[0] for h in raw_headers]
63 populate_content_length = b"content-length" in keys
64 populate_content_type = b"content-type" in keys
65
66 body = getattr(self, "body", None)
67 if body is not None and populate_content_length:
68 content_length = str(len(body))
69 raw_headers.append((b"content-length", content_length.encode("latin-1")))
70
71 content_type = self.media_type
72 if content_type is not None and populate_content_type:
73 if content_type.startswith("text/"):
74 content_type += "; charset=" + self.charset
75 raw_headers.append((b"content-type", content_type.encode("latin-1")))
76
77 self.raw_headers = raw_headers
78
79 @property
80 def headers(self) -> MutableHeaders:
81 if not hasattr(self, "_headers"):
82 self._headers = MutableHeaders(raw=self.raw_headers)
83 return self._headers
84
85 def set_cookie(
86 self,
87 key: str,
88 value: str = "",
89 max_age: int = None,
90 expires: int = None,
91 path: str = "/",
92 domain: str = None,
93 secure: bool = False,
94 httponly: bool = False,
95 ) -> None:
96 cookie = http.cookies.SimpleCookie()
97 cookie[key] = value
98 if max_age is not None:
99 cookie[key]["max-age"] = max_age # type: ignore
100 if expires is not None:
101 cookie[key]["expires"] = expires # type: ignore
102 if path is not None:
103 cookie[key]["path"] = path
104 if domain is not None:
105 cookie[key]["domain"] = domain
106 if secure:
107 cookie[key]["secure"] = True # type: ignore
108 if httponly:
109 cookie[key]["httponly"] = True # type: ignore
110 cookie_val = cookie.output(header="").strip()
111 self.raw_headers.append((b"set-cookie", cookie_val.encode("latin-1")))
112
113 def delete_cookie(self, key: str, path: str = "/", domain: str = None) -> None:
114 self.set_cookie(key, expires=0, max_age=0, path=path, domain=domain)
115
116 async def __call__(self, receive: Receive, send: Send) -> None:
117 await send(
118 {
119 "type": "http.response.start",
120 "status": self.status_code,
121 "headers": self.raw_headers,
122 }
123 )
124 await send({"type": "http.response.body", "body": self.body})
125
126 if self.background is not None:
127 await self.background()
128
129
130 class HTMLResponse(Response):
131 media_type = "text/html"
132
133
134 class PlainTextResponse(Response):
135 media_type = "text/plain"
136
137
138 class JSONResponse(Response):
139 media_type = "application/json"
140
141 def render(self, content: typing.Any) -> bytes:
142 return json.dumps(
143 content,
144 ensure_ascii=False,
145 allow_nan=False,
146 indent=None,
147 separators=(",", ":"),
148 ).encode("utf-8")
149
150
151 class UJSONResponse(JSONResponse):
152 media_type = "application/json"
153
154 def render(self, content: typing.Any) -> bytes:
155 return ujson.dumps(content, ensure_ascii=False).encode("utf-8")
156
157
158 class RedirectResponse(Response):
159 def __init__(
160 self, url: typing.Union[str, URL], status_code: int = 302, headers: dict = None
161 ) -> None:
162 super().__init__(content=b"", status_code=status_code, headers=headers)
163 self.headers["location"] = quote_plus(str(url), safe=":/#?&=@[]!$&'()*+,;")
164
165
166 class StreamingResponse(Response):
167 def __init__(
168 self,
169 content: typing.Any,
170 status_code: int = 200,
171 headers: dict = None,
172 media_type: str = None,
173 background: BackgroundTask = None,
174 ) -> None:
175 self.body_iterator = content
176 self.status_code = status_code
177 self.media_type = self.media_type if media_type is None else media_type
178 self.background = background
179 self.init_headers(headers)
180
181 async def __call__(self, receive: Receive, send: Send) -> None:
182 await send(
183 {
184 "type": "http.response.start",
185 "status": self.status_code,
186 "headers": self.raw_headers,
187 }
188 )
189 async for chunk in self.body_iterator:
190 if not isinstance(chunk, bytes):
191 chunk = chunk.encode(self.charset)
192 await send({"type": "http.response.body", "body": chunk, "more_body": True})
193 await send({"type": "http.response.body", "body": b"", "more_body": False})
194
195 if self.background is not None:
196 await self.background()
197
198
199 class FileResponse(Response):
200 chunk_size = 4096
201
202 def __init__(
203 self,
204 path: str,
205 headers: dict = None,
206 media_type: str = None,
207 background: BackgroundTask = None,
208 filename: str = None,
209 stat_result: os.stat_result = None,
210 method: str = None,
211 ) -> None:
212 assert aiofiles is not None, "'aiofiles' must be installed to use FileResponse"
213 self.path = path
214 self.status_code = 200
215 self.filename = filename
216 self.send_header_only = method is not None and method.upper() == "HEAD"
217 if media_type is None:
218 media_type = guess_type(filename or path)[0] or "text/plain"
219 self.media_type = media_type
220 self.background = background
221 self.init_headers(headers)
222 if self.filename is not None:
223 content_disposition = 'attachment; filename="{}"'.format(self.filename)
224 self.headers.setdefault("content-disposition", content_disposition)
225 self.stat_result = stat_result
226 if stat_result is not None:
227 self.set_stat_headers(stat_result)
228
229 def set_stat_headers(self, stat_result: os.stat_result) -> None:
230 content_length = str(stat_result.st_size)
231 last_modified = formatdate(stat_result.st_mtime, usegmt=True)
232 etag_base = str(stat_result.st_mtime) + "-" + str(stat_result.st_size)
233 etag = hashlib.md5(etag_base.encode()).hexdigest()
234 self.headers.setdefault("content-length", content_length)
235 self.headers.setdefault("last-modified", last_modified)
236 self.headers.setdefault("etag", etag)
237
238 async def __call__(self, receive: Receive, send: Send) -> None:
239 if self.stat_result is None:
240 try:
241 stat_result = await aio_stat(self.path)
242 self.set_stat_headers(stat_result)
243 except FileNotFoundError:
244 raise RuntimeError(f"File at path {self.path} does not exist.")
245 else:
246 mode = stat_result.st_mode
247 if not stat.S_ISREG(mode):
248 raise RuntimeError(f"File at path {self.path} is not a file.")
249 await send(
250 {
251 "type": "http.response.start",
252 "status": self.status_code,
253 "headers": self.raw_headers,
254 }
255 )
256 if self.send_header_only:
257 await send({"type": "http.response.body"})
258 else:
259 async with aiofiles.open(self.path, mode="rb") as file:
260 more_body = True
261 while more_body:
262 chunk = await file.read(self.chunk_size)
263 more_body = len(chunk) == self.chunk_size
264 await send(
265 {
266 "type": "http.response.body",
267 "body": chunk,
268 "more_body": more_body,
269 }
270 )
271 if self.background is not None:
272 await self.background()
273
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/starlette/responses.py b/starlette/responses.py
--- a/starlette/responses.py
+++ b/starlette/responses.py
@@ -31,13 +31,16 @@
def __init__(
self,
- content: typing.Any,
+ content: typing.Any = None,
status_code: int = 200,
headers: dict = None,
media_type: str = None,
background: BackgroundTask = None,
) -> None:
- self.body = self.render(content)
+ if content is None:
+ self.body = b""
+ else:
+ self.body = self.render(content)
self.status_code = status_code
if media_type is not None:
self.media_type = media_type
@@ -63,8 +66,8 @@
populate_content_length = b"content-length" in keys
populate_content_type = b"content-type" in keys
- body = getattr(self, "body", None)
- if body is not None and populate_content_length:
+ body = getattr(self, "body", b"")
+ if body and populate_content_length:
content_length = str(len(body))
raw_headers.append((b"content-length", content_length.encode("latin-1")))
| {"golden_diff": "diff --git a/starlette/responses.py b/starlette/responses.py\n--- a/starlette/responses.py\n+++ b/starlette/responses.py\n@@ -31,13 +31,16 @@\n \n def __init__(\n self,\n- content: typing.Any,\n+ content: typing.Any = None,\n status_code: int = 200,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n ) -> None:\n- self.body = self.render(content)\n+ if content is None:\n+ self.body = b\"\"\n+ else:\n+ self.body = self.render(content)\n self.status_code = status_code\n if media_type is not None:\n self.media_type = media_type\n@@ -63,8 +66,8 @@\n populate_content_length = b\"content-length\" in keys\n populate_content_type = b\"content-type\" in keys\n \n- body = getattr(self, \"body\", None)\n- if body is not None and populate_content_length:\n+ body = getattr(self, \"body\", b\"\")\n+ if body and populate_content_length:\n content_length = str(len(body))\n raw_headers.append((b\"content-length\", content_length.encode(\"latin-1\")))\n", "issue": "Response's content default to b''\nclose https://github.com/encode/starlette/issues/201\n", "before_files": [{"content": "import hashlib\nimport http.cookies\nimport json\nimport os\nimport stat\nimport typing\nfrom email.utils import formatdate\nfrom mimetypes import guess_type\nfrom urllib.parse import quote_plus\n\nfrom starlette.background import BackgroundTask\nfrom starlette.datastructures import URL, MutableHeaders\nfrom starlette.types import Receive, Send\n\ntry:\n import aiofiles\n from aiofiles.os import stat as aio_stat\nexcept ImportError: # pragma: nocover\n aiofiles = None # type: ignore\n aio_stat = None # type: ignore\n\ntry:\n import ujson\nexcept ImportError: # pragma: nocover\n ujson = None # type: ignore\n\n\nclass Response:\n media_type = None\n charset = \"utf-8\"\n\n def __init__(\n self,\n content: typing.Any,\n status_code: int = 200,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n ) -> None:\n self.body = self.render(content)\n self.status_code = status_code\n if media_type is not None:\n self.media_type = media_type\n self.background = background\n self.init_headers(headers)\n\n def render(self, content: typing.Any) -> bytes:\n if isinstance(content, bytes):\n return content\n return content.encode(self.charset)\n\n def init_headers(self, headers: typing.Mapping[str, str] = None) -> None:\n if headers is None:\n raw_headers = [] # type: typing.List[typing.Tuple[bytes, bytes]]\n populate_content_length = True\n populate_content_type = True\n else:\n raw_headers = [\n (k.lower().encode(\"latin-1\"), v.encode(\"latin-1\"))\n for k, v in headers.items()\n ]\n keys = [h[0] for h in raw_headers]\n populate_content_length = b\"content-length\" in keys\n populate_content_type = b\"content-type\" in keys\n\n body = getattr(self, \"body\", None)\n if body is not None and populate_content_length:\n content_length = str(len(body))\n raw_headers.append((b\"content-length\", content_length.encode(\"latin-1\")))\n\n content_type = self.media_type\n if content_type is not None and populate_content_type:\n if content_type.startswith(\"text/\"):\n content_type += \"; charset=\" + self.charset\n raw_headers.append((b\"content-type\", content_type.encode(\"latin-1\")))\n\n self.raw_headers = raw_headers\n\n @property\n def headers(self) -> MutableHeaders:\n if not hasattr(self, \"_headers\"):\n self._headers = MutableHeaders(raw=self.raw_headers)\n return self._headers\n\n def set_cookie(\n self,\n key: str,\n value: str = \"\",\n max_age: int = None,\n expires: int = None,\n path: str = \"/\",\n domain: str = None,\n secure: bool = False,\n httponly: bool = False,\n ) -> None:\n cookie = http.cookies.SimpleCookie()\n cookie[key] = value\n if max_age is not None:\n cookie[key][\"max-age\"] = max_age # type: ignore\n if expires is not None:\n cookie[key][\"expires\"] = expires # type: ignore\n if path is not None:\n cookie[key][\"path\"] = path\n if domain is not None:\n cookie[key][\"domain\"] = domain\n if secure:\n cookie[key][\"secure\"] = True # type: ignore\n if httponly:\n cookie[key][\"httponly\"] = True # type: ignore\n cookie_val = cookie.output(header=\"\").strip()\n self.raw_headers.append((b\"set-cookie\", cookie_val.encode(\"latin-1\")))\n\n def delete_cookie(self, key: str, path: str = \"/\", domain: str = None) -> None:\n self.set_cookie(key, expires=0, max_age=0, path=path, domain=domain)\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n await send(\n {\n \"type\": \"http.response.start\",\n \"status\": self.status_code,\n \"headers\": self.raw_headers,\n }\n )\n await send({\"type\": \"http.response.body\", \"body\": self.body})\n\n if self.background is not None:\n await self.background()\n\n\nclass HTMLResponse(Response):\n media_type = \"text/html\"\n\n\nclass PlainTextResponse(Response):\n media_type = \"text/plain\"\n\n\nclass JSONResponse(Response):\n media_type = \"application/json\"\n\n def render(self, content: typing.Any) -> bytes:\n return json.dumps(\n content,\n ensure_ascii=False,\n allow_nan=False,\n indent=None,\n separators=(\",\", \":\"),\n ).encode(\"utf-8\")\n\n\nclass UJSONResponse(JSONResponse):\n media_type = \"application/json\"\n\n def render(self, content: typing.Any) -> bytes:\n return ujson.dumps(content, ensure_ascii=False).encode(\"utf-8\")\n\n\nclass RedirectResponse(Response):\n def __init__(\n self, url: typing.Union[str, URL], status_code: int = 302, headers: dict = None\n ) -> None:\n super().__init__(content=b\"\", status_code=status_code, headers=headers)\n self.headers[\"location\"] = quote_plus(str(url), safe=\":/#?&=@[]!$&'()*+,;\")\n\n\nclass StreamingResponse(Response):\n def __init__(\n self,\n content: typing.Any,\n status_code: int = 200,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n ) -> None:\n self.body_iterator = content\n self.status_code = status_code\n self.media_type = self.media_type if media_type is None else media_type\n self.background = background\n self.init_headers(headers)\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n await send(\n {\n \"type\": \"http.response.start\",\n \"status\": self.status_code,\n \"headers\": self.raw_headers,\n }\n )\n async for chunk in self.body_iterator:\n if not isinstance(chunk, bytes):\n chunk = chunk.encode(self.charset)\n await send({\"type\": \"http.response.body\", \"body\": chunk, \"more_body\": True})\n await send({\"type\": \"http.response.body\", \"body\": b\"\", \"more_body\": False})\n\n if self.background is not None:\n await self.background()\n\n\nclass FileResponse(Response):\n chunk_size = 4096\n\n def __init__(\n self,\n path: str,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n filename: str = None,\n stat_result: os.stat_result = None,\n method: str = None,\n ) -> None:\n assert aiofiles is not None, \"'aiofiles' must be installed to use FileResponse\"\n self.path = path\n self.status_code = 200\n self.filename = filename\n self.send_header_only = method is not None and method.upper() == \"HEAD\"\n if media_type is None:\n media_type = guess_type(filename or path)[0] or \"text/plain\"\n self.media_type = media_type\n self.background = background\n self.init_headers(headers)\n if self.filename is not None:\n content_disposition = 'attachment; filename=\"{}\"'.format(self.filename)\n self.headers.setdefault(\"content-disposition\", content_disposition)\n self.stat_result = stat_result\n if stat_result is not None:\n self.set_stat_headers(stat_result)\n\n def set_stat_headers(self, stat_result: os.stat_result) -> None:\n content_length = str(stat_result.st_size)\n last_modified = formatdate(stat_result.st_mtime, usegmt=True)\n etag_base = str(stat_result.st_mtime) + \"-\" + str(stat_result.st_size)\n etag = hashlib.md5(etag_base.encode()).hexdigest()\n self.headers.setdefault(\"content-length\", content_length)\n self.headers.setdefault(\"last-modified\", last_modified)\n self.headers.setdefault(\"etag\", etag)\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n if self.stat_result is None:\n try:\n stat_result = await aio_stat(self.path)\n self.set_stat_headers(stat_result)\n except FileNotFoundError:\n raise RuntimeError(f\"File at path {self.path} does not exist.\")\n else:\n mode = stat_result.st_mode\n if not stat.S_ISREG(mode):\n raise RuntimeError(f\"File at path {self.path} is not a file.\")\n await send(\n {\n \"type\": \"http.response.start\",\n \"status\": self.status_code,\n \"headers\": self.raw_headers,\n }\n )\n if self.send_header_only:\n await send({\"type\": \"http.response.body\"})\n else:\n async with aiofiles.open(self.path, mode=\"rb\") as file:\n more_body = True\n while more_body:\n chunk = await file.read(self.chunk_size)\n more_body = len(chunk) == self.chunk_size\n await send(\n {\n \"type\": \"http.response.body\",\n \"body\": chunk,\n \"more_body\": more_body,\n }\n )\n if self.background is not None:\n await self.background()\n", "path": "starlette/responses.py"}], "after_files": [{"content": "import hashlib\nimport http.cookies\nimport json\nimport os\nimport stat\nimport typing\nfrom email.utils import formatdate\nfrom mimetypes import guess_type\nfrom urllib.parse import quote_plus\n\nfrom starlette.background import BackgroundTask\nfrom starlette.datastructures import URL, MutableHeaders\nfrom starlette.types import Receive, Send\n\ntry:\n import aiofiles\n from aiofiles.os import stat as aio_stat\nexcept ImportError: # pragma: nocover\n aiofiles = None # type: ignore\n aio_stat = None # type: ignore\n\ntry:\n import ujson\nexcept ImportError: # pragma: nocover\n ujson = None # type: ignore\n\n\nclass Response:\n media_type = None\n charset = \"utf-8\"\n\n def __init__(\n self,\n content: typing.Any = None,\n status_code: int = 200,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n ) -> None:\n if content is None:\n self.body = b\"\"\n else:\n self.body = self.render(content)\n self.status_code = status_code\n if media_type is not None:\n self.media_type = media_type\n self.background = background\n self.init_headers(headers)\n\n def render(self, content: typing.Any) -> bytes:\n if isinstance(content, bytes):\n return content\n return content.encode(self.charset)\n\n def init_headers(self, headers: typing.Mapping[str, str] = None) -> None:\n if headers is None:\n raw_headers = [] # type: typing.List[typing.Tuple[bytes, bytes]]\n populate_content_length = True\n populate_content_type = True\n else:\n raw_headers = [\n (k.lower().encode(\"latin-1\"), v.encode(\"latin-1\"))\n for k, v in headers.items()\n ]\n keys = [h[0] for h in raw_headers]\n populate_content_length = b\"content-length\" in keys\n populate_content_type = b\"content-type\" in keys\n\n body = getattr(self, \"body\", b\"\")\n if body and populate_content_length:\n content_length = str(len(body))\n raw_headers.append((b\"content-length\", content_length.encode(\"latin-1\")))\n\n content_type = self.media_type\n if content_type is not None and populate_content_type:\n if content_type.startswith(\"text/\"):\n content_type += \"; charset=\" + self.charset\n raw_headers.append((b\"content-type\", content_type.encode(\"latin-1\")))\n\n self.raw_headers = raw_headers\n\n @property\n def headers(self) -> MutableHeaders:\n if not hasattr(self, \"_headers\"):\n self._headers = MutableHeaders(raw=self.raw_headers)\n return self._headers\n\n def set_cookie(\n self,\n key: str,\n value: str = \"\",\n max_age: int = None,\n expires: int = None,\n path: str = \"/\",\n domain: str = None,\n secure: bool = False,\n httponly: bool = False,\n ) -> None:\n cookie = http.cookies.SimpleCookie()\n cookie[key] = value\n if max_age is not None:\n cookie[key][\"max-age\"] = max_age # type: ignore\n if expires is not None:\n cookie[key][\"expires\"] = expires # type: ignore\n if path is not None:\n cookie[key][\"path\"] = path\n if domain is not None:\n cookie[key][\"domain\"] = domain\n if secure:\n cookie[key][\"secure\"] = True # type: ignore\n if httponly:\n cookie[key][\"httponly\"] = True # type: ignore\n cookie_val = cookie.output(header=\"\").strip()\n self.raw_headers.append((b\"set-cookie\", cookie_val.encode(\"latin-1\")))\n\n def delete_cookie(self, key: str, path: str = \"/\", domain: str = None) -> None:\n self.set_cookie(key, expires=0, max_age=0, path=path, domain=domain)\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n await send(\n {\n \"type\": \"http.response.start\",\n \"status\": self.status_code,\n \"headers\": self.raw_headers,\n }\n )\n await send({\"type\": \"http.response.body\", \"body\": self.body})\n\n if self.background is not None:\n await self.background()\n\n\nclass HTMLResponse(Response):\n media_type = \"text/html\"\n\n\nclass PlainTextResponse(Response):\n media_type = \"text/plain\"\n\n\nclass JSONResponse(Response):\n media_type = \"application/json\"\n\n def render(self, content: typing.Any) -> bytes:\n return json.dumps(\n content,\n ensure_ascii=False,\n allow_nan=False,\n indent=None,\n separators=(\",\", \":\"),\n ).encode(\"utf-8\")\n\n\nclass UJSONResponse(JSONResponse):\n media_type = \"application/json\"\n\n def render(self, content: typing.Any) -> bytes:\n return ujson.dumps(content, ensure_ascii=False).encode(\"utf-8\")\n\n\nclass RedirectResponse(Response):\n def __init__(\n self, url: typing.Union[str, URL], status_code: int = 302, headers: dict = None\n ) -> None:\n super().__init__(content=b\"\", status_code=status_code, headers=headers)\n self.headers[\"location\"] = quote_plus(str(url), safe=\":/#?&=@[]!$&'()*+,;\")\n\n\nclass StreamingResponse(Response):\n def __init__(\n self,\n content: typing.Any,\n status_code: int = 200,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n ) -> None:\n self.body_iterator = content\n self.status_code = status_code\n self.media_type = self.media_type if media_type is None else media_type\n self.background = background\n self.init_headers(headers)\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n await send(\n {\n \"type\": \"http.response.start\",\n \"status\": self.status_code,\n \"headers\": self.raw_headers,\n }\n )\n async for chunk in self.body_iterator:\n if not isinstance(chunk, bytes):\n chunk = chunk.encode(self.charset)\n await send({\"type\": \"http.response.body\", \"body\": chunk, \"more_body\": True})\n await send({\"type\": \"http.response.body\", \"body\": b\"\", \"more_body\": False})\n\n if self.background is not None:\n await self.background()\n\n\nclass FileResponse(Response):\n chunk_size = 4096\n\n def __init__(\n self,\n path: str,\n headers: dict = None,\n media_type: str = None,\n background: BackgroundTask = None,\n filename: str = None,\n stat_result: os.stat_result = None,\n method: str = None,\n ) -> None:\n assert aiofiles is not None, \"'aiofiles' must be installed to use FileResponse\"\n self.path = path\n self.status_code = 200\n self.filename = filename\n self.send_header_only = method is not None and method.upper() == \"HEAD\"\n if media_type is None:\n media_type = guess_type(filename or path)[0] or \"text/plain\"\n self.media_type = media_type\n self.background = background\n self.init_headers(headers)\n if self.filename is not None:\n content_disposition = 'attachment; filename=\"{}\"'.format(self.filename)\n self.headers.setdefault(\"content-disposition\", content_disposition)\n self.stat_result = stat_result\n if stat_result is not None:\n self.set_stat_headers(stat_result)\n\n def set_stat_headers(self, stat_result: os.stat_result) -> None:\n content_length = str(stat_result.st_size)\n last_modified = formatdate(stat_result.st_mtime, usegmt=True)\n etag_base = str(stat_result.st_mtime) + \"-\" + str(stat_result.st_size)\n etag = hashlib.md5(etag_base.encode()).hexdigest()\n self.headers.setdefault(\"content-length\", content_length)\n self.headers.setdefault(\"last-modified\", last_modified)\n self.headers.setdefault(\"etag\", etag)\n\n async def __call__(self, receive: Receive, send: Send) -> None:\n if self.stat_result is None:\n try:\n stat_result = await aio_stat(self.path)\n self.set_stat_headers(stat_result)\n except FileNotFoundError:\n raise RuntimeError(f\"File at path {self.path} does not exist.\")\n else:\n mode = stat_result.st_mode\n if not stat.S_ISREG(mode):\n raise RuntimeError(f\"File at path {self.path} is not a file.\")\n await send(\n {\n \"type\": \"http.response.start\",\n \"status\": self.status_code,\n \"headers\": self.raw_headers,\n }\n )\n if self.send_header_only:\n await send({\"type\": \"http.response.body\"})\n else:\n async with aiofiles.open(self.path, mode=\"rb\") as file:\n more_body = True\n while more_body:\n chunk = await file.read(self.chunk_size)\n more_body = len(chunk) == self.chunk_size\n await send(\n {\n \"type\": \"http.response.body\",\n \"body\": chunk,\n \"more_body\": more_body,\n }\n )\n if self.background is not None:\n await self.background()\n", "path": "starlette/responses.py"}]} | 3,042 | 280 |
gh_patches_debug_32978 | rasdani/github-patches | git_diff | sunpy__sunpy-2770 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Solar Cycle Gallery example out of date
The example includes the following text
> For this example we will use the SunPy sample data, if you want the current data, delete the argument to the create function. i.e. noaa = lc.NOAAIndicesLightCurve.create()
This text is inline and therefore not checked during build so was not caught. This should be fixed and this behavior should be discouraged.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/plotting/solar_cycle_example.py`
Content:
```
1 """
2 ===============
3 The Solar Cycle
4 ===============
5
6 This example shows the current and possible next solar cycle.
7 """
8 from __future__ import print_function, division
9
10 import datetime
11 import matplotlib.pyplot as plt
12
13 import sunpy.timeseries as ts
14 from sunpy.data.sample import NOAAINDICES_TIMESERIES, NOAAPREDICT_TIMESERIES
15
16 ###############################################################################
17 # For this example we will use the SunPy sample data, if you want the current
18 # data, delete the argument to the ``create`` function. i.e.
19 # ``noaa = lc.NOAAIndicesLightCurve.create()``
20
21 noaa = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')
22 noaa_predict = ts.TimeSeries(NOAAPREDICT_TIMESERIES, source='noaapredictindices')
23
24 ###############################################################################
25 # Next lets grab the data again to create a new data structure that we will
26 # shift by 12 years to simulate the next solar cycle. We will truncate the
27 # data to only plot what is necessary.
28
29 noaa2 = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')
30 noaa2.data = noaa2.data.shift(2, freq=datetime.timedelta(days=365*12))
31 noaa2 = noaa2.truncate('2021/04/01', '2030/01/01')
32
33 ###############################################################################
34 # Finally lets plot everything together with some arbitrary range for the
35 # strength of the next solar cycle.
36
37 plt.plot(noaa.data.index, noaa.data['sunspot RI'], label='Sunspot Number')
38 plt.plot(noaa_predict.data.index, noaa_predict.data['sunspot'],
39 color='grey', label='Near-term Prediction')
40 plt.fill_between(noaa_predict.data.index, noaa_predict.data['sunspot low'],
41 noaa_predict.data['sunspot high'], alpha=0.3, color='grey')
42
43 plt.fill_between(noaa2.data.index, noaa2.data['sunspot RI smooth']*0.4,
44 noaa2.data['sunspot RI smooth']*1.3, alpha=0.3, color='grey',
45 label='Next Cycle Predict')
46 plt.ylim(0)
47 plt.text('2011-01-01', 120, 'Cycle 24', fontsize=16)
48 plt.text('2024-01-01', 120, 'Cycle 25', fontsize=16)
49 plt.ylabel('Sunspot Number')
50 plt.xlabel('Year')
51 plt.legend(loc=2, framealpha=0.5)
52 plt.show()
53
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/plotting/solar_cycle_example.py b/examples/plotting/solar_cycle_example.py
--- a/examples/plotting/solar_cycle_example.py
+++ b/examples/plotting/solar_cycle_example.py
@@ -14,25 +14,25 @@
from sunpy.data.sample import NOAAINDICES_TIMESERIES, NOAAPREDICT_TIMESERIES
###############################################################################
-# For this example we will use the SunPy sample data, if you want the current
-# data, delete the argument to the ``create`` function. i.e.
-# ``noaa = lc.NOAAIndicesLightCurve.create()``
+# For this example we will use the SunPy sample data. This code snippet grabs
+# the most current NOAA solar cycle data as a ``TimeSeries``
+# (see :ref:`timeseries_code_ref`).
noaa = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')
noaa_predict = ts.TimeSeries(NOAAPREDICT_TIMESERIES, source='noaapredictindices')
###############################################################################
-# Next lets grab the data again to create a new data structure that we will
-# shift by 12 years to simulate the next solar cycle. We will truncate the
-# data to only plot what is necessary.
+# Next, we grab a new copy of the data and shift it forward 12 years to
+# simulate the next solar cycle. We will also truncate the data to ensure
+# that we only plot what is necessary.
noaa2 = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')
noaa2.data = noaa2.data.shift(2, freq=datetime.timedelta(days=365*12))
noaa2 = noaa2.truncate('2021/04/01', '2030/01/01')
###############################################################################
-# Finally lets plot everything together with some arbitrary range for the
-# strength of the next solar cycle.
+# Finally, we plot both ``noaa`` and ``noaa2`` together, with an arbitrary
+# range for the strength of the next solar cycle.
plt.plot(noaa.data.index, noaa.data['sunspot RI'], label='Sunspot Number')
plt.plot(noaa_predict.data.index, noaa_predict.data['sunspot'],
| {"golden_diff": "diff --git a/examples/plotting/solar_cycle_example.py b/examples/plotting/solar_cycle_example.py\n--- a/examples/plotting/solar_cycle_example.py\n+++ b/examples/plotting/solar_cycle_example.py\n@@ -14,25 +14,25 @@\n from sunpy.data.sample import NOAAINDICES_TIMESERIES, NOAAPREDICT_TIMESERIES\n \n ###############################################################################\n-# For this example we will use the SunPy sample data, if you want the current\n-# data, delete the argument to the ``create`` function. i.e.\n-# ``noaa = lc.NOAAIndicesLightCurve.create()``\n+# For this example we will use the SunPy sample data. This code snippet grabs\n+# the most current NOAA solar cycle data as a ``TimeSeries``\n+# (see :ref:`timeseries_code_ref`).\n \n noaa = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')\n noaa_predict = ts.TimeSeries(NOAAPREDICT_TIMESERIES, source='noaapredictindices')\n \n ###############################################################################\n-# Next lets grab the data again to create a new data structure that we will\n-# shift by 12 years to simulate the next solar cycle. We will truncate the\n-# data to only plot what is necessary.\n+# Next, we grab a new copy of the data and shift it forward 12 years to\n+# simulate the next solar cycle. We will also truncate the data to ensure\n+# that we only plot what is necessary.\n \n noaa2 = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')\n noaa2.data = noaa2.data.shift(2, freq=datetime.timedelta(days=365*12))\n noaa2 = noaa2.truncate('2021/04/01', '2030/01/01')\n \n ###############################################################################\n-# Finally lets plot everything together with some arbitrary range for the\n-# strength of the next solar cycle.\n+# Finally, we plot both ``noaa`` and ``noaa2`` together, with an arbitrary\n+# range for the strength of the next solar cycle.\n \n plt.plot(noaa.data.index, noaa.data['sunspot RI'], label='Sunspot Number')\n plt.plot(noaa_predict.data.index, noaa_predict.data['sunspot'],\n", "issue": "Solar Cycle Gallery example out of date\nThe example includes the following text \r\n\r\n> For this example we will use the SunPy sample data, if you want the current data, delete the argument to the create function. i.e. noaa = lc.NOAAIndicesLightCurve.create()\r\n\r\nThis text is inline and therefore not checked during build so was not caught. This should be fixed and this behavior should be discouraged.\n", "before_files": [{"content": "\"\"\"\n===============\nThe Solar Cycle\n===============\n\nThis example shows the current and possible next solar cycle.\n\"\"\"\nfrom __future__ import print_function, division\n\nimport datetime\nimport matplotlib.pyplot as plt\n\nimport sunpy.timeseries as ts\nfrom sunpy.data.sample import NOAAINDICES_TIMESERIES, NOAAPREDICT_TIMESERIES\n\n###############################################################################\n# For this example we will use the SunPy sample data, if you want the current\n# data, delete the argument to the ``create`` function. i.e.\n# ``noaa = lc.NOAAIndicesLightCurve.create()``\n\nnoaa = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')\nnoaa_predict = ts.TimeSeries(NOAAPREDICT_TIMESERIES, source='noaapredictindices')\n\n###############################################################################\n# Next lets grab the data again to create a new data structure that we will\n# shift by 12 years to simulate the next solar cycle. We will truncate the\n# data to only plot what is necessary.\n\nnoaa2 = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')\nnoaa2.data = noaa2.data.shift(2, freq=datetime.timedelta(days=365*12))\nnoaa2 = noaa2.truncate('2021/04/01', '2030/01/01')\n\n###############################################################################\n# Finally lets plot everything together with some arbitrary range for the\n# strength of the next solar cycle.\n\nplt.plot(noaa.data.index, noaa.data['sunspot RI'], label='Sunspot Number')\nplt.plot(noaa_predict.data.index, noaa_predict.data['sunspot'],\n color='grey', label='Near-term Prediction')\nplt.fill_between(noaa_predict.data.index, noaa_predict.data['sunspot low'],\n noaa_predict.data['sunspot high'], alpha=0.3, color='grey')\n\nplt.fill_between(noaa2.data.index, noaa2.data['sunspot RI smooth']*0.4,\n noaa2.data['sunspot RI smooth']*1.3, alpha=0.3, color='grey',\n label='Next Cycle Predict')\nplt.ylim(0)\nplt.text('2011-01-01', 120, 'Cycle 24', fontsize=16)\nplt.text('2024-01-01', 120, 'Cycle 25', fontsize=16)\nplt.ylabel('Sunspot Number')\nplt.xlabel('Year')\nplt.legend(loc=2, framealpha=0.5)\nplt.show()\n", "path": "examples/plotting/solar_cycle_example.py"}], "after_files": [{"content": "\"\"\"\n===============\nThe Solar Cycle\n===============\n\nThis example shows the current and possible next solar cycle.\n\"\"\"\nfrom __future__ import print_function, division\n\nimport datetime\nimport matplotlib.pyplot as plt\n\nimport sunpy.timeseries as ts\nfrom sunpy.data.sample import NOAAINDICES_TIMESERIES, NOAAPREDICT_TIMESERIES\n\n###############################################################################\n# For this example we will use the SunPy sample data. This code snippet grabs\n# the most current NOAA solar cycle data as a ``TimeSeries``\n# (see :ref:`timeseries_code_ref`).\n\nnoaa = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')\nnoaa_predict = ts.TimeSeries(NOAAPREDICT_TIMESERIES, source='noaapredictindices')\n\n###############################################################################\n# Next, we grab a new copy of the data and shift it forward 12 years to\n# simulate the next solar cycle. We will also truncate the data to ensure\n# that we only plot what is necessary.\n\nnoaa2 = ts.TimeSeries(NOAAINDICES_TIMESERIES, source='noaaindices')\nnoaa2.data = noaa2.data.shift(2, freq=datetime.timedelta(days=365*12))\nnoaa2 = noaa2.truncate('2021/04/01', '2030/01/01')\n\n###############################################################################\n# Finally, we plot both ``noaa`` and ``noaa2`` together, with an arbitrary\n# range for the strength of the next solar cycle.\n\nplt.plot(noaa.data.index, noaa.data['sunspot RI'], label='Sunspot Number')\nplt.plot(noaa_predict.data.index, noaa_predict.data['sunspot'],\n color='grey', label='Near-term Prediction')\nplt.fill_between(noaa_predict.data.index, noaa_predict.data['sunspot low'],\n noaa_predict.data['sunspot high'], alpha=0.3, color='grey')\n\nplt.fill_between(noaa2.data.index, noaa2.data['sunspot RI smooth']*0.4,\n noaa2.data['sunspot RI smooth']*1.3, alpha=0.3, color='grey',\n label='Next Cycle Predict')\nplt.ylim(0)\nplt.text('2011-01-01', 120, 'Cycle 24', fontsize=16)\nplt.text('2024-01-01', 120, 'Cycle 25', fontsize=16)\nplt.ylabel('Sunspot Number')\nplt.xlabel('Year')\nplt.legend(loc=2, framealpha=0.5)\nplt.show()\n", "path": "examples/plotting/solar_cycle_example.py"}]} | 1,004 | 504 |
gh_patches_debug_16583 | rasdani/github-patches | git_diff | nerfstudio-project__nerfstudio-1067 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
`ns-train semantic-nerfw` fails looking for images_4 png instead of jpg
**Describe the bug**
`ns-train semantic-nerfw` fails looking for image png instead of jpg
**To Reproduce**
Steps to reproduce the behavior:
1. Install nerfstudio. (0.1.10, 0.1.11, latest main)
2. `ns-download-data friends` complains, so you must download from the GDrive link and extract into data/friends manually
3. `ns-train semantic-nerfw`
4. See error about PIL/Image.py -- but notice that it is looking for image png, rather than jpg which is present and specified in cameras.json
**Expected behavior**
Training should not fail.
`ns-train semantic-nerfw` fails looking for images_4 png instead of jpg
**Describe the bug**
`ns-train semantic-nerfw` fails looking for image png instead of jpg
**To Reproduce**
Steps to reproduce the behavior:
1. Install nerfstudio. (0.1.10, 0.1.11, latest main)
2. `ns-download-data friends` complains, so you must download from the GDrive link and extract into data/friends manually
3. `ns-train semantic-nerfw`
4. See error about PIL/Image.py -- but notice that it is looking for image png, rather than jpg which is present and specified in cameras.json
**Expected behavior**
Training should not fail.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `nerfstudio/data/dataparsers/friends_dataparser.py`
Content:
```
1 # Copyright 2022 The Nerfstudio Team. All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Data parser for friends dataset"""
16 from __future__ import annotations
17
18 from dataclasses import dataclass, field
19 from pathlib import Path
20 from typing import Type
21
22 import torch
23 from rich.console import Console
24
25 from nerfstudio.cameras.cameras import Cameras, CameraType
26 from nerfstudio.data.dataparsers.base_dataparser import (
27 DataParser,
28 DataParserConfig,
29 DataparserOutputs,
30 Semantics,
31 )
32 from nerfstudio.data.scene_box import SceneBox
33 from nerfstudio.utils.io import load_from_json
34
35 CONSOLE = Console()
36
37
38 @dataclass
39 class FriendsDataParserConfig(DataParserConfig):
40 """Friends dataset parser config"""
41
42 _target: Type = field(default_factory=lambda: Friends)
43 """target class to instantiate"""
44 data: Path = Path("data/friends/TBBT-big_living_room")
45 """Directory specifying location of data."""
46 include_semantics: bool = True
47 """whether or not to include loading of semantics data"""
48 downscale_factor: int = 4
49 scene_scale: float = 2.0
50 """
51 Sets the bounding cube to have edge length of this size.
52 The longest dimension of the Friends axis-aligned bbox will be scaled to this value.
53 """
54
55
56 @dataclass
57 class Friends(DataParser):
58 """Friends Dataset"""
59
60 config: FriendsDataParserConfig
61
62 def _generate_dataparser_outputs(self, split="train"): # pylint: disable=unused-argument,too-many-statements
63
64 cameras_json = load_from_json(self.config.data / "cameras.json")
65 frames = cameras_json["frames"]
66 bbox = torch.tensor(cameras_json["bbox"])
67
68 downscale_suffix = f"_{self.config.downscale_factor}" if self.config.downscale_factor != 1 else ""
69 images_folder = f"images{downscale_suffix}"
70 segmentations_folder = f"segmentations{downscale_suffix}"
71
72 image_filenames = []
73 fx = []
74 fy = []
75 cx = []
76 cy = []
77 camera_to_worlds = []
78 for frame in frames:
79 # unpack data
80 image_filename = self.config.data / images_folder / frame["image_name"]
81 intrinsics = torch.tensor(frame["intrinsics"])
82 camtoworld = torch.tensor(frame["camtoworld"])[:3]
83 # append data
84 image_filenames.append(image_filename)
85 fx.append(intrinsics[0, 0])
86 fy.append(intrinsics[1, 1])
87 cx.append(intrinsics[0, 2])
88 cy.append(intrinsics[1, 2])
89 camera_to_worlds.append(camtoworld)
90 fx = torch.stack(fx)
91 fy = torch.stack(fy)
92 cx = torch.stack(cx)
93 cy = torch.stack(cy)
94 camera_to_worlds = torch.stack(camera_to_worlds)
95
96 # rotate the cameras and box 90 degrees about the x axis to put the z axis up
97 rotation = torch.tensor([[1, 0, 0], [0, 0, -1], [0, 1, 0]], dtype=torch.float32)
98 camera_to_worlds[:, :3] = rotation @ camera_to_worlds[:, :3]
99 bbox = (rotation @ bbox.T).T
100
101 scene_scale = self.config.scene_scale
102
103 # -- set the scene box ---
104 scene_box = SceneBox(aabb=bbox)
105 # center the box and adjust the cameras too
106 center = scene_box.get_center()
107 scene_box.aabb -= center
108 camera_to_worlds[..., 3] -= center
109 # scale the longest dimension to match the cube size
110 lengths = scene_box.aabb[1] - scene_box.aabb[0]
111 longest_dim = torch.argmax(lengths)
112 longest_length = lengths[longest_dim]
113 scale = scene_scale / longest_length
114 scene_box.aabb = scene_box.aabb * scale # box
115 camera_to_worlds[..., 3] *= scale # cameras
116
117 # --- semantics ---
118 if self.config.include_semantics:
119 filenames = [
120 Path(
121 str(image_filename)
122 .replace(f"/{images_folder}/", f"/{segmentations_folder}/thing/")
123 .replace(".jpg", ".png")
124 )
125 for image_filename in image_filenames
126 ]
127 panoptic_classes = load_from_json(self.config.data / "panoptic_classes.json")
128 classes = panoptic_classes["thing"]
129 colors = torch.tensor(panoptic_classes["thing_colors"], dtype=torch.float32) / 255.0
130 semantics = Semantics(filenames=filenames, classes=classes, colors=colors, mask_classes=["person"])
131
132 assert torch.all(cx[0] == cx), "Not all cameras have the same cx. Our Cameras class does not support this."
133 assert torch.all(cy[0] == cy), "Not all cameras have the same cy. Our Cameras class does not support this."
134
135 cameras = Cameras(
136 fx=fx,
137 fy=fy,
138 cx=float(cx[0]),
139 cy=float(cy[0]),
140 camera_to_worlds=camera_to_worlds,
141 camera_type=CameraType.PERSPECTIVE,
142 )
143 cameras.rescale_output_resolution(scaling_factor=1.0 / self.config.downscale_factor)
144
145 dataparser_outputs = DataparserOutputs(
146 image_filenames=image_filenames,
147 cameras=cameras,
148 scene_box=scene_box,
149 metadata={"semantics": semantics} if self.config.include_semantics else {},
150 )
151 return dataparser_outputs
152
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/nerfstudio/data/dataparsers/friends_dataparser.py b/nerfstudio/data/dataparsers/friends_dataparser.py
--- a/nerfstudio/data/dataparsers/friends_dataparser.py
+++ b/nerfstudio/data/dataparsers/friends_dataparser.py
@@ -116,12 +116,11 @@
# --- semantics ---
if self.config.include_semantics:
+ empty_path = Path()
+ replace_this_path = str(empty_path / images_folder / empty_path)
+ with_this_path = str(empty_path / segmentations_folder / "thing" / empty_path)
filenames = [
- Path(
- str(image_filename)
- .replace(f"/{images_folder}/", f"/{segmentations_folder}/thing/")
- .replace(".jpg", ".png")
- )
+ Path(str(image_filename).replace(replace_this_path, with_this_path).replace(".jpg", ".png"))
for image_filename in image_filenames
]
panoptic_classes = load_from_json(self.config.data / "panoptic_classes.json")
| {"golden_diff": "diff --git a/nerfstudio/data/dataparsers/friends_dataparser.py b/nerfstudio/data/dataparsers/friends_dataparser.py\n--- a/nerfstudio/data/dataparsers/friends_dataparser.py\n+++ b/nerfstudio/data/dataparsers/friends_dataparser.py\n@@ -116,12 +116,11 @@\n \n # --- semantics ---\n if self.config.include_semantics:\n+ empty_path = Path()\n+ replace_this_path = str(empty_path / images_folder / empty_path)\n+ with_this_path = str(empty_path / segmentations_folder / \"thing\" / empty_path)\n filenames = [\n- Path(\n- str(image_filename)\n- .replace(f\"/{images_folder}/\", f\"/{segmentations_folder}/thing/\")\n- .replace(\".jpg\", \".png\")\n- )\n+ Path(str(image_filename).replace(replace_this_path, with_this_path).replace(\".jpg\", \".png\"))\n for image_filename in image_filenames\n ]\n panoptic_classes = load_from_json(self.config.data / \"panoptic_classes.json\")\n", "issue": "`ns-train semantic-nerfw` fails looking for images_4 png instead of jpg\n**Describe the bug**\r\n`ns-train semantic-nerfw` fails looking for image png instead of jpg\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Install nerfstudio. (0.1.10, 0.1.11, latest main)\r\n2. `ns-download-data friends` complains, so you must download from the GDrive link and extract into data/friends manually\r\n3. `ns-train semantic-nerfw`\r\n4. See error about PIL/Image.py -- but notice that it is looking for image png, rather than jpg which is present and specified in cameras.json\r\n\r\n**Expected behavior**\r\nTraining should not fail.\n`ns-train semantic-nerfw` fails looking for images_4 png instead of jpg\n**Describe the bug**\r\n`ns-train semantic-nerfw` fails looking for image png instead of jpg\r\n\r\n**To Reproduce**\r\nSteps to reproduce the behavior:\r\n1. Install nerfstudio. (0.1.10, 0.1.11, latest main)\r\n2. `ns-download-data friends` complains, so you must download from the GDrive link and extract into data/friends manually\r\n3. `ns-train semantic-nerfw`\r\n4. See error about PIL/Image.py -- but notice that it is looking for image png, rather than jpg which is present and specified in cameras.json\r\n\r\n**Expected behavior**\r\nTraining should not fail.\n", "before_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Data parser for friends dataset\"\"\"\nfrom __future__ import annotations\n\nfrom dataclasses import dataclass, field\nfrom pathlib import Path\nfrom typing import Type\n\nimport torch\nfrom rich.console import Console\n\nfrom nerfstudio.cameras.cameras import Cameras, CameraType\nfrom nerfstudio.data.dataparsers.base_dataparser import (\n DataParser,\n DataParserConfig,\n DataparserOutputs,\n Semantics,\n)\nfrom nerfstudio.data.scene_box import SceneBox\nfrom nerfstudio.utils.io import load_from_json\n\nCONSOLE = Console()\n\n\n@dataclass\nclass FriendsDataParserConfig(DataParserConfig):\n \"\"\"Friends dataset parser config\"\"\"\n\n _target: Type = field(default_factory=lambda: Friends)\n \"\"\"target class to instantiate\"\"\"\n data: Path = Path(\"data/friends/TBBT-big_living_room\")\n \"\"\"Directory specifying location of data.\"\"\"\n include_semantics: bool = True\n \"\"\"whether or not to include loading of semantics data\"\"\"\n downscale_factor: int = 4\n scene_scale: float = 2.0\n \"\"\"\n Sets the bounding cube to have edge length of this size.\n The longest dimension of the Friends axis-aligned bbox will be scaled to this value.\n \"\"\"\n\n\n@dataclass\nclass Friends(DataParser):\n \"\"\"Friends Dataset\"\"\"\n\n config: FriendsDataParserConfig\n\n def _generate_dataparser_outputs(self, split=\"train\"): # pylint: disable=unused-argument,too-many-statements\n\n cameras_json = load_from_json(self.config.data / \"cameras.json\")\n frames = cameras_json[\"frames\"]\n bbox = torch.tensor(cameras_json[\"bbox\"])\n\n downscale_suffix = f\"_{self.config.downscale_factor}\" if self.config.downscale_factor != 1 else \"\"\n images_folder = f\"images{downscale_suffix}\"\n segmentations_folder = f\"segmentations{downscale_suffix}\"\n\n image_filenames = []\n fx = []\n fy = []\n cx = []\n cy = []\n camera_to_worlds = []\n for frame in frames:\n # unpack data\n image_filename = self.config.data / images_folder / frame[\"image_name\"]\n intrinsics = torch.tensor(frame[\"intrinsics\"])\n camtoworld = torch.tensor(frame[\"camtoworld\"])[:3]\n # append data\n image_filenames.append(image_filename)\n fx.append(intrinsics[0, 0])\n fy.append(intrinsics[1, 1])\n cx.append(intrinsics[0, 2])\n cy.append(intrinsics[1, 2])\n camera_to_worlds.append(camtoworld)\n fx = torch.stack(fx)\n fy = torch.stack(fy)\n cx = torch.stack(cx)\n cy = torch.stack(cy)\n camera_to_worlds = torch.stack(camera_to_worlds)\n\n # rotate the cameras and box 90 degrees about the x axis to put the z axis up\n rotation = torch.tensor([[1, 0, 0], [0, 0, -1], [0, 1, 0]], dtype=torch.float32)\n camera_to_worlds[:, :3] = rotation @ camera_to_worlds[:, :3]\n bbox = (rotation @ bbox.T).T\n\n scene_scale = self.config.scene_scale\n\n # -- set the scene box ---\n scene_box = SceneBox(aabb=bbox)\n # center the box and adjust the cameras too\n center = scene_box.get_center()\n scene_box.aabb -= center\n camera_to_worlds[..., 3] -= center\n # scale the longest dimension to match the cube size\n lengths = scene_box.aabb[1] - scene_box.aabb[0]\n longest_dim = torch.argmax(lengths)\n longest_length = lengths[longest_dim]\n scale = scene_scale / longest_length\n scene_box.aabb = scene_box.aabb * scale # box\n camera_to_worlds[..., 3] *= scale # cameras\n\n # --- semantics ---\n if self.config.include_semantics:\n filenames = [\n Path(\n str(image_filename)\n .replace(f\"/{images_folder}/\", f\"/{segmentations_folder}/thing/\")\n .replace(\".jpg\", \".png\")\n )\n for image_filename in image_filenames\n ]\n panoptic_classes = load_from_json(self.config.data / \"panoptic_classes.json\")\n classes = panoptic_classes[\"thing\"]\n colors = torch.tensor(panoptic_classes[\"thing_colors\"], dtype=torch.float32) / 255.0\n semantics = Semantics(filenames=filenames, classes=classes, colors=colors, mask_classes=[\"person\"])\n\n assert torch.all(cx[0] == cx), \"Not all cameras have the same cx. Our Cameras class does not support this.\"\n assert torch.all(cy[0] == cy), \"Not all cameras have the same cy. Our Cameras class does not support this.\"\n\n cameras = Cameras(\n fx=fx,\n fy=fy,\n cx=float(cx[0]),\n cy=float(cy[0]),\n camera_to_worlds=camera_to_worlds,\n camera_type=CameraType.PERSPECTIVE,\n )\n cameras.rescale_output_resolution(scaling_factor=1.0 / self.config.downscale_factor)\n\n dataparser_outputs = DataparserOutputs(\n image_filenames=image_filenames,\n cameras=cameras,\n scene_box=scene_box,\n metadata={\"semantics\": semantics} if self.config.include_semantics else {},\n )\n return dataparser_outputs\n", "path": "nerfstudio/data/dataparsers/friends_dataparser.py"}], "after_files": [{"content": "# Copyright 2022 The Nerfstudio Team. All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Data parser for friends dataset\"\"\"\nfrom __future__ import annotations\n\nfrom dataclasses import dataclass, field\nfrom pathlib import Path\nfrom typing import Type\n\nimport torch\nfrom rich.console import Console\n\nfrom nerfstudio.cameras.cameras import Cameras, CameraType\nfrom nerfstudio.data.dataparsers.base_dataparser import (\n DataParser,\n DataParserConfig,\n DataparserOutputs,\n Semantics,\n)\nfrom nerfstudio.data.scene_box import SceneBox\nfrom nerfstudio.utils.io import load_from_json\n\nCONSOLE = Console()\n\n\n@dataclass\nclass FriendsDataParserConfig(DataParserConfig):\n \"\"\"Friends dataset parser config\"\"\"\n\n _target: Type = field(default_factory=lambda: Friends)\n \"\"\"target class to instantiate\"\"\"\n data: Path = Path(\"data/friends/TBBT-big_living_room\")\n \"\"\"Directory specifying location of data.\"\"\"\n include_semantics: bool = True\n \"\"\"whether or not to include loading of semantics data\"\"\"\n downscale_factor: int = 4\n scene_scale: float = 2.0\n \"\"\"\n Sets the bounding cube to have edge length of this size.\n The longest dimension of the Friends axis-aligned bbox will be scaled to this value.\n \"\"\"\n\n\n@dataclass\nclass Friends(DataParser):\n \"\"\"Friends Dataset\"\"\"\n\n config: FriendsDataParserConfig\n\n def _generate_dataparser_outputs(self, split=\"train\"): # pylint: disable=unused-argument,too-many-statements\n\n cameras_json = load_from_json(self.config.data / \"cameras.json\")\n frames = cameras_json[\"frames\"]\n bbox = torch.tensor(cameras_json[\"bbox\"])\n\n downscale_suffix = f\"_{self.config.downscale_factor}\" if self.config.downscale_factor != 1 else \"\"\n images_folder = f\"images{downscale_suffix}\"\n segmentations_folder = f\"segmentations{downscale_suffix}\"\n\n image_filenames = []\n fx = []\n fy = []\n cx = []\n cy = []\n camera_to_worlds = []\n for frame in frames:\n # unpack data\n image_filename = self.config.data / images_folder / frame[\"image_name\"]\n intrinsics = torch.tensor(frame[\"intrinsics\"])\n camtoworld = torch.tensor(frame[\"camtoworld\"])[:3]\n # append data\n image_filenames.append(image_filename)\n fx.append(intrinsics[0, 0])\n fy.append(intrinsics[1, 1])\n cx.append(intrinsics[0, 2])\n cy.append(intrinsics[1, 2])\n camera_to_worlds.append(camtoworld)\n fx = torch.stack(fx)\n fy = torch.stack(fy)\n cx = torch.stack(cx)\n cy = torch.stack(cy)\n camera_to_worlds = torch.stack(camera_to_worlds)\n\n # rotate the cameras and box 90 degrees about the x axis to put the z axis up\n rotation = torch.tensor([[1, 0, 0], [0, 0, -1], [0, 1, 0]], dtype=torch.float32)\n camera_to_worlds[:, :3] = rotation @ camera_to_worlds[:, :3]\n bbox = (rotation @ bbox.T).T\n\n scene_scale = self.config.scene_scale\n\n # -- set the scene box ---\n scene_box = SceneBox(aabb=bbox)\n # center the box and adjust the cameras too\n center = scene_box.get_center()\n scene_box.aabb -= center\n camera_to_worlds[..., 3] -= center\n # scale the longest dimension to match the cube size\n lengths = scene_box.aabb[1] - scene_box.aabb[0]\n longest_dim = torch.argmax(lengths)\n longest_length = lengths[longest_dim]\n scale = scene_scale / longest_length\n scene_box.aabb = scene_box.aabb * scale # box\n camera_to_worlds[..., 3] *= scale # cameras\n\n # --- semantics ---\n if self.config.include_semantics:\n empty_path = Path()\n replace_this_path = str(empty_path / images_folder / empty_path)\n with_this_path = str(empty_path / segmentations_folder / \"thing\" / empty_path)\n filenames = [\n Path(str(image_filename).replace(replace_this_path, with_this_path).replace(\".jpg\", \".png\"))\n for image_filename in image_filenames\n ]\n panoptic_classes = load_from_json(self.config.data / \"panoptic_classes.json\")\n classes = panoptic_classes[\"thing\"]\n colors = torch.tensor(panoptic_classes[\"thing_colors\"], dtype=torch.float32) / 255.0\n semantics = Semantics(filenames=filenames, classes=classes, colors=colors, mask_classes=[\"person\"])\n\n assert torch.all(cx[0] == cx), \"Not all cameras have the same cx. Our Cameras class does not support this.\"\n assert torch.all(cy[0] == cy), \"Not all cameras have the same cy. Our Cameras class does not support this.\"\n\n cameras = Cameras(\n fx=fx,\n fy=fy,\n cx=float(cx[0]),\n cy=float(cy[0]),\n camera_to_worlds=camera_to_worlds,\n camera_type=CameraType.PERSPECTIVE,\n )\n cameras.rescale_output_resolution(scaling_factor=1.0 / self.config.downscale_factor)\n\n dataparser_outputs = DataparserOutputs(\n image_filenames=image_filenames,\n cameras=cameras,\n scene_box=scene_box,\n metadata={\"semantics\": semantics} if self.config.include_semantics else {},\n )\n return dataparser_outputs\n", "path": "nerfstudio/data/dataparsers/friends_dataparser.py"}]} | 2,261 | 241 |
gh_patches_debug_42513 | rasdani/github-patches | git_diff | sql-machine-learning__elasticdl-57 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change PS to run in graph mode.
在multi-thread下面, 如果ps enable eager mode, 在同一个process下面,所有thread都是在eager mode下面了。 eager mode 可以run graph, 反之则不行。
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/elasticdl/tflib/ps/ps.py`
Content:
```
1 import threading
2 import queue
3 import numpy as np
4 import tensorflow.contrib.eager as tfe
5 import tensorflow as tf
6 tf.enable_eager_execution()
7
8
9 class ParameterServer(object):
10 def __init__(self, optimizer, vars):
11 self._opt = optimizer
12 self._vars = {}
13 for k, v in vars.items():
14 if (not isinstance(v, np.ndarray)
15 or v.dtype not in (np.float32, np.float64)):
16 raise ValueError(
17 'Initial value for variable %s is not of float type ndarray' %
18 k)
19 self._vars[k] = tfe.Variable(v, name=k)
20 self._step = 0
21 self._grad_q = queue.Queue()
22 self._lock = threading.Lock()
23 self._runner = threading.Thread(target=self._run, name='ps-runner')
24 self._exiting = False
25 self._min_step_cv = threading.Condition()
26
27 def pull(self, names=None, min_step=0, blocking=True, timeout=None):
28 with self._min_step_cv:
29 self._min_step_cv.wait_for(
30 lambda: not blocking or min_step <= self._step,
31 timeout=timeout)
32 with self._lock:
33 if min_step > self._step:
34 raise LookupError(
35 'Required step is not ready yet: %s' %
36 min_step)
37 if names:
38 res = {k: self._vars[k].numpy() for k in names}
39 else:
40 res = {k: v.numpy() for k, v in self._vars.items()}
41 return self._step, res
42
43 def push(self, base_step, sub_step, grads):
44 with self._lock:
45 if base_step > self._step:
46 raise ValueError(
47 'Illegal base step %s, parameter server step is %s' %
48 (base_step, self._step))
49
50 if sub_step < 0:
51 raise ValueError('Illegal sub step %s' % sub_step)
52
53 for k, g in grads.items():
54 v = self._vars[k]
55 if g.dtype != v.dtype.as_numpy_dtype or g.shape != v.shape:
56 raise ValueError('Incompatible gradient for variable %s' % k)
57 # TODO(l.zou): use @dataclass when python 3.7 is available.
58 self._grad_q.put((base_step, sub_step, grads))
59
60 def _compute(self, grads):
61 grads_vars = [(g, self._vars[k]) for k, g in grads.items()]
62 with self._lock:
63 self._opt.apply_gradients(grads_vars)
64 with self._min_step_cv:
65 self._step += 1
66 self._min_step_cv.notify_all()
67
68 def _run(self):
69 while not self._exiting:
70 # TODO(l.zou): How to properly accumulate and decay grads?
71 try:
72 base_step, sub_step, grads = self._grad_q.get(timeout=1.0)
73 self._compute(grads)
74 except queue.Empty:
75 pass
76
77 def start(self):
78 self._runner.start()
79
80 def join(self):
81 self._exiting = True
82 self._runner.join()
83
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/python/elasticdl/tflib/ps/ps.py b/python/elasticdl/tflib/ps/ps.py
--- a/python/elasticdl/tflib/ps/ps.py
+++ b/python/elasticdl/tflib/ps/ps.py
@@ -1,22 +1,12 @@
import threading
import queue
import numpy as np
-import tensorflow.contrib.eager as tfe
import tensorflow as tf
-tf.enable_eager_execution()
+from tensorflow.python.ops import array_ops
class ParameterServer(object):
def __init__(self, optimizer, vars):
- self._opt = optimizer
- self._vars = {}
- for k, v in vars.items():
- if (not isinstance(v, np.ndarray)
- or v.dtype not in (np.float32, np.float64)):
- raise ValueError(
- 'Initial value for variable %s is not of float type ndarray' %
- k)
- self._vars[k] = tfe.Variable(v, name=k)
self._step = 0
self._grad_q = queue.Queue()
self._lock = threading.Lock()
@@ -24,6 +14,23 @@
self._exiting = False
self._min_step_cv = threading.Condition()
+ self._grads_vars = {}
+ for k, v in vars.items():
+ if (not isinstance(v, np.ndarray)
+ or v.dtype not in (np.float32, np.float64)):
+ raise ValueError(
+ 'Initial value for variable %s is not of float type ndarray' %
+ k)
+ # TODO: In graph mode we don't need to keep track of variables by ourselves.
+ self._grads_vars[k] = (array_ops.placeholder(dtype=v.dtype), tf.Variable(v, name=k))
+
+ self._opt = optimizer
+ self._apply_grad_op = self._opt.apply_gradients(self._grads_vars.values())
+
+ self._sess = tf.Session()
+ init_op = tf.global_variables_initializer()
+ self._sess.run(init_op)
+
def pull(self, names=None, min_step=0, blocking=True, timeout=None):
with self._min_step_cv:
self._min_step_cv.wait_for(
@@ -35,9 +42,9 @@
'Required step is not ready yet: %s' %
min_step)
if names:
- res = {k: self._vars[k].numpy() for k in names}
+ res = {k: self._grads_vars[k][1].eval(self._sess) for k in names}
else:
- res = {k: v.numpy() for k, v in self._vars.items()}
+ res = {k: v[1].eval(self._sess) for k, v in self._grads_vars.items()}
return self._step, res
def push(self, base_step, sub_step, grads):
@@ -51,16 +58,16 @@
raise ValueError('Illegal sub step %s' % sub_step)
for k, g in grads.items():
- v = self._vars[k]
+ v = self._grads_vars[k][1]
if g.dtype != v.dtype.as_numpy_dtype or g.shape != v.shape:
raise ValueError('Incompatible gradient for variable %s' % k)
# TODO(l.zou): use @dataclass when python 3.7 is available.
self._grad_q.put((base_step, sub_step, grads))
def _compute(self, grads):
- grads_vars = [(g, self._vars[k]) for k, g in grads.items()]
with self._lock:
- self._opt.apply_gradients(grads_vars)
+ feed_dict = {self._grads_vars[k][0]:v for k, v in grads.items()}
+ self._sess.run(self._apply_grad_op, feed_dict=feed_dict)
with self._min_step_cv:
self._step += 1
self._min_step_cv.notify_all()
@@ -80,3 +87,4 @@
def join(self):
self._exiting = True
self._runner.join()
+ self._sess.close()
| {"golden_diff": "diff --git a/python/elasticdl/tflib/ps/ps.py b/python/elasticdl/tflib/ps/ps.py\n--- a/python/elasticdl/tflib/ps/ps.py\n+++ b/python/elasticdl/tflib/ps/ps.py\n@@ -1,22 +1,12 @@\n import threading\n import queue\n import numpy as np\n-import tensorflow.contrib.eager as tfe\n import tensorflow as tf\n-tf.enable_eager_execution()\n+from tensorflow.python.ops import array_ops\n \n \n class ParameterServer(object):\n def __init__(self, optimizer, vars):\n- self._opt = optimizer\n- self._vars = {}\n- for k, v in vars.items():\n- if (not isinstance(v, np.ndarray)\n- or v.dtype not in (np.float32, np.float64)):\n- raise ValueError(\n- 'Initial value for variable %s is not of float type ndarray' %\n- k)\n- self._vars[k] = tfe.Variable(v, name=k)\n self._step = 0\n self._grad_q = queue.Queue()\n self._lock = threading.Lock()\n@@ -24,6 +14,23 @@\n self._exiting = False\n self._min_step_cv = threading.Condition()\n \n+ self._grads_vars = {}\n+ for k, v in vars.items():\n+ if (not isinstance(v, np.ndarray)\n+ or v.dtype not in (np.float32, np.float64)):\n+ raise ValueError(\n+ 'Initial value for variable %s is not of float type ndarray' %\n+ k)\n+ # TODO: In graph mode we don't need to keep track of variables by ourselves.\n+ self._grads_vars[k] = (array_ops.placeholder(dtype=v.dtype), tf.Variable(v, name=k))\n+\n+ self._opt = optimizer\n+ self._apply_grad_op = self._opt.apply_gradients(self._grads_vars.values())\n+\n+ self._sess = tf.Session()\n+ init_op = tf.global_variables_initializer()\n+ self._sess.run(init_op)\n+\n def pull(self, names=None, min_step=0, blocking=True, timeout=None):\n with self._min_step_cv:\n self._min_step_cv.wait_for(\n@@ -35,9 +42,9 @@\n 'Required step is not ready yet: %s' %\n min_step)\n if names:\n- res = {k: self._vars[k].numpy() for k in names}\n+ res = {k: self._grads_vars[k][1].eval(self._sess) for k in names}\n else:\n- res = {k: v.numpy() for k, v in self._vars.items()}\n+ res = {k: v[1].eval(self._sess) for k, v in self._grads_vars.items()}\n return self._step, res\n \n def push(self, base_step, sub_step, grads):\n@@ -51,16 +58,16 @@\n raise ValueError('Illegal sub step %s' % sub_step)\n \n for k, g in grads.items():\n- v = self._vars[k]\n+ v = self._grads_vars[k][1]\n if g.dtype != v.dtype.as_numpy_dtype or g.shape != v.shape:\n raise ValueError('Incompatible gradient for variable %s' % k)\n # TODO(l.zou): use @dataclass when python 3.7 is available.\n self._grad_q.put((base_step, sub_step, grads))\n \n def _compute(self, grads):\n- grads_vars = [(g, self._vars[k]) for k, g in grads.items()]\n with self._lock:\n- self._opt.apply_gradients(grads_vars)\n+ feed_dict = {self._grads_vars[k][0]:v for k, v in grads.items()}\n+ self._sess.run(self._apply_grad_op, feed_dict=feed_dict)\n with self._min_step_cv:\n self._step += 1\n self._min_step_cv.notify_all()\n@@ -80,3 +87,4 @@\n def join(self):\n self._exiting = True\n self._runner.join()\n+ self._sess.close()\n", "issue": "Change PS to run in graph mode.\n\u5728multi-thread\u4e0b\u9762\uff0c \u5982\u679cps enable eager mode, \u5728\u540c\u4e00\u4e2aprocess\u4e0b\u9762\uff0c\u6240\u6709thread\u90fd\u662f\u5728eager mode\u4e0b\u9762\u4e86\u3002 eager mode \u53ef\u4ee5run graph, \u53cd\u4e4b\u5219\u4e0d\u884c\u3002\n", "before_files": [{"content": "import threading\nimport queue\nimport numpy as np\nimport tensorflow.contrib.eager as tfe\nimport tensorflow as tf\ntf.enable_eager_execution()\n\n\nclass ParameterServer(object):\n def __init__(self, optimizer, vars):\n self._opt = optimizer\n self._vars = {}\n for k, v in vars.items():\n if (not isinstance(v, np.ndarray)\n or v.dtype not in (np.float32, np.float64)):\n raise ValueError(\n 'Initial value for variable %s is not of float type ndarray' %\n k)\n self._vars[k] = tfe.Variable(v, name=k)\n self._step = 0\n self._grad_q = queue.Queue()\n self._lock = threading.Lock()\n self._runner = threading.Thread(target=self._run, name='ps-runner')\n self._exiting = False\n self._min_step_cv = threading.Condition()\n\n def pull(self, names=None, min_step=0, blocking=True, timeout=None):\n with self._min_step_cv:\n self._min_step_cv.wait_for(\n lambda: not blocking or min_step <= self._step,\n timeout=timeout)\n with self._lock:\n if min_step > self._step:\n raise LookupError(\n 'Required step is not ready yet: %s' %\n min_step)\n if names:\n res = {k: self._vars[k].numpy() for k in names}\n else:\n res = {k: v.numpy() for k, v in self._vars.items()}\n return self._step, res\n\n def push(self, base_step, sub_step, grads):\n with self._lock:\n if base_step > self._step:\n raise ValueError(\n 'Illegal base step %s, parameter server step is %s' %\n (base_step, self._step))\n\n if sub_step < 0:\n raise ValueError('Illegal sub step %s' % sub_step)\n\n for k, g in grads.items():\n v = self._vars[k]\n if g.dtype != v.dtype.as_numpy_dtype or g.shape != v.shape:\n raise ValueError('Incompatible gradient for variable %s' % k)\n # TODO(l.zou): use @dataclass when python 3.7 is available.\n self._grad_q.put((base_step, sub_step, grads))\n\n def _compute(self, grads):\n grads_vars = [(g, self._vars[k]) for k, g in grads.items()]\n with self._lock:\n self._opt.apply_gradients(grads_vars)\n with self._min_step_cv:\n self._step += 1\n self._min_step_cv.notify_all()\n\n def _run(self):\n while not self._exiting:\n # TODO(l.zou): How to properly accumulate and decay grads?\n try:\n base_step, sub_step, grads = self._grad_q.get(timeout=1.0)\n self._compute(grads)\n except queue.Empty:\n pass\n\n def start(self):\n self._runner.start()\n\n def join(self):\n self._exiting = True\n self._runner.join()\n", "path": "python/elasticdl/tflib/ps/ps.py"}], "after_files": [{"content": "import threading\nimport queue\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.python.ops import array_ops\n\n\nclass ParameterServer(object):\n def __init__(self, optimizer, vars):\n self._step = 0\n self._grad_q = queue.Queue()\n self._lock = threading.Lock()\n self._runner = threading.Thread(target=self._run, name='ps-runner')\n self._exiting = False\n self._min_step_cv = threading.Condition()\n\n self._grads_vars = {}\n for k, v in vars.items():\n if (not isinstance(v, np.ndarray)\n or v.dtype not in (np.float32, np.float64)):\n raise ValueError(\n 'Initial value for variable %s is not of float type ndarray' %\n k)\n # TODO: In graph mode we don't need to keep track of variables by ourselves.\n self._grads_vars[k] = (array_ops.placeholder(dtype=v.dtype), tf.Variable(v, name=k))\n\n self._opt = optimizer\n self._apply_grad_op = self._opt.apply_gradients(self._grads_vars.values())\n\n self._sess = tf.Session()\n init_op = tf.global_variables_initializer()\n self._sess.run(init_op)\n\n def pull(self, names=None, min_step=0, blocking=True, timeout=None):\n with self._min_step_cv:\n self._min_step_cv.wait_for(\n lambda: not blocking or min_step <= self._step,\n timeout=timeout)\n with self._lock:\n if min_step > self._step:\n raise LookupError(\n 'Required step is not ready yet: %s' %\n min_step)\n if names:\n res = {k: self._grads_vars[k][1].eval(self._sess) for k in names}\n else:\n res = {k: v[1].eval(self._sess) for k, v in self._grads_vars.items()}\n return self._step, res\n\n def push(self, base_step, sub_step, grads):\n with self._lock:\n if base_step > self._step:\n raise ValueError(\n 'Illegal base step %s, parameter server step is %s' %\n (base_step, self._step))\n\n if sub_step < 0:\n raise ValueError('Illegal sub step %s' % sub_step)\n\n for k, g in grads.items():\n v = self._grads_vars[k][1]\n if g.dtype != v.dtype.as_numpy_dtype or g.shape != v.shape:\n raise ValueError('Incompatible gradient for variable %s' % k)\n # TODO(l.zou): use @dataclass when python 3.7 is available.\n self._grad_q.put((base_step, sub_step, grads))\n\n def _compute(self, grads):\n with self._lock:\n feed_dict = {self._grads_vars[k][0]:v for k, v in grads.items()}\n self._sess.run(self._apply_grad_op, feed_dict=feed_dict)\n with self._min_step_cv:\n self._step += 1\n self._min_step_cv.notify_all()\n\n def _run(self):\n while not self._exiting:\n # TODO(l.zou): How to properly accumulate and decay grads?\n try:\n base_step, sub_step, grads = self._grad_q.get(timeout=1.0)\n self._compute(grads)\n except queue.Empty:\n pass\n\n def start(self):\n self._runner.start()\n\n def join(self):\n self._exiting = True\n self._runner.join()\n self._sess.close()\n", "path": "python/elasticdl/tflib/ps/ps.py"}]} | 1,147 | 926 |
gh_patches_debug_21313 | rasdani/github-patches | git_diff | RedHatInsights__insights-core-2563 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Reporting the wrong number of cores_total
Hi folks...
I think we are noticing a bug that comes from a misunderstanding of cpuinfos processor[N]."cpu_cores" value.
That value is not a count of cores per "cpu". Instead it is a count of the cores on the logical cpus parent package.
i.e. for 2x 6 core CPUs each cpu stanza (12 of them) should show "cpu cores : 6"
But there are not 12x6 cpus. There are 12.
In a big.little arch with 1x 4 core and 1x 2 core you'd see
processor : 0
cpu cores : 4
...
processor : 1
cpu cores : 4
...
processor : 2
cpu cores : 4
...
processor : 3
cpu cores : 4
...
processor : 4
cpu cores : 2
...
processor : 5
cpu cores : 2
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `insights/parsers/cpuinfo.py`
Content:
```
1 """
2 CpuInfo - file ``/proc/cpuinfo``
3 ================================
4
5 This parser reads the content of the ``/proc/cpuinfo`` file and parses it
6 into a dictionary of lists, keyed on the left hand column of the cpuinfo
7 output.
8
9 The object also provides properties for the standard information about the
10 CPU and motherboard architecture.
11
12 Sample input::
13
14 processor : 0
15 vendor_id : GenuineIntel
16 cpu family : 6
17 model : 45
18 model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz
19 stepping : 2
20 microcode : 1808
21 cpu MHz : 2900.000
22 cache size : 20480 KB
23 physical id : 0
24 siblings : 1
25 core id : 0
26 cpu cores : 1
27 apicid : 0
28 flags : fpu vme de pse tsc msr pae mce
29 address sizes : 40 bits physical, 48 bits virtual
30 bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit
31
32 processor : 1
33 vendor_id : GenuineIntel
34 cpu family : 6
35 model : 45
36 model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz
37 stepping : 2
38 microcode : 1808
39 cpu MHz : 2900.000
40 cache size : 20480 KB
41 physical id : 2
42 siblings : 1
43 core id : 0
44 cpu cores : 1
45 apicid : 2
46 flags : fpu vme de pse tsc msr pae mce
47 address sizes : 40 bits physical, 48 bits virtual
48 bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit
49
50 Examples:
51
52 >>> cpu_info.cpu_count
53 2
54 >>> sorted(cpu_info.apicid)
55 ['0', '2']
56 >>> cpu_info.socket_count
57 2
58 >>> cpu_info.vendor
59 'GenuineIntel'
60 >>> "fpu" in cpu_info.flags
61 True
62 >>> cpu_info.model_name
63 'Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz'
64 >>> cpu_info.get_processor_by_index(0)['cpus']
65 '0'
66 >>> cpu_info.get_processor_by_index(0)['vendors']
67 'GenuineIntel'
68 """
69
70 from collections import defaultdict
71 from .. import Parser, parser, defaults, get_active_lines, LegacyItemAccess
72 from insights.specs import Specs
73
74
75 @parser(Specs.cpuinfo)
76 class CpuInfo(LegacyItemAccess, Parser):
77 """
78 CpuInfo parser - able to be used as a dictionary through the
79 LegacyItemAccess mixin class.
80
81 The following items are remapped into lists, with the element number
82 corresponding to the CPU. For example, given the following input::
83
84 processor : 1
85 vendor_id : GenuineIntel
86 cpu family : 6
87 model : 45
88 model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz
89 stepping : 2
90 microcode : 1808
91 cpu MHz : 2900.000
92 cache size : 20480 KB
93 physical id : 2
94 siblings : 1
95 core id : 0
96 cpu cores : 1
97 apicid : 2
98 address sizes : 40 bits physical, 48 bits virtual
99 bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit
100
101 The following keys would be lists of:
102
103 * **cpus** - the *processor* line (e.g. ``1``)
104 * **sockets** - the *physical id* line (e.g. ``2``)
105 * **vendors** - the *vendor_id* line (e.g. ``GenuineIntel``)
106 * **models** - the *model name* line (e.g. ``Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz``)
107 * **model_ids** - the *model* line (e.g. ``45``)
108 * **families** - the *cpu family* line (e.g. ``6``)
109 * **clockspeeds** - the *cpu MHz* line (e.g. ``2900.000``)
110 * **cache_sizes** - the *cache size* line (e.g. ``20480 KB``)
111 * **cpu_cores** - the *cpu cores* line (e.g. ``1``)
112 * **apicid** - the *apicid* line (e.g. ``1``)
113 * **stepping** - the *stepping* line (e.g. ``2``)
114 * **address_sizes** - the *address sizes* line (e.g. ``40 bits physical, 48 bits virtual``)
115 * **bugs** - the *bugs* line (e.g. ``cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit``)
116 """
117
118 def parse_content(self, content):
119
120 self.data = defaultdict(list)
121 mappings = {
122 "processor": "cpus",
123 "physical id": "sockets",
124 "vendor_id": "vendors",
125 "model name": "models",
126 "model": "model_ids",
127 "cpu family": "families",
128 "cpu MHz": "clockspeeds",
129 "cache size": "cache_sizes",
130 "cpu cores": "cpu_cores",
131 "apicid": "apicid",
132 "flags": "flags",
133 "stepping": "stepping",
134 "Features": "features",
135 "CPU implementer": "cpu_implementer",
136 "CPU architecture": "cpu_architecture",
137 "CPU variant": "cpu_variant",
138 "CPU part": "cpu_part",
139 "CPU revision": "cpu_revision",
140 "cpu": "cpu",
141 "revision": "revision",
142 "address sizes": "address_sizes",
143 "bugs": "bugs",
144 "apicid": "apicid"
145 }
146
147 for line in get_active_lines(content, comment_char="COMMAND>"):
148 key, value = [p.strip() for p in line.split(":", 1)]
149 if key in mappings:
150 self.data[mappings[key]].append(value)
151
152 if "cpu" in self.data and "POWER" in self.data["cpu"][0]:
153 # this works differently than on x86 and is not per-cpu
154 del self.data["model_ids"]
155
156 self.data = dict(self.data)
157
158 def __iter__(self):
159 """
160 Iterating through this object will yield the ``get_processor_by_index``
161 information for each CPU.
162 """
163 for idx in range(len(self["cpus"])):
164 yield self.get_processor_by_index(idx)
165
166 @property
167 @defaults()
168 def cpu_speed(self):
169 """
170 str: Returns the CPU speed of the first CPU.
171 """
172 return self.data["clockspeeds"][0]
173
174 @property
175 @defaults()
176 def cache_size(self):
177 """
178 str: Returns the cache size of the first CPU.
179 """
180 return self.data["cache_sizes"][0]
181
182 @property
183 @defaults()
184 def cpu_count(self):
185 """
186 str: Returns the number of CPUs.
187 """
188 return len(self.data.get("cpus", []))
189
190 @property
191 @defaults()
192 def apicid(self):
193 """
194 str: Returns the apicid of the processor.
195 """
196 return self.data["apicid"]
197
198 @property
199 @defaults()
200 def socket_count(self):
201 """
202 str: Returns the number of sockets. This is distinct from the number
203 of CPUs.
204 """
205 return len(set(self.data.get("sockets", [])))
206
207 @property
208 @defaults()
209 def model_name(self):
210 """
211 str: Returns the model name of the first CPU.
212 """
213 return self.data["models"][0]
214
215 @property
216 @defaults()
217 def model_number(self):
218 """
219 str: Returns the model ID of the first CPU.
220 """
221 return self.data["model_ids"][0]
222
223 @property
224 @defaults()
225 def flags(self):
226 """
227 list: Returns a list of feature flags for the first CPU.
228 """
229 return self.data["flags"][0].split()
230
231 @property
232 @defaults()
233 def vendor(self):
234 """
235 str: Returns the vendor of the first CPU.
236 """
237 return self.data["vendors"][0]
238
239 @property
240 @defaults()
241 def core_total(self):
242 """
243 str: Returns the total number of cores for the server if available, else None.
244 """
245 if self.data and 'cpu_cores' in self.data:
246 return sum([int(c) for c in self.data['cpu_cores']])
247 else:
248 return None
249
250 def get_processor_by_index(self, index):
251 """
252 Construct a dictionary of the information stored for the given CPU.
253
254 Parameters:
255 index (int): The CPU index to retrieve.
256
257 Returns:
258 dict: A dictionary of the information for that CPU.
259 """
260 return dict((k, v[index]) for k, v in self.data.items())
261
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/insights/parsers/cpuinfo.py b/insights/parsers/cpuinfo.py
--- a/insights/parsers/cpuinfo.py
+++ b/insights/parsers/cpuinfo.py
@@ -240,10 +240,24 @@
@defaults()
def core_total(self):
"""
- str: Returns the total number of cores for the server if available, else None.
+ int: Returns the total number of cores for the server if available, else None.
+
+ .. warning::
+ This function is deprecated. Please use the
+ :py:class:`insights.parsers.lscpu.LsCPU` class attribute
+ ``info['Cores per socket']`` and ``info['Sockets']`` values instead.
"""
if self.data and 'cpu_cores' in self.data:
- return sum([int(c) for c in self.data['cpu_cores']])
+ # I guess we can't get this fancey on older versions of RHEL
+ # return sum({e['sockets']: int(e['cpu_cores']) for e in self}.values())
+ physical_dict = {}
+ for e in self:
+ # we should rename sockets here to physical_ids as cpuinfo
+ # has it there can be many physical_ids per socket
+ # see fgrep 'physical id' /proc/cpuinfo on a single
+ # package system
+ physical_dict[e['sockets']] = int(e['cpu_cores'])
+ return sum(physical_dict.values())
else:
return None
| {"golden_diff": "diff --git a/insights/parsers/cpuinfo.py b/insights/parsers/cpuinfo.py\n--- a/insights/parsers/cpuinfo.py\n+++ b/insights/parsers/cpuinfo.py\n@@ -240,10 +240,24 @@\n @defaults()\n def core_total(self):\n \"\"\"\n- str: Returns the total number of cores for the server if available, else None.\n+ int: Returns the total number of cores for the server if available, else None.\n+\n+ .. warning::\n+ This function is deprecated. Please use the\n+ :py:class:`insights.parsers.lscpu.LsCPU` class attribute\n+ ``info['Cores per socket']`` and ``info['Sockets']`` values instead.\n \"\"\"\n if self.data and 'cpu_cores' in self.data:\n- return sum([int(c) for c in self.data['cpu_cores']])\n+ # I guess we can't get this fancey on older versions of RHEL\n+ # return sum({e['sockets']: int(e['cpu_cores']) for e in self}.values())\n+ physical_dict = {}\n+ for e in self:\n+ # we should rename sockets here to physical_ids as cpuinfo\n+ # has it there can be many physical_ids per socket\n+ # see fgrep 'physical id' /proc/cpuinfo on a single\n+ # package system\n+ physical_dict[e['sockets']] = int(e['cpu_cores'])\n+ return sum(physical_dict.values())\n else:\n return None\n", "issue": "Reporting the wrong number of cores_total\nHi folks...\r\n\r\nI think we are noticing a bug that comes from a misunderstanding of cpuinfos processor[N].\"cpu_cores\" value.\r\n\r\nThat value is not a count of cores per \"cpu\". Instead it is a count of the cores on the logical cpus parent package.\r\n\r\ni.e. for 2x 6 core CPUs each cpu stanza (12 of them) should show \"cpu cores : 6\"\r\nBut there are not 12x6 cpus. There are 12.\r\n\r\nIn a big.little arch with 1x 4 core and 1x 2 core you'd see\r\nprocessor : 0\r\ncpu cores : 4\r\n...\r\nprocessor : 1\r\ncpu cores : 4\r\n...\r\nprocessor : 2\r\ncpu cores : 4\r\n...\r\nprocessor : 3\r\ncpu cores : 4\r\n...\r\nprocessor : 4\r\ncpu cores : 2\r\n...\r\nprocessor : 5\r\ncpu cores : 2\r\n\n", "before_files": [{"content": "\"\"\"\nCpuInfo - file ``/proc/cpuinfo``\n================================\n\nThis parser reads the content of the ``/proc/cpuinfo`` file and parses it\ninto a dictionary of lists, keyed on the left hand column of the cpuinfo\noutput.\n\nThe object also provides properties for the standard information about the\nCPU and motherboard architecture.\n\nSample input::\n\n processor : 0\n vendor_id : GenuineIntel\n cpu family : 6\n model : 45\n model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz\n stepping : 2\n microcode : 1808\n cpu MHz : 2900.000\n cache size : 20480 KB\n physical id : 0\n siblings : 1\n core id : 0\n cpu cores : 1\n apicid : 0\n flags : fpu vme de pse tsc msr pae mce\n address sizes : 40 bits physical, 48 bits virtual\n bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit\n\n processor : 1\n vendor_id : GenuineIntel\n cpu family : 6\n model : 45\n model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz\n stepping : 2\n microcode : 1808\n cpu MHz : 2900.000\n cache size : 20480 KB\n physical id : 2\n siblings : 1\n core id : 0\n cpu cores : 1\n apicid : 2\n flags : fpu vme de pse tsc msr pae mce\n address sizes : 40 bits physical, 48 bits virtual\n bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit\n\nExamples:\n\n >>> cpu_info.cpu_count\n 2\n >>> sorted(cpu_info.apicid)\n ['0', '2']\n >>> cpu_info.socket_count\n 2\n >>> cpu_info.vendor\n 'GenuineIntel'\n >>> \"fpu\" in cpu_info.flags\n True\n >>> cpu_info.model_name\n 'Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz'\n >>> cpu_info.get_processor_by_index(0)['cpus']\n '0'\n >>> cpu_info.get_processor_by_index(0)['vendors']\n 'GenuineIntel'\n\"\"\"\n\nfrom collections import defaultdict\nfrom .. import Parser, parser, defaults, get_active_lines, LegacyItemAccess\nfrom insights.specs import Specs\n\n\n@parser(Specs.cpuinfo)\nclass CpuInfo(LegacyItemAccess, Parser):\n \"\"\"\n CpuInfo parser - able to be used as a dictionary through the\n LegacyItemAccess mixin class.\n\n The following items are remapped into lists, with the element number\n corresponding to the CPU. For example, given the following input::\n\n processor : 1\n vendor_id : GenuineIntel\n cpu family : 6\n model : 45\n model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz\n stepping : 2\n microcode : 1808\n cpu MHz : 2900.000\n cache size : 20480 KB\n physical id : 2\n siblings : 1\n core id : 0\n cpu cores : 1\n apicid : 2\n address sizes : 40 bits physical, 48 bits virtual\n bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit\n\n The following keys would be lists of:\n\n * **cpus** - the *processor* line (e.g. ``1``)\n * **sockets** - the *physical id* line (e.g. ``2``)\n * **vendors** - the *vendor_id* line (e.g. ``GenuineIntel``)\n * **models** - the *model name* line (e.g. ``Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz``)\n * **model_ids** - the *model* line (e.g. ``45``)\n * **families** - the *cpu family* line (e.g. ``6``)\n * **clockspeeds** - the *cpu MHz* line (e.g. ``2900.000``)\n * **cache_sizes** - the *cache size* line (e.g. ``20480 KB``)\n * **cpu_cores** - the *cpu cores* line (e.g. ``1``)\n * **apicid** - the *apicid* line (e.g. ``1``)\n * **stepping** - the *stepping* line (e.g. ``2``)\n * **address_sizes** - the *address sizes* line (e.g. ``40 bits physical, 48 bits virtual``)\n * **bugs** - the *bugs* line (e.g. ``cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit``)\n \"\"\"\n\n def parse_content(self, content):\n\n self.data = defaultdict(list)\n mappings = {\n \"processor\": \"cpus\",\n \"physical id\": \"sockets\",\n \"vendor_id\": \"vendors\",\n \"model name\": \"models\",\n \"model\": \"model_ids\",\n \"cpu family\": \"families\",\n \"cpu MHz\": \"clockspeeds\",\n \"cache size\": \"cache_sizes\",\n \"cpu cores\": \"cpu_cores\",\n \"apicid\": \"apicid\",\n \"flags\": \"flags\",\n \"stepping\": \"stepping\",\n \"Features\": \"features\",\n \"CPU implementer\": \"cpu_implementer\",\n \"CPU architecture\": \"cpu_architecture\",\n \"CPU variant\": \"cpu_variant\",\n \"CPU part\": \"cpu_part\",\n \"CPU revision\": \"cpu_revision\",\n \"cpu\": \"cpu\",\n \"revision\": \"revision\",\n \"address sizes\": \"address_sizes\",\n \"bugs\": \"bugs\",\n \"apicid\": \"apicid\"\n }\n\n for line in get_active_lines(content, comment_char=\"COMMAND>\"):\n key, value = [p.strip() for p in line.split(\":\", 1)]\n if key in mappings:\n self.data[mappings[key]].append(value)\n\n if \"cpu\" in self.data and \"POWER\" in self.data[\"cpu\"][0]:\n # this works differently than on x86 and is not per-cpu\n del self.data[\"model_ids\"]\n\n self.data = dict(self.data)\n\n def __iter__(self):\n \"\"\"\n Iterating through this object will yield the ``get_processor_by_index``\n information for each CPU.\n \"\"\"\n for idx in range(len(self[\"cpus\"])):\n yield self.get_processor_by_index(idx)\n\n @property\n @defaults()\n def cpu_speed(self):\n \"\"\"\n str: Returns the CPU speed of the first CPU.\n \"\"\"\n return self.data[\"clockspeeds\"][0]\n\n @property\n @defaults()\n def cache_size(self):\n \"\"\"\n str: Returns the cache size of the first CPU.\n \"\"\"\n return self.data[\"cache_sizes\"][0]\n\n @property\n @defaults()\n def cpu_count(self):\n \"\"\"\n str: Returns the number of CPUs.\n \"\"\"\n return len(self.data.get(\"cpus\", []))\n\n @property\n @defaults()\n def apicid(self):\n \"\"\"\n str: Returns the apicid of the processor.\n \"\"\"\n return self.data[\"apicid\"]\n\n @property\n @defaults()\n def socket_count(self):\n \"\"\"\n str: Returns the number of sockets. This is distinct from the number\n of CPUs.\n \"\"\"\n return len(set(self.data.get(\"sockets\", [])))\n\n @property\n @defaults()\n def model_name(self):\n \"\"\"\n str: Returns the model name of the first CPU.\n \"\"\"\n return self.data[\"models\"][0]\n\n @property\n @defaults()\n def model_number(self):\n \"\"\"\n str: Returns the model ID of the first CPU.\n \"\"\"\n return self.data[\"model_ids\"][0]\n\n @property\n @defaults()\n def flags(self):\n \"\"\"\n list: Returns a list of feature flags for the first CPU.\n \"\"\"\n return self.data[\"flags\"][0].split()\n\n @property\n @defaults()\n def vendor(self):\n \"\"\"\n str: Returns the vendor of the first CPU.\n \"\"\"\n return self.data[\"vendors\"][0]\n\n @property\n @defaults()\n def core_total(self):\n \"\"\"\n str: Returns the total number of cores for the server if available, else None.\n \"\"\"\n if self.data and 'cpu_cores' in self.data:\n return sum([int(c) for c in self.data['cpu_cores']])\n else:\n return None\n\n def get_processor_by_index(self, index):\n \"\"\"\n Construct a dictionary of the information stored for the given CPU.\n\n Parameters:\n index (int): The CPU index to retrieve.\n\n Returns:\n dict: A dictionary of the information for that CPU.\n \"\"\"\n return dict((k, v[index]) for k, v in self.data.items())\n", "path": "insights/parsers/cpuinfo.py"}], "after_files": [{"content": "\"\"\"\nCpuInfo - file ``/proc/cpuinfo``\n================================\n\nThis parser reads the content of the ``/proc/cpuinfo`` file and parses it\ninto a dictionary of lists, keyed on the left hand column of the cpuinfo\noutput.\n\nThe object also provides properties for the standard information about the\nCPU and motherboard architecture.\n\nSample input::\n\n processor : 0\n vendor_id : GenuineIntel\n cpu family : 6\n model : 45\n model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz\n stepping : 2\n microcode : 1808\n cpu MHz : 2900.000\n cache size : 20480 KB\n physical id : 0\n siblings : 1\n core id : 0\n cpu cores : 1\n apicid : 0\n flags : fpu vme de pse tsc msr pae mce\n address sizes : 40 bits physical, 48 bits virtual\n bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit\n\n processor : 1\n vendor_id : GenuineIntel\n cpu family : 6\n model : 45\n model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz\n stepping : 2\n microcode : 1808\n cpu MHz : 2900.000\n cache size : 20480 KB\n physical id : 2\n siblings : 1\n core id : 0\n cpu cores : 1\n apicid : 2\n flags : fpu vme de pse tsc msr pae mce\n address sizes : 40 bits physical, 48 bits virtual\n bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit\n\nExamples:\n\n >>> cpu_info.cpu_count\n 2\n >>> sorted(cpu_info.apicid)\n ['0', '2']\n >>> cpu_info.socket_count\n 2\n >>> cpu_info.vendor\n 'GenuineIntel'\n >>> \"fpu\" in cpu_info.flags\n True\n >>> cpu_info.model_name\n 'Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz'\n >>> cpu_info.get_processor_by_index(0)['cpus']\n '0'\n >>> cpu_info.get_processor_by_index(0)['vendors']\n 'GenuineIntel'\n\"\"\"\n\nfrom collections import defaultdict\nfrom .. import Parser, parser, defaults, get_active_lines, LegacyItemAccess\nfrom insights.specs import Specs\n\n\n@parser(Specs.cpuinfo)\nclass CpuInfo(LegacyItemAccess, Parser):\n \"\"\"\n CpuInfo parser - able to be used as a dictionary through the\n LegacyItemAccess mixin class.\n\n The following items are remapped into lists, with the element number\n corresponding to the CPU. For example, given the following input::\n\n processor : 1\n vendor_id : GenuineIntel\n cpu family : 6\n model : 45\n model name : Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz\n stepping : 2\n microcode : 1808\n cpu MHz : 2900.000\n cache size : 20480 KB\n physical id : 2\n siblings : 1\n core id : 0\n cpu cores : 1\n apicid : 2\n address sizes : 40 bits physical, 48 bits virtual\n bugs : cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit\n\n The following keys would be lists of:\n\n * **cpus** - the *processor* line (e.g. ``1``)\n * **sockets** - the *physical id* line (e.g. ``2``)\n * **vendors** - the *vendor_id* line (e.g. ``GenuineIntel``)\n * **models** - the *model name* line (e.g. ``Intel(R) Xeon(R) CPU E5-2690 0 @ 2.90GHz``)\n * **model_ids** - the *model* line (e.g. ``45``)\n * **families** - the *cpu family* line (e.g. ``6``)\n * **clockspeeds** - the *cpu MHz* line (e.g. ``2900.000``)\n * **cache_sizes** - the *cache size* line (e.g. ``20480 KB``)\n * **cpu_cores** - the *cpu cores* line (e.g. ``1``)\n * **apicid** - the *apicid* line (e.g. ``1``)\n * **stepping** - the *stepping* line (e.g. ``2``)\n * **address_sizes** - the *address sizes* line (e.g. ``40 bits physical, 48 bits virtual``)\n * **bugs** - the *bugs* line (e.g. ``cpu_meltdown spectre_v1 spectre_v2 spec_store_bypass l1tf mds swapgs taa itlb_multihit``)\n \"\"\"\n\n def parse_content(self, content):\n\n self.data = defaultdict(list)\n mappings = {\n \"processor\": \"cpus\",\n \"physical id\": \"sockets\",\n \"vendor_id\": \"vendors\",\n \"model name\": \"models\",\n \"model\": \"model_ids\",\n \"cpu family\": \"families\",\n \"cpu MHz\": \"clockspeeds\",\n \"cache size\": \"cache_sizes\",\n \"cpu cores\": \"cpu_cores\",\n \"apicid\": \"apicid\",\n \"flags\": \"flags\",\n \"stepping\": \"stepping\",\n \"Features\": \"features\",\n \"CPU implementer\": \"cpu_implementer\",\n \"CPU architecture\": \"cpu_architecture\",\n \"CPU variant\": \"cpu_variant\",\n \"CPU part\": \"cpu_part\",\n \"CPU revision\": \"cpu_revision\",\n \"cpu\": \"cpu\",\n \"revision\": \"revision\",\n \"address sizes\": \"address_sizes\",\n \"bugs\": \"bugs\",\n \"apicid\": \"apicid\"\n }\n\n for line in get_active_lines(content, comment_char=\"COMMAND>\"):\n key, value = [p.strip() for p in line.split(\":\", 1)]\n if key in mappings:\n self.data[mappings[key]].append(value)\n\n if \"cpu\" in self.data and \"POWER\" in self.data[\"cpu\"][0]:\n # this works differently than on x86 and is not per-cpu\n del self.data[\"model_ids\"]\n\n self.data = dict(self.data)\n\n def __iter__(self):\n \"\"\"\n Iterating through this object will yield the ``get_processor_by_index``\n information for each CPU.\n \"\"\"\n for idx in range(len(self[\"cpus\"])):\n yield self.get_processor_by_index(idx)\n\n @property\n @defaults()\n def cpu_speed(self):\n \"\"\"\n str: Returns the CPU speed of the first CPU.\n \"\"\"\n return self.data[\"clockspeeds\"][0]\n\n @property\n @defaults()\n def cache_size(self):\n \"\"\"\n str: Returns the cache size of the first CPU.\n \"\"\"\n return self.data[\"cache_sizes\"][0]\n\n @property\n @defaults()\n def cpu_count(self):\n \"\"\"\n str: Returns the number of CPUs.\n \"\"\"\n return len(self.data.get(\"cpus\", []))\n\n @property\n @defaults()\n def apicid(self):\n \"\"\"\n str: Returns the apicid of the processor.\n \"\"\"\n return self.data[\"apicid\"]\n\n @property\n @defaults()\n def socket_count(self):\n \"\"\"\n str: Returns the number of sockets. This is distinct from the number\n of CPUs.\n \"\"\"\n return len(set(self.data.get(\"sockets\", [])))\n\n @property\n @defaults()\n def model_name(self):\n \"\"\"\n str: Returns the model name of the first CPU.\n \"\"\"\n return self.data[\"models\"][0]\n\n @property\n @defaults()\n def model_number(self):\n \"\"\"\n str: Returns the model ID of the first CPU.\n \"\"\"\n return self.data[\"model_ids\"][0]\n\n @property\n @defaults()\n def flags(self):\n \"\"\"\n list: Returns a list of feature flags for the first CPU.\n \"\"\"\n return self.data[\"flags\"][0].split()\n\n @property\n @defaults()\n def vendor(self):\n \"\"\"\n str: Returns the vendor of the first CPU.\n \"\"\"\n return self.data[\"vendors\"][0]\n\n @property\n @defaults()\n def core_total(self):\n \"\"\"\n int: Returns the total number of cores for the server if available, else None.\n\n .. warning::\n This function is deprecated. Please use the\n :py:class:`insights.parsers.lscpu.LsCPU` class attribute\n ``info['Cores per socket']`` and ``info['Sockets']`` values instead.\n \"\"\"\n if self.data and 'cpu_cores' in self.data:\n # I guess we can't get this fancey on older versions of RHEL\n # return sum({e['sockets']: int(e['cpu_cores']) for e in self}.values())\n physical_dict = {}\n for e in self:\n # we should rename sockets here to physical_ids as cpuinfo\n # has it there can be many physical_ids per socket\n # see fgrep 'physical id' /proc/cpuinfo on a single\n # package system\n physical_dict[e['sockets']] = int(e['cpu_cores'])\n return sum(physical_dict.values())\n else:\n return None\n\n def get_processor_by_index(self, index):\n \"\"\"\n Construct a dictionary of the information stored for the given CPU.\n\n Parameters:\n index (int): The CPU index to retrieve.\n\n Returns:\n dict: A dictionary of the information for that CPU.\n \"\"\"\n return dict((k, v[index]) for k, v in self.data.items())\n", "path": "insights/parsers/cpuinfo.py"}]} | 3,386 | 341 |
gh_patches_debug_36975 | rasdani/github-patches | git_diff | pulp__pulpcore-2318 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Clean up TaskReservedResources/task-table at migration to new-tasking-system
See https://bugzilla.redhat.com/show_bug.cgi?id=2031154 for details.
Migration that needs to be updated to purge taskreservedresource entries: 0064_add_new_style_task_columns.py
This wants to be cherrypicked into 3.14/15/16 (after which the offending table no longer exists)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `pulpcore/app/migrations/0064_add_new_style_task_columns.py`
Content:
```
1 # Generated by Django 2.2.20 on 2021-04-27 07:51
2
3 import django.contrib.postgres.fields
4 import django.contrib.postgres.fields.jsonb
5 from django.db import migrations, models
6
7
8 def copy_reserved_resources_record(apps, schema_editor):
9 Task = apps.get_model('core', 'Task')
10 for task in Task.objects.iterator():
11 task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))
12 task.save()
13
14
15 def noop(apps, schema_editor):
16 pass
17
18
19 class Migration(migrations.Migration):
20
21 dependencies = [
22 ('core', '0063_repository_retained_versions'),
23 ]
24
25 operations = [
26 migrations.AddField(
27 model_name='task',
28 name='args',
29 field=django.contrib.postgres.fields.jsonb.JSONField(null=True),
30 ),
31 migrations.AddField(
32 model_name='task',
33 name='kwargs',
34 field=django.contrib.postgres.fields.jsonb.JSONField(null=True),
35 ),
36 migrations.AddField(
37 model_name='task',
38 name='_reserved_resources_record',
39 field=django.contrib.postgres.fields.ArrayField(base_field=models.CharField(max_length=256), null=True, size=None),
40 ),
41 migrations.AlterField(
42 model_name='task',
43 name='_resource_job_id',
44 field=models.UUIDField(null=True),
45 ),
46 migrations.AlterField(
47 model_name='progressreport',
48 name='state',
49 field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')], default='waiting'),
50 ),
51 migrations.AlterField(
52 model_name='task',
53 name='state',
54 field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')]),
55 ),
56 migrations.AddIndex(
57 model_name='task',
58 index=models.Index(fields=['pulp_created'], name='core_task_pulp_cr_10223f_idx'),
59 ),
60 migrations.RunPython(
61 code=copy_reserved_resources_record,
62 reverse_code=noop,
63 ),
64 migrations.RemoveField(
65 model_name='taskreservedresourcerecord',
66 name='resource',
67 ),
68 migrations.RemoveField(
69 model_name='taskreservedresourcerecord',
70 name='task',
71 ),
72 migrations.DeleteModel(
73 name='ReservedResourceRecord',
74 ),
75 migrations.DeleteModel(
76 name='TaskReservedResourceRecord',
77 ),
78 migrations.RenameField(
79 model_name='task',
80 old_name='_reserved_resources_record',
81 new_name='reserved_resources_record',
82 ),
83 ]
84
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/pulpcore/app/migrations/0064_add_new_style_task_columns.py b/pulpcore/app/migrations/0064_add_new_style_task_columns.py
--- a/pulpcore/app/migrations/0064_add_new_style_task_columns.py
+++ b/pulpcore/app/migrations/0064_add_new_style_task_columns.py
@@ -4,16 +4,34 @@
import django.contrib.postgres.fields.jsonb
from django.db import migrations, models
+TASK_BATCH_SIZE = 1000
+
def copy_reserved_resources_record(apps, schema_editor):
Task = apps.get_model('core', 'Task')
- for task in Task.objects.iterator():
+
+ # Update _reserved_resource_record for all tasks, 1000 tasks at a time.
+ # When we hit 1K tasks, go to the db for the batch.
+ # Make sure to update the final batch!
+ tasks = []
+ for task in Task.objects.iterator(chunk_size=TASK_BATCH_SIZE):
task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))
- task.save()
+ tasks.append(task)
+ if len(tasks) == TASK_BATCH_SIZE:
+ Task.objects.bulk_update(tasks, ["_reserved_resources_record"])
+ tasks.clear()
+
+ # Update last set of tasks
+ if len(tasks) > 0:
+ Task.objects.bulk_update(tasks, ["_reserved_resources_record"])
+
+def purge_reservedresources(apps, schema_editor):
+ TaskReservedResource = apps.get_model('core', 'TaskReservedResource')
+ TaskReservedResource.objects.all().delete()
-def noop(apps, schema_editor):
- pass
+ ReservedResource = apps.get_model('core', 'ReservedResource')
+ ReservedResource.objects.all().delete()
class Migration(migrations.Migration):
@@ -23,6 +41,12 @@
]
operations = [
+ # Purge any ReservedResource entries - if there are any, they're orphans
+ migrations.RunPython(
+ code=purge_reservedresources,
+ reverse_code=migrations.RunPython.noop,
+ ),
+ # Update entities for the new task-system
migrations.AddField(
model_name='task',
name='args',
@@ -59,7 +83,7 @@
),
migrations.RunPython(
code=copy_reserved_resources_record,
- reverse_code=noop,
+ reverse_code=migrations.RunPython.noop,
),
migrations.RemoveField(
model_name='taskreservedresourcerecord',
@@ -80,4 +104,5 @@
old_name='_reserved_resources_record',
new_name='reserved_resources_record',
),
+
]
| {"golden_diff": "diff --git a/pulpcore/app/migrations/0064_add_new_style_task_columns.py b/pulpcore/app/migrations/0064_add_new_style_task_columns.py\n--- a/pulpcore/app/migrations/0064_add_new_style_task_columns.py\n+++ b/pulpcore/app/migrations/0064_add_new_style_task_columns.py\n@@ -4,16 +4,34 @@\n import django.contrib.postgres.fields.jsonb\n from django.db import migrations, models\n \n+TASK_BATCH_SIZE = 1000\n+\n \n def copy_reserved_resources_record(apps, schema_editor):\n Task = apps.get_model('core', 'Task')\n- for task in Task.objects.iterator():\n+\n+ # Update _reserved_resource_record for all tasks, 1000 tasks at a time.\n+ # When we hit 1K tasks, go to the db for the batch.\n+ # Make sure to update the final batch!\n+ tasks = []\n+ for task in Task.objects.iterator(chunk_size=TASK_BATCH_SIZE):\n task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))\n- task.save()\n+ tasks.append(task)\n+ if len(tasks) == TASK_BATCH_SIZE:\n+ Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n+ tasks.clear()\n+\n+ # Update last set of tasks\n+ if len(tasks) > 0:\n+ Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n+\n \n+def purge_reservedresources(apps, schema_editor):\n+ TaskReservedResource = apps.get_model('core', 'TaskReservedResource')\n+ TaskReservedResource.objects.all().delete()\n \n-def noop(apps, schema_editor):\n- pass\n+ ReservedResource = apps.get_model('core', 'ReservedResource')\n+ ReservedResource.objects.all().delete()\n \n \n class Migration(migrations.Migration):\n@@ -23,6 +41,12 @@\n ]\n \n operations = [\n+ # Purge any ReservedResource entries - if there are any, they're orphans\n+ migrations.RunPython(\n+ code=purge_reservedresources,\n+ reverse_code=migrations.RunPython.noop,\n+ ),\n+ # Update entities for the new task-system\n migrations.AddField(\n model_name='task',\n name='args',\n@@ -59,7 +83,7 @@\n ),\n migrations.RunPython(\n code=copy_reserved_resources_record,\n- reverse_code=noop,\n+ reverse_code=migrations.RunPython.noop,\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n@@ -80,4 +104,5 @@\n old_name='_reserved_resources_record',\n new_name='reserved_resources_record',\n ),\n+\n ]\n", "issue": "Clean up TaskReservedResources/task-table at migration to new-tasking-system\nSee https://bugzilla.redhat.com/show_bug.cgi?id=2031154 for details.\r\n\r\nMigration that needs to be updated to purge taskreservedresource entries: 0064_add_new_style_task_columns.py\r\n\r\nThis wants to be cherrypicked into 3.14/15/16 (after which the offending table no longer exists)\n", "before_files": [{"content": "# Generated by Django 2.2.20 on 2021-04-27 07:51\n\nimport django.contrib.postgres.fields\nimport django.contrib.postgres.fields.jsonb\nfrom django.db import migrations, models\n\n\ndef copy_reserved_resources_record(apps, schema_editor):\n Task = apps.get_model('core', 'Task')\n for task in Task.objects.iterator():\n task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))\n task.save()\n\n\ndef noop(apps, schema_editor):\n pass\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0063_repository_retained_versions'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='task',\n name='args',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='kwargs',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='_reserved_resources_record',\n field=django.contrib.postgres.fields.ArrayField(base_field=models.CharField(max_length=256), null=True, size=None),\n ),\n migrations.AlterField(\n model_name='task',\n name='_resource_job_id',\n field=models.UUIDField(null=True),\n ),\n migrations.AlterField(\n model_name='progressreport',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')], default='waiting'),\n ),\n migrations.AlterField(\n model_name='task',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')]),\n ),\n migrations.AddIndex(\n model_name='task',\n index=models.Index(fields=['pulp_created'], name='core_task_pulp_cr_10223f_idx'),\n ),\n migrations.RunPython(\n code=copy_reserved_resources_record,\n reverse_code=noop,\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='resource',\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='task',\n ),\n migrations.DeleteModel(\n name='ReservedResourceRecord',\n ),\n migrations.DeleteModel(\n name='TaskReservedResourceRecord',\n ),\n migrations.RenameField(\n model_name='task',\n old_name='_reserved_resources_record',\n new_name='reserved_resources_record',\n ),\n ]\n", "path": "pulpcore/app/migrations/0064_add_new_style_task_columns.py"}], "after_files": [{"content": "# Generated by Django 2.2.20 on 2021-04-27 07:51\n\nimport django.contrib.postgres.fields\nimport django.contrib.postgres.fields.jsonb\nfrom django.db import migrations, models\n\nTASK_BATCH_SIZE = 1000\n\n\ndef copy_reserved_resources_record(apps, schema_editor):\n Task = apps.get_model('core', 'Task')\n\n # Update _reserved_resource_record for all tasks, 1000 tasks at a time.\n # When we hit 1K tasks, go to the db for the batch.\n # Make sure to update the final batch!\n tasks = []\n for task in Task.objects.iterator(chunk_size=TASK_BATCH_SIZE):\n task._reserved_resources_record = list(task.reserved_resources_record.values_list('resource', flat=True))\n tasks.append(task)\n if len(tasks) == TASK_BATCH_SIZE:\n Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n tasks.clear()\n\n # Update last set of tasks\n if len(tasks) > 0:\n Task.objects.bulk_update(tasks, [\"_reserved_resources_record\"])\n\n\ndef purge_reservedresources(apps, schema_editor):\n TaskReservedResource = apps.get_model('core', 'TaskReservedResource')\n TaskReservedResource.objects.all().delete()\n\n ReservedResource = apps.get_model('core', 'ReservedResource')\n ReservedResource.objects.all().delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('core', '0063_repository_retained_versions'),\n ]\n\n operations = [\n # Purge any ReservedResource entries - if there are any, they're orphans\n migrations.RunPython(\n code=purge_reservedresources,\n reverse_code=migrations.RunPython.noop,\n ),\n # Update entities for the new task-system\n migrations.AddField(\n model_name='task',\n name='args',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='kwargs',\n field=django.contrib.postgres.fields.jsonb.JSONField(null=True),\n ),\n migrations.AddField(\n model_name='task',\n name='_reserved_resources_record',\n field=django.contrib.postgres.fields.ArrayField(base_field=models.CharField(max_length=256), null=True, size=None),\n ),\n migrations.AlterField(\n model_name='task',\n name='_resource_job_id',\n field=models.UUIDField(null=True),\n ),\n migrations.AlterField(\n model_name='progressreport',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')], default='waiting'),\n ),\n migrations.AlterField(\n model_name='task',\n name='state',\n field=models.TextField(choices=[('waiting', 'Waiting'), ('skipped', 'Skipped'), ('running', 'Running'), ('completed', 'Completed'), ('failed', 'Failed'), ('canceled', 'Canceled'), ('canceling', 'Canceling')]),\n ),\n migrations.AddIndex(\n model_name='task',\n index=models.Index(fields=['pulp_created'], name='core_task_pulp_cr_10223f_idx'),\n ),\n migrations.RunPython(\n code=copy_reserved_resources_record,\n reverse_code=migrations.RunPython.noop,\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='resource',\n ),\n migrations.RemoveField(\n model_name='taskreservedresourcerecord',\n name='task',\n ),\n migrations.DeleteModel(\n name='ReservedResourceRecord',\n ),\n migrations.DeleteModel(\n name='TaskReservedResourceRecord',\n ),\n migrations.RenameField(\n model_name='task',\n old_name='_reserved_resources_record',\n new_name='reserved_resources_record',\n ),\n\n ]\n", "path": "pulpcore/app/migrations/0064_add_new_style_task_columns.py"}]} | 1,140 | 600 |
gh_patches_debug_15125 | rasdani/github-patches | git_diff | ray-project__ray-7362 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[tune] GPU utilization getting checked for cluster with no gpu
<!--Please include [tune], [rllib], [autoscaler] etc. in the issue title if relevant-->
### What is the problem?
Trivial issue, which does not actually impact performance as far as I can tell, but it seems if you launch a cluster with a configuration that sets gpus = 0, then there might be a check which avoids this error message...
```
(pid=4628) Exception in thread Thread-2:
(pid=4628) Traceback (most recent call last):
(pid=4628) File "/usr/lib/python3.6/threading.py", line 916, in _bootstrap_inner
(pid=4628) self.run()
(pid=4628) File "/home/ubuntu/algo/lib/python3.6/site-packages/ray/tune/utils/util.py", line 89, in run
(pid=4628) self._read_utilization()
(pid=4628) File "/home/ubuntu/algo/lib/python3.6/site-packages/ray/tune/utils/util.py", line 65, in _read_utilization
(pid=4628) for gpu in GPUtil.getGPUs():
(pid=4628) File "/home/ubuntu/algo/lib/python3.6/site-packages/GPUtil/GPUtil.py", line 102, in getGPUs
(pid=4628) deviceIds = int(vals[i])
(pid=4628) ValueError: invalid literal for int() with base 10: "NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running."
```
*Ray version and other system information (Python version, TensorFlow version, OS):*
Ray 0.8.1, TF 2.1, RHEL 7.7
### Reproduction (REQUIRED)
Please provide a script that can be run to reproduce the issue. The script should have **no external library dependencies** (i.e., use fake or mock data / environments):
If we cannot run your script, we cannot fix your issue.
- [ ] I have verified my script runs in a clean environment and reproduces the issue.
- [ ] I have verified the issue also occurs with the [latest wheels](https://ray.readthedocs.io/en/latest/installation.html).
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `python/ray/tune/utils/util.py`
Content:
```
1 import copy
2 import logging
3 import threading
4 import time
5 from collections import defaultdict
6 from threading import Thread
7
8 import numpy as np
9 import ray
10 import psutil
11
12 logger = logging.getLogger(__name__)
13
14 try:
15 import GPUtil
16 except ImportError:
17 GPUtil = None
18
19 _pinned_objects = []
20 PINNED_OBJECT_PREFIX = "ray.tune.PinnedObject:"
21 START_OF_TIME = time.time()
22
23
24 class UtilMonitor(Thread):
25 """Class for system usage utilization monitoring.
26
27 It keeps track of CPU, RAM, GPU, VRAM usage (each gpu separately) by
28 pinging for information every x seconds in a separate thread.
29
30 Requires psutil and GPUtil to be installed. Can be enabled with
31 tune.run(config={"log_sys_usage": True}).
32 """
33
34 def __init__(self, start=True, delay=0.7):
35 self.stopped = True
36 if GPUtil is None and start:
37 logger.warning("Install gputil for GPU system monitoring.")
38
39 if psutil is None and start:
40 logger.warning("Install psutil to monitor system performance.")
41
42 if GPUtil is None and psutil is None:
43 return
44
45 super(UtilMonitor, self).__init__()
46 self.delay = delay # Time between calls to GPUtil
47 self.values = defaultdict(list)
48 self.lock = threading.Lock()
49 self.daemon = True
50 if start:
51 self.start()
52
53 def _read_utilization(self):
54 with self.lock:
55 if psutil is not None:
56 self.values["cpu_util_percent"].append(
57 float(psutil.cpu_percent(interval=None)))
58 self.values["ram_util_percent"].append(
59 float(getattr(psutil.virtual_memory(), "percent")))
60 if GPUtil is not None:
61 for gpu in GPUtil.getGPUs():
62 self.values["gpu_util_percent" + str(gpu.id)].append(
63 float(gpu.load))
64 self.values["vram_util_percent" + str(gpu.id)].append(
65 float(gpu.memoryUtil))
66
67 def get_data(self):
68 if self.stopped:
69 return {}
70
71 with self.lock:
72 ret_values = copy.deepcopy(self.values)
73 for key, val in self.values.items():
74 del val[:]
75 return {
76 "perf": {
77 k: np.mean(v)
78 for k, v in ret_values.items() if len(v) > 0
79 }
80 }
81
82 def run(self):
83 self.stopped = False
84 while not self.stopped:
85 self._read_utilization()
86 time.sleep(self.delay)
87
88 def stop(self):
89 self.stopped = True
90
91
92 def pin_in_object_store(obj):
93 """Deprecated, use ray.put(value, weakref=False) instead."""
94
95 obj_id = ray.put(obj, weakref=False)
96 _pinned_objects.append(obj_id)
97 return obj_id
98
99
100 def get_pinned_object(pinned_id):
101 """Deprecated."""
102
103 return ray.get(pinned_id)
104
105
106 class warn_if_slow:
107 """Prints a warning if a given operation is slower than 100ms.
108
109 Example:
110 >>> with warn_if_slow("some_operation"):
111 ... ray.get(something)
112 """
113
114 DEFAULT_THRESHOLD = 0.5
115
116 def __init__(self, name, threshold=None):
117 self.name = name
118 self.threshold = threshold or self.DEFAULT_THRESHOLD
119 self.too_slow = False
120
121 def __enter__(self):
122 self.start = time.time()
123 return self
124
125 def __exit__(self, type, value, traceback):
126 now = time.time()
127 if now - self.start > self.threshold and now - START_OF_TIME > 60.0:
128 self.too_slow = True
129 logger.warning(
130 "The `%s` operation took %s seconds to complete, "
131 "which may be a performance bottleneck.", self.name,
132 now - self.start)
133
134
135 def merge_dicts(d1, d2):
136 """
137 Args:
138 d1 (dict): Dict 1.
139 d2 (dict): Dict 2.
140
141 Returns:
142 dict: A new dict that is d1 and d2 deep merged.
143 """
144 merged = copy.deepcopy(d1)
145 deep_update(merged, d2, True, [])
146 return merged
147
148
149 def deep_update(original,
150 new_dict,
151 new_keys_allowed=False,
152 whitelist=None,
153 override_all_if_type_changes=None):
154 """Updates original dict with values from new_dict recursively.
155
156 If new key is introduced in new_dict, then if new_keys_allowed is not
157 True, an error will be thrown. Further, for sub-dicts, if the key is
158 in the whitelist, then new subkeys can be introduced.
159
160 Args:
161 original (dict): Dictionary with default values.
162 new_dict (dict): Dictionary with values to be updated
163 new_keys_allowed (bool): Whether new keys are allowed.
164 whitelist (Optional[List[str]]): List of keys that correspond to dict
165 values where new subkeys can be introduced. This is only at the top
166 level.
167 override_all_if_type_changes(Optional[List[str]]): List of top level
168 keys with value=dict, for which we always simply override the
169 entire value (dict), iff the "type" key in that value dict changes.
170 """
171 whitelist = whitelist or []
172 override_all_if_type_changes = override_all_if_type_changes or []
173
174 for k, value in new_dict.items():
175 if k not in original and not new_keys_allowed:
176 raise Exception("Unknown config parameter `{}` ".format(k))
177
178 # Both orginal value and new one are dicts.
179 if isinstance(original.get(k), dict) and isinstance(value, dict):
180 # Check old type vs old one. If different, override entire value.
181 if k in override_all_if_type_changes and \
182 "type" in value and "type" in original[k] and \
183 value["type"] != original[k]["type"]:
184 original[k] = value
185 # Whitelisted key -> ok to add new subkeys.
186 elif k in whitelist:
187 deep_update(original[k], value, True)
188 # Non-whitelisted key.
189 else:
190 deep_update(original[k], value, new_keys_allowed)
191 # Original value not a dict OR new value not a dict:
192 # Override entire value.
193 else:
194 original[k] = value
195 return original
196
197
198 def flatten_dict(dt, delimiter="/"):
199 dt = copy.deepcopy(dt)
200 while any(isinstance(v, dict) for v in dt.values()):
201 remove = []
202 add = {}
203 for key, value in dt.items():
204 if isinstance(value, dict):
205 for subkey, v in value.items():
206 add[delimiter.join([key, subkey])] = v
207 remove.append(key)
208 dt.update(add)
209 for k in remove:
210 del dt[k]
211 return dt
212
213
214 def _to_pinnable(obj):
215 """Converts obj to a form that can be pinned in object store memory.
216
217 Currently only numpy arrays are pinned in memory, if you have a strong
218 reference to the array value.
219 """
220
221 return (obj, np.zeros(1))
222
223
224 def _from_pinnable(obj):
225 """Retrieve from _to_pinnable format."""
226
227 return obj[0]
228
229
230 def validate_save_restore(trainable_cls,
231 config=None,
232 num_gpus=0,
233 use_object_store=False):
234 """Helper method to check if your Trainable class will resume correctly.
235
236 Args:
237 trainable_cls: Trainable class for evaluation.
238 config (dict): Config to pass to Trainable when testing.
239 num_gpus (int): GPU resources to allocate when testing.
240 use_object_store (bool): Whether to save and restore to Ray's object
241 store. Recommended to set this to True if planning to use
242 algorithms that pause training (i.e., PBT, HyperBand).
243 """
244 assert ray.is_initialized(), "Need Ray to be initialized."
245 remote_cls = ray.remote(num_gpus=num_gpus)(trainable_cls)
246 trainable_1 = remote_cls.remote(config=config)
247 trainable_2 = remote_cls.remote(config=config)
248
249 from ray.tune.result import TRAINING_ITERATION
250
251 for _ in range(3):
252 res = ray.get(trainable_1.train.remote())
253
254 assert res.get(TRAINING_ITERATION), (
255 "Validation will not pass because it requires `training_iteration` "
256 "to be returned.")
257
258 if use_object_store:
259 restore_check = trainable_2.restore_from_object.remote(
260 trainable_1.save_to_object.remote())
261 ray.get(restore_check)
262 else:
263 restore_check = ray.get(
264 trainable_2.restore.remote(trainable_1.save.remote()))
265
266 res = ray.get(trainable_2.train.remote())
267 assert res[TRAINING_ITERATION] == 4
268
269 res = ray.get(trainable_2.train.remote())
270 assert res[TRAINING_ITERATION] == 5
271 return True
272
273
274 if __name__ == "__main__":
275 ray.init()
276 X = pin_in_object_store("hello")
277 print(X)
278 result = get_pinned_object(X)
279 print(result)
280
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/python/ray/tune/utils/util.py b/python/ray/tune/utils/util.py
--- a/python/ray/tune/utils/util.py
+++ b/python/ray/tune/utils/util.py
@@ -58,7 +58,12 @@
self.values["ram_util_percent"].append(
float(getattr(psutil.virtual_memory(), "percent")))
if GPUtil is not None:
- for gpu in GPUtil.getGPUs():
+ gpu_list = []
+ try:
+ gpu_list = GPUtil.getGPUs()
+ except Exception:
+ logger.debug("GPUtil failed to retrieve GPUs.")
+ for gpu in gpu_list:
self.values["gpu_util_percent" + str(gpu.id)].append(
float(gpu.load))
self.values["vram_util_percent" + str(gpu.id)].append(
| {"golden_diff": "diff --git a/python/ray/tune/utils/util.py b/python/ray/tune/utils/util.py\n--- a/python/ray/tune/utils/util.py\n+++ b/python/ray/tune/utils/util.py\n@@ -58,7 +58,12 @@\n self.values[\"ram_util_percent\"].append(\n float(getattr(psutil.virtual_memory(), \"percent\")))\n if GPUtil is not None:\n- for gpu in GPUtil.getGPUs():\n+ gpu_list = []\n+ try:\n+ gpu_list = GPUtil.getGPUs()\n+ except Exception:\n+ logger.debug(\"GPUtil failed to retrieve GPUs.\")\n+ for gpu in gpu_list:\n self.values[\"gpu_util_percent\" + str(gpu.id)].append(\n float(gpu.load))\n self.values[\"vram_util_percent\" + str(gpu.id)].append(\n", "issue": "[tune] GPU utilization getting checked for cluster with no gpu\n<!--Please include [tune], [rllib], [autoscaler] etc. in the issue title if relevant-->\r\n\r\n### What is the problem?\r\n\r\nTrivial issue, which does not actually impact performance as far as I can tell, but it seems if you launch a cluster with a configuration that sets gpus = 0, then there might be a check which avoids this error message...\r\n\r\n\r\n```\r\n(pid=4628) Exception in thread Thread-2: \r\n(pid=4628) Traceback (most recent call last):\r\n(pid=4628) File \"/usr/lib/python3.6/threading.py\", line 916, in _bootstrap_inner\r\n(pid=4628) self.run()\r\n(pid=4628) File \"/home/ubuntu/algo/lib/python3.6/site-packages/ray/tune/utils/util.py\", line 89, in run\r\n(pid=4628) self._read_utilization()\r\n(pid=4628) File \"/home/ubuntu/algo/lib/python3.6/site-packages/ray/tune/utils/util.py\", line 65, in _read_utilization\r\n(pid=4628) for gpu in GPUtil.getGPUs():\r\n(pid=4628) File \"/home/ubuntu/algo/lib/python3.6/site-packages/GPUtil/GPUtil.py\", line 102, in getGPUs\r\n(pid=4628) deviceIds = int(vals[i])\r\n(pid=4628) ValueError: invalid literal for int() with base 10: \"NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.\"\r\n```\r\n\r\n\r\n\r\n*Ray version and other system information (Python version, TensorFlow version, OS):*\r\nRay 0.8.1, TF 2.1, RHEL 7.7\r\n\r\n### Reproduction (REQUIRED)\r\nPlease provide a script that can be run to reproduce the issue. The script should have **no external library dependencies** (i.e., use fake or mock data / environments):\r\n\r\nIf we cannot run your script, we cannot fix your issue.\r\n\r\n- [ ] I have verified my script runs in a clean environment and reproduces the issue.\r\n- [ ] I have verified the issue also occurs with the [latest wheels](https://ray.readthedocs.io/en/latest/installation.html).\r\n\n", "before_files": [{"content": "import copy\nimport logging\nimport threading\nimport time\nfrom collections import defaultdict\nfrom threading import Thread\n\nimport numpy as np\nimport ray\nimport psutil\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import GPUtil\nexcept ImportError:\n GPUtil = None\n\n_pinned_objects = []\nPINNED_OBJECT_PREFIX = \"ray.tune.PinnedObject:\"\nSTART_OF_TIME = time.time()\n\n\nclass UtilMonitor(Thread):\n \"\"\"Class for system usage utilization monitoring.\n\n It keeps track of CPU, RAM, GPU, VRAM usage (each gpu separately) by\n pinging for information every x seconds in a separate thread.\n\n Requires psutil and GPUtil to be installed. Can be enabled with\n tune.run(config={\"log_sys_usage\": True}).\n \"\"\"\n\n def __init__(self, start=True, delay=0.7):\n self.stopped = True\n if GPUtil is None and start:\n logger.warning(\"Install gputil for GPU system monitoring.\")\n\n if psutil is None and start:\n logger.warning(\"Install psutil to monitor system performance.\")\n\n if GPUtil is None and psutil is None:\n return\n\n super(UtilMonitor, self).__init__()\n self.delay = delay # Time between calls to GPUtil\n self.values = defaultdict(list)\n self.lock = threading.Lock()\n self.daemon = True\n if start:\n self.start()\n\n def _read_utilization(self):\n with self.lock:\n if psutil is not None:\n self.values[\"cpu_util_percent\"].append(\n float(psutil.cpu_percent(interval=None)))\n self.values[\"ram_util_percent\"].append(\n float(getattr(psutil.virtual_memory(), \"percent\")))\n if GPUtil is not None:\n for gpu in GPUtil.getGPUs():\n self.values[\"gpu_util_percent\" + str(gpu.id)].append(\n float(gpu.load))\n self.values[\"vram_util_percent\" + str(gpu.id)].append(\n float(gpu.memoryUtil))\n\n def get_data(self):\n if self.stopped:\n return {}\n\n with self.lock:\n ret_values = copy.deepcopy(self.values)\n for key, val in self.values.items():\n del val[:]\n return {\n \"perf\": {\n k: np.mean(v)\n for k, v in ret_values.items() if len(v) > 0\n }\n }\n\n def run(self):\n self.stopped = False\n while not self.stopped:\n self._read_utilization()\n time.sleep(self.delay)\n\n def stop(self):\n self.stopped = True\n\n\ndef pin_in_object_store(obj):\n \"\"\"Deprecated, use ray.put(value, weakref=False) instead.\"\"\"\n\n obj_id = ray.put(obj, weakref=False)\n _pinned_objects.append(obj_id)\n return obj_id\n\n\ndef get_pinned_object(pinned_id):\n \"\"\"Deprecated.\"\"\"\n\n return ray.get(pinned_id)\n\n\nclass warn_if_slow:\n \"\"\"Prints a warning if a given operation is slower than 100ms.\n\n Example:\n >>> with warn_if_slow(\"some_operation\"):\n ... ray.get(something)\n \"\"\"\n\n DEFAULT_THRESHOLD = 0.5\n\n def __init__(self, name, threshold=None):\n self.name = name\n self.threshold = threshold or self.DEFAULT_THRESHOLD\n self.too_slow = False\n\n def __enter__(self):\n self.start = time.time()\n return self\n\n def __exit__(self, type, value, traceback):\n now = time.time()\n if now - self.start > self.threshold and now - START_OF_TIME > 60.0:\n self.too_slow = True\n logger.warning(\n \"The `%s` operation took %s seconds to complete, \"\n \"which may be a performance bottleneck.\", self.name,\n now - self.start)\n\n\ndef merge_dicts(d1, d2):\n \"\"\"\n Args:\n d1 (dict): Dict 1.\n d2 (dict): Dict 2.\n\n Returns:\n dict: A new dict that is d1 and d2 deep merged.\n \"\"\"\n merged = copy.deepcopy(d1)\n deep_update(merged, d2, True, [])\n return merged\n\n\ndef deep_update(original,\n new_dict,\n new_keys_allowed=False,\n whitelist=None,\n override_all_if_type_changes=None):\n \"\"\"Updates original dict with values from new_dict recursively.\n\n If new key is introduced in new_dict, then if new_keys_allowed is not\n True, an error will be thrown. Further, for sub-dicts, if the key is\n in the whitelist, then new subkeys can be introduced.\n\n Args:\n original (dict): Dictionary with default values.\n new_dict (dict): Dictionary with values to be updated\n new_keys_allowed (bool): Whether new keys are allowed.\n whitelist (Optional[List[str]]): List of keys that correspond to dict\n values where new subkeys can be introduced. This is only at the top\n level.\n override_all_if_type_changes(Optional[List[str]]): List of top level\n keys with value=dict, for which we always simply override the\n entire value (dict), iff the \"type\" key in that value dict changes.\n \"\"\"\n whitelist = whitelist or []\n override_all_if_type_changes = override_all_if_type_changes or []\n\n for k, value in new_dict.items():\n if k not in original and not new_keys_allowed:\n raise Exception(\"Unknown config parameter `{}` \".format(k))\n\n # Both orginal value and new one are dicts.\n if isinstance(original.get(k), dict) and isinstance(value, dict):\n # Check old type vs old one. If different, override entire value.\n if k in override_all_if_type_changes and \\\n \"type\" in value and \"type\" in original[k] and \\\n value[\"type\"] != original[k][\"type\"]:\n original[k] = value\n # Whitelisted key -> ok to add new subkeys.\n elif k in whitelist:\n deep_update(original[k], value, True)\n # Non-whitelisted key.\n else:\n deep_update(original[k], value, new_keys_allowed)\n # Original value not a dict OR new value not a dict:\n # Override entire value.\n else:\n original[k] = value\n return original\n\n\ndef flatten_dict(dt, delimiter=\"/\"):\n dt = copy.deepcopy(dt)\n while any(isinstance(v, dict) for v in dt.values()):\n remove = []\n add = {}\n for key, value in dt.items():\n if isinstance(value, dict):\n for subkey, v in value.items():\n add[delimiter.join([key, subkey])] = v\n remove.append(key)\n dt.update(add)\n for k in remove:\n del dt[k]\n return dt\n\n\ndef _to_pinnable(obj):\n \"\"\"Converts obj to a form that can be pinned in object store memory.\n\n Currently only numpy arrays are pinned in memory, if you have a strong\n reference to the array value.\n \"\"\"\n\n return (obj, np.zeros(1))\n\n\ndef _from_pinnable(obj):\n \"\"\"Retrieve from _to_pinnable format.\"\"\"\n\n return obj[0]\n\n\ndef validate_save_restore(trainable_cls,\n config=None,\n num_gpus=0,\n use_object_store=False):\n \"\"\"Helper method to check if your Trainable class will resume correctly.\n\n Args:\n trainable_cls: Trainable class for evaluation.\n config (dict): Config to pass to Trainable when testing.\n num_gpus (int): GPU resources to allocate when testing.\n use_object_store (bool): Whether to save and restore to Ray's object\n store. Recommended to set this to True if planning to use\n algorithms that pause training (i.e., PBT, HyperBand).\n \"\"\"\n assert ray.is_initialized(), \"Need Ray to be initialized.\"\n remote_cls = ray.remote(num_gpus=num_gpus)(trainable_cls)\n trainable_1 = remote_cls.remote(config=config)\n trainable_2 = remote_cls.remote(config=config)\n\n from ray.tune.result import TRAINING_ITERATION\n\n for _ in range(3):\n res = ray.get(trainable_1.train.remote())\n\n assert res.get(TRAINING_ITERATION), (\n \"Validation will not pass because it requires `training_iteration` \"\n \"to be returned.\")\n\n if use_object_store:\n restore_check = trainable_2.restore_from_object.remote(\n trainable_1.save_to_object.remote())\n ray.get(restore_check)\n else:\n restore_check = ray.get(\n trainable_2.restore.remote(trainable_1.save.remote()))\n\n res = ray.get(trainable_2.train.remote())\n assert res[TRAINING_ITERATION] == 4\n\n res = ray.get(trainable_2.train.remote())\n assert res[TRAINING_ITERATION] == 5\n return True\n\n\nif __name__ == \"__main__\":\n ray.init()\n X = pin_in_object_store(\"hello\")\n print(X)\n result = get_pinned_object(X)\n print(result)\n", "path": "python/ray/tune/utils/util.py"}], "after_files": [{"content": "import copy\nimport logging\nimport threading\nimport time\nfrom collections import defaultdict\nfrom threading import Thread\n\nimport numpy as np\nimport ray\nimport psutil\n\nlogger = logging.getLogger(__name__)\n\ntry:\n import GPUtil\nexcept ImportError:\n GPUtil = None\n\n_pinned_objects = []\nPINNED_OBJECT_PREFIX = \"ray.tune.PinnedObject:\"\nSTART_OF_TIME = time.time()\n\n\nclass UtilMonitor(Thread):\n \"\"\"Class for system usage utilization monitoring.\n\n It keeps track of CPU, RAM, GPU, VRAM usage (each gpu separately) by\n pinging for information every x seconds in a separate thread.\n\n Requires psutil and GPUtil to be installed. Can be enabled with\n tune.run(config={\"log_sys_usage\": True}).\n \"\"\"\n\n def __init__(self, start=True, delay=0.7):\n self.stopped = True\n if GPUtil is None and start:\n logger.warning(\"Install gputil for GPU system monitoring.\")\n\n if psutil is None and start:\n logger.warning(\"Install psutil to monitor system performance.\")\n\n if GPUtil is None and psutil is None:\n return\n\n super(UtilMonitor, self).__init__()\n self.delay = delay # Time between calls to GPUtil\n self.values = defaultdict(list)\n self.lock = threading.Lock()\n self.daemon = True\n if start:\n self.start()\n\n def _read_utilization(self):\n with self.lock:\n if psutil is not None:\n self.values[\"cpu_util_percent\"].append(\n float(psutil.cpu_percent(interval=None)))\n self.values[\"ram_util_percent\"].append(\n float(getattr(psutil.virtual_memory(), \"percent\")))\n if GPUtil is not None:\n gpu_list = []\n try:\n gpu_list = GPUtil.getGPUs()\n except Exception:\n logger.debug(\"GPUtil failed to retrieve GPUs.\")\n for gpu in gpu_list:\n self.values[\"gpu_util_percent\" + str(gpu.id)].append(\n float(gpu.load))\n self.values[\"vram_util_percent\" + str(gpu.id)].append(\n float(gpu.memoryUtil))\n\n def get_data(self):\n if self.stopped:\n return {}\n\n with self.lock:\n ret_values = copy.deepcopy(self.values)\n for key, val in self.values.items():\n del val[:]\n return {\n \"perf\": {\n k: np.mean(v)\n for k, v in ret_values.items() if len(v) > 0\n }\n }\n\n def run(self):\n self.stopped = False\n while not self.stopped:\n self._read_utilization()\n time.sleep(self.delay)\n\n def stop(self):\n self.stopped = True\n\n\ndef pin_in_object_store(obj):\n \"\"\"Deprecated, use ray.put(value, weakref=False) instead.\"\"\"\n\n obj_id = ray.put(obj, weakref=False)\n _pinned_objects.append(obj_id)\n return obj_id\n\n\ndef get_pinned_object(pinned_id):\n \"\"\"Deprecated.\"\"\"\n\n return ray.get(pinned_id)\n\n\nclass warn_if_slow:\n \"\"\"Prints a warning if a given operation is slower than 100ms.\n\n Example:\n >>> with warn_if_slow(\"some_operation\"):\n ... ray.get(something)\n \"\"\"\n\n DEFAULT_THRESHOLD = 0.5\n\n def __init__(self, name, threshold=None):\n self.name = name\n self.threshold = threshold or self.DEFAULT_THRESHOLD\n self.too_slow = False\n\n def __enter__(self):\n self.start = time.time()\n return self\n\n def __exit__(self, type, value, traceback):\n now = time.time()\n if now - self.start > self.threshold and now - START_OF_TIME > 60.0:\n self.too_slow = True\n logger.warning(\n \"The `%s` operation took %s seconds to complete, \"\n \"which may be a performance bottleneck.\", self.name,\n now - self.start)\n\n\ndef merge_dicts(d1, d2):\n \"\"\"\n Args:\n d1 (dict): Dict 1.\n d2 (dict): Dict 2.\n\n Returns:\n dict: A new dict that is d1 and d2 deep merged.\n \"\"\"\n merged = copy.deepcopy(d1)\n deep_update(merged, d2, True, [])\n return merged\n\n\ndef deep_update(original,\n new_dict,\n new_keys_allowed=False,\n whitelist=None,\n override_all_if_type_changes=None):\n \"\"\"Updates original dict with values from new_dict recursively.\n\n If new key is introduced in new_dict, then if new_keys_allowed is not\n True, an error will be thrown. Further, for sub-dicts, if the key is\n in the whitelist, then new subkeys can be introduced.\n\n Args:\n original (dict): Dictionary with default values.\n new_dict (dict): Dictionary with values to be updated\n new_keys_allowed (bool): Whether new keys are allowed.\n whitelist (Optional[List[str]]): List of keys that correspond to dict\n values where new subkeys can be introduced. This is only at the top\n level.\n override_all_if_type_changes(Optional[List[str]]): List of top level\n keys with value=dict, for which we always simply override the\n entire value (dict), iff the \"type\" key in that value dict changes.\n \"\"\"\n whitelist = whitelist or []\n override_all_if_type_changes = override_all_if_type_changes or []\n\n for k, value in new_dict.items():\n if k not in original and not new_keys_allowed:\n raise Exception(\"Unknown config parameter `{}` \".format(k))\n\n # Both orginal value and new one are dicts.\n if isinstance(original.get(k), dict) and isinstance(value, dict):\n # Check old type vs old one. If different, override entire value.\n if k in override_all_if_type_changes and \\\n \"type\" in value and \"type\" in original[k] and \\\n value[\"type\"] != original[k][\"type\"]:\n original[k] = value\n # Whitelisted key -> ok to add new subkeys.\n elif k in whitelist:\n deep_update(original[k], value, True)\n # Non-whitelisted key.\n else:\n deep_update(original[k], value, new_keys_allowed)\n # Original value not a dict OR new value not a dict:\n # Override entire value.\n else:\n original[k] = value\n return original\n\n\ndef flatten_dict(dt, delimiter=\"/\"):\n dt = copy.deepcopy(dt)\n while any(isinstance(v, dict) for v in dt.values()):\n remove = []\n add = {}\n for key, value in dt.items():\n if isinstance(value, dict):\n for subkey, v in value.items():\n add[delimiter.join([key, subkey])] = v\n remove.append(key)\n dt.update(add)\n for k in remove:\n del dt[k]\n return dt\n\n\ndef _to_pinnable(obj):\n \"\"\"Converts obj to a form that can be pinned in object store memory.\n\n Currently only numpy arrays are pinned in memory, if you have a strong\n reference to the array value.\n \"\"\"\n\n return (obj, np.zeros(1))\n\n\ndef _from_pinnable(obj):\n \"\"\"Retrieve from _to_pinnable format.\"\"\"\n\n return obj[0]\n\n\ndef validate_save_restore(trainable_cls,\n config=None,\n num_gpus=0,\n use_object_store=False):\n \"\"\"Helper method to check if your Trainable class will resume correctly.\n\n Args:\n trainable_cls: Trainable class for evaluation.\n config (dict): Config to pass to Trainable when testing.\n num_gpus (int): GPU resources to allocate when testing.\n use_object_store (bool): Whether to save and restore to Ray's object\n store. Recommended to set this to True if planning to use\n algorithms that pause training (i.e., PBT, HyperBand).\n \"\"\"\n assert ray.is_initialized(), \"Need Ray to be initialized.\"\n remote_cls = ray.remote(num_gpus=num_gpus)(trainable_cls)\n trainable_1 = remote_cls.remote(config=config)\n trainable_2 = remote_cls.remote(config=config)\n\n from ray.tune.result import TRAINING_ITERATION\n\n for _ in range(3):\n res = ray.get(trainable_1.train.remote())\n\n assert res.get(TRAINING_ITERATION), (\n \"Validation will not pass because it requires `training_iteration` \"\n \"to be returned.\")\n\n if use_object_store:\n restore_check = trainable_2.restore_from_object.remote(\n trainable_1.save_to_object.remote())\n ray.get(restore_check)\n else:\n restore_check = ray.get(\n trainable_2.restore.remote(trainable_1.save.remote()))\n\n res = ray.get(trainable_2.train.remote())\n assert res[TRAINING_ITERATION] == 4\n\n res = ray.get(trainable_2.train.remote())\n assert res[TRAINING_ITERATION] == 5\n return True\n\n\nif __name__ == \"__main__\":\n ray.init()\n X = pin_in_object_store(\"hello\")\n print(X)\n result = get_pinned_object(X)\n print(result)\n", "path": "python/ray/tune/utils/util.py"}]} | 3,494 | 183 |
gh_patches_debug_18751 | rasdani/github-patches | git_diff | aio-libs__aiohttp-3860 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
web access log show utc time instead local time with timezone.
## Long story short
in web_.log.py:
```
def _format_t(request: BaseRequest,
response: StreamResponse,
time: float) -> str:
now = datetime.datetime.utcnow()
start_time = now - datetime.timedelta(seconds=time)
return start_time.strftime('[%d/%b/%Y:%H:%M:%S +0000]')
```
the logged time is fixed and is a utc time, not a local time. there's not a easy way to setting it.
## Expected behaviour
```
INFO:aiohttp.access:127.0.0.1 [18/Jun/2019:04:56:22 -8]
```
## Actual behaviour
```
INFO:aiohttp.access:127.0.0.1 [18/Jun/2019:04:56:22 +0000]
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `aiohttp/web_log.py`
Content:
```
1 import datetime
2 import functools
3 import logging
4 import os
5 import re
6 from collections import namedtuple
7 from typing import Callable, Dict, Iterable, List, Tuple # noqa
8
9 from .abc import AbstractAccessLogger
10 from .web_request import BaseRequest
11 from .web_response import StreamResponse
12
13 KeyMethod = namedtuple('KeyMethod', 'key method')
14
15
16 class AccessLogger(AbstractAccessLogger):
17 """Helper object to log access.
18
19 Usage:
20 log = logging.getLogger("spam")
21 log_format = "%a %{User-Agent}i"
22 access_logger = AccessLogger(log, log_format)
23 access_logger.log(request, response, time)
24
25 Format:
26 %% The percent sign
27 %a Remote IP-address (IP-address of proxy if using reverse proxy)
28 %t Time when the request was started to process
29 %P The process ID of the child that serviced the request
30 %r First line of request
31 %s Response status code
32 %b Size of response in bytes, including HTTP headers
33 %T Time taken to serve the request, in seconds
34 %Tf Time taken to serve the request, in seconds with floating fraction
35 in .06f format
36 %D Time taken to serve the request, in microseconds
37 %{FOO}i request.headers['FOO']
38 %{FOO}o response.headers['FOO']
39 %{FOO}e os.environ['FOO']
40
41 """
42 LOG_FORMAT_MAP = {
43 'a': 'remote_address',
44 't': 'request_start_time',
45 'P': 'process_id',
46 'r': 'first_request_line',
47 's': 'response_status',
48 'b': 'response_size',
49 'T': 'request_time',
50 'Tf': 'request_time_frac',
51 'D': 'request_time_micro',
52 'i': 'request_header',
53 'o': 'response_header',
54 }
55
56 LOG_FORMAT = '%a %t "%r" %s %b "%{Referer}i" "%{User-Agent}i"'
57 FORMAT_RE = re.compile(r'%(\{([A-Za-z0-9\-_]+)\}([ioe])|[atPrsbOD]|Tf?)')
58 CLEANUP_RE = re.compile(r'(%[^s])')
59 _FORMAT_CACHE = {} # type: Dict[str, Tuple[str, List[KeyMethod]]]
60
61 def __init__(self, logger: logging.Logger,
62 log_format: str=LOG_FORMAT) -> None:
63 """Initialise the logger.
64
65 logger is a logger object to be used for logging.
66 log_format is a string with apache compatible log format description.
67
68 """
69 super().__init__(logger, log_format=log_format)
70
71 _compiled_format = AccessLogger._FORMAT_CACHE.get(log_format)
72 if not _compiled_format:
73 _compiled_format = self.compile_format(log_format)
74 AccessLogger._FORMAT_CACHE[log_format] = _compiled_format
75
76 self._log_format, self._methods = _compiled_format
77
78 def compile_format(self, log_format: str) -> Tuple[str, List[KeyMethod]]:
79 """Translate log_format into form usable by modulo formatting
80
81 All known atoms will be replaced with %s
82 Also methods for formatting of those atoms will be added to
83 _methods in appropriate order
84
85 For example we have log_format = "%a %t"
86 This format will be translated to "%s %s"
87 Also contents of _methods will be
88 [self._format_a, self._format_t]
89 These method will be called and results will be passed
90 to translated string format.
91
92 Each _format_* method receive 'args' which is list of arguments
93 given to self.log
94
95 Exceptions are _format_e, _format_i and _format_o methods which
96 also receive key name (by functools.partial)
97
98 """
99 # list of (key, method) tuples, we don't use an OrderedDict as users
100 # can repeat the same key more than once
101 methods = list()
102
103 for atom in self.FORMAT_RE.findall(log_format):
104 if atom[1] == '':
105 format_key1 = self.LOG_FORMAT_MAP[atom[0]]
106 m = getattr(AccessLogger, '_format_%s' % atom[0])
107 key_method = KeyMethod(format_key1, m)
108 else:
109 format_key2 = (self.LOG_FORMAT_MAP[atom[2]], atom[1])
110 m = getattr(AccessLogger, '_format_%s' % atom[2])
111 key_method = KeyMethod(format_key2,
112 functools.partial(m, atom[1]))
113
114 methods.append(key_method)
115
116 log_format = self.FORMAT_RE.sub(r'%s', log_format)
117 log_format = self.CLEANUP_RE.sub(r'%\1', log_format)
118 return log_format, methods
119
120 @staticmethod
121 def _format_i(key: str,
122 request: BaseRequest,
123 response: StreamResponse,
124 time: float) -> str:
125 if request is None:
126 return '(no headers)'
127
128 # suboptimal, make istr(key) once
129 return request.headers.get(key, '-')
130
131 @staticmethod
132 def _format_o(key: str,
133 request: BaseRequest,
134 response: StreamResponse,
135 time: float) -> str:
136 # suboptimal, make istr(key) once
137 return response.headers.get(key, '-')
138
139 @staticmethod
140 def _format_a(request: BaseRequest,
141 response: StreamResponse,
142 time: float) -> str:
143 if request is None:
144 return '-'
145 ip = request.remote
146 return ip if ip is not None else '-'
147
148 @staticmethod
149 def _format_t(request: BaseRequest,
150 response: StreamResponse,
151 time: float) -> str:
152 now = datetime.datetime.utcnow()
153 start_time = now - datetime.timedelta(seconds=time)
154 return start_time.strftime('[%d/%b/%Y:%H:%M:%S +0000]')
155
156 @staticmethod
157 def _format_P(request: BaseRequest,
158 response: StreamResponse,
159 time: float) -> str:
160 return "<%s>" % os.getpid()
161
162 @staticmethod
163 def _format_r(request: BaseRequest,
164 response: StreamResponse,
165 time: float) -> str:
166 if request is None:
167 return '-'
168 return '%s %s HTTP/%s.%s' % (request.method, request.path_qs,
169 request.version.major,
170 request.version.minor)
171
172 @staticmethod
173 def _format_s(request: BaseRequest,
174 response: StreamResponse,
175 time: float) -> int:
176 return response.status
177
178 @staticmethod
179 def _format_b(request: BaseRequest,
180 response: StreamResponse,
181 time: float) -> int:
182 return response.body_length
183
184 @staticmethod
185 def _format_T(request: BaseRequest,
186 response: StreamResponse,
187 time: float) -> str:
188 return str(round(time))
189
190 @staticmethod
191 def _format_Tf(request: BaseRequest,
192 response: StreamResponse,
193 time: float) -> str:
194 return '%06f' % time
195
196 @staticmethod
197 def _format_D(request: BaseRequest,
198 response: StreamResponse,
199 time: float) -> str:
200 return str(round(time * 1000000))
201
202 def _format_line(self,
203 request: BaseRequest,
204 response: StreamResponse,
205 time: float) -> Iterable[Tuple[str,
206 Callable[[BaseRequest,
207 StreamResponse,
208 float],
209 str]]]:
210 return [(key, method(request, response, time))
211 for key, method in self._methods]
212
213 def log(self,
214 request: BaseRequest,
215 response: StreamResponse,
216 time: float) -> None:
217 try:
218 fmt_info = self._format_line(request, response, time)
219
220 values = list()
221 extra = dict()
222 for key, value in fmt_info:
223 values.append(value)
224
225 if key.__class__ is str:
226 extra[key] = value
227 else:
228 k1, k2 = key
229 dct = extra.get(k1, {})
230 dct[k2] = value # type: ignore
231 extra[k1] = dct # type: ignore
232
233 self.logger.info(self._log_format % tuple(values), extra=extra)
234 except Exception:
235 self.logger.exception("Error in logging")
236
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/aiohttp/web_log.py b/aiohttp/web_log.py
--- a/aiohttp/web_log.py
+++ b/aiohttp/web_log.py
@@ -4,6 +4,7 @@
import os
import re
from collections import namedtuple
+from time import timezone
from typing import Callable, Dict, Iterable, List, Tuple # noqa
from .abc import AbstractAccessLogger
@@ -149,9 +150,10 @@
def _format_t(request: BaseRequest,
response: StreamResponse,
time: float) -> str:
- now = datetime.datetime.utcnow()
+ tz = datetime.timezone(datetime.timedelta(seconds=-timezone))
+ now = datetime.datetime.now(tz)
start_time = now - datetime.timedelta(seconds=time)
- return start_time.strftime('[%d/%b/%Y:%H:%M:%S +0000]')
+ return start_time.strftime('[%d/%b/%Y:%H:%M:%S %z]')
@staticmethod
def _format_P(request: BaseRequest,
| {"golden_diff": "diff --git a/aiohttp/web_log.py b/aiohttp/web_log.py\n--- a/aiohttp/web_log.py\n+++ b/aiohttp/web_log.py\n@@ -4,6 +4,7 @@\n import os\n import re\n from collections import namedtuple\n+from time import timezone\n from typing import Callable, Dict, Iterable, List, Tuple # noqa\n \n from .abc import AbstractAccessLogger\n@@ -149,9 +150,10 @@\n def _format_t(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n- now = datetime.datetime.utcnow()\n+ tz = datetime.timezone(datetime.timedelta(seconds=-timezone))\n+ now = datetime.datetime.now(tz)\n start_time = now - datetime.timedelta(seconds=time)\n- return start_time.strftime('[%d/%b/%Y:%H:%M:%S +0000]')\n+ return start_time.strftime('[%d/%b/%Y:%H:%M:%S %z]')\n \n @staticmethod\n def _format_P(request: BaseRequest,\n", "issue": "web access log show utc time instead local time with timezone.\n## Long story short\r\nin web_.log.py:\r\n```\r\n def _format_t(request: BaseRequest,\r\n response: StreamResponse,\r\n time: float) -> str:\r\n now = datetime.datetime.utcnow()\r\n start_time = now - datetime.timedelta(seconds=time)\r\n return start_time.strftime('[%d/%b/%Y:%H:%M:%S +0000]')\r\n```\r\nthe logged time is fixed and is a utc time, not a local time. there's not a easy way to setting it.\r\n\r\n## Expected behaviour\r\n\r\n```\r\nINFO:aiohttp.access:127.0.0.1 [18/Jun/2019:04:56:22 -8]\r\n```\r\n## Actual behaviour\r\n\r\n```\r\nINFO:aiohttp.access:127.0.0.1 [18/Jun/2019:04:56:22 +0000]\r\n```\n", "before_files": [{"content": "import datetime\nimport functools\nimport logging\nimport os\nimport re\nfrom collections import namedtuple\nfrom typing import Callable, Dict, Iterable, List, Tuple # noqa\n\nfrom .abc import AbstractAccessLogger\nfrom .web_request import BaseRequest\nfrom .web_response import StreamResponse\n\nKeyMethod = namedtuple('KeyMethod', 'key method')\n\n\nclass AccessLogger(AbstractAccessLogger):\n \"\"\"Helper object to log access.\n\n Usage:\n log = logging.getLogger(\"spam\")\n log_format = \"%a %{User-Agent}i\"\n access_logger = AccessLogger(log, log_format)\n access_logger.log(request, response, time)\n\n Format:\n %% The percent sign\n %a Remote IP-address (IP-address of proxy if using reverse proxy)\n %t Time when the request was started to process\n %P The process ID of the child that serviced the request\n %r First line of request\n %s Response status code\n %b Size of response in bytes, including HTTP headers\n %T Time taken to serve the request, in seconds\n %Tf Time taken to serve the request, in seconds with floating fraction\n in .06f format\n %D Time taken to serve the request, in microseconds\n %{FOO}i request.headers['FOO']\n %{FOO}o response.headers['FOO']\n %{FOO}e os.environ['FOO']\n\n \"\"\"\n LOG_FORMAT_MAP = {\n 'a': 'remote_address',\n 't': 'request_start_time',\n 'P': 'process_id',\n 'r': 'first_request_line',\n 's': 'response_status',\n 'b': 'response_size',\n 'T': 'request_time',\n 'Tf': 'request_time_frac',\n 'D': 'request_time_micro',\n 'i': 'request_header',\n 'o': 'response_header',\n }\n\n LOG_FORMAT = '%a %t \"%r\" %s %b \"%{Referer}i\" \"%{User-Agent}i\"'\n FORMAT_RE = re.compile(r'%(\\{([A-Za-z0-9\\-_]+)\\}([ioe])|[atPrsbOD]|Tf?)')\n CLEANUP_RE = re.compile(r'(%[^s])')\n _FORMAT_CACHE = {} # type: Dict[str, Tuple[str, List[KeyMethod]]]\n\n def __init__(self, logger: logging.Logger,\n log_format: str=LOG_FORMAT) -> None:\n \"\"\"Initialise the logger.\n\n logger is a logger object to be used for logging.\n log_format is a string with apache compatible log format description.\n\n \"\"\"\n super().__init__(logger, log_format=log_format)\n\n _compiled_format = AccessLogger._FORMAT_CACHE.get(log_format)\n if not _compiled_format:\n _compiled_format = self.compile_format(log_format)\n AccessLogger._FORMAT_CACHE[log_format] = _compiled_format\n\n self._log_format, self._methods = _compiled_format\n\n def compile_format(self, log_format: str) -> Tuple[str, List[KeyMethod]]:\n \"\"\"Translate log_format into form usable by modulo formatting\n\n All known atoms will be replaced with %s\n Also methods for formatting of those atoms will be added to\n _methods in appropriate order\n\n For example we have log_format = \"%a %t\"\n This format will be translated to \"%s %s\"\n Also contents of _methods will be\n [self._format_a, self._format_t]\n These method will be called and results will be passed\n to translated string format.\n\n Each _format_* method receive 'args' which is list of arguments\n given to self.log\n\n Exceptions are _format_e, _format_i and _format_o methods which\n also receive key name (by functools.partial)\n\n \"\"\"\n # list of (key, method) tuples, we don't use an OrderedDict as users\n # can repeat the same key more than once\n methods = list()\n\n for atom in self.FORMAT_RE.findall(log_format):\n if atom[1] == '':\n format_key1 = self.LOG_FORMAT_MAP[atom[0]]\n m = getattr(AccessLogger, '_format_%s' % atom[0])\n key_method = KeyMethod(format_key1, m)\n else:\n format_key2 = (self.LOG_FORMAT_MAP[atom[2]], atom[1])\n m = getattr(AccessLogger, '_format_%s' % atom[2])\n key_method = KeyMethod(format_key2,\n functools.partial(m, atom[1]))\n\n methods.append(key_method)\n\n log_format = self.FORMAT_RE.sub(r'%s', log_format)\n log_format = self.CLEANUP_RE.sub(r'%\\1', log_format)\n return log_format, methods\n\n @staticmethod\n def _format_i(key: str,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n if request is None:\n return '(no headers)'\n\n # suboptimal, make istr(key) once\n return request.headers.get(key, '-')\n\n @staticmethod\n def _format_o(key: str,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n # suboptimal, make istr(key) once\n return response.headers.get(key, '-')\n\n @staticmethod\n def _format_a(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n if request is None:\n return '-'\n ip = request.remote\n return ip if ip is not None else '-'\n\n @staticmethod\n def _format_t(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n now = datetime.datetime.utcnow()\n start_time = now - datetime.timedelta(seconds=time)\n return start_time.strftime('[%d/%b/%Y:%H:%M:%S +0000]')\n\n @staticmethod\n def _format_P(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return \"<%s>\" % os.getpid()\n\n @staticmethod\n def _format_r(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n if request is None:\n return '-'\n return '%s %s HTTP/%s.%s' % (request.method, request.path_qs,\n request.version.major,\n request.version.minor)\n\n @staticmethod\n def _format_s(request: BaseRequest,\n response: StreamResponse,\n time: float) -> int:\n return response.status\n\n @staticmethod\n def _format_b(request: BaseRequest,\n response: StreamResponse,\n time: float) -> int:\n return response.body_length\n\n @staticmethod\n def _format_T(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return str(round(time))\n\n @staticmethod\n def _format_Tf(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return '%06f' % time\n\n @staticmethod\n def _format_D(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return str(round(time * 1000000))\n\n def _format_line(self,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> Iterable[Tuple[str,\n Callable[[BaseRequest,\n StreamResponse,\n float],\n str]]]:\n return [(key, method(request, response, time))\n for key, method in self._methods]\n\n def log(self,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> None:\n try:\n fmt_info = self._format_line(request, response, time)\n\n values = list()\n extra = dict()\n for key, value in fmt_info:\n values.append(value)\n\n if key.__class__ is str:\n extra[key] = value\n else:\n k1, k2 = key\n dct = extra.get(k1, {})\n dct[k2] = value # type: ignore\n extra[k1] = dct # type: ignore\n\n self.logger.info(self._log_format % tuple(values), extra=extra)\n except Exception:\n self.logger.exception(\"Error in logging\")\n", "path": "aiohttp/web_log.py"}], "after_files": [{"content": "import datetime\nimport functools\nimport logging\nimport os\nimport re\nfrom collections import namedtuple\nfrom time import timezone\nfrom typing import Callable, Dict, Iterable, List, Tuple # noqa\n\nfrom .abc import AbstractAccessLogger\nfrom .web_request import BaseRequest\nfrom .web_response import StreamResponse\n\nKeyMethod = namedtuple('KeyMethod', 'key method')\n\n\nclass AccessLogger(AbstractAccessLogger):\n \"\"\"Helper object to log access.\n\n Usage:\n log = logging.getLogger(\"spam\")\n log_format = \"%a %{User-Agent}i\"\n access_logger = AccessLogger(log, log_format)\n access_logger.log(request, response, time)\n\n Format:\n %% The percent sign\n %a Remote IP-address (IP-address of proxy if using reverse proxy)\n %t Time when the request was started to process\n %P The process ID of the child that serviced the request\n %r First line of request\n %s Response status code\n %b Size of response in bytes, including HTTP headers\n %T Time taken to serve the request, in seconds\n %Tf Time taken to serve the request, in seconds with floating fraction\n in .06f format\n %D Time taken to serve the request, in microseconds\n %{FOO}i request.headers['FOO']\n %{FOO}o response.headers['FOO']\n %{FOO}e os.environ['FOO']\n\n \"\"\"\n LOG_FORMAT_MAP = {\n 'a': 'remote_address',\n 't': 'request_start_time',\n 'P': 'process_id',\n 'r': 'first_request_line',\n 's': 'response_status',\n 'b': 'response_size',\n 'T': 'request_time',\n 'Tf': 'request_time_frac',\n 'D': 'request_time_micro',\n 'i': 'request_header',\n 'o': 'response_header',\n }\n\n LOG_FORMAT = '%a %t \"%r\" %s %b \"%{Referer}i\" \"%{User-Agent}i\"'\n FORMAT_RE = re.compile(r'%(\\{([A-Za-z0-9\\-_]+)\\}([ioe])|[atPrsbOD]|Tf?)')\n CLEANUP_RE = re.compile(r'(%[^s])')\n _FORMAT_CACHE = {} # type: Dict[str, Tuple[str, List[KeyMethod]]]\n\n def __init__(self, logger: logging.Logger,\n log_format: str=LOG_FORMAT) -> None:\n \"\"\"Initialise the logger.\n\n logger is a logger object to be used for logging.\n log_format is a string with apache compatible log format description.\n\n \"\"\"\n super().__init__(logger, log_format=log_format)\n\n _compiled_format = AccessLogger._FORMAT_CACHE.get(log_format)\n if not _compiled_format:\n _compiled_format = self.compile_format(log_format)\n AccessLogger._FORMAT_CACHE[log_format] = _compiled_format\n\n self._log_format, self._methods = _compiled_format\n\n def compile_format(self, log_format: str) -> Tuple[str, List[KeyMethod]]:\n \"\"\"Translate log_format into form usable by modulo formatting\n\n All known atoms will be replaced with %s\n Also methods for formatting of those atoms will be added to\n _methods in appropriate order\n\n For example we have log_format = \"%a %t\"\n This format will be translated to \"%s %s\"\n Also contents of _methods will be\n [self._format_a, self._format_t]\n These method will be called and results will be passed\n to translated string format.\n\n Each _format_* method receive 'args' which is list of arguments\n given to self.log\n\n Exceptions are _format_e, _format_i and _format_o methods which\n also receive key name (by functools.partial)\n\n \"\"\"\n # list of (key, method) tuples, we don't use an OrderedDict as users\n # can repeat the same key more than once\n methods = list()\n\n for atom in self.FORMAT_RE.findall(log_format):\n if atom[1] == '':\n format_key1 = self.LOG_FORMAT_MAP[atom[0]]\n m = getattr(AccessLogger, '_format_%s' % atom[0])\n key_method = KeyMethod(format_key1, m)\n else:\n format_key2 = (self.LOG_FORMAT_MAP[atom[2]], atom[1])\n m = getattr(AccessLogger, '_format_%s' % atom[2])\n key_method = KeyMethod(format_key2,\n functools.partial(m, atom[1]))\n\n methods.append(key_method)\n\n log_format = self.FORMAT_RE.sub(r'%s', log_format)\n log_format = self.CLEANUP_RE.sub(r'%\\1', log_format)\n return log_format, methods\n\n @staticmethod\n def _format_i(key: str,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n if request is None:\n return '(no headers)'\n\n # suboptimal, make istr(key) once\n return request.headers.get(key, '-')\n\n @staticmethod\n def _format_o(key: str,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n # suboptimal, make istr(key) once\n return response.headers.get(key, '-')\n\n @staticmethod\n def _format_a(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n if request is None:\n return '-'\n ip = request.remote\n return ip if ip is not None else '-'\n\n @staticmethod\n def _format_t(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n tz = datetime.timezone(datetime.timedelta(seconds=-timezone))\n now = datetime.datetime.now(tz)\n start_time = now - datetime.timedelta(seconds=time)\n return start_time.strftime('[%d/%b/%Y:%H:%M:%S %z]')\n\n @staticmethod\n def _format_P(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return \"<%s>\" % os.getpid()\n\n @staticmethod\n def _format_r(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n if request is None:\n return '-'\n return '%s %s HTTP/%s.%s' % (request.method, request.path_qs,\n request.version.major,\n request.version.minor)\n\n @staticmethod\n def _format_s(request: BaseRequest,\n response: StreamResponse,\n time: float) -> int:\n return response.status\n\n @staticmethod\n def _format_b(request: BaseRequest,\n response: StreamResponse,\n time: float) -> int:\n return response.body_length\n\n @staticmethod\n def _format_T(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return str(round(time))\n\n @staticmethod\n def _format_Tf(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return '%06f' % time\n\n @staticmethod\n def _format_D(request: BaseRequest,\n response: StreamResponse,\n time: float) -> str:\n return str(round(time * 1000000))\n\n def _format_line(self,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> Iterable[Tuple[str,\n Callable[[BaseRequest,\n StreamResponse,\n float],\n str]]]:\n return [(key, method(request, response, time))\n for key, method in self._methods]\n\n def log(self,\n request: BaseRequest,\n response: StreamResponse,\n time: float) -> None:\n try:\n fmt_info = self._format_line(request, response, time)\n\n values = list()\n extra = dict()\n for key, value in fmt_info:\n values.append(value)\n\n if key.__class__ is str:\n extra[key] = value\n else:\n k1, k2 = key\n dct = extra.get(k1, {})\n dct[k2] = value # type: ignore\n extra[k1] = dct # type: ignore\n\n self.logger.info(self._log_format % tuple(values), extra=extra)\n except Exception:\n self.logger.exception(\"Error in logging\")\n", "path": "aiohttp/web_log.py"}]} | 2,904 | 229 |
gh_patches_debug_8531 | rasdani/github-patches | git_diff | deepset-ai__haystack-7909 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
SASEvaluator returns score even when `predicted_answers` contains `None`
In a RAG pipeline, there are cases where the prompt instructs the LLM to return a placeholder answer if there is missing information in the context, such as "No answer". See an [example](https://github.com/deepset-ai/haystack-evaluation/blob/cbfcde5afcaf7574aa82b1ad6b5ce307c8a7c97e/evaluations/architectures/basic_rag.py#L10) in our evaluation repository.
In that case, it makes sense to replace the predicted answer in the RAG pipeline with `None`, instead of computing any metric on the placeholder answer. However, the SASEvaluator returns a score even if `None` is passed.
**Example**:
```
from haystack.components.evaluators import SASEvaluator
sas = SASEvaluator(model="sentence-transformers/all-mpnet-base-v2")
sas.warm_up()
sas.run(predicted_answers=[None, "Whatever"], ground_truth_answers=["Whatever", "Another whatever"])
```
the output is:
```
{'score': 0.46286168694496155,
'individual_scores': [0.26153379678726196, 0.6641895771026611]}
```
**Expected**
```
{'score': 0.6641895771026611,
'individual_scores': [None, 0.6641895771026611]}
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `haystack/components/evaluators/sas_evaluator.py`
Content:
```
1 # SPDX-FileCopyrightText: 2022-present deepset GmbH <[email protected]>
2 #
3 # SPDX-License-Identifier: Apache-2.0
4
5 from typing import Any, Dict, List, Optional
6
7 from numpy import mean as np_mean
8
9 from haystack import component, default_from_dict, default_to_dict
10 from haystack.lazy_imports import LazyImport
11 from haystack.utils import ComponentDevice, expit
12 from haystack.utils.auth import Secret, deserialize_secrets_inplace
13
14 with LazyImport(message="Run 'pip install \"sentence-transformers>=2.3.0\"'") as sas_import:
15 from sentence_transformers import CrossEncoder, SentenceTransformer, util
16 from transformers import AutoConfig
17
18
19 @component
20 class SASEvaluator:
21 """
22 SASEvaluator computes the Semantic Answer Similarity (SAS) between a list of predictions and a one of ground truths.
23
24 It's usually used in Retrieval Augmented Generation (RAG) pipelines to evaluate the quality of the generated
25 answers. The SAS is computed using a pre-trained model from the Hugging Face model hub. The model can be either a
26 Bi-Encoder or a Cross-Encoder. The choice of the model is based on the `model` parameter.
27
28 Usage example:
29 ```python
30 from haystack.components.evaluators.sas_evaluator import SASEvaluator
31
32 evaluator = SASEvaluator(model="cross-encoder/ms-marco-MiniLM-L-6-v2")
33 evaluator.warm_up()
34 ground_truths = [
35 "A construction budget of US $2.3 billion",
36 "The Eiffel Tower, completed in 1889, symbolizes Paris's cultural magnificence.",
37 "The Meiji Restoration in 1868 transformed Japan into a modernized world power.",
38 ]
39 predictions = [
40 "A construction budget of US $2.3 billion",
41 "The Eiffel Tower, completed in 1889, symbolizes Paris's cultural magnificence.",
42 "The Meiji Restoration in 1868 transformed Japan into a modernized world power.",
43 ]
44 result = evaluator.run(
45 ground_truths_answers=ground_truths, predicted_answers=predictions
46 )
47
48 print(result["score"])
49 # 0.9999673763910929
50
51 print(result["individual_scores"])
52 # [0.9999765157699585, 0.999968409538269, 0.9999572038650513]
53 ```
54 """
55
56 def __init__(
57 self,
58 model: str = "sentence-transformers/paraphrase-multilingual-mpnet-base-v2",
59 batch_size: int = 32,
60 device: Optional[ComponentDevice] = None,
61 token: Secret = Secret.from_env_var("HF_API_TOKEN", strict=False),
62 ):
63 """
64 Creates a new instance of SASEvaluator.
65
66 :param model:
67 SentenceTransformers semantic textual similarity model, should be path or string pointing to a downloadable
68 model.
69 :param batch_size:
70 Number of prediction-label pairs to encode at once.
71 :param device:
72 The device on which the model is loaded. If `None`, the default device is automatically selected.
73 :param token:
74 The Hugging Face token for HTTP bearer authorization.
75 You can find your HF token in your [account settings](https://huggingface.co/settings/tokens)
76 """
77 sas_import.check()
78
79 self._model = model
80 self._batch_size = batch_size
81 self._device = device
82 self._token = token
83 self._similarity_model = None
84
85 def to_dict(self) -> Dict[str, Any]:
86 """
87 Serialize this component to a dictionary.
88
89 :returns:
90 The serialized component as a dictionary.
91 """
92 return default_to_dict(
93 self,
94 model=self._model,
95 batch_size=self._batch_size,
96 device=self._device.to_dict() if self._device else None,
97 token=self._token.to_dict() if self._token else None,
98 )
99
100 @classmethod
101 def from_dict(cls, data: Dict[str, Any]) -> "SASEvaluator":
102 """
103 Deserialize this component from a dictionary.
104
105 :param data:
106 The dictionary representation of this component.
107 :returns:
108 The deserialized component instance.
109 """
110 deserialize_secrets_inplace(data["init_parameters"], keys=["token"])
111 if device := data.get("init_parameters", {}).get("device"):
112 data["init_parameters"]["device"] = ComponentDevice.from_dict(device)
113 return default_from_dict(cls, data)
114
115 def warm_up(self):
116 """
117 Initializes the component.
118 """
119 if self._similarity_model:
120 return
121
122 token = self._token.resolve_value() if self._token else None
123 config = AutoConfig.from_pretrained(self._model, use_auth_token=token)
124 cross_encoder_used = False
125 if config.architectures:
126 cross_encoder_used = any(arch.endswith("ForSequenceClassification") for arch in config.architectures)
127 device = ComponentDevice.resolve_device(self._device).to_torch_str()
128 # Based on the Model string we can load either Bi-Encoders or Cross Encoders.
129 # Similarity computation changes for both approaches
130 if cross_encoder_used:
131 self._similarity_model = CrossEncoder(
132 self._model,
133 device=device,
134 tokenizer_args={"use_auth_token": token},
135 automodel_args={"use_auth_token": token},
136 )
137 else:
138 self._similarity_model = SentenceTransformer(self._model, device=device, use_auth_token=token)
139
140 @component.output_types(score=float, individual_scores=List[float])
141 def run(self, ground_truth_answers: List[str], predicted_answers: List[str]) -> Dict[str, Any]:
142 """
143 SASEvaluator component run method.
144
145 Run the SASEvaluator to compute the Semantic Answer Similarity (SAS) between a list of predicted answers
146 and a list of ground truth answers. Both must be list of strings of same length.
147
148 :param ground_truth_answers:
149 A list of expected answers for each question.
150 :param predicted_answers:
151 A list of generated answers for each question.
152 :returns:
153 A dictionary with the following outputs:
154 - `score`: Mean SAS score over all the predictions/ground-truth pairs.
155 - `individual_scores`: A list of similarity scores for each prediction/ground-truth pair.
156 """
157 if len(ground_truth_answers) != len(predicted_answers):
158 raise ValueError("The number of predictions and labels must be the same.")
159
160 if len(predicted_answers) == 0:
161 return {"score": 0.0, "individual_scores": [0.0]}
162
163 if not self._similarity_model:
164 msg = "The model has not been initialized. Call warm_up() before running the evaluator."
165 raise RuntimeError(msg)
166
167 if isinstance(self._similarity_model, CrossEncoder):
168 # For Cross Encoders we create a list of pairs of predictions and labels
169 sentence_pairs = list(zip(predicted_answers, ground_truth_answers))
170 similarity_scores = self._similarity_model.predict(
171 sentence_pairs, batch_size=self._batch_size, convert_to_numpy=True
172 )
173
174 # All Cross Encoders do not return a set of logits scores that are normalized
175 # We normalize scores if they are larger than 1
176 if (similarity_scores > 1).any():
177 similarity_scores = expit(similarity_scores)
178
179 # Convert scores to list of floats from numpy array
180 similarity_scores = similarity_scores.tolist()
181
182 else:
183 # For Bi-encoders we create embeddings separately for predictions and labels
184 predictions_embeddings = self._similarity_model.encode(
185 predicted_answers, batch_size=self._batch_size, convert_to_tensor=True
186 )
187 label_embeddings = self._similarity_model.encode(
188 ground_truth_answers, batch_size=self._batch_size, convert_to_tensor=True
189 )
190
191 # Compute cosine-similarities
192 similarity_scores = [
193 float(util.cos_sim(p, l).cpu().numpy()) for p, l in zip(predictions_embeddings, label_embeddings)
194 ]
195
196 sas_score = np_mean(similarity_scores)
197
198 return {"score": sas_score, "individual_scores": similarity_scores}
199
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/haystack/components/evaluators/sas_evaluator.py b/haystack/components/evaluators/sas_evaluator.py
--- a/haystack/components/evaluators/sas_evaluator.py
+++ b/haystack/components/evaluators/sas_evaluator.py
@@ -157,6 +157,9 @@
if len(ground_truth_answers) != len(predicted_answers):
raise ValueError("The number of predictions and labels must be the same.")
+ if any(answer is None for answer in predicted_answers):
+ raise ValueError("Predicted answers must not contain None values.")
+
if len(predicted_answers) == 0:
return {"score": 0.0, "individual_scores": [0.0]}
| {"golden_diff": "diff --git a/haystack/components/evaluators/sas_evaluator.py b/haystack/components/evaluators/sas_evaluator.py\n--- a/haystack/components/evaluators/sas_evaluator.py\n+++ b/haystack/components/evaluators/sas_evaluator.py\n@@ -157,6 +157,9 @@\n if len(ground_truth_answers) != len(predicted_answers):\n raise ValueError(\"The number of predictions and labels must be the same.\")\n \n+ if any(answer is None for answer in predicted_answers):\n+ raise ValueError(\"Predicted answers must not contain None values.\")\n+\n if len(predicted_answers) == 0:\n return {\"score\": 0.0, \"individual_scores\": [0.0]}\n", "issue": "SASEvaluator returns score even when `predicted_answers` contains `None`\nIn a RAG pipeline, there are cases where the prompt instructs the LLM to return a placeholder answer if there is missing information in the context, such as \"No answer\". See an [example](https://github.com/deepset-ai/haystack-evaluation/blob/cbfcde5afcaf7574aa82b1ad6b5ce307c8a7c97e/evaluations/architectures/basic_rag.py#L10) in our evaluation repository.\r\n\r\nIn that case, it makes sense to replace the predicted answer in the RAG pipeline with `None`, instead of computing any metric on the placeholder answer. However, the SASEvaluator returns a score even if `None` is passed.\r\n\r\n**Example**:\r\n```\r\nfrom haystack.components.evaluators import SASEvaluator\r\n\r\nsas = SASEvaluator(model=\"sentence-transformers/all-mpnet-base-v2\")\r\nsas.warm_up()\r\nsas.run(predicted_answers=[None, \"Whatever\"], ground_truth_answers=[\"Whatever\", \"Another whatever\"])\r\n```\r\n\r\nthe output is:\r\n\r\n```\r\n{'score': 0.46286168694496155,\r\n 'individual_scores': [0.26153379678726196, 0.6641895771026611]}\r\n```\r\n\r\n**Expected**\r\n\r\n```\r\n{'score': 0.6641895771026611,\r\n 'individual_scores': [None, 0.6641895771026611]}\r\n```\n", "before_files": [{"content": "# SPDX-FileCopyrightText: 2022-present deepset GmbH <[email protected]>\n#\n# SPDX-License-Identifier: Apache-2.0\n\nfrom typing import Any, Dict, List, Optional\n\nfrom numpy import mean as np_mean\n\nfrom haystack import component, default_from_dict, default_to_dict\nfrom haystack.lazy_imports import LazyImport\nfrom haystack.utils import ComponentDevice, expit\nfrom haystack.utils.auth import Secret, deserialize_secrets_inplace\n\nwith LazyImport(message=\"Run 'pip install \\\"sentence-transformers>=2.3.0\\\"'\") as sas_import:\n from sentence_transformers import CrossEncoder, SentenceTransformer, util\n from transformers import AutoConfig\n\n\n@component\nclass SASEvaluator:\n \"\"\"\n SASEvaluator computes the Semantic Answer Similarity (SAS) between a list of predictions and a one of ground truths.\n\n It's usually used in Retrieval Augmented Generation (RAG) pipelines to evaluate the quality of the generated\n answers. The SAS is computed using a pre-trained model from the Hugging Face model hub. The model can be either a\n Bi-Encoder or a Cross-Encoder. The choice of the model is based on the `model` parameter.\n\n Usage example:\n ```python\n from haystack.components.evaluators.sas_evaluator import SASEvaluator\n\n evaluator = SASEvaluator(model=\"cross-encoder/ms-marco-MiniLM-L-6-v2\")\n evaluator.warm_up()\n ground_truths = [\n \"A construction budget of US $2.3 billion\",\n \"The Eiffel Tower, completed in 1889, symbolizes Paris's cultural magnificence.\",\n \"The Meiji Restoration in 1868 transformed Japan into a modernized world power.\",\n ]\n predictions = [\n \"A construction budget of US $2.3 billion\",\n \"The Eiffel Tower, completed in 1889, symbolizes Paris's cultural magnificence.\",\n \"The Meiji Restoration in 1868 transformed Japan into a modernized world power.\",\n ]\n result = evaluator.run(\n ground_truths_answers=ground_truths, predicted_answers=predictions\n )\n\n print(result[\"score\"])\n # 0.9999673763910929\n\n print(result[\"individual_scores\"])\n # [0.9999765157699585, 0.999968409538269, 0.9999572038650513]\n ```\n \"\"\"\n\n def __init__(\n self,\n model: str = \"sentence-transformers/paraphrase-multilingual-mpnet-base-v2\",\n batch_size: int = 32,\n device: Optional[ComponentDevice] = None,\n token: Secret = Secret.from_env_var(\"HF_API_TOKEN\", strict=False),\n ):\n \"\"\"\n Creates a new instance of SASEvaluator.\n\n :param model:\n SentenceTransformers semantic textual similarity model, should be path or string pointing to a downloadable\n model.\n :param batch_size:\n Number of prediction-label pairs to encode at once.\n :param device:\n The device on which the model is loaded. If `None`, the default device is automatically selected.\n :param token:\n The Hugging Face token for HTTP bearer authorization.\n You can find your HF token in your [account settings](https://huggingface.co/settings/tokens)\n \"\"\"\n sas_import.check()\n\n self._model = model\n self._batch_size = batch_size\n self._device = device\n self._token = token\n self._similarity_model = None\n\n def to_dict(self) -> Dict[str, Any]:\n \"\"\"\n Serialize this component to a dictionary.\n\n :returns:\n The serialized component as a dictionary.\n \"\"\"\n return default_to_dict(\n self,\n model=self._model,\n batch_size=self._batch_size,\n device=self._device.to_dict() if self._device else None,\n token=self._token.to_dict() if self._token else None,\n )\n\n @classmethod\n def from_dict(cls, data: Dict[str, Any]) -> \"SASEvaluator\":\n \"\"\"\n Deserialize this component from a dictionary.\n\n :param data:\n The dictionary representation of this component.\n :returns:\n The deserialized component instance.\n \"\"\"\n deserialize_secrets_inplace(data[\"init_parameters\"], keys=[\"token\"])\n if device := data.get(\"init_parameters\", {}).get(\"device\"):\n data[\"init_parameters\"][\"device\"] = ComponentDevice.from_dict(device)\n return default_from_dict(cls, data)\n\n def warm_up(self):\n \"\"\"\n Initializes the component.\n \"\"\"\n if self._similarity_model:\n return\n\n token = self._token.resolve_value() if self._token else None\n config = AutoConfig.from_pretrained(self._model, use_auth_token=token)\n cross_encoder_used = False\n if config.architectures:\n cross_encoder_used = any(arch.endswith(\"ForSequenceClassification\") for arch in config.architectures)\n device = ComponentDevice.resolve_device(self._device).to_torch_str()\n # Based on the Model string we can load either Bi-Encoders or Cross Encoders.\n # Similarity computation changes for both approaches\n if cross_encoder_used:\n self._similarity_model = CrossEncoder(\n self._model,\n device=device,\n tokenizer_args={\"use_auth_token\": token},\n automodel_args={\"use_auth_token\": token},\n )\n else:\n self._similarity_model = SentenceTransformer(self._model, device=device, use_auth_token=token)\n\n @component.output_types(score=float, individual_scores=List[float])\n def run(self, ground_truth_answers: List[str], predicted_answers: List[str]) -> Dict[str, Any]:\n \"\"\"\n SASEvaluator component run method.\n\n Run the SASEvaluator to compute the Semantic Answer Similarity (SAS) between a list of predicted answers\n and a list of ground truth answers. Both must be list of strings of same length.\n\n :param ground_truth_answers:\n A list of expected answers for each question.\n :param predicted_answers:\n A list of generated answers for each question.\n :returns:\n A dictionary with the following outputs:\n - `score`: Mean SAS score over all the predictions/ground-truth pairs.\n - `individual_scores`: A list of similarity scores for each prediction/ground-truth pair.\n \"\"\"\n if len(ground_truth_answers) != len(predicted_answers):\n raise ValueError(\"The number of predictions and labels must be the same.\")\n\n if len(predicted_answers) == 0:\n return {\"score\": 0.0, \"individual_scores\": [0.0]}\n\n if not self._similarity_model:\n msg = \"The model has not been initialized. Call warm_up() before running the evaluator.\"\n raise RuntimeError(msg)\n\n if isinstance(self._similarity_model, CrossEncoder):\n # For Cross Encoders we create a list of pairs of predictions and labels\n sentence_pairs = list(zip(predicted_answers, ground_truth_answers))\n similarity_scores = self._similarity_model.predict(\n sentence_pairs, batch_size=self._batch_size, convert_to_numpy=True\n )\n\n # All Cross Encoders do not return a set of logits scores that are normalized\n # We normalize scores if they are larger than 1\n if (similarity_scores > 1).any():\n similarity_scores = expit(similarity_scores)\n\n # Convert scores to list of floats from numpy array\n similarity_scores = similarity_scores.tolist()\n\n else:\n # For Bi-encoders we create embeddings separately for predictions and labels\n predictions_embeddings = self._similarity_model.encode(\n predicted_answers, batch_size=self._batch_size, convert_to_tensor=True\n )\n label_embeddings = self._similarity_model.encode(\n ground_truth_answers, batch_size=self._batch_size, convert_to_tensor=True\n )\n\n # Compute cosine-similarities\n similarity_scores = [\n float(util.cos_sim(p, l).cpu().numpy()) for p, l in zip(predictions_embeddings, label_embeddings)\n ]\n\n sas_score = np_mean(similarity_scores)\n\n return {\"score\": sas_score, \"individual_scores\": similarity_scores}\n", "path": "haystack/components/evaluators/sas_evaluator.py"}], "after_files": [{"content": "# SPDX-FileCopyrightText: 2022-present deepset GmbH <[email protected]>\n#\n# SPDX-License-Identifier: Apache-2.0\n\nfrom typing import Any, Dict, List, Optional\n\nfrom numpy import mean as np_mean\n\nfrom haystack import component, default_from_dict, default_to_dict\nfrom haystack.lazy_imports import LazyImport\nfrom haystack.utils import ComponentDevice, expit\nfrom haystack.utils.auth import Secret, deserialize_secrets_inplace\n\nwith LazyImport(message=\"Run 'pip install \\\"sentence-transformers>=2.3.0\\\"'\") as sas_import:\n from sentence_transformers import CrossEncoder, SentenceTransformer, util\n from transformers import AutoConfig\n\n\n@component\nclass SASEvaluator:\n \"\"\"\n SASEvaluator computes the Semantic Answer Similarity (SAS) between a list of predictions and a one of ground truths.\n\n It's usually used in Retrieval Augmented Generation (RAG) pipelines to evaluate the quality of the generated\n answers. The SAS is computed using a pre-trained model from the Hugging Face model hub. The model can be either a\n Bi-Encoder or a Cross-Encoder. The choice of the model is based on the `model` parameter.\n\n Usage example:\n ```python\n from haystack.components.evaluators.sas_evaluator import SASEvaluator\n\n evaluator = SASEvaluator(model=\"cross-encoder/ms-marco-MiniLM-L-6-v2\")\n evaluator.warm_up()\n ground_truths = [\n \"A construction budget of US $2.3 billion\",\n \"The Eiffel Tower, completed in 1889, symbolizes Paris's cultural magnificence.\",\n \"The Meiji Restoration in 1868 transformed Japan into a modernized world power.\",\n ]\n predictions = [\n \"A construction budget of US $2.3 billion\",\n \"The Eiffel Tower, completed in 1889, symbolizes Paris's cultural magnificence.\",\n \"The Meiji Restoration in 1868 transformed Japan into a modernized world power.\",\n ]\n result = evaluator.run(\n ground_truths_answers=ground_truths, predicted_answers=predictions\n )\n\n print(result[\"score\"])\n # 0.9999673763910929\n\n print(result[\"individual_scores\"])\n # [0.9999765157699585, 0.999968409538269, 0.9999572038650513]\n ```\n \"\"\"\n\n def __init__(\n self,\n model: str = \"sentence-transformers/paraphrase-multilingual-mpnet-base-v2\",\n batch_size: int = 32,\n device: Optional[ComponentDevice] = None,\n token: Secret = Secret.from_env_var(\"HF_API_TOKEN\", strict=False),\n ):\n \"\"\"\n Creates a new instance of SASEvaluator.\n\n :param model:\n SentenceTransformers semantic textual similarity model, should be path or string pointing to a downloadable\n model.\n :param batch_size:\n Number of prediction-label pairs to encode at once.\n :param device:\n The device on which the model is loaded. If `None`, the default device is automatically selected.\n :param token:\n The Hugging Face token for HTTP bearer authorization.\n You can find your HF token in your [account settings](https://huggingface.co/settings/tokens)\n \"\"\"\n sas_import.check()\n\n self._model = model\n self._batch_size = batch_size\n self._device = device\n self._token = token\n self._similarity_model = None\n\n def to_dict(self) -> Dict[str, Any]:\n \"\"\"\n Serialize this component to a dictionary.\n\n :returns:\n The serialized component as a dictionary.\n \"\"\"\n return default_to_dict(\n self,\n model=self._model,\n batch_size=self._batch_size,\n device=self._device.to_dict() if self._device else None,\n token=self._token.to_dict() if self._token else None,\n )\n\n @classmethod\n def from_dict(cls, data: Dict[str, Any]) -> \"SASEvaluator\":\n \"\"\"\n Deserialize this component from a dictionary.\n\n :param data:\n The dictionary representation of this component.\n :returns:\n The deserialized component instance.\n \"\"\"\n deserialize_secrets_inplace(data[\"init_parameters\"], keys=[\"token\"])\n if device := data.get(\"init_parameters\", {}).get(\"device\"):\n data[\"init_parameters\"][\"device\"] = ComponentDevice.from_dict(device)\n return default_from_dict(cls, data)\n\n def warm_up(self):\n \"\"\"\n Initializes the component.\n \"\"\"\n if self._similarity_model:\n return\n\n token = self._token.resolve_value() if self._token else None\n config = AutoConfig.from_pretrained(self._model, use_auth_token=token)\n cross_encoder_used = False\n if config.architectures:\n cross_encoder_used = any(arch.endswith(\"ForSequenceClassification\") for arch in config.architectures)\n device = ComponentDevice.resolve_device(self._device).to_torch_str()\n # Based on the Model string we can load either Bi-Encoders or Cross Encoders.\n # Similarity computation changes for both approaches\n if cross_encoder_used:\n self._similarity_model = CrossEncoder(\n self._model,\n device=device,\n tokenizer_args={\"use_auth_token\": token},\n automodel_args={\"use_auth_token\": token},\n )\n else:\n self._similarity_model = SentenceTransformer(self._model, device=device, use_auth_token=token)\n\n @component.output_types(score=float, individual_scores=List[float])\n def run(self, ground_truth_answers: List[str], predicted_answers: List[str]) -> Dict[str, Any]:\n \"\"\"\n SASEvaluator component run method.\n\n Run the SASEvaluator to compute the Semantic Answer Similarity (SAS) between a list of predicted answers\n and a list of ground truth answers. Both must be list of strings of same length.\n\n :param ground_truth_answers:\n A list of expected answers for each question.\n :param predicted_answers:\n A list of generated answers for each question.\n :returns:\n A dictionary with the following outputs:\n - `score`: Mean SAS score over all the predictions/ground-truth pairs.\n - `individual_scores`: A list of similarity scores for each prediction/ground-truth pair.\n \"\"\"\n if len(ground_truth_answers) != len(predicted_answers):\n raise ValueError(\"The number of predictions and labels must be the same.\")\n\n if any(answer is None for answer in predicted_answers):\n raise ValueError(\"Predicted answers must not contain None values.\")\n\n if len(predicted_answers) == 0:\n return {\"score\": 0.0, \"individual_scores\": [0.0]}\n\n if not self._similarity_model:\n msg = \"The model has not been initialized. Call warm_up() before running the evaluator.\"\n raise RuntimeError(msg)\n\n if isinstance(self._similarity_model, CrossEncoder):\n # For Cross Encoders we create a list of pairs of predictions and labels\n sentence_pairs = list(zip(predicted_answers, ground_truth_answers))\n similarity_scores = self._similarity_model.predict(\n sentence_pairs, batch_size=self._batch_size, convert_to_numpy=True\n )\n\n # All Cross Encoders do not return a set of logits scores that are normalized\n # We normalize scores if they are larger than 1\n if (similarity_scores > 1).any():\n similarity_scores = expit(similarity_scores)\n\n # Convert scores to list of floats from numpy array\n similarity_scores = similarity_scores.tolist()\n\n else:\n # For Bi-encoders we create embeddings separately for predictions and labels\n predictions_embeddings = self._similarity_model.encode(\n predicted_answers, batch_size=self._batch_size, convert_to_tensor=True\n )\n label_embeddings = self._similarity_model.encode(\n ground_truth_answers, batch_size=self._batch_size, convert_to_tensor=True\n )\n\n # Compute cosine-similarities\n similarity_scores = [\n float(util.cos_sim(p, l).cpu().numpy()) for p, l in zip(predictions_embeddings, label_embeddings)\n ]\n\n sas_score = np_mean(similarity_scores)\n\n return {\"score\": sas_score, \"individual_scores\": similarity_scores}\n", "path": "haystack/components/evaluators/sas_evaluator.py"}]} | 2,945 | 166 |
gh_patches_debug_4301 | rasdani/github-patches | git_diff | gratipay__gratipay.com-3348 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
viewing history for a closed account 500s
https://app.getsentry.com/gratipay/gratipay-com/group/62465010/
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `gratipay/utils/history.py`
Content:
```
1 from datetime import datetime
2 from decimal import Decimal
3
4 from aspen import Response
5 from psycopg2 import IntegrityError
6
7
8 def get_end_of_year_balance(db, participant, year, current_year):
9 if year == current_year:
10 return participant.balance
11 if year < participant.claimed_time.year:
12 return Decimal('0.00')
13
14 balance = db.one("""
15 SELECT balance
16 FROM balances_at
17 WHERE participant = %s
18 AND "at" = %s
19 """, (participant.id, datetime(year+1, 1, 1)))
20 if balance is not None:
21 return balance
22
23 username = participant.username
24 start_balance = get_end_of_year_balance(db, participant, year-1, current_year)
25 delta = db.one("""
26 SELECT (
27 SELECT COALESCE(sum(amount), 0) AS a
28 FROM exchanges
29 WHERE participant = %(username)s
30 AND extract(year from timestamp) = %(year)s
31 AND amount > 0
32 AND (status is null OR status = 'succeeded')
33 ) + (
34 SELECT COALESCE(sum(amount-fee), 0) AS a
35 FROM exchanges
36 WHERE participant = %(username)s
37 AND extract(year from timestamp) = %(year)s
38 AND amount < 0
39 AND (status is null OR status <> 'failed')
40 ) + (
41 SELECT COALESCE(sum(-amount), 0) AS a
42 FROM transfers
43 WHERE tipper = %(username)s
44 AND extract(year from timestamp) = %(year)s
45 ) + (
46 SELECT COALESCE(sum(amount), 0) AS a
47 FROM transfers
48 WHERE tippee = %(username)s
49 AND extract(year from timestamp) = %(year)s
50 ) AS delta
51 """, locals())
52 balance = start_balance + delta
53 try:
54 db.run("""
55 INSERT INTO balances_at
56 (participant, at, balance)
57 VALUES (%s, %s, %s)
58 """, (participant.id, datetime(year+1, 1, 1), balance))
59 except IntegrityError:
60 pass
61 return balance
62
63
64 def iter_payday_events(db, participant, year=None):
65 """Yields payday events for the given participant.
66 """
67 current_year = datetime.utcnow().year
68 year = year or current_year
69
70 username = participant.username
71 exchanges = db.all("""
72 SELECT *
73 FROM exchanges
74 WHERE participant=%(username)s
75 AND extract(year from timestamp) = %(year)s
76 """, locals(), back_as=dict)
77 transfers = db.all("""
78 SELECT *
79 FROM transfers
80 WHERE (tipper=%(username)s OR tippee=%(username)s)
81 AND extract(year from timestamp) = %(year)s
82 """, locals(), back_as=dict)
83
84 if not (exchanges or transfers):
85 return
86
87 if transfers:
88 yield dict(
89 kind='totals',
90 given=sum(t['amount'] for t in transfers if t['tipper'] == username and t['context'] != 'take'),
91 received=sum(t['amount'] for t in transfers if t['tippee'] == username),
92 )
93
94 payday_dates = db.all("""
95 SELECT ts_start::date
96 FROM paydays
97 ORDER BY ts_start ASC
98 """)
99
100 balance = get_end_of_year_balance(db, participant, year, current_year)
101 prev_date = None
102 get_timestamp = lambda e: e['timestamp']
103 events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)
104 for event in events:
105
106 event['balance'] = balance
107
108 event_date = event['timestamp'].date()
109 if event_date != prev_date:
110 if prev_date:
111 yield dict(kind='day-close', balance=balance)
112 day_open = dict(kind='day-open', date=event_date, balance=balance)
113 if payday_dates:
114 while payday_dates and payday_dates[-1] > event_date:
115 payday_dates.pop()
116 payday_date = payday_dates[-1] if payday_dates else None
117 if event_date == payday_date:
118 day_open['payday_number'] = len(payday_dates) - 1
119 yield day_open
120 prev_date = event_date
121
122 if 'fee' in event:
123 if event['amount'] > 0:
124 kind = 'charge'
125 if event['status'] in (None, 'succeeded'):
126 balance -= event['amount']
127 else:
128 kind = 'credit'
129 if event['status'] != 'failed':
130 balance -= event['amount'] - event['fee']
131 else:
132 kind = 'transfer'
133 if event['tippee'] == username:
134 balance -= event['amount']
135 else:
136 balance += event['amount']
137 event['kind'] = kind
138
139 yield event
140
141 yield dict(kind='day-close', balance=balance)
142
143
144 def export_history(participant, year, mode, key, back_as='namedtuple', require_key=False):
145 db = participant.db
146 params = dict(username=participant.username, year=year)
147 out = {}
148 if mode == 'aggregate':
149 out['given'] = lambda: db.all("""
150 SELECT tippee, sum(amount) AS amount
151 FROM transfers
152 WHERE tipper = %(username)s
153 AND extract(year from timestamp) = %(year)s
154 GROUP BY tippee
155 """, params, back_as=back_as)
156 out['taken'] = lambda: db.all("""
157 SELECT tipper AS team, sum(amount) AS amount
158 FROM transfers
159 WHERE tippee = %(username)s
160 AND context = 'take'
161 AND extract(year from timestamp) = %(year)s
162 GROUP BY tipper
163 """, params, back_as=back_as)
164 else:
165 out['exchanges'] = lambda: db.all("""
166 SELECT timestamp, amount, fee, status, note
167 FROM exchanges
168 WHERE participant = %(username)s
169 AND extract(year from timestamp) = %(year)s
170 ORDER BY timestamp ASC
171 """, params, back_as=back_as)
172 out['given'] = lambda: db.all("""
173 SELECT timestamp, tippee, amount, context
174 FROM transfers
175 WHERE tipper = %(username)s
176 AND extract(year from timestamp) = %(year)s
177 ORDER BY timestamp ASC
178 """, params, back_as=back_as)
179 out['taken'] = lambda: db.all("""
180 SELECT timestamp, tipper AS team, amount
181 FROM transfers
182 WHERE tippee = %(username)s
183 AND context = 'take'
184 AND extract(year from timestamp) = %(year)s
185 ORDER BY timestamp ASC
186 """, params, back_as=back_as)
187 out['received'] = lambda: db.all("""
188 SELECT timestamp, amount, context
189 FROM transfers
190 WHERE tippee = %(username)s
191 AND context NOT IN ('take', 'take-over')
192 AND extract(year from timestamp) = %(year)s
193 ORDER BY timestamp ASC
194 """, params, back_as=back_as)
195
196 if key:
197 try:
198 return out[key]()
199 except KeyError:
200 raise Response(400, "bad key `%s`" % key)
201 elif require_key:
202 raise Response(400, "missing `key` parameter")
203 else:
204 return {k: v() for k, v in out.items()}
205
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/gratipay/utils/history.py b/gratipay/utils/history.py
--- a/gratipay/utils/history.py
+++ b/gratipay/utils/history.py
@@ -8,7 +8,8 @@
def get_end_of_year_balance(db, participant, year, current_year):
if year == current_year:
return participant.balance
- if year < participant.claimed_time.year:
+ start = participant.claimed_time or participant.ctime
+ if year < start.year:
return Decimal('0.00')
balance = db.one("""
| {"golden_diff": "diff --git a/gratipay/utils/history.py b/gratipay/utils/history.py\n--- a/gratipay/utils/history.py\n+++ b/gratipay/utils/history.py\n@@ -8,7 +8,8 @@\n def get_end_of_year_balance(db, participant, year, current_year):\n if year == current_year:\n return participant.balance\n- if year < participant.claimed_time.year:\n+ start = participant.claimed_time or participant.ctime\n+ if year < start.year:\n return Decimal('0.00')\n \n balance = db.one(\"\"\"\n", "issue": "viewing history for a closed account 500s\nhttps://app.getsentry.com/gratipay/gratipay-com/group/62465010/\n\n", "before_files": [{"content": "from datetime import datetime\nfrom decimal import Decimal\n\nfrom aspen import Response\nfrom psycopg2 import IntegrityError\n\n\ndef get_end_of_year_balance(db, participant, year, current_year):\n if year == current_year:\n return participant.balance\n if year < participant.claimed_time.year:\n return Decimal('0.00')\n\n balance = db.one(\"\"\"\n SELECT balance\n FROM balances_at\n WHERE participant = %s\n AND \"at\" = %s\n \"\"\", (participant.id, datetime(year+1, 1, 1)))\n if balance is not None:\n return balance\n\n username = participant.username\n start_balance = get_end_of_year_balance(db, participant, year-1, current_year)\n delta = db.one(\"\"\"\n SELECT (\n SELECT COALESCE(sum(amount), 0) AS a\n FROM exchanges\n WHERE participant = %(username)s\n AND extract(year from timestamp) = %(year)s\n AND amount > 0\n AND (status is null OR status = 'succeeded')\n ) + (\n SELECT COALESCE(sum(amount-fee), 0) AS a\n FROM exchanges\n WHERE participant = %(username)s\n AND extract(year from timestamp) = %(year)s\n AND amount < 0\n AND (status is null OR status <> 'failed')\n ) + (\n SELECT COALESCE(sum(-amount), 0) AS a\n FROM transfers\n WHERE tipper = %(username)s\n AND extract(year from timestamp) = %(year)s\n ) + (\n SELECT COALESCE(sum(amount), 0) AS a\n FROM transfers\n WHERE tippee = %(username)s\n AND extract(year from timestamp) = %(year)s\n ) AS delta\n \"\"\", locals())\n balance = start_balance + delta\n try:\n db.run(\"\"\"\n INSERT INTO balances_at\n (participant, at, balance)\n VALUES (%s, %s, %s)\n \"\"\", (participant.id, datetime(year+1, 1, 1), balance))\n except IntegrityError:\n pass\n return balance\n\n\ndef iter_payday_events(db, participant, year=None):\n \"\"\"Yields payday events for the given participant.\n \"\"\"\n current_year = datetime.utcnow().year\n year = year or current_year\n\n username = participant.username\n exchanges = db.all(\"\"\"\n SELECT *\n FROM exchanges\n WHERE participant=%(username)s\n AND extract(year from timestamp) = %(year)s\n \"\"\", locals(), back_as=dict)\n transfers = db.all(\"\"\"\n SELECT *\n FROM transfers\n WHERE (tipper=%(username)s OR tippee=%(username)s)\n AND extract(year from timestamp) = %(year)s\n \"\"\", locals(), back_as=dict)\n\n if not (exchanges or transfers):\n return\n\n if transfers:\n yield dict(\n kind='totals',\n given=sum(t['amount'] for t in transfers if t['tipper'] == username and t['context'] != 'take'),\n received=sum(t['amount'] for t in transfers if t['tippee'] == username),\n )\n\n payday_dates = db.all(\"\"\"\n SELECT ts_start::date\n FROM paydays\n ORDER BY ts_start ASC\n \"\"\")\n\n balance = get_end_of_year_balance(db, participant, year, current_year)\n prev_date = None\n get_timestamp = lambda e: e['timestamp']\n events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)\n for event in events:\n\n event['balance'] = balance\n\n event_date = event['timestamp'].date()\n if event_date != prev_date:\n if prev_date:\n yield dict(kind='day-close', balance=balance)\n day_open = dict(kind='day-open', date=event_date, balance=balance)\n if payday_dates:\n while payday_dates and payday_dates[-1] > event_date:\n payday_dates.pop()\n payday_date = payday_dates[-1] if payday_dates else None\n if event_date == payday_date:\n day_open['payday_number'] = len(payday_dates) - 1\n yield day_open\n prev_date = event_date\n\n if 'fee' in event:\n if event['amount'] > 0:\n kind = 'charge'\n if event['status'] in (None, 'succeeded'):\n balance -= event['amount']\n else:\n kind = 'credit'\n if event['status'] != 'failed':\n balance -= event['amount'] - event['fee']\n else:\n kind = 'transfer'\n if event['tippee'] == username:\n balance -= event['amount']\n else:\n balance += event['amount']\n event['kind'] = kind\n\n yield event\n\n yield dict(kind='day-close', balance=balance)\n\n\ndef export_history(participant, year, mode, key, back_as='namedtuple', require_key=False):\n db = participant.db\n params = dict(username=participant.username, year=year)\n out = {}\n if mode == 'aggregate':\n out['given'] = lambda: db.all(\"\"\"\n SELECT tippee, sum(amount) AS amount\n FROM transfers\n WHERE tipper = %(username)s\n AND extract(year from timestamp) = %(year)s\n GROUP BY tippee\n \"\"\", params, back_as=back_as)\n out['taken'] = lambda: db.all(\"\"\"\n SELECT tipper AS team, sum(amount) AS amount\n FROM transfers\n WHERE tippee = %(username)s\n AND context = 'take'\n AND extract(year from timestamp) = %(year)s\n GROUP BY tipper\n \"\"\", params, back_as=back_as)\n else:\n out['exchanges'] = lambda: db.all(\"\"\"\n SELECT timestamp, amount, fee, status, note\n FROM exchanges\n WHERE participant = %(username)s\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n out['given'] = lambda: db.all(\"\"\"\n SELECT timestamp, tippee, amount, context\n FROM transfers\n WHERE tipper = %(username)s\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n out['taken'] = lambda: db.all(\"\"\"\n SELECT timestamp, tipper AS team, amount\n FROM transfers\n WHERE tippee = %(username)s\n AND context = 'take'\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n out['received'] = lambda: db.all(\"\"\"\n SELECT timestamp, amount, context\n FROM transfers\n WHERE tippee = %(username)s\n AND context NOT IN ('take', 'take-over')\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n\n if key:\n try:\n return out[key]()\n except KeyError:\n raise Response(400, \"bad key `%s`\" % key)\n elif require_key:\n raise Response(400, \"missing `key` parameter\")\n else:\n return {k: v() for k, v in out.items()}\n", "path": "gratipay/utils/history.py"}], "after_files": [{"content": "from datetime import datetime\nfrom decimal import Decimal\n\nfrom aspen import Response\nfrom psycopg2 import IntegrityError\n\n\ndef get_end_of_year_balance(db, participant, year, current_year):\n if year == current_year:\n return participant.balance\n start = participant.claimed_time or participant.ctime\n if year < start.year:\n return Decimal('0.00')\n\n balance = db.one(\"\"\"\n SELECT balance\n FROM balances_at\n WHERE participant = %s\n AND \"at\" = %s\n \"\"\", (participant.id, datetime(year+1, 1, 1)))\n if balance is not None:\n return balance\n\n username = participant.username\n start_balance = get_end_of_year_balance(db, participant, year-1, current_year)\n delta = db.one(\"\"\"\n SELECT (\n SELECT COALESCE(sum(amount), 0) AS a\n FROM exchanges\n WHERE participant = %(username)s\n AND extract(year from timestamp) = %(year)s\n AND amount > 0\n AND (status is null OR status = 'succeeded')\n ) + (\n SELECT COALESCE(sum(amount-fee), 0) AS a\n FROM exchanges\n WHERE participant = %(username)s\n AND extract(year from timestamp) = %(year)s\n AND amount < 0\n AND (status is null OR status <> 'failed')\n ) + (\n SELECT COALESCE(sum(-amount), 0) AS a\n FROM transfers\n WHERE tipper = %(username)s\n AND extract(year from timestamp) = %(year)s\n ) + (\n SELECT COALESCE(sum(amount), 0) AS a\n FROM transfers\n WHERE tippee = %(username)s\n AND extract(year from timestamp) = %(year)s\n ) AS delta\n \"\"\", locals())\n balance = start_balance + delta\n try:\n db.run(\"\"\"\n INSERT INTO balances_at\n (participant, at, balance)\n VALUES (%s, %s, %s)\n \"\"\", (participant.id, datetime(year+1, 1, 1), balance))\n except IntegrityError:\n pass\n return balance\n\n\ndef iter_payday_events(db, participant, year=None):\n \"\"\"Yields payday events for the given participant.\n \"\"\"\n current_year = datetime.utcnow().year\n year = year or current_year\n\n username = participant.username\n exchanges = db.all(\"\"\"\n SELECT *\n FROM exchanges\n WHERE participant=%(username)s\n AND extract(year from timestamp) = %(year)s\n \"\"\", locals(), back_as=dict)\n transfers = db.all(\"\"\"\n SELECT *\n FROM transfers\n WHERE (tipper=%(username)s OR tippee=%(username)s)\n AND extract(year from timestamp) = %(year)s\n \"\"\", locals(), back_as=dict)\n\n if not (exchanges or transfers):\n return\n\n if transfers:\n yield dict(\n kind='totals',\n given=sum(t['amount'] for t in transfers if t['tipper'] == username and t['context'] != 'take'),\n received=sum(t['amount'] for t in transfers if t['tippee'] == username),\n )\n\n payday_dates = db.all(\"\"\"\n SELECT ts_start::date\n FROM paydays\n ORDER BY ts_start ASC\n \"\"\")\n\n balance = get_end_of_year_balance(db, participant, year, current_year)\n prev_date = None\n get_timestamp = lambda e: e['timestamp']\n events = sorted(exchanges+transfers, key=get_timestamp, reverse=True)\n for event in events:\n\n event['balance'] = balance\n\n event_date = event['timestamp'].date()\n if event_date != prev_date:\n if prev_date:\n yield dict(kind='day-close', balance=balance)\n day_open = dict(kind='day-open', date=event_date, balance=balance)\n if payday_dates:\n while payday_dates and payday_dates[-1] > event_date:\n payday_dates.pop()\n payday_date = payday_dates[-1] if payday_dates else None\n if event_date == payday_date:\n day_open['payday_number'] = len(payday_dates) - 1\n yield day_open\n prev_date = event_date\n\n if 'fee' in event:\n if event['amount'] > 0:\n kind = 'charge'\n if event['status'] in (None, 'succeeded'):\n balance -= event['amount']\n else:\n kind = 'credit'\n if event['status'] != 'failed':\n balance -= event['amount'] - event['fee']\n else:\n kind = 'transfer'\n if event['tippee'] == username:\n balance -= event['amount']\n else:\n balance += event['amount']\n event['kind'] = kind\n\n yield event\n\n yield dict(kind='day-close', balance=balance)\n\n\ndef export_history(participant, year, mode, key, back_as='namedtuple', require_key=False):\n db = participant.db\n params = dict(username=participant.username, year=year)\n out = {}\n if mode == 'aggregate':\n out['given'] = lambda: db.all(\"\"\"\n SELECT tippee, sum(amount) AS amount\n FROM transfers\n WHERE tipper = %(username)s\n AND extract(year from timestamp) = %(year)s\n GROUP BY tippee\n \"\"\", params, back_as=back_as)\n out['taken'] = lambda: db.all(\"\"\"\n SELECT tipper AS team, sum(amount) AS amount\n FROM transfers\n WHERE tippee = %(username)s\n AND context = 'take'\n AND extract(year from timestamp) = %(year)s\n GROUP BY tipper\n \"\"\", params, back_as=back_as)\n else:\n out['exchanges'] = lambda: db.all(\"\"\"\n SELECT timestamp, amount, fee, status, note\n FROM exchanges\n WHERE participant = %(username)s\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n out['given'] = lambda: db.all(\"\"\"\n SELECT timestamp, tippee, amount, context\n FROM transfers\n WHERE tipper = %(username)s\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n out['taken'] = lambda: db.all(\"\"\"\n SELECT timestamp, tipper AS team, amount\n FROM transfers\n WHERE tippee = %(username)s\n AND context = 'take'\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n out['received'] = lambda: db.all(\"\"\"\n SELECT timestamp, amount, context\n FROM transfers\n WHERE tippee = %(username)s\n AND context NOT IN ('take', 'take-over')\n AND extract(year from timestamp) = %(year)s\n ORDER BY timestamp ASC\n \"\"\", params, back_as=back_as)\n\n if key:\n try:\n return out[key]()\n except KeyError:\n raise Response(400, \"bad key `%s`\" % key)\n elif require_key:\n raise Response(400, \"missing `key` parameter\")\n else:\n return {k: v() for k, v in out.items()}\n", "path": "gratipay/utils/history.py"}]} | 2,388 | 123 |
gh_patches_debug_17883 | rasdani/github-patches | git_diff | encode__httpx-2803 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Change the type of `Extensions` from `Mapping` to `MutableMapping`.
### Discussed in https://github.com/encode/httpx/discussions/2793
<div type='discussions-op-text'>
<sup>Originally posted by **karosis88** July 28, 2023</sup>
I'm working on a library that implements HTTP Caching for httpx and httpcore (it provides transports and connection pools), and I'd like to add an extension that simply indicates whether or not the response was taken from the cache.
Unfortunately, the type of extension is Mapping, so this is an error for mypy.
```python
response = httpx.Response(200)
response.extensions['my_custom_extension'] = 'something'
```
OUTPUT
```
error: Unsupported target for indexed assignment ("Mapping[Str, Any]") [index]
```
The solution is to simply change the extension type from `Mapping` to `MutableMapping`, allowing us to add custom extensions after the response has been created.
[See also this pr](https://github.com/karosis88/hishel/pull/4)</div>
---
I believe the only change needed is in the "_models.py" file.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `httpx/_types.py`
Content:
```
1 """
2 Type definitions for type checking purposes.
3 """
4
5 import ssl
6 from http.cookiejar import CookieJar
7 from typing import (
8 IO,
9 TYPE_CHECKING,
10 Any,
11 AsyncIterable,
12 AsyncIterator,
13 Callable,
14 Dict,
15 Iterable,
16 Iterator,
17 List,
18 Mapping,
19 NamedTuple,
20 Optional,
21 Sequence,
22 Tuple,
23 Union,
24 )
25
26 if TYPE_CHECKING: # pragma: no cover
27 from ._auth import Auth # noqa: F401
28 from ._config import Proxy, Timeout # noqa: F401
29 from ._models import Cookies, Headers, Request # noqa: F401
30 from ._urls import URL, QueryParams # noqa: F401
31
32
33 PrimitiveData = Optional[Union[str, int, float, bool]]
34
35 RawURL = NamedTuple(
36 "RawURL",
37 [
38 ("raw_scheme", bytes),
39 ("raw_host", bytes),
40 ("port", Optional[int]),
41 ("raw_path", bytes),
42 ],
43 )
44
45 URLTypes = Union["URL", str]
46
47 QueryParamTypes = Union[
48 "QueryParams",
49 Mapping[str, Union[PrimitiveData, Sequence[PrimitiveData]]],
50 List[Tuple[str, PrimitiveData]],
51 Tuple[Tuple[str, PrimitiveData], ...],
52 str,
53 bytes,
54 ]
55
56 HeaderTypes = Union[
57 "Headers",
58 Mapping[str, str],
59 Mapping[bytes, bytes],
60 Sequence[Tuple[str, str]],
61 Sequence[Tuple[bytes, bytes]],
62 ]
63
64 CookieTypes = Union["Cookies", CookieJar, Dict[str, str], List[Tuple[str, str]]]
65
66 CertTypes = Union[
67 # certfile
68 str,
69 # (certfile, keyfile)
70 Tuple[str, Optional[str]],
71 # (certfile, keyfile, password)
72 Tuple[str, Optional[str], Optional[str]],
73 ]
74 VerifyTypes = Union[str, bool, ssl.SSLContext]
75 TimeoutTypes = Union[
76 Optional[float],
77 Tuple[Optional[float], Optional[float], Optional[float], Optional[float]],
78 "Timeout",
79 ]
80 ProxiesTypes = Union[URLTypes, "Proxy", Dict[URLTypes, Union[None, URLTypes, "Proxy"]]]
81
82 AuthTypes = Union[
83 Tuple[Union[str, bytes], Union[str, bytes]],
84 Callable[["Request"], "Request"],
85 "Auth",
86 ]
87
88 RequestContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]
89 ResponseContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]
90 ResponseExtensions = Mapping[str, Any]
91
92 RequestData = Mapping[str, Any]
93
94 FileContent = Union[IO[bytes], bytes, str]
95 FileTypes = Union[
96 # file (or bytes)
97 FileContent,
98 # (filename, file (or bytes))
99 Tuple[Optional[str], FileContent],
100 # (filename, file (or bytes), content_type)
101 Tuple[Optional[str], FileContent, Optional[str]],
102 # (filename, file (or bytes), content_type, headers)
103 Tuple[Optional[str], FileContent, Optional[str], Mapping[str, str]],
104 ]
105 RequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]
106
107 RequestExtensions = Mapping[str, Any]
108
109
110 class SyncByteStream:
111 def __iter__(self) -> Iterator[bytes]:
112 raise NotImplementedError(
113 "The '__iter__' method must be implemented."
114 ) # pragma: no cover
115 yield b"" # pragma: no cover
116
117 def close(self) -> None:
118 """
119 Subclasses can override this method to release any network resources
120 after a request/response cycle is complete.
121 """
122
123
124 class AsyncByteStream:
125 async def __aiter__(self) -> AsyncIterator[bytes]:
126 raise NotImplementedError(
127 "The '__aiter__' method must be implemented."
128 ) # pragma: no cover
129 yield b"" # pragma: no cover
130
131 async def aclose(self) -> None:
132 pass
133
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/httpx/_types.py b/httpx/_types.py
--- a/httpx/_types.py
+++ b/httpx/_types.py
@@ -16,6 +16,7 @@
Iterator,
List,
Mapping,
+ MutableMapping,
NamedTuple,
Optional,
Sequence,
@@ -87,7 +88,7 @@
RequestContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]
ResponseContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]
-ResponseExtensions = Mapping[str, Any]
+ResponseExtensions = MutableMapping[str, Any]
RequestData = Mapping[str, Any]
@@ -104,7 +105,7 @@
]
RequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]
-RequestExtensions = Mapping[str, Any]
+RequestExtensions = MutableMapping[str, Any]
class SyncByteStream:
| {"golden_diff": "diff --git a/httpx/_types.py b/httpx/_types.py\n--- a/httpx/_types.py\n+++ b/httpx/_types.py\n@@ -16,6 +16,7 @@\n Iterator,\n List,\n Mapping,\n+ MutableMapping,\n NamedTuple,\n Optional,\n Sequence,\n@@ -87,7 +88,7 @@\n \n RequestContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]\n ResponseContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]\n-ResponseExtensions = Mapping[str, Any]\n+ResponseExtensions = MutableMapping[str, Any]\n \n RequestData = Mapping[str, Any]\n \n@@ -104,7 +105,7 @@\n ]\n RequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]\n \n-RequestExtensions = Mapping[str, Any]\n+RequestExtensions = MutableMapping[str, Any]\n \n \n class SyncByteStream:\n", "issue": "Change the type of `Extensions` from `Mapping` to `MutableMapping`.\n### Discussed in https://github.com/encode/httpx/discussions/2793\r\n\r\n<div type='discussions-op-text'>\r\n\r\n<sup>Originally posted by **karosis88** July 28, 2023</sup>\r\nI'm working on a library that implements HTTP Caching for httpx and httpcore (it provides transports and connection pools), and I'd like to add an extension that simply indicates whether or not the response was taken from the cache.\r\n\r\nUnfortunately, the type of extension is Mapping, so this is an error for mypy.\r\n\r\n\r\n```python\r\nresponse = httpx.Response(200)\r\nresponse.extensions['my_custom_extension'] = 'something'\r\n```\r\n\r\nOUTPUT \r\n```\r\nerror: Unsupported target for indexed assignment (\"Mapping[Str, Any]\") [index]\r\n```\r\n\r\nThe solution is to simply change the extension type from `Mapping` to `MutableMapping`, allowing us to add custom extensions after the response has been created.\r\n\r\n[See also this pr](https://github.com/karosis88/hishel/pull/4)</div>\r\n\r\n---\r\n\r\nI believe the only change needed is in the \"_models.py\" file.\n", "before_files": [{"content": "\"\"\"\nType definitions for type checking purposes.\n\"\"\"\n\nimport ssl\nfrom http.cookiejar import CookieJar\nfrom typing import (\n IO,\n TYPE_CHECKING,\n Any,\n AsyncIterable,\n AsyncIterator,\n Callable,\n Dict,\n Iterable,\n Iterator,\n List,\n Mapping,\n NamedTuple,\n Optional,\n Sequence,\n Tuple,\n Union,\n)\n\nif TYPE_CHECKING: # pragma: no cover\n from ._auth import Auth # noqa: F401\n from ._config import Proxy, Timeout # noqa: F401\n from ._models import Cookies, Headers, Request # noqa: F401\n from ._urls import URL, QueryParams # noqa: F401\n\n\nPrimitiveData = Optional[Union[str, int, float, bool]]\n\nRawURL = NamedTuple(\n \"RawURL\",\n [\n (\"raw_scheme\", bytes),\n (\"raw_host\", bytes),\n (\"port\", Optional[int]),\n (\"raw_path\", bytes),\n ],\n)\n\nURLTypes = Union[\"URL\", str]\n\nQueryParamTypes = Union[\n \"QueryParams\",\n Mapping[str, Union[PrimitiveData, Sequence[PrimitiveData]]],\n List[Tuple[str, PrimitiveData]],\n Tuple[Tuple[str, PrimitiveData], ...],\n str,\n bytes,\n]\n\nHeaderTypes = Union[\n \"Headers\",\n Mapping[str, str],\n Mapping[bytes, bytes],\n Sequence[Tuple[str, str]],\n Sequence[Tuple[bytes, bytes]],\n]\n\nCookieTypes = Union[\"Cookies\", CookieJar, Dict[str, str], List[Tuple[str, str]]]\n\nCertTypes = Union[\n # certfile\n str,\n # (certfile, keyfile)\n Tuple[str, Optional[str]],\n # (certfile, keyfile, password)\n Tuple[str, Optional[str], Optional[str]],\n]\nVerifyTypes = Union[str, bool, ssl.SSLContext]\nTimeoutTypes = Union[\n Optional[float],\n Tuple[Optional[float], Optional[float], Optional[float], Optional[float]],\n \"Timeout\",\n]\nProxiesTypes = Union[URLTypes, \"Proxy\", Dict[URLTypes, Union[None, URLTypes, \"Proxy\"]]]\n\nAuthTypes = Union[\n Tuple[Union[str, bytes], Union[str, bytes]],\n Callable[[\"Request\"], \"Request\"],\n \"Auth\",\n]\n\nRequestContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]\nResponseContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]\nResponseExtensions = Mapping[str, Any]\n\nRequestData = Mapping[str, Any]\n\nFileContent = Union[IO[bytes], bytes, str]\nFileTypes = Union[\n # file (or bytes)\n FileContent,\n # (filename, file (or bytes))\n Tuple[Optional[str], FileContent],\n # (filename, file (or bytes), content_type)\n Tuple[Optional[str], FileContent, Optional[str]],\n # (filename, file (or bytes), content_type, headers)\n Tuple[Optional[str], FileContent, Optional[str], Mapping[str, str]],\n]\nRequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]\n\nRequestExtensions = Mapping[str, Any]\n\n\nclass SyncByteStream:\n def __iter__(self) -> Iterator[bytes]:\n raise NotImplementedError(\n \"The '__iter__' method must be implemented.\"\n ) # pragma: no cover\n yield b\"\" # pragma: no cover\n\n def close(self) -> None:\n \"\"\"\n Subclasses can override this method to release any network resources\n after a request/response cycle is complete.\n \"\"\"\n\n\nclass AsyncByteStream:\n async def __aiter__(self) -> AsyncIterator[bytes]:\n raise NotImplementedError(\n \"The '__aiter__' method must be implemented.\"\n ) # pragma: no cover\n yield b\"\" # pragma: no cover\n\n async def aclose(self) -> None:\n pass\n", "path": "httpx/_types.py"}], "after_files": [{"content": "\"\"\"\nType definitions for type checking purposes.\n\"\"\"\n\nimport ssl\nfrom http.cookiejar import CookieJar\nfrom typing import (\n IO,\n TYPE_CHECKING,\n Any,\n AsyncIterable,\n AsyncIterator,\n Callable,\n Dict,\n Iterable,\n Iterator,\n List,\n Mapping,\n MutableMapping,\n NamedTuple,\n Optional,\n Sequence,\n Tuple,\n Union,\n)\n\nif TYPE_CHECKING: # pragma: no cover\n from ._auth import Auth # noqa: F401\n from ._config import Proxy, Timeout # noqa: F401\n from ._models import Cookies, Headers, Request # noqa: F401\n from ._urls import URL, QueryParams # noqa: F401\n\n\nPrimitiveData = Optional[Union[str, int, float, bool]]\n\nRawURL = NamedTuple(\n \"RawURL\",\n [\n (\"raw_scheme\", bytes),\n (\"raw_host\", bytes),\n (\"port\", Optional[int]),\n (\"raw_path\", bytes),\n ],\n)\n\nURLTypes = Union[\"URL\", str]\n\nQueryParamTypes = Union[\n \"QueryParams\",\n Mapping[str, Union[PrimitiveData, Sequence[PrimitiveData]]],\n List[Tuple[str, PrimitiveData]],\n Tuple[Tuple[str, PrimitiveData], ...],\n str,\n bytes,\n]\n\nHeaderTypes = Union[\n \"Headers\",\n Mapping[str, str],\n Mapping[bytes, bytes],\n Sequence[Tuple[str, str]],\n Sequence[Tuple[bytes, bytes]],\n]\n\nCookieTypes = Union[\"Cookies\", CookieJar, Dict[str, str], List[Tuple[str, str]]]\n\nCertTypes = Union[\n # certfile\n str,\n # (certfile, keyfile)\n Tuple[str, Optional[str]],\n # (certfile, keyfile, password)\n Tuple[str, Optional[str], Optional[str]],\n]\nVerifyTypes = Union[str, bool, ssl.SSLContext]\nTimeoutTypes = Union[\n Optional[float],\n Tuple[Optional[float], Optional[float], Optional[float], Optional[float]],\n \"Timeout\",\n]\nProxiesTypes = Union[URLTypes, \"Proxy\", Dict[URLTypes, Union[None, URLTypes, \"Proxy\"]]]\n\nAuthTypes = Union[\n Tuple[Union[str, bytes], Union[str, bytes]],\n Callable[[\"Request\"], \"Request\"],\n \"Auth\",\n]\n\nRequestContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]\nResponseContent = Union[str, bytes, Iterable[bytes], AsyncIterable[bytes]]\nResponseExtensions = MutableMapping[str, Any]\n\nRequestData = Mapping[str, Any]\n\nFileContent = Union[IO[bytes], bytes, str]\nFileTypes = Union[\n # file (or bytes)\n FileContent,\n # (filename, file (or bytes))\n Tuple[Optional[str], FileContent],\n # (filename, file (or bytes), content_type)\n Tuple[Optional[str], FileContent, Optional[str]],\n # (filename, file (or bytes), content_type, headers)\n Tuple[Optional[str], FileContent, Optional[str], Mapping[str, str]],\n]\nRequestFiles = Union[Mapping[str, FileTypes], Sequence[Tuple[str, FileTypes]]]\n\nRequestExtensions = MutableMapping[str, Any]\n\n\nclass SyncByteStream:\n def __iter__(self) -> Iterator[bytes]:\n raise NotImplementedError(\n \"The '__iter__' method must be implemented.\"\n ) # pragma: no cover\n yield b\"\" # pragma: no cover\n\n def close(self) -> None:\n \"\"\"\n Subclasses can override this method to release any network resources\n after a request/response cycle is complete.\n \"\"\"\n\n\nclass AsyncByteStream:\n async def __aiter__(self) -> AsyncIterator[bytes]:\n raise NotImplementedError(\n \"The '__aiter__' method must be implemented.\"\n ) # pragma: no cover\n yield b\"\" # pragma: no cover\n\n async def aclose(self) -> None:\n pass\n", "path": "httpx/_types.py"}]} | 1,666 | 205 |
gh_patches_debug_6089 | rasdani/github-patches | git_diff | encode__starlette-1459 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Raising Exceptions in sub-applications routes
### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
Let's start with this PR: #1262
It's about preventing raise `anyio.ExceptionGroup` in views under a `BaseHTTPMiddleware`. PR resolve that problem with nonlocal variable that stores our exception. But in the case of sub-applications, it does not work.
As I can see (fyi I am not good at asyncio), in the case below, we reach and read a response before we raise an exception and store it to our nonlocal variable:
fragment of `BaseHTTPMiddleware.__call__`
```python
async def call_next(request: Request) -> Response:
app_exc: typing.Optional[Exception] = None
send_stream, recv_stream = anyio.create_memory_object_stream()
async def coro() -> None:
nonlocal app_exc
async with send_stream:
try:
task = await self.app(scope, request.receive, send_stream.send)
except Exception as exc:
app_exc = exc
task_group.start_soon(coro)
try:
message = await recv_stream.receive()
except anyio.EndOfStream:
if app_exc is not None:
raise app_exc
raise RuntimeError("No response returned.")
...
response = StreamingResponse(
status_code=message["status"], content=body_stream()
)
response.raw_headers = message["headers"]
return response
```
in this moment: `except anyio.EndOfStream:` exception still no raised.
### Steps to reproduce the bug
```python
import httpx
import pytest
from fastapi import FastAPI, APIRouter
from starlette.middleware import Middleware
from starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint
from starlette.requests import Request
from starlette.responses import Response
from starlette.routing import Route
class SomeError(Exception):
pass
class SomeMiddleware(BaseHTTPMiddleware):
async def dispatch(
self, request: Request, call_next: RequestResponseEndpoint
) -> Response:
return await call_next(request)
# Drop (or use not BaseHTTPMiddleware based) middleware and test works fine
app = FastAPI(middleware=[Middleware(SomeMiddleware), ])
async def simple_route(request: Request):
raise SomeError
another_router = APIRouter(
routes=[Route('/simple-route/', simple_route, methods=['GET'])]
)
sub_app = FastAPI()
sub_app.include_router(another_router)
app.router.mount(f'/api', sub_app)
@pytest.mark.asyncio
async def test_simple_route():
async with httpx.AsyncClient(app=app) as client:
with pytest.raises(SomeError):
await client.get("http://testserver/api/simple-route/")
```
### Expected behavior
An exception was raised and caught by pytest exception
### Actual behavior
An exception wasn't raised
### Debugging material
_No response_
### Environment
macOS Monterey 12.0.1, starlette 0.17.1, Python 3.9.9
### Additional context
_No response_
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `starlette/middleware/base.py`
Content:
```
1 import typing
2
3 import anyio
4
5 from starlette.requests import Request
6 from starlette.responses import Response, StreamingResponse
7 from starlette.types import ASGIApp, Receive, Scope, Send
8
9 RequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]
10 DispatchFunction = typing.Callable[
11 [Request, RequestResponseEndpoint], typing.Awaitable[Response]
12 ]
13
14
15 class BaseHTTPMiddleware:
16 def __init__(self, app: ASGIApp, dispatch: DispatchFunction = None) -> None:
17 self.app = app
18 self.dispatch_func = self.dispatch if dispatch is None else dispatch
19
20 async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
21 if scope["type"] != "http":
22 await self.app(scope, receive, send)
23 return
24
25 async def call_next(request: Request) -> Response:
26 app_exc: typing.Optional[Exception] = None
27 send_stream, recv_stream = anyio.create_memory_object_stream()
28
29 async def coro() -> None:
30 nonlocal app_exc
31
32 async with send_stream:
33 try:
34 await self.app(scope, request.receive, send_stream.send)
35 except Exception as exc:
36 app_exc = exc
37
38 task_group.start_soon(coro)
39
40 try:
41 message = await recv_stream.receive()
42 except anyio.EndOfStream:
43 if app_exc is not None:
44 raise app_exc
45 raise RuntimeError("No response returned.")
46
47 assert message["type"] == "http.response.start"
48
49 async def body_stream() -> typing.AsyncGenerator[bytes, None]:
50 async with recv_stream:
51 async for message in recv_stream:
52 assert message["type"] == "http.response.body"
53 yield message.get("body", b"")
54
55 response = StreamingResponse(
56 status_code=message["status"], content=body_stream()
57 )
58 response.raw_headers = message["headers"]
59 return response
60
61 async with anyio.create_task_group() as task_group:
62 request = Request(scope, receive=receive)
63 response = await self.dispatch_func(request, call_next)
64 await response(scope, receive, send)
65 task_group.cancel_scope.cancel()
66
67 async def dispatch(
68 self, request: Request, call_next: RequestResponseEndpoint
69 ) -> Response:
70 raise NotImplementedError() # pragma: no cover
71
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/starlette/middleware/base.py b/starlette/middleware/base.py
--- a/starlette/middleware/base.py
+++ b/starlette/middleware/base.py
@@ -52,6 +52,9 @@
assert message["type"] == "http.response.body"
yield message.get("body", b"")
+ if app_exc is not None:
+ raise app_exc
+
response = StreamingResponse(
status_code=message["status"], content=body_stream()
)
| {"golden_diff": "diff --git a/starlette/middleware/base.py b/starlette/middleware/base.py\n--- a/starlette/middleware/base.py\n+++ b/starlette/middleware/base.py\n@@ -52,6 +52,9 @@\n assert message[\"type\"] == \"http.response.body\"\n yield message.get(\"body\", b\"\")\n \n+ if app_exc is not None:\n+ raise app_exc\n+\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n", "issue": "Raising Exceptions in sub-applications routes\n### Checklist\r\n\r\n- [X] The bug is reproducible against the latest release or `master`.\r\n- [X] There are no similar issues or pull requests to fix it yet.\r\n\r\n### Describe the bug\r\n\r\nLet's start with this PR: #1262\r\n\r\nIt's about preventing raise `anyio.ExceptionGroup` in views under a `BaseHTTPMiddleware`. PR resolve that problem with nonlocal variable that stores our exception. But in the case of sub-applications, it does not work. \r\n\r\nAs I can see (fyi I am not good at asyncio), in the case below, we reach and read a response before we raise an exception and store it to our nonlocal variable:\r\n\r\nfragment of `BaseHTTPMiddleware.__call__`\r\n```python\r\nasync def call_next(request: Request) -> Response:\r\n app_exc: typing.Optional[Exception] = None\r\n send_stream, recv_stream = anyio.create_memory_object_stream()\r\n\r\n async def coro() -> None:\r\n nonlocal app_exc\r\n\r\n async with send_stream:\r\n try:\r\n task = await self.app(scope, request.receive, send_stream.send)\r\n except Exception as exc:\r\n app_exc = exc\r\n\r\n task_group.start_soon(coro)\r\n\r\n try:\r\n message = await recv_stream.receive()\r\n except anyio.EndOfStream:\r\n if app_exc is not None:\r\n raise app_exc\r\n raise RuntimeError(\"No response returned.\")\r\n \r\n ...\r\n response = StreamingResponse(\r\n status_code=message[\"status\"], content=body_stream()\r\n )\r\n response.raw_headers = message[\"headers\"]\r\n return response\r\n```\r\n\r\nin this moment: `except anyio.EndOfStream:` exception still no raised.\r\n\r\n### Steps to reproduce the bug\r\n\r\n```python\r\nimport httpx\r\nimport pytest\r\nfrom fastapi import FastAPI, APIRouter\r\nfrom starlette.middleware import Middleware\r\nfrom starlette.middleware.base import BaseHTTPMiddleware, RequestResponseEndpoint\r\nfrom starlette.requests import Request\r\nfrom starlette.responses import Response\r\nfrom starlette.routing import Route\r\n\r\n\r\nclass SomeError(Exception):\r\n pass\r\n\r\n\r\nclass SomeMiddleware(BaseHTTPMiddleware):\r\n async def dispatch(\r\n self, request: Request, call_next: RequestResponseEndpoint\r\n ) -> Response:\r\n return await call_next(request)\r\n\r\n# Drop (or use not BaseHTTPMiddleware based) middleware and test works fine\r\napp = FastAPI(middleware=[Middleware(SomeMiddleware), ])\r\n\r\n\r\nasync def simple_route(request: Request):\r\n raise SomeError\r\n\r\n\r\nanother_router = APIRouter(\r\n routes=[Route('/simple-route/', simple_route, methods=['GET'])]\r\n)\r\nsub_app = FastAPI()\r\nsub_app.include_router(another_router)\r\napp.router.mount(f'/api', sub_app)\r\n\r\n\r\[email protected]\r\nasync def test_simple_route():\r\n async with httpx.AsyncClient(app=app) as client:\r\n with pytest.raises(SomeError):\r\n await client.get(\"http://testserver/api/simple-route/\")\r\n\r\n```\r\n\r\n### Expected behavior\r\n\r\nAn exception was raised and caught by pytest exception\r\n\r\n### Actual behavior\r\n\r\nAn exception wasn't raised\r\n\r\n### Debugging material\r\n\r\n_No response_\r\n\r\n### Environment\r\n\r\nmacOS Monterey 12.0.1, starlette 0.17.1, Python 3.9.9\r\n\r\n\r\n### Additional context\r\n\r\n_No response_\n", "before_files": [{"content": "import typing\n\nimport anyio\n\nfrom starlette.requests import Request\nfrom starlette.responses import Response, StreamingResponse\nfrom starlette.types import ASGIApp, Receive, Scope, Send\n\nRequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\nDispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n]\n\n\nclass BaseHTTPMiddleware:\n def __init__(self, app: ASGIApp, dispatch: DispatchFunction = None) -> None:\n self.app = app\n self.dispatch_func = self.dispatch if dispatch is None else dispatch\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n async def call_next(request: Request) -> Response:\n app_exc: typing.Optional[Exception] = None\n send_stream, recv_stream = anyio.create_memory_object_stream()\n\n async def coro() -> None:\n nonlocal app_exc\n\n async with send_stream:\n try:\n await self.app(scope, request.receive, send_stream.send)\n except Exception as exc:\n app_exc = exc\n\n task_group.start_soon(coro)\n\n try:\n message = await recv_stream.receive()\n except anyio.EndOfStream:\n if app_exc is not None:\n raise app_exc\n raise RuntimeError(\"No response returned.\")\n\n assert message[\"type\"] == \"http.response.start\"\n\n async def body_stream() -> typing.AsyncGenerator[bytes, None]:\n async with recv_stream:\n async for message in recv_stream:\n assert message[\"type\"] == \"http.response.body\"\n yield message.get(\"body\", b\"\")\n\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n response.raw_headers = message[\"headers\"]\n return response\n\n async with anyio.create_task_group() as task_group:\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, call_next)\n await response(scope, receive, send)\n task_group.cancel_scope.cancel()\n\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n raise NotImplementedError() # pragma: no cover\n", "path": "starlette/middleware/base.py"}], "after_files": [{"content": "import typing\n\nimport anyio\n\nfrom starlette.requests import Request\nfrom starlette.responses import Response, StreamingResponse\nfrom starlette.types import ASGIApp, Receive, Scope, Send\n\nRequestResponseEndpoint = typing.Callable[[Request], typing.Awaitable[Response]]\nDispatchFunction = typing.Callable[\n [Request, RequestResponseEndpoint], typing.Awaitable[Response]\n]\n\n\nclass BaseHTTPMiddleware:\n def __init__(self, app: ASGIApp, dispatch: DispatchFunction = None) -> None:\n self.app = app\n self.dispatch_func = self.dispatch if dispatch is None else dispatch\n\n async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:\n if scope[\"type\"] != \"http\":\n await self.app(scope, receive, send)\n return\n\n async def call_next(request: Request) -> Response:\n app_exc: typing.Optional[Exception] = None\n send_stream, recv_stream = anyio.create_memory_object_stream()\n\n async def coro() -> None:\n nonlocal app_exc\n\n async with send_stream:\n try:\n await self.app(scope, request.receive, send_stream.send)\n except Exception as exc:\n app_exc = exc\n\n task_group.start_soon(coro)\n\n try:\n message = await recv_stream.receive()\n except anyio.EndOfStream:\n if app_exc is not None:\n raise app_exc\n raise RuntimeError(\"No response returned.\")\n\n assert message[\"type\"] == \"http.response.start\"\n\n async def body_stream() -> typing.AsyncGenerator[bytes, None]:\n async with recv_stream:\n async for message in recv_stream:\n assert message[\"type\"] == \"http.response.body\"\n yield message.get(\"body\", b\"\")\n\n if app_exc is not None:\n raise app_exc\n\n response = StreamingResponse(\n status_code=message[\"status\"], content=body_stream()\n )\n response.raw_headers = message[\"headers\"]\n return response\n\n async with anyio.create_task_group() as task_group:\n request = Request(scope, receive=receive)\n response = await self.dispatch_func(request, call_next)\n await response(scope, receive, send)\n task_group.cancel_scope.cancel()\n\n async def dispatch(\n self, request: Request, call_next: RequestResponseEndpoint\n ) -> Response:\n raise NotImplementedError() # pragma: no cover\n", "path": "starlette/middleware/base.py"}]} | 1,581 | 107 |
gh_patches_debug_5943 | rasdani/github-patches | git_diff | paperless-ngx__paperless-ngx-5320 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Configuration: User-Arguments are mandatory
### Description
See the following Screenshot.

I don't think, user args should be mandatory, since the documentation says "additionally specify arguments".
### Steps to reproduce
1. Click on "Configuration"
2. Fill in some Values
3. Click "Save"
4. User-Args are mandatory
In order to save a Configuration, the user now has to enter an empty json which is not very user-friendly.
### Webserver logs
```bash
not applicable
```
### Browser logs
_No response_
### Paperless-ngx version
2.3.2
### Host OS
Synology DSM 6.2.X
### Installation method
Docker - official image
### Browser
Chrome
### Configuration changes
none of interest
### Other
_No response_
### Please confirm the following
- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.
- [X] I have already searched for relevant existing issues and discussions before opening this report.
- [X] I have updated the title field above with a concise description.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/paperless/serialisers.py`
Content:
```
1 import logging
2
3 from django.contrib.auth.models import Group
4 from django.contrib.auth.models import Permission
5 from django.contrib.auth.models import User
6 from rest_framework import serializers
7
8 from paperless.models import ApplicationConfiguration
9
10 logger = logging.getLogger("paperless.settings")
11
12
13 class ObfuscatedUserPasswordField(serializers.Field):
14 """
15 Sends *** string instead of password in the clear
16 """
17
18 def to_representation(self, value):
19 return "**********" if len(value) > 0 else ""
20
21 def to_internal_value(self, data):
22 return data
23
24
25 class UserSerializer(serializers.ModelSerializer):
26 password = ObfuscatedUserPasswordField(required=False)
27 user_permissions = serializers.SlugRelatedField(
28 many=True,
29 queryset=Permission.objects.all(),
30 slug_field="codename",
31 required=False,
32 )
33 inherited_permissions = serializers.SerializerMethodField()
34
35 class Meta:
36 model = User
37 fields = (
38 "id",
39 "username",
40 "email",
41 "password",
42 "first_name",
43 "last_name",
44 "date_joined",
45 "is_staff",
46 "is_active",
47 "is_superuser",
48 "groups",
49 "user_permissions",
50 "inherited_permissions",
51 )
52
53 def get_inherited_permissions(self, obj):
54 return obj.get_group_permissions()
55
56 def update(self, instance, validated_data):
57 if "password" in validated_data:
58 if len(validated_data.get("password").replace("*", "")) > 0:
59 instance.set_password(validated_data.get("password"))
60 instance.save()
61 validated_data.pop("password")
62 super().update(instance, validated_data)
63 return instance
64
65 def create(self, validated_data):
66 groups = None
67 if "groups" in validated_data:
68 groups = validated_data.pop("groups")
69 user_permissions = None
70 if "user_permissions" in validated_data:
71 user_permissions = validated_data.pop("user_permissions")
72 password = None
73 if (
74 "password" in validated_data
75 and len(validated_data.get("password").replace("*", "")) > 0
76 ):
77 password = validated_data.pop("password")
78 user = User.objects.create(**validated_data)
79 # set groups
80 if groups:
81 user.groups.set(groups)
82 # set permissions
83 if user_permissions:
84 user.user_permissions.set(user_permissions)
85 # set password
86 if password:
87 user.set_password(password)
88 user.save()
89 return user
90
91
92 class GroupSerializer(serializers.ModelSerializer):
93 permissions = serializers.SlugRelatedField(
94 many=True,
95 queryset=Permission.objects.all(),
96 slug_field="codename",
97 )
98
99 class Meta:
100 model = Group
101 fields = (
102 "id",
103 "name",
104 "permissions",
105 )
106
107
108 class ProfileSerializer(serializers.ModelSerializer):
109 email = serializers.EmailField(allow_null=False)
110 password = ObfuscatedUserPasswordField(required=False, allow_null=False)
111 auth_token = serializers.SlugRelatedField(read_only=True, slug_field="key")
112
113 class Meta:
114 model = User
115 fields = (
116 "email",
117 "password",
118 "first_name",
119 "last_name",
120 "auth_token",
121 )
122
123
124 class ApplicationConfigurationSerializer(serializers.ModelSerializer):
125 user_args = serializers.JSONField(binary=True)
126
127 class Meta:
128 model = ApplicationConfiguration
129 fields = "__all__"
130
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/paperless/serialisers.py b/src/paperless/serialisers.py
--- a/src/paperless/serialisers.py
+++ b/src/paperless/serialisers.py
@@ -122,7 +122,12 @@
class ApplicationConfigurationSerializer(serializers.ModelSerializer):
- user_args = serializers.JSONField(binary=True)
+ user_args = serializers.JSONField(binary=True, allow_null=True)
+
+ def run_validation(self, data):
+ if "user_args" in data and data["user_args"] == "":
+ data["user_args"] = None
+ return super().run_validation(data)
class Meta:
model = ApplicationConfiguration
| {"golden_diff": "diff --git a/src/paperless/serialisers.py b/src/paperless/serialisers.py\n--- a/src/paperless/serialisers.py\n+++ b/src/paperless/serialisers.py\n@@ -122,7 +122,12 @@\n \n \n class ApplicationConfigurationSerializer(serializers.ModelSerializer):\n- user_args = serializers.JSONField(binary=True)\n+ user_args = serializers.JSONField(binary=True, allow_null=True)\n+\n+ def run_validation(self, data):\n+ if \"user_args\" in data and data[\"user_args\"] == \"\":\n+ data[\"user_args\"] = None\n+ return super().run_validation(data)\n \n class Meta:\n model = ApplicationConfiguration\n", "issue": "Configuration: User-Arguments are mandatory\n### Description\r\n\r\nSee the following Screenshot. \r\n\r\n\r\n\r\nI don't think, user args should be mandatory, since the documentation says \"additionally specify arguments\".\r\n\r\n### Steps to reproduce\r\n\r\n1. Click on \"Configuration\"\r\n2. Fill in some Values\r\n3. Click \"Save\"\r\n4. User-Args are mandatory\r\n\r\nIn order to save a Configuration, the user now has to enter an empty json which is not very user-friendly.\r\n\r\n### Webserver logs\r\n\r\n```bash\r\nnot applicable\r\n```\r\n\r\n\r\n### Browser logs\r\n\r\n_No response_\r\n\r\n### Paperless-ngx version\r\n\r\n2.3.2\r\n\r\n### Host OS\r\n\r\nSynology DSM 6.2.X\r\n\r\n### Installation method\r\n\r\nDocker - official image\r\n\r\n### Browser\r\n\r\nChrome\r\n\r\n### Configuration changes\r\n\r\nnone of interest\r\n\r\n### Other\r\n\r\n_No response_\r\n\r\n### Please confirm the following\r\n\r\n- [X] I believe this issue is a bug that affects all users of Paperless-ngx, not something specific to my installation.\r\n- [X] I have already searched for relevant existing issues and discussions before opening this report.\r\n- [X] I have updated the title field above with a concise description.\n", "before_files": [{"content": "import logging\n\nfrom django.contrib.auth.models import Group\nfrom django.contrib.auth.models import Permission\nfrom django.contrib.auth.models import User\nfrom rest_framework import serializers\n\nfrom paperless.models import ApplicationConfiguration\n\nlogger = logging.getLogger(\"paperless.settings\")\n\n\nclass ObfuscatedUserPasswordField(serializers.Field):\n \"\"\"\n Sends *** string instead of password in the clear\n \"\"\"\n\n def to_representation(self, value):\n return \"**********\" if len(value) > 0 else \"\"\n\n def to_internal_value(self, data):\n return data\n\n\nclass UserSerializer(serializers.ModelSerializer):\n password = ObfuscatedUserPasswordField(required=False)\n user_permissions = serializers.SlugRelatedField(\n many=True,\n queryset=Permission.objects.all(),\n slug_field=\"codename\",\n required=False,\n )\n inherited_permissions = serializers.SerializerMethodField()\n\n class Meta:\n model = User\n fields = (\n \"id\",\n \"username\",\n \"email\",\n \"password\",\n \"first_name\",\n \"last_name\",\n \"date_joined\",\n \"is_staff\",\n \"is_active\",\n \"is_superuser\",\n \"groups\",\n \"user_permissions\",\n \"inherited_permissions\",\n )\n\n def get_inherited_permissions(self, obj):\n return obj.get_group_permissions()\n\n def update(self, instance, validated_data):\n if \"password\" in validated_data:\n if len(validated_data.get(\"password\").replace(\"*\", \"\")) > 0:\n instance.set_password(validated_data.get(\"password\"))\n instance.save()\n validated_data.pop(\"password\")\n super().update(instance, validated_data)\n return instance\n\n def create(self, validated_data):\n groups = None\n if \"groups\" in validated_data:\n groups = validated_data.pop(\"groups\")\n user_permissions = None\n if \"user_permissions\" in validated_data:\n user_permissions = validated_data.pop(\"user_permissions\")\n password = None\n if (\n \"password\" in validated_data\n and len(validated_data.get(\"password\").replace(\"*\", \"\")) > 0\n ):\n password = validated_data.pop(\"password\")\n user = User.objects.create(**validated_data)\n # set groups\n if groups:\n user.groups.set(groups)\n # set permissions\n if user_permissions:\n user.user_permissions.set(user_permissions)\n # set password\n if password:\n user.set_password(password)\n user.save()\n return user\n\n\nclass GroupSerializer(serializers.ModelSerializer):\n permissions = serializers.SlugRelatedField(\n many=True,\n queryset=Permission.objects.all(),\n slug_field=\"codename\",\n )\n\n class Meta:\n model = Group\n fields = (\n \"id\",\n \"name\",\n \"permissions\",\n )\n\n\nclass ProfileSerializer(serializers.ModelSerializer):\n email = serializers.EmailField(allow_null=False)\n password = ObfuscatedUserPasswordField(required=False, allow_null=False)\n auth_token = serializers.SlugRelatedField(read_only=True, slug_field=\"key\")\n\n class Meta:\n model = User\n fields = (\n \"email\",\n \"password\",\n \"first_name\",\n \"last_name\",\n \"auth_token\",\n )\n\n\nclass ApplicationConfigurationSerializer(serializers.ModelSerializer):\n user_args = serializers.JSONField(binary=True)\n\n class Meta:\n model = ApplicationConfiguration\n fields = \"__all__\"\n", "path": "src/paperless/serialisers.py"}], "after_files": [{"content": "import logging\n\nfrom django.contrib.auth.models import Group\nfrom django.contrib.auth.models import Permission\nfrom django.contrib.auth.models import User\nfrom rest_framework import serializers\n\nfrom paperless.models import ApplicationConfiguration\n\nlogger = logging.getLogger(\"paperless.settings\")\n\n\nclass ObfuscatedUserPasswordField(serializers.Field):\n \"\"\"\n Sends *** string instead of password in the clear\n \"\"\"\n\n def to_representation(self, value):\n return \"**********\" if len(value) > 0 else \"\"\n\n def to_internal_value(self, data):\n return data\n\n\nclass UserSerializer(serializers.ModelSerializer):\n password = ObfuscatedUserPasswordField(required=False)\n user_permissions = serializers.SlugRelatedField(\n many=True,\n queryset=Permission.objects.all(),\n slug_field=\"codename\",\n required=False,\n )\n inherited_permissions = serializers.SerializerMethodField()\n\n class Meta:\n model = User\n fields = (\n \"id\",\n \"username\",\n \"email\",\n \"password\",\n \"first_name\",\n \"last_name\",\n \"date_joined\",\n \"is_staff\",\n \"is_active\",\n \"is_superuser\",\n \"groups\",\n \"user_permissions\",\n \"inherited_permissions\",\n )\n\n def get_inherited_permissions(self, obj):\n return obj.get_group_permissions()\n\n def update(self, instance, validated_data):\n if \"password\" in validated_data:\n if len(validated_data.get(\"password\").replace(\"*\", \"\")) > 0:\n instance.set_password(validated_data.get(\"password\"))\n instance.save()\n validated_data.pop(\"password\")\n super().update(instance, validated_data)\n return instance\n\n def create(self, validated_data):\n groups = None\n if \"groups\" in validated_data:\n groups = validated_data.pop(\"groups\")\n user_permissions = None\n if \"user_permissions\" in validated_data:\n user_permissions = validated_data.pop(\"user_permissions\")\n password = None\n if (\n \"password\" in validated_data\n and len(validated_data.get(\"password\").replace(\"*\", \"\")) > 0\n ):\n password = validated_data.pop(\"password\")\n user = User.objects.create(**validated_data)\n # set groups\n if groups:\n user.groups.set(groups)\n # set permissions\n if user_permissions:\n user.user_permissions.set(user_permissions)\n # set password\n if password:\n user.set_password(password)\n user.save()\n return user\n\n\nclass GroupSerializer(serializers.ModelSerializer):\n permissions = serializers.SlugRelatedField(\n many=True,\n queryset=Permission.objects.all(),\n slug_field=\"codename\",\n )\n\n class Meta:\n model = Group\n fields = (\n \"id\",\n \"name\",\n \"permissions\",\n )\n\n\nclass ProfileSerializer(serializers.ModelSerializer):\n email = serializers.EmailField(allow_null=False)\n password = ObfuscatedUserPasswordField(required=False, allow_null=False)\n auth_token = serializers.SlugRelatedField(read_only=True, slug_field=\"key\")\n\n class Meta:\n model = User\n fields = (\n \"email\",\n \"password\",\n \"first_name\",\n \"last_name\",\n \"auth_token\",\n )\n\n\nclass ApplicationConfigurationSerializer(serializers.ModelSerializer):\n user_args = serializers.JSONField(binary=True, allow_null=True)\n\n def run_validation(self, data):\n if \"user_args\" in data and data[\"user_args\"] == \"\":\n data[\"user_args\"] = None\n return super().run_validation(data)\n\n class Meta:\n model = ApplicationConfiguration\n fields = \"__all__\"\n", "path": "src/paperless/serialisers.py"}]} | 1,555 | 150 |
gh_patches_debug_19925 | rasdani/github-patches | git_diff | mne-tools__mne-python-10868 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
update path handling in examples/inverse/morph_surface_stc.py
all of our `data_path` functions now return `pathlib.Path` objects, which allows things like the following:
https://github.com/mne-tools/mne-python/blob/37a9e5587443109515a85cdc4396af4e014ecf82/examples/datasets/brainstorm_data.py#L32-L35
Compare this to the old pattern (using `os.path.join`, often imported as `op.join`):
```py
raw_path = os.path.join(data_path, 'MEG', 'bst_raw',
'subj001_somatosensory_20111109_01_AUX-f.ds')
```
or the *really* old pattern (using the `+` operator on plain strings):
```py
raw_path = (data_path + '/MEG/bst_raw/' +
'subj001_somatosensory_20111109_01_AUX-f.ds')
```
Update the paths in the file mentioned in the issue title to use the new pathlib-style, which is considered the modern, best-practice way to handle file paths.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/inverse/morph_surface_stc.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 .. _ex-morph-surface:
4
5 =============================
6 Morph surface source estimate
7 =============================
8
9 This example demonstrates how to morph an individual subject's
10 :class:`mne.SourceEstimate` to a common reference space. We achieve this using
11 :class:`mne.SourceMorph`. Pre-computed data will be morphed based on
12 a spherical representation of the cortex computed using the spherical
13 registration of :ref:`FreeSurfer <tut-freesurfer-mne>`
14 (https://surfer.nmr.mgh.harvard.edu/fswiki/SurfaceRegAndTemplates)
15 :footcite:`GreveEtAl2013`. This
16 transform will be used to morph the surface vertices of the subject towards the
17 reference vertices. Here we will use 'fsaverage' as a reference space (see
18 https://surfer.nmr.mgh.harvard.edu/fswiki/FsAverage).
19
20 The transformation will be applied to the surface source estimate. A plot
21 depicting the successful morph will be created for the spherical and inflated
22 surface representation of ``'fsaverage'``, overlaid with the morphed surface
23 source estimate.
24
25 .. note:: For background information about morphing see :ref:`ch_morph`.
26 """
27 # Author: Tommy Clausner <[email protected]>
28 #
29 # License: BSD-3-Clause
30
31 # %%
32 import os
33 import os.path as op
34
35 import mne
36 from mne.datasets import sample
37
38 print(__doc__)
39
40 # %%
41 # Setup paths
42
43 data_path = sample.data_path()
44 sample_dir = op.join(data_path, 'MEG', 'sample')
45 subjects_dir = op.join(data_path, 'subjects')
46 fname_src = op.join(subjects_dir, 'sample', 'bem', 'sample-oct-6-src.fif')
47 fname_fwd = op.join(sample_dir, 'sample_audvis-meg-oct-6-fwd.fif')
48 fname_fsaverage_src = os.path.join(subjects_dir, 'fsaverage', 'bem',
49 'fsaverage-ico-5-src.fif')
50
51 fname_stc = os.path.join(sample_dir, 'sample_audvis-meg')
52
53 # %%
54 # Load example data
55
56 # Read stc from file
57 stc = mne.read_source_estimate(fname_stc, subject='sample')
58
59 # %%
60 # Setting up SourceMorph for SourceEstimate
61 # -----------------------------------------
62 #
63 # In MNE, surface source estimates represent the source space simply as
64 # lists of vertices (see :ref:`tut-source-estimate-class`).
65 # This list can either be obtained from :class:`mne.SourceSpaces` (src) or from
66 # the ``stc`` itself. If you use the source space, be sure to use the
67 # source space from the forward or inverse operator, because vertices
68 # can be excluded during forward computation due to proximity to the BEM
69 # inner skull surface:
70
71 src_orig = mne.read_source_spaces(fname_src)
72 print(src_orig) # n_used=4098, 4098
73 fwd = mne.read_forward_solution(fname_fwd)
74 print(fwd['src']) # n_used=3732, 3766
75 print([len(v) for v in stc.vertices])
76
77 # %%
78 # We also need to specify the set of vertices to morph to. This can be done
79 # using the ``spacing`` parameter, but for consistency it's better to pass the
80 # ``src_to`` parameter.
81 #
82 # .. note::
83 # Since the default values of :func:`mne.compute_source_morph` are
84 # ``spacing=5, subject_to='fsaverage'``, in this example
85 # we could actually omit the ``src_to`` and ``subject_to`` arguments
86 # below. The ico-5 ``fsaverage`` source space contains the
87 # special values ``[np.arange(10242)] * 2``, but in general this will
88 # not be true for other spacings or other subjects. Thus it is recommended
89 # to always pass the destination ``src`` for consistency.
90 #
91 # Initialize SourceMorph for SourceEstimate
92
93 src_to = mne.read_source_spaces(fname_fsaverage_src)
94 print(src_to[0]['vertno']) # special, np.arange(10242)
95 morph = mne.compute_source_morph(stc, subject_from='sample',
96 subject_to='fsaverage', src_to=src_to,
97 subjects_dir=subjects_dir)
98
99 # %%
100 # Apply morph to (Vector) SourceEstimate
101 # --------------------------------------
102 #
103 # The morph will be applied to the source estimate data, by giving it as the
104 # first argument to the morph we computed above.
105
106 stc_fsaverage = morph.apply(stc)
107
108 # %%
109 # Plot results
110 # ------------
111
112 # Define plotting parameters
113 surfer_kwargs = dict(
114 hemi='lh', subjects_dir=subjects_dir,
115 clim=dict(kind='value', lims=[8, 12, 15]), views='lateral',
116 initial_time=0.09, time_unit='s', size=(800, 800),
117 smoothing_steps=5)
118
119 # As spherical surface
120 brain = stc_fsaverage.plot(surface='sphere', **surfer_kwargs)
121
122 # Add title
123 brain.add_text(0.1, 0.9, 'Morphed to fsaverage (spherical)', 'title',
124 font_size=16)
125
126 # %%
127 # As inflated surface
128 brain_inf = stc_fsaverage.plot(surface='inflated', **surfer_kwargs)
129
130 # Add title
131 brain_inf.add_text(0.1, 0.9, 'Morphed to fsaverage (inflated)', 'title',
132 font_size=16)
133
134 # %%
135 # Reading and writing SourceMorph from and to disk
136 # ------------------------------------------------
137 #
138 # An instance of SourceMorph can be saved, by calling
139 # :meth:`morph.save <mne.SourceMorph.save>`.
140 #
141 # This method allows for specification of a filename under which the ``morph``
142 # will be save in ".h5" format. If no file extension is provided, "-morph.h5"
143 # will be appended to the respective defined filename::
144 #
145 # >>> morph.save('my-file-name')
146 #
147 # Reading a saved source morph can be achieved by using
148 # :func:`mne.read_source_morph`::
149 #
150 # >>> morph = mne.read_source_morph('my-file-name-morph.h5')
151 #
152 # Once the environment is set up correctly, no information such as
153 # ``subject_from`` or ``subjects_dir`` must be provided, since it can be
154 # inferred from the data and use morph to 'fsaverage' by default. SourceMorph
155 # can further be used without creating an instance and assigning it to a
156 # variable. Instead :func:`mne.compute_source_morph` and
157 # :meth:`mne.SourceMorph.apply` can be
158 # easily chained into a handy one-liner. Taking this together the shortest
159 # possible way to morph data directly would be:
160
161 stc_fsaverage = mne.compute_source_morph(stc,
162 subjects_dir=subjects_dir).apply(stc)
163
164 # %%
165 # For more examples, check out :ref:`examples using SourceMorph.apply
166 # <sphx_glr_backreferences_mne.SourceMorph.apply>`.
167 #
168 #
169 # References
170 # ----------
171 # .. footbibliography::
172
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/inverse/morph_surface_stc.py b/examples/inverse/morph_surface_stc.py
--- a/examples/inverse/morph_surface_stc.py
+++ b/examples/inverse/morph_surface_stc.py
@@ -29,9 +29,6 @@
# License: BSD-3-Clause
# %%
-import os
-import os.path as op
-
import mne
from mne.datasets import sample
@@ -41,14 +38,13 @@
# Setup paths
data_path = sample.data_path()
-sample_dir = op.join(data_path, 'MEG', 'sample')
-subjects_dir = op.join(data_path, 'subjects')
-fname_src = op.join(subjects_dir, 'sample', 'bem', 'sample-oct-6-src.fif')
-fname_fwd = op.join(sample_dir, 'sample_audvis-meg-oct-6-fwd.fif')
-fname_fsaverage_src = os.path.join(subjects_dir, 'fsaverage', 'bem',
- 'fsaverage-ico-5-src.fif')
-
-fname_stc = os.path.join(sample_dir, 'sample_audvis-meg')
+sample_dir = data_path / 'MEG' / 'sample'
+subjects_dir = data_path / 'subjects'
+fname_src = subjects_dir / 'sample' / 'bem' / 'sample-oct-6-src.fif'
+fname_fwd = sample_dir / 'sample_audvis-meg-oct-6-fwd.fif'
+fname_fsaverage_src = (subjects_dir / 'fsaverage' / 'bem' /
+ 'fsaverage-ico-5-src.fif')
+fname_stc = sample_dir / 'sample_audvis-meg'
# %%
# Load example data
| {"golden_diff": "diff --git a/examples/inverse/morph_surface_stc.py b/examples/inverse/morph_surface_stc.py\n--- a/examples/inverse/morph_surface_stc.py\n+++ b/examples/inverse/morph_surface_stc.py\n@@ -29,9 +29,6 @@\n # License: BSD-3-Clause\n \n # %%\n-import os\n-import os.path as op\n-\n import mne\n from mne.datasets import sample\n \n@@ -41,14 +38,13 @@\n # Setup paths\n \n data_path = sample.data_path()\n-sample_dir = op.join(data_path, 'MEG', 'sample')\n-subjects_dir = op.join(data_path, 'subjects')\n-fname_src = op.join(subjects_dir, 'sample', 'bem', 'sample-oct-6-src.fif')\n-fname_fwd = op.join(sample_dir, 'sample_audvis-meg-oct-6-fwd.fif')\n-fname_fsaverage_src = os.path.join(subjects_dir, 'fsaverage', 'bem',\n- 'fsaverage-ico-5-src.fif')\n-\n-fname_stc = os.path.join(sample_dir, 'sample_audvis-meg')\n+sample_dir = data_path / 'MEG' / 'sample'\n+subjects_dir = data_path / 'subjects'\n+fname_src = subjects_dir / 'sample' / 'bem' / 'sample-oct-6-src.fif'\n+fname_fwd = sample_dir / 'sample_audvis-meg-oct-6-fwd.fif'\n+fname_fsaverage_src = (subjects_dir / 'fsaverage' / 'bem' /\n+ 'fsaverage-ico-5-src.fif')\n+fname_stc = sample_dir / 'sample_audvis-meg'\n \n # %%\n # Load example data\n", "issue": "update path handling in examples/inverse/morph_surface_stc.py\nall of our `data_path` functions now return `pathlib.Path` objects, which allows things like the following:\r\n\r\nhttps://github.com/mne-tools/mne-python/blob/37a9e5587443109515a85cdc4396af4e014ecf82/examples/datasets/brainstorm_data.py#L32-L35\r\n\r\nCompare this to the old pattern (using `os.path.join`, often imported as `op.join`):\r\n\r\n```py\r\nraw_path = os.path.join(data_path, 'MEG', 'bst_raw',\r\n 'subj001_somatosensory_20111109_01_AUX-f.ds')\r\n```\r\n\r\nor the *really* old pattern (using the `+` operator on plain strings):\r\n\r\n```py\r\nraw_path = (data_path + '/MEG/bst_raw/' +\r\n 'subj001_somatosensory_20111109_01_AUX-f.ds')\r\n```\r\n\r\nUpdate the paths in the file mentioned in the issue title to use the new pathlib-style, which is considered the modern, best-practice way to handle file paths.\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n.. _ex-morph-surface:\n\n=============================\nMorph surface source estimate\n=============================\n\nThis example demonstrates how to morph an individual subject's\n:class:`mne.SourceEstimate` to a common reference space. We achieve this using\n:class:`mne.SourceMorph`. Pre-computed data will be morphed based on\na spherical representation of the cortex computed using the spherical\nregistration of :ref:`FreeSurfer <tut-freesurfer-mne>`\n(https://surfer.nmr.mgh.harvard.edu/fswiki/SurfaceRegAndTemplates)\n:footcite:`GreveEtAl2013`. This\ntransform will be used to morph the surface vertices of the subject towards the\nreference vertices. Here we will use 'fsaverage' as a reference space (see\nhttps://surfer.nmr.mgh.harvard.edu/fswiki/FsAverage).\n\nThe transformation will be applied to the surface source estimate. A plot\ndepicting the successful morph will be created for the spherical and inflated\nsurface representation of ``'fsaverage'``, overlaid with the morphed surface\nsource estimate.\n\n.. note:: For background information about morphing see :ref:`ch_morph`.\n\"\"\"\n# Author: Tommy Clausner <[email protected]>\n#\n# License: BSD-3-Clause\n\n# %%\nimport os\nimport os.path as op\n\nimport mne\nfrom mne.datasets import sample\n\nprint(__doc__)\n\n# %%\n# Setup paths\n\ndata_path = sample.data_path()\nsample_dir = op.join(data_path, 'MEG', 'sample')\nsubjects_dir = op.join(data_path, 'subjects')\nfname_src = op.join(subjects_dir, 'sample', 'bem', 'sample-oct-6-src.fif')\nfname_fwd = op.join(sample_dir, 'sample_audvis-meg-oct-6-fwd.fif')\nfname_fsaverage_src = os.path.join(subjects_dir, 'fsaverage', 'bem',\n 'fsaverage-ico-5-src.fif')\n\nfname_stc = os.path.join(sample_dir, 'sample_audvis-meg')\n\n# %%\n# Load example data\n\n# Read stc from file\nstc = mne.read_source_estimate(fname_stc, subject='sample')\n\n# %%\n# Setting up SourceMorph for SourceEstimate\n# -----------------------------------------\n#\n# In MNE, surface source estimates represent the source space simply as\n# lists of vertices (see :ref:`tut-source-estimate-class`).\n# This list can either be obtained from :class:`mne.SourceSpaces` (src) or from\n# the ``stc`` itself. If you use the source space, be sure to use the\n# source space from the forward or inverse operator, because vertices\n# can be excluded during forward computation due to proximity to the BEM\n# inner skull surface:\n\nsrc_orig = mne.read_source_spaces(fname_src)\nprint(src_orig) # n_used=4098, 4098\nfwd = mne.read_forward_solution(fname_fwd)\nprint(fwd['src']) # n_used=3732, 3766\nprint([len(v) for v in stc.vertices])\n\n# %%\n# We also need to specify the set of vertices to morph to. This can be done\n# using the ``spacing`` parameter, but for consistency it's better to pass the\n# ``src_to`` parameter.\n#\n# .. note::\n# Since the default values of :func:`mne.compute_source_morph` are\n# ``spacing=5, subject_to='fsaverage'``, in this example\n# we could actually omit the ``src_to`` and ``subject_to`` arguments\n# below. The ico-5 ``fsaverage`` source space contains the\n# special values ``[np.arange(10242)] * 2``, but in general this will\n# not be true for other spacings or other subjects. Thus it is recommended\n# to always pass the destination ``src`` for consistency.\n#\n# Initialize SourceMorph for SourceEstimate\n\nsrc_to = mne.read_source_spaces(fname_fsaverage_src)\nprint(src_to[0]['vertno']) # special, np.arange(10242)\nmorph = mne.compute_source_morph(stc, subject_from='sample',\n subject_to='fsaverage', src_to=src_to,\n subjects_dir=subjects_dir)\n\n# %%\n# Apply morph to (Vector) SourceEstimate\n# --------------------------------------\n#\n# The morph will be applied to the source estimate data, by giving it as the\n# first argument to the morph we computed above.\n\nstc_fsaverage = morph.apply(stc)\n\n# %%\n# Plot results\n# ------------\n\n# Define plotting parameters\nsurfer_kwargs = dict(\n hemi='lh', subjects_dir=subjects_dir,\n clim=dict(kind='value', lims=[8, 12, 15]), views='lateral',\n initial_time=0.09, time_unit='s', size=(800, 800),\n smoothing_steps=5)\n\n# As spherical surface\nbrain = stc_fsaverage.plot(surface='sphere', **surfer_kwargs)\n\n# Add title\nbrain.add_text(0.1, 0.9, 'Morphed to fsaverage (spherical)', 'title',\n font_size=16)\n\n# %%\n# As inflated surface\nbrain_inf = stc_fsaverage.plot(surface='inflated', **surfer_kwargs)\n\n# Add title\nbrain_inf.add_text(0.1, 0.9, 'Morphed to fsaverage (inflated)', 'title',\n font_size=16)\n\n# %%\n# Reading and writing SourceMorph from and to disk\n# ------------------------------------------------\n#\n# An instance of SourceMorph can be saved, by calling\n# :meth:`morph.save <mne.SourceMorph.save>`.\n#\n# This method allows for specification of a filename under which the ``morph``\n# will be save in \".h5\" format. If no file extension is provided, \"-morph.h5\"\n# will be appended to the respective defined filename::\n#\n# >>> morph.save('my-file-name')\n#\n# Reading a saved source morph can be achieved by using\n# :func:`mne.read_source_morph`::\n#\n# >>> morph = mne.read_source_morph('my-file-name-morph.h5')\n#\n# Once the environment is set up correctly, no information such as\n# ``subject_from`` or ``subjects_dir`` must be provided, since it can be\n# inferred from the data and use morph to 'fsaverage' by default. SourceMorph\n# can further be used without creating an instance and assigning it to a\n# variable. Instead :func:`mne.compute_source_morph` and\n# :meth:`mne.SourceMorph.apply` can be\n# easily chained into a handy one-liner. Taking this together the shortest\n# possible way to morph data directly would be:\n\nstc_fsaverage = mne.compute_source_morph(stc,\n subjects_dir=subjects_dir).apply(stc)\n\n# %%\n# For more examples, check out :ref:`examples using SourceMorph.apply\n# <sphx_glr_backreferences_mne.SourceMorph.apply>`.\n#\n#\n# References\n# ----------\n# .. footbibliography::\n", "path": "examples/inverse/morph_surface_stc.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n.. _ex-morph-surface:\n\n=============================\nMorph surface source estimate\n=============================\n\nThis example demonstrates how to morph an individual subject's\n:class:`mne.SourceEstimate` to a common reference space. We achieve this using\n:class:`mne.SourceMorph`. Pre-computed data will be morphed based on\na spherical representation of the cortex computed using the spherical\nregistration of :ref:`FreeSurfer <tut-freesurfer-mne>`\n(https://surfer.nmr.mgh.harvard.edu/fswiki/SurfaceRegAndTemplates)\n:footcite:`GreveEtAl2013`. This\ntransform will be used to morph the surface vertices of the subject towards the\nreference vertices. Here we will use 'fsaverage' as a reference space (see\nhttps://surfer.nmr.mgh.harvard.edu/fswiki/FsAverage).\n\nThe transformation will be applied to the surface source estimate. A plot\ndepicting the successful morph will be created for the spherical and inflated\nsurface representation of ``'fsaverage'``, overlaid with the morphed surface\nsource estimate.\n\n.. note:: For background information about morphing see :ref:`ch_morph`.\n\"\"\"\n# Author: Tommy Clausner <[email protected]>\n#\n# License: BSD-3-Clause\n\n# %%\nimport mne\nfrom mne.datasets import sample\n\nprint(__doc__)\n\n# %%\n# Setup paths\n\ndata_path = sample.data_path()\nsample_dir = data_path / 'MEG' / 'sample'\nsubjects_dir = data_path / 'subjects'\nfname_src = subjects_dir / 'sample' / 'bem' / 'sample-oct-6-src.fif'\nfname_fwd = sample_dir / 'sample_audvis-meg-oct-6-fwd.fif'\nfname_fsaverage_src = (subjects_dir / 'fsaverage' / 'bem' /\n 'fsaverage-ico-5-src.fif')\nfname_stc = sample_dir / 'sample_audvis-meg'\n\n# %%\n# Load example data\n\n# Read stc from file\nstc = mne.read_source_estimate(fname_stc, subject='sample')\n\n# %%\n# Setting up SourceMorph for SourceEstimate\n# -----------------------------------------\n#\n# In MNE, surface source estimates represent the source space simply as\n# lists of vertices (see :ref:`tut-source-estimate-class`).\n# This list can either be obtained from :class:`mne.SourceSpaces` (src) or from\n# the ``stc`` itself. If you use the source space, be sure to use the\n# source space from the forward or inverse operator, because vertices\n# can be excluded during forward computation due to proximity to the BEM\n# inner skull surface:\n\nsrc_orig = mne.read_source_spaces(fname_src)\nprint(src_orig) # n_used=4098, 4098\nfwd = mne.read_forward_solution(fname_fwd)\nprint(fwd['src']) # n_used=3732, 3766\nprint([len(v) for v in stc.vertices])\n\n# %%\n# We also need to specify the set of vertices to morph to. This can be done\n# using the ``spacing`` parameter, but for consistency it's better to pass the\n# ``src_to`` parameter.\n#\n# .. note::\n# Since the default values of :func:`mne.compute_source_morph` are\n# ``spacing=5, subject_to='fsaverage'``, in this example\n# we could actually omit the ``src_to`` and ``subject_to`` arguments\n# below. The ico-5 ``fsaverage`` source space contains the\n# special values ``[np.arange(10242)] * 2``, but in general this will\n# not be true for other spacings or other subjects. Thus it is recommended\n# to always pass the destination ``src`` for consistency.\n#\n# Initialize SourceMorph for SourceEstimate\n\nsrc_to = mne.read_source_spaces(fname_fsaverage_src)\nprint(src_to[0]['vertno']) # special, np.arange(10242)\nmorph = mne.compute_source_morph(stc, subject_from='sample',\n subject_to='fsaverage', src_to=src_to,\n subjects_dir=subjects_dir)\n\n# %%\n# Apply morph to (Vector) SourceEstimate\n# --------------------------------------\n#\n# The morph will be applied to the source estimate data, by giving it as the\n# first argument to the morph we computed above.\n\nstc_fsaverage = morph.apply(stc)\n\n# %%\n# Plot results\n# ------------\n\n# Define plotting parameters\nsurfer_kwargs = dict(\n hemi='lh', subjects_dir=subjects_dir,\n clim=dict(kind='value', lims=[8, 12, 15]), views='lateral',\n initial_time=0.09, time_unit='s', size=(800, 800),\n smoothing_steps=5)\n\n# As spherical surface\nbrain = stc_fsaverage.plot(surface='sphere', **surfer_kwargs)\n\n# Add title\nbrain.add_text(0.1, 0.9, 'Morphed to fsaverage (spherical)', 'title',\n font_size=16)\n\n# %%\n# As inflated surface\nbrain_inf = stc_fsaverage.plot(surface='inflated', **surfer_kwargs)\n\n# Add title\nbrain_inf.add_text(0.1, 0.9, 'Morphed to fsaverage (inflated)', 'title',\n font_size=16)\n\n# %%\n# Reading and writing SourceMorph from and to disk\n# ------------------------------------------------\n#\n# An instance of SourceMorph can be saved, by calling\n# :meth:`morph.save <mne.SourceMorph.save>`.\n#\n# This method allows for specification of a filename under which the ``morph``\n# will be save in \".h5\" format. If no file extension is provided, \"-morph.h5\"\n# will be appended to the respective defined filename::\n#\n# >>> morph.save('my-file-name')\n#\n# Reading a saved source morph can be achieved by using\n# :func:`mne.read_source_morph`::\n#\n# >>> morph = mne.read_source_morph('my-file-name-morph.h5')\n#\n# Once the environment is set up correctly, no information such as\n# ``subject_from`` or ``subjects_dir`` must be provided, since it can be\n# inferred from the data and use morph to 'fsaverage' by default. SourceMorph\n# can further be used without creating an instance and assigning it to a\n# variable. Instead :func:`mne.compute_source_morph` and\n# :meth:`mne.SourceMorph.apply` can be\n# easily chained into a handy one-liner. Taking this together the shortest\n# possible way to morph data directly would be:\n\nstc_fsaverage = mne.compute_source_morph(stc,\n subjects_dir=subjects_dir).apply(stc)\n\n# %%\n# For more examples, check out :ref:`examples using SourceMorph.apply\n# <sphx_glr_backreferences_mne.SourceMorph.apply>`.\n#\n#\n# References\n# ----------\n# .. footbibliography::\n", "path": "examples/inverse/morph_surface_stc.py"}]} | 2,531 | 381 |
gh_patches_debug_34233 | rasdani/github-patches | git_diff | bokeh__bokeh-10360 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
webdriver failing to find installed firefox/geckodriver
Can't get export examples running on binder even though everything is installed and on the path:
<img width="1130" alt="Screen Shot 2020-06-02 at 8 23 16 PM" src="https://user-images.githubusercontent.com/1078448/83592297-e9459c80-a50e-11ea-90d1-7189fcc93af0.png">
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `bokeh/io/webdriver.py`
Content:
```
1 #-----------------------------------------------------------------------------
2 # Copyright (c) 2012 - 2020, Anaconda, Inc., and Bokeh Contributors.
3 # All rights reserved.
4 #
5 # The full license is in the file LICENSE.txt, distributed with this software.
6 #-----------------------------------------------------------------------------
7 '''
8
9 '''
10
11 #-----------------------------------------------------------------------------
12 # Boilerplate
13 #-----------------------------------------------------------------------------
14 import logging # isort:skip
15 log = logging.getLogger(__name__)
16
17 #-----------------------------------------------------------------------------
18 # Imports
19 #-----------------------------------------------------------------------------
20
21 from ..util.dependencies import import_required # isort:skip
22 import_required("selenium.webdriver",
23 "To use bokeh.io image export functions you need selenium "
24 "('conda install selenium' or 'pip install selenium')")
25
26 # Standard library imports
27 import atexit
28 import shutil
29 from os.path import devnull
30 from typing import List, Optional
31
32 # External imports
33 from selenium import webdriver
34 from selenium.webdriver.remote.webdriver import WebDriver
35 from typing_extensions import Literal
36
37 #-----------------------------------------------------------------------------
38 # Globals and constants
39 #-----------------------------------------------------------------------------
40
41 DriverKind = Literal["firefox", "chromium"]
42
43 __all__ = (
44 'webdriver_control',
45 )
46
47 #-----------------------------------------------------------------------------
48 # General API
49 #-----------------------------------------------------------------------------
50
51 #-----------------------------------------------------------------------------
52 # Dev API
53 #-----------------------------------------------------------------------------
54
55 def create_firefox_webdriver() -> WebDriver:
56 from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
57 binary = FirefoxBinary(_detect("firefox"))
58 options = webdriver.firefox.options.Options()
59 options.add_argument("--headless")
60 return webdriver.Firefox(firefox_binary=binary, options=options, service_log_path=devnull)
61
62 def create_chromium_webdriver() -> WebDriver:
63 options = webdriver.chrome.options.Options()
64 options.add_argument("--headless")
65 options.add_argument("--hide-scrollbars")
66 options.add_argument("--force-device-scale-factor=1")
67 options.add_argument("--force-color-profile=srgb")
68 return webdriver.Chrome(options=options)
69
70 #-----------------------------------------------------------------------------
71 # Private API
72 #-----------------------------------------------------------------------------
73
74 def _detect(executable: str) -> Optional[str]:
75 return shutil.which(executable)
76
77 def _try_create_firefox_webdriver() -> Optional[WebDriver]:
78 try:
79 return create_firefox_webdriver()
80 except Exception:
81 return None
82
83 def _try_create_chromium_webdriver() -> Optional[WebDriver]:
84 try:
85 return create_chromium_webdriver()
86 except Exception:
87 return None
88
89 class _WebdriverState:
90 '''
91
92 '''
93
94 reuse: bool
95 kind: Optional[DriverKind]
96
97 current: Optional[WebDriver]
98 _drivers: List[WebDriver]
99
100 def __init__(self, *, kind: Optional[DriverKind] = None, reuse: bool = True):
101 self.kind = kind
102 self.reuse = reuse
103 self.current = None
104 self._drivers = set()
105
106 def terminate(self, driver: WebDriver) -> None:
107 self._drivers.remove(driver)
108 driver.quit()
109
110 def reset(self) -> None:
111 if self.current is not None:
112 self.terminate(self.current)
113 self.current = None
114
115 def get(self) -> WebDriver:
116 if not self.reuse or self.current is None:
117 self.reset()
118 self.current = self.create()
119 return self.current
120
121 def create(self, kind: Optional[DriverKind] = None) -> WebDriver:
122 driver = self._create(kind)
123 self._drivers.add(driver)
124 return driver
125
126 def _create(self, kind: Optional[DriverKind]) -> WebDriver:
127 driver_kind = kind or self.kind
128
129 if driver_kind is None:
130 driver = _try_create_chromium_webdriver()
131 if driver is not None:
132 self.kind = "chromium"
133 return driver
134
135 driver = _try_create_firefox_webdriver()
136 if driver is not None:
137 self.kind = "firefox"
138 return driver
139
140 raise RuntimeError("Neither firefox and geckodriver nor a variant of chromium browser and " \
141 "chromedriver are available on system PATH. You can install the former " \
142 "with 'conda install -c conda-forge firefox geckodriver'.")
143 elif driver_kind == "chromium":
144 return create_chromium_webdriver()
145 elif driver_kind == "firefox":
146 return create_firefox_webdriver()
147 else:
148 raise ValueError(f"'{driver_kind}' is not a recognized webdriver kind")
149
150 def cleanup(self) -> None:
151 self.reset()
152 for driver in list(self._drivers):
153 self.terminate(driver)
154
155 #-----------------------------------------------------------------------------
156 # Code
157 #-----------------------------------------------------------------------------
158
159 webdriver_control = _WebdriverState()
160
161 atexit.register(lambda: webdriver_control.cleanup())
162
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/bokeh/io/webdriver.py b/bokeh/io/webdriver.py
--- a/bokeh/io/webdriver.py
+++ b/bokeh/io/webdriver.py
@@ -25,8 +25,9 @@
# Standard library imports
import atexit
-import shutil
-from os.path import devnull
+import os
+from os.path import devnull, dirname, isfile, join
+from shutil import which
from typing import List, Optional
# External imports
@@ -53,11 +54,38 @@
#-----------------------------------------------------------------------------
def create_firefox_webdriver() -> WebDriver:
+ firefox = which("firefox")
+ if firefox is None:
+ raise RuntimeError("firefox is not installed or not present on PATH")
+
+ geckodriver = which("geckodriver")
+ if geckodriver is None:
+ raise RuntimeError("geckodriver is not installed or not present on PATH")
+
+ firefox_paths = [
+ join(dirname(firefox), "FirefoxApp", "firefox"),
+ join(dirname(firefox), "FirefoxApp", "Contents", "MacOS", "firefox"),
+ ]
+
+ for firefox_path in firefox_paths:
+ if _is_executable(firefox_path):
+ binary_path = firefox_path
+ break
+ else:
+ binary_path = firefox
+
from selenium.webdriver.firefox.firefox_binary import FirefoxBinary
- binary = FirefoxBinary(_detect("firefox"))
+ binary = FirefoxBinary(binary_path)
+
options = webdriver.firefox.options.Options()
options.add_argument("--headless")
- return webdriver.Firefox(firefox_binary=binary, options=options, service_log_path=devnull)
+
+ return webdriver.Firefox(
+ options=options,
+ firefox_binary=binary,
+ executable_path=geckodriver,
+ service_log_path=devnull,
+ )
def create_chromium_webdriver() -> WebDriver:
options = webdriver.chrome.options.Options()
@@ -71,8 +99,8 @@
# Private API
#-----------------------------------------------------------------------------
-def _detect(executable: str) -> Optional[str]:
- return shutil.which(executable)
+def _is_executable(path: str) -> bool:
+ return isfile(path) and os.access(path, os.X_OK)
def _try_create_firefox_webdriver() -> Optional[WebDriver]:
try:
| {"golden_diff": "diff --git a/bokeh/io/webdriver.py b/bokeh/io/webdriver.py\n--- a/bokeh/io/webdriver.py\n+++ b/bokeh/io/webdriver.py\n@@ -25,8 +25,9 @@\n \n # Standard library imports\n import atexit\n-import shutil\n-from os.path import devnull\n+import os\n+from os.path import devnull, dirname, isfile, join\n+from shutil import which\n from typing import List, Optional\n \n # External imports\n@@ -53,11 +54,38 @@\n #-----------------------------------------------------------------------------\n \n def create_firefox_webdriver() -> WebDriver:\n+ firefox = which(\"firefox\")\n+ if firefox is None:\n+ raise RuntimeError(\"firefox is not installed or not present on PATH\")\n+\n+ geckodriver = which(\"geckodriver\")\n+ if geckodriver is None:\n+ raise RuntimeError(\"geckodriver is not installed or not present on PATH\")\n+\n+ firefox_paths = [\n+ join(dirname(firefox), \"FirefoxApp\", \"firefox\"),\n+ join(dirname(firefox), \"FirefoxApp\", \"Contents\", \"MacOS\", \"firefox\"),\n+ ]\n+\n+ for firefox_path in firefox_paths:\n+ if _is_executable(firefox_path):\n+ binary_path = firefox_path\n+ break\n+ else:\n+ binary_path = firefox\n+\n from selenium.webdriver.firefox.firefox_binary import FirefoxBinary\n- binary = FirefoxBinary(_detect(\"firefox\"))\n+ binary = FirefoxBinary(binary_path)\n+\n options = webdriver.firefox.options.Options()\n options.add_argument(\"--headless\")\n- return webdriver.Firefox(firefox_binary=binary, options=options, service_log_path=devnull)\n+\n+ return webdriver.Firefox(\n+ options=options,\n+ firefox_binary=binary,\n+ executable_path=geckodriver,\n+ service_log_path=devnull,\n+ )\n \n def create_chromium_webdriver() -> WebDriver:\n options = webdriver.chrome.options.Options()\n@@ -71,8 +99,8 @@\n # Private API\n #-----------------------------------------------------------------------------\n \n-def _detect(executable: str) -> Optional[str]:\n- return shutil.which(executable)\n+def _is_executable(path: str) -> bool:\n+ return isfile(path) and os.access(path, os.X_OK)\n \n def _try_create_firefox_webdriver() -> Optional[WebDriver]:\n try:\n", "issue": "webdriver failing to find installed firefox/geckodriver\nCan't get export examples running on binder even though everything is installed and on the path:\r\n\r\n<img width=\"1130\" alt=\"Screen Shot 2020-06-02 at 8 23 16 PM\" src=\"https://user-images.githubusercontent.com/1078448/83592297-e9459c80-a50e-11ea-90d1-7189fcc93af0.png\">\r\n\r\n\n", "before_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2020, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n'''\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nimport logging # isort:skip\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\nfrom ..util.dependencies import import_required # isort:skip\nimport_required(\"selenium.webdriver\",\n \"To use bokeh.io image export functions you need selenium \"\n \"('conda install selenium' or 'pip install selenium')\")\n\n# Standard library imports\nimport atexit\nimport shutil\nfrom os.path import devnull\nfrom typing import List, Optional\n\n# External imports\nfrom selenium import webdriver\nfrom selenium.webdriver.remote.webdriver import WebDriver\nfrom typing_extensions import Literal\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\nDriverKind = Literal[\"firefox\", \"chromium\"]\n\n__all__ = (\n 'webdriver_control',\n)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\ndef create_firefox_webdriver() -> WebDriver:\n from selenium.webdriver.firefox.firefox_binary import FirefoxBinary\n binary = FirefoxBinary(_detect(\"firefox\"))\n options = webdriver.firefox.options.Options()\n options.add_argument(\"--headless\")\n return webdriver.Firefox(firefox_binary=binary, options=options, service_log_path=devnull)\n\ndef create_chromium_webdriver() -> WebDriver:\n options = webdriver.chrome.options.Options()\n options.add_argument(\"--headless\")\n options.add_argument(\"--hide-scrollbars\")\n options.add_argument(\"--force-device-scale-factor=1\")\n options.add_argument(\"--force-color-profile=srgb\")\n return webdriver.Chrome(options=options)\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\ndef _detect(executable: str) -> Optional[str]:\n return shutil.which(executable)\n\ndef _try_create_firefox_webdriver() -> Optional[WebDriver]:\n try:\n return create_firefox_webdriver()\n except Exception:\n return None\n\ndef _try_create_chromium_webdriver() -> Optional[WebDriver]:\n try:\n return create_chromium_webdriver()\n except Exception:\n return None\n\nclass _WebdriverState:\n '''\n\n '''\n\n reuse: bool\n kind: Optional[DriverKind]\n\n current: Optional[WebDriver]\n _drivers: List[WebDriver]\n\n def __init__(self, *, kind: Optional[DriverKind] = None, reuse: bool = True):\n self.kind = kind\n self.reuse = reuse\n self.current = None\n self._drivers = set()\n\n def terminate(self, driver: WebDriver) -> None:\n self._drivers.remove(driver)\n driver.quit()\n\n def reset(self) -> None:\n if self.current is not None:\n self.terminate(self.current)\n self.current = None\n\n def get(self) -> WebDriver:\n if not self.reuse or self.current is None:\n self.reset()\n self.current = self.create()\n return self.current\n\n def create(self, kind: Optional[DriverKind] = None) -> WebDriver:\n driver = self._create(kind)\n self._drivers.add(driver)\n return driver\n\n def _create(self, kind: Optional[DriverKind]) -> WebDriver:\n driver_kind = kind or self.kind\n\n if driver_kind is None:\n driver = _try_create_chromium_webdriver()\n if driver is not None:\n self.kind = \"chromium\"\n return driver\n\n driver = _try_create_firefox_webdriver()\n if driver is not None:\n self.kind = \"firefox\"\n return driver\n\n raise RuntimeError(\"Neither firefox and geckodriver nor a variant of chromium browser and \" \\\n \"chromedriver are available on system PATH. You can install the former \" \\\n \"with 'conda install -c conda-forge firefox geckodriver'.\")\n elif driver_kind == \"chromium\":\n return create_chromium_webdriver()\n elif driver_kind == \"firefox\":\n return create_firefox_webdriver()\n else:\n raise ValueError(f\"'{driver_kind}' is not a recognized webdriver kind\")\n\n def cleanup(self) -> None:\n self.reset()\n for driver in list(self._drivers):\n self.terminate(driver)\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\nwebdriver_control = _WebdriverState()\n\natexit.register(lambda: webdriver_control.cleanup())\n", "path": "bokeh/io/webdriver.py"}], "after_files": [{"content": "#-----------------------------------------------------------------------------\n# Copyright (c) 2012 - 2020, Anaconda, Inc., and Bokeh Contributors.\n# All rights reserved.\n#\n# The full license is in the file LICENSE.txt, distributed with this software.\n#-----------------------------------------------------------------------------\n'''\n\n'''\n\n#-----------------------------------------------------------------------------\n# Boilerplate\n#-----------------------------------------------------------------------------\nimport logging # isort:skip\nlog = logging.getLogger(__name__)\n\n#-----------------------------------------------------------------------------\n# Imports\n#-----------------------------------------------------------------------------\n\nfrom ..util.dependencies import import_required # isort:skip\nimport_required(\"selenium.webdriver\",\n \"To use bokeh.io image export functions you need selenium \"\n \"('conda install selenium' or 'pip install selenium')\")\n\n# Standard library imports\nimport atexit\nimport os\nfrom os.path import devnull, dirname, isfile, join\nfrom shutil import which\nfrom typing import List, Optional\n\n# External imports\nfrom selenium import webdriver\nfrom selenium.webdriver.remote.webdriver import WebDriver\nfrom typing_extensions import Literal\n\n#-----------------------------------------------------------------------------\n# Globals and constants\n#-----------------------------------------------------------------------------\n\nDriverKind = Literal[\"firefox\", \"chromium\"]\n\n__all__ = (\n 'webdriver_control',\n)\n\n#-----------------------------------------------------------------------------\n# General API\n#-----------------------------------------------------------------------------\n\n#-----------------------------------------------------------------------------\n# Dev API\n#-----------------------------------------------------------------------------\n\ndef create_firefox_webdriver() -> WebDriver:\n firefox = which(\"firefox\")\n if firefox is None:\n raise RuntimeError(\"firefox is not installed or not present on PATH\")\n\n geckodriver = which(\"geckodriver\")\n if geckodriver is None:\n raise RuntimeError(\"geckodriver is not installed or not present on PATH\")\n\n firefox_paths = [\n join(dirname(firefox), \"FirefoxApp\", \"firefox\"),\n join(dirname(firefox), \"FirefoxApp\", \"Contents\", \"MacOS\", \"firefox\"),\n ]\n\n for firefox_path in firefox_paths:\n if _is_executable(firefox_path):\n binary_path = firefox_path\n break\n else:\n binary_path = firefox\n\n from selenium.webdriver.firefox.firefox_binary import FirefoxBinary\n binary = FirefoxBinary(binary_path)\n\n options = webdriver.firefox.options.Options()\n options.add_argument(\"--headless\")\n\n return webdriver.Firefox(\n options=options,\n firefox_binary=binary,\n executable_path=geckodriver,\n service_log_path=devnull,\n )\n\ndef create_chromium_webdriver() -> WebDriver:\n options = webdriver.chrome.options.Options()\n options.add_argument(\"--headless\")\n options.add_argument(\"--hide-scrollbars\")\n options.add_argument(\"--force-device-scale-factor=1\")\n options.add_argument(\"--force-color-profile=srgb\")\n return webdriver.Chrome(options=options)\n\n#-----------------------------------------------------------------------------\n# Private API\n#-----------------------------------------------------------------------------\n\ndef _is_executable(path: str) -> bool:\n return isfile(path) and os.access(path, os.X_OK)\n\ndef _try_create_firefox_webdriver() -> Optional[WebDriver]:\n try:\n return create_firefox_webdriver()\n except Exception:\n return None\n\ndef _try_create_chromium_webdriver() -> Optional[WebDriver]:\n try:\n return create_chromium_webdriver()\n except Exception:\n return None\n\nclass _WebdriverState:\n '''\n\n '''\n\n reuse: bool\n kind: Optional[DriverKind]\n\n current: Optional[WebDriver]\n _drivers: List[WebDriver]\n\n def __init__(self, *, kind: Optional[DriverKind] = None, reuse: bool = True):\n self.kind = kind\n self.reuse = reuse\n self.current = None\n self._drivers = set()\n\n def terminate(self, driver: WebDriver) -> None:\n self._drivers.remove(driver)\n driver.quit()\n\n def reset(self) -> None:\n if self.current is not None:\n self.terminate(self.current)\n self.current = None\n\n def get(self) -> WebDriver:\n if not self.reuse or self.current is None:\n self.reset()\n self.current = self.create()\n return self.current\n\n def create(self, kind: Optional[DriverKind] = None) -> WebDriver:\n driver = self._create(kind)\n self._drivers.add(driver)\n return driver\n\n def _create(self, kind: Optional[DriverKind]) -> WebDriver:\n driver_kind = kind or self.kind\n\n if driver_kind is None:\n driver = _try_create_chromium_webdriver()\n if driver is not None:\n self.kind = \"chromium\"\n return driver\n\n driver = _try_create_firefox_webdriver()\n if driver is not None:\n self.kind = \"firefox\"\n return driver\n\n raise RuntimeError(\"Neither firefox and geckodriver nor a variant of chromium browser and \" \\\n \"chromedriver are available on system PATH. You can install the former \" \\\n \"with 'conda install -c conda-forge firefox geckodriver'.\")\n elif driver_kind == \"chromium\":\n return create_chromium_webdriver()\n elif driver_kind == \"firefox\":\n return create_firefox_webdriver()\n else:\n raise ValueError(f\"'{driver_kind}' is not a recognized webdriver kind\")\n\n def cleanup(self) -> None:\n self.reset()\n for driver in list(self._drivers):\n self.terminate(driver)\n\n#-----------------------------------------------------------------------------\n# Code\n#-----------------------------------------------------------------------------\n\nwebdriver_control = _WebdriverState()\n\natexit.register(lambda: webdriver_control.cleanup())\n", "path": "bokeh/io/webdriver.py"}]} | 1,733 | 530 |
gh_patches_debug_38225 | rasdani/github-patches | git_diff | medtagger__MedTagger-506 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Check for sent Label in E2E Tests
## Current Behavior
There are no checks on Labels sent to REST API.
## Expected Behavior
E2E Tests should also check if Label on the backend side was properly created.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `backend/medtagger/config.py`
Content:
```
1 """Module responsible for reading data from application configuration."""
2 import os
3 from typing import Any
4
5
6 class AppConfiguration:
7 """Class that represents application configuration."""
8
9 def __init__(self) -> None:
10 """Initialize application configuration."""
11 pass
12
13 @staticmethod
14 def get(namespace: str, key: str, fallback: Any = None) -> Any:
15 """Return value of a given configuration entry.
16
17 :param namespace: name of a namespace for given entry
18 :param key: key for which it should return value from given namespace
19 :param fallback: default value returned if key was not found
20 :return: value for given entry
21 """
22 variable_name = 'MEDTAGGER__' + namespace.upper() + '_' + key.upper()
23 return os.environ.get(variable_name, fallback)
24
25 @staticmethod
26 def getint(namespace: str, key: str, fallback: int = 0) -> int:
27 """Return integer value for given key in namespace."""
28 return int(AppConfiguration.get(namespace, key, fallback))
29
30 @staticmethod
31 def getboolean(namespace: str, key: str, fallback: bool = False) -> bool:
32 """Return boolean value for given key in namespace."""
33 return bool(AppConfiguration.getint(namespace, key, fallback))
34
```
Path: `backend/medtagger/api/exceptions.py`
Content:
```
1 """Exceptions used across whole API."""
2 from medtagger.exceptions import MedTaggerException
3
4
5 class BaseHTTPException(MedTaggerException):
6 """Base class for all HTTP Exceptions."""
7
8 pass
9
10
11 class UnauthorizedException(BaseHTTPException):
12 """Exception designed to use once there was an authorization error during business logic processing."""
13
14 pass
15
16
17 class NotFoundException(BaseHTTPException):
18 """Exception designed to use while the object that user was looking for could not be found."""
19
20 pass
21
22
23 class InvalidArgumentsException(BaseHTTPException):
24 """Exception designed to use with invalid arguments (400 status code)."""
25
26 pass
27
28
29 class AccessForbiddenException(BaseHTTPException):
30 """Exception designed to use while the user does not have a privilege to perform action."""
31
32 pass
33
```
Path: `backend/medtagger/exceptions.py`
Content:
```
1 """All available Exceptions for whole project."""
2
3
4 class MedTaggerException(Exception):
5 """Base class for all HTTP Exceptions."""
6
7 pass
8
9
10 class UnsupportedActionException(MedTaggerException):
11 """Exception for unsupported Action."""
12
13 pass
14
15
16 class InvalidResponseException(MedTaggerException):
17 """Exception for invalid Response."""
18
19 pass
20
21
22 class InternalErrorException(MedTaggerException):
23 """Exception designed to use to indicate internal errors (like DB/Storage error)."""
24
25 pass
26
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/backend/medtagger/api/exceptions.py b/backend/medtagger/api/exceptions.py
--- a/backend/medtagger/api/exceptions.py
+++ b/backend/medtagger/api/exceptions.py
@@ -5,28 +5,28 @@
class BaseHTTPException(MedTaggerException):
"""Base class for all HTTP Exceptions."""
- pass
+ pass # pylint: disable=unnecessary-pass
class UnauthorizedException(BaseHTTPException):
"""Exception designed to use once there was an authorization error during business logic processing."""
- pass
+ pass # pylint: disable=unnecessary-pass
class NotFoundException(BaseHTTPException):
"""Exception designed to use while the object that user was looking for could not be found."""
- pass
+ pass # pylint: disable=unnecessary-pass
class InvalidArgumentsException(BaseHTTPException):
"""Exception designed to use with invalid arguments (400 status code)."""
- pass
+ pass # pylint: disable=unnecessary-pass
class AccessForbiddenException(BaseHTTPException):
"""Exception designed to use while the user does not have a privilege to perform action."""
- pass
+ pass # pylint: disable=unnecessary-pass
diff --git a/backend/medtagger/config.py b/backend/medtagger/config.py
--- a/backend/medtagger/config.py
+++ b/backend/medtagger/config.py
@@ -6,10 +6,6 @@
class AppConfiguration:
"""Class that represents application configuration."""
- def __init__(self) -> None:
- """Initialize application configuration."""
- pass
-
@staticmethod
def get(namespace: str, key: str, fallback: Any = None) -> Any:
"""Return value of a given configuration entry.
diff --git a/backend/medtagger/exceptions.py b/backend/medtagger/exceptions.py
--- a/backend/medtagger/exceptions.py
+++ b/backend/medtagger/exceptions.py
@@ -4,22 +4,22 @@
class MedTaggerException(Exception):
"""Base class for all HTTP Exceptions."""
- pass
+ pass # pylint: disable=unnecessary-pass
class UnsupportedActionException(MedTaggerException):
"""Exception for unsupported Action."""
- pass
+ pass # pylint: disable=unnecessary-pass
class InvalidResponseException(MedTaggerException):
"""Exception for invalid Response."""
- pass
+ pass # pylint: disable=unnecessary-pass
class InternalErrorException(MedTaggerException):
"""Exception designed to use to indicate internal errors (like DB/Storage error)."""
- pass
+ pass # pylint: disable=unnecessary-pass
| {"golden_diff": "diff --git a/backend/medtagger/api/exceptions.py b/backend/medtagger/api/exceptions.py\n--- a/backend/medtagger/api/exceptions.py\n+++ b/backend/medtagger/api/exceptions.py\n@@ -5,28 +5,28 @@\n class BaseHTTPException(MedTaggerException):\n \"\"\"Base class for all HTTP Exceptions.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class UnauthorizedException(BaseHTTPException):\n \"\"\"Exception designed to use once there was an authorization error during business logic processing.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class NotFoundException(BaseHTTPException):\n \"\"\"Exception designed to use while the object that user was looking for could not be found.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class InvalidArgumentsException(BaseHTTPException):\n \"\"\"Exception designed to use with invalid arguments (400 status code).\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class AccessForbiddenException(BaseHTTPException):\n \"\"\"Exception designed to use while the user does not have a privilege to perform action.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\ndiff --git a/backend/medtagger/config.py b/backend/medtagger/config.py\n--- a/backend/medtagger/config.py\n+++ b/backend/medtagger/config.py\n@@ -6,10 +6,6 @@\n class AppConfiguration:\n \"\"\"Class that represents application configuration.\"\"\"\n \n- def __init__(self) -> None:\n- \"\"\"Initialize application configuration.\"\"\"\n- pass\n-\n @staticmethod\n def get(namespace: str, key: str, fallback: Any = None) -> Any:\n \"\"\"Return value of a given configuration entry.\ndiff --git a/backend/medtagger/exceptions.py b/backend/medtagger/exceptions.py\n--- a/backend/medtagger/exceptions.py\n+++ b/backend/medtagger/exceptions.py\n@@ -4,22 +4,22 @@\n class MedTaggerException(Exception):\n \"\"\"Base class for all HTTP Exceptions.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class UnsupportedActionException(MedTaggerException):\n \"\"\"Exception for unsupported Action.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class InvalidResponseException(MedTaggerException):\n \"\"\"Exception for invalid Response.\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n \n \n class InternalErrorException(MedTaggerException):\n \"\"\"Exception designed to use to indicate internal errors (like DB/Storage error).\"\"\"\n \n- pass\n+ pass # pylint: disable=unnecessary-pass\n", "issue": "Check for sent Label in E2E Tests\n## Current Behavior\r\n\r\nThere are no checks on Labels sent to REST API.\r\n\r\n## Expected Behavior\r\n\r\nE2E Tests should also check if Label on the backend side was properly created.\n", "before_files": [{"content": "\"\"\"Module responsible for reading data from application configuration.\"\"\"\nimport os\nfrom typing import Any\n\n\nclass AppConfiguration:\n \"\"\"Class that represents application configuration.\"\"\"\n\n def __init__(self) -> None:\n \"\"\"Initialize application configuration.\"\"\"\n pass\n\n @staticmethod\n def get(namespace: str, key: str, fallback: Any = None) -> Any:\n \"\"\"Return value of a given configuration entry.\n\n :param namespace: name of a namespace for given entry\n :param key: key for which it should return value from given namespace\n :param fallback: default value returned if key was not found\n :return: value for given entry\n \"\"\"\n variable_name = 'MEDTAGGER__' + namespace.upper() + '_' + key.upper()\n return os.environ.get(variable_name, fallback)\n\n @staticmethod\n def getint(namespace: str, key: str, fallback: int = 0) -> int:\n \"\"\"Return integer value for given key in namespace.\"\"\"\n return int(AppConfiguration.get(namespace, key, fallback))\n\n @staticmethod\n def getboolean(namespace: str, key: str, fallback: bool = False) -> bool:\n \"\"\"Return boolean value for given key in namespace.\"\"\"\n return bool(AppConfiguration.getint(namespace, key, fallback))\n", "path": "backend/medtagger/config.py"}, {"content": "\"\"\"Exceptions used across whole API.\"\"\"\nfrom medtagger.exceptions import MedTaggerException\n\n\nclass BaseHTTPException(MedTaggerException):\n \"\"\"Base class for all HTTP Exceptions.\"\"\"\n\n pass\n\n\nclass UnauthorizedException(BaseHTTPException):\n \"\"\"Exception designed to use once there was an authorization error during business logic processing.\"\"\"\n\n pass\n\n\nclass NotFoundException(BaseHTTPException):\n \"\"\"Exception designed to use while the object that user was looking for could not be found.\"\"\"\n\n pass\n\n\nclass InvalidArgumentsException(BaseHTTPException):\n \"\"\"Exception designed to use with invalid arguments (400 status code).\"\"\"\n\n pass\n\n\nclass AccessForbiddenException(BaseHTTPException):\n \"\"\"Exception designed to use while the user does not have a privilege to perform action.\"\"\"\n\n pass\n", "path": "backend/medtagger/api/exceptions.py"}, {"content": "\"\"\"All available Exceptions for whole project.\"\"\"\n\n\nclass MedTaggerException(Exception):\n \"\"\"Base class for all HTTP Exceptions.\"\"\"\n\n pass\n\n\nclass UnsupportedActionException(MedTaggerException):\n \"\"\"Exception for unsupported Action.\"\"\"\n\n pass\n\n\nclass InvalidResponseException(MedTaggerException):\n \"\"\"Exception for invalid Response.\"\"\"\n\n pass\n\n\nclass InternalErrorException(MedTaggerException):\n \"\"\"Exception designed to use to indicate internal errors (like DB/Storage error).\"\"\"\n\n pass\n", "path": "backend/medtagger/exceptions.py"}], "after_files": [{"content": "\"\"\"Module responsible for reading data from application configuration.\"\"\"\nimport os\nfrom typing import Any\n\n\nclass AppConfiguration:\n \"\"\"Class that represents application configuration.\"\"\"\n\n @staticmethod\n def get(namespace: str, key: str, fallback: Any = None) -> Any:\n \"\"\"Return value of a given configuration entry.\n\n :param namespace: name of a namespace for given entry\n :param key: key for which it should return value from given namespace\n :param fallback: default value returned if key was not found\n :return: value for given entry\n \"\"\"\n variable_name = 'MEDTAGGER__' + namespace.upper() + '_' + key.upper()\n return os.environ.get(variable_name, fallback)\n\n @staticmethod\n def getint(namespace: str, key: str, fallback: int = 0) -> int:\n \"\"\"Return integer value for given key in namespace.\"\"\"\n return int(AppConfiguration.get(namespace, key, fallback))\n\n @staticmethod\n def getboolean(namespace: str, key: str, fallback: bool = False) -> bool:\n \"\"\"Return boolean value for given key in namespace.\"\"\"\n return bool(AppConfiguration.getint(namespace, key, fallback))\n", "path": "backend/medtagger/config.py"}, {"content": "\"\"\"Exceptions used across whole API.\"\"\"\nfrom medtagger.exceptions import MedTaggerException\n\n\nclass BaseHTTPException(MedTaggerException):\n \"\"\"Base class for all HTTP Exceptions.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass UnauthorizedException(BaseHTTPException):\n \"\"\"Exception designed to use once there was an authorization error during business logic processing.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass NotFoundException(BaseHTTPException):\n \"\"\"Exception designed to use while the object that user was looking for could not be found.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass InvalidArgumentsException(BaseHTTPException):\n \"\"\"Exception designed to use with invalid arguments (400 status code).\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass AccessForbiddenException(BaseHTTPException):\n \"\"\"Exception designed to use while the user does not have a privilege to perform action.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n", "path": "backend/medtagger/api/exceptions.py"}, {"content": "\"\"\"All available Exceptions for whole project.\"\"\"\n\n\nclass MedTaggerException(Exception):\n \"\"\"Base class for all HTTP Exceptions.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass UnsupportedActionException(MedTaggerException):\n \"\"\"Exception for unsupported Action.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass InvalidResponseException(MedTaggerException):\n \"\"\"Exception for invalid Response.\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n\n\nclass InternalErrorException(MedTaggerException):\n \"\"\"Exception designed to use to indicate internal errors (like DB/Storage error).\"\"\"\n\n pass # pylint: disable=unnecessary-pass\n", "path": "backend/medtagger/exceptions.py"}]} | 1,053 | 602 |
gh_patches_debug_61378 | rasdani/github-patches | git_diff | Lightning-AI__torchmetrics-1288 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
inplace operation in pairwise_cosine_similarity
## 🐛 Bug
Hello !
The x, y values are modified inplace in the `pairwise_cosine_similarity` function.
This is not documented and may cause bugs that are difficult to find.
Thank you.
### To Reproduce
```python
import torch
from torchmetrics.functional import pairwise_cosine_similarity
x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)
y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)
print("Result:", pairwise_cosine_similarity(x, y))
print("X:", x)
print("Y:", y)
"""Out[0]
Result: tensor([[0.5547, 0.8682],
[0.5145, 0.8437],
[0.5300, 0.8533]])
X: tensor([[0.5547, 0.8321],
[0.5145, 0.8575],
[0.5300, 0.8480]])
Y: tensor([[1.0000, 0.0000],
[0.8944, 0.4472]])
"""
```
### Environment
torchmetrics==0.10.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/torchmetrics/functional/pairwise/cosine.py`
Content:
```
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 from typing import Optional
15
16 import torch
17 from torch import Tensor
18 from typing_extensions import Literal
19
20 from torchmetrics.functional.pairwise.helpers import _check_input, _reduce_distance_matrix
21 from torchmetrics.utilities.compute import _safe_matmul
22
23
24 def _pairwise_cosine_similarity_update(
25 x: Tensor, y: Optional[Tensor] = None, zero_diagonal: Optional[bool] = None
26 ) -> Tensor:
27 """Calculates the pairwise cosine similarity matrix.
28
29 Args:
30 x: tensor of shape ``[N,d]``
31 y: tensor of shape ``[M,d]``
32 zero_diagonal: determines if the diagonal of the distance matrix should be set to zero
33 """
34 x, y, zero_diagonal = _check_input(x, y, zero_diagonal)
35
36 norm = torch.norm(x, p=2, dim=1)
37 x /= norm.unsqueeze(1)
38 norm = torch.norm(y, p=2, dim=1)
39 y /= norm.unsqueeze(1)
40
41 distance = _safe_matmul(x, y)
42 if zero_diagonal:
43 distance.fill_diagonal_(0)
44 return distance
45
46
47 def pairwise_cosine_similarity(
48 x: Tensor,
49 y: Optional[Tensor] = None,
50 reduction: Literal["mean", "sum", "none", None] = None,
51 zero_diagonal: Optional[bool] = None,
52 ) -> Tensor:
53 r"""Calculates pairwise cosine similarity:
54
55 .. math::
56 s_{cos}(x,y) = \frac{<x,y>}{||x|| \cdot ||y||}
57 = \frac{\sum_{d=1}^D x_d \cdot y_d }{\sqrt{\sum_{d=1}^D x_i^2} \cdot \sqrt{\sum_{d=1}^D y_i^2}}
58
59 If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise
60 between the rows of :math:`x` and :math:`y`.
61 If only :math:`x` is passed in, the calculation will be performed between the rows of :math:`x`.
62
63 Args:
64 x: Tensor with shape ``[N, d]``
65 y: Tensor with shape ``[M, d]``, optional
66 reduction: reduction to apply along the last dimension. Choose between `'mean'`, `'sum'`
67 (applied along column dimension) or `'none'`, `None` for no reduction
68 zero_diagonal: if the diagonal of the distance matrix should be set to 0. If only :math:`x` is given
69 this defaults to ``True`` else if :math:`y` is also given it defaults to ``False``
70
71 Returns:
72 A ``[N,N]`` matrix of distances if only ``x`` is given, else a ``[N,M]`` matrix
73
74 Example:
75 >>> import torch
76 >>> from torchmetrics.functional import pairwise_cosine_similarity
77 >>> x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)
78 >>> y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)
79 >>> pairwise_cosine_similarity(x, y)
80 tensor([[0.5547, 0.8682],
81 [0.5145, 0.8437],
82 [0.5300, 0.8533]])
83 >>> pairwise_cosine_similarity(x)
84 tensor([[0.0000, 0.9989, 0.9996],
85 [0.9989, 0.0000, 0.9998],
86 [0.9996, 0.9998, 0.0000]])
87 """
88 distance = _pairwise_cosine_similarity_update(x, y, zero_diagonal)
89 return _reduce_distance_matrix(distance, reduction)
90
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/torchmetrics/functional/pairwise/cosine.py b/src/torchmetrics/functional/pairwise/cosine.py
--- a/src/torchmetrics/functional/pairwise/cosine.py
+++ b/src/torchmetrics/functional/pairwise/cosine.py
@@ -34,9 +34,9 @@
x, y, zero_diagonal = _check_input(x, y, zero_diagonal)
norm = torch.norm(x, p=2, dim=1)
- x /= norm.unsqueeze(1)
+ x = x / norm.unsqueeze(1)
norm = torch.norm(y, p=2, dim=1)
- y /= norm.unsqueeze(1)
+ y = y / norm.unsqueeze(1)
distance = _safe_matmul(x, y)
if zero_diagonal:
| {"golden_diff": "diff --git a/src/torchmetrics/functional/pairwise/cosine.py b/src/torchmetrics/functional/pairwise/cosine.py\n--- a/src/torchmetrics/functional/pairwise/cosine.py\n+++ b/src/torchmetrics/functional/pairwise/cosine.py\n@@ -34,9 +34,9 @@\n x, y, zero_diagonal = _check_input(x, y, zero_diagonal)\n \n norm = torch.norm(x, p=2, dim=1)\n- x /= norm.unsqueeze(1)\n+ x = x / norm.unsqueeze(1)\n norm = torch.norm(y, p=2, dim=1)\n- y /= norm.unsqueeze(1)\n+ y = y / norm.unsqueeze(1)\n \n distance = _safe_matmul(x, y)\n if zero_diagonal:\n", "issue": "inplace operation in pairwise_cosine_similarity\n## \ud83d\udc1b Bug\r\nHello !\r\nThe x, y values are modified inplace in the `pairwise_cosine_similarity` function. \r\nThis is not documented and may cause bugs that are difficult to find. \r\nThank you.\r\n\r\n### To Reproduce\r\n\r\n```python\r\nimport torch\r\nfrom torchmetrics.functional import pairwise_cosine_similarity\r\nx = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)\r\ny = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)\r\nprint(\"Result:\", pairwise_cosine_similarity(x, y))\r\nprint(\"X:\", x)\r\nprint(\"Y:\", y)\r\n\"\"\"Out[0]\r\nResult: tensor([[0.5547, 0.8682],\r\n [0.5145, 0.8437],\r\n [0.5300, 0.8533]])\r\nX: tensor([[0.5547, 0.8321],\r\n [0.5145, 0.8575],\r\n [0.5300, 0.8480]])\r\nY: tensor([[1.0000, 0.0000],\r\n [0.8944, 0.4472]])\r\n\"\"\"\r\n```\r\n\r\n### Environment\r\ntorchmetrics==0.10.0\r\n\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Optional\n\nimport torch\nfrom torch import Tensor\nfrom typing_extensions import Literal\n\nfrom torchmetrics.functional.pairwise.helpers import _check_input, _reduce_distance_matrix\nfrom torchmetrics.utilities.compute import _safe_matmul\n\n\ndef _pairwise_cosine_similarity_update(\n x: Tensor, y: Optional[Tensor] = None, zero_diagonal: Optional[bool] = None\n) -> Tensor:\n \"\"\"Calculates the pairwise cosine similarity matrix.\n\n Args:\n x: tensor of shape ``[N,d]``\n y: tensor of shape ``[M,d]``\n zero_diagonal: determines if the diagonal of the distance matrix should be set to zero\n \"\"\"\n x, y, zero_diagonal = _check_input(x, y, zero_diagonal)\n\n norm = torch.norm(x, p=2, dim=1)\n x /= norm.unsqueeze(1)\n norm = torch.norm(y, p=2, dim=1)\n y /= norm.unsqueeze(1)\n\n distance = _safe_matmul(x, y)\n if zero_diagonal:\n distance.fill_diagonal_(0)\n return distance\n\n\ndef pairwise_cosine_similarity(\n x: Tensor,\n y: Optional[Tensor] = None,\n reduction: Literal[\"mean\", \"sum\", \"none\", None] = None,\n zero_diagonal: Optional[bool] = None,\n) -> Tensor:\n r\"\"\"Calculates pairwise cosine similarity:\n\n .. math::\n s_{cos}(x,y) = \\frac{<x,y>}{||x|| \\cdot ||y||}\n = \\frac{\\sum_{d=1}^D x_d \\cdot y_d }{\\sqrt{\\sum_{d=1}^D x_i^2} \\cdot \\sqrt{\\sum_{d=1}^D y_i^2}}\n\n If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise\n between the rows of :math:`x` and :math:`y`.\n If only :math:`x` is passed in, the calculation will be performed between the rows of :math:`x`.\n\n Args:\n x: Tensor with shape ``[N, d]``\n y: Tensor with shape ``[M, d]``, optional\n reduction: reduction to apply along the last dimension. Choose between `'mean'`, `'sum'`\n (applied along column dimension) or `'none'`, `None` for no reduction\n zero_diagonal: if the diagonal of the distance matrix should be set to 0. If only :math:`x` is given\n this defaults to ``True`` else if :math:`y` is also given it defaults to ``False``\n\n Returns:\n A ``[N,N]`` matrix of distances if only ``x`` is given, else a ``[N,M]`` matrix\n\n Example:\n >>> import torch\n >>> from torchmetrics.functional import pairwise_cosine_similarity\n >>> x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)\n >>> y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)\n >>> pairwise_cosine_similarity(x, y)\n tensor([[0.5547, 0.8682],\n [0.5145, 0.8437],\n [0.5300, 0.8533]])\n >>> pairwise_cosine_similarity(x)\n tensor([[0.0000, 0.9989, 0.9996],\n [0.9989, 0.0000, 0.9998],\n [0.9996, 0.9998, 0.0000]])\n \"\"\"\n distance = _pairwise_cosine_similarity_update(x, y, zero_diagonal)\n return _reduce_distance_matrix(distance, reduction)\n", "path": "src/torchmetrics/functional/pairwise/cosine.py"}], "after_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nfrom typing import Optional\n\nimport torch\nfrom torch import Tensor\nfrom typing_extensions import Literal\n\nfrom torchmetrics.functional.pairwise.helpers import _check_input, _reduce_distance_matrix\nfrom torchmetrics.utilities.compute import _safe_matmul\n\n\ndef _pairwise_cosine_similarity_update(\n x: Tensor, y: Optional[Tensor] = None, zero_diagonal: Optional[bool] = None\n) -> Tensor:\n \"\"\"Calculates the pairwise cosine similarity matrix.\n\n Args:\n x: tensor of shape ``[N,d]``\n y: tensor of shape ``[M,d]``\n zero_diagonal: determines if the diagonal of the distance matrix should be set to zero\n \"\"\"\n x, y, zero_diagonal = _check_input(x, y, zero_diagonal)\n\n norm = torch.norm(x, p=2, dim=1)\n x = x / norm.unsqueeze(1)\n norm = torch.norm(y, p=2, dim=1)\n y = y / norm.unsqueeze(1)\n\n distance = _safe_matmul(x, y)\n if zero_diagonal:\n distance.fill_diagonal_(0)\n return distance\n\n\ndef pairwise_cosine_similarity(\n x: Tensor,\n y: Optional[Tensor] = None,\n reduction: Literal[\"mean\", \"sum\", \"none\", None] = None,\n zero_diagonal: Optional[bool] = None,\n) -> Tensor:\n r\"\"\"Calculates pairwise cosine similarity:\n\n .. math::\n s_{cos}(x,y) = \\frac{<x,y>}{||x|| \\cdot ||y||}\n = \\frac{\\sum_{d=1}^D x_d \\cdot y_d }{\\sqrt{\\sum_{d=1}^D x_i^2} \\cdot \\sqrt{\\sum_{d=1}^D y_i^2}}\n\n If both :math:`x` and :math:`y` are passed in, the calculation will be performed pairwise\n between the rows of :math:`x` and :math:`y`.\n If only :math:`x` is passed in, the calculation will be performed between the rows of :math:`x`.\n\n Args:\n x: Tensor with shape ``[N, d]``\n y: Tensor with shape ``[M, d]``, optional\n reduction: reduction to apply along the last dimension. Choose between `'mean'`, `'sum'`\n (applied along column dimension) or `'none'`, `None` for no reduction\n zero_diagonal: if the diagonal of the distance matrix should be set to 0. If only :math:`x` is given\n this defaults to ``True`` else if :math:`y` is also given it defaults to ``False``\n\n Returns:\n A ``[N,N]`` matrix of distances if only ``x`` is given, else a ``[N,M]`` matrix\n\n Example:\n >>> import torch\n >>> from torchmetrics.functional import pairwise_cosine_similarity\n >>> x = torch.tensor([[2, 3], [3, 5], [5, 8]], dtype=torch.float32)\n >>> y = torch.tensor([[1, 0], [2, 1]], dtype=torch.float32)\n >>> pairwise_cosine_similarity(x, y)\n tensor([[0.5547, 0.8682],\n [0.5145, 0.8437],\n [0.5300, 0.8533]])\n >>> pairwise_cosine_similarity(x)\n tensor([[0.0000, 0.9989, 0.9996],\n [0.9989, 0.0000, 0.9998],\n [0.9996, 0.9998, 0.0000]])\n \"\"\"\n distance = _pairwise_cosine_similarity_update(x, y, zero_diagonal)\n return _reduce_distance_matrix(distance, reduction)\n", "path": "src/torchmetrics/functional/pairwise/cosine.py"}]} | 1,760 | 185 |
gh_patches_debug_1038 | rasdani/github-patches | git_diff | mathesar-foundation__mathesar-341 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Individually run API tests don't build tables database
## Description
Running a individual test in `mathesar` that doesn't use the `engine` or `test_db` fixture will not have the tables databases built for the test. As a result, many will error when trying to access the tables database.
## Expected behavior
The tables database should always be built.
## To Reproduce
Run any test in `mathesar` that doesn't use `engine` or `test_db`. Ex:
```
docker exec mathesar_web_1 pytest mathesar/tests/views/api/test_schema_api.py::test_schema_update
```
## Additional context
Introduced due to the changes in #329, since `pytest-django` no longer creates the tables db for us.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `conftest.py`
Content:
```
1 """
2 This file should provide utilities for setting up test DBs and the like. It's
3 intended to be the containment zone for anything specific about the testing
4 environment (e.g., the login info for the Postgres instance for testing)
5 """
6 import pytest
7 from sqlalchemy import create_engine, text
8 from config.settings import DATABASES
9
10 TEST_DB = "mathesar_db_test"
11
12
13 @pytest.fixture(scope="session")
14 def test_db_name():
15 return TEST_DB
16
17
18 @pytest.fixture(scope="session")
19 def test_db():
20 superuser_engine = _get_superuser_engine()
21 with superuser_engine.connect() as conn:
22 conn.execution_options(isolation_level="AUTOCOMMIT")
23 conn.execute(text(f"DROP DATABASE IF EXISTS {TEST_DB} WITH (FORCE)"))
24 conn.execute(text(f"CREATE DATABASE {TEST_DB}"))
25 yield TEST_DB
26 with superuser_engine.connect() as conn:
27 conn.execution_options(isolation_level="AUTOCOMMIT")
28 conn.execute(text(f"DROP DATABASE {TEST_DB} WITH (FORCE)"))
29
30
31 @pytest.fixture(scope="session")
32 def engine(test_db):
33 return create_engine(
34 _get_connection_string(
35 DATABASES["default"]["USER"],
36 DATABASES["default"]["PASSWORD"],
37 DATABASES["default"]["HOST"],
38 test_db,
39 ),
40 future=True,
41 )
42
43
44 def _get_superuser_engine():
45 return create_engine(
46 _get_connection_string(
47 username=DATABASES["default"]["USER"],
48 password=DATABASES["default"]["PASSWORD"],
49 hostname=DATABASES["default"]["HOST"],
50 database=DATABASES["default"]["NAME"],
51 ),
52 future=True,
53 )
54
55
56 def _get_connection_string(username, password, hostname, database):
57 return f"postgresql://{username}:{password}@{hostname}/{database}"
58
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/conftest.py b/conftest.py
--- a/conftest.py
+++ b/conftest.py
@@ -15,7 +15,7 @@
return TEST_DB
[email protected](scope="session")
[email protected](scope="session", autouse=True)
def test_db():
superuser_engine = _get_superuser_engine()
with superuser_engine.connect() as conn:
| {"golden_diff": "diff --git a/conftest.py b/conftest.py\n--- a/conftest.py\n+++ b/conftest.py\n@@ -15,7 +15,7 @@\n return TEST_DB\n \n \[email protected](scope=\"session\")\[email protected](scope=\"session\", autouse=True)\n def test_db():\n superuser_engine = _get_superuser_engine()\n with superuser_engine.connect() as conn:\n", "issue": "Individually run API tests don't build tables database\n## Description\r\nRunning a individual test in `mathesar` that doesn't use the `engine` or `test_db` fixture will not have the tables databases built for the test. As a result, many will error when trying to access the tables database.\r\n\r\n## Expected behavior\r\nThe tables database should always be built.\r\n\r\n## To Reproduce\r\nRun any test in `mathesar` that doesn't use `engine` or `test_db`. Ex:\r\n```\r\ndocker exec mathesar_web_1 pytest mathesar/tests/views/api/test_schema_api.py::test_schema_update\r\n```\r\n\r\n## Additional context\r\nIntroduced due to the changes in #329, since `pytest-django` no longer creates the tables db for us.\r\n\n", "before_files": [{"content": "\"\"\"\nThis file should provide utilities for setting up test DBs and the like. It's\nintended to be the containment zone for anything specific about the testing\nenvironment (e.g., the login info for the Postgres instance for testing)\n\"\"\"\nimport pytest\nfrom sqlalchemy import create_engine, text\nfrom config.settings import DATABASES\n\nTEST_DB = \"mathesar_db_test\"\n\n\[email protected](scope=\"session\")\ndef test_db_name():\n return TEST_DB\n\n\[email protected](scope=\"session\")\ndef test_db():\n superuser_engine = _get_superuser_engine()\n with superuser_engine.connect() as conn:\n conn.execution_options(isolation_level=\"AUTOCOMMIT\")\n conn.execute(text(f\"DROP DATABASE IF EXISTS {TEST_DB} WITH (FORCE)\"))\n conn.execute(text(f\"CREATE DATABASE {TEST_DB}\"))\n yield TEST_DB\n with superuser_engine.connect() as conn:\n conn.execution_options(isolation_level=\"AUTOCOMMIT\")\n conn.execute(text(f\"DROP DATABASE {TEST_DB} WITH (FORCE)\"))\n\n\[email protected](scope=\"session\")\ndef engine(test_db):\n return create_engine(\n _get_connection_string(\n DATABASES[\"default\"][\"USER\"],\n DATABASES[\"default\"][\"PASSWORD\"],\n DATABASES[\"default\"][\"HOST\"],\n test_db,\n ),\n future=True,\n )\n\n\ndef _get_superuser_engine():\n return create_engine(\n _get_connection_string(\n username=DATABASES[\"default\"][\"USER\"],\n password=DATABASES[\"default\"][\"PASSWORD\"],\n hostname=DATABASES[\"default\"][\"HOST\"],\n database=DATABASES[\"default\"][\"NAME\"],\n ),\n future=True,\n )\n\n\ndef _get_connection_string(username, password, hostname, database):\n return f\"postgresql://{username}:{password}@{hostname}/{database}\"\n", "path": "conftest.py"}], "after_files": [{"content": "\"\"\"\nThis file should provide utilities for setting up test DBs and the like. It's\nintended to be the containment zone for anything specific about the testing\nenvironment (e.g., the login info for the Postgres instance for testing)\n\"\"\"\nimport pytest\nfrom sqlalchemy import create_engine, text\nfrom config.settings import DATABASES\n\nTEST_DB = \"mathesar_db_test\"\n\n\[email protected](scope=\"session\")\ndef test_db_name():\n return TEST_DB\n\n\[email protected](scope=\"session\", autouse=True)\ndef test_db():\n superuser_engine = _get_superuser_engine()\n with superuser_engine.connect() as conn:\n conn.execution_options(isolation_level=\"AUTOCOMMIT\")\n conn.execute(text(f\"DROP DATABASE IF EXISTS {TEST_DB} WITH (FORCE)\"))\n conn.execute(text(f\"CREATE DATABASE {TEST_DB}\"))\n yield TEST_DB\n with superuser_engine.connect() as conn:\n conn.execution_options(isolation_level=\"AUTOCOMMIT\")\n conn.execute(text(f\"DROP DATABASE {TEST_DB} WITH (FORCE)\"))\n\n\[email protected](scope=\"session\")\ndef engine(test_db):\n return create_engine(\n _get_connection_string(\n DATABASES[\"default\"][\"USER\"],\n DATABASES[\"default\"][\"PASSWORD\"],\n DATABASES[\"default\"][\"HOST\"],\n test_db,\n ),\n future=True,\n )\n\n\ndef _get_superuser_engine():\n return create_engine(\n _get_connection_string(\n username=DATABASES[\"default\"][\"USER\"],\n password=DATABASES[\"default\"][\"PASSWORD\"],\n hostname=DATABASES[\"default\"][\"HOST\"],\n database=DATABASES[\"default\"][\"NAME\"],\n ),\n future=True,\n )\n\n\ndef _get_connection_string(username, password, hostname, database):\n return f\"postgresql://{username}:{password}@{hostname}/{database}\"\n", "path": "conftest.py"}]} | 904 | 90 |
gh_patches_debug_23746 | rasdani/github-patches | git_diff | mitmproxy__mitmproxy-3114 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
tcp_message script not working
Hi,
I tried to execute the TCP message replace script from the doc but it seems is not working. I don't know if this is a issue with the doc script or with mitmproxy.
The script was unchanged.
##### Steps to reproduce the problem:
1. mitmdump --mode transparent --tcp-host ".*" -k -s examples/complex/tcp_message.py
Loading script: examples/tcp_message.py
Proxy server listening at http://*:8080
192.168.1.241:37604: clientconnect
::ffff:192.168.1.241:37604: Certificate verification error for None: hostname 'no-hostname' doesn't match either of '*.local.org', 'local.org'
::ffff:192.168.1.241:37604: Ignoring server verification error, continuing with connection
Addon error: Traceback (most recent call last):
File "examples/tcp_message.py", line 16, in tcp_message
modified_msg = tcp_msg.message.replace("foo", "bar")
AttributeError: 'TCPFlow' object has no attribute 'message'
192.168.1.241:37604 -> tcp -> 10.0.0.2:5443
Addon error: Traceback (most recent call last):
File "examples/tcp_message.py", line 16, in tcp_message
modified_msg = tcp_msg.message.replace("foo", "bar")
AttributeError: 'TCPFlow' object has no attribute 'message'
192.168.1.241:37604 <- tcp <- 10.0.0.2:5443
##### System information
<!-- Paste the output of "mitmproxy --version" here. -->
mitmdump --version
Mitmproxy: 3.0.4
Python: 3.6.0
OpenSSL: OpenSSL 1.1.0h 27 Mar 2018
Platform: Linux-3.19.0-65-generic-x86_64-with-debian-jessie-sid
<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `examples/complex/tcp_message.py`
Content:
```
1 """
2 tcp_message Inline Script Hook API Demonstration
3 ------------------------------------------------
4
5 * modifies packets containing "foo" to "bar"
6 * prints various details for each packet.
7
8 example cmdline invocation:
9 mitmdump -T --host --tcp ".*" -q -s examples/tcp_message.py
10 """
11 from mitmproxy.utils import strutils
12 from mitmproxy import ctx
13
14
15 def tcp_message(tcp_msg):
16 modified_msg = tcp_msg.message.replace("foo", "bar")
17
18 is_modified = False if modified_msg == tcp_msg.message else True
19 tcp_msg.message = modified_msg
20
21 ctx.log.info(
22 "[tcp_message{}] from {} {} to {} {}:\r\n{}".format(
23 " (modified)" if is_modified else "",
24 "client" if tcp_msg.sender == tcp_msg.client_conn else "server",
25 tcp_msg.sender.address,
26 "server" if tcp_msg.receiver == tcp_msg.server_conn else "client",
27 tcp_msg.receiver.address, strutils.bytes_to_escaped_str(tcp_msg.message))
28 )
29
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/examples/complex/tcp_message.py b/examples/complex/tcp_message.py
--- a/examples/complex/tcp_message.py
+++ b/examples/complex/tcp_message.py
@@ -6,23 +6,22 @@
* prints various details for each packet.
example cmdline invocation:
-mitmdump -T --host --tcp ".*" -q -s examples/tcp_message.py
+mitmdump --rawtcp --tcp-host ".*" -s examples/complex/tcp_message.py
"""
from mitmproxy.utils import strutils
from mitmproxy import ctx
+from mitmproxy import tcp
-def tcp_message(tcp_msg):
- modified_msg = tcp_msg.message.replace("foo", "bar")
-
- is_modified = False if modified_msg == tcp_msg.message else True
- tcp_msg.message = modified_msg
+def tcp_message(flow: tcp.TCPFlow):
+ message = flow.messages[-1]
+ old_content = message.content
+ message.content = old_content.replace(b"foo", b"bar")
ctx.log.info(
- "[tcp_message{}] from {} {} to {} {}:\r\n{}".format(
- " (modified)" if is_modified else "",
- "client" if tcp_msg.sender == tcp_msg.client_conn else "server",
- tcp_msg.sender.address,
- "server" if tcp_msg.receiver == tcp_msg.server_conn else "client",
- tcp_msg.receiver.address, strutils.bytes_to_escaped_str(tcp_msg.message))
+ "[tcp_message{}] from {} to {}:\n{}".format(
+ " (modified)" if message.content != old_content else "",
+ "client" if message.from_client else "server",
+ "server" if message.from_client else "client",
+ strutils.bytes_to_escaped_str(message.content))
)
| {"golden_diff": "diff --git a/examples/complex/tcp_message.py b/examples/complex/tcp_message.py\n--- a/examples/complex/tcp_message.py\n+++ b/examples/complex/tcp_message.py\n@@ -6,23 +6,22 @@\n * prints various details for each packet.\n \n example cmdline invocation:\n-mitmdump -T --host --tcp \".*\" -q -s examples/tcp_message.py\n+mitmdump --rawtcp --tcp-host \".*\" -s examples/complex/tcp_message.py\n \"\"\"\n from mitmproxy.utils import strutils\n from mitmproxy import ctx\n+from mitmproxy import tcp\n \n \n-def tcp_message(tcp_msg):\n- modified_msg = tcp_msg.message.replace(\"foo\", \"bar\")\n-\n- is_modified = False if modified_msg == tcp_msg.message else True\n- tcp_msg.message = modified_msg\n+def tcp_message(flow: tcp.TCPFlow):\n+ message = flow.messages[-1]\n+ old_content = message.content\n+ message.content = old_content.replace(b\"foo\", b\"bar\")\n \n ctx.log.info(\n- \"[tcp_message{}] from {} {} to {} {}:\\r\\n{}\".format(\n- \" (modified)\" if is_modified else \"\",\n- \"client\" if tcp_msg.sender == tcp_msg.client_conn else \"server\",\n- tcp_msg.sender.address,\n- \"server\" if tcp_msg.receiver == tcp_msg.server_conn else \"client\",\n- tcp_msg.receiver.address, strutils.bytes_to_escaped_str(tcp_msg.message))\n+ \"[tcp_message{}] from {} to {}:\\n{}\".format(\n+ \" (modified)\" if message.content != old_content else \"\",\n+ \"client\" if message.from_client else \"server\",\n+ \"server\" if message.from_client else \"client\",\n+ strutils.bytes_to_escaped_str(message.content))\n )\n", "issue": "tcp_message script not working\nHi,\r\n\r\nI tried to execute the TCP message replace script from the doc but it seems is not working. I don't know if this is a issue with the doc script or with mitmproxy.\r\n\r\nThe script was unchanged.\r\n\r\n##### Steps to reproduce the problem:\r\n\r\n1. mitmdump --mode transparent --tcp-host \".*\" -k -s examples/complex/tcp_message.py\r\n\r\nLoading script: examples/tcp_message.py\r\nProxy server listening at http://*:8080\r\n192.168.1.241:37604: clientconnect\r\n::ffff:192.168.1.241:37604: Certificate verification error for None: hostname 'no-hostname' doesn't match either of '*.local.org', 'local.org'\r\n::ffff:192.168.1.241:37604: Ignoring server verification error, continuing with connection\r\nAddon error: Traceback (most recent call last):\r\n File \"examples/tcp_message.py\", line 16, in tcp_message\r\n modified_msg = tcp_msg.message.replace(\"foo\", \"bar\")\r\nAttributeError: 'TCPFlow' object has no attribute 'message'\r\n\r\n192.168.1.241:37604 -> tcp -> 10.0.0.2:5443\r\nAddon error: Traceback (most recent call last):\r\n File \"examples/tcp_message.py\", line 16, in tcp_message\r\n modified_msg = tcp_msg.message.replace(\"foo\", \"bar\")\r\nAttributeError: 'TCPFlow' object has no attribute 'message'\r\n\r\n192.168.1.241:37604 <- tcp <- 10.0.0.2:5443\r\n\r\n##### System information\r\n\r\n<!-- Paste the output of \"mitmproxy --version\" here. -->\r\n\r\nmitmdump --version\r\nMitmproxy: 3.0.4 \r\nPython: 3.6.0\r\nOpenSSL: OpenSSL 1.1.0h 27 Mar 2018\r\nPlatform: Linux-3.19.0-65-generic-x86_64-with-debian-jessie-sid\r\n\r\n<!-- Please use the mitmproxy forums (https://discourse.mitmproxy.org/) for support/how-to questions. Thanks! :) -->\r\n\n", "before_files": [{"content": "\"\"\"\ntcp_message Inline Script Hook API Demonstration\n------------------------------------------------\n\n* modifies packets containing \"foo\" to \"bar\"\n* prints various details for each packet.\n\nexample cmdline invocation:\nmitmdump -T --host --tcp \".*\" -q -s examples/tcp_message.py\n\"\"\"\nfrom mitmproxy.utils import strutils\nfrom mitmproxy import ctx\n\n\ndef tcp_message(tcp_msg):\n modified_msg = tcp_msg.message.replace(\"foo\", \"bar\")\n\n is_modified = False if modified_msg == tcp_msg.message else True\n tcp_msg.message = modified_msg\n\n ctx.log.info(\n \"[tcp_message{}] from {} {} to {} {}:\\r\\n{}\".format(\n \" (modified)\" if is_modified else \"\",\n \"client\" if tcp_msg.sender == tcp_msg.client_conn else \"server\",\n tcp_msg.sender.address,\n \"server\" if tcp_msg.receiver == tcp_msg.server_conn else \"client\",\n tcp_msg.receiver.address, strutils.bytes_to_escaped_str(tcp_msg.message))\n )\n", "path": "examples/complex/tcp_message.py"}], "after_files": [{"content": "\"\"\"\ntcp_message Inline Script Hook API Demonstration\n------------------------------------------------\n\n* modifies packets containing \"foo\" to \"bar\"\n* prints various details for each packet.\n\nexample cmdline invocation:\nmitmdump --rawtcp --tcp-host \".*\" -s examples/complex/tcp_message.py\n\"\"\"\nfrom mitmproxy.utils import strutils\nfrom mitmproxy import ctx\nfrom mitmproxy import tcp\n\n\ndef tcp_message(flow: tcp.TCPFlow):\n message = flow.messages[-1]\n old_content = message.content\n message.content = old_content.replace(b\"foo\", b\"bar\")\n\n ctx.log.info(\n \"[tcp_message{}] from {} to {}:\\n{}\".format(\n \" (modified)\" if message.content != old_content else \"\",\n \"client\" if message.from_client else \"server\",\n \"server\" if message.from_client else \"client\",\n strutils.bytes_to_escaped_str(message.content))\n )\n", "path": "examples/complex/tcp_message.py"}]} | 1,044 | 387 |
gh_patches_debug_13366 | rasdani/github-patches | git_diff | ansible__awx-13022 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Genrated certificate in install bundle for Execution node is valid only for 10 days
### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.
### Bug Summary
The certificate for receptor in install bundle (`*.tar.gz`) for execution node that generated by AWX is valid only for 10 days.
In my understanding currently there is no automated certificate renewal feature in both AWX and Receptor, so I guess the execution environment will be invalidated after 10 days.
Therefore frequently renewal (generating bundle and invoke playbook again) by hand might be required.
```bash
$ ls -l
total 24
-rw-rw-r--. 1 kuro kuro 11278 Oct 7 05:12 ansible.log
drwxrwxr-x. 2 kuro kuro 21 Oct 7 05:09 group_vars
-rw-r--r--. 1 kuro kuro 406 Jan 1 1970 install_receptor.yml
-rw-r--r--. 1 kuro kuro 159 Oct 7 05:10 inventory.yml
drwxrwxr-x. 3 kuro kuro 44 Oct 7 05:09 receptor
-rw-r--r--. 1 kuro kuro 137 Jan 1 1970 requirements.yml
$ openssl x509 -text -in receptor/tls/receptor.crt -noout | grep Not
Not Before: Oct 6 20:09:21 2022 GMT
Not After : Oct 16 20:09:21 2022 GMT 👈👈👈
```
Installer (playbook) just place certificate on execution node without any modification, so deployed execution node uses certificate that included in the install bandle as is.
I have no idea if this is a _bug_ or _designed behavior_, but just in case I'm creating this issue.
### AWX version
21.7.0
### Select the relevant components
- [ ] UI
- [X] API
- [ ] Docs
- [ ] Collection
- [ ] CLI
- [ ] Other
### Installation method
kubernetes
### Modifications
no
### Ansible version
N/A
### Operating system
CentOS 8 Stream
### Web browser
Chrome
### Steps to reproduce
1. Deploy AWX 21.7.0 on any platform
2. Add new instance and generate install bundle for the instance
3. Extract install bundle and ensure `Not After` in the `receptor.crt` by `openssl x509 -text -in receptor/tls/receptor.crt -noout`
### Expected results
Certificate and execution environment are valid for enough life time.
### Actual results
Not tested enough, I guess my execution environment will be expired in 10 days if I won't make any manual renewal for the certs.
### Additional information
@TheRealHaoLiu @jbradberry
Thanks for excellent feature; execution node! It works as expected in my environment in this few days :)
Sorry for annoying you by this mention, but I want to confirm that this is designed or not.
I found that there is hard-coded `days=10` in your commit.
https://github.com/ansible/awx/blob/150c55c72a4d1d896474c9d3aaaceeb1b69ee253/awx/api/views/instance_install_bundle.py#L181
According to your comment on `awx-operator` repository, it seems that you've designed it as _10 years_ instead of _10 days_ I guess...?; https://github.com/ansible/awx-operator/pull/1012#issuecomment-1208423340
Please let me know it's not recommended that trying to use generated certs in the long term, or if you have an easier way to renew certs.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `awx/api/views/instance_install_bundle.py`
Content:
```
1 # Copyright (c) 2018 Red Hat, Inc.
2 # All Rights Reserved.
3
4 import datetime
5 import io
6 import ipaddress
7 import os
8 import tarfile
9
10 import asn1
11 from awx.api import serializers
12 from awx.api.generics import GenericAPIView, Response
13 from awx.api.permissions import IsSystemAdminOrAuditor
14 from awx.main import models
15 from cryptography import x509
16 from cryptography.hazmat.primitives import hashes, serialization
17 from cryptography.hazmat.primitives.asymmetric import rsa
18 from cryptography.x509 import DNSName, IPAddress, ObjectIdentifier, OtherName
19 from cryptography.x509.oid import NameOID
20 from django.http import HttpResponse
21 from django.template.loader import render_to_string
22 from django.utils.translation import gettext_lazy as _
23 from rest_framework import status
24
25 # Red Hat has an OID namespace (RHANANA). Receptor has its own designation under that.
26 RECEPTOR_OID = "1.3.6.1.4.1.2312.19.1"
27
28 # generate install bundle for the instance
29 # install bundle directory structure
30 # ├── install_receptor.yml (playbook)
31 # ├── inventory.yml
32 # ├── group_vars
33 # │ └── all.yml
34 # ├── receptor
35 # │ ├── tls
36 # │ │ ├── ca
37 # │ │ │ └── receptor-ca.crt
38 # │ │ ├── receptor.crt
39 # │ │ └── receptor.key
40 # │ └── work-public-key.pem
41 # └── requirements.yml
42 class InstanceInstallBundle(GenericAPIView):
43
44 name = _('Install Bundle')
45 model = models.Instance
46 serializer_class = serializers.InstanceSerializer
47 permission_classes = (IsSystemAdminOrAuditor,)
48
49 def get(self, request, *args, **kwargs):
50 instance_obj = self.get_object()
51
52 if instance_obj.node_type not in ('execution',):
53 return Response(
54 data=dict(msg=_('Install bundle can only be generated for execution nodes.')),
55 status=status.HTTP_400_BAD_REQUEST,
56 )
57
58 with io.BytesIO() as f:
59 with tarfile.open(fileobj=f, mode='w:gz') as tar:
60 # copy /etc/receptor/tls/ca/receptor-ca.crt to receptor/tls/ca in the tar file
61 tar.add(
62 os.path.realpath('/etc/receptor/tls/ca/receptor-ca.crt'), arcname=f"{instance_obj.hostname}_install_bundle/receptor/tls/ca/receptor-ca.crt"
63 )
64
65 # copy /etc/receptor/signing/work-public-key.pem to receptor/work-public-key.pem
66 tar.add('/etc/receptor/signing/work-public-key.pem', arcname=f"{instance_obj.hostname}_install_bundle/receptor/work-public-key.pem")
67
68 # generate and write the receptor key to receptor/tls/receptor.key in the tar file
69 key, cert = generate_receptor_tls(instance_obj)
70
71 key_tarinfo = tarfile.TarInfo(f"{instance_obj.hostname}_install_bundle/receptor/tls/receptor.key")
72 key_tarinfo.size = len(key)
73 tar.addfile(key_tarinfo, io.BytesIO(key))
74
75 cert_tarinfo = tarfile.TarInfo(f"{instance_obj.hostname}_install_bundle/receptor/tls/receptor.crt")
76 cert_tarinfo.size = len(cert)
77 tar.addfile(cert_tarinfo, io.BytesIO(cert))
78
79 # generate and write install_receptor.yml to the tar file
80 playbook = generate_playbook().encode('utf-8')
81 playbook_tarinfo = tarfile.TarInfo(f"{instance_obj.hostname}_install_bundle/install_receptor.yml")
82 playbook_tarinfo.size = len(playbook)
83 tar.addfile(playbook_tarinfo, io.BytesIO(playbook))
84
85 # generate and write inventory.yml to the tar file
86 inventory_yml = generate_inventory_yml(instance_obj).encode('utf-8')
87 inventory_yml_tarinfo = tarfile.TarInfo(f"{instance_obj.hostname}_install_bundle/inventory.yml")
88 inventory_yml_tarinfo.size = len(inventory_yml)
89 tar.addfile(inventory_yml_tarinfo, io.BytesIO(inventory_yml))
90
91 # generate and write group_vars/all.yml to the tar file
92 group_vars = generate_group_vars_all_yml(instance_obj).encode('utf-8')
93 group_vars_tarinfo = tarfile.TarInfo(f"{instance_obj.hostname}_install_bundle/group_vars/all.yml")
94 group_vars_tarinfo.size = len(group_vars)
95 tar.addfile(group_vars_tarinfo, io.BytesIO(group_vars))
96
97 # generate and write requirements.yml to the tar file
98 requirements_yml = generate_requirements_yml().encode('utf-8')
99 requirements_yml_tarinfo = tarfile.TarInfo(f"{instance_obj.hostname}_install_bundle/requirements.yml")
100 requirements_yml_tarinfo.size = len(requirements_yml)
101 tar.addfile(requirements_yml_tarinfo, io.BytesIO(requirements_yml))
102
103 # respond with the tarfile
104 f.seek(0)
105 response = HttpResponse(f.read(), status=status.HTTP_200_OK)
106 response['Content-Disposition'] = f"attachment; filename={instance_obj.hostname}_install_bundle.tar.gz"
107 return response
108
109
110 def generate_playbook():
111 return render_to_string("instance_install_bundle/install_receptor.yml")
112
113
114 def generate_requirements_yml():
115 return render_to_string("instance_install_bundle/requirements.yml")
116
117
118 def generate_inventory_yml(instance_obj):
119 return render_to_string("instance_install_bundle/inventory.yml", context=dict(instance=instance_obj))
120
121
122 def generate_group_vars_all_yml(instance_obj):
123 return render_to_string("instance_install_bundle/group_vars/all.yml", context=dict(instance=instance_obj))
124
125
126 def generate_receptor_tls(instance_obj):
127 # generate private key for the receptor
128 key = rsa.generate_private_key(public_exponent=65537, key_size=2048)
129
130 # encode receptor hostname to asn1
131 hostname = instance_obj.hostname
132 encoder = asn1.Encoder()
133 encoder.start()
134 encoder.write(hostname.encode(), nr=asn1.Numbers.UTF8String)
135 hostname_asn1 = encoder.output()
136
137 san_params = [
138 DNSName(hostname),
139 OtherName(ObjectIdentifier(RECEPTOR_OID), hostname_asn1),
140 ]
141
142 try:
143 san_params.append(IPAddress(ipaddress.IPv4Address(hostname)))
144 except ipaddress.AddressValueError:
145 pass
146
147 # generate certificate for the receptor
148 csr = (
149 x509.CertificateSigningRequestBuilder()
150 .subject_name(
151 x509.Name(
152 [
153 x509.NameAttribute(NameOID.COMMON_NAME, hostname),
154 ]
155 )
156 )
157 .add_extension(
158 x509.SubjectAlternativeName(san_params),
159 critical=False,
160 )
161 .sign(key, hashes.SHA256())
162 )
163
164 # sign csr with the receptor ca key from /etc/receptor/ca/receptor-ca.key
165 with open('/etc/receptor/tls/ca/receptor-ca.key', 'rb') as f:
166 ca_key = serialization.load_pem_private_key(
167 f.read(),
168 password=None,
169 )
170
171 with open('/etc/receptor/tls/ca/receptor-ca.crt', 'rb') as f:
172 ca_cert = x509.load_pem_x509_certificate(f.read())
173
174 cert = (
175 x509.CertificateBuilder()
176 .subject_name(csr.subject)
177 .issuer_name(ca_cert.issuer)
178 .public_key(csr.public_key())
179 .serial_number(x509.random_serial_number())
180 .not_valid_before(datetime.datetime.utcnow())
181 .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=10))
182 .add_extension(
183 csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).value,
184 critical=csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).critical,
185 )
186 .sign(ca_key, hashes.SHA256())
187 )
188
189 key = key.private_bytes(
190 encoding=serialization.Encoding.PEM,
191 format=serialization.PrivateFormat.TraditionalOpenSSL,
192 encryption_algorithm=serialization.NoEncryption(),
193 )
194
195 cert = cert.public_bytes(
196 encoding=serialization.Encoding.PEM,
197 )
198
199 return key, cert
200
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/awx/api/views/instance_install_bundle.py b/awx/api/views/instance_install_bundle.py
--- a/awx/api/views/instance_install_bundle.py
+++ b/awx/api/views/instance_install_bundle.py
@@ -178,7 +178,7 @@
.public_key(csr.public_key())
.serial_number(x509.random_serial_number())
.not_valid_before(datetime.datetime.utcnow())
- .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=10))
+ .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=3650))
.add_extension(
csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).value,
critical=csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).critical,
| {"golden_diff": "diff --git a/awx/api/views/instance_install_bundle.py b/awx/api/views/instance_install_bundle.py\n--- a/awx/api/views/instance_install_bundle.py\n+++ b/awx/api/views/instance_install_bundle.py\n@@ -178,7 +178,7 @@\n .public_key(csr.public_key())\n .serial_number(x509.random_serial_number())\n .not_valid_before(datetime.datetime.utcnow())\n- .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=10))\n+ .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=3650))\n .add_extension(\n csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).value,\n critical=csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).critical,\n", "issue": "Genrated certificate in install bundle for Execution node is valid only for 10 days\n### Please confirm the following\r\n\r\n- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).\r\n- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.\r\n- [X] I understand that AWX is open source software provided for free and that I might not receive a timely response.\r\n\r\n### Bug Summary\r\n\r\nThe certificate for receptor in install bundle (`*.tar.gz`) for execution node that generated by AWX is valid only for 10 days.\r\n\r\nIn my understanding currently there is no automated certificate renewal feature in both AWX and Receptor, so I guess the execution environment will be invalidated after 10 days. \r\n\r\nTherefore frequently renewal (generating bundle and invoke playbook again) by hand might be required.\r\n\r\n```bash\r\n$ ls -l\r\ntotal 24\r\n-rw-rw-r--. 1 kuro kuro 11278 Oct 7 05:12 ansible.log\r\ndrwxrwxr-x. 2 kuro kuro 21 Oct 7 05:09 group_vars\r\n-rw-r--r--. 1 kuro kuro 406 Jan 1 1970 install_receptor.yml\r\n-rw-r--r--. 1 kuro kuro 159 Oct 7 05:10 inventory.yml\r\ndrwxrwxr-x. 3 kuro kuro 44 Oct 7 05:09 receptor\r\n-rw-r--r--. 1 kuro kuro 137 Jan 1 1970 requirements.yml\r\n\r\n$ openssl x509 -text -in receptor/tls/receptor.crt -noout | grep Not\r\n Not Before: Oct 6 20:09:21 2022 GMT\r\n Not After : Oct 16 20:09:21 2022 GMT \ud83d\udc48\ud83d\udc48\ud83d\udc48\r\n```\r\n\r\nInstaller (playbook) just place certificate on execution node without any modification, so deployed execution node uses certificate that included in the install bandle as is. \r\n\r\nI have no idea if this is a _bug_ or _designed behavior_, but just in case I'm creating this issue.\r\n\r\n### AWX version\r\n\r\n21.7.0\r\n\r\n### Select the relevant components\r\n\r\n- [ ] UI\r\n- [X] API\r\n- [ ] Docs\r\n- [ ] Collection\r\n- [ ] CLI\r\n- [ ] Other\r\n\r\n### Installation method\r\n\r\nkubernetes\r\n\r\n### Modifications\r\n\r\nno\r\n\r\n### Ansible version\r\n\r\nN/A\r\n\r\n### Operating system\r\n\r\nCentOS 8 Stream\r\n\r\n### Web browser\r\n\r\nChrome\r\n\r\n### Steps to reproduce\r\n\r\n1. Deploy AWX 21.7.0 on any platform\r\n2. Add new instance and generate install bundle for the instance\r\n3. Extract install bundle and ensure `Not After` in the `receptor.crt` by `openssl x509 -text -in receptor/tls/receptor.crt -noout`\r\n\r\n### Expected results\r\n\r\nCertificate and execution environment are valid for enough life time.\r\n\r\n### Actual results\r\n\r\nNot tested enough, I guess my execution environment will be expired in 10 days if I won't make any manual renewal for the certs.\r\n\r\n### Additional information\r\n\r\n@TheRealHaoLiu @jbradberry \r\nThanks for excellent feature; execution node! It works as expected in my environment in this few days :)\r\nSorry for annoying you by this mention, but I want to confirm that this is designed or not.\r\n\r\nI found that there is hard-coded `days=10` in your commit.\r\nhttps://github.com/ansible/awx/blob/150c55c72a4d1d896474c9d3aaaceeb1b69ee253/awx/api/views/instance_install_bundle.py#L181\r\n\r\nAccording to your comment on `awx-operator` repository, it seems that you've designed it as _10 years_ instead of _10 days_ I guess...?; https://github.com/ansible/awx-operator/pull/1012#issuecomment-1208423340\r\n\r\nPlease let me know it's not recommended that trying to use generated certs in the long term, or if you have an easier way to renew certs.\n", "before_files": [{"content": "# Copyright (c) 2018 Red Hat, Inc.\n# All Rights Reserved.\n\nimport datetime\nimport io\nimport ipaddress\nimport os\nimport tarfile\n\nimport asn1\nfrom awx.api import serializers\nfrom awx.api.generics import GenericAPIView, Response\nfrom awx.api.permissions import IsSystemAdminOrAuditor\nfrom awx.main import models\nfrom cryptography import x509\nfrom cryptography.hazmat.primitives import hashes, serialization\nfrom cryptography.hazmat.primitives.asymmetric import rsa\nfrom cryptography.x509 import DNSName, IPAddress, ObjectIdentifier, OtherName\nfrom cryptography.x509.oid import NameOID\nfrom django.http import HttpResponse\nfrom django.template.loader import render_to_string\nfrom django.utils.translation import gettext_lazy as _\nfrom rest_framework import status\n\n# Red Hat has an OID namespace (RHANANA). Receptor has its own designation under that.\nRECEPTOR_OID = \"1.3.6.1.4.1.2312.19.1\"\n\n# generate install bundle for the instance\n# install bundle directory structure\n# \u251c\u2500\u2500 install_receptor.yml (playbook)\n# \u251c\u2500\u2500 inventory.yml\n# \u251c\u2500\u2500 group_vars\n# \u2502 \u2514\u2500\u2500 all.yml\n# \u251c\u2500\u2500 receptor\n# \u2502 \u251c\u2500\u2500 tls\n# \u2502 \u2502 \u251c\u2500\u2500 ca\n# \u2502 \u2502 \u2502 \u2514\u2500\u2500 receptor-ca.crt\n# \u2502 \u2502 \u251c\u2500\u2500 receptor.crt\n# \u2502 \u2502 \u2514\u2500\u2500 receptor.key\n# \u2502 \u2514\u2500\u2500 work-public-key.pem\n# \u2514\u2500\u2500 requirements.yml\nclass InstanceInstallBundle(GenericAPIView):\n\n name = _('Install Bundle')\n model = models.Instance\n serializer_class = serializers.InstanceSerializer\n permission_classes = (IsSystemAdminOrAuditor,)\n\n def get(self, request, *args, **kwargs):\n instance_obj = self.get_object()\n\n if instance_obj.node_type not in ('execution',):\n return Response(\n data=dict(msg=_('Install bundle can only be generated for execution nodes.')),\n status=status.HTTP_400_BAD_REQUEST,\n )\n\n with io.BytesIO() as f:\n with tarfile.open(fileobj=f, mode='w:gz') as tar:\n # copy /etc/receptor/tls/ca/receptor-ca.crt to receptor/tls/ca in the tar file\n tar.add(\n os.path.realpath('/etc/receptor/tls/ca/receptor-ca.crt'), arcname=f\"{instance_obj.hostname}_install_bundle/receptor/tls/ca/receptor-ca.crt\"\n )\n\n # copy /etc/receptor/signing/work-public-key.pem to receptor/work-public-key.pem\n tar.add('/etc/receptor/signing/work-public-key.pem', arcname=f\"{instance_obj.hostname}_install_bundle/receptor/work-public-key.pem\")\n\n # generate and write the receptor key to receptor/tls/receptor.key in the tar file\n key, cert = generate_receptor_tls(instance_obj)\n\n key_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/receptor/tls/receptor.key\")\n key_tarinfo.size = len(key)\n tar.addfile(key_tarinfo, io.BytesIO(key))\n\n cert_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/receptor/tls/receptor.crt\")\n cert_tarinfo.size = len(cert)\n tar.addfile(cert_tarinfo, io.BytesIO(cert))\n\n # generate and write install_receptor.yml to the tar file\n playbook = generate_playbook().encode('utf-8')\n playbook_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/install_receptor.yml\")\n playbook_tarinfo.size = len(playbook)\n tar.addfile(playbook_tarinfo, io.BytesIO(playbook))\n\n # generate and write inventory.yml to the tar file\n inventory_yml = generate_inventory_yml(instance_obj).encode('utf-8')\n inventory_yml_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/inventory.yml\")\n inventory_yml_tarinfo.size = len(inventory_yml)\n tar.addfile(inventory_yml_tarinfo, io.BytesIO(inventory_yml))\n\n # generate and write group_vars/all.yml to the tar file\n group_vars = generate_group_vars_all_yml(instance_obj).encode('utf-8')\n group_vars_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/group_vars/all.yml\")\n group_vars_tarinfo.size = len(group_vars)\n tar.addfile(group_vars_tarinfo, io.BytesIO(group_vars))\n\n # generate and write requirements.yml to the tar file\n requirements_yml = generate_requirements_yml().encode('utf-8')\n requirements_yml_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/requirements.yml\")\n requirements_yml_tarinfo.size = len(requirements_yml)\n tar.addfile(requirements_yml_tarinfo, io.BytesIO(requirements_yml))\n\n # respond with the tarfile\n f.seek(0)\n response = HttpResponse(f.read(), status=status.HTTP_200_OK)\n response['Content-Disposition'] = f\"attachment; filename={instance_obj.hostname}_install_bundle.tar.gz\"\n return response\n\n\ndef generate_playbook():\n return render_to_string(\"instance_install_bundle/install_receptor.yml\")\n\n\ndef generate_requirements_yml():\n return render_to_string(\"instance_install_bundle/requirements.yml\")\n\n\ndef generate_inventory_yml(instance_obj):\n return render_to_string(\"instance_install_bundle/inventory.yml\", context=dict(instance=instance_obj))\n\n\ndef generate_group_vars_all_yml(instance_obj):\n return render_to_string(\"instance_install_bundle/group_vars/all.yml\", context=dict(instance=instance_obj))\n\n\ndef generate_receptor_tls(instance_obj):\n # generate private key for the receptor\n key = rsa.generate_private_key(public_exponent=65537, key_size=2048)\n\n # encode receptor hostname to asn1\n hostname = instance_obj.hostname\n encoder = asn1.Encoder()\n encoder.start()\n encoder.write(hostname.encode(), nr=asn1.Numbers.UTF8String)\n hostname_asn1 = encoder.output()\n\n san_params = [\n DNSName(hostname),\n OtherName(ObjectIdentifier(RECEPTOR_OID), hostname_asn1),\n ]\n\n try:\n san_params.append(IPAddress(ipaddress.IPv4Address(hostname)))\n except ipaddress.AddressValueError:\n pass\n\n # generate certificate for the receptor\n csr = (\n x509.CertificateSigningRequestBuilder()\n .subject_name(\n x509.Name(\n [\n x509.NameAttribute(NameOID.COMMON_NAME, hostname),\n ]\n )\n )\n .add_extension(\n x509.SubjectAlternativeName(san_params),\n critical=False,\n )\n .sign(key, hashes.SHA256())\n )\n\n # sign csr with the receptor ca key from /etc/receptor/ca/receptor-ca.key\n with open('/etc/receptor/tls/ca/receptor-ca.key', 'rb') as f:\n ca_key = serialization.load_pem_private_key(\n f.read(),\n password=None,\n )\n\n with open('/etc/receptor/tls/ca/receptor-ca.crt', 'rb') as f:\n ca_cert = x509.load_pem_x509_certificate(f.read())\n\n cert = (\n x509.CertificateBuilder()\n .subject_name(csr.subject)\n .issuer_name(ca_cert.issuer)\n .public_key(csr.public_key())\n .serial_number(x509.random_serial_number())\n .not_valid_before(datetime.datetime.utcnow())\n .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=10))\n .add_extension(\n csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).value,\n critical=csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).critical,\n )\n .sign(ca_key, hashes.SHA256())\n )\n\n key = key.private_bytes(\n encoding=serialization.Encoding.PEM,\n format=serialization.PrivateFormat.TraditionalOpenSSL,\n encryption_algorithm=serialization.NoEncryption(),\n )\n\n cert = cert.public_bytes(\n encoding=serialization.Encoding.PEM,\n )\n\n return key, cert\n", "path": "awx/api/views/instance_install_bundle.py"}], "after_files": [{"content": "# Copyright (c) 2018 Red Hat, Inc.\n# All Rights Reserved.\n\nimport datetime\nimport io\nimport ipaddress\nimport os\nimport tarfile\n\nimport asn1\nfrom awx.api import serializers\nfrom awx.api.generics import GenericAPIView, Response\nfrom awx.api.permissions import IsSystemAdminOrAuditor\nfrom awx.main import models\nfrom cryptography import x509\nfrom cryptography.hazmat.primitives import hashes, serialization\nfrom cryptography.hazmat.primitives.asymmetric import rsa\nfrom cryptography.x509 import DNSName, IPAddress, ObjectIdentifier, OtherName\nfrom cryptography.x509.oid import NameOID\nfrom django.http import HttpResponse\nfrom django.template.loader import render_to_string\nfrom django.utils.translation import gettext_lazy as _\nfrom rest_framework import status\n\n# Red Hat has an OID namespace (RHANANA). Receptor has its own designation under that.\nRECEPTOR_OID = \"1.3.6.1.4.1.2312.19.1\"\n\n# generate install bundle for the instance\n# install bundle directory structure\n# \u251c\u2500\u2500 install_receptor.yml (playbook)\n# \u251c\u2500\u2500 inventory.yml\n# \u251c\u2500\u2500 group_vars\n# \u2502 \u2514\u2500\u2500 all.yml\n# \u251c\u2500\u2500 receptor\n# \u2502 \u251c\u2500\u2500 tls\n# \u2502 \u2502 \u251c\u2500\u2500 ca\n# \u2502 \u2502 \u2502 \u2514\u2500\u2500 receptor-ca.crt\n# \u2502 \u2502 \u251c\u2500\u2500 receptor.crt\n# \u2502 \u2502 \u2514\u2500\u2500 receptor.key\n# \u2502 \u2514\u2500\u2500 work-public-key.pem\n# \u2514\u2500\u2500 requirements.yml\nclass InstanceInstallBundle(GenericAPIView):\n\n name = _('Install Bundle')\n model = models.Instance\n serializer_class = serializers.InstanceSerializer\n permission_classes = (IsSystemAdminOrAuditor,)\n\n def get(self, request, *args, **kwargs):\n instance_obj = self.get_object()\n\n if instance_obj.node_type not in ('execution',):\n return Response(\n data=dict(msg=_('Install bundle can only be generated for execution nodes.')),\n status=status.HTTP_400_BAD_REQUEST,\n )\n\n with io.BytesIO() as f:\n with tarfile.open(fileobj=f, mode='w:gz') as tar:\n # copy /etc/receptor/tls/ca/receptor-ca.crt to receptor/tls/ca in the tar file\n tar.add(\n os.path.realpath('/etc/receptor/tls/ca/receptor-ca.crt'), arcname=f\"{instance_obj.hostname}_install_bundle/receptor/tls/ca/receptor-ca.crt\"\n )\n\n # copy /etc/receptor/signing/work-public-key.pem to receptor/work-public-key.pem\n tar.add('/etc/receptor/signing/work-public-key.pem', arcname=f\"{instance_obj.hostname}_install_bundle/receptor/work-public-key.pem\")\n\n # generate and write the receptor key to receptor/tls/receptor.key in the tar file\n key, cert = generate_receptor_tls(instance_obj)\n\n key_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/receptor/tls/receptor.key\")\n key_tarinfo.size = len(key)\n tar.addfile(key_tarinfo, io.BytesIO(key))\n\n cert_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/receptor/tls/receptor.crt\")\n cert_tarinfo.size = len(cert)\n tar.addfile(cert_tarinfo, io.BytesIO(cert))\n\n # generate and write install_receptor.yml to the tar file\n playbook = generate_playbook().encode('utf-8')\n playbook_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/install_receptor.yml\")\n playbook_tarinfo.size = len(playbook)\n tar.addfile(playbook_tarinfo, io.BytesIO(playbook))\n\n # generate and write inventory.yml to the tar file\n inventory_yml = generate_inventory_yml(instance_obj).encode('utf-8')\n inventory_yml_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/inventory.yml\")\n inventory_yml_tarinfo.size = len(inventory_yml)\n tar.addfile(inventory_yml_tarinfo, io.BytesIO(inventory_yml))\n\n # generate and write group_vars/all.yml to the tar file\n group_vars = generate_group_vars_all_yml(instance_obj).encode('utf-8')\n group_vars_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/group_vars/all.yml\")\n group_vars_tarinfo.size = len(group_vars)\n tar.addfile(group_vars_tarinfo, io.BytesIO(group_vars))\n\n # generate and write requirements.yml to the tar file\n requirements_yml = generate_requirements_yml().encode('utf-8')\n requirements_yml_tarinfo = tarfile.TarInfo(f\"{instance_obj.hostname}_install_bundle/requirements.yml\")\n requirements_yml_tarinfo.size = len(requirements_yml)\n tar.addfile(requirements_yml_tarinfo, io.BytesIO(requirements_yml))\n\n # respond with the tarfile\n f.seek(0)\n response = HttpResponse(f.read(), status=status.HTTP_200_OK)\n response['Content-Disposition'] = f\"attachment; filename={instance_obj.hostname}_install_bundle.tar.gz\"\n return response\n\n\ndef generate_playbook():\n return render_to_string(\"instance_install_bundle/install_receptor.yml\")\n\n\ndef generate_requirements_yml():\n return render_to_string(\"instance_install_bundle/requirements.yml\")\n\n\ndef generate_inventory_yml(instance_obj):\n return render_to_string(\"instance_install_bundle/inventory.yml\", context=dict(instance=instance_obj))\n\n\ndef generate_group_vars_all_yml(instance_obj):\n return render_to_string(\"instance_install_bundle/group_vars/all.yml\", context=dict(instance=instance_obj))\n\n\ndef generate_receptor_tls(instance_obj):\n # generate private key for the receptor\n key = rsa.generate_private_key(public_exponent=65537, key_size=2048)\n\n # encode receptor hostname to asn1\n hostname = instance_obj.hostname\n encoder = asn1.Encoder()\n encoder.start()\n encoder.write(hostname.encode(), nr=asn1.Numbers.UTF8String)\n hostname_asn1 = encoder.output()\n\n san_params = [\n DNSName(hostname),\n OtherName(ObjectIdentifier(RECEPTOR_OID), hostname_asn1),\n ]\n\n try:\n san_params.append(IPAddress(ipaddress.IPv4Address(hostname)))\n except ipaddress.AddressValueError:\n pass\n\n # generate certificate for the receptor\n csr = (\n x509.CertificateSigningRequestBuilder()\n .subject_name(\n x509.Name(\n [\n x509.NameAttribute(NameOID.COMMON_NAME, hostname),\n ]\n )\n )\n .add_extension(\n x509.SubjectAlternativeName(san_params),\n critical=False,\n )\n .sign(key, hashes.SHA256())\n )\n\n # sign csr with the receptor ca key from /etc/receptor/ca/receptor-ca.key\n with open('/etc/receptor/tls/ca/receptor-ca.key', 'rb') as f:\n ca_key = serialization.load_pem_private_key(\n f.read(),\n password=None,\n )\n\n with open('/etc/receptor/tls/ca/receptor-ca.crt', 'rb') as f:\n ca_cert = x509.load_pem_x509_certificate(f.read())\n\n cert = (\n x509.CertificateBuilder()\n .subject_name(csr.subject)\n .issuer_name(ca_cert.issuer)\n .public_key(csr.public_key())\n .serial_number(x509.random_serial_number())\n .not_valid_before(datetime.datetime.utcnow())\n .not_valid_after(datetime.datetime.utcnow() + datetime.timedelta(days=3650))\n .add_extension(\n csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).value,\n critical=csr.extensions.get_extension_for_class(x509.SubjectAlternativeName).critical,\n )\n .sign(ca_key, hashes.SHA256())\n )\n\n key = key.private_bytes(\n encoding=serialization.Encoding.PEM,\n format=serialization.PrivateFormat.TraditionalOpenSSL,\n encryption_algorithm=serialization.NoEncryption(),\n )\n\n cert = cert.public_bytes(\n encoding=serialization.Encoding.PEM,\n )\n\n return key, cert\n", "path": "awx/api/views/instance_install_bundle.py"}]} | 3,503 | 175 |
gh_patches_debug_758 | rasdani/github-patches | git_diff | vllm-project__vllm-2337 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[v0.2.7] Release Tracker
**ETA**: Jan 3rd - 4th
## Major changes
TBD
## PRs to be merged before the release
- [x] #2221
- [ ] ~~#2293~~ (deferred)
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `vllm/__init__.py`
Content:
```
1 """vLLM: a high-throughput and memory-efficient inference engine for LLMs"""
2
3 from vllm.engine.arg_utils import AsyncEngineArgs, EngineArgs
4 from vllm.engine.async_llm_engine import AsyncLLMEngine
5 from vllm.engine.llm_engine import LLMEngine
6 from vllm.engine.ray_utils import initialize_cluster
7 from vllm.entrypoints.llm import LLM
8 from vllm.outputs import CompletionOutput, RequestOutput
9 from vllm.sampling_params import SamplingParams
10
11 __version__ = "0.2.6"
12
13 __all__ = [
14 "LLM",
15 "SamplingParams",
16 "RequestOutput",
17 "CompletionOutput",
18 "LLMEngine",
19 "EngineArgs",
20 "AsyncLLMEngine",
21 "AsyncEngineArgs",
22 "initialize_cluster",
23 ]
24
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/vllm/__init__.py b/vllm/__init__.py
--- a/vllm/__init__.py
+++ b/vllm/__init__.py
@@ -8,7 +8,7 @@
from vllm.outputs import CompletionOutput, RequestOutput
from vllm.sampling_params import SamplingParams
-__version__ = "0.2.6"
+__version__ = "0.2.7"
__all__ = [
"LLM",
| {"golden_diff": "diff --git a/vllm/__init__.py b/vllm/__init__.py\n--- a/vllm/__init__.py\n+++ b/vllm/__init__.py\n@@ -8,7 +8,7 @@\n from vllm.outputs import CompletionOutput, RequestOutput\n from vllm.sampling_params import SamplingParams\n \n-__version__ = \"0.2.6\"\n+__version__ = \"0.2.7\"\n \n __all__ = [\n \"LLM\",\n", "issue": "[v0.2.7] Release Tracker\n**ETA**: Jan 3rd - 4th\r\n\r\n## Major changes\r\n\r\nTBD\r\n\r\n## PRs to be merged before the release\r\n\r\n- [x] #2221 \r\n- [ ] ~~#2293~~ (deferred)\n", "before_files": [{"content": "\"\"\"vLLM: a high-throughput and memory-efficient inference engine for LLMs\"\"\"\n\nfrom vllm.engine.arg_utils import AsyncEngineArgs, EngineArgs\nfrom vllm.engine.async_llm_engine import AsyncLLMEngine\nfrom vllm.engine.llm_engine import LLMEngine\nfrom vllm.engine.ray_utils import initialize_cluster\nfrom vllm.entrypoints.llm import LLM\nfrom vllm.outputs import CompletionOutput, RequestOutput\nfrom vllm.sampling_params import SamplingParams\n\n__version__ = \"0.2.6\"\n\n__all__ = [\n \"LLM\",\n \"SamplingParams\",\n \"RequestOutput\",\n \"CompletionOutput\",\n \"LLMEngine\",\n \"EngineArgs\",\n \"AsyncLLMEngine\",\n \"AsyncEngineArgs\",\n \"initialize_cluster\",\n]\n", "path": "vllm/__init__.py"}], "after_files": [{"content": "\"\"\"vLLM: a high-throughput and memory-efficient inference engine for LLMs\"\"\"\n\nfrom vllm.engine.arg_utils import AsyncEngineArgs, EngineArgs\nfrom vllm.engine.async_llm_engine import AsyncLLMEngine\nfrom vllm.engine.llm_engine import LLMEngine\nfrom vllm.engine.ray_utils import initialize_cluster\nfrom vllm.entrypoints.llm import LLM\nfrom vllm.outputs import CompletionOutput, RequestOutput\nfrom vllm.sampling_params import SamplingParams\n\n__version__ = \"0.2.7\"\n\n__all__ = [\n \"LLM\",\n \"SamplingParams\",\n \"RequestOutput\",\n \"CompletionOutput\",\n \"LLMEngine\",\n \"EngineArgs\",\n \"AsyncLLMEngine\",\n \"AsyncEngineArgs\",\n \"initialize_cluster\",\n]\n", "path": "vllm/__init__.py"}]} | 541 | 108 |
gh_patches_debug_12904 | rasdani/github-patches | git_diff | netket__netket-611 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Floating Point Error in Lattice.py
I tried generating a periodic Kagome lattice using lattice.py:
>>> kagome = nk.graph.Lattice(basis_vectors=[[2.,0.],[1.,np.sqrt(3)]],extent=[2,2],atoms_coord=[[0.,0.],[1./2.,np.sqrt(3)/2.],[1.,0.]])
Only half of the edges appeared:
>>>kagome.n_edges()
12
The bug is related to floating points, some distances are registered as 0.99999... and some are registered as 1.0
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `netket/graph/lattice.py`
Content:
```
1 # Copyright 2020, 2021 The NetKet Authors - All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from .graph import NetworkX
16 from scipy.spatial import cKDTree
17 from scipy.sparse import find, triu
18 import numpy as _np
19 import itertools
20 import networkx as _nx
21 import warnings
22
23
24 def get_edges(atoms_positions, cutoff):
25 kdtree = cKDTree(atoms_positions)
26 dist_matrix = kdtree.sparse_distance_matrix(kdtree, cutoff)
27 id1, id2, values = find(triu(dist_matrix))
28 pairs = []
29 min_dists = {} # keys are nodes, values are min dists
30 for node in _np.unique(_np.concatenate((id1, id2))):
31 min_dist = _np.min(values[(id1 == node) | (id2 == node)])
32 min_dists[node] = min_dist
33 for node in _np.unique(id1):
34 min_dist = _np.min(values[id1 == node])
35 mask = (id1 == node) & (values == min_dist)
36 first = id1[mask]
37 second = id2[mask]
38 for pair in zip(first, second):
39 if min_dist == min_dists[pair[0]] and min_dist == min_dists[pair[1]]:
40 pairs.append(pair)
41 return pairs
42
43
44 def create_points(basis_vectors, extent, atom_coords, pbc):
45 shell_vec = _np.zeros(extent.size, dtype=int)
46 shift_vec = _np.zeros(extent.size, dtype=int)
47 # note: by modifying these, the number of shells can be tuned.
48 shell_vec[pbc] = 2
49 shift_vec[pbc] = 1
50 ranges = tuple([list(range(ex)) for ex in extent + shell_vec])
51 atoms = []
52 cellANDlabel_to_site = {}
53 for s_cell in itertools.product(*ranges):
54 s_coord_cell = _np.asarray(s_cell) - shift_vec
55 if _np.any(s_coord_cell < 0) or _np.any(s_coord_cell > (extent - 1)):
56 inside = False
57 else:
58 inside = True
59 atom_count = len(atoms)
60 for i, atom_coord in enumerate(atom_coords):
61 s_coord_atom = s_coord_cell + atom_coord
62 r_coord_atom = _np.matmul(basis_vectors.T, s_coord_atom)
63 atoms.append(
64 {
65 "Label": i,
66 "cell": s_coord_cell,
67 "r_coord": r_coord_atom,
68 "inside": inside,
69 }
70 )
71 if tuple(s_coord_cell) not in cellANDlabel_to_site.keys():
72 cellANDlabel_to_site[tuple(s_coord_cell)] = {}
73 cellANDlabel_to_site[tuple(s_coord_cell)][i] = atom_count + i
74 return atoms, cellANDlabel_to_site
75
76
77 def get_true_edges(basis_vectors, atoms, cellANDlabel_to_site, extent):
78 atoms_positions = dicts_to_array(atoms, "r_coord")
79 naive_edges = get_edges(
80 atoms_positions, _np.linalg.norm(basis_vectors, axis=1).max()
81 )
82 true_edges = []
83 for node1, node2 in naive_edges:
84 atom1 = atoms[node1]
85 atom2 = atoms[node2]
86 if atom1["inside"] and atom2["inside"]:
87 true_edges.append((node1, node2))
88 elif atom1["inside"] or atom2["inside"]:
89 cell1 = atom1["cell"] % extent
90 cell2 = atom2["cell"] % extent
91 node1 = cellANDlabel_to_site[tuple(cell1)][atom1["Label"]]
92 node2 = cellANDlabel_to_site[tuple(cell2)][atom2["Label"]]
93 edge = (node1, node2)
94 if edge not in true_edges and (node2, node1) not in true_edges:
95 true_edges.append(edge)
96 return true_edges
97
98
99 def dicts_to_array(dicts, key):
100 result = []
101 for d in dicts:
102 result.append(d[key])
103 return _np.asarray(result)
104
105
106 class Lattice(NetworkX):
107 """A lattice built translating a unit cell and adding edges between nearest neighbours sites.
108
109 The unit cell is defined by the ``basis_vectors`` and it can contain an arbitrary number of atoms.
110 Each atom is located at an arbitrary position and is labelled by an integer number,
111 meant to distinguish between the different atoms within the unit cell.
112 Periodic boundary conditions can also be imposed along the desired directions.
113 There are three different ways to refer to the lattice sites. A site can be labelled
114 by a simple integer number (the site index) or by its coordinates (actual position in space).
115 """
116
117 def __init__(self, basis_vectors, extent, *, pbc: bool = True, atoms_coord=[]):
118 """
119 Constructs a new ``Lattice`` given its side length and the features of the unit cell.
120
121 Args:
122 basis_vectors: The basis vectors of the unit cell.
123 extent: The number of copies of the unit cell.
124 pbc: If ``True`` then the constructed lattice
125 will have periodic boundary conditions, otherwise
126 open boundary conditions are imposed (default=``True``).
127 atoms_coord: The coordinates of different atoms in the unit cell (default=one atom at the origin).
128
129 Examples:
130 Constructs a rectangular 3X4 lattice with periodic boundary conditions.
131
132 >>> import netket
133 >>> g=netket.graph.Lattice(basis_vectors=[[1,0],[0,1]],extent=[3,4])
134 >>> print(g.n_nodes)
135 12
136
137 """
138
139 self._basis_vectors = _np.asarray(basis_vectors)
140 if self._basis_vectors.ndim != 2:
141 raise ValueError("Every vector must have the same dimension.")
142 if self._basis_vectors.shape[0] != self._basis_vectors.shape[1]:
143 raise ValueError(
144 "basis_vectors must be a basis for the N-dimensional vector space you chose"
145 )
146
147 if not atoms_coord:
148 atoms_coord = [_np.zeros(self._basis_vectors.shape[0])]
149 atoms_coord = _np.asarray(atoms_coord)
150 atoms_coord_fractional = _np.asarray(
151 [
152 _np.matmul(_np.linalg.inv(self._basis_vectors.T), atom_coord)
153 for atom_coord in atoms_coord
154 ]
155 )
156 if atoms_coord_fractional.min() < 0 or atoms_coord_fractional.max() >= 1:
157 # Maybe there is another way to state this. I want to avoid that there exists the possibility that two atoms from different cells are at the same position:
158 raise ValueError(
159 "atoms must reside inside their corresponding unit cell, which includes only the 0-faces in fractional coordinates."
160 )
161 uniques = _np.unique(atoms_coord, axis=0)
162 if len(atoms_coord) != uniques.shape[0]:
163 atoms_coord = _np.asarray(uniques)
164 warnings.warn(
165 f"Some atom positions are not unique. Duplicates were dropped, and now atom positions are {atoms_coord}",
166 UserWarning,
167 )
168
169 self._atoms_coord = atoms_coord
170
171 if isinstance(pbc, bool):
172 self._pbc = [pbc] * self._basis_vectors.shape[1]
173 elif (
174 not isinstance(pbc, list)
175 or len(pbc) != self._basis_vectors.shape[1]
176 or sum([1 for pbci in pbc if isinstance(pbci, bool)])
177 != self._basis_vectors.shape[1]
178 ):
179 raise ValueError(
180 "pbc must be either a boolean or a list of booleans with the same dimension as the vector space you chose."
181 )
182 else:
183 self._pbc = pbc
184
185 extent = _np.asarray(extent)
186 self.extent = extent
187
188 atoms, cellANDlabel_to_site = create_points(
189 self._basis_vectors, extent, atoms_coord_fractional, pbc
190 )
191 edges = get_true_edges(self._basis_vectors, atoms, cellANDlabel_to_site, extent)
192 graph = _nx.MultiGraph(edges)
193
194 # Rename atoms
195 old_nodes = sorted(set([node for edge in edges for node in edge]))
196 self._atoms = [atoms[old_node] for old_node in old_nodes]
197 self._coord_to_site = {
198 tuple(atom["r_coord"]): new_site
199 for new_site, atom in enumerate(self._atoms)
200 }
201 new_nodes = {old_node: new_node for new_node, old_node in enumerate(old_nodes)}
202 graph = _nx.relabel_nodes(graph, new_nodes)
203
204 # Order node names
205 nodes = sorted(graph.nodes())
206 edges = list(graph.edges())
207 graph = _nx.MultiGraph()
208 graph.add_nodes_from(nodes)
209 graph.add_edges_from(edges)
210
211 super().__init__(graph)
212
213 @property
214 def basis_vectors(self):
215 return self._basis_vectors
216
217 @property
218 def atoms_coord(self):
219 """
220 Coordinates of atoms in the unit cell.
221 """
222 return self._atoms_coord
223
224 def atom_label(self, site):
225 return self._atoms[site]["Label"]
226
227 def site_to_coord(self, site):
228 return self._atoms[site]["r_coord"]
229
230 def coord_to_site(self, coord):
231 return self._coord_to_site[tuple(coord)]
232
233 def site_to_vector(self, site):
234 return self._atoms[site]["cell"]
235
236 def vector_to_coord(self, vector):
237 return _np.matmul(self._basis_vectors, vector)
238
239 def __repr__(self):
240 return "Lattice(n_nodes={})\n extent={}\n basis_vectors={}".format(
241 self.n_nodes, self.extent.tolist(), self.basis_vectors.tolist()
242 )
243
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/netket/graph/lattice.py b/netket/graph/lattice.py
--- a/netket/graph/lattice.py
+++ b/netket/graph/lattice.py
@@ -32,11 +32,13 @@
min_dists[node] = min_dist
for node in _np.unique(id1):
min_dist = _np.min(values[id1 == node])
- mask = (id1 == node) & (values == min_dist)
+ mask = (id1 == node) & (_np.isclose(values, min_dist))
first = id1[mask]
second = id2[mask]
for pair in zip(first, second):
- if min_dist == min_dists[pair[0]] and min_dist == min_dists[pair[1]]:
+ if _np.isclose(min_dist, min_dists[pair[0]]) and _np.isclose(
+ min_dist, min_dists[pair[1]]
+ ):
pairs.append(pair)
return pairs
| {"golden_diff": "diff --git a/netket/graph/lattice.py b/netket/graph/lattice.py\n--- a/netket/graph/lattice.py\n+++ b/netket/graph/lattice.py\n@@ -32,11 +32,13 @@\n min_dists[node] = min_dist\n for node in _np.unique(id1):\n min_dist = _np.min(values[id1 == node])\n- mask = (id1 == node) & (values == min_dist)\n+ mask = (id1 == node) & (_np.isclose(values, min_dist))\n first = id1[mask]\n second = id2[mask]\n for pair in zip(first, second):\n- if min_dist == min_dists[pair[0]] and min_dist == min_dists[pair[1]]:\n+ if _np.isclose(min_dist, min_dists[pair[0]]) and _np.isclose(\n+ min_dist, min_dists[pair[1]]\n+ ):\n pairs.append(pair)\n return pairs\n", "issue": "Floating Point Error in Lattice.py\nI tried generating a periodic Kagome lattice using lattice.py:\r\n\r\n>>> kagome = nk.graph.Lattice(basis_vectors=[[2.,0.],[1.,np.sqrt(3)]],extent=[2,2],atoms_coord=[[0.,0.],[1./2.,np.sqrt(3)/2.],[1.,0.]])\r\n\r\nOnly half of the edges appeared:\r\n\r\n>>>kagome.n_edges()\r\n12\r\n\r\nThe bug is related to floating points, some distances are registered as 0.99999... and some are registered as 1.0\r\n\n", "before_files": [{"content": "# Copyright 2020, 2021 The NetKet Authors - All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom .graph import NetworkX\nfrom scipy.spatial import cKDTree\nfrom scipy.sparse import find, triu\nimport numpy as _np\nimport itertools\nimport networkx as _nx\nimport warnings\n\n\ndef get_edges(atoms_positions, cutoff):\n kdtree = cKDTree(atoms_positions)\n dist_matrix = kdtree.sparse_distance_matrix(kdtree, cutoff)\n id1, id2, values = find(triu(dist_matrix))\n pairs = []\n min_dists = {} # keys are nodes, values are min dists\n for node in _np.unique(_np.concatenate((id1, id2))):\n min_dist = _np.min(values[(id1 == node) | (id2 == node)])\n min_dists[node] = min_dist\n for node in _np.unique(id1):\n min_dist = _np.min(values[id1 == node])\n mask = (id1 == node) & (values == min_dist)\n first = id1[mask]\n second = id2[mask]\n for pair in zip(first, second):\n if min_dist == min_dists[pair[0]] and min_dist == min_dists[pair[1]]:\n pairs.append(pair)\n return pairs\n\n\ndef create_points(basis_vectors, extent, atom_coords, pbc):\n shell_vec = _np.zeros(extent.size, dtype=int)\n shift_vec = _np.zeros(extent.size, dtype=int)\n # note: by modifying these, the number of shells can be tuned.\n shell_vec[pbc] = 2\n shift_vec[pbc] = 1\n ranges = tuple([list(range(ex)) for ex in extent + shell_vec])\n atoms = []\n cellANDlabel_to_site = {}\n for s_cell in itertools.product(*ranges):\n s_coord_cell = _np.asarray(s_cell) - shift_vec\n if _np.any(s_coord_cell < 0) or _np.any(s_coord_cell > (extent - 1)):\n inside = False\n else:\n inside = True\n atom_count = len(atoms)\n for i, atom_coord in enumerate(atom_coords):\n s_coord_atom = s_coord_cell + atom_coord\n r_coord_atom = _np.matmul(basis_vectors.T, s_coord_atom)\n atoms.append(\n {\n \"Label\": i,\n \"cell\": s_coord_cell,\n \"r_coord\": r_coord_atom,\n \"inside\": inside,\n }\n )\n if tuple(s_coord_cell) not in cellANDlabel_to_site.keys():\n cellANDlabel_to_site[tuple(s_coord_cell)] = {}\n cellANDlabel_to_site[tuple(s_coord_cell)][i] = atom_count + i\n return atoms, cellANDlabel_to_site\n\n\ndef get_true_edges(basis_vectors, atoms, cellANDlabel_to_site, extent):\n atoms_positions = dicts_to_array(atoms, \"r_coord\")\n naive_edges = get_edges(\n atoms_positions, _np.linalg.norm(basis_vectors, axis=1).max()\n )\n true_edges = []\n for node1, node2 in naive_edges:\n atom1 = atoms[node1]\n atom2 = atoms[node2]\n if atom1[\"inside\"] and atom2[\"inside\"]:\n true_edges.append((node1, node2))\n elif atom1[\"inside\"] or atom2[\"inside\"]:\n cell1 = atom1[\"cell\"] % extent\n cell2 = atom2[\"cell\"] % extent\n node1 = cellANDlabel_to_site[tuple(cell1)][atom1[\"Label\"]]\n node2 = cellANDlabel_to_site[tuple(cell2)][atom2[\"Label\"]]\n edge = (node1, node2)\n if edge not in true_edges and (node2, node1) not in true_edges:\n true_edges.append(edge)\n return true_edges\n\n\ndef dicts_to_array(dicts, key):\n result = []\n for d in dicts:\n result.append(d[key])\n return _np.asarray(result)\n\n\nclass Lattice(NetworkX):\n \"\"\"A lattice built translating a unit cell and adding edges between nearest neighbours sites.\n\n The unit cell is defined by the ``basis_vectors`` and it can contain an arbitrary number of atoms.\n Each atom is located at an arbitrary position and is labelled by an integer number,\n meant to distinguish between the different atoms within the unit cell.\n Periodic boundary conditions can also be imposed along the desired directions.\n There are three different ways to refer to the lattice sites. A site can be labelled\n by a simple integer number (the site index) or by its coordinates (actual position in space).\n \"\"\"\n\n def __init__(self, basis_vectors, extent, *, pbc: bool = True, atoms_coord=[]):\n \"\"\"\n Constructs a new ``Lattice`` given its side length and the features of the unit cell.\n\n Args:\n basis_vectors: The basis vectors of the unit cell.\n extent: The number of copies of the unit cell.\n pbc: If ``True`` then the constructed lattice\n will have periodic boundary conditions, otherwise\n open boundary conditions are imposed (default=``True``).\n atoms_coord: The coordinates of different atoms in the unit cell (default=one atom at the origin).\n\n Examples:\n Constructs a rectangular 3X4 lattice with periodic boundary conditions.\n\n >>> import netket\n >>> g=netket.graph.Lattice(basis_vectors=[[1,0],[0,1]],extent=[3,4])\n >>> print(g.n_nodes)\n 12\n\n \"\"\"\n\n self._basis_vectors = _np.asarray(basis_vectors)\n if self._basis_vectors.ndim != 2:\n raise ValueError(\"Every vector must have the same dimension.\")\n if self._basis_vectors.shape[0] != self._basis_vectors.shape[1]:\n raise ValueError(\n \"basis_vectors must be a basis for the N-dimensional vector space you chose\"\n )\n\n if not atoms_coord:\n atoms_coord = [_np.zeros(self._basis_vectors.shape[0])]\n atoms_coord = _np.asarray(atoms_coord)\n atoms_coord_fractional = _np.asarray(\n [\n _np.matmul(_np.linalg.inv(self._basis_vectors.T), atom_coord)\n for atom_coord in atoms_coord\n ]\n )\n if atoms_coord_fractional.min() < 0 or atoms_coord_fractional.max() >= 1:\n # Maybe there is another way to state this. I want to avoid that there exists the possibility that two atoms from different cells are at the same position:\n raise ValueError(\n \"atoms must reside inside their corresponding unit cell, which includes only the 0-faces in fractional coordinates.\"\n )\n uniques = _np.unique(atoms_coord, axis=0)\n if len(atoms_coord) != uniques.shape[0]:\n atoms_coord = _np.asarray(uniques)\n warnings.warn(\n f\"Some atom positions are not unique. Duplicates were dropped, and now atom positions are {atoms_coord}\",\n UserWarning,\n )\n\n self._atoms_coord = atoms_coord\n\n if isinstance(pbc, bool):\n self._pbc = [pbc] * self._basis_vectors.shape[1]\n elif (\n not isinstance(pbc, list)\n or len(pbc) != self._basis_vectors.shape[1]\n or sum([1 for pbci in pbc if isinstance(pbci, bool)])\n != self._basis_vectors.shape[1]\n ):\n raise ValueError(\n \"pbc must be either a boolean or a list of booleans with the same dimension as the vector space you chose.\"\n )\n else:\n self._pbc = pbc\n\n extent = _np.asarray(extent)\n self.extent = extent\n\n atoms, cellANDlabel_to_site = create_points(\n self._basis_vectors, extent, atoms_coord_fractional, pbc\n )\n edges = get_true_edges(self._basis_vectors, atoms, cellANDlabel_to_site, extent)\n graph = _nx.MultiGraph(edges)\n\n # Rename atoms\n old_nodes = sorted(set([node for edge in edges for node in edge]))\n self._atoms = [atoms[old_node] for old_node in old_nodes]\n self._coord_to_site = {\n tuple(atom[\"r_coord\"]): new_site\n for new_site, atom in enumerate(self._atoms)\n }\n new_nodes = {old_node: new_node for new_node, old_node in enumerate(old_nodes)}\n graph = _nx.relabel_nodes(graph, new_nodes)\n\n # Order node names\n nodes = sorted(graph.nodes())\n edges = list(graph.edges())\n graph = _nx.MultiGraph()\n graph.add_nodes_from(nodes)\n graph.add_edges_from(edges)\n\n super().__init__(graph)\n\n @property\n def basis_vectors(self):\n return self._basis_vectors\n\n @property\n def atoms_coord(self):\n \"\"\"\n Coordinates of atoms in the unit cell.\n \"\"\"\n return self._atoms_coord\n\n def atom_label(self, site):\n return self._atoms[site][\"Label\"]\n\n def site_to_coord(self, site):\n return self._atoms[site][\"r_coord\"]\n\n def coord_to_site(self, coord):\n return self._coord_to_site[tuple(coord)]\n\n def site_to_vector(self, site):\n return self._atoms[site][\"cell\"]\n\n def vector_to_coord(self, vector):\n return _np.matmul(self._basis_vectors, vector)\n\n def __repr__(self):\n return \"Lattice(n_nodes={})\\n extent={}\\n basis_vectors={}\".format(\n self.n_nodes, self.extent.tolist(), self.basis_vectors.tolist()\n )\n", "path": "netket/graph/lattice.py"}], "after_files": [{"content": "# Copyright 2020, 2021 The NetKet Authors - All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom .graph import NetworkX\nfrom scipy.spatial import cKDTree\nfrom scipy.sparse import find, triu\nimport numpy as _np\nimport itertools\nimport networkx as _nx\nimport warnings\n\n\ndef get_edges(atoms_positions, cutoff):\n kdtree = cKDTree(atoms_positions)\n dist_matrix = kdtree.sparse_distance_matrix(kdtree, cutoff)\n id1, id2, values = find(triu(dist_matrix))\n pairs = []\n min_dists = {} # keys are nodes, values are min dists\n for node in _np.unique(_np.concatenate((id1, id2))):\n min_dist = _np.min(values[(id1 == node) | (id2 == node)])\n min_dists[node] = min_dist\n for node in _np.unique(id1):\n min_dist = _np.min(values[id1 == node])\n mask = (id1 == node) & (_np.isclose(values, min_dist))\n first = id1[mask]\n second = id2[mask]\n for pair in zip(first, second):\n if _np.isclose(min_dist, min_dists[pair[0]]) and _np.isclose(\n min_dist, min_dists[pair[1]]\n ):\n pairs.append(pair)\n return pairs\n\n\ndef create_points(basis_vectors, extent, atom_coords, pbc):\n shell_vec = _np.zeros(extent.size, dtype=int)\n shift_vec = _np.zeros(extent.size, dtype=int)\n # note: by modifying these, the number of shells can be tuned.\n shell_vec[pbc] = 2\n shift_vec[pbc] = 1\n ranges = tuple([list(range(ex)) for ex in extent + shell_vec])\n atoms = []\n cellANDlabel_to_site = {}\n for s_cell in itertools.product(*ranges):\n s_coord_cell = _np.asarray(s_cell) - shift_vec\n if _np.any(s_coord_cell < 0) or _np.any(s_coord_cell > (extent - 1)):\n inside = False\n else:\n inside = True\n atom_count = len(atoms)\n for i, atom_coord in enumerate(atom_coords):\n s_coord_atom = s_coord_cell + atom_coord\n r_coord_atom = _np.matmul(basis_vectors.T, s_coord_atom)\n atoms.append(\n {\n \"Label\": i,\n \"cell\": s_coord_cell,\n \"r_coord\": r_coord_atom,\n \"inside\": inside,\n }\n )\n if tuple(s_coord_cell) not in cellANDlabel_to_site.keys():\n cellANDlabel_to_site[tuple(s_coord_cell)] = {}\n cellANDlabel_to_site[tuple(s_coord_cell)][i] = atom_count + i\n return atoms, cellANDlabel_to_site\n\n\ndef get_true_edges(basis_vectors, atoms, cellANDlabel_to_site, extent):\n atoms_positions = dicts_to_array(atoms, \"r_coord\")\n naive_edges = get_edges(\n atoms_positions, _np.linalg.norm(basis_vectors, axis=1).max()\n )\n true_edges = []\n for node1, node2 in naive_edges:\n atom1 = atoms[node1]\n atom2 = atoms[node2]\n if atom1[\"inside\"] and atom2[\"inside\"]:\n true_edges.append((node1, node2))\n elif atom1[\"inside\"] or atom2[\"inside\"]:\n cell1 = atom1[\"cell\"] % extent\n cell2 = atom2[\"cell\"] % extent\n node1 = cellANDlabel_to_site[tuple(cell1)][atom1[\"Label\"]]\n node2 = cellANDlabel_to_site[tuple(cell2)][atom2[\"Label\"]]\n edge = (node1, node2)\n if edge not in true_edges and (node2, node1) not in true_edges:\n true_edges.append(edge)\n return true_edges\n\n\ndef dicts_to_array(dicts, key):\n result = []\n for d in dicts:\n result.append(d[key])\n return _np.asarray(result)\n\n\nclass Lattice(NetworkX):\n \"\"\"A lattice built translating a unit cell and adding edges between nearest neighbours sites.\n\n The unit cell is defined by the ``basis_vectors`` and it can contain an arbitrary number of atoms.\n Each atom is located at an arbitrary position and is labelled by an integer number,\n meant to distinguish between the different atoms within the unit cell.\n Periodic boundary conditions can also be imposed along the desired directions.\n There are three different ways to refer to the lattice sites. A site can be labelled\n by a simple integer number (the site index) or by its coordinates (actual position in space).\n \"\"\"\n\n def __init__(self, basis_vectors, extent, *, pbc: bool = True, atoms_coord=[]):\n \"\"\"\n Constructs a new ``Lattice`` given its side length and the features of the unit cell.\n\n Args:\n basis_vectors: The basis vectors of the unit cell.\n extent: The number of copies of the unit cell.\n pbc: If ``True`` then the constructed lattice\n will have periodic boundary conditions, otherwise\n open boundary conditions are imposed (default=``True``).\n atoms_coord: The coordinates of different atoms in the unit cell (default=one atom at the origin).\n\n Examples:\n Constructs a rectangular 3X4 lattice with periodic boundary conditions.\n\n >>> import netket\n >>> g=netket.graph.Lattice(basis_vectors=[[1,0],[0,1]],extent=[3,4])\n >>> print(g.n_nodes)\n 12\n\n \"\"\"\n\n self._basis_vectors = _np.asarray(basis_vectors)\n if self._basis_vectors.ndim != 2:\n raise ValueError(\"Every vector must have the same dimension.\")\n if self._basis_vectors.shape[0] != self._basis_vectors.shape[1]:\n raise ValueError(\n \"basis_vectors must be a basis for the N-dimensional vector space you chose\"\n )\n\n if not atoms_coord:\n atoms_coord = [_np.zeros(self._basis_vectors.shape[0])]\n atoms_coord = _np.asarray(atoms_coord)\n atoms_coord_fractional = _np.asarray(\n [\n _np.matmul(_np.linalg.inv(self._basis_vectors.T), atom_coord)\n for atom_coord in atoms_coord\n ]\n )\n if atoms_coord_fractional.min() < 0 or atoms_coord_fractional.max() >= 1:\n # Maybe there is another way to state this. I want to avoid that there exists the possibility that two atoms from different cells are at the same position:\n raise ValueError(\n \"atoms must reside inside their corresponding unit cell, which includes only the 0-faces in fractional coordinates.\"\n )\n uniques = _np.unique(atoms_coord, axis=0)\n if len(atoms_coord) != uniques.shape[0]:\n atoms_coord = _np.asarray(uniques)\n warnings.warn(\n f\"Some atom positions are not unique. Duplicates were dropped, and now atom positions are {atoms_coord}\",\n UserWarning,\n )\n\n self._atoms_coord = atoms_coord\n\n if isinstance(pbc, bool):\n self._pbc = [pbc] * self._basis_vectors.shape[1]\n elif (\n not isinstance(pbc, list)\n or len(pbc) != self._basis_vectors.shape[1]\n or sum([1 for pbci in pbc if isinstance(pbci, bool)])\n != self._basis_vectors.shape[1]\n ):\n raise ValueError(\n \"pbc must be either a boolean or a list of booleans with the same dimension as the vector space you chose.\"\n )\n else:\n self._pbc = pbc\n\n extent = _np.asarray(extent)\n self.extent = extent\n\n atoms, cellANDlabel_to_site = create_points(\n self._basis_vectors, extent, atoms_coord_fractional, pbc\n )\n edges = get_true_edges(self._basis_vectors, atoms, cellANDlabel_to_site, extent)\n graph = _nx.MultiGraph(edges)\n\n # Rename atoms\n old_nodes = sorted(set([node for edge in edges for node in edge]))\n self._atoms = [atoms[old_node] for old_node in old_nodes]\n self._coord_to_site = {\n tuple(atom[\"r_coord\"]): new_site\n for new_site, atom in enumerate(self._atoms)\n }\n new_nodes = {old_node: new_node for new_node, old_node in enumerate(old_nodes)}\n graph = _nx.relabel_nodes(graph, new_nodes)\n\n # Order node names\n nodes = sorted(graph.nodes())\n edges = list(graph.edges())\n graph = _nx.MultiGraph()\n graph.add_nodes_from(nodes)\n graph.add_edges_from(edges)\n\n super().__init__(graph)\n\n @property\n def basis_vectors(self):\n return self._basis_vectors\n\n @property\n def atoms_coord(self):\n \"\"\"\n Coordinates of atoms in the unit cell.\n \"\"\"\n return self._atoms_coord\n\n def atom_label(self, site):\n return self._atoms[site][\"Label\"]\n\n def site_to_coord(self, site):\n return self._atoms[site][\"r_coord\"]\n\n def coord_to_site(self, coord):\n return self._coord_to_site[tuple(coord)]\n\n def site_to_vector(self, site):\n return self._atoms[site][\"cell\"]\n\n def vector_to_coord(self, vector):\n return _np.matmul(self._basis_vectors, vector)\n\n def __repr__(self):\n return \"Lattice(n_nodes={})\\n extent={}\\n basis_vectors={}\".format(\n self.n_nodes, self.extent.tolist(), self.basis_vectors.tolist()\n )\n", "path": "netket/graph/lattice.py"}]} | 3,218 | 218 |
gh_patches_debug_107 | rasdani/github-patches | git_diff | getsentry__sentry-5098 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
MYSQL_PWD not recognized as sensitive field
In Sentry 8.11.0, the data key `MYSQL_PWD` is not treated as sensitive and is transmitted in cleartext and shown in the UI, while things that look like mysql connection string are rendered as `mysql://readonly:[Filtered]@db1.example.com/`
MYSQL_PWD is the standard way of providing a password to mysql cli tools, and I'd argue any field that ends in _PWD is unsafe.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `src/sentry/constants.py`
Content:
```
1 """
2 sentry.constants
3 ~~~~~~~~~~~~~~~~
4
5 These settings act as the default (base) settings for the Sentry-provided
6 web-server
7
8 :copyright: (c) 2010-2014 by the Sentry Team, see AUTHORS for more details.
9 :license: BSD, see LICENSE for more details.
10 """
11 from __future__ import absolute_import, print_function
12
13 import logging
14 import os.path
15 import six
16
17 from collections import OrderedDict
18 from django.conf import settings
19 from django.utils.translation import ugettext_lazy as _
20 from operator import attrgetter
21
22
23 def get_all_languages():
24 results = []
25 for path in os.listdir(os.path.join(MODULE_ROOT, 'locale')):
26 if path.startswith('.'):
27 continue
28 if '_' in path:
29 pre, post = path.split('_', 1)
30 path = '{}-{}'.format(pre, post.lower())
31 results.append(path)
32 return results
33
34 MODULE_ROOT = os.path.dirname(__import__('sentry').__file__)
35 DATA_ROOT = os.path.join(MODULE_ROOT, 'data')
36
37 SORT_OPTIONS = OrderedDict((
38 ('priority', _('Priority')),
39 ('date', _('Last Seen')),
40 ('new', _('First Seen')),
41 ('freq', _('Frequency')),
42 ))
43
44 SEARCH_SORT_OPTIONS = OrderedDict((
45 ('score', _('Score')),
46 ('date', _('Last Seen')),
47 ('new', _('First Seen')),
48 ))
49
50 # XXX: Deprecated: use GroupStatus instead
51 STATUS_UNRESOLVED = 0
52 STATUS_RESOLVED = 1
53 STATUS_IGNORED = 2
54
55 STATUS_CHOICES = {
56 'resolved': STATUS_RESOLVED,
57 'unresolved': STATUS_UNRESOLVED,
58 'ignored': STATUS_IGNORED,
59
60 # TODO(dcramer): remove in 9.0
61 'muted': STATUS_IGNORED,
62 }
63
64 # Normalize counts to the 15 minute marker. This value MUST be less than 60. A
65 # value of 0 would store counts for every minute, and is the lowest level of
66 # accuracy provided.
67 MINUTE_NORMALIZATION = 15
68
69 MAX_TAG_KEY_LENGTH = 32
70 MAX_TAG_VALUE_LENGTH = 200
71 MAX_CULPRIT_LENGTH = 200
72 MAX_EMAIL_FIELD_LENGTH = 75
73
74 # Team slugs which may not be used. Generally these are top level URL patterns
75 # which we don't want to worry about conflicts on.
76 RESERVED_ORGANIZATION_SLUGS = frozenset((
77 'admin', 'manage', 'login', 'account', 'register', 'api',
78 'accept', 'organizations', 'teams', 'projects', 'help',
79 'docs', 'logout', '404', '500', '_static', 'out', 'debug',
80 'remote', 'get-cli', 'blog', 'welcome', 'features',
81 'customers', 'integrations', 'signup', 'pricing',
82 'subscribe', 'enterprise', 'about', 'jobs', 'thanks', 'guide',
83 'privacy', 'security', 'terms', 'from', 'sponsorship', 'for',
84 'at', 'platforms', 'branding', 'vs', 'answers', '_admin',
85 'support',
86 ))
87
88 LOG_LEVELS = {
89 logging.DEBUG: 'debug',
90 logging.INFO: 'info',
91 logging.WARNING: 'warning',
92 logging.ERROR: 'error',
93 logging.FATAL: 'fatal',
94 }
95 DEFAULT_LOG_LEVEL = 'error'
96 DEFAULT_LOGGER_NAME = ''
97 LOG_LEVELS_MAP = {v: k for k, v in six.iteritems(LOG_LEVELS)}
98
99
100 # Default alerting threshold values
101 DEFAULT_ALERT_PROJECT_THRESHOLD = (500, 25) # 500%, 25 events
102 DEFAULT_ALERT_GROUP_THRESHOLD = (1000, 25) # 1000%, 25 events
103
104 # Default paginator value
105 EVENTS_PER_PAGE = 15
106
107 # Default sort option for the group stream
108 DEFAULT_SORT_OPTION = 'date'
109
110 # Setup languages for only available locales
111 LANGUAGE_MAP = dict(settings.LANGUAGES)
112 LANGUAGES = [(k, LANGUAGE_MAP[k]) for k in get_all_languages() if k in LANGUAGE_MAP]
113
114 # TODO(dcramer): We eventually want to make this user-editable
115 TAG_LABELS = {
116 'exc_type': 'Exception Type',
117 'sentry:user': 'User',
118 'sentry:filename': 'File',
119 'sentry:function': 'Function',
120 'sentry:release': 'Release',
121 'os': 'OS',
122 'url': 'URL',
123 'server_name': 'Server',
124 }
125
126 # TODO(dcramer): once this is more flushed out we want this to be extendable
127 SENTRY_RULES = (
128 'sentry.rules.actions.notify_event.NotifyEventAction',
129 'sentry.rules.actions.notify_event_service.NotifyEventServiceAction',
130 'sentry.rules.conditions.every_event.EveryEventCondition',
131 'sentry.rules.conditions.first_seen_event.FirstSeenEventCondition',
132 'sentry.rules.conditions.regression_event.RegressionEventCondition',
133 'sentry.rules.conditions.tagged_event.TaggedEventCondition',
134 'sentry.rules.conditions.event_frequency.EventFrequencyCondition',
135 'sentry.rules.conditions.event_frequency.EventUniqueUserFrequencyCondition',
136 'sentry.rules.conditions.event_attribute.EventAttributeCondition',
137 'sentry.rules.conditions.level.LevelCondition',
138 )
139
140 # methods as defined by http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html + PATCH
141 HTTP_METHODS = ('GET', 'POST', 'PUT', 'OPTIONS', 'HEAD', 'DELETE', 'TRACE', 'CONNECT', 'PATCH')
142
143 CLIENT_RESERVED_ATTRS = (
144 'project',
145 'errors',
146 'event_id',
147 'message',
148 'checksum',
149 'culprit',
150 'fingerprint',
151 'level',
152 'time_spent',
153 'logger',
154 'server_name',
155 'site',
156 'received',
157 'timestamp',
158 'extra',
159 'modules',
160 'tags',
161 'platform',
162 'release',
163 'environment',
164 )
165
166 DEFAULT_SCRUBBED_FIELDS = (
167 'password',
168 'secret',
169 'passwd',
170 'authorization',
171 'api_key',
172 'apikey',
173 'access_token',
174 'auth',
175 'credentials',
176 )
177
178 VALID_PLATFORMS = set([
179 'as3',
180 'c',
181 'cfml',
182 'cocoa',
183 'csharp',
184 'go',
185 'java',
186 'javascript',
187 'node',
188 'objc',
189 'other',
190 'perl',
191 'php',
192 'python',
193 'ruby',
194 'elixir',
195 'haskell',
196 'groovy',
197 ])
198
199 OK_PLUGIN_ENABLED = _("The {name} integration has been enabled.")
200
201 OK_PLUGIN_DISABLED = _("The {name} integration has been disabled.")
202
203 OK_PLUGIN_SAVED = _('Configuration for the {name} integration has been saved.')
204
205 WARN_SESSION_EXPIRED = 'Your session has expired.' # TODO: translate this
206
207 # Key to use when ordering a list of events manually
208 EVENT_ORDERING_KEY = attrgetter('datetime', 'id')
209
210 FILTER_MASK = '[Filtered]'
211
212 # Maximum length of a symbol
213 MAX_SYM = 256
214
215 # Known dsym mimetypes
216 KNOWN_DSYM_TYPES = {
217 'application/x-mach-binary': 'macho'
218 }
219
220 NATIVE_UNKNOWN_STRING = '<unknown>'
221
222
223 class ObjectStatus(object):
224 VISIBLE = 0
225 HIDDEN = 1
226 PENDING_DELETION = 2
227 DELETION_IN_PROGRESS = 3
228
229 @classmethod
230 def as_choices(cls):
231 return (
232 (cls.VISIBLE, 'visible'),
233 (cls.HIDDEN, 'hidden'),
234 (cls.PENDING_DELETION, 'pending_deletion'),
235 (cls.DELETION_IN_PROGRESS, 'deletion_in_progress'),
236 )
237
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/src/sentry/constants.py b/src/sentry/constants.py
--- a/src/sentry/constants.py
+++ b/src/sentry/constants.py
@@ -173,6 +173,7 @@
'access_token',
'auth',
'credentials',
+ 'mysql_pwd',
)
VALID_PLATFORMS = set([
| {"golden_diff": "diff --git a/src/sentry/constants.py b/src/sentry/constants.py\n--- a/src/sentry/constants.py\n+++ b/src/sentry/constants.py\n@@ -173,6 +173,7 @@\n 'access_token',\n 'auth',\n 'credentials',\n+ 'mysql_pwd',\n )\n \n VALID_PLATFORMS = set([\n", "issue": "MYSQL_PWD not recognized as sensitive field\nIn Sentry 8.11.0, the data key `MYSQL_PWD` is not treated as sensitive and is transmitted in cleartext and shown in the UI, while things that look like mysql connection string are rendered as `mysql://readonly:[Filtered]@db1.example.com/`\r\n\r\nMYSQL_PWD is the standard way of providing a password to mysql cli tools, and I'd argue any field that ends in _PWD is unsafe.\n", "before_files": [{"content": "\"\"\"\nsentry.constants\n~~~~~~~~~~~~~~~~\n\nThese settings act as the default (base) settings for the Sentry-provided\nweb-server\n\n:copyright: (c) 2010-2014 by the Sentry Team, see AUTHORS for more details.\n:license: BSD, see LICENSE for more details.\n\"\"\"\nfrom __future__ import absolute_import, print_function\n\nimport logging\nimport os.path\nimport six\n\nfrom collections import OrderedDict\nfrom django.conf import settings\nfrom django.utils.translation import ugettext_lazy as _\nfrom operator import attrgetter\n\n\ndef get_all_languages():\n results = []\n for path in os.listdir(os.path.join(MODULE_ROOT, 'locale')):\n if path.startswith('.'):\n continue\n if '_' in path:\n pre, post = path.split('_', 1)\n path = '{}-{}'.format(pre, post.lower())\n results.append(path)\n return results\n\nMODULE_ROOT = os.path.dirname(__import__('sentry').__file__)\nDATA_ROOT = os.path.join(MODULE_ROOT, 'data')\n\nSORT_OPTIONS = OrderedDict((\n ('priority', _('Priority')),\n ('date', _('Last Seen')),\n ('new', _('First Seen')),\n ('freq', _('Frequency')),\n))\n\nSEARCH_SORT_OPTIONS = OrderedDict((\n ('score', _('Score')),\n ('date', _('Last Seen')),\n ('new', _('First Seen')),\n))\n\n# XXX: Deprecated: use GroupStatus instead\nSTATUS_UNRESOLVED = 0\nSTATUS_RESOLVED = 1\nSTATUS_IGNORED = 2\n\nSTATUS_CHOICES = {\n 'resolved': STATUS_RESOLVED,\n 'unresolved': STATUS_UNRESOLVED,\n 'ignored': STATUS_IGNORED,\n\n # TODO(dcramer): remove in 9.0\n 'muted': STATUS_IGNORED,\n}\n\n# Normalize counts to the 15 minute marker. This value MUST be less than 60. A\n# value of 0 would store counts for every minute, and is the lowest level of\n# accuracy provided.\nMINUTE_NORMALIZATION = 15\n\nMAX_TAG_KEY_LENGTH = 32\nMAX_TAG_VALUE_LENGTH = 200\nMAX_CULPRIT_LENGTH = 200\nMAX_EMAIL_FIELD_LENGTH = 75\n\n# Team slugs which may not be used. Generally these are top level URL patterns\n# which we don't want to worry about conflicts on.\nRESERVED_ORGANIZATION_SLUGS = frozenset((\n 'admin', 'manage', 'login', 'account', 'register', 'api',\n 'accept', 'organizations', 'teams', 'projects', 'help',\n 'docs', 'logout', '404', '500', '_static', 'out', 'debug',\n 'remote', 'get-cli', 'blog', 'welcome', 'features',\n 'customers', 'integrations', 'signup', 'pricing',\n 'subscribe', 'enterprise', 'about', 'jobs', 'thanks', 'guide',\n 'privacy', 'security', 'terms', 'from', 'sponsorship', 'for',\n 'at', 'platforms', 'branding', 'vs', 'answers', '_admin',\n 'support',\n))\n\nLOG_LEVELS = {\n logging.DEBUG: 'debug',\n logging.INFO: 'info',\n logging.WARNING: 'warning',\n logging.ERROR: 'error',\n logging.FATAL: 'fatal',\n}\nDEFAULT_LOG_LEVEL = 'error'\nDEFAULT_LOGGER_NAME = ''\nLOG_LEVELS_MAP = {v: k for k, v in six.iteritems(LOG_LEVELS)}\n\n\n# Default alerting threshold values\nDEFAULT_ALERT_PROJECT_THRESHOLD = (500, 25) # 500%, 25 events\nDEFAULT_ALERT_GROUP_THRESHOLD = (1000, 25) # 1000%, 25 events\n\n# Default paginator value\nEVENTS_PER_PAGE = 15\n\n# Default sort option for the group stream\nDEFAULT_SORT_OPTION = 'date'\n\n# Setup languages for only available locales\nLANGUAGE_MAP = dict(settings.LANGUAGES)\nLANGUAGES = [(k, LANGUAGE_MAP[k]) for k in get_all_languages() if k in LANGUAGE_MAP]\n\n# TODO(dcramer): We eventually want to make this user-editable\nTAG_LABELS = {\n 'exc_type': 'Exception Type',\n 'sentry:user': 'User',\n 'sentry:filename': 'File',\n 'sentry:function': 'Function',\n 'sentry:release': 'Release',\n 'os': 'OS',\n 'url': 'URL',\n 'server_name': 'Server',\n}\n\n# TODO(dcramer): once this is more flushed out we want this to be extendable\nSENTRY_RULES = (\n 'sentry.rules.actions.notify_event.NotifyEventAction',\n 'sentry.rules.actions.notify_event_service.NotifyEventServiceAction',\n 'sentry.rules.conditions.every_event.EveryEventCondition',\n 'sentry.rules.conditions.first_seen_event.FirstSeenEventCondition',\n 'sentry.rules.conditions.regression_event.RegressionEventCondition',\n 'sentry.rules.conditions.tagged_event.TaggedEventCondition',\n 'sentry.rules.conditions.event_frequency.EventFrequencyCondition',\n 'sentry.rules.conditions.event_frequency.EventUniqueUserFrequencyCondition',\n 'sentry.rules.conditions.event_attribute.EventAttributeCondition',\n 'sentry.rules.conditions.level.LevelCondition',\n)\n\n# methods as defined by http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html + PATCH\nHTTP_METHODS = ('GET', 'POST', 'PUT', 'OPTIONS', 'HEAD', 'DELETE', 'TRACE', 'CONNECT', 'PATCH')\n\nCLIENT_RESERVED_ATTRS = (\n 'project',\n 'errors',\n 'event_id',\n 'message',\n 'checksum',\n 'culprit',\n 'fingerprint',\n 'level',\n 'time_spent',\n 'logger',\n 'server_name',\n 'site',\n 'received',\n 'timestamp',\n 'extra',\n 'modules',\n 'tags',\n 'platform',\n 'release',\n 'environment',\n)\n\nDEFAULT_SCRUBBED_FIELDS = (\n 'password',\n 'secret',\n 'passwd',\n 'authorization',\n 'api_key',\n 'apikey',\n 'access_token',\n 'auth',\n 'credentials',\n)\n\nVALID_PLATFORMS = set([\n 'as3',\n 'c',\n 'cfml',\n 'cocoa',\n 'csharp',\n 'go',\n 'java',\n 'javascript',\n 'node',\n 'objc',\n 'other',\n 'perl',\n 'php',\n 'python',\n 'ruby',\n 'elixir',\n 'haskell',\n 'groovy',\n])\n\nOK_PLUGIN_ENABLED = _(\"The {name} integration has been enabled.\")\n\nOK_PLUGIN_DISABLED = _(\"The {name} integration has been disabled.\")\n\nOK_PLUGIN_SAVED = _('Configuration for the {name} integration has been saved.')\n\nWARN_SESSION_EXPIRED = 'Your session has expired.' # TODO: translate this\n\n# Key to use when ordering a list of events manually\nEVENT_ORDERING_KEY = attrgetter('datetime', 'id')\n\nFILTER_MASK = '[Filtered]'\n\n# Maximum length of a symbol\nMAX_SYM = 256\n\n# Known dsym mimetypes\nKNOWN_DSYM_TYPES = {\n 'application/x-mach-binary': 'macho'\n}\n\nNATIVE_UNKNOWN_STRING = '<unknown>'\n\n\nclass ObjectStatus(object):\n VISIBLE = 0\n HIDDEN = 1\n PENDING_DELETION = 2\n DELETION_IN_PROGRESS = 3\n\n @classmethod\n def as_choices(cls):\n return (\n (cls.VISIBLE, 'visible'),\n (cls.HIDDEN, 'hidden'),\n (cls.PENDING_DELETION, 'pending_deletion'),\n (cls.DELETION_IN_PROGRESS, 'deletion_in_progress'),\n )\n", "path": "src/sentry/constants.py"}], "after_files": [{"content": "\"\"\"\nsentry.constants\n~~~~~~~~~~~~~~~~\n\nThese settings act as the default (base) settings for the Sentry-provided\nweb-server\n\n:copyright: (c) 2010-2014 by the Sentry Team, see AUTHORS for more details.\n:license: BSD, see LICENSE for more details.\n\"\"\"\nfrom __future__ import absolute_import, print_function\n\nimport logging\nimport os.path\nimport six\n\nfrom collections import OrderedDict\nfrom django.conf import settings\nfrom django.utils.translation import ugettext_lazy as _\nfrom operator import attrgetter\n\n\ndef get_all_languages():\n results = []\n for path in os.listdir(os.path.join(MODULE_ROOT, 'locale')):\n if path.startswith('.'):\n continue\n if '_' in path:\n pre, post = path.split('_', 1)\n path = '{}-{}'.format(pre, post.lower())\n results.append(path)\n return results\n\nMODULE_ROOT = os.path.dirname(__import__('sentry').__file__)\nDATA_ROOT = os.path.join(MODULE_ROOT, 'data')\n\nSORT_OPTIONS = OrderedDict((\n ('priority', _('Priority')),\n ('date', _('Last Seen')),\n ('new', _('First Seen')),\n ('freq', _('Frequency')),\n))\n\nSEARCH_SORT_OPTIONS = OrderedDict((\n ('score', _('Score')),\n ('date', _('Last Seen')),\n ('new', _('First Seen')),\n))\n\n# XXX: Deprecated: use GroupStatus instead\nSTATUS_UNRESOLVED = 0\nSTATUS_RESOLVED = 1\nSTATUS_IGNORED = 2\n\nSTATUS_CHOICES = {\n 'resolved': STATUS_RESOLVED,\n 'unresolved': STATUS_UNRESOLVED,\n 'ignored': STATUS_IGNORED,\n\n # TODO(dcramer): remove in 9.0\n 'muted': STATUS_IGNORED,\n}\n\n# Normalize counts to the 15 minute marker. This value MUST be less than 60. A\n# value of 0 would store counts for every minute, and is the lowest level of\n# accuracy provided.\nMINUTE_NORMALIZATION = 15\n\nMAX_TAG_KEY_LENGTH = 32\nMAX_TAG_VALUE_LENGTH = 200\nMAX_CULPRIT_LENGTH = 200\nMAX_EMAIL_FIELD_LENGTH = 75\n\n# Team slugs which may not be used. Generally these are top level URL patterns\n# which we don't want to worry about conflicts on.\nRESERVED_ORGANIZATION_SLUGS = frozenset((\n 'admin', 'manage', 'login', 'account', 'register', 'api',\n 'accept', 'organizations', 'teams', 'projects', 'help',\n 'docs', 'logout', '404', '500', '_static', 'out', 'debug',\n 'remote', 'get-cli', 'blog', 'welcome', 'features',\n 'customers', 'integrations', 'signup', 'pricing',\n 'subscribe', 'enterprise', 'about', 'jobs', 'thanks', 'guide',\n 'privacy', 'security', 'terms', 'from', 'sponsorship', 'for',\n 'at', 'platforms', 'branding', 'vs', 'answers', '_admin',\n 'support',\n))\n\nLOG_LEVELS = {\n logging.DEBUG: 'debug',\n logging.INFO: 'info',\n logging.WARNING: 'warning',\n logging.ERROR: 'error',\n logging.FATAL: 'fatal',\n}\nDEFAULT_LOG_LEVEL = 'error'\nDEFAULT_LOGGER_NAME = ''\nLOG_LEVELS_MAP = {v: k for k, v in six.iteritems(LOG_LEVELS)}\n\n\n# Default alerting threshold values\nDEFAULT_ALERT_PROJECT_THRESHOLD = (500, 25) # 500%, 25 events\nDEFAULT_ALERT_GROUP_THRESHOLD = (1000, 25) # 1000%, 25 events\n\n# Default paginator value\nEVENTS_PER_PAGE = 15\n\n# Default sort option for the group stream\nDEFAULT_SORT_OPTION = 'date'\n\n# Setup languages for only available locales\nLANGUAGE_MAP = dict(settings.LANGUAGES)\nLANGUAGES = [(k, LANGUAGE_MAP[k]) for k in get_all_languages() if k in LANGUAGE_MAP]\n\n# TODO(dcramer): We eventually want to make this user-editable\nTAG_LABELS = {\n 'exc_type': 'Exception Type',\n 'sentry:user': 'User',\n 'sentry:filename': 'File',\n 'sentry:function': 'Function',\n 'sentry:release': 'Release',\n 'os': 'OS',\n 'url': 'URL',\n 'server_name': 'Server',\n}\n\n# TODO(dcramer): once this is more flushed out we want this to be extendable\nSENTRY_RULES = (\n 'sentry.rules.actions.notify_event.NotifyEventAction',\n 'sentry.rules.actions.notify_event_service.NotifyEventServiceAction',\n 'sentry.rules.conditions.every_event.EveryEventCondition',\n 'sentry.rules.conditions.first_seen_event.FirstSeenEventCondition',\n 'sentry.rules.conditions.regression_event.RegressionEventCondition',\n 'sentry.rules.conditions.tagged_event.TaggedEventCondition',\n 'sentry.rules.conditions.event_frequency.EventFrequencyCondition',\n 'sentry.rules.conditions.event_frequency.EventUniqueUserFrequencyCondition',\n 'sentry.rules.conditions.event_attribute.EventAttributeCondition',\n 'sentry.rules.conditions.level.LevelCondition',\n)\n\n# methods as defined by http://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html + PATCH\nHTTP_METHODS = ('GET', 'POST', 'PUT', 'OPTIONS', 'HEAD', 'DELETE', 'TRACE', 'CONNECT', 'PATCH')\n\nCLIENT_RESERVED_ATTRS = (\n 'project',\n 'errors',\n 'event_id',\n 'message',\n 'checksum',\n 'culprit',\n 'fingerprint',\n 'level',\n 'time_spent',\n 'logger',\n 'server_name',\n 'site',\n 'received',\n 'timestamp',\n 'extra',\n 'modules',\n 'tags',\n 'platform',\n 'release',\n 'environment',\n)\n\nDEFAULT_SCRUBBED_FIELDS = (\n 'password',\n 'secret',\n 'passwd',\n 'authorization',\n 'api_key',\n 'apikey',\n 'access_token',\n 'auth',\n 'credentials',\n 'mysql_pwd',\n)\n\nVALID_PLATFORMS = set([\n 'as3',\n 'c',\n 'cfml',\n 'cocoa',\n 'csharp',\n 'go',\n 'java',\n 'javascript',\n 'node',\n 'objc',\n 'other',\n 'perl',\n 'php',\n 'python',\n 'ruby',\n 'elixir',\n 'haskell',\n 'groovy',\n])\n\nOK_PLUGIN_ENABLED = _(\"The {name} integration has been enabled.\")\n\nOK_PLUGIN_DISABLED = _(\"The {name} integration has been disabled.\")\n\nOK_PLUGIN_SAVED = _('Configuration for the {name} integration has been saved.')\n\nWARN_SESSION_EXPIRED = 'Your session has expired.' # TODO: translate this\n\n# Key to use when ordering a list of events manually\nEVENT_ORDERING_KEY = attrgetter('datetime', 'id')\n\nFILTER_MASK = '[Filtered]'\n\n# Maximum length of a symbol\nMAX_SYM = 256\n\n# Known dsym mimetypes\nKNOWN_DSYM_TYPES = {\n 'application/x-mach-binary': 'macho'\n}\n\nNATIVE_UNKNOWN_STRING = '<unknown>'\n\n\nclass ObjectStatus(object):\n VISIBLE = 0\n HIDDEN = 1\n PENDING_DELETION = 2\n DELETION_IN_PROGRESS = 3\n\n @classmethod\n def as_choices(cls):\n return (\n (cls.VISIBLE, 'visible'),\n (cls.HIDDEN, 'hidden'),\n (cls.PENDING_DELETION, 'pending_deletion'),\n (cls.DELETION_IN_PROGRESS, 'deletion_in_progress'),\n )\n", "path": "src/sentry/constants.py"}]} | 2,649 | 73 |
gh_patches_debug_7314 | rasdani/github-patches | git_diff | chainer__chainer-552 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
where doesn't work with int16 and float64 on cuda6.5
On only cuda 6.5, this code doesn't work:
```
x = cupy.array([1,2,3], dtype=cupy.int16)
y = cupy.array([1,2,3], dtype=cupy.float64)
c = cupy.array([1,0,1], dtype=cupy.bool_)
cupy.where(c, x, y)
```
Other combinations such as (int16, float32) and (int32, float64) correctly work.
Maybe this is a bug on cuda 6.5, and fixed on 7.0.
Note that `cupy.where(c, y, x)` can work.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `cupy/sorting/search.py`
Content:
```
1 from cupy import elementwise
2 from cupy import reduction
3
4
5 def argmax(a, axis=None, dtype=None, out=None, keepdims=False):
6 """Returns the indices of the maximum along an axis.
7
8 Args:
9 a (cupy.ndarray): Array to take argmax.
10 axis (int): Along which axis to find the maximum. ``a`` is flattened by
11 default.
12 dtype: Data type specifier.
13 out (cupy.ndarray): Output array.
14 keepdims (bool): If True, the axis ``axis`` is preserved as an axis of
15 length one.
16
17 Returns:
18 cupy.ndarray: The indices of the maximum of ``a`` along an axis.
19
20 .. seealso:: :func:`numpy.argmax`
21
22 """
23 return reduction.argmax(a, axis=axis, dtype=dtype, out=out,
24 keepdims=keepdims)
25
26
27 # TODO(okuta): Implement nanargmax
28
29
30 def argmin(a, axis=None, dtype=None, out=None, keepdims=False):
31 """Returns the indices of the minimum along an axis.
32
33 Args:
34 a (cupy.ndarray): Array to take argmin.
35 axis (int): Along which axis to find the minimum. ``a`` is flattened by
36 default.
37 dtype: Data type specifier.
38 out (cupy.ndarray): Output array.
39 keepdims (bool): If True, the axis ``axis`` is preserved as an axis of
40 length one.
41
42 Returns:
43 cupy.ndarray: The indices of the minimum of ``a`` along an axis.
44
45 .. seealso:: :func:`numpy.argmin`
46
47 """
48 return reduction.argmin(a, axis=axis, dtype=dtype, out=out,
49 keepdims=keepdims)
50
51
52 # TODO(okuta): Implement nanargmin
53
54
55 # TODO(okuta): Implement argwhere
56
57
58 # TODO(okuta): Implement nonzero
59
60
61 # TODO(okuta): Implement flatnonzero
62
63
64 def where(condition, x=None, y=None):
65 """Return elements, either from x or y, depending on condition.
66
67 .. note::
68
69 Currently Cupy doesn't support ``where(condition)``, that Numpy
70 supports.
71
72 Args:
73 condition (cupy.ndarray): When True, take x, otherwise take y.
74 x (cupy.ndarray): Values from which to choose on ``True``.
75 y (cupy.ndarray): Values from which to choose on ``False``.
76
77 Returns:
78 cupy.ndarray: Each element of output contains elements of ``x`` when
79 ``condition`` is ``True``, otherwise elements of ``y``.
80
81 """
82
83 missing = (x is None, y is None).count(True)
84
85 if missing == 1:
86 raise ValueError("Must provide both 'x' and 'y' or neither.")
87 if missing == 2:
88 # TODO(unno): return nonzero(cond)
89 return NotImplementedError()
90
91 return _where_ufunc(condition.astype('?'), x, y)
92
93 _where_ufunc = elementwise.create_ufunc(
94 'cupy_where',
95 ('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',
96 '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f', '?dd->d'),
97 'out0 = in0 ? in1 : in2')
98
99
100 # TODO(okuta): Implement searchsorted
101
102
103 # TODO(okuta): Implement extract
104
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/cupy/sorting/search.py b/cupy/sorting/search.py
--- a/cupy/sorting/search.py
+++ b/cupy/sorting/search.py
@@ -93,7 +93,12 @@
_where_ufunc = elementwise.create_ufunc(
'cupy_where',
('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',
- '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f', '?dd->d'),
+ '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f',
+ # On CUDA 6.5 these combinations don't work correctly (on CUDA >=7.0, it
+ # works).
+ # See issue #551.
+ '?hd->d', '?Hd->d',
+ '?dd->d'),
'out0 = in0 ? in1 : in2')
| {"golden_diff": "diff --git a/cupy/sorting/search.py b/cupy/sorting/search.py\n--- a/cupy/sorting/search.py\n+++ b/cupy/sorting/search.py\n@@ -93,7 +93,12 @@\n _where_ufunc = elementwise.create_ufunc(\n 'cupy_where',\n ('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',\n- '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f', '?dd->d'),\n+ '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f',\n+ # On CUDA 6.5 these combinations don't work correctly (on CUDA >=7.0, it\n+ # works).\n+ # See issue #551.\n+ '?hd->d', '?Hd->d',\n+ '?dd->d'),\n 'out0 = in0 ? in1 : in2')\n", "issue": "where doesn't work with int16 and float64 on cuda6.5\nOn only cuda 6.5, this code doesn't work:\n\n```\nx = cupy.array([1,2,3], dtype=cupy.int16)\ny = cupy.array([1,2,3], dtype=cupy.float64)\nc = cupy.array([1,0,1], dtype=cupy.bool_)\ncupy.where(c, x, y)\n```\n\nOther combinations such as (int16, float32) and (int32, float64) correctly work.\nMaybe this is a bug on cuda 6.5, and fixed on 7.0.\n\nNote that `cupy.where(c, y, x)` can work.\n\n", "before_files": [{"content": "from cupy import elementwise\nfrom cupy import reduction\n\n\ndef argmax(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the indices of the maximum along an axis.\n\n Args:\n a (cupy.ndarray): Array to take argmax.\n axis (int): Along which axis to find the maximum. ``a`` is flattened by\n default.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If True, the axis ``axis`` is preserved as an axis of\n length one.\n\n Returns:\n cupy.ndarray: The indices of the maximum of ``a`` along an axis.\n\n .. seealso:: :func:`numpy.argmax`\n\n \"\"\"\n return reduction.argmax(a, axis=axis, dtype=dtype, out=out,\n keepdims=keepdims)\n\n\n# TODO(okuta): Implement nanargmax\n\n\ndef argmin(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the indices of the minimum along an axis.\n\n Args:\n a (cupy.ndarray): Array to take argmin.\n axis (int): Along which axis to find the minimum. ``a`` is flattened by\n default.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If True, the axis ``axis`` is preserved as an axis of\n length one.\n\n Returns:\n cupy.ndarray: The indices of the minimum of ``a`` along an axis.\n\n .. seealso:: :func:`numpy.argmin`\n\n \"\"\"\n return reduction.argmin(a, axis=axis, dtype=dtype, out=out,\n keepdims=keepdims)\n\n\n# TODO(okuta): Implement nanargmin\n\n\n# TODO(okuta): Implement argwhere\n\n\n# TODO(okuta): Implement nonzero\n\n\n# TODO(okuta): Implement flatnonzero\n\n\ndef where(condition, x=None, y=None):\n \"\"\"Return elements, either from x or y, depending on condition.\n\n .. note::\n\n Currently Cupy doesn't support ``where(condition)``, that Numpy\n supports.\n\n Args:\n condition (cupy.ndarray): When True, take x, otherwise take y.\n x (cupy.ndarray): Values from which to choose on ``True``.\n y (cupy.ndarray): Values from which to choose on ``False``.\n\n Returns:\n cupy.ndarray: Each element of output contains elements of ``x`` when\n ``condition`` is ``True``, otherwise elements of ``y``.\n\n \"\"\"\n\n missing = (x is None, y is None).count(True)\n\n if missing == 1:\n raise ValueError(\"Must provide both 'x' and 'y' or neither.\")\n if missing == 2:\n # TODO(unno): return nonzero(cond)\n return NotImplementedError()\n\n return _where_ufunc(condition.astype('?'), x, y)\n\n_where_ufunc = elementwise.create_ufunc(\n 'cupy_where',\n ('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',\n '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f', '?dd->d'),\n 'out0 = in0 ? in1 : in2')\n\n\n# TODO(okuta): Implement searchsorted\n\n\n# TODO(okuta): Implement extract\n", "path": "cupy/sorting/search.py"}], "after_files": [{"content": "from cupy import elementwise\nfrom cupy import reduction\n\n\ndef argmax(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the indices of the maximum along an axis.\n\n Args:\n a (cupy.ndarray): Array to take argmax.\n axis (int): Along which axis to find the maximum. ``a`` is flattened by\n default.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If True, the axis ``axis`` is preserved as an axis of\n length one.\n\n Returns:\n cupy.ndarray: The indices of the maximum of ``a`` along an axis.\n\n .. seealso:: :func:`numpy.argmax`\n\n \"\"\"\n return reduction.argmax(a, axis=axis, dtype=dtype, out=out,\n keepdims=keepdims)\n\n\n# TODO(okuta): Implement nanargmax\n\n\ndef argmin(a, axis=None, dtype=None, out=None, keepdims=False):\n \"\"\"Returns the indices of the minimum along an axis.\n\n Args:\n a (cupy.ndarray): Array to take argmin.\n axis (int): Along which axis to find the minimum. ``a`` is flattened by\n default.\n dtype: Data type specifier.\n out (cupy.ndarray): Output array.\n keepdims (bool): If True, the axis ``axis`` is preserved as an axis of\n length one.\n\n Returns:\n cupy.ndarray: The indices of the minimum of ``a`` along an axis.\n\n .. seealso:: :func:`numpy.argmin`\n\n \"\"\"\n return reduction.argmin(a, axis=axis, dtype=dtype, out=out,\n keepdims=keepdims)\n\n\n# TODO(okuta): Implement nanargmin\n\n\n# TODO(okuta): Implement argwhere\n\n\n# TODO(okuta): Implement nonzero\n\n\n# TODO(okuta): Implement flatnonzero\n\n\ndef where(condition, x=None, y=None):\n \"\"\"Return elements, either from x or y, depending on condition.\n\n .. note::\n\n Currently Cupy doesn't support ``where(condition)``, that Numpy\n supports.\n\n Args:\n condition (cupy.ndarray): When True, take x, otherwise take y.\n x (cupy.ndarray): Values from which to choose on ``True``.\n y (cupy.ndarray): Values from which to choose on ``False``.\n\n Returns:\n cupy.ndarray: Each element of output contains elements of ``x`` when\n ``condition`` is ``True``, otherwise elements of ``y``.\n\n \"\"\"\n\n missing = (x is None, y is None).count(True)\n\n if missing == 1:\n raise ValueError(\"Must provide both 'x' and 'y' or neither.\")\n if missing == 2:\n # TODO(unno): return nonzero(cond)\n return NotImplementedError()\n\n return _where_ufunc(condition.astype('?'), x, y)\n\n_where_ufunc = elementwise.create_ufunc(\n 'cupy_where',\n ('???->?', '?bb->b', '?BB->B', '?hh->h', '?HH->H', '?ii->i', '?II->I',\n '?ll->l', '?LL->L', '?qq->q', '?QQ->Q', '?ee->e', '?ff->f',\n # On CUDA 6.5 these combinations don't work correctly (on CUDA >=7.0, it\n # works).\n # See issue #551.\n '?hd->d', '?Hd->d',\n '?dd->d'),\n 'out0 = in0 ? in1 : in2')\n\n\n# TODO(okuta): Implement searchsorted\n\n\n# TODO(okuta): Implement extract\n", "path": "cupy/sorting/search.py"}]} | 1,397 | 246 |
gh_patches_debug_7069 | rasdani/github-patches | git_diff | pytorch__pytorch-928 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Importing scipy.misc after torch causes segfault
As shown in below. Is this something expected?
This seems most closely related to https://github.com/pytorch/pytorch/issues/595, but it is closed without any specific solutions.
```
(venv) $ pip freeze
appdirs==1.4.0
numpy==1.12.0
packaging==16.8
pyparsing==2.1.10
PyYAML==3.12
scipy==0.18.1
six==1.10.0
torch==0.1.9.post2
(venv) $ python -c 'import torch, scipy.misc'
Segmentation fault (core dumped)
(venv) $ python -c 'import scipy.misc, torch'
(venv) $ echo 'import torch, scipy.misc' > spam.py
(venv) $ python spam.py
Segmentation fault (core dumped)
(venv) $ gdb --args python spam.py
GNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1
Copyright (C) 2014 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law. Type "show copying"
and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from python...(no debugging symbols found)...done.
(gdb) run
Starting program: /tmp/venv/bin/python spam.py
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
[New Thread 0x7fffc7088700 (LWP 5549)]
[New Thread 0x7fffc6887700 (LWP 5550)]
[New Thread 0x7fffc4086700 (LWP 5551)]
[New Thread 0x7fffc1885700 (LWP 5552)]
[New Thread 0x7fffbf084700 (LWP 5553)]
[New Thread 0x7fffbc883700 (LWP 5554)]
[New Thread 0x7fffba082700 (LWP 5555)]
[New Thread 0x7fffb7881700 (LWP 5556)]
[New Thread 0x7fffb5080700 (LWP 5557)]
[New Thread 0x7fffb287f700 (LWP 5558)]
[New Thread 0x7fffb007e700 (LWP 5559)]
Program received signal SIGSEGV, Segmentation fault.
0x00007fffc9d65fc0 in PyArray_API () from /tmp/venv/local/lib/python2.7/site-packages/numpy/core/multiarray.so
```
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `torch/__init__.py`
Content:
```
1 """
2 The torch package contains data structures for multi-dimensional
3 tensors and mathematical operations over these are defined.
4 Additionally, it provides many utilities for efficient serializing of
5 Tensors and arbitrary types, and other useful utilities.
6
7 It has a CUDA counterpart, that enables you to run your tensor computations
8 on an NVIDIA GPU with compute capability >= 2.0.
9 """
10
11 import sys
12 from ._utils import _import_dotted_name
13 from .version import __version__
14
15 __all__ = [
16 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type',
17 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed',
18 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack',
19 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage',
20 'ShortStorage', 'CharStorage', 'ByteStorage',
21 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor',
22 'ShortTensor', 'CharTensor', 'ByteTensor',
23 ]
24
25 ################################################################################
26 # Load the extension module
27 ################################################################################
28
29 # Loading the extension with RTLD_GLOBAL option allows to not link extension
30 # modules against the _C shared object. Their missing THP symbols will be
31 # automatically filled by the dynamic loader.
32 import os as _dl_flags
33
34 # first check if the os package has the required flags
35 if not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):
36 try:
37 # next try if DLFCN exists
38 import DLFCN as _dl_flags
39 except ImportError:
40 # as a last attempt, use compile-time constants
41 import torch._dl as _dl_flags
42
43 old_flags = sys.getdlopenflags()
44 sys.setdlopenflags(_dl_flags.RTLD_GLOBAL | _dl_flags.RTLD_NOW)
45
46 from torch._C import *
47
48 __all__ += [name for name in dir(_C)
49 if name[0] != '_' and
50 not name.endswith('Base')]
51
52 sys.setdlopenflags(old_flags)
53 del _dl_flags
54 del old_flags
55
56 ################################################################################
57 # Define basic utilities
58 ################################################################################
59
60
61 def typename(o):
62 module = ''
63 class_name = ''
64 if hasattr(o, '__module__') and o.__module__ != 'builtins' \
65 and o.__module__ != '__builtin__' and o.__module__ is not None:
66 module = o.__module__ + '.'
67
68 if hasattr(o, '__qualname__'):
69 class_name = o.__qualname__
70 elif hasattr(o, '__name__'):
71 class_name = o.__name__
72 else:
73 class_name = o.__class__.__name__
74
75 return module + class_name
76
77
78 def is_tensor(obj):
79 r"""Returns True if `obj` is a pytorch tensor.
80
81 Args:
82 obj (Object): Object to test
83 """
84 return obj.__class__ in _tensor_classes
85
86
87 def is_storage(obj):
88 r"""Returns True if `obj` is a pytorch storage object.
89
90 Args:
91 obj (Object): Object to test
92 """
93 return obj.__class__ in _storage_classes
94
95
96 def set_default_tensor_type(t):
97 global Tensor
98 global Storage
99 Tensor = _import_dotted_name(t)
100 Storage = _import_dotted_name(t.replace('Tensor', 'Storage'))
101 _C._set_default_tensor_type(Tensor)
102
103
104 def set_rng_state(new_state):
105 r"""Sets the random number generator state.
106
107 Args:
108 new_state (torch.ByteTensor): The desired state
109 """
110 default_generator.set_state(new_state)
111
112
113 def get_rng_state():
114 r"""Returns the random number generator state as a ByteTensor."""
115 return default_generator.get_state()
116
117
118 def manual_seed(seed):
119 r"""Sets the seed for generating random numbers. And returns a
120 `torch._C.Generator` object.
121
122 Args:
123 seed (int or long): The desired seed.
124 """
125 return default_generator.manual_seed(seed)
126
127
128 def initial_seed():
129 r"""Returns the initial seed for generating random numbers as a
130 python `long`.
131 """
132 return default_generator.initial_seed()
133
134
135 from .serialization import save, load
136 from ._tensor_str import set_printoptions
137
138 ################################################################################
139 # Define Storage and Tensor classes
140 ################################################################################
141
142 from .storage import _StorageBase
143 from .tensor import _TensorBase
144
145
146 class DoubleStorage(_C.DoubleStorageBase, _StorageBase):
147 pass
148
149
150 class FloatStorage(_C.FloatStorageBase, _StorageBase):
151 pass
152
153
154 class HalfStorage(_C.HalfStorageBase, _StorageBase):
155 pass
156
157
158 class LongStorage(_C.LongStorageBase, _StorageBase):
159 pass
160
161
162 class IntStorage(_C.IntStorageBase, _StorageBase):
163 pass
164
165
166 class ShortStorage(_C.ShortStorageBase, _StorageBase):
167 pass
168
169
170 class CharStorage(_C.CharStorageBase, _StorageBase):
171 pass
172
173
174 class ByteStorage(_C.ByteStorageBase, _StorageBase):
175 pass
176
177
178 class DoubleTensor(_C.DoubleTensorBase, _TensorBase):
179
180 def is_signed(self):
181 return True
182
183 @classmethod
184 def storage_type(cls):
185 return DoubleStorage
186
187
188 class FloatTensor(_C.FloatTensorBase, _TensorBase):
189
190 def is_signed(self):
191 return True
192
193 @classmethod
194 def storage_type(cls):
195 return FloatStorage
196
197
198 class HalfTensor(_C.HalfTensorBase, _TensorBase):
199
200 def is_signed(self):
201 return True
202
203 @classmethod
204 def storage_type(cls):
205 return HalfStorage
206
207
208 class LongTensor(_C.LongTensorBase, _TensorBase):
209
210 def is_signed(self):
211 return True
212
213 @classmethod
214 def storage_type(cls):
215 return LongStorage
216
217
218 class IntTensor(_C.IntTensorBase, _TensorBase):
219
220 def is_signed(self):
221 return True
222
223 @classmethod
224 def storage_type(cls):
225 return IntStorage
226
227
228 class ShortTensor(_C.ShortTensorBase, _TensorBase):
229
230 def is_signed(self):
231 return True
232
233 @classmethod
234 def storage_type(cls):
235 return ShortStorage
236
237
238 class CharTensor(_C.CharTensorBase, _TensorBase):
239
240 def is_signed(self):
241 # TODO
242 return False
243
244 @classmethod
245 def storage_type(cls):
246 return CharStorage
247
248
249 class ByteTensor(_C.ByteTensorBase, _TensorBase):
250
251 def is_signed(self):
252 return False
253
254 @classmethod
255 def storage_type(cls):
256 return ByteStorage
257
258
259 _storage_classes = {
260 DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,
261 CharStorage, ByteStorage,
262 }
263
264 _tensor_classes = {
265 DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,
266 CharTensor, ByteTensor,
267 }
268
269
270 set_default_tensor_type('torch.FloatTensor')
271
272 ################################################################################
273 # Import interface functions defined in Python
274 ################################################################################
275
276 from .functional import *
277
278 ################################################################################
279 # Initialize extension
280 ################################################################################
281
282 # Shared memory manager needs to know the exact location of manager executable
283 import os
284 manager_path = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'lib', 'torch_shm_manager')
285 if sys.version_info[0] >= 3:
286 manager_path = bytes(manager_path, 'ascii')
287
288 _C._initExtension(manager_path)
289
290 del os
291 del manager_path
292
293 ################################################################################
294 # Remove unnecessary members
295 ################################################################################
296
297 del DoubleStorageBase
298 del FloatStorageBase
299 del LongStorageBase
300 del IntStorageBase
301 del ShortStorageBase
302 del CharStorageBase
303 del ByteStorageBase
304 del DoubleTensorBase
305 del FloatTensorBase
306 del LongTensorBase
307 del IntTensorBase
308 del ShortTensorBase
309 del CharTensorBase
310 del ByteTensorBase
311
312 del SparseDoubleTensorBase
313 del SparseFloatTensorBase
314 del SparseLongTensorBase
315 del SparseIntTensorBase
316 del SparseShortTensorBase
317 del SparseCharTensorBase
318 del SparseByteTensorBase
319
320 ################################################################################
321 # Import most common subpackages
322 ################################################################################
323
324 import torch.cuda
325 import torch.autograd
326 import torch.nn
327 import torch.optim
328 import torch.multiprocessing
329
330 # attach docstrings to torch and tensor functions
331 from . import _torch_docs, _tensor_docs
332 del _torch_docs, _tensor_docs
333
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/torch/__init__.py b/torch/__init__.py
--- a/torch/__init__.py
+++ b/torch/__init__.py
@@ -31,6 +31,13 @@
# automatically filled by the dynamic loader.
import os as _dl_flags
+# if we have numpy, it *must* be imported before the call to setdlopenflags()
+# or there is risk that later c modules will segfault when importing numpy
+try:
+ import numpy as np
+except:
+ pass
+
# first check if the os package has the required flags
if not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):
try:
| {"golden_diff": "diff --git a/torch/__init__.py b/torch/__init__.py\n--- a/torch/__init__.py\n+++ b/torch/__init__.py\n@@ -31,6 +31,13 @@\n # automatically filled by the dynamic loader.\n import os as _dl_flags\n \n+# if we have numpy, it *must* be imported before the call to setdlopenflags()\n+# or there is risk that later c modules will segfault when importing numpy\n+try:\n+ import numpy as np\n+except:\n+ pass\n+\n # first check if the os package has the required flags\n if not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):\n try:\n", "issue": "Importing scipy.misc after torch causes segfault\nAs shown in below. Is this something expected?\r\nThis seems most closely related to https://github.com/pytorch/pytorch/issues/595, but it is closed without any specific solutions.\r\n```\r\n(venv) $ pip freeze\r\nappdirs==1.4.0\r\nnumpy==1.12.0\r\npackaging==16.8\r\npyparsing==2.1.10\r\nPyYAML==3.12\r\nscipy==0.18.1\r\nsix==1.10.0\r\ntorch==0.1.9.post2\r\n\r\n(venv) $ python -c 'import torch, scipy.misc'\r\nSegmentation fault (core dumped)\r\n\r\n(venv) $ python -c 'import scipy.misc, torch'\r\n\r\n(venv) $ echo 'import torch, scipy.misc' > spam.py\r\n\r\n(venv) $ python spam.py\r\nSegmentation fault (core dumped)\r\n\r\n(venv) $ gdb --args python spam.py\r\nGNU gdb (Ubuntu 7.7.1-0ubuntu5~14.04.2) 7.7.1\r\nCopyright (C) 2014 Free Software Foundation, Inc.\r\nLicense GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>\r\nThis is free software: you are free to change and redistribute it.\r\nThere is NO WARRANTY, to the extent permitted by law. Type \"show copying\"\r\nand \"show warranty\" for details.\r\nThis GDB was configured as \"x86_64-linux-gnu\".\r\nType \"show configuration\" for configuration details.\r\nFor bug reporting instructions, please see:\r\n<http://www.gnu.org/software/gdb/bugs/>.\r\nFind the GDB manual and other documentation resources online at:\r\n<http://www.gnu.org/software/gdb/documentation/>.\r\nFor help, type \"help\".\r\nType \"apropos word\" to search for commands related to \"word\"...\r\nReading symbols from python...(no debugging symbols found)...done.\r\n(gdb) run\r\nStarting program: /tmp/venv/bin/python spam.py\r\n[Thread debugging using libthread_db enabled]\r\nUsing host libthread_db library \"/lib/x86_64-linux-gnu/libthread_db.so.1\".\r\n[New Thread 0x7fffc7088700 (LWP 5549)]\r\n[New Thread 0x7fffc6887700 (LWP 5550)]\r\n[New Thread 0x7fffc4086700 (LWP 5551)]\r\n[New Thread 0x7fffc1885700 (LWP 5552)]\r\n[New Thread 0x7fffbf084700 (LWP 5553)]\r\n[New Thread 0x7fffbc883700 (LWP 5554)]\r\n[New Thread 0x7fffba082700 (LWP 5555)]\r\n[New Thread 0x7fffb7881700 (LWP 5556)]\r\n[New Thread 0x7fffb5080700 (LWP 5557)]\r\n[New Thread 0x7fffb287f700 (LWP 5558)]\r\n[New Thread 0x7fffb007e700 (LWP 5559)]\r\n\r\nProgram received signal SIGSEGV, Segmentation fault.\r\n0x00007fffc9d65fc0 in PyArray_API () from /tmp/venv/local/lib/python2.7/site-packages/numpy/core/multiarray.so\r\n```\n", "before_files": [{"content": "\"\"\"\nThe torch package contains data structures for multi-dimensional\ntensors and mathematical operations over these are defined.\nAdditionally, it provides many utilities for efficient serializing of\nTensors and arbitrary types, and other useful utilities.\n\nIt has a CUDA counterpart, that enables you to run your tensor computations\non an NVIDIA GPU with compute capability >= 2.0.\n\"\"\"\n\nimport sys\nfrom ._utils import _import_dotted_name\nfrom .version import __version__\n\n__all__ = [\n 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type',\n 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed',\n 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack',\n 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage',\n 'ShortStorage', 'CharStorage', 'ByteStorage',\n 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor',\n 'ShortTensor', 'CharTensor', 'ByteTensor',\n]\n\n################################################################################\n# Load the extension module\n################################################################################\n\n# Loading the extension with RTLD_GLOBAL option allows to not link extension\n# modules against the _C shared object. Their missing THP symbols will be\n# automatically filled by the dynamic loader.\nimport os as _dl_flags\n\n# first check if the os package has the required flags\nif not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):\n try:\n # next try if DLFCN exists\n import DLFCN as _dl_flags\n except ImportError:\n # as a last attempt, use compile-time constants\n import torch._dl as _dl_flags\n\nold_flags = sys.getdlopenflags()\nsys.setdlopenflags(_dl_flags.RTLD_GLOBAL | _dl_flags.RTLD_NOW)\n\nfrom torch._C import *\n\n__all__ += [name for name in dir(_C)\n if name[0] != '_' and\n not name.endswith('Base')]\n\nsys.setdlopenflags(old_flags)\ndel _dl_flags\ndel old_flags\n\n################################################################################\n# Define basic utilities\n################################################################################\n\n\ndef typename(o):\n module = ''\n class_name = ''\n if hasattr(o, '__module__') and o.__module__ != 'builtins' \\\n and o.__module__ != '__builtin__' and o.__module__ is not None:\n module = o.__module__ + '.'\n\n if hasattr(o, '__qualname__'):\n class_name = o.__qualname__\n elif hasattr(o, '__name__'):\n class_name = o.__name__\n else:\n class_name = o.__class__.__name__\n\n return module + class_name\n\n\ndef is_tensor(obj):\n r\"\"\"Returns True if `obj` is a pytorch tensor.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return obj.__class__ in _tensor_classes\n\n\ndef is_storage(obj):\n r\"\"\"Returns True if `obj` is a pytorch storage object.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return obj.__class__ in _storage_classes\n\n\ndef set_default_tensor_type(t):\n global Tensor\n global Storage\n Tensor = _import_dotted_name(t)\n Storage = _import_dotted_name(t.replace('Tensor', 'Storage'))\n _C._set_default_tensor_type(Tensor)\n\n\ndef set_rng_state(new_state):\n r\"\"\"Sets the random number generator state.\n\n Args:\n new_state (torch.ByteTensor): The desired state\n \"\"\"\n default_generator.set_state(new_state)\n\n\ndef get_rng_state():\n r\"\"\"Returns the random number generator state as a ByteTensor.\"\"\"\n return default_generator.get_state()\n\n\ndef manual_seed(seed):\n r\"\"\"Sets the seed for generating random numbers. And returns a\n `torch._C.Generator` object.\n\n Args:\n seed (int or long): The desired seed.\n \"\"\"\n return default_generator.manual_seed(seed)\n\n\ndef initial_seed():\n r\"\"\"Returns the initial seed for generating random numbers as a\n python `long`.\n \"\"\"\n return default_generator.initial_seed()\n\n\nfrom .serialization import save, load\nfrom ._tensor_str import set_printoptions\n\n################################################################################\n# Define Storage and Tensor classes\n################################################################################\n\nfrom .storage import _StorageBase\nfrom .tensor import _TensorBase\n\n\nclass DoubleStorage(_C.DoubleStorageBase, _StorageBase):\n pass\n\n\nclass FloatStorage(_C.FloatStorageBase, _StorageBase):\n pass\n\n\nclass HalfStorage(_C.HalfStorageBase, _StorageBase):\n pass\n\n\nclass LongStorage(_C.LongStorageBase, _StorageBase):\n pass\n\n\nclass IntStorage(_C.IntStorageBase, _StorageBase):\n pass\n\n\nclass ShortStorage(_C.ShortStorageBase, _StorageBase):\n pass\n\n\nclass CharStorage(_C.CharStorageBase, _StorageBase):\n pass\n\n\nclass ByteStorage(_C.ByteStorageBase, _StorageBase):\n pass\n\n\nclass DoubleTensor(_C.DoubleTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return DoubleStorage\n\n\nclass FloatTensor(_C.FloatTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return FloatStorage\n\n\nclass HalfTensor(_C.HalfTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return HalfStorage\n\n\nclass LongTensor(_C.LongTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return LongStorage\n\n\nclass IntTensor(_C.IntTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return IntStorage\n\n\nclass ShortTensor(_C.ShortTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return ShortStorage\n\n\nclass CharTensor(_C.CharTensorBase, _TensorBase):\n\n def is_signed(self):\n # TODO\n return False\n\n @classmethod\n def storage_type(cls):\n return CharStorage\n\n\nclass ByteTensor(_C.ByteTensorBase, _TensorBase):\n\n def is_signed(self):\n return False\n\n @classmethod\n def storage_type(cls):\n return ByteStorage\n\n\n_storage_classes = {\n DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,\n CharStorage, ByteStorage,\n}\n\n_tensor_classes = {\n DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,\n CharTensor, ByteTensor,\n}\n\n\nset_default_tensor_type('torch.FloatTensor')\n\n################################################################################\n# Import interface functions defined in Python\n################################################################################\n\nfrom .functional import *\n\n################################################################################\n# Initialize extension\n################################################################################\n\n# Shared memory manager needs to know the exact location of manager executable\nimport os\nmanager_path = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'lib', 'torch_shm_manager')\nif sys.version_info[0] >= 3:\n manager_path = bytes(manager_path, 'ascii')\n\n_C._initExtension(manager_path)\n\ndel os\ndel manager_path\n\n################################################################################\n# Remove unnecessary members\n################################################################################\n\ndel DoubleStorageBase\ndel FloatStorageBase\ndel LongStorageBase\ndel IntStorageBase\ndel ShortStorageBase\ndel CharStorageBase\ndel ByteStorageBase\ndel DoubleTensorBase\ndel FloatTensorBase\ndel LongTensorBase\ndel IntTensorBase\ndel ShortTensorBase\ndel CharTensorBase\ndel ByteTensorBase\n\ndel SparseDoubleTensorBase\ndel SparseFloatTensorBase\ndel SparseLongTensorBase\ndel SparseIntTensorBase\ndel SparseShortTensorBase\ndel SparseCharTensorBase\ndel SparseByteTensorBase\n\n################################################################################\n# Import most common subpackages\n################################################################################\n\nimport torch.cuda\nimport torch.autograd\nimport torch.nn\nimport torch.optim\nimport torch.multiprocessing\n\n# attach docstrings to torch and tensor functions\nfrom . import _torch_docs, _tensor_docs\ndel _torch_docs, _tensor_docs\n", "path": "torch/__init__.py"}], "after_files": [{"content": "\"\"\"\nThe torch package contains data structures for multi-dimensional\ntensors and mathematical operations over these are defined.\nAdditionally, it provides many utilities for efficient serializing of\nTensors and arbitrary types, and other useful utilities.\n\nIt has a CUDA counterpart, that enables you to run your tensor computations\non an NVIDIA GPU with compute capability >= 2.0.\n\"\"\"\n\nimport sys\nfrom ._utils import _import_dotted_name\nfrom .version import __version__\n\n__all__ = [\n 'typename', 'is_tensor', 'is_storage', 'set_default_tensor_type',\n 'set_rng_state', 'get_rng_state', 'manual_seed', 'initial_seed',\n 'save', 'load', 'set_printoptions', 'chunk', 'split', 'stack',\n 'DoubleStorage', 'FloatStorage', 'LongStorage', 'IntStorage',\n 'ShortStorage', 'CharStorage', 'ByteStorage',\n 'DoubleTensor', 'FloatTensor', 'LongTensor', 'IntTensor',\n 'ShortTensor', 'CharTensor', 'ByteTensor',\n]\n\n################################################################################\n# Load the extension module\n################################################################################\n\n# Loading the extension with RTLD_GLOBAL option allows to not link extension\n# modules against the _C shared object. Their missing THP symbols will be\n# automatically filled by the dynamic loader.\nimport os as _dl_flags\n\n# if we have numpy, it *must* be imported before the call to setdlopenflags()\n# or there is risk that later c modules will segfault when importing numpy\ntry:\n import numpy as np\nexcept:\n pass\n\n# first check if the os package has the required flags\nif not hasattr(_dl_flags, 'RTLD_GLOBAL') or not hasattr(_dl_flags, 'RTLD_NOW'):\n try:\n # next try if DLFCN exists\n import DLFCN as _dl_flags\n except ImportError:\n # as a last attempt, use compile-time constants\n import torch._dl as _dl_flags\n\nold_flags = sys.getdlopenflags()\nsys.setdlopenflags(_dl_flags.RTLD_GLOBAL | _dl_flags.RTLD_NOW)\n\nfrom torch._C import *\n\n__all__ += [name for name in dir(_C)\n if name[0] != '_' and\n not name.endswith('Base')]\n\nsys.setdlopenflags(old_flags)\ndel _dl_flags\ndel old_flags\n\n################################################################################\n# Define basic utilities\n################################################################################\n\n\ndef typename(o):\n module = ''\n class_name = ''\n if hasattr(o, '__module__') and o.__module__ != 'builtins' \\\n and o.__module__ != '__builtin__' and o.__module__ is not None:\n module = o.__module__ + '.'\n\n if hasattr(o, '__qualname__'):\n class_name = o.__qualname__\n elif hasattr(o, '__name__'):\n class_name = o.__name__\n else:\n class_name = o.__class__.__name__\n\n return module + class_name\n\n\ndef is_tensor(obj):\n r\"\"\"Returns True if `obj` is a pytorch tensor.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return obj.__class__ in _tensor_classes\n\n\ndef is_storage(obj):\n r\"\"\"Returns True if `obj` is a pytorch storage object.\n\n Args:\n obj (Object): Object to test\n \"\"\"\n return obj.__class__ in _storage_classes\n\n\ndef set_default_tensor_type(t):\n global Tensor\n global Storage\n Tensor = _import_dotted_name(t)\n Storage = _import_dotted_name(t.replace('Tensor', 'Storage'))\n _C._set_default_tensor_type(Tensor)\n\n\ndef set_rng_state(new_state):\n r\"\"\"Sets the random number generator state.\n\n Args:\n new_state (torch.ByteTensor): The desired state\n \"\"\"\n default_generator.set_state(new_state)\n\n\ndef get_rng_state():\n r\"\"\"Returns the random number generator state as a ByteTensor.\"\"\"\n return default_generator.get_state()\n\n\ndef manual_seed(seed):\n r\"\"\"Sets the seed for generating random numbers. And returns a\n `torch._C.Generator` object.\n\n Args:\n seed (int or long): The desired seed.\n \"\"\"\n return default_generator.manual_seed(seed)\n\n\ndef initial_seed():\n r\"\"\"Returns the initial seed for generating random numbers as a\n python `long`.\n \"\"\"\n return default_generator.initial_seed()\n\n\nfrom .serialization import save, load\nfrom ._tensor_str import set_printoptions\n\n################################################################################\n# Define Storage and Tensor classes\n################################################################################\n\nfrom .storage import _StorageBase\nfrom .tensor import _TensorBase\n\n\nclass DoubleStorage(_C.DoubleStorageBase, _StorageBase):\n pass\n\n\nclass FloatStorage(_C.FloatStorageBase, _StorageBase):\n pass\n\n\nclass HalfStorage(_C.HalfStorageBase, _StorageBase):\n pass\n\n\nclass LongStorage(_C.LongStorageBase, _StorageBase):\n pass\n\n\nclass IntStorage(_C.IntStorageBase, _StorageBase):\n pass\n\n\nclass ShortStorage(_C.ShortStorageBase, _StorageBase):\n pass\n\n\nclass CharStorage(_C.CharStorageBase, _StorageBase):\n pass\n\n\nclass ByteStorage(_C.ByteStorageBase, _StorageBase):\n pass\n\n\nclass DoubleTensor(_C.DoubleTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return DoubleStorage\n\n\nclass FloatTensor(_C.FloatTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return FloatStorage\n\n\nclass HalfTensor(_C.HalfTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return HalfStorage\n\n\nclass LongTensor(_C.LongTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return LongStorage\n\n\nclass IntTensor(_C.IntTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return IntStorage\n\n\nclass ShortTensor(_C.ShortTensorBase, _TensorBase):\n\n def is_signed(self):\n return True\n\n @classmethod\n def storage_type(cls):\n return ShortStorage\n\n\nclass CharTensor(_C.CharTensorBase, _TensorBase):\n\n def is_signed(self):\n # TODO\n return False\n\n @classmethod\n def storage_type(cls):\n return CharStorage\n\n\nclass ByteTensor(_C.ByteTensorBase, _TensorBase):\n\n def is_signed(self):\n return False\n\n @classmethod\n def storage_type(cls):\n return ByteStorage\n\n\n_storage_classes = {\n DoubleStorage, FloatStorage, LongStorage, IntStorage, ShortStorage,\n CharStorage, ByteStorage,\n}\n\n_tensor_classes = {\n DoubleTensor, FloatTensor, LongTensor, IntTensor, ShortTensor,\n CharTensor, ByteTensor,\n}\n\n\nset_default_tensor_type('torch.FloatTensor')\n\n################################################################################\n# Import interface functions defined in Python\n################################################################################\n\nfrom .functional import *\n\n################################################################################\n# Initialize extension\n################################################################################\n\n# Shared memory manager needs to know the exact location of manager executable\nimport os\nmanager_path = os.path.join(os.path.abspath(os.path.dirname(__file__)), 'lib', 'torch_shm_manager')\nif sys.version_info[0] >= 3:\n manager_path = bytes(manager_path, 'ascii')\n\n_C._initExtension(manager_path)\n\ndel os\ndel manager_path\n\n################################################################################\n# Remove unnecessary members\n################################################################################\n\ndel DoubleStorageBase\ndel FloatStorageBase\ndel LongStorageBase\ndel IntStorageBase\ndel ShortStorageBase\ndel CharStorageBase\ndel ByteStorageBase\ndel DoubleTensorBase\ndel FloatTensorBase\ndel LongTensorBase\ndel IntTensorBase\ndel ShortTensorBase\ndel CharTensorBase\ndel ByteTensorBase\n\ndel SparseDoubleTensorBase\ndel SparseFloatTensorBase\ndel SparseLongTensorBase\ndel SparseIntTensorBase\ndel SparseShortTensorBase\ndel SparseCharTensorBase\ndel SparseByteTensorBase\n\n################################################################################\n# Import most common subpackages\n################################################################################\n\nimport torch.cuda\nimport torch.autograd\nimport torch.nn\nimport torch.optim\nimport torch.multiprocessing\n\n# attach docstrings to torch and tensor functions\nfrom . import _torch_docs, _tensor_docs\ndel _torch_docs, _tensor_docs\n", "path": "torch/__init__.py"}]} | 3,763 | 158 |
gh_patches_debug_41259 | rasdani/github-patches | git_diff | rucio__rucio-2603 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
Optimize the update of the final states in the necromancer
Motivation
----------
Currently the necromancer update up-to 10000000 bad replicas states in one transaction
Modification
------------
Update by chunks
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `lib/rucio/rse/protocols/__init__.py`
Content:
```
1 # Copyright European Organization for Nuclear Research (CERN)
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # You may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
6
7 # These are all protocols which are considered in good health
8 # based on generally available support libraries, native dependencies,
9 # and implementations in Rucio
10 supported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https', 'storm']
11
```
Path: `lib/rucio/daemons/badreplicas/necromancer.py`
Content:
```
1 # Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 #
15 # Authors:
16 # - Cedric Serfon <[email protected]>, 2014-2017
17 # - Vincent Garonne <[email protected]>, 2015-2018
18 # - Mario Lassnig <[email protected]>, 2015
19 # - Wen Guan <[email protected]>, 2015
20 # - Hannes Hansen <[email protected]>, 2018-2019
21 #
22 # PY3K COMPATIBLE
23
24 import logging
25 import os
26 import socket
27 import threading
28 import time
29
30 from sys import exc_info, stdout, argv
31 from traceback import format_exception
32
33 from rucio.db.sqla.constants import ReplicaState
34 from rucio.common.config import config_get
35 from rucio.common.exception import DatabaseException
36 from rucio.core import monitor, heartbeat
37 from rucio.core.replica import list_bad_replicas, get_replicas_state, list_bad_replicas_history, update_bad_replicas_history
38 from rucio.core.rule import update_rules_for_lost_replica, update_rules_for_bad_replica
39
40
41 logging.basicConfig(stream=stdout,
42 level=getattr(logging,
43 config_get('common', 'loglevel',
44 raise_exception=False,
45 default='DEBUG').upper()),
46 format='%(asctime)s\t%(process)d\t%(levelname)s\t%(message)s')
47
48 graceful_stop = threading.Event()
49
50
51 def necromancer(thread=0, bulk=5, once=False):
52 """
53 Creates a Necromancer Worker that gets a list of bad replicas for a given hash,
54 identify lost DIDs and for non-lost ones, set the locks and rules for reevaluation.
55
56 :param thread: Thread number at startup.
57 :param bulk: The number of requests to process.
58 :param once: Run only once.
59 """
60
61 sleep_time = 60
62 update_history_threshold = 3600
63 update_history_time = time.time()
64
65 executable = ' '.join(argv)
66 hostname = socket.getfqdn()
67 pid = os.getpid()
68 hb_thread = threading.current_thread()
69 heartbeat.sanity_check(executable=executable, hostname=hostname)
70
71 while not graceful_stop.is_set():
72
73 heart_beat = heartbeat.live(executable, hostname, pid, hb_thread)
74 prepend_str = 'Thread [%i/%i] : ' % (heart_beat['assign_thread'] + 1, heart_beat['nr_threads'])
75
76 stime = time.time()
77 replicas = []
78 try:
79 replicas = list_bad_replicas(limit=bulk, thread=heart_beat['assign_thread'], total_threads=heart_beat['nr_threads'])
80
81 for replica in replicas:
82 scope, name, rse_id, rse = replica['scope'], replica['name'], replica['rse_id'], replica['rse']
83 logging.info(prepend_str + 'Working on %s:%s on %s' % (scope, name, rse))
84
85 list_replicas = get_replicas_state(scope=scope, name=name)
86 if ReplicaState.AVAILABLE not in list_replicas and ReplicaState.TEMPORARY_UNAVAILABLE not in list_replicas:
87 logging.info(prepend_str + 'File %s:%s has no other available or temporary available replicas, it will be marked as lost' % (scope, name))
88 try:
89 update_rules_for_lost_replica(scope=scope, name=name, rse_id=rse_id, nowait=True)
90 monitor.record_counter(counters='necromancer.badfiles.lostfile', delta=1)
91 except DatabaseException as error:
92 logging.info(prepend_str + '%s' % (str(error)))
93
94 else:
95 rep = list_replicas.get(ReplicaState.AVAILABLE, [])
96 unavailable_rep = list_replicas.get(ReplicaState.TEMPORARY_UNAVAILABLE, [])
97 logging.info(prepend_str + 'File %s:%s can be recovered. Available sources : %s + Unavailable sources : %s' % (scope, name, str(rep), str(unavailable_rep)))
98 try:
99 update_rules_for_bad_replica(scope=scope, name=name, rse_id=rse_id, nowait=True)
100 monitor.record_counter(counters='necromancer.badfiles.recovering', delta=1)
101 except DatabaseException as error:
102 logging.info(prepend_str + '%s' % (str(error)))
103
104 logging.info(prepend_str + 'It took %s seconds to process %s replicas' % (str(time.time() - stime), str(len(replicas))))
105 except Exception:
106 exc_type, exc_value, exc_traceback = exc_info()
107 logging.critical(prepend_str + ''.join(format_exception(exc_type, exc_value, exc_traceback)).strip())
108
109 if once:
110 break
111 else:
112 now = time.time()
113 if (now - update_history_time) > update_history_threshold:
114 logging.info(prepend_str + 'Last update of history table %s seconds ago. Running update.' % (now - update_history_time))
115 bad_replicas = list_bad_replicas_history(limit=10000000,
116 thread=heart_beat['assign_thread'],
117 total_threads=heart_beat['nr_threads'])
118 for rse_id in bad_replicas:
119 update_bad_replicas_history(bad_replicas[rse_id], rse_id)
120 logging.info(prepend_str + 'History table updated in %s seconds' % (time.time() - now))
121 update_history_time = time.time()
122
123 tottime = time.time() - stime
124 if len(replicas) == bulk:
125 logging.info(prepend_str + 'Processed maximum number of replicas according to the bulk size. Restart immediately next cycle')
126 elif tottime < sleep_time:
127 logging.info(prepend_str + 'Will sleep for %s seconds' % (str(sleep_time - tottime)))
128 time.sleep(sleep_time - tottime)
129 continue
130
131 logging.info(prepend_str + 'Graceful stop requested')
132 heartbeat.die(executable, hostname, pid, hb_thread)
133 logging.info(prepend_str + 'Graceful stop done')
134
135
136 def run(threads=1, bulk=100, once=False):
137 """
138 Starts up the necromancer threads.
139 """
140
141 if once:
142 logging.info('Will run only one iteration in a single threaded mode')
143 necromancer(bulk=bulk, once=once)
144 else:
145 logging.info('starting necromancer threads')
146 thread_list = [threading.Thread(target=necromancer, kwargs={'once': once,
147 'thread': i,
148 'bulk': bulk}) for i in range(0, threads)]
149 [t.start() for t in thread_list]
150
151 logging.info('waiting for interrupts')
152
153 # Interruptible joins require a timeout.
154 while thread_list:
155 thread_list = [thread.join(timeout=3.14) for thread in thread_list if thread and thread.isAlive()]
156
157
158 def stop(signum=None, frame=None):
159 """
160 Graceful exit.
161 """
162 graceful_stop.set()
163
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/lib/rucio/daemons/badreplicas/necromancer.py b/lib/rucio/daemons/badreplicas/necromancer.py
--- a/lib/rucio/daemons/badreplicas/necromancer.py
+++ b/lib/rucio/daemons/badreplicas/necromancer.py
@@ -13,7 +13,7 @@
# limitations under the License.
#
# Authors:
-# - Cedric Serfon <[email protected]>, 2014-2017
+# - Cedric Serfon <[email protected]>, 2014-2019
# - Vincent Garonne <[email protected]>, 2015-2018
# - Mario Lassnig <[email protected]>, 2015
# - Wen Guan <[email protected]>, 2015
@@ -21,17 +21,21 @@
#
# PY3K COMPATIBLE
+from __future__ import division
+
import logging
import os
import socket
import threading
import time
+from math import ceil
from sys import exc_info, stdout, argv
from traceback import format_exception
from rucio.db.sqla.constants import ReplicaState
from rucio.common.config import config_get
+from rucio.common.utils import chunks
from rucio.common.exception import DatabaseException
from rucio.core import monitor, heartbeat
from rucio.core.replica import list_bad_replicas, get_replicas_state, list_bad_replicas_history, update_bad_replicas_history
@@ -112,11 +116,18 @@
now = time.time()
if (now - update_history_time) > update_history_threshold:
logging.info(prepend_str + 'Last update of history table %s seconds ago. Running update.' % (now - update_history_time))
- bad_replicas = list_bad_replicas_history(limit=10000000,
+ bad_replicas = list_bad_replicas_history(limit=1000000,
thread=heart_beat['assign_thread'],
total_threads=heart_beat['nr_threads'])
for rse_id in bad_replicas:
- update_bad_replicas_history(bad_replicas[rse_id], rse_id)
+ chunk_size = 1000
+ nchunk = int(ceil(len(bad_replicas[rse_id]) / chunk_size))
+ logging.debug(prepend_str + 'Update history for rse_id %s' % (rse_id))
+ cnt = 0
+ for chunk in chunks(bad_replicas[rse_id], chunk_size):
+ logging.debug(prepend_str + ' History for rse_id %s : chunk %i/%i' % (rse_id, cnt, nchunk))
+ cnt += 1
+ update_bad_replicas_history(chunk, rse_id)
logging.info(prepend_str + 'History table updated in %s seconds' % (time.time() - now))
update_history_time = time.time()
diff --git a/lib/rucio/rse/protocols/__init__.py b/lib/rucio/rse/protocols/__init__.py
--- a/lib/rucio/rse/protocols/__init__.py
+++ b/lib/rucio/rse/protocols/__init__.py
@@ -7,4 +7,4 @@
# These are all protocols which are considered in good health
# based on generally available support libraries, native dependencies,
# and implementations in Rucio
-supported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https']
+supported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https', 'storm']
| {"golden_diff": "diff --git a/lib/rucio/daemons/badreplicas/necromancer.py b/lib/rucio/daemons/badreplicas/necromancer.py\n--- a/lib/rucio/daemons/badreplicas/necromancer.py\n+++ b/lib/rucio/daemons/badreplicas/necromancer.py\n@@ -13,7 +13,7 @@\n # limitations under the License.\n #\n # Authors:\n-# - Cedric Serfon <[email protected]>, 2014-2017\n+# - Cedric Serfon <[email protected]>, 2014-2019\n # - Vincent Garonne <[email protected]>, 2015-2018\n # - Mario Lassnig <[email protected]>, 2015\n # - Wen Guan <[email protected]>, 2015\n@@ -21,17 +21,21 @@\n #\n # PY3K COMPATIBLE\n \n+from __future__ import division\n+\n import logging\n import os\n import socket\n import threading\n import time\n \n+from math import ceil\n from sys import exc_info, stdout, argv\n from traceback import format_exception\n \n from rucio.db.sqla.constants import ReplicaState\n from rucio.common.config import config_get\n+from rucio.common.utils import chunks\n from rucio.common.exception import DatabaseException\n from rucio.core import monitor, heartbeat\n from rucio.core.replica import list_bad_replicas, get_replicas_state, list_bad_replicas_history, update_bad_replicas_history\n@@ -112,11 +116,18 @@\n now = time.time()\n if (now - update_history_time) > update_history_threshold:\n logging.info(prepend_str + 'Last update of history table %s seconds ago. Running update.' % (now - update_history_time))\n- bad_replicas = list_bad_replicas_history(limit=10000000,\n+ bad_replicas = list_bad_replicas_history(limit=1000000,\n thread=heart_beat['assign_thread'],\n total_threads=heart_beat['nr_threads'])\n for rse_id in bad_replicas:\n- update_bad_replicas_history(bad_replicas[rse_id], rse_id)\n+ chunk_size = 1000\n+ nchunk = int(ceil(len(bad_replicas[rse_id]) / chunk_size))\n+ logging.debug(prepend_str + 'Update history for rse_id %s' % (rse_id))\n+ cnt = 0\n+ for chunk in chunks(bad_replicas[rse_id], chunk_size):\n+ logging.debug(prepend_str + ' History for rse_id %s : chunk %i/%i' % (rse_id, cnt, nchunk))\n+ cnt += 1\n+ update_bad_replicas_history(chunk, rse_id)\n logging.info(prepend_str + 'History table updated in %s seconds' % (time.time() - now))\n update_history_time = time.time()\n \ndiff --git a/lib/rucio/rse/protocols/__init__.py b/lib/rucio/rse/protocols/__init__.py\n--- a/lib/rucio/rse/protocols/__init__.py\n+++ b/lib/rucio/rse/protocols/__init__.py\n@@ -7,4 +7,4 @@\n # These are all protocols which are considered in good health\n # based on generally available support libraries, native dependencies,\n # and implementations in Rucio\n-supported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https']\n+supported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https', 'storm']\n", "issue": "Optimize the update of the final states in the necromancer\nMotivation\r\n----------\r\nCurrently the necromancer update up-to 10000000 bad replicas states in one transaction\r\n\r\n\r\nModification\r\n------------\r\nUpdate by chunks\r\n\r\n\n", "before_files": [{"content": "# Copyright European Organization for Nuclear Research (CERN)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# You may not use this file except in compliance with the License.\n# You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0\n\n# These are all protocols which are considered in good health\n# based on generally available support libraries, native dependencies,\n# and implementations in Rucio\nsupported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https', 'storm']\n", "path": "lib/rucio/rse/protocols/__init__.py"}, {"content": "# Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Cedric Serfon <[email protected]>, 2014-2017\n# - Vincent Garonne <[email protected]>, 2015-2018\n# - Mario Lassnig <[email protected]>, 2015\n# - Wen Guan <[email protected]>, 2015\n# - Hannes Hansen <[email protected]>, 2018-2019\n#\n# PY3K COMPATIBLE\n\nimport logging\nimport os\nimport socket\nimport threading\nimport time\n\nfrom sys import exc_info, stdout, argv\nfrom traceback import format_exception\n\nfrom rucio.db.sqla.constants import ReplicaState\nfrom rucio.common.config import config_get\nfrom rucio.common.exception import DatabaseException\nfrom rucio.core import monitor, heartbeat\nfrom rucio.core.replica import list_bad_replicas, get_replicas_state, list_bad_replicas_history, update_bad_replicas_history\nfrom rucio.core.rule import update_rules_for_lost_replica, update_rules_for_bad_replica\n\n\nlogging.basicConfig(stream=stdout,\n level=getattr(logging,\n config_get('common', 'loglevel',\n raise_exception=False,\n default='DEBUG').upper()),\n format='%(asctime)s\\t%(process)d\\t%(levelname)s\\t%(message)s')\n\ngraceful_stop = threading.Event()\n\n\ndef necromancer(thread=0, bulk=5, once=False):\n \"\"\"\n Creates a Necromancer Worker that gets a list of bad replicas for a given hash,\n identify lost DIDs and for non-lost ones, set the locks and rules for reevaluation.\n\n :param thread: Thread number at startup.\n :param bulk: The number of requests to process.\n :param once: Run only once.\n \"\"\"\n\n sleep_time = 60\n update_history_threshold = 3600\n update_history_time = time.time()\n\n executable = ' '.join(argv)\n hostname = socket.getfqdn()\n pid = os.getpid()\n hb_thread = threading.current_thread()\n heartbeat.sanity_check(executable=executable, hostname=hostname)\n\n while not graceful_stop.is_set():\n\n heart_beat = heartbeat.live(executable, hostname, pid, hb_thread)\n prepend_str = 'Thread [%i/%i] : ' % (heart_beat['assign_thread'] + 1, heart_beat['nr_threads'])\n\n stime = time.time()\n replicas = []\n try:\n replicas = list_bad_replicas(limit=bulk, thread=heart_beat['assign_thread'], total_threads=heart_beat['nr_threads'])\n\n for replica in replicas:\n scope, name, rse_id, rse = replica['scope'], replica['name'], replica['rse_id'], replica['rse']\n logging.info(prepend_str + 'Working on %s:%s on %s' % (scope, name, rse))\n\n list_replicas = get_replicas_state(scope=scope, name=name)\n if ReplicaState.AVAILABLE not in list_replicas and ReplicaState.TEMPORARY_UNAVAILABLE not in list_replicas:\n logging.info(prepend_str + 'File %s:%s has no other available or temporary available replicas, it will be marked as lost' % (scope, name))\n try:\n update_rules_for_lost_replica(scope=scope, name=name, rse_id=rse_id, nowait=True)\n monitor.record_counter(counters='necromancer.badfiles.lostfile', delta=1)\n except DatabaseException as error:\n logging.info(prepend_str + '%s' % (str(error)))\n\n else:\n rep = list_replicas.get(ReplicaState.AVAILABLE, [])\n unavailable_rep = list_replicas.get(ReplicaState.TEMPORARY_UNAVAILABLE, [])\n logging.info(prepend_str + 'File %s:%s can be recovered. Available sources : %s + Unavailable sources : %s' % (scope, name, str(rep), str(unavailable_rep)))\n try:\n update_rules_for_bad_replica(scope=scope, name=name, rse_id=rse_id, nowait=True)\n monitor.record_counter(counters='necromancer.badfiles.recovering', delta=1)\n except DatabaseException as error:\n logging.info(prepend_str + '%s' % (str(error)))\n\n logging.info(prepend_str + 'It took %s seconds to process %s replicas' % (str(time.time() - stime), str(len(replicas))))\n except Exception:\n exc_type, exc_value, exc_traceback = exc_info()\n logging.critical(prepend_str + ''.join(format_exception(exc_type, exc_value, exc_traceback)).strip())\n\n if once:\n break\n else:\n now = time.time()\n if (now - update_history_time) > update_history_threshold:\n logging.info(prepend_str + 'Last update of history table %s seconds ago. Running update.' % (now - update_history_time))\n bad_replicas = list_bad_replicas_history(limit=10000000,\n thread=heart_beat['assign_thread'],\n total_threads=heart_beat['nr_threads'])\n for rse_id in bad_replicas:\n update_bad_replicas_history(bad_replicas[rse_id], rse_id)\n logging.info(prepend_str + 'History table updated in %s seconds' % (time.time() - now))\n update_history_time = time.time()\n\n tottime = time.time() - stime\n if len(replicas) == bulk:\n logging.info(prepend_str + 'Processed maximum number of replicas according to the bulk size. Restart immediately next cycle')\n elif tottime < sleep_time:\n logging.info(prepend_str + 'Will sleep for %s seconds' % (str(sleep_time - tottime)))\n time.sleep(sleep_time - tottime)\n continue\n\n logging.info(prepend_str + 'Graceful stop requested')\n heartbeat.die(executable, hostname, pid, hb_thread)\n logging.info(prepend_str + 'Graceful stop done')\n\n\ndef run(threads=1, bulk=100, once=False):\n \"\"\"\n Starts up the necromancer threads.\n \"\"\"\n\n if once:\n logging.info('Will run only one iteration in a single threaded mode')\n necromancer(bulk=bulk, once=once)\n else:\n logging.info('starting necromancer threads')\n thread_list = [threading.Thread(target=necromancer, kwargs={'once': once,\n 'thread': i,\n 'bulk': bulk}) for i in range(0, threads)]\n [t.start() for t in thread_list]\n\n logging.info('waiting for interrupts')\n\n # Interruptible joins require a timeout.\n while thread_list:\n thread_list = [thread.join(timeout=3.14) for thread in thread_list if thread and thread.isAlive()]\n\n\ndef stop(signum=None, frame=None):\n \"\"\"\n Graceful exit.\n \"\"\"\n graceful_stop.set()\n", "path": "lib/rucio/daemons/badreplicas/necromancer.py"}], "after_files": [{"content": "# Copyright European Organization for Nuclear Research (CERN)\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# You may not use this file except in compliance with the License.\n# You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0\n\n# These are all protocols which are considered in good health\n# based on generally available support libraries, native dependencies,\n# and implementations in Rucio\nsupported_protocols = ['gsiftp', 'srm', 'root', 'davs', 'http', 'https', 'file', 's3', 's3+rucio', 's3+https', 'storm']\n", "path": "lib/rucio/rse/protocols/__init__.py"}, {"content": "# Copyright 2014-2018 CERN for the benefit of the ATLAS collaboration.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n# Authors:\n# - Cedric Serfon <[email protected]>, 2014-2019\n# - Vincent Garonne <[email protected]>, 2015-2018\n# - Mario Lassnig <[email protected]>, 2015\n# - Wen Guan <[email protected]>, 2015\n# - Hannes Hansen <[email protected]>, 2018-2019\n#\n# PY3K COMPATIBLE\n\nfrom __future__ import division\n\nimport logging\nimport os\nimport socket\nimport threading\nimport time\n\nfrom math import ceil\nfrom sys import exc_info, stdout, argv\nfrom traceback import format_exception\n\nfrom rucio.db.sqla.constants import ReplicaState\nfrom rucio.common.config import config_get\nfrom rucio.common.utils import chunks\nfrom rucio.common.exception import DatabaseException\nfrom rucio.core import monitor, heartbeat\nfrom rucio.core.replica import list_bad_replicas, get_replicas_state, list_bad_replicas_history, update_bad_replicas_history\nfrom rucio.core.rule import update_rules_for_lost_replica, update_rules_for_bad_replica\n\n\nlogging.basicConfig(stream=stdout,\n level=getattr(logging,\n config_get('common', 'loglevel',\n raise_exception=False,\n default='DEBUG').upper()),\n format='%(asctime)s\\t%(process)d\\t%(levelname)s\\t%(message)s')\n\ngraceful_stop = threading.Event()\n\n\ndef necromancer(thread=0, bulk=5, once=False):\n \"\"\"\n Creates a Necromancer Worker that gets a list of bad replicas for a given hash,\n identify lost DIDs and for non-lost ones, set the locks and rules for reevaluation.\n\n :param thread: Thread number at startup.\n :param bulk: The number of requests to process.\n :param once: Run only once.\n \"\"\"\n\n sleep_time = 60\n update_history_threshold = 3600\n update_history_time = time.time()\n\n executable = ' '.join(argv)\n hostname = socket.getfqdn()\n pid = os.getpid()\n hb_thread = threading.current_thread()\n heartbeat.sanity_check(executable=executable, hostname=hostname)\n\n while not graceful_stop.is_set():\n\n heart_beat = heartbeat.live(executable, hostname, pid, hb_thread)\n prepend_str = 'Thread [%i/%i] : ' % (heart_beat['assign_thread'] + 1, heart_beat['nr_threads'])\n\n stime = time.time()\n replicas = []\n try:\n replicas = list_bad_replicas(limit=bulk, thread=heart_beat['assign_thread'], total_threads=heart_beat['nr_threads'])\n\n for replica in replicas:\n scope, name, rse_id, rse = replica['scope'], replica['name'], replica['rse_id'], replica['rse']\n logging.info(prepend_str + 'Working on %s:%s on %s' % (scope, name, rse))\n\n list_replicas = get_replicas_state(scope=scope, name=name)\n if ReplicaState.AVAILABLE not in list_replicas and ReplicaState.TEMPORARY_UNAVAILABLE not in list_replicas:\n logging.info(prepend_str + 'File %s:%s has no other available or temporary available replicas, it will be marked as lost' % (scope, name))\n try:\n update_rules_for_lost_replica(scope=scope, name=name, rse_id=rse_id, nowait=True)\n monitor.record_counter(counters='necromancer.badfiles.lostfile', delta=1)\n except DatabaseException as error:\n logging.info(prepend_str + '%s' % (str(error)))\n\n else:\n rep = list_replicas.get(ReplicaState.AVAILABLE, [])\n unavailable_rep = list_replicas.get(ReplicaState.TEMPORARY_UNAVAILABLE, [])\n logging.info(prepend_str + 'File %s:%s can be recovered. Available sources : %s + Unavailable sources : %s' % (scope, name, str(rep), str(unavailable_rep)))\n try:\n update_rules_for_bad_replica(scope=scope, name=name, rse_id=rse_id, nowait=True)\n monitor.record_counter(counters='necromancer.badfiles.recovering', delta=1)\n except DatabaseException as error:\n logging.info(prepend_str + '%s' % (str(error)))\n\n logging.info(prepend_str + 'It took %s seconds to process %s replicas' % (str(time.time() - stime), str(len(replicas))))\n except Exception:\n exc_type, exc_value, exc_traceback = exc_info()\n logging.critical(prepend_str + ''.join(format_exception(exc_type, exc_value, exc_traceback)).strip())\n\n if once:\n break\n else:\n now = time.time()\n if (now - update_history_time) > update_history_threshold:\n logging.info(prepend_str + 'Last update of history table %s seconds ago. Running update.' % (now - update_history_time))\n bad_replicas = list_bad_replicas_history(limit=1000000,\n thread=heart_beat['assign_thread'],\n total_threads=heart_beat['nr_threads'])\n for rse_id in bad_replicas:\n chunk_size = 1000\n nchunk = int(ceil(len(bad_replicas[rse_id]) / chunk_size))\n logging.debug(prepend_str + 'Update history for rse_id %s' % (rse_id))\n cnt = 0\n for chunk in chunks(bad_replicas[rse_id], chunk_size):\n logging.debug(prepend_str + ' History for rse_id %s : chunk %i/%i' % (rse_id, cnt, nchunk))\n cnt += 1\n update_bad_replicas_history(chunk, rse_id)\n logging.info(prepend_str + 'History table updated in %s seconds' % (time.time() - now))\n update_history_time = time.time()\n\n tottime = time.time() - stime\n if len(replicas) == bulk:\n logging.info(prepend_str + 'Processed maximum number of replicas according to the bulk size. Restart immediately next cycle')\n elif tottime < sleep_time:\n logging.info(prepend_str + 'Will sleep for %s seconds' % (str(sleep_time - tottime)))\n time.sleep(sleep_time - tottime)\n continue\n\n logging.info(prepend_str + 'Graceful stop requested')\n heartbeat.die(executable, hostname, pid, hb_thread)\n logging.info(prepend_str + 'Graceful stop done')\n\n\ndef run(threads=1, bulk=100, once=False):\n \"\"\"\n Starts up the necromancer threads.\n \"\"\"\n\n if once:\n logging.info('Will run only one iteration in a single threaded mode')\n necromancer(bulk=bulk, once=once)\n else:\n logging.info('starting necromancer threads')\n thread_list = [threading.Thread(target=necromancer, kwargs={'once': once,\n 'thread': i,\n 'bulk': bulk}) for i in range(0, threads)]\n [t.start() for t in thread_list]\n\n logging.info('waiting for interrupts')\n\n # Interruptible joins require a timeout.\n while thread_list:\n thread_list = [thread.join(timeout=3.14) for thread in thread_list if thread and thread.isAlive()]\n\n\ndef stop(signum=None, frame=None):\n \"\"\"\n Graceful exit.\n \"\"\"\n graceful_stop.set()\n", "path": "lib/rucio/daemons/badreplicas/necromancer.py"}]} | 2,568 | 892 |
gh_patches_debug_43198 | rasdani/github-patches | git_diff | pallets__werkzeug-1284 | We are currently solving the following issue within our repository. Here is the issue text:
--- BEGIN ISSUE ---
[feature request] werkzeug.contrib.profiler.ProfilerMiddleware custom file name formatting
It would be nice to allow users to customize the output file name format when using the ProfilerMiddleware.
Currently, the file name format is `'%(method)s.%(path)s.%(elapsed)06dms.%(time)d'`, which when multiple invocations have occurred leads to the profile files being ordered by their respective elapsed times. Having the ability to customize this format allows profiling users to make use of the resultant profile files in additional ways.
I propose the `profiler.ProfilerMiddleware` is changed to allow users to customize the format of the profile filenames for their specific needs.
--- END ISSUE ---
Below are some code segments, each from a relevant file. One or more of these files may contain bugs.
--- BEGIN FILES ---
Path: `werkzeug/contrib/profiler.py`
Content:
```
1 # -*- coding: utf-8 -*-
2 """
3 werkzeug.contrib.profiler
4 ~~~~~~~~~~~~~~~~~~~~~~~~~
5
6 This module provides a simple WSGI profiler middleware for finding
7 bottlenecks in web application. It uses the :mod:`profile` or
8 :mod:`cProfile` module to do the profiling and writes the stats to the
9 stream provided (defaults to stderr).
10
11 Example usage::
12
13 from werkzeug.contrib.profiler import ProfilerMiddleware
14 app = ProfilerMiddleware(app)
15
16 :copyright: (c) 2014 by the Werkzeug Team, see AUTHORS for more details.
17 :license: BSD, see LICENSE for more details.
18 """
19 import sys
20 import time
21 import os.path
22 try:
23 try:
24 from cProfile import Profile
25 except ImportError:
26 from profile import Profile
27 from pstats import Stats
28 available = True
29 except ImportError:
30 available = False
31
32
33 class MergeStream(object):
34
35 """An object that redirects `write` calls to multiple streams.
36 Use this to log to both `sys.stdout` and a file::
37
38 f = open('profiler.log', 'w')
39 stream = MergeStream(sys.stdout, f)
40 profiler = ProfilerMiddleware(app, stream)
41 """
42
43 def __init__(self, *streams):
44 if not streams:
45 raise TypeError('at least one stream must be given')
46 self.streams = streams
47
48 def write(self, data):
49 for stream in self.streams:
50 stream.write(data)
51
52
53 class ProfilerMiddleware(object):
54
55 """Simple profiler middleware. Wraps a WSGI application and profiles
56 a request. This intentionally buffers the response so that timings are
57 more exact.
58
59 By giving the `profile_dir` argument, pstat.Stats files are saved to that
60 directory, one file per request. Without it, a summary is printed to
61 `stream` instead.
62
63 For the exact meaning of `sort_by` and `restrictions` consult the
64 :mod:`profile` documentation.
65
66 .. versionadded:: 0.9
67 Added support for `restrictions` and `profile_dir`.
68
69 :param app: the WSGI application to profile.
70 :param stream: the stream for the profiled stats. defaults to stderr.
71 :param sort_by: a tuple of columns to sort the result by.
72 :param restrictions: a tuple of profiling strictions, not used if dumping
73 to `profile_dir`.
74 :param profile_dir: directory name to save pstat files
75 """
76
77 def __init__(self, app, stream=None,
78 sort_by=('time', 'calls'), restrictions=(), profile_dir=None):
79 if not available:
80 raise RuntimeError('the profiler is not available because '
81 'profile or pstat is not installed.')
82 self._app = app
83 self._stream = stream or sys.stdout
84 self._sort_by = sort_by
85 self._restrictions = restrictions
86 self._profile_dir = profile_dir
87
88 def __call__(self, environ, start_response):
89 response_body = []
90
91 def catching_start_response(status, headers, exc_info=None):
92 start_response(status, headers, exc_info)
93 return response_body.append
94
95 def runapp():
96 appiter = self._app(environ, catching_start_response)
97 response_body.extend(appiter)
98 if hasattr(appiter, 'close'):
99 appiter.close()
100
101 p = Profile()
102 start = time.time()
103 p.runcall(runapp)
104 body = b''.join(response_body)
105 elapsed = time.time() - start
106
107 if self._profile_dir is not None:
108 prof_filename = os.path.join(self._profile_dir,
109 '%s.%s.%06dms.%d.prof' % (
110 environ['REQUEST_METHOD'],
111 environ.get('PATH_INFO').strip(
112 '/').replace('/', '.') or 'root',
113 elapsed * 1000.0,
114 time.time()
115 ))
116 p.dump_stats(prof_filename)
117
118 else:
119 stats = Stats(p, stream=self._stream)
120 stats.sort_stats(*self._sort_by)
121
122 self._stream.write('-' * 80)
123 self._stream.write('\nPATH: %r\n' % environ.get('PATH_INFO'))
124 stats.print_stats(*self._restrictions)
125 self._stream.write('-' * 80 + '\n\n')
126
127 return [body]
128
129
130 def make_action(app_factory, hostname='localhost', port=5000,
131 threaded=False, processes=1, stream=None,
132 sort_by=('time', 'calls'), restrictions=()):
133 """Return a new callback for :mod:`werkzeug.script` that starts a local
134 server with the profiler enabled.
135
136 ::
137
138 from werkzeug.contrib import profiler
139 action_profile = profiler.make_action(make_app)
140 """
141 def action(hostname=('h', hostname), port=('p', port),
142 threaded=threaded, processes=processes):
143 """Start a new development server."""
144 from werkzeug.serving import run_simple
145 app = ProfilerMiddleware(app_factory(), stream, sort_by, restrictions)
146 run_simple(hostname, port, app, False, None, threaded, processes)
147 return action
148
```
--- END FILES ---
Please first localize the bug based on the issue statement, and then generate a patch according to the `git diff` format fenced by three backticks.
Here is an example:
```diff
diff --git a/examples/server_async.py b/examples/server_async.py
--- a/examples/server_async.py
+++ b/examples/server_async.py
@@ -313,4 +313,4 @@
if __name__ == "__main__":
- asyncio.run(run_async_server("."), debug=True)
+ asyncio.run(run_async_server(), debug=True)
diff --git a/examples/server_sync.py b/examples/server_sync.py
--- a/examples/server_sync.py
+++ b/examples/server_sync.py
@@ -313,5 +313,5 @@
if __name__ == "__main__":
- server = run_sync_server(".")
+ server = run_sync_server()
server.shutdown()
```
| diff --git a/werkzeug/contrib/profiler.py b/werkzeug/contrib/profiler.py
--- a/werkzeug/contrib/profiler.py
+++ b/werkzeug/contrib/profiler.py
@@ -9,7 +9,6 @@
stream provided (defaults to stderr).
Example usage::
-
from werkzeug.contrib.profiler import ProfilerMiddleware
app = ProfilerMiddleware(app)
@@ -60,22 +59,43 @@
directory, one file per request. Without it, a summary is printed to
`stream` instead.
+ The file name format can be customized by passing
+ ``filename_format``. If it is a string, it will be formatted using
+ :meth:`str.format` with the following fields available:
+
+ - ``{method}`` - the request method; GET, POST, etc
+ - ``{path}`` - the request path or 'root' should one not exist
+ - ``{elapsed}`` - the elapsed time of the request
+ - ``{time}`` - the time of the request
+
+ If it is a callable, it will be called with the WSGI ``environ``
+ dict and should return a filename. Either way, the ``'.prof'``
+ extension will be appended to the name. The default format is
+ ``'{method}.{path}.{elapsed:06d}ms.{time:d}'``.
+
For the exact meaning of `sort_by` and `restrictions` consult the
:mod:`profile` documentation.
.. versionadded:: 0.9
Added support for `restrictions` and `profile_dir`.
+ .. versionadded:: 0.15
+ Added ``profile_file_name_format``.
+
:param app: the WSGI application to profile.
:param stream: the stream for the profiled stats. defaults to stderr.
:param sort_by: a tuple of columns to sort the result by.
- :param restrictions: a tuple of profiling strictions, not used if dumping
+ :param restrictions: a tuple of profiling restrictions, not used if dumping
to `profile_dir`.
:param profile_dir: directory name to save pstat files
+ :param filename_format: format of the filename excluding the extension.
"""
- def __init__(self, app, stream=None,
- sort_by=('time', 'calls'), restrictions=(), profile_dir=None):
+ def __init__(
+ self, app, stream=None,
+ sort_by=('time', 'calls'), restrictions=(), profile_dir=None,
+ filename_format='%(method)s.%(path)s.%(elapsed)06dms.%(time)d'
+ ):
if not available:
raise RuntimeError('the profiler is not available because '
'profile or pstat is not installed.')
@@ -84,6 +104,7 @@
self._sort_by = sort_by
self._restrictions = restrictions
self._profile_dir = profile_dir
+ self._filename_format = filename_format
def __call__(self, environ, start_response):
response_body = []
@@ -105,14 +126,18 @@
elapsed = time.time() - start
if self._profile_dir is not None:
- prof_filename = os.path.join(self._profile_dir,
- '%s.%s.%06dms.%d.prof' % (
- environ['REQUEST_METHOD'],
- environ.get('PATH_INFO').strip(
- '/').replace('/', '.') or 'root',
- elapsed * 1000.0,
- time.time()
- ))
+ if callable(self._filename_format):
+ filename = self._filename_format(environ)
+ else:
+ filename = self._filename_format.format(
+ method=environ['REQUEST_METHOD'],
+ path=(
+ environ.get('PATH_INFO').strip('/').replace('/', '.')
+ or 'root'),
+ elapsed=elapsed * 1000.0,
+ time=time.time(),
+ )
+ prof_filename = os.path.join(self._profile_dir, filename + '.prof')
p.dump_stats(prof_filename)
else:
| {"golden_diff": "diff --git a/werkzeug/contrib/profiler.py b/werkzeug/contrib/profiler.py\n--- a/werkzeug/contrib/profiler.py\n+++ b/werkzeug/contrib/profiler.py\n@@ -9,7 +9,6 @@\n stream provided (defaults to stderr).\n \n Example usage::\n-\n from werkzeug.contrib.profiler import ProfilerMiddleware\n app = ProfilerMiddleware(app)\n \n@@ -60,22 +59,43 @@\n directory, one file per request. Without it, a summary is printed to\n `stream` instead.\n \n+ The file name format can be customized by passing\n+ ``filename_format``. If it is a string, it will be formatted using\n+ :meth:`str.format` with the following fields available:\n+\n+ - ``{method}`` - the request method; GET, POST, etc\n+ - ``{path}`` - the request path or 'root' should one not exist\n+ - ``{elapsed}`` - the elapsed time of the request\n+ - ``{time}`` - the time of the request\n+\n+ If it is a callable, it will be called with the WSGI ``environ``\n+ dict and should return a filename. Either way, the ``'.prof'``\n+ extension will be appended to the name. The default format is\n+ ``'{method}.{path}.{elapsed:06d}ms.{time:d}'``.\n+\n For the exact meaning of `sort_by` and `restrictions` consult the\n :mod:`profile` documentation.\n \n .. versionadded:: 0.9\n Added support for `restrictions` and `profile_dir`.\n \n+ .. versionadded:: 0.15\n+ Added ``profile_file_name_format``.\n+\n :param app: the WSGI application to profile.\n :param stream: the stream for the profiled stats. defaults to stderr.\n :param sort_by: a tuple of columns to sort the result by.\n- :param restrictions: a tuple of profiling strictions, not used if dumping\n+ :param restrictions: a tuple of profiling restrictions, not used if dumping\n to `profile_dir`.\n :param profile_dir: directory name to save pstat files\n+ :param filename_format: format of the filename excluding the extension.\n \"\"\"\n \n- def __init__(self, app, stream=None,\n- sort_by=('time', 'calls'), restrictions=(), profile_dir=None):\n+ def __init__(\n+ self, app, stream=None,\n+ sort_by=('time', 'calls'), restrictions=(), profile_dir=None,\n+ filename_format='%(method)s.%(path)s.%(elapsed)06dms.%(time)d'\n+ ):\n if not available:\n raise RuntimeError('the profiler is not available because '\n 'profile or pstat is not installed.')\n@@ -84,6 +104,7 @@\n self._sort_by = sort_by\n self._restrictions = restrictions\n self._profile_dir = profile_dir\n+ self._filename_format = filename_format\n \n def __call__(self, environ, start_response):\n response_body = []\n@@ -105,14 +126,18 @@\n elapsed = time.time() - start\n \n if self._profile_dir is not None:\n- prof_filename = os.path.join(self._profile_dir,\n- '%s.%s.%06dms.%d.prof' % (\n- environ['REQUEST_METHOD'],\n- environ.get('PATH_INFO').strip(\n- '/').replace('/', '.') or 'root',\n- elapsed * 1000.0,\n- time.time()\n- ))\n+ if callable(self._filename_format):\n+ filename = self._filename_format(environ)\n+ else:\n+ filename = self._filename_format.format(\n+ method=environ['REQUEST_METHOD'],\n+ path=(\n+ environ.get('PATH_INFO').strip('/').replace('/', '.')\n+ or 'root'),\n+ elapsed=elapsed * 1000.0,\n+ time=time.time(),\n+ )\n+ prof_filename = os.path.join(self._profile_dir, filename + '.prof')\n p.dump_stats(prof_filename)\n \n else:\n", "issue": "[feature request] werkzeug.contrib.profiler.ProfilerMiddleware custom file name formatting\nIt would be nice to allow users to customize the output file name format when using the ProfilerMiddleware.\r\n\r\nCurrently, the file name format is `'%(method)s.%(path)s.%(elapsed)06dms.%(time)d'`, which when multiple invocations have occurred leads to the profile files being ordered by their respective elapsed times. Having the ability to customize this format allows profiling users to make use of the resultant profile files in additional ways.\r\n\r\nI propose the `profiler.ProfilerMiddleware` is changed to allow users to customize the format of the profile filenames for their specific needs.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n werkzeug.contrib.profiler\n ~~~~~~~~~~~~~~~~~~~~~~~~~\n\n This module provides a simple WSGI profiler middleware for finding\n bottlenecks in web application. It uses the :mod:`profile` or\n :mod:`cProfile` module to do the profiling and writes the stats to the\n stream provided (defaults to stderr).\n\n Example usage::\n\n from werkzeug.contrib.profiler import ProfilerMiddleware\n app = ProfilerMiddleware(app)\n\n :copyright: (c) 2014 by the Werkzeug Team, see AUTHORS for more details.\n :license: BSD, see LICENSE for more details.\n\"\"\"\nimport sys\nimport time\nimport os.path\ntry:\n try:\n from cProfile import Profile\n except ImportError:\n from profile import Profile\n from pstats import Stats\n available = True\nexcept ImportError:\n available = False\n\n\nclass MergeStream(object):\n\n \"\"\"An object that redirects `write` calls to multiple streams.\n Use this to log to both `sys.stdout` and a file::\n\n f = open('profiler.log', 'w')\n stream = MergeStream(sys.stdout, f)\n profiler = ProfilerMiddleware(app, stream)\n \"\"\"\n\n def __init__(self, *streams):\n if not streams:\n raise TypeError('at least one stream must be given')\n self.streams = streams\n\n def write(self, data):\n for stream in self.streams:\n stream.write(data)\n\n\nclass ProfilerMiddleware(object):\n\n \"\"\"Simple profiler middleware. Wraps a WSGI application and profiles\n a request. This intentionally buffers the response so that timings are\n more exact.\n\n By giving the `profile_dir` argument, pstat.Stats files are saved to that\n directory, one file per request. Without it, a summary is printed to\n `stream` instead.\n\n For the exact meaning of `sort_by` and `restrictions` consult the\n :mod:`profile` documentation.\n\n .. versionadded:: 0.9\n Added support for `restrictions` and `profile_dir`.\n\n :param app: the WSGI application to profile.\n :param stream: the stream for the profiled stats. defaults to stderr.\n :param sort_by: a tuple of columns to sort the result by.\n :param restrictions: a tuple of profiling strictions, not used if dumping\n to `profile_dir`.\n :param profile_dir: directory name to save pstat files\n \"\"\"\n\n def __init__(self, app, stream=None,\n sort_by=('time', 'calls'), restrictions=(), profile_dir=None):\n if not available:\n raise RuntimeError('the profiler is not available because '\n 'profile or pstat is not installed.')\n self._app = app\n self._stream = stream or sys.stdout\n self._sort_by = sort_by\n self._restrictions = restrictions\n self._profile_dir = profile_dir\n\n def __call__(self, environ, start_response):\n response_body = []\n\n def catching_start_response(status, headers, exc_info=None):\n start_response(status, headers, exc_info)\n return response_body.append\n\n def runapp():\n appiter = self._app(environ, catching_start_response)\n response_body.extend(appiter)\n if hasattr(appiter, 'close'):\n appiter.close()\n\n p = Profile()\n start = time.time()\n p.runcall(runapp)\n body = b''.join(response_body)\n elapsed = time.time() - start\n\n if self._profile_dir is not None:\n prof_filename = os.path.join(self._profile_dir,\n '%s.%s.%06dms.%d.prof' % (\n environ['REQUEST_METHOD'],\n environ.get('PATH_INFO').strip(\n '/').replace('/', '.') or 'root',\n elapsed * 1000.0,\n time.time()\n ))\n p.dump_stats(prof_filename)\n\n else:\n stats = Stats(p, stream=self._stream)\n stats.sort_stats(*self._sort_by)\n\n self._stream.write('-' * 80)\n self._stream.write('\\nPATH: %r\\n' % environ.get('PATH_INFO'))\n stats.print_stats(*self._restrictions)\n self._stream.write('-' * 80 + '\\n\\n')\n\n return [body]\n\n\ndef make_action(app_factory, hostname='localhost', port=5000,\n threaded=False, processes=1, stream=None,\n sort_by=('time', 'calls'), restrictions=()):\n \"\"\"Return a new callback for :mod:`werkzeug.script` that starts a local\n server with the profiler enabled.\n\n ::\n\n from werkzeug.contrib import profiler\n action_profile = profiler.make_action(make_app)\n \"\"\"\n def action(hostname=('h', hostname), port=('p', port),\n threaded=threaded, processes=processes):\n \"\"\"Start a new development server.\"\"\"\n from werkzeug.serving import run_simple\n app = ProfilerMiddleware(app_factory(), stream, sort_by, restrictions)\n run_simple(hostname, port, app, False, None, threaded, processes)\n return action\n", "path": "werkzeug/contrib/profiler.py"}], "after_files": [{"content": "# -*- coding: utf-8 -*-\n\"\"\"\n werkzeug.contrib.profiler\n ~~~~~~~~~~~~~~~~~~~~~~~~~\n\n This module provides a simple WSGI profiler middleware for finding\n bottlenecks in web application. It uses the :mod:`profile` or\n :mod:`cProfile` module to do the profiling and writes the stats to the\n stream provided (defaults to stderr).\n\n Example usage::\n from werkzeug.contrib.profiler import ProfilerMiddleware\n app = ProfilerMiddleware(app)\n\n :copyright: (c) 2014 by the Werkzeug Team, see AUTHORS for more details.\n :license: BSD, see LICENSE for more details.\n\"\"\"\nimport sys\nimport time\nimport os.path\ntry:\n try:\n from cProfile import Profile\n except ImportError:\n from profile import Profile\n from pstats import Stats\n available = True\nexcept ImportError:\n available = False\n\n\nclass MergeStream(object):\n\n \"\"\"An object that redirects `write` calls to multiple streams.\n Use this to log to both `sys.stdout` and a file::\n\n f = open('profiler.log', 'w')\n stream = MergeStream(sys.stdout, f)\n profiler = ProfilerMiddleware(app, stream)\n \"\"\"\n\n def __init__(self, *streams):\n if not streams:\n raise TypeError('at least one stream must be given')\n self.streams = streams\n\n def write(self, data):\n for stream in self.streams:\n stream.write(data)\n\n\nclass ProfilerMiddleware(object):\n\n \"\"\"Simple profiler middleware. Wraps a WSGI application and profiles\n a request. This intentionally buffers the response so that timings are\n more exact.\n\n By giving the `profile_dir` argument, pstat.Stats files are saved to that\n directory, one file per request. Without it, a summary is printed to\n `stream` instead.\n\n The file name format can be customized by passing\n ``filename_format``. If it is a string, it will be formatted using\n :meth:`str.format` with the following fields available:\n\n - ``{method}`` - the request method; GET, POST, etc\n - ``{path}`` - the request path or 'root' should one not exist\n - ``{elapsed}`` - the elapsed time of the request\n - ``{time}`` - the time of the request\n\n If it is a callable, it will be called with the WSGI ``environ``\n dict and should return a filename. Either way, the ``'.prof'``\n extension will be appended to the name. The default format is\n ``'{method}.{path}.{elapsed:06d}ms.{time:d}'``.\n\n For the exact meaning of `sort_by` and `restrictions` consult the\n :mod:`profile` documentation.\n\n .. versionadded:: 0.9\n Added support for `restrictions` and `profile_dir`.\n\n .. versionadded:: 0.15\n Added ``profile_file_name_format``.\n\n :param app: the WSGI application to profile.\n :param stream: the stream for the profiled stats. defaults to stderr.\n :param sort_by: a tuple of columns to sort the result by.\n :param restrictions: a tuple of profiling restrictions, not used if dumping\n to `profile_dir`.\n :param profile_dir: directory name to save pstat files\n :param filename_format: format of the filename excluding the extension.\n \"\"\"\n\n def __init__(\n self, app, stream=None,\n sort_by=('time', 'calls'), restrictions=(), profile_dir=None,\n filename_format='%(method)s.%(path)s.%(elapsed)06dms.%(time)d'\n ):\n if not available:\n raise RuntimeError('the profiler is not available because '\n 'profile or pstat is not installed.')\n self._app = app\n self._stream = stream or sys.stdout\n self._sort_by = sort_by\n self._restrictions = restrictions\n self._profile_dir = profile_dir\n self._filename_format = filename_format\n\n def __call__(self, environ, start_response):\n response_body = []\n\n def catching_start_response(status, headers, exc_info=None):\n start_response(status, headers, exc_info)\n return response_body.append\n\n def runapp():\n appiter = self._app(environ, catching_start_response)\n response_body.extend(appiter)\n if hasattr(appiter, 'close'):\n appiter.close()\n\n p = Profile()\n start = time.time()\n p.runcall(runapp)\n body = b''.join(response_body)\n elapsed = time.time() - start\n\n if self._profile_dir is not None:\n if callable(self._filename_format):\n filename = self._filename_format(environ)\n else:\n filename = self._filename_format.format(\n method=environ['REQUEST_METHOD'],\n path=(\n environ.get('PATH_INFO').strip('/').replace('/', '.')\n or 'root'),\n elapsed=elapsed * 1000.0,\n time=time.time(),\n )\n prof_filename = os.path.join(self._profile_dir, filename + '.prof')\n p.dump_stats(prof_filename)\n\n else:\n stats = Stats(p, stream=self._stream)\n stats.sort_stats(*self._sort_by)\n\n self._stream.write('-' * 80)\n self._stream.write('\\nPATH: %r\\n' % environ.get('PATH_INFO'))\n stats.print_stats(*self._restrictions)\n self._stream.write('-' * 80 + '\\n\\n')\n\n return [body]\n\n\ndef make_action(app_factory, hostname='localhost', port=5000,\n threaded=False, processes=1, stream=None,\n sort_by=('time', 'calls'), restrictions=()):\n \"\"\"Return a new callback for :mod:`werkzeug.script` that starts a local\n server with the profiler enabled.\n\n ::\n\n from werkzeug.contrib import profiler\n action_profile = profiler.make_action(make_app)\n \"\"\"\n def action(hostname=('h', hostname), port=('p', port),\n threaded=threaded, processes=processes):\n \"\"\"Start a new development server.\"\"\"\n from werkzeug.serving import run_simple\n app = ProfilerMiddleware(app_factory(), stream, sort_by, restrictions)\n run_simple(hostname, port, app, False, None, threaded, processes)\n return action\n", "path": "werkzeug/contrib/profiler.py"}]} | 1,864 | 935 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.